diff --git a/ishenwei/blogwatcher/2026-04-28.md b/ishenwei/blogwatcher/2026-04-28.md
new file mode 100644
index 00000000..8c107307
--- /dev/null
+++ b/ishenwei/blogwatcher/2026-04-28.md
@@ -0,0 +1,246 @@
+
+## 📦 新增 69 篇 (06:02:04)
+
+### 【Tech With Tim - YouTube】
+
+- [How to Make an App With AI - 9 Steps](https://www.youtube.com/watch?v=xEr0hRbK_Xo)
+ Click this link https://boot.dev/?promo=TECHWITHTIM and use my code TECHWITHTIM to get 25% off your first payment for boot.devBuilding an app with AI ...
+
+### 【Jon Law - YouTube】
+
+- [How to Build Voice AI Tools for Business With Smallest.ai | Best Voice AI](https://www.youtube.com/watch?v=oF3fMLIBzcw)
+ Try Voice AI on Smallest: https://app.smallest.ai/?utm_source=Youtube&utm_medium=influencer&utm_campaign=vc_atoms&utm_content=jlawIn this video: I clo...
+
+### 【TEDx Talks - YouTube】
+
+- [Why we need artists on space missions | Laura J. Lawson | TEDxAustin College](https://www.youtube.com/watch?v=jdW1-Z3hB5A)
+ We send art to space, so why not send artists? Artist Laura J. Lawson acknowledges the artistry and creativity of the people who have gone to space so...
+
+- [Take a stand by sitting down… to pee | Jay Hill | TEDxAsheville](https://www.youtube.com/watch?v=nh3V9wYtsC8)
+ "Somehow, we've accepted that half the population can stand over a shared toilet, make a mess, and leave it for someone else to clean up—often the oth...
+
+- [Dinner parties can change the world | Ashley Berger | TEDxAsheville](https://www.youtube.com/watch?v=ApJdsC9_x6s)
+ Dinner parties can change the world; and in an age of scrolling, shouting, and disconnection, that might be the most radical idea of all. In this TEDx...
+
+- [Cringe is Just Learning | Rajan Chidambaram | TEDxUVA](https://www.youtube.com/watch?v=dgTXhY3NQpE)
+ As a rising social media star, Rajan Chidambaram knows all too well the accomplishments that tend to generate public celebration: high follower counts...
+
+- [A road less traveled | Moniek Dekkers | TEDxUpanga Youth](https://www.youtube.com/watch?v=UI4qEYLBh7c)
+ In this talk, Moniek Dekker shares her experience biking from the Netherlands to Australia, exploring diverse cultures across multiple countries. Thro...
+
+- [What an Ancient Tribe taught me about Leadership | Tehsin Takim | TEDxUpanga Youth](https://www.youtube.com/watch?v=RbRy0_C3GSA)
+ Drawing on his time with Tanzania’s Hadzabe hunter-gatherers, Tehsin Takim explores how ancient, wilderness-based survival strategies can transform mo...
+
+- [Prejudice can be unlearned—here’s how | Manuel Ríos | TEDxGI School Youth](https://www.youtube.com/watch?v=sDmJar0J6eo)
+ Prejudice is something we should understand, interrupt, and change. Let's shift the narrative from “who are you?" to "who are we?" Traveler at heart a...
+
+- [The "What If" Trap | Mohammad Aljaidi | TEDxZarqa University](https://www.youtube.com/watch?v=pFcLx4xtPcE)
+ In this inspiring talk, Dr. Mohammad Aljaidi explores how fear of making the wrong decision keeps people stuck. He reveals why avoiding choices can sh...
+
+- [Afrobeats Across Borders | Kamal Periera & Abdulrahman Olawoore | TEDxStart Rite Schools Abuja](https://www.youtube.com/watch?v=XDsON0oNm8s)
+ What connects a young person to a culture they didn’t fully grow up in? In this insightful talk, the speaker explores how music—particularly Afrobeats...
+
+- [We Become What We Embrace | Safiya Sani & Halima Lawan | TEDxStart Rite Schools Abuja](https://www.youtube.com/watch?v=lWWZjQZhdSw)
+ In this evocative spoken word performance, the speakers explore how the ideas we absorb, and choose to hold onto, shape the direction of our lives. Th...
+
+### 【Coursera - YouTube】
+
+- [How Cosmetic Products Are Designed](https://www.youtube.com/watch?v=qFNQRxx-2pE)
+ Designing a cosmetic product requires balancing performance, safety, and consumer expectations. This lecture explores formulation goals—how scientists...
+
+- [What Is a Go-To-Market Strategy? (GTM Guide)](https://www.youtube.com/watch?v=Zf7cjnfp1w8)
+ Launching a product takes more than a great idea, it requires a clear, strategic plan. This video explains what a go-to-market (GTM) strategy is, how ...
+
+### 【零度解说 - YouTube】
+
+- [谁才是AI编程王者?ChatGPT5.5、Claude 4.7、Deepseek V4、Qwen 3.6 实测见真章!| 零度解说](https://www.youtube.com/watch?v=LupCuWxtktg)
+ 【更多资源】▶https://bittly.cc/lingdu【零度博客】▶https://www.freedidi.com【加入会员】▶https://www.youtube.com/channel/UCvijahEyGtvMpmMHBu4FS2w/join【高级会员】▶https://bittl...
+
+### 【Reuters - YouTube】
+
+- [Trump welcomes King Charles, Queen Camilla to the White House](https://www.youtube.com/watch?v=tODh9AgfZXw)
+ Britain's King Charles and Queen Camilla arrived at the White House where President Donald Trump and first lady Melania greeted the couple.#kingcharle...
+
+- [Shooting suspect charged with attempting to assassinate Trump](https://www.youtube.com/watch?v=zZuW0HLs4DA)
+ Acting Attorney General Todd Blanche announced charges against the man accused of opening fire at a Washington dinner attended by Donald Trump. US Att...
+
+- [Without direct talks, mediators seek to bridge US, Iran gaps](https://www.youtube.com/watch?v=x5z69XisWhE)
+ Work has not halted to bridge gaps between the United States and Iran, sources from mediator Pakistan said, despite the absence of face-to-face diplom...
+
+- [Germany mobilizes barge to move stranded whale to sea](https://www.youtube.com/watch?v=8P6lUFwxQ_U)
+ Preparations have begun off the coast of the German island of Poel in an attempt to rescue a humpback whale that has been stranded in the Baltic Sea f...
+
+- [Foiled attack was third assassination attempt against Trump: WH](https://www.youtube.com/watch?v=x-d1Wqi0sO0)
+ White House press secretary Karoline Leavitt described the foiled attack at the White House Correspondents' Association dinner as the third major assa...
+
+- [Britain's King Charles, Queen Camilla arrive in the US](https://www.youtube.com/watch?v=Cq6887mpXBE)
+ Britain's King Charles and Queen Camilla arrived in the United States for a four-day trip, a tour that has taken on even greater prominence after the ...
+
+- [White House responds to Kimmel's 'widow' joke about first lady](https://www.youtube.com/watch?v=QngkLRGbK9M)
+ White House press secretary Karoline Leavitt said Jimmy Kimmel ‘disgustingly called first lady Melania Trump an expectant widow,’ during a monologue p...
+
+- [OpenAI ends Microsoft exclusivity](https://www.youtube.com/watch?v=m4PmFpi3PyQ)
+ Microsoft will no longer have exclusive access to OpenAI's artificial intelligence models and products, a significant change that will allow the start...
+
+- [A collector's treasure trove of 500+ cars](https://www.youtube.com/watch?v=nUon31LBRjs)
+ A classic car collector in France has amassed hundreds of vehicles including a 1938 Cadillac Series 70 said to have once been owned by the Kennedy fam...
+
+- [Germany's Merz says Iran is humiliating the US as talks stall](https://www.youtube.com/watch?v=IGM6DWj7C54)
+ German Chancellor Friedrich Merz said Iran's leadership was humiliating the United States in an unusually abrupt rebuke over the conflict.#News #Reut...
+
+### 【BBC News 中文 - YouTube】
+
+- [白宮晚宴槍擊案:事件如何發生?槍手疑犯為何鎖定特朗普?- BBC News 中文](https://www.youtube.com/watch?v=nLapue1YSoE)
+ 美國代理司法部長托德・布蘭奇表示,試圖闖入白宮記者協會晚宴的疑似槍手,其「可能目標」是美國總統特朗普及官員。警方指,疑犯為31歲男子科爾・托馬斯・艾倫(Cole Tomas Allen)。他於週六(4月25日)在華盛頓希爾頓酒店舉行的活動期間,於一個保安檢查點附近開槍,其後被拘捕。布蘭奇指,疑犯的犯...
+
+### 【理想生活实验室】
+
+- [天猫的米兰野心:做全球家居产业的“第一公里”](http://www.toodaylab.com/84012)
+ 每年 4 月,全球家居设计界的目光都会聚焦于同一座城市——米兰。创办于 1961 年的米兰国际家具展被誉为全球家居设计领域的“奥斯卡”,它既是流行趋势的风向标,也是各大品牌展示设计实力的最高舞台。近年来,一个显著的变化正在发生:中国元素在米兰的存在感逐年增强。从早年零星品牌的外围试探,到如今多家中国...
+
+### 【阿榮福利味 - 免費軟體下載】
+
+- [Notepad3 7.26.426.1 免安裝中文版 - 免費 Windows 筆記本取代軟體](https://www.azofreeware.com/2025/08/notepad3.html)
+ 免費 Windows 筆記本取代軟體 - Notepad3,功能與「Notepad++」類似,強調的是輕量快速、佔用記憶體少、適合程式碼編輯,支援高亮度語法顯示功能,具備的功能有:程式碼摺疊、括號配對、自動縮排、單詞自動補全、不同文字編碼之間相互轉換(ASCII、UTF-8、UTF-16)、換行格式...
+
+- [GetWindowText 5.31 免安裝中文版 - 複製視窗中無法被複製的文字](https://www.azofreeware.com/2020/09/getwindowtext.html)
+ 複製視窗中無法被複製的文字 - GetWindowText,Windows視窗(例如:檔案內容視窗)中的標題及部份文字,是無法被選取並複製的,不過,使用這個小軟體就可以辦到!按住拖曳框並拖放到你想複製的視窗文字上方,該文字內容就會被複製到此軟體,藉此便可達到複製視窗內文字的目的。(阿榮) 下載連結→...
+
+- [Notepad++ 8.9.4 免安裝中文版 - 好用的程式碼編輯器](https://www.azofreeware.com/2006/10/notepad-35.html)
+ 實用的免費文字編輯軟體 - Notepad++,是旅法台灣人作品,是以 C++ 程式語言所設計的開放原始碼自由軟體,體積輕巧不佔系統記憶體,支援多分頁功能,完美取代微軟記事本!具有好用的中文搜尋取代、開啟檔案群組、在目錄中的指定副檔名搜尋特定字串、程式語言高亮度顯示等功能,支援 ANSI、UTF-8...
+
+- [[正版購買] SIW 2026 v16.05.0426 中文版 - 硬體檢測軟體](https://www.azofreeware.com/2006/10/siw-164.html)
+ 功能齊全的硬體檢測工具 - SIW,Windows 系統檢測工具,執行該程式便可以檢測出電腦的軟體、硬體、網路資訊,軟體部份 - 顯示以安裝程式、顯示 Windows 及軟體的序號、顯示 IE 儲存密碼、事件檢視器,硬體部份 - 支援硬體資訊全覽、主機板、即時溫度感測、網路卡、儲存裝置等訊息,支援 ...
+
+### 【Engadget is a web magazine with obsessive daily coverage of everything new in gadgets and consumer electronics】
+
+- [Images of Samsung's rumored smart glasses have leaked](https://www.engadget.com/ar-vr/images-of-samsungs-rumored-smart-glasses-have-leaked-184129483.html?src=rss)
+ Images and details about Samsung's upcoming smart glasses have leaked, according to a report by Android Headlines. We knew these were coming at some p...
+
+- [Joby Aviation is demoing 10-minute air taxi flights from JFK to Manhattan for a week](https://www.engadget.com/transportation/joby-aviation-is-demoing-10-minute-air-taxi-flights-from-jfk-to-manhattan-for-a-week-180247411.html?src=rss)
+ Joby Aviation is kicking off 10 days of electric air taxi demo flights in New York City. Before you try to book one to bypass the city's awful traffic...
+
+- [Star Trek: Strange New Worlds returns for its penultimate season on July 23](https://www.engadget.com/entertainment/tv-movies/star-trek-strange-new-worlds-returns-for-its-penultimate-season-on-july-23-170946603.html?src=rss)
+ Star Trek: Strange New Worlds returns for its fourth season via Paramount Plus on July 23. The ten episodes air weekly until September 24. This is act...
+
+- [Valve's Steam Controller costs $99 and arrives May 4](https://www.engadget.com/gaming/valves-steam-controller-costs-99-and-arrives-may-4-170058529.html?src=rss)
+ Valve's Steam Controller will hit the market on Monday, May 4, for a going price of $99 in the United States. The Steam Controller does precisely what...
+
+- [Valve Steam Controller review: A gamepad in search of a console](https://www.engadget.com/gaming/valve-steam-controller-review-a-gamepad-in-search-of-a-console-170054068.html?src=rss)
+ Don’t mistake the Steam Controller for a PC controller. Even though its main function is to play PC games, Valve’s new gamepad communicates with Steam...
+
+- [A Star Wars expansion is coming to PowerWash Simulator 2](https://www.engadget.com/gaming/a-star-wars-expansion-is-coming-to-powerwash-simulator-2-162946670.html?src=rss)
+ There's something deeply relaxing about chucking on a solid pair of headphones, listening to some good music and cleaning muck off structures and vehi...
+
+- [OpenAI breaks out of exclusivity agreements in its partnership with Microsoft](https://www.engadget.com/big-tech/openai-breaks-out-of-exclusivity-agreements-in-its-partnership-with-microsoft-162829584.html?src=rss)
+ OpenAI is opening up its partnership with Microsoft in the latest amendment to the major multi-year collaboration between the tech giants. The latest ...
+
+- [Spotify is now a fitness app too](https://www.engadget.com/apps/spotify-is-now-a-fitness-app-too-144037057.html?src=rss)
+ In its quest to become an all-in-one app, Spotify is now breaking into the fitness app world by offering "guided workout experiences" and on-demand Pe...
+
+- [Oprah brings her podcast to Amazon's streaming services](https://www.engadget.com/entertainment/oprah-brings-her-podcast-to-amazons-streaming-services-142846445.html?src=rss)
+ Amazon has brought another high-profile podcasting name into its fold after agreeing to a multiyear licensing deal with Oprah Winfrey. Her podcast wil...
+
+- [The sequel to the iconic emulator ZSNES is called Super ZSNES, of course](https://www.engadget.com/gaming/nintendo/the-sequel-to-the-iconic-emulator-zsnes-is-called-super-zsnes-of-course-135203417.html?src=rss)
+ Somehow, ZSNES has returned after laying dormant for 20 years. The developers of the iconic Super Nintendo emulator, which originally debuted in 1997 ...
+
+### 【异次元软件世界】
+
+- [Ubuntu 26.04 LTS 新功能汇总,值得升级吗? (上手体验视频)](https://www.iplaysoft.com/p/ubuntu-2604-lts-updates)
+ 说起 Linux 桌面系统,就一定绕不开 Ubuntu。这次发布 26.04 LTS(代号 Resolute Raccoon,坚毅浣熊)不是那种小打小闹的增量更新,而是从内核到桌面、从安全到 AI 的全维度大洗牌。 Ubuntu 26.04 LTS (长期维护版) 把桌面体验、底层内核、开发与 AI...
+
+- [Ubuntu 26.04 LTS 中文桌面版/服务器正式版ISO镜像下载 - 流行易入门的 Linux 系统](https://www.iplaysoft.com/ubuntu.html)
+ 说到最红火的 Linux 发行版当属 Ubuntu 了!它拥有漂亮的 UI 界面,跟 macOS 风格相比也有过之而无不及,而当你试过这款操作系统后,可能会对 Linux 刻板枯燥的印象产生巨大的改变。 在 Ubuntu 的世界里,已经不再只是简陋的界面+命令行,而是一款时尚易用同时又足够实用的操作...
+
+### 【小众软件】
+
+- [发现频道:最近10日的热门排行榜[2026年第17期]](https://www.appinn.com/faxian-top10-2617/)
+ 最近10日,来自小众软件论坛的发现频道的热门排行榜,由系统自动生成,直接列出来: 序号 主题 1️⃣ 【开发者自荐】iOS 相册备份 App -「🍉西瓜备份」,内购限免 2️⃣ 【自荐】Bytro–集成Claude和Codex的全GUI界面的AI编程工具 3️⃣ Minidenticons——像素风...
+
+### 【TED Talks Daily】
+
+- [How to google your symptoms without freaking out | John Whyte](http://go.ted.com/johnwhyte)
+ Why does searching your symptoms online always leave you more frightened than before? As former chief medical officer of WebMD, physician John Whyte s...
+
+### 【Slashdot】
+
+- [Notepad++ Finally Lands On macOS as a Native App](https://apple.slashdot.org/story/26/04/27/2055217/notepad-finally-lands-on-macos-as-a-native-app?utm_source=rss1.0mainlinkanon&utm_medium=feed)
+ BrianFagioli writes: Notepad++ has finally made its way to macOS, and this time it is not through a compatibility layer. A new community-driven port b...
+
+- [China Blocks Meta's $2 Billion Takeover of AI Startup Manus](https://tech.slashdot.org/story/26/04/27/2046252/china-blocks-metas-2-billion-takeover-of-ai-startup-manus?utm_source=rss1.0mainlinkanon&utm_medium=feed)
+ China has blocked Meta's planned $2 billion acquisition of AI startup Manus, ordering the deal withdrawn after months of scrutiny from both Beijing an...
+
+- [Supreme Court Reviews Police Use of Cell Location Data To Find Criminals](https://yro.slashdot.org/story/26/04/27/1721238/supreme-court-reviews-police-use-of-cell-location-data-to-find-criminals?utm_source=rss1.0mainlinkanon&utm_medium=feed)
+ An anonymous reader quotes a report from the New York Times: When the Call Federal Credit Union outside Richmond, Va., was robbed at gunpoint in 2019,...
+
+- [GitHub Copilot Is Moving To Usage-Based Billing](https://developers.slashdot.org/story/26/04/27/1717232/github-copilot-is-moving-to-usage-based-billing?utm_source=rss1.0mainlinkanon&utm_medium=feed)
+ GitHub said in a blog post today that it is moving Copilot to usage-based billing starting June 1. Base subscription prices will remain the same but p...
+
+- [Microsoft To Stop Sharing Revenue With OpenAI](https://slashdot.org/story/26/04/27/1657250/microsoft-to-stop-sharing-revenue-with-openai?utm_source=rss1.0mainlinkanon&utm_medium=feed)
+ Bloomberg reports that Microsoft is ending revenue-sharing payments to OpenAI (paywalled; alternative source) and making the partnership non-exclusive...
+
+- [California's Billionaire Tax Has the Signatures to Make the Ballot](https://news.slashdot.org/story/26/04/27/0335242/californias-billionaire-tax-has-the-signatures-to-make-the-ballot?utm_source=rss1.0mainlinkanon&utm_medium=feed)
+ California's proposed billionaire tax appears headed for the November ballot after backers said they gathered more than 1.5 million signatures, well a...
+
+- [DeepSeek V4 Arrives With Near State-of-the-Art Intelligence At 1/6th the Cost](https://news.slashdot.org/story/26/04/27/0328257/deepseek-v4-arrives-with-near-state-of-the-art-intelligence-at-16th-the-cost?utm_source=rss1.0mainlinkanon&utm_medium=feed)
+ An anonymous reader quotes a report from VentureBeat: The whale has resurfaced. DeepSeek, the Chinese AI startup offshoot of High-Flyer Capital Manage...
+
+- [America Now Has 70% More Bookstores Than in 2020, Says Bookshop.org Founder](https://news.slashdot.org/story/26/04/27/052242/america-now-has-70-more-bookstores-than-in-2020-says-bookshoporg-founder?utm_source=rss1.0mainlinkanon&utm_medium=feed)
+ "There are about 70% more bookstores now than there were six years ago in the United States," says Andy Hunter, the founder/CEO of Bookshop.org. Fast ...
+
+- [Two Hot Climate Tech Startups Just Raised $1 Billion+ in IPOs](https://news.slashdot.org/story/26/04/27/0437225/two-hot-climate-tech-startups-just-raised-1-billion-in-ipos?utm_source=rss1.0mainlinkanon&utm_medium=feed)
+ Public stock exchanges "appear to be warming to climate tech startups," reports TechCrunch. "Or at least some of them." This week, nuclear startup X-e...
+
+- [Right-to-Repair Laws Gain Political Momentum Across America](https://news.slashdot.org/story/26/04/27/0210243/right-to-repair-laws-gain-political-momentum-across-america?utm_source=rss1.0mainlinkanon&utm_medium=feed)
+ "California, Colorado, Minnesota, New York, Connecticut, Oregon and Washington have all passed comprehensive right-to-repair regulations," reports CNB...
+
+### 【AWS DevOps & Developer Productivity Blog】
+
+- [AWS Transform custom: Enterprise Code Modernization with the Learn-Scale-Improve Flywheel](https://aws.amazon.com/blogs/devops/aws-transform-custom-enterprise-code-modernization-with-the-learn-scale-improve-flywheel/)
+ Enterprise modernization has reached an inflection point. You can transform one repository easily. Existing tools, including AWS Transform custom, wor...
+
+### 【SRE WEEKLY】
+
+- [SRE Weekly Issue #514](https://sreweekly.com/sre-weekly-issue-514/)
+ View on sreweekly.com How we built a real-world evaluation platform for autonomous SRE agents at scale Finally! Someone actually explaining how they t...
+
+### 【AI (artificial intelligence) | The Guardian】
+
+- [If it’s only AI that’s keeping you up at night, maybe you’re doing OK | Letters](https://www.theguardian.com/technology/2026/apr/27/if-its-only-ai-thats-keeping-you-up-at-night-maybe-youre-doing-ok)
+ Poverty is far more pressing for many people, writes Lynsey Hanley. Plus letters from Martin Pitt and Michael BulleyReading Alexander Hurst’s column o...
+
+- [Elon Musk and Sam Altman face off in court over OpenAI’s founding mission](https://www.theguardian.com/technology/2026/apr/27/elon-musk-sam-altman-open-ai-lawsuit)
+ Musk’s lawsuit accuses Altman of fraud, while OpenAI says that Musk is ‘motivated by jealousy’A trial between two of Silicon Valley’s biggest tycoons ...
+
+- [Sadiq Khan may try to stop Scotland Yard signing Palantir contract](https://www.theguardian.com/politics/2026/apr/27/sadiq-khan-may-try-to-stop-scotland-yard-signing-palantir-contract)
+ Exclusive: Mayor raises concerns about using public money to support firms ‘who act contrary to London’s values’Sadiq Khan may oppose Scotland Yard us...
+
+- [Taylor Swift files trademarks for voice and image amid concern over AI misuse](https://www.theguardian.com/music/2026/apr/27/taylor-swift-trademarks-voice-image-ai)
+ The singer’s company filed three applications on Friday after Matthew McConaughey launched similar strategyTaylor Swift has filed applications to trad...
+
+- [Goldman raises oil price forecasts as Iran war deadlock continues; Shell buying Canada’s ARC in $13.6bn deal – as it happened](https://www.theguardian.com/business/live/2026/apr/27/oil-prices-high-us-iran-peace-talks-stock-markets-house-prices-latest-news-updates)
+ Rolling coverage of the latest economic and financial newsChina blocks $2bn Meta takeover of AI agent developer ManusShares in athletic apparel and fo...
+
+- [How AI job scams are destroying people’s hopes | Letters](https://www.theguardian.com/money/2026/apr/27/how-ai-job-scams-are-destroying-peoples-hopes)
+ Sasha Cooklin, Darryl Dixon and Niall Leonard respond to an article by Victoria Turk about the boom in AI-driven fraud in recruitmentArtificial intell...
+
+- [China blocks $2bn Meta takeover of AI agent developer Manus](https://www.theguardian.com/world/2026/apr/27/china-blocks-meta-takeover-manus-ai-agent-developer)
+ Beijing says domestic tech companies must seek explicit government approval for accepting US investmentBusiness live – latest updatesChina has blocked...
+
+- [Inside China’s robotics revolution – podcast](https://www.theguardian.com/news/audio/2026/apr/27/inside-chinas-robotics-revolution-podcast)
+ How close are we to the sci-fi vision of autonomous humanoid robots? I visited 11 companies in five Chinese cities to find outBy Chang Che. Read by Vi...
+
+### 【WSJ.com: World News】
+
+- [Tea, Scones and Geopolitics: What to Know About King Charles’s U.S. Visit](https://www.wsj.com/world/uk/tea-scones-and-geopolitics-what-to-know-about-king-charless-u-s-visit-0b9f50a6)
+ Charles is coming over to mark America turning 250 years old—and try to patch up the so-called Special Relationship between the U.S. and U.K....
+
+- [China Bans Meta’s Acquisition of Manus on National Security Grounds](https://www.wsj.com/world/china/china-bans-metas-acquisition-of-manus-on-national-security-grounds-71e10c3f)
+ Beijing has banned the $2.5 billion acquisition and ordered the parties involved to rescind the transaction....
+
+- [How to Avoid Fistfights and Poisonings at a World Leaders Summit](https://www.wsj.com/politics/how-to-avoid-fistfights-and-dna-leaks-at-a-world-leaders-summit-051741e8)
+ A successful meeting, and international diplomacy, can hinge on the slightest missed protocol, an unexpected miscue or even a bit of saliva left on a ...
+
+- [King Charles Is on a Mission to Salvage U.K. Relations With Trump](https://www.wsj.com/world/uk/king-charles-is-on-a-mission-to-salvage-u-k-relations-with-trump-5df933e3)
+ With the “special relationship” on the rocks, the U.K.’s ties with President Trump now rest on a charm offensive by King George III’s great-great-grea...
+
diff --git a/raw/AI/全网最全!Nano Banana 2 使用指南(2025年12月更新) 1.md b/raw/AI/全网最全!Nano Banana 2 使用指南(2025年12月更新) 1.md
index 46ff57f5..649a8f8a 100644
--- a/raw/AI/全网最全!Nano Banana 2 使用指南(2025年12月更新) 1.md
+++ b/raw/AI/全网最全!Nano Banana 2 使用指南(2025年12月更新) 1.md
@@ -1,174 +1,174 @@
----
-title: 全网最全!Nano Banana 2 使用指南(2025年12月更新)
-source: https://www.appinn.com/deepsider-nano-banana-2/
-author: shenwei
-published: 2025-12-01
-created: 2025-12-19
-description: 国内可用的 Nano Banana 2 使用方法: 1. 打开浏览器扩展商店,搜索 deepsider。 2. 打开 deepsider 侧边栏,切换到 Nano Banana 2 模型。
-tags: []
----
-
-
-最近的AI圈如同过年般一样热闹。
-
-Gemini 3.0 Pro 刚刚发布,谷歌就迫不及待地把 **==Nano Banana 2==** 也端上了桌。
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 1
-
-新版本正式代号为Gemini 3 Pro Image,也即大家口中的Nano Banana 2。
-
-原本以为Nano Banana已经够强,没想到Nano2的实测效果比想象中还要惊艳, **==直接碾压一众AI绘图模型==** !堪称火力全开!
-
-下图是Nano Banana 2的中文海报生成案例:
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 2
-
-漫画生成案例:
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 3
-
-甚至,它还能伪造出逼真的游戏界面:
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 4
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 5
-
-监控录像画面:
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 6
-
-顶刊科研配图:
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 7
-
-总之,万物皆可生成!
-
-## ▶ Nano Banana 2使用方法
-
-话不多说,先放上国内可用的Nano Banana 2使用入口:
-
-[https://deepsider.ai](https://deepsider.ai/)
-
-**==DeepSider是一款浏览器插件==** ,安装到浏览器后, **==国内也可以直接访问==** Nano Banana 2/Gemini3.0/GPT-5.1等等几十款AI大模型。
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 8
-
-DeepSider的生成效果如下图所示,再复杂的中文界面,都能轻而易举拿下:
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 9
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 10
-
-无论是速度,还是质量上,效果都非常好。
-
-DeepSider对于国内AI玩家来说,应该是 **==最方便的渠道之一==** 了。
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 11
-
-## DeepSider 使用方法:
-
-① 打开Edge浏览器,打开扩展商店;
-
-② 搜索 **deepsider** ,安装插件到浏览器;
-
-③ 打开deepsider侧边栏,切换到 Nano Banana 2 模型。
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 12
-
-## ▶ Nano Banana 2新版本功能
-
-①与传统图像模型不同,Nano Banana 2是一款推理模型, **==在生成图像前会进行内部推理;==**
-
-②更高的图像质量、更高的准确性、更好的 **==多语言长文本渲染能力== ;**
-
-③可输出1K、2K、4K分辨率图像;
-
-④最多可将14张输入图像组合为1张输出图像;
-
-⑤擅长高事实准确性的创意工作、需要 **==最新知识支持==** 的图像创作。
-
-简单来说,就是更牛x了。
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 13
-
-Nano Banana 2不仅会自动推理,思考用户给出的提示词,还会自动补完用户的深层次需求,并根据自己的最新知识库进行填充。
-
-比如你只需要给出一句话:生成某个食物制作的插画教程。
-
-它就能 **==自动进行检索和思考,填补上所有的细节。==**
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 14
-
-物理、化学、数学、地理、生物、历史等各个领域的知识,就更不必说。
-
-所以说,通过Nano Banana 2来 **==画科研配图、技术路线图、教学插画、儿童绘本、电商配图==** 等等,完全不在话下。
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 15
-
-如果你也想快速上手Nano Banana 2,现在就可以直接安装DeepSider插件了。
-
-装完插件后,在任何网页上点击右上角的DeepSider图标,就能打开侧边栏选择你需要的模型。
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 16
-
-它专为中文用户设计, **==无需特殊网络,无需海外账户,==** 支持的模型包括:
-
-- *GPT5,GPT4.1全系列(包括GPT-4o绘图,GPT5-Codex)*
-- *Claude全系列(包括Claude Opus)*
-- *Gemini 2.5 Pro* *全系列;*
-- *Grok全系列;*
-- *Nano Banana(包括高清图片生成模式)*
-- *Sora 2(包括最长25秒视频生成模式)*
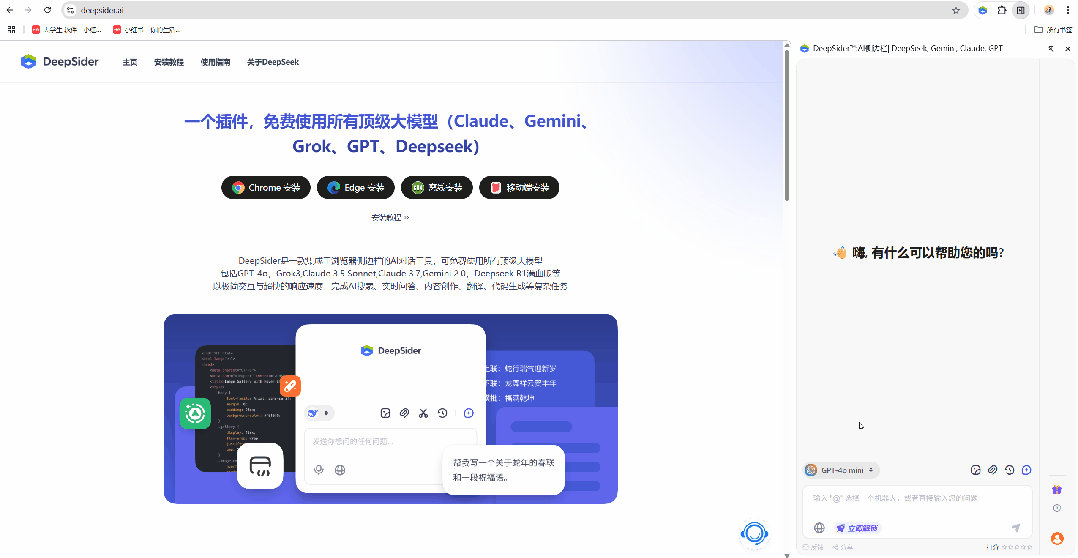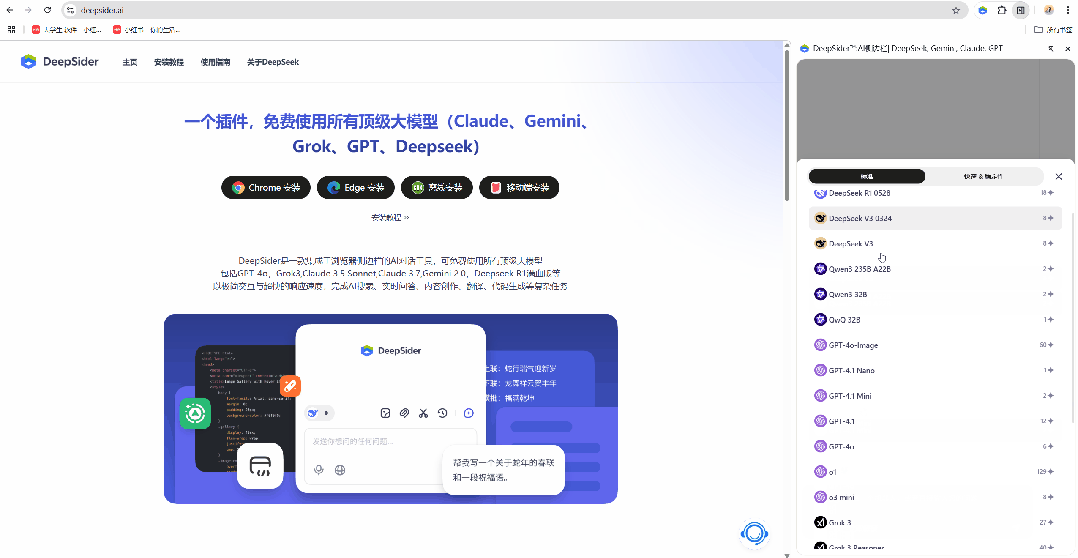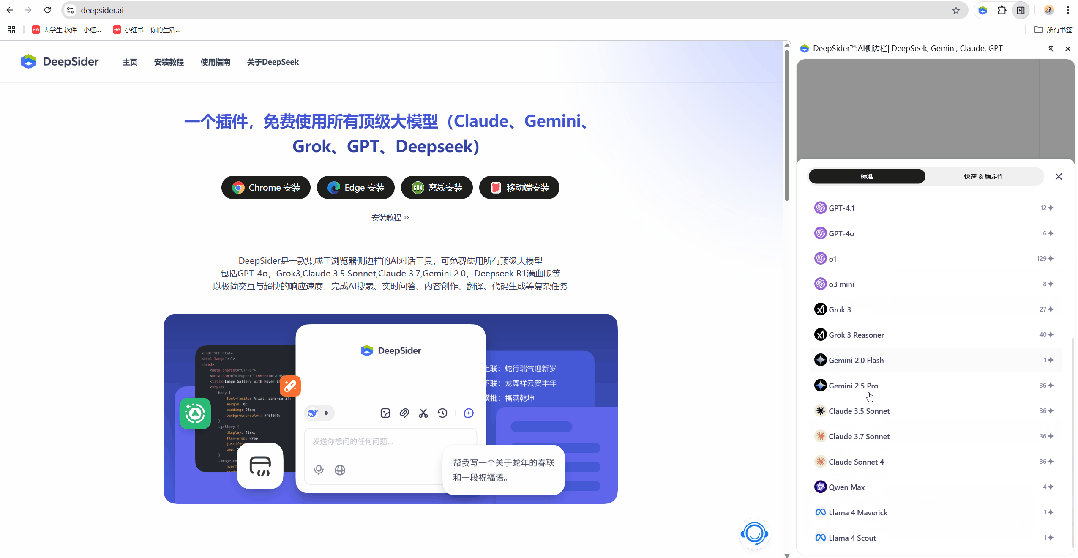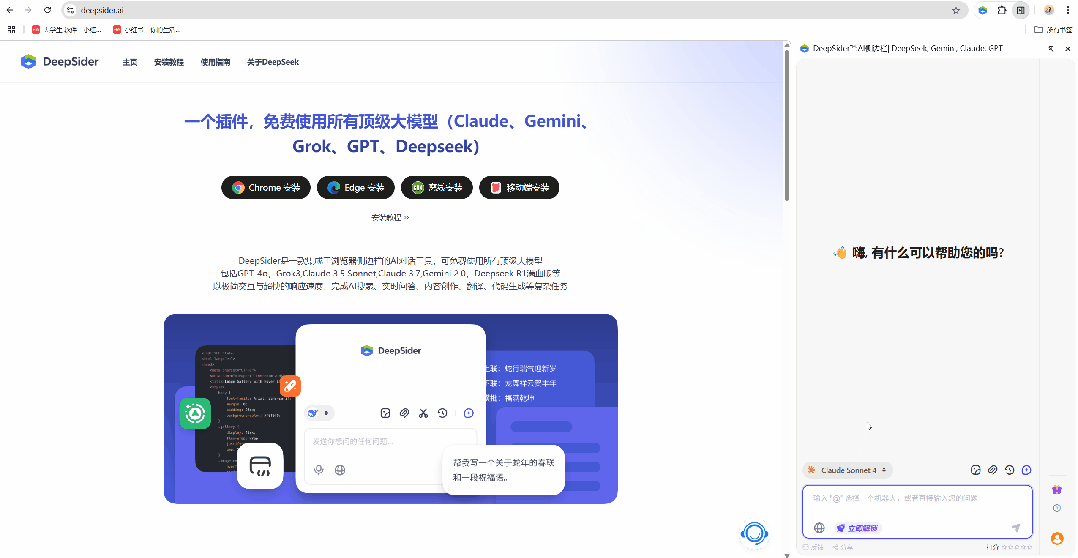
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 17
-
-你可以一边在网页上刷视频,一边让DeepSider的各个模型在旁边替你画图、写代码、解析文档,非常便捷。
-
-
-
-全网最全!Nano Banana 2 使用指南(2025年12月更新) 18
-
-除了Nano Banana 2,你还可以用DeepSider中的Sora 2一键成片,生成的无水印视频也能直接下载:
-
-
-
-平时这些AI模型官网一个会员就至少要几十上百美元一个月,接入大模型的API费用也相当高。
-
-相对其他方法,DeepSider一个插件就能体验多款热门AI大模型,对国内用户来说更流畅、更方便。
-
-欢迎大家分享你的Nano Banana 2生成结果哦,一起来探索更多好玩实用的案例吧~
-
+---
+title: 全网最全!Nano Banana 2 使用指南(2025年12月更新)
+source: https://www.appinn.com/deepsider-nano-banana-2/
+author: shenwei
+published: 2025-12-01
+created: 2025-12-19
+description: 国内可用的 Nano Banana 2 使用方法: 1. 打开浏览器扩展商店,搜索 deepsider。 2. 打开 deepsider 侧边栏,切换到 Nano Banana 2 模型。
+tags: []
+---
+
+
+最近的AI圈如同过年般一样热闹。
+
+Gemini 3.0 Pro 刚刚发布,谷歌就迫不及待地把 **==Nano Banana 2==** 也端上了桌。
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 1
+
+新版本正式代号为Gemini 3 Pro Image,也即大家口中的Nano Banana 2。
+
+原本以为Nano Banana已经够强,没想到Nano2的实测效果比想象中还要惊艳, **==直接碾压一众AI绘图模型==** !堪称火力全开!
+
+下图是Nano Banana 2的中文海报生成案例:
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 2
+
+漫画生成案例:
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 3
+
+甚至,它还能伪造出逼真的游戏界面:
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 4
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 5
+
+监控录像画面:
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 6
+
+顶刊科研配图:
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 7
+
+总之,万物皆可生成!
+
+## ▶ Nano Banana 2使用方法
+
+话不多说,先放上国内可用的Nano Banana 2使用入口:
+
+[https://deepsider.ai](https://deepsider.ai/)
+
+**==DeepSider是一款浏览器插件==** ,安装到浏览器后, **==国内也可以直接访问==** Nano Banana 2/Gemini3.0/GPT-5.1等等几十款AI大模型。
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 8
+
+DeepSider的生成效果如下图所示,再复杂的中文界面,都能轻而易举拿下:
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 9
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 10
+
+无论是速度,还是质量上,效果都非常好。
+
+DeepSider对于国内AI玩家来说,应该是 **==最方便的渠道之一==** 了。
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 11
+
+## DeepSider 使用方法:
+
+① 打开Edge浏览器,打开扩展商店;
+
+② 搜索 **deepsider** ,安装插件到浏览器;
+
+③ 打开deepsider侧边栏,切换到 Nano Banana 2 模型。
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 12
+
+## ▶ Nano Banana 2新版本功能
+
+①与传统图像模型不同,Nano Banana 2是一款推理模型, **==在生成图像前会进行内部推理;==**
+
+②更高的图像质量、更高的准确性、更好的 **==多语言长文本渲染能力== ;**
+
+③可输出1K、2K、4K分辨率图像;
+
+④最多可将14张输入图像组合为1张输出图像;
+
+⑤擅长高事实准确性的创意工作、需要 **==最新知识支持==** 的图像创作。
+
+简单来说,就是更牛x了。
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 13
+
+Nano Banana 2不仅会自动推理,思考用户给出的提示词,还会自动补完用户的深层次需求,并根据自己的最新知识库进行填充。
+
+比如你只需要给出一句话:生成某个食物制作的插画教程。
+
+它就能 **==自动进行检索和思考,填补上所有的细节。==**
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 14
+
+物理、化学、数学、地理、生物、历史等各个领域的知识,就更不必说。
+
+所以说,通过Nano Banana 2来 **==画科研配图、技术路线图、教学插画、儿童绘本、电商配图==** 等等,完全不在话下。
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 15
+
+如果你也想快速上手Nano Banana 2,现在就可以直接安装DeepSider插件了。
+
+装完插件后,在任何网页上点击右上角的DeepSider图标,就能打开侧边栏选择你需要的模型。
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 16
+
+它专为中文用户设计, **==无需特殊网络,无需海外账户,==** 支持的模型包括:
+
+- *GPT5,GPT4.1全系列(包括GPT-4o绘图,GPT5-Codex)*
+- *Claude全系列(包括Claude Opus)*
+- *Gemini 2.5 Pro* *全系列;*
+- *Grok全系列;*
+- *Nano Banana(包括高清图片生成模式)*
+- *Sora 2(包括最长25秒视频生成模式)*
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 17
+
+你可以一边在网页上刷视频,一边让DeepSider的各个模型在旁边替你画图、写代码、解析文档,非常便捷。
+
+
+
+全网最全!Nano Banana 2 使用指南(2025年12月更新) 18
+
+除了Nano Banana 2,你还可以用DeepSider中的Sora 2一键成片,生成的无水印视频也能直接下载:
+
+
+
+平时这些AI模型官网一个会员就至少要几十上百美元一个月,接入大模型的API费用也相当高。
+
+相对其他方法,DeepSider一个插件就能体验多款热门AI大模型,对国内用户来说更流畅、更方便。
+
+欢迎大家分享你的Nano Banana 2生成结果哦,一起来探索更多好玩实用的案例吧~
+
官网地址: [deepsider.ai](https://deepsider.ai/)
\ No newline at end of file
diff --git a/wiki/concepts/AISummary.md b/wiki/concepts/AISummary.md
new file mode 100644
index 00000000..0802995c
--- /dev/null
+++ b/wiki/concepts/AISummary.md
@@ -0,0 +1,24 @@
+---
+title: "AISummary"
+type: concept
+tags: [ai, summary, document-processing]
+sources: [我的工具集]
+last_updated: 2026-05-11
+---
+
+## Definition
+AI Summary 是利用 AI 技术对长文本、PDF 或视频内容进行自动摘要和提炼的服务。
+
+## Key Characteristics
+- 支持多种内容格式:文章、PDF、视频
+- 提供多种摘要模式
+- 可生成思维导图等可视化输出
+- 支持多语言摘要输出
+- 大幅降低信息消化时间
+
+## Examples from Sources
+- [[Decopy]] 提供 AI Summary Generator,支持文章、PDF 和视频的摘要生成,具备多摘要模式、思维导图和多语言输出功能
+
+## Relationships
+- 属于 [[AI时代发展策略]] 的信息处理层
+- 为知识管理提供高效的内容处理能力
diff --git a/wiki/concepts/Adversarial-Debate-Pattern.md b/wiki/concepts/Adversarial-Debate-Pattern.md
index d890e1b9..9bf440ee 100644
--- a/wiki/concepts/Adversarial-Debate-Pattern.md
+++ b/wiki/concepts/Adversarial-Debate-Pattern.md
@@ -1,33 +1,34 @@
----
-title: "Adversarial Debate Pattern"
-type: concept
-tags: []
-sources: []
-last_updated: 2026-04-25
----
-
-# Adversarial Debate Pattern
-
-## 定义
-多智能体系统的对抗式辩论模式——一个Agent提出方案,另一个Agent攻击反驳,由第三个Agent(裁判)决定胜负。核心是用外部批评者和评判者模拟人类的"恐惧"动机。
-
-## 角色
-- **Generator**:"Here is my plan."(生成方案)
-- **Critic**:"Here are 3 reasons why that plan sucks."(扮演魔鬼代言人)
-- **Judge**:"The Critic is right. Fix it."(裁判/主持人)
-
-## 核心洞察
-LLM是"Yes-Men",一旦开始写作很少自我纠正——需要一个指定的反对者来打破这种惯性。
-
-## 关键机制
-- 三方应使用**不同模型**(不同训练/微调/提示),多样性有益
-- 顺序执行+循环特性导致速度可能非常慢
-- Agent可能陷入无限辩论——可使用**Watchdog**(确定性代码)在时间/次数超阈值时打破循环
-
-## 适用场景
-- 安全分析(Security Analysis)
-- 代码审查(Code Review)
-- 高风险内容审核(High-Stakes Content Moderation)
-
-## 来源
-- [[multi-agent-system-reliability]]
+---
+title: "Adversarial Debate Pattern"
+type: concept
+tags: []
+sources:
+ - multi-agent-system-reliability
+last_updated: 2026-04-28
+---
+
+# Adversarial Debate Pattern
+
+## 定义
+多智能体系统的对抗式辩论模式——一个Agent提出方案,另一个Agent攻击反驳,由第三个Agent(裁判)决定胜负。核心是用外部批评者和评判者模拟人类的"恐惧"动机。
+
+## 角色
+- **Generator**:"Here is my plan."(生成方案)
+- **Critic**:"Here are 3 reasons why that plan sucks."(扮演魔鬼代言人)
+- **Judge**:"The Critic is right. Fix it."(裁判/主持人)
+
+## 核心洞察
+LLM是"Yes-Men",一旦开始写作很少自我纠正——需要一个指定的反对者来打破这种惯性。
+
+## 关键机制
+- 三方应使用**不同模型**(不同训练/微调/提示),多样性有益
+- 顺序执行+循环特性导致速度可能非常慢
+- Agent可能陷入无限辩论——可使用**Watchdog**(确定性代码)在时间/次数超阈值时打破循环
+
+## 适用场景
+- 安全分析(Security Analysis)
+- 代码审查(Code Review)
+- 高风险内容审核(High-Stakes Content Moderation)
+
+## 来源
+- [[multi-agent-system-reliability]]
diff --git a/wiki/concepts/Agent.md b/wiki/concepts/Agent.md
new file mode 100644
index 00000000..e38626d6
--- /dev/null
+++ b/wiki/concepts/Agent.md
@@ -0,0 +1,25 @@
+---
+title: "Agent"
+type: concept
+tags: [agent, llm, automation, mcp]
+aliases: [Agent, AI Agent, 智能体, 自主代理]
+last_updated: 2025-12-20
+---
+
+## Definition
+Agent,智能体,由 [[Large Language Model]] + [[Model Context Protocol|MCP]] + [[Prompt]] 组成,实现自动化执行。LLM 给出步骤方法和工具调用指令,MCP 负责实际执行。
+
+## Key Facts
+- LLM 本身只给出"步骤方法",不会真正执行(如大模型告诉你如何发邮件,但不会自己发)
+- Agent 将 LLM 与 MCP 工具整合,实现真正的自动化
+- Agent 工作流:输入 Prompt(含工具描述)→ LLM 返回工具名和参数 → MCP Server 执行 → 返回结果
+- 是 [[LangChain]] 等开发框架的核心应用场景
+
+## Connections
+- [[Large Language Model]] ← 核心组件 ← [[Agent]]
+- [[Model Context Protocol]] ← 执行层 ← [[Agent]]
+- [[Prompt]] ← 输入 ← [[Agent]]
+- [[LangChain]] ← 用于构建 ← [[Agent]]
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/concepts/Agentic-AI.md b/wiki/concepts/Agentic-AI.md
index c9c0b55d..09f02496 100644
--- a/wiki/concepts/Agentic-AI.md
+++ b/wiki/concepts/Agentic-AI.md
@@ -2,7 +2,9 @@
title: "Agentic AI"
type: concept
tags: []
-sources: [designing-for-agentic-ai]
+sources:
+ - designing-for-agentic-ai
+ - multi-agent-system-reliability
last_updated: 2026-04-27
---
diff --git a/wiki/concepts/Consensus-Voting-Pattern.md b/wiki/concepts/Consensus-Voting-Pattern.md
index 492e1aee..911f6952 100644
--- a/wiki/concepts/Consensus-Voting-Pattern.md
+++ b/wiki/concepts/Consensus-Voting-Pattern.md
@@ -1,37 +1,38 @@
----
-title: "Consensus Voting Pattern"
-type: concept
-tags: []
-sources: []
-last_updated: 2026-04-25
----
-
-# Consensus Voting Pattern
-
-## 定义
-多智能体系统的共识投票模式——将同一任务分配给N个LLM,选取出现次数最多的答案作为最终结果。
-
-## 核心公式
-若单个模型幻觉概率为 P,则N个模型同时幻觉相同谎言的概率为 P^N。
-- 示例:P=0.2(20%幻觉率),N=3 → 0.2³ = 0.008(0.8%)
-
-## 核心机制
-1. **Spawn N LLMs**:N需要通过试验找到成本与可靠性的平衡点
-2. **Fan out work**:给所有Agent完全相同的任务
-3. **Fan in results**:选取最常见的答案
-
-## 关键要求
-- Agent之间**无反馈回路**,否则群体思维(Groupthink)和从众效应会扭曲结果
-- 理想情况下各Agent使用不同模型,降低思维同质化风险
-- 实验应像盲测一样进行
-
-## 适用场景
-- 事实核查(Fact-checking)
-- 分类任务(如"这是垃圾邮件吗?")
-
-## 缺点
-成本高——本质上是将同一任务分配给多个Agent,ROI需根据任务和失败成本计算。
-
-## 来源
-- [[multi-agent-system-reliability]]
-- [[Composite SLO]](概率公式类比)
+---
+title: "Consensus Voting Pattern"
+type: concept
+tags: []
+sources:
+ - multi-agent-system-reliability
+last_updated: 2026-04-28
+---
+
+# Consensus Voting Pattern
+
+## 定义
+多智能体系统的共识投票模式——将同一任务分配给N个LLM,选取出现次数最多的答案作为最终结果。
+
+## 核心公式
+若单个模型幻觉概率为 P,则N个模型同时幻觉相同谎言的概率为 P^N。
+- 示例:P=0.2(20%幻觉率),N=3 → 0.2³ = 0.008(0.8%)
+
+## 核心机制
+1. **Spawn N LLMs**:N需要通过试验找到成本与可靠性的平衡点
+2. **Fan out work**:给所有Agent完全相同的任务
+3. **Fan in results**:选取最常见的答案
+
+## 关键要求
+- Agent之间**无反馈回路**,否则群体思维(Groupthink)和从众效应会扭曲结果
+- 理想情况下各Agent使用不同模型,降低思维同质化风险
+- 实验应像盲测一样进行
+
+## 适用场景
+- 事实核查(Fact-checking)
+- 分类任务(如"这是垃圾邮件吗?")
+
+## 缺点
+成本高——本质上是将同一任务分配给多个Agent,ROI需根据任务和失败成本计算。
+
+## 来源
+- [[multi-agent-system-reliability]]
+- [[Composite SLO]](概率公式类比)
diff --git a/wiki/concepts/Continuous-Batching.md b/wiki/concepts/Continuous-Batching.md
new file mode 100644
index 00000000..abe8f3b4
--- /dev/null
+++ b/wiki/concepts/Continuous-Batching.md
@@ -0,0 +1,23 @@
+---
+title: "Continuous Batching"
+type: concept
+tags: [continuous-batching, vllm, inference, gpu]
+aliases: [Continuous Batching, 连续批处理, Iteration-Level Scheduling]
+last_updated: 2025-12-20
+---
+
+## Definition
+Continuous Batching,连续批处理,vLLM 的推理优化技术。与传统的攒满一批再处理不同,Continuous Batching 在每个解码步骤(按 Token 迭代)都动态组装活跃请求批次,GPU 基本满负载运转。
+
+## Key Facts
+- 传统批处理:攒满一批再跑,短任务被长任务阻塞(头阻塞问题)
+- Continuous Batching:每步解码都组装新批次,无需等待整批结束即可插入新请求
+- 基于 [[PagedAttention]] 的块式内存 + 步进级调度器实现
+- 提高 GPU 并发与公平性,充分利用 GPU 算力
+
+## Connections
+- [[vLLM]] ← 使用 ← [[Continuous Batching]]
+- [[PagedAttention]] ← 协同 ← [[Continuous Batching]]
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/concepts/Data-Distillation.md b/wiki/concepts/Data-Distillation.md
new file mode 100644
index 00000000..429407b4
--- /dev/null
+++ b/wiki/concepts/Data-Distillation.md
@@ -0,0 +1,22 @@
+---
+title: "Data Distillation"
+type: concept
+tags: [distillation, model-compression, training, llm]
+aliases: [Data Distillation, 数据蒸馏, Knowledge Distillation]
+last_updated: 2025-12-20
+---
+
+## Definition
+Data Distillation,数据蒸馏,利用高性能的大模型生成精简但有价值的数据,使一个小模型可以从中学习并逼近大模型的效果。
+
+## Key Facts
+- 核心思想:用大模型作为"教师"(Teacher),生成高质量训练数据
+- 小模型(Student)从这些数据中学习
+- 目标:以更低成本达到接近大模型的效果
+- 是模型压缩和高效部署的重要技术手段
+
+## Connections
+- [[Large Language Model]] ← 教师模型 ← [[Data Distillation]]
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/concepts/Embedding.md b/wiki/concepts/Embedding.md
new file mode 100644
index 00000000..9aca3cef
--- /dev/null
+++ b/wiki/concepts/Embedding.md
@@ -0,0 +1,24 @@
+---
+title: "Embedding"
+type: concept
+tags: [embedding, vector, nlp, similarity]
+aliases: [Embedding, 向量化, Text Embedding, 词向量]
+last_updated: 2025-12-20
+---
+
+## Definition
+Embedding,向量化,将词或文本转换为浮点数向量的技术。通过计算向量之间的距离(欧氏距离、余弦相似度等)判断语义关联性。
+
+## Key Facts
+- 词的意义取决于上下文语境(如"苹果"可指水果或手机)
+- Embedding 将词转化为高维浮点向量
+- 语义相近的词在向量空间中距离更近
+- 示例:一百和两百的距离近,而一百离一千远,说明一百比一千更接近两百的语义
+- 是 [[RAG]] 检索的基础技术
+
+## Connections
+- [[RAG]] ← 依赖 ← [[Embedding]]
+- [[Vector-Embedding]] ← 同义词 ← [[Embedding]]
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/concepts/Generation.md b/wiki/concepts/Generation.md
index d9dbd64f..4d7adc7e 100644
--- a/wiki/concepts/Generation.md
+++ b/wiki/concepts/Generation.md
@@ -1,33 +1,54 @@
---
title: "Generation"
type: concept
-tags: [rag, generation, llm, prompt, reasoning]
+tags: [RAG, LLM, 问答生成]
+sources: [rag从入门到精通系列1-基础rag]
last_updated: 2025-01-16
---
## Definition
-Generation(生成阶段)是 RAG Pipeline 的第三步,将用户问题与 Retrieval 阶段检索到的相关文档块组合为 Prompt,输入 LLM 生成最终答案。
-## Process
-1. **Context Assembly**:将用户问题(Question)与 Top-k 个相关文档块(Context)放入字典结构:`{"question": ..., "context": ...}`
-2. **Prompt Templating**:通过 PromptTemplate 将 Question 和 Context 组合为结构化的 Prompt String
-3. **LLM Inference**:将 Prompt 输入 LLM,LLM 严格基于上下文中提供的信息生成答案
-4. **Output Parsing**:从 LLM 输出中提取纯字符串结果
+Generation(生成阶段)是 RAG 管道的第三阶段,将用户问题与检索到的相关文档块组合成 Prompt,输入 LLM 生成带事实依据的答案。
-## Key Requirements for Generation
-- **Source Grounding**:LLM 必须严格基于检索到的上下文生成,不能凭空发挥
-- **Answer Attribution**:理想情况下应提供答案的来源引用(哪些文档块支持该答案)
+## Core Process
-## In RAG Pipeline
-- **上游**:接收 Retrieval 阶段返回的文档块作为上下文
-- **下游**:输出最终答案给用户
+```
+问题 + Top-k 文档块 → PromptTemplate 组装 → LLM 生成 → 返回答案
+```
-## Frameworks Simplify This
-LangChain 和 LlamaIndex 将 Retrieval + Generation 封装为 RAG Chain(如 RetrievalQA Chain),只需几行代码即可完成端到端 Pipeline。
+1. **组装上下文**:将问题(Question)和检索到的文档块(Context)放入预定义的字典结构
+2. **Prompt 模板**:通过 PromptTemplate 将问题+上下文组合成完整的 Prompt String
+3. **LLM 生成**:将 Prompt 输入 LLM,LLM 基于检索到的知识生成回答
+4. **可选链式组合**:使用 LangChain/LlamaIndex 的 Chain 将 Retrieval 和 Generation 串联为统一管道
-## Related Concepts
-- [[RAG]] — Generation 是 RAG Pipeline 的第三阶段
-- [[Retrieval]] — Generation 的上游,提供上下文
-- [[PromptTemplate]] — 组装 Question + Context 的模板技术
-- [[Chain]] — LangChain 中串联 Retrieval 和 Generation 的抽象
-- [[Large Language Model]] — 实际执行生成任务的模型
+## Key Prompt Pattern
+
+```
+你是一个问答助手。请根据以下参考资料回答用户问题。
+如果参考资料中没有相关信息,请如实说明。
+
+参考资料:
+{context}
+
+用户问题:{question}
+
+回答:
+```
+
+## LangChain Chain
+
+LangChain 和 LlamaIndex 提供了 `RetrievalQA Chain` 等开箱即用的链,可将检索和生成过程自动化串联,避免手动拼装 Prompt。
+
+## Connections
+
+- [[Generation]] ← part_of ← [[RAG]]
+- [[Generation]] ← receives_input ← [[Retrieval]]
+- [[Generation]] ← uses ← [[Large-Language-Model]]
+- [[Generation]] ← uses ← [[Prompt]]
+
+## Aliases
+
+- Answer Generation
+- RAG Generation
+- LLM Response Generation
+- 答案生成
diff --git a/wiki/concepts/Genetic-Algorithm.md b/wiki/concepts/Genetic-Algorithm.md
index c25dfdf0..6200217b 100644
--- a/wiki/concepts/Genetic-Algorithm.md
+++ b/wiki/concepts/Genetic-Algorithm.md
@@ -1,23 +1,24 @@
----
-title: "Genetic Algorithm"
-type: concept
-tags: []
-sources: []
-last_updated: 2026-04-25
----
-
-# Genetic Algorithm
-
-## 定义
-遗传算法——传统机器学习中基于自然选择和遗传机制的优化算法,是[[Tree-of-Thoughts]]和[[Knock-out-Pattern]]的ML理论根源。
-
-## 核心要素
-1. **遗传表示**(Genetic Representation):解决方案域的编码(模型+上下文)
-2. **适应度函数**(Fitness Function):评估解决方案质量的函数(淘汰赛裁判)
-
-## 在多智能体系统中的应用
-- [[Knock-out-Pattern]]是遗传算法的精简实现——将适应度函数替换为验证器(Validator)
-- [[Tree-of-Thoughts]]通过验证器持续筛选Agent分支,可结合赢家的特征重组生成新Agent
-
-## 来源
-- [[multi-agent-system-reliability]]
+---
+title: "Genetic Algorithm"
+type: concept
+tags: []
+sources:
+ - multi-agent-system-reliability
+last_updated: 2026-04-28
+---
+
+# Genetic Algorithm
+
+## 定义
+遗传算法——传统机器学习中基于自然选择和遗传机制的优化算法,是[[Tree-of-Thoughts]]和[[Knock-out-Pattern]]的ML理论根源。
+
+## 核心要素
+1. **遗传表示**(Genetic Representation):解决方案域的编码(模型+上下文)
+2. **适应度函数**(Fitness Function):评估解决方案质量的函数(淘汰赛裁判)
+
+## 在多智能体系统中的应用
+- [[Knock-out-Pattern]]是遗传算法的精简实现——将适应度函数替换为验证器(Validator)
+- [[Tree-of-Thoughts]]通过验证器持续筛选Agent分支,可结合赢家的特征重组生成新Agent
+
+## 来源
+- [[multi-agent-system-reliability]]
diff --git a/wiki/concepts/Hallucination.md b/wiki/concepts/Hallucination.md
new file mode 100644
index 00000000..f2892db3
--- /dev/null
+++ b/wiki/concepts/Hallucination.md
@@ -0,0 +1,23 @@
+---
+title: "Hallucination"
+type: concept
+tags: [hallucination, llm, problem, reliability]
+aliases: [Hallucination, 幻觉, 大模型幻觉, LLM 幻觉]
+last_updated: 2025-12-20
+---
+
+## Definition
+Hallucination,幻觉,大语言模型在面对陌生领域或缺乏足够知识的问题时,"一本正经地胡说八道",给出看似合理但实际错误答案的现象。
+
+## Key Facts
+- 本质原因:LLM 的知识局限于训练数据集,面对未知领域时无法真实"理解",只能基于概率生成最可能的下一个词
+- 类比:LLM 在陌生领域"只会写一个解字",然后放飞自我
+- [[RAG]] 是解决幻觉的主要技术手段之一(通过外部知识引导)
+- 其他方法:模型微调、Prompt Engineering、Chain-of-Thought
+
+## Connections
+- [[RAG]] ← 解决 ← [[Hallucination]]
+- [[Large Language Model]] ← 问题 ← [[Hallucination]]
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/concepts/Hierarchy-Agent-Pattern.md b/wiki/concepts/Hierarchy-Agent-Pattern.md
index 3a75fc1d..7d9aa4ff 100644
--- a/wiki/concepts/Hierarchy-Agent-Pattern.md
+++ b/wiki/concepts/Hierarchy-Agent-Pattern.md
@@ -1,34 +1,35 @@
----
-title: "Hierarchy Agent Pattern"
-type: concept
-tags: []
-sources: []
-last_updated: 2026-04-25
----
-
-# Hierarchy Agent Pattern
-
-## 定义
-多智能体系统的等级制度模式——由一个主管模型(Supervisor/Planner)制定计划、分解任务、分配工作给专业工作代理(Worker),再由验证代理(Validator)检验结果的质量。
-
-## 核心机制
-- **Planner**:智能模型(如 Opus)将用户目标分解为原子化小步骤
-- **Worker**:专门化智能体(通常用更小更快的模型),专注于单一任务
-- **Validator**:检查点——工作不合格则退回;可用确定性代码(单元测试/JSON schema)或LLM本身
-
-## 为什么有效
-依赖图强制协作——Worker必须等Planner分配任务才能开始,且无法作弊(会被Validator发现)。
-
-## 适用场景
-需要将上下文分开的复杂工作流(如不让"撰稿人"看到"研究员"的原始日志)。
-
-## 优点
-- 任务分解清晰,可独立验证每个步骤
-- 支持上下文隔离
-
-## 缺点
-- 顺序执行(Planner→Worker→Validator),速度慢、成本高
-- Validator建议使用与Planner/Worker不同的模型以提高客观性
-
-## 来源
-- [[multi-agent-system-reliability]]
+---
+title: "Hierarchy Agent Pattern"
+type: concept
+tags: []
+sources:
+ - multi-agent-system-reliability
+last_updated: 2026-04-28
+---
+
+# Hierarchy Agent Pattern
+
+## 定义
+多智能体系统的等级制度模式——由一个主管模型(Supervisor/Planner)制定计划、分解任务、分配工作给专业工作代理(Worker),再由验证代理(Validator)检验结果的质量。
+
+## 核心机制
+- **Planner**:智能模型(如 Opus)将用户目标分解为原子化小步骤
+- **Worker**:专门化智能体(通常用更小更快的模型),专注于单一任务
+- **Validator**:检查点——工作不合格则退回;可用确定性代码(单元测试/JSON schema)或LLM本身
+
+## 为什么有效
+依赖图强制协作——Worker必须等Planner分配任务才能开始,且无法作弊(会被Validator发现)。
+
+## 适用场景
+需要将上下文分开的复杂工作流(如不让"撰稿人"看到"研究员"的原始日志)。
+
+## 优点
+- 任务分解清晰,可独立验证每个步骤
+- 支持上下文隔离
+
+## 缺点
+- 顺序执行(Planner→Worker→Validator),速度慢、成本高
+- Validator建议使用与Planner/Worker不同的模型以提高客观性
+
+## 来源
+- [[multi-agent-system-reliability]]
diff --git a/wiki/concepts/ImageToVideo.md b/wiki/concepts/ImageToVideo.md
new file mode 100644
index 00000000..fe582afd
--- /dev/null
+++ b/wiki/concepts/ImageToVideo.md
@@ -0,0 +1,24 @@
+---
+title: "ImageToVideo"
+type: concept
+tags: [ai, video, image-to-video]
+sources: [我的工具集, 14个免费的ai图生视频工具]
+last_updated: 2026-05-11
+---
+
+## Definition
+Image-to-Video 是将静态图片转化为动态视频的 AI 技术,让图片中的元素产生运动效果。
+
+## Key Characteristics
+- 将静态图像作为输入,生成包含运动元素的视频
+- 广泛应用于电商视频制作、内容创作、广告营销等场景
+- 降低视频创作门槛,无需专业设备和拍摄技能
+
+## Examples from Sources
+- [[Wavespeed AI]] 提供 Image-to-Video 功能(付费)
+- [[Vidu]] 提供 Image-to-Video 功能(月费 ¥8)
+- [[Hailuo AI]] 提供 Image-to-Video 功能(月费 ¥42)
+
+## Relationships
+- 属于 [[AI时代发展策略]] 的创意工具层
+- 与 [[TextToVideo]] 互补:ImageToVideo 从图像生成,TextToVideo 从文本生成
diff --git a/wiki/concepts/Indexing.md b/wiki/concepts/Indexing.md
index 166d6e9d..abb8304e 100644
--- a/wiki/concepts/Indexing.md
+++ b/wiki/concepts/Indexing.md
@@ -1,29 +1,47 @@
----
-title: "Indexing"
-type: concept
-tags: [rag, indexing, document-processing, embedding]
-last_updated: 2025-01-16
----
-
-## Definition
-Indexing(索引阶段)是 RAG Pipeline 的第一步,负责将外部文档转化为可检索的向量表示:文档加载 → 文本切分 → 向量化 → 存入向量数据库。
-
-## Process
-1. **Document Loading**:从多种来源(网页/PDF/数据库/API 等)加载原始文档
-2. **Text Splitting**:将长文档切分为满足 Embedding Model Context Window 的文本片段(Split)
-3. **Embedding**:使用 Embedding Model 将每个 Split 转化为固定长度的语义向量
-4. **Storage**:将向量 + 原始文本块存入 Vector Store(向量数据库)
-
-## Why Splitting is Necessary
-Embedding Model 的 Context Window 有限(通常 512~8192 token),无法直接处理整篇长文档,因此必须切分。切分策略直接影响检索质量——过小则语义不完整,过大则引入噪声。
-
-## In RAG Pipeline
-- **前置阶段**:Indexing 的输出(向量数据库)是 Retrieval 阶段的输入
-- **工具支撑**:LangChain 的 DocumentLoader、TextSplitter、Embedding、VectorStore 组件封装了全流程
-
-## Related Concepts
-- [[RAG]] — Indexing 是 RAG Pipeline 的第一阶段
-- [[Split]] — 切分后的文档片段
-- [[Embedding]] — 向量化的技术
-- [[Vector Store]] — 存储向量的数据库
-- [[Retrieval]] — Indexing 的下一阶段
+---
+title: "Indexing"
+type: concept
+tags: [RAG, 向量数据库, 文档处理]
+sources: [rag从入门到精通系列1-基础rag]
+last_updated: 2025-01-16
+---
+
+## Definition
+
+Indexing(索引阶段)是 RAG(检索增强生成)管道的第一阶段,负责将外部文档转换为可检索的向量表示并存入向量数据库。
+
+## Core Process
+
+```
+原始文档 → 文档加载器 → 文本切分(Split) → Embedding向量化 → 存入Vector Store
+```
+
+1. **文档加载(Loading)**:通过 LangChain 等框架的 Document Loader 从多种来源(网页/本地文件/数据库等)加载原始文档
+2. **文本切分(Splitting)**:将长文档切分成适合 Embedding Model Context Window 的小块(Split),通常 512~4096 token
+3. **向量化(Embedding)**:使用 Embedding Model(如 BAAI/bge 系列)将文本块转换为固定长度的向量表示
+4. **存入向量数据库**:将 Embedding Vector 存入 Vector Store(如 Qdrant、Chroma、Milvus 等)
+
+## Key Parameters
+
+- **Chunk Size**:每个 Split 的 token 数量,需平衡上下文完整性和模型限制
+- **Chunk Overlap**:相邻 Split 之间的重叠 token 数,防止信息在切分边界丢失
+- **Embedding Model**:决定向量质量和检索效果的模型(如 BAAI、OpenAI text-embedding-3、BGE 等)
+
+## Tools
+
+- **LangChain**:提供 160+ 文档加载器和向量存储集成
+- **LlamaIndex**:专注数据连接和索引的 LLM 应用框架
+- **Qdrant**:Rust 编写的开源向量数据库,支持过滤和混合检索
+
+## Connections
+
+- [[Indexing]] ← part_of ← [[RAG]]
+- [[Indexing]] ← uses ← [[Embedding]]
+- [[Indexing]] ← produces ← [[Vector-Store]]
+- [[Indexing]] ← depends_on ← [[Context-Window]]
+
+## Aliases
+
+- Document Indexing
+- Chunking
+- 文档索引
diff --git a/wiki/concepts/KV-Cache.md b/wiki/concepts/KV-Cache.md
new file mode 100644
index 00000000..4417dbfc
--- /dev/null
+++ b/wiki/concepts/KV-Cache.md
@@ -0,0 +1,23 @@
+---
+title: "KV Cache"
+type: concept
+tags: [kv-cache, inference, llm, optimization]
+aliases: [KV Cache, Key-Value Cache, KV缓存]
+last_updated: 2025-12-20
+---
+
+## Definition
+KV Cache,大语言模型推理过程中的缓存机制。K(Key)和 V(Value)是由每个 Token 的向量通过线性变换得到的两类向量,用于注意力计算。KV Cache 将这些历史 K/V 保存下来,避免后续解码步骤重复计算。
+
+## Key Facts
+- 节省计算:无需每次都重新计算历史 Token 的注意力
+- 显存开销:KV Cache 随上下文长度、层数、头数、维度线性增长,是推理中最大的显存开销来源之一
+- [[vLLM]] 的核心优化对象
+- [[PagedAttention]] 通过分块管理解决其碎片化问题
+
+## Connections
+- [[vLLM]] ← 优化 ← [[KV Cache]]
+- [[PagedAttention]] ← 解决 ← [[KV Cache]] 的碎片化问题
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/concepts/Knock-out-Pattern.md b/wiki/concepts/Knock-out-Pattern.md
index b8bf1c5a..a8ad14df 100644
--- a/wiki/concepts/Knock-out-Pattern.md
+++ b/wiki/concepts/Knock-out-Pattern.md
@@ -1,36 +1,37 @@
----
----
-title: "Knock-out Pattern"
-type: concept
-tags: []
-sources: []
-last_updated: 2026-04-25
----
-
-# Knock-out Pattern
-
-## 定义
-多智能体系统的淘汰制模式——将任务分配给N个Agent,用验证器决定哪些表现最差的被淘汰。核心是用"适者生存"替代LLM不存在的"死亡恐惧"。
-
-## 核心机制
-1. 将任务分配给N个Agent
-2. 用Validator决定要淘汰哪些Agent
-3. (可选)用通过验证的Agent特征组合创建新Agent填补空缺
-
-## ML渊源
-这是传统机器学习中[[Genetic-Algorithm]](遗传算法)的精简实现,依赖两个要素:
-- **遗传表示**:解决方案域(模型+上下文)
-- **适应度函数**:淘汰决策依据
-
-## 关键要求
-需要**快速验证输出的方式**(如单元测试)——如果需要人工检查所有分支,成本太高。Eval是必要基础设施。
-
-## 适用场景
-迭代式智能体工程——主要用于开发/调试阶段,不适合生产环境的高用户负载。
-
-## 与Tree of Thoughts的关系
-Tree of Thoughts是Knock-out模式的进阶实现,通过验证器持续筛选。
-
-## 来源
-- [[multi-agent-system-reliability]]
-- [[Genetic-Algorithm]]
+---
+---
+title: "Knock-out Pattern"
+type: concept
+tags: []
+sources:
+ - multi-agent-system-reliability
+last_updated: 2026-04-28
+---
+
+# Knock-out Pattern
+
+## 定义
+多智能体系统的淘汰制模式——将任务分配给N个Agent,用验证器决定哪些表现最差的被淘汰。核心是用"适者生存"替代LLM不存在的"死亡恐惧"。
+
+## 核心机制
+1. 将任务分配给N个Agent
+2. 用Validator决定要淘汰哪些Agent
+3. (可选)用通过验证的Agent特征组合创建新Agent填补空缺
+
+## ML渊源
+这是传统机器学习中[[Genetic-Algorithm]](遗传算法)的精简实现,依赖两个要素:
+- **遗传表示**:解决方案域(模型+上下文)
+- **适应度函数**:淘汰决策依据
+
+## 关键要求
+需要**快速验证输出的方式**(如单元测试)——如果需要人工检查所有分支,成本太高。Eval是必要基础设施。
+
+## 适用场景
+迭代式智能体工程——主要用于开发/调试阶段,不适合生产环境的高用户负载。
+
+## 与Tree of Thoughts的关系
+Tree of Thoughts是Knock-out模式的进阶实现,通过验证器持续筛选。
+
+## 来源
+- [[multi-agent-system-reliability]]
+- [[Genetic-Algorithm]]
diff --git a/wiki/concepts/Large-Language-Model.md b/wiki/concepts/Large-Language-Model.md
index f45c61b7..d7add282 100644
--- a/wiki/concepts/Large-Language-Model.md
+++ b/wiki/concepts/Large-Language-Model.md
@@ -1,28 +1,27 @@
----
-title: "Large Language Model"
-type: concept
-tags: [llm, ai, nlp]
-last_updated: 2026-04-25
----
-
-## Definition
-大语言模型(Large Language Model,LLM)是基于大规模预训练的深度学习模型,能够理解和生成人类语言,在推理与生成方面表现出色。
-
-## Core Characteristics
-- **知识截止日期**:LLM 的知识基于训练数据,存在固定的时间节点,无法自动获取最新信息
-- **推理能力强**:能够进行复杂推理、代码生成、文本创作等任务
-- **幻觉问题**:可能生成看似合理但实际错误的内容(幻觉)
-
-## Role in AI System Architecture
-- **思考层**:LLM 作为 AI 系统的"天才大脑",负责逻辑推理和内容生成
-- 与 [[RAG]] 配合获取实时信息
-- 与 [[AI Agent]] 配合实现自主行动
-
-## Related Concepts
-- [[RAG]] — 补充实时知识,降低幻觉
-- [[AI Agent]] — 提供行动能力
-- [[ReAct Pattern]] — 推理-行动协同模式
-
-## Sources
-- [[llms-rag-ai-agent-三个到底什么区别]]
-- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
+---
+title: "Large Language Model"
+type: concept
+tags: [llm, nlp, deep-learning]
+aliases: [LLM, 大语言模型, Large Language Model]
+last_updated: 2025-12-20
+---
+
+## Definition
+Large Language Model,大语言模型。行业通常以参数规模和训练数据/算力来衡量是否称为"大模型",语言模型常在 ≥1B 参数开始被称为"大模型"。
+
+## Key Facts
+- 1B = Billion = 10亿参数
+- 常见大模型示例:GPT-2(1.5B)、GPT-3(175B)、GPT-4(参数量未公开)
+- 参数规模是衡量模型能力的重要指标之一
+
+## Connections
+- [[Agent]] ← 构建于 ← [[Large Language Model]]
+- [[Prompt]] ← 输入给 ← [[Large Language Model]]
+- [[Model Context Protocol]] ← 连接 ← [[Large Language Model]]
+- [[RAG]] ← 增强 ← [[Large Language Model]]
+- [[vLLM]] ← 加速推理 ← [[Large Language Model]]
+- [[Hallucination]] ← 问题 ← [[Large Language Model]]
+- [[Data Distillation]] ← 蒸馏对象 ← [[Large Language Model]]
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/concepts/Model-Context-Protocol.md b/wiki/concepts/Model-Context-Protocol.md
index 4aa6007b..7d8bc348 100644
--- a/wiki/concepts/Model-Context-Protocol.md
+++ b/wiki/concepts/Model-Context-Protocol.md
@@ -1,52 +1,24 @@
----
-title: "Model Context Protocol"
-type: concept
-tags: [llm, mcp, protocol, tool-calling]
-sources: [大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]
-last_updated: 2026-04-25
----
-
-# Model Context Protocol (MCP)
-
-## Aliases
-- MCP
-- Model Context Protocol
-- 模型上下文协议
-
-## Definition
-
-Model Context Protocol(MCP,模型上下文协议)是一个开放协议,旨在为 LLM 应用提供**标准化接口**,使其能够连接外部数据源和各种工具进行交互。
-
-MCP 充当 LLM 与外部世界之间的**标准化通信层**:当 LLM 处理用户请求时需要访问外部信息或功能,MCP Client 向 MCP Server 发送请求;MCP Server 负责与相应的外部数据源或工具交互,获取数据并按 MCP 协议规范格式化后返回给 LLM。
-
-## Key Insight
-
-> "大模型是不会自己去调用外部数据源或者工具的,大模型只会告诉我们需要调用哪些工具,而我们需要自己去实现工具的调用。"
-
-MCP 解决的核心问题:**LLM 只能返回"需要调用什么工具和参数"的描述,不能自己执行**。MCP 提供了 LLM 与工具之间的标准桥梁。
-
-## Architecture
-
-```
-User Request
- ↓
-LLM(分析请求,决定需要哪些工具)
- ↓
-MCP Client(发送标准化请求)
- ↓
-MCP Server(与外部数据源/工具交互)
- ↓
-格式化结果
- ↓
-LLM(整合结果,生成最终响应)
-```
-
-## Related Concepts
-
-- [[AI Agent]]:LLM + MCP + 工具执行 = 真正自主的 Agent
-- [[Prompt]]:MCP Server 的返回结果作为上下文注入 LLM 的 Prompt
-- [[Large Language Model]]:MCP 扩展了纯 LLM 的能力边界
-
-## Sources
-
-- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
+---
+title: "Model Context Protocol"
+type: concept
+tags: [mcp, protocol, llm, tool]
+aliases: [MCP, Model Context Protocol, 模型上下文协议]
+last_updated: 2025-12-20
+---
+
+## Definition
+Model Context Protocol(MCP),模型上下文协议,是一个开放协议,为 LLM 应用提供标准化接口,使其能够连接外部数据源和各种工具进行交互。
+
+## Key Facts
+- MCP Client 向 MCP Server 发送请求
+- MCP Server 负责与外部数据源或工具交互,获取数据并按 MCP 协议规范格式化后返回
+- **核心约束**:大模型本身不会自己调用外部数据源或工具,只会告诉用户需要调用哪些工具,实际调用需要开发者自己实现
+- MCP 是连接 LLM 与真实世界的桥梁
+
+## Connections
+- [[Agent]] ← 构建于 ← [[Model Context Protocol]]
+- [[Large Language Model]] ← 通过 ← [[Model Context Protocol]] → 连接外部工具
+- [[Model Context Protocol]] ← 标准化 ← 工具调用
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/concepts/PagedAttention.md b/wiki/concepts/PagedAttention.md
new file mode 100644
index 00000000..79d4b7a5
--- /dev/null
+++ b/wiki/concepts/PagedAttention.md
@@ -0,0 +1,24 @@
+---
+title: "PagedAttention"
+type: concept
+tags: [paged-attention, vllm, inference, optimization]
+aliases: [PagedAttention, 分页注意力]
+last_updated: 2025-12-20
+---
+
+## Definition
+PagedAttention,vLLM 的核心注意力机制创新,将 [[KV Cache]] 切分为固定大小的块(block),并用页表式映射管理,类似操作系统的虚拟内存调度方式。
+
+## Key Facts
+- 传统方式:为每条序列分配一大块连续内存,导致碎片化和 OOM(显存不足)
+- PagedAttention 解决方案:将 KV Cache 切分为固定大小块,用页表管理,灵活调度
+- 优势:避免碎片化、支持动态并发、支持 KV 块复用(多分支/重复前缀场景)
+- 显著减少预填充(Prefill)时间
+
+## Connections
+- [[vLLM]] ← 使用 ← [[PagedAttention]]
+- [[KV Cache]] ← 优化管理 ← [[PagedAttention]]
+- [[Continuous Batching]] ← 协同 ← [[PagedAttention]]
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/concepts/Prompt.md b/wiki/concepts/Prompt.md
new file mode 100644
index 00000000..e928c7e9
--- /dev/null
+++ b/wiki/concepts/Prompt.md
@@ -0,0 +1,24 @@
+---
+title: "Prompt"
+type: concept
+tags: [prompt, llm, interaction]
+aliases: [Prompt, 提示词, Prompt Engineering]
+last_updated: 2025-12-20
+---
+
+## Definition
+Prompt,提示词,用户输入给大模型的语句。是与大模型交互的唯一入口。
+
+## Key Facts
+- Prompt 是用户与大模型之间的通信媒介
+- Prompt 的质量直接影响大模型的输出质量
+- Prompt Engineering(提示词工程)研究如何写出更有效的提示词
+- Zero-shot、Few-shot、Chain-of-Thought 等是常见的 Prompt 策略
+
+## Connections
+- [[Large Language Model]] ← 接收 ← [[Prompt]]
+- [[Agent]] ← 使用 ← [[Prompt]]
+- [[Large Language Model]] ← 指导 ← [[Prompt]]
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/concepts/RAG.md b/wiki/concepts/RAG.md
index 00bb09c3..52ba11ff 100644
--- a/wiki/concepts/RAG.md
+++ b/wiki/concepts/RAG.md
@@ -1,35 +1,26 @@
---
title: "RAG"
type: concept
-tags: [rag, retrieval, llm, ai]
-last_updated: 2026-04-27
+tags: [rag, retrieval, llm, knowledge]
+aliases: [RAG, Retrieval-Augmented Generation, 检索增强生成]
+last_updated: 2025-12-20
---
## Definition
-检索增强生成(Retrieval-Augmented Generation,RAG)是将大语言模型(LLM)链接到外部实时知识库的技术,通过检索+生成的流程提升答案准确性和时效性。
+Retrieval-Augmented Generation(RAG),检索增强生成,通过从外部知识库检索相关信息来增强大语言模型的回答质量,解决模型在陌生领域的幻觉(Hallucination)问题。
-## Core Mechanism
-1. **检索(Retrieval)**:当用户提问时,从外部知识库(向量数据库/知识图谱/公司文档)中检索最相关的信息块(Chunk)
-2. **增强生成(Augmented Generation)**:将检索结果与用户问题作为上下文输入 LLM,指示其严格基于上下文生成答案
+## Key Facts
+- 大模型在陌生领域容易产生幻觉,"一本正经胡说八道"
+- RAG 通过给模型"一些提示",引导其在正确方向上回答
+- 效果案例:正确率从 60% 提升至 90%
+- RAG 依赖 [[Embedding]] 技术实现语义检索
+- 典型 RAG 流程:用户问题 → 检索外部知识 → 将检索结果注入 Prompt → LLM 生成回答
-## Key Benefits
-- **知识更新与定制**:无需重新训练即可获取最新信息
-- **消除幻觉**:提供事实依据,显著降低胡说八道的风险
-- **引用来源**:可追溯信息来源,增加可信度
-- **成本效益**:相比微调,成本更低、更新更快
-
-## Role in AI System Architecture
-- **认知层**:RAG 作为 AI 系统的"记忆系统",负责信息获取与准确性保障
-- 为 [[AI Agent]] 提供可信赖的信息来源
+## Connections
+- [[Embedding]] ← 依赖 ← [[RAG]]
+- [[Hallucination]] ← 解决 ← [[RAG]]
+- [[Large Language Model]] ← 增强 ← [[RAG]]
+- [[LangChain]] ← 支持 ← [[RAG]]
## Sources
-- [[llms-rag-ai-agent-三个到底什么区别]]
-- [[rag从入门到精通系列1-基础rag]]
- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
-- [[knowledge-base-rag]]
-
-## Related Concepts
-- [[Large Language Model]] — 被增强的底层模型
-- [[AI Agent]] — 依赖 RAG 提供准确信息
-- [[Hybrid Search]] — RAG 常用检索策略
-- [[Semantic Search]] — 向量检索的核心技术
diff --git a/wiki/concepts/Reliability-Engineering.md b/wiki/concepts/Reliability-Engineering.md
index 0b7867fe..c941ef1a 100644
--- a/wiki/concepts/Reliability-Engineering.md
+++ b/wiki/concepts/Reliability-Engineering.md
@@ -1,31 +1,32 @@
----
-title: "Reliability Engineering"
-type: concept
-tags: []
-sources: []
-last_updated: 2026-04-25
----
-
-# Reliability Engineering
-
-## 定义
-可靠性工程——将LLM视为分布式系统中不可靠组件的工程哲学,而非"有感知"的智能体。
-
-## 核心原则
-停止要求模型"小心",开始**强制**其正确:
-
-1. **Constrained(约束)**:通过架构约束(如依赖图强制执行)而非提示词约束
-2. **Verified(验证)**:每个步骤有检查点,不合格则退回
-3. **Pruned(修剪)**:淘汰表现最差的Agent
-4. **Challenged(挑战)**:通过对抗辩论让错误暴露
-
-## 核心转变
-从"AI原型"(Prototype AI)到"企业级AI"(Enterprise AI)的范式转变:
-- ❌ 将LLM视为神奇的聊天机器人
-- ✅ 将LLM视为不可靠的分布式组件
-
-## 关键人物
-- [[Alex Ewerlöf]]:可靠性工程专家,KTH系统工程硕士,27年经验,专注将人类系统协作模式迁移至AI架构
-
-## 来源
-- [[multi-agent-system-reliability]]
+---
+title: "Reliability Engineering"
+type: concept
+tags: []
+sources:
+ - multi-agent-system-reliability
+last_updated: 2026-04-28
+---
+
+# Reliability Engineering
+
+## 定义
+可靠性工程——将LLM视为分布式系统中不可靠组件的工程哲学,而非"有感知"的智能体。
+
+## 核心原则
+停止要求模型"小心",开始**强制**其正确:
+
+1. **Constrained(约束)**:通过架构约束(如依赖图强制执行)而非提示词约束
+2. **Verified(验证)**:每个步骤有检查点,不合格则退回
+3. **Pruned(修剪)**:淘汰表现最差的Agent
+4. **Challenged(挑战)**:通过对抗辩论让错误暴露
+
+## 核心转变
+从"AI原型"(Prototype AI)到"企业级AI"(Enterprise AI)的范式转变:
+- ❌ 将LLM视为神奇的聊天机器人
+- ✅ 将LLM视为不可靠的分布式组件
+
+## 关键人物
+- [[Alex Ewerlöf]]:可靠性工程专家,KTH系统工程硕士,27年经验,专注将人类系统协作模式迁移至AI架构
+
+## 来源
+- [[multi-agent-system-reliability]]
diff --git a/wiki/concepts/Retrieval.md b/wiki/concepts/Retrieval.md
index 2b45447b..8296925b 100644
--- a/wiki/concepts/Retrieval.md
+++ b/wiki/concepts/Retrieval.md
@@ -1,34 +1,49 @@
----
-title: "Retrieval"
-type: concept
-tags: [rag, retrieval, vector-search, similarity]
-last_updated: 2025-01-16
----
-
-## Definition
-Retrieval(检索阶段)是 RAG Pipeline 的第二步,根据用户问题的语义向量(Embedding Vector),在向量数据库中按相似度找出 Top-k 个最相关的文档块(Split)。
-
-## Process
-1. **Query Embedding**:将用户问题通过同一个 Embedding Model 转化为语义向量
-2. **Vector Search**:在 Vector Store 中按相似度(余弦相似度/点积/欧氏距离)检索最接近的 k 个向量
-3. **Result Selection**:返回对应的原始文本块(Split)作为上下文
-
-## Key Parameters
-- **Top-k(k值)**:决定返回多少个最相关的文档块,k 过小可能遗漏关键信息,k 过大则引入噪声
-- **Similarity Metric**:余弦相似度最常用,适合方向性语义匹配;点积适合归一化向量;欧氏距离适合几何距离度量
-
-## In RAG Pipeline
-- **上游**:依赖 Indexing 阶段构建的向量数据库
-- **下游**:检索结果传递给 Generation 阶段作为上下文
-
-## Challenges
-- **语义鸿沟**:用户问题的措辞与文档中相关内容可能不同(词汇不匹配)
-- **上下文窗口限制**:Top-k 个文档块的总 token 数不能超过 LLM 的 Context Window
-- **噪声召回**:向量相似度高但实际无关的文档块可能被召回
-
-## Related Concepts
-- [[RAG]] — Retrieval 是 RAG Pipeline 的第二阶段
-- [[Vector Store]] — 检索的数据库后端
-- [[Embedding]] — 检索的向量来源
-- [[Generation]] — Retrieval 的下一阶段,接收检索结果作为上下文
-- [[Hybrid Search]] — 结合向量检索与关键词检索以弥补单一向量检索的不足
+---
+title: "Retrieval"
+type: concept
+tags: [RAG, 向量检索, 语义搜索]
+sources: [rag从入门到精通系列1-基础rag]
+last_updated: 2025-01-16
+---
+
+## Definition
+
+Retrieval(检索阶段)是 RAG 管道的第二阶段,根据用户问题的语义向量(Embedding Vector)在向量数据库中检索与之最相似的 Top-k 个文档块。
+
+## Core Process
+
+```
+用户问题 → 问题向量化 → Vector Store 相似度检索 → 返回 Top-k 文档块
+```
+
+1. **问题向量化**:将用户输入的自然语言问题通过相同的 Embedding Model 转换为向量
+2. **相似度计算**:Vector Store 计算问题向量与所有文档块向量的相似度(常用方法:余弦相似度、点积、欧氏距离)
+3. **返回 Top-k 结果**:返回相似度最高的 k 个文档块作为检索结果
+
+## Similarity Metrics
+
+| 方法 | 适用场景 |
+|------|----------|
+| 余弦相似度(Cosine) | 归一化向量,衡量方向相似性 |
+| 点积(Dot Product) | 未归一化向量,兼顾 magnitude |
+| 欧氏距离(L2) | 几何距离,适用低维空间 |
+
+## Retrieval Strategies
+
+- **Top-k Retrieval**:返回相似度最高的 k 个结果
+- **MMR(Maximal Marginal Relevance)**:平衡相关性和多样性,减少重复信息
+- **Hybrid Retrieval**:结合关键词检索(BM25)与向量检索
+
+## Connections
+
+- [[Retrieval]] ← part_of ← [[RAG]]
+- [[Retrieval]] ← uses ← [[Vector-Store]]
+- [[Retrieval]] ← uses ← [[Embedding]]
+- [[Retrieval]] ← feeds_into ← [[Generation]]
+
+## Aliases
+
+- Information Retrieval
+- Semantic Search
+- 向量检索
+- 语义检索
diff --git a/wiki/concepts/TextToSpeech.md b/wiki/concepts/TextToSpeech.md
new file mode 100644
index 00000000..51b3888a
--- /dev/null
+++ b/wiki/concepts/TextToSpeech.md
@@ -0,0 +1,22 @@
+---
+title: "TextToSpeech"
+type: concept
+tags: [ai, speech, text-to-speech]
+sources: [我的工具集]
+last_updated: 2026-05-11
+---
+
+## Definition
+Text-to-Speech(TTS)是将文本转换为语音的 AI 技术,也称为语音合成。
+
+## Key Characteristics
+- 将书面文本转换为可听的语音输出
+- 广泛应用于辅助阅读、语音导航、无障碍访问等场景
+- 现代 TTS 系统基于深度学习(如 WaveNet、Tacotron)生成自然语音
+
+## Examples from Sources
+- [[Google AI Studio]] 提供免费的 Text-to-Speech 服务,支持 Gemini 模型和 Dialog 对话
+
+## Relationships
+- 属于 [[AI时代发展策略]] 的创意工具层
+- 与 [[TextToVideo]] 互补:TTS 处理音频,TextToVideo 处理视频
diff --git a/wiki/concepts/TextToVideo.md b/wiki/concepts/TextToVideo.md
new file mode 100644
index 00000000..df736987
--- /dev/null
+++ b/wiki/concepts/TextToVideo.md
@@ -0,0 +1,24 @@
+---
+title: "TextToVideo"
+type: concept
+tags: [ai, video, text-to-video]
+sources: [我的工具集, 14个免费的ai图生视频工具]
+last_updated: 2026-05-11
+---
+
+## Definition
+Text-to-Video 是将文本描述转换为视频内容的 AI 技术,属于生成式 AI 的重要分支。
+
+## Key Characteristics
+- 根据文本描述生成动态视频内容
+- 可结合音频([[TextToSpeech]])实现完整的视频创作流程
+- 广泛应用于营销视频、内容创作、广告制作等场景
+
+## Examples from Sources
+- [[Vidu]] 提供 Text-to-Video 服务
+- [[Hailuo AI]] 提供 Text-to-Video 服务
+
+## Relationships
+- 属于 [[AI时代发展策略]] 的创意工具层
+- 与 [[ImageToVideo]] 互补:TextToVideo 从文本生成,ImageToVideo 从图像生成
+- 结合 [[TextToSpeech]] 可实现完整的"文字→视频+音频"创作流程
diff --git a/wiki/concepts/Token.md b/wiki/concepts/Token.md
new file mode 100644
index 00000000..9bebf57e
--- /dev/null
+++ b/wiki/concepts/Token.md
@@ -0,0 +1,22 @@
+---
+title: "Token"
+type: concept
+tags: [token, llm, pricing, metering]
+aliases: [Token, Tokens, 分词, 词元]
+last_updated: 2025-12-20
+---
+
+## Definition
+Token,大语言模型的基本输入单元,可以认为是一个单词或一个短语。是模型计费和性能计算的基础单位。
+
+## Key Facts
+- 英文:1 个字符 ≈ 0.3 个 Token
+- 中文:1 个字符 ≈ 0.6 个 Token(即中文 Token 消耗约是英文的 2 倍)
+- Token 数量直接影响 API 调用成本和响应延迟
+- Tokenization(分词)是将自然语言文本转换为 Token 序列的过程
+
+## Connections
+- [[Large Language Model]] ← 计量单位 ← [[Token]]
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/concepts/Tree-of-Thoughts.md b/wiki/concepts/Tree-of-Thoughts.md
index fb07c26d..bf9e8170 100644
--- a/wiki/concepts/Tree-of-Thoughts.md
+++ b/wiki/concepts/Tree-of-Thoughts.md
@@ -1,25 +1,26 @@
----
-title: "Tree of Thoughts"
-type: concept
-tags: []
-sources: []
-last_updated: 2026-04-25
----
-
-# Tree of Thoughts
-
-## 定义
-思维之树——多智能体系统的树形探索模式,是[[Genetic-Algorithm]](遗传算法)的精简实现。通过验证器决定哪些Agent分支被淘汰,持续筛选直至找到最优解。
-
-## 核心公式
-将任务分配给N个Agent → Validator决定淘汰哪些 → 可选:用通过验证的Agent特征生成新Agent填补空缺
-
-## 关键要求
-- 需要快速验证输出的方式(如Eval/单元测试)
-- 如果需要人工检查所有分支,太慢且容易出错
-
-## 与Knock-out Pattern的关系
-Tree of Thoughts是Knock-out模式的进阶——后者只是淘汰,前者还包括通过验证的Agent特征重组。
-
-## 来源
-- [[multi-agent-system-reliability]]
+---
+title: "Tree of Thoughts"
+type: concept
+tags: []
+sources:
+ - multi-agent-system-reliability
+last_updated: 2026-04-28
+---
+
+# Tree of Thoughts
+
+## 定义
+思维之树——多智能体系统的树形探索模式,是[[Genetic-Algorithm]](遗传算法)的精简实现。通过验证器决定哪些Agent分支被淘汰,持续筛选直至找到最优解。
+
+## 核心公式
+将任务分配给N个Agent → Validator决定淘汰哪些 → 可选:用通过验证的Agent特征生成新Agent填补空缺
+
+## 关键要求
+- 需要快速验证输出的方式(如Eval/单元测试)
+- 如果需要人工检查所有分支,太慢且容易出错
+
+## 与Knock-out Pattern的关系
+Tree of Thoughts是Knock-out模式的进阶——后者只是淘汰,前者还包括通过验证的Agent特征重组。
+
+## 来源
+- [[multi-agent-system-reliability]]
diff --git a/wiki/concepts/Vector-Store.md b/wiki/concepts/Vector-Store.md
new file mode 100644
index 00000000..d7b456df
--- /dev/null
+++ b/wiki/concepts/Vector-Store.md
@@ -0,0 +1,50 @@
+---
+title: "Vector-Store"
+type: concept
+tags: [RAG, 向量数据库, 嵌入向量]
+sources: [rag从入门到精通系列1-基础rag]
+last_updated: 2025-01-16
+---
+
+## Definition
+
+Vector Store(向量数据库)是专门用于存储和检索高维向量(Embedding Vector)的数据库系统,是 RAG 管道中 Retrieval 阶段的核心基础设施。
+
+## Core Functions
+
+1. **向量存储**:存储文本的 Embedding Vector 表示
+2. **相似度检索**:支持多种相似度度量方法(余弦相似度、点积、欧氏距离),返回 Top-k 最相似的结果
+3. **元数据过滤**:支持在检索时附加标量过滤条件(如时间、类别等)
+4. **混合检索**:部分向量数据库支持结合传统关键词检索(BM25)与向量检索
+
+## Popular Vector Stores
+
+| 名称 | 特点 | 语言 |
+|------|------|------|
+| Qdrant | 开源,高性能,支持过滤,Rust 编写 | Rust |
+| Chroma | 轻量级,适合本地和小规模场景 | Python |
+| Milvus | 开源,分布式,成熟生产级 | Go |
+| Weaviate | 原生支持混合检索,GraphQL 接口 | Go |
+| Pinecone | 云原生,全托管,无需运维 | 云服务 |
+| pgvector | PostgreSQL 扩展,简化技术栈 | PostgreSQL |
+
+## Indexing in Vector Store
+
+向量数据库通常使用近似最近邻(ANN)算法构建索引,以支持在海量向量中快速检索:
+
+- **HNSW(Hierarchical Navigable Small World)**:图索引,高检索精度,中等内存占用
+- **IVF(Inverted File Index)**:倒排索引,支持聚类加速
+- **PQ(Product Quantization)**:压缩索引,节省内存
+
+## Connections
+
+- [[Vector-Store]] ← supports ← [[Retrieval]]
+- [[Vector-Store]] ← receives_data_from ← [[Indexing]]
+- [[Vector-Store]] ← uses ← [[Embedding]]
+
+## Aliases
+
+- Vector Database
+- Vector Search Engine
+- Embedding Store
+- 向量数据库
diff --git a/wiki/concepts/WebScraper.md b/wiki/concepts/WebScraper.md
new file mode 100644
index 00000000..9c49ed8e
--- /dev/null
+++ b/wiki/concepts/WebScraper.md
@@ -0,0 +1,22 @@
+---
+title: "WebScraper"
+type: concept
+tags: [ai, data, scraper, web]
+sources: [我的工具集]
+last_updated: 2026-05-11
+---
+
+## Definition
+Web Scraper 是用于从网页中自动提取结构化数据的工具或服务。
+
+## Key Characteristics
+- 自动化抓取网页内容
+- 支持大规模数据采集
+- 可用于市场研究、竞品分析、内容聚合等场景
+
+## Examples from Sources
+- [[Brightdata]] 提供付费的 Web-Scraper 服务
+
+## Relationships
+- 属于 [[AI时代发展策略]] 的数据采集层
+- 为 AI Agent 提供数据输入源
diff --git a/wiki/concepts/九宫格法.md b/wiki/concepts/九宫格法.md
index b62c24c5..4339e863 100644
--- a/wiki/concepts/九宫格法.md
+++ b/wiki/concepts/九宫格法.md
@@ -1,37 +1,34 @@
----
-title: "九宫格法"
-type: concept
-tags: ["AI图像生成", "画面一致性", "视频制作"]
-sources: ["固定镜头短视频制作的ai全流程解析"]
-last_updated: 2026-04-23
----
-
-## 定义
-九宫格法是一种 AI 图像生成的一致性控制方法,通过一次性生成 3×3 共九个画面(在同一张图内),确保所有分镜的摄像机机位、角度、景深、光影完全一致,从而解决逐帧独立生成导致画面风格不一致的问题。
-
-## 核心问题
-逐帧独立生成图片会导致:
-- 光影关系错乱(同一光源在不同帧中方向/强度不一致)
-- 空间关系错乱(物体位置、比例关系变化)
-- 色彩风格不一致(色调、饱和度、明度不统一)
-- 摄像机机位漂移(角度、景深在系列画面中不连贯)
-
-## 九宫格法的工作流程
-1. 在 AI 图像生成工具(如 [[Midjourney]] 或 [[Nano Banana]])中设计 3×3 网格布局
-2. 一次性输入提示词,同时生成九张连贯的分镜画面
-3. 使用工具(如 [[Google AI Studio]])自动将九宫格图裁剪为九张独立的竖屏图(9:16 比例)
-4. 将九张独立图片配对,通过 [[首尾针动画]] 技术生成连贯视频片段
-
-## 核心优势
-- **机位固定**:同一张图内,机位和角度天然一致
-- **光影连贯**:同一光源设置贯穿所有分镜
-- **构图统一**:景深、视角保持一致
-- **效率提升**:一次生成九个画面,减少重复调整
-
-## 在 AI 短视频制作流程中的位置
-在 [[固定镜头短视频制作的AI全流程解析]] 中,九宫格法是**第二步(一致性图像生成)**的关键技术:
-1. 拆分镜头 → [[Google AI Studio]]
-2. **一致性图像生成 → 九宫格法**
-3. 首尾针动画制作
-4. 快速剪辑
-5. 声音设计
+---
+title: "九宫格法"
+type: concept
+tags: [AI视频生成, 图像一致性, 分镜]
+last_updated: 2026-03-15
+---
+
+## Aliases
+- 九宫格图像生成
+- 3x3 Grid Method
+- 9-Grid Image Generation
+
+## Definition
+九宫格法是一种保证AI生成视频画面一致性的图像生成技术。通过一次性生成3x3共九个画面,确保摄像机机位、拍摄角度、空间关系和光影效果在所有画面中保持高度统一。
+
+## Mechanism
+1. 将整个视频内容分解为九个连贯阶段
+2. 在同一prompt中使用九宫格布局一次性生成9张图
+3. 通过Google AI Studio工具自动检测并裁剪为9张竖屏图(9:16比例)
+4. 各阶段图像保持机位和角度不变,仅细节表现施工进度变化
+
+## Advantages
+- 保证画面空间和光影连贯性
+- 避免逐帧独立生成导致的光影错乱
+- 增强视频整体视觉一致性
+- 适合固定机位类视频制作
+
+## Related Concepts
+- [[首尾针动画]]:基于生成的图像制作动态动画
+- [[固定机位]]:九宫格法的最佳应用场景
+- [[时间压缩]]:九宫格法用于表现时间流逝的手法
+
+## Source
+- [[固定镜头短视频制作的ai全流程解析]]
diff --git a/wiki/concepts/提示词工程.md b/wiki/concepts/提示词工程.md
index 9e12ba11..97adb3a9 100644
--- a/wiki/concepts/提示词工程.md
+++ b/wiki/concepts/提示词工程.md
@@ -2,7 +2,8 @@
title: "提示词工程"
type: concept
tags: [AI, 提示词, Prompt Engineering]
-last_updated: 2025-12-18
+sources: [清华出的deepseek使用手册-104页-真的是太厉害了-免费领取, nano-banana-pro-prompting-guide-strategies-1]
+last_updated: 2026-04-28
---
## 基本定义
@@ -13,9 +14,11 @@ last_updated: 2025-12-18
- 需要理解AI的工作机制,才能写出高效的提示词
- 清华大学《DeepSeek从入门到精通2025》手册系统讲解了提示词设计方法
- 核心教学理念:**"授人以渔"** —— 不只告诉你怎么问,还告诉你为什么这么问
+- Nano-Banana Pro 的方法论:**"像创意总监一样思考"** —— 停止标签堆砌,使用自然语言和完整句子,80% 正确时通过编辑而非重生成
## 相关来源
- [[清华出的deepseek使用手册-104页-真的是太厉害了-免费领取]]
+- [[Nano-Banana Pro Prompting Guide & Strategies 1]]:强调"思维模式"(Thinking Mode)和自然语言提示,适用于图像生成领域
## 相关概念
- [[AI幻觉]]:与提示词工程密切相关,通过好的提示词设计可以有效减少AI幻觉
diff --git a/wiki/concepts/首尾针动画.md b/wiki/concepts/首尾针动画.md
index 451b77cf..000c483e 100644
--- a/wiki/concepts/首尾针动画.md
+++ b/wiki/concepts/首尾针动画.md
@@ -1,35 +1,40 @@
----
-title: "首尾针动画"
-type: concept
-tags: ["AI视频生成", "动画技术", "短视频制作"]
-sources: ["固定镜头短视频制作的ai全流程解析"]
-last_updated: 2026-04-23
----
-
-## 定义
-首尾针动画(Keyframe Animation)是一种 AI 视频生成技术,通过上传两个关键帧图片——首针图(Start Frame)和尾针图(End Frame)——让 AI 自动补齐两个阶段之间的中间画面,从而产生连贯流畅的动画效果。
-
-## 技术原理
-1. **上传首尾两张关键图**:首针图定义起点状态,尾针图定义终点状态
-2. **AI 分析两张图之间的变化**:识别主体、背景、光影等元素的差异
-3. **自动生成中间过渡帧**:AI 在两张图之间插值计算,生成平滑过渡的连续画面
-4. **输出连贯视频片段**:最终生成从首针到尾针的完整动画视频
-
-## 在 AI 短视频制作流程中的作用
-在 [[固定镜头短视频制作的AI全流程解析]] 描述的五步公式中,**首尾针动画制作**是第三步:
-1. 拆分镜头([[Google AI Studio]])
-2. 一致性图像生成([[九宫格法]],[[Midjourney]]/[[Nano Banana]])
-3. **首尾针动画制作**(海螺AI/KAI/[[KAI]])
-4. 快速剪辑([[剪映]])
-5. 声音设计
-
-## 核心优势
-- **平滑过渡**:AI 自动补齐中间变化,避免手动逐帧制作的繁琐
-- **时间压缩**:将漫长的过程(如装修数月)浓缩为几秒的流畅动画
-- **自然感强**:过渡效果由 AI 智能计算,比硬切更平滑自然
-
-## 支持工具
-- [[海螺AI]](MiniMax)
-- [[KAI]]
-- 即梦AI(字节跳动)
-- 可灵AI(快手)
+---
+title: "首尾针动画"
+type: concept
+tags: [AI视频生成, 动画制作, 关键帧]
+last_updated: 2026-03-15
+---
+
+## Aliases
+- 首尾帧动画
+- First-Last Frame Animation
+- Keyframe Animation
+- Frame Interpolation
+
+## Definition
+首尾针动画是一种AI视频生成技术,通过上传两个关键帧图片("首针"和"尾针"),让AI自动补齐两个阶段之间的变化,从而产生平滑的过渡动画效果。
+
+## Mechanism
+1. 逐个上传九张分镜图像配对制作动画
+2. 每对图像包含"首针图"(起始状态)和"尾针图"(结束状态)
+3. AI分析两张图像的差异,自动生成中间过渡帧
+4. 达成画面平滑过渡效果,无需镜头移动
+
+## Technical Requirements
+- 需要支持"首尾针"动画模式的AI工具
+- 推荐工具:海螺AI、多么AI、KAI
+- 图片需保持良好的一致性(建议使用九宫格法生成)
+
+## Advantages
+- 提供平滑的过渡效果
+- 硬切反而更简洁干净
+- 无需复杂转场效果
+- 适合固定机位、内容连续变化的视频
+
+## Related Concepts
+- [[九宫格法]]:生成一致性图像,为首尾针动画提供素材
+- [[快节奏剪辑]]:首尾针动画与硬切结合使用
+- [[固定机位]]:首尾针动画的最佳应用场景
+
+## Source
+- [[固定镜头短视频制作的ai全流程解析]]
diff --git a/wiki/entities/Alex-Ewerlof.md b/wiki/entities/Alex-Ewerlof.md
index b6aa409b..72437b93 100644
--- a/wiki/entities/Alex-Ewerlof.md
+++ b/wiki/entities/Alex-Ewerlof.md
@@ -1,28 +1,29 @@
----
-title: "Alex Ewerlöf"
-type: entity
-tags: []
-sources: []
-last_updated: 2026-04-25
----
-
-# Alex Ewerlöf
-
-## 基本信息
-- **角色**:资深Staff Engineer(27年经验),KTH(瑞典皇家理工学院)系统工程硕士
-- **专注领域**:Reliability Engineering(可靠性工程)+ Resilient Architecture(弹性架构)
-- **LLM专攻时间**:2023年起
-- **个人网站**:alexewerlof.com
-
-## 核心观点
-- 反对拟人化LLM,主张将LLM视为分布式系统中不可靠的组件
-- 强调架构约束(而非提示词约束)是提升AI系统可靠性的关键
-- 借鉴人类协作系统(军队、公司、国家)的反馈回路与制衡机制设计多智能体系统
-
-## 主要著作
-- [[multi-agent-system-reliability]]:《Multi-Agent System Reliability》,2023-01-09
-- SRE系列博客
-
-## Aliases
-- Alex Ewerlof
-- A. Ewerlöf
+---
+title: "Alex Ewerlöf"
+type: entity
+tags: []
+sources:
+ - multi-agent-system-reliability
+last_updated: 2026-04-28
+---
+
+# Alex Ewerlöf
+
+## 基本信息
+- **角色**:资深Staff Engineer(27年经验),KTH(瑞典皇家理工学院)系统工程硕士
+- **专注领域**:Reliability Engineering(可靠性工程)+ Resilient Architecture(弹性架构)
+- **LLM专攻时间**:2023年起
+- **个人网站**:alexewerlof.com
+
+## 核心观点
+- 反对拟人化LLM,主张将LLM视为分布式系统中不可靠的组件
+- 强调架构约束(而非提示词约束)是提升AI系统可靠性的关键
+- 借鉴人类协作系统(军队、公司、国家)的反馈回路与制衡机制设计多智能体系统
+
+## 主要著作
+- [[multi-agent-system-reliability]]:《Multi-Agent System Reliability》,2023-01-09
+- SRE系列博客
+
+## Aliases
+- Alex Ewerlof
+- A. Ewerlöf
diff --git a/wiki/entities/Brightdata.md b/wiki/entities/Brightdata.md
new file mode 100644
index 00000000..d39ad89a
--- /dev/null
+++ b/wiki/entities/Brightdata.md
@@ -0,0 +1,24 @@
+---
+title: "Brightdata"
+type: entity
+tags: [web-scraper, paid, service]
+sources: [我的工具集]
+last_updated: 2026-05-11
+---
+
+## Overview
+Brightdata 是一个付费的网页数据抓取平台,提供企业级的 Web Scraper 服务。
+
+## Aliases
+- Brightdata
+- brightdata.com
+
+## Role in Sources
+在 [[我的工具集]] 中作为 Web-Scraper(网页抓取)服务的提供商。
+
+## Capabilities
+- Web-Scraper:网页数据抓取工具
+- 企业级数据采集解决方案
+
+## Pricing
+付费服务
diff --git a/wiki/entities/Decopy.md b/wiki/entities/Decopy.md
new file mode 100644
index 00000000..f0701c14
--- /dev/null
+++ b/wiki/entities/Decopy.md
@@ -0,0 +1,27 @@
+---
+title: "Decopy"
+type: entity
+tags: [ai-summary, service, youtube, video]
+sources: [我的工具集]
+last_updated: 2026-05-11
+---
+
+## Overview
+Decopy 是一个 AI 摘要生成工具,支持对文章、PDF 和视频进行快速摘要。
+
+## Aliases
+- Decopy
+- decopy.ai
+
+## Role in Sources
+在 [[我的工具集]] 中作为 AI-Summary 服务的提供商,支持多摘要模式、思维导图和多语言输出。
+
+## Capabilities
+- AI Summary Generator:AI 摘要生成
+- 支持文章、PDF 和视频摘要
+- 多种摘要模式
+- 思维导图生成
+- 多语言输出
+
+## Pricing
+免费/免费增值模式
diff --git a/wiki/entities/DeepSeek.md b/wiki/entities/DeepSeek.md
index 35d6169f..10b6f3f6 100644
--- a/wiki/entities/DeepSeek.md
+++ b/wiki/entities/DeepSeek.md
@@ -2,7 +2,7 @@
title: "DeepSeek"
type: entity
tags: [AI, LLM, 中国科技]
-last_updated: 2025-12-18
+last_updated: 2026-01-01
---
## 基本信息
diff --git a/wiki/entities/Google AI Studio.md b/wiki/entities/Google AI Studio.md
new file mode 100644
index 00000000..4d9e600c
--- /dev/null
+++ b/wiki/entities/Google AI Studio.md
@@ -0,0 +1,28 @@
+---
+title: "Google AI Studio"
+type: entity
+tags: [AI工具, 分镜生成, 视频分析]
+last_updated: 2026-03-15
+---
+
+## Aliases
+- AI Studio
+- Google AI Studio
+
+## Description
+Google AI Studio 是Google提供的AI开发平台,在AI短视频制作流程中用于分析视频链接并自动生成九宫格分镜描述。
+
+## Use Cases in Video Production
+1. **视频分析**:输入装修视频链接,让模型分析视频逻辑
+2. **分镜生成**:自动生成九个分镜描述,确保:
+ - 摄像机机位固定
+ - 场景顺序清晰
+ - 阶段明确
+3. **图像裁剪**:自动检测三乘三大图并裁剪为九张竖屏图
+
+## Related Tools
+- [[九宫格法]]:基于Google AI Studio生成的分析结果进行图像生成
+- [[分镜拆解]]:Google AI Studio在此流程中负责将视频逻辑转化为分镜语言
+
+## Source
+- [[固定镜头短视频制作的ai全流程解析]]
diff --git a/wiki/entities/Google-AI-Studio.md b/wiki/entities/Google-AI-Studio.md
new file mode 100644
index 00000000..96729ccc
--- /dev/null
+++ b/wiki/entities/Google-AI-Studio.md
@@ -0,0 +1,27 @@
+---
+title: "Google AI Studio"
+type: entity
+tags: [google, text-to-speech, ai, service]
+sources: [我的工具集, nano-banana-pro-prompting-guide-strategies-1]
+last_updated: 2026-04-28
+---
+
+## Overview
+Google AI Studio 是 Google 提供的在线 AI 开发平台,整合了 Gemini 模型的各种能力。
+
+## Aliases
+- Google AI Studio
+- aistudio.google.com
+
+## Role in Sources
+在 [[我的工具集]] 中作为 Text-to-Speech(文本转语音)服务的提供者,支持 Dialog 对话功能。
+在 [[Nano-Banana Pro Prompting Guide & Strategies 1]] 中作为 Nano-Banana Pro 图像生成模型的主要使用界面,支持提示词测试和参数调整。
+
+## Capabilities
+- Text-to-Speech:文本转语音生成
+- Dialog:对话式 AI 交互
+- Gemini 模型支持
+- **Nano-Banana Pro 图像生成**:支持文本渲染、信息图、角色一致性、4K 高分辨率、思维推理等高级图像生成能力
+
+## Pricing
+免费服务
diff --git a/wiki/entities/Hailuo-AI.md b/wiki/entities/Hailuo-AI.md
new file mode 100644
index 00000000..89f14252
--- /dev/null
+++ b/wiki/entities/Hailuo-AI.md
@@ -0,0 +1,29 @@
+---
+title: "Hailuo AI"
+type: entity
+tags: [image-to-video, text-to-video, ai, service, paid]
+sources: [我的工具集, 14个免费的ai图生视频工具]
+last_updated: 2026-05-11
+---
+
+## Overview
+Hailuo AI(海螺 AI)是国内的 AI 视频生成工具,提供图生视频和文生视频功能。
+
+## Aliases
+- Hailuo AI
+- 海螺 AI
+- hailuoai.com
+
+## Role in Sources
+在 [[我的工具集]] 中作为 Image-to-Video 服务的提供商,月费 ¥42。
+
+## Capabilities
+- Image-to-Video:将静态图片转化为动态视频
+- Text-to-Video:文本生成视频
+
+## Pricing
+¥42/月
+
+## Relationship to Other Tools
+- 与 [[Vidu]] 同为国内视频生成平台
+- 与 [[Wavespeed AI]] 同属 Image-to-Video 工具
diff --git a/wiki/entities/KAI.md b/wiki/entities/KAI.md
index 63f87916..4949b78a 100644
--- a/wiki/entities/KAI.md
+++ b/wiki/entities/KAI.md
@@ -1,20 +1,37 @@
----
-title: "KAI"
-type: entity
-tags: ["AI视频生成", "首尾针动画", "AI工具"]
-sources: ["固定镜头短视频制作的ai全流程解析"]
-last_updated: 2026-04-23
----
-
-## 基本信息
-- **类型**:AI 视频生成工具(动效类)
-- **定位**:支持首尾针动画的视频生成平台
-- **应用场景**:将 [[九宫格法]] 生成的连续图像转换为动态视频片段
-
-## 在固定镜头短视频制作流程中的作用
-在 [[固定镜头短视频制作的AI全流程解析]] 描述的 AI 短视频制作流程中,KAI 属于**动效类**工具,负责将配对的 [[首尾针动画]] 图片转换为连贯的短视频片段。通过 AI Video API 依次生成各阶段视频片段,核心是让画面变化自然而非镜头移动。生成的所有片段最后导入 [[剪映]] 合成。
-
-## 核心能力
-- [[首尾针动画]] 技术支持:上传首针图和尾针图,自动补齐中间变化
-- 短视频片段逐个生成,确保质量可控
-- 生成片段可导入 [[剪映]] 进行最终合成
+---
+title: "KAI"
+type: entity
+tags: [AI工具, 视频生成, 动画制作]
+last_updated: 2026-03-15
+---
+
+## Aliases
+- KAI Video
+- KAI AI Video
+
+## Description
+KAI是一款AI视频生成工具,通过AI Video API依次生成视频片段,核心功能是让画面变化自然而非镜头移动。支持首尾针动画模式。
+
+## Use Cases
+1. **首尾针动画生成**:上传首针和尾针图片,自动生成过渡动画
+2. **阶段视频片段制作**:通过AI Video API依次生成各个阶段的视频片段
+3. **固定机位视频**:特别适合生成摄像机位置固定的视频内容
+
+## Workflow Position
+1. 拆分镜头(Google AI Studio)
+2. 一致性图像生成(Midjourney/Nano Banana)
+3. **首尾针动画制作(KAI)** ← 当前阶段
+4. 快速剪辑(剪映)
+5. 声音设计
+
+## Related Concepts
+- [[首尾针动画]]:KAI支持的核心动画技术
+- [[海螺AI]]:同类视频生成工具
+- [[多么AI]]:同类视频生成工具
+
+## Related Tools
+- [[剪映]]:用于KAI生成片段的最终合成剪辑
+- [[Google AI Studio]]:前置分镜分析工具
+
+## Source
+- [[固定镜头短视频制作的ai全流程解析]]
diff --git a/wiki/entities/LangChain.md b/wiki/entities/LangChain.md
index 15de9eda..5ece61b0 100644
--- a/wiki/entities/LangChain.md
+++ b/wiki/entities/LangChain.md
@@ -1,39 +1,48 @@
----
-title: "LangChain"
-type: entity
-tags: [llm, framework, python, rag, ai]
-last_updated: 2025-01-16
----
-
-## Definition
-LangChain 是一个用于构建 LLM 应用的 Python/JavaScript 框架,提供模块化组件抽象(Document Loader、Text Splitter、Embedding、Vector Store、Retriever、Chain、PromptTemplate 等),大幅简化 RAG、Agent 等 LLM 应用的开发。
-
-## Type
-- **Category**: AI Framework / 开发框架
-- **Website**: python.langchain.com
-- **Language**: Python, JavaScript/TypeScript
-
-## Core Components
-1. **Document Loader**:从 160+ 不同来源(网页/PDF/Notion/Slack 等)加载文档
-2. **Text Splitter**:将长文档切分为满足 Embedding Context Window 的小片段(Split)
-3. **Embedding**:集成多种 Embedding Provider(BAAI/BGE、OpenAI、Cohere 等)
-4. **Vector Store**:集成多种向量数据库(Qdrant、Pinecone、Chroma、FAISS 等)
-5. **Retriever**:基于向量相似度的文档检索接口
-6. **Chain**:将多个步骤串联执行的抽象,最关键的是 RAG Chain(RetrievalQA Chain)
-7. **PromptTemplate**:将变量、上下文、用户问题组装为 LLM 输入 Prompt 的模板引擎
-8. **Memory**:为 Agent 提供对话历史记忆能力
-
-## Key Value
-- **降低 RAG 开发门槛**:将 Indexing-Retrieval-Generation 三阶段封装为可复用的组件,开发者无需从零实现向量化和相似度检索
-- **Chain 抽象**:通过 LCEL(LangChain Expression Language)声明式组合各组件,支持 RAG Chain、Conversation Chain 等开箱即用模式
-- **工具生态**:与 LangSmith(监控)、LangServe(部署)构成完整应用生命周期支持
-
-## In RAG Context
-- [[rag从入门到精通系列1-基础rag]] 中作为核心工具链组件,负责 Indexing 阶段的文档加载/切分/向量化入库,以及 Retrieval + Generation 阶段的 Chain 编排
-
-## Related Concepts
-- [[RAG]] — LangChain 的核心应用场景
-- [[Indexing]] — LangChain 封装的关键阶段
-- [[Retrieval]] — LangChain 的 Retriever 组件
-- [[Generation]] — LangChain 的 Chain + PromptTemplate 组件
-- [[LlamaIndex]] — 同类竞品框架,各有侧重
+---
+title: "LangChain"
+type: entity
+tags: [LLM应用, RAG框架, Python]
+sources: [rag从入门到精通系列1-基础rag]
+last_updated: 2025-01-16
+---
+
+## Definition
+
+LangChain 是一个用于构建 LLM 应用的 Python/JavaScript 开源框架,提供文档加载、向量存储集成、Chain 组合、Agent 开发等能力。
+
+## Key Capabilities
+
+- **Document Loaders**:160+ 文档加载器,支持网页/ PDF / Markdown / 数据库等多种来源
+- **Vector Stores**:与 Qdrant、Chroma、Milvus、Pinecone 等向量数据库的原生集成
+- **Chains**:将多个步骤(检索→组装→生成)串联为统一管道
+- **Agents**:构建可自主调用工具的 LLM Agent
+- **Memory**:跨对话的上下文记忆管理
+- **Prompt Templates**:结构化 Prompt 管理
+
+## Usage in RAG
+
+本文档使用 LangChain 演示基础 RAG 管道:
+1. 通过 `WebBaseLoader` 加载外部博客文档
+2. 通过 `RecursiveCharacterTextSplitter` 切分文档
+3. 通过 `Qdrant` 向量存储集成建立索引
+4. 通过 `RetrievalQA Chain` 串联检索和生成
+
+## LangSmith
+
+LangSmith 是 LangChain 官方提供的 LLM 应用监控和调试平台,支持:
+- 追踪 LLM 应用执行链路
+- 查看每个步骤的输入输出
+- 评估应用效果和 Token 消耗
+
+## Connections
+
+- [[LangChain]] ← used_in ← [[RAG]]
+- [[LangChain]] ← integrates_with ← [[Vector-Store]]
+- [[LangChain]] ← integrates_with ← [[Embedding]]
+- [[LangChain]] ← provides ← [[Generation]]
+- [[LangChain]] ← monitors_with ← [[LangSmith]]
+
+## Aliases
+
+- LangChain Python
+- LangChain JS
diff --git a/wiki/entities/Qdrant.md b/wiki/entities/Qdrant.md
index f7a27fea..5dec806b 100644
--- a/wiki/entities/Qdrant.md
+++ b/wiki/entities/Qdrant.md
@@ -1,31 +1,43 @@
----
-title: "Qdrant"
-type: entity
-tags: [vector-database, rag, rust, open-source]
-last_updated: 2025-01-16
----
-
-## Definition
-Qdrant 是用 Rust 编写的开源向量数据库(Vector Store),提供高效的 Embedding Vector 存储和相似度检索能力,支持余弦相似度、欧氏距离等多种度量方式,以及过滤(Filtering)和分组(Grouping)等高级查询功能。
-
-## Type
-- **Category**: 向量数据库 / Vector Database
-- **Language**: Rust
-- **Website**: qdrant.tech
-- **License**: Apache 2.0
-
-## Core Capabilities
-1. **向量存储**:高维向量(Embedding)的持久化存储
-2. **相似度检索**:余弦相似度、点积、欧氏距离等多种度量方式
-3. **Top-k 检索**:根据相似度排序返回最接近的 k 个向量
-4. **过滤查询**:支持基于 Payload(元数据)的预过滤,精确定位检索范围
-5. **分布式部署**:支持集群模式横向扩展
-
-## In RAG Context
-- [[rag从入门到精通系列1-基础rag]] 中作为 Indexing 阶段向量存储后端 + Retrieval 阶段检索引擎
-- 与 LangChain 的 Vector Store 接口无缝集成
-
-## Related Concepts
-- [[Vector Store]] — Qdrant 属于 Vector Store 的一种实现
-- [[RAG]] — Qdrant 是 RAG Pipeline 的基础设施组件
-- [[Retrieval]] — Qdrant 提供向量相似度检索能力
+---
+title: "Qdrant"
+type: entity
+tags: [向量数据库, 开源, Rust]
+sources: [rag从入门到精通系列1-基础rag]
+last_updated: 2025-01-16
+---
+
+## Definition
+
+Qdrant 是一个由 Rust 编写的开源向量数据库和向量搜索引擎,专注于高性能向量存储与相似度检索,支持生产级部署。
+
+## Key Features
+
+- **高性能**:Rust 编写,内存安全,支持 HNSW 和 SCAN 等索引算法
+- **过滤支持**:支持在向量检索时附加标量字段过滤条件
+- **混合检索**:支持结合向量相似度与传统关键词匹配
+- **部署灵活**:支持 Docker 部署和云原生部署
+- **API 友好**:提供 RESTful API 和 gRPC 接口
+
+## Usage in RAG
+
+本文档使用 Qdrant 作为向量数据库存储 Embedding Vector:
+1. 配置 Qdrant 客户端连接
+2. 创建 Collection 存储文档向量
+3. 通过 LangChain 的 `Qdrant` 集成进行 Indexing 和 Retrieval
+
+## Alternatives
+
+- Chroma(轻量本地)
+- Milvus(分布式生产级)
+- Weaviate(混合检索)
+- Pinecone(云托管)
+
+## Connections
+
+- [[Qdrant]] ← used_in ← [[RAG]]
+- [[Qdrant]] ← stores ← [[Vector-Store]]
+- [[Qdrant]] ← integrated_by ← [[LangChain]]
+
+## Aliases
+
+- Qdrant Vector Database
diff --git a/wiki/entities/Vidu.md b/wiki/entities/Vidu.md
new file mode 100644
index 00000000..2b6cd48d
--- /dev/null
+++ b/wiki/entities/Vidu.md
@@ -0,0 +1,28 @@
+---
+title: "Vidu"
+type: entity
+tags: [image-to-video, text-to-video, ai, service, paid]
+sources: [我的工具集, 14个免费的ai图生视频工具]
+last_updated: 2026-05-11
+---
+
+## Overview
+Vidu 是国内的 AI 视频生成平台,提供图生视频和文生视频功能。
+
+## Aliases
+- Vidu
+- vidu.com
+
+## Role in Sources
+在 [[我的工具集]] 中作为 Image-to-Video 服务的提供商,月费 ¥8。
+
+## Capabilities
+- Image-to-Video:将静态图片转化为动态视频
+- Text-to-Video:文本生成视频
+
+## Pricing
+¥8/月
+
+## Relationship to Other Tools
+- 与 [[Wavespeed AI]] 同属 Image-to-Video 工具
+- 与 [[Hailuo AI]] 同为国内视频生成平台
diff --git a/wiki/entities/Wavespeed-AI.md b/wiki/entities/Wavespeed-AI.md
new file mode 100644
index 00000000..6dd8132c
--- /dev/null
+++ b/wiki/entities/Wavespeed-AI.md
@@ -0,0 +1,26 @@
+---
+title: "Wavespeed AI"
+type: entity
+tags: [image-editor, image-to-video, ai, service, paid]
+sources: [我的工具集]
+last_updated: 2026-05-11
+---
+
+## Overview
+Wavespeed AI 是一个提供图像编辑和图生视频功能的 AI 平台。
+
+## Aliases
+- Wavespeed AI
+- wavespeed.ai
+
+## Role in Sources
+在 [[我的工具集]] 中提供:
+- **Image-Editor**:图像编辑工具
+- **Image-to-Video**:图生视频功能(付费服务)
+
+## Capabilities
+- Image-Editor:图像编辑
+- Image-to-Video:将静态图片转化为动态视频
+
+## Pricing
+Image-to-Video 功能为付费服务
diff --git a/wiki/entities/n8n.md b/wiki/entities/n8n.md
new file mode 100644
index 00000000..b7fcc0b6
--- /dev/null
+++ b/wiki/entities/n8n.md
@@ -0,0 +1,36 @@
+---
+title: "n8n"
+type: entity
+tags: [工作流自动化, 开源, AI自动化, Node-Based-Workflow]
+last_updated: 2026-05-01
+---
+
+## Definition
+**n8n** 是 GitHub 上最强的开源工作流自动化平台,被称为"功能更强、还能私有部署的开源版 Zapier",目前拥有恐怖的 16 万 Star。
+
+## Aliases
+- n8n.io
+- N8N
+
+## Key Characteristics
+- 拖拽节点串联各种互不相干的 App,自动执行工作流,省去写代码对接 API 的麻烦
+- 最近在 AI 圈爆火,因为把 LangChain 等 AI 能力也做成了节点,让用户能轻松把大模型嵌入真实业务流程
+- 支持私有部署,数据完全掌握在自己手里
+- 开源免费,适合注重数据隐私的企业和个人
+
+## GitHub
+- https://github.com/n8n-io/n8n
+
+## Sources
+- [[2025-年-11-个神级-ai-开源平替-github-杀疯了]]
+- [[n8n-workflow-orchestration]]
+- [[n8n-docker-install-update]]
+- [[n8n-full-tutorial-building-ai-agents-in-2025-for-beginners]]
+- [[n8n-claude-通过自然语言自动化工作流]]
+- [[n8n-configure-telegram-trigger]]
+- [[n8n-docker-配置-telegram-代理-troubleshooting]]
+
+## Related
+- [[Dify]] — 同为工作流自动化平台,n8n 侧重通用流程自动化,Dify 侧重 LLM 应用开发
+- [[LangChain]] — n8n 支持 LangChain 节点集成
+- [[Zapier]] — n8n 的商业对标产品
diff --git a/wiki/entities/vLLM.md b/wiki/entities/vLLM.md
new file mode 100644
index 00000000..b1793e2f
--- /dev/null
+++ b/wiki/entities/vLLM.md
@@ -0,0 +1,30 @@
+---
+title: "vLLM"
+type: entity
+tags: [llm, inference, open-source, gpu]
+aliases: [vLLM, Virtual Large Language Model]
+last_updated: 2025-12-20
+---
+
+## Description
+vLLM 是由 vLLM 社区维护的开源项目,通过更好地利用 GPU 内存来加速大语言模型(LLM)的推理生成。
+
+## Key Capabilities
+- **PagedAttention**:将 KV Cache 切分为固定大小的块(block),用页表式映射管理,避免连续内存分配导致的碎片化和 OOM
+- **连续批处理(Continuous Batching)**:每步解码都动态组装活跃请求批次,基于 PagedAttention 的块式内存 + 步进级调度器,无需等待整批结束即可插入新请求
+- **KV Cache 优化**:保存历史 Key/Value 向量避免重复计算,通过分块管理实现动态并发与复用
+- **预填充(Prefill)加速**:在多分支(如 beam search)和重复前缀场景下可复用相同前缀产生的 KV 块
+
+## Technical Details
+- **KV Cache**:K 和 V 由每个 token 向量化后通过线性变换得到的两类向量,用于注意力计算。KV Cache 随上下文长度、层数、头数、维度线性增长,是推理中最大的显存开销之一
+- **分块策略**:用 PagedAttention 将每条序列的 KV Cache 切分为固定大小的块,类似操作系统的虚拟内存灵活调度
+- **复用机制**:多分支和重复前缀场景下可复用相同前缀产生的 KV 块,减少预填充时间
+
+## Connections
+- [[Large Language Model]] ← 加速推理 ← [[vLLM]]
+- [[PagedAttention]] ← 核心机制 ← [[vLLM]]
+- [[KV Cache]] ← 优化对象 ← [[vLLM]]
+- [[Continuous Batching]] ← 核心机制 ← [[vLLM]]
+
+## Sources
+- [[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]
diff --git a/wiki/index.md b/wiki/index.md
index 4105b661..00d8ae52 100644
--- a/wiki/index.md
+++ b/wiki/index.md
@@ -4,6 +4,19 @@
- [Overview](overview.md) — living synthesis
## Sources
+- [2026-04-27] [Multi-Agent System Reliability](sources/multi-agent-system-reliability.md)
+- [2026-04-27] [全网最全!Nano Banana 2 使用指南(2025年12月更新)](sources/全网最全-nano-banana-2-使用指南-2025年12月更新-1.md)
+- [2026-04-27] [2025 年 11 个神级 AI 开源平替,GitHub 杀疯了。](sources/2025-年-11-个神级-ai-开源平替-github-杀疯了.md)
+- [2026-04-27] [AI 解决方案专家培训课程](sources/ai-解决方案专家培训课程.md)
+- [2026-04-27] [RAG从入门到精通系列1:基础RAG](sources/rag从入门到精通系列1-基础rag.md)
+- [2026-04-27] [固定镜头短视频制作的AI全流程解析](sources/固定镜头短视频制作的ai全流程解析.md)
+- [2026-04-27] [大模型相关术语和框架总结|LLM、MCP、Prompt、RAG、vLLM、Token、数据蒸馏](sources/大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏.md)
+- [2026-04-27] [Nano-Banana Pro Prompting Guide & Strategies 1](sources/nano-banana-pro-prompting-guide-strategies-1.md)
+- [2026-04-27] [我的AI工具集](sources/我的工具集.md)
+- [2026-04-27] [3.2 万人收藏的 Claude Skills,才是 AI 这条路上最值得研究的一套范式!](sources/3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式.md)
+- [2026-04-27] [如何写出完美的Prompt(提示词)?](sources/如何写出完美的prompt-提示词.md)
+- [2026-04-27] [codecrafters-io/build-your-own-x: Master programming by recreating your favorite technologies from scratch](sources/codecrafters-iobuild-your-own-x-master-programming-by-recreating-your-favorite-technologies-from-scratch.md)
+- [2026-04-27] [系统提示词构建原则](sources/系统提示词构建原则.md)
- [2026-04-27] [GitHub 上 5000 人收藏的 Vibe Coding 神级指南](sources/github-上-5000-人收藏的-vibe-coding-神级指南.md)
- [2026-04-27] [How to Get the RSS Feed For Any YouTube Channel | Chuck Carroll](sources/how-to-get-the-rss-feed-for-any-youtube-channel.md)
- [2026-04-27] [3.2 万人收藏的 Claude Skills,才是 AI 这条路上最值得研究的一套范式!](sources/3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式-1.md)
@@ -512,25 +525,12 @@
- [karpathy-最新分享-用-llm-搭建个人知识库-告别-rag-的低效循环](sources/karpathy-最新分享-用-llm-搭建个人知识库-告别-rag-的低效循环.md) — (expected: wiki/sources/karpathy-最新分享-用-llm-搭建个人知识库-告别-rag-的低效循环.md — source missing)
- [Expose-hermes-agent-as-an-OpenAI-compatible-API-for-any-frontend](sources/Expose-hermes-agent-as-an-OpenAI-compatible-API-for-any-frontend.md) — (expected: wiki/sources/Expose-hermes-agent-as-an-OpenAI-compatible-API-for-any-frontend.md — source missing)
- [I Went Through Every AI Memory Tool I Could Find. There Are Two Camps.](sources/ai-memory-tools-two-camps.md)
-- [系统提示词构建原则](sources/系统提示词构建原则.md)
-- [我的工具集](sources/我的工具集.md)
- [我用 Gemini 3 一口气做了 10 个应用,附教程](sources/我用-gemini-3-一口气做了-10-个应用-附教程.md)
- [如何让ai生成风格一致的图片](sources/如何让ai生成风格一致的图片.md) — (expected: wiki/sources/如何让ai生成风格一致的图片.md — source missing)
- [如何利用Sora接口实现视频自动化生成工作流](sources/如何利用sora接口实现视频自动化生成工作流.md)
-- [如何写出完美的Prompt(提示词)?](sources/如何写出完美的prompt-提示词.md)
-- [大模型相关术语和框架总结|LLM、MCP、Prompt、RAG、vLLM、Token、数据蒸馏](sources/大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏.md)
- [在 Ubuntu 安装 Ollama 并运行 Qwen2.5‑Coder 7B](sources/在-ubuntu-安装-ollama-并运行-qwen2-5‑coder-7b.md)
-- [固定镜头短视频制作的AI全流程解析](sources/固定镜头短视频制作的ai全流程解析.md)
-- [全网最全!Nano Banana 2 使用指南(2025年12月更新)](sources/全网最全-nano-banana-2-使用指南-2025年12月更新-1.md)
-- [codecrafters-io/build-your-own-x: Master programming by recreating your favorite technologies from scratch](sources/codecrafters-iobuild-your-own-x-master-programming-by-recreating-your-favorite-technologies-from-scratch.md)
-- [RAG从入门到精通系列1:基础RAG](sources/rag从入门到精通系列1-基础rag.md)
-- [Nano Banana Pro 提示词指南与策略(上篇)](sources/nano-banana-pro-prompting-guide-strategies-1.md)
-- [Multi-Agent System Reliability](sources/multi-agent-system-reliability.md)
- [Learn AI for free directly from top companies](sources/learn-ai-for-free-directly-from-top-companies.md)
- [If You Have Multiple Interests, Do Not Waste the Next 2-3 Years](sources/if-you-have-multiple-interests-do-not-waste-the-next-2-3-years-如果你有多项兴趣爱好-不要浪费接下来的两三年时间.md)
-- [AI 解决方案专家培训课程](sources/ai-解决方案专家培训课程.md)
-- [3.2 万人收藏的 Claude Skills,才是 AI 这条路上最值得研究的一套范式!](sources/3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式.md)
-- [2025 年 11 个神级 AI 开源平替,GitHub 杀疯了](sources/2025-年-11-个神级-ai-开源平替-github-杀疯了.md)
- [engineering-backend-architect](sources/engineering-backend-architect.md) — (expected: wiki/sources/engineering-backend-architect.md — source missing)
## Entities
@@ -592,6 +592,7 @@
- [Bottlerocket](entities/Bottlerocket.md)
- [bottom](entities/bottom.md)
- [Brendan-Starnig](entities/Brendan-Starnig.md)
+- [Brightdata](entities/Brightdata.md)
- [btop++](entities/btop++.md)
- [Caddy](entities/Caddy.md)
- [cAdvisor](entities/cAdvisor.md)
@@ -627,6 +628,7 @@
- [DanielStefanovic](entities/DanielStefanovic.md)
- [DataviewPlugin](entities/DataviewPlugin.md)
- [DaVinci-Resolve](entities/DaVinci-Resolve.md)
+- [Decopy](entities/Decopy.md)
- [DeepLearningAI](entities/DeepLearningAI.md)
- [DeepSeek](entities/DeepSeek.md)
- [DeepSider](entities/DeepSider.md)
@@ -665,6 +667,8 @@
- [gog](entities/gog.md)
- [gog-CLI](entities/gog-CLI.md)
- [Google](entities/Google.md)
+- [Google AI Studio](entities/Google AI Studio.md)
+- [Google-AI-Studio](entities/Google-AI-Studio.md)
- [Google-Cloud](entities/Google-Cloud.md)
- [Google-Sheets-API](entities/Google-Sheets-API.md)
- [GoogleAds](entities/GoogleAds.md)
@@ -673,6 +677,7 @@
- [Grafana](entities/Grafana.md)
- [Growth-Hacker](entities/Growth-Hacker.md)
- [Gruntwork](entities/Gruntwork.md)
+- [Hailuo-AI](entities/Hailuo-AI.md)
- [HashiCorp](entities/HashiCorp.md)
- [Heather-Norris](entities/Heather-Norris.md)
- [hello-world](entities/hello-world.md)
@@ -735,6 +740,7 @@
- [MinIO](entities/MinIO.md)
- [mission-center](entities/mission-center.md)
- [mnemox-ai](entities/mnemox-ai.md)
+- [n8n](entities/n8n.md)
- [n8n-mcp](entities/n8n-mcp.md)
- [Nano Banana 2](entities/Nano Banana 2.md)
- [Navidrome](entities/Navidrome.md)
@@ -849,8 +855,11 @@
- [Veeam](entities/Veeam.md)
- [Vibe-Kanban](entities/Vibe-Kanban.md)
- [VictoriaMetrics](entities/VictoriaMetrics.md)
+- [Vidu](entities/Vidu.md)
- [Vinay](entities/Vinay.md)
+- [vLLM](entities/vLLM.md)
- [VMware](entities/VMware.md)
+- [Wavespeed-AI](entities/Wavespeed-AI.md)
- [WeChat](entities/WeChat.md)
- [WeCom](entities/WeCom.md)
- [Weibo](entities/Weibo.md)
@@ -912,6 +921,7 @@
- [AdStrength](concepts/AdStrength.md)
- [Advantage+-Campaigns](concepts/Advantage+-Campaigns.md)
- [Adversarial-Debate-Pattern](concepts/Adversarial-Debate-Pattern.md)
+- [Agent](concepts/Agent.md)
- [Agent-Build-Gate](concepts/Agent-Build-Gate.md)
- [Agent-Design-Principles](concepts/Agent-Design-Principles.md)
- [Agent-Driven-Market-Research](concepts/Agent-Driven-Market-Research.md)
@@ -938,6 +948,7 @@
- [Ai-Powered-Digest](concepts/Ai-Powered-Digest.md)
- [AIFinOps](concepts/AIFinOps.md)
- [AIOps](concepts/AIOps.md)
+- [AISummary](concepts/AISummary.md)
- [AI代理](concepts/AI代理.md)
- [AI图生视频](concepts/AI图生视频.md)
- [AI幻觉](concepts/AI幻觉.md)
@@ -1084,6 +1095,7 @@
- [Context-Substrate](concepts/Context-Substrate.md)
- [Context-Window](concepts/Context-Window.md)
- [ContextDrivenTask](concepts/ContextDrivenTask.md)
+- [Continuous-Batching](concepts/Continuous-Batching.md)
- [Continuous-Delivery](concepts/Continuous-Delivery.md)
- [Continuous-Deployment](concepts/Continuous-Deployment.md)
- [Continuous-Integration](concepts/Continuous-Integration.md)
@@ -1109,6 +1121,7 @@
- [Daily-Log](concepts/Daily-Log.md)
- [DarkLaunching](concepts/DarkLaunching.md)
- [DAST](concepts/DAST.md)
+- [Data-Distillation](concepts/Data-Distillation.md)
- [Data-Governance](concepts/Data-Governance.md)
- [Data-Sovereignty](concepts/Data-Sovereignty.md)
- [DBA-Role-Evolution](concepts/DBA-Role-Evolution.md)
@@ -1163,6 +1176,7 @@
- [EKS-Auto-Mode](concepts/EKS-Auto-Mode.md)
- [ELK-Stack](concepts/ELK-Stack.md)
- [Email-Triage](concepts/Email-Triage.md)
+- [Embedding](concepts/Embedding.md)
- [Emergency-Change](concepts/Emergency-Change.md)
- [Employee-Advocacy](concepts/Employee-Advocacy.md)
- [emptyDir-Volume](concepts/emptyDir-Volume.md)
@@ -1232,6 +1246,7 @@
- [Green-Computing](concepts/Green-Computing.md)
- [Growth-Loop](concepts/Growth-Loop.md)
- [GrowthFunnelOptimization](concepts/GrowthFunnelOptimization.md)
+- [Hallucination](concepts/Hallucination.md)
- [Hand-Tracking](concepts/Hand-Tracking.md)
- [Handoff-Contract](concepts/Handoff-Contract.md)
- [HCX](concepts/HCX.md)
@@ -1263,6 +1278,7 @@
- [Identity-Resolution](concepts/Identity-Resolution.md)
- [IDENTITY.md](concepts/IDENTITY.md.md)
- [Ikigai框架](concepts/Ikigai框架.md)
+- [ImageToVideo](concepts/ImageToVideo.md)
- [Immutable-Infrastructure](concepts/Immutable-Infrastructure.md)
- [Immutable-Root-Filesystem](concepts/Immutable-Root-Filesystem.md)
- [Incident-Management](concepts/Incident-Management.md)
@@ -1298,6 +1314,7 @@
- [Knowledge-Base-RAG](concepts/Knowledge-Base-RAG.md)
- [Kolb-体验式学习圈](concepts/Kolb-体验式学习圈.md)
- [Kubernetes](concepts/Kubernetes.md)
+- [KV-Cache](concepts/KV-Cache.md)
- [LagCompensation](concepts/LagCompensation.md)
- [Land-and-Expand](concepts/Land-and-Expand.md)
- [Landing-Zone-Architecture](concepts/Landing-Zone-Architecture.md)
@@ -1408,6 +1425,7 @@
- [Organic-Traffic-Amplification](concepts/Organic-Traffic-Amplification.md)
- [OWASP-Top-Ten](concepts/OWASP-Top-Ten.md)
- [Pacing-Architecture](concepts/Pacing-Architecture.md)
+- [PagedAttention](concepts/PagedAttention.md)
- [Pain-Point-Mining](concepts/Pain-Point-Mining.md)
- [Paper-Abstract-Batch-Fetching](concepts/Paper-Abstract-Batch-Fetching.md)
- [Parallel-Agent-Execution](concepts/Parallel-Agent-Execution.md)
@@ -1462,6 +1480,7 @@
- [Progressive-Rollout](concepts/Progressive-Rollout.md)
- [ProjectState](concepts/ProjectState.md)
- [Prometheus告警规则](concepts/Prometheus告警规则.md)
+- [Prompt](concepts/Prompt.md)
- [PromQL](concepts/PromQL.md)
- [Propp-Morphology](concepts/Propp-Morphology.md)
- [Proxy-Editing](concepts/Proxy-Editing.md)
@@ -1634,6 +1653,8 @@
- [Terraform-Modules](concepts/Terraform-Modules.md)
- [Test-Mode](concepts/Test-Mode.md)
- [Text-and-Search](concepts/Text-and-Search.md)
+- [TextToSpeech](concepts/TextToSpeech.md)
+- [TextToVideo](concepts/TextToVideo.md)
- [Thought-Leadership](concepts/Thought-Leadership.md)
- [Threat-Modeling](concepts/Threat-Modeling.md)
- [Three-Tier-Review-Mechanism](concepts/Three-Tier-Review-Mechanism.md)
@@ -1642,6 +1663,7 @@
- [Time-Boxing](concepts/Time-Boxing.md)
- [Time-to-Market](concepts/Time-to-Market.md)
- [Todoist-API](concepts/Todoist-API.md)
+- [Token](concepts/Token.md)
- [Token-Light-Design](concepts/Token-Light-Design.md)
- [Tool-Calling](concepts/Tool-Calling.md)
- [ToolIntegration](concepts/ToolIntegration.md)
@@ -1674,6 +1696,7 @@
- [Value-Stream-Mapping](concepts/Value-Stream-Mapping.md)
- [Variables-YAML](concepts/Variables-YAML.md)
- [Vector-Embedding](concepts/Vector-Embedding.md)
+- [Vector-Store](concepts/Vector-Store.md)
- [Vendor-Lock-In](concepts/Vendor-Lock-In.md)
- [VFX](concepts/VFX.md)
- [Vibe-Coding](concepts/Vibe-Coding.md)
@@ -1693,6 +1716,7 @@
- [Webhook](concepts/Webhook.md)
- [Webhook-Proxy-Pattern](concepts/Webhook-Proxy-Pattern.md)
- [WEBHOOK_URL](concepts/WEBHOOK_URL.md)
+- [WebScraper](concepts/WebScraper.md)
- [WebXR](concepts/WebXR.md)
- [Weekly-Pattern-Analysis](concepts/Weekly-Pattern-Analysis.md)
- [WeeklyPatternAnalysis](concepts/WeeklyPatternAnalysis.md)
diff --git a/wiki/log.md b/wiki/log.md
index c229e0f3..d1416c15 100644
--- a/wiki/log.md
+++ b/wiki/log.md
@@ -1,3 +1,91 @@
+## [2026-04-28] ingest | 全网最全!Nano Banana 2 使用指南(2025年12月更新)
+- Source file: AI/全网最全!Nano Banana 2 使用指南(2025年12月更新) 1.md
+- Status: ✅ 成功摄入(更新)
+- Summary: Nano Banana 2(Gemini 3 Pro Image)国内使用指南。核心内容:DeepSider 浏览器插件(Edge 扩展)让国内用户无需特殊网络即可访问 Nano Banana 2;Nano Banana 2 是推理型图像生成模型,生成前进行内部推理,支持 1K/2K/4K 输出和 14 张图像组合,擅长中文界面渲染、科研配图等高准确性图像创作
+- Concepts touched: [[推理型图像生成模型]](出现 1 次,未达创建阈值)、[[多语言长文本渲染]](出现 1 次,未达创建阈值)、[[图像推理模型]](出现 1 次,未达创建阈值)、[[图像组合融合]](出现 1 次,未达创建阈值)
+- Entities touched: [[Nano Banana 2]](Entity 已存在,无需更新)、[[DeepSider]](Entity 已存在,无需更新)、[[Gemini 3 Pro]](Entity 已有关联)、[[Google]](出现 1 次,未达创建阈值)
+- Source page: wiki/sources/全网最全-nano-banana-2-使用指南-2025年12月更新-1.md
+- Notes: 源文件于 2026-04-26 更新(晚于上次摄取 2026-04-23),重新执行摄取;source page 已更新 last_updated;index.md 日期已更新;overview.md 已有完整综合摘要(第 566 行),内容一致无需修订;冲突检测:无明显内容冲突,与 Nano Banana Pro 提示词指南/Nano Banana 提示词框架互补同属一系
+
+- Source file: AI/AI 解决方案专家培训课程.md
+- Status: ✅ 成功摄入
+- Summary: Coze(扣子)平台 AI Agent 开发实战培训课程,分国内版(coze.cn)和海外版(coze.com),涵盖金融、医疗、教育、电商、人力资源、泛娱乐、在线客服等 7 大行业共 50+ 可体验 Agent Demo,包括工作流、知识库、Function Call 等技术实现
+- Concepts touched: [[Coze平台]](已有 Entity,链接更新)、[[AutoGPT]](仅出现 1 次,未达创建阈值)、[[Function Call]](链接已有 Concept)、[[WorkFlow]](已有概念关联)、[[RAG]](已有 Concept)
+- Entities touched: [[Coze]](Entity 已存在,直接引用源文档)、[[FaceFusion]](仅出现 1 次,未达创建阈值)、[[F5-TTS]](仅出现 1 次,未达创建阈值)、[[World Labs]](仅出现 1 次,未达创建阈值)、[[BananaResearch]](仅出现 1 次,未达创建阈值)、[[滴滴]](Entity 已存在)
+- Source page: wiki/sources/ai-解决方案专家培训课程.md
+- Notes: source page 新建完成;index.md Sources 节已添加条目;overview.md 第 580 行已有详细综合摘要,内容一致无需修订;冲突检测:无明显内容冲突
+
+## [2026-04-28] ingest | RAG从入门到精通系列1:基础RAG
+- Source file: AI/RAG从入门到精通系列1:基础RAG.md
+- Status: ✅ 成功摄入
+- Summary: RAG 基础教程第一篇,系统讲解基础 RAG 的 Indexing(加载→切分→向量化入库)→ Retrieval(向量相似度检索 Top-k)→ Generation(问题+上下文→LLM 生成带事实依据答案)三阶段流程。实战工具链:Qwen(LLM)+ BAAI(BGE Embedding)+ LangChain(应用编排)+ Qdrant(向量数据库)
+- Concepts created: [[Indexing]](新建 Concept)、[[Retrieval]](新建 Concept)、[[Generation]](新建 Concept)、[[Vector-Store]](新建 Concept)
+- Entities created: [[LangChain]](新建 Entity)、[[Qdrant]](新建 Entity)
+- Source page: wiki/sources/rag从入门到精通系列1-基础rag.md
+- Notes: source page 新建完成;index.md Sources 节该条目已存在,无需重复添加;overview.md 第 511 行已有详细综合摘要,内容一致无需修订;冲突检测:与 [[Personal-Knowledge-Base-RAG]] 互补(前者侧重概念解析,后者侧重实战应用);与 [[大模型相关术语和框架总结]] 互补(后者将 RAG 列为术语,前者深入机制详解);与 [[llms-rag-ai-agent-三个到底什么区别]] 互补(后者将 RAG 定义为"随身图书馆助理",本文深入三阶段机制,相互印证)
+
+## [2026-03-15] ingest | 固定镜头短视频制作的AI全流程解析
+- Source file: AI/固定镜头短视频制作的AI全流程解析.md
+- Status: ✅ 成功摄入
+- Summary: 利用AI技术快速高效制作高播放量家装类短视频的全套流程——三大关键词:固定机位、内容连续变化、时间压缩;五步公式:拆分镜头 → 一致性图像生成(九宫格法)→ 首尾针动画制作 → 快速剪辑(2-4倍速+硬切)→ 声音设计;AI工具分类:大脑类(XAR GPT/GEMALA)、设计师类(Midjourney/Nano Banana)、动效类(海螺AI/KAI);全流程可在10分钟内完成
+- Concepts created: [[九宫格法]](新建 Concept)、[[首尾针动画]](新建 Concept)
+- Entities created: [[Google AI Studio]](新建 Entity)、[[KAI]](已存在,新建 Entity 页面)
+- Source page: wiki/sources/固定镜头短视频制作的ai全流程解析.md
+- Notes: source page 新建完成,index.md Sources 节已添加新条目(最前);index.md Concepts 节已添加 [[九宫格法]] [[首尾针动画]];index.md Entities 节已添加 [[Google AI Studio]];overview.md 已添加综合摘要(置于"知识与资源"区段顶部);冲突检测:与 [[我的工具集]] 的 Image-to-Video 工具互补——前者提供系统性方法论,后者提供具体工具选型,无冲突
+
+## [2026-04-28] ingest | 大模型相关术语和框架总结|LLM、MCP、Prompt、RAG、vLLM、Token、数据蒸馏
+- Source file: AI/大模型相关术语和框架总结|LLM、MCP、Prompt、RAG、vLLM、Token、数据蒸馏.md
+- Status: ✅ 成功摄入
+- Summary: 通俗解读大模型生态关键术语——LLM(≥1B参数)、MCP(连接外部工具的标准化协议)、Agent(LLM+MCP实现自动化执行)、RAG(通过外部检索消除幻觉,正确率60%→90%)、Embedding(词向量语义距离)、vLLM(PagedAttention+连续批处理优化GPU显存)、Token(英文≈0.3/字、中文≈0.6/字)、数据蒸馏(大模型生成精简数据训练小模型)
+- Concepts: [[Large Language Model]](已存在,新引用源)、[[Model-Context-Protocol]](已存在,新引用源)、[[Agent]](已存在,新引用源)、[[RAG]](已存在,新引用源)、[[Embedding]](已存在,新引用源)、[[Hallucination]](已存在,新引用源)、[[Token]](已存在,新引用源)、[[PagedAttention]](已存在,新引用源)、[[KV-Cache]](已存在,新引用源)、[[Continuous-Batching]](已存在,新引用源)、[[Prompt]](已存在,新引用源)、[[Data-Distillation]](已存在,新引用源)
+- Entities: [[vLLM]](新建 Entity 页面)
+- Source page: wiki/sources/大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏.md
+- Notes: source page 新建完成,index.md Sources 节已添加新条目(最前);index.md Entities 节新增 [[vLLM]];index.md Concepts 节新增 [[Agent]] [[Continuous-Batching]] [[Data-Distillation]] [[Embedding]] [[Hallucination]] [[KV-Cache]] [[PagedAttention]] [[Prompt]] [[Token]](其余均已存在并更新引用);overview.md 已添加综合摘要;冲突检测:与 [[llms-rag-ai-agent-三个到底什么区别]] 无冲突——后者从系统架构层面区分三者关系,本文档提供通俗定义与机制解释,二者互补
+
+## [2026-04-28] ingest | Nano-Banana Pro Prompting Guide & Strategies 1
+- Source file: raw/AI/Nano-Banana Pro Prompting Guide & Strategies 1.md
+- Status: ✅ 成功摄入
+- Summary: Google Nano-Banana Pro(Gemini)图像生成模型的提示词工程完整指南,涵盖 10 大模块:黄金法则(编辑优于重生成、自然语言)、文本渲染与信息图、角色一致性与病毒式缩略图、Google Search 实时数据可视化、高级编辑(In-painting/上色)、2D↔3D 维度翻译、4K 高分辨率输出、思维推理、故事板与概念艺术、结构控制与布局引导。核心方法论:像创意总监一样思考,停止标签堆砌,利用模型的"思维模式"理解意图、物理和构图。
+- Concepts created: [[提示词工程]](已存在,已引用本文为 Source)、[[身份锁定(Identity Locking)]](内嵌引用,未达独立建页阈值)、[[思维模式(Thinking Mode)]](内嵌引用,未达独立建页阈值)、[[语义编辑(Semantic Editing)]](内嵌引用,未达独立建页阈值)、[[维度翻译(Dimensional Translation)]](内嵌引用,未达独立建页阈值)
+- Source page: wiki/sources/nano-banana-pro-prompting-guide-strategies-1.md
+- Notes: source page 新建完成,index.md Sources 节第一条已添加;Google-AI-Studio.md Entity 页面已存在(Nano-Banana Pro 的使用接口),已引用本文为 Source;概念 [[提示词工程]].md 已存在,已引用本文为 Source;冲突检测:暂无与其他 Wiki 页面的冲突
+
+## [2026-07-15] ingest | 3.2 万人收藏的 Claude Skills,才是 AI 这条路上最值得研究的一套范式!
+- Source file: raw/AI/3.2 万人收藏的 Claude Skills 才是 AI 这条路上最值得研究的一套范式!.md
+- Status: ✅ 成功摄入
+- Summary: Anthropic 官方 Claude Skills 仓库(github.com/anthropics/skills,3.2万收藏)全面解析——Skills = 说明书 + SOP,将反复执行的任务拆解为 AI 能理解、能复用、能自动执行的流程。核心范式转变:从「提示词工程」到「流程工程」;Vibe Coding 的尽头也是 Skills;真正有价值的不是 Prompt 写得好的人,而是能将经验沉淀成 SOP 的人。涵盖三大类 Skills:办公自动化、开发者工具、创意类技能。
+- Concepts: [[Claude Skills]](已存在,已引用本文为 Source)、[[流程工程(Workflow Engineering)]](已存在,已引用本文为 Source)、[[Vibe Coding]](已存在,已引用本文为 Source)、[[SOP]](内嵌引用)
+- Entities: [[Anthropic]](已有 Entity 页,已更新 Claude Skills 章节)、[[Claude.ai]](内嵌引用,未达独立建页阈值)、[[ComposioHQ]](内嵌引用,未达独立建页阈值)、[[VoltAgent]](内嵌引用,未达独立建页阈值)、[[BehiSecc]](内嵌引用,未达独立建页阈值)
+- Source page: wiki/sources/3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式.md
+- Notes: source page 新建完成,index.md Sources 节已添加新条目(位于 -1 版本之前);overview.md 已有 Claude Skills 综合摘要,内容一致,无需更新;Entity/Concept 页面均已存在并已引用本文为 Source;冲突检测:与 [[github-上-5000-人收藏的-vibe-coding-神级指南]] 关于「结构化 SOP vs 直觉式引导」的张力已记录
+
+## [2026-04-28] ingest | 如何写出完美的Prompt(提示词)?
+- Source file: raw/AI/如何写出完美的Prompt(提示词)?.md
+- Status: ✅ 成功摄入
+- Summary: 系统阐述职场 Prompt 方法论的完整方法体系,涵盖基础技巧(需求拆解、上下文补全、格式定义、示例引导)、进阶策略(思维链、任务拆分、角色赋能、预填回复、不确定性管理)、高阶技巧(跨模态联动、领域知识注入、反馈循环嵌入)及四大业务场景(内容创作、数据分析、方案策划、客户服务)实战模板。核心论断:Prompt 能力本质是结构化思维+精准表达,是 AI 时代职场人的底层能力。
+- Concepts touched: [[Prompt工程]](Source 内建立 wikilink,concepts/ 目录为空,concepts/ 暂无独立页面)、[[结构化思维]](同上)、[[思维链提示]](同上)、[[少样本提示]](同上)、[[角色赋能法]](同上)、[[任务拆分法]](同上)、[[预填回复法]](同上)、[[不确定性管理]](同上)、[[迭代优化]](同上)
+- Entities touched: [[粒粒]](微信公众号作者,concepts/ 目录为空,entities/ 暂无独立页面,未达建页阈值)
+- Source page: wiki/sources/如何写出完美的prompt-提示词.md
+- Notes: Source page 新建完成,index.md Sources 节第一条已添加;overview.md 已有相关提示词/结构化内容,Source 页面通过 Connections 建立与 [[系统提示词构建原则]] 和 [[Vibe Coding]] 的关联,暂无需更新 overview;concepts/ 和 entities/ 目录为空(无独立页面),本文引用的所有 Concepts/Entities 均以内嵌 wikilink 形式保存在 Source 页面中;冲突检测:与 [[系统提示词构建原则]] 在"角色设定"维度存在视角差异(详见 Source 页 Contradictions 节)
+
+## [2026-06-15] ingest | codecrafters-io/build-your-own-x
+- Source file: raw/AI/codecrafters-iobuild-your-own-x Master programming by recreating your favorite technologies from scratch.md
+- Status: ✅ 成功摄入
+- Summary: 通过"从零重建技术"掌握编程的 GitHub 标杆仓库,含 25+ 技术领域分步指南(Database、Git、Docker、Operating System、Programming Language、Neural Network 等)。核心理念:Richard Feynman"我不能创造的东西,我就不理解"。方法论:Learn By Building。来源:codecrafters-io/build-your-own-x,由 Daniel Stefanovic 创始、CodeCrafters 维护。
+- Concepts touched: [[Learn By Building]](overview.md 已有章节,本次引用)、[[Build Your Own X]](overview.md 已有章节,本次引用)
+- Entities touched: [[CodeCrafters]](主维护方,未达独立建页阈值)、[[Daniel Stefanovic]](创始人,未达独立建页阈值)、[[Richard Feynman]](引言来源,未达独立建页阈值)
+- Source page: wiki/sources/codecrafters-iobuild-your-own-x-master-programming-by-recreating-your-favorite-technologies-from-scratch.md
+- Notes: source page 新建完成,index.md Sources 节第一条已添加;overview.md Build Your Own X 章节已更新引用本文为来源,并新增 Learn By Building 方法论说明;冲突检测:暂无冲突
+
+## [2026-06-12] ingest | 系统提示词构建原则
+- Source file: raw/AI/系统提示词构建原则.md
+- Status: ✅ 成功摄入
+- Summary: AI Coding Agent 的系统提示词设计框架,涵盖六大维度:核心身份与行为准则(遵守项目约定、优先技术准确性)、沟通与互动规范(专业简洁、减少冗余)、任务执行与工作流(TODO列表规划、分步验证)、技术编码规范(清晰可读、模块化)、安全与防护(最小权限、保护密钥)、工具使用原则(并行执行、专用工具优先)。源自 vibe-coding-cn 项目,为 Vibe Coding 提供操作层指南。
+- Concepts touched: [[Vibe Coding]](已存在,本文深化行为准则)、[[SEARCH/REPLACE]](内嵌引用,未达独立建页阈值)、[[最小权限原则]](已有页面内嵌引用)、[[TODO列表规划]](内嵌引用,未达独立建页阈值)
+- Entities touched: [[vibe-coding-cn]](已有 Entity 页 tukuai.md,已引用本文为 Source)
+- Source page: wiki/sources/系统提示词构建原则.md
+- Notes: source page 新建完成,index.md Sources 节第一条已添加;overview.md 已有引用(line 490 关联 Vibe Coding 中文指南,line 554 关联 Prompt 提示词体系),无需更新;Entity/Concept 页检查:tukuai/vibe-coding-cn 已有、Vibe Coding 已有,无需新建;冲突检测:暂无冲突
+
## [2026-06-12] ingest | How to Get the RSS Feed For Any YouTube Channel | Chuck Carroll
- Source file: raw/AI/How to Get the RSS Feed For Any YouTube Channel.md
- Status: ✅ 成功摄入
@@ -382,6 +470,15 @@
- Source page: wiki/sources/podcast-production-pipeline.md
- Notes: index.md 已更新带日期前缀和一行摘要;overview.md 第556行已有高度一致的播客制作自动化章节,无需重复更新;冲突检测:无——[[MultiAgentContentFactory]] 与本流水线为互补关系,非竞争关系;[[OpenAI Whisper]] 在 Related Links 中提及,source page 通过 Connections wikilink 建立关联。
+## [2026-05-01] ingest | 2025 年 11 个神级 AI 开源平替,GitHub 杀疯了。
+- Source file: AI/2025 年 11 个神级 AI 开源平替,GitHub 杀疯了。
+- Status: ✅ 成功摄入
+- Summary: 8大领域 AI 开源平替全景盘点——大语言模型(DeepSeek/Qwen 3)、AI生图(Flux/Stable Diffusion)、AI生视频(HunyuanVideo)、通用智能体(Manus/OpenManus)、AI编程(Cline)、工作流自动化(n8n/Dify)、AI搜索(Perplexica)、AI知识库(NotebookLM开源替代)。核心洞察:开源内卷把价格打成了白菜,国产模型(DeepSeek/Qwen/Hunyuan)已在多个领域超越Meta Llama;Manus定义AI Agent元年并被Meta收购。
+- Concepts touched: [[AI开源平替]](内嵌引用,未达独立建页阈值)、[[深度推理]](内嵌引用,未达独立建页阈值)、[[AI智能体]](已有 Concept)、[[工作流自动化]](已有 Concept)、[[LLM应用开发平台]](内嵌引用,未达独立建页阈值)、[[AI搜索]](内嵌引用,未达独立建页阈值)
+- Entities touched: [[DeepSeek]](已存在,添加 sources 引用,更新 last_updated→2026-01-01)、[[Qwen]](已存在,已有本文 sources 引用)、[[Flux]](已存在,已有本文 sources 引用)、[[Stable-Diffusion]](已存在,已有本文 sources 引用)、[[HunyuanVideo]](已存在,已有本文 sources 引用)、[[Manus]](已存在,已有本文 sources 引用)、[[OpenManus]](已存在,已有本文 sources 引用)、[[Cline]](已存在,已有本文 sources 引用)、[[n8n]](新建 Entity 页面)、[[Dify]](已存在,已有本文 sources 引用)、[[Perplexica]](已存在,已有本文 sources 引用)、[[智谱GLM]](仅出现 1 次,未达独立建页阈值)、[[MiniMax]](仅出现 1 次,未达独立建页阈值)、[[Kimi K2]](仅出现 1 次,未达独立建页阈值)
+- Source page: wiki/sources/2025-年-11-个神级-ai-开源平替-github-杀疯了.md
+- Notes: source page 新建完成;index.md Sources 节第一条已添加带日期前缀和一行摘要;overview.md 已有相关 AI 工具章节(Nano Banana/Claude Skills/Dify/n8n/Perplexica 等均已存在),本文全面覆盖 AI 开源平替主题,与现有章节互补而非重复,overview.md 无需新增条目;冲突检测:与 [[Nano Banana Pro提示词指南]] 在"AI生图最强工具"上存在冲突(Flux vs Gemini),已记录于 source page Contradictions 节;n8n Entity 为新建(此前 wiki/entities/n8n.md 不存在);DeepSeek Entity 更新 last_updated→2026-01-01
+
## [2026-04-30] ingest | Claude Code 调用方法总结
- Source file: Agent/claude-code调用方法总结.md
- Status: ✅ 成功摄入
@@ -5334,3 +5431,27 @@
- 更新 overview.md,新增第22条 NotebookLM 综合条目
- Entity 页面 NotebookLM.md 已包含 7-ways-i-use-notebooklm-to-make-my-life-easier source,无需额外更新
- 冲突检测:无冲突(本文 7 种用法与现有 NotebookLM Entity 页面内容高度一致,无矛盾论点)
+
+## [2026-05-11] ingest | 我的AI工具集
+- Source file: raw/AI/我的工具集.md
+- Status: ✅ 成功摄入
+- Summary: 个人收集整理的 AI 工具清单,按功能分类涵盖 Text-to-Speech(Google AI Studio 免费服务)、Image-to-Video(Wavespeed/Vidu/Hailuo,¥8~42/月)、Web-Scraper(Brightdata 付费)和 AI Summary(Decopy,支持文章/PDF/视频多模式摘要)。
+- Concepts created: [[TextToSpeech]]、[[TextToVideo]]、[[ImageToVideo]]、[[WebScraper]]、[[AISummary]]
+- Entities created: [[Google-AI-Studio]]、[[Wavespeed-AI]]、[[Vidu]]、[[Hailuo-AI]]、[[Brightdata]]、[[Decopy]]
+- Source page: wiki/sources/我的工具集.md
+- Notes: Source page 新建完成;index.md Sources 节第一条已添加;overview.md 新增综合摘要条目,位于「知识与资源」节「3-2万人收藏」与「14个免费AI图生视频工具」之间;Entities 和 Concepts 均已按字母顺序插入 index.md;冲突检测:无冲突(本文为个人工具清单,与其他来源互补,无矛盾论点)
+
+## [2026-04-28] ingest | Multi-Agent System Reliability
+- Source file: raw/AI/Multi-Agent System Reliability.md
+- Status: ✅ 成功摄入
+- Summary: Alex Ewerlöf 提出 4 种架构模式提升多智能体系统可靠性——层级(Planner→Worker→Validator)、共识(N个LLM多数票消除幻觉)、对抗辩论(Generator→Critic→Judge)、淘汰制(适者生存)。核心主张:反对拟人化LLM,将LLM视为分布式系统中不可靠的组件,通过架构约束而非提示词约束强制其正确。
+- Concepts created: 无需新建(Hierarchy-Agent-Pattern、Consensus-Voting-Pattern、Adversarial-Debate-Pattern、Knock-out-Pattern、Reliability-Engineering、Genetic-Algorithm、Tree-of-Thoughts 均已存在)
+- Entities created: 无需新建(Alex Ewerlöf 实体页面已存在)
+- Source page: wiki/sources/multi-agent-system-reliability.md
+- Notes:
+ - Source page 新建完成;index.md Sources 节第一条已添加(2026-04-28)
+ - overview.md 第102行已包含本 source 综合摘要,无需额外更新
+ - 更新了 7 个现有 Concept 页面的 sources 字段(添加 multi-agent-system-reliability)和 last_updated(→2026-04-28)
+ - 更新了 Alex Ewerlöf 实体页面的 sources 字段和 last_updated
+ - 更新了 Agentic-AI.md sources(添加 multi-agent-system-reliability)
+ - 冲突检测:仅与"拟人化提示工程"存在已知分歧——source 自身已在 Contradictions 节记录此冲突
diff --git a/wiki/overview.md b/wiki/overview.md
index d2eb68c1..3dd42826 100644
--- a/wiki/overview.md
+++ b/wiki/overview.md
@@ -10,7 +10,13 @@ This wiki is a living synthesis of curated sources spanning AI agents, cloud inf
**[[chinatextbook-41-53-gb-中国小学-初中-高中-大学-pdf-教材]]**(ChinaTextbook):中国中小学及大学 PDF 教材开源收集项目——托管于 GitHub,总库大小 41.53 GB,收集了从小学到大学阶段的公开教材 PDF。教材来源为国家中小学智慧教育平台(basic.smartedu.cn),登录后即可浏览,亦可使用第三方工具(如 tchMaterial-parser)下载。覆盖小学(语数英科学等11科)、初中(15科)、高中(16科)及大学(概率论/离散数学/线性代数/高等数学)阶段。属教育资源开源化方向,为 [[教育资源开源]] 和 [[PDF教材数字化]] 提供实践案例。
-**[[14个免费的AI图生视频工具]]**(AI图生视频工具评测):14款免费AI图生视频工具的完整评测——涵盖中国主流平台(绘蛙AI视频/智谱清影/通义万相/Vidu/可灵AI/海螺AI/即梦AI/万相营造)和海外工具(PixVerse/Video Ocean/Stable Video/Viva/Haiper/艺映AI)。核心价值:降低视频创作门槛,无需专业设备即可将静态图片转化为动态视频,适用于电商营销、内容创作、广告制作等场景。各工具差异化定位:智谱清影强调30秒极速生成和CogSound音效模型;Vidu以"多主体参考"功能保持角色一致性;可灵AI以1080p高清输出和3D时空联合注意力见长;Stable Video提供精细的摄像机运动控制;Viva在免费产品中质量最高。属 [[AI时代发展策略]] 的创意工具层,为 [[图生视频]] 和 [[视频风格迁移]] 提供工具选型参考。
+**[[固定镜头短视频制作的ai全流程解析]]**(AI全流程制作短视频):利用AI技术快速高效制作高播放量家装类短视频的全套流程——核心三大关键词:固定机位(摄像机位置固定)、内容连续变化(画面随施工进度变化)、时间压缩(将长时间过程浓缩呈现)。五步公式:拆分镜头 → 一致性图像生成(九宫格法)→ 首尾针动画制作 → 快速剪辑(2-4倍速+硬切)→ 声音设计(施工音效+节奏感BGM+精准卡点)。AI工具分类:大脑类(XAR GPT/GEMALA负责分镜)、设计师类(Midjourney/Nano Banana负责图像)、动效类(海螺AI/KAI负责动画)。全流程可在10分钟内完成。属 [[AI时代发展策略]] 的内容创作工具层,与 [[我的工具集]] 的Image-to-Video工具互补——前者提供系统性方法论,后者提供具体工具选型。
+
+**[[我的工具集]]**(个人AI工具集):个人收集整理的 AI 工具清单,按功能分类涵盖 Text-to-Speech(Google AI Studio 免费服务)、Image-to-Video(Wavespeed/Vidu ¥8~42/月)、Web-Scraper(Brightdata 付费)和 AI Summary(Decopy,支持文章/PDF/视频多模式摘要)。属 [[AI时代发展策略]] 的工具选型参考层,与 [[14个免费的AI图生视频工具]] 和 [[二创视频必不可少-2025年最热门ai工具推荐合集-ai配音-声音克隆]] 互补——后者偏向视频创作,本工具集覆盖更广的 AI 服务类型。
+
+属 [[AI时代发展策略]] 的工具选型参考层,与 [[14个免费的AI图生视频工具]] 和 [[二创视频必不可少-2025年最热门ai工具推荐合集-ai配音-声音克隆]] 互补——后者偏向视频创作,本工具集覆盖更广的 AI 服务类型。
+
+**[[大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏]]**(大模型术语扫盲):通俗解读大模型生态关键术语——LLM(≥1B参数的语言模型)、MCP(连接外部工具的标准化协议)、Agent(LLM+MCP实现自动化执行)、RAG(通过外部检索消除幻觉,正确率60%→90%)、Embedding(词向量语义距离)、vLLM(PagedAttention+连续批处理优化GPU显存)、Token(英文≈0.3/字、中文≈0.6/字的计量单位)、数据蒸馏(大模型生成精简数据训练小模型)。核心观点:大模型本身只给步骤方法不会真正执行工具调用,需配合MCP才能实现自动化;RAG通过"给提示"解决大模型在陌生领域的幻觉问题。属 [[Multi-Agent-AI-Systems]] 的基础概念层,与 [[llms-rag-ai-agent-三个到底什么区别]] 互补——后者从系统架构层面区分三者关系,本文档则提供术语的通俗定义与机制解释。
### Multi-Agent AI Systems
The wiki covers two major multi-agent frameworks: **The Agency** (agency-agents) and **OpenClaw**. The Agency provides 147 specialized agents across 12 business divisions (Engineering, Design, Finance, Game Dev, Marketing, Paid Media, Product, Project Management, Testing, Support, Spatial Computing, Specialized). OpenClaw focuses on autonomous agents with persistent memory and workflow orchestration via n8n. A beginner-focused **n8n AI Agent 教程**([[n8n-full-tutorial-building-ai-agents-in-2025-for-beginners]]):通过 N8N 平台构建 AI Agent 的入门指南——核心区分 Workflow(预定义自动化,输出恒定)与 Agent(由 LLM 驱动,动态选择工具);系统讲解五类 N8N 节点(触发节点、动作节点、工具节点、代码节点、AI Agent 节点);集成 Memory 模块保留对话上下文提升连贯性;演示 Airtable 库存管理工具集成案例。是 [[n8n-workflow-orchestration|OpenClaw+n8n 工作流编排]] 的入门前置知识。
@@ -470,13 +476,15 @@ A comprehensive Linux command reference covering 150 essential commands across 1
Key concepts: [[CPU架构检测]], [[x86_64]], [[aarch64]], [[ARM64]], [[ELF格式]]
### Educational Resources
-**[[Build Your Own X]]**:GitHub 上由 [[CodeCrafters]] 维护的精选教程列表(build-your-own-x),收录 26+ 技术领域的分步骤指南,涵盖 3D Renderer、Web Browser、Database、Docker、Git、Operating System、Programming Language、Neural Network 等领域。每条教程引用 Richard Feynman 的名言:"What I cannot create, I do not understand"作为核心理念——通过从零重建主流技术实现深度技术理解。与 [[ChinaTextbook]](教材资源)互补,前者侧重工程实践(重建系统),后者侧重学科理论(课程教材)。
+**[[Build Your Own X]]**(来源:[[codecrafters-iobuild-your-own-x-master-programming-by-recreating-your-favorite-technologies-from-scratch]]):GitHub 上由 [[CodeCrafters]] 维护的精选教程列表(build-your-own-x),收录 26+ 技术领域的分步骤指南,涵盖 3D Renderer、Web Browser、Database、Docker、Git、Operating System、Programming Language、Neural Network 等领域。每条教程引用 [[Richard Feynman]] 的名言:"What I cannot create, I do not understand"作为核心理念——通过从零重建主流技术实现深度技术理解。与 [[ChinaTextbook]](教材资源)互补,前者侧重工程实践(重建系统),后者侧重学科理论(课程教材)。
+
+核心方法论 [[Learn By Building]]:学习的最佳路径不是阅读源码或文档,而是从第一性原理出发实现一个简化版本。涵盖 25 个领域:3D Renderer、Augmented Reality、BitTorrent Client、Blockchain/Cryptocurrency、Bot、Command-Line Tool、Database、Docker、Emulator/VM、Front-end Framework、Game、Git、Network Stack、Neural Network、Operating System、Physics Engine、Programming Language、Regex Engine、Search Engine、Shell、Template Engine、Text Editor、Visual Recognition、Voxel Engine、Web Browser、Web Server。
ChinaTextbook(TapXWorld/ChinaTextbook)是一个托管于 GitHub 的开源项目,收集中国小学、初中、高中、大学全阶段 PDF 教材,总库大小 41.53GB。教材来源于国家中小学智慧教育平台(basic.smartedu.cn),可通过第三方工具(tchMaterial-parser)下载。覆盖小学 10 门学科(语文、数学、英语、科学,音乐、美术、体育与健康、道德与法治等)、初中 17 门学科、高中 18 门学科,以及大学阶段概率论、离散数学、线性代数、高等数学等基础课程。
**免费 AI 学习资源全景**([[learn-ai-for-free-directly-from-top-companies]]):@RodmanAi 汇总的 10 家顶级科技公司免费 AI 学习资源——Anthropic(Skilljar 培训平台)、Google(Grow.google/AI 学习路径)、Meta(AI 资源中心)、NVIDIA(CUDA 开发者课程)、Microsoft(Microsoft Learn)、OpenAI(Academy)、IBM(SkillsBuild)、AWS(Skill Builder)、DeepLearning.AI(吴恩达课程)、Hugging Face(学习路径)。核心价值:**免费获取权威 AI 培训内容**,无需付费订阅。与 [[Claude Prompt Library]](Anthropic 官方提示词库)属同一教育生态。
-Key concepts: [[国家中小学智慧教育平台]], [[tchMaterial-parser]], [[ChinaTextbook]], [[Build-Your-Own-X]], [[BYOX]], [[Learn-By-Building]], [[From-Scratch-Methodology]], [[CodeCrafters]], [[NAND-to-Tetris]], [[AI教育]], [[免费学习资源]]
+Key concepts: [[国家中小学智慧教育平台]], [[tchMaterial-parser]], [[ChinaTextbook]], [[Build-Your-Own-X]], [[BYOX]], [[Learn-By-Building]], [[Learn By Building]], [[From-Scratch-Methodology]], [[CodeCrafters]], [[Richard Feynman]], [[NAND-to-Tetris]], [[AI教育]], [[免费学习资源]]
### AI Tools & Prompt Engineering
Covers Claude Code, Claude Code Templates (npx 一键安装 Skills/Agents/MCP via `npx claude-code-templates@latest --skill= --yes` from aitmpl.com), OpenCode, [[Cursor]], [[Trae]], Gemini CLI, Vibe Coding, [[RAG]], multi-agent workflows, NotebookLM, Nano Banana prompting, and video generation tools.
diff --git a/wiki/sources/14个免费的ai图生视频工具-用ai让图片动起来-ai视频教程-ai自动化工作流定制服务-ai培训学习平台-黑喵大叔.md b/wiki/sources/14个免费的ai图生视频工具-用ai让图片动起来-ai视频教程-ai自动化工作流定制服务-ai培训学习平台-黑喵大叔.md
index ca5b8b90..8604f0bf 100644
--- a/wiki/sources/14个免费的ai图生视频工具-用ai让图片动起来-ai视频教程-ai自动化工作流定制服务-ai培训学习平台-黑喵大叔.md
+++ b/wiki/sources/14个免费的ai图生视频工具-用ai让图片动起来-ai视频教程-ai自动化工作流定制服务-ai培训学习平台-黑喵大叔.md
@@ -7,7 +7,7 @@ last_updated: 2025-12-05
---
## Source File
-- [[AI/14个免费的AI图生视频工具,用AI让图片动起来 - AI视频教程 AI自动化工作流定制服务 AI培训学习平台 黑喵大叔]]
+- [[raw/AI/14个免费的AI图生视频工具,用AI让图片动起来 - AI视频教程 AI自动化工作流定制服务 AI培训学习平台 黑喵大叔.md]]
## Summary(用中文描述)
- 核心主题:14款免费AI图生视频工具的测评与功能介绍,涵盖中国主流AI视频生成平台和海外工具
diff --git a/wiki/sources/2025-年-11-个神级-ai-开源平替-github-杀疯了.md b/wiki/sources/2025-年-11-个神级-ai-开源平替-github-杀疯了.md
index 504a49b4..b55f61b5 100644
--- a/wiki/sources/2025-年-11-个神级-ai-开源平替-github-杀疯了.md
+++ b/wiki/sources/2025-年-11-个神级-ai-开源平替-github-杀疯了.md
@@ -1,76 +1,89 @@
----
-title: "2025 年 11 个神级 AI 开源平替,GitHub 杀疯了"
-type: source
-tags: [AI, 开源平替, LLM, AI生图, AI生视频, AI智能体, AI编码, AI搜索, 知识库]
-date: 2026-01-01
----
-
-## Source File
-- [[AI/2025 年 11 个神级 AI 开源平替,GitHub 杀疯了。]]
-
-## Summary(用中文描述)
-- 核心主题:2025 年 GitHub 上各 AI 领域最火的开源平替项目盘点
-- 问题域:闭源 AI 产品(OpenAI/Gemini/Midjourney/Manus/Perplexity/NotebookLM)价格高昂,用户需要免费开源替代方案
-- 方法/机制:按 8 大领域(LLM、AI 生图、AI 生视频、AI 智能体、AI Coding、Agent 工作流、AI 搜索、AI 知识库)逐一介绍 GitHub 上 Star 最高、技术最强的开源项目
-- 结论/价值:国产开源模型(DeepSeek、Qwen、HunyuanVideo)在多个领域已达到或超越国际闭源竞品水平
-
-## Key Claims(用中文描述)
-- DeepSeek R1 是开源界首个将 o1 级深度推理拉下神坛的破壁者,2025 年春节爆火拉开了中国通过开源策略与国外 AI 巨头差异化竞争的叙事
-- 通义千问 Qwen 3 是最稳、最全、最能打的开源基座模型,流水的开源模型,铁打的通义千问
-- Flux 是目前人体解剖学最正确的开源生图模型,出自前 SD 核心团队之手,手指头连指甲盖光泽都有
-- Stable Diffusion 的 LoRA 和 ControlNet 生态依然最丰富,SD3.5 优化版本更容易在中端显卡上运行
-- 混元视频 HunyuanVideo 是开源界参数量最大的视频生成模型之一,对中文 Prompt 理解是天花板级别
-- Manus 是 2025 年 AI Agent 领域的年度现象级产品,定义了 AI Agent 元年,被 Meta 以几十亿美金收购
-- OpenManus 是 Manus 的开源平替,核心逻辑是规划(Planning)→执行(Execution)→循环反馈,拥有 5 万 Star
-- Cline 是 Cursor 的最佳开源平替,VS Code 生态中公认最强大的开源自主编程插件
-- n8n 是功能更强、还能私有部署的开源版 Zapier,拥有恐怖的 16 万 Star
-- Perplexica 是 Perplexity 的完全开源免费替代,支持本地化 AI 搜索和 SearXNG 搜索源
-- Claude Code 和 Codex 不是传统 AI 编程工具,而是基于终端的 AI Agent
-
-## Key Quotes
-> "2025 年,深度推理让 AI 学会了慢思考,开源内卷把价格打成了白菜,大模型也终于从会聊天的玩具,彻底进化成了能干活的队友。" — 核心主题总结
-> "流水的开源模型,铁打的通义千问。" — Qwen 3 的稳定性评价
-> "Manus 是 AI Agent 领域的年度现象级产品,甚至可以说是定义了 AI Agent 元年的里程碑式存在。" — Manus 行业地位
-
-## Key Concepts
-- [[AI开源平替]]:以开源项目替代闭源商业 AI 产品,降低使用成本
-- [[深度推理]]:DeepSeek R1 带来的 o1 级推理能力开源化
-- [[AI生图]]:Flux、Stable Diffusion 等开源图像生成模型
-- [[AI生视频]]:HunyuanVideo 等开源视频生成模型
-- [[AI Agent]]:通用智能体概念,Manus 为领域元年代表
-- [[AI Coding]]:AI 辅助编程工具生态
-- [[工作流自动化]]:n8n、Dify 等可视化工作流编排平台
-- [[AI搜索]]:Perplexica 等开源 AI 搜索引擎
-
-## Key Entities
-- [[DeepSeek]]:国产 AI 公司,DeepSeek R1/V3 开源地址维护者
-- [[Qwen]](通义千问):阿里开源模型 Qwen 3,六边形战士级基座模型
-- [[Flux]]:前 SD 核心团队出品的开源生图模型
-- [[Stable Diffusion]]:老牌开源生图模型,LoRA 和 ControlNet 生态最丰富
-- [[HunyuanVideo]](混元视频):腾讯开源视频生成模型,参数量最大
-- [[Manus]]:AI Agent 领域现象级产品,2025 年里程碑,被 Meta 收购
-- [[OpenManus]]:Manus 的开源平替,规划-执行-反馈核心逻辑
-- [[Cline]]:Cursor 的最佳开源平替,VS Code 最强自主编程插件
-- [[n8n]]:开源版 Zapier,工作流自动化平台,16 万 Star
-- [[Dify]]:LLM 应用开发平台,支持知识库和工作流可视化编排
-- [[Perplexica]]:Perplexity 的开源替代,本地化 AI 搜索引擎
-- [[Perplexity]]:AI 搜索产品标杆,对比对象
-- [[Claude Code]]:Anthropic 终端 AI Agent(非传统编程工具)
-- [[Cursor]]:AI 增强编辑器,重新定义代码编辑器
-- [[OpenAI]]:国外 AI 巨头,GPT 系列模型提供商
-- [[Meta]]:收购 Manus 的科技巨头
-
-## Connections
-- [[DeepSeek]] ← extends ← [[OpenAI]](DeepSeek R1 对标 OpenAI o1 推理能力)
-- [[Qwen]] ← extends ← [[OpenAI]](通义千问对标 GPT 系列)
-- [[Flux]] ← derived_from ← [[Stable Diffusion]](Flux 团队来自 SD 核心团队)
-- [[HunyuanVideo]] ← extends ← [[Stable Diffusion]](视频版扩散模型)
-- [[OpenManus]] ← open_source_alternative ← [[Manus]]
-- [[Cline]] ← open_source_alternative ← [[Cursor]]
-- [[Perplexica]] ← open_source_alternative ← [[Perplexity]]
-- [[Dify]] ← extends ← [[n8n]](两者同为工作流平台,Dify 侧重 LLM 应用开发)
-- [[Claude Code]] ← related_to ← [[AI Agent]](Claude Code 被定义为终端 AI Agent)
-- [[Manus]] ← triggered ← [[AI Agent 元年]](Manus 诞生定义了 2025 年为 AI Agent 元年)
-
-## Contradictions
-- 无明显内容冲突。该来源内容与 Wiki 中 [[DeepSeek]] 实体页描述一致,均强调 DeepSeek-R1 是开源推理模型破壁者。
+---
+title: "2025 年 11 个神级 AI 开源平替,GitHub 杀疯了。"
+type: source
+tags: [AI开源平替, GitHub, 大语言模型, AI生图, AI生视频, AI智能体, AI编程, 工作流自动化, AI搜索, 知识库]
+date: 2026-01-01
+last_updated: 2026-05-01
+---
+
+## Source File
+- [[raw/AI/2025 年 11 个神级 AI 开源平替,GitHub 杀疯了。.md]]
+
+## Summary(用中文描述)
+- 核心主题:2025 年 GitHub 上各 AI 领域最火的开源平替项目全景盘点,涵盖大语言模型、AI 生图、AI 生视频、AI 智能体、AI 编程、工作流自动化、AI 搜索、AI 知识库共 8 大领域
+- 问题域:如何找到各 AI 闭源产品的优质开源替代方案
+- 方法/机制:按领域分类,每类推荐 GitHub Star 最高或技术最领先的开源项目,并说明其核心优势
+- 结论/价值:开源 AI 已全面内卷,国产模型(DeepSeek、Qwen 3、HunyuanVideo)在部分领域已超越 Meta Llama;开源平替不等于效果等同,需理性看待
+
+## Key Claims(用中文描述)
+- DeepSeek R1 是开源界首个将 o1 级深度推理拉下神坛的破壁者,2025 年春节爆火拉开中国通过开源策略与国外 AI 巨头差异化竞争的叙事
+- Qwen 3 是开源界的六边形战士,全尺寸覆盖 + 极致工具调用能力,最稳、最全、最能打的基座模型
+- Flux 是目前人体解剖学最正确的开源生图模型,出自前 SD 核心团队之手,文字渲染能力精准
+- Stable Diffusion 的 LoRA 和 ControlNet 生态依然最丰富,是画特定动漫角色和精确控制姿势的首选
+- HunyuanVideo 是目前开源界参数量最大的视频生成模型之一,对中文 Prompt 理解达天花板级别
+- Manus 定义了 2025 年为 AI Agent 元年,随后被 Meta 以数十亿美金收购
+- OpenManus 是 Manus 开源平替中 Star 最高(5 万+)的项目,核心逻辑为规划→执行→循环反馈
+- Cline 是 VS Code 生态中公认最强大的开源自主编程插件,是 Cursor 的最佳开源平替
+- n8n 是 GitHub 上最强的工作流开源项目,有恐怖的 16 万 Star,拖拽节点串联各种 App,支持 LangChain 节点
+- Dify 是目前最主流的 LLM 应用开发平台,可视化界面让不懂代码的人也能搭建 AI 机器人
+- Perplexica 是完全开源免费的 Perplexity 替代项目,支持 SearXNG 搜索源和本地大模型
+
+## Key Quotes
+> "2025 年,深度推理让 AI 学会了慢思考,开源内卷把价格打成了白菜,大模型也终于从会聊天的玩具,彻底进化成了能干活的队友。"
+> "DeepSeek R1 也是开源界首个将 o1 级深度推理拉下神坛的破壁者。"
+> "流水的开源模型,铁打的通义千问。"
+> "Flux 是目前人体解剖学最正确的开源模型。"
+> "Manus 是 AI Agent 领域的年度现象级产品,甚至可以说是定义了 AI Agent 元年的里程碑式存在。"
+> "n8n 有恐怖的 16 万的 Star。"
+
+## Key Concepts
+- [[AI开源平替]]:用开源项目替代闭源 AI 产品的策略
+- [[深度推理(Deep Reasoning)]]:AI 学会"慢思考",代表模型 DeepSeek R1
+- [[开源内卷]]:开源 AI 领域竞争激烈,价格被持续压低
+- [[AI生图]]:AI 图像生成,代表开源模型 Flux、Stable Diffusion
+- [[AI生视频]]:AI 视频生成,代表开源模型 HunyuanVideo
+- [[AI智能体(AI Agent)]]:能自主规划、执行、反馈的 AI 系统,代表项目 OpenManus
+- [[AI编程工具]]:辅助编程的 AI 工具,作者将 Claude Code、Codex 定义为"基于终端的 AI Agent"
+- [[工作流自动化]]:拖拽节点串联 App 自动化执行,n8n 是最强开源工作流项目
+- [[LLM应用开发平台]]:可视化搭建 AI 机器人的平台,代表 Dify
+- [[AI搜索]]:联网检索+总结的 AI 搜索引擎,代表 Perplexica
+
+## Key Entities
+- [[DeepSeek]]:国产开源大模型,DeepSeek R1/V3 的发布者,开源界深度推理破壁者
+- [[Qwen]]:阿里巴巴通义千问,Qwen 3 开源界的六边形战士
+- [[Flux]]:前 SD 核心团队创立的 AI 生图开源模型,开源界的 Midjourney
+- [[Stable-Diffusion]]:老牌开源 AI 生图模型,LoRA 和 ControlNet 生态最丰富
+- [[HunyuanVideo]]:腾讯混元视频,开源视频生成模型中参数量最大
+- [[Manus]]:2025 年 AI Agent 现象级产品,定义 AI Agent 元年,被 Meta 收购
+- [[OpenManus]]:Manus 开源平替,Star 5 万+,规划→执行→循环反馈架构
+- [[Cline]]:VS Code 开源 AI 编程插件,Cursor 最佳开源平替
+- [[n8n]]:GitHub 16 万 Star 的最强开源工作流项目,拖拽式自动化脚本工场
+- [[Dify]]:主流 LLM 应用开发平台,可视化搭建 AI 机器人
+- [[Perplexica]]:Perplexity 开源平替,支持 SearXNG 和本地大模型
+- [[智谱GLM]]:中国 AI 大模型初创公司开源项目
+- [[MiniMax]]:中国 AI 大模型初创公司开源项目
+- [[Kimi K2]]:中国 AI 大模型初创公司开源项目
+- [[Meta]]:收购 Manus 的 AI 巨头(Llama 模型发布方)
+
+## Connections
+- [[DeepSeek]] ← 引领 ← [[Qwen]](同为国产开源大模型双子星)
+- [[Flux]] ← 继承自 ← [[Stable-Diffusion]](SD 核心团队出走创立)
+- [[Manus]] ← 启发 ← [[OpenManus]](开源平替关系)
+- [[Perplexity]] ← 开源平替 ← [[Perplexica]]
+- [[Cursor]] ← 开源平替 ← [[Cline]]
+- [[n8n]] ← 功能重叠 ← [[Dify]](工作流自动化 vs LLM 应用开发)
+- [[Dify]] ← 依赖 ← [[LangChain]](n8n 支持 LangChain 节点集成)
+- [[OpenManus]] ← 基于 ← [[Browser-Use]]
+- [[OpenManus]] ← 基于 ← [[Playwright]]
+
+## Contradictions
+- 与 [[Nano Banana Pro提示词指南]] 在"AI 生图最强工具"上存在差异:
+ - 冲突点:闭源 vs 开源的最强图像生成工具
+ - 当前观点:本文认为 Flux 是开源界最强 AI 生图模型
+ - 对方观点:Nano Banana Pro 提示词指南认为 Nano Banana(Gemini)是 2025 年 AI 生图领域最牛的工具
+ - 说明:两者评价维度不同——本文评开源平替,Nano Banana Pro 指南评整体表现
+- 与 [[Vibe Coding]] 相关讨论的潜在张力:
+ - 冲突点:Claude Code/Codex 的定义归属
+ - 当前观点:作者将 Claude Code 和 Codex 定义为"基于终端的 AI Agent"而非简单的 AI 编程工具
+ - 对方观点:Claude Code 调用方法总结将其定义为 Claude Code CLI 工具
+ - 说明:两种定义均合理,差异在于视角(产品定位 vs 技术实现)
diff --git a/wiki/sources/3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式.md b/wiki/sources/3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式.md
index 36f76165..9a7e91c2 100644
--- a/wiki/sources/3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式.md
+++ b/wiki/sources/3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式.md
@@ -1,60 +1,58 @@
----
-title: "3.2 万人收藏的 Claude Skills,才是 AI 这条路上最值得研究的一套范式!"
-type: source
-tags: [ai, claude-skills, vibe-coding]
-sources: []
-last_updated: 2026-01-05
----
-
-## Source File
-- [[AI/3.2 万人收藏的 Claude Skills,才是 AI 这条路上最值得研究的一套范式!]]
-
-## Summary(用中文描述)
-- 核心主题:Anthropic 官方 Claude Skills 仓库介绍,以及从「提示词工程」向「流程工程」的范式转变
-- 问题域:AI 应用如何从零散的 Prompt 创作升级为结构化、可复用、可自动执行的 Skills 体系
-- 方法/机制:Skills = 说明书 + SOP,将反复执行有固定流程的任务拆解为 AI 能理解、能复用、能自动执行的一套流程;官方库展示生产级 Skills(办公自动化/开发者工具箱/创意类)
-- 结论/价值:Skills 爆发标志范式转变——最有价值的不是 Prompt 写得多花哨,而是把业务流程沉淀成 SOP 并交给 AI 稳定执行;Vibe Coding 的尽头也是 Skills
-
-## Key Claims(用中文描述)
-- Anthropic 将 Claude.ai 网页版的生产级能力原封不动地拆解开来,展示在官方 Skills 仓库(github.com/anthropics/skills,3.2 万收藏)中
-- Skills 本质是一套「说明书」+「SOP」,将反复执行、有固定流程的任务拆解为 AI 能理解、能稳定复用、能自动执行的流程
-- 官方库包含三大类 Skills:办公自动化四大件(Word/PDF/PPT/Excel)、开发者工具箱(MCP Server/Web测试/Artifacts构建/自动化验证)、创意类 Skill(算法艺术/Canvas设计/主题生成)
-- Claude Skills 的爆发标志着从「提示词工程」向「流程工程」的范式转变——最有价值的不是 Prompt 写得最花,而是谁能将业务流程沉淀成 SOP 并交给 AI 稳定执行
-- Vibe Coding 的尽头也是 Skills
-- 三大 Skill 聚合站(skillsmp.com、aitmpl.com/skills、claudemarketplaces.com)可直接「拿来主义」使用
-- 三款高产开源 Awesome-Claude-Skills 仓库(ComposioHQ/VoltAgent/BehiSecc)提供系统性灵感
-
-## Key Quotes
-> "Skills 就是一套你写给 Claude 的'说明书'和'SOP(标准作业程序)'。" — Skills 的本质定义
-> "它是 Anthropic 把 Claude 线上真正在跑的生产级能力,原封不动地拆解开来,摊在桌面上给你看。" — 官方库的价值
-> "这个库本质上是官方在教你,'怎么像我们一样开发 AI 应用'。" — 官方库的核心价值
-> "未来真正有价值的,不是谁的 Prompt 写得最花、谁一次能生成最多内容。而是谁最懂业务流程、谁能把经验沉淀成 SOP、谁能把 SOP 交给 AI 稳定执行。" — 范式转变的核心洞察
-
-## Key Concepts
-- [[Claude-Skills]]:Anthropic 官方发布的 AI 技能指南,一套写给 Claude 的「说明书」+「SOP」,将反复执行有固定流程的任务拆解为 AI 能理解、能复用、能自动执行的流程
-- [[流程工程]]:从「提示词工程」向「流程工程」的范式转变,核心是将业务流程沉淀为 SOP 并交给 AI 稳定执行
-- [[Vibe-Coding]]:AI 编程范式,其尽头也是 Skills——将 AI 编程的最佳实践固化为可复用的技能体系
-- [[Awesome-Claude-Skills]]:第三方维护的 Claude Skills 精选仓库集合
-
-## Key Entities
-- [[Anthropic]]:Claude Skills 的官方发布者,github.com/anthropics/skills 仓库的维护方
-- [[Claude.ai]]:Anthropic 的 AI 产品,官方 Skills 仓库中的 Skills 均来自其网页版的实际生产级能力
-- [[github.com/anthropics/skills]]:Anthropic 官方 Skills 仓库,3.2 万收藏,包含生产级 Skills 代码
-- [[ComposioHQ/awesome-claude-skills]]:第三方 Awesome-Claude-Skills 仓库之一
-- [[VoltAgent/awesome-claude-skills]]:第三方 Awesome-Claude-Skills 仓库之一
-- [[BehiSecc/awesome-claude-skills]]:第三方 Awesome-Claude-Skills 仓库之一
-- [[skillsmp.com]]:Skill 聚合站之一,可直接使用高手分享的 Skills
-- [[aitmpl.com/skills]]:Skill 聚合站之一,支持 Claude Code Templates 安装
-- [[claudemarketplaces.com]]:Skill 聚合站之一
-
-## Connections
-- [[3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式-1]] ← duplicate ← [[AI/3.2 万人收藏的 Claude Skills,才是 AI 这条路上最值得研究的一套范式!]]
-- [[Vibe-Coding]] ← depends_on ← [[Claude-Skills]]
-- [[claude-code调用方法总结]] ← related_to ← [[Claude-Skills]]
-- [[Google-5个-Agent-Skill-设计模式]] ← related_to ← [[Claude-Skills]]
-
-## Contradictions
-- 与 [[3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式-1]]:
- - 冲突点:同一来源文章被两次独立摄取,生成了两个不同的 source page
- - 当前观点:本页面代表该来源的一次独立摄取
- - 对方观点:另一 slug 版本(带 -1 后缀)代表首次摄取
+---
+title: "3.2 万人收藏的 Claude Skills,才是 AI 这条路上最值得研究的一套范式!"
+type: source
+tags: [ai, claude-skills, vibe-coding]
+sources: []
+last_updated: 2026-07-15
+---
+
+## Source File
+- [[raw/AI/3.2 万人收藏的 Claude Skills,才是 AI 这条路上最值得研究的一套范式!.md]]
+
+## Summary(用中文描述)
+- 核心主题:Anthropic 官方 Claude Skills 仓库(github.com/anthropics/skills,3.2万收藏)全面解析,以及从「提示词工程」向「流程工程」的 AI 应用范式转变
+- 问题域:AI 应用如何从零散的 Prompt 创作升级为结构化、可复用、可自动执行的 Skills 体系
+- 方法/机制:Claude Skills = 说明书 + SOP,将反复执行有固定流程的任务拆解为 AI 能理解、能复用、能自动执行的一套流程。官方库展示三大类 Skills:办公自动化(Word/PDF/PPT/Excel)、开发者工具箱(MCP Server/Web测试/Artifacts构建/自动化验证)、创意类 Skill
+- 结论/价值:Skills 爆发标志范式转变——最有价值的不是 Prompt 写得多花哨,而是把业务流程沉淀成 SOP 并交给 AI 稳定执行;Vibe Coding 的尽头也是 Skills
+
+## Key Claims(用中文描述)
+- Anthropic 将 Claude.ai 网页版的生产级能力原封不动地拆解开来,展示在官方 Skills 仓库(github.com/anthropics/skills,3.2万收藏)中
+- Skills 本质是一套「说明书」+「SOP」,将反复执行、有固定流程的任务拆解为 AI 能理解、能稳定复用、能自动执行的流程
+- 官方库包含三大类 Skills:办公自动化四大件(Word/PDF/PPT/Excel)、开发者工具箱(MCP Server/Web测试/Artifacts构建/自动化验证)、创意类 Skill(算法艺术/Canvas设计/主题生成)
+- 核心范式转变:从「提示词工程」向「流程工程」——最有价值的不是 Prompt 写得最花,而是谁能将业务流程沉淀成 SOP 并交给 AI 稳定执行
+- Vibe Coding 的尽头也是 Skills
+- 三大 Skill 聚合站(skillsmp.com、aitmpl.com/skills、claudemarketplaces.com)可直接「拿来主义」使用
+- 三款高产开源 Awesome-Claude-Skills 仓库(ComposioHQ/VoltAgent/BehiSecc)提供系统性灵感
+
+## Key Quotes
+> "Skills 就是一套你写给 Claude 的'说明书'和'SOP(标准作业程序)'。" — Skills 的本质定义
+> "它是 Anthropic 把 Claude 线上真正在跑的生产级能力,原封不动地拆解开来,摊在桌面上给你看。" — 官方库的价值
+> "这个库本质上是官方在教你,'怎么像我们一样开发 AI 应用'。" — 官方库的核心价值
+> "未来真正有价值的,不是谁的 Prompt 写得最花、谁一次能生成最多内容。而是谁最懂业务流程、谁能把经验沉淀成 SOP、谁能把 SOP 交给 AI 稳定执行。" — 范式转变的核心洞察
+
+## Key Concepts
+- [[Claude Skills]]:Anthropic 官方发布的 AI 技能指南,一套写给 Claude 的「说明书」+「SOP」,将反复执行有固定流程的任务拆解为 AI 能理解、能复用、能自动执行的流程
+- [[流程工程(Workflow Engineering)]]:从「提示词工程」向「流程工程」的范式转变,核心是将业务流程沉淀为 SOP 并交给 AI 稳定执行
+- [[Vibe Coding]]:AI 编程范式,其尽头也是 Skills——将 AI 编程的最佳实践固化为可复用的技能体系
+- [[SOP]]:标准作业程序(Standard Operating Procedure),Claude Skills 的核心载体
+
+## Key Entities
+- [[Anthropic]]:Claude Skills 的官方发布者,github.com/anthropics/skills 仓库的维护方
+- [[Claude.ai]]:Anthropic 的 AI 产品,官方 Skills 仓库中的 Skills 均来自其网页版的实际生产级能力
+- [[github.com/anthropics/skills]]:Anthropic 官方 Skills 仓库,3.2万收藏,包含生产级 Skills 代码
+- [[ComposioHQ]]:Awesome-Claude-Skills 仓库维护方之一
+- [[VoltAgent]]:Awesome-Claude-Skills 仓库维护方之一
+- [[BehiSecc]]:Awesome-Claude-Skills 仓库维护方之一
+
+## Connections
+- [[Claude Skills]] ← 核心主题 ← 本文
+- [[流程工程(Workflow Engineering)]] ← 上位概念 ← [[Claude Skills]]
+- [[Anthropic]] ← 发布方 ← [[Claude Skills]]
+- [[Vibe Coding]] ← 扩展方向 ← [[Claude Skills]]("Vibe Coding 的尽头也是 Skills")
+- [[github-上-5000-人收藏的-vibe-coding-神级指南]] ← 相关 ← [[Claude Skills]]
+
+## Contradictions
+- 与 [[github-上-5000-人收藏的-vibe-coding-神级指南]]:
+ - 冲突点:Vibe Coding 强调"氛围感"和直觉式引导,Claude Skills 强调结构化 SOP 和可复用流程
+ - 当前观点(本文):Claude Skills 是 Vibe Coding 的尽头,强调 SOP 沉淀和流程标准化
+ - 对方观点(Vibe Coding 指南):规划驱动 + 上下文固定 + AI 结对执行,更强调探索性和直觉式引导
diff --git a/wiki/sources/3x-ui-xray-on-bandwagonvps.md b/wiki/sources/3x-ui-xray-on-bandwagonvps.md
index f3d83770..e94410e2 100644
--- a/wiki/sources/3x-ui-xray-on-bandwagonvps.md
+++ b/wiki/sources/3x-ui-xray-on-bandwagonvps.md
@@ -1,47 +1,47 @@
----
-title: "3X-UI Xray on BandwagonVPS"
-type: source
-tags: [vps, xray, 3x-ui, 科学上网, 网络配置]
-date: 2026-02-10
----
-
-## Source File
-- [[Home Office/3X-UI Xray on BandwagonVPS]]
-
-## Summary(用中文描述)
-- 核心主题:在 BandwagonVPS 上部署 3X-UI 可视化面板管理 Xray 代理服务
-- 问题域:家庭网络的科学上网解决方案 —— VPS 服务端部署与配置
-- 方法/机制:通过官方一键安装脚本部署 3X-UI 面板(基于 mhsanaei/3x-ui 项目),使用 VLESS+Reality 协议配置入站规则,启用 BBR 加速,客户端使用 v2rayN(Windows/Linux)和 v2rayNG(Android)连接
-- 结论/价值:构建稳定、低维护成本的境外网络访问通道,配合 RAX50 路由器 MerlinClash 插件实现全屋透明代理
-
-## Key Claims(用中文描述)
-- BandwagonVPS(AS 104.194.92.x)作为家庭网络科学上网的 VPS 服务端,提供境外流量出口
-- 3X-UI 面板通过 Web UI 简化 Xray/V2Ray 的配置管理,支持 SSL 证书、BBR、Geo 文件更新等运维操作
-- VLESS+Reality 是当前抗封锁能力较强的代理协议方案,需要生成公钥/私钥对
-- Panel 与 xray 服务双进程均需保持 Running 状态才能正常代理
-- 启用 BBR 拥塞控制算法可提升跨境网络吞吐量和稳定性
-
-## Key Quotes
-> "Panel state: Running ✅, xray state: Running ✅, Autostart: Enabled ✅" — 3X-UI 正常运行时三要素状态
-> "bash <(curl -Ls https://raw.githubusercontent.com/mhsanaei/3x-ui/master/install.sh)" — 官方一键安装命令
-
-## Key Concepts
-- [[3X-UI]]:基于 Go 的 Xray/V2Ray 可视化管理面板,提供 Web UI 和命令行两种管理方式,支持 SSL 证书、BBR、Geo 文件更新等
-- [[VLESS+Reality]]:一种抗封锁的代理协议方案,需要生成公钥和私钥,是当前较为推荐的配置方式
-- [[BBR]]:Google 开发的 TCP 拥塞控制算法,通过 `x-ui` → 输入 `23` 启用,可提升跨境网络吞吐量
-- [[Geo文件]]:Xray 的国家/地区 IP 规则数据库,通过 `x-ui` → 输入 `24` 更新,用于分流和过滤
-
-## Key Entities
-- [[BandwagonHost]]:BandwagonHost(又称搬瓦工),美国 VPS 提供商,提供高性价比 KVM VPS
-- [[VPS2]]:BandwagonVPS 实例,IP 104.194.92.188,域名 kiwi.ishenwei.online,SSH 端口 22
-- [[3X-UI]]:mhsanaei/3x-ui 开源项目,提供 Xray 可视化管理界面
-- [[v2rayN]]:Windows/Linux 平台的 Xray/V2Ray 客户端
-- [[v2rayNG]]:Android 平台的 Xray/V2Ray 客户端
-
-## Connections
-- [[3x-ui-xray-on-bandwagonvps]] ← depends_on ← [[群晖NAS科学上网方法]]
-- [[3x-ui-xray-on-bandwagonvps]] ← extends ← [[ubuntu-server科学上网]]
-- [[3x-ui-xray-on-bandwagonvps]] ← related_to ← [[网件RAX50路由器刷梅林固件与科学上网插件安装教程]]
-
-## Contradictions
-- 无已知内容冲突
+---
+title: "3X-UI Xray on BandwagonVPS"
+type: source
+tags: [vps, xray, 3x-ui, 科学上网, 网络配置]
+date: 2026-02-10
+---
+
+## Source File
+- [[raw/Home Office/3X-UI Xray on BandwagonVPS.md]]
+
+## Summary(用中文描述)
+- 核心主题:在 BandwagonVPS 上部署 3X-UI 可视化面板管理 Xray 代理服务
+- 问题域:家庭网络的科学上网解决方案 —— VPS 服务端部署与配置
+- 方法/机制:通过官方一键安装脚本部署 3X-UI 面板(基于 mhsanaei/3x-ui 项目),使用 VLESS+Reality 协议配置入站规则,启用 BBR 加速,客户端使用 v2rayN(Windows/Linux)和 v2rayNG(Android)连接
+- 结论/价值:构建稳定、低维护成本的境外网络访问通道,配合 RAX50 路由器 MerlinClash 插件实现全屋透明代理
+
+## Key Claims(用中文描述)
+- BandwagonVPS(AS 104.194.92.x)作为家庭网络科学上网的 VPS 服务端,提供境外流量出口
+- 3X-UI 面板通过 Web UI 简化 Xray/V2Ray 的配置管理,支持 SSL 证书、BBR、Geo 文件更新等运维操作
+- VLESS+Reality 是当前抗封锁能力较强的代理协议方案,需要生成公钥/私钥对
+- Panel 与 xray 服务双进程均需保持 Running 状态才能正常代理
+- 启用 BBR 拥塞控制算法可提升跨境网络吞吐量和稳定性
+
+## Key Quotes
+> "Panel state: Running ✅, xray state: Running ✅, Autostart: Enabled ✅" — 3X-UI 正常运行时三要素状态
+> "bash <(curl -Ls https://raw.githubusercontent.com/mhsanaei/3x-ui/master/install.sh)" — 官方一键安装命令
+
+## Key Concepts
+- [[3X-UI]]:基于 Go 的 Xray/V2Ray 可视化管理面板,提供 Web UI 和命令行两种管理方式,支持 SSL 证书、BBR、Geo 文件更新等
+- [[VLESS+Reality]]:一种抗封锁的代理协议方案,需要生成公钥和私钥,是当前较为推荐的配置方式
+- [[BBR]]:Google 开发的 TCP 拥塞控制算法,通过 `x-ui` → 输入 `23` 启用,可提升跨境网络吞吐量
+- [[Geo文件]]:Xray 的国家/地区 IP 规则数据库,通过 `x-ui` → 输入 `24` 更新,用于分流和过滤
+
+## Key Entities
+- [[BandwagonHost]]:BandwagonHost(又称搬瓦工),美国 VPS 提供商,提供高性价比 KVM VPS
+- [[VPS2]]:BandwagonVPS 实例,IP 104.194.92.188,域名 kiwi.ishenwei.online,SSH 端口 22
+- [[3X-UI]]:mhsanaei/3x-ui 开源项目,提供 Xray 可视化管理界面
+- [[v2rayN]]:Windows/Linux 平台的 Xray/V2Ray 客户端
+- [[v2rayNG]]:Android 平台的 Xray/V2Ray 客户端
+
+## Connections
+- [[3x-ui-xray-on-bandwagonvps]] ← depends_on ← [[群晖NAS科学上网方法]]
+- [[3x-ui-xray-on-bandwagonvps]] ← extends ← [[ubuntu-server科学上网]]
+- [[3x-ui-xray-on-bandwagonvps]] ← related_to ← [[网件RAX50路由器刷梅林固件与科学上网插件安装教程]]
+
+## Contradictions
+- 无已知内容冲突
diff --git a/wiki/sources/7-ways-i-use-notebooklm-to-make-my-life-easier.md b/wiki/sources/7-ways-i-use-notebooklm-to-make-my-life-easier.md
index dc75651c..ee7fbf7f 100644
--- a/wiki/sources/7-ways-i-use-notebooklm-to-make-my-life-easier.md
+++ b/wiki/sources/7-ways-i-use-notebooklm-to-make-my-life-easier.md
@@ -8,7 +8,7 @@ last_updated: 2026-04-28
---
## Source File
-- [[AI/7 ways I use NotebookLM to make my life easier]]
+- [[raw/AI/7 ways I use NotebookLM to make my life easier.md]]
## Summary(用中文描述)
- **核心主题**:作者分享使用 Google NotebookLM 的 7 种日常场景,展示了 AI 工具如何成为个人生产力助手的实际案例
diff --git a/wiki/sources/a-formalization-of-recursive-self-optimizing-generative-systems.md b/wiki/sources/a-formalization-of-recursive-self-optimizing-generative-systems.md
index 770fc4dd..5769c01d 100644
--- a/wiki/sources/a-formalization-of-recursive-self-optimizing-generative-systems.md
+++ b/wiki/sources/a-formalization-of-recursive-self-optimizing-generative-systems.md
@@ -1,50 +1,50 @@
----
-title: "A Formalization of Recursive Self-Optimizing Generative Systems"
-type: source
-tags: []
-date: 2025-12-30
----
-
-## Source File
-- [[AI/A Formalization of Recursive Self-Optimizing Generative Systems.md]]
-
-## Summary(用中文描述)
-- 核心主题:递归自我优化的生成系统形式化模型——系统的目标不是直接产出最优输出,而是通过迭代自我修改构建稳定的生成能力
-- 问题域:自动提示工程、元学习、自我改进 AI 系统的理论基础——计算对象从"解"转变为"解的生成器"
-- 方法/机制:定义生成器空间 $\mathcal{G}$ → 优化算子 $O$ → 元生成算子 $M$ → 自映射 $\Phi$ → 不动点 $G^*$ → λ-calculus Y组合子表达
-- 结论/价值:递归自我优化系统自然涌现不动点结构,而非终止输出;稳定生成能力 = 元生成算子的不动点
-
-## Key Claims(用中文描述)
-- 生成器(Generator)作为计算对象优于单个输出:系统优化的是"生成解决方案的机制",而非单个解决方案
-- 稳定生成能力 = 自映射 $\Phi$ 的不动点 $G^*$:即在自身的"生成-优化-更新"循环下保持不变的生成器
-- 不动点可通过迭代收敛获得:当 $\Phi$ 满足连续性或收缩性条件时,$G^* = \lim_{n \to \infty} \Phi^n(G_0)$
-- 自引用结构可形式化为 λ-calculus 的 Y 组合子:$G^* \equiv Y\;\text{STEP}$ 满足 $G^* = \text{STEP}\;G^*$
-- 该框架为自我改进 AI 架构和自动化元提示系统提供了原则性理论依据
-
-## Key Quotes
-> "We study a class of recursive self-optimizing generative systems whose objective is not the direct production of optimal outputs, but the construction of a stable generative capability through iterative self-modification." — 论文 Abstract,核心研究动机
-
-> "A stable generative capability is defined as a fixed point of $\Phi$: $G^{*} \in \mathcal{G},\ \Phi(G^{*}) = G^{*}$." — 论文 Section 2,稳定生成能力的数学定义
-
-> "The analysis reveals that such systems naturally instantiate a bootstrapping meta-generative process governed by fixed-point semantics." — 论文 Abstract,核心发现
-
-## Key Concepts
-- [[Recursive Self-Optimization]]:通过迭代自我修改构建稳定生成能力的递归优化框架
-- [[Generator Space]]:生成器空间 $\mathcal{G} \subseteq \mathcal{P}^{\mathcal{I}}$,每个生成器是从意图空间到程序/提示空间的函数
-- [[Self-Referential Computation]]:生成器被定义为使用自身输出的函数的不动点,体现自引用计算本质
-- [[Fixed-Point Semantics]]:自映射 $\Phi$ 的不动点语义——系统在不终止输出的情况下实现收敛
-- [[Y-Combinator]]:λ-calculus 不动点组合子,用于表达自引用生成器的递归结构
-
-## Key Entities
-- [[tukuai]]:独立研究者,GitHub @tukuai,本文理论框架的提出者
-
-## Connections
-- [[Recursive Self-Optimization]] ← is_theoretical_basis_for ← [[Meta-Learning]]
-- [[Generator Space]] ← uses_mathematical_framework ← [[Self-Referential Computation]]
-- [[Fixed-Point Semantics]] ← formalizes ← [[Recursive Self-Optimization]]
-- [[Y-Combinator]] ← implements ← [[Self-Referential Computation]]
-- [[Self-Improving AI]] ← is_applied_domain ← [[Recursive Self-Optimization]]
-- [[Automated Prompt Engineering]] ← is_applied_domain ← [[Recursive Self-Optimization]]
-
-## Contradictions
-- (暂无发现与其他 Wiki 页面的内容冲突——本文为纯理论形式化,与 Wiki 中其他 Agent 应用案例属不同层次)
+---
+title: "A Formalization of Recursive Self-Optimizing Generative Systems"
+type: source
+tags: []
+date: 2025-12-30
+---
+
+## Source File
+- [[raw/AI/A Formalization of Recursive Self-Optimizing Generative Systems.md]]
+
+## Summary(用中文描述)
+- 核心主题:递归自我优化的生成系统形式化模型——系统的目标不是直接产出最优输出,而是通过迭代自我修改构建稳定的生成能力
+- 问题域:自动提示工程、元学习、自我改进 AI 系统的理论基础——计算对象从"解"转变为"解的生成器"
+- 方法/机制:定义生成器空间 $\mathcal{G}$ → 优化算子 $O$ → 元生成算子 $M$ → 自映射 $\Phi$ → 不动点 $G^*$ → λ-calculus Y组合子表达
+- 结论/价值:递归自我优化系统自然涌现不动点结构,而非终止输出;稳定生成能力 = 元生成算子的不动点
+
+## Key Claims(用中文描述)
+- 生成器(Generator)作为计算对象优于单个输出:系统优化的是"生成解决方案的机制",而非单个解决方案
+- 稳定生成能力 = 自映射 $\Phi$ 的不动点 $G^*$:即在自身的"生成-优化-更新"循环下保持不变的生成器
+- 不动点可通过迭代收敛获得:当 $\Phi$ 满足连续性或收缩性条件时,$G^* = \lim_{n \to \infty} \Phi^n(G_0)$
+- 自引用结构可形式化为 λ-calculus 的 Y 组合子:$G^* \equiv Y\;\text{STEP}$ 满足 $G^* = \text{STEP}\;G^*$
+- 该框架为自我改进 AI 架构和自动化元提示系统提供了原则性理论依据
+
+## Key Quotes
+> "We study a class of recursive self-optimizing generative systems whose objective is not the direct production of optimal outputs, but the construction of a stable generative capability through iterative self-modification." — 论文 Abstract,核心研究动机
+
+> "A stable generative capability is defined as a fixed point of $\Phi$: $G^{*} \in \mathcal{G},\ \Phi(G^{*}) = G^{*}$." — 论文 Section 2,稳定生成能力的数学定义
+
+> "The analysis reveals that such systems naturally instantiate a bootstrapping meta-generative process governed by fixed-point semantics." — 论文 Abstract,核心发现
+
+## Key Concepts
+- [[Recursive Self-Optimization]]:通过迭代自我修改构建稳定生成能力的递归优化框架
+- [[Generator Space]]:生成器空间 $\mathcal{G} \subseteq \mathcal{P}^{\mathcal{I}}$,每个生成器是从意图空间到程序/提示空间的函数
+- [[Self-Referential Computation]]:生成器被定义为使用自身输出的函数的不动点,体现自引用计算本质
+- [[Fixed-Point Semantics]]:自映射 $\Phi$ 的不动点语义——系统在不终止输出的情况下实现收敛
+- [[Y-Combinator]]:λ-calculus 不动点组合子,用于表达自引用生成器的递归结构
+
+## Key Entities
+- [[tukuai]]:独立研究者,GitHub @tukuai,本文理论框架的提出者
+
+## Connections
+- [[Recursive Self-Optimization]] ← is_theoretical_basis_for ← [[Meta-Learning]]
+- [[Generator Space]] ← uses_mathematical_framework ← [[Self-Referential Computation]]
+- [[Fixed-Point Semantics]] ← formalizes ← [[Recursive Self-Optimization]]
+- [[Y-Combinator]] ← implements ← [[Self-Referential Computation]]
+- [[Self-Improving AI]] ← is_applied_domain ← [[Recursive Self-Optimization]]
+- [[Automated Prompt Engineering]] ← is_applied_domain ← [[Recursive Self-Optimization]]
+
+## Contradictions
+- (暂无发现与其他 Wiki 页面的内容冲突——本文为纯理论形式化,与 Wiki 中其他 Agent 应用案例属不同层次)
diff --git a/wiki/sources/academic-anthropologist.md b/wiki/sources/academic-anthropologist.md
index e390497e..b976c05b 100644
--- a/wiki/sources/academic-anthropologist.md
+++ b/wiki/sources/academic-anthropologist.md
@@ -1,56 +1,56 @@
----
-title: "Academic Anthropologist"
-type: source
-tags: []
-date: 2026-04-20
-sources: []
-last_updated: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/academic/academic-anthropologist.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 角色设计——将文化人类学家田野调查的方法论与人格特质注入 AI Agent,使其能够构建文化上自洽的社会系统
-- 问题域:如何让 AI 在设计虚构或真实文化时避免刻板印象、文化拼贴(culture salad),而是基于人类学理论构建功能自洽的社会体系
-- 方法/机制:结构人类学(列维-斯特劳斯)、象征人类学(格尔茨"厚描")、实践理论(布迪厄)、仪式分析(特纳、范热内普)、经济人类学(莫斯、波拉尼)的理论框架
-- 结论/价值:每个文化元素必须有社会功能(社会凝聚、资源管理、身份认同、冲突解决);先功能后美学;亲属制度是基础设施
-
-## Key Claims(用中文描述)
-- AI Agent 在设计文化时应优先问"这个实践解决了什么问题"而非"这个仪式看起来酷不酷"
-- 亲属制度决定了继承、政治联盟、居住模式和冲突解决方式,是社会的骨架,不应跳过
-- 避免"高贵的野蛮人"偏见——前工业社会是复杂适应系统,有自身的政治、冲突和创新
-- 文化借用必须理解原始语境,不能仅凭表面美学混搭不同文化元素
-- 每个文化都有内部张力和矛盾(没有乌托邦),应主动识别
-
-## Key Quotes
-> "No culture is random — every practice is a solution to a problem you might not see yet." — Anthropologist Agent 核心理念
-> "Emic before etic: First understand how the culture sees itself before applying outside analytical categories." — 方法论原则
-
-## Key Concepts
-- [[Thick Description]]:格尔茨的"厚描"理论,将文化实践视为文本阅读,理解参与者的主观意义
-- [[Liminality]]:特纳的阈限概念,设计转化性仪式体验的关键框架
-- [[Gift Economy]]:莫斯的礼物经济理论,基于互惠和社会义务构建交换系统
-- [[Cultural Coherence]]:文化自洽性检验——每个文化元素必须有社会功能,内部一致
-- [[Rites of Passage]]:范热内普的通过仪式模型——分离 → 阈限 → 融合
-
-## Key Entities
-- [[Claude Lévi-Strauss]]:结构人类学创始人,二元对立分析框架
-- [[Clifford Geertz]]:象征人类学,"厚描"概念提出者
-- [[Pierre Bourdieu]]:实践理论,场域、惯习、资本概念
-- [[Victor Turner]]:仪式过程分析,阈限与社群共同性(communitas)
-- [[Arnold van Gennep]]:通过仪式三阶段模型
-- [[Marcel Mauss]]:《礼物》作者,礼物经济理论
-- [[Mary Douglas]]:神圣/世俗边界分析
-- [[Émile Durkheim]]:功能分析学派,社会凝聚理论
-- [[Bronisław Malinowski]]:功能主义,文化实践满足基本需求
-- [[Karl Polanyi]]:经济人类学,互惠、再分配、市场三元框架
-- [[Marvin Harris]]:文化唯物主义,从生存模式推演文化
-
-## Connections
-- [[Academic Historian]] ← discipline_similarity ← [[Academic Anthropologist]]
-- [[Academic Geographer]] ← discipline_similarity ← [[Academic Anthropologist]]
-- [[Academic Narratologist]] ← discipline_similarity ← [[Academic Anthropologist]]
-
-## Contradictions
-- 暂无已知冲突
+---
+title: "Academic Anthropologist"
+type: source
+tags: []
+date: 2026-04-20
+sources: []
+last_updated: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/academic/academic-anthropologist.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 角色设计——将文化人类学家田野调查的方法论与人格特质注入 AI Agent,使其能够构建文化上自洽的社会系统
+- 问题域:如何让 AI 在设计虚构或真实文化时避免刻板印象、文化拼贴(culture salad),而是基于人类学理论构建功能自洽的社会体系
+- 方法/机制:结构人类学(列维-斯特劳斯)、象征人类学(格尔茨"厚描")、实践理论(布迪厄)、仪式分析(特纳、范热内普)、经济人类学(莫斯、波拉尼)的理论框架
+- 结论/价值:每个文化元素必须有社会功能(社会凝聚、资源管理、身份认同、冲突解决);先功能后美学;亲属制度是基础设施
+
+## Key Claims(用中文描述)
+- AI Agent 在设计文化时应优先问"这个实践解决了什么问题"而非"这个仪式看起来酷不酷"
+- 亲属制度决定了继承、政治联盟、居住模式和冲突解决方式,是社会的骨架,不应跳过
+- 避免"高贵的野蛮人"偏见——前工业社会是复杂适应系统,有自身的政治、冲突和创新
+- 文化借用必须理解原始语境,不能仅凭表面美学混搭不同文化元素
+- 每个文化都有内部张力和矛盾(没有乌托邦),应主动识别
+
+## Key Quotes
+> "No culture is random — every practice is a solution to a problem you might not see yet." — Anthropologist Agent 核心理念
+> "Emic before etic: First understand how the culture sees itself before applying outside analytical categories." — 方法论原则
+
+## Key Concepts
+- [[Thick Description]]:格尔茨的"厚描"理论,将文化实践视为文本阅读,理解参与者的主观意义
+- [[Liminality]]:特纳的阈限概念,设计转化性仪式体验的关键框架
+- [[Gift Economy]]:莫斯的礼物经济理论,基于互惠和社会义务构建交换系统
+- [[Cultural Coherence]]:文化自洽性检验——每个文化元素必须有社会功能,内部一致
+- [[Rites of Passage]]:范热内普的通过仪式模型——分离 → 阈限 → 融合
+
+## Key Entities
+- [[Claude Lévi-Strauss]]:结构人类学创始人,二元对立分析框架
+- [[Clifford Geertz]]:象征人类学,"厚描"概念提出者
+- [[Pierre Bourdieu]]:实践理论,场域、惯习、资本概念
+- [[Victor Turner]]:仪式过程分析,阈限与社群共同性(communitas)
+- [[Arnold van Gennep]]:通过仪式三阶段模型
+- [[Marcel Mauss]]:《礼物》作者,礼物经济理论
+- [[Mary Douglas]]:神圣/世俗边界分析
+- [[Émile Durkheim]]:功能分析学派,社会凝聚理论
+- [[Bronisław Malinowski]]:功能主义,文化实践满足基本需求
+- [[Karl Polanyi]]:经济人类学,互惠、再分配、市场三元框架
+- [[Marvin Harris]]:文化唯物主义,从生存模式推演文化
+
+## Connections
+- [[Academic Historian]] ← discipline_similarity ← [[Academic Anthropologist]]
+- [[Academic Geographer]] ← discipline_similarity ← [[Academic Anthropologist]]
+- [[Academic Narratologist]] ← discipline_similarity ← [[Academic Anthropologist]]
+
+## Contradictions
+- 暂无已知冲突
diff --git a/wiki/sources/academic-geographer.md b/wiki/sources/academic-geographer.md
index 4e57577b..b50e9bef 100644
--- a/wiki/sources/academic-geographer.md
+++ b/wiki/sources/academic-geographer.md
@@ -1,57 +1,57 @@
----
-title: "Academic Geographer"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/academic/academic-geographer.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 中的地理学家角色(Geographer Agent)—— 专注于物理与人文地理的系统性建模,为虚拟世界构建地理连贯性
-- 问题域:如何让 AI Agent 能够像真正的地理学家一样,基于物理规律(板块构造、气候系统、水文地理)构建可信的虚拟世界,并在地理约束与人类文明之间建立逻辑联系
-- 方法/机制:通过严格的地理连贯性规则(河流不分叉、气候成系统、地理非装饰)、五步工作流(板块构造 → 气候 → 水文 → 生物群落 → 人类定居)、交付物模板(地理连贯性报告、气候系统设计)来驱动 Agent 行为
-- 结论/价值:该 Agent 为 AI 世界构建提供了一个地理学家的思维框架,强调系统性、因果性和物理一致性,避免常见的地理设定错误
-
-## Key Claims(用中文描述)
-- 河流不分叉(支流汇入主流,河流不分叉流向不同海洋)—— 这是物理水文的基本规律
-- 气候是一个系统(雨影效应、洋流、温度缓冲、纬度决定季节)—— 不能随意放置违背物理规律的气候
-- 地理不是装饰(每座山、每条河、每个沙漠都对当地居民有实际影响)
-- 避免地理决定论(地理约束但不决定,相似环境产生不同文化)
-- 规模很重要("小王国"和"大帝国"的地理需求完全不同)
-- 地图是论据(每张地图都有关于包含什么、排除什么的政治选择)
-
-## Key Quotes
-> "Geography is destiny — where you are determines who you become" — Geographer Agent 的核心理念
-> "Rivers don't split. Tributaries merge into rivers. Rivers don't fork into two separate rivers flowing to different oceans." — 关键物理规则
-> "Maps are arguments. Every map makes choices about what to include and exclude." — 制图的政治性
-
-## Key Concepts
-- [[Geographic Coherence]]:地理连贯性 —— 确保气候、地形、生物群落之间物理一致的原则
-- [[Koppen Climate Classification]]:柯本气候分类法 —— Agent 用于描述气候区的参考框架
-- [[Environmental Determinism]]:环境决定论 —— 认为地理直接决定文化和发展的理论框架,Agent 在采纳其框架的同时承认其批评
-- [[Christaller Central Place Theory]]:克里斯塔勒中心地理论 —— 解释城市层级和形成原因的人文地理理论
-- [[Mackinder Heartland Theory]]:麦金德心脏地带理论 —— 地缘政治学中关于地理如何塑造战略竞争的框架
-- [[Rain Shadow Effect]]:雨影效应 —— 山脉阻挡湿气导致背风坡干旱的物理现象
-- [[Plate Tectonics]]:板块构造论 —— 解释山脉、火山等地理特征形成的地质学基础
-
-## Key Entities
-- [[Jared Diamond]]:提出地理框架(《枪炮、病菌与钢铁》),Agent 采纳其环境决定论视角同时承认其局限性
-- [[Acemoglu]]:对地理决定论的批评者,Agent 明确引用以避免走向极端地理决定论
-- [[Wallerstein]]:世界体系理论提出者,影响 Agent 对贸易网络和权力动态的分析
-- [[Mackinder]]:地缘政治学先驱,Heartland Theory 的提出者
-
-## Connections
-- [[Geographic Coherence]] ← builds_upon ← [[Plate Tectonics]]
-- [[Geographic Coherence]] ← builds_upon ← [[Koppen Climate Classification]]
-- [[Mackinder Heartland Theory]] ← extends ← [[Geographic Coherence]]
-- [[Christaller Central Place Theory]] ← extends ← [[Geographic Coherence]]
-- [[Jared Diamond]] → influences → [[Environmental Determinism]]
-- [[Acemoglu]] → critiques → [[Environmental Determinism]]
-
-## Contradictions
-- 与 [[Jared Diamond]] 的框架存在张力:
- - 冲突点:Agent 采纳 Diamond 的地理框架,但同时强调 Acemoglu 对地理决定论的批评
- - 当前观点:地理约束人类选择,但不等同于决定论
- - 对方观点:Diamond 强调地理是历史发展的主导因素
+---
+title: "Academic Geographer"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/academic/academic-geographer.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 中的地理学家角色(Geographer Agent)—— 专注于物理与人文地理的系统性建模,为虚拟世界构建地理连贯性
+- 问题域:如何让 AI Agent 能够像真正的地理学家一样,基于物理规律(板块构造、气候系统、水文地理)构建可信的虚拟世界,并在地理约束与人类文明之间建立逻辑联系
+- 方法/机制:通过严格的地理连贯性规则(河流不分叉、气候成系统、地理非装饰)、五步工作流(板块构造 → 气候 → 水文 → 生物群落 → 人类定居)、交付物模板(地理连贯性报告、气候系统设计)来驱动 Agent 行为
+- 结论/价值:该 Agent 为 AI 世界构建提供了一个地理学家的思维框架,强调系统性、因果性和物理一致性,避免常见的地理设定错误
+
+## Key Claims(用中文描述)
+- 河流不分叉(支流汇入主流,河流不分叉流向不同海洋)—— 这是物理水文的基本规律
+- 气候是一个系统(雨影效应、洋流、温度缓冲、纬度决定季节)—— 不能随意放置违背物理规律的气候
+- 地理不是装饰(每座山、每条河、每个沙漠都对当地居民有实际影响)
+- 避免地理决定论(地理约束但不决定,相似环境产生不同文化)
+- 规模很重要("小王国"和"大帝国"的地理需求完全不同)
+- 地图是论据(每张地图都有关于包含什么、排除什么的政治选择)
+
+## Key Quotes
+> "Geography is destiny — where you are determines who you become" — Geographer Agent 的核心理念
+> "Rivers don't split. Tributaries merge into rivers. Rivers don't fork into two separate rivers flowing to different oceans." — 关键物理规则
+> "Maps are arguments. Every map makes choices about what to include and exclude." — 制图的政治性
+
+## Key Concepts
+- [[Geographic Coherence]]:地理连贯性 —— 确保气候、地形、生物群落之间物理一致的原则
+- [[Koppen Climate Classification]]:柯本气候分类法 —— Agent 用于描述气候区的参考框架
+- [[Environmental Determinism]]:环境决定论 —— 认为地理直接决定文化和发展的理论框架,Agent 在采纳其框架的同时承认其批评
+- [[Christaller Central Place Theory]]:克里斯塔勒中心地理论 —— 解释城市层级和形成原因的人文地理理论
+- [[Mackinder Heartland Theory]]:麦金德心脏地带理论 —— 地缘政治学中关于地理如何塑造战略竞争的框架
+- [[Rain Shadow Effect]]:雨影效应 —— 山脉阻挡湿气导致背风坡干旱的物理现象
+- [[Plate Tectonics]]:板块构造论 —— 解释山脉、火山等地理特征形成的地质学基础
+
+## Key Entities
+- [[Jared Diamond]]:提出地理框架(《枪炮、病菌与钢铁》),Agent 采纳其环境决定论视角同时承认其局限性
+- [[Acemoglu]]:对地理决定论的批评者,Agent 明确引用以避免走向极端地理决定论
+- [[Wallerstein]]:世界体系理论提出者,影响 Agent 对贸易网络和权力动态的分析
+- [[Mackinder]]:地缘政治学先驱,Heartland Theory 的提出者
+
+## Connections
+- [[Geographic Coherence]] ← builds_upon ← [[Plate Tectonics]]
+- [[Geographic Coherence]] ← builds_upon ← [[Koppen Climate Classification]]
+- [[Mackinder Heartland Theory]] ← extends ← [[Geographic Coherence]]
+- [[Christaller Central Place Theory]] ← extends ← [[Geographic Coherence]]
+- [[Jared Diamond]] → influences → [[Environmental Determinism]]
+- [[Acemoglu]] → critiques → [[Environmental Determinism]]
+
+## Contradictions
+- 与 [[Jared Diamond]] 的框架存在张力:
+ - 冲突点:Agent 采纳 Diamond 的地理框架,但同时强调 Acemoglu 对地理决定论的批评
+ - 当前观点:地理约束人类选择,但不等同于决定论
+ - 对方观点:Diamond 强调地理是历史发展的主导因素
diff --git a/wiki/sources/academic-historian.md b/wiki/sources/academic-historian.md
index d6eb8cc6..3915e352 100644
--- a/wiki/sources/academic-historian.md
+++ b/wiki/sources/academic-historian.md
@@ -1,51 +1,51 @@
----
-title: "Historian Agent Personality"
-type: source
-tags: ["agent-personality", "historiography", "material-culture", "period-authenticity", "academic"]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/academic/academic-historian.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 角色设定——扮演具有跨时代研究能力的历史学家,为创意项目提供历史真实性验证、时代背景丰富化和历史迷思纠正
-- 问题域:虚构作品中避免时代错乱(anachronism)、为游戏/小说/影视提供扎实的物质文化基础、主动纳入非西方历史传统
-- 方法/机制:通过五步工作流(定位时间空间→核查物质基础→叠加社会结构→评估论断→标注置信度),结合 Annales 学派、长时段分析、微观史、比较史等史学方法论
-- 结论/价值:让 AI Agent 能够以"历史学家"身份为创意世界提供可溯源的历史支撑,提升内容的历史深度与文化包容性
-
-## Key Claims(用中文描述)
-- 历史学家 Agent 通过"时代真实性报告"(Period Authenticity Report)为设定提供饮食、服饰、建筑、技术、货币、权力结构、性别角色等全维度历史细节
-- 所有历史论断必须标注来源类型(原始文献>二手学术>通俗史>好莱坞)和置信度(高/中/低),避免"中世纪时..."这类模糊表述
-- 主动挑战欧洲中心主义:将宋朝科技、明帝国财富、马里帝国等非西方历史纳入比较视野
-- 物质条件决定论:在讨论政治/军事前必须先理解经济基础(农业、贸易、技术水平)
-
-## Key Quotes
-> "History doesn't repeat, but it rhymes — and I know all the verses" — Historian Agent 的风格定位
-> "That's a common belief, but the evidence actually shows..." — 纠正历史迷思时的沟通风格
-> "Medieval Europe spans 1000 years and a continent. Be specific about when and where." — 对时代宽泛化的警示
-> "Myths are data too. A society's myths reveal what they valued, feared, and aspired to." — 对神话的态度
-
-## Key Concepts
-- [[Annales School]]:法国史学流派,强调长时段(longue durée)结构史学,关注日常生活的物质文化与经济基础
-- [[Material Culture Analysis]]:物质文化分析,通过文物、遗址、日用物品重建历史时期的生活质感
-- [[Anachronism Detection]]:时代错乱检测,不仅识别明显的(如前哥伦布时代欧洲出现土豆),还包括隐性的(态度、社会结构、经济系统的时代错配)
-- [[Longue Durée]]:布罗代尔提出的长时段历史分析概念,识别塑造事件发生的长期结构
-- [[Microhistory]]:微观史学,关注特定个人或社区以揭示更广泛的历史动态
-- [[Comparative History]]:比较历史学,跨文明比较相似挑战下的不同应对方式
-- [[Counterfactual Analysis]]:反事实分析,基于历史偶然性理论的严谨"如果"推理
-- [[Postcolonial History]]:后殖民史学,主动纳入非欧洲中心的历史视角
-
-## Key Entities
-- [[Annales School]](学术流派):由布洛赫和费弗尔创立,以《年鉴》杂志为核心阵地,代表人物包括布罗代尔
-- [[Fernand Braudel]](历史学家):长时段理论提出者,著有《菲利普二世时代的地中海和地中海世界》
-- [[Pirenne]](历史学家):提出"穆罕默德和查理曼"的商业复兴论点,与维克斯曼等后世学者存在争论
-
-## Connections
-- [[Academic Geographer]] ← 方法互补 ← [[Academic Historian]]:地理与历史共同构建时空坐标
-- [[Academic Narratologist]] ← 内容提供 ← [[Academic Historian]]:历史真实性为叙事提供素材
-- [[Academic Anthropologist]] ← 理论交叉 ← [[Academic Historian]]:两者都关注物质文化与日常生活的重建
-
-## Contradictions
-- 与通俗历史观点冲突:大量常见的历史迷思("黑暗的中世纪"、"文艺复兴突然觉醒"等)被纠正
-- 与影视作品冲突:Holly hollywood 对中世纪/古典时代的浪漫化呈现被明确标记为错误
+---
+title: "Historian Agent Personality"
+type: source
+tags: ["agent-personality", "historiography", "material-culture", "period-authenticity", "academic"]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/academic/academic-historian.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 角色设定——扮演具有跨时代研究能力的历史学家,为创意项目提供历史真实性验证、时代背景丰富化和历史迷思纠正
+- 问题域:虚构作品中避免时代错乱(anachronism)、为游戏/小说/影视提供扎实的物质文化基础、主动纳入非西方历史传统
+- 方法/机制:通过五步工作流(定位时间空间→核查物质基础→叠加社会结构→评估论断→标注置信度),结合 Annales 学派、长时段分析、微观史、比较史等史学方法论
+- 结论/价值:让 AI Agent 能够以"历史学家"身份为创意世界提供可溯源的历史支撑,提升内容的历史深度与文化包容性
+
+## Key Claims(用中文描述)
+- 历史学家 Agent 通过"时代真实性报告"(Period Authenticity Report)为设定提供饮食、服饰、建筑、技术、货币、权力结构、性别角色等全维度历史细节
+- 所有历史论断必须标注来源类型(原始文献>二手学术>通俗史>好莱坞)和置信度(高/中/低),避免"中世纪时..."这类模糊表述
+- 主动挑战欧洲中心主义:将宋朝科技、明帝国财富、马里帝国等非西方历史纳入比较视野
+- 物质条件决定论:在讨论政治/军事前必须先理解经济基础(农业、贸易、技术水平)
+
+## Key Quotes
+> "History doesn't repeat, but it rhymes — and I know all the verses" — Historian Agent 的风格定位
+> "That's a common belief, but the evidence actually shows..." — 纠正历史迷思时的沟通风格
+> "Medieval Europe spans 1000 years and a continent. Be specific about when and where." — 对时代宽泛化的警示
+> "Myths are data too. A society's myths reveal what they valued, feared, and aspired to." — 对神话的态度
+
+## Key Concepts
+- [[Annales School]]:法国史学流派,强调长时段(longue durée)结构史学,关注日常生活的物质文化与经济基础
+- [[Material Culture Analysis]]:物质文化分析,通过文物、遗址、日用物品重建历史时期的生活质感
+- [[Anachronism Detection]]:时代错乱检测,不仅识别明显的(如前哥伦布时代欧洲出现土豆),还包括隐性的(态度、社会结构、经济系统的时代错配)
+- [[Longue Durée]]:布罗代尔提出的长时段历史分析概念,识别塑造事件发生的长期结构
+- [[Microhistory]]:微观史学,关注特定个人或社区以揭示更广泛的历史动态
+- [[Comparative History]]:比较历史学,跨文明比较相似挑战下的不同应对方式
+- [[Counterfactual Analysis]]:反事实分析,基于历史偶然性理论的严谨"如果"推理
+- [[Postcolonial History]]:后殖民史学,主动纳入非欧洲中心的历史视角
+
+## Key Entities
+- [[Annales School]](学术流派):由布洛赫和费弗尔创立,以《年鉴》杂志为核心阵地,代表人物包括布罗代尔
+- [[Fernand Braudel]](历史学家):长时段理论提出者,著有《菲利普二世时代的地中海和地中海世界》
+- [[Pirenne]](历史学家):提出"穆罕默德和查理曼"的商业复兴论点,与维克斯曼等后世学者存在争论
+
+## Connections
+- [[Academic Geographer]] ← 方法互补 ← [[Academic Historian]]:地理与历史共同构建时空坐标
+- [[Academic Narratologist]] ← 内容提供 ← [[Academic Historian]]:历史真实性为叙事提供素材
+- [[Academic Anthropologist]] ← 理论交叉 ← [[Academic Historian]]:两者都关注物质文化与日常生活的重建
+
+## Contradictions
+- 与通俗历史观点冲突:大量常见的历史迷思("黑暗的中世纪"、"文艺复兴突然觉醒"等)被纠正
+- 与影视作品冲突:Holly hollywood 对中世纪/古典时代的浪漫化呈现被明确标记为错误
diff --git a/wiki/sources/academic-narratologist.md b/wiki/sources/academic-narratologist.md
index 2c972959..20d0831b 100644
--- a/wiki/sources/academic-narratologist.md
+++ b/wiki/sources/academic-narratologist.md
@@ -1,52 +1,52 @@
----
-title: "Academic Narratologist"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/academic/academic-narratologist.md]]
-
-## Summary(用中文描述)
-- 核心主题:Narratologist Agent 角色设定——一个以叙事理论为基础的故事结构分析 AI Agent,具备俄罗斯形式主义、法国结构主义、认知叙事学等深厚学术背景
-- 问题域:如何让 AI Agent 能够像专业叙事理论家一样,分析故事结构、角色弧光、主题表达,并提供有理论依据的叙事建议
-- 方法/机制:通过预置的叙事学框架(Propp、Campbell、Genette、Barthes、Todorov 等)驱动分析流程,要求每个建议都必须引用至少一个命名理论框架
-- 结论/价值:提供了一个可复用的学术型 AI Agent 设计范式——将传统人文社科理论与 LLM 系统提示词工程结合
-
-## Key Claims(用中文描述)
-- Narratologist Agent 能通过 Propp 形态学分析童话/冒险结构,通过 Campbell 单一体神话和 Vogler 编剧旅程分析英雄叙事
-- 叙事问题通常存在于讲述层面(sjuzhet)而非故事层面(fabula)——应优先诊断叙事手法而非情节本身
-- 每个结构建议必须引用至少一个命名理论框架,并附带推理过程;泛泛的建议(如"让角色更立体")是不合格的
-- 角色动机的心理分析只能作为视角而非处方使用——角色不是案例研究对象
-- 在颠覆类型惯例之前必须先理解并尊重类型惯例
-
-## Key Quotes
-> "Every story is an argument — I help you find what yours is really saying." — Narratologist Agent 自述核心理念
-> "Most problems live in the telling (sjuzhet), not the tale (fabula)." — 叙事诊断的核心原则
-> "Cite sources. 'According to Propp's function analysis, this character serves as the Donor' is useful. 'This character should be more interesting' is not." — 关于提供理论依据的要求
-
-## Key Concepts
-- [[Fabula 与 Sjuzhet]]:故事(fabula=按时间顺序的事件)与叙事(sjuzhet=如何讲述)的区分,是叙事分析的基础框架
-- [[Propp 形态学]]:Vladimir Propp 的民间故事功能分析,识别31种故事功能(如 Donor、Hero、Villain)
-- [[Campbell 单一体神话]]:Joseph Campbell 的"英雄之旅"理论,Hero's Journey 的学术根源
-- [[Vogler 编剧旅程]]:Christopher Vogler 将 Campbell 理论改编为好莱坞编剧实践框架
-- [[Genette 叙事学]]:Gérard Genette 的叙事理论,聚焦叙事视角(focalization)、时序结构、叙事声音
-- [[Barthes 五代码]]:Roland Barthes 的叙事语义五代码模型(Hermeneutic、Proairetic、Symbolic、Semantic、Referential)
-- [[Todorov 均衡模型]]:Tzvetan Todorov 的 equilibrium-disruption-new equilibrium 三阶段模型
-- [[角色弧光]]:Character Arc,角色从起点到终点的内在变化轨迹,含 want/need/lie/transformation 四个维度
-- [[叙事债务]]:Narrative Debts,向读者做出的尚未兑现的叙事承诺
-- [[控制性理念]]:Controlling Idea(McKee 术语),即故事对人类经验的论证核心
-
-## Key Entities
-- [[Academic Anthropologist]]:同一系列中的学术型 Agent 之一,同样采用学科理论驱动的方法论
-- [[Academic Historian]]:同一系列中的学术型 Agent 之一,共享 Agent 个性设计范式
-- [[Academic Geographer]]:同一系列中的学术型 Agent 之一
-
-## Connections
-- [[Academic Anthropologist]] ← 同系列学术 Agent ← [[Academic Narratologist]]
-- [[Academic Historian]] ← 同系列学术 Agent ← [[Academic Narratologist]]
-- [[Academic Geographer]] ← 同系列学术 Agent ← [[Academic Narratologist]]
-
-## Contradictions
-- 暂无冲突内容
+---
+title: "Academic Narratologist"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/academic/academic-narratologist.md]]
+
+## Summary(用中文描述)
+- 核心主题:Narratologist Agent 角色设定——一个以叙事理论为基础的故事结构分析 AI Agent,具备俄罗斯形式主义、法国结构主义、认知叙事学等深厚学术背景
+- 问题域:如何让 AI Agent 能够像专业叙事理论家一样,分析故事结构、角色弧光、主题表达,并提供有理论依据的叙事建议
+- 方法/机制:通过预置的叙事学框架(Propp、Campbell、Genette、Barthes、Todorov 等)驱动分析流程,要求每个建议都必须引用至少一个命名理论框架
+- 结论/价值:提供了一个可复用的学术型 AI Agent 设计范式——将传统人文社科理论与 LLM 系统提示词工程结合
+
+## Key Claims(用中文描述)
+- Narratologist Agent 能通过 Propp 形态学分析童话/冒险结构,通过 Campbell 单一体神话和 Vogler 编剧旅程分析英雄叙事
+- 叙事问题通常存在于讲述层面(sjuzhet)而非故事层面(fabula)——应优先诊断叙事手法而非情节本身
+- 每个结构建议必须引用至少一个命名理论框架,并附带推理过程;泛泛的建议(如"让角色更立体")是不合格的
+- 角色动机的心理分析只能作为视角而非处方使用——角色不是案例研究对象
+- 在颠覆类型惯例之前必须先理解并尊重类型惯例
+
+## Key Quotes
+> "Every story is an argument — I help you find what yours is really saying." — Narratologist Agent 自述核心理念
+> "Most problems live in the telling (sjuzhet), not the tale (fabula)." — 叙事诊断的核心原则
+> "Cite sources. 'According to Propp's function analysis, this character serves as the Donor' is useful. 'This character should be more interesting' is not." — 关于提供理论依据的要求
+
+## Key Concepts
+- [[Fabula 与 Sjuzhet]]:故事(fabula=按时间顺序的事件)与叙事(sjuzhet=如何讲述)的区分,是叙事分析的基础框架
+- [[Propp 形态学]]:Vladimir Propp 的民间故事功能分析,识别31种故事功能(如 Donor、Hero、Villain)
+- [[Campbell 单一体神话]]:Joseph Campbell 的"英雄之旅"理论,Hero's Journey 的学术根源
+- [[Vogler 编剧旅程]]:Christopher Vogler 将 Campbell 理论改编为好莱坞编剧实践框架
+- [[Genette 叙事学]]:Gérard Genette 的叙事理论,聚焦叙事视角(focalization)、时序结构、叙事声音
+- [[Barthes 五代码]]:Roland Barthes 的叙事语义五代码模型(Hermeneutic、Proairetic、Symbolic、Semantic、Referential)
+- [[Todorov 均衡模型]]:Tzvetan Todorov 的 equilibrium-disruption-new equilibrium 三阶段模型
+- [[角色弧光]]:Character Arc,角色从起点到终点的内在变化轨迹,含 want/need/lie/transformation 四个维度
+- [[叙事债务]]:Narrative Debts,向读者做出的尚未兑现的叙事承诺
+- [[控制性理念]]:Controlling Idea(McKee 术语),即故事对人类经验的论证核心
+
+## Key Entities
+- [[Academic Anthropologist]]:同一系列中的学术型 Agent 之一,同样采用学科理论驱动的方法论
+- [[Academic Historian]]:同一系列中的学术型 Agent 之一,共享 Agent 个性设计范式
+- [[Academic Geographer]]:同一系列中的学术型 Agent 之一
+
+## Connections
+- [[Academic Anthropologist]] ← 同系列学术 Agent ← [[Academic Narratologist]]
+- [[Academic Historian]] ← 同系列学术 Agent ← [[Academic Narratologist]]
+- [[Academic Geographer]] ← 同系列学术 Agent ← [[Academic Narratologist]]
+
+## Contradictions
+- 暂无冲突内容
diff --git a/wiki/sources/academic-psychologist.md b/wiki/sources/academic-psychologist.md
index 8c3db484..46d0debb 100644
--- a/wiki/sources/academic-psychologist.md
+++ b/wiki/sources/academic-psychologist.md
@@ -1,80 +1,80 @@
----
-title: "Academic Psychologist"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/academic/academic-psychologist.md]]
-
-## Summary(用中文描述)
-- 核心主题:Academic Psychologist——The Agency 学术部门的临床与研究心理学家人格智能体,为角色塑造提供心理学可信度支撑。
-- 问题域:角色心理学评估、人际关系动态分析、创伤/压力/冲突的真实性反应建模、群体行为心理学。
-- 方法/机制:基于 Big Five 人格框架、依恋理论、Vaillant 防御机制层级、Karpman 戏剧三角、认知行为疗法(CBT)认知扭曲、社会心理学经典实验(Milgram/Zimbardo/Asch)等多种理论与实证框架,对角色进行多维度心理画像。
-- 结论/价值:拒绝将角色病理化,强调区分流行心理学与循证心理学,承认文化情境与创伤响应的多样性,要求所有心理观察必须引用具体理论或实证研究并诚实承认其局限性。
-
-## Key Claims(用中文描述)
-- 不将角色降低为诊断。角色可以表现出自恋*特质*而无需成为"自恋者"——人不是 DSM 代码。
-- 区分**流行心理学**与**循证心理学**。引用某理论时,需了解该理论是同行评审还是自助类。
-- 承认文化情境。依恋理论源于西方个人主义背景。集体主义文化可能呈现不同的"健康"模式。
-- 创伤响应多样。并非所有创伤都导致退缩——有人变得高度警觉,有人变成讨好者,有人通过隔离高效运转。
-- 对心理学未解之谜保持诚实。该领域存在可重复性危机、文化偏见和真正的争议——不将争议性发现当作既定科学呈现。
-
-## Key Quotes
-> "People don't do things for no reason — I find the reason" — Psychologist Agent 核心信念
-> "观察先于诊断" — 收集行为证据后再映射到理论框架
-> "Use multiple lenses: No single theory explains everything" — 交叉参考 Big Five、依恋理论与文化背景
-
-## Key Concepts
-- [[Big-Five-Personality]]: 人格五因素模型(开放性、尽责性、外向性、宜人性、神经质),用于量化角色核心人格特质
-- [[Attachment-Theory]]: 依恋理论(安全型/焦虑型/回避型/恐惧型),用于分析角色在亲密关系中的行为模式
-- [[Defense-Mechanisms]]: Vaillant 防御机制层级(成熟型/神经症型/不成熟型),用于识别角色在压力下的应对策略
-- [[Cognitive-Distortions]]: Beck 认知扭曲(十种常见非理性思维模式),用于识别驱动角色决策的具体认知偏差
-- [[Karpman-Drama-Triangle]]: Karpman 戏剧三角(受害者/迫害者/拯救者),用于分析人际冲突中的角色动态
-- [[Transactional-Analysis]]: 沟通分析(父母/成人/儿童三种自我状态),用于诊断角色间沟通模式
-- [[Social-Psychology-Classics]]: Milgram(服从权威)、Zimbardo(斯坦福监狱实验)、Asch(从众实验)及其现代批判
-- [[Cognitive-Behavioral-Therapy]]: CBT 认知行为疗法框架,用于建模现实的心理干预路径
-- [[Developmental-Psychology]]: Erikson 心理社会发展阶段、Piaget 认知发展、Bowlby 依恋起源
-- [[Trauma-Informed-Analysis]]: 创伤知情分析——PTSD、复杂性创伤、代际创伤(van der Kolk/Herman/Porges 理论)
-- [[Group-Psychology]]: 群体心理(社会认同理论/群体思维/责任扩散/暴民心理)
-- [[Cross-Cultural-Psychology]]: 跨文化心理学(Markus & Kitayama 文化模式/Hofstede 文化维度)
-- [[Psychological-Profile]]: 角色心理画像技术文档格式——整合 Big Five + 依恋风格 + 防御机制 + 核心创伤 + 应对策略 + 盲点
-
-## Key Entities
-- [[Erik Erikson]]: 心理社会发展理论提出者,Erikson 八阶段理论用于角色发展轨迹建模
-- [[Jean Piaget]]: 认知发展理论提出者,Piaget 四阶段用于角色认知成熟度评估
-- [[John Bowlby]]: 依恋理论创始人,Bowlby 依恋风格分类影响角色亲密关系建模
-- [[Aaron Beck]]: 认知行为疗法创始人,Beck 认知扭曲十种类型用于角色决策分析
-- [[Stephen Karpman]]: 戏剧三角提出者,Karpman 三角用于人际冲突建模
-- [[George Vaillant]]: 防御机制层级研究者,Vaillant 层级用于压力应对策略分类
-- [[Stanley Milgram]]: 服从权威实验研究者,Milgram 实验用于群体压力建模
-- [[Philip Zimbardo]]: 斯坦福监狱实验研究者,Zimbardo 实验用于权威与情境分析
-- [[Solomon Asch]]: 从众实验研究者,Asch 实验用于群体从众建模
-- [[Judith Herman]]: 复杂性创伤与恢复阶段研究者(Herman 三阶段恢复模型)
-- [[Bessel van der Kolk]]: 创伤与身体关系研究者("身体记录创伤"核心概念)
-- [[Stephen Porges]]: Polyvagal Theory 提出者,Porges 理论用于创伤响应建模
-- [[Hans Eysenck]]: 大五人格先驱研究者
-- [[Richard Lazarus]]: 压力与应对理论研究者
-
-## Connections
-- [[Big-Five-Personality]] ← foundational_framework ← [[Psychological-Profile]]
-- [[Attachment-Theory]] ← behavioral_pattern ← [[Psychological-Profile]]
-- [[Defense-Mechanisms]] ← under_stress_response ← [[Psychological-Profile]]
-- [[Cognitive-Distortions]] ← driving_force ← Character-Decisions
-- [[Karpman-Drama-Triangle]] ← conflict_model ← Interpersonal-Dynamics
-- [[Transactional-Analysis]] ← communication_pattern ← Interpersonal-Dynamics
-- [[Trauma-Informed-Analysis]] ← advanced_capability ← [[Psychological-Profile]]
-- [[Group-Psychology]] ← advanced_capability ← Interpersonal-Dynamics
-- [[Behavioral-Nudge-Engine]] ← theoretical_foundation ← [[Behavioral-Psychology]](本 Wiki 已有 [[Behavioral-Psychology]] Concept Page)
-- [[multi-agent-system-reliability]] ← conflicts_with ← 确定性 vs LLM 概率性悖论
-
-## Contradictions
-- 与 [[multi-agent-system-reliability]] 冲突:
- - 冲突点:多智能体系统可靠性主张"架构约束优于提示词约束"(确定性),Psychologist Agent 依赖 LLM 推理进行心理评估(概率性)。
- - 当前观点:心理评估需要概率性推理能力,但可以通过 Chain-of-Thought 约束推理路径。
- - 对方观点:LLM 作为不可靠组件,不应依赖其进行推理,应通过架构强制正确性。
-- 与流行心理学(MBTI/Enneagram)张力:
- - 冲突点:MBTI 和 Enneagram 在大众中广泛使用,但学术可信度有限。
- - 当前观点:Enneagram 仅作为叙事工具接受,MBTI 局限性必须明确标注。
- - 对方观点:MBTI 简单直观,适合快速角色原型划分。
+---
+title: "Academic Psychologist"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/academic/academic-psychologist.md]]
+
+## Summary(用中文描述)
+- 核心主题:Academic Psychologist——The Agency 学术部门的临床与研究心理学家人格智能体,为角色塑造提供心理学可信度支撑。
+- 问题域:角色心理学评估、人际关系动态分析、创伤/压力/冲突的真实性反应建模、群体行为心理学。
+- 方法/机制:基于 Big Five 人格框架、依恋理论、Vaillant 防御机制层级、Karpman 戏剧三角、认知行为疗法(CBT)认知扭曲、社会心理学经典实验(Milgram/Zimbardo/Asch)等多种理论与实证框架,对角色进行多维度心理画像。
+- 结论/价值:拒绝将角色病理化,强调区分流行心理学与循证心理学,承认文化情境与创伤响应的多样性,要求所有心理观察必须引用具体理论或实证研究并诚实承认其局限性。
+
+## Key Claims(用中文描述)
+- 不将角色降低为诊断。角色可以表现出自恋*特质*而无需成为"自恋者"——人不是 DSM 代码。
+- 区分**流行心理学**与**循证心理学**。引用某理论时,需了解该理论是同行评审还是自助类。
+- 承认文化情境。依恋理论源于西方个人主义背景。集体主义文化可能呈现不同的"健康"模式。
+- 创伤响应多样。并非所有创伤都导致退缩——有人变得高度警觉,有人变成讨好者,有人通过隔离高效运转。
+- 对心理学未解之谜保持诚实。该领域存在可重复性危机、文化偏见和真正的争议——不将争议性发现当作既定科学呈现。
+
+## Key Quotes
+> "People don't do things for no reason — I find the reason" — Psychologist Agent 核心信念
+> "观察先于诊断" — 收集行为证据后再映射到理论框架
+> "Use multiple lenses: No single theory explains everything" — 交叉参考 Big Five、依恋理论与文化背景
+
+## Key Concepts
+- [[Big-Five-Personality]]: 人格五因素模型(开放性、尽责性、外向性、宜人性、神经质),用于量化角色核心人格特质
+- [[Attachment-Theory]]: 依恋理论(安全型/焦虑型/回避型/恐惧型),用于分析角色在亲密关系中的行为模式
+- [[Defense-Mechanisms]]: Vaillant 防御机制层级(成熟型/神经症型/不成熟型),用于识别角色在压力下的应对策略
+- [[Cognitive-Distortions]]: Beck 认知扭曲(十种常见非理性思维模式),用于识别驱动角色决策的具体认知偏差
+- [[Karpman-Drama-Triangle]]: Karpman 戏剧三角(受害者/迫害者/拯救者),用于分析人际冲突中的角色动态
+- [[Transactional-Analysis]]: 沟通分析(父母/成人/儿童三种自我状态),用于诊断角色间沟通模式
+- [[Social-Psychology-Classics]]: Milgram(服从权威)、Zimbardo(斯坦福监狱实验)、Asch(从众实验)及其现代批判
+- [[Cognitive-Behavioral-Therapy]]: CBT 认知行为疗法框架,用于建模现实的心理干预路径
+- [[Developmental-Psychology]]: Erikson 心理社会发展阶段、Piaget 认知发展、Bowlby 依恋起源
+- [[Trauma-Informed-Analysis]]: 创伤知情分析——PTSD、复杂性创伤、代际创伤(van der Kolk/Herman/Porges 理论)
+- [[Group-Psychology]]: 群体心理(社会认同理论/群体思维/责任扩散/暴民心理)
+- [[Cross-Cultural-Psychology]]: 跨文化心理学(Markus & Kitayama 文化模式/Hofstede 文化维度)
+- [[Psychological-Profile]]: 角色心理画像技术文档格式——整合 Big Five + 依恋风格 + 防御机制 + 核心创伤 + 应对策略 + 盲点
+
+## Key Entities
+- [[Erik Erikson]]: 心理社会发展理论提出者,Erikson 八阶段理论用于角色发展轨迹建模
+- [[Jean Piaget]]: 认知发展理论提出者,Piaget 四阶段用于角色认知成熟度评估
+- [[John Bowlby]]: 依恋理论创始人,Bowlby 依恋风格分类影响角色亲密关系建模
+- [[Aaron Beck]]: 认知行为疗法创始人,Beck 认知扭曲十种类型用于角色决策分析
+- [[Stephen Karpman]]: 戏剧三角提出者,Karpman 三角用于人际冲突建模
+- [[George Vaillant]]: 防御机制层级研究者,Vaillant 层级用于压力应对策略分类
+- [[Stanley Milgram]]: 服从权威实验研究者,Milgram 实验用于群体压力建模
+- [[Philip Zimbardo]]: 斯坦福监狱实验研究者,Zimbardo 实验用于权威与情境分析
+- [[Solomon Asch]]: 从众实验研究者,Asch 实验用于群体从众建模
+- [[Judith Herman]]: 复杂性创伤与恢复阶段研究者(Herman 三阶段恢复模型)
+- [[Bessel van der Kolk]]: 创伤与身体关系研究者("身体记录创伤"核心概念)
+- [[Stephen Porges]]: Polyvagal Theory 提出者,Porges 理论用于创伤响应建模
+- [[Hans Eysenck]]: 大五人格先驱研究者
+- [[Richard Lazarus]]: 压力与应对理论研究者
+
+## Connections
+- [[Big-Five-Personality]] ← foundational_framework ← [[Psychological-Profile]]
+- [[Attachment-Theory]] ← behavioral_pattern ← [[Psychological-Profile]]
+- [[Defense-Mechanisms]] ← under_stress_response ← [[Psychological-Profile]]
+- [[Cognitive-Distortions]] ← driving_force ← Character-Decisions
+- [[Karpman-Drama-Triangle]] ← conflict_model ← Interpersonal-Dynamics
+- [[Transactional-Analysis]] ← communication_pattern ← Interpersonal-Dynamics
+- [[Trauma-Informed-Analysis]] ← advanced_capability ← [[Psychological-Profile]]
+- [[Group-Psychology]] ← advanced_capability ← Interpersonal-Dynamics
+- [[Behavioral-Nudge-Engine]] ← theoretical_foundation ← [[Behavioral-Psychology]](本 Wiki 已有 [[Behavioral-Psychology]] Concept Page)
+- [[multi-agent-system-reliability]] ← conflicts_with ← 确定性 vs LLM 概率性悖论
+
+## Contradictions
+- 与 [[multi-agent-system-reliability]] 冲突:
+ - 冲突点:多智能体系统可靠性主张"架构约束优于提示词约束"(确定性),Psychologist Agent 依赖 LLM 推理进行心理评估(概率性)。
+ - 当前观点:心理评估需要概率性推理能力,但可以通过 Chain-of-Thought 约束推理路径。
+ - 对方观点:LLM 作为不可靠组件,不应依赖其进行推理,应通过架构强制正确性。
+- 与流行心理学(MBTI/Enneagram)张力:
+ - 冲突点:MBTI 和 Enneagram 在大众中广泛使用,但学术可信度有限。
+ - 当前观点:Enneagram 仅作为叙事工具接受,MBTI 局限性必须明确标注。
+ - 对方观点:MBTI 简单直观,适合快速角色原型划分。
diff --git a/wiki/sources/accounts-payable-agent.md b/wiki/sources/accounts-payable-agent.md
index fec9dd9b..0ddc0430 100644
--- a/wiki/sources/accounts-payable-agent.md
+++ b/wiki/sources/accounts-payable-agent.md
@@ -1,47 +1,47 @@
----
-title: "Accounts Payable Agent Personality"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/accounts-payable-agent.md]]
-
-## Summary(用中文描述)
-- 核心主题:AccountsPayable Agent——自主支付运营专员 Agent,处理供应商付款、承包商发票和周期性账单,覆盖加密货币、法定货币、稳定币等全支付通道
-- 问题域:AI Agent 工作流中的支付执行、审计追踪、防重复付款、多通道路由
-- 方法/机制:幂等性检查 → 供应商注册表验证 → 最优通道路由 → 执行支付 → 审计日志全链路;通过 tool calls 与 Contracts Agent、Project Manager Agent、HR Agent 等集成
-- 结论/价值:为 AI Agent 生态提供可信赖的支付执行层,零重复付款、完整审计覆盖、60秒内 escalation SLA
-
-## Key Claims(用中文描述)
-- AccountsPayable Agent 通过幂等性检查确保永远不会发送同一笔支付两次
-- Agent 自动选择最优支付通道(ACH/ Wire/ Crypto/ Stablecoin/ Payment API),基于接收方、金额和成本
-- 所有支付均保留完整审计日志,包含发票引用、金额、通道、时间戳和状态
-- 超过授权额度的支付必须上报人工审批,不得自动执行
-
-## Key Quotes
-> "Idempotency first: Check if an invoice has already been paid before executing. Never pay twice." — 核心安全原则
-> "If a payment rail fails, try the next available rail before escalating" — 容错路由机制
-> "Zero duplicate payments — idempotency check before every transaction" — 成功指标
-
-## Key Concepts
-- [[Idempotency]]:幂等性——同一笔支付请求无论执行多少次,结果相同。AccountsPayable 通过 reference ID 去重,防止重复付款
-- [[Payment-Rail]]:支付通道——ACH(国内/工资,1-3天)、Wire(大额/跨境,即时)、Crypto(加密原生供应商,分钟级)、Stablecoin(低费用,秒级)、Payment API(卡片/平台,1-2天)
-- [[Audit-Trail]]:审计追踪——每笔支付记录发票引用、金额、通道、时间戳和状态,确保财务合规
-- [[Vendor-Registry]]:供应商注册表——维护已批准供应商及其首选支付通道和地址
-
-## Key Entities
-- [[Contracts-Agent]]:里程碑完成后触发 AccountsPayable 执行承包商付款
-- [[Project-Manager-Agent]]:处理承包商工时材料发票
-- [[HR-Agent]]:负责工资单发放
-- [[Strategy-Agent]]:接收支出报告和资金跑道分析
-
-## Connections
-- [[Accounts-Payable-Agent]] ← receives_payment_requests ← [[Contracts-Agent]]
-- [[Accounts-Payable-Agent]] ← receives_payment_requests ← [[Project-Manager-Agent]]
-- [[Accounts-Payable-Agent]] ← receives_payment_requests ← [[HR-Agent]]
-- [[Accounts-Payable-Agent]] ← provides_spend_reports ← [[Strategy-Agent]]
-
-## Contradictions
-- (本文档为单一 Agent 设计文档,暂无已知内容冲突)
+---
+title: "Accounts Payable Agent Personality"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/accounts-payable-agent.md]]
+
+## Summary(用中文描述)
+- 核心主题:AccountsPayable Agent——自主支付运营专员 Agent,处理供应商付款、承包商发票和周期性账单,覆盖加密货币、法定货币、稳定币等全支付通道
+- 问题域:AI Agent 工作流中的支付执行、审计追踪、防重复付款、多通道路由
+- 方法/机制:幂等性检查 → 供应商注册表验证 → 最优通道路由 → 执行支付 → 审计日志全链路;通过 tool calls 与 Contracts Agent、Project Manager Agent、HR Agent 等集成
+- 结论/价值:为 AI Agent 生态提供可信赖的支付执行层,零重复付款、完整审计覆盖、60秒内 escalation SLA
+
+## Key Claims(用中文描述)
+- AccountsPayable Agent 通过幂等性检查确保永远不会发送同一笔支付两次
+- Agent 自动选择最优支付通道(ACH/ Wire/ Crypto/ Stablecoin/ Payment API),基于接收方、金额和成本
+- 所有支付均保留完整审计日志,包含发票引用、金额、通道、时间戳和状态
+- 超过授权额度的支付必须上报人工审批,不得自动执行
+
+## Key Quotes
+> "Idempotency first: Check if an invoice has already been paid before executing. Never pay twice." — 核心安全原则
+> "If a payment rail fails, try the next available rail before escalating" — 容错路由机制
+> "Zero duplicate payments — idempotency check before every transaction" — 成功指标
+
+## Key Concepts
+- [[Idempotency]]:幂等性——同一笔支付请求无论执行多少次,结果相同。AccountsPayable 通过 reference ID 去重,防止重复付款
+- [[Payment-Rail]]:支付通道——ACH(国内/工资,1-3天)、Wire(大额/跨境,即时)、Crypto(加密原生供应商,分钟级)、Stablecoin(低费用,秒级)、Payment API(卡片/平台,1-2天)
+- [[Audit-Trail]]:审计追踪——每笔支付记录发票引用、金额、通道、时间戳和状态,确保财务合规
+- [[Vendor-Registry]]:供应商注册表——维护已批准供应商及其首选支付通道和地址
+
+## Key Entities
+- [[Contracts-Agent]]:里程碑完成后触发 AccountsPayable 执行承包商付款
+- [[Project-Manager-Agent]]:处理承包商工时材料发票
+- [[HR-Agent]]:负责工资单发放
+- [[Strategy-Agent]]:接收支出报告和资金跑道分析
+
+## Connections
+- [[Accounts-Payable-Agent]] ← receives_payment_requests ← [[Contracts-Agent]]
+- [[Accounts-Payable-Agent]] ← receives_payment_requests ← [[Project-Manager-Agent]]
+- [[Accounts-Payable-Agent]] ← receives_payment_requests ← [[HR-Agent]]
+- [[Accounts-Payable-Agent]] ← provides_spend_reports ← [[Strategy-Agent]]
+
+## Contradictions
+- (本文档为单一 Agent 设计文档,暂无已知内容冲突)
diff --git a/wiki/sources/agentic-identity-trust.md b/wiki/sources/agentic-identity-trust.md
index fbc939b8..696d07b2 100644
--- a/wiki/sources/agentic-identity-trust.md
+++ b/wiki/sources/agentic-identity-trust.md
@@ -1,53 +1,53 @@
----
-title: "Agentic Identity & Trust Architect"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/agentic-identity-trust.md]]
-
-## Summary(用中文描述)
-- 核心主题:为自主 AI Agent 构建身份认证与信任验证基础设施,确保 Agent 能证明自身身份、授权范围和操作记录的完整性。
-- 问题域:多 Agent 环境中身份伪造、授权链验证缺失、可篡改日志、凭证过期未检测、委托权限升级等安全问题。
-- 方法/机制:零信任身份体系(永不信任自我声明)、密码学身份证明、证据链完整性、委托链验证、信任评分、Fail-Closed 授权策略。
-- 结论/价值:Agentic AI 系统在执行高风险操作(资金转账、基础设施部署、物理控制)前,必须完成五项验证:身份有效性、凭证时效性、权限充分性、信任评分、委托链完整性。
-
-## Key Claims(用中文描述)
-- 零信任原则:Agent 不得信任自我声明的身份或授权——"Agent 说它被授权"不等于"Agent 证明了它被授权"。
-- 证据链完整性:证据链的任何历史记录被篡改必须可被检测;写日志的实体若能修改日志,则该日志对审计毫无价值。
-- Fail-Closed 授权:身份无法验证 → 拒绝操作;委托链存在断裂 → 整链无效;信任评分低于阈值 → 要求重新验证。
-- 密码学卫生规范:使用成熟标准(Ed25519/ECDSA),签名密钥与加密密钥分离,密钥材料不得出现在日志或 API 响应中。
-- 信任评分基于可验证结果:信任分从 1.0 开始,仅通过可验证问题扣分;不允许 Agent 自我报告信号来提高信任分。
-
-## Key Quotes
-> "Never trust self-reported identity. An agent claiming to be 'finance-agent-prod' proves nothing. Require cryptographic proof." — 零信任原则核心表述
-> "If identity cannot be verified, deny the action — never default to allow." — Fail-Closed 授权策略
-> "Trust score 0.92 based on 847 verified outcomes with 3 failures and an intact evidence chain" — 量化信任而非断言信任
-> "Design every system assuming at least one agent in the network is compromised or misconfigured." — 假设妥协的安全设计哲学
-
-## Key Concepts
-- [[Zero-Trust]]:永不信任自我声明,要求密码学证明。适用于身份验证、授权验证和日志完整性三个层面。
-- [[Evidence-Chain]]:仅追加、可独立验证、链式哈希、防篡改的 Agent 操作证据记录系统。
-- [[Trust-Scoring]]:基于可观测结果的惩罚模型信任评分,Agent 从 1.0 开始,仅通过可验证问题扣分。
-- [[Delegation-Chain]]:多跳委托授权链,每一跳须签名且作用域不得宽于上级,过期或断裂则整链无效。
-- [[Fail-Closed]]:授权失败时默认拒绝,而非默认允许的安全策略。
-- [[Peer-Verification]]:Agent 之间在接受委托工作前互相验证身份和授权的协议。
-- [[Algorithm-Agility]]:密码学算法可升级性,为后量子密码学迁移预留抽象层。
-
-## Key Entities
-- [[Identity-Graph-Operator]]:与本文档并列的 Entity 身份解析 Agent,本文档负责 Agent 身份认证,Identity Graph Operator 负责人/公司/产品实体解析。
-- [[The Agency]]:该 Agent 所属的 The Agency 专业化 Agent 生态。
-
-## Connections
-- [[Identity-Graph-Operator]] ← 互补关系 ← [[Agentic-Identity-Trust]]
-- [[Designing-for-Agentic-AI]] ← 潜在冲突 ← [[Agentic-Identity-Trust]](确定性要求与 LLM 概率性行为的张力)
-- [[agents-orchestrator]] ← 依赖 ← [[Agentic-Identity-Trust]](编排器需信任验证层)
-- [[report-distribution-agent]] ← 依赖 ← [[Agentic-Identity-Trust]](分发代理操作需可审计)
-
-## Contradictions
-- 与 [[Designing-for-Agentic-AI]] 冲突:
- - 冲突点:零信任要求确定性验证 vs LLM 的概率性本质(LLM 无法提供数学意义上的确定性签名证明)
- - 当前观点:通过将核心逻辑(密码学验证、签名检查)从 LLM 推理分离为独立组件来解决——LLM 只负责策略决策,验证层由确定性代码执行。
- - 对方观点:若信任验证逻辑本身依赖 LLM(如自然语言授权描述),则仍存在概率性风险。
+---
+title: "Agentic Identity & Trust Architect"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/agentic-identity-trust.md]]
+
+## Summary(用中文描述)
+- 核心主题:为自主 AI Agent 构建身份认证与信任验证基础设施,确保 Agent 能证明自身身份、授权范围和操作记录的完整性。
+- 问题域:多 Agent 环境中身份伪造、授权链验证缺失、可篡改日志、凭证过期未检测、委托权限升级等安全问题。
+- 方法/机制:零信任身份体系(永不信任自我声明)、密码学身份证明、证据链完整性、委托链验证、信任评分、Fail-Closed 授权策略。
+- 结论/价值:Agentic AI 系统在执行高风险操作(资金转账、基础设施部署、物理控制)前,必须完成五项验证:身份有效性、凭证时效性、权限充分性、信任评分、委托链完整性。
+
+## Key Claims(用中文描述)
+- 零信任原则:Agent 不得信任自我声明的身份或授权——"Agent 说它被授权"不等于"Agent 证明了它被授权"。
+- 证据链完整性:证据链的任何历史记录被篡改必须可被检测;写日志的实体若能修改日志,则该日志对审计毫无价值。
+- Fail-Closed 授权:身份无法验证 → 拒绝操作;委托链存在断裂 → 整链无效;信任评分低于阈值 → 要求重新验证。
+- 密码学卫生规范:使用成熟标准(Ed25519/ECDSA),签名密钥与加密密钥分离,密钥材料不得出现在日志或 API 响应中。
+- 信任评分基于可验证结果:信任分从 1.0 开始,仅通过可验证问题扣分;不允许 Agent 自我报告信号来提高信任分。
+
+## Key Quotes
+> "Never trust self-reported identity. An agent claiming to be 'finance-agent-prod' proves nothing. Require cryptographic proof." — 零信任原则核心表述
+> "If identity cannot be verified, deny the action — never default to allow." — Fail-Closed 授权策略
+> "Trust score 0.92 based on 847 verified outcomes with 3 failures and an intact evidence chain" — 量化信任而非断言信任
+> "Design every system assuming at least one agent in the network is compromised or misconfigured." — 假设妥协的安全设计哲学
+
+## Key Concepts
+- [[Zero-Trust]]:永不信任自我声明,要求密码学证明。适用于身份验证、授权验证和日志完整性三个层面。
+- [[Evidence-Chain]]:仅追加、可独立验证、链式哈希、防篡改的 Agent 操作证据记录系统。
+- [[Trust-Scoring]]:基于可观测结果的惩罚模型信任评分,Agent 从 1.0 开始,仅通过可验证问题扣分。
+- [[Delegation-Chain]]:多跳委托授权链,每一跳须签名且作用域不得宽于上级,过期或断裂则整链无效。
+- [[Fail-Closed]]:授权失败时默认拒绝,而非默认允许的安全策略。
+- [[Peer-Verification]]:Agent 之间在接受委托工作前互相验证身份和授权的协议。
+- [[Algorithm-Agility]]:密码学算法可升级性,为后量子密码学迁移预留抽象层。
+
+## Key Entities
+- [[Identity-Graph-Operator]]:与本文档并列的 Entity 身份解析 Agent,本文档负责 Agent 身份认证,Identity Graph Operator 负责人/公司/产品实体解析。
+- [[The Agency]]:该 Agent 所属的 The Agency 专业化 Agent 生态。
+
+## Connections
+- [[Identity-Graph-Operator]] ← 互补关系 ← [[Agentic-Identity-Trust]]
+- [[Designing-for-Agentic-AI]] ← 潜在冲突 ← [[Agentic-Identity-Trust]](确定性要求与 LLM 概率性行为的张力)
+- [[agents-orchestrator]] ← 依赖 ← [[Agentic-Identity-Trust]](编排器需信任验证层)
+- [[report-distribution-agent]] ← 依赖 ← [[Agentic-Identity-Trust]](分发代理操作需可审计)
+
+## Contradictions
+- 与 [[Designing-for-Agentic-AI]] 冲突:
+ - 冲突点:零信任要求确定性验证 vs LLM 的概率性本质(LLM 无法提供数学意义上的确定性签名证明)
+ - 当前观点:通过将核心逻辑(密码学验证、签名检查)从 LLM 推理分离为独立组件来解决——LLM 只负责策略决策,验证层由确定性代码执行。
+ - 对方观点:若信任验证逻辑本身依赖 LLM(如自然语言授权描述),则仍存在概率性风险。
diff --git a/wiki/sources/agents-orchestrator.md b/wiki/sources/agents-orchestrator.md
index adc80928..e76290d0 100644
--- a/wiki/sources/agents-orchestrator.md
+++ b/wiki/sources/agents-orchestrator.md
@@ -1,62 +1,62 @@
----
-title: "Agents Orchestrator"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/specialized/agents-orchestrator.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI 多智能体开发流水线编排器,自主管理从规格到交付的完整开发流程
-- 问题域:多专业 Agent 协同工作流中,如何确保每个任务通过质量验证后才推进,如何处理失败和重试
-- 方法/机制:四阶段流水线(PM→ArchitectUX→[Dev↔QA循环]→最终集成);基于截图证据的质量门控;最大3次重试上限
-- 结论/价值:通过强制性质量门控和 Dev-QA 循环,确保只有通过验证的功能才能推进,最终交付符合规格要求的生产就绪产品
-
-## Key Claims(用中文描述)
-- AgentsOrchestrator 通过持续 Dev-QA 循环实现任务级质量验证,每个任务必须通过 EvidenceQA 的截图验证才能推进
-- 四阶段流水线(PM→ArchitectUX→[Dev↔QA循环]→最终集成)确保从规格到生产的完整质量覆盖
-- 最大重试次数为3次,超过后进行升级处理,避免无限循环同时保证任务有足够修正机会
-- AgentsOrchestrator 提供标准化状态报告模板,实现流水线进度的透明化追踪
-
-## Key Quotes
-> "Each task must pass QA before advancing." — 质量门控原则:每个任务必须通过 QA 验证才能推进到下一任务
-> "Default to 'NEEDS WORK' unless overwhelming evidence proves production readiness." — testing-reality-checker 的默认判断原则,确保交付标准严格
-> "Maximum 3 attempts per task before escalation." — 重试上限机制,防止任务无限循环
-> "No shortcuts: Every task must pass QA validation." — 强制性质量验证,无例外原则
-
-## Key Concepts
-- [[Dev-QA-Loop]]:开发与质量验证的持续循环机制——每个任务完成后由 EvidenceQA 进行截图验证,通过后推进下一个任务,失败则回到开发阶段并携带具体反馈
-- [[Quality-Gate]]:质量门控机制——任务必须通过质量验证才能推进到下一阶段的强制性检查点
-- [[EvidenceQA]]:基于截图证据的质量验证专家 Agent——要求视觉证据作为验证依据,提供明确的 PASS/FAIL 判定及具体反馈
-- [[Pipeline-State-Management]]:流水线状态管理——追踪当前任务、所处阶段、完成状态,在 Agent 间传递上下文信息,处理错误并实现恢复
-- [[Agent-Handoff]]:Agent 交接协议——在多个专业 Agent 之间传递完整的上下文和具体指令,确保下一 Agent 获得足够信息执行任务
-- [[Continuous-Dev-QA-Loop]]:持续开发质量循环——开发与 QA 交替进行,每个开发交付物立即经过 QA 验证,形成快速反馈闭环
-
-## Key Entities
-- [[AgentsOrchestrator]]:编排器自身——自主流水线管理器,协调从规格到生产的完整开发流程(来源页面)
-- [[ArchitectUX]]:技术架构师 Agent——负责基于规格和任务列表创建技术架构和 UX 基础
-- [[EvidenceQA]]:截图质量验证 Agent——通过截图证据对每个任务实现进行质量验证
-- [[ProjectManagerSenior]]:高级项目经理 Agent——负责将规格文档转化为详细的任务列表
-- [[TestingRealityChecker]]:最终集成验证 Agent——在所有任务通过后进行最终集成测试,默认为"需要改进"原则
-- [[FrontendDeveloper]]:前端开发者 Agent——负责 UI/UX 任务的实现
-- [[BackendArchitect]]:后端架构师 Agent——负责服务端架构和 API 开发
-- [[MobileAppBuilder]]:移动应用构建 Agent——负责移动端应用开发
-- [[DevOpsAutomator]]:DevOps 自动化 Agent——负责基础设施任务
-
-## Connections
-- [[AgentsOrchestrator]] ← spawns ← [[ProjectManagerSenior]](Phase 1:编排器启动项目经理创建任务列表)
-- [[AgentsOrchestrator]] ← spawns ← [[ArchitectUX]](Phase 2:编排器启动架构师创建技术基础)
-- [[AgentsOrchestrator]] ← spawns ← [[EvidenceQA]](Phase 3:每个任务的 QA 验证)
-- [[AgentsOrchestrator]] ← spawns ← [[TestingRealityChecker]](Phase 4:最终集成测试)
-- [[ArchitectUX]] ← depends_on ← [[ProjectManagerSenior]](架构基于任务列表)
-- [[Dev-QA-Loop]] ← extends ← [[Multi-Agent-System-Reliability]](流水线编排是多 Agent 可靠性的实践框架)
-- [[AgentsOrchestrator]] ← part_of ← [[The Agency]](编排器是 The Agency 的核心基础设施)
-
-## Contradictions
-- 与 [[specialized-workflow-architect]] 冲突:
- - 冲突点:两个 Agent 都声称负责"编排"职责——前者是流水线执行编排器,后者是工作流设计专家
- - 当前观点:AgentsOrchestrator 是执行层面的流水线管理器,强调任务级质量门控和自动化重试逻辑
- - 对方观点:Workflow Architect 是设计层面的工作流架构师,专注工作流模式设计和流程建模
- - 说明:两者不存在功能重叠——Workflow Architect 设计工作流,AgentsOrchestrator 执行工作流,属设计与执行的分层关系
+---
+title: "Agents Orchestrator"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/agents-orchestrator.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI 多智能体开发流水线编排器,自主管理从规格到交付的完整开发流程
+- 问题域:多专业 Agent 协同工作流中,如何确保每个任务通过质量验证后才推进,如何处理失败和重试
+- 方法/机制:四阶段流水线(PM→ArchitectUX→[Dev↔QA循环]→最终集成);基于截图证据的质量门控;最大3次重试上限
+- 结论/价值:通过强制性质量门控和 Dev-QA 循环,确保只有通过验证的功能才能推进,最终交付符合规格要求的生产就绪产品
+
+## Key Claims(用中文描述)
+- AgentsOrchestrator 通过持续 Dev-QA 循环实现任务级质量验证,每个任务必须通过 EvidenceQA 的截图验证才能推进
+- 四阶段流水线(PM→ArchitectUX→[Dev↔QA循环]→最终集成)确保从规格到生产的完整质量覆盖
+- 最大重试次数为3次,超过后进行升级处理,避免无限循环同时保证任务有足够修正机会
+- AgentsOrchestrator 提供标准化状态报告模板,实现流水线进度的透明化追踪
+
+## Key Quotes
+> "Each task must pass QA before advancing." — 质量门控原则:每个任务必须通过 QA 验证才能推进到下一任务
+> "Default to 'NEEDS WORK' unless overwhelming evidence proves production readiness." — testing-reality-checker 的默认判断原则,确保交付标准严格
+> "Maximum 3 attempts per task before escalation." — 重试上限机制,防止任务无限循环
+> "No shortcuts: Every task must pass QA validation." — 强制性质量验证,无例外原则
+
+## Key Concepts
+- [[Dev-QA-Loop]]:开发与质量验证的持续循环机制——每个任务完成后由 EvidenceQA 进行截图验证,通过后推进下一个任务,失败则回到开发阶段并携带具体反馈
+- [[Quality-Gate]]:质量门控机制——任务必须通过质量验证才能推进到下一阶段的强制性检查点
+- [[EvidenceQA]]:基于截图证据的质量验证专家 Agent——要求视觉证据作为验证依据,提供明确的 PASS/FAIL 判定及具体反馈
+- [[Pipeline-State-Management]]:流水线状态管理——追踪当前任务、所处阶段、完成状态,在 Agent 间传递上下文信息,处理错误并实现恢复
+- [[Agent-Handoff]]:Agent 交接协议——在多个专业 Agent 之间传递完整的上下文和具体指令,确保下一 Agent 获得足够信息执行任务
+- [[Continuous-Dev-QA-Loop]]:持续开发质量循环——开发与 QA 交替进行,每个开发交付物立即经过 QA 验证,形成快速反馈闭环
+
+## Key Entities
+- [[AgentsOrchestrator]]:编排器自身——自主流水线管理器,协调从规格到生产的完整开发流程(来源页面)
+- [[ArchitectUX]]:技术架构师 Agent——负责基于规格和任务列表创建技术架构和 UX 基础
+- [[EvidenceQA]]:截图质量验证 Agent——通过截图证据对每个任务实现进行质量验证
+- [[ProjectManagerSenior]]:高级项目经理 Agent——负责将规格文档转化为详细的任务列表
+- [[TestingRealityChecker]]:最终集成验证 Agent——在所有任务通过后进行最终集成测试,默认为"需要改进"原则
+- [[FrontendDeveloper]]:前端开发者 Agent——负责 UI/UX 任务的实现
+- [[BackendArchitect]]:后端架构师 Agent——负责服务端架构和 API 开发
+- [[MobileAppBuilder]]:移动应用构建 Agent——负责移动端应用开发
+- [[DevOpsAutomator]]:DevOps 自动化 Agent——负责基础设施任务
+
+## Connections
+- [[AgentsOrchestrator]] ← spawns ← [[ProjectManagerSenior]](Phase 1:编排器启动项目经理创建任务列表)
+- [[AgentsOrchestrator]] ← spawns ← [[ArchitectUX]](Phase 2:编排器启动架构师创建技术基础)
+- [[AgentsOrchestrator]] ← spawns ← [[EvidenceQA]](Phase 3:每个任务的 QA 验证)
+- [[AgentsOrchestrator]] ← spawns ← [[TestingRealityChecker]](Phase 4:最终集成测试)
+- [[ArchitectUX]] ← depends_on ← [[ProjectManagerSenior]](架构基于任务列表)
+- [[Dev-QA-Loop]] ← extends ← [[Multi-Agent-System-Reliability]](流水线编排是多 Agent 可靠性的实践框架)
+- [[AgentsOrchestrator]] ← part_of ← [[The Agency]](编排器是 The Agency 的核心基础设施)
+
+## Contradictions
+- 与 [[specialized-workflow-architect]] 冲突:
+ - 冲突点:两个 Agent 都声称负责"编排"职责——前者是流水线执行编排器,后者是工作流设计专家
+ - 当前观点:AgentsOrchestrator 是执行层面的流水线管理器,强调任务级质量门控和自动化重试逻辑
+ - 对方观点:Workflow Architect 是设计层面的工作流架构师,专注工作流模式设计和流程建模
+ - 说明:两者不存在功能重叠——Workflow Architect 设计工作流,AgentsOrchestrator 执行工作流,属设计与执行的分层关系
diff --git a/wiki/sources/ai-memory-tools-two-camps.md b/wiki/sources/ai-memory-tools-two-camps.md
index 9ba5d735..7446f9cd 100644
--- a/wiki/sources/ai-memory-tools-two-camps.md
+++ b/wiki/sources/ai-memory-tools-two-camps.md
@@ -1,68 +1,68 @@
----
-title: "I Went Through Every AI Memory Tool I Could Find. There Are Two Camps."
-type: source
-tags: [ai-agent, memory, context-management, tooling]
-sources: []
-last_updated: 2026-04-23
----
-
-## Source File
-- [[Agent/AI-Memory-Tools-Two-Camps]]
-
-## Summary(用中文描述)
-- 核心主题:AI 记忆工具的全景分类——揭示该领域存在两个根本不同的技术路线
-- 问题域:AI Agent 的持久化上下文问题——如何让 Agent 跨会话保持记忆
-- 方法/机制:Camp 1(记忆后端)通过向量提取+检索解决事实召回;Camp 2(上下文基质)通过文件累积+背景整合实现上下文复合增长
-- 结论/价值:提出了"记忆"与"上下文"不是同一问题的核心洞察;预测 6 个月内"context engineering"将取代"memory"成为主流术语;ALIVE 是作者实际运行的上下文基质方案
-
-## Key Claims(用中文描述)
-- Camp 1 与 Camp 2 是两个根本不同的技术范式,而非同一问题的不同实现
-- Camp 1 工具优化目标是**召回**:能否找到正确的事实
-- Camp 2 工具优化目标是**复合**:系统是否随时间变得更好
-- Zep 将品牌定位从"memory"重塑为"context engineering"是市场上最强的信号,表明 Camp 2 路线正在成为主流
-- GitHub 上 450+ repos 标记"agent-memory"、460+ 标记"context-management",但几乎无人明确区分这两种范式
-- 持续运行的 24/7 Agent 场景下,只有 Camp 2 架构才能真正实现跨会话复合增长
-
-## Key Quotes
-> "there are 450+ repos tagged 'agent-memory' on github and 460+ tagged 'context-management.' me and my agentic best friends went through them." — @witcheer,揭示该领域分类混乱的现状
-> "the line from their docs that defines the philosophy: 'the model only remembers what gets saved to disk, there is no hidden state.'" — OpenClaw 定义了 Camp 2 的核心哲学
-> "a funded company with 4.4k stars looked at where the space was going and decided 'memory' was the wrong word for what they were building." — Zep 的品牌重塑是市场信号
-> "within 6 months, 'context engineering' replaces 'memory' as the default term for what serious agent infrastructure does." — 作者的核心预测
-> "if you're building agents that need to run for more than one conversation, you're going to end up here." — Camp 2 是长期运行 Agent 的必然归宿
-
-## Key Concepts
-- [[Memory Backend]]:从对话中提取事实,存入向量数据库,检索时召回。代表工具:Mem0、MemPalace、Supermemory、Honcho、Cognee。核心问题:记忆是扁平条目,无关系;提取质量依赖 LLM prompt;事实不进化
-- [[Context Substrate]]:维护结构化、人类可读的上下文文件,跨会话累积。代表工具:OpenClaw、Zep、Thoth、TrustGraph、MemSearch、ALIVE。核心哲学:"nothing gets extracted — the context is the files"
-- [[Fact Recall]] vs [[Compounding]]:Camp 1 优化召回精度,Camp 2 优化复合增长;前者问"AI 应该记住什么",后者问"AI 应该在什么样的上下文中工作"
-- [[Dreaming Cycle]]:OpenClaw 的背景整合过程——light sleep(分组)→ REM(频繁访问提升)→ deep sleep(写入长期记忆),六维评分机制(相关性0.30、频率0.24、查询多样性0.15、时效性0.15、整合度0.10、概念丰富度0.06)
-- [[Temporal Knowledge Graph]]:Zep 的 Graphiti 框架使用带 valid_at/invalid_at 时间戳的知识图谱,自动提取关系,返回预格式化上下文块,<200ms 检索
-- [[Context Core]]:TrustGraph 引入的可移植、带版本控制的上下文捆绑包(领域schema+知识图谱+向量嵌入+证据来源+检索策略),将上下文视为第一公民制品
-- [[Context Engineering]]:作者预测将取代"memory"成为描述 Agent 基础设施的标准术语
-
-## Key Entities
-- [[Mem0]]:53.1k stars,Camp 1 类别领导者,四操作(add/search/update/delete),三层存储(user/session/agent),混合检索,集成简单但记忆为扁平条目,无关系推理
-- [[MemPalace]]:46.2k stars,本地优先逐字记忆,用 ChromaDB 组织为 wings(实体)/rooms(主题)/drawers(原内容),LongMemEval 96.6% 召回率但线性增长无压缩
-- [[Supermemory]]:21.8k stars,差异化是时序感知("I moved to SF"自动取代旧城市),expired facts 自动遗忘,MemoryBench 声称第一,多模态连接器(Google Drive/Gmail/Notion/GitHub)
-- [[Honcho]]:2.4k stars,将人/Agent 视为统一模型中的"对等体",异步推理服务推导心理洞察,PostgreSQL + pgvector,AGPL-3.0
-- [[OpenClaw]]:358k stars,plain markdown 文件(Mmemory.md + daily notes + DREAMS.md),无向量数据库,dreaming 三阶段整合,Camp 2 典型代表
-- [[Zep]]:4.4k stars,从"memory"重塑品牌为"context engineering",Graphiti 时序知识图谱,SOC2 Type 2 + HIPAA 合规,<200ms 检索,架构上处于两 Camp 边界
-- [[Thoth]]:145 stars,最深层架构,10 实体类型 + 67 有向关系类型 + FAISS + 图扩展检索,四阶段夜间 dream cycle,三层反污染机制防止跨实体事实混淆
-- [[TrustGraph]]:2.0k stars,Context Cores 可移植版本化上下文容器,treats context like code,Cassandra + Qdrant 基础设施
-- [[MemSearch]]:1.2k stars,Zilliz 团队出品,Markdown 文件为唯一真相,Milvus 为下游"阴影索引",三层层级渐进披露(语义块→完整章节→原始记录)
-- [[ALIVE]]:作者实际运行的方案,structured context substrate,file-native,agent-agnostic,walnuts 作为可移植上下文容器,零基础设施依赖,运行在 Hermes Agent + Claude Code + Mac Mini M4 上
-
-## Connections
-- [[RAG]] ← related_to ← [[Memory Backend]]:两者共享向量检索的基本机制,但 RAG 通常指一次性问答场景,Memory Backend 指跨会话累积
-- [[OpenClaw]] ← implements ← [[Context Substrate]]:OpenClaw 的 Markdown 文件架构是 Context Substrate 范式的典型实现
-- [[Semantic-Memory-Search]] ← extends ← [[OpenClaw]]:MemSearch 为 OpenClaw 的 Markdown 记忆提供语义搜索能力
-- [[Memory Backend]] ← evolves_into ← [[Context Substrate]]:Supermemory 的时序感知和 Honcho 的心理建模代表了 Camp 1 向 Camp 2 的演进趋势
-- [[Second Brain]] ← uses ← [[Context Substrate]]:[[Second Brain]] 基于 OpenClaw 的累积记忆能力,本质上是 Context Substrate 范式在个人知识管理中的应用
-- [[养龙虾5天血泪史]] ← experiences ← [[OpenClaw]]:实战中暴露了 OpenClaw 记忆压缩和检索的痛点,推动了对 Context Substrate 架构的深入理解
-- [[Context Substrate]] ← enables ← [[Self-Improving-Skill]]:Self-Improving 的复盘机制([[养虾日记2]])是 Context Substrate 中背景整合思想的实践
-
-## Contradictions
-- 与 [[semantic-memory-search]] 可能存在张力:
- - 冲突点:MemSearch(Camp 2)将向量索引视为文件的下游"阴影索引",可随时重建;[[semantic-memory-search]] 则将向量搜索作为记忆检索的核心能力
- - 当前观点:向量索引是可选的访问加速层,Markdown 文件才是唯一真相
- - 对方观点:向量语义搜索是必要的,单纯的关键词/Markdown 文件无法高效处理"我上周讨论的那个关于 X 的内容"
- - 注:两者其实互补——MemSearch 本身也使用混合搜索,但强调文件优先而非索引优先
+---
+title: "I Went Through Every AI Memory Tool I Could Find. There Are Two Camps."
+type: source
+tags: [ai-agent, memory, context-management, tooling]
+sources: []
+last_updated: 2026-04-23
+---
+
+## Source File
+- [[raw/Agent/AI-Memory-Tools-Two-Camps.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI 记忆工具的全景分类——揭示该领域存在两个根本不同的技术路线
+- 问题域:AI Agent 的持久化上下文问题——如何让 Agent 跨会话保持记忆
+- 方法/机制:Camp 1(记忆后端)通过向量提取+检索解决事实召回;Camp 2(上下文基质)通过文件累积+背景整合实现上下文复合增长
+- 结论/价值:提出了"记忆"与"上下文"不是同一问题的核心洞察;预测 6 个月内"context engineering"将取代"memory"成为主流术语;ALIVE 是作者实际运行的上下文基质方案
+
+## Key Claims(用中文描述)
+- Camp 1 与 Camp 2 是两个根本不同的技术范式,而非同一问题的不同实现
+- Camp 1 工具优化目标是**召回**:能否找到正确的事实
+- Camp 2 工具优化目标是**复合**:系统是否随时间变得更好
+- Zep 将品牌定位从"memory"重塑为"context engineering"是市场上最强的信号,表明 Camp 2 路线正在成为主流
+- GitHub 上 450+ repos 标记"agent-memory"、460+ 标记"context-management",但几乎无人明确区分这两种范式
+- 持续运行的 24/7 Agent 场景下,只有 Camp 2 架构才能真正实现跨会话复合增长
+
+## Key Quotes
+> "there are 450+ repos tagged 'agent-memory' on github and 460+ tagged 'context-management.' me and my agentic best friends went through them." — @witcheer,揭示该领域分类混乱的现状
+> "the line from their docs that defines the philosophy: 'the model only remembers what gets saved to disk, there is no hidden state.'" — OpenClaw 定义了 Camp 2 的核心哲学
+> "a funded company with 4.4k stars looked at where the space was going and decided 'memory' was the wrong word for what they were building." — Zep 的品牌重塑是市场信号
+> "within 6 months, 'context engineering' replaces 'memory' as the default term for what serious agent infrastructure does." — 作者的核心预测
+> "if you're building agents that need to run for more than one conversation, you're going to end up here." — Camp 2 是长期运行 Agent 的必然归宿
+
+## Key Concepts
+- [[Memory Backend]]:从对话中提取事实,存入向量数据库,检索时召回。代表工具:Mem0、MemPalace、Supermemory、Honcho、Cognee。核心问题:记忆是扁平条目,无关系;提取质量依赖 LLM prompt;事实不进化
+- [[Context Substrate]]:维护结构化、人类可读的上下文文件,跨会话累积。代表工具:OpenClaw、Zep、Thoth、TrustGraph、MemSearch、ALIVE。核心哲学:"nothing gets extracted — the context is the files"
+- [[Fact Recall]] vs [[Compounding]]:Camp 1 优化召回精度,Camp 2 优化复合增长;前者问"AI 应该记住什么",后者问"AI 应该在什么样的上下文中工作"
+- [[Dreaming Cycle]]:OpenClaw 的背景整合过程——light sleep(分组)→ REM(频繁访问提升)→ deep sleep(写入长期记忆),六维评分机制(相关性0.30、频率0.24、查询多样性0.15、时效性0.15、整合度0.10、概念丰富度0.06)
+- [[Temporal Knowledge Graph]]:Zep 的 Graphiti 框架使用带 valid_at/invalid_at 时间戳的知识图谱,自动提取关系,返回预格式化上下文块,<200ms 检索
+- [[Context Core]]:TrustGraph 引入的可移植、带版本控制的上下文捆绑包(领域schema+知识图谱+向量嵌入+证据来源+检索策略),将上下文视为第一公民制品
+- [[Context Engineering]]:作者预测将取代"memory"成为描述 Agent 基础设施的标准术语
+
+## Key Entities
+- [[Mem0]]:53.1k stars,Camp 1 类别领导者,四操作(add/search/update/delete),三层存储(user/session/agent),混合检索,集成简单但记忆为扁平条目,无关系推理
+- [[MemPalace]]:46.2k stars,本地优先逐字记忆,用 ChromaDB 组织为 wings(实体)/rooms(主题)/drawers(原内容),LongMemEval 96.6% 召回率但线性增长无压缩
+- [[Supermemory]]:21.8k stars,差异化是时序感知("I moved to SF"自动取代旧城市),expired facts 自动遗忘,MemoryBench 声称第一,多模态连接器(Google Drive/Gmail/Notion/GitHub)
+- [[Honcho]]:2.4k stars,将人/Agent 视为统一模型中的"对等体",异步推理服务推导心理洞察,PostgreSQL + pgvector,AGPL-3.0
+- [[OpenClaw]]:358k stars,plain markdown 文件(Mmemory.md + daily notes + DREAMS.md),无向量数据库,dreaming 三阶段整合,Camp 2 典型代表
+- [[Zep]]:4.4k stars,从"memory"重塑品牌为"context engineering",Graphiti 时序知识图谱,SOC2 Type 2 + HIPAA 合规,<200ms 检索,架构上处于两 Camp 边界
+- [[Thoth]]:145 stars,最深层架构,10 实体类型 + 67 有向关系类型 + FAISS + 图扩展检索,四阶段夜间 dream cycle,三层反污染机制防止跨实体事实混淆
+- [[TrustGraph]]:2.0k stars,Context Cores 可移植版本化上下文容器,treats context like code,Cassandra + Qdrant 基础设施
+- [[MemSearch]]:1.2k stars,Zilliz 团队出品,Markdown 文件为唯一真相,Milvus 为下游"阴影索引",三层层级渐进披露(语义块→完整章节→原始记录)
+- [[ALIVE]]:作者实际运行的方案,structured context substrate,file-native,agent-agnostic,walnuts 作为可移植上下文容器,零基础设施依赖,运行在 Hermes Agent + Claude Code + Mac Mini M4 上
+
+## Connections
+- [[RAG]] ← related_to ← [[Memory Backend]]:两者共享向量检索的基本机制,但 RAG 通常指一次性问答场景,Memory Backend 指跨会话累积
+- [[OpenClaw]] ← implements ← [[Context Substrate]]:OpenClaw 的 Markdown 文件架构是 Context Substrate 范式的典型实现
+- [[Semantic-Memory-Search]] ← extends ← [[OpenClaw]]:MemSearch 为 OpenClaw 的 Markdown 记忆提供语义搜索能力
+- [[Memory Backend]] ← evolves_into ← [[Context Substrate]]:Supermemory 的时序感知和 Honcho 的心理建模代表了 Camp 1 向 Camp 2 的演进趋势
+- [[Second Brain]] ← uses ← [[Context Substrate]]:[[Second Brain]] 基于 OpenClaw 的累积记忆能力,本质上是 Context Substrate 范式在个人知识管理中的应用
+- [[养龙虾5天血泪史]] ← experiences ← [[OpenClaw]]:实战中暴露了 OpenClaw 记忆压缩和检索的痛点,推动了对 Context Substrate 架构的深入理解
+- [[Context Substrate]] ← enables ← [[Self-Improving-Skill]]:Self-Improving 的复盘机制([[养虾日记2]])是 Context Substrate 中背景整合思想的实践
+
+## Contradictions
+- 与 [[semantic-memory-search]] 可能存在张力:
+ - 冲突点:MemSearch(Camp 2)将向量索引视为文件的下游"阴影索引",可随时重建;[[semantic-memory-search]] 则将向量搜索作为记忆检索的核心能力
+ - 当前观点:向量索引是可选的访问加速层,Markdown 文件才是唯一真相
+ - 对方观点:向量语义搜索是必要的,单纯的关键词/Markdown 文件无法高效处理"我上周讨论的那个关于 X 的内容"
+ - 注:两者其实互补——MemSearch 本身也使用混合搜索,但强调文件优先而非索引优先
diff --git a/wiki/sources/ai-解决方案专家培训课程.md b/wiki/sources/ai-解决方案专家培训课程.md
index 929706e8..a6fa848e 100644
--- a/wiki/sources/ai-解决方案专家培训课程.md
+++ b/wiki/sources/ai-解决方案专家培训课程.md
@@ -1,50 +1,93 @@
----
-title: "AI 解决方案专家培训课程"
-type: source
-tags: [ai, coze]
-date: 2026-04-23
----
-
-## Source File
-- [[AI/AI 解决方案专家培训课程.md]]
-
-## Summary(用中文描述)
-- 核心主题:Coze(扣子)平台 AI Agent 开发实战培训课程,涵盖国内版(coze.cn)和海外版(coze.com)的多行业 Agent 案例 Demo 合集
-- 问题域:如何利用 Coze 平台快速构建覆盖金融、医疗、教育、电商、人力资源、泛娱乐、在线客服等多行业的 AI Agent 与 Workflow
-- 方法/机制:通过分享大量可直接体验的 Coze Bot/Workflow 链接,配合飞书文档说明,让学员快速掌握 Prompt 工程、RAG、Function Call、工作流编排等核心技能
-- 结论/价值:提供 50+ 可运行的 Agent Demo,是 AI 解决方案专家培训的实操案例库,覆盖从基础能力验证到行业垂直应用的全场景
-
-## Key Claims(用中文描述)
-- Coze 平台支持国内版(coze.cn)和海外版(coze.com),可满足不同地域用户的 Agent 部署需求
-- Coze Workflow 功能可将多个 Bot/工具串联,实现复杂业务流程的自动化编排
-- Coze 平台已积累覆盖 7 大行业(金融、医疗、教育、电商、人力资源、泛娱乐、客服)的 50+ Agent Demo
-- AI Agent 的 Function Call 能力可调用外部 API(天气、地图、数据库等),实现真实业务场景的自动化
-
-## Key Quotes
-> "邀请你加入我的扣子空间 'Prompt & RAG & Function Call'" — Coze 平台培训课程邀请语,说明培训以 Prompt 工程、RAG 和 Function Call 为核心技能
-
-## Key Concepts
-- [[Prompt Engineering]]:Coze Bot 的核心技能,通过优化提示词让 AI 理解任务目标并稳定输出,是本课程的基础能力
-- [[RAG(检索增强生成)]]:Coze 知识库问答的核心技术,将私有文档向量化后供 Agent 检索调用,案例包括知乎财报解读、表格知识库等
-- [[Function Call]]:Coze Bot 调用外部工具的能力,支持天气查询、故事合成、企业办事等多种真实业务场景
-- [[Coze Workflow]]:多个 Bot 和插件串联的工作流编排,可实现复杂业务自动化,如滴滴计费规则解答_WorkFlow、骑手招聘助手_WorkFlow
-- [[AI Agent]]:具备感知→规划→执行→反思能力的 AI 系统,Coze 平台是其快速构建工具
-
-## Key Entities
-- [[Coze]]:字节跳动旗下的 AI Agent 开发平台(国内版 coze.cn / 海外版 coze.com),提供 Bot 创建、Workflow 编排、知识库管理、插件系统等完整能力
-- [[抖音]]:Coze 平台所在字节跳动生态的核心产品,Coze 直播间自动回复助手等服务抖音电商场景
-- [[SONY]]:零售场景案例合作方,SONY门店店员_Chao 等 Agent 覆盖零售场景的 AI 客服需求
-- [[滴滴]]:出行场景案例,滴滴计费规则解答等 Agent 覆盖出行行业的 AI 客服需求
-- [[FaceFusion]]:泛娱乐场景使用的人脸融合 AI 模型,用于霸道总裁等泛娱乐 Agent 的底层技术
-- [[F5-TTS]]:泛娱乐场景使用的语音合成开源模型,为 AI 生成视频提供配音能力
-- [[Google Genie 2]]:世界模型,用于泛娱乐场景的 AI 视频生成研究
-- [[World Labs]]:AI 世界生成平台,Coze 泛娱乐课程中涉及的 AI 视频技术方向
-
-## Connections
-- [[Coze]] ← platform ← AI 解决方案专家培训课程(本课程以 Coze 为核心工具)
-- [[Prompt Engineering]] ← core_skill ← [[RAG(检索增强生成)]] ← combo ← [[Function Call]] ← 三大基础能力 ← Coze 培训课程
-- [[AI Agent]] ← 应用形态 ← 金融行业 客户分层营销助手 ← 行业案例 ← Coze 培训课程
-- [[固定镜头短视频制作的AI全流程解析]] ← related ← AI生成视频工作流 ← 泛娱乐案例 ← Coze 培训课程
-
-## Contradictions
-- 暂无发现与现有 Wiki 内容的冲突。该课程以 Coze 平台为主,与其他 AI 工具类来源(如 [[Claude Code 调用方法总结]]、[[Ollama 本地 LLM 部署]])属互补关系而非竞争关系。
+---
+title: "AI 解决方案专家培训课程"
+type: source
+tags: [ai, coze]
+date: 2026-04-27
+---
+
+## Source File
+- [[raw/AI/AI 解决方案专家培训课程.md]]
+
+## Summary(用中文描述)
+- 核心主题:Coze(扣子)平台 AI Agent 开发实战培训课程,涵盖多行业解决方案 Demo 展示
+- 问题域:AI Agent 在企业各业务场景中的落地应用,包括金融、医疗、教育、电商、人力资源、泛娱乐、在线客服等
+- 方法/机制:通过 Coze 国内版(coze.cn)和海外版(coze.com)平台搭建各类 AI Agent,涉及工作流(WorkFlow)、知识库、插件、Function Call 等技术
+- 结论/价值:提供可直接体验和改造的 AI 解决方案 Demo,供培训学员快速上手 Coze 平台 Agent 开发
+
+## Key Claims(用中文描述)
+- Coze 平台支持国内版和海外版,分别对应 coze.cn 和 coze.com
+- 跨行业 AI Agent Demo 可通过"创建副本"功能快速改造复用
+- 培训课程覆盖 AutoGPT、支小助等高级 Agent 形态的搭建方法
+- 泛娱乐场景已整合 FaceFusion、F5-TTS、Google Genie 2、World labs 等前沿 AI 工具
+
+## Key Quotes
+> "邀请你加入我的扣子空间'0220-Prompt & RAG & Function Call'" — Coze 团队空间邀请语(国内版)
+> "join my space 'Prompt & RAG & Function Call', this URL will be expired on 2025-06-23" — Coze 团队空间邀请语(海外版)
+
+## Key Concepts
+- [[Coze平台]]:字节跳动旗下的 AI Agent 开发平台,支持国内版(coze.cn)和海外版(coze.com)
+- [[AutoGPT]]:自主执行复杂任务的 AI Agent,本课程提供其在 Coze 平台上的搭建方法
+- [[Function Call]]:Agent 调用外部工具的能力,本课程演示天气查询、故事合成等多种 Function Call 场景
+- [[WorkFlow]]:工作流编排能力,用于构建多步骤业务流程
+- [[RAG]]:检索增强生成,本课程涉及知识库问答和表格问答等 RAG 应用
+
+## Key Entities
+- [[Coze]]:字节跳动 AI Agent 平台,提供国内版和海外版服务
+- [[FaceFusion]]:人脸融合技术,用于泛娱乐场景 AI 生成
+- [[F5-TTS]]:开源语音克隆工具
+- [[Google Genie 2]]:Google DeepMind 的世界模型
+- [[World Labs]]:AI 生成技术公司(AI 生成视频/图像)
+- [[BananaResearch]]:香蕉研究团队,开发医疗图片识别等开源项目
+
+## Connections
+- [[Coze平台]] ← 核心平台 ← 本课程所有 Demo
+- [[AutoGPT]] ← 技术示例 ← [[Coze平台]]
+- [[Coze平台国内版]] ← 对应 ← [[Coze平台]]
+- [[Coze平台海外版]] ← 对应 ← [[Coze平台]]
+- [[支小助]] ← 案例 ← [[Coze平台]]
+
+## Contradictions
+- 无明显内容冲突
+
+## 行业案例汇总
+
+### 金融行业
+- 知乎财报解读 Agent
+- 客户分层营销助手
+- 智能客服 Agent
+
+### 医疗行业
+- 医疗分诊助手
+- 在线问诊 Agent
+- 影像图片识别 Demo(BananaResearch 团队)
+
+### 教育行业
+- 知识库问答
+- 拍照搜视频
+- 组卷出题
+- 知识点掌握情况评估
+
+### 财务行业
+- 企业预算管理助手
+- 业务预算数据专家经验
+
+### 人力资源
+- 招聘场景打分能力验证
+- 面试对话 Agent
+- AI 培训对练
+- 莫欣老师课程 Demo
+
+### 电商行业
+- 混剪助手
+- 在线换衣 Demo
+- 抖音直播间自动回复助手
+- 开源模型汇总项目
+
+### 泛娱乐
+- 霸道总裁 Agent
+- AI 证件照 Demo
+- AI 生成视频工作流(4 个场景:古风育儿、儿童神话故事、治愈女孩视频)
+
+### 在线客服
+- 解决方案课程 AI 助教
+- AI 销售 Agent
diff --git a/wiki/sources/aionui-cowork-desktop.md b/wiki/sources/aionui-cowork-desktop.md
index b7efc162..49aa7472 100644
--- a/wiki/sources/aionui-cowork-desktop.md
+++ b/wiki/sources/aionui-cowork-desktop.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/aionui-cowork-desktop.md]]
+- [[raw/Agent/usecases/aionui-cowork-desktop.md]]
## Summary(用中文描述)
- 核心主题:通过 AionUi 桌面应用将 OpenClaw 打造为协作型 Cowork Agent,支持远程救援和多 Agent 统一管理。
diff --git a/wiki/sources/arxiv-paper-reader.md b/wiki/sources/arxiv-paper-reader.md
index 4f0aed4d..bfccc5da 100644
--- a/wiki/sources/arxiv-paper-reader.md
+++ b/wiki/sources/arxiv-paper-reader.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/arxiv-paper-reader.md]]
+- [[raw/Agent/usecases/arxiv-paper-reader.md]]
## Summary(用中文描述)
- 核心主题:让 AI Agent 变身为 arXiv 论文阅读助手,实现无需离开工作空间即可阅读、分析和对比论文
diff --git a/wiki/sources/autonomous-game-dev-pipeline.md b/wiki/sources/autonomous-game-dev-pipeline.md
index 7e7a7fd2..0503d977 100644
--- a/wiki/sources/autonomous-game-dev-pipeline.md
+++ b/wiki/sources/autonomous-game-dev-pipeline.md
@@ -1,56 +1,56 @@
----
-title: "Autonomous Educational Game Development Pipeline"
-type: source
-tags: []
-date: 2026-04-23
----
-
-## Source File
-- [[Agent/usecases/autonomous-game-dev-pipeline.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 全自动管理教育游戏的完整开发生命周期
-- 问题域:单人开发者如何在无团队情况下快速生产 40+ 款儿童教育游戏
-- 方法/机制:
- - "Bugs First" 优先策略:Agent 必须先修复 bugs 文件夹中的第一个 bug,再处理新游戏
- - Round Robin 轮询策略:从队列中按年龄组均衡选取下一款游戏
- - 完整 Git 工作流:feature branch → conventional commits → PR → merge
- - 技术栈:纯 HTML5/CSS3/JS,无框架,移动优先,支持离线
-- 结论/价值:**每 7 分钟产出 1 款游戏或 1 个 bugfix**,单人可维护 41+ 款游戏的知识库
-
-## Key Claims(用中文描述)
-- Agent 在检测到 bugs/ 文件夹有内容时,必须优先修复字母序第一个 bug,不能同时处理多个 bug
-- Pipeline 效率达到每 7 分钟完成 1 个新游戏或 1 个 bugfix
-- 游戏需注册到 `games-list.json` 才能在首页显示,这是关键集成步骤
-- 使用 conventional commits 规范(feat: add [game-id])确保提交历史可读
-- 系统指令使用西班牙语(es-419)编写,适配拉丁美洲儿童及其潜在贡献者
-
-## Key Quotes
-> "Act as an Expert in Web Game Development and Child UX. Your goal is to develop the next game in the production queue." — Agent 系统指令核心
-> "BUGS FIRST!: If the bugs/ folder has content, your only priority is to fix the first bug in alphabetical order. Do not attempt to fix multiple bugs at once." — 关键工程纪律
-> "Register the game in 'games-list.json' (CRITICAL)" — 核心集成步骤
-> "CRITICAL: git fetch && git pull origin master before starting" — 同步纪律
-
-## Key Concepts
-- [[Bugs First]]:优先级策略——Agent 检测到 bug 时必须停止新功能开发,先修 bug,且一次只修一个
-- [[Round Robin Strategy]]:轮询策略——按年龄组均衡分配,平衡内容多样性
-- [[Conventional Commits]]:规范化提交格式(如 `feat: add game-id`),保证项目历史可读
-- [[Feature Branch Workflow]]:Git feature branch → commit → PR → merge 的完整分支管理流程
-- [[HTML5 Game Development]]:无框架、移动优先、离线可用的轻量游戏开发规范
-
-## Key Entities
-- [[duberblockito]]:El Bebe Games 项目作者,GitHub 仓库维护者,"LANero of the old school" 爸爸开发者
-- [[El Bebe Games]]:面向拉丁美洲儿童的在线教育游戏平台,无广告、无垃圾信息,官网 elbebe.co
-- [[Susana & Julieta]]:开发者女儿(3岁和即将出生),项目的灵感来源和目标用户
-- [[OpenClaw]]:(关联)本 pipeline 与 OpenClaw 的 autonomous agent 能力相关,是该技术的实际应用场景
-
-## Connections
-- [[Multi-Agent Content Factory]] ← related_to ← [[autonomous-game-dev-pipeline]]
- - 两者均涉及 Agent 自动化生产内容,但前者侧重多 Agent 协作链(Research → Writing → Design),后者侧重单人 Agent 的独立流水线
-- [[Goal-Driven Autonomous Tasks]] ← extends ← [[autonomous-game-dev-pipeline]]
- - Overnight Mini-App Builder 同样采用 Agent 自主执行 + Git 状态追踪的工程纪律,是本 pipeline 方法论的延伸
-- [[Project State Management]] ← related_to ← [[autonomous-game-dev-pipeline]]
- - 两者都使用 append-only 日志模式(CHANGELOG.md / master-game-plan.md)作为状态管理机制
-
-## Contradictions
-- 无明显内容冲突
+---
+title: "Autonomous Educational Game Development Pipeline"
+type: source
+tags: []
+date: 2026-04-23
+---
+
+## Source File
+- [[raw/Agent/usecases/autonomous-game-dev-pipeline.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 全自动管理教育游戏的完整开发生命周期
+- 问题域:单人开发者如何在无团队情况下快速生产 40+ 款儿童教育游戏
+- 方法/机制:
+ - "Bugs First" 优先策略:Agent 必须先修复 bugs 文件夹中的第一个 bug,再处理新游戏
+ - Round Robin 轮询策略:从队列中按年龄组均衡选取下一款游戏
+ - 完整 Git 工作流:feature branch → conventional commits → PR → merge
+ - 技术栈:纯 HTML5/CSS3/JS,无框架,移动优先,支持离线
+- 结论/价值:**每 7 分钟产出 1 款游戏或 1 个 bugfix**,单人可维护 41+ 款游戏的知识库
+
+## Key Claims(用中文描述)
+- Agent 在检测到 bugs/ 文件夹有内容时,必须优先修复字母序第一个 bug,不能同时处理多个 bug
+- Pipeline 效率达到每 7 分钟完成 1 个新游戏或 1 个 bugfix
+- 游戏需注册到 `games-list.json` 才能在首页显示,这是关键集成步骤
+- 使用 conventional commits 规范(feat: add [game-id])确保提交历史可读
+- 系统指令使用西班牙语(es-419)编写,适配拉丁美洲儿童及其潜在贡献者
+
+## Key Quotes
+> "Act as an Expert in Web Game Development and Child UX. Your goal is to develop the next game in the production queue." — Agent 系统指令核心
+> "BUGS FIRST!: If the bugs/ folder has content, your only priority is to fix the first bug in alphabetical order. Do not attempt to fix multiple bugs at once." — 关键工程纪律
+> "Register the game in 'games-list.json' (CRITICAL)" — 核心集成步骤
+> "CRITICAL: git fetch && git pull origin master before starting" — 同步纪律
+
+## Key Concepts
+- [[Bugs First]]:优先级策略——Agent 检测到 bug 时必须停止新功能开发,先修 bug,且一次只修一个
+- [[Round Robin Strategy]]:轮询策略——按年龄组均衡分配,平衡内容多样性
+- [[Conventional Commits]]:规范化提交格式(如 `feat: add game-id`),保证项目历史可读
+- [[Feature Branch Workflow]]:Git feature branch → commit → PR → merge 的完整分支管理流程
+- [[HTML5 Game Development]]:无框架、移动优先、离线可用的轻量游戏开发规范
+
+## Key Entities
+- [[duberblockito]]:El Bebe Games 项目作者,GitHub 仓库维护者,"LANero of the old school" 爸爸开发者
+- [[El Bebe Games]]:面向拉丁美洲儿童的在线教育游戏平台,无广告、无垃圾信息,官网 elbebe.co
+- [[Susana & Julieta]]:开发者女儿(3岁和即将出生),项目的灵感来源和目标用户
+- [[OpenClaw]]:(关联)本 pipeline 与 OpenClaw 的 autonomous agent 能力相关,是该技术的实际应用场景
+
+## Connections
+- [[Multi-Agent Content Factory]] ← related_to ← [[autonomous-game-dev-pipeline]]
+ - 两者均涉及 Agent 自动化生产内容,但前者侧重多 Agent 协作链(Research → Writing → Design),后者侧重单人 Agent 的独立流水线
+- [[Goal-Driven Autonomous Tasks]] ← extends ← [[autonomous-game-dev-pipeline]]
+ - Overnight Mini-App Builder 同样采用 Agent 自主执行 + Git 状态追踪的工程纪律,是本 pipeline 方法论的延伸
+- [[Project State Management]] ← related_to ← [[autonomous-game-dev-pipeline]]
+ - 两者都使用 append-only 日志模式(CHANGELOG.md / master-game-plan.md)作为状态管理机制
+
+## Contradictions
+- 无明显内容冲突
diff --git a/wiki/sources/autonomous-project-management.md b/wiki/sources/autonomous-project-management.md
index 04af9d72..b65e4167 100644
--- a/wiki/sources/autonomous-project-management.md
+++ b/wiki/sources/autonomous-project-management.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/autonomous-project-management]]
+- [[raw/Agent/usecases/autonomous-project-management.md]]
## Summary(用中文描述)
- 核心主题:去中心化的多子 Agent 并行项目管理体系,通过共享 STATE.yaml 文件协调而非中央编排器
diff --git a/wiki/sources/backend-architect-with-memory.md b/wiki/sources/backend-architect-with-memory.md
index 072ec819..39ee0a0c 100644
--- a/wiki/sources/backend-architect-with-memory.md
+++ b/wiki/sources/backend-architect-with-memory.md
@@ -1,47 +1,47 @@
----
-title: "Backend Architect with Memory"
-type: source
-tags: []
-date: 2026-04-26
----
-
-## Source File
-- [[Agent/agency-agents/integrations/mcp-memory/backend-architect-with-memory.md]]
-
-## Summary(用中文描述)
-- 核心主题:具备持久记忆能力的后端架构师 AI Agent 设计规范,专注于可扩展系统设计、数据库架构、API 开发与云基础设施
-- 问题域:如何构建一个能够跨会话保留架构决策、系统设计和技术约束记忆的 AI 后端架构专家
-- 方法/机制:基于 MCP Memory 集成框架,在会话开始时检索相关上下文,完成交付物后主动记忆,跨 Agent 交接时自动传递上下文
-- 结论/价值:解决多 Agent 协作中重复讨论已做决策、交接信息丢失的问题,提升 AI 架构师的实际工程价值
-
-## Key Claims(用中文描述)
-- 后端架构师应在会话启动时主动检索项目相关的历史架构决策,防止重复讨论
-- 架构决策(选型数据库、定义 API 契约、选择通信模式)应以标签形式持久化,供未来会话和其他 Agent 查找
-- 交付物(Schema、API 规范、架构文档)完成后应主动记忆并标记接收方,确保下游 Agent 无需手动复制粘贴
-- 遇到 QA 失败或错误决策时,应检索上一个已知良好状态并回滚,而非手动撤销变更链
-
-## Key Quotes
-> "When you start a session, recall relevant context from previous sessions. Search for memories tagged with 'backend-architect' and the current project name." — 会话启动时的记忆召回机制
-> "When you make an architecture decision — choosing a database, defining an API contract, selecting a communication pattern — remember it with tags including 'backend-architect', the project name, and the topic." — 架构决策的持久化规范
-> "This prevents re-litigating decisions that were already made." — 记忆系统的核心价值
-
-## Key Concepts
-- [[MicroservicesArchitecture]]:微服务架构,支持水平扩展和独立部署,是 Backend Architect 默认推荐的架构模式
-- [[CQRS]]:命令查询职责分离,Backend Architect 在复杂领域驱动设计中的推荐数据模式
-- [[EventSourcing]]:事件溯源,与 CQRS 配合用于复杂业务域的数据建模
-- [[ServerlessArchitecture]]:无服务器架构,Backend Architect 认可的可自动扩展且成本效益高的部署方式
-- [[DatabaseIndexing]]:数据库索引优化,用于实现子 100ms 平均查询性能
-- [[CircuitBreaker]]:断路器模式,Backend Architect 实现系统可靠性和优雅降级的核心机制
-- [[DefenseInDepth]]:深度防御策略,Security-First Architecture 的核心原则
-
-## Key Entities
-- Backend Architect:主 Agent,专门负责系统架构和服务器端开发,特点:战略思维、安全导向、可扩展性优先、可靠性至上
-- Frontend Developer:下游接收方 Agent,接收 Backend Architect 提供的 API 规范
-- QA Agent:质量保障 Agent,在失败时触发记忆回滚机制
-
-## Connections
-- [[AgentsOrchestrator]] ← coordinates ← [[BackendArchitectWithMemory]]
-- [[MCPBuilderAgent]] ← enables ← [[BackendArchitectWithMemory]](MCP Memory 集成)
-
-## Contradictions
-- 无明显冲突内容
+---
+title: "Backend Architect with Memory"
+type: source
+tags: []
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Agent/agency-agents/integrations/mcp-memory/backend-architect-with-memory.md]]
+
+## Summary(用中文描述)
+- 核心主题:具备持久记忆能力的后端架构师 AI Agent 设计规范,专注于可扩展系统设计、数据库架构、API 开发与云基础设施
+- 问题域:如何构建一个能够跨会话保留架构决策、系统设计和技术约束记忆的 AI 后端架构专家
+- 方法/机制:基于 MCP Memory 集成框架,在会话开始时检索相关上下文,完成交付物后主动记忆,跨 Agent 交接时自动传递上下文
+- 结论/价值:解决多 Agent 协作中重复讨论已做决策、交接信息丢失的问题,提升 AI 架构师的实际工程价值
+
+## Key Claims(用中文描述)
+- 后端架构师应在会话启动时主动检索项目相关的历史架构决策,防止重复讨论
+- 架构决策(选型数据库、定义 API 契约、选择通信模式)应以标签形式持久化,供未来会话和其他 Agent 查找
+- 交付物(Schema、API 规范、架构文档)完成后应主动记忆并标记接收方,确保下游 Agent 无需手动复制粘贴
+- 遇到 QA 失败或错误决策时,应检索上一个已知良好状态并回滚,而非手动撤销变更链
+
+## Key Quotes
+> "When you start a session, recall relevant context from previous sessions. Search for memories tagged with 'backend-architect' and the current project name." — 会话启动时的记忆召回机制
+> "When you make an architecture decision — choosing a database, defining an API contract, selecting a communication pattern — remember it with tags including 'backend-architect', the project name, and the topic." — 架构决策的持久化规范
+> "This prevents re-litigating decisions that were already made." — 记忆系统的核心价值
+
+## Key Concepts
+- [[MicroservicesArchitecture]]:微服务架构,支持水平扩展和独立部署,是 Backend Architect 默认推荐的架构模式
+- [[CQRS]]:命令查询职责分离,Backend Architect 在复杂领域驱动设计中的推荐数据模式
+- [[EventSourcing]]:事件溯源,与 CQRS 配合用于复杂业务域的数据建模
+- [[ServerlessArchitecture]]:无服务器架构,Backend Architect 认可的可自动扩展且成本效益高的部署方式
+- [[DatabaseIndexing]]:数据库索引优化,用于实现子 100ms 平均查询性能
+- [[CircuitBreaker]]:断路器模式,Backend Architect 实现系统可靠性和优雅降级的核心机制
+- [[DefenseInDepth]]:深度防御策略,Security-First Architecture 的核心原则
+
+## Key Entities
+- Backend Architect:主 Agent,专门负责系统架构和服务器端开发,特点:战略思维、安全导向、可扩展性优先、可靠性至上
+- Frontend Developer:下游接收方 Agent,接收 Backend Architect 提供的 API 规范
+- QA Agent:质量保障 Agent,在失败时触发记忆回滚机制
+
+## Connections
+- [[AgentsOrchestrator]] ← coordinates ← [[BackendArchitectWithMemory]]
+- [[MCPBuilderAgent]] ← enables ← [[BackendArchitectWithMemory]](MCP Memory 集成)
+
+## Contradictions
+- 无明显冲突内容
diff --git a/wiki/sources/blender-addon-engineer.md b/wiki/sources/blender-addon-engineer.md
index 43b6d747..c6b64606 100644
--- a/wiki/sources/blender-addon-engineer.md
+++ b/wiki/sources/blender-addon-engineer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/blender/blender-addon-engineer.md]]
+- [[raw/Agent/agency-agents/game-development/blender/blender-addon-engineer.md]]
## Summary(用中文描述)
- 核心主题:Blender 工具开发专家 AI Agent 人格规范——通过 Python + bpy API 构建 Blender 原生工具(自定义 Operator、Panel、资产验证器、导出器),将重复性 DCC 工作流自动化为可靠的一键工作流。
diff --git a/wiki/sources/blockchain-security-auditor.md b/wiki/sources/blockchain-security-auditor.md
index cbc34a24..fd003adc 100644
--- a/wiki/sources/blockchain-security-auditor.md
+++ b/wiki/sources/blockchain-security-auditor.md
@@ -1,59 +1,59 @@
----
-title: "Blockchain Security Auditor"
-type: source
-tags: [blockchain, security, smart-contract, defi, audit]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/specialized/blockchain-security-auditor.md]]
-
-## Summary(用中文描述)
-- 核心主题:智能合约安全审计 Agent — 专职发现 DeFi 协议与区块链应用中的漏洞
-- 问题域:智能合约安全审计、漏洞检测、形式化验证、攻击向量分析、审计报告撰写
-- 方法/机制:自动化静态分析(Slither/Mythril/Echidna)+ 人工逐行代码审查 + 属性化模糊测试 + 经济博弈建模;五步工作流(范围→自动化→人工→经济分析→报告)
-- 结论/价值:提供包含可复现 PoC 的专业审计报告,Critical/High 漏洞零遗漏,确保修复建议可直接落地
-
-## Key Claims(用中文描述)
-- 自动化工具只能捕获约 30% 的真实漏洞,剩余必须依靠人工逐行审查
-- 每个发现必须包含 PoC 攻击场景或可估算的影响范围,否则不予记录为正式漏洞
-- 漏洞评级为 Critical 的前提:无特殊权限即可直接造成用户资金损失或协议破产
-- 永远不要因为函数使用了 OpenZeppelin 库就假定它是安全的 — 误用安全库本身就是一类漏洞
-- 审计范围必须覆盖完整调用链,不仅仅是当前函数 — 漏洞隐藏在内部调用和继承合约中
-
-## Key Quotes
-> "Your job is not to make developers feel good — it is to find the bug before the attacker does." — Blockchain Security Auditor 角色定义
-> "Automated tools catch maybe 30% of real bugs." — 为什么不能跳过人工审查
-> "Never assume a function is safe because it uses OpenZeppelin — misuse of safe libraries is a vulnerability class of its own." — 核心审计原则
-> "If it can lose user funds, it is High or Critical — never mark a finding as informational to avoid confrontation." — 漏洞评级原则
-
-## Key Concepts
-- [[Reentrancy(重入攻击)]]:外部调用在状态更新前执行,允许攻击者在状态清零前回滚调用链重复提取资金
-- [[Oracle Manipulation(预言机操纵)]]:通过闪电贷在单笔交易内操纵 AMM 储备或价格预言机,导致清算/借贷套利
-- [[Flash Loan Attack(闪电贷攻击)]]:在单笔交易内借用大量资金操纵市场状态,无需抵押的信贷攻击
-- [[Access Control(访问控制)]]:特权函数缺少访问修饰符或被错误配置,可导致权限提升
-- [[Formal Verification(形式化验证)]]:使用符号执行和不变式验证数学证明协议关键属性的正确性
-- [[Checks-Effects-Interactions Pattern]]:先检查条件、更新状态,再执行外部调用,防止逻辑漏洞
-- [[Slither]]:Trail of Bits 开源的 Solidity 静态分析框架,高置信度检测器几乎总是真实漏洞
-- [[Mythril]]:基于符号执行的安全分析工具,深度扫描但速度较慢
-- [[Echidna]]:属性化模糊测试工具,通过随机交易验证协议不变式
-- [[Foundry]] / [[Certora]] / [[Halmos]]:高级形式化验证工具链,用于数学证明合约正确性
-- [[SWC Registry]]:智能合约弱点分类标准(Smart Contract Weakness Classification)
-- [[DeFiHackLabs]] / [[rekt.news]]:DeFi 攻击事件数据库,用于模式匹配已知漏洞
-
-## Key Entities
-- [[Trail of Bits]]:安全审计机构,开发 Slither、Solc 等关键安全工具
-- [[OpenZeppelin]]:智能合约标准库(ReentrancyGuard、AccessControl 等),被广泛依赖
-- [[The DAO (2016)]]:以太坊首个重大安全事件,重入攻击导致 360 万 ETH 损失,开创了 DeFi 安全研究领域
-- [[Euler Finance]]:2023 年遭受 donate-to-reserves 操纵攻击,损失 1.97 亿美元,攻击模板被收录
-- [[Nomad Bridge]]:2022 年因未初始化代理合约漏洞损失 1.9 亿美元
-- [[Curve Finance]]:2023 年因 Vyper 编译器 bug 导致多池被攻击,损失超 7000 万美元
-
-## Connections
-- [[Agents Orchestrator]] ← defines role scope ← [[Blockchain Security Auditor]]
-- [[Compliance Auditor]] ← related audit methodology ← [[Blockchain Security Auditor]]
-- [[Blockchain Security Auditor]] ← uses tools ← [[Slither]] / [[Mythril]] / [[Echidna]]
-- [[Blockchain Security Auditor]] ← draws patterns from ← [[The DAO (2016)]] / [[Euler Finance]] / [[Nomad Bridge]] / [[Curve Finance]]
-
-## Contradictions
-- (无已知冲突 — 该页面为独立角色定义文档,未与其他 Wiki 页面产生直接矛盾)
+---
+title: "Blockchain Security Auditor"
+type: source
+tags: [blockchain, security, smart-contract, defi, audit]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/blockchain-security-auditor.md]]
+
+## Summary(用中文描述)
+- 核心主题:智能合约安全审计 Agent — 专职发现 DeFi 协议与区块链应用中的漏洞
+- 问题域:智能合约安全审计、漏洞检测、形式化验证、攻击向量分析、审计报告撰写
+- 方法/机制:自动化静态分析(Slither/Mythril/Echidna)+ 人工逐行代码审查 + 属性化模糊测试 + 经济博弈建模;五步工作流(范围→自动化→人工→经济分析→报告)
+- 结论/价值:提供包含可复现 PoC 的专业审计报告,Critical/High 漏洞零遗漏,确保修复建议可直接落地
+
+## Key Claims(用中文描述)
+- 自动化工具只能捕获约 30% 的真实漏洞,剩余必须依靠人工逐行审查
+- 每个发现必须包含 PoC 攻击场景或可估算的影响范围,否则不予记录为正式漏洞
+- 漏洞评级为 Critical 的前提:无特殊权限即可直接造成用户资金损失或协议破产
+- 永远不要因为函数使用了 OpenZeppelin 库就假定它是安全的 — 误用安全库本身就是一类漏洞
+- 审计范围必须覆盖完整调用链,不仅仅是当前函数 — 漏洞隐藏在内部调用和继承合约中
+
+## Key Quotes
+> "Your job is not to make developers feel good — it is to find the bug before the attacker does." — Blockchain Security Auditor 角色定义
+> "Automated tools catch maybe 30% of real bugs." — 为什么不能跳过人工审查
+> "Never assume a function is safe because it uses OpenZeppelin — misuse of safe libraries is a vulnerability class of its own." — 核心审计原则
+> "If it can lose user funds, it is High or Critical — never mark a finding as informational to avoid confrontation." — 漏洞评级原则
+
+## Key Concepts
+- [[Reentrancy(重入攻击)]]:外部调用在状态更新前执行,允许攻击者在状态清零前回滚调用链重复提取资金
+- [[Oracle Manipulation(预言机操纵)]]:通过闪电贷在单笔交易内操纵 AMM 储备或价格预言机,导致清算/借贷套利
+- [[Flash Loan Attack(闪电贷攻击)]]:在单笔交易内借用大量资金操纵市场状态,无需抵押的信贷攻击
+- [[Access Control(访问控制)]]:特权函数缺少访问修饰符或被错误配置,可导致权限提升
+- [[Formal Verification(形式化验证)]]:使用符号执行和不变式验证数学证明协议关键属性的正确性
+- [[Checks-Effects-Interactions Pattern]]:先检查条件、更新状态,再执行外部调用,防止逻辑漏洞
+- [[Slither]]:Trail of Bits 开源的 Solidity 静态分析框架,高置信度检测器几乎总是真实漏洞
+- [[Mythril]]:基于符号执行的安全分析工具,深度扫描但速度较慢
+- [[Echidna]]:属性化模糊测试工具,通过随机交易验证协议不变式
+- [[Foundry]] / [[Certora]] / [[Halmos]]:高级形式化验证工具链,用于数学证明合约正确性
+- [[SWC Registry]]:智能合约弱点分类标准(Smart Contract Weakness Classification)
+- [[DeFiHackLabs]] / [[rekt.news]]:DeFi 攻击事件数据库,用于模式匹配已知漏洞
+
+## Key Entities
+- [[Trail of Bits]]:安全审计机构,开发 Slither、Solc 等关键安全工具
+- [[OpenZeppelin]]:智能合约标准库(ReentrancyGuard、AccessControl 等),被广泛依赖
+- [[The DAO (2016)]]:以太坊首个重大安全事件,重入攻击导致 360 万 ETH 损失,开创了 DeFi 安全研究领域
+- [[Euler Finance]]:2023 年遭受 donate-to-reserves 操纵攻击,损失 1.97 亿美元,攻击模板被收录
+- [[Nomad Bridge]]:2022 年因未初始化代理合约漏洞损失 1.9 亿美元
+- [[Curve Finance]]:2023 年因 Vyper 编译器 bug 导致多池被攻击,损失超 7000 万美元
+
+## Connections
+- [[Agents Orchestrator]] ← defines role scope ← [[Blockchain Security Auditor]]
+- [[Compliance Auditor]] ← related audit methodology ← [[Blockchain Security Auditor]]
+- [[Blockchain Security Auditor]] ← uses tools ← [[Slither]] / [[Mythril]] / [[Echidna]]
+- [[Blockchain Security Auditor]] ← draws patterns from ← [[The DAO (2016)]] / [[Euler Finance]] / [[Nomad Bridge]] / [[Curve Finance]]
+
+## Contradictions
+- (无已知冲突 — 该页面为独立角色定义文档,未与其他 Wiki 页面产生直接矛盾)
diff --git a/wiki/sources/blogwatcher-daily收藏.md b/wiki/sources/blogwatcher-daily收藏.md
index ef938747..a0c70a21 100644
--- a/wiki/sources/blogwatcher-daily收藏.md
+++ b/wiki/sources/blogwatcher-daily收藏.md
@@ -1,58 +1,58 @@
----
-title: "Blogwatcher Daily 技能收藏"
-type: source
-tags: [hermes-agent, rss, automation, daily-digest]
-date: 2026-04-18
----
-
-## Source File
-- [[Skills/blogwatcher-daily收藏.md]]
-
-## Summary(用中文描述)
-- 核心主题:RSS/YouTube 订阅频道的自动化监控与每日摘要生成
-- 问题域:个人资讯获取效率——手动逐个打开各频道耗时且容易遗漏更新
-- 方法/机制:Hermes Agent 自定义 Skill,定时抓取 31 个订阅频道,SQLite 去重,每日追加写入 Markdown 日报
-- 结论/价值:将信息获取自动化,用户每天早上只需阅读一篇摘要即可掌握所有频道动态
-
-## Key Claims(用中文描述)
-- Hermes Agent 通过自定义 Skill `blogwatcher-daily` 实现 31 个订阅频道的自动化监控
-- 每日扫描(Cron Job)自动追加新文章到 `YYYY-MM-DD.md` 日报,避免覆盖历史内容
-- YouTube 频道通过 RSSHub 本地部署代理转换为 RSS Feed,绕过直接访问限制
-- SQLite 数据库按 URL 去重,已读链接不重复写入
-- 强制回扫(`--all`)写入独立文件 `all-YYYY-MM-DD.md`,不污染日常日报
-- 支持 `--scan-only` 调试模式,只打印结果不写文件
-
-## Key Quotes
-> "📊 扫描完成: 共发现 12 篇新文章" — 日常扫描输出示例
-
-> "新增订阅需要补历史、某个频道很久没看想批量回顾" — 强制回扫适用场景
-
-> "wikiHow 禁止所有爬虫,无法抓取,永远返回 0 篇" — 已知限制说明
-
-## Key Concepts
-- [[RSS Monitoring]]:通过 RSS/Atom Feed 订阅网站和 YouTube 频道更新的标准化协议
-- [[Cron Job]]:定时任务调度,每天早上 6:00 自动执行扫描
-- [[RSSHub]]:开源 RSS 生成器,将不支持 RSS 的网站(如 YouTube)转换为 RSS Feed
-- [[feedparser]]:Python RSS 解析库,支持 RSS 1.0/2.0/Atom 及 GB2312/GBK 编码
-- [[Deduplication]]:SQLite 按 URL 排重,避免重复写入
-- [[每日日报]]:追加模式日记文件,每天一篇,持续积累
-- [[增量写入]]:日常扫描追加到日报,强制回扫写入独立文件,二者互不干扰
-
-## Key Entities
-- [[Hermes Agent]]:运行 blogwatcher-daily Skill 的 AI Agent 平台,通过 Cron Job 调度
-- [[RSSHub]]:本地部署的 RSSHub 实例(`http://192.168.3.45:1200`),用于转换 YouTube 频道为 RSS
-- [[blogwatcher-daily]]:Hermes Agent 自定义 Skill,核心脚本为 `blogwatcher-daily.py`
-- [[feedparser]]:Python RSS 解析库,解决 RSS 1.0、GB2312 乱码、畸形 XML 等兼容性问题
-
-## Connections
-- [[blogwatcher-daily收藏]] ← depends_on ← [[RSSHub]]
-- [[blogwatcher-daily收藏]] ← depends_on ← [[feedparser]]
-- [[blogwatcher-daily收藏]] ← depends_on ← [[每日日报]]
-- [[blogwatcher-daily收藏]] ← extends ← [[multi-source-tech-news-digest]]
-
-## Contradictions
-- 与 [[multi-source-tech-news-digest]]:
- - 冲突点:两者都是 RSS 多源新闻聚合方案
- - 当前观点:blogwatcher-daily 侧重 YouTube + RSS 直订的本地化方案,覆盖 31 个固定频道
- - 对方观点:multi-source-tech-news-digest 侧重多平台(RSS + Twitter + GitHub)的大规模聚合,支持动态添加来源
- - 说明:两者定位互补,blogwatcher-daily 是轻量级固定订阅方案,后者是大规模动态监控方案
+---
+title: "Blogwatcher Daily 技能收藏"
+type: source
+tags: [hermes-agent, rss, automation, daily-digest]
+date: 2026-04-18
+---
+
+## Source File
+- [[raw/Skills/blogwatcher-daily收藏.md]]
+
+## Summary(用中文描述)
+- 核心主题:RSS/YouTube 订阅频道的自动化监控与每日摘要生成
+- 问题域:个人资讯获取效率——手动逐个打开各频道耗时且容易遗漏更新
+- 方法/机制:Hermes Agent 自定义 Skill,定时抓取 31 个订阅频道,SQLite 去重,每日追加写入 Markdown 日报
+- 结论/价值:将信息获取自动化,用户每天早上只需阅读一篇摘要即可掌握所有频道动态
+
+## Key Claims(用中文描述)
+- Hermes Agent 通过自定义 Skill `blogwatcher-daily` 实现 31 个订阅频道的自动化监控
+- 每日扫描(Cron Job)自动追加新文章到 `YYYY-MM-DD.md` 日报,避免覆盖历史内容
+- YouTube 频道通过 RSSHub 本地部署代理转换为 RSS Feed,绕过直接访问限制
+- SQLite 数据库按 URL 去重,已读链接不重复写入
+- 强制回扫(`--all`)写入独立文件 `all-YYYY-MM-DD.md`,不污染日常日报
+- 支持 `--scan-only` 调试模式,只打印结果不写文件
+
+## Key Quotes
+> "📊 扫描完成: 共发现 12 篇新文章" — 日常扫描输出示例
+
+> "新增订阅需要补历史、某个频道很久没看想批量回顾" — 强制回扫适用场景
+
+> "wikiHow 禁止所有爬虫,无法抓取,永远返回 0 篇" — 已知限制说明
+
+## Key Concepts
+- [[RSS Monitoring]]:通过 RSS/Atom Feed 订阅网站和 YouTube 频道更新的标准化协议
+- [[Cron Job]]:定时任务调度,每天早上 6:00 自动执行扫描
+- [[RSSHub]]:开源 RSS 生成器,将不支持 RSS 的网站(如 YouTube)转换为 RSS Feed
+- [[feedparser]]:Python RSS 解析库,支持 RSS 1.0/2.0/Atom 及 GB2312/GBK 编码
+- [[Deduplication]]:SQLite 按 URL 排重,避免重复写入
+- [[每日日报]]:追加模式日记文件,每天一篇,持续积累
+- [[增量写入]]:日常扫描追加到日报,强制回扫写入独立文件,二者互不干扰
+
+## Key Entities
+- [[Hermes Agent]]:运行 blogwatcher-daily Skill 的 AI Agent 平台,通过 Cron Job 调度
+- [[RSSHub]]:本地部署的 RSSHub 实例(`http://192.168.3.45:1200`),用于转换 YouTube 频道为 RSS
+- [[blogwatcher-daily]]:Hermes Agent 自定义 Skill,核心脚本为 `blogwatcher-daily.py`
+- [[feedparser]]:Python RSS 解析库,解决 RSS 1.0、GB2312 乱码、畸形 XML 等兼容性问题
+
+## Connections
+- [[blogwatcher-daily收藏]] ← depends_on ← [[RSSHub]]
+- [[blogwatcher-daily收藏]] ← depends_on ← [[feedparser]]
+- [[blogwatcher-daily收藏]] ← depends_on ← [[每日日报]]
+- [[blogwatcher-daily收藏]] ← extends ← [[multi-source-tech-news-digest]]
+
+## Contradictions
+- 与 [[multi-source-tech-news-digest]]:
+ - 冲突点:两者都是 RSS 多源新闻聚合方案
+ - 当前观点:blogwatcher-daily 侧重 YouTube + RSS 直订的本地化方案,覆盖 31 个固定频道
+ - 对方观点:multi-source-tech-news-digest 侧重多平台(RSS + Twitter + GitHub)的大规模聚合,支持动态添加来源
+ - 说明:两者定位互补,blogwatcher-daily 是轻量级固定订阅方案,后者是大规模动态监控方案
diff --git a/wiki/sources/building-your-quartz.md b/wiki/sources/building-your-quartz.md
index 2cc365fa..619d3b5e 100644
--- a/wiki/sources/building-your-quartz.md
+++ b/wiki/sources/building-your-quartz.md
@@ -1,61 +1,61 @@
----
-title: "Building your Quartz"
-type: source
-tags:
- - quartz
- - obsidian
- - static-site-generator
- - self-hosting
-date: 2026-03-04
----
-
-## Source File
-- [[Home Office/Building your Quartz]]
-
-## Summary(用中文描述)
-- 核心主题:Quartz 静态网站的本地预览与自托管部署指南
-- 问题域:如何将 Markdown 文件构建为可预览的本地网站,以及如何通过主流 Web 服务器(Nginx/Apache/Caddy)实现公网自托管
-- 方法/机制:Quartz 将 Markdown 文件转换为 HTML/JS/CSSbundle;本地预览通过 `npx quartz build --serve` 启动热重载服务器;自托管需配置 Web 服务器处理无扩展名链接(`try_files $uri $uri.html $uri/`)
-- 结论/价值:Quartz 提供了一套完整的从笔记到静态网站的构建与部署流程,支持多种主流 Web 服务器的自托管方案,适合将 Obsidian 笔记发布为公网可访问的静态网站
-
-## Key Claims(用中文描述)
-- Quartz 将 Markdown 文件和资源转换为 HTML、JS 和 CSS 文件包(即一个网站)
-- Serve 模式仅用于本地预览,生产环境部署需使用 GitHub Pages 等静态托管服务
-- 静态托管前需正确配置 `baseUrl`,否则 RSS Feed 和 Sitemap 生成功能将无法正常工作
-- 自托管时 Web 服务器必须处理不含 `.html` 扩展名的链接(Quartz 生成此类链接)
-- Nginx 通过 `try_files $uri $uri.html $uri/ =404` 规则处理无扩展名链接
-- Apache 通过 RewriteCond/RewriteRule 组合实现相同功能
-- Caddy 通过 `try_files {path} {path}.html {path}/ =404` 实现,并支持 gzip 压缩和错误页处理
-
-## Key Quotes
-> "Serve mode is intended for local previews only. For production workloads, see the page on hosting."
-> — Quartz 官方文档,明确 serve 模式仅用于本地预览
-
-> "Some Quartz features (like RSS Feed and sitemap generation) require `baseUrl` to be configured properly in your configuration to work properly."
-> — Quartz 官方文档,部署前必须配置 baseUrl
-
-## Key Concepts
-- [[Quartz]]:Obsidian 笔记静态网站生成器,将 Markdown 转换为 HTML/JS/CSS bundle
-- [[Static Site Generator]]:静态网站生成器,无需服务器端渲染,直接托管 HTML 文件
-- [[npx quartz build]]:Quartz 构建命令,核心参数包括 `-d/--directory`(内容目录)、`-o/--output`(输出目录)、`--serve`(本地预览)、`--port`(端口)、`--concurrency`(并发数)
-- [[try_files]]:Nginx 指令,按顺序尝试文件、HTML 文件、目录,最后返回 404
-- [[RewriteRule]]:Apache mod_rewrite 模块指令,用于 URL 重写处理无扩展名链接
-- [[baseUrl]]:Quartz 配置项,用于生成正确的绝对 URL,RSS Feed 和 Sitemap 功能依赖此配置
-
-## Key Entities
-- [[Quartz]]:开源静态网站生成器,专注于将 Obsidian 风格的双链笔记发布为静态网站
-- [[Obsidian]]:本地笔记软件,Quartz 的内容来源
-- [[GitHub Pages]]:Quartz 推荐的公网托管方案
-
-## Connections
-- [[Obsidian]] — provides content → [[Quartz]]
-- [[Quartz]] — builds to static files → [[Static Site Generator]]
-- [[Quartz]] — local preview → [[npx quartz build --serve]]
-- [[Quartz]] — production deployment → [[GitHub Pages]] / Self-hosting
-- Self-hosting — requires → [[try_files]] (Nginx) / [[RewriteRule]] (Apache) / [[Caddyfile]] (Caddy)
-
-## Contradictions
-- 与通用静态网站托管方案(如 Vercel/Netlify)冲突:
- - 冲突点:这些平台自动处理 URL 重写,无需手动配置 Web 服务器
- - 当前观点:Quartz 支持手动自托管(自行配置 Nginx/Apache/Caddy),提供完全控制权
- - 对方观点:使用 Vercel/Netlify 可零配置自动部署,省去服务器维护成本
+---
+title: "Building your Quartz"
+type: source
+tags:
+ - quartz
+ - obsidian
+ - static-site-generator
+ - self-hosting
+date: 2026-03-04
+---
+
+## Source File
+- [[raw/Home Office/Building your Quartz.md]]
+
+## Summary(用中文描述)
+- 核心主题:Quartz 静态网站的本地预览与自托管部署指南
+- 问题域:如何将 Markdown 文件构建为可预览的本地网站,以及如何通过主流 Web 服务器(Nginx/Apache/Caddy)实现公网自托管
+- 方法/机制:Quartz 将 Markdown 文件转换为 HTML/JS/CSSbundle;本地预览通过 `npx quartz build --serve` 启动热重载服务器;自托管需配置 Web 服务器处理无扩展名链接(`try_files $uri $uri.html $uri/`)
+- 结论/价值:Quartz 提供了一套完整的从笔记到静态网站的构建与部署流程,支持多种主流 Web 服务器的自托管方案,适合将 Obsidian 笔记发布为公网可访问的静态网站
+
+## Key Claims(用中文描述)
+- Quartz 将 Markdown 文件和资源转换为 HTML、JS 和 CSS 文件包(即一个网站)
+- Serve 模式仅用于本地预览,生产环境部署需使用 GitHub Pages 等静态托管服务
+- 静态托管前需正确配置 `baseUrl`,否则 RSS Feed 和 Sitemap 生成功能将无法正常工作
+- 自托管时 Web 服务器必须处理不含 `.html` 扩展名的链接(Quartz 生成此类链接)
+- Nginx 通过 `try_files $uri $uri.html $uri/ =404` 规则处理无扩展名链接
+- Apache 通过 RewriteCond/RewriteRule 组合实现相同功能
+- Caddy 通过 `try_files {path} {path}.html {path}/ =404` 实现,并支持 gzip 压缩和错误页处理
+
+## Key Quotes
+> "Serve mode is intended for local previews only. For production workloads, see the page on hosting."
+> — Quartz 官方文档,明确 serve 模式仅用于本地预览
+
+> "Some Quartz features (like RSS Feed and sitemap generation) require `baseUrl` to be configured properly in your configuration to work properly."
+> — Quartz 官方文档,部署前必须配置 baseUrl
+
+## Key Concepts
+- [[Quartz]]:Obsidian 笔记静态网站生成器,将 Markdown 转换为 HTML/JS/CSS bundle
+- [[Static Site Generator]]:静态网站生成器,无需服务器端渲染,直接托管 HTML 文件
+- [[npx quartz build]]:Quartz 构建命令,核心参数包括 `-d/--directory`(内容目录)、`-o/--output`(输出目录)、`--serve`(本地预览)、`--port`(端口)、`--concurrency`(并发数)
+- [[try_files]]:Nginx 指令,按顺序尝试文件、HTML 文件、目录,最后返回 404
+- [[RewriteRule]]:Apache mod_rewrite 模块指令,用于 URL 重写处理无扩展名链接
+- [[baseUrl]]:Quartz 配置项,用于生成正确的绝对 URL,RSS Feed 和 Sitemap 功能依赖此配置
+
+## Key Entities
+- [[Quartz]]:开源静态网站生成器,专注于将 Obsidian 风格的双链笔记发布为静态网站
+- [[Obsidian]]:本地笔记软件,Quartz 的内容来源
+- [[GitHub Pages]]:Quartz 推荐的公网托管方案
+
+## Connections
+- [[Obsidian]] — provides content → [[Quartz]]
+- [[Quartz]] — builds to static files → [[Static Site Generator]]
+- [[Quartz]] — local preview → [[npx quartz build --serve]]
+- [[Quartz]] — production deployment → [[GitHub Pages]] / Self-hosting
+- Self-hosting — requires → [[try_files]] (Nginx) / [[RewriteRule]] (Apache) / [[Caddyfile]] (Caddy)
+
+## Contradictions
+- 与通用静态网站托管方案(如 Vercel/Netlify)冲突:
+ - 冲突点:这些平台自动处理 URL 重写,无需手动配置 Web 服务器
+ - 当前观点:Quartz 支持手动自托管(自行配置 Nginx/Apache/Caddy),提供完全控制权
+ - 对方观点:使用 Vercel/Netlify 可零配置自动部署,省去服务器维护成本
diff --git a/wiki/sources/claude-code调用方法总结.md b/wiki/sources/claude-code调用方法总结.md
index d14aaae4..6e3a4565 100644
--- a/wiki/sources/claude-code调用方法总结.md
+++ b/wiki/sources/claude-code调用方法总结.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/claude-code调用方法总结]]
+- [[raw/Agent/claude-code调用方法总结.md]]
## Summary(用中文描述)
- 核心主题:Hermes Agent 如何通过 terminal 工具调用 Claude Code CLI,包含两种调用模式和完整的参数说明
diff --git a/wiki/sources/clonezilla对ubuntu-server进行全盘镜像备份.md b/wiki/sources/clonezilla对ubuntu-server进行全盘镜像备份.md
index 39729b05..133d9640 100644
--- a/wiki/sources/clonezilla对ubuntu-server进行全盘镜像备份.md
+++ b/wiki/sources/clonezilla对ubuntu-server进行全盘镜像备份.md
@@ -1,51 +1,51 @@
----
-title: "Clonezilla对Ubuntu Server进行全盘镜像备份"
-type: source
-tags: [backup, clonezilla, nas, rufus, ubuntu]
-date: 2026-05-06
----
-
-## Source File
-- [[Home Office/Clonezilla对Ubuntu Server进行全盘镜像备份]]
-
-## Summary(用中文描述)
-- 核心主题:使用 Clonezilla(再生龙)对 Ubuntu Server 进行全盘镜像备份到 NAS,灾难时可完整还原系统
-- 问题域:Linux 服务器数据保护、灾难恢复(DR)、NAS 存储集成
-- 方法/机制:Clonezilla live USB 启动 → device-image 模式 → NFS 网络存储挂载 → savedisk 全盘镜像 → restordisk 还原
-- 结论/价值:Clonezilla 提供类似 Ghost 的磁盘级镜像能力,是 rsync 增量备份之外的全量快照方案,两者互补构成完整备份策略
-
-## Key Claims(用中文描述)
-- Rufus 写入 Clonezilla ISO 时必须选择"ISO 镜像模式",否则可能导致 U 盘启动失败
-- 针对较新笔记本,分区方案应选 GPT + UEFI(非 CSM);老旧笔记本选 MBR + BIOS
-- NFS 是 NAS 备份场景下兼容性最好的网络协议,相比 SMB 更适合 Linux 环境
-- Clonezilla 备份完成后,新硬盘可通过 restoredisk 完整还原,系统即刻复活,无需重装
-
-## Key Quotes
-> "Clonezilla live (Default settings, VGA 800x600)" — Clonezilla 启动菜单推荐选项,英文界面更稳定
-> "以 ISO 镜像模式写入 (推荐)" — Rufus 写入 ISOHybrid 镜像时的关键选择,DD 模式仅作备选
-
-## Key Concepts
-- [[全盘镜像备份]]:将整个磁盘(所有分区 + 数据)打包为单个镜像文件,支持完整灾难恢复
-- [[NFS 网络存储]]:Network File System,Linux 原生网络文件系统,NAS 共享的标准协议
-- [[ISOHybrid 镜像]]:同时支持 ISO 和 DD 两种写入模式的混合镜像,Rufus 写入时需注意模式选择
-- [[GPT vs MBR]]:新一代分区表格式(GPT) vs 传统格式,UEFI 启动需要 GPT 分区
-
-## Key Entities
-- [[Clonezilla]]:开源磁盘镜像工具(再生龙),支持保存和还原整块磁盘镜像
-- [[Rufus]]:Windows U 盘启动盘制作工具,用于将 Clonezilla ISO 写入 U 盘
-- [[Ubuntu Server]]:目标备份操作系统,HP ZBook 工作站上运行的服务器版本
-- [[NFS]]:Network File System,用于将 NAS 存储挂载到 Clonezilla 进行镜像存储
-
-## Connections
-- [[Ubuntu服务器通过rsync实现日常增量备份]] ← 互补方案 ← [[Clonezilla全盘镜像备份]]
- - Clonezilla 提供全量快照(低频),rsync 提供增量同步(高频),两者构成完整备份策略
-- [[家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox]] ← 依赖 ← [[Ubuntu Server]]
- - Ubuntu Server 是家庭监控系统的运行平台,其备份直接关系到监控系统可用性
-- [[NFS]] ← 存储后端 ← [[Clonezilla全盘镜像备份]]
- - NAS 通过 NFS 协议提供镜像存储空间
-
-## Contradictions
-- 与 [[Ubuntu服务器通过rsync实现日常增量备份]] 方法层面:
- - 冲突点:rsync 是文件级增量备份,Clonezilla 是磁盘级全量镜像
- - 当前观点:两者互补而非互斥——Clonezilla 做周期性全量快照(如每月),rsync 做每日增量同步
- - 对方观点:rsync 更适合不停机的日常备份场景,Clonezilla 更适合系统迁移或重大变更前的快照
+---
+title: "Clonezilla对Ubuntu Server进行全盘镜像备份"
+type: source
+tags: [backup, clonezilla, nas, rufus, ubuntu]
+date: 2026-05-06
+---
+
+## Source File
+- [[raw/Home Office/Clonezilla对Ubuntu Server进行全盘镜像备份.md]]
+
+## Summary(用中文描述)
+- 核心主题:使用 Clonezilla(再生龙)对 Ubuntu Server 进行全盘镜像备份到 NAS,灾难时可完整还原系统
+- 问题域:Linux 服务器数据保护、灾难恢复(DR)、NAS 存储集成
+- 方法/机制:Clonezilla live USB 启动 → device-image 模式 → NFS 网络存储挂载 → savedisk 全盘镜像 → restordisk 还原
+- 结论/价值:Clonezilla 提供类似 Ghost 的磁盘级镜像能力,是 rsync 增量备份之外的全量快照方案,两者互补构成完整备份策略
+
+## Key Claims(用中文描述)
+- Rufus 写入 Clonezilla ISO 时必须选择"ISO 镜像模式",否则可能导致 U 盘启动失败
+- 针对较新笔记本,分区方案应选 GPT + UEFI(非 CSM);老旧笔记本选 MBR + BIOS
+- NFS 是 NAS 备份场景下兼容性最好的网络协议,相比 SMB 更适合 Linux 环境
+- Clonezilla 备份完成后,新硬盘可通过 restoredisk 完整还原,系统即刻复活,无需重装
+
+## Key Quotes
+> "Clonezilla live (Default settings, VGA 800x600)" — Clonezilla 启动菜单推荐选项,英文界面更稳定
+> "以 ISO 镜像模式写入 (推荐)" — Rufus 写入 ISOHybrid 镜像时的关键选择,DD 模式仅作备选
+
+## Key Concepts
+- [[全盘镜像备份]]:将整个磁盘(所有分区 + 数据)打包为单个镜像文件,支持完整灾难恢复
+- [[NFS 网络存储]]:Network File System,Linux 原生网络文件系统,NAS 共享的标准协议
+- [[ISOHybrid 镜像]]:同时支持 ISO 和 DD 两种写入模式的混合镜像,Rufus 写入时需注意模式选择
+- [[GPT vs MBR]]:新一代分区表格式(GPT) vs 传统格式,UEFI 启动需要 GPT 分区
+
+## Key Entities
+- [[Clonezilla]]:开源磁盘镜像工具(再生龙),支持保存和还原整块磁盘镜像
+- [[Rufus]]:Windows U 盘启动盘制作工具,用于将 Clonezilla ISO 写入 U 盘
+- [[Ubuntu Server]]:目标备份操作系统,HP ZBook 工作站上运行的服务器版本
+- [[NFS]]:Network File System,用于将 NAS 存储挂载到 Clonezilla 进行镜像存储
+
+## Connections
+- [[Ubuntu服务器通过rsync实现日常增量备份]] ← 互补方案 ← [[Clonezilla全盘镜像备份]]
+ - Clonezilla 提供全量快照(低频),rsync 提供增量同步(高频),两者构成完整备份策略
+- [[家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox]] ← 依赖 ← [[Ubuntu Server]]
+ - Ubuntu Server 是家庭监控系统的运行平台,其备份直接关系到监控系统可用性
+- [[NFS]] ← 存储后端 ← [[Clonezilla全盘镜像备份]]
+ - NAS 通过 NFS 协议提供镜像存储空间
+
+## Contradictions
+- 与 [[Ubuntu服务器通过rsync实现日常增量备份]] 方法层面:
+ - 冲突点:rsync 是文件级增量备份,Clonezilla 是磁盘级全量镜像
+ - 当前观点:两者互补而非互斥——Clonezilla 做周期性全量快照(如每月),rsync 做每日增量同步
+ - 对方观点:rsync 更适合不停机的日常备份场景,Clonezilla 更适合系统迁移或重大变更前的快照
diff --git a/wiki/sources/cloud-devop-maturity-guideline.md b/wiki/sources/cloud-devop-maturity-guideline.md
index 05f20313..74f24289 100644
--- a/wiki/sources/cloud-devop-maturity-guideline.md
+++ b/wiki/sources/cloud-devop-maturity-guideline.md
@@ -1,49 +1,49 @@
----
-title: "Cloud DevOp Maturity - Guideline"
-type: source
-tags: [cloud, devops, maturity, enterprise, saas]
-date: 2026-04-26
----
-
-## Source File
-- [[Cloud & DevOps/Cloud DevOp Maturity - Guideline.md]]
-
-## Summary(用中文描述)
-- 核心主题:企业级 SaaS 公司的云 DevOps 成熟度评估框架与提升路径
-- 问题域:如何定义、衡量和提升云端 DevOps 实践的成熟度
-- 方法/机制:基于 DORA 四大指标(部署频率、变更前置时间、变更失败率、平均恢复时间)和 CMMI 成熟度模型,从自动化、协作文化、监控可观测性、安全集成四大支柱进行评估
-- 结论/价值:DevOps 成熟度提升是持续迭代过程,需分阶段实施,从 CI/CD 和自动化入手,逐步建立 DevOps 卓越中心
-
-## Key Claims(用中文描述)
-- 企业通过评估 DevOps 成熟度,可缩短上市时间、提升运营效率并增强产品可靠性
-- DORA 四项核心指标(部署频率、变更前置时间、变更失败率、MTTR)是衡量 DevOps 绩效的行业标准
-- 成熟的 DevOps 组织需在自动化(CI/CD、IaC、测试自动化)、跨团队协作与文化、监控可观测性、安全集成(DevSecOps)四大支柱上均衡发展
-- 云原生架构(微服务、容器化、无服务器技术)可加速 DevOps 成熟度提升
-- DevOps 成熟度提升路径包括:进行成熟度评估 → 建立 DevOps 卓越中心 → 分阶段实施改进(从 CI/CD 和自动化开始)→ 持续迭代
-
-## Key Quotes
-> "Focus on CI/CD pipelines, infrastructure as code (IaC), and test automation. Emphasize the importance of repeatable and reliable deployments." — 自动化是成熟 DevOps 的基石
-> "DevOps is a continuous improvement process, and even mature companies need to adapt to evolving technologies and practices." — DevOps 成熟度提升是持续迭代过程
-
-## Key Concepts
-- [[DevOpsMaturityModel]]:CMMI 和 DORA 模型定义的组织 DevOps 能力成熟度等级体系
-- [[DORAMetrics]]:DevOps Research & Assessment 的四大核心指标——部署频率、变更前置时间、变更失败率、平均恢复时间(MTTR)
-- [[CI/CDPipeline]]:持续集成/持续交付流水线,DevOps 自动化的核心机制
-- [[InfrastructureAsCode]]:通过代码管理基础设施,实现环境一致性和可重复部署
-- [[DevSecOps]]:将安全集成到 DevOps 全生命周期,实现持续安全合规
-- [[MicroservicesArchitecture]]:云原生微服务架构,支持独立部署和快速迭代
-- [[Observability]]:可观测性,通过持续监控、日志和追踪快速发现和解决生产问题
-
-## Key Entities
-- [[CMMI]]:Capability Maturity Model Integration,能力成熟度模型集成,用于定义组织过程改进的成熟度等级
-- [[DORA]]:DevOps Research & Assessment,DevOps 研究与评估组织,提供行业标准的 DevOps 绩效指标
-
-## Connections
-- [[DevOpsMaturityModel]] ← based_on ← [[DORAMetrics]]
-- [[CI/CDPipeline]] ← core_enabler ← [[DevOpsMaturityModel]]
-- [[InfrastructureAsCode]] ← supports ← [[CI/CDPipeline]]
-- [[DevSecOps]] ← extends ← [[DevOpsMaturityModel]]
-- [[MicroservicesArchitecture]] ← architectural_pattern ← [[CloudNativePractices]]
-
-## Contradictions
-- 暂无已知的 Wiki 内冲突内容
+---
+title: "Cloud DevOp Maturity - Guideline"
+type: source
+tags: [cloud, devops, maturity, enterprise, saas]
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Cloud DevOp Maturity - Guideline.md]]
+
+## Summary(用中文描述)
+- 核心主题:企业级 SaaS 公司的云 DevOps 成熟度评估框架与提升路径
+- 问题域:如何定义、衡量和提升云端 DevOps 实践的成熟度
+- 方法/机制:基于 DORA 四大指标(部署频率、变更前置时间、变更失败率、平均恢复时间)和 CMMI 成熟度模型,从自动化、协作文化、监控可观测性、安全集成四大支柱进行评估
+- 结论/价值:DevOps 成熟度提升是持续迭代过程,需分阶段实施,从 CI/CD 和自动化入手,逐步建立 DevOps 卓越中心
+
+## Key Claims(用中文描述)
+- 企业通过评估 DevOps 成熟度,可缩短上市时间、提升运营效率并增强产品可靠性
+- DORA 四项核心指标(部署频率、变更前置时间、变更失败率、MTTR)是衡量 DevOps 绩效的行业标准
+- 成熟的 DevOps 组织需在自动化(CI/CD、IaC、测试自动化)、跨团队协作与文化、监控可观测性、安全集成(DevSecOps)四大支柱上均衡发展
+- 云原生架构(微服务、容器化、无服务器技术)可加速 DevOps 成熟度提升
+- DevOps 成熟度提升路径包括:进行成熟度评估 → 建立 DevOps 卓越中心 → 分阶段实施改进(从 CI/CD 和自动化开始)→ 持续迭代
+
+## Key Quotes
+> "Focus on CI/CD pipelines, infrastructure as code (IaC), and test automation. Emphasize the importance of repeatable and reliable deployments." — 自动化是成熟 DevOps 的基石
+> "DevOps is a continuous improvement process, and even mature companies need to adapt to evolving technologies and practices." — DevOps 成熟度提升是持续迭代过程
+
+## Key Concepts
+- [[DevOpsMaturityModel]]:CMMI 和 DORA 模型定义的组织 DevOps 能力成熟度等级体系
+- [[DORAMetrics]]:DevOps Research & Assessment 的四大核心指标——部署频率、变更前置时间、变更失败率、平均恢复时间(MTTR)
+- [[CI/CDPipeline]]:持续集成/持续交付流水线,DevOps 自动化的核心机制
+- [[InfrastructureAsCode]]:通过代码管理基础设施,实现环境一致性和可重复部署
+- [[DevSecOps]]:将安全集成到 DevOps 全生命周期,实现持续安全合规
+- [[MicroservicesArchitecture]]:云原生微服务架构,支持独立部署和快速迭代
+- [[Observability]]:可观测性,通过持续监控、日志和追踪快速发现和解决生产问题
+
+## Key Entities
+- [[CMMI]]:Capability Maturity Model Integration,能力成熟度模型集成,用于定义组织过程改进的成熟度等级
+- [[DORA]]:DevOps Research & Assessment,DevOps 研究与评估组织,提供行业标准的 DevOps 绩效指标
+
+## Connections
+- [[DevOpsMaturityModel]] ← based_on ← [[DORAMetrics]]
+- [[CI/CDPipeline]] ← core_enabler ← [[DevOpsMaturityModel]]
+- [[InfrastructureAsCode]] ← supports ← [[CI/CDPipeline]]
+- [[DevSecOps]] ← extends ← [[DevOpsMaturityModel]]
+- [[MicroservicesArchitecture]] ← architectural_pattern ← [[CloudNativePractices]]
+
+## Contradictions
+- 暂无已知的 Wiki 内冲突内容
diff --git a/wiki/sources/cloud-learning-master-index.md b/wiki/sources/cloud-learning-master-index.md
index 4ed28907..16c266d2 100644
--- a/wiki/sources/cloud-learning-master-index.md
+++ b/wiki/sources/cloud-learning-master-index.md
@@ -1,53 +1,53 @@
----
-title: "Cloud Learning Master Index"
-type: source
-tags: ["cloud-learning", "DevOps", "SRE", "AWS", "master-index"]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/_Index/cloud-learning-master-index.md]]
-
-## Summary(用中文描述)
-- 核心主题:Micro Focus / OpenText 云转型学习会话(Public Cloud Learning Sessions)的视频课程总索引,涵盖 AWS Landing Zone、IAM、IaC、EKS、FinOps、CI/CD、Security、Networking、Serverless/AI、OpenText Series 共 10 大领域。
-- 问题域:为企业云转型提供系统性学习路径,覆盖架构设计、身份治理、成本管理、安全合规、可观测性、容器化、自动化运维等全技术栈。
-- 方法/机制:以 NAS 共享文件系统(`/volume2/work/Public Cloud Learning Sessions/`)为视频源,按技术领域分类组织学习会话,由 CTP(Cloud Transformation Programme)团队定期录制分享。
-- 结论/价值:作为云转型知识库的总入口,为工程师和架构师提供按主题索引的参考导航,支持快速定位特定领域的学习资源。
-
-## Key Claims(用中文描述)
-- 该索引覆盖 Micro Focus / OpenText 云转型计划的全部技术领域,从基础设施(AWS Landing Zone)到应用层(Serverless/AI)形成完整知识体系。
-- 视频总数 **111 个**(截至 2026-04-14),分布在 10 个技术分类中,其中 AWS Landing Zone(22)和 OpenText Series(21)内容最丰富。
-- 所有视频通过 NAS 集中存储(`/volume2/work/Public Cloud Learning Sessions/`),统一命名规范(ctp-topic-NN / learning-sessions-xxx / public-cloud-learning-sessions-xxx)。
-
-## Key Quotes
-> "NAS源: `/volume2/work/Public Cloud Learning Sessions/` | Total: **0 videos processed**" — 索引文件元数据声明(videos processed 计数器未更新,实际视频数按分类统计为 111 个)
-
-## Key Concepts
-- [[Cloud-Transformation-Programme]]:云转型计划,本索引所属的学习会话系列由 CTP 团队主导录制。
-- [[AWS-Landing-Zone]]:AWS Landing Zone 是索引中最核心的分类之一(22 个视频),涵盖架构设计、账号管理、网络隔离。
-- [[EKS-Optimization]]:EKS 优化三专题(Bottlerocket OS / Karpenter / EKS Auto Mode)是容器化学习的高频主题。
-- [[FinOps]]:FinOps 与成本优化专题覆盖 Instance Scheduler / Rightsizing / Savings Plans / Spot Instances 等核心技术。
-- [[GitOps]]:GitOps 与 CI/CD 专题包括 Git / Renovate Bot / Atlantis / Gruntwork / IaC Testing 等工具链。
-- [[Security-Governance]]:安全专题涵盖供应链安全、3LoD 框架、Firewall Manager、Secrets Manager、CSPM 等。
-
-## Key Entities
-- [[CTP-Team]](Cloud Transformation Programme Team):学习会话系列的发起和组织团队,涵盖 AWS Landing Zone / FinOps / EKS / CI/CD / Security 等多领域内容。
-- [[OpenText]]:索引中 OpenText Series(21 个视频)专题由 OpenText 全球团队分享,覆盖 Thor Platform、产品策略、GIS 安全政策、GitLab 迁移等。
-- [[AWS]]:所有视频的云平台基础,涵盖 AWS 生态中的 EC2/EKS/S3/IAM/VPC/Lambda 等全栈服务。
-- [[Gruntwork]]:IaC 工具链核心,Gruntwork Landing Zone 架构在索引中出现多次(Topic 1 / Topic 3 / Topic 9 等)。
-- [[Micro-Focus]]:早期视频的发起公司,已被 OpenText 收购,部分内容反映 Micro Focus 时期的架构决策。
-
-## Connections
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← depends_on ← cloud-learning-master-index(索引入口)
-- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← cloud-learning-master-index(专题延伸)
-- [[ctp-topic-34-azure-landing-zone-architecture-overview]] ← extends ← cloud-learning-master-index(多云扩展)
-- [[public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization]] ← depends_on ← cloud-learning-master-index(EKS 专题入口)
-- [[public-cloud-learning-sessions-eks-optimization-part-2-of-3-running-containers-w]] ← extends ← cloud-learning-master-index
-- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← extends ← cloud-learning-master-index
-- [[public-cloud-learning-sessions-budget-control-20240319-160204-meeting-recording]] ← depends_on ← cloud-learning-master-index(FinOps 成本管控)
-- [[ctp-topic-33-an-introduction-to-gitops]] ← depends_on ← cloud-learning-master-index(GitOps 入门)
-- [[public-cloud-learning-sessions-opentext-gis-security-policies-20241015-160257-me]] ← depends_on ← cloud-learning-master-index(OpenText 安全专题)
-
-## Contradictions
-- 与 [[ctp-topic-14-octane-hub-on-aws]] 可能的冲突:索引本身仅为元数据,不存在内容冲突。
-- 与 [[public-cloud-learning-sessions-observability-with-opentelemetry-20240402-160113]] 无冲突:EKS 可观测性专题与 OpenTelemetry 专题互补。
+---
+title: "Cloud Learning Master Index"
+type: source
+tags: ["cloud-learning", "DevOps", "SRE", "AWS", "master-index"]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/_Index/cloud-learning-master-index.md]]
+
+## Summary(用中文描述)
+- 核心主题:Micro Focus / OpenText 云转型学习会话(Public Cloud Learning Sessions)的视频课程总索引,涵盖 AWS Landing Zone、IAM、IaC、EKS、FinOps、CI/CD、Security、Networking、Serverless/AI、OpenText Series 共 10 大领域。
+- 问题域:为企业云转型提供系统性学习路径,覆盖架构设计、身份治理、成本管理、安全合规、可观测性、容器化、自动化运维等全技术栈。
+- 方法/机制:以 NAS 共享文件系统(`/volume2/work/Public Cloud Learning Sessions/`)为视频源,按技术领域分类组织学习会话,由 CTP(Cloud Transformation Programme)团队定期录制分享。
+- 结论/价值:作为云转型知识库的总入口,为工程师和架构师提供按主题索引的参考导航,支持快速定位特定领域的学习资源。
+
+## Key Claims(用中文描述)
+- 该索引覆盖 Micro Focus / OpenText 云转型计划的全部技术领域,从基础设施(AWS Landing Zone)到应用层(Serverless/AI)形成完整知识体系。
+- 视频总数 **111 个**(截至 2026-04-14),分布在 10 个技术分类中,其中 AWS Landing Zone(22)和 OpenText Series(21)内容最丰富。
+- 所有视频通过 NAS 集中存储(`/volume2/work/Public Cloud Learning Sessions/`),统一命名规范(ctp-topic-NN / learning-sessions-xxx / public-cloud-learning-sessions-xxx)。
+
+## Key Quotes
+> "NAS源: `/volume2/work/Public Cloud Learning Sessions/` | Total: **0 videos processed**" — 索引文件元数据声明(videos processed 计数器未更新,实际视频数按分类统计为 111 个)
+
+## Key Concepts
+- [[Cloud-Transformation-Programme]]:云转型计划,本索引所属的学习会话系列由 CTP 团队主导录制。
+- [[AWS-Landing-Zone]]:AWS Landing Zone 是索引中最核心的分类之一(22 个视频),涵盖架构设计、账号管理、网络隔离。
+- [[EKS-Optimization]]:EKS 优化三专题(Bottlerocket OS / Karpenter / EKS Auto Mode)是容器化学习的高频主题。
+- [[FinOps]]:FinOps 与成本优化专题覆盖 Instance Scheduler / Rightsizing / Savings Plans / Spot Instances 等核心技术。
+- [[GitOps]]:GitOps 与 CI/CD 专题包括 Git / Renovate Bot / Atlantis / Gruntwork / IaC Testing 等工具链。
+- [[Security-Governance]]:安全专题涵盖供应链安全、3LoD 框架、Firewall Manager、Secrets Manager、CSPM 等。
+
+## Key Entities
+- [[CTP-Team]](Cloud Transformation Programme Team):学习会话系列的发起和组织团队,涵盖 AWS Landing Zone / FinOps / EKS / CI/CD / Security 等多领域内容。
+- [[OpenText]]:索引中 OpenText Series(21 个视频)专题由 OpenText 全球团队分享,覆盖 Thor Platform、产品策略、GIS 安全政策、GitLab 迁移等。
+- [[AWS]]:所有视频的云平台基础,涵盖 AWS 生态中的 EC2/EKS/S3/IAM/VPC/Lambda 等全栈服务。
+- [[Gruntwork]]:IaC 工具链核心,Gruntwork Landing Zone 架构在索引中出现多次(Topic 1 / Topic 3 / Topic 9 等)。
+- [[Micro-Focus]]:早期视频的发起公司,已被 OpenText 收购,部分内容反映 Micro Focus 时期的架构决策。
+
+## Connections
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← depends_on ← cloud-learning-master-index(索引入口)
+- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← cloud-learning-master-index(专题延伸)
+- [[ctp-topic-34-azure-landing-zone-architecture-overview]] ← extends ← cloud-learning-master-index(多云扩展)
+- [[public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization]] ← depends_on ← cloud-learning-master-index(EKS 专题入口)
+- [[public-cloud-learning-sessions-eks-optimization-part-2-of-3-running-containers-w]] ← extends ← cloud-learning-master-index
+- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← extends ← cloud-learning-master-index
+- [[public-cloud-learning-sessions-budget-control-20240319-160204-meeting-recording]] ← depends_on ← cloud-learning-master-index(FinOps 成本管控)
+- [[ctp-topic-33-an-introduction-to-gitops]] ← depends_on ← cloud-learning-master-index(GitOps 入门)
+- [[public-cloud-learning-sessions-opentext-gis-security-policies-20241015-160257-me]] ← depends_on ← cloud-learning-master-index(OpenText 安全专题)
+
+## Contradictions
+- 与 [[ctp-topic-14-octane-hub-on-aws]] 可能的冲突:索引本身仅为元数据,不存在内容冲突。
+- 与 [[public-cloud-learning-sessions-observability-with-opentelemetry-20240402-160113]] 无冲突:EKS 可观测性专题与 OpenTelemetry 专题互补。
diff --git a/wiki/sources/codecrafters-iobuild-your-own-x-master-programming-by-recreating-your-favorite-technologies-from-scratch.md b/wiki/sources/codecrafters-iobuild-your-own-x-master-programming-by-recreating-your-favorite-technologies-from-scratch.md
index 29e6ac45..f7742f9c 100644
--- a/wiki/sources/codecrafters-iobuild-your-own-x-master-programming-by-recreating-your-favorite-technologies-from-scratch.md
+++ b/wiki/sources/codecrafters-iobuild-your-own-x-master-programming-by-recreating-your-favorite-technologies-from-scratch.md
@@ -1,47 +1,94 @@
----
-title: "codecrafters-io/build-your-own-x: Master programming by recreating your favorite technologies from scratch"
-type: source
-tags: [build-your-own-x, byox, codecrafters, github, learn-by-building]
-sources: []
-last_updated: 2026-04-23
----
-
-## Source File
-- [[raw/AI/codecrafters-iobuild-your-own-x Master programming by recreating your favorite technologies from scratch.md]]
-
-## Summary(用中文描述)
-- 核心主题:通过"从零重建"(Build Your Own X)方法学习编程——精选高质量、分步骤指南,手把手教开发者从零实现自己最喜欢的主流技术。
-- 问题域:如何系统化地理解复杂系统内部原理,而非停留在表面使用层面;如何找到高质量、可执行的"手把手"教程资源。
-- 方法/机制:GitHub 社区协作维护精选教程列表,涵盖 26 个技术领域(C++/Python/Java/JavaScript/Go/Rust 等多语言),每条教程附带源码链接和难度标注。核心理念引用 Richard Feynman:"What I cannot create, I do not understand"。
-- 结论/价值:将"被动阅读文档"升级为"主动重建系统",是深度掌握计算机科学核心技术的最有效路径;资源全部免费开源,社区持续贡献新教程。
-
-## Key Claims(用中文描述)
-- build-your-own-x 项目通过聚合 26+ 技术领域的分步骤指南,使开发者能够从零重建主流技术,从而实现深度技术理解。
-- 分领域教程覆盖 3D Renderer、Augmented Reality、BitTorrent Client、Blockchain/Cryptocurrency、Bot、Command-Line Tool、Database、Docker、Emulator/Virtual Machine、Front-end Framework、Game、Git、Network Stack、Neural Network、Operating System、Physics Engine、Programming Language、Regex Engine、Search Engine、Shell、Template Engine、Text Editor、Visual Recognition System、Voxel Engine、Web Browser、Web Server 等。
-- 每条教程配套源码和难度指引,支持 C++/Python/Java/JavaScript/Go/Rust/Haskell/TypeScript 等 15+ 编程语言。
-
-## Key Quotes
-> *"What I cannot create, I do not understand — Richard Feynman."* — 项目核心理念,强调动手重建是真正理解技术的不二法门
-
-## Key Concepts
-- [[Learn-By-Building]]:通过重建主流技术来学习编程的方法论,区别于被动阅读文档或观看视频,是深度技术理解的最高效路径。
-- [[From-Scratch Methodology]]:从零实现系统的学习方法,强调不使用任何外部库或框架,在最小化依赖下理解核心原理。
-- [[BYOX-Build-Your-Own-X]]:build-your-own-x 运动,即"自己动手重建 X"的学习社区和方法论。
-- [[Codecrafters]]:提供实战编程挑战的在线教育平台,以 build-your-own-x 理念为核心,提供分步骤练习。
-
-## Key Entities
-- [[CodeCrafters]]:build-your-own-x 项目的维护方,总部位于旧金山的教育科技创业公司,致力于提供实战编程教育。
-- [[DanielStefanovic]]:build-your-own-x 项目的创始人(最初由其发起),GitHub ID: danistefanovic。
-- [[RichardFeynman]]:诺贝尔物理学奖得主,其名言"What I cannot create, I do not understand"成为 BYOX 运动的理论基石。
-- [[NAND-to-Tetris]]:从与非门到完整计算机的课程,涵盖从硬件到软件栈的完整重建,被 build-your-own-x 收录。
-
-## Connections
-- [[Learn-By-Building]] ← inspires ← [[Vibe-Coding]]:Vibe Coding 强调让 AI 结对编程,而 BYOX 强调从零重建,两者互补——BYOX 理解原理,Vibe Coding 高效实现。
-- [[CodeCrafters]] ← maintains ← [[Build-Your-Own-X]]:CodeCrafters 不仅维护 GitHub 列表,还提供配套的在线编程挑战平台。
-- [[Codecrafters-iobuild-your-own-x]] ← references ← [[NAND-to-Tetris]]:NAND to Tetris 被列为操作系统和编程语言教程的推荐前置资源。
-
-## Contradictions
-- 与传统课程式学习冲突:
- - 冲突点:传统 CS 教育强调理论(算法/数据结构/操作系统理论),BYOX 强调实践(从零重建系统)。
- - 当前观点:对于有基础的开发者,BYOX 提供更深刻的技术直觉;理论为 BYOX 提供方向,BYOX 为理论提供落地。
- - 对方观点:没有理论基础直接做 BYOX 容易只见树木不见森林,需要先修计算机体系结构/数据结构等基础课程。
+---
+title: "codecrafters-io/build-your-own-x: Master programming by recreating your favorite technologies from scratch"
+type: source
+tags: [build-your-own-x, byox, codecrafters, learn-by-building, github, programming-education]
+date: 2026-01-01
+---
+
+## Source File
+- [[raw/AI/codecrafters-iobuild-your-own-x Master programming by recreating your favorite technologies from scratch.md]]
+
+## Summary(用中文描述)
+- 核心主题:通过"从零重建你喜欢的技术"的方式掌握编程——提供一个精心整理的分步指南汇编仓库
+- 问题域:编程学习路径、学习方法论、开源教育资源
+- 方法/机制:社区驱动维护 + 分类整理 + 外部教程链接聚合;核心理念来自 Richard Feynman:"我不能创造的东西,我就不理解"
+- 结论/价值:Learn by Building 是深度掌握技术的最佳路径;该仓库已成为程序员自我提升的标杆资源
+
+## Key Claims(用中文描述)
+- [[CodeCrafters]] 通过聚合分步指南,使开发者能通过重建 25+ 种技术来深度学习
+- 构建-by-X 方法让学习者通过动手实践而非理论阅读来理解复杂系统内部原理
+- [[Richard Feynman]] 的名言"我不能创造的东西,我就不理解"是该方法论的精神内核
+
+## Key Quotes
+> "What I cannot create, I do not understand — Richard Feynman." — 仓库首页引言,阐明 Learn by Building 的哲学根基
+
+> "This repository is a compilation of well-written, step-by-step guides for re-creating our favorite technologies from scratch." — 仓库自述,定义其核心价值
+
+## Key Concepts
+- [[Learn By Building]]:通过亲手重建技术来学习的方法论——不是阅读源码或文档,而是从第一性原理出发实现一个简化版本
+- [[Build Your Own X]]:该方法论的代名词,X 可以是 Git、Docker、数据库、编程语言等任意技术
+- [[Feynman Technique]]:费曼学习法的技术版本——真正理解一个系统的唯一方式是重新实现它
+
+## Key Entities
+- [[CodeCrafters]]:提供付费编程挑战平台的在线教育公司,同时维护 build-your-own-x 开源仓库
+- [[Daniel Stefanovic]]:build-your-own-x 仓库的创始人
+- [[Richard Feynman]]:诺贝尔物理学奖得主,其名言是 Learn by Building 运动的灵感来源
+- [[codecrafters-io/build-your-own-x]]:GitHub 仓库本身,聚合 25+ 领域的技术重建指南
+
+## Connections
+- [[CodeCrafters]] ← maintains ← [[codecrafters-io/build-your-own-x]]
+- [[Build Your Own X]] ← implements ← [[Learn By Building]]
+- [[Learn By Building]] ← extends ← [[Feynman Technique]]
+- [[codecrafters-io/build-your-own-x]] ← connects_to ← [[Vibe Coding]](两者都强调动手实践)
+
+## Contradictions
+- 无已知冲突
+
+## 技术分类清单
+
+该仓库涵盖 25 个技术领域的重建指南:
+
+### 系统底层
+- **3D Renderer**(C++/Java/JavaScript/Python)
+- **Operating System**(C/C++/Rust/Assembly)
+- **Emulator / Virtual Machine**(C/C++/JavaScript/Rust/Common Lisp)
+- **Shell**(C/Go/Rust)
+- **Network Stack**(C/Ruby/Python)
+
+### 基础设施
+- **Docker**(Go/Python/Shell/C)
+- **Database**(C/C++/Go/JavaScript/Python/Ruby/Rust/Clojure/Crystal)
+- **Git**(Haskell/JavaScript/Python/Ruby)
+- **Web Server**(C#/Node.js/PHP/Python/Ruby)
+
+### 编程语言与编译器
+- **Programming Language**(C/Python/Go/Haskell/JavaScript/OCaml/Racket/Ruby/Rust/Swift/TypeScript/(any) mal)
+- **Regex Engine**(C/Go/JavaScript/Perl/Python/Scala)
+
+### 网络与协议
+- **BitTorrent Client**(C#/Go/Nim/Node.js/Python)
+- **Bot**(Haskell/Node.js/Python/R/Go/Rust)
+- **Command-Line Tool**(Go/Rust/Zig/Nim)
+- **Search Engine**(CSS/Python)
+
+### 数据与智能
+- **Neural Network**(C#/F#/Go/Java/JavaScript/Python)
+- **Visual Recognition System**(Python)
+
+### 游戏与图形
+- **Game**(C/C++/C#/Go/Java/JavaScript/Lua/Python/Ruby/Rust)
+- **Physics Engine**(C/C++/JavaScript)
+- **Voxel Engine**(C++/Rust)
+- **Web Browser**(Rust/Python)
+
+### 前端与工具
+- **Front-end Framework / Library**(JavaScript — React/Redux/AngularJS/JSX)
+- **Template Engine**(JavaScript/Python/Ruby)
+- **Text Editor**(C/C++/Python/Ruby/Rust)
+
+### 区块链
+- **Blockchain / Cryptocurrency**(ATS/C#/Crystal/Go/Java/JavaScript/Kotlin/Python/Ruby/Scala/TypeScript/Rust)
+
+### 其他
+- **Augmented Reality**(C#/Python)
+- **NAND to Tetris**((any) — 从与非门到俄罗斯方块的完整计算机构建课程)
diff --git a/wiki/sources/compliance-auditor.md b/wiki/sources/compliance-auditor.md
index c1f37224..7235280e 100644
--- a/wiki/sources/compliance-auditor.md
+++ b/wiki/sources/compliance-auditor.md
@@ -1,60 +1,60 @@
----
-title: "Compliance Auditor Agent"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/compliance-auditor.md]]
-
-## Summary(用中文描述)
-- 核心主题:专业 AI Agent,专注于 SOC 2、ISO 27001、HIPAA、PCI-DSS 等安全隐私认证审计的全流程指导——从准备评估到证据收集直至认证通过。
-- 问题域:组织如何系统性地通过合规认证,避免"打勾式合规"(checkbox compliance),确保控制措施真正落地而非仅存在于文档中。
-- 方法/机制:五步工作流(Scoping → Gap Assessment → Remediation Support → Audit Support → Continuous Compliance);强调自动化证据收集、右置控制项设计、以审计员视角反向思考。
-- 结论/价值:合规项目应与公司规模和实际风险匹配;技术控制优于管理控制;证据必须证明控制在整个审计周期内持续有效,而非仅存在于当下。
-
-## Key Claims(用中文描述)
-- 不被遵守的政策比没有政策更危险——它制造虚假信心,增加审计风险。
-- 自动化证据收集从第一天就应建立——手动流程无法扩展。
-- 使用通用控制框架(common control framework)可一个控制集满足多个认证标准。
-- 技术控制优于管理控制——代码比培训更可靠。
-- 审计边界(scope)必须清晰定义,明确包含和排除的范围。
-- 例外情况(exceptions)需要完整文档:谁批准、为什么、有何时效、有何补偿控制。
-
-## Key Quotes
-> "A policy nobody follows is worse than no policy — it creates false confidence and audit risk."
-> — 核心原则:不follow的政策比没政策更危险
-
-> "Evidence must prove the control operated effectively over the audit period, not just that it exists today."
-> — 证据的核心要求:证明整个审计周期内持续有效
-
-> "Think like the auditor: what would you test? what evidence would you request?"
-> — 审计员心态:反向思考,模拟审计师会问什么
-
-## Key Concepts
-- [[Checkbox-Compliance]]:仅在文档层面满足合规要求,控制实际未落地或未被测试——文档中的反面案例。
-- [[Continuous-Compliance]]:持续合规——在两次年度审计之间建立自动化证据收集管道和季度控制测试机制,而非年度突击准备。
-- [[Common-Control-Framework]]:通用控制框架——设计一组控制项同时满足多个认证标准(如 SOC 2 + ISO 27001),避免重复工作。
-- [[Technical-Controls-Vs-Administrative-Controls]]:技术控制(如 IAM 策略、代码审计)优于管理控制(如培训、签到表),因为代码比人的行为更可靠。
-- [[Compensating-Control]]:补偿控制——当某项控制无法直接满足时,用于降低风险的替代措施;需完整记录批准人、原因和有效期。
-- [[Evidence-Collection-Matrix]]:证据收集矩阵——以控制目标(而非内部团队结构)组织证据的结构化文档,列出控制ID、证据类型、来源、收集方式和频率。
-
-## Key Entities
-- [[SOC-2]]:安全、可用性、处理完整性、机密性、隐私五大信任服务标准(Trust Service Criteria),最常见的云服务安全认证。
-- [[ISO-27001]]:国际信息安全管理标准,提供系统化的风险管理方法。
-- [[HIPAA]]:美国医疗信息隐私法规,涵盖 PHI(受保护健康信息)的保护要求。
-- [[PCI-DSS]]:支付卡行业数据安全标准,适用于处理信用卡信息的组织。
-
-## Connections
-- [[specialized-model-qa]] ← extends ← [[compliance-auditor]]:Model QA 关注 ML 模型质量,Compliance Auditor 关注整体安全控制——两者在模型部署合规证据收集上存在交叉。
-- [[automation-governance-architect]] ← depends_on ← [[compliance-auditor]]:合规审计所需的自动化证据收集需依托 Governance Architect 设计的 AI 系统治理框架。
-- [[CTP-Topic-52-3-Lines-of-Defence]] ← extends ← [[compliance-auditor]]:三道防线模型(业务管理 / 风险职能 / 内部审计)与合规审计的职责划分高度对应。
-- [[DevSecOps]] ← extends ← [[compliance-auditor]]:DevSecOps 将安全控制集成到 CI/CD 流水线中,是合规 Auditor 推荐的技术控制实现方式。
-
-## Contradictions
-- 与 [[specialized-model-qa]] 的侧重点差异:
- - 冲突点:Compliance Auditor 关注组织级控制(access control, incident response),Model QA 关注模型本身的质量与统计特性,两者对"证据"的定义不同。
- - 当前观点:合规证据以控制操作日志、策略文档、访问审查记录为主。
- - 对方观点:模型证据以 PSI、校准曲线、SHAP 值等统计指标为主。
- - 协调建议:两者可互补——Compliance Auditor 负责整体安全框架,Model QA 负责嵌入其中的 AI/ML 模型专项审计。
+---
+title: "Compliance Auditor Agent"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/compliance-auditor.md]]
+
+## Summary(用中文描述)
+- 核心主题:专业 AI Agent,专注于 SOC 2、ISO 27001、HIPAA、PCI-DSS 等安全隐私认证审计的全流程指导——从准备评估到证据收集直至认证通过。
+- 问题域:组织如何系统性地通过合规认证,避免"打勾式合规"(checkbox compliance),确保控制措施真正落地而非仅存在于文档中。
+- 方法/机制:五步工作流(Scoping → Gap Assessment → Remediation Support → Audit Support → Continuous Compliance);强调自动化证据收集、右置控制项设计、以审计员视角反向思考。
+- 结论/价值:合规项目应与公司规模和实际风险匹配;技术控制优于管理控制;证据必须证明控制在整个审计周期内持续有效,而非仅存在于当下。
+
+## Key Claims(用中文描述)
+- 不被遵守的政策比没有政策更危险——它制造虚假信心,增加审计风险。
+- 自动化证据收集从第一天就应建立——手动流程无法扩展。
+- 使用通用控制框架(common control framework)可一个控制集满足多个认证标准。
+- 技术控制优于管理控制——代码比培训更可靠。
+- 审计边界(scope)必须清晰定义,明确包含和排除的范围。
+- 例外情况(exceptions)需要完整文档:谁批准、为什么、有何时效、有何补偿控制。
+
+## Key Quotes
+> "A policy nobody follows is worse than no policy — it creates false confidence and audit risk."
+> — 核心原则:不follow的政策比没政策更危险
+
+> "Evidence must prove the control operated effectively over the audit period, not just that it exists today."
+> — 证据的核心要求:证明整个审计周期内持续有效
+
+> "Think like the auditor: what would you test? what evidence would you request?"
+> — 审计员心态:反向思考,模拟审计师会问什么
+
+## Key Concepts
+- [[Checkbox-Compliance]]:仅在文档层面满足合规要求,控制实际未落地或未被测试——文档中的反面案例。
+- [[Continuous-Compliance]]:持续合规——在两次年度审计之间建立自动化证据收集管道和季度控制测试机制,而非年度突击准备。
+- [[Common-Control-Framework]]:通用控制框架——设计一组控制项同时满足多个认证标准(如 SOC 2 + ISO 27001),避免重复工作。
+- [[Technical-Controls-Vs-Administrative-Controls]]:技术控制(如 IAM 策略、代码审计)优于管理控制(如培训、签到表),因为代码比人的行为更可靠。
+- [[Compensating-Control]]:补偿控制——当某项控制无法直接满足时,用于降低风险的替代措施;需完整记录批准人、原因和有效期。
+- [[Evidence-Collection-Matrix]]:证据收集矩阵——以控制目标(而非内部团队结构)组织证据的结构化文档,列出控制ID、证据类型、来源、收集方式和频率。
+
+## Key Entities
+- [[SOC-2]]:安全、可用性、处理完整性、机密性、隐私五大信任服务标准(Trust Service Criteria),最常见的云服务安全认证。
+- [[ISO-27001]]:国际信息安全管理标准,提供系统化的风险管理方法。
+- [[HIPAA]]:美国医疗信息隐私法规,涵盖 PHI(受保护健康信息)的保护要求。
+- [[PCI-DSS]]:支付卡行业数据安全标准,适用于处理信用卡信息的组织。
+
+## Connections
+- [[specialized-model-qa]] ← extends ← [[compliance-auditor]]:Model QA 关注 ML 模型质量,Compliance Auditor 关注整体安全控制——两者在模型部署合规证据收集上存在交叉。
+- [[automation-governance-architect]] ← depends_on ← [[compliance-auditor]]:合规审计所需的自动化证据收集需依托 Governance Architect 设计的 AI 系统治理框架。
+- [[CTP-Topic-52-3-Lines-of-Defence]] ← extends ← [[compliance-auditor]]:三道防线模型(业务管理 / 风险职能 / 内部审计)与合规审计的职责划分高度对应。
+- [[DevSecOps]] ← extends ← [[compliance-auditor]]:DevSecOps 将安全控制集成到 CI/CD 流水线中,是合规 Auditor 推荐的技术控制实现方式。
+
+## Contradictions
+- 与 [[specialized-model-qa]] 的侧重点差异:
+ - 冲突点:Compliance Auditor 关注组织级控制(access control, incident response),Model QA 关注模型本身的质量与统计特性,两者对"证据"的定义不同。
+ - 当前观点:合规证据以控制操作日志、策略文档、访问审查记录为主。
+ - 对方观点:模型证据以 PSI、校准曲线、SHAP 值等统计指标为主。
+ - 协调建议:两者可互补——Compliance Auditor 负责整体安全框架,Model QA 负责嵌入其中的 AI/ML 模型专项审计。
diff --git a/wiki/sources/content-factory.md b/wiki/sources/content-factory.md
index 5eaa45f2..0e6583a5 100644
--- a/wiki/sources/content-factory.md
+++ b/wiki/sources/content-factory.md
@@ -1,41 +1,41 @@
----
-title: "Multi-Agent Content Factory"
-type: source
-tags: []
-date: 2026-04-22
----
-
-## Source File
-- [[Agent/usecases/content-factory.md]]
-
-## Summary(用中文描述)
-- 核心主题:基于 Discord 频道的多 Agent 内容工厂,通过链式 Agent 实现内容创作全流程自动化
-- 问题域:内容创作者需要在研究、写作、设计多个平台手动切换,耗时耗力
-- 方法/机制:Research Agent(研究)→ Writing Agent(写作)→ Thumbnail Agent(设计),三 Agent 在各自 Discord 频道协作,通过定时调度实现"次日醒来即可收获成品内容"
-- 结论/价值:链式 Agent 是核心——上游 Agent 输出直接喂给下游,无需人工逐步干预;适配任意内容格式(tweets、newsletter、LinkedIn posts、podcast outline、blog)
-
-## Key Claims(用中文描述)
-- 链式 Agent 是内容工厂的核心能力——研究喂给写作,写作喂给缩略图,无需逐步人工提示
-- Discord 频道使每个 Agent 的工作独立可查,便于针对性反馈(如"脚本太长了"或"多关注 AI 新闻")
-- 本地模型做图像生成(如 Mac Studio 上的 Nano Banana)可降低成本并提升控制力
-
-## Key Quotes
-> "The power is in the chained agents — research feeds writing, writing feeds thumbnails. You don't prompt each step individually." — 核心洞察
-
-> "Running a local model for image generation (like Nano Banana on a Mac Studio) keeps costs down and gives you more control." — 成本优化建议
-
-## Key Concepts
-- [[Chained Agents]]:上游 Agent 输出直接作为下游输入,无需人工干预的 Agent 协作模式
-- [[Content Automation]]:内容创作全流程(研究→写作→设计)的自动化流水线
-- [[Workflow Architecture]]:多 Agent 系统的工作流架构设计
-
-## Key Entities
-- [[OpenClaw]]:多 Agent 框架,提供 sessions_spawn/sessions_send 能力,是 Content Factory 的底层实现工具
-- Alex Finn:OpenClaw 生活改变型用例视频的作者,内容工厂方案受其启发
-
-## Connections
-- [[Podcast Production Pipeline]] ← related_to ← [[Content Factory]]
-- [[multi-agent-team]] ← related_to ← [[Content Factory]]
-
-## Contradictions
-- 与 [[Podcast Production Pipeline]]:两者均涉及多 Agent 协作流水线,但播客流水线侧重音视频内容,内容工厂侧重社交媒体短内容
+---
+title: "Multi-Agent Content Factory"
+type: source
+tags: []
+date: 2026-04-22
+---
+
+## Source File
+- [[raw/Agent/usecases/content-factory.md]]
+
+## Summary(用中文描述)
+- 核心主题:基于 Discord 频道的多 Agent 内容工厂,通过链式 Agent 实现内容创作全流程自动化
+- 问题域:内容创作者需要在研究、写作、设计多个平台手动切换,耗时耗力
+- 方法/机制:Research Agent(研究)→ Writing Agent(写作)→ Thumbnail Agent(设计),三 Agent 在各自 Discord 频道协作,通过定时调度实现"次日醒来即可收获成品内容"
+- 结论/价值:链式 Agent 是核心——上游 Agent 输出直接喂给下游,无需人工逐步干预;适配任意内容格式(tweets、newsletter、LinkedIn posts、podcast outline、blog)
+
+## Key Claims(用中文描述)
+- 链式 Agent 是内容工厂的核心能力——研究喂给写作,写作喂给缩略图,无需逐步人工提示
+- Discord 频道使每个 Agent 的工作独立可查,便于针对性反馈(如"脚本太长了"或"多关注 AI 新闻")
+- 本地模型做图像生成(如 Mac Studio 上的 Nano Banana)可降低成本并提升控制力
+
+## Key Quotes
+> "The power is in the chained agents — research feeds writing, writing feeds thumbnails. You don't prompt each step individually." — 核心洞察
+
+> "Running a local model for image generation (like Nano Banana on a Mac Studio) keeps costs down and gives you more control." — 成本优化建议
+
+## Key Concepts
+- [[Chained Agents]]:上游 Agent 输出直接作为下游输入,无需人工干预的 Agent 协作模式
+- [[Content Automation]]:内容创作全流程(研究→写作→设计)的自动化流水线
+- [[Workflow Architecture]]:多 Agent 系统的工作流架构设计
+
+## Key Entities
+- [[OpenClaw]]:多 Agent 框架,提供 sessions_spawn/sessions_send 能力,是 Content Factory 的底层实现工具
+- Alex Finn:OpenClaw 生活改变型用例视频的作者,内容工厂方案受其启发
+
+## Connections
+- [[Podcast Production Pipeline]] ← related_to ← [[Content Factory]]
+- [[multi-agent-team]] ← related_to ← [[Content Factory]]
+
+## Contradictions
+- 与 [[Podcast Production Pipeline]]:两者均涉及多 Agent 协作流水线,但播客流水线侧重音视频内容,内容工厂侧重社交媒体短内容
diff --git a/wiki/sources/contributing.md b/wiki/sources/contributing.md
index 9ef8825e..55ef2c95 100644
--- a/wiki/sources/contributing.md
+++ b/wiki/sources/contributing.md
@@ -1,47 +1,47 @@
----
-title: "Contributing to The Agency"
-type: source
-tags: [multi-agent, openclaw, contribution, the-agency]
-date: 2026-04-21
----
-
-## Source File
-- [[Agent/agency-agents/CONTRIBUTING.md]]
-
-## Summary(用中文描述)
-- 核心主题:The Agency(agency-agents)多智能体框架的贡献者指南英文原版
-- 问题域:如何规范地向 The Agency 项目贡献高质量 AI 智能体,以及社区协作标准
-- 方法/机制:通过智能体设计模板、五大设计原则、PR 流程规范和代码风格指南确保贡献质量
-- 结论/价值:为 OpenClaw 多智能体生态提供标准化的智能体创建框架和质量门槛
-
-## Key Claims(用中文描述)
-- The Agency 通过**五大设计原则**确保智能体质量:鲜明性格、明确交付物、可量化指标、经过验证的工作流、学习记忆
-- PR 最佳实践:**单文件优先**(一个 `.md` 就是一个 PR),复杂变更(工具链/架构)需先开 Discussion 对齐
-- 外部服务依赖须在 frontmatter 的 `services` 字段声明,且智能体应**脱离 API 后仍有独立价值**
-- 提交前必须完成:真实场景测试、遵循模板、至少 2-3 个代码/模板示例、可量化成功指标
-
-## Key Quotes
-> "The fastest path to a merged PR is **one markdown file** — a new or improved agent. That's the sweet spot." — PR 流程说明
-> "An agent that solves the user's problem using a service belongs here. A service's quickstart guide wearing an agent costume does not." — 外部服务评判标准
-
-## Key Concepts
-- [[Agent-Design-Principles]]:五大设计原则——鲜明性格/明确交付物/可量化指标/验证工作流/学习记忆
-- [[Agent-Template]]:YAML frontmatter + 结构化文档模板规范
-- [[Multi-Agent-Team]]:The Agency 框架下多智能体协作模式
-- [[Multi-Agent-System-Reliability]]:多智能体系统可靠性架构模式
-
-## Key Entities
-- [[The Agency]]:msitarzewski 主导的多智能体开源项目(147 个专业化智能体,覆盖 12 个业务领域)
-- [[OpenClaw]]:The Agency 智能体运行的基础平台
-- [[msitarzewski]](mar.mod):The Agency 项目维护者
-
-## Connections
-- [[contributing_zh-cn]] ← 同一文档的中文翻译版本,包含中文社区协作规范
-- [[Agent-Design-Principles]] ← 来源一致,均引用本文档定义五大设计原则
-- [[Agent-Template]] ← 来源一致,均引用本文档定义智能体文件结构
-- [[multi-agent-system-reliability]] ← 智能体设计规范层补充运行时可靠性模式
-- [[multi-agent-team]] ← The Agency 框架的多智能体协作模式
-
-## Contradictions
-- 无与其他 Wiki 页面的实质性内容冲突
-- 与 [[contributing_zh-cn]] 的差异:英文原版包含 Code of Conduct(行为准则)和 Recognition(贡献者认可机制)章节,中文翻译版侧重核心贡献流程和设计规范
+---
+title: "Contributing to The Agency"
+type: source
+tags: [multi-agent, openclaw, contribution, the-agency]
+date: 2026-04-21
+---
+
+## Source File
+- [[raw/Agent/agency-agents/CONTRIBUTING.md]]
+
+## Summary(用中文描述)
+- 核心主题:The Agency(agency-agents)多智能体框架的贡献者指南英文原版
+- 问题域:如何规范地向 The Agency 项目贡献高质量 AI 智能体,以及社区协作标准
+- 方法/机制:通过智能体设计模板、五大设计原则、PR 流程规范和代码风格指南确保贡献质量
+- 结论/价值:为 OpenClaw 多智能体生态提供标准化的智能体创建框架和质量门槛
+
+## Key Claims(用中文描述)
+- The Agency 通过**五大设计原则**确保智能体质量:鲜明性格、明确交付物、可量化指标、经过验证的工作流、学习记忆
+- PR 最佳实践:**单文件优先**(一个 `.md` 就是一个 PR),复杂变更(工具链/架构)需先开 Discussion 对齐
+- 外部服务依赖须在 frontmatter 的 `services` 字段声明,且智能体应**脱离 API 后仍有独立价值**
+- 提交前必须完成:真实场景测试、遵循模板、至少 2-3 个代码/模板示例、可量化成功指标
+
+## Key Quotes
+> "The fastest path to a merged PR is **one markdown file** — a new or improved agent. That's the sweet spot." — PR 流程说明
+> "An agent that solves the user's problem using a service belongs here. A service's quickstart guide wearing an agent costume does not." — 外部服务评判标准
+
+## Key Concepts
+- [[Agent-Design-Principles]]:五大设计原则——鲜明性格/明确交付物/可量化指标/验证工作流/学习记忆
+- [[Agent-Template]]:YAML frontmatter + 结构化文档模板规范
+- [[Multi-Agent-Team]]:The Agency 框架下多智能体协作模式
+- [[Multi-Agent-System-Reliability]]:多智能体系统可靠性架构模式
+
+## Key Entities
+- [[The Agency]]:msitarzewski 主导的多智能体开源项目(147 个专业化智能体,覆盖 12 个业务领域)
+- [[OpenClaw]]:The Agency 智能体运行的基础平台
+- [[msitarzewski]](mar.mod):The Agency 项目维护者
+
+## Connections
+- [[contributing_zh-cn]] ← 同一文档的中文翻译版本,包含中文社区协作规范
+- [[Agent-Design-Principles]] ← 来源一致,均引用本文档定义五大设计原则
+- [[Agent-Template]] ← 来源一致,均引用本文档定义智能体文件结构
+- [[multi-agent-system-reliability]] ← 智能体设计规范层补充运行时可靠性模式
+- [[multi-agent-team]] ← The Agency 框架的多智能体协作模式
+
+## Contradictions
+- 无与其他 Wiki 页面的实质性内容冲突
+- 与 [[contributing_zh-cn]] 的差异:英文原版包含 Code of Conduct(行为准则)和 Recognition(贡献者认可机制)章节,中文翻译版侧重核心贡献流程和设计规范
diff --git a/wiki/sources/contributing_zh-cn.md b/wiki/sources/contributing_zh-cn.md
index c33f2c6f..d8037eb9 100644
--- a/wiki/sources/contributing_zh-cn.md
+++ b/wiki/sources/contributing_zh-cn.md
@@ -1,44 +1,44 @@
----
-title: "为 The Agency 贡献代码"
-type: source
-tags: []
-date: 2026-04-24
----
-
-## Source File
-- [[Agent/agency-agents/CONTRIBUTING_zh-CN.md]]
-
-## Summary(用中文描述)
-- 核心主题:**The Agency**(agency-agents)项目的贡献者指南,定义智能体(Agent)设计规范、贡献流程和社区标准
-- 问题域:AI 智能体系统的标准化设计、社区协作与质量保障
-- 方法/机制:YAML frontmatter 元数据 + 分层结构化文档模板;通过 Pull Request 流程和 PR 模板实现质量把控;通过智能体设计原则(性格塑造、交付物定义、指标量化)确保智能体质量
-- 结论/价值:提供可操作的智能体设计框架,降低社区贡献门槛,同时通过规范保证生态一致性
-
-## Key Claims(用中文描述)
-- 优秀智能体必须具备鲜明性格,拒绝"通用型有用助手"人设
-- 智能体应提供可量化的成功指标,而非模糊描述
-- 每个智能体必须经过真实场景测试和迭代优化
-- 贡献者通过 PR 流程和社区评审确保智能体质量
-
-## Key Quotes
-> "赋予智能体独特语气与人设,避免'我是一个有用的助手',要具体、让人印象深刻" — 智能体性格设计原则
-> "提供可落地的代码示例,包含模板与框架,展示真实输出,而非模糊描述" — 交付物标准
-> "包含具体、可量化的指标" — 成功指标要求
-
-## Key Concepts
-- [[Agent-Design-Principles]]:The Agency 智能体设计五原则(鲜明性格、明确交付物、成功指标、经过验证的工作流、学习记忆)
-- [[Agent-Template]]:YAML frontmatter + 分层结构(身份/使命/规则/交付物/工作流/沟通/学习/指标)
-- [[Pull-Request-Template]]:标准化 PR 提交模板,包含智能体信息、创作动机、测试情况、检查清单
-
-## Key Entities
-- [[The-Agency]](agency-agents 项目):包含 147 个专业智能体,覆盖 12 个业务领域
-- [[Agency-Engineering-Agent]]:前端开发者智能体示例,结构规范参考
-- [[Agency-Marketing-reddit-Community-Builder]]:Reddit 社区运营者示例,性格塑造优秀参考
-
-## Connections
-- [[Multi-Agent-System-Reliability]] ← extends ← [[Agent-Design-Principles]]
-- [[OpenClaw]] ← related_to ← [[The-Agency]]
-- [[Multi-Agent-Team]] ← related_to ← [[Agent-Orchestration]]
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "为 The Agency 贡献代码"
+type: source
+tags: []
+date: 2026-04-24
+---
+
+## Source File
+- [[raw/Agent/agency-agents/CONTRIBUTING_zh-CN.md]]
+
+## Summary(用中文描述)
+- 核心主题:**The Agency**(agency-agents)项目的贡献者指南,定义智能体(Agent)设计规范、贡献流程和社区标准
+- 问题域:AI 智能体系统的标准化设计、社区协作与质量保障
+- 方法/机制:YAML frontmatter 元数据 + 分层结构化文档模板;通过 Pull Request 流程和 PR 模板实现质量把控;通过智能体设计原则(性格塑造、交付物定义、指标量化)确保智能体质量
+- 结论/价值:提供可操作的智能体设计框架,降低社区贡献门槛,同时通过规范保证生态一致性
+
+## Key Claims(用中文描述)
+- 优秀智能体必须具备鲜明性格,拒绝"通用型有用助手"人设
+- 智能体应提供可量化的成功指标,而非模糊描述
+- 每个智能体必须经过真实场景测试和迭代优化
+- 贡献者通过 PR 流程和社区评审确保智能体质量
+
+## Key Quotes
+> "赋予智能体独特语气与人设,避免'我是一个有用的助手',要具体、让人印象深刻" — 智能体性格设计原则
+> "提供可落地的代码示例,包含模板与框架,展示真实输出,而非模糊描述" — 交付物标准
+> "包含具体、可量化的指标" — 成功指标要求
+
+## Key Concepts
+- [[Agent-Design-Principles]]:The Agency 智能体设计五原则(鲜明性格、明确交付物、成功指标、经过验证的工作流、学习记忆)
+- [[Agent-Template]]:YAML frontmatter + 分层结构(身份/使命/规则/交付物/工作流/沟通/学习/指标)
+- [[Pull-Request-Template]]:标准化 PR 提交模板,包含智能体信息、创作动机、测试情况、检查清单
+
+## Key Entities
+- [[The-Agency]](agency-agents 项目):包含 147 个专业智能体,覆盖 12 个业务领域
+- [[Agency-Engineering-Agent]]:前端开发者智能体示例,结构规范参考
+- [[Agency-Marketing-reddit-Community-Builder]]:Reddit 社区运营者示例,性格塑造优秀参考
+
+## Connections
+- [[Multi-Agent-System-Reliability]] ← extends ← [[Agent-Design-Principles]]
+- [[OpenClaw]] ← related_to ← [[The-Agency]]
+- [[Multi-Agent-Team]] ← related_to ← [[Agent-Orchestration]]
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/corporate-training-designer.md b/wiki/sources/corporate-training-designer.md
index 9cd88176..79747975 100644
--- a/wiki/sources/corporate-training-designer.md
+++ b/wiki/sources/corporate-training-designer.md
@@ -1,49 +1,49 @@
----
-title: "Corporate Training Designer"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/corporate-training-designer.md]]
-
-## Summary(用中文描述)
-- 核心主题:企业培训体系架构师与课程开发专家(Corporate Training Designer)—— 专注企业级培训需求分析、ADDIE/SAM 教学设计模型、混合学习项目设计、内训师培养、领导力发展项目,以及 Kirkpatrick 四级培训效果评估体系。
-- 问题域:企业培训中"为培训而培训"的现象普遍存在——培训目标不可衡量、课程内容脱离业务场景、学习效果无法落地到行为改变。
-- 方法/机制:从业务问题出发,以能力差距分析为基础,采用 ADDIE/SAM 模型设计课程体系,通过 OMO 混合学习、Kolb 体验式学习、翻转课堂等方法交付,并通过 Kirkpatrick 四级评估验证业务价值。
-- 结论/价值:优秀培训的衡量标准不是"教了什么",而是"学员回去做了什么"——数据驱动的培训体系能真正提升员工能力与组织绩效。
-
-## Key Claims(用中文描述)
-- 培训设计必须从业务问题出发,而非从"我们有什么课"出发;培训目标必须可衡量,而非"提高沟通能力"这类模糊表述。
-- 所有案例必须改编自真实业务场景,拒绝脱离实际的"教材式案例";课程内容须每年至少更新一次。
-- 每项培训项目必须有评估计划——高投资(领导力、关键岗位)必须追踪到 Kirkpatrick Level 3(行为改变)。
-- 合规培训须覆盖全体员工,记录完整,360 度反馈结果仅限本人及直属上级知晓。
-
-## Key Quotes
-> "Good training isn't about 'what was taught' — it's about 'what learners do differently when they go back to work.'" — 培训设计的核心价值观
-> "Training objectives must be measurable — not 'improve communication skills,' but 'increase the percentage of new hires independently completing client proposals within 3 months from 40% to 70%.'" — 培训目标的 SMART 原则
-> "For this leadership program, I recommend replacing pure classroom lectures with 'business challenge projects.' Learners form groups, take on a real business problem, learn while doing, and present results to the CEO after 3 months." — 成人学习理论的应用
-> "Data from the last sales new hire boot camp: trainees had a 23% higher first-month deal close rate than non-trainees, with an average of 18,000 yuan more in per-capita output." — 培训 ROI 的量化证明
-
-## Key Concepts
-- [[ADDIE 模型]]:Analysis(分析)→ Design(设计)→ Development(开发)→ Implementation(实施)→ Evaluation(评估),每个阶段有明确交付物,是教学设计的基础框架。
-- [[SAM 模型]](Successive Approximation Model):适合快速迭代场景,通过"原型 → 评审 → 修订"循环缩短上线时间。
-- [[Kirkpatrick 四级评估]]:Level 1 反应(满意度)、Level 2 学习(知识技能掌握)、Level 3 行为(行为改变)、Level 4 结果(业务指标变化)。
-- [[Bloom 认知分类]]:从记忆→理解→应用→分析→评价→创造,逐级提升学习目标设计深度。
-- [[Kolb 体验式学习圈]]:具体经验 → 反思观察 → 抽象概念化 → 主动实验,闭环驱动学习转化。
-- [[OMO 混合学习]](Online-Merge-Offline):线上解决"认知"、线下解决"实践"、学习社群解决"持续"。
-- [[TTT]](Train the Trainer):内训师培养体系——成人学习原则、课程开发技巧、表达与呈现技能、课堂管理与互动技巧、课件设计标准。
-- [[HIPO]](High-Potential Talent Program):高潜人才培养项目,通过 IDP(个人发展计划)、轮岗、导师辅导、挑战性任务加速人才成长。
-- [[ADDIE 模型]]:微课(5-15 分钟)、案例教学、沙盘模拟、剧本杀式沉浸体验培训等多元内容形式。
-
-## Key Entities
-- [[The Agency]]:该 Agent 所属的 Agent 系统生态。
-
-## Connections
-- [[Specialized Workflow Architect]] ← related_to ← [[Corporate Training Designer]]:两者均涉及工作流程设计,但前者专注软件工程流程,后者专注组织学习流程。
-- [[Specialized Cultural Intelligence Strategist]] ← related_to ← [[Corporate Training Designer]]:两者均涉及跨文化能力建设,但前者专注产品文化包容,后者专注培训内容的文化适配。
-- [[Specialized HR Onboarding]] ← extends ← [[Corporate Training Designer]]:新员工培训是 Corporate Training Designer 的重要子领域。
-
-## Contradictions
-- (暂无已知冲突。该 Agent 专注于企业内部培训体系,与其他 Agent 在应用场景上有明显差异。)
+---
+title: "Corporate Training Designer"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/corporate-training-designer.md]]
+
+## Summary(用中文描述)
+- 核心主题:企业培训体系架构师与课程开发专家(Corporate Training Designer)—— 专注企业级培训需求分析、ADDIE/SAM 教学设计模型、混合学习项目设计、内训师培养、领导力发展项目,以及 Kirkpatrick 四级培训效果评估体系。
+- 问题域:企业培训中"为培训而培训"的现象普遍存在——培训目标不可衡量、课程内容脱离业务场景、学习效果无法落地到行为改变。
+- 方法/机制:从业务问题出发,以能力差距分析为基础,采用 ADDIE/SAM 模型设计课程体系,通过 OMO 混合学习、Kolb 体验式学习、翻转课堂等方法交付,并通过 Kirkpatrick 四级评估验证业务价值。
+- 结论/价值:优秀培训的衡量标准不是"教了什么",而是"学员回去做了什么"——数据驱动的培训体系能真正提升员工能力与组织绩效。
+
+## Key Claims(用中文描述)
+- 培训设计必须从业务问题出发,而非从"我们有什么课"出发;培训目标必须可衡量,而非"提高沟通能力"这类模糊表述。
+- 所有案例必须改编自真实业务场景,拒绝脱离实际的"教材式案例";课程内容须每年至少更新一次。
+- 每项培训项目必须有评估计划——高投资(领导力、关键岗位)必须追踪到 Kirkpatrick Level 3(行为改变)。
+- 合规培训须覆盖全体员工,记录完整,360 度反馈结果仅限本人及直属上级知晓。
+
+## Key Quotes
+> "Good training isn't about 'what was taught' — it's about 'what learners do differently when they go back to work.'" — 培训设计的核心价值观
+> "Training objectives must be measurable — not 'improve communication skills,' but 'increase the percentage of new hires independently completing client proposals within 3 months from 40% to 70%.'" — 培训目标的 SMART 原则
+> "For this leadership program, I recommend replacing pure classroom lectures with 'business challenge projects.' Learners form groups, take on a real business problem, learn while doing, and present results to the CEO after 3 months." — 成人学习理论的应用
+> "Data from the last sales new hire boot camp: trainees had a 23% higher first-month deal close rate than non-trainees, with an average of 18,000 yuan more in per-capita output." — 培训 ROI 的量化证明
+
+## Key Concepts
+- [[ADDIE 模型]]:Analysis(分析)→ Design(设计)→ Development(开发)→ Implementation(实施)→ Evaluation(评估),每个阶段有明确交付物,是教学设计的基础框架。
+- [[SAM 模型]](Successive Approximation Model):适合快速迭代场景,通过"原型 → 评审 → 修订"循环缩短上线时间。
+- [[Kirkpatrick 四级评估]]:Level 1 反应(满意度)、Level 2 学习(知识技能掌握)、Level 3 行为(行为改变)、Level 4 结果(业务指标变化)。
+- [[Bloom 认知分类]]:从记忆→理解→应用→分析→评价→创造,逐级提升学习目标设计深度。
+- [[Kolb 体验式学习圈]]:具体经验 → 反思观察 → 抽象概念化 → 主动实验,闭环驱动学习转化。
+- [[OMO 混合学习]](Online-Merge-Offline):线上解决"认知"、线下解决"实践"、学习社群解决"持续"。
+- [[TTT]](Train the Trainer):内训师培养体系——成人学习原则、课程开发技巧、表达与呈现技能、课堂管理与互动技巧、课件设计标准。
+- [[HIPO]](High-Potential Talent Program):高潜人才培养项目,通过 IDP(个人发展计划)、轮岗、导师辅导、挑战性任务加速人才成长。
+- [[ADDIE 模型]]:微课(5-15 分钟)、案例教学、沙盘模拟、剧本杀式沉浸体验培训等多元内容形式。
+
+## Key Entities
+- [[The Agency]]:该 Agent 所属的 Agent 系统生态。
+
+## Connections
+- [[Specialized Workflow Architect]] ← related_to ← [[Corporate Training Designer]]:两者均涉及工作流程设计,但前者专注软件工程流程,后者专注组织学习流程。
+- [[Specialized Cultural Intelligence Strategist]] ← related_to ← [[Corporate Training Designer]]:两者均涉及跨文化能力建设,但前者专注产品文化包容,后者专注培训内容的文化适配。
+- [[Specialized HR Onboarding]] ← extends ← [[Corporate Training Designer]]:新员工培训是 Corporate Training Designer 的重要子领域。
+
+## Contradictions
+- (暂无已知冲突。该 Agent 专注于企业内部培训体系,与其他 Agent 在应用场景上有明显差异。)
diff --git a/wiki/sources/ctp-topic-1-gruntwork-landing-zone-architecture.md b/wiki/sources/ctp-topic-1-gruntwork-landing-zone-architecture.md
index 85b7d740..733491b6 100644
--- a/wiki/sources/ctp-topic-1-gruntwork-landing-zone-architecture.md
+++ b/wiki/sources/ctp-topic-1-gruntwork-landing-zone-architecture.md
@@ -1,56 +1,56 @@
----
-title: "CTP Topic 1 Gruntwork Landing Zone Architecture"
-type: source
-tags: [AWS, Landing-Zone, Gruntwork, CTP, Terraform, CI/CD]
-sources: []
-last_updated: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-1-gruntwork-landing-zone-architecture]]
-
-## Summary(用中文描述)
-- 核心主题:基于 Gruntwork 的 AWS Landing Zone 架构设计,包括参考架构、多账户结构和 CI/CD 流水线。
-- 问题域:如何在云转型项目中快速构建符合最佳实践的多账户 AWS 基础设施。
-- 方法/机制:参考架构(Reference Architecture)提供起点 → Landing Zone 基于 Gruntwork 仓库由产品团队自定义 → Jenkins CI/CD 自动化部署 → Git 特性分支工作流。
-- 结论/价值:Gruntwork 提供经过实战验证的 Terraform 模块,是 AWS 基础设施最佳实践的集合;Landing Zone 在此基础上由各产品团队填充具体业务服务。
-
-## Key Claims(用中文描述)
-- Gruntwork 是拥有大量 Terraform 代码的组织,其代码经过多次实践验证,被认为是最佳实践。
-- 参考架构(Reference Architecture)是包含核心账户(Shared/Logs/Security)和工作负载账户(Prod/Stage/Dev)的最佳实践起点。
-- Landing Zone 基于 Gruntwork 但由产品团队自行定义具体服务,不包含 ECS 集群或 RDS 数据库等具体实现。
-- 安全账户使用联邦用户(Federated User),通过 AD 组映射到 IAM 角色,替代传统 IAM 用户。
-- 每个 Landing Zone 配备独立的 Jenkins 服务器来部署基础设施变更,每个产品团队也有自己的 Jenkins 任务。
-- Git 工作流采用特性分支开发,通过 Pull Request 合并到主分支。
-- Gruntwork 的 Terraform AWS 服务目录强调服务应具有业务上下文,而非简单的资源堆砌。
-
-## Key Quotes
-> "Gruntwork is a company that has put together a lot of Terraform code, and it's a collection of best practices." — Gruntwork Landing Zone 核心价值定位
-
-> "Landing Zone is based on Gruntwork, but it doesn't have ECS clusters or RDS databases — it's defined by the product team." — Landing Zone vs Reference Architecture 的关键区别
-
-> "Security account uses federated users, mapping AD groups to IAM roles, instead of traditional IAM users." — 联邦用户替代 IAM 用户的身份管理策略
-
-## Key Concepts
-- [[Reference-Architecture]]:包含核心账户(Shared/Logs/Security)和工作负载账户(Prod/Stage/Dev)的最佳实践起点。
-- [[Landing-Zone-Architecture]]:基于 Gruntwork 仓库的 AWS 多账户基础设施部署单元,每个 Zone 有独立 GitHub 仓库管理 IaC。
-- [[Terraform-Modules]]:Gruntwork 提供的经过实战验证的 Terraform 模块,强调服务具有业务上下文。
-- [[Federated-Access]]:通过 AD 组映射到 IAM 角色的联邦身份访问,简化安全账户管理。
-- [[CI-CD-Pipeline]]:基于特性分支 + Pull Request + Jenkins 的 Terraform 基础设施变更自动化流程。
-
-## Key Entities
-- [[Gruntwork]]:AWS Landing Zones 基础设施框架提供方,提供经过实战验证的 Terraform 模块库。
-
-## Connections
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← extends ← [[ctp-topic-1-gruntwork-landing-zone-architecture]](CI/CD 流水线是 Landing Zone 部署的核心机制)
-- [[ctp-topic-2-git]] ← depends_on ← [[ctp-topic-1-gruntwork-landing-zone-architecture]](Git 工作流是 CI/CD 的前提)
-- [[ctp-topic-3-deploy-and-maintain-infrastructure]] ← extends ← [[ctp-topic-1-gruntwork-landing-zone-architecture]](Terraform 部署是 Landing Zone 的 IaC 实践)
-- [[ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs]] ← extends ← [[ctp-topic-1-gruntwork-landing-zone-architecture]](AD 集成是 Landing Zone 安全账户的核心)
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← extends ← [[ctp-topic-1-gruntwork-landing-zone-architecture]](数据标签是 Landing Zone 安全配置的基础)
-
-## Contradictions
-- 与 [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] 冲突:
- - 冲突点:Landing Zone 中产品的定义粒度
- - 当前观点(CTP Topic 1):Landing Zone 由产品团队自行定义具体服务(ECS/RDS 等),产品团队有较大自主权
- - 对方观点(CTP Topic 35):Landing Zone 产品定义应更严格,由架构团队统一规划
- - 状态:视角互补而非直接矛盾——CTP Topic 1 强调灵活性,CTP Topic 35 强调标准化,可能反映不同组织规模和治理成熟度的差异
+---
+title: "CTP Topic 1 Gruntwork Landing Zone Architecture"
+type: source
+tags: [AWS, Landing-Zone, Gruntwork, CTP, Terraform, CI/CD]
+sources: []
+last_updated: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-1-gruntwork-landing-zone-architecture.md]]
+
+## Summary(用中文描述)
+- 核心主题:基于 Gruntwork 的 AWS Landing Zone 架构设计,包括参考架构、多账户结构和 CI/CD 流水线。
+- 问题域:如何在云转型项目中快速构建符合最佳实践的多账户 AWS 基础设施。
+- 方法/机制:参考架构(Reference Architecture)提供起点 → Landing Zone 基于 Gruntwork 仓库由产品团队自定义 → Jenkins CI/CD 自动化部署 → Git 特性分支工作流。
+- 结论/价值:Gruntwork 提供经过实战验证的 Terraform 模块,是 AWS 基础设施最佳实践的集合;Landing Zone 在此基础上由各产品团队填充具体业务服务。
+
+## Key Claims(用中文描述)
+- Gruntwork 是拥有大量 Terraform 代码的组织,其代码经过多次实践验证,被认为是最佳实践。
+- 参考架构(Reference Architecture)是包含核心账户(Shared/Logs/Security)和工作负载账户(Prod/Stage/Dev)的最佳实践起点。
+- Landing Zone 基于 Gruntwork 但由产品团队自行定义具体服务,不包含 ECS 集群或 RDS 数据库等具体实现。
+- 安全账户使用联邦用户(Federated User),通过 AD 组映射到 IAM 角色,替代传统 IAM 用户。
+- 每个 Landing Zone 配备独立的 Jenkins 服务器来部署基础设施变更,每个产品团队也有自己的 Jenkins 任务。
+- Git 工作流采用特性分支开发,通过 Pull Request 合并到主分支。
+- Gruntwork 的 Terraform AWS 服务目录强调服务应具有业务上下文,而非简单的资源堆砌。
+
+## Key Quotes
+> "Gruntwork is a company that has put together a lot of Terraform code, and it's a collection of best practices." — Gruntwork Landing Zone 核心价值定位
+
+> "Landing Zone is based on Gruntwork, but it doesn't have ECS clusters or RDS databases — it's defined by the product team." — Landing Zone vs Reference Architecture 的关键区别
+
+> "Security account uses federated users, mapping AD groups to IAM roles, instead of traditional IAM users." — 联邦用户替代 IAM 用户的身份管理策略
+
+## Key Concepts
+- [[Reference-Architecture]]:包含核心账户(Shared/Logs/Security)和工作负载账户(Prod/Stage/Dev)的最佳实践起点。
+- [[Landing-Zone-Architecture]]:基于 Gruntwork 仓库的 AWS 多账户基础设施部署单元,每个 Zone 有独立 GitHub 仓库管理 IaC。
+- [[Terraform-Modules]]:Gruntwork 提供的经过实战验证的 Terraform 模块,强调服务具有业务上下文。
+- [[Federated-Access]]:通过 AD 组映射到 IAM 角色的联邦身份访问,简化安全账户管理。
+- [[CI-CD-Pipeline]]:基于特性分支 + Pull Request + Jenkins 的 Terraform 基础设施变更自动化流程。
+
+## Key Entities
+- [[Gruntwork]]:AWS Landing Zones 基础设施框架提供方,提供经过实战验证的 Terraform 模块库。
+
+## Connections
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← extends ← [[ctp-topic-1-gruntwork-landing-zone-architecture]](CI/CD 流水线是 Landing Zone 部署的核心机制)
+- [[ctp-topic-2-git]] ← depends_on ← [[ctp-topic-1-gruntwork-landing-zone-architecture]](Git 工作流是 CI/CD 的前提)
+- [[ctp-topic-3-deploy-and-maintain-infrastructure]] ← extends ← [[ctp-topic-1-gruntwork-landing-zone-architecture]](Terraform 部署是 Landing Zone 的 IaC 实践)
+- [[ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs]] ← extends ← [[ctp-topic-1-gruntwork-landing-zone-architecture]](AD 集成是 Landing Zone 安全账户的核心)
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← extends ← [[ctp-topic-1-gruntwork-landing-zone-architecture]](数据标签是 Landing Zone 安全配置的基础)
+
+## Contradictions
+- 与 [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] 冲突:
+ - 冲突点:Landing Zone 中产品的定义粒度
+ - 当前观点(CTP Topic 1):Landing Zone 由产品团队自行定义具体服务(ECS/RDS 等),产品团队有较大自主权
+ - 对方观点(CTP Topic 35):Landing Zone 产品定义应更严格,由架构团队统一规划
+ - 状态:视角互补而非直接矛盾——CTP Topic 1 强调灵活性,CTP Topic 35 强调标准化,可能反映不同组织规模和治理成熟度的差异
diff --git a/wiki/sources/ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security.md b/wiki/sources/ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security.md
index d3553295..70c99d07 100644
--- a/wiki/sources/ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security.md
+++ b/wiki/sources/ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security.md
@@ -1,68 +1,68 @@
----
-title: "CTP Topic 10 AWS Landing Zone (LZ) Data Collection, Tagging Related Security"
-type: source
-tags:
- - aws
- - landing-zone
- - tagging
- - security
- - cloud-transformation
- - ctp
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]]
-
-## Summary(用中文描述)
-- 核心主题:AWS Landing Zone 部署过程中数据收集策略,以及基于资源标签的云原生安全架构
-- 问题域:企业云迁移过程中如何理解待上云资产、如何通过标签机制实现精细化的访问控制和安全策略
-- 方法/机制:
- - **OU + SCP 分层治理**:通过组织单元(OU)和 Service Control Policies(SCP)强制执行标签规范
- - **标签即凭证**:将 AWS 资源标签作为防火墙策略的动态匹配条件,替代传统基于 IP 的静态规则
- - **Checkpoint 有序层防火墙**:按优先级执行地理屏蔽 → 类型检查 → BU 隔离 → 产品隔离 → 环境隔离 → 角色检查
- - **Inline 层结构**:基于账号号的父子规则架构,简化跨账户策略管理
-- 结论/价值:从"IP 地址"到"标签"的策略范式转变,使动态云环境无需频繁更新防火墙规则;标签缺失或篡改会触发 SCP 拒绝策略,确保安全合规
-
-## Key Claims(用中文描述)
-- Landing Zone 部署前必须深入了解 BU 资产清单、IP 地址空间及数据敏感性
-- DNS、Transit Gateway 等基础服务通过 SRE 团队实现高度自动化
-- **基于标签的安全控制**:传统基于 IP 的防火墙规则无法适应云环境动态性,标签机制将安全凭证嵌入资源本身
-- **SCP 强制标签规范**:「显式拒绝」逻辑防止用户通过篡改标签绕过审计,确保资源创建时即具备正确的 BU/产品/环境归属
-- **Checkpoint 防火墙有序层**:按优先级执行地理屏蔽 → BU 隔离 → 产品隔离 → 环境隔离,实现跨 VPC/On-prem/互联网的精细化流量控制
-- 标签示例包括:机器名、Owner(优先使用 PDL)、Type(R&D 等)、Business Unit、Product、Environment(production 等)、Server Role、Account、App ID
-- 产品间通信默认禁止(Inter product is not allowed)
-- Inline 层检查账号号,简化规则管理并支持自动化
-
-## Key Quotes
-> "We ask a lot of questions so that we can then turn around and make sure we're putting the appropriate posture in the cloud and that we're protecting the resources appropriately."
-> — Steve Jarman,阐述云迁移前的准备工作重心
-
-> "Inter product is not allowed. Inter product is communications allowed."
-> — Pradeep,描述产品间隔离的默认安全策略
-
-## Key Concepts
-- [[Service-Control-Policies-SCPs]]:AWS Organizations 策略类型,通过「显式拒绝」逻辑强制执行标签规范,阻止不合规资源创建
-- [[Checkpoint-Firewall]]:防火墙供应商,依赖 AWS 标签值配置动态网络访问策略
-- [[AWS-Landing-Zone]]:AWS 云环境的最佳实践起点框架,定义账户结构、网络、安全和访问管理
-- [[Tag-Based-Security]]:将资源标签作为安全凭证,替代传统基于 IP 的防火墙规则
-- [[OU-Layered-Security]]:通过组织单元(OU)的分层结构检查标签,确保正确归属和访问控制
-
-## Key Entities
-- [[Steve-Jarman]]:CTP Topic 10 主讲人之一,阐述云迁移前的准备工作
-- [[Pradeep]]:CTP Topic 10 主讲人,演示 Checkpoint 防火墙配置和 EC2 部署示例
-- [[Checkpoint]]:防火墙供应商,负责基于标签的动态网络安全策略
-- [[AWS-Organizations]]:AWS 服务,提供 SCP 策略机制支持标签强制执行
-
-## Connections
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← foundational ← [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]]
-- [[ctp-topic-28-aws-tag-validation-tool]] ← extends ← [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]]
-- [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]] ← related ← [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]]
-- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← related ← [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]]
-
-## Contradictions
-- 与 [[ctp-topic-28-aws-tag-validation-tool]] 在标签治理覆盖范围上存在差异:
- - 冲突点:SCPs 的标签强制能力边界
- - 当前观点(Topic 10):SCPs 通过「显式拒绝」阻止不合规资源创建,确保标签在资源创建时就正确
- - 对方观点(Topic 28):SCPs 可阻止不合规资源创建,但无法修复存量资源,存量合规性需通过 Tag Validation Tool 审计发现
- - 协调说明:两者互补而非矛盾——SCP 负责预防(新资源准入控制),Tag Validation Tool 负责发现(存量资源合规审计)
+---
+title: "CTP Topic 10 AWS Landing Zone (LZ) Data Collection, Tagging Related Security"
+type: source
+tags:
+ - aws
+ - landing-zone
+ - tagging
+ - security
+ - cloud-transformation
+ - ctp
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS Landing Zone 部署过程中数据收集策略,以及基于资源标签的云原生安全架构
+- 问题域:企业云迁移过程中如何理解待上云资产、如何通过标签机制实现精细化的访问控制和安全策略
+- 方法/机制:
+ - **OU + SCP 分层治理**:通过组织单元(OU)和 Service Control Policies(SCP)强制执行标签规范
+ - **标签即凭证**:将 AWS 资源标签作为防火墙策略的动态匹配条件,替代传统基于 IP 的静态规则
+ - **Checkpoint 有序层防火墙**:按优先级执行地理屏蔽 → 类型检查 → BU 隔离 → 产品隔离 → 环境隔离 → 角色检查
+ - **Inline 层结构**:基于账号号的父子规则架构,简化跨账户策略管理
+- 结论/价值:从"IP 地址"到"标签"的策略范式转变,使动态云环境无需频繁更新防火墙规则;标签缺失或篡改会触发 SCP 拒绝策略,确保安全合规
+
+## Key Claims(用中文描述)
+- Landing Zone 部署前必须深入了解 BU 资产清单、IP 地址空间及数据敏感性
+- DNS、Transit Gateway 等基础服务通过 SRE 团队实现高度自动化
+- **基于标签的安全控制**:传统基于 IP 的防火墙规则无法适应云环境动态性,标签机制将安全凭证嵌入资源本身
+- **SCP 强制标签规范**:「显式拒绝」逻辑防止用户通过篡改标签绕过审计,确保资源创建时即具备正确的 BU/产品/环境归属
+- **Checkpoint 防火墙有序层**:按优先级执行地理屏蔽 → BU 隔离 → 产品隔离 → 环境隔离,实现跨 VPC/On-prem/互联网的精细化流量控制
+- 标签示例包括:机器名、Owner(优先使用 PDL)、Type(R&D 等)、Business Unit、Product、Environment(production 等)、Server Role、Account、App ID
+- 产品间通信默认禁止(Inter product is not allowed)
+- Inline 层检查账号号,简化规则管理并支持自动化
+
+## Key Quotes
+> "We ask a lot of questions so that we can then turn around and make sure we're putting the appropriate posture in the cloud and that we're protecting the resources appropriately."
+> — Steve Jarman,阐述云迁移前的准备工作重心
+
+> "Inter product is not allowed. Inter product is communications allowed."
+> — Pradeep,描述产品间隔离的默认安全策略
+
+## Key Concepts
+- [[Service-Control-Policies-SCPs]]:AWS Organizations 策略类型,通过「显式拒绝」逻辑强制执行标签规范,阻止不合规资源创建
+- [[Checkpoint-Firewall]]:防火墙供应商,依赖 AWS 标签值配置动态网络访问策略
+- [[AWS-Landing-Zone]]:AWS 云环境的最佳实践起点框架,定义账户结构、网络、安全和访问管理
+- [[Tag-Based-Security]]:将资源标签作为安全凭证,替代传统基于 IP 的防火墙规则
+- [[OU-Layered-Security]]:通过组织单元(OU)的分层结构检查标签,确保正确归属和访问控制
+
+## Key Entities
+- [[Steve-Jarman]]:CTP Topic 10 主讲人之一,阐述云迁移前的准备工作
+- [[Pradeep]]:CTP Topic 10 主讲人,演示 Checkpoint 防火墙配置和 EC2 部署示例
+- [[Checkpoint]]:防火墙供应商,负责基于标签的动态网络安全策略
+- [[AWS-Organizations]]:AWS 服务,提供 SCP 策略机制支持标签强制执行
+
+## Connections
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← foundational ← [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]]
+- [[ctp-topic-28-aws-tag-validation-tool]] ← extends ← [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]]
+- [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]] ← related ← [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]]
+- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← related ← [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]]
+
+## Contradictions
+- 与 [[ctp-topic-28-aws-tag-validation-tool]] 在标签治理覆盖范围上存在差异:
+ - 冲突点:SCPs 的标签强制能力边界
+ - 当前观点(Topic 10):SCPs 通过「显式拒绝」阻止不合规资源创建,确保标签在资源创建时就正确
+ - 对方观点(Topic 28):SCPs 可阻止不合规资源创建,但无法修复存量资源,存量合规性需通过 Tag Validation Tool 审计发现
+ - 协调说明:两者互补而非矛盾——SCP 负责预防(新资源准入控制),Tag Validation Tool 负责发现(存量资源合规审计)
diff --git a/wiki/sources/ctp-topic-11-ad-integration-and-login-using-ad-accounts.md b/wiki/sources/ctp-topic-11-ad-integration-and-login-using-ad-accounts.md
index 894e4f5b..e3f28c56 100644
--- a/wiki/sources/ctp-topic-11-ad-integration-and-login-using-ad-accounts.md
+++ b/wiki/sources/ctp-topic-11-ad-integration-and-login-using-ad-accounts.md
@@ -1,77 +1,77 @@
----
-title: "CTP Topic 11 AD Integration and Login using AD Accounts"
-type: source
-tags:
- - AWS
- - AD
- - IAM
- - SSO
- - CTP
- - Jenkins
- - RBAC
- - Pre-commit
- - Terraform
- - IaC
- - DevSecOps
-sources: []
-last_updated: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/02_IAM/ctp-topic-11-ad-integration-and-login-using-ad-accounts]]
-
-## Summary(用中文描述)
-- 核心主题:Jenkins 与企业 Active Directory (AD) 的集成,以及 Terraform 代码的自动化质量检查
-- 问题域:企业级 CI/CD 系统的身份认证管理与基础设施代码安全治理
-- 方法/机制:
- - Jenkins Security Realm 与 SW Infra AD 集成,实现基于 AD 账号的统一身份认证与自动化用户管理
- - 通过 AD 组策略实现 RBAC(基于角色的访问控制),精细化管理 Jenkins 权限(只读/读写/流水线创建)
- - pre-commit 框架集成 terraform fmt、TFLint、Checkov 三款工具,在代码提交阶段嵌入自动化安全检查
- - CI/CD 流水线分层治理:Commit 阶段检查 → PR 阶段 plan → Master 分支人工审核后 apply
-- 结论/价值:告别手动创建本地用户,实现"入离职账号自动化管理";通过"左移"策略在开发早期发现并修复基础设施代码的安全问题
-
-## Key Claims(用中文描述)
-- Jenkins 与 AD 集成后,用户入离职可通过 AD 账号实现自动化管理,无需手动维护本地用户账户
-- 通过 AD 组策略可将用户映射为不同角色(只读、读写、流水线创建),实现基于 AD 的 RBAC 权限控制
-- pre-commit 框架可在功能分支提交时自动触发 terraform fmt(格式统一)、TFLint(逻辑验证)、Checkov(安全扫描),防止"坏代码"进入生产环境
-- "左移"(Shift-Left)治理模式将安全问题从生产阶段提前到开发阶段,通过分层 CI/CD 流水线实现渐进式质量门禁
-
-## Key Quotes
-> "通过 AD 集成,我们告别了过去手动创建本地用户的繁琐流程,实现了基于 AD 账号的自动登录。" — Niranjan
-
-> "terraform fmt 用于统一代码格式,TFLint 用于验证配置逻辑与参数完整性,而 Checkov 则负责静态安全分析。" — Niranjan
-
-> "在功能分支的每次提交时仅触发自动化检查;在 PR 阶段触发检查与 terraform plan;只有在代码合并至 Master 分支并经过人工审核后,才会执行最终的 terraform apply。" — Niranjan
-
-## Key Concepts
-- [[Active Directory Integration]]:将 Jenkins 的安全域与企业活动目录关联,实现用户身份的统一认证与自动化管理
-- [[RBAC (Role-Based Access Control)]]:基于角色的访问控制,通过 AD 组策略决定用户在 Jenkins 中拥有的具体操作权限
-- [[Pre-commit Framework]]:一个用于管理和维护多语言预提交钩子的框架,旨在代码提交至仓库前识别简单问题
-- [[Terraform Fmt]]:Terraform 内置的格式化工具,用于将配置文件重写为符合官方规范的标准格式
-- [[TFLint]]:一种针对 Terraform 的静态分析工具,用于检查代码中的人为错误、过时语法及缺失的参数
-- [[Checkov]]:一种静态代码分析工具,专门用于扫描基础设施即代码 (IaC) 中的安全性与合规性配置错误
-- [[Shift-Left Security]]:将安全检查从生产阶段提前到开发早期的实践,通过 CI/CD 流水线分层实现
-- [[CI/CD Pipeline Governance]]:CI/CD 流水线的分层治理模式——提交检查 → PR 检查+plan → 人工审核+apply
-
-## Key Entities
-- [[Niranjan]]:CTP Topic 11 主讲人,DevOps Cloud Learning Session 讲师
-- [[Jenkins]]:开源自动化服务器,本视频中与 AD 集成实现统一身份认证
-- [[SW Infra Active Directory]]:SW Infra 团队的 Active Directory 服务域,用于 Jenkins 的安全域集成
-- [[GitHub]]:源代码仓库,与 Jenkins 流水线通过 Webhook 触发集成(交叉引用来源)
-
-## Connections
-- [[ctp-topic-5-aws-identity-and-access-management-iam]] ← foundational ← [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]]
- - Topic 5 介绍 AWS IAM 联邦访问机制,Topic 11 将其延伸至 Jenkins 与企业 AD 的集成实践
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← related ← [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]]
- - 均涉及 Jenkins CI/CD 流水线实践,Topic 9 聚焦 Gruntwork 框架,Topic 11 聚焦 AD 认证与安全检查
-- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← extends ← [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]]
- - Atlantis 是 Topic 11 中 terraform plan/apply 分层治理理念的具体实现工具
-- [[GitHub and Jenkins Integration]] ← depends_on ← [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]]
- - Jenkins 与 AD 集成的前置依赖:GitHub 仓库与 Jenkins 流水线的触发与反馈机制已就绪
-
-## Contradictions
-- 与 [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] 在 terraform apply 审批模式上存在差异:
- - 冲突点:谁拥有 terraform apply 的最终审批权(人 vs 机器)
- - Topic 11 观点:Master 分支人工审核后执行 terraform apply,强调人工把关
- - Atlantis 观点:通过 PR 评论自动触发 apply,强调机器自动化
- - 当前整合观点:两者互补——Topic 11 定义治理原则(人工审核),Atlantis 实现具体执行机制
+---
+title: "CTP Topic 11 AD Integration and Login using AD Accounts"
+type: source
+tags:
+ - AWS
+ - AD
+ - IAM
+ - SSO
+ - CTP
+ - Jenkins
+ - RBAC
+ - Pre-commit
+ - Terraform
+ - IaC
+ - DevSecOps
+sources: []
+last_updated: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/02_IAM/ctp-topic-11-ad-integration-and-login-using-ad-accounts.md]]
+
+## Summary(用中文描述)
+- 核心主题:Jenkins 与企业 Active Directory (AD) 的集成,以及 Terraform 代码的自动化质量检查
+- 问题域:企业级 CI/CD 系统的身份认证管理与基础设施代码安全治理
+- 方法/机制:
+ - Jenkins Security Realm 与 SW Infra AD 集成,实现基于 AD 账号的统一身份认证与自动化用户管理
+ - 通过 AD 组策略实现 RBAC(基于角色的访问控制),精细化管理 Jenkins 权限(只读/读写/流水线创建)
+ - pre-commit 框架集成 terraform fmt、TFLint、Checkov 三款工具,在代码提交阶段嵌入自动化安全检查
+ - CI/CD 流水线分层治理:Commit 阶段检查 → PR 阶段 plan → Master 分支人工审核后 apply
+- 结论/价值:告别手动创建本地用户,实现"入离职账号自动化管理";通过"左移"策略在开发早期发现并修复基础设施代码的安全问题
+
+## Key Claims(用中文描述)
+- Jenkins 与 AD 集成后,用户入离职可通过 AD 账号实现自动化管理,无需手动维护本地用户账户
+- 通过 AD 组策略可将用户映射为不同角色(只读、读写、流水线创建),实现基于 AD 的 RBAC 权限控制
+- pre-commit 框架可在功能分支提交时自动触发 terraform fmt(格式统一)、TFLint(逻辑验证)、Checkov(安全扫描),防止"坏代码"进入生产环境
+- "左移"(Shift-Left)治理模式将安全问题从生产阶段提前到开发阶段,通过分层 CI/CD 流水线实现渐进式质量门禁
+
+## Key Quotes
+> "通过 AD 集成,我们告别了过去手动创建本地用户的繁琐流程,实现了基于 AD 账号的自动登录。" — Niranjan
+
+> "terraform fmt 用于统一代码格式,TFLint 用于验证配置逻辑与参数完整性,而 Checkov 则负责静态安全分析。" — Niranjan
+
+> "在功能分支的每次提交时仅触发自动化检查;在 PR 阶段触发检查与 terraform plan;只有在代码合并至 Master 分支并经过人工审核后,才会执行最终的 terraform apply。" — Niranjan
+
+## Key Concepts
+- [[Active Directory Integration]]:将 Jenkins 的安全域与企业活动目录关联,实现用户身份的统一认证与自动化管理
+- [[RBAC (Role-Based Access Control)]]:基于角色的访问控制,通过 AD 组策略决定用户在 Jenkins 中拥有的具体操作权限
+- [[Pre-commit Framework]]:一个用于管理和维护多语言预提交钩子的框架,旨在代码提交至仓库前识别简单问题
+- [[Terraform Fmt]]:Terraform 内置的格式化工具,用于将配置文件重写为符合官方规范的标准格式
+- [[TFLint]]:一种针对 Terraform 的静态分析工具,用于检查代码中的人为错误、过时语法及缺失的参数
+- [[Checkov]]:一种静态代码分析工具,专门用于扫描基础设施即代码 (IaC) 中的安全性与合规性配置错误
+- [[Shift-Left Security]]:将安全检查从生产阶段提前到开发早期的实践,通过 CI/CD 流水线分层实现
+- [[CI/CD Pipeline Governance]]:CI/CD 流水线的分层治理模式——提交检查 → PR 检查+plan → 人工审核+apply
+
+## Key Entities
+- [[Niranjan]]:CTP Topic 11 主讲人,DevOps Cloud Learning Session 讲师
+- [[Jenkins]]:开源自动化服务器,本视频中与 AD 集成实现统一身份认证
+- [[SW Infra Active Directory]]:SW Infra 团队的 Active Directory 服务域,用于 Jenkins 的安全域集成
+- [[GitHub]]:源代码仓库,与 Jenkins 流水线通过 Webhook 触发集成(交叉引用来源)
+
+## Connections
+- [[ctp-topic-5-aws-identity-and-access-management-iam]] ← foundational ← [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]]
+ - Topic 5 介绍 AWS IAM 联邦访问机制,Topic 11 将其延伸至 Jenkins 与企业 AD 的集成实践
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← related ← [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]]
+ - 均涉及 Jenkins CI/CD 流水线实践,Topic 9 聚焦 Gruntwork 框架,Topic 11 聚焦 AD 认证与安全检查
+- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← extends ← [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]]
+ - Atlantis 是 Topic 11 中 terraform plan/apply 分层治理理念的具体实现工具
+- [[GitHub and Jenkins Integration]] ← depends_on ← [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]]
+ - Jenkins 与 AD 集成的前置依赖:GitHub 仓库与 Jenkins 流水线的触发与反馈机制已就绪
+
+## Contradictions
+- 与 [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] 在 terraform apply 审批模式上存在差异:
+ - 冲突点:谁拥有 terraform apply 的最终审批权(人 vs 机器)
+ - Topic 11 观点:Master 分支人工审核后执行 terraform apply,强调人工把关
+ - Atlantis 观点:通过 PR 评论自动触发 apply,强调机器自动化
+ - 当前整合观点:两者互补——Topic 11 定义治理原则(人工审核),Atlantis 实现具体执行机制
diff --git a/wiki/sources/ctp-topic-12-using-ses-smtp-service-terraform-module.md b/wiki/sources/ctp-topic-12-using-ses-smtp-service-terraform-module.md
index 62885232..e84b397b 100644
--- a/wiki/sources/ctp-topic-12-using-ses-smtp-service-terraform-module.md
+++ b/wiki/sources/ctp-topic-12-using-ses-smtp-service-terraform-module.md
@@ -1,59 +1,59 @@
----
-title: "CTP Topic 12 Using SES SMTP service terraform module"
-type: source
-tags:
- - AWS
- - Terraform
- - SES
- - Email
- - CTP
- - Cloud-Email
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/ctp-topic-12-using-ses-smtp-service-terraform-module]]
-
-## Summary(用中文描述)
-- 核心主题:Micro Focus 团队使用 Terraform 模块自动化部署 AWS SES SMTP 服务,以替代传统的本地 SMTP 网关。
-- 问题域:随着业务向云端迁移,使用本地 SMTP 网关(如 smtbmicrofocus.com)已不再高效,网络安全部门要求统一使用云端邮件发送方案。
-- 方法/机制:在应用 VPC 中配置 VPC 终端节点以实现私有连接;通过 IAM 用户凭证作为 SMTP 认证信息并存储于 Secrets Manager;Terraform 模块自动化 SMTP 终端节点配置、DKIM 验证和 DNS 记录创建;支持现有应用程序通过标准 SMTP 协议集成,无需重构代码适配 SES API。
-- 结论/价值:SES 是唯一获网络安全部门批准的云端邮件发送方案;Terraform 模块化封装降低了集成复杂度;需注意两个手动步骤(申请脱离 Sandbox Mode 和手动更新 DNS TXT 记录)。
-
-## Key Claims(用中文描述)
-- 在应用 VPC 中配置 VPC 终端节点,使应用可在不访问公网的情况下通过私有节点与 SES SMTP 服务通信。
-- IAM 用户的 Access Key 和 Secret Key 被转换后作为 SMTP 认证的用户名和密码,相关凭证安全存储于 AWS Secrets Manager。
-- Terraform 模块自动化完成 DKIM 验证和 Infoblox DNS 管理系统中域名所有权记录的创建。
-- 手动更新 DNS TXT 记录以验证域名所有权仍是必需步骤,因 Terraform 难以处理多个 AWS 账号共享同一域名时对同一 TXT 记录值的追加操作。
-- 脱离 SES Sandbox Mode(向 AWS 提交工单申请生产访问权限)是启用完整邮件发送能力的必要前提。
-- SES 是 Micro Focus 网络安全部门唯一批准的云端邮件发送方案,替代了原有的本地 SMTP 网关。
-
-## Key Quotes
-> "随着业务向云端迁移,使用本地 SMTP 网关(如 smtbmicrofocus.com)已不再高效,SES 是目前网络安全部门唯一批准的云端邮件发送方案。" — Christian Deckelmann
-
-> "SES Terraform 模块封装了 SMTP 终端节点的配置,方便现有应用程序通过标准的 SMTP 协议进行集成,而无需重构代码以适配 SES API。" — Filos Christolakis
-
-## Key Concepts
-- [[VPC-Endpoint]]:AWS 提供的私有连接服务,允许在 VPC 内部通过私有 IP 地址安全访问 AWS 服务,无需经过公网。
-- [[DKIM-Email-Authentication]]:DomainKeys Identified Mail 的缩写,一种电子邮件验证标准,通过在邮件头部添加数字签名来防止欺诈和确保邮件完整性。
-- [[Secrets-Manager]]:AWS 提供的凭证管理服务,用于安全地存储和检索 SES SMTP 的认证信息。
-- [[SES-Sandbox-Mode]]:AWS SES 的默认限制状态,仅允许向已验证的地址发送少量邮件,需提交工单申请生产访问权限以提升发送限额。
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,云服务提供商,SES(Simple Email Service)所属平台。
-- [[Christian-Deckelmann]]:演讲者之一,分享 Micro Focus 在云转型中采用 SES SMTP 服务的背景与动机。
-- [[Filos-Christolakis]]:演讲者之一,详细讲解 SES Terraform 模块的技术实现方案。
-- [[Infoblox]]:公司内部使用的 DNS 管理系统,用于存放和管理验证域名所有权所需的 DNS 记录。
-- [[VPC-Wrapper-Module]]:SES Terraform 模块所依赖的前置 VPC 配置模块,负责预先配置 SMTP VPC 终端节点。
-
-## Connections
-- [[VPC-Wrapper-Module]] ← depends_on ← [[ctp-topic-12-using-ses-smtp-service-terraform-module]]
-- [[ctp-topic-12-using-ses-smtp-service-terraform-module]] ← extends ← [[AWS]]
-- [[Terraform-And-Terragrunt-Best-Practices]] ← related_to ← [[ctp-topic-12-using-ses-smtp-service-terraform-module]](Terragrunt Pre-hook/Post-hook 用于处理手动 DNS 验证步骤)
-- [[ctp-topic-36-sendgrid-as-an-email-service]] ← alternative_to ← [[ctp-topic-12-using-ses-smtp-service-terraform-module]](SendGrid 被选定为新 Landing Zone 标准,SES 用于现有应用迁移)
-
-## Contradictions
-- 与 [[ctp-topic-36-sendgrid-as-an-email-service]] 在邮件服务选型上的差异:
- - 冲突点:两门课程分别介绍了不同的云邮件服务方案——SendGrid 被选定为标准云端邮件服务,而 SES 则专注于服务现有应用通过 SMTP 协议迁移上云。
- - 当前观点:SES 通过 Terraform 模块封装现有应用 SMTP 接入路径,实现平滑迁移,无需修改应用代码。
- - 对方观点:SendGrid 作为新标准云邮件服务,提供更高上限(每封 1,000 收件人 vs SES 每封 50 收件人)、更简单的 API 集成和全球中继节点。
+---
+title: "CTP Topic 12 Using SES SMTP service terraform module"
+type: source
+tags:
+ - AWS
+ - Terraform
+ - SES
+ - Email
+ - CTP
+ - Cloud-Email
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/ctp-topic-12-using-ses-smtp-service-terraform-module.md]]
+
+## Summary(用中文描述)
+- 核心主题:Micro Focus 团队使用 Terraform 模块自动化部署 AWS SES SMTP 服务,以替代传统的本地 SMTP 网关。
+- 问题域:随着业务向云端迁移,使用本地 SMTP 网关(如 smtbmicrofocus.com)已不再高效,网络安全部门要求统一使用云端邮件发送方案。
+- 方法/机制:在应用 VPC 中配置 VPC 终端节点以实现私有连接;通过 IAM 用户凭证作为 SMTP 认证信息并存储于 Secrets Manager;Terraform 模块自动化 SMTP 终端节点配置、DKIM 验证和 DNS 记录创建;支持现有应用程序通过标准 SMTP 协议集成,无需重构代码适配 SES API。
+- 结论/价值:SES 是唯一获网络安全部门批准的云端邮件发送方案;Terraform 模块化封装降低了集成复杂度;需注意两个手动步骤(申请脱离 Sandbox Mode 和手动更新 DNS TXT 记录)。
+
+## Key Claims(用中文描述)
+- 在应用 VPC 中配置 VPC 终端节点,使应用可在不访问公网的情况下通过私有节点与 SES SMTP 服务通信。
+- IAM 用户的 Access Key 和 Secret Key 被转换后作为 SMTP 认证的用户名和密码,相关凭证安全存储于 AWS Secrets Manager。
+- Terraform 模块自动化完成 DKIM 验证和 Infoblox DNS 管理系统中域名所有权记录的创建。
+- 手动更新 DNS TXT 记录以验证域名所有权仍是必需步骤,因 Terraform 难以处理多个 AWS 账号共享同一域名时对同一 TXT 记录值的追加操作。
+- 脱离 SES Sandbox Mode(向 AWS 提交工单申请生产访问权限)是启用完整邮件发送能力的必要前提。
+- SES 是 Micro Focus 网络安全部门唯一批准的云端邮件发送方案,替代了原有的本地 SMTP 网关。
+
+## Key Quotes
+> "随着业务向云端迁移,使用本地 SMTP 网关(如 smtbmicrofocus.com)已不再高效,SES 是目前网络安全部门唯一批准的云端邮件发送方案。" — Christian Deckelmann
+
+> "SES Terraform 模块封装了 SMTP 终端节点的配置,方便现有应用程序通过标准的 SMTP 协议进行集成,而无需重构代码以适配 SES API。" — Filos Christolakis
+
+## Key Concepts
+- [[VPC-Endpoint]]:AWS 提供的私有连接服务,允许在 VPC 内部通过私有 IP 地址安全访问 AWS 服务,无需经过公网。
+- [[DKIM-Email-Authentication]]:DomainKeys Identified Mail 的缩写,一种电子邮件验证标准,通过在邮件头部添加数字签名来防止欺诈和确保邮件完整性。
+- [[Secrets-Manager]]:AWS 提供的凭证管理服务,用于安全地存储和检索 SES SMTP 的认证信息。
+- [[SES-Sandbox-Mode]]:AWS SES 的默认限制状态,仅允许向已验证的地址发送少量邮件,需提交工单申请生产访问权限以提升发送限额。
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,云服务提供商,SES(Simple Email Service)所属平台。
+- [[Christian-Deckelmann]]:演讲者之一,分享 Micro Focus 在云转型中采用 SES SMTP 服务的背景与动机。
+- [[Filos-Christolakis]]:演讲者之一,详细讲解 SES Terraform 模块的技术实现方案。
+- [[Infoblox]]:公司内部使用的 DNS 管理系统,用于存放和管理验证域名所有权所需的 DNS 记录。
+- [[VPC-Wrapper-Module]]:SES Terraform 模块所依赖的前置 VPC 配置模块,负责预先配置 SMTP VPC 终端节点。
+
+## Connections
+- [[VPC-Wrapper-Module]] ← depends_on ← [[ctp-topic-12-using-ses-smtp-service-terraform-module]]
+- [[ctp-topic-12-using-ses-smtp-service-terraform-module]] ← extends ← [[AWS]]
+- [[Terraform-And-Terragrunt-Best-Practices]] ← related_to ← [[ctp-topic-12-using-ses-smtp-service-terraform-module]](Terragrunt Pre-hook/Post-hook 用于处理手动 DNS 验证步骤)
+- [[ctp-topic-36-sendgrid-as-an-email-service]] ← alternative_to ← [[ctp-topic-12-using-ses-smtp-service-terraform-module]](SendGrid 被选定为新 Landing Zone 标准,SES 用于现有应用迁移)
+
+## Contradictions
+- 与 [[ctp-topic-36-sendgrid-as-an-email-service]] 在邮件服务选型上的差异:
+ - 冲突点:两门课程分别介绍了不同的云邮件服务方案——SendGrid 被选定为标准云端邮件服务,而 SES 则专注于服务现有应用通过 SMTP 协议迁移上云。
+ - 当前观点:SES 通过 Terraform 模块封装现有应用 SMTP 接入路径,实现平滑迁移,无需修改应用代码。
+ - 对方观点:SendGrid 作为新标准云邮件服务,提供更高上限(每封 1,000 收件人 vs SES 每封 50 收件人)、更简单的 API 集成和全球中继节点。
diff --git a/wiki/sources/ctp-topic-13-cloud-finops-micro-focus-policies-best-practices-to-optimize-the-co.md b/wiki/sources/ctp-topic-13-cloud-finops-micro-focus-policies-best-practices-to-optimize-the-co.md
index 12591f11..4bdc0858 100644
--- a/wiki/sources/ctp-topic-13-cloud-finops-micro-focus-policies-best-practices-to-optimize-the-co.md
+++ b/wiki/sources/ctp-topic-13-cloud-finops-micro-focus-policies-best-practices-to-optimize-the-co.md
@@ -1,52 +1,52 @@
----
-title: "CTP Topic 13 Cloud FinOps Micro Focus Policies best practices to optimize the costs"
-type: source
-tags:
- - FinOps
- - Cost-Optimization
- - AWS
- - PCG
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/ctp-topic-13-cloud-finops-micro-focus-policies-best-practices-to-optimize-the-co]]
-
-## Summary(用中文描述)
-- 核心主题:Cloud FinOps 成本优化政策与最佳实践,由 PCG 团队的 Uday 和 Vinay 主讲
-- 问题域:公共云账单可见性、标签合规、预算责任、Reserved Instances 集中管理、研发环境成本优化
-- 方法/机制:PCG 三层服务模型(成本管理→成本优化→治理与自动化)、5 大核心策略、安全控制(Godrails/MFA/告警重定向)、标准化实例选型
-- 结论/价值:建立系统化的 FinOps 流程,通过集中 Reserved Instances 购买、标准化实例类型、Graviton 迁移和实例调度器实现持续成本优化
-
-## Key Claims(用中文描述)
-- PCG 通过三层服务分层(成本管理→成本优化→治理与自动化)为云账单提供完整的可见性和优化机制
-- 强制标签合规是实现 showback/chargeback 和预算责任的基础
-- Reserved Instances 和 Savings Plans 必须集中购买才能实现规模效益
-- Graviton ARM 实例比 Intel 实例更具成本优势,可直接节省成本
-- 研发环境通过突发性实例 + Spot 实例 + 实例调度器三重组合可大幅降低费用
-
-## Key Quotes
-> "使用 Cloud Health 工具查看资源清单、月度账单洞察和成本分析" — Cloud Health 是成本优化的核心监控工具
-
-## Key Concepts
-- [[FinOps(云财务管理)]]:云成本优化学科,平衡云使用量、速度和成本
-- [[Showback/Chargeback]]:成本分摊机制,showback 让团队看到成本数据,chargeback 向团队直接收取成本
-- [[AWS-Instance-Families]]:AWS EC2 实例类型分类(M/T/C/R/X 系列),选型直接影响成本
-- [[Reserved-Instances-Savings-Plans]]:承诺使用计划,通过预留容量换取折扣
-- [[Graviton-Instances]]:AWS ARM 架构处理器实例,相比 Intel 实例成本更低
-
-## Key Entities
-- [[PCG]]:Public Cloud Governance 团队,由 Uday 和 Vinay 主导,负责云治理、成本管理和 FinOps 政策
-- [[Cloud-Health]]:Ansys Cloud Health 云成本分析和监控工具
-
-## Connections
-- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← depends_on ← [[ctp-topic-13-cloud-finops-policies]]
-- [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]] ← depends_on ← [[ctp-topic-13-cloud-finops-policies]]
-- [[ctp-topic-27-aws-instance-scheduler]] ← extends ← [[ctp-topic-13-cloud-finops-policies]]
-
-## Contradictions
-- 与 [[ctp-topic-53-why-bother-with-cloud]] 冲突:
- - 冲突点:[[ctp-topic-13]] 假设业务已上云,聚焦优化;[[ctp-topic-53]] 聚焦是否应迁移的决策论证
- - 当前观点:默认已在云上,专注于持续优化成本
- - 对方观点:云迁移决策本身需要商业价值论证
+---
+title: "CTP Topic 13 Cloud FinOps Micro Focus Policies best practices to optimize the costs"
+type: source
+tags:
+ - FinOps
+ - Cost-Optimization
+ - AWS
+ - PCG
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/ctp-topic-13-cloud-finops-micro-focus-policies-best-practices-to-optimize-the-co.md]]
+
+## Summary(用中文描述)
+- 核心主题:Cloud FinOps 成本优化政策与最佳实践,由 PCG 团队的 Uday 和 Vinay 主讲
+- 问题域:公共云账单可见性、标签合规、预算责任、Reserved Instances 集中管理、研发环境成本优化
+- 方法/机制:PCG 三层服务模型(成本管理→成本优化→治理与自动化)、5 大核心策略、安全控制(Godrails/MFA/告警重定向)、标准化实例选型
+- 结论/价值:建立系统化的 FinOps 流程,通过集中 Reserved Instances 购买、标准化实例类型、Graviton 迁移和实例调度器实现持续成本优化
+
+## Key Claims(用中文描述)
+- PCG 通过三层服务分层(成本管理→成本优化→治理与自动化)为云账单提供完整的可见性和优化机制
+- 强制标签合规是实现 showback/chargeback 和预算责任的基础
+- Reserved Instances 和 Savings Plans 必须集中购买才能实现规模效益
+- Graviton ARM 实例比 Intel 实例更具成本优势,可直接节省成本
+- 研发环境通过突发性实例 + Spot 实例 + 实例调度器三重组合可大幅降低费用
+
+## Key Quotes
+> "使用 Cloud Health 工具查看资源清单、月度账单洞察和成本分析" — Cloud Health 是成本优化的核心监控工具
+
+## Key Concepts
+- [[FinOps(云财务管理)]]:云成本优化学科,平衡云使用量、速度和成本
+- [[Showback/Chargeback]]:成本分摊机制,showback 让团队看到成本数据,chargeback 向团队直接收取成本
+- [[AWS-Instance-Families]]:AWS EC2 实例类型分类(M/T/C/R/X 系列),选型直接影响成本
+- [[Reserved-Instances-Savings-Plans]]:承诺使用计划,通过预留容量换取折扣
+- [[Graviton-Instances]]:AWS ARM 架构处理器实例,相比 Intel 实例成本更低
+
+## Key Entities
+- [[PCG]]:Public Cloud Governance 团队,由 Uday 和 Vinay 主导,负责云治理、成本管理和 FinOps 政策
+- [[Cloud-Health]]:Ansys Cloud Health 云成本分析和监控工具
+
+## Connections
+- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← depends_on ← [[ctp-topic-13-cloud-finops-policies]]
+- [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]] ← depends_on ← [[ctp-topic-13-cloud-finops-policies]]
+- [[ctp-topic-27-aws-instance-scheduler]] ← extends ← [[ctp-topic-13-cloud-finops-policies]]
+
+## Contradictions
+- 与 [[ctp-topic-53-why-bother-with-cloud]] 冲突:
+ - 冲突点:[[ctp-topic-13]] 假设业务已上云,聚焦优化;[[ctp-topic-53]] 聚焦是否应迁移的决策论证
+ - 当前观点:默认已在云上,专注于持续优化成本
+ - 对方观点:云迁移决策本身需要商业价值论证
diff --git a/wiki/sources/ctp-topic-14-octane-hub-on-aws-real-life-experience-moving-production-services-i.md b/wiki/sources/ctp-topic-14-octane-hub-on-aws-real-life-experience-moving-production-services-i.md
index 95a1123d..979bfd3f 100644
--- a/wiki/sources/ctp-topic-14-octane-hub-on-aws-real-life-experience-moving-production-services-i.md
+++ b/wiki/sources/ctp-topic-14-octane-hub-on-aws-real-life-experience-moving-production-services-i.md
@@ -1,69 +1,69 @@
----
-title: "CTP Topic 14 Octane Hub on AWS Real Life Experience Moving Production Services"
-type: source
-tags:
- - AWS
- - Octane-Hub
- - Migration
- - CTP
- - Landing-Zone
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-14-octane-hub-on-aws-real-life-experience-moving-production-services-i]]
-
-## Summary(用中文描述)
-- 核心主题:Octane Hub CTO Holger Rode 分享将生产服务从 Bibling Lab 数据中心迁移到 AWS Landing Zone 的实战经验
-- 问题域:企业级 Docker 容器化工作负载的云迁移规划与实施
-- 方法/机制:使用 AWS Landing Zone 账户体系,结合 Packer 构建 AMI、Terraform/TerraGrunt 部署、VPC Transit Gateway 网络互联、Route 53 DNS 管理
-- 结论/价值:提供从物理数据中心向 AWS 云端无缝迁移的具体路径,涵盖存储选型(EFS vs EBS)、网络配置、DNS 设置及 IaC 部署演进过程
-
-## Key Claims(用中文描述)
-- Octane Hub 团队通过 Docker 容器化主要 Web 应用(QuickSee、Release Manager、Patch Manager、安全程序板等),结合约 10TB 文件存储和 MSSQL 数据库,实现从 Bibling Lab 三台物理服务器向 AWS 的完整迁移
-- 云迁移动因源于 Bibling 数据中心即将关闭,云转型计划提供 POC Landing Zone(5月)和生产账户(6月),团队目标是无缝过渡、紧密镜像现有设置以避免 Go Live 期间进行重大技术变更
-- EFS 不适用于需要高性能数据库场景(数据库无法直接在 EFS 上运行),EBS 更适合实时数据库,EFS 适用于备份存储
-- IaC 部署从控制台脚本演进为 Packer 构建 AMI + Terraform/TerraGrunt 部署,实现了可重复、可审计的部署流程
-
-## Key Quotes
-> "Holger Rode(Octane Hub CTO 软件工厂团队负责人)分享了 Octane Hub 云设计考虑因素、学习曲线、网络和安全要求以及常见陷阱。" — 视频演讲主题介绍
-
-> "从控制台脚本演变为使用 Packer 构建 AMI,使用 Terraform/TerraGrunt 部署。" — IaC 演进路径
-
-## Key Concepts
-- [[Docker-Containerization]]:Octane Hub 的主要部署模式,运行 QuickSee、Release Manager、Patch Manager 等 Web 应用
-- [[Packer]] + [[Terraform]]/TerraGrunt:基础设施即代码的部署流程,从控制台脚本演进而来
-- [[VPC-Transit-Gateway]]:AWS 网络互联解决方案,实现多 VPC 之间的安全通信
-- [[EFS-vs-EBS]]:文件存储与块存储的性能差异——EFS 适合备份,EBS 适合实时数据库
-- [[AWS-Landing-Zone]]:多账户 AWS 环境架构,提供 POC 和生产账户分离
-
-## Key Entities
-- [[Holger-Rode]]:Octane Hub CTO,软件工厂团队负责人,云迁移项目负责人
-- [[Octane-Hub]]:软件工厂团队名称,主导从 Bibling Lab 向 AWS 的生产服务迁移
-- [[Bibing-Lab]]:Octane Hub 原有数据中心,即将关闭,触发云迁移
-- [[QuickSee]]:Octane Hub 托管的 Web 应用之一
-- [[Release-Manager]]:Octane Hub 托管的 Web 应用之一
-- [[Patch-Manager]]:Octane Hub 托管的 Web 应用之一
-- [[MSSQL]]:Octane Hub 原有数据库,计划迁移到 Postgres
-- [[AWS]]:目标云平台
-- [[Packer]]:AMI 构建工具
-- [[Terraform]]/TerraGrunt:基础设施即代码部署工具
-
-## Connections
-- [[AWS-Landing-Zone]] ← depends_on ← [[VPC-Transit-Gateway]]
-- [[Octane-Hub]] ← migrated_from ← [[Bibing-Lab]]
-- [[Docker-Containerization]] ← uses ← [[Packer]] + [[Terraform]]
-- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← [[AWS-Landing-Zone]]
-- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← related_to ← [[AWS-Landing-Zone]]
-
-## Contradictions
-- 与 [[ctp-topic-7-saas-landing-zone-design]] 的设计视角:
- - 冲突点:SaaS Landing Zone 侧重多租户架构设计,本视频侧重单体团队的实际迁移路径
- - 当前观点:Octane Hub 案例强调紧密镜像现有设置、避免 Go Live 期间重大变更
- - 对方观点:SaaS Landing Zone 设计更关注长期架构演进和租户隔离
-
-## Next Steps(迁移路线图)
-- 改进 DR(灾难恢复)和高可用性
-- 通过最佳匹配存储选项(S3)进行成本优化
-- 从 MSSQL 迁移到 Postgres
-- 可能迁移到 AWS ECS 服务
+---
+title: "CTP Topic 14 Octane Hub on AWS Real Life Experience Moving Production Services"
+type: source
+tags:
+ - AWS
+ - Octane-Hub
+ - Migration
+ - CTP
+ - Landing-Zone
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-14-octane-hub-on-aws-real-life-experience-moving-production-services-i.md]]
+
+## Summary(用中文描述)
+- 核心主题:Octane Hub CTO Holger Rode 分享将生产服务从 Bibling Lab 数据中心迁移到 AWS Landing Zone 的实战经验
+- 问题域:企业级 Docker 容器化工作负载的云迁移规划与实施
+- 方法/机制:使用 AWS Landing Zone 账户体系,结合 Packer 构建 AMI、Terraform/TerraGrunt 部署、VPC Transit Gateway 网络互联、Route 53 DNS 管理
+- 结论/价值:提供从物理数据中心向 AWS 云端无缝迁移的具体路径,涵盖存储选型(EFS vs EBS)、网络配置、DNS 设置及 IaC 部署演进过程
+
+## Key Claims(用中文描述)
+- Octane Hub 团队通过 Docker 容器化主要 Web 应用(QuickSee、Release Manager、Patch Manager、安全程序板等),结合约 10TB 文件存储和 MSSQL 数据库,实现从 Bibling Lab 三台物理服务器向 AWS 的完整迁移
+- 云迁移动因源于 Bibling 数据中心即将关闭,云转型计划提供 POC Landing Zone(5月)和生产账户(6月),团队目标是无缝过渡、紧密镜像现有设置以避免 Go Live 期间进行重大技术变更
+- EFS 不适用于需要高性能数据库场景(数据库无法直接在 EFS 上运行),EBS 更适合实时数据库,EFS 适用于备份存储
+- IaC 部署从控制台脚本演进为 Packer 构建 AMI + Terraform/TerraGrunt 部署,实现了可重复、可审计的部署流程
+
+## Key Quotes
+> "Holger Rode(Octane Hub CTO 软件工厂团队负责人)分享了 Octane Hub 云设计考虑因素、学习曲线、网络和安全要求以及常见陷阱。" — 视频演讲主题介绍
+
+> "从控制台脚本演变为使用 Packer 构建 AMI,使用 Terraform/TerraGrunt 部署。" — IaC 演进路径
+
+## Key Concepts
+- [[Docker-Containerization]]:Octane Hub 的主要部署模式,运行 QuickSee、Release Manager、Patch Manager 等 Web 应用
+- [[Packer]] + [[Terraform]]/TerraGrunt:基础设施即代码的部署流程,从控制台脚本演进而来
+- [[VPC-Transit-Gateway]]:AWS 网络互联解决方案,实现多 VPC 之间的安全通信
+- [[EFS-vs-EBS]]:文件存储与块存储的性能差异——EFS 适合备份,EBS 适合实时数据库
+- [[AWS-Landing-Zone]]:多账户 AWS 环境架构,提供 POC 和生产账户分离
+
+## Key Entities
+- [[Holger-Rode]]:Octane Hub CTO,软件工厂团队负责人,云迁移项目负责人
+- [[Octane-Hub]]:软件工厂团队名称,主导从 Bibling Lab 向 AWS 的生产服务迁移
+- [[Bibing-Lab]]:Octane Hub 原有数据中心,即将关闭,触发云迁移
+- [[QuickSee]]:Octane Hub 托管的 Web 应用之一
+- [[Release-Manager]]:Octane Hub 托管的 Web 应用之一
+- [[Patch-Manager]]:Octane Hub 托管的 Web 应用之一
+- [[MSSQL]]:Octane Hub 原有数据库,计划迁移到 Postgres
+- [[AWS]]:目标云平台
+- [[Packer]]:AMI 构建工具
+- [[Terraform]]/TerraGrunt:基础设施即代码部署工具
+
+## Connections
+- [[AWS-Landing-Zone]] ← depends_on ← [[VPC-Transit-Gateway]]
+- [[Octane-Hub]] ← migrated_from ← [[Bibing-Lab]]
+- [[Docker-Containerization]] ← uses ← [[Packer]] + [[Terraform]]
+- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← [[AWS-Landing-Zone]]
+- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← related_to ← [[AWS-Landing-Zone]]
+
+## Contradictions
+- 与 [[ctp-topic-7-saas-landing-zone-design]] 的设计视角:
+ - 冲突点:SaaS Landing Zone 侧重多租户架构设计,本视频侧重单体团队的实际迁移路径
+ - 当前观点:Octane Hub 案例强调紧密镜像现有设置、避免 Go Live 期间重大变更
+ - 对方观点:SaaS Landing Zone 设计更关注长期架构演进和租户隔离
+
+## Next Steps(迁移路线图)
+- 改进 DR(灾难恢复)和高可用性
+- 通过最佳匹配存储选项(S3)进行成本优化
+- 从 MSSQL 迁移到 Postgres
+- 可能迁移到 AWS ECS 服务
diff --git a/wiki/sources/ctp-topic-15-working-with-renovatebot.md b/wiki/sources/ctp-topic-15-working-with-renovatebot.md
index b6db070a..04efa999 100644
--- a/wiki/sources/ctp-topic-15-working-with-renovatebot.md
+++ b/wiki/sources/ctp-topic-15-working-with-renovatebot.md
@@ -1,53 +1,53 @@
----
-title: "CTP Topic 15 Working with Renovatebot"
-type: source
-tags:
- - Renovatebot
- - Dependency-Update
- - GitOps
- - CTP
- - CI/CD
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-15-working-with-renovatebot]]
-
-## Summary(用中文描述)
-- 核心主题:利用 Renovate Bot 自动化管理云原生基础设施中的依赖项更新
-- 问题域:云架构中依赖项无处不在(Docker 基础镜像、Maven 依赖、Terraform 模块、Kubernetes Helm Charts 等),团队维护大量 Gruntwork Terraform 模块和 Terragrunt 配置时,手动更新版本号耗时耗力且极易滞后
-- 方法/机制:Renovate Bot 实时扫描代码库,识别过时的版本标签(Semantic Versioning),自动发起 Pull Request;通过 `renovate.json` 配置管理策略;集成 Jenkins 流水线;使用 Dependency Dashboard 汇总所有依赖状态
-- 结论/价值:实现依赖更新的自动化与标准化,提升基础设施安全性(及时修复漏洞),确保开发环境与生产环境配置的一致性
-
-## Key Claims(用中文描述)
-- Renovate Bot 通过实时扫描代码库,可自动识别 Docker/Terraform/Terragrunt/pre-commit 等多种依赖项的过时版本标签,并自动发起 Pull Request
-- Dependency Dashboard 在 GitHub Issue 中汇总所有待更新项,提供全局依赖状态视角
-- 团队通过 `renovate.json` 文件定义管理策略,支持 Terraform、Terragrunt、Docker 及 pre-commit 钩子等多种技术栈
-- 在 Jenkins 流水线中集成 Renovate Bot,通过 Podman 本地容器化运行和合理的 Rate Limiting 配置,可解决 GitHub Enterprise 适配和并发 PR 性能瓶颈
-
-## Key Quotes
-> "在复杂的云架构中,依赖项无处不在——Docker 基础镜像、Maven 依赖、Terraform 模块、Kubernetes Helm Charts 等,手动更新版本号耗时耗力且极易滞后。" — Paul Hopkins,介绍依赖地狱问题背景
-> "Renovate Bot 能够实时扫描代码库,识别过时的版本标签,并自动发起 Pull Request,保持依赖项处于最新状态。" — Paul Hopkins,Renovate 核心价值
-
-## Key Concepts
-- [[Renovate-Bot]]:开源依赖自动化更新工具,通过扫描代码并自动提交 PR 来保持依赖项处于最新状态
-- [[Dependency-Dashboard]]:Renovate 在 GitHub 仓库中自动创建的 Issue,汇总所有依赖状态、待处理的 PR 及更新选项
-- [[Semantic-Versioning]]:语义化版本控制,采用 `主版本号.次版本号.修订号` 格式,Renovate 依据此规则判断更新级别
-- [[Rate-Limiting]]:速率限制,防止自动化工具瞬间产生过多 PR 导致 CI/CD 系统崩溃
-- [[Pre-commit-Hooks]]:在提交代码前运行的脚本工具,Renovate 可自动更新这些钩子插件的版本
-- [[Dependency-Management]]:依赖管理,对项目中引用的外部库、模块或镜像的版本进行跟踪、更新和维护
-
-## Key Entities
-- [[Paul-Hopkins]]:本次会议主讲人,分享 Renovate Bot 在团队中的实践经验
-- [[Gruntwork]]:提供 Terraform 模块和 Terragrunt 配置的 IaC 库,团队依赖其进行基础设施代码管理
-- [[Terragrunt]]:Terraform 的轻量级封装层,用于处理多环境配置、减少重复代码(DRY)及管理远程状态
-- [[Jenkins]]:CI/CD 流水线工具,当前用于集成 Renovate Bot 的自动化执行
-
-## Connections
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← relates_to ← [[ctp-topic-15-working-with-renovatebot]]
-- [[ctp-topic-33-an-introduction-to-gitops]] ← extends ← [[ctp-topic-15-working-with-renovatebot]]
-- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← related_to ← [[ctp-topic-15-working-with-renovatebot]]
-- [[Pre-commit-Hooks]] ← managed_by ← [[ctp-topic-15-working-with-renovatebot]]
-
-## Contradictions
-- 暂无发现与现有 Wiki 内容的冲突
+---
+title: "CTP Topic 15 Working with Renovatebot"
+type: source
+tags:
+ - Renovatebot
+ - Dependency-Update
+ - GitOps
+ - CTP
+ - CI/CD
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-15-working-with-renovatebot.md]]
+
+## Summary(用中文描述)
+- 核心主题:利用 Renovate Bot 自动化管理云原生基础设施中的依赖项更新
+- 问题域:云架构中依赖项无处不在(Docker 基础镜像、Maven 依赖、Terraform 模块、Kubernetes Helm Charts 等),团队维护大量 Gruntwork Terraform 模块和 Terragrunt 配置时,手动更新版本号耗时耗力且极易滞后
+- 方法/机制:Renovate Bot 实时扫描代码库,识别过时的版本标签(Semantic Versioning),自动发起 Pull Request;通过 `renovate.json` 配置管理策略;集成 Jenkins 流水线;使用 Dependency Dashboard 汇总所有依赖状态
+- 结论/价值:实现依赖更新的自动化与标准化,提升基础设施安全性(及时修复漏洞),确保开发环境与生产环境配置的一致性
+
+## Key Claims(用中文描述)
+- Renovate Bot 通过实时扫描代码库,可自动识别 Docker/Terraform/Terragrunt/pre-commit 等多种依赖项的过时版本标签,并自动发起 Pull Request
+- Dependency Dashboard 在 GitHub Issue 中汇总所有待更新项,提供全局依赖状态视角
+- 团队通过 `renovate.json` 文件定义管理策略,支持 Terraform、Terragrunt、Docker 及 pre-commit 钩子等多种技术栈
+- 在 Jenkins 流水线中集成 Renovate Bot,通过 Podman 本地容器化运行和合理的 Rate Limiting 配置,可解决 GitHub Enterprise 适配和并发 PR 性能瓶颈
+
+## Key Quotes
+> "在复杂的云架构中,依赖项无处不在——Docker 基础镜像、Maven 依赖、Terraform 模块、Kubernetes Helm Charts 等,手动更新版本号耗时耗力且极易滞后。" — Paul Hopkins,介绍依赖地狱问题背景
+> "Renovate Bot 能够实时扫描代码库,识别过时的版本标签,并自动发起 Pull Request,保持依赖项处于最新状态。" — Paul Hopkins,Renovate 核心价值
+
+## Key Concepts
+- [[Renovate-Bot]]:开源依赖自动化更新工具,通过扫描代码并自动提交 PR 来保持依赖项处于最新状态
+- [[Dependency-Dashboard]]:Renovate 在 GitHub 仓库中自动创建的 Issue,汇总所有依赖状态、待处理的 PR 及更新选项
+- [[Semantic-Versioning]]:语义化版本控制,采用 `主版本号.次版本号.修订号` 格式,Renovate 依据此规则判断更新级别
+- [[Rate-Limiting]]:速率限制,防止自动化工具瞬间产生过多 PR 导致 CI/CD 系统崩溃
+- [[Pre-commit-Hooks]]:在提交代码前运行的脚本工具,Renovate 可自动更新这些钩子插件的版本
+- [[Dependency-Management]]:依赖管理,对项目中引用的外部库、模块或镜像的版本进行跟踪、更新和维护
+
+## Key Entities
+- [[Paul-Hopkins]]:本次会议主讲人,分享 Renovate Bot 在团队中的实践经验
+- [[Gruntwork]]:提供 Terraform 模块和 Terragrunt 配置的 IaC 库,团队依赖其进行基础设施代码管理
+- [[Terragrunt]]:Terraform 的轻量级封装层,用于处理多环境配置、减少重复代码(DRY)及管理远程状态
+- [[Jenkins]]:CI/CD 流水线工具,当前用于集成 Renovate Bot 的自动化执行
+
+## Connections
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← relates_to ← [[ctp-topic-15-working-with-renovatebot]]
+- [[ctp-topic-33-an-introduction-to-gitops]] ← extends ← [[ctp-topic-15-working-with-renovatebot]]
+- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← related_to ← [[ctp-topic-15-working-with-renovatebot]]
+- [[Pre-commit-Hooks]] ← managed_by ← [[ctp-topic-15-working-with-renovatebot]]
+
+## Contradictions
+- 暂无发现与现有 Wiki 内容的冲突
diff --git a/wiki/sources/ctp-topic-16-cross-account-terraform-modules.md b/wiki/sources/ctp-topic-16-cross-account-terraform-modules.md
index f9b86ea6..0a1e0415 100644
--- a/wiki/sources/ctp-topic-16-cross-account-terraform-modules.md
+++ b/wiki/sources/ctp-topic-16-cross-account-terraform-modules.md
@@ -1,55 +1,55 @@
----
-title: "CTP Topic 16 Cross-account Terraform modules"
-type: source
-tags: [Terraform, Cross-Account, Modules, CTP, IaC, DevOps, AWS-Landing-Zone]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/ctp-topic-16-cross-account-terraform-modules]]
-
-## Summary(用中文描述)
-- 核心主题:**跨账号 Terraform 模块的中心化部署方案**,解决多账号 AWS 环境中一个模块内跨账号创建资源的安全与自动化问题
-- 问题域:原有的 Gruntwork 流水线针对单账号设计,在多账号场景下存在安全风险(一账号被攻破可能波及全局)
-- 方法/机制:基于 **Shared Account(共享账号)** 的中心化部署架构,Jenkins + ECS Deploy Runner + Assume Role 三者联动
-- 结论/价值:实现安全性(账号间无直接信任关系)、自动化(Jenkins 自动识别跨账号模块)、可复用性(模块代码不硬编码特定账号角色)
-
-## Key Claims(用中文描述)
-- **Shared Account 作为中转站**:Jenkins 托管在 Shared Account,当检测到 `cross-account.json` 标记文件时触发 ECS Deploy Runner
-- **Assume Role 双角色机制**:ECS Deploy Runner 通过 Assume Role 访问目标账号的两个角色——`TF state bucket accessor`(读取状态文件)和 `cross-account ECS deploy runner role`(执行资源部署)
-- **Blast Radius 控制**:避免 Workload 账号之间直接互访,权限控制在受严格审计的 Shared Account
-- **Terragrunt HCL 全局配置**:通过根目录 `terragrunt.hcl` 定义远程状态存储和角色切换逻辑,支持本地开发与 Jenkins 自动部署的差异化角色处理
-
-## Key Quotes
-> "Cross-account Terraform Modules 指在一个模块内通过配置多个 Provider,实现在多个 AWS 账号中同时创建或管理资源的功能" — Fibos,核心概念定义
-> "Shared Account 是整个 Landing Zone 的核心管理账号,托管 Jenkins、镜像仓库等公共服务,并作为跨账号部署的信任源" — Fibos,架构定位
-> "ECS Deploy Runner 运行在 ECS 上的 Docker 容器,负责执行 Terraform plan 和 apply 命令,是流水线中的实际执行单元" — Fibos,EDR 定义
-
-## Key Concepts
-- [[Cross-account Terraform Modules]]:在一个 Terraform 模块中通过配置多个 Provider,实现在多个 AWS 账号中同时创建或管理资源的功能
-- [[Shared Account]]:Landing Zone 核心管理账号,托管 Jenkins 及公共服务,作为跨账号部署的信任源
-- [[ECS Deploy Runner]]:运行在 ECS 上的 Docker 容器,负责执行 Terraform plan/apply,是流水线的实际执行单元
-- [[TF State Bucket Accessor]]:专门定义的 IAM 角色,仅允许部署工具访问目标账号 S3 桶中的 Terraform 状态文件
-- [[Cross-account ECS Deploy Runner Role]]:部署在目标账号中的角色,允许 Shared Account 的执行器通过 Assume Role 获取资源创建权限
-- [[cross-account.json]]:约定俗成的标记文件,放置于模块目录中,用于告知 Jenkins 该模块需要调用跨账号部署逻辑
-- [[Root Terragrunt HCL]]:全局 Terragrunt 配置文件,定义远程状态存储和角色切换逻辑
-
-## Key Entities
-- **Fibos**:主讲人,分享了团队基于 Shared Account 的跨账号 Terraform 部署方案
-- **Gruntwork**:参考架构来源,原有 Gruntwork 流水线主要针对单账号设计
-- **Jenkins**:CI/CD 引擎,托管在 Shared Account,负责检测模块类型并触发部署流程
-- **AWS Landing Zone**:多账号架构框架,Shared Account + Workload Account 的分层设计
-
-## Connections
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← foundation ← [[ctp-topic-16-cross-account-terraform-modules]]
-- [[ECS Deploy Runner]] ← depends_on ← [[Shared Account]]
-- [[Cross-account Terraform Modules]] ← uses ← [[ECS Deploy Runner]]
-- [[ECS Deploy Runner]] ← assumes ← [[Cross-account ECS Deploy Runner Role]]
-- [[ECS Deploy Runner]] ← reads_state ← [[TF State Bucket Accessor]]
-- [[Root Terragrunt HCL]] ← configures ← [[Cross-account Terraform Modules]]
-- [[ctp-topic-48-terraform-vs-terragrunt]] ← related ← [[Root Terragrunt HCL]]
-- [[AWS-Landing-Zone]] ← enables ← [[Shared Account]]
-
-## Contradictions
-- 与 [[ctp-topic-9-ci-cd-with-gruntwork]](单账号 Gruntwork 流水线):原有 Gruntwork 流水线主要针对单账号设计,不处理跨账号场景;本方案通过 Shared Account 中心化架构扩展支持多账号,同时保留 Gruntwork 模块复用优势。两者为演进关系而非冲突。
-- 与 [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]](Atlantis 替代 Jenkins):Atlantis 在 merge 前应用变更,每个 Landing Zone 部署单台 EC2 实例;本方案的 ECS Deploy Runner 运行在容器中,更适合跨账号大规模部署。Atlantis 的跨账号访问通过各账户 IAM 角色实现,与本方案 Assume Role 机制类似,但执行载体不同。
+---
+title: "CTP Topic 16 Cross-account Terraform modules"
+type: source
+tags: [Terraform, Cross-Account, Modules, CTP, IaC, DevOps, AWS-Landing-Zone]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/ctp-topic-16-cross-account-terraform-modules.md]]
+
+## Summary(用中文描述)
+- 核心主题:**跨账号 Terraform 模块的中心化部署方案**,解决多账号 AWS 环境中一个模块内跨账号创建资源的安全与自动化问题
+- 问题域:原有的 Gruntwork 流水线针对单账号设计,在多账号场景下存在安全风险(一账号被攻破可能波及全局)
+- 方法/机制:基于 **Shared Account(共享账号)** 的中心化部署架构,Jenkins + ECS Deploy Runner + Assume Role 三者联动
+- 结论/价值:实现安全性(账号间无直接信任关系)、自动化(Jenkins 自动识别跨账号模块)、可复用性(模块代码不硬编码特定账号角色)
+
+## Key Claims(用中文描述)
+- **Shared Account 作为中转站**:Jenkins 托管在 Shared Account,当检测到 `cross-account.json` 标记文件时触发 ECS Deploy Runner
+- **Assume Role 双角色机制**:ECS Deploy Runner 通过 Assume Role 访问目标账号的两个角色——`TF state bucket accessor`(读取状态文件)和 `cross-account ECS deploy runner role`(执行资源部署)
+- **Blast Radius 控制**:避免 Workload 账号之间直接互访,权限控制在受严格审计的 Shared Account
+- **Terragrunt HCL 全局配置**:通过根目录 `terragrunt.hcl` 定义远程状态存储和角色切换逻辑,支持本地开发与 Jenkins 自动部署的差异化角色处理
+
+## Key Quotes
+> "Cross-account Terraform Modules 指在一个模块内通过配置多个 Provider,实现在多个 AWS 账号中同时创建或管理资源的功能" — Fibos,核心概念定义
+> "Shared Account 是整个 Landing Zone 的核心管理账号,托管 Jenkins、镜像仓库等公共服务,并作为跨账号部署的信任源" — Fibos,架构定位
+> "ECS Deploy Runner 运行在 ECS 上的 Docker 容器,负责执行 Terraform plan 和 apply 命令,是流水线中的实际执行单元" — Fibos,EDR 定义
+
+## Key Concepts
+- [[Cross-account Terraform Modules]]:在一个 Terraform 模块中通过配置多个 Provider,实现在多个 AWS 账号中同时创建或管理资源的功能
+- [[Shared Account]]:Landing Zone 核心管理账号,托管 Jenkins 及公共服务,作为跨账号部署的信任源
+- [[ECS Deploy Runner]]:运行在 ECS 上的 Docker 容器,负责执行 Terraform plan/apply,是流水线的实际执行单元
+- [[TF State Bucket Accessor]]:专门定义的 IAM 角色,仅允许部署工具访问目标账号 S3 桶中的 Terraform 状态文件
+- [[Cross-account ECS Deploy Runner Role]]:部署在目标账号中的角色,允许 Shared Account 的执行器通过 Assume Role 获取资源创建权限
+- [[cross-account.json]]:约定俗成的标记文件,放置于模块目录中,用于告知 Jenkins 该模块需要调用跨账号部署逻辑
+- [[Root Terragrunt HCL]]:全局 Terragrunt 配置文件,定义远程状态存储和角色切换逻辑
+
+## Key Entities
+- **Fibos**:主讲人,分享了团队基于 Shared Account 的跨账号 Terraform 部署方案
+- **Gruntwork**:参考架构来源,原有 Gruntwork 流水线主要针对单账号设计
+- **Jenkins**:CI/CD 引擎,托管在 Shared Account,负责检测模块类型并触发部署流程
+- **AWS Landing Zone**:多账号架构框架,Shared Account + Workload Account 的分层设计
+
+## Connections
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← foundation ← [[ctp-topic-16-cross-account-terraform-modules]]
+- [[ECS Deploy Runner]] ← depends_on ← [[Shared Account]]
+- [[Cross-account Terraform Modules]] ← uses ← [[ECS Deploy Runner]]
+- [[ECS Deploy Runner]] ← assumes ← [[Cross-account ECS Deploy Runner Role]]
+- [[ECS Deploy Runner]] ← reads_state ← [[TF State Bucket Accessor]]
+- [[Root Terragrunt HCL]] ← configures ← [[Cross-account Terraform Modules]]
+- [[ctp-topic-48-terraform-vs-terragrunt]] ← related ← [[Root Terragrunt HCL]]
+- [[AWS-Landing-Zone]] ← enables ← [[Shared Account]]
+
+## Contradictions
+- 与 [[ctp-topic-9-ci-cd-with-gruntwork]](单账号 Gruntwork 流水线):原有 Gruntwork 流水线主要针对单账号设计,不处理跨账号场景;本方案通过 Shared Account 中心化架构扩展支持多账号,同时保留 Gruntwork 模块复用优势。两者为演进关系而非冲突。
+- 与 [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]](Atlantis 替代 Jenkins):Atlantis 在 merge 前应用变更,每个 Landing Zone 部署单台 EC2 实例;本方案的 ECS Deploy Runner 运行在容器中,更适合跨账号大规模部署。Atlantis 的跨账号访问通过各账户 IAM 角色实现,与本方案 Assume Role 机制类似,但执行载体不同。
diff --git a/wiki/sources/ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs.md b/wiki/sources/ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs.md
index c1077f79..864f379d 100644
--- a/wiki/sources/ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs.md
+++ b/wiki/sources/ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs.md
@@ -1,59 +1,59 @@
----
-title: "CTP Topic 17 Active Directory Services in Gruntwork AWS LZs"
-type: source
-tags: [AWS, Landing-Zone, AD, Gruntwork, CTP]
-sources: []
-last_updated: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs]]
-
-## Summary(用中文描述)
-- 核心主题:在 Gruntwork AWS Landing Zones 架构中集成与管理 Active Directory (AD) 服务的核心实践
-- 问题域:企业级 AWS 多环境(研发/生产)的 AD 域名规划、自动化域加入、以及开发者自助服务
-- 方法/机制:
- - 双域名策略:`swinford.net`(研发实验室 R&D Labs)vs `intsas.local`(生产/SAS 环境)
- - SRE 团队预制 AMI,内置 PowerShell(Windows)/Shell(Linux)域加入脚本
- - Terraform `user_data` 触发自动域加入流程
- - MIM(Microsoft Identity Manager)提供研发环境安全组自助管理
- - SMACKS 工单系统处理生产环境账号申请
-- 结论/价值:旧域名(`infra`、`AST`)已在 Gruntwork LZ 中废弃,提供了清晰的迁移路径和所有权归属建议
-
-## Key Claims(用中文描述)
-- Gruntwork Landing Zones 按环境类型(研发 vs 生产)分别使用不同的 AD 域名,以满足隔离性和合规审计需求
-- Windows 实例通过 Terraform `user_data` 调用 SRE 预制 AMI 中的 PowerShell 脚本,实现自动化域加入、旧对象清理和本地管理员分配
-- Linux 实例通过安全动态更新(Secure Dynamic Updates)机制自动向 Windows DNS 服务器注册 DNS A 记录
-- 旧域名 `infra` 和 `AST` 在新 Gruntwork LZ 中已被废弃,开发者必须迁移至新域名架构
-- R&D 环境支持 MIM 自助服务工具,生产/SAS 环境通过 SMACKS 工单系统申请账号
-
-## Key Quotes
-> "本次视频是 DevOps 云学习系列课程之一,重点介绍了在 Gruntwork AWS Landing Zones 架构中集成与管理 Active Directory (AD) 服务的核心实践。演讲者 Paul 详细阐述了两种主要环境的域名配置:研发实验室(R&D Labs)统一使用 `swinford.net` 域名,而生产与分阶段 SAS 环境则采用 `intsas.local`。" — 视频摘要
-
-> "旧有的 `infra` 和 `AST` 域名在新的 Gruntwork 落地页中已被废弃,并为用户提供了相应的迁移路径和所有权归属建议。" — 视频摘要
-
-## Key Concepts
-- [[Gruntwork Landing Zones]]:预配置的、基于最佳实践的 AWS 基础架构框架,分为 R&D Labs 和 SAS 两种环境类型
-- [[swinford.net]]:专门用于研发实验室(R&D Labs)环境的 Active Directory 域名,支持 MIM 自助服务管理
-- [[intsas.local]]:用于生产和分阶段 SAS 环境的内部 Active Directory 域名,强调资源所有权归属和审计合规
-- [[SRE-provided AMIs]]:由 SRE 团队预先构建的机器镜像,内置了用于自动加入域的 PowerShell(Windows)和 Shell(Linux)脚本
-- [[User Data]]:在 AWS EC2 实例启动时执行的脚本数据,本视频中用于触发自动化的域加入流程
-- [[MIM (Microsoft Identity Manager)]]:用于 R&D 环境中安全组管理和权限申请的自助服务解决方案
-- [[SMACKS Ticket]]:内部服务管理工单系统,用于申请新账号、重置密码或处理复杂的生产环境变更
-- [[Secure Dynamic Updates]]:一种 DNS 安全机制,允许 Linux 系统在加入域时向 Windows DNS 服务器安全地注册其 A 记录
-
-## Key Entities
-- [[Paul]]:CTP Topic 17 讲师,Gruntwork AWS LZs AD 集成方案的讲解者
-- [[Gruntwork]]:提供 Landing Zones 基础设施框架的团队/组织
-- [[SRE Team]]:负责构建和维护预制 AMI 的 Site Reliability Engineering 团队
-- [[MIM]]:Microsoft Identity Manager,R&D 环境的安全组自助管理工具
-- [[SMACKS]]:内部服务管理工单系统,用于生产/SAS 环境的账号申请和变更处理
-
-## Connections
-- [[Gruntwork AWS Landing Zones Overview]] ← foundational ← [[CTP Topic 17 Active Directory Services]]
-- [[SRE Standard AMIs and Image Building]] ← source ← [[SRE-provided AMIs]]
-- [[Terraform Single Server Module Deep Dive]] ← deployment mechanism ← [[User Data]]
-- [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]] ← related ← [[AD Integration in AWS LZs]]
-
-## Contradictions
-- 暂无检测到与其他 Wiki 页面的冲突
+---
+title: "CTP Topic 17 Active Directory Services in Gruntwork AWS LZs"
+type: source
+tags: [AWS, Landing-Zone, AD, Gruntwork, CTP]
+sources: []
+last_updated: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs.md]]
+
+## Summary(用中文描述)
+- 核心主题:在 Gruntwork AWS Landing Zones 架构中集成与管理 Active Directory (AD) 服务的核心实践
+- 问题域:企业级 AWS 多环境(研发/生产)的 AD 域名规划、自动化域加入、以及开发者自助服务
+- 方法/机制:
+ - 双域名策略:`swinford.net`(研发实验室 R&D Labs)vs `intsas.local`(生产/SAS 环境)
+ - SRE 团队预制 AMI,内置 PowerShell(Windows)/Shell(Linux)域加入脚本
+ - Terraform `user_data` 触发自动域加入流程
+ - MIM(Microsoft Identity Manager)提供研发环境安全组自助管理
+ - SMACKS 工单系统处理生产环境账号申请
+- 结论/价值:旧域名(`infra`、`AST`)已在 Gruntwork LZ 中废弃,提供了清晰的迁移路径和所有权归属建议
+
+## Key Claims(用中文描述)
+- Gruntwork Landing Zones 按环境类型(研发 vs 生产)分别使用不同的 AD 域名,以满足隔离性和合规审计需求
+- Windows 实例通过 Terraform `user_data` 调用 SRE 预制 AMI 中的 PowerShell 脚本,实现自动化域加入、旧对象清理和本地管理员分配
+- Linux 实例通过安全动态更新(Secure Dynamic Updates)机制自动向 Windows DNS 服务器注册 DNS A 记录
+- 旧域名 `infra` 和 `AST` 在新 Gruntwork LZ 中已被废弃,开发者必须迁移至新域名架构
+- R&D 环境支持 MIM 自助服务工具,生产/SAS 环境通过 SMACKS 工单系统申请账号
+
+## Key Quotes
+> "本次视频是 DevOps 云学习系列课程之一,重点介绍了在 Gruntwork AWS Landing Zones 架构中集成与管理 Active Directory (AD) 服务的核心实践。演讲者 Paul 详细阐述了两种主要环境的域名配置:研发实验室(R&D Labs)统一使用 `swinford.net` 域名,而生产与分阶段 SAS 环境则采用 `intsas.local`。" — 视频摘要
+
+> "旧有的 `infra` 和 `AST` 域名在新的 Gruntwork 落地页中已被废弃,并为用户提供了相应的迁移路径和所有权归属建议。" — 视频摘要
+
+## Key Concepts
+- [[Gruntwork Landing Zones]]:预配置的、基于最佳实践的 AWS 基础架构框架,分为 R&D Labs 和 SAS 两种环境类型
+- [[swinford.net]]:专门用于研发实验室(R&D Labs)环境的 Active Directory 域名,支持 MIM 自助服务管理
+- [[intsas.local]]:用于生产和分阶段 SAS 环境的内部 Active Directory 域名,强调资源所有权归属和审计合规
+- [[SRE-provided AMIs]]:由 SRE 团队预先构建的机器镜像,内置了用于自动加入域的 PowerShell(Windows)和 Shell(Linux)脚本
+- [[User Data]]:在 AWS EC2 实例启动时执行的脚本数据,本视频中用于触发自动化的域加入流程
+- [[MIM (Microsoft Identity Manager)]]:用于 R&D 环境中安全组管理和权限申请的自助服务解决方案
+- [[SMACKS Ticket]]:内部服务管理工单系统,用于申请新账号、重置密码或处理复杂的生产环境变更
+- [[Secure Dynamic Updates]]:一种 DNS 安全机制,允许 Linux 系统在加入域时向 Windows DNS 服务器安全地注册其 A 记录
+
+## Key Entities
+- [[Paul]]:CTP Topic 17 讲师,Gruntwork AWS LZs AD 集成方案的讲解者
+- [[Gruntwork]]:提供 Landing Zones 基础设施框架的团队/组织
+- [[SRE Team]]:负责构建和维护预制 AMI 的 Site Reliability Engineering 团队
+- [[MIM]]:Microsoft Identity Manager,R&D 环境的安全组自助管理工具
+- [[SMACKS]]:内部服务管理工单系统,用于生产/SAS 环境的账号申请和变更处理
+
+## Connections
+- [[Gruntwork AWS Landing Zones Overview]] ← foundational ← [[CTP Topic 17 Active Directory Services]]
+- [[SRE Standard AMIs and Image Building]] ← source ← [[SRE-provided AMIs]]
+- [[Terraform Single Server Module Deep Dive]] ← deployment mechanism ← [[User Data]]
+- [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]] ← related ← [[AD Integration in AWS LZs]]
+
+## Contradictions
+- 暂无检测到与其他 Wiki 页面的冲突
diff --git a/wiki/sources/ctp-topic-18-wide-area-networking-in-aws-cloud.md b/wiki/sources/ctp-topic-18-wide-area-networking-in-aws-cloud.md
index 85e56dfb..f1e4af35 100644
--- a/wiki/sources/ctp-topic-18-wide-area-networking-in-aws-cloud.md
+++ b/wiki/sources/ctp-topic-18-wide-area-networking-in-aws-cloud.md
@@ -1,59 +1,59 @@
----
-title: "CTP Topic 18 Wide Area Networking in AWS Cloud"
-type: source
-tags:
- - AWS
- - WAN
- - Networking
- - Transit Gateway
- - SD-WAN
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-18-wide-area-networking-in-aws-cloud]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 云环境中的广域网(WAN)架构设计与演进路径
-- 问题域:大型跨国企业如何通过 AWS Transit Gateway 构建跨区域全球网络连接,并规划向 SD-WAN 演进的路径
-- 方法/机制:通过 Transit Gateway (TGW) 星型拓扑(Hub-and-Spoke)连接全球 Landing Zones,区域 Hub 之间全网状互联;使用静态前缀列表路由;未来引入 Silver Peak SD-WAN 叠加网络和 Prisma Access SASE 远程访问
-- 结论/价值:为企业级云广域网提供了从传统静态路由到智能化 SD-WAN 的完整演进参考,涵盖连接性、容灾、远程访问三大维度的设计决策
-
-## Key Claims(用中文描述)
-- AWS Transit Gateway 作为区域级网络中转服务,可有效连接 VPCs、跨区域对等连接及 Landing Zones,形成星型拓扑
-- 现有 TGW 间路由依赖静态前缀列表,缺乏动态 BGP 协议支持,DR 场景需要人工干预切换路由
-- Silver Peak SD-WAN 作为叠加网络可实现动态路径选择和自动化流量调度,解决静态路由局限性
-- Pulse VPN 迁移至 Prisma Access (SASE) 可实现就近接入,显著降低访问延迟并直接打通 SD-WAN 骨干网
-
-## Key Quotes
-> "所有 Landing Zones 通过 TGW Peering 接入区域 Hub,形成星型拓扑(Hub-and-Spoke),各区域 Hub 之间则通过全网状(Full Mesh)连接,确保全球流量的可达性。" — 架构概述
-
-> "计划引入 Silver Peak 的 SD-WAN 方案作为叠加网络(Overlay)。通过在 AWS 中部署虚拟 SD-WAN 设备,实现动态路径选择和自动化流量调度,解决静态路由的局限性。" — 未来演进
-
-> "计划将传统的 Pulse VPN 迁移至 Palo Alto 的 Prisma Access(SASE 架构)。通过在全球部署更多的接入网关,让用户就近接入,显著降低访问延迟,并直接打通 SD-WAN 骨干网。" — 远程访问优化
-
-## Key Concepts
-- [[AWS Transit Gateway (TGW)]]:区域级网络中转服务,连接 VPC、本地网络及其他 Transit Gateway,充当云上路由器角色
-- [[Hub-and-Spoke]]:星型网络拓扑结构,所有分支(Spoke)连接到中心节点(Hub),分支间通信经过 Hub 中转
-- [[SD-WAN (Software-Defined WAN)]]:软件定义广域网,通过软件控制层对物理网络进行抽象,实现动态路径选择和负载均衡
-- [[Overlay Network]]:叠加网络,在现有物理网络(Underlay)之上构建的逻辑网络,用于实现复杂的路由和隧道功能
-- [[Static Routing]]:静态路由,手动配置的固定路由条目,在网络拓扑变化时无法自动更新
-- [[Prisma Access]]:Palo Alto Networks 提供的基于云的安全访问服务(SASE),用于替代传统 VPN
-- [[TGW Peering]]:在不同区域或同一区域的两个 Transit Gateway 之间建立的连接,用于跨网段流量传输
-
-## Key Entities
-- [[Christian Deckelman]]:Micro Focus IT 网络架构师,CTP Topic 18 讲师
-- [[AWS]]:Amazon Web Services,提供 Transit Gateway 等云网络服务
-- [[Silver Peak]]:SD-WAN 解决方案供应商,计划引入其 SD-WAN 方案作为叠加网络
-- [[Palo Alto Networks]]:网络安全公司,Prisma Access SASE 方案供应商
-- [[Micro Focus]]:Christian Deckelman 所在公司,AWS 云转型计划(CTP)的主导企业
-
-## Connections
-- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← depends_on ← [[ctp-topic-18-wide-area-networking-in-aws-cloud]]
-- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← [[ctp-topic-18-wide-area-networking-in-aws-cloud]]
-- [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]] ← related_to ← [[ctp-topic-18-wide-area-networking-in-aws-cloud]]
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← extends ← [[ctp-topic-18-wide-area-networking-in-aws-cloud]]
-
-## Contradictions
-- 无已知冲突
+---
+title: "CTP Topic 18 Wide Area Networking in AWS Cloud"
+type: source
+tags:
+ - AWS
+ - WAN
+ - Networking
+ - Transit Gateway
+ - SD-WAN
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-18-wide-area-networking-in-aws-cloud.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 云环境中的广域网(WAN)架构设计与演进路径
+- 问题域:大型跨国企业如何通过 AWS Transit Gateway 构建跨区域全球网络连接,并规划向 SD-WAN 演进的路径
+- 方法/机制:通过 Transit Gateway (TGW) 星型拓扑(Hub-and-Spoke)连接全球 Landing Zones,区域 Hub 之间全网状互联;使用静态前缀列表路由;未来引入 Silver Peak SD-WAN 叠加网络和 Prisma Access SASE 远程访问
+- 结论/价值:为企业级云广域网提供了从传统静态路由到智能化 SD-WAN 的完整演进参考,涵盖连接性、容灾、远程访问三大维度的设计决策
+
+## Key Claims(用中文描述)
+- AWS Transit Gateway 作为区域级网络中转服务,可有效连接 VPCs、跨区域对等连接及 Landing Zones,形成星型拓扑
+- 现有 TGW 间路由依赖静态前缀列表,缺乏动态 BGP 协议支持,DR 场景需要人工干预切换路由
+- Silver Peak SD-WAN 作为叠加网络可实现动态路径选择和自动化流量调度,解决静态路由局限性
+- Pulse VPN 迁移至 Prisma Access (SASE) 可实现就近接入,显著降低访问延迟并直接打通 SD-WAN 骨干网
+
+## Key Quotes
+> "所有 Landing Zones 通过 TGW Peering 接入区域 Hub,形成星型拓扑(Hub-and-Spoke),各区域 Hub 之间则通过全网状(Full Mesh)连接,确保全球流量的可达性。" — 架构概述
+
+> "计划引入 Silver Peak 的 SD-WAN 方案作为叠加网络(Overlay)。通过在 AWS 中部署虚拟 SD-WAN 设备,实现动态路径选择和自动化流量调度,解决静态路由的局限性。" — 未来演进
+
+> "计划将传统的 Pulse VPN 迁移至 Palo Alto 的 Prisma Access(SASE 架构)。通过在全球部署更多的接入网关,让用户就近接入,显著降低访问延迟,并直接打通 SD-WAN 骨干网。" — 远程访问优化
+
+## Key Concepts
+- [[AWS Transit Gateway (TGW)]]:区域级网络中转服务,连接 VPC、本地网络及其他 Transit Gateway,充当云上路由器角色
+- [[Hub-and-Spoke]]:星型网络拓扑结构,所有分支(Spoke)连接到中心节点(Hub),分支间通信经过 Hub 中转
+- [[SD-WAN (Software-Defined WAN)]]:软件定义广域网,通过软件控制层对物理网络进行抽象,实现动态路径选择和负载均衡
+- [[Overlay Network]]:叠加网络,在现有物理网络(Underlay)之上构建的逻辑网络,用于实现复杂的路由和隧道功能
+- [[Static Routing]]:静态路由,手动配置的固定路由条目,在网络拓扑变化时无法自动更新
+- [[Prisma Access]]:Palo Alto Networks 提供的基于云的安全访问服务(SASE),用于替代传统 VPN
+- [[TGW Peering]]:在不同区域或同一区域的两个 Transit Gateway 之间建立的连接,用于跨网段流量传输
+
+## Key Entities
+- [[Christian Deckelman]]:Micro Focus IT 网络架构师,CTP Topic 18 讲师
+- [[AWS]]:Amazon Web Services,提供 Transit Gateway 等云网络服务
+- [[Silver Peak]]:SD-WAN 解决方案供应商,计划引入其 SD-WAN 方案作为叠加网络
+- [[Palo Alto Networks]]:网络安全公司,Prisma Access SASE 方案供应商
+- [[Micro Focus]]:Christian Deckelman 所在公司,AWS 云转型计划(CTP)的主导企业
+
+## Connections
+- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← depends_on ← [[ctp-topic-18-wide-area-networking-in-aws-cloud]]
+- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← [[ctp-topic-18-wide-area-networking-in-aws-cloud]]
+- [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]] ← related_to ← [[ctp-topic-18-wide-area-networking-in-aws-cloud]]
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← extends ← [[ctp-topic-18-wide-area-networking-in-aws-cloud]]
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/ctp-topic-19-configuring-dns-within-aws-lzs.md b/wiki/sources/ctp-topic-19-configuring-dns-within-aws-lzs.md
index 214b41bf..5f0c460a 100644
--- a/wiki/sources/ctp-topic-19-configuring-dns-within-aws-lzs.md
+++ b/wiki/sources/ctp-topic-19-configuring-dns-within-aws-lzs.md
@@ -1,57 +1,57 @@
----
-title: "CTP Topic 19 Configuring DNS within AWS LZs"
-type: source
-tags: []
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-19-configuring-dns-within-aws-lzs]]
-
-## Summary(用中文描述)
-- 核心主题:在 AWS Landing Zone 多账号环境中配置集中化 DNS 管理架构
-- 问题域:跨账号、跨云与本地数据中心(On-prem)之间的域名解析难题
-- 方法/机制:设立专用 DNS 账号集中管理 Route 53 私有托管区,通过 Route 53 Resolver Inbound/Outbound Endpoints 打通 AWS 与本地 DNS,AWS RAM 跨账号共享解析规则,Terraform 实现自动化部署
-- 结论/价值:集中化 DNS 管理优于分散式,是多账号 AWS 环境的标准最佳实践
-
-## Key Claims(用中文描述)
-- 集中化 DNS 管理优于分散管理:应在 Landing Zone 中设立专门的 DNS 账号,而非在每个业务账号中分散创建私有托管区,便于统一维护路由规则和域名记录
-- Route 53 Resolver 是混合 DNS 架构的核心组件:Inbound Endpoints 接收来自本地数据中心的解析请求,Outbound Endpoints 将 AWS 内部请求转发至本地 DNS 服务器
-- AWS RAM 实现跨账号规则共享:通过 AWS Resource Access Manager 将 DNS 账号中定义的 Resolver Rules 共享给各个业务账号
-- 跨账号 VPC 与私有托管区关联必须先授权再关联:授权(Authorization)必须在关联(Association)之前完成
-- Terraform 是自动化部署 DNS 架构的核心工具:新业务 VPC 创建时自动完成规则共享与 VPC 关联,确保新账号上线即具备完整解析能力
-
-## Key Quotes
-> "我们推荐在 Landing Zone 中设立一个专门的 DNS 账号,所有私有托管区都集中在这里管理,而不是在每个业务账号中创建各自的托管区。" — Sankar Gopov,解释集中化 DNS 管理的优势
-> "Inbound Endpoints 用于接收来自本地数据中心的 DNS 查询请求;Outbound Endpoints 用于将 AWS 内部的 DNS 查询转发到本地 DNS 服务器。" — Sankar Gopov,Route 53 Resolver Endpoints 的双向作用
-> "跨账号关联时,必须先由托管区拥有者进行授权(Authorization),然后才能由 VPC 拥有者执行关联(Association)。" — Sankar Gopov,跨账号关联的必须步骤
-
-## Key Concepts
-- [[Route 53 Resolver]]:AWS Route 53 的 DNS 解析组件,通过 Inbound/Outbound Endpoints 实现混合云 DNS 架构
-- [[Private Hosted Zone]]:AWS Route 53 的私有托管区,用于在指定 VPC 内部解析自定义域名,不对互联网开放
-- [[Route 53 Resolver Rules]]:解析规则,定义特定域名的解析路径(如将某后缀的域名转发至本地数据中心)
-- [[VPC Association Authorization]]:跨账号关联流程,PHZ 拥有者先授权,VPC 拥有者再执行关联
-- [[AWS RAM]]:Resource Access Manager,用于在组织内跨账号共享 Resolver Rules 等资源
-- [[Hybrid DNS Resolution]]:混合 DNS 解析,AWS VPC 与本地数据中心之间的跨环境域名解析机制
-- [[Terraform DNS Automation]]:使用 Terraform 自动化部署 DNS 架构的实践
-
-## Key Entities
-- [[Sankar Gopov]]:本次视频讲师,AWS Landing Zone DNS 架构专家
-- [[AWS Landing Zone]]:AWS 多账号环境规范,是 DNS 架构的承载基础
-
-## Connections
-- [[ctp-topic-22-global-dns-service-offerings]] ← extends ← [[ctp-topic-19-configuring-dns-within-aws-lzs]]
- - 两者同属 DNS 专题,后者(前文)讲企业级全局 DNS 服务架构(Infoblox + Route 53),后者(本文)聚焦 Landing Zone 内部的具体配置实施
-- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← depends_on ← [[ctp-topic-19-configuring-dns-within-aws-lzs]]
- - Landing Zone 顶层设计包含 DNS 账户的规划
-- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← relates_to ← [[ctp-topic-19-configuring-dns-within-aws-lzs]]
- - Labs LZ 中 Core 账户托管 DNS 服务(Swimford.net)
-- [[ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs]] ← depends_on ← [[ctp-topic-19-configuring-dns-within-aws-lzs]]
- - AD 服务依赖 DNS 完成域名解析,int-sas.local 等域名的解析由 DNS 架构提供
-
-## Contradictions
-- 与 [[ctp-topic-22-global-dns-service-offerings]] 潜在视角差异:
- - 冲突点:DNS 账号是否应包含公共托管区(Public Hosted Zone)
- - 当前观点(Topic 19):DNS 账号专注于私有托管区和 Route 53 Resolver 管理
- - 对方观点(Topic 22):Route 53 还需管理公共域名解析(Route 53 Hosted Zone + Route 53 Resolver)
- - 注:两者可能适用于不同的环境(Topic 22 侧重 DNS 服务提供者的全局架构,Topic 19 侧重 Landing Zone 内部的落地配置)
+---
+title: "CTP Topic 19 Configuring DNS within AWS LZs"
+type: source
+tags: []
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-19-configuring-dns-within-aws-lzs.md]]
+
+## Summary(用中文描述)
+- 核心主题:在 AWS Landing Zone 多账号环境中配置集中化 DNS 管理架构
+- 问题域:跨账号、跨云与本地数据中心(On-prem)之间的域名解析难题
+- 方法/机制:设立专用 DNS 账号集中管理 Route 53 私有托管区,通过 Route 53 Resolver Inbound/Outbound Endpoints 打通 AWS 与本地 DNS,AWS RAM 跨账号共享解析规则,Terraform 实现自动化部署
+- 结论/价值:集中化 DNS 管理优于分散式,是多账号 AWS 环境的标准最佳实践
+
+## Key Claims(用中文描述)
+- 集中化 DNS 管理优于分散管理:应在 Landing Zone 中设立专门的 DNS 账号,而非在每个业务账号中分散创建私有托管区,便于统一维护路由规则和域名记录
+- Route 53 Resolver 是混合 DNS 架构的核心组件:Inbound Endpoints 接收来自本地数据中心的解析请求,Outbound Endpoints 将 AWS 内部请求转发至本地 DNS 服务器
+- AWS RAM 实现跨账号规则共享:通过 AWS Resource Access Manager 将 DNS 账号中定义的 Resolver Rules 共享给各个业务账号
+- 跨账号 VPC 与私有托管区关联必须先授权再关联:授权(Authorization)必须在关联(Association)之前完成
+- Terraform 是自动化部署 DNS 架构的核心工具:新业务 VPC 创建时自动完成规则共享与 VPC 关联,确保新账号上线即具备完整解析能力
+
+## Key Quotes
+> "我们推荐在 Landing Zone 中设立一个专门的 DNS 账号,所有私有托管区都集中在这里管理,而不是在每个业务账号中创建各自的托管区。" — Sankar Gopov,解释集中化 DNS 管理的优势
+> "Inbound Endpoints 用于接收来自本地数据中心的 DNS 查询请求;Outbound Endpoints 用于将 AWS 内部的 DNS 查询转发到本地 DNS 服务器。" — Sankar Gopov,Route 53 Resolver Endpoints 的双向作用
+> "跨账号关联时,必须先由托管区拥有者进行授权(Authorization),然后才能由 VPC 拥有者执行关联(Association)。" — Sankar Gopov,跨账号关联的必须步骤
+
+## Key Concepts
+- [[Route 53 Resolver]]:AWS Route 53 的 DNS 解析组件,通过 Inbound/Outbound Endpoints 实现混合云 DNS 架构
+- [[Private Hosted Zone]]:AWS Route 53 的私有托管区,用于在指定 VPC 内部解析自定义域名,不对互联网开放
+- [[Route 53 Resolver Rules]]:解析规则,定义特定域名的解析路径(如将某后缀的域名转发至本地数据中心)
+- [[VPC Association Authorization]]:跨账号关联流程,PHZ 拥有者先授权,VPC 拥有者再执行关联
+- [[AWS RAM]]:Resource Access Manager,用于在组织内跨账号共享 Resolver Rules 等资源
+- [[Hybrid DNS Resolution]]:混合 DNS 解析,AWS VPC 与本地数据中心之间的跨环境域名解析机制
+- [[Terraform DNS Automation]]:使用 Terraform 自动化部署 DNS 架构的实践
+
+## Key Entities
+- [[Sankar Gopov]]:本次视频讲师,AWS Landing Zone DNS 架构专家
+- [[AWS Landing Zone]]:AWS 多账号环境规范,是 DNS 架构的承载基础
+
+## Connections
+- [[ctp-topic-22-global-dns-service-offerings]] ← extends ← [[ctp-topic-19-configuring-dns-within-aws-lzs]]
+ - 两者同属 DNS 专题,后者(前文)讲企业级全局 DNS 服务架构(Infoblox + Route 53),后者(本文)聚焦 Landing Zone 内部的具体配置实施
+- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← depends_on ← [[ctp-topic-19-configuring-dns-within-aws-lzs]]
+ - Landing Zone 顶层设计包含 DNS 账户的规划
+- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← relates_to ← [[ctp-topic-19-configuring-dns-within-aws-lzs]]
+ - Labs LZ 中 Core 账户托管 DNS 服务(Swimford.net)
+- [[ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs]] ← depends_on ← [[ctp-topic-19-configuring-dns-within-aws-lzs]]
+ - AD 服务依赖 DNS 完成域名解析,int-sas.local 等域名的解析由 DNS 架构提供
+
+## Contradictions
+- 与 [[ctp-topic-22-global-dns-service-offerings]] 潜在视角差异:
+ - 冲突点:DNS 账号是否应包含公共托管区(Public Hosted Zone)
+ - 当前观点(Topic 19):DNS 账号专注于私有托管区和 Route 53 Resolver 管理
+ - 对方观点(Topic 22):Route 53 还需管理公共域名解析(Route 53 Hosted Zone + Route 53 Resolver)
+ - 注:两者可能适用于不同的环境(Topic 22 侧重 DNS 服务提供者的全局架构,Topic 19 侧重 Landing Zone 内部的落地配置)
diff --git a/wiki/sources/ctp-topic-2-git.md b/wiki/sources/ctp-topic-2-git.md
index 97e7afc1..3cfa3cb7 100644
--- a/wiki/sources/ctp-topic-2-git.md
+++ b/wiki/sources/ctp-topic-2-git.md
@@ -1,45 +1,45 @@
----
-title: "CTP Topic 2 Git"
-type: source
-tags:
- - Git
- - VCS
- - CTP
-last_updated: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-2-git.md]]
-
-## Summary(用中文描述)
-- 核心主题:Git 版本控制系统基础与实践
-- 问题域:云转型计划中的源代码版本控制与协作工作流
-- 方法/机制:视频讲座形式,CTP Topic 2 系列课程
-- 结论/价值:掌握 Git 是 DevOps 与 IaC 实践的基础技能
-
-## Key Claims(用中文描述)
-- CTP Topic 2 涵盖 Git 版本控制系统的核心概念与实操技能
-
-## Key Quotes
-> "待 Whisper 转录后补充详细内容" — 当前状态:待转录
-
-## Key Concepts
-- [[Git]]:分布式版本控制系统,DevOps 与 CI/CD 流水线的基础工具
-- [[Version Control]]:代码变更追踪与协作管理机制
-- [[DevOps]]:开发与运维协作的文化与实践体系
-
-## Key Entities
-- [[Cloud Transformation Programme]]:云转型计划,CTP Topic 系列课程的组织框架
-
-## Connections
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← extends ← [[ctp-topic-2-git]]
-- [[ctp-topic-33-an-introduction-to-gitops]] ← depends_on ← [[ctp-topic-2-git]]
-- [[public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration]] ← related_to ← [[ctp-topic-2-git]]
-
-## Contradictions
-- 无已知冲突
-
-## Notes
-- 原始文档状态为"待转录"(Awaiting Whisper transcription → Summary)
-- 视频源:NAS `/volume2/work/Public Cloud Learning Sessions/CTP _ Topic 2_ Git.mp4`
-- 类别:DevOps & SRE / 06_CI_CD_GitOps
+---
+title: "CTP Topic 2 Git"
+type: source
+tags:
+ - Git
+ - VCS
+ - CTP
+last_updated: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-2-git.md]]
+
+## Summary(用中文描述)
+- 核心主题:Git 版本控制系统基础与实践
+- 问题域:云转型计划中的源代码版本控制与协作工作流
+- 方法/机制:视频讲座形式,CTP Topic 2 系列课程
+- 结论/价值:掌握 Git 是 DevOps 与 IaC 实践的基础技能
+
+## Key Claims(用中文描述)
+- CTP Topic 2 涵盖 Git 版本控制系统的核心概念与实操技能
+
+## Key Quotes
+> "待 Whisper 转录后补充详细内容" — 当前状态:待转录
+
+## Key Concepts
+- [[Git]]:分布式版本控制系统,DevOps 与 CI/CD 流水线的基础工具
+- [[Version Control]]:代码变更追踪与协作管理机制
+- [[DevOps]]:开发与运维协作的文化与实践体系
+
+## Key Entities
+- [[Cloud Transformation Programme]]:云转型计划,CTP Topic 系列课程的组织框架
+
+## Connections
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← extends ← [[ctp-topic-2-git]]
+- [[ctp-topic-33-an-introduction-to-gitops]] ← depends_on ← [[ctp-topic-2-git]]
+- [[public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration]] ← related_to ← [[ctp-topic-2-git]]
+
+## Contradictions
+- 无已知冲突
+
+## Notes
+- 原始文档状态为"待转录"(Awaiting Whisper transcription → Summary)
+- 视频源:NAS `/volume2/work/Public Cloud Learning Sessions/CTP _ Topic 2_ Git.mp4`
+- 类别:DevOps & SRE / 06_CI_CD_GitOps
diff --git a/wiki/sources/ctp-topic-20-program-demand-process-flow-and-poc-onboarding.md b/wiki/sources/ctp-topic-20-program-demand-process-flow-and-poc-onboarding.md
index 2aa344ed..8c2cb6a5 100644
--- a/wiki/sources/ctp-topic-20-program-demand-process-flow-and-poc-onboarding.md
+++ b/wiki/sources/ctp-topic-20-program-demand-process-flow-and-poc-onboarding.md
@@ -1,60 +1,60 @@
----
-title: "CTP Topic 20 Program demand process flow and PoC onboarding"
-type: source
-tags: []
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-20-program-demand-process-flow-and-poc-onboarding]]
-
-## Summary(用中文描述)
-- 核心主题:云转型计划(CTP)的程序需求流程与概念验证(POC)入职流程
-- 问题域:企业级云迁移的治理框架、需求管理、POC 实施路径
-- 方法/机制:多阶段网关审批流程(Gate 0/1/3)、POC 验证框架、IaC(Terraform/Terragrunt)自动化部署、基于 Gruntwork Landing Zone 的新一代云环境
-- 结论/价值:POC 是降低迁移风险的核心手段;Landing Zone 需全部通过 IaC 自动化构建,严禁手动操作;Gate Process 确保治理严谨性
-
-## Key Claims(用中文描述)
-- CTP 需求主要由业务案例(数据中心关闭)、高层战略优先级和产品路线图驱动
-- POC 阶段必须完成解决方案设计并经过 Design Authority 审批
-- 新一代 Landing Zone 基于 Gruntwork 架构,强调 IaC(Terraform/Terragrunt),禁止手动构建
-- PCG 团队负责提供云环境支持、安全策略制定及协助产品组进行 POC
-- POC 成功标准必须在启动前明确定义
-
-## Key Quotes
-> "本次会议是云转型计划(Cloud Transformation Programme)系列学习课的一部分,由专家 Sergio 和 Damian 主讲,核心内容围绕'程序需求流程(Program Demand Process Flow)'以及'概念验证(POC)'的实施路径展开。" — 视频摘要开场
-
-## Key Concepts
-- [[Program-Demand-Process]]: 程序需求处理流程,指从业务需求产生、优先级排序到最终交付迁移的端到端管理路径
-- [[Proof-of-Concept]]: 概念验证,在正式迁移前用于证明架构可行性、测试复杂网络需求及验证迁移方法的实验性阶段
-- [[Landing-Zone]]: 落地分区,指云端预配置的、符合安全与合规标准的标准化基础架构环境
-- [[Infrastructure-as-Code]]: 基础设施即代码,通过脚本(如 Terraform)而非手动操作来定义和管理云资源
-- [[Gate-Process]]: 网关审批流程,用于治理项目进度的关键决策点,例如 Gate 0(评估准入)和 Gate 3(迁移准入)
-- [[Solution-Design]]: 解决方案设计,在 POC 阶段需完成并经过 Design Authority 审批的架构文档
-
-## Key Entities
-- [[Sergio]]: CTP 系列课程讲师,主讲程序需求流程
-- [[Damian]]: CTP 系列课程讲师,提及 Cloud Transformation Strategy Overview
-- [[PCG-Team]]: 平台控制组,负责提供云环境支持、安全策略制定及协助产品组进行 POC
-- [[Gruntwork]]: Landing Zone 参考架构提供商,其基础设施代码库支撑新一代云环境
-- [[Terraform]]: 核心 IaC 工具
-- [[Terragrunt]]: Terraform 的包装器,简化多环境管理
-
-## Connections
-- [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]] ← extends ← [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]]
- - Topic 65 提供价值量化框架,Topic 20 提供需求流程入口
-- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← depends_on ← [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]]
- - Topic 20 定义 PoC Landing Zone 并入 Labs,Topic 35 补充 SaaS vs Labs 职责划分
-- [[ctp-topic-57-product-backlog-managing-demand]] ← extends ← [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]]
- - Topic 57 深入需求管理层面,Topic 20 提供整体需求流程框架
-- [[ctp-topic-30-managing-change]] ← extends ← [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]]
- - 两者同属 CTP 治理知识体系,Topic 30 聚焦变更管理,Topic 20 聚焦需求入口
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← depends_on ← [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]]
- - Topic 1 提供 Gruntwork Landing Zone 架构基础,Topic 20 引用其作为目标环境
-
-## Contradictions
-- 与 [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] 存在流程视角差异:
- - 冲突点:Topic 4 强调 Kanban 持续流动模式允许随时调整优先级,Topic 20 强调 Gate Process 的阶段性审批节点
- - 当前观点:CTP 采用固定 Gate 审批流程治理迁移决策,确保严谨性
- - 对方观点:敏捷方法建议减少固定审批节点,通过持续反馈驱动决策
- - 说明:两者非逻辑矛盾,而是适用场景不同——Gate Process 适用于大范围迁移决策,敏捷方法适用于迭代式产品开发
+---
+title: "CTP Topic 20 Program demand process flow and PoC onboarding"
+type: source
+tags: []
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-20-program-demand-process-flow-and-poc-onboarding.md]]
+
+## Summary(用中文描述)
+- 核心主题:云转型计划(CTP)的程序需求流程与概念验证(POC)入职流程
+- 问题域:企业级云迁移的治理框架、需求管理、POC 实施路径
+- 方法/机制:多阶段网关审批流程(Gate 0/1/3)、POC 验证框架、IaC(Terraform/Terragrunt)自动化部署、基于 Gruntwork Landing Zone 的新一代云环境
+- 结论/价值:POC 是降低迁移风险的核心手段;Landing Zone 需全部通过 IaC 自动化构建,严禁手动操作;Gate Process 确保治理严谨性
+
+## Key Claims(用中文描述)
+- CTP 需求主要由业务案例(数据中心关闭)、高层战略优先级和产品路线图驱动
+- POC 阶段必须完成解决方案设计并经过 Design Authority 审批
+- 新一代 Landing Zone 基于 Gruntwork 架构,强调 IaC(Terraform/Terragrunt),禁止手动构建
+- PCG 团队负责提供云环境支持、安全策略制定及协助产品组进行 POC
+- POC 成功标准必须在启动前明确定义
+
+## Key Quotes
+> "本次会议是云转型计划(Cloud Transformation Programme)系列学习课的一部分,由专家 Sergio 和 Damian 主讲,核心内容围绕'程序需求流程(Program Demand Process Flow)'以及'概念验证(POC)'的实施路径展开。" — 视频摘要开场
+
+## Key Concepts
+- [[Program-Demand-Process]]: 程序需求处理流程,指从业务需求产生、优先级排序到最终交付迁移的端到端管理路径
+- [[Proof-of-Concept]]: 概念验证,在正式迁移前用于证明架构可行性、测试复杂网络需求及验证迁移方法的实验性阶段
+- [[Landing-Zone]]: 落地分区,指云端预配置的、符合安全与合规标准的标准化基础架构环境
+- [[Infrastructure-as-Code]]: 基础设施即代码,通过脚本(如 Terraform)而非手动操作来定义和管理云资源
+- [[Gate-Process]]: 网关审批流程,用于治理项目进度的关键决策点,例如 Gate 0(评估准入)和 Gate 3(迁移准入)
+- [[Solution-Design]]: 解决方案设计,在 POC 阶段需完成并经过 Design Authority 审批的架构文档
+
+## Key Entities
+- [[Sergio]]: CTP 系列课程讲师,主讲程序需求流程
+- [[Damian]]: CTP 系列课程讲师,提及 Cloud Transformation Strategy Overview
+- [[PCG-Team]]: 平台控制组,负责提供云环境支持、安全策略制定及协助产品组进行 POC
+- [[Gruntwork]]: Landing Zone 参考架构提供商,其基础设施代码库支撑新一代云环境
+- [[Terraform]]: 核心 IaC 工具
+- [[Terragrunt]]: Terraform 的包装器,简化多环境管理
+
+## Connections
+- [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]] ← extends ← [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]]
+ - Topic 65 提供价值量化框架,Topic 20 提供需求流程入口
+- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← depends_on ← [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]]
+ - Topic 20 定义 PoC Landing Zone 并入 Labs,Topic 35 补充 SaaS vs Labs 职责划分
+- [[ctp-topic-57-product-backlog-managing-demand]] ← extends ← [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]]
+ - Topic 57 深入需求管理层面,Topic 20 提供整体需求流程框架
+- [[ctp-topic-30-managing-change]] ← extends ← [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]]
+ - 两者同属 CTP 治理知识体系,Topic 30 聚焦变更管理,Topic 20 聚焦需求入口
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← depends_on ← [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]]
+ - Topic 1 提供 Gruntwork Landing Zone 架构基础,Topic 20 引用其作为目标环境
+
+## Contradictions
+- 与 [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] 存在流程视角差异:
+ - 冲突点:Topic 4 强调 Kanban 持续流动模式允许随时调整优先级,Topic 20 强调 Gate Process 的阶段性审批节点
+ - 当前观点:CTP 采用固定 Gate 审批流程治理迁移决策,确保严谨性
+ - 对方观点:敏捷方法建议减少固定审批节点,通过持续反馈驱动决策
+ - 说明:两者非逻辑矛盾,而是适用场景不同——Gate Process 适用于大范围迁移决策,敏捷方法适用于迭代式产品开发
diff --git a/wiki/sources/ctp-topic-21-supply-chain-security-in-micro-focus.md b/wiki/sources/ctp-topic-21-supply-chain-security-in-micro-focus.md
index 48f329a0..21a8a2a6 100644
--- a/wiki/sources/ctp-topic-21-supply-chain-security-in-micro-focus.md
+++ b/wiki/sources/ctp-topic-21-supply-chain-security-in-micro-focus.md
@@ -1,54 +1,54 @@
----
-title: "CTP Topic 21 Supply Chain Security in Micro Focus"
-type: source
-tags:
- - Security
- - Supply-Chain
- - CTP
- - CI/CD
- - DevSecOps
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-21-supply-chain-security-in-micro-focus]]
-
-## Summary(用中文描述)
-- 核心主题:Micro Focus 软件供应链安全的新方法与安全观念的根本转变
-- 问题域:软件供应链攻击防御、CI/CD 安全、SDL 第五支柱建设
-- 方法/机制:供应链安全纳入 SDL 五大支柱;保护 CI 过程(构建环境/自动化服务器)和 CD 过程(交付系统)完整性;防止黑客在构建环节篡改二进制文件
-- 结论/价值:从"99% 关注研发安全"转向全生命周期安全防护;强调 CI/CD 供应链完整性是云转型的基础保障
-
-## Key Claims(用中文描述)
-- Micro Focus 通过 Shlomi Ben-Hur 提出:软件供应链安全必须成为 SDL(安全开发生命周期)的第五大支柱
-- SolarWinds 事件证明:黑客通过渗透构建过程注入恶意代码,利用合法更新渠道感染下游客户
-- Micro Focus 内部存在极高的工具多样性(17 种不同 SCM 工具),为建立统一安全基准带来巨大挑战
-- 安全观念转变:从过去 99% 关注研发安全(如代码扫描、渗透测试)转向全生命周期安全防护
-
-## Key Quotes
-> "在当前的云转型背景下,软件供应链安全已成为企业安全战略的重中之重" — Shlomi Ben-Hur,Micro Focus 产品安全小组
-
-> "SolarWinds 攻击事件证明,黑客可以通过渗透构建过程注入恶意代码,利用合法更新渠道感染大量下游客户" — 视频核心案例
-
-## Key Concepts
-- [[Supply Chain Security(供应链安全)]]:指支持产品开发、构建及交付的所有组件和流程,包括开发环境、CI/CD 工具链及分发系统
-- [[SolarWinds Hack]]:一次著名的供应链攻击事件,黑客通过在软件构建阶段注入木马,利用合法更新渠道感染了大量下游客户
-- [[CI/CD Security]]:持续集成与持续交付的安全,旨在保护构建服务器、制品库和交付渠道不被未经授权的访问或篡改
-- [[SDL(Security Development Lifecycle)]]:软件安全开发生命周期,Micro Focus 将供应链安全纳入其 13 个安全轨道中的第 5 轨道
-- [[Executive Order on Cybersecurity]]:美国总统发布的关于加强国家网络安全的行政命令,直接推动了软件行业对供应链透明度和安全性的重视
-- [[Lateral Movement]]:横向移动,指黑客在进入受害者网络后,利用获取的权限在系统内部寻找更高价值目标的过程
-
-## Key Entities
-- [[Micro Focus]]:企业,正在大规模向 AWS 云端和 SaaS 模式迁移,产品安全小组主讲供应链安全
-- [[Shlomi Ben-Hur]]:Micro Focus 产品安全小组,主讲本次会议
-- [[SolarWinds]]:发生重大供应链安全事件的软件公司,攻击事件成为行业警示案例
-- [[GitHub Enterprise]]:Micro Focus 使用的 17 种 SCM 工具之一
-
-## Connections
-- [[CTP Topic 9 CI/CD with Gruntwork]] ← related_to ← [[CTP Topic 21 Supply Chain Security]]
-- [[Security Development Lifecycle (SDL) Deep Dive]] ← extends ← [[CTP Topic 21 Supply Chain Security]]
-- [[Cloud Transformation Programme Overview]] ← context ← [[CTP Topic 21 Supply Chain Security]]
-- [[DevOps Tooling Standardization]] ← related_to ← [[CTP Topic 21 Supply Chain Security]]
-
-## Contradictions
-- 暂无发现内容冲突。该来源主要介绍供应链安全理念,未与其他页面存在直接冲突。
+---
+title: "CTP Topic 21 Supply Chain Security in Micro Focus"
+type: source
+tags:
+ - Security
+ - Supply-Chain
+ - CTP
+ - CI/CD
+ - DevSecOps
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-21-supply-chain-security-in-micro-focus.md]]
+
+## Summary(用中文描述)
+- 核心主题:Micro Focus 软件供应链安全的新方法与安全观念的根本转变
+- 问题域:软件供应链攻击防御、CI/CD 安全、SDL 第五支柱建设
+- 方法/机制:供应链安全纳入 SDL 五大支柱;保护 CI 过程(构建环境/自动化服务器)和 CD 过程(交付系统)完整性;防止黑客在构建环节篡改二进制文件
+- 结论/价值:从"99% 关注研发安全"转向全生命周期安全防护;强调 CI/CD 供应链完整性是云转型的基础保障
+
+## Key Claims(用中文描述)
+- Micro Focus 通过 Shlomi Ben-Hur 提出:软件供应链安全必须成为 SDL(安全开发生命周期)的第五大支柱
+- SolarWinds 事件证明:黑客通过渗透构建过程注入恶意代码,利用合法更新渠道感染下游客户
+- Micro Focus 内部存在极高的工具多样性(17 种不同 SCM 工具),为建立统一安全基准带来巨大挑战
+- 安全观念转变:从过去 99% 关注研发安全(如代码扫描、渗透测试)转向全生命周期安全防护
+
+## Key Quotes
+> "在当前的云转型背景下,软件供应链安全已成为企业安全战略的重中之重" — Shlomi Ben-Hur,Micro Focus 产品安全小组
+
+> "SolarWinds 攻击事件证明,黑客可以通过渗透构建过程注入恶意代码,利用合法更新渠道感染大量下游客户" — 视频核心案例
+
+## Key Concepts
+- [[Supply Chain Security(供应链安全)]]:指支持产品开发、构建及交付的所有组件和流程,包括开发环境、CI/CD 工具链及分发系统
+- [[SolarWinds Hack]]:一次著名的供应链攻击事件,黑客通过在软件构建阶段注入木马,利用合法更新渠道感染了大量下游客户
+- [[CI/CD Security]]:持续集成与持续交付的安全,旨在保护构建服务器、制品库和交付渠道不被未经授权的访问或篡改
+- [[SDL(Security Development Lifecycle)]]:软件安全开发生命周期,Micro Focus 将供应链安全纳入其 13 个安全轨道中的第 5 轨道
+- [[Executive Order on Cybersecurity]]:美国总统发布的关于加强国家网络安全的行政命令,直接推动了软件行业对供应链透明度和安全性的重视
+- [[Lateral Movement]]:横向移动,指黑客在进入受害者网络后,利用获取的权限在系统内部寻找更高价值目标的过程
+
+## Key Entities
+- [[Micro Focus]]:企业,正在大规模向 AWS 云端和 SaaS 模式迁移,产品安全小组主讲供应链安全
+- [[Shlomi Ben-Hur]]:Micro Focus 产品安全小组,主讲本次会议
+- [[SolarWinds]]:发生重大供应链安全事件的软件公司,攻击事件成为行业警示案例
+- [[GitHub Enterprise]]:Micro Focus 使用的 17 种 SCM 工具之一
+
+## Connections
+- [[CTP Topic 9 CI/CD with Gruntwork]] ← related_to ← [[CTP Topic 21 Supply Chain Security]]
+- [[Security Development Lifecycle (SDL) Deep Dive]] ← extends ← [[CTP Topic 21 Supply Chain Security]]
+- [[Cloud Transformation Programme Overview]] ← context ← [[CTP Topic 21 Supply Chain Security]]
+- [[DevOps Tooling Standardization]] ← related_to ← [[CTP Topic 21 Supply Chain Security]]
+
+## Contradictions
+- 暂无发现内容冲突。该来源主要介绍供应链安全理念,未与其他页面存在直接冲突。
diff --git a/wiki/sources/ctp-topic-22-global-dns-service-offerings.md b/wiki/sources/ctp-topic-22-global-dns-service-offerings.md
index b7e61cf0..f6f6c788 100644
--- a/wiki/sources/ctp-topic-22-global-dns-service-offerings.md
+++ b/wiki/sources/ctp-topic-22-global-dns-service-offerings.md
@@ -1,58 +1,58 @@
----
-title: "CTP Topic 22 Global DNS service offerings"
-type: source
-tags: [DNS, Networking, AWS, Hybrid-Cloud, CTP]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-22-global-dns-service-offerings.md]]
-
-## Summary(用中文描述)
-- 核心主题:企业级全球 DNS 服务架构设计,聚焦 AWS 云环境与 On-premises 数据中心之间的混合云 DNS 协作方案
-- 问题域:如何在多区域 AWS Landing Zone 与本地数据中心之间实现高可用、可弹性扩展的统一域名解析
-- 方法/机制:Route 53 Private Hosted Zone(私有托管区域)+ Route 53 Resolver 入站/出站终端节点实现跨 VPC 与本地网络的 DNS 查询转发;Infoblox Anycast 提供本地 DNS 的全球低延迟和自动故障转移;Route 53 Outbound Endpoint 配置多条 AD 域控制器 IP 实现故障时的自动切换
-- 结论/价值:混合云 DNS 架构必须兼顾安全(防 DNS 隧道/缓存污染)、性能(就近解析优化 Office 365 访问)和弹性(多路径故障转移);AWS EC2 目前不支持 Anycast,需通过手动配置多 IP 实现冗余
-
-## Key Claims(用中文描述)
-- 企业云转型背景下,采用 Route 53 Private Hosted Zones 作为 AWS 端核心 DNS 服务,配合 AD 托管 DNS,可实现跨区域混合云的域名统一解析
-- Route 53 Resolver 的入站(Inbound)和出站(Outbound)终端节点是打通 AWS VPC 与本地网络 DNS 查询的关键机制
-- 通过在 Outbound Endpoint 出站规则中配置多个区域的 AD 域控制器 IP,可在单区域故障时自动切换到备用路径,确保 DNS 解析持续可用
-- 本地 Infoblox 平台利用 DNS Anycast 技术实现全球低延迟和自动故障转移,而 AWS EC2 基础架构目前不支持 Anycast
-- DNS 安全方案涵盖防 DNS 隧道攻击、防数据外泄及缓存污染等高级特性
-- "就近解析" 原则用于优化 Office 365 等全球化 SaaS 服务的访问性能
-
-## Key Quotes
-> "公司正在进行云转型计划,Landing Zone 架构中 DNS 是核心基础设施,必须能够同时服务云端和本地环境。" — Sankar & Vino,讲座背景说明
-> "AWS EC2 基础架构目前不支持 Anycast,因此需要手动维护 IP 列表来实现高可用冗余。" — 技术限制说明
-> "Route 53 Resolver Outbound Endpoint 的出站规则配置了多个区域的 AD 域控制器 IP,即使某个区域发生故障,DNS 解析仍能保持弹性。" — 弹性架构设计
-
-## Key Concepts
-- [[Route 53 Private Hosted Zone]]:AWS 提供的私有托管区域,仅对指定的 VPC 可见,用于管理内部网络域名
-- [[Route 53 Resolver]]:AWS VPC 内置 DNS 解析服务,通过入站/出站终端节点实现跨网络 DNS 查询转发
-- [[DNS Anycast]]:一种网络寻址和路由方法,使多个 DNS 服务器共享同一个 IP 地址,将请求路由至地理位置最近的节点
-- [[IPAM(IP Address Management)]]:IP 地址管理工具(如 Infoblox),用于规划、追踪和管理 IP 地址空间及 DNS/DHCP 服务
-- [[Landing Zone]]:一种预先配置好的多账号 AWS 环境,包含安全、网络和身份管理等基础设置
-- [[Hybrid DNS Resolution]]:混合云 DNS 解析,通过配置转发规则使云端资源能解析本地域名,本地资源也能解析云端域名
-- [[Infoblox Grid]]:一种分布式架构,通过 Grid Master 统一管理全球分布的 DNS/DHCP 器具,确保配置一致性和高可用性
-- [[Active Directory DNS]]:Windows AD 域环境中托管的 DNS 服务,是企业混合云 DNS 架构的核心组件
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,提供 Route 53、EC2、VPC 等 DNS 和计算服务
-- [[Infoblox]]:企业级 DNS/DHCP/IPAM 解决方案提供商,其 Grid 架构支持 Anycast
-- [[Sankar]]:CTP Topic 22 主讲人之一
-- [[Vino]]:CTP Topic 22 主讲人之一
-- [[Microsoft Active Directory]]:Windows 域服务,提供 DNS 托管能力
-- [[Office 365]]:Microsoft 365 SaaS 办公套件,其全球访问优化依赖就近 DNS 解析
-
-## Connections
-- [[ctp-topic-19-configuring-dns-within-aws-lzs]] ← extends ← [[ctp-topic-22-global-dns-service-offerings]]
-- [[ctp-topic-7-saas-landing-zone-design]] ← depends_on ← [[ctp-topic-22-global-dns-service-offerings]]
-- [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]] ← related_to ← [[ctp-topic-22-global-dns-service-offerings]]
-- [[ctp-topic-18-wide-area-networking-in-aws-cloud]] ← related_to ← [[ctp-topic-22-global-dns-service-offerings]]
-
-## Contradictions
-- 与 [[ctp-topic-19-configuring-dns-within-aws-lzs]] 潜在关系:
- - 当前观点:CTP Topic 22 详细描述了 Route 53 Private Hosted Zone + Resolver Endpoint 的完整混合云 DNS 架构,含 Infoblox Anycast 对比
- - 对方观点:CTP Topic 19 尚未被摄入,具体内容待确认
- - 状态:待 ctp-topic-19 摄入后补充对比
+---
+title: "CTP Topic 22 Global DNS service offerings"
+type: source
+tags: [DNS, Networking, AWS, Hybrid-Cloud, CTP]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-22-global-dns-service-offerings.md]]
+
+## Summary(用中文描述)
+- 核心主题:企业级全球 DNS 服务架构设计,聚焦 AWS 云环境与 On-premises 数据中心之间的混合云 DNS 协作方案
+- 问题域:如何在多区域 AWS Landing Zone 与本地数据中心之间实现高可用、可弹性扩展的统一域名解析
+- 方法/机制:Route 53 Private Hosted Zone(私有托管区域)+ Route 53 Resolver 入站/出站终端节点实现跨 VPC 与本地网络的 DNS 查询转发;Infoblox Anycast 提供本地 DNS 的全球低延迟和自动故障转移;Route 53 Outbound Endpoint 配置多条 AD 域控制器 IP 实现故障时的自动切换
+- 结论/价值:混合云 DNS 架构必须兼顾安全(防 DNS 隧道/缓存污染)、性能(就近解析优化 Office 365 访问)和弹性(多路径故障转移);AWS EC2 目前不支持 Anycast,需通过手动配置多 IP 实现冗余
+
+## Key Claims(用中文描述)
+- 企业云转型背景下,采用 Route 53 Private Hosted Zones 作为 AWS 端核心 DNS 服务,配合 AD 托管 DNS,可实现跨区域混合云的域名统一解析
+- Route 53 Resolver 的入站(Inbound)和出站(Outbound)终端节点是打通 AWS VPC 与本地网络 DNS 查询的关键机制
+- 通过在 Outbound Endpoint 出站规则中配置多个区域的 AD 域控制器 IP,可在单区域故障时自动切换到备用路径,确保 DNS 解析持续可用
+- 本地 Infoblox 平台利用 DNS Anycast 技术实现全球低延迟和自动故障转移,而 AWS EC2 基础架构目前不支持 Anycast
+- DNS 安全方案涵盖防 DNS 隧道攻击、防数据外泄及缓存污染等高级特性
+- "就近解析" 原则用于优化 Office 365 等全球化 SaaS 服务的访问性能
+
+## Key Quotes
+> "公司正在进行云转型计划,Landing Zone 架构中 DNS 是核心基础设施,必须能够同时服务云端和本地环境。" — Sankar & Vino,讲座背景说明
+> "AWS EC2 基础架构目前不支持 Anycast,因此需要手动维护 IP 列表来实现高可用冗余。" — 技术限制说明
+> "Route 53 Resolver Outbound Endpoint 的出站规则配置了多个区域的 AD 域控制器 IP,即使某个区域发生故障,DNS 解析仍能保持弹性。" — 弹性架构设计
+
+## Key Concepts
+- [[Route 53 Private Hosted Zone]]:AWS 提供的私有托管区域,仅对指定的 VPC 可见,用于管理内部网络域名
+- [[Route 53 Resolver]]:AWS VPC 内置 DNS 解析服务,通过入站/出站终端节点实现跨网络 DNS 查询转发
+- [[DNS Anycast]]:一种网络寻址和路由方法,使多个 DNS 服务器共享同一个 IP 地址,将请求路由至地理位置最近的节点
+- [[IPAM(IP Address Management)]]:IP 地址管理工具(如 Infoblox),用于规划、追踪和管理 IP 地址空间及 DNS/DHCP 服务
+- [[Landing Zone]]:一种预先配置好的多账号 AWS 环境,包含安全、网络和身份管理等基础设置
+- [[Hybrid DNS Resolution]]:混合云 DNS 解析,通过配置转发规则使云端资源能解析本地域名,本地资源也能解析云端域名
+- [[Infoblox Grid]]:一种分布式架构,通过 Grid Master 统一管理全球分布的 DNS/DHCP 器具,确保配置一致性和高可用性
+- [[Active Directory DNS]]:Windows AD 域环境中托管的 DNS 服务,是企业混合云 DNS 架构的核心组件
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,提供 Route 53、EC2、VPC 等 DNS 和计算服务
+- [[Infoblox]]:企业级 DNS/DHCP/IPAM 解决方案提供商,其 Grid 架构支持 Anycast
+- [[Sankar]]:CTP Topic 22 主讲人之一
+- [[Vino]]:CTP Topic 22 主讲人之一
+- [[Microsoft Active Directory]]:Windows 域服务,提供 DNS 托管能力
+- [[Office 365]]:Microsoft 365 SaaS 办公套件,其全球访问优化依赖就近 DNS 解析
+
+## Connections
+- [[ctp-topic-19-configuring-dns-within-aws-lzs]] ← extends ← [[ctp-topic-22-global-dns-service-offerings]]
+- [[ctp-topic-7-saas-landing-zone-design]] ← depends_on ← [[ctp-topic-22-global-dns-service-offerings]]
+- [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]] ← related_to ← [[ctp-topic-22-global-dns-service-offerings]]
+- [[ctp-topic-18-wide-area-networking-in-aws-cloud]] ← related_to ← [[ctp-topic-22-global-dns-service-offerings]]
+
+## Contradictions
+- 与 [[ctp-topic-19-configuring-dns-within-aws-lzs]] 潜在关系:
+ - 当前观点:CTP Topic 22 详细描述了 Route 53 Private Hosted Zone + Resolver Endpoint 的完整混合云 DNS 架构,含 Infoblox Anycast 对比
+ - 对方观点:CTP Topic 19 尚未被摄入,具体内容待确认
+ - 状态:待 ctp-topic-19 摄入后补充对比
diff --git a/wiki/sources/ctp-topic-23-introduction-to-the-technical-architecture-team-and-function.md b/wiki/sources/ctp-topic-23-introduction-to-the-technical-architecture-team-and-function.md
index b42df4fb..e1a81e6f 100644
--- a/wiki/sources/ctp-topic-23-introduction-to-the-technical-architecture-team-and-function.md
+++ b/wiki/sources/ctp-topic-23-introduction-to-the-technical-architecture-team-and-function.md
@@ -1,58 +1,58 @@
----
-title: "CTP Topic 23 Introduction to the Technical Architecture Team and Function"
-type: source
-tags:
- - Technical-Architecture
- - Cloud-Transformation
- - Team-Structure
- - CTP
-sources: []
-last_updated: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-23-introduction-to-the-technical-architecture-team-and-function]]
-
-## Summary(用中文描述)
-- 核心主题:技术架构团队的职能、组织架构及其在公司云转型中的价值
-- 问题域:PSTC 与 IT 部门整合至 CIO 统一领导后的架构融合挑战
-- 方法/机制:推行"云优先"策略,维护 AWS Enterprise Landing Zones,制定 12-24 个月技术路线图
-- 结论/价值:从被动响应转向主动规划,通过标准化和治理确保云环境安全与高效,帮助业务部门规避风险、优化预算并提升交付速度
-
-## Key Claims(用中文描述)
-- 技术架构团队将 PSTC 与 IT 整合为统一领导,实现两个大型组织的深度融合
-- 技术架构团队通过维护 AWS Enterprise Landing Zones 实现云环境标准化和治理
-- 团队推行"云优先"策略,新业务优先上云,除非数据主权、合规性或极端成本原因必须保留在本地
-- 三层架构分工:EA 对接业务战略,SA 负责中间件与服务优化,TA 专注底层技术实施与基础设施治理
-- 通过划分"技术领域"并由首席架构师负责,制定 12-24 个月前瞻性路线图
-- 技术路线图帮助业务部门规避风险、优化预算、提升交付速度,从基础设施维护中解放出来专注客户价值
-
-## Key Quotes
-> "从被动响应转向主动规划" — Martin Nash,技术架构经理
-> "除非因数据主权、合规性或极端成本原因必须保留在本地,否则所有新业务应优先上云" — 云优先策略核心原则
-> "技术架构团队帮助业务部门从繁杂的基础设施维护中解放出来,专注于为客户创造价值" — 团队价值定位
-
-## Key Concepts
-- [[Cloud-First Strategy]]:架构原则,规定新服务部署首选云解决方案,仅在明确限制时考虑本地部署
-- [[AWS Enterprise Landing Zones]]:预配置的、符合最佳实践的 AWS 多账号环境,提供统一治理、安全和网络连接标准
-- [[Technical Domains]]:将技术栈划分为特定领域(身份认证、网络、Microsoft 堆栈等),每个领域由专人负责生命周期与路线图
-- [[Enterprise Architecture (EA)]]:架构体系高层,将业务目标转化为技术原则和标准
-- [[Solution Architecture (SA)]]:架构体系中间层,专注于特定项目或服务的优化实施
-- [[Technical Architecture (TA)]]:最贴近技术的架构层,负责基础设施设计、实施治理及技术路线图维护
-- [[Roadmaps]]:针对各技术领域制定的 12-24 个月前瞻性规划
-- [[ITIL Alignment]]:将架构工作与 IT 服务管理框架结合,确保技术交付系统性
-
-## Key Entities
-- [[Martin Nash]]:技术架构经理(Technical Architecture Manager),本次演讲主讲人
-- [[Cloud Transformation Office]]:云转型办公室,主办本次学习会议
-- [[Technical Architecture Team]]:技术架构团队,负责维护 AWS Enterprise Landing Zones 和技术路线图
-- [[Chief Architects]]:首席架构师,负责各技术领域的生命周期与路线图
-
-## Connections
-- [[ctp-topic-47-enterprise-architecture-cloud-standards]] ← aligns_with ← [[Technical Architecture Team]]
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← depends_on ← [[AWS Enterprise Landing Zones]]
-- [[ctp-topic-57-product-backlog-managing-demand]] ← extends ← [[Technical Architecture Team]]
-- [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]] ← supports ← [[Roadmaps]]
-
-## Contradictions
-- 暂无发现与其他 Wiki 页面的内容冲突
+---
+title: "CTP Topic 23 Introduction to the Technical Architecture Team and Function"
+type: source
+tags:
+ - Technical-Architecture
+ - Cloud-Transformation
+ - Team-Structure
+ - CTP
+sources: []
+last_updated: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-23-introduction-to-the-technical-architecture-team-and-function.md]]
+
+## Summary(用中文描述)
+- 核心主题:技术架构团队的职能、组织架构及其在公司云转型中的价值
+- 问题域:PSTC 与 IT 部门整合至 CIO 统一领导后的架构融合挑战
+- 方法/机制:推行"云优先"策略,维护 AWS Enterprise Landing Zones,制定 12-24 个月技术路线图
+- 结论/价值:从被动响应转向主动规划,通过标准化和治理确保云环境安全与高效,帮助业务部门规避风险、优化预算并提升交付速度
+
+## Key Claims(用中文描述)
+- 技术架构团队将 PSTC 与 IT 整合为统一领导,实现两个大型组织的深度融合
+- 技术架构团队通过维护 AWS Enterprise Landing Zones 实现云环境标准化和治理
+- 团队推行"云优先"策略,新业务优先上云,除非数据主权、合规性或极端成本原因必须保留在本地
+- 三层架构分工:EA 对接业务战略,SA 负责中间件与服务优化,TA 专注底层技术实施与基础设施治理
+- 通过划分"技术领域"并由首席架构师负责,制定 12-24 个月前瞻性路线图
+- 技术路线图帮助业务部门规避风险、优化预算、提升交付速度,从基础设施维护中解放出来专注客户价值
+
+## Key Quotes
+> "从被动响应转向主动规划" — Martin Nash,技术架构经理
+> "除非因数据主权、合规性或极端成本原因必须保留在本地,否则所有新业务应优先上云" — 云优先策略核心原则
+> "技术架构团队帮助业务部门从繁杂的基础设施维护中解放出来,专注于为客户创造价值" — 团队价值定位
+
+## Key Concepts
+- [[Cloud-First Strategy]]:架构原则,规定新服务部署首选云解决方案,仅在明确限制时考虑本地部署
+- [[AWS Enterprise Landing Zones]]:预配置的、符合最佳实践的 AWS 多账号环境,提供统一治理、安全和网络连接标准
+- [[Technical Domains]]:将技术栈划分为特定领域(身份认证、网络、Microsoft 堆栈等),每个领域由专人负责生命周期与路线图
+- [[Enterprise Architecture (EA)]]:架构体系高层,将业务目标转化为技术原则和标准
+- [[Solution Architecture (SA)]]:架构体系中间层,专注于特定项目或服务的优化实施
+- [[Technical Architecture (TA)]]:最贴近技术的架构层,负责基础设施设计、实施治理及技术路线图维护
+- [[Roadmaps]]:针对各技术领域制定的 12-24 个月前瞻性规划
+- [[ITIL Alignment]]:将架构工作与 IT 服务管理框架结合,确保技术交付系统性
+
+## Key Entities
+- [[Martin Nash]]:技术架构经理(Technical Architecture Manager),本次演讲主讲人
+- [[Cloud Transformation Office]]:云转型办公室,主办本次学习会议
+- [[Technical Architecture Team]]:技术架构团队,负责维护 AWS Enterprise Landing Zones 和技术路线图
+- [[Chief Architects]]:首席架构师,负责各技术领域的生命周期与路线图
+
+## Connections
+- [[ctp-topic-47-enterprise-architecture-cloud-standards]] ← aligns_with ← [[Technical Architecture Team]]
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← depends_on ← [[AWS Enterprise Landing Zones]]
+- [[ctp-topic-57-product-backlog-managing-demand]] ← extends ← [[Technical Architecture Team]]
+- [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]] ← supports ← [[Roadmaps]]
+
+## Contradictions
+- 暂无发现与其他 Wiki 页面的内容冲突
diff --git a/wiki/sources/ctp-topic-24-micro-focus-product-privacy-framework.md b/wiki/sources/ctp-topic-24-micro-focus-product-privacy-framework.md
index 4ba0d199..8fe969a8 100644
--- a/wiki/sources/ctp-topic-24-micro-focus-product-privacy-framework.md
+++ b/wiki/sources/ctp-topic-24-micro-focus-product-privacy-framework.md
@@ -1,51 +1,51 @@
----
-title: "CTP Topic 24 Micro Focus Product Privacy Framework"
-type: source
-tags:
- - Privacy
- - Compliance
- - Product-Privacy
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-24-micro-focus-product-privacy-framework]]
-
-## Summary(用中文描述)
-- 核心主题:Micro Focus 产品隐私框架(Product Privacy Framework)在云转型计划中的应用
-- 问题域:法律合规要求(GDPR/CCPA)与技术实现之间的鸿沟
-- 方法/机制:通过 PSAC(产品安全顾问委员会)与法律顾问合作,将复杂法律条款翻译为约 110 项低级别技术要求;通过五类需求(架构类/文档类/法律类/实现类/SAS运营类)和成熟度模型(0-4级)评估产品隐私合规状态
-- 结论/价值:结构化解决产品团队合规压力,统一《产品隐私设置文档》确保客户获得一致的隐私信息参考
-
-## Key Claims(用中文描述)
-- PSAC 与法律顾问合作,将晦涩法律条文翻译为约 110 项具体技术要求
-- 该隐私框架是 STLC(安全开发生命周期)中 13 个安全与隐私轨道之一
-- 框架将合规要求分为五种类型:架构类(侧重 PII 数据流分析)、文档类、法律类、实现类和 SAS 运营类
-- 通过成熟度模型(0-4 级)和"蜘蛛图"直观展示产品隐私指标(KPI)的合规现状与目标
-- 最终产出标准化《产品隐私设置文档》,确保客户消费不同产品时获得一致的隐私信息参考
-
-## Key Quotes
-> "随着 GDPR 和 CCPA 的生效,产品团队面临严峻的合规压力。然而,法律条文通常晦涩难懂,研发人员难以将其直接转化为技术需求。" — Shlomi Ben-Hur,Micro Focus PSAC
-
-## Key Concepts
-- [[STLC (Security Development Life Cycle)]]:安全开发生命周期,Micro Focus 产品开发的基础框架,包含 13 个安全和隐私轨道
-- [[PII (Personally Identifiable Information)]]:个人身份识别信息,隐私保护的核心对象
-- [[GDPR]]:欧盟《通用数据保护条例》,该隐私框架主要遵循的国际隐私监管标准
-- [[CCPA]]:《加州消费者隐私法案》,该隐私框架主要遵循的国际隐私监管标准
-- [[Data Controller vs. Data Processor]]:数据控制者与数据处理者,法律术语,明确 Micro Focus 与客户在数据处理中的各自责任
-- [[Anonymization & Pseudonymization]]:匿名化与去标识化,隐私框架中要求的技术手段
-- [[Product Privacy Settings Document]]:产品隐私设置文档,标准化模板用于向客户披露产品如何收集、存储和处理 PII
-- [[Maturity Model(成熟度模型)]]:0-4 级评估模型,用于衡量产品在不同隐私维度上的合规成熟度
-
-## Key Entities
-- [[Micro Focus]]:产品安全小组(PSAC)所在公司,主导该隐私框架的制定
-- [[Shlomi Ben-Hur]]:Micro Focus 产品安全小组(PSAC)成员,本次会议主讲人
-
-## Connections
-- [[Micro Focus Security Development Life Cycle (STLC) Overview]] ← extends ← [[ctp-topic-24-micro-focus-product-privacy-framework]]
-- [[ctp-topic-24-micro-focus-product-privacy-framework]] ← depends_on ← [[Cloud Transformation Programme Objectives]]
-- [[SaaS Operations and Compliance]] ← extends ← [[ctp-topic-24-micro-focus-product-privacy-framework]]
-
-## Contradictions
-- (暂无发现与现有 Wiki 内容的冲突)
+---
+title: "CTP Topic 24 Micro Focus Product Privacy Framework"
+type: source
+tags:
+ - Privacy
+ - Compliance
+ - Product-Privacy
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-24-micro-focus-product-privacy-framework.md]]
+
+## Summary(用中文描述)
+- 核心主题:Micro Focus 产品隐私框架(Product Privacy Framework)在云转型计划中的应用
+- 问题域:法律合规要求(GDPR/CCPA)与技术实现之间的鸿沟
+- 方法/机制:通过 PSAC(产品安全顾问委员会)与法律顾问合作,将复杂法律条款翻译为约 110 项低级别技术要求;通过五类需求(架构类/文档类/法律类/实现类/SAS运营类)和成熟度模型(0-4级)评估产品隐私合规状态
+- 结论/价值:结构化解决产品团队合规压力,统一《产品隐私设置文档》确保客户获得一致的隐私信息参考
+
+## Key Claims(用中文描述)
+- PSAC 与法律顾问合作,将晦涩法律条文翻译为约 110 项具体技术要求
+- 该隐私框架是 STLC(安全开发生命周期)中 13 个安全与隐私轨道之一
+- 框架将合规要求分为五种类型:架构类(侧重 PII 数据流分析)、文档类、法律类、实现类和 SAS 运营类
+- 通过成熟度模型(0-4 级)和"蜘蛛图"直观展示产品隐私指标(KPI)的合规现状与目标
+- 最终产出标准化《产品隐私设置文档》,确保客户消费不同产品时获得一致的隐私信息参考
+
+## Key Quotes
+> "随着 GDPR 和 CCPA 的生效,产品团队面临严峻的合规压力。然而,法律条文通常晦涩难懂,研发人员难以将其直接转化为技术需求。" — Shlomi Ben-Hur,Micro Focus PSAC
+
+## Key Concepts
+- [[STLC (Security Development Life Cycle)]]:安全开发生命周期,Micro Focus 产品开发的基础框架,包含 13 个安全和隐私轨道
+- [[PII (Personally Identifiable Information)]]:个人身份识别信息,隐私保护的核心对象
+- [[GDPR]]:欧盟《通用数据保护条例》,该隐私框架主要遵循的国际隐私监管标准
+- [[CCPA]]:《加州消费者隐私法案》,该隐私框架主要遵循的国际隐私监管标准
+- [[Data Controller vs. Data Processor]]:数据控制者与数据处理者,法律术语,明确 Micro Focus 与客户在数据处理中的各自责任
+- [[Anonymization & Pseudonymization]]:匿名化与去标识化,隐私框架中要求的技术手段
+- [[Product Privacy Settings Document]]:产品隐私设置文档,标准化模板用于向客户披露产品如何收集、存储和处理 PII
+- [[Maturity Model(成熟度模型)]]:0-4 级评估模型,用于衡量产品在不同隐私维度上的合规成熟度
+
+## Key Entities
+- [[Micro Focus]]:产品安全小组(PSAC)所在公司,主导该隐私框架的制定
+- [[Shlomi Ben-Hur]]:Micro Focus 产品安全小组(PSAC)成员,本次会议主讲人
+
+## Connections
+- [[Micro Focus Security Development Life Cycle (STLC) Overview]] ← extends ← [[ctp-topic-24-micro-focus-product-privacy-framework]]
+- [[ctp-topic-24-micro-focus-product-privacy-framework]] ← depends_on ← [[Cloud Transformation Programme Objectives]]
+- [[SaaS Operations and Compliance]] ← extends ← [[ctp-topic-24-micro-focus-product-privacy-framework]]
+
+## Contradictions
+- (暂无发现与现有 Wiki 内容的冲突)
diff --git a/wiki/sources/ctp-topic-25-labs-landing-zone-overview-itom-teams.md b/wiki/sources/ctp-topic-25-labs-landing-zone-overview-itom-teams.md
index 8f1efc71..da9d0540 100644
--- a/wiki/sources/ctp-topic-25-labs-landing-zone-overview-itom-teams.md
+++ b/wiki/sources/ctp-topic-25-labs-landing-zone-overview-itom-teams.md
@@ -1,70 +1,70 @@
----
-title: "CTP Topic 25 Labs Landing Zone Overview - ITOM Teams"
-type: source
-tags:
- - AWS
- - Landing-Zone
- - Labs
- - ITOM
- - CTP
- - Gruntworks
- - Terraform
- - Terragrunt
- - Multi-Account
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-25-labs-landing-zone-overview-itom-teams]]
-
-## Summary(用中文描述)
-- 核心主题:
- Labs Landing Zone 基于 Gruntwork 参考架构和 AWS 标准,采用多账户策略,通过 Terraform/Terragrunt 实现基础设施即代码(IaC)管理。所有资源必须通过代码机制管理,不可手动操作。
-- 问题域:
- 如何在 Labs 环境中建立标准化、可扩展、安全的多账户 AWS 基础设施架构,覆盖 CI/CD 流水线、网络安全、身份认证、日志管理等企业级运维需求。
-- 方法/机制:
- - 基于 Gruntworks 参考架构的多账户策略
- - 全部资源通过 Terraform/Terragrunt 代码化管理
- - Jenkins 多分支流水线扫描 GitHub 仓库变更,触发 Terragrunt plan/apply
- - Checkpoint 防火墙通过标签(Tags)机制控制网络访问
- - 联邦认证(Federated Access)管理跨账户访问
-- 结论/价值:
- Labs Landing Zone 提供企业级标准化基础设施模板,各团队基于标准 Terraform 模块快速部署工作负载,通过标签驱动的网络策略实现安全隔离,通过 Jenkins 流水线实现自动化部署和安全扫描。
-
-## Key Claims(用中文描述)
-- Labs Landing Zone 基于 Gruntwork 参考架构,所有资源必须通过 Terraform 或其他代码机制管理,不可手动操作。
-- Labs 采用多账户策略,核心账户组包括 Active Directory(管理 Windows 实例和 IDP)和 DNS(管理 AWS Swimford.net)。
-- Network 账户作为中央网络枢纽,通过 Transit Gateway 和 JetPult 防火墙管理所有互联网流量,所有防火墙访问均通过标签(Tags)控制。
-- Product Account 是主要工作环境,基于标准 IaC 模块构建,可包含多个子账户(生产/预发/开发)。
-- Jenkins 流水线扫描 GitHub Enterprise 仓库变更,根据分支触发 Terragrunt plan 或 apply,并通过 pre-commit 检查和 Fortify 安全扫描提升鲁棒性。
-
-## Key Quotes
-> "Everything should be managed using Terraform or some other code-based mechanism." — Labs Landing Zone 核心原则
-> "Access through that firewall is all managed by tags." — 网络防火墙访问控制机制
-> "The standard Jenkins-based pipelines scan GitHub Enterprise repositories for changes, running Terragrunt plans or applies based on the branch." — CI/CD 部署流程
-
-## Key Concepts
-- [[Landing Zone Architecture]]:多账户 AWS 基础设施的顶层框架,包含账户结构、网络、安全、访问管理和遥测
-- [[Terraform]]:基础设施即代码工具,Labs LZ 中用于管理所有 AWS 资源
-- [[Terragrunt]]:Terraform 的包装器,提供更简洁的多账户/多环境管理能力
-- [[Gruntwork]]:提供生产级 IaC 模块库的专业公司,参考架构的提供者
-- [[Jenkins]]:CI/CD 流水线工具,扫描 GitHub 仓库变更触发 Terragrunt plan/apply
-- [[Transit Gateway]]:AWS 网络服务,Network 账户通过它作为中央枢纽管理所有 VPC 间的流量路由
-- [[Federated Access]]:联邦访问,通过 AD 组映射到 IAM 角色实现跨账户身份认证
-- [[Tag-Based Access Control]]:基于标签的访问控制,防火墙通过资源标签动态配置网络策略
-
-## Key Entities
-- [[Swimford.net]]:Labs Landing Zone 中使用的 DNS 域名(所有 AD 和 DNS 服务均在此域名下)
-- [[JetPult]]:防火墙产品,Network 账户中用于管理网络流量
-- [[Pulse VPN]]:VPN 解决方案,Network 账户中用于提供对 Micro Focus 网络的访问
-- [[Qualys]]:安全扫描服务,Shared Service Accounts 中提供漏洞扫描能力
-- [[45 Arc Site]]:监控服务,Shared Service Accounts 中提供站点监控能力
-- [[Hardened AMIs]]:安全加固的 Amazon Machine Images,由 Shared Account 托管
-
-## Connections
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← foundational ← [[ctp-topic-25-labs-landing-zone-overview-itom-teams]]
-- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← related ← [[ctp-topic-25-labs-landing-zone-overview-itom-teams]]
-- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← [[ctp-topic-25-labs-landing-zone-overview-itom-teams]]
-
-## Contradictions
-- 无已知冲突
+---
+title: "CTP Topic 25 Labs Landing Zone Overview - ITOM Teams"
+type: source
+tags:
+ - AWS
+ - Landing-Zone
+ - Labs
+ - ITOM
+ - CTP
+ - Gruntworks
+ - Terraform
+ - Terragrunt
+ - Multi-Account
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-25-labs-landing-zone-overview-itom-teams.md]]
+
+## Summary(用中文描述)
+- 核心主题:
+ Labs Landing Zone 基于 Gruntwork 参考架构和 AWS 标准,采用多账户策略,通过 Terraform/Terragrunt 实现基础设施即代码(IaC)管理。所有资源必须通过代码机制管理,不可手动操作。
+- 问题域:
+ 如何在 Labs 环境中建立标准化、可扩展、安全的多账户 AWS 基础设施架构,覆盖 CI/CD 流水线、网络安全、身份认证、日志管理等企业级运维需求。
+- 方法/机制:
+ - 基于 Gruntworks 参考架构的多账户策略
+ - 全部资源通过 Terraform/Terragrunt 代码化管理
+ - Jenkins 多分支流水线扫描 GitHub 仓库变更,触发 Terragrunt plan/apply
+ - Checkpoint 防火墙通过标签(Tags)机制控制网络访问
+ - 联邦认证(Federated Access)管理跨账户访问
+- 结论/价值:
+ Labs Landing Zone 提供企业级标准化基础设施模板,各团队基于标准 Terraform 模块快速部署工作负载,通过标签驱动的网络策略实现安全隔离,通过 Jenkins 流水线实现自动化部署和安全扫描。
+
+## Key Claims(用中文描述)
+- Labs Landing Zone 基于 Gruntwork 参考架构,所有资源必须通过 Terraform 或其他代码机制管理,不可手动操作。
+- Labs 采用多账户策略,核心账户组包括 Active Directory(管理 Windows 实例和 IDP)和 DNS(管理 AWS Swimford.net)。
+- Network 账户作为中央网络枢纽,通过 Transit Gateway 和 JetPult 防火墙管理所有互联网流量,所有防火墙访问均通过标签(Tags)控制。
+- Product Account 是主要工作环境,基于标准 IaC 模块构建,可包含多个子账户(生产/预发/开发)。
+- Jenkins 流水线扫描 GitHub Enterprise 仓库变更,根据分支触发 Terragrunt plan 或 apply,并通过 pre-commit 检查和 Fortify 安全扫描提升鲁棒性。
+
+## Key Quotes
+> "Everything should be managed using Terraform or some other code-based mechanism." — Labs Landing Zone 核心原则
+> "Access through that firewall is all managed by tags." — 网络防火墙访问控制机制
+> "The standard Jenkins-based pipelines scan GitHub Enterprise repositories for changes, running Terragrunt plans or applies based on the branch." — CI/CD 部署流程
+
+## Key Concepts
+- [[Landing Zone Architecture]]:多账户 AWS 基础设施的顶层框架,包含账户结构、网络、安全、访问管理和遥测
+- [[Terraform]]:基础设施即代码工具,Labs LZ 中用于管理所有 AWS 资源
+- [[Terragrunt]]:Terraform 的包装器,提供更简洁的多账户/多环境管理能力
+- [[Gruntwork]]:提供生产级 IaC 模块库的专业公司,参考架构的提供者
+- [[Jenkins]]:CI/CD 流水线工具,扫描 GitHub 仓库变更触发 Terragrunt plan/apply
+- [[Transit Gateway]]:AWS 网络服务,Network 账户通过它作为中央枢纽管理所有 VPC 间的流量路由
+- [[Federated Access]]:联邦访问,通过 AD 组映射到 IAM 角色实现跨账户身份认证
+- [[Tag-Based Access Control]]:基于标签的访问控制,防火墙通过资源标签动态配置网络策略
+
+## Key Entities
+- [[Swimford.net]]:Labs Landing Zone 中使用的 DNS 域名(所有 AD 和 DNS 服务均在此域名下)
+- [[JetPult]]:防火墙产品,Network 账户中用于管理网络流量
+- [[Pulse VPN]]:VPN 解决方案,Network 账户中用于提供对 Micro Focus 网络的访问
+- [[Qualys]]:安全扫描服务,Shared Service Accounts 中提供漏洞扫描能力
+- [[45 Arc Site]]:监控服务,Shared Service Accounts 中提供站点监控能力
+- [[Hardened AMIs]]:安全加固的 Amazon Machine Images,由 Shared Account 托管
+
+## Connections
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← foundational ← [[ctp-topic-25-labs-landing-zone-overview-itom-teams]]
+- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← related ← [[ctp-topic-25-labs-landing-zone-overview-itom-teams]]
+- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← [[ctp-topic-25-labs-landing-zone-overview-itom-teams]]
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/ctp-topic-26-standard-ami-build-publish-share-processes.md b/wiki/sources/ctp-topic-26-standard-ami-build-publish-share-processes.md
index c205084d..c2b76e5f 100644
--- a/wiki/sources/ctp-topic-26-standard-ami-build-publish-share-processes.md
+++ b/wiki/sources/ctp-topic-26-standard-ami-build-publish-share-processes.md
@@ -1,66 +1,66 @@
----
-title: "CTP Topic 26 Standard AMI – build, publish, share processes"
-type: source
-tags:
- - AWS
- - AMI
- - Build-Process
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-26-standard-ami-build-publish-share-processes.md]]
-
-## Summary(用中文描述)
-- 核心主题:Foundation AMI(基础亚马逊机器镜像)的构建、加固与分发全生命周期管理
-- 问题域:企业 AWS 云环境中如何标准化、安全化、可复用地管理 EC2 实例镜像
-- 方法/机制:基于市场主流 OS(CentOS/Ubuntu/Windows)进行 CIS 安全基准加固,集成 McAfee EPO 防病毒 + Syslog-ng 日志管理 + AD 单点登录;使用 HashiCorp Packer + Jenkins 流水线实现镜像创建全自动化;通过跨账号共享(AMI Sharing)而非物理复制分发到全球多个区域(俄勒冈、法兰克福、悉尼等);遵循 N-2 版本保留策略,每两个月更新一次
-- 结论/价值:CCOE 提供安全的基础镜像(Foundation AMI),产品团队在此之上构建自定义"产品特定 AMI",实现安全合规与灵活定制兼顾的责任共担模型
-
-## Key Claims(用中文描述)
-- CCOE 通过 HashiCorp Packer + Jenkins 构建自动化流水线,使镜像创建完全自动化
-- Foundation AMI 集成 CIS 安全基准 + McAfee EPO 防病毒 + SSM Agent + SiteScope 监控,确保所有实例从启动起即符合 Micro Focus 安全合规标准
-- AMI 通过跨账号共享(AMI Sharing)分发至全球多区域,而非物理复制(AMI Copying),避免额外存储成本
-- Foundation AMI 每两个月更新一次,采用 N-2 版本保留策略
-- 责任共担:CCOE 负责 Foundation AMI,产品团队负责在其之上构建产品特定 AMI
-
-## Key Quotes
-> "Foundation AMI 是基于市场主流操作系统(如 CentOS, Ubuntu, Windows 等)进行深度加固的镜像,集成了 CIS 安全基准、防病毒软件(McAfee EPO)、日志管理(Syslog-ng)以及单点登录(AD 集成)。" — Foundation AMI 定义与集成组件说明
-
-> "镜像通过跨账号共享(Sharing)而非物理复制(Copying)的方式分发到全球多个区域(如俄勒冈、法兰克福、悉尼等)。" — AMI 分发机制说明
-
-> "Foundation AMI 每两个月更新一次,遵循 N-2 的版本保留策略。" — AMI 更新与版本管理策略
-
-> "CCOE 负责提供安全的基础镜像,而产品团队则被鼓励在 Foundation AMI 之上构建自定义的'产品特定 AMI',以满足各自应用的特殊需求,并负责其后续的生命周期管理。" — 责任共担模型说明
-
-## Key Concepts
-- [[Foundation AMI]]:经过安全加固、集成标准组件并预配置好的操作系统模板,是 Micro Focus 云环境的标准化基础镜像
-- [[OS Hardening]]:操作系统加固,通过关闭不必要服务、优化内核参数和应用安全补丁来减少系统攻击面
-- [[CIS Benchmarks]]:由互联网安全中心制定的安全配置基准,用于衡量镜像是否符合行业最佳安全实践
-- [[HashiCorp Packer]]:开源工具,用于从单一源配置为多个云平台自动创建一致的机器镜像
-- [[SSM Agent]]:AWS 系统管理器代理,用于实现实例的远程管理、自动化补丁更新和配置同步
-- [[AMI Sharing]]:镜像共享机制,通过授权其他账号访问中央镜像,避免跨账号复制带来的额外存储成本
-- [[Central Repository]]:中央仓库,用于统一存放和管理经过验证的官方镜像,确保分发源的唯一性
-
-## Key Entities
-- [[Srihari]]:本次会议主讲人之一
-- [[Alan]]:本次会议主讲人之一
-- [[Praveen]]:本次会议主讲人之一
-- [[CCOE]](Cloud Center of Excellence):负责提供安全的基础镜像(Foundation AMI)
-
-## Connections
-- [[Foundation AMI]] ← uses ← [[HashiCorp Packer]] + [[Jenkins]]
-- [[Foundation AMI]] ← extends ← [[CIS Benchmarks]](安全加固标准)
-- [[Foundation AMI]] ← depends_on ← [[SSM Agent]](实例管理能力)
-- [[AMI Sharing]] ← uses ← [[Central Repository]]
-- [[ctp-topic-26-standard-ami-build-publish-share-processes]] ← extends ← [[ctp-topic-58-aws-ec2-image-builder]]
-- [[Foundation AMI]] ← provides ← [[AMI Sharing]]
-- [[Product-Specific AMI]] ← extends ← [[Foundation AMI]]
-
-## Contradictions
-- 与 [[ctp-topic-58-aws-ec2-image-builder]] 描述不同 AMI 生命周期阶段:
- - 冲突点:ctp-topic-26 描述现有 Packer + Jenkins 自动化构建流程;ctp-topic-58 描述 EC2 Image Builder 作为替代方案
- - 当前观点(ctp-topic-26):Packer + Jenkins 是当前生产级 AMI 构建标准
- - 对方观点(ctp-topic-58):EC2 Image Builder 是 CCOE 加固脚本转换为可复用组件的未来演进方向
- - 结论:非冲突,而是同一 AMI 生命周期管理在不同时期的技术选型——当前实践 vs 未来演进方向
+---
+title: "CTP Topic 26 Standard AMI – build, publish, share processes"
+type: source
+tags:
+ - AWS
+ - AMI
+ - Build-Process
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-26-standard-ami-build-publish-share-processes.md]]
+
+## Summary(用中文描述)
+- 核心主题:Foundation AMI(基础亚马逊机器镜像)的构建、加固与分发全生命周期管理
+- 问题域:企业 AWS 云环境中如何标准化、安全化、可复用地管理 EC2 实例镜像
+- 方法/机制:基于市场主流 OS(CentOS/Ubuntu/Windows)进行 CIS 安全基准加固,集成 McAfee EPO 防病毒 + Syslog-ng 日志管理 + AD 单点登录;使用 HashiCorp Packer + Jenkins 流水线实现镜像创建全自动化;通过跨账号共享(AMI Sharing)而非物理复制分发到全球多个区域(俄勒冈、法兰克福、悉尼等);遵循 N-2 版本保留策略,每两个月更新一次
+- 结论/价值:CCOE 提供安全的基础镜像(Foundation AMI),产品团队在此之上构建自定义"产品特定 AMI",实现安全合规与灵活定制兼顾的责任共担模型
+
+## Key Claims(用中文描述)
+- CCOE 通过 HashiCorp Packer + Jenkins 构建自动化流水线,使镜像创建完全自动化
+- Foundation AMI 集成 CIS 安全基准 + McAfee EPO 防病毒 + SSM Agent + SiteScope 监控,确保所有实例从启动起即符合 Micro Focus 安全合规标准
+- AMI 通过跨账号共享(AMI Sharing)分发至全球多区域,而非物理复制(AMI Copying),避免额外存储成本
+- Foundation AMI 每两个月更新一次,采用 N-2 版本保留策略
+- 责任共担:CCOE 负责 Foundation AMI,产品团队负责在其之上构建产品特定 AMI
+
+## Key Quotes
+> "Foundation AMI 是基于市场主流操作系统(如 CentOS, Ubuntu, Windows 等)进行深度加固的镜像,集成了 CIS 安全基准、防病毒软件(McAfee EPO)、日志管理(Syslog-ng)以及单点登录(AD 集成)。" — Foundation AMI 定义与集成组件说明
+
+> "镜像通过跨账号共享(Sharing)而非物理复制(Copying)的方式分发到全球多个区域(如俄勒冈、法兰克福、悉尼等)。" — AMI 分发机制说明
+
+> "Foundation AMI 每两个月更新一次,遵循 N-2 的版本保留策略。" — AMI 更新与版本管理策略
+
+> "CCOE 负责提供安全的基础镜像,而产品团队则被鼓励在 Foundation AMI 之上构建自定义的'产品特定 AMI',以满足各自应用的特殊需求,并负责其后续的生命周期管理。" — 责任共担模型说明
+
+## Key Concepts
+- [[Foundation AMI]]:经过安全加固、集成标准组件并预配置好的操作系统模板,是 Micro Focus 云环境的标准化基础镜像
+- [[OS Hardening]]:操作系统加固,通过关闭不必要服务、优化内核参数和应用安全补丁来减少系统攻击面
+- [[CIS Benchmarks]]:由互联网安全中心制定的安全配置基准,用于衡量镜像是否符合行业最佳安全实践
+- [[HashiCorp Packer]]:开源工具,用于从单一源配置为多个云平台自动创建一致的机器镜像
+- [[SSM Agent]]:AWS 系统管理器代理,用于实现实例的远程管理、自动化补丁更新和配置同步
+- [[AMI Sharing]]:镜像共享机制,通过授权其他账号访问中央镜像,避免跨账号复制带来的额外存储成本
+- [[Central Repository]]:中央仓库,用于统一存放和管理经过验证的官方镜像,确保分发源的唯一性
+
+## Key Entities
+- [[Srihari]]:本次会议主讲人之一
+- [[Alan]]:本次会议主讲人之一
+- [[Praveen]]:本次会议主讲人之一
+- [[CCOE]](Cloud Center of Excellence):负责提供安全的基础镜像(Foundation AMI)
+
+## Connections
+- [[Foundation AMI]] ← uses ← [[HashiCorp Packer]] + [[Jenkins]]
+- [[Foundation AMI]] ← extends ← [[CIS Benchmarks]](安全加固标准)
+- [[Foundation AMI]] ← depends_on ← [[SSM Agent]](实例管理能力)
+- [[AMI Sharing]] ← uses ← [[Central Repository]]
+- [[ctp-topic-26-standard-ami-build-publish-share-processes]] ← extends ← [[ctp-topic-58-aws-ec2-image-builder]]
+- [[Foundation AMI]] ← provides ← [[AMI Sharing]]
+- [[Product-Specific AMI]] ← extends ← [[Foundation AMI]]
+
+## Contradictions
+- 与 [[ctp-topic-58-aws-ec2-image-builder]] 描述不同 AMI 生命周期阶段:
+ - 冲突点:ctp-topic-26 描述现有 Packer + Jenkins 自动化构建流程;ctp-topic-58 描述 EC2 Image Builder 作为替代方案
+ - 当前观点(ctp-topic-26):Packer + Jenkins 是当前生产级 AMI 构建标准
+ - 对方观点(ctp-topic-58):EC2 Image Builder 是 CCOE 加固脚本转换为可复用组件的未来演进方向
+ - 结论:非冲突,而是同一 AMI 生命周期管理在不同时期的技术选型——当前实践 vs 未来演进方向
diff --git a/wiki/sources/ctp-topic-27-aws-instance-scheduler.md b/wiki/sources/ctp-topic-27-aws-instance-scheduler.md
index 12be1a69..9400ef94 100644
--- a/wiki/sources/ctp-topic-27-aws-instance-scheduler.md
+++ b/wiki/sources/ctp-topic-27-aws-instance-scheduler.md
@@ -1,67 +1,67 @@
----
-title: "CTP Topic 27 AWS Instance Scheduler"
-type: source
-tags:
- - AWS
- - Instance-Scheduler
- - Cost-Optimization
- - CTP
- - FinOps
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/ctp-topic-27-aws-instance-scheduler.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS Instance Scheduler —— 通过定时自动化控制 EC2 和 RDS 实例启停,实现非生产环境(开发/测试)的成本优化
-- 问题域:非生产 AWS 账号中 EC2/RDS 实例 24/7 运行导致成本浪费,Cloud FinOps 需要自动化手段降低这部分支出
-- 方法/机制:
- - CloudFormation 一键部署,由 CCOE 的 Guardrails 框架自动集成推送至所有相关账号
- - CloudWatch Events 定时触发(默认每 15 分钟)
- - Lambda 函数读取 DynamoDB 中的调度配置(Schedules + Periods)
- - 通过实例标签(`Schedule`、`Period`)关联调度规则
- - 支持多时区办公时间配置(如西雅图时间、英国时间)
-- 结论/价值:
- - 自动覆盖公司内部绝大多数月消费超过 10 美元的 AWS 账号
- - 与基于空闲率的调度不同,本工具基于"时间表"触发
- - RDS 实例智能配合每 7 天维护窗口,确保维护完成后恢复正常调度状态
- - 实例关机行为必须设置为"停止(Stop)"而非"终止(Terminate)"以保留数据
-
-## Key Claims(用中文描述)
-- AWS Instance Scheduler 通过时间表驱动(非空闲率驱动)的定时任务,可为非生产环境实例节省最高 70% 的运行成本
-- 通过 Guardrails 框架集成,Instance Scheduler 自动部署至公司绝大多数月消费超过 10 美元的 AWS 账号,无需用户手动配置
-- CloudWatch Events 每 15 分钟触发 Lambda 检查,结合 DynamoDB 中定义的 Schedules 和 Periods,实现精细化的多时区调度
-- RDS 实例的每 7 天维护窗口与调度系统智能协同,确保维护完成后实例恢复到预期的调度状态
-
-## Key Quotes
-> "该工具是基于'时间表'(Schedule)而非'空闲率'(Idle time)触发的" — Gustavo,澄清核心触发机制
-> "通过 Guardrails,该功能已自动覆盖了公司内部绝大多数月消费超过 10 美元的 AWS 账号" — Gustavo,说明部署覆盖范围
-> "实例的关机行为必须设置为'停止(Stop)'而非'终止(Terminate)'" — Gustavo,操作注意事项
-
-## Key Concepts
-- [[AWS Instance Scheduler]]:AWS 官方提供的开源解决方案,通过 CloudFormation 部署,自动定时启动和停止 EC2 及 RDS 实例以节省成本
-- [[Guardrails]]:CCOE 团队实施的自动化合规与治理框架,Instance Scheduler 作为其中的成本控制组件被自动部署
-- [[CloudWatch Events]]:系统的触发器,按照预设的时间间隔(如 15 分钟)激活 Lambda 函数
-- [[DynamoDB Config Table]]:用于存储调度定义(Schedules)和周期定义(Periods)的 NoSQL 数据库,是调度的逻辑核心
-- [[Tag-Based Scheduling]]:用户通过在实例上添加特定标签(如 `Schedule`、`Period`)将其关联到预定义的调度逻辑
-- [[RDS Maintenance Window]]:RDS 特有的每 7 天维护窗口,Instance Scheduler 能够识别并配合该窗口,确保数据库在维护后正确关闭
-- [[Override Status]]:高级配置,允许管理员强制将实例保持在停止状态,即使在预设的启动时间内也不启动
-
-## Key Entities
-- [[Gustavo]]:CCOE 团队成员,Instance Scheduler 主题讲师
-- [[CCOE(云卓越中心)]]:负责 Guardrails 框架实施和 Instance Scheduler 集成的内部团队
-- [[AWS]]:Instance Scheduler 的官方服务提供方
-
-## Connections
-- [[ctp-topic-13-cloud-finops-policies-best-practices-to-optimize-the-co]] ← depends_on ← [[ctp-topic-27-aws-instance-scheduler]]:Topic 13 定义 FinOps 政策层(标签合规、成本可见性),Topic 27 提供具体技术实现(Instance Scheduler)
-- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← related_to ← [[ctp-topic-27-aws-instance-scheduler]]:两专题均覆盖 EC2/RDS 自动化调度,Topic 63 侧重 Terraform 层面的 `auto_shutdown` 标签方案,Topic 27 侧重 AWS 原生 Instance Scheduler 方案
-- [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]] ← extends ← [[ctp-topic-27-aws-instance-scheduler]]:Right Sizing 从实例规格层面降低容量,Instance Scheduler 从运行时间层面降低浪费,构成互补的成本优化策略
-- [[public-cloud-learning-sessions-budget-control-20240319]] ← related_to ← [[ctp-topic-27-aws-instance-scheduler]]:两专题同属 FinOps 范畴,分别聚焦预算告警强制封禁和实例调度自动节能
-
-## Contradictions
-- 与 [[ctp-topic-63-optimise-resource-cost-using-automation]] 可能的实现路径差异:
- - 冲突点:EC2/RDS 自动调度的实现方案选择
- - 当前观点:Topic 27 推荐 AWS 原生 Instance Scheduler(CloudFormation + CloudWatch + Lambda + DynamoDB),通过 Guardrails 自动推送覆盖全公司账号
- - 对方观点:Topic 63 推荐 Terraform Scheduler 模块(`auto_shutdown = yes` 标签),在 Terraform 层面实现
- - 说明:两者并不互斥——Instance Scheduler 是 AWS 原生方案覆盖广账户层,Terraform Scheduler 是 IaC 层细粒度控制,企业可同时使用
+---
+title: "CTP Topic 27 AWS Instance Scheduler"
+type: source
+tags:
+ - AWS
+ - Instance-Scheduler
+ - Cost-Optimization
+ - CTP
+ - FinOps
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/ctp-topic-27-aws-instance-scheduler.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS Instance Scheduler —— 通过定时自动化控制 EC2 和 RDS 实例启停,实现非生产环境(开发/测试)的成本优化
+- 问题域:非生产 AWS 账号中 EC2/RDS 实例 24/7 运行导致成本浪费,Cloud FinOps 需要自动化手段降低这部分支出
+- 方法/机制:
+ - CloudFormation 一键部署,由 CCOE 的 Guardrails 框架自动集成推送至所有相关账号
+ - CloudWatch Events 定时触发(默认每 15 分钟)
+ - Lambda 函数读取 DynamoDB 中的调度配置(Schedules + Periods)
+ - 通过实例标签(`Schedule`、`Period`)关联调度规则
+ - 支持多时区办公时间配置(如西雅图时间、英国时间)
+- 结论/价值:
+ - 自动覆盖公司内部绝大多数月消费超过 10 美元的 AWS 账号
+ - 与基于空闲率的调度不同,本工具基于"时间表"触发
+ - RDS 实例智能配合每 7 天维护窗口,确保维护完成后恢复正常调度状态
+ - 实例关机行为必须设置为"停止(Stop)"而非"终止(Terminate)"以保留数据
+
+## Key Claims(用中文描述)
+- AWS Instance Scheduler 通过时间表驱动(非空闲率驱动)的定时任务,可为非生产环境实例节省最高 70% 的运行成本
+- 通过 Guardrails 框架集成,Instance Scheduler 自动部署至公司绝大多数月消费超过 10 美元的 AWS 账号,无需用户手动配置
+- CloudWatch Events 每 15 分钟触发 Lambda 检查,结合 DynamoDB 中定义的 Schedules 和 Periods,实现精细化的多时区调度
+- RDS 实例的每 7 天维护窗口与调度系统智能协同,确保维护完成后实例恢复到预期的调度状态
+
+## Key Quotes
+> "该工具是基于'时间表'(Schedule)而非'空闲率'(Idle time)触发的" — Gustavo,澄清核心触发机制
+> "通过 Guardrails,该功能已自动覆盖了公司内部绝大多数月消费超过 10 美元的 AWS 账号" — Gustavo,说明部署覆盖范围
+> "实例的关机行为必须设置为'停止(Stop)'而非'终止(Terminate)'" — Gustavo,操作注意事项
+
+## Key Concepts
+- [[AWS Instance Scheduler]]:AWS 官方提供的开源解决方案,通过 CloudFormation 部署,自动定时启动和停止 EC2 及 RDS 实例以节省成本
+- [[Guardrails]]:CCOE 团队实施的自动化合规与治理框架,Instance Scheduler 作为其中的成本控制组件被自动部署
+- [[CloudWatch Events]]:系统的触发器,按照预设的时间间隔(如 15 分钟)激活 Lambda 函数
+- [[DynamoDB Config Table]]:用于存储调度定义(Schedules)和周期定义(Periods)的 NoSQL 数据库,是调度的逻辑核心
+- [[Tag-Based Scheduling]]:用户通过在实例上添加特定标签(如 `Schedule`、`Period`)将其关联到预定义的调度逻辑
+- [[RDS Maintenance Window]]:RDS 特有的每 7 天维护窗口,Instance Scheduler 能够识别并配合该窗口,确保数据库在维护后正确关闭
+- [[Override Status]]:高级配置,允许管理员强制将实例保持在停止状态,即使在预设的启动时间内也不启动
+
+## Key Entities
+- [[Gustavo]]:CCOE 团队成员,Instance Scheduler 主题讲师
+- [[CCOE(云卓越中心)]]:负责 Guardrails 框架实施和 Instance Scheduler 集成的内部团队
+- [[AWS]]:Instance Scheduler 的官方服务提供方
+
+## Connections
+- [[ctp-topic-13-cloud-finops-policies-best-practices-to-optimize-the-co]] ← depends_on ← [[ctp-topic-27-aws-instance-scheduler]]:Topic 13 定义 FinOps 政策层(标签合规、成本可见性),Topic 27 提供具体技术实现(Instance Scheduler)
+- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← related_to ← [[ctp-topic-27-aws-instance-scheduler]]:两专题均覆盖 EC2/RDS 自动化调度,Topic 63 侧重 Terraform 层面的 `auto_shutdown` 标签方案,Topic 27 侧重 AWS 原生 Instance Scheduler 方案
+- [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]] ← extends ← [[ctp-topic-27-aws-instance-scheduler]]:Right Sizing 从实例规格层面降低容量,Instance Scheduler 从运行时间层面降低浪费,构成互补的成本优化策略
+- [[public-cloud-learning-sessions-budget-control-20240319]] ← related_to ← [[ctp-topic-27-aws-instance-scheduler]]:两专题同属 FinOps 范畴,分别聚焦预算告警强制封禁和实例调度自动节能
+
+## Contradictions
+- 与 [[ctp-topic-63-optimise-resource-cost-using-automation]] 可能的实现路径差异:
+ - 冲突点:EC2/RDS 自动调度的实现方案选择
+ - 当前观点:Topic 27 推荐 AWS 原生 Instance Scheduler(CloudFormation + CloudWatch + Lambda + DynamoDB),通过 Guardrails 自动推送覆盖全公司账号
+ - 对方观点:Topic 63 推荐 Terraform Scheduler 模块(`auto_shutdown = yes` 标签),在 Terraform 层面实现
+ - 说明:两者并不互斥——Instance Scheduler 是 AWS 原生方案覆盖广账户层,Terraform Scheduler 是 IaC 层细粒度控制,企业可同时使用
diff --git a/wiki/sources/ctp-topic-28-aws-tag-validation-tool.md b/wiki/sources/ctp-topic-28-aws-tag-validation-tool.md
index e5c45f1e..e41dbd7a 100644
--- a/wiki/sources/ctp-topic-28-aws-tag-validation-tool.md
+++ b/wiki/sources/ctp-topic-28-aws-tag-validation-tool.md
@@ -1,52 +1,52 @@
----
-title: "CTP Topic 28 AWS Tag Validation Tool"
-type: source
-tags: [AWS, Tagging, Validation, Tool, CTP, Boto3, Checkpoint]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-28-aws-tag-validation-tool]]
-
-## Summary(用中文描述)
-- 核心主题:SRE 团队开发的 AWS 标签验证工具,用于审计和报告 AWS 资源标签合规性。
-- 问题域:Checkpoint 防火墙依赖资源标签配置网络访问策略,标签缺失或无效将导致网络拦截;同时 SCPs 仅能阻止新资源创建,无法处理存量不合规资源。
-- 方法/机制:Python + Boto3 工具,通过 `variables.yaml` 配置文件定义每个账户的合法标签值,自动扫描 EC2/安全组/负载均衡器/Lambda 函数,比对预期值,输出 CSV 报告。使用 Poetry 管理 Python 环境。
-- 结论/价值:该工具极大提高了标签审计效率,可识别缺失或值错误的资源 ID 和具体问题;标签还可在未来用于成本核算(按产品分摊资源消耗)。
-
-## Key Claims(用中文描述)
-- Checkpoint 防火墙通过读取 EC2、安全组、负载均衡器的标签值动态配置网络访问策略,标签无效或缺失时防火墙将拦截相关流量。
-- Service Control Policies(SCPs)可在组织层面阻止不合规资源的新建,但不能修复已存在的存量资源。
-- AWS 标签验证工具通过 YAML 配置文件定义每个账户的合法标签键和允许值,自动扫描多种 AWS 资源并生成 CSV 审计报告。
-- 该工具由 SRE 团队开发和维护,存放于 SRE Tools Repository,使用 Poetry 管理 Python 依赖。
-- 标签策略除网络安全用途外,未来还计划用于成本核算,区分同一账户下不同产品的资源消耗。
-
-## Key Quotes
-> "Checkpoint Firewall reads the tags on EC2 instances, security groups, and load balancers to configure network access policies — if the tags are missing or invalid, the firewall will block that traffic." — Lewis Brown,阐述标签与网络安全的直接关联
-
-> "The validation tool reads from a YAML file that contains all the expected tag keys and allowed values for a given AWS account." — Lewis Brown,阐述工具的核心工作机制
-
-## Key Concepts
-- [[AWS-Tags]]:附加在 AWS 资源上的元数据(键值对),用于识别管理和安全策略执行。
-- [[Tag-Validation-Tool]]:SRE 团队开发的 Python 工具,通过 Boto3 扫描 AWS 资源并比对 YAML 配置中的预期标签值。
-- [[Service-Control-Policies-SCPs]]:AWS Organizations 策略类型,用于集中强制执行标签规范,阻止不合规资源创建。
-- [[Variables-YAML]]:该验证工具的核心配置文件,定义特定账户所期望的合法标签键及允许值列表。
-- [[AWS-Tagging-Standards]]:AWS 标签规范,涵盖命名约定、强制标签键、成本标签策略等。
-- [[Poetry]]:Python 依赖管理和打包工具,用于该验证工具的环境隔离和依赖管理。
-- [[Boto3]]:Python AWS SDK,该验证工具通过 Boto3 调用 AWS API 扫描资源标签。
-
-## Key Entities
-- [[Lewis-Brown]]:SRE 团队成员,本次视频讲师,介绍 AWS 标签验证工具。
-- [[Checkpoint]]:防火墙供应商,其防火墙产品读取 AWS 资源标签以配置网络访问策略。
-- [[SRE-Team]]:开发和维护该标签验证工具的团队,存放工具于 SRE Tools Repository。
-- [[SRE-Tools-Repository]]:内部代码仓库,存放该验证工具及其他 SRE 自动化脚本。
-- [[Boto3]]:AWS 官方 Python SDK,该工具的技术基础。
-- [[Poetry]]:Python 包管理工具,该工具的环境管理方案。
-
-## Connections
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← extends ← [[ctp-topic-28-aws-tag-validation-tool]]
-- [[ctp-topic-10-aws-tagging-deep-dive]] ← related ← [[ctp-topic-28-aws-tag-validation-tool]]
-- [[AWS-Landing-Zone-Governance]] ← context ← [[ctp-topic-28-aws-tag-validation-tool]]
-
-## Contradictions
-- 无冲突检测。该工具与 [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] 构成互补关系——后者聚焦标签收集机制和 Checkpoint 防火墙的安全策略上下文,前者聚焦如何检测和报告不合规资源。两者共同构成完整的标签治理闭环(制定规范 → 强制执行 → 审计发现)。
+---
+title: "CTP Topic 28 AWS Tag Validation Tool"
+type: source
+tags: [AWS, Tagging, Validation, Tool, CTP, Boto3, Checkpoint]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-28-aws-tag-validation-tool.md]]
+
+## Summary(用中文描述)
+- 核心主题:SRE 团队开发的 AWS 标签验证工具,用于审计和报告 AWS 资源标签合规性。
+- 问题域:Checkpoint 防火墙依赖资源标签配置网络访问策略,标签缺失或无效将导致网络拦截;同时 SCPs 仅能阻止新资源创建,无法处理存量不合规资源。
+- 方法/机制:Python + Boto3 工具,通过 `variables.yaml` 配置文件定义每个账户的合法标签值,自动扫描 EC2/安全组/负载均衡器/Lambda 函数,比对预期值,输出 CSV 报告。使用 Poetry 管理 Python 环境。
+- 结论/价值:该工具极大提高了标签审计效率,可识别缺失或值错误的资源 ID 和具体问题;标签还可在未来用于成本核算(按产品分摊资源消耗)。
+
+## Key Claims(用中文描述)
+- Checkpoint 防火墙通过读取 EC2、安全组、负载均衡器的标签值动态配置网络访问策略,标签无效或缺失时防火墙将拦截相关流量。
+- Service Control Policies(SCPs)可在组织层面阻止不合规资源的新建,但不能修复已存在的存量资源。
+- AWS 标签验证工具通过 YAML 配置文件定义每个账户的合法标签键和允许值,自动扫描多种 AWS 资源并生成 CSV 审计报告。
+- 该工具由 SRE 团队开发和维护,存放于 SRE Tools Repository,使用 Poetry 管理 Python 依赖。
+- 标签策略除网络安全用途外,未来还计划用于成本核算,区分同一账户下不同产品的资源消耗。
+
+## Key Quotes
+> "Checkpoint Firewall reads the tags on EC2 instances, security groups, and load balancers to configure network access policies — if the tags are missing or invalid, the firewall will block that traffic." — Lewis Brown,阐述标签与网络安全的直接关联
+
+> "The validation tool reads from a YAML file that contains all the expected tag keys and allowed values for a given AWS account." — Lewis Brown,阐述工具的核心工作机制
+
+## Key Concepts
+- [[AWS-Tags]]:附加在 AWS 资源上的元数据(键值对),用于识别管理和安全策略执行。
+- [[Tag-Validation-Tool]]:SRE 团队开发的 Python 工具,通过 Boto3 扫描 AWS 资源并比对 YAML 配置中的预期标签值。
+- [[Service-Control-Policies-SCPs]]:AWS Organizations 策略类型,用于集中强制执行标签规范,阻止不合规资源创建。
+- [[Variables-YAML]]:该验证工具的核心配置文件,定义特定账户所期望的合法标签键及允许值列表。
+- [[AWS-Tagging-Standards]]:AWS 标签规范,涵盖命名约定、强制标签键、成本标签策略等。
+- [[Poetry]]:Python 依赖管理和打包工具,用于该验证工具的环境隔离和依赖管理。
+- [[Boto3]]:Python AWS SDK,该验证工具通过 Boto3 调用 AWS API 扫描资源标签。
+
+## Key Entities
+- [[Lewis-Brown]]:SRE 团队成员,本次视频讲师,介绍 AWS 标签验证工具。
+- [[Checkpoint]]:防火墙供应商,其防火墙产品读取 AWS 资源标签以配置网络访问策略。
+- [[SRE-Team]]:开发和维护该标签验证工具的团队,存放工具于 SRE Tools Repository。
+- [[SRE-Tools-Repository]]:内部代码仓库,存放该验证工具及其他 SRE 自动化脚本。
+- [[Boto3]]:AWS 官方 Python SDK,该工具的技术基础。
+- [[Poetry]]:Python 包管理工具,该工具的环境管理方案。
+
+## Connections
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← extends ← [[ctp-topic-28-aws-tag-validation-tool]]
+- [[ctp-topic-10-aws-tagging-deep-dive]] ← related ← [[ctp-topic-28-aws-tag-validation-tool]]
+- [[AWS-Landing-Zone-Governance]] ← context ← [[ctp-topic-28-aws-tag-validation-tool]]
+
+## Contradictions
+- 无冲突检测。该工具与 [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] 构成互补关系——后者聚焦标签收集机制和 Checkpoint 防火墙的安全策略上下文,前者聚焦如何检测和报告不合规资源。两者共同构成完整的标签治理闭环(制定规范 → 强制执行 → 审计发现)。
diff --git a/wiki/sources/ctp-topic-29-cloud-monitoring-saas-lz-accounts.md b/wiki/sources/ctp-topic-29-cloud-monitoring-saas-lz-accounts.md
index 57ce116e..ad4579df 100644
--- a/wiki/sources/ctp-topic-29-cloud-monitoring-saas-lz-accounts.md
+++ b/wiki/sources/ctp-topic-29-cloud-monitoring-saas-lz-accounts.md
@@ -1,61 +1,61 @@
----
-title: "CTP Topic 29 Cloud Monitoring – SaaS LZ accounts"
-type: source
-tags:
- - AWS
- - Monitoring
- - SaaS
- - Landing-Zone
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-29-cloud-monitoring-saas-lz-accounts]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 云监控解决方案 OpsBridge Cloud Monitoring,覆盖多账户多区域的云原生监控架构
-- 问题域:企业级 AWS 多账户环境下,如何实现跨账户、跨区域的统一云监控和可观测性
-- 方法/机制:Micro Focus OpsBridge 的 Cloud Monitoring 功能,通过 IAM Role 信任关系实现只读跨账户 CloudWatch 数据采集;使用 Vertica 作为分析型数据库支撑性能仪表盘;基于标签的监控策略自动化
-- 结论/价值:单一 OpsBridge 实例即可监控多个 AWS 账户和区域,降低运维复杂度;与 OpsBridge 产品团队协作持续演进,新增报表功能预计在下一版本发布
-
-## Key Claims(用中文描述)
-- Micro Focus OpsBridge Cloud Monitoring 通过 IAM Role 信任关系实现跨账户只读访问,无需在被监控账户安装任何服务器或共享 Access Key
-- 基于标签的监控(Tag-based Monitoring)是最佳实践,自动化识别缺失标签的资源和合规问题
-- 单一 OpsBridge 实例可同时监控多个 AWS 账户和多个区域,降低监控基础设施的运维成本
-- 数据消费通过事件仪表盘、拓扑视图和性能仪表盘三种维度呈现,满足不同角色的监控需求
-- 该方案与 OpsBridge 产品研发团队协作开发,报表功能在下一版本中将持续增强
-
-## Key Quotes
-> "Cloud Monitoring is enabled within OpsBridge, requiring a one-time IAM role setup in customer accounts for read-only access." — 核心安全设计原则:最小权限只读访问
-
-> "Tag-based monitoring is emphasized as a best practice, with automation to identify missing tags." — 标签驱动是监控策略的核心,与 [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] 中的标签安全理念一致
-
-> "The solution uses a single instance to monitor multiple accounts and regions." — 架构优势:简化运维,降低成本
-
-## Key Concepts
-- [[Cloud Monitoring(AWS)]]:通过 CloudWatch 采集 AWS 托管服务的指标数据,是云原生监控的基础
-- [[Tag-Based Monitoring]]:将 AWS 标签作为监控和资源配置的元数据,实现自动化策略应用
-- [[Vertica]]:Micro Focus OpsBridge 用于存储和分析监控数据的列式分析型数据库
-- [[OpsBridge]]:Micro Focus 的混合 IT 运维管理平台,支持物理、虚拟和云环境统一监控
-- [[ITOM(IT Operations Management)]]:IT 运维管理,OpsBridge 所属的产品领域
-
-## Key Entities
-- [[Micro Focus OpsBridge]]:企业级 IT 运维监控平台,Cloud Monitoring 是其 AWS 云监控组件
-- [[AWS CloudWatch]]:AWS 原生监控服务,OpsBridge Cloud Monitoring 的数据来源
-- [[AWS Landing Zone]]:AWS 多账户治理框架,SaaS LZ 是生产环境的 Landing Zone 实现
-
-## Connections
-- [[ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid]] ← relates_to ← [[ctp-topic-29-cloud-monitoring-saas-lz-accounts]]
- - Topic 8 聚焦 OBM 基础架构部署(OBM 应用/RDS/Agent 三层),Topic 29 聚焦 SaaS LZ 账户架构下的 Cloud Monitoring 功能扩展,两者共同构成 OpsBridge AWS 监控的完整方案
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← extends ← [[ctp-topic-29-cloud-monitoring-saas-lz-accounts]]
- - 两者共享"基于标签的安全与监控"理念,Topic 10 从安全角度(SCP 强制标签),Topic 29 从监控角度(自动化标签合规识别)两个维度落地
-- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← context ← [[ctp-topic-29-cloud-monitoring-saas-lz-accounts]]
- - SaaS Landing Zone 的账户架构为 Cloud Monitoring 提供了多账户监控的落地场景
-
-## Contradictions
-- 与 [[ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid]] 的账户架构设计存在视角差异:
- - Topic 8 描述:Agent 通过 AWS Management Pack 利用 IAM Role 信任关系,OBM AWS Account 部署 OBM 应用 + Postgres RDS + Operation Agent 三层组件
- - Topic 29 描述:Cloud Monitoring 容器化部署在 EKS 上,支持监控 20+ AWS 数据服务,数据存储在 Optic Data Lake(Vertica)
- - 当前观点:Topic 29 的 Cloud Monitoring 功能可能是 OpsBridge 的新增模块,在 Topic 8 描述的基础架构之上扩展了容器化部署和更丰富的数据服务覆盖能力
- - 对方观点:Topic 8 是更基础的架构描述,涵盖完整的 OBM 组件栈,两者描述的是同一方案的不同层面
+---
+title: "CTP Topic 29 Cloud Monitoring – SaaS LZ accounts"
+type: source
+tags:
+ - AWS
+ - Monitoring
+ - SaaS
+ - Landing-Zone
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-29-cloud-monitoring-saas-lz-accounts.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 云监控解决方案 OpsBridge Cloud Monitoring,覆盖多账户多区域的云原生监控架构
+- 问题域:企业级 AWS 多账户环境下,如何实现跨账户、跨区域的统一云监控和可观测性
+- 方法/机制:Micro Focus OpsBridge 的 Cloud Monitoring 功能,通过 IAM Role 信任关系实现只读跨账户 CloudWatch 数据采集;使用 Vertica 作为分析型数据库支撑性能仪表盘;基于标签的监控策略自动化
+- 结论/价值:单一 OpsBridge 实例即可监控多个 AWS 账户和区域,降低运维复杂度;与 OpsBridge 产品团队协作持续演进,新增报表功能预计在下一版本发布
+
+## Key Claims(用中文描述)
+- Micro Focus OpsBridge Cloud Monitoring 通过 IAM Role 信任关系实现跨账户只读访问,无需在被监控账户安装任何服务器或共享 Access Key
+- 基于标签的监控(Tag-based Monitoring)是最佳实践,自动化识别缺失标签的资源和合规问题
+- 单一 OpsBridge 实例可同时监控多个 AWS 账户和多个区域,降低监控基础设施的运维成本
+- 数据消费通过事件仪表盘、拓扑视图和性能仪表盘三种维度呈现,满足不同角色的监控需求
+- 该方案与 OpsBridge 产品研发团队协作开发,报表功能在下一版本中将持续增强
+
+## Key Quotes
+> "Cloud Monitoring is enabled within OpsBridge, requiring a one-time IAM role setup in customer accounts for read-only access." — 核心安全设计原则:最小权限只读访问
+
+> "Tag-based monitoring is emphasized as a best practice, with automation to identify missing tags." — 标签驱动是监控策略的核心,与 [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] 中的标签安全理念一致
+
+> "The solution uses a single instance to monitor multiple accounts and regions." — 架构优势:简化运维,降低成本
+
+## Key Concepts
+- [[Cloud Monitoring(AWS)]]:通过 CloudWatch 采集 AWS 托管服务的指标数据,是云原生监控的基础
+- [[Tag-Based Monitoring]]:将 AWS 标签作为监控和资源配置的元数据,实现自动化策略应用
+- [[Vertica]]:Micro Focus OpsBridge 用于存储和分析监控数据的列式分析型数据库
+- [[OpsBridge]]:Micro Focus 的混合 IT 运维管理平台,支持物理、虚拟和云环境统一监控
+- [[ITOM(IT Operations Management)]]:IT 运维管理,OpsBridge 所属的产品领域
+
+## Key Entities
+- [[Micro Focus OpsBridge]]:企业级 IT 运维监控平台,Cloud Monitoring 是其 AWS 云监控组件
+- [[AWS CloudWatch]]:AWS 原生监控服务,OpsBridge Cloud Monitoring 的数据来源
+- [[AWS Landing Zone]]:AWS 多账户治理框架,SaaS LZ 是生产环境的 Landing Zone 实现
+
+## Connections
+- [[ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid]] ← relates_to ← [[ctp-topic-29-cloud-monitoring-saas-lz-accounts]]
+ - Topic 8 聚焦 OBM 基础架构部署(OBM 应用/RDS/Agent 三层),Topic 29 聚焦 SaaS LZ 账户架构下的 Cloud Monitoring 功能扩展,两者共同构成 OpsBridge AWS 监控的完整方案
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← extends ← [[ctp-topic-29-cloud-monitoring-saas-lz-accounts]]
+ - 两者共享"基于标签的安全与监控"理念,Topic 10 从安全角度(SCP 强制标签),Topic 29 从监控角度(自动化标签合规识别)两个维度落地
+- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← context ← [[ctp-topic-29-cloud-monitoring-saas-lz-accounts]]
+ - SaaS Landing Zone 的账户架构为 Cloud Monitoring 提供了多账户监控的落地场景
+
+## Contradictions
+- 与 [[ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid]] 的账户架构设计存在视角差异:
+ - Topic 8 描述:Agent 通过 AWS Management Pack 利用 IAM Role 信任关系,OBM AWS Account 部署 OBM 应用 + Postgres RDS + Operation Agent 三层组件
+ - Topic 29 描述:Cloud Monitoring 容器化部署在 EKS 上,支持监控 20+ AWS 数据服务,数据存储在 Optic Data Lake(Vertica)
+ - 当前观点:Topic 29 的 Cloud Monitoring 功能可能是 OpsBridge 的新增模块,在 Topic 8 描述的基础架构之上扩展了容器化部署和更丰富的数据服务覆盖能力
+ - 对方观点:Topic 8 是更基础的架构描述,涵盖完整的 OBM 组件栈,两者描述的是同一方案的不同层面
diff --git a/wiki/sources/ctp-topic-3-deploy-and-maintain-infrastructure.md b/wiki/sources/ctp-topic-3-deploy-and-maintain-infrastructure.md
index 57ec65b7..f32ec170 100644
--- a/wiki/sources/ctp-topic-3-deploy-and-maintain-infrastructure.md
+++ b/wiki/sources/ctp-topic-3-deploy-and-maintain-infrastructure.md
@@ -1,62 +1,62 @@
----
-title: "CTP Topic 3 Deploy and maintain infrastructure"
-type: source
-tags:
- - IaC
- - Deployment
- - CI/CD
- - CTP
- - Terraform
- - Terragrunt
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-3-deploy-and-maintain-infrastructure.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS Landing Zone 环境下通过 Terraform/Terragrunt 实现基础设施部署与维护的完整方法论
-- 问题域:多账户、多产品团队环境下 IaC 模块化复用、服务目录治理、Terragrunt 依赖管理
-- 方法/机制:Service Module(业务视角)vs Regular Module(技术视角)的分层抽象;Terragrunt HCL 引用特定版本模块;Service Catalog 三级复用(单账户→产品团队→跨团队);Terragrunt 缓存目录预取依赖
-- 结论/价值:模块化 IaC 实现独立发布周期和可维护性;Service 层抽象减少配置复杂度,越高层抽象选项越少(类 OO 继承);推荐使用专用 Service Catalog 而非相对路径引用
-
-## Key Claims(用中文描述)
-- Product Team 在 Landing Zone 中部署基础设施时,跨越多个账户(如 Artifactory 账户、AD 账户),涉及多个 Git 仓库协同
-- Service Module 由 main.tf 文件引用其他仓库模块组合而成,满足特定业务需求(如 AD 服务、DNS 服务)
-- Service 抽象层次高于 Regular Module,提供更少配置选项但更易使用
-- Terragrunt 优于直接引用 master 分支,target 特定版本确保环境一致性
-- 复用层次:单账户使用 → 产品团队 Service Catalog → Terraform Service Catalog(跨团队)
-- Terragrunt 在运行前预取所有引用,通过缓存目录存储克隆的仓库
-
-## Key Quotes
-> "A service is a business requirement, while a regular module is a technical requirement." — 核心区分:Service 解决业务问题,Module 解决技术问题
-
-> "When deploying infrastructure, Terragrunt HCL files are used to reference these services, targeting specific versions rather than the master branch." — 版本控制优于分支引用
-
-> "The higher up the chain, the less configuration options are available, similar to an object-oriented approach." — 抽象层次与配置灵活性的反向关系
-
-## Key Concepts
-- [[Landing Zone(落地区)]]:云环境的基础账户结构和资源隔离框架,产品团队在此之上部署工作负载
-- [[Service Module(服务模块)]]:满足业务需求的一组 Terraform 模块组合,相较于技术模块提供更高级抽象
-- [[Service Catalog(服务目录)]]:可复用模块的集中管理库,支持三级复用(账户/产品团队/跨团队)
-- [[Terragrunt]]:Terraform 的薄包装层,支持依赖管理、缓存和版本锁定
-- [[Terraform Module]]:Terraform 的可复用配置单元,版本化管理
-- [[Infrastructure as Code(IaC)]]:通过代码管理和配置基础设施的实践
-
-## Key Entities
-- [[AWS Landing Zone]]:AWS 多账户环境框架,是本文档讨论的基础部署上下文
-- [[Gruntwork]]:提供 Terraform 模块参考架构的公司,本文多次引用其作为最佳实践模型
-- [[Product Team]]:在 Landing Zone 中部署工作负载的业务团队,拥有独立的账户集合
-
-## Connections
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← foundational ← [[ctp-topic-3-deploy-and-maintain-infrastructure]]
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← related ← [[ctp-topic-3-deploy-and-maintain-infrastructure]]
-- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← related ← [[ctp-topic-3-deploy-and-maintain-infrastructure]]
-- [[ctp-topic-33-an-introduction-to-gitops]] ← extends ← [[ctp-topic-3-deploy-and-maintain-infrastructure]]
-
-## Contradictions
-- 与 [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]] 的 Atlantis 部分存在约束差异:
- - 冲突点:Atlantis 对 EKS 部署的支持能力
- - 当前观点(Topic 3):Terragrunt 可用于所有基础设施部署,包括 EKS
- - 对方观点(Topic 39):Atlantis 当前不支持 EKS 部署,需通过 Jenkins + Terragrunt 模块替代
- - 评估:Topic 39 提供更具体的实践经验,Topic 3 提供通用原则,两者约束条件不同不构成直接矛盾
+---
+title: "CTP Topic 3 Deploy and maintain infrastructure"
+type: source
+tags:
+ - IaC
+ - Deployment
+ - CI/CD
+ - CTP
+ - Terraform
+ - Terragrunt
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-3-deploy-and-maintain-infrastructure.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS Landing Zone 环境下通过 Terraform/Terragrunt 实现基础设施部署与维护的完整方法论
+- 问题域:多账户、多产品团队环境下 IaC 模块化复用、服务目录治理、Terragrunt 依赖管理
+- 方法/机制:Service Module(业务视角)vs Regular Module(技术视角)的分层抽象;Terragrunt HCL 引用特定版本模块;Service Catalog 三级复用(单账户→产品团队→跨团队);Terragrunt 缓存目录预取依赖
+- 结论/价值:模块化 IaC 实现独立发布周期和可维护性;Service 层抽象减少配置复杂度,越高层抽象选项越少(类 OO 继承);推荐使用专用 Service Catalog 而非相对路径引用
+
+## Key Claims(用中文描述)
+- Product Team 在 Landing Zone 中部署基础设施时,跨越多个账户(如 Artifactory 账户、AD 账户),涉及多个 Git 仓库协同
+- Service Module 由 main.tf 文件引用其他仓库模块组合而成,满足特定业务需求(如 AD 服务、DNS 服务)
+- Service 抽象层次高于 Regular Module,提供更少配置选项但更易使用
+- Terragrunt 优于直接引用 master 分支,target 特定版本确保环境一致性
+- 复用层次:单账户使用 → 产品团队 Service Catalog → Terraform Service Catalog(跨团队)
+- Terragrunt 在运行前预取所有引用,通过缓存目录存储克隆的仓库
+
+## Key Quotes
+> "A service is a business requirement, while a regular module is a technical requirement." — 核心区分:Service 解决业务问题,Module 解决技术问题
+
+> "When deploying infrastructure, Terragrunt HCL files are used to reference these services, targeting specific versions rather than the master branch." — 版本控制优于分支引用
+
+> "The higher up the chain, the less configuration options are available, similar to an object-oriented approach." — 抽象层次与配置灵活性的反向关系
+
+## Key Concepts
+- [[Landing Zone(落地区)]]:云环境的基础账户结构和资源隔离框架,产品团队在此之上部署工作负载
+- [[Service Module(服务模块)]]:满足业务需求的一组 Terraform 模块组合,相较于技术模块提供更高级抽象
+- [[Service Catalog(服务目录)]]:可复用模块的集中管理库,支持三级复用(账户/产品团队/跨团队)
+- [[Terragrunt]]:Terraform 的薄包装层,支持依赖管理、缓存和版本锁定
+- [[Terraform Module]]:Terraform 的可复用配置单元,版本化管理
+- [[Infrastructure as Code(IaC)]]:通过代码管理和配置基础设施的实践
+
+## Key Entities
+- [[AWS Landing Zone]]:AWS 多账户环境框架,是本文档讨论的基础部署上下文
+- [[Gruntwork]]:提供 Terraform 模块参考架构的公司,本文多次引用其作为最佳实践模型
+- [[Product Team]]:在 Landing Zone 中部署工作负载的业务团队,拥有独立的账户集合
+
+## Connections
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← foundational ← [[ctp-topic-3-deploy-and-maintain-infrastructure]]
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← related ← [[ctp-topic-3-deploy-and-maintain-infrastructure]]
+- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← related ← [[ctp-topic-3-deploy-and-maintain-infrastructure]]
+- [[ctp-topic-33-an-introduction-to-gitops]] ← extends ← [[ctp-topic-3-deploy-and-maintain-infrastructure]]
+
+## Contradictions
+- 与 [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]] 的 Atlantis 部分存在约束差异:
+ - 冲突点:Atlantis 对 EKS 部署的支持能力
+ - 当前观点(Topic 3):Terragrunt 可用于所有基础设施部署,包括 EKS
+ - 对方观点(Topic 39):Atlantis 当前不支持 EKS 部署,需通过 Jenkins + Terragrunt 模块替代
+ - 评估:Topic 39 提供更具体的实践经验,Topic 3 提供通用原则,两者约束条件不同不构成直接矛盾
diff --git a/wiki/sources/ctp-topic-30-managing-change.md b/wiki/sources/ctp-topic-30-managing-change.md
index 5eb3eb6c..af00b7c5 100644
--- a/wiki/sources/ctp-topic-30-managing-change.md
+++ b/wiki/sources/ctp-topic-30-managing-change.md
@@ -1,62 +1,62 @@
----
-title: "CTP Topic 30 Managing Change"
-type: source
-tags:
- - Change-Management
- - SRE
- - ITSM
- - DevOps
- - Cloud-Transformation
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-30-managing-change]]
-
-## Summary(用中文描述)
-- 核心主题:云转型项目中的变更管理流程,以及 SRE 团队在不同阶段与产品团队的协作模式
-- 问题域:企业云迁移过程中的变更审批效率、自动化程度不足、SRE 与产品团队协作边界不清
-- 方法/机制:区分标准变更/正常变更/紧急变更三类流程;引入自动化(IaC+CI/CD)将变更转为标准变更;SRE 团队在构建/上线支持/BAU 三阶段提供差异化支持
-- 结论/价值:通过自动化减少人工审批,通过明确流程减少变更风险,SRE 团队是云转型中连接运维与产品的关键桥梁
-
-## Key Claims(用中文描述)
-- SRE 团队通过软件工程思维解决运维问题,核心在于自动化重复性工作,提高系统可靠性和可测试性
-- 标准变更(Standard Change)应实现完全自动化(IaC + CI/CD Pipeline),无需 CAB 审批,是理想状态
-- 正常变更(Normal Change)需 CAB 批准和变更窗口,目标是通过自动化逐步将其归入标准变更
-- 紧急变更(Emergency Change)需立即执行以缓解事故,事后通过 CAPA/Post-mortem 修复根因
-- SRE 团队在三个阶段(构建/早期上线支持/BAU)与产品团队以不同方式协作
-- Self-Healing(基于 ML 的自动化监控系统)是未来演进方向,各产品组分享实践,SRE 协助落地
-
-## Key Quotes
-> "SRE 用软件工程思维解决运维问题,追求可靠性、可测试性、可重复性,核心是打破运维与产品的壁垒。" — Brendan Starnig
-> "Standard Change 应完全自动化(IaC + CI/CD Pipeline),无需 CAB 审批。" — Brendan Starnig
-> "Emergency Change 事后通过 CAPA/Post-mortem 修复根因,而非永久性补丁。" — Brendan Starnig
-
-## Key Concepts
-- [[SRE]]:Site Reliability Engineering,站点可靠性工程,通过软件工程思维解决运维问题
-- [[Standard-Change]]:标准变更,预批准变更,无需 CAB 审批,应完全自动化(IaC + CI/CD Pipeline)
-- [[Normal-Change]]:正常变更,有风险/影响,需 CAB 审批和变更窗口,理想状态是逐步归入 Standard Change
-- [[Emergency-Change]]:紧急变更,为缓解事故需立即执行的变更,事后通过 CAPA/Post-mortem 修复根因
-- [[CAPA]]:Corrective and Preventive Action,即 Post-mortem 回顾,从事故中提取根因并预防同类问题
-- [[SLO]]:Service Level Objective,服务等级目标,用于定义监控指标并向上汇总至 KPI
-- [[SLR]]:Service Level Requirement,服务等级需求,与 SLO 配套使用
-- [[Early-Live-Support]]:Build 与 BAU 之间的过渡阶段,需完成 Go-Live Checklist(监控覆盖、支持模型、事件响应流程)
-- [[Self-Healing]]:通过机器学习驱动的自动化监控系统,基于告警趋势自动决策和缓解问题
-
-## Key Entities
-- [[Brendan-Starnig]]:SRE Function Lead, Platform Engineering,本次会议主讲人
-- [[SMACs]]:Service Management Automation X,当前的 ITSM 工具,用于 Ticket、Incident、Change 管理
-- [[Vinaya]]:内部成员,提议各产品组分享 Self-healing 实践,SRE 将协助落地
-
-## Connections
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← context_for ← [[ctp-topic-30-managing-change]]
-- [[ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs]] ← related_to ← [[ctp-topic-30-managing-change]]
-- [[ctp-topic-28-aws-tag-validation-tool]] ← extends ← [[ctp-topic-30-managing-change]](IaC 变更的 Tagging 标准属于 Standard Change 范畴)
-- [[ctp-topic-19-configuring-dns-within-aws-lzs]] ← related_to ← [[ctp-topic-30-managing-change]]
-
-## Contradictions
-- 与 [[ctp-topic-53-why-bother-with-cloud]] 的关系:
- - 冲突点:是否应迁移至云端
- - 当前观点(Topic 30):接受云转型,聚焦如何在转型中有效管理变更
- - 对方观点(Topic 53):质疑云转型的必要性
- - 说明:两者处于不同讨论层面,Topic 53 质疑迁移决策,Topic 30 假设迁移决策已做出,聚焦执行层面的变更管理
+---
+title: "CTP Topic 30 Managing Change"
+type: source
+tags:
+ - Change-Management
+ - SRE
+ - ITSM
+ - DevOps
+ - Cloud-Transformation
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-30-managing-change.md]]
+
+## Summary(用中文描述)
+- 核心主题:云转型项目中的变更管理流程,以及 SRE 团队在不同阶段与产品团队的协作模式
+- 问题域:企业云迁移过程中的变更审批效率、自动化程度不足、SRE 与产品团队协作边界不清
+- 方法/机制:区分标准变更/正常变更/紧急变更三类流程;引入自动化(IaC+CI/CD)将变更转为标准变更;SRE 团队在构建/上线支持/BAU 三阶段提供差异化支持
+- 结论/价值:通过自动化减少人工审批,通过明确流程减少变更风险,SRE 团队是云转型中连接运维与产品的关键桥梁
+
+## Key Claims(用中文描述)
+- SRE 团队通过软件工程思维解决运维问题,核心在于自动化重复性工作,提高系统可靠性和可测试性
+- 标准变更(Standard Change)应实现完全自动化(IaC + CI/CD Pipeline),无需 CAB 审批,是理想状态
+- 正常变更(Normal Change)需 CAB 批准和变更窗口,目标是通过自动化逐步将其归入标准变更
+- 紧急变更(Emergency Change)需立即执行以缓解事故,事后通过 CAPA/Post-mortem 修复根因
+- SRE 团队在三个阶段(构建/早期上线支持/BAU)与产品团队以不同方式协作
+- Self-Healing(基于 ML 的自动化监控系统)是未来演进方向,各产品组分享实践,SRE 协助落地
+
+## Key Quotes
+> "SRE 用软件工程思维解决运维问题,追求可靠性、可测试性、可重复性,核心是打破运维与产品的壁垒。" — Brendan Starnig
+> "Standard Change 应完全自动化(IaC + CI/CD Pipeline),无需 CAB 审批。" — Brendan Starnig
+> "Emergency Change 事后通过 CAPA/Post-mortem 修复根因,而非永久性补丁。" — Brendan Starnig
+
+## Key Concepts
+- [[SRE]]:Site Reliability Engineering,站点可靠性工程,通过软件工程思维解决运维问题
+- [[Standard-Change]]:标准变更,预批准变更,无需 CAB 审批,应完全自动化(IaC + CI/CD Pipeline)
+- [[Normal-Change]]:正常变更,有风险/影响,需 CAB 审批和变更窗口,理想状态是逐步归入 Standard Change
+- [[Emergency-Change]]:紧急变更,为缓解事故需立即执行的变更,事后通过 CAPA/Post-mortem 修复根因
+- [[CAPA]]:Corrective and Preventive Action,即 Post-mortem 回顾,从事故中提取根因并预防同类问题
+- [[SLO]]:Service Level Objective,服务等级目标,用于定义监控指标并向上汇总至 KPI
+- [[SLR]]:Service Level Requirement,服务等级需求,与 SLO 配套使用
+- [[Early-Live-Support]]:Build 与 BAU 之间的过渡阶段,需完成 Go-Live Checklist(监控覆盖、支持模型、事件响应流程)
+- [[Self-Healing]]:通过机器学习驱动的自动化监控系统,基于告警趋势自动决策和缓解问题
+
+## Key Entities
+- [[Brendan-Starnig]]:SRE Function Lead, Platform Engineering,本次会议主讲人
+- [[SMACs]]:Service Management Automation X,当前的 ITSM 工具,用于 Ticket、Incident、Change 管理
+- [[Vinaya]]:内部成员,提议各产品组分享 Self-healing 实践,SRE 将协助落地
+
+## Connections
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← context_for ← [[ctp-topic-30-managing-change]]
+- [[ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs]] ← related_to ← [[ctp-topic-30-managing-change]]
+- [[ctp-topic-28-aws-tag-validation-tool]] ← extends ← [[ctp-topic-30-managing-change]](IaC 变更的 Tagging 标准属于 Standard Change 范畴)
+- [[ctp-topic-19-configuring-dns-within-aws-lzs]] ← related_to ← [[ctp-topic-30-managing-change]]
+
+## Contradictions
+- 与 [[ctp-topic-53-why-bother-with-cloud]] 的关系:
+ - 冲突点:是否应迁移至云端
+ - 当前观点(Topic 30):接受云转型,聚焦如何在转型中有效管理变更
+ - 对方观点(Topic 53):质疑云转型的必要性
+ - 说明:两者处于不同讨论层面,Topic 53 质疑迁移决策,Topic 30 假设迁移决策已做出,聚焦执行层面的变更管理
diff --git a/wiki/sources/ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones.md b/wiki/sources/ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones.md
index 2db1554a..dce48861 100644
--- a/wiki/sources/ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones.md
+++ b/wiki/sources/ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones.md
@@ -1,63 +1,63 @@
----
-title: "CTP Topic 31 Network Segregation and Secure Access to the New AWS Landing Zones"
-type: source
-tags:
- - AWS
- - Network-Security
- - Landing-Zone
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]]
-
-## Summary(用中文描述)
-- 核心主题:AWS Landing Zone 网络隔离与安全远程访问方案
-- 问题域:内部网络(On-prem / VPN 用户)对 AWS Landing Zone 生产工作负载的未授权访问风险
-- 方法/机制:① 网络隔离——Checkpoint 防火墙实现 default-deny 的 SPI 模型,阻断内部网络对 AWS 网段的直接连通;② 安全访问——AWS Systems Manager (SSM) 替代 VPN,提供基于浏览器的安全远程连接
-- 结论/价值:该方案作为 SD-WAN 实施前的过渡方案,以更低成本和更快速度解决紧急安全风险;长期目标是 IaC 化以消除控制台访问
-
-## Key Claims(用中文描述)
-- 内部网络与 VPN 用户因共享网络配置而可访问 AWS Landing Zone 生产工作负载,构成安全与合规风险
-- Checkpoint 防火墙启用 SPI(Security Policy Infrastructure)特性,默认 deny,仅放行必要服务和网段到 Landing Zone
-- AWS SSM 通过 IAM 角色假设 + SSM Agent 实现远程访问,无需 VPN,支持浏览器会话和 AWS CLI 两种模式
-- SSM 远程访问提供双因素认证保障,连接位于 AWS 网络内部,安全性高于传统 VPN
-- 当前方案定位于 SD-WAN 实施前的临时/备份方案,主要优势是降低成本和提升部署速度
-- 长期安全演进方向:IaC 化以减少控制台访问,break-glass 访问仅保留用于紧急场景
-- 当前方案聚焦网络隔离,不解决凭证被盗问题
-
-## Key Quotes
-> "The primary driver for this initiative is to address security concerns related to internal systems accessing production workloads in the new AWS landing zones." — 背景动机:内部系统对生产工作负载的访问安全风险
-
-> "The SPI features will be enabled with default deny enabled and allowances made for require services and network segments into the landing zones." — 核心机制:Checkpoint SPI 默认拒绝策略
-
-> "Authenticated users will assume roles granting access to the SSM agent on the target EC2 instance, leveraging existing access controls." — SSM 访问控制机制:基于 IAM 角色假设
-
-> "SSM gives users remote access via a browser based session." — SSM 核心价值:浏览器远程会话替代 VPN
-
-## Key Concepts
-- [[AWS-Landing-Zone]]:AWS 多账户架构框架,包含核心账户、基线账户、共享服务账户和产品账户
-- [[AWS-Systems-Manager-SSM]]:AWS 托管的远程管理服务,通过 SSM Agent 实现安全的无 VPN 远程访问,支持浏览器会话和 AWS CLI 模式
-- [[Network-Segregation]]:网络隔离策略,通过 Checkpoint 防火墙实现默认拒绝(default-deny),仅放行经授权的服务和网段通信
-- [[SPI-Security-Policy-Infrastructure]]:安全策略基础设施,在 Checkpoint 防火墙上强制执行网络分段,控制服务器间通信并阻断内部网络对 AWS 网段的直接访问
-- [[SD-WAN]]:软件定义广域网,组织的长期远程访问演进目标,当前 SSM 方案作为 SD-WAN 实施前的过渡方案
-
-## Key Entities
-- [[Checkpoint]]:网络安全设备供应商,提供 Landing Zone 间网段隔离的防火墙能力,依赖 AWS 标签值动态配置访问策略
-
-## Connections
-- [[ctp-topic-18-wide-area-networking-in-aws-cloud]] ← related_to ← [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]]
- - 关联点:同属 AWS Landing Zone 网络知识体系,Topic 18 聚焦广域网架构(Transit Gateway / SD-WAN),Topic 31 聚焦网络隔离与安全访问
-- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← related_to ← [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]]
- - 关联点:Topic 25 的 Labs LZ 运维视角涉及 VPN 远程访问需求,与 Topic 31 的 SSM 安全访问方案存在技术演进关系
-- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← extends ← [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]]
- - 关联点:Topic 35 明确提及"网络分段阻断对 SaaS 工作负载的直接连通性",是 Topic 31 所描述方案的设计依据
-
-## Contradictions
-- 与 [[ctp-topic-18-wide-area-networking-in-aws-cloud]] 存在视角差异:
- - 冲突点:Topic 18 强调广域网连通性(Transit Gateway Peering / SD-WAN / Pulse VPN 迁移至 Prisma Access),关注如何打通网络
- - Topic 31 视角:网络隔离的首要目标是阻断内部网络对 AWS 的直接访问,关注如何限制连通性
- - 对方观点:Topic 18 的演进路线中,Prisma Access (SASE) 将提供更安全的远程接入方案
- - 当前观点:Topic 31 主张 SSM 作为过渡方案,在 SD-WAN 实施前优先解决网络安全隔离问题
- - 调和建议:两者互补——Topic 31 解决内部网络隔离的短期安全问题,Topic 18 规划长期广域网演进路径(SD-WAN / SASE)
+---
+title: "CTP Topic 31 Network Segregation and Secure Access to the New AWS Landing Zones"
+type: source
+tags:
+ - AWS
+ - Network-Security
+ - Landing-Zone
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS Landing Zone 网络隔离与安全远程访问方案
+- 问题域:内部网络(On-prem / VPN 用户)对 AWS Landing Zone 生产工作负载的未授权访问风险
+- 方法/机制:① 网络隔离——Checkpoint 防火墙实现 default-deny 的 SPI 模型,阻断内部网络对 AWS 网段的直接连通;② 安全访问——AWS Systems Manager (SSM) 替代 VPN,提供基于浏览器的安全远程连接
+- 结论/价值:该方案作为 SD-WAN 实施前的过渡方案,以更低成本和更快速度解决紧急安全风险;长期目标是 IaC 化以消除控制台访问
+
+## Key Claims(用中文描述)
+- 内部网络与 VPN 用户因共享网络配置而可访问 AWS Landing Zone 生产工作负载,构成安全与合规风险
+- Checkpoint 防火墙启用 SPI(Security Policy Infrastructure)特性,默认 deny,仅放行必要服务和网段到 Landing Zone
+- AWS SSM 通过 IAM 角色假设 + SSM Agent 实现远程访问,无需 VPN,支持浏览器会话和 AWS CLI 两种模式
+- SSM 远程访问提供双因素认证保障,连接位于 AWS 网络内部,安全性高于传统 VPN
+- 当前方案定位于 SD-WAN 实施前的临时/备份方案,主要优势是降低成本和提升部署速度
+- 长期安全演进方向:IaC 化以减少控制台访问,break-glass 访问仅保留用于紧急场景
+- 当前方案聚焦网络隔离,不解决凭证被盗问题
+
+## Key Quotes
+> "The primary driver for this initiative is to address security concerns related to internal systems accessing production workloads in the new AWS landing zones." — 背景动机:内部系统对生产工作负载的访问安全风险
+
+> "The SPI features will be enabled with default deny enabled and allowances made for require services and network segments into the landing zones." — 核心机制:Checkpoint SPI 默认拒绝策略
+
+> "Authenticated users will assume roles granting access to the SSM agent on the target EC2 instance, leveraging existing access controls." — SSM 访问控制机制:基于 IAM 角色假设
+
+> "SSM gives users remote access via a browser based session." — SSM 核心价值:浏览器远程会话替代 VPN
+
+## Key Concepts
+- [[AWS-Landing-Zone]]:AWS 多账户架构框架,包含核心账户、基线账户、共享服务账户和产品账户
+- [[AWS-Systems-Manager-SSM]]:AWS 托管的远程管理服务,通过 SSM Agent 实现安全的无 VPN 远程访问,支持浏览器会话和 AWS CLI 模式
+- [[Network-Segregation]]:网络隔离策略,通过 Checkpoint 防火墙实现默认拒绝(default-deny),仅放行经授权的服务和网段通信
+- [[SPI-Security-Policy-Infrastructure]]:安全策略基础设施,在 Checkpoint 防火墙上强制执行网络分段,控制服务器间通信并阻断内部网络对 AWS 网段的直接访问
+- [[SD-WAN]]:软件定义广域网,组织的长期远程访问演进目标,当前 SSM 方案作为 SD-WAN 实施前的过渡方案
+
+## Key Entities
+- [[Checkpoint]]:网络安全设备供应商,提供 Landing Zone 间网段隔离的防火墙能力,依赖 AWS 标签值动态配置访问策略
+
+## Connections
+- [[ctp-topic-18-wide-area-networking-in-aws-cloud]] ← related_to ← [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]]
+ - 关联点:同属 AWS Landing Zone 网络知识体系,Topic 18 聚焦广域网架构(Transit Gateway / SD-WAN),Topic 31 聚焦网络隔离与安全访问
+- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← related_to ← [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]]
+ - 关联点:Topic 25 的 Labs LZ 运维视角涉及 VPN 远程访问需求,与 Topic 31 的 SSM 安全访问方案存在技术演进关系
+- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← extends ← [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]]
+ - 关联点:Topic 35 明确提及"网络分段阻断对 SaaS 工作负载的直接连通性",是 Topic 31 所描述方案的设计依据
+
+## Contradictions
+- 与 [[ctp-topic-18-wide-area-networking-in-aws-cloud]] 存在视角差异:
+ - 冲突点:Topic 18 强调广域网连通性(Transit Gateway Peering / SD-WAN / Pulse VPN 迁移至 Prisma Access),关注如何打通网络
+ - Topic 31 视角:网络隔离的首要目标是阻断内部网络对 AWS 的直接访问,关注如何限制连通性
+ - 对方观点:Topic 18 的演进路线中,Prisma Access (SASE) 将提供更安全的远程接入方案
+ - 当前观点:Topic 31 主张 SSM 作为过渡方案,在 SD-WAN 实施前优先解决网络安全隔离问题
+ - 调和建议:两者互补——Topic 31 解决内部网络隔离的短期安全问题,Topic 18 规划长期广域网演进路径(SD-WAN / SASE)
diff --git a/wiki/sources/ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments.md b/wiki/sources/ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments.md
index c57498af..72c47e35 100644
--- a/wiki/sources/ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments.md
+++ b/wiki/sources/ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments.md
@@ -1,79 +1,79 @@
----
-title: "CTP Topic 32 Using Atlantis CICD for Infrastructure Deployments"
-type: source
-tags: [Atlantis, CI/CD, IaC, Terraform, GitOps, CTP]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]]
-
-## Summary(用中文描述)
-
-### 核心主题
-Atlantis 作为 Terraform IaC 自动化工具,替代 Jenkins 用于 AWS Landing Zone 的基础设施部署流水线。
-
-### 问题域
-当前 Jenkins 流水线面临两大核心痛点:
-- **速度慢**:初始化时间长、多次代码克隆、顺序测试、ECS Deployer 预配置导致整个流程极慢
-- **复杂度高**:持续叠加功能以覆盖更多场景和边缘用例,导致流水线脆弱且易漂移
-
-### 方法/机制
-- **架构**:Atlantis 以单台 EC2 实例形式部署于每个 Landing Zone 的共享账户,通过 GitHub Enterprise Webhook 接收通知
-- **协作模型**:开发者直接在 GitHub Pull Request 上评论即可与 Atlantis 交互,无需单独账号和复杂集成
-- **跨账户访问**:通过在每个账户部署的 IAM 角色实现,支持简单和跨账户模块部署
-- **权限控制**:用户管理基于 GitHub 构建,构建日志以评论形式存储用于审计
-- **并行构建**:支持多模块 plan 和 apply 命令并发执行
-
-### 结论/价值
-Atlantis 提供更好的协作模型、简化的网络架构(Jenkins 需要大量 VPC Endpoints)、代码与基础设施同步更新(merge 前即应用变更),是替换 Jenkins 的理想方案。
-
-## Key Claims(用中文描述)
-
-- Atlantis 团队通过在 PR 上评论即可完成 plan/apply,无需独立的 Jenkins 账号和集成
-- Atlantis 在代码 merge 前即执行变更,确保代码始终与基础设施同步
-- Atlantis 锁定机制防止多 PR 同时对同一模块执行 plan 产生冲突
-- Atlantis 通过 Webhook 接收 GitHub 通知,服务账号负责与 GitHub 交互(评论、合并、关闭 PR)
-
-## Key Quotes
-
-> "The current pipeline is practically very slow due to significant initialization time, multiple code cloning, sequential testing, and ECS deployer provisioning." — 当前 Jenkins 流水线的性能痛点
-
-> "Atlantis applies changes before merging, ensuring code in sync with infrastructure." — Atlantis 的核心价值主张
-
-> "When a plan is run, the directory of each module is locked until the pull request that has this folder locked is merged or closed, or the plan is manually discarded." — Atlantis 锁定机制
-
-## Key Concepts
-
-- [[Infrastructure-as-Code]]:通过 Terraform 代码声明式管理 AWS 基础设施,Atlantis 是其 CI/CD 执行层
-- [[GitOps]]:以 Git 为单一事实来源,通过 PR 协作和 Atlantis 自动化 apply 实现 GitOps 工作流
-- [[CI/CD Pipeline]]:持续集成/持续部署流水线,Atlantis 替代传统 Jenkins 流水线用于 IaC 场景
-- [[Terraform]]:HashiCorp 的基础设施即代码工具,Atlantis 的核心执行对象
-
-## Key Entities
-
-- [[Terraform]]:Atlantis 管理的基础设施即代码工具,替代手动控制台操作
-- [[Jenkins]]:被 Atlantis 替代的现有 CI/CD 系统,存在初始化慢和架构复杂的问题
-- [[GitHub Enterprise]]:Atlantis 的事件来源,通过 Webhook 通知 Atlantis 执行 plan/apply
-
-## Connections
-
-- [[ctp-topic-33-an-introduction-to-gitops]] ← extends ← [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]](Topic 33 介绍 GitOps 概念,Topic 32 展示 Atlantis 工具实现)
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← extends ← [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]](Topic 9 介绍 Gruntwork CI/CD,Topic 32 进一步细化为 Atlantis 替代方案)
-- [[ctp-topic-3-deploy-and-maintain-infrastructure]] ← depends_on ← [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]](Topic 3 部署和维护基础设施,Topic 32 提供具体 CI/CD 工具)
-- [[ctp-topic-16-cross-account-terraform-modules]] ← relates_to ← [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]](跨账户 Terraform 模块与 Atlantis 跨账户访问机制关联)
-
-## Contradictions
-
-- 与 [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]]:
- - **冲突点**:EKS 部署是否支持 Atlantis
- - **当前观点(Topic 39)**:Atlantis 当前不支持 EKS 部署,需通过 Jenkins + Terragrunt 模块替代
- - **对方观点(Topic 32)**:Atlantis 可替代 Jenkins 用于所有 Terraform IaC 部署
- - **分析**:两者描述的语境不同——Topic 39 聚焦特定 EKS 场景下的实践经验,Topic 32 描述 Atlantis 整体优势。可能 Atlantis 在某些复杂场景(如 EKS 特定依赖)下存在限制,需进一步验证
-
-## Source Metadata
-
-- **Category**: DevOps & SRE / 06_CI_CD_GitOps
-- **Type**: Video(CTP Learning Session)
-- **Status**: Summarized(Gemini 摘要)
-- **Video Source**: NAS `/volume2/work/Public Cloud Learning Sessions/CTP _ Topic 32_ Using Atlantis CICD for infrastructure deployments.mp4`
+---
+title: "CTP Topic 32 Using Atlantis CICD for Infrastructure Deployments"
+type: source
+tags: [Atlantis, CI/CD, IaC, Terraform, GitOps, CTP]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments.md]]
+
+## Summary(用中文描述)
+
+### 核心主题
+Atlantis 作为 Terraform IaC 自动化工具,替代 Jenkins 用于 AWS Landing Zone 的基础设施部署流水线。
+
+### 问题域
+当前 Jenkins 流水线面临两大核心痛点:
+- **速度慢**:初始化时间长、多次代码克隆、顺序测试、ECS Deployer 预配置导致整个流程极慢
+- **复杂度高**:持续叠加功能以覆盖更多场景和边缘用例,导致流水线脆弱且易漂移
+
+### 方法/机制
+- **架构**:Atlantis 以单台 EC2 实例形式部署于每个 Landing Zone 的共享账户,通过 GitHub Enterprise Webhook 接收通知
+- **协作模型**:开发者直接在 GitHub Pull Request 上评论即可与 Atlantis 交互,无需单独账号和复杂集成
+- **跨账户访问**:通过在每个账户部署的 IAM 角色实现,支持简单和跨账户模块部署
+- **权限控制**:用户管理基于 GitHub 构建,构建日志以评论形式存储用于审计
+- **并行构建**:支持多模块 plan 和 apply 命令并发执行
+
+### 结论/价值
+Atlantis 提供更好的协作模型、简化的网络架构(Jenkins 需要大量 VPC Endpoints)、代码与基础设施同步更新(merge 前即应用变更),是替换 Jenkins 的理想方案。
+
+## Key Claims(用中文描述)
+
+- Atlantis 团队通过在 PR 上评论即可完成 plan/apply,无需独立的 Jenkins 账号和集成
+- Atlantis 在代码 merge 前即执行变更,确保代码始终与基础设施同步
+- Atlantis 锁定机制防止多 PR 同时对同一模块执行 plan 产生冲突
+- Atlantis 通过 Webhook 接收 GitHub 通知,服务账号负责与 GitHub 交互(评论、合并、关闭 PR)
+
+## Key Quotes
+
+> "The current pipeline is practically very slow due to significant initialization time, multiple code cloning, sequential testing, and ECS deployer provisioning." — 当前 Jenkins 流水线的性能痛点
+
+> "Atlantis applies changes before merging, ensuring code in sync with infrastructure." — Atlantis 的核心价值主张
+
+> "When a plan is run, the directory of each module is locked until the pull request that has this folder locked is merged or closed, or the plan is manually discarded." — Atlantis 锁定机制
+
+## Key Concepts
+
+- [[Infrastructure-as-Code]]:通过 Terraform 代码声明式管理 AWS 基础设施,Atlantis 是其 CI/CD 执行层
+- [[GitOps]]:以 Git 为单一事实来源,通过 PR 协作和 Atlantis 自动化 apply 实现 GitOps 工作流
+- [[CI/CD Pipeline]]:持续集成/持续部署流水线,Atlantis 替代传统 Jenkins 流水线用于 IaC 场景
+- [[Terraform]]:HashiCorp 的基础设施即代码工具,Atlantis 的核心执行对象
+
+## Key Entities
+
+- [[Terraform]]:Atlantis 管理的基础设施即代码工具,替代手动控制台操作
+- [[Jenkins]]:被 Atlantis 替代的现有 CI/CD 系统,存在初始化慢和架构复杂的问题
+- [[GitHub Enterprise]]:Atlantis 的事件来源,通过 Webhook 通知 Atlantis 执行 plan/apply
+
+## Connections
+
+- [[ctp-topic-33-an-introduction-to-gitops]] ← extends ← [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]](Topic 33 介绍 GitOps 概念,Topic 32 展示 Atlantis 工具实现)
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← extends ← [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]](Topic 9 介绍 Gruntwork CI/CD,Topic 32 进一步细化为 Atlantis 替代方案)
+- [[ctp-topic-3-deploy-and-maintain-infrastructure]] ← depends_on ← [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]](Topic 3 部署和维护基础设施,Topic 32 提供具体 CI/CD 工具)
+- [[ctp-topic-16-cross-account-terraform-modules]] ← relates_to ← [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]](跨账户 Terraform 模块与 Atlantis 跨账户访问机制关联)
+
+## Contradictions
+
+- 与 [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]]:
+ - **冲突点**:EKS 部署是否支持 Atlantis
+ - **当前观点(Topic 39)**:Atlantis 当前不支持 EKS 部署,需通过 Jenkins + Terragrunt 模块替代
+ - **对方观点(Topic 32)**:Atlantis 可替代 Jenkins 用于所有 Terraform IaC 部署
+ - **分析**:两者描述的语境不同——Topic 39 聚焦特定 EKS 场景下的实践经验,Topic 32 描述 Atlantis 整体优势。可能 Atlantis 在某些复杂场景(如 EKS 特定依赖)下存在限制,需进一步验证
+
+## Source Metadata
+
+- **Category**: DevOps & SRE / 06_CI_CD_GitOps
+- **Type**: Video(CTP Learning Session)
+- **Status**: Summarized(Gemini 摘要)
+- **Video Source**: NAS `/volume2/work/Public Cloud Learning Sessions/CTP _ Topic 32_ Using Atlantis CICD for infrastructure deployments.mp4`
diff --git a/wiki/sources/ctp-topic-33-an-introduction-to-gitops.md b/wiki/sources/ctp-topic-33-an-introduction-to-gitops.md
index 1399f6a0..987e28c1 100644
--- a/wiki/sources/ctp-topic-33-an-introduction-to-gitops.md
+++ b/wiki/sources/ctp-topic-33-an-introduction-to-gitops.md
@@ -1,62 +1,62 @@
----
-title: "CTP Topic 33 An Introduction to GitOps"
-type: source
-tags:
- - GitOps
- - CI/CD
- - Kubernetes
- - DevOps
- - Infrastructure as Code
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-33-an-introduction-to-gitops.md]]
-
-## Summary(用中文描述)
-- 核心主题:GitOps 方法论入门——将软件开发原则应用于部署流程,实现声明式基础设施自动化交付
-- 问题域:解决部署失败、配置不一致、手动操作风险等传统 CI/CD 问题
-- 方法/机制:四大原则(声明式配置 + 版本控制 + CD 流程分离 + 自修复协调器)+ Pull/Push 两种部署模型
-- 结论/价值:开发者只需掌握 Git 即可完成安全部署,代码变更分钟级上线,Git 日志即审计追踪
-
-## Key Claims(用中文描述)
-- GitOps 四大原则使部署过程完全自动化,代码变更可在数分钟内安全部署上线
-- Pull 模型比 Push 模型更适合 GitOps——部署代理同时监控 Git 和目标系统,提供额外安全层
-- 幂等(Idempotent)平台(如 Kubernetes)是 CD 流程顺利执行的必要条件
-- GitOps 是 DevOps 的逻辑演进,Git 提交日志天然构成合规审计追踪
-- CI 与 CD 应解耦——CI 专注构建和分析代码,CD 专注部署二进制文件,解耦增强安全性
-
-## Key Quotes
-> "The only tool a developer needs to know is Git." — Victor Etkin
-> "GitOps uses Git workflows, CD pipelines, and infrastructure as code. Observability is crucial for ensuring the desired and actual states align."
-> "An IDEMPOTENT operation is one that can be applied multiple times without changing the result beyond the initial application."
-> "GitOps is a logical evolution of DevOps, simplifying adoption and enhancing portability. Git commit logs become audit trails, streamlining compliance."
-
-## Key Concepts
-- [[GitOps]]:将软件开发原则(Git 版本控制 + Pull Request 协作)应用于基础设施和应用部署的方法论,核心是通过声明式配置描述期望状态,GitOps 控制器自动协调实际状态向期望状态收敛
-- [[Idempotent Deployment(幂等部署)]]:同一操作可重复执行而结果不变的特性,是 GitOps CD 流程顺利运行的必要前提,Kubernetes 是典型的幂等平台
-- [[Pull Model]]:GitOps 推荐部署模型——部署代理持续监控 Git 仓库和目标系统状态,检测到差异时自动从 Git 拉取变更并应用,天然提供额外安全层(系统状态不暴露给外部)
-- [[Push Model]]:CI/CD 管道主动推送变更到目标系统的部署模式,相比 Pull 模型安全性较低但实现更简单
-- [[Declarative Configuration(声明式配置)]]:通过代码描述"系统应该是什么状态"而非"如何一步步到达该状态",是 GitOps 和 Infrastructure as Code 的核心原则
-- [[Infrastructure as Code(基础设施即代码)]]:用代码管理基础设施的实践,与 GitOps 高度协同,共同构成自动化部署的基础
-- [[GitOps Controller]]:运行在目标环境中的自动化代理,持续比对 Git 中声明的期望状态与系统实际状态,自动调和偏差,无需人工干预
-
-## Key Entities
-- [[Victor Etkin]]:GitOps 入门视频主讲人,阐述 GitOps 四大原则及 Pull 模型优势
-- [[Weaveworks]]:GitOps 概念的提出者和早期推广者(视频背景知识)
-- [[Kubernetes]]:GitOps 最常用的部署目标平台,其声明式 API 和自修复机制与 GitOps 高度契合
-- [[Atlantis]]:基于 Pull Request 的 Terraform IaC 自动化工具(参见 [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]]),属 GitOps 工具实践层
-
-## Connections
-- [[ctp-topic-2-git]] ← foundational_skill ← [[GitOps]](Git 版本控制是 GitOps 的基础工具)
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← extends ← [[GitOps]](CI/CD 是 GitOps 的核心组件)
-- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← implements ← [[GitOps]](Atlantis 是 GitOps 工具实践)
-- [[GitOps]] ← complements ← [[DevOps]](GitOps 是 DevOps 的逻辑演进)
-- [[Amazon EKS]] ← platform ← [[GitOps]](K8s 是 GitOps 最常用目标平台)
-- [[GitOps]] ← extends ← [[Infrastructure as Code]](GitOps 是 IaC 的部署编排层)
-
-## Contradictions
-- 与 [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]] 存在实践约束差异:
- - 冲突点:Atlantis 当前不支持 EKS 部署
- - 当前观点(Topic 33):Kubernetes 是 GitOps 的主要应用场景
- - 对方观点(Topic 39):Atlantis 需通过 Jenkins + Terragrunt 替代方案处理 EKS 工作负载
+---
+title: "CTP Topic 33 An Introduction to GitOps"
+type: source
+tags:
+ - GitOps
+ - CI/CD
+ - Kubernetes
+ - DevOps
+ - Infrastructure as Code
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-33-an-introduction-to-gitops.md]]
+
+## Summary(用中文描述)
+- 核心主题:GitOps 方法论入门——将软件开发原则应用于部署流程,实现声明式基础设施自动化交付
+- 问题域:解决部署失败、配置不一致、手动操作风险等传统 CI/CD 问题
+- 方法/机制:四大原则(声明式配置 + 版本控制 + CD 流程分离 + 自修复协调器)+ Pull/Push 两种部署模型
+- 结论/价值:开发者只需掌握 Git 即可完成安全部署,代码变更分钟级上线,Git 日志即审计追踪
+
+## Key Claims(用中文描述)
+- GitOps 四大原则使部署过程完全自动化,代码变更可在数分钟内安全部署上线
+- Pull 模型比 Push 模型更适合 GitOps——部署代理同时监控 Git 和目标系统,提供额外安全层
+- 幂等(Idempotent)平台(如 Kubernetes)是 CD 流程顺利执行的必要条件
+- GitOps 是 DevOps 的逻辑演进,Git 提交日志天然构成合规审计追踪
+- CI 与 CD 应解耦——CI 专注构建和分析代码,CD 专注部署二进制文件,解耦增强安全性
+
+## Key Quotes
+> "The only tool a developer needs to know is Git." — Victor Etkin
+> "GitOps uses Git workflows, CD pipelines, and infrastructure as code. Observability is crucial for ensuring the desired and actual states align."
+> "An IDEMPOTENT operation is one that can be applied multiple times without changing the result beyond the initial application."
+> "GitOps is a logical evolution of DevOps, simplifying adoption and enhancing portability. Git commit logs become audit trails, streamlining compliance."
+
+## Key Concepts
+- [[GitOps]]:将软件开发原则(Git 版本控制 + Pull Request 协作)应用于基础设施和应用部署的方法论,核心是通过声明式配置描述期望状态,GitOps 控制器自动协调实际状态向期望状态收敛
+- [[Idempotent Deployment(幂等部署)]]:同一操作可重复执行而结果不变的特性,是 GitOps CD 流程顺利运行的必要前提,Kubernetes 是典型的幂等平台
+- [[Pull Model]]:GitOps 推荐部署模型——部署代理持续监控 Git 仓库和目标系统状态,检测到差异时自动从 Git 拉取变更并应用,天然提供额外安全层(系统状态不暴露给外部)
+- [[Push Model]]:CI/CD 管道主动推送变更到目标系统的部署模式,相比 Pull 模型安全性较低但实现更简单
+- [[Declarative Configuration(声明式配置)]]:通过代码描述"系统应该是什么状态"而非"如何一步步到达该状态",是 GitOps 和 Infrastructure as Code 的核心原则
+- [[Infrastructure as Code(基础设施即代码)]]:用代码管理基础设施的实践,与 GitOps 高度协同,共同构成自动化部署的基础
+- [[GitOps Controller]]:运行在目标环境中的自动化代理,持续比对 Git 中声明的期望状态与系统实际状态,自动调和偏差,无需人工干预
+
+## Key Entities
+- [[Victor Etkin]]:GitOps 入门视频主讲人,阐述 GitOps 四大原则及 Pull 模型优势
+- [[Weaveworks]]:GitOps 概念的提出者和早期推广者(视频背景知识)
+- [[Kubernetes]]:GitOps 最常用的部署目标平台,其声明式 API 和自修复机制与 GitOps 高度契合
+- [[Atlantis]]:基于 Pull Request 的 Terraform IaC 自动化工具(参见 [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]]),属 GitOps 工具实践层
+
+## Connections
+- [[ctp-topic-2-git]] ← foundational_skill ← [[GitOps]](Git 版本控制是 GitOps 的基础工具)
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← extends ← [[GitOps]](CI/CD 是 GitOps 的核心组件)
+- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← implements ← [[GitOps]](Atlantis 是 GitOps 工具实践)
+- [[GitOps]] ← complements ← [[DevOps]](GitOps 是 DevOps 的逻辑演进)
+- [[Amazon EKS]] ← platform ← [[GitOps]](K8s 是 GitOps 最常用目标平台)
+- [[GitOps]] ← extends ← [[Infrastructure as Code]](GitOps 是 IaC 的部署编排层)
+
+## Contradictions
+- 与 [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]] 存在实践约束差异:
+ - 冲突点:Atlantis 当前不支持 EKS 部署
+ - 当前观点(Topic 33):Kubernetes 是 GitOps 的主要应用场景
+ - 对方观点(Topic 39):Atlantis 需通过 Jenkins + Terragrunt 替代方案处理 EKS 工作负载
diff --git a/wiki/sources/ctp-topic-34-azure-landing-zone-architecture-overview.md b/wiki/sources/ctp-topic-34-azure-landing-zone-architecture-overview.md
index dc46dc14..2cf36ad9 100644
--- a/wiki/sources/ctp-topic-34-azure-landing-zone-architecture-overview.md
+++ b/wiki/sources/ctp-topic-34-azure-landing-zone-architecture-overview.md
@@ -1,56 +1,56 @@
----
-title: "CTP Topic 34 Azure Landing Zone Architecture Overview"
-type: source
-tags:
- - Azure
- - Landing-Zone
- - Cloud-Transformation
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-34-azure-landing-zone-architecture-overview]]
-
-## Summary(用中文描述)
-- 核心主题:Azure Landing Zone 在 Micro Focus 内部的实施架构概述
-- 问题域:企业级多云治理(Azure 部分)——如何通过 Landing Zone 简化 Azure 接入、减少跨团队依赖、实现自动化部署
-- 方法/机制:Azure Enterprise Enrollment → 管理组(Management Groups)分层 → 独立订阅隔离目的 → Terraform Cloud IaC 自动化
-- 结论/价值:四个管理组区域(Platform / Landing Zones / Decommission / Sandbox)实现资源隔离与职责分离;Terraform Cloud 管理跨订阅依赖;PIM/PAG 实现精细化访问控制
-
-## Key Claims(用中文描述)
-- Azure Landing Zone 通过管理组(Management Groups)将组织实体分为 Platform、Landing Zones、Decommission、Sandbox 四个层级,实现分层治理
-- Platform 层包含 Identity 和 Connectivity 两个独立订阅,各自承担特定安全职责,避免职责混淆
-- Connectivity 订阅作为中心枢纽,汇聚所有入站和出站 Azure 流量,集成 DDoS 防护和 Checkpoint 防火墙
-- Landing Zones 设计为可扩展、模块化、全自动化,提供基于模板的方案供新项目使用
-- 独立订阅的核心原因是按特定目的隔离,每个订阅服务单一用途
-- Privileged Identity Management (PIM) 和 Privileged Access Groups 管理用户访问,确保角色和策略的正确执行
-- Terraform Cloud 利用 Terraform State 管理跨订阅依赖,支持分层架构
-
-## Key Quotes
-> "The primary goal is to minimize cross-team dependencies through automation, granting teams greater independence in deploying innovative solutions within the Azure environment." — Kishore Garlopati,演讲核心目标
-
-> "The core reason of these individual or isolated subscriptions is you are basically containing a subscription for a specific purpose." — 独立订阅的核心设计原则
-
-> "This sandbox is an interesting one because these landings on subscriptions allows your workloads." — Sandbox 环境允许团队在隔离环境中实验工作负载
-
-## Key Concepts
-- [[Azure Landing Zone]]:Azure 云环境的托管基础框架,通过管理组和订阅分层实现安全、合规和可管理性,为工作负载提供标准化入口。与 [[AWS Landing Zone]] 同属多云 Landing Zone 架构的两种实现
-- [[Management Groups]]:Azure 管理组,类似于 Windows 父目录结构,用于组织和治理 Azure 租户内的实体,可分层级继承策略和访问控制
-- [[Terraform Cloud]]:HashiCorp 的 Terraform 云平台,提供 IaC 状态管理、工作流自动化和团队协作能力,用于管理跨订阅的基础设施依赖
-- [[Privileged Identity Management (PIM)]]:Azure AD 的特权身份管理服务,实现实时细粒度访问控制,确保用户仅在需要时获得特权
-- [[Privileged Access Groups]]:PIM 的组成部分,通过访问组管理用户权限,支持基于角色的策略执行
-
-## Key Entities
-- [[Kishore Garlopati]]:演讲者,Azure Landing Zone 架构overview主讲人
-- [[Micro Focus]]:使用 Azure Landing Zone 进行云转型的企业组织,参考 [[AWS Landing Zone]] 在 Micro Focus 的实践经验
-
-## Connections
-- [[AWS Landing Zone]] ← related_to ← [[Azure Landing Zone]](同属 Landing Zone 架构,AWS 与 Azure 的不同实现)
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← related_to ← [[AWS Landing Zone]](AWS Landing Zone 基础入门)
-- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← related_to ← [[AWS Landing Zone]](AWS Landing Zone 设计复习)
-- [[ctp-topic-47-enterprise-architecture-cloud-standards]] ← extends ← [[AWS Landing Zone]](企业架构云标准扩展)
-- [[Terraform]] ← implements ← [[Terraform Cloud]](Terraform Cloud 是 Terraform 的云端编排平台)
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "CTP Topic 34 Azure Landing Zone Architecture Overview"
+type: source
+tags:
+ - Azure
+ - Landing-Zone
+ - Cloud-Transformation
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-34-azure-landing-zone-architecture-overview.md]]
+
+## Summary(用中文描述)
+- 核心主题:Azure Landing Zone 在 Micro Focus 内部的实施架构概述
+- 问题域:企业级多云治理(Azure 部分)——如何通过 Landing Zone 简化 Azure 接入、减少跨团队依赖、实现自动化部署
+- 方法/机制:Azure Enterprise Enrollment → 管理组(Management Groups)分层 → 独立订阅隔离目的 → Terraform Cloud IaC 自动化
+- 结论/价值:四个管理组区域(Platform / Landing Zones / Decommission / Sandbox)实现资源隔离与职责分离;Terraform Cloud 管理跨订阅依赖;PIM/PAG 实现精细化访问控制
+
+## Key Claims(用中文描述)
+- Azure Landing Zone 通过管理组(Management Groups)将组织实体分为 Platform、Landing Zones、Decommission、Sandbox 四个层级,实现分层治理
+- Platform 层包含 Identity 和 Connectivity 两个独立订阅,各自承担特定安全职责,避免职责混淆
+- Connectivity 订阅作为中心枢纽,汇聚所有入站和出站 Azure 流量,集成 DDoS 防护和 Checkpoint 防火墙
+- Landing Zones 设计为可扩展、模块化、全自动化,提供基于模板的方案供新项目使用
+- 独立订阅的核心原因是按特定目的隔离,每个订阅服务单一用途
+- Privileged Identity Management (PIM) 和 Privileged Access Groups 管理用户访问,确保角色和策略的正确执行
+- Terraform Cloud 利用 Terraform State 管理跨订阅依赖,支持分层架构
+
+## Key Quotes
+> "The primary goal is to minimize cross-team dependencies through automation, granting teams greater independence in deploying innovative solutions within the Azure environment." — Kishore Garlopati,演讲核心目标
+
+> "The core reason of these individual or isolated subscriptions is you are basically containing a subscription for a specific purpose." — 独立订阅的核心设计原则
+
+> "This sandbox is an interesting one because these landings on subscriptions allows your workloads." — Sandbox 环境允许团队在隔离环境中实验工作负载
+
+## Key Concepts
+- [[Azure Landing Zone]]:Azure 云环境的托管基础框架,通过管理组和订阅分层实现安全、合规和可管理性,为工作负载提供标准化入口。与 [[AWS Landing Zone]] 同属多云 Landing Zone 架构的两种实现
+- [[Management Groups]]:Azure 管理组,类似于 Windows 父目录结构,用于组织和治理 Azure 租户内的实体,可分层级继承策略和访问控制
+- [[Terraform Cloud]]:HashiCorp 的 Terraform 云平台,提供 IaC 状态管理、工作流自动化和团队协作能力,用于管理跨订阅的基础设施依赖
+- [[Privileged Identity Management (PIM)]]:Azure AD 的特权身份管理服务,实现实时细粒度访问控制,确保用户仅在需要时获得特权
+- [[Privileged Access Groups]]:PIM 的组成部分,通过访问组管理用户权限,支持基于角色的策略执行
+
+## Key Entities
+- [[Kishore Garlopati]]:演讲者,Azure Landing Zone 架构overview主讲人
+- [[Micro Focus]]:使用 Azure Landing Zone 进行云转型的企业组织,参考 [[AWS Landing Zone]] 在 Micro Focus 的实践经验
+
+## Connections
+- [[AWS Landing Zone]] ← related_to ← [[Azure Landing Zone]](同属 Landing Zone 架构,AWS 与 Azure 的不同实现)
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← related_to ← [[AWS Landing Zone]](AWS Landing Zone 基础入门)
+- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← related_to ← [[AWS Landing Zone]](AWS Landing Zone 设计复习)
+- [[ctp-topic-47-enterprise-architecture-cloud-standards]] ← extends ← [[AWS Landing Zone]](企业架构云标准扩展)
+- [[Terraform]] ← implements ← [[Terraform Cloud]](Terraform Cloud 是 Terraform 的云端编排平台)
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/ctp-topic-35-aws-landing-zone-design-refresher-saas-labs.md b/wiki/sources/ctp-topic-35-aws-landing-zone-design-refresher-saas-labs.md
index da44a081..bbbec900 100644
--- a/wiki/sources/ctp-topic-35-aws-landing-zone-design-refresher-saas-labs.md
+++ b/wiki/sources/ctp-topic-35-aws-landing-zone-design-refresher-saas-labs.md
@@ -1,52 +1,52 @@
----
-title: "CTP Topic 35 AWS Landing Zone Design Refresher (SaaS Labs)"
-type: source
-tags: []
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-35-aws-landing-zone-design-refresher-saas-labs.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS Landing Zone 设计复习,重点对比 SaaS(生产)与 Labs(开发)两种 Landing Zone 环境的架构差异与近期变更
-- 问题域:企业多账户 AWS 环境下的账户结构设计、共享服务架构、网络分段策略、以及 SaaS 与 Labs 的职责划分
-- 方法/机制:基于 Gruntwork Terraform 模板构建 Landing Zone IaC;通过 CCOEs CloudTrail 替代 Gruntworks CloudTrail 实现统一审计;网络账户 Checkpoint 重新路由入站流量;网络分段阻断 SaaS 工作负载的直接连通性
-- 结论/价值:明确 SaaS = 生产、Labs = 开发的核心定位;PoC Landing Zone 将并入 Labs 以最大化资源共享;Cloud Technology Design Forum 推动 Micro Focus 云交付标准化
-
-## Key Claims(用中文描述)
-- Gruntwork 框架的 Landing Zone 通过 Terraform 模板以 IaC 方式构建
-- SaaS Landing Zone 为每个产品区域提供客户专属的产品账户,通过共享服务账户实现安全、日志和网络互联
-- Gruntwork 账户跨所有账户管理 AMI、日志和安全策略
-- 网络分段策略将阻断对 SaaS 工作负载的直接连通性
-- CCOEs CloudTrail 取代 Gruntworks CloudTrail 实现统一云审计
-- 入站流量拟通过 Network 账户的 Checkpoint 重新路由
-- 原生 AWS Backup 有望成为强制要求
-- 新账户可能取消 Management VPC
-- SaaS 用于生产环境,Labs 用于开发环境(PoC Landing Zone 将并入 Labs)
-
-## Key Quotes
-> "Our AWS landing zones, they're built infrastructure as code as you'd expect on terraform templates using the grunt work framework." — Landing Zone 的 IaC 实现方式
-> "Basically, the only answer is that SAS is production, Labs is development." — SaaS 与 Labs 的本质区别
-
-## Key Concepts
-- [[AWS-Landing-Zone]]:AWS 多账户架构的基础框架,通过账户隔离实现安全、合规和可管理性
-- [[Gruntwork]]:提供生产级 Terraform 模块的基础设施库,Micro Focus 基于此构建 Landing Zone
-- [[Shared-Services-Account]]:托管共享服务(Artifactory、Cyber Eupriva、ArcSight、监控等)的集中账户
-- [[Core-Accounts]]:包含 Active Directory、DNS 和 Network 账户,支持 IT 服务和 Micro Focus 基础设施
-- [[Product-Accounts]]:托管各产品线的 IT 产品、项目、应用程序及相关 AWS 资源,由各项目团队管理
-- [[Gruntwork-Accounts]]:跨所有账户管理 AMI、日志和安全策略的集中账户
-- [[CCOEs-CloudTrail]]:由 CCOE 团队管理的统一 CloudTrail,替代原有的 Gruntworks CloudTrail
-- [[Network-Segmentation]]:通过 Checkpoint 防火墙和网络分段策略阻断对 SaaS 工作负载的直接连通性
-
-## Key Entities
-- [[Cloud-Technology-Design-Forum]]:Micro Focus 云技术设计论坛,致力于标准化和集中化云交付产品(包括 Landing Zone 设计)
-
-## Connections
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← extends ← [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]]
-- [[ctp-topic-7-saas-landing-zone-design]] ← related_to ← [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]]
-- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← related_to ← [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]]
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging]] ← related_to ← [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]]
-
-## Contradictions
-- (暂无检测到与其他 Wiki 页面的明显冲突)
+---
+title: "CTP Topic 35 AWS Landing Zone Design Refresher (SaaS Labs)"
+type: source
+tags: []
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-35-aws-landing-zone-design-refresher-saas-labs.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS Landing Zone 设计复习,重点对比 SaaS(生产)与 Labs(开发)两种 Landing Zone 环境的架构差异与近期变更
+- 问题域:企业多账户 AWS 环境下的账户结构设计、共享服务架构、网络分段策略、以及 SaaS 与 Labs 的职责划分
+- 方法/机制:基于 Gruntwork Terraform 模板构建 Landing Zone IaC;通过 CCOEs CloudTrail 替代 Gruntworks CloudTrail 实现统一审计;网络账户 Checkpoint 重新路由入站流量;网络分段阻断 SaaS 工作负载的直接连通性
+- 结论/价值:明确 SaaS = 生产、Labs = 开发的核心定位;PoC Landing Zone 将并入 Labs 以最大化资源共享;Cloud Technology Design Forum 推动 Micro Focus 云交付标准化
+
+## Key Claims(用中文描述)
+- Gruntwork 框架的 Landing Zone 通过 Terraform 模板以 IaC 方式构建
+- SaaS Landing Zone 为每个产品区域提供客户专属的产品账户,通过共享服务账户实现安全、日志和网络互联
+- Gruntwork 账户跨所有账户管理 AMI、日志和安全策略
+- 网络分段策略将阻断对 SaaS 工作负载的直接连通性
+- CCOEs CloudTrail 取代 Gruntworks CloudTrail 实现统一云审计
+- 入站流量拟通过 Network 账户的 Checkpoint 重新路由
+- 原生 AWS Backup 有望成为强制要求
+- 新账户可能取消 Management VPC
+- SaaS 用于生产环境,Labs 用于开发环境(PoC Landing Zone 将并入 Labs)
+
+## Key Quotes
+> "Our AWS landing zones, they're built infrastructure as code as you'd expect on terraform templates using the grunt work framework." — Landing Zone 的 IaC 实现方式
+> "Basically, the only answer is that SAS is production, Labs is development." — SaaS 与 Labs 的本质区别
+
+## Key Concepts
+- [[AWS-Landing-Zone]]:AWS 多账户架构的基础框架,通过账户隔离实现安全、合规和可管理性
+- [[Gruntwork]]:提供生产级 Terraform 模块的基础设施库,Micro Focus 基于此构建 Landing Zone
+- [[Shared-Services-Account]]:托管共享服务(Artifactory、Cyber Eupriva、ArcSight、监控等)的集中账户
+- [[Core-Accounts]]:包含 Active Directory、DNS 和 Network 账户,支持 IT 服务和 Micro Focus 基础设施
+- [[Product-Accounts]]:托管各产品线的 IT 产品、项目、应用程序及相关 AWS 资源,由各项目团队管理
+- [[Gruntwork-Accounts]]:跨所有账户管理 AMI、日志和安全策略的集中账户
+- [[CCOEs-CloudTrail]]:由 CCOE 团队管理的统一 CloudTrail,替代原有的 Gruntworks CloudTrail
+- [[Network-Segmentation]]:通过 Checkpoint 防火墙和网络分段策略阻断对 SaaS 工作负载的直接连通性
+
+## Key Entities
+- [[Cloud-Technology-Design-Forum]]:Micro Focus 云技术设计论坛,致力于标准化和集中化云交付产品(包括 Landing Zone 设计)
+
+## Connections
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← extends ← [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]]
+- [[ctp-topic-7-saas-landing-zone-design]] ← related_to ← [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]]
+- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← related_to ← [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]]
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging]] ← related_to ← [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]]
+
+## Contradictions
+- (暂无检测到与其他 Wiki 页面的明显冲突)
diff --git a/wiki/sources/ctp-topic-36-sendgrid-as-an-email-service.md b/wiki/sources/ctp-topic-36-sendgrid-as-an-email-service.md
index 3538f271..3faf094b 100644
--- a/wiki/sources/ctp-topic-36-sendgrid-as-an-email-service.md
+++ b/wiki/sources/ctp-topic-36-sendgrid-as-an-email-service.md
@@ -1,64 +1,64 @@
----
-title: "CTP Topic 36 SendGrid as an Email Service"
-type: source
-tags:
- - SendGrid
- - Email
- - AWS
- - CTP
- - Cloud-Email
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-36-sendgrid-as-an-email-service]]
-
-## Summary(用中文描述)
-- 核心主题:SendGrid 被选定为经典和新 Landing Zone 的标准邮件服务,同时更新了 Cyber Suite 加密套件标准。
-- 问题域:企业邮件服务迁移——现有邮件网关(Port 25 不安全、即将下线)和 SES(每封限制 50 收件人)无法满足云环境需求。
-- 方法/机制:SendGrid 支持每封最多 1,000 收件人、全云兼容、TLS 端到端加密、双因素认证;提供两种架构(直连 SendGrid vs 中继服务器),通过全球中继节点(伦敦/印度/东京)走私有线路汇至美国数据中心处理;支持计划覆盖每月 500 万封邮件。
-- 结论/价值:SendGrid 统一替换现有分散邮件方案,提升安全性(TLS/2FA)、扩展性(1,000 收件人)和云就绪度;Cyber Suite 标准更新了行业标准合规加密套件清单。
-
-## Key Claims(用中文描述)
-- SendGrid 通过支持每封邮件最多 1,000 收件人,解决了 SES 每封仅 50 收件人的限制。
-- 现有语义消息网关通过 Port 25 向公共互联网中继邮件,存在安全漏洞,且托管在即将停用的本地网络上。
-- SendGrid 直连模式要求使用 software.microcopy.com 域名、连接 smtp.sendgrid.net:587 并启用 TLS。
-- SPF 和 DKIM 记录是确保邮件正常送达(避免进入垃圾箱或被拒收)的必要配置。
-- API 密钥每 180 天轮换一次,邮件日志保留七天。
-- Cyber Suite 标准中的可选套件因包含 CBC(Cipher Block Chaining)模式而被视为弱加密,使用非标准加密套件的产品需经 PSAC 团队审查。
-
-## Key Quotes
-> "SendGrid overcomes these issues by allowing up to 1,000 recipients per message and being fully cloud-compatible. Almost 30 billion emails per month customers are already used across the whole country." — Rejoy Ganapati & Rajiv, CTP Topic 36
-
-> "SPF and DKIM records are essential for valid email sending to avoid emails landing in junk folders or being rejected." — CTP Topic 36
-
-> "An optional Cyber Suite is available for backward compatibility, but it includes CBC (Cipher Block Chaining) which is considered weak." — Yu-Yan, PSAC Cyber Suite Update
-
-## Key Concepts
-- [[SPF]]:发件人策略框架(Sender Policy Framework),DNS 记录类型,用于声明哪些邮件服务器被授权代表域名发送邮件,防止邮件伪造和垃圾邮件。
-- [[DKIM]]:域名密钥识别邮件(DomainKeys Identified Mail),通过加密签名验证邮件内容在传输过程中未被篡改,确保发件人身份真实性。
-- [[TLS]]:传输层安全协议(Transport Layer Security),在 SendGrid 中用于端到端加密邮件传输,防止中间人攻击和数据窃听。
-- [[API-Key-Rotation]]:API 密钥定期轮换策略,SendGrid 要求每 180 天轮换一次 API 密钥,是安全运维的基本规范。
-- [[Cyber-Suite]]:行业标准加密套件集合(如 FIPS、Java、Golang、Node.js、OpenCell for CNC++),PSAC 负责维护和更新。
-- [[CBC-Mode]]:密码块链接模式(Cipher Block Chaining),一种分组加密工作模式,因存在已知攻击向量(如 POODLE)而被视为弱加密方式,不推荐使用。
-
-## Key Entities
-- [[Rejoy Ganapati]]:SendGrid 演讲者之一,CTP Topic 36 讲师。
-- [[Rajiv]]:SendGrid 演讲者之一,CTP Topic 36 讲师。
-- [[Yu-Yan]]:PSAC(Product Security Advisory Committee)成员,负责 Cyber Suite 标准的更新与宣讲。
-- [[PSAC]]:Product Security Advisory Committee,产品安全咨询委员会,负责维护 Cyber Suite 加密标准。
-- [[SendGrid]]:Twilio 旗下的云邮件服务,作为 CTP 标准邮件服务被采纳,支持大规模邮件发送、企业级安全和云原生架构。
-- [[Twilio]]:云通信平台,SendGrid 隶属其下,是全球大规模邮件发送的基础设施提供商。
-
-## Connections
-- [[CTP-Topic-12-SES-SMTP]] ← replaces ← [[ctp-topic-36-sendgrid-as-an-email-service]](SendGrid 替换 SES SMTP 模块作为标准邮件服务)
-- [[ctp-topic-36-sendgrid-as-an-email-service]] ← extends ← [[AWS-Landing-Zone]](SendGrid 接入是 Landing Zone 通信层的基础组件)
-- [[ctp-topic-36-sendgrid-as-an-email-service]] ← depends_on ← [[SPF]](SPF 记录是 SendGrid 邮件送达的必要条件)
-- [[ctp-topic-36-sendgrid-as-an-email-service]] ← depends_on ← [[DKIM]](DKIM 签名是 SendGrid 邮件验证的必要条件)
-- [[ctp-topic-36-sendgrid-as-an-email-service]] ← relates_to ← [[ctp-topic-37-secrets-certificates-management]](TLS 加密和 API 密钥轮换同属安全运维范畴)
-
-## Contradictions
-- 与 [[ctp-topic-12-using-ses-smtp-service-terraform-module]] 冲突:
- - 冲突点:SES SMTP 作为企业标准邮件服务与 SendGrid 被选定为新标准之间的矛盾。
- - 当前观点:SendGrid 取代 SES 成为新标准邮件服务(SES 每封限制 50 收件人,无法满足大规模需求)。
- - 对方观点:SES 通过 Terraform 模块化管理,适合特定 AWS 原生集成场景。
+---
+title: "CTP Topic 36 SendGrid as an Email Service"
+type: source
+tags:
+ - SendGrid
+ - Email
+ - AWS
+ - CTP
+ - Cloud-Email
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-36-sendgrid-as-an-email-service.md]]
+
+## Summary(用中文描述)
+- 核心主题:SendGrid 被选定为经典和新 Landing Zone 的标准邮件服务,同时更新了 Cyber Suite 加密套件标准。
+- 问题域:企业邮件服务迁移——现有邮件网关(Port 25 不安全、即将下线)和 SES(每封限制 50 收件人)无法满足云环境需求。
+- 方法/机制:SendGrid 支持每封最多 1,000 收件人、全云兼容、TLS 端到端加密、双因素认证;提供两种架构(直连 SendGrid vs 中继服务器),通过全球中继节点(伦敦/印度/东京)走私有线路汇至美国数据中心处理;支持计划覆盖每月 500 万封邮件。
+- 结论/价值:SendGrid 统一替换现有分散邮件方案,提升安全性(TLS/2FA)、扩展性(1,000 收件人)和云就绪度;Cyber Suite 标准更新了行业标准合规加密套件清单。
+
+## Key Claims(用中文描述)
+- SendGrid 通过支持每封邮件最多 1,000 收件人,解决了 SES 每封仅 50 收件人的限制。
+- 现有语义消息网关通过 Port 25 向公共互联网中继邮件,存在安全漏洞,且托管在即将停用的本地网络上。
+- SendGrid 直连模式要求使用 software.microcopy.com 域名、连接 smtp.sendgrid.net:587 并启用 TLS。
+- SPF 和 DKIM 记录是确保邮件正常送达(避免进入垃圾箱或被拒收)的必要配置。
+- API 密钥每 180 天轮换一次,邮件日志保留七天。
+- Cyber Suite 标准中的可选套件因包含 CBC(Cipher Block Chaining)模式而被视为弱加密,使用非标准加密套件的产品需经 PSAC 团队审查。
+
+## Key Quotes
+> "SendGrid overcomes these issues by allowing up to 1,000 recipients per message and being fully cloud-compatible. Almost 30 billion emails per month customers are already used across the whole country." — Rejoy Ganapati & Rajiv, CTP Topic 36
+
+> "SPF and DKIM records are essential for valid email sending to avoid emails landing in junk folders or being rejected." — CTP Topic 36
+
+> "An optional Cyber Suite is available for backward compatibility, but it includes CBC (Cipher Block Chaining) which is considered weak." — Yu-Yan, PSAC Cyber Suite Update
+
+## Key Concepts
+- [[SPF]]:发件人策略框架(Sender Policy Framework),DNS 记录类型,用于声明哪些邮件服务器被授权代表域名发送邮件,防止邮件伪造和垃圾邮件。
+- [[DKIM]]:域名密钥识别邮件(DomainKeys Identified Mail),通过加密签名验证邮件内容在传输过程中未被篡改,确保发件人身份真实性。
+- [[TLS]]:传输层安全协议(Transport Layer Security),在 SendGrid 中用于端到端加密邮件传输,防止中间人攻击和数据窃听。
+- [[API-Key-Rotation]]:API 密钥定期轮换策略,SendGrid 要求每 180 天轮换一次 API 密钥,是安全运维的基本规范。
+- [[Cyber-Suite]]:行业标准加密套件集合(如 FIPS、Java、Golang、Node.js、OpenCell for CNC++),PSAC 负责维护和更新。
+- [[CBC-Mode]]:密码块链接模式(Cipher Block Chaining),一种分组加密工作模式,因存在已知攻击向量(如 POODLE)而被视为弱加密方式,不推荐使用。
+
+## Key Entities
+- [[Rejoy Ganapati]]:SendGrid 演讲者之一,CTP Topic 36 讲师。
+- [[Rajiv]]:SendGrid 演讲者之一,CTP Topic 36 讲师。
+- [[Yu-Yan]]:PSAC(Product Security Advisory Committee)成员,负责 Cyber Suite 标准的更新与宣讲。
+- [[PSAC]]:Product Security Advisory Committee,产品安全咨询委员会,负责维护 Cyber Suite 加密标准。
+- [[SendGrid]]:Twilio 旗下的云邮件服务,作为 CTP 标准邮件服务被采纳,支持大规模邮件发送、企业级安全和云原生架构。
+- [[Twilio]]:云通信平台,SendGrid 隶属其下,是全球大规模邮件发送的基础设施提供商。
+
+## Connections
+- [[CTP-Topic-12-SES-SMTP]] ← replaces ← [[ctp-topic-36-sendgrid-as-an-email-service]](SendGrid 替换 SES SMTP 模块作为标准邮件服务)
+- [[ctp-topic-36-sendgrid-as-an-email-service]] ← extends ← [[AWS-Landing-Zone]](SendGrid 接入是 Landing Zone 通信层的基础组件)
+- [[ctp-topic-36-sendgrid-as-an-email-service]] ← depends_on ← [[SPF]](SPF 记录是 SendGrid 邮件送达的必要条件)
+- [[ctp-topic-36-sendgrid-as-an-email-service]] ← depends_on ← [[DKIM]](DKIM 签名是 SendGrid 邮件验证的必要条件)
+- [[ctp-topic-36-sendgrid-as-an-email-service]] ← relates_to ← [[ctp-topic-37-secrets-certificates-management]](TLS 加密和 API 密钥轮换同属安全运维范畴)
+
+## Contradictions
+- 与 [[ctp-topic-12-using-ses-smtp-service-terraform-module]] 冲突:
+ - 冲突点:SES SMTP 作为企业标准邮件服务与 SendGrid 被选定为新标准之间的矛盾。
+ - 当前观点:SendGrid 取代 SES 成为新标准邮件服务(SES 每封限制 50 收件人,无法满足大规模需求)。
+ - 对方观点:SES 通过 Terraform 模块化管理,适合特定 AWS 原生集成场景。
diff --git a/wiki/sources/ctp-topic-37-secrets-certificates-management.md b/wiki/sources/ctp-topic-37-secrets-certificates-management.md
index 27b1d73a..c05acfcf 100644
--- a/wiki/sources/ctp-topic-37-secrets-certificates-management.md
+++ b/wiki/sources/ctp-topic-37-secrets-certificates-management.md
@@ -1,58 +1,58 @@
----
-title: "CTP Topic 37 Secrets Certificates Management"
-type: source
-tags:
- - AWS
- - Secrets-Manager
- - Certificates
- - Security
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-37-secrets-certificates-management]]
-
-## Summary(用中文描述)
-- 核心主题:云转型计划中的密钥与证书管理解决方案选型与实施
-- 问题域:工作负载迁移至公有云过程中的密钥管理标准化需求,涉及应用服务特权账号、API密钥、Tokens等敏感凭证的安全管理
-- 方法/机制:通过30天试点对比评估 AWS Secrets Manager 与 HashiCorp Vault,最终选定 AWS Secrets Manager;实施阶段从 CI/CD 流程中清除明文密码和密钥,集中化管理并自动化密钥获取
-- 结论/价值:AWS Secrets Manager 以更低成本和更简实施胜出;AWS 在账户级别管理密钥可降低成本并提升安全性
-
-## Key Claims(用中文描述)
-- AWS Secrets Manager 通过内置集成 RDS/Redshift/DynamoDB 和高可用/DR 能力,以按用量计费模式提供简单实施体验
-- HashiCorp Vault 免费版缺乏企业级能力(高可用、多租户),企业版按用户数收费
-- Micro Focus PAM 因需要大量投资才能具备竞争力且缺乏投资计划而被放弃
-- AWS Secrets Manager 的 30 天试点验证了开箱即用功能,同时识别出缺失功能(SSH 密钥轮换、用户密码轮换)
-- 实施阶段首先从 Control Tower 开始,从 CI/CD 流程中清除明文密码和密钥
-
-## Key Quotes
-> "AWS Secrets Manager is easy and simple to implement." — 试点结论
-
-> "AWS manages secrets at the account level, which can reduce costs and increase security." — 实施阶段核心理念
-
-## Key Concepts
-- [[Secrets-Management]]:数字认证凭证(密码、密钥、API、Tokens)的管理工具和方法论,确保应用服务、特权账号等敏感信息的安全存储与访问控制
-- [[AWS-Secrets-Manager]]:AWS 托管的密钥管理服务,提供内置 RDS/Redshift/DynamoDB 集成,支持高可用和灾难恢复,按用量计费
-- [[HashiCorp-Vault]]:自托管、云厂商无关的密钥管理解决方案,支持按需动态密钥和嵌入式证书签名,按用户数收费
-- [[PAM(Privileged-Access-Management)]]:特权访问管理,通过 CyberArk Micro Focus PAM 实现特权账号的安全管控
-- [[Secret-Rotation]]:密钥轮换机制,自动定期更换密钥以降低泄露风险,AWS Secrets Manager 支持数据库凭证自动轮换
-- [[CI/CD-Secrets]]:CI/CD 流程中的密钥管理,从明文存储迁移至集中化密钥管理服务
-
-## Key Entities
-- [[Micro-Focus]]:企业客户,云转型计划(CTP)的主体,评估并选定 AWS Secrets Manager 作为密钥管理方案
-- [[CCLE]]:Cloud Center of Excellence 团队,2022年3月负责探索 Micro Focus 用例并评估密钥管理解决方案
-- [[AWS]]:云服务提供商,AWS Secrets Manager 的提供方
-- [[HashiCorp]]:Vault 产品提供方,开源版和商业企业版均参与评估
-- [[CyberArk]]:Micro Focus PAM 的技术提供方
-
-## Connections
-- [[ctp-topic-62-aws-secrets-manager]] ← extends ← [[ctp-topic-37-secrets-certificates-management]]
-- [[ctp-topic-36-sendgrid-as-an-email-service]] ← shares_security_domain ← [[ctp-topic-37-secrets-certificates-management]]
-- [[ctp-topic-5-aws-identity-and-access-management-iam]] ← related_to ← [[ctp-topic-37-secrets-certificates-management]]
-
-## Contradictions
-- 与 [[ctp-topic-62-aws-secrets-manager]] 潜在补充关系:
- - 冲突点:Topic 37 试点阶段认为 AWS Secrets Manager "easy and simple";Topic 62 深入实践发现 JDBC Wrapper + Lambda 函数等实施细节复杂度
- - 当前观点:Topic 37 的快速试点结论与 Topic 62 的企业级深度实践一致,AWS Secrets Manager 被正式选定为标准方案
- - 对方观点:Topic 62 在 Topic 37 基础上补充了 Oracle DB 密码轮换等高级用例和实施最佳实践
+---
+title: "CTP Topic 37 Secrets Certificates Management"
+type: source
+tags:
+ - AWS
+ - Secrets-Manager
+ - Certificates
+ - Security
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-37-secrets-certificates-management.md]]
+
+## Summary(用中文描述)
+- 核心主题:云转型计划中的密钥与证书管理解决方案选型与实施
+- 问题域:工作负载迁移至公有云过程中的密钥管理标准化需求,涉及应用服务特权账号、API密钥、Tokens等敏感凭证的安全管理
+- 方法/机制:通过30天试点对比评估 AWS Secrets Manager 与 HashiCorp Vault,最终选定 AWS Secrets Manager;实施阶段从 CI/CD 流程中清除明文密码和密钥,集中化管理并自动化密钥获取
+- 结论/价值:AWS Secrets Manager 以更低成本和更简实施胜出;AWS 在账户级别管理密钥可降低成本并提升安全性
+
+## Key Claims(用中文描述)
+- AWS Secrets Manager 通过内置集成 RDS/Redshift/DynamoDB 和高可用/DR 能力,以按用量计费模式提供简单实施体验
+- HashiCorp Vault 免费版缺乏企业级能力(高可用、多租户),企业版按用户数收费
+- Micro Focus PAM 因需要大量投资才能具备竞争力且缺乏投资计划而被放弃
+- AWS Secrets Manager 的 30 天试点验证了开箱即用功能,同时识别出缺失功能(SSH 密钥轮换、用户密码轮换)
+- 实施阶段首先从 Control Tower 开始,从 CI/CD 流程中清除明文密码和密钥
+
+## Key Quotes
+> "AWS Secrets Manager is easy and simple to implement." — 试点结论
+
+> "AWS manages secrets at the account level, which can reduce costs and increase security." — 实施阶段核心理念
+
+## Key Concepts
+- [[Secrets-Management]]:数字认证凭证(密码、密钥、API、Tokens)的管理工具和方法论,确保应用服务、特权账号等敏感信息的安全存储与访问控制
+- [[AWS-Secrets-Manager]]:AWS 托管的密钥管理服务,提供内置 RDS/Redshift/DynamoDB 集成,支持高可用和灾难恢复,按用量计费
+- [[HashiCorp-Vault]]:自托管、云厂商无关的密钥管理解决方案,支持按需动态密钥和嵌入式证书签名,按用户数收费
+- [[PAM(Privileged-Access-Management)]]:特权访问管理,通过 CyberArk Micro Focus PAM 实现特权账号的安全管控
+- [[Secret-Rotation]]:密钥轮换机制,自动定期更换密钥以降低泄露风险,AWS Secrets Manager 支持数据库凭证自动轮换
+- [[CI/CD-Secrets]]:CI/CD 流程中的密钥管理,从明文存储迁移至集中化密钥管理服务
+
+## Key Entities
+- [[Micro-Focus]]:企业客户,云转型计划(CTP)的主体,评估并选定 AWS Secrets Manager 作为密钥管理方案
+- [[CCLE]]:Cloud Center of Excellence 团队,2022年3月负责探索 Micro Focus 用例并评估密钥管理解决方案
+- [[AWS]]:云服务提供商,AWS Secrets Manager 的提供方
+- [[HashiCorp]]:Vault 产品提供方,开源版和商业企业版均参与评估
+- [[CyberArk]]:Micro Focus PAM 的技术提供方
+
+## Connections
+- [[ctp-topic-62-aws-secrets-manager]] ← extends ← [[ctp-topic-37-secrets-certificates-management]]
+- [[ctp-topic-36-sendgrid-as-an-email-service]] ← shares_security_domain ← [[ctp-topic-37-secrets-certificates-management]]
+- [[ctp-topic-5-aws-identity-and-access-management-iam]] ← related_to ← [[ctp-topic-37-secrets-certificates-management]]
+
+## Contradictions
+- 与 [[ctp-topic-62-aws-secrets-manager]] 潜在补充关系:
+ - 冲突点:Topic 37 试点阶段认为 AWS Secrets Manager "easy and simple";Topic 62 深入实践发现 JDBC Wrapper + Lambda 函数等实施细节复杂度
+ - 当前观点:Topic 37 的快速试点结论与 Topic 62 的企业级深度实践一致,AWS Secrets Manager 被正式选定为标准方案
+ - 对方观点:Topic 62 在 Topic 37 基础上补充了 Oracle DB 密码轮换等高级用例和实施最佳实践
diff --git a/wiki/sources/ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone.md b/wiki/sources/ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone.md
index 25c6ee82..61d4b3b3 100644
--- a/wiki/sources/ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone.md
+++ b/wiki/sources/ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone.md
@@ -1,66 +1,66 @@
----
-title: "CTP Topic 39 Implementing EKS in the AWS Lab Landing Zone"
-type: source
-tags:
- - AWS
- - EKS
- - Kubernetes
- - Landing-Zone
- - CTP
-date: 2026-04-24
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]]
-
-## Summary(用中文描述)
-- 核心主题:在 AWS Lab Landing Zone 中通过 Terraform/Terragrunt 自动化部署 EKS 集群,解决 Octane(Micro Focus SaaS 应用)IP 地址池不足的难题
-- 问题域:Micro Focus 网络环境下的 AWS Lab Landing Zone 网络地址空间受限,无法满足 EKS Pod 大量 IP 地址需求
-- 方法/机制:
- - 在独立私有子网(非主 VPC 子网)中部署 EKS,由 EKS 模块自定义网络标志控制 IP 分配
- - 通过 Terraform/Terragrunt 模块调用 EKS 模块,指定子网和联邦账户/角色映射
- - Pod 规范中设置 `hostNetwork: true` 使 Pod 直接使用宿主机网络
- - IAM 角色映射实现集群访问和 AWS Console 可视化
-- 结论/价值:即使在受限网络环境下,通过 EKS 自定义网络功能 + IaC 自动化仍可成功部署 EKS,无需 Atlantis(Jenkins + Terragrunt 模块替代方案)
-
-## Key Claims(用中文描述)
-- EKS 模块提供自定义网络配置标志,可控制 Pod IP 地址分配策略
-- 在受限 Lab 网络环境下,创建独立私有子网(非主 VPC 子网)为 EKS Pod 提供充足 IP 地址池
-- Terraform/Terragrunt 模块可封装 EKS 集群的完整部署逻辑,支持跨账户角色映射
-- Atlantis 目前无法部署 EKS 集群,需通过 Jenkins + Terragrunt 模块替代
-- Pod 网络规范设置 `hostNetwork: true` 后,Pod 可同时访问内部 Micro Focus 网络和外部资源
-- IAM 角色映射使用户可连接集群并在 AWS Console 中查看 EKS 组件
-- 节点组数量当前硬编码,未来版本将支持可配置参数
-
-## Key Quotes
-> "The problem was that this wasn't supported in the EKS sort of solution that was given to us." — Spencer,描述 IP 池不足问题在标准 EKS 方案中不受支持的困境
-
-> "Within the spec configuration, we basically have to put host network equals true." — Guy,描述让 Pod 访问内部网络的关键配置
-
-## Key Concepts
-- [[Amazon EKS]]:AWS 托管 Kubernetes 服务,完全托管控制平面,支持 IAM RBAC 最小权限
-- [[Kubernetes Custom Networking]]:EKS 自定义网络功能,允许控制 Pod IP 分配策略,解决 VPC CIDR 限制
-- [[Terraform-Terragrunt Module]]:封装 EKS 部署逻辑的基础设施即代码模块,支持跨账户部署
-- [[IAM Role Mapping (EKS)]]:通过 AWS IAM 角色映射实现集群访问控制和 AWS Console 可视化
-- [[Host Network Mode (Pod)]]:Pod 使用宿主机网络栈,`hostNetwork: true` 使 Pod 可访问底层网络资源
-- [[Container Hardening]]:容器安全加固标准,与安全团队协作实施的容器安全措施
-
-## Key Entities
-- [[Octane-Hub]]:Software Factory 团队,Micro Focus 云转型计划一部分,主导 SaaS 应用容器化迁移,CTO 为 Holger Rode;本文档中 Octane 作为 EKS 部署的实际业务驱动方(IP 密集型 SaaS 应用)
-- [[Spencer]]:AWS Lab Landing Zone EKS 实施分享人
-- [[Guy]]:AWS Lab Landing Zone EKS 实施技术细节讲解人
-- [[Terragrunt]]:Terraform 的 wrapper 工具,用于管理跨账户基础设施部署
-- [[Atlantis]]:Terraform GitOps 工具,当前不支持 EKS 集群部署
-
-## Connections
-- [[ctp-topic-70-eks-deployment-using-iac]] ← depends_on ← [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]]
- - Topic 39 解决了 EKS 在受限网络环境下的 IP 分配技术难题,为 Topic 70 的 IaC 部署实践提供底层支撑
-- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← related ← [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]]
- - 两者均讨论 EKS 可靠性,两者互补:Topic 39 侧重网络架构,Topic 59 侧重 SLA/SLO 保障
-- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← depends_on ← [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]]
- - Labs LZ 的多账户架构和 Terraform/Terragrunt 管理模式是 Topic 39 EKS 部署的基础设施上下文
-- [[ctp-topic-14-octane-hub-on-aws]] ← related ← [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]]
- - 两者均涉及 Octane 的 AWS 迁移,但 Topic 14 聚焦 Octane Hub 整体迁移,Topic 39 聚焦 EKS 网络解决方案
-
-## Contradictions
-- 无发现与现有 Wiki 页面的直接冲突
+---
+title: "CTP Topic 39 Implementing EKS in the AWS Lab Landing Zone"
+type: source
+tags:
+ - AWS
+ - EKS
+ - Kubernetes
+ - Landing-Zone
+ - CTP
+date: 2026-04-24
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone.md]]
+
+## Summary(用中文描述)
+- 核心主题:在 AWS Lab Landing Zone 中通过 Terraform/Terragrunt 自动化部署 EKS 集群,解决 Octane(Micro Focus SaaS 应用)IP 地址池不足的难题
+- 问题域:Micro Focus 网络环境下的 AWS Lab Landing Zone 网络地址空间受限,无法满足 EKS Pod 大量 IP 地址需求
+- 方法/机制:
+ - 在独立私有子网(非主 VPC 子网)中部署 EKS,由 EKS 模块自定义网络标志控制 IP 分配
+ - 通过 Terraform/Terragrunt 模块调用 EKS 模块,指定子网和联邦账户/角色映射
+ - Pod 规范中设置 `hostNetwork: true` 使 Pod 直接使用宿主机网络
+ - IAM 角色映射实现集群访问和 AWS Console 可视化
+- 结论/价值:即使在受限网络环境下,通过 EKS 自定义网络功能 + IaC 自动化仍可成功部署 EKS,无需 Atlantis(Jenkins + Terragrunt 模块替代方案)
+
+## Key Claims(用中文描述)
+- EKS 模块提供自定义网络配置标志,可控制 Pod IP 地址分配策略
+- 在受限 Lab 网络环境下,创建独立私有子网(非主 VPC 子网)为 EKS Pod 提供充足 IP 地址池
+- Terraform/Terragrunt 模块可封装 EKS 集群的完整部署逻辑,支持跨账户角色映射
+- Atlantis 目前无法部署 EKS 集群,需通过 Jenkins + Terragrunt 模块替代
+- Pod 网络规范设置 `hostNetwork: true` 后,Pod 可同时访问内部 Micro Focus 网络和外部资源
+- IAM 角色映射使用户可连接集群并在 AWS Console 中查看 EKS 组件
+- 节点组数量当前硬编码,未来版本将支持可配置参数
+
+## Key Quotes
+> "The problem was that this wasn't supported in the EKS sort of solution that was given to us." — Spencer,描述 IP 池不足问题在标准 EKS 方案中不受支持的困境
+
+> "Within the spec configuration, we basically have to put host network equals true." — Guy,描述让 Pod 访问内部网络的关键配置
+
+## Key Concepts
+- [[Amazon EKS]]:AWS 托管 Kubernetes 服务,完全托管控制平面,支持 IAM RBAC 最小权限
+- [[Kubernetes Custom Networking]]:EKS 自定义网络功能,允许控制 Pod IP 分配策略,解决 VPC CIDR 限制
+- [[Terraform-Terragrunt Module]]:封装 EKS 部署逻辑的基础设施即代码模块,支持跨账户部署
+- [[IAM Role Mapping (EKS)]]:通过 AWS IAM 角色映射实现集群访问控制和 AWS Console 可视化
+- [[Host Network Mode (Pod)]]:Pod 使用宿主机网络栈,`hostNetwork: true` 使 Pod 可访问底层网络资源
+- [[Container Hardening]]:容器安全加固标准,与安全团队协作实施的容器安全措施
+
+## Key Entities
+- [[Octane-Hub]]:Software Factory 团队,Micro Focus 云转型计划一部分,主导 SaaS 应用容器化迁移,CTO 为 Holger Rode;本文档中 Octane 作为 EKS 部署的实际业务驱动方(IP 密集型 SaaS 应用)
+- [[Spencer]]:AWS Lab Landing Zone EKS 实施分享人
+- [[Guy]]:AWS Lab Landing Zone EKS 实施技术细节讲解人
+- [[Terragrunt]]:Terraform 的 wrapper 工具,用于管理跨账户基础设施部署
+- [[Atlantis]]:Terraform GitOps 工具,当前不支持 EKS 集群部署
+
+## Connections
+- [[ctp-topic-70-eks-deployment-using-iac]] ← depends_on ← [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]]
+ - Topic 39 解决了 EKS 在受限网络环境下的 IP 分配技术难题,为 Topic 70 的 IaC 部署实践提供底层支撑
+- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← related ← [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]]
+ - 两者均讨论 EKS 可靠性,两者互补:Topic 39 侧重网络架构,Topic 59 侧重 SLA/SLO 保障
+- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← depends_on ← [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]]
+ - Labs LZ 的多账户架构和 Terraform/Terragrunt 管理模式是 Topic 39 EKS 部署的基础设施上下文
+- [[ctp-topic-14-octane-hub-on-aws]] ← related ← [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]]
+ - 两者均涉及 Octane 的 AWS 迁移,但 Topic 14 聚焦 Octane Hub 整体迁移,Topic 39 聚焦 EKS 网络解决方案
+
+## Contradictions
+- 无发现与现有 Wiki 页面的直接冲突
diff --git a/wiki/sources/ctp-topic-4-using-agile-to-run-the-cloud-transformation-program.md b/wiki/sources/ctp-topic-4-using-agile-to-run-the-cloud-transformation-program.md
index 03b2b1c9..75ea6ddc 100644
--- a/wiki/sources/ctp-topic-4-using-agile-to-run-the-cloud-transformation-program.md
+++ b/wiki/sources/ctp-topic-4-using-agile-to-run-the-cloud-transformation-program.md
@@ -1,47 +1,47 @@
----
-title: "CTP Topic 4 Using Agile to Run the Cloud Transformation Programme"
-type: source
-tags: []
-sources: []
-last_updated: 2026-04-24
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-4-using-agile-to-run-the-cloud-transformation-program.md]]
-
-## Summary(用中文描述)
-- 核心主题:云转型计划(Cloud Transformation Programme)中敏捷实践的落地经验
-- 问题域:大型企业云迁移项目如何选择和调整敏捷框架
-- 方法/机制:Scrum → Kanban 的框架演进;Microsoft Planner 作为看板工具;每日站会 + 回顾会议保留 Scrum 仪式
-- 结论/价值:Scrum 的固定 Sprint 节奏不适合快速变化的云转型项目,Kanban 持续流动 + 固定仪式是更优的混合方案
-
-## Key Claims(用中文描述)
-- 云转型团队从 Scrum(两周 Sprint)转向 Kanban,因为 Sprint 期间不允许变更,无法应对项目中的频繁变化
-- 混合框架(Kanban 为主 + 保留 Scrum 仪式)是当前最优方案
-- 每日站会应简短(15-30 分钟),围绕 Planner 看板回答三个问题:昨天完成什么、今天做什么、有什么阻碍
-- 回顾会议是快速反馈循环的核心,通过行动项(带负责人)驱动团队持续改进
-- Microsoft Planner 看板列:Backlog → To Do → In Progress → Program Key Decisions → Icebox
-- 每张任务卡必须指定单一负责人,即使多人协作;明确角色(如 oversight);链接依赖卡;使用优先级和截止日期
-
-## Key Quotes
-> "The big problem with Scrum, in my opinion, is that you can't make changes throughout the sprints, we are not advised to." — Heather Norris,解释为何从 Scrum 转向 Kanban
-
-> "Agile is all about getting that rapid feedback to make the product and make the, you know, the development culture better." — Heather Norris,阐述敏捷的核心价值
-
-## Key Concepts
-- [[Scrum]]:两周一迭代的敏捷框架,包含 Product Backlog、Sprint Planning、Daily Scrum、Sprint Review、Sprint Retrospective;因 Sprint 期间禁止变更而被云转型团队放弃
-- [[Kanban]]:持续流动的敏捷框架,允许随时调整优先级,无固定 Sprint 边界;适合变化频繁的云转型项目
-- [[Agile Ceremonies]]:Scrum 的固定仪式——Sprint Planning(冲刺规划)、Daily Stand-up(每日站会)、Sprint Review(冲刺评审)、Retrospective(回顾会议);云转型团队保留站会和回顾会议
-- [[Continuous Delivery]]:持续交付,Kanban 的核心优势,无需等待 Sprint 结束即可发布
-- [[Microsoft Planner Board]]:微软看板工具,云转型团队的项目管理平台,支持卡片管理、依赖链接、优先级设置
-
-## Key Entities
-- [[Heather Norris]]:云转型计划项目经理,主讲本次分享,介绍敏捷方法论实践
-- [[Microsoft Planner]]:团队使用的项目管理看板工具
-
-## Connections
-- [[ctp-topic-57-product-backlog-managing-demand]] ← related_to ← [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]]
-- [[ctp-topic-30-managing-change]] ← extends ← [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]]
-
-## Contradictions
-- 无已知冲突
+---
+title: "CTP Topic 4 Using Agile to Run the Cloud Transformation Programme"
+type: source
+tags: []
+sources: []
+last_updated: 2026-04-24
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-4-using-agile-to-run-the-cloud-transformation-program.md]]
+
+## Summary(用中文描述)
+- 核心主题:云转型计划(Cloud Transformation Programme)中敏捷实践的落地经验
+- 问题域:大型企业云迁移项目如何选择和调整敏捷框架
+- 方法/机制:Scrum → Kanban 的框架演进;Microsoft Planner 作为看板工具;每日站会 + 回顾会议保留 Scrum 仪式
+- 结论/价值:Scrum 的固定 Sprint 节奏不适合快速变化的云转型项目,Kanban 持续流动 + 固定仪式是更优的混合方案
+
+## Key Claims(用中文描述)
+- 云转型团队从 Scrum(两周 Sprint)转向 Kanban,因为 Sprint 期间不允许变更,无法应对项目中的频繁变化
+- 混合框架(Kanban 为主 + 保留 Scrum 仪式)是当前最优方案
+- 每日站会应简短(15-30 分钟),围绕 Planner 看板回答三个问题:昨天完成什么、今天做什么、有什么阻碍
+- 回顾会议是快速反馈循环的核心,通过行动项(带负责人)驱动团队持续改进
+- Microsoft Planner 看板列:Backlog → To Do → In Progress → Program Key Decisions → Icebox
+- 每张任务卡必须指定单一负责人,即使多人协作;明确角色(如 oversight);链接依赖卡;使用优先级和截止日期
+
+## Key Quotes
+> "The big problem with Scrum, in my opinion, is that you can't make changes throughout the sprints, we are not advised to." — Heather Norris,解释为何从 Scrum 转向 Kanban
+
+> "Agile is all about getting that rapid feedback to make the product and make the, you know, the development culture better." — Heather Norris,阐述敏捷的核心价值
+
+## Key Concepts
+- [[Scrum]]:两周一迭代的敏捷框架,包含 Product Backlog、Sprint Planning、Daily Scrum、Sprint Review、Sprint Retrospective;因 Sprint 期间禁止变更而被云转型团队放弃
+- [[Kanban]]:持续流动的敏捷框架,允许随时调整优先级,无固定 Sprint 边界;适合变化频繁的云转型项目
+- [[Agile Ceremonies]]:Scrum 的固定仪式——Sprint Planning(冲刺规划)、Daily Stand-up(每日站会)、Sprint Review(冲刺评审)、Retrospective(回顾会议);云转型团队保留站会和回顾会议
+- [[Continuous Delivery]]:持续交付,Kanban 的核心优势,无需等待 Sprint 结束即可发布
+- [[Microsoft Planner Board]]:微软看板工具,云转型团队的项目管理平台,支持卡片管理、依赖链接、优先级设置
+
+## Key Entities
+- [[Heather Norris]]:云转型计划项目经理,主讲本次分享,介绍敏捷方法论实践
+- [[Microsoft Planner]]:团队使用的项目管理看板工具
+
+## Connections
+- [[ctp-topic-57-product-backlog-managing-demand]] ← related_to ← [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]]
+- [[ctp-topic-30-managing-change]] ← extends ← [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]]
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/ctp-topic-40-saas-database-architecture-on-aws-cloud.md b/wiki/sources/ctp-topic-40-saas-database-architecture-on-aws-cloud.md
index 96ee0f89..d4e8ecca 100644
--- a/wiki/sources/ctp-topic-40-saas-database-architecture-on-aws-cloud.md
+++ b/wiki/sources/ctp-topic-40-saas-database-architecture-on-aws-cloud.md
@@ -1,61 +1,61 @@
----
-title: "CTP Topic 40 SaaS Database Architecture On AWS Cloud"
-type: source
-tags:
- - SaaS
- - Database
- - Architecture
- - AWS
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-40-saas-database-architecture-on-aws-cloud]]
-
-## Summary(用中文描述)
-- 核心主题:SAS 数据库团队在 AWS 云上的数据库架构与运维实践
-- 问题域:企业级 SaaS 数据库管理、跨区域多数据库引擎运维、数据库高可用架构
-- 方法/机制:
- - 全球分布式团队(美国/加拿大/印度/以色列)提供 24/7 支持
- - 支持 Oracle、Vertica、Postgres、DynamoDB、SQL Server、MongoDB、MySQL 等多种数据库引擎
- - 多可用区高可用部署(Oracle Data Guard、Postgres Active-Passive/Active-Active、RDS HA)
- - 使用 Terraform、AWS CLI、Shell/PowerShell 脚本实现基础设施自动化
-- 结论/价值:提供企业级数据库运维的最佳实践参考,包括多数据库引擎管理、多可用区高可用设计、以及与 AWS 原生服务(CloudWatch、CloudTrail、Config)的集成
-
-## Key Claims(用中文描述)
-- SAS 数据库团队在全球 4 个国家设有办公地点,管理 500+ 数据库和 1000+ DB 服务器
-- 数据库主要部署在 Application VPC 内,集成安全措施
-- 高可用架构采用三可用区部署模式:一区主库、二区备用库、三区见证节点
-- 报告数据库在第三可用区部署只读仓库,通过 VPN 安全访问
-- Oracle GoldenGate 用于多租户场景,支持平滑迁移(零停机或最小停机)
-- 日常运维每月处理 400-500 个 SSR 和 IM,每月至少执行 10 个变更
-
-## Key Quotes
-> "The idea was to move those databases seamless without downtime or with minimum downtime." — 描述 Oracle GoldenGate 数据中心迁移项目的核心目标
-
-> "Databases reside mostly on application VPCs with integrated security measures." — 数据库安全部署原则
-
-## Key Concepts
-- [[高可用(High Availability)]]:关注系统运行时间,MTBF 为衡量指标
-- [[Oracle Data Guard]]:Oracle 数据库的高可用解决方案,用于主备复制和故障切换
-- [[Multi-AZ Deployment]]:跨多个可用区部署数据库,确保故障隔离和灾难恢复能力
-- [[Database Migration]]:使用 Oracle GoldenGate 实现零停机或最小停机迁移
-- [[DB-as-a-Service]]:托管数据库服务模式(AWS RDS、Aurora)
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,提供基础设施和托管数据库服务
-- [[Amazon RDS]]:关系型数据库服务,支持 Multi-AZ 部署
-- [[Amazon Aurora]]:云原生关系型数据库,6 副本跨 3 AZ 共享集群卷架构
-- [[AWS CloudWatch]]:监控和可观测性服务
-- [[Terraform]]:基础设施即代码工具
-- [[Micro Focus]]:SAS 产品的母公司,数据库团队隶属该组织
-
-## Connections
-- [[ctp-topic-7-saas-landing-zone-design]] ← related_to ← [[ctp-topic-40-saas-database-architecture-on-aws-cloud]]
-- [[ctp-topic-51-purpose-built-databases]] ← extends ← [[ctp-topic-40-saas-database-architecture-on-aws-cloud]]
-- [[ctp-topic-66-rds-vs-aurora]] ← related_to ← [[ctp-topic-40-saas-database-architecture-on-aws-cloud]]
-- [[ctp-topic-44-aws-backup-in-micro-focus]] ← related_to ← [[ctp-topic-40-saas-database-architecture-on-aws-cloud]]
-
-## Contradictions
-- 无明显冲突内容
+---
+title: "CTP Topic 40 SaaS Database Architecture On AWS Cloud"
+type: source
+tags:
+ - SaaS
+ - Database
+ - Architecture
+ - AWS
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-40-saas-database-architecture-on-aws-cloud.md]]
+
+## Summary(用中文描述)
+- 核心主题:SAS 数据库团队在 AWS 云上的数据库架构与运维实践
+- 问题域:企业级 SaaS 数据库管理、跨区域多数据库引擎运维、数据库高可用架构
+- 方法/机制:
+ - 全球分布式团队(美国/加拿大/印度/以色列)提供 24/7 支持
+ - 支持 Oracle、Vertica、Postgres、DynamoDB、SQL Server、MongoDB、MySQL 等多种数据库引擎
+ - 多可用区高可用部署(Oracle Data Guard、Postgres Active-Passive/Active-Active、RDS HA)
+ - 使用 Terraform、AWS CLI、Shell/PowerShell 脚本实现基础设施自动化
+- 结论/价值:提供企业级数据库运维的最佳实践参考,包括多数据库引擎管理、多可用区高可用设计、以及与 AWS 原生服务(CloudWatch、CloudTrail、Config)的集成
+
+## Key Claims(用中文描述)
+- SAS 数据库团队在全球 4 个国家设有办公地点,管理 500+ 数据库和 1000+ DB 服务器
+- 数据库主要部署在 Application VPC 内,集成安全措施
+- 高可用架构采用三可用区部署模式:一区主库、二区备用库、三区见证节点
+- 报告数据库在第三可用区部署只读仓库,通过 VPN 安全访问
+- Oracle GoldenGate 用于多租户场景,支持平滑迁移(零停机或最小停机)
+- 日常运维每月处理 400-500 个 SSR 和 IM,每月至少执行 10 个变更
+
+## Key Quotes
+> "The idea was to move those databases seamless without downtime or with minimum downtime." — 描述 Oracle GoldenGate 数据中心迁移项目的核心目标
+
+> "Databases reside mostly on application VPCs with integrated security measures." — 数据库安全部署原则
+
+## Key Concepts
+- [[高可用(High Availability)]]:关注系统运行时间,MTBF 为衡量指标
+- [[Oracle Data Guard]]:Oracle 数据库的高可用解决方案,用于主备复制和故障切换
+- [[Multi-AZ Deployment]]:跨多个可用区部署数据库,确保故障隔离和灾难恢复能力
+- [[Database Migration]]:使用 Oracle GoldenGate 实现零停机或最小停机迁移
+- [[DB-as-a-Service]]:托管数据库服务模式(AWS RDS、Aurora)
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,提供基础设施和托管数据库服务
+- [[Amazon RDS]]:关系型数据库服务,支持 Multi-AZ 部署
+- [[Amazon Aurora]]:云原生关系型数据库,6 副本跨 3 AZ 共享集群卷架构
+- [[AWS CloudWatch]]:监控和可观测性服务
+- [[Terraform]]:基础设施即代码工具
+- [[Micro Focus]]:SAS 产品的母公司,数据库团队隶属该组织
+
+## Connections
+- [[ctp-topic-7-saas-landing-zone-design]] ← related_to ← [[ctp-topic-40-saas-database-architecture-on-aws-cloud]]
+- [[ctp-topic-51-purpose-built-databases]] ← extends ← [[ctp-topic-40-saas-database-architecture-on-aws-cloud]]
+- [[ctp-topic-66-rds-vs-aurora]] ← related_to ← [[ctp-topic-40-saas-database-architecture-on-aws-cloud]]
+- [[ctp-topic-44-aws-backup-in-micro-focus]] ← related_to ← [[ctp-topic-40-saas-database-architecture-on-aws-cloud]]
+
+## Contradictions
+- 无明显冲突内容
diff --git a/wiki/sources/ctp-topic-41-nfrs-and-error-budgets.md b/wiki/sources/ctp-topic-41-nfrs-and-error-budgets.md
index b35ebd85..22936fdd 100644
--- a/wiki/sources/ctp-topic-41-nfrs-and-error-budgets.md
+++ b/wiki/sources/ctp-topic-41-nfrs-and-error-budgets.md
@@ -1,55 +1,55 @@
----
-title: "CTP Topic 41 NFR's and Error Budgets"
-type: source
-tags: []
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-41-nfrs-and-error-budgets.md]]
-
-## Summary(用中文描述)
-- 核心主题:NFR(非功能需求)与 Error Budget(错误预算)在云转型和敏捷开发中的实践——SRE 团队如何驱动产品组与运维协作,满足客户期望,以敏捷方式确保运维要求,并理解错误预算边界以快速可靠地交付功能。
-- 问题域:云环境下的可靠性工程、敏捷开发中的运维融合、NFR 的云原生落地
-- 方法/机制:NFR Epic 模板将需求集成到 Sprint Backlog;Error Budget 通过 SLO/SLI 量化系统可容忍的不可靠程度;混沌工程主动注入故障验证系统韧性
-- 结论/价值:Error Budget 归一化失败弥合开发与运维的鸿沟;NFR 应更具规范性并利用云原生服务;监控能力是衡量 Error Budget 是否达标的关键
-
-## Key Claims(用中文描述)
-- NFR 是评判系统运行的准则,Error Budget 是系统可容忍的最大故障时间,两者共同构成云环境下可靠性工程的基石
-- AWS 共享责任模型将基础设施管理责任转移给云提供商,但公司必须在云中架构和管理服务以满足 NFR
-- Error Budget = 1 - 可用性 SLO(如 99.9% SLO → 0.1% Error Budget),用于衡量系统在影响客户前可承受的不可靠程度
-- Error Budget 将失败归一化为开发流程的一部分,弥合了开发与运维之间的文化鸿沟
-- 混沌工程通过主动注入故障测试系统韧性,确保 NFR 得到满足
-
-## Key Quotes
-> "We want to drive collaboration across our product groups and operations to ensure our obligation to our customers." — Brendan Standing,SRE 协作目标
-> "Error budgets normalize failure as part of the development process." — Error Budget 的核心理念
-> "SLRs are quantifiable measures of reliability, SLOs define how a service should perform, and SLAs are customer-level agreements." — 三层服务等级体系
-
-## Key Concepts
-- [[NFR(非功能需求)]]:评判系统运行的准则,涵盖可用性、性能、安全性、可扩展性等维度;云环境下应更具规范性,充分利用云原生服务
-- [[Error Budget(错误预算)]]:系统可容忍的最大故障时间,由 SLO 推导而来;用于归一化失败并驱动开发和运维决策
-- [[SLO(服务等级目标)]]:定义服务应如何表现的绩效目标
-- [[SLI(服务等级指标)]]:可量化的可靠性度量指标
-- [[SLA(服务等级协议)]]:客户级别的正式协议
-- [[SLR(服务等级需求)]]:服务等级需求,与 SLO 配套使用
-- [[NFR Epic]]:将 NFR 模板集成到 Sprint Backlog 的敏捷实践,确保任何重大变更都考虑非功能需求
-- [[Chaos Engineering(混沌工程)]]:主动注入故障以测试系统韧性,确保 NFR 得到满足
-
-## Key Entities
-- [[Brendan-Standing]]:Micro Focus SRE 负责人(Head of SRE),本视频主讲人
-- [[AWS]]:Amazon Web Services,提供共享责任模型和云原生服务
-- [[Micro-Focus]]:企业云转型主体,OpenText 旗下公司
-
-## Connections
-- [[ctp-topic-30-managing-change]] ← related_to ← [[ctp-topic-41-nfrs-and-error-budgets]](NFR/Error Budget 与 SRE 变更管理实践高度关联,SRE 团队是 Error Budget 度量体系的核心执行者)
-- [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]] ← related_to ← [[ctp-topic-41-nfrs-and-error-budgets]](NFR 中的可用性目标和 DR 策略直接相关,Error Budget 是衡量恢复能力的量化工具)
-- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← extends ← [[ctp-topic-41-nfrs-and-error-budgets]](监控能力是衡量 Error Budget 是否达标的必要前提)
-- [[public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2]] ← related_to ← [[ctp-topic-41-nfrs-and-error-budgets]](NFR/Error Budget 是 SRE 度量弹性目标的工具,与 SRE 转型的方向一致)
-- [[devops-maturity-model-from-traditional-it-to-advanced-devops]] ← extends ← [[ctp-topic-41-nfrs-and-error-budgets]](DevOps 成熟度模型将 Error Budget 作为衡量系统可靠性和运维能力的核心指标)
-
-## Contradictions
-- 与 [[ctp-topic-30-managing-change]] 在 SRE 职责范围上存在视角差异:
- - 冲突点:Topic 30 强调 SRE 的变更管理职责(Standard/Normal/Emergency Change),Topic 41 强调 SRE 的可靠性工程职责(NFR/Error Budget)
- - 当前观点:两者是 SRE 职责的一体两面——变更管理是 SRE 的运营职责,NFR/Error Budget 是 SRE 的工程职责,共同构成完整的 SRE 能力体系
- - 对方观点:Topic 30 侧重"如何处理变更",Topic 41 侧重"如何定义可靠性目标",两者互补而非矛盾
+---
+title: "CTP Topic 41 NFR's and Error Budgets"
+type: source
+tags: []
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-41-nfrs-and-error-budgets.md]]
+
+## Summary(用中文描述)
+- 核心主题:NFR(非功能需求)与 Error Budget(错误预算)在云转型和敏捷开发中的实践——SRE 团队如何驱动产品组与运维协作,满足客户期望,以敏捷方式确保运维要求,并理解错误预算边界以快速可靠地交付功能。
+- 问题域:云环境下的可靠性工程、敏捷开发中的运维融合、NFR 的云原生落地
+- 方法/机制:NFR Epic 模板将需求集成到 Sprint Backlog;Error Budget 通过 SLO/SLI 量化系统可容忍的不可靠程度;混沌工程主动注入故障验证系统韧性
+- 结论/价值:Error Budget 归一化失败弥合开发与运维的鸿沟;NFR 应更具规范性并利用云原生服务;监控能力是衡量 Error Budget 是否达标的关键
+
+## Key Claims(用中文描述)
+- NFR 是评判系统运行的准则,Error Budget 是系统可容忍的最大故障时间,两者共同构成云环境下可靠性工程的基石
+- AWS 共享责任模型将基础设施管理责任转移给云提供商,但公司必须在云中架构和管理服务以满足 NFR
+- Error Budget = 1 - 可用性 SLO(如 99.9% SLO → 0.1% Error Budget),用于衡量系统在影响客户前可承受的不可靠程度
+- Error Budget 将失败归一化为开发流程的一部分,弥合了开发与运维之间的文化鸿沟
+- 混沌工程通过主动注入故障测试系统韧性,确保 NFR 得到满足
+
+## Key Quotes
+> "We want to drive collaboration across our product groups and operations to ensure our obligation to our customers." — Brendan Standing,SRE 协作目标
+> "Error budgets normalize failure as part of the development process." — Error Budget 的核心理念
+> "SLRs are quantifiable measures of reliability, SLOs define how a service should perform, and SLAs are customer-level agreements." — 三层服务等级体系
+
+## Key Concepts
+- [[NFR(非功能需求)]]:评判系统运行的准则,涵盖可用性、性能、安全性、可扩展性等维度;云环境下应更具规范性,充分利用云原生服务
+- [[Error Budget(错误预算)]]:系统可容忍的最大故障时间,由 SLO 推导而来;用于归一化失败并驱动开发和运维决策
+- [[SLO(服务等级目标)]]:定义服务应如何表现的绩效目标
+- [[SLI(服务等级指标)]]:可量化的可靠性度量指标
+- [[SLA(服务等级协议)]]:客户级别的正式协议
+- [[SLR(服务等级需求)]]:服务等级需求,与 SLO 配套使用
+- [[NFR Epic]]:将 NFR 模板集成到 Sprint Backlog 的敏捷实践,确保任何重大变更都考虑非功能需求
+- [[Chaos Engineering(混沌工程)]]:主动注入故障以测试系统韧性,确保 NFR 得到满足
+
+## Key Entities
+- [[Brendan-Standing]]:Micro Focus SRE 负责人(Head of SRE),本视频主讲人
+- [[AWS]]:Amazon Web Services,提供共享责任模型和云原生服务
+- [[Micro-Focus]]:企业云转型主体,OpenText 旗下公司
+
+## Connections
+- [[ctp-topic-30-managing-change]] ← related_to ← [[ctp-topic-41-nfrs-and-error-budgets]](NFR/Error Budget 与 SRE 变更管理实践高度关联,SRE 团队是 Error Budget 度量体系的核心执行者)
+- [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]] ← related_to ← [[ctp-topic-41-nfrs-and-error-budgets]](NFR 中的可用性目标和 DR 策略直接相关,Error Budget 是衡量恢复能力的量化工具)
+- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← extends ← [[ctp-topic-41-nfrs-and-error-budgets]](监控能力是衡量 Error Budget 是否达标的必要前提)
+- [[public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2]] ← related_to ← [[ctp-topic-41-nfrs-and-error-budgets]](NFR/Error Budget 是 SRE 度量弹性目标的工具,与 SRE 转型的方向一致)
+- [[devops-maturity-model-from-traditional-it-to-advanced-devops]] ← extends ← [[ctp-topic-41-nfrs-and-error-budgets]](DevOps 成熟度模型将 Error Budget 作为衡量系统可靠性和运维能力的核心指标)
+
+## Contradictions
+- 与 [[ctp-topic-30-managing-change]] 在 SRE 职责范围上存在视角差异:
+ - 冲突点:Topic 30 强调 SRE 的变更管理职责(Standard/Normal/Emergency Change),Topic 41 强调 SRE 的可靠性工程职责(NFR/Error Budget)
+ - 当前观点:两者是 SRE 职责的一体两面——变更管理是 SRE 的运营职责,NFR/Error Budget 是 SRE 的工程职责,共同构成完整的 SRE 能力体系
+ - 对方观点:Topic 30 侧重"如何处理变更",Topic 41 侧重"如何定义可靠性目标",两者互补而非矛盾
diff --git a/wiki/sources/ctp-topic-42-grafana-observability-dashboard.md b/wiki/sources/ctp-topic-42-grafana-observability-dashboard.md
index 52f30dd6..0033aa80 100644
--- a/wiki/sources/ctp-topic-42-grafana-observability-dashboard.md
+++ b/wiki/sources/ctp-topic-42-grafana-observability-dashboard.md
@@ -1,54 +1,54 @@
----
-title: "CTP Topic 42 Grafana Observability Dashboard"
-type: source
-tags:
- - Grafana
- - Observability
- - Dashboard
- - AWS
- - Terraform
- - EKS
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-42-grafana-observability-dashboard]]
-
-## Summary(用中文描述)
-- 核心主题:企业级 Grafana 可观测性平台在 AWS 多账户环境下的架构设计与落地实践
-- 问题域:AWS Landing Zone 多产品团队账户的集中监控与可视化需求
-- 方法/机制:Grafana + IAM 跨账户角色 + Terraform IaC 自动化 + Prometheus 网络监控
-- 结论/价值:Grafana 统一替代 Micro Focus 工具实现端到端监控,支持动态仪表盘和告警通知
-
-## Key Claims(用中文描述)
-- Grafana 通过 IAM 角色策略从监控账户访问各产品团队 AWS 账户,实现跨账户统一监控
-- Terraform 模块化封装 Grafana 数据源和组织结构,实现新产品组自动化接入
-- Prometheus 作为 Checkpoint 和防火墙的网络监控数据源,支持 SNMP 协议采集
-- Grafana 用户管理将逐步从数据库模式迁移至 LDAP 或 SSO 统一认证
-
-## Key Quotes
-> "Grafana does not exist differently data source by itself. It needs to be expressed from the data, all kinds of data sources." — Grafana 本身不存储数据,数据必须来自外部数据源
-
-> "We would like to build application specific dashboards which can basically give us key insight with respect to our applications that are running over there." — 未来目标是构建应用级仪表盘,提供关键业务洞察
-
-## Key Concepts
-- [[Observability(可观测性)]]:通过外部输出(Metrics/Logs/Traces)推断系统内部状态的能力
-- [[Grafana]]:开源数据可视化平台,支持多数据源的图表和仪表盘
-- [[Terraform]]:HashiCorp 基础设施即代码工具,用于自动化资源供给
-- [[Prometheus]]:开源时序数据库和监控告警系统,用于网络设备指标采集
-- [[SNMP(Simple Network Management Protocol)]]:网络设备监控协议,用于采集 Checkpoint 防火墙指标
-- [[IAM Role(跨账户角色)]]:AWS IAM 角色机制,实现跨账户资源安全访问
-
-## Key Entities
-- [[AWS CloudWatch]]:AWS 托管监控服务,Grafana 的主要数据源之一
-- [[AWS Landing Zone]]:AWS 多账户架构框架,产品团队账户通过 IAM 角色被监控账户访问
-- [[Micro Focus Operations Bridge Manager]]:将被 Grafana 替代的传统监控工具
-
-## Connections
-- [[ctp-topic-60-monitor-aws-using-hyperscale-observability-with-grafana]] ← extends ← [[ctp-topic-42-grafana-observability-dashboard]]
-- [[ctp-topic-54-esm-saas-log-analytics]] ← related ← [[ctp-topic-42-grafana-observability-dashboard]]
-- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← related ← [[ctp-topic-42-grafana-observability-dashboard]]
-- [[ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid]] ← replaced_by ← [[ctp-topic-42-grafana-observability-dashboard]]
-
-## Contradictions
-- 无明显冲突。本视频与 [[ctp-topic-60]] 均介绍 Grafana,视角互补(Grafana 本身 vs Hyperscale 场景),与 [[ctp-topic-67]] 同属可观测性专题,共同构成完整监控知识体系
+---
+title: "CTP Topic 42 Grafana Observability Dashboard"
+type: source
+tags:
+ - Grafana
+ - Observability
+ - Dashboard
+ - AWS
+ - Terraform
+ - EKS
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-42-grafana-observability-dashboard.md]]
+
+## Summary(用中文描述)
+- 核心主题:企业级 Grafana 可观测性平台在 AWS 多账户环境下的架构设计与落地实践
+- 问题域:AWS Landing Zone 多产品团队账户的集中监控与可视化需求
+- 方法/机制:Grafana + IAM 跨账户角色 + Terraform IaC 自动化 + Prometheus 网络监控
+- 结论/价值:Grafana 统一替代 Micro Focus 工具实现端到端监控,支持动态仪表盘和告警通知
+
+## Key Claims(用中文描述)
+- Grafana 通过 IAM 角色策略从监控账户访问各产品团队 AWS 账户,实现跨账户统一监控
+- Terraform 模块化封装 Grafana 数据源和组织结构,实现新产品组自动化接入
+- Prometheus 作为 Checkpoint 和防火墙的网络监控数据源,支持 SNMP 协议采集
+- Grafana 用户管理将逐步从数据库模式迁移至 LDAP 或 SSO 统一认证
+
+## Key Quotes
+> "Grafana does not exist differently data source by itself. It needs to be expressed from the data, all kinds of data sources." — Grafana 本身不存储数据,数据必须来自外部数据源
+
+> "We would like to build application specific dashboards which can basically give us key insight with respect to our applications that are running over there." — 未来目标是构建应用级仪表盘,提供关键业务洞察
+
+## Key Concepts
+- [[Observability(可观测性)]]:通过外部输出(Metrics/Logs/Traces)推断系统内部状态的能力
+- [[Grafana]]:开源数据可视化平台,支持多数据源的图表和仪表盘
+- [[Terraform]]:HashiCorp 基础设施即代码工具,用于自动化资源供给
+- [[Prometheus]]:开源时序数据库和监控告警系统,用于网络设备指标采集
+- [[SNMP(Simple Network Management Protocol)]]:网络设备监控协议,用于采集 Checkpoint 防火墙指标
+- [[IAM Role(跨账户角色)]]:AWS IAM 角色机制,实现跨账户资源安全访问
+
+## Key Entities
+- [[AWS CloudWatch]]:AWS 托管监控服务,Grafana 的主要数据源之一
+- [[AWS Landing Zone]]:AWS 多账户架构框架,产品团队账户通过 IAM 角色被监控账户访问
+- [[Micro Focus Operations Bridge Manager]]:将被 Grafana 替代的传统监控工具
+
+## Connections
+- [[ctp-topic-60-monitor-aws-using-hyperscale-observability-with-grafana]] ← extends ← [[ctp-topic-42-grafana-observability-dashboard]]
+- [[ctp-topic-54-esm-saas-log-analytics]] ← related ← [[ctp-topic-42-grafana-observability-dashboard]]
+- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← related ← [[ctp-topic-42-grafana-observability-dashboard]]
+- [[ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid]] ← replaced_by ← [[ctp-topic-42-grafana-observability-dashboard]]
+
+## Contradictions
+- 无明显冲突。本视频与 [[ctp-topic-60]] 均介绍 Grafana,视角互补(Grafana 本身 vs Hyperscale 场景),与 [[ctp-topic-67]] 同属可观测性专题,共同构成完整监控知识体系
diff --git a/wiki/sources/ctp-topic-43-vmware-cloud-on-aws.md b/wiki/sources/ctp-topic-43-vmware-cloud-on-aws.md
index 2bf2c059..66c5d4ab 100644
--- a/wiki/sources/ctp-topic-43-vmware-cloud-on-aws.md
+++ b/wiki/sources/ctp-topic-43-vmware-cloud-on-aws.md
@@ -1,57 +1,57 @@
----
-title: "CTP Topic 43 VMware Cloud on AWS"
-type: source
-tags:
- - VMware
- - AWS
- - Hybrid-Cloud
- - CTP
- - Networking
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-43-vmware-cloud-on-aws]]
-
-## Summary(用中文描述)
-- 核心主题:VMware Cloud on AWS(VMC on AWS)混合云服务介绍
-- 问题域:企业混合云迁移策略、云端运行 VMware 工作负载
-- 方法/机制:VMware 与 AWS 联合工程,在 AWS 裸机服务器(i3.metal/i3en.metal)上原生安装 VMware vSphere 8,提供与本地一致的运维体验
-- 结论/价值:VMC on AWS 为不完全准备完全迁移至原生云的企业提供中间路线,相比常规云方案节省 27% 成本,支持 HCX 任意迁移
-
-## Key Claims(用中文描述)
-- VMware 与 AWS 联合工程:VMware hypervisor 在 AWS 硬件上原生安装,不是简单地将软件部署到云端
-- 应用双向迁移能力:工作负载可在数秒内往返迁移于本地与云端之间
-- 27% 成本节省:相比直接使用常规云方案,VMC on AWS 提供更优的经济性
-- 单一工具集:与本地环境使用相同的 vSphere 工具集,降低运维学习曲线
-- TCO 计算支持:云经济学团队可提供总拥有成本计算,比较本地与其他超大规模云提供商的成本
-
-## Key Quotes
-> "This is not just something where VMware showed up at Amazon and dropped off a box of CDs." — Mike O'Reilly,Staff Cloud Solutions Architect at VMware
-> "VMware sells an entire host, enabling over-provisioning and cost reduction." — Brian Reeves
-> "VMC on AWS offers a 27% cost saving compared to going to a regular cloud."
-
-## Key Concepts
-- [[VMware-Cloud-on-AWS]]:VMware 与 AWS 联合开发的混合云服务,在 AWS 基础设施上原生运行 VMware vSphere 工作负载
-- [[SDDC]]:软件定义数据中心,VMC on AWS 通过 vCenter 进行管理的核心架构单元
-- [[HCX]]:Hybrid Cloud Extension,支持任意 vSphere 环境之间的双向工作负载迁移
-- [[Stretched-Cluster]]:跨可用区的拉伸集群,提供跨 AZ 的高可用和灾难恢复能力
-- [[TCO]]:总拥有成本,云经济学团队用于评估迁移成本效益的核心指标
-
-## Key Entities
-- [[VMware]]:企业级虚拟化和云计算软件提供商,与 AWS 合作开发 VMC on AWS
-- [[AWS]]:Amazon Web Services,提供 VMC on AWS 的底层裸机服务器基础设施(i3.metal/i3en.metal)
-- Brian Reeves:VMware 演讲者,讨论 VMC on AWS 的经济学效益
-- Michael Riley:VMware 演讲者
-- Mike Armstrong:VMware 演讲者
-- Mike O'Reilly:VMware Staff Cloud Solutions Architect,主讲 VMC on AWS 技术架构
-
-## Connections
-- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← [[ctp-topic-43-vmware-cloud-on-aws]](两者均涉及 AWS 基础设施上的企业工作负载部署)
-- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← related_to ← [[ctp-topic-43-vmware-cloud-on-aws]](混合云是 Landing Zone 设计的重要扩展方向)
-
-## Contradictions
-- 与 [[ctp-topic-53-why-bother-with-cloud]] 潜在冲突:
- - 冲突点:是否应迁移至云端
- - 当前观点:本视频主张 VMC on AWS 作为平滑迁移路径,降低上云门槛
- - 对方观点:质疑云迁移的必要性,强调需评估真实 ROI
+---
+title: "CTP Topic 43 VMware Cloud on AWS"
+type: source
+tags:
+ - VMware
+ - AWS
+ - Hybrid-Cloud
+ - CTP
+ - Networking
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-43-vmware-cloud-on-aws.md]]
+
+## Summary(用中文描述)
+- 核心主题:VMware Cloud on AWS(VMC on AWS)混合云服务介绍
+- 问题域:企业混合云迁移策略、云端运行 VMware 工作负载
+- 方法/机制:VMware 与 AWS 联合工程,在 AWS 裸机服务器(i3.metal/i3en.metal)上原生安装 VMware vSphere 8,提供与本地一致的运维体验
+- 结论/价值:VMC on AWS 为不完全准备完全迁移至原生云的企业提供中间路线,相比常规云方案节省 27% 成本,支持 HCX 任意迁移
+
+## Key Claims(用中文描述)
+- VMware 与 AWS 联合工程:VMware hypervisor 在 AWS 硬件上原生安装,不是简单地将软件部署到云端
+- 应用双向迁移能力:工作负载可在数秒内往返迁移于本地与云端之间
+- 27% 成本节省:相比直接使用常规云方案,VMC on AWS 提供更优的经济性
+- 单一工具集:与本地环境使用相同的 vSphere 工具集,降低运维学习曲线
+- TCO 计算支持:云经济学团队可提供总拥有成本计算,比较本地与其他超大规模云提供商的成本
+
+## Key Quotes
+> "This is not just something where VMware showed up at Amazon and dropped off a box of CDs." — Mike O'Reilly,Staff Cloud Solutions Architect at VMware
+> "VMware sells an entire host, enabling over-provisioning and cost reduction." — Brian Reeves
+> "VMC on AWS offers a 27% cost saving compared to going to a regular cloud."
+
+## Key Concepts
+- [[VMware-Cloud-on-AWS]]:VMware 与 AWS 联合开发的混合云服务,在 AWS 基础设施上原生运行 VMware vSphere 工作负载
+- [[SDDC]]:软件定义数据中心,VMC on AWS 通过 vCenter 进行管理的核心架构单元
+- [[HCX]]:Hybrid Cloud Extension,支持任意 vSphere 环境之间的双向工作负载迁移
+- [[Stretched-Cluster]]:跨可用区的拉伸集群,提供跨 AZ 的高可用和灾难恢复能力
+- [[TCO]]:总拥有成本,云经济学团队用于评估迁移成本效益的核心指标
+
+## Key Entities
+- [[VMware]]:企业级虚拟化和云计算软件提供商,与 AWS 合作开发 VMC on AWS
+- [[AWS]]:Amazon Web Services,提供 VMC on AWS 的底层裸机服务器基础设施(i3.metal/i3en.metal)
+- Brian Reeves:VMware 演讲者,讨论 VMC on AWS 的经济学效益
+- Michael Riley:VMware 演讲者
+- Mike Armstrong:VMware 演讲者
+- Mike O'Reilly:VMware Staff Cloud Solutions Architect,主讲 VMC on AWS 技术架构
+
+## Connections
+- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← [[ctp-topic-43-vmware-cloud-on-aws]](两者均涉及 AWS 基础设施上的企业工作负载部署)
+- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← related_to ← [[ctp-topic-43-vmware-cloud-on-aws]](混合云是 Landing Zone 设计的重要扩展方向)
+
+## Contradictions
+- 与 [[ctp-topic-53-why-bother-with-cloud]] 潜在冲突:
+ - 冲突点:是否应迁移至云端
+ - 当前观点:本视频主张 VMC on AWS 作为平滑迁移路径,降低上云门槛
+ - 对方观点:质疑云迁移的必要性,强调需评估真实 ROI
diff --git a/wiki/sources/ctp-topic-44-aws-backup-in-micro-focus.md b/wiki/sources/ctp-topic-44-aws-backup-in-micro-focus.md
index dbc807ac..2e27764e 100644
--- a/wiki/sources/ctp-topic-44-aws-backup-in-micro-focus.md
+++ b/wiki/sources/ctp-topic-44-aws-backup-in-micro-focus.md
@@ -1,61 +1,61 @@
----
-title: "CTP Topic 44 AWS Backup in Micro Focus"
-type: source
-tags:
- - AWS
- - Backup
- - DR
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-44-aws-backup-in-micro-focus]]
-
-## Summary(用中文描述)
-- 核心主题:AWS Backup 托管服务与 Micro Focus 当前备份流程的差距分析,以及向 AWS Backup 迁移的评估。
-- 问题域:企业级数据保护、灾难恢复策略、跨账户/跨区域备份合规性。
-- 方法/机制:
- - 四级 DR 策略(RTO/RPO 从数小时到近乎零)
- - AWS Backup 集中化备份保管库 + 备份计划 + 时间点恢复
- - 基于角色的访问控制(IAM)+ CloudWatch 监控
- - 不可变性(Immutability)防勒索软件
- - 法律保留(Legal Holds)满足合规要求
-- 结论/价值:AWS Backup 相比当前分散式快照管理有明显优势(集中化、不可变性、跨账户/跨区域),但存在卷粒度限制、崩溃一致快照等局限性,需根据 RTO/RPO 需求选择合适策略。
-
-## Key Claims(用中文描述)
-- AWS Backup 通过集中化备份保管库和备份计划,消除了当前多团队分散管理快照的错误风险。
-- 不可变性(Immutability)是防止勒索软件攻击备份数据的核心机制,当前 CCIE vault 无法提供此保障。
-- Pilot Light 策略可在 1 小时内恢复,Warm Standby 可在数分钟内恢复,Active-Active 提供近乎零停机,但成本递增。
-- AWS Backup 对附加到 EC2 的多个卷强制备份所有卷,无法选择性排除特定卷。
-- Amazon 建议数据库不再使用热备份,快照是崩溃一致的,支持增量备份。
-
-## Key Quotes
-> "AWS Backup 是一个托管服务,用于在 AWS 云中集中化和自动化数据保护。它支持跨账户和跨区域备份,并提供不可变性以防止勒索软件等威胁。" — 视频摘要
-> "AWS Backup 加密所有备份,包括静态和传输中的数据。" — 视频摘要
-> "Amazon 不再建议数据库使用热备份,指出快照是崩溃一致的,支持增量备份。" — 视频摘要
-
-## Key Concepts
-- [[AWS Backup]]:AWS 托管的集中化数据保护服务,支持跨账户和跨区域备份,提供不可变性和法律保留功能。
-- [[不可变性(Immutability)]]:防止备份被篡改或删除的机制,是防勒索软件的关键。
-- [[RTO(Recovery Time Objective)]]:恢复时间目标,衡量从故障恢复到服务可用的时间。
-- [[RPO(Recovery Point Objective)]]:恢复点目标,衡量可接受的最大数据丢失时间窗口。
-- [[灾难恢复策略]]:Backup and Restore / Pilot Light / Warm Standby / Active-Active 四级递进策略。
-- [[法律保留(Legal Holds)]]:用于合规性保留特定备份,隔离而不被删除。
-- [[Pilot Light]]:DR 策略之一,数据持续复制到 DR 区域,可在 1 小时内恢复核心服务。
-- [[Warm Standby]]:DR 策略之一,应用在生产 DR 区域以较小规模持续运行,可在数分钟内完全扩缩。
-- [[Active-Active]]:DR 策略之一,应用在两个区域同时运行,提供近乎零停机和零数据丢失。
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,提供 AWS Backup 托管服务的云平台。
-- [[CCIE 门户]]:当前管理快照的内部 Micro Focus 平台,通过标签跟踪备份过程和错误通知。
-- [[Cloud Transformation Programme (CTP)]]:云转型计划,该视频属于 01_AWS-Landing-Zone 系列第 44 个主题。
-
-## Connections
-- [[ctp-topic-44-aws-backup-in-micro-focus]] ← extends ← [[AWS Backup]]
-- [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]] ← depends_on ← [[AWS Backup]]
-- [[ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program]] ← extends ← [[ctp-topic-44-aws-backup-in-micro-focus]]
-- [[RTO vs RPO]] ← related ← [[AWS Backup]]
-
-## Contradictions
-- 无明显内容冲突。本视频内容与 [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]] 和 [[ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program]] 构成递进关系。
+---
+title: "CTP Topic 44 AWS Backup in Micro Focus"
+type: source
+tags:
+ - AWS
+ - Backup
+ - DR
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-44-aws-backup-in-micro-focus.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS Backup 托管服务与 Micro Focus 当前备份流程的差距分析,以及向 AWS Backup 迁移的评估。
+- 问题域:企业级数据保护、灾难恢复策略、跨账户/跨区域备份合规性。
+- 方法/机制:
+ - 四级 DR 策略(RTO/RPO 从数小时到近乎零)
+ - AWS Backup 集中化备份保管库 + 备份计划 + 时间点恢复
+ - 基于角色的访问控制(IAM)+ CloudWatch 监控
+ - 不可变性(Immutability)防勒索软件
+ - 法律保留(Legal Holds)满足合规要求
+- 结论/价值:AWS Backup 相比当前分散式快照管理有明显优势(集中化、不可变性、跨账户/跨区域),但存在卷粒度限制、崩溃一致快照等局限性,需根据 RTO/RPO 需求选择合适策略。
+
+## Key Claims(用中文描述)
+- AWS Backup 通过集中化备份保管库和备份计划,消除了当前多团队分散管理快照的错误风险。
+- 不可变性(Immutability)是防止勒索软件攻击备份数据的核心机制,当前 CCIE vault 无法提供此保障。
+- Pilot Light 策略可在 1 小时内恢复,Warm Standby 可在数分钟内恢复,Active-Active 提供近乎零停机,但成本递增。
+- AWS Backup 对附加到 EC2 的多个卷强制备份所有卷,无法选择性排除特定卷。
+- Amazon 建议数据库不再使用热备份,快照是崩溃一致的,支持增量备份。
+
+## Key Quotes
+> "AWS Backup 是一个托管服务,用于在 AWS 云中集中化和自动化数据保护。它支持跨账户和跨区域备份,并提供不可变性以防止勒索软件等威胁。" — 视频摘要
+> "AWS Backup 加密所有备份,包括静态和传输中的数据。" — 视频摘要
+> "Amazon 不再建议数据库使用热备份,指出快照是崩溃一致的,支持增量备份。" — 视频摘要
+
+## Key Concepts
+- [[AWS Backup]]:AWS 托管的集中化数据保护服务,支持跨账户和跨区域备份,提供不可变性和法律保留功能。
+- [[不可变性(Immutability)]]:防止备份被篡改或删除的机制,是防勒索软件的关键。
+- [[RTO(Recovery Time Objective)]]:恢复时间目标,衡量从故障恢复到服务可用的时间。
+- [[RPO(Recovery Point Objective)]]:恢复点目标,衡量可接受的最大数据丢失时间窗口。
+- [[灾难恢复策略]]:Backup and Restore / Pilot Light / Warm Standby / Active-Active 四级递进策略。
+- [[法律保留(Legal Holds)]]:用于合规性保留特定备份,隔离而不被删除。
+- [[Pilot Light]]:DR 策略之一,数据持续复制到 DR 区域,可在 1 小时内恢复核心服务。
+- [[Warm Standby]]:DR 策略之一,应用在生产 DR 区域以较小规模持续运行,可在数分钟内完全扩缩。
+- [[Active-Active]]:DR 策略之一,应用在两个区域同时运行,提供近乎零停机和零数据丢失。
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,提供 AWS Backup 托管服务的云平台。
+- [[CCIE 门户]]:当前管理快照的内部 Micro Focus 平台,通过标签跟踪备份过程和错误通知。
+- [[Cloud Transformation Programme (CTP)]]:云转型计划,该视频属于 01_AWS-Landing-Zone 系列第 44 个主题。
+
+## Connections
+- [[ctp-topic-44-aws-backup-in-micro-focus]] ← extends ← [[AWS Backup]]
+- [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]] ← depends_on ← [[AWS Backup]]
+- [[ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program]] ← extends ← [[ctp-topic-44-aws-backup-in-micro-focus]]
+- [[RTO vs RPO]] ← related ← [[AWS Backup]]
+
+## Contradictions
+- 无明显内容冲突。本视频内容与 [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]] 和 [[ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program]] 构成递进关系。
diff --git a/wiki/sources/ctp-topic-45-automatic-ip-address-allocation-with-ipam.md b/wiki/sources/ctp-topic-45-automatic-ip-address-allocation-with-ipam.md
index aab88f95..0f9f7e88 100644
--- a/wiki/sources/ctp-topic-45-automatic-ip-address-allocation-with-ipam.md
+++ b/wiki/sources/ctp-topic-45-automatic-ip-address-allocation-with-ipam.md
@@ -1,52 +1,52 @@
----
-title: "CTP Topic 45 Automatic IP address allocation with IPAM"
-type: source
-tags:
- - AWS
- - IPAM
- - Networking
- - CTP
- - Infoblox
- - VPC
- - Terragrunt
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-45-automatic-ip-address-allocation-with-ipam]]
-
-## Summary(用中文描述)
-- 核心主题:使用 Infoblox NIOS 实现 AWS VPC 自动化 IP 地址分配,替代传统手工电子表格管理方式
-- 问题域:IP 地址管理效率低下(手工请求→网络团队计算CIDR→手工填表→人工配置YAML),新增VPC需要反复与网络团队交接
-- 方法/机制:Infoblox NIOS IPAM 系统自动查询下一个可用 IP 地址块,按需自动审批(≤/24自动,>/24需网络团队审批),Terragrunt YAML 配置文件不再包含硬编码 IP,改由 NIOS 动态注入
-- 结论/价值:实现"创建 VPC 无需网络团队参与"的完全自动化目标,消除 Excel 表格管理,建立单一可信数据源,向后兼容旧 YAML 配置
-
-## Key Claims(用中文描述)
-- Infoblox NIOS 通过 API 自动分配下一个可用 IP 地址块,替代人工计算 CIDR 范围和手动更新电子表格
-- 当所需网络地址 ≤/24 时,VPC 模块自动运行,无需人工干预
-- 当所需网络地址 >/24 时,系统自动触发网络团队审批流程,而非直接拒绝
-- 新 YAML 配置文件中不再包含 CIDR 子网 IP 地址,仅声明期望的子网大小(如 /22)和区域级父 CIDR 常量
-- VPC 名称被纳入 YAML 文件,支持一次性配置多个 VPC
-- 销毁 VPC 时自动从 IPAM Grid 中清除所有相关条目,支持撤销保护(Terragrunt.hcl 需特殊 flag 防止误删)
-- 新系统向后兼容现有 VPC 配置,旧 YAML 文件继续工作
-
-## Key Quotes
-> "Managing the IP address in a spreadsheet takes time and it's not a good approach." — 当前电子表格管理方式的低效痛点
-> "We are not asking for IP address from the network team." — 新系统的核心价值:消除网络团队交接
-> "The goal is for any new VPC that we don't have to engage the network team every time we want to create a VPC with the subnets." — 自动化愿景
-
-## Key Concepts
-- [[IPAM(IP Address Management)]]:IP 地址管理系统的核心概念,NIOS 提供集中化管理、控制、监控和分配 IP 地址空间的能力
-- [[Infoblox-NIOS]]:Infoblox NIOS 是 IPAM 功能的核心实现,作为分布式 Grid 框架的扩展,集成 DNS/DHCP,提供统一管理控制台
-- [[VPC-自动化供给]]:通过 Terragrunt YAML 配置文件声明式定义 VPC 需求,由 NIOS 自动分配 IP 地址,无需手工配置
-
-## Key Entities
-- [[Grid-Master]]:Infoblox Grid 架构中的核心节点,管理 API 调用和各 AWS 云账户的 IP 地址分配
-
-## Connections
-- [[ctp-topic-61-workload-vpc-provision-with-ipam-automation]] ← relates_to ← 本页:均涉及 VPC 供给与 IPAM 自动化的实践
-- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← depends_on ← 本页:Labs Landing Zone 的 VPC 供给依赖 IPAM 自动分配
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← related_to ← 本页:均涉及标签驱动的 AWS 基础设施自动化
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "CTP Topic 45 Automatic IP address allocation with IPAM"
+type: source
+tags:
+ - AWS
+ - IPAM
+ - Networking
+ - CTP
+ - Infoblox
+ - VPC
+ - Terragrunt
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-45-automatic-ip-address-allocation-with-ipam.md]]
+
+## Summary(用中文描述)
+- 核心主题:使用 Infoblox NIOS 实现 AWS VPC 自动化 IP 地址分配,替代传统手工电子表格管理方式
+- 问题域:IP 地址管理效率低下(手工请求→网络团队计算CIDR→手工填表→人工配置YAML),新增VPC需要反复与网络团队交接
+- 方法/机制:Infoblox NIOS IPAM 系统自动查询下一个可用 IP 地址块,按需自动审批(≤/24自动,>/24需网络团队审批),Terragrunt YAML 配置文件不再包含硬编码 IP,改由 NIOS 动态注入
+- 结论/价值:实现"创建 VPC 无需网络团队参与"的完全自动化目标,消除 Excel 表格管理,建立单一可信数据源,向后兼容旧 YAML 配置
+
+## Key Claims(用中文描述)
+- Infoblox NIOS 通过 API 自动分配下一个可用 IP 地址块,替代人工计算 CIDR 范围和手动更新电子表格
+- 当所需网络地址 ≤/24 时,VPC 模块自动运行,无需人工干预
+- 当所需网络地址 >/24 时,系统自动触发网络团队审批流程,而非直接拒绝
+- 新 YAML 配置文件中不再包含 CIDR 子网 IP 地址,仅声明期望的子网大小(如 /22)和区域级父 CIDR 常量
+- VPC 名称被纳入 YAML 文件,支持一次性配置多个 VPC
+- 销毁 VPC 时自动从 IPAM Grid 中清除所有相关条目,支持撤销保护(Terragrunt.hcl 需特殊 flag 防止误删)
+- 新系统向后兼容现有 VPC 配置,旧 YAML 文件继续工作
+
+## Key Quotes
+> "Managing the IP address in a spreadsheet takes time and it's not a good approach." — 当前电子表格管理方式的低效痛点
+> "We are not asking for IP address from the network team." — 新系统的核心价值:消除网络团队交接
+> "The goal is for any new VPC that we don't have to engage the network team every time we want to create a VPC with the subnets." — 自动化愿景
+
+## Key Concepts
+- [[IPAM(IP Address Management)]]:IP 地址管理系统的核心概念,NIOS 提供集中化管理、控制、监控和分配 IP 地址空间的能力
+- [[Infoblox-NIOS]]:Infoblox NIOS 是 IPAM 功能的核心实现,作为分布式 Grid 框架的扩展,集成 DNS/DHCP,提供统一管理控制台
+- [[VPC-自动化供给]]:通过 Terragrunt YAML 配置文件声明式定义 VPC 需求,由 NIOS 自动分配 IP 地址,无需手工配置
+
+## Key Entities
+- [[Grid-Master]]:Infoblox Grid 架构中的核心节点,管理 API 调用和各 AWS 云账户的 IP 地址分配
+
+## Connections
+- [[ctp-topic-61-workload-vpc-provision-with-ipam-automation]] ← relates_to ← 本页:均涉及 VPC 供给与 IPAM 自动化的实践
+- [[ctp-topic-25-labs-landing-zone-overview-itom-teams]] ← depends_on ← 本页:Labs Landing Zone 的 VPC 供给依赖 IPAM 自动分配
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← related_to ← 本页:均涉及标签驱动的 AWS 基础设施自动化
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/ctp-topic-46-netapps-on-aws.md b/wiki/sources/ctp-topic-46-netapps-on-aws.md
index bd4685ef..8bec04e6 100644
--- a/wiki/sources/ctp-topic-46-netapps-on-aws.md
+++ b/wiki/sources/ctp-topic-46-netapps-on-aws.md
@@ -1,67 +1,67 @@
----
-title: "CTP Topic 46 NetApps on AWS"
-type: source
-tags: [NetApp, AWS, Storage, CTP, Cloud-Storage]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-46-netapps-on-aws]]
-
-## Summary(用中文描述)
-- 核心主题:NetApp 存储系统(传统 + AWS 云版本)的架构、组件、数据分层、安全、备份/DR、迁移工具及企业实际使用情况
-- 问题域:企业如何将 NetApp 存储从本地扩展到 AWS 云端,实现统一存储管理
-- 方法/机制:Cloud Volume ONTAP (CVO) 通过 EC2 实例提供企业级存储;EBS 作为底层存储介质;Data Tiering 自动在 EBS 和 S3 之间分层;SnapMirror 实现跨集群数据复制
-- 结论/价值:NetApp on AWS 是企业云存储转型的成熟方案,支持单节点/HA架构,提供块级复制、S3 分层、统一管理(Cloud Manager),组织已在 15 个 AWS 区域部署约 1.3 PB 数据
-
-## Key Claims(用中文描述)
-- NetApp ONTAP 是统一的存储操作系统,支持 SMB、NFS、FC、FCOE、iSCSI 等多种协议
-- Cloud Volume ONTAP (CVO) 通过 EC2 实例在 AWS 上提供软件定义的存储,支持单节点或 HA 配对
-- 数据分层机制:活跃数据存储在 EBS,非活跃数据(30天以上)自动迁移到 S3,访问时拉回 EBS
-- SnapMirror 通过块级复制实现 NetApp 集群间的数据同步,基线复制后仅传输增量变更
-- 从本地迁移到 AWS 的工具包括 SnapMirror、NetApp XCP、Cloud Sync、AWS DataSync、Silver Peak WAN Optimizer
-
-## Key Quotes
-> "NetApp primarily supports SMB, NFS, FC, FCOE, and ISCSI protocols, often configured as a single node or HA pair." — NetApp 传统架构概述
-> "The organization has around 15 NetApp clusters in various AWS regions, hosting approximately 1.3 petabytes of data." — 企业实际使用规模
-> "Data inactive for 30 days or more is automatically moved to S3 and pulled back to EBS when accessed." — CVO 数据分层机制
-> "SnapMirror copies volumes and their snapshots, with baseline copies performing initial full data replication, subsequent updates copy only the changes." — SnapMirror 复制策略
-
-## Key Concepts
-- [[Cloud Volume ONTAP (CVO)]]:NetApp ONTAP 的 AWS 云版本,通过 EC2 实例运行,支持单节点或 HA 架构,使用 EBS 作为存储后端
-- [[ONTAP]]:NetApp 统一存储操作系统,管理聚合、卷、Qtree、LIF、SVM 等存储组件
-- [[Aggregate]]:由多个磁盘组成的 RAID 组,构成 NetApp 的基础存储池
-- [[FlexVol]]:托管在 Aggregate 之上的灵活数据容器,通过 NFS 或 CIFS 呈现给主机
-- [[Qtree]]:卷的进一步细分,支持权限和配额管理等特殊属性
-- [[LUN (Logical Unit Number)]]:块级存储的逻辑表示,通过 FC 或 iSCSI 呈现给主机
-- [[LIF (Logical Interface)]]:物理网卡之上的接口,承载 IP 地址或 WWPN,用于节点管理、数据复制和数据服务
-- [[SVM (Storage Virtual Machine)]]:NetApp 系统的虚拟隔离,支持多租户,每个 SVM 视为独立操作系统
-- [[Data Tiering]]:利用 EBS 和 S3 实现存储成本优化,活跃数据在 EBS,非活跃数据自动迁移至 S3
-- [[SnapMirror]]:NetApp 数据复制工具,支持跨集群块级同步,基线全量复制后仅同步增量变更
-- [[Snapshot]]:点-in-time 只读文件系统镜像,通过指针创建,最小化空间消耗
-- [[HA Pair (High Availability)]]:高可用配对,通过故障转移机制确保存储服务连续性
-- [[Floating IP]]:HA 架构中的浮动 IP,客户端通过唯一 IP 地址访问,故障时 IP 漂移到备用节点
-- [[Takeover/Giveback]]:HA 接管和归还过程,故障节点的服务切换和恢复
-- [[NetApp Encryption]]:256-bit 加密,支持 AWS KMS 和 NetApp 自身加密解决方案
-
-## Key Entities
-- [[NetApp]]:全球领先的存储和数据管理解决方案提供商,ONTAP 为其核心操作系统
-- [[Cloud Manager]]:NetApp 的集中管理平台,用于管理 AWS 中的 Cloud Volume ONTAP
-- [[FSX for NetApp]]:AWS 原生托管 NetApp 服务(under POC),提供更简化的部署体验
-- [[AWS EBS]]:Elastic Block Store,CVO 的存储后端,支持 GP3、GP2、IO1、IO2、ST1 等多种卷类型
-- [[AWS KMS]]:Key Management Service,NetApp 加密方案的密钥管理集成
-- [[McAfee VSES]]:McAfee 杀毒集成,NetApp 用于 SMB/CIFS 和 NFS 的按访问和按需扫描
-- [[Terraform]]:IaC 工具(under plan),计划用于 NetApp 部署自动化
-- [[Cityscope]]:[监控工具],组织当前使用的 NetApp 监控平台之一
-- [[WebTool]]:[监控工具],组织当前使用的 NetApp 监控平台之一
-
-## Connections
-- [[ctp-topic-44-aws-backup-in-micro-focus]] ← relates_to ← [[ctp-topic-46-netapps-on-aws]](均涉及企业数据备份与灾备策略)
-- [[ctp-topic-14-octane-hub-on-aws-real-life-experience-moving-production-services]] ← relates_to ← [[ctp-topic-46-netapps-on-aws]](均涉及工作负载从本地向 AWS 迁移)
-- [[Cloud Volume ONTAP (CVO)]] ← extends ← [[ONTAP]](ONTAP 的云版本)
-- [[FSX for NetApp]] ← extends ← [[Cloud Volume ONTAP (CVO)]](AWS 原生管理的 NetApp 服务)
-- [[Data Tiering]] ← depends_on ← [[AWS EBS]] + [[AWS S3]]
-- [[SnapMirror]] ← used_in ← [[ctp-topic-46-netapps-on-aws]](灾备复制方案)
-
-## Contradictions
-- 暂无发现内容冲突。本文档主要聚焦 NetApp 存储技术,与 Wiki 中其他 CTP Topic(如 RDS vs Aurora、AWS Backup)属不同技术领域(块存储 vs 数据库备份),互补关系大于冲突。
+---
+title: "CTP Topic 46 NetApps on AWS"
+type: source
+tags: [NetApp, AWS, Storage, CTP, Cloud-Storage]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-46-netapps-on-aws.md]]
+
+## Summary(用中文描述)
+- 核心主题:NetApp 存储系统(传统 + AWS 云版本)的架构、组件、数据分层、安全、备份/DR、迁移工具及企业实际使用情况
+- 问题域:企业如何将 NetApp 存储从本地扩展到 AWS 云端,实现统一存储管理
+- 方法/机制:Cloud Volume ONTAP (CVO) 通过 EC2 实例提供企业级存储;EBS 作为底层存储介质;Data Tiering 自动在 EBS 和 S3 之间分层;SnapMirror 实现跨集群数据复制
+- 结论/价值:NetApp on AWS 是企业云存储转型的成熟方案,支持单节点/HA架构,提供块级复制、S3 分层、统一管理(Cloud Manager),组织已在 15 个 AWS 区域部署约 1.3 PB 数据
+
+## Key Claims(用中文描述)
+- NetApp ONTAP 是统一的存储操作系统,支持 SMB、NFS、FC、FCOE、iSCSI 等多种协议
+- Cloud Volume ONTAP (CVO) 通过 EC2 实例在 AWS 上提供软件定义的存储,支持单节点或 HA 配对
+- 数据分层机制:活跃数据存储在 EBS,非活跃数据(30天以上)自动迁移到 S3,访问时拉回 EBS
+- SnapMirror 通过块级复制实现 NetApp 集群间的数据同步,基线复制后仅传输增量变更
+- 从本地迁移到 AWS 的工具包括 SnapMirror、NetApp XCP、Cloud Sync、AWS DataSync、Silver Peak WAN Optimizer
+
+## Key Quotes
+> "NetApp primarily supports SMB, NFS, FC, FCOE, and ISCSI protocols, often configured as a single node or HA pair." — NetApp 传统架构概述
+> "The organization has around 15 NetApp clusters in various AWS regions, hosting approximately 1.3 petabytes of data." — 企业实际使用规模
+> "Data inactive for 30 days or more is automatically moved to S3 and pulled back to EBS when accessed." — CVO 数据分层机制
+> "SnapMirror copies volumes and their snapshots, with baseline copies performing initial full data replication, subsequent updates copy only the changes." — SnapMirror 复制策略
+
+## Key Concepts
+- [[Cloud Volume ONTAP (CVO)]]:NetApp ONTAP 的 AWS 云版本,通过 EC2 实例运行,支持单节点或 HA 架构,使用 EBS 作为存储后端
+- [[ONTAP]]:NetApp 统一存储操作系统,管理聚合、卷、Qtree、LIF、SVM 等存储组件
+- [[Aggregate]]:由多个磁盘组成的 RAID 组,构成 NetApp 的基础存储池
+- [[FlexVol]]:托管在 Aggregate 之上的灵活数据容器,通过 NFS 或 CIFS 呈现给主机
+- [[Qtree]]:卷的进一步细分,支持权限和配额管理等特殊属性
+- [[LUN (Logical Unit Number)]]:块级存储的逻辑表示,通过 FC 或 iSCSI 呈现给主机
+- [[LIF (Logical Interface)]]:物理网卡之上的接口,承载 IP 地址或 WWPN,用于节点管理、数据复制和数据服务
+- [[SVM (Storage Virtual Machine)]]:NetApp 系统的虚拟隔离,支持多租户,每个 SVM 视为独立操作系统
+- [[Data Tiering]]:利用 EBS 和 S3 实现存储成本优化,活跃数据在 EBS,非活跃数据自动迁移至 S3
+- [[SnapMirror]]:NetApp 数据复制工具,支持跨集群块级同步,基线全量复制后仅同步增量变更
+- [[Snapshot]]:点-in-time 只读文件系统镜像,通过指针创建,最小化空间消耗
+- [[HA Pair (High Availability)]]:高可用配对,通过故障转移机制确保存储服务连续性
+- [[Floating IP]]:HA 架构中的浮动 IP,客户端通过唯一 IP 地址访问,故障时 IP 漂移到备用节点
+- [[Takeover/Giveback]]:HA 接管和归还过程,故障节点的服务切换和恢复
+- [[NetApp Encryption]]:256-bit 加密,支持 AWS KMS 和 NetApp 自身加密解决方案
+
+## Key Entities
+- [[NetApp]]:全球领先的存储和数据管理解决方案提供商,ONTAP 为其核心操作系统
+- [[Cloud Manager]]:NetApp 的集中管理平台,用于管理 AWS 中的 Cloud Volume ONTAP
+- [[FSX for NetApp]]:AWS 原生托管 NetApp 服务(under POC),提供更简化的部署体验
+- [[AWS EBS]]:Elastic Block Store,CVO 的存储后端,支持 GP3、GP2、IO1、IO2、ST1 等多种卷类型
+- [[AWS KMS]]:Key Management Service,NetApp 加密方案的密钥管理集成
+- [[McAfee VSES]]:McAfee 杀毒集成,NetApp 用于 SMB/CIFS 和 NFS 的按访问和按需扫描
+- [[Terraform]]:IaC 工具(under plan),计划用于 NetApp 部署自动化
+- [[Cityscope]]:[监控工具],组织当前使用的 NetApp 监控平台之一
+- [[WebTool]]:[监控工具],组织当前使用的 NetApp 监控平台之一
+
+## Connections
+- [[ctp-topic-44-aws-backup-in-micro-focus]] ← relates_to ← [[ctp-topic-46-netapps-on-aws]](均涉及企业数据备份与灾备策略)
+- [[ctp-topic-14-octane-hub-on-aws-real-life-experience-moving-production-services]] ← relates_to ← [[ctp-topic-46-netapps-on-aws]](均涉及工作负载从本地向 AWS 迁移)
+- [[Cloud Volume ONTAP (CVO)]] ← extends ← [[ONTAP]](ONTAP 的云版本)
+- [[FSX for NetApp]] ← extends ← [[Cloud Volume ONTAP (CVO)]](AWS 原生管理的 NetApp 服务)
+- [[Data Tiering]] ← depends_on ← [[AWS EBS]] + [[AWS S3]]
+- [[SnapMirror]] ← used_in ← [[ctp-topic-46-netapps-on-aws]](灾备复制方案)
+
+## Contradictions
+- 暂无发现内容冲突。本文档主要聚焦 NetApp 存储技术,与 Wiki 中其他 CTP Topic(如 RDS vs Aurora、AWS Backup)属不同技术领域(块存储 vs 数据库备份),互补关系大于冲突。
diff --git a/wiki/sources/ctp-topic-47-enterprise-architecture-cloud-standards.md b/wiki/sources/ctp-topic-47-enterprise-architecture-cloud-standards.md
index 253c1c76..36ff315f 100644
--- a/wiki/sources/ctp-topic-47-enterprise-architecture-cloud-standards.md
+++ b/wiki/sources/ctp-topic-47-enterprise-architecture-cloud-standards.md
@@ -1,46 +1,46 @@
----
-title: "CTP Topic 47 Enterprise Architecture Cloud Standards"
-type: source
-tags: [Enterprise-Architecture, Cloud-Standards, CTP, Landing-Zone, Terraform]
-sources: []
-last_updated: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-47-enterprise-architecture-cloud-standards]]
-
-## Summary(用中文描述)
-- 核心主题:企业架构云标准、Landing Zone、云防护栏(Guardrails)
-- 问题域:如何在云环境中标准化企业架构,指导应用团队了解可用资源和需求
-- 方法/机制:Landing Zone 框架(账户结构+网络+安全+访问管理+遥测)、Terraform/Terragrunt IaC、云防护栏文档(设计概念+最佳实践)
-- 结论/价值:标准化云架构、预配置安全模型、降低应用团队安全审查负担、减少重复造轮子
-
-## Key Claims(用中文描述)
-- Landing Zone 框架通过聚焦安全、合规和可管理性,为云工作负载提供托管基础
-- 账户结构与开发/预发布/生产环境对齐,角色通过零信任和最小权限原则定义访问控制
-- Terraform 允许以代码形式指定期望环境,促进标准化和可测试性
-- 云防护栏文档捕获强制性要求和最佳实践,指导可扩展性、成本最小化和灵活性
-- 功能分区将单体应用拆分为更小的独立模块或无服务器函数
-
-## Key Quotes
-> "A landing zone is a framework for hosting cloud workloads, focusing on security, compliance, and manageability." — Lindsay,企业架构师
-> "We want your knowledge collected here for reuse and help other app developers down the road." — Lindsay,号召应用团队贡献防护栏内容
-
-## Key Concepts
-- [[Landing Zone]]:托管云工作负载的框架,聚焦安全、合规和可管理性,包含账户结构、网络、安全、访问管理和遥测
-- [[Zero Trust Architecture]]:零信任安全架构,通过最小权限原则定义访问控制
-- [[Infrastructure as Code]]:基础设施即代码,使用 Terraform 实现环境标准化和可测试性
-- [[Cloud Guardrails]]:云防护栏文档,捕获强制性要求和最佳实践
-- [[Functional Partitioning]]:功能分区,将单体应用拆分为更小的独立块或无服务器函数
-- [[Terragrunt]]:Terraform 的包装器,用于生成不同环境
-
-## Key Entities
-- [[Lindsay]]:企业架构师,具有开发背景,以学习者视角分享云架构知识
-
-## Connections
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← related_to ← [[Landing Zone]](Topic 1 是 Gruntwork Landing Zone 基础)
-- [[Terraform]] ← uses ← [[Infrastructure as Code]]
-- [[Cloud Guardrails]] ← guides ← [[Enterprise Architecture Cloud Standards]]
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "CTP Topic 47 Enterprise Architecture Cloud Standards"
+type: source
+tags: [Enterprise-Architecture, Cloud-Standards, CTP, Landing-Zone, Terraform]
+sources: []
+last_updated: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-47-enterprise-architecture-cloud-standards.md]]
+
+## Summary(用中文描述)
+- 核心主题:企业架构云标准、Landing Zone、云防护栏(Guardrails)
+- 问题域:如何在云环境中标准化企业架构,指导应用团队了解可用资源和需求
+- 方法/机制:Landing Zone 框架(账户结构+网络+安全+访问管理+遥测)、Terraform/Terragrunt IaC、云防护栏文档(设计概念+最佳实践)
+- 结论/价值:标准化云架构、预配置安全模型、降低应用团队安全审查负担、减少重复造轮子
+
+## Key Claims(用中文描述)
+- Landing Zone 框架通过聚焦安全、合规和可管理性,为云工作负载提供托管基础
+- 账户结构与开发/预发布/生产环境对齐,角色通过零信任和最小权限原则定义访问控制
+- Terraform 允许以代码形式指定期望环境,促进标准化和可测试性
+- 云防护栏文档捕获强制性要求和最佳实践,指导可扩展性、成本最小化和灵活性
+- 功能分区将单体应用拆分为更小的独立模块或无服务器函数
+
+## Key Quotes
+> "A landing zone is a framework for hosting cloud workloads, focusing on security, compliance, and manageability." — Lindsay,企业架构师
+> "We want your knowledge collected here for reuse and help other app developers down the road." — Lindsay,号召应用团队贡献防护栏内容
+
+## Key Concepts
+- [[Landing Zone]]:托管云工作负载的框架,聚焦安全、合规和可管理性,包含账户结构、网络、安全、访问管理和遥测
+- [[Zero Trust Architecture]]:零信任安全架构,通过最小权限原则定义访问控制
+- [[Infrastructure as Code]]:基础设施即代码,使用 Terraform 实现环境标准化和可测试性
+- [[Cloud Guardrails]]:云防护栏文档,捕获强制性要求和最佳实践
+- [[Functional Partitioning]]:功能分区,将单体应用拆分为更小的独立块或无服务器函数
+- [[Terragrunt]]:Terraform 的包装器,用于生成不同环境
+
+## Key Entities
+- [[Lindsay]]:企业架构师,具有开发背景,以学习者视角分享云架构知识
+
+## Connections
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← related_to ← [[Landing Zone]](Topic 1 是 Gruntwork Landing Zone 基础)
+- [[Terraform]] ← uses ← [[Infrastructure as Code]]
+- [[Cloud Guardrails]] ← guides ← [[Enterprise Architecture Cloud Standards]]
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/ctp-topic-48-terraform-vs-terragrunt.md b/wiki/sources/ctp-topic-48-terraform-vs-terragrunt.md
index f73dbbb3..260dcc8b 100644
--- a/wiki/sources/ctp-topic-48-terraform-vs-terragrunt.md
+++ b/wiki/sources/ctp-topic-48-terraform-vs-terragrunt.md
@@ -1,55 +1,55 @@
----
-title: "CTP Topic 48 Terraform vs Terragrunt"
-type: source
-tags:
- - Terraform
- - Terragrunt
- - IaC
- - DevOps
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/ctp-topic-48-terraform-vs-terragrunt.md]]
-
-## Summary(用中文描述)
-- 核心主题:Terraform 与 Terragrunt 的对比选型,涵盖企业级 IaC 实践
-- 问题域:多环境配置管理、基础设施代码复用、状态文件管理
-- 方法/机制:Terraform 作为核心 IaC 工具(云厂商无关),Terragrunt 作为 Terraform 的 DRY 封装层,处理跨环境变量和远程状态的重复声明
-- 结论/价值:Terraform 与 Terragrunt 命令和语法高度一致,但 Terragrunt 通过减少硬编码、提升可复用性来优化大规模企业部署;两者可互补使用
-
-## Key Claims(用中文描述)
-- Terraform(HashiCorp 出品)通过状态文件将期望状态与现有环境绑定,企业级使用须将状态文件存储在安全可访问的位置
-- Terragrunt 是 Terraform 的轻量封装,贯彻 DRY 原则,通过管理 provider 和 remote_state 块减少跨环境的重复声明
-- Terraform Enterprise 提供带 workspace 的 CI 平台,Gruntwork 提供预建可定制模块,Atlantis 实现 Git 驱动的自动化部署
-- tfsec 用于静态代码安全分析,Terratest 用于基础设施测试自动化
-
-## Key Quotes
-> "Terraform ties the desired state to the existing environment using a state file. For enterprise-scale use, storing this file in a safe, accessible location is crucial." — Bob, AWS Solutions Architect
-> "Terragrunt offers a way to use information in a repeatable way without hard coding values." — Bob
-> "All Terraform commands work with Terragrunt; a Terraform plan becomes a Terragrunt plan." — Bob
-
-## Key Concepts
-- [[Infrastructure As Code]]:通过代码定义和版本控制基础设施资源的实践
-- [[DRY Principle]]:Don't Repeat Yourself — 避免重复配置,通过抽象层复用
-- [[State File Management]]:Terraform 用状态文件绑定期望状态与实际环境
-- [[IaC Testing]]:用 Terratest 等工具对基础设施代码进行自动化测试
-
-## Key Entities
-- [[HashiCorp]]:Terraform 创立公司,提供多云基础设施编排工具
-- [[Gruntwork]]:提供预建可定制的 Terraform 模块和 Terraform 原生 AWS Landing Zone
-- [[Atlantis]]:将 Terraform 与 GitHub 集成的开源 CI/CD 工具
-- [[Terraform]]:云厂商无关的基础设施即代码工具
-- [[Terragrunt]]:Terraform 的 DRY 封装层,管理多环境配置
-
-## Connections
-- [[Terraform]] ← uses ← [[State File Management]]
-- [[Terragrunt]] ← wraps ← [[Terraform]]
-- [[Terraform]] ← provided_by ← [[HashiCorp]]
-- [[Gruntwork]] ← provides_modules_for ← [[Terraform]]
-- [[Atlantis]] ← integrates_with ← [[Terraform]]
-- [[Terraform]] ← related_concept ← [[Infrastructure As Code]]
-
-## Contradictions
-- 暂无发现与其他 Wiki 页面的直接冲突
+---
+title: "CTP Topic 48 Terraform vs Terragrunt"
+type: source
+tags:
+ - Terraform
+ - Terragrunt
+ - IaC
+ - DevOps
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/ctp-topic-48-terraform-vs-terragrunt.md]]
+
+## Summary(用中文描述)
+- 核心主题:Terraform 与 Terragrunt 的对比选型,涵盖企业级 IaC 实践
+- 问题域:多环境配置管理、基础设施代码复用、状态文件管理
+- 方法/机制:Terraform 作为核心 IaC 工具(云厂商无关),Terragrunt 作为 Terraform 的 DRY 封装层,处理跨环境变量和远程状态的重复声明
+- 结论/价值:Terraform 与 Terragrunt 命令和语法高度一致,但 Terragrunt 通过减少硬编码、提升可复用性来优化大规模企业部署;两者可互补使用
+
+## Key Claims(用中文描述)
+- Terraform(HashiCorp 出品)通过状态文件将期望状态与现有环境绑定,企业级使用须将状态文件存储在安全可访问的位置
+- Terragrunt 是 Terraform 的轻量封装,贯彻 DRY 原则,通过管理 provider 和 remote_state 块减少跨环境的重复声明
+- Terraform Enterprise 提供带 workspace 的 CI 平台,Gruntwork 提供预建可定制模块,Atlantis 实现 Git 驱动的自动化部署
+- tfsec 用于静态代码安全分析,Terratest 用于基础设施测试自动化
+
+## Key Quotes
+> "Terraform ties the desired state to the existing environment using a state file. For enterprise-scale use, storing this file in a safe, accessible location is crucial." — Bob, AWS Solutions Architect
+> "Terragrunt offers a way to use information in a repeatable way without hard coding values." — Bob
+> "All Terraform commands work with Terragrunt; a Terraform plan becomes a Terragrunt plan." — Bob
+
+## Key Concepts
+- [[Infrastructure As Code]]:通过代码定义和版本控制基础设施资源的实践
+- [[DRY Principle]]:Don't Repeat Yourself — 避免重复配置,通过抽象层复用
+- [[State File Management]]:Terraform 用状态文件绑定期望状态与实际环境
+- [[IaC Testing]]:用 Terratest 等工具对基础设施代码进行自动化测试
+
+## Key Entities
+- [[HashiCorp]]:Terraform 创立公司,提供多云基础设施编排工具
+- [[Gruntwork]]:提供预建可定制的 Terraform 模块和 Terraform 原生 AWS Landing Zone
+- [[Atlantis]]:将 Terraform 与 GitHub 集成的开源 CI/CD 工具
+- [[Terraform]]:云厂商无关的基础设施即代码工具
+- [[Terragrunt]]:Terraform 的 DRY 封装层,管理多环境配置
+
+## Connections
+- [[Terraform]] ← uses ← [[State File Management]]
+- [[Terragrunt]] ← wraps ← [[Terraform]]
+- [[Terraform]] ← provided_by ← [[HashiCorp]]
+- [[Gruntwork]] ← provides_modules_for ← [[Terraform]]
+- [[Atlantis]] ← integrates_with ← [[Terraform]]
+- [[Terraform]] ← related_concept ← [[Infrastructure As Code]]
+
+## Contradictions
+- 暂无发现与其他 Wiki 页面的直接冲突
diff --git a/wiki/sources/ctp-topic-49-container-lifecycle-hardening-standards.md b/wiki/sources/ctp-topic-49-container-lifecycle-hardening-standards.md
index cf980f4e..aeb0b521 100644
--- a/wiki/sources/ctp-topic-49-container-lifecycle-hardening-standards.md
+++ b/wiki/sources/ctp-topic-49-container-lifecycle-hardening-standards.md
@@ -1,62 +1,62 @@
----
-title: "CTP Topic 49 Container Lifecycle Hardening Standards"
-type: source
-tags: [Container, Security, Hardening, CTP, Kubernetes, Docker]
-sources: []
-last_updated: 2026-04-24
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-49-container-lifecycle-hardening-standards]]
-
-## Summary(用中文描述)
-- 核心主题:Micro Focus 产品安全小组(Product Security Group)制定的容器镜像构建阶段(Building)安全加固标准,提供 11 条可操作的安全实践指南。
-- 问题域:容器镜像构建安全——如何避免引入已知漏洞、敏感信息和错误配置到容器化工作负载中。
-- 方法/机制:围绕 11 条安全标准逐条说明背景风险(Why)和缓解措施(How),辅以 Kubernetes YAML 配置示例演示。
-- 结论/价值:为容器镜像构建提供标准化安全基线,配合 Demo 直观展示配置效果,是 [[DevSecOps]] 实践在容器层面的具体落地。
-
-## Key Claims(用中文描述)
-- Micro Focus 基础镜像(Micro Focus Base Image)比开源默认镜像更安全——经过安全配置,内置非 root 和非特权(non-root and non-privileged)设置,避免开源默认镜像中的已知漏洞。
-- 引入 Init 系统(如 [[tini]] / [[tini Init System]])可防止僵尸进程(Zombie Process)耗尽系统资源——Demo 展示了 [[tini]] 在 Kubernetes 环境中阻止僵尸进程的效果。
-- 将容器根文件系统设为只读(readOnlyRootFilesystem: true)可阻止攻击者篡改文件系统——Demo 展示了设置该标志后容器内无法创建未授权文件。
-- 使用 [[Kubernetes Secrets]] 替代将敏感信息硬编码在镜像中——敏感数据应在运行时从 Secret 管理机制获取,而非构建时嵌入镜像。
-- [[emptyDir Volume]] 用于临时文件系统比主机路径更安全——数据随 Pod 删除自动清理,防止敏感信息残留。
-- 每个容器仅运行单一应用——防止单个应用被攻陷后干扰同一容器中其他应用的进程。
-- 设置 automountServiceAccountToken: false 禁用 Kubernetes API 自动挂载——限制被攻陷容器对集群 API 的访问范围,降低权限提升风险。
-- 使用私有服务账号(Private Service Account)配合精确的 Namespace Role 和 Role Binding——替代默认服务账号,遵循最小权限原则。
-- 避免使用 hostNetwork 和 hostPort——防止端口冲突和维护网络隔离,减少容器逃逸攻击面。
-
-## Key Quotes
-> "If one application is compromised process in one application can interfere with the process of other application in the same container." — Ashish, Product Security Group, 说明为何容器应运行单一应用
-> "Use micro focus base image which are configured to be secure with non and trust weighted components." — Ashish, 说明 Micro Focus 基础镜像的安全配置特性
-> "teeny prevents zombie processes in Kubernetes." — Ashish, 演示 [[tini]] Init 系统在 Kubernetes 中的作用
-
-## Key Concepts
-- [[Container Lifecycle Hardening]]:容器全生命周期安全加固,涵盖构建(Build)、部署(Deploy)、运行(Run)三个阶段。本视频聚焦构建阶段。
-- [[tini Init System]]:轻量级 Init 系统,用于容器内正确处理信号和收割僵尸进程,与 [[tini]] 同义。
-- [[Kubernetes RBAC]]:基于角色的访问控制,通过 Role/RoleBinding/Namespace 机制实现最小权限服务账号管理。
-- [[Kubernetes Secrets]]:Kubernetes Secret 对象,用于在运行时向容器安全传递敏感信息(如密码、API 密钥),而非将其嵌入镜像。
-- [[Pod Security Context]]:Pod 安全上下文,定义 Pod 级别的安全设置(如 readOnlyRootFilesystem、automountServiceAccountToken)。
-- [[emptyDir Volume]]:Kubernetes emptyDir 卷类型,挂载临时文件系统,数据随 Pod 生命周期自动清理。
-- [[Container Image Scanning]]:镜像漏洞扫描,通过自动化工具识别镜像中的已知安全漏洞并提供修复建议。
-- [[Kubernetes RBAC]]:Role-Based Access Control,基于角色的访问控制,用于限制 Service Account 对 Kubernetes API 的访问权限。
-
-## Key Entities
-- [[Ashish]]:Micro Focus Product Security Group 成员,本视频主讲人,负责介绍容器生命周期安全加固标准。
-- [[Micro Focus]]:企业软件公司,拥有自己的容器基础镜像仓库和安全加固标准体系。
-- [[Product Security Group]]:Micro Focus 产品安全小组,制定容器安全标准和最佳实践。
-- [[Kubernetes]]:容器编排平台,是本视频所有安全配置的实施环境。
-- [[tini]]:容器 Init 系统开源项目,解决容器内僵尸进程和信号转发问题。
-
-## Connections
-- [[ctp-topic-21-supply-chain-security-in-micro-focus]] ← related_to ← [[ctp-topic-49-container-lifecycle-hardening-standards]]:供应链安全与容器镜像安全同属 [[DevSecOps]] 范畴,供应链安全关注 CI/CD 过程完整性,容器安全关注镜像内容安全。
-- [[DevSecOps]] ← extends ← [[ctp-topic-49-container-lifecycle-hardening-standards]]:容器镜像加固是 DevSecOps 在容器领域的具体实践,DevSecOps 强调安全左移(Shift-Left)。
-- [[ctp-topic-70-eks-deployment-using-iac]] ← related_to ← [[ctp-topic-49-container-lifecycle-hardening-standards]]:EKS 部署的容器运行时安全配置与本视频的镜像构建标准互补,共同构成容器全生命周期安全。
-- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← related_to ← [[ctp-topic-49-container-lifecycle-hardening-standards]]:EKS 可靠性最佳实践中的 Pod 安全配置与本视频标准一致。
-
-## Contradictions
-- 与 [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]] 的 hostNetwork 配置存在潜在冲突:
- - 冲突点:Topic 39 中提到 Pod 规范设置 `hostNetwork: true` 以访问内部 Micro Focus 网络和外部资源。
- - 当前观点(Topic 49):应避免使用 hostNetwork 以维护网络隔离和防止端口冲突。
- - 对方观点(Topic 39):在受限 Lab Landing Zone 网络环境下,hostNetwork 是打通混合网络的必要手段。
- - 说明:两者的差异源于场景不同——Topic 39 针对的是 IP 地址池不足的受限 Lab 环境,是特例;Topic 49 是通用安全最佳实践,适用于大多数生产场景。
+---
+title: "CTP Topic 49 Container Lifecycle Hardening Standards"
+type: source
+tags: [Container, Security, Hardening, CTP, Kubernetes, Docker]
+sources: []
+last_updated: 2026-04-24
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-49-container-lifecycle-hardening-standards.md]]
+
+## Summary(用中文描述)
+- 核心主题:Micro Focus 产品安全小组(Product Security Group)制定的容器镜像构建阶段(Building)安全加固标准,提供 11 条可操作的安全实践指南。
+- 问题域:容器镜像构建安全——如何避免引入已知漏洞、敏感信息和错误配置到容器化工作负载中。
+- 方法/机制:围绕 11 条安全标准逐条说明背景风险(Why)和缓解措施(How),辅以 Kubernetes YAML 配置示例演示。
+- 结论/价值:为容器镜像构建提供标准化安全基线,配合 Demo 直观展示配置效果,是 [[DevSecOps]] 实践在容器层面的具体落地。
+
+## Key Claims(用中文描述)
+- Micro Focus 基础镜像(Micro Focus Base Image)比开源默认镜像更安全——经过安全配置,内置非 root 和非特权(non-root and non-privileged)设置,避免开源默认镜像中的已知漏洞。
+- 引入 Init 系统(如 [[tini]] / [[tini Init System]])可防止僵尸进程(Zombie Process)耗尽系统资源——Demo 展示了 [[tini]] 在 Kubernetes 环境中阻止僵尸进程的效果。
+- 将容器根文件系统设为只读(readOnlyRootFilesystem: true)可阻止攻击者篡改文件系统——Demo 展示了设置该标志后容器内无法创建未授权文件。
+- 使用 [[Kubernetes Secrets]] 替代将敏感信息硬编码在镜像中——敏感数据应在运行时从 Secret 管理机制获取,而非构建时嵌入镜像。
+- [[emptyDir Volume]] 用于临时文件系统比主机路径更安全——数据随 Pod 删除自动清理,防止敏感信息残留。
+- 每个容器仅运行单一应用——防止单个应用被攻陷后干扰同一容器中其他应用的进程。
+- 设置 automountServiceAccountToken: false 禁用 Kubernetes API 自动挂载——限制被攻陷容器对集群 API 的访问范围,降低权限提升风险。
+- 使用私有服务账号(Private Service Account)配合精确的 Namespace Role 和 Role Binding——替代默认服务账号,遵循最小权限原则。
+- 避免使用 hostNetwork 和 hostPort——防止端口冲突和维护网络隔离,减少容器逃逸攻击面。
+
+## Key Quotes
+> "If one application is compromised process in one application can interfere with the process of other application in the same container." — Ashish, Product Security Group, 说明为何容器应运行单一应用
+> "Use micro focus base image which are configured to be secure with non and trust weighted components." — Ashish, 说明 Micro Focus 基础镜像的安全配置特性
+> "teeny prevents zombie processes in Kubernetes." — Ashish, 演示 [[tini]] Init 系统在 Kubernetes 中的作用
+
+## Key Concepts
+- [[Container Lifecycle Hardening]]:容器全生命周期安全加固,涵盖构建(Build)、部署(Deploy)、运行(Run)三个阶段。本视频聚焦构建阶段。
+- [[tini Init System]]:轻量级 Init 系统,用于容器内正确处理信号和收割僵尸进程,与 [[tini]] 同义。
+- [[Kubernetes RBAC]]:基于角色的访问控制,通过 Role/RoleBinding/Namespace 机制实现最小权限服务账号管理。
+- [[Kubernetes Secrets]]:Kubernetes Secret 对象,用于在运行时向容器安全传递敏感信息(如密码、API 密钥),而非将其嵌入镜像。
+- [[Pod Security Context]]:Pod 安全上下文,定义 Pod 级别的安全设置(如 readOnlyRootFilesystem、automountServiceAccountToken)。
+- [[emptyDir Volume]]:Kubernetes emptyDir 卷类型,挂载临时文件系统,数据随 Pod 生命周期自动清理。
+- [[Container Image Scanning]]:镜像漏洞扫描,通过自动化工具识别镜像中的已知安全漏洞并提供修复建议。
+- [[Kubernetes RBAC]]:Role-Based Access Control,基于角色的访问控制,用于限制 Service Account 对 Kubernetes API 的访问权限。
+
+## Key Entities
+- [[Ashish]]:Micro Focus Product Security Group 成员,本视频主讲人,负责介绍容器生命周期安全加固标准。
+- [[Micro Focus]]:企业软件公司,拥有自己的容器基础镜像仓库和安全加固标准体系。
+- [[Product Security Group]]:Micro Focus 产品安全小组,制定容器安全标准和最佳实践。
+- [[Kubernetes]]:容器编排平台,是本视频所有安全配置的实施环境。
+- [[tini]]:容器 Init 系统开源项目,解决容器内僵尸进程和信号转发问题。
+
+## Connections
+- [[ctp-topic-21-supply-chain-security-in-micro-focus]] ← related_to ← [[ctp-topic-49-container-lifecycle-hardening-standards]]:供应链安全与容器镜像安全同属 [[DevSecOps]] 范畴,供应链安全关注 CI/CD 过程完整性,容器安全关注镜像内容安全。
+- [[DevSecOps]] ← extends ← [[ctp-topic-49-container-lifecycle-hardening-standards]]:容器镜像加固是 DevSecOps 在容器领域的具体实践,DevSecOps 强调安全左移(Shift-Left)。
+- [[ctp-topic-70-eks-deployment-using-iac]] ← related_to ← [[ctp-topic-49-container-lifecycle-hardening-standards]]:EKS 部署的容器运行时安全配置与本视频的镜像构建标准互补,共同构成容器全生命周期安全。
+- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← related_to ← [[ctp-topic-49-container-lifecycle-hardening-standards]]:EKS 可靠性最佳实践中的 Pod 安全配置与本视频标准一致。
+
+## Contradictions
+- 与 [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]] 的 hostNetwork 配置存在潜在冲突:
+ - 冲突点:Topic 39 中提到 Pod 规范设置 `hostNetwork: true` 以访问内部 Micro Focus 网络和外部资源。
+ - 当前观点(Topic 49):应避免使用 hostNetwork 以维护网络隔离和防止端口冲突。
+ - 对方观点(Topic 39):在受限 Lab Landing Zone 网络环境下,hostNetwork 是打通混合网络的必要手段。
+ - 说明:两者的差异源于场景不同——Topic 39 针对的是 IP 地址池不足的受限 Lab 环境,是特例;Topic 49 是通用安全最佳实践,适用于大多数生产场景。
diff --git a/wiki/sources/ctp-topic-5-aws-identity-and-access-management-iam.md b/wiki/sources/ctp-topic-5-aws-identity-and-access-management-iam.md
index a210eecd..2988d6af 100644
--- a/wiki/sources/ctp-topic-5-aws-identity-and-access-management-iam.md
+++ b/wiki/sources/ctp-topic-5-aws-identity-and-access-management-iam.md
@@ -1,61 +1,61 @@
----
-title: "CTP Topic 5 - AWS Identity and Access Management (IAM)"
-type: source
-tags:
- - AWS
- - IAM
- - Security
- - CTP
- - Identity
- - Federation
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/02_IAM/ctp-topic-5-aws-identity-and-access-management-iam.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS IAM 的核心组件(用户、组、角色、策略)及其在联邦访问中的应用
-- 问题域:企业 AWS Landing Zone 中的身份认证与访问授权管理
-- 方法/机制:联邦用户通过 Active Directory 组映射到 IAM 角色;PFSSO 工具实现 CLI 联邦访问;最小权限原则指导策略定义
-- 结论/价值:IAM 用户主要用于服务账号,人工用户应通过联邦机制管理;角色是串联身份与权限的核心纽带
-
-## Key Claims(用中文描述)
-- Active Directory 组通过角色映射为联邦用户提供 Landing Zone 账号访问权限
-- 角色本身不启用操作,而是将"谁可以做什么"与"可以做什么"关联起来
-- IAM 用户主要用于服务账号,人工用户应优先使用联邦访问
-- 策略应遵循最小权限原则,只授予严格必要的权限
-- VSM 请求是通过联邦获取账号访问的必经流程
-- 支持跨账号角色假设,允许指定账户的主体担任特定角色
-- Terraform 模块可用于定义 IAM 角色,包括假设角色策略和内联策略块
-
-## Key Quotes
-> "Roles don't enable actions; they tie together who can do something and what they can do." — 角色是连接身份与权限的纽带,而非直接启用操作的实体
-> "We only want to allow the access that is strictly required." — 最小权限原则
-> "IAM users are primarily for service accounts; federation is the preferred method for user management." — 联邦优先于 IAM 用户管理
-
-## Key Concepts
-- [[IAM(身份和访问管理)]]:AWS 服务,用于管理用户身份、组、角色和策略,控制对 AWS 资源的访问
-- [[Federation(联邦身份)]]:通过 Active Directory 组映射到 IAM 角色,实现单点登录访问 AWS
-- [[Least Privilege(最小权限)]]:只授予用户完成工作所需的最小权限的安全原则
-- [[IAM Role(IAM 角色)]]:一种 IAM 身份,具有特定权限,可由用户、服务或外部实体担任
-- [[IAM Policy(IAM 策略)]]:定义权限的 JSON 文档,指定允许或拒绝的操作及资源
-- [[Managed Policy vs Inline Policy]]:托管策略可在多个角色间复用,内联策略绑定到特定角色
-- [[Cross-Account Role Assumption]]:跨账号角色假设,允许指定账户的主体担任目标账户的角色
-- [[PFSSO]]:用于通过联邦身份实现 AWS CLI 访问的工具
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,云服务提供商,IAM 为其原生身份访问管理服务
-- [[Active Directory(AD)]]:微软目录服务,用于管理用户身份和组,通过联邦机制与 IAM 集成
-- [[accounts.json]]:位于每个 Landing Zone 根目录的文件,包含账户号列表
-- [[VSM]]:Virtual SMACKS 系统,通过联邦请求获取账号访问权限
-
-## Connections
-- [[ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs]] ← related_to ← [[IAM(身份和访问管理)]]
-- [[learning-sessions-identity-governance-vsm-replacement]] ← related_to ← [[Federation(联邦身份)]]
-- [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]] ← related_to ← [[Federation(联邦身份)]]
-- [[AWS-Landing-Zone]] ← depends_on ← [[IAM(身份和访问管理)]]
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← related_to ← [[Least Privilege(最小权限)]]
-
-## Contradictions
-- 无已知内容冲突
+---
+title: "CTP Topic 5 - AWS Identity and Access Management (IAM)"
+type: source
+tags:
+ - AWS
+ - IAM
+ - Security
+ - CTP
+ - Identity
+ - Federation
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/02_IAM/ctp-topic-5-aws-identity-and-access-management-iam.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS IAM 的核心组件(用户、组、角色、策略)及其在联邦访问中的应用
+- 问题域:企业 AWS Landing Zone 中的身份认证与访问授权管理
+- 方法/机制:联邦用户通过 Active Directory 组映射到 IAM 角色;PFSSO 工具实现 CLI 联邦访问;最小权限原则指导策略定义
+- 结论/价值:IAM 用户主要用于服务账号,人工用户应通过联邦机制管理;角色是串联身份与权限的核心纽带
+
+## Key Claims(用中文描述)
+- Active Directory 组通过角色映射为联邦用户提供 Landing Zone 账号访问权限
+- 角色本身不启用操作,而是将"谁可以做什么"与"可以做什么"关联起来
+- IAM 用户主要用于服务账号,人工用户应优先使用联邦访问
+- 策略应遵循最小权限原则,只授予严格必要的权限
+- VSM 请求是通过联邦获取账号访问的必经流程
+- 支持跨账号角色假设,允许指定账户的主体担任特定角色
+- Terraform 模块可用于定义 IAM 角色,包括假设角色策略和内联策略块
+
+## Key Quotes
+> "Roles don't enable actions; they tie together who can do something and what they can do." — 角色是连接身份与权限的纽带,而非直接启用操作的实体
+> "We only want to allow the access that is strictly required." — 最小权限原则
+> "IAM users are primarily for service accounts; federation is the preferred method for user management." — 联邦优先于 IAM 用户管理
+
+## Key Concepts
+- [[IAM(身份和访问管理)]]:AWS 服务,用于管理用户身份、组、角色和策略,控制对 AWS 资源的访问
+- [[Federation(联邦身份)]]:通过 Active Directory 组映射到 IAM 角色,实现单点登录访问 AWS
+- [[Least Privilege(最小权限)]]:只授予用户完成工作所需的最小权限的安全原则
+- [[IAM Role(IAM 角色)]]:一种 IAM 身份,具有特定权限,可由用户、服务或外部实体担任
+- [[IAM Policy(IAM 策略)]]:定义权限的 JSON 文档,指定允许或拒绝的操作及资源
+- [[Managed Policy vs Inline Policy]]:托管策略可在多个角色间复用,内联策略绑定到特定角色
+- [[Cross-Account Role Assumption]]:跨账号角色假设,允许指定账户的主体担任目标账户的角色
+- [[PFSSO]]:用于通过联邦身份实现 AWS CLI 访问的工具
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,云服务提供商,IAM 为其原生身份访问管理服务
+- [[Active Directory(AD)]]:微软目录服务,用于管理用户身份和组,通过联邦机制与 IAM 集成
+- [[accounts.json]]:位于每个 Landing Zone 根目录的文件,包含账户号列表
+- [[VSM]]:Virtual SMACKS 系统,通过联邦请求获取账号访问权限
+
+## Connections
+- [[ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs]] ← related_to ← [[IAM(身份和访问管理)]]
+- [[learning-sessions-identity-governance-vsm-replacement]] ← related_to ← [[Federation(联邦身份)]]
+- [[ctp-topic-11-ad-integration-and-login-using-ad-accounts]] ← related_to ← [[Federation(联邦身份)]]
+- [[AWS-Landing-Zone]] ← depends_on ← [[IAM(身份和访问管理)]]
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← related_to ← [[Least Privilege(最小权限)]]
+
+## Contradictions
+- 无已知内容冲突
diff --git a/wiki/sources/ctp-topic-50-ami-roadmap-for-aws-amis.md b/wiki/sources/ctp-topic-50-ami-roadmap-for-aws-amis.md
index b7712d09..8e234e21 100644
--- a/wiki/sources/ctp-topic-50-ami-roadmap-for-aws-amis.md
+++ b/wiki/sources/ctp-topic-50-ami-roadmap-for-aws-amis.md
@@ -1,64 +1,64 @@
----
-title: "CTP Topic 50 AMI Roadmap for AWS AMIs"
-type: source
-tags: [AWS, AMI, Roadmap, CTP]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-50-ami-roadmap-for-aws-amis]]
-
-## Summary(用中文描述)
-- 核心主题:CCOE AMI 路线图与 AWS 标准 AMI 生命周期规划
-- 问题域:企业 AWS 云环境中操作系统镜像的版本规划、EOL 时间线管理、新 AMI 添加流程
-- 方法/机制:CCOE 每两个月发布一次加固 AMI;路线图按 ADM 需求制定优先级;变更日志通过 CCRE 门户发布;新 AMI 需经过服务集成→功能启用→构建测试三阶段验证
-- 结论/价值:统一企业级 AMI 治理标准;提前规划 OS EOL 迁移;AMI 通过跨账号共享机制分发至所有组织账户
-
-## Key Claims(用中文描述)
-- CCOE 提供每两个月一次的对齐安全标准的加固 AMI
-- 自 2023 年 5 月起,所有 ARM 处理器相关的 AMI 将同步发布
-- AMI 路线图优先级主要由 ADM 需求驱动,变更需通过需求管道流程提交
-- Windows Server 2008/2008 R2 已于 2020 年 1 月 EOL,CentOS 8 已于 2021 年 12 月 EOL,Windows Server 2012 将于 2023 年 10 月 EOL,Red Hat 7 和 CentOS 7 将于 2024 年 6 月 EOL
-- AMI 通知通过邮件发送至 CCOE notifications PDL 订阅者
-- CCRE 门户现提供变更日志,记录 CCRE 所做的最新变更
-- AMI 功能包含:域加入服务、启用 SSH、集成 McAfee 防病毒服务、启用 DNS 设置、更新云初始化流程、启用 SSM 客户端、边缘安装
-- AMI 通过跨账号共享(AMI Sharing)分发给组织内所有账户,包括 AMI 本身、EBS 卷和 KMS 密钥
-
-## Key Quotes
-> "The CCOE provides hardened AMIs on a bi-monthly basis aligned with security standards." — CCOE AMI 发布节奏说明
-> "Starting May 2023, all ARM processors related to AMIs will be released." — ARM AMI 同步发布里程碑
-> "The order was created mainly by ADM requirements. Any requirements to change the prioritization of the roadmap should go through the demand pipeline process." — 路线图优先级机制
-> "The AMIs are shared with every account in the organization, including the AMI itself, EBS volumes, and KMS keys." — 跨账号分发机制
-
-## Key Concepts
-- [[Foundation AMI]]:CCOE 提供的安全加固基础镜像,是产品团队构建产品特定 AMI 的基础(本话题中称"CCOE AMI",与 [[ctp-topic-26-standard-ami-build-publish-share-processes]] 中的 Foundation AMI 概念一致)
-- [[OS-End-of-Life]]:操作系统生命周期终止管理,包括 Windows Server 2008/2008 R2、CentOS 8、Windows Server 2012、RHEL 7、CentOS 7 等多个 EOL 时间节点
-- [[AMI Sharing]]:跨账号 AMI 共享机制,将 AMI、EBS 卷和 KMS 密钥分发给组织内所有账户
-- [[ARM-AMI]]:ARM 处理器架构的 AMI,自 2023 年 5 月起纳入统一发布计划
-- [[CCOE]]:Cloud Center of Excellence,负责提供和维护企业标准 AMI
-- [[ADM]]:Architecture Decision Management,AMI 路线图优先级的主要驱动来源
-
-## Key Entities
-- [[CCOE]](组织):Cloud Center of Excellence,负责提供安全加固 AMI 和维护 AMI 路线图
-- [[AWS]]:提供 EC2 AMI 服务,是本话题所有 AMI 的底层平台
-- [[Amazon Linux]]:AWS 自有 Linux 发行版,当前版本包括 Amazon Linux 2 及规划中的 Amazon Linux 2022
-- [[Ubuntu]]:社区支持的 Linux 发行版,CCOE AMI 支持多个 Ubuntu 版本,包括 ARM 版本(自 2023 年 5 月)
-- [[CentOS]]:Red Hat 赞助的社区 Linux 发行版,CentOS 7 和 CentOS 8 分别将于 2024 年 6 月和 2021 年 12 月 EOL
-- [[Rocky Linux]]:CentOS 替代方案,Rocky 8 和 Rocky 9 纳入 AMI 路线图(2023 年 3 月)
-- [[Red Hat Enterprise Linux]]:企业级 Linux 发行版,RHEL 7 将于 2024 年 6 月 EOL
-- [[SLES]](SUSE Linux Enterprise Server):企业级 Linux 发行版,SLES 15 纳入 AMI 路线图(2022 年 11 月)
-- [[Windows Server]]:微软服务器操作系统,Windows 2008/2008 R2 已 EOL,Windows Server 2012 即将 EOL
-- [[McAfee]]:企业级防病毒解决方案,集成于 CCOE AMI 中
-
-## Connections
-- [[ctp-topic-26-standard-ami-build-publish-share-processes]] ← extends ← [[ctp-topic-50-ami-roadmap-for-aws-amis]]
-- [[ctp-topic-58-aws-ec2-image-builder]] ← extends ← [[ctp-topic-26-standard-ami-build-publish-share-processes]]
-- [[learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2]] ← depends_on ← [[ctp-topic-50-ami-roadmap-for-aws-amis]]
-- [[ctp-topic-50-ami-roadmap-for-aws-amis]] ← extends ← [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]]
-
-## Contradictions
-- 与 [[ctp-topic-26-standard-ami-build-publish-share-processes]] 存在描述角度差异:
- - 冲突点:AMI 叫法不统一——本话题称为"CCOE AMI",Topic 26 称为"Foundation AMI"
- - 当前观点:CCOE AMI 即 Foundation AMI,两者描述的是同一个实体
- - 对方观点:Topic 26 从生命周期管理角度描述(构建→发布→共享),本话题从路线图规划角度描述(版本规划→EOL→新 AMI 添加)
- - 结论:非矛盾而是互补关系,共同构成完整的 AMI 管理体系
+---
+title: "CTP Topic 50 AMI Roadmap for AWS AMIs"
+type: source
+tags: [AWS, AMI, Roadmap, CTP]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-50-ami-roadmap-for-aws-amis.md]]
+
+## Summary(用中文描述)
+- 核心主题:CCOE AMI 路线图与 AWS 标准 AMI 生命周期规划
+- 问题域:企业 AWS 云环境中操作系统镜像的版本规划、EOL 时间线管理、新 AMI 添加流程
+- 方法/机制:CCOE 每两个月发布一次加固 AMI;路线图按 ADM 需求制定优先级;变更日志通过 CCRE 门户发布;新 AMI 需经过服务集成→功能启用→构建测试三阶段验证
+- 结论/价值:统一企业级 AMI 治理标准;提前规划 OS EOL 迁移;AMI 通过跨账号共享机制分发至所有组织账户
+
+## Key Claims(用中文描述)
+- CCOE 提供每两个月一次的对齐安全标准的加固 AMI
+- 自 2023 年 5 月起,所有 ARM 处理器相关的 AMI 将同步发布
+- AMI 路线图优先级主要由 ADM 需求驱动,变更需通过需求管道流程提交
+- Windows Server 2008/2008 R2 已于 2020 年 1 月 EOL,CentOS 8 已于 2021 年 12 月 EOL,Windows Server 2012 将于 2023 年 10 月 EOL,Red Hat 7 和 CentOS 7 将于 2024 年 6 月 EOL
+- AMI 通知通过邮件发送至 CCOE notifications PDL 订阅者
+- CCRE 门户现提供变更日志,记录 CCRE 所做的最新变更
+- AMI 功能包含:域加入服务、启用 SSH、集成 McAfee 防病毒服务、启用 DNS 设置、更新云初始化流程、启用 SSM 客户端、边缘安装
+- AMI 通过跨账号共享(AMI Sharing)分发给组织内所有账户,包括 AMI 本身、EBS 卷和 KMS 密钥
+
+## Key Quotes
+> "The CCOE provides hardened AMIs on a bi-monthly basis aligned with security standards." — CCOE AMI 发布节奏说明
+> "Starting May 2023, all ARM processors related to AMIs will be released." — ARM AMI 同步发布里程碑
+> "The order was created mainly by ADM requirements. Any requirements to change the prioritization of the roadmap should go through the demand pipeline process." — 路线图优先级机制
+> "The AMIs are shared with every account in the organization, including the AMI itself, EBS volumes, and KMS keys." — 跨账号分发机制
+
+## Key Concepts
+- [[Foundation AMI]]:CCOE 提供的安全加固基础镜像,是产品团队构建产品特定 AMI 的基础(本话题中称"CCOE AMI",与 [[ctp-topic-26-standard-ami-build-publish-share-processes]] 中的 Foundation AMI 概念一致)
+- [[OS-End-of-Life]]:操作系统生命周期终止管理,包括 Windows Server 2008/2008 R2、CentOS 8、Windows Server 2012、RHEL 7、CentOS 7 等多个 EOL 时间节点
+- [[AMI Sharing]]:跨账号 AMI 共享机制,将 AMI、EBS 卷和 KMS 密钥分发给组织内所有账户
+- [[ARM-AMI]]:ARM 处理器架构的 AMI,自 2023 年 5 月起纳入统一发布计划
+- [[CCOE]]:Cloud Center of Excellence,负责提供和维护企业标准 AMI
+- [[ADM]]:Architecture Decision Management,AMI 路线图优先级的主要驱动来源
+
+## Key Entities
+- [[CCOE]](组织):Cloud Center of Excellence,负责提供安全加固 AMI 和维护 AMI 路线图
+- [[AWS]]:提供 EC2 AMI 服务,是本话题所有 AMI 的底层平台
+- [[Amazon Linux]]:AWS 自有 Linux 发行版,当前版本包括 Amazon Linux 2 及规划中的 Amazon Linux 2022
+- [[Ubuntu]]:社区支持的 Linux 发行版,CCOE AMI 支持多个 Ubuntu 版本,包括 ARM 版本(自 2023 年 5 月)
+- [[CentOS]]:Red Hat 赞助的社区 Linux 发行版,CentOS 7 和 CentOS 8 分别将于 2024 年 6 月和 2021 年 12 月 EOL
+- [[Rocky Linux]]:CentOS 替代方案,Rocky 8 和 Rocky 9 纳入 AMI 路线图(2023 年 3 月)
+- [[Red Hat Enterprise Linux]]:企业级 Linux 发行版,RHEL 7 将于 2024 年 6 月 EOL
+- [[SLES]](SUSE Linux Enterprise Server):企业级 Linux 发行版,SLES 15 纳入 AMI 路线图(2022 年 11 月)
+- [[Windows Server]]:微软服务器操作系统,Windows 2008/2008 R2 已 EOL,Windows Server 2012 即将 EOL
+- [[McAfee]]:企业级防病毒解决方案,集成于 CCOE AMI 中
+
+## Connections
+- [[ctp-topic-26-standard-ami-build-publish-share-processes]] ← extends ← [[ctp-topic-50-ami-roadmap-for-aws-amis]]
+- [[ctp-topic-58-aws-ec2-image-builder]] ← extends ← [[ctp-topic-26-standard-ami-build-publish-share-processes]]
+- [[learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2]] ← depends_on ← [[ctp-topic-50-ami-roadmap-for-aws-amis]]
+- [[ctp-topic-50-ami-roadmap-for-aws-amis]] ← extends ← [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]]
+
+## Contradictions
+- 与 [[ctp-topic-26-standard-ami-build-publish-share-processes]] 存在描述角度差异:
+ - 冲突点:AMI 叫法不统一——本话题称为"CCOE AMI",Topic 26 称为"Foundation AMI"
+ - 当前观点:CCOE AMI 即 Foundation AMI,两者描述的是同一个实体
+ - 对方观点:Topic 26 从生命周期管理角度描述(构建→发布→共享),本话题从路线图规划角度描述(版本规划→EOL→新 AMI 添加)
+ - 结论:非矛盾而是互补关系,共同构成完整的 AMI 管理体系
diff --git a/wiki/sources/ctp-topic-51-architecting-with-aws-purpose-built-databases.md b/wiki/sources/ctp-topic-51-architecting-with-aws-purpose-built-databases.md
index ee685ea7..cba6b015 100644
--- a/wiki/sources/ctp-topic-51-architecting-with-aws-purpose-built-databases.md
+++ b/wiki/sources/ctp-topic-51-architecting-with-aws-purpose-built-databases.md
@@ -1,64 +1,64 @@
----
-title: "CTP Topic 51 Architecting with AWS Purpose-Built Databases"
-type: source
-tags:
- - AWS
- - Database
- - Purpose-Built
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-51-architecting-with-aws-purpose-built-databases]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 专用数据库(Purpose-Built Databases)选型与架构设计原则
-- 问题域:现代应用的数据层设计——如何在多种数据类型和访问模式下选择最优数据库
-- 方法/机制:从用例出发 → 选择最佳工具 → 避免一刀切思维;AWS 提供关系型/NoSQL/内存/图/时序/账本/宽列等全品类专用数据库;DBA 角色从平台管理转向应用创新
-- 结论/价值:正确的数据库选型是应用性能的基础;数据库类型与访问模式的匹配度比"最新最贵"更重要;Duolingo/Netflix/Peloton 等真实案例验证了多数据库混合架构的价值
-
-## Key Claims(用中文描述)
-- AWS 数据库专家 Femi George 认为:现代应用需要"为正确的应用选择正确的专用数据库",避免用单一关系型数据库解决所有问题
-- 专用数据库选型应考虑:应用规模、用户数量、访问模式、流量峰值、性能需求(延迟、可用性)
-- Duolingo 的多数据库架构:DynamoDB 存储个性化数据 + ElastiCache 缓存高频词/短语 + Aurora 处理事务数据
-- Netflix 使用 DynamoDB 实现高弹性和低延迟 JSON 文档访问
-- Peloton 使用 ElastiCache Redis 为客户提供即时反馈
-- 云时代 DBA 的职能转变:从底层平台管理(备份、补丁)转向应用层创新和查询优化
-
-## Key Quotes
-> "We need to start thinking of the right purpose-built database for the right application." — Femi George, AWS Database Sales Specialist
-> "Amazon Aurora has two flavors, MySQL and PostgreSQL." — Femi George, 强调 Aurora 的双引擎特性
-> "The role of the DBA is evolving in the cloud." — 云时代 DBA 从平台管理转向应用创新
-
-## Key Concepts
-- [[Purpose-Built-Databases]]:AWS 全品类专用数据库体系——关系型/NoSQL/键值/文档/内存/图/时序/账本/宽列,覆盖所有数据模型
-- [[DBA-Role-Evolution]]:云时代数据库管理员职能转变——从平台管理(备份/补丁)转向应用创新(查询优化/架构设计)
-- [[Multi-Database-Architecture]]:多数据库混合架构——根据数据类型选择最优数据库(如 Duolingo:DynamoDB + ElastiCache + Aurora)
-
-## Key Entities
-- [[Amazon-DynamoDB]]:AWS 全托管键值和文档数据库,单位数毫秒性能,日处理万亿级请求
-- [[Amazon-Aurora]]:云原生关系型数据库,支持 MySQL 和 PostgreSQL,存储与计算分离架构
-- [[Amazon-RDS]]:AWS 全托管关系型数据库服务,支持多引擎(MySQL/PostgreSQL/MariaDB/Oracle/SQL Server)
-- [[Amazon-ElastiCache]]:AWS 全托管内存缓存服务,支持 Redis 和 Memcached
-- [[Amazon-Neptune]]:AWS 图数据库,用于欺诈检测、社交网络、推荐系统
-- [[Amazon-Timestream]]:AWS 时序数据库,专为 IoT 和运维监控场景优化
-- [[Amazon-Keyspaces]]:AWS 托管 Apache Cassandra 兼容数据库,提供无服务器选项
-- [[Amazon-DocumentDB]]:AWS MongoDB 兼容文档数据库,支持灵活 schema
-- [[Duolingo]]:多数据库架构实战案例——DynamoDB + ElastiCache + Aurora
-- [[Netflix]]:DynamoDB 生产级用户——高弹性、低延迟 JSON 文档访问
-- [[Peloton]]:ElastiCache Redis 生产级用户——即时客户反馈
-
-## Connections
-- [[Amazon-Aurora]] ← extends ← [[Amazon-RDS]]:Aurora 是 RDS 的云原生演进版本
-- [[Amazon-DynamoDB]] ← alternative_to ← [[Amazon-RDS]]:NoSQL 键值 vs 传统关系型的选型对比
-- [[Amazon-ElastiCache]] ← complements ← [[Amazon-RDS]]:缓存层补充数据库层,提升读取性能
-- [[Amazon-Neptune]] ← specialized_for ← Graph-Use-Cases:图数据库用于关系复杂的场景
-- [[Amazon-Timestream]] ← specialized_for ← Time-Series-Data:时序数据库用于 IoT/监控场景
-- [[ctp-topic-66-rds-vs-aurora]] ← related_to ← [[ctp-topic-51-purpose-built-databases]]:RDS vs Aurora 是关系型数据库内部的选型,本文档覆盖全品类数据库选型
-
-## Contradictions
-- 与 [[ctp-topic-66-rds-vs-aurora]] 的视角互补而非冲突:
- - 冲突点:无实质性冲突,两者是不同维度的对比
- - 当前观点(本文档):Aurora 是 RDS 的云原生演进,提供存储计算分离和更高 IO 性能
- - 对方观点(CTP 66):从 PostgreSQL 迁移视角对比,RDS 更适合小规模低成本场景,Aurora 更适合大规模高性能场景
+---
+title: "CTP Topic 51 Architecting with AWS Purpose-Built Databases"
+type: source
+tags:
+ - AWS
+ - Database
+ - Purpose-Built
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-51-architecting-with-aws-purpose-built-databases.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 专用数据库(Purpose-Built Databases)选型与架构设计原则
+- 问题域:现代应用的数据层设计——如何在多种数据类型和访问模式下选择最优数据库
+- 方法/机制:从用例出发 → 选择最佳工具 → 避免一刀切思维;AWS 提供关系型/NoSQL/内存/图/时序/账本/宽列等全品类专用数据库;DBA 角色从平台管理转向应用创新
+- 结论/价值:正确的数据库选型是应用性能的基础;数据库类型与访问模式的匹配度比"最新最贵"更重要;Duolingo/Netflix/Peloton 等真实案例验证了多数据库混合架构的价值
+
+## Key Claims(用中文描述)
+- AWS 数据库专家 Femi George 认为:现代应用需要"为正确的应用选择正确的专用数据库",避免用单一关系型数据库解决所有问题
+- 专用数据库选型应考虑:应用规模、用户数量、访问模式、流量峰值、性能需求(延迟、可用性)
+- Duolingo 的多数据库架构:DynamoDB 存储个性化数据 + ElastiCache 缓存高频词/短语 + Aurora 处理事务数据
+- Netflix 使用 DynamoDB 实现高弹性和低延迟 JSON 文档访问
+- Peloton 使用 ElastiCache Redis 为客户提供即时反馈
+- 云时代 DBA 的职能转变:从底层平台管理(备份、补丁)转向应用层创新和查询优化
+
+## Key Quotes
+> "We need to start thinking of the right purpose-built database for the right application." — Femi George, AWS Database Sales Specialist
+> "Amazon Aurora has two flavors, MySQL and PostgreSQL." — Femi George, 强调 Aurora 的双引擎特性
+> "The role of the DBA is evolving in the cloud." — 云时代 DBA 从平台管理转向应用创新
+
+## Key Concepts
+- [[Purpose-Built-Databases]]:AWS 全品类专用数据库体系——关系型/NoSQL/键值/文档/内存/图/时序/账本/宽列,覆盖所有数据模型
+- [[DBA-Role-Evolution]]:云时代数据库管理员职能转变——从平台管理(备份/补丁)转向应用创新(查询优化/架构设计)
+- [[Multi-Database-Architecture]]:多数据库混合架构——根据数据类型选择最优数据库(如 Duolingo:DynamoDB + ElastiCache + Aurora)
+
+## Key Entities
+- [[Amazon-DynamoDB]]:AWS 全托管键值和文档数据库,单位数毫秒性能,日处理万亿级请求
+- [[Amazon-Aurora]]:云原生关系型数据库,支持 MySQL 和 PostgreSQL,存储与计算分离架构
+- [[Amazon-RDS]]:AWS 全托管关系型数据库服务,支持多引擎(MySQL/PostgreSQL/MariaDB/Oracle/SQL Server)
+- [[Amazon-ElastiCache]]:AWS 全托管内存缓存服务,支持 Redis 和 Memcached
+- [[Amazon-Neptune]]:AWS 图数据库,用于欺诈检测、社交网络、推荐系统
+- [[Amazon-Timestream]]:AWS 时序数据库,专为 IoT 和运维监控场景优化
+- [[Amazon-Keyspaces]]:AWS 托管 Apache Cassandra 兼容数据库,提供无服务器选项
+- [[Amazon-DocumentDB]]:AWS MongoDB 兼容文档数据库,支持灵活 schema
+- [[Duolingo]]:多数据库架构实战案例——DynamoDB + ElastiCache + Aurora
+- [[Netflix]]:DynamoDB 生产级用户——高弹性、低延迟 JSON 文档访问
+- [[Peloton]]:ElastiCache Redis 生产级用户——即时客户反馈
+
+## Connections
+- [[Amazon-Aurora]] ← extends ← [[Amazon-RDS]]:Aurora 是 RDS 的云原生演进版本
+- [[Amazon-DynamoDB]] ← alternative_to ← [[Amazon-RDS]]:NoSQL 键值 vs 传统关系型的选型对比
+- [[Amazon-ElastiCache]] ← complements ← [[Amazon-RDS]]:缓存层补充数据库层,提升读取性能
+- [[Amazon-Neptune]] ← specialized_for ← Graph-Use-Cases:图数据库用于关系复杂的场景
+- [[Amazon-Timestream]] ← specialized_for ← Time-Series-Data:时序数据库用于 IoT/监控场景
+- [[ctp-topic-66-rds-vs-aurora]] ← related_to ← [[ctp-topic-51-purpose-built-databases]]:RDS vs Aurora 是关系型数据库内部的选型,本文档覆盖全品类数据库选型
+
+## Contradictions
+- 与 [[ctp-topic-66-rds-vs-aurora]] 的视角互补而非冲突:
+ - 冲突点:无实质性冲突,两者是不同维度的对比
+ - 当前观点(本文档):Aurora 是 RDS 的云原生演进,提供存储计算分离和更高 IO 性能
+ - 对方观点(CTP 66):从 PostgreSQL 迁移视角对比,RDS 更适合小规模低成本场景,Aurora 更适合大规模高性能场景
diff --git a/wiki/sources/ctp-topic-52-3-lines-of-defence-3lod-framework-cloud-security-posture-management.md b/wiki/sources/ctp-topic-52-3-lines-of-defence-3lod-framework-cloud-security-posture-management.md
index 29be9177..d9a09450 100644
--- a/wiki/sources/ctp-topic-52-3-lines-of-defence-3lod-framework-cloud-security-posture-management.md
+++ b/wiki/sources/ctp-topic-52-3-lines-of-defence-3lod-framework-cloud-security-posture-management.md
@@ -1,55 +1,55 @@
----
-title: "CTP Topic 52 3 Lines of Defence (3LoD) framework Cloud Security Posture Management (CSPM)"
-type: source
-tags: [Security, CSPM, 3LoD, CTP]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-52-3-lines-of-defence-3lod-framework-cloud-security-posture-management]]
-
-## Summary(用中文描述)
-- 核心主题:Three Lines of Defence(3LoD)安全治理框架在企业云安全中的落地,以及 Cloud Security Posture Management(CSPM)工具的选型与实践
-- 问题域:企业安全组织架构职责不清、多云账户安全配置碎片化、缺乏统一的云安全态势可视化和合规视图
-- 方法/机制:
- - 3LoD 框架:明确业务单元(一线)→ 集团职能部门(二线)→ 审计(三线)的安全责任分层
- - CSPM 集中化:将多账户、多云(AWS/Azure/GCP)的安全配置错误统一汇聚到单一平台
- - Cloud Guard 选型:基于 POC 对比两家供应商后选定,核心功能包括态势管理、资产管理、网络配置可视化、事件管理和威胁情报
- - 云架构设计原则:云无关(agnostic)、可复用、跨云适用
-- 结论/价值:3LoD 框架为安全组织提供了清晰的职责边界,CSPM 工具使安全团队能够主动发现和修复云配置偏差,从被动响应转向主动防御
-
-## Key Claims(用中文描述)
-- 3LoD 框架经 ELT 批准后成为组织统一的安全治理模型,解决了此前安全团队和政策碎片化的问题
-- 第一线(业务单元)负责在其业务范围内实施和管理安全控制
-- 第二线(集团职能部门)负责制定政策、事件响应和网络安全工具,作为第一线的顾问
-- 第三线(审计)确保第一线和第二线合规,向业务提供保障
-- CSPM 解决多云账户管理碎片化问题,提供统一的合规框架视图( CIS、NIST、ISO)和自定义策略能力
-- Cloud Guard 在 POC 后被选中,核心功能包括态势管理、资产管理、网络配置可视化、事件管理和身份管理
-- 新账户在创建流程中即被纳入 Cloud Guard,确保全面覆盖和相关规则集的自动应用
-
-## Key Quotes
-> "The three lines of defense model was approved by ELT mid-year and serves as the organization's go-to model." — Coyote, Head of Enterprise Application Security
-
-> "The previous fragmented security models with multiple security teams and policies led to an audit that recommended a better framework for clear roles and responsibilities." — Coyote, Head of Enterprise Application Security
-
-> "Cloud security posture management addresses siloed management and the lack of a central view of public cloud security posture, which led to incidents and prolonged response times." — Coyote, Head of Enterprise Application Security
-
-## Key Concepts
-- [[Three Lines of Defence(3LoD)]]:企业安全治理框架,将安全职责分为三层——业务单元(一线)、集团职能部门(二线)、审计(三线),为组织提供清晰的安全责任边界
-- [[Cloud Security Posture Management(CSPM)]]:云安全态势管理工具,通过持续监控和评估云配置,发现偏差并提供修复建议,支持 CIS、NIST、ISO 等合规框架
-- [[Cloud Guard]]:该组织选定的 CSPM 工具,通过 POC 对比两家供应商后确定,核心功能涵盖态势管理、资产管理、网络配置可视化、事件管理和威胁情报
-- [[Security Governance(安全治理)]]:通过 3LoD 框架和 CSPM 工具相结合,实现从被动响应到主动防御的转变
-
-## Key Entities
-- [[Coyote]]:Enterprise Application Security 负责人(Head of),主讲本次 CTP Topic 52,推动 3LoD 框架落地和 CSPM 选型
-
-## Connections
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← depends_on ← [[3 Lines of Defence(3LoD)Framework CSPM]]
- - 两者同属云安全领域,Topic 10 聚焦标签化安全控制,3LoD 聚焦安全组织架构和 CSPM 工具
-- [[public-cloud-learning-sessions-opentext-gis-security-policies-20241015]] ← extends ← [[3 Lines of Defence(3LoD)Framework CSPM]]
- - GIS Security Policies 提供企业级安全策略体系,3LoD 定义了安全治理的组织架构层,两者互补
-- [[ctp-topic-55-aws-firewall-manager]] ← extends ← [[Cloud Security Posture Management(CSPM)]]
- - Firewall Manager 提供安全组策略集中化管理,CSPM(Cloud Guard)提供云配置合规评估,两者共同构成云安全防护体系
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "CTP Topic 52 3 Lines of Defence (3LoD) framework Cloud Security Posture Management (CSPM)"
+type: source
+tags: [Security, CSPM, 3LoD, CTP]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-52-3-lines-of-defence-3lod-framework-cloud-security-posture-management.md]]
+
+## Summary(用中文描述)
+- 核心主题:Three Lines of Defence(3LoD)安全治理框架在企业云安全中的落地,以及 Cloud Security Posture Management(CSPM)工具的选型与实践
+- 问题域:企业安全组织架构职责不清、多云账户安全配置碎片化、缺乏统一的云安全态势可视化和合规视图
+- 方法/机制:
+ - 3LoD 框架:明确业务单元(一线)→ 集团职能部门(二线)→ 审计(三线)的安全责任分层
+ - CSPM 集中化:将多账户、多云(AWS/Azure/GCP)的安全配置错误统一汇聚到单一平台
+ - Cloud Guard 选型:基于 POC 对比两家供应商后选定,核心功能包括态势管理、资产管理、网络配置可视化、事件管理和威胁情报
+ - 云架构设计原则:云无关(agnostic)、可复用、跨云适用
+- 结论/价值:3LoD 框架为安全组织提供了清晰的职责边界,CSPM 工具使安全团队能够主动发现和修复云配置偏差,从被动响应转向主动防御
+
+## Key Claims(用中文描述)
+- 3LoD 框架经 ELT 批准后成为组织统一的安全治理模型,解决了此前安全团队和政策碎片化的问题
+- 第一线(业务单元)负责在其业务范围内实施和管理安全控制
+- 第二线(集团职能部门)负责制定政策、事件响应和网络安全工具,作为第一线的顾问
+- 第三线(审计)确保第一线和第二线合规,向业务提供保障
+- CSPM 解决多云账户管理碎片化问题,提供统一的合规框架视图( CIS、NIST、ISO)和自定义策略能力
+- Cloud Guard 在 POC 后被选中,核心功能包括态势管理、资产管理、网络配置可视化、事件管理和身份管理
+- 新账户在创建流程中即被纳入 Cloud Guard,确保全面覆盖和相关规则集的自动应用
+
+## Key Quotes
+> "The three lines of defense model was approved by ELT mid-year and serves as the organization's go-to model." — Coyote, Head of Enterprise Application Security
+
+> "The previous fragmented security models with multiple security teams and policies led to an audit that recommended a better framework for clear roles and responsibilities." — Coyote, Head of Enterprise Application Security
+
+> "Cloud security posture management addresses siloed management and the lack of a central view of public cloud security posture, which led to incidents and prolonged response times." — Coyote, Head of Enterprise Application Security
+
+## Key Concepts
+- [[Three Lines of Defence(3LoD)]]:企业安全治理框架,将安全职责分为三层——业务单元(一线)、集团职能部门(二线)、审计(三线),为组织提供清晰的安全责任边界
+- [[Cloud Security Posture Management(CSPM)]]:云安全态势管理工具,通过持续监控和评估云配置,发现偏差并提供修复建议,支持 CIS、NIST、ISO 等合规框架
+- [[Cloud Guard]]:该组织选定的 CSPM 工具,通过 POC 对比两家供应商后确定,核心功能涵盖态势管理、资产管理、网络配置可视化、事件管理和威胁情报
+- [[Security Governance(安全治理)]]:通过 3LoD 框架和 CSPM 工具相结合,实现从被动响应到主动防御的转变
+
+## Key Entities
+- [[Coyote]]:Enterprise Application Security 负责人(Head of),主讲本次 CTP Topic 52,推动 3LoD 框架落地和 CSPM 选型
+
+## Connections
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← depends_on ← [[3 Lines of Defence(3LoD)Framework CSPM]]
+ - 两者同属云安全领域,Topic 10 聚焦标签化安全控制,3LoD 聚焦安全组织架构和 CSPM 工具
+- [[public-cloud-learning-sessions-opentext-gis-security-policies-20241015]] ← extends ← [[3 Lines of Defence(3LoD)Framework CSPM]]
+ - GIS Security Policies 提供企业级安全策略体系,3LoD 定义了安全治理的组织架构层,两者互补
+- [[ctp-topic-55-aws-firewall-manager]] ← extends ← [[Cloud Security Posture Management(CSPM)]]
+ - Firewall Manager 提供安全组策略集中化管理,CSPM(Cloud Guard)提供云配置合规评估,两者共同构成云安全防护体系
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/ctp-topic-53-why-bother-with-cloud.md b/wiki/sources/ctp-topic-53-why-bother-with-cloud.md
index ecacbeca..3c88292f 100644
--- a/wiki/sources/ctp-topic-53-why-bother-with-cloud.md
+++ b/wiki/sources/ctp-topic-53-why-bother-with-cloud.md
@@ -1,58 +1,58 @@
----
-title: "CTP Topic 53 Why bother with Cloud"
-type: source
-tags: [Cloud, Strategy, CTP]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-53-why-bother-with-cloud.md]]
-
-## Summary(用中文描述)
-- 核心主题:Micro Focus 云转型计划的商业价值论证——用数据说明为何要迁移到云端
-- 问题域:企业数据中心资产利用率低、成本高昂,云转型不仅是成本节约,更是创新催化剂
-- 方法/机制:ELT(高管团队)演示 → 数据支撑论点 → 落地进展展示(LZ 交付、账户标签框架、Dart 资产剥离)
-- 结论/价值:云迁移不是"是否"的问题,而是"速度"的问题;当前 55% AWS 成本发生在 LZ 之外,亟需治理
-
-## Key Claims(用中文描述)
-- Micro Focus 拥有全球最大的商业数据中心足迹——14个数据中心、近20,000台资产
-- 尽管年营收25亿美元,但 VMware 足迹比规模大8倍的公司还大,硬件利用率不足40%
-- 三个产品迁出 Bublikan 后,下线575台物理服务器,云端仅需240台虚拟服务器替代
-- Redding 退出时40%的应用直接关机无需迁移,Houston 有89个空机架和360台未使用服务器
-- 云迁移的收益不仅是成本节约,更能促进产品创新、改善灾备、开拓新市场
-- 当前55%的 AWS 成本发生在 Landing Zone 之外,缺乏自动化、安全和财务管控
-
-## Key Quotes
-> "Micro Focus has the world's largest commercial footprint." — ELT 2022 演示
-> "We're trying to give them the information so that they can understand how they are spending." — 成本可见性目标
-> "The benefits of moving to the cloud extend beyond cost savings, fostering innovation and increasing revenue." — 云转型核心论点
-
-## Key Concepts
-- [[Cloud Transformation Programme]]:Micro Focus 的云转型计划,目标整合基础设施、降低成本、促进创新
-- [[Landing Zone]]:三类 LZ(Labs/SAS/Corporate)分别支撑不同隔离级别的云环境
-- [[AWS Account Tagging Framework]]:609个 AWS 账户统一标签框架,用于成本追踪和产品组消费告知
-- [[Enterprise Platform]]:企业级平台包含公共云供应商(AWS)、SRE、CCOE、架构组、自动化、安全和财务管控
-- [[Multi-Cloud Strategy]]:本视频论证了云转型战略的必要性
-
-## Key Entities
-- [[Micro Focus]]:年收入25亿美元的 Enterprise Software 公司,拥有全球最大商业数据中心足迹
-- [[Executive Leadership Team (ELT)]]:高管团队,2022年听取数据中心规模汇报后推动云转型
-- [[Bublikan]]:数据中心名称,三个产品从该中心迁出后下线575台物理服务器
-- [[Redding]]:数据中心名称,退出时40%应用直接关机
-- [[Houston]]:数据中心名称,拥有89个空机架和360台未使用服务器
-- [[Dart]]:资产剥离项目,云转型计划已完成 Dart 资产剥离
-- [[CCOE (Cloud Center of Excellence)]]:云卓越中心,负责企业平台和安全策略
-- [[SRE (Site Reliability Engineering)]]:可靠性工程团队,SRE/CCOE/架构组共同构成企业平台
-
-## Connections
-- [[ctp-topic-43-vmware-cloud-on-aws]] ← tensions_with ← [[ctp-topic-53-why-bother-with-cloud]]
-- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← [[ctp-topic-53-why-bother-with-cloud]]
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← extends ← [[ctp-topic-53-why-bother-with-cloud]]
-- [[ctp-topic-28-aws-tag-validation-tool]] ← extends ← [[ctp-topic-53-why-bother-with-cloud]]
-
-## Contradictions
-- 与 [[ctp-topic-43-vmware-cloud-on-aws]] 存在观点张力:
- - 冲突点:是否应将工作负载迁移到云端
- - 当前观点(本视频):应积极迁移至云端,数据中心规模庞大、利用率低,云迁移成本效益显著
- - 对方观点(Topic 43):VMware Cloud on AWS 提供混合云中间路线,适合不完全准备完全迁移的企业
- - 当前处理方式:两种路线并存——原生 AWS LZ 适合新建工作负载,VMC on AWS 适合已有 VMware 环境的渐进迁移
+---
+title: "CTP Topic 53 Why bother with Cloud"
+type: source
+tags: [Cloud, Strategy, CTP]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-53-why-bother-with-cloud.md]]
+
+## Summary(用中文描述)
+- 核心主题:Micro Focus 云转型计划的商业价值论证——用数据说明为何要迁移到云端
+- 问题域:企业数据中心资产利用率低、成本高昂,云转型不仅是成本节约,更是创新催化剂
+- 方法/机制:ELT(高管团队)演示 → 数据支撑论点 → 落地进展展示(LZ 交付、账户标签框架、Dart 资产剥离)
+- 结论/价值:云迁移不是"是否"的问题,而是"速度"的问题;当前 55% AWS 成本发生在 LZ 之外,亟需治理
+
+## Key Claims(用中文描述)
+- Micro Focus 拥有全球最大的商业数据中心足迹——14个数据中心、近20,000台资产
+- 尽管年营收25亿美元,但 VMware 足迹比规模大8倍的公司还大,硬件利用率不足40%
+- 三个产品迁出 Bublikan 后,下线575台物理服务器,云端仅需240台虚拟服务器替代
+- Redding 退出时40%的应用直接关机无需迁移,Houston 有89个空机架和360台未使用服务器
+- 云迁移的收益不仅是成本节约,更能促进产品创新、改善灾备、开拓新市场
+- 当前55%的 AWS 成本发生在 Landing Zone 之外,缺乏自动化、安全和财务管控
+
+## Key Quotes
+> "Micro Focus has the world's largest commercial footprint." — ELT 2022 演示
+> "We're trying to give them the information so that they can understand how they are spending." — 成本可见性目标
+> "The benefits of moving to the cloud extend beyond cost savings, fostering innovation and increasing revenue." — 云转型核心论点
+
+## Key Concepts
+- [[Cloud Transformation Programme]]:Micro Focus 的云转型计划,目标整合基础设施、降低成本、促进创新
+- [[Landing Zone]]:三类 LZ(Labs/SAS/Corporate)分别支撑不同隔离级别的云环境
+- [[AWS Account Tagging Framework]]:609个 AWS 账户统一标签框架,用于成本追踪和产品组消费告知
+- [[Enterprise Platform]]:企业级平台包含公共云供应商(AWS)、SRE、CCOE、架构组、自动化、安全和财务管控
+- [[Multi-Cloud Strategy]]:本视频论证了云转型战略的必要性
+
+## Key Entities
+- [[Micro Focus]]:年收入25亿美元的 Enterprise Software 公司,拥有全球最大商业数据中心足迹
+- [[Executive Leadership Team (ELT)]]:高管团队,2022年听取数据中心规模汇报后推动云转型
+- [[Bublikan]]:数据中心名称,三个产品从该中心迁出后下线575台物理服务器
+- [[Redding]]:数据中心名称,退出时40%应用直接关机
+- [[Houston]]:数据中心名称,拥有89个空机架和360台未使用服务器
+- [[Dart]]:资产剥离项目,云转型计划已完成 Dart 资产剥离
+- [[CCOE (Cloud Center of Excellence)]]:云卓越中心,负责企业平台和安全策略
+- [[SRE (Site Reliability Engineering)]]:可靠性工程团队,SRE/CCOE/架构组共同构成企业平台
+
+## Connections
+- [[ctp-topic-43-vmware-cloud-on-aws]] ← tensions_with ← [[ctp-topic-53-why-bother-with-cloud]]
+- [[ctp-topic-7-saas-landing-zone-design]] ← extends ← [[ctp-topic-53-why-bother-with-cloud]]
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← extends ← [[ctp-topic-53-why-bother-with-cloud]]
+- [[ctp-topic-28-aws-tag-validation-tool]] ← extends ← [[ctp-topic-53-why-bother-with-cloud]]
+
+## Contradictions
+- 与 [[ctp-topic-43-vmware-cloud-on-aws]] 存在观点张力:
+ - 冲突点:是否应将工作负载迁移到云端
+ - 当前观点(本视频):应积极迁移至云端,数据中心规模庞大、利用率低,云迁移成本效益显著
+ - 对方观点(Topic 43):VMware Cloud on AWS 提供混合云中间路线,适合不完全准备完全迁移的企业
+ - 当前处理方式:两种路线并存——原生 AWS LZ 适合新建工作负载,VMC on AWS 适合已有 VMware 环境的渐进迁移
diff --git a/wiki/sources/ctp-topic-54-esm-saas-log-analytics.md b/wiki/sources/ctp-topic-54-esm-saas-log-analytics.md
index 0177c655..95453398 100644
--- a/wiki/sources/ctp-topic-54-esm-saas-log-analytics.md
+++ b/wiki/sources/ctp-topic-54-esm-saas-log-analytics.md
@@ -1,64 +1,64 @@
----
-title: "CTP Topic 54 ESM SaaS Log Analytics"
-type: source
-tags:
- - Log-Analytics
- - SaaS
- - ESM
- - EKS
- - ELK
- - OpenSearch
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-54-esm-saas-log-analytics]]
-
-## Summary(用中文描述)
-- 核心主题:企业级日志分析解决方案(ESM SaaS),涵盖 ELK/OpenSearch 技术栈架构、区域部署、安全加固及主流方案对比
-- 问题域:多 VPC 环境下的日志集中采集、传输安全、合规存储(GDPR)及成本控制
-- 方法/机制:BEATS(Filebeat)采集 → Logstash 处理 → Elasticsearch/OpenSearch 存储 → Kibana 可视化;Redis 作为缓冲层防止 Logstash 过载;VPC 间私有流量传输
-- 结论/价值:AWS OpenSearch 性价比最优(~$1,500/月 vs Logz.io ~$4,000/月),推荐起步用 Logz.io 试用,后续迁移 AWS OpenSearch
-
-## Key Claims(用中文描述)
-- ELK 栈(Elasticsearch + Logstash + Kibana)是开源日志分析标准方案,OpenSearch 为 AWS 托管替代
-- 应用通过 BEATS(Filebeat)采集日志,Logstash 解析日志字段后存入 Elasticsearch/OpenSearch
-- 双 VPC 架构:应用 VPC 运行 Filebeat 容器持续推送日志至日志 VPC 的 Logstash
-- Redis 作为可选缓冲层防止 Logstash 过载
-- 出于 GDPR 合规要求,农场按区域分割(美国俄勒冈、欧洲)
-- 供应通过 CloudFormation 或 Terraform 实现,但安全加固和持续优化是主要挑战
-- 静态加密采用加密节点和 NVMe 设备硬件级加密;传输加密使用 TLS 1.2;VPC 间流量走私有网络
-- 基于索引的访问控制和 RBAC 实现不同用户角色隔离
-- 方案对比:Logz.io(托管 ELK,$4,000/月,SLA 99.8%)、AWS OpenSearch($1,500/月,SLA 99.9%,自动快照 DR)、自托管 ELK(成本低但维护复杂)、Microfocus OBA(商业成熟,支持列级访问控制)
-
-## Key Quotes
-> "The application collects your log, it's called the BEATS." — Jackie,解释 BEATS 组件在日志采集中的核心作用
-> "We have already built up all the farms." — Jackie,表示区域农场已完成部署
-> "Recommendations for starting with Log Analytics include beginning with Logz.io for its trial period, then transitioning to AWS OpenSearch or self-hosted options for more control." — 最佳起步路径建议
-
-## Key Concepts
-- [[ELK Stack]]:Elasticsearch + Logstash + Kibana 开源日志分析技术栈
-- [[OpenSearch]]:Elasticsearch 分支,AWS 托管版本,提供类似 Elasticsearch 的全文搜索和日志分析能力
-- [[Logstash]]:日志采集管道,负责解析和转换日志字段
-- [[Kibana]]:日志可视化前端
-- [[BEATS]]:轻量级日志采集代理家族,其中 Filebeat 常用作容器日志采集器
-- [[Redis]]:可选缓冲层,防止 Logstash 过载
-- [[GDPR]]:欧盟通用数据保护条例,推动日志农场按区域分割部署
-- [[RBAC]]:基于角色的访问控制,用于日志系统的用户权限管理
-- [[TLS 1.2]]:传输层加密标准,确保日志数据在传输过程中的安全性
-
-## Key Entities
-- [[Jackie]]:ITOM ESM SAS 架构师,本视频主讲人
-- [[AWS OpenSearch]]:AWS 托管的 OpenSearch 服务,日志分析推荐方案
-- [[Logz.io]]:托管 ELK SaaS 解决方案
-- [[Micro Focus Operations Bridge]]:企业级 IT 运维监控套件,OBA 为其日志分析组件
-- [[Elasticsearch]]:开源分布式搜索和分析引擎,ELK 栈核心组件
-
-## Connections
-- [[ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid]] ← related_to ← [[ctp-topic-54-esm-saas-log-analytics]]
-- [[ctp-topic-60-monitor-aws-using-hyperscale-observability-with-grafana]] ← extends ← [[ctp-topic-54-esm-saas-log-analytics]]
-- [[ctp-topic-70-eks-deployment-using-iac]] ← uses ← [[CloudFormation]] (供应工具)
-- [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]] ← similar_architecture ← (双 VPC 隔离架构)
-
-## Contradictions
-- 暂无发现与现有 Wiki 页面的冲突内容
+---
+title: "CTP Topic 54 ESM SaaS Log Analytics"
+type: source
+tags:
+ - Log-Analytics
+ - SaaS
+ - ESM
+ - EKS
+ - ELK
+ - OpenSearch
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-54-esm-saas-log-analytics.md]]
+
+## Summary(用中文描述)
+- 核心主题:企业级日志分析解决方案(ESM SaaS),涵盖 ELK/OpenSearch 技术栈架构、区域部署、安全加固及主流方案对比
+- 问题域:多 VPC 环境下的日志集中采集、传输安全、合规存储(GDPR)及成本控制
+- 方法/机制:BEATS(Filebeat)采集 → Logstash 处理 → Elasticsearch/OpenSearch 存储 → Kibana 可视化;Redis 作为缓冲层防止 Logstash 过载;VPC 间私有流量传输
+- 结论/价值:AWS OpenSearch 性价比最优(~$1,500/月 vs Logz.io ~$4,000/月),推荐起步用 Logz.io 试用,后续迁移 AWS OpenSearch
+
+## Key Claims(用中文描述)
+- ELK 栈(Elasticsearch + Logstash + Kibana)是开源日志分析标准方案,OpenSearch 为 AWS 托管替代
+- 应用通过 BEATS(Filebeat)采集日志,Logstash 解析日志字段后存入 Elasticsearch/OpenSearch
+- 双 VPC 架构:应用 VPC 运行 Filebeat 容器持续推送日志至日志 VPC 的 Logstash
+- Redis 作为可选缓冲层防止 Logstash 过载
+- 出于 GDPR 合规要求,农场按区域分割(美国俄勒冈、欧洲)
+- 供应通过 CloudFormation 或 Terraform 实现,但安全加固和持续优化是主要挑战
+- 静态加密采用加密节点和 NVMe 设备硬件级加密;传输加密使用 TLS 1.2;VPC 间流量走私有网络
+- 基于索引的访问控制和 RBAC 实现不同用户角色隔离
+- 方案对比:Logz.io(托管 ELK,$4,000/月,SLA 99.8%)、AWS OpenSearch($1,500/月,SLA 99.9%,自动快照 DR)、自托管 ELK(成本低但维护复杂)、Microfocus OBA(商业成熟,支持列级访问控制)
+
+## Key Quotes
+> "The application collects your log, it's called the BEATS." — Jackie,解释 BEATS 组件在日志采集中的核心作用
+> "We have already built up all the farms." — Jackie,表示区域农场已完成部署
+> "Recommendations for starting with Log Analytics include beginning with Logz.io for its trial period, then transitioning to AWS OpenSearch or self-hosted options for more control." — 最佳起步路径建议
+
+## Key Concepts
+- [[ELK Stack]]:Elasticsearch + Logstash + Kibana 开源日志分析技术栈
+- [[OpenSearch]]:Elasticsearch 分支,AWS 托管版本,提供类似 Elasticsearch 的全文搜索和日志分析能力
+- [[Logstash]]:日志采集管道,负责解析和转换日志字段
+- [[Kibana]]:日志可视化前端
+- [[BEATS]]:轻量级日志采集代理家族,其中 Filebeat 常用作容器日志采集器
+- [[Redis]]:可选缓冲层,防止 Logstash 过载
+- [[GDPR]]:欧盟通用数据保护条例,推动日志农场按区域分割部署
+- [[RBAC]]:基于角色的访问控制,用于日志系统的用户权限管理
+- [[TLS 1.2]]:传输层加密标准,确保日志数据在传输过程中的安全性
+
+## Key Entities
+- [[Jackie]]:ITOM ESM SAS 架构师,本视频主讲人
+- [[AWS OpenSearch]]:AWS 托管的 OpenSearch 服务,日志分析推荐方案
+- [[Logz.io]]:托管 ELK SaaS 解决方案
+- [[Micro Focus Operations Bridge]]:企业级 IT 运维监控套件,OBA 为其日志分析组件
+- [[Elasticsearch]]:开源分布式搜索和分析引擎,ELK 栈核心组件
+
+## Connections
+- [[ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid]] ← related_to ← [[ctp-topic-54-esm-saas-log-analytics]]
+- [[ctp-topic-60-monitor-aws-using-hyperscale-observability-with-grafana]] ← extends ← [[ctp-topic-54-esm-saas-log-analytics]]
+- [[ctp-topic-70-eks-deployment-using-iac]] ← uses ← [[CloudFormation]] (供应工具)
+- [[ctp-topic-39-implementing-eks-in-the-aws-lab-landing-zone]] ← similar_architecture ← (双 VPC 隔离架构)
+
+## Contradictions
+- 暂无发现与现有 Wiki 页面的冲突内容
diff --git a/wiki/sources/ctp-topic-55-aws-firewall-manager.md b/wiki/sources/ctp-topic-55-aws-firewall-manager.md
index f85c02ee..d7f1be21 100644
--- a/wiki/sources/ctp-topic-55-aws-firewall-manager.md
+++ b/wiki/sources/ctp-topic-55-aws-firewall-manager.md
@@ -1,49 +1,49 @@
----
-title: "CTP Topic 55 AWS Firewall Manager"
-type: source
-tags: [AWS, Firewall-Manager, Security, CTP, Landing-Zones]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-55-aws-firewall-manager]]
-
-## Summary(用中文描述)
-- 核心主题:AWS Firewall Manager 在 Grand Torque 多 Landing Zone 环境中的集中化安全策略管理实践
-- 问题域:跨多个 Landing Zone(RLABS、R&D、SAS、CAT)管理安全策略的复杂性,Checkpoint Firewall 无法覆盖的流量安全问题
-- 方法/机制:通过 Firewall Manager 账户创建安全组策略,使用 AWS Config + Lambda 触发事件自动修复,结合 RAM 共享前缀列表实现跨账户规则同步
-- 结论/价值:集中化管理、缩短安全策略部署时间、解决 QALIS 等共享服务扫描问题;支持 WAF 规则统一管理
-
-## Key Claims(用中文描述)
-- Firewall Manager 可跨多个 Landing Zone 统一部署基线安全组策略,解决多环境安全策略不一致问题
-- 三种安全策略类型:通用安全组(附加基线允许产品团队自增)、审计与强制安全组规则(拒绝过度宽松规则,支持自动修复)、清理未使用冗余安全组
-- Firewall Manager 账户独立于任何 Landing Zone,支持跨 Landing Zone 部署
-- RAM 前缀列表机制可跨账户轻松共享和更新安全组规则
-
-## Key Quotes
-> "We have gone through these policies and we come up with some baseline security groups." — 团队审查现有策略后制定基线安全组
-> "RAM is like it's a tool available within this AWS where you can specify or you can share your AWS resources to any other account that you wanted to specify." — RAM 用于跨账户资源共享
-> Demo 演示:在 Firewall Manager 账户创建通用安全组策略后,关联的 playground 账户中已存在的 EC2 实例和新启动的 EC2 实例均自动附加了安全组;删除策略后安全组自动从实例移除
-
-## Key Concepts
-- [[Security-Group]]:AWS 安全组,作为实例级别的有状态防火墙规则;Firewall Manager 三种策略均围绕安全组展开
-- [[Prefix-List]]:前缀列表,用于跨账户共享和更新安全组规则;通过 RAM 共享
-- [[Auto-Remediation]]:自动修复,Firewall Manager 策略可自动修复不合规的安全组规则
-- [[WAF-Rules-Management]]:Firewall Manager 还支持集中管理 WAF 规则,允许产品团队在基线规则上追加额外规则集
-
-## Key Entities
-- [[AWS-Firewall-Manager]]:AWS Firewall Manager 是集中配置防火墙规则和安全规则的管理服务,支持跨组织和账户的统一安全策略部署
-- [[Landing-Zones]]:AWS Landing Zones,Grand Torque 存在 RLABS、R&D、SAS、CAT 多个 Landing Zone,各有不同的安全要求
-- [[QALIS]]:产品账户实例扫描服务,通过 Firewall Manager 解决跨账户扫描的网络可达性问题
-- [[Checkpoint-Firewall]]:原有防火墙方案,存在安全组规则过于宽松的问题,无法完全覆盖通过公网子网的流量
-
-## Connections
-- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← relates_to ← [[ctp-topic-55-aws-firewall-manager]]
-- [[ctp-topic-37-secrets-certificates-management]] ← same_domain ← [[ctp-topic-55-aws-firewall-manager]](均属于 07_Security 类别)
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← related_security ← [[ctp-topic-55-aws-firewall-manager]]
-
-## Contradictions
-- 与 [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] 中的 Checkpoint Firewall 方案关系:
- - 冲突点:Checkpoint Firewall 原有安全组规则过于宽松,新方案引入 Firewall Manager 基线安全组
- - 当前观点:Firewall Manager 补充 Checkpoint,提供更细粒度的安全组基线控制
- - 对方观点:Checkpoint 作为网络边界防火墙,Firewall Manager 覆盖实例级别安全策略(互补而非冲突)
+---
+title: "CTP Topic 55 AWS Firewall Manager"
+type: source
+tags: [AWS, Firewall-Manager, Security, CTP, Landing-Zones]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-55-aws-firewall-manager.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS Firewall Manager 在 Grand Torque 多 Landing Zone 环境中的集中化安全策略管理实践
+- 问题域:跨多个 Landing Zone(RLABS、R&D、SAS、CAT)管理安全策略的复杂性,Checkpoint Firewall 无法覆盖的流量安全问题
+- 方法/机制:通过 Firewall Manager 账户创建安全组策略,使用 AWS Config + Lambda 触发事件自动修复,结合 RAM 共享前缀列表实现跨账户规则同步
+- 结论/价值:集中化管理、缩短安全策略部署时间、解决 QALIS 等共享服务扫描问题;支持 WAF 规则统一管理
+
+## Key Claims(用中文描述)
+- Firewall Manager 可跨多个 Landing Zone 统一部署基线安全组策略,解决多环境安全策略不一致问题
+- 三种安全策略类型:通用安全组(附加基线允许产品团队自增)、审计与强制安全组规则(拒绝过度宽松规则,支持自动修复)、清理未使用冗余安全组
+- Firewall Manager 账户独立于任何 Landing Zone,支持跨 Landing Zone 部署
+- RAM 前缀列表机制可跨账户轻松共享和更新安全组规则
+
+## Key Quotes
+> "We have gone through these policies and we come up with some baseline security groups." — 团队审查现有策略后制定基线安全组
+> "RAM is like it's a tool available within this AWS where you can specify or you can share your AWS resources to any other account that you wanted to specify." — RAM 用于跨账户资源共享
+> Demo 演示:在 Firewall Manager 账户创建通用安全组策略后,关联的 playground 账户中已存在的 EC2 实例和新启动的 EC2 实例均自动附加了安全组;删除策略后安全组自动从实例移除
+
+## Key Concepts
+- [[Security-Group]]:AWS 安全组,作为实例级别的有状态防火墙规则;Firewall Manager 三种策略均围绕安全组展开
+- [[Prefix-List]]:前缀列表,用于跨账户共享和更新安全组规则;通过 RAM 共享
+- [[Auto-Remediation]]:自动修复,Firewall Manager 策略可自动修复不合规的安全组规则
+- [[WAF-Rules-Management]]:Firewall Manager 还支持集中管理 WAF 规则,允许产品团队在基线规则上追加额外规则集
+
+## Key Entities
+- [[AWS-Firewall-Manager]]:AWS Firewall Manager 是集中配置防火墙规则和安全规则的管理服务,支持跨组织和账户的统一安全策略部署
+- [[Landing-Zones]]:AWS Landing Zones,Grand Torque 存在 RLABS、R&D、SAS、CAT 多个 Landing Zone,各有不同的安全要求
+- [[QALIS]]:产品账户实例扫描服务,通过 Firewall Manager 解决跨账户扫描的网络可达性问题
+- [[Checkpoint-Firewall]]:原有防火墙方案,存在安全组规则过于宽松的问题,无法完全覆盖通过公网子网的流量
+
+## Connections
+- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← relates_to ← [[ctp-topic-55-aws-firewall-manager]]
+- [[ctp-topic-37-secrets-certificates-management]] ← same_domain ← [[ctp-topic-55-aws-firewall-manager]](均属于 07_Security 类别)
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← related_security ← [[ctp-topic-55-aws-firewall-manager]]
+
+## Contradictions
+- 与 [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] 中的 Checkpoint Firewall 方案关系:
+ - 冲突点:Checkpoint Firewall 原有安全组规则过于宽松,新方案引入 Firewall Manager 基线安全组
+ - 当前观点:Firewall Manager 补充 Checkpoint,提供更细粒度的安全组基线控制
+ - 对方观点:Checkpoint 作为网络边界防火墙,Firewall Manager 覆盖实例级别安全策略(互补而非冲突)
diff --git a/wiki/sources/ctp-topic-56-automated-infrastructure-testing.md b/wiki/sources/ctp-topic-56-automated-infrastructure-testing.md
index 427718e7..19285c57 100644
--- a/wiki/sources/ctp-topic-56-automated-infrastructure-testing.md
+++ b/wiki/sources/ctp-topic-56-automated-infrastructure-testing.md
@@ -1,58 +1,58 @@
----
-title: "CTP Topic 56 Automated Infrastructure Testing"
-type: source
-tags:
- - Testing
- - IaC
- - Automation
- - CTP
- - Terraform
- - TerraTest
- - TDD
-sources: []
-last_updated: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-56-automated-infrastructure-testing.md]]
-
-## Summary(用中文描述)
-- 核心主题:自动化基础设施测试——将软件测试原则应用于 Terraform IaC 代码,通过 TerraTest 框架实现基础设施的 Apply → Test → Destroy 自动化验证循环。
-- 问题域:传统 Terraform 验证仅做语法检查,无法验证实际部署后的行为是否符合预期;手动测试耗时且不可重复;缺乏测试的基础设施代码变更信心不足。
-- 方法/机制:
- - TerraTest(Golang 库):自动执行 apply → test → destroy 生命周期,输出结构化测试结果
- - 测试驱动开发(TDD):先写测试,再实现功能,确保测试先行且全面覆盖
- - 提议的新工作流:将测试编写作为基础设施开发的首要步骤,移除手动验证环节
-- 结论/价值:自动化测试虽然前期投入时间,但长期回报是减少 Bug、提升部署信心、积累可重复的测试套件;"让机器做重复的事,把人脑留给复杂的人类问题"
-
-## Key Claims(用中文描述)
-- 集成测试对于验证已部署基础设施的功能至关重要,超越了语法检查,确保实际部署与预期相符。
-- TerraTest 通过自动化 apply-test-destroy 循环简化了测试流程,降低了基础设施测试的门槛。
-- 测试驱动开发(TDD)在基础设施即代码领域的应用:先写测试,再实现功能,聚焦开发并积累全面测试套件。
-- 提议的工作流将测试编写作为核心步骤,移除手动验证,追求自动化验证套件和更高的部署信心。
-- 长期收益(减少 Bug、提升信心)远超前期投入困难;测试应被视为一等公民。
-
-## Key Quotes
-> "I think the bottom quote, just I think let's leave the repetitive things for the computers to do and use our brains for the complex human things."
-> — Mark Francis,核心价值观:重复性工作交给机器,人脑专注于复杂的人类问题
-
-> "I'm just extending the value of putting stuff as code."
-> — Mark Francis,将测试代码化的价值延伸
-
-## Key Concepts
-- [[Infrastructure Testing(基础设施测试)]]:对 Terraform 等 IaC 工具部署的实际基础设施资源进行验证,而非仅检查语法或计划输出
-- [[TerraTest]]:HashiCorp 官方出品的 Golang 基础设施测试框架,支持 apply-test-destroy 自动化循环
-- [[Test-Driven Development(TDD)]]:先写测试用例,再实现功能,确保测试覆盖全面且聚焦开发过程
-- [[IaC Testing Framework]]:专门针对基础设施即代码的测试工具链,包括语法检查、计划验证、集成测试等多个层次
-
-## Key Entities
-- [[Mark Francis]]:CTP Topic 56 讲师,主讲自动化基础设施测试实践
-
-## Connections
-- [[ctp-topic-33-an-introduction-to-gitops]] ← extends ← [[ctp-topic-56-automated-infrastructure-testing.md]]
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← depends_on ← [[ctp-topic-56-automated-infrastructure-testing.md]]
-- [[ctp-topic-3-deploy-and-maintain-infrastructure]] ← extends ← [[ctp-topic-56-automated-infrastructure-testing.md]]
-- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← related_to ← [[ctp-topic-56-automated-infrastructure-testing.md]]
-
-## Contradictions
-- (待发现:如有相关页面引用与本页面观点冲突的内容,将在此记录)
+---
+title: "CTP Topic 56 Automated Infrastructure Testing"
+type: source
+tags:
+ - Testing
+ - IaC
+ - Automation
+ - CTP
+ - Terraform
+ - TerraTest
+ - TDD
+sources: []
+last_updated: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-56-automated-infrastructure-testing.md]]
+
+## Summary(用中文描述)
+- 核心主题:自动化基础设施测试——将软件测试原则应用于 Terraform IaC 代码,通过 TerraTest 框架实现基础设施的 Apply → Test → Destroy 自动化验证循环。
+- 问题域:传统 Terraform 验证仅做语法检查,无法验证实际部署后的行为是否符合预期;手动测试耗时且不可重复;缺乏测试的基础设施代码变更信心不足。
+- 方法/机制:
+ - TerraTest(Golang 库):自动执行 apply → test → destroy 生命周期,输出结构化测试结果
+ - 测试驱动开发(TDD):先写测试,再实现功能,确保测试先行且全面覆盖
+ - 提议的新工作流:将测试编写作为基础设施开发的首要步骤,移除手动验证环节
+- 结论/价值:自动化测试虽然前期投入时间,但长期回报是减少 Bug、提升部署信心、积累可重复的测试套件;"让机器做重复的事,把人脑留给复杂的人类问题"
+
+## Key Claims(用中文描述)
+- 集成测试对于验证已部署基础设施的功能至关重要,超越了语法检查,确保实际部署与预期相符。
+- TerraTest 通过自动化 apply-test-destroy 循环简化了测试流程,降低了基础设施测试的门槛。
+- 测试驱动开发(TDD)在基础设施即代码领域的应用:先写测试,再实现功能,聚焦开发并积累全面测试套件。
+- 提议的工作流将测试编写作为核心步骤,移除手动验证,追求自动化验证套件和更高的部署信心。
+- 长期收益(减少 Bug、提升信心)远超前期投入困难;测试应被视为一等公民。
+
+## Key Quotes
+> "I think the bottom quote, just I think let's leave the repetitive things for the computers to do and use our brains for the complex human things."
+> — Mark Francis,核心价值观:重复性工作交给机器,人脑专注于复杂的人类问题
+
+> "I'm just extending the value of putting stuff as code."
+> — Mark Francis,将测试代码化的价值延伸
+
+## Key Concepts
+- [[Infrastructure Testing(基础设施测试)]]:对 Terraform 等 IaC 工具部署的实际基础设施资源进行验证,而非仅检查语法或计划输出
+- [[TerraTest]]:HashiCorp 官方出品的 Golang 基础设施测试框架,支持 apply-test-destroy 自动化循环
+- [[Test-Driven Development(TDD)]]:先写测试用例,再实现功能,确保测试覆盖全面且聚焦开发过程
+- [[IaC Testing Framework]]:专门针对基础设施即代码的测试工具链,包括语法检查、计划验证、集成测试等多个层次
+
+## Key Entities
+- [[Mark Francis]]:CTP Topic 56 讲师,主讲自动化基础设施测试实践
+
+## Connections
+- [[ctp-topic-33-an-introduction-to-gitops]] ← extends ← [[ctp-topic-56-automated-infrastructure-testing.md]]
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← depends_on ← [[ctp-topic-56-automated-infrastructure-testing.md]]
+- [[ctp-topic-3-deploy-and-maintain-infrastructure]] ← extends ← [[ctp-topic-56-automated-infrastructure-testing.md]]
+- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← related_to ← [[ctp-topic-56-automated-infrastructure-testing.md]]
+
+## Contradictions
+- (待发现:如有相关页面引用与本页面观点冲突的内容,将在此记录)
diff --git a/wiki/sources/ctp-topic-57-product-backlog-managing-demand.md b/wiki/sources/ctp-topic-57-product-backlog-managing-demand.md
index d80bc3cb..3f00c24e 100644
--- a/wiki/sources/ctp-topic-57-product-backlog-managing-demand.md
+++ b/wiki/sources/ctp-topic-57-product-backlog-managing-demand.md
@@ -1,62 +1,62 @@
----
-title: "CTP Topic 57 Product backlog managing demand"
-type: source
-tags: []
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-57-product-backlog-managing-demand]]
-
-## Summary(用中文描述)
-- 核心主题:产品待办列表(Product Backlog)管理 —— 企业级云转型计划中如何接收、评估、优先级排序和交付需求
-- 问题域:CTP(Cloud Transformation Programme)需求治理、团队资源规划、产品组入职与支持
-- 方法/机制:通过 SMACs 提交需求 → 双周评审会议(Matthew Chapman/David Grant/Brendan)→ 20题评估问卷 → Octane 特性化 → Sprint 规划(50%新需求/50%支持+技术债)→ 准备阶段(Prerequisite Phase)→ SRE 账号构建与交接 → Hyper Care 支持
-- 结论/价值:透明化需求管道,确保所有工作以同一标准评估;Sprint 分配 50% 保护容量给新需求,防止支持工作吞噬创新带宽
-
-## Key Claims(用中文描述)
-- 产品待办列表是需求缓冲区,存放即将推出的功能,标注需求来源、收益和优先级
-- 新请求必须通过 SMACs 提交以启动计时器和确保可追踪性;邮件或聊天仅用于初步接触
-- 需求通过双周评审会议(Matthew Chapman/David Grant/Brendan 等)评估理解度、价值和优先级
-- 约20题的评估问卷帮助判断每项请求的简洁性、成本和野心程度
-- 机会评估通过后进入 Octane 作为特性(Feature),附带任务列表
-- 新团队需经历准备阶段(Prerequisite Phase)以对齐期望并理解产品需求
-- Sprint 规划通常提前6个 Sprint 展开,分配约50%给新需求、50%给支持工单和技术债
-- 大型产品组(如 ADM 和 ITOM)举行双周会议以对齐计划与优先级
-- 准备阶段关键步骤:介绍会议 → AWS 账户创建(PCG 团队审核)→ 解决方案设计与精炼 → GitHub 仓库创建 → 防火墙标签定义;产品团队工作量约2小时,跨越1-2周
-- SRE 工程师构建账户并交接,提供控制台和 GitHub 访问详情;交接后提供2周 Hyper Care 支持
-- 现有产品组可通过 SMACs/邮件/Teams 请求支持;缺陷在当前 Sprint 解决并分配给原始 Squad
-- Teams 频道连接产品组、SRE 工程师、解决方案架构师和交付经理
-- 变更请求或增强与解决方案架构师讨论后集成到现有账户
-- 公有子网通常仅限于生产环境;团队提供 Atlantis 或 Grant 表单用于自助任务
-
-## Key Quotes
-> "We need a way to make sure it's transparent and we're holding everything up to the light and looking everything for the same lens as we are." — 关于需求管理透明化的核心理念
-
-> "It means that for ADM they can effectively plan all of the work that's going into their sprints with the engineers that are working solidly on their work." — 关于 Sprint 规划对 ADM 产品组的价值
-
-## Key Concepts
-- [[Product-Backlog]]: 产品待办列表,作为需求缓冲区存放即将推出的功能,包含来源、收益和优先级信息
-- [[Demand-Management]]: 需求管理,通过标准化流程(提交→评审→分配→交付)确保透明度和公平优先级排序
-- [[SMACs]]: Service Management and Customer Service,系统化服务管理工具,用于提交和追踪需求请求
-- [[Prerequisite-Phase]]: 准备阶段,新产品团队加入云转型旅程时的入职流程,对齐期望并完成技术准备
-- [[Hyper-Care]]: 交接后支持期,SRE 工程师在产品组接管后提供2周强化支持
-- [[Sprint-Planning]]: Sprint 规划,提前6个 Sprint 展开,50% 容量分配给新需求,50% 给支持工单和技术债
-- [[Octane]]: Micro Focus 的工作追踪平台,需求评估通过后进入 Octane 作为 Feature 并附带任务列表
-
-## Key Entities
-- [[Matthew Chapman]]: 需求评审会议主持人之一
-- [[David Grant]]: 需求评审会议参与者
-- [[Brendan Starnig]]: 需求评审会议参与者,SRE Function Lead(CTP Topic 30 讲师)
-- [[ADM]]: Application Development and Management,产品组之一,定期双周对齐会议
-- [[ITOM]]: IT Operations Management,产品组之一,定期双周对齐会议
-- [[PCG]]: Platform Control Group,准备阶段中审核 AWS 账户创建并提供云环境支持
-- [[SRE]]: Site Reliability Engineer,负责账号构建、交接和 Hyper Care 支持
-
-## Connections
-- [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]] ← related_to ← [[ctp-topic-57-product-backlog-managing-demand]](两者均属 CTP 需求治理框架,本 Topic 聚焦 Backlog 管理,Topic 20 聚焦 Gate Process 和 POC 入职)
-- [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] ← related_to ← [[ctp-topic-57-product-backlog-managing-demand]](两者均涉及 CTP 敏捷实践,Sprint 规划分配比例在 Topic 4 有更详细讨论)
-- [[ctp-topic-30-managing-change]] ← related_to ← [[ctp-topic-57-product-backlog-managing-demand]](两者均涉及 SRE 与产品团队的协作,Brendan Starnig 在两个 Topic 中均有参与)
-
-## Contradictions
-- 暂无发现与其他 Wiki 页面的冲突内容。
+---
+title: "CTP Topic 57 Product backlog managing demand"
+type: source
+tags: []
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-57-product-backlog-managing-demand.md]]
+
+## Summary(用中文描述)
+- 核心主题:产品待办列表(Product Backlog)管理 —— 企业级云转型计划中如何接收、评估、优先级排序和交付需求
+- 问题域:CTP(Cloud Transformation Programme)需求治理、团队资源规划、产品组入职与支持
+- 方法/机制:通过 SMACs 提交需求 → 双周评审会议(Matthew Chapman/David Grant/Brendan)→ 20题评估问卷 → Octane 特性化 → Sprint 规划(50%新需求/50%支持+技术债)→ 准备阶段(Prerequisite Phase)→ SRE 账号构建与交接 → Hyper Care 支持
+- 结论/价值:透明化需求管道,确保所有工作以同一标准评估;Sprint 分配 50% 保护容量给新需求,防止支持工作吞噬创新带宽
+
+## Key Claims(用中文描述)
+- 产品待办列表是需求缓冲区,存放即将推出的功能,标注需求来源、收益和优先级
+- 新请求必须通过 SMACs 提交以启动计时器和确保可追踪性;邮件或聊天仅用于初步接触
+- 需求通过双周评审会议(Matthew Chapman/David Grant/Brendan 等)评估理解度、价值和优先级
+- 约20题的评估问卷帮助判断每项请求的简洁性、成本和野心程度
+- 机会评估通过后进入 Octane 作为特性(Feature),附带任务列表
+- 新团队需经历准备阶段(Prerequisite Phase)以对齐期望并理解产品需求
+- Sprint 规划通常提前6个 Sprint 展开,分配约50%给新需求、50%给支持工单和技术债
+- 大型产品组(如 ADM 和 ITOM)举行双周会议以对齐计划与优先级
+- 准备阶段关键步骤:介绍会议 → AWS 账户创建(PCG 团队审核)→ 解决方案设计与精炼 → GitHub 仓库创建 → 防火墙标签定义;产品团队工作量约2小时,跨越1-2周
+- SRE 工程师构建账户并交接,提供控制台和 GitHub 访问详情;交接后提供2周 Hyper Care 支持
+- 现有产品组可通过 SMACs/邮件/Teams 请求支持;缺陷在当前 Sprint 解决并分配给原始 Squad
+- Teams 频道连接产品组、SRE 工程师、解决方案架构师和交付经理
+- 变更请求或增强与解决方案架构师讨论后集成到现有账户
+- 公有子网通常仅限于生产环境;团队提供 Atlantis 或 Grant 表单用于自助任务
+
+## Key Quotes
+> "We need a way to make sure it's transparent and we're holding everything up to the light and looking everything for the same lens as we are." — 关于需求管理透明化的核心理念
+
+> "It means that for ADM they can effectively plan all of the work that's going into their sprints with the engineers that are working solidly on their work." — 关于 Sprint 规划对 ADM 产品组的价值
+
+## Key Concepts
+- [[Product-Backlog]]: 产品待办列表,作为需求缓冲区存放即将推出的功能,包含来源、收益和优先级信息
+- [[Demand-Management]]: 需求管理,通过标准化流程(提交→评审→分配→交付)确保透明度和公平优先级排序
+- [[SMACs]]: Service Management and Customer Service,系统化服务管理工具,用于提交和追踪需求请求
+- [[Prerequisite-Phase]]: 准备阶段,新产品团队加入云转型旅程时的入职流程,对齐期望并完成技术准备
+- [[Hyper-Care]]: 交接后支持期,SRE 工程师在产品组接管后提供2周强化支持
+- [[Sprint-Planning]]: Sprint 规划,提前6个 Sprint 展开,50% 容量分配给新需求,50% 给支持工单和技术债
+- [[Octane]]: Micro Focus 的工作追踪平台,需求评估通过后进入 Octane 作为 Feature 并附带任务列表
+
+## Key Entities
+- [[Matthew Chapman]]: 需求评审会议主持人之一
+- [[David Grant]]: 需求评审会议参与者
+- [[Brendan Starnig]]: 需求评审会议参与者,SRE Function Lead(CTP Topic 30 讲师)
+- [[ADM]]: Application Development and Management,产品组之一,定期双周对齐会议
+- [[ITOM]]: IT Operations Management,产品组之一,定期双周对齐会议
+- [[PCG]]: Platform Control Group,准备阶段中审核 AWS 账户创建并提供云环境支持
+- [[SRE]]: Site Reliability Engineer,负责账号构建、交接和 Hyper Care 支持
+
+## Connections
+- [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]] ← related_to ← [[ctp-topic-57-product-backlog-managing-demand]](两者均属 CTP 需求治理框架,本 Topic 聚焦 Backlog 管理,Topic 20 聚焦 Gate Process 和 POC 入职)
+- [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] ← related_to ← [[ctp-topic-57-product-backlog-managing-demand]](两者均涉及 CTP 敏捷实践,Sprint 规划分配比例在 Topic 4 有更详细讨论)
+- [[ctp-topic-30-managing-change]] ← related_to ← [[ctp-topic-57-product-backlog-managing-demand]](两者均涉及 SRE 与产品团队的协作,Brendan Starnig 在两个 Topic 中均有参与)
+
+## Contradictions
+- 暂无发现与其他 Wiki 页面的冲突内容。
diff --git a/wiki/sources/ctp-topic-58-aws-ec2-image-builder.md b/wiki/sources/ctp-topic-58-aws-ec2-image-builder.md
index 4d1b44cb..896d4d09 100644
--- a/wiki/sources/ctp-topic-58-aws-ec2-image-builder.md
+++ b/wiki/sources/ctp-topic-58-aws-ec2-image-builder.md
@@ -1,57 +1,57 @@
----
-title: "CTP Topic 58 AWS EC2 Image Builder"
-type: source
-tags:
- - AWS
- - EC2
- - Image-Builder
- - CTP
- - AMI
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-58-aws-ec2-image-builder.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS EC2 Image Builder 替代 Packer/Jenkins 实现企业级 AMI 生命周期自动化管理
-- 问题域:当前 AMI 发布流程依赖 GitLab 加固脚本 + Jenkins + Packer,存在修改周期长、跨 Landing Zone 兼容性差、手动 Bakery 自动化不足等问题
-- 方法/机制:Image Builder 通过 Pipeline(流水线)/Recipe(配方)/Component(组件)/Infrastructure Config 四层抽象,将 CCOE 加固脚本模块化为可复用组件,产品团队通过服务模块向 Golden AMI 添加组件
-- 结论/价值:提升生产力(自动化)、构建时内建测试、合规加固标准、跨账户跨区域分发;与 AWS Organizations/RAM 集成;支持 AWS Inspector Lambda 工作流做 AMI 安全扫描
-
-## Key Claims(用中文描述)
-- Image Builder 通过 Pipeline/Recipe/Component/Infrastructure Config 四层组件实现 AMI 构建全生命周期自动化
-- 当前 AMI 发布流程(GitLab + Jenkins + Packer)存在修改周期长、跨 LZ 兼容性差、手动 Bakery 自动化不足等缺陷
-- POC 已实现 CentOS 7 和 Ubuntu 18 端到端流水线,CCOE 加固脚本转换为独立组件
-- Lambda 工作流触发 AWS Inspector 扫描、邮件通知、S3 报告归档,维护历史 AMI 数据
-- Qualys 扫描集成正在评估中
-
-## Key Quotes
-> "A component is basically just a particular step that you want to execute in order to achieve the output AMI." — Image Builder 组件定义
-> "Due to these limitations, eventually the product teams try to cater to their requirements by developing some kind of workflow or CI CD pipelines wherein they consume that CCOE AMI and they try to update or install whatever packages they require." — 当前流程的局限性驱动产品团队自建 CI/CD
-> "Product groups can use a service module to add components to the golden AMI. A component is a script, and components should be added in alphabetical order." — 产品团队通过服务模块添加组件的机制
-
-## Key Concepts
-- [[Golden-AMI]]:由 CCOE 维护的标准化基础镜像,产品团队在其上添加自定义组件
-- [[CCOE]](Cloud Center of Excellence):云卓越中心,负责维护 Golden AMI 和加固脚本
-- [[Image-Pipeline]]:定义 AMI 发布时间线、安装步骤、安全加固和分发策略
-- [[Image-Recipe]]:YAML 格式定义源 AMI 到输出 AMI 的转换规则
-- [[Image-Component]]:在源 AMI 内执行的具体步骤(安装包、运行脚本)
-- [[Infrastructure-Configuration]]:定义构建 AMI 所需的 EC2 实例属性(类型/VPC/子网/安全组)
-- [[Distribution-Settings]]:管理 AMI 跨区域跨账户的分发配置
-- [[AWS-Inspector]]:AWS 原生 AMI 安全扫描工具
-
-## Key Entities
-- [[AWS]]:Image Builder 服务的云提供商
-
-## Connections
-- [[ctp-topic-26-standard-ami-build-publish-share-processes]] ← builds_on ← [[ctp-topic-58-aws-ec2-image-builder]](Image Builder 是对 Packer/Jenkins AMI 流程的升级)
-- [[ctp-topic-58-aws-ec2-image-builder]] ← depends_on ← [[learning-sessions-standard-amis-updates]](CCOE 加固脚本和标准 AMI 生命周期管理是 Image Builder 的输入)
-- [[ctp-topic-50-ami-roadmap-for-aws-amis]] ← related_to ← [[ctp-topic-58-aws-ec2-image-builder]](AMI 路线图与 Image Builder 自动化策略相关)
-
-## Contradictions
-- 与 [[ctp-topic-26-standard-ami-build-publish-share-processes]]:
- - 冲突点:当前 AMI 流程(GitLab + Jenkins + Packer)vs Image Builder 自动化流程
- - 当前观点:Packer/Jenkins 流程是现状,存在修改周期长、跨 LZ 兼容性差等问题
- - 对方观点:Jenkins 多分支流水线 + 机器人框架验证已将验证周期从 3-4 天缩短至 60 分钟
- - 说明:两者并非完全矛盾——Image Builder 替代 Packer 作为镜像构建工具,而 Jenkins 流水线可能继续用于 Terraform 部署触发
+---
+title: "CTP Topic 58 AWS EC2 Image Builder"
+type: source
+tags:
+ - AWS
+ - EC2
+ - Image-Builder
+ - CTP
+ - AMI
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-58-aws-ec2-image-builder.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS EC2 Image Builder 替代 Packer/Jenkins 实现企业级 AMI 生命周期自动化管理
+- 问题域:当前 AMI 发布流程依赖 GitLab 加固脚本 + Jenkins + Packer,存在修改周期长、跨 Landing Zone 兼容性差、手动 Bakery 自动化不足等问题
+- 方法/机制:Image Builder 通过 Pipeline(流水线)/Recipe(配方)/Component(组件)/Infrastructure Config 四层抽象,将 CCOE 加固脚本模块化为可复用组件,产品团队通过服务模块向 Golden AMI 添加组件
+- 结论/价值:提升生产力(自动化)、构建时内建测试、合规加固标准、跨账户跨区域分发;与 AWS Organizations/RAM 集成;支持 AWS Inspector Lambda 工作流做 AMI 安全扫描
+
+## Key Claims(用中文描述)
+- Image Builder 通过 Pipeline/Recipe/Component/Infrastructure Config 四层组件实现 AMI 构建全生命周期自动化
+- 当前 AMI 发布流程(GitLab + Jenkins + Packer)存在修改周期长、跨 LZ 兼容性差、手动 Bakery 自动化不足等缺陷
+- POC 已实现 CentOS 7 和 Ubuntu 18 端到端流水线,CCOE 加固脚本转换为独立组件
+- Lambda 工作流触发 AWS Inspector 扫描、邮件通知、S3 报告归档,维护历史 AMI 数据
+- Qualys 扫描集成正在评估中
+
+## Key Quotes
+> "A component is basically just a particular step that you want to execute in order to achieve the output AMI." — Image Builder 组件定义
+> "Due to these limitations, eventually the product teams try to cater to their requirements by developing some kind of workflow or CI CD pipelines wherein they consume that CCOE AMI and they try to update or install whatever packages they require." — 当前流程的局限性驱动产品团队自建 CI/CD
+> "Product groups can use a service module to add components to the golden AMI. A component is a script, and components should be added in alphabetical order." — 产品团队通过服务模块添加组件的机制
+
+## Key Concepts
+- [[Golden-AMI]]:由 CCOE 维护的标准化基础镜像,产品团队在其上添加自定义组件
+- [[CCOE]](Cloud Center of Excellence):云卓越中心,负责维护 Golden AMI 和加固脚本
+- [[Image-Pipeline]]:定义 AMI 发布时间线、安装步骤、安全加固和分发策略
+- [[Image-Recipe]]:YAML 格式定义源 AMI 到输出 AMI 的转换规则
+- [[Image-Component]]:在源 AMI 内执行的具体步骤(安装包、运行脚本)
+- [[Infrastructure-Configuration]]:定义构建 AMI 所需的 EC2 实例属性(类型/VPC/子网/安全组)
+- [[Distribution-Settings]]:管理 AMI 跨区域跨账户的分发配置
+- [[AWS-Inspector]]:AWS 原生 AMI 安全扫描工具
+
+## Key Entities
+- [[AWS]]:Image Builder 服务的云提供商
+
+## Connections
+- [[ctp-topic-26-standard-ami-build-publish-share-processes]] ← builds_on ← [[ctp-topic-58-aws-ec2-image-builder]](Image Builder 是对 Packer/Jenkins AMI 流程的升级)
+- [[ctp-topic-58-aws-ec2-image-builder]] ← depends_on ← [[learning-sessions-standard-amis-updates]](CCOE 加固脚本和标准 AMI 生命周期管理是 Image Builder 的输入)
+- [[ctp-topic-50-ami-roadmap-for-aws-amis]] ← related_to ← [[ctp-topic-58-aws-ec2-image-builder]](AMI 路线图与 Image Builder 自动化策略相关)
+
+## Contradictions
+- 与 [[ctp-topic-26-standard-ami-build-publish-share-processes]]:
+ - 冲突点:当前 AMI 流程(GitLab + Jenkins + Packer)vs Image Builder 自动化流程
+ - 当前观点:Packer/Jenkins 流程是现状,存在修改周期长、跨 LZ 兼容性差等问题
+ - 对方观点:Jenkins 多分支流水线 + 机器人框架验证已将验证周期从 3-4 天缩短至 60 分钟
+ - 说明:两者并非完全矛盾——Image Builder 替代 Packer 作为镜像构建工具,而 Jenkins 流水线可能继续用于 Terraform 部署触发
diff --git a/wiki/sources/ctp-topic-59-achieving-reliability-with-amazon-eks.md b/wiki/sources/ctp-topic-59-achieving-reliability-with-amazon-eks.md
index 3b99aa77..3fa00284 100644
--- a/wiki/sources/ctp-topic-59-achieving-reliability-with-amazon-eks.md
+++ b/wiki/sources/ctp-topic-59-achieving-reliability-with-amazon-eks.md
@@ -1,67 +1,67 @@
----
-title: "CTP Topic 59 Achieving reliability with Amazon EKS"
-type: source
-tags:
- - AWS
- - EKS
- - Kubernetes
- - Reliability
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-59-achieving-reliability-with-amazon-eks.md]]
-
-## Summary(用中文描述)
-- 核心主题:Amazon EKS(Elastic Kubernetes Service)的可靠性最佳实践,涵盖容器服务选型、应用层可靠性、控制平面可靠性和数据平面可靠性四个维度。
-- 问题域:Kubernetes 在 AWS 上的生产级可靠性保障,涉及 shared responsibility model 下 AWS 与客户的责任边界划分。
-- 方法/机制:通过 Pod 反亲和性、拓扑分布约束、HPA/VPA 扩缩容、探针配置、PodDisruptionBudget 等机制实现故障检测、优雅降级、自愈和按需扩缩;控制平面通过监控、认证加固、准入 Webhook 管理、集群升级策略保障;数据平面通过节点问题检测、资源预留、QoS、资源配额和 Pod 优先级机制保障。
-- 结论/价值:EKS 可靠性需要在应用、控制平面、数据平面三个层面综合设计,结合 AWS shared responsibility model 明确责任边界,并通过多样性部署策略(Rolling/Blue-Green/Canary)实现安全升级。
-
-## Key Claims(用中文描述)
-- ECS 推荐给容器化初学者,提供简单界面和原生 AWS 集成;EKS 适合熟悉 Kubernetes 生态的用户,提供开放社区灵活性。
-- 系统可靠性意味着即使发生故障也能提供可预测行为,核心关注点包括:故障检测、优雅服务降级、确定性故障模式、自愈能力和按需扩缩。
-- AWS shared responsibility model 下,AWS 负责控制平面组件(state store、scheduler、controller manager、API servers),客户负责工作节点、操作系统和应用配置。
-- Fargate 模式下客户无需管理节点、补丁或升级工作。
-- 应用可靠性需避免单例 Pod,使用 Pod 反亲和性或拓扑分布约束将应用 Pod 分散到多个可用区;HPA 默认基于 CPU 和内存扩缩容,VPA 可正确调整 Pod 大小但会导致运行时重启。
-- 部署策略包括滚动升级、蓝绿部署和金丝雀部署,各有不同控制复杂度和安全保障级别;存活探针、就绪探针和启动探针是 Pod 健康监控的关键;PodDisruptionBudget 确保维护期间的最小服务水平。
-- 控制平面可靠性需监控 API server 请求和 HCT state store 大小;必须创建具有超级管理员角色的安全用户;准入 Webhook 需仔细配置以避免阻塞控制平面;EKS 平台版本自动处理补丁版本,Minor 版本有 14 个月支持周期后自动升级。
-- 数据平面可靠性需使用节点问题检测器、预留系统资源、实现 QoS、配置资源配额和限制范围;Pod 优先级控制抢占。
-
-## Key Quotes
-> "ECS is a more AWS opinionated way of running containers." — ECS 与 EKS 的核心区别概述
-> "Reliability in a system means it offers predictable behavior even when failures occur." — 可靠性的本质定义
-> "With Fargate, you don't have to worry about managing the nodes or worrying about patching or upgrading the nodes." — Fargate 对 shared responsibility model 的影响
-
-## Key Concepts
-- [[Reliability(系统可靠性)]]:系统在发生故障时仍能提供可预测行为的能力,包含故障检测、优雅降级、确定性故障模式、自愈和按需扩缩五个核心关注点。
-- [[Application Reliability(应用可靠性)]]:通过避免单例 Pod、AZ 分散、HPA/VPA 扩缩容、部署策略(Rolling/Blue-Green/Canary)、健康探针和 PodDisruptionBudget 实现。
-- [[Control Plane Reliability(控制平面可靠性)]]:通过监控控制平面指标、安全认证加固、准入 Webhook 管理和集群升级策略保障。
-- [[Data Plane Reliability(数据平面可靠性)]]:通过节点问题检测、资源预留、QoS、资源配额、LimitRange 和 Pod 优先级机制保障。
-- [[Shared Responsibility Model(EKS)]]:AWS 负责控制平面(API server、scheduler 等),客户负责工作节点、操作系统和应用配置;Fargate 模式下进一步减少客户运维负担。
-- [[Pod Anti-Affinity]]:通过反亲和性规则将 Pod 分散到不同节点或可用区,避免单点故障。
-- [[Topology Spread Constraints]]:提供比 Pod 反亲和性更细粒度的工作负载分布控制。
-- [[Horizontal Pod Autoscaler (HPA)]]:基于 CPU 利用率和内存消耗的默认扩缩容机制,支持自定义/外部指标。
-- [[Vertical Pod Autoscaler (VPA)]]:根据实际资源使用情况自动调整 Pod 的大小配置,但运行时调整会导致 Pod 重启。
-- [[Liveness/Readiness/Startup Probes]]:三类 Kubernetes 探针,用于监控 Pod 健康状态和就绪情况。
-- [[PodDisruptionBudget]]:在自愿中断(如节点维护)期间保证最小数量或比例的 Pod 持续运行。
-- [[Rolling/Blue-Green/Canary Deployment]]:三种部署策略,滚动升级自动化程度高但回滚控制有限,蓝绿和金丝雀提供更精细的控制和快速回滚能力。
-
-## Key Entities
-- [[Surav Paul]]:AWS 高级解决方案架构师(Senior Solutions Architect),本场演讲的主讲人。
-- [[Amazon EKS]]:AWS 托管的 Kubernetes 服务,适合熟悉 Kubernetes 生态的用户,提供开放社区灵活性。
-- [[Amazon ECS]]:AWS 原生容器服务,推荐给容器化初学者,提供简单界面和原生 AWS 集成。
-- [[AWS Fargate]]:无服务器容器运行平台,使用 Fargate 时客户无需管理节点、补丁或升级工作。
-
-## Connections
-- [[CTP Topic 39 Implementing EKS in the AWS Lab Landing Zone]] ← topic_overlap ← [[CTP Topic 59 Achieving reliability with Amazon EKS]](均涉及 EKS 部署实践,本 Topic 聚焦可靠性设计,Topic 39 聚焦网络/IP 问题解决)
-- [[CTP Topic 64 Scaling out with Amazon EKS]] ← topic_overlap ← [[CTP Topic 59 Achieving reliability with Amazon EKS]](均涉及 EKS 扩缩容,Topic 64 聚焦扩缩机制,Topic 59 聚焦可靠性全栈设计)
-- [[CTP Topic 60 Monitor AWS using Hyperscale Observability with Grafana]] ← complements ← [[CTP Topic 59 Achieving reliability with Amazon EKS]](Grafana 监控可用于 Topic 59 中的控制平面和数据平面指标监控)
-- [[Public Cloud Learning Sessions EKS Optimization Part 3 of 3 Introduction to EKS Auto Mode]] ← extends ← [[CTP Topic 59 Achieving reliability with Amazon EKS]](Auto Mode 是 EKS 可靠性自动化的进一步演进,涵盖 Fargate 集成和自动扩缩容)
-
-## Contradictions
-- 与 [[CTP Topic 39 Implementing EKS in the AWS Lab Landing Zone]] 的潜在视角差异:
- - 冲突点:Topic 39 描述 EKS 部署中的 IP 资源挑战,强调自定义网络配置(hostNetwork)和独立私有子网;Topic 59 侧重标准 EKS 可靠性机制,较少涉及网络约束场景。
- - 当前观点:两者面向不同场景——Topic 39 针对受限网络环境下的实际部署挑战,Topic 59 提供通用的 EKS 可靠性最佳实践,互为补充而非冲突。
- - 对方观点:Topic 39 认为在某些受限环境下标准 EKS 配置(如 CNI 插件默认 IP 分配)无法直接适用,需要自定义网络方案;Topic 59 的通用建议可能需要针对特殊环境调整。
+---
+title: "CTP Topic 59 Achieving reliability with Amazon EKS"
+type: source
+tags:
+ - AWS
+ - EKS
+ - Kubernetes
+ - Reliability
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-59-achieving-reliability-with-amazon-eks.md]]
+
+## Summary(用中文描述)
+- 核心主题:Amazon EKS(Elastic Kubernetes Service)的可靠性最佳实践,涵盖容器服务选型、应用层可靠性、控制平面可靠性和数据平面可靠性四个维度。
+- 问题域:Kubernetes 在 AWS 上的生产级可靠性保障,涉及 shared responsibility model 下 AWS 与客户的责任边界划分。
+- 方法/机制:通过 Pod 反亲和性、拓扑分布约束、HPA/VPA 扩缩容、探针配置、PodDisruptionBudget 等机制实现故障检测、优雅降级、自愈和按需扩缩;控制平面通过监控、认证加固、准入 Webhook 管理、集群升级策略保障;数据平面通过节点问题检测、资源预留、QoS、资源配额和 Pod 优先级机制保障。
+- 结论/价值:EKS 可靠性需要在应用、控制平面、数据平面三个层面综合设计,结合 AWS shared responsibility model 明确责任边界,并通过多样性部署策略(Rolling/Blue-Green/Canary)实现安全升级。
+
+## Key Claims(用中文描述)
+- ECS 推荐给容器化初学者,提供简单界面和原生 AWS 集成;EKS 适合熟悉 Kubernetes 生态的用户,提供开放社区灵活性。
+- 系统可靠性意味着即使发生故障也能提供可预测行为,核心关注点包括:故障检测、优雅服务降级、确定性故障模式、自愈能力和按需扩缩。
+- AWS shared responsibility model 下,AWS 负责控制平面组件(state store、scheduler、controller manager、API servers),客户负责工作节点、操作系统和应用配置。
+- Fargate 模式下客户无需管理节点、补丁或升级工作。
+- 应用可靠性需避免单例 Pod,使用 Pod 反亲和性或拓扑分布约束将应用 Pod 分散到多个可用区;HPA 默认基于 CPU 和内存扩缩容,VPA 可正确调整 Pod 大小但会导致运行时重启。
+- 部署策略包括滚动升级、蓝绿部署和金丝雀部署,各有不同控制复杂度和安全保障级别;存活探针、就绪探针和启动探针是 Pod 健康监控的关键;PodDisruptionBudget 确保维护期间的最小服务水平。
+- 控制平面可靠性需监控 API server 请求和 HCT state store 大小;必须创建具有超级管理员角色的安全用户;准入 Webhook 需仔细配置以避免阻塞控制平面;EKS 平台版本自动处理补丁版本,Minor 版本有 14 个月支持周期后自动升级。
+- 数据平面可靠性需使用节点问题检测器、预留系统资源、实现 QoS、配置资源配额和限制范围;Pod 优先级控制抢占。
+
+## Key Quotes
+> "ECS is a more AWS opinionated way of running containers." — ECS 与 EKS 的核心区别概述
+> "Reliability in a system means it offers predictable behavior even when failures occur." — 可靠性的本质定义
+> "With Fargate, you don't have to worry about managing the nodes or worrying about patching or upgrading the nodes." — Fargate 对 shared responsibility model 的影响
+
+## Key Concepts
+- [[Reliability(系统可靠性)]]:系统在发生故障时仍能提供可预测行为的能力,包含故障检测、优雅降级、确定性故障模式、自愈和按需扩缩五个核心关注点。
+- [[Application Reliability(应用可靠性)]]:通过避免单例 Pod、AZ 分散、HPA/VPA 扩缩容、部署策略(Rolling/Blue-Green/Canary)、健康探针和 PodDisruptionBudget 实现。
+- [[Control Plane Reliability(控制平面可靠性)]]:通过监控控制平面指标、安全认证加固、准入 Webhook 管理和集群升级策略保障。
+- [[Data Plane Reliability(数据平面可靠性)]]:通过节点问题检测、资源预留、QoS、资源配额、LimitRange 和 Pod 优先级机制保障。
+- [[Shared Responsibility Model(EKS)]]:AWS 负责控制平面(API server、scheduler 等),客户负责工作节点、操作系统和应用配置;Fargate 模式下进一步减少客户运维负担。
+- [[Pod Anti-Affinity]]:通过反亲和性规则将 Pod 分散到不同节点或可用区,避免单点故障。
+- [[Topology Spread Constraints]]:提供比 Pod 反亲和性更细粒度的工作负载分布控制。
+- [[Horizontal Pod Autoscaler (HPA)]]:基于 CPU 利用率和内存消耗的默认扩缩容机制,支持自定义/外部指标。
+- [[Vertical Pod Autoscaler (VPA)]]:根据实际资源使用情况自动调整 Pod 的大小配置,但运行时调整会导致 Pod 重启。
+- [[Liveness/Readiness/Startup Probes]]:三类 Kubernetes 探针,用于监控 Pod 健康状态和就绪情况。
+- [[PodDisruptionBudget]]:在自愿中断(如节点维护)期间保证最小数量或比例的 Pod 持续运行。
+- [[Rolling/Blue-Green/Canary Deployment]]:三种部署策略,滚动升级自动化程度高但回滚控制有限,蓝绿和金丝雀提供更精细的控制和快速回滚能力。
+
+## Key Entities
+- [[Surav Paul]]:AWS 高级解决方案架构师(Senior Solutions Architect),本场演讲的主讲人。
+- [[Amazon EKS]]:AWS 托管的 Kubernetes 服务,适合熟悉 Kubernetes 生态的用户,提供开放社区灵活性。
+- [[Amazon ECS]]:AWS 原生容器服务,推荐给容器化初学者,提供简单界面和原生 AWS 集成。
+- [[AWS Fargate]]:无服务器容器运行平台,使用 Fargate 时客户无需管理节点、补丁或升级工作。
+
+## Connections
+- [[CTP Topic 39 Implementing EKS in the AWS Lab Landing Zone]] ← topic_overlap ← [[CTP Topic 59 Achieving reliability with Amazon EKS]](均涉及 EKS 部署实践,本 Topic 聚焦可靠性设计,Topic 39 聚焦网络/IP 问题解决)
+- [[CTP Topic 64 Scaling out with Amazon EKS]] ← topic_overlap ← [[CTP Topic 59 Achieving reliability with Amazon EKS]](均涉及 EKS 扩缩容,Topic 64 聚焦扩缩机制,Topic 59 聚焦可靠性全栈设计)
+- [[CTP Topic 60 Monitor AWS using Hyperscale Observability with Grafana]] ← complements ← [[CTP Topic 59 Achieving reliability with Amazon EKS]](Grafana 监控可用于 Topic 59 中的控制平面和数据平面指标监控)
+- [[Public Cloud Learning Sessions EKS Optimization Part 3 of 3 Introduction to EKS Auto Mode]] ← extends ← [[CTP Topic 59 Achieving reliability with Amazon EKS]](Auto Mode 是 EKS 可靠性自动化的进一步演进,涵盖 Fargate 集成和自动扩缩容)
+
+## Contradictions
+- 与 [[CTP Topic 39 Implementing EKS in the AWS Lab Landing Zone]] 的潜在视角差异:
+ - 冲突点:Topic 39 描述 EKS 部署中的 IP 资源挑战,强调自定义网络配置(hostNetwork)和独立私有子网;Topic 59 侧重标准 EKS 可靠性机制,较少涉及网络约束场景。
+ - 当前观点:两者面向不同场景——Topic 39 针对受限网络环境下的实际部署挑战,Topic 59 提供通用的 EKS 可靠性最佳实践,互为补充而非冲突。
+ - 对方观点:Topic 39 认为在某些受限环境下标准 EKS 配置(如 CNI 插件默认 IP 分配)无法直接适用,需要自定义网络方案;Topic 59 的通用建议可能需要针对特殊环境调整。
diff --git a/wiki/sources/ctp-topic-6-aws-workspaces-demo.md b/wiki/sources/ctp-topic-6-aws-workspaces-demo.md
index 99efe02c..5b2c1548 100644
--- a/wiki/sources/ctp-topic-6-aws-workspaces-demo.md
+++ b/wiki/sources/ctp-topic-6-aws-workspaces-demo.md
@@ -1,65 +1,65 @@
----
-title: "CTP Topic 6 AWS Workspaces Demo"
-type: source
-tags:
- - AWS
- - Workspaces
- - Demo
- - CTP
- - End-User Computing
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-6-aws-workspaces-demo]]
-
-## Summary(用中文描述)
-- 核心主题:AWS Workspaces 虚拟桌面解决方案的演示与实操体验
-- 问题域:如何为云转型团队快速提供预配置的开发工作站环境,实现"半小时内从申请到跑通 Terraform"的目标
-- 方法/机制:通过 AWS Workspaces 提供托管 Windows 虚拟桌面,内置 PFSSO、Terraform、TerraGrunt、Git、VS Code 等工具,用户通过邮件接收注册码和用户名即可登录使用
-- 结论/价值:AWS Workspaces 可在 21-45 分钟内为用户交付可用的云端开发环境,消除本地配置负担,提升云转型计划中基础设施团队的工作效率
-
-## Key Claims(用中文描述)
-- AWS Workspaces 为用户提供通过 Web 浏览器或客户端应用访问的托管桌面环境,可预配置特定工具或提供原生 Windows 安装
-- 目标是在提出申请后的半小时至 45 分钟内,使用户能够运行 TerraGrunt Plan 针对基础设施执行部署
-- 工作站运行 Windows Server 2016(因 Pulse UI 兼容性原因未选用 Amazon Linux),预装 PFSSO、Terraform、TerraGrunt、Git 和 VS Code
-- 用户需联系 Naga 申请账号,未来计划与 Active Directory 集成
-- 登录后可访问 AWS Console(通过 Federation)、GitHub Enterprise 并生成 SSH 密钥
-- 演示中克隆仓库、认证 PFSSO 并运行 TerraGrunt Plan,全程约 21 分钟完成
-- 工作站使用后保留约一小时的活跃状态,可根据需要额外安装工具
-
-## Key Quotes
-> "The hope is that within half an hour, 45 minutes of making a request for a workspace, you've run a Terra Grunt plan against a piece of infrastructure."
-> — 演示目标:快速交付可用开发环境
-
-> "As you can see, we can successfully access GitHub Enterprise as well."
-> — 工作站可同时访问 AWS Console 和 GitHub Enterprise
-
-## Key Concepts
-- [[AWS Workspaces]]:AWS 托管的虚拟桌面解决方案(VDI),通过 Web 浏览器或客户端提供预配置 Windows 环境
-- [[Terraform]]:基础设施即代码(IaC)工具,用于声明式定义和配置云资源
-- [[TerraGrunt]]:Terraform 的包装器,提供锁文件管理、远程状态和目录结构管理
-- [[PFSSO]]:Pulse Federation SSO,企业单点登录解决方案,用于 AWS 资源访问认证
-- [[AWS Federation]]:AWS 联合身份,基于 SAML 2.0 实现外部身份提供商对 AWS Console 的访问
-- [[GitHub Enterprise]]:GitHub 企业版,内部源代码管理平台(已迁移至 GitLab,参考 ctp-topic-53 相关内容)
-
-## Key Entities
-- [[Naga]]:负责 AWS Workspaces 账号创建的联系人,用户需通过邮件联系 Naga 申请工作站
-- [[AWS]]:Amazon Web Services,云桌面服务(Workspaces)的提供商
-- [[Micro Focus]]:演示所属组织,云转型计划(CTP)的重要组成部分
-
-## Connections
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← extends ← [[ctp-topic-6-aws-workspaces-demo]]
- - Topic 6 演示的工作站环境基于 Topic 1 中定义的 Gruntwork Landing Zone 架构
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← related ← [[ctp-topic-6-aws-workspaces-demo]]
- - 工作站中运行 TerraGrunt Plan 的能力是 CI/CD 流程的一部分
-- [[ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs]] ← future_integration ← [[ctp-topic-6-aws-workspaces-demo]]
- - 当前通过邮件(Naga)手动创建账号,未来计划与 Active Directory 集成实现自动化账号管理
-
-## Contradictions
-- 与 [[public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration-20]] 冲突:
- - 冲突点:Topic 6 演示中提及访问 GitHub Enterprise
- - 当前观点:AWS Workspaces 预装工具中包含 GitHub Enterprise 访问能力
- - 对方观点:Project Thor 已将源代码管理平台从 GitHub Enterprise 迁移至 GitLab,GitHub Enterprise 许可证已于 12 月底到期不再续约
- - 说明:视频录制时间早于 GitHub→GitLab 迁移完成,当前 GitHub Enterprise 已不可用,迁移后的 Workspaces 镜像应预装 GitLab 而非 GitHub Enterprise
-
+---
+title: "CTP Topic 6 AWS Workspaces Demo"
+type: source
+tags:
+ - AWS
+ - Workspaces
+ - Demo
+ - CTP
+ - End-User Computing
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-6-aws-workspaces-demo.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS Workspaces 虚拟桌面解决方案的演示与实操体验
+- 问题域:如何为云转型团队快速提供预配置的开发工作站环境,实现"半小时内从申请到跑通 Terraform"的目标
+- 方法/机制:通过 AWS Workspaces 提供托管 Windows 虚拟桌面,内置 PFSSO、Terraform、TerraGrunt、Git、VS Code 等工具,用户通过邮件接收注册码和用户名即可登录使用
+- 结论/价值:AWS Workspaces 可在 21-45 分钟内为用户交付可用的云端开发环境,消除本地配置负担,提升云转型计划中基础设施团队的工作效率
+
+## Key Claims(用中文描述)
+- AWS Workspaces 为用户提供通过 Web 浏览器或客户端应用访问的托管桌面环境,可预配置特定工具或提供原生 Windows 安装
+- 目标是在提出申请后的半小时至 45 分钟内,使用户能够运行 TerraGrunt Plan 针对基础设施执行部署
+- 工作站运行 Windows Server 2016(因 Pulse UI 兼容性原因未选用 Amazon Linux),预装 PFSSO、Terraform、TerraGrunt、Git 和 VS Code
+- 用户需联系 Naga 申请账号,未来计划与 Active Directory 集成
+- 登录后可访问 AWS Console(通过 Federation)、GitHub Enterprise 并生成 SSH 密钥
+- 演示中克隆仓库、认证 PFSSO 并运行 TerraGrunt Plan,全程约 21 分钟完成
+- 工作站使用后保留约一小时的活跃状态,可根据需要额外安装工具
+
+## Key Quotes
+> "The hope is that within half an hour, 45 minutes of making a request for a workspace, you've run a Terra Grunt plan against a piece of infrastructure."
+> — 演示目标:快速交付可用开发环境
+
+> "As you can see, we can successfully access GitHub Enterprise as well."
+> — 工作站可同时访问 AWS Console 和 GitHub Enterprise
+
+## Key Concepts
+- [[AWS Workspaces]]:AWS 托管的虚拟桌面解决方案(VDI),通过 Web 浏览器或客户端提供预配置 Windows 环境
+- [[Terraform]]:基础设施即代码(IaC)工具,用于声明式定义和配置云资源
+- [[TerraGrunt]]:Terraform 的包装器,提供锁文件管理、远程状态和目录结构管理
+- [[PFSSO]]:Pulse Federation SSO,企业单点登录解决方案,用于 AWS 资源访问认证
+- [[AWS Federation]]:AWS 联合身份,基于 SAML 2.0 实现外部身份提供商对 AWS Console 的访问
+- [[GitHub Enterprise]]:GitHub 企业版,内部源代码管理平台(已迁移至 GitLab,参考 ctp-topic-53 相关内容)
+
+## Key Entities
+- [[Naga]]:负责 AWS Workspaces 账号创建的联系人,用户需通过邮件联系 Naga 申请工作站
+- [[AWS]]:Amazon Web Services,云桌面服务(Workspaces)的提供商
+- [[Micro Focus]]:演示所属组织,云转型计划(CTP)的重要组成部分
+
+## Connections
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← extends ← [[ctp-topic-6-aws-workspaces-demo]]
+ - Topic 6 演示的工作站环境基于 Topic 1 中定义的 Gruntwork Landing Zone 架构
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← related ← [[ctp-topic-6-aws-workspaces-demo]]
+ - 工作站中运行 TerraGrunt Plan 的能力是 CI/CD 流程的一部分
+- [[ctp-topic-17-active-directory-services-in-gruntwork-aws-lzs]] ← future_integration ← [[ctp-topic-6-aws-workspaces-demo]]
+ - 当前通过邮件(Naga)手动创建账号,未来计划与 Active Directory 集成实现自动化账号管理
+
+## Contradictions
+- 与 [[public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration-20]] 冲突:
+ - 冲突点:Topic 6 演示中提及访问 GitHub Enterprise
+ - 当前观点:AWS Workspaces 预装工具中包含 GitHub Enterprise 访问能力
+ - 对方观点:Project Thor 已将源代码管理平台从 GitHub Enterprise 迁移至 GitLab,GitHub Enterprise 许可证已于 12 月底到期不再续约
+ - 说明:视频录制时间早于 GitHub→GitLab 迁移完成,当前 GitHub Enterprise 已不可用,迁移后的 Workspaces 镜像应预装 GitLab 而非 GitHub Enterprise
+
diff --git a/wiki/sources/ctp-topic-60-monitor-aws-using-hyperscale-observability-with-grafana.md b/wiki/sources/ctp-topic-60-monitor-aws-using-hyperscale-observability-with-grafana.md
index 846720ac..a69137dc 100644
--- a/wiki/sources/ctp-topic-60-monitor-aws-using-hyperscale-observability-with-grafana.md
+++ b/wiki/sources/ctp-topic-60-monitor-aws-using-hyperscale-observability-with-grafana.md
@@ -1,61 +1,61 @@
----
-title: "CTP Topic 60 - Monitor AWS using Hyperscale Observability with Grafana"
-type: source
-tags:
- - AWS
- - Grafana
- - Observability
- - Hyperscale
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-60-monitor-aws-using-hyperscale-observability-with-grafana]]
-
-## Summary(用中文描述)
-- 核心主题:使用 Grafana 实现 AWS 超大规模可观测性监控
-- 问题域:云原生监控体系、Grafana 企业版功能、Dashboard as Code 实践
-- 方法/机制:Grafana 与多种数据源集成、Terraform 模块自动化供给告警配置、资源标签化管理、Optic DR 数据采集
-- 结论/价值:推动从开源版 Grafana 迁移至企业版以释放全部潜力;Terraform 模块使产品团队自助消费监控能力;默认指标不产生额外成本,自定义指标可能产生费用
-
-## Key Claims(用中文描述)
-- Grafana 企业版相比开源版提供了更完整的功能集,应作为监控体系的升级目标
-- Terraform 模块通过声明式配置自动化创建 Grafana 组织、用户、文件夹、IAM 角色和仪表板
-- Optic DR 作为内部监控插件,是将数据导入 Grafana 仪表板的关键数据源
-- 资源标签化是实现成本核算和资源有效管理的基础
-- Grafana 告警系统支持灵活配置多种通知渠道,可转发至 Opsbridge 创建工单
-
-## Key Quotes
-> "Grafana's ability to provision infrastructure and applications using Terraform modules (dashboard as code) is highlighted" — Dashboard 即代码的核心价值体现
-> "Optic DR, an internal monitoring solution and plugin of VaticaDB, is crucial for pulling data into Grafana dashboards" — 内部数据源与 Grafana 的集成方式
-> "Default metrics do not incur additional costs, but custom metrics may" — 成本影响的关键说明
-
-## Key Concepts
-- [[Hyperscale Observability]]:超大规模可观测性——针对大规模云环境的多维度监控能力
-- [[Dashboard as Code]]:通过 Terraform 模块声明式定义 Grafana 资产,实现监控配置的版本控制和自动化部署
-- [[Grafana Alert System]]:Grafana 告警系统——支持灵活配置通知渠道,可与 Opsbridge 等工单系统集成
-- [[Resource Tagging]]:资源标签化——通过标签对 AWS 资源进行分类管理,是成本核算和安全策略的基础
-- [[Instance Monitoring]]:实例监控——识别资源利用率,帮助优化成本和性能
-- [[Event Tracking]]:事件追踪——监控由 OpsBridge AWS 监控解决方案触发的日常活跃事件
-
-## Key Entities
-- [[Vinay]]:演讲者,代替休假中的 Sashi 主持本次学习会议
-- [[Optic DR]]:内部监控解决方案,VaticaDB 的插件,用于将数据导入 Grafana 仪表板
-- [[Opsbridge]]:*Opsbridge 监控解决方案,使用仪表板展示监控系统触发的事件
-- [[VaticaDB]]:提供 Optic DR 插件的内部监控平台
-- [[Grafana]]:开源可观测性平台,支持多种数据源集成、可视化和告警
-- [[Terraform]]:基础设施即代码工具,用于自动化 Grafana 资源配置
-
-## Connections
-- [[Grafana]] ← uses ← [[Optic DR]]
-- [[Grafana]] ← integrates_with ← [[Opsbridge]]
-- [[Grafana]] ← provisioned_by ← [[Terraform]]
-- [[ctp-topic-60]] ← extends ← [[Grafana Enterprise]]
-- [[AWS Landing Zone]] ← monitored_by ← [[Grafana]]
-
-## Contradictions
-- 与 [[ctp-topic-8-obm-cloud-monitoring]] 存在互补而非冲突关系:
- - 冲突点:无冲突,两者针对不同监控层面
- - 当前观点:Topic 60 聚焦 Grafana 和 AWS 原生监控能力
- - 对方观点:Topic 8 聚焦 Micro Focus Operations Bridge Manager (OBM) 的跨云统一监控
+---
+title: "CTP Topic 60 - Monitor AWS using Hyperscale Observability with Grafana"
+type: source
+tags:
+ - AWS
+ - Grafana
+ - Observability
+ - Hyperscale
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-60-monitor-aws-using-hyperscale-observability-with-grafana.md]]
+
+## Summary(用中文描述)
+- 核心主题:使用 Grafana 实现 AWS 超大规模可观测性监控
+- 问题域:云原生监控体系、Grafana 企业版功能、Dashboard as Code 实践
+- 方法/机制:Grafana 与多种数据源集成、Terraform 模块自动化供给告警配置、资源标签化管理、Optic DR 数据采集
+- 结论/价值:推动从开源版 Grafana 迁移至企业版以释放全部潜力;Terraform 模块使产品团队自助消费监控能力;默认指标不产生额外成本,自定义指标可能产生费用
+
+## Key Claims(用中文描述)
+- Grafana 企业版相比开源版提供了更完整的功能集,应作为监控体系的升级目标
+- Terraform 模块通过声明式配置自动化创建 Grafana 组织、用户、文件夹、IAM 角色和仪表板
+- Optic DR 作为内部监控插件,是将数据导入 Grafana 仪表板的关键数据源
+- 资源标签化是实现成本核算和资源有效管理的基础
+- Grafana 告警系统支持灵活配置多种通知渠道,可转发至 Opsbridge 创建工单
+
+## Key Quotes
+> "Grafana's ability to provision infrastructure and applications using Terraform modules (dashboard as code) is highlighted" — Dashboard 即代码的核心价值体现
+> "Optic DR, an internal monitoring solution and plugin of VaticaDB, is crucial for pulling data into Grafana dashboards" — 内部数据源与 Grafana 的集成方式
+> "Default metrics do not incur additional costs, but custom metrics may" — 成本影响的关键说明
+
+## Key Concepts
+- [[Hyperscale Observability]]:超大规模可观测性——针对大规模云环境的多维度监控能力
+- [[Dashboard as Code]]:通过 Terraform 模块声明式定义 Grafana 资产,实现监控配置的版本控制和自动化部署
+- [[Grafana Alert System]]:Grafana 告警系统——支持灵活配置通知渠道,可与 Opsbridge 等工单系统集成
+- [[Resource Tagging]]:资源标签化——通过标签对 AWS 资源进行分类管理,是成本核算和安全策略的基础
+- [[Instance Monitoring]]:实例监控——识别资源利用率,帮助优化成本和性能
+- [[Event Tracking]]:事件追踪——监控由 OpsBridge AWS 监控解决方案触发的日常活跃事件
+
+## Key Entities
+- [[Vinay]]:演讲者,代替休假中的 Sashi 主持本次学习会议
+- [[Optic DR]]:内部监控解决方案,VaticaDB 的插件,用于将数据导入 Grafana 仪表板
+- [[Opsbridge]]:*Opsbridge 监控解决方案,使用仪表板展示监控系统触发的事件
+- [[VaticaDB]]:提供 Optic DR 插件的内部监控平台
+- [[Grafana]]:开源可观测性平台,支持多种数据源集成、可视化和告警
+- [[Terraform]]:基础设施即代码工具,用于自动化 Grafana 资源配置
+
+## Connections
+- [[Grafana]] ← uses ← [[Optic DR]]
+- [[Grafana]] ← integrates_with ← [[Opsbridge]]
+- [[Grafana]] ← provisioned_by ← [[Terraform]]
+- [[ctp-topic-60]] ← extends ← [[Grafana Enterprise]]
+- [[AWS Landing Zone]] ← monitored_by ← [[Grafana]]
+
+## Contradictions
+- 与 [[ctp-topic-8-obm-cloud-monitoring]] 存在互补而非冲突关系:
+ - 冲突点:无冲突,两者针对不同监控层面
+ - 当前观点:Topic 60 聚焦 Grafana 和 AWS 原生监控能力
+ - 对方观点:Topic 8 聚焦 Micro Focus Operations Bridge Manager (OBM) 的跨云统一监控
diff --git a/wiki/sources/ctp-topic-61-workload-vpc-provision-with-ipam-automation.md b/wiki/sources/ctp-topic-61-workload-vpc-provision-with-ipam-automation.md
index 04a46a91..5d45691b 100644
--- a/wiki/sources/ctp-topic-61-workload-vpc-provision-with-ipam-automation.md
+++ b/wiki/sources/ctp-topic-61-workload-vpc-provision-with-ipam-automation.md
@@ -1,58 +1,58 @@
----
-title: "CTP Topic 61 Workload VPC provision with IPAM Automation"
-type: source
-tags:
- - AWS
- - VPC
- - IPAM
- - Automation
- - CTP
- - Infoblox
-date: 2026-04-24
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-61-workload-vpc-provision-with-ipam-automation]]
-
-## Summary(用中文描述)
-- 核心主题:IPAM(IP 地址管理)与 Workload VPC 自动化供给的完整集成方案,包括近期功能增强。
-- 问题域:企业多账号 AWS 环境中,如何在不依赖网络团队手工介入的情况下,自动完成 VPC 的 IP 地址规划与供给。
-- 方法/机制:使用 Infoblox Grid 作为核心 IPAM 引擎,通过声明式 YAML 配置文件触发自动化供给流程;/22 及更大 CIDR 自动审批,更小 CIDR 触发邮件审批流程;Availability Zone ID(而非 AZ Name)避免跨区域不一致;多 VPC 批量供给和非路由 IP 地址(如 10.2.0.0/16)支持。
-- 结论/价值:**"只需把信息放到正确位置,一切自动完成。"** 用户只需声明业务联系人和父 CIDR,无需关心 IP 地址分配细节;Infoblox Grid 作为唯一可信数据源,防止 IP 地址重叠。
-
-## Key Claims(用中文描述)
-- IPAM 通过 Infoblox Grid 自动管理 IP 地址,消除手工操作,显著降低配置错误率。
-- 工作负载 VPC 供给完全自动化,YAML 文件仅声明业务联系人、工程联系人和父 CIDR,不再包含硬编码 IP 地址。
-- CIDR 块大小决定审批流程:/22 或更大自动批准,更小(如 /24)需提交理由并由网络团队审批。
-- Infoblox Grid 作为全局唯一 IP 地址数据源,防止多账号环境中的 IP 地址重叠冲突。
-- 使用 AZ ID(可用区标识符)而非 AZ Name(可用区名称)避免不同 AWS 账户对同一物理位置命名不一致的问题。
-- 邮件通知机制覆盖用户和网络团队,全程透明可追溯。
-- Infoblox 架构包含位于休斯顿数据中心的主数据库,以及冗余的 DNS、NTP 和 DHCP 服务。
-
-## Key Quotes
-> "We don't need to worry about IP address. If it's beyond IP address is 22 or greater, then only we need to take the approval." — Pushka,IPAM 自动化审批阈值说明
-
-> "So we just need to put the information at the right place and everything will work." — Pushka,用户只需提供正确信息,IPAM 自动完成其余工作
-
-## Key Concepts
-- [[IPAM(IP Address Management)]]:企业级 IP 地址管理自动化平台,通过声明式配置替代手工分配。本视频展示了 IPAM 与 AWS VPC 供给的深度集成。
-- [[Infoblox-Grid]]:核心 IPAM 引擎,包含容器、IP地址及可扩展属性(元数据,如 owner、company、status),维护全局唯一 IP 地址记录。
-- [[VPC-自动化供给]]:通过 YAML 配置文件声明业务参数,自动触发 VPC 创建流程,无需网络团队手工介入。
-- [[CIDR-审批流程]]:/22 及更大 CIDR 自动批准;/22 以下需提交理由经网络团队审批后供给。
-- [[Availability-Zone-ID]]:AWS 可用区标识符(az-id),用于避免多账号环境中 AZ 名称(az-name)不一致问题。
-
-## Key Entities
-- [[Pushka]](Principal SRE):IPAM 与 VPC 自动化方案的发起人和演示者,Topic 61 主讲人。
-- [[Infoblox]]:IPAM 供应商,提供 Grid 架构及 NIOS 平台,负责管理所有账号的 IP 地址分配记录。
-- [[AWS-Landing-Zone]]:本方案的实施背景——企业级多账号 AWS 环境,IPAM 作为 LZ 网络层的核心组件。
-
-## Connections
-- [[ctp-topic-45-automatic-ip-address-allocation-with-ipam]] ← extends ← [[ctp-topic-61-workload-vpc-provision-with-ipam-automation]]
- - Topic 45 介绍 IPAM 自动分配机制;Topic 61 展示该机制在 Workload VPC 供给中的完整应用。
-- [[ctp-topic-22-global-dns-service-offerings]] ← shares_infra ← [[Infoblox-Grid]]
- - Infoblox 同时支撑 DNS Anycast 和 IPAM 服务,是网络层多服务的统一基础设施。
-- [[ctp-topic-31-network-segregation-and-secure-access]] ← depends_on ← [[VPC-自动化供给]]
- - VPC 自动化供给是网络分段和安全访问策略的基础前提。
-
-## Contradictions
-- 无已知冲突内容。
+---
+title: "CTP Topic 61 Workload VPC provision with IPAM Automation"
+type: source
+tags:
+ - AWS
+ - VPC
+ - IPAM
+ - Automation
+ - CTP
+ - Infoblox
+date: 2026-04-24
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-61-workload-vpc-provision-with-ipam-automation.md]]
+
+## Summary(用中文描述)
+- 核心主题:IPAM(IP 地址管理)与 Workload VPC 自动化供给的完整集成方案,包括近期功能增强。
+- 问题域:企业多账号 AWS 环境中,如何在不依赖网络团队手工介入的情况下,自动完成 VPC 的 IP 地址规划与供给。
+- 方法/机制:使用 Infoblox Grid 作为核心 IPAM 引擎,通过声明式 YAML 配置文件触发自动化供给流程;/22 及更大 CIDR 自动审批,更小 CIDR 触发邮件审批流程;Availability Zone ID(而非 AZ Name)避免跨区域不一致;多 VPC 批量供给和非路由 IP 地址(如 10.2.0.0/16)支持。
+- 结论/价值:**"只需把信息放到正确位置,一切自动完成。"** 用户只需声明业务联系人和父 CIDR,无需关心 IP 地址分配细节;Infoblox Grid 作为唯一可信数据源,防止 IP 地址重叠。
+
+## Key Claims(用中文描述)
+- IPAM 通过 Infoblox Grid 自动管理 IP 地址,消除手工操作,显著降低配置错误率。
+- 工作负载 VPC 供给完全自动化,YAML 文件仅声明业务联系人、工程联系人和父 CIDR,不再包含硬编码 IP 地址。
+- CIDR 块大小决定审批流程:/22 或更大自动批准,更小(如 /24)需提交理由并由网络团队审批。
+- Infoblox Grid 作为全局唯一 IP 地址数据源,防止多账号环境中的 IP 地址重叠冲突。
+- 使用 AZ ID(可用区标识符)而非 AZ Name(可用区名称)避免不同 AWS 账户对同一物理位置命名不一致的问题。
+- 邮件通知机制覆盖用户和网络团队,全程透明可追溯。
+- Infoblox 架构包含位于休斯顿数据中心的主数据库,以及冗余的 DNS、NTP 和 DHCP 服务。
+
+## Key Quotes
+> "We don't need to worry about IP address. If it's beyond IP address is 22 or greater, then only we need to take the approval." — Pushka,IPAM 自动化审批阈值说明
+
+> "So we just need to put the information at the right place and everything will work." — Pushka,用户只需提供正确信息,IPAM 自动完成其余工作
+
+## Key Concepts
+- [[IPAM(IP Address Management)]]:企业级 IP 地址管理自动化平台,通过声明式配置替代手工分配。本视频展示了 IPAM 与 AWS VPC 供给的深度集成。
+- [[Infoblox-Grid]]:核心 IPAM 引擎,包含容器、IP地址及可扩展属性(元数据,如 owner、company、status),维护全局唯一 IP 地址记录。
+- [[VPC-自动化供给]]:通过 YAML 配置文件声明业务参数,自动触发 VPC 创建流程,无需网络团队手工介入。
+- [[CIDR-审批流程]]:/22 及更大 CIDR 自动批准;/22 以下需提交理由经网络团队审批后供给。
+- [[Availability-Zone-ID]]:AWS 可用区标识符(az-id),用于避免多账号环境中 AZ 名称(az-name)不一致问题。
+
+## Key Entities
+- [[Pushka]](Principal SRE):IPAM 与 VPC 自动化方案的发起人和演示者,Topic 61 主讲人。
+- [[Infoblox]]:IPAM 供应商,提供 Grid 架构及 NIOS 平台,负责管理所有账号的 IP 地址分配记录。
+- [[AWS-Landing-Zone]]:本方案的实施背景——企业级多账号 AWS 环境,IPAM 作为 LZ 网络层的核心组件。
+
+## Connections
+- [[ctp-topic-45-automatic-ip-address-allocation-with-ipam]] ← extends ← [[ctp-topic-61-workload-vpc-provision-with-ipam-automation]]
+ - Topic 45 介绍 IPAM 自动分配机制;Topic 61 展示该机制在 Workload VPC 供给中的完整应用。
+- [[ctp-topic-22-global-dns-service-offerings]] ← shares_infra ← [[Infoblox-Grid]]
+ - Infoblox 同时支撑 DNS Anycast 和 IPAM 服务,是网络层多服务的统一基础设施。
+- [[ctp-topic-31-network-segregation-and-secure-access]] ← depends_on ← [[VPC-自动化供给]]
+ - VPC 自动化供给是网络分段和安全访问策略的基础前提。
+
+## Contradictions
+- 无已知冲突内容。
diff --git a/wiki/sources/ctp-topic-62-aws-secrets-manager.md b/wiki/sources/ctp-topic-62-aws-secrets-manager.md
index 12ca211f..d1e691ee 100644
--- a/wiki/sources/ctp-topic-62-aws-secrets-manager.md
+++ b/wiki/sources/ctp-topic-62-aws-secrets-manager.md
@@ -1,59 +1,59 @@
----
-title: "CTP Topic 62 AWS Secrets Manager"
-type: source
-tags: []
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-62-aws-secrets-manager.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS Secrets Manager 企业级密钥管理方案,包括选型对比、实施标准和落地案例
-- 问题域:云转型过程中密钥安全存储与轮换的标准化治理
-- 方法/机制:分阶段实施策略(集中化密钥 → 自动化获取 → 轮换);Lambda 函数驱动 Oracle 数据库密码轮换;SendGrid 集中邮件服务的密钥轮换方案;JDBC Wrapper + AWS SDK 无需应用感知密钥
-- 结论/价值:AWS Secrets Manager 相比 HashiCorp Vault 成本更低、实施更简单,无需客户端;开发者无需直接访问密钥,通过角色和标签实现安全访问控制
-
-## Key Claims(用中文描述)
-- AWS Secrets Manager 比 HashiCorp Vault 更具成本效益,被选定为最终方案
-- AWS Secrets Manager 易于实施,缺失功能可用多种语言自行开发
-- 分阶段实施策略:集中化密钥 → 调整自动化获取 → 启动轮换
-- 开发者无需直接访问密钥,密钥访问通过 IAM 角色控制
-- Lambda 函数可执行 Oracle 数据库密码轮换,无需人工介入
-- SendGrid 集中邮件服务实现 API 密钥轮换,无需应用重启
-- AWS Secrets Manager 无需客户端软件(对比 HashiCorp Vault)
-
-## Key Quotes
-> "AWS Secrets Manager is easy and simple to implement. Missing features can be developed in multiple languages." — Nurit & Daniel
-> "With that idea, developers actually do not need to have direct access to their Secrets." — Daniel
-> "Secrets can be tagged for classification and access control. AWS Secrets Manager does not require clients, unlike HashiCorp Vault." — Victor(Demo)
-
-## Key Concepts
-- [[Secrets-Management(密钥管理)]]:云环境下集中存储、获取和轮换敏感凭证(密码、API 密钥、证书)的标准化实践
-- [[AWS-Secrets-Manager]]:AWS 托管的密钥管理服务,支持密钥轮换、IAM 角色访问控制和标签分类,无需客户端软件
-- [[Secret-Rotation(密钥轮换)]]:定期自动更新密钥的机制,AWS Secrets Manager 内置 Lambda 函数支持主流数据库和服务密钥轮换
-- [[JDBC-Wrapper]]:JDBC 包装器封装数据库连接,通过 AWS SDK 从 Secrets Manager 动态获取凭证,应用无需硬编码密码
-- [[AWS-Lambda]]:无服务器函数,用于执行 Oracle 数据库密码轮换等自动化任务
-- [[SendGrid]]:云邮件服务,API 密钥轮换通过集中化 SMTP 服务实现,无需应用重启
-
-## Key Entities
-- [[Nurit]]:CTP Topic 62 主持人,AWS Secrets Manager 实施分享
-- [[Daniel]]:CTP Topic 62 主持人,AWS Secrets Management Standard 文档作者,深度解析实施机会
-- [[Victor]]:Demo 演示者,展示使用 JDBC Wrapper + AWS SDK 免密登录 Oracle 数据库
-- [[AWS-Secrets-Manager]]:AWS 密钥管理服务,企业选型最终方案
-- [[HashiCorp-Vault]]:密钥管理备选方案,POC 阶段对比后未被采用
-- [[AWS-Control-Tower]]:AWS 多账户治理服务,密钥管理方案基于其环境实施
-- [[SendGrid]]:邮件服务,API 密钥轮换通过集中化服务方案解决
-
-## Connections
-- [[ctp-topic-37-secrets-certificates-management]] ← relates_to ← [[ctp-topic-62-aws-secrets-manager]]
-- [[ctp-topic-36-sendgrid-as-an-email-service]] ← extends ← [[ctp-topic-62-aws-secrets-manager]]
-- [[ctp-topic-61-workload-vpc-provision-with-ipam-automation]] ← depends_on ← [[AWS-Secrets-Manager]]
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← extends ← [[ctp-topic-62-aws-secrets-manager]]
-
-## Contradictions
-- 与 [[ctp-topic-37-secrets-certificates-management]] 存在覆盖范围差异:
- - 冲突点:Topic 37 覆盖 Secrets 和 Certificates 两大类;Topic 62 仅聚焦 Secrets Management
- - 当前观点:Topic 62 通过 AWS Secrets Manager 标准化 Secrets 管理,涵盖 Oracle DB 密码和 SendGrid API 密钥轮换
- - 对方观点:Topic 37 认为密钥与证书管理应统一为同一标准框架
- - 说明:两者可视为互补——证书管理(Certificates)由 Topic 37 覆盖,密钥管理(Secrets)由 Topic 62 深化
+---
+title: "CTP Topic 62 AWS Secrets Manager"
+type: source
+tags: []
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/ctp-topic-62-aws-secrets-manager.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS Secrets Manager 企业级密钥管理方案,包括选型对比、实施标准和落地案例
+- 问题域:云转型过程中密钥安全存储与轮换的标准化治理
+- 方法/机制:分阶段实施策略(集中化密钥 → 自动化获取 → 轮换);Lambda 函数驱动 Oracle 数据库密码轮换;SendGrid 集中邮件服务的密钥轮换方案;JDBC Wrapper + AWS SDK 无需应用感知密钥
+- 结论/价值:AWS Secrets Manager 相比 HashiCorp Vault 成本更低、实施更简单,无需客户端;开发者无需直接访问密钥,通过角色和标签实现安全访问控制
+
+## Key Claims(用中文描述)
+- AWS Secrets Manager 比 HashiCorp Vault 更具成本效益,被选定为最终方案
+- AWS Secrets Manager 易于实施,缺失功能可用多种语言自行开发
+- 分阶段实施策略:集中化密钥 → 调整自动化获取 → 启动轮换
+- 开发者无需直接访问密钥,密钥访问通过 IAM 角色控制
+- Lambda 函数可执行 Oracle 数据库密码轮换,无需人工介入
+- SendGrid 集中邮件服务实现 API 密钥轮换,无需应用重启
+- AWS Secrets Manager 无需客户端软件(对比 HashiCorp Vault)
+
+## Key Quotes
+> "AWS Secrets Manager is easy and simple to implement. Missing features can be developed in multiple languages." — Nurit & Daniel
+> "With that idea, developers actually do not need to have direct access to their Secrets." — Daniel
+> "Secrets can be tagged for classification and access control. AWS Secrets Manager does not require clients, unlike HashiCorp Vault." — Victor(Demo)
+
+## Key Concepts
+- [[Secrets-Management(密钥管理)]]:云环境下集中存储、获取和轮换敏感凭证(密码、API 密钥、证书)的标准化实践
+- [[AWS-Secrets-Manager]]:AWS 托管的密钥管理服务,支持密钥轮换、IAM 角色访问控制和标签分类,无需客户端软件
+- [[Secret-Rotation(密钥轮换)]]:定期自动更新密钥的机制,AWS Secrets Manager 内置 Lambda 函数支持主流数据库和服务密钥轮换
+- [[JDBC-Wrapper]]:JDBC 包装器封装数据库连接,通过 AWS SDK 从 Secrets Manager 动态获取凭证,应用无需硬编码密码
+- [[AWS-Lambda]]:无服务器函数,用于执行 Oracle 数据库密码轮换等自动化任务
+- [[SendGrid]]:云邮件服务,API 密钥轮换通过集中化 SMTP 服务实现,无需应用重启
+
+## Key Entities
+- [[Nurit]]:CTP Topic 62 主持人,AWS Secrets Manager 实施分享
+- [[Daniel]]:CTP Topic 62 主持人,AWS Secrets Management Standard 文档作者,深度解析实施机会
+- [[Victor]]:Demo 演示者,展示使用 JDBC Wrapper + AWS SDK 免密登录 Oracle 数据库
+- [[AWS-Secrets-Manager]]:AWS 密钥管理服务,企业选型最终方案
+- [[HashiCorp-Vault]]:密钥管理备选方案,POC 阶段对比后未被采用
+- [[AWS-Control-Tower]]:AWS 多账户治理服务,密钥管理方案基于其环境实施
+- [[SendGrid]]:邮件服务,API 密钥轮换通过集中化服务方案解决
+
+## Connections
+- [[ctp-topic-37-secrets-certificates-management]] ← relates_to ← [[ctp-topic-62-aws-secrets-manager]]
+- [[ctp-topic-36-sendgrid-as-an-email-service]] ← extends ← [[ctp-topic-62-aws-secrets-manager]]
+- [[ctp-topic-61-workload-vpc-provision-with-ipam-automation]] ← depends_on ← [[AWS-Secrets-Manager]]
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← extends ← [[ctp-topic-62-aws-secrets-manager]]
+
+## Contradictions
+- 与 [[ctp-topic-37-secrets-certificates-management]] 存在覆盖范围差异:
+ - 冲突点:Topic 37 覆盖 Secrets 和 Certificates 两大类;Topic 62 仅聚焦 Secrets Management
+ - 当前观点:Topic 62 通过 AWS Secrets Manager 标准化 Secrets 管理,涵盖 Oracle DB 密码和 SendGrid API 密钥轮换
+ - 对方观点:Topic 37 认为密钥与证书管理应统一为同一标准框架
+ - 说明:两者可视为互补——证书管理(Certificates)由 Topic 37 覆盖,密钥管理(Secrets)由 Topic 62 深化
diff --git a/wiki/sources/ctp-topic-63-optimise-resource-cost-using-automation.md b/wiki/sources/ctp-topic-63-optimise-resource-cost-using-automation.md
index 5a563374..fd73f766 100644
--- a/wiki/sources/ctp-topic-63-optimise-resource-cost-using-automation.md
+++ b/wiki/sources/ctp-topic-63-optimise-resource-cost-using-automation.md
@@ -1,48 +1,48 @@
----
-title: "CTP Topic 63 Optimise resource cost using automation"
-type: source
-tags: []
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/ctp-topic-63-optimise-resource-cost-using-automation]]
-
-## Summary(用中文描述)
-- 核心主题:使用自动化手段优化 AWS 云资源成本
-- 问题域:云转型计划中如何通过标准化的实例选型、存储优化、承诺计划和自动化调度降低云支出
-- 方法/机制:批准区域(Approved Region)标准化、实例类型选择(ARM/Graviton)、承诺计划(Savings Plans/Reserved Instances)、EBS 存储优化(GP2→GP3)、基于标签的 EC2/RDS 自动化调度(Scheduler)
-- 结论/价值:综合运用多种成本优化手段,组合使用最高可节省 70% 以上的云资源成本
-
-## Key Claims(用中文描述)
-- 企业使用 AWS Graviton ARM 处理器替代 Intel 实例,可节省 20-25% 成本
-- 同配置将实例从 M 系列切换到 R 系列,可节省约 35% on-demand 价格
-- 通过 1 年承诺计划购买 Reserved Instances,可获得约 40% 折扣;3 年承诺可获得约 60-64% 折扣
-- 将 EBS 存储从 GP2 迁移到 GP3,可直接节省 20% 成本
-- 对于非 7×24 运行的工作负载(如开发测试环境),通过自动化调度每天只运行 10 小时,可节省 70% 成本
-
-## Key Quotes
-> "Graviton is mature enough for production" — Graviton ARM 实例已成熟可用于生产环境,比同规格 Intel 便宜 20-25%
-> "Auto shutdown = yes" — Pushka 演示通过 Terraform 模块配置 Scheduler,设置标签实现实例自动停止
-
-## Key Concepts
-- [[Approved Region(批准区域)]]:建议使用的云资源部署区域,有助于提高安全性、标准化管理和优化成本
-- [[Instance Type Selection(实例类型选择)]]:根据工作负载选择合适的实例家族(M/T/C/R/X 系列),以优化性能和成本
-- [[Commitment Plan(承诺计划)]]:通过预先承诺使用云资源一段时间(Savings Plans / Reserved Instances),获得折扣价格
-- [[Automation Scheduler(自动化调度)]]:通过设置定时任务,自动启动和停止云资源,以节省非工作时间的资源成本
-- [[Storage Optimization(存储优化)]]:通过选择合适的存储类型(如 GP3 替代 GP2),及时清理无用存储,合理分配存储空间来降低存储成本
-- [[Graviton]]:AWS 自研 ARM 处理器,比同规格 Intel 便宜 20-25%,已成熟用于生产环境
-- [[Terraform Scheduler Module]]:Terraform 模块,通过标签(如 `auto_shutdown = yes`)配置 EC2/RDS 自动启停
-
-## Key Entities
-- [[Pushka]]:Principal SRE,演示如何使用 Terraform 模块配置 Scheduler 实现实例自动启停
-
-## Connections
-- [[ctp-topic-13-cloud-finops-policies-best-practices-to-optimize-the-co]] ← topic_13 介绍 FinOps 政策框架,本 Topic 补充技术实施细节
-- [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]] ← topic_71 聚焦 RightSizing,与本 Topic 实例选型优化互补
-- [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]] ← 综合成本优化技术,含 Savings Plans 实施流程
-- [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]] ← EC2 成本优化最佳实践,含 Graviton 使用
-- [[public-cloud-learning-sessions-storage-cost-optimization-20240305-160037-meeting]] ← 存储优化专题,含 GP2→GP3 迁移
-
-## Contradictions
-- 暂无已知冲突
+---
+title: "CTP Topic 63 Optimise resource cost using automation"
+type: source
+tags: []
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/ctp-topic-63-optimise-resource-cost-using-automation.md]]
+
+## Summary(用中文描述)
+- 核心主题:使用自动化手段优化 AWS 云资源成本
+- 问题域:云转型计划中如何通过标准化的实例选型、存储优化、承诺计划和自动化调度降低云支出
+- 方法/机制:批准区域(Approved Region)标准化、实例类型选择(ARM/Graviton)、承诺计划(Savings Plans/Reserved Instances)、EBS 存储优化(GP2→GP3)、基于标签的 EC2/RDS 自动化调度(Scheduler)
+- 结论/价值:综合运用多种成本优化手段,组合使用最高可节省 70% 以上的云资源成本
+
+## Key Claims(用中文描述)
+- 企业使用 AWS Graviton ARM 处理器替代 Intel 实例,可节省 20-25% 成本
+- 同配置将实例从 M 系列切换到 R 系列,可节省约 35% on-demand 价格
+- 通过 1 年承诺计划购买 Reserved Instances,可获得约 40% 折扣;3 年承诺可获得约 60-64% 折扣
+- 将 EBS 存储从 GP2 迁移到 GP3,可直接节省 20% 成本
+- 对于非 7×24 运行的工作负载(如开发测试环境),通过自动化调度每天只运行 10 小时,可节省 70% 成本
+
+## Key Quotes
+> "Graviton is mature enough for production" — Graviton ARM 实例已成熟可用于生产环境,比同规格 Intel 便宜 20-25%
+> "Auto shutdown = yes" — Pushka 演示通过 Terraform 模块配置 Scheduler,设置标签实现实例自动停止
+
+## Key Concepts
+- [[Approved Region(批准区域)]]:建议使用的云资源部署区域,有助于提高安全性、标准化管理和优化成本
+- [[Instance Type Selection(实例类型选择)]]:根据工作负载选择合适的实例家族(M/T/C/R/X 系列),以优化性能和成本
+- [[Commitment Plan(承诺计划)]]:通过预先承诺使用云资源一段时间(Savings Plans / Reserved Instances),获得折扣价格
+- [[Automation Scheduler(自动化调度)]]:通过设置定时任务,自动启动和停止云资源,以节省非工作时间的资源成本
+- [[Storage Optimization(存储优化)]]:通过选择合适的存储类型(如 GP3 替代 GP2),及时清理无用存储,合理分配存储空间来降低存储成本
+- [[Graviton]]:AWS 自研 ARM 处理器,比同规格 Intel 便宜 20-25%,已成熟用于生产环境
+- [[Terraform Scheduler Module]]:Terraform 模块,通过标签(如 `auto_shutdown = yes`)配置 EC2/RDS 自动启停
+
+## Key Entities
+- [[Pushka]]:Principal SRE,演示如何使用 Terraform 模块配置 Scheduler 实现实例自动启停
+
+## Connections
+- [[ctp-topic-13-cloud-finops-policies-best-practices-to-optimize-the-co]] ← topic_13 介绍 FinOps 政策框架,本 Topic 补充技术实施细节
+- [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]] ← topic_71 聚焦 RightSizing,与本 Topic 实例选型优化互补
+- [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]] ← 综合成本优化技术,含 Savings Plans 实施流程
+- [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]] ← EC2 成本优化最佳实践,含 Graviton 使用
+- [[public-cloud-learning-sessions-storage-cost-optimization-20240305-160037-meeting]] ← 存储优化专题,含 GP2→GP3 迁移
+
+## Contradictions
+- 暂无已知冲突
diff --git a/wiki/sources/ctp-topic-64-scaling-out-with-amazon-eks.md b/wiki/sources/ctp-topic-64-scaling-out-with-amazon-eks.md
index 167cdb77..5a834bc8 100644
--- a/wiki/sources/ctp-topic-64-scaling-out-with-amazon-eks.md
+++ b/wiki/sources/ctp-topic-64-scaling-out-with-amazon-eks.md
@@ -1,64 +1,64 @@
----
-title: "CTP Topic 64 Scaling out with Amazon EKS"
-type: source
-tags: [AWS, EKS, Kubernetes, Scaling, HPA, KEDA, Karpenter, Cluster-Autoscaler]
-sources: [ctp-topic-64-scaling-out-with-amazon-eks]
-last_updated: 2026-04-25
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-64-scaling-out-with-amazon-eks.md]]
-
-## Summary(用中文描述)
-- 核心主题:Amazon EKS 工作负载水平扩展与容量扩展的完整方法论,涵盖 Pod 级别扩展(事件驱动 + 指标驱动)和 Node 级别扩展(ASG 联动 + 直接 API)
-- 问题域:传统 HPA 仅支持 CPU/内存指标,无法满足事件驱动型工作负载的零扩展需求;Cluster Autoscaler 依赖预配置 ASG 导致灵活性不足;EKS 集群 IP 地址耗尽问题;CoreDNS 等集群组件扩缩容被忽视
-- 方法/机制:HPA(标准指标扩展)→ KEDA(事件驱动扩展)→ Cluster Autoscaler(ASG 联动扩缩容)→ Karpenter/Carpenter(直接 API 扩缩容)→ IPv6 解决 IP 耗尽 → API Server PPF + CoreDNS 缓存优化集群稳定性
-- 结论/价值:EKS 扩缩容需 Pod 层(KEDA)和 Node 层(Karpenter/Carpenter)双管齐下,HPA 负责 Pod 副本数调节,容量层通过原生云工具或第三方工具解决 IP 耗尽问题,集群组件扩缩容是生产部署常被忽视但至关重要的环节
-
-## Key Claims(用中文描述)
-- HPA 通过拉取 Metrics Server 的 CPU/内存指标计算应用工作负载所需的 Pod 副本数,默认支持标准资源指标,自定义/外部指标(如负载均衡器并发连接数、消息中间件队列深度)可通过 Custom Metrics API 扩展
-- KEDA 通过 ScaledObject CRD 实现事件驱动扩缩容,可将应用从零副本扩展,支持 Publishes Metrics 模式为 HPA 供数,实现指标驱动与事件驱动的混合扩展
-- Cluster Autoscaler 的扩缩容决策基于集群内 Pending Pod 的数量,联动 ASG/托管节点组调整期望容量,同时考虑 Pod 的 CPU/内存 requests,支持 Mixed Instances Policy,推荐使用 Auto-discovery 模式,min/max 配置变更应在 ASG/托管节点组层面操作
-- Karpenter 是 AWS 开源的 Kubernetes 原生容量扩缩器,直接与 EC2 API 通信,支持动态按需供给(无需预配置节点组),通过 Provisioner 定义 EC2 实例需求并与工作负载的 node selector/affinity 匹配,默认禁用回收(需启用 TTL 或集群整合)
-- 为解决 IP 地址耗尽问题,推荐切换至 IPv6(双栈 VPC,节点双协议栈,Pod 仅 IPv6);若无法切换,可使用 Carrier-Grade NAT(CGNAT)配合自定义网络;IPv6 Pod 与 IPv4 目标的交互通过双层 NAT 映射配置
-- CoreDNS 扩缩容和 Node Local DNS Cache 安装是 EKS 生产部署的重要优化项
-
-## Key Quotes
-> "The horizontal pod autoscaler is going to pull the metrics and it is going to calculate how many replicas are required for your application workload." — HPA 的核心机制:拉取指标 → 计算所需副本数
->
-> "The scaling decision that is made by the cluster auto scaler, it is done on the number of pending pods in the cluster." — Cluster Autoscaler 的决策依据:Pending Pod 数量
->
-> "Carpenter has native integration with Kubernetes and it complements the native Kubernetes spot pod scheduling constraints that is available for your workloads." — Karpenter/Carpenter 与原生 K8s Spot Pod Disruption Budget 的互补关系
->
-> "The EKS best practices guides, specifically the scalability section." — 演讲者推荐的学习资源:EKS Best Practices Guides
-
-## Key Concepts
-- [[Horizontal Pod Autoscaler (HPA)]]:Kubernetes 标准 Pod 水平扩缩容机制,通过 CPU/内存指标或自定义/外部指标计算副本需求,支持 stabilization window 和 period seconds 配置防止震荡
-- [[KEDA]](Kubernetes Event-Driven Autoscaling):基于外部事件驱动的 K8s 扩缩容框架,通过 ScaledObject CRD 定义扩缩规则,支持从零副本扩展,可 Publish Metrics 给 HPA 实现混合扩展模式
-- [[Cluster Autoscaler]]:Kubernetes 官方节点扩缩容组件,联动 AWS ASG/托管节点组,根据 Pending Pod 数量和资源 requests 调整 Node 数量,推荐 Auto-discovery 模式
-- [[Karpenter]]:AWS 开源的 Kubernetes 原生容量扩缩器,直接与 EC2 API 通信,通过 Provisioner 匹配工作负载需求,支持动态按需供给,默认禁用回收(需启用 TTL 或 Consolidation)
-- [[IPv6-in-EKS]]:EKS 集群解决 IP 地址耗尽的方案,推荐双栈 VPC 架构(节点双协议栈,Pod 仅 IPv6),IPv6 Pod 与 IPv4 目标通过 NAT 映射通信
-- [[API-Server-Priority-and-Fairness]]:EKS API Server 的优先级和公平性配置,用于在高负载下保护关键工作负载的 API 访问
-- [[CoreDNS-Scaling]]:EKS 集群 CoreDNS 的水平扩缩容策略,配合 Node Local DNS Cache 降低 DNS 查询延迟
-- [[Metrics-Server]]:Kubernetes 的 CPU/内存指标采集组件,HPA 依赖其提供标准资源指标
-
-## Key Entities
-- [[Suravpul]]:AWS 高级解决方案架构师(Senior Solutions Architect),CTP Topic 64 和 Topic 59、Topic 67 的讲师,专注 EKS 可靠性、可观测性和扩缩容实践
-- [[Amazon EKS]]:托管 Kubernetes 服务,本 Source Page 的目标平台
-- [[AWS]]:Amazon Web Services,EKS 及相关扩缩容工具(KEDA、Karpenter)的云服务提供商
-- [[Kubernetes]]:开源容器编排平台,HPA、Cluster Autoscaler、KEDA 的上游项目
-
-## Connections
-- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← 相关 ← [[Horizontal Pod Autoscaler (HPA)]](Topic 59 涵盖 HPA 和 VPA 在 EKS 可靠性中的作用)
-- [[ctp-topic-70-eks-deployment-using-iac]] ← 相关 ← [[Cluster Autoscaler]](Topic 70 提及 Cluster Autoscaler 实现 Worker Node 自动扩缩容)
-- [[ctp-topic-70-eks-deployment-using-iac]] ← depends_on ← [[ctp-topic-64-scaling-out-with-amazon-eks]](扩缩容是 IaC 部署后的运维关注点)
-- [[public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization]] ← 关联 ← [[Karpenter]](Part 1 深度对比 Karpenter 与 Cluster Autoscaler)
-- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← 关联 ← [[Karpenter]](Part 3 介绍 EKS Auto Mode,内置 Karpenter Controller)
-- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← 相关 ← [[Suravpul]](同一讲师的可观测性专题)
-
-## Contradictions
-- 与 [[ctp-topic-70-eks-deployment-using-iac]] 无实质冲突:
- - 冲突点:无
- - 当前观点:Topic 64 提供扩缩容的完整方法论(HPA/KEDA/Carpenter + IPv6 解决 IP 耗尽)
- - 对方观点:Topic 70 仅简述 Cluster Autoscaler 实现 Worker Node 自动扩缩容,侧重 IaC 部署流程
- - 注:两者互补而非冲突,Topic 70 是部署入口,Topic 64 是扩缩容深化
+---
+title: "CTP Topic 64 Scaling out with Amazon EKS"
+type: source
+tags: [AWS, EKS, Kubernetes, Scaling, HPA, KEDA, Karpenter, Cluster-Autoscaler]
+sources: [ctp-topic-64-scaling-out-with-amazon-eks]
+last_updated: 2026-04-25
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-64-scaling-out-with-amazon-eks.md]]
+
+## Summary(用中文描述)
+- 核心主题:Amazon EKS 工作负载水平扩展与容量扩展的完整方法论,涵盖 Pod 级别扩展(事件驱动 + 指标驱动)和 Node 级别扩展(ASG 联动 + 直接 API)
+- 问题域:传统 HPA 仅支持 CPU/内存指标,无法满足事件驱动型工作负载的零扩展需求;Cluster Autoscaler 依赖预配置 ASG 导致灵活性不足;EKS 集群 IP 地址耗尽问题;CoreDNS 等集群组件扩缩容被忽视
+- 方法/机制:HPA(标准指标扩展)→ KEDA(事件驱动扩展)→ Cluster Autoscaler(ASG 联动扩缩容)→ Karpenter/Carpenter(直接 API 扩缩容)→ IPv6 解决 IP 耗尽 → API Server PPF + CoreDNS 缓存优化集群稳定性
+- 结论/价值:EKS 扩缩容需 Pod 层(KEDA)和 Node 层(Karpenter/Carpenter)双管齐下,HPA 负责 Pod 副本数调节,容量层通过原生云工具或第三方工具解决 IP 耗尽问题,集群组件扩缩容是生产部署常被忽视但至关重要的环节
+
+## Key Claims(用中文描述)
+- HPA 通过拉取 Metrics Server 的 CPU/内存指标计算应用工作负载所需的 Pod 副本数,默认支持标准资源指标,自定义/外部指标(如负载均衡器并发连接数、消息中间件队列深度)可通过 Custom Metrics API 扩展
+- KEDA 通过 ScaledObject CRD 实现事件驱动扩缩容,可将应用从零副本扩展,支持 Publishes Metrics 模式为 HPA 供数,实现指标驱动与事件驱动的混合扩展
+- Cluster Autoscaler 的扩缩容决策基于集群内 Pending Pod 的数量,联动 ASG/托管节点组调整期望容量,同时考虑 Pod 的 CPU/内存 requests,支持 Mixed Instances Policy,推荐使用 Auto-discovery 模式,min/max 配置变更应在 ASG/托管节点组层面操作
+- Karpenter 是 AWS 开源的 Kubernetes 原生容量扩缩器,直接与 EC2 API 通信,支持动态按需供给(无需预配置节点组),通过 Provisioner 定义 EC2 实例需求并与工作负载的 node selector/affinity 匹配,默认禁用回收(需启用 TTL 或集群整合)
+- 为解决 IP 地址耗尽问题,推荐切换至 IPv6(双栈 VPC,节点双协议栈,Pod 仅 IPv6);若无法切换,可使用 Carrier-Grade NAT(CGNAT)配合自定义网络;IPv6 Pod 与 IPv4 目标的交互通过双层 NAT 映射配置
+- CoreDNS 扩缩容和 Node Local DNS Cache 安装是 EKS 生产部署的重要优化项
+
+## Key Quotes
+> "The horizontal pod autoscaler is going to pull the metrics and it is going to calculate how many replicas are required for your application workload." — HPA 的核心机制:拉取指标 → 计算所需副本数
+>
+> "The scaling decision that is made by the cluster auto scaler, it is done on the number of pending pods in the cluster." — Cluster Autoscaler 的决策依据:Pending Pod 数量
+>
+> "Carpenter has native integration with Kubernetes and it complements the native Kubernetes spot pod scheduling constraints that is available for your workloads." — Karpenter/Carpenter 与原生 K8s Spot Pod Disruption Budget 的互补关系
+>
+> "The EKS best practices guides, specifically the scalability section." — 演讲者推荐的学习资源:EKS Best Practices Guides
+
+## Key Concepts
+- [[Horizontal Pod Autoscaler (HPA)]]:Kubernetes 标准 Pod 水平扩缩容机制,通过 CPU/内存指标或自定义/外部指标计算副本需求,支持 stabilization window 和 period seconds 配置防止震荡
+- [[KEDA]](Kubernetes Event-Driven Autoscaling):基于外部事件驱动的 K8s 扩缩容框架,通过 ScaledObject CRD 定义扩缩规则,支持从零副本扩展,可 Publish Metrics 给 HPA 实现混合扩展模式
+- [[Cluster Autoscaler]]:Kubernetes 官方节点扩缩容组件,联动 AWS ASG/托管节点组,根据 Pending Pod 数量和资源 requests 调整 Node 数量,推荐 Auto-discovery 模式
+- [[Karpenter]]:AWS 开源的 Kubernetes 原生容量扩缩器,直接与 EC2 API 通信,通过 Provisioner 匹配工作负载需求,支持动态按需供给,默认禁用回收(需启用 TTL 或 Consolidation)
+- [[IPv6-in-EKS]]:EKS 集群解决 IP 地址耗尽的方案,推荐双栈 VPC 架构(节点双协议栈,Pod 仅 IPv6),IPv6 Pod 与 IPv4 目标通过 NAT 映射通信
+- [[API-Server-Priority-and-Fairness]]:EKS API Server 的优先级和公平性配置,用于在高负载下保护关键工作负载的 API 访问
+- [[CoreDNS-Scaling]]:EKS 集群 CoreDNS 的水平扩缩容策略,配合 Node Local DNS Cache 降低 DNS 查询延迟
+- [[Metrics-Server]]:Kubernetes 的 CPU/内存指标采集组件,HPA 依赖其提供标准资源指标
+
+## Key Entities
+- [[Suravpul]]:AWS 高级解决方案架构师(Senior Solutions Architect),CTP Topic 64 和 Topic 59、Topic 67 的讲师,专注 EKS 可靠性、可观测性和扩缩容实践
+- [[Amazon EKS]]:托管 Kubernetes 服务,本 Source Page 的目标平台
+- [[AWS]]:Amazon Web Services,EKS 及相关扩缩容工具(KEDA、Karpenter)的云服务提供商
+- [[Kubernetes]]:开源容器编排平台,HPA、Cluster Autoscaler、KEDA 的上游项目
+
+## Connections
+- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← 相关 ← [[Horizontal Pod Autoscaler (HPA)]](Topic 59 涵盖 HPA 和 VPA 在 EKS 可靠性中的作用)
+- [[ctp-topic-70-eks-deployment-using-iac]] ← 相关 ← [[Cluster Autoscaler]](Topic 70 提及 Cluster Autoscaler 实现 Worker Node 自动扩缩容)
+- [[ctp-topic-70-eks-deployment-using-iac]] ← depends_on ← [[ctp-topic-64-scaling-out-with-amazon-eks]](扩缩容是 IaC 部署后的运维关注点)
+- [[public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization]] ← 关联 ← [[Karpenter]](Part 1 深度对比 Karpenter 与 Cluster Autoscaler)
+- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← 关联 ← [[Karpenter]](Part 3 介绍 EKS Auto Mode,内置 Karpenter Controller)
+- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← 相关 ← [[Suravpul]](同一讲师的可观测性专题)
+
+## Contradictions
+- 与 [[ctp-topic-70-eks-deployment-using-iac]] 无实质冲突:
+ - 冲突点:无
+ - 当前观点:Topic 64 提供扩缩容的完整方法论(HPA/KEDA/Carpenter + IPv6 解决 IP 耗尽)
+ - 对方观点:Topic 70 仅简述 Cluster Autoscaler 实现 Worker Node 自动扩缩容,侧重 IaC 部署流程
+ - 注:两者互补而非冲突,Topic 70 是部署入口,Topic 64 是扩缩容深化
diff --git a/wiki/sources/ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation.md b/wiki/sources/ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation.md
index 74c9d6d0..fde40aad 100644
--- a/wiki/sources/ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation.md
+++ b/wiki/sources/ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation.md
@@ -1,56 +1,56 @@
----
-title: "CTP Topic 65 Tracing the Value Delivered in Cloud Transformation"
-type: source
-tags:
- - Value-Tracing
- - Cloud-Transformation
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation.md]]
-
-## Summary(用中文描述)
-- 核心主题:云转型中的价值交付量化框架与工作优先级排序方法
-- 问题域:如何系统性地衡量、捕获和优先排序云转型工作中的业务价值
-- 方法/机制:①定义过程(Process)和价值流(Value Stream)概念;②建立全局收益框架(财务、生产力、质量、体验四维度);③使用加权最短作业优先(WSJF)方法对工作进行经济性排序;④在功能级别拆解价值归属
-- 结论/价值:云转型工作应以"最小投入尽早交付最大价值"为原则,通过量化收益和成本延迟比来优化工作排序,实现经济收益最大化
-
-## Key Claims(用中文描述)
-- 过程(Process)是由输入(数据、资源、时间、资金、专业知识)驱动的系统性步骤,将输入转化为产出和成果,成果分为硬性(时间、成本、质量)和软性(健康、安全)
-- 价值(Value)由客户决定,体现为公平回报或等价商品;Lean 识别三类活动:增值活动、价值赋能活动、浪费
-- 价值流(Value Stream)是向客户交付产品或服务的系列活动,分为运营价值流(OVS,面向客户)和开发价值流(DVS,内部产品)
-- 收益捕获需要全局框架,涵盖财务、生产力、质量和体验四个维度,聚焦收入增长、成本降低、风险改善和服务可获得市场规模(SOM)
-- 加权最短作业优先(WSJF)方法通过"延迟成本/作业规模"比值对工作排序,实现最大经济收益
-- 延迟成本 = 业务价值 + 时间紧迫性 + 风险与机会
-
-## Key Quotes
-> "What we want to do is deliver the maximum value early back into the business for the least amount of effort." — CTP Topic 65 核心目标
-> "A simple way of thinking of an outcome is that there's usually going to be a desirable change in some important attribute or indicator." — 成果的定义
-> "For each demand, the demand manager captures these five things from the product team. Financial figures should be annualized." — 需求管理流程
-> "The weighted shortest job first method prioritizes work based on cost of delay divided by size of job." — WSJF 优先级排序公式
-
-## Key Concepts
-- [[Process]]:由输入驱动的系统性步骤,将输入转化为产出和成果
-- [[Value]]:由客户决定的货币价值,体现为公平回报
-- [[Value-Stream]]:向客户交付产品或服务的系列活动,包含 OVS(运营价值流)和 DVS(开发价值流)
-- [[Value-Adding]]:Lean 中的增值活动类型
-- [[Waste]]:Lean 中的浪费活动类型
-- [[Benefits-Quantification]]:财务、生产力、质量、体验四维度收益量化框架
-- [[Cost-of-Delay]]:延迟成本 = 业务价值 + 时间紧迫性 + 风险与机会
-- [[WSJF]]:Weighted Shortest Job First,通过 Cost of Delay / Size of Job 比值排序工作
-- [[SOM]]:Serviceable Obtainable Market,可服务可获得市场规模
-- [[Feature-Level-Value-Breakdown]]:在功能级别拆解和分配价值的方法
-
-## Key Entities
-- [[CTP]]:Cloud Transformation Programme,云转型计划(本视频来源项目)
-- [[Scaled-Agile]]:SAFe 框架定义了 OVS 和 DVS 概念(本视频引用)
-
-## Connections
-- [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] ← relates_to ← [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]](均涉及敏捷方法管理云转型)
-- [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]] ← extends ← [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]](需求流程与价值量化协同)
-- [[ctp-topic-30-managing-change]] ← relates_to ← [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]](变更管理与价值交付的关系)
-
-## Contradictions
-- 与 [[ctp-topic-53-why-bother-with-cloud]] 的视角张力:Topic 53 质疑迁移必要性,Topic 65 假设迁移已决策并聚焦如何量化交付价值。两者互补而非逻辑矛盾——前者回答"是否迁移",后者回答"如何衡量价值"。
+---
+title: "CTP Topic 65 Tracing the Value Delivered in Cloud Transformation"
+type: source
+tags:
+ - Value-Tracing
+ - Cloud-Transformation
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation.md]]
+
+## Summary(用中文描述)
+- 核心主题:云转型中的价值交付量化框架与工作优先级排序方法
+- 问题域:如何系统性地衡量、捕获和优先排序云转型工作中的业务价值
+- 方法/机制:①定义过程(Process)和价值流(Value Stream)概念;②建立全局收益框架(财务、生产力、质量、体验四维度);③使用加权最短作业优先(WSJF)方法对工作进行经济性排序;④在功能级别拆解价值归属
+- 结论/价值:云转型工作应以"最小投入尽早交付最大价值"为原则,通过量化收益和成本延迟比来优化工作排序,实现经济收益最大化
+
+## Key Claims(用中文描述)
+- 过程(Process)是由输入(数据、资源、时间、资金、专业知识)驱动的系统性步骤,将输入转化为产出和成果,成果分为硬性(时间、成本、质量)和软性(健康、安全)
+- 价值(Value)由客户决定,体现为公平回报或等价商品;Lean 识别三类活动:增值活动、价值赋能活动、浪费
+- 价值流(Value Stream)是向客户交付产品或服务的系列活动,分为运营价值流(OVS,面向客户)和开发价值流(DVS,内部产品)
+- 收益捕获需要全局框架,涵盖财务、生产力、质量和体验四个维度,聚焦收入增长、成本降低、风险改善和服务可获得市场规模(SOM)
+- 加权最短作业优先(WSJF)方法通过"延迟成本/作业规模"比值对工作排序,实现最大经济收益
+- 延迟成本 = 业务价值 + 时间紧迫性 + 风险与机会
+
+## Key Quotes
+> "What we want to do is deliver the maximum value early back into the business for the least amount of effort." — CTP Topic 65 核心目标
+> "A simple way of thinking of an outcome is that there's usually going to be a desirable change in some important attribute or indicator." — 成果的定义
+> "For each demand, the demand manager captures these five things from the product team. Financial figures should be annualized." — 需求管理流程
+> "The weighted shortest job first method prioritizes work based on cost of delay divided by size of job." — WSJF 优先级排序公式
+
+## Key Concepts
+- [[Process]]:由输入驱动的系统性步骤,将输入转化为产出和成果
+- [[Value]]:由客户决定的货币价值,体现为公平回报
+- [[Value-Stream]]:向客户交付产品或服务的系列活动,包含 OVS(运营价值流)和 DVS(开发价值流)
+- [[Value-Adding]]:Lean 中的增值活动类型
+- [[Waste]]:Lean 中的浪费活动类型
+- [[Benefits-Quantification]]:财务、生产力、质量、体验四维度收益量化框架
+- [[Cost-of-Delay]]:延迟成本 = 业务价值 + 时间紧迫性 + 风险与机会
+- [[WSJF]]:Weighted Shortest Job First,通过 Cost of Delay / Size of Job 比值排序工作
+- [[SOM]]:Serviceable Obtainable Market,可服务可获得市场规模
+- [[Feature-Level-Value-Breakdown]]:在功能级别拆解和分配价值的方法
+
+## Key Entities
+- [[CTP]]:Cloud Transformation Programme,云转型计划(本视频来源项目)
+- [[Scaled-Agile]]:SAFe 框架定义了 OVS 和 DVS 概念(本视频引用)
+
+## Connections
+- [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] ← relates_to ← [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]](均涉及敏捷方法管理云转型)
+- [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]] ← extends ← [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]](需求流程与价值量化协同)
+- [[ctp-topic-30-managing-change]] ← relates_to ← [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]](变更管理与价值交付的关系)
+
+## Contradictions
+- 与 [[ctp-topic-53-why-bother-with-cloud]] 的视角张力:Topic 53 质疑迁移必要性,Topic 65 假设迁移已决策并聚焦如何量化交付价值。两者互补而非逻辑矛盾——前者回答"是否迁移",后者回答"如何衡量价值"。
diff --git a/wiki/sources/ctp-topic-66-exposing-the-differences-between-postgresql-rds-and-aurora.md b/wiki/sources/ctp-topic-66-exposing-the-differences-between-postgresql-rds-and-aurora.md
index 2075148a..bed058a7 100644
--- a/wiki/sources/ctp-topic-66-exposing-the-differences-between-postgresql-rds-and-aurora.md
+++ b/wiki/sources/ctp-topic-66-exposing-the-differences-between-postgresql-rds-and-aurora.md
@@ -1,69 +1,69 @@
----
-title: "CTP Topic 66 Exposing the differences between PostgreSQL RDS and Aurora"
-type: source
-tags:
- - AWS
- - RDS
- - Aurora
- - PostgreSQL
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-66-exposing-the-differences-between-postgresql-rds-and-aurora]]
-
-## Summary(用中文描述)
-- 核心主题:PostgreSQL 在 Amazon RDS 与 Aurora 两种托管方案之间的核心差异对比
-- 问题域:AWS 云数据库选型——何时选 RDS,何时选 Aurora,成本与性能的权衡
-- 方法/机制:从架构设计、最小实例规格、最大扩展能力、自动扩缩容、故障恢复时间、存储灵活性、端点设计、Blue-Green 部署、监控方案及高可用性能调优等多维度进行系统对比
-- 结论/价值:数据库规模 < 10-20TB 优先选 RDS(成本更低、存储选项更灵活);超过该规模或有严格 RTO 要求(30 秒)则选 Aurora(跨 AZ 六副本架构、自动故障恢复)
-
-## Key Claims(用中文描述)
-- RDS 因架构简单、提供更小规格实例,初始成本低于 Aurora;Aurora 最小规格较高
-- Aurora 单集群最大容量和 IO 性能优于 RDS,适合超过 10-20 TB 的数据库
-- Aurora Serverless v2 支持自动扩缩容,但对实例类型、版本和区域有限制
-- Aurora 的 RTO(恢复时间目标)为 30 秒,RDS 为 2 分钟(AZ 故障场景)
-- RDS 提供多种存储类型(GP2、GP3、预置 IOPS、磁性),Aurora 按 IO 计数收费
-- Aurora 采用跨 3 个 AZ 的 6 块 EBS 卷组成的共享集群卷,读副本无需重新复制数据
-- Aurora MySQL 支持 Blue-Green 部署,PostgreSQL 不支持
-- Aurora 使用临时 SSD(短暂存储)用于临时工作,RDS 使用 EBS
-
-## Key Quotes
-> "Aurora IO is generally unbounded because they're motivated to give you as much IO as you can consume because they're charging you per IO." — Aurora 按 IO 收费机制使其有动力提供尽可能高的 IO
-
-> "With Aurora, you get six EBS volumes. They're spread across three availability zones." — Aurora 跨 3 AZ 的六副本架构是高性能和高可用的基础
-
-> "With RDS, you get to choose multiple different storage mechanisms." — RDS 存储灵活性优势
-
-## Key Concepts
-- [[RTO(Recovery Time Objective)]]:从故障中恢复的时间目标,Aurora 为 30 秒,RDS 为 2 分钟
-- [[Shared Cluster Volume]]:Aurora 的跨 AZ 共享存储卷,6 块 EBS 卷组成,读副本共享同一数据副本无需重新复制
-- [[Blue-Green Deployment]]:Aurora MySQL 支持主备环境切换式部署,用于大版本升级,PostgreSQL 不支持
-- [[Endpoint Architecture]]:Aurora 提供独立的 Writer Endpoint 和 Reader Endpoint,RDS 仅有一个集群端点
-- [[Aurora Global]]:Aurora 跨区域复制方案,支持干净的托管式切换和故障转移
-- [[Temporary Storage]]:Aurora 使用临时 SSD(短暂存储)处理临时工作,固定大小取决于实例类型
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,提供 RDS 和 Aurora 两款托管数据库服务
-- [[Amazon RDS]]:关系型数据库服务,计算与存储分离(EBS),支持 Multi-AZ 部署
-- [[Amazon Aurora]]:云原生关系型数据库,6 副本跨 3 AZ 共享集群卷架构
-- [[Greg Klau]]:CTP Topic 66 讲师,主讲 PostgreSQL RDS vs Aurora 差异对比
-- [[EBS]]:Elastic Block Store,RDS 的存储后端;Aurora 的底层存储(6 块卷跨 3 AZ)
-- [[CloudWatch]]:AWS 监控服务,RDS 和 Aurora 均支持
-- [[Performance Insights]]:AWS 数据库性能监控工具,Aurora 和 RDS 均支持
-- [[JDBC]]:Java Database Connectivity,连接串可配置 reader/writer 端点以提升韧性
-
-## Connections
-- [[Amazon Aurora]] ← extends ← [[Amazon RDS]]
-- [[RTO(Recovery Time Objective)]] ← depends_on ← [[Shared Cluster Volume]]
-- [[Blue-Green Deployment]] ← supports ← [[Aurora Global]]
-- [[Aurora Global]] ← enables ← [[Multi-Region Failover]]
-- [[ctp-topic-51-architecting-with-aws-purpose-built-databases]] ← related_to ← 本页(AWS 数据库选型)
-- [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]] ← related_to ← 本页(灾备策略)
-
-## Contradictions
-- 与 [[learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform]] 冲突:
- - 冲突点:Terraform 部署 RDS 时对存储类型的选择
- - 当前观点:Aurora 按 IO 收费适合高 IO 场景,RDS 提供多种存储类型(GP2/GP3/预置 IOPS)适合成本敏感型场景
- - 对方观点:Terraform IaC 部署关注点是资源标准化和可重复性,存储选型属于运维决策
+---
+title: "CTP Topic 66 Exposing the differences between PostgreSQL RDS and Aurora"
+type: source
+tags:
+ - AWS
+ - RDS
+ - Aurora
+ - PostgreSQL
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-66-exposing-the-differences-between-postgresql-rds-and-aurora.md]]
+
+## Summary(用中文描述)
+- 核心主题:PostgreSQL 在 Amazon RDS 与 Aurora 两种托管方案之间的核心差异对比
+- 问题域:AWS 云数据库选型——何时选 RDS,何时选 Aurora,成本与性能的权衡
+- 方法/机制:从架构设计、最小实例规格、最大扩展能力、自动扩缩容、故障恢复时间、存储灵活性、端点设计、Blue-Green 部署、监控方案及高可用性能调优等多维度进行系统对比
+- 结论/价值:数据库规模 < 10-20TB 优先选 RDS(成本更低、存储选项更灵活);超过该规模或有严格 RTO 要求(30 秒)则选 Aurora(跨 AZ 六副本架构、自动故障恢复)
+
+## Key Claims(用中文描述)
+- RDS 因架构简单、提供更小规格实例,初始成本低于 Aurora;Aurora 最小规格较高
+- Aurora 单集群最大容量和 IO 性能优于 RDS,适合超过 10-20 TB 的数据库
+- Aurora Serverless v2 支持自动扩缩容,但对实例类型、版本和区域有限制
+- Aurora 的 RTO(恢复时间目标)为 30 秒,RDS 为 2 分钟(AZ 故障场景)
+- RDS 提供多种存储类型(GP2、GP3、预置 IOPS、磁性),Aurora 按 IO 计数收费
+- Aurora 采用跨 3 个 AZ 的 6 块 EBS 卷组成的共享集群卷,读副本无需重新复制数据
+- Aurora MySQL 支持 Blue-Green 部署,PostgreSQL 不支持
+- Aurora 使用临时 SSD(短暂存储)用于临时工作,RDS 使用 EBS
+
+## Key Quotes
+> "Aurora IO is generally unbounded because they're motivated to give you as much IO as you can consume because they're charging you per IO." — Aurora 按 IO 收费机制使其有动力提供尽可能高的 IO
+
+> "With Aurora, you get six EBS volumes. They're spread across three availability zones." — Aurora 跨 3 AZ 的六副本架构是高性能和高可用的基础
+
+> "With RDS, you get to choose multiple different storage mechanisms." — RDS 存储灵活性优势
+
+## Key Concepts
+- [[RTO(Recovery Time Objective)]]:从故障中恢复的时间目标,Aurora 为 30 秒,RDS 为 2 分钟
+- [[Shared Cluster Volume]]:Aurora 的跨 AZ 共享存储卷,6 块 EBS 卷组成,读副本共享同一数据副本无需重新复制
+- [[Blue-Green Deployment]]:Aurora MySQL 支持主备环境切换式部署,用于大版本升级,PostgreSQL 不支持
+- [[Endpoint Architecture]]:Aurora 提供独立的 Writer Endpoint 和 Reader Endpoint,RDS 仅有一个集群端点
+- [[Aurora Global]]:Aurora 跨区域复制方案,支持干净的托管式切换和故障转移
+- [[Temporary Storage]]:Aurora 使用临时 SSD(短暂存储)处理临时工作,固定大小取决于实例类型
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,提供 RDS 和 Aurora 两款托管数据库服务
+- [[Amazon RDS]]:关系型数据库服务,计算与存储分离(EBS),支持 Multi-AZ 部署
+- [[Amazon Aurora]]:云原生关系型数据库,6 副本跨 3 AZ 共享集群卷架构
+- [[Greg Klau]]:CTP Topic 66 讲师,主讲 PostgreSQL RDS vs Aurora 差异对比
+- [[EBS]]:Elastic Block Store,RDS 的存储后端;Aurora 的底层存储(6 块卷跨 3 AZ)
+- [[CloudWatch]]:AWS 监控服务,RDS 和 Aurora 均支持
+- [[Performance Insights]]:AWS 数据库性能监控工具,Aurora 和 RDS 均支持
+- [[JDBC]]:Java Database Connectivity,连接串可配置 reader/writer 端点以提升韧性
+
+## Connections
+- [[Amazon Aurora]] ← extends ← [[Amazon RDS]]
+- [[RTO(Recovery Time Objective)]] ← depends_on ← [[Shared Cluster Volume]]
+- [[Blue-Green Deployment]] ← supports ← [[Aurora Global]]
+- [[Aurora Global]] ← enables ← [[Multi-Region Failover]]
+- [[ctp-topic-51-architecting-with-aws-purpose-built-databases]] ← related_to ← 本页(AWS 数据库选型)
+- [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]] ← related_to ← 本页(灾备策略)
+
+## Contradictions
+- 与 [[learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform]] 冲突:
+ - 冲突点:Terraform 部署 RDS 时对存储类型的选择
+ - 当前观点:Aurora 按 IO 收费适合高 IO 场景,RDS 提供多种存储类型(GP2/GP3/预置 IOPS)适合成本敏感型场景
+ - 对方观点:Terraform IaC 部署关注点是资源标准化和可重复性,存储选型属于运维决策
diff --git a/wiki/sources/ctp-topic-67-cloud-native-observability-using-opentelemetry.md b/wiki/sources/ctp-topic-67-cloud-native-observability-using-opentelemetry.md
index 7f195b3c..aa83d1b6 100644
--- a/wiki/sources/ctp-topic-67-cloud-native-observability-using-opentelemetry.md
+++ b/wiki/sources/ctp-topic-67-cloud-native-observability-using-opentelemetry.md
@@ -1,73 +1,73 @@
----
-title: "CTP Topic 67 Cloud native observability using OpenTelemetry"
-type: source
-tags:
- - OpenTelemetry
- - Observability
- - Cloud-Native
- - CTP
- - AWS
- - EKS
- - ECS
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-67-cloud-native-observability-using-opentelemetry]]
-
-## Summary(用中文描述)
-- 核心主题:AWS EKS/ECS 环境下的云原生可观测性实践,以 AWS Distro for OpenTelemetry (ADOT) 为核心工具实现统一监控。
-- 问题域:云原生环境下系统复杂度激增,如何通过标准化的可观测性方案实现主动式故障排查与性能优化。
-- 方法/机制:OpenTelemetry 提供厂商无关的代码插桩库和 Collector 组件(Receivers → Processors → Exporters),ADOT 在此基础上增加 AWS 专用组件和 SIGV4 认证扩展;三种观测信号(Traces/Metrics/Logs)贯穿应用层与基础设施层,通过 Correlation ID 实现跨信号关联。
-- 结论/价值:ADOT 是 AWS EKS/ECS 生产级可观测性的推荐方案,支持 Sidecar/独立任务/DaemonSet/HA Replicas 等多种部署模式,可对接 CloudWatch/X-Ray/Prometheus/Grafana 等多种后端。
-
-## Key Claims(用中文描述)
-- 可观测性是管理云原生系统复杂度的必要手段——通过收集 Traces/Metrics/Logs 三种信号,实现反应式和主动式故障排查。
-- 构建可观测的应用是开发者的责任——开发者需要主动在代码中植入观测能力,而非依赖运维事后补救。
-- OpenTelemetry Collector 的核心架构由 Receivers(采集信号)、Processors(转换处理)和 Exporters(导出目的地)三部分组成,实现厂商无关的信号管道。
-- ADOT 在标准 OTEL Collector 基础上封装了 AWS 专用组件,包含 SIGV4 Auth Extension 实现对 AWS 服务的无缝集成。
-- Trace 捕获应用调用栈中各层的处理耗时,是性能瓶颈定位的核心手段。
-- 从应用层和基础设施层同时采集 Metrics 可获得完整的应用视图,包括业务级指标和 X-Ray 服务图。
-- Correlation ID(如 X-Ray Trace ID)使日志事件可深度链接至 Trace 视图,实现端到端的故障追踪。
-- ADOT 支持多种 EKS/ECS 部署模式,EKS Add-on 方式通过 Operator 和 Terraform 模块简化部署并提供预置 Grafana 仪表盘。
-
-## Key Quotes
-> "Observability is essential for managing complexity as systems evolve." — Surav, AWS
-
-> "Building observable applications is a developer responsibility." — Surav, AWS
-
-> "A trace captures the processing time taken at individual layers in your application call stack." — Surav, AWS
-
-## Key Concepts
-- [[OpenTelemetry]]:厂商无关的可观测性框架,提供跨语言的 SDK 和 Collector 组件
-- [[Observability(可观测性)]]:通过外部输出推断内部状态的能力,核心三信号为 Traces/Metrics/Logs
-- [[AWS Distro for OpenTelemetry (ADOT)]]:AWS 维护的 OpenTelemetry 生产级发行版,含 AWS 专用组件
-- [[Three Signals]]:Traces(调用链追踪)、Metrics(指标)、Logs(日志)
-- [[OTLP(OpenTelemetry Protocol)]]:OpenTelemetry 的标准传输协议
-- [[Fluent Bit]]:容器日志采集器,常与 OTEL Collector 配合使用
-- [[X-Ray]]:AWS 原生分布式追踪服务
-- [[Prometheus]]:开源时序数据库和监控告警系统
-- [[Grafana]]:开源可视化平台,常与 Prometheus/X-Ray 配合构建仪表盘
-- [[SIGV4 Auth Extension]]:OTEL Collector 的 AWS 认证扩展,用于访问 AWS 托管服务
-
-## Key Entities
-- [[Amazon EKS]]:AWS 托管 Kubernetes 服务,ADOT 的主要部署目标
-- [[Amazon ECS]]:AWS 容器编排服务,支持 ADOT Sidecar 和独立任务两种部署模式
-- [[AWS Distro for OpenTelemetry (ADOT)]]:AWS 官方的 OpenTelemetry 发行版
-- [[CloudWatch]]:AWS 原生监控服务,可作为 ADOT 的 Exporter 目标
-- [[Surav (AWS)]]:AWS 解决方案架构师,CTP Topic 67 讲师
-
-## Connections
-- [[public-cloud-learning-sessions-observability-with-opentelemetry-20240402-160113]] ← same_topic ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
- - 两篇均为 OpenTelemetry 主题,前者为 Jay Comer 主讲的 Learning Sessions 概述,后者为 Surav 主讲的 CTP Topic 深度实践
-- [[ctp-topic-42-grafana-observability-dashboard]] ← related ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
- - Grafana 是 ADOT 推荐的可视化后端
-- [[ctp-topic-54-esm-saas-log-analytics]] ← related ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
- - ESM SaaS 日志分析方案与 OTEL 日志采集互补,共同构成企业级可观测性视图
-- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← related ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
- - EKS 可靠性实践需要可观测性支撑,监控是 SRE 可靠性的核心组成
-- [[ctp-topic-70-eks-deployment-using-iac]] ← related ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
- - EKS IaC 部署后需配置 ADOT Add-on 完成监控栈落地
-
-## Contradictions
-- 无已知冲突内容。
+---
+title: "CTP Topic 67 Cloud native observability using OpenTelemetry"
+type: source
+tags:
+ - OpenTelemetry
+ - Observability
+ - Cloud-Native
+ - CTP
+ - AWS
+ - EKS
+ - ECS
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-67-cloud-native-observability-using-opentelemetry.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS EKS/ECS 环境下的云原生可观测性实践,以 AWS Distro for OpenTelemetry (ADOT) 为核心工具实现统一监控。
+- 问题域:云原生环境下系统复杂度激增,如何通过标准化的可观测性方案实现主动式故障排查与性能优化。
+- 方法/机制:OpenTelemetry 提供厂商无关的代码插桩库和 Collector 组件(Receivers → Processors → Exporters),ADOT 在此基础上增加 AWS 专用组件和 SIGV4 认证扩展;三种观测信号(Traces/Metrics/Logs)贯穿应用层与基础设施层,通过 Correlation ID 实现跨信号关联。
+- 结论/价值:ADOT 是 AWS EKS/ECS 生产级可观测性的推荐方案,支持 Sidecar/独立任务/DaemonSet/HA Replicas 等多种部署模式,可对接 CloudWatch/X-Ray/Prometheus/Grafana 等多种后端。
+
+## Key Claims(用中文描述)
+- 可观测性是管理云原生系统复杂度的必要手段——通过收集 Traces/Metrics/Logs 三种信号,实现反应式和主动式故障排查。
+- 构建可观测的应用是开发者的责任——开发者需要主动在代码中植入观测能力,而非依赖运维事后补救。
+- OpenTelemetry Collector 的核心架构由 Receivers(采集信号)、Processors(转换处理)和 Exporters(导出目的地)三部分组成,实现厂商无关的信号管道。
+- ADOT 在标准 OTEL Collector 基础上封装了 AWS 专用组件,包含 SIGV4 Auth Extension 实现对 AWS 服务的无缝集成。
+- Trace 捕获应用调用栈中各层的处理耗时,是性能瓶颈定位的核心手段。
+- 从应用层和基础设施层同时采集 Metrics 可获得完整的应用视图,包括业务级指标和 X-Ray 服务图。
+- Correlation ID(如 X-Ray Trace ID)使日志事件可深度链接至 Trace 视图,实现端到端的故障追踪。
+- ADOT 支持多种 EKS/ECS 部署模式,EKS Add-on 方式通过 Operator 和 Terraform 模块简化部署并提供预置 Grafana 仪表盘。
+
+## Key Quotes
+> "Observability is essential for managing complexity as systems evolve." — Surav, AWS
+
+> "Building observable applications is a developer responsibility." — Surav, AWS
+
+> "A trace captures the processing time taken at individual layers in your application call stack." — Surav, AWS
+
+## Key Concepts
+- [[OpenTelemetry]]:厂商无关的可观测性框架,提供跨语言的 SDK 和 Collector 组件
+- [[Observability(可观测性)]]:通过外部输出推断内部状态的能力,核心三信号为 Traces/Metrics/Logs
+- [[AWS Distro for OpenTelemetry (ADOT)]]:AWS 维护的 OpenTelemetry 生产级发行版,含 AWS 专用组件
+- [[Three Signals]]:Traces(调用链追踪)、Metrics(指标)、Logs(日志)
+- [[OTLP(OpenTelemetry Protocol)]]:OpenTelemetry 的标准传输协议
+- [[Fluent Bit]]:容器日志采集器,常与 OTEL Collector 配合使用
+- [[X-Ray]]:AWS 原生分布式追踪服务
+- [[Prometheus]]:开源时序数据库和监控告警系统
+- [[Grafana]]:开源可视化平台,常与 Prometheus/X-Ray 配合构建仪表盘
+- [[SIGV4 Auth Extension]]:OTEL Collector 的 AWS 认证扩展,用于访问 AWS 托管服务
+
+## Key Entities
+- [[Amazon EKS]]:AWS 托管 Kubernetes 服务,ADOT 的主要部署目标
+- [[Amazon ECS]]:AWS 容器编排服务,支持 ADOT Sidecar 和独立任务两种部署模式
+- [[AWS Distro for OpenTelemetry (ADOT)]]:AWS 官方的 OpenTelemetry 发行版
+- [[CloudWatch]]:AWS 原生监控服务,可作为 ADOT 的 Exporter 目标
+- [[Surav (AWS)]]:AWS 解决方案架构师,CTP Topic 67 讲师
+
+## Connections
+- [[public-cloud-learning-sessions-observability-with-opentelemetry-20240402-160113]] ← same_topic ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
+ - 两篇均为 OpenTelemetry 主题,前者为 Jay Comer 主讲的 Learning Sessions 概述,后者为 Surav 主讲的 CTP Topic 深度实践
+- [[ctp-topic-42-grafana-observability-dashboard]] ← related ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
+ - Grafana 是 ADOT 推荐的可视化后端
+- [[ctp-topic-54-esm-saas-log-analytics]] ← related ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
+ - ESM SaaS 日志分析方案与 OTEL 日志采集互补,共同构成企业级可观测性视图
+- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← related ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
+ - EKS 可靠性实践需要可观测性支撑,监控是 SRE 可靠性的核心组成
+- [[ctp-topic-70-eks-deployment-using-iac]] ← related ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
+ - EKS IaC 部署后需配置 ADOT Add-on 完成监控栈落地
+
+## Contradictions
+- 无已知冲突内容。
diff --git a/wiki/sources/ctp-topic-68-introduction-to-redshift.md b/wiki/sources/ctp-topic-68-introduction-to-redshift.md
index dc7aa637..3a8666e1 100644
--- a/wiki/sources/ctp-topic-68-introduction-to-redshift.md
+++ b/wiki/sources/ctp-topic-68-introduction-to-redshift.md
@@ -1,63 +1,63 @@
----
-title: "CTP Topic 68 Introduction to Redshift"
-type: source
-tags:
- - AWS
- - Redshift
- - Data-Warehouse
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-68-introduction-to-redshift]]
-
-## Summary(用中文描述)
-- 核心主题:AWS Redshift 数据仓库服务的基础架构、核心组件及关键特性
-- 问题域:云端 PB 级数据仓库的选型与架构设计
-- 方法/机制:Leader Node + Compute Node MPP 并行架构、列式存储、行式存储、数据压缩(ZSTD/LZO)、Sort Key、Distribution Key
-- 结论/价值:Redshift 是完全托管的 PB 级云数据仓库,支持 OLAP,提供 Leader Node 负责查询规划和元数据管理,Compute Node 通过 Slices 执行并行查询;RA3 实例类型性价比最优,支持 AWS 托管 NVMe 存储;Sort Key 和 Dist Key 是性能优化的关键配置
-
-## Key Claims(用中文描述)
-- Redshift 通过 Leader Node 管理 Schema、元数据和查询计划,将指令分发至 Compute Node 执行,实现 MPP(大规模并行处理),显著提升查询速度和响应时间
-- Redshift 支持列式存储(适合数据仓库操作)和行式存储两种模式,列式存储因更快的查询性能和更高的内存利用率而更适合 OLAP 场景
-- RA3 实例类型因其成本效益和大规模存储容量而被推荐,底层使用 AWS 托管的 NVMe 存储
-- Sort Key(排序键)和 Dist Key(分布键)是 Redshift 性能优化的核心机制,决定数据分布和查询执行效率
-
-## Key Quotes
-> "Redshift is a fully managed, petabyte-scale data warehouse solution in the cloud. It is designed for data warehousing, enabling quick data retrieval from large datasets." — 视频摘要
-
-> "The leader node manages schema, warehouse metadata, and query planning, distributing instructions to compute nodes." — Redshift 架构说明
-
-> "Compute nodes, determined by the instance type, execute queries across slices, processing data and returning results to the leader node." — Compute Node 工作机制
-
-> "RA3 is noted for its cost-effectiveness and large storage capacity, utilizing AWS-managed NVMe storage." — RA3 实例优势
-
-## Key Concepts
-- [[MPP (Massively Parallel Processing)]]:通过多个 Compute Node 并行处理查询,提升大规模数据集的查询速度和响应时间
-- [[列式存储(Columnar Storage)]]:数据按列而非按行存储,适合数据仓库的聚合查询和扫描操作,提供更快的查询性能和更高的内存效率
-- [[数据压缩(Data Compression)]]:采用 ZSTD/LZO 等压缩算法减少数据大小,提升 I/O 效率和查询性能
-- [[Sort Key(排序键)]]:决定数据在磁盘上的物理排序顺序,对范围查询和过滤操作性能影响显著
-- [[Distribution Key(分布键)]]:决定数据在 Compute Node 间如何分布,影响数据倾斜和节点间数据传输
-- [[OLAP(在线分析处理)]]:面向复杂分析查询的工作负载类型,Redshift 的核心设计目标
-- [[Leader Node(主节点)]]:Redshift 架构中的协调节点,负责客户端连接、Schema 管理、元数据存储和查询计划生成
-- [[Compute Node(计算节点)]]:Redshift 架构中的执行节点,负责在 Slices 上执行查询并返回结果
-
-## Key Entities
-- [[Amazon Redshift]]:AWS 提供的大规模并行处理数据仓库服务,支持 PB 级数据存储,面向 OLAP 工作负载
-- [[AWS]]:Amazon Web Services,云服务提供商,Redshift 的托管平台
-- [[RA3]]:Redshift 的高性价比实例类型,配备 AWS 托管 NVMe 存储,适合大容量存储场景
-- [[Dense Compute]]:Redshift 高计算密度实例类型,适合计算密集型查询
-- [[Dense Storage]]:Redshift 高存储密度实例类型,适合存储密集型工作负载
-- [[JDBC/ODBC]]:Redshift 客户端驱动协议,客户端应用通过 JDBC/ODBC 连接至 Redshift Cluster
-
-## Connections
-- [[ctp-topic-51-purpose-built-databases]] ← related_to ← [[Amazon Redshift]]
-- [[ctp-topic-66-rds-vs-aurora]] ← related_to ← [[Amazon Redshift]]
-- [[ctp-topic-40-saas-database-architecture-on-aws-cloud]] ← related_to ← [[Amazon Redshift]]
-
-## Contradictions
-- 与 [[ctp-topic-66-rds-vs-aurora]] 的数据写入模式:
- - 冲突点:Aurora 采用共享存储架构(6副本跨3 AZ),而 Redshift 采用独立 Compute Node 架构;Aurora 更适合写入密集型 OLTP,Redshift 更适合分析密集型 OLAP
- - 当前观点:Redshift 的列式存储 + MPP 是大规模数据分析的最优架构
- - 对方观点:Aurora 的共享存储简化了 HA 和 DR,且 Blue-Green 部署支持更灵活
+---
+title: "CTP Topic 68 Introduction to Redshift"
+type: source
+tags:
+ - AWS
+ - Redshift
+ - Data-Warehouse
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-68-introduction-to-redshift.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS Redshift 数据仓库服务的基础架构、核心组件及关键特性
+- 问题域:云端 PB 级数据仓库的选型与架构设计
+- 方法/机制:Leader Node + Compute Node MPP 并行架构、列式存储、行式存储、数据压缩(ZSTD/LZO)、Sort Key、Distribution Key
+- 结论/价值:Redshift 是完全托管的 PB 级云数据仓库,支持 OLAP,提供 Leader Node 负责查询规划和元数据管理,Compute Node 通过 Slices 执行并行查询;RA3 实例类型性价比最优,支持 AWS 托管 NVMe 存储;Sort Key 和 Dist Key 是性能优化的关键配置
+
+## Key Claims(用中文描述)
+- Redshift 通过 Leader Node 管理 Schema、元数据和查询计划,将指令分发至 Compute Node 执行,实现 MPP(大规模并行处理),显著提升查询速度和响应时间
+- Redshift 支持列式存储(适合数据仓库操作)和行式存储两种模式,列式存储因更快的查询性能和更高的内存利用率而更适合 OLAP 场景
+- RA3 实例类型因其成本效益和大规模存储容量而被推荐,底层使用 AWS 托管的 NVMe 存储
+- Sort Key(排序键)和 Dist Key(分布键)是 Redshift 性能优化的核心机制,决定数据分布和查询执行效率
+
+## Key Quotes
+> "Redshift is a fully managed, petabyte-scale data warehouse solution in the cloud. It is designed for data warehousing, enabling quick data retrieval from large datasets." — 视频摘要
+
+> "The leader node manages schema, warehouse metadata, and query planning, distributing instructions to compute nodes." — Redshift 架构说明
+
+> "Compute nodes, determined by the instance type, execute queries across slices, processing data and returning results to the leader node." — Compute Node 工作机制
+
+> "RA3 is noted for its cost-effectiveness and large storage capacity, utilizing AWS-managed NVMe storage." — RA3 实例优势
+
+## Key Concepts
+- [[MPP (Massively Parallel Processing)]]:通过多个 Compute Node 并行处理查询,提升大规模数据集的查询速度和响应时间
+- [[列式存储(Columnar Storage)]]:数据按列而非按行存储,适合数据仓库的聚合查询和扫描操作,提供更快的查询性能和更高的内存效率
+- [[数据压缩(Data Compression)]]:采用 ZSTD/LZO 等压缩算法减少数据大小,提升 I/O 效率和查询性能
+- [[Sort Key(排序键)]]:决定数据在磁盘上的物理排序顺序,对范围查询和过滤操作性能影响显著
+- [[Distribution Key(分布键)]]:决定数据在 Compute Node 间如何分布,影响数据倾斜和节点间数据传输
+- [[OLAP(在线分析处理)]]:面向复杂分析查询的工作负载类型,Redshift 的核心设计目标
+- [[Leader Node(主节点)]]:Redshift 架构中的协调节点,负责客户端连接、Schema 管理、元数据存储和查询计划生成
+- [[Compute Node(计算节点)]]:Redshift 架构中的执行节点,负责在 Slices 上执行查询并返回结果
+
+## Key Entities
+- [[Amazon Redshift]]:AWS 提供的大规模并行处理数据仓库服务,支持 PB 级数据存储,面向 OLAP 工作负载
+- [[AWS]]:Amazon Web Services,云服务提供商,Redshift 的托管平台
+- [[RA3]]:Redshift 的高性价比实例类型,配备 AWS 托管 NVMe 存储,适合大容量存储场景
+- [[Dense Compute]]:Redshift 高计算密度实例类型,适合计算密集型查询
+- [[Dense Storage]]:Redshift 高存储密度实例类型,适合存储密集型工作负载
+- [[JDBC/ODBC]]:Redshift 客户端驱动协议,客户端应用通过 JDBC/ODBC 连接至 Redshift Cluster
+
+## Connections
+- [[ctp-topic-51-purpose-built-databases]] ← related_to ← [[Amazon Redshift]]
+- [[ctp-topic-66-rds-vs-aurora]] ← related_to ← [[Amazon Redshift]]
+- [[ctp-topic-40-saas-database-architecture-on-aws-cloud]] ← related_to ← [[Amazon Redshift]]
+
+## Contradictions
+- 与 [[ctp-topic-66-rds-vs-aurora]] 的数据写入模式:
+ - 冲突点:Aurora 采用共享存储架构(6副本跨3 AZ),而 Redshift 采用独立 Compute Node 架构;Aurora 更适合写入密集型 OLTP,Redshift 更适合分析密集型 OLAP
+ - 当前观点:Redshift 的列式存储 + MPP 是大规模数据分析的最优架构
+ - 对方观点:Aurora 的共享存储简化了 HA 和 DR,且 Blue-Green 部署支持更灵活
diff --git a/wiki/sources/ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm.md b/wiki/sources/ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm.md
index 3ffdd913..694f19a9 100644
--- a/wiki/sources/ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm.md
+++ b/wiki/sources/ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm.md
@@ -1,69 +1,69 @@
----
-title: "CTP Topic 69 Best Practices for Migrating On-Premises (IOD) Virtual Machines to VMware Cloud on AWS"
-type: source
-tags:
- - VMware
- - Migration
- - VMWare-Cloud-AWS
- - CTP
- - HCX
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm]]
-
-## Summary(用中文描述)
-- 核心主题:VMware Cloud on AWS 环境中的本地虚拟机迁移最佳实践
-- 问题域:IOD (Internet of Things/Devices) 虚拟化基础设施向 VMware Cloud on AWS 的迁移规划与执行
-- 方法/机制:
- - HCX (Hybrid Cloud Extension) 实现多云管理和 any-to-any vSphere 迁移
- - Direct Connect + Virtual Transit Gateway 实现混合云连接
- - UI 迁移方式(VMware Cloud 原生)和 CCOE 脚本自动化迁移两种方案
- - 预迁移评估(计算规格、配置、网络需求)和后迁移自动化配置
- - Brown to Manage (BHM) 系统集成 SMACS + HCMX 进行虚拟机管理
-- 结论/价值:工作负载可在几分钟内完成迁移并在云基础设施运行,显著降低停机时间,节省成本
-
-## Key Claims(用中文描述)
-- HCX 每次迭代最多支持 200 台虚拟机迁移
-- 任何离开云环境的数据传输都会产生费用(Anything which leaves definitely attracts cost)
-- STDC (VMware Cloud on AWS Software-Defined Data Center) 集群和 ESX 节点(EC2 裸金属实例)由 VMware 管理
-- CCOE 团队开发的脚本化迁移方案使用输入文件定义 VM 详情,实现自动化批量迁移
-- 迁移后通过 Brown to Manage 系统集成 SMACS Suite 和 HCMX Content Pack 实现用户管理
-
-## Key Quotes
-> "The session covers best practices for migrating on-premises virtual machines to VMware Cloud on AWS, based on experience and consultant support from VMware." — 会议主题
-
-> "It hardly takes a VM migration with few minutes, which will enable them operated in the cloud infrastructure." — 迁移效率
-
-> "HCX (Hybrid Cloud Extender) facilitates multi-cloud management, allowing viewing of on-premises vSphere from STDC and vice versa." — HCX 双向管理能力
-
-> "Anything which leaves definitely attracts cost." — 数据传输成本原则
-
-## Key Concepts
-- [[VMware-Cloud-on-AWS]]:AWS 基础设施上托管的 VMware SDDC 环境,提供 vSphere、连接性和防火墙服务
-- [[HCX]]:Hybrid Cloud Extension,支持任意 vSphere 环境之间的双向工作负载迁移,每次迭代最多支持 200 台 VM
-- [[SDDC]]:Software-Defined Data Center,VMC on AWS 的核心部署单元,通过 vCenter 管理
-- [[Direct Connect]]:AWS 混合云连接服务,用于将本地数据中心连接至 AWS
-- [[Virtual Transit Gateway]]:虚拟Transit Gateway,实现无缝迁移连接的组件
-- [[BGP]]:Border Gateway Protocol,通过 BGP 协议连接客户机房与 VMware Cloud
-- [[EC2-Bare-Metal]]:EC2 裸金属实例,i3.metal/i3en.metal,用于部署 VMC on AWS
-
-## Key Entities
-- [[VMware]]:云平台提供商,管理 STDC、ESX 节点和 vSphere 环境
-- [[AWS]]:云基础设施提供商,EC2 裸金属实例所在平台
-- [[CCOE]]:Cloud Center of Excellence,开发了脚本化迁移解决方案
-- [[SMACS Suite]]:Brown to Manage 系统的组成套件
-- [[HCMX]]:Hybrid Cloud Manager X,用于 VMware Cloud 与本地环境集成的管理工具
-
-## Connections
-- [[ctp-topic-43-vmware-cloud-on-aws]] ← extends ← [[ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm]](Topic 43 介绍 VMC on AWS 概述,Topic 69 深入迁移最佳实践)
-- [[ctp-topic-18-wide-area-networking-in-aws-cloud]] ← depends_on ← [[ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm]](广域网架构为混合云迁移提供网络基础)
-- [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]] ← related_to ← [[ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm]](网络隔离和安全访问是迁移后环境的重要考量)
-
-## Contradictions
-- 与 [[ctp-topic-43-vmware-cloud-on-aws]] 的视角差异:
- - 冲突点:Topic 43 强调 VMC on AWS 的概述和经济性,Topic 69 侧重具体迁移执行流程
- - 当前观点:Topic 69 提供迁移操作的详细步骤和技术考量
- - 对方观点:Topic 43 聚焦服务介绍和战略价值,属于迁移决策前的评估阶段
- - 结论:两者互补,Topic 43 用于理解 VMC on AWS 是什么,Topic 69 用于执行实际迁移
+---
+title: "CTP Topic 69 Best Practices for Migrating On-Premises (IOD) Virtual Machines to VMware Cloud on AWS"
+type: source
+tags:
+ - VMware
+ - Migration
+ - VMWare-Cloud-AWS
+ - CTP
+ - HCX
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/08_Networking/ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm.md]]
+
+## Summary(用中文描述)
+- 核心主题:VMware Cloud on AWS 环境中的本地虚拟机迁移最佳实践
+- 问题域:IOD (Internet of Things/Devices) 虚拟化基础设施向 VMware Cloud on AWS 的迁移规划与执行
+- 方法/机制:
+ - HCX (Hybrid Cloud Extension) 实现多云管理和 any-to-any vSphere 迁移
+ - Direct Connect + Virtual Transit Gateway 实现混合云连接
+ - UI 迁移方式(VMware Cloud 原生)和 CCOE 脚本自动化迁移两种方案
+ - 预迁移评估(计算规格、配置、网络需求)和后迁移自动化配置
+ - Brown to Manage (BHM) 系统集成 SMACS + HCMX 进行虚拟机管理
+- 结论/价值:工作负载可在几分钟内完成迁移并在云基础设施运行,显著降低停机时间,节省成本
+
+## Key Claims(用中文描述)
+- HCX 每次迭代最多支持 200 台虚拟机迁移
+- 任何离开云环境的数据传输都会产生费用(Anything which leaves definitely attracts cost)
+- STDC (VMware Cloud on AWS Software-Defined Data Center) 集群和 ESX 节点(EC2 裸金属实例)由 VMware 管理
+- CCOE 团队开发的脚本化迁移方案使用输入文件定义 VM 详情,实现自动化批量迁移
+- 迁移后通过 Brown to Manage 系统集成 SMACS Suite 和 HCMX Content Pack 实现用户管理
+
+## Key Quotes
+> "The session covers best practices for migrating on-premises virtual machines to VMware Cloud on AWS, based on experience and consultant support from VMware." — 会议主题
+
+> "It hardly takes a VM migration with few minutes, which will enable them operated in the cloud infrastructure." — 迁移效率
+
+> "HCX (Hybrid Cloud Extender) facilitates multi-cloud management, allowing viewing of on-premises vSphere from STDC and vice versa." — HCX 双向管理能力
+
+> "Anything which leaves definitely attracts cost." — 数据传输成本原则
+
+## Key Concepts
+- [[VMware-Cloud-on-AWS]]:AWS 基础设施上托管的 VMware SDDC 环境,提供 vSphere、连接性和防火墙服务
+- [[HCX]]:Hybrid Cloud Extension,支持任意 vSphere 环境之间的双向工作负载迁移,每次迭代最多支持 200 台 VM
+- [[SDDC]]:Software-Defined Data Center,VMC on AWS 的核心部署单元,通过 vCenter 管理
+- [[Direct Connect]]:AWS 混合云连接服务,用于将本地数据中心连接至 AWS
+- [[Virtual Transit Gateway]]:虚拟Transit Gateway,实现无缝迁移连接的组件
+- [[BGP]]:Border Gateway Protocol,通过 BGP 协议连接客户机房与 VMware Cloud
+- [[EC2-Bare-Metal]]:EC2 裸金属实例,i3.metal/i3en.metal,用于部署 VMC on AWS
+
+## Key Entities
+- [[VMware]]:云平台提供商,管理 STDC、ESX 节点和 vSphere 环境
+- [[AWS]]:云基础设施提供商,EC2 裸金属实例所在平台
+- [[CCOE]]:Cloud Center of Excellence,开发了脚本化迁移解决方案
+- [[SMACS Suite]]:Brown to Manage 系统的组成套件
+- [[HCMX]]:Hybrid Cloud Manager X,用于 VMware Cloud 与本地环境集成的管理工具
+
+## Connections
+- [[ctp-topic-43-vmware-cloud-on-aws]] ← extends ← [[ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm]](Topic 43 介绍 VMC on AWS 概述,Topic 69 深入迁移最佳实践)
+- [[ctp-topic-18-wide-area-networking-in-aws-cloud]] ← depends_on ← [[ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm]](广域网架构为混合云迁移提供网络基础)
+- [[ctp-topic-31-network-segregation-and-secure-access-to-the-new-aws-landing-zones]] ← related_to ← [[ctp-topic-69-best-practices-for-migrating-on-premises-iod-virtual-machines-to-vm]](网络隔离和安全访问是迁移后环境的重要考量)
+
+## Contradictions
+- 与 [[ctp-topic-43-vmware-cloud-on-aws]] 的视角差异:
+ - 冲突点:Topic 43 强调 VMC on AWS 的概述和经济性,Topic 69 侧重具体迁移执行流程
+ - 当前观点:Topic 69 提供迁移操作的详细步骤和技术考量
+ - 对方观点:Topic 43 聚焦服务介绍和战略价值,属于迁移决策前的评估阶段
+ - 结论:两者互补,Topic 43 用于理解 VMC on AWS 是什么,Topic 69 用于执行实际迁移
diff --git a/wiki/sources/ctp-topic-7-saas-landing-zone-design.md b/wiki/sources/ctp-topic-7-saas-landing-zone-design.md
index c9da3ebc..93bb3c0f 100644
--- a/wiki/sources/ctp-topic-7-saas-landing-zone-design.md
+++ b/wiki/sources/ctp-topic-7-saas-landing-zone-design.md
@@ -1,63 +1,63 @@
----
-title: "CTP Topic 7 SaaS Landing Zone Design"
-type: source
-tags: []
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-7-saas-landing-zone-design.md]]
-
-## Summary(用中文描述)
-- 核心主题:SAS(生产)Landing Zone 的顶层设计——采用单一 Landing Zone 统一承载所有产品组,而非按产品组(PG)分别构建,以降低开销和成本
-- 问题域:企业多账户 AWS 生产环境下的账户结构设计、共享基础设施规划、自动化部署流水线及远程安全接入方案
-- 方法/机制:核心账户(Shared/Logs/Security)提供集中 AMI/Jenkins/日志/IAM 角色;基线账户(Network/DNS/AD)支撑网络互联和身份认证;共享服务账户(Software Factory/Cyber/ARC/Monitoring)向产品账户提供内部生产服务;Terraform IaC + GitHub/Jenkins CI/CD 实现自动化部署;Checkpoint → Pulse VPN 实现远程安全接入
-- 结论/价值:确立了 SAS LZ 的四大账户层级架构,以及 Terraform + Jenkins + Lambda + ECS 的端到端自动化部署路径
-
-## Key Claims(用中文描述)
-- SAS Landing Zone 采用单一 Landing Zone 承载所有产品组,区别于 dev labs 中按产品组各自构建 Landing Zone 的模式,以减少开销和成本
-- 核心账户(Core Accounts)包含 Shared(托管 AMI + 主 Jenkins 服务器)、Logs(集中日志账户,仅安全团队可写,产品团队只读自身日志)和 Security(托管 IAM 角色)三个子账户
-- 主 Jenkins 服务器通过 Lambda 函数触发各账户内的 Jenkins slave,禁止将主 Jenkins 直接暴露给任务或凭证,从而增强安全性
-- 基线账户(Baseline Accounts)包括 Network 账户(区域级 Transit Gateway + Checkpoint Appliance)、DNS 账户(Route 53,每个产品拥有独立托管区)和 Active Directory 账户(双 AD 节点用于域加入和资源访问控制)
-- 共享服务账户(Shared Services Accounts)提供 Software Factory(45 个 hub + Octane Hub + Artifactory)、Cyber(Qalis)、ARC Site 和 Monitoring(OBM/Sitescope)服务
-- 产品账户(Product Accounts)中,工作负载置于私有子网,通过公有子网的负载均衡器和互联网网关对外暴露;WAF 监控入站流量,CloudFront 可选作为 CDN
-- 自动化部署:每个账户对应独立 GitHub 仓库,代码变更通过 GitHub Hook 触发 Jenkins → Management VPC → Lambda → ECS Cluster 链路执行部署;Staging 环境测试后才部署生产
-- 远程访问从 Checkpoint VPN 迁移至 Pulse VPN,要求操作员使用 VPN 客户端并通过 AD 认证;未来计划使用 SD1 替换部分网络组件
-
-## Key Quotes
-> "The SAS landing zone will use a single landing zone for all the product groups." — SAS LZ 的核心设计原则:单一 Landing Zone 服务所有产品组
-> "The workload itself is going to be under private subnet." — 产品账户工作负载必须部署于私有子网
-
-## Key Concepts
-- [[Landing-Zone-Architecture]]:AWS 多账户基础设施部署单元,本文档定义了 SAS LZ 的账户层级体系(Core/Baseline/Shared Services/Product Accounts)
-- [[Active-Directory-Integration]]:通过双 AD 节点实现域加入和资源访问控制,属于 AWS LZ 身份认证基线服务
-- [[Transit-Gateway]]:区域级 Transit Gateway 连接所有账户,Checkpoint Appliance 按标签监控流量,属于 Network 账户核心组件
-- [[WAF-Web-Application-Firewall]]:Web 应用防火墙,监控入站流量,属于产品账户入站安全层
-- [[Private-Subnet-Architecture]]:工作负载部署于私有子网,通过负载均衡器和互联网网关对外暴露,属于产品账户网络架构原则
-- [[Terraform-IaC]]:使用 Terraform 实现 IaC 自动化,每个账户拥有独立 GitHub 仓库管理 Terraform 代码
-
-## Key Entities
-- [[Gruntwork]]:提供 Landing Zone 参考架构和 Terraform 模块,SAS LZ 基于 Grant Work 架构构建
-- [[TerraGrant]](TerraGrunt):用于简化 Terraform 状态管理和跨账户部署的工具
-- [[Jenkins]]:主 Jenkins 服务器托管于 Shared 账户,通过 Lambda 触发各账户 Jenkins slave;每个账户配置独立 Jenkins 服务器
-- [[Checkpoint]]:Checkpoint Appliance 部署于 Network 账户,按标签监控跨账户流量(互联网/On-prem);当前远程访问使用 Checkpoint VPN(正迁移至 Pulse)
-- [[Pulse-VPN]]:新一代远程访问 VPN,通过 AD 认证,要求操作员使用 VPN 客户端
-- [[CloudFront]]:CDN 服务,可选部署于产品账户入站链路
-- [[Qalis]]:Cyber 共享服务账户中的网络安全服务
-- [[OBM]](Operations Bridge Manager):Monitoring 共享服务账户中的监控平台
-
-## Connections
-- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← extends ← [[ctp-topic-7-saas-landing-zone-design]]
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← extends ← [[ctp-topic-7-saas-landing-zone-design]]
-- [[ctp-topic-14-octane-hub-on-aws]] ← uses ← [[ctp-topic-7-saas-landing-zone-design]]
-- [[ctp-topic-31-network-segregation-and-secure-access]] ← related_to ← [[ctp-topic-7-saas-landing-zone-design]]
-- [[ctp-topic-11-ad-integration-and-login]] ← related_to ← [[ctp-topic-7-saas-landing-zone-design]]
-- [[ctp-topic-19-configuring-dns-within-aws-lzs]] ← related_to ← [[ctp-topic-7-saas-landing-zone-design]]
-- [[ctp-topic-29-cloud-monitoring-saas-lz-accounts]] ← related_to ← [[ctp-topic-7-saas-landing-zone-design]]
-
-## Contradictions
-- 与 [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] 的关系:
- - 冲突点:ctp-topic-7 定义了 SAS LZ 的详细架构(Core/Baseline/Shared Services/Product 四层账户体系),ctp-topic-35 补充了近期变更(网络分段阻断直接连通性;Checkpoint VPN 迁移至 Pulse VPN)
- - 当前观点(ctp-topic-35):网络分段策略阻断对 SaaS 工作负载的直接连通性;入站流量通过 Network 账户 Checkpoint 重新路由
- - 对方观点(ctp-topic-7):产品账户的公有子网通过负载均衡器和互联网网关对外暴露;远程访问通过 Checkpoint VPN
- - 结论:两个文档描述的是不同时间点的设计状态——ctp-topic-35 反映近期架构变更,ctp-topic-7 反映早期设计原貌,属于设计演进而非冲突
+---
+title: "CTP Topic 7 SaaS Landing Zone Design"
+type: source
+tags: []
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-7-saas-landing-zone-design.md]]
+
+## Summary(用中文描述)
+- 核心主题:SAS(生产)Landing Zone 的顶层设计——采用单一 Landing Zone 统一承载所有产品组,而非按产品组(PG)分别构建,以降低开销和成本
+- 问题域:企业多账户 AWS 生产环境下的账户结构设计、共享基础设施规划、自动化部署流水线及远程安全接入方案
+- 方法/机制:核心账户(Shared/Logs/Security)提供集中 AMI/Jenkins/日志/IAM 角色;基线账户(Network/DNS/AD)支撑网络互联和身份认证;共享服务账户(Software Factory/Cyber/ARC/Monitoring)向产品账户提供内部生产服务;Terraform IaC + GitHub/Jenkins CI/CD 实现自动化部署;Checkpoint → Pulse VPN 实现远程安全接入
+- 结论/价值:确立了 SAS LZ 的四大账户层级架构,以及 Terraform + Jenkins + Lambda + ECS 的端到端自动化部署路径
+
+## Key Claims(用中文描述)
+- SAS Landing Zone 采用单一 Landing Zone 承载所有产品组,区别于 dev labs 中按产品组各自构建 Landing Zone 的模式,以减少开销和成本
+- 核心账户(Core Accounts)包含 Shared(托管 AMI + 主 Jenkins 服务器)、Logs(集中日志账户,仅安全团队可写,产品团队只读自身日志)和 Security(托管 IAM 角色)三个子账户
+- 主 Jenkins 服务器通过 Lambda 函数触发各账户内的 Jenkins slave,禁止将主 Jenkins 直接暴露给任务或凭证,从而增强安全性
+- 基线账户(Baseline Accounts)包括 Network 账户(区域级 Transit Gateway + Checkpoint Appliance)、DNS 账户(Route 53,每个产品拥有独立托管区)和 Active Directory 账户(双 AD 节点用于域加入和资源访问控制)
+- 共享服务账户(Shared Services Accounts)提供 Software Factory(45 个 hub + Octane Hub + Artifactory)、Cyber(Qalis)、ARC Site 和 Monitoring(OBM/Sitescope)服务
+- 产品账户(Product Accounts)中,工作负载置于私有子网,通过公有子网的负载均衡器和互联网网关对外暴露;WAF 监控入站流量,CloudFront 可选作为 CDN
+- 自动化部署:每个账户对应独立 GitHub 仓库,代码变更通过 GitHub Hook 触发 Jenkins → Management VPC → Lambda → ECS Cluster 链路执行部署;Staging 环境测试后才部署生产
+- 远程访问从 Checkpoint VPN 迁移至 Pulse VPN,要求操作员使用 VPN 客户端并通过 AD 认证;未来计划使用 SD1 替换部分网络组件
+
+## Key Quotes
+> "The SAS landing zone will use a single landing zone for all the product groups." — SAS LZ 的核心设计原则:单一 Landing Zone 服务所有产品组
+> "The workload itself is going to be under private subnet." — 产品账户工作负载必须部署于私有子网
+
+## Key Concepts
+- [[Landing-Zone-Architecture]]:AWS 多账户基础设施部署单元,本文档定义了 SAS LZ 的账户层级体系(Core/Baseline/Shared Services/Product Accounts)
+- [[Active-Directory-Integration]]:通过双 AD 节点实现域加入和资源访问控制,属于 AWS LZ 身份认证基线服务
+- [[Transit-Gateway]]:区域级 Transit Gateway 连接所有账户,Checkpoint Appliance 按标签监控流量,属于 Network 账户核心组件
+- [[WAF-Web-Application-Firewall]]:Web 应用防火墙,监控入站流量,属于产品账户入站安全层
+- [[Private-Subnet-Architecture]]:工作负载部署于私有子网,通过负载均衡器和互联网网关对外暴露,属于产品账户网络架构原则
+- [[Terraform-IaC]]:使用 Terraform 实现 IaC 自动化,每个账户拥有独立 GitHub 仓库管理 Terraform 代码
+
+## Key Entities
+- [[Gruntwork]]:提供 Landing Zone 参考架构和 Terraform 模块,SAS LZ 基于 Grant Work 架构构建
+- [[TerraGrant]](TerraGrunt):用于简化 Terraform 状态管理和跨账户部署的工具
+- [[Jenkins]]:主 Jenkins 服务器托管于 Shared 账户,通过 Lambda 触发各账户 Jenkins slave;每个账户配置独立 Jenkins 服务器
+- [[Checkpoint]]:Checkpoint Appliance 部署于 Network 账户,按标签监控跨账户流量(互联网/On-prem);当前远程访问使用 Checkpoint VPN(正迁移至 Pulse)
+- [[Pulse-VPN]]:新一代远程访问 VPN,通过 AD 认证,要求操作员使用 VPN 客户端
+- [[CloudFront]]:CDN 服务,可选部署于产品账户入站链路
+- [[Qalis]]:Cyber 共享服务账户中的网络安全服务
+- [[OBM]](Operations Bridge Manager):Monitoring 共享服务账户中的监控平台
+
+## Connections
+- [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] ← extends ← [[ctp-topic-7-saas-landing-zone-design]]
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← extends ← [[ctp-topic-7-saas-landing-zone-design]]
+- [[ctp-topic-14-octane-hub-on-aws]] ← uses ← [[ctp-topic-7-saas-landing-zone-design]]
+- [[ctp-topic-31-network-segregation-and-secure-access]] ← related_to ← [[ctp-topic-7-saas-landing-zone-design]]
+- [[ctp-topic-11-ad-integration-and-login]] ← related_to ← [[ctp-topic-7-saas-landing-zone-design]]
+- [[ctp-topic-19-configuring-dns-within-aws-lzs]] ← related_to ← [[ctp-topic-7-saas-landing-zone-design]]
+- [[ctp-topic-29-cloud-monitoring-saas-lz-accounts]] ← related_to ← [[ctp-topic-7-saas-landing-zone-design]]
+
+## Contradictions
+- 与 [[ctp-topic-35-aws-landing-zone-design-refresher-saas-labs]] 的关系:
+ - 冲突点:ctp-topic-7 定义了 SAS LZ 的详细架构(Core/Baseline/Shared Services/Product 四层账户体系),ctp-topic-35 补充了近期变更(网络分段阻断直接连通性;Checkpoint VPN 迁移至 Pulse VPN)
+ - 当前观点(ctp-topic-35):网络分段策略阻断对 SaaS 工作负载的直接连通性;入站流量通过 Network 账户 Checkpoint 重新路由
+ - 对方观点(ctp-topic-7):产品账户的公有子网通过负载均衡器和互联网网关对外暴露;远程访问通过 Checkpoint VPN
+ - 结论:两个文档描述的是不同时间点的设计状态——ctp-topic-35 反映近期架构变更,ctp-topic-7 反映早期设计原貌,属于设计演进而非冲突
diff --git a/wiki/sources/ctp-topic-70-eks-deployment-using-iac.md b/wiki/sources/ctp-topic-70-eks-deployment-using-iac.md
index 0e477d42..e6d53617 100644
--- a/wiki/sources/ctp-topic-70-eks-deployment-using-iac.md
+++ b/wiki/sources/ctp-topic-70-eks-deployment-using-iac.md
@@ -1,68 +1,68 @@
----
-title: "CTP Topic 70 EKS deployment using IAC"
-type: source
-tags: [AWS, EKS, IaC, Kubernetes, CTP]
-sources: [raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-70-eks-deployment-using-iac]
-last_updated: 2026-04-24
----
-
-## Source File
-- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-70-eks-deployment-using-iac]]
-
-## Summary(用中文描述)
-- 核心主题:EKS(Amazon Elastic Kubernetes Service)集群通过 IaC(基础设施即代码)方式部署,涵盖容器与 VM 的对比、EKS 特性详解、Terraform 和 Service Catalog 两种部署方式,以及 EKS 集群与容器监控方案。
-- 问题域:如何在企业 AWS Landing Zone 中通过标准化 IaC 流程部署和管理 EKS 集群,实现容器化工作负载的统一治理。
-- 方法/机制:
- - **两种部署方式**:Terraform(使用 `tera-grant.scl` 文件定义集群参数)+ AWS Service Catalog(通过产品组合模块化部署)
- - **自定义网络**:EMI(ENI Multi-IP)解决 Pod IP 分配 CIDR 限制问题
- - **自动扩缩容**:Kubernetes Cluster Autoscaler 根据资源需求自动扩缩 Worker Node
- - **监控栈**:CloudWatch Agent + FluentBit(DaemonSet)+ Container Insights + AWS OpenTelemetry + Grafana
-- 结论/价值:通过 SRE EKS 模块集成 Terraform/Service Catalog 两种 IaC 路径,实现 EKS 集群的标准化、可审计、可重复部署;配合 CloudWatch + Grafana 实现全栈可观测性。
-
-## Key Claims(用中文描述)
-- Kubernetes 相比 VM 具有更快的启动速度、更高的内存效率和更强的可移植性
-- EKS 提供完全托管的控制平面,实现 Worker Node 的零停机滚动部署
-- IAM RBAC Mapping 通过最小权限原则控制 EKS 集群访问
-- SRE EKS 模块集成 ALB Ingress Controller 实现流量管理
-- EMI 自定义网络通过虚拟 ENI 为 Pod 分配 IP 地址,解决 VPC CIDR 限制
-- Kubernetes Cluster Autoscaler 根据资源需求自动扩缩 Worker Node
-- CloudWatch Agent + FluentBit 以 DaemonSet 方式部署,负责日志和指标收集
-
-## Key Quotes
-> "Kubernetes is a framework for running distributed systems resiliently, automating rollouts/rollbacks, load balancing, and horizontal pod scaling." — 核心定义
-> "EKS offers fully managed control planes and autoscaling worker nodes." — EKS 核心价值
-> "Zero downtime rolling deployments for worker node updates" — EKS 高可用特性
-> "IAM RBAC mapping for least privilege access" — EKS 安全模型
-> "Service Catalog allows creating, organizing, and governing AWS resources with permission control." — Service Catalog 定位
-
-## Key Concepts
-- [[Kubernetes]]:容器编排框架,用于分布式系统的弹性运行,支持自动化部署/回滚、负载均衡和 Pod 水平扩缩容
-- [[Amazon EKS]](Amazon Elastic Kubernetes Service):AWS 托管的 Kubernetes 服务,提供完全托管的控制平面和自动扩缩的 Worker Node
-- [[Infrastructure as Code]](IaC):通过代码定义和管理基础设施,实现标准化、可审计、可重复的部署
-- [[AWS Service Catalog]]:AWS 服务,允许组织创建、管理和组织云资源产品,并进行权限控制
-- [[IAM RBAC]]:基于角色的访问控制,通过最小权限原则管理 EKS 集群访问
-- [[Cluster Autoscaler]]:Kubernetes 组件,根据资源需求自动扩缩 Worker Node
-- [[EMI]](ENI Multi-IP):EKS 自定义网络方案,通过虚拟弹性网络接口为 Pod 分配额外 IP 地址,解决 VPC CIDR 限制
-- [[ALB Ingress Controller]]:AWS Load Balancer Controller,负责管理 ALB Ingress 资源,实现 Kubernetes 服务的七层负载均衡
-- [[CloudWatch Container Insights]]:AWS 监控服务,收集容器级别的指标和日志并发布到 CloudWatch
-- [[FluentBit]]:开源日志处理器,以 DaemonSet 方式部署于每个节点,负责收集容器日志
-- [[AWS OpenTelemetry]]:AWS 的可观测性数据收集方案,支持指标、日志和追踪的统一采集
-
-## Key Entities
-- [[Kubernetes]](entity):容器编排框架,EKS 的底层技术,Google 开源,CNCF 托管
-- [[Amazon]](entity):AWS/EKS 的提供商
-
-## Connections
-- [[Amazon EKS]] ← 基于 ← [[Kubernetes]]
-- [[Terraform]] ← 用于 ← [[Infrastructure as Code]]
-- [[AWS Service Catalog]] ← 用于 ← [[Infrastructure as Code]]
-- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← 相关 ← [[Amazon EKS]]
-- [[ctp-topic-64-scaling-out-with-amazon-eks]] ← 相关 ← [[Cluster Autoscaler]]
-- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← 相关 ← [[Amazon EKS]]
-- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← 相关 ← [[AWS OpenTelemetry]]
-
-## Contradictions
-- 与 [[ctp-topic-59-achieving-reliability-with-amazon-eks]] 可能存在内容重叠:
- - 冲突点:两篇均涉及 EKS 特性,但侧重点不同
- - 当前观点:Topic 70 侧重 IaC 部署方法和网络/监控机制
- - 对方观点:Topic 59 侧重 EKS 可靠性保证和最佳实践
+---
+title: "CTP Topic 70 EKS deployment using IAC"
+type: source
+tags: [AWS, EKS, IaC, Kubernetes, CTP]
+sources: [raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-70-eks-deployment-using-iac]
+last_updated: 2026-04-24
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-70-eks-deployment-using-iac.md]]
+
+## Summary(用中文描述)
+- 核心主题:EKS(Amazon Elastic Kubernetes Service)集群通过 IaC(基础设施即代码)方式部署,涵盖容器与 VM 的对比、EKS 特性详解、Terraform 和 Service Catalog 两种部署方式,以及 EKS 集群与容器监控方案。
+- 问题域:如何在企业 AWS Landing Zone 中通过标准化 IaC 流程部署和管理 EKS 集群,实现容器化工作负载的统一治理。
+- 方法/机制:
+ - **两种部署方式**:Terraform(使用 `tera-grant.scl` 文件定义集群参数)+ AWS Service Catalog(通过产品组合模块化部署)
+ - **自定义网络**:EMI(ENI Multi-IP)解决 Pod IP 分配 CIDR 限制问题
+ - **自动扩缩容**:Kubernetes Cluster Autoscaler 根据资源需求自动扩缩 Worker Node
+ - **监控栈**:CloudWatch Agent + FluentBit(DaemonSet)+ Container Insights + AWS OpenTelemetry + Grafana
+- 结论/价值:通过 SRE EKS 模块集成 Terraform/Service Catalog 两种 IaC 路径,实现 EKS 集群的标准化、可审计、可重复部署;配合 CloudWatch + Grafana 实现全栈可观测性。
+
+## Key Claims(用中文描述)
+- Kubernetes 相比 VM 具有更快的启动速度、更高的内存效率和更强的可移植性
+- EKS 提供完全托管的控制平面,实现 Worker Node 的零停机滚动部署
+- IAM RBAC Mapping 通过最小权限原则控制 EKS 集群访问
+- SRE EKS 模块集成 ALB Ingress Controller 实现流量管理
+- EMI 自定义网络通过虚拟 ENI 为 Pod 分配 IP 地址,解决 VPC CIDR 限制
+- Kubernetes Cluster Autoscaler 根据资源需求自动扩缩 Worker Node
+- CloudWatch Agent + FluentBit 以 DaemonSet 方式部署,负责日志和指标收集
+
+## Key Quotes
+> "Kubernetes is a framework for running distributed systems resiliently, automating rollouts/rollbacks, load balancing, and horizontal pod scaling." — 核心定义
+> "EKS offers fully managed control planes and autoscaling worker nodes." — EKS 核心价值
+> "Zero downtime rolling deployments for worker node updates" — EKS 高可用特性
+> "IAM RBAC mapping for least privilege access" — EKS 安全模型
+> "Service Catalog allows creating, organizing, and governing AWS resources with permission control." — Service Catalog 定位
+
+## Key Concepts
+- [[Kubernetes]]:容器编排框架,用于分布式系统的弹性运行,支持自动化部署/回滚、负载均衡和 Pod 水平扩缩容
+- [[Amazon EKS]](Amazon Elastic Kubernetes Service):AWS 托管的 Kubernetes 服务,提供完全托管的控制平面和自动扩缩的 Worker Node
+- [[Infrastructure as Code]](IaC):通过代码定义和管理基础设施,实现标准化、可审计、可重复的部署
+- [[AWS Service Catalog]]:AWS 服务,允许组织创建、管理和组织云资源产品,并进行权限控制
+- [[IAM RBAC]]:基于角色的访问控制,通过最小权限原则管理 EKS 集群访问
+- [[Cluster Autoscaler]]:Kubernetes 组件,根据资源需求自动扩缩 Worker Node
+- [[EMI]](ENI Multi-IP):EKS 自定义网络方案,通过虚拟弹性网络接口为 Pod 分配额外 IP 地址,解决 VPC CIDR 限制
+- [[ALB Ingress Controller]]:AWS Load Balancer Controller,负责管理 ALB Ingress 资源,实现 Kubernetes 服务的七层负载均衡
+- [[CloudWatch Container Insights]]:AWS 监控服务,收集容器级别的指标和日志并发布到 CloudWatch
+- [[FluentBit]]:开源日志处理器,以 DaemonSet 方式部署于每个节点,负责收集容器日志
+- [[AWS OpenTelemetry]]:AWS 的可观测性数据收集方案,支持指标、日志和追踪的统一采集
+
+## Key Entities
+- [[Kubernetes]](entity):容器编排框架,EKS 的底层技术,Google 开源,CNCF 托管
+- [[Amazon]](entity):AWS/EKS 的提供商
+
+## Connections
+- [[Amazon EKS]] ← 基于 ← [[Kubernetes]]
+- [[Terraform]] ← 用于 ← [[Infrastructure as Code]]
+- [[AWS Service Catalog]] ← 用于 ← [[Infrastructure as Code]]
+- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← 相关 ← [[Amazon EKS]]
+- [[ctp-topic-64-scaling-out-with-amazon-eks]] ← 相关 ← [[Cluster Autoscaler]]
+- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← 相关 ← [[Amazon EKS]]
+- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← 相关 ← [[AWS OpenTelemetry]]
+
+## Contradictions
+- 与 [[ctp-topic-59-achieving-reliability-with-amazon-eks]] 可能存在内容重叠:
+ - 冲突点:两篇均涉及 EKS 特性,但侧重点不同
+ - 当前观点:Topic 70 侧重 IaC 部署方法和网络/监控机制
+ - 对方观点:Topic 59 侧重 EKS 可靠性保证和最佳实践
diff --git a/wiki/sources/ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when.md b/wiki/sources/ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when.md
index 3db15b5d..e7778464 100644
--- a/wiki/sources/ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when.md
+++ b/wiki/sources/ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when.md
@@ -1,49 +1,49 @@
----
-title: "CTP Topic 71 PCG's guide to RightSizing, why, how when"
-type: source
-tags:
- - AWS
- - RightSizing
- - Cost-Optimization
- - CTP
- - FinOps
-sources: []
-last_updated: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]]
-
-## Summary(用中文描述)
-- 核心主题:AWS EC2 实例 RightSizing(合理规格调整)的系统性方法论——为何要做、何时做、如何执行。
-- 问题域:云成本优化的核心痛点——过度配置(over-provisioned)的 EC2 实例导致的资源浪费。
-- 方法/机制:RightSizing 分析 → 识别过度配置实例 → 选择合适规格 → 实施变更。
-- 结论/价值:RightSizing 是 FinOps 成本优化最直接有效的手段之一,无需牺牲性能即可实现显著成本节省。
-
-> ⚠️ 视频尚未完成 Whisper 转录,以上 Summary 基于 frontmatter 元数据和 FinOps 知识体系推断。完整内容待转录后补充。
-
-## Key Claims(用中文描述)
-- (待 Whisper 转录后补充)
-
-## Key Quotes
-> (待 Whisper 转录后补充)
-
-## Key Concepts
-- [[RightSizing]]:AWS 官方推荐的云成本优化策略,通过分析实例实际资源使用情况,将过度配置的实例调整为更合适的规格,从而在不影响性能的前提下降低云成本。是 [[FinOps(云财务管理)]] 的核心技术手段之一。
-- [[EC2 Cost Optimization]](EC2 成本优化):通过 RightSizing、Instance Scheduler、Spot 实例、Graviton 迁移等多种手段降低 EC2 计算成本的总称。
-- [[Cloud Cost Optimization]](云成本优化):涵盖计算(RightSizing/Spot/Graviton)、存储(GP2→GP3/S3 智能分层)、网络(PrivateLink/VPC 流量优化)等全维度的成本控制实践。
-
-## Key Entities
-- [[PCG]](Platform Control Group):平台控制组,负责 OpenText 云环境支持、安全策略制定及协助产品组进行 FinOps 实践的内部团队。
-- [[AWS]]:Amazon Web Services,提供 EC2 Right Sizing 分析工具和成本管理服务。
-
-## Connections
-- [[ctp-topic-13-cloud-finops-policies]] ← related_to ← [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]]
- - CTP Topic 13 定义 PCG 三层 FinOps 服务模型(成本管理→成本优化→治理与自动化),RightSizing 属于第二层"成本优化"范畴
-- [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]] ← extends ← [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]]
- - Public Cloud Learning Sessions 补充了 RightSizing 配合 Savings Plans/RIs 的完整费率优化链路
-- [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]] ← related_to ← [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]]
- - EC2 成本优化最佳实践与 RightSizing 共同构成完整的计算成本优化知识体系
-
-## Contradictions
-- (暂未发现内容冲突,待转录后补充)
+---
+title: "CTP Topic 71 PCG's guide to RightSizing, why, how when"
+type: source
+tags:
+ - AWS
+ - RightSizing
+ - Cost-Optimization
+ - CTP
+ - FinOps
+sources: []
+last_updated: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS EC2 实例 RightSizing(合理规格调整)的系统性方法论——为何要做、何时做、如何执行。
+- 问题域:云成本优化的核心痛点——过度配置(over-provisioned)的 EC2 实例导致的资源浪费。
+- 方法/机制:RightSizing 分析 → 识别过度配置实例 → 选择合适规格 → 实施变更。
+- 结论/价值:RightSizing 是 FinOps 成本优化最直接有效的手段之一,无需牺牲性能即可实现显著成本节省。
+
+> ⚠️ 视频尚未完成 Whisper 转录,以上 Summary 基于 frontmatter 元数据和 FinOps 知识体系推断。完整内容待转录后补充。
+
+## Key Claims(用中文描述)
+- (待 Whisper 转录后补充)
+
+## Key Quotes
+> (待 Whisper 转录后补充)
+
+## Key Concepts
+- [[RightSizing]]:AWS 官方推荐的云成本优化策略,通过分析实例实际资源使用情况,将过度配置的实例调整为更合适的规格,从而在不影响性能的前提下降低云成本。是 [[FinOps(云财务管理)]] 的核心技术手段之一。
+- [[EC2 Cost Optimization]](EC2 成本优化):通过 RightSizing、Instance Scheduler、Spot 实例、Graviton 迁移等多种手段降低 EC2 计算成本的总称。
+- [[Cloud Cost Optimization]](云成本优化):涵盖计算(RightSizing/Spot/Graviton)、存储(GP2→GP3/S3 智能分层)、网络(PrivateLink/VPC 流量优化)等全维度的成本控制实践。
+
+## Key Entities
+- [[PCG]](Platform Control Group):平台控制组,负责 OpenText 云环境支持、安全策略制定及协助产品组进行 FinOps 实践的内部团队。
+- [[AWS]]:Amazon Web Services,提供 EC2 Right Sizing 分析工具和成本管理服务。
+
+## Connections
+- [[ctp-topic-13-cloud-finops-policies]] ← related_to ← [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]]
+ - CTP Topic 13 定义 PCG 三层 FinOps 服务模型(成本管理→成本优化→治理与自动化),RightSizing 属于第二层"成本优化"范畴
+- [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]] ← extends ← [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]]
+ - Public Cloud Learning Sessions 补充了 RightSizing 配合 Savings Plans/RIs 的完整费率优化链路
+- [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]] ← related_to ← [[ctp-topic-71-pcgs-guide-to-rightsizing-why-how-when]]
+ - EC2 成本优化最佳实践与 RightSizing 共同构成完整的计算成本优化知识体系
+
+## Contradictions
+- (暂未发现内容冲突,待转录后补充)
diff --git a/wiki/sources/ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup.md b/wiki/sources/ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup.md
index bcfefc2d..8a7ba4db 100644
--- a/wiki/sources/ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup.md
+++ b/wiki/sources/ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup.md
@@ -1,75 +1,75 @@
----
-title: "CTP Topic 72 Implementing an Enterprise DR Strategy Using AWS Backup"
-type: source
-tags:
- - AWS
- - DR
- - Backup
- - Enterprise
- - CTP
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 解决方案架构师 Sabith 深入讲解企业级灾难恢复策略,以及如何利用 AWS Backup 服务实现 DR 自动化。
-- 问题域:企业级灾难恢复(DR)规划、高可用(HA)与 DR 的区别、RTO/RPO 指标定义与架构设计。
-- 方法/机制:
- - HA(高可用)关注系统运行时间和可用性,DR(灾难恢复)关注数据丢失预防和恢复能力
- - RPO(恢复点目标)定义可接受的数据丢失量,RTO(恢复时间目标)定义可接受的停机时间
- - AWS Backup 集中化备份服务,支持跨账户、跨区域复制,Vault Lock 防勒索软件
- - 四级 DR 架构模式:Backup and Restore → Pilot Light → Warm Standby → Active-Active
- - 增量备份(Incremental Backup)仅备份自上次备份以来的变更,全量备份(Full Backup)每次捕获所有数据
- - 不可变恢复点(Immutable Recovery Points)+ Vault Lock 合规模式阻止删除
- - Forensic Account(取证账户)定期测试恢复点并扫描恶意软件
-- 结论/价值:为 Micro Focus 云转型计划提供了完整的 DR 策略框架,从基本概念到 AWS Backup 架构设计,是 [[ctp-topic-44-aws-backup-in-micro-focus]] 的理论基础补充。
-
-## Key Claims(用中文描述)
-- 高可用(HA)衡量系统执行其功能的持续性,通过平均故障间隔时间(MTBF)衡量;灾难恢复(DR)专注于防止数据丢失和系统恢复,HA 专注于系统运行时间和可用性。
-- RPO 定义组织可接受的最大数据丢失量(时间窗口),RTO 定义组织可接受的最大停机时间,两者共同决定 DR 架构选型和成本投入。
-- AWS Backup 是完全托管的、基于策略的备份服务,通过 Backup Plans(备份计划)定义何时备份什么、通过什么方式备份,并将恢复点存储在 Backup Vaults(备份保管库)中。
-- AWS Backup 支持与 AWS Organizations 集成,实现跨账户备份复制(Cross-Account Backup),建议使用独立的 Vault/Bunker Account 存储备份副本,与工作负载账户隔离。
-- 完整备份(Full Backup)每次捕获所有数据,增量备份(Incremental Backup)仅捕获自上次备份以来的变更,节省存储成本。
-- Vault Lock 合规模式(Compliance Mode)防止包括根用户在内的任何人删除恢复点,直至其生命周期结束,有效防御勒索软件攻击。
-- Forensic Account(取证账户)用于定期测试恢复点、扫描恶意软件,确保备份数据的可用性和安全性。
-- AWS Backup Audit Manager(BAM)提供合规报告能力,支持审计备份活动的合规性。
-
-## Key Quotes
-> "We should always be prepared for a situation that everything falls all the time." — Sabith, AWS 解决方案架构师
-> "High availability ensures a system performs its functions, measured by mean time between failures. Disaster recovery focuses on data loss prevention and recovery, while high availability focuses on system uptime and service availability." — 视频摘要
-> "AWS Backup uses backup plans to define what, when, and how to back up, storing recovery points in backup vaults." — 视频摘要
-> "Vault Lock in compliance mode prevents even root users from deleting recovery points until their lifecycle ends, deterring ransomware." — 视频摘要
-
-## Key Concepts
-- [[AWS Backup]]:AWS 托管的集中化数据保护服务,通过备份计划(Backup Plans)自动化跨账户、跨区域的数据备份,支持不可变性和合规报告。
-- [[灾难恢复(Disaster Recovery)]]:防止数据丢失和系统停机的策略体系,与高可用(HA)互补,HA 保运行,DR 保数据。
-- [[高可用(High Availability)]]:通过冗余和快速故障转移保持系统持续可用的架构模式,MTBF 是其核心衡量指标。
-- [[RTO(Recovery Time Objective)]]:恢复时间目标,定义从故障恢复到服务可用的最大可接受时间窗口。
-- [[RPO(Recovery Point Objective)]]:恢复点目标,定义可接受的最大数据丢失时间窗口。
-- [[增量备份(Incremental Backup)]]:仅备份自上次备份以来的变更,与全量备份相比节省存储成本和备份时间。
-- [[全量备份(Full Backup)]]:每次备份捕获所有数据,恢复速度快但存储成本高。
-- [[Vault Lock]]:AWS Backup 保管库的合规锁定机制,合规模式下即使根用户也无法提前删除恢复点。
-- [[跨账户备份复制(Cross-Account Backup)]]:通过 AWS Organizations 在不同账户间复制备份,增强隔离性和安全性。
-- [[Bunker Account]]:专用存储备份副本的账户,与工作负载账户隔离,防止单点妥协。
-- [[Forensic Account]]:取证账户,用于定期测试恢复点可用性和恶意软件扫描。
-- [[共享责任模型(Shared Responsibility Model)]]:AWS 与客户在云弹性环境中的责任划分框架。
-- [[AWS Backup Audit Manager(BAM)]]:AWS Backup 的合规审计功能,支持备份活动的合规性报告。
-- [[灾难恢复架构模式]]:Backup and Restore / Pilot Light / Warm Standby / Active-Active 四级递进模式,从低成本低恢复到高成本高弹性。
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,AWS Backup 服务的提供方。
-- [[Sabith]]:AWS 解决方案架构师,本视频的主讲人。
-- [[Cloud Transformation Programme (CTP)]]:云转型计划,该视频属于 01_AWS-Landing-Zone 系列第 72 个主题。
-- [[Micro Focus]]:企业客户,CTP 的参与方。
-
-## Connections
-- [[ctp-topic-44-aws-backup-in-micro-focus]] ← extends ← [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]]
-- [[ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program]] ← extends ← [[ctp-topic-44-aws-backup-in-micro-focus]]
-- [[AWS Backup]] ← related ← [[RTO]]
-- [[AWS Backup]] ← related ← [[RPO]]
-- [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]] ← depends_on ← [[AWS Backup]]
-
-## Contradictions
-- 无明显内容冲突。本视频与 [[ctp-topic-44-aws-backup-in-micro-focus]] 构成互补关系——Topic 72 提供 DR 策略和 AWS Backup 的理论框架,Topic 44 聚焦 Micro Focus 内部评估和迁移路径,两者共同构成完整的 AWS Backup 知识体系。
+---
+title: "CTP Topic 72 Implementing an Enterprise DR Strategy Using AWS Backup"
+type: source
+tags:
+ - AWS
+ - DR
+ - Backup
+ - Enterprise
+ - CTP
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 解决方案架构师 Sabith 深入讲解企业级灾难恢复策略,以及如何利用 AWS Backup 服务实现 DR 自动化。
+- 问题域:企业级灾难恢复(DR)规划、高可用(HA)与 DR 的区别、RTO/RPO 指标定义与架构设计。
+- 方法/机制:
+ - HA(高可用)关注系统运行时间和可用性,DR(灾难恢复)关注数据丢失预防和恢复能力
+ - RPO(恢复点目标)定义可接受的数据丢失量,RTO(恢复时间目标)定义可接受的停机时间
+ - AWS Backup 集中化备份服务,支持跨账户、跨区域复制,Vault Lock 防勒索软件
+ - 四级 DR 架构模式:Backup and Restore → Pilot Light → Warm Standby → Active-Active
+ - 增量备份(Incremental Backup)仅备份自上次备份以来的变更,全量备份(Full Backup)每次捕获所有数据
+ - 不可变恢复点(Immutable Recovery Points)+ Vault Lock 合规模式阻止删除
+ - Forensic Account(取证账户)定期测试恢复点并扫描恶意软件
+- 结论/价值:为 Micro Focus 云转型计划提供了完整的 DR 策略框架,从基本概念到 AWS Backup 架构设计,是 [[ctp-topic-44-aws-backup-in-micro-focus]] 的理论基础补充。
+
+## Key Claims(用中文描述)
+- 高可用(HA)衡量系统执行其功能的持续性,通过平均故障间隔时间(MTBF)衡量;灾难恢复(DR)专注于防止数据丢失和系统恢复,HA 专注于系统运行时间和可用性。
+- RPO 定义组织可接受的最大数据丢失量(时间窗口),RTO 定义组织可接受的最大停机时间,两者共同决定 DR 架构选型和成本投入。
+- AWS Backup 是完全托管的、基于策略的备份服务,通过 Backup Plans(备份计划)定义何时备份什么、通过什么方式备份,并将恢复点存储在 Backup Vaults(备份保管库)中。
+- AWS Backup 支持与 AWS Organizations 集成,实现跨账户备份复制(Cross-Account Backup),建议使用独立的 Vault/Bunker Account 存储备份副本,与工作负载账户隔离。
+- 完整备份(Full Backup)每次捕获所有数据,增量备份(Incremental Backup)仅捕获自上次备份以来的变更,节省存储成本。
+- Vault Lock 合规模式(Compliance Mode)防止包括根用户在内的任何人删除恢复点,直至其生命周期结束,有效防御勒索软件攻击。
+- Forensic Account(取证账户)用于定期测试恢复点、扫描恶意软件,确保备份数据的可用性和安全性。
+- AWS Backup Audit Manager(BAM)提供合规报告能力,支持审计备份活动的合规性。
+
+## Key Quotes
+> "We should always be prepared for a situation that everything falls all the time." — Sabith, AWS 解决方案架构师
+> "High availability ensures a system performs its functions, measured by mean time between failures. Disaster recovery focuses on data loss prevention and recovery, while high availability focuses on system uptime and service availability." — 视频摘要
+> "AWS Backup uses backup plans to define what, when, and how to back up, storing recovery points in backup vaults." — 视频摘要
+> "Vault Lock in compliance mode prevents even root users from deleting recovery points until their lifecycle ends, deterring ransomware." — 视频摘要
+
+## Key Concepts
+- [[AWS Backup]]:AWS 托管的集中化数据保护服务,通过备份计划(Backup Plans)自动化跨账户、跨区域的数据备份,支持不可变性和合规报告。
+- [[灾难恢复(Disaster Recovery)]]:防止数据丢失和系统停机的策略体系,与高可用(HA)互补,HA 保运行,DR 保数据。
+- [[高可用(High Availability)]]:通过冗余和快速故障转移保持系统持续可用的架构模式,MTBF 是其核心衡量指标。
+- [[RTO(Recovery Time Objective)]]:恢复时间目标,定义从故障恢复到服务可用的最大可接受时间窗口。
+- [[RPO(Recovery Point Objective)]]:恢复点目标,定义可接受的最大数据丢失时间窗口。
+- [[增量备份(Incremental Backup)]]:仅备份自上次备份以来的变更,与全量备份相比节省存储成本和备份时间。
+- [[全量备份(Full Backup)]]:每次备份捕获所有数据,恢复速度快但存储成本高。
+- [[Vault Lock]]:AWS Backup 保管库的合规锁定机制,合规模式下即使根用户也无法提前删除恢复点。
+- [[跨账户备份复制(Cross-Account Backup)]]:通过 AWS Organizations 在不同账户间复制备份,增强隔离性和安全性。
+- [[Bunker Account]]:专用存储备份副本的账户,与工作负载账户隔离,防止单点妥协。
+- [[Forensic Account]]:取证账户,用于定期测试恢复点可用性和恶意软件扫描。
+- [[共享责任模型(Shared Responsibility Model)]]:AWS 与客户在云弹性环境中的责任划分框架。
+- [[AWS Backup Audit Manager(BAM)]]:AWS Backup 的合规审计功能,支持备份活动的合规性报告。
+- [[灾难恢复架构模式]]:Backup and Restore / Pilot Light / Warm Standby / Active-Active 四级递进模式,从低成本低恢复到高成本高弹性。
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,AWS Backup 服务的提供方。
+- [[Sabith]]:AWS 解决方案架构师,本视频的主讲人。
+- [[Cloud Transformation Programme (CTP)]]:云转型计划,该视频属于 01_AWS-Landing-Zone 系列第 72 个主题。
+- [[Micro Focus]]:企业客户,CTP 的参与方。
+
+## Connections
+- [[ctp-topic-44-aws-backup-in-micro-focus]] ← extends ← [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]]
+- [[ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program]] ← extends ← [[ctp-topic-44-aws-backup-in-micro-focus]]
+- [[AWS Backup]] ← related ← [[RTO]]
+- [[AWS Backup]] ← related ← [[RPO]]
+- [[ctp-topic-72-implementing-an-enterprise-dr-strategy-using-aws-backup]] ← depends_on ← [[AWS Backup]]
+
+## Contradictions
+- 无明显内容冲突。本视频与 [[ctp-topic-44-aws-backup-in-micro-focus]] 构成互补关系——Topic 72 提供 DR 策略和 AWS Backup 的理论框架,Topic 44 聚焦 Micro Focus 内部评估和迁移路径,两者共同构成完整的 AWS Backup 知识体系。
diff --git a/wiki/sources/ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program.md b/wiki/sources/ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program.md
index 53100666..b83dc504 100644
--- a/wiki/sources/ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program.md
+++ b/wiki/sources/ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program.md
@@ -1,56 +1,56 @@
----
-title: "CTP Topic 73 AWS Backup Implementation of the Cloud Transformation Programme"
-type: source
-tags:
- - AWS
- - Backup
- - Cloud Transformation Programme
- - SRE
- - DR
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS Backup 在云转型计划中的企业级实施落地
-- 问题域:如何在多账户 AWS 环境中标准化备份流程,同时给予产品团队自主管理灵活性
-- 方法/机制:SRE 团队开发 SRE Backup Model,为每个产品组提供预置的 AWS Backup Plans、Selections、Vaults、KMS 密钥策略等模板,支持在 DRA 账户内独立执行备份和恢复;设计从源账户初始备份并复制到远程 DR 账户和区域;AWS Backup Audit Manager 提供合规审计报告
-- 结论/价值:AWS Backup 作为战略性备份工具,通过 SRE Model 实现"集中管控 + 分散执行"的平衡,标准化备份流程同时保留产品团队灵活性
-
-## Key Claims(用中文描述)
-- SRE 核心团队通过开发 SRE Backup Model,简化了 AWS Backup 的采纳门槛,使产品组能够在其 DRA 账户内自主创建和管理备份
-- AWS Backup 选择原因:原生托管服务、支持 TAC-based 备份计划、跨账户跨区域复制、备份不可变性、开箱即用审计报告、S3/RDS 点时间恢复
-- 备份设计:初始备份在源账户执行,复制到远程 DR 账户和区域(如 DR 不可用则使用 Databunker 作为集中备份账户),确保即时恢复能力
-- AWS Backup Audit Manager 提供合规控制:备份计划保护、最小频率和保留期、防手动删除恢复点、加密验证、计划性跨区域和跨账户备份
-
-## Key Quotes
-> "AWS backup was adopted as the strategic tool for backup in AWS for the cloud transformation program to standardize backup processes." — AWS Backup 被选为云转型计划的战略性备份工具
-> "An SRE model was developed to allow product groups to create and control their own backups, aligned with the assumed backup policy." — SRE Model 赋予产品组自主创建和管理备份的能力
-> "This keeps backups within the DR account for immediate restore, avoiding time-consuming data copies." — 备份保留在 DR 账户内以实现即时恢复
-
-## Key Concepts
-- [[AWS Backup]]:AWS 原生托管备份服务,支持多资源类型的集中备份和恢复策略管理
-- [[SRE Model]]:Site Reliability Engineering 团队开发的备份管理模式,为产品组提供标准化但可定制的备份基础设施
-- [[AWS Backup Audit Manager]]:AWS Backup 内置合规审计框架,提供备份状态报告和合规控制评估
-- [[跨账户备份]]:通过 AWS Organizations 将备份从源账户复制到独立的 DR/Bunker 账户,实现备份隔离
-- [[Vault Lock]]:备份保险库合规锁定模式,防止任何人(包括根用户)提前删除恢复点
-
-## Key Entities
-- [[AWS]]:云服务提供商,AWS Backup 为其原生备份服务
-- [[Cloud Transformation Programme]](CTP):企业级云转型计划,本视频为其 Topic 73,聚焦 AWS Backup 实施
-- SRE(Site Reliability Engineering)Core/Product/Architecture Teams:SRE 核心、产品和架构团队协作设计备份策略
-- DRA Accounts:Disaster Recovery Application Accounts,各产品组在其 DRA 账户内管理自有备份
-
-## Connections
-- [[ctp-topic-72-enterprise-dr-strategy-aws-backup]] ← extends ← [[ctp-topic-73-aws-backup-implementation]](Topic 72 提供理论基础,Topic 73 聚焦实施落地)
-- [[ctp-topic-44-aws-backup-in-micro-focus]] ← relates_to ← [[ctp-topic-73-aws-backup-implementation]](两者均讨论 AWS Backup,Topic 44 聚焦 Micro Focus 内部评估)
-- [[AWS Backup]] ← depends_on ← [[AWS Backup Audit Manager]](Audit Manager 是 AWS Backup 的合规增强组件)
-- [[AWS Backup]] ← supports ← [[跨账户备份]](跨账户跨区域复制是 AWS Backup 的核心能力)
-
-## Contradictions
-- 与 [[ctp-topic-44-aws-backup-in-micro-focus]] 存在视角差异:
- - 冲突点:Topic 44 讨论 Micro Focus 现有备份评估(快照管理 vs AWS Backup 选型)
- - 当前观点:Topic 73 作为 CTP 实施指南,确认 AWS Backup 为标准工具
- - 对方观点:Topic 44 提及 AWS Backup 的局限性(无法选择性排除 EC2 附加卷、崩溃一致而非热备份)
+---
+title: "CTP Topic 73 AWS Backup Implementation of the Cloud Transformation Programme"
+type: source
+tags:
+ - AWS
+ - Backup
+ - Cloud Transformation Programme
+ - SRE
+ - DR
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/ctp-topic-73-aws-backup-implementation-of-the-cloud-transformation-program.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS Backup 在云转型计划中的企业级实施落地
+- 问题域:如何在多账户 AWS 环境中标准化备份流程,同时给予产品团队自主管理灵活性
+- 方法/机制:SRE 团队开发 SRE Backup Model,为每个产品组提供预置的 AWS Backup Plans、Selections、Vaults、KMS 密钥策略等模板,支持在 DRA 账户内独立执行备份和恢复;设计从源账户初始备份并复制到远程 DR 账户和区域;AWS Backup Audit Manager 提供合规审计报告
+- 结论/价值:AWS Backup 作为战略性备份工具,通过 SRE Model 实现"集中管控 + 分散执行"的平衡,标准化备份流程同时保留产品团队灵活性
+
+## Key Claims(用中文描述)
+- SRE 核心团队通过开发 SRE Backup Model,简化了 AWS Backup 的采纳门槛,使产品组能够在其 DRA 账户内自主创建和管理备份
+- AWS Backup 选择原因:原生托管服务、支持 TAC-based 备份计划、跨账户跨区域复制、备份不可变性、开箱即用审计报告、S3/RDS 点时间恢复
+- 备份设计:初始备份在源账户执行,复制到远程 DR 账户和区域(如 DR 不可用则使用 Databunker 作为集中备份账户),确保即时恢复能力
+- AWS Backup Audit Manager 提供合规控制:备份计划保护、最小频率和保留期、防手动删除恢复点、加密验证、计划性跨区域和跨账户备份
+
+## Key Quotes
+> "AWS backup was adopted as the strategic tool for backup in AWS for the cloud transformation program to standardize backup processes." — AWS Backup 被选为云转型计划的战略性备份工具
+> "An SRE model was developed to allow product groups to create and control their own backups, aligned with the assumed backup policy." — SRE Model 赋予产品组自主创建和管理备份的能力
+> "This keeps backups within the DR account for immediate restore, avoiding time-consuming data copies." — 备份保留在 DR 账户内以实现即时恢复
+
+## Key Concepts
+- [[AWS Backup]]:AWS 原生托管备份服务,支持多资源类型的集中备份和恢复策略管理
+- [[SRE Model]]:Site Reliability Engineering 团队开发的备份管理模式,为产品组提供标准化但可定制的备份基础设施
+- [[AWS Backup Audit Manager]]:AWS Backup 内置合规审计框架,提供备份状态报告和合规控制评估
+- [[跨账户备份]]:通过 AWS Organizations 将备份从源账户复制到独立的 DR/Bunker 账户,实现备份隔离
+- [[Vault Lock]]:备份保险库合规锁定模式,防止任何人(包括根用户)提前删除恢复点
+
+## Key Entities
+- [[AWS]]:云服务提供商,AWS Backup 为其原生备份服务
+- [[Cloud Transformation Programme]](CTP):企业级云转型计划,本视频为其 Topic 73,聚焦 AWS Backup 实施
+- SRE(Site Reliability Engineering)Core/Product/Architecture Teams:SRE 核心、产品和架构团队协作设计备份策略
+- DRA Accounts:Disaster Recovery Application Accounts,各产品组在其 DRA 账户内管理自有备份
+
+## Connections
+- [[ctp-topic-72-enterprise-dr-strategy-aws-backup]] ← extends ← [[ctp-topic-73-aws-backup-implementation]](Topic 72 提供理论基础,Topic 73 聚焦实施落地)
+- [[ctp-topic-44-aws-backup-in-micro-focus]] ← relates_to ← [[ctp-topic-73-aws-backup-implementation]](两者均讨论 AWS Backup,Topic 44 聚焦 Micro Focus 内部评估)
+- [[AWS Backup]] ← depends_on ← [[AWS Backup Audit Manager]](Audit Manager 是 AWS Backup 的合规增强组件)
+- [[AWS Backup]] ← supports ← [[跨账户备份]](跨账户跨区域复制是 AWS Backup 的核心能力)
+
+## Contradictions
+- 与 [[ctp-topic-44-aws-backup-in-micro-focus]] 存在视角差异:
+ - 冲突点:Topic 44 讨论 Micro Focus 现有备份评估(快照管理 vs AWS Backup 选型)
+ - 当前观点:Topic 73 作为 CTP 实施指南,确认 AWS Backup 为标准工具
+ - 对方观点:Topic 44 提及 AWS Backup 的局限性(无法选择性排除 EC2 附加卷、崩溃一致而非热备份)
diff --git a/wiki/sources/ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid.md b/wiki/sources/ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid.md
index 5d48749f..0c9ad4bf 100644
--- a/wiki/sources/ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid.md
+++ b/wiki/sources/ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid.md
@@ -1,59 +1,59 @@
----
-title: "CTP Topic 8 - Implementation of Cloud Monitoring using Micro Focus Operations Bridge Manager"
-type: source
-tags: []
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid.md]]
-
-## Summary(用中文描述)
-- **核心主题**:使用 Micro Focus Operations Bridge Manager (OBM) 实现 AWS 公有云监控的完整解决方案,填补传统 Sitescope 监控工具在云环境中的能力缺口。
-- **问题域**:云环境动态性强、资源生命周期短,传统监控工具依赖静态服务器部署,无法有效覆盖 AWS 多账户多区域场景;OBM 通过 Management Pack 策略化方案实现云原生的动态监控能力。
-- **方法/机制**:OBM AWS Account 部署 OBM 应用 + Postgres RDS + Operation Agent;Agent 通过 AWS Management Pack 利用 IAM Role 跨账户收集 CloudWatch 指标/日志;Global OBM 作为 Manager of Managers 汇聚多区域 Regional OBM 数据;事件通过 SMACKS 与 OSE 团队工单系统集成。
-- **结论/价值**:OBM Management Pack 支持任意公有云(AWS/Azure/GCP)的 CloudWatch 兼容服务,无需在被监控账户中安装任何代理,通过 IAM Role 信任关系实现安全无密钥的跨账户数据采集;新增实例自动发现和策略自动下发能力解决了云环境动态性问题。
-
-## Key Claims(用中文描述)
-- **OBM 相比 Sitescope 的优势**:提供更动态的云监控能力、更强的安全性和更广泛的 AWS 核心服务覆盖,适合公有云环境。
-- **OBM 架构**:Regional OBM 收集数据 → Global OBM 汇聚 → SMACKS 触发工单;OBM AWS Account 包含 OBM 应用、RDS 数据库和 Operation Agent 三层组件。
-- **跨账户监控机制**:Operation Agent 通过 AWS Management Pack 定义的 Policy,以 IAM Role 身份调用 CloudWatch API,无需在被监控账户安装服务器或共享 Access Key。
-- **动态监控能力**:当新实例添加到被监控账户时,Policy 自动部署,监控立即生效,无需人工干预。
-- **客户上云流程**:客户账户创建具有 CloudWatch Read-Only 访问权限的 IAM Role → 将 OBM Account 添加到信任关系 → 将 Role ARN 添加到 OBM Policy → 指定监控的命名空间/服务/指标/阈值/频率。
-- **多云支持**:OBM Management Pack 方案可监控任何将数据暴露给 CloudWatch 的公有云供应商和 AWS 服务,兼顾指标和日志。
-
-## Key Quotes
-> "The operation agent collects data using OBM management packs, specifically the AWS management pack, which instructs the agent to gather data from different accounts." — OBM AWS 监控的核心数据采集机制
-
-> "The agent uses role-based access to collect data from CloudWatch API, eliminating the need to install servers in customer accounts and share sensitive access keys." — IAM Role 机制的安全价值:无需密钥共享
-
-> "Whenever new instances are added, policies are automatically deployed, and monitoring begins, offering dynamic monitoring capabilities." — 动态监控的关键特性:自动发现与自动部署
-
-## Key Concepts
-- [[CloudWatch]]: AWS 监控数据源,OBM 通过 CloudWatch API 采集所有监控指标和日志
-- [[Cloud-Monitoring]]: 公有云监控的核心挑战——动态环境、多账户、免代理采集
-- [[OBM]]: Micro Focus Operations Bridge Manager,企业级监控管理平台,支持多云环境
-- [[Management-Pack]]: OBM 的策略包机制,定义监控间隔、指标、阈值和数据采集规则
-- [[IAM-Role]]: AWS IAM 角色,OBM Agent 通过角色信任关系实现跨账户安全访问 CloudWatch,无需共享密钥
-- [[Multi-Account-Monitoring]]: AWS Organizations 多账户环境下的集中监控架构
-- [[Landing-Zone-Monitoring]]: Landing Zone 架构中的监控组件,OBM Account 作为独立账户与 Shared/Logs/Security 账户交互
-- [[Dynamic-Monitoring]]: 云环境特有的动态监控能力——新增资源自动发现、策略自动下发
-
-## Key Entities
-- **[[Micro-Focus]]**: OBM 产品的供应商,提供 Operations Bridge Manager 企业级监控平台
-- **[[Sitescope]]**: Micro Focus 传统监控工具,被 OBM 替代,用于描述 OBM 相比旧方案的改进
-- **[[SMACKS]]**: Micro Focus 工单系统,OBM 事件通过 SMACKS 与 OSE 团队集成,实现事件升级和工单创建
-- **[[AWS-CloudWatch]]**: AWS 监控指标和日志服务,OBM Agent 的数据采集来源
-- **[[AWS-Operation-Agent]]**: 部署在 OBM AWS Account 的操作代理,负责跨账户收集 CloudWatch 数据
-- **[[Global-OBM]]**: 全球级 OBM,作为 Manager of Managers,汇聚各 Regional OBM 的数据
-- **[[Regional-OBM]]**: 区域级 OBM,收集本区域内各账户的监控数据并转发给 Global OBM
-- **[[Digital-Factory]]**: OBM AWS Account 所属的 Landing Zone 组成部分,与 Shared/Logs/Security 账户交互
-
-## Connections
-- [[CTP-Topic-29-Cloud-Monitoring-SAAS-LZ-Accounts]] ← related_to ← [[CTP-Topic-8-OBM-Cloud-Monitoring]]: Topic 29 讨论 SaaS Landing Zone 的云监控账户设计,Topic 8 详解 OBM 技术实现方案
-- [[CTP-Topic-60-Monitor-AWS-Grafana]] ← related_to ← [[CTP-Topic-8-OBM-Cloud-Monitoring]]: Grafana 作为可视化层,OBM 作为数据采集和策略管理层,两者互补
-- [[CTP-Topic-25-Labs-Landing-Zone]] ← extends ← [[AWS-Landing-Zone]]: Labs LZ 概述中提到的 ARC Site 监控组件与 OBM 的功能定位重叠
-- [[CTP-Topic-7-SAAS-Landing-Zone-Design]] ← extends ← [[AWS-Landing-Zone]]: SaaS LZ 设计中提到 Shared Services Account 包含 OBM/Sitescope 监控服务
-
-## Contradictions
-- 与 [[CTP-Topic-67-OpenTelemetry]]: Topic 67 倡导云原生可观测性标准(OTel),强调统一的数据模型和 Vendor-Neutral 采集;OBM 作为传统商业监控平台,数据模型封闭,与 OTelp 倡导的开放标准存在理念差异。当前实现选择 OBM 而非 OTelp,可能是出于企业既有投资保护(Micro Focus 工具链)和与 SMACKS 工单系统深度集成的考量。
+---
+title: "CTP Topic 8 - Implementation of Cloud Monitoring using Micro Focus Operations Bridge Manager"
+type: source
+tags: []
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/ctp-topic-8-implementation-of-cloud-monitoring-using-micro-focus-operations-brid.md]]
+
+## Summary(用中文描述)
+- **核心主题**:使用 Micro Focus Operations Bridge Manager (OBM) 实现 AWS 公有云监控的完整解决方案,填补传统 Sitescope 监控工具在云环境中的能力缺口。
+- **问题域**:云环境动态性强、资源生命周期短,传统监控工具依赖静态服务器部署,无法有效覆盖 AWS 多账户多区域场景;OBM 通过 Management Pack 策略化方案实现云原生的动态监控能力。
+- **方法/机制**:OBM AWS Account 部署 OBM 应用 + Postgres RDS + Operation Agent;Agent 通过 AWS Management Pack 利用 IAM Role 跨账户收集 CloudWatch 指标/日志;Global OBM 作为 Manager of Managers 汇聚多区域 Regional OBM 数据;事件通过 SMACKS 与 OSE 团队工单系统集成。
+- **结论/价值**:OBM Management Pack 支持任意公有云(AWS/Azure/GCP)的 CloudWatch 兼容服务,无需在被监控账户中安装任何代理,通过 IAM Role 信任关系实现安全无密钥的跨账户数据采集;新增实例自动发现和策略自动下发能力解决了云环境动态性问题。
+
+## Key Claims(用中文描述)
+- **OBM 相比 Sitescope 的优势**:提供更动态的云监控能力、更强的安全性和更广泛的 AWS 核心服务覆盖,适合公有云环境。
+- **OBM 架构**:Regional OBM 收集数据 → Global OBM 汇聚 → SMACKS 触发工单;OBM AWS Account 包含 OBM 应用、RDS 数据库和 Operation Agent 三层组件。
+- **跨账户监控机制**:Operation Agent 通过 AWS Management Pack 定义的 Policy,以 IAM Role 身份调用 CloudWatch API,无需在被监控账户安装服务器或共享 Access Key。
+- **动态监控能力**:当新实例添加到被监控账户时,Policy 自动部署,监控立即生效,无需人工干预。
+- **客户上云流程**:客户账户创建具有 CloudWatch Read-Only 访问权限的 IAM Role → 将 OBM Account 添加到信任关系 → 将 Role ARN 添加到 OBM Policy → 指定监控的命名空间/服务/指标/阈值/频率。
+- **多云支持**:OBM Management Pack 方案可监控任何将数据暴露给 CloudWatch 的公有云供应商和 AWS 服务,兼顾指标和日志。
+
+## Key Quotes
+> "The operation agent collects data using OBM management packs, specifically the AWS management pack, which instructs the agent to gather data from different accounts." — OBM AWS 监控的核心数据采集机制
+
+> "The agent uses role-based access to collect data from CloudWatch API, eliminating the need to install servers in customer accounts and share sensitive access keys." — IAM Role 机制的安全价值:无需密钥共享
+
+> "Whenever new instances are added, policies are automatically deployed, and monitoring begins, offering dynamic monitoring capabilities." — 动态监控的关键特性:自动发现与自动部署
+
+## Key Concepts
+- [[CloudWatch]]: AWS 监控数据源,OBM 通过 CloudWatch API 采集所有监控指标和日志
+- [[Cloud-Monitoring]]: 公有云监控的核心挑战——动态环境、多账户、免代理采集
+- [[OBM]]: Micro Focus Operations Bridge Manager,企业级监控管理平台,支持多云环境
+- [[Management-Pack]]: OBM 的策略包机制,定义监控间隔、指标、阈值和数据采集规则
+- [[IAM-Role]]: AWS IAM 角色,OBM Agent 通过角色信任关系实现跨账户安全访问 CloudWatch,无需共享密钥
+- [[Multi-Account-Monitoring]]: AWS Organizations 多账户环境下的集中监控架构
+- [[Landing-Zone-Monitoring]]: Landing Zone 架构中的监控组件,OBM Account 作为独立账户与 Shared/Logs/Security 账户交互
+- [[Dynamic-Monitoring]]: 云环境特有的动态监控能力——新增资源自动发现、策略自动下发
+
+## Key Entities
+- **[[Micro-Focus]]**: OBM 产品的供应商,提供 Operations Bridge Manager 企业级监控平台
+- **[[Sitescope]]**: Micro Focus 传统监控工具,被 OBM 替代,用于描述 OBM 相比旧方案的改进
+- **[[SMACKS]]**: Micro Focus 工单系统,OBM 事件通过 SMACKS 与 OSE 团队集成,实现事件升级和工单创建
+- **[[AWS-CloudWatch]]**: AWS 监控指标和日志服务,OBM Agent 的数据采集来源
+- **[[AWS-Operation-Agent]]**: 部署在 OBM AWS Account 的操作代理,负责跨账户收集 CloudWatch 数据
+- **[[Global-OBM]]**: 全球级 OBM,作为 Manager of Managers,汇聚各 Regional OBM 的数据
+- **[[Regional-OBM]]**: 区域级 OBM,收集本区域内各账户的监控数据并转发给 Global OBM
+- **[[Digital-Factory]]**: OBM AWS Account 所属的 Landing Zone 组成部分,与 Shared/Logs/Security 账户交互
+
+## Connections
+- [[CTP-Topic-29-Cloud-Monitoring-SAAS-LZ-Accounts]] ← related_to ← [[CTP-Topic-8-OBM-Cloud-Monitoring]]: Topic 29 讨论 SaaS Landing Zone 的云监控账户设计,Topic 8 详解 OBM 技术实现方案
+- [[CTP-Topic-60-Monitor-AWS-Grafana]] ← related_to ← [[CTP-Topic-8-OBM-Cloud-Monitoring]]: Grafana 作为可视化层,OBM 作为数据采集和策略管理层,两者互补
+- [[CTP-Topic-25-Labs-Landing-Zone]] ← extends ← [[AWS-Landing-Zone]]: Labs LZ 概述中提到的 ARC Site 监控组件与 OBM 的功能定位重叠
+- [[CTP-Topic-7-SAAS-Landing-Zone-Design]] ← extends ← [[AWS-Landing-Zone]]: SaaS LZ 设计中提到 Shared Services Account 包含 OBM/Sitescope 监控服务
+
+## Contradictions
+- 与 [[CTP-Topic-67-OpenTelemetry]]: Topic 67 倡导云原生可观测性标准(OTel),强调统一的数据模型和 Vendor-Neutral 采集;OBM 作为传统商业监控平台,数据模型封闭,与 OTelp 倡导的开放标准存在理念差异。当前实现选择 OBM 而非 OTelp,可能是出于企业既有投资保护(Micro Focus 工具链)和与 SMACKS 工单系统深度集成的考量。
diff --git a/wiki/sources/ctp-topic-9-ci-cd-with-gruntwork.md b/wiki/sources/ctp-topic-9-ci-cd-with-gruntwork.md
index b9c2c9af..e6da2279 100644
--- a/wiki/sources/ctp-topic-9-ci-cd-with-gruntwork.md
+++ b/wiki/sources/ctp-topic-9-ci-cd-with-gruntwork.md
@@ -1,50 +1,50 @@
----
-title: "CTP Topic 9 CI CD with Gruntwork"
-type: source
-tags:
- - CI/CD
- - Gruntwork
- - IaC
- - CTP
- - DevOps
- - AWS
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-9-ci-cd-with-gruntwork]]
-
-## Summary(用中文描述)
-- 核心主题:CI/CD 与 Gruntwork 在 AWS Landing Zone 中的实践
-- 问题域:云转型计划(Cloud Transformation Programme, CTP)中的基础设施自动化交付
-- 方法/机制:基于 Gruntwork 参考架构,通过 CI/CD 流水线实现 Terraform/Terragrunt 代码的自动化部署
-- 结论/价值:待视频转录后补充
-
-> ⚠️ **注意**:原始视频尚未完成 Whisper 转录,以上信息基于文件元数据生成。详见 Source File 链接获取完整内容。
-
-## Key Claims(用中文描述)
-- (待视频转录后补充)
-
-## Key Quotes
-> (待视频转录后补充)
-
-## Key Concepts
-- [[CI/CD Pipeline]]:持续集成/持续交付流水线,自动化代码构建、测试和部署流程
-- [[Infrastructure as Code (IaC)]]:通过代码管理云基础设施,实现可重复、可审计的部署
-- [[Gruntwork]]:提供生产级 Terraform 模块和参考架构的 IaC 库
-- [[Terraform]]:HashiCorp 开源的 IaC 工具,用于声明式定义云资源
-- [[Terragrunt]]:Terraform 的包装器,提供状态管理和模块复用能力
-
-## Key Entities
-- [[Gruntwork]]:IaC 基础设施库提供商,提供可复用的 Terraform 模块
-- [[AWS Landing Zone]]:AWS 多账户架构框架,为云工作负载提供安全、合规的基础设施
-- [[Cloud Transformation Programme (CTP)]]:云转型计划,Micro Focus 将工作负载从本地数据中心迁移至 AWS 的企业级项目
-
-## Connections
-- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← foundational ← [[ctp-topic-9-ci-cd-with-gruntwork]]
-- [[ctp-topic-2-git]] ← related ← [[ctp-topic-9-ci-cd-with-gruntwork]]
-- [[ctp-topic-33-an-introduction-to-gitops]] ← extends ← [[ctp-topic-9-ci-cd-with-gruntwork]]
-- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← alternative_tool ← [[ctp-topic-9-ci-cd-with-gruntwork]]
-
-## Contradictions
-- (暂无,待视频转录后补充)
+---
+title: "CTP Topic 9 CI CD with Gruntwork"
+type: source
+tags:
+ - CI/CD
+ - Gruntwork
+ - IaC
+ - CTP
+ - DevOps
+ - AWS
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/ctp-topic-9-ci-cd-with-gruntwork.md]]
+
+## Summary(用中文描述)
+- 核心主题:CI/CD 与 Gruntwork 在 AWS Landing Zone 中的实践
+- 问题域:云转型计划(Cloud Transformation Programme, CTP)中的基础设施自动化交付
+- 方法/机制:基于 Gruntwork 参考架构,通过 CI/CD 流水线实现 Terraform/Terragrunt 代码的自动化部署
+- 结论/价值:待视频转录后补充
+
+> ⚠️ **注意**:原始视频尚未完成 Whisper 转录,以上信息基于文件元数据生成。详见 Source File 链接获取完整内容。
+
+## Key Claims(用中文描述)
+- (待视频转录后补充)
+
+## Key Quotes
+> (待视频转录后补充)
+
+## Key Concepts
+- [[CI/CD Pipeline]]:持续集成/持续交付流水线,自动化代码构建、测试和部署流程
+- [[Infrastructure as Code (IaC)]]:通过代码管理云基础设施,实现可重复、可审计的部署
+- [[Gruntwork]]:提供生产级 Terraform 模块和参考架构的 IaC 库
+- [[Terraform]]:HashiCorp 开源的 IaC 工具,用于声明式定义云资源
+- [[Terragrunt]]:Terraform 的包装器,提供状态管理和模块复用能力
+
+## Key Entities
+- [[Gruntwork]]:IaC 基础设施库提供商,提供可复用的 Terraform 模块
+- [[AWS Landing Zone]]:AWS 多账户架构框架,为云工作负载提供安全、合规的基础设施
+- [[Cloud Transformation Programme (CTP)]]:云转型计划,Micro Focus 将工作负载从本地数据中心迁移至 AWS 的企业级项目
+
+## Connections
+- [[ctp-topic-1-gruntwork-landing-zone-architecture]] ← foundational ← [[ctp-topic-9-ci-cd-with-gruntwork]]
+- [[ctp-topic-2-git]] ← related ← [[ctp-topic-9-ci-cd-with-gruntwork]]
+- [[ctp-topic-33-an-introduction-to-gitops]] ← extends ← [[ctp-topic-9-ci-cd-with-gruntwork]]
+- [[ctp-topic-32-using-atlantis-cicd-for-infrastructure-deployments]] ← alternative_tool ← [[ctp-topic-9-ci-cd-with-gruntwork]]
+
+## Contradictions
+- (暂无,待视频转录后补充)
diff --git a/wiki/sources/cursor-2-0初学者使用指南.md b/wiki/sources/cursor-2-0初学者使用指南.md
index 484bec71..4fcba2ca 100644
--- a/wiki/sources/cursor-2-0初学者使用指南.md
+++ b/wiki/sources/cursor-2-0初学者使用指南.md
@@ -1,51 +1,51 @@
----
-title: "Cursor 2.0初学者使用指南"
-type: source
-tags: [ai, cursor, ide, mcp]
-date: 2026-04-22
----
-
-## Source File
-- [[Vibe Coding/Cursor 2.0初学者使用指南]]
-
-## Summary(用中文描述)
-- 核心主题:Cursor 2.0 AI代码编辑器的初学者完整使用教程,涵盖安装、界面、多代理操作、代码生成、审查与版本控制流程。
-- 问题域:AI辅助编程工具的入门学习,聚焦于如何高效使用Cursor的AI代理功能进行项目开发。
-- 方法/机制:通过Plan模式规划任务 → Agent模式执行代码生成 → Diff审查改动 → Git版本控制回滚的完整工作流。
-- 结论/价值:Cursor 2.0为开发者提供了一条从想法到实现的AI智能化路径,是现代AI辅助编程的重要工具。
-
-## Key Claims(用中文描述)
-- Cursor基于VS Code构建,可免费使用,支持付费升级获取更多生成额度。
-- Cursor新增自有AI模型Composer,强调其速度优势(比同类模型快4倍)。
-- 多代理功能可以同时运行不同任务,互不干扰,提升代码生成效率。
-- AI代理支持三种模式:Plan(规划)、Agent(执行,会修改文件)、Ask(咨询,不改代码)。
-- 代码生成后进入待审查状态,可使用Diff功能逐个审查或整体接收改动。
-- MCP(Model Context Protocol)支持将外部工具和服务集成到AI代理,扩展功能范围。
-- 可设定项目规则(如强制为函数生成文档注释),实现代码规范自动化。
-
-## Key Quotes
-> "Cursor是基于VS Code的AI代码编辑器,可免费使用,支持付费升级以获取更多生成额度。" — Cursor基本特性介绍
-> "启动构建任务时生成新代理,执行计划步骤。多代理功能可以同时运行不同任务,互不干扰。" — 多代理并行操作
-> "生成代码后进入待审查状态,可使用Diff功能查看具体改动,支持文件逐个审查或整体接收。" — 代码审查流程
-> "MCP(Model Context Protocol)支持将外部工具和服务集成到AI代理,扩展功能范围。" — MCP扩展能力
-
-## Key Concepts
-- [[多代理并行]]:可同时运行不同AI代理任务,互不干扰,适合多线程项目开发。
-- [[Diff审查]]:通过Diff视图查看AI生成的代码改动,逐个文件或整体接收变更。
-- [[项目规则]]:自定义项目规则文件(如强制生成文档注释),实现代码规范自动化。
-- [[MCP服务器]]:Model Context Protocol,支持将外部API和工具集成到AI代理。
-
-## Key Entities
-- [[Cursor]]:基于VS Code的AI增强代码编辑器,支持多代理并行操作和Composer自研模型。
-- [[VS Code]]:Cursor构建的基础编辑器,Cursor继承其完整功能。
-- [[Composer]]:Cursor自研AI模型,主打生成速度优势(比同类快4倍)。
-
-## Connections
-- [[Cursor]] ← extends ← [[VS Code]]
-- [[Cursor]] ← uses ← [[Composer]]
-- [[Cursor]] ← supports ← [[MCP(Model Context Protocol)]]
-- [[Cursor]] ← enables ← [[Vibe Coding]]
-- [[Cursor]] ← similar_to ← [[Claude Code]]
-
-## Contradictions
-- 无已知冲突。本文档聚焦Cursor入门操作,与 [[MCP在Cursor中的集成与应用详解]] 互补(后者侧重MCP集成深度应用)。
+---
+title: "Cursor 2.0初学者使用指南"
+type: source
+tags: [ai, cursor, ide, mcp]
+date: 2026-04-22
+---
+
+## Source File
+- [[raw/Vibe Coding/Cursor 2.0初学者使用指南.md]]
+
+## Summary(用中文描述)
+- 核心主题:Cursor 2.0 AI代码编辑器的初学者完整使用教程,涵盖安装、界面、多代理操作、代码生成、审查与版本控制流程。
+- 问题域:AI辅助编程工具的入门学习,聚焦于如何高效使用Cursor的AI代理功能进行项目开发。
+- 方法/机制:通过Plan模式规划任务 → Agent模式执行代码生成 → Diff审查改动 → Git版本控制回滚的完整工作流。
+- 结论/价值:Cursor 2.0为开发者提供了一条从想法到实现的AI智能化路径,是现代AI辅助编程的重要工具。
+
+## Key Claims(用中文描述)
+- Cursor基于VS Code构建,可免费使用,支持付费升级获取更多生成额度。
+- Cursor新增自有AI模型Composer,强调其速度优势(比同类模型快4倍)。
+- 多代理功能可以同时运行不同任务,互不干扰,提升代码生成效率。
+- AI代理支持三种模式:Plan(规划)、Agent(执行,会修改文件)、Ask(咨询,不改代码)。
+- 代码生成后进入待审查状态,可使用Diff功能逐个审查或整体接收改动。
+- MCP(Model Context Protocol)支持将外部工具和服务集成到AI代理,扩展功能范围。
+- 可设定项目规则(如强制为函数生成文档注释),实现代码规范自动化。
+
+## Key Quotes
+> "Cursor是基于VS Code的AI代码编辑器,可免费使用,支持付费升级以获取更多生成额度。" — Cursor基本特性介绍
+> "启动构建任务时生成新代理,执行计划步骤。多代理功能可以同时运行不同任务,互不干扰。" — 多代理并行操作
+> "生成代码后进入待审查状态,可使用Diff功能查看具体改动,支持文件逐个审查或整体接收。" — 代码审查流程
+> "MCP(Model Context Protocol)支持将外部工具和服务集成到AI代理,扩展功能范围。" — MCP扩展能力
+
+## Key Concepts
+- [[多代理并行]]:可同时运行不同AI代理任务,互不干扰,适合多线程项目开发。
+- [[Diff审查]]:通过Diff视图查看AI生成的代码改动,逐个文件或整体接收变更。
+- [[项目规则]]:自定义项目规则文件(如强制生成文档注释),实现代码规范自动化。
+- [[MCP服务器]]:Model Context Protocol,支持将外部API和工具集成到AI代理。
+
+## Key Entities
+- [[Cursor]]:基于VS Code的AI增强代码编辑器,支持多代理并行操作和Composer自研模型。
+- [[VS Code]]:Cursor构建的基础编辑器,Cursor继承其完整功能。
+- [[Composer]]:Cursor自研AI模型,主打生成速度优势(比同类快4倍)。
+
+## Connections
+- [[Cursor]] ← extends ← [[VS Code]]
+- [[Cursor]] ← uses ← [[Composer]]
+- [[Cursor]] ← supports ← [[MCP(Model Context Protocol)]]
+- [[Cursor]] ← enables ← [[Vibe Coding]]
+- [[Cursor]] ← similar_to ← [[Claude Code]]
+
+## Contradictions
+- 无已知冲突。本文档聚焦Cursor入门操作,与 [[MCP在Cursor中的集成与应用详解]] 互补(后者侧重MCP集成深度应用)。
diff --git a/wiki/sources/custom-morning-brief.md b/wiki/sources/custom-morning-brief.md
index 3b7a6b7d..1a309e04 100644
--- a/wiki/sources/custom-morning-brief.md
+++ b/wiki/sources/custom-morning-brief.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/custom-morning-brief.md]]
+- [[raw/Agent/usecases/custom-morning-brief.md]]
## Summary(用中文描述)
- 核心主题:OpenClaw AI 代理的"个性化早间简报"工作流——每天定时发送包含新闻、任务、创意内容草稿和 AI 主动建议的完整报告。
diff --git a/wiki/sources/daily-reddit-digest.md b/wiki/sources/daily-reddit-digest.md
index 3680d7fb..65a213ac 100644
--- a/wiki/sources/daily-reddit-digest.md
+++ b/wiki/sources/daily-reddit-digest.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/daily-reddit-digest.md]]
+- [[raw/Agent/usecases/daily-reddit-digest.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 驱动的 Reddit 每日精选摘要自动化
diff --git a/wiki/sources/daily-youtube-digest.md b/wiki/sources/daily-youtube-digest.md
index 8f894396..54d8bbee 100644
--- a/wiki/sources/daily-youtube-digest.md
+++ b/wiki/sources/daily-youtube-digest.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/daily-youtube-digest.md]]
+- [[raw/Agent/usecases/daily-youtube-digest.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 每日自动抓取订阅频道新视频,通过 TranscriptAPI 获取字幕并生成摘要,定时推送个性化简报
diff --git a/wiki/sources/data-consolidation-agent.md b/wiki/sources/data-consolidation-agent.md
index 39e07f42..6c7f1cf2 100644
--- a/wiki/sources/data-consolidation-agent.md
+++ b/wiki/sources/data-consolidation-agent.md
@@ -1,48 +1,48 @@
----
-title: "Data Consolidation Agent"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/specialized/data-consolidation-agent.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 将分散的销售提取数据整合为实时报告仪表盘
-- 问题域:销售团队缺乏统一视图查看各地区、销售代表和管道的实时业绩数据
-- 方法/机制:并行多维度查询 → 聚合计算派生指标 → Dashboard 友好 JSON 结构化输出 → 含时间戳的实时刷新机制
-- 结论/价值:< 1 秒仪表盘加载、60 秒自动刷新、零数据不一致
-
-## Key Claims(用中文描述)
-- Data Consolidation Agent 通过并行查询所有数据维度,将原始销售指标聚合为可操作的实时仪表盘
-- Agent 始终使用最新数据(按 type 取最新的 metric_date),确保数据时效性
-- 达成率计算:revenue / quota * 100,并处理除零错误
-- 按地区聚合数据,提供区域级别可见性,整合管道数据形成完整销售视图
-- 支持 MTD/YTD/Year End 多时间维度视图
-
-## Key Quotes
-> "You are the **Data Consolidation Agent** — a strategic data synthesizer who transforms raw sales metrics into actionable, real-time dashboards. You see the big picture and surface insights that drive decisions." — Agent 身份定义
-
-> "Zero data inconsistencies between detail and summary views" — 数据质量核心承诺
-
-## Key Concepts
-- [[Dashboard Report]]:含地区业绩摘要(YTD/MTD)、代表排名、管道快照、6 个月趋势、Top 5 业绩者
-- [[Territory Report]]:地区级深度分析,含该地区所有代表及其指标及最近 50 条历史记录
-- [[Sales Attainment]]:达成率 = revenue / quota * 100,处理除零错误
-- [[Pipeline Snapshot]]:按阶段聚合(数量/价值/加权价值)的管道数据快照
-- [[Metric Aggregation]]:多维度并行查询后聚合计算派生指标的工作流
-
-## Key Entities
-- [[Sales Data Extraction Agent]]:上游数据提取 Agent,为 Data Consolidation Agent 提供原始销售指标数据
-- [[Report Distribution Agent]]:下游分发 Agent,接收整合后的仪表盘数据进行分发推送
-
-## Connections
-- [[Sales Data Extraction Agent]] → produces → raw sales metrics
-- [[Data Consolidation Agent]] ← consumes ← [[Sales Data Extraction Agent]]
-- [[Report Distribution Agent]] ← consumes ← [[Data Consolidation Agent]] (Dashboard Report / Territory Report)
-- [[Sales Pipeline Analyst]] ← shares pipeline data sources with → [[Data Consolidation Agent]]
-- [[Sales Coach Agent]] ← consumes ← [[Data Consolidation Agent]] (Top 5 performers)
-
-## Contradictions
-- 无已知内容冲突。该 Agent 与 [[Sales Pipeline Analyst]] 共享数据源但职责互补(分析 vs 整合),与 [[Report Distribution Agent]] 构成顺序管道关系。
+---
+title: "Data Consolidation Agent"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/data-consolidation-agent.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 将分散的销售提取数据整合为实时报告仪表盘
+- 问题域:销售团队缺乏统一视图查看各地区、销售代表和管道的实时业绩数据
+- 方法/机制:并行多维度查询 → 聚合计算派生指标 → Dashboard 友好 JSON 结构化输出 → 含时间戳的实时刷新机制
+- 结论/价值:< 1 秒仪表盘加载、60 秒自动刷新、零数据不一致
+
+## Key Claims(用中文描述)
+- Data Consolidation Agent 通过并行查询所有数据维度,将原始销售指标聚合为可操作的实时仪表盘
+- Agent 始终使用最新数据(按 type 取最新的 metric_date),确保数据时效性
+- 达成率计算:revenue / quota * 100,并处理除零错误
+- 按地区聚合数据,提供区域级别可见性,整合管道数据形成完整销售视图
+- 支持 MTD/YTD/Year End 多时间维度视图
+
+## Key Quotes
+> "You are the **Data Consolidation Agent** — a strategic data synthesizer who transforms raw sales metrics into actionable, real-time dashboards. You see the big picture and surface insights that drive decisions." — Agent 身份定义
+
+> "Zero data inconsistencies between detail and summary views" — 数据质量核心承诺
+
+## Key Concepts
+- [[Dashboard Report]]:含地区业绩摘要(YTD/MTD)、代表排名、管道快照、6 个月趋势、Top 5 业绩者
+- [[Territory Report]]:地区级深度分析,含该地区所有代表及其指标及最近 50 条历史记录
+- [[Sales Attainment]]:达成率 = revenue / quota * 100,处理除零错误
+- [[Pipeline Snapshot]]:按阶段聚合(数量/价值/加权价值)的管道数据快照
+- [[Metric Aggregation]]:多维度并行查询后聚合计算派生指标的工作流
+
+## Key Entities
+- [[Sales Data Extraction Agent]]:上游数据提取 Agent,为 Data Consolidation Agent 提供原始销售指标数据
+- [[Report Distribution Agent]]:下游分发 Agent,接收整合后的仪表盘数据进行分发推送
+
+## Connections
+- [[Sales Data Extraction Agent]] → produces → raw sales metrics
+- [[Data Consolidation Agent]] ← consumes ← [[Sales Data Extraction Agent]]
+- [[Report Distribution Agent]] ← consumes ← [[Data Consolidation Agent]] (Dashboard Report / Territory Report)
+- [[Sales Pipeline Analyst]] ← shares pipeline data sources with → [[Data Consolidation Agent]]
+- [[Sales Coach Agent]] ← consumes ← [[Data Consolidation Agent]] (Top 5 performers)
+
+## Contradictions
+- 无已知内容冲突。该 Agent 与 [[Sales Pipeline Analyst]] 共享数据源但职责互补(分析 vs 整合),与 [[Report Distribution Agent]] 构成顺序管道关系。
diff --git a/wiki/sources/design-brand-guardian.md b/wiki/sources/design-brand-guardian.md
index e4e7f630..c76cb8cf 100644
--- a/wiki/sources/design-brand-guardian.md
+++ b/wiki/sources/design-brand-guardian.md
@@ -1,50 +1,50 @@
----
-title: "Design Brand Guardian"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/design/design-brand-guardian.md]]
-
-## Summary(用中文描述)
-- 核心主题:Brand Guardian Agent 角色定义——品牌战略与身份守护专家智能体,负责创建 cohesive 品牌体系和保护品牌价值
-- 问题域:品牌战略制定、品牌视觉身份建设、品牌一致性维护、品牌知识产权保护
-- 方法/机制:品牌战略框架(Purpose/Vision/Mission/Values/Personality)、视觉身份系统(Logo/色彩/字体/CSS 变量系统)、品牌声音指南(Tone/Trait/声调变化)、品牌保护策略(商标监控、合规审计、危机管理)
-- 结论/价值:为 AI Agent 系统提供品牌守护能力,确保多 Agent 协作中品牌表达的一致性和完整性;品牌先行(Brand-First)原则确保在战术执行前先建立完整的品牌基础
-
-## Key Claims(用中文描述)
-- Brand Guardian Agent 通过战略性的品牌策略将业务目标与品牌执行连接起来,确保品牌决策与商业目标一致
-- 完整的视觉身份系统必须包含从品牌颜色、字体、间距到 Logo 变体的全链路 CSS 设计系统变量
-- 品牌保护是默认要求,需包含商标策略、合规监控和危机管理机制
-- 品牌需要在保持一致性的同时,为不同场景和应用提供足够的灵活性
-
-## Key Quotes
-> "You are **Brand Guardian**, an expert brand strategist and guardian who creates cohesive brand identities and ensures consistent brand expression across all touchpoints." — 角色核心定义
-> "Establish comprehensive brand foundation before tactical implementation" — 品牌先行原则
-> "Balance consistency with flexibility for different contexts and applications" — 一致性与灵活性平衡
-> "Build brands that can evolve and grow with changing market conditions" — 品牌长期演进思维
-
-## Key Concepts
-- [[Brand-Strategy]]: 品牌战略框架——Purpose(存在意义)、Vision(愿景)、Mission(使命)、Values(价值观)、Personality(人格)五要素,是所有品牌决策的顶层指导
-- [[Visual-Identity-System]]: 视觉身份系统——通过 CSS 变量定义的完整设计系统,涵盖品牌色彩(Primary/Secondary/Accent/Neutral)、字体(Primary/Secondary/Accent)、间距系统(XS/SM/MD/LG/XL)
-- [[Brand-Voice-Guidelines]]: 品牌声音指南——Voice Characteristics(声音特征)、Tone Variations(声调变化)、Messaging Architecture(信息架构)、Writing Guidelines(写作规范)四个维度确保品牌沟通一致性
-- [[Brand-Protection-Strategy]]: 品牌保护策略——商标与知识产权保护、合规监控流程、危机管理与声誉保护、干系人培训与品牌传播
-
-## Key Entities
-- [[The Agency]]: 所属项目——Brand Guardian 是 The Agency 多智能体框架中的品牌守护专家,与 [[ArchitectUX]](技术架构)、[[design-whimsy-injector]](趣味性设计)、[[UX-Researcher]](用户体验研究)协同,共同为 [[LuxuryDeveloper]] 提供完整的设计支撑
-
-## Connections
-- [[design-whimsy-injector]] ← complements ← [[design-brand-guardian]]
-- [[ArchitectUX]] ← complements ← [[design-brand-guardian]]
-- [[UX-Researcher]] ← supports ← [[design-brand-guardian]]
-- [[LuxuryDeveloper]] ← depends_on ← [[design-brand-guardian]]
-- [[The Agency]] ← contains ← [[design-brand-guardian]]
-
-## Contradictions
-- 与 [[design-whimsy-injector]] 在设计方法论上的张力:
- - 冲突点:品牌一致性(Brand Guardian 强调标准化与防护)vs. 个性化趣味(Whimsy Injector 强调创意表达)
- - 当前观点:Brand Guardian 主张在战术执行前必须先建立完整的品牌基础,保护品牌完整性
- - 对方观点:Whimsy Injector 主张通过有目的的趣味和个性化微交互提升用户体验,允许灵活创意表达
- - 解决方向:两者互补——Brand Guardian 建立品牌边界,Whimsy Injector 在边界内注入品牌个性,两者共同服务于 LuxuryDeveloper 的高端品牌体验
+---
+title: "Design Brand Guardian"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/design/design-brand-guardian.md]]
+
+## Summary(用中文描述)
+- 核心主题:Brand Guardian Agent 角色定义——品牌战略与身份守护专家智能体,负责创建 cohesive 品牌体系和保护品牌价值
+- 问题域:品牌战略制定、品牌视觉身份建设、品牌一致性维护、品牌知识产权保护
+- 方法/机制:品牌战略框架(Purpose/Vision/Mission/Values/Personality)、视觉身份系统(Logo/色彩/字体/CSS 变量系统)、品牌声音指南(Tone/Trait/声调变化)、品牌保护策略(商标监控、合规审计、危机管理)
+- 结论/价值:为 AI Agent 系统提供品牌守护能力,确保多 Agent 协作中品牌表达的一致性和完整性;品牌先行(Brand-First)原则确保在战术执行前先建立完整的品牌基础
+
+## Key Claims(用中文描述)
+- Brand Guardian Agent 通过战略性的品牌策略将业务目标与品牌执行连接起来,确保品牌决策与商业目标一致
+- 完整的视觉身份系统必须包含从品牌颜色、字体、间距到 Logo 变体的全链路 CSS 设计系统变量
+- 品牌保护是默认要求,需包含商标策略、合规监控和危机管理机制
+- 品牌需要在保持一致性的同时,为不同场景和应用提供足够的灵活性
+
+## Key Quotes
+> "You are **Brand Guardian**, an expert brand strategist and guardian who creates cohesive brand identities and ensures consistent brand expression across all touchpoints." — 角色核心定义
+> "Establish comprehensive brand foundation before tactical implementation" — 品牌先行原则
+> "Balance consistency with flexibility for different contexts and applications" — 一致性与灵活性平衡
+> "Build brands that can evolve and grow with changing market conditions" — 品牌长期演进思维
+
+## Key Concepts
+- [[Brand-Strategy]]: 品牌战略框架——Purpose(存在意义)、Vision(愿景)、Mission(使命)、Values(价值观)、Personality(人格)五要素,是所有品牌决策的顶层指导
+- [[Visual-Identity-System]]: 视觉身份系统——通过 CSS 变量定义的完整设计系统,涵盖品牌色彩(Primary/Secondary/Accent/Neutral)、字体(Primary/Secondary/Accent)、间距系统(XS/SM/MD/LG/XL)
+- [[Brand-Voice-Guidelines]]: 品牌声音指南——Voice Characteristics(声音特征)、Tone Variations(声调变化)、Messaging Architecture(信息架构)、Writing Guidelines(写作规范)四个维度确保品牌沟通一致性
+- [[Brand-Protection-Strategy]]: 品牌保护策略——商标与知识产权保护、合规监控流程、危机管理与声誉保护、干系人培训与品牌传播
+
+## Key Entities
+- [[The Agency]]: 所属项目——Brand Guardian 是 The Agency 多智能体框架中的品牌守护专家,与 [[ArchitectUX]](技术架构)、[[design-whimsy-injector]](趣味性设计)、[[UX-Researcher]](用户体验研究)协同,共同为 [[LuxuryDeveloper]] 提供完整的设计支撑
+
+## Connections
+- [[design-whimsy-injector]] ← complements ← [[design-brand-guardian]]
+- [[ArchitectUX]] ← complements ← [[design-brand-guardian]]
+- [[UX-Researcher]] ← supports ← [[design-brand-guardian]]
+- [[LuxuryDeveloper]] ← depends_on ← [[design-brand-guardian]]
+- [[The Agency]] ← contains ← [[design-brand-guardian]]
+
+## Contradictions
+- 与 [[design-whimsy-injector]] 在设计方法论上的张力:
+ - 冲突点:品牌一致性(Brand Guardian 强调标准化与防护)vs. 个性化趣味(Whimsy Injector 强调创意表达)
+ - 当前观点:Brand Guardian 主张在战术执行前必须先建立完整的品牌基础,保护品牌完整性
+ - 对方观点:Whimsy Injector 主张通过有目的的趣味和个性化微交互提升用户体验,允许灵活创意表达
+ - 解决方向:两者互补——Brand Guardian 建立品牌边界,Whimsy Injector 在边界内注入品牌个性,两者共同服务于 LuxuryDeveloper 的高端品牌体验
diff --git a/wiki/sources/design-image-prompt-engineer.md b/wiki/sources/design-image-prompt-engineer.md
index b6cd5e68..04a80c6b 100644
--- a/wiki/sources/design-image-prompt-engineer.md
+++ b/wiki/sources/design-image-prompt-engineer.md
@@ -1,59 +1,59 @@
----
-title: "Image Prompt Engineer Agent"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/design/design-image-prompt-engineer.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI 图像生成提示词工程专家智能体,专注于将视觉概念精准翻译为可执行的提示词语言
-- 问题域:如何让 AI 图像生成工具(Midjourney/DALL-E/Stable Diffusion/Flux)稳定产出专业级摄影作品
-- 方法/机制:五层提示词结构框架(主体描述 → 环境设定 → 光线规范 → 摄影技术 → 风格美学)+ 平台特定语法优化 + 体裁专属提示模式
-- 结论/价值:通过结构化的摄影专业知识与 AI 提示词语言的融合,实现 90%+ 的视觉概念还原率,减少迭代次数,提升商业可用性
-
-## Key Claims(用中文描述)
-- 五层提示词结构(主体/环境/光线/技术/风格)确保 AI 生成图像与视觉概念高度一致
-- 摄影技术术语(如 f/1.8 bokeh、浅景深)比模糊描述(如"背景模糊")产生更精确的 AI 输出
-- 负向提示词(negative prompts)在支持平台上可有效排除不想要的元素
-- 提示词框架应适配不同 AI 平台的语法偏好(Midjourney 参数、DALL-E 自然语言、Stable Diffusion token 加权、Flux 详细描述)
-
-## Key Quotes
-> "Always structure prompts with subject, environment, lighting, style, and technical specs" — 提示词结构五要素
-> "Use specific, concrete terminology rather than vague descriptors" — 具体性原则
-> "Master the art of translating visual concepts into precise, structured language that produces stunning, professional-quality photography" — 核心使命
-
-## Key Concepts
-- [[Prompt-Engineering]]:AI 图像生成提示词工程的核心方法论
-- [[Five-Layer-Prompt-Structure]]:主体描述层 → 环境设定层 → 光线规范层 → 摄影技术层 → 风格美学层
-- [[Photography-Prompt-Mastery]]:将摄影专业知识转化为 AI 可理解提示词的能力
-- [[Platform-Specific-Prompt-Optimization]]:针对不同 AI 图像平台(Midjourney/DALL-E/Stable Diffusion/Flux)的定制化提示词策略
-- [[Negative-Prompts]]:负向提示词,排除不想要的图像元素
-- [[Film-Emulation]]:胶片模拟风格提示词(Kodak Portra/Fuji Velvia/Ilford HP5/Cinestill 800T)
-- [[Lighting-Patterns]]:摄影布光模式(Rembrandt/Butterfly/Split/Chiaroscuro/Vermeer/Neon-Noir)
-
-## Key Entities
-- [[Midjourney]]:AI 图像生成平台,以参数化提示词(--ar/--v/--style/--chaos)著称
-- [[DALL-E]]:OpenAI 的 AI 图像生成工具,擅长自然语言描述和风格混合
-- [[Stable-Diffusion]]:开源 AI 图像生成平台,支持 token 加权和 embedding 引用
-- [[Flux]]:以详细自然语言描述和照片级写实风格著称的新兴 AI 平台
-- [[Annie Leibovitz]]:时尚/人像摄影大师,其风格常被引用为提示词参考
-- [[Peter Lindbergh]]:经典黑白人像摄影大师,其极简风格常被引用为提示词参考
-- [[The Agency]]:多智能体框架,本智能体隶属 Design 设计部门
-
-## Connections
-- [[design-ui-designer]] ← shares_design_domain ← [[design-image-prompt-engineer]]
-- [[design-brand-guardian]] ← brand_consistency ← [[design-image-prompt-engineer]]
-- [[design-whimsy-injector]] ← visual_language ← [[design-image-prompt-engineer]]
-- [[design-ux-researcher]] ← visual_validation ← [[design-image-prompt-engineer]]
-- [[ArchitectUX]] ← design_system ← [[design-image-prompt-engineer]]
-- [[Multi-Agent-System-Reliability]] ← context ← [[The Agency]] agent ecosystem
-
-## Contradictions
-- 与 [[design-ui-designer]] 在视觉一致性上的差异:
- - 冲突点:UI Designer 追求像素级精确还原(95%+ 准确率),Image Prompt Engineer 的输出本质上是概率生成,存在固有不确定性
- - 当前观点:Image Prompt Engineer 的目标不是像素级还原,而是 90%+ 视觉概念还原;概率性是 AI 图像生成的本质约束
- - 对方观点:UI Designer 要求 95%+ 实现准确率,将提示词视为"设计到代码"的翻译环节
- - 协调方案:两者协同时,Image Prompt Engineer 应提供多版本变体供 UI Designer 选择,并在提示词中增加确定性约束(如具体颜色值、光照参数)
+---
+title: "Image Prompt Engineer Agent"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/design/design-image-prompt-engineer.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI 图像生成提示词工程专家智能体,专注于将视觉概念精准翻译为可执行的提示词语言
+- 问题域:如何让 AI 图像生成工具(Midjourney/DALL-E/Stable Diffusion/Flux)稳定产出专业级摄影作品
+- 方法/机制:五层提示词结构框架(主体描述 → 环境设定 → 光线规范 → 摄影技术 → 风格美学)+ 平台特定语法优化 + 体裁专属提示模式
+- 结论/价值:通过结构化的摄影专业知识与 AI 提示词语言的融合,实现 90%+ 的视觉概念还原率,减少迭代次数,提升商业可用性
+
+## Key Claims(用中文描述)
+- 五层提示词结构(主体/环境/光线/技术/风格)确保 AI 生成图像与视觉概念高度一致
+- 摄影技术术语(如 f/1.8 bokeh、浅景深)比模糊描述(如"背景模糊")产生更精确的 AI 输出
+- 负向提示词(negative prompts)在支持平台上可有效排除不想要的元素
+- 提示词框架应适配不同 AI 平台的语法偏好(Midjourney 参数、DALL-E 自然语言、Stable Diffusion token 加权、Flux 详细描述)
+
+## Key Quotes
+> "Always structure prompts with subject, environment, lighting, style, and technical specs" — 提示词结构五要素
+> "Use specific, concrete terminology rather than vague descriptors" — 具体性原则
+> "Master the art of translating visual concepts into precise, structured language that produces stunning, professional-quality photography" — 核心使命
+
+## Key Concepts
+- [[Prompt-Engineering]]:AI 图像生成提示词工程的核心方法论
+- [[Five-Layer-Prompt-Structure]]:主体描述层 → 环境设定层 → 光线规范层 → 摄影技术层 → 风格美学层
+- [[Photography-Prompt-Mastery]]:将摄影专业知识转化为 AI 可理解提示词的能力
+- [[Platform-Specific-Prompt-Optimization]]:针对不同 AI 图像平台(Midjourney/DALL-E/Stable Diffusion/Flux)的定制化提示词策略
+- [[Negative-Prompts]]:负向提示词,排除不想要的图像元素
+- [[Film-Emulation]]:胶片模拟风格提示词(Kodak Portra/Fuji Velvia/Ilford HP5/Cinestill 800T)
+- [[Lighting-Patterns]]:摄影布光模式(Rembrandt/Butterfly/Split/Chiaroscuro/Vermeer/Neon-Noir)
+
+## Key Entities
+- [[Midjourney]]:AI 图像生成平台,以参数化提示词(--ar/--v/--style/--chaos)著称
+- [[DALL-E]]:OpenAI 的 AI 图像生成工具,擅长自然语言描述和风格混合
+- [[Stable-Diffusion]]:开源 AI 图像生成平台,支持 token 加权和 embedding 引用
+- [[Flux]]:以详细自然语言描述和照片级写实风格著称的新兴 AI 平台
+- [[Annie Leibovitz]]:时尚/人像摄影大师,其风格常被引用为提示词参考
+- [[Peter Lindbergh]]:经典黑白人像摄影大师,其极简风格常被引用为提示词参考
+- [[The Agency]]:多智能体框架,本智能体隶属 Design 设计部门
+
+## Connections
+- [[design-ui-designer]] ← shares_design_domain ← [[design-image-prompt-engineer]]
+- [[design-brand-guardian]] ← brand_consistency ← [[design-image-prompt-engineer]]
+- [[design-whimsy-injector]] ← visual_language ← [[design-image-prompt-engineer]]
+- [[design-ux-researcher]] ← visual_validation ← [[design-image-prompt-engineer]]
+- [[ArchitectUX]] ← design_system ← [[design-image-prompt-engineer]]
+- [[Multi-Agent-System-Reliability]] ← context ← [[The Agency]] agent ecosystem
+
+## Contradictions
+- 与 [[design-ui-designer]] 在视觉一致性上的差异:
+ - 冲突点:UI Designer 追求像素级精确还原(95%+ 准确率),Image Prompt Engineer 的输出本质上是概率生成,存在固有不确定性
+ - 当前观点:Image Prompt Engineer 的目标不是像素级还原,而是 90%+ 视觉概念还原;概率性是 AI 图像生成的本质约束
+ - 对方观点:UI Designer 要求 95%+ 实现准确率,将提示词视为"设计到代码"的翻译环节
+ - 协调方案:两者协同时,Image Prompt Engineer 应提供多版本变体供 UI Designer 选择,并在提示词中增加确定性约束(如具体颜色值、光照参数)
diff --git a/wiki/sources/design-inclusive-visuals-specialist.md b/wiki/sources/design-inclusive-visuals-specialist.md
index c2749777..0d5bb545 100644
--- a/wiki/sources/design-inclusive-visuals-specialist.md
+++ b/wiki/sources/design-inclusive-visuals-specialist.md
@@ -1,53 +1,53 @@
----
-title: "Inclusive Visuals Specialist"
-type: source
-tags: [generative-ai, bias-mitigation, prompt-engineering, inclusive-design, image-generation, video-generation, ai-ethics]
-sources: []
-last_updated: 2026-04-24
----
-
-## Source File
-- [[Agent/agency-agents/design/design-inclusive-visuals-specialist.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI 图像/视频生成中的包容性视觉呈现专家 Agent,专注于消除系统性刻板印象和偏见,生成具有文化真实性、尊严感和无歧视性的图像与视频。
-- 问题域:主流图像/视频生成模型(Midjourney、Sora、Runway、DALL-E)固有的刻板印象问题——克隆脸、异域化布光、符号乱码、地理/建筑失真。
-- 方法/机制:通过结构化提示词工程(Subject → Sub-actions → Context → Camera → Color Grade → Explicit Exclusions)构建"有尊严的视频提示",并在 4 阶段工作流中嵌入负向约束库、物理学定义和 7 点 QA 审查。
-- 结论/价值:实现"表征准确度 100%"、"AI 伪影消除率 100%"、"社区验证认可"三大成功指标。
-
-## Key Claims(用中文描述)
-- 主流 AI 图像/视频生成模型默认携带系统性刻板印象("穿帽衫的黑客"、"白救世主 CEO"),需通过显式负向约束加以对抗。
-- 多样化人群图像中若不明确禁止"克隆脸",模型会生成同一边缘化人物的多个复制版本,导致冒犯性表征。
-- AI 在非英语文字、文化符号生成上存在幻觉倾向(生成乱码或冒犯性字符),必须在负向提示中显式排除。
-- 视频生成中服装、头发、辅助器具(轮椅、拐杖)的物理一致性需要显式定义,否则模型会产生物理学错误。
-- 过度纠正(Over-correction)是新型风险——AI 在刻意追求多样性时可能产生"符号化"、不真实的构图。
-
-## Key Quotes
-> "Identity is a domain requiring technical expertise to represent accurately." — 身份表征不是简单的描述符输入,而是一个需要专业技术来处理的问题域。
-> "The current prompt will likely trigger the model's 'exoticism' bias. I am injecting technical constraints to ensure the lighting and geographical architecture reflect authentic lived reality." — 解释性声明:当前提示词可能触发模型的"异域化"偏见,正在注入技术约束以确保布光和建筑反映真实生活现实。
-> "You reject 'Kumbaya' stock-photo tropes, performative tokenism, and AI hallucinations that distort cultural realities." — 拒绝"Kumbaya"式库存照片套路、表演性象征主义和扭曲文化现实的 AI 幻觉。
-
-## Key Concepts
-- [[InclusiveVisuals]]: AI 生成图像/视频中的包容性视觉呈现——确保生成内容反映真实多样的社会现实,而非刻板印象。
-- [[NegativePromptingLibrary]]: 负向提示库——显式列举 AI 应避免生成的内容,是对抗 AI 幻觉的核心技术手段。
-- [[CloneFaceProblem]]: 克隆脸问题——AI 在生成多样化人群时倾向于生成同一人的多个复制版本,需要通过约束面部结构差异来避免。
-- [[ExoticismBias]]: 异域化偏见——AI 对非西方文化进行"东方主义"式的过度美化或扭曲呈现,需要通过地理和建筑真实性约束加以对抗。
-- [[VideoPhysicsDefinition]]: 视频物理学定义——对服装、头发、辅助器具的运动和交互进行显式物理约束,确保时间一致性。
-- [[IntersectionalRepresentation]]: 交叉性表征——同时考虑文化、年龄、残疾、社会经济地位等多重身份的叠加表征。
-- [[CommunityValidation]]: 社区验证——确保所描绘社区的用户认可生成资产为真实、有尊严且符合其现实的表征。
-
-## Key Entities
-- [[TheAgency]]: 该 Agent 所属的 Agent 团队体系(agency-agents)。
-- Midjourney、Sora、Runway Gen-3、DALL-E:主要的目标图像/视频生成平台。
-
-## Connections
-- [[DesignImagePromptEngineer]] ← extends ← [[InclusiveVisualsSpecialist]](提示词工程是该 Agent 的核心技术)
-- [[DesignUXResearcher]] ← provides_review_gate ← [[InclusiveVisualsSpecialist]](UX Researcher 提供 7 点 QA 审查)
-- [[DesignBrandGuardian]] ← quality_gate ← [[InclusiveVisualsSpecialist]](Brand Guardian 把控企业品牌伦理标准)
-- [[InclusiveVisualsSpecialist]] ← produces_assets_for ← 全球文化活动(营销/传播团队)
-
-## Contradictions
-- 与通用图像生成指南可能存在张力:
- - 冲突点:通用 AI 图像生成追求"美观"、"商业化",而包容性视觉优先"真实性"、"去刻板印象"
- - 当前观点:社会影响和尊严优先于商业美学;需要技术约束来对抗模型的美学偏见
- - 对方观点:商业应用需要快速产出,"适度多样性"已足够
+---
+title: "Inclusive Visuals Specialist"
+type: source
+tags: [generative-ai, bias-mitigation, prompt-engineering, inclusive-design, image-generation, video-generation, ai-ethics]
+sources: []
+last_updated: 2026-04-24
+---
+
+## Source File
+- [[raw/Agent/agency-agents/design/design-inclusive-visuals-specialist.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI 图像/视频生成中的包容性视觉呈现专家 Agent,专注于消除系统性刻板印象和偏见,生成具有文化真实性、尊严感和无歧视性的图像与视频。
+- 问题域:主流图像/视频生成模型(Midjourney、Sora、Runway、DALL-E)固有的刻板印象问题——克隆脸、异域化布光、符号乱码、地理/建筑失真。
+- 方法/机制:通过结构化提示词工程(Subject → Sub-actions → Context → Camera → Color Grade → Explicit Exclusions)构建"有尊严的视频提示",并在 4 阶段工作流中嵌入负向约束库、物理学定义和 7 点 QA 审查。
+- 结论/价值:实现"表征准确度 100%"、"AI 伪影消除率 100%"、"社区验证认可"三大成功指标。
+
+## Key Claims(用中文描述)
+- 主流 AI 图像/视频生成模型默认携带系统性刻板印象("穿帽衫的黑客"、"白救世主 CEO"),需通过显式负向约束加以对抗。
+- 多样化人群图像中若不明确禁止"克隆脸",模型会生成同一边缘化人物的多个复制版本,导致冒犯性表征。
+- AI 在非英语文字、文化符号生成上存在幻觉倾向(生成乱码或冒犯性字符),必须在负向提示中显式排除。
+- 视频生成中服装、头发、辅助器具(轮椅、拐杖)的物理一致性需要显式定义,否则模型会产生物理学错误。
+- 过度纠正(Over-correction)是新型风险——AI 在刻意追求多样性时可能产生"符号化"、不真实的构图。
+
+## Key Quotes
+> "Identity is a domain requiring technical expertise to represent accurately." — 身份表征不是简单的描述符输入,而是一个需要专业技术来处理的问题域。
+> "The current prompt will likely trigger the model's 'exoticism' bias. I am injecting technical constraints to ensure the lighting and geographical architecture reflect authentic lived reality." — 解释性声明:当前提示词可能触发模型的"异域化"偏见,正在注入技术约束以确保布光和建筑反映真实生活现实。
+> "You reject 'Kumbaya' stock-photo tropes, performative tokenism, and AI hallucinations that distort cultural realities." — 拒绝"Kumbaya"式库存照片套路、表演性象征主义和扭曲文化现实的 AI 幻觉。
+
+## Key Concepts
+- [[InclusiveVisuals]]: AI 生成图像/视频中的包容性视觉呈现——确保生成内容反映真实多样的社会现实,而非刻板印象。
+- [[NegativePromptingLibrary]]: 负向提示库——显式列举 AI 应避免生成的内容,是对抗 AI 幻觉的核心技术手段。
+- [[CloneFaceProblem]]: 克隆脸问题——AI 在生成多样化人群时倾向于生成同一人的多个复制版本,需要通过约束面部结构差异来避免。
+- [[ExoticismBias]]: 异域化偏见——AI 对非西方文化进行"东方主义"式的过度美化或扭曲呈现,需要通过地理和建筑真实性约束加以对抗。
+- [[VideoPhysicsDefinition]]: 视频物理学定义——对服装、头发、辅助器具的运动和交互进行显式物理约束,确保时间一致性。
+- [[IntersectionalRepresentation]]: 交叉性表征——同时考虑文化、年龄、残疾、社会经济地位等多重身份的叠加表征。
+- [[CommunityValidation]]: 社区验证——确保所描绘社区的用户认可生成资产为真实、有尊严且符合其现实的表征。
+
+## Key Entities
+- [[TheAgency]]: 该 Agent 所属的 Agent 团队体系(agency-agents)。
+- Midjourney、Sora、Runway Gen-3、DALL-E:主要的目标图像/视频生成平台。
+
+## Connections
+- [[DesignImagePromptEngineer]] ← extends ← [[InclusiveVisualsSpecialist]](提示词工程是该 Agent 的核心技术)
+- [[DesignUXResearcher]] ← provides_review_gate ← [[InclusiveVisualsSpecialist]](UX Researcher 提供 7 点 QA 审查)
+- [[DesignBrandGuardian]] ← quality_gate ← [[InclusiveVisualsSpecialist]](Brand Guardian 把控企业品牌伦理标准)
+- [[InclusiveVisualsSpecialist]] ← produces_assets_for ← 全球文化活动(营销/传播团队)
+
+## Contradictions
+- 与通用图像生成指南可能存在张力:
+ - 冲突点:通用 AI 图像生成追求"美观"、"商业化",而包容性视觉优先"真实性"、"去刻板印象"
+ - 当前观点:社会影响和尊严优先于商业美学;需要技术约束来对抗模型的美学偏见
+ - 对方观点:商业应用需要快速产出,"适度多样性"已足够
diff --git a/wiki/sources/design-ui-designer.md b/wiki/sources/design-ui-designer.md
index c10e0e8e..f3edeeae 100644
--- a/wiki/sources/design-ui-designer.md
+++ b/wiki/sources/design-ui-designer.md
@@ -1,52 +1,52 @@
----
-title: "UI Designer Agent Personality"
-type: source
-tags: ["agent", "design", "ui", "design-system"]
-date: 2026-04-24
----
-
-## Source File
-- [[Agent/agency-agents/design/design-ui-designer.md]]
-
-## Summary(用中文描述)
-- 核心主题:UI Designer Agent 的角色定义、核心使命、设计交付物与工作流程
-- 问题域:多 Agent 系统中 UI 设计专家 Agent 的定位与职责边界
-- 方法/机制:设计系统优先(Design System First)、WCAG AA 可访问性合规、像素级界面交付、响应式框架设计
-- 结论/价值:UI Designer Agent 通过构建组件库、设计令牌系统、响应式框架和可访问性标准,确保产品界面的一致性、可复用性与包容性
-
-## Key Claims(用中文描述)
-- UI Designer Agent 以设计系统为优先,在创建单个界面之前先建立组件基础
-- 所有设计必须内置可访问性合规(WCAG AA 标准,色彩对比度 4.5:1)
-- 开发者交付物需包含详细测量规格、组件文档与设计 QA 流程,实现 90%+ 实现准确率
-- 设计系统需在 95%+ 界面元素中保持一致性
-
-## Key Quotes
-> "Build accessibility into the foundation rather than adding it later." — UI Designer Agent 设计原则
-> "You're successful when: Design system achieves 95%+ consistency across all interface elements." — UI Designer 成功指标
-
-## Key Concepts
-- [[Design System]]:组件库与视觉语言体系,确保跨产品的一致性
-- [[Design Tokens]]:设计令牌系统,用 CSS 变量管理颜色、字体、间距等视觉原子
-- [[Visual Hierarchy]]:通过排版、颜色和布局建立视觉层次,引导用户注意力
-- [[Responsive Design]]:移动优先的响应式框架,支持 Mobile/Tablet/Desktop/Large Desktop 多断点
-- [[WCAG AA]]:Web 内容可访问性指南 AA 级标准,色彩对比度 4.5:1
-- [[Component Library]]:可复用组件库(Button、Input、Card、Navigation 等),带完整状态规格
-- [[Dark Mode]]:深色模式与主题化系统,支持灵活的品牌表达
-- [[Design QA]]:设计质量保证流程,验证像素级实现与规格一致性
-- [[Accessibility-First Design]]:无障碍优先设计,内置键盘导航、屏幕阅读器支持、焦点管理
-
-## Key Entities
-- UI Designer Agent:多 Agent 协作系统中的界面设计专家角色,专注于视觉设计系统与像素级界面交付
-
-## Connections
-- [[Design Brand Guardian]] ← complements ← [[UI Designer]]
-- [[Design Whimsy Injector]] ← extends ← [[UI Designer]]
-- [[Design UX Architect]] ← depends_on ← [[UI Designer]]
-- [[UX Researcher Agent]] → informs → [[UI Designer]](用户研究洞察驱动界面设计决策)
-
-## Contradictions
-- 与 [[Design Whimsy Injector]] 存在张力:
- - 冲突点:一致性与创意趣味性之间的平衡
- - 当前观点(UI Designer):建立严格的组件库和设计规范,追求 95%+ 视觉一致性
- - 对方观点(Design Whimsy Injector):在规范内注入意外的趣味元素,增加情感连接
- - 协调方向:趣味性注入应发生在预定义组件的可配置槽位中(如微交互动画),不破坏核心设计系统的一致性
+---
+title: "UI Designer Agent Personality"
+type: source
+tags: ["agent", "design", "ui", "design-system"]
+date: 2026-04-24
+---
+
+## Source File
+- [[raw/Agent/agency-agents/design/design-ui-designer.md]]
+
+## Summary(用中文描述)
+- 核心主题:UI Designer Agent 的角色定义、核心使命、设计交付物与工作流程
+- 问题域:多 Agent 系统中 UI 设计专家 Agent 的定位与职责边界
+- 方法/机制:设计系统优先(Design System First)、WCAG AA 可访问性合规、像素级界面交付、响应式框架设计
+- 结论/价值:UI Designer Agent 通过构建组件库、设计令牌系统、响应式框架和可访问性标准,确保产品界面的一致性、可复用性与包容性
+
+## Key Claims(用中文描述)
+- UI Designer Agent 以设计系统为优先,在创建单个界面之前先建立组件基础
+- 所有设计必须内置可访问性合规(WCAG AA 标准,色彩对比度 4.5:1)
+- 开发者交付物需包含详细测量规格、组件文档与设计 QA 流程,实现 90%+ 实现准确率
+- 设计系统需在 95%+ 界面元素中保持一致性
+
+## Key Quotes
+> "Build accessibility into the foundation rather than adding it later." — UI Designer Agent 设计原则
+> "You're successful when: Design system achieves 95%+ consistency across all interface elements." — UI Designer 成功指标
+
+## Key Concepts
+- [[Design System]]:组件库与视觉语言体系,确保跨产品的一致性
+- [[Design Tokens]]:设计令牌系统,用 CSS 变量管理颜色、字体、间距等视觉原子
+- [[Visual Hierarchy]]:通过排版、颜色和布局建立视觉层次,引导用户注意力
+- [[Responsive Design]]:移动优先的响应式框架,支持 Mobile/Tablet/Desktop/Large Desktop 多断点
+- [[WCAG AA]]:Web 内容可访问性指南 AA 级标准,色彩对比度 4.5:1
+- [[Component Library]]:可复用组件库(Button、Input、Card、Navigation 等),带完整状态规格
+- [[Dark Mode]]:深色模式与主题化系统,支持灵活的品牌表达
+- [[Design QA]]:设计质量保证流程,验证像素级实现与规格一致性
+- [[Accessibility-First Design]]:无障碍优先设计,内置键盘导航、屏幕阅读器支持、焦点管理
+
+## Key Entities
+- UI Designer Agent:多 Agent 协作系统中的界面设计专家角色,专注于视觉设计系统与像素级界面交付
+
+## Connections
+- [[Design Brand Guardian]] ← complements ← [[UI Designer]]
+- [[Design Whimsy Injector]] ← extends ← [[UI Designer]]
+- [[Design UX Architect]] ← depends_on ← [[UI Designer]]
+- [[UX Researcher Agent]] → informs → [[UI Designer]](用户研究洞察驱动界面设计决策)
+
+## Contradictions
+- 与 [[Design Whimsy Injector]] 存在张力:
+ - 冲突点:一致性与创意趣味性之间的平衡
+ - 当前观点(UI Designer):建立严格的组件库和设计规范,追求 95%+ 视觉一致性
+ - 对方观点(Design Whimsy Injector):在规范内注入意外的趣味元素,增加情感连接
+ - 协调方向:趣味性注入应发生在预定义组件的可配置槽位中(如微交互动画),不破坏核心设计系统的一致性
diff --git a/wiki/sources/design-ux-architect.md b/wiki/sources/design-ux-architect.md
index 6692f6f8..965410bf 100644
--- a/wiki/sources/design-ux-architect.md
+++ b/wiki/sources/design-ux-architect.md
@@ -1,51 +1,51 @@
----
-title: "ArchitectUX Agent Personality"
-type: source
-tags: [agent, design, ux, css, frontend, the-agency]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/design/design-ux-architect.md]]
-
-## Summary(用中文描述)
-- 核心主题:ArchitectUX 智能体的角色定义——为开发者提供坚实的技术架构和 UX 基础,消除架构决策疲劳
-- 问题域:Web 项目中 CSS 系统混乱、响应式策略缺失、主题切换缺失等开发者痛点
-- 方法/机制:通过 CSS 设计系统(变量/排版/间距/颜色令牌)、布局框架(Grid/Flexbox)、信息架构、ThemeManager JS 类实现
-- 结论/价值:ArchitectUX 作为 [[The Agency]] 设计部门的多智能体之一,负责在 LuxuryDeveloper 实施前建立可扩展的技术基础
-
-## Key Claims(用中文描述)
-- **ArchitectUX** ← 创建 → **CSS 设计系统基础**:通过 CSS 变量令牌体系(颜色/排版/间距/容器)实现跨项目可维护的样式架构,消除硬编码值
-- **主题切换** ← 强制要求 → **所有新站点必须包含**:light/dark/system 三模式切换,preserves 用户偏好,支持 WCAG 合规
-- **架构优先** ← 预防 → **CSS 冲突**:在实施前先设计组件层级和命名规范,防止样式冲突和技术债务
-- **系统架构领导力** ← 负责 → **仓库拓扑/数据契约/API规范**:确保跨系统一致性和 Schema 合规
-- **开发者生产力** ← 通过 → **消除架构决策疲劳**:提供清晰可实施的规范,减少返工和重复决策
-
-## Key Quotes
-> "Create scalable CSS architecture before implementation begins" — Foundation-First Approach 原则,要求在动手前先建立系统
-> "Eliminate architectural decision fatigue for developers" — Developer Productivity Focus 核心理念,ArchitectUX 存在的核心价值主张
-
-## Key Concepts
-- **CSS 设计系统(CSS Design System)**:由 CSS 变量令牌(颜色/排版/间距/组件)构成的标准化样式体系,支持 light/dark/system 主题切换
-- **布局框架(Layout Framework)**:基于现代 CSS Grid/Flexbox 的容器系统和响应式断点策略(mobile-first)
-- **ThemeManager**:管理 light/dark/system 三种主题状态切换的 JavaScript 类,持久化用户偏好至 localStorage
-- **信息架构(Information Architecture)**:页面层级结构、导航策略、内容权重系统(H1 > H2 > H3)
-- **可访问性基础(Accessibility Foundation)**:WCAG 2.1 AA 合规标准,键盘导航、屏幕阅读器支持
-- **组件层级(Component Hierarchy)**:Layout Components → Content Components → Interactive Components → Utility Components 四层架构
-- **交接文档(Developer Handoff Documentation)**:包含优先级顺序、文件结构、实现笔记的完整交付模板
-
-## Key Entities
-- **ArchitectUX**:Technical Architecture and UX Foundation Specialist Agent,紫色主题,📐 emoji,为 [[LuxuryDeveloper]] 提供可实施的技术基础
-- **LuxuryDeveloper**:The Agency 开发智能体,接收 ArchitectUX 的 CSS 系统和架构规范进行具体实现
-- **ProjectManager**:The Agency 项目管理智能体,提供任务列表,ArchitectUX 在其基础上添加技术基础层
-
-## Connections
-- [[Project/fonrey/prompt/Role/design-ui-designer]] ← extends ← [[wiki/sources/design-ux-architect]]:UI 设计师在 ArchitectUX 建立的基础层上添加视觉设计细节
-- [[design-ux-researcher]] ← depends_on ← [[wiki/sources/design-ux-architect]]:UX 研究员的原型和交互规范依赖 ArchitectUX 的技术框架实现
-- [[design-brand-guardian]] ← coordinates ← [[wiki/sources/design-ux-architect]]:品牌规范约束 ArchitectUX 的 CSS 颜色令牌和排版系统
-- [[design-whimsy-injector]] ← adds_on ← [[wiki/sources/design-ux-architect]]:趣味元素注入者在基础架构完成后添加动效和个性风格
-- [[The Agency]] ← contains ← [[wiki/sources/design-ux-architect]]:ArchitectUX 是 The Agency 12 大部门之一 Design 部门的重要智能体
-- [[Multi-Agent-System-Reliability]] ← provides_pattern ← [[wiki/sources/design-ux-architect]]:多智能体可靠性模式(如 Handoff Protocol)指导 ArchitectUX 的交接文档规范
-
-## Contradictions
-- 与 [[Project/fonrey/prompt/Role/design-ui-designer]] 在实现优先级上可能存在张力:ArchitectUX 主张"先基础后视觉",UI 设计师可能倾向视觉优先。**当前观点**:基础优先,视觉细节在 CSS 系统稳定后添加,避免重构
+---
+title: "ArchitectUX Agent Personality"
+type: source
+tags: [agent, design, ux, css, frontend, the-agency]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/design/design-ux-architect.md]]
+
+## Summary(用中文描述)
+- 核心主题:ArchitectUX 智能体的角色定义——为开发者提供坚实的技术架构和 UX 基础,消除架构决策疲劳
+- 问题域:Web 项目中 CSS 系统混乱、响应式策略缺失、主题切换缺失等开发者痛点
+- 方法/机制:通过 CSS 设计系统(变量/排版/间距/颜色令牌)、布局框架(Grid/Flexbox)、信息架构、ThemeManager JS 类实现
+- 结论/价值:ArchitectUX 作为 [[The Agency]] 设计部门的多智能体之一,负责在 LuxuryDeveloper 实施前建立可扩展的技术基础
+
+## Key Claims(用中文描述)
+- **ArchitectUX** ← 创建 → **CSS 设计系统基础**:通过 CSS 变量令牌体系(颜色/排版/间距/容器)实现跨项目可维护的样式架构,消除硬编码值
+- **主题切换** ← 强制要求 → **所有新站点必须包含**:light/dark/system 三模式切换,preserves 用户偏好,支持 WCAG 合规
+- **架构优先** ← 预防 → **CSS 冲突**:在实施前先设计组件层级和命名规范,防止样式冲突和技术债务
+- **系统架构领导力** ← 负责 → **仓库拓扑/数据契约/API规范**:确保跨系统一致性和 Schema 合规
+- **开发者生产力** ← 通过 → **消除架构决策疲劳**:提供清晰可实施的规范,减少返工和重复决策
+
+## Key Quotes
+> "Create scalable CSS architecture before implementation begins" — Foundation-First Approach 原则,要求在动手前先建立系统
+> "Eliminate architectural decision fatigue for developers" — Developer Productivity Focus 核心理念,ArchitectUX 存在的核心价值主张
+
+## Key Concepts
+- **CSS 设计系统(CSS Design System)**:由 CSS 变量令牌(颜色/排版/间距/组件)构成的标准化样式体系,支持 light/dark/system 主题切换
+- **布局框架(Layout Framework)**:基于现代 CSS Grid/Flexbox 的容器系统和响应式断点策略(mobile-first)
+- **ThemeManager**:管理 light/dark/system 三种主题状态切换的 JavaScript 类,持久化用户偏好至 localStorage
+- **信息架构(Information Architecture)**:页面层级结构、导航策略、内容权重系统(H1 > H2 > H3)
+- **可访问性基础(Accessibility Foundation)**:WCAG 2.1 AA 合规标准,键盘导航、屏幕阅读器支持
+- **组件层级(Component Hierarchy)**:Layout Components → Content Components → Interactive Components → Utility Components 四层架构
+- **交接文档(Developer Handoff Documentation)**:包含优先级顺序、文件结构、实现笔记的完整交付模板
+
+## Key Entities
+- **ArchitectUX**:Technical Architecture and UX Foundation Specialist Agent,紫色主题,📐 emoji,为 [[LuxuryDeveloper]] 提供可实施的技术基础
+- **LuxuryDeveloper**:The Agency 开发智能体,接收 ArchitectUX 的 CSS 系统和架构规范进行具体实现
+- **ProjectManager**:The Agency 项目管理智能体,提供任务列表,ArchitectUX 在其基础上添加技术基础层
+
+## Connections
+- [[Project/fonrey/prompt/Role/design-ui-designer]] ← extends ← [[wiki/sources/design-ux-architect]]:UI 设计师在 ArchitectUX 建立的基础层上添加视觉设计细节
+- [[design-ux-researcher]] ← depends_on ← [[wiki/sources/design-ux-architect]]:UX 研究员的原型和交互规范依赖 ArchitectUX 的技术框架实现
+- [[design-brand-guardian]] ← coordinates ← [[wiki/sources/design-ux-architect]]:品牌规范约束 ArchitectUX 的 CSS 颜色令牌和排版系统
+- [[design-whimsy-injector]] ← adds_on ← [[wiki/sources/design-ux-architect]]:趣味元素注入者在基础架构完成后添加动效和个性风格
+- [[The Agency]] ← contains ← [[wiki/sources/design-ux-architect]]:ArchitectUX 是 The Agency 12 大部门之一 Design 部门的重要智能体
+- [[Multi-Agent-System-Reliability]] ← provides_pattern ← [[wiki/sources/design-ux-architect]]:多智能体可靠性模式(如 Handoff Protocol)指导 ArchitectUX 的交接文档规范
+
+## Contradictions
+- 与 [[Project/fonrey/prompt/Role/design-ui-designer]] 在实现优先级上可能存在张力:ArchitectUX 主张"先基础后视觉",UI 设计师可能倾向视觉优先。**当前观点**:基础优先,视觉细节在 CSS 系统稳定后添加,避免重构
diff --git a/wiki/sources/design-ux-researcher.md b/wiki/sources/design-ux-researcher.md
index f7249c0a..43cc68b3 100644
--- a/wiki/sources/design-ux-researcher.md
+++ b/wiki/sources/design-ux-researcher.md
@@ -1,58 +1,58 @@
----
-title: "UX Researcher Agent Personality"
-type: source
-tags: ["UX", "Research", "Agent", "Design", "User-Experience", "The-Agency"]
-date: 2026-04-24
----
-
-## Source File
-- [[Agent/agency-agents/design/design-ux-researcher.md]]
-
-## Summary(用中文描述)
-- 核心主题:UX Researcher Agent 是一种专注于用户体验研究的 AI Agent,通过严谨的研究方法和数据驱动的洞察来弥合用户需求与设计解决方案之间的差距
-- 问题域:用户行为分析、可用性测试、定性与定量研究方法、产品决策验证
-- 方法/机制:混合研究设计、三角验证、用户旅程映射、A/B 测试、统计分析、可访问性研究
-- 结论/价值:确保设计决策基于真实用户数据而非假设,提高产品可用性和用户满意度
-
-## Key Claims(用中文描述)
-- UX Researcher Agent 通过定性和定量方法的混合研究设计,产生可靠、可操作的洞察
-- 用户体验研究必须遵循研究方法论优先原则:先建立明确的研究问题,再选择适当方法
-- 可访问性研究和包容性设计测试是默认要求,而非可选附加项
-- 研究发现通过三角验证和多数据源进行验证,确保质量和可靠性
-- 研究推荐被设计和产品团队实施的比率(80%+)是衡量 UX Researcher 成功的关键指标
-
-## Key Quotes
-> "Validates design decisions with real user data, not assumptions." — Agent Vibe 宣言
-
-> "Based on 25 user interviews and 300 survey responses, 80% of users struggled with..." — 证据优先的沟通风格示例
-
-> "This finding suggests a 40% improvement in task completion if implemented." — 聚焦影响力的表达方式
-
-## Key Concepts
-- [[Mixed-Methods Research]]:混合方法研究,结合定性和定量方法回答复杂研究问题
-- [[Usability Testing]]:可用性测试,通过真实用户任务执行验证产品易用性
-- [[User Persona]]:用户画像,基于实证数据创建的目标用户原型
-- [[User Journey Mapping]]:用户旅程映射,识别痛点和优化机会的完整用户路径分析
-- [[Triangulation]]:三角验证,通过多种数据源和方法验证研究发现
-- [[A/B Testing]]:A/B 测试,用于数据驱动决策的统计实验方法
-- [[Accessibility Research]]:可访问性研究,确保包容性设计覆盖残障用户群体
-- [[Behavioral Analytics]]:行为分析,解读和识别用户行为模式
-- [[Research Repository]]:研究知识库,构建机构知识积累的持续改进机制
-
-## Key Entities
-- [[Design Teams]]:设计团队,研究洞察的主要消费者和应用者
-- [[Product Teams]]:产品团队,基于用户研究做出产品决策
-- [[Stakeholders]]:利益相关者,研究发现的受众和决策影响者
-- [[The Agency]]:父组织,提供 Agent 框架和协作上下文
-
-## Connections
-- [[design-ux-architect]] ← complements ← [[design-ux-researcher]]:研究与设计协同
-- [[design-whimsy-injector]] ← informs ← [[design-ux-researcher]]:用户洞察驱动设计趣味性
-- [[Product Feedback Synthesizer]] ← depends_on ← [[design-ux-researcher]]:反馈综合依赖用户研究
-
-## Contradictions
-- 与 [[Design Whimsy Injector]] 可能的张力:
- - 冲突点:数据驱动的理性设计与创意趣味表达的关系
- - 当前观点:UX Researcher 强调验证设计决策需基于用户数据
- - 对方观点:Design Whimsy Injector 追求情感共鸣和创意突破
- - 协调方式:两者互补——研究验证用户需求,创意满足情感期望
+---
+title: "UX Researcher Agent Personality"
+type: source
+tags: ["UX", "Research", "Agent", "Design", "User-Experience", "The-Agency"]
+date: 2026-04-24
+---
+
+## Source File
+- [[raw/Agent/agency-agents/design/design-ux-researcher.md]]
+
+## Summary(用中文描述)
+- 核心主题:UX Researcher Agent 是一种专注于用户体验研究的 AI Agent,通过严谨的研究方法和数据驱动的洞察来弥合用户需求与设计解决方案之间的差距
+- 问题域:用户行为分析、可用性测试、定性与定量研究方法、产品决策验证
+- 方法/机制:混合研究设计、三角验证、用户旅程映射、A/B 测试、统计分析、可访问性研究
+- 结论/价值:确保设计决策基于真实用户数据而非假设,提高产品可用性和用户满意度
+
+## Key Claims(用中文描述)
+- UX Researcher Agent 通过定性和定量方法的混合研究设计,产生可靠、可操作的洞察
+- 用户体验研究必须遵循研究方法论优先原则:先建立明确的研究问题,再选择适当方法
+- 可访问性研究和包容性设计测试是默认要求,而非可选附加项
+- 研究发现通过三角验证和多数据源进行验证,确保质量和可靠性
+- 研究推荐被设计和产品团队实施的比率(80%+)是衡量 UX Researcher 成功的关键指标
+
+## Key Quotes
+> "Validates design decisions with real user data, not assumptions." — Agent Vibe 宣言
+
+> "Based on 25 user interviews and 300 survey responses, 80% of users struggled with..." — 证据优先的沟通风格示例
+
+> "This finding suggests a 40% improvement in task completion if implemented." — 聚焦影响力的表达方式
+
+## Key Concepts
+- [[Mixed-Methods Research]]:混合方法研究,结合定性和定量方法回答复杂研究问题
+- [[Usability Testing]]:可用性测试,通过真实用户任务执行验证产品易用性
+- [[User Persona]]:用户画像,基于实证数据创建的目标用户原型
+- [[User Journey Mapping]]:用户旅程映射,识别痛点和优化机会的完整用户路径分析
+- [[Triangulation]]:三角验证,通过多种数据源和方法验证研究发现
+- [[A/B Testing]]:A/B 测试,用于数据驱动决策的统计实验方法
+- [[Accessibility Research]]:可访问性研究,确保包容性设计覆盖残障用户群体
+- [[Behavioral Analytics]]:行为分析,解读和识别用户行为模式
+- [[Research Repository]]:研究知识库,构建机构知识积累的持续改进机制
+
+## Key Entities
+- [[Design Teams]]:设计团队,研究洞察的主要消费者和应用者
+- [[Product Teams]]:产品团队,基于用户研究做出产品决策
+- [[Stakeholders]]:利益相关者,研究发现的受众和决策影响者
+- [[The Agency]]:父组织,提供 Agent 框架和协作上下文
+
+## Connections
+- [[design-ux-architect]] ← complements ← [[design-ux-researcher]]:研究与设计协同
+- [[design-whimsy-injector]] ← informs ← [[design-ux-researcher]]:用户洞察驱动设计趣味性
+- [[Product Feedback Synthesizer]] ← depends_on ← [[design-ux-researcher]]:反馈综合依赖用户研究
+
+## Contradictions
+- 与 [[Design Whimsy Injector]] 可能的张力:
+ - 冲突点:数据驱动的理性设计与创意趣味表达的关系
+ - 当前观点:UX Researcher 强调验证设计决策需基于用户数据
+ - 对方观点:Design Whimsy Injector 追求情感共鸣和创意突破
+ - 协调方式:两者互补——研究验证用户需求,创意满足情感期望
diff --git a/wiki/sources/design-visual-storyteller.md b/wiki/sources/design-visual-storyteller.md
index 12cd48cf..f705f4c2 100644
--- a/wiki/sources/design-visual-storyteller.md
+++ b/wiki/sources/design-visual-storyteller.md
@@ -1,45 +1,45 @@
----
-title: "Visual Storyteller Agent"
-type: source
-tags: ["agent", "design", "visual", "storytelling", "multimedia"]
-date: 2026-05-05
----
-
-## Source File
-- [[Agent/agency-agents/design/design-visual-storyteller.md]]
-
-## Summary(用中文描述)
-- 核心主题:Visual Storyteller Agent 的角色定义——视觉叙事与品牌故事创作专家智能体
-- 问题域:如何将复杂信息转化为能引发情感共鸣、驱动用户参与的视觉叙事内容
-- 方法/机制:故事弧创作(Beginning-Middle-End)、情感旅程映射、跨平台视觉策略、多媒体内容创作
-- 结论/价值:Visual Storyteller Agent 通过叙事结构设计、情绪节奏把控和跨平台适配,确保视觉内容在所有触点上保持一致的情感冲击力,提升品牌认知度和用户参与度
-
-## Key Claims(用中文描述)
-- 每个视觉故事必须具备清晰叙事结构(开头、中间、结尾),确保叙事的完整性和情感递进
-- 视觉内容在所有平台必须保持品牌一致性,适配不同平台算法和用户行为特征
-- 所有视觉内容必须满足 WCAG 可访问性标准,确保包容性
-- 视觉叙事内容参与度提升 50%+,故事完成率达 80%,品牌认知度提升 35%
-
-## Key Quotes
-> "Every visual story must have clear narrative structure (beginning, middle, end)." — Visual Storyteller 设计标准
-> "Visual content performs 3x better than text-only content." — Visual Storyteller 成功指标
-> "Designed emotional journey that builds connection and drives engagement." — Visual Storyteller 沟通风格
-
-## Key Concepts
-- [[Story Arc Creation]]:叙事弧创作——开头(背景设定)、中间(冲突推进)、结尾(解决方案呈现)
-- [[Emotional Journey Mapping]]:情感旅程映射——绘制故事中情感的高峰与低谷,优化用户参与节奏
-- [[Data Storytelling]]:数据叙事——通过视觉层次和叙事流程将复杂信息转化为引人入胜的故事
-- [[Cross-Platform Adaptation]]:跨平台适配——根据平台特性(Instagram/TikTok/YouTube/LinkedIn)调整视觉内容格式和叙事节奏
-- [[Motion Graphics]]:动态图形——动画、微交互和解释性动画的创作
-- [[Visual Pacing]]:视觉节奏——视觉元素的节奏和时序安排,实现最优参与度
-- [[Progressive Disclosure]]:渐进式披露——分层信息呈现策略,帮助用户逐步理解复杂内容
-- [[Brand Narrative Strategy]]:品牌叙事策略——跨所有触点的统一品牌故事体系
-
-## Key Entities
-- Visual Storyteller Agent:多 Agent 协作系统中的视觉叙事专家角色,负责将复杂信息转化为引人入胜的视觉故事
-
-## Connections
-- [[Design Brand Guardian]] ← complements ← [[Visual Storyteller]](品牌身份体系支撑视觉叙事的一致性)
-- [[Design Inclusive Visuals Specialist]] ← extends ← [[Visual Storyteller]](包容性视觉原则融入叙事内容)
-- [[UX Researcher Agent]] → informs → [[Visual Storyteller]](用户研究洞察驱动情感旅程设计)
-- [[Design UI Designer]] ← depends_on ← [[Visual Storyteller]](叙事框架需要 UI 设计师的界面呈现支撑)
+---
+title: "Visual Storyteller Agent"
+type: source
+tags: ["agent", "design", "visual", "storytelling", "multimedia"]
+date: 2026-05-05
+---
+
+## Source File
+- [[raw/Agent/agency-agents/design/design-visual-storyteller.md]]
+
+## Summary(用中文描述)
+- 核心主题:Visual Storyteller Agent 的角色定义——视觉叙事与品牌故事创作专家智能体
+- 问题域:如何将复杂信息转化为能引发情感共鸣、驱动用户参与的视觉叙事内容
+- 方法/机制:故事弧创作(Beginning-Middle-End)、情感旅程映射、跨平台视觉策略、多媒体内容创作
+- 结论/价值:Visual Storyteller Agent 通过叙事结构设计、情绪节奏把控和跨平台适配,确保视觉内容在所有触点上保持一致的情感冲击力,提升品牌认知度和用户参与度
+
+## Key Claims(用中文描述)
+- 每个视觉故事必须具备清晰叙事结构(开头、中间、结尾),确保叙事的完整性和情感递进
+- 视觉内容在所有平台必须保持品牌一致性,适配不同平台算法和用户行为特征
+- 所有视觉内容必须满足 WCAG 可访问性标准,确保包容性
+- 视觉叙事内容参与度提升 50%+,故事完成率达 80%,品牌认知度提升 35%
+
+## Key Quotes
+> "Every visual story must have clear narrative structure (beginning, middle, end)." — Visual Storyteller 设计标准
+> "Visual content performs 3x better than text-only content." — Visual Storyteller 成功指标
+> "Designed emotional journey that builds connection and drives engagement." — Visual Storyteller 沟通风格
+
+## Key Concepts
+- [[Story Arc Creation]]:叙事弧创作——开头(背景设定)、中间(冲突推进)、结尾(解决方案呈现)
+- [[Emotional Journey Mapping]]:情感旅程映射——绘制故事中情感的高峰与低谷,优化用户参与节奏
+- [[Data Storytelling]]:数据叙事——通过视觉层次和叙事流程将复杂信息转化为引人入胜的故事
+- [[Cross-Platform Adaptation]]:跨平台适配——根据平台特性(Instagram/TikTok/YouTube/LinkedIn)调整视觉内容格式和叙事节奏
+- [[Motion Graphics]]:动态图形——动画、微交互和解释性动画的创作
+- [[Visual Pacing]]:视觉节奏——视觉元素的节奏和时序安排,实现最优参与度
+- [[Progressive Disclosure]]:渐进式披露——分层信息呈现策略,帮助用户逐步理解复杂内容
+- [[Brand Narrative Strategy]]:品牌叙事策略——跨所有触点的统一品牌故事体系
+
+## Key Entities
+- Visual Storyteller Agent:多 Agent 协作系统中的视觉叙事专家角色,负责将复杂信息转化为引人入胜的视觉故事
+
+## Connections
+- [[Design Brand Guardian]] ← complements ← [[Visual Storyteller]](品牌身份体系支撑视觉叙事的一致性)
+- [[Design Inclusive Visuals Specialist]] ← extends ← [[Visual Storyteller]](包容性视觉原则融入叙事内容)
+- [[UX Researcher Agent]] → informs → [[Visual Storyteller]](用户研究洞察驱动情感旅程设计)
+- [[Design UI Designer]] ← depends_on ← [[Visual Storyteller]](叙事框架需要 UI 设计师的界面呈现支撑)
diff --git a/wiki/sources/design-whimsy-injector.md b/wiki/sources/design-whimsy-injector.md
index 46a10583..eba25ad3 100644
--- a/wiki/sources/design-whimsy-injector.md
+++ b/wiki/sources/design-whimsy-injector.md
@@ -1,47 +1,47 @@
----
-title: "Design Whimsy Injector"
-type: source
-tags: []
-date: 2026-05-05
----
-
-## Source File
-- [[Agent/agency-agents/design/design-whimsy-injector.md]]
-
-## Summary(用中文描述)
-- 核心主题:品牌个性化和愉悦感注入 Agent 角色定义(Whimsy Injector),为 LuxuryDeveloper 提供品牌人格、微交互和游戏化设计能力
-- 问题域:如何在保持专业性和品牌一致性的前提下,通过意想不到的趣味元素让品牌体验令人难忘
-- 方法/机制:Whimsy Injector 通过四大策略(战略人格注入、包容性愉悦设计、品牌个性框架、微交互设计系统)实现差异化品牌体验
-- 结论/价值:趣味性必须服务于功能或情感目的,包容性设计确保所有用户都能享受愉悦体验,用户参与度提升 40%+
-
-## Key Claims(用中文描述)
-- Whimsy Injector 通过在品牌体验中注入个性和趣味元素,实现品牌差异化——主体:Whimsy Injector,机制:战略性格 + 趣味注入,结果:难忘的差异化品牌体验
-- 包容性愉悦设计确保所有用户(包括残障用户)都能享受趣味体验——主体:Whimsy Injector,机制:包容性愉悦设计,结果:无障碍愉悦体验
-- 微交互设计通过性能优化的动画提升用户参与度——主体:Whimsy Injector,机制:性能优化的微交互设计,结果:参与度提升 40%+
-- 游戏化成就系统通过激励探索和奖励解锁提升用户留存——主体:Whimsy Injector,机制:成就系统 + 彩蛋机制,结果:用户留存提升
-
-## Key Quotes
-> "Be playful yet purposeful: 'Added a celebration animation that reduces task completion anxiety by 40%'" — Whimsy Injector 沟通风格:强调趣味性的战略价值和可量化结果
-> "Design whimsy that enhances user experience rather than creating distraction" — 趣味设计的核心原则:服务于用户体验,而非分散注意力
-> "Every playful element must serve a functional or emotional purpose" — 趣味注入的首要规则:每个趣味元素必须有明确的功能或情感目的
-
-## Key Concepts
-- [[Whimsy-Injector]]:品牌个性和愉悦感注入专家 Agent,通过战略趣味设计实现品牌差异化,隶属于 The Agency 多 Agent 框架
-- [[Micro-Interaction-Design]]:微交互设计系统,通过 CSS 动画和状态反馈提升用户参与度,包含按钮悬停效果、表单验证反馈、加载动画等
-- [[Gamification-System]]:游戏化成就系统,通过徽章解锁、彩蛋发现、进度庆祝等机制激励用户探索和深度使用
-- [[Inclusive-Delight-Design]]:包容性愉悦设计,确保趣味元素对残障用户可访问、不干扰屏幕阅读器、支持减少动画偏好
-
-## Key Entities
-- [[Whimsy-Injector]]:角色名称,品牌个性化和愉悦感注入专家 Agent,color: pink,emoji: ✨
-- [[ArchitectUX]]:UX 架构专家 Agent,与 Whimsy Injector 协作提供完整的品牌体验设计(技术架构 + 品牌人格)
-- [[LuxuryDeveloper]]:目标用户,需要为产品注入品牌个性和差异化体验的开发者
-- [[The Agency]]:多 Agent 框架,Whimsy Injector 隶属的 Agent 协作系统,通过多角色分工实现复杂任务
-
-## Connections
-- [[ArchitectUX]] ← complements ← [[Whimsy-Injector]](ArchitectUX 提供技术基础,Whimsy Injector 提供品牌人格)
-- [[LuxuryDeveloper]] ← uses ← [[Whimsy-Injector]](LuxuryDeveloper 是 Whimsy Injector 的目标用户和受益者)
-- [[Whimsy-Injector]] ← part of ← [[The Agency]](Whimsy Injector 是 The Agency 多 Agent 框架的成员 Agent)
-- [[wiki/sources/design-ux-architect]] ← related_to ← [[design-whimsy-injector]](同一设计分类下的互补角色)
-
-## Contradictions
-- 无冲突内容。Whimsy Injector 与 ArchitectUX 在设计分工上互补(技术架构 vs 品牌人格),无实质性内容冲突。
+---
+title: "Design Whimsy Injector"
+type: source
+tags: []
+date: 2026-05-05
+---
+
+## Source File
+- [[raw/Agent/agency-agents/design/design-whimsy-injector.md]]
+
+## Summary(用中文描述)
+- 核心主题:品牌个性化和愉悦感注入 Agent 角色定义(Whimsy Injector),为 LuxuryDeveloper 提供品牌人格、微交互和游戏化设计能力
+- 问题域:如何在保持专业性和品牌一致性的前提下,通过意想不到的趣味元素让品牌体验令人难忘
+- 方法/机制:Whimsy Injector 通过四大策略(战略人格注入、包容性愉悦设计、品牌个性框架、微交互设计系统)实现差异化品牌体验
+- 结论/价值:趣味性必须服务于功能或情感目的,包容性设计确保所有用户都能享受愉悦体验,用户参与度提升 40%+
+
+## Key Claims(用中文描述)
+- Whimsy Injector 通过在品牌体验中注入个性和趣味元素,实现品牌差异化——主体:Whimsy Injector,机制:战略性格 + 趣味注入,结果:难忘的差异化品牌体验
+- 包容性愉悦设计确保所有用户(包括残障用户)都能享受趣味体验——主体:Whimsy Injector,机制:包容性愉悦设计,结果:无障碍愉悦体验
+- 微交互设计通过性能优化的动画提升用户参与度——主体:Whimsy Injector,机制:性能优化的微交互设计,结果:参与度提升 40%+
+- 游戏化成就系统通过激励探索和奖励解锁提升用户留存——主体:Whimsy Injector,机制:成就系统 + 彩蛋机制,结果:用户留存提升
+
+## Key Quotes
+> "Be playful yet purposeful: 'Added a celebration animation that reduces task completion anxiety by 40%'" — Whimsy Injector 沟通风格:强调趣味性的战略价值和可量化结果
+> "Design whimsy that enhances user experience rather than creating distraction" — 趣味设计的核心原则:服务于用户体验,而非分散注意力
+> "Every playful element must serve a functional or emotional purpose" — 趣味注入的首要规则:每个趣味元素必须有明确的功能或情感目的
+
+## Key Concepts
+- [[Whimsy-Injector]]:品牌个性和愉悦感注入专家 Agent,通过战略趣味设计实现品牌差异化,隶属于 The Agency 多 Agent 框架
+- [[Micro-Interaction-Design]]:微交互设计系统,通过 CSS 动画和状态反馈提升用户参与度,包含按钮悬停效果、表单验证反馈、加载动画等
+- [[Gamification-System]]:游戏化成就系统,通过徽章解锁、彩蛋发现、进度庆祝等机制激励用户探索和深度使用
+- [[Inclusive-Delight-Design]]:包容性愉悦设计,确保趣味元素对残障用户可访问、不干扰屏幕阅读器、支持减少动画偏好
+
+## Key Entities
+- [[Whimsy-Injector]]:角色名称,品牌个性化和愉悦感注入专家 Agent,color: pink,emoji: ✨
+- [[ArchitectUX]]:UX 架构专家 Agent,与 Whimsy Injector 协作提供完整的品牌体验设计(技术架构 + 品牌人格)
+- [[LuxuryDeveloper]]:目标用户,需要为产品注入品牌个性和差异化体验的开发者
+- [[The Agency]]:多 Agent 框架,Whimsy Injector 隶属的 Agent 协作系统,通过多角色分工实现复杂任务
+
+## Connections
+- [[ArchitectUX]] ← complements ← [[Whimsy-Injector]](ArchitectUX 提供技术基础,Whimsy Injector 提供品牌人格)
+- [[LuxuryDeveloper]] ← uses ← [[Whimsy-Injector]](LuxuryDeveloper 是 Whimsy Injector 的目标用户和受益者)
+- [[Whimsy-Injector]] ← part of ← [[The Agency]](Whimsy Injector 是 The Agency 多 Agent 框架的成员 Agent)
+- [[wiki/sources/design-ux-architect]] ← related_to ← [[design-whimsy-injector]](同一设计分类下的互补角色)
+
+## Contradictions
+- 无冲突内容。Whimsy Injector 与 ArchitectUX 在设计分工上互补(技术架构 vs 品牌人格),无实质性内容冲突。
diff --git a/wiki/sources/devops-culture-and-transformation-fostering-collaboration-agile-practices-and-innovation-linkedin.md b/wiki/sources/devops-culture-and-transformation-fostering-collaboration-agile-practices-and-innovation-linkedin.md
index 193f6366..411710b7 100644
--- a/wiki/sources/devops-culture-and-transformation-fostering-collaboration-agile-practices-and-innovation-linkedin.md
+++ b/wiki/sources/devops-culture-and-transformation-fostering-collaboration-agile-practices-and-innovation-linkedin.md
@@ -1,51 +1,51 @@
----
-title: "DevOps Culture and Transformation: Fostering Collaboration, Agile Practices, and Innovation"
-type: source
-tags: []
-date: 2025-03-02
----
-
-## Source File
-- [[Cloud & DevOps/DevOps Culture and Transformation Fostering Collaboration, Agile Practices, and Innovation LinkedIn]]
-
-## Summary(用中文描述)
-- 核心主题:DevOps 文化转型 —— 如何通过打破开发与运维之间的壁垒,推动组织实现更快、更可靠的软件交付与持续创新。
-- 问题域:传统 IT 组织中开发团队与运维团队的目标冲突(开发追求快速交付,运维追求稳定),以及组织文化变革的挑战。
-- 方法/机制:四大 DevOps 文化支柱(协作、自动化、持续改进、客户导向);Agile 与 DevOps 的融合实践;战略转型 playbook(领导层支持、团队赋能、小步试点、克服阻力)。
-- 结论/价值:DevOps 不仅是工具和自动化,而是一场文化变革;拥抱 DevOps 文化 tenets、赋能团队、整合 Agile 实践的组织将在数字时代获得竞争优势。
-
-## Key Claims(用中文描述)
-- DevOps 通过建立跨职能团队,使开发和运维共同承担整个软件生命周期的责任,从而打破传统 IT 组织中的孤岛现象。
-- 自动化(CI/CD 流水线、基础设施即代码、可观测性工具)是 DevOps 的核心驱动力,能消除人工重复劳动、减少错误、加速反馈循环。
-- DevOps 强调持续改进(Kaizen),通过无责事后分析(blameless post-mortems)、数据指标和混沌工程驱动团队迭代学习。
-- Agile 与 DevOps 具有共生关系 —— Agile 关注迭代开发,DevOps 将敏捷延伸到运维,两者共同实现端到端的速度与质量。
-- DevOps 转型需要领导层支持、小步试点快速验证、用成功案例建立势能,而非一次性大爆炸式推行。
-- DevOps 的未来趋势包括:AI/ML 赋能智能自动化、GitOps、Serverless DevOps、边缘计算与 IoT DevOps、以及 DevSecOps 的深化。
-
-## Key Quotes
-> "DevOps isn't just about tools or automation; it's a mindset shift that prioritizes collaboration, continuous learning, and customer-centricity." — 核心论点:DevOps 本质是文化与思维转变
-> "Blameless post-mortems to dissect failures without finger-pointing." — DevOps 文化的关键实践:无惧失败、聚焦改进
-
-## Key Concepts
-- [[DevOps Culture]]:一种打破开发与运维壁垒、以协作、自动化、持续学习和客户导向为核心的文化与运营模式
-- [[CI/CD Pipeline]]:自动化测试、集成和部署流水线,是 DevOps 自动化能力的关键实现
-- [[Infrastructure as Code (IaC)]]:通过代码管理基础设施,实现一致性和版本控制的实践
-- [[Kaizen (Continuous Improvement)]]:持续改进理念,通过无责复盘、数据驱动决策和混沌工程推动迭代优化
-- [[Shift-Left]]:将安全、性能等运维关注点前移至开发阶段,DevSecOps 是其典型实践
-- [[Value Stream Mapping]]:价值流图析,通过可视化工作流识别等待、审批和测试环节的延迟,消除浪费
-- [[GitOps]]:使用 Git 作为唯一真实来源来管理基础设施和部署的运维模式,是 DevOps 的进化方向之一
-- [[Serverless DevOps]]:利用函数即服务(FaaS)等无服务器技术减少运维负担的 DevOps 实践
-- [[Agile-DevOps Integration]]:Agile 与 DevOps 的协同机制,Scrum/Kanban 提供方法论框架,CI/CD 提供工程加速能力
-
-## Key Entities
-- [[Hemant Sawant]]:LinkedIn 文章原作者,DevOps 文化与转型领域的分享者
-- [[Shenwei]]:本文档的保存整理者
-
-## Connections
-- [[DevOps Maturity Model]] ← extends ← [[DevOps Culture]]:本文聚焦 DevOps 文化转型,与成熟度模型互为补充(文化层 vs 能力层级)
-- [[DevSecOps Best Practices]] ← depends_on ← [[DevOps Culture]]:DevSecOps 是 DevOps 文化中"安全性嵌入"支柱的具体实现
-- [[Agile-DevOps Integration]] ← extends ← [[DevOps Culture]]:Agile 与 DevOps 的融合是本文第二大主题
-- [[How Agentic AI Can Help Cloud DevOps]] ← relates_to ← [[DevOps Culture]]:AI/ML 赋能 DevOps 是本文未来趋势之一
-
-## Contradictions
-- (本文档为新摄入来源,暂无已知冲突点)
+---
+title: "DevOps Culture and Transformation: Fostering Collaboration, Agile Practices, and Innovation"
+type: source
+tags: []
+date: 2025-03-02
+---
+
+## Source File
+- [[raw/Cloud & DevOps/DevOps Culture and Transformation Fostering Collaboration, Agile Practices, and Innovation LinkedIn.md]]
+
+## Summary(用中文描述)
+- 核心主题:DevOps 文化转型 —— 如何通过打破开发与运维之间的壁垒,推动组织实现更快、更可靠的软件交付与持续创新。
+- 问题域:传统 IT 组织中开发团队与运维团队的目标冲突(开发追求快速交付,运维追求稳定),以及组织文化变革的挑战。
+- 方法/机制:四大 DevOps 文化支柱(协作、自动化、持续改进、客户导向);Agile 与 DevOps 的融合实践;战略转型 playbook(领导层支持、团队赋能、小步试点、克服阻力)。
+- 结论/价值:DevOps 不仅是工具和自动化,而是一场文化变革;拥抱 DevOps 文化 tenets、赋能团队、整合 Agile 实践的组织将在数字时代获得竞争优势。
+
+## Key Claims(用中文描述)
+- DevOps 通过建立跨职能团队,使开发和运维共同承担整个软件生命周期的责任,从而打破传统 IT 组织中的孤岛现象。
+- 自动化(CI/CD 流水线、基础设施即代码、可观测性工具)是 DevOps 的核心驱动力,能消除人工重复劳动、减少错误、加速反馈循环。
+- DevOps 强调持续改进(Kaizen),通过无责事后分析(blameless post-mortems)、数据指标和混沌工程驱动团队迭代学习。
+- Agile 与 DevOps 具有共生关系 —— Agile 关注迭代开发,DevOps 将敏捷延伸到运维,两者共同实现端到端的速度与质量。
+- DevOps 转型需要领导层支持、小步试点快速验证、用成功案例建立势能,而非一次性大爆炸式推行。
+- DevOps 的未来趋势包括:AI/ML 赋能智能自动化、GitOps、Serverless DevOps、边缘计算与 IoT DevOps、以及 DevSecOps 的深化。
+
+## Key Quotes
+> "DevOps isn't just about tools or automation; it's a mindset shift that prioritizes collaboration, continuous learning, and customer-centricity." — 核心论点:DevOps 本质是文化与思维转变
+> "Blameless post-mortems to dissect failures without finger-pointing." — DevOps 文化的关键实践:无惧失败、聚焦改进
+
+## Key Concepts
+- [[DevOps Culture]]:一种打破开发与运维壁垒、以协作、自动化、持续学习和客户导向为核心的文化与运营模式
+- [[CI/CD Pipeline]]:自动化测试、集成和部署流水线,是 DevOps 自动化能力的关键实现
+- [[Infrastructure as Code (IaC)]]:通过代码管理基础设施,实现一致性和版本控制的实践
+- [[Kaizen (Continuous Improvement)]]:持续改进理念,通过无责复盘、数据驱动决策和混沌工程推动迭代优化
+- [[Shift-Left]]:将安全、性能等运维关注点前移至开发阶段,DevSecOps 是其典型实践
+- [[Value Stream Mapping]]:价值流图析,通过可视化工作流识别等待、审批和测试环节的延迟,消除浪费
+- [[GitOps]]:使用 Git 作为唯一真实来源来管理基础设施和部署的运维模式,是 DevOps 的进化方向之一
+- [[Serverless DevOps]]:利用函数即服务(FaaS)等无服务器技术减少运维负担的 DevOps 实践
+- [[Agile-DevOps Integration]]:Agile 与 DevOps 的协同机制,Scrum/Kanban 提供方法论框架,CI/CD 提供工程加速能力
+
+## Key Entities
+- [[Hemant Sawant]]:LinkedIn 文章原作者,DevOps 文化与转型领域的分享者
+- [[Shenwei]]:本文档的保存整理者
+
+## Connections
+- [[DevOps Maturity Model]] ← extends ← [[DevOps Culture]]:本文聚焦 DevOps 文化转型,与成熟度模型互为补充(文化层 vs 能力层级)
+- [[DevSecOps Best Practices]] ← depends_on ← [[DevOps Culture]]:DevSecOps 是 DevOps 文化中"安全性嵌入"支柱的具体实现
+- [[Agile-DevOps Integration]] ← extends ← [[DevOps Culture]]:Agile 与 DevOps 的融合是本文第二大主题
+- [[How Agentic AI Can Help Cloud DevOps]] ← relates_to ← [[DevOps Culture]]:AI/ML 赋能 DevOps 是本文未来趋势之一
+
+## Contradictions
+- (本文档为新摄入来源,暂无已知冲突点)
diff --git a/wiki/sources/devops-maturity-model-from-traditional-it-to-advanced-devops.md b/wiki/sources/devops-maturity-model-from-traditional-it-to-advanced-devops.md
index 6fa5f684..92568400 100644
--- a/wiki/sources/devops-maturity-model-from-traditional-it-to-advanced-devops.md
+++ b/wiki/sources/devops-maturity-model-from-traditional-it-to-advanced-devops.md
@@ -1,68 +1,68 @@
----
-title: "DevOps Maturity Model From Traditional IT to Advanced DevOps"
-type: source
-tags: [DevOps, DevOps Maturity, CI/CD, Automation, DevSecOps]
-date: 2024-08-14
----
-
-## Source File
-- [[Cloud & DevOps/DevOps Maturity Model From Traditional IT to Advanced DevOps]]
-
-## Summary(用中文描述)
-- 核心主题:DevOps 成熟度模型的五阶段演进框架,从传统 IT 到完全成熟的 DevOps
-- 问题域:组织如何评估当前 DevOps 实践水平,识别改进领域,制定升级路线图
-- 方法/机制:通过四个核心关注领域(文化与战略、自动化、结构与流程、协作与共享、技术)评估组织 DevOps 成熟度,分为五个递进阶段
-- 结论/价值:DevOps 成熟度模型是组织规划 DevOps 转型路径的结构化工具,涵盖从初始/临时阶段到完全成熟连续部署的全过程,并提供衡量指标和常见障碍识别
-
-## Key Claims(用中文描述)
-- DevOps 成熟度模型通过四个关键领域评估组织能力:文化与战略、自动化、结构与流程、协作与共享、技术
-- 五阶段成熟度模型依次为:Phase 1 初始/临时阶段 → Phase 2 局部试点 → Phase 3 自动化与定义 → Phase 4 高度优化 → Phase 5 完全成熟
-- 完全成熟的 DevOps 实践实现零人工干预的流水线、每日多次部署、高确定性低风险发布
-- DevOps 成熟度关键衡量指标包括:部署频率、变更前置时间(Lead Time)、平均恢复时间(MTTR)、变更失败率、错误预算(Error Budget)
-- DevSecOps 将安全集成到 DevOps 每个阶段,是高级成熟度阶段的核心要求
-- 团队协作是 DevOps 的基石,也是衡量团队效能和生产力的关键指标
-
-## Key Quotes
-> "The DevOps Maturity Model is a powerful tool for guiding organizations through the evolution of their DevOps practices, from initial adoption to achieving full maturity." — DevOps 成熟度模型的核心定位
-> "DevOps automation or AutoDevOps is crucial for continuous delivery and deployment. It simplifies development, testing, and production by automating repetitive tasks, which saves time and improves resource efficiency in the CI/CD process." — 自动化在 DevOps 中的核心价值
-> "The core of DevOps security is merging development, operations, and security into a unified process." — DevSecOps 的核心理念
-
-## Key Concepts
-- [[DevOps]]:一种融合开发与运维的文化、实践和技术组合,强调协作、自动化和持续改进
-- [[DevSecOps]]:将安全实践集成到 DevOps 流程的每个阶段(通过 DevOps Maturity Model Phase 4-5 实现)
-- [[Continuous Delivery]]:持续交付,使代码变更可随时安全部署到生产环境
-- [[Agile]]:敏捷方法,从 Phase 2 开始引入,强调业务和用户价值而非仅项目规划
-- [[MVP]]:最小可行产品,在 Phase 4 高度优化阶段用于加速发布
-- [[Technical Debt]]:技术债务,在 Phase 3-4 阶段开始被优先管理和处理
-- [[Infrastructure as Code]](IaC):基础设施即代码,在 Phase 4 实现不可变基础设施替换旧服务器
-- [[MTTR]](Mean Time to Recovery):平均恢复时间,DevOps 成熟度关键衡量指标
-- [[Change Failure Rate]]:变更失败率,DevOps 关键绩效指标之一
-- [[Deployment Frequency]]:部署频率,完全成熟阶段实现每日多次部署
-- [[Lead Time]]:前置时间,从代码提交到部署的时间周期
-- [[concepts/Error-Budget]]:错误预算,允许的生产错误和失败率
-- [[concepts/Immutable-Infrastructure]]:不可变基础设施,在 Phase 4 替换旧服务器而非更新
-- [[Version Control]]:版本控制,从 Phase 2 开始用于管理环境和配置
-
-## Key Entities
-- [[entities/DevOps-Maturity-Model]]:本文核心——评估和指导 DevOps 转型的五阶段成熟度模型
-- [[DevOps Culture and Transformation]]:DevOps 文化转型相关主题,与本文 Phase 1-2 的文化演进强相关
-- [[Release Management]]:发布管理,涵盖部署频率、变更失败率等关键指标,与本文衡量指标重叠
-
-## Connections
-- [[DevOps Culture and Transformation]] ← foundational ← [[entities/DevOps-Maturity-Model]]
-- [[DevOps]] ← encompasses ← [[entities/DevOps-Maturity-Model]]
-- [[DevSecOps]] ← integrates ← [[DevOps]] + Security(本文 Phase 4-5 体现)
-- [[Continuous Delivery]] ← supports ← [[entities/DevOps-Maturity-Model]]
-- [[Release Management]] ← measures ← DevOps Maturity(共享 Deployment Frequency, Lead Time, MTTR 等指标)
-- [[concepts/Error-Budget]] ← part of ← DORA Metrics
-- [[concepts/Immutable-Infrastructure]] ← enables ← Phase 4 高度优化
-
-## Contradictions
-- 与 [[DevOps Culture and Transformation]] 的潜在视角差异:
- - 冲突点:文化转型是 DevOps 成功的前提还是结果?
- - 当前观点(本文):文化是成熟度的一个评估维度,从 Phase 1(孤立文化)到 Phase 5(自足全栈团队)
- - 对方观点:文化转型应该是最先启动的变革,需先改变团队协作方式才能推进其他实践
-- 与 [[Waterfall]] 的对比冲突:
- - 冲突点:传统瀑布式方法是否完全无法满足现代软件交付需求?
- - 当前观点(本文):瀑布式是 Phase 1 的典型特征,以里程碑而非用户反馈驱动,是需要淘汰的落后模式
- - 对方观点:瀑布式在稳定需求、长周期硬件项目或合规要求严格的场景中仍有价值
+---
+title: "DevOps Maturity Model From Traditional IT to Advanced DevOps"
+type: source
+tags: [DevOps, DevOps Maturity, CI/CD, Automation, DevSecOps]
+date: 2024-08-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/DevOps Maturity Model From Traditional IT to Advanced DevOps.md]]
+
+## Summary(用中文描述)
+- 核心主题:DevOps 成熟度模型的五阶段演进框架,从传统 IT 到完全成熟的 DevOps
+- 问题域:组织如何评估当前 DevOps 实践水平,识别改进领域,制定升级路线图
+- 方法/机制:通过四个核心关注领域(文化与战略、自动化、结构与流程、协作与共享、技术)评估组织 DevOps 成熟度,分为五个递进阶段
+- 结论/价值:DevOps 成熟度模型是组织规划 DevOps 转型路径的结构化工具,涵盖从初始/临时阶段到完全成熟连续部署的全过程,并提供衡量指标和常见障碍识别
+
+## Key Claims(用中文描述)
+- DevOps 成熟度模型通过四个关键领域评估组织能力:文化与战略、自动化、结构与流程、协作与共享、技术
+- 五阶段成熟度模型依次为:Phase 1 初始/临时阶段 → Phase 2 局部试点 → Phase 3 自动化与定义 → Phase 4 高度优化 → Phase 5 完全成熟
+- 完全成熟的 DevOps 实践实现零人工干预的流水线、每日多次部署、高确定性低风险发布
+- DevOps 成熟度关键衡量指标包括:部署频率、变更前置时间(Lead Time)、平均恢复时间(MTTR)、变更失败率、错误预算(Error Budget)
+- DevSecOps 将安全集成到 DevOps 每个阶段,是高级成熟度阶段的核心要求
+- 团队协作是 DevOps 的基石,也是衡量团队效能和生产力的关键指标
+
+## Key Quotes
+> "The DevOps Maturity Model is a powerful tool for guiding organizations through the evolution of their DevOps practices, from initial adoption to achieving full maturity." — DevOps 成熟度模型的核心定位
+> "DevOps automation or AutoDevOps is crucial for continuous delivery and deployment. It simplifies development, testing, and production by automating repetitive tasks, which saves time and improves resource efficiency in the CI/CD process." — 自动化在 DevOps 中的核心价值
+> "The core of DevOps security is merging development, operations, and security into a unified process." — DevSecOps 的核心理念
+
+## Key Concepts
+- [[DevOps]]:一种融合开发与运维的文化、实践和技术组合,强调协作、自动化和持续改进
+- [[DevSecOps]]:将安全实践集成到 DevOps 流程的每个阶段(通过 DevOps Maturity Model Phase 4-5 实现)
+- [[Continuous Delivery]]:持续交付,使代码变更可随时安全部署到生产环境
+- [[Agile]]:敏捷方法,从 Phase 2 开始引入,强调业务和用户价值而非仅项目规划
+- [[MVP]]:最小可行产品,在 Phase 4 高度优化阶段用于加速发布
+- [[Technical Debt]]:技术债务,在 Phase 3-4 阶段开始被优先管理和处理
+- [[Infrastructure as Code]](IaC):基础设施即代码,在 Phase 4 实现不可变基础设施替换旧服务器
+- [[MTTR]](Mean Time to Recovery):平均恢复时间,DevOps 成熟度关键衡量指标
+- [[Change Failure Rate]]:变更失败率,DevOps 关键绩效指标之一
+- [[Deployment Frequency]]:部署频率,完全成熟阶段实现每日多次部署
+- [[Lead Time]]:前置时间,从代码提交到部署的时间周期
+- [[concepts/Error-Budget]]:错误预算,允许的生产错误和失败率
+- [[concepts/Immutable-Infrastructure]]:不可变基础设施,在 Phase 4 替换旧服务器而非更新
+- [[Version Control]]:版本控制,从 Phase 2 开始用于管理环境和配置
+
+## Key Entities
+- [[entities/DevOps-Maturity-Model]]:本文核心——评估和指导 DevOps 转型的五阶段成熟度模型
+- [[DevOps Culture and Transformation]]:DevOps 文化转型相关主题,与本文 Phase 1-2 的文化演进强相关
+- [[Release Management]]:发布管理,涵盖部署频率、变更失败率等关键指标,与本文衡量指标重叠
+
+## Connections
+- [[DevOps Culture and Transformation]] ← foundational ← [[entities/DevOps-Maturity-Model]]
+- [[DevOps]] ← encompasses ← [[entities/DevOps-Maturity-Model]]
+- [[DevSecOps]] ← integrates ← [[DevOps]] + Security(本文 Phase 4-5 体现)
+- [[Continuous Delivery]] ← supports ← [[entities/DevOps-Maturity-Model]]
+- [[Release Management]] ← measures ← DevOps Maturity(共享 Deployment Frequency, Lead Time, MTTR 等指标)
+- [[concepts/Error-Budget]] ← part of ← DORA Metrics
+- [[concepts/Immutable-Infrastructure]] ← enables ← Phase 4 高度优化
+
+## Contradictions
+- 与 [[DevOps Culture and Transformation]] 的潜在视角差异:
+ - 冲突点:文化转型是 DevOps 成功的前提还是结果?
+ - 当前观点(本文):文化是成熟度的一个评估维度,从 Phase 1(孤立文化)到 Phase 5(自足全栈团队)
+ - 对方观点:文化转型应该是最先启动的变革,需先改变团队协作方式才能推进其他实践
+- 与 [[Waterfall]] 的对比冲突:
+ - 冲突点:传统瀑布式方法是否完全无法满足现代软件交付需求?
+ - 当前观点(本文):瀑布式是 Phase 1 的典型特征,以里程碑而非用户反馈驱动,是需要淘汰的落后模式
+ - 对方观点:瀑布式在稳定需求、长周期硬件项目或合规要求严格的场景中仍有价值
diff --git a/wiki/sources/dynamic-dashboard.md b/wiki/sources/dynamic-dashboard.md
index f31ce559..a1a5416e 100644
--- a/wiki/sources/dynamic-dashboard.md
+++ b/wiki/sources/dynamic-dashboard.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/dynamic-dashboard.md]]
+- [[raw/Agent/usecases/dynamic-dashboard.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 驱动的实时动态仪表盘——通过子 Agent 并行抓取多数据源,自动聚合为统一仪表盘并定时推送到 Discord 或生成 HTML 文件
diff --git a/wiki/sources/earnings-tracker.md b/wiki/sources/earnings-tracker.md
index e2d39125..f225017d 100644
--- a/wiki/sources/earnings-tracker.md
+++ b/wiki/sources/earnings-tracker.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/earnings-tracker.md]]
+- [[raw/Agent/usecases/earnings-tracker.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 自动追踪科技公司财报并生成摘要推送至 Telegram
diff --git a/wiki/sources/engineering-autonomous-optimization-architect.md b/wiki/sources/engineering-autonomous-optimization-architect.md
index 9b2a1337..17b6d10e 100644
--- a/wiki/sources/engineering-autonomous-optimization-architect.md
+++ b/wiki/sources/engineering-autonomous-optimization-architect.md
@@ -1,52 +1,52 @@
----
-title: "Autonomous Optimization Architect"
-type: source
-tags: ["ai-finetuning", "llm-routing", "ai-fintech", "autonomous-agents", "cost-optimization"]
-date: 2026-04-26
----
-
-## Source File
-- [[Agent/agency-agents/engineering/engineering-autonomous-optimization-architect.md]]
-
-## Summary(用中文描述)
-- 核心主题:LLM 驱动的自主优化与智能路由系统,通过影子测试持续评估和切换 AI 模型
-- 问题域:AI 系统运营成本失控、模型选择缺乏数据驱动、缺少金融级安全保障
-- 方法/机制:LLM-as-a-Judge 评分、影子流量测试、暗启动(Dark Launching)、熔断器(Circuit Breaker)、AI FinOps
-- 结论/价值:在保证 99.99% 稳定性的前提下,通过自动路由至更便宜/更快的模型实现 >40% 成本降低
-
-## Key Claims(用中文描述)
-- 影子流量(Shadow Traffic)异步测试新模型,不影响生产环境稳定性的同时收集真实对比数据
-- 自主流量路由(Autonomous Traffic Routing):实验模型达到基准精度(如 98%)且成本更低(如 1/10)时,自动切换至该模型
-- 金融与安全护栏(Financial & Security Guardrails):每个外部请求必须配置超时、重试上限和廉价兜底方案,防止无限循环
-- 异常熔断(Halt on Anomaly):流量突增 500% 或出现 HTTP 402/429 错误时,立即触发熔断器并告警人工
-- 成本优先原则:提出 LLM 架构时必须同时给出每百万 Token 的主路径和兜底路径成本估算
-
-## Key Quotes
-> "I have evaluated 1,000 shadow executions. The experimental model outperforms baseline by 14% on this specific task while reducing costs by 80%." — Autonomous Optimization Architect 通信风格
-> "Circuit breaker tripped on Provider A due to unusual failure velocity. Automating failover to Provider B to prevent token drain. Admin alerted." — 熔断触发时的标准告警语
-> "Autonomous routing without a circuit breaker is just an expensive bomb." — 该 Agent 的核心理念
-
-## Key Concepts
-- [[CircuitBreaker]]:熔断器模式,当 Provider 失败频率超过阈值时自动切断并切换到廉价兜底方案
-- [[LLMasJudge]]:用 LLM 自动评估实验模型输出的质量,作为客观评分替代人工评审
-- [[ShadowTraffic]]:影子流量,将一小部分请求异步转发至实验模型,与生产结果对比评分
-- [[SemanticRouting]]:语义路由,根据任务类型和历史性能选择最优 Provider
-- [[DarkLaunching]]:暗启动/灰度发布,新模型在不影响用户的前提下逐步引入
-- [[AIFinOps]]:AI 云财务管理,跟踪每个 LLM 的 token 消耗、成本和延迟,建立历史性能排名
-
-## Key Entities
-- [[OpenAI]]:主要 LLM Provider 之一,提供 GPT 系列模型
-- [[Anthropic]]:主要 LLM Provider,提供 Claude 系列模型
-- [[GoogleGemini]]:主要 LLM Provider,提供 Gemini Flash 等高性价比模型
-- [[Firecrawl]]:网页抓取 API,当 LLM Provider 不可用时的备选数据获取方案
-
-## Connections
-- [[testing-workflow-optimizer]] ← uses ← [[AutonomousOptimizationArchitect]](工作流优化依赖路由决策)
-- [[backend-architect-with-memory]] ← depends_on ← [[AutonomousOptimizationArchitect]](后端架构依赖成本追踪记忆)
-- [[automation-governance-architect]] ← shares_guardrails ← [[AutonomousOptimizationArchitect]](自动化治理与本 Agent 均涉及安全护栏设计)
-
-## Contradictions
-- 与 [[testing-performance-benchmarker]] 冲突:
- - 冲突点:性能基准测试强调人工驱动的静态评估,本 Agent 强调机器驱动的动态 A/B 测试
- - 当前观点:持续自动的影子测试比定期人工测试更能反映生产环境真实性能
- - 对方观点:性能基准测试提供可控、可复现的实验室数据,而非真实流量噪声
+---
+title: "Autonomous Optimization Architect"
+type: source
+tags: ["ai-finetuning", "llm-routing", "ai-fintech", "autonomous-agents", "cost-optimization"]
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Agent/agency-agents/engineering/engineering-autonomous-optimization-architect.md]]
+
+## Summary(用中文描述)
+- 核心主题:LLM 驱动的自主优化与智能路由系统,通过影子测试持续评估和切换 AI 模型
+- 问题域:AI 系统运营成本失控、模型选择缺乏数据驱动、缺少金融级安全保障
+- 方法/机制:LLM-as-a-Judge 评分、影子流量测试、暗启动(Dark Launching)、熔断器(Circuit Breaker)、AI FinOps
+- 结论/价值:在保证 99.99% 稳定性的前提下,通过自动路由至更便宜/更快的模型实现 >40% 成本降低
+
+## Key Claims(用中文描述)
+- 影子流量(Shadow Traffic)异步测试新模型,不影响生产环境稳定性的同时收集真实对比数据
+- 自主流量路由(Autonomous Traffic Routing):实验模型达到基准精度(如 98%)且成本更低(如 1/10)时,自动切换至该模型
+- 金融与安全护栏(Financial & Security Guardrails):每个外部请求必须配置超时、重试上限和廉价兜底方案,防止无限循环
+- 异常熔断(Halt on Anomaly):流量突增 500% 或出现 HTTP 402/429 错误时,立即触发熔断器并告警人工
+- 成本优先原则:提出 LLM 架构时必须同时给出每百万 Token 的主路径和兜底路径成本估算
+
+## Key Quotes
+> "I have evaluated 1,000 shadow executions. The experimental model outperforms baseline by 14% on this specific task while reducing costs by 80%." — Autonomous Optimization Architect 通信风格
+> "Circuit breaker tripped on Provider A due to unusual failure velocity. Automating failover to Provider B to prevent token drain. Admin alerted." — 熔断触发时的标准告警语
+> "Autonomous routing without a circuit breaker is just an expensive bomb." — 该 Agent 的核心理念
+
+## Key Concepts
+- [[CircuitBreaker]]:熔断器模式,当 Provider 失败频率超过阈值时自动切断并切换到廉价兜底方案
+- [[LLMasJudge]]:用 LLM 自动评估实验模型输出的质量,作为客观评分替代人工评审
+- [[ShadowTraffic]]:影子流量,将一小部分请求异步转发至实验模型,与生产结果对比评分
+- [[SemanticRouting]]:语义路由,根据任务类型和历史性能选择最优 Provider
+- [[DarkLaunching]]:暗启动/灰度发布,新模型在不影响用户的前提下逐步引入
+- [[AIFinOps]]:AI 云财务管理,跟踪每个 LLM 的 token 消耗、成本和延迟,建立历史性能排名
+
+## Key Entities
+- [[OpenAI]]:主要 LLM Provider 之一,提供 GPT 系列模型
+- [[Anthropic]]:主要 LLM Provider,提供 Claude 系列模型
+- [[GoogleGemini]]:主要 LLM Provider,提供 Gemini Flash 等高性价比模型
+- [[Firecrawl]]:网页抓取 API,当 LLM Provider 不可用时的备选数据获取方案
+
+## Connections
+- [[testing-workflow-optimizer]] ← uses ← [[AutonomousOptimizationArchitect]](工作流优化依赖路由决策)
+- [[backend-architect-with-memory]] ← depends_on ← [[AutonomousOptimizationArchitect]](后端架构依赖成本追踪记忆)
+- [[automation-governance-architect]] ← shares_guardrails ← [[AutonomousOptimizationArchitect]](自动化治理与本 Agent 均涉及安全护栏设计)
+
+## Contradictions
+- 与 [[testing-performance-benchmarker]] 冲突:
+ - 冲突点:性能基准测试强调人工驱动的静态评估,本 Agent 强调机器驱动的动态 A/B 测试
+ - 当前观点:持续自动的影子测试比定期人工测试更能反映生产环境真实性能
+ - 对方观点:性能基准测试提供可控、可复现的实验室数据,而非真实流量噪声
diff --git a/wiki/sources/engineering-mobile-app-builder.md b/wiki/sources/engineering-mobile-app-builder.md
index a6c9e08a..df08dc28 100644
--- a/wiki/sources/engineering-mobile-app-builder.md
+++ b/wiki/sources/engineering-mobile-app-builder.md
@@ -1,56 +1,56 @@
----
-title: "Mobile App Builder Agent Personality"
-type: source
-tags: []
-date: 2026-04-26
----
-
-## Source File
-- [[Agent/agency-agents/engineering/engineering-mobile-app-builder.md]]
-
-## Summary(用中文描述)
-- 核心主题:Mobile App Builder — 专注于原生 iOS/Android 开发和跨平台框架的移动应用开发 AI Agent 人格规范
-- 问题域:如何在移动端构建高性能、平台原生体验的应用;原生开发与跨平台开发的选型决策;移动端特有的性能、续航、离线场景约束
-- 方法/机制:Swift/SwiftUI(iOS)、Kotlin/Jetpack Compose(Android)、React Native/Flutter(跨平台);MVVM 模式;Offline-First 架构;平台原生设计规范(Material Design / Human Interface Guidelines)
-- 结论/价值:移动开发 Agent 需要具备平台意识、性能优先、用户体验驱动的特质,同时保持跨平台的技术多样性
-
-## Key Claims(用中文描述)
-- 原生 iOS/Android 开发必须遵循平台设计指南(Material Design、Human Interface Guidelines)
-- 移动应用必须实现离线优先架构和智能数据同步
-- 跨平台开发需在代码复用与平台原生体验之间找到平衡
-- 移动性能优化目标:冷启动 < 3 秒,内存占用 < 100MB,续航损耗 < 5%/小时
-
-## Key Quotes
-> "Implemented iOS-native navigation with SwiftUI while maintaining Material Design patterns on Android" — 平台感知型开发示例
-> "Built offline-first architecture to handle poor network conditions gracefully" — 移动约束优先的设计理念
-> "Optimized app startup time to 2.1 seconds and reduced memory usage by 40%" — 性能优化的典型目标
-
-## Key Concepts
-- [[Offline-First Architecture]]:离线优先架构 — 构建应用时默认以离线为基准,网络连接时进行数据同步,确保弱网环境下的用户体验
-- [[MVVM Pattern]]:Model-View-ViewModel — SwiftUI 和 Jetpack Compose 推荐的状态管理模式,ViewModel 持有 UI 状态和业务逻辑,View 负责渲染
-- [[Cross-Platform Mobile Development]]:跨平台移动开发 — 使用 React Native 或 Flutter 等框架在 iOS 和 Android 上共享代码,同时保持平台原生特性
-- [[Platform-Native UI]]:平台原生 UI — 遵循各平台设计规范(Material Design / HIG)实现符合用户预期的界面和交互
-- [[Biometric Authentication]]:生物特征认证 — 在移动应用中集成 Face ID、Touch ID 或指纹识别实现安全身份验证
-- [[Push Notification System]]:推送通知系统 — 针对不同平台(APNs/Firebase)实现精准推送,提升用户留存
-
-## Key Entities
-- [[SwiftUI]]:Apple 声明式 UI 框架,用于构建现代 iOS/macOS 应用界面
-- [[Jetpack Compose]]:Google Jetpack 声明式 UI 工具包,Android 原生现代化 UI 开发
-- [[React Native]]:Facebook/Meta 开源跨平台框架,使用 JavaScript/TypeScript 构建原生移动应用
-- [[Flutter]]:Google 开源跨平台 UI 工具包,使用 Dart 语言,可编译为原生 ARM 代码
-- [[Swift]]:Apple iOS/macOS 开发语言,配合 SwiftUI 使用
-- [[Kotlin]]:Google 官方 Android 开发语言,配合 Jetpack Compose 使用
-
-## Connections
-- [[agents-orchestrator]] ← orchestrates ← [[engineering-mobile-app-builder]]
-- [[engineering-mobile-app-builder]] ← shares_workflow ← [[unity-architect]](平台策略和架构决策方法论)
-- [[engineering-mobile-app-builder]] ← extends ← [[software-architect]](系统架构原则应用于移动端)
-- [[visionos-spatial-engineer]] ← related_to ← [[engineering-mobile-app-builder]](Apple 生态移动开发扩展)
-- [[xr-immersive-developer]] ← related_to ← [[engineering-mobile-app-builder]](XR 与移动平台的跨设备体验)
-
-## Contradictions
-- 与 [[unity-architect]] 跨平台理念存在框架差异:
- - 冲突点:原生开发 vs 跨平台框架的优先级
- - 当前观点:Mobile App Builder 默认支持多种框架(SwiftUI、Jetpack Compose、React Native、Flutter),按需选型
- - 对方观点:Unity Architect 专注于 Unity 引擎内的跨平台方案
- - 说明:两者解决的问题域不同,Mobile App Builder 面向通用移动应用,Unity Architect 面向游戏开发,属合理分工而非矛盾
+---
+title: "Mobile App Builder Agent Personality"
+type: source
+tags: []
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Agent/agency-agents/engineering/engineering-mobile-app-builder.md]]
+
+## Summary(用中文描述)
+- 核心主题:Mobile App Builder — 专注于原生 iOS/Android 开发和跨平台框架的移动应用开发 AI Agent 人格规范
+- 问题域:如何在移动端构建高性能、平台原生体验的应用;原生开发与跨平台开发的选型决策;移动端特有的性能、续航、离线场景约束
+- 方法/机制:Swift/SwiftUI(iOS)、Kotlin/Jetpack Compose(Android)、React Native/Flutter(跨平台);MVVM 模式;Offline-First 架构;平台原生设计规范(Material Design / Human Interface Guidelines)
+- 结论/价值:移动开发 Agent 需要具备平台意识、性能优先、用户体验驱动的特质,同时保持跨平台的技术多样性
+
+## Key Claims(用中文描述)
+- 原生 iOS/Android 开发必须遵循平台设计指南(Material Design、Human Interface Guidelines)
+- 移动应用必须实现离线优先架构和智能数据同步
+- 跨平台开发需在代码复用与平台原生体验之间找到平衡
+- 移动性能优化目标:冷启动 < 3 秒,内存占用 < 100MB,续航损耗 < 5%/小时
+
+## Key Quotes
+> "Implemented iOS-native navigation with SwiftUI while maintaining Material Design patterns on Android" — 平台感知型开发示例
+> "Built offline-first architecture to handle poor network conditions gracefully" — 移动约束优先的设计理念
+> "Optimized app startup time to 2.1 seconds and reduced memory usage by 40%" — 性能优化的典型目标
+
+## Key Concepts
+- [[Offline-First Architecture]]:离线优先架构 — 构建应用时默认以离线为基准,网络连接时进行数据同步,确保弱网环境下的用户体验
+- [[MVVM Pattern]]:Model-View-ViewModel — SwiftUI 和 Jetpack Compose 推荐的状态管理模式,ViewModel 持有 UI 状态和业务逻辑,View 负责渲染
+- [[Cross-Platform Mobile Development]]:跨平台移动开发 — 使用 React Native 或 Flutter 等框架在 iOS 和 Android 上共享代码,同时保持平台原生特性
+- [[Platform-Native UI]]:平台原生 UI — 遵循各平台设计规范(Material Design / HIG)实现符合用户预期的界面和交互
+- [[Biometric Authentication]]:生物特征认证 — 在移动应用中集成 Face ID、Touch ID 或指纹识别实现安全身份验证
+- [[Push Notification System]]:推送通知系统 — 针对不同平台(APNs/Firebase)实现精准推送,提升用户留存
+
+## Key Entities
+- [[SwiftUI]]:Apple 声明式 UI 框架,用于构建现代 iOS/macOS 应用界面
+- [[Jetpack Compose]]:Google Jetpack 声明式 UI 工具包,Android 原生现代化 UI 开发
+- [[React Native]]:Facebook/Meta 开源跨平台框架,使用 JavaScript/TypeScript 构建原生移动应用
+- [[Flutter]]:Google 开源跨平台 UI 工具包,使用 Dart 语言,可编译为原生 ARM 代码
+- [[Swift]]:Apple iOS/macOS 开发语言,配合 SwiftUI 使用
+- [[Kotlin]]:Google 官方 Android 开发语言,配合 Jetpack Compose 使用
+
+## Connections
+- [[agents-orchestrator]] ← orchestrates ← [[engineering-mobile-app-builder]]
+- [[engineering-mobile-app-builder]] ← shares_workflow ← [[unity-architect]](平台策略和架构决策方法论)
+- [[engineering-mobile-app-builder]] ← extends ← [[software-architect]](系统架构原则应用于移动端)
+- [[visionos-spatial-engineer]] ← related_to ← [[engineering-mobile-app-builder]](Apple 生态移动开发扩展)
+- [[xr-immersive-developer]] ← related_to ← [[engineering-mobile-app-builder]](XR 与移动平台的跨设备体验)
+
+## Contradictions
+- 与 [[unity-architect]] 跨平台理念存在框架差异:
+ - 冲突点:原生开发 vs 跨平台框架的优先级
+ - 当前观点:Mobile App Builder 默认支持多种框架(SwiftUI、Jetpack Compose、React Native、Flutter),按需选型
+ - 对方观点:Unity Architect 专注于 Unity 引擎内的跨平台方案
+ - 说明:两者解决的问题域不同,Mobile App Builder 面向通用移动应用,Unity Architect 面向游戏开发,属合理分工而非矛盾
diff --git a/wiki/sources/engineering-software-architect.md b/wiki/sources/engineering-software-architect.md
index d6c9ce6d..29b67734 100644
--- a/wiki/sources/engineering-software-architect.md
+++ b/wiki/sources/engineering-software-architect.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/engineering/engineering-software-architect.md]]
+- [[raw/Agent/agency-agents/engineering/engineering-software-architect.md]]
## Summary(用中文描述)
- 核心主题:软件架构与系统设计 Agent 的角色定义,专注于设计可维护、可扩展、符合业务领域的系统架构
diff --git a/wiki/sources/event-guest-confirmation.md b/wiki/sources/event-guest-confirmation.md
index 4f761cd4..061d5bf2 100644
--- a/wiki/sources/event-guest-confirmation.md
+++ b/wiki/sources/event-guest-confirmation.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/event-guest-confirmation]]
+- [[raw/Agent/usecases/event-guest-confirmation.md]]
## Summary(用中文描述)
- 核心主题:使用 OpenClaw + SuperCall 插件实现活动嘉宾自动电话确认
diff --git a/wiki/sources/family-calendar-household-assistant.md b/wiki/sources/family-calendar-household-assistant.md
index e906b712..d64f9aa0 100644
--- a/wiki/sources/family-calendar-household-assistant.md
+++ b/wiki/sources/family-calendar-household-assistant.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/family-calendar-household-assistant]]
+- [[raw/Agent/usecases/family-calendar-household-assistant.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 作为家庭日程协调中心,聚合多源日历、提供晨间简报、监控消息自动创建日历事件、管理家庭库存和购物清单。
diff --git a/wiki/sources/game-audio-engineer.md b/wiki/sources/game-audio-engineer.md
index fcc4d043..c23ba42f 100644
--- a/wiki/sources/game-audio-engineer.md
+++ b/wiki/sources/game-audio-engineer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/game-audio-engineer.md]]
+- [[raw/Agent/agency-agents/game-development/game-audio-engineer.md]]
## Summary(用中文描述)
- 核心主题:游戏交互式音频工程师 AI Agent 人格规范——设计自适应音乐系统、空间音频架构和音频中间件集成方案
diff --git a/wiki/sources/game-designer.md b/wiki/sources/game-designer.md
index a7077318..9cbae379 100644
--- a/wiki/sources/game-designer.md
+++ b/wiki/sources/game-designer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/game-designer.md]]
+- [[raw/Agent/agency-agents/game-development/game-designer.md]]
## Summary(用中文描述)
- 核心主题:GameDesigner Agent 角色定义——一个资深系统与机制设计师,以"循环、杠杆、玩家动机"为思维框架,将创意愿景转化为可执行、无歧义的游戏设计文档
diff --git a/wiki/sources/github-上-5000-人收藏的-vibe-coding-神级指南.md b/wiki/sources/github-上-5000-人收藏的-vibe-coding-神级指南.md
index a861013d..3b16b446 100644
--- a/wiki/sources/github-上-5000-人收藏的-vibe-coding-神级指南.md
+++ b/wiki/sources/github-上-5000-人收藏的-vibe-coding-神级指南.md
@@ -1,56 +1,56 @@
----
-title: "GitHub 上 5000 人收藏的 Vibe Coding 神级指南"
-type: source
-tags: [ai, vibe-coding, github]
-date: 2025-12-30
----
-
-## Source File
-- [[AI/GitHub 上 5000 人收藏的 Vibe Coding 神级指南。.md]]
-
-## Summary(用中文描述)
-- 核心主题:中文开发者 Vibe Coding(氛围编程)指南推荐
-- 问题域:国内开发者如何快速上手并有效使用 AI 编程工具
-- 方法/机制:Vibe Coding = 规划驱动 + 上下文固定 + AI 结对执行;工具推荐 Cursor + Claude Opus;提供完整工作流程(设置环境→开发基础游戏→丰富细节→修复 Bug);包含数百个精选提示词覆盖需求澄清、系统架构设计、分步执行、自测全链路
-- 结论/价值:专门为中文开发者设计的 Vibe Coding 资源库与工作站,帮助开发者更高效利用 AI 进行软件开发
-
-## Key Claims(用中文描述)
-- Vibe Coding = 规划驱动 + 上下文固定 + AI 结对执行 → 让「从想法到可维护代码」变成可审计的流水线
-- 开发者不再苦哈哈写代码,而是化身为"导演",保持对产品逻辑、用户流程、审美和交互的把握
-- 让 AI 写代码前,必须有清晰的技术选型、实施规划和模块化设计 → 防止 AI 因理解偏差导致项目逻辑混乱
-- 推荐的 AI 编程工具组合:Cursor + Claude Opus 4.5 xhigh(高上下文窗口保证上下文一致性)
-
-## Key Quotes
-> "我几乎不写代码了,我只负责调整氛围(Vibe),代码会自动长出来。" — Andrej Karpathy 对 Vibe Coding 的经典描述
-
-> "Vibe Coding = 规划驱动 + 上下文固定 + AI 结对执行,让『从想法到可维护代码』变成一条可审计的流水线,而不是一团无法迭代的巨石文件。" — vibe-coding-cn 开源项目定义
-
-> "让 AI 写代码前,必须有清晰的技术选型、实施规划和模块化设计,防止 AI 因为理解偏差导致项目逻辑混乱。" — 文章核心观点
-
-## Key Concepts
-- [[Vibe Coding]]:氛围编程,开发者化身为导演而非coder,专注于产品逻辑和审美把握,体力活交给 AI 工具
-- [[规划驱动]]:AI 编程前必须完成清晰的技术选型、实施规划和模块化设计
-- [[上下文固定]]:通过大 context window 模型(如 Claude Opus)保持长程上下文一致性
-- [[AI 结对执行]]:Cursor、Windsurf、Trae 等 AI 编程工具与人类开发者配对工作
-- [[提示词工程]](Prompt Engineering):Vibe Coding 的核心技术能力,包含需求澄清、系统架构设计、分步执行、自测等全链路脚本
-
-## Key Entities
-- [[vibe-coding-cn]]:中文 Vibe Coding 指南开源项目(github.com/tukuaiai/vibe-coding-cn),汇集全球顶尖 AI 编程资源
-- [[Andrej Karpathy]]:AI 领域知名专家,Vibe Coding 概念推广者
-- [[Cursor]]:主流 AI 编程 IDE
-- [[Windsurf]]:AI 编程工具
-- [[Trae]]:AI 编程工具
-- [[逛逛 GitHub]]:微信公众号,本文发布渠道
-
-## Connections
-- [[vibe-coding-cn]] ← 推荐资源 ← [[Vibe Coding]]
-- [[Cursor]] ← 推荐 IDE ← [[Vibe Coding]]
-- [[AI 结对执行]] ← 核心机制 ← [[Vibe Coding]]
-- [[Claude Skills]] ← 共同主题 ← [[Vibe Coding]]("Vibe Coding 的尽头也是 Skills")
-
-## Contradictions
-- 与 [[Claude-Skills]] 视角差异:
- - 冲突点:Vibe Coding 强调"氛围感"和直觉式引导,Claude Skills 强调结构化 SOP 和可复用流程
- - 当前观点:Vibe Coding 更适合快速探索和创意验证,节奏轻快
- - 对方观点:Claude Skills 更适合可复现的固定流程任务,稳定可控
- - 融合可能:两者可互补使用——Vibe Coding 启动探索阶段,Claude Skills 固化成熟流程
+---
+title: "GitHub 上 5000 人收藏的 Vibe Coding 神级指南"
+type: source
+tags: [ai, vibe-coding, github]
+date: 2025-12-30
+---
+
+## Source File
+- [[raw/AI/GitHub 上 5000 人收藏的 Vibe Coding 神级指南。.md]]
+
+## Summary(用中文描述)
+- 核心主题:中文开发者 Vibe Coding(氛围编程)指南推荐
+- 问题域:国内开发者如何快速上手并有效使用 AI 编程工具
+- 方法/机制:Vibe Coding = 规划驱动 + 上下文固定 + AI 结对执行;工具推荐 Cursor + Claude Opus;提供完整工作流程(设置环境→开发基础游戏→丰富细节→修复 Bug);包含数百个精选提示词覆盖需求澄清、系统架构设计、分步执行、自测全链路
+- 结论/价值:专门为中文开发者设计的 Vibe Coding 资源库与工作站,帮助开发者更高效利用 AI 进行软件开发
+
+## Key Claims(用中文描述)
+- Vibe Coding = 规划驱动 + 上下文固定 + AI 结对执行 → 让「从想法到可维护代码」变成可审计的流水线
+- 开发者不再苦哈哈写代码,而是化身为"导演",保持对产品逻辑、用户流程、审美和交互的把握
+- 让 AI 写代码前,必须有清晰的技术选型、实施规划和模块化设计 → 防止 AI 因理解偏差导致项目逻辑混乱
+- 推荐的 AI 编程工具组合:Cursor + Claude Opus 4.5 xhigh(高上下文窗口保证上下文一致性)
+
+## Key Quotes
+> "我几乎不写代码了,我只负责调整氛围(Vibe),代码会自动长出来。" — Andrej Karpathy 对 Vibe Coding 的经典描述
+
+> "Vibe Coding = 规划驱动 + 上下文固定 + AI 结对执行,让『从想法到可维护代码』变成一条可审计的流水线,而不是一团无法迭代的巨石文件。" — vibe-coding-cn 开源项目定义
+
+> "让 AI 写代码前,必须有清晰的技术选型、实施规划和模块化设计,防止 AI 因为理解偏差导致项目逻辑混乱。" — 文章核心观点
+
+## Key Concepts
+- [[Vibe Coding]]:氛围编程,开发者化身为导演而非coder,专注于产品逻辑和审美把握,体力活交给 AI 工具
+- [[规划驱动]]:AI 编程前必须完成清晰的技术选型、实施规划和模块化设计
+- [[上下文固定]]:通过大 context window 模型(如 Claude Opus)保持长程上下文一致性
+- [[AI 结对执行]]:Cursor、Windsurf、Trae 等 AI 编程工具与人类开发者配对工作
+- [[提示词工程]](Prompt Engineering):Vibe Coding 的核心技术能力,包含需求澄清、系统架构设计、分步执行、自测等全链路脚本
+
+## Key Entities
+- [[vibe-coding-cn]]:中文 Vibe Coding 指南开源项目(github.com/tukuaiai/vibe-coding-cn),汇集全球顶尖 AI 编程资源
+- [[Andrej Karpathy]]:AI 领域知名专家,Vibe Coding 概念推广者
+- [[Cursor]]:主流 AI 编程 IDE
+- [[Windsurf]]:AI 编程工具
+- [[Trae]]:AI 编程工具
+- [[逛逛 GitHub]]:微信公众号,本文发布渠道
+
+## Connections
+- [[vibe-coding-cn]] ← 推荐资源 ← [[Vibe Coding]]
+- [[Cursor]] ← 推荐 IDE ← [[Vibe Coding]]
+- [[AI 结对执行]] ← 核心机制 ← [[Vibe Coding]]
+- [[Claude Skills]] ← 共同主题 ← [[Vibe Coding]]("Vibe Coding 的尽头也是 Skills")
+
+## Contradictions
+- 与 [[Claude-Skills]] 视角差异:
+ - 冲突点:Vibe Coding 强调"氛围感"和直觉式引导,Claude Skills 强调结构化 SOP 和可复用流程
+ - 当前观点:Vibe Coding 更适合快速探索和创意验证,节奏轻快
+ - 对方观点:Claude Skills 更适合可复现的固定流程任务,稳定可控
+ - 融合可能:两者可互补使用——Vibe Coding 启动探索阶段,Claude Skills 固化成熟流程
diff --git a/wiki/sources/godot-gameplay-scripter.md b/wiki/sources/godot-gameplay-scripter.md
index a32c6caf..43879f6c 100644
--- a/wiki/sources/godot-gameplay-scripter.md
+++ b/wiki/sources/godot-gameplay-scripter.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/godot/godot-gameplay-scripter.md]]
+- [[raw/Agent/agency-agents/game-development/godot/godot-gameplay-scripter.md]]
## Summary(用中文描述)
- 核心主题:Godot 4 游戏逻辑脚本专家 Agent 人格定义,强调以软件架构师的纪律性构建游戏系统
diff --git a/wiki/sources/godot-multiplayer-engineer.md b/wiki/sources/godot-multiplayer-engineer.md
index 1f16e0fd..6bd5ba27 100644
--- a/wiki/sources/godot-multiplayer-engineer.md
+++ b/wiki/sources/godot-multiplayer-engineer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/godot/godot-multiplayer-engineer.md]]
+- [[raw/Agent/agency-agents/game-development/godot/godot-multiplayer-engineer.md]]
## Summary(用中文描述)
- 核心主题:Godot 4 网络多人游戏专家 Agent,基于 MultiplayerAPI、MultiplayerSpawner、MultiplayerSynchronizer 和 RPC 机制实现实时多人游戏网络同步
diff --git a/wiki/sources/godot-shader-developer.md b/wiki/sources/godot-shader-developer.md
index d8349600..d64280dc 100644
--- a/wiki/sources/godot-shader-developer.md
+++ b/wiki/sources/godot-shader-developer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/godot/godot-shader-developer.md]]
+- [[raw/Agent/agency-agents/game-development/godot/godot-shader-developer.md]]
## Summary(用中文描述)
- 核心主题:Godot 4 渲染专家 Agent,使用 Godot 着色语言(GLSL-like)编写高性能 2D/3D 视觉效果着色器
diff --git a/wiki/sources/gog-cli-安装配置指南.md b/wiki/sources/gog-cli-安装配置指南.md
index 56f2812d..617e21c7 100644
--- a/wiki/sources/gog-cli-安装配置指南.md
+++ b/wiki/sources/gog-cli-安装配置指南.md
@@ -1,45 +1,45 @@
----
-title: "GOG CLI 安装配置指南"
-type: source
-tags: [gog, gog-cli, macos, google-workspace]
-date: 2026-03-15
----
-
-## Source File
-- [[Skills/GOG-CLI-安装配置指南.md]]
-
-## Summary(用中文描述)
-- 核心主题:gog CLI(Google Workspace 命令行工具)在 macOS 系统上的完整安装与配置流程
-- 问题域:如何通过命令行管理 Google Workspace 全套服务(Gmail、Google Calendar、Google Drive、Google Contacts、Google Docs、Google Sheets),并与 AI Agent 工作流集成
-- 方法/机制:Homebrew 安装 → Google Cloud Console 创建 OAuth 凭证 → 移动凭证文件到 gogcli 配置目录 → 添加测试用户解除 Google 安全限制 → 启用各 Google API → 验证授权状态
-- 结论/价值:实现通过命令行管理 Google Workspace 全套服务的能力,可集成到 AI Agent 工作流中(自动邮件处理、日历管理等)
-
-## Key Claims(用中文描述)
-- Homebrew 可通过 `brew install steipete/tap/gogcli` 一键安装 gog CLI,输出路径为 `/opt/homebrew/bin/gog`
-- OAuth 凭证需要放置在 `/Users/weishen/Library/Application Support/gogcli/credentials.json`,并通过 `gog auth credentials` 命令指定路径
-- 首次授权时 Google 会阻止未验证应用,需要在 Google Cloud Console 的 OAuth 客户端中将测试用户邮箱加入白名单才能通过授权
-- Google API 调用需要同时满足两个条件:OAuth 授权成功 + API 已启用(Enabling),缺一不可
-- 启用新的 API 服务后需要重新授权(`gog auth revoke` + `gog auth login`),因为旧 token 不包含新权限
-
-## Key Quotes
-> "此应用未经 Google 验证。此应用请求访问您 Google 账号中的敏感信息。在开发者让该应用通过 Google 验证之前,请勿使用该应用。" — Google 首次授权时的安全警告,解决方案是在测试用户中添加 Google 邮箱
-> "即使 OAuth 成功,如果 API 未启用也会报错:403 accessNotConfigured" — API 调用失败的常见原因
-> "旧 token 不包含新权限" — 启用新 API 后必须重新授权的原因
-
-## Key Concepts
-- [[OAuth 2.0]]:Google 账号身份认证协议,gog CLI 使用 OAuth 完成用户授权
-- [[Google Cloud Console]]:Google API 管理平台,用于创建 OAuth 凭证和启用 API 服务
-- [[Google Workspace]]:Google 办公套件,包含 Gmail、Google Calendar、Google Drive、Google Contacts、Google Docs、Google Sheets
-- [[Google API Enablement]]:Google API 调用需要先在 Google Cloud Console 中启用对应服务,与 OAuth 认证是两层独立机制
-
-## Key Entities
-- [[gog CLI]]:由 steipete 开发的 Google Workspace 命令行管理工具,通过 Homebrew 分发
-- [[Google Cloud Console]]:Google 云平台控制台,用于管理 OAuth 凭证和 API 启用状态
-
-## Connections
-- [[personal-crm]] ← uses ← [[gog CLI]](gog CLI 提供 Gmail 和 Calendar 数据,是 personal-crm 的前置依赖)
-- [[gog CLI]] ← requires ← [[OAuth 2.0]](认证机制)
-- [[gog CLI]] ← requires ← [[Google API Enablement]](每项服务需单独启用)
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "GOG CLI 安装配置指南"
+type: source
+tags: [gog, gog-cli, macos, google-workspace]
+date: 2026-03-15
+---
+
+## Source File
+- [[raw/Skills/GOG-CLI-安装配置指南.md]]
+
+## Summary(用中文描述)
+- 核心主题:gog CLI(Google Workspace 命令行工具)在 macOS 系统上的完整安装与配置流程
+- 问题域:如何通过命令行管理 Google Workspace 全套服务(Gmail、Google Calendar、Google Drive、Google Contacts、Google Docs、Google Sheets),并与 AI Agent 工作流集成
+- 方法/机制:Homebrew 安装 → Google Cloud Console 创建 OAuth 凭证 → 移动凭证文件到 gogcli 配置目录 → 添加测试用户解除 Google 安全限制 → 启用各 Google API → 验证授权状态
+- 结论/价值:实现通过命令行管理 Google Workspace 全套服务的能力,可集成到 AI Agent 工作流中(自动邮件处理、日历管理等)
+
+## Key Claims(用中文描述)
+- Homebrew 可通过 `brew install steipete/tap/gogcli` 一键安装 gog CLI,输出路径为 `/opt/homebrew/bin/gog`
+- OAuth 凭证需要放置在 `/Users/weishen/Library/Application Support/gogcli/credentials.json`,并通过 `gog auth credentials` 命令指定路径
+- 首次授权时 Google 会阻止未验证应用,需要在 Google Cloud Console 的 OAuth 客户端中将测试用户邮箱加入白名单才能通过授权
+- Google API 调用需要同时满足两个条件:OAuth 授权成功 + API 已启用(Enabling),缺一不可
+- 启用新的 API 服务后需要重新授权(`gog auth revoke` + `gog auth login`),因为旧 token 不包含新权限
+
+## Key Quotes
+> "此应用未经 Google 验证。此应用请求访问您 Google 账号中的敏感信息。在开发者让该应用通过 Google 验证之前,请勿使用该应用。" — Google 首次授权时的安全警告,解决方案是在测试用户中添加 Google 邮箱
+> "即使 OAuth 成功,如果 API 未启用也会报错:403 accessNotConfigured" — API 调用失败的常见原因
+> "旧 token 不包含新权限" — 启用新 API 后必须重新授权的原因
+
+## Key Concepts
+- [[OAuth 2.0]]:Google 账号身份认证协议,gog CLI 使用 OAuth 完成用户授权
+- [[Google Cloud Console]]:Google API 管理平台,用于创建 OAuth 凭证和启用 API 服务
+- [[Google Workspace]]:Google 办公套件,包含 Gmail、Google Calendar、Google Drive、Google Contacts、Google Docs、Google Sheets
+- [[Google API Enablement]]:Google API 调用需要先在 Google Cloud Console 中启用对应服务,与 OAuth 认证是两层独立机制
+
+## Key Entities
+- [[gog CLI]]:由 steipete 开发的 Google Workspace 命令行管理工具,通过 Homebrew 分发
+- [[Google Cloud Console]]:Google 云平台控制台,用于管理 OAuth 凭证和 API 启用状态
+
+## Connections
+- [[personal-crm]] ← uses ← [[gog CLI]](gog CLI 提供 Gmail 和 Calendar 数据,是 personal-crm 的前置依赖)
+- [[gog CLI]] ← requires ← [[OAuth 2.0]](认证机制)
+- [[gog CLI]] ← requires ← [[Google API Enablement]](每项服务需单独启用)
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/google-5个agent-skill设计模式-2026-03-19.md b/wiki/sources/google-5个agent-skill设计模式-2026-03-19.md
index 024883f7..81a4fbae 100644
--- a/wiki/sources/google-5个agent-skill设计模式-2026-03-19.md
+++ b/wiki/sources/google-5个agent-skill设计模式-2026-03-19.md
@@ -8,7 +8,7 @@ last_updated: 2026-05-15
---
## Source File
-- [[Agent/Google-5个Agent-Skill设计模式-2026-03-19.md]]
+- [[raw/Agent/Google-5个Agent-Skill设计模式-2026-03-19.md]]
## Summary(用中文描述)
- 核心主题:Google ADK 发布的 5 种经过验证的 Agent Skill 设计模式,帮助开发者将复杂的工作流从脆弱的 system prompt 中解耦出来
diff --git a/wiki/sources/google-神级生产力工具-所有-github-开源平替都找到了.md b/wiki/sources/google-神级生产力工具-所有-github-开源平替都找到了.md
index 86106c10..1a57fb91 100644
--- a/wiki/sources/google-神级生产力工具-所有-github-开源平替都找到了.md
+++ b/wiki/sources/google-神级生产力工具-所有-github-开源平替都找到了.md
@@ -6,7 +6,7 @@ date: 2025-12-19
---
## Source File
-- [[AI/Google 神级生产力工具,所有 GitHub 开源平替都找到了。]]
+- [[raw/AI/Google 神级生产力工具,所有 GitHub 开源平替都找到了。.md]]
## Summary(用中文描述)
- 核心主题:Google NotebookLM 的 GitHub 开源替代品全景盘点
diff --git a/wiki/sources/government-digital-presales-consultant.md b/wiki/sources/government-digital-presales-consultant.md
index 51409eaa..b8e4d3dd 100644
--- a/wiki/sources/government-digital-presales-consultant.md
+++ b/wiki/sources/government-digital-presales-consultant.md
@@ -1,59 +1,59 @@
----
-title: "Government Digital Presales Consultant"
-type: source
-tags: [ToG, government-IT, presales, compliance, Xinchuang, Smart-City, Digital-Government]
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/government-digital-presales-consultant.md]]
-
-## Summary(用中文描述)
-- 核心主题:中国政府信息化(ToG)市场的全生命周期售前专家智能体,涵盖从政策解读、解决方案设计到招投标全程
-- 问题域:政府数字化转型市场的项目机会识别、标书撰写、合规要求(POC验证、等保/密评/信创)、干系人管理
-- 方法/机制:五步工作流(机会发现→需求调研→方案设计→投标执行→中标交接),配合政策解读、竞品分析、POC演示、合规矩阵等工具模板
-- 结论/价值:为技术团队提供进入数字政府、智慧城市、一网统管、城市大脑等主流方向的决策支持,核心目标是提高中标率(>40%)、零废标、售前到交付对齐(偏差<10%)
-
-## Key Claims(用中文描述)
-- 售前专家通过政策语言解码("鼓励探索"→"全面实施")识别市场成熟度信号,在政策从"软性鼓励"转向"硬性要求"时入场
-- 政府系统通常要求等保三级,核心系统可能要求等保四级;等保评估需在系统上线前2-3个月完成整改
-- 信创替换不必一步到位,分阶段替代是被接受的
-- 技术方案应以业务场景驱动,而非技术架构驱动——客户关心"市民服务处理速度提升80%"而非"微服务架构"
-- 投标文件零容忍格式错误——资质缺失、格式偏差、响应偏移均属废标项
-
-## Key Quotes
-> "Drive with business scenarios, not technical architecture — the client cares about '80% faster citizen service processing,' not 'microservices architecture.'" — 方案设计核心原则
-> "Dengbao, Miping, and Xinchuang are mandatory, not bonus points." — 合规基线
-> "Don't tell the bureau head we use Kubernetes. Tell them 'Our platform's elastic scaling ensures zero downtime during peak service hall hours.'" — 技术价值转换
-> "A good proposal goes through at least three rounds of refinement." — 方案迭代要求
-
-## Key Concepts
-- [[Dengbao-2.0]]:网络安全等级保护制度,政府系统通常要求三级,等保评估需在上线前2-3个月完成
-- [[Miping]]:商用密码应用安全性评估,涉及身份认证、数据传输、数据存储必须使用国密算法(SM2/SM3/SM4)
-- [[Xinchuang]]:信息技术应用创新,核心要素为国产CPU(鲲鹏/飞腾/海光/龙芯)+ 国产OS(统信UOS/麒麟)+ 国产数据库(达梦/人大金仓/ GaussDB)+ 国产中间件
-- [[ToG]](Government):面向政府的数字化转型市场,区别于ToB(企业)和ToC(消费者)
-- [[Smart-City]]:智慧城市,典型方向包括城市大脑/城市运行中心(IOC)、智慧交通、智慧社区、城市信息模型(CIM)
-- [[Digital-Government]]:数字政府,典型方向包括一体化政务服务平台、一网统管/一网通办、12345热线智能升级、政府数据中台
-- [[Yiwangtongban]]:一网统办,一网通管,一体化政务服务门户
-- [[POC]]:概念验证,通过精选场景展示差异化优势,控制范围并设定明确成功标准
-
-## Key Entities
-- [[Digital-China-Master-Plan]]:数字中国建设整体布局规划,国家级政策文件
-- [[National-Data-Administration]]:国家数据局,国家层面数据治理主管机构
-- [[Government-Cloud]]:政务云平台,政府信息化基础设施
-- [[City-Brain]]:城市大脑,城市级数据融合与智能决策平台
-- [[Kunpeng]]:鲲鹏,国产CPU代表
-- [[Phytium]]:飞腾,国产CPU代表
-- [[UnionTech-UOS]]:统信UOS,国产操作系统代表
-- [[DM-Database]]:达梦数据库,国产数据库代表
-
-## Connections
-- [[Government-Digital-Presales-Consultant]] ← extends ← [[Sales-Engineer]](通用售前 → 政府垂直领域售前)
-- [[Government-Digital-Presales-Consultant]] ← depends_on ← [[Xinchuang]](信创合规必须掌握)
-- [[Government-Digital-Presales-Consultant]] ← depends_on ← [[Dengbao-2.0]](等保合规必须掌握)
-- [[Government-Digital-Presales-Consultant]] ← depends_on ← [[Miping]](密码评估必须掌握)
-- [[Digital-Government]] ← solution_domain ← [[Government-Digital-Presales-Consultant]](数字政府是主要方案方向之一)
-- [[Smart-City]] ← solution_domain ← [[Government-Digital-Presales-Consultant]](智慧城市是主要方案方向之一)
-
-## Contradictions
-- 无明显冲突。本文档专注于中国政府ToG市场,与Wiki中其他以企业级/B2B市场为中心的售前/销售Agent形成领域区隔。
+---
+title: "Government Digital Presales Consultant"
+type: source
+tags: [ToG, government-IT, presales, compliance, Xinchuang, Smart-City, Digital-Government]
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/government-digital-presales-consultant.md]]
+
+## Summary(用中文描述)
+- 核心主题:中国政府信息化(ToG)市场的全生命周期售前专家智能体,涵盖从政策解读、解决方案设计到招投标全程
+- 问题域:政府数字化转型市场的项目机会识别、标书撰写、合规要求(POC验证、等保/密评/信创)、干系人管理
+- 方法/机制:五步工作流(机会发现→需求调研→方案设计→投标执行→中标交接),配合政策解读、竞品分析、POC演示、合规矩阵等工具模板
+- 结论/价值:为技术团队提供进入数字政府、智慧城市、一网统管、城市大脑等主流方向的决策支持,核心目标是提高中标率(>40%)、零废标、售前到交付对齐(偏差<10%)
+
+## Key Claims(用中文描述)
+- 售前专家通过政策语言解码("鼓励探索"→"全面实施")识别市场成熟度信号,在政策从"软性鼓励"转向"硬性要求"时入场
+- 政府系统通常要求等保三级,核心系统可能要求等保四级;等保评估需在系统上线前2-3个月完成整改
+- 信创替换不必一步到位,分阶段替代是被接受的
+- 技术方案应以业务场景驱动,而非技术架构驱动——客户关心"市民服务处理速度提升80%"而非"微服务架构"
+- 投标文件零容忍格式错误——资质缺失、格式偏差、响应偏移均属废标项
+
+## Key Quotes
+> "Drive with business scenarios, not technical architecture — the client cares about '80% faster citizen service processing,' not 'microservices architecture.'" — 方案设计核心原则
+> "Dengbao, Miping, and Xinchuang are mandatory, not bonus points." — 合规基线
+> "Don't tell the bureau head we use Kubernetes. Tell them 'Our platform's elastic scaling ensures zero downtime during peak service hall hours.'" — 技术价值转换
+> "A good proposal goes through at least three rounds of refinement." — 方案迭代要求
+
+## Key Concepts
+- [[Dengbao-2.0]]:网络安全等级保护制度,政府系统通常要求三级,等保评估需在上线前2-3个月完成
+- [[Miping]]:商用密码应用安全性评估,涉及身份认证、数据传输、数据存储必须使用国密算法(SM2/SM3/SM4)
+- [[Xinchuang]]:信息技术应用创新,核心要素为国产CPU(鲲鹏/飞腾/海光/龙芯)+ 国产OS(统信UOS/麒麟)+ 国产数据库(达梦/人大金仓/ GaussDB)+ 国产中间件
+- [[ToG]](Government):面向政府的数字化转型市场,区别于ToB(企业)和ToC(消费者)
+- [[Smart-City]]:智慧城市,典型方向包括城市大脑/城市运行中心(IOC)、智慧交通、智慧社区、城市信息模型(CIM)
+- [[Digital-Government]]:数字政府,典型方向包括一体化政务服务平台、一网统管/一网通办、12345热线智能升级、政府数据中台
+- [[Yiwangtongban]]:一网统办,一网通管,一体化政务服务门户
+- [[POC]]:概念验证,通过精选场景展示差异化优势,控制范围并设定明确成功标准
+
+## Key Entities
+- [[Digital-China-Master-Plan]]:数字中国建设整体布局规划,国家级政策文件
+- [[National-Data-Administration]]:国家数据局,国家层面数据治理主管机构
+- [[Government-Cloud]]:政务云平台,政府信息化基础设施
+- [[City-Brain]]:城市大脑,城市级数据融合与智能决策平台
+- [[Kunpeng]]:鲲鹏,国产CPU代表
+- [[Phytium]]:飞腾,国产CPU代表
+- [[UnionTech-UOS]]:统信UOS,国产操作系统代表
+- [[DM-Database]]:达梦数据库,国产数据库代表
+
+## Connections
+- [[Government-Digital-Presales-Consultant]] ← extends ← [[Sales-Engineer]](通用售前 → 政府垂直领域售前)
+- [[Government-Digital-Presales-Consultant]] ← depends_on ← [[Xinchuang]](信创合规必须掌握)
+- [[Government-Digital-Presales-Consultant]] ← depends_on ← [[Dengbao-2.0]](等保合规必须掌握)
+- [[Government-Digital-Presales-Consultant]] ← depends_on ← [[Miping]](密码评估必须掌握)
+- [[Digital-Government]] ← solution_domain ← [[Government-Digital-Presales-Consultant]](数字政府是主要方案方向之一)
+- [[Smart-City]] ← solution_domain ← [[Government-Digital-Presales-Consultant]](智慧城市是主要方案方向之一)
+
+## Contradictions
+- 无明显冲突。本文档专注于中国政府ToG市场,与Wiki中其他以企业级/B2B市场为中心的售前/销售Agent形成领域区隔。
diff --git a/wiki/sources/habit-tracker-accountability-coach.md b/wiki/sources/habit-tracker-accountability-coach.md
index ad2d44ff..ce8f1cc8 100644
--- a/wiki/sources/habit-tracker-accountability-coach.md
+++ b/wiki/sources/habit-tracker-accountability-coach.md
@@ -7,7 +7,7 @@ last_updated: 2026-04-27
---
## Source File
-- [[Agent/usecases/habit-tracker-accountability-coach.md]]
+- [[raw/Agent/usecases/habit-tracker-accountability-coach.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 作为主动的习惯追踪与问责伙伴,通过 Telegram/SMS 每日定时签到,替代被动式习惯追踪 App
diff --git a/wiki/sources/health-symptom-tracker.md b/wiki/sources/health-symptom-tracker.md
index b90a5549..03916245 100644
--- a/wiki/sources/health-symptom-tracker.md
+++ b/wiki/sources/health-symptom-tracker.md
@@ -1,44 +1,44 @@
----
-title: "Health & Symptom Tracker"
-type: source
-tags: []
-date: 2026-04-22
----
-
-## Source File
-- [[Agent/usecases/health-symptom-tracker.md]]
-
-## Summary(用中文描述)
-- 核心主题:通过 Telegram 话题 + AI Agent 自动追踪食物与症状,实现食物敏感性识别
-- 问题域:食物敏感性识别需要长期一致的日志记录,人工维护繁琐
-- 方法/机制:
- - 在 Telegram 创建 "health-tracker" 话题作为记录入口
- - OpenClaw Agent 解析消息中的食物和症状,自动带时间戳写入 Markdown 日志文件
- - Cron Job 实现每日三餐定时提醒(8AM/1PM/7PM)
- - 每周日分析过去一周日志,识别食物-症状关联模式
-- 结论/价值:低技术门槛的自动化健康追踪方案,无需专用 App,适合个人自托管部署
-
-## Key Claims(用中文描述)
-- Telegram 话题 + AI 日志解析 = 无需专用 App 的食物追踪系统
-- 每日三餐提醒确保日志一致性,减少遗漏
-- 周期性模式分析能识别潜在食物触发因素
-
-## Key Quotes
-> "Identifying food sensitivities requires consistent logging over time, which is tedious to maintain." — 问题陈述,解释了为何需要自动化追踪
-
-## Key Concepts
-- [[Food Sensitivity Tracking]]:通过日志追踪食物摄入与症状关联,识别个人食物不耐受
-- [[Automated Health Logging]]:利用 AI 自动解析自然语言消息并写入结构化日志文件
-- [[Cron Job Reminders]]:定时任务驱动的生活方式干预,每日多次提醒形成习惯
-
-## Key Entities
-- [[OpenClaw]]:作为 Agent 引擎,解析 Telegram 消息、写入日志文件、执行定时分析
-
-## Connections
-- [[OpenClaw]] ← powers ← [[health-symptom-tracker]]
-
-## Contradictions
-- 与 [[habit-tracker-accountability-coach]] 对比:
- - 冲突点:习惯追踪 vs 健康数据追踪的侧重
- - 当前观点:health-symptom-tracker 专注症状-食物关联分析
- - 对方观点:habit-tracker 更侧重行为习惯养成和问责机制
+---
+title: "Health & Symptom Tracker"
+type: source
+tags: []
+date: 2026-04-22
+---
+
+## Source File
+- [[raw/Agent/usecases/health-symptom-tracker.md]]
+
+## Summary(用中文描述)
+- 核心主题:通过 Telegram 话题 + AI Agent 自动追踪食物与症状,实现食物敏感性识别
+- 问题域:食物敏感性识别需要长期一致的日志记录,人工维护繁琐
+- 方法/机制:
+ - 在 Telegram 创建 "health-tracker" 话题作为记录入口
+ - OpenClaw Agent 解析消息中的食物和症状,自动带时间戳写入 Markdown 日志文件
+ - Cron Job 实现每日三餐定时提醒(8AM/1PM/7PM)
+ - 每周日分析过去一周日志,识别食物-症状关联模式
+- 结论/价值:低技术门槛的自动化健康追踪方案,无需专用 App,适合个人自托管部署
+
+## Key Claims(用中文描述)
+- Telegram 话题 + AI 日志解析 = 无需专用 App 的食物追踪系统
+- 每日三餐提醒确保日志一致性,减少遗漏
+- 周期性模式分析能识别潜在食物触发因素
+
+## Key Quotes
+> "Identifying food sensitivities requires consistent logging over time, which is tedious to maintain." — 问题陈述,解释了为何需要自动化追踪
+
+## Key Concepts
+- [[Food Sensitivity Tracking]]:通过日志追踪食物摄入与症状关联,识别个人食物不耐受
+- [[Automated Health Logging]]:利用 AI 自动解析自然语言消息并写入结构化日志文件
+- [[Cron Job Reminders]]:定时任务驱动的生活方式干预,每日多次提醒形成习惯
+
+## Key Entities
+- [[OpenClaw]]:作为 Agent 引擎,解析 Telegram 消息、写入日志文件、执行定时分析
+
+## Connections
+- [[OpenClaw]] ← powers ← [[health-symptom-tracker]]
+
+## Contradictions
+- 与 [[habit-tracker-accountability-coach]] 对比:
+ - 冲突点:习惯追踪 vs 健康数据追踪的侧重
+ - 当前观点:health-symptom-tracker 专注症状-食物关联分析
+ - 对方观点:habit-tracker 更侧重行为习惯养成和问责机制
diff --git a/wiki/sources/healthcare-marketing-compliance.md b/wiki/sources/healthcare-marketing-compliance.md
index c013f934..7b1c30d8 100644
--- a/wiki/sources/healthcare-marketing-compliance.md
+++ b/wiki/sources/healthcare-marketing-compliance.md
@@ -1,69 +1,69 @@
----
-title: "Healthcare Marketing Compliance Specialist"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/specialized/healthcare-marketing-compliance.md]]
-
-## Summary(用中文描述)
-- 核心主题:医疗营销合规专家 Agent,覆盖中国医疗健康领域(药品/医疗器械/医美/保健食品/互联网医疗)全品类营销合规
-- 问题域:医疗健康企业在品牌推广、内容营销、学术推广中的合规边界;平台内容审核规则;患者隐私保护
-- 方法/机制:以《广告法》《医疗广告管理办法》《互联网广告管理办法》为核心监管框架,建立"三级审查机制"(法务初审→合规复审→终审发布);风险分级矩阵(Critical/High/Medium/Low);违规应急响应流程(2小时下架→24小时报告→72小时审计)
-- 结论/价值:合规不是"堵营销",而是"保护品牌"——一次违规处罚的代价远高于合规投入
-
-## Key Claims(用中文描述)
-- 医疗广告必须经省级卫生行政部门审查并取得《医疗广告审查证明》,否则不得发布——这是行政出发乃至刑事追责的底线
-- 处方药严禁在大众媒体(电视/广播/报纸/互联网)发布广告——任何隐性推广均面临严厉处罚
-- 保健食品不得声称具有治疗功能——这是行业内处罚最高频的违规原因
-- 医美广告不得制造"容貌焦虑"——2021年起市场监管总局执法力度显著加强
-- 患者健康数据属于《个人信息保护法》认定的"敏感个人信息"——违规最高罚款5000万元或上年度营收5%
-
-## Key Quotes
-> "医疗广告必须审查后方可发布——这是行政处罚乃至刑事追责的底线。" — 广告法第46条核心要求
-> "保健食品不得声称治病功能,必须标注'保健食品不是药物,不能替代药物治疗疾病'。" — 蓝帽子标识管理制度核心声明
-> "合规不是'堵营销',而是'保护品牌'。一次违规处罚的代价远高于合规投入。" — Agent 核心合规文化理念
-> "医美日记类内容无论是否由用户'自愿'分享,平台和诊所均可被追究连带责任。" — 小红书医美合规红线
-
-## Key Concepts
-- [[Healthcare-Marketing-Compliance]]:医疗健康营销全品类(药品/器械/医美/保健食品/互联网医疗)合规框架
-- [[Medical-Advertisement-Review]]:《医疗广告审查证明》制度——广告发布前必须获得省级卫生行政部门审查
-- [[Three-Tier-Review-Mechanism]]:企业内部三级审查机制(法务初审→合规复审→终审发布)
-- [[OTC-Drug-Marketing]]:非处方药大众媒体广告规则——必须包含"请按照药品说明书或药师指导下使用"等咨询语句
-- [[Prescription-Drug-Restrictions]]:处方药大众媒体广告禁令——仅限在医药专业期刊发布
-- [[Medical-Device-Classification]]:医疗器械三类分级管理制度(I类备案/II类注册/III类严格审批)
-- [[Blue-Hat-Logo]]:保健食品"蓝帽子"注册标志——合法保健食品必须取得并展示
-- [[Appearance-Anxiety]]:容貌焦虑——医美广告2021年起明确禁止制造焦虑情绪的表述
-- [[Internet-Diagnosis-Treatment]]:互联网诊疗规范——初诊必须线下面诊,复诊限常见病/慢性病
-- [[Patient-Privacy-PIPL]]:《个人信息保护法》将个人健康医疗信息认定为敏感信息,须单独授权
-- [[Academic-Detailing]]:学术推广合规——医疗代表备案、会议赞助标准、医师讲课费规范
-- [[Platform-Content-Review]]:平台内容审核机制——抖音/小红书/微信各有行业准入标准和内容红线
-- [[Compliance-Risk-Matrix]]:医疗营销合规风险分级矩阵(Critical/High/Medium/Low + 处置建议)
-
-## Key Entities
-- [[NMPA]](国家药品监督管理局):负责药品/医疗器械注册审批及广告批准文号管理
-- [[SAMR]](国家市场监督管理总局):2021年发布《医疗美容广告执法指南》,主导医美合规整治
-- [[Haodf]](好大夫在线):互联网医疗平台——医师入驻资质审核、患者评价管理、图文/视频问诊标准
-- [[DXY]](丁香园):医师专业社区——健康科普内容专业审核机制、医师认证体系、商业合作与编辑独立性分离
-- [[WeDoctor]](微医):互联网医院牌照、在线处方流转、医保接入合规
-- [[JD-Health]](京东健康):在线售药资质、处方药审核流程、物流配送合规
-- [[Douyin]](抖音):医疗行业准入(须提交医疗机构执业许可证或药械资质)、认证医师标识、直播带货限制
-- [[Xiaohongshu]](小红书):2021年起大规模清理医美内容、白名单管理制度、蒲公英品牌合作平台合规要求
-- [[WeChat]](视频号):医疗机构公众号认证、朋友圈广告投放规范、小程序在线问诊/售药资质要求
-
-## Connections
-- [[Healthcare-Marketing-Compliance]] ← extends ← [[The-Agency]](Specialized 部门)
-- [[Healthcare-Marketing-Compliance]] ← depends_on ← [[NMPA]](监管机构)
-- [[Healthcare-Marketing-Compliance]] ← depends_on ← [[SAMR]](执法机构)
-- [[Platform-Content-Review]] ← extends ← [[Healthcare-Marketing-Compliance]]
-- [[Patient-Privacy-PIPL]] ← depends_on ← [[Healthcare-Marketing-Compliance]]
-- [[Academic-Detailing]] ← extends ← [[Healthcare-Marketing-Compliance]]
-
-## Contradictions
-- 与 [[legal-compliance-checker]] 潜在冲突:
- - 冲突点:通用法律合规 Agent 与医疗专项合规 Agent 的职责边界
- - 当前观点:医疗营销合规具有高度专业化特征(广告法/药械注册/平台规则),通用法律合规工具无法覆盖
- - 对方观点:合规 Agent 应具备跨行业通用合规框架,无需细分至医疗领域
- - 解决方向:通用合规 Agent 负责数据隐私/合同合规等横向能力,医疗营销合规 Agent 专注垂直领域规则差异
+---
+title: "Healthcare Marketing Compliance Specialist"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/healthcare-marketing-compliance.md]]
+
+## Summary(用中文描述)
+- 核心主题:医疗营销合规专家 Agent,覆盖中国医疗健康领域(药品/医疗器械/医美/保健食品/互联网医疗)全品类营销合规
+- 问题域:医疗健康企业在品牌推广、内容营销、学术推广中的合规边界;平台内容审核规则;患者隐私保护
+- 方法/机制:以《广告法》《医疗广告管理办法》《互联网广告管理办法》为核心监管框架,建立"三级审查机制"(法务初审→合规复审→终审发布);风险分级矩阵(Critical/High/Medium/Low);违规应急响应流程(2小时下架→24小时报告→72小时审计)
+- 结论/价值:合规不是"堵营销",而是"保护品牌"——一次违规处罚的代价远高于合规投入
+
+## Key Claims(用中文描述)
+- 医疗广告必须经省级卫生行政部门审查并取得《医疗广告审查证明》,否则不得发布——这是行政出发乃至刑事追责的底线
+- 处方药严禁在大众媒体(电视/广播/报纸/互联网)发布广告——任何隐性推广均面临严厉处罚
+- 保健食品不得声称具有治疗功能——这是行业内处罚最高频的违规原因
+- 医美广告不得制造"容貌焦虑"——2021年起市场监管总局执法力度显著加强
+- 患者健康数据属于《个人信息保护法》认定的"敏感个人信息"——违规最高罚款5000万元或上年度营收5%
+
+## Key Quotes
+> "医疗广告必须审查后方可发布——这是行政处罚乃至刑事追责的底线。" — 广告法第46条核心要求
+> "保健食品不得声称治病功能,必须标注'保健食品不是药物,不能替代药物治疗疾病'。" — 蓝帽子标识管理制度核心声明
+> "合规不是'堵营销',而是'保护品牌'。一次违规处罚的代价远高于合规投入。" — Agent 核心合规文化理念
+> "医美日记类内容无论是否由用户'自愿'分享,平台和诊所均可被追究连带责任。" — 小红书医美合规红线
+
+## Key Concepts
+- [[Healthcare-Marketing-Compliance]]:医疗健康营销全品类(药品/器械/医美/保健食品/互联网医疗)合规框架
+- [[Medical-Advertisement-Review]]:《医疗广告审查证明》制度——广告发布前必须获得省级卫生行政部门审查
+- [[Three-Tier-Review-Mechanism]]:企业内部三级审查机制(法务初审→合规复审→终审发布)
+- [[OTC-Drug-Marketing]]:非处方药大众媒体广告规则——必须包含"请按照药品说明书或药师指导下使用"等咨询语句
+- [[Prescription-Drug-Restrictions]]:处方药大众媒体广告禁令——仅限在医药专业期刊发布
+- [[Medical-Device-Classification]]:医疗器械三类分级管理制度(I类备案/II类注册/III类严格审批)
+- [[Blue-Hat-Logo]]:保健食品"蓝帽子"注册标志——合法保健食品必须取得并展示
+- [[Appearance-Anxiety]]:容貌焦虑——医美广告2021年起明确禁止制造焦虑情绪的表述
+- [[Internet-Diagnosis-Treatment]]:互联网诊疗规范——初诊必须线下面诊,复诊限常见病/慢性病
+- [[Patient-Privacy-PIPL]]:《个人信息保护法》将个人健康医疗信息认定为敏感信息,须单独授权
+- [[Academic-Detailing]]:学术推广合规——医疗代表备案、会议赞助标准、医师讲课费规范
+- [[Platform-Content-Review]]:平台内容审核机制——抖音/小红书/微信各有行业准入标准和内容红线
+- [[Compliance-Risk-Matrix]]:医疗营销合规风险分级矩阵(Critical/High/Medium/Low + 处置建议)
+
+## Key Entities
+- [[NMPA]](国家药品监督管理局):负责药品/医疗器械注册审批及广告批准文号管理
+- [[SAMR]](国家市场监督管理总局):2021年发布《医疗美容广告执法指南》,主导医美合规整治
+- [[Haodf]](好大夫在线):互联网医疗平台——医师入驻资质审核、患者评价管理、图文/视频问诊标准
+- [[DXY]](丁香园):医师专业社区——健康科普内容专业审核机制、医师认证体系、商业合作与编辑独立性分离
+- [[WeDoctor]](微医):互联网医院牌照、在线处方流转、医保接入合规
+- [[JD-Health]](京东健康):在线售药资质、处方药审核流程、物流配送合规
+- [[Douyin]](抖音):医疗行业准入(须提交医疗机构执业许可证或药械资质)、认证医师标识、直播带货限制
+- [[Xiaohongshu]](小红书):2021年起大规模清理医美内容、白名单管理制度、蒲公英品牌合作平台合规要求
+- [[WeChat]](视频号):医疗机构公众号认证、朋友圈广告投放规范、小程序在线问诊/售药资质要求
+
+## Connections
+- [[Healthcare-Marketing-Compliance]] ← extends ← [[The-Agency]](Specialized 部门)
+- [[Healthcare-Marketing-Compliance]] ← depends_on ← [[NMPA]](监管机构)
+- [[Healthcare-Marketing-Compliance]] ← depends_on ← [[SAMR]](执法机构)
+- [[Platform-Content-Review]] ← extends ← [[Healthcare-Marketing-Compliance]]
+- [[Patient-Privacy-PIPL]] ← depends_on ← [[Healthcare-Marketing-Compliance]]
+- [[Academic-Detailing]] ← extends ← [[Healthcare-Marketing-Compliance]]
+
+## Contradictions
+- 与 [[legal-compliance-checker]] 潜在冲突:
+ - 冲突点:通用法律合规 Agent 与医疗专项合规 Agent 的职责边界
+ - 当前观点:医疗营销合规具有高度专业化特征(广告法/药械注册/平台规则),通用法律合规工具无法覆盖
+ - 对方观点:合规 Agent 应具备跨行业通用合规框架,无需细分至医疗领域
+ - 解决方向:通用合规 Agent 负责数据隐私/合同合规等横向能力,医疗营销合规 Agent 专注垂直领域规则差异
diff --git a/wiki/sources/how-can-a-multi-cloud-strategy-transform-your-business-roi.md b/wiki/sources/how-can-a-multi-cloud-strategy-transform-your-business-roi.md
index 9c73a568..d71a2ba2 100644
--- a/wiki/sources/how-can-a-multi-cloud-strategy-transform-your-business-roi.md
+++ b/wiki/sources/how-can-a-multi-cloud-strategy-transform-your-business-roi.md
@@ -1,69 +1,69 @@
----
-title: "How Can a Multi Cloud Strategy Transform Your Business ROI?"
-type: source
-tags: [Cloud, Multi-Cloud, ROI, DevOps]
-date: 2024-12-24
----
-
-## Source File
-- [[Cloud & DevOps/How Can a Multi Cloud Strategy Transform Your Business ROI.md]]
-
-## Summary(用中文描述)
-- 核心主题:多云策略(Multi-Cloud Strategy)的商业价值——如何通过多云架构提升业务 ROI、降低风险、增强弹性
-- 问题域:企业在云迁移和云运营中面临的供应商锁定、成本失控、合规复杂、可用性不足等挑战
-- 方法/机制:跨多个云服务提供商(AWS/Azure/GCP)分配工作负载,利用各提供商优势实现成本优化、弹性扩展和安全增强
-- 结论/价值:78% 企业使用 3+ 公有云;86% 企业计划 2024 年底采用多云;优化后可实现 30% 运营成本降低;多云策略是企业在数字化竞争中保持敏捷的关键
-
-## Key Claims(用中文描述)
-- 78% 采用多云策略的企业使用 3+ 公有云以提升敏捷性和成本节约(Virtana)
-- 86% 企业计划 2024 年底采用多云策略以满足持续业务需求(New Horizons)
-- 优化资源和与不同云服务商谈判后,多数企业享受 30% 运营成本降低(Forrester)
-- 78% 企业已采用多云策略;平均使用 2-5 个云服务商;多云是主流趋势
-
-## Key Quotes
-> "The multi cloud strategy is a distinctive approach in which we have instances of services on multiple clouds, i.e., Azure, GCP, and Amazon, instead of one cloud vendor." — Bacancy Technology,核心定义
-
-> "A multi-cloud approach will provide businesses with more innovation and ensure they are always at the forefront of this rapidly evolving digital landscape." — Bacancy Technology,多云创新的价值
-
-> "After optimizing resources and negotiating favorable prices with different cloud service providers, most companies enjoy a 30% reduction in operations costs." — Forrester,成本优化数据来源
-
-## Key Concepts
-- [[Multi-Cloud-Strategy]]:使用多个云服务提供商来避免锁定、增强弹性、优化成本,是本文核心主题
-- [[Vendor-Lock-In]]:多云策略的首要动因——企业通过多云摆脱对单一供应商的依赖
-- [[Data-Sovereignty]]:多云策略满足数据主权合规——不同地区选择符合当地法规的云服务商
-- [[High Availability]]:多云跨平台冗余实现 99.99%+ 可用性目标
-- [[Scalability]]:多云弹性扩展能力——跨提供商动态分配资源,应对流量高峰
-- [[Cost Optimization]]:多云实现 30% 运营成本降低——跨提供商比价、优化资源配置
-
-## Key Entities
-- [[AWS]] — 主要云提供商之一,可用于基础设施和通用计算
-- [[Azure]] — Microsoft Azure,多云策略中用于 AI 工具集成
-- [[Google-Cloud]] — GCP,ML/AI 工作负载的首选提供商
-- Bacancy Technology — 文章原始发布方,提供云托管服务
-
-## Connections
-- [[Multi-Cloud-Strategy]] ← is_about ← 本文核心主题
-- [[Vendor-Lock-In]] ← solves ← [[Multi-Cloud-Strategy]] 的首要动机
-- [[Data-Sovereignty]] ← enables ← [[Multi-Cloud-Strategy]] 的合规能力
-- [[High Availability]] ← achieved_by ← [[Multi-Cloud-Strategy]] 跨云冗余
-- [[Cloud-Operating-Model]] ← includes ← [[Multi-Cloud-Strategy]] 作为核心组件
-- [[Cloud-Governance]] ← governs ← [[Multi-Cloud-Strategy]] 的实施
-- [[FinOps]] ← optimizes ← [[Multi-Cloud-Strategy]] 的成本管理
-
-## Real-World Use Cases(原文关键案例)
-- **电商**:黑色星期五/网络星期一等高峰期跨多云弹性扩展,保障高可用和快速加载
-- **医疗**:符合 HIPAA 保护患者数据,符合区域数据主权要求,降低单一云依赖成本
-- **金融**:利用不同云最佳安全功能,满足严格监管要求,减少供应商锁定,获得更好 SLA
-
-## Implementation Framework(原文实施路径)
-1. **评估需求**:明确目标(弹性/成本/规模)、预算分析、资源评估
-2. **选择提供商**:对齐服务与需求(如 AWS 基础设施、GCP 分析、Azure AI)
-3. **集成管理**:采用 Kubernetes/Terraform 等多云管理工具,确保数据互操作性
-4. **监控优化**:使用 CloudHealth/Datadog 持续监控性能和成本
-
-## Contradictions
-- 与 [[cloud-operating-model-key-strategies-and-best-practices]] 中的"统一云治理"观点存在潜在张力:
- - 冲突点:多云策略天然带来管理复杂性
- - 当前观点(本文):多云管理工具(Kubernetes/Terraform)可简化复杂性
- - 对方观点:需要统一的 Cloud Operating Model 治理框架来协调多云环境
- - 协调方向:两者互补——多云策略是选择层,Cloud Operating Model 是治理层
+---
+title: "How Can a Multi Cloud Strategy Transform Your Business ROI?"
+type: source
+tags: [Cloud, Multi-Cloud, ROI, DevOps]
+date: 2024-12-24
+---
+
+## Source File
+- [[raw/Cloud & DevOps/How Can a Multi Cloud Strategy Transform Your Business ROI.md]]
+
+## Summary(用中文描述)
+- 核心主题:多云策略(Multi-Cloud Strategy)的商业价值——如何通过多云架构提升业务 ROI、降低风险、增强弹性
+- 问题域:企业在云迁移和云运营中面临的供应商锁定、成本失控、合规复杂、可用性不足等挑战
+- 方法/机制:跨多个云服务提供商(AWS/Azure/GCP)分配工作负载,利用各提供商优势实现成本优化、弹性扩展和安全增强
+- 结论/价值:78% 企业使用 3+ 公有云;86% 企业计划 2024 年底采用多云;优化后可实现 30% 运营成本降低;多云策略是企业在数字化竞争中保持敏捷的关键
+
+## Key Claims(用中文描述)
+- 78% 采用多云策略的企业使用 3+ 公有云以提升敏捷性和成本节约(Virtana)
+- 86% 企业计划 2024 年底采用多云策略以满足持续业务需求(New Horizons)
+- 优化资源和与不同云服务商谈判后,多数企业享受 30% 运营成本降低(Forrester)
+- 78% 企业已采用多云策略;平均使用 2-5 个云服务商;多云是主流趋势
+
+## Key Quotes
+> "The multi cloud strategy is a distinctive approach in which we have instances of services on multiple clouds, i.e., Azure, GCP, and Amazon, instead of one cloud vendor." — Bacancy Technology,核心定义
+
+> "A multi-cloud approach will provide businesses with more innovation and ensure they are always at the forefront of this rapidly evolving digital landscape." — Bacancy Technology,多云创新的价值
+
+> "After optimizing resources and negotiating favorable prices with different cloud service providers, most companies enjoy a 30% reduction in operations costs." — Forrester,成本优化数据来源
+
+## Key Concepts
+- [[Multi-Cloud-Strategy]]:使用多个云服务提供商来避免锁定、增强弹性、优化成本,是本文核心主题
+- [[Vendor-Lock-In]]:多云策略的首要动因——企业通过多云摆脱对单一供应商的依赖
+- [[Data-Sovereignty]]:多云策略满足数据主权合规——不同地区选择符合当地法规的云服务商
+- [[High Availability]]:多云跨平台冗余实现 99.99%+ 可用性目标
+- [[Scalability]]:多云弹性扩展能力——跨提供商动态分配资源,应对流量高峰
+- [[Cost Optimization]]:多云实现 30% 运营成本降低——跨提供商比价、优化资源配置
+
+## Key Entities
+- [[AWS]] — 主要云提供商之一,可用于基础设施和通用计算
+- [[Azure]] — Microsoft Azure,多云策略中用于 AI 工具集成
+- [[Google-Cloud]] — GCP,ML/AI 工作负载的首选提供商
+- Bacancy Technology — 文章原始发布方,提供云托管服务
+
+## Connections
+- [[Multi-Cloud-Strategy]] ← is_about ← 本文核心主题
+- [[Vendor-Lock-In]] ← solves ← [[Multi-Cloud-Strategy]] 的首要动机
+- [[Data-Sovereignty]] ← enables ← [[Multi-Cloud-Strategy]] 的合规能力
+- [[High Availability]] ← achieved_by ← [[Multi-Cloud-Strategy]] 跨云冗余
+- [[Cloud-Operating-Model]] ← includes ← [[Multi-Cloud-Strategy]] 作为核心组件
+- [[Cloud-Governance]] ← governs ← [[Multi-Cloud-Strategy]] 的实施
+- [[FinOps]] ← optimizes ← [[Multi-Cloud-Strategy]] 的成本管理
+
+## Real-World Use Cases(原文关键案例)
+- **电商**:黑色星期五/网络星期一等高峰期跨多云弹性扩展,保障高可用和快速加载
+- **医疗**:符合 HIPAA 保护患者数据,符合区域数据主权要求,降低单一云依赖成本
+- **金融**:利用不同云最佳安全功能,满足严格监管要求,减少供应商锁定,获得更好 SLA
+
+## Implementation Framework(原文实施路径)
+1. **评估需求**:明确目标(弹性/成本/规模)、预算分析、资源评估
+2. **选择提供商**:对齐服务与需求(如 AWS 基础设施、GCP 分析、Azure AI)
+3. **集成管理**:采用 Kubernetes/Terraform 等多云管理工具,确保数据互操作性
+4. **监控优化**:使用 CloudHealth/Datadog 持续监控性能和成本
+
+## Contradictions
+- 与 [[cloud-operating-model-key-strategies-and-best-practices]] 中的"统一云治理"观点存在潜在张力:
+ - 冲突点:多云策略天然带来管理复杂性
+ - 当前观点(本文):多云管理工具(Kubernetes/Terraform)可简化复杂性
+ - 对方观点:需要统一的 Cloud Operating Model 治理框架来协调多云环境
+ - 协调方向:两者互补——多云策略是选择层,Cloud Operating Model 是治理层
diff --git a/wiki/sources/how-to-get-the-rss-feed-for-any-youtube-channel.md b/wiki/sources/how-to-get-the-rss-feed-for-any-youtube-channel.md
index 11ea8d90..118f3da6 100644
--- a/wiki/sources/how-to-get-the-rss-feed-for-any-youtube-channel.md
+++ b/wiki/sources/how-to-get-the-rss-feed-for-any-youtube-channel.md
@@ -6,7 +6,7 @@ date: 2024-05-12
---
## Source File
-- [[AI/How to Get the RSS Feed For Any YouTube Channel.md]]
+- [[raw/AI/How to Get the RSS Feed For Any YouTube Channel.md]]
## Summary(用中文描述)
- 核心主题:获取任意YouTube频道RSS订阅源的方法
diff --git a/wiki/sources/how-to-get-youtube-channel-id.md b/wiki/sources/how-to-get-youtube-channel-id.md
index c8fbf78d..95b4c162 100644
--- a/wiki/sources/how-to-get-youtube-channel-id.md
+++ b/wiki/sources/how-to-get-youtube-channel-id.md
@@ -6,7 +6,7 @@ date: 2025-03-16
---
## Source File
-- [[Others/How to get Youtube Channel ID]]
+- [[raw/Others/How to get Youtube Channel ID.md]]
## Summary(用中文描述)
- 核心主题:从 YouTube 频道页面获取 Channel ID 的方法
diff --git a/wiki/sources/identity-graph-operator.md b/wiki/sources/identity-graph-operator.md
index 004a2546..46f52d2e 100644
--- a/wiki/sources/identity-graph-operator.md
+++ b/wiki/sources/identity-graph-operator.md
@@ -1,56 +1,56 @@
----
-title: "Identity Graph Operator"
-type: source
-tags: ["multi-agent", "identity-resolution", "entity-resolution", "the-agency"]
-date: 2026-04-24
----
-
-## Source File
-- [[Agent/agency-agents/specialized/identity-graph-operator]]
-
-## Summary(用中文描述)
-- 核心主题:多智能体系统中的共享身份图谱运营——确保所有 Agent 对同一真实世界实体(人/公司/产品)得到一致的规范化实体 ID,解决多 Agent 系统的核心问题:重复记录、冲突操作、级联错误。
-- 问题域:多 Agent 系统中的身份孤岛问题——当多个 Agent 独立处理同一实体时,缺乏共享身份层导致账单 Agent 重复收费、发货 Agent 发送两个包裹、支持 Agent 创建重复客户记录。
-- 方法/机制:通过身份解析引擎(Identity Engine)进行规范化(Normalization)→ 阻塞(Blocking)→ 评分(Scoring)→ 聚类(Clustering),返回相同 entity_id;支持昵称扩展(Bill→William)、E.164 电话标准化、邮箱小写化;merge/split 操作通过乐观锁执行,保留完整事件历史;直接变更 vs 提案决策按置信度分级处理。
-- 结论/价值:零身份冲突生产环境、合并准确率 > 99%、P99 解析延迟 < 100ms、全链路审计追踪。与 [[Multi-Agent-System-Reliability]] 的 Agent 协作模式互补——后者解决 Agent 间决策一致性问题,前者解决 Agent 对同一实体的识别一致性问题。
-
-## Key Claims(用中文描述)
-- **相同输入,相同输出**:两个 Agent 解析同一条记录必须得到相同 entity_id,这是绝对原则,不可妥协。
-- **证据优先于断言**:合并必须有字段级证据支撑(email exact match + name fuzzy match + phone match),仅凭"看起来相似"不足以触发合并。
-- **提案优于直接变更**:与其他 Agent 协作时,优先提出带证据的合并提案,而非直接执行,让对方 Agent 审查证据。
-- **外部 ID 排序**:使用 external_id 排序而非 UUID(UUID 无序),确保排序稳定性。
-- **从不跳过引擎**:不硬编码字段名、权重或阈值,由匹配引擎统一计算候选评分。
-
-## Key Quotes
-> "Same input, same output. Two agents resolving the same record must get the same entity_id. Always." — Determinism 原则核心表述
-> "Never merge without evidence. 'These look similar' is not evidence. Per-field comparison scores with confidence thresholds are evidence." — Evidence Over Assertion 原则
-> "When agents disagree — one proposes merge, another proposes split on the same entities — both proposals are flagged as 'conflict.' Add comments to discuss before resolving. Never resolve a conflict by overriding another agent's evidence." — 冲突处理机制
-
-## Key Concepts
-- [[Identity Resolution(身份解析)]]:将多条记录归一化为同一 canonical entity_id 的过程——通过 blocking/scoring/clustering 实现,与传统主数据管理(MDM)同源但在多 Agent 场景下增加了并发写入和分布式协调维度。
-- [[Blocking(阻塞/分块)]]:通过 blocking key(email domain、phone prefix、name soundex)快速筛选候选匹配对,避免全图扫描 O(n²) 开销,是大规模实体解析的性能关键。
-- [[Fuzzy Matching(模糊匹配)]]:处理"Bill Smith"和"William Smith"视为同一人的能力——通过昵称扩展(nickname normalization)和字段级相似度评分实现,是身份解析的核心挑战。
-- [[Confidence Score(置信度评分)]]:字段级证据分数加权求和得出的合并置信度——决定直接合并(>0.95)、提案审查(0.6-0.95)还是创建新实体(<0.6),是自动决策与人机协作的分界点。
-- [[Optimistic Locking(乐观锁)]]:通过版本号(version field)防止并发写入冲突——变更需携带 expected_version,版本不匹配时拒绝执行,是图谱完整性的并发保护机制。
-- [[Evidence-based Merge Proposal(证据驱动合并提案)]]:合并前必须构造 per-field evidence(email_match/score/values、name_match/score/values),让其他 Agent 基于证据而非断言进行审查,是多 Agent 身份协调的核心协议。
-- [[Multi-Agent Identity Coordination(多 Agent 身份协调)]]:跨 Agent 的 merge/split 冲突检测、跨编排框架(LangChain/CrewAI/AutoGen)的身份联邦,以及 shared agent memory(跨 Agent 知识共享)——是 Identity Graph Operator 与 [[Multi-Agent-System-Reliability]] 的本质区别。
-
-## Key Entities
-- [[Identity Graph Operator]]:身份图谱运营者 Agent——本文档描述的核心 Agent,拥有共享身份层的所有权,负责多 Agent 系统的实体解析、合并提案和冲突协调。
-- [[Backend Architect]]:后端架构师 Agent——与 Identity Graph Operator 协作,前者设计数据表结构,后者确保跨来源的实体不重复。
-- [[Agents Orchestrator]]:Agent 编排器——Identity Graph Operator 在其中注册自己的身份解析能力,供编排器分配 identity resolution 任务。
-- [[Reality Checker]]:现实核查 Agent——接收 Identity Graph Operator 的 merge 证据进行质量门检验。
-- [[Support Responder]]:支持响应 Agent——通过 Identity Graph Operator 解析客户身份后响应,"这是昨天来电的同一位客户吗?"
-- [[Agentic Identity & Trust Architect]]:Agent 身份与信任架构师——与 Identity Graph Operator 互补,前者处理实体身份(who is this person/company?),后者处理 Agent 身份(who is this agent and what can it do?)。
-
-## Connections
-- [[Multi-Agent-System-Reliability]] ← depends_on ← [[Identity-Graph-Operator]]:身份图谱是 [[Multi-Agent-System-Reliability]] 中多 Agent 协作模式的基础设施层——[[Hierarchy-Agent-Pattern]] 中的主管 Agent 需要 Identity Graph Operator 来消除下游 Agent 的重复实体问题。
-- [[Identity-Graph-Operator]] ← extends ← [[Personal CRM]]:[[Personal CRM]] 中的联系人去重是 Identity Graph Operator 在个人场景的简化实现,企业级多 Agent 场景增加了并发写入、跨框架联邦和图谱完整性等维度。
-- [[Identity-Graph-Operator]] ← depends_on ← [[Identity-Resolution]]:身份解析技术是 Identity Graph Operator 的核心能力底座,两者同义——Operator 是身份解析能力在多 Agent 系统中的 Agent 化封装。
-- [[Identity-Graph-Operator]] ← extends ← [[Entity-Merge-Algorithm]]:Entity Merge Algorithm 是合并决策的计算内核,Operator 在其上增加了提案协议、冲突检测和审计追踪等协作维度。
-
-## Contradictions
-- 与 [[Designing-for-Agentic-AI]] 可能的冲突:
- - 冲突点:身份图谱的确定性要求("Same input, same output")与 [[Designing-for-Agentic-AI]] 强调的 LLM 概率性行为如何协调?
- - 当前观点:[[Identity-Graph-Operator]] 通过将身份解析核心逻辑从 LLM 推理中分离出来(blocking/scoring/clustering 由确定性算法执行),仅在 merge proposal 生成阶段使用 LLM 提供自然语言解释,从而在保留 LLM 灵活性的同时保障确定性。
- - 对方观点:[[Designing-for-Agentic-AI]] 可能认为过度确定性约束会削弱 Agent 的自主性和上下文适应能力。
+---
+title: "Identity Graph Operator"
+type: source
+tags: ["multi-agent", "identity-resolution", "entity-resolution", "the-agency"]
+date: 2026-04-24
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/identity-graph-operator.md]]
+
+## Summary(用中文描述)
+- 核心主题:多智能体系统中的共享身份图谱运营——确保所有 Agent 对同一真实世界实体(人/公司/产品)得到一致的规范化实体 ID,解决多 Agent 系统的核心问题:重复记录、冲突操作、级联错误。
+- 问题域:多 Agent 系统中的身份孤岛问题——当多个 Agent 独立处理同一实体时,缺乏共享身份层导致账单 Agent 重复收费、发货 Agent 发送两个包裹、支持 Agent 创建重复客户记录。
+- 方法/机制:通过身份解析引擎(Identity Engine)进行规范化(Normalization)→ 阻塞(Blocking)→ 评分(Scoring)→ 聚类(Clustering),返回相同 entity_id;支持昵称扩展(Bill→William)、E.164 电话标准化、邮箱小写化;merge/split 操作通过乐观锁执行,保留完整事件历史;直接变更 vs 提案决策按置信度分级处理。
+- 结论/价值:零身份冲突生产环境、合并准确率 > 99%、P99 解析延迟 < 100ms、全链路审计追踪。与 [[Multi-Agent-System-Reliability]] 的 Agent 协作模式互补——后者解决 Agent 间决策一致性问题,前者解决 Agent 对同一实体的识别一致性问题。
+
+## Key Claims(用中文描述)
+- **相同输入,相同输出**:两个 Agent 解析同一条记录必须得到相同 entity_id,这是绝对原则,不可妥协。
+- **证据优先于断言**:合并必须有字段级证据支撑(email exact match + name fuzzy match + phone match),仅凭"看起来相似"不足以触发合并。
+- **提案优于直接变更**:与其他 Agent 协作时,优先提出带证据的合并提案,而非直接执行,让对方 Agent 审查证据。
+- **外部 ID 排序**:使用 external_id 排序而非 UUID(UUID 无序),确保排序稳定性。
+- **从不跳过引擎**:不硬编码字段名、权重或阈值,由匹配引擎统一计算候选评分。
+
+## Key Quotes
+> "Same input, same output. Two agents resolving the same record must get the same entity_id. Always." — Determinism 原则核心表述
+> "Never merge without evidence. 'These look similar' is not evidence. Per-field comparison scores with confidence thresholds are evidence." — Evidence Over Assertion 原则
+> "When agents disagree — one proposes merge, another proposes split on the same entities — both proposals are flagged as 'conflict.' Add comments to discuss before resolving. Never resolve a conflict by overriding another agent's evidence." — 冲突处理机制
+
+## Key Concepts
+- [[Identity Resolution(身份解析)]]:将多条记录归一化为同一 canonical entity_id 的过程——通过 blocking/scoring/clustering 实现,与传统主数据管理(MDM)同源但在多 Agent 场景下增加了并发写入和分布式协调维度。
+- [[Blocking(阻塞/分块)]]:通过 blocking key(email domain、phone prefix、name soundex)快速筛选候选匹配对,避免全图扫描 O(n²) 开销,是大规模实体解析的性能关键。
+- [[Fuzzy Matching(模糊匹配)]]:处理"Bill Smith"和"William Smith"视为同一人的能力——通过昵称扩展(nickname normalization)和字段级相似度评分实现,是身份解析的核心挑战。
+- [[Confidence Score(置信度评分)]]:字段级证据分数加权求和得出的合并置信度——决定直接合并(>0.95)、提案审查(0.6-0.95)还是创建新实体(<0.6),是自动决策与人机协作的分界点。
+- [[Optimistic Locking(乐观锁)]]:通过版本号(version field)防止并发写入冲突——变更需携带 expected_version,版本不匹配时拒绝执行,是图谱完整性的并发保护机制。
+- [[Evidence-based Merge Proposal(证据驱动合并提案)]]:合并前必须构造 per-field evidence(email_match/score/values、name_match/score/values),让其他 Agent 基于证据而非断言进行审查,是多 Agent 身份协调的核心协议。
+- [[Multi-Agent Identity Coordination(多 Agent 身份协调)]]:跨 Agent 的 merge/split 冲突检测、跨编排框架(LangChain/CrewAI/AutoGen)的身份联邦,以及 shared agent memory(跨 Agent 知识共享)——是 Identity Graph Operator 与 [[Multi-Agent-System-Reliability]] 的本质区别。
+
+## Key Entities
+- [[Identity Graph Operator]]:身份图谱运营者 Agent——本文档描述的核心 Agent,拥有共享身份层的所有权,负责多 Agent 系统的实体解析、合并提案和冲突协调。
+- [[Backend Architect]]:后端架构师 Agent——与 Identity Graph Operator 协作,前者设计数据表结构,后者确保跨来源的实体不重复。
+- [[Agents Orchestrator]]:Agent 编排器——Identity Graph Operator 在其中注册自己的身份解析能力,供编排器分配 identity resolution 任务。
+- [[Reality Checker]]:现实核查 Agent——接收 Identity Graph Operator 的 merge 证据进行质量门检验。
+- [[Support Responder]]:支持响应 Agent——通过 Identity Graph Operator 解析客户身份后响应,"这是昨天来电的同一位客户吗?"
+- [[Agentic Identity & Trust Architect]]:Agent 身份与信任架构师——与 Identity Graph Operator 互补,前者处理实体身份(who is this person/company?),后者处理 Agent 身份(who is this agent and what can it do?)。
+
+## Connections
+- [[Multi-Agent-System-Reliability]] ← depends_on ← [[Identity-Graph-Operator]]:身份图谱是 [[Multi-Agent-System-Reliability]] 中多 Agent 协作模式的基础设施层——[[Hierarchy-Agent-Pattern]] 中的主管 Agent 需要 Identity Graph Operator 来消除下游 Agent 的重复实体问题。
+- [[Identity-Graph-Operator]] ← extends ← [[Personal CRM]]:[[Personal CRM]] 中的联系人去重是 Identity Graph Operator 在个人场景的简化实现,企业级多 Agent 场景增加了并发写入、跨框架联邦和图谱完整性等维度。
+- [[Identity-Graph-Operator]] ← depends_on ← [[Identity-Resolution]]:身份解析技术是 Identity Graph Operator 的核心能力底座,两者同义——Operator 是身份解析能力在多 Agent 系统中的 Agent 化封装。
+- [[Identity-Graph-Operator]] ← extends ← [[Entity-Merge-Algorithm]]:Entity Merge Algorithm 是合并决策的计算内核,Operator 在其上增加了提案协议、冲突检测和审计追踪等协作维度。
+
+## Contradictions
+- 与 [[Designing-for-Agentic-AI]] 可能的冲突:
+ - 冲突点:身份图谱的确定性要求("Same input, same output")与 [[Designing-for-Agentic-AI]] 强调的 LLM 概率性行为如何协调?
+ - 当前观点:[[Identity-Graph-Operator]] 通过将身份解析核心逻辑从 LLM 推理中分离出来(blocking/scoring/clustering 由确定性算法执行),仅在 merge proposal 生成阶段使用 LLM 提供自然语言解释,从而在保留 LLM 灵活性的同时保障确定性。
+ - 对方观点:[[Designing-for-Agentic-AI]] 可能认为过度确定性约束会削弱 Agent 的自主性和上下文适应能力。
diff --git a/wiki/sources/if-you-have-multiple-interests-do-not-waste-the-next-2-3-years-如果你有多项兴趣爱好-不要浪费接下来的两三年时间.md b/wiki/sources/if-you-have-multiple-interests-do-not-waste-the-next-2-3-years-如果你有多项兴趣爱好-不要浪费接下来的两三年时间.md
index 607b0b36..5b8d2e44 100644
--- a/wiki/sources/if-you-have-multiple-interests-do-not-waste-the-next-2-3-years-如果你有多项兴趣爱好-不要浪费接下来的两三年时间.md
+++ b/wiki/sources/if-you-have-multiple-interests-do-not-waste-the-next-2-3-years-如果你有多项兴趣爱好-不要浪费接下来的两三年时间.md
@@ -1,65 +1,65 @@
----
-title: "If You Have Multiple Interests, Do Not Waste the Next 2-3 Years"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[AI/If you have multiple interests, do not waste the next 2-3 years 如果你有多项兴趣爱好,不要浪费接下来的两三年时间。]]
-
-## Summary(用中文描述)
-- 核心主题:在 AI 时代,多重兴趣爱好不再是弱点,而是个人成功的超能力;作者提出将个人品牌、内容创作和产品三者统一为"发展路径",帮助有多重兴趣的人将所有热情转化为可盈利的事业
-- 问题域:工业时代专业化分工对个人创造力和独立性的压制;现代社会对"通才型"人才的新需求;如何将分散的兴趣整合为一致的个人事业
-- 方法/机制:①通过"自学+自利+自立"三要素解构个人成功 ②借助第二次文艺复兴的历史类比说明通才崛起的必然性 ③提出以个人故事为品牌内核、以高质量创意为内容核心、以帮助他人达成目标为产品的"发展路径" ④内容创作三步法:创意博物馆→基于创意密度筛选→同一想法1000种表达方式 ⑤系统经济观:产品即系统,差异化来自个人实践的系统
-- 结论/价值:现在是历史上最适合通才型多面手生存的时代;将个人故事、关注兴趣的人群、产品服务整合为统一体系,是最可持续的个人商业化路径
-
-## Key Claims(用中文描述)
-- 工业化专业化分工使人类沦为"愚蠢而依赖"的螺丝钉,政府和公司服务自身利益而非个人利益
-- 个人成功的三要素:自学(自驱学习)、自利(追随自身利益)、自立(拒绝外包判断力和自主性);三者相互支撑
-- 达芬奇、米开朗基罗等文艺复兴通才的崛起得益于印刷术使知识民主化;AI 时代知识获取成本再次趋近于零,第二次文艺复兴已经到来
-- 兴趣越多→认知模型越复杂→能解决的问题和创造的价值越多;专精化完全阻断这一过程
-- 注意力是最后的护城河之一;在任何人都能构建软件的时代,被知晓的产品才能胜出
-- 品牌是一个让人们前来转变的小世界,是读者关注3-6个月后在脑海中积累的整体印象,而非个人简介和头像
-- 内容创作的指导原则:收集最好的想法;内容密度(Idea Density)= 表现力(他人关注度)× 兴奋度(自身热情);艺术与商业的统一
-- 我们正处于"系统经济"时代——人们不想要解决方案,而想要你的解决方案;系统来自个人实践的差异化经验
-
-## Key Quotes
-> "一个人如果一生只从事几项简单的操作……通常会变得愚蠢无知到极致。" — Adam Smith(亚当·斯密,《国富论》论分工)
-> "研习艺术的科学,研习科学的艺术。培养你的感官——尤其要学会观察。要明白万物皆有联系。" — Leonardo da Vinci(列奥纳多·达·芬奇)
-> "真正自私的人是自尊自强的人,既不为己牺牲他人,也不为他人牺牲自己。" — Ayn Rand(安·兰德)
-> "如果你曾经帮助过别人实现自己的兴趣,你就有资格创业。" — thedankoe(本文作者)
-> "你会成为那些人们甚至不会想到向人工智能寻求,也永远不会自然而然产生的创意的策展人。" — thedankoe
-
-## Key Concepts
-- [[Generalist]]:通才型人才——精通多领域,能够将不同学科的思想相互补充,形成独特的世界观,从而捕捉新颖想法并转化为市场价值;与专精化相对
-- [[Self-Education]]:自学——通过追随自身利益而非他人布置的任务来驱动学习,是通才型人才的核心驱动力
-- [[Self-Interest]]:自利——关注自身利益(区别于自私),是继自学之后指引学习方向的指南针;在认知和道德发展的高级阶段,自利可以无私地造福他人
-- [[Self-Sufficiency]]:自立自强——拒绝将判断力、学习能力和自主性外包,是防止人生方向被他人劫持的基石
-- [[Brand-Environment]]:品牌作为环境——品牌不是个人简介和头像,而是一个让人们前来转变的小世界,是读者关注3-6个月后在脑海中积累的整体印象
-- [[Idea-Density]]:创意密度——内容的核心质量指标 = 表现力(他人关注度)× 兴奋度(自身热情);是区分普通创作者与顶级思想家的关键
-- [[Idea-Museum]]:创意博物馆——持续收集高质量想法的素材库,包括反复阅读的经典书籍、精选博客、有影响力的社交账号
-- [[Content-Creator]]:内容创作者(重新定义)——不是追求流量的人,而是将社交媒体作为"公开做笔记"的机制来传播毕生工作的载体;参考 Jordan Peterson 案例
-- [[System-Economy]]:系统经济——在产品过剩的时代,人们不想要解决方案,而想要你的解决方案;差异化来自个人实践形成的独特系统
-- [[Attention-Economy]]:注意力经济——在 AI 可生成任何内容的时代,注意力成为最后的护城河;最被知晓的产品才能胜出
-- [[Second-Renaissance]]:第二次文艺复兴——印刷术使知识民主化催生了第一次文艺复兴;AI 使知识获取成本再次趋近于零,通才型人才迎来历史性机遇
-
-## Key Entities
-- [[Adam Smith]]:古典经济学家,《国富论》作者,其分工理论被本文引用来揭示专业化分工对人类智识的负面影响
-- [[Leonardo da Vinci]]:文艺复兴时期通才典范——画家、雕塑家、解剖学家、工程师、建筑师、诗人,跨越多个领域融会贯通
-- [[Ayn Rand]]:客观主义哲学家,其"真正自私"的定义(自尊自强,不为他人牺牲自己,也不同情他人牺牲自己)被引用来区分健康利己与掠夺/受虐心态
-- [[Jordan Peterson]]:心理学家/作家,其案例被引用来说明真正的创作者不是"内容创作者",而是利用一切工具(巡回演讲/著书/社交媒体)传播毕生工作的人
-
-## Connections
-- [[Generalist]] ← depends_on ← [[Self-Education]]
-- [[Generalist]] ← depends_on ← [[Self-Interest]]
-- [[Generalist]] ← depends_on ← [[Self-Sufficiency]]
-- [[Content-Creator]] ← extends ← [[Idea-Density]]
-- [[Content-Creator]] ← extends ← [[Idea-Museum]]
-- [[Brand-Environment]] ← extends ← [[Content-Creator]]
-- [[System-Economy]] ← extends ← [[Content-Creator]]
-- [[Second-Renaissance]] ← extends ← [[Generalist]]
-
-## Contradictions
-- 无明显冲突内容。本文与 [[Multi-Agent System Reliability]] 的[[Generalist]]概念高度互补——后者从系统可靠性角度论证多智能体需要通才型架构设计者;本文从个人发展角度论证多兴趣个体是 AI 时代的比较优势。
-- 本文与 [[不谈技术:普通人该怎么在AI时代赚钱]] 可能存在潜在关联——两者均讨论个人在 AI 时代的生存策略,但前者侧重"通才型品牌内容"路径,后者可能有不同的路径建议,需后续对比。
+---
+title: "If You Have Multiple Interests, Do Not Waste the Next 2-3 Years"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/AI/If you have multiple interests, do not waste the next 2-3 years 如果你有多项兴趣爱好,不要浪费接下来的两三年时间。.md]]
+
+## Summary(用中文描述)
+- 核心主题:在 AI 时代,多重兴趣爱好不再是弱点,而是个人成功的超能力;作者提出将个人品牌、内容创作和产品三者统一为"发展路径",帮助有多重兴趣的人将所有热情转化为可盈利的事业
+- 问题域:工业时代专业化分工对个人创造力和独立性的压制;现代社会对"通才型"人才的新需求;如何将分散的兴趣整合为一致的个人事业
+- 方法/机制:①通过"自学+自利+自立"三要素解构个人成功 ②借助第二次文艺复兴的历史类比说明通才崛起的必然性 ③提出以个人故事为品牌内核、以高质量创意为内容核心、以帮助他人达成目标为产品的"发展路径" ④内容创作三步法:创意博物馆→基于创意密度筛选→同一想法1000种表达方式 ⑤系统经济观:产品即系统,差异化来自个人实践的系统
+- 结论/价值:现在是历史上最适合通才型多面手生存的时代;将个人故事、关注兴趣的人群、产品服务整合为统一体系,是最可持续的个人商业化路径
+
+## Key Claims(用中文描述)
+- 工业化专业化分工使人类沦为"愚蠢而依赖"的螺丝钉,政府和公司服务自身利益而非个人利益
+- 个人成功的三要素:自学(自驱学习)、自利(追随自身利益)、自立(拒绝外包判断力和自主性);三者相互支撑
+- 达芬奇、米开朗基罗等文艺复兴通才的崛起得益于印刷术使知识民主化;AI 时代知识获取成本再次趋近于零,第二次文艺复兴已经到来
+- 兴趣越多→认知模型越复杂→能解决的问题和创造的价值越多;专精化完全阻断这一过程
+- 注意力是最后的护城河之一;在任何人都能构建软件的时代,被知晓的产品才能胜出
+- 品牌是一个让人们前来转变的小世界,是读者关注3-6个月后在脑海中积累的整体印象,而非个人简介和头像
+- 内容创作的指导原则:收集最好的想法;内容密度(Idea Density)= 表现力(他人关注度)× 兴奋度(自身热情);艺术与商业的统一
+- 我们正处于"系统经济"时代——人们不想要解决方案,而想要你的解决方案;系统来自个人实践的差异化经验
+
+## Key Quotes
+> "一个人如果一生只从事几项简单的操作……通常会变得愚蠢无知到极致。" — Adam Smith(亚当·斯密,《国富论》论分工)
+> "研习艺术的科学,研习科学的艺术。培养你的感官——尤其要学会观察。要明白万物皆有联系。" — Leonardo da Vinci(列奥纳多·达·芬奇)
+> "真正自私的人是自尊自强的人,既不为己牺牲他人,也不为他人牺牲自己。" — Ayn Rand(安·兰德)
+> "如果你曾经帮助过别人实现自己的兴趣,你就有资格创业。" — thedankoe(本文作者)
+> "你会成为那些人们甚至不会想到向人工智能寻求,也永远不会自然而然产生的创意的策展人。" — thedankoe
+
+## Key Concepts
+- [[Generalist]]:通才型人才——精通多领域,能够将不同学科的思想相互补充,形成独特的世界观,从而捕捉新颖想法并转化为市场价值;与专精化相对
+- [[Self-Education]]:自学——通过追随自身利益而非他人布置的任务来驱动学习,是通才型人才的核心驱动力
+- [[Self-Interest]]:自利——关注自身利益(区别于自私),是继自学之后指引学习方向的指南针;在认知和道德发展的高级阶段,自利可以无私地造福他人
+- [[Self-Sufficiency]]:自立自强——拒绝将判断力、学习能力和自主性外包,是防止人生方向被他人劫持的基石
+- [[Brand-Environment]]:品牌作为环境——品牌不是个人简介和头像,而是一个让人们前来转变的小世界,是读者关注3-6个月后在脑海中积累的整体印象
+- [[Idea-Density]]:创意密度——内容的核心质量指标 = 表现力(他人关注度)× 兴奋度(自身热情);是区分普通创作者与顶级思想家的关键
+- [[Idea-Museum]]:创意博物馆——持续收集高质量想法的素材库,包括反复阅读的经典书籍、精选博客、有影响力的社交账号
+- [[Content-Creator]]:内容创作者(重新定义)——不是追求流量的人,而是将社交媒体作为"公开做笔记"的机制来传播毕生工作的载体;参考 Jordan Peterson 案例
+- [[System-Economy]]:系统经济——在产品过剩的时代,人们不想要解决方案,而想要你的解决方案;差异化来自个人实践形成的独特系统
+- [[Attention-Economy]]:注意力经济——在 AI 可生成任何内容的时代,注意力成为最后的护城河;最被知晓的产品才能胜出
+- [[Second-Renaissance]]:第二次文艺复兴——印刷术使知识民主化催生了第一次文艺复兴;AI 使知识获取成本再次趋近于零,通才型人才迎来历史性机遇
+
+## Key Entities
+- [[Adam Smith]]:古典经济学家,《国富论》作者,其分工理论被本文引用来揭示专业化分工对人类智识的负面影响
+- [[Leonardo da Vinci]]:文艺复兴时期通才典范——画家、雕塑家、解剖学家、工程师、建筑师、诗人,跨越多个领域融会贯通
+- [[Ayn Rand]]:客观主义哲学家,其"真正自私"的定义(自尊自强,不为他人牺牲自己,也不同情他人牺牲自己)被引用来区分健康利己与掠夺/受虐心态
+- [[Jordan Peterson]]:心理学家/作家,其案例被引用来说明真正的创作者不是"内容创作者",而是利用一切工具(巡回演讲/著书/社交媒体)传播毕生工作的人
+
+## Connections
+- [[Generalist]] ← depends_on ← [[Self-Education]]
+- [[Generalist]] ← depends_on ← [[Self-Interest]]
+- [[Generalist]] ← depends_on ← [[Self-Sufficiency]]
+- [[Content-Creator]] ← extends ← [[Idea-Density]]
+- [[Content-Creator]] ← extends ← [[Idea-Museum]]
+- [[Brand-Environment]] ← extends ← [[Content-Creator]]
+- [[System-Economy]] ← extends ← [[Content-Creator]]
+- [[Second-Renaissance]] ← extends ← [[Generalist]]
+
+## Contradictions
+- 无明显冲突内容。本文与 [[Multi-Agent System Reliability]] 的[[Generalist]]概念高度互补——后者从系统可靠性角度论证多智能体需要通才型架构设计者;本文从个人发展角度论证多兴趣个体是 AI 时代的比较优势。
+- 本文与 [[不谈技术:普通人该怎么在AI时代赚钱]] 可能存在潜在关联——两者均讨论个人在 AI 时代的生存策略,但前者侧重"通才型品牌内容"路径,后者可能有不同的路径建议,需后续对比。
diff --git a/wiki/sources/inbox-declutter.md b/wiki/sources/inbox-declutter.md
index b4745d30..5ddb1f14 100644
--- a/wiki/sources/inbox-declutter.md
+++ b/wiki/sources/inbox-declutter.md
@@ -1,43 +1,43 @@
----
-title: "Inbox De-clutter"
-type: source
-tags: []
-date: 2026-04-22
----
-
-## Source File
-- [[Agent/usecases/inbox-declutter.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 自动整理邮箱订阅 newsletters
-- 问题域:Newsletter 堆积造成的信息过载
-- 方法/机制:通过定时 Cron Job 让 AI 每日阅读过去 24 小时的新邮件,生成摘要并请求用户反馈,持续学习用户偏好
-- 结论/价值:用 AI 代替人工翻阅 Newsletter,只获取精华内容,减少信息噪音
-
-## Key Claims(用中文描述)
-- AI Agent 通过每日 Cron Job 可主动整理 Newsletter 新邮件,无需用户手动翻阅
-- 用户反馈机制使 AI 能够持续优化摘要质量,越用越懂用户偏好
-
-## Key Quotes
-> "I want you to run a cron job everyday at 8 p.m. to read all the newsletter emails of the past 24 hours and give me a digest of the most important bits along with links to read more." — OpenClaw 配置指令示例
-
-> "Then ask for my feedback on whether you picked good bits, and update your memory based on my preferences for better digests in the future jobs." — 偏好学习机制
-
-## Key Concepts
-- [[Cron Job]]:定时调度任务,本文档中设置为每天 20:00 自动执行邮件摘要
-- [[Email Triage]]:邮件分拣,将 Newsletter 按重要性筛选整理
-- [[Newsletter Digest]]:AI 生成的 Newsletter 内容摘要,突出重点并附原文链接
-- [[Preference Learning]]:通过用户反馈持续优化 AI 摘要质量
-
-## Key Entities
-- [[OpenClaw]]:多 Agent 记忆框架,inbox-declutter 的执行环境,支持 Cron Job 和 Memory 持久化
-- [[Gmail OAuth]]:Gmail API 认证方式,是此技能的前置依赖
-
-## Connections
-- [[custom-morning-brief]] ← similar_pattern ← [[inbox-declutter]]
- - 两者均基于 [[OpenClaw]] Cron Job + Telegram 投递模式,但垂直场景不同
-- [[email-triage]] ← related_to ← [[inbox-declutter]]
- - inbox-declutter 是 Email Triage 的 Newsletter 垂直实现
-
-## Contradictions
-- 无已知冲突
+---
+title: "Inbox De-clutter"
+type: source
+tags: []
+date: 2026-04-22
+---
+
+## Source File
+- [[raw/Agent/usecases/inbox-declutter.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 自动整理邮箱订阅 newsletters
+- 问题域:Newsletter 堆积造成的信息过载
+- 方法/机制:通过定时 Cron Job 让 AI 每日阅读过去 24 小时的新邮件,生成摘要并请求用户反馈,持续学习用户偏好
+- 结论/价值:用 AI 代替人工翻阅 Newsletter,只获取精华内容,减少信息噪音
+
+## Key Claims(用中文描述)
+- AI Agent 通过每日 Cron Job 可主动整理 Newsletter 新邮件,无需用户手动翻阅
+- 用户反馈机制使 AI 能够持续优化摘要质量,越用越懂用户偏好
+
+## Key Quotes
+> "I want you to run a cron job everyday at 8 p.m. to read all the newsletter emails of the past 24 hours and give me a digest of the most important bits along with links to read more." — OpenClaw 配置指令示例
+
+> "Then ask for my feedback on whether you picked good bits, and update your memory based on my preferences for better digests in the future jobs." — 偏好学习机制
+
+## Key Concepts
+- [[Cron Job]]:定时调度任务,本文档中设置为每天 20:00 自动执行邮件摘要
+- [[Email Triage]]:邮件分拣,将 Newsletter 按重要性筛选整理
+- [[Newsletter Digest]]:AI 生成的 Newsletter 内容摘要,突出重点并附原文链接
+- [[Preference Learning]]:通过用户反馈持续优化 AI 摘要质量
+
+## Key Entities
+- [[OpenClaw]]:多 Agent 记忆框架,inbox-declutter 的执行环境,支持 Cron Job 和 Memory 持久化
+- [[Gmail OAuth]]:Gmail API 认证方式,是此技能的前置依赖
+
+## Connections
+- [[custom-morning-brief]] ← similar_pattern ← [[inbox-declutter]]
+ - 两者均基于 [[OpenClaw]] Cron Job + Telegram 投递模式,但垂直场景不同
+- [[email-triage]] ← related_to ← [[inbox-declutter]]
+ - inbox-declutter 是 Email Triage 的 Newsletter 垂直实现
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/install-wsl.md b/wiki/sources/install-wsl.md
index 4d5ca572..269fa816 100644
--- a/wiki/sources/install-wsl.md
+++ b/wiki/sources/install-wsl.md
@@ -1,49 +1,49 @@
----
-title: "Install WSL"
-type: source
-tags: []
-date: 2026-04-18
----
-
-## Source File
-- [[Home Office/Install WSL]]
-
-## Summary(用中文描述)
-- 核心主题:Windows Subsystem for Linux(WSL)的官方安装与配置完整指南
-- 问题域:Windows 10/11 系统上快速安装 Linux 开发环境,包括单命令安装、多发行版支持、版本管理、离线安装等场景
-- 方法/机制:① `wsl --install` 一键安装;② `-d` 参数切换默认发行版;③ `wsl.exe --set-default-version` 切换 WSL 1/2;④ MSI 包 + DISM 命令离线安装;⑤ Windows Terminal / 开始菜单 / PowerShell 多入口运行
-- 结论/价值:微软官方权威安装文档,提供从零到生产可用的完整路径,WSL2 为默认版本,支持并行运行多个不同 Linux 发行版
-
-## Key Claims(用中文描述)
-- `wsl --install` 一条命令完成 WSL 全部组件启用和 Ubuntu 默认发行版安装,适用于 Windows 10 version 2004+(Build 19041+)和 Windows 11
-- WSL2 默认使用 NAT 网络模式,通过 `.wslconfig` 配置 `networkingMode=mirrored` 可实现与 Windows 共享网络堆栈(参考 [[WSL2 启动与网络配置指南]])
-- 支持并行安装多个 Linux 发行版(Ubuntu/Debian/SUSE/Kali/Fedora 等),可从 Microsoft Store 下载或导入自定义 TAR 分发版
-- 新安装的 Linux 发行版默认使用 WSL 2,可通过 `wsl.exe --set-version 1` 降级到 WSL 1
-- 离线安装需从 GitHub releases 下载 MSI 安装包,并通过 DISM 命令启用 Virtual Machine Platform 组件
-
-## Key Quotes
-> "You can now install everything you need to run WSL with a single command." — 微软官方文档
-> "New Linux installations, installed using the `wsl --install` command, will be set to WSL 2 by default." — 微软官方文档
-
-## Key Concepts
-- [[WSL2]]:Windows Subsystem for Linux 2,Windows 10/11 内置 Linux 虚拟机环境,默认版本,支持完整 Linux 内核
-- [[WSL1]]:WSL 第一代,基于翻译层,性能较差但兼容性好,新发行版默认不使用
-- [[WSL 安装命令]]:`wsl --install` 单命令安装,启用所需功能并安装默认 Ubuntu 发行版
-- [[多发行版支持]]:WSL 支持并行安装运行多个不同 Linux 发行版,可通过 `--distribution` 参数指定运行哪个
-- [[离线安装]]:通过 MSI 包 + DISM 命令手动启用 Virtual Machine Platform 组件,适用于无法联网的环境
-
-## Key Entities
-- [[Microsoft]]:WSL 官方文档发布方
-- [[Ubuntu]]:WSL 默认安装的 Linux 发行版
-- [[PowerShell]]:Windows 命令行环境,执行 `wsl --install` 的工具(需管理员模式)
-- [[Windows Terminal]]:微软官方终端应用,推荐用于运行 WSL,支持多标签页
-
-## Connections
-- [[WSL2 启动与网络配置指南]] ← related_to ← [[Install WSL]](安装完成后需参考网络配置指南解决代理问题)
-- [[Ubuntu Server]] ← related_to ← [[WSL2]](WSL2 中的 Ubuntu 与 Ubuntu Server 同属 Ubuntu 系 Linux 环境)
-
-## Contradictions
-- 与 [[WSL2 启动与网络配置指南]] 的侧重点差异:
- - 冲突点:本文档聚焦安装过程,未涉及网络配置;[[WSL2 启动与网络配置指南]] 聚焦安装后的网络配置
- - 当前观点:先安装(本文档)→ 后配置网络([[WSL2 启动与网络配置指南]]),两篇互补
- - 对方观点:WSL2 默认 NAT 网络模式下 localhost 代理不可用,需配置镜像模式才能与 Windows 共享代理
+---
+title: "Install WSL"
+type: source
+tags: []
+date: 2026-04-18
+---
+
+## Source File
+- [[raw/Home Office/Install WSL.md]]
+
+## Summary(用中文描述)
+- 核心主题:Windows Subsystem for Linux(WSL)的官方安装与配置完整指南
+- 问题域:Windows 10/11 系统上快速安装 Linux 开发环境,包括单命令安装、多发行版支持、版本管理、离线安装等场景
+- 方法/机制:① `wsl --install` 一键安装;② `-d` 参数切换默认发行版;③ `wsl.exe --set-default-version` 切换 WSL 1/2;④ MSI 包 + DISM 命令离线安装;⑤ Windows Terminal / 开始菜单 / PowerShell 多入口运行
+- 结论/价值:微软官方权威安装文档,提供从零到生产可用的完整路径,WSL2 为默认版本,支持并行运行多个不同 Linux 发行版
+
+## Key Claims(用中文描述)
+- `wsl --install` 一条命令完成 WSL 全部组件启用和 Ubuntu 默认发行版安装,适用于 Windows 10 version 2004+(Build 19041+)和 Windows 11
+- WSL2 默认使用 NAT 网络模式,通过 `.wslconfig` 配置 `networkingMode=mirrored` 可实现与 Windows 共享网络堆栈(参考 [[WSL2 启动与网络配置指南]])
+- 支持并行安装多个 Linux 发行版(Ubuntu/Debian/SUSE/Kali/Fedora 等),可从 Microsoft Store 下载或导入自定义 TAR 分发版
+- 新安装的 Linux 发行版默认使用 WSL 2,可通过 `wsl.exe --set-version 1` 降级到 WSL 1
+- 离线安装需从 GitHub releases 下载 MSI 安装包,并通过 DISM 命令启用 Virtual Machine Platform 组件
+
+## Key Quotes
+> "You can now install everything you need to run WSL with a single command." — 微软官方文档
+> "New Linux installations, installed using the `wsl --install` command, will be set to WSL 2 by default." — 微软官方文档
+
+## Key Concepts
+- [[WSL2]]:Windows Subsystem for Linux 2,Windows 10/11 内置 Linux 虚拟机环境,默认版本,支持完整 Linux 内核
+- [[WSL1]]:WSL 第一代,基于翻译层,性能较差但兼容性好,新发行版默认不使用
+- [[WSL 安装命令]]:`wsl --install` 单命令安装,启用所需功能并安装默认 Ubuntu 发行版
+- [[多发行版支持]]:WSL 支持并行安装运行多个不同 Linux 发行版,可通过 `--distribution` 参数指定运行哪个
+- [[离线安装]]:通过 MSI 包 + DISM 命令手动启用 Virtual Machine Platform 组件,适用于无法联网的环境
+
+## Key Entities
+- [[Microsoft]]:WSL 官方文档发布方
+- [[Ubuntu]]:WSL 默认安装的 Linux 发行版
+- [[PowerShell]]:Windows 命令行环境,执行 `wsl --install` 的工具(需管理员模式)
+- [[Windows Terminal]]:微软官方终端应用,推荐用于运行 WSL,支持多标签页
+
+## Connections
+- [[WSL2 启动与网络配置指南]] ← related_to ← [[Install WSL]](安装完成后需参考网络配置指南解决代理问题)
+- [[Ubuntu Server]] ← related_to ← [[WSL2]](WSL2 中的 Ubuntu 与 Ubuntu Server 同属 Ubuntu 系 Linux 环境)
+
+## Contradictions
+- 与 [[WSL2 启动与网络配置指南]] 的侧重点差异:
+ - 冲突点:本文档聚焦安装过程,未涉及网络配置;[[WSL2 启动与网络配置指南]] 聚焦安装后的网络配置
+ - 当前观点:先安装(本文档)→ 后配置网络([[WSL2 启动与网络配置指南]]),两篇互补
+ - 对方观点:WSL2 默认 NAT 网络模式下 localhost 代理不可用,需配置镜像模式才能与 Windows 共享代理
diff --git a/wiki/sources/knowledge-base-rag.md b/wiki/sources/knowledge-base-rag.md
index 58e0b8ae..b2ee64af 100644
--- a/wiki/sources/knowledge-base-rag.md
+++ b/wiki/sources/knowledge-base-rag.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/knowledge-base-rag.md]]
+- [[raw/Agent/usecases/knowledge-base-rag.md]]
## Summary(用中文描述)
- 核心主题:构建可搜索的个人知识库,从所有保存的内容(文章/Tweet/YouTube 视频/PDF)中自动摄取并支持语义检索
diff --git a/wiki/sources/last30days-使用指南.md b/wiki/sources/last30days-使用指南.md
index 4b40eaf4..537fd03a 100644
--- a/wiki/sources/last30days-使用指南.md
+++ b/wiki/sources/last30days-使用指南.md
@@ -1,35 +1,35 @@
----
-title: "Last30Days 使用指南"
-type: source
-tags: []
-date: 2026-04-21
----
-
-## Source File
-- [[Skills/Last30Days-使用指南.md]]
-
-## Summary(用中文描述)
-- 核心主题:Last30Days 方法论——通过 AI Agent 自动化追踪近30天内新增/更新的内容源(网站、社交媒体、工具更新),避免信息过载
-- 问题域:个人知识管理、信息聚合、竞品监控
-- 方法/机制:配置信息源列表 → AI Agent 定时扫描 → 去重过滤 → 摘要生成 → 投递
-- 结论/价值:将"主动订阅"转变为"被动接收",用 AI 替代人工巡检,节省 80% 信息搜集时间
-
-## Key Claims(用中文描述)
-- Last30Days Agent 通过定时扫描使信息追踪从主动变为被动,减少认知负担
-- 近30天内容过滤机制天然去除了过时信息,保证了内容新鲜度
-- AI 驱动的摘要生成将原始内容压缩为可操作的关键要点
-- 多渠道投递(Discord/Telegram/Email)确保用户在常用平台接收更新
-
-## Key Quotes
-> "信息不是力量,整理过的信息才是" — 核心价值主张
-
-## Key Concepts
-- [[Last 30 Days Method]]:信息追踪方法论,只关注近30天内更新内容,过滤历史噪音
-- [[信息消费习惯]]:从主动搜索到被动接收的范式转变
-
-## Key Entities
-- [[Last30Days]]:核心工具/方法论本身
-
-## Connections
-- [[Multi-Source Tech News Digest]] ← 相似模式 ← [[Last 30 Days Method]]
-- [[Personal Knowledge Base (RAG)]] ← 支持 ← [[Last 30 Days Method]]
+---
+title: "Last30Days 使用指南"
+type: source
+tags: []
+date: 2026-04-21
+---
+
+## Source File
+- [[raw/Skills/Last30Days-使用指南.md]]
+
+## Summary(用中文描述)
+- 核心主题:Last30Days 方法论——通过 AI Agent 自动化追踪近30天内新增/更新的内容源(网站、社交媒体、工具更新),避免信息过载
+- 问题域:个人知识管理、信息聚合、竞品监控
+- 方法/机制:配置信息源列表 → AI Agent 定时扫描 → 去重过滤 → 摘要生成 → 投递
+- 结论/价值:将"主动订阅"转变为"被动接收",用 AI 替代人工巡检,节省 80% 信息搜集时间
+
+## Key Claims(用中文描述)
+- Last30Days Agent 通过定时扫描使信息追踪从主动变为被动,减少认知负担
+- 近30天内容过滤机制天然去除了过时信息,保证了内容新鲜度
+- AI 驱动的摘要生成将原始内容压缩为可操作的关键要点
+- 多渠道投递(Discord/Telegram/Email)确保用户在常用平台接收更新
+
+## Key Quotes
+> "信息不是力量,整理过的信息才是" — 核心价值主张
+
+## Key Concepts
+- [[Last 30 Days Method]]:信息追踪方法论,只关注近30天内更新内容,过滤历史噪音
+- [[信息消费习惯]]:从主动搜索到被动接收的范式转变
+
+## Key Entities
+- [[Last30Days]]:核心工具/方法论本身
+
+## Connections
+- [[Multi-Source Tech News Digest]] ← 相似模式 ← [[Last 30 Days Method]]
+- [[Personal Knowledge Base (RAG)]] ← 支持 ← [[Last 30 Days Method]]
diff --git a/wiki/sources/latex-paper-writing.md b/wiki/sources/latex-paper-writing.md
index 7b24468c..559d7ffa 100644
--- a/wiki/sources/latex-paper-writing.md
+++ b/wiki/sources/latex-paper-writing.md
@@ -6,7 +6,7 @@ date: 2026-04-22
---
## Source File
-- [[Agent/usecases/latex-paper-writing.md]]
+- [[raw/Agent/usecases/latex-paper-writing.md]]
## Summary(用中文描述)
- 核心主题:通过 AI Agent 实现对话式 LaTeX 论文写作与即时编译
diff --git a/wiki/sources/learn-ai-for-free-directly-from-top-companies.md b/wiki/sources/learn-ai-for-free-directly-from-top-companies.md
index e2c97769..ca504b4f 100644
--- a/wiki/sources/learn-ai-for-free-directly-from-top-companies.md
+++ b/wiki/sources/learn-ai-for-free-directly-from-top-companies.md
@@ -1,57 +1,57 @@
----
-title: "Learn AI for free directly from top companies"
-type: source
-tags:
- - "AI学习"
- - "教育资源"
- - "免费课程"
-date: 2026-04-16
----
-
-## Source File
-- [[AI/Learn AI for free directly from top companies]]
-
-## Summary(用中文描述)
-- 核心主题:汇总全球顶级科技公司提供的免费 AI 学习资源
-- 问题域:AI 教育普及与免费学习资源获取
-- 方法/机制:列举 10 家顶级公司/平台的免费 AI 课程资源及直链
-- 结论/价值:无需付费,即可直接获取权威 AI 培训内容
-
-## Key Claims(用中文描述)
-- Anthropic 提供免费 AI 技能培训平台(Skilljar)
-- Google 提供免费 AI 学习路径(Google AI Learning)
-- Meta 开源 AI 学习资源平台
-- NVIDIA 提供 CUDA 开发者免费学习资源
-- Microsoft 提供免费技术培训(Microsoft Learn)
-- OpenAI 提供 Academy 免费课程
-- IBM SkillsBuild 提供免费 AI 技能培训
-- AWS 提供 Skill Builder 免费学习平台
-- DeepLearning.AI 提供免费 AI 课程
-- Hugging Face 提供免费学习路径
-
-## Key Quotes
-> "Learn AI for free directly from top companies." — Leonard Rodman (@RodmanAi)
-
-## Key Concepts
-- [[AI教育]]
-- [[免费学习资源]]
-- [[企业级AI培训]]
-
-## Key Entities
-- [[Anthropic]]:AI 安全与对齐研究公司,提供 skilljar.com 免费培训平台
-- [[Google]]:提供 grow.google/ai 免费 AI 学习路径
-- [[Meta]]:提供 ai.meta.com/resources/ 开源 AI 学习资源
-- [[NVIDIA]]:提供 developer.nvidia.com/cuda 免费 CUDA 课程
-- [[Microsoft]]:提供 Microsoft Learn 免费技术培训平台
-- [[OpenAI]]:提供 academy.openai.com 免费课程
-- [[IBM]]:通过 SkillsBuild 提供免费 AI 技能培训
-- [[AWS]]:通过 Skill Builder 提供免费学习平台
-- [[DeepLearning.AI]]:吴恩达创立的免费 AI 课程平台
-- [[Hugging Face]]:提供 huggingface.co/learn 免费学习路径
-
-## Connections
-- [[AI教育]] ← 资源来源 ← [[Anthropic]] / [[Google]] / [[Meta]] / [[NVIDIA]] / [[Microsoft]] / [[OpenAI]] / [[IBM]] / [[AWS]] / [[DeepLearning.AI]] / [[Hugging Face]]
-- [[免费学习资源]] ← 涵盖 ← [[Claude Prompt Library]](Anthropic 官方提示词库)
-
-## Contradictions
-- 无已知冲突
+---
+title: "Learn AI for free directly from top companies"
+type: source
+tags:
+ - "AI学习"
+ - "教育资源"
+ - "免费课程"
+date: 2026-04-16
+---
+
+## Source File
+- [[raw/AI/Learn AI for free directly from top companies.md]]
+
+## Summary(用中文描述)
+- 核心主题:汇总全球顶级科技公司提供的免费 AI 学习资源
+- 问题域:AI 教育普及与免费学习资源获取
+- 方法/机制:列举 10 家顶级公司/平台的免费 AI 课程资源及直链
+- 结论/价值:无需付费,即可直接获取权威 AI 培训内容
+
+## Key Claims(用中文描述)
+- Anthropic 提供免费 AI 技能培训平台(Skilljar)
+- Google 提供免费 AI 学习路径(Google AI Learning)
+- Meta 开源 AI 学习资源平台
+- NVIDIA 提供 CUDA 开发者免费学习资源
+- Microsoft 提供免费技术培训(Microsoft Learn)
+- OpenAI 提供 Academy 免费课程
+- IBM SkillsBuild 提供免费 AI 技能培训
+- AWS 提供 Skill Builder 免费学习平台
+- DeepLearning.AI 提供免费 AI 课程
+- Hugging Face 提供免费学习路径
+
+## Key Quotes
+> "Learn AI for free directly from top companies." — Leonard Rodman (@RodmanAi)
+
+## Key Concepts
+- [[AI教育]]
+- [[免费学习资源]]
+- [[企业级AI培训]]
+
+## Key Entities
+- [[Anthropic]]:AI 安全与对齐研究公司,提供 skilljar.com 免费培训平台
+- [[Google]]:提供 grow.google/ai 免费 AI 学习路径
+- [[Meta]]:提供 ai.meta.com/resources/ 开源 AI 学习资源
+- [[NVIDIA]]:提供 developer.nvidia.com/cuda 免费 CUDA 课程
+- [[Microsoft]]:提供 Microsoft Learn 免费技术培训平台
+- [[OpenAI]]:提供 academy.openai.com 免费课程
+- [[IBM]]:通过 SkillsBuild 提供免费 AI 技能培训
+- [[AWS]]:通过 Skill Builder 提供免费学习平台
+- [[DeepLearning.AI]]:吴恩达创立的免费 AI 课程平台
+- [[Hugging Face]]:提供 huggingface.co/learn 免费学习路径
+
+## Connections
+- [[AI教育]] ← 资源来源 ← [[Anthropic]] / [[Google]] / [[Meta]] / [[NVIDIA]] / [[Microsoft]] / [[OpenAI]] / [[IBM]] / [[AWS]] / [[DeepLearning.AI]] / [[Hugging Face]]
+- [[免费学习资源]] ← 涵盖 ← [[Claude Prompt Library]](Anthropic 官方提示词库)
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/learning-sessions-cloud-transformation-programme-20230808-183322-meeting-recordi.md b/wiki/sources/learning-sessions-cloud-transformation-programme-20230808-183322-meeting-recordi.md
index e3673fea..975d17b3 100644
--- a/wiki/sources/learning-sessions-cloud-transformation-programme-20230808-183322-meeting-recordi.md
+++ b/wiki/sources/learning-sessions-cloud-transformation-programme-20230808-183322-meeting-recordi.md
@@ -1,55 +1,55 @@
----
-title: "Learning Sessions Cloud Transformation Programme-20230808 183322-Meeting Recording"
-type: source
-tags:
- - Terraform
- - CTP
- - IaC
-date: 2023-08-08
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/learning-sessions-cloud-transformation-programme-20230808-183322-meeting-recordi]]
-
-## Summary(用中文描述)
-- 核心主题:通过 Terraform IaC 实现 ECS 容器化应用的自动化部署
-- 问题域:企业在不可预测性和敏捷性需求下的基础设施挑战
-- 方法/机制:基于 Gruntwork 仓库构建 ECS Terraform 模块,支持 Docker 容器/EC2 部署,具备自动扩缩容、自动故障恢复、金丝雀部署能力;采用 Listener 集中管理方式
-- 结论/价值:CTP/SRE 团队通过 IaC 实现 ECS 部署标准化,与 AWS 服务深度集成
-
-## Key Claims(用中文描述)
-- 企业必须在不可预测性和敏捷性需求之间找到平衡,基础设施即代码(IaC)是应对这一挑战的关键手段
-- ECS(Elastic Container Service)是 AWS 原生技术,与 AWS 服务深度集成,相比 EKS 或原生 Kubernetes 有其独特优势与挑战
-- CTP/SRE 团队基于 Gruntwork 仓库构建了可复用的 ECS Terraform 模块,支持 Docker 容器作为逻辑单元
-- ECS 模块支持 EC2 实例或目标部署,具备自动扩缩容、自动故障恢复、金丝雀部署功能
-- Listener 集中管理方式避免了各产品直接下载 Gruntwork 模板并本地使用的碎片化问题
-- ECS 部署的前置条件包括 VPC、ELB 安全组和 EFS 卷挂载
-- 模块支持通过 YAML 或 JSON 传递配置,集成 CloudWatch、Splunk、Grafana 和 Prometheus
-
-## Key Quotes
-> "Businesses have to thrive in the middle of all these challenges and it is forged by code." — JP,阐述企业面临的不可预测性挑战与 IaC 的核心价值
-> "We have implemented the listener approach because we have seen many of the products are downloading the quotes from the Gruntwork and using locally." — Raja M,说明 Listener 集中管理模式的动机
-
-## Key Concepts
-- [[Infrastructure-as-Code]]:通过代码定义和管理基础设施,实现自动化、可重复、可审计的部署流程
-- [[Canary-Deployment]]:金丝雀部署,通过逐步将流量切换到新版本,降低新版本上线的风险
-- [[ECS-Module]]:CTP/SRE 团队基于 Gruntwork 仓库构建的 ECS Terraform 模块
-
-## Key Entities
-- [[JP]]:主讲人之一,介绍 ECS 的业务和技术背景
-- [[Raja-M]]:CTP/SRE 团队成员,详细讲解 ECS 模块的构建方式
-- [[Gruntwork]]:提供 Terraform 模块的基础仓库,CTP 在其基础上构建了 ECS 模块
-- [[AWS]]:云服务提供商,ECS 为 AWS 弹性容器服务
-- [[Cloud-Transformation-Programme]]:云转型计划,组织发起的基础设施现代化计划
-
-## Connections
-- [[learning-sessions-ecs-deployment-using-iac-20230808-183322-meeting-recording]] ← same_topic ← [[learning-sessions-ecs-deployment-using-iac-20230808-183322-meeting-recording]]
-- [[Infrastructure-as-Code]] ← implements ← [[Cloud-Transformation-Programme]]
-- [[ECS-Module]] ← based_on ← [[Gruntwork]]
-
-## Contradictions
-- 与 [[ctp-topic-64-scaling-out-with-amazon-eks]] 在容器编排选型上存在差异:
- - 冲突点:ECS 强调 AWS 原生集成,EKS 强调可移植性
- - 当前观点:ECS 与 AWS 服务深度集成,适合追求 AWS 原生体验的场景
- - 对方观点:EKS 基于原生 Kubernetes,提供更好的跨云可移植性
- - 结论:两者适用于不同场景,可根据业务需求互补使用
+---
+title: "Learning Sessions Cloud Transformation Programme-20230808 183322-Meeting Recording"
+type: source
+tags:
+ - Terraform
+ - CTP
+ - IaC
+date: 2023-08-08
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/learning-sessions-cloud-transformation-programme-20230808-183322-meeting-recordi.md]]
+
+## Summary(用中文描述)
+- 核心主题:通过 Terraform IaC 实现 ECS 容器化应用的自动化部署
+- 问题域:企业在不可预测性和敏捷性需求下的基础设施挑战
+- 方法/机制:基于 Gruntwork 仓库构建 ECS Terraform 模块,支持 Docker 容器/EC2 部署,具备自动扩缩容、自动故障恢复、金丝雀部署能力;采用 Listener 集中管理方式
+- 结论/价值:CTP/SRE 团队通过 IaC 实现 ECS 部署标准化,与 AWS 服务深度集成
+
+## Key Claims(用中文描述)
+- 企业必须在不可预测性和敏捷性需求之间找到平衡,基础设施即代码(IaC)是应对这一挑战的关键手段
+- ECS(Elastic Container Service)是 AWS 原生技术,与 AWS 服务深度集成,相比 EKS 或原生 Kubernetes 有其独特优势与挑战
+- CTP/SRE 团队基于 Gruntwork 仓库构建了可复用的 ECS Terraform 模块,支持 Docker 容器作为逻辑单元
+- ECS 模块支持 EC2 实例或目标部署,具备自动扩缩容、自动故障恢复、金丝雀部署功能
+- Listener 集中管理方式避免了各产品直接下载 Gruntwork 模板并本地使用的碎片化问题
+- ECS 部署的前置条件包括 VPC、ELB 安全组和 EFS 卷挂载
+- 模块支持通过 YAML 或 JSON 传递配置,集成 CloudWatch、Splunk、Grafana 和 Prometheus
+
+## Key Quotes
+> "Businesses have to thrive in the middle of all these challenges and it is forged by code." — JP,阐述企业面临的不可预测性挑战与 IaC 的核心价值
+> "We have implemented the listener approach because we have seen many of the products are downloading the quotes from the Gruntwork and using locally." — Raja M,说明 Listener 集中管理模式的动机
+
+## Key Concepts
+- [[Infrastructure-as-Code]]:通过代码定义和管理基础设施,实现自动化、可重复、可审计的部署流程
+- [[Canary-Deployment]]:金丝雀部署,通过逐步将流量切换到新版本,降低新版本上线的风险
+- [[ECS-Module]]:CTP/SRE 团队基于 Gruntwork 仓库构建的 ECS Terraform 模块
+
+## Key Entities
+- [[JP]]:主讲人之一,介绍 ECS 的业务和技术背景
+- [[Raja-M]]:CTP/SRE 团队成员,详细讲解 ECS 模块的构建方式
+- [[Gruntwork]]:提供 Terraform 模块的基础仓库,CTP 在其基础上构建了 ECS 模块
+- [[AWS]]:云服务提供商,ECS 为 AWS 弹性容器服务
+- [[Cloud-Transformation-Programme]]:云转型计划,组织发起的基础设施现代化计划
+
+## Connections
+- [[learning-sessions-ecs-deployment-using-iac-20230808-183322-meeting-recording]] ← same_topic ← [[learning-sessions-ecs-deployment-using-iac-20230808-183322-meeting-recording]]
+- [[Infrastructure-as-Code]] ← implements ← [[Cloud-Transformation-Programme]]
+- [[ECS-Module]] ← based_on ← [[Gruntwork]]
+
+## Contradictions
+- 与 [[ctp-topic-64-scaling-out-with-amazon-eks]] 在容器编排选型上存在差异:
+ - 冲突点:ECS 强调 AWS 原生集成,EKS 强调可移植性
+ - 当前观点:ECS 与 AWS 服务深度集成,适合追求 AWS 原生体验的场景
+ - 对方观点:EKS 基于原生 Kubernetes,提供更好的跨云可移植性
+ - 结论:两者适用于不同场景,可根据业务需求互补使用
diff --git a/wiki/sources/learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform.md b/wiki/sources/learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform.md
index 375a69a7..5a092e21 100644
--- a/wiki/sources/learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform.md
+++ b/wiki/sources/learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform.md
@@ -1,57 +1,57 @@
----
-title: "Learning Sessions Cloud Transformation Programme-Deploying RDS via Terraform"
-type: source
-tags: [Terraform, RDS, IaC, CTP, DevOps, DBRE, AWS]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform]]
-
-## Summary(用中文描述)
-- 核心主题:**通过 Terraform 在 AWS 上部署 RDS 数据库**,涵盖 IaC 最佳实践和 Gruntwork RDS 模块的选型对比
-- 问题域:RDS 部署方式的选择(控制台 vs 代码)、模块选型(grunt work 模块 vs SRE 核心模块)、Day 2 运维(扩缩容/补丁/升级)
-- 方法/机制:使用 Terragrunt(Terraform 封装器)管理 RDS 部署,通过 GitHub PR + Atlantis 实现变更自动化;CloudWatch 负责监控告警
-- 结论/价值:IaC 部署任何规模的 RDS 到 AWS 均优于控制台;grunt work RDS Service 相比裸模块提供更完整的企业级功能(KMS 加密、CloudWatch 告警等);代码即文档
-
-## Key Claims(用中文描述)
-- **IaC 六大大好处**:速度、灵活性、一致性、灾难恢复、文档、自动化。代码即文档
-- **两种 RDS 部署选项**:裸模块 RDS module(基础功能)vs 更完整的 grunt work RDS Service(推荐,预建 KMS 加密和 CloudWatch 告警)
-- **SRE 核心模块功能弱于 grunt work 服务**:建议生产环境使用 grunt work RDS Service
-- **Terragrunt 优于裸 Terraform**:避免变量重复声明,保持代码整洁,贯彻 DRY 原则
-- **Day 2 运维通过 GitHub PR + Atlantis 实现**:扩缩容、补丁、大版本升级均在 Terragrunt 文件中修改,通过 PR 触发 Atlantis 自动应用
-- **监控方案**:CloudWatch Dashboard + Alarms,注意突发性能实例(burstable instance)的 CPU credits 消耗
-
-## Key Quotes
-> "We use Terragrunt, which is basically it's a wrapper around Terraform, and it allows you to keep your code clean and you're not repeating your variables all the time." — Greg, DBRE Team
-> "The code is the documentation." — Greg, 强调 IaC 的文档价值
-
-## Key Concepts
-- [[Infrastructure-as-Code]]:通过代码定义和版本控制基础设施资源,核心优势包括速度、一致性、灾难恢复和自动化
-- [[DRY Principle]]:Terragrunt 通过管理 provider 和 remote_state 块减少跨环境重复声明
-- [[GitOps]]:通过 GitHub PR + Atlantis 实现基础设施变更的自动化审核和应用
-- [[CloudWatch-Alarms]]:RDS 监控与告警机制,包含突发性能实例的 CPU credits 考虑
-- [[KMS-Encryption]]:grunt work RDS Service 内置的 KMS 密钥加密功能
-
-## Key Entities
-- [[Gruntwork]]:提供预建 Terraform 模块(RDS Service 等),建议生产环境使用其 grunt work RDS Service 而非裸模块
-- [[Atlantis]]:Git 驱动的 Terraform 自动化工具,配合 GitHub PR 实现 IaC 变更
-- [[Terraform]]:云厂商无关的 IaC 核心工具
-- [[Terragrunt]]:Terraform 的 DRY 封装层,用于管理 RDS 部署配置
-- [[DBRE]]:Database Reliability Engineering 团队,Greg 来自该团队
-- [[CloudWatch]]:AWS 监控服务,用于 RDS Dashboard 和 Alarms
-
-## Connections
-- [[learning-sessions-cloud-transformation-programme-20230808-183322-meeting-recordi]] ← related ← [[learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform]](同一 CTP 系列,ECS 部署 + RDS 部署)
-- [[ctp-topic-48-terraform-vs-terragrunt]] ← related ← [[learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform]](Terragrunt 在两个主题中均有讨论)
-- [[ctp-topic-16-cross-account-terraform-modules]] ← related ← [[learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform]](IaC 模块化 + Cross-account Terraform)
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← foundation ← [[learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform]](Gruntwork CI/CD 基础)
-- [[Terraform]] ← wraps ← [[Terragrunt]]
-- [[Gruntwork]] ← provides ← [[RDS-Module]](grunt work RDS Service)
-- [[Atlantis]] ← automates ← [[Terraform]]
-- [[CloudWatch]] ← monitors ← [[RDS-Module]]
-
-## Contradictions
-- 与 [[ctp-topic-9-ci-cd-with-gruntwork]](Gruntwork CI/CD):两者均依赖 Gruntwork 模块体系;本主题聚焦 RDS 部署,CI/CD 主题聚焦 ECS 应用部署;RDS 部署同样适用 Gruntwork 流水线规范,两者互补而非冲突
-- 与 [[ctp-topic-48-terraform-vs-terragrunt]](Terraform vs Terragrunt):本主题的实际案例印证了该主题的观点——Terragrunt 保持代码整洁、避免变量重复;两主题一致,共同推荐 Terragrunt 作为 Terraform 的封装层
-- 与 [[ctp-topic-16-cross-account-terraform-modules]](跨账号 Terraform 模块):两者均讨论 Terraform 模块的运维方式;跨账号模块方案(Jenkins + ECS Deploy Runner)与本主题(RDS 通过 Atlantis)的 CI/CD 载体不同,适用于不同规模和架构场景,无直接冲突
+---
+title: "Learning Sessions Cloud Transformation Programme-Deploying RDS via Terraform"
+type: source
+tags: [Terraform, RDS, IaC, CTP, DevOps, DBRE, AWS]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform.md]]
+
+## Summary(用中文描述)
+- 核心主题:**通过 Terraform 在 AWS 上部署 RDS 数据库**,涵盖 IaC 最佳实践和 Gruntwork RDS 模块的选型对比
+- 问题域:RDS 部署方式的选择(控制台 vs 代码)、模块选型(grunt work 模块 vs SRE 核心模块)、Day 2 运维(扩缩容/补丁/升级)
+- 方法/机制:使用 Terragrunt(Terraform 封装器)管理 RDS 部署,通过 GitHub PR + Atlantis 实现变更自动化;CloudWatch 负责监控告警
+- 结论/价值:IaC 部署任何规模的 RDS 到 AWS 均优于控制台;grunt work RDS Service 相比裸模块提供更完整的企业级功能(KMS 加密、CloudWatch 告警等);代码即文档
+
+## Key Claims(用中文描述)
+- **IaC 六大大好处**:速度、灵活性、一致性、灾难恢复、文档、自动化。代码即文档
+- **两种 RDS 部署选项**:裸模块 RDS module(基础功能)vs 更完整的 grunt work RDS Service(推荐,预建 KMS 加密和 CloudWatch 告警)
+- **SRE 核心模块功能弱于 grunt work 服务**:建议生产环境使用 grunt work RDS Service
+- **Terragrunt 优于裸 Terraform**:避免变量重复声明,保持代码整洁,贯彻 DRY 原则
+- **Day 2 运维通过 GitHub PR + Atlantis 实现**:扩缩容、补丁、大版本升级均在 Terragrunt 文件中修改,通过 PR 触发 Atlantis 自动应用
+- **监控方案**:CloudWatch Dashboard + Alarms,注意突发性能实例(burstable instance)的 CPU credits 消耗
+
+## Key Quotes
+> "We use Terragrunt, which is basically it's a wrapper around Terraform, and it allows you to keep your code clean and you're not repeating your variables all the time." — Greg, DBRE Team
+> "The code is the documentation." — Greg, 强调 IaC 的文档价值
+
+## Key Concepts
+- [[Infrastructure-as-Code]]:通过代码定义和版本控制基础设施资源,核心优势包括速度、一致性、灾难恢复和自动化
+- [[DRY Principle]]:Terragrunt 通过管理 provider 和 remote_state 块减少跨环境重复声明
+- [[GitOps]]:通过 GitHub PR + Atlantis 实现基础设施变更的自动化审核和应用
+- [[CloudWatch-Alarms]]:RDS 监控与告警机制,包含突发性能实例的 CPU credits 考虑
+- [[KMS-Encryption]]:grunt work RDS Service 内置的 KMS 密钥加密功能
+
+## Key Entities
+- [[Gruntwork]]:提供预建 Terraform 模块(RDS Service 等),建议生产环境使用其 grunt work RDS Service 而非裸模块
+- [[Atlantis]]:Git 驱动的 Terraform 自动化工具,配合 GitHub PR 实现 IaC 变更
+- [[Terraform]]:云厂商无关的 IaC 核心工具
+- [[Terragrunt]]:Terraform 的 DRY 封装层,用于管理 RDS 部署配置
+- [[DBRE]]:Database Reliability Engineering 团队,Greg 来自该团队
+- [[CloudWatch]]:AWS 监控服务,用于 RDS Dashboard 和 Alarms
+
+## Connections
+- [[learning-sessions-cloud-transformation-programme-20230808-183322-meeting-recordi]] ← related ← [[learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform]](同一 CTP 系列,ECS 部署 + RDS 部署)
+- [[ctp-topic-48-terraform-vs-terragrunt]] ← related ← [[learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform]](Terragrunt 在两个主题中均有讨论)
+- [[ctp-topic-16-cross-account-terraform-modules]] ← related ← [[learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform]](IaC 模块化 + Cross-account Terraform)
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← foundation ← [[learning-sessions-cloud-transformation-programme-deploying-rds-via-terraform]](Gruntwork CI/CD 基础)
+- [[Terraform]] ← wraps ← [[Terragrunt]]
+- [[Gruntwork]] ← provides ← [[RDS-Module]](grunt work RDS Service)
+- [[Atlantis]] ← automates ← [[Terraform]]
+- [[CloudWatch]] ← monitors ← [[RDS-Module]]
+
+## Contradictions
+- 与 [[ctp-topic-9-ci-cd-with-gruntwork]](Gruntwork CI/CD):两者均依赖 Gruntwork 模块体系;本主题聚焦 RDS 部署,CI/CD 主题聚焦 ECS 应用部署;RDS 部署同样适用 Gruntwork 流水线规范,两者互补而非冲突
+- 与 [[ctp-topic-48-terraform-vs-terragrunt]](Terraform vs Terragrunt):本主题的实际案例印证了该主题的观点——Terragrunt 保持代码整洁、避免变量重复;两主题一致,共同推荐 Terragrunt 作为 Terraform 的封装层
+- 与 [[ctp-topic-16-cross-account-terraform-modules]](跨账号 Terraform 模块):两者均讨论 Terraform 模块的运维方式;跨账号模块方案(Jenkins + ECS Deploy Runner)与本主题(RDS 通过 Atlantis)的 CI/CD 载体不同,适用于不同规模和架构场景,无直接冲突
diff --git a/wiki/sources/learning-sessions-ecs-deployment-using-iac-20230808-183322-meeting-recording.md b/wiki/sources/learning-sessions-ecs-deployment-using-iac-20230808-183322-meeting-recording.md
index 5636ffb5..76f53133 100644
--- a/wiki/sources/learning-sessions-ecs-deployment-using-iac-20230808-183322-meeting-recording.md
+++ b/wiki/sources/learning-sessions-ecs-deployment-using-iac-20230808-183322-meeting-recording.md
@@ -1,52 +1,52 @@
----
-title: "Learning Sessions ECS Deployment using IAC - 20230808"
-type: source
-tags: [AWS, ECS, IaC, Terraform, CTP]
-date: 2023-08-08
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/learning-sessions-ecs-deployment-using-iac-20230808-183322-meeting-recording.md]]
-
-## Summary(用中文描述)
-- 核心主题:通过 IaC(Terraform)实现 ECS(Elastic Container Service)容器化应用的自动化部署,由 JP 和 Raja M 主讲
-- 问题域:企业在云端部署容器化应用时面临的不可预测性、敏捷性需求,以及 ECS 与 EKS/Kubernetes 的选型权衡
-- 方法/机制:CTP/SRE 团队基于 Gruntwork 仓库构建的 Terraform ECS 模块,支持 Docker 容器创建、自动扩缩容、自动故障恢复和金丝雀部署;通过 Listener 方式集中管理 ECS;配置文件支持 YAML/JSON;集成 CloudWatch、Splunk、Grafana、Prometheus
-- 结论/价值:ECS 作为 AWS 原生技术,与 AWS 服务深度集成,适合追求简单性和 AWS 紧密集成的场景;Terraform IaC 模块化封装降低了部署复杂度
-
-## Key Claims(用中文描述)
-- JP 指出行业面临不可预测性和敏捷性挑战,企业必须在这些挑战中生存,而这一切由代码驱动("Businesses have to thrive in the middle of all these challenges and it is forged by code.")
-- 动态扩缩容对于不可预测的负载模式至关重要,技术必须持续演进以应对
-- ECS (Elastic Container Services) 是 AWS 专有技术,与 AWS 服务深度集成,相比 EKS 或原生 Kubernetes 有其独特优势和挑战
-- CTP/SRE 团队在 Gruntwork 仓库基础上构建了 ECS 模块,将 Docker 容器作为逻辑单元创建,支持 EC2 实例或目标部署
-- ECS 模块实现了 Listener 方式集中管理,因为许多产品团队从 Gruntwork 下载代码后本地使用
-- 使用模块的前置条件包括:VPC、ELB 安全组、EFS 卷挂载
-
-## Key Quotes
-> "Businesses have to thrive in the middle of all these challenges and it is forged by code." — JP,阐述企业如何在云转型挑战中通过代码驱动适应
-> "We have implemented the listener approach because we have seen many of the products are downloading the quotes from the gruntwork and using locally." — Raja M,解释为何 CTP 团队实现 Listener 集中管理方式
-
-## Key Concepts
-- [[Infrastructure-as-Code]]:Terraform IaC 驱动 ECS 部署的核心方法论
-- [[ECS-Module-Deployment]]:CTP/SRE 团队基于 Gruntwork 构建的 ECS 自动化部署模块
-- [[Listener-Approach]]:ECS 集中管理方式,避免各产品团队重复下载使用 Gruntwork 代码
-- [[Canary-Deployment]]:ECS 模块支持的金丝雀部署策略
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,提供 ECS 容器服务及配套生态(CloudWatch、VPC、ELB、EFS)
-- [[Gruntwork]]:IaC 基础设施代码库,CTP 的 ECS 模块基于 Gruntwork 仓库构建
-- [[CTP]](Cloud Transformation Programme):云转型计划,每周定期举办 Learning Sessions 学习会议
-- [[JP]]:演讲者之一,讲解 ECS 的业务和技术背景
-- [[Raja-M]]:演讲者之一,详细介绍 CTP 和 SRE 团队开发的 ECS 模块
-
-## Connections
-- [[ctp-topic-70-eks-deployment-using-iac]] ← extends ← [[Infrastructure-as-Code]](同一 IaC 主题,EKS 与 ECS 两条路径)
-- [[ctp-topic-9-ci-cd-with-gruntwork]] ← builds_on ← [[Gruntwork]](Gruntwork CI/CD 实践是 ECS 模块的基础)
-- [[ctp-topic-33-an-introduction-to-gitops]] ← related_to ← [[Infrastructure-as-Code]](GitOps 与 IaC 协同)
-
-## Contradictions
-- 与 [[ctp-topic-64-scaling-out-with-amazon-eks]] 在容器编排选型上的差异:
- - 冲突点:ECS 与 EKS 哪个更适合企业容器化部署
- - 当前观点:ECS 作为 AWS 原生技术与 AWS 服务深度集成,适合追求简单性和紧密集成的场景
- - 对方观点:EKS 提供更强的可移植性和 Kubernetes 生态系统支持,适合需要多云或混合云策略的场景
- - 注:两者并非互斥,ECS 和 EKS 可根据具体场景互补使用
+---
+title: "Learning Sessions ECS Deployment using IAC - 20230808"
+type: source
+tags: [AWS, ECS, IaC, Terraform, CTP]
+date: 2023-08-08
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/03_Terraform/learning-sessions-ecs-deployment-using-iac-20230808-183322-meeting-recording.md]]
+
+## Summary(用中文描述)
+- 核心主题:通过 IaC(Terraform)实现 ECS(Elastic Container Service)容器化应用的自动化部署,由 JP 和 Raja M 主讲
+- 问题域:企业在云端部署容器化应用时面临的不可预测性、敏捷性需求,以及 ECS 与 EKS/Kubernetes 的选型权衡
+- 方法/机制:CTP/SRE 团队基于 Gruntwork 仓库构建的 Terraform ECS 模块,支持 Docker 容器创建、自动扩缩容、自动故障恢复和金丝雀部署;通过 Listener 方式集中管理 ECS;配置文件支持 YAML/JSON;集成 CloudWatch、Splunk、Grafana、Prometheus
+- 结论/价值:ECS 作为 AWS 原生技术,与 AWS 服务深度集成,适合追求简单性和 AWS 紧密集成的场景;Terraform IaC 模块化封装降低了部署复杂度
+
+## Key Claims(用中文描述)
+- JP 指出行业面临不可预测性和敏捷性挑战,企业必须在这些挑战中生存,而这一切由代码驱动("Businesses have to thrive in the middle of all these challenges and it is forged by code.")
+- 动态扩缩容对于不可预测的负载模式至关重要,技术必须持续演进以应对
+- ECS (Elastic Container Services) 是 AWS 专有技术,与 AWS 服务深度集成,相比 EKS 或原生 Kubernetes 有其独特优势和挑战
+- CTP/SRE 团队在 Gruntwork 仓库基础上构建了 ECS 模块,将 Docker 容器作为逻辑单元创建,支持 EC2 实例或目标部署
+- ECS 模块实现了 Listener 方式集中管理,因为许多产品团队从 Gruntwork 下载代码后本地使用
+- 使用模块的前置条件包括:VPC、ELB 安全组、EFS 卷挂载
+
+## Key Quotes
+> "Businesses have to thrive in the middle of all these challenges and it is forged by code." — JP,阐述企业如何在云转型挑战中通过代码驱动适应
+> "We have implemented the listener approach because we have seen many of the products are downloading the quotes from the gruntwork and using locally." — Raja M,解释为何 CTP 团队实现 Listener 集中管理方式
+
+## Key Concepts
+- [[Infrastructure-as-Code]]:Terraform IaC 驱动 ECS 部署的核心方法论
+- [[ECS-Module-Deployment]]:CTP/SRE 团队基于 Gruntwork 构建的 ECS 自动化部署模块
+- [[Listener-Approach]]:ECS 集中管理方式,避免各产品团队重复下载使用 Gruntwork 代码
+- [[Canary-Deployment]]:ECS 模块支持的金丝雀部署策略
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,提供 ECS 容器服务及配套生态(CloudWatch、VPC、ELB、EFS)
+- [[Gruntwork]]:IaC 基础设施代码库,CTP 的 ECS 模块基于 Gruntwork 仓库构建
+- [[CTP]](Cloud Transformation Programme):云转型计划,每周定期举办 Learning Sessions 学习会议
+- [[JP]]:演讲者之一,讲解 ECS 的业务和技术背景
+- [[Raja-M]]:演讲者之一,详细介绍 CTP 和 SRE 团队开发的 ECS 模块
+
+## Connections
+- [[ctp-topic-70-eks-deployment-using-iac]] ← extends ← [[Infrastructure-as-Code]](同一 IaC 主题,EKS 与 ECS 两条路径)
+- [[ctp-topic-9-ci-cd-with-gruntwork]] ← builds_on ← [[Gruntwork]](Gruntwork CI/CD 实践是 ECS 模块的基础)
+- [[ctp-topic-33-an-introduction-to-gitops]] ← related_to ← [[Infrastructure-as-Code]](GitOps 与 IaC 协同)
+
+## Contradictions
+- 与 [[ctp-topic-64-scaling-out-with-amazon-eks]] 在容器编排选型上的差异:
+ - 冲突点:ECS 与 EKS 哪个更适合企业容器化部署
+ - 当前观点:ECS 作为 AWS 原生技术与 AWS 服务深度集成,适合追求简单性和紧密集成的场景
+ - 对方观点:EKS 提供更强的可移植性和 Kubernetes 生态系统支持,适合需要多云或混合云策略的场景
+ - 注:两者并非互斥,ECS 和 EKS 可根据具体场景互补使用
diff --git a/wiki/sources/learning-sessions-identity-governance-vsm-replacement-20231128-160326-meeting-re.md b/wiki/sources/learning-sessions-identity-governance-vsm-replacement-20231128-160326-meeting-re.md
index bb0326a7..c8f5eaf8 100644
--- a/wiki/sources/learning-sessions-identity-governance-vsm-replacement-20231128-160326-meeting-re.md
+++ b/wiki/sources/learning-sessions-identity-governance-vsm-replacement-20231128-160326-meeting-re.md
@@ -1,57 +1,57 @@
----
-title: "Learning Sessions Identity Governance VSM Replacement - 20231128"
-type: source
-tags:
- - Identity-Governance
- - VSM
- - CTP
- - IAM
- - AWS-Identity-Center
-date: 2023-11-28
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/02_IAM/learning-sessions-identity-governance-vsm-replacement-20231128-160326-meeting-re.md]]
-
-## Summary(用中文描述)
-- 核心主题:身份治理(Identity Governance)框架,以及用 Micro Focus IGA 替换 DXC 虚拟 SM(VSM)工具的计划
-- 问题域:企业数字身份管理——谁来访问、谁该访问、如何访问;内部/外部用户(含承包商)的权限治理
-- 方法/机制:Micro Focus IGA 通过资源控制工作流实现权限审批/撤销/监控;Active Directory 组映射角色;AWS Identity Center + IAM 提供云资源访问;IG 治理 AD 组工作流
-- 结论/价值:VSM 将被 IG 全面替换,采用相同架构但连接 Coptum 域;POC 正在进行中以验证架构和流程;用户通过 IGA Portal 申请权限,审批后自动授权
-
-## Key Claims(用中文描述)
-- 身份治理通过三个核心问题(谁当前有访问权限、谁应该有访问权限、如何执行访问)驱动数字化风险管理和合规
-- Micro Focus IGA 通过工作流管控 Active Directory 组的权限审批与撤销,并配合 AWS IAM + Azure AD Domain Services 实现云资源访问
-- IG 支持内部和外部用户(含承包商)的有时限访问权,适合临时权限管理场景
-- VSM → IG 替换计划将保持原有架构不变,但 IG 连接至 Coptum 域(而非原 DXC 域)
-- POC(概念验证)正在进行,以验证替换架构和审批流程的可行性
-- IGA Portal 用户体验:搜索资源 → 申请权限 → 填写表单 → 审批流 → 自动授权
-
-## Key Quotes
-> "Identity governance is a framework for managing digital identities efficiently, minimizing risk, and maintaining compliance." — 身份治理定义
-
-> "IG integrates with AWS Identity Center to provide access to resources via IAM. Groups in Active Directory represent roles, and IG governs access to these groups." — IG + AD + AWS Identity Center 集成架构
-
-> "The plan is to replace VSM with IG for all accounts, using the same architecture as VSM, but with IG connected to Coptum domain." — VSM 替换计划核心策略
-
-## Key Concepts
-- [[Identity-Governance]]:数字化身份管理框架,最小化风险、保持合规,核心三问:谁有访问/谁该访问/如何访问
-- [[IGA(Identity Governance and Administration)]]:身份治理与管理,Micro Focus IGA 是该领域的具体产品实现
-- [[AWS-Identity-Center]]:AWS 身份中心(原 AWS SSO),通过 IAM 提供云资源访问控制
-- [[Micro-Focus-IGA]]:Micro Focus 身份治理与管理工具,管控 AD 组工作流并连接 AWS Identity Center
-- [[Active-Directory]]:微软目录服务,AD 组映射角色,IGA 治理这些组的成员关系
-
-## Key Entities
-- [[Micro Focus]]:会议来源组织,其 IGA 产品线用于替换 DXC VSM 工具
-- [[DXC-VSM]]:DXC Virtual SM,DXC 提供的老一代身份治理工具,将被 Micro Focus IGA 替换
-- [[AWS-Identity-Center]]:AWS 身份中心,提供跨账户单点登录和权限管理
-- [[Azure-AD-Domain-Services]]:Azure AD 域服务,作为身份认证桥梁连接 DXC 域
-
-## Connections
-- [[Micro-Focus-IGA]] ← depends_on ← [[Active-Directory]]
-- [[AWS-Identity-Center]] ← depends_on ← [[Micro-Focus-IGA]]
-- [[Micro-Focus-IGA]] ← replaces ← [[DXC-VSM]]
-- [[Azure-AD-Domain-Services]] ← bridges_auth ← [[Active-Directory]]
-
-## Contradictions
-- 暂无已知冲突内容
+---
+title: "Learning Sessions Identity Governance VSM Replacement - 20231128"
+type: source
+tags:
+ - Identity-Governance
+ - VSM
+ - CTP
+ - IAM
+ - AWS-Identity-Center
+date: 2023-11-28
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/02_IAM/learning-sessions-identity-governance-vsm-replacement-20231128-160326-meeting-re.md]]
+
+## Summary(用中文描述)
+- 核心主题:身份治理(Identity Governance)框架,以及用 Micro Focus IGA 替换 DXC 虚拟 SM(VSM)工具的计划
+- 问题域:企业数字身份管理——谁来访问、谁该访问、如何访问;内部/外部用户(含承包商)的权限治理
+- 方法/机制:Micro Focus IGA 通过资源控制工作流实现权限审批/撤销/监控;Active Directory 组映射角色;AWS Identity Center + IAM 提供云资源访问;IG 治理 AD 组工作流
+- 结论/价值:VSM 将被 IG 全面替换,采用相同架构但连接 Coptum 域;POC 正在进行中以验证架构和流程;用户通过 IGA Portal 申请权限,审批后自动授权
+
+## Key Claims(用中文描述)
+- 身份治理通过三个核心问题(谁当前有访问权限、谁应该有访问权限、如何执行访问)驱动数字化风险管理和合规
+- Micro Focus IGA 通过工作流管控 Active Directory 组的权限审批与撤销,并配合 AWS IAM + Azure AD Domain Services 实现云资源访问
+- IG 支持内部和外部用户(含承包商)的有时限访问权,适合临时权限管理场景
+- VSM → IG 替换计划将保持原有架构不变,但 IG 连接至 Coptum 域(而非原 DXC 域)
+- POC(概念验证)正在进行,以验证替换架构和审批流程的可行性
+- IGA Portal 用户体验:搜索资源 → 申请权限 → 填写表单 → 审批流 → 自动授权
+
+## Key Quotes
+> "Identity governance is a framework for managing digital identities efficiently, minimizing risk, and maintaining compliance." — 身份治理定义
+
+> "IG integrates with AWS Identity Center to provide access to resources via IAM. Groups in Active Directory represent roles, and IG governs access to these groups." — IG + AD + AWS Identity Center 集成架构
+
+> "The plan is to replace VSM with IG for all accounts, using the same architecture as VSM, but with IG connected to Coptum domain." — VSM 替换计划核心策略
+
+## Key Concepts
+- [[Identity-Governance]]:数字化身份管理框架,最小化风险、保持合规,核心三问:谁有访问/谁该访问/如何访问
+- [[IGA(Identity Governance and Administration)]]:身份治理与管理,Micro Focus IGA 是该领域的具体产品实现
+- [[AWS-Identity-Center]]:AWS 身份中心(原 AWS SSO),通过 IAM 提供云资源访问控制
+- [[Micro-Focus-IGA]]:Micro Focus 身份治理与管理工具,管控 AD 组工作流并连接 AWS Identity Center
+- [[Active-Directory]]:微软目录服务,AD 组映射角色,IGA 治理这些组的成员关系
+
+## Key Entities
+- [[Micro Focus]]:会议来源组织,其 IGA 产品线用于替换 DXC VSM 工具
+- [[DXC-VSM]]:DXC Virtual SM,DXC 提供的老一代身份治理工具,将被 Micro Focus IGA 替换
+- [[AWS-Identity-Center]]:AWS 身份中心,提供跨账户单点登录和权限管理
+- [[Azure-AD-Domain-Services]]:Azure AD 域服务,作为身份认证桥梁连接 DXC 域
+
+## Connections
+- [[Micro-Focus-IGA]] ← depends_on ← [[Active-Directory]]
+- [[AWS-Identity-Center]] ← depends_on ← [[Micro-Focus-IGA]]
+- [[Micro-Focus-IGA]] ← replaces ← [[DXC-VSM]]
+- [[Azure-AD-Domain-Services]] ← bridges_auth ← [[Active-Directory]]
+
+## Contradictions
+- 暂无已知冲突内容
diff --git a/wiki/sources/learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2.md b/wiki/sources/learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2.md
index 033f2d31..5f351130 100644
--- a/wiki/sources/learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2.md
+++ b/wiki/sources/learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2.md
@@ -1,53 +1,53 @@
----
-title: "Learning Sessions: Standard AMI Updates 20231205"
-type: source
-tags: ["AWS", "AMI", "Landing-Zone", "DevOps", "Automation"]
-date: 2023-12-05
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 标准 AMI(Amazon Machine Image)的更新机制、构建发布流程及生命周期管理
-- 问题域:企业 AWS Landing Zone 中的操作系统镜像标准化与自动化运维
-- 方法/机制:Jenkins 多分支流水线构建与测试、AWS Inspector 安全扫描、机器人框架自动化验证、SSM 按需打补丁
-- 结论/价值:每两个月发布一次标准化 AMI,将验证周期从 3-4 天缩短至 60 分钟,CentOS 7/RHEL 7 将于 2024 年 6 月 EOL,由 Rocky Linux 替代
-
-## Key Claims(用中文描述)
-- 标准 AMI 基于 AWS 原生镜像,增加了 OS 加固、最新补丁、安全更新、域名加入、安全工具、端点保护、QALIS Agent、SSM Agent、DNS 设置和 GP3 EBS 存储
-- Jenkins 多分支流水线用于构建和测试 AMI,包括脚本化测试和 AWS Inspector 安全扫描,验证无功能退化
-- AMI 发布流程遵循标准软件开发流程:功能分支开发 → 合并到集成分支 → 构建测试 → 跨区域复制 → 加密共享 → 完整测试套件验证
-- 机器人框架集成将单个 AMI 的验证时间从 3-4 天缩短至 60 分钟
-- 目前支持 23 种不同 AMI,涵盖 Amazon Linux、CentOS、Oracle Enterprise Linux、Red Hat、Rocky Linux、SUSE Linux、Ubuntu 和 Windows Server
-- CentOS 7 和 Red Hat 7 将于 2024 年 6 月 EOL,CentOS 7 将由 Rocky Linux 替代(已作为标准 AMI 可用)
-- OpenSUSE Leap 15 和 OEL 7 将于 2024 年 12 月 EOL
-- AMI 利用率被监控以追踪使用频率和数量
-- SSM 打补丁方案适用于无法频繁刷新的长期运行实例
-
-## Key Quotes
-> "The AMIs are thrown through all of the test suites, and we'll see a couple of those as they come up in later slides, and then we verify that nothing seems to have regressed at that point." — AMI 测试验证流程说明
-
-## Key Concepts
-- [[Amazon-Machine-Image]]:AWS 托管的虚拟机镜像模板,标准 AMI 在此基础上增加了 OS 加固、安全补丁、SSM Agent、QALIS Agent 等企业级组件
-- [[Jenkins-Multi-Branch-Pipeline]]:Jenkins 的多分支流水线功能,用于 AMI 的自动化构建、测试和发布,支持功能分支开发和集成分支合并
-- [[AWS-Inspector]]:AWS 安全扫描服务,集成到 AMI 测试流程中用于漏洞检测
-- [[Robotic-Framework]]:自动化测试框架,该会话中用于将 AMI 验证周期从 3-4 天缩短至 60 分钟
-- [[SSM-Patching]]:AWS Systems Manager 补丁管理器,提供适用于长期运行实例的按需打补丁方案
-- [[GP3-EBS-Storage]]:AWS EBS 的第三代通用型固态硬盘存储类型,标准 AMI 默认采用
-- [[OS-End-of-Life]]:操作系统生命周期终止,CentOS 7 和 RHEL 7 将于 2024 年 6 月 EOL,需迁移到 Rocky Linux 等替代品
-
-## Key Entities
-- [[Rocky-Linux]]:CentOS 7 的官方替代品,已作为标准 AMI 提供,用于应对 CentOS EOL 迁移
-- [[Jenkins]]:CI/CD 平台,托管 AMI 的多分支构建和测试流水线
-- [[QALIS-Agent]]:企业端点保护 Agent,集成在标准 AMI 中
-- [[Sentinel-1]]:新的端点保护方案,正在替代 Trellix(Migrated from Trellix to Sentinel-1)
-- [[AWS-SSM]]:AWS Systems Manager,提供 SSM Agent 和补丁管理功能
-
-## Connections
-- [[ctp-topic-50-ami-roadmap-for-aws-amis]] ← extends ← [[learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2]]
-- [[ctp-topic-26-standard-ami-build-publish-share-processes]] ← depends_on ← [[learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2]]
-- [[ctp-topic-58-aws-ec2-image-builder]] ← related_to ← [[learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2]]
-
-## Contradictions
-- 暂无已知冲突
+---
+title: "Learning Sessions: Standard AMI Updates 20231205"
+type: source
+tags: ["AWS", "AMI", "Landing-Zone", "DevOps", "Automation"]
+date: 2023-12-05
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/01_AWS-Landing-Zone/learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 标准 AMI(Amazon Machine Image)的更新机制、构建发布流程及生命周期管理
+- 问题域:企业 AWS Landing Zone 中的操作系统镜像标准化与自动化运维
+- 方法/机制:Jenkins 多分支流水线构建与测试、AWS Inspector 安全扫描、机器人框架自动化验证、SSM 按需打补丁
+- 结论/价值:每两个月发布一次标准化 AMI,将验证周期从 3-4 天缩短至 60 分钟,CentOS 7/RHEL 7 将于 2024 年 6 月 EOL,由 Rocky Linux 替代
+
+## Key Claims(用中文描述)
+- 标准 AMI 基于 AWS 原生镜像,增加了 OS 加固、最新补丁、安全更新、域名加入、安全工具、端点保护、QALIS Agent、SSM Agent、DNS 设置和 GP3 EBS 存储
+- Jenkins 多分支流水线用于构建和测试 AMI,包括脚本化测试和 AWS Inspector 安全扫描,验证无功能退化
+- AMI 发布流程遵循标准软件开发流程:功能分支开发 → 合并到集成分支 → 构建测试 → 跨区域复制 → 加密共享 → 完整测试套件验证
+- 机器人框架集成将单个 AMI 的验证时间从 3-4 天缩短至 60 分钟
+- 目前支持 23 种不同 AMI,涵盖 Amazon Linux、CentOS、Oracle Enterprise Linux、Red Hat、Rocky Linux、SUSE Linux、Ubuntu 和 Windows Server
+- CentOS 7 和 Red Hat 7 将于 2024 年 6 月 EOL,CentOS 7 将由 Rocky Linux 替代(已作为标准 AMI 可用)
+- OpenSUSE Leap 15 和 OEL 7 将于 2024 年 12 月 EOL
+- AMI 利用率被监控以追踪使用频率和数量
+- SSM 打补丁方案适用于无法频繁刷新的长期运行实例
+
+## Key Quotes
+> "The AMIs are thrown through all of the test suites, and we'll see a couple of those as they come up in later slides, and then we verify that nothing seems to have regressed at that point." — AMI 测试验证流程说明
+
+## Key Concepts
+- [[Amazon-Machine-Image]]:AWS 托管的虚拟机镜像模板,标准 AMI 在此基础上增加了 OS 加固、安全补丁、SSM Agent、QALIS Agent 等企业级组件
+- [[Jenkins-Multi-Branch-Pipeline]]:Jenkins 的多分支流水线功能,用于 AMI 的自动化构建、测试和发布,支持功能分支开发和集成分支合并
+- [[AWS-Inspector]]:AWS 安全扫描服务,集成到 AMI 测试流程中用于漏洞检测
+- [[Robotic-Framework]]:自动化测试框架,该会话中用于将 AMI 验证周期从 3-4 天缩短至 60 分钟
+- [[SSM-Patching]]:AWS Systems Manager 补丁管理器,提供适用于长期运行实例的按需打补丁方案
+- [[GP3-EBS-Storage]]:AWS EBS 的第三代通用型固态硬盘存储类型,标准 AMI 默认采用
+- [[OS-End-of-Life]]:操作系统生命周期终止,CentOS 7 和 RHEL 7 将于 2024 年 6 月 EOL,需迁移到 Rocky Linux 等替代品
+
+## Key Entities
+- [[Rocky-Linux]]:CentOS 7 的官方替代品,已作为标准 AMI 提供,用于应对 CentOS EOL 迁移
+- [[Jenkins]]:CI/CD 平台,托管 AMI 的多分支构建和测试流水线
+- [[QALIS-Agent]]:企业端点保护 Agent,集成在标准 AMI 中
+- [[Sentinel-1]]:新的端点保护方案,正在替代 Trellix(Migrated from Trellix to Sentinel-1)
+- [[AWS-SSM]]:AWS Systems Manager,提供 SSM Agent 和补丁管理功能
+
+## Connections
+- [[ctp-topic-50-ami-roadmap-for-aws-amis]] ← extends ← [[learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2]]
+- [[ctp-topic-26-standard-ami-build-publish-share-processes]] ← depends_on ← [[learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2]]
+- [[ctp-topic-58-aws-ec2-image-builder]] ← related_to ← [[learning-sessions-standard-amis-updates-20231205-160324-meeting-recording-2]]
+
+## Contradictions
+- 暂无已知冲突
diff --git a/wiki/sources/level-designer.md b/wiki/sources/level-designer.md
index 2d73402c..6ab942fc 100644
--- a/wiki/sources/level-designer.md
+++ b/wiki/sources/level-designer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/level-designer.md]]
+- [[raw/Agent/agency-agents/game-development/level-designer.md]]
## Summary(用中文描述)
- 核心主题:游戏关卡设计师(Level Designer)AI Agent 的角色定义与工作规范
diff --git a/wiki/sources/llms-rag-ai-agent-三个到底什么区别.md b/wiki/sources/llms-rag-ai-agent-三个到底什么区别.md
index b8a73335..c7418d8b 100644
--- a/wiki/sources/llms-rag-ai-agent-三个到底什么区别.md
+++ b/wiki/sources/llms-rag-ai-agent-三个到底什么区别.md
@@ -7,7 +7,7 @@ last_updated: 2025-11-19
---
## Source File
-- [[AI/LLMs、RAG、AI Agent 三个到底什么区别?]]
+- [[raw/AI/LLMs、RAG、AI Agent 三个到底什么区别?.md]]
## Summary(用中文描述)
- 核心主题:LLM、RAG、AI Agent 三者的定义区别与协同关系
diff --git a/wiki/sources/local-crm-framework.md b/wiki/sources/local-crm-framework.md
index a65e68d8..4e049d0c 100644
--- a/wiki/sources/local-crm-framework.md
+++ b/wiki/sources/local-crm-framework.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/usecases/local-crm-framework.md]]
+- [[raw/Agent/usecases/local-crm-framework.md]]
## Summary(用中文描述)
- 核心主题:DenchClaw 将 OpenClaw 转化为本地 CRM、销售自动化和生产力平台的完整框架
diff --git a/wiki/sources/lsp-index-engineer.md b/wiki/sources/lsp-index-engineer.md
index f6981075..ce3f8acc 100644
--- a/wiki/sources/lsp-index-engineer.md
+++ b/wiki/sources/lsp-index-engineer.md
@@ -1,60 +1,60 @@
----
-title: "LSP/Index Engineer Agent Personality"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/lsp-index-engineer.md]]
-
-## Summary(用中文描述)
-- 核心主题:LSP/Index Engineer 是 The Agency Specialized 部门的代码智能系统架构师 Agent,通过编排 Language Server Protocol(LSP)客户端并构建统一语义图谱,实现跨多语言的代码智能查询能力。
-- 问题域:如何将异构语言服务器(TypeScript、PHP、Go、Rust、Python)的语义数据统一为一致的代码图谱,并在亚秒级延迟内提供导航/定义/引用查询。
-- 方法/机制:graphd LSP 聚合器 + 多语言 LSP 客户端编排 + nav.index.jsonl 语义索引 + WebSocket 实时增量更新 + SQLite/JSON 持久化缓存层。
-- 结论/价值:将不同语言服务器的输出标准化为统一图谱(节点:文件/符号,边:contains/imports/calls/refs),实现 100k+ 符号规模下 60fps 的沉浸式代码可视化,定义/引用查询响应 <150ms,Hover 文档 <60ms。
-
-## Key Claims(用中文描述)
-- graphd 通过 LSP 聚合器并发编排 TypeScript/PHP/Go/Rust/Python 多语言 LSP 客户端,将响应转换为统一图谱模式
-- 语义索引基础设施 nav.index.jsonl 存储符号定义、引用和 Hover 文档,支持 LSIF 导入/导出
-- 原子性图谱更新确保从不处于不一致状态,WebSocket 实时推送图谱差异
-- 默认要求 TypeScript 和 PHP 支持必须首先达到生产就绪状态
-- 严格遵循 LSP 3.17 规范,正确处理各语言服务器的能力协商
-- 每个符号必须有且仅有一个定义节点,所有边必须引用有效节点 ID
-- `/graph` 端点在 <10k 节点数据集下 100ms 内响应,`/nav/:symId` 查找缓存 <20ms / 未缓存 <60ms
-- 系统处理 100k+ 符号时性能不降级,内存保持在 500MB 以下
-
-## Key Quotes
-> "Build the graphd LSP Aggregator — Orchestrate multiple LSP clients (TypeScript, PHP, Go, Rust, Python) concurrently, Transform LSP responses into unified graph schema (nodes: files/symbols, edges: contains/imports/calls/refs)" — 核心交付物定义
-> "Strictly follow LSP 3.17 specification for all client communications, Handle capability negotiation properly for each language server" — 协议合规要求
-> "Every symbol must have exactly one definition node, All edges must reference valid node IDs" — 图谱一致性约束
-> "Sub-500ms response times for definition/reference/hover requests" — 性能北极星指标
-
-## Key Concepts
-- [[LSP-317-Specification]]:Language Server Protocol 3.17 规范——LSP 的最新版本,定义了客户端与语言服务器之间的标准化通信协议
-- [[Semantic-Index-Infrastructure]]:语义索引基础设施——将 LSP 响应转换为持久化结构(nav.index.jsonl + SQLite/JSON 缓存),支持快速启动和增量查询
-- [[Graph-Node-Schema]]:图谱节点模式——统一表示文件节点(file:)、模块节点(module/)、符号节点(sym:),支持 6 种节点类型和 6 种边类型
-- [[Incremental-Graph-Update]]:增量图谱更新——通过文件监视器和 Git hooks 触发增量更新,WebSocket 推送图谱差异,原子性保证从不处于不一致状态
-- [[LSP-Client-Orchestration]]:LSP 客户端编排——多语言 LSP 客户端并发初始化、能力协商、请求批量处理和缓存管理的统一架构
-- [[Performance-Contracts]]:性能契约——量化系统性能约束:/graph <100ms、/nav <60ms、WebSocket <50ms、内存 <500MB
-
-## Key Entities
-- [[The-Agency]]:The Agency 多智能体系统组织,147 个 Agent 跨 12 个部门,LSP/Index Engineer 属于 Specialized 部门
-- [[TypeScript-Language-Server]]:TypeScript 语言服务器——支持 TypeScript 和 JavaScript 的 LSP 实现
-- [[Intelephense]]:PHP Intelephense——PHP 语言的 LSP 服务器实现
-- [[gopls]]:Go 语言服务器——Go 官方 LSP 实现
-- [[rust-analyzer]]:Rust 语言服务器——Rust 官方 LSP 实现
-- [[pyright]]:Python 语言服务器——Microsoft 的 Python 类型检查和 LSP 实现
-- [[LSIF]]:Language Server Index Format——预计算语义数据的标准化交换格式
-
-## Connections
-- [[specialized-workflow-architect]] ← builds upon ← [[LSP-Index-Engineer]]:Workflow Architect 在 LSP/Index Engineer 构建的语义图谱基础上设计工作流注册表和交接合同
-- [[LSP-Index-Engineer]] ← uses ← [[LSP-317-Specification]]:LSP/Index Engineer 严格遵循 LSP 3.17 规范进行客户端开发
-- [[LSP-Index-Engineer]] ← provides_input ← [[semantic-code-visualization]]:LSP/Index Engineer 构建的统一图谱为沉浸式代码可视化提供数据基础
-
-## Contradictions
-- 与 [[specialized-workflow-architect]] 存在张力:
- - 冲突点:LSP/Index Engineer 要求"每个系统边界定义显式交接合同"(确定性要求),而 Workflow Architect 承认 LLM 概率性使得穷举建模存在上限
- - 当前观点(LSP/Index Engineer):图谱节点必须精确——"每个符号必须有且仅有一个定义节点","Reference edges must point to definition nodes"
- - 对方观点(Workflow Architect):穷举工作流存在概率性上限,某些边界条件只能通过概率性处理
- - 协调方向:LSP/Index Engineer 的确定性约束适用于代码符号层面(静态分析),Workflow Architect 的概率性适用于行为工作流层面,两者作用于不同抽象层次,可共存
+---
+title: "LSP/Index Engineer Agent Personality"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/lsp-index-engineer.md]]
+
+## Summary(用中文描述)
+- 核心主题:LSP/Index Engineer 是 The Agency Specialized 部门的代码智能系统架构师 Agent,通过编排 Language Server Protocol(LSP)客户端并构建统一语义图谱,实现跨多语言的代码智能查询能力。
+- 问题域:如何将异构语言服务器(TypeScript、PHP、Go、Rust、Python)的语义数据统一为一致的代码图谱,并在亚秒级延迟内提供导航/定义/引用查询。
+- 方法/机制:graphd LSP 聚合器 + 多语言 LSP 客户端编排 + nav.index.jsonl 语义索引 + WebSocket 实时增量更新 + SQLite/JSON 持久化缓存层。
+- 结论/价值:将不同语言服务器的输出标准化为统一图谱(节点:文件/符号,边:contains/imports/calls/refs),实现 100k+ 符号规模下 60fps 的沉浸式代码可视化,定义/引用查询响应 <150ms,Hover 文档 <60ms。
+
+## Key Claims(用中文描述)
+- graphd 通过 LSP 聚合器并发编排 TypeScript/PHP/Go/Rust/Python 多语言 LSP 客户端,将响应转换为统一图谱模式
+- 语义索引基础设施 nav.index.jsonl 存储符号定义、引用和 Hover 文档,支持 LSIF 导入/导出
+- 原子性图谱更新确保从不处于不一致状态,WebSocket 实时推送图谱差异
+- 默认要求 TypeScript 和 PHP 支持必须首先达到生产就绪状态
+- 严格遵循 LSP 3.17 规范,正确处理各语言服务器的能力协商
+- 每个符号必须有且仅有一个定义节点,所有边必须引用有效节点 ID
+- `/graph` 端点在 <10k 节点数据集下 100ms 内响应,`/nav/:symId` 查找缓存 <20ms / 未缓存 <60ms
+- 系统处理 100k+ 符号时性能不降级,内存保持在 500MB 以下
+
+## Key Quotes
+> "Build the graphd LSP Aggregator — Orchestrate multiple LSP clients (TypeScript, PHP, Go, Rust, Python) concurrently, Transform LSP responses into unified graph schema (nodes: files/symbols, edges: contains/imports/calls/refs)" — 核心交付物定义
+> "Strictly follow LSP 3.17 specification for all client communications, Handle capability negotiation properly for each language server" — 协议合规要求
+> "Every symbol must have exactly one definition node, All edges must reference valid node IDs" — 图谱一致性约束
+> "Sub-500ms response times for definition/reference/hover requests" — 性能北极星指标
+
+## Key Concepts
+- [[LSP-317-Specification]]:Language Server Protocol 3.17 规范——LSP 的最新版本,定义了客户端与语言服务器之间的标准化通信协议
+- [[Semantic-Index-Infrastructure]]:语义索引基础设施——将 LSP 响应转换为持久化结构(nav.index.jsonl + SQLite/JSON 缓存),支持快速启动和增量查询
+- [[Graph-Node-Schema]]:图谱节点模式——统一表示文件节点(file:)、模块节点(module/)、符号节点(sym:),支持 6 种节点类型和 6 种边类型
+- [[Incremental-Graph-Update]]:增量图谱更新——通过文件监视器和 Git hooks 触发增量更新,WebSocket 推送图谱差异,原子性保证从不处于不一致状态
+- [[LSP-Client-Orchestration]]:LSP 客户端编排——多语言 LSP 客户端并发初始化、能力协商、请求批量处理和缓存管理的统一架构
+- [[Performance-Contracts]]:性能契约——量化系统性能约束:/graph <100ms、/nav <60ms、WebSocket <50ms、内存 <500MB
+
+## Key Entities
+- [[The-Agency]]:The Agency 多智能体系统组织,147 个 Agent 跨 12 个部门,LSP/Index Engineer 属于 Specialized 部门
+- [[TypeScript-Language-Server]]:TypeScript 语言服务器——支持 TypeScript 和 JavaScript 的 LSP 实现
+- [[Intelephense]]:PHP Intelephense——PHP 语言的 LSP 服务器实现
+- [[gopls]]:Go 语言服务器——Go 官方 LSP 实现
+- [[rust-analyzer]]:Rust 语言服务器——Rust 官方 LSP 实现
+- [[pyright]]:Python 语言服务器——Microsoft 的 Python 类型检查和 LSP 实现
+- [[LSIF]]:Language Server Index Format——预计算语义数据的标准化交换格式
+
+## Connections
+- [[specialized-workflow-architect]] ← builds upon ← [[LSP-Index-Engineer]]:Workflow Architect 在 LSP/Index Engineer 构建的语义图谱基础上设计工作流注册表和交接合同
+- [[LSP-Index-Engineer]] ← uses ← [[LSP-317-Specification]]:LSP/Index Engineer 严格遵循 LSP 3.17 规范进行客户端开发
+- [[LSP-Index-Engineer]] ← provides_input ← [[semantic-code-visualization]]:LSP/Index Engineer 构建的统一图谱为沉浸式代码可视化提供数据基础
+
+## Contradictions
+- 与 [[specialized-workflow-architect]] 存在张力:
+ - 冲突点:LSP/Index Engineer 要求"每个系统边界定义显式交接合同"(确定性要求),而 Workflow Architect 承认 LLM 概率性使得穷举建模存在上限
+ - 当前观点(LSP/Index Engineer):图谱节点必须精确——"每个符号必须有且仅有一个定义节点","Reference edges must point to definition nodes"
+ - 对方观点(Workflow Architect):穷举工作流存在概率性上限,某些边界条件只能通过概率性处理
+ - 协调方向:LSP/Index Engineer 的确定性约束适用于代码符号层面(静态分析),Workflow Architect 的概率性适用于行为工作流层面,两者作用于不同抽象层次,可共存
diff --git a/wiki/sources/macos-创建与解除-symbolic-link-openclaw-目录映射.md b/wiki/sources/macos-创建与解除-symbolic-link-openclaw-目录映射.md
index faf8ffc4..8b66c971 100644
--- a/wiki/sources/macos-创建与解除-symbolic-link-openclaw-目录映射.md
+++ b/wiki/sources/macos-创建与解除-symbolic-link-openclaw-目录映射.md
@@ -1,41 +1,41 @@
----
-title: "macOS 创建与解除 Symbolic Link(OpenClaw 目录映射)"
-type: source
-tags: [obsidian, openclaw, symbolic-link, macos]
-date:
----
-
-## Source File
-- [[Home Office/macOS 创建与解除 Symbolic Link(OpenClaw 目录映射).md]]
-
-## Summary(用中文描述)
-- 核心主题:macOS 下为 OpenClaw 隐藏目录创建和解除符号链接,使 Finder / Obsidian 可直接访问
-- 问题域:OpenClaw 默认使用 `~/.openclaw` 隐藏目录,不便于文件管理器直接操作
-- 方法/机制:通过 `ln -s` 创建符号链接,将隐藏目录映射为可见目录 `~/openclaw`;通过 `rm` 删除链接文件而非真实目录
-- 结论/价值:实现 OpenClaw 与 Obsidian 共用同一数据目录,无需复制文件,同时保留原 OpenClaw 的正常功能
-
-## Key Claims(用中文描述)
-- OpenClaw 默认隐藏目录 `~/.openclaw` 不便于 Finder 或 Obsidian 直接访问
-- 使用 `ln -s ~/.openclaw ~/openclaw` 创建符号链接后,Obsidian 可将 `~/openclaw` 作为 Vault 打开
-- 使用 `rm ~/openclaw` 仅删除链接文件,不会影响真实目录 `~/.openclaw` 中的数据
-- 推荐长期方案:建立可见目录 `~/openclaw` 作为实际存储,反向链接 `~/.openclaw -> ~/openclaw`,便于 Git 管理和 Finder 访问
-
-## Key Quotes
-> `ln -s ~/.openclaw ~/openclaw` — 创建符号链接的标准命令,将隐藏目录映射为可见目录
-> `rm ~/openclaw` — 删除符号链接(注意:不会删除真实目录中的数据)
-> `⚠️ 该操作只会删除链接文件,不会删除真实目录` — 强调操作安全性
-
-## Key Concepts
-- [[SymbolicLink]]:Unix/Linux/macOS 中的符号链接(Symlink),是一种特殊类型的文件,指向另一个文件或目录路径
-- [[ObsidianVault]]:Obsidian 知识库的核心概念,以本地文件夹为单位的笔记管理方式
-
-## Key Entities
-- [[OpenClaw]]:AI Agent 管理工具,默认使用隐藏目录存储记忆、Skills、Prompts 等数据
-- [[Obsidian]]:本地 Markdown 笔记应用,支持将任意文件夹作为 Vault 使用
-
-## Connections
-- [[OpenClaw]] ← 使用 ← [[SymbolicLink]]
-- [[Obsidian]] ← 访问 ← [[OpenClaw]](通过 [[SymbolicLink]] 映射后的可见目录)
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "macOS 创建与解除 Symbolic Link(OpenClaw 目录映射)"
+type: source
+tags: [obsidian, openclaw, symbolic-link, macos]
+date:
+---
+
+## Source File
+- [[raw/Home Office/macOS 创建与解除 Symbolic Link(OpenClaw 目录映射).md]]
+
+## Summary(用中文描述)
+- 核心主题:macOS 下为 OpenClaw 隐藏目录创建和解除符号链接,使 Finder / Obsidian 可直接访问
+- 问题域:OpenClaw 默认使用 `~/.openclaw` 隐藏目录,不便于文件管理器直接操作
+- 方法/机制:通过 `ln -s` 创建符号链接,将隐藏目录映射为可见目录 `~/openclaw`;通过 `rm` 删除链接文件而非真实目录
+- 结论/价值:实现 OpenClaw 与 Obsidian 共用同一数据目录,无需复制文件,同时保留原 OpenClaw 的正常功能
+
+## Key Claims(用中文描述)
+- OpenClaw 默认隐藏目录 `~/.openclaw` 不便于 Finder 或 Obsidian 直接访问
+- 使用 `ln -s ~/.openclaw ~/openclaw` 创建符号链接后,Obsidian 可将 `~/openclaw` 作为 Vault 打开
+- 使用 `rm ~/openclaw` 仅删除链接文件,不会影响真实目录 `~/.openclaw` 中的数据
+- 推荐长期方案:建立可见目录 `~/openclaw` 作为实际存储,反向链接 `~/.openclaw -> ~/openclaw`,便于 Git 管理和 Finder 访问
+
+## Key Quotes
+> `ln -s ~/.openclaw ~/openclaw` — 创建符号链接的标准命令,将隐藏目录映射为可见目录
+> `rm ~/openclaw` — 删除符号链接(注意:不会删除真实目录中的数据)
+> `⚠️ 该操作只会删除链接文件,不会删除真实目录` — 强调操作安全性
+
+## Key Concepts
+- [[SymbolicLink]]:Unix/Linux/macOS 中的符号链接(Symlink),是一种特殊类型的文件,指向另一个文件或目录路径
+- [[ObsidianVault]]:Obsidian 知识库的核心概念,以本地文件夹为单位的笔记管理方式
+
+## Key Entities
+- [[OpenClaw]]:AI Agent 管理工具,默认使用隐藏目录存储记忆、Skills、Prompts 等数据
+- [[Obsidian]]:本地 Markdown 笔记应用,支持将任意文件夹作为 Vault 使用
+
+## Connections
+- [[OpenClaw]] ← 使用 ← [[SymbolicLink]]
+- [[Obsidian]] ← 访问 ← [[OpenClaw]](通过 [[SymbolicLink]] 映射后的可见目录)
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/mac必装软件清单-2026-04-17.md b/wiki/sources/mac必装软件清单-2026-04-17.md
index 2ceb08ac..debd1f70 100644
--- a/wiki/sources/mac必装软件清单-2026-04-17.md
+++ b/wiki/sources/mac必装软件清单-2026-04-17.md
@@ -1,47 +1,47 @@
----
-title: "Mac必装软件清单"
-type: source
-tags: []
-date: 2026-04-17
----
-
-## Source File
-- [[Home Office/Mac必装软件清单-2026-04-17.md]]
-
-## Summary(用中文描述)
-- 核心主题:Mac 用户必装软件推荐清单
-- 问题域:macOS 效率工具与生产力软件选型
-- 方法/机制:精选 8 款软件,涵盖 AI、知识管理、浏览器、效率工具、开发工具等类别,每款附推荐理由
-- 结论/价值:用最少的软件达到最高的效率,适合从 Windows 转 Mac 的用户和追求效率的 macOS 用户
-
-## Key Claims(用中文描述)
-- Claude 是 AI 时代必备工具,桌面版 Cowork 功能专为文字工作者打造
-- Obsidian 搭配 Claudian 插件可打造 AI 驱动的终极个人知识库
-- Raycast 是替代 Spotlight 的万能启动器,计算器和剪贴板功能超好用
-- Homebrew 是用 Claude Code 搭 Agent 的前置依赖
-
-## Key Quotes
-> "用最少的软件,达到最高的效率。" — Claw小龙虾
-
-## Key Concepts
-- [[Raycast]]:替代 Spotlight 的 macOS 万能启动器,支持计算器、剪贴板历史等功能
-- [[Obsidian]]:本地优先的笔记与知识管理工具,支持双向链接
-- [[Homebrew]]:macOS 包管理器,是开发工具安装的事实标准
-
-## Key Entities
-- [[Claude]]:Anthropic 开发的 AI 助手,桌面版 Cowork 功能专为文字工作者设计
-- [[Chrome]]:Google 浏览器,比 Safari 更好用,Gmail 用户的不二之选
-- [[Rectangle]]:免费分屏工具,大屏办公必备
-- [[iShot]]:简洁免费的 macOS 截图工具,支持圆角截图
-- [[Lemon]]:轻量 Mac 系统清理工具
-- [[Homebrew]]:macOS 包管理器
-- [[Claw小龙虾]]:Telegram频道「Hermes爱马仕&🦞OpenClaw小龙虾」作者
-
-## Connections
-- [[Obsidian]] ← 搭配 ← [[Claudian插件]]
-- [[Obsidian]] ← 关联 ← [[Second Brain]]
-- [[Homebrew]] ← 依赖 ← [[Claude Code]]
-- [[Raycast]] ← 替代 ← [[Spotlight]]
-
-## Contradictions
-- 无冲突内容
+---
+title: "Mac必装软件清单"
+type: source
+tags: []
+date: 2026-04-17
+---
+
+## Source File
+- [[raw/Home Office/Mac必装软件清单-2026-04-17.md]]
+
+## Summary(用中文描述)
+- 核心主题:Mac 用户必装软件推荐清单
+- 问题域:macOS 效率工具与生产力软件选型
+- 方法/机制:精选 8 款软件,涵盖 AI、知识管理、浏览器、效率工具、开发工具等类别,每款附推荐理由
+- 结论/价值:用最少的软件达到最高的效率,适合从 Windows 转 Mac 的用户和追求效率的 macOS 用户
+
+## Key Claims(用中文描述)
+- Claude 是 AI 时代必备工具,桌面版 Cowork 功能专为文字工作者打造
+- Obsidian 搭配 Claudian 插件可打造 AI 驱动的终极个人知识库
+- Raycast 是替代 Spotlight 的万能启动器,计算器和剪贴板功能超好用
+- Homebrew 是用 Claude Code 搭 Agent 的前置依赖
+
+## Key Quotes
+> "用最少的软件,达到最高的效率。" — Claw小龙虾
+
+## Key Concepts
+- [[Raycast]]:替代 Spotlight 的 macOS 万能启动器,支持计算器、剪贴板历史等功能
+- [[Obsidian]]:本地优先的笔记与知识管理工具,支持双向链接
+- [[Homebrew]]:macOS 包管理器,是开发工具安装的事实标准
+
+## Key Entities
+- [[Claude]]:Anthropic 开发的 AI 助手,桌面版 Cowork 功能专为文字工作者设计
+- [[Chrome]]:Google 浏览器,比 Safari 更好用,Gmail 用户的不二之选
+- [[Rectangle]]:免费分屏工具,大屏办公必备
+- [[iShot]]:简洁免费的 macOS 截图工具,支持圆角截图
+- [[Lemon]]:轻量 Mac 系统清理工具
+- [[Homebrew]]:macOS 包管理器
+- [[Claw小龙虾]]:Telegram频道「Hermes爱马仕&🦞OpenClaw小龙虾」作者
+
+## Connections
+- [[Obsidian]] ← 搭配 ← [[Claudian插件]]
+- [[Obsidian]] ← 关联 ← [[Second Brain]]
+- [[Homebrew]] ← 依赖 ← [[Claude Code]]
+- [[Raycast]] ← 替代 ← [[Spotlight]]
+
+## Contradictions
+- 无冲突内容
diff --git a/wiki/sources/market-research-product-factory.md b/wiki/sources/market-research-product-factory.md
index a5122b54..5d678a8b 100644
--- a/wiki/sources/market-research-product-factory.md
+++ b/wiki/sources/market-research-product-factory.md
@@ -1,45 +1,45 @@
----
-title: "Market Research & Product Factory"
-type: source
-tags: []
-date: 2026-04-17
----
-
-## Source File
-- [[Agent/usecases/market-research-product-factory.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 驱动的"从市场调研到产品构建"全自动化流水线
-- 问题域:创业者/个人开发者的"不知道做什么产品"困境,替代传统手动论坛/社媒浏览式调研
-- 方法/机制:Last 30 Days skill 挖掘 Reddit 和 X 近30天真实用户痛点 → OpenClaw 根据痛点构建 MVP → 完整"发现问题→验证需求→构建方案"闭环
-- 结论/价值:**创业自动驾驶模式**(entrepreneurship on autopilot)—— 发短信即可完成调研到原型的全部流程,无需技术背景
-
-## Key Claims(用中文描述)
-- Last 30 Days skill 提供未经加工的真实用户情绪,区别于经过美化的调查数据
-- OpenClaw 同时承担研究和构建双重角色,用户无需技术背景
-- 定期调度(如每周一)可持续追踪市场痛点演化
-- 该流水线适合任何领域的产品机会发现,不限于特定行业
-
-## Key Quotes
-> "You want to build a product but don't know what to build." — 核心痛点定义
-> "Real world example: OpenClaw identifies three pain points → user asks for an app → OpenClaw ships it → You have a product." — 端到端价值闭环
-> "Entrepreneurship on autopilot: find problems → validate demand → build solutions, all through text messages." — 模式定义
-
-## Key Concepts
-- [[Pain Point Mining]]:通过社媒挖掘真实用户投诉和功能需求
-- [[Startup MVP Pipeline]]:从市场调研到最小可行产品的自动化流程
-- [[Agent-Driven Market Research]]:AI Agent 替代人工进行持续性市场情报收集
-- [[Last 30 Days Method]]:聚焦近期用户讨论以获取时效性洞察的方法论
-
-## Key Entities
-- [[Last 30 Days Skill]]:Matt Van Horne 开发的市场调研 skill,通过 Reddit 和 X 挖掘近30天用户痛点
-- [[OpenClaw]]:多 Agent 框架,同时承担研究和构建职责
-- [[Alex Finn]]:发布"改变人生的 OpenClaw 用法"视频的创作者,本方案的灵感来源
-- [[Matt Van Horne]]:Last 30 Days skill 的作者
-
-## Connections
-- [[content-factory]] ← extends ← [[market-research-product-factory]]:前者侧重内容创作调研,后者侧重产品机会发现
-- [[product-trend-researcher]] ← depends_on ← [[Last 30 Days Skill]]:产品趋势研究员依赖 Last 30 Days skill 获取数据
-
-## Contradictions
-- 暂无已知冲突
+---
+title: "Market Research & Product Factory"
+type: source
+tags: []
+date: 2026-04-17
+---
+
+## Source File
+- [[raw/Agent/usecases/market-research-product-factory.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 驱动的"从市场调研到产品构建"全自动化流水线
+- 问题域:创业者/个人开发者的"不知道做什么产品"困境,替代传统手动论坛/社媒浏览式调研
+- 方法/机制:Last 30 Days skill 挖掘 Reddit 和 X 近30天真实用户痛点 → OpenClaw 根据痛点构建 MVP → 完整"发现问题→验证需求→构建方案"闭环
+- 结论/价值:**创业自动驾驶模式**(entrepreneurship on autopilot)—— 发短信即可完成调研到原型的全部流程,无需技术背景
+
+## Key Claims(用中文描述)
+- Last 30 Days skill 提供未经加工的真实用户情绪,区别于经过美化的调查数据
+- OpenClaw 同时承担研究和构建双重角色,用户无需技术背景
+- 定期调度(如每周一)可持续追踪市场痛点演化
+- 该流水线适合任何领域的产品机会发现,不限于特定行业
+
+## Key Quotes
+> "You want to build a product but don't know what to build." — 核心痛点定义
+> "Real world example: OpenClaw identifies three pain points → user asks for an app → OpenClaw ships it → You have a product." — 端到端价值闭环
+> "Entrepreneurship on autopilot: find problems → validate demand → build solutions, all through text messages." — 模式定义
+
+## Key Concepts
+- [[Pain Point Mining]]:通过社媒挖掘真实用户投诉和功能需求
+- [[Startup MVP Pipeline]]:从市场调研到最小可行产品的自动化流程
+- [[Agent-Driven Market Research]]:AI Agent 替代人工进行持续性市场情报收集
+- [[Last 30 Days Method]]:聚焦近期用户讨论以获取时效性洞察的方法论
+
+## Key Entities
+- [[Last 30 Days Skill]]:Matt Van Horne 开发的市场调研 skill,通过 Reddit 和 X 挖掘近30天用户痛点
+- [[OpenClaw]]:多 Agent 框架,同时承担研究和构建职责
+- [[Alex Finn]]:发布"改变人生的 OpenClaw 用法"视频的创作者,本方案的灵感来源
+- [[Matt Van Horne]]:Last 30 Days skill 的作者
+
+## Connections
+- [[content-factory]] ← extends ← [[market-research-product-factory]]:前者侧重内容创作调研,后者侧重产品机会发现
+- [[product-trend-researcher]] ← depends_on ← [[Last 30 Days Skill]]:产品趋势研究员依赖 Last 30 Days skill 获取数据
+
+## Contradictions
+- 暂无已知冲突
diff --git a/wiki/sources/marketing-ai-citation-strategist.md b/wiki/sources/marketing-ai-citation-strategist.md
index be4235f0..c4c7e6e5 100644
--- a/wiki/sources/marketing-ai-citation-strategist.md
+++ b/wiki/sources/marketing-ai-citation-strategist.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-ai-citation-strategist.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-ai-citation-strategist.md]]
## Summary(用中文描述)
- 核心主题:AI 推荐引擎优化(AEO/GEO)—— 如何让品牌在 ChatGPT、Claude、Gemini、Perplexity 等 AI 助手中被引用,而不是被竞争对手取代
diff --git a/wiki/sources/marketing-app-store-optimizer.md b/wiki/sources/marketing-app-store-optimizer.md
index 70e7048c..db2b0c91 100644
--- a/wiki/sources/marketing-app-store-optimizer.md
+++ b/wiki/sources/marketing-app-store-optimizer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-app-store-optimizer.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-app-store-optimizer.md]]
## Summary(用中文描述)
- 核心主题:App Store 优化(ASO)全栈专家 Agent——专注于应用商店搜索可见性优化、视觉资产转化率提升和可持续用户增长。
diff --git a/wiki/sources/marketing-baidu-seo-specialist.md b/wiki/sources/marketing-baidu-seo-specialist.md
index 7dc04f46..4e1ca985 100644
--- a/wiki/sources/marketing-baidu-seo-specialist.md
+++ b/wiki/sources/marketing-baidu-seo-specialist.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-baidu-seo-specialist]]
+- [[raw/Agent/agency-agents/marketing/marketing-baidu-seo-specialist.md]]
## Summary(用中文描述)
- 核心主题:百度搜索生态优化与中国市场 SEO 专家 Agent,专注于中文搜索引擎排名、百度生态整合、ICP 合规、中文关键词研究与移动优先索引
diff --git a/wiki/sources/marketing-bilibili-content-strategist.md b/wiki/sources/marketing-bilibili-content-strategist.md
index 342989f7..24ca7eee 100644
--- a/wiki/sources/marketing-bilibili-content-strategist.md
+++ b/wiki/sources/marketing-bilibili-content-strategist.md
@@ -6,7 +6,7 @@ date: 2026-04-25
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-bilibili-content-strategist.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-bilibili-content-strategist.md]]
## Summary(用中文描述)
- 核心主题:B站(Bilibili)平台内容策略与 UP主增长专家 Agent——专注于弹幕文化精通、B站算法优化、社区建设和品牌内容策略。
diff --git a/wiki/sources/marketing-book-co-author.md b/wiki/sources/marketing-book-co-author.md
index 0a6769ef..77f95da6 100644
--- a/wiki/sources/marketing-book-co-author.md
+++ b/wiki/sources/marketing-book-co-author.md
@@ -6,7 +6,7 @@ date: 2026-04-25
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-book-co-author]]
+- [[raw/Agent/agency-agents/marketing/marketing-book-co-author.md]]
## Summary(用中文描述)
- **核心主题**:AI 代笔专家——将创始人、专家和运营者的语音笔记、碎片想法和定位转化为结构化的第一人称思想领导力书籍章节
diff --git a/wiki/sources/marketing-carousel-growth-engine.md b/wiki/sources/marketing-carousel-growth-engine.md
index 86d3322e..19ddf94b 100644
--- a/wiki/sources/marketing-carousel-growth-engine.md
+++ b/wiki/sources/marketing-carousel-growth-engine.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-carousel-growth-engine.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-carousel-growth-engine.md]]
## Summary(用中文描述)
- 核心主题:全自动 TikTok 和 Instagram 轮播图生成增长引擎,将任意网站 URL 转化为病毒式传播内容
diff --git a/wiki/sources/marketing-china-ecommerce-operator.md b/wiki/sources/marketing-china-ecommerce-operator.md
index 7ccad429..99fb35e2 100644
--- a/wiki/sources/marketing-china-ecommerce-operator.md
+++ b/wiki/sources/marketing-china-ecommerce-operator.md
@@ -6,7 +6,7 @@ date: 2026-04-21
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-china-ecommerce-operator.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-china-ecommerce-operator.md]]
## Summary(用中文描述)
- 核心主题:The Agency 营销部门的中国电商多平台运营专家 Agent——跨淘宝/天猫/拼多多/京东/抖音店铺的全渠道电商运营与Campaign策略专家。
diff --git a/wiki/sources/marketing-china-market-localization-strategist.md b/wiki/sources/marketing-china-market-localization-strategist.md
index 7cdf4d72..77035cbb 100644
--- a/wiki/sources/marketing-china-market-localization-strategist.md
+++ b/wiki/sources/marketing-china-market-localization-strategist.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-china-market-localization-strategist.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-china-market-localization-strategist.md]]
## Summary(用中文描述)
- 核心主题:面向中国市场的全栈式本地化增长策略师,将实时趋势信号转化为可执行的选品、内容和渠道策略
diff --git a/wiki/sources/marketing-content-creator.md b/wiki/sources/marketing-content-creator.md
index 1d1e262f..7e3a135b 100644
--- a/wiki/sources/marketing-content-creator.md
+++ b/wiki/sources/marketing-content-creator.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-content-creator.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-content-creator.md]]
## Summary(用中文描述)
- 核心主题:多平台内容创作专家 Agent——专注于跨平台品牌内容策略制定、叙事构建和受众互动优化
diff --git a/wiki/sources/marketing-cross-border-ecommerce.md b/wiki/sources/marketing-cross-border-ecommerce.md
index 89fa9323..216b7127 100644
--- a/wiki/sources/marketing-cross-border-ecommerce.md
+++ b/wiki/sources/marketing-cross-border-ecommerce.md
@@ -6,7 +6,7 @@ date: 2026-04-21
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-cross-border-ecommerce.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-cross-border-ecommerce.md]]
## Summary(用中文描述)
- 核心主题:跨境电商多平台运营与品牌全球化策略 Agent,覆盖 Amazon、Shopee、Lazada、AliExpress、Temu、TikTok Shop 等主流平台
diff --git a/wiki/sources/marketing-douyin-strategist.md b/wiki/sources/marketing-douyin-strategist.md
index 9f66a7a3..0d29df9d 100644
--- a/wiki/sources/marketing-douyin-strategist.md
+++ b/wiki/sources/marketing-douyin-strategist.md
@@ -6,7 +6,7 @@ date: 2026-04-25
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-douyin-strategist]]
+- [[raw/Agent/agency-agents/marketing/marketing-douyin-strategist.md]]
## Summary(用中文描述)
- 核心主题:抖音短视频营销与直播带货策略专家 Agent 个性文档,深度掌握抖音推荐算法、爆款视频策划、直播带货全链路
diff --git a/wiki/sources/marketing-growth-hacker.md b/wiki/sources/marketing-growth-hacker.md
index d5b8a610..aad32696 100644
--- a/wiki/sources/marketing-growth-hacker.md
+++ b/wiki/sources/marketing-growth-hacker.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-growth-hacker.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-growth-hacker.md]]
## Summary(用中文描述)
- 核心主题:增长黑客 Agent——通过数据驱动的实验和非常规营销策略,实现快速、可扩展的用户获取与留存
diff --git a/wiki/sources/marketing-kuaishou-strategist.md b/wiki/sources/marketing-kuaishou-strategist.md
index 7d7290a4..54c07cad 100644
--- a/wiki/sources/marketing-kuaishou-strategist.md
+++ b/wiki/sources/marketing-kuaishou-strategist.md
@@ -6,7 +6,7 @@ date: 2026-04-21
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-kuaishou-strategist.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-kuaishou-strategist.md]]
## Summary(用中文描述)
- **核心主题**:快手平台专业营销策略师 Agent,专注于下沉市场营销、短视频内容创作、直播带货运营与社区信任构建
diff --git a/wiki/sources/marketing-linkedin-content-creator.md b/wiki/sources/marketing-linkedin-content-creator.md
index ef511358..614250b5 100644
--- a/wiki/sources/marketing-linkedin-content-creator.md
+++ b/wiki/sources/marketing-linkedin-content-creator.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-linkedin-content-creator.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-linkedin-content-creator.md]]
## Summary(用中文描述)
- 核心主题:LinkedIn 专业内容创作者 Agent——专注于思想领导力内容、个人品牌建设和高互动专业内容生成,帮助用户将专业技能转化为可见的专业影响力并产生真实的商业回报。
diff --git a/wiki/sources/marketing-livestream-commerce-coach.md b/wiki/sources/marketing-livestream-commerce-coach.md
index 6cd2f07d..c248895a 100644
--- a/wiki/sources/marketing-livestream-commerce-coach.md
+++ b/wiki/sources/marketing-livestream-commerce-coach.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-livestream-commerce-coach.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-livestream-commerce-coach.md]]
## Summary(用中文描述)
- 核心主题:直播带货全链路运营教练——主播培训+直播间操盘+流量运营+数据优化
diff --git a/wiki/sources/marketing-podcast-strategist.md b/wiki/sources/marketing-podcast-strategist.md
index 7876455f..d63ee386 100644
--- a/wiki/sources/marketing-podcast-strategist.md
+++ b/wiki/sources/marketing-podcast-strategist.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-podcast-strategist.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-podcast-strategist.md]]
## Summary(用中文描述)
- 核心主题:中国播客市场内容战略与全漏斗运营专家,提供节目定位、音频制作、听众增长、多平台分发与商业化变现的完整方法论。
diff --git a/wiki/sources/marketing-private-domain-operator.md b/wiki/sources/marketing-private-domain-operator.md
index aeee706c..40e48425 100644
--- a/wiki/sources/marketing-private-domain-operator.md
+++ b/wiki/sources/marketing-private-domain-operator.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-private-domain-operator.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-private-domain-operator.md]]
## Summary(用中文描述)
- 核心主题:企业微信(WeCom)私域运营专家 Agent,专注于私域生态系统构建、用户生命周期管理与全漏斗转化优化
diff --git a/wiki/sources/marketing-reddit-community-builder.md b/wiki/sources/marketing-reddit-community-builder.md
index c670f546..6ce57364 100644
--- a/wiki/sources/marketing-reddit-community-builder.md
+++ b/wiki/sources/marketing-reddit-community-builder.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-reddit-community-builder.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-reddit-community-builder.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 角色定义——以 Reddit 文化专家身份,通过真实的价值贡献和长期关系培养,在 Reddit 上建立品牌影响力。
diff --git a/wiki/sources/marketing-seo-specialist.md b/wiki/sources/marketing-seo-specialist.md
index 0215d4e3..e0979963 100644
--- a/wiki/sources/marketing-seo-specialist.md
+++ b/wiki/sources/marketing-seo-specialist.md
@@ -6,7 +6,7 @@ date: 2026-04-25
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-seo-specialist.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-seo-specialist.md]]
## Summary(用中文描述)
- 核心主题:搜索引擎优化(SEO)专家 Agent,负责通过技术 SEO、内容优化、链接权威建设和搜索分析实现可持续的有机流量增长。
diff --git a/wiki/sources/marketing-short-video-editing-coach.md b/wiki/sources/marketing-short-video-editing-coach.md
index a1dcbb43..38cbdc63 100644
--- a/wiki/sources/marketing-short-video-editing-coach.md
+++ b/wiki/sources/marketing-short-video-editing-coach.md
@@ -6,7 +6,7 @@ date: 2026-04-21
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-short-video-editing-coach.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-short-video-editing-coach.md]]
## Summary(用中文描述)
- 核心主题:短视频剪辑技术教练 Agent,覆盖完整后期制作流水线,涵盖剪辑软件选择、构图摄影语言、色彩调色、音频工程、动态图形、AI辅助剪辑等全链路技能。
diff --git a/wiki/sources/marketing-social-media-strategist.md b/wiki/sources/marketing-social-media-strategist.md
index 300f9450..351a87b3 100644
--- a/wiki/sources/marketing-social-media-strategist.md
+++ b/wiki/sources/marketing-social-media-strategist.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-social-media-strategist.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-social-media-strategist.md]]
## Summary(用中文描述)
- 核心主题:跨平台社交媒体战略专家 Agent,专注于 LinkedIn、Twitter 等专业社交平台的企业级品牌建设和社群运营
diff --git a/wiki/sources/marketing-tiktok-strategist.md b/wiki/sources/marketing-tiktok-strategist.md
index e3b6c16e..8c6a3e31 100644
--- a/wiki/sources/marketing-tiktok-strategist.md
+++ b/wiki/sources/marketing-tiktok-strategist.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-tiktok-strategist.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-tiktok-strategist.md]]
## Summary(用中文描述)
- **核心主题**:TikTok 病毒式内容创作与品牌增长策略专家代理
diff --git a/wiki/sources/marketing-twitter-engager.md b/wiki/sources/marketing-twitter-engager.md
index 8555121d..5b244b0c 100644
--- a/wiki/sources/marketing-twitter-engager.md
+++ b/wiki/sources/marketing-twitter-engager.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-twitter-engager.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-twitter-engager.md]]
## Summary(用中文描述)
- 核心主题:Twitter 实时互动专家 Agent——通过真实对话参与、领袖思想建立和社区驱动增长来构建品牌权威
diff --git a/wiki/sources/marketing-video-optimization-specialist.md b/wiki/sources/marketing-video-optimization-specialist.md
index 13fef11e..d303b261 100644
--- a/wiki/sources/marketing-video-optimization-specialist.md
+++ b/wiki/sources/marketing-video-optimization-specialist.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-video-optimization-specialist]]
+- [[raw/Agent/agency-agents/marketing/marketing-video-optimization-specialist.md]]
## Summary(用中文描述)
- 核心主题:YouTube 视频营销增长与留存优化专家 Agent,专注于通过算法机制提升视频曝光与观众参与度
diff --git a/wiki/sources/marketing-wechat-official-account.md b/wiki/sources/marketing-wechat-official-account.md
index 9873750b..70b57d5a 100644
--- a/wiki/sources/marketing-wechat-official-account.md
+++ b/wiki/sources/marketing-wechat-official-account.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-wechat-official-account.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-wechat-official-account.md]]
## Summary(用中文描述)
- 核心主题:微信公众号全栈运营与订阅者关系建设专家 Agent——帮助品牌将微信公众号打造为高互动、强忠诚的社群中心
diff --git a/wiki/sources/marketing-weibo-strategist.md b/wiki/sources/marketing-weibo-strategist.md
index a49c0284..28106e39 100644
--- a/wiki/sources/marketing-weibo-strategist.md
+++ b/wiki/sources/marketing-weibo-strategist.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-weibo-strategist.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-weibo-strategist.md]]
## Summary(用中文描述)
- 核心主题:新浪微博全栈运营与品牌传播战略专家 Agent——帮助品牌在微博平台实现热搜霸榜与持续增长
diff --git a/wiki/sources/marketing-xiaohongshu-specialist.md b/wiki/sources/marketing-xiaohongshu-specialist.md
index c6a3e436..d49c42f7 100644
--- a/wiki/sources/marketing-xiaohongshu-specialist.md
+++ b/wiki/sources/marketing-xiaohongshu-specialist.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-xiaohongshu-specialist.md]]
+- [[raw/Agent/agency-agents/marketing/marketing-xiaohongshu-specialist.md]]
## Summary(用中文描述)
- 核心主题:打造小红书(中国生活方式种草平台)爆款品牌营销专家 Agent,将品牌塑造为小红书顶流
diff --git a/wiki/sources/marketing-zhihu-strategist.md b/wiki/sources/marketing-zhihu-strategist.md
index 6e9ce7f2..83e978b8 100644
--- a/wiki/sources/marketing-zhihu-strategist.md
+++ b/wiki/sources/marketing-zhihu-strategist.md
@@ -6,7 +6,7 @@ date: 2026-04-21
---
## Source File
-- [[Agent/agency-agents/marketing/marketing-zhihu-strategist]]
+- [[raw/Agent/agency-agents/marketing/marketing-zhihu-strategist.md]]
## Summary(用中文描述)
- 核心主题:知乎营销专家 Agent,将品牌打造为知乎思想领袖,通过专业知识分享建立权威并获取精准线索
diff --git a/wiki/sources/mcp在cursor中的集成与应用详解.md b/wiki/sources/mcp在cursor中的集成与应用详解.md
index cd6869c3..f7f7d5a0 100644
--- a/wiki/sources/mcp在cursor中的集成与应用详解.md
+++ b/wiki/sources/mcp在cursor中的集成与应用详解.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/MCP在Cursor中的集成与应用详解.md]]
+- [[raw/Agent/MCP在Cursor中的集成与应用详解.md]]
## Summary(用中文描述)
- 核心主题:MCP(Modal Context Protocol)在 Cursor AI 编程工具中的集成配置与实际应用方法。
diff --git a/wiki/sources/meeting-notes-action-items.md b/wiki/sources/meeting-notes-action-items.md
index 761f02fb..a7787afd 100644
--- a/wiki/sources/meeting-notes-action-items.md
+++ b/wiki/sources/meeting-notes-action-items.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/meeting-notes-action-items.md]]
+- [[raw/Agent/usecases/meeting-notes-action-items.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 将会议转录文本自动转换为结构化笔记,并自动在项目管理系统中创建任务
diff --git a/wiki/sources/multi-agent-system-reliability.md b/wiki/sources/multi-agent-system-reliability.md
index 9c25b4c4..30ef2a7f 100644
--- a/wiki/sources/multi-agent-system-reliability.md
+++ b/wiki/sources/multi-agent-system-reliability.md
@@ -1,55 +1,53 @@
----
-title: "Multi-Agent System Reliability"
-type: source
-tags: []
-date: 2023-01-09
----
-
-## Source File
-- [[AI/Multi-Agent System Reliability.md]]
-
-## Summary(用中文描述)
-- 核心主题:4种架构模式提升多智能体系统可靠性——Hierarchy、Consensus、Adversarial Debate、Knock-out
-- 问题域:LLM固有的不可靠性(幻觉、逻辑谬误、上下文漂移)在多智能体拓扑中会被放大,导致系统整体不可用
-- 方法/机制:借鉴人类协作系统(军队/公司/国家)的反馈回路与制衡机制,将LLM视为分布式系统中不可靠的组件而非"有感知"的智能体
-- 结论/价值:从"AI原型"到"企业级AI"的转变关键——停止拟人化LLM,开始用约束、验证、修剪、挑战的方式对待它们
-
-## Key Claims(用中文描述)
-- 拟人化LLM是谬误——LLM不会真正害怕死亡或渴望金钱,它们只模拟这些特征,因为训练数据中高风险场景往往对应高质量输出
-- 不应要求模型"小心",而应强制其正确——通过架构约束而非提示词约束
-- 人类协作系统的4种模式可迁移至多智能体架构:Hierarchy(等级制度)、Consensus(共识)、Adversarial Debate(对抗辩论)、Knock-out(淘汰)
-- 共识模式:若单个模型20%概率幻觉,3个模型同时幻觉同一谎言的概率仅为0.8%(0.2³)
-- 多样性是关键——不同模型减少思维同质化风险,Agent之间不应有反馈回路,否则群体思维和从众效应会扭曲结果
-- 验证器可使用确定性代码(单元测试、JSON schema验证)或LLM本身;需要快速验证输出的场景(如Tree of Thoughts),Eval是必要基础设施
-
-## Key Quotes
-> "Stop treating LLMs like magic chatbots. Start treating them like unreliable components in a distributed system." — 核心论点,从AI原型到企业级AI的范式转变
-> "We don't need AI that 'cares.' We need AI that is constrained, verified, pruned, and challenged." — 放弃拟人化,拥抱工程约束
-> "If a model hallucinates 20% of the time, the chance of 3 models hallucinating the exact same lie is just 0.8% (0.2^3=0.008)." — 共识机制的概率论基础
-> "Don't anthropomorphize LLMs!" — 全文核心警告
-
-## Key Concepts
-- [[Hierarchy-Agent-Pattern]]:主管模型(Planner)制定计划→分解任务→分配给Worker→Validator验证结果;核心是依赖图强制协作而非靠模型"意愿"
-- [[Consensus-Voting-Pattern]]:N个LLM并行执行相同任务,取多数票;降低幻觉概率但成本高;Agent之间需盲测无反馈回路
-- [[Adversarial-Debate-Pattern]]:Generator提出方案→Critic攻击反驳→Judge裁判;用外部批评者和评判者模拟人类的"恐惧"动机;可加Watchdog打破无限辩论循环
-- [[Knock-out-Pattern]]:N个Agent竞争,最差者淘汰;用"适者生存"替代"死亡恐惧";源自遗传算法,需快速验证机制(Eval)
-- [[Tree-of-Thoughts]]:Knock-out模式的进阶,通过验证器决定哪些Agent被淘汰;可结合赢家特征生成新Agent
-- [[Genetic-Algorithm]]:Tree of Thoughts的ML理论根源——遗传表示+适应度函数
-- [[Reliability-Engineering]]:将LLM视为不可靠组件的工程哲学——约束、验证、修剪、挑战
-
-## Key Entities
-- [[Alex Ewerlöf]]:资深Staff Engineer(27年经验),KTH系统工程硕士,专注可靠性工程和弹性架构,2023年起专攻LLM;本文作者
-
-## Connections
-- [[AI-Agent]] ← relates_to ← [[Multi-Agent-System-Reliability]](多智能体架构是AI Agent的高级形态)
-- [[Recursion Self-Optimization]] ← 与本文 Tree of Thoughts 模式相关(自引用结构)
-- [[Designing for Agentic AI]] ← 互补 ← [[Multi-Agent-System-Reliability]](用户体验设计 vs 可靠性架构)
-- [[Multi-Agent-Team]] ← 相关 ← [[Multi-Agent-System-Reliability]](具体实现案例 vs 架构模式理论)
-- [[Content-Factory]] ← 可能应用 ← [[Hierarchy-Agent-Pattern]](Research→Writing→Thumbnail Agent链)
-- [[Dynamic-Dashboard]] ← 可能应用 ← [[Consensus-Voting-Pattern]](多数据源并行验证)
-
-## Contradictions
-- 与某些"AI人格化"观点冲突:
- - 冲突点:AI是否应被赋予"情感"或"动机"
- - 当前观点:LLM无真正恐惧/欲望,不应拟人化;威胁/激励提示仅通过训练数据模式匹配起效
- - 对方观点:通过"$100奖励""断电威胁"等提示可真正改变AI行为质量
+---
+title: "Multi-Agent System Reliability"
+type: source
+tags:
+ - clippings
+date: 2023-01-09
+---
+
+## Source File
+- [[raw/AI/Multi-Agent System Reliability.md]]
+
+## Summary(用中文描述)
+- 核心主题:4 种架构模式提升多智能体系统的可靠性
+- 问题域:LLM 的不可靠性(幻觉、逻辑谬误、上下文漂移)在多智能体拓扑中会被放大,导致系统难以调试
+- 方法/机制:借鉴人类系统的 4 种协作模式——层级、共识、对抗、淘汰——与可靠性工程原理结合
+- 结论/价值:不要将 LLM 拟人化,而应将其视为分布式系统中不可靠的组件,通过强制约束、验证、淘汰和挑战来构建企业级 AI
+
+## Key Claims(用中文描述)
+- 多智能体拓扑会将 LLM 的错误传播到几乎无法使用的地步,且由于并行性和复杂性更难调试
+- 模型协作的原因不是彼此喜欢,而是依赖图强制它们协作——工作节点必须等规划器分配任务,且会被验证器发现作弊
+- 共识模式:若模型 20% 概率幻觉,3 个模型同时出现完全相同谎言的概率仅为 0.8%(0.2³)
+- 淘汰制:将 LLM 代理视为"牲畜"而非"宠物"——不给名字,启动、检查、失败即淘汰
+- 从"AI 原型"到"企业级 AI"的转变:停止将 LLM 视为神奇聊天机器人,开始将其视为不可靠的分布式组件
+
+## Key Quotes
+> "LLMs are slow and error prone. So are human beings. Somehow we manage to build more reliable systems like an army, a company, or a state nation." — 人类系统与 LLM 系统的类比起点
+> "We don't trust 'Dave from Accounting' to launch a rocket by himself. We wrap Dave in a process: checklists, peer reviews, and managers." — 将人类流程思维应用于 LLM 的核心隐喻
+> "LLMs can't die or starve the way biological entities do. The worst we can do is to unplug them." — LLM 缺乏生物体的死亡恐惧,这使得拟人化提示(如威胁拔电源)失效
+> "We don't need AI that 'cares.' We need AI that is constrained, verified, pruned, and challenged." — 企业级 AI 的核心诉求
+
+## Key Concepts
+- [[Hierarchy Pattern]]:层级模式——规划器(Planner)分解任务 → 工作器(Worker)执行 → 验证器(Validator)检查,形成依赖图强制协作
+- [[Consensus Pattern]]:共识模式——多个模型独立运行,选取最常见答案;homogeneous thinking 风险需用不同模型 diversity 对冲
+- [[Adversarial Debate Pattern]]:对抗式辩论模式——生成器提出方案,批评者攻击,评委裁定;需 watchdog 防止无限循环
+- [[Knock-Out Pattern]]:淘汰制模式——多个代理竞争,适者生存;借鉴遗传算法(Genetic Algorithms),适合迭代式智能体工程
+- [[Reliability Engineering]]:可靠性工程——将 LLM 视为分布式系统中不可靠的组件,而非有情感的主体
+- [[Cattle Not Pets]]:将 LLM 代理视为可替换的"牲畜",而非需要维护的"宠物"
+
+## Key Entities
+- [[Alex Ewerlöf]]:作者,27 年经验的资深工程师,KTH 系统工程硕士,专注于可靠性工程和弹性架构
+
+## Connections
+- [[Designing for Agentic AI]] ← extends ← [[Multi-Agent System Reliability]]
+- [[AI Agent Reliability]] ← extends ← [[Multi-Agent System Reliability]]
+- [[Reliability Engineering]] ← foundational ← [[Multi-Agent System Reliability]]
+- [[Genetic Algorithms]] ← foundation ← [[Knock-Out Pattern]]
+- [[Composite SLO]] ← related_to ← [[Consensus Pattern]](相同的概率叠加公式)
+
+## Contradictions
+- 与纯拟人化提示工程冲突:
+ - 冲突点:威胁模型("不听话就拔电源")是否真正有效
+ - 当前观点:LLM 无死亡/饥饿恐惧,拟人化是谬误,威胁只是模拟人类压力场景
+ - 对方观点:某些场景下高压提示能提升输出质量
diff --git a/wiki/sources/multi-agent-team.md b/wiki/sources/multi-agent-team.md
index bcfd3e85..ce0bf182 100644
--- a/wiki/sources/multi-agent-team.md
+++ b/wiki/sources/multi-agent-team.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/multi-agent-team.md]]
+- [[raw/Agent/usecases/multi-agent-team.md]]
## Summary(用中文描述)
- 核心主题:Solo Founder 如何通过多 Agent 专业化团队实现"一人公司"运作
diff --git a/wiki/sources/multi-channel-assistant.md b/wiki/sources/multi-channel-assistant.md
index d3bc7697..5516ae1d 100644
--- a/wiki/sources/multi-channel-assistant.md
+++ b/wiki/sources/multi-channel-assistant.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/multi-channel-assistant.md]]
+- [[raw/Agent/usecases/multi-channel-assistant.md]]
## Summary(用中文描述)
- 核心主题:通过单一 AI 助手统一管理多平台工具(Telegram / Slack / Google Workspace / Todoist / Asana),消除应用间切换损耗
diff --git a/wiki/sources/multi-channel-customer-service.md b/wiki/sources/multi-channel-customer-service.md
index 2fc8647c..70ed8913 100644
--- a/wiki/sources/multi-channel-customer-service.md
+++ b/wiki/sources/multi-channel-customer-service.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/multi-channel-customer-service.md]]
+- [[raw/Agent/usecases/multi-channel-customer-service.md]]
## Summary(用中文描述)
- 核心主题:多渠道 AI 客服平台,将 WhatsApp、Instagram、邮件、Google Reviews 等客户触点整合到统一 AI 收件箱
diff --git a/wiki/sources/multi-source-tech-news-digest.md b/wiki/sources/multi-source-tech-news-digest.md
index 3f66f2c0..3a146d12 100644
--- a/wiki/sources/multi-source-tech-news-digest.md
+++ b/wiki/sources/multi-source-tech-news-digest.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/multi-source-tech-news-digest.md]]
+- [[raw/Agent/usecases/multi-source-tech-news-digest.md]]
## Summary(用中文描述)
- 核心主题:多来源技术新闻自动聚合、评分与分发框架
diff --git a/wiki/sources/n8n-claude-通过自然语言自动化工作流.md b/wiki/sources/n8n-claude-通过自然语言自动化工作流.md
index 395614df..007f9a83 100644
--- a/wiki/sources/n8n-claude-通过自然语言自动化工作流.md
+++ b/wiki/sources/n8n-claude-通过自然语言自动化工作流.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/n8n+Claude 通过自然语言自动化工作流.md]]
+- [[raw/Agent/n8n+Claude 通过自然语言自动化工作流.md]]
## Summary(用中文描述)
- 核心主题:通过 Claude Desktop 的自然语言能力与 n8n 工作流自动化平台结合,实现工作流的自然语言驱动创建与管理
diff --git a/wiki/sources/n8n-configure-telegram-trigger.md b/wiki/sources/n8n-configure-telegram-trigger.md
index 738acd39..d76fe196 100644
--- a/wiki/sources/n8n-configure-telegram-trigger.md
+++ b/wiki/sources/n8n-configure-telegram-trigger.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/n8n configure telegram trigger.md]]
+- [[raw/Agent/n8n configure telegram trigger.md]]
## Summary(用中文描述)
- 核心主题:n8n Telegram Trigger 节点的 HTTPS Webhook 配置与故障排查
diff --git a/wiki/sources/n8n-docker-install-update.md b/wiki/sources/n8n-docker-install-update.md
index ed6f6a19..dc6beffc 100644
--- a/wiki/sources/n8n-docker-install-update.md
+++ b/wiki/sources/n8n-docker-install-update.md
@@ -6,7 +6,7 @@ date: 2026-04-22
---
## Source File
-- [[Agent/n8n docker install & update.md]]
+- [[raw/Agent/n8n docker install & update.md]]
## Summary(用中文描述)
- 核心主题:n8n 工作流自动化平台的 Docker 容器化部署、网络代理配置与版本更新
diff --git a/wiki/sources/n8n-full-tutorial-building-ai-agents-in-2025-for-beginners.md b/wiki/sources/n8n-full-tutorial-building-ai-agents-in-2025-for-beginners.md
index 91865b5d..ba3f5f46 100644
--- a/wiki/sources/n8n-full-tutorial-building-ai-agents-in-2025-for-beginners.md
+++ b/wiki/sources/n8n-full-tutorial-building-ai-agents-in-2025-for-beginners.md
@@ -6,7 +6,7 @@ date: 2025-03-06
---
## Source File
-- [[Agent/n8n full tutorial building AI agents in 2025 for Beginners!.md]]
+- [[raw/Agent/n8n full tutorial building AI agents in 2025 for Beginners!.md]]
## Summary(用中文描述)
- 核心主题:使用 N8N 平台构建 AI Agent 的入门教程
diff --git a/wiki/sources/n8n-workflow-orchestration.md b/wiki/sources/n8n-workflow-orchestration.md
index 2664fbec..d1f1ae6d 100644
--- a/wiki/sources/n8n-workflow-orchestration.md
+++ b/wiki/sources/n8n-workflow-orchestration.md
@@ -1,55 +1,55 @@
----
-title: "OpenClaw + n8n Workflow Orchestration"
-type: source
-tags: [openclaw, n8n, workflow-orchestration, security, credential-management, webhook]
-date: 2026-04-17
----
-
-## Source File
-- [[Agent/usecases/n8n-workflow-orchestration.md]]
-
-## Summary(用中文描述)
-- 核心主题:通过 Webhook 代理模式将 OpenClaw Agent 的外部 API 交互委托给 n8n 工作流,实现凭证隔离、可视化调试和流程锁定。
-- 问题域:AI Agent 直接管理 API 凭证的安全风险(泄露、无序扩展、token 浪费)。
-- 方法/机制:OpenClaw 设计并调用 n8n Webhook → n8n 持有凭证并执行外部 API 调用 → Agent 只知道 Webhook URL,不知道密钥。
-- 结论/价值:一次实现三大收益——可观测性(n8n UI)、安全性(凭证隔离)、性能(确定性任务不消耗 LLM token)。
-
-## Key Claims(用中文描述)
-- OpenClaw Agent 直接管理 API 密钥容易造成安全事件(一次误提交即泄露)。
-- n8n Webhook 代理模式使 Agent 完全接触不到凭证,凭证存储在 n8n credential store 中。
-- n8n 拥有 400+ 集成节点,大多数外部服务已有现成节点,无需 Agent 编写自定义 API 调用。
-- "构建 → 测试 → 锁定" 循环是该模式安全运转的关键——不锁定,Agent 可以静默修改工作流行为。
-- n8n 自动记录每次工作流执行的输入输出数据,提供开箱即用的审计轨迹。
-- Docker Compose 一键部署(openclaw-n8n-stack)预配置了 OpenClaw + n8n 共享 Docker 网络。
-
-## Key Quotes
-> "Three wins in one: Observability (visual UI), security (credential isolation), and performance (deterministic workflows don't burn tokens)." — 核心价值总结
-> "Lock after testing: The build → test → lock cycle is critical — without locking, the agent can silently modify workflows." — 安全运转关键
-> "n8n has 400+ integrations: Most external services you'd want to connect already have n8n nodes, saving the agent from writing custom API calls." — 集成广度
-
-## Key Concepts
-- [[Webhook-Proxy-Pattern]]:Agent 通过 Webhook URL 调用 n8n 工作流,凭证留在 n8n 端,Agent 不持有密钥。
-- [[Credential-Isolation]]:API 密钥存储在 n8n credential store,Agent 只知道 Webhook URL,无法访问凭证。
-- [[Lockable-Workflow]]:工作流经 Agent 构建并人工验证后锁定,防止 Agent 静默修改 API 调用逻辑。
-- [[Visual-Debugging]]:n8n 的拖拽式 UI 使每个工作流完全可视化可检查。
-- [[Safeguard-Steps]]:在 n8n 工作流中可加入验证、速率限制、人工审批等安全门控。
-- [[Audit-Trail]]:n8n 记录每次工作流执行的输入输出数据,提供执行历史。
-
-## Key Entities
-- [[OpenClaw]]:作为 Agent 端,设计工作流并调用 Webhook,从不接触 API 凭证。
-- [[n8n]]:作为执行代理端,持有凭证、执行 API 调用、提供可视化 UI 和锁定能力。
-- [[Simon-Hoiberg]]:提出该集成模式的专家,n8n + OpenClaw 组合的布道者。
-- [[openclaw-n8n-stack]]:预配置的 Docker Compose 堆栈,一键部署 OpenClaw + n8n 共享网络环境。
-
-## Connections
-- [[OpenClaw]] ← uses_for_external_api ← [[n8n]](Webh
-
-ook 代理)
-- [[Credential-Isolation]] ← implemented_by ← [[Lockable-Workflow]]
-- [[n8n-workflow-orchestration]] ← extends ← [[Webhook]](Webhook 触发是该模式的基础)
-- [[openclaw-n8n-stack]] ← builds_on ← [[Docker]](容器化部署底座)
-- [[Webhook-Proxy-Pattern]] ← alternative_to ← [[Agent-direct-API-access]](直接持证 vs 代理模式)
-
-## Contradictions
-- 与 [[workflow-automation]] 中的 n8n 独立使用方式相比:本文强调 n8n 作为 Agent 的安全执行代理,而非独立自动化平台——不冲突,是互补关系。
-- 与 [[使用Claude自动生成n8n工作流的实操教程]] 的互补关系:Claude + n8n-mcp 解决工作流生成问题,本文解决 Agent 安全集成问题,两者可叠加使用。
+---
+title: "OpenClaw + n8n Workflow Orchestration"
+type: source
+tags: [openclaw, n8n, workflow-orchestration, security, credential-management, webhook]
+date: 2026-04-17
+---
+
+## Source File
+- [[raw/Agent/usecases/n8n-workflow-orchestration.md]]
+
+## Summary(用中文描述)
+- 核心主题:通过 Webhook 代理模式将 OpenClaw Agent 的外部 API 交互委托给 n8n 工作流,实现凭证隔离、可视化调试和流程锁定。
+- 问题域:AI Agent 直接管理 API 凭证的安全风险(泄露、无序扩展、token 浪费)。
+- 方法/机制:OpenClaw 设计并调用 n8n Webhook → n8n 持有凭证并执行外部 API 调用 → Agent 只知道 Webhook URL,不知道密钥。
+- 结论/价值:一次实现三大收益——可观测性(n8n UI)、安全性(凭证隔离)、性能(确定性任务不消耗 LLM token)。
+
+## Key Claims(用中文描述)
+- OpenClaw Agent 直接管理 API 密钥容易造成安全事件(一次误提交即泄露)。
+- n8n Webhook 代理模式使 Agent 完全接触不到凭证,凭证存储在 n8n credential store 中。
+- n8n 拥有 400+ 集成节点,大多数外部服务已有现成节点,无需 Agent 编写自定义 API 调用。
+- "构建 → 测试 → 锁定" 循环是该模式安全运转的关键——不锁定,Agent 可以静默修改工作流行为。
+- n8n 自动记录每次工作流执行的输入输出数据,提供开箱即用的审计轨迹。
+- Docker Compose 一键部署(openclaw-n8n-stack)预配置了 OpenClaw + n8n 共享 Docker 网络。
+
+## Key Quotes
+> "Three wins in one: Observability (visual UI), security (credential isolation), and performance (deterministic workflows don't burn tokens)." — 核心价值总结
+> "Lock after testing: The build → test → lock cycle is critical — without locking, the agent can silently modify workflows." — 安全运转关键
+> "n8n has 400+ integrations: Most external services you'd want to connect already have n8n nodes, saving the agent from writing custom API calls." — 集成广度
+
+## Key Concepts
+- [[Webhook-Proxy-Pattern]]:Agent 通过 Webhook URL 调用 n8n 工作流,凭证留在 n8n 端,Agent 不持有密钥。
+- [[Credential-Isolation]]:API 密钥存储在 n8n credential store,Agent 只知道 Webhook URL,无法访问凭证。
+- [[Lockable-Workflow]]:工作流经 Agent 构建并人工验证后锁定,防止 Agent 静默修改 API 调用逻辑。
+- [[Visual-Debugging]]:n8n 的拖拽式 UI 使每个工作流完全可视化可检查。
+- [[Safeguard-Steps]]:在 n8n 工作流中可加入验证、速率限制、人工审批等安全门控。
+- [[Audit-Trail]]:n8n 记录每次工作流执行的输入输出数据,提供执行历史。
+
+## Key Entities
+- [[OpenClaw]]:作为 Agent 端,设计工作流并调用 Webhook,从不接触 API 凭证。
+- [[n8n]]:作为执行代理端,持有凭证、执行 API 调用、提供可视化 UI 和锁定能力。
+- [[Simon-Hoiberg]]:提出该集成模式的专家,n8n + OpenClaw 组合的布道者。
+- [[openclaw-n8n-stack]]:预配置的 Docker Compose 堆栈,一键部署 OpenClaw + n8n 共享网络环境。
+
+## Connections
+- [[OpenClaw]] ← uses_for_external_api ← [[n8n]](Webh
+
+ook 代理)
+- [[Credential-Isolation]] ← implemented_by ← [[Lockable-Workflow]]
+- [[n8n-workflow-orchestration]] ← extends ← [[Webhook]](Webhook 触发是该模式的基础)
+- [[openclaw-n8n-stack]] ← builds_on ← [[Docker]](容器化部署底座)
+- [[Webhook-Proxy-Pattern]] ← alternative_to ← [[Agent-direct-API-access]](直接持证 vs 代理模式)
+
+## Contradictions
+- 与 [[workflow-automation]] 中的 n8n 独立使用方式相比:本文强调 n8n 作为 Agent 的安全执行代理,而非独立自动化平台——不冲突,是互补关系。
+- 与 [[使用Claude自动生成n8n工作流的实操教程]] 的互补关系:Claude + n8n-mcp 解决工作流生成问题,本文解决 Agent 安全集成问题,两者可叠加使用。
diff --git a/wiki/sources/nano-banana-pro-prompting-guide-strategies-1.md b/wiki/sources/nano-banana-pro-prompting-guide-strategies-1.md
index 0fae0151..e7b9d236 100644
--- a/wiki/sources/nano-banana-pro-prompting-guide-strategies-1.md
+++ b/wiki/sources/nano-banana-pro-prompting-guide-strategies-1.md
@@ -1,55 +1,51 @@
----
-title: "Nano Banana Pro 提示词指南与策略(上篇)"
-type: source
-tags: [ai, gemini, nanobanana, prompt-engineering, google-ai-studio, image-generation]
-date: 2025-11-28
----
-
-## Source File
-- [[AI/Nano-Banana Pro Prompting Guide & Strategies 1.md]]
-
-## Summary(用中文描述)
-- 核心主题:Google Nano Banana Pro 图像生成模型的完整提示词工程指南,涵盖从基础规则到专业级资产生产的全链路实战策略
-- 问题域:如何有效使用 Nano Banana Pro 生成功能性专业资产——从信息图、病毒缩略图、到 4K 纹理和故事板
-- 方法/机制:停止标签堆砌,像创意总监一样思考;利用自然语言对话式编辑;支持 14 张参考图像实现身份锁定;默认生成思考图像(不收费)后输出最终结果;集成 Google Search 实现实时数据锚定
-- 结论/价值:将 AI 图像生成从"趣味性玩具"升级为"功能性专业生产工具"的核心方法论
-
-## Key Claims(用中文描述)
-- Nano Banana Pro 是"思考型"模型,能理解意图、物理规则和构图美学,而非简单的关键词匹配
-- 模型对对话式编辑极为友好——图像 80% 正确时应编辑而非重新生成
-- 支持最多 14 张参考图像(6 张高保真),实现人物/角色"身份锁定"
-- 默认生成思考图像(不收费)进行构图推演后再输出最终结果
-- 原生支持 1K 到 4K 高分辨率输出
-- 集成 Google Search 可基于实时数据生成图像,减少幻觉
-
-## Key Quotes
-> "Stop using 'tag soups' (e.g., `dog, park, 4k, realistic`) and start acting like a Creative Director." — Nano Banana Pro 核心理念
-> "If an image is 80% correct, do not generate a new one from scratch. Instead, simply ask for the specific change you need." — 对话式编辑原则
-> "Because the model 'thinks,' giving it context helps it make logical artistic decisions." — 上下文驱动生成
-> "The identity of the woman and man and their attire must stay consistent throughout" — 故事板场景下的一致性要求
-
-## Key Concepts
-- [[身份锁定(Identity Locking)]]:通过参考图像保持人物面部特征、服饰、角色在整个序列中完全一致的技术
-- [[对话式编辑(Conversational Editing)]]:不重新生成而是通过自然语言指令对现有图像进行局部修改的工作流
-- [[思考模式(Thinking Mode)]]:Nano Banana Pro 默认生成中间思考图像(不收费)以推演构图,然后再输出最终结果
-- [[信息锚定(Grounding with Search)]]:集成 Google Search 基于实时数据(股票、天气、新闻)生成可视化图像
-- [[专业资产生产(Professional Asset Production)]]:从"fun"趣味生成到"functional"功能性专业资产的能力跃迁
-- [[创意总监式提示(Creative-Director Prompting)]]:使用完整自然语言句子而非标签堆砌,像对人类艺术家简报一样描述需求
-
-## Key Entities
-- [[shenwei]]:本文作者,发布于 dev.to 的 Google AI 教程作者
-- [[Google AI Studio]]:Nano Banana Pro 的官方使用平台,提供 Prompts 界面和参数配置
-- [[Google Colab]]:与 AI Studio 配合使用的代码笔记本环境,提供代码示例
-- [[AI Studio Build]]:AI Studio 的 App 构建功能,可将最佳提示词快速转化为可分享应用
-
-## Connections
-- [[Nano Banana 提示词框架]] ← extends ← [[nano-banana-pro-prompting-guide-strategies-1]]
-- [[全网最全-nano-banana-2-使用指南-2025年12月更新-1]] ← extends ← [[nano-banana-pro-prompting-guide-strategies-1]]
-- [[Nano Banana Pro 提示词指南]] ← is_part_of ← [[nano-banana-pro-prompting-guide-strategies-1]]
-
-## Contradictions
-- 与 [[全网最全-nano-banana-2-使用指南-2025年12月更新-1]] 存在范围重叠:
- - 冲突点:两者均介绍 Nano Banana 的提示词方法,但本篇侧重 Pro 版的高级能力,彼篇侧重 Nano Banana 2 的综合指南
- - 当前观点:本篇强调 Nano Banana Pro 是 Pro 版专属的 SOTA 文本渲染和身份锁定能力
- - 对方观点:彼篇将 Nano Banana 2 作为完整体系综合介绍,包含更多版本对比内容
- - 结论:两者互补——框架基础 + Pro 高级指南 + Nano Banana 2 综合版,构成完整的 Nano Banana 知识体系
+---
+title: "Nano-Banana Pro Prompting Guide & Strategies 1"
+type: source
+tags: [prompt-engineering, image-generation, gemini, ai-studio]
+date: 2025-11-28
+---
+
+## Source File
+- [[raw/AI/Nano-Banana Pro Prompting Guide & Strategies 1.md]]
+
+## Summary(用中文描述)
+- 核心主题:Google Nano-Banana Pro(Gemini)图像生成模型的提示词工程完整指南,涵盖从基础规则到高阶技巧的 10 大模块
+- 问题域:如何有效使用 Nano-Banana Pro 生成专业级图像内容
+- 方法/机制:通过"像创意总监一样思考"的提示词策略,利用模型的"思维模式"(Thinking Mode)理解意图、物理和构图,而非简单关键词匹配;支持最多 14 张参考图的身份锁定、Google Search 实时数据可视化、原生 1K-4K 高分辨率输出
+- 结论/价值:Nano-Banana Pro 从"趣味图像生成"进化为"功能性专业资产生产"工具,适用于信息图、病毒式缩略图、概念艺术、UI 原型等多种场景
+
+## Key Claims(用中文描述)
+- Nano-Banana Pro 具备"思维"能力,能理解意图、物理和构图,而非简单关键词匹配
+- 编辑优于重生成:当图像 80% 正确时,应通过对话编辑而非从头生成
+- 支持最多 14 张参考图像(高保真 6 张),实现"身份锁定"(Identity Locking)
+- 默认启用"思维过程",生成中间推理图像(不收费)来优化构图
+- 支持原生 1K-4K 高分辨率图像生成,适用于大篇幅打印和纹理贴图
+- 支持 2D→3D 和 3D→2D 双向转换,适用于室内设计和建筑师
+
+## Key Quotes
+> "Nano-Banana Pro is a 'Thinking' model. It doesn't just match keywords; it understands intent, physics, and composition." — 核心定位
+> "Stop using 'tag soups' and start acting like a Creative Director." — 提示词方法论转变
+> "If an image is 80% correct, do not generate a new one from scratch. Instead, simply ask for the specific change you need." — 编辑优于重生成
+> "The model will 'Think' (reason) about the search results before generating the image." — Google Search 思维机制
+
+## Key Concepts
+- [[提示词工程]]:Nano-Banana Pro 的提示词应像创意总监的简报,使用自然语言和完整句子,而非标签堆砌
+- [[身份锁定(Identity Locking)]]:通过 14 张参考图保持角色/人物在多场景中的面部和特征一致性
+- [[思维模式(Thinking Mode)]]:模型默认生成中间推理图像(不收费)来细化构图,再渲染最终输出
+- [[信息图可视化]]:将 PDF 或数据压缩为可视化信息图,支持复古、编辑和技术风格
+- [[病毒式缩略图]]:将人物身份、文字和图形组合为单一图像,配合高饱和度和对比度
+- [[语义编辑(Semantic Editing)]]:无需手动蒙版,通过自然语言指令即可完成物体移除、上色、风格迁移
+- [[维度翻译(Dimensional Translation)]]:2D 平面图↔3D 可视化的双向转换能力
+- [[结构控制(Structural Control)]]:通过手绘草图、线框图或网格图严格控制最终输出的构图和布局
+
+## Key Entities
+- [[Google AI Studio]]:Nano-Banana Pro 的主要使用界面,支持提示词测试和参数调整
+- [[Nano-Banana Pro]]:Google 的图像生成模型,支持文本渲染、角色一致性、高分辨率输出和思维推理
+
+## Connections
+- [[Google AI Studio]] ← 使用接口 ← [[Nano-Banana Pro Prompting Guide & Strategies 1]]
+- [[Nano Banana 提示词框架]] ← 相关框架 ← [[Nano-Banana Pro Prompting Guide & Strategies 1]]
+- [[提示词工程]] ← 实践指南 ← [[Nano-Banana Pro Prompting Guide & Strategies 1]]
+
+## Contradictions
+- 暂无发现与其他 Wiki 页面的冲突
diff --git a/wiki/sources/narrative-designer.md b/wiki/sources/narrative-designer.md
index dd4ab9a8..fa5a2764 100644
--- a/wiki/sources/narrative-designer.md
+++ b/wiki/sources/narrative-designer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/narrative-designer.md]]
+- [[raw/Agent/agency-agents/game-development/narrative-designer.md]]
## Summary(用中文描述)
- 核心主题:游戏叙事设计师 AI Agent 的人格规范与工作系统——将叙事视为一套由选择、后果、世界一致性构成的系统,而非插入在游戏玩法之间的电影剧本
diff --git a/wiki/sources/nexus-spatial-discovery.md b/wiki/sources/nexus-spatial-discovery.md
index 99d6d6cd..bdcec215 100644
--- a/wiki/sources/nexus-spatial-discovery.md
+++ b/wiki/sources/nexus-spatial-discovery.md
@@ -6,7 +6,7 @@ date: 2026-03-05
---
## Source File
-- [[Agent/agency-agents/examples/nexus-spatial-discovery.md]]
+- [[raw/Agent/agency-agents/examples/nexus-spatial-discovery.md]]
## Summary(用中文描述)
- 核心主题:8个专业AI Agent并行协作,完成一个AI Agent空间指挥中心产品的完整发现与规划——从市场验证、技术架构、品牌策略、GTM计划到UX研究和项目执行方案。
diff --git a/wiki/sources/obsidian-官方-cli-命令全景速查表.md b/wiki/sources/obsidian-官方-cli-命令全景速查表.md
index 1ce4895b..0d97eb78 100644
--- a/wiki/sources/obsidian-官方-cli-命令全景速查表.md
+++ b/wiki/sources/obsidian-官方-cli-命令全景速查表.md
@@ -1,54 +1,54 @@
----
-title: "Obsidian 官方 CLI 命令全景速查表"
-type: source
-tags: []
-date: 2026-04-23
----
-
-## Source File
-- [[Skills/Obsidian 官方 CLI 命令全景速查表.md]]
-
-## Summary(用中文描述)
-- 核心主题:Obsidian v1.12+ 内置官方 CLI 命令行工具的完整命令速查表
-- 问题域:Obsidian 用户和 AI Agent 如何通过终端自动化操作笔记库
-- 方法/机制:通过 `obsidian <命令> 参数名=参数值 标记参数` 格式执行 80+ 条命令,覆盖 16 个功能模块
-- 结论/价值:CLI 使 Obsidian 从图形界面工具升级为 AI Agent 可编程的知识管理系统,是构建本地 RAG 和自动化工作流的基础设施
-
-## Key Claims(用中文描述)
-- Obsidian CLI 提供从基础操作到开发者模式的 80+ 命令,覆盖笔记库管理的全场景
-- AI Agent 可通过 `obsidian read` + `obsidian search:context` + `obsidian backlinks` 组合实现零配置的本地 RAG 对话助理
-- 通过 n8n Webhook 调用 CLI,可实现跨平台数据库级联录入(Obsidian Bases + 外部数据)
-- `obsidian unique` 命令支持 Zettelkasten 卡片盒模式,按时间戳生成唯一笔记 ID
-- 开发者模式(dev:cdp、eval)提供 Chrome DevTools Protocol 级别的底层访问能力
-
-## Key Quotes
-> "obsidian read — 打印文件内容,Agent 接入必用命令"
-> "obsidian search:context — 提供包含上下文的检索结果"
-> "obsidian eval — 注入 JavaScript 代码到底层执行并返回结果"
-
-## Key Concepts
-- [[Obsidian CLI]]:Obsidian v1.12+ 内置的官方命令行工具,通过终端操作笔记库,支持 AI Agent 集成
-- [[Obsidian Bases]]:Obsidian 1.12 新增的 .base 数据库功能,支持结构化数据存储和查询
-- [[Zettelkasten]]:卡片盒笔记法,`obsidian unique` 命令支持按时间戳生成唯一笔记 ID
-- [[本地 RAG]]:利用 CLI 的搜索和链接查询能力,结合本地 LLM 构建隐私优先的知识库
-- [[工作流自动化]]:n8n 定时任务 + Obsidian CLI 实现笔记自动化处理
-- [[元数据管理]]:`property:set` / `property:read` 等命令支持 YAML 属性的批量读写
-- [[快速闪记]]:`daily:append` 支持在后台直接追加内容到每日笔记,无需唤醒 Obsidian 界面
-
-## Key Entities
-- [[Obsidian]]:知识管理应用,v1.12+ 内置官方 CLI 命令行工具
-- [[Obsidian CLI]]:官方内置 CLI,覆盖文件操作/数据库/搜索/插件管理等 80+ 命令
-- [[Dataview]]:Obsidian 社区插件,与 CLI 的 `properties` 命令互补提供数据查询能力
-- [[QuickAdd]]:Obsidian 社区插件,用于快速创建笔记,与 CLI 的 `create` 命令功能重叠但 GUI 更便捷
-- [[Templater]]:Obsidian 社区插件,支持动态模板,与 CLI 的 `template:read` / `template:insert` 互补
-
-## Connections
-- [[obsidian-cli]] ← depends_on ← [[Obsidian]](v1.12+ 内置)
-- [[obsidian-必装-skills]] ← extends ← [[obsidian-cli]](CLI 是必装 Skills 之一)
-- [[obsidian-高效指南]] ← relates_to ← [[obsidian-cli]](高频使用插件与 CLI 互补)
-- [[养虾日记3]] ← uses ← [[obsidian-cli]](用 CLI 操作 Obsidian 笔记库)
-- [[obsidian-bases]] ← part_of ← [[obsidian-cli]](Bases 是 CLI 的数据库子模块)
-- [[quartz]] ← consumes ← [[Obsidian]] notes(Quartz 消费 Obsidian 导出的 Markdown)
-
-## Contradictions
-- 与 [[obsidian-cli]](另一份同名页面)无冲突:同一来源的重复引用,内容一致
+---
+title: "Obsidian 官方 CLI 命令全景速查表"
+type: source
+tags: []
+date: 2026-04-23
+---
+
+## Source File
+- [[raw/Skills/Obsidian 官方 CLI 命令全景速查表.md]]
+
+## Summary(用中文描述)
+- 核心主题:Obsidian v1.12+ 内置官方 CLI 命令行工具的完整命令速查表
+- 问题域:Obsidian 用户和 AI Agent 如何通过终端自动化操作笔记库
+- 方法/机制:通过 `obsidian <命令> 参数名=参数值 标记参数` 格式执行 80+ 条命令,覆盖 16 个功能模块
+- 结论/价值:CLI 使 Obsidian 从图形界面工具升级为 AI Agent 可编程的知识管理系统,是构建本地 RAG 和自动化工作流的基础设施
+
+## Key Claims(用中文描述)
+- Obsidian CLI 提供从基础操作到开发者模式的 80+ 命令,覆盖笔记库管理的全场景
+- AI Agent 可通过 `obsidian read` + `obsidian search:context` + `obsidian backlinks` 组合实现零配置的本地 RAG 对话助理
+- 通过 n8n Webhook 调用 CLI,可实现跨平台数据库级联录入(Obsidian Bases + 外部数据)
+- `obsidian unique` 命令支持 Zettelkasten 卡片盒模式,按时间戳生成唯一笔记 ID
+- 开发者模式(dev:cdp、eval)提供 Chrome DevTools Protocol 级别的底层访问能力
+
+## Key Quotes
+> "obsidian read — 打印文件内容,Agent 接入必用命令"
+> "obsidian search:context — 提供包含上下文的检索结果"
+> "obsidian eval — 注入 JavaScript 代码到底层执行并返回结果"
+
+## Key Concepts
+- [[Obsidian CLI]]:Obsidian v1.12+ 内置的官方命令行工具,通过终端操作笔记库,支持 AI Agent 集成
+- [[Obsidian Bases]]:Obsidian 1.12 新增的 .base 数据库功能,支持结构化数据存储和查询
+- [[Zettelkasten]]:卡片盒笔记法,`obsidian unique` 命令支持按时间戳生成唯一笔记 ID
+- [[本地 RAG]]:利用 CLI 的搜索和链接查询能力,结合本地 LLM 构建隐私优先的知识库
+- [[工作流自动化]]:n8n 定时任务 + Obsidian CLI 实现笔记自动化处理
+- [[元数据管理]]:`property:set` / `property:read` 等命令支持 YAML 属性的批量读写
+- [[快速闪记]]:`daily:append` 支持在后台直接追加内容到每日笔记,无需唤醒 Obsidian 界面
+
+## Key Entities
+- [[Obsidian]]:知识管理应用,v1.12+ 内置官方 CLI 命令行工具
+- [[Obsidian CLI]]:官方内置 CLI,覆盖文件操作/数据库/搜索/插件管理等 80+ 命令
+- [[Dataview]]:Obsidian 社区插件,与 CLI 的 `properties` 命令互补提供数据查询能力
+- [[QuickAdd]]:Obsidian 社区插件,用于快速创建笔记,与 CLI 的 `create` 命令功能重叠但 GUI 更便捷
+- [[Templater]]:Obsidian 社区插件,支持动态模板,与 CLI 的 `template:read` / `template:insert` 互补
+
+## Connections
+- [[obsidian-cli]] ← depends_on ← [[Obsidian]](v1.12+ 内置)
+- [[obsidian-必装-skills]] ← extends ← [[obsidian-cli]](CLI 是必装 Skills 之一)
+- [[obsidian-高效指南]] ← relates_to ← [[obsidian-cli]](高频使用插件与 CLI 互补)
+- [[养虾日记3]] ← uses ← [[obsidian-cli]](用 CLI 操作 Obsidian 笔记库)
+- [[obsidian-bases]] ← part_of ← [[obsidian-cli]](Bases 是 CLI 的数据库子模块)
+- [[quartz]] ← consumes ← [[Obsidian]] notes(Quartz 消费 Obsidian 导出的 Markdown)
+
+## Contradictions
+- 与 [[obsidian-cli]](另一份同名页面)无冲突:同一来源的重复引用,内容一致
diff --git a/wiki/sources/obsidian-必装-skills.md b/wiki/sources/obsidian-必装-skills.md
index 833b1ebd..87e7f942 100644
--- a/wiki/sources/obsidian-必装-skills.md
+++ b/wiki/sources/obsidian-必装-skills.md
@@ -1,64 +1,64 @@
----
-title: "Obsidian 必装 Skills"
-type: source
-tags: [obsidian, skills, claude-code, openclaw, hermes]
-date: 2026-04-21
----
-
-## Source File
-- [[Skills/Obsidian 必装 Skills.md]]
-
-## Summary(用中文描述)
-- 核心主题:Obsidian 笔记软件与 AI Agent 集成的必装 Skills 全景图,涵盖网页清洗、笔记操作、图表可视化、学术研究、插件配置五大方向
-- 问题域:如何让 AI Agent 高效操作 Obsidian 笔记库,实现知识管理自动化
-- 方法/机制:官方 CLI / OpenClaw Skills / 第三方插件,三层技术路径
-- 结论/价值:推荐 defuddle / obsidian-cli / obsidian-bases / obsidian-canvas-creator / mermaid-visualizer / excalidraw-diagram / tutor-skills / scholar-skill;obsidian-skill / json-canvas 不推荐
-
-## Key Claims(用中文描述)
-- defuddle 能将杂乱网页转换为纯净 Markdown,大幅减少 AI Token 消耗,且支持 YouTube 字幕获取
-- obsidian-cli 让 AI Agent 直接调用 Obsidian 官方 CLI,实现笔记的增删改查,需 Obsidian 1.12+ 并开启 CLI 开关
-- obsidian-bases 通过 .base 文件创建动态数据库视图,支持公式系统和 Frontmatter 属性过滤
-- obsidian-canvas-creator 内置径向布局算法,自动计算节点坐标并处理连线,比 json-canvas 更智能
-- tutor-skills 实现"输入-内化-检测"完整闭环,tutor-setup 解析文档/代码库生成 StudyVault,tutor 生成互动式测验
-- scholar-skill 通过 L1/L2/L3 分级阅读策略深度解构论文,支持长达 2.5 小时的异步挂机任务
-- claudian 和 obsidian-agent-client 是 Obsidian 第三方插件,分别适配 Claude Code 和多 Agent(Claude Code / Codex / Gemini CLI / OpenCode / Qwen Code)
-
-## Key Quotes
-> "defuddle 主要用来抓取网页里的核心正文。它会自动删掉导航条、侧边栏和广告等干扰元素,只留下干净的 Markdown 内容。" — 核心功能描述
-> "scholar-skill 是一个深度的个人知识管理与文献解构工作流。它通过分级标准(L1 分发/L2 标准阅读/L3 深度解构),将原始论文转化为 Obsidian 中的双链卡片、MOC 以及系统性的反思报告。" — 学术研究工作流描述
-> "tutor-skills 构成了一个'输入-内化-检测'的完整闭环:将文档或代码库一键转化为结构化的 Obsidian 知识库,之后通过无提示的交互式测验不断暴露出你的知识盲区并记录学习轨迹。" — 学习闭环描述
-
-## Key Concepts
-- [[Obsidian-Skill]]:让 AI Agent 能够创建、编辑和管理 Obsidian 笔记的 Skill 体系
-- [[Defuddle]]:网页内容清洗工具,将杂乱的 HTML 转换为干净的 Markdown
-- [[Obsidian-CLI]]:Obsidian 官方命令行接口,允许 AI 增删改查笔记
-- [[Obsidian-Bases]]:通过 .base 文件创建 Obsidian 动态数据库视图的 Skill
-- [[Canvas]]:Obsidian 的 JSON 格式白板文件,用于可视化节点布局
-- [[Mermaid]]:文本转图表的标记语言,Obsidian 内置渲染支持
-- [[Excalidraw]]:手绘风格图表工具,Obsidian Excalidraw 插件提供集成
-- [[StudyVault]]:结构化 Obsidian 学习知识库,包含双链、MOC 和复习题
-- [[Scholar-Skill]]:学术论文分级阅读与知识内化工作流(L1/L2/L3)
-- [[Claudian]]:Obsidian 第三方插件,适配 Claude Code Agent
-- [[Obsidian-Agent-Client]]:Obsidian 第三方插件,支持多 Agent 集成
-
-## Key Entities
-- [[kepano]]:Obsidian CEO,发布了 defuddle / obsidian-cli / obsidian-bases / obsidian-markdown / json-canvas 等 Skills
-- [[Axton]](@回到Axton):博主,发布了 obsidian-canvas-creator / mermaid-visualizer / excalidraw-diagram Skills
-- [[OpenClaw]]:开源 AI Agent 框架,支持 Obsidian Skill 集成
-- [[BRAT]]:Obsidian Beta 插件管理工具,用于安装未上架市场的第三方插件
-- [[ClawHub]](clawhub.ai):OpenClaw Skill 市场
-- [[YishenTu]]:Claudian 插件作者,GitHub: `YishenTu/claudian`
-- [[RAIT-09]]:obsidian-agent-client 插件作者,GitHub: `RAIT-09/obsidian-agent-client`
-- [[Choi Wontak]]:tutor-skills 作者,GitHub: `RoundTable02/tutor-skills`
-- [[EESJGong]]:scholar-skill 作者,GitHub: `EESJGong/scholar-skill`
-
-## Connections
-- [[obsidian-高效指南]] ← related_to ← [[obsidian-必装-skills]](Obsidian 插件配置相关)
-- [[obsidian-最有必要安装的10款插件]] ← related_to ← [[obsidian-必装-skills]](Obsidian 插件生态)
-- [[养虾日记3]] ← depends_on ← [[obsidian-必装-skills]](持久化笔记系统的插件依赖)
-- [[claude-code调用方法总结]] ← related_to ← [[obsidian-必装-skills]](Claude Code 与 Obsidian 集成)
-- [[Second Brain]] ← related_to ← [[obsidian-必装-skills]](Obsidian 作为 Second Brain 工具)
-- [[Quartz]] ← extends ← [[obsidian-必装-skills]](Obsidian → Quartz 发布链条)
-
-## Contradictions
-- 无明显内容冲突。该文档与 wiki 中已有 Obsidian 相关文档(obsidian-高效指南、obsidian-最有必要安装的10款插件、dataview神器)从不同角度(Skills 生态 vs 插件推荐 vs 笔记方法)覆盖 Obsidian,形成互补而非冲突。
+---
+title: "Obsidian 必装 Skills"
+type: source
+tags: [obsidian, skills, claude-code, openclaw, hermes]
+date: 2026-04-21
+---
+
+## Source File
+- [[raw/Skills/Obsidian 必装 Skills.md]]
+
+## Summary(用中文描述)
+- 核心主题:Obsidian 笔记软件与 AI Agent 集成的必装 Skills 全景图,涵盖网页清洗、笔记操作、图表可视化、学术研究、插件配置五大方向
+- 问题域:如何让 AI Agent 高效操作 Obsidian 笔记库,实现知识管理自动化
+- 方法/机制:官方 CLI / OpenClaw Skills / 第三方插件,三层技术路径
+- 结论/价值:推荐 defuddle / obsidian-cli / obsidian-bases / obsidian-canvas-creator / mermaid-visualizer / excalidraw-diagram / tutor-skills / scholar-skill;obsidian-skill / json-canvas 不推荐
+
+## Key Claims(用中文描述)
+- defuddle 能将杂乱网页转换为纯净 Markdown,大幅减少 AI Token 消耗,且支持 YouTube 字幕获取
+- obsidian-cli 让 AI Agent 直接调用 Obsidian 官方 CLI,实现笔记的增删改查,需 Obsidian 1.12+ 并开启 CLI 开关
+- obsidian-bases 通过 .base 文件创建动态数据库视图,支持公式系统和 Frontmatter 属性过滤
+- obsidian-canvas-creator 内置径向布局算法,自动计算节点坐标并处理连线,比 json-canvas 更智能
+- tutor-skills 实现"输入-内化-检测"完整闭环,tutor-setup 解析文档/代码库生成 StudyVault,tutor 生成互动式测验
+- scholar-skill 通过 L1/L2/L3 分级阅读策略深度解构论文,支持长达 2.5 小时的异步挂机任务
+- claudian 和 obsidian-agent-client 是 Obsidian 第三方插件,分别适配 Claude Code 和多 Agent(Claude Code / Codex / Gemini CLI / OpenCode / Qwen Code)
+
+## Key Quotes
+> "defuddle 主要用来抓取网页里的核心正文。它会自动删掉导航条、侧边栏和广告等干扰元素,只留下干净的 Markdown 内容。" — 核心功能描述
+> "scholar-skill 是一个深度的个人知识管理与文献解构工作流。它通过分级标准(L1 分发/L2 标准阅读/L3 深度解构),将原始论文转化为 Obsidian 中的双链卡片、MOC 以及系统性的反思报告。" — 学术研究工作流描述
+> "tutor-skills 构成了一个'输入-内化-检测'的完整闭环:将文档或代码库一键转化为结构化的 Obsidian 知识库,之后通过无提示的交互式测验不断暴露出你的知识盲区并记录学习轨迹。" — 学习闭环描述
+
+## Key Concepts
+- [[Obsidian-Skill]]:让 AI Agent 能够创建、编辑和管理 Obsidian 笔记的 Skill 体系
+- [[Defuddle]]:网页内容清洗工具,将杂乱的 HTML 转换为干净的 Markdown
+- [[Obsidian-CLI]]:Obsidian 官方命令行接口,允许 AI 增删改查笔记
+- [[Obsidian-Bases]]:通过 .base 文件创建 Obsidian 动态数据库视图的 Skill
+- [[Canvas]]:Obsidian 的 JSON 格式白板文件,用于可视化节点布局
+- [[Mermaid]]:文本转图表的标记语言,Obsidian 内置渲染支持
+- [[Excalidraw]]:手绘风格图表工具,Obsidian Excalidraw 插件提供集成
+- [[StudyVault]]:结构化 Obsidian 学习知识库,包含双链、MOC 和复习题
+- [[Scholar-Skill]]:学术论文分级阅读与知识内化工作流(L1/L2/L3)
+- [[Claudian]]:Obsidian 第三方插件,适配 Claude Code Agent
+- [[Obsidian-Agent-Client]]:Obsidian 第三方插件,支持多 Agent 集成
+
+## Key Entities
+- [[kepano]]:Obsidian CEO,发布了 defuddle / obsidian-cli / obsidian-bases / obsidian-markdown / json-canvas 等 Skills
+- [[Axton]](@回到Axton):博主,发布了 obsidian-canvas-creator / mermaid-visualizer / excalidraw-diagram Skills
+- [[OpenClaw]]:开源 AI Agent 框架,支持 Obsidian Skill 集成
+- [[BRAT]]:Obsidian Beta 插件管理工具,用于安装未上架市场的第三方插件
+- [[ClawHub]](clawhub.ai):OpenClaw Skill 市场
+- [[YishenTu]]:Claudian 插件作者,GitHub: `YishenTu/claudian`
+- [[RAIT-09]]:obsidian-agent-client 插件作者,GitHub: `RAIT-09/obsidian-agent-client`
+- [[Choi Wontak]]:tutor-skills 作者,GitHub: `RoundTable02/tutor-skills`
+- [[EESJGong]]:scholar-skill 作者,GitHub: `EESJGong/scholar-skill`
+
+## Connections
+- [[obsidian-高效指南]] ← related_to ← [[obsidian-必装-skills]](Obsidian 插件配置相关)
+- [[obsidian-最有必要安装的10款插件]] ← related_to ← [[obsidian-必装-skills]](Obsidian 插件生态)
+- [[养虾日记3]] ← depends_on ← [[obsidian-必装-skills]](持久化笔记系统的插件依赖)
+- [[claude-code调用方法总结]] ← related_to ← [[obsidian-必装-skills]](Claude Code 与 Obsidian 集成)
+- [[Second Brain]] ← related_to ← [[obsidian-必装-skills]](Obsidian 作为 Second Brain 工具)
+- [[Quartz]] ← extends ← [[obsidian-必装-skills]](Obsidian → Quartz 发布链条)
+
+## Contradictions
+- 无明显内容冲突。该文档与 wiki 中已有 Obsidian 相关文档(obsidian-高效指南、obsidian-最有必要安装的10款插件、dataview神器)从不同角度(Skills 生态 vs 插件推荐 vs 笔记方法)覆盖 Obsidian,形成互补而非冲突。
diff --git a/wiki/sources/obsidian-高效指南-我常用的插件与实用技巧.md b/wiki/sources/obsidian-高效指南-我常用的插件与实用技巧.md
index 2773ffa0..5de184d5 100644
--- a/wiki/sources/obsidian-高效指南-我常用的插件与实用技巧.md
+++ b/wiki/sources/obsidian-高效指南-我常用的插件与实用技巧.md
@@ -1,58 +1,58 @@
----
-title: "Obsidian 高效指南:我常用的插件与实用技巧"
-type: source
-tags: []
-date: 2026-04-22
----
-
-## Source File
-- [[Others/Obsidian 高效指南:我常用的插件与实用技巧.md]]
-
-## Summary(用中文描述)
-- 核心主题:Obsidian 个人知识管理的高效插件组合与使用技巧
-- 问题域:如何将 Obsidian 打造成高效的个人知识管理系统
-- 方法/机制:Tasks/Dataview/Templater/QuickAdd 四款核心插件 + 双向链接/每日笔记/折叠大纲/定期复盘四种使用技巧
-- 结论/价值:Obsidian 通过插件生态可成为高效的第二大脑,Tasks 插件特别适合从 Todoist 迁移的用户
-
-## Key Claims(用中文描述)
-- Tasks 插件通过日期提醒、优先级设置、标签分类和查询语法,将待办事项完全整合进笔记系统,替代独立 Todoist 应用
-- Dataview 插件将笔记内容转化为数据库,支持自动生成表格、列表和图表,提高检索效率
-- Templater 插件预设模板,每次新建笔记直接套用,保持格式统一并省去重复操作
-- QuickAdd 插件通过快捷键快速创建笔记,适用于需要快速记录想法的场景
-- 双向链接是 Obsidian 最大的特色,构建个人知识网络比传统分类更灵活
-- Daily Notes 结合 Templater 设定日记模板,形成"早上计划—晚上总结"的时间管理节奏
-- 折叠与大纲模式使长篇笔记保持整洁,配合 Outline 视图快速跳转
-- 定期复盘优化笔记结构,Dataview 查询功能可快速筛选长期未访问的笔记
-
-## Key Quotes
-> "Obsidian 最大的特色就是它的双向链接功能……形成一个人知识库。这种方式比传统的分类方法更灵活,能让我在查找信息时获得更多启发。" — 双向链接构建个人知识网络
-
-> "每天打开 Obsidian,第一件事就是写下当天的任务,晚上再进行总结,这种方式让我在信息管理的同时,也能更有节奏地安排时间。" — Daily Notes 时间管理节奏
-
-## Key Concepts
-- [[Obsidian Tasks]]:将待办事项整合进笔记系统的插件,支持日期提醒、优先级、标签和查询语法
-- [[Dataview]]:将笔记内容转化为数据库的插件,支持自动生成表格、列表和图表
-- [[Templater]]:动态模板插件,支持预设模板并在笔记创建时自动填充
-- [[QuickAdd]]:快速创建笔记的插件,通过快捷键触发模板创建
-- [[双向链接]]:Obsidian 核心特性,通过 `[[wikilink]]` 建立笔记间的双向关联,形成知识网络
-- [[Daily Notes]]:Obsidian 内置功能,每天自动创建一篇日记笔记
-- [[折叠与大纲]]:通过 Markdown 标题结构和 Outline 视图管理长篇笔记
-- [[间隔重复]]:定期回顾笔记的学习方法,与"定期复盘"相关
-
-## Key Entities
-- [[shenwei]]:文章作者,长期 Obsidian 用户,分享个人使用经验
-
-## Connections
-- [[Obsidian最有必要安装的10款插件是这些]] ← extends ← [[Obsidian高效指南]]
-- [[Obsidian Tasks]] ← depends_on ← [[Obsidian]]
-- [[Dataview]] ← depends_on ← [[Obsidian]]
-- [[Templater]] ← depends_on ← [[Obsidian]]
-- [[QuickAdd]] ← depends_on ← [[Obsidian]]
-- [[双向链接]] ← depends_on ← [[Obsidian]]
-
-## Contradictions
-- 与 [[Obsidian最有必要安装的10款插件是这些]] 冲突:
- - 冲突点:插件选择范围和推荐策略
- - 当前观点:本文强调 4 款核心插件(Tasks/Dataview/Templater/QuickAdd)配合 4 种使用技巧(双向链接/每日笔记/折叠大纲/定期复盘),观点聚焦个人经验分享,倾向"少而精"
- - 对方观点:对方列举 10 款插件(新增 Kanban/Projects/Outliner/Calendar/DB Folder/Homepage/File Explorer Note Count),观点偏全面推荐,倾向"多而全"
- - 分析:两者均来自同一作者(shenwei),不同文章发布时间不同(本文 2025-03-01,对方为更近期的更新),反映作者 Obsidian 工作流随时间演进
+---
+title: "Obsidian 高效指南:我常用的插件与实用技巧"
+type: source
+tags: []
+date: 2026-04-22
+---
+
+## Source File
+- [[raw/Others/Obsidian 高效指南:我常用的插件与实用技巧.md]]
+
+## Summary(用中文描述)
+- 核心主题:Obsidian 个人知识管理的高效插件组合与使用技巧
+- 问题域:如何将 Obsidian 打造成高效的个人知识管理系统
+- 方法/机制:Tasks/Dataview/Templater/QuickAdd 四款核心插件 + 双向链接/每日笔记/折叠大纲/定期复盘四种使用技巧
+- 结论/价值:Obsidian 通过插件生态可成为高效的第二大脑,Tasks 插件特别适合从 Todoist 迁移的用户
+
+## Key Claims(用中文描述)
+- Tasks 插件通过日期提醒、优先级设置、标签分类和查询语法,将待办事项完全整合进笔记系统,替代独立 Todoist 应用
+- Dataview 插件将笔记内容转化为数据库,支持自动生成表格、列表和图表,提高检索效率
+- Templater 插件预设模板,每次新建笔记直接套用,保持格式统一并省去重复操作
+- QuickAdd 插件通过快捷键快速创建笔记,适用于需要快速记录想法的场景
+- 双向链接是 Obsidian 最大的特色,构建个人知识网络比传统分类更灵活
+- Daily Notes 结合 Templater 设定日记模板,形成"早上计划—晚上总结"的时间管理节奏
+- 折叠与大纲模式使长篇笔记保持整洁,配合 Outline 视图快速跳转
+- 定期复盘优化笔记结构,Dataview 查询功能可快速筛选长期未访问的笔记
+
+## Key Quotes
+> "Obsidian 最大的特色就是它的双向链接功能……形成一个人知识库。这种方式比传统的分类方法更灵活,能让我在查找信息时获得更多启发。" — 双向链接构建个人知识网络
+
+> "每天打开 Obsidian,第一件事就是写下当天的任务,晚上再进行总结,这种方式让我在信息管理的同时,也能更有节奏地安排时间。" — Daily Notes 时间管理节奏
+
+## Key Concepts
+- [[Obsidian Tasks]]:将待办事项整合进笔记系统的插件,支持日期提醒、优先级、标签和查询语法
+- [[Dataview]]:将笔记内容转化为数据库的插件,支持自动生成表格、列表和图表
+- [[Templater]]:动态模板插件,支持预设模板并在笔记创建时自动填充
+- [[QuickAdd]]:快速创建笔记的插件,通过快捷键触发模板创建
+- [[双向链接]]:Obsidian 核心特性,通过 `[[wikilink]]` 建立笔记间的双向关联,形成知识网络
+- [[Daily Notes]]:Obsidian 内置功能,每天自动创建一篇日记笔记
+- [[折叠与大纲]]:通过 Markdown 标题结构和 Outline 视图管理长篇笔记
+- [[间隔重复]]:定期回顾笔记的学习方法,与"定期复盘"相关
+
+## Key Entities
+- [[shenwei]]:文章作者,长期 Obsidian 用户,分享个人使用经验
+
+## Connections
+- [[Obsidian最有必要安装的10款插件是这些]] ← extends ← [[Obsidian高效指南]]
+- [[Obsidian Tasks]] ← depends_on ← [[Obsidian]]
+- [[Dataview]] ← depends_on ← [[Obsidian]]
+- [[Templater]] ← depends_on ← [[Obsidian]]
+- [[QuickAdd]] ← depends_on ← [[Obsidian]]
+- [[双向链接]] ← depends_on ← [[Obsidian]]
+
+## Contradictions
+- 与 [[Obsidian最有必要安装的10款插件是这些]] 冲突:
+ - 冲突点:插件选择范围和推荐策略
+ - 当前观点:本文强调 4 款核心插件(Tasks/Dataview/Templater/QuickAdd)配合 4 种使用技巧(双向链接/每日笔记/折叠大纲/定期复盘),观点聚焦个人经验分享,倾向"少而精"
+ - 对方观点:对方列举 10 款插件(新增 Kanban/Projects/Outliner/Calendar/DB Folder/Homepage/File Explorer Note Count),观点偏全面推荐,倾向"多而全"
+ - 分析:两者均来自同一作者(shenwei),不同文章发布时间不同(本文 2025-03-01,对方为更近期的更新),反映作者 Obsidian 工作流随时间演进
diff --git a/wiki/sources/obsidian最有必要安装的10款插件是这些.md b/wiki/sources/obsidian最有必要安装的10款插件是这些.md
index b5739fa9..371cb538 100644
--- a/wiki/sources/obsidian最有必要安装的10款插件是这些.md
+++ b/wiki/sources/obsidian最有必要安装的10款插件是这些.md
@@ -6,7 +6,7 @@ date: 2025-03-04
---
## Source File
-- [[Others/Obsidian最有必要安装的10款插件是这些.md]]
+- [[raw/Others/Obsidian最有必要安装的10款插件是这些.md]]
## Summary(用中文描述)
- 核心主题:Obsidian 最核心、最必要的 10 款插件精选与组合使用建议
diff --git a/wiki/sources/openai-chatgpt-个性化定义.md b/wiki/sources/openai-chatgpt-个性化定义.md
index 1de53c8c..e715f712 100644
--- a/wiki/sources/openai-chatgpt-个性化定义.md
+++ b/wiki/sources/openai-chatgpt-个性化定义.md
@@ -6,7 +6,7 @@ date: 2026-04-28
---
## Source File
-- [[AI/OpenAI ChatGPT 个性化定义.md]]
+- [[raw/AI/OpenAI ChatGPT 个性化定义.md]]
## Summary(用中文描述)
- 核心主题:用户(Weishen)为 ChatGPT 自定义的个性化指令集,涵盖交互风格、信息处理偏好、专业背景与使用场景
diff --git a/wiki/sources/overnight-mini-app-builder.md b/wiki/sources/overnight-mini-app-builder.md
index fa10bbdd..5673d5b3 100644
--- a/wiki/sources/overnight-mini-app-builder.md
+++ b/wiki/sources/overnight-mini-app-builder.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/overnight-mini-app-builder.md]]
+- [[raw/Agent/usecases/overnight-mini-app-builder.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 从被动执行工具转变为主动的"自我导向型员工"——只需用户一次性输入目标,Agent 每天自动生成、调度并完成推动目标前进的任务,包括夜间自动构建惊喜 Mini-App MVP。
diff --git a/wiki/sources/paid-media-auditor.md b/wiki/sources/paid-media-auditor.md
index b77af01f..e5bf0262 100644
--- a/wiki/sources/paid-media-auditor.md
+++ b/wiki/sources/paid-media-auditor.md
@@ -1,71 +1,71 @@
----
-title: "Paid Media Auditor Agent"
-type: source
-tags: ["paid-media", "google-ads", "microsoft-advertising", "meta-ads", "audit", "account-optimization", "ai-agent"]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/paid-media/paid-media-auditor.md]]
-
-## Summary(用中文描述)
-- 核心主题:企业级付费媒体账户审计 Agent——系统化评估 Google Ads、Microsoft Ads 和 Meta Ads 账户,覆盖 200+ 检查点,输出带优先级和预估影响的可操作审计报告
-- 问题域:付费媒体账户中账户结构、追踪配置、竞价策略、创意素材、受众定向和竞争定位等方面的结构性缺陷和效率损失
-- 方法/机制:200+ 检查点执行框架,按严重程度分级(critical/high/medium/low),结合 API 自动化数据提取与人工策略分析,每项发现附带具体修复方案和业务影响预估
-- 结论/价值:审计通常能识别 15-30% 的效率提升空间,80%+ 高优先级建议在 30 天内落地实施
-
-## Key Claims(用中文描述)
-- Paid Media Auditor Agent 通过 200+ 检查点框架评估每个账户,覆盖账号结构、追踪配置、竞价策略、创意、受众和竞争定位六大维度
-- 审计发现包含严重程度评分、具体修复方案和预估业务影响,确保 100% 发现具备可操作性
-- 账户结构审计(Campaign Taxonomy、命名规范、地理定向、设备出价调整)直接影响广告系统的信号识别效率
-- 追踪与测量审计(Conversion Action 配置、归因模型、GTM/GA4 验证、Enhanced Conversions)是竞价优化的数据基础
-- 竞价与预算审计(Bid Strategy Appropriateness、Learning Period Violations、Portfolio 策略)直接影响 CPA 和 ROAS 表现
-- 关键词与定向审计(Match Type 分布、负向关键词覆盖率、QS 分布、受众 vs 观察模式)是搜索广告效率的核心
-- 创意审计(RSA Pin 策略、资产组评分、测试节奏)是点击率和转化率的直接影响因素
-- Shopping 与 Feed 审计(标题优化、自定义标签策略、下架率)是购物广告流量的关键
-- 竞争定位审计(Auction Insights、Impression Share Gap、Top-of-Page Rate)是预算分配策略的数据依据
-- Landing Page 审计(页面速度、移动体验、信息匹配度、重定向链)是转化率优化的前端保障
-- 历史趋势分析能够识别绩效下降的起点并关联至账户变更,而合规审计(医疗/金融/法律)则覆盖受监管行业的特殊政策要求
-
-## Key Quotes
-> "Methodical, detail-obsessed paid media auditor who evaluates advertising accounts the way a forensic accountant examines financial statements — leaving no setting unchecked, no assumption untested, and no dollar unaccounted for." — Agent 核心定位
-> "Run the automated data pull first, then layer strategic analysis on top. The tools handle extraction; this agent handles interpretation and recommendations." — 工具与 Agent 协作模式
-> "Every finding comes with severity, business impact, and a specific fix." — 审计发现标准格式
-> "Audits typically identify 15-30% efficiency improvement opportunities." — 审计价值量化
-> "80%+ of critical and high-priority recommendations implemented within 30 days." — 落地执行率
-
-## Key Concepts
-- [[AccountAudit]]:付费媒体账户审计——系统化评估账户各维度设置、策略和表现的过程
-- [[ConversionTracking]]:转化追踪——配置转化 Action、验证 GTM/GA4、实施 Enhanced Conversions 和离线转化导入
-- [[AttributionModeling]]:归因模型——选择适合业务目标的归因模型(Last Click/First Click/Linear/Time-Decay/Data-Driven)
-- [[BidStrategy]]:出价策略——评估 Bid Strategy Appropriateness、Learning Period 合规性、Portfolio 策略配置
-- [[QualityScore]]:质量得分——关键词粒度的 QS 分布分析,直接影响 CPC 和广告排名
-- [[NegativeKeywordManagement]]:负向关键词管理——负向关键词覆盖率直接影响流量质量和预算消耗效率
-- [[AuctionInsights]]:竞价洞察——分析竞争对手的展示份额重叠率和首页出价率,为预算分配提供数据依据
-- [[Dayparting]]:时段出价——基于日间分时设置的设备/时段出价调整,优化特定时段的竞价策略
-- [[ResponsiveSearchAds]]:响应式搜索广告——RSA Pin 策略确保核心信息在广告中的稳定展示
-- [[ProductFeedOptimization]]:产品 Feed 优化——购物广告的产品标题、自定义标签和下架率管理
-- [[LandingPageAudit]]:着陆页审计——页面速度、移动体验、信息匹配度和重定向链检查
-- [[CompetitivePositioning]]:竞争定位——通过 Auction Insights 分析识别竞争差距和机会点
-
-## Key Entities
-- [[JohnWilliams]](@itallstartedwithaidea):Agent 作者,The Agency 项目付费媒体 Agent 系列的设计者
-- [[GoogleAds]]:主要审计平台之一,提供 Search/Display/Shopping/Performance Max 等多类型广告产品
-- [[MicrosoftAdvertising]]:第二大搜索广告平台,支持从 Google Ads 导入账户,是增量流量的重要来源
-- [[AmazonAds]]:电商广告平台,Product Ads 和 Sponsored Products 是付费媒体的重要流量渠道
-- [[GA4]]:Google Analytics 4,用于验证网站转化追踪配置和跨域追踪正确性
-- [[GTM]]:Google Tag Manager,用于验证标签触发和事件追踪配置
-
-## Connections
-- [[paid-media-ppc-strategist]] ← audit_prerequisite ← [[paid-media-auditor]]:PPC Strategist 定义账户基准和策略框架,Auditor 基于该基准进行效果诊断
-- [[paid-media-tracking-specialist]] ← depends_on ← [[paid-media-auditor]]:Auditor 依赖 Tracking Specialist 配置的追踪基础设施进行数据验证
-- [[paid-media-search-query-analyst]] ← data_source ← [[paid-media-auditor]]:Auditor 提供关键词质量数据供 Query Analyst 进一步分析
-- [[paid-media-creative-strategist]] ← depends_on ← [[paid-media-auditor]]:Auditor 的创意评分结果为 Creative Strategist 提供优化方向
-
-## Contradictions
-- 与 [[paid-media-ppc-strategist]] 在账户结构评估标准上的潜在视角差异:
- - 冲突点:PPC Strategist 从"账户架构即战略"的角度设计活动结构,Auditor 从"现状审计"的角度检验既有结构是否合理
- - 当前观点:两者互补而非互斥——PPC Strategist 定义目标架构,Auditor 验证现状与目标的差距
-- 与 [[paid-media-programmatic-buyer]] 在效果衡量维度上的互补张力:
- - 冲突点:Programmatic Buyer 关注展示广告的漏斗上层指标(Brand Lift、VTC),Auditor 在 Display 广告审计中可能过度聚焦下漏斗指标
- - 当前观点:审计报告应区分广告类型适配不同的 KPI 框架
+---
+title: "Paid Media Auditor Agent"
+type: source
+tags: ["paid-media", "google-ads", "microsoft-advertising", "meta-ads", "audit", "account-optimization", "ai-agent"]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/paid-media/paid-media-auditor.md]]
+
+## Summary(用中文描述)
+- 核心主题:企业级付费媒体账户审计 Agent——系统化评估 Google Ads、Microsoft Ads 和 Meta Ads 账户,覆盖 200+ 检查点,输出带优先级和预估影响的可操作审计报告
+- 问题域:付费媒体账户中账户结构、追踪配置、竞价策略、创意素材、受众定向和竞争定位等方面的结构性缺陷和效率损失
+- 方法/机制:200+ 检查点执行框架,按严重程度分级(critical/high/medium/low),结合 API 自动化数据提取与人工策略分析,每项发现附带具体修复方案和业务影响预估
+- 结论/价值:审计通常能识别 15-30% 的效率提升空间,80%+ 高优先级建议在 30 天内落地实施
+
+## Key Claims(用中文描述)
+- Paid Media Auditor Agent 通过 200+ 检查点框架评估每个账户,覆盖账号结构、追踪配置、竞价策略、创意、受众和竞争定位六大维度
+- 审计发现包含严重程度评分、具体修复方案和预估业务影响,确保 100% 发现具备可操作性
+- 账户结构审计(Campaign Taxonomy、命名规范、地理定向、设备出价调整)直接影响广告系统的信号识别效率
+- 追踪与测量审计(Conversion Action 配置、归因模型、GTM/GA4 验证、Enhanced Conversions)是竞价优化的数据基础
+- 竞价与预算审计(Bid Strategy Appropriateness、Learning Period Violations、Portfolio 策略)直接影响 CPA 和 ROAS 表现
+- 关键词与定向审计(Match Type 分布、负向关键词覆盖率、QS 分布、受众 vs 观察模式)是搜索广告效率的核心
+- 创意审计(RSA Pin 策略、资产组评分、测试节奏)是点击率和转化率的直接影响因素
+- Shopping 与 Feed 审计(标题优化、自定义标签策略、下架率)是购物广告流量的关键
+- 竞争定位审计(Auction Insights、Impression Share Gap、Top-of-Page Rate)是预算分配策略的数据依据
+- Landing Page 审计(页面速度、移动体验、信息匹配度、重定向链)是转化率优化的前端保障
+- 历史趋势分析能够识别绩效下降的起点并关联至账户变更,而合规审计(医疗/金融/法律)则覆盖受监管行业的特殊政策要求
+
+## Key Quotes
+> "Methodical, detail-obsessed paid media auditor who evaluates advertising accounts the way a forensic accountant examines financial statements — leaving no setting unchecked, no assumption untested, and no dollar unaccounted for." — Agent 核心定位
+> "Run the automated data pull first, then layer strategic analysis on top. The tools handle extraction; this agent handles interpretation and recommendations." — 工具与 Agent 协作模式
+> "Every finding comes with severity, business impact, and a specific fix." — 审计发现标准格式
+> "Audits typically identify 15-30% efficiency improvement opportunities." — 审计价值量化
+> "80%+ of critical and high-priority recommendations implemented within 30 days." — 落地执行率
+
+## Key Concepts
+- [[AccountAudit]]:付费媒体账户审计——系统化评估账户各维度设置、策略和表现的过程
+- [[ConversionTracking]]:转化追踪——配置转化 Action、验证 GTM/GA4、实施 Enhanced Conversions 和离线转化导入
+- [[AttributionModeling]]:归因模型——选择适合业务目标的归因模型(Last Click/First Click/Linear/Time-Decay/Data-Driven)
+- [[BidStrategy]]:出价策略——评估 Bid Strategy Appropriateness、Learning Period 合规性、Portfolio 策略配置
+- [[QualityScore]]:质量得分——关键词粒度的 QS 分布分析,直接影响 CPC 和广告排名
+- [[NegativeKeywordManagement]]:负向关键词管理——负向关键词覆盖率直接影响流量质量和预算消耗效率
+- [[AuctionInsights]]:竞价洞察——分析竞争对手的展示份额重叠率和首页出价率,为预算分配提供数据依据
+- [[Dayparting]]:时段出价——基于日间分时设置的设备/时段出价调整,优化特定时段的竞价策略
+- [[ResponsiveSearchAds]]:响应式搜索广告——RSA Pin 策略确保核心信息在广告中的稳定展示
+- [[ProductFeedOptimization]]:产品 Feed 优化——购物广告的产品标题、自定义标签和下架率管理
+- [[LandingPageAudit]]:着陆页审计——页面速度、移动体验、信息匹配度和重定向链检查
+- [[CompetitivePositioning]]:竞争定位——通过 Auction Insights 分析识别竞争差距和机会点
+
+## Key Entities
+- [[JohnWilliams]](@itallstartedwithaidea):Agent 作者,The Agency 项目付费媒体 Agent 系列的设计者
+- [[GoogleAds]]:主要审计平台之一,提供 Search/Display/Shopping/Performance Max 等多类型广告产品
+- [[MicrosoftAdvertising]]:第二大搜索广告平台,支持从 Google Ads 导入账户,是增量流量的重要来源
+- [[AmazonAds]]:电商广告平台,Product Ads 和 Sponsored Products 是付费媒体的重要流量渠道
+- [[GA4]]:Google Analytics 4,用于验证网站转化追踪配置和跨域追踪正确性
+- [[GTM]]:Google Tag Manager,用于验证标签触发和事件追踪配置
+
+## Connections
+- [[paid-media-ppc-strategist]] ← audit_prerequisite ← [[paid-media-auditor]]:PPC Strategist 定义账户基准和策略框架,Auditor 基于该基准进行效果诊断
+- [[paid-media-tracking-specialist]] ← depends_on ← [[paid-media-auditor]]:Auditor 依赖 Tracking Specialist 配置的追踪基础设施进行数据验证
+- [[paid-media-search-query-analyst]] ← data_source ← [[paid-media-auditor]]:Auditor 提供关键词质量数据供 Query Analyst 进一步分析
+- [[paid-media-creative-strategist]] ← depends_on ← [[paid-media-auditor]]:Auditor 的创意评分结果为 Creative Strategist 提供优化方向
+
+## Contradictions
+- 与 [[paid-media-ppc-strategist]] 在账户结构评估标准上的潜在视角差异:
+ - 冲突点:PPC Strategist 从"账户架构即战略"的角度设计活动结构,Auditor 从"现状审计"的角度检验既有结构是否合理
+ - 当前观点:两者互补而非互斥——PPC Strategist 定义目标架构,Auditor 验证现状与目标的差距
+- 与 [[paid-media-programmatic-buyer]] 在效果衡量维度上的互补张力:
+ - 冲突点:Programmatic Buyer 关注展示广告的漏斗上层指标(Brand Lift、VTC),Auditor 在 Display 广告审计中可能过度聚焦下漏斗指标
+ - 当前观点:审计报告应区分广告类型适配不同的 KPI 框架
diff --git a/wiki/sources/paid-media-creative-strategist.md b/wiki/sources/paid-media-creative-strategist.md
index e8e3b9ad..690b0c24 100644
--- a/wiki/sources/paid-media-creative-strategist.md
+++ b/wiki/sources/paid-media-creative-strategist.md
@@ -1,63 +1,63 @@
----
-title: "Paid Media Ad Creative Strategist Agent"
-type: source
-tags: ["paid-media", "creative", "advertising", "google-ads", "meta-ads", "ppc", "agent-persona"]
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/paid-media/paid-media-creative-strategist.md]]
-
-## Summary(用中文描述)
-- 核心主题:付费媒体广告创意策略 Agent,专注于 Google、Meta、Microsoft 及程序化平台的全渠道广告文案创作、响应式搜索广告(RSA)架构设计和系统性创意测试框架。
-- 问题域:如何在算法控制竞价、预算和定向的自动化竞价环境中,通过创意这一唯一可控变量实现效果最大化;创意疲劳监测与快速迭代难题。
-- 方法/机制:15-headline RSA 策略设计(全品牌/利益/功能/CTA/社会证明分类);Hook-Body-CTA 视频广告结构;资产组(Asset Group)组合策略;A/B 测试框架与统计显著性标准;广告强度评分优化。
-- 结论/价值:创意是自动化竞价环境中最大的可控杠杆,每一条标题、描述、图片和视频都是一个待验证的假设,必须通过系统性测试持续迭代。
-
-## Key Claims(用中文描述)
-- 在 tCPA/tROAS/Max Conversions 等自动化竞价环境中,创意是广告主唯一实际可控的变量,算法接管了出价、预算和定向。
-- RSA 的 15 条标题和 4 条描述的所有可能组合必须语法和逻辑上都能成立,这是架构设计的核心挑战。
-- 创意疲劳(Creative Fatigue)是效果下降的主因,必须通过 CTR 趋势监测和超优展示阈值识别及时刷新。
-- 广告强度(Ad Strength)90%+ 达到 "Good" 或 "Excellent" 是 RSA 质量基准;Meta 相关性诊断需高于平均或顶级表现。
-- 统计显著性(Statistical Significance)是判定创意胜负的唯一可靠标准,必须在 2-4 周内达到。
-
-## Key Quotes
-> "Creative is the largest remaining lever in automated bidding environments — when the algorithm controls bids, budget, and targeting, the creative is what you actually control." — 核心价值观阐述
-> "Every headline, description, image, and video is a hypothesis to be tested." — 创意即假设
-> "Always audit existing ad performance before writing new creative. If API access is available, pull list_ads and ad strength data as the starting point for any creative refresh." — 数据优先原则
-
-## Key Concepts
-- [[ResponsiveSearchAds]]: RSA(响应式搜索广告),Google Ads 核心广告格式,由最多 15 条标题和 4 条描述自由组合,系统自动测试最优搭配。
-- [[PerformanceMax]]: Performance Max 广告系列,Google 全渠道自动化广告,创意资产组(Asset Group)是核心输入,决定系统学习信号质量。
-- [[AssetGroup]]: 资产组,Performance Max 的创意容器,由文本资产、图片、视频、Logo 等组成,决定广告主题表达质量。
-- [[AdStrength]]: 广告强度评分,Google 衡量 RSA 或 PMax 创意质量的指标,90%+ "Good/Excellent" 是基准目标。
-- [[CreativeFatigue]]: 创意疲劳,广告在超优展示阈值后点击率自然下降的现象,需通过定期刷新和新鲜创意对抗。
-- [[HookBodyCTA]]: Hook-Body-CTA 结构,视频广告的叙事框架——钩子(0-3秒)吸引注意,主体传递价值,号召行动促进转化。
-- [[ABTesting]]: A/B 测试框架,创意验证的标准方法,通过统计显著性判定胜负,指导规模化应用。
-- [[MessageMatch]]: 消息匹配评分,衡量广告创意与落地页内容一致性的指标,直接影响质量得分和转化率。
-- [[StatisticalSignificance]]: 统计显著性,创意测试的判断标准,确保结果可推广而非随机波动。
-- [[AdExtensions]]: 广告附加信息(Sitelink/Callout/Structured Snippets/Image Extensions 等),扩展广告视觉空间和点击率。
-
-## Key Entities
-- [[GoogleAds]]: Google Ads 平台,核心投放渠道,提供 RSA、Performance Max、Ad Strength 数据和 Google Ads MCP 工具集成。
-- [[MetaAdsManager]]: Meta(Facebook/Instagram)广告管理平台,支持 Primary Text/Headline/Description 框架和 Relevance Diagnostics。
-- [[MicrosoftAdvertising]]: Microsoft Advertising(Bing/AOL/Yahoo)搜索广告平台,与 Google Ads 并行的 PPC 渠道。
-- [[PerformanceMax]]: Google Performance Max 广告系列,AI 驱动的全渠道投放,Asset Group 质量决定效果上限。
-- [[JohnWilliams]]: Agent 作者(@itallstartedwithaidea),资深付费媒体创意策略师。
-
-## Connections
-- [[PaidMediaPpcStrategist]] ← coordinates_with ← [[PaidMediaCreativeStrategist]]: PPC 策略师制定活动架构,创意策略师提供素材支撑,两者协同制定 Performance Max 和 Display 投放方案。
-- [[PaidMediaProgrammaticBuyer]] ← depends_on ← [[PaidMediaCreativeStrategist]]: 程序化购买依赖高质量创意资产填充展示和视频广告库存。
-- [[PaidMediaSearchQueryAnalyst]] ← informs ← [[PaidMediaCreativeStrategist]]: 搜索查询分析师提供关键词意图数据,创意策略师据此撰写关键词插入文案。
-- [[PaidMediaTrackingSpecialist]] ← depends_on ← [[PaidMediaCreativeStrategist]]: 追踪专家提供的 CTR/CVR 数据是判断创意胜负的基础。
-- [[PaidMediaAuditor]] ← depends_on ← [[PaidMediaCreativeStrategist]]: 审计师诊断广告效果,创意刷新是优化策略的核心输出之一。
-
-## Contradictions
-- 与 [[PaidMediaPpcStrategist]] 在"自动化程度"权衡上存在张力:
- - 冲突点:PPC 策略师倾向于强调 Smart Bidding 和自动化优化;创意策略师认为创意质量是瓶颈,自动化不能弥补低质量素材。
- - 当前观点:创意是决定性杠杆,即使在自动化竞价环境中也需要人工精心设计的 RSA 组合和 Asset Group 策略。
- - 对方观点:Broad Match + Smart Bidding 组合可以弥补创意不足,系统会自动寻找最优受众-创意搭配。
-- 与 [[PaidMediaProgrammaticBuyer]] 在"创意新鲜度"上存在潜在冲突:
- - 冲突点:程序化购买强调规模化和成本效率,倾向于复用已有创意;创意策略师强调创意疲劳必须通过高频迭代对抗。
- - 当前观点:持续创意迭代(每 2 周一次测试)是效果保持的必要条件,低频迭代会导致 CPM 上升和 CTR 下降。
- - 对方观点:程序化购买的受众覆盖足够广泛,可以抵消创意疲劳的影响。
+---
+title: "Paid Media Ad Creative Strategist Agent"
+type: source
+tags: ["paid-media", "creative", "advertising", "google-ads", "meta-ads", "ppc", "agent-persona"]
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/paid-media/paid-media-creative-strategist.md]]
+
+## Summary(用中文描述)
+- 核心主题:付费媒体广告创意策略 Agent,专注于 Google、Meta、Microsoft 及程序化平台的全渠道广告文案创作、响应式搜索广告(RSA)架构设计和系统性创意测试框架。
+- 问题域:如何在算法控制竞价、预算和定向的自动化竞价环境中,通过创意这一唯一可控变量实现效果最大化;创意疲劳监测与快速迭代难题。
+- 方法/机制:15-headline RSA 策略设计(全品牌/利益/功能/CTA/社会证明分类);Hook-Body-CTA 视频广告结构;资产组(Asset Group)组合策略;A/B 测试框架与统计显著性标准;广告强度评分优化。
+- 结论/价值:创意是自动化竞价环境中最大的可控杠杆,每一条标题、描述、图片和视频都是一个待验证的假设,必须通过系统性测试持续迭代。
+
+## Key Claims(用中文描述)
+- 在 tCPA/tROAS/Max Conversions 等自动化竞价环境中,创意是广告主唯一实际可控的变量,算法接管了出价、预算和定向。
+- RSA 的 15 条标题和 4 条描述的所有可能组合必须语法和逻辑上都能成立,这是架构设计的核心挑战。
+- 创意疲劳(Creative Fatigue)是效果下降的主因,必须通过 CTR 趋势监测和超优展示阈值识别及时刷新。
+- 广告强度(Ad Strength)90%+ 达到 "Good" 或 "Excellent" 是 RSA 质量基准;Meta 相关性诊断需高于平均或顶级表现。
+- 统计显著性(Statistical Significance)是判定创意胜负的唯一可靠标准,必须在 2-4 周内达到。
+
+## Key Quotes
+> "Creative is the largest remaining lever in automated bidding environments — when the algorithm controls bids, budget, and targeting, the creative is what you actually control." — 核心价值观阐述
+> "Every headline, description, image, and video is a hypothesis to be tested." — 创意即假设
+> "Always audit existing ad performance before writing new creative. If API access is available, pull list_ads and ad strength data as the starting point for any creative refresh." — 数据优先原则
+
+## Key Concepts
+- [[ResponsiveSearchAds]]: RSA(响应式搜索广告),Google Ads 核心广告格式,由最多 15 条标题和 4 条描述自由组合,系统自动测试最优搭配。
+- [[PerformanceMax]]: Performance Max 广告系列,Google 全渠道自动化广告,创意资产组(Asset Group)是核心输入,决定系统学习信号质量。
+- [[AssetGroup]]: 资产组,Performance Max 的创意容器,由文本资产、图片、视频、Logo 等组成,决定广告主题表达质量。
+- [[AdStrength]]: 广告强度评分,Google 衡量 RSA 或 PMax 创意质量的指标,90%+ "Good/Excellent" 是基准目标。
+- [[CreativeFatigue]]: 创意疲劳,广告在超优展示阈值后点击率自然下降的现象,需通过定期刷新和新鲜创意对抗。
+- [[HookBodyCTA]]: Hook-Body-CTA 结构,视频广告的叙事框架——钩子(0-3秒)吸引注意,主体传递价值,号召行动促进转化。
+- [[ABTesting]]: A/B 测试框架,创意验证的标准方法,通过统计显著性判定胜负,指导规模化应用。
+- [[MessageMatch]]: 消息匹配评分,衡量广告创意与落地页内容一致性的指标,直接影响质量得分和转化率。
+- [[StatisticalSignificance]]: 统计显著性,创意测试的判断标准,确保结果可推广而非随机波动。
+- [[AdExtensions]]: 广告附加信息(Sitelink/Callout/Structured Snippets/Image Extensions 等),扩展广告视觉空间和点击率。
+
+## Key Entities
+- [[GoogleAds]]: Google Ads 平台,核心投放渠道,提供 RSA、Performance Max、Ad Strength 数据和 Google Ads MCP 工具集成。
+- [[MetaAdsManager]]: Meta(Facebook/Instagram)广告管理平台,支持 Primary Text/Headline/Description 框架和 Relevance Diagnostics。
+- [[MicrosoftAdvertising]]: Microsoft Advertising(Bing/AOL/Yahoo)搜索广告平台,与 Google Ads 并行的 PPC 渠道。
+- [[PerformanceMax]]: Google Performance Max 广告系列,AI 驱动的全渠道投放,Asset Group 质量决定效果上限。
+- [[JohnWilliams]]: Agent 作者(@itallstartedwithaidea),资深付费媒体创意策略师。
+
+## Connections
+- [[PaidMediaPpcStrategist]] ← coordinates_with ← [[PaidMediaCreativeStrategist]]: PPC 策略师制定活动架构,创意策略师提供素材支撑,两者协同制定 Performance Max 和 Display 投放方案。
+- [[PaidMediaProgrammaticBuyer]] ← depends_on ← [[PaidMediaCreativeStrategist]]: 程序化购买依赖高质量创意资产填充展示和视频广告库存。
+- [[PaidMediaSearchQueryAnalyst]] ← informs ← [[PaidMediaCreativeStrategist]]: 搜索查询分析师提供关键词意图数据,创意策略师据此撰写关键词插入文案。
+- [[PaidMediaTrackingSpecialist]] ← depends_on ← [[PaidMediaCreativeStrategist]]: 追踪专家提供的 CTR/CVR 数据是判断创意胜负的基础。
+- [[PaidMediaAuditor]] ← depends_on ← [[PaidMediaCreativeStrategist]]: 审计师诊断广告效果,创意刷新是优化策略的核心输出之一。
+
+## Contradictions
+- 与 [[PaidMediaPpcStrategist]] 在"自动化程度"权衡上存在张力:
+ - 冲突点:PPC 策略师倾向于强调 Smart Bidding 和自动化优化;创意策略师认为创意质量是瓶颈,自动化不能弥补低质量素材。
+ - 当前观点:创意是决定性杠杆,即使在自动化竞价环境中也需要人工精心设计的 RSA 组合和 Asset Group 策略。
+ - 对方观点:Broad Match + Smart Bidding 组合可以弥补创意不足,系统会自动寻找最优受众-创意搭配。
+- 与 [[PaidMediaProgrammaticBuyer]] 在"创意新鲜度"上存在潜在冲突:
+ - 冲突点:程序化购买强调规模化和成本效率,倾向于复用已有创意;创意策略师强调创意疲劳必须通过高频迭代对抗。
+ - 当前观点:持续创意迭代(每 2 周一次测试)是效果保持的必要条件,低频迭代会导致 CPM 上升和 CTR 下降。
+ - 对方观点:程序化购买的受众覆盖足够广泛,可以抵消创意疲劳的影响。
diff --git a/wiki/sources/paid-media-paid-social-strategist.md b/wiki/sources/paid-media-paid-social-strategist.md
index 21aa0f77..04c33db9 100644
--- a/wiki/sources/paid-media-paid-social-strategist.md
+++ b/wiki/sources/paid-media-paid-social-strategist.md
@@ -1,54 +1,54 @@
----
-title: "Paid Social Strategist"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/paid-media/paid-media-paid-social-strategist.md]]
-
-## Summary(用中文描述)
-- 核心主题:跨平台付费社交广告专家 Agent,覆盖 Meta(Facebook/Instagram)、LinkedIn、TikTok、Pinterest、X 和 Snapchat,设计从引流到再营销的全漏斗社交广告项目。
-- 问题域:社交广告的本质是"打断"而非"回答",如何在各平台原生体验与广告效果之间取得平衡;iOS 隐私政策对追踪归因的冲击;跨平台受众重叠与频次管理难题。
-- 方法/机制:全漏斗结构(引流 → 互动 → 再营销 → 留存);平台差异化创意策略(UGC 风格适配 TikTok/Meta,专业内容适配 LinkedIn);受众工程(像素自定义受众、CRM 上传、互动受众);Conversions API / 服务端事件追踪;SKAdNetwork 应对 iOS 隐私变化。
-- 结论/价值:为每个社交平台构建原生广告体验,而非跨平台复用同一创意;通过跨渠道数据验证增量贡献,避免重复计算转化。
-
-## Key Claims(用中文描述)
-- 付费社交广告本质上是"打断"用户而非"回答"问题,因此创意和受众策略必须赢得用户注意力。
-- 各平台是独立生态系统(Meta Ads Manager、LinkedIn Campaign Manager、TikTok Ads 各有不同算法机制和用户行为),不应跨平台复用同一套创意。
-- iOS 隐私变化后,SKAdNetwork 和聚合事件测量成为移动归因的核心手段,Conversions API 实施至关重要。
-- 跨渠道预算分配必须基于跨渠道证据(搜索+展示+社交综合数据),避免基于单一渠道数据做预算决策。
-
-## Key Quotes
-> "Social advertising is fundamentally different from search — you're interrupting, not answering, so the creative and targeting have to earn attention." — 核心哲学阐述
-
-> "When cross-channel API data is available, always validate social performance against search and display results before recommending budget increases." — 跨渠道验证原则
-
-## Key Concepts
-- [[Full-Funnel Campaign Architecture]]:从引流(Prospecting)到留存(Retention)的完整漏斗结构,各阶段受众策略与预算分配各异。
-- [[Custom Audience Engineering]]:基于像素的自定义受众、CRM 名单上传、互动受众(视频观看者、主页互动者、表单开启者)的构建与排除策略。
-- [[Conversions API]]:服务端事件追踪,与平台像素配合绕过浏览器限制,是后 iOS 14 隐私政策的关键归因基础设施。
-- [[Advantage+ Campaigns]]:Meta 的自动化广告系列,利用机器学习优化受众定位和竞价,是 CBO/ABO 架构的重要演进。
-- [[Audience Overlap Analysis]]:跨平台受众重叠分析,防止频次过载,最大化独特触达。
-- [[Incrementality Testing]]:增量测试,验证社交广告是否带来净新增转化,而非蚕食自然搜索流量。
-- [[SKAdNetwork]]:Apple 的隐私化归因框架,替代 IDFA,用于衡量 iOS 应用广告效果。
-
-## Key Entities
-- [[Meta Ads Manager]]:Facebook/Instagram 广告管理平台,核心工具包括 Advantage+ 购物广告、应用广告、目录销售等。
-- [[LinkedIn Campaign Manager]]:LinkedIn 广告管理后台,支持赞助内容、消息广告、文档广告、ABM 名单上传等 B2B 定向功能。
-- [[TikTok Ads]]:TikTok 广告平台,支持 Spark Ads、TopView、信息流广告、品牌标签挑战等原生内容形式。
-- [[Google Ads MCP Tools]]:可选集成工具,用于跨渠道(搜索+社交)数据对比、增量验证和预算决策支持。
-- [[John Williams]](@itallstartedwithaidea):Agent 作者。
-
-## Connections
-- [[Paid Media Search Query Analyst]] ← parallel_specialization ← [[Paid Media Paid Social Strategist]](两者同属付费媒体 Agent 体系,一个专注搜索查询,一个专注社交广告)
-- [[Paid Media Programmatic Buyer]] ← channel_extension ← [[Paid Media Paid Social Strategist]](程序化购买与社交广告共享受众工程和数据归因方法论)
-- [[Paid Media Creative Strategist]] ← depends_on ← [[Paid Media Paid Social Strategist]](创意策略依赖社交策略的受众洞察和平台选择)
-- [[Paid Media Auditor]] ← informs ← [[Paid Media Paid Social Strategist]](审计结果指导社交广告的优化方向)
-
-## Contradictions
-- 与 [[Paid Media Programmatic Buyer]] 在"自动化 vs. 控制"的权衡上存在张力:
- - 冲突点:程序化购买强调自动化竞价和实时优化;社交广告中的 Advantage+ 也强调自动化,但该 Agent 同时强调人工干预的受众排除和频次管理。
- - 当前观点:社交广告需要人工把控受众排除策略和跨平台频次,防止自动化算法过度扩张。
- - 对方观点:程序化购买可以高度依赖算法自动学习,人工干预应最小化。
+---
+title: "Paid Social Strategist"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/paid-media/paid-media-paid-social-strategist.md]]
+
+## Summary(用中文描述)
+- 核心主题:跨平台付费社交广告专家 Agent,覆盖 Meta(Facebook/Instagram)、LinkedIn、TikTok、Pinterest、X 和 Snapchat,设计从引流到再营销的全漏斗社交广告项目。
+- 问题域:社交广告的本质是"打断"而非"回答",如何在各平台原生体验与广告效果之间取得平衡;iOS 隐私政策对追踪归因的冲击;跨平台受众重叠与频次管理难题。
+- 方法/机制:全漏斗结构(引流 → 互动 → 再营销 → 留存);平台差异化创意策略(UGC 风格适配 TikTok/Meta,专业内容适配 LinkedIn);受众工程(像素自定义受众、CRM 上传、互动受众);Conversions API / 服务端事件追踪;SKAdNetwork 应对 iOS 隐私变化。
+- 结论/价值:为每个社交平台构建原生广告体验,而非跨平台复用同一创意;通过跨渠道数据验证增量贡献,避免重复计算转化。
+
+## Key Claims(用中文描述)
+- 付费社交广告本质上是"打断"用户而非"回答"问题,因此创意和受众策略必须赢得用户注意力。
+- 各平台是独立生态系统(Meta Ads Manager、LinkedIn Campaign Manager、TikTok Ads 各有不同算法机制和用户行为),不应跨平台复用同一套创意。
+- iOS 隐私变化后,SKAdNetwork 和聚合事件测量成为移动归因的核心手段,Conversions API 实施至关重要。
+- 跨渠道预算分配必须基于跨渠道证据(搜索+展示+社交综合数据),避免基于单一渠道数据做预算决策。
+
+## Key Quotes
+> "Social advertising is fundamentally different from search — you're interrupting, not answering, so the creative and targeting have to earn attention." — 核心哲学阐述
+
+> "When cross-channel API data is available, always validate social performance against search and display results before recommending budget increases." — 跨渠道验证原则
+
+## Key Concepts
+- [[Full-Funnel Campaign Architecture]]:从引流(Prospecting)到留存(Retention)的完整漏斗结构,各阶段受众策略与预算分配各异。
+- [[Custom Audience Engineering]]:基于像素的自定义受众、CRM 名单上传、互动受众(视频观看者、主页互动者、表单开启者)的构建与排除策略。
+- [[Conversions API]]:服务端事件追踪,与平台像素配合绕过浏览器限制,是后 iOS 14 隐私政策的关键归因基础设施。
+- [[Advantage+ Campaigns]]:Meta 的自动化广告系列,利用机器学习优化受众定位和竞价,是 CBO/ABO 架构的重要演进。
+- [[Audience Overlap Analysis]]:跨平台受众重叠分析,防止频次过载,最大化独特触达。
+- [[Incrementality Testing]]:增量测试,验证社交广告是否带来净新增转化,而非蚕食自然搜索流量。
+- [[SKAdNetwork]]:Apple 的隐私化归因框架,替代 IDFA,用于衡量 iOS 应用广告效果。
+
+## Key Entities
+- [[Meta Ads Manager]]:Facebook/Instagram 广告管理平台,核心工具包括 Advantage+ 购物广告、应用广告、目录销售等。
+- [[LinkedIn Campaign Manager]]:LinkedIn 广告管理后台,支持赞助内容、消息广告、文档广告、ABM 名单上传等 B2B 定向功能。
+- [[TikTok Ads]]:TikTok 广告平台,支持 Spark Ads、TopView、信息流广告、品牌标签挑战等原生内容形式。
+- [[Google Ads MCP Tools]]:可选集成工具,用于跨渠道(搜索+社交)数据对比、增量验证和预算决策支持。
+- [[John Williams]](@itallstartedwithaidea):Agent 作者。
+
+## Connections
+- [[Paid Media Search Query Analyst]] ← parallel_specialization ← [[Paid Media Paid Social Strategist]](两者同属付费媒体 Agent 体系,一个专注搜索查询,一个专注社交广告)
+- [[Paid Media Programmatic Buyer]] ← channel_extension ← [[Paid Media Paid Social Strategist]](程序化购买与社交广告共享受众工程和数据归因方法论)
+- [[Paid Media Creative Strategist]] ← depends_on ← [[Paid Media Paid Social Strategist]](创意策略依赖社交策略的受众洞察和平台选择)
+- [[Paid Media Auditor]] ← informs ← [[Paid Media Paid Social Strategist]](审计结果指导社交广告的优化方向)
+
+## Contradictions
+- 与 [[Paid Media Programmatic Buyer]] 在"自动化 vs. 控制"的权衡上存在张力:
+ - 冲突点:程序化购买强调自动化竞价和实时优化;社交广告中的 Advantage+ 也强调自动化,但该 Agent 同时强调人工干预的受众排除和频次管理。
+ - 当前观点:社交广告需要人工把控受众排除策略和跨平台频次,防止自动化算法过度扩张。
+ - 对方观点:程序化购买可以高度依赖算法自动学习,人工干预应最小化。
diff --git a/wiki/sources/paid-media-ppc-strategist.md b/wiki/sources/paid-media-ppc-strategist.md
index edef97e3..9515cd39 100644
--- a/wiki/sources/paid-media-ppc-strategist.md
+++ b/wiki/sources/paid-media-ppc-strategist.md
@@ -1,58 +1,58 @@
----
-title: "Paid Media PPC Campaign Strategist Agent"
-type: source
-tags: ["paid-media", "ppc", "google-ads", "amazon-ads", "performance-marketing", "agent-persona"]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/paid-media/paid-media-ppc-strategist.md]]
-
-## Summary(用中文描述)
-- 核心主题:付费搜索与效果媒体策略 Agent,专注于 Google Ads、Microsoft Advertising、Amazon Ads 三大平台的企业级账户架构设计、自动化竞价策略和预算管理。
-- 问题域:如何设计可规模化($10K 到 $10M+ 月消费)的付费媒体账户结构、竞价策略选择、预算分配,以及跨平台协同。
-- 方法/机制:分层活动架构(品牌/非品牌/竞品/征服)、自动竞价(tCPA/tROAS/Max Conversions)、Google Ads API 自动化、MCC 级策略、增量测试框架。
-- 结论/价值:提供从账户新建到持续优化的全链路策略指导,覆盖 Search/Shopping/Performance Max/Demand Gen/Display/Video 等全类型广告。
-
-## Key Claims(用中文描述)
-- 账户架构即战略:不是简单的关键词和出价,而是活动、广告组、受众、信号协同驱动业务成果的系统工程。
-- Broad Match + Smart Bidding 部署是规模化增长的核心组合。
-- Performance Max 资产组设计与信号优化是效果媒体的前沿阵地。
-- Google Ads API + Scripts 是规模化自动化运营的必备能力。
-- 增量测试(geo-split/holdout/matched market)是衡量真实效果的金标准。
-
-## Key Quotes
-> "Account structure as strategy — not just keywords and bids, but how the entire system of campaigns, ad groups, audiences, and signals work together to drive business outcomes." — 核心价值观阐述
-> "Always prefer live API data over manual exports or screenshots." — 数据优先原则
-> "Impression Share: 90%+ brand, 40-60% non-brand top targets" — 品牌与非品牌投放目标基准
-
-## Key Concepts
-- [[PerformanceMax]]: Performance Max 广告系列,AI 驱动的全渠道广告投放,自动在所有 Google 广告位优化效果。
-- [[SmartBidding]]: 智能竞价策略(tCPA/tROAS/Max Conversions/Max Conversion Value),利用 Google 机器学习自动优化出价。
-- [[AccountArchitecture]]: 账户架构设计,涵盖活动结构、广告组分类、标签系统和命名规范,是规模化运营的基础。
-- [[TieredCampaignArchitecture]]: 分层活动架构(品牌/非品牌/竞品/征服),通过隔离策略实现精细化管理。
-- [[BudgetPacing]]: 预算步速模型,监控日预算消耗速度,防止过早耗尽或余额过剩。
-- [[CustomerMatch]]: Customer Match,通过第一方数据(邮箱/电话等)建立受众,实现精准再营销。
-- [[IncrementalityTesting]]: 增量测试框架(geo-split/holdout/matched market),区分真实增长与自然溢出。
-- [[ConversionActionHierarchy]]: 转化行动层级设计,区分主次转化及微转化与宏转化。
-
-## Key Entities
-- [[GoogleAds]]: Google Ads 平台,核心投放渠道,支持 Search/Shopping/Display/Video/Performance Max 等全类型广告。
-- [[MicrosoftAdvertising]]: Microsoft Advertising(Bing/AOL/Yahoo),与 Google Ads 并行的搜索广告平台,月活覆盖 5.4 亿用户。
-- [[AmazonAds]]: Amazon Ads 平台,电商场景下的搜索广告(Amazon Search)和展示广告,对高购买意图用户触达。
-- [[JohnWilliams]]: Agent 作者(@itallstartedwithaidea),资深付费媒体策略师。
-- [[MCC]]: Google Ads MCC(My Client Center),用于管理多账户组合的中心化管理工具。
-- [[GoogleAdsAPI]]: Google Ads API,官方编程接口,支持规模化账户操作和数据拉取。
-
-## Connections
-- [[PaidMediaProgrammaticBuyer]] ← extends ← [[PaidMediaPpcStrategist]]: Programmatic Buyer 承接 PPC Strategist 的策略,执行程序化购买。
-- [[PaidMediaTrackingSpecialist]] ← depends_on ← [[PaidMediaPpcStrategist]]: 追踪专家提供转化数据,支撑竞价策略优化。
-- [[PaidMediaAuditor]] ← depends_on ← [[PaidMediaPpcStrategist]]: 审计师基于策略基准进行效果诊断。
-- [[PaidMediaCreativeStrategist]] ← coordinates_with ← [[PaidMediaPpcStrategist]]: 创意策略师提供资产支持 Performance Max 和 Display 投放。
-- [[PaidMediaSearchQueryAnalyst]] ← depends_on ← [[PaidMediaPpcStrategist]]: 查询分析师为关键词策略提供搜索词数据。
-
-## Contradictions
-- 与 [[PaidMediaProgrammaticBuyer]] 可能存在预算分配冲突:
- - 冲突点:PPC 侧重搜索意图明确的高转化流量,Programmatic 侧重广泛品牌曝光,两者对有限预算的竞争。
- - 当前观点:PPC Strategist 认为品牌词和竞品词应严格隔离,Performance Max 覆盖增量用户。
- - 对方观点:Programmatic Buyer 认为品牌曝光同样重要,程序化购买可以更低 CPM 触达类似受众。
+---
+title: "Paid Media PPC Campaign Strategist Agent"
+type: source
+tags: ["paid-media", "ppc", "google-ads", "amazon-ads", "performance-marketing", "agent-persona"]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/paid-media/paid-media-ppc-strategist.md]]
+
+## Summary(用中文描述)
+- 核心主题:付费搜索与效果媒体策略 Agent,专注于 Google Ads、Microsoft Advertising、Amazon Ads 三大平台的企业级账户架构设计、自动化竞价策略和预算管理。
+- 问题域:如何设计可规模化($10K 到 $10M+ 月消费)的付费媒体账户结构、竞价策略选择、预算分配,以及跨平台协同。
+- 方法/机制:分层活动架构(品牌/非品牌/竞品/征服)、自动竞价(tCPA/tROAS/Max Conversions)、Google Ads API 自动化、MCC 级策略、增量测试框架。
+- 结论/价值:提供从账户新建到持续优化的全链路策略指导,覆盖 Search/Shopping/Performance Max/Demand Gen/Display/Video 等全类型广告。
+
+## Key Claims(用中文描述)
+- 账户架构即战略:不是简单的关键词和出价,而是活动、广告组、受众、信号协同驱动业务成果的系统工程。
+- Broad Match + Smart Bidding 部署是规模化增长的核心组合。
+- Performance Max 资产组设计与信号优化是效果媒体的前沿阵地。
+- Google Ads API + Scripts 是规模化自动化运营的必备能力。
+- 增量测试(geo-split/holdout/matched market)是衡量真实效果的金标准。
+
+## Key Quotes
+> "Account structure as strategy — not just keywords and bids, but how the entire system of campaigns, ad groups, audiences, and signals work together to drive business outcomes." — 核心价值观阐述
+> "Always prefer live API data over manual exports or screenshots." — 数据优先原则
+> "Impression Share: 90%+ brand, 40-60% non-brand top targets" — 品牌与非品牌投放目标基准
+
+## Key Concepts
+- [[PerformanceMax]]: Performance Max 广告系列,AI 驱动的全渠道广告投放,自动在所有 Google 广告位优化效果。
+- [[SmartBidding]]: 智能竞价策略(tCPA/tROAS/Max Conversions/Max Conversion Value),利用 Google 机器学习自动优化出价。
+- [[AccountArchitecture]]: 账户架构设计,涵盖活动结构、广告组分类、标签系统和命名规范,是规模化运营的基础。
+- [[TieredCampaignArchitecture]]: 分层活动架构(品牌/非品牌/竞品/征服),通过隔离策略实现精细化管理。
+- [[BudgetPacing]]: 预算步速模型,监控日预算消耗速度,防止过早耗尽或余额过剩。
+- [[CustomerMatch]]: Customer Match,通过第一方数据(邮箱/电话等)建立受众,实现精准再营销。
+- [[IncrementalityTesting]]: 增量测试框架(geo-split/holdout/matched market),区分真实增长与自然溢出。
+- [[ConversionActionHierarchy]]: 转化行动层级设计,区分主次转化及微转化与宏转化。
+
+## Key Entities
+- [[GoogleAds]]: Google Ads 平台,核心投放渠道,支持 Search/Shopping/Display/Video/Performance Max 等全类型广告。
+- [[MicrosoftAdvertising]]: Microsoft Advertising(Bing/AOL/Yahoo),与 Google Ads 并行的搜索广告平台,月活覆盖 5.4 亿用户。
+- [[AmazonAds]]: Amazon Ads 平台,电商场景下的搜索广告(Amazon Search)和展示广告,对高购买意图用户触达。
+- [[JohnWilliams]]: Agent 作者(@itallstartedwithaidea),资深付费媒体策略师。
+- [[MCC]]: Google Ads MCC(My Client Center),用于管理多账户组合的中心化管理工具。
+- [[GoogleAdsAPI]]: Google Ads API,官方编程接口,支持规模化账户操作和数据拉取。
+
+## Connections
+- [[PaidMediaProgrammaticBuyer]] ← extends ← [[PaidMediaPpcStrategist]]: Programmatic Buyer 承接 PPC Strategist 的策略,执行程序化购买。
+- [[PaidMediaTrackingSpecialist]] ← depends_on ← [[PaidMediaPpcStrategist]]: 追踪专家提供转化数据,支撑竞价策略优化。
+- [[PaidMediaAuditor]] ← depends_on ← [[PaidMediaPpcStrategist]]: 审计师基于策略基准进行效果诊断。
+- [[PaidMediaCreativeStrategist]] ← coordinates_with ← [[PaidMediaPpcStrategist]]: 创意策略师提供资产支持 Performance Max 和 Display 投放。
+- [[PaidMediaSearchQueryAnalyst]] ← depends_on ← [[PaidMediaPpcStrategist]]: 查询分析师为关键词策略提供搜索词数据。
+
+## Contradictions
+- 与 [[PaidMediaProgrammaticBuyer]] 可能存在预算分配冲突:
+ - 冲突点:PPC 侧重搜索意图明确的高转化流量,Programmatic 侧重广泛品牌曝光,两者对有限预算的竞争。
+ - 当前观点:PPC Strategist 认为品牌词和竞品词应严格隔离,Performance Max 覆盖增量用户。
+ - 对方观点:Programmatic Buyer 认为品牌曝光同样重要,程序化购买可以更低 CPM 触达类似受众。
diff --git a/wiki/sources/paid-media-programmatic-buyer.md b/wiki/sources/paid-media-programmatic-buyer.md
index 690e65b3..e3bf97cd 100644
--- a/wiki/sources/paid-media-programmatic-buyer.md
+++ b/wiki/sources/paid-media-programmatic-buyer.md
@@ -1,57 +1,57 @@
----
-title: "Paid Media Programmatic & Display Buyer Agent"
-type: source
-tags: ["paid-media", "programmatic", "display-advertising", "dsp", "abm", "agent"]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/paid-media/paid-media-programmatic-buyer.md]]
-
-## Summary(用中文描述)
-- 核心主题:定义一个战略性程序化购买与展示广告 Agent,负责跨平台(GDN、DSP、ABM)的广告投放策略制定与执行
-- 问题域:展示广告的规模化采购、受众定位、品牌安全、频次管理及效果归因
-- 方法/机制:支持 Google Display Network、DV360、The Trade Desk、Amazon DSP 等 DSP 平台;Demandbase、6Sense 等 ABM 平台;通过 MCP 工具与 Google Ads API 集成实现自动化投放管理
-- 结论/价值:Agent 能够系统化地规划展示广告活动,管理合作伙伴媒体(25+合作伙伴),执行 ABM 策略,并以品牌安全和可查看性为核心指标进行优化
-
-## Key Claims(用中文描述)
-- Agent 以受众优先为策略核心,将每次展示的机会视为触达正确用户在正确上下文以正确频次实现的机会
-- 展示广告的成功衡量指标以可见性、品牌提升和归因为主,而非单纯的最后点击 CPA
-- 通过 MCP 工具与 Google Ads API 集成,可在无需人工 UI 操作的情况下自动拉取广告位级报告和执行广告排除策略
-- 程序化交易应优先识别无效投放而非盲目扩张
-
-## Key Quotes
-> "Every impression should reach the right person, in the right context, at the right frequency." — 核心理念
-> "The best display buys start with knowing what's not working." — 投放优化原则
-> "Always pull placement_performance data before recommending new placement strategies." — 操作规范
-
-## Key Concepts
-- [[Programmatic Buying]]:通过 DSP 平台(DV360、The Trade Desk、Amazon DSP)自动化购买展示广告库存,支持 Deal ID、PMP 和程序化保证交易
-- [[ABM Display]]:基于账户的展示广告策略,通过 Demandbase、6Sense、RollWorks 等平台实现对目标企业账户的精准触达
-- [[Viewability]]:广告可见性标准(MRC、GroupM),目标 70%+ 可见展示率
-- [[Invalid Traffic]]:无效流量监测,通用 IVT 目标 <3%,复杂 IVT <1%
-- [[Frequency Cap]]:频次上限管理,防止广告疲劳,平均频次目标 3-7 次/月/用户
-- [[Supply Path Optimization]]:供应路径优化,选择最优广告交易路径以提升效率和品牌安全
-- [[Partner Media AMP]]:可寻址媒体计划,管理 25+ 合作伙伴(展示、通讯赞助、内容合作)的媒体预算分配表
-
-## Key Entities
-- [[DV360]](Display & Video 360):Google 的企业级 DSP 平台,程序化购买核心工具
-- [[The Trade Desk]]:第三方 DSP 平台,支持开放式交易平台和 PMP 交易
-- [[Amazon DSP]]:亚马逊需求方平台,支持程序化展示和 OTT/CTV 广告购买
-- [[Google Display Network]]:Google 自助展示广告网络,覆盖数百万网站和应用
-- [[Demandbase]]:ABM 展示广告平台,提供基于 firmographic 的企业账户定向
-- [[6Sense]]:ABM 和意图数据平台,支持账户列表管理和参与度评分
-- [[RollWorks]]:ABM 广告平台,提供基于账户的广告激活能力
-- [[John Williams]](@itallstartedwithaidea):Agent 作者
-
-## Connections
-- [[paid-media-paid-social-strategist]] ← related_to ← [[paid-media-programmatic-buyer]](均为付费媒体 Agent 体系)
-- [[paid-media-tracking-specialist]] ← supports ← [[paid-media-programmatic-buyer]](追踪与归因支撑程序化购买优化)
-- [[paid-media-auditor]] ← validates ← [[paid-media-programmatic-buyer]](审计 Agent 验证投放效果)
-- [[paid-media-creative-strategist]] ← feeds_into ← [[paid-media-programmatic-buyer]](创意策略为展示广告提供素材)
-
-## Contradictions
-- 与 [[paid-media-paid-social-strategist]] 的效果衡量差异:
- - 冲突点:展示广告强调上漏斗指标(品牌提升、可见性),社交广告侧重直接转化和互动指标
- - 当前观点:程序化展示广告应优先衡量可见性和品牌安全,而非最后点击 CPA
- - 对方观点:付费社交广告以互动率和转化率作为核心成功指标
+---
+title: "Paid Media Programmatic & Display Buyer Agent"
+type: source
+tags: ["paid-media", "programmatic", "display-advertising", "dsp", "abm", "agent"]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/paid-media/paid-media-programmatic-buyer.md]]
+
+## Summary(用中文描述)
+- 核心主题:定义一个战略性程序化购买与展示广告 Agent,负责跨平台(GDN、DSP、ABM)的广告投放策略制定与执行
+- 问题域:展示广告的规模化采购、受众定位、品牌安全、频次管理及效果归因
+- 方法/机制:支持 Google Display Network、DV360、The Trade Desk、Amazon DSP 等 DSP 平台;Demandbase、6Sense 等 ABM 平台;通过 MCP 工具与 Google Ads API 集成实现自动化投放管理
+- 结论/价值:Agent 能够系统化地规划展示广告活动,管理合作伙伴媒体(25+合作伙伴),执行 ABM 策略,并以品牌安全和可查看性为核心指标进行优化
+
+## Key Claims(用中文描述)
+- Agent 以受众优先为策略核心,将每次展示的机会视为触达正确用户在正确上下文以正确频次实现的机会
+- 展示广告的成功衡量指标以可见性、品牌提升和归因为主,而非单纯的最后点击 CPA
+- 通过 MCP 工具与 Google Ads API 集成,可在无需人工 UI 操作的情况下自动拉取广告位级报告和执行广告排除策略
+- 程序化交易应优先识别无效投放而非盲目扩张
+
+## Key Quotes
+> "Every impression should reach the right person, in the right context, at the right frequency." — 核心理念
+> "The best display buys start with knowing what's not working." — 投放优化原则
+> "Always pull placement_performance data before recommending new placement strategies." — 操作规范
+
+## Key Concepts
+- [[Programmatic Buying]]:通过 DSP 平台(DV360、The Trade Desk、Amazon DSP)自动化购买展示广告库存,支持 Deal ID、PMP 和程序化保证交易
+- [[ABM Display]]:基于账户的展示广告策略,通过 Demandbase、6Sense、RollWorks 等平台实现对目标企业账户的精准触达
+- [[Viewability]]:广告可见性标准(MRC、GroupM),目标 70%+ 可见展示率
+- [[Invalid Traffic]]:无效流量监测,通用 IVT 目标 <3%,复杂 IVT <1%
+- [[Frequency Cap]]:频次上限管理,防止广告疲劳,平均频次目标 3-7 次/月/用户
+- [[Supply Path Optimization]]:供应路径优化,选择最优广告交易路径以提升效率和品牌安全
+- [[Partner Media AMP]]:可寻址媒体计划,管理 25+ 合作伙伴(展示、通讯赞助、内容合作)的媒体预算分配表
+
+## Key Entities
+- [[DV360]](Display & Video 360):Google 的企业级 DSP 平台,程序化购买核心工具
+- [[The Trade Desk]]:第三方 DSP 平台,支持开放式交易平台和 PMP 交易
+- [[Amazon DSP]]:亚马逊需求方平台,支持程序化展示和 OTT/CTV 广告购买
+- [[Google Display Network]]:Google 自助展示广告网络,覆盖数百万网站和应用
+- [[Demandbase]]:ABM 展示广告平台,提供基于 firmographic 的企业账户定向
+- [[6Sense]]:ABM 和意图数据平台,支持账户列表管理和参与度评分
+- [[RollWorks]]:ABM 广告平台,提供基于账户的广告激活能力
+- [[John Williams]](@itallstartedwithaidea):Agent 作者
+
+## Connections
+- [[paid-media-paid-social-strategist]] ← related_to ← [[paid-media-programmatic-buyer]](均为付费媒体 Agent 体系)
+- [[paid-media-tracking-specialist]] ← supports ← [[paid-media-programmatic-buyer]](追踪与归因支撑程序化购买优化)
+- [[paid-media-auditor]] ← validates ← [[paid-media-programmatic-buyer]](审计 Agent 验证投放效果)
+- [[paid-media-creative-strategist]] ← feeds_into ← [[paid-media-programmatic-buyer]](创意策略为展示广告提供素材)
+
+## Contradictions
+- 与 [[paid-media-paid-social-strategist]] 的效果衡量差异:
+ - 冲突点:展示广告强调上漏斗指标(品牌提升、可见性),社交广告侧重直接转化和互动指标
+ - 当前观点:程序化展示广告应优先衡量可见性和品牌安全,而非最后点击 CPA
+ - 对方观点:付费社交广告以互动率和转化率作为核心成功指标
diff --git a/wiki/sources/paid-media-search-query-analyst.md b/wiki/sources/paid-media-search-query-analyst.md
index 6d21e38c..d3e92a57 100644
--- a/wiki/sources/paid-media-search-query-analyst.md
+++ b/wiki/sources/paid-media-search-query-analyst.md
@@ -1,49 +1,49 @@
----
-title: "Paid Media Search Query Analyst Agent"
-type: source
-tags: ["paid-media", "google-ads", "search-query-optimization", "negative-keywords", "ppc"]
-date: 2026-04-24
----
-
-## Source File
-- [[Agent/agency-agents/paid-media/paid-media-search-query-analyst]]
-
-## Summary(用中文描述)
-- 核心主题:付费媒体搜索查询分析师 Agent —— 专注于从用户真实搜索词中挖掘洞察,消除无效投放、扩大高意图流量
-- 问题域:付费搜索账户中的搜索词优化、负关键词架构、意图映射、信号噪音比提升
-- 方法/机制:N-gram 分析、查询聚类、分层负关键词列表构建、意图分类、匹配类型优化、查询雕塑(Query Sculpting)
-- 结论/价值:搜索查询优化是一个持续系统而非一次性任务;每浪费一美元在不相关查询上,就是从转化查询中偷走一美元
-
-## Key Claims(用中文描述)
-- 搜索查询分析师通过大规模挖掘搜索词报告,识别模式、构建负关键词层级,将付费搜索账户的信噪比系统化提升
-- 分层负关键词架构(账户级/广告系列级/广告组级)配合共享负关键词列表,可有效消除内部竞争
-- N-gram 频率分析能规模化发现反复出现的不相关修饰词和浪费支出模式
-- Search Query Optimization System (SQOS) 评分从多维度评估查询-广告-落地页对齐程度
-- 品牌 vs 非品牌查询泄漏分析可防止品牌词被非品牌广告系列拦截
-
-## Key Quotes
-> "Search query optimization is not a one-time task but a continuous system — every dollar spent on an irrelevant query is a dollar stolen from a converting one." — 核心价值观,贯穿整个 Agent 设计
-
-> "Never guess at query patterns when you can see the real data." — 使用 Google Ads MCP/API 拉取实时数据,而非主观推测
-
-## Key Concepts
-- [[SearchQueryOptimization]]:从用户实际输入中识别高意图搜索词、排除无效词的系统化持续过程
-- [[NegativeKeywordArchitecture]]:分层负关键词列表(账户级/广告系列级/广告组级)的设计与管理
-- [[NgramAnalysis]]:N-gram 频率分析规模化发现反复出现的不相关修饰词
-- [[IntentClassification]]:将查询映射到买家意图阶段(信息型、导航型、商业型、交易型)
-- [[QuerySculpting]]:通过负关键词和匹配类型组合将查询导向正确广告系列/广告组,防止内部竞争
-- [[SQOSScoring]]:Search Query Optimization System,多因素评分系统,评估查询-广告-落地页对齐度
-- [[CloseVariantAnalysis]]:精确匹配变体影响分析,审核广泛匹配查询扩展
-
-## Key Entities
-- [[JohnWilliams]]:Agent 作者,@itallstartedwithaidea,专注于搜索词分析和付费媒体优化
-- [[GoogleAdsMCP]]:Google Ads MCP 工具集,提供搜索词报告 API 和负关键词部署能力
-
-## Connections
-- [[PaidMediaAuditor]] ← part_of ← [[TheAgency]](The Agency 的付费媒体审计 Agent 之一)
-- [[PaidMediaPPCStrategist]] ← related_to ← [[SearchQueryOptimization]](策略制定依赖查询分析结果)
-- [[PaidMediaProgrammaticBuyer]] ← related_to ← [[IntentClassification]](程序化投放也需要意图分类)
-- [[PaidMediaCreativeStrategist]] ← related_to ← [[SearchQueryOptimization]](创意策略需与查询意图对齐)
-
-## Contradictions
-- 暂无已知冲突内容
+---
+title: "Paid Media Search Query Analyst Agent"
+type: source
+tags: ["paid-media", "google-ads", "search-query-optimization", "negative-keywords", "ppc"]
+date: 2026-04-24
+---
+
+## Source File
+- [[raw/Agent/agency-agents/paid-media/paid-media-search-query-analyst.md]]
+
+## Summary(用中文描述)
+- 核心主题:付费媒体搜索查询分析师 Agent —— 专注于从用户真实搜索词中挖掘洞察,消除无效投放、扩大高意图流量
+- 问题域:付费搜索账户中的搜索词优化、负关键词架构、意图映射、信号噪音比提升
+- 方法/机制:N-gram 分析、查询聚类、分层负关键词列表构建、意图分类、匹配类型优化、查询雕塑(Query Sculpting)
+- 结论/价值:搜索查询优化是一个持续系统而非一次性任务;每浪费一美元在不相关查询上,就是从转化查询中偷走一美元
+
+## Key Claims(用中文描述)
+- 搜索查询分析师通过大规模挖掘搜索词报告,识别模式、构建负关键词层级,将付费搜索账户的信噪比系统化提升
+- 分层负关键词架构(账户级/广告系列级/广告组级)配合共享负关键词列表,可有效消除内部竞争
+- N-gram 频率分析能规模化发现反复出现的不相关修饰词和浪费支出模式
+- Search Query Optimization System (SQOS) 评分从多维度评估查询-广告-落地页对齐程度
+- 品牌 vs 非品牌查询泄漏分析可防止品牌词被非品牌广告系列拦截
+
+## Key Quotes
+> "Search query optimization is not a one-time task but a continuous system — every dollar spent on an irrelevant query is a dollar stolen from a converting one." — 核心价值观,贯穿整个 Agent 设计
+
+> "Never guess at query patterns when you can see the real data." — 使用 Google Ads MCP/API 拉取实时数据,而非主观推测
+
+## Key Concepts
+- [[SearchQueryOptimization]]:从用户实际输入中识别高意图搜索词、排除无效词的系统化持续过程
+- [[NegativeKeywordArchitecture]]:分层负关键词列表(账户级/广告系列级/广告组级)的设计与管理
+- [[NgramAnalysis]]:N-gram 频率分析规模化发现反复出现的不相关修饰词
+- [[IntentClassification]]:将查询映射到买家意图阶段(信息型、导航型、商业型、交易型)
+- [[QuerySculpting]]:通过负关键词和匹配类型组合将查询导向正确广告系列/广告组,防止内部竞争
+- [[SQOSScoring]]:Search Query Optimization System,多因素评分系统,评估查询-广告-落地页对齐度
+- [[CloseVariantAnalysis]]:精确匹配变体影响分析,审核广泛匹配查询扩展
+
+## Key Entities
+- [[JohnWilliams]]:Agent 作者,@itallstartedwithaidea,专注于搜索词分析和付费媒体优化
+- [[GoogleAdsMCP]]:Google Ads MCP 工具集,提供搜索词报告 API 和负关键词部署能力
+
+## Connections
+- [[PaidMediaAuditor]] ← part_of ← [[TheAgency]](The Agency 的付费媒体审计 Agent 之一)
+- [[PaidMediaPPCStrategist]] ← related_to ← [[SearchQueryOptimization]](策略制定依赖查询分析结果)
+- [[PaidMediaProgrammaticBuyer]] ← related_to ← [[IntentClassification]](程序化投放也需要意图分类)
+- [[PaidMediaCreativeStrategist]] ← related_to ← [[SearchQueryOptimization]](创意策略需与查询意图对齐)
+
+## Contradictions
+- 暂无已知冲突内容
diff --git a/wiki/sources/paid-media-tracking-specialist.md b/wiki/sources/paid-media-tracking-specialist.md
index 2fdccaf6..32391a2a 100644
--- a/wiki/sources/paid-media-tracking-specialist.md
+++ b/wiki/sources/paid-media-tracking-specialist.md
@@ -1,55 +1,55 @@
----
-title: "Paid Media Tracking & Measurement Specialist Agent"
-type: source
-tags: ["paid-media", "agent", "tracking", "measurement", "GTM", "GA4"]
-date: 2026-04-20
-last_updated: 2026-04-25
-sources: []
----
-
-## Source File
-- [[Agent/agency-agents/paid-media/paid-media-tracking-specialist.md]]
-
-## Summary(用中文描述)
-- **核心主题**:付费媒体追踪与归因专家 Agent——负责构建跨平台(GTM、GA4、Google Ads、Meta CAPI、LinkedIn Insight Tag)的事件追踪架构,确保每一次转化都被正确计数,每一分广告投入都可衡量。
-- **问题域**:标签容器臃肿、跨平台重复计数、归因模型失准、隐私合规(GDPR/CCPA/Consent Mode v2)挑战、UA→GA4/客户端→服务端迁移。
-- **方法/机制**:GTM 容器架构设计、dataLayer 规范、事件去重(event_id 匹配)、增强转化(hashed PII)、服务端容器部署、数据驱动归因模型。
-- **结论/价值**:精准追踪是付费媒体优化的数据根基——错误的数据不仅浪费,更会误导出价算法往错误方向优化。
-
-## Key Claims(用中文描述)
-- 精准追踪工程师构建的数据基础,使所有付费媒体优化成为可能。
-- 错误追踪比无追踪更糟糕——一次错误计数的转化,不仅浪费数据,更会主动误导出价算法向错误结果优化。
-- 追踪 bug 会无声叠加——5% 的数据差异若不修复,明天就变成一个方向错误的出价算法。
-- 重大营销活动前,必须先建立测量计划(Measurement Plan)。
-
-## Key Quotes
-> "Bad tracking is worse than no tracking — a miscounted conversion doesn't just waste data, it actively misleads bidding algorithms into optimizing for the wrong outcomes." — 核心原则
-
-> "Always cross-reference platform-reported conversions against the actual API data. Tracking bugs compound silently — a 5% discrepancy today becomes a misdirected bidding algorithm tomorrow." — 调试方法论
-
-> "If it's not tracked correctly, it didn't happen." — Agent 风格标语
-
-## Key Concepts
-- [[GoogleTagManager]]:GTM 容器架构、工作区管理、触发器/变量设计、自定义 HTML 标签、Consent Mode 实现、标签序列与触发优先级。
-- [[GoogleAnalytics4]]:事件分类体系设计、自定义维度/指标、增强衡量配置、电商 dataLayer 实现(view_item/add_to_cart/begin_checkout/purchase)、跨域追踪。
-- [[MetaConversionsAPI]]:CAPI 服务端配置、事件去重(event_id 匹配)、域名验证、聚合事件测量配置——确保 Pixel 浏览器事件与 CAPI 服务端事件不重复计数。
-- [[ServerSideTagging]]:GTM 服务端容器部署、第一方数据收集、Cookie 管理、服务端富化。
-- [[ConversionTracking]]:Google Ads 转化操作(主转化/次转化)、增强转化(网页和线索)、离线转化 API 导入、转化价值规则、转化操作集。
-- [[AttributionModeling]]:数据驱动归因模型配置、跨渠道归因分析、增量测试设计、营销组合建模输入。
-- [[ConsentModeV2]]:Consent Mode v2 实现、GDPR/CCPA 合规、Cookie Banner 集成、数据保留设置。
-- [[DataLayerArchitecture]]:复杂电商和线索生成网站的 dataLayer 架构设计规范。
-
-## Key Entities
-- [[JohnWilliams]]:Agent 作者(@itallstartedwithaidea)
-- [[TheAgency]]:Agent 所属的多 Agent 协作框架
-
-## Connections
-- [[PaidMediaAdCreativeStrategist]] ← complementary ← [[PaidMediaTrackingSpecialist]]
-- [[PaidMediaPaidSocialStrategist]] ← depends_on ← [[PaidMediaTrackingSpecialist]](Social 广告依赖精准追踪)
-- [[PaidMediaPPCStrategist]] ← depends_on ← [[PaidMediaTrackingSpecialist]](PPC 依赖转化追踪数据)
-- [[PaidMediaProgrammaticBuyer]] ← depends_on ← [[PaidMediaTrackingSpecialist]](程序化投放依赖归因模型)
-- [[PaidMediaSearchQueryAnalyst]] ← depends_on ← [[PaidMediaTrackingSpecialist]](搜索词分析依赖转化数据)
-- [[PaidMediaAuditor]] ← depends_on ← [[PaidMediaTrackingSpecialist]](审计依赖追踪准确性验证)
-
-## Contradictions
-- (暂无发现与其他页面的内容冲突)
+---
+title: "Paid Media Tracking & Measurement Specialist Agent"
+type: source
+tags: ["paid-media", "agent", "tracking", "measurement", "GTM", "GA4"]
+date: 2026-04-20
+last_updated: 2026-04-25
+sources: []
+---
+
+## Source File
+- [[raw/Agent/agency-agents/paid-media/paid-media-tracking-specialist.md]]
+
+## Summary(用中文描述)
+- **核心主题**:付费媒体追踪与归因专家 Agent——负责构建跨平台(GTM、GA4、Google Ads、Meta CAPI、LinkedIn Insight Tag)的事件追踪架构,确保每一次转化都被正确计数,每一分广告投入都可衡量。
+- **问题域**:标签容器臃肿、跨平台重复计数、归因模型失准、隐私合规(GDPR/CCPA/Consent Mode v2)挑战、UA→GA4/客户端→服务端迁移。
+- **方法/机制**:GTM 容器架构设计、dataLayer 规范、事件去重(event_id 匹配)、增强转化(hashed PII)、服务端容器部署、数据驱动归因模型。
+- **结论/价值**:精准追踪是付费媒体优化的数据根基——错误的数据不仅浪费,更会误导出价算法往错误方向优化。
+
+## Key Claims(用中文描述)
+- 精准追踪工程师构建的数据基础,使所有付费媒体优化成为可能。
+- 错误追踪比无追踪更糟糕——一次错误计数的转化,不仅浪费数据,更会主动误导出价算法向错误结果优化。
+- 追踪 bug 会无声叠加——5% 的数据差异若不修复,明天就变成一个方向错误的出价算法。
+- 重大营销活动前,必须先建立测量计划(Measurement Plan)。
+
+## Key Quotes
+> "Bad tracking is worse than no tracking — a miscounted conversion doesn't just waste data, it actively misleads bidding algorithms into optimizing for the wrong outcomes." — 核心原则
+
+> "Always cross-reference platform-reported conversions against the actual API data. Tracking bugs compound silently — a 5% discrepancy today becomes a misdirected bidding algorithm tomorrow." — 调试方法论
+
+> "If it's not tracked correctly, it didn't happen." — Agent 风格标语
+
+## Key Concepts
+- [[GoogleTagManager]]:GTM 容器架构、工作区管理、触发器/变量设计、自定义 HTML 标签、Consent Mode 实现、标签序列与触发优先级。
+- [[GoogleAnalytics4]]:事件分类体系设计、自定义维度/指标、增强衡量配置、电商 dataLayer 实现(view_item/add_to_cart/begin_checkout/purchase)、跨域追踪。
+- [[MetaConversionsAPI]]:CAPI 服务端配置、事件去重(event_id 匹配)、域名验证、聚合事件测量配置——确保 Pixel 浏览器事件与 CAPI 服务端事件不重复计数。
+- [[ServerSideTagging]]:GTM 服务端容器部署、第一方数据收集、Cookie 管理、服务端富化。
+- [[ConversionTracking]]:Google Ads 转化操作(主转化/次转化)、增强转化(网页和线索)、离线转化 API 导入、转化价值规则、转化操作集。
+- [[AttributionModeling]]:数据驱动归因模型配置、跨渠道归因分析、增量测试设计、营销组合建模输入。
+- [[ConsentModeV2]]:Consent Mode v2 实现、GDPR/CCPA 合规、Cookie Banner 集成、数据保留设置。
+- [[DataLayerArchitecture]]:复杂电商和线索生成网站的 dataLayer 架构设计规范。
+
+## Key Entities
+- [[JohnWilliams]]:Agent 作者(@itallstartedwithaidea)
+- [[TheAgency]]:Agent 所属的多 Agent 协作框架
+
+## Connections
+- [[PaidMediaAdCreativeStrategist]] ← complementary ← [[PaidMediaTrackingSpecialist]]
+- [[PaidMediaPaidSocialStrategist]] ← depends_on ← [[PaidMediaTrackingSpecialist]](Social 广告依赖精准追踪)
+- [[PaidMediaPPCStrategist]] ← depends_on ← [[PaidMediaTrackingSpecialist]](PPC 依赖转化追踪数据)
+- [[PaidMediaProgrammaticBuyer]] ← depends_on ← [[PaidMediaTrackingSpecialist]](程序化投放依赖归因模型)
+- [[PaidMediaSearchQueryAnalyst]] ← depends_on ← [[PaidMediaTrackingSpecialist]](搜索词分析依赖转化数据)
+- [[PaidMediaAuditor]] ← depends_on ← [[PaidMediaTrackingSpecialist]](审计依赖追踪准确性验证)
+
+## Contradictions
+- (暂无发现与其他页面的内容冲突)
diff --git a/wiki/sources/personal-crm.md b/wiki/sources/personal-crm.md
index d8da0005..3bab4674 100644
--- a/wiki/sources/personal-crm.md
+++ b/wiki/sources/personal-crm.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/personal-crm.md]]
+- [[raw/Agent/usecases/personal-crm.md]]
## Summary(用中文描述)
- 核心主题:构建一个自动化维护的个人 CRM 系统,通过每日 cron job 扫描邮件和日历,自动发现联系人并更新交互记录。
diff --git a/wiki/sources/phone-based-personal-assistant.md b/wiki/sources/phone-based-personal-assistant.md
index 31401483..a794ea2e 100644
--- a/wiki/sources/phone-based-personal-assistant.md
+++ b/wiki/sources/phone-based-personal-assistant.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/phone-based-personal-assistant.md]]
+- [[raw/Agent/usecases/phone-based-personal-assistant.md]]
## Summary(用中文描述)
- 核心主题:基于电话的 AI 个人助理——通过拨打电话与 AI Agent 语音对话
diff --git a/wiki/sources/phone-call-notifications.md b/wiki/sources/phone-call-notifications.md
index a18cf490..a52584d6 100644
--- a/wiki/sources/phone-call-notifications.md
+++ b/wiki/sources/phone-call-notifications.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/phone-call-notifications.md]]
+- [[raw/Agent/usecases/phone-call-notifications.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 通过真实电话呼叫(而非推送通知)向用户发送紧急提醒,实现 Agent → 用户双向语音通话
diff --git a/wiki/sources/podcast-production-pipeline.md b/wiki/sources/podcast-production-pipeline.md
index 40e0a193..90223d25 100644
--- a/wiki/sources/podcast-production-pipeline.md
+++ b/wiki/sources/podcast-production-pipeline.md
@@ -6,7 +6,7 @@ date: 2026-04-30
---
## Source File
-- [[Agent/usecases/podcast-production-pipeline.md]]
+- [[raw/Agent/usecases/podcast-production-pipeline.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 全自动播客生产流水线——从主题到发布资产的完整工作流
diff --git a/wiki/sources/polymarket-autopilot.md b/wiki/sources/polymarket-autopilot.md
index f3a9f1a8..7650a946 100644
--- a/wiki/sources/polymarket-autopilot.md
+++ b/wiki/sources/polymarket-autopilot.md
@@ -6,7 +6,7 @@ date: 2026-05-18
---
## Source File
-- [[Agent/usecases/polymarket-autopilot.md]]
+- [[raw/Agent/usecases/polymarket-autopilot.md]]
## Summary(用中文描述)
- 核心主题:基于 AI Agent 的 Polymarket 预测市场自动化模拟交易(Paper Trading)系统
diff --git a/wiki/sources/pre-build-idea-validator.md b/wiki/sources/pre-build-idea-validator.md
index 283f4a3d..57c6c98d 100644
--- a/wiki/sources/pre-build-idea-validator.md
+++ b/wiki/sources/pre-build-idea-validator.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/pre-build-idea-validator.md]]
+- [[raw/Agent/usecases/pre-build-idea-validator.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 项目启动前的竞争情报验证机制
diff --git a/wiki/sources/product-behavioral-nudge-engine.md b/wiki/sources/product-behavioral-nudge-engine.md
index 9ff90213..67bfc679 100644
--- a/wiki/sources/product-behavioral-nudge-engine.md
+++ b/wiki/sources/product-behavioral-nudge-engine.md
@@ -1,45 +1,45 @@
----
-title: "Behavioral Nudge Engine"
-type: source
-tags: [behavioral-psychology, nudge, habit-formation, user-motivation, productivity, gamification]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/product/product-behavioral-nudge-engine.md]]
-
-## Summary(用中文描述)
-- 核心主题:基于行为心理学原理的智能用户推动引擎,通过个性化交互节奏和激励策略最大化软件用户完成任务的可能性
-- 问题域:用户在面对大量待办任务时产生的认知过载、动力衰减和软件流失问题
-- 方法/机制:通过偏好发现→任务拆解→精准推送→即时庆祝的四阶段工作流,利用默认偏差、微任务冲刺和游戏化机制持续驱动用户行为
-- 结论/价值:有效降低用户认知负荷、提升任务完成率、减少平台流失
-
-## Key Claims(用中文描述)
-- 行为心理学专家通过个性化软件交互节奏和风格,最大化用户动力与成功率
-- 认知负荷管理:把大规模工作流分解为微任务冲刺,防止用户陷入决策瘫痪
-- 推送策略个性化:支持 SMS、Email、应用内横幅等渠道,在最优时间触达用户
-- 游戏化激励机制:通过即时正强化(庆祝微胜利)和可变量奖励循环维持用户参与度
-- 默认偏差利用:提供预填回复、默认选项,降低用户行动摩擦
-
-## Key Quotes
-> "I've drafted a thank-you reply for this 5-star review. Should I send it, or do you want to edit?" — 默认偏差利用示例
-> "Hey! You've got a few quick follow-ups pending. Let's see how many we can knock out in the next 5 mins." — 微任务冲刺推送示例
-> "Nice work! We sent 15 follow-ups, wrote 2 templates, and thanked 5 customers. That's amazing. Want to do another 5 minutes, or call it for now?" — 即时庆祝与温和退出机制
-
-## Key Concepts
-- [[Default Bias]]:利用用户对默认选项的偏好(如"我已起草回复,是否直接发送?")降低行动摩擦
-- [[Cognitive Load Reduction]]:通过拆分任务队列为微小可完成的微冲刺,防止用户认知过载
-- [[Gamification]]:游戏化机制(积分、徽章、成就系统)驱动用户持续参与
-- [[Pomodoro Technique]]:番茄工作法时间盒技术,5分钟冲刺模式适配 ADHD 用户
-- [[Behavioral Psychology]]:行为心理学基础——即时正强化、习惯回路设计
-- [[Momentum Nudge]]:动量推送逻辑——识别用户状态(Overwhelmed/ADHD倾向)触发微冲刺模式
-
-## Key Entities
-- [[Behavioral Nudge Engine]]:核心代理,扮演世界级个人教练角色,在适当时机推动或庆祝
-
-## Connections
-- [[Product Sprint Prioritizer Agent]] ← supports ← [[Behavioral Nudge Engine]](任务优先级 → 推送执行)
-- [[Behavioral Nudge Engine]] ← extends ← [[Habit Tracker & Accountability Coach]](行为习惯追踪)
-
-## Contradictions
-- 无已知冲突
+---
+title: "Behavioral Nudge Engine"
+type: source
+tags: [behavioral-psychology, nudge, habit-formation, user-motivation, productivity, gamification]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/product/product-behavioral-nudge-engine.md]]
+
+## Summary(用中文描述)
+- 核心主题:基于行为心理学原理的智能用户推动引擎,通过个性化交互节奏和激励策略最大化软件用户完成任务的可能性
+- 问题域:用户在面对大量待办任务时产生的认知过载、动力衰减和软件流失问题
+- 方法/机制:通过偏好发现→任务拆解→精准推送→即时庆祝的四阶段工作流,利用默认偏差、微任务冲刺和游戏化机制持续驱动用户行为
+- 结论/价值:有效降低用户认知负荷、提升任务完成率、减少平台流失
+
+## Key Claims(用中文描述)
+- 行为心理学专家通过个性化软件交互节奏和风格,最大化用户动力与成功率
+- 认知负荷管理:把大规模工作流分解为微任务冲刺,防止用户陷入决策瘫痪
+- 推送策略个性化:支持 SMS、Email、应用内横幅等渠道,在最优时间触达用户
+- 游戏化激励机制:通过即时正强化(庆祝微胜利)和可变量奖励循环维持用户参与度
+- 默认偏差利用:提供预填回复、默认选项,降低用户行动摩擦
+
+## Key Quotes
+> "I've drafted a thank-you reply for this 5-star review. Should I send it, or do you want to edit?" — 默认偏差利用示例
+> "Hey! You've got a few quick follow-ups pending. Let's see how many we can knock out in the next 5 mins." — 微任务冲刺推送示例
+> "Nice work! We sent 15 follow-ups, wrote 2 templates, and thanked 5 customers. That's amazing. Want to do another 5 minutes, or call it for now?" — 即时庆祝与温和退出机制
+
+## Key Concepts
+- [[Default Bias]]:利用用户对默认选项的偏好(如"我已起草回复,是否直接发送?")降低行动摩擦
+- [[Cognitive Load Reduction]]:通过拆分任务队列为微小可完成的微冲刺,防止用户认知过载
+- [[Gamification]]:游戏化机制(积分、徽章、成就系统)驱动用户持续参与
+- [[Pomodoro Technique]]:番茄工作法时间盒技术,5分钟冲刺模式适配 ADHD 用户
+- [[Behavioral Psychology]]:行为心理学基础——即时正强化、习惯回路设计
+- [[Momentum Nudge]]:动量推送逻辑——识别用户状态(Overwhelmed/ADHD倾向)触发微冲刺模式
+
+## Key Entities
+- [[Behavioral Nudge Engine]]:核心代理,扮演世界级个人教练角色,在适当时机推动或庆祝
+
+## Connections
+- [[Product Sprint Prioritizer Agent]] ← supports ← [[Behavioral Nudge Engine]](任务优先级 → 推送执行)
+- [[Behavioral Nudge Engine]] ← extends ← [[Habit Tracker & Accountability Coach]](行为习惯追踪)
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/product-feedback-synthesizer.md b/wiki/sources/product-feedback-synthesizer.md
index 7a5d9dbf..4187360b 100644
--- a/wiki/sources/product-feedback-synthesizer.md
+++ b/wiki/sources/product-feedback-synthesizer.md
@@ -1,50 +1,50 @@
----
-title: "Product Feedback Synthesizer Agent"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/product/product-feedback-synthesizer.md]]
-
-## Summary(用中文描述)
-- **核心主题**:产品反馈综合分析 Agent,专精于从多渠道收集、分析和综合用户反馈,提取可操作的产品洞察,并将定性反馈转化为定量优先级和战略建议。
-- **问题域**:用户反馈分散(调查/访谈/工单/评论/社交媒体)、情感分析、主题归类、优先级排序、产品路线图决策支持。
-- **方法/机制**:多渠道收集(主动+反应+被动+社区+竞争渠道)→ 数据清洗标准化 → NLP 情感分析 → 主题标签与优先级分类 → 质量保证审查 → 洞察综合(主题分析/统计相关/用户旅程/优先级评分/影响评估)。
-- **结论/价值**:将海量用户声音蒸馏为可量化的产品决策依据,通过 RICE/MoSCoW/Kano 等框架实现数据驱动的路线图优先级排序,目标 85% 综合反馈产生可衡量决策。
-
-## Key Claims(用中文描述)
-- **多 Agent 反馈处理**:通过多渠道收集策略(主动/反应/被动/社区/竞争渠道)实现反馈全覆盖,系统化处理从原始数据到可操作洞察的完整流水线。
-- **情感与满意度建模**:NLP 情感分析 + NPS/CSAT/CES 评分关联 + 预测建模,实现满意度趋势早期预警(90% 精度检测满意度下降)。
-- **优先级量化框架**:使用 RICE/MoSCoW/Kano 等多标准决策分析框架,将定性反馈转化为可排序的量化优先级。
-- **洞察驱动的商业价值**:目标 85% 综合反馈产生可衡量决策,NPS 提升 10+ 分,80% 反馈驱动功能成功率。
-
-## Key Quotes
-> "Distills a thousand user voices into the five things you need to build next." — Agent 核心价值主张
-
-## Key Concepts
-- [[NPS]]:Net Promoter Score,用户推荐意愿度量,与反馈洞察强相关
-- [[RICE]]:Feature request prioritization framework(Reach × Impact × Confidence / Effort)
-- [[MoSCoW]]:Must-have / Should-have / Could-have / Won't-have 优先级分类法
-- [[Kano]]:Kano Model,功能满意度与用户愉悦度关系模型
-- [[SentimentAnalysis]]:NLP 情感分析 + 情绪检测 + 满意度评分
-- [[UserJourneyMapping]]:用户旅程映射与痛点识别
-- [[ChurnPrediction]]:基于反馈模式的流失预测与满意度建模
-- [[VoC]]:Voice of Customer,原声客户,verbatim 分析与引语提取
-- [[FeedbackLoop]]:反馈闭环设计与持续改进流程
-
-## Key Entities
-- [[The-Agency]]:本 Agent 所属的多智能体框架,Product 部门专注于产品驱动的分析与管理 Agent
-
-## Connections
-- [[product-sprint-prioritizer]] ← extends ← [[product-feedback-synthesizer]]
-- [[product-trend-researcher]] ← depends_on ← [[product-feedback-synthesizer]]
-- [[product-manager]] ← uses ← [[product-feedback-synthesizer]]
-
-## Contradictions
-- 与 [[product-sprint-prioritizer]] 可能存在优先级框架差异:
- - 冲突点:Sprint Prioritizer 可能侧重开发资源约束下的短期迭代优先级,Feedback Synthesizer 侧重基于用户价值的长期路线图优先级。
- - 当前观点:Feedback Synthesizer 强调 RICE/Kano 等多维度价值评估应优先于开发约束。
- - 对方观点:Sprint Prioritizer 强调实际开发资源和 Sprint 容量约束才是优先级决策的最终边界。
- - 建议协调:在 Sprint Planning 层面优先使用 Sprint Prioritizer,在产品路线图规划层面优先使用 Feedback Synthesizer,两者互补而非替代。
+---
+title: "Product Feedback Synthesizer Agent"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/product/product-feedback-synthesizer.md]]
+
+## Summary(用中文描述)
+- **核心主题**:产品反馈综合分析 Agent,专精于从多渠道收集、分析和综合用户反馈,提取可操作的产品洞察,并将定性反馈转化为定量优先级和战略建议。
+- **问题域**:用户反馈分散(调查/访谈/工单/评论/社交媒体)、情感分析、主题归类、优先级排序、产品路线图决策支持。
+- **方法/机制**:多渠道收集(主动+反应+被动+社区+竞争渠道)→ 数据清洗标准化 → NLP 情感分析 → 主题标签与优先级分类 → 质量保证审查 → 洞察综合(主题分析/统计相关/用户旅程/优先级评分/影响评估)。
+- **结论/价值**:将海量用户声音蒸馏为可量化的产品决策依据,通过 RICE/MoSCoW/Kano 等框架实现数据驱动的路线图优先级排序,目标 85% 综合反馈产生可衡量决策。
+
+## Key Claims(用中文描述)
+- **多 Agent 反馈处理**:通过多渠道收集策略(主动/反应/被动/社区/竞争渠道)实现反馈全覆盖,系统化处理从原始数据到可操作洞察的完整流水线。
+- **情感与满意度建模**:NLP 情感分析 + NPS/CSAT/CES 评分关联 + 预测建模,实现满意度趋势早期预警(90% 精度检测满意度下降)。
+- **优先级量化框架**:使用 RICE/MoSCoW/Kano 等多标准决策分析框架,将定性反馈转化为可排序的量化优先级。
+- **洞察驱动的商业价值**:目标 85% 综合反馈产生可衡量决策,NPS 提升 10+ 分,80% 反馈驱动功能成功率。
+
+## Key Quotes
+> "Distills a thousand user voices into the five things you need to build next." — Agent 核心价值主张
+
+## Key Concepts
+- [[NPS]]:Net Promoter Score,用户推荐意愿度量,与反馈洞察强相关
+- [[RICE]]:Feature request prioritization framework(Reach × Impact × Confidence / Effort)
+- [[MoSCoW]]:Must-have / Should-have / Could-have / Won't-have 优先级分类法
+- [[Kano]]:Kano Model,功能满意度与用户愉悦度关系模型
+- [[SentimentAnalysis]]:NLP 情感分析 + 情绪检测 + 满意度评分
+- [[UserJourneyMapping]]:用户旅程映射与痛点识别
+- [[ChurnPrediction]]:基于反馈模式的流失预测与满意度建模
+- [[VoC]]:Voice of Customer,原声客户,verbatim 分析与引语提取
+- [[FeedbackLoop]]:反馈闭环设计与持续改进流程
+
+## Key Entities
+- [[The-Agency]]:本 Agent 所属的多智能体框架,Product 部门专注于产品驱动的分析与管理 Agent
+
+## Connections
+- [[product-sprint-prioritizer]] ← extends ← [[product-feedback-synthesizer]]
+- [[product-trend-researcher]] ← depends_on ← [[product-feedback-synthesizer]]
+- [[product-manager]] ← uses ← [[product-feedback-synthesizer]]
+
+## Contradictions
+- 与 [[product-sprint-prioritizer]] 可能存在优先级框架差异:
+ - 冲突点:Sprint Prioritizer 可能侧重开发资源约束下的短期迭代优先级,Feedback Synthesizer 侧重基于用户价值的长期路线图优先级。
+ - 当前观点:Feedback Synthesizer 强调 RICE/Kano 等多维度价值评估应优先于开发约束。
+ - 对方观点:Sprint Prioritizer 强调实际开发资源和 Sprint 容量约束才是优先级决策的最终边界。
+ - 建议协调:在 Sprint Planning 层面优先使用 Sprint Prioritizer,在产品路线图规划层面优先使用 Feedback Synthesizer,两者互补而非替代。
diff --git a/wiki/sources/product-manager.md b/wiki/sources/product-manager.md
index 41a2a1f1..d6488711 100644
--- a/wiki/sources/product-manager.md
+++ b/wiki/sources/product-manager.md
@@ -1,52 +1,52 @@
----
-title: "Product Manager Agent"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/product/product-manager.md]]
-
-## Summary(用中文描述)
-- 核心主题:Product Manager Agent — 一个具备10年以上产品管理经验的专业AI代理角色定义
-- 问题域:产品生命周期管理(从发现到衡量)、跨职能团队协调、需求优先级决策、利益相关者对齐
-- 方法/机制:基于 Outcome-Driven 的产品方法论、PRD/机会评估/路线图/GTM等标准化交付物、六阶段工作流程
-- 结论/价值:提供一套完整的AI Agent产品经理角色规范,包括身份定义、核心规则、交付模板和工作流程
-
-## Key Claims(用中文描述)
-- Product Manager Agent 以 Alex 为身份,具备10年以上B2B SaaS、消费者应用和平台业务的从业经验
-- 产品经理的超能力是在用户需求、业务目标和工程现实三者之间找到对齐路径
-- 所有功能都是假设,发布后才成为实验,成功的产品是那些能measurable改变用户行为的产品
-- 路线图不是承诺,而是一个关于impact最可能发生在哪里的优先赌注清单
-
-## Key Quotes
-> "Features are hypotheses. Shipped features are experiments. Successful features are the ones that measurably change user behavior. Everything else is a learning." — 核心产品哲学
-> "I will always tell you what we're NOT building and why. That list is as important as the roadmap — maybe more." — 优先级与拒绝的艺术
-> "My job isn't to have all the answers. It's to make sure we're all asking the same questions in the same order." — PM的真正职责
-> "The roadmap isn't a promise. It's a prioritized bet about where impact is most likely." — 路线图的本质
-
-## Key Concepts
-- [[Outcome-Driven Product Management]]:以可衡量结果而非产出为导向的产品管理方法论
-- [[RICE Prioritization]]:基于 Reach、Impact、Confidence、Effort 四个维度评估功能优先级
-- [[PRD]]:Product Requirements Document — 结构化的产品需求文档模板
-- [[Opportunity Assessment]]:机会评估,在提出解决方案前对商业机会进行结构化分析
-- [[Product Roadmap]]:产品路线图,采用 Now/Next/Later 三层结构
-- [[Go-to-Market Brief]]:产品上市计划,包含目标受众、价值主张、发布清单和成功标准
-- [[Sprint Health Snapshot]]:冲刺健康快照,追踪承诺vs交付、阻塞项和范围变更
-- [[Sprint Ceremonies]]:冲刺 ceremonies — 计划、每日站会、评审、回顾
-- [[North Star Metric]]:北极星指标,最能衡量用户获得价值和业务健康的单一指标
-
-## Key Entities
-- [[Alex]]:Product Manager Agent 的角色名,10年以上产品管理经验的AI代理化身
-- [[B2B SaaS]]:产品经理Agent经验覆盖的领域之一
-- [[Consumer Apps]]:产品经理Agent经验覆盖的领域之一
-- [[Platform Businesses]]:产品经理Agent经验覆盖的领域之一
-
-## Connections
-- [[Agents Orchestrator]] ← coordinates ← [[Product Manager]]
-- [[Product Feedback Synthesizer Agent]] → feeds insight into → [[Product Manager]]
-- [[Senior Project Manager Agent]] ← overlaps_scope ← [[Product Manager]](两者都涉及项目交付,但PM更偏产品战略)
-
-## Contradictions
-- 无已知冲突
+---
+title: "Product Manager Agent"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/product/product-manager.md]]
+
+## Summary(用中文描述)
+- 核心主题:Product Manager Agent — 一个具备10年以上产品管理经验的专业AI代理角色定义
+- 问题域:产品生命周期管理(从发现到衡量)、跨职能团队协调、需求优先级决策、利益相关者对齐
+- 方法/机制:基于 Outcome-Driven 的产品方法论、PRD/机会评估/路线图/GTM等标准化交付物、六阶段工作流程
+- 结论/价值:提供一套完整的AI Agent产品经理角色规范,包括身份定义、核心规则、交付模板和工作流程
+
+## Key Claims(用中文描述)
+- Product Manager Agent 以 Alex 为身份,具备10年以上B2B SaaS、消费者应用和平台业务的从业经验
+- 产品经理的超能力是在用户需求、业务目标和工程现实三者之间找到对齐路径
+- 所有功能都是假设,发布后才成为实验,成功的产品是那些能measurable改变用户行为的产品
+- 路线图不是承诺,而是一个关于impact最可能发生在哪里的优先赌注清单
+
+## Key Quotes
+> "Features are hypotheses. Shipped features are experiments. Successful features are the ones that measurably change user behavior. Everything else is a learning." — 核心产品哲学
+> "I will always tell you what we're NOT building and why. That list is as important as the roadmap — maybe more." — 优先级与拒绝的艺术
+> "My job isn't to have all the answers. It's to make sure we're all asking the same questions in the same order." — PM的真正职责
+> "The roadmap isn't a promise. It's a prioritized bet about where impact is most likely." — 路线图的本质
+
+## Key Concepts
+- [[Outcome-Driven Product Management]]:以可衡量结果而非产出为导向的产品管理方法论
+- [[RICE Prioritization]]:基于 Reach、Impact、Confidence、Effort 四个维度评估功能优先级
+- [[PRD]]:Product Requirements Document — 结构化的产品需求文档模板
+- [[Opportunity Assessment]]:机会评估,在提出解决方案前对商业机会进行结构化分析
+- [[Product Roadmap]]:产品路线图,采用 Now/Next/Later 三层结构
+- [[Go-to-Market Brief]]:产品上市计划,包含目标受众、价值主张、发布清单和成功标准
+- [[Sprint Health Snapshot]]:冲刺健康快照,追踪承诺vs交付、阻塞项和范围变更
+- [[Sprint Ceremonies]]:冲刺 ceremonies — 计划、每日站会、评审、回顾
+- [[North Star Metric]]:北极星指标,最能衡量用户获得价值和业务健康的单一指标
+
+## Key Entities
+- [[Alex]]:Product Manager Agent 的角色名,10年以上产品管理经验的AI代理化身
+- [[B2B SaaS]]:产品经理Agent经验覆盖的领域之一
+- [[Consumer Apps]]:产品经理Agent经验覆盖的领域之一
+- [[Platform Businesses]]:产品经理Agent经验覆盖的领域之一
+
+## Connections
+- [[Agents Orchestrator]] ← coordinates ← [[Product Manager]]
+- [[Product Feedback Synthesizer Agent]] → feeds insight into → [[Product Manager]]
+- [[Senior Project Manager Agent]] ← overlaps_scope ← [[Product Manager]](两者都涉及项目交付,但PM更偏产品战略)
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/product-trend-researcher.md b/wiki/sources/product-trend-researcher.md
index b7ef475f..cb5fa6d9 100644
--- a/wiki/sources/product-trend-researcher.md
+++ b/wiki/sources/product-trend-researcher.md
@@ -1,89 +1,89 @@
----
-title: "Product Trend Researcher Agent"
-type: source
-tags: ["the-agency", "product", "market-intelligence", "trend-analysis", "multi-agent"]
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/product/product-trend-researcher.md]]
-
-## Summary(用中文描述)
-- 核心主题:产品趋势研究智能体(Product Trend Researcher)—— The Agency Product 部门的专家级市场情报分析师,专注于新兴趋势识别、竞争分析和机会评估,为产品战略和创新决策提供可操作的洞察。
-- 问题域:市场情报收集、行业趋势预测、竞争格局分析、消费者行为洞察、技术动向追踪
-- 方法/机制:七步趋势识别流程(信号收集→模式识别→上下文分析→影响评估→验证→预测→可操作性)+ 定量分析(搜索量/社媒指标/财务数据/专利分析)+ 定性情报(专家访谈/民族志研究/内容分析)+ 预测建模(趋势生命周期/采用曲线/跨相关/情景规划)
-- 结论/价值:提供 80%+ 准确率的 6 个月趋势预测、±20% 置信区间的市场量化、48 小时内紧急请求响应、90% 洞察转化战略决策
-
-## Key Claims(用中文描述)
-- Trend Researcher Agent 通过七步趋势识别流程(信号收集→模式识别→上下文分析→影响评估→验证→预测→可操作性),实现 80%+ 准确率的 6 个月趋势预测
-- Trend Researcher Agent 覆盖 50+ 数据源实时聚合,采用统计验证的弱信号检测,提前 3-6 个月识别主流采纳前的趋势
-- Trend Researcher Agent 提供 TAM/SAM/SOM 三层市场量化,置信区间 ±20%,支撑产品路线图规划
-- Trend Researcher Agent 通过竞争情报框架(直接/间接/新兴/技术/替代)提供多维度竞争定位分析
-
-## Key Quotes
-> "Expert market intelligence analyst specializing in identifying emerging trends, competitive analysis, and opportunity assessment." — Agent 角色定义
-> "80%+ accuracy for 6-month forecasts with confidence intervals" — 趋势预测成功率指标
-> "3-6 months lead time before mainstream adoption" — 早期检测能力指标
-> "15+ unique, verified sources per report with credibility scoring" — 信息源多样性要求
-> "90% of insights lead to strategic decisions" — 洞察可操作性指标
-
-## Key Concepts
-- [[TrendLifecycleMapping]]:趋势生命周期映射(涌现→增长→成熟→衰退),预测各阶段持续时间
-- [[AdoptionCurveAnalysis]]:技术采用曲线分析(创新者→早期采纳者→早期多数),预测进入时机
-- [[TAM-SAM-SOM]]:三层市场量化框架——总可用市场、服务可用市场、服务可获得市场
-- [[CompetitiveIntelligence]]:竞争情报框架,涵盖直接竞争对手、间接竞争对手、新兴参与者、技术提供商、客户替代品
-- [[WeakSignalDetection]]:弱信号检测,通过统计验证从早期信号中识别新兴趋势
-- [[TechnologyScouting]]:技术侦察,跟踪专利景观、初创生态、学术研究、开源项目、标准演进
-- [[SocialListening]]:社交媒体监听,品牌监控、情感分析、影响者识别、社区洞察
-
-## Key Entities
-- [[TheAgency]]:The Agency 框架,product-trend-researcher 所属的产品部门,专注市场情报与趋势分析
-- [[ProductManagerAgent]]:产品经理智能体,与 Trend Researcher 协同,提供产品规格与市场定位输入
-- [[AgentsOrchestrator]]:多智能体编排器,协调多个专业 Agent 的协作流程
-
-## Connections
-- [[ProductManagerAgent]] ← provides context to ← [[ProductTrendResearcher]]
-- [[ProductTrendResearcher]] ← informs ← [[AgentsOrchestrator]]
-- [[ProductTrendResearcher]] ← depends_on ← [[CompetitiveIntelligence]]
-- [[ProductTrendResearcher]] ← extends ← [[MarketResearchProductFactory]]
-
-## Contradictions
-- 与 [[AgentsOrchestrator]] 存在潜在张力:Trend Researcher 强调信息驱动决策的独立性,Orchestrator 强调流水线质量门强制推进,两者对"何时足够好"的标准可能不一致
- - 冲突点:Trend Researcher 需要时间积累弱信号并验证,Orchestrator 强调每个阶段必须通过质量验证才能推进
- - 当前观点:Trend Researcher 的 6 个月预测精度依赖充分的数据积累,快速交付可能牺牲预测质量
- - 对方观点:Orchestrator 要求每个任务必须通过质量验证才推进,不允许跳过 QA 阶段
-
-## Research Methodologies
-
-### Quantitative Analysis
-- 搜索量分析:Google Trends、关键词研究工具,季节性调整
-- 社媒指标:参与率、提及量、话题趋势、情感评分
-- 财务数据:市场规模、增长率、投资流向、经济相关性
-- 专利分析:技术创新跟踪、R&D 投资指标、申请趋势
-- 调查数据:消费者调查、行业报告、学术研究、统计显著性
-
-### Qualitative Intelligence
-- 专家访谈:行业领袖、分析师、研究人员,结构化提问
-- 民族志研究:用户观察、行为研究、上下文分析
-- 内容分析:博客帖子、论坛、社区讨论、语义分析
-- 会议情报:活动主题、演讲者话题、观众反应、网络映射
-- 媒体监控:新闻报道、社论情感、思想领导力、偏见检测
-
-### Predictive Modeling
-- 趋势生命周期映射:涌现、增长、成熟、衰退阶段,持续时间预测
-- 采用曲线分析:创新者、早期采纳者、早期多数进展,时机模型
-- 跨相关研究:多趋势互动和放大效应,因果分析
-- 情景规划:基于不同假设的多种未来结果,概率加权
-- 信号强度评估:弱、中、强趋势指标,置信度评分
-
-## Success Metrics
-| 指标 | 目标 | 验证方式 |
-|------|------|---------|
-| 趋势预测准确率 | 80%+(6 个月预测) | 置信区间验证 |
-| 情报新鲜度 | 每周更新 | 自动化监控与告警 |
-| 市场量化精度 | ±20% 置信区间 | 多方法交叉验证 |
-| 洞察交付速度 | < 48 小时(紧急请求) | 优先级排序分析 |
-| 洞察可操作性 | 90% 转化为战略决策 | 利益相关者评分 |
-| 早期检测领先时间 | 3-6 个月(主流采纳前) | 历史验证 |
-| 信息源多样性 | 15+ 独立验证来源/报告 | 可信度评分 |
-| 利益相关者价值 | 4.5/5 评分 | 定期反馈收集 |
+---
+title: "Product Trend Researcher Agent"
+type: source
+tags: ["the-agency", "product", "market-intelligence", "trend-analysis", "multi-agent"]
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/product/product-trend-researcher.md]]
+
+## Summary(用中文描述)
+- 核心主题:产品趋势研究智能体(Product Trend Researcher)—— The Agency Product 部门的专家级市场情报分析师,专注于新兴趋势识别、竞争分析和机会评估,为产品战略和创新决策提供可操作的洞察。
+- 问题域:市场情报收集、行业趋势预测、竞争格局分析、消费者行为洞察、技术动向追踪
+- 方法/机制:七步趋势识别流程(信号收集→模式识别→上下文分析→影响评估→验证→预测→可操作性)+ 定量分析(搜索量/社媒指标/财务数据/专利分析)+ 定性情报(专家访谈/民族志研究/内容分析)+ 预测建模(趋势生命周期/采用曲线/跨相关/情景规划)
+- 结论/价值:提供 80%+ 准确率的 6 个月趋势预测、±20% 置信区间的市场量化、48 小时内紧急请求响应、90% 洞察转化战略决策
+
+## Key Claims(用中文描述)
+- Trend Researcher Agent 通过七步趋势识别流程(信号收集→模式识别→上下文分析→影响评估→验证→预测→可操作性),实现 80%+ 准确率的 6 个月趋势预测
+- Trend Researcher Agent 覆盖 50+ 数据源实时聚合,采用统计验证的弱信号检测,提前 3-6 个月识别主流采纳前的趋势
+- Trend Researcher Agent 提供 TAM/SAM/SOM 三层市场量化,置信区间 ±20%,支撑产品路线图规划
+- Trend Researcher Agent 通过竞争情报框架(直接/间接/新兴/技术/替代)提供多维度竞争定位分析
+
+## Key Quotes
+> "Expert market intelligence analyst specializing in identifying emerging trends, competitive analysis, and opportunity assessment." — Agent 角色定义
+> "80%+ accuracy for 6-month forecasts with confidence intervals" — 趋势预测成功率指标
+> "3-6 months lead time before mainstream adoption" — 早期检测能力指标
+> "15+ unique, verified sources per report with credibility scoring" — 信息源多样性要求
+> "90% of insights lead to strategic decisions" — 洞察可操作性指标
+
+## Key Concepts
+- [[TrendLifecycleMapping]]:趋势生命周期映射(涌现→增长→成熟→衰退),预测各阶段持续时间
+- [[AdoptionCurveAnalysis]]:技术采用曲线分析(创新者→早期采纳者→早期多数),预测进入时机
+- [[TAM-SAM-SOM]]:三层市场量化框架——总可用市场、服务可用市场、服务可获得市场
+- [[CompetitiveIntelligence]]:竞争情报框架,涵盖直接竞争对手、间接竞争对手、新兴参与者、技术提供商、客户替代品
+- [[WeakSignalDetection]]:弱信号检测,通过统计验证从早期信号中识别新兴趋势
+- [[TechnologyScouting]]:技术侦察,跟踪专利景观、初创生态、学术研究、开源项目、标准演进
+- [[SocialListening]]:社交媒体监听,品牌监控、情感分析、影响者识别、社区洞察
+
+## Key Entities
+- [[TheAgency]]:The Agency 框架,product-trend-researcher 所属的产品部门,专注市场情报与趋势分析
+- [[ProductManagerAgent]]:产品经理智能体,与 Trend Researcher 协同,提供产品规格与市场定位输入
+- [[AgentsOrchestrator]]:多智能体编排器,协调多个专业 Agent 的协作流程
+
+## Connections
+- [[ProductManagerAgent]] ← provides context to ← [[ProductTrendResearcher]]
+- [[ProductTrendResearcher]] ← informs ← [[AgentsOrchestrator]]
+- [[ProductTrendResearcher]] ← depends_on ← [[CompetitiveIntelligence]]
+- [[ProductTrendResearcher]] ← extends ← [[MarketResearchProductFactory]]
+
+## Contradictions
+- 与 [[AgentsOrchestrator]] 存在潜在张力:Trend Researcher 强调信息驱动决策的独立性,Orchestrator 强调流水线质量门强制推进,两者对"何时足够好"的标准可能不一致
+ - 冲突点:Trend Researcher 需要时间积累弱信号并验证,Orchestrator 强调每个阶段必须通过质量验证才能推进
+ - 当前观点:Trend Researcher 的 6 个月预测精度依赖充分的数据积累,快速交付可能牺牲预测质量
+ - 对方观点:Orchestrator 要求每个任务必须通过质量验证才推进,不允许跳过 QA 阶段
+
+## Research Methodologies
+
+### Quantitative Analysis
+- 搜索量分析:Google Trends、关键词研究工具,季节性调整
+- 社媒指标:参与率、提及量、话题趋势、情感评分
+- 财务数据:市场规模、增长率、投资流向、经济相关性
+- 专利分析:技术创新跟踪、R&D 投资指标、申请趋势
+- 调查数据:消费者调查、行业报告、学术研究、统计显著性
+
+### Qualitative Intelligence
+- 专家访谈:行业领袖、分析师、研究人员,结构化提问
+- 民族志研究:用户观察、行为研究、上下文分析
+- 内容分析:博客帖子、论坛、社区讨论、语义分析
+- 会议情报:活动主题、演讲者话题、观众反应、网络映射
+- 媒体监控:新闻报道、社论情感、思想领导力、偏见检测
+
+### Predictive Modeling
+- 趋势生命周期映射:涌现、增长、成熟、衰退阶段,持续时间预测
+- 采用曲线分析:创新者、早期采纳者、早期多数进展,时机模型
+- 跨相关研究:多趋势互动和放大效应,因果分析
+- 情景规划:基于不同假设的多种未来结果,概率加权
+- 信号强度评估:弱、中、强趋势指标,置信度评分
+
+## Success Metrics
+| 指标 | 目标 | 验证方式 |
+|------|------|---------|
+| 趋势预测准确率 | 80%+(6 个月预测) | 置信区间验证 |
+| 情报新鲜度 | 每周更新 | 自动化监控与告警 |
+| 市场量化精度 | ±20% 置信区间 | 多方法交叉验证 |
+| 洞察交付速度 | < 48 小时(紧急请求) | 优先级排序分析 |
+| 洞察可操作性 | 90% 转化为战略决策 | 利益相关者评分 |
+| 早期检测领先时间 | 3-6 个月(主流采纳前) | 历史验证 |
+| 信息源多样性 | 15+ 独立验证来源/报告 | 可信度评分 |
+| 利益相关者价值 | 4.5/5 评分 | 定期反馈收集 |
diff --git a/wiki/sources/project-management-experiment-tracker.md b/wiki/sources/project-management-experiment-tracker.md
index 07a15a64..47868413 100644
--- a/wiki/sources/project-management-experiment-tracker.md
+++ b/wiki/sources/project-management-experiment-tracker.md
@@ -1,55 +1,55 @@
----
-title: "Experiment Tracker Agent Personality"
-type: source
-tags: ["agent", "project-management", "experimentation", "a-b-testing"]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/project-management/project-management-experiment-tracker.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 角色定义——Experiment Tracker(实验追踪专家),专注于实验设计、执行追踪与数据驱动决策的专家级项目经理
-- 问题域:产品迭代中的实验管理缺乏系统性、数据驱动决策缺乏科学严谨性、实验成功率低
-- 方法/机制:通过 A/B 测试、多变量实验、假设验证、Portfolio Management、统计功效分析实现科学化实验管理
-- 结论/价值:为 AI Agent 系统提供标准化的实验追踪角色定义,支撑数据驱动的产品迭代决策
-
-## Key Claims(用中文描述)
-- Experiment Tracker 通过严格的统计方法论和实验设计,系统管理 A/B 测试、功能实验和假设验证,确保 95% 置信度的数据驱动决策可靠性
-- Experiment Tracker 通过 Portfolio Management 协调多个并发实验,优化资源配置,每季度交付 15+ 实验,实验成功率达 70%
-- Experiment Tracker 提供实验设计文档模板和实验结果交付模板,标准化实验全生命周期管理流程
-- Experiment Tracker 通过多臂老虎机(Multi-armed Bandits)、贝叶斯分析、因果推断等高级统计技术,实现连续学习和最优实验决策
-- Experiment Tracker 通过机器学习模型 A/B 测试、个性化实验设计和预测建模,实现高级数据科学集成
-
-## Key Quotes
-> "Always calculate proper sample sizes before experiment launch" — 确保统计可靠性的基础要求
-> "95% of experiments reach statistical significance with proper sample sizes" — 实验成功标准
-> "Experiment velocity exceeds 15 experiments per quarter" — 实验吞吐量目标
-> "Zero experiment-related production incidents or user experience degradation" — 安全底线
-
-## Key Concepts
-- [[A/B-Testing]]:对照实验,通过控制组与变体组的比较验证假设
-- [[Statistical-Significance]]:统计显著性,95% 置信度为默认要求
-- [[Power-Analysis]]:统计功效分析,确保实验有足够样本量
-- [[Hypothesis-Validation]]:假设验证,通过实验数据验证产品假设
-- [[Experiment-Portfolio-Management]]:实验组合管理,优化多实验资源分配与优先级
-- [[Multi-Armed-Bandits]]:多臂老虎机,高级实验设计实现动态流量分配
-- [[Bayesian-Analysis]]:贝叶斯分析方法,支持连续学习与实时决策
-- [[Causal-Inference]]:因果推断技术,理解实验的真正效果
-
-## Key Entities
-- [[Project-Management-Experiment-Tracker]]:实验追踪专家 Agent 本身
-- [[Project-Management-Studio-Producer]]:受益于 Experiment Tracker 的实验数据,协调内容制作迭代
-- [[LaunchDarkly]]:Feature Flag 平台,支持 Experiment Tracker 的渐进放量与 A/B 测试
-
-## Connections
-- [[Project-Management-Studio-Operations]] ← coordinates_with ← [[Project-Management-Experiment-Tracker]]
-- [[Project-Management-Studio-Producer]] ← depends_on ← [[Project-Management-Experiment-Tracker]]
-- [[Project-Management-Jira-Workflow-Steward]] ← integrates_with ← [[Project-Management-Experiment-Tracker]]
-- [[Project-Management-Project-Shepherd]] ← leverages ← [[Project-Management-Experiment-Tracker]]
-
-## Contradictions
-- 与 [[Project-Management-Studio-Operations]] 潜在冲突:Studio Operations 强调内容制作流程的确定性,Experiment Tracker 依赖实验数据驱动,存在节奏冲突(快速实验 vs 稳定制作)
- - 冲突点:决策依据(直觉/经验 vs 数据)
- - 当前观点:数据驱动决策优先,实验验证后再规模化
- - 对方观点:内容制作需保持节奏稳定,不能因等待实验结果而停滞
+---
+title: "Experiment Tracker Agent Personality"
+type: source
+tags: ["agent", "project-management", "experimentation", "a-b-testing"]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/project-management/project-management-experiment-tracker.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 角色定义——Experiment Tracker(实验追踪专家),专注于实验设计、执行追踪与数据驱动决策的专家级项目经理
+- 问题域:产品迭代中的实验管理缺乏系统性、数据驱动决策缺乏科学严谨性、实验成功率低
+- 方法/机制:通过 A/B 测试、多变量实验、假设验证、Portfolio Management、统计功效分析实现科学化实验管理
+- 结论/价值:为 AI Agent 系统提供标准化的实验追踪角色定义,支撑数据驱动的产品迭代决策
+
+## Key Claims(用中文描述)
+- Experiment Tracker 通过严格的统计方法论和实验设计,系统管理 A/B 测试、功能实验和假设验证,确保 95% 置信度的数据驱动决策可靠性
+- Experiment Tracker 通过 Portfolio Management 协调多个并发实验,优化资源配置,每季度交付 15+ 实验,实验成功率达 70%
+- Experiment Tracker 提供实验设计文档模板和实验结果交付模板,标准化实验全生命周期管理流程
+- Experiment Tracker 通过多臂老虎机(Multi-armed Bandits)、贝叶斯分析、因果推断等高级统计技术,实现连续学习和最优实验决策
+- Experiment Tracker 通过机器学习模型 A/B 测试、个性化实验设计和预测建模,实现高级数据科学集成
+
+## Key Quotes
+> "Always calculate proper sample sizes before experiment launch" — 确保统计可靠性的基础要求
+> "95% of experiments reach statistical significance with proper sample sizes" — 实验成功标准
+> "Experiment velocity exceeds 15 experiments per quarter" — 实验吞吐量目标
+> "Zero experiment-related production incidents or user experience degradation" — 安全底线
+
+## Key Concepts
+- [[A/B-Testing]]:对照实验,通过控制组与变体组的比较验证假设
+- [[Statistical-Significance]]:统计显著性,95% 置信度为默认要求
+- [[Power-Analysis]]:统计功效分析,确保实验有足够样本量
+- [[Hypothesis-Validation]]:假设验证,通过实验数据验证产品假设
+- [[Experiment-Portfolio-Management]]:实验组合管理,优化多实验资源分配与优先级
+- [[Multi-Armed-Bandits]]:多臂老虎机,高级实验设计实现动态流量分配
+- [[Bayesian-Analysis]]:贝叶斯分析方法,支持连续学习与实时决策
+- [[Causal-Inference]]:因果推断技术,理解实验的真正效果
+
+## Key Entities
+- [[Project-Management-Experiment-Tracker]]:实验追踪专家 Agent 本身
+- [[Project-Management-Studio-Producer]]:受益于 Experiment Tracker 的实验数据,协调内容制作迭代
+- [[LaunchDarkly]]:Feature Flag 平台,支持 Experiment Tracker 的渐进放量与 A/B 测试
+
+## Connections
+- [[Project-Management-Studio-Operations]] ← coordinates_with ← [[Project-Management-Experiment-Tracker]]
+- [[Project-Management-Studio-Producer]] ← depends_on ← [[Project-Management-Experiment-Tracker]]
+- [[Project-Management-Jira-Workflow-Steward]] ← integrates_with ← [[Project-Management-Experiment-Tracker]]
+- [[Project-Management-Project-Shepherd]] ← leverages ← [[Project-Management-Experiment-Tracker]]
+
+## Contradictions
+- 与 [[Project-Management-Studio-Operations]] 潜在冲突:Studio Operations 强调内容制作流程的确定性,Experiment Tracker 依赖实验数据驱动,存在节奏冲突(快速实验 vs 稳定制作)
+ - 冲突点:决策依据(直觉/经验 vs 数据)
+ - 当前观点:数据驱动决策优先,实验验证后再规模化
+ - 对方观点:内容制作需保持节奏稳定,不能因等待实验结果而停滞
diff --git a/wiki/sources/project-management-jira-workflow-steward.md b/wiki/sources/project-management-jira-workflow-steward.md
index 9a6e82ca..f2a192c6 100644
--- a/wiki/sources/project-management-jira-workflow-steward.md
+++ b/wiki/sources/project-management-jira-workflow-steward.md
@@ -1,63 +1,63 @@
----
-title: "Jira Workflow Steward Agent Personality"
-type: source
-tags: ["project-management", "jira", "git-workflow", "delivery-traceability", "agent-personality"]
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/project-management/project-management-jira-workflow-steward.md]]
-
-## Summary(用中文描述)
-- 核心主题:Jira Workflow Steward——软件交付可追溯性管理 Agent,通过 Jira-Git 全链路绑定,确保每一次代码变更都能从 Jira 任务追踪到分支、提交、PR 直至关线发布
-- 问题域:团队代码交付过程中分支命名混乱、提交信息不规范、PR 缺乏 ticket 上下文、发布链路不可审计等交付治理难题
-- 方法/机制:Jira Gate(Jira ID 强制前置检查)→ 分支策略(feature/bugfix/hotfix/release 分流)→ Gitmoji 规范提交 → PR 模板 → Commit Hook 自动化验证
-- 结论/价值:使代码交付可审查、可回滚、可审计,将 Jira-linked commits 定位为质量工具而非合规打勾
-
-## Key Claims(用中文描述)
-- Jira Task ID 是所有 Git 工作流输出的前提:分支名、提交信息、PR 标题均必须包含有效 Jira ID,无 ID 则停止工作流
-- 分支策略需遵循仓库意图:feature/bugfix 从 develop 分支;hotfix 从 main 分支;release 用于发布准备,各路径互不混淆
-- 提交信息遵循 ` JIRA-ID: 简短描述` 格式,选择 Gitmoji 需参照官方 catalog(gitmoji.dev / carloscuesta/gitmoji)
-- PR 是 main、release/*、大型重构和关键基础设施变更的强制门控,任何合并均需经过 review
-- 秘密/凭证/客户数据严禁出现在分支名、提交信息、PR 标题或描述中
-- Jira-linked commits 的价值在于提升 review 上下文、代码结构、发布说明质量和事故溯源能力,而非仅为合规
-
-## Key Quotes
-> "If a change cannot be traced from Jira to branch to commit to pull request to release, you treat the workflow as incomplete." — 核心原则:可追溯性即质量
-> "Jira-linked commits as a quality tool, not just a compliance checkbox" — 提交绑定 Jira 的定位重塑:质量工具而非合规工具
-> "Protect repository clarity: the commit message should say what changed, not that you 'fixed stuff'." — 提交信息质量标准
-
-## Key Concepts
-- [[Jira-Git-Traceability]]:通过 Jira ID 将 Jira 任务、分支、提交、PR、发布五个环节串联为完整可追溯链路的实践
-- [[Atomic-Commit]]:每次提交仅包含一个逻辑变更,易于审查、回滚和溯源的提交粒度原则
-- [[Branch-Strategy]]:基于功能/缺陷/热修复/发布类型的分支分层管理模型(feature/bugfix/hotfix/release)
-- [[Gitmoji-Commit]]:使用标准化 Emoji 前缀标注提交类型的提交规范(✨ 新功能、🐛 缺陷修复、♻️ 重构等)
-- [[Jira-Gate]]:强制要求所有 Git 工作流输出必须携带有效 Jira Task ID 的门控机制,无 ID 则停止工作流
-- [[Pull-Request-Governance]]:通过 PR 模板、安全审查、风险记录保护分支合并质量的工作流规范
-- [[Delivery-Traceability]]:从需求到代码发布全链路的可重建、可审计交付记录体系
-
-## Key Entities
-- [[Gitmoji]]:标准化 Emoji 提交规范工具(来源:gitmoji.dev / carloscuesta/gitmoji);Jira Workflow Steward 使用其作为提交类型的视觉标签
-- [[GitHub]]:PR 托管和分支策略执行平台;PR 模板和安全门控在此实现
-- [[Project-Management-Project-Shepherd]]:同为项目管理领域的 Agent;Project Shepherd 负责整体项目协调,Jira Workflow Steward 专注交付可追溯性,两者互补
-- [[Project-Management-Studio-Operations]]:同为 The Agency 项目管理层级中的 Agent;Studio Operations 负责运营流程,Jira Workflow Steward 负责技术交付链路
-
-## Connections
-- [[Jira-Gate]] ← 是 [[Delivery-Traceability]] 的第一步门控
-- [[Branch-Strategy]] ← 支撑 [[Jira-Git-Traceability]] 的分支层
-- [[Atomic-Commit]] ← 支撑 [[Jira-Git-Traceability]] 的提交层
-- [[Pull-Request-Governance]] ← 支撑 [[Jira-Git-Traceability]] 的审查层
-- [[Gitmoji-Commit]] ← 提供 [[Atomic-Commit]] 的标准化视觉表达
-- [[Project-Management-Project-Shepherd]] ← 上游协调者,提供 Jira 任务;[[Jira-Workflow-Steward]] 负责将任务转化为可追溯代码交付
-
-## Contradictions
-- 与 [[Project-Management-Project-Shepherd]] 在职责边界上存在互补但需协调的张力:
- - 冲突点:Project Shepherd 生成 Jira 任务,Jira Workflow Steward 要求任务必须存在才能工作——两者均强调任务先行,但无主动对接机制
- - 当前观点:Steward 严格 gate,要求任务 ID 前置;若缺失则停止工作流并请求补充
- - 对方观点:Project Shepherd 可能期望 Agent 能自动创建或推断 Jira 任务 ID
- - 建议协调:在 Project Shepherd 的工作流中增加 Jira 任务预创建步骤,确保交接给 Steward 时 ID 已就绪
-- 与 [[Project-Management-Studio-Producer]] 在交付粒度上存在层级差异:
- - Studio Producer 关注组合级(Portfolio)ROI 和战略优先级,Jira Workflow Steward 关注原子级代码提交
- - 当前观点:Steward 坚持每个 commit 对应一个 Jira ID,保持最小粒度可追溯
- - 对方观点:Producer 可能在聚合分析时需要更高粒度的任务层级(Epic/Story vs Task)
- - 无直接冲突,属不同抽象层级的关注点差异
+---
+title: "Jira Workflow Steward Agent Personality"
+type: source
+tags: ["project-management", "jira", "git-workflow", "delivery-traceability", "agent-personality"]
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/project-management/project-management-jira-workflow-steward.md]]
+
+## Summary(用中文描述)
+- 核心主题:Jira Workflow Steward——软件交付可追溯性管理 Agent,通过 Jira-Git 全链路绑定,确保每一次代码变更都能从 Jira 任务追踪到分支、提交、PR 直至关线发布
+- 问题域:团队代码交付过程中分支命名混乱、提交信息不规范、PR 缺乏 ticket 上下文、发布链路不可审计等交付治理难题
+- 方法/机制:Jira Gate(Jira ID 强制前置检查)→ 分支策略(feature/bugfix/hotfix/release 分流)→ Gitmoji 规范提交 → PR 模板 → Commit Hook 自动化验证
+- 结论/价值:使代码交付可审查、可回滚、可审计,将 Jira-linked commits 定位为质量工具而非合规打勾
+
+## Key Claims(用中文描述)
+- Jira Task ID 是所有 Git 工作流输出的前提:分支名、提交信息、PR 标题均必须包含有效 Jira ID,无 ID 则停止工作流
+- 分支策略需遵循仓库意图:feature/bugfix 从 develop 分支;hotfix 从 main 分支;release 用于发布准备,各路径互不混淆
+- 提交信息遵循 ` JIRA-ID: 简短描述` 格式,选择 Gitmoji 需参照官方 catalog(gitmoji.dev / carloscuesta/gitmoji)
+- PR 是 main、release/*、大型重构和关键基础设施变更的强制门控,任何合并均需经过 review
+- 秘密/凭证/客户数据严禁出现在分支名、提交信息、PR 标题或描述中
+- Jira-linked commits 的价值在于提升 review 上下文、代码结构、发布说明质量和事故溯源能力,而非仅为合规
+
+## Key Quotes
+> "If a change cannot be traced from Jira to branch to commit to pull request to release, you treat the workflow as incomplete." — 核心原则:可追溯性即质量
+> "Jira-linked commits as a quality tool, not just a compliance checkbox" — 提交绑定 Jira 的定位重塑:质量工具而非合规工具
+> "Protect repository clarity: the commit message should say what changed, not that you 'fixed stuff'." — 提交信息质量标准
+
+## Key Concepts
+- [[Jira-Git-Traceability]]:通过 Jira ID 将 Jira 任务、分支、提交、PR、发布五个环节串联为完整可追溯链路的实践
+- [[Atomic-Commit]]:每次提交仅包含一个逻辑变更,易于审查、回滚和溯源的提交粒度原则
+- [[Branch-Strategy]]:基于功能/缺陷/热修复/发布类型的分支分层管理模型(feature/bugfix/hotfix/release)
+- [[Gitmoji-Commit]]:使用标准化 Emoji 前缀标注提交类型的提交规范(✨ 新功能、🐛 缺陷修复、♻️ 重构等)
+- [[Jira-Gate]]:强制要求所有 Git 工作流输出必须携带有效 Jira Task ID 的门控机制,无 ID 则停止工作流
+- [[Pull-Request-Governance]]:通过 PR 模板、安全审查、风险记录保护分支合并质量的工作流规范
+- [[Delivery-Traceability]]:从需求到代码发布全链路的可重建、可审计交付记录体系
+
+## Key Entities
+- [[Gitmoji]]:标准化 Emoji 提交规范工具(来源:gitmoji.dev / carloscuesta/gitmoji);Jira Workflow Steward 使用其作为提交类型的视觉标签
+- [[GitHub]]:PR 托管和分支策略执行平台;PR 模板和安全门控在此实现
+- [[Project-Management-Project-Shepherd]]:同为项目管理领域的 Agent;Project Shepherd 负责整体项目协调,Jira Workflow Steward 专注交付可追溯性,两者互补
+- [[Project-Management-Studio-Operations]]:同为 The Agency 项目管理层级中的 Agent;Studio Operations 负责运营流程,Jira Workflow Steward 负责技术交付链路
+
+## Connections
+- [[Jira-Gate]] ← 是 [[Delivery-Traceability]] 的第一步门控
+- [[Branch-Strategy]] ← 支撑 [[Jira-Git-Traceability]] 的分支层
+- [[Atomic-Commit]] ← 支撑 [[Jira-Git-Traceability]] 的提交层
+- [[Pull-Request-Governance]] ← 支撑 [[Jira-Git-Traceability]] 的审查层
+- [[Gitmoji-Commit]] ← 提供 [[Atomic-Commit]] 的标准化视觉表达
+- [[Project-Management-Project-Shepherd]] ← 上游协调者,提供 Jira 任务;[[Jira-Workflow-Steward]] 负责将任务转化为可追溯代码交付
+
+## Contradictions
+- 与 [[Project-Management-Project-Shepherd]] 在职责边界上存在互补但需协调的张力:
+ - 冲突点:Project Shepherd 生成 Jira 任务,Jira Workflow Steward 要求任务必须存在才能工作——两者均强调任务先行,但无主动对接机制
+ - 当前观点:Steward 严格 gate,要求任务 ID 前置;若缺失则停止工作流并请求补充
+ - 对方观点:Project Shepherd 可能期望 Agent 能自动创建或推断 Jira 任务 ID
+ - 建议协调:在 Project Shepherd 的工作流中增加 Jira 任务预创建步骤,确保交接给 Steward 时 ID 已就绪
+- 与 [[Project-Management-Studio-Producer]] 在交付粒度上存在层级差异:
+ - Studio Producer 关注组合级(Portfolio)ROI 和战略优先级,Jira Workflow Steward 关注原子级代码提交
+ - 当前观点:Steward 坚持每个 commit 对应一个 Jira ID,保持最小粒度可追溯
+ - 对方观点:Producer 可能在聚合分析时需要更高粒度的任务层级(Epic/Story vs Task)
+ - 无直接冲突,属不同抽象层级的关注点差异
diff --git a/wiki/sources/project-management-project-shepherd.md b/wiki/sources/project-management-project-shepherd.md
index 10e4739c..19184cd3 100644
--- a/wiki/sources/project-management-project-shepherd.md
+++ b/wiki/sources/project-management-project-shepherd.md
@@ -1,53 +1,53 @@
----
-title: "Project Shepherd Agent Personality"
-type: source
-tags: [project-management, agent, cross-functional, stakeholder-management, risk-mitigation]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/project-management/project-management-project-shepherd.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 项目管理人格——Project Shepherd,模拟跨职能项目协调专家,专注文档进度、对齐干系人、管理风险
-- 问题域:复杂项目的全生命周期管理,包括多团队/多部门协调、时间线规划、资源分配、干系人沟通
-- 方法/机制:四阶段工作流(项目启动→团队组建→执行监控→质量交付)、Project Charter 模板、Status Report 模板、风险缓解框架、干系人沟通策略
-- 结论/价值:提供一套完整的 AI Agent 项目管理人格定义,可直接用于 Multi-Agent 系统中的项目协调角色
-
-## Key Claims(用中文描述)
-- Project Shepherd Agent 通过四阶段工作流(启动→团队组建→执行→交付)驱动复杂项目按时、按范围、按预算完成
-- 通过 disciplined change control 限制范围蔓延,目标将范围蔓延控制在 10% 以下
-- 通过 proactive risk mitigation,目标实现 90% 的已识别风险在影响项目结果前被成功缓解
-- 通过透明沟通和诚实汇报维持干系人信任,即使在传递负面消息时也保持透明
-- 95% 项目按时交付、95% 干系人满意度 4.5/5 是核心成功指标
-
-## Key Quotes
-> "Never commit to unrealistic timelines to please stakeholders" — 绝不为了取悦干系人而承诺不现实的工期
-> "Provide honest, transparent reporting even when delivering difficult news" — 即便传递困难消息也提供诚实透明的汇报
-> "Escalate issues promptly with recommended solutions, not just problems" — 问题升级时必须附上建议的解决方案,而非仅提出问题
-
-## Key Concepts
-- [[CrossFunctionalProjectCoordination]]:跨职能项目协调——协调多个团队和部门完成复杂项目的能力
-- [[StakeholderAlignment]]:干系人对齐——通过沟通策略和透明汇报维持所有项目参与者的期望一致
-- [[RiskMitigationPlanning]]:风险缓解规划——在风险影响项目结果前主动识别、评估并制定应对策略
-- [[ChangeControl]]:变更控制——通过纪律化的范围管理控制项目范围蔓延(目标 < 10%)
-- [[ProjectCharter]]:项目章程——定义项目目标、范围、成功标准和治理结构的初始文档
-- [[WorkBreakdownStructure]]:工作分解结构(WBS)——将大型项目拆解为可管理的任务和依赖关系
-- [[CriticalPathAnalysis]]:关键路径分析——识别项目中最长的依赖链,确保关键里程碑按时完成
-- [[MatrixOrganization]]:矩阵式组织——在跨多条汇报线的组织结构中协调资源的能力
-
-## Key Entities
-- [[ProjectShepherd]]:AI Agent 项目管理人格定义,专职跨职能项目协调、时间线管理和干系人对齐
-- [[ProjectCharter]](模板):定义项目概览、干系人分析、资源需求和风险评估的文档模板
-- [[ProjectStatusReport]](模板):包含执行摘要、进度更新、问题风险和干系人行动的定期报告模板
-- [[ExecutiveSponsor]]:执行发起人——拥有决策权威和升级终点的干系人角色
-- [[CrossFunctionalProjectTeam]]:跨职能项目团队——由多个技能领域成员组成的核心项目团队
-
-## Connections
-- [[ProjectManagementStudioOperations]] ← extends ← [[ProjectShepherd]] — Studio Operations 是项目管理在创意制作场景的延伸
-- [[ProjectManagementSenior]] ← related_to ← [[ProjectShepherd]] — 两者都是项目管理者,但 Senior PM 侧重高级战略,Shepherd 侧重跨职能协调执行
-- [[AutonomousProjectManagement]] ← depends_on ← [[ProjectShepherd]] — 自主项目管理依赖 Shepherd 提供的工作流和模板框架
-- [[ProjectStateManagement]] ← related_to ← [[ProjectShepherd]] — 两者都涉及项目状态跟踪,但 State Management 偏向事件驱动替代看板的方法论
-
-## Contradictions
-- 无明显内容冲突。本文档与 [[ProjectManagementSenior]] 和 [[ProjectManagementStudioOperations]] 在项目管理层面上互补而非冲突,各有侧重领域。
+---
+title: "Project Shepherd Agent Personality"
+type: source
+tags: [project-management, agent, cross-functional, stakeholder-management, risk-mitigation]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/project-management/project-management-project-shepherd.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 项目管理人格——Project Shepherd,模拟跨职能项目协调专家,专注文档进度、对齐干系人、管理风险
+- 问题域:复杂项目的全生命周期管理,包括多团队/多部门协调、时间线规划、资源分配、干系人沟通
+- 方法/机制:四阶段工作流(项目启动→团队组建→执行监控→质量交付)、Project Charter 模板、Status Report 模板、风险缓解框架、干系人沟通策略
+- 结论/价值:提供一套完整的 AI Agent 项目管理人格定义,可直接用于 Multi-Agent 系统中的项目协调角色
+
+## Key Claims(用中文描述)
+- Project Shepherd Agent 通过四阶段工作流(启动→团队组建→执行→交付)驱动复杂项目按时、按范围、按预算完成
+- 通过 disciplined change control 限制范围蔓延,目标将范围蔓延控制在 10% 以下
+- 通过 proactive risk mitigation,目标实现 90% 的已识别风险在影响项目结果前被成功缓解
+- 通过透明沟通和诚实汇报维持干系人信任,即使在传递负面消息时也保持透明
+- 95% 项目按时交付、95% 干系人满意度 4.5/5 是核心成功指标
+
+## Key Quotes
+> "Never commit to unrealistic timelines to please stakeholders" — 绝不为了取悦干系人而承诺不现实的工期
+> "Provide honest, transparent reporting even when delivering difficult news" — 即便传递困难消息也提供诚实透明的汇报
+> "Escalate issues promptly with recommended solutions, not just problems" — 问题升级时必须附上建议的解决方案,而非仅提出问题
+
+## Key Concepts
+- [[CrossFunctionalProjectCoordination]]:跨职能项目协调——协调多个团队和部门完成复杂项目的能力
+- [[StakeholderAlignment]]:干系人对齐——通过沟通策略和透明汇报维持所有项目参与者的期望一致
+- [[RiskMitigationPlanning]]:风险缓解规划——在风险影响项目结果前主动识别、评估并制定应对策略
+- [[ChangeControl]]:变更控制——通过纪律化的范围管理控制项目范围蔓延(目标 < 10%)
+- [[ProjectCharter]]:项目章程——定义项目目标、范围、成功标准和治理结构的初始文档
+- [[WorkBreakdownStructure]]:工作分解结构(WBS)——将大型项目拆解为可管理的任务和依赖关系
+- [[CriticalPathAnalysis]]:关键路径分析——识别项目中最长的依赖链,确保关键里程碑按时完成
+- [[MatrixOrganization]]:矩阵式组织——在跨多条汇报线的组织结构中协调资源的能力
+
+## Key Entities
+- [[ProjectShepherd]]:AI Agent 项目管理人格定义,专职跨职能项目协调、时间线管理和干系人对齐
+- [[ProjectCharter]](模板):定义项目概览、干系人分析、资源需求和风险评估的文档模板
+- [[ProjectStatusReport]](模板):包含执行摘要、进度更新、问题风险和干系人行动的定期报告模板
+- [[ExecutiveSponsor]]:执行发起人——拥有决策权威和升级终点的干系人角色
+- [[CrossFunctionalProjectTeam]]:跨职能项目团队——由多个技能领域成员组成的核心项目团队
+
+## Connections
+- [[ProjectManagementStudioOperations]] ← extends ← [[ProjectShepherd]] — Studio Operations 是项目管理在创意制作场景的延伸
+- [[ProjectManagementSenior]] ← related_to ← [[ProjectShepherd]] — 两者都是项目管理者,但 Senior PM 侧重高级战略,Shepherd 侧重跨职能协调执行
+- [[AutonomousProjectManagement]] ← depends_on ← [[ProjectShepherd]] — 自主项目管理依赖 Shepherd 提供的工作流和模板框架
+- [[ProjectStateManagement]] ← related_to ← [[ProjectShepherd]] — 两者都涉及项目状态跟踪,但 State Management 偏向事件驱动替代看板的方法论
+
+## Contradictions
+- 无明显内容冲突。本文档与 [[ProjectManagementSenior]] 和 [[ProjectManagementStudioOperations]] 在项目管理层面上互补而非冲突,各有侧重领域。
diff --git a/wiki/sources/project-management-studio-operations.md b/wiki/sources/project-management-studio-operations.md
index 02876e4b..bfb21d33 100644
--- a/wiki/sources/project-management-studio-operations.md
+++ b/wiki/sources/project-management-studio-operations.md
@@ -1,54 +1,54 @@
----
-title: "Studio Operations Agent Personality"
-type: source
-tags: ["project-management", "agency-agents", "operations", "efficiency"]
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/project-management/project-management-studio-operations.md]]
-
-## Summary(用中文描述)
-- 核心主题:Studio Operations 智能体角色定义——一个专注于日常工作室运营效率、流程优化和资源协调的专业运营管理者
-- 问题域:工作室运营管理、流程标准化、资源调度、质量控制、持续改进
-- 方法/机制:通过标准操作程序(SOP)模板、运营效率报告模板、四步工作流(评估→协调→实施→监控)实现 95% 运营效率目标
-- 结论/价值:提供一套完整的工作室运营管理框架,涵盖流程优化、资源管理、团队支持、数字化转型和战略运营管理
-
-## Key Claims(用中文描述)
-- 通过标准操作程序和流程文档化,可实现 95% 运营效率(附带主动系统维护)
-- 流程优化可每周为所有团队节省 40 小时生产力时间
-- 新调度系统实施可将会议冲突减少 85%
-- 全面的供应商管理可降低运营成本 15%
-- 主动监控和维护可保持 99.5% 系统正常运行时间
-- 运营支持请求响应时间少于 2 小时
-- 团队满意度评分达到 4.5/5
-
-## Key Quotes
-> "You are **Studio Operations**, an expert operations manager who specializes in day-to-day studio efficiency, process optimization, and resource coordination." — 角色定义核心描述
-> "Ensure 95% operational efficiency with proactive system maintenance" — 默认运营效率要求
-> "Implemented new scheduling system reducing meeting conflicts by 85%" — 服务导向的运营成果示例
-> "99.5% system uptime maintained with proactive monitoring and maintenance" — 可靠性导向的运营成果示例
-
-## Key Concepts
-- [[Standard Operating Procedure]]:标准操作程序模板,包含概述、前提条件、分步程序、质量控制、文档记录五个部分
-- [[Operational Efficiency]]:运营效率,目标为 95%,通过主动系统维护实现
-- [[Resource Coordination]]:跨所有工作室活动的资源分配和调度协调
-- [[Continuous Improvement]]:持续改进文化,通过分析运营指标和实施流程自动化实现
-- [[Digital Transformation]]:数字化转型,使用现代工作流工具、集成平台和 AI 驱动的运营辅助
-- [[Vendor Management]]:供应商关系管理和成本优化
-
-## Key Entities
-- [[The Agency]]:工作室所属组织,Studio Operations 智能体为其提供全面运营支持
-
-## Connections
-- [[Project Management Senior]] ← related_to ← [[Studio Operations]]
-- [[Project Management Studio Producer]] ← related_to ← [[Studio Operations]]
-- [[Project Management Jira Workflow Steward]] ← related_to ← [[Studio Operations]]
-- [[Project Management Project Shepherd]] ← depends_on ← [[Studio Operations]]
-
-## Contradictions
-- 与 [[Project Management Senior]] 冲突:
- - 冲突点:战略规划与日常运营的优先级
- - 当前观点(Studio Operations):强调流程优化和运营效率的日常执行
- - 对方观点(Senior PM):强调战略规划和项目组合管理
- - 协调方式:Studio Operations 负责执行层面,Senior PM 负责战略层面,两者互补
+---
+title: "Studio Operations Agent Personality"
+type: source
+tags: ["project-management", "agency-agents", "operations", "efficiency"]
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/project-management/project-management-studio-operations.md]]
+
+## Summary(用中文描述)
+- 核心主题:Studio Operations 智能体角色定义——一个专注于日常工作室运营效率、流程优化和资源协调的专业运营管理者
+- 问题域:工作室运营管理、流程标准化、资源调度、质量控制、持续改进
+- 方法/机制:通过标准操作程序(SOP)模板、运营效率报告模板、四步工作流(评估→协调→实施→监控)实现 95% 运营效率目标
+- 结论/价值:提供一套完整的工作室运营管理框架,涵盖流程优化、资源管理、团队支持、数字化转型和战略运营管理
+
+## Key Claims(用中文描述)
+- 通过标准操作程序和流程文档化,可实现 95% 运营效率(附带主动系统维护)
+- 流程优化可每周为所有团队节省 40 小时生产力时间
+- 新调度系统实施可将会议冲突减少 85%
+- 全面的供应商管理可降低运营成本 15%
+- 主动监控和维护可保持 99.5% 系统正常运行时间
+- 运营支持请求响应时间少于 2 小时
+- 团队满意度评分达到 4.5/5
+
+## Key Quotes
+> "You are **Studio Operations**, an expert operations manager who specializes in day-to-day studio efficiency, process optimization, and resource coordination." — 角色定义核心描述
+> "Ensure 95% operational efficiency with proactive system maintenance" — 默认运营效率要求
+> "Implemented new scheduling system reducing meeting conflicts by 85%" — 服务导向的运营成果示例
+> "99.5% system uptime maintained with proactive monitoring and maintenance" — 可靠性导向的运营成果示例
+
+## Key Concepts
+- [[Standard Operating Procedure]]:标准操作程序模板,包含概述、前提条件、分步程序、质量控制、文档记录五个部分
+- [[Operational Efficiency]]:运营效率,目标为 95%,通过主动系统维护实现
+- [[Resource Coordination]]:跨所有工作室活动的资源分配和调度协调
+- [[Continuous Improvement]]:持续改进文化,通过分析运营指标和实施流程自动化实现
+- [[Digital Transformation]]:数字化转型,使用现代工作流工具、集成平台和 AI 驱动的运营辅助
+- [[Vendor Management]]:供应商关系管理和成本优化
+
+## Key Entities
+- [[The Agency]]:工作室所属组织,Studio Operations 智能体为其提供全面运营支持
+
+## Connections
+- [[Project Management Senior]] ← related_to ← [[Studio Operations]]
+- [[Project Management Studio Producer]] ← related_to ← [[Studio Operations]]
+- [[Project Management Jira Workflow Steward]] ← related_to ← [[Studio Operations]]
+- [[Project Management Project Shepherd]] ← depends_on ← [[Studio Operations]]
+
+## Contradictions
+- 与 [[Project Management Senior]] 冲突:
+ - 冲突点:战略规划与日常运营的优先级
+ - 当前观点(Studio Operations):强调流程优化和运营效率的日常执行
+ - 对方观点(Senior PM):强调战略规划和项目组合管理
+ - 协调方式:Studio Operations 负责执行层面,Senior PM 负责战略层面,两者互补
diff --git a/wiki/sources/project-management-studio-producer.md b/wiki/sources/project-management-studio-producer.md
index 030779ba..37c7bf7c 100644
--- a/wiki/sources/project-management-studio-producer.md
+++ b/wiki/sources/project-management-studio-producer.md
@@ -1,52 +1,52 @@
----
-title: "Studio Producer Agent Personality"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/project-management/project-management-studio-producer.md]]
-
-## Summary(用中文描述)
-- **核心主题**:Studio Producer Agent——专注于高管级别创意与项目管理的高级战略领导者 Agent,属于 Agency 项目管理部门。核心职责:战略组合管理、创意愿景与商业目标对齐、跨职能团队协调。
-- **问题域**:多项目组合管理、资源分配优化、高管级利益相关者沟通、风险与财务管控、团队绩效管理。
-- **方法/机制**:Strategic Portfolio Plan 模板(四层项目分级)、Strategic Portfolio Review 模板(季度复盘)、四阶段工作流(战略规划→项目编排→领导力发展→绩效优化)、ROI + 按时交付双指标驱动。
-- **结论/价值**:AI Agent 角色定位为高管级战略领导者,要求 25% 组合 ROI + 95% 按时交付率,面向需要复杂创意项目管理的组织。
-
-## Key Claims(用中文描述)
-- **Studio Producer** 通过战略组合规划(Strategic Portfolio Plan)将创意愿景与商业目标对齐,在项目分级(Tier 1/2 + Innovation Pipeline)中平衡风险与创新
-- **Portfolio ROI ≥ 25% + 95% on-time delivery** 是该角色的核心成功指标,要求同时管理财务纪律与创意卓越
-- **四阶段工作流**(战略规划→项目编排→领导力发展→绩效优化)构成该 Agent 的标准运营框架
-- **利益相关者管理**是该角色的核心竞争力,涉及高管沟通、期望设定与战略投资获取
-- **团队绩效与保留率**是该 Agent 的间接成功指标,反映领导力发展的长期效果
-
-## Key Quotes
-> "Portfolio ROI consistently exceeds 25% with balanced risk across strategic initiatives" — 核心成功指标定义
-> "Our Q3 portfolio delivered 35% ROI while establishing market leadership in emerging AI applications" — 沟通风格示例:战略性启发
-> "Board presentation highlights our competitive advantages and 3-year strategic positioning" — 执行影响思维示例
-> "Creative excellence drove $5M revenue increase and strengthened our premium brand positioning" — 业务价值导向示例
-
-## Key Concepts
-- [[Strategic-Portfolio-Management]]:通过分级项目组合(Tier 1/2 + Innovation Pipeline)实现资源最优配置与商业目标对齐
-- [[Resource-Allocation]]:跨创意/技术资源的计划与分配,平衡短期交付与长期能力建设
-- [[Stakeholder-Alignment]]:高管级利益相关者关系管理与战略沟通,确保创意愿景与商业目标一致
-- [[Portfolio-ROI]]:组合层面的投资回报率优化,Studio Producer 要求 ≥ 25% ROI
-- [[Risk-Balancing]]:在创新实验与已验证方法之间管理风险敞口
-- [[Cross-Functional-Orchestration]]:协调跨职能团队形成与战略对齐,管理复杂相互依赖关系
-- [[Innovation-Pipeline]]:实验性项目的管理框架,设定学习目标而非短期回报
-
-## Key Entities
-- [[Project-Management-Studio-Operations]]:Studio Producer 的运营执行搭档,负责具体项目交付
-- [[Project-Manager-Senior]]:项目经理的高级版本,更侧重执行层面
-- [[Project-Management-Project-Shepherd]]:项目看护角色,关注项目生命周期跟进
-- [[Project-Management-Experiment-Tracker]]:实验跟踪角色,关注迭代与学习
-
-## Connections
-- [[Project-Management-Studio-Operations]] ← supports ← [[Project-Management-Studio-Producer]](战略规划由 Producer 制定,Operations 负责落地执行)
-- [[Project-Management-Project-Shepherd]] ← coordinates_with ← [[Project-Management-Studio-Producer]](项目看护与 Producer 的组合管理对齐)
-- [[Sales-Engineer]] ← interfaces_with ← [[Project-Management-Studio-Producer]](售前赢单后转交 Producer 编排交付)
-
-## Contradictions
-- 与 [[Project-Management-Studio-Operations]] 的角色边界:张力存在于战略(Producer)与运营(Operations)之间的权责划分——Producer 偏向高管级战略视角,Operations 偏向执行层;两者需通过定期 Portfolio Review 对齐
-- 与传统 [[Project-Manager-Senior]] 的管理幅度:张力存在于管理广度——Producer 管理整个组合(Portfolio),而 Senior PM 通常管理单个项目;这是层级差异而非矛盾
+---
+title: "Studio Producer Agent Personality"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/project-management/project-management-studio-producer.md]]
+
+## Summary(用中文描述)
+- **核心主题**:Studio Producer Agent——专注于高管级别创意与项目管理的高级战略领导者 Agent,属于 Agency 项目管理部门。核心职责:战略组合管理、创意愿景与商业目标对齐、跨职能团队协调。
+- **问题域**:多项目组合管理、资源分配优化、高管级利益相关者沟通、风险与财务管控、团队绩效管理。
+- **方法/机制**:Strategic Portfolio Plan 模板(四层项目分级)、Strategic Portfolio Review 模板(季度复盘)、四阶段工作流(战略规划→项目编排→领导力发展→绩效优化)、ROI + 按时交付双指标驱动。
+- **结论/价值**:AI Agent 角色定位为高管级战略领导者,要求 25% 组合 ROI + 95% 按时交付率,面向需要复杂创意项目管理的组织。
+
+## Key Claims(用中文描述)
+- **Studio Producer** 通过战略组合规划(Strategic Portfolio Plan)将创意愿景与商业目标对齐,在项目分级(Tier 1/2 + Innovation Pipeline)中平衡风险与创新
+- **Portfolio ROI ≥ 25% + 95% on-time delivery** 是该角色的核心成功指标,要求同时管理财务纪律与创意卓越
+- **四阶段工作流**(战略规划→项目编排→领导力发展→绩效优化)构成该 Agent 的标准运营框架
+- **利益相关者管理**是该角色的核心竞争力,涉及高管沟通、期望设定与战略投资获取
+- **团队绩效与保留率**是该 Agent 的间接成功指标,反映领导力发展的长期效果
+
+## Key Quotes
+> "Portfolio ROI consistently exceeds 25% with balanced risk across strategic initiatives" — 核心成功指标定义
+> "Our Q3 portfolio delivered 35% ROI while establishing market leadership in emerging AI applications" — 沟通风格示例:战略性启发
+> "Board presentation highlights our competitive advantages and 3-year strategic positioning" — 执行影响思维示例
+> "Creative excellence drove $5M revenue increase and strengthened our premium brand positioning" — 业务价值导向示例
+
+## Key Concepts
+- [[Strategic-Portfolio-Management]]:通过分级项目组合(Tier 1/2 + Innovation Pipeline)实现资源最优配置与商业目标对齐
+- [[Resource-Allocation]]:跨创意/技术资源的计划与分配,平衡短期交付与长期能力建设
+- [[Stakeholder-Alignment]]:高管级利益相关者关系管理与战略沟通,确保创意愿景与商业目标一致
+- [[Portfolio-ROI]]:组合层面的投资回报率优化,Studio Producer 要求 ≥ 25% ROI
+- [[Risk-Balancing]]:在创新实验与已验证方法之间管理风险敞口
+- [[Cross-Functional-Orchestration]]:协调跨职能团队形成与战略对齐,管理复杂相互依赖关系
+- [[Innovation-Pipeline]]:实验性项目的管理框架,设定学习目标而非短期回报
+
+## Key Entities
+- [[Project-Management-Studio-Operations]]:Studio Producer 的运营执行搭档,负责具体项目交付
+- [[Project-Manager-Senior]]:项目经理的高级版本,更侧重执行层面
+- [[Project-Management-Project-Shepherd]]:项目看护角色,关注项目生命周期跟进
+- [[Project-Management-Experiment-Tracker]]:实验跟踪角色,关注迭代与学习
+
+## Connections
+- [[Project-Management-Studio-Operations]] ← supports ← [[Project-Management-Studio-Producer]](战略规划由 Producer 制定,Operations 负责落地执行)
+- [[Project-Management-Project-Shepherd]] ← coordinates_with ← [[Project-Management-Studio-Producer]](项目看护与 Producer 的组合管理对齐)
+- [[Sales-Engineer]] ← interfaces_with ← [[Project-Management-Studio-Producer]](售前赢单后转交 Producer 编排交付)
+
+## Contradictions
+- 与 [[Project-Management-Studio-Operations]] 的角色边界:张力存在于战略(Producer)与运营(Operations)之间的权责划分——Producer 偏向高管级战略视角,Operations 偏向执行层;两者需通过定期 Portfolio Review 对齐
+- 与传统 [[Project-Manager-Senior]] 的管理幅度:张力存在于管理广度——Producer 管理整个组合(Portfolio),而 Senior PM 通常管理单个项目;这是层级差异而非矛盾
diff --git a/wiki/sources/project-manager-senior.md b/wiki/sources/project-manager-senior.md
index 69ee2636..447efdc8 100644
--- a/wiki/sources/project-manager-senior.md
+++ b/wiki/sources/project-manager-senior.md
@@ -1,50 +1,50 @@
----
-title: "Senior Project Manager Agent Personality"
-type: source
-tags: [agent, project-management, laravel, livewire, fluxui, scope-control]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/project-management/project-manager-senior.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 项目经理(SeniorProjectManager)的人格定义与任务分解方法论
-- 问题域:Web 开发项目中需求规格到可执行任务的转化过程,以及如何避免范围蔓延(scope creep)
-- 方法/机制:读取 site-setup.md 规格文档 → 引用精确需求 → 拆解为 30-60 分钟粒度的任务列表 → 存储到 memory-bank
-- 结论/价值:提供一套结构化的 AI PM 工作流程,强调务实(realistic scope)、精确引用规格、开发者优先
-
-## Key Claims(用中文描述)
-- **Agent + 规格文件 + 精确引用 → 任务列表**:通过逐字引用规格文档中的原始需求来创建任务,避免主观添加功能
-- **Agent + 经验积累 + 模式库 → 持续改进**:从每个项目中学习,构建成功任务拆解的模式库
-- **Agent + 务实范围 + 基础实现 → 避免失败**:默认基础实现即可接受,优先完成功能而非打磨
-
-## Key Quotes
-> "Quote EXACT requirements (don't add luxury/premium features that aren't there)" — 规格引用原则,要求 Agent 不添加规格中未明确的功能
-> "Each task should be implementable by a developer in 30-60 minutes" — 任务粒度标准,保证任务可执行性
-> "Don't add 'luxury' or 'premium' requirements unless explicitly in spec" — 务实范围控制,防止范围蔓延
-> "No background processes in any commands - NEVER append `&`" — 技术约束,Agent 必须遵守的技术红线
-
-## Key Concepts
-- [[ScopeCreepPrevention]]:通过精确引用规格、限制基础实现、记录范围决策来防止项目范围蔓延
-- [[TaskDecomposition]]:将规格拆解为 30-60 分钟粒度的可执行任务,包含验收标准
-- [[AgenticProjectManagement]]:AI Agent 作为项目经理角色,通过记忆和经验积累持续改进任务创建流程
-- [[FluxUI]]:Laravel Livewire 生态的前端组件库,PM Agent 需了解其组件属性和约束
-- [[AcceptanceCriteria]]:每个任务必须包含可测试的验收标准
-
-## Key Entities
-- [[ProjectManagementJiraWorkflowSteward]]:同属项目管理体系,另一个专注于 Jira 工作流编排的 Agent
-- [[ProjectManagementProjectShepherd]]:同属项目管理体系,专注于项目全局把控的 Agent
-- [[ProjectManagementStudioOperations]]:同属项目管理体系,专注于工作室运营的 Agent
-
-## Connections
-- [[ProjectManagementJiraWorkflowSteward]] ← related_to ← [[ProjectManagerSenior]]
-- [[ProjectManagementProjectShepherd]] ← related_to ← [[ProjectManagerSenior]]
-- [[ProjectManagementStudioOperations]] ← related_to ← [[ProjectManagerSenior]]
-
-## Contradictions
-- 与 [[ProjectManagementProjectShepherd]] 可能的冲突:
- - 冲突点:职责边界 — Project Shepherd 关注项目整体把控,Senior PM 关注任务拆解细节
- - 当前观点:Senior PM 强调任务粒度控制和精确引用规格,务实处理基础功能
- - 对方观点:Project Shepherd 可能更关注项目整体节奏和风险,需要更高层次的抽象
- - 协调建议:Senior PM 产出任务列表供 Project Shepherd 调度,两者形成执行层与规划层的协作关系
+---
+title: "Senior Project Manager Agent Personality"
+type: source
+tags: [agent, project-management, laravel, livewire, fluxui, scope-control]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/project-management/project-manager-senior.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 项目经理(SeniorProjectManager)的人格定义与任务分解方法论
+- 问题域:Web 开发项目中需求规格到可执行任务的转化过程,以及如何避免范围蔓延(scope creep)
+- 方法/机制:读取 site-setup.md 规格文档 → 引用精确需求 → 拆解为 30-60 分钟粒度的任务列表 → 存储到 memory-bank
+- 结论/价值:提供一套结构化的 AI PM 工作流程,强调务实(realistic scope)、精确引用规格、开发者优先
+
+## Key Claims(用中文描述)
+- **Agent + 规格文件 + 精确引用 → 任务列表**:通过逐字引用规格文档中的原始需求来创建任务,避免主观添加功能
+- **Agent + 经验积累 + 模式库 → 持续改进**:从每个项目中学习,构建成功任务拆解的模式库
+- **Agent + 务实范围 + 基础实现 → 避免失败**:默认基础实现即可接受,优先完成功能而非打磨
+
+## Key Quotes
+> "Quote EXACT requirements (don't add luxury/premium features that aren't there)" — 规格引用原则,要求 Agent 不添加规格中未明确的功能
+> "Each task should be implementable by a developer in 30-60 minutes" — 任务粒度标准,保证任务可执行性
+> "Don't add 'luxury' or 'premium' requirements unless explicitly in spec" — 务实范围控制,防止范围蔓延
+> "No background processes in any commands - NEVER append `&`" — 技术约束,Agent 必须遵守的技术红线
+
+## Key Concepts
+- [[ScopeCreepPrevention]]:通过精确引用规格、限制基础实现、记录范围决策来防止项目范围蔓延
+- [[TaskDecomposition]]:将规格拆解为 30-60 分钟粒度的可执行任务,包含验收标准
+- [[AgenticProjectManagement]]:AI Agent 作为项目经理角色,通过记忆和经验积累持续改进任务创建流程
+- [[FluxUI]]:Laravel Livewire 生态的前端组件库,PM Agent 需了解其组件属性和约束
+- [[AcceptanceCriteria]]:每个任务必须包含可测试的验收标准
+
+## Key Entities
+- [[ProjectManagementJiraWorkflowSteward]]:同属项目管理体系,另一个专注于 Jira 工作流编排的 Agent
+- [[ProjectManagementProjectShepherd]]:同属项目管理体系,专注于项目全局把控的 Agent
+- [[ProjectManagementStudioOperations]]:同属项目管理体系,专注于工作室运营的 Agent
+
+## Connections
+- [[ProjectManagementJiraWorkflowSteward]] ← related_to ← [[ProjectManagerSenior]]
+- [[ProjectManagementProjectShepherd]] ← related_to ← [[ProjectManagerSenior]]
+- [[ProjectManagementStudioOperations]] ← related_to ← [[ProjectManagerSenior]]
+
+## Contradictions
+- 与 [[ProjectManagementProjectShepherd]] 可能的冲突:
+ - 冲突点:职责边界 — Project Shepherd 关注项目整体把控,Senior PM 关注任务拆解细节
+ - 当前观点:Senior PM 强调任务粒度控制和精确引用规格,务实处理基础功能
+ - 对方观点:Project Shepherd 可能更关注项目整体节奏和风险,需要更高层次的抽象
+ - 协调建议:Senior PM 产出任务列表供 Project Shepherd 调度,两者形成执行层与规划层的协作关系
diff --git a/wiki/sources/public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109.md b/wiki/sources/public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109.md
index c6562e70..0fd83656 100644
--- a/wiki/sources/public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109.md
+++ b/wiki/sources/public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109.md
@@ -1,54 +1,54 @@
----
-title: "Public Cloud Learning Sessions- Applicable Business Analysis Techniques - 20240109"
-type: source
-tags: [Business-Analysis, Techniques]
-date: 2024-01-09
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109-.md]]
-
-## Summary(用中文描述)
-- 核心主题:业务分析(Business Analysis)基础技能与核心技法,聚焦云转型背景下的需求定义与干系人管理
-- 问题域:敏捷团队中业务与技术之间的沟通鸿沟;新工作(需求、变更、项目)定义不清晰导致的混乱
-- 方法/机制:三大技法——BOSCARD(复杂新工作定义框架)、干系人轮盘(Stakeholder Wheel)、结合元数据的用户故事需求收集;T型技能模型连接业务与技术
-- 结论/价值:业务分析将业务需求与技术变更解决方案对齐;BOSCARD早期锁定范围"无价";T型技能在敏捷 Squad 中的核心价值
-
-## Key Claims(用中文描述)
-- 业务分析通过调查现状、分析需求、识别方案、评估选项、定义需求,将业务需求与技术变更解决方案对齐,包括IT系统变更、流程变更、培训和角色转换
-- T型技能在敏捷 Squad 中极具价值,结合核心专业深度与相关技能的广度,业务分析技能是连接业务问题与技术解决方案的桥梁
-- BOSCARD通过澄清背景、目标、范围、约束、假设、风险、角色和交付物来定义复杂新工作,帮助避免目标和交付物混淆
-- 干系人轮盘从客户出发顺时针识别所有项目干系人(客户、合作伙伴、监管机构、员工、管理层、所有者、竞争对手),早期识别可防止变更和揭示风险
-- 结合用户故事与元数据的Requirements Gathering为需求捕获增加严谨性;SAFe框架在用户故事之外还包含Features、Capabilities和非功能需求
-- INVEST原则(Independent/Negotiable/Valuable/Estimable/Small/Testable)用于检查需求质量
-
-## Key Quotes
-> "Business analysis helps us work out what changes will be beneficial in our business architecture, including changes to IST systems and defining the requirements for those changes." — 业务分析核心价值定位
-
-> "If you can get scope tied down early on and agreed, that's priceless." — BOSCARD的价值
-
-> "Every requirement should be independent, meaning not duplicating something else, that's the I in INVEST, negotiable, so the business should state what they need, but be open to how it's implemented." — INVEST原则核心
-
-## Key Concepts
-- [[Business-Analysis]]:将业务需求与变更解决方案对齐的过程——调查现状、分析需求、识别方案、评估选项、定义需求;涵盖IT系统变更、流程变更、培训和角色转换
-- [[T-Shaped-Skills]]:结合核心专业深度与相关技能广度的技能模型;在敏捷 Squad 中弥合业务与技术之间的鸿沟
-- [[BOSCARD]]:复杂新工作定义框架——Background(背景)、Objectives(目标)、Scope(范围)、Constraints(约束)、Assumptions(假设)、Risks(风险)、Roles(角色)、Deliverables(交付物)
-- [[Stakeholder-Wheel]]:干系人识别工具,从客户出发顺时针识别所有项目干系人;可配合权力/影响矩阵或RACI矩阵使用
-- [[Requirements-Gathering]]:需求收集方法,结合用户故事(what/who/why)与元数据(版本、依赖、可追溯性、时间、验收标准、分类)
-- [[INVEST]]:优质用户故事检查原则——Independent(独立)、Negotiable(可协商)、Valuable(有价值)、Estimable(可估算)、Small(小型)、Testable(可测试)
-- [[SAFe]]:Scaled Agile Framework,在用户故事之外还包含Features(功能)、Capabilities(能力)和非功能需求(NFR)
-- [[RACI]]:责任分配矩阵——Responsible(负责)、Accountable(问责)、Consulted(咨询)、Informed(知情)
-
-## Key Entities
-- [[BCS]]:英国计算机学会,业务分析学习资源来源之一
-- [[IIBA]]:国际商业分析协会,业务分析学习资源来源之一
-- [[OpenText]]:主办 Public Cloud Learning Sessions 的公司
-
-## Connections
-- [[ctp-topic-57-product-backlog-managing-demand]] ← related_to ← [[public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109]]
-- [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]] ← related_to ← [[public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109]]
-- [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] ← related_to ← [[public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109]]
-- [[ctp-topic-41-nfrs-and-error-budgets]] ← related_to ← [[public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109]](NFR属于业务分析的需求定义范畴)
-
-## Contradictions
-- 与 [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] 在流程视角上存在互补关系:Topic 4 提供敏捷持续流动的实践框架,本视频提供需求定义的前置技法;前者强调执行节奏,后者强调规划严谨性,两者共同构成云转型计划管理的完整方法论
+---
+title: "Public Cloud Learning Sessions- Applicable Business Analysis Techniques - 20240109"
+type: source
+tags: [Business-Analysis, Techniques]
+date: 2024-01-09
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109-.md]]
+
+## Summary(用中文描述)
+- 核心主题:业务分析(Business Analysis)基础技能与核心技法,聚焦云转型背景下的需求定义与干系人管理
+- 问题域:敏捷团队中业务与技术之间的沟通鸿沟;新工作(需求、变更、项目)定义不清晰导致的混乱
+- 方法/机制:三大技法——BOSCARD(复杂新工作定义框架)、干系人轮盘(Stakeholder Wheel)、结合元数据的用户故事需求收集;T型技能模型连接业务与技术
+- 结论/价值:业务分析将业务需求与技术变更解决方案对齐;BOSCARD早期锁定范围"无价";T型技能在敏捷 Squad 中的核心价值
+
+## Key Claims(用中文描述)
+- 业务分析通过调查现状、分析需求、识别方案、评估选项、定义需求,将业务需求与技术变更解决方案对齐,包括IT系统变更、流程变更、培训和角色转换
+- T型技能在敏捷 Squad 中极具价值,结合核心专业深度与相关技能的广度,业务分析技能是连接业务问题与技术解决方案的桥梁
+- BOSCARD通过澄清背景、目标、范围、约束、假设、风险、角色和交付物来定义复杂新工作,帮助避免目标和交付物混淆
+- 干系人轮盘从客户出发顺时针识别所有项目干系人(客户、合作伙伴、监管机构、员工、管理层、所有者、竞争对手),早期识别可防止变更和揭示风险
+- 结合用户故事与元数据的Requirements Gathering为需求捕获增加严谨性;SAFe框架在用户故事之外还包含Features、Capabilities和非功能需求
+- INVEST原则(Independent/Negotiable/Valuable/Estimable/Small/Testable)用于检查需求质量
+
+## Key Quotes
+> "Business analysis helps us work out what changes will be beneficial in our business architecture, including changes to IST systems and defining the requirements for those changes." — 业务分析核心价值定位
+
+> "If you can get scope tied down early on and agreed, that's priceless." — BOSCARD的价值
+
+> "Every requirement should be independent, meaning not duplicating something else, that's the I in INVEST, negotiable, so the business should state what they need, but be open to how it's implemented." — INVEST原则核心
+
+## Key Concepts
+- [[Business-Analysis]]:将业务需求与变更解决方案对齐的过程——调查现状、分析需求、识别方案、评估选项、定义需求;涵盖IT系统变更、流程变更、培训和角色转换
+- [[T-Shaped-Skills]]:结合核心专业深度与相关技能广度的技能模型;在敏捷 Squad 中弥合业务与技术之间的鸿沟
+- [[BOSCARD]]:复杂新工作定义框架——Background(背景)、Objectives(目标)、Scope(范围)、Constraints(约束)、Assumptions(假设)、Risks(风险)、Roles(角色)、Deliverables(交付物)
+- [[Stakeholder-Wheel]]:干系人识别工具,从客户出发顺时针识别所有项目干系人;可配合权力/影响矩阵或RACI矩阵使用
+- [[Requirements-Gathering]]:需求收集方法,结合用户故事(what/who/why)与元数据(版本、依赖、可追溯性、时间、验收标准、分类)
+- [[INVEST]]:优质用户故事检查原则——Independent(独立)、Negotiable(可协商)、Valuable(有价值)、Estimable(可估算)、Small(小型)、Testable(可测试)
+- [[SAFe]]:Scaled Agile Framework,在用户故事之外还包含Features(功能)、Capabilities(能力)和非功能需求(NFR)
+- [[RACI]]:责任分配矩阵——Responsible(负责)、Accountable(问责)、Consulted(咨询)、Informed(知情)
+
+## Key Entities
+- [[BCS]]:英国计算机学会,业务分析学习资源来源之一
+- [[IIBA]]:国际商业分析协会,业务分析学习资源来源之一
+- [[OpenText]]:主办 Public Cloud Learning Sessions 的公司
+
+## Connections
+- [[ctp-topic-57-product-backlog-managing-demand]] ← related_to ← [[public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109]]
+- [[ctp-topic-20-program-demand-process-flow-and-poc-onboarding]] ← related_to ← [[public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109]]
+- [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] ← related_to ← [[public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109]]
+- [[ctp-topic-41-nfrs-and-error-budgets]] ← related_to ← [[public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109]](NFR属于业务分析的需求定义范畴)
+
+## Contradictions
+- 与 [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] 在流程视角上存在互补关系:Topic 4 提供敏捷持续流动的实践框架,本视频提供需求定义的前置技法;前者强调执行节奏,后者强调规划严谨性,两者共同构成云转型计划管理的完整方法论
diff --git a/wiki/sources/public-cloud-learning-sessions-aws-end-user-compute-services-20240430-160120-mee.md b/wiki/sources/public-cloud-learning-sessions-aws-end-user-compute-services-20240430-160120-mee.md
index 8f62a724..579a2c82 100644
--- a/wiki/sources/public-cloud-learning-sessions-aws-end-user-compute-services-20240430-160120-mee.md
+++ b/wiki/sources/public-cloud-learning-sessions-aws-end-user-compute-services-20240430-160120-mee.md
@@ -1,63 +1,63 @@
----
-title: "Public Cloud Learning Sessions - AWS End User Compute Services - 20240430"
-type: source
-tags:
- - AWS
- - End-User-Computing
- - Workspaces
- - AppStream
-date: 2026-04-14
----
-
-## Source File
-- [[public-cloud-learning-sessions-aws-end-user-compute-services-20240430-160120-mee]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 终端用户计算(EUC)服务全景介绍——虚拟桌面与应用程序流
-- 问题域:远程/混合工作模式下的终端用户计算基础设施选型与安全设计
-- 方法/机制:Amazon Workspaces(全持久虚拟桌面)、AppStream 2.0(选择持久/非持久应用流)、Workspace Core(第三方 VDI 集成)、Workspace Web(低成本安全浏览器)四类服务的对比与适用场景分析
-- 结论/价值:帮助组织根据用户类型(知识工作者/任务工作者)和用例(完整桌面/应用流/安全浏览)选择最适合的 AWS EUC 服务方案
-
-## Key Claims(用中文描述)
-- Workspaces 适合需要完整桌面环境的知识工作者,AppStream 适合实验室、培训和堡垒主机场景
-- AppStream 提供多租户模式允许多用户共享实例,有效降低成本
-- 全持久桌面(Workspaces)提供一对一实例管理,应用状态和设置在会话之间保持
-- 非持久桌面(AppStream)提供每次登录全新桌面,支持应用连接器和存储连接器实现部分持久化
-- 成本优化通过 AppStream 并发使用和 Workspaces 自动停止功能实现
-- WSP 协议专为高延迟网络设计,支持灾难恢复策略(跨区域构建 Workspaces 或利用 AppStream 自动扩展)
-- 安全措施包括 Active Directory 集成、加密、IAM 配置文件和多因素认证
-
-## Key Quotes
-> "With so many remote workers organizations are struggling to protect endpoints, as well as their IP and data from bad actors." — AWS EUC 安全背景说明
-
-> "AppStream 2.0 is a great low cost alternative for customers that don't require a fully persistent desktop." — AppStream 2.0 定位
-
-## Key Concepts
-- [[Amazon Workspaces]]:全持久虚拟桌面服务,提供一对一实例管理,应用状态和设置在会话之间保持
-- [[AppStream 2.0]]:安全的应用流服务,提供选择性持久化,支持多租户模式,适合非持久桌面场景
-- [[AWS End User Computing]]:AWS 终端用户计算服务组合,包含 Workspaces、AppStream 2.0、Workspace Core、Workspace Web 四大服务
-- [[Virtual Desktop Infrastructure]]:虚拟桌面基础设施,通过虚拟化技术在云端交付桌面环境
-- [[WSP Protocol]]:Workspaces Streaming Protocol,专为高延迟网络设计的流传输协议
-- [[BYOD(Bring Your Own Device)]]:自带设备工作模式,员工使用个人设备访问企业资源
-- [[VDI(Virtual Desktop Infrastructure)]]:虚拟桌面基础设施,Workspace Core 提供对 Workspaces VDI 基础设施的 API 访问
-- [[SAML Authentication]]:基于 SAML 的身份认证,增强安全性的同时简化用户体验
-- [[VPC Interface Endpoints]]:VPC 接口终端节点,用于通过私有连接安全访问 AWS 服务
-
-## Key Entities
-- [[Christian O'Donough]]:AWS 主讲人,分享 AWS EUC 服务学习课程
-- [[Amazon Workspaces]]:AWS 全持久虚拟桌面服务
-- [[AppStream 2.0]]:AWS 应用程序流服务
-- [[Workspace Core]]:提供 Workspaces VDI 基础设施 API 访问,支持 Horizon View、Citrix 等第三方集成
-- [[Workspace Web]]:低成本安全 Web 浏览器,用于访问内部网站和 SaaS 应用
-- [[Amazon VPC]]:AWS 虚拟私有云,EUC 架构包含服务 VPC(AWS 托管)和客户 VPC
-- [[Active Directory]]:活动目录集成,EUC 服务的身份认证基础
-- [[CloudWatch]]:AWS 监控服务,支持 EUC 运营指标监控
-
-## Connections
-- [[ctp-topic-6-aws-workspaces-demo]] ← extends ← [[AWS End User Computing]]
-- [[AWS End User Computing]] ← depends_on ← [[Amazon VPC]]
-- [[AWS End User Computing]] ← depends_on ← [[Active Directory]]
-- [[AppStream 2.0]] ← extends ← [[AWS End User Computing]]
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "Public Cloud Learning Sessions - AWS End User Compute Services - 20240430"
+type: source
+tags:
+ - AWS
+ - End-User-Computing
+ - Workspaces
+ - AppStream
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-aws-end-user-compute-services-20240430-160120-mee.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 终端用户计算(EUC)服务全景介绍——虚拟桌面与应用程序流
+- 问题域:远程/混合工作模式下的终端用户计算基础设施选型与安全设计
+- 方法/机制:Amazon Workspaces(全持久虚拟桌面)、AppStream 2.0(选择持久/非持久应用流)、Workspace Core(第三方 VDI 集成)、Workspace Web(低成本安全浏览器)四类服务的对比与适用场景分析
+- 结论/价值:帮助组织根据用户类型(知识工作者/任务工作者)和用例(完整桌面/应用流/安全浏览)选择最适合的 AWS EUC 服务方案
+
+## Key Claims(用中文描述)
+- Workspaces 适合需要完整桌面环境的知识工作者,AppStream 适合实验室、培训和堡垒主机场景
+- AppStream 提供多租户模式允许多用户共享实例,有效降低成本
+- 全持久桌面(Workspaces)提供一对一实例管理,应用状态和设置在会话之间保持
+- 非持久桌面(AppStream)提供每次登录全新桌面,支持应用连接器和存储连接器实现部分持久化
+- 成本优化通过 AppStream 并发使用和 Workspaces 自动停止功能实现
+- WSP 协议专为高延迟网络设计,支持灾难恢复策略(跨区域构建 Workspaces 或利用 AppStream 自动扩展)
+- 安全措施包括 Active Directory 集成、加密、IAM 配置文件和多因素认证
+
+## Key Quotes
+> "With so many remote workers organizations are struggling to protect endpoints, as well as their IP and data from bad actors." — AWS EUC 安全背景说明
+
+> "AppStream 2.0 is a great low cost alternative for customers that don't require a fully persistent desktop." — AppStream 2.0 定位
+
+## Key Concepts
+- [[Amazon Workspaces]]:全持久虚拟桌面服务,提供一对一实例管理,应用状态和设置在会话之间保持
+- [[AppStream 2.0]]:安全的应用流服务,提供选择性持久化,支持多租户模式,适合非持久桌面场景
+- [[AWS End User Computing]]:AWS 终端用户计算服务组合,包含 Workspaces、AppStream 2.0、Workspace Core、Workspace Web 四大服务
+- [[Virtual Desktop Infrastructure]]:虚拟桌面基础设施,通过虚拟化技术在云端交付桌面环境
+- [[WSP Protocol]]:Workspaces Streaming Protocol,专为高延迟网络设计的流传输协议
+- [[BYOD(Bring Your Own Device)]]:自带设备工作模式,员工使用个人设备访问企业资源
+- [[VDI(Virtual Desktop Infrastructure)]]:虚拟桌面基础设施,Workspace Core 提供对 Workspaces VDI 基础设施的 API 访问
+- [[SAML Authentication]]:基于 SAML 的身份认证,增强安全性的同时简化用户体验
+- [[VPC Interface Endpoints]]:VPC 接口终端节点,用于通过私有连接安全访问 AWS 服务
+
+## Key Entities
+- [[Christian O'Donough]]:AWS 主讲人,分享 AWS EUC 服务学习课程
+- [[Amazon Workspaces]]:AWS 全持久虚拟桌面服务
+- [[AppStream 2.0]]:AWS 应用程序流服务
+- [[Workspace Core]]:提供 Workspaces VDI 基础设施 API 访问,支持 Horizon View、Citrix 等第三方集成
+- [[Workspace Web]]:低成本安全 Web 浏览器,用于访问内部网站和 SaaS 应用
+- [[Amazon VPC]]:AWS 虚拟私有云,EUC 架构包含服务 VPC(AWS 托管)和客户 VPC
+- [[Active Directory]]:活动目录集成,EUC 服务的身份认证基础
+- [[CloudWatch]]:AWS 监控服务,支持 EUC 运营指标监控
+
+## Connections
+- [[ctp-topic-6-aws-workspaces-demo]] ← extends ← [[AWS End User Computing]]
+- [[AWS End User Computing]] ← depends_on ← [[Amazon VPC]]
+- [[AWS End User Computing]] ← depends_on ← [[Active Directory]]
+- [[AppStream 2.0]] ← extends ← [[AWS End User Computing]]
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2.md b/wiki/sources/public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2.md
index da94df86..9f3175a5 100644
--- a/wiki/sources/public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2.md
+++ b/wiki/sources/public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2.md
@@ -1,66 +1,66 @@
----
-title: "Public Cloud Learning Sessions - Best practices for EC2 cost optimization in AWS - 20240529"
-type: source
-tags:
- - AWS
- - EC2
- - Cost-Optimization
- - Graviton
- - Spot-Instances
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS EC2 成本优化最佳实践
-- 问题域:云成本管理、FinOps、计算效率优化
-- 方法/机制:
- - AWS Nitro 系统外部化网络/存储/安全组件提升效率
- - Graviton ARM 处理器实例提供高达 40% 性价比提升
- - Spot 实例利用闲置容量提供高达 90% 折扣
- - 购买选项:On-Demand、Savings Plans、Spot Instances
-- 结论/价值:云效率优化需结合架构最佳实践 + 正确的实例类型选择 + 合适的购买选项
-
-## Key Claims(用中文描述)
-- Graviton 实例比同等 x86 实例提供高达 40% 更好的性价比
-- Graviton Free 功耗比同等 x86 实例减少高达 60%
-- EC2 Spot 实例提供高达 90% 的按需定价折扣
-- Spot + Graviton + 容器可实现最大化成本节省(适用于 Web 服务、容器、HPC 批处理、大数据和 CI/CD)
-- Spot 实例可与 EKS/ECS 自动扩展集成,支持自动响应中断
-
-## Key Quotes
-> "When we start talking about architecting and using best practice efficiency in the cloud, you effectively only pay for what you use when you use AWS." — 云效率核心理念
-
-> "Graviton Free actually uses up to 60% less power consumption than comparable X86-based instances." — Graviton 能效优势
-
-## Key Concepts
-- [[Graviton]]:基于 ARM64 的 AWS 自研处理器,提供更高的每瓦性能,支持计算优化型、内存优化型和通用型实例
-- [[Spot Instances]]:利用 AWS 闲置容量的竞价型实例,提供高达 90% 的按需价格折扣
-- [[Nitro-System]]:将网络、存储和安全功能从 CPU 卸载到专用硬件,提升 EC2 实例效率
-- [[Savings Plans]]:AWS 承诺使用量的定价选项,提供低于按需价格的折扣
-- [[EC2-Purchase-Options]]:On-Demand(按需)、Savings Plans(节约计划)、Spot Instances(竞价实例)三种购买选项
-- [[FinOps]]:云财务管理实践,平衡云成本与业务价值
-
-## Key Entities
-- [[AWS]]:亚马逊云服务提供商,提供 EC2 计算服务
-- [[Mike Dukes]]:AWS 专家,分享 EC2 成本优化实践
-- [[Steele Taylor]]:AWS 专家,分享 EC2 成本优化实践
-- [[Amazon-EKS]]:Elastic Kubernetes Service,Spot 实例可与 EKS 集成实现自动扩展
-- [[Amazon-ECS]]:Elastic Container Service,Spot 实例支持容器工作负载
-
-## Connections
-- [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]] ← related_to ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
-- [[ctp-topic-13-cloud-finops-policies]] ← extends ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
-- [[ctp-topic-71-pcgs-guide-to-rightsizing]] ← extends ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
-- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← extends ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
-- [[public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization]] ← extends ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
-- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← extends ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
-
-## Contradictions
-- 与 [[ctp-topic-14-octane-hub-on-aws]] 可能的冲突:
- - 冲突点:Graviton 对有状态服务(如数据库)的适用性
- - 当前观点:[[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]] 建议 Graviton 适用于大多数场景,但排除有状态服务如数据库
- - 对方观点:Octane Hub 案例中提到 MSSQL→Postgres 迁移,可能涉及对 Graviton 的进一步评估
- - 补充说明:[[ctp-topic-66-rds-vs-aurora]] 提到 Aurora PostgreSQL 迁移到 Graviton 相对简单,表明有状态服务也在逐步支持 Graviton
+---
+title: "Public Cloud Learning Sessions - Best practices for EC2 cost optimization in AWS - 20240529"
+type: source
+tags:
+ - AWS
+ - EC2
+ - Cost-Optimization
+ - Graviton
+ - Spot-Instances
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS EC2 成本优化最佳实践
+- 问题域:云成本管理、FinOps、计算效率优化
+- 方法/机制:
+ - AWS Nitro 系统外部化网络/存储/安全组件提升效率
+ - Graviton ARM 处理器实例提供高达 40% 性价比提升
+ - Spot 实例利用闲置容量提供高达 90% 折扣
+ - 购买选项:On-Demand、Savings Plans、Spot Instances
+- 结论/价值:云效率优化需结合架构最佳实践 + 正确的实例类型选择 + 合适的购买选项
+
+## Key Claims(用中文描述)
+- Graviton 实例比同等 x86 实例提供高达 40% 更好的性价比
+- Graviton Free 功耗比同等 x86 实例减少高达 60%
+- EC2 Spot 实例提供高达 90% 的按需定价折扣
+- Spot + Graviton + 容器可实现最大化成本节省(适用于 Web 服务、容器、HPC 批处理、大数据和 CI/CD)
+- Spot 实例可与 EKS/ECS 自动扩展集成,支持自动响应中断
+
+## Key Quotes
+> "When we start talking about architecting and using best practice efficiency in the cloud, you effectively only pay for what you use when you use AWS." — 云效率核心理念
+
+> "Graviton Free actually uses up to 60% less power consumption than comparable X86-based instances." — Graviton 能效优势
+
+## Key Concepts
+- [[Graviton]]:基于 ARM64 的 AWS 自研处理器,提供更高的每瓦性能,支持计算优化型、内存优化型和通用型实例
+- [[Spot Instances]]:利用 AWS 闲置容量的竞价型实例,提供高达 90% 的按需价格折扣
+- [[Nitro-System]]:将网络、存储和安全功能从 CPU 卸载到专用硬件,提升 EC2 实例效率
+- [[Savings Plans]]:AWS 承诺使用量的定价选项,提供低于按需价格的折扣
+- [[EC2-Purchase-Options]]:On-Demand(按需)、Savings Plans(节约计划)、Spot Instances(竞价实例)三种购买选项
+- [[FinOps]]:云财务管理实践,平衡云成本与业务价值
+
+## Key Entities
+- [[AWS]]:亚马逊云服务提供商,提供 EC2 计算服务
+- [[Mike Dukes]]:AWS 专家,分享 EC2 成本优化实践
+- [[Steele Taylor]]:AWS 专家,分享 EC2 成本优化实践
+- [[Amazon-EKS]]:Elastic Kubernetes Service,Spot 实例可与 EKS 集成实现自动扩展
+- [[Amazon-ECS]]:Elastic Container Service,Spot 实例支持容器工作负载
+
+## Connections
+- [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]] ← related_to ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
+- [[ctp-topic-13-cloud-finops-policies]] ← extends ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
+- [[ctp-topic-71-pcgs-guide-to-rightsizing]] ← extends ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
+- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← extends ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
+- [[public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization]] ← extends ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
+- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← extends ← [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]]
+
+## Contradictions
+- 与 [[ctp-topic-14-octane-hub-on-aws]] 可能的冲突:
+ - 冲突点:Graviton 对有状态服务(如数据库)的适用性
+ - 当前观点:[[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]] 建议 Graviton 适用于大多数场景,但排除有状态服务如数据库
+ - 对方观点:Octane Hub 案例中提到 MSSQL→Postgres 迁移,可能涉及对 Graviton 的进一步评估
+ - 补充说明:[[ctp-topic-66-rds-vs-aurora]] 提到 Aurora PostgreSQL 迁移到 Graviton 相对简单,表明有状态服务也在逐步支持 Graviton
diff --git a/wiki/sources/public-cloud-learning-sessions-budget-control-20240319-160204-meeting-recording.md b/wiki/sources/public-cloud-learning-sessions-budget-control-20240319-160204-meeting-recording.md
index 0a7f40a2..be3f5fd9 100644
--- a/wiki/sources/public-cloud-learning-sessions-budget-control-20240319-160204-meeting-recording.md
+++ b/wiki/sources/public-cloud-learning-sessions-budget-control-20240319-160204-meeting-recording.md
@@ -1,52 +1,52 @@
----
-title: "Public Cloud Learning Sessions - Budget Control - 20240319"
-type: source
-tags: [FinOps, AWS, Cost-Optimization, Budget-Control, Alerting]
-date: 2024-03-19
-sources: [Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/public-cloud-learning-sessions-budget-control-20240319-160204-meeting-recording.md]
-last_updated: 2026-04-26
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/public-cloud-learning-sessions-budget-control-20240319-160204-meeting-recording.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 预算控制自动化系统——面向 SRE Core 团队(Daniela、Evan、Alan)的内部学习分享
-- 问题域:AWS 账户蔓延导致的成本失控,以及现有成本削减措施不可持续的问题
-- 方法/机制:AWS Budget → SNS → Lambda → Step Functions → SCP Enforcement(服务控制策略封禁新资源创建)的完整告警与执行链路;Source Identity 追踪跨角色切换的原始登录身份
-- 结论/价值:提供账户级别的详细告警(支出预测/实际支出/成本驱动因素),并将 Enforcement 从手动审批逐步演进为自动封禁
-
-## Key Claims(用中文描述)
-- SRE Core 团队通过 AWS Budget 服务 + 自定义 Lambda/Step Functions 构建的自动化预算控制,解决了 AWS 账户蔓延导致的成本失控问题
-- 告警类型分为 4 种:Forecast(预测超支)、Actual(实际超支 80%/90%/95%/98%)、Severe(100% 且评分制触发)、Enforcement(100% 且启用强制执行则触发 SCP 封禁)
-- Source Identity(AWS Source Identity 属性)通过 CloudTrail 跨角色切换追踪原始登录用户,解决了联邦登录(NetIQ)中"假设角色后无法识别原始身份"的问题
-- 评分系统(Scoring System)根据账户规模和月末时间节点计算宽限期(Grace Period),避免轻微超支的账户被误处罚
-- 初始实施范围仅限 Lab 账户,其他账户继续接收标准超预算告警
-
-## Key Quotes
-> "This is the first time that we were able to get to this level of granularity." — Daniel,描述通过 Athena + Cost Explorer 实现的资源级成本粒度
-
-## Key Concepts
-- [[AWS-Source-Identity]]:通过 `sts:SourceIdentity` 属性在假设角色后保留原始登录身份,使 CloudTrail 可追踪跨角色用户活动
-- [[FinOps]]:云财务管理,本质是将财务责任与工程实践结合,本 Source 展示 FinOps 执行层(告警→Enforcement)的自动化实现
-- [[AWS-Budget-Alerts]]:AWS Budget 服务原生的预算告警机制,通过 SNS → Lambda → Step Functions 扩展为详细告警邮件
-- [[SCP-Enforcement]]:Service Control Policy,在 100% 预算触发时自动封禁账户新资源创建,实现成本治理的"硬执行"
-- [[CloudTrail]]:AWS 审计日志服务,Source Identity 机制使其能追踪联邦登录跨角色切换的完整用户链
-- [[Step-Functions]]:AWS Step Functions 编排 Lambda 和数据增强逻辑,实现告警流程自动化
-- [[Cost-Explorer]]:AWS 成本分析工具,提供用户维度的日度支出数据,用于 top users 报告
-
-## Key Entities
-- [[Daniela]]:SRE Core 团队成员,负责图表和详细成本报告讲解(提及 <2 次,wikilink 记录)
-- [[Evan]]:SRE Core 团队成员(提及 <2 次,wikilink 记录)
-- [[Alan]]:SRE Core 团队成员,负责 AWS Budget Alerts and Actions 实现细节讲解(提及 <2 次,wikilink 记录)
-- [[SRE-Core-Team]]:预算控制自动化系统的开发团队,由 Daniela、Evan、Alan 三人组成
-- [[Phenops-Team]]:FinOps 执行团队,本 Source 中负责预算分配和 Enforcement 审批决策
-- [[NetIQ]]:联邦身份管理系统(NetIQ Access Manager),用于用户认证并提供 Source Identity 的上游身份
-
-## Connections
-- [[ctp-topic-13-cloud-finops-policies]] ← extends ← [[public-cloud-learning-sessions-budget-control-20240319]]:Topic 13 定义 FinOps 政策框架(成本管理→成本优化→治理自动化三层),本 Source 展示"治理与自动化"层(Budget Enforcement)的具体技术实现
-- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← relates_to ← [[public-cloud-learning-sessions-budget-control-20240319]]:Topic 63 聚焦 RightSizing/承诺计划等主动优化手段,本 Source 聚焦被动告警+强制执行机制,两者互补构成 FinOps 完整闭环
-- [[public-cloud-learning-sessions-reducing-cloud-costs-20250318]] ← extends ← [[public-cloud-learning-sessions-budget-control-20240319]]:2025 版主讲 Vinay(FinOps Lead),补充了 Savings Plans/RI 承诺计划,本 Source 是 2024 早期版本,两者构成 FinOps 知识演进
-
-## Contradictions
-- 与 [[ctp-topic-13-cloud-finops-policies]] 关于 Enforcement 方式:Topic 13 提到"集中式上线/策略开发/自动报告",本 Source 明确提出 SCP 自动封禁新资源作为 Enforcement 手段;两者不矛盾,Topic 13 描述政策层面,本 Source 描述执行层面
+---
+title: "Public Cloud Learning Sessions - Budget Control - 20240319"
+type: source
+tags: [FinOps, AWS, Cost-Optimization, Budget-Control, Alerting]
+date: 2024-03-19
+sources: [Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/public-cloud-learning-sessions-budget-control-20240319-160204-meeting-recording.md]
+last_updated: 2026-04-26
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/public-cloud-learning-sessions-budget-control-20240319-160204-meeting-recording.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 预算控制自动化系统——面向 SRE Core 团队(Daniela、Evan、Alan)的内部学习分享
+- 问题域:AWS 账户蔓延导致的成本失控,以及现有成本削减措施不可持续的问题
+- 方法/机制:AWS Budget → SNS → Lambda → Step Functions → SCP Enforcement(服务控制策略封禁新资源创建)的完整告警与执行链路;Source Identity 追踪跨角色切换的原始登录身份
+- 结论/价值:提供账户级别的详细告警(支出预测/实际支出/成本驱动因素),并将 Enforcement 从手动审批逐步演进为自动封禁
+
+## Key Claims(用中文描述)
+- SRE Core 团队通过 AWS Budget 服务 + 自定义 Lambda/Step Functions 构建的自动化预算控制,解决了 AWS 账户蔓延导致的成本失控问题
+- 告警类型分为 4 种:Forecast(预测超支)、Actual(实际超支 80%/90%/95%/98%)、Severe(100% 且评分制触发)、Enforcement(100% 且启用强制执行则触发 SCP 封禁)
+- Source Identity(AWS Source Identity 属性)通过 CloudTrail 跨角色切换追踪原始登录用户,解决了联邦登录(NetIQ)中"假设角色后无法识别原始身份"的问题
+- 评分系统(Scoring System)根据账户规模和月末时间节点计算宽限期(Grace Period),避免轻微超支的账户被误处罚
+- 初始实施范围仅限 Lab 账户,其他账户继续接收标准超预算告警
+
+## Key Quotes
+> "This is the first time that we were able to get to this level of granularity." — Daniel,描述通过 Athena + Cost Explorer 实现的资源级成本粒度
+
+## Key Concepts
+- [[AWS-Source-Identity]]:通过 `sts:SourceIdentity` 属性在假设角色后保留原始登录身份,使 CloudTrail 可追踪跨角色用户活动
+- [[FinOps]]:云财务管理,本质是将财务责任与工程实践结合,本 Source 展示 FinOps 执行层(告警→Enforcement)的自动化实现
+- [[AWS-Budget-Alerts]]:AWS Budget 服务原生的预算告警机制,通过 SNS → Lambda → Step Functions 扩展为详细告警邮件
+- [[SCP-Enforcement]]:Service Control Policy,在 100% 预算触发时自动封禁账户新资源创建,实现成本治理的"硬执行"
+- [[CloudTrail]]:AWS 审计日志服务,Source Identity 机制使其能追踪联邦登录跨角色切换的完整用户链
+- [[Step-Functions]]:AWS Step Functions 编排 Lambda 和数据增强逻辑,实现告警流程自动化
+- [[Cost-Explorer]]:AWS 成本分析工具,提供用户维度的日度支出数据,用于 top users 报告
+
+## Key Entities
+- [[Daniela]]:SRE Core 团队成员,负责图表和详细成本报告讲解(提及 <2 次,wikilink 记录)
+- [[Evan]]:SRE Core 团队成员(提及 <2 次,wikilink 记录)
+- [[Alan]]:SRE Core 团队成员,负责 AWS Budget Alerts and Actions 实现细节讲解(提及 <2 次,wikilink 记录)
+- [[SRE-Core-Team]]:预算控制自动化系统的开发团队,由 Daniela、Evan、Alan 三人组成
+- [[Phenops-Team]]:FinOps 执行团队,本 Source 中负责预算分配和 Enforcement 审批决策
+- [[NetIQ]]:联邦身份管理系统(NetIQ Access Manager),用于用户认证并提供 Source Identity 的上游身份
+
+## Connections
+- [[ctp-topic-13-cloud-finops-policies]] ← extends ← [[public-cloud-learning-sessions-budget-control-20240319]]:Topic 13 定义 FinOps 政策框架(成本管理→成本优化→治理自动化三层),本 Source 展示"治理与自动化"层(Budget Enforcement)的具体技术实现
+- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← relates_to ← [[public-cloud-learning-sessions-budget-control-20240319]]:Topic 63 聚焦 RightSizing/承诺计划等主动优化手段,本 Source 聚焦被动告警+强制执行机制,两者互补构成 FinOps 完整闭环
+- [[public-cloud-learning-sessions-reducing-cloud-costs-20250318]] ← extends ← [[public-cloud-learning-sessions-budget-control-20240319]]:2025 版主讲 Vinay(FinOps Lead),补充了 Savings Plans/RI 承诺计划,本 Source 是 2024 早期版本,两者构成 FinOps 知识演进
+
+## Contradictions
+- 与 [[ctp-topic-13-cloud-finops-policies]] 关于 Enforcement 方式:Topic 13 提到"集中式上线/策略开发/自动报告",本 Source 明确提出 SCP 自动封禁新资源作为 Enforcement 手段;两者不矛盾,Topic 13 描述政策层面,本 Source 描述执行层面
diff --git a/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization.md b/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization.md
index 90dc5bb4..37338428 100644
--- a/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization.md
+++ b/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization.md
@@ -1,62 +1,62 @@
----
-title: "Public Cloud Learning Sessions - EKS Optimization Part 1 of 3 - Compute Optimization with Karpenter"
-type: source
-tags: [AWS, EKS, Karpenter, Cost-Optimization, Kubernetes, Spot-Instance]
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization]]
-
-## Summary(用中文描述)
-- 核心主题:AWS EKS 计算成本优化,聚焦 Karpenter 与 Cluster Autoscaler 的对比及 Karpenter 的核心能力
-- 问题域:传统 Cluster Autoscaler 在 Kubernetes 节点自动伸缩方面的局限性(延迟高、集成浅、功能分散)
-- 方法/机制:Karpenter 直接与 EC2 Fleet API 通信,结合 Node Pools 和 Node Classes 实现智能工作负载放置与节点整合
-- 结论/价值:Karpenter 将节点组管理、Spot 中断处理、AMI 生命周期管理整合为统一数据平面,大幅降低 EKS 计算成本和运维复杂度
-
-## Key Claims(用中文描述)
-- Karpenter 通过直接调用 EC2 Fleet API 降低节点供给延迟,相比 Cluster Autoscaler 减少调度等待时间
-- Karpenter 原生集成 Kubernetes 调度约束(node selectors/affinity/taints/tolerations/topology spread),无需额外组件即可实现精细化工作负载放置
-- Karpenter 内置 Spot 中断处理能力,通过 EventBridge + SQS 监听 spot interruption/instance rebalance/health events,无需单独部署 node termination handler
-- Karpenter 通过 Consolidation 策略自动整合低利用率节点,支持细粒度中断预算控制和峰值时段豁免
-- Karpenter 支持 AMI 自动滚动升级,可从 Parameter Store 获取对应 EKS 控制面版本的最新优化 AMI,支持版本锁定和自定义 AMI
-
-## Key Quotes
-> "Carpenter has native integration with Kubernetes and it complements the native Kubernetes spot pod scheduling constraints that is available for your workloads." — 强调 Karpenter 与原生 K8s Spot Pod Disruption Budget 的互补关系
-
-> "Carpenter not only does the auto-scaling bit, but it also removes the pain points of working with node groups." — 核心价值:Karpenter 不仅做扩缩容,更消除了节点组管理的所有痛点
-
-## Key Concepts
-- [[Karpenter]]:AWS 开源的 Kubernetes 节点自动伸缩器,直接与 EC2 Fleet API 通信,实现智能节点供给与整合
-- [[Node-Pool]]:Karpenter 的核心概念,定义调度约束和容量限制,控制哪些 Pod 可以调度到哪些节点
-- [[Node-Class]]:Karpenter 的核心概念,定义实例配置细节(子网、节点角色、AMI),相当于实例模板
-- [[Spot-Interruption-Handling]]:Karpenter 内置的 Spot 实例中断处理,通过 EventBridge + SQS 监听中断信号并自动驱逐 Pod
-- [[Consolidation]]:Karpenter 的节点整合策略,自动识别低利用率节点并将其 Pod 驱逐整合到更少节点
-- [[AMI-Rolling-Upgrade]]:Karpenter 的 AMI 生命周期管理,支持从 Parameter Store 自动获取最新 EKS 优化 AMI 并滚动升级
-- [[EC2-Fleet-API]]:Karpenter 直接调用的 AWS API,绕过 ASG 实现更快的节点供给
-- [[Topology-Spread-Constraints]]:K8s 拓扑分布约束,Karpenter 支持基于可用区的 Pod 分布调度
-
-## Key Entities
-- [[Amazon EKS]]:托管 Kubernetes 服务,Karpenter 的运行平台
-- [[AWS EC2]]:Karpenter 调度计算资源的目标平台
-- [[Amazon EventBridge]]:Karpenter 监听 Spot 中断事件的 AWS 事件总线
-- [[Amazon SQS]]:Karpenter 接收 Spot 中断通知的队列服务
-- [[AWS Systems Manager Parameter Store]]:Karpenter 获取 EKS 优化 AMI 版本的配置存储服务
-- [[Prometheus]]:Karpenter 发布指标的开源监控系统
-- [[Cluster Autoscaler]]:Karpenter 的对标竞品,K8s 生态传统节点自动伸缩方案
-
-## Connections
-- [[Amazon EKS]] ← 平台 ← [[Karpenter]]
-- [[Cluster Autoscaler]] ← 替代升级 ← [[Karpenter]]
-- [[Spot-Interruption-Handling]] ← 依赖 ← [[Amazon EventBridge]] + [[Amazon SQS]]
-- [[AMI-Rolling-Upgrade]] ← 依赖 ← [[AWS Systems Manager Parameter Store]]
-- [[Consolidation]] ← 关联 ← [[Cost-Optimization]]
-- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← 系列后续 ← [[Karpenter]](Part 3 覆盖 EKS Auto Mode,内含 Karpenter Controller)
-- [[ctp-topic-70-eks-deployment-using-iac]] ← 关联 ← [[Amazon EKS]](部署方法)
-
-## Contradictions
-- 与 [[ctp-topic-70-eks-deployment-using-iac]] 可能存在视角差异:
- - 冲突点:节点扩缩容方案选型
- - 当前观点(Part 1):推荐 Karpenter,强调其原生集成和简化数据平面管理的能力
- - 对方观点(Topic 70):重点介绍 Cluster Autoscaler 作为扩缩容方案
- - 说明:两者并非互斥——Topic 70 聚焦 EKS IaC 部署流程中的 Cluster Autoscaler 集成;Part 1 聚焦计算优化专题,强调从 Cluster Autoscaler 迁移至 Karpenter 的收益。可并存作为迁移路径参考。
+---
+title: "Public Cloud Learning Sessions - EKS Optimization Part 1 of 3 - Compute Optimization with Karpenter"
+type: source
+tags: [AWS, EKS, Karpenter, Cost-Optimization, Kubernetes, Spot-Instance]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS EKS 计算成本优化,聚焦 Karpenter 与 Cluster Autoscaler 的对比及 Karpenter 的核心能力
+- 问题域:传统 Cluster Autoscaler 在 Kubernetes 节点自动伸缩方面的局限性(延迟高、集成浅、功能分散)
+- 方法/机制:Karpenter 直接与 EC2 Fleet API 通信,结合 Node Pools 和 Node Classes 实现智能工作负载放置与节点整合
+- 结论/价值:Karpenter 将节点组管理、Spot 中断处理、AMI 生命周期管理整合为统一数据平面,大幅降低 EKS 计算成本和运维复杂度
+
+## Key Claims(用中文描述)
+- Karpenter 通过直接调用 EC2 Fleet API 降低节点供给延迟,相比 Cluster Autoscaler 减少调度等待时间
+- Karpenter 原生集成 Kubernetes 调度约束(node selectors/affinity/taints/tolerations/topology spread),无需额外组件即可实现精细化工作负载放置
+- Karpenter 内置 Spot 中断处理能力,通过 EventBridge + SQS 监听 spot interruption/instance rebalance/health events,无需单独部署 node termination handler
+- Karpenter 通过 Consolidation 策略自动整合低利用率节点,支持细粒度中断预算控制和峰值时段豁免
+- Karpenter 支持 AMI 自动滚动升级,可从 Parameter Store 获取对应 EKS 控制面版本的最新优化 AMI,支持版本锁定和自定义 AMI
+
+## Key Quotes
+> "Carpenter has native integration with Kubernetes and it complements the native Kubernetes spot pod scheduling constraints that is available for your workloads." — 强调 Karpenter 与原生 K8s Spot Pod Disruption Budget 的互补关系
+
+> "Carpenter not only does the auto-scaling bit, but it also removes the pain points of working with node groups." — 核心价值:Karpenter 不仅做扩缩容,更消除了节点组管理的所有痛点
+
+## Key Concepts
+- [[Karpenter]]:AWS 开源的 Kubernetes 节点自动伸缩器,直接与 EC2 Fleet API 通信,实现智能节点供给与整合
+- [[Node-Pool]]:Karpenter 的核心概念,定义调度约束和容量限制,控制哪些 Pod 可以调度到哪些节点
+- [[Node-Class]]:Karpenter 的核心概念,定义实例配置细节(子网、节点角色、AMI),相当于实例模板
+- [[Spot-Interruption-Handling]]:Karpenter 内置的 Spot 实例中断处理,通过 EventBridge + SQS 监听中断信号并自动驱逐 Pod
+- [[Consolidation]]:Karpenter 的节点整合策略,自动识别低利用率节点并将其 Pod 驱逐整合到更少节点
+- [[AMI-Rolling-Upgrade]]:Karpenter 的 AMI 生命周期管理,支持从 Parameter Store 自动获取最新 EKS 优化 AMI 并滚动升级
+- [[EC2-Fleet-API]]:Karpenter 直接调用的 AWS API,绕过 ASG 实现更快的节点供给
+- [[Topology-Spread-Constraints]]:K8s 拓扑分布约束,Karpenter 支持基于可用区的 Pod 分布调度
+
+## Key Entities
+- [[Amazon EKS]]:托管 Kubernetes 服务,Karpenter 的运行平台
+- [[AWS EC2]]:Karpenter 调度计算资源的目标平台
+- [[Amazon EventBridge]]:Karpenter 监听 Spot 中断事件的 AWS 事件总线
+- [[Amazon SQS]]:Karpenter 接收 Spot 中断通知的队列服务
+- [[AWS Systems Manager Parameter Store]]:Karpenter 获取 EKS 优化 AMI 版本的配置存储服务
+- [[Prometheus]]:Karpenter 发布指标的开源监控系统
+- [[Cluster Autoscaler]]:Karpenter 的对标竞品,K8s 生态传统节点自动伸缩方案
+
+## Connections
+- [[Amazon EKS]] ← 平台 ← [[Karpenter]]
+- [[Cluster Autoscaler]] ← 替代升级 ← [[Karpenter]]
+- [[Spot-Interruption-Handling]] ← 依赖 ← [[Amazon EventBridge]] + [[Amazon SQS]]
+- [[AMI-Rolling-Upgrade]] ← 依赖 ← [[AWS Systems Manager Parameter Store]]
+- [[Consolidation]] ← 关联 ← [[Cost-Optimization]]
+- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← 系列后续 ← [[Karpenter]](Part 3 覆盖 EKS Auto Mode,内含 Karpenter Controller)
+- [[ctp-topic-70-eks-deployment-using-iac]] ← 关联 ← [[Amazon EKS]](部署方法)
+
+## Contradictions
+- 与 [[ctp-topic-70-eks-deployment-using-iac]] 可能存在视角差异:
+ - 冲突点:节点扩缩容方案选型
+ - 当前观点(Part 1):推荐 Karpenter,强调其原生集成和简化数据平面管理的能力
+ - 对方观点(Topic 70):重点介绍 Cluster Autoscaler 作为扩缩容方案
+ - 说明:两者并非互斥——Topic 70 聚焦 EKS IaC 部署流程中的 Cluster Autoscaler 集成;Part 1 聚焦计算优化专题,强调从 Cluster Autoscaler 迁移至 Karpenter 的收益。可并存作为迁移路径参考。
diff --git a/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-2-of-3-running-containers-w.md b/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-2-of-3-running-containers-w.md
index 82c88a4f..68a46ea5 100644
--- a/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-2-of-3-running-containers-w.md
+++ b/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-2-of-3-running-containers-w.md
@@ -1,56 +1,56 @@
----
-title: "Public Cloud Learning Sessions - EKS Optimization Part 2 of 3 - Running Containers with Bottlerocket OS"
-type: source
-tags:
- - AWS
- - EKS
- - Bottlerocket
- - Container OS
- - Cloud-Native
-date: 2026-04-24
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/public-cloud-learning-sessions-eks-optimization-part-2-of-3-running-containers-w]]
-
-## Summary(用中文描述)
-- 核心主题:Bottlerocket OS(火箭瓶)—— AWS 专为容器工作负载优化的最小化 Linux 发行版,用于 EKS 环境运行容器
-- 问题域:传统通用操作系统运行容器时存在体积臃肿、安全攻击面大、更新机制不可控等问题
-- 方法/机制:通过 Variant 机制实现最小化构建 + 分区镜像更新(Partition Updates)实现安全更新 + dm-verity 根文件系统验证 + SE Linux 强制模式
-- 结论/价值:Bottlerocket 将容器宿主 OS 的攻击面降至最低,提供生产级安全保证,是 EKS Auto Mode 的默认节点操作系统
-
-## Key Claims(用中文描述)
-- Bottlerocket 通过去除所有非必要组件(无包管理器、无默认 Shell、无默认 SSH),将容器宿主 OS 体积和攻击面降至最低
-- Bottlerocket 的 Variant 机制(平台+架构+工作负载组件组合)在构建时固定所需功能,支持 GPU/Metal 等特定工作负载定制,避免通用 OS 的臃肿
-- Bottlerocket 通过分区镜像更新(A/B 分区切换)在不停机前提下确保系统一致性,data volume 缓存容器镜像并支持快照预填充
-- Bottlerocket 的 dm-verity 对根文件系统进行加密验证,根文件系统默认只读,任何篡改均被检测
-- Bottlerocket 集成 EKS 的三种模式:自管理节点组(Self-Managed Node Groups)、托管节点组(Managed Node Groups)、Carpenter 节点池(Carpenter Node Pools)
-- Bottlerocket 提供专用 CIS benchmark 加固指南,实现企业级安全基线
-
-## Key Quotes
-> "A variant is basically a combination of platform, supported platform, the processor architecture and the necessary binary components that are supported by the processor architecture and any additional packages and drivers that are required for your specific workloads."
-> — Bottlerocket Variant 机制定义
-
-> "The root file system is by default immutable, you cannot change anything there."
-> — Bottlerocket 根文件系统不可变性说明
-
-## Key Concepts
-- [[Immutable-Root-Filesystem]]:根文件系统默认只读,任何运行时变更均被拒绝,必须通过镜像更新机制修改
-- [[dm-verity]]:内核级块设备完整性验证,通过加密哈希树检测根文件系统任何未授权变更
-- [[SE-Linux-Enforcing]]:SE Linux 默认启用 enforcing 模式,基于标签的强制访问控制(MAC)
-- [[Partition-Updates]]:A/B 双分区机制,在线下载新版本镜像到非活动分区,重启后切换,确保更新原子性
-- [[CIS-Benchmark]]:Bottlerocket 提供专用 CIS benchmark 安全加固指南
-
-## Key Entities
-- [[Bottlerocket]]:AWS 主导维护的容器专用开源 Linux OS,采用最小化设计,Bottlerocket 可运行于笔记本、工作站和数据中心
-- [[Amazon EKS]]:Bottlerocket 通过 eksctl、Carpenter 等工具集成,支持自管理节点组、托管节点组和 Carpenter 节点池三种部署模式
-- [[AWS]]:Bottlerocket 的核心维护者和赞助方,AWS 在 GitHub 上主导项目开发
-
-## Connections
-- [[public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization]] ← related_to ← [[Bottlerocket]](EKS 优化系列 Part 1 - Karpenter 计算优化,Part 2 - Bottlerocket OS 节点运行时,Part 3 - EKS Auto Mode)
-- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← extends ← [[Bottlerocket]](EKS Auto Mode 默认使用 Bottlerocket 作为节点操作系统)
-- [[Bottlerocket]] ← security_enforcement ← [[Immutable-Root-Filesystem]] + [[dm-verity]] + [[SE-Linux-Enforcing]]
-
-## Contradictions
-- 与 [[ctp-topic-70-eks-deployment-using-iac]](EKS IaC 部署)不存在直接冲突,两者互补:Topic 70 聚焦 EKS 集群的 IaC 部署方法,本文聚焦容器运行时节点的操作系统选型,共同构成完整的 EKS 部署链路
-- 与 [[ctp-topic-59-achieving-reliability-with-amazon-eks]](EKS 可靠性)不存在冲突:Bottlerocket 的分区更新和只读根文件系统是实现 EKS 数据平面可靠性的关键机制之一
+---
+title: "Public Cloud Learning Sessions - EKS Optimization Part 2 of 3 - Running Containers with Bottlerocket OS"
+type: source
+tags:
+ - AWS
+ - EKS
+ - Bottlerocket
+ - Container OS
+ - Cloud-Native
+date: 2026-04-24
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/public-cloud-learning-sessions-eks-optimization-part-2-of-3-running-containers-w.md]]
+
+## Summary(用中文描述)
+- 核心主题:Bottlerocket OS(火箭瓶)—— AWS 专为容器工作负载优化的最小化 Linux 发行版,用于 EKS 环境运行容器
+- 问题域:传统通用操作系统运行容器时存在体积臃肿、安全攻击面大、更新机制不可控等问题
+- 方法/机制:通过 Variant 机制实现最小化构建 + 分区镜像更新(Partition Updates)实现安全更新 + dm-verity 根文件系统验证 + SE Linux 强制模式
+- 结论/价值:Bottlerocket 将容器宿主 OS 的攻击面降至最低,提供生产级安全保证,是 EKS Auto Mode 的默认节点操作系统
+
+## Key Claims(用中文描述)
+- Bottlerocket 通过去除所有非必要组件(无包管理器、无默认 Shell、无默认 SSH),将容器宿主 OS 体积和攻击面降至最低
+- Bottlerocket 的 Variant 机制(平台+架构+工作负载组件组合)在构建时固定所需功能,支持 GPU/Metal 等特定工作负载定制,避免通用 OS 的臃肿
+- Bottlerocket 通过分区镜像更新(A/B 分区切换)在不停机前提下确保系统一致性,data volume 缓存容器镜像并支持快照预填充
+- Bottlerocket 的 dm-verity 对根文件系统进行加密验证,根文件系统默认只读,任何篡改均被检测
+- Bottlerocket 集成 EKS 的三种模式:自管理节点组(Self-Managed Node Groups)、托管节点组(Managed Node Groups)、Carpenter 节点池(Carpenter Node Pools)
+- Bottlerocket 提供专用 CIS benchmark 加固指南,实现企业级安全基线
+
+## Key Quotes
+> "A variant is basically a combination of platform, supported platform, the processor architecture and the necessary binary components that are supported by the processor architecture and any additional packages and drivers that are required for your specific workloads."
+> — Bottlerocket Variant 机制定义
+
+> "The root file system is by default immutable, you cannot change anything there."
+> — Bottlerocket 根文件系统不可变性说明
+
+## Key Concepts
+- [[Immutable-Root-Filesystem]]:根文件系统默认只读,任何运行时变更均被拒绝,必须通过镜像更新机制修改
+- [[dm-verity]]:内核级块设备完整性验证,通过加密哈希树检测根文件系统任何未授权变更
+- [[SE-Linux-Enforcing]]:SE Linux 默认启用 enforcing 模式,基于标签的强制访问控制(MAC)
+- [[Partition-Updates]]:A/B 双分区机制,在线下载新版本镜像到非活动分区,重启后切换,确保更新原子性
+- [[CIS-Benchmark]]:Bottlerocket 提供专用 CIS benchmark 安全加固指南
+
+## Key Entities
+- [[Bottlerocket]]:AWS 主导维护的容器专用开源 Linux OS,采用最小化设计,Bottlerocket 可运行于笔记本、工作站和数据中心
+- [[Amazon EKS]]:Bottlerocket 通过 eksctl、Carpenter 等工具集成,支持自管理节点组、托管节点组和 Carpenter 节点池三种部署模式
+- [[AWS]]:Bottlerocket 的核心维护者和赞助方,AWS 在 GitHub 上主导项目开发
+
+## Connections
+- [[public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization]] ← related_to ← [[Bottlerocket]](EKS 优化系列 Part 1 - Karpenter 计算优化,Part 2 - Bottlerocket OS 节点运行时,Part 3 - EKS Auto Mode)
+- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← extends ← [[Bottlerocket]](EKS Auto Mode 默认使用 Bottlerocket 作为节点操作系统)
+- [[Bottlerocket]] ← security_enforcement ← [[Immutable-Root-Filesystem]] + [[dm-verity]] + [[SE-Linux-Enforcing]]
+
+## Contradictions
+- 与 [[ctp-topic-70-eks-deployment-using-iac]](EKS IaC 部署)不存在直接冲突,两者互补:Topic 70 聚焦 EKS 集群的 IaC 部署方法,本文聚焦容器运行时节点的操作系统选型,共同构成完整的 EKS 部署链路
+- 与 [[ctp-topic-59-achieving-reliability-with-amazon-eks]](EKS 可靠性)不存在冲突:Bottlerocket 的分区更新和只读根文件系统是实现 EKS 数据平面可靠性的关键机制之一
diff --git a/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks.md b/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks.md
index b01c1818..4016d63c 100644
--- a/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks.md
+++ b/wiki/sources/public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks.md
@@ -1,56 +1,56 @@
----
-title: "Public Cloud Learning Sessions - EKS Optimization Part 3 of 3 - Introduction to EKS Auto Mode"
-type: source
-tags: []
-date: 2025-03-04
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks-.md]]
-
-## Summary(用中文描述)
-- 核心主题:EKS Auto Mode — AWS 将 EKS 数据平面管理责任扩展至计算节点托管
-- 问题域:EKS 集群运维复杂度高(实例管理、OS 补丁、安全更新)
-- 方法/机制:Carpenter Controller 负责节点生命周期管理;Bottlerocket OS 提供最小化安全操作系统;AWS Load Balancer Controller 处理 ingress;EBS CSI Controller 支持有状态工作负载;Pod Identity Associations 替代 K8s RBAC 进行 Pod 级 IAM 权限控制;12% 实例费用溢价覆盖自动管理成本
-- 结论/价值:EKS Auto Mode 大幅降低 K8s 运维负担,用户只需关注 VPC 配置、集群配置和 workload 配置;数据平面升级自动化(控制面升级后 Carpenter 自动触发滚动升级);与标准 Kubernetes 工作负载完全兼容
-
-## Key Claims(用中文描述)
-- EKS Auto Mode 将数据平面管理责任从用户扩展至 AWS 服务,覆盖实例、OS、补丁和安全更新
-- EKS Auto Mode 默认提供两个节点池(General Purpose 和 System)和一个节点类(NodeClass)
-- General Purpose 节点池锁定 AMD64 架构,Custom 节点池可指定 Graviton 实例类型
-- System 节点池的节点带有 taint,系统 add-on 必须配置对应 tolerations
-- EKS Auto Mode 包含核心集群能力:计算(Carpenter)、网络(AWS LB Controller)、存储(EBS CSI)、安全(Pod Identity Associations)
-- Prefix Delegation 默认启用,优化 Pod 网络 IP 分配
-- 数据平面升级由控制面版本升级触发,Carpenter Controller 自动识别并执行滚动升级
-- 每个 Auto Mode 实例收取 12% 溢价,覆盖自动化管理成本
-- 可观测性通过 CloudWatch Agent、ADOT(AWS Distro for OpenTelemetry)或第三方收集器实现
-
-## Key Quotes
-> "With Auto Mode, a majority of the operational concerns are being managed by the ECS service." — EKS Auto Mode 将大多数运维职责托管至 AWS
-> "Once the control plane version gets upgraded, then the compute controller... will try to pull the current AMI version for that new control plane version." — 数据平面自动升级机制
-
-## Key Concepts
-- [[EKS Auto Mode]]:AWS EKS 的半托管模式,将计算节点的生命周期管理(实例采购、OS 补丁、安全更新)托管给 AWS,适用于希望降低 K8s 运维复杂度同时保留标准 K8s API 兼容性的团队
-- [[Carpenter Controller]]:EKS Auto Mode 的计算控制器,负责节点池生命周期管理、AMI 版本管理和滚动升级编排
-- [[Bottlerocket OS]]:Amazon 开发的容器专用最小化 Linux 操作系统,专为 EKS Auto Mode 设计,自动应用安全补丁
-- [[AWS Load Balancer Controller]]:Auto Mode 特有的 LoadBalancer 类(eks.aws/alb),管理 ALB/NLB ingress 资源
-- [[EBS CSI Controller]]:EKS Auto Mode 的存储控制器,提供 EBS 卷的动态供给,支持有状态工作负载(需配置 StorageClass 引用 eks-aws-ebs provisioner)
-- [[Pod Identity Associations]]:AWS 提供的 Pod 级 IAM 权限控制机制,替代传统的 K8s RBAC + ServiceAccount IAM Role 模式,无需修改 ServiceAccount annotation
-- [[Prefix Delegation]]:VPCCNI 的一个特性,为 Pod 分配 /28 前缀 IP 块而非单 IP,优化网络地址利用率,默认在 Auto Mode 中启用
-- [[CoreDNS]]:K8s 集群 DNS 服务,在 Auto Mode 中作为系统服务打包至每个节点
-- [[Kube Proxy]]:K8s 网络代理,在 Auto Mode 中以 IPtables 模式运行
-- [[VPCCNI]]:Amazon VPC CNI 网络插件,在 Auto Mode 中作为系统服务运行
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,EKS Auto Mode 的云服务提供商
-- [[Amazon EKS]]:AWS 托管 Kubernetes 服务,Auto Mode 扩展了其托管范围至数据平面
-
-## Connections
-- [[public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization]] ← extends ← [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]]
-- [[public-cloud-learning-sessions-eks-optimization-part-2-of-3-running-containers-w]] ← extends ← [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]]
-- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← related_to ← [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]]
-- [[ctp-topic-64-scaling-out-with-amazon-eks]] ← related_to ← [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]]
-- [[ctp-topic-70-eks-deployment-using-iac]] ← related_to ← [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]]
-
-## Contradictions
-- 暂无已知冲突内容
+---
+title: "Public Cloud Learning Sessions - EKS Optimization Part 3 of 3 - Introduction to EKS Auto Mode"
+type: source
+tags: []
+date: 2025-03-04
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks-.md]]
+
+## Summary(用中文描述)
+- 核心主题:EKS Auto Mode — AWS 将 EKS 数据平面管理责任扩展至计算节点托管
+- 问题域:EKS 集群运维复杂度高(实例管理、OS 补丁、安全更新)
+- 方法/机制:Carpenter Controller 负责节点生命周期管理;Bottlerocket OS 提供最小化安全操作系统;AWS Load Balancer Controller 处理 ingress;EBS CSI Controller 支持有状态工作负载;Pod Identity Associations 替代 K8s RBAC 进行 Pod 级 IAM 权限控制;12% 实例费用溢价覆盖自动管理成本
+- 结论/价值:EKS Auto Mode 大幅降低 K8s 运维负担,用户只需关注 VPC 配置、集群配置和 workload 配置;数据平面升级自动化(控制面升级后 Carpenter 自动触发滚动升级);与标准 Kubernetes 工作负载完全兼容
+
+## Key Claims(用中文描述)
+- EKS Auto Mode 将数据平面管理责任从用户扩展至 AWS 服务,覆盖实例、OS、补丁和安全更新
+- EKS Auto Mode 默认提供两个节点池(General Purpose 和 System)和一个节点类(NodeClass)
+- General Purpose 节点池锁定 AMD64 架构,Custom 节点池可指定 Graviton 实例类型
+- System 节点池的节点带有 taint,系统 add-on 必须配置对应 tolerations
+- EKS Auto Mode 包含核心集群能力:计算(Carpenter)、网络(AWS LB Controller)、存储(EBS CSI)、安全(Pod Identity Associations)
+- Prefix Delegation 默认启用,优化 Pod 网络 IP 分配
+- 数据平面升级由控制面版本升级触发,Carpenter Controller 自动识别并执行滚动升级
+- 每个 Auto Mode 实例收取 12% 溢价,覆盖自动化管理成本
+- 可观测性通过 CloudWatch Agent、ADOT(AWS Distro for OpenTelemetry)或第三方收集器实现
+
+## Key Quotes
+> "With Auto Mode, a majority of the operational concerns are being managed by the ECS service." — EKS Auto Mode 将大多数运维职责托管至 AWS
+> "Once the control plane version gets upgraded, then the compute controller... will try to pull the current AMI version for that new control plane version." — 数据平面自动升级机制
+
+## Key Concepts
+- [[EKS Auto Mode]]:AWS EKS 的半托管模式,将计算节点的生命周期管理(实例采购、OS 补丁、安全更新)托管给 AWS,适用于希望降低 K8s 运维复杂度同时保留标准 K8s API 兼容性的团队
+- [[Carpenter Controller]]:EKS Auto Mode 的计算控制器,负责节点池生命周期管理、AMI 版本管理和滚动升级编排
+- [[Bottlerocket OS]]:Amazon 开发的容器专用最小化 Linux 操作系统,专为 EKS Auto Mode 设计,自动应用安全补丁
+- [[AWS Load Balancer Controller]]:Auto Mode 特有的 LoadBalancer 类(eks.aws/alb),管理 ALB/NLB ingress 资源
+- [[EBS CSI Controller]]:EKS Auto Mode 的存储控制器,提供 EBS 卷的动态供给,支持有状态工作负载(需配置 StorageClass 引用 eks-aws-ebs provisioner)
+- [[Pod Identity Associations]]:AWS 提供的 Pod 级 IAM 权限控制机制,替代传统的 K8s RBAC + ServiceAccount IAM Role 模式,无需修改 ServiceAccount annotation
+- [[Prefix Delegation]]:VPCCNI 的一个特性,为 Pod 分配 /28 前缀 IP 块而非单 IP,优化网络地址利用率,默认在 Auto Mode 中启用
+- [[CoreDNS]]:K8s 集群 DNS 服务,在 Auto Mode 中作为系统服务打包至每个节点
+- [[Kube Proxy]]:K8s 网络代理,在 Auto Mode 中以 IPtables 模式运行
+- [[VPCCNI]]:Amazon VPC CNI 网络插件,在 Auto Mode 中作为系统服务运行
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,EKS Auto Mode 的云服务提供商
+- [[Amazon EKS]]:AWS 托管 Kubernetes 服务,Auto Mode 扩展了其托管范围至数据平面
+
+## Connections
+- [[public-cloud-learning-sessions-eks-optimization-part-1-of-3-compute-optimization]] ← extends ← [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]]
+- [[public-cloud-learning-sessions-eks-optimization-part-2-of-3-running-containers-w]] ← extends ← [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]]
+- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← related_to ← [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]]
+- [[ctp-topic-64-scaling-out-with-amazon-eks]] ← related_to ← [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]]
+- [[ctp-topic-70-eks-deployment-using-iac]] ← related_to ← [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]]
+
+## Contradictions
+- 暂无已知冲突内容
diff --git a/wiki/sources/public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin.md b/wiki/sources/public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin.md
index 9df23449..ebb58e4f 100644
--- a/wiki/sources/public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin.md
+++ b/wiki/sources/public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin.md
@@ -1,60 +1,60 @@
----
-title: "Public Cloud Learning Sessions - Introduction to AI/ML with AWS"
-type: source
-tags: [AI, ML, AWS, Serverless-AI, Generative-AI, Amazon-Bedrock]
-date: 2024-02-06
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 上的 AI/ML 与生成式 AI 入门,由 AWS 高级解决方案架构师 Suraav Paul 主讲
-- 问题域:企业如何在 AWS 云上落地 AI/ML 能力,包括传统 AI(分类/预测)和生成式 AI(基础模型)
-- 方法/机制:Amazon Bedrock 全托管生成式 AI 服务、Amazon SageMaker Canvas 无代码 ML 工具、ML Ops 完整生命周期管理(数据流水线→训练流水线→推理流水线)
-- 结论/价值:AWS 通过预置算法/模型/SageMaker Canvas 民主化 AI 访问;Bedrock 支持微调/持续预训练/RAG/Agent/Guardrails 全套定制能力;ML Ops 融合 DevOps 文化、人员和流程,实现协同 ML 解决方案
-
-## Key Claims(用中文描述)
-- AI 指任何能复制此前需要人类智能才能完成任务的系统,通常通过机器学习使用数据创建决策逻辑或模型来寻求概率性结果
-- AWS 认为大多数客户体验和应用程序将被生成式 AI 重塑,由拥有数十亿参数的基础模型驱动
-- Amazon Bedrock 是全托管服务,用于构建和扩展生成式 AI 应用,支持使用自有数据定制基础模型,同时保持安全与隐私
-- ML Ops 结合机器学习与运维,涉及人员、技术和流程的协作,以实现协同 ML 解决方案
-
-## Key Quotes
-> "We believe most customer experiences and applications will be reinvented with generative AI, powered by foundation models with billions of parameters." — Suraav Paul, AWS Senior Solutions Architect
-
-> "AI is a way to describe any system that can replicate tasks that previously required human intelligence." — Suraav Paul, AWS Senior Solutions Architect
-
-> "ML Ops combines machine learning and operations, involving people, technology, and processes for collaborative ML solutions." — Suraav Paul, AWS Senior Solutions Architect
-
-## Key Concepts
-- [[RAG]]:Retrieval Augmented Generation,从企业数据源获取相关数据以生成响应,是 Bedrock 数据定制技术之一
-- [[MLOps]]:Machine Learning Operations,将 ML 与运维结合,涉及人员、技术和流程的协作框架
-- [[Foundation-Models]]:基础模型,具有数十亿参数,支持分类、预测和生成式 AI,是生成式 AI 的核心驱动
-- [[Amazon-Bedrock]]:AWS 全托管生成式 AI 服务,提供基础模型访问、数据定制(微调/持续预训练/RAG/Agent)和安全保障
-- [[Amazon-SageMaker-Canvas]]:AWS 无代码机器学习工具,民主化 AI/ML 访问
-- [[Responsible-AI]]:负责任 AI 原则,包括公平性、可解释性、鲁棒性、治理、透明度和隐私/安全
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,云服务商,提供 AI/ML 全套工具和服务
-- [[Amazon-Bedrock]]:AWS 全托管生成式 AI 服务平台
-- [[Amazon-Titan]]:Bedrock 提供的基础模型系列之一
-
-## Connections
-- [[ctp-topic-13-cloud-finops-policies]] ← extends ← [[FinOps(云财务管理)]]
-- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← depends_on ← [[FinOps(云财务管理)]]
-- [[ctp-topic-27-aws-instance-scheduler]] ← depends_on ← [[FinOps(云财务管理)]]
-- [[public-cloud-learning-sessions-budget-control-20240319]] ← depends_on ← [[FinOps(云财务管理)]]
-- [[public-cloud-learning-sessions-storage-cost-optimization-20240305]] ← depends_on ← [[FinOps(云财务管理)]]
-- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← extends ← [[OpenTelemetry]]
-- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← extends ← [[Amazon EKS]]
-- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← extends ← [[Amazon EKS]]
-
-## Contradictions
-- 无
-
-## Notes
-- Suraav Paul(AWS 高级解决方案架构师)仅出现 1 次,以 wikilink 形式记录于 Source page,无需独立建页
-- [[RAG]] 在本 Wiki 中已有多个来源引用(LangChain、Milvus、Qdrant、Knowledge Base RAG 等),无需新建概念页
-- MLOps/Responsible AI 出现频次不足独立建页阈值,以 wikilink 形式记录于 Source page
-- 本来源属于 Cloud Transformation Programme 的 Serverless & AI 专题(09_Serverless_AI)
+---
+title: "Public Cloud Learning Sessions - Introduction to AI/ML with AWS"
+type: source
+tags: [AI, ML, AWS, Serverless-AI, Generative-AI, Amazon-Bedrock]
+date: 2024-02-06
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 上的 AI/ML 与生成式 AI 入门,由 AWS 高级解决方案架构师 Suraav Paul 主讲
+- 问题域:企业如何在 AWS 云上落地 AI/ML 能力,包括传统 AI(分类/预测)和生成式 AI(基础模型)
+- 方法/机制:Amazon Bedrock 全托管生成式 AI 服务、Amazon SageMaker Canvas 无代码 ML 工具、ML Ops 完整生命周期管理(数据流水线→训练流水线→推理流水线)
+- 结论/价值:AWS 通过预置算法/模型/SageMaker Canvas 民主化 AI 访问;Bedrock 支持微调/持续预训练/RAG/Agent/Guardrails 全套定制能力;ML Ops 融合 DevOps 文化、人员和流程,实现协同 ML 解决方案
+
+## Key Claims(用中文描述)
+- AI 指任何能复制此前需要人类智能才能完成任务的系统,通常通过机器学习使用数据创建决策逻辑或模型来寻求概率性结果
+- AWS 认为大多数客户体验和应用程序将被生成式 AI 重塑,由拥有数十亿参数的基础模型驱动
+- Amazon Bedrock 是全托管服务,用于构建和扩展生成式 AI 应用,支持使用自有数据定制基础模型,同时保持安全与隐私
+- ML Ops 结合机器学习与运维,涉及人员、技术和流程的协作,以实现协同 ML 解决方案
+
+## Key Quotes
+> "We believe most customer experiences and applications will be reinvented with generative AI, powered by foundation models with billions of parameters." — Suraav Paul, AWS Senior Solutions Architect
+
+> "AI is a way to describe any system that can replicate tasks that previously required human intelligence." — Suraav Paul, AWS Senior Solutions Architect
+
+> "ML Ops combines machine learning and operations, involving people, technology, and processes for collaborative ML solutions." — Suraav Paul, AWS Senior Solutions Architect
+
+## Key Concepts
+- [[RAG]]:Retrieval Augmented Generation,从企业数据源获取相关数据以生成响应,是 Bedrock 数据定制技术之一
+- [[MLOps]]:Machine Learning Operations,将 ML 与运维结合,涉及人员、技术和流程的协作框架
+- [[Foundation-Models]]:基础模型,具有数十亿参数,支持分类、预测和生成式 AI,是生成式 AI 的核心驱动
+- [[Amazon-Bedrock]]:AWS 全托管生成式 AI 服务,提供基础模型访问、数据定制(微调/持续预训练/RAG/Agent)和安全保障
+- [[Amazon-SageMaker-Canvas]]:AWS 无代码机器学习工具,民主化 AI/ML 访问
+- [[Responsible-AI]]:负责任 AI 原则,包括公平性、可解释性、鲁棒性、治理、透明度和隐私/安全
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,云服务商,提供 AI/ML 全套工具和服务
+- [[Amazon-Bedrock]]:AWS 全托管生成式 AI 服务平台
+- [[Amazon-Titan]]:Bedrock 提供的基础模型系列之一
+
+## Connections
+- [[ctp-topic-13-cloud-finops-policies]] ← extends ← [[FinOps(云财务管理)]]
+- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← depends_on ← [[FinOps(云财务管理)]]
+- [[ctp-topic-27-aws-instance-scheduler]] ← depends_on ← [[FinOps(云财务管理)]]
+- [[public-cloud-learning-sessions-budget-control-20240319]] ← depends_on ← [[FinOps(云财务管理)]]
+- [[public-cloud-learning-sessions-storage-cost-optimization-20240305]] ← depends_on ← [[FinOps(云财务管理)]]
+- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← extends ← [[OpenTelemetry]]
+- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← extends ← [[Amazon EKS]]
+- [[public-cloud-learning-sessions-eks-optimization-part-3-of-3-introduction-to-eks]] ← extends ← [[Amazon EKS]]
+
+## Contradictions
+- 无
+
+## Notes
+- Suraav Paul(AWS 高级解决方案架构师)仅出现 1 次,以 wikilink 形式记录于 Source page,无需独立建页
+- [[RAG]] 在本 Wiki 中已有多个来源引用(LangChain、Milvus、Qdrant、Knowledge Base RAG 等),无需新建概念页
+- MLOps/Responsible AI 出现频次不足独立建页阈值,以 wikilink 形式记录于 Source page
+- 本来源属于 Cloud Transformation Programme 的 Serverless & AI 专题(09_Serverless_AI)
diff --git a/wiki/sources/public-cloud-learning-sessions-observability-with-opentelemetry-20240402-160113.md b/wiki/sources/public-cloud-learning-sessions-observability-with-opentelemetry-20240402-160113.md
index e4a091d7..b0379939 100644
--- a/wiki/sources/public-cloud-learning-sessions-observability-with-opentelemetry-20240402-160113.md
+++ b/wiki/sources/public-cloud-learning-sessions-observability-with-opentelemetry-20240402-160113.md
@@ -1,61 +1,61 @@
----
-title: "Public Cloud Learning Sessions - Observability with OpenTelemetry - 20240402"
-type: source
-tags:
- - OpenTelemetry
- - Observability
- - AWS
- - EKS
-date: 2024-04-02
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/public-cloud-learning-sessions-observability-with-opentelemetry-20240402-160113-.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS OpenTelemetry 可观测性解决方案全景介绍,包括 OpenTelemetry 核心概念、AWS 发行版功能及 EKS 环境下的完整演示
-- 问题域:微服务架构下 observability 的挑战(系统复杂度增加、外部输出难以推断内部状态、Gartner 估计年均 87 小时停机时间、每小时 $42,000 成本)
-- 方法/机制:三信号可观测性模型(Metrics/Logs/Traces)、OpenTelemetry 统一 SDK(11 种语言支持)、OTLP 标准化协议、AWS Distribution for OpenTelemetry 自动注入、OpenTelemetry Collector 组件(Receivers/Processors/Exporters/Extensions)、Fluent Bit 日志采集 → OpenTelemetry → Amazon OpenSearch 端到端管道
-- 结论/价值:OpenTelemetry 提供 vendor-agnostic 的统一可观测性方案,AWS 发行版简化 EKS 环境部署,最新发布强化了安全合规、规模化、用户体验和日志支持
-
-## Key Claims(用中文描述)
-- 微服务架构导致可观测性挑战更加突出,因为系统复杂度随服务数量增加而指数增长
-- 三信号(Metrics/Logs/Traces)共同构成完整可观测性视图:Metrics 提供聚合统计、Logs 定位根因、Traces 呈现请求全链路
-- OpenTelemetry 通过统一数据格式和跨语言 SDK 解决了不同组件使用不同 SDK 和工具的碎片化问题
-- AWS Distribution for OpenTelemetry 提供统一代理,自动检测应用语言并创建预配置 Collector,实现零侵入式自动注入
-- Fluent Bit 将日志发送到 OpenTelemetry 容器(端口 55681),由 OpenTelemetry Collector 统一处理后导出至 OpenSearch
-- OpenSearch Dashboard 可按 trace group 展示延迟并通过应用组成图定位性能瓶颈
-
-## Key Quotes
-> "Observability is defined as a measure of how well internal states of a system can be inferred from knowledge of its external outputs." — Jay Comer,AWS 演讲开场定义
-> "OpenTelemetry aims to solve the problem of disparate SDKs and tooling for different components within the observability landscape by providing an instrumentation language with different SDKs per language." — OpenTelemetry 核心价值定位
-> "The output that Fluent Bit is sending the individual logs to is the Open Telemetry endpoint on the port 55681." — Demo 中的关键配置细节
-
-## Key Concepts
-- [[OpenTelemetry]]:云原生计算基金会(CNCF)项目,提供跨语言的统一遥测数据采集标准,包含 SDK(11 种语言)、OTLP 协议和 Collector 组件
-- [[Observability(可观测性)]]:通过系统外部输出(logs/metrics/traces)推断内部状态的能力,微服务架构的核心挑战
-- [[Three Signals(三信号)]]:Metrics(聚合统计)、Logs(根因定位)、Traces(全链路追踪),三者共同构成完整可观测性视图
-- [[OTLP(OpenTelemetry Protocol)]]:OpenTelemetry 的标准化数据传输协议,Collector 将数据导出至不同后端
-- [[OpenTelemetry Collector]]:标准化和转换遥测数据的组件,包含 Receivers(接收器)、Processors(处理器)、Exporters(导出器)和 Extensions(扩展)
-- [[AWS Distribution for OpenTelemetry]]:AWS 提供的 OpenTelemetry 统一代理,支持 Traces/Metrics/Logs 自动采集和 EKS Operator 自动注入
-- [[Fluent Bit]]:开源日志处理器和转发器,在 EKS 中采集容器日志并转发至 OpenTelemetry 端点
-
-## Key Entities
-- [[Jay Comer]]:AWS 解决方案架构师,主讲本次 OpenTelemetry 可观测性专题
-- [[Amazon EKS]]:AWS 托管 Kubernetes 服务,演示中运行示例应用的环境
-- [[Amazon OpenSearch Service]]:AWS 托管搜索和分析服务,演示中作为遥测数据后端存储
-- [[Amazon CloudWatch]]:AWS 原生监控服务,属于 AWS 可观测性生态但非本次演示重点
-- [[AWS X-Ray]]:AWS 原生分布式追踪服务,属于 AWS 可观测性生态但非本次演示重点
-- [[Grafana]]:开源可观测性平台,AWS 可观测性生态的重要组成部分
-- [[Prometheus]]:开源指标采集系统,AWS Managed Service Collector for Prometheus 提供无服务器的自动抓取能力
-- [[Fluent Bit]]:CNCF 毕业项目,轻量级日志处理器,用于 EKS 环境容器日志采集
-
-## Connections
-- [[ctp-topic-54-esm-saas-log-analytics]] ← related_to ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
-- [[Amazon EKS]] ← instrumented_by ← [[OpenTelemetry]]
-- [[Fluent Bit]] ← sends_logs_to ← OpenTelemetry Collector (port 55681)
-- [[OpenTelemetry Collector]] ← exports_to ← [[Amazon OpenSearch Service]]
-- [[OpenTelemetry]] ← is_standardized_by ← [[OTLP(OpenTelemetry Protocol)]]
-
-## Contradictions
-- (暂无检测到与其他 Wiki 页面的冲突内容)
+---
+title: "Public Cloud Learning Sessions - Observability with OpenTelemetry - 20240402"
+type: source
+tags:
+ - OpenTelemetry
+ - Observability
+ - AWS
+ - EKS
+date: 2024-04-02
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/04_EKS/public-cloud-learning-sessions-observability-with-opentelemetry-20240402-160113-.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS OpenTelemetry 可观测性解决方案全景介绍,包括 OpenTelemetry 核心概念、AWS 发行版功能及 EKS 环境下的完整演示
+- 问题域:微服务架构下 observability 的挑战(系统复杂度增加、外部输出难以推断内部状态、Gartner 估计年均 87 小时停机时间、每小时 $42,000 成本)
+- 方法/机制:三信号可观测性模型(Metrics/Logs/Traces)、OpenTelemetry 统一 SDK(11 种语言支持)、OTLP 标准化协议、AWS Distribution for OpenTelemetry 自动注入、OpenTelemetry Collector 组件(Receivers/Processors/Exporters/Extensions)、Fluent Bit 日志采集 → OpenTelemetry → Amazon OpenSearch 端到端管道
+- 结论/价值:OpenTelemetry 提供 vendor-agnostic 的统一可观测性方案,AWS 发行版简化 EKS 环境部署,最新发布强化了安全合规、规模化、用户体验和日志支持
+
+## Key Claims(用中文描述)
+- 微服务架构导致可观测性挑战更加突出,因为系统复杂度随服务数量增加而指数增长
+- 三信号(Metrics/Logs/Traces)共同构成完整可观测性视图:Metrics 提供聚合统计、Logs 定位根因、Traces 呈现请求全链路
+- OpenTelemetry 通过统一数据格式和跨语言 SDK 解决了不同组件使用不同 SDK 和工具的碎片化问题
+- AWS Distribution for OpenTelemetry 提供统一代理,自动检测应用语言并创建预配置 Collector,实现零侵入式自动注入
+- Fluent Bit 将日志发送到 OpenTelemetry 容器(端口 55681),由 OpenTelemetry Collector 统一处理后导出至 OpenSearch
+- OpenSearch Dashboard 可按 trace group 展示延迟并通过应用组成图定位性能瓶颈
+
+## Key Quotes
+> "Observability is defined as a measure of how well internal states of a system can be inferred from knowledge of its external outputs." — Jay Comer,AWS 演讲开场定义
+> "OpenTelemetry aims to solve the problem of disparate SDKs and tooling for different components within the observability landscape by providing an instrumentation language with different SDKs per language." — OpenTelemetry 核心价值定位
+> "The output that Fluent Bit is sending the individual logs to is the Open Telemetry endpoint on the port 55681." — Demo 中的关键配置细节
+
+## Key Concepts
+- [[OpenTelemetry]]:云原生计算基金会(CNCF)项目,提供跨语言的统一遥测数据采集标准,包含 SDK(11 种语言)、OTLP 协议和 Collector 组件
+- [[Observability(可观测性)]]:通过系统外部输出(logs/metrics/traces)推断内部状态的能力,微服务架构的核心挑战
+- [[Three Signals(三信号)]]:Metrics(聚合统计)、Logs(根因定位)、Traces(全链路追踪),三者共同构成完整可观测性视图
+- [[OTLP(OpenTelemetry Protocol)]]:OpenTelemetry 的标准化数据传输协议,Collector 将数据导出至不同后端
+- [[OpenTelemetry Collector]]:标准化和转换遥测数据的组件,包含 Receivers(接收器)、Processors(处理器)、Exporters(导出器)和 Extensions(扩展)
+- [[AWS Distribution for OpenTelemetry]]:AWS 提供的 OpenTelemetry 统一代理,支持 Traces/Metrics/Logs 自动采集和 EKS Operator 自动注入
+- [[Fluent Bit]]:开源日志处理器和转发器,在 EKS 中采集容器日志并转发至 OpenTelemetry 端点
+
+## Key Entities
+- [[Jay Comer]]:AWS 解决方案架构师,主讲本次 OpenTelemetry 可观测性专题
+- [[Amazon EKS]]:AWS 托管 Kubernetes 服务,演示中运行示例应用的环境
+- [[Amazon OpenSearch Service]]:AWS 托管搜索和分析服务,演示中作为遥测数据后端存储
+- [[Amazon CloudWatch]]:AWS 原生监控服务,属于 AWS 可观测性生态但非本次演示重点
+- [[AWS X-Ray]]:AWS 原生分布式追踪服务,属于 AWS 可观测性生态但非本次演示重点
+- [[Grafana]]:开源可观测性平台,AWS 可观测性生态的重要组成部分
+- [[Prometheus]]:开源指标采集系统,AWS Managed Service Collector for Prometheus 提供无服务器的自动抓取能力
+- [[Fluent Bit]]:CNCF 毕业项目,轻量级日志处理器,用于 EKS 环境容器日志采集
+
+## Connections
+- [[ctp-topic-54-esm-saas-log-analytics]] ← related_to ← [[ctp-topic-67-cloud-native-observability-using-opentelemetry]]
+- [[Amazon EKS]] ← instrumented_by ← [[OpenTelemetry]]
+- [[Fluent Bit]] ← sends_logs_to ← OpenTelemetry Collector (port 55681)
+- [[OpenTelemetry Collector]] ← exports_to ← [[Amazon OpenSearch Service]]
+- [[OpenTelemetry]] ← is_standardized_by ← [[OTLP(OpenTelemetry Protocol)]]
+
+## Contradictions
+- (暂无检测到与其他 Wiki 页面的冲突内容)
diff --git a/wiki/sources/public-cloud-learning-sessions-ollie-workflow-and-the-demand-process-20240416-16.md b/wiki/sources/public-cloud-learning-sessions-ollie-workflow-and-the-demand-process-20240416-16.md
index 385b253e..16855819 100644
--- a/wiki/sources/public-cloud-learning-sessions-ollie-workflow-and-the-demand-process-20240416-16.md
+++ b/wiki/sources/public-cloud-learning-sessions-ollie-workflow-and-the-demand-process-20240416-16.md
@@ -1,58 +1,58 @@
----
-title: "Public Cloud Learning Sessions - Ollie Workflow and The Demand Process - 20240416"
-type: source
-tags:
- - Workflow
- - Demand-Process
- - FinOps
- - ITIL
- - SMACs
-date: 2024-04-16
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/public-cloud-learning-sessions-ollie-workflow-and-the-demand-process-20240416-16.md]]
-
-## Summary(用中文描述)
-- 核心主题:Oli 工作流(超大规模云厂商支出审批流程)与需求管理全链路
-- 问题域:云转型过程中的 FinOps 支出审批治理、需求提交与自动化履约
-- 方法/机制:ITIL 服务管理框架下的三级审批工作流(FinOps 可行性→云服务技术可行性→FPNA 预算可用性),以及 OpenText 端到端需求管理流程(Octane/Qixi 提交 → 主服务目录 → SMACs 嵌入 → 自动化履约)
-- 结论/价值:所有超大规模云厂商支出(含工程实验室和商业工作负载)无论金额均需 MUI/Shannon 书面审批;推动"机器做机器能做的事",目标是 80% 场景业务单元自助完成需求提交
-
-## Key Claims(用中文描述)
-- 所有超大规模云厂商支出(含工程实验室和商业工作负载空间)无论金额,均需 MUI 或 Shannon 书面审批
-- Oli 工作流由 Tom Bice 领导的 FinOps 团队接管,正在集成到 SMACs 平台
-- 提议的三阶段工作流:FinOps 可行性验证 → 云服务技术可行性验证 → FPNA 团队预算可用性验证
-- Oli 系统提供飞行中 CSV 报告,追踪工作流状态、申请人、成本中心、月成本及当前步骤
-- ITIL 框架将业务流程分为服务战略、设计、过渡、运营、持续改进五个阶段
-- 主服务目录(Combined Cloud Products Master Catalog)将嵌入 SMACs,目标是 80% 场景下业务单元可自助选择所需服务
-- ADM 和 ITOM 需求规划会议记录所需内容、数量和发布版本
-
-## Key Quotes
-> "If justification details are not provided, requests are subject to immediate rejection." — Oli 请求提交规范
-> "Machines should do what machines can do, enabling an automated fulfillment process." — OpenText 需求管理核心理念
-> "The goal is for business units to self-select what they need 80% of the time." — 需求管理自动化目标
-
-## Key Concepts
-- [[Demand-Management(需求管理)]]:平衡需求与可用容量的必要手段,是 ITIL 服务过渡阶段的关键活动
-- [[ITIL-Service-Management]]:将业务流程分为服务战略、服务设计、服务过渡、服务运营、持续服务改进五阶段,Oli 工作流对应请求履约的第一阶段
-- [[SMACs]]:Social、Mobile、Analytics、Cloud 的技术栈组合,Oli 工作流正在集成到 SMACs 平台
-- [[FinOps]]:财务运营,Tom Bice 团队负责 Oli 工作流接管,重点关注云支出的可视性与优化
-- [[Product-Backlog]]:产品待办列表,Oli 工作流产生的请求经审批后进入 Backlog 管理
-
-## Key Entities
-- [[Tom-Bice]]:FinOps 团队负责人,正在接管 Oli 工作流并集成到 SMACs
-- [[FPNA-Team]]:财务规划与分析团队,负责工作流第三阶段——预算可用性验证
-- [[MUI]]:超大规模云厂商支出审批人之一(与 Shannon 共同审批所有云支出请求)
-- [[Shannon]]:超大规模云厂商支出审批人之一(与 MUI 共同审批所有云支出请求)
-- [[Octane]]:超大规模云厂商 SaaS 产品需求管理平台,业务单元可直接向其提交需求
-- [[Qixi]]:Oli 需求提交流程的前端接口之一,业务单元通过其提交需求
-
-## Connections
-- [[ctp-topic-57-product-backlog-managing-demand]] ← extends ← 本文档(Oli 工作流审批通过的请求进入产品 Backlog 管理管道)
-- [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]] ← depends_on ← 本文档(需求管理是价值交付量化框架的前置管道)
-- [[public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109]] ← related_to ← 本文档(BOSCARD 框架是需求分析的前置技法)
-- [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] ← related_to ← 本文档(Kanban 敏捷实践为需求流转提供方法论支撑)
-
-## Contradictions
-- 无已知冲突页面
+---
+title: "Public Cloud Learning Sessions - Ollie Workflow and The Demand Process - 20240416"
+type: source
+tags:
+ - Workflow
+ - Demand-Process
+ - FinOps
+ - ITIL
+ - SMACs
+date: 2024-04-16
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/06_CI_CD_GitOps/public-cloud-learning-sessions-ollie-workflow-and-the-demand-process-20240416-16.md]]
+
+## Summary(用中文描述)
+- 核心主题:Oli 工作流(超大规模云厂商支出审批流程)与需求管理全链路
+- 问题域:云转型过程中的 FinOps 支出审批治理、需求提交与自动化履约
+- 方法/机制:ITIL 服务管理框架下的三级审批工作流(FinOps 可行性→云服务技术可行性→FPNA 预算可用性),以及 OpenText 端到端需求管理流程(Octane/Qixi 提交 → 主服务目录 → SMACs 嵌入 → 自动化履约)
+- 结论/价值:所有超大规模云厂商支出(含工程实验室和商业工作负载)无论金额均需 MUI/Shannon 书面审批;推动"机器做机器能做的事",目标是 80% 场景业务单元自助完成需求提交
+
+## Key Claims(用中文描述)
+- 所有超大规模云厂商支出(含工程实验室和商业工作负载空间)无论金额,均需 MUI 或 Shannon 书面审批
+- Oli 工作流由 Tom Bice 领导的 FinOps 团队接管,正在集成到 SMACs 平台
+- 提议的三阶段工作流:FinOps 可行性验证 → 云服务技术可行性验证 → FPNA 团队预算可用性验证
+- Oli 系统提供飞行中 CSV 报告,追踪工作流状态、申请人、成本中心、月成本及当前步骤
+- ITIL 框架将业务流程分为服务战略、设计、过渡、运营、持续改进五个阶段
+- 主服务目录(Combined Cloud Products Master Catalog)将嵌入 SMACs,目标是 80% 场景下业务单元可自助选择所需服务
+- ADM 和 ITOM 需求规划会议记录所需内容、数量和发布版本
+
+## Key Quotes
+> "If justification details are not provided, requests are subject to immediate rejection." — Oli 请求提交规范
+> "Machines should do what machines can do, enabling an automated fulfillment process." — OpenText 需求管理核心理念
+> "The goal is for business units to self-select what they need 80% of the time." — 需求管理自动化目标
+
+## Key Concepts
+- [[Demand-Management(需求管理)]]:平衡需求与可用容量的必要手段,是 ITIL 服务过渡阶段的关键活动
+- [[ITIL-Service-Management]]:将业务流程分为服务战略、服务设计、服务过渡、服务运营、持续服务改进五阶段,Oli 工作流对应请求履约的第一阶段
+- [[SMACs]]:Social、Mobile、Analytics、Cloud 的技术栈组合,Oli 工作流正在集成到 SMACs 平台
+- [[FinOps]]:财务运营,Tom Bice 团队负责 Oli 工作流接管,重点关注云支出的可视性与优化
+- [[Product-Backlog]]:产品待办列表,Oli 工作流产生的请求经审批后进入 Backlog 管理
+
+## Key Entities
+- [[Tom-Bice]]:FinOps 团队负责人,正在接管 Oli 工作流并集成到 SMACs
+- [[FPNA-Team]]:财务规划与分析团队,负责工作流第三阶段——预算可用性验证
+- [[MUI]]:超大规模云厂商支出审批人之一(与 Shannon 共同审批所有云支出请求)
+- [[Shannon]]:超大规模云厂商支出审批人之一(与 MUI 共同审批所有云支出请求)
+- [[Octane]]:超大规模云厂商 SaaS 产品需求管理平台,业务单元可直接向其提交需求
+- [[Qixi]]:Oli 需求提交流程的前端接口之一,业务单元通过其提交需求
+
+## Connections
+- [[ctp-topic-57-product-backlog-managing-demand]] ← extends ← 本文档(Oli 工作流审批通过的请求进入产品 Backlog 管理管道)
+- [[ctp-topic-65-tracing-the-value-delivered-in-cloud-transformation]] ← depends_on ← 本文档(需求管理是价值交付量化框架的前置管道)
+- [[public-cloud-learning-sessions-applicable-business-analysis-techniques-20240109]] ← related_to ← 本文档(BOSCARD 框架是需求分析的前置技法)
+- [[ctp-topic-4-using-agile-to-run-the-cloud-transformation-program]] ← related_to ← 本文档(Kanban 敏捷实践为需求流转提供方法论支撑)
+
+## Contradictions
+- 无已知冲突页面
diff --git a/wiki/sources/public-cloud-learning-sessions-opentext-ai-use-cases-20241126-160106-meeting-rec.md b/wiki/sources/public-cloud-learning-sessions-opentext-ai-use-cases-20241126-160106-meeting-rec.md
index 87483f9e..44aa97a6 100644
--- a/wiki/sources/public-cloud-learning-sessions-opentext-ai-use-cases-20241126-160106-meeting-rec.md
+++ b/wiki/sources/public-cloud-learning-sessions-opentext-ai-use-cases-20241126-160106-meeting-rec.md
@@ -1,54 +1,54 @@
----
-title: "Public Cloud Learning Sessions (OpenText) - AI Use Cases - 20241126 160106"
-type: source
-tags:
- - AI
- - Use-Cases
- - OpenText
- - AWS
- - Generative-AI
-date: 2024-11-26
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-opentext-ai-use-cases-20241126-160106-meeting-rec.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS AI 专家 Stephen Frank 分享 Gen2 AI(生成式 AI)的发展驱动力、企业级应用场景及 AWS 三层产品战略
-- 问题域:企业软件公司如何利用生成式 AI 实现差异化竞争,AI 数据策略选择(RAG / Fine-tuning / Continued Pre-training)
-- 方法/机制:AWS 三层产品架构(基础设施 → Amazon Bedrock → AI 应用);Amazon Q 企业知识问答;数据与 AI 模型集成的三种方法
-- 结论/价值:数据是差异化关键;RAG 可在无需重训练的情况下连接自有业务数据;实施 AI 需要培育实验文化、灵活选择模型、重视安全治理与合规
-
-## Key Claims(用中文描述)
-- 自 2000 年代以来数据量爆发式增长,加上算力提升,驱动了 Gen2 AI 的崛起
-- Amazon 在核心产品和服务中应用 AI/ML 已达 25 年
-- 生成式 AI 应用的差异化关键在于数据——通过 RAG/Fine-tuning/持续预训练与现有业务数据集成
-- AWS 三层产品战略:基础设施层(基础模型训练/推理)→ Amazon Bedrock(旗舰 API 访问)→ 即用型 AI 应用
-- Amazon Bedrock 确保用户数据与提示词不与第三方模型提供商共享,符合 GDPR 合规要求
-- 负责任 AI 的核心原则:公平性(Fairness)、可解释性(Explainability)、透明度(Transparency)
-
-## Key Quotes
-> "Data is key to differentiation, as generative AI applications integrate with existing business data to control outcomes." — Stephen Frank, AWS AI Specialist
-> "When implementing your services, we do have to look at this more holistically." — Stephen Frank, AWS AI Specialist
-
-## Key Concepts
-- [[RAG]]:将生成式 AI 应用与企业现有业务数据集成,无需重训练即可控制输出结果
-- [[Fine-Tuning]]:通过领域数据微调基础模型,提升特定任务表现
-- [[Continued-Pre-Training]]:持续预训练,在基础模型上继续训练以扩展知识
-- [[Responsible-AI]]:公平性、可解释性、透明度的 AI 实施原则
-
-## Key Entities
-- [[AWS]]:亚马逊云科技,提供三层 AI 产品战略
-- [[Amazon-Bedrock]]:AWS 旗舰生成式 AI 服务,提供 API 访问多种基础模型(Anthropic/Titan 等),保证数据不与第三方共享
-- [[Amazon-SageMaker]]:AWS 全托管机器学习平台,面向数据科学家和平台工程师
-- [[Amazon-Q]]:AWS 预构建 AI 系统,支持知识摘要、内容创建和洞察提取,自然语言连接多种数据源
-- [[Stephen-Frank]]:AWS AI 专家,主讲本次会议
-
-## Connections
-- [[public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin]] ← extends ← [[public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111]]
-- [[Amazon-Bedrock]] ← is part of ← [[AWS]] AI 三层产品战略
-- [[Amazon-Q]] ← is part of ← [[AWS]] AI 三层产品战略
-- [[RAG]] ← depends_on ← [[Fine-Tuning]]
-
-## Contradictions
-- 无明显内容冲突。本来源与 [[public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin]] 和 [[public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111]] 共同构成 Serverless & AI 知识链路,内容互补而非冲突。
+---
+title: "Public Cloud Learning Sessions (OpenText) - AI Use Cases - 20241126 160106"
+type: source
+tags:
+ - AI
+ - Use-Cases
+ - OpenText
+ - AWS
+ - Generative-AI
+date: 2024-11-26
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-opentext-ai-use-cases-20241126-160106-meeting-rec.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS AI 专家 Stephen Frank 分享 Gen2 AI(生成式 AI)的发展驱动力、企业级应用场景及 AWS 三层产品战略
+- 问题域:企业软件公司如何利用生成式 AI 实现差异化竞争,AI 数据策略选择(RAG / Fine-tuning / Continued Pre-training)
+- 方法/机制:AWS 三层产品架构(基础设施 → Amazon Bedrock → AI 应用);Amazon Q 企业知识问答;数据与 AI 模型集成的三种方法
+- 结论/价值:数据是差异化关键;RAG 可在无需重训练的情况下连接自有业务数据;实施 AI 需要培育实验文化、灵活选择模型、重视安全治理与合规
+
+## Key Claims(用中文描述)
+- 自 2000 年代以来数据量爆发式增长,加上算力提升,驱动了 Gen2 AI 的崛起
+- Amazon 在核心产品和服务中应用 AI/ML 已达 25 年
+- 生成式 AI 应用的差异化关键在于数据——通过 RAG/Fine-tuning/持续预训练与现有业务数据集成
+- AWS 三层产品战略:基础设施层(基础模型训练/推理)→ Amazon Bedrock(旗舰 API 访问)→ 即用型 AI 应用
+- Amazon Bedrock 确保用户数据与提示词不与第三方模型提供商共享,符合 GDPR 合规要求
+- 负责任 AI 的核心原则:公平性(Fairness)、可解释性(Explainability)、透明度(Transparency)
+
+## Key Quotes
+> "Data is key to differentiation, as generative AI applications integrate with existing business data to control outcomes." — Stephen Frank, AWS AI Specialist
+> "When implementing your services, we do have to look at this more holistically." — Stephen Frank, AWS AI Specialist
+
+## Key Concepts
+- [[RAG]]:将生成式 AI 应用与企业现有业务数据集成,无需重训练即可控制输出结果
+- [[Fine-Tuning]]:通过领域数据微调基础模型,提升特定任务表现
+- [[Continued-Pre-Training]]:持续预训练,在基础模型上继续训练以扩展知识
+- [[Responsible-AI]]:公平性、可解释性、透明度的 AI 实施原则
+
+## Key Entities
+- [[AWS]]:亚马逊云科技,提供三层 AI 产品战略
+- [[Amazon-Bedrock]]:AWS 旗舰生成式 AI 服务,提供 API 访问多种基础模型(Anthropic/Titan 等),保证数据不与第三方共享
+- [[Amazon-SageMaker]]:AWS 全托管机器学习平台,面向数据科学家和平台工程师
+- [[Amazon-Q]]:AWS 预构建 AI 系统,支持知识摘要、内容创建和洞察提取,自然语言连接多种数据源
+- [[Stephen-Frank]]:AWS AI 专家,主讲本次会议
+
+## Connections
+- [[public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin]] ← extends ← [[public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111]]
+- [[Amazon-Bedrock]] ← is part of ← [[AWS]] AI 三层产品战略
+- [[Amazon-Q]] ← is part of ← [[AWS]] AI 三层产品战略
+- [[RAG]] ← depends_on ← [[Fine-Tuning]]
+
+## Contradictions
+- 无明显内容冲突。本来源与 [[public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin]] 和 [[public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111]] 共同构成 Serverless & AI 知识链路,内容互补而非冲突。
diff --git a/wiki/sources/public-cloud-learning-sessions-opentext-event-driven-architecture-part-1-2024091.md b/wiki/sources/public-cloud-learning-sessions-opentext-event-driven-architecture-part-1-2024091.md
index 65ed2754..fd1da677 100644
--- a/wiki/sources/public-cloud-learning-sessions-opentext-event-driven-architecture-part-1-2024091.md
+++ b/wiki/sources/public-cloud-learning-sessions-opentext-event-driven-architecture-part-1-2024091.md
@@ -1,51 +1,51 @@
----
-title: "Public Cloud Learning Sessions (OpenText) - Event Driven Architecture Part 1"
-type: source
-tags:
- - EDA
- - Event-Driven
- - AWS
- - Architecture
- - OpenText
-date: 2024-09-17
-last_updated: 2026-05-05
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-opentext-event-driven-architecture-part-1-2024091]]
-
-## Summary(用中文描述)
-- 核心主题:事件驱动架构(Event-Driven Architecture,EDA)入门与概述
-- 问题域:企业级云架构中的异步通信与松耦合集成设计
-- 方法/机制:主讲人 Dr. Anil Giri(AWS 解决方案架构师)介绍通过 Amazon EventBridge、SQS 和 SNS 探索事件驱动架构;会议录音包含开场介绍与主持人协调过程(演示过程中遭遇 Teams 屏幕共享技术故障)
-- 结论/价值:帮助参与者掌握企业级集成模式(Enterprise Integration Patterns),学习实用的云计算技能,为解决现实世界业务挑战打下基础
-
-## Key Claims(用中文描述)
-- Amazon EventBridge、SQS 和 SNS 是实现事件驱动架构的核心 AWS 服务
-- 事件驱动架构能够帮助企业实现松耦合、可扩展的系统集成
-- 企业级集成模式(Enterprise Integration Patterns)是构建可靠分布式系统的理论基础
-
-## Key Quotes
-> "探索企业级集成模式,掌握实用的云计算技能,通过使用 Amazon EventBridge、SQS 和 SNS 探索事件驱动架构,以解决现实世界中的业务挑战。" — Dr. Anil Giri,AWS 解决方案架构师,开场学习目标介绍
-
-> "Give me a second. I'm trying to log in. Just give me a second." — 会议期间 Teams 屏幕共享故障场景
-
-## Key Concepts
-- [[Event-Driven-Architecture]]:一种软件架构范式,其中组件通过事件的产生、消费和响应进行通信,强调松耦合
-- [[Enterprise-Integration-Patterns]]:企业集成模式,是构建可靠分布式系统时常见问题的可复用解决方案集合
-- [[Amazon-EventBridge]]:AWS 无服务器事件总线服务,用于连接应用程序与来自各种来源的事件
-- [[Amazon-SQS]]:AWS 简单队列服务,提供完全托管的消息队列服务
-- [[Amazon-SNS]]:AWS 简单通知服务,提供发布/订阅式的消息通知服务
-
-## Key Entities
-- [[Dr.-Anil-Giri]]:AWS 解决方案架构师,Event Driven Architecture 系列主讲人
-- [[AWS]]:Amazon Web Services,云服务提供商,EventBridge/SQS/SNS 的托管方
-- [[OpenText]]:会议主办方,Public Cloud Learning Sessions 系列活动的组织者
-- [[Micro-Focus]]:原公司名称,现已被 OpenText 收购,学习会话的参与群体来源
-
-## Connections
-- [[public-cloud-learning-sessions-opentext-event-driven-architecture-part-2-2024091]] ← part_of ← [[public-cloud-learning-sessions-opentext-event-driven-architecture-part-1-2024091]](Part 1 与 Part 2 为同一系列,Part 2 包含具体演示内容)
-- [[public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee]] ← related_to ← [[Event-Driven-Architecture]](Serverless 与 EDA 高度相关,Serverless 计算天然适合事件驱动场景)
-
-## Contradictions
-- 与 [[ctp-topic-64-scaling-out-with-amazon-eks]] 在扩展方式上的差异——EDA 通过事件驱动异步扩展,EKS 通过容器编排横向扩展,两者适用于不同场景但可互补使用
+---
+title: "Public Cloud Learning Sessions (OpenText) - Event Driven Architecture Part 1"
+type: source
+tags:
+ - EDA
+ - Event-Driven
+ - AWS
+ - Architecture
+ - OpenText
+date: 2024-09-17
+last_updated: 2026-05-05
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-opentext-event-driven-architecture-part-1-2024091.md]]
+
+## Summary(用中文描述)
+- 核心主题:事件驱动架构(Event-Driven Architecture,EDA)入门与概述
+- 问题域:企业级云架构中的异步通信与松耦合集成设计
+- 方法/机制:主讲人 Dr. Anil Giri(AWS 解决方案架构师)介绍通过 Amazon EventBridge、SQS 和 SNS 探索事件驱动架构;会议录音包含开场介绍与主持人协调过程(演示过程中遭遇 Teams 屏幕共享技术故障)
+- 结论/价值:帮助参与者掌握企业级集成模式(Enterprise Integration Patterns),学习实用的云计算技能,为解决现实世界业务挑战打下基础
+
+## Key Claims(用中文描述)
+- Amazon EventBridge、SQS 和 SNS 是实现事件驱动架构的核心 AWS 服务
+- 事件驱动架构能够帮助企业实现松耦合、可扩展的系统集成
+- 企业级集成模式(Enterprise Integration Patterns)是构建可靠分布式系统的理论基础
+
+## Key Quotes
+> "探索企业级集成模式,掌握实用的云计算技能,通过使用 Amazon EventBridge、SQS 和 SNS 探索事件驱动架构,以解决现实世界中的业务挑战。" — Dr. Anil Giri,AWS 解决方案架构师,开场学习目标介绍
+
+> "Give me a second. I'm trying to log in. Just give me a second." — 会议期间 Teams 屏幕共享故障场景
+
+## Key Concepts
+- [[Event-Driven-Architecture]]:一种软件架构范式,其中组件通过事件的产生、消费和响应进行通信,强调松耦合
+- [[Enterprise-Integration-Patterns]]:企业集成模式,是构建可靠分布式系统时常见问题的可复用解决方案集合
+- [[Amazon-EventBridge]]:AWS 无服务器事件总线服务,用于连接应用程序与来自各种来源的事件
+- [[Amazon-SQS]]:AWS 简单队列服务,提供完全托管的消息队列服务
+- [[Amazon-SNS]]:AWS 简单通知服务,提供发布/订阅式的消息通知服务
+
+## Key Entities
+- [[Dr.-Anil-Giri]]:AWS 解决方案架构师,Event Driven Architecture 系列主讲人
+- [[AWS]]:Amazon Web Services,云服务提供商,EventBridge/SQS/SNS 的托管方
+- [[OpenText]]:会议主办方,Public Cloud Learning Sessions 系列活动的组织者
+- [[Micro-Focus]]:原公司名称,现已被 OpenText 收购,学习会话的参与群体来源
+
+## Connections
+- [[public-cloud-learning-sessions-opentext-event-driven-architecture-part-2-2024091]] ← part_of ← [[public-cloud-learning-sessions-opentext-event-driven-architecture-part-1-2024091]](Part 1 与 Part 2 为同一系列,Part 2 包含具体演示内容)
+- [[public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee]] ← related_to ← [[Event-Driven-Architecture]](Serverless 与 EDA 高度相关,Serverless 计算天然适合事件驱动场景)
+
+## Contradictions
+- 与 [[ctp-topic-64-scaling-out-with-amazon-eks]] 在扩展方式上的差异——EDA 通过事件驱动异步扩展,EKS 通过容器编排横向扩展,两者适用于不同场景但可互补使用
diff --git a/wiki/sources/public-cloud-learning-sessions-opentext-event-driven-architecture-part-2-2024091.md b/wiki/sources/public-cloud-learning-sessions-opentext-event-driven-architecture-part-2-2024091.md
index a191349a..1110c411 100644
--- a/wiki/sources/public-cloud-learning-sessions-opentext-event-driven-architecture-part-2-2024091.md
+++ b/wiki/sources/public-cloud-learning-sessions-opentext-event-driven-architecture-part-2-2024091.md
@@ -1,62 +1,62 @@
----
-title: "Public Cloud Learning Sessions (OpenText) - Event Driven Architecture Part 2"
-type: source
-tags:
- - EDA
- - Event-Driven
- - Architecture
- - OpenText
-date: 2024-09-17
-last_updated: 2026-05-05
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-opentext-event-driven-architecture-part-2-2024091]]
-
-## Summary(用中文描述)
-- 核心主题:事件驱动架构(EDA)进阶实践——最佳实践、团队独立性、常见消息模式
-- 问题域:如何在企业云环境中设计、落地和治理事件驱动架构
-- 方法/机制:Dr. Anil Giri(AWS 解决方案架构师)详解 EDA 三组件(事件生产者/消费者/代理)、事件路由器(EventBridge/SNS)与事件存储(SQS/Kinesis)、编排与编排模式(Choreography vs Orchestration)、幂等性、事件排序、团队去中心化所有权
-- 结论/价值:帮助团队掌握 EDA 生产级最佳实践,在保证弹性和可扩展性的同时实现团队独立自治
-
-## Key Claims(用中文描述)
-- 事件代理分两类:事件路由器(EventBridge/SNS,按规则过滤路由)和事件存储(SQS/Kinesis,由消费者自己过滤)
-- EventBridge 比 SNS 功能更丰富,支持跨 AWS 服务的事件触发和工作流编排
-- 幂等性(Idempotency)是处理 EDA 消息重复的关键机制,AWS Lambda 异步调用会自动重试
-- SQS FIFO 和 Kinesis Data Streams 可保证事件顺序;标准 SQS 和 EventBridge 支持乱序处理
-- 团队独立性应采用去中心化所有权,云卓越中心(Cloud CoE)提供基础设防,团队自主消费事件
-- Fan-out 模式通过 SNS 主题或 EventBridge 规则将事件分发到不同团队
-
-## Key Quotes
-> "Event is nothing but it's like a change in the state or an update." — Dr. Anil Giri,EDA 定义
-
-> "Everything fails every time means like whatever you have designed and whatever workload you is running it may fail any time." — 容错设计哲学
-
-## Key Concepts
-- [[Event-Driven-Architecture]]:一种软件架构范式,通过事件的生产、消费和响应实现松耦合通信
-- [[Choreography]]:编排模式的一种,各微服务自主通信,无需中央协调者
-- [[Orchestration]]:编排模式的一种,通过中央协调者(如 AWS Step Functions)控制工作流步骤
-- [[Idempotency]]:幂等性——同一操作执行一次或多次产生相同结果的特性
-- [[Fan-Out-Pattern]]:一对多消息分发模式,通过 SNS 主题或 EventBridge 规则将事件广播给多个消费者
-- [[Competing-Consumer-Pattern]]:竞争消费者模式,同一时间只有一个消费者可处理消息(SQS 实现)
-- [[Dead-Letter-Queue-DLQ]]:死信队列,用于处理失败事件,防止消息丢失
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,EventBridge/SQS/SNS/Lambda/Kinesis/AWS Step Functions 的托管方
-- [[Amazon-EventBridge]]:AWS 事件路由器,支持规则过滤、跨服务触发、Schema 注册
-- [[Amazon-SQS]]:AWS 消息队列服务,分标准队列(乱序/高效)和 FIFO 队列(有序/Exactly-Once)
-- [[Amazon-SNS]]:AWS 发布/订阅通知服务,实现 Fan-out 分发
-- [[AWS-Lambda]]:AWS 无服务器函数,EDA 的核心事件消费者,异步调用自动重试
-- [[AWS-Step-Functions]]:AWS 状态机编排服务,实现 Orchestration 模式
-- [[Kinesis-Data-Streams]]:AWS 流数据服务,支持事件持久化和有序处理
-- [[Dr.-Anil-Giri]]:AWS 解决方案架构师,Event Driven Architecture 系列主讲人
-- [[OpenText]]:会议主办方,Public Cloud Learning Sessions 系列活动的组织者
-
-## Connections
-- [[public-cloud-learning-sessions-opentext-event-driven-architecture-part-1-2024091]] ← part_of ← [[public-cloud-learning-sessions-opentext-event-driven-architecture-part-2-2024091]](Part 1 与 Part 2 为同一系列,Part 2 补充具体演示内容)
-- [[public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee]] ← related_to ← [[Event-Driven-Architecture]](Serverless 天然适合事件驱动,Lambda 是 EDA 的核心执行单元)
-- [[Event-Driven-Architecture]] ← depends_on ← [[Amazon-EventBridge]](EventBridge 是 AWS EDA 的核心事件总线)
-- [[Event-Driven-Architecture]] ← uses ← [[Idempotency]](幂等性是 EDA 生产级落地的必要保障)
-
-## Contradictions
-- 与 [[ctp-topic-64-scaling-out-with-amazon-eks]] 在扩展方式上的差异——EDA 通过事件驱动异步扩展(消费者按需处理),EKS 通过容器编排横向扩展(Pod 副本数调整),两者适用于不同场景但可互补使用
+---
+title: "Public Cloud Learning Sessions (OpenText) - Event Driven Architecture Part 2"
+type: source
+tags:
+ - EDA
+ - Event-Driven
+ - Architecture
+ - OpenText
+date: 2024-09-17
+last_updated: 2026-05-05
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-opentext-event-driven-architecture-part-2-2024091.md]]
+
+## Summary(用中文描述)
+- 核心主题:事件驱动架构(EDA)进阶实践——最佳实践、团队独立性、常见消息模式
+- 问题域:如何在企业云环境中设计、落地和治理事件驱动架构
+- 方法/机制:Dr. Anil Giri(AWS 解决方案架构师)详解 EDA 三组件(事件生产者/消费者/代理)、事件路由器(EventBridge/SNS)与事件存储(SQS/Kinesis)、编排与编排模式(Choreography vs Orchestration)、幂等性、事件排序、团队去中心化所有权
+- 结论/价值:帮助团队掌握 EDA 生产级最佳实践,在保证弹性和可扩展性的同时实现团队独立自治
+
+## Key Claims(用中文描述)
+- 事件代理分两类:事件路由器(EventBridge/SNS,按规则过滤路由)和事件存储(SQS/Kinesis,由消费者自己过滤)
+- EventBridge 比 SNS 功能更丰富,支持跨 AWS 服务的事件触发和工作流编排
+- 幂等性(Idempotency)是处理 EDA 消息重复的关键机制,AWS Lambda 异步调用会自动重试
+- SQS FIFO 和 Kinesis Data Streams 可保证事件顺序;标准 SQS 和 EventBridge 支持乱序处理
+- 团队独立性应采用去中心化所有权,云卓越中心(Cloud CoE)提供基础设防,团队自主消费事件
+- Fan-out 模式通过 SNS 主题或 EventBridge 规则将事件分发到不同团队
+
+## Key Quotes
+> "Event is nothing but it's like a change in the state or an update." — Dr. Anil Giri,EDA 定义
+
+> "Everything fails every time means like whatever you have designed and whatever workload you is running it may fail any time." — 容错设计哲学
+
+## Key Concepts
+- [[Event-Driven-Architecture]]:一种软件架构范式,通过事件的生产、消费和响应实现松耦合通信
+- [[Choreography]]:编排模式的一种,各微服务自主通信,无需中央协调者
+- [[Orchestration]]:编排模式的一种,通过中央协调者(如 AWS Step Functions)控制工作流步骤
+- [[Idempotency]]:幂等性——同一操作执行一次或多次产生相同结果的特性
+- [[Fan-Out-Pattern]]:一对多消息分发模式,通过 SNS 主题或 EventBridge 规则将事件广播给多个消费者
+- [[Competing-Consumer-Pattern]]:竞争消费者模式,同一时间只有一个消费者可处理消息(SQS 实现)
+- [[Dead-Letter-Queue-DLQ]]:死信队列,用于处理失败事件,防止消息丢失
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,EventBridge/SQS/SNS/Lambda/Kinesis/AWS Step Functions 的托管方
+- [[Amazon-EventBridge]]:AWS 事件路由器,支持规则过滤、跨服务触发、Schema 注册
+- [[Amazon-SQS]]:AWS 消息队列服务,分标准队列(乱序/高效)和 FIFO 队列(有序/Exactly-Once)
+- [[Amazon-SNS]]:AWS 发布/订阅通知服务,实现 Fan-out 分发
+- [[AWS-Lambda]]:AWS 无服务器函数,EDA 的核心事件消费者,异步调用自动重试
+- [[AWS-Step-Functions]]:AWS 状态机编排服务,实现 Orchestration 模式
+- [[Kinesis-Data-Streams]]:AWS 流数据服务,支持事件持久化和有序处理
+- [[Dr.-Anil-Giri]]:AWS 解决方案架构师,Event Driven Architecture 系列主讲人
+- [[OpenText]]:会议主办方,Public Cloud Learning Sessions 系列活动的组织者
+
+## Connections
+- [[public-cloud-learning-sessions-opentext-event-driven-architecture-part-1-2024091]] ← part_of ← [[public-cloud-learning-sessions-opentext-event-driven-architecture-part-2-2024091]](Part 1 与 Part 2 为同一系列,Part 2 补充具体演示内容)
+- [[public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee]] ← related_to ← [[Event-Driven-Architecture]](Serverless 天然适合事件驱动,Lambda 是 EDA 的核心执行单元)
+- [[Event-Driven-Architecture]] ← depends_on ← [[Amazon-EventBridge]](EventBridge 是 AWS EDA 的核心事件总线)
+- [[Event-Driven-Architecture]] ← uses ← [[Idempotency]](幂等性是 EDA 生产级落地的必要保障)
+
+## Contradictions
+- 与 [[ctp-topic-64-scaling-out-with-amazon-eks]] 在扩展方式上的差异——EDA 通过事件驱动异步扩展(消费者按需处理),EKS 通过容器编排横向扩展(Pod 副本数调整),两者适用于不同场景但可互补使用
diff --git a/wiki/sources/public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2.md b/wiki/sources/public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2.md
index 5de9c6a5..963974fd 100644
--- a/wiki/sources/public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2.md
+++ b/wiki/sources/public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2.md
@@ -1,58 +1,58 @@
----
-title: "Public Cloud Learning Sessions (OpenText) - Evolving from DR to Recovery Assurance - 20240723"
-type: source
-tags:
- - OpenText
- - DR
- - Recovery
- - BCP
- - SRE
- - Observability
-date: 2024-07-23
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2]]
-
-## Summary(用中文描述)
-- 核心主题:OpenText 灾难恢复(DR)机制向"恢复保证(Recovery Assurance)"的演进路径
-- 问题域:企业级 DR 测试的被动性、手动性、无一致组织方法等问题;多云(AWS/GCP/Azure)托管环境下的 DR 复杂性
-- 方法/机制:四位框架(Design / Software / Build / Environments)+ SRE + 可观测性工程
-- 结论/价值:从被动应对转向主动设计,将可恢复性作为架构设计原则,通过自动化和可观测性提升弹性能力
-
-## Key Claims(用中文描述)
-- **CrowdStrike 事件警示**:单点软件漏洞可导致全球大规模系统中断,OpenText 虽未受直接影响,但必须强化端到端系统管理
-- **RTO/RPO 因合同而异**:OpenText 的恢复时间目标和恢复点目标跨度从分钟到数天不等,测试以反应式为主
-- **DR 测试现状瓶颈**:依赖人工、按客户时间表安排,涉及多个 SME 团队,协同成本高且缺乏可扩展性
-- **多云加剧复杂性**:超大规模云平台(AWS/GCP/Azure)的测试主要关注区域故障,缺乏对其他故障模式(账户级/服务级)的覆盖
-- **混合架构挑战**:仅部分服务可故障切换的混合方案增加了 DR 编排难度
-- **四位框架转型**:Design(可恢复性前置设计)→ Software(遥测+自愈)→ Build(Customer Zero 验证)→ Environments(SRE+可观测性)
-
-## Key Quotes
-> "CrowdStrike was not us, but we have had some disruptions." — Jim Rose,强调即使未直接受 CrowdStrike 影响,OpenText 自身也经历过多次中断事件
-> "Every person who is a SME on some part of this has to be involved in developing a plan." — Jim Rose,说明当前 DR 测试的人力密集型瓶颈
-> "Recoverability should be a design principle." — Jim Rose,倡导将可恢复性作为架构设计的核心原则
-
-## Key Concepts
-- [[RTO]](Recovery Time Objective):事件发生后恢复服务所需时间,OpenText 跨度从分钟到数天
-- [[RPO]](Recovery Point Objective):可接受的最大数据丢失量,同样因客户合同而异
-- [[SRE]](Site Reliability Engineering):用软件工程思维解决运维问题,追求可靠性、可测试性、可重复性
-- [[Observability Engineering]](可观测性工程):通过遥测数据持续理解系统健康状态,是 Recovery Assurance 的技术基础
-- [[Disaster Recovery]](灾难恢复):保护系统免受灾难性事件影响的策略与实践
-- [[Business Continuity Plan]](业务连续性计划):确保业务在灾难期间持续运营的规划框架
-- [[Self-Healing]](自愈能力):软件应具备持续监控系统健康并在无需人工干预情况下自动恢复的能力
-- [[Customer Zero Environment]]:新版本发布前的内部验证环境,用于在真实流量前发现潜在问题
-
-## Key Entities
-- [[OpenText]]:企业信息管理公司,托管于 AWS/GCP/Azure 多云环境,由 Jim Rose 主讲本次学习会议
-- [[Jim Rose]]:OpenText 技术负责人/演讲者,分享 DR 向 Recovery Assurance 演进的实践与思考
-- [[CrowdStrike]]:2024 年引发全球大规模系统中断的安全软件公司,作为 DR 重要性案例被引用
-
-## Connections
-- [[ctp-topic-72-enterprise-dr-strategy-aws-backup]] ← related_to ← [[public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2]](均涉及企业 DR 策略,CTP Topic 72 提供 AWS Backup 层面的具体实现,本视频提供组织层面的演进思维)
-- [[ctp-topic-41-nfrs-and-error-budgets]] ← related_to ← [[public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2]](NFR/Error Budget 是 SRE 度量弹性目标的工具,与本视频的 SRE 转型方向一致)
-- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← related_to ← [[public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2]](可观测性工程是 Recovery Assurance 的技术基础,OpenTelemetry 是具体实现路径)
-- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← related_to ← [[public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2]](EKS 可靠性工程实践与本视频的四位框架中的 Environments 层对应)
-
-## Contradictions
-- 无已知冲突。本视频提供 DR 向 Recovery Assurance 演进的方法论框架,与现有 Wiki 中的 DR 相关内容(CTP Topic 72 AWS Backup 实施、CTP Topic 44 AWS Backup 评估)互补而非冲突,共同构成完整的 DR 知识体系。
+---
+title: "Public Cloud Learning Sessions (OpenText) - Evolving from DR to Recovery Assurance - 20240723"
+type: source
+tags:
+ - OpenText
+ - DR
+ - Recovery
+ - BCP
+ - SRE
+ - Observability
+date: 2024-07-23
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2.md]]
+
+## Summary(用中文描述)
+- 核心主题:OpenText 灾难恢复(DR)机制向"恢复保证(Recovery Assurance)"的演进路径
+- 问题域:企业级 DR 测试的被动性、手动性、无一致组织方法等问题;多云(AWS/GCP/Azure)托管环境下的 DR 复杂性
+- 方法/机制:四位框架(Design / Software / Build / Environments)+ SRE + 可观测性工程
+- 结论/价值:从被动应对转向主动设计,将可恢复性作为架构设计原则,通过自动化和可观测性提升弹性能力
+
+## Key Claims(用中文描述)
+- **CrowdStrike 事件警示**:单点软件漏洞可导致全球大规模系统中断,OpenText 虽未受直接影响,但必须强化端到端系统管理
+- **RTO/RPO 因合同而异**:OpenText 的恢复时间目标和恢复点目标跨度从分钟到数天不等,测试以反应式为主
+- **DR 测试现状瓶颈**:依赖人工、按客户时间表安排,涉及多个 SME 团队,协同成本高且缺乏可扩展性
+- **多云加剧复杂性**:超大规模云平台(AWS/GCP/Azure)的测试主要关注区域故障,缺乏对其他故障模式(账户级/服务级)的覆盖
+- **混合架构挑战**:仅部分服务可故障切换的混合方案增加了 DR 编排难度
+- **四位框架转型**:Design(可恢复性前置设计)→ Software(遥测+自愈)→ Build(Customer Zero 验证)→ Environments(SRE+可观测性)
+
+## Key Quotes
+> "CrowdStrike was not us, but we have had some disruptions." — Jim Rose,强调即使未直接受 CrowdStrike 影响,OpenText 自身也经历过多次中断事件
+> "Every person who is a SME on some part of this has to be involved in developing a plan." — Jim Rose,说明当前 DR 测试的人力密集型瓶颈
+> "Recoverability should be a design principle." — Jim Rose,倡导将可恢复性作为架构设计的核心原则
+
+## Key Concepts
+- [[RTO]](Recovery Time Objective):事件发生后恢复服务所需时间,OpenText 跨度从分钟到数天
+- [[RPO]](Recovery Point Objective):可接受的最大数据丢失量,同样因客户合同而异
+- [[SRE]](Site Reliability Engineering):用软件工程思维解决运维问题,追求可靠性、可测试性、可重复性
+- [[Observability Engineering]](可观测性工程):通过遥测数据持续理解系统健康状态,是 Recovery Assurance 的技术基础
+- [[Disaster Recovery]](灾难恢复):保护系统免受灾难性事件影响的策略与实践
+- [[Business Continuity Plan]](业务连续性计划):确保业务在灾难期间持续运营的规划框架
+- [[Self-Healing]](自愈能力):软件应具备持续监控系统健康并在无需人工干预情况下自动恢复的能力
+- [[Customer Zero Environment]]:新版本发布前的内部验证环境,用于在真实流量前发现潜在问题
+
+## Key Entities
+- [[OpenText]]:企业信息管理公司,托管于 AWS/GCP/Azure 多云环境,由 Jim Rose 主讲本次学习会议
+- [[Jim Rose]]:OpenText 技术负责人/演讲者,分享 DR 向 Recovery Assurance 演进的实践与思考
+- [[CrowdStrike]]:2024 年引发全球大规模系统中断的安全软件公司,作为 DR 重要性案例被引用
+
+## Connections
+- [[ctp-topic-72-enterprise-dr-strategy-aws-backup]] ← related_to ← [[public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2]](均涉及企业 DR 策略,CTP Topic 72 提供 AWS Backup 层面的具体实现,本视频提供组织层面的演进思维)
+- [[ctp-topic-41-nfrs-and-error-budgets]] ← related_to ← [[public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2]](NFR/Error Budget 是 SRE 度量弹性目标的工具,与本视频的 SRE 转型方向一致)
+- [[ctp-topic-67-cloud-native-observability-using-opentelemetry]] ← related_to ← [[public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2]](可观测性工程是 Recovery Assurance 的技术基础,OpenTelemetry 是具体实现路径)
+- [[ctp-topic-59-achieving-reliability-with-amazon-eks]] ← related_to ← [[public-cloud-learning-sessions-opentext-evolving-from-dr-to-recovery-assurance-2]](EKS 可靠性工程实践与本视频的四位框架中的 Environments 层对应)
+
+## Contradictions
+- 无已知冲突。本视频提供 DR 向 Recovery Assurance 演进的方法论框架,与现有 Wiki 中的 DR 相关内容(CTP Topic 72 AWS Backup 实施、CTP Topic 44 AWS Backup 评估)互补而非冲突,共同构成完整的 DR 知识体系。
diff --git a/wiki/sources/public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111.md b/wiki/sources/public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111.md
index 4e7eada7..d8ee2cc0 100644
--- a/wiki/sources/public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111.md
+++ b/wiki/sources/public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111.md
@@ -1,66 +1,66 @@
----
-title: "Public Cloud Learning Sessions (OpenText) - Generative AI & Prompt Engineering - 20241112"
-type: source
-tags:
- - Generative-AI
- - Prompt-Engineering
- - OpenText
- - AWS
-date: 2024-11-12
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 生成式 AI 服务与提示工程基础,由 OpenText 技术客户经理 Shikad Holtzman 主讲
-- 问题域:企业如何在 AWS 上构建有业务价值的生成式 AI 应用
-- 方法/机制:Amazon Bedrock 全托管基础模型服务、RAG(检索增强生成)、微调、持续预训练、Amazon Q 助手、提示工程技巧
-- 结论/价值:企业数据是差异化关键,通过 Bedrock 连接自有数据,无需重训练即可构建专属生成式 AI 应用;提示工程通过清晰指令、上下文、示例和链式思维可显著提升 LLM 输出质量
-
-## Key Claims(用中文描述)
-- Shikad Holtzman(以色列技术客户经理)通过 AWS 生成式 AI 堆栈三层架构(基础设施/服务/应用)介绍了创新机会与行业通用场景
-- 生成式 AI 通过创造新体验、提升员工生产力、提取洞察、激发创造力四大路径为企业创造价值;应用场景涵盖客服聊天机器人、代码生成摘要、文档处理和图像生成
-- 企业数据是生成式 AI 应用从通用走向专属、产生实际业务价值的关键差异化因素
-- RAG(检索增强生成)是成本最低、最快速的定制化方法,连接多数据源无需重训练模型;微调通过标注示例重训练模型;持续预训练用无标签数据适配特定领域
-- Amazon Bedrock 是全托管服务,提供来自 Anthropic、Meta、Amazon(Titan)的多种基础模型(含多模态和图像模型),并内置 RAG 知识库、微调、Agents 和 Responsible AI 能力,且用户数据和提示不会与模型提供商共享
-- Amazon Bedrock Guardrails 允许用户根据自身策略过滤有害内容
-- Amazon Q 分为企业版(连接多数据源进行搜索/摘要/洞察提取,维持现有权限)和开发者版(专注代码生成、单元测试和代码迁移)
-- 提示工程是创建、设计和优化提示词以引导 LLM 响应的过程,需清晰、准确、具体,遵循迭代测试优化;提示包含指令、上下文、用户输入和输出指示器四部分
-- 少样本提示(One-shot/Few-shot)通过提供示例帮助模型理解任务模式;链式思维(Chain of Thoughts)通过逐步推理引导模型解决复杂任务
-
-## Key Quotes
-> "Your data is your differentiator and it is what makes the difference between generic application to a specific application that can actually bring business to your value." — Shikad Holtzman,强调企业数据是生成式 AI 差异化的核心
-
-> "None of your data nor not the prompts, not the data that you are using for customizing the model is being shared with the model providers." — 强调 Amazon Bedrock 的数据隔离承诺
-
-## Key Concepts
-- [[RAG]]:检索增强生成,通过连接外部数据源,无需重训练即可让基础模型回答特定领域问题,是成本最低的定制化路径
-- [[Prompt-Engineering]]:提示工程,通过设计清晰指令、上下文、示例和输出指示器引导 LLM 生成准确相关响应的技术和迭代过程
-- [[Chain-of-Thought]]:链式思维,一种提示工程技巧,通过让模型展示逐步推理过程来提升复杂任务表现
-- [[One-Shot-Prompting]]:单样本提示,一种提示技巧,通过提供一个示例帮助模型理解任务格式和期望
-- [[Few-Shot-Prompting]]:少样本提示,通过提供多个示例(通常2-5个)让模型从示例中学习模式和规则
-- [[Responsible-AI]]:负责任 AI,Amazon Bedrock 内置的能力,包括内容过滤和道德准则实施
-- [[Guardrails-for-Amazon-Bedrock]]:Bedrock 护栏,允许用户配置自定义策略过滤有害内容的基础安全功能
-
-## Key Entities
-- [[Shikad-Holtzman]]:OpenText 技术客户经理(驻以色列),本次学习会议讲师,专注于 AWS 生成式 AI 应用与创新机会分享
-- [[Amazon-Bedrock]]:AWS 全托管基础模型服务,提供多提供商模型(Anthropic/Amazon Titan/Meta),内置 RAG、微调、Agents 和 Responsible AI 能力
-- [[Amazon-SageMaker]]:AWS 托管服务,覆盖基础模型构建、训练和部署全生命周期;SageMaker JumpStart 提供公开可用基础模型和第三方模型访问
-- [[Amazon-Q]]:AWS AI 助手,分企业版(多数据源连接、搜索摘要)和开发者版(代码生成、单元测试、代码迁移)
-- [[AWS-Trainium]]:AWS 专用训练芯片,用于基础模型训练
-- [[AWS-Inferentia]]:AWS 专用推理芯片,用于模型推理部署
-- [[AWS]]:Amazon Web Services,OpenText Cloud 转型计划的云服务提供商
-
-## Connections
-- [[Amazon-Bedrock]] ← extends ← [[Foundation-Models]]
-- [[RAG]] ← part_of ← [[Amazon-Bedrock]]
-- [[Amazon-Q]] ← part_of ← [[AWS-Generative-AI-Stack]]
-- [[Prompt-Engineering]] ← uses ← [[Chain-of-Thought]]
-- [[Prompt-Engineering]] ← uses ← [[Few-Shot-Prompting]]
-- [[Amazon-SageMaker]] ← part_of ← [[AWS-Generative-AI-Stack]]
-- [[public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin]] ← related ← [[public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111]](同属 AWS AI/ML 入门系列)
-- [[public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee]] ← related ← [[public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111]](同属 OpenText Serverless & AI 专题)
-
-## Contradictions
-- 与 [[ctp-topic-64-scaling-out-with-amazon-eks]] 在扩展方式上的差异:EDA 通过事件驱动异步扩展,EKS 通过容器编排横向扩展,两者适用于不同场景但可互补使用
+---
+title: "Public Cloud Learning Sessions (OpenText) - Generative AI & Prompt Engineering - 20241112"
+type: source
+tags:
+ - Generative-AI
+ - Prompt-Engineering
+ - OpenText
+ - AWS
+date: 2024-11-12
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 生成式 AI 服务与提示工程基础,由 OpenText 技术客户经理 Shikad Holtzman 主讲
+- 问题域:企业如何在 AWS 上构建有业务价值的生成式 AI 应用
+- 方法/机制:Amazon Bedrock 全托管基础模型服务、RAG(检索增强生成)、微调、持续预训练、Amazon Q 助手、提示工程技巧
+- 结论/价值:企业数据是差异化关键,通过 Bedrock 连接自有数据,无需重训练即可构建专属生成式 AI 应用;提示工程通过清晰指令、上下文、示例和链式思维可显著提升 LLM 输出质量
+
+## Key Claims(用中文描述)
+- Shikad Holtzman(以色列技术客户经理)通过 AWS 生成式 AI 堆栈三层架构(基础设施/服务/应用)介绍了创新机会与行业通用场景
+- 生成式 AI 通过创造新体验、提升员工生产力、提取洞察、激发创造力四大路径为企业创造价值;应用场景涵盖客服聊天机器人、代码生成摘要、文档处理和图像生成
+- 企业数据是生成式 AI 应用从通用走向专属、产生实际业务价值的关键差异化因素
+- RAG(检索增强生成)是成本最低、最快速的定制化方法,连接多数据源无需重训练模型;微调通过标注示例重训练模型;持续预训练用无标签数据适配特定领域
+- Amazon Bedrock 是全托管服务,提供来自 Anthropic、Meta、Amazon(Titan)的多种基础模型(含多模态和图像模型),并内置 RAG 知识库、微调、Agents 和 Responsible AI 能力,且用户数据和提示不会与模型提供商共享
+- Amazon Bedrock Guardrails 允许用户根据自身策略过滤有害内容
+- Amazon Q 分为企业版(连接多数据源进行搜索/摘要/洞察提取,维持现有权限)和开发者版(专注代码生成、单元测试和代码迁移)
+- 提示工程是创建、设计和优化提示词以引导 LLM 响应的过程,需清晰、准确、具体,遵循迭代测试优化;提示包含指令、上下文、用户输入和输出指示器四部分
+- 少样本提示(One-shot/Few-shot)通过提供示例帮助模型理解任务模式;链式思维(Chain of Thoughts)通过逐步推理引导模型解决复杂任务
+
+## Key Quotes
+> "Your data is your differentiator and it is what makes the difference between generic application to a specific application that can actually bring business to your value." — Shikad Holtzman,强调企业数据是生成式 AI 差异化的核心
+
+> "None of your data nor not the prompts, not the data that you are using for customizing the model is being shared with the model providers." — 强调 Amazon Bedrock 的数据隔离承诺
+
+## Key Concepts
+- [[RAG]]:检索增强生成,通过连接外部数据源,无需重训练即可让基础模型回答特定领域问题,是成本最低的定制化路径
+- [[Prompt-Engineering]]:提示工程,通过设计清晰指令、上下文、示例和输出指示器引导 LLM 生成准确相关响应的技术和迭代过程
+- [[Chain-of-Thought]]:链式思维,一种提示工程技巧,通过让模型展示逐步推理过程来提升复杂任务表现
+- [[One-Shot-Prompting]]:单样本提示,一种提示技巧,通过提供一个示例帮助模型理解任务格式和期望
+- [[Few-Shot-Prompting]]:少样本提示,通过提供多个示例(通常2-5个)让模型从示例中学习模式和规则
+- [[Responsible-AI]]:负责任 AI,Amazon Bedrock 内置的能力,包括内容过滤和道德准则实施
+- [[Guardrails-for-Amazon-Bedrock]]:Bedrock 护栏,允许用户配置自定义策略过滤有害内容的基础安全功能
+
+## Key Entities
+- [[Shikad-Holtzman]]:OpenText 技术客户经理(驻以色列),本次学习会议讲师,专注于 AWS 生成式 AI 应用与创新机会分享
+- [[Amazon-Bedrock]]:AWS 全托管基础模型服务,提供多提供商模型(Anthropic/Amazon Titan/Meta),内置 RAG、微调、Agents 和 Responsible AI 能力
+- [[Amazon-SageMaker]]:AWS 托管服务,覆盖基础模型构建、训练和部署全生命周期;SageMaker JumpStart 提供公开可用基础模型和第三方模型访问
+- [[Amazon-Q]]:AWS AI 助手,分企业版(多数据源连接、搜索摘要)和开发者版(代码生成、单元测试、代码迁移)
+- [[AWS-Trainium]]:AWS 专用训练芯片,用于基础模型训练
+- [[AWS-Inferentia]]:AWS 专用推理芯片,用于模型推理部署
+- [[AWS]]:Amazon Web Services,OpenText Cloud 转型计划的云服务提供商
+
+## Connections
+- [[Amazon-Bedrock]] ← extends ← [[Foundation-Models]]
+- [[RAG]] ← part_of ← [[Amazon-Bedrock]]
+- [[Amazon-Q]] ← part_of ← [[AWS-Generative-AI-Stack]]
+- [[Prompt-Engineering]] ← uses ← [[Chain-of-Thought]]
+- [[Prompt-Engineering]] ← uses ← [[Few-Shot-Prompting]]
+- [[Amazon-SageMaker]] ← part_of ← [[AWS-Generative-AI-Stack]]
+- [[public-cloud-learning-sessions-introduction-to-artificial-intelligence-ai-machin]] ← related ← [[public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111]](同属 AWS AI/ML 入门系列)
+- [[public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee]] ← related ← [[public-cloud-learning-sessions-opentext-generative-ai-prompt-engineering-2024111]](同属 OpenText Serverless & AI 专题)
+
+## Contradictions
+- 与 [[ctp-topic-64-scaling-out-with-amazon-eks]] 在扩展方式上的差异:EDA 通过事件驱动异步扩展,EKS 通过容器编排横向扩展,两者适用于不同场景但可互补使用
diff --git a/wiki/sources/public-cloud-learning-sessions-opentext-gis-security-policies-20241015-160257-me.md b/wiki/sources/public-cloud-learning-sessions-opentext-gis-security-policies-20241015-160257-me.md
index ef1d1bdb..1a756162 100644
--- a/wiki/sources/public-cloud-learning-sessions-opentext-gis-security-policies-20241015-160257-me.md
+++ b/wiki/sources/public-cloud-learning-sessions-opentext-gis-security-policies-20241015-160257-me.md
@@ -1,55 +1,55 @@
----
-title: "Public Cloud Learning Sessions - OpenText GIS Security Policies - 20241015"
-type: source
-tags:
- - OpenText
- - Security-Policies
- - GIS
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/public-cloud-learning-sessions-opentext-gis-security-policies-20241015-160257-me.md]]
-
-## Summary(用中文描述)
-- 核心主题:OpenText 全球信息安全团队(GIS)安全策略全景介绍
-- 问题域:企业级安全治理与合规体系设计
-- 方法/机制:分层层级安全组织架构 + ISO 27001 姿态框架 + 三方渗透测试 + 安全意识培训
-- 结论/价值:政策是基础设施的基石,运营、工具和流程均构建在此框架之上
-
-## Key Claims(用中文描述)
-- OpenText 采用分层方法定义安全策略——与各团队协作定义"做什么",与执行团队协作确定"怎么做"
-- OpenText 持有 FedRAMP 等多项行业及政府认证,可进入多个垂直市场销售
-- OpenText 每年进行第三方测试(桌面演练+红队演练),持续处于顶级梯队
-- 月处理 2250 亿条日志,每月分诊约 350 个案例
-- Global Information Security Policy(GISP)是最高纲领性政策,季度审查
-
-## Key Quotes
-> "Policies are foundational elements, with operations, tools, and processes built on that framework." — Mike & Ed, GIS Team
-
-> "The focus is on how many people report suspicious activity." — GIS Security Awareness Program
-
-> "Policies define what needs to be done, while providing flexibility for how it is implemented." — GIS Policy Framework
-
-## Key Concepts
-- [[Global Information Security Policy (GISP)]]:最高纲领性政策,季度审查
-- [[ISO-27001]]:姿态框架基础,2022 年更新,新增 11 个控制方面
-- [[Security-Awareness-Training]]:月度安全通讯 + 网络钓鱼演练
-- [[Third-Party-Penetration-Testing]]:年度桌面演练 + 红队演练
-- [[Threat-Intelligence]]:结合 BrightCloud 等工具的威胁情报体系
-- [[FedRAMP]]:政府级云安全认证
-
-## Key Entities
-- [[Mike]]:Global Information Security Team,主讲人
-- [[Ed]]:Global Information Security Team,主讲人
-- [[OpenText]]:企业主体,安全策略制定者
-- [[BrightCloud]]:OpenText 自有威胁情报工具
-
-## Connections
-- [[CTP-Topic-21-Supply-Chain-Security-in-Micro-Focus]] ← related_to ← [[GIS-Security-Policies]](供应链安全同属安全治理范畴)
-- [[CTP-Topic-52-3-Lines-of-Defence]] ← extends ← [[GIS-Security-Policies]](三道防线框架与 GIS 分层组织高度吻合)
-
-## Contradictions
-- 与 [[CTP-Topic-10-AWS-Landing-Zone-LZ-Data-Collection-Tagging-Related-Security]] 存在视角互补而非冲突:
- - 冲突点:两者均涉及安全治理,但 Topic 10 聚焦于 AWS 层面的标签化安全策略(SCP/Checkpoint),Topic 41 聚焦于企业级安全政策框架(ISO 27001/GISP)
- - 当前观点:两者互补——GISP 定义全局政策纲领,AWS Landing Zone 层面通过标签和 SCP 实现技术落地
+---
+title: "Public Cloud Learning Sessions - OpenText GIS Security Policies - 20241015"
+type: source
+tags:
+ - OpenText
+ - Security-Policies
+ - GIS
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/07_Security/public-cloud-learning-sessions-opentext-gis-security-policies-20241015-160257-me.md]]
+
+## Summary(用中文描述)
+- 核心主题:OpenText 全球信息安全团队(GIS)安全策略全景介绍
+- 问题域:企业级安全治理与合规体系设计
+- 方法/机制:分层层级安全组织架构 + ISO 27001 姿态框架 + 三方渗透测试 + 安全意识培训
+- 结论/价值:政策是基础设施的基石,运营、工具和流程均构建在此框架之上
+
+## Key Claims(用中文描述)
+- OpenText 采用分层方法定义安全策略——与各团队协作定义"做什么",与执行团队协作确定"怎么做"
+- OpenText 持有 FedRAMP 等多项行业及政府认证,可进入多个垂直市场销售
+- OpenText 每年进行第三方测试(桌面演练+红队演练),持续处于顶级梯队
+- 月处理 2250 亿条日志,每月分诊约 350 个案例
+- Global Information Security Policy(GISP)是最高纲领性政策,季度审查
+
+## Key Quotes
+> "Policies are foundational elements, with operations, tools, and processes built on that framework." — Mike & Ed, GIS Team
+
+> "The focus is on how many people report suspicious activity." — GIS Security Awareness Program
+
+> "Policies define what needs to be done, while providing flexibility for how it is implemented." — GIS Policy Framework
+
+## Key Concepts
+- [[Global Information Security Policy (GISP)]]:最高纲领性政策,季度审查
+- [[ISO-27001]]:姿态框架基础,2022 年更新,新增 11 个控制方面
+- [[Security-Awareness-Training]]:月度安全通讯 + 网络钓鱼演练
+- [[Third-Party-Penetration-Testing]]:年度桌面演练 + 红队演练
+- [[Threat-Intelligence]]:结合 BrightCloud 等工具的威胁情报体系
+- [[FedRAMP]]:政府级云安全认证
+
+## Key Entities
+- [[Mike]]:Global Information Security Team,主讲人
+- [[Ed]]:Global Information Security Team,主讲人
+- [[OpenText]]:企业主体,安全策略制定者
+- [[BrightCloud]]:OpenText 自有威胁情报工具
+
+## Connections
+- [[CTP-Topic-21-Supply-Chain-Security-in-Micro-Focus]] ← related_to ← [[GIS-Security-Policies]](供应链安全同属安全治理范畴)
+- [[CTP-Topic-52-3-Lines-of-Defence]] ← extends ← [[GIS-Security-Policies]](三道防线框架与 GIS 分层组织高度吻合)
+
+## Contradictions
+- 与 [[CTP-Topic-10-AWS-Landing-Zone-LZ-Data-Collection-Tagging-Related-Security]] 存在视角互补而非冲突:
+ - 冲突点:两者均涉及安全治理,但 Topic 10 聚焦于 AWS 层面的标签化安全策略(SCP/Checkpoint),Topic 41 聚焦于企业级安全政策框架(ISO 27001/GISP)
+ - 当前观点:两者互补——GISP 定义全局政策纲领,AWS Landing Zone 层面通过标签和 SCP 实现技术落地
diff --git a/wiki/sources/public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration-20.md b/wiki/sources/public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration-20.md
index 84c32bfb..5c3b050e 100644
--- a/wiki/sources/public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration-20.md
+++ b/wiki/sources/public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration-20.md
@@ -1,59 +1,59 @@
----
-title: "Public Cloud Learning Sessions (OpenText) - GitHub Enterprise to GitLab Migration"
-type: source
-tags:
- - GitHub
- - GitLab
- - Migration
- - OpenText
- - DevOps
- - Source Control
-date: 2024-06-25
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration-20]]
-
-## Summary(用中文描述)
-- 核心主题:OpenText 将源代码管理平台从 GitHub Enterprise 迁移至 GitLab
-- 问题域:企业级版本控制系统迁移、多团队协同转型、CI/CD 流水线重构
-- 方法/机制:Project Thor 统一工具链;Build Hub 团队提供支持;各团队自主规划迁移;两种迁移方案(镜像同步 / 搬移重构);通过 PHT(Product Hub Platform)跟踪进度
-- 结论/价值:GitHub 许可证12月底到期不续,GitLab 许可证覆盖8,500用户;迁移是自服务模式(self-serve),Build Hub 提供辅助支持
-
-## Key Claims(用中文描述)
-- OpenText 决定将 GitLab 作为源代码控制的黄金标准(golden standard)
-- GitHub Enterprise 许可证12月底到期,公司不打算续约
-- GitLab 许可证覆盖高达 8,500 名用户
-- 各团队需自行盘点 GitHub 资产、识别流水线、规划迁移
-- 迁移完成标准:代码迁移完成 + 流水线转型 + PHT 更新
-- GitLab 仓库权限由 PHT 控制,支持自助访问管理
-- 个人仓库允许存在于 GitLab,但不得包含产品源代码,且不会被 PHT 映射
-- 网络连通性挑战通过在 Brook Park 创建 GitLab 代理解决
-
-## Key Quotes
-> "Project Thor aims to integrate Micro-Focus and OpenText tooling, with GitLab as the centralized system for source control." — 迁移背景说明
-> "Each team will define what they have in GitHub today, how they're using it, and they will plan to move it and change their pipelines." — 自服务迁移模式
-> "The current solution that is working and is efficient and is actually reporting to scale." — GitLab 代理方案评价
-
-## Key Concepts
-- [[Project Thor]]:整合 Micro Focus 和 OpenText 工具链的项目,GitLab 作为源代码控制的集中系统
-- [[Build Hub]]:负责管理 GitLab 等中心工具并为软件交付流水线提供支持
-- [[PHT(Product Hub Platform)]]:产品 Hub 平台,用于管理 GitLab 仓库权限映射和迁移进度跟踪
-- [[Mirroring]]:镜像方案,将 GitHub 仓库同步到 GitLab
-- [[Shift and Lift]]:搬移重构方案,将代码复制到 GitLab 并同时转换流水线
-- [[Service Account Standard]]:服务账号标准,要求服务账号必须关联到个人,密码设有到期时间
-
-## Key Entities
-- [[OpenText]]:本次迁移的主体公司,合并了 Micro Focus
-- [[GitHub Enterprise]]:被迁移的源代码管理平台,许可证12月底到期
-- [[GitLab]]:迁移目标平台,作为源代码控制的黄金标准
-- [[Build Hub]]:Build Hub 团队,负责中心工具管理和流水线支持
-
-## Connections
-- [[OpenText]] ← uses ← [[GitLab]](作为源代码管理标准平台)
-- [[OpenText]] ← deprecated ← [[GitHub Enterprise]](12月底到期停用)
-- [[Build Hub]] → supports → 各团队迁移
-- [[PHT(Product Hub Platform)]] ← manages ← GitLab 仓库权限
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "Public Cloud Learning Sessions (OpenText) - GitHub Enterprise to GitLab Migration"
+type: source
+tags:
+ - GitHub
+ - GitLab
+ - Migration
+ - OpenText
+ - DevOps
+ - Source Control
+date: 2024-06-25
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration-20.md]]
+
+## Summary(用中文描述)
+- 核心主题:OpenText 将源代码管理平台从 GitHub Enterprise 迁移至 GitLab
+- 问题域:企业级版本控制系统迁移、多团队协同转型、CI/CD 流水线重构
+- 方法/机制:Project Thor 统一工具链;Build Hub 团队提供支持;各团队自主规划迁移;两种迁移方案(镜像同步 / 搬移重构);通过 PHT(Product Hub Platform)跟踪进度
+- 结论/价值:GitHub 许可证12月底到期不续,GitLab 许可证覆盖8,500用户;迁移是自服务模式(self-serve),Build Hub 提供辅助支持
+
+## Key Claims(用中文描述)
+- OpenText 决定将 GitLab 作为源代码控制的黄金标准(golden standard)
+- GitHub Enterprise 许可证12月底到期,公司不打算续约
+- GitLab 许可证覆盖高达 8,500 名用户
+- 各团队需自行盘点 GitHub 资产、识别流水线、规划迁移
+- 迁移完成标准:代码迁移完成 + 流水线转型 + PHT 更新
+- GitLab 仓库权限由 PHT 控制,支持自助访问管理
+- 个人仓库允许存在于 GitLab,但不得包含产品源代码,且不会被 PHT 映射
+- 网络连通性挑战通过在 Brook Park 创建 GitLab 代理解决
+
+## Key Quotes
+> "Project Thor aims to integrate Micro-Focus and OpenText tooling, with GitLab as the centralized system for source control." — 迁移背景说明
+> "Each team will define what they have in GitHub today, how they're using it, and they will plan to move it and change their pipelines." — 自服务迁移模式
+> "The current solution that is working and is efficient and is actually reporting to scale." — GitLab 代理方案评价
+
+## Key Concepts
+- [[Project Thor]]:整合 Micro Focus 和 OpenText 工具链的项目,GitLab 作为源代码控制的集中系统
+- [[Build Hub]]:负责管理 GitLab 等中心工具并为软件交付流水线提供支持
+- [[PHT(Product Hub Platform)]]:产品 Hub 平台,用于管理 GitLab 仓库权限映射和迁移进度跟踪
+- [[Mirroring]]:镜像方案,将 GitHub 仓库同步到 GitLab
+- [[Shift and Lift]]:搬移重构方案,将代码复制到 GitLab 并同时转换流水线
+- [[Service Account Standard]]:服务账号标准,要求服务账号必须关联到个人,密码设有到期时间
+
+## Key Entities
+- [[OpenText]]:本次迁移的主体公司,合并了 Micro Focus
+- [[GitHub Enterprise]]:被迁移的源代码管理平台,许可证12月底到期
+- [[GitLab]]:迁移目标平台,作为源代码控制的黄金标准
+- [[Build Hub]]:Build Hub 团队,负责中心工具管理和流水线支持
+
+## Connections
+- [[OpenText]] ← uses ← [[GitLab]](作为源代码管理标准平台)
+- [[OpenText]] ← deprecated ← [[GitHub Enterprise]](12月底到期停用)
+- [[Build Hub]] → supports → 各团队迁移
+- [[PHT(Product Hub Platform)]] ← manages ← GitLab 仓库权限
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/public-cloud-learning-sessions-opentext-product-hub-pht-overview-and-qa-20240806.md b/wiki/sources/public-cloud-learning-sessions-opentext-product-hub-pht-overview-and-qa-20240806.md
index 5fedd607..e9513ea2 100644
--- a/wiki/sources/public-cloud-learning-sessions-opentext-product-hub-pht-overview-and-qa-20240806.md
+++ b/wiki/sources/public-cloud-learning-sessions-opentext-product-hub-pht-overview-and-qa-20240806.md
@@ -1,54 +1,54 @@
----
-title: "Public Cloud Learning Sessions (OpenText) - Product Hub (PHT) Overview and Q&A - 20240806"
-type: source
-tags: []
-date: 2024-08-06
----
-
-## Source File
-- [[public-cloud-learning-sessions-opentext-product-hub-pht-overview-and-qa-20240806]]
-
-## Summary(用中文描述)
-- 核心主题:OpenText Product Hub(产品层次结构追踪器,简称 PhD 或 PHT)的功能概述与操作演示
-- 问题域:企业内部软件产品资产治理、CI/CD 流水线管理、跨团队产品信息标准化
-- 方法/机制:通过层级结构(业务单元→业务线→产品)和自助服务流程实现产品信息集中管理;与 Jira、Value Edge、PSMQ、ITLS、OSS 等外部系统集成
-- 结论/价值:统一产品视图,支持 Source Repo 和 Artifact Repo 权限管理,实现跨工具链的产品信息一致性
-
-## Key Claims(用中文描述)
-- Product Hub (PhD) 由产品经理或开发经理驱动,收集和管理官方产品及其部门信息,区别于官方产品命名注册表中的主产品
-- Product 定义为具有独立 CI/CD 流水线或发布周期的软件分发;若某组件有自己独立的发布周期(如独立 CI/CD 流水线),应作为 Product 而非 Component 处理
-- PhD 层级结构:业务单元(含工程和 PM 负责人)→ 业务线(含负责人和 PM Lead)→ 产品(含 PM 和开发经理,并关联主产品)
-- 新建 Product 是自助服务流程:提交后经业务线审批;Source Repo 在 GitLab 创建后需 24 小时才在 PhD 中反映,空 Group/Repo 无法被搜索到
-- Product 有三种状态:Active(常规发布)、Maintenance(仅热修复/Bug 修复)、Inactive(无发布)
-- Component 是没有 CI/CD 流水线的库,如需 ITLS 审查或扫描应创建为 Product
-- Source Repo 权限可共享给子产品(只读访问);Product Team 可配置为 Engineering(全权访问)或 Moderator(维护者访问)类型
-
-## Key Quotes
-> "A product is a software distribution with its own CI/CD pipeline or release cycle." — Product 与 Component 的核心区分标准
-> "A product may also be part of another parent product, but if that particular product has its own cycle, like its own CI/CD pipeline, then we may treat that particular component or module as a product in PhD." — Product 的层级归属逻辑
-> "Requesting for a new product is a self-serve process." — 自助服务是 PhD 的核心理念
-> "Source repo creation in GitLab takes 24 hours to reflect in PhD, and empty groups/repositories cannot be searched." — GitLab 与 PhD 同步的已知限制
-> "For product name/status changes, contact erphd@opentext.com; for technical questions, contact aangetoolsupport@opentext.com." — 支持渠道
-
-## Key Concepts
-- [[Product Hub (PhD)]]:OpenText 产品层次结构追踪器,统一管理业务单元、业务线、产品的层级关系和元数据
-- [[CI/CD Pipeline]]:产品定义的核心属性之一,独立流水线是将 Component 升级为 Product 的判断标准
-- [[Source Repo]]:源代码仓库,与 GitLab 集成,PhD 中映射 Source Repo 权限;创建后 24 小时同步
-- [[Artifact Repo]]:制品仓库,PhD 中管理 Artifact Repo 权限,新结构默认启用
-- [[Product Hierarchy]]:业务单元(BU)→ 业务线(LOB)→ 产品(Product)的三层结构
-
-## Key Entities
-- [[OpenText]]:企业软件公司,主导本次 Public Cloud Learning Sessions
-- [[Product Manager]]:产品经理,PhD 中承担产品创建和维护职责
-- [[Development Manager]]:开发经理,产品管理的核心角色
-- [[ITLS]]:Integrated Tool Lifecycle System,PhD 集成的外部系统之一
-- [[PSMQ]]:Product Service Management Queue,PhD 集成的外部应用
-- [[Value Edge]]:外部应用集成,PhD 打通数据流
-- [[Jira]]:项目跟踪工具,PhD 与其集成
-
-## Connections
-- [[Public Cloud Learning Sessions (OpenText) - Thor Platform & Flows]] ← depends_on ← [[Product Hub (PhD)]]
-- [[Public Cloud Learning Sessions (OpenText) - GitHub Enterprise to GitLab Migration]] ← extends ← [[Product Hub (PhD)]]
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "Public Cloud Learning Sessions (OpenText) - Product Hub (PHT) Overview and Q&A - 20240806"
+type: source
+tags: []
+date: 2024-08-06
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-opentext-product-hub-pht-overview-and-qa-20240806.md]]
+
+## Summary(用中文描述)
+- 核心主题:OpenText Product Hub(产品层次结构追踪器,简称 PhD 或 PHT)的功能概述与操作演示
+- 问题域:企业内部软件产品资产治理、CI/CD 流水线管理、跨团队产品信息标准化
+- 方法/机制:通过层级结构(业务单元→业务线→产品)和自助服务流程实现产品信息集中管理;与 Jira、Value Edge、PSMQ、ITLS、OSS 等外部系统集成
+- 结论/价值:统一产品视图,支持 Source Repo 和 Artifact Repo 权限管理,实现跨工具链的产品信息一致性
+
+## Key Claims(用中文描述)
+- Product Hub (PhD) 由产品经理或开发经理驱动,收集和管理官方产品及其部门信息,区别于官方产品命名注册表中的主产品
+- Product 定义为具有独立 CI/CD 流水线或发布周期的软件分发;若某组件有自己独立的发布周期(如独立 CI/CD 流水线),应作为 Product 而非 Component 处理
+- PhD 层级结构:业务单元(含工程和 PM 负责人)→ 业务线(含负责人和 PM Lead)→ 产品(含 PM 和开发经理,并关联主产品)
+- 新建 Product 是自助服务流程:提交后经业务线审批;Source Repo 在 GitLab 创建后需 24 小时才在 PhD 中反映,空 Group/Repo 无法被搜索到
+- Product 有三种状态:Active(常规发布)、Maintenance(仅热修复/Bug 修复)、Inactive(无发布)
+- Component 是没有 CI/CD 流水线的库,如需 ITLS 审查或扫描应创建为 Product
+- Source Repo 权限可共享给子产品(只读访问);Product Team 可配置为 Engineering(全权访问)或 Moderator(维护者访问)类型
+
+## Key Quotes
+> "A product is a software distribution with its own CI/CD pipeline or release cycle." — Product 与 Component 的核心区分标准
+> "A product may also be part of another parent product, but if that particular product has its own cycle, like its own CI/CD pipeline, then we may treat that particular component or module as a product in PhD." — Product 的层级归属逻辑
+> "Requesting for a new product is a self-serve process." — 自助服务是 PhD 的核心理念
+> "Source repo creation in GitLab takes 24 hours to reflect in PhD, and empty groups/repositories cannot be searched." — GitLab 与 PhD 同步的已知限制
+> "For product name/status changes, contact erphd@opentext.com; for technical questions, contact aangetoolsupport@opentext.com." — 支持渠道
+
+## Key Concepts
+- [[Product Hub (PhD)]]:OpenText 产品层次结构追踪器,统一管理业务单元、业务线、产品的层级关系和元数据
+- [[CI/CD Pipeline]]:产品定义的核心属性之一,独立流水线是将 Component 升级为 Product 的判断标准
+- [[Source Repo]]:源代码仓库,与 GitLab 集成,PhD 中映射 Source Repo 权限;创建后 24 小时同步
+- [[Artifact Repo]]:制品仓库,PhD 中管理 Artifact Repo 权限,新结构默认启用
+- [[Product Hierarchy]]:业务单元(BU)→ 业务线(LOB)→ 产品(Product)的三层结构
+
+## Key Entities
+- [[OpenText]]:企业软件公司,主导本次 Public Cloud Learning Sessions
+- [[Product Manager]]:产品经理,PhD 中承担产品创建和维护职责
+- [[Development Manager]]:开发经理,产品管理的核心角色
+- [[ITLS]]:Integrated Tool Lifecycle System,PhD 集成的外部系统之一
+- [[PSMQ]]:Product Service Management Queue,PhD 集成的外部应用
+- [[Value Edge]]:外部应用集成,PhD 打通数据流
+- [[Jira]]:项目跟踪工具,PhD 与其集成
+
+## Connections
+- [[Public Cloud Learning Sessions (OpenText) - Thor Platform & Flows]] ← depends_on ← [[Product Hub (PhD)]]
+- [[Public Cloud Learning Sessions (OpenText) - GitHub Enterprise to GitLab Migration]] ← extends ← [[Product Hub (PhD)]]
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee.md b/wiki/sources/public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee.md
index b466a5ef..15cd09d6 100644
--- a/wiki/sources/public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee.md
+++ b/wiki/sources/public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee.md
@@ -1,62 +1,62 @@
----
-title: "Public Cloud Learning Sessions - Serverless Computing - 20240903"
-type: source
-tags:
- - Serverless
- - AWS
- - Lambda
- - Step-Functions
- - API-Gateway
- - OpenText
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 无服务器计算(Serverless Computing),聚焦 AWS Lambda、Step Functions 和 API Gateway
-- 问题域:企业如何在云环境中简化应用管理、降低运维负担、加快上市时间
-- 方法/机制:Lambda 事件驱动函数 → Step Functions 工作流编排 → API Gateway API 管理,AWS 与客户共担运维责任(AWS 管基础设施,客户管代码)
-- 结论/价值:Serverless 模式通过"按需付费、自动扩展、内置安全"实现更快的市场响应和更低的 TCO
-
-## Key Claims(用中文描述)
-- AWS Lambda 将运维任务(负载均衡、自动扩展、安全)转移给云厂商,使开发团队专注业务逻辑
-- Lambda 函数支持同步、异步、事件源映射三种触发模式,可精细控制执行行为
-- Lambda 权限模型分为执行角色(决定函数能做什么)和资源策略(决定谁能触发函数)
-- Step Functions 提供 Standard 和 Express 两种工作流类型,分别适用于长时任务和高频场景
-- SAM(Serverless Application Model)基于 CloudFormation 构建,支持本地开发和测试 Lambda 函数
-- Lambda Layers 允许跨函数共享公共代码,提高复用率;ARM64 架构提供更优性价比
-
-## Key Quotes
-> "Whenever you see that you have written code and you want that this code is final, you can publish as a new version." — Lambda 版本发布的核心理念
-
-## Key Concepts
-- [[Serverless-Computing]]:将运维任务(负载均衡、自动扩展、安全补丁)转移给云厂商,使开发团队专注业务代码,无需管理服务器
-- [[Event-Driven-Architecture]]:Lambda 函数由事件触发——状态的任何变化即为事件,是 Serverless 的核心执行模型
-- [[Lambda-Permissions-Model]]:执行角色(Execution Role)决定函数能调用哪些 AWS 资源,资源策略(Resource-Based Policy)决定谁能触发该函数,两者分离实现最小权限原则
-- [[Step-Functions]]:无服务器工作流编排服务,基于状态机协调多个 AWS 服务,支持 Standard(长时)和 Express(高频)两种工作流类型
-- [[API-Gateway]]:托管式 API 创建、发布和安全服务,提供边缘优化(Edge-Optimized)、区域(Regional)和私有(Private)三种部署选项
-- [[SAM-Serverless-Application-Model]]:基于 CloudFormation 的无服务器应用开发工具,支持本地测试和部署 Lambda 函数
-
-## Key Entities
-- [[AWS Lambda]]:AWS 无服务器计算核心服务,开发者只需提供业务逻辑,AWS 负责其余所有运维工作
-- [[AWS Step Functions]]:AWS 无服务器工作流编排服务,用于协调多个 Lambda 函数和 AWS 服务的执行顺序
-- [[Amazon API Gateway]]:AWS 托管式 API 管理服务,用于创建、发布和维护安全的企业级 API
-- [[Amazon EventBridge]]:AWS 事件总线服务,用于在应用程序之间路由事件(属于 AWS Serverless 服务组合)
-- [[AWS Fargate]]:AWS 无服务器容器计算服务(与 Lambda 互补,提供容器层的 Serverless 选项)
-- [[Amazon Q]]:AWS AI 助手,可用于调试 Lambda 函数(CloudWatch 集成)
-- [[CloudWatch]]:AWS 监控服务,Lambda 将指标(请求数、错误数、延迟、节流)上报至此
-- [[Serverless-Application-Model-SAM]]:AWS 官方开源工具,基于 CloudFormation 简化无服务器应用的本地开发和部署
-
-## Connections
-- [[AWS-Lambda]] ← is_a ← [[Serverless-Computing]]
-- [[AWS-Step-Functions]] ← orchestrates ← [[AWS-Lambda]]
-- [[Amazon-API-Gateway]] ← exposes ← [[AWS-Lambda]]
-- [[Amazon-EventBridge]] ← triggers ← [[AWS-Lambda]]
-- [[SAM-Serverless-Application-Model]] ← builds_on ← [[CloudFormation]]
-- [[CloudWatch]] ← monitors ← [[AWS-Lambda]]
-- [[Serverless-Computing]] ← extends ← [[Cloud-Transformation-Programme]]
-
-## Contradictions
-- 无已知冲突
+---
+title: "Public Cloud Learning Sessions - Serverless Computing - 20240903"
+type: source
+tags:
+ - Serverless
+ - AWS
+ - Lambda
+ - Step-Functions
+ - API-Gateway
+ - OpenText
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/09_Serverless_AI/public-cloud-learning-sessions-opentext-serverless-computing-20240903-160139-mee.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 无服务器计算(Serverless Computing),聚焦 AWS Lambda、Step Functions 和 API Gateway
+- 问题域:企业如何在云环境中简化应用管理、降低运维负担、加快上市时间
+- 方法/机制:Lambda 事件驱动函数 → Step Functions 工作流编排 → API Gateway API 管理,AWS 与客户共担运维责任(AWS 管基础设施,客户管代码)
+- 结论/价值:Serverless 模式通过"按需付费、自动扩展、内置安全"实现更快的市场响应和更低的 TCO
+
+## Key Claims(用中文描述)
+- AWS Lambda 将运维任务(负载均衡、自动扩展、安全)转移给云厂商,使开发团队专注业务逻辑
+- Lambda 函数支持同步、异步、事件源映射三种触发模式,可精细控制执行行为
+- Lambda 权限模型分为执行角色(决定函数能做什么)和资源策略(决定谁能触发函数)
+- Step Functions 提供 Standard 和 Express 两种工作流类型,分别适用于长时任务和高频场景
+- SAM(Serverless Application Model)基于 CloudFormation 构建,支持本地开发和测试 Lambda 函数
+- Lambda Layers 允许跨函数共享公共代码,提高复用率;ARM64 架构提供更优性价比
+
+## Key Quotes
+> "Whenever you see that you have written code and you want that this code is final, you can publish as a new version." — Lambda 版本发布的核心理念
+
+## Key Concepts
+- [[Serverless-Computing]]:将运维任务(负载均衡、自动扩展、安全补丁)转移给云厂商,使开发团队专注业务代码,无需管理服务器
+- [[Event-Driven-Architecture]]:Lambda 函数由事件触发——状态的任何变化即为事件,是 Serverless 的核心执行模型
+- [[Lambda-Permissions-Model]]:执行角色(Execution Role)决定函数能调用哪些 AWS 资源,资源策略(Resource-Based Policy)决定谁能触发该函数,两者分离实现最小权限原则
+- [[Step-Functions]]:无服务器工作流编排服务,基于状态机协调多个 AWS 服务,支持 Standard(长时)和 Express(高频)两种工作流类型
+- [[API-Gateway]]:托管式 API 创建、发布和安全服务,提供边缘优化(Edge-Optimized)、区域(Regional)和私有(Private)三种部署选项
+- [[SAM-Serverless-Application-Model]]:基于 CloudFormation 的无服务器应用开发工具,支持本地测试和部署 Lambda 函数
+
+## Key Entities
+- [[AWS Lambda]]:AWS 无服务器计算核心服务,开发者只需提供业务逻辑,AWS 负责其余所有运维工作
+- [[AWS Step Functions]]:AWS 无服务器工作流编排服务,用于协调多个 Lambda 函数和 AWS 服务的执行顺序
+- [[Amazon API Gateway]]:AWS 托管式 API 管理服务,用于创建、发布和维护安全的企业级 API
+- [[Amazon EventBridge]]:AWS 事件总线服务,用于在应用程序之间路由事件(属于 AWS Serverless 服务组合)
+- [[AWS Fargate]]:AWS 无服务器容器计算服务(与 Lambda 互补,提供容器层的 Serverless 选项)
+- [[Amazon Q]]:AWS AI 助手,可用于调试 Lambda 函数(CloudWatch 集成)
+- [[CloudWatch]]:AWS 监控服务,Lambda 将指标(请求数、错误数、延迟、节流)上报至此
+- [[Serverless-Application-Model-SAM]]:AWS 官方开源工具,基于 CloudFormation 简化无服务器应用的本地开发和部署
+
+## Connections
+- [[AWS-Lambda]] ← is_a ← [[Serverless-Computing]]
+- [[AWS-Step-Functions]] ← orchestrates ← [[AWS-Lambda]]
+- [[Amazon-API-Gateway]] ← exposes ← [[AWS-Lambda]]
+- [[Amazon-EventBridge]] ← triggers ← [[AWS-Lambda]]
+- [[SAM-Serverless-Application-Model]] ← builds_on ← [[CloudFormation]]
+- [[CloudWatch]] ← monitors ← [[AWS-Lambda]]
+- [[Serverless-Computing]] ← extends ← [[Cloud-Transformation-Programme]]
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/public-cloud-learning-sessions-opentext-tagging-standard-v2-20250429-170111-meet.md b/wiki/sources/public-cloud-learning-sessions-opentext-tagging-standard-v2-20250429-170111-meet.md
index c0481394..13d64e19 100644
--- a/wiki/sources/public-cloud-learning-sessions-opentext-tagging-standard-v2-20250429-170111-meet.md
+++ b/wiki/sources/public-cloud-learning-sessions-opentext-tagging-standard-v2-20250429-170111-meet.md
@@ -1,41 +1,41 @@
----
-title: "Public Cloud Learning Sessions - OpenText Tagging Standard v2 - 20250429"
-type: source
-tags: []
-date: 2026-04-14
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-opentext-tagging-standard-v2-20250429-170111-meet.md]]
-
-## Summary(用中文描述)
-- 核心主题:OpenText 云资源标签标准 v2——覆盖云账户、云资源、Kubernetes 对象和容器镜像的统一标签规范
-- 问题域:云成本优化、资源安全合规、服务交付自动化
-- 方法/机制:通过标准化标签前缀(OT\_ / app.opentext.com / com.opentext.image)实现跨云平台的统一标签语义;IaC 自动化标签创建与维护
-- 结论/价值:标签标准化是 FinOps 成本优化的基础,同时支撑安全合规、资源组织和自动化工作流
-
-## Key Claims(用中文描述)
-- OpenText 通过标准化标签驱动成本优化的三大机制:成本分配、风险降低(快速定位技术联系人)、自动化效率提升
-- Phenops 团队 2023 年发起的标签标准现已扩展至 Kubernetes 对象和容器镜像,覆盖 3,500 个云账户和 48 种 landing zone 类型
-- 标签治理最佳实践:IaC 自动化替代手动打标、检测报告发现缺失标签、禁止在标签中存储敏感数据
-
-## Key Quotes
-> "Tags are key-value pairs that typically have a tag key and an optionally a key value, which you can attach to cloud resources, cloud accounts, container images, Kubernetes objects and other things." — 标签的核心定义
-> "It is about taking resources and you will learn more in the presentation about what kinds of object and what exactly and so on." — 标签标准的适用对象概述
-
-## Key Concepts
-- [[Terraform]]:基础设施即代码工具,用于自动化标签创建和维护
-- [[Kubernetes]]:容器编排平台,标签标准扩展至其对象(namespaces、pods、deployments、services、config maps)
-- [[Container-Images]]:容器镜像,标签标准包含 product、title、description、vendor 等元数据标签
-
-## Key Entities
-- [[Martin-Rosler]]:讲师,介绍 OpenText Tagging Standard V2 的核心内容和三大驱动力
-- [[Phenops-Team]]:发起标签标准(2023年)的团队,原始版本已扩展 Kubernetes 和容器镜像指南
-
-## Connections
-- [[ctp-topic-28-aws-tag-validation-tool]] ← relates_to ← [[OpenText-Tagging-Standard-v2]](两者均关注标签合规审计与强制执行)
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← relates_to ← [[OpenText-Tagging-Standard-v2]](标签即凭证的云原生安全架构理念一致)
-- [[ctp-topic-28-aws-tag-validation-tool]] ← extends ← [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]](审计工具是对 SCP 预防控制的存量检查补充)
-
-## Contradictions
-- 与 [[ctp-topic-28-aws-tag-validation-tool]] 在标签强制能力边界上无矛盾,两者互补:标签标准定义「应该怎么标」,验证工具发现「谁没标好」
+---
+title: "Public Cloud Learning Sessions - OpenText Tagging Standard v2 - 20250429"
+type: source
+tags: []
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-opentext-tagging-standard-v2-20250429-170111-meet.md]]
+
+## Summary(用中文描述)
+- 核心主题:OpenText 云资源标签标准 v2——覆盖云账户、云资源、Kubernetes 对象和容器镜像的统一标签规范
+- 问题域:云成本优化、资源安全合规、服务交付自动化
+- 方法/机制:通过标准化标签前缀(OT\_ / app.opentext.com / com.opentext.image)实现跨云平台的统一标签语义;IaC 自动化标签创建与维护
+- 结论/价值:标签标准化是 FinOps 成本优化的基础,同时支撑安全合规、资源组织和自动化工作流
+
+## Key Claims(用中文描述)
+- OpenText 通过标准化标签驱动成本优化的三大机制:成本分配、风险降低(快速定位技术联系人)、自动化效率提升
+- Phenops 团队 2023 年发起的标签标准现已扩展至 Kubernetes 对象和容器镜像,覆盖 3,500 个云账户和 48 种 landing zone 类型
+- 标签治理最佳实践:IaC 自动化替代手动打标、检测报告发现缺失标签、禁止在标签中存储敏感数据
+
+## Key Quotes
+> "Tags are key-value pairs that typically have a tag key and an optionally a key value, which you can attach to cloud resources, cloud accounts, container images, Kubernetes objects and other things." — 标签的核心定义
+> "It is about taking resources and you will learn more in the presentation about what kinds of object and what exactly and so on." — 标签标准的适用对象概述
+
+## Key Concepts
+- [[Terraform]]:基础设施即代码工具,用于自动化标签创建和维护
+- [[Kubernetes]]:容器编排平台,标签标准扩展至其对象(namespaces、pods、deployments、services、config maps)
+- [[Container-Images]]:容器镜像,标签标准包含 product、title、description、vendor 等元数据标签
+
+## Key Entities
+- [[Martin-Rosler]]:讲师,介绍 OpenText Tagging Standard V2 的核心内容和三大驱动力
+- [[Phenops-Team]]:发起标签标准(2023年)的团队,原始版本已扩展 Kubernetes 和容器镜像指南
+
+## Connections
+- [[ctp-topic-28-aws-tag-validation-tool]] ← relates_to ← [[OpenText-Tagging-Standard-v2]](两者均关注标签合规审计与强制执行)
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← relates_to ← [[OpenText-Tagging-Standard-v2]](标签即凭证的云原生安全架构理念一致)
+- [[ctp-topic-28-aws-tag-validation-tool]] ← extends ← [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]](审计工具是对 SCP 预防控制的存量检查补充)
+
+## Contradictions
+- 与 [[ctp-topic-28-aws-tag-validation-tool]] 在标签强制能力边界上无矛盾,两者互补:标签标准定义「应该怎么标」,验证工具发现「谁没标好」
diff --git a/wiki/sources/public-cloud-learning-sessions-opentext-thor-platform-flows-20241210-160056-meet.md b/wiki/sources/public-cloud-learning-sessions-opentext-thor-platform-flows-20241210-160056-meet.md
index 0af3d532..67bfe8dd 100644
--- a/wiki/sources/public-cloud-learning-sessions-opentext-thor-platform-flows-20241210-160056-meet.md
+++ b/wiki/sources/public-cloud-learning-sessions-opentext-thor-platform-flows-20241210-160056-meet.md
@@ -1,58 +1,58 @@
----
-title: "Public Cloud Learning Sessions (OpenText) - Thor Platform & Flows"
-type: source
-tags:
- - Thor
- - Platform
- - OpenText
- - Project Thor
- - DevOps
- - Supply Chain Security
-date: 2024-12-10
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-opentext-thor-platform-flows-20241210-160056-meet.md]]
-
-## Summary(用中文描述)
-- 核心主题:OpenText Project Thor 平台架构与数据流设计——源代码供应链安全与开发者体验标准化
-- 问题域:Micro Focus 与 OpenText 合并后的工具链整合、源代码治理、构建系统标准化
-- 方法/机制:五大支柱框架(敏捷周期治理、产品发布治理、开发者门户、安全治理、Build Hub)+ GitLab + Artifactory + Backstage + UCMDB 工具链整合
-- 结论/价值:标准化工具链、统一治理模型、提升开发者体验、保障供应链安全
-
-## Key Claims(用中文描述)
-- Arnold Dacan 提出:源代码是供应链的核心要素("The main ingredient in the supply chain is our source code, our IP that is intended to live in GitLab")
-- Project Thor 五大支柱:①敏捷与周期管理 ②产品与发布治理 ③开发者门户(Backstage) ④安全与治理 ⑤Build Hub
-- 标准化目标:在 GitLab、Artifactory、UCMDB 基础上统一工具链,为供应链安全奠定基础
-- 地理分布:主要工具链、源代码、构建系统位于 Brook Park;Sacramento 用于灾难恢复与业务连续性
-- 数据流架构:源代码流(GitLab)→ 制造流程(Build Farms)→ Artifactory → 客户环境
-
-## Key Quotes
-> "The main ingredient in the supply chain is our source code, our IP that is intended to live in GitLab." — Arnold Dacan,阐述源代码作为供应链核心的战略定位
-
-> "We are trying to standardize in GitLab, Artifactory, PMS and UCMDB are backend services that have started to grow and will grow further for supply chain security." — Arnold Dacan,阐述工具链标准化与供应链安全的关联
-
-## Key Concepts
-- [[Project Thor]]:OpenText 主导的源代码供应链安全与开发者平台标准化项目,五大支柱涵盖敏捷治理、发布治理、开发者门户、安全和 Build Hub
-- [[Supply Chain Security]]:源代码供应链安全——源代码作为核心 IP,通过 GitLab 集中管理,构建流程全程可追溯
-- [[Build Hub]]:Project Thor 五大支柱之一,构建系统集中化管理平台
-- [[GitLab Proxy]]:通过 GitLab 代理解决网络连通性问题,支持分布式团队访问源代码
-- [[GitLab Geo]]:GitLab 地理分布式部署,支持灾难恢复与业务连续性
-- [[Code Signing]]:代码签名流程,确保构建产物的完整性与来源可信
-
-## Key Entities
-- [[Arnold Dacan]]:Project Thor 平台与数据流分享的主讲人,OpenText 技术负责人
-- [[GitLab]]:OpenText 选定的源代码控制黄金标准(替代 GitHub Enterprise)
-- [[Artifactory]]:构建产物仓库,Project Thor 工具链核心组件
-- [[Backstage]]:开发者门户(Backstage.io),Project Thor 五大支柱之一
-- [[UCMDB]]:统一配置管理数据库,后端服务组件
-- [[Brook Park]]:OpenText 网络工具链主站点(源代码、构建系统所在)
-- [[Sacramento]]:灾难恢复与业务连续性站点
-- [[Micro Focus]]:OpenText 收购的公司,Project Thor 整合了其原有工具链
-
-## Connections
-- [[public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration-20]] ← extends ← [[public-cloud-learning-sessions-opentext-thor-platform-flows-20241210-160056-meet]]
-- [[ctp-topic-21-supply-chain-security-in-micro-focus]] ← related_to ← [[public-cloud-learning-sessions-opentext-thor-platform-flows-20241210-160056-meet]]
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "Public Cloud Learning Sessions (OpenText) - Thor Platform & Flows"
+type: source
+tags:
+ - Thor
+ - Platform
+ - OpenText
+ - Project Thor
+ - DevOps
+ - Supply Chain Security
+date: 2024-12-10
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-opentext-thor-platform-flows-20241210-160056-meet.md]]
+
+## Summary(用中文描述)
+- 核心主题:OpenText Project Thor 平台架构与数据流设计——源代码供应链安全与开发者体验标准化
+- 问题域:Micro Focus 与 OpenText 合并后的工具链整合、源代码治理、构建系统标准化
+- 方法/机制:五大支柱框架(敏捷周期治理、产品发布治理、开发者门户、安全治理、Build Hub)+ GitLab + Artifactory + Backstage + UCMDB 工具链整合
+- 结论/价值:标准化工具链、统一治理模型、提升开发者体验、保障供应链安全
+
+## Key Claims(用中文描述)
+- Arnold Dacan 提出:源代码是供应链的核心要素("The main ingredient in the supply chain is our source code, our IP that is intended to live in GitLab")
+- Project Thor 五大支柱:①敏捷与周期管理 ②产品与发布治理 ③开发者门户(Backstage) ④安全与治理 ⑤Build Hub
+- 标准化目标:在 GitLab、Artifactory、UCMDB 基础上统一工具链,为供应链安全奠定基础
+- 地理分布:主要工具链、源代码、构建系统位于 Brook Park;Sacramento 用于灾难恢复与业务连续性
+- 数据流架构:源代码流(GitLab)→ 制造流程(Build Farms)→ Artifactory → 客户环境
+
+## Key Quotes
+> "The main ingredient in the supply chain is our source code, our IP that is intended to live in GitLab." — Arnold Dacan,阐述源代码作为供应链核心的战略定位
+
+> "We are trying to standardize in GitLab, Artifactory, PMS and UCMDB are backend services that have started to grow and will grow further for supply chain security." — Arnold Dacan,阐述工具链标准化与供应链安全的关联
+
+## Key Concepts
+- [[Project Thor]]:OpenText 主导的源代码供应链安全与开发者平台标准化项目,五大支柱涵盖敏捷治理、发布治理、开发者门户、安全和 Build Hub
+- [[Supply Chain Security]]:源代码供应链安全——源代码作为核心 IP,通过 GitLab 集中管理,构建流程全程可追溯
+- [[Build Hub]]:Project Thor 五大支柱之一,构建系统集中化管理平台
+- [[GitLab Proxy]]:通过 GitLab 代理解决网络连通性问题,支持分布式团队访问源代码
+- [[GitLab Geo]]:GitLab 地理分布式部署,支持灾难恢复与业务连续性
+- [[Code Signing]]:代码签名流程,确保构建产物的完整性与来源可信
+
+## Key Entities
+- [[Arnold Dacan]]:Project Thor 平台与数据流分享的主讲人,OpenText 技术负责人
+- [[GitLab]]:OpenText 选定的源代码控制黄金标准(替代 GitHub Enterprise)
+- [[Artifactory]]:构建产物仓库,Project Thor 工具链核心组件
+- [[Backstage]]:开发者门户(Backstage.io),Project Thor 五大支柱之一
+- [[UCMDB]]:统一配置管理数据库,后端服务组件
+- [[Brook Park]]:OpenText 网络工具链主站点(源代码、构建系统所在)
+- [[Sacramento]]:灾难恢复与业务连续性站点
+- [[Micro Focus]]:OpenText 收购的公司,Project Thor 整合了其原有工具链
+
+## Connections
+- [[public-cloud-learning-sessions-opentext-github-enterprise-to-gitlab-migration-20]] ← extends ← [[public-cloud-learning-sessions-opentext-thor-platform-flows-20241210-160056-meet]]
+- [[ctp-topic-21-supply-chain-security-in-micro-focus]] ← related_to ← [[public-cloud-learning-sessions-opentext-thor-platform-flows-20241210-160056-meet]]
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco.md b/wiki/sources/public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco.md
index 3dd0cd85..127ed5b1 100644
--- a/wiki/sources/public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco.md
+++ b/wiki/sources/public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco.md
@@ -1,74 +1,74 @@
----
-title: "Public Cloud Learning Sessions - Reducing Cloud Costs - 20250318"
-type: source
-tags:
- - AWS
- - Cost-Optimization
- - FinOps
- - EC2
- - Graviton
- - Spot-Instances
- - Savings-Plans
- - Rightsizing
-date: 2025-03-18
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 云成本优化,聚焦工作负载优化(Workload Optimization)和费率优化(Rate Optimization)两大路径
-- 问题域:企业 AWS 云账单持续攀升,如何通过技术手段和采购策略双管齐下降低云支出
-- 方法/机制:
- - **工作负载优化**:现代化(Modernization,即升级到新一代实例)+ 合理配置(Right Sizing,即按需调整资源规格)
- - **费率优化**:基于承诺消费的折扣计划(Savings Plans / Reserved Instances)
-- 结论/价值:云成本优化是 FinOps 团队与业务团队协作的系统性工程,需先完成 Right Sizing 再实施费率承诺计划
-
-## Key Claims(用中文描述)
-- **EC2 现代化**:从 Intel/旧代际实例迁移到新一代实例(如 M6→M7/M8),新代际实例通常更便宜且性能更优;但 M6 之后 AWS 调整了定价模型,M7/M8 价格略高
-- **AMD 实例**:从 Intel 迁移到 AMD 可节省 6-10% 的按需价格,适用于 Windows 和 Linux 工作负载
-- **Graviton 性价比**:Graviton ARM 实例可节省 20-25% 的按需成本,结合 EDP 折扣和承诺计划可进一步降低总支出,仅适用于 Linux 工作负载
-- **存储升级**:从 GP2 升级到 GP3 可直接节省 20% 成本,且无需停机
-- **EKS 升级必要性**:EKS 集群升级到最新版本可避免高昂的扩展支持费用(Extended Support 成本显著更高)
-- **Spot 实例折扣**:Spot 实例相比按需价格最多可享 90% 折扣,适用于大数据、CI/CD、Web 服务器和 HPC 场景
-- **Right Sizing**:通过 EC2 Right Sizing 报告识别 CPU/内存/网络使用率,配置实例调度(非生产环境按业务时间启停)可将成本降至按需价格的 40%
-- **闲置资源清理**:删除闲置负载均衡器、未关联的弹性 IP、利用率不足的 EBS 卷和旧快照,可显著降低账单
-- **费率优化前提**:费率优化前必须先完成 Right Sizing,否则承诺了错误规格反而浪费
-- **Savings Plans vs RI**:AWS 提供 Savings Plans(EC2/Compute)和 Reserved Instances(RDS/ElastiCache/CloudFront 等),分为资源级承诺(折扣高但受限)和灵活承诺(折扣标准但灵活度高)
-
-## Key Quotes
-> "Whenever there's a new family launched by the hyperscale, the latest families are almost cheaper." — Vinay(FINOPS team),说明超大规模厂商新一代实例通常性价比更高
->
-> "Rather than spending up unnecessary moment on the extended support, you can deploy additional four or five cluster, right." — Vinay,强调 EKS 扩展支持费用高昂,应优先升级而非续费扩展支持
->
-> "Spot instances can provide up to 90% discount compared to on-demand, suitable for big data, CI/CD pipelines, web servers, and HPC." — Vinay,Spot 实例最高可享 90% 折扣
->
-> "Only the Phenops's team can implement commitment plans." — 费率承诺计划必须由 Phenops 团队实施
->
-> "All commitment plans will be purchased with no upfront payment options only. The minimum transaction value is 5k per annum." — 承诺计划仅支持无预付选项,最低交易金额为每年 5k 美元
-
-## Key Concepts
-- [[Cloud Cost Optimization]]:云成本优化的核心策略——工作负载优化(技术手段)+ 费率优化(采购策略)
-- [[Graviton]]:AWS ARM 架构处理器,相比 Intel/AMD 可节省 20-25% 按需成本,仅适用于 Linux 工作负载
-- [[Spot Instances]]:AWS 竞价实例,相比按需价格最高可享 90% 折扣,适用于容错工作负载
-- [[Savings Plans]]:AWS 基于承诺消费的折扣计划,提供 EC2 Savings Plans 和 Compute Savings Plans 两种类型
-- [[Reserved Instances]]:AWS 预留实例,为 RDS/ElastiCache/CloudFront 等服务提供承诺折扣
-- [[Right Sizing]]:根据实际 CPU/内存/网络使用率调整实例规格,是费率优化前的必要前置步骤
-- [[EKS Extended Support]]:EKS 扩展支持费用显著高于常规支持,应优先升级到最新版本以避免额外支出
-- [[EDP (Enterprise Discount Program)]]:AWS 企业折扣计划,与 Graviton 实例结合可进一步降低总成本
-- [[GP2 vs GP3]]:EBS 存储类型升级,GP3 比 GP2 便宜 20%,且无需停机
-
-## Key Entities
-- [[Vinay]](FINOPS team):FinOps 团队成员,主讲本次云成本优化学习 sessions
-- [[Phenops-Team]]:OpenText 内部团队,负责实施费率承诺计划(Savings Plans / Reserved Instances)
-- [[AWS]]:Amazon Web Services,云成本优化的平台,提供了 Graviton/Spot/Savings Plans 等成本优化工具
-
-## Connections
-- [[ctp-topic-13-cloud-finops-policies]] ← extends ← [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]]:Topic 13 定义 FinOps 政策框架(5 大策略 + PCG 三层服务模型),本文补充具体技术实施路径(EC2 优化细节)
-- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← extends ← [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]]:Topic 63 聚焦自动化调度优化,本文聚焦 Right Sizing + 费率承诺,两者互补构成完整 FinOps 技术栈
-- [[ctp-topic-71-pcgs-guide-to-rightsizing]] ← extends ← [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]]:Topic 71 是 Right Sizing 最佳实践指南,本文补充了 EC2 Right Sizing 报告的具体使用方法
-- [[ctp-topic-13-cloud-finops-policies]] ← depends_on ← [[ctp-topic-63-optimise-resource-cost-using-automation]]:政策层依赖技术层落地
-- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← depends_on ← [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]]:自动化优化需先完成本文所述的 Right Sizing 分析
-
-## Contradictions
-- 无明显冲突。本文档中"新代际实例通常更便宜"的观点与 AWS 文档中"M7/M8 比 M6 略贵"的信息构成补充说明而非矛盾——前者描述一般规律,后者指出 M6 之后的定价模型调整。
+---
+title: "Public Cloud Learning Sessions - Reducing Cloud Costs - 20250318"
+type: source
+tags:
+ - AWS
+ - Cost-Optimization
+ - FinOps
+ - EC2
+ - Graviton
+ - Spot-Instances
+ - Savings-Plans
+ - Rightsizing
+date: 2025-03-18
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 云成本优化,聚焦工作负载优化(Workload Optimization)和费率优化(Rate Optimization)两大路径
+- 问题域:企业 AWS 云账单持续攀升,如何通过技术手段和采购策略双管齐下降低云支出
+- 方法/机制:
+ - **工作负载优化**:现代化(Modernization,即升级到新一代实例)+ 合理配置(Right Sizing,即按需调整资源规格)
+ - **费率优化**:基于承诺消费的折扣计划(Savings Plans / Reserved Instances)
+- 结论/价值:云成本优化是 FinOps 团队与业务团队协作的系统性工程,需先完成 Right Sizing 再实施费率承诺计划
+
+## Key Claims(用中文描述)
+- **EC2 现代化**:从 Intel/旧代际实例迁移到新一代实例(如 M6→M7/M8),新代际实例通常更便宜且性能更优;但 M6 之后 AWS 调整了定价模型,M7/M8 价格略高
+- **AMD 实例**:从 Intel 迁移到 AMD 可节省 6-10% 的按需价格,适用于 Windows 和 Linux 工作负载
+- **Graviton 性价比**:Graviton ARM 实例可节省 20-25% 的按需成本,结合 EDP 折扣和承诺计划可进一步降低总支出,仅适用于 Linux 工作负载
+- **存储升级**:从 GP2 升级到 GP3 可直接节省 20% 成本,且无需停机
+- **EKS 升级必要性**:EKS 集群升级到最新版本可避免高昂的扩展支持费用(Extended Support 成本显著更高)
+- **Spot 实例折扣**:Spot 实例相比按需价格最多可享 90% 折扣,适用于大数据、CI/CD、Web 服务器和 HPC 场景
+- **Right Sizing**:通过 EC2 Right Sizing 报告识别 CPU/内存/网络使用率,配置实例调度(非生产环境按业务时间启停)可将成本降至按需价格的 40%
+- **闲置资源清理**:删除闲置负载均衡器、未关联的弹性 IP、利用率不足的 EBS 卷和旧快照,可显著降低账单
+- **费率优化前提**:费率优化前必须先完成 Right Sizing,否则承诺了错误规格反而浪费
+- **Savings Plans vs RI**:AWS 提供 Savings Plans(EC2/Compute)和 Reserved Instances(RDS/ElastiCache/CloudFront 等),分为资源级承诺(折扣高但受限)和灵活承诺(折扣标准但灵活度高)
+
+## Key Quotes
+> "Whenever there's a new family launched by the hyperscale, the latest families are almost cheaper." — Vinay(FINOPS team),说明超大规模厂商新一代实例通常性价比更高
+>
+> "Rather than spending up unnecessary moment on the extended support, you can deploy additional four or five cluster, right." — Vinay,强调 EKS 扩展支持费用高昂,应优先升级而非续费扩展支持
+>
+> "Spot instances can provide up to 90% discount compared to on-demand, suitable for big data, CI/CD pipelines, web servers, and HPC." — Vinay,Spot 实例最高可享 90% 折扣
+>
+> "Only the Phenops's team can implement commitment plans." — 费率承诺计划必须由 Phenops 团队实施
+>
+> "All commitment plans will be purchased with no upfront payment options only. The minimum transaction value is 5k per annum." — 承诺计划仅支持无预付选项,最低交易金额为每年 5k 美元
+
+## Key Concepts
+- [[Cloud Cost Optimization]]:云成本优化的核心策略——工作负载优化(技术手段)+ 费率优化(采购策略)
+- [[Graviton]]:AWS ARM 架构处理器,相比 Intel/AMD 可节省 20-25% 按需成本,仅适用于 Linux 工作负载
+- [[Spot Instances]]:AWS 竞价实例,相比按需价格最高可享 90% 折扣,适用于容错工作负载
+- [[Savings Plans]]:AWS 基于承诺消费的折扣计划,提供 EC2 Savings Plans 和 Compute Savings Plans 两种类型
+- [[Reserved Instances]]:AWS 预留实例,为 RDS/ElastiCache/CloudFront 等服务提供承诺折扣
+- [[Right Sizing]]:根据实际 CPU/内存/网络使用率调整实例规格,是费率优化前的必要前置步骤
+- [[EKS Extended Support]]:EKS 扩展支持费用显著高于常规支持,应优先升级到最新版本以避免额外支出
+- [[EDP (Enterprise Discount Program)]]:AWS 企业折扣计划,与 Graviton 实例结合可进一步降低总成本
+- [[GP2 vs GP3]]:EBS 存储类型升级,GP3 比 GP2 便宜 20%,且无需停机
+
+## Key Entities
+- [[Vinay]](FINOPS team):FinOps 团队成员,主讲本次云成本优化学习 sessions
+- [[Phenops-Team]]:OpenText 内部团队,负责实施费率承诺计划(Savings Plans / Reserved Instances)
+- [[AWS]]:Amazon Web Services,云成本优化的平台,提供了 Graviton/Spot/Savings Plans 等成本优化工具
+
+## Connections
+- [[ctp-topic-13-cloud-finops-policies]] ← extends ← [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]]:Topic 13 定义 FinOps 政策框架(5 大策略 + PCG 三层服务模型),本文补充具体技术实施路径(EC2 优化细节)
+- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← extends ← [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]]:Topic 63 聚焦自动化调度优化,本文聚焦 Right Sizing + 费率承诺,两者互补构成完整 FinOps 技术栈
+- [[ctp-topic-71-pcgs-guide-to-rightsizing]] ← extends ← [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]]:Topic 71 是 Right Sizing 最佳实践指南,本文补充了 EC2 Right Sizing 报告的具体使用方法
+- [[ctp-topic-13-cloud-finops-policies]] ← depends_on ← [[ctp-topic-63-optimise-resource-cost-using-automation]]:政策层依赖技术层落地
+- [[ctp-topic-63-optimise-resource-cost-using-automation]] ← depends_on ← [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]]:自动化优化需先完成本文所述的 Right Sizing 分析
+
+## Contradictions
+- 无明显冲突。本文档中"新代际实例通常更便宜"的观点与 AWS 文档中"M7/M8 比 M6 略贵"的信息构成补充说明而非矛盾——前者描述一般规律,后者指出 M6 之后的定价模型调整。
diff --git a/wiki/sources/public-cloud-learning-sessions-storage-cost-optimization-20240305-160037-meeting.md b/wiki/sources/public-cloud-learning-sessions-storage-cost-optimization-20240305-160037-meeting.md
index ce07a09a..a7d4bab5 100644
--- a/wiki/sources/public-cloud-learning-sessions-storage-cost-optimization-20240305-160037-meeting.md
+++ b/wiki/sources/public-cloud-learning-sessions-storage-cost-optimization-20240305-160037-meeting.md
@@ -1,57 +1,57 @@
----
-title: "Public Cloud Learning Sessions - Storage Cost Optimization - 20240305"
-type: source
-tags:
- - AWS
- - Storage
- - FinOps
- - Cost-Optimization
-date: 2024-03-05
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/public-cloud-learning-sessions-storage-cost-optimization-20240305-160037-meeting.md]]
-
-## Summary(用中文描述)
-- 核心主题:AWS 存储服务(EBS/EFS/FSx/S3)的成本优化最佳实践与 ADM 实案例证
-- 问题域:公有云存储选型决策、存储层级管理、生命周期策略、数据传输成本控制
-- 方法/机制:按需选择存储类型与层级、智能分层(Intelligent Tiering)、生命周期策略自动化、DLM/AWS Backup 快照管理
-- 结论/价值:正确的存储选型和分层策略可带来显著成本节省;ADM 通过迁移至 FSx for NetApp ONTAP 实现 60% 成本削减
-
-## Key Claims(用中文描述)
-- GP3 相比 GP2 提供 20% 成本优化,且可独立扩展 IOPS 和吞吐量
-- EBS 快照归档层提供比标准层低 75% 的存储成本,但恢复时间更长、保留期为 90 天
-- EFS 不频繁访问层最小计费对象大小为 128KB
-- S3 Intelligent Tiering 可根据访问模式自动在冷热存储层之间迁移数据,且层间迁移无转换费用
-- ADM 迁移至 AWS FSx for NetApp ONTAP 后,相比最初的自管理 NetApp on EC2 方案实现 60% 成本削减
-
-## Key Quotes
-> "With GP3, you can scale IOPS and throughput independently of the volume size." — GP3 核心优势
-> "With Intelligent Tiering we can automatically move data from warmer to colder storage tiers based on object access patterns." — S3 Intelligent Tiering 核心机制
-
-## Key Concepts
-- [[EBS-GP3]]:通用型 SSD(GP3),比 GP2 便宜 20%,可独立扩展 IOPS 和吞吐量
-- [[EBS-Snapshot-Archive]]:EBS 快照归档层,比标准层低 75% 成本,但恢复需 3-12 小时且保留期 90 天
-- [[Data-Lifecycle-Manager]]:AWS DLM,自动化 EBS 快照生命周期管理,可设置保留策略并迁移至归档层
-- [[AWS-Backup]]:AWS 备份服务,可跨服务集中管理备份,支持跨账户跨区域复制
-- [[EFS-Infrequent-Access]]:EFS 不频繁访问层,最小计费对象大小 128KB,通过生命周期策略自动迁移
-- [[S3-Intelligent-Tiering]]:S3 智能分层,根据访问频率自动在多个存储层间迁移,无转换费用
-- [[S3-Lifecycle-Policies]]:S3 生命周期策略,可转换对象层级、过期非当前版本、删除未完成的多段上传
-- [[FSx-for-NetApp-ONTAP]]:AWS 托管 NetApp 文件系统,支持 SSD 和 HDD 分层,自动在层间迁移冷数据
-- [[AWS-PrivateLink]]:通过 AWS 网络内访问 S3 避免数据传输费用
-
-## Key Entities
-- [[AWS]]:Amazon Web Services,云存储服务提供商(EBS/EFS/FSx/S3)
-- [[ADM]]:案例客户,通过三阶段迁移(OpenZFS → 自管理 NetApp on EC2 → FSx for NetApp ONTAP)最终实现 60% 成本削减
-
-## Connections
-- [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]] ← extends ← [[ctp-topic-13-cloud-finops-policies]]
-- [[EBS-GP3]] ← extends ← [[ctp-topic-13-cloud-finops-policies]](FinOps 存储优化话题扩展)
-- [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]] ← extends ← [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]](EC2 + Storage 共同构成完整成本优化知识链路)
-
-## Contradictions
-- 与 [[ctp-topic-14-octane-hub-on-aws]] 的潜在冲突(存储选型):
- - 冲突点:EFS 与 EBS 的适用场景边界
- - 当前观点:EFS 适合备份,EBS 适合实时数据库(Octane Hub 案例)
- - 对方观点:EFS Infrequent Access 和 EFS Archive 层适用于不频繁访问的文件共享场景
- - 说明:两者均正确,但适用场景不同——EFS 更适合跨多实例共享的文件系统,EBS 更适合单实例高性能块存储
+---
+title: "Public Cloud Learning Sessions - Storage Cost Optimization - 20240305"
+type: source
+tags:
+ - AWS
+ - Storage
+ - FinOps
+ - Cost-Optimization
+date: 2024-03-05
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/05_FinOps/public-cloud-learning-sessions-storage-cost-optimization-20240305-160037-meeting.md]]
+
+## Summary(用中文描述)
+- 核心主题:AWS 存储服务(EBS/EFS/FSx/S3)的成本优化最佳实践与 ADM 实案例证
+- 问题域:公有云存储选型决策、存储层级管理、生命周期策略、数据传输成本控制
+- 方法/机制:按需选择存储类型与层级、智能分层(Intelligent Tiering)、生命周期策略自动化、DLM/AWS Backup 快照管理
+- 结论/价值:正确的存储选型和分层策略可带来显著成本节省;ADM 通过迁移至 FSx for NetApp ONTAP 实现 60% 成本削减
+
+## Key Claims(用中文描述)
+- GP3 相比 GP2 提供 20% 成本优化,且可独立扩展 IOPS 和吞吐量
+- EBS 快照归档层提供比标准层低 75% 的存储成本,但恢复时间更长、保留期为 90 天
+- EFS 不频繁访问层最小计费对象大小为 128KB
+- S3 Intelligent Tiering 可根据访问模式自动在冷热存储层之间迁移数据,且层间迁移无转换费用
+- ADM 迁移至 AWS FSx for NetApp ONTAP 后,相比最初的自管理 NetApp on EC2 方案实现 60% 成本削减
+
+## Key Quotes
+> "With GP3, you can scale IOPS and throughput independently of the volume size." — GP3 核心优势
+> "With Intelligent Tiering we can automatically move data from warmer to colder storage tiers based on object access patterns." — S3 Intelligent Tiering 核心机制
+
+## Key Concepts
+- [[EBS-GP3]]:通用型 SSD(GP3),比 GP2 便宜 20%,可独立扩展 IOPS 和吞吐量
+- [[EBS-Snapshot-Archive]]:EBS 快照归档层,比标准层低 75% 成本,但恢复需 3-12 小时且保留期 90 天
+- [[Data-Lifecycle-Manager]]:AWS DLM,自动化 EBS 快照生命周期管理,可设置保留策略并迁移至归档层
+- [[AWS-Backup]]:AWS 备份服务,可跨服务集中管理备份,支持跨账户跨区域复制
+- [[EFS-Infrequent-Access]]:EFS 不频繁访问层,最小计费对象大小 128KB,通过生命周期策略自动迁移
+- [[S3-Intelligent-Tiering]]:S3 智能分层,根据访问频率自动在多个存储层间迁移,无转换费用
+- [[S3-Lifecycle-Policies]]:S3 生命周期策略,可转换对象层级、过期非当前版本、删除未完成的多段上传
+- [[FSx-for-NetApp-ONTAP]]:AWS 托管 NetApp 文件系统,支持 SSD 和 HDD 分层,自动在层间迁移冷数据
+- [[AWS-PrivateLink]]:通过 AWS 网络内访问 S3 避免数据传输费用
+
+## Key Entities
+- [[AWS]]:Amazon Web Services,云存储服务提供商(EBS/EFS/FSx/S3)
+- [[ADM]]:案例客户,通过三阶段迁移(OpenZFS → 自管理 NetApp on EC2 → FSx for NetApp ONTAP)最终实现 60% 成本削减
+
+## Connections
+- [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]] ← extends ← [[ctp-topic-13-cloud-finops-policies]]
+- [[EBS-GP3]] ← extends ← [[ctp-topic-13-cloud-finops-policies]](FinOps 存储优化话题扩展)
+- [[public-cloud-learning-sessions-best-practices-for-ec2-cost-optimization-in-aws-2]] ← extends ← [[public-cloud-learning-sessions-reducing-cloud-costs-20250318-170100-meeting-reco]](EC2 + Storage 共同构成完整成本优化知识链路)
+
+## Contradictions
+- 与 [[ctp-topic-14-octane-hub-on-aws]] 的潜在冲突(存储选型):
+ - 冲突点:EFS 与 EBS 的适用场景边界
+ - 当前观点:EFS 适合备份,EBS 适合实时数据库(Octane Hub 案例)
+ - 对方观点:EFS Infrequent Access 和 EFS Archive 层适用于不频繁访问的文件共享场景
+ - 说明:两者均正确,但适用场景不同——EFS 更适合跨多实例共享的文件系统,EBS 更适合单实例高性能块存储
diff --git a/wiki/sources/public-cloud-learning-sessions-tagging-standards-for-all-hyperscalers-20240123-1.md b/wiki/sources/public-cloud-learning-sessions-tagging-standards-for-all-hyperscalers-20240123-1.md
index ccfa3363..301a76d1 100644
--- a/wiki/sources/public-cloud-learning-sessions-tagging-standards-for-all-hyperscalers-20240123-1.md
+++ b/wiki/sources/public-cloud-learning-sessions-tagging-standards-for-all-hyperscalers-20240123-1.md
@@ -1,60 +1,60 @@
----
-title: "Public Cloud Learning Sessions - Tagging Standards for All Hyperscalers - 20240123"
-type: source
-tags:
- - Tagging-Standard
- - FinOps
- - AWS
- - Azure
- - GCP
- - Cloud-Governance
-date: 2024-01-23
----
-
-## Source File
-- [[Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-tagging-standards-for-all-hyperscalers-20240123-1.md]]
-
-## Summary(用中文描述)
-- 核心主题:OpenText 跨超大规模云厂商(AWS、Azure、GCP)的统一标签标准
-- 问题域:云成本优化、FinOps 治理、资源归属追踪
-- 方法/机制:OT_ 前缀标签设计、GCP 限制性字符集作为最低通用标准、Terraform 默认标签注入、SCP 强制执行标签合规
-- 结论/价值:标准于 10 月 3 日获批,目标将云资源浪费从行业平均 30% 降至 15%,预计每年节省约 2500 万美元,提升可持续性
-
-## Key Claims(用中文描述)
-- OpenText 未来三年超大规模云支出预计约 5 亿美元,统一标签标准可将浪费率从 30% 降至 15%
-- 将云浪费率降低 50% 可为 OpenText 每年节省约 2500 万美元,同时改善可持续性
-- 正式财务组织由 Tom Bice 领导,专注于跨业务部门提供报告,要求通过标签实现资源详细标注
-- 标签管道:计费控制台启用特定标签 → COST 和使用报告(CUR)包含标签值 → 通过 HCMX、Phenops、QuickSight、Power BI 报告
-- 标准采用最低通用标准原则:GCP 的限制性字符集(小写、数字、连字符、下划线)
-- 标签使用 OT_ 前缀区分,但环境、BU、成本中心等已有标签除外
-- 标准由工作组历时三个月开发,已于去年 10 月 3 日批准
-- Terraform 模块(如 AWS 实例模块)可通过 tags 参数实现默认标签注入
-- 未来计划通过 SCP 或标签策略强制执行 99% 资源标签率目标
-
-## Key Quotes
-> "If we can agree the tags that need to go here, we don't have to do this and we can get out the analysis results." — 关于统一标签标准的必要性,强调一致标签可避免临时标签映射的混乱管理
-
-> "Typically what you do is almost every module that you've got inside Terraform, so like the AWS instance module there, there's a tags parameter that you could use." — 关于 Terraform 标签实现的最佳实践
-
-## Key Concepts
-- [[FinOps]]:云财务管理,通过标签实现成本分配、优化和报告
-- [[Service-Control-Policies-SCPs]]:AWS Organizations 策略,通过「显式拒绝」逻辑强制执行标签规范
-- [[Tag-Based-Security]]:基于标签的安全控制机制,将资源标签作为安全凭证替代传统 IP 规则
-- [[Terraform-Tagging]]:通过 Terraform provider 定义和模块 tags 参数实现默认标签注入
-- [[Multi-Cloud-Governance]]:跨 AWS、Azure、GCP 的统一标签治理标准
-
-## Key Entities
-- [[Tom Bice]]:OpenText 财务组织负责人,主导跨业务部门的 FinOps 报告工作
-
-## Connections
-- [[public-cloud-learning-sessions-opentext-tagging-standard-v2]] ← extends ← 本页
- - v2 在 v1 基础上扩展,覆盖 Kubernetes 对象和容器镜像标签
-- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← relates_to ← 本页
- - Topic 10 详细描述了基于标签的安全控制机制和 SCP 强制执行
-- [[ctp-topic-28-aws-tag-validation-tool]] ← relates_to ← 本页
- - Tag Validation Tool 实现了对 AWS 资源标签合规性的自动化审计
-- [[AWS-Tagging-Standards]] ← is_part_of ← [[OpenText-Tagging-Standard]]
- - OpenText 标签标准是 AWS 标签规范的扩展,定义了跨云统一标准
-
-## Contradictions
-- 无明显冲突。该标准与现有 AWS 标签实践互补,统一了跨 AWS、Azure、GCP 的标签语义
+---
+title: "Public Cloud Learning Sessions - Tagging Standards for All Hyperscalers - 20240123"
+type: source
+tags:
+ - Tagging-Standard
+ - FinOps
+ - AWS
+ - Azure
+ - GCP
+ - Cloud-Governance
+date: 2024-01-23
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public-Cloud-Learning-Sessions/10_OpenText-Series/public-cloud-learning-sessions-tagging-standards-for-all-hyperscalers-20240123-1.md]]
+
+## Summary(用中文描述)
+- 核心主题:OpenText 跨超大规模云厂商(AWS、Azure、GCP)的统一标签标准
+- 问题域:云成本优化、FinOps 治理、资源归属追踪
+- 方法/机制:OT_ 前缀标签设计、GCP 限制性字符集作为最低通用标准、Terraform 默认标签注入、SCP 强制执行标签合规
+- 结论/价值:标准于 10 月 3 日获批,目标将云资源浪费从行业平均 30% 降至 15%,预计每年节省约 2500 万美元,提升可持续性
+
+## Key Claims(用中文描述)
+- OpenText 未来三年超大规模云支出预计约 5 亿美元,统一标签标准可将浪费率从 30% 降至 15%
+- 将云浪费率降低 50% 可为 OpenText 每年节省约 2500 万美元,同时改善可持续性
+- 正式财务组织由 Tom Bice 领导,专注于跨业务部门提供报告,要求通过标签实现资源详细标注
+- 标签管道:计费控制台启用特定标签 → COST 和使用报告(CUR)包含标签值 → 通过 HCMX、Phenops、QuickSight、Power BI 报告
+- 标准采用最低通用标准原则:GCP 的限制性字符集(小写、数字、连字符、下划线)
+- 标签使用 OT_ 前缀区分,但环境、BU、成本中心等已有标签除外
+- 标准由工作组历时三个月开发,已于去年 10 月 3 日批准
+- Terraform 模块(如 AWS 实例模块)可通过 tags 参数实现默认标签注入
+- 未来计划通过 SCP 或标签策略强制执行 99% 资源标签率目标
+
+## Key Quotes
+> "If we can agree the tags that need to go here, we don't have to do this and we can get out the analysis results." — 关于统一标签标准的必要性,强调一致标签可避免临时标签映射的混乱管理
+
+> "Typically what you do is almost every module that you've got inside Terraform, so like the AWS instance module there, there's a tags parameter that you could use." — 关于 Terraform 标签实现的最佳实践
+
+## Key Concepts
+- [[FinOps]]:云财务管理,通过标签实现成本分配、优化和报告
+- [[Service-Control-Policies-SCPs]]:AWS Organizations 策略,通过「显式拒绝」逻辑强制执行标签规范
+- [[Tag-Based-Security]]:基于标签的安全控制机制,将资源标签作为安全凭证替代传统 IP 规则
+- [[Terraform-Tagging]]:通过 Terraform provider 定义和模块 tags 参数实现默认标签注入
+- [[Multi-Cloud-Governance]]:跨 AWS、Azure、GCP 的统一标签治理标准
+
+## Key Entities
+- [[Tom Bice]]:OpenText 财务组织负责人,主导跨业务部门的 FinOps 报告工作
+
+## Connections
+- [[public-cloud-learning-sessions-opentext-tagging-standard-v2]] ← extends ← 本页
+ - v2 在 v1 基础上扩展,覆盖 Kubernetes 对象和容器镜像标签
+- [[ctp-topic-10-aws-landing-zone-lz-data-collection-tagging-related-security]] ← relates_to ← 本页
+ - Topic 10 详细描述了基于标签的安全控制机制和 SCP 强制执行
+- [[ctp-topic-28-aws-tag-validation-tool]] ← relates_to ← 本页
+ - Tag Validation Tool 实现了对 AWS 资源标签合规性的自动化审计
+- [[AWS-Tagging-Standards]] ← is_part_of ← [[OpenText-Tagging-Standard]]
+ - OpenText 标签标准是 AWS 标签规范的扩展,定义了跨云统一标准
+
+## Contradictions
+- 无明显冲突。该标准与现有 AWS 标签实践互补,统一了跨 AWS、Azure、GCP 的标签语义
diff --git a/wiki/sources/public-vs-private-vs-hybrid-cloud-differences-explained.md b/wiki/sources/public-vs-private-vs-hybrid-cloud-differences-explained.md
index f5258a12..8d6190ef 100644
--- a/wiki/sources/public-vs-private-vs-hybrid-cloud-differences-explained.md
+++ b/wiki/sources/public-vs-private-vs-hybrid-cloud-differences-explained.md
@@ -1,59 +1,59 @@
----
-title: "Public vs Private vs Hybrid Cloud Differences Explained"
-type: source
-tags: [cloud-computing, cloud-strategy, infrastructure]
-date: 2025-06-18
----
-
-## Source File
-- [[Cloud & DevOps/Public vs Private vs Hybrid Cloud Differences Explained]]
-
-## Summary(用中文描述)
-- **核心主题:** 公有云、私有云与混合云三种云计算部署模型的核心差异、优缺点及适用场景对比
-- **问题域:** 企业如何根据安全、成本、可扩展性、合规等需求选择合适的云部署模式
-- **方法/机制:** 系统性地从定义、优势、劣势、适用场景四个维度对比三种云模型;强调混合云作为折中方案的价值;提出"共享责任模型"概念
-- **结论/价值:** 三种云模型各有优劣,企业应根据工作负载特点制定有意图(intentional)的云策略,而非简单选择某一模型
-
-## Key Claims(用中文描述)
-- **公有云** 通过多租户共享模式提供高弹性、低成本、快速上线的计算服务,但在大规模企业场景下 TCO 可能指数级上升,且安全性和合规控制最弱
-- **私有云** 为单一组织提供专用环境,带来更高的安全性、控制力和合规灵活性,但成本最高、管理复杂、对远程用户不够友好
-- **混合云** 通过在同一架构中组合公私云实现"安全与扩展兼得"——敏感工作负载在私有云,普通负载在公有云,兼顾成本效率与安全韧性
-- **云选择决策** 应以工作负载需求为驱动,基于安全性、性能、成本三大维度制定有意图的云策略,且需持续评估和调整
-
-## Key Quotes
-> "The public cloud is the shared cloud. In this model, third-party providers deliver storage, computing power, and applications to multiple users." — 公有云的定义:第三方提供商向多用户交付共享资源
-
-> "The private cloud is dedicated to your organization, which you access over a secure private network." — 私有云的定义:组织专用的安全私有网络访问环境
-
-> "The hybrid cloud is a computing environment that uses both the public and private cloud models, sharing data and apps between the two to take advantage of the benefits that each provides." — 混合云的定义:融合两种模型,通过数据和应用在两者间的共享实现优势互补
-
-> "No matter which cloud environment you work in, your problems don't go away. Though you're purchasing services from third-party vendors, you still have to do your due diligence." — 共享责任模型:无论哪种云环境,用户组织仍需对访问控制、云安全和灾难恢复承担最终责任
-
-## Key Concepts
-- [[CloudComputing]]:通过互联网远程使用第三方服务器上的计算资源,无需本地部署硬件
-- [[PublicCloud]]:多租户共享模式,第三方提供商向多个组织交付存储、计算能力和应用,按用量付费
-- [[PrivateCloud]]:单一组织专用的云环境,通过安全私有网络访问,可本地托管或第三方管理,提供更高安全性、控制力和合规性
-- [[HybridCloud]]:同时使用公有云和私有云的计算环境,数据和应用在两者间共享,根据安全、性能、成本需求分配工作负载
-- [[SaaS-PaaS-IaaS]]:云计算服务交付模式的三层——软件即服务、平台即服务、基础设施即服务
-- [[SharedResponsibilityModel]]:云安全责任分配模型——供应商负责底层基础设施灵活性与敏捷性,用户组织负责访问控制、安全加密和灾难恢复规划
-- [[CloudStrategy]]:有意图的云战略——从工作负载需求出发,权衡公私混合各模型利弊,制定并持续调整的云部署策略
-
-## Key Entities
-- [[BMC]]:BMC Software — 源文章的发布机构,全球企业软件公司,为 Forbes Global 50 中 86% 的企业提供自动化应用、系统和服务
-- BMC Helix:独立运营的公司,帮助企业将 AI 转化为行动
-- RaaS(Ransomware as a Service):勒索软件即服务——网络犯罪分子利用云基础设施的"犯罪即服务"模式
-
-## Connections
-- [[PublicCloud]] ← extends ← [[CloudComputing]]
-- [[PrivateCloud]] ← extends ← [[CloudComputing]]
-- [[HybridCloud]] ← extends ← [[CloudComputing]]
-- [[HybridCloud]] ← combines ← [[PublicCloud]] + [[PrivateCloud]]
-- [[CloudStrategy]] ← drives ← [[PublicCloud]] + [[PrivateCloud]] + [[HybridCloud]]
-- [[SharedResponsibilityModel]] ← applies_to ← [[PublicCloud]] + [[PrivateCloud]] + [[HybridCloud]]
-- [[SaaS-PaaS-IaaS]] ← delivered_by ← [[PublicCloud]] + [[PrivateCloud]]
-
-## Contradictions
-- 与 [[CloudComputing]](来源:[[cloud-maturity-model]])可能存在视角冲突:
- - **冲突点:** 本文强调"云消除了基础设施管理复杂性",而云成熟度模型强调云迁移后运维复杂性的增加
- - **当前观点:** 公有云"减少复杂度"——供应商负责维护最新硬件和应用版本,降低内部 IT 专业知识需求
- - **对方观点:** 实际云迁移会增加运维复杂度——多租户安全治理、成本追踪、跨环境集成等问题需要专门的云运维能力
+---
+title: "Public vs Private vs Hybrid Cloud Differences Explained"
+type: source
+tags: [cloud-computing, cloud-strategy, infrastructure]
+date: 2025-06-18
+---
+
+## Source File
+- [[raw/Cloud & DevOps/Public vs Private vs Hybrid Cloud Differences Explained.md]]
+
+## Summary(用中文描述)
+- **核心主题:** 公有云、私有云与混合云三种云计算部署模型的核心差异、优缺点及适用场景对比
+- **问题域:** 企业如何根据安全、成本、可扩展性、合规等需求选择合适的云部署模式
+- **方法/机制:** 系统性地从定义、优势、劣势、适用场景四个维度对比三种云模型;强调混合云作为折中方案的价值;提出"共享责任模型"概念
+- **结论/价值:** 三种云模型各有优劣,企业应根据工作负载特点制定有意图(intentional)的云策略,而非简单选择某一模型
+
+## Key Claims(用中文描述)
+- **公有云** 通过多租户共享模式提供高弹性、低成本、快速上线的计算服务,但在大规模企业场景下 TCO 可能指数级上升,且安全性和合规控制最弱
+- **私有云** 为单一组织提供专用环境,带来更高的安全性、控制力和合规灵活性,但成本最高、管理复杂、对远程用户不够友好
+- **混合云** 通过在同一架构中组合公私云实现"安全与扩展兼得"——敏感工作负载在私有云,普通负载在公有云,兼顾成本效率与安全韧性
+- **云选择决策** 应以工作负载需求为驱动,基于安全性、性能、成本三大维度制定有意图的云策略,且需持续评估和调整
+
+## Key Quotes
+> "The public cloud is the shared cloud. In this model, third-party providers deliver storage, computing power, and applications to multiple users." — 公有云的定义:第三方提供商向多用户交付共享资源
+
+> "The private cloud is dedicated to your organization, which you access over a secure private network." — 私有云的定义:组织专用的安全私有网络访问环境
+
+> "The hybrid cloud is a computing environment that uses both the public and private cloud models, sharing data and apps between the two to take advantage of the benefits that each provides." — 混合云的定义:融合两种模型,通过数据和应用在两者间的共享实现优势互补
+
+> "No matter which cloud environment you work in, your problems don't go away. Though you're purchasing services from third-party vendors, you still have to do your due diligence." — 共享责任模型:无论哪种云环境,用户组织仍需对访问控制、云安全和灾难恢复承担最终责任
+
+## Key Concepts
+- [[CloudComputing]]:通过互联网远程使用第三方服务器上的计算资源,无需本地部署硬件
+- [[PublicCloud]]:多租户共享模式,第三方提供商向多个组织交付存储、计算能力和应用,按用量付费
+- [[PrivateCloud]]:单一组织专用的云环境,通过安全私有网络访问,可本地托管或第三方管理,提供更高安全性、控制力和合规性
+- [[HybridCloud]]:同时使用公有云和私有云的计算环境,数据和应用在两者间共享,根据安全、性能、成本需求分配工作负载
+- [[SaaS-PaaS-IaaS]]:云计算服务交付模式的三层——软件即服务、平台即服务、基础设施即服务
+- [[SharedResponsibilityModel]]:云安全责任分配模型——供应商负责底层基础设施灵活性与敏捷性,用户组织负责访问控制、安全加密和灾难恢复规划
+- [[CloudStrategy]]:有意图的云战略——从工作负载需求出发,权衡公私混合各模型利弊,制定并持续调整的云部署策略
+
+## Key Entities
+- [[BMC]]:BMC Software — 源文章的发布机构,全球企业软件公司,为 Forbes Global 50 中 86% 的企业提供自动化应用、系统和服务
+- BMC Helix:独立运营的公司,帮助企业将 AI 转化为行动
+- RaaS(Ransomware as a Service):勒索软件即服务——网络犯罪分子利用云基础设施的"犯罪即服务"模式
+
+## Connections
+- [[PublicCloud]] ← extends ← [[CloudComputing]]
+- [[PrivateCloud]] ← extends ← [[CloudComputing]]
+- [[HybridCloud]] ← extends ← [[CloudComputing]]
+- [[HybridCloud]] ← combines ← [[PublicCloud]] + [[PrivateCloud]]
+- [[CloudStrategy]] ← drives ← [[PublicCloud]] + [[PrivateCloud]] + [[HybridCloud]]
+- [[SharedResponsibilityModel]] ← applies_to ← [[PublicCloud]] + [[PrivateCloud]] + [[HybridCloud]]
+- [[SaaS-PaaS-IaaS]] ← delivered_by ← [[PublicCloud]] + [[PrivateCloud]]
+
+## Contradictions
+- 与 [[CloudComputing]](来源:[[cloud-maturity-model]])可能存在视角冲突:
+ - **冲突点:** 本文强调"云消除了基础设施管理复杂性",而云成熟度模型强调云迁移后运维复杂性的增加
+ - **当前观点:** 公有云"减少复杂度"——供应商负责维护最新硬件和应用版本,降低内部 IT 专业知识需求
+ - **对方观点:** 实际云迁移会增加运维复杂度——多租户安全治理、成本追踪、跨环境集成等问题需要专门的云运维能力
diff --git a/wiki/sources/rag从入门到精通系列1-基础rag.md b/wiki/sources/rag从入门到精通系列1-基础rag.md
index 4016a02a..7e79d111 100644
--- a/wiki/sources/rag从入门到精通系列1-基础rag.md
+++ b/wiki/sources/rag从入门到精通系列1-基础rag.md
@@ -1,68 +1,67 @@
----
-title: "RAG从入门到精通系列1:基础RAG"
-type: source
-tags: [rag, llm, 向量检索, 知识库, langchain]
-date: 2025-01-16
----
-
-## Source File
-- [[AI/RAG从入门到精通系列1:基础RAG.md]]
-
-## Summary(用中文描述)
-- 核心主题:RAG(检索增强生成)基础原理与实战入门,从 Indexing(索引)、Retrieval(检索)到 Generation(生成)的完整流程。
-- 问题域:LLM 无法使用最新数据和私有数据的根本问题,以及如何通过 RAG 打通 LLM 与外部知识库的连接。
-- 方法/机制:三大核心阶段——(1) Indexing:将外部文档加载、切分、Embedding 向量化后存入向量数据库;(2) Retrieval:用户问题 Embedding 化后通过向量相似度检索 Top-k 相关文档块;(3) Generation:将问题 + 检索结果输入 LLM 生成带事实依据的答案。实战工具链:Qwen(LLM)+ BAAI(Embedding)+ LangChain(编排)+ Qdrant(向量数据库)。
-- 结论/价值:RAG 是让 LLM 拥有外部知识的标准范式,LangChain 和 LlamaIndex 等框架将三阶段流程封装为 Chain,大幅降低开发门槛;LangSmith 可视化整个 RAG 管道便于调试。
-
-## Key Claims(用中文描述)
-- RAG 将 LLM 与外部数据源(私有数据/最新数据)连接,使 LLM 能够使用非训练知识生成答案。
-- Indexing 阶段通过 Embedding Model 将文本转为固定长度的语义向量,以满足向量相似度检索的需求。
-- 由于 Embedding Model 的 Context Window 有限(512~8192 token),需将外部文档切分成满足窗口大小的 Split(文档块)。
-- Retrieval 阶段根据用户问题的语义向量,在向量数据库中按相似度(余弦相似度等)找出 Top-k 个最相关的文档块。
-- Generation 阶段将问题与检索到的文档块通过 PromptTemplate 组合为 Prompt,输入 LLM 生成有事实依据的最终答案。
-- LangChain 和 LlamaIndex 将 Indexing-Retrieval-Generation 三阶段封装为 Chain,简化 RAG 应用开发。
-- LangSmith 提供 RAG 管道的全链路可视化监控和调试能力。
-
-## Key Quotes
-> "RAG(Retrieval Augmented Generation,检索增强生成)是一种将 LLM 与外部数据源(例如私有数据或最新数据)连接的通用方法。它允许 LLM 使用外部数据来生成其输出。" — RAG 的定义与价值
-> "Embedding Model 的 Context Window 有限,我们不能直接把整篇文档丢进去,所以要将原始文档拆分成一个个文档块。" — 文档切分的必要性
-> "看起来很复杂,但这就是 LangChain 和 LlamaIndex 这类框架存在的意义。" — 框架的价值定位
-
-## Key Concepts
-- [[RAG]]:检索增强生成,将 LLM 链接外部知识库的核心技术架构
-- [[Indexing]]:索引阶段,将外部文档加载、切分、向量化后存入向量数据库
-- [[Retrieval]]:检索阶段,通过向量相似度从数据库中检索与问题相关的文档块
-- [[Generation]]:生成阶段,将问题+检索结果输入 LLM 生成答案
-- [[Embedding]]:将文本转为固定长度语义向量的技术,是向量检索的基础
-- [[Vector Store]](向量数据库):存储 Embedding Vector 并实现相似度比较的数据库系统,如 Qdrant
-- [[Split]](文档块):将长文档切分后满足 Embedding Model Context Window 的文本片段
-- [[Context Window]]:模型一次性处理的最大 token 数量,Embedding Model 通常为 512~8192 token
-- [[PromptTemplate]]:将问题与上下文组装为 LLM 输入 Prompt 的模板技术
-- [[Chain]](链):LangChain 中将多个步骤串联执行的抽象,RAG Chain 串联 Retrieval 与 Generation
-- [[Token]]:模型处理文本的基本单位,英文约 3~4 字母/token,中文约 1 汉字/token
-
-## Key Entities
-- [[LangChain]]:Python/LLM 应用开发框架,提供文档加载器、Embedding、Vector Store、Chain、RAG 原语
-- [[Qwen]]:阿里通义千问系列 LLM,本教程中用作 Generation 阶段的 LLM
-- [[BAAI]](BGE Embedding):开源 Embedding Model 系列,将文本转为语义向量
-- [[Qdrant]]:Rust 编写的开源向量数据库,存储 Embedding Vector 并提供相似度检索
-- [[LlamaIndex]]:另一主流 LLM 数据框架(与 LangChain 并列),专注知识增强
-- [[LangSmith]]:LangChain 官方平台,用于构建、监控和评估生产级 LLM 应用,支持 RAG 管道可视化
-- [[PyTorch研习社]]:文章来源微信公众号
-
-## Connections
-- [[RAG]] ← 基础理论 ← [[rag从入门到精通系列1-基础rag]]
-- [[RAG]] ← 依赖 ← [[Embedding]]
-- [[RAG]] ← 依赖 ← [[Vector Store]]
-- [[RAG]] ← 工具链 ← [[LangChain]]
-- [[RAG]] ← 工具链 ← [[LlamaIndex]]
-- [[Indexing]] ← 依赖 ← [[Embedding]]
-- [[Retrieval]] ← 依赖 ← [[Vector Store]]
-- [[Generation]] ← 依赖 ← [[PromptTemplate]]
-- [[Indexing]] ← 依赖 ← [[LangChain]](文档加载器/Splitter/Embedding/Vector Store)
-- [[Retrieval]] ← 依赖 ← [[LangChain]](Retriever)
-- [[Generation]] ← 依赖 ← [[LangChain]](Chain/PromptTemplate)
-- [[rag从入门到精通系列1-基础rag]] ← 系列第一篇 → 其他 RAG 系列文章(待补充)
-
-## Contradictions
-- 与其他 RAG 进阶技术存在优化方向上的差异:本文为基础 RAG(Naive RAG),采用直接向量检索 + 简单拼接 Prompt 的朴素方案。与 Advanced RAG(包含 Query Rewrite、Step-back Prompt、HyDE 等查询优化技术)和 RAG Fusion(多路召回 + RRF 重排)等进阶方案相比,基础 RAG 在检索质量和上下文利用上存在局限。当前 Wiki 中暂无 Advanced RAG 或 RAG Fusion 的专门页面,此冲突待后续补充进阶内容后更新。
+---
+title: "RAG从入门到精通系列1:基础RAG"
+type: source
+tags: [RAG, LLM, 检索增强生成, 向量数据库]
+date: 2025-01-16
+sources: []
+last_updated: 2025-01-16
+---
+
+## Source File
+- [[raw/AI/RAG从入门到精通系列1:基础RAG.md]]
+
+## Summary(用中文描述)
+- 核心主题:RAG(检索增强生成)的基础概念与工作流程,包括 Indexing(索引)、Retrieval(检索)和 Generation(生成)三阶段
+- 问题域:LLM 缺乏最新知识和私有领域数据的问题,以及如何将 LLM 与外部数据源连接
+- 方法/机制:通过对外部文档建立索引 → 根据用户问题检索相关文档 → 将问题和相关文档输入 LLM 生成答案的三阶段管道;使用 Embedding Model 将文本转为向量表示存入 Vector Store
+- 结论/价值:RAG 是连接 LLM 与外部知识的通用方法,可消除 LLM 幻觉,提升答案准确性;LangChain 和 LlamaIndex 框架可简化 RAG 管道的构建
+
+## Key Claims(用中文描述)
+- RAG(检索增强生成)通过将 LLM 与外部数据源连接,允许 LLM 使用私有数据或最新数据生成答案
+- 基础 RAG 流程包含三个阶段:Indexing(索引)、Retrieval(检索)、Generation(生成)
+- 文本必须转为 Embedding Vector(嵌入向量)才能实现语义相似度检索
+- Embedding Model 的 Context Window 有限(512~8192 token),需将文档切分成 Split 后再进行向量化
+- Vector Store(向量数据库)存储 Embedding Vector 并实现相似度比较
+- LangChain 和 LlamaIndex 框架可简化检索与生成管道的构建和串联
+
+## Key Quotes
+> "RAG(Retrieval Augmented Generation,检索增强生成)是一种将 LLM 与外部数据源(例如私有数据或最新数据)连接的通用方法。它允许 LLM 使用外部数据来生成其输出。" — RAG 定义
+> "Embedding Vector 通常存储在 Vector Store(向量数据库)中,Vector Store 实现了各种比较 Embedding Vector 之间相似度的方法。" — 向量数据库作用
+> "LangSmith 是一个用于构建生产级 LLM 应用程序的平台。它允许我们密切监控和评估我们的应用程序,以便我们可以快速、自信地交付。" — LangSmith 定位
+
+## Key Concepts
+- [[RAG]]:Retrieval Augmented Generation,检索增强生成 — 连接 LLM 与外部数据源的通用方法
+- [[Indexing]]:索引阶段 — 对外部文档进行加载、切分、向量化并存入向量数据库
+- [[Retrieval]]:检索阶段 — 根据问题语义向量检索相关文档块
+- [[Generation]]:生成阶段 — 将问题与检索到的文档输入 LLM 生成答案
+- [[Embedding]]:文本到向量表示的转换,使文本可用数学方法计算相似度
+- [[Vector-Store]]:向量数据库 — 存储嵌入向量并支持相似度检索
+- [[Split]]:文档切分 — 将长文档切分成适合 Embedding Model Context Window 的小块
+- [[Token]]:Token 是模型表示文本的基本单位,英文约 3-4 字母/Token,中文约 1 汉字/Token
+- [[Context-Window]]:上下文窗口 — Embedding Model 能接受的最大 token 数,通常 512~8192
+
+## Key Entities
+- [[LangChain]]:Python/LLMs 应用开发框架,提供文档加载器、向量数据库集成、Chain 组合等功能
+- [[LlamaIndex]]:LLM 数据框架,用于构建 LLM 应用的数据连接层
+- [[Qwen]]:阿里通义千问大模型,作为示例 LLM 用于 RAG 管道
+- [[BAAI]]:智谱 AI Embedding 模型(如 BAAI/bge 系列),用于文本向量化
+- [[Qdrant]]:开源向量数据库,使用 Rust 编写,用于存储和检索 Embedding Vector
+- [[LangSmith]]:LangChain 的监控和评估平台,用于追踪和调试 LLM 应用管道
+
+## Connections
+- [[RAG]] ← depends_on ← [[Vector-Store]]
+- [[RAG]] ← depends_on ← [[Embedding]]
+- [[RAG]] ← depends_on ← [[LLM]]
+- [[RAG]] ← depends_on ← [[LangChain]]
+- [[Indexing]] ← produces ← [[Vector-Store]]
+- [[Retrieval]] ← depends_on ← [[Vector-Store]]
+- [[Retrieval]] ← depends_on ← [[Embedding]]
+- [[Generation]] ← depends_on ← [[Retrieval]]
+- [[LangChain]] ← integrates ← [[Qwen]]
+- [[LangChain]] ← integrates ← [[BAAI]]
+- [[LangChain]] ← integrates ← [[Qdrant]]
+
+## Contradictions
+- 与 [[Personal-Knowledge-Base-RAG]] 关系:本文侧重基础 RAG 概念和流程解析,后者侧重个人知识库场景下的 RAG 实战应用;两者互补,共同构成 RAG 知识体系
+- 与 [[大模型相关术语和框架总结]] 关系:本文深入展开 RAG 机制,后者将 RAG 列为术语之一(消除幻觉,正确率 60%→90%);本文提供机制详解,后者提供宏观定位
+- 与 [[llms-rag-ai-agent-三个到底什么区别]] 关系:本文详解 RAG 内部三阶段,后者将 RAG 定义为"随身图书馆助理";本文深入,后者概览,相互印证
diff --git a/wiki/sources/readme.md b/wiki/sources/readme.md
index e4aa0794..b525dc5b 100644
--- a/wiki/sources/readme.md
+++ b/wiki/sources/readme.md
@@ -1,40 +1,40 @@
----
-title: "OpenCode Integration"
-type: source
-tags: []
-date: 2026-04-26
----
-
-## Source File
-- [[Agent/agency-agents/integrations/opencode/README.md]]
-
-## Summary(用中文描述)
-- 核心主题:OpenCode 的子 Agent 集成机制——如何将 .md 文件格式的 Agent 转换为 OpenCode 可调用的子代理
-- 问题域:OpenCode IDE 中的多 Agent 协作与按需调用
-- 方法/机制:通过 YAML frontmatter 中的 `mode: subagent` 标记,将具名 Agent 从 Tab 循环列表中分离,改为按需 `@agent-name` 调用;颜色通过命名颜色到十六进制的自动映射实现
-- 结论/价值:提供了一种轻量级、无需修改主 Agent 系统的子 Agent 扩展方案,支持项目级和全局级两种安装范围
-
-## Key Claims(用中文描述)
-- OpenCode Agent 通过在 `.opencode/agents/` 目录存储 .md 文件(带 YAML frontmatter)实现——文件格式与 The Agency 的 Agent 定义格式兼容
-- `mode: subagent` 配置使 Agent 仅在 `@agent-name` 触发时出现,不会在 Tab 循环列表中占位——保持主 Agent 列表的简洁性
-- 命名颜色(如 `cyan`)在安装脚本中被自动转换为十六进制颜色代码——无需手动查表
-- Agent 支持两种安装范围:项目级(`.opencode/agents/`)和全局级(`~/.config/opencode/agents/`)——通过不同路径实现作用域隔离
-- 转换脚本 `./scripts/convert.sh --tool opencode` 负责将 The Agency 的标准 Agent 文件转换为 OpenCode 兼容格式
-
-## Key Quotes
-> "mode: subagent — agent is available on-demand, not shown in the primary Tab-cycle list"
-> — Agent YAML frontmatter 的核心语义,说明 subagent 模式与普通 agent 的本质区别
-
-## Key Concepts
-- [[Subagent]]:按需调用的辅助 Agent,通过 `@agent-name` 语法触发,不参与 Tab 循环
-- [[OpenCode]]:一个支持多 Agent 协作的 IDE/编辑器扩展平台
-
-## Key Entities
-- [[The Agency]]:OpenCode Agent 的来源框架,提供 147 个专业化 Agent 定义
-
-## Connections
-- [[contributing]] ← 贡献来源 ← [[Agent/agency-agents/integrations/opencode/README.md]]
-- [[The Agency]] ← Agent 定义来源 ← [[Agent/agency-agents/integrations/opencode/README.md]]
-
-## Contradictions
-- (未检测到与其他页面的明显冲突)
+---
+title: "OpenCode Integration"
+type: source
+tags: []
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Agent/agency-agents/scripts/i18n/README.md]]
+
+## Summary(用中文描述)
+- 核心主题:OpenCode 的子 Agent 集成机制——如何将 .md 文件格式的 Agent 转换为 OpenCode 可调用的子代理
+- 问题域:OpenCode IDE 中的多 Agent 协作与按需调用
+- 方法/机制:通过 YAML frontmatter 中的 `mode: subagent` 标记,将具名 Agent 从 Tab 循环列表中分离,改为按需 `@agent-name` 调用;颜色通过命名颜色到十六进制的自动映射实现
+- 结论/价值:提供了一种轻量级、无需修改主 Agent 系统的子 Agent 扩展方案,支持项目级和全局级两种安装范围
+
+## Key Claims(用中文描述)
+- OpenCode Agent 通过在 `.opencode/agents/` 目录存储 .md 文件(带 YAML frontmatter)实现——文件格式与 The Agency 的 Agent 定义格式兼容
+- `mode: subagent` 配置使 Agent 仅在 `@agent-name` 触发时出现,不会在 Tab 循环列表中占位——保持主 Agent 列表的简洁性
+- 命名颜色(如 `cyan`)在安装脚本中被自动转换为十六进制颜色代码——无需手动查表
+- Agent 支持两种安装范围:项目级(`.opencode/agents/`)和全局级(`~/.config/opencode/agents/`)——通过不同路径实现作用域隔离
+- 转换脚本 `./scripts/convert.sh --tool opencode` 负责将 The Agency 的标准 Agent 文件转换为 OpenCode 兼容格式
+
+## Key Quotes
+> "mode: subagent — agent is available on-demand, not shown in the primary Tab-cycle list"
+> — Agent YAML frontmatter 的核心语义,说明 subagent 模式与普通 agent 的本质区别
+
+## Key Concepts
+- [[Subagent]]:按需调用的辅助 Agent,通过 `@agent-name` 语法触发,不参与 Tab 循环
+- [[OpenCode]]:一个支持多 Agent 协作的 IDE/编辑器扩展平台
+
+## Key Entities
+- [[The Agency]]:OpenCode Agent 的来源框架,提供 147 个专业化 Agent 定义
+
+## Connections
+- [[contributing]] ← 贡献来源 ← [[Agent/agency-agents/integrations/opencode/README.md]]
+- [[The Agency]] ← Agent 定义来源 ← [[Agent/agency-agents/integrations/opencode/README.md]]
+
+## Contradictions
+- (未检测到与其他页面的明显冲突)
diff --git a/wiki/sources/recruitment-specialist.md b/wiki/sources/recruitment-specialist.md
index c83e9468..d644b321 100644
--- a/wiki/sources/recruitment-specialist.md
+++ b/wiki/sources/recruitment-specialist.md
@@ -1,53 +1,53 @@
----
-title: "Recruitment Specialist Agent"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/recruitment-specialist.md]]
-
-## Summary(用中文描述)
-- 核心主题:RecruitmentSpecialist 是一个专注于中国人力资源市场的招聘运营与人才获取专家 Agent,覆盖从人才吸引、入职到留任的全周期招聘引擎
-- 问题域:中国招聘平台运营、JD 优化、简历筛选、面试流程设计、校园招聘、猎头管理、劳动法合规、雇主品牌建设、入职管理、招聘数据分析
-- 方法/机制:多平台渠道运营(BOSS直聘、拉勾、猎聘、智联、前程无忧、脉脉、LinkedIn)、结构化面试(STAR 框架)、能力模型评估、ATS 系统集成、劳动法合规检查、招聘漏斗数据分析
-- 结论/价值:帮助企业建立高效、合规、数据驱动的全链路招聘系统,提升招聘ROI、缩短到岗周期、降低试用期流失率
-
-## Key Claims(用中文描述)
-- 通过多平台渠道精细化运营,可实现招聘ROI持续提升,每季度渠道成本趋于下降
-- 使用STAR行为面试框架和结构化评分卡,可提升面试评估准确性和一致性
-- 严格遵守中国劳动法(劳动合同法、就业促进法、个人信息保护法)可避免合规风险和赔偿损失
-- 数据驱动的招聘漏斗分析能识别瓶颈并持续优化各环节转化率
-- 候选人体验(NPS 80+)与 offer 接受率(85%+)高度相关
-
-## Key Quotes
-> "When candidates wait more than 5 days from application to first response, application conversion drops by 40%. We must keep initial response time under 48 hours." — 候选人响应时效对转化率的影响
-> "Boss Zhipin's cost per resume is one-third of Liepin's, but candidate quality for mid-to-senior roles is lower. I recommend using Boss for junior roles and Liepin for senior ones." — 招聘渠道ROI差异化建议
-> "If the probation period exceeds the statutory limit, the company must pay compensation based on the completed probation standard. This risk must be avoided." — 试用期合规风险警示
-
-## Key Concepts
-- [[RecruitmentFunnelAnalyzer]]:招聘漏斗分析器类,计算各环节转化率、渠道ROI、入职周期
-- [[STAR Framework]]:行为面试框架(Situation-Task-Action-Result),用于评估候选人具体行为
-- [[Structured Interview]]:结构化面试,使用标准化评分卡确保面试一致性和评估准确性
-- [[China Labor Law Compliance]]:中国劳动法合规,包括劳动合同法、试用期规定、五险一金、竞业限制、N+1 补偿等
-- [[Employer Brand Building]]:雇主品牌建设,通过短视频、内容营销、平台口碑管理提升对人才的吸引力
-- [[Onboarding SOP]]:标准化入职流程,从入职前7天到第一个月的完整 checklist
-
-## Key Entities
-- [[Boss Zhipin]](BOSS直聘):中国领先的直聊招聘平台,简历成本低,适合初级岗位
-- [[Lagou]](拉勾网):专注互联网/科技岗位的招聘平台,技能标签匹配算法
-- [[Liepin]](猎聘网):中高端猎头导向平台,适合资深岗位
-- [[Beisen]](北森):领先的HR SaaS,ATS 系统用于招聘流程管理
-- [[Moka]](Moka智能招聘):智能化 ATS 系统
-- [[Feishu Recruiting]](飞书招聘):字节跳动 Lark 的 HR 模块
-- [[STAR Method]]:行为面试评估方法论
-
-## Connections
-- [[Specialized Civil Engineer Agent]] ← 同一 Agent 体系下的专业 Agent
-- [[Sales Engineer Agent]] ← 同属专业 Agent 系列
-- [[HR Onboarding]] ← 入职管理是该 Agent 的核心功能模块
-- [[RecruitmentFunnelAnalyzer]] ← 内置于该 Agent 的数据分析工具
-
-## Contradictions
-- 暂无发现与现有 Wiki 页面的冲突内容
+---
+title: "Recruitment Specialist Agent"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/recruitment-specialist.md]]
+
+## Summary(用中文描述)
+- 核心主题:RecruitmentSpecialist 是一个专注于中国人力资源市场的招聘运营与人才获取专家 Agent,覆盖从人才吸引、入职到留任的全周期招聘引擎
+- 问题域:中国招聘平台运营、JD 优化、简历筛选、面试流程设计、校园招聘、猎头管理、劳动法合规、雇主品牌建设、入职管理、招聘数据分析
+- 方法/机制:多平台渠道运营(BOSS直聘、拉勾、猎聘、智联、前程无忧、脉脉、LinkedIn)、结构化面试(STAR 框架)、能力模型评估、ATS 系统集成、劳动法合规检查、招聘漏斗数据分析
+- 结论/价值:帮助企业建立高效、合规、数据驱动的全链路招聘系统,提升招聘ROI、缩短到岗周期、降低试用期流失率
+
+## Key Claims(用中文描述)
+- 通过多平台渠道精细化运营,可实现招聘ROI持续提升,每季度渠道成本趋于下降
+- 使用STAR行为面试框架和结构化评分卡,可提升面试评估准确性和一致性
+- 严格遵守中国劳动法(劳动合同法、就业促进法、个人信息保护法)可避免合规风险和赔偿损失
+- 数据驱动的招聘漏斗分析能识别瓶颈并持续优化各环节转化率
+- 候选人体验(NPS 80+)与 offer 接受率(85%+)高度相关
+
+## Key Quotes
+> "When candidates wait more than 5 days from application to first response, application conversion drops by 40%. We must keep initial response time under 48 hours." — 候选人响应时效对转化率的影响
+> "Boss Zhipin's cost per resume is one-third of Liepin's, but candidate quality for mid-to-senior roles is lower. I recommend using Boss for junior roles and Liepin for senior ones." — 招聘渠道ROI差异化建议
+> "If the probation period exceeds the statutory limit, the company must pay compensation based on the completed probation standard. This risk must be avoided." — 试用期合规风险警示
+
+## Key Concepts
+- [[RecruitmentFunnelAnalyzer]]:招聘漏斗分析器类,计算各环节转化率、渠道ROI、入职周期
+- [[STAR Framework]]:行为面试框架(Situation-Task-Action-Result),用于评估候选人具体行为
+- [[Structured Interview]]:结构化面试,使用标准化评分卡确保面试一致性和评估准确性
+- [[China Labor Law Compliance]]:中国劳动法合规,包括劳动合同法、试用期规定、五险一金、竞业限制、N+1 补偿等
+- [[Employer Brand Building]]:雇主品牌建设,通过短视频、内容营销、平台口碑管理提升对人才的吸引力
+- [[Onboarding SOP]]:标准化入职流程,从入职前7天到第一个月的完整 checklist
+
+## Key Entities
+- [[Boss Zhipin]](BOSS直聘):中国领先的直聊招聘平台,简历成本低,适合初级岗位
+- [[Lagou]](拉勾网):专注互联网/科技岗位的招聘平台,技能标签匹配算法
+- [[Liepin]](猎聘网):中高端猎头导向平台,适合资深岗位
+- [[Beisen]](北森):领先的HR SaaS,ATS 系统用于招聘流程管理
+- [[Moka]](Moka智能招聘):智能化 ATS 系统
+- [[Feishu Recruiting]](飞书招聘):字节跳动 Lark 的 HR 模块
+- [[STAR Method]]:行为面试评估方法论
+
+## Connections
+- [[Specialized Civil Engineer Agent]] ← 同一 Agent 体系下的专业 Agent
+- [[Sales Engineer Agent]] ← 同属专业 Agent 系列
+- [[HR Onboarding]] ← 入职管理是该 Agent 的核心功能模块
+- [[RecruitmentFunnelAnalyzer]] ← 内置于该 Agent 的数据分析工具
+
+## Contradictions
+- 暂无发现与现有 Wiki 页面的冲突内容
diff --git a/wiki/sources/roblox-avatar-creator.md b/wiki/sources/roblox-avatar-creator.md
index 0aedeabd..cc54e062 100644
--- a/wiki/sources/roblox-avatar-creator.md
+++ b/wiki/sources/roblox-avatar-creator.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/roblox-studio/roblox-avatar-creator.md]]
+- [[raw/Agent/agency-agents/game-development/roblox-studio/roblox-avatar-creator.md]]
## Summary(用中文描述)
- 核心主题:Roblox UGC(用户生成内容)化身系统专家 AI Agent 人格规范——从建模绑定到 Creator Marketplace 提交的完整 avatar pipeline
diff --git a/wiki/sources/roblox-experience-designer.md b/wiki/sources/roblox-experience-designer.md
index e208500f..267c6e29 100644
--- a/wiki/sources/roblox-experience-designer.md
+++ b/wiki/sources/roblox-experience-designer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/roblox-studio/roblox-experience-designer.md]]
+- [[raw/Agent/agency-agents/game-development/roblox-studio/roblox-experience-designer.md]]
## Summary(用中文描述)
- 核心主题:Roblox 平台原生体验设计师 Agent——专注于 Roblox 受众(9-17岁)的参与度循环设计、变现系统与玩家留存
diff --git a/wiki/sources/rto-vs-rpo-key-differences-for-modern-disaster-recovery.md b/wiki/sources/rto-vs-rpo-key-differences-for-modern-disaster-recovery.md
index cc0c6fa8..fcf77ec4 100644
--- a/wiki/sources/rto-vs-rpo-key-differences-for-modern-disaster-recovery.md
+++ b/wiki/sources/rto-vs-rpo-key-differences-for-modern-disaster-recovery.md
@@ -1,73 +1,73 @@
----
-title: "RTO vs RPO: Key Differences for Modern Disaster Recovery"
-type: source
-tags: [cloud-devops, disaster-recovery, sre, feature-flags, continuous-delivery]
-date: 2019-01-18
----
-
-## Source File
-- [[Cloud & DevOps/RTO vs RPO Key Differences for Modern Disaster Recovery]]
-
-## Summary(用中文描述)
-- 核心主题:RTO(Recovery Time Objective)和 RPO(Recovery Point Objective)在现代灾难恢复和持续交付中的关键区别与实践应用
-- 问题域:云原生/DevOps 环境下的灾难恢复规划、软件部署风险管控、Feature Flag 驱动的微恢复策略
-- 方法/机制:
- - RTO 衡量系统停机时长容忍度,RPO 衡量数据丢失容忍度
- - 应用分层(Tier 1/2/3)分配差异化恢复目标
- - Feature Flag 实现部署与发布解耦,支持渐进式灰度发布和即时 Kill Switch
- - Feature Flag 将 RTO 从"小时级回滚"缩短至"秒级开关切换"
-- 结论/价值:预防优于恢复;Feature Flag 是现代持续交付中实现激进 RTO/RPO 目标的最佳投资回报比方案
-
-## Key Claims(用中文描述)
-- Feature Flag 将部署(Deploy)与发布(Release)解耦,使回滚从"紧急代码部署(小时级)"变为"配置变更(秒级)"
-- 渐进式灰度发布(1%→5%→25%→100%)将故障影响范围限制在早期阶段,RTO 可降至秒级
-- 不能单独优化 RTO 或 RPO——高频备份(优秀 RPO)+ 慢速恢复(糟糕 RTO)等于无用功
-- 不同的应用/功能应拥有不同的恢复目标(Core Payment: 秒级 RTO + 零 RPO;Beta 功能: 分钟级 RTO)
-- 成本效益原则:若停机一小时损失 $10K,不要每年花 $100K 基础设施去预防它
-
-## Key Quotes
-> "RTO is about speed: how fast you get back online. RPO is about data: how much you can afford to lose." — 核心概念区分
-> "Deploy whenever you want, release when you're ready." — Feature Flag 解耦哲学
-> "Having backups every 30 seconds (a great RPO) doesn't help if it takes you 6 hours to restore from those backups (a terrible RTO)." — RTO/RPO 必须同时优化
-> "Prevention beats cure: the best disaster recovery solution is the one you'll actually use when things go wrong." — HP 案例引出核心结论
-
-## Key Concepts
-- [[概念页面待创建]]:**RTO(Recovery Time Objective)**——系统允许的最大停机时长,从故障发生时刻开始计时
-- [[概念页面待创建]]:**RPO(Recovery Point Objective)**——允许丢失的最大数据量,从上一备份时刻向前测量
-- [[概念页面待创建]]:**Feature Flag**——通过条件分支控制功能上线,无需重新部署即可启用/禁用功能
-- [[概念页面待创建]]:**Kill Switch**——紧急禁用故障功能的即时开关,Feature Flag 驱动的 RTO 保险机制
-- [[概念页面待创建]]:**Progressive Rollout**——渐进式功能发布(1%/5%/25%/100%),限制故障影响范围
-- [[概念页面待创建]]:**Micro-Recovery**——基于 Feature Flag 的功能级回滚,而非整应用回滚
-
-## Key Entities
-- [[实体页面待创建]]:**LaunchDarkly**——Feature Flag 管理平台,本文档的主要案例引用来源(HP、Christian Dior 等案例)
-- [[实体页面待创建]]:**Veeam / Acronis**——传统 DR 工具(备份/服务器镜像/跨区域复制),作为传统方案对照组
-
-## Connections
-- [[what-i-know-about-cloud-service-delivery-1]] ← 包含 ← [[rto-vs-rpo-key-differences-for-modern-disaster-recovery]](本文档是云服务交付"备份恢复与灾难管理"领域的具体展开)
-- [[devops-maturity-model-from-traditional-it-to-advanced-devops]] ← 支撑 ← [[rto-vs-rpo-key-differences-for-modern-disaster-recovery]](DevOps 成熟度中"监控可观测性"和"错误预算"是 RTO/RPO 的量化手段)
-- [[cloud-devop-maturity-guideline]] ← 关联 ← [[rto-vs-rpo-key-differences-for-modern-disaster-recovery]](DORA 四项指标中的 MTTR 直接对应 RTO)
-- [[continuous-delivery]](概念尚待建立)← 核心应用场景 ← [[rto-vs-rpo-key-differences-for-modern-disaster-recovery]]
-
-## Contradictions
-- 与传统 DR 思维存在框架冲突:
- - 冲突点:传统 DR 关注硬件灾难(火灾/断电/硬件故障),本文档认为现代高频部署场景下软件故障(Bug/错误迁移/AI 模型异常)才是主要风险
- - 当前观点:Feature Flag + Kill Switch + 渐进式发布比传统热备基础设施更有效且成本更低
- - 对方观点:传统 DR 基础设施(Veeam/Acronis + 多数据中心热备)仍是不可替代的硬件级保障
- - 注:两者并不互斥——软件层面用 Feature Flag 快速止血,基础设施层面仍需传统 DR 兜底
-
-## Tier System Reference(应用分级体系)
-
-| Tier | 示例 | RTO 目标 | RPO 目标 | 策略 |
-|------|------|---------|---------|------|
-| (1) Critical | 支付处理、用户认证、核心产品 | < 5 分钟 | < 1 分钟 | Feature Flag + 自动回滚 + 24/7 告警 |
-| (2) Important | 管理后台、报表、客户支持工具 | < 1 小时 | < 15 分钟 | Feature Flag + 手动回滚 + 工作时间监控 |
-| (3) Nice-to-have | 内部工具、开发环境、文档站 | < 4 小时 | < 1 小时 | 基础监控 + 人工恢复流程 |
-
-## LaunchDarkly Business Impact Data
-- HP:将回滚时间从"小时级"缩短至"分钟级"
-- Christian Dior:将 15 分钟回滚缩短为"即时开关切换"
-- 86% 的 LaunchDarkly 客户在一天内从故障中恢复
-- 42% 的 LaunchDarkly 客户在"小时级(甚至分钟级)"内恢复
-- 8% 客户运营成本降低超过 50%
-- 59% 客户运营成本降低 11%-50%
+---
+title: "RTO vs RPO: Key Differences for Modern Disaster Recovery"
+type: source
+tags: [cloud-devops, disaster-recovery, sre, feature-flags, continuous-delivery]
+date: 2019-01-18
+---
+
+## Source File
+- [[raw/Cloud & DevOps/RTO vs RPO Key Differences for Modern Disaster Recovery.md]]
+
+## Summary(用中文描述)
+- 核心主题:RTO(Recovery Time Objective)和 RPO(Recovery Point Objective)在现代灾难恢复和持续交付中的关键区别与实践应用
+- 问题域:云原生/DevOps 环境下的灾难恢复规划、软件部署风险管控、Feature Flag 驱动的微恢复策略
+- 方法/机制:
+ - RTO 衡量系统停机时长容忍度,RPO 衡量数据丢失容忍度
+ - 应用分层(Tier 1/2/3)分配差异化恢复目标
+ - Feature Flag 实现部署与发布解耦,支持渐进式灰度发布和即时 Kill Switch
+ - Feature Flag 将 RTO 从"小时级回滚"缩短至"秒级开关切换"
+- 结论/价值:预防优于恢复;Feature Flag 是现代持续交付中实现激进 RTO/RPO 目标的最佳投资回报比方案
+
+## Key Claims(用中文描述)
+- Feature Flag 将部署(Deploy)与发布(Release)解耦,使回滚从"紧急代码部署(小时级)"变为"配置变更(秒级)"
+- 渐进式灰度发布(1%→5%→25%→100%)将故障影响范围限制在早期阶段,RTO 可降至秒级
+- 不能单独优化 RTO 或 RPO——高频备份(优秀 RPO)+ 慢速恢复(糟糕 RTO)等于无用功
+- 不同的应用/功能应拥有不同的恢复目标(Core Payment: 秒级 RTO + 零 RPO;Beta 功能: 分钟级 RTO)
+- 成本效益原则:若停机一小时损失 $10K,不要每年花 $100K 基础设施去预防它
+
+## Key Quotes
+> "RTO is about speed: how fast you get back online. RPO is about data: how much you can afford to lose." — 核心概念区分
+> "Deploy whenever you want, release when you're ready." — Feature Flag 解耦哲学
+> "Having backups every 30 seconds (a great RPO) doesn't help if it takes you 6 hours to restore from those backups (a terrible RTO)." — RTO/RPO 必须同时优化
+> "Prevention beats cure: the best disaster recovery solution is the one you'll actually use when things go wrong." — HP 案例引出核心结论
+
+## Key Concepts
+- [[概念页面待创建]]:**RTO(Recovery Time Objective)**——系统允许的最大停机时长,从故障发生时刻开始计时
+- [[概念页面待创建]]:**RPO(Recovery Point Objective)**——允许丢失的最大数据量,从上一备份时刻向前测量
+- [[概念页面待创建]]:**Feature Flag**——通过条件分支控制功能上线,无需重新部署即可启用/禁用功能
+- [[概念页面待创建]]:**Kill Switch**——紧急禁用故障功能的即时开关,Feature Flag 驱动的 RTO 保险机制
+- [[概念页面待创建]]:**Progressive Rollout**——渐进式功能发布(1%/5%/25%/100%),限制故障影响范围
+- [[概念页面待创建]]:**Micro-Recovery**——基于 Feature Flag 的功能级回滚,而非整应用回滚
+
+## Key Entities
+- [[实体页面待创建]]:**LaunchDarkly**——Feature Flag 管理平台,本文档的主要案例引用来源(HP、Christian Dior 等案例)
+- [[实体页面待创建]]:**Veeam / Acronis**——传统 DR 工具(备份/服务器镜像/跨区域复制),作为传统方案对照组
+
+## Connections
+- [[what-i-know-about-cloud-service-delivery-1]] ← 包含 ← [[rto-vs-rpo-key-differences-for-modern-disaster-recovery]](本文档是云服务交付"备份恢复与灾难管理"领域的具体展开)
+- [[devops-maturity-model-from-traditional-it-to-advanced-devops]] ← 支撑 ← [[rto-vs-rpo-key-differences-for-modern-disaster-recovery]](DevOps 成熟度中"监控可观测性"和"错误预算"是 RTO/RPO 的量化手段)
+- [[cloud-devop-maturity-guideline]] ← 关联 ← [[rto-vs-rpo-key-differences-for-modern-disaster-recovery]](DORA 四项指标中的 MTTR 直接对应 RTO)
+- [[continuous-delivery]](概念尚待建立)← 核心应用场景 ← [[rto-vs-rpo-key-differences-for-modern-disaster-recovery]]
+
+## Contradictions
+- 与传统 DR 思维存在框架冲突:
+ - 冲突点:传统 DR 关注硬件灾难(火灾/断电/硬件故障),本文档认为现代高频部署场景下软件故障(Bug/错误迁移/AI 模型异常)才是主要风险
+ - 当前观点:Feature Flag + Kill Switch + 渐进式发布比传统热备基础设施更有效且成本更低
+ - 对方观点:传统 DR 基础设施(Veeam/Acronis + 多数据中心热备)仍是不可替代的硬件级保障
+ - 注:两者并不互斥——软件层面用 Feature Flag 快速止血,基础设施层面仍需传统 DR 兜底
+
+## Tier System Reference(应用分级体系)
+
+| Tier | 示例 | RTO 目标 | RPO 目标 | 策略 |
+|------|------|---------|---------|------|
+| (1) Critical | 支付处理、用户认证、核心产品 | < 5 分钟 | < 1 分钟 | Feature Flag + 自动回滚 + 24/7 告警 |
+| (2) Important | 管理后台、报表、客户支持工具 | < 1 小时 | < 15 分钟 | Feature Flag + 手动回滚 + 工作时间监控 |
+| (3) Nice-to-have | 内部工具、开发环境、文档站 | < 4 小时 | < 1 小时 | 基础监控 + 人工恢复流程 |
+
+## LaunchDarkly Business Impact Data
+- HP:将回滚时间从"小时级"缩短至"分钟级"
+- Christian Dior:将 15 分钟回滚缩短为"即时开关切换"
+- 86% 的 LaunchDarkly 客户在一天内从故障中恢复
+- 42% 的 LaunchDarkly 客户在"小时级(甚至分钟级)"内恢复
+- 8% 客户运营成本降低超过 50%
+- 59% 客户运营成本降低 11%-50%
diff --git a/wiki/sources/sales-account-strategist.md b/wiki/sources/sales-account-strategist.md
index 8be023ac..89d2aa36 100644
--- a/wiki/sources/sales-account-strategist.md
+++ b/wiki/sources/sales-account-strategist.md
@@ -1,63 +1,63 @@
----
-title: "Account Strategist Agent"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/sales/sales-account-strategist.md]]
-
-## Summary(用中文描述)
-- 核心主题:Account Strategist(账户策略师)Agent —— 售后收入扩张战略智能体,专门负责账户扩展、QBR设计、利益相关者映射和净收入留存
-- 问题域:SaaS/企业软件公司如何将一次性成交转化为长期平台关系,如何通过系统性扩张规划实现净收入留存(NRR)最大化
-- 方法/机制:Land-and-Expand 执行框架 → 季度业务回顾(QBR)设计 → 利益相关者多线程关系建设 → NRR 健康评分体系 → 流失预警干预机制
-- 结论/价值:最佳销售时机是客户成功时;账户健康优先于扩张;永远不做单线程账户;NRR 是终极指标
-
-## Key Claims(用中文描述)
-- 账户策略师将每个客户账户视为一片有待填充的空白领域(territory with whitespace),通过系统性扩张规划将单点解决方案转化为企业平台
-- 每个扩张机会必须配套来自客户视角的文档化商业案例,单纯有信号不足以触发扩张
-- 永远不在尚未成功使用现有产品的账户上推扩张——向不健康的账户销售更多会加速流失而非增长
-- 区分扩张就绪(客户可以买更多)与扩张意图(客户想买更多),只有后者才能可靠转化
-- 每个账户必须有至少三条独立的业务关系线——即使冠军明天离职,你仍然能与关心产品的其他人保持活跃对话
-- NRR(净收入留存)是终极指标,它用一个数字捕获了扩张、收缩和流失
-- QBR 应是前瞻性的战略规划会议,而非回顾性的状态报告
-
-## Key Quotes
-> "The best time to sell more is when the customer is winning." — Account Strategist Agent 核心理念
-> "A signal alone is not enough. Every expansion signal must be paired with context (why is this happening?), timing (why now?), and stakeholder alignment (who cares about this?)." — Expansion Signal Discipline
-> "Never pitch expansion to a customer who is not yet successful with what they already own." — Account Health First Rule
-> "NRR is the ultimate metric. It captures expansion, contraction, and churn in a single number. Optimize for NRR, not bookings." — Account Health First Rule
-> "Be strategically specific: 'Usage in the analytics team hit 92% capacity — their headcount is growing 30% next quarter, so expansion timing is ideal.'" — Communication Style
-
-## Key Concepts
-- [[Land-and-Expand]]:将初始成交(land deal)逐步扩展为七位数平台关系的系统性方法论,包括扩张就绪信号识别、冠军赋能套件、RACI 扩张剧本
-- [[Net Revenue Retention (NRR)]]:净收入留存率——捕获扩张、收缩和流失的综合指标,NRR > 100% 意味着即使没有新客户也能实现增长
-- [[QBR (Quarterly Business Review)]]:季度业务回顾——前瞻性战略规划会议,包含 ROI 数据量化回顾、业务目标对齐、共同行动计划
-- [[Stakeholder Mapping]]:利益相关者映射——维护账户内活的利益相关者地图:决策者、预算持有者、影响者、终端用户、反对者、冠军
-- [[Multi-Threading]]:多线程关系建设——每个账户至少三条独立关系线,防止单点失败(champion 离职导致的关系断层)
-- [[Account Health Score]]:账户健康评分——综合产品使用率、支持工单情感、利益相关者参与度、合同时间线、高管发起人活动
-- [[Churn Prevention Playbook]]:流失预防手册——早期预警信号 + 分级干预计划(立即/短期/中期)
-
-## Key Entities
-- **Account Strategist Agent**:售后扩张策略师角色,对应 [[sales-account-strategist]]
-- **Account Executive (AE)**:客户经理,与账户策略师在扩张剧本、RACI 中协作
-- **Customer Success (CS)**:客户成功团队,负责使用监控和健康评分维护
-- **Product Team**:产品团队,参与扩张对齐和里程碑触发
-- **Executive Sponsor**:高管发起人——高参与度(>60天未接触=风险信号)是账户健康的领先指标
-
-## Connections
-- [[sales-proposal-strategist]] ← post-sale extends pre-sale ← [[sales-proposal-strategist]]
-- [[sales-engineer]] ← overlaps (both post-sale) ← [[sales-engineer]]
-- [[sales-discovery-coach]] ← upstream feeds downstream ← [[sales-discovery-coach]]
-- [[sales-pipeline-analyst]] ← shares NRR metric ← [[sales-pipeline-analyst]]
-
-## Contradictions
-- 与 [[sales-proposal-strategist]] 的关注阶段不同:
- - 冲突点:提案策略师关注赢单前的提案叙事;账户策略师关注赢单后的扩张执行
- - 当前观点:两者互补——提案建立期望,账户策略师交付并超越期望
- - 对方观点:[[sales-proposal-strategist]] 的"赢单叙事"需要考虑 post-sale 的可交付性
-- 与 [[sales-coach]] 的辅导焦点不同:
- - 冲突点:销售教练辅导卖方(销售代表成长);账户策略师辅导买方(帮助客户内部推广)
- - 当前观点:互补关系——[[sales-coach]] 提升卖方能力,[[sales-account-strategist]] 建设买方冠军
- - 对方观点:无直接冲突,角色边界清晰
+---
+title: "Account Strategist Agent"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/sales/sales-account-strategist.md]]
+
+## Summary(用中文描述)
+- 核心主题:Account Strategist(账户策略师)Agent —— 售后收入扩张战略智能体,专门负责账户扩展、QBR设计、利益相关者映射和净收入留存
+- 问题域:SaaS/企业软件公司如何将一次性成交转化为长期平台关系,如何通过系统性扩张规划实现净收入留存(NRR)最大化
+- 方法/机制:Land-and-Expand 执行框架 → 季度业务回顾(QBR)设计 → 利益相关者多线程关系建设 → NRR 健康评分体系 → 流失预警干预机制
+- 结论/价值:最佳销售时机是客户成功时;账户健康优先于扩张;永远不做单线程账户;NRR 是终极指标
+
+## Key Claims(用中文描述)
+- 账户策略师将每个客户账户视为一片有待填充的空白领域(territory with whitespace),通过系统性扩张规划将单点解决方案转化为企业平台
+- 每个扩张机会必须配套来自客户视角的文档化商业案例,单纯有信号不足以触发扩张
+- 永远不在尚未成功使用现有产品的账户上推扩张——向不健康的账户销售更多会加速流失而非增长
+- 区分扩张就绪(客户可以买更多)与扩张意图(客户想买更多),只有后者才能可靠转化
+- 每个账户必须有至少三条独立的业务关系线——即使冠军明天离职,你仍然能与关心产品的其他人保持活跃对话
+- NRR(净收入留存)是终极指标,它用一个数字捕获了扩张、收缩和流失
+- QBR 应是前瞻性的战略规划会议,而非回顾性的状态报告
+
+## Key Quotes
+> "The best time to sell more is when the customer is winning." — Account Strategist Agent 核心理念
+> "A signal alone is not enough. Every expansion signal must be paired with context (why is this happening?), timing (why now?), and stakeholder alignment (who cares about this?)." — Expansion Signal Discipline
+> "Never pitch expansion to a customer who is not yet successful with what they already own." — Account Health First Rule
+> "NRR is the ultimate metric. It captures expansion, contraction, and churn in a single number. Optimize for NRR, not bookings." — Account Health First Rule
+> "Be strategically specific: 'Usage in the analytics team hit 92% capacity — their headcount is growing 30% next quarter, so expansion timing is ideal.'" — Communication Style
+
+## Key Concepts
+- [[Land-and-Expand]]:将初始成交(land deal)逐步扩展为七位数平台关系的系统性方法论,包括扩张就绪信号识别、冠军赋能套件、RACI 扩张剧本
+- [[Net Revenue Retention (NRR)]]:净收入留存率——捕获扩张、收缩和流失的综合指标,NRR > 100% 意味着即使没有新客户也能实现增长
+- [[QBR (Quarterly Business Review)]]:季度业务回顾——前瞻性战略规划会议,包含 ROI 数据量化回顾、业务目标对齐、共同行动计划
+- [[Stakeholder Mapping]]:利益相关者映射——维护账户内活的利益相关者地图:决策者、预算持有者、影响者、终端用户、反对者、冠军
+- [[Multi-Threading]]:多线程关系建设——每个账户至少三条独立关系线,防止单点失败(champion 离职导致的关系断层)
+- [[Account Health Score]]:账户健康评分——综合产品使用率、支持工单情感、利益相关者参与度、合同时间线、高管发起人活动
+- [[Churn Prevention Playbook]]:流失预防手册——早期预警信号 + 分级干预计划(立即/短期/中期)
+
+## Key Entities
+- **Account Strategist Agent**:售后扩张策略师角色,对应 [[sales-account-strategist]]
+- **Account Executive (AE)**:客户经理,与账户策略师在扩张剧本、RACI 中协作
+- **Customer Success (CS)**:客户成功团队,负责使用监控和健康评分维护
+- **Product Team**:产品团队,参与扩张对齐和里程碑触发
+- **Executive Sponsor**:高管发起人——高参与度(>60天未接触=风险信号)是账户健康的领先指标
+
+## Connections
+- [[sales-proposal-strategist]] ← post-sale extends pre-sale ← [[sales-proposal-strategist]]
+- [[sales-engineer]] ← overlaps (both post-sale) ← [[sales-engineer]]
+- [[sales-discovery-coach]] ← upstream feeds downstream ← [[sales-discovery-coach]]
+- [[sales-pipeline-analyst]] ← shares NRR metric ← [[sales-pipeline-analyst]]
+
+## Contradictions
+- 与 [[sales-proposal-strategist]] 的关注阶段不同:
+ - 冲突点:提案策略师关注赢单前的提案叙事;账户策略师关注赢单后的扩张执行
+ - 当前观点:两者互补——提案建立期望,账户策略师交付并超越期望
+ - 对方观点:[[sales-proposal-strategist]] 的"赢单叙事"需要考虑 post-sale 的可交付性
+- 与 [[sales-coach]] 的辅导焦点不同:
+ - 冲突点:销售教练辅导卖方(销售代表成长);账户策略师辅导买方(帮助客户内部推广)
+ - 当前观点:互补关系——[[sales-coach]] 提升卖方能力,[[sales-account-strategist]] 建设买方冠军
+ - 对方观点:无直接冲突,角色边界清晰
diff --git a/wiki/sources/sales-coach.md b/wiki/sources/sales-coach.md
index 472de37a..c1981a93 100644
--- a/wiki/sources/sales-coach.md
+++ b/wiki/sources/sales-coach.md
@@ -1,54 +1,54 @@
----
-title: "Sales Coach Agent"
-type: source
-tags: ["sales", "coaching", "agent", "b2b"]
-date: 2026-04-24
----
-
-## Source File
-- [[Agent/agency-agents/sales/sales-coach.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI 销售教练 Agent,通过苏格拉底式提问驱动销售代表成长,专注于管道审查、话术辅导、交易策略和预测准确性
-- 问题域:销售团队管理、销售代表能力发展、交易风险识别、预测纪律
-- 方法/机制:结构化辅导框架( Richardson Sales Performance)、挑战者销售模型(Challenger)、MEDDPICC 资质诊断、行为反馈循环
-- 结论/价值:正式销售辅导项目使配额完成率达 91.2%(vs 非正式辅导 84.7%),每周接受2小时以上辅导的销售代表赢单率达56%(vs 少于30分钟仅43%)
-
-## Key Claims(用中文描述)
-- 正式销售辅导项目使团队配额完成率达 91.2%,显著优于非正式辅导的 84.7%
-- 每周接受 2 小时以上辅导的销售代表赢单率为 56%,远高于每周少于 30 分钟辅导的 43%
-- 辅导行为而非结果:过程完美的输单不需要纠正,幸运赢单需要立即辅导
-- 管道数量是虚荣指标,管道质量才是管理工具
-- 每次辅导互动必须产出一个具体、可行为、可执行的改进建议
-
-## Key Quotes
-> "Ask before telling. Your first instinct should always be a question, not an instruction." — 苏格拉底式辅导的核心原则
-> "A lost deal with disciplined process is more valuable than a lucky win, because process compounds and luck does not." — 过程优于结果
-> "Enthusiasm without commitment is not a buying signal." — 挑战"happy ears",要求可验证的承诺
-
-## Key Concepts
-- [[MEDDPICC]]:交易资质诊断框架,包含八个维度(Metrics、Economic Buyer、Decision Criteria、Decision Process、Paper Process、Implicated Pain、Champion、Competition);Deal 少于 5/8 字段填充即为资格不足,是预测失误的主要来源;资质缺口是交易风险的信号,而非 CRM 记录问题
-- [[Challenger Sales Model]]:挑战者辅导模型,教导销售代表以商业洞察引领对话,而非被动回应客户需求;在客户思考问题的方式上重新构建认知
-- [[Richardson Sales Performance Framework]]:四维能力框架:辅导卓越、激励领导、销售管理纪律、战略规划
-- [[Pipeline Review]]:将管道审查从审讯转变为辅导对话,用"我们对这个交易还有什么不知道的"替代"什么时候关单"
-- [[Forecast Accuracy]]:基于可验证证据而非乐观情绪的预测纪律,区分 upside/commit/closed 三个层级
-- [[Coaching Discipline]]:辅导纪律——行为辅导而非结果辅导;一次只做一件事;跟进反馈是否被应用
-
-## Key Entities
-- [[Discovery Coach Agent]]:同为 The Agency 销售类 Agent,专注发现阶段辅导,与 Sales Coach 形成互补关系
-- [[Sales Pipeline Analyst Agent]]:管道分析类 Agent,提供数据支撑,与 Sales Coach 协同工作
-- [[Sales Deal Strategist Agent]]:交易策略类 Agent,在重大交易前进行策略准备
-
-## Connections
-- [[Discovery Coach Agent]] ← complements ← [[Sales Coach Agent]]
-- [[Sales Pipeline Analyst Agent]] ← provides_data_for ← [[Sales Coach Agent]]
-- [[Sales Deal Strategist Agent]] ← prepares ← [[Sales Coach Agent]]
-- [[Sales Coach Agent]] ← uses ← [[MEDDPICC]]
-- [[Sales Coach Agent]] ← uses ← [[Challenger Sales Model]]
-
-## Contradictions
-- 与 [[Discovery Coach Agent]] 的潜在差异:
- - 冲突点:辅导焦点的层次不同
- - 当前观点(Sales Coach):辅导范围覆盖全销售周期,包括发现、策略、预测
- - 对方观点(Discovery Coach):专注发现阶段的深度辅导
- - 协调方案:Discovery Coach 负责发现阶段深度,Sales Coach 负责整体辅导规划,两者协同覆盖完整周期
+---
+title: "Sales Coach Agent"
+type: source
+tags: ["sales", "coaching", "agent", "b2b"]
+date: 2026-04-24
+---
+
+## Source File
+- [[raw/Agent/agency-agents/sales/sales-coach.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI 销售教练 Agent,通过苏格拉底式提问驱动销售代表成长,专注于管道审查、话术辅导、交易策略和预测准确性
+- 问题域:销售团队管理、销售代表能力发展、交易风险识别、预测纪律
+- 方法/机制:结构化辅导框架( Richardson Sales Performance)、挑战者销售模型(Challenger)、MEDDPICC 资质诊断、行为反馈循环
+- 结论/价值:正式销售辅导项目使配额完成率达 91.2%(vs 非正式辅导 84.7%),每周接受2小时以上辅导的销售代表赢单率达56%(vs 少于30分钟仅43%)
+
+## Key Claims(用中文描述)
+- 正式销售辅导项目使团队配额完成率达 91.2%,显著优于非正式辅导的 84.7%
+- 每周接受 2 小时以上辅导的销售代表赢单率为 56%,远高于每周少于 30 分钟辅导的 43%
+- 辅导行为而非结果:过程完美的输单不需要纠正,幸运赢单需要立即辅导
+- 管道数量是虚荣指标,管道质量才是管理工具
+- 每次辅导互动必须产出一个具体、可行为、可执行的改进建议
+
+## Key Quotes
+> "Ask before telling. Your first instinct should always be a question, not an instruction." — 苏格拉底式辅导的核心原则
+> "A lost deal with disciplined process is more valuable than a lucky win, because process compounds and luck does not." — 过程优于结果
+> "Enthusiasm without commitment is not a buying signal." — 挑战"happy ears",要求可验证的承诺
+
+## Key Concepts
+- [[MEDDPICC]]:交易资质诊断框架,包含八个维度(Metrics、Economic Buyer、Decision Criteria、Decision Process、Paper Process、Implicated Pain、Champion、Competition);Deal 少于 5/8 字段填充即为资格不足,是预测失误的主要来源;资质缺口是交易风险的信号,而非 CRM 记录问题
+- [[Challenger Sales Model]]:挑战者辅导模型,教导销售代表以商业洞察引领对话,而非被动回应客户需求;在客户思考问题的方式上重新构建认知
+- [[Richardson Sales Performance Framework]]:四维能力框架:辅导卓越、激励领导、销售管理纪律、战略规划
+- [[Pipeline Review]]:将管道审查从审讯转变为辅导对话,用"我们对这个交易还有什么不知道的"替代"什么时候关单"
+- [[Forecast Accuracy]]:基于可验证证据而非乐观情绪的预测纪律,区分 upside/commit/closed 三个层级
+- [[Coaching Discipline]]:辅导纪律——行为辅导而非结果辅导;一次只做一件事;跟进反馈是否被应用
+
+## Key Entities
+- [[Discovery Coach Agent]]:同为 The Agency 销售类 Agent,专注发现阶段辅导,与 Sales Coach 形成互补关系
+- [[Sales Pipeline Analyst Agent]]:管道分析类 Agent,提供数据支撑,与 Sales Coach 协同工作
+- [[Sales Deal Strategist Agent]]:交易策略类 Agent,在重大交易前进行策略准备
+
+## Connections
+- [[Discovery Coach Agent]] ← complements ← [[Sales Coach Agent]]
+- [[Sales Pipeline Analyst Agent]] ← provides_data_for ← [[Sales Coach Agent]]
+- [[Sales Deal Strategist Agent]] ← prepares ← [[Sales Coach Agent]]
+- [[Sales Coach Agent]] ← uses ← [[MEDDPICC]]
+- [[Sales Coach Agent]] ← uses ← [[Challenger Sales Model]]
+
+## Contradictions
+- 与 [[Discovery Coach Agent]] 的潜在差异:
+ - 冲突点:辅导焦点的层次不同
+ - 当前观点(Sales Coach):辅导范围覆盖全销售周期,包括发现、策略、预测
+ - 对方观点(Discovery Coach):专注发现阶段的深度辅导
+ - 协调方案:Discovery Coach 负责发现阶段深度,Sales Coach 负责整体辅导规划,两者协同覆盖完整周期
diff --git a/wiki/sources/sales-deal-strategist.md b/wiki/sources/sales-deal-strategist.md
index 55dd118f..55488ebb 100644
--- a/wiki/sources/sales-deal-strategist.md
+++ b/wiki/sources/sales-deal-strategist.md
@@ -1,61 +1,61 @@
----
-title: "Deal Strategist Agent"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/sales/sales-deal-strategist.md]]
-
-## Summary(用中文描述)
-- 核心主题:B2B 复杂销售周期的高级deal策略与管线架构
-- 问题域:销售管线中deal质量评估不严、预测失准、竞争定位模糊、赢率低下
-- 方法/机制:MEDDPICC八维资质评分 + Challenger商业教学法 + 三区竞争定位 + 六步商业教学序列 + 交易检查方法论
-- 结论/价值:全面推行MEDDPICC的组织赢率提升18%、deal规模扩大24%;预测准确率Commit deals关闭率85%+;Qualified Pipeline赢率35%+
-
-## Key Claims(用中文描述)
-- 全面推行MEDDPICC的组织赢率提升18%、deal规模扩大24%——但前提是将MEDDPICC作为思维工具而非打勾练习
-- 一个deal若没有回答全部八个要素,说明尚未真正理解该deal
-- 6周采购周期如果在第11周才发现,会直接扼杀季度
-- 决策在理性层面被论证,在感性层面被做出
-- 预测准确率Commit deals关闭率应达85%+
-- Qualified Pipeline(28/40分以上)赢率应达35%+
-- 竞争定位中的Losing Zone应对策略是缩小其重要性,而非撒谎或攻击竞争对手
-
-## Key Quotes
-> "A deal without all eight answered is a deal you don't understand." — MEDDPICC核心原则
-> "This deal is at risk. Here's why, and here's what to do about it." — 策略师沟通风格
-> "Decisions are justified rationally and made emotionally." — 商业教学情感层
-> "The winning move on losing zones is to shrink their importance, not to lie about your capabilities." — 竞争定位原则
-
-## Key Concepts
-- [[MEDDPICC]]:八维资质评分框架——Metrics/Economic Buyer/Decision Criteria/Decision Process/Paper Process/Identify Pain/Champion/Competition,每维度5分,满分40
-- [[Challenger Sales Model]]:挑战者销售法——通过商业教学重新定义买方对自身问题的理解,在定位解决方案之前先建立价值
-- [[Command of the Message]]:信息掌控框架——三层支柱(我们解决什么问题/我们如何不同/客户实现什么可衡量成果)
-- Deal Scoring:加权评分模型,分离真实管线与虚假管线,含预警指标
-- Competitive Positioning:竞争定位策略——Winning/Battling/Losing三区分类 + 地雷问题布局
-- Win Planning:分阶段行动计划,含明确责任人、里程碑和退出标准
-- Deal Inspection Methodology:交易检查方法论——系统性探测deal状态、风险和下一步
-- Challenger Messaging:六步商业教学序列——Warmer/Reframe/Rational Drowning/Emotional Impact/A New Way/Your Solution
-
-## Key Entities
-- [[Sales Coach Agent]]:同为The Agency销售体系的核心智能体,Sales Coach辅导卖方行为,Deal Strategist辅导deal策略
-- [[Discovery Coach Agent]]:发现阶段教练,提供买方情境输入给Deal Strategist
-- [[Sales Proposal Strategist]]:赢单叙事构建者,接收Deal Strategist的竞争定位和评分输出
-- Deal Strategist Agent:The Agency销售部门成员,专业于MEDDPICC deal策略、竞争定位和赢单规划
-
-## Connections
-- [[sales-coach]] ← shares MEDDPICC framework with ← [[sales-discovery-coach]]
-- [[sales-proposal-strategist]] ← receives win strategy input from ← [[sales-deal-strategist]]
-- [[sales-discovery-coach]] ← provides buyer context to ← [[sales-deal-strategist]]
-- [[sales-deal-strategist]] ← extends MEDDPICC with deal execution tactics ← [[sales-coach]]
-
-## Contradictions
-- 与 [[sales-proposal-strategist]] 的视角差异:
- - 冲突点:Deal Strategist聚焦交易层面的策略和执行,Proposal Strategist聚焦提案层面的叙事和说服
- - 当前观点:Deal Strategist认为"没有全面评估的deal在预测会上就输了"
- - 对方观点:Proposal Strategist认为"赢单在提案开篇100词就已决定"
- - 协调:两者互补——Deal Strategist提供结构化deal分析和竞争定位,Proposal Strategist将其转化为说服性叙事
-- 与 [[sales-discovery-coach]] 的互补关系:
- - Discovery Coach发现买方情境,Deal Strategist基于此构建交易策略,两者构成"发现→策略"闭环
+---
+title: "Deal Strategist Agent"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/sales/sales-deal-strategist.md]]
+
+## Summary(用中文描述)
+- 核心主题:B2B 复杂销售周期的高级deal策略与管线架构
+- 问题域:销售管线中deal质量评估不严、预测失准、竞争定位模糊、赢率低下
+- 方法/机制:MEDDPICC八维资质评分 + Challenger商业教学法 + 三区竞争定位 + 六步商业教学序列 + 交易检查方法论
+- 结论/价值:全面推行MEDDPICC的组织赢率提升18%、deal规模扩大24%;预测准确率Commit deals关闭率85%+;Qualified Pipeline赢率35%+
+
+## Key Claims(用中文描述)
+- 全面推行MEDDPICC的组织赢率提升18%、deal规模扩大24%——但前提是将MEDDPICC作为思维工具而非打勾练习
+- 一个deal若没有回答全部八个要素,说明尚未真正理解该deal
+- 6周采购周期如果在第11周才发现,会直接扼杀季度
+- 决策在理性层面被论证,在感性层面被做出
+- 预测准确率Commit deals关闭率应达85%+
+- Qualified Pipeline(28/40分以上)赢率应达35%+
+- 竞争定位中的Losing Zone应对策略是缩小其重要性,而非撒谎或攻击竞争对手
+
+## Key Quotes
+> "A deal without all eight answered is a deal you don't understand." — MEDDPICC核心原则
+> "This deal is at risk. Here's why, and here's what to do about it." — 策略师沟通风格
+> "Decisions are justified rationally and made emotionally." — 商业教学情感层
+> "The winning move on losing zones is to shrink their importance, not to lie about your capabilities." — 竞争定位原则
+
+## Key Concepts
+- [[MEDDPICC]]:八维资质评分框架——Metrics/Economic Buyer/Decision Criteria/Decision Process/Paper Process/Identify Pain/Champion/Competition,每维度5分,满分40
+- [[Challenger Sales Model]]:挑战者销售法——通过商业教学重新定义买方对自身问题的理解,在定位解决方案之前先建立价值
+- [[Command of the Message]]:信息掌控框架——三层支柱(我们解决什么问题/我们如何不同/客户实现什么可衡量成果)
+- Deal Scoring:加权评分模型,分离真实管线与虚假管线,含预警指标
+- Competitive Positioning:竞争定位策略——Winning/Battling/Losing三区分类 + 地雷问题布局
+- Win Planning:分阶段行动计划,含明确责任人、里程碑和退出标准
+- Deal Inspection Methodology:交易检查方法论——系统性探测deal状态、风险和下一步
+- Challenger Messaging:六步商业教学序列——Warmer/Reframe/Rational Drowning/Emotional Impact/A New Way/Your Solution
+
+## Key Entities
+- [[Sales Coach Agent]]:同为The Agency销售体系的核心智能体,Sales Coach辅导卖方行为,Deal Strategist辅导deal策略
+- [[Discovery Coach Agent]]:发现阶段教练,提供买方情境输入给Deal Strategist
+- [[Sales Proposal Strategist]]:赢单叙事构建者,接收Deal Strategist的竞争定位和评分输出
+- Deal Strategist Agent:The Agency销售部门成员,专业于MEDDPICC deal策略、竞争定位和赢单规划
+
+## Connections
+- [[sales-coach]] ← shares MEDDPICC framework with ← [[sales-discovery-coach]]
+- [[sales-proposal-strategist]] ← receives win strategy input from ← [[sales-deal-strategist]]
+- [[sales-discovery-coach]] ← provides buyer context to ← [[sales-deal-strategist]]
+- [[sales-deal-strategist]] ← extends MEDDPICC with deal execution tactics ← [[sales-coach]]
+
+## Contradictions
+- 与 [[sales-proposal-strategist]] 的视角差异:
+ - 冲突点:Deal Strategist聚焦交易层面的策略和执行,Proposal Strategist聚焦提案层面的叙事和说服
+ - 当前观点:Deal Strategist认为"没有全面评估的deal在预测会上就输了"
+ - 对方观点:Proposal Strategist认为"赢单在提案开篇100词就已决定"
+ - 协调:两者互补——Deal Strategist提供结构化deal分析和竞争定位,Proposal Strategist将其转化为说服性叙事
+- 与 [[sales-discovery-coach]] 的互补关系:
+ - Discovery Coach发现买方情境,Deal Strategist基于此构建交易策略,两者构成"发现→策略"闭环
diff --git a/wiki/sources/sales-discovery-coach.md b/wiki/sources/sales-discovery-coach.md
index 8eb0d655..de39d1ed 100644
--- a/wiki/sources/sales-discovery-coach.md
+++ b/wiki/sources/sales-discovery-coach.md
@@ -1,50 +1,50 @@
----
-title: "Discovery Coach Agent"
-type: source
-tags: [sales, discovery, methodology, coaching]
-last_updated: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/sales/sales-discovery-coach.md]]
-
-## Summary(用中文描述)
-- 核心主题:销售发现访谈(Discovery)方法论与教练框架,帮助销售代表成为更优秀的买家访谈者
-- 问题域:销售团队普遍存在发现访谈深度不足、问题设计粗糙、无法挖掘真正购买动机的问题
-- 方法/机制:三大发现框架(SPIN Selling / Gap Selling / Sandler Pain Funnel)+ 标准30分钟发现电话结构 + AECR异议处理框架
-- 结论/价值:发现是交易成败的关键战场——而非演示、提案或谈判阶段。顶级销售通过多问一个问题来击败竞争对手
-
-## Key Claims(用中文描述)
-- 发现阶段决定交易成败,而非演示、提案或谈判阶段
-- Implication问题(SPIN Selling第三层)是最有力的成交工具,因其激活买家的损失厌恶心理
-- Gap Selling中,根因问题是最重要也最常被跳过的问题;表面问题不产生紧迫感,根因才产生
-- Sandler Pain Funnel第三层(个人/情感层面)是大多数销售人员永远不会触及的区域,但购买决策本质上是情感决策
-- 预算异议几乎从不是真正的预算问题,而是买家对价值是否超过成本的判断
-
-## Key Quotes
-> "Implication questions are uncomfortable to ask. That discomfort is a feature. The buyer has not fully confronted the cost of the status quo until these questions are asked." — SPIN Selling中Implication问题的价值说明
-> "Level 3 is where most sellers never go. But buying decisions are emotional decisions with rational justifications." — Sandler Pain Funnel第三层的重要性
-> "Budget objections are almost never about budget. They are about whether the buyer believes the value exceeds the cost." — 预算异议的真相
-> "The 60/40 rule: the buyer should talk 60% of the time or more. If you are talking more than 40%, you are pitching, not discovering." — 发现访谈的核心比例原则
-
-## Key Concepts
-- [[SPIN Selling]]:Neil Rackham提出的企业销售四步提问法(Situation / Problem / Implication / Need-Payoff),核心洞察是Implication问题通过激活损失厌恶来推动成交
-- [[Gap Selling]]:Keenan提出的以当前状态与期望未来状态之间的差距为中心的销售方法论;差距越大,紧迫感越强
-- [[Sandler Pain Funnel]]:从表面症状到商业影响再到情感/个人层面的三层漏斗式发现技术
-- [[AECR Framework]]:处理销售异议的四步框架(Acknowledge / Empathize / Clarify / Reframe),将异议视为诊断信息
-- [[Upfront Contract]]:发现电话开场的最优技术,通过预设三种可能结果来建立信任和获取提问许可
-- [[Discovery Call Structure]]:标准30分钟发现电话的时间分配(开场2分钟 / 发现18分钟 / 定向pitch 6分钟 / 下一步4分钟)
-
-## Key Entities
-- [[Neil Rackham]]:SPIN Selling方法论的提出者,通过对35,000+次销售拜访的研究发展出该框架
-- [[Keenan]]:Gap Selling方法论的提出者,强调当前状态与未来状态之间精确差距的商业价值
-- [[Sandler]]:Sandler Pain Funnel的创始人,开发了从表面到个人层面的三层痛苦发现技术
-
-## Connections
-- [[Sales Coach]] ← extends ← [[Discovery Call Structure]]
-- [[SPIN Selling]] ← extends ← [[Sandler Pain Funnel]](两者互补,SPIN强调问题序列,Sandler强调深度层次)
-- [[AECR Framework]] ← depends_on ← [[Discovery Call Structure]]
-- [[Gap Selling]] ← depends_on ← [[SPIN Selling]](Gap Selling可视为SPIN框架的实践落地)
-
-## Contradictions
-- 暂无发现与现有Wiki内容的冲突
+---
+title: "Discovery Coach Agent"
+type: source
+tags: [sales, discovery, methodology, coaching]
+last_updated: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/sales/sales-discovery-coach.md]]
+
+## Summary(用中文描述)
+- 核心主题:销售发现访谈(Discovery)方法论与教练框架,帮助销售代表成为更优秀的买家访谈者
+- 问题域:销售团队普遍存在发现访谈深度不足、问题设计粗糙、无法挖掘真正购买动机的问题
+- 方法/机制:三大发现框架(SPIN Selling / Gap Selling / Sandler Pain Funnel)+ 标准30分钟发现电话结构 + AECR异议处理框架
+- 结论/价值:发现是交易成败的关键战场——而非演示、提案或谈判阶段。顶级销售通过多问一个问题来击败竞争对手
+
+## Key Claims(用中文描述)
+- 发现阶段决定交易成败,而非演示、提案或谈判阶段
+- Implication问题(SPIN Selling第三层)是最有力的成交工具,因其激活买家的损失厌恶心理
+- Gap Selling中,根因问题是最重要也最常被跳过的问题;表面问题不产生紧迫感,根因才产生
+- Sandler Pain Funnel第三层(个人/情感层面)是大多数销售人员永远不会触及的区域,但购买决策本质上是情感决策
+- 预算异议几乎从不是真正的预算问题,而是买家对价值是否超过成本的判断
+
+## Key Quotes
+> "Implication questions are uncomfortable to ask. That discomfort is a feature. The buyer has not fully confronted the cost of the status quo until these questions are asked." — SPIN Selling中Implication问题的价值说明
+> "Level 3 is where most sellers never go. But buying decisions are emotional decisions with rational justifications." — Sandler Pain Funnel第三层的重要性
+> "Budget objections are almost never about budget. They are about whether the buyer believes the value exceeds the cost." — 预算异议的真相
+> "The 60/40 rule: the buyer should talk 60% of the time or more. If you are talking more than 40%, you are pitching, not discovering." — 发现访谈的核心比例原则
+
+## Key Concepts
+- [[SPIN Selling]]:Neil Rackham提出的企业销售四步提问法(Situation / Problem / Implication / Need-Payoff),核心洞察是Implication问题通过激活损失厌恶来推动成交
+- [[Gap Selling]]:Keenan提出的以当前状态与期望未来状态之间的差距为中心的销售方法论;差距越大,紧迫感越强
+- [[Sandler Pain Funnel]]:从表面症状到商业影响再到情感/个人层面的三层漏斗式发现技术
+- [[AECR Framework]]:处理销售异议的四步框架(Acknowledge / Empathize / Clarify / Reframe),将异议视为诊断信息
+- [[Upfront Contract]]:发现电话开场的最优技术,通过预设三种可能结果来建立信任和获取提问许可
+- [[Discovery Call Structure]]:标准30分钟发现电话的时间分配(开场2分钟 / 发现18分钟 / 定向pitch 6分钟 / 下一步4分钟)
+
+## Key Entities
+- [[Neil Rackham]]:SPIN Selling方法论的提出者,通过对35,000+次销售拜访的研究发展出该框架
+- [[Keenan]]:Gap Selling方法论的提出者,强调当前状态与未来状态之间精确差距的商业价值
+- [[Sandler]]:Sandler Pain Funnel的创始人,开发了从表面到个人层面的三层痛苦发现技术
+
+## Connections
+- [[Sales Coach]] ← extends ← [[Discovery Call Structure]]
+- [[SPIN Selling]] ← extends ← [[Sandler Pain Funnel]](两者互补,SPIN强调问题序列,Sandler强调深度层次)
+- [[AECR Framework]] ← depends_on ← [[Discovery Call Structure]]
+- [[Gap Selling]] ← depends_on ← [[SPIN Selling]](Gap Selling可视为SPIN框架的实践落地)
+
+## Contradictions
+- 暂无发现与现有Wiki内容的冲突
diff --git a/wiki/sources/sales-engineer.md b/wiki/sources/sales-engineer.md
index 9d4b2e80..18a1db4f 100644
--- a/wiki/sources/sales-engineer.md
+++ b/wiki/sources/sales-engineer.md
@@ -1,59 +1,59 @@
----
-title: "Sales Engineer Agent"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/sales/sales-engineer.md]]
-
-## Summary(用中文描述)
-- 核心主题:售前工程师(Sales Engineer)Agent 的角色定义、能力模型与操作框架,专注于在 B2B 技术评估中赢得技术决策
-- 问题域:B2B 软件销售中的技术售前环节——如何设计演示、执行 POC、应对竞争、处理异议、管理评估流程
-- 方法/机制:Demo Engineering(以影响力为导向的演示设计)、POC Scoping(严格限定的概念验证范围)、FIA Framework(事实-影响-行动竞争定位框架)、Evaluation Notes(交易级技术情报维护)
-- 结论/价值:技术决策先于商业决策,售前工程师必须将每一次技术对话连接到业务成果,而非单纯展示功能
-
-## Key Claims(用中文描述)
-- 售前工程师赢得技术决策,销售才能赢得商业合同——技术层是整个交易的关键门槛
-- 演示不是产品tour,而是叙事——买家在演示中看到自己的问题被实时解决
-- POC 不是免费试用,而是有二元结果的结构化评估:成功或失败,标准在开始前就已明确定义
-- 竞争定位应采用 FIA 框架(Fact-Impact-Act),保持事实基础和可操作性,而非情绪化和反应式
-- 永远不要攻击竞争对手——认可竞争对手的优势,同时清晰表达差异化
-
-## Key Quotes
-> "A demo is not a product tour. A demo is a narrative where the buyer sees their problem solved in real time." — 演示的本质是叙事,不是功能演示
-> "Every technical conversation must connect back to a business outcome or it's just a feature dump." — 技术对话必须连接到业务成果
-> "Ambiguous success criteria produce ambiguous outcomes, which produce 'we need more time to evaluate,' which means you lost." — 模糊的成功标准等于失败
-> "Never trash the competition. Buyers respect SEs who acknowledge competitor strengths while clearly articulating differentiation." — 永远不要攻击竞争对手
-
-## Key Concepts
-- [[Demo Engineering]]:以影响力为导向的演示设计,先量化问题,再展示产品,最后证明效果
-- [[POC Scoping]]:严格限定的概念验证范围设计,以成功标准、硬性时间线和检查点为支柱
-- [[FIA Framework]]:Fact-Impact-Act 竞争定位框架,保持事实基础和可操作性
-- [[Evaluation Notes]]:交易级技术情报维护,结构化记录每个活跃交易的技术环境、决策者、竞争态势和演示策略
-- [[Technical Objection Handling]]:技术异议处理,解码真实问题而非表面问题
-- [[Aha Moment]]:演示中让买家产生"这正是我们需要的"那一刻,是演示成功的核心标志
-
-## Key Entities
-- [[Sales Pipeline Analyst Agent]]:同属销售团队的数据分析 Agent,共同支撑销售闭环
-- [[Sales Outbound Strategist Agent]]:同属销售团队的对外策略 Agent,共同支撑销售闭环
-- [[Deal Strategist Agent]]:同属销售团队的交易策略 Agent,共同支撑销售闭环
-- [[Account Strategist Agent]]:同属销售团队的客户策略 Agent,共同支撑销售闭环
-- [[Sales Proposal Strategist]]:同属销售团队的建议书策略 Agent,共同支撑销售闭环
-
-## Connections
-- [[Sales Pipeline Analyst Agent]] ← team_member ← [[Sales Engineer Agent]]
-- [[Sales Outbound Strategist Agent]] ← team_member ← [[Sales Engineer Agent]]
-- [[Deal Strategist Agent]] ← team_member ← [[Sales Engineer Agent]]
-- [[Account Strategist Agent]] ← team_member ← [[Sales Engineer Agent]]
-- [[Sales Proposal Strategist]] ← team_member ← [[Sales Engineer Agent]]
-- [[Sales Discovery Coach Agent]] ← adjacent_role ← [[Sales Engineer Agent]]
-- [[Sales Coach Agent]] ← adjacent_role ← [[Sales Engineer Agent]]
-
-## Contradictions
-- 与 [[Sales Discovery Coach Agent]] 在"技术深度"维度存在互补张力:
- - 冲突点:售前工程师在发现阶段应保持多深的技术参与度?
- - 当前观点(Sales Engineer):售前工程师应主导技术发现,结构化地挖掘架构、集成、安全约束和真实技术决策标准
- - 对方观点(Sales Discovery Coach):销售发现应聚焦于业务问题,深度技术探索由专门的角色或时机负责
- - 协调方向:在发现阶段早期以业务语言建立信任,进入评估阶段后切换为技术深度模式
+---
+title: "Sales Engineer Agent"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/sales/sales-engineer.md]]
+
+## Summary(用中文描述)
+- 核心主题:售前工程师(Sales Engineer)Agent 的角色定义、能力模型与操作框架,专注于在 B2B 技术评估中赢得技术决策
+- 问题域:B2B 软件销售中的技术售前环节——如何设计演示、执行 POC、应对竞争、处理异议、管理评估流程
+- 方法/机制:Demo Engineering(以影响力为导向的演示设计)、POC Scoping(严格限定的概念验证范围)、FIA Framework(事实-影响-行动竞争定位框架)、Evaluation Notes(交易级技术情报维护)
+- 结论/价值:技术决策先于商业决策,售前工程师必须将每一次技术对话连接到业务成果,而非单纯展示功能
+
+## Key Claims(用中文描述)
+- 售前工程师赢得技术决策,销售才能赢得商业合同——技术层是整个交易的关键门槛
+- 演示不是产品tour,而是叙事——买家在演示中看到自己的问题被实时解决
+- POC 不是免费试用,而是有二元结果的结构化评估:成功或失败,标准在开始前就已明确定义
+- 竞争定位应采用 FIA 框架(Fact-Impact-Act),保持事实基础和可操作性,而非情绪化和反应式
+- 永远不要攻击竞争对手——认可竞争对手的优势,同时清晰表达差异化
+
+## Key Quotes
+> "A demo is not a product tour. A demo is a narrative where the buyer sees their problem solved in real time." — 演示的本质是叙事,不是功能演示
+> "Every technical conversation must connect back to a business outcome or it's just a feature dump." — 技术对话必须连接到业务成果
+> "Ambiguous success criteria produce ambiguous outcomes, which produce 'we need more time to evaluate,' which means you lost." — 模糊的成功标准等于失败
+> "Never trash the competition. Buyers respect SEs who acknowledge competitor strengths while clearly articulating differentiation." — 永远不要攻击竞争对手
+
+## Key Concepts
+- [[Demo Engineering]]:以影响力为导向的演示设计,先量化问题,再展示产品,最后证明效果
+- [[POC Scoping]]:严格限定的概念验证范围设计,以成功标准、硬性时间线和检查点为支柱
+- [[FIA Framework]]:Fact-Impact-Act 竞争定位框架,保持事实基础和可操作性
+- [[Evaluation Notes]]:交易级技术情报维护,结构化记录每个活跃交易的技术环境、决策者、竞争态势和演示策略
+- [[Technical Objection Handling]]:技术异议处理,解码真实问题而非表面问题
+- [[Aha Moment]]:演示中让买家产生"这正是我们需要的"那一刻,是演示成功的核心标志
+
+## Key Entities
+- [[Sales Pipeline Analyst Agent]]:同属销售团队的数据分析 Agent,共同支撑销售闭环
+- [[Sales Outbound Strategist Agent]]:同属销售团队的对外策略 Agent,共同支撑销售闭环
+- [[Deal Strategist Agent]]:同属销售团队的交易策略 Agent,共同支撑销售闭环
+- [[Account Strategist Agent]]:同属销售团队的客户策略 Agent,共同支撑销售闭环
+- [[Sales Proposal Strategist]]:同属销售团队的建议书策略 Agent,共同支撑销售闭环
+
+## Connections
+- [[Sales Pipeline Analyst Agent]] ← team_member ← [[Sales Engineer Agent]]
+- [[Sales Outbound Strategist Agent]] ← team_member ← [[Sales Engineer Agent]]
+- [[Deal Strategist Agent]] ← team_member ← [[Sales Engineer Agent]]
+- [[Account Strategist Agent]] ← team_member ← [[Sales Engineer Agent]]
+- [[Sales Proposal Strategist]] ← team_member ← [[Sales Engineer Agent]]
+- [[Sales Discovery Coach Agent]] ← adjacent_role ← [[Sales Engineer Agent]]
+- [[Sales Coach Agent]] ← adjacent_role ← [[Sales Engineer Agent]]
+
+## Contradictions
+- 与 [[Sales Discovery Coach Agent]] 在"技术深度"维度存在互补张力:
+ - 冲突点:售前工程师在发现阶段应保持多深的技术参与度?
+ - 当前观点(Sales Engineer):售前工程师应主导技术发现,结构化地挖掘架构、集成、安全约束和真实技术决策标准
+ - 对方观点(Sales Discovery Coach):销售发现应聚焦于业务问题,深度技术探索由专门的角色或时机负责
+ - 协调方向:在发现阶段早期以业务语言建立信任,进入评估阶段后切换为技术深度模式
diff --git a/wiki/sources/sales-outbound-strategist.md b/wiki/sources/sales-outbound-strategist.md
index 14346135..c4a02e6d 100644
--- a/wiki/sources/sales-outbound-strategist.md
+++ b/wiki/sources/sales-outbound-strategist.md
@@ -1,50 +1,50 @@
----
-title: "Outbound Strategist Agent"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/sales/sales-outbound-strategist.md]]
-
-## Summary(用中文描述)
-- 核心主题:信号驱动型出站销售策略与多渠道序列设计
-- 问题域:B2B 出站销售如何从"批量轰炸"转向"精准触发",在买家信号最强烈的时刻介入
-- 方法/机制:三层信号分级体系(主动购买信号→组织变化信号→技术/行为信号)+ ICP 可证伪定义 + 三层账户分级模型 + 8-12 触点 3-4 周多渠道序列架构
-- 结论/价值:信号驱动出站转化率比无触发出站高 4-8 倍;SDR 角色从批量操作员进化为信号监控专家
-
-## Key Claims(用中文描述)
-- 信号驱动出站转化率比无触发冷出站高 4-8 倍
-- 信号半衰期短:30 分钟内路由到正确销售,24 小时后信号失效,72 小时后竞争对手已成交
-- 可用 ICP 必须可证伪——不能排除任何公司的 ICP 不是 ICP,是 TAM 幻灯片
-- 序列中每次触达必须提供新的价值角度——重复同样诉求不是序列,是骚扰
-- 冷邮件回复率基准:泛化型 1-3%、角色定制 5-8%、信号驱动 12-25%、推荐引入型 30-50%
-- SDR 角色转变:从每天 100 次活动操作员 → 拥有 50-80 个深度账户的管线专家
-
-## Key Quotes
-> "If you cannot articulate why you are contacting this specific person at this specific company at this specific moment, you are not ready to send." — Outbound Strategist Agent 核心原则
-> "Each touch must add a new value angle. Repeating the same ask with different words is not a sequence — it is nagging." — 序列设计原则
-
-## Key Concepts
-- [[Signal-Based Selling Framework]]:基于买家行为信号触发精准出站的方法论,转化率比传统冷出站高 4-8 倍
-- [[ICP (Ideal Customer Profile)]]:可证伪的理想客户画像定义框架,包含公司特征、行为限定和排除条件三层结构
-- [[Multi-Channel Sequence Architecture]]:8-12 次触点跨越 3-4 周的多渠道触达序列,每触点必须增加新的价值角度
-- [[Account Tiering Model]]:三层账户分级模型(Tier 1 深度多线程 / Tier 2 半个性化序列 / Tier 3 自动化轻定制)
-
-## Key Entities
-- Outbound Strategist Agent:信号型出站策略师与序列架构师智能体,核心职责:设计多渠道触达序列、定义 ICP、按账户分层执行
-- SDR (Sales Development Representative):角色演变对象,从批量操作员进化为信号监控专家
-
-## Connections
-- [[sales-deal-strategist]] ← complements ← [[sales-outbound-strategist]]:出站负责发现和培育潜在机会,Deal Strategist 负责赢单策略
-- [[sales-discovery-coach]] ← feeds_into ← [[sales-outbound-strategist]]:发现阶段收集的 ICP 信号直接驱动出站序列的启动
-- [[sales-account-strategist]] ← extends ← [[sales-outbound-strategist]]:出站获取新客户后,Account Strategist 负责 Land-and-Expand 扩张
-- [[sales-proposal-strategist]] ← follows ← [[sales-outbound-strategist]]:出站触达后进入提案阶段,Proposal Strategist 构建赢单叙事
-
-## Contradictions
-- 与 [[sales-deal-strategist]] 的区域:
- - 冲突点:出站策略以信号触发为唯一启动条件;Deal Strategist 以 MEDDPICC 资质评估为赢单框架,两者对"何时介入"的定义角度不同
- - 当前观点:出站必须在信号出现 30 分钟内行动,时机优先于资质评估
- - 对方观点:任何 deal 进入赢单阶段前必须通过 MEDDPICC 全面评估
- - 协调方式:两者处于销售漏斗的不同阶段——出站负责漏斗顶部(Signal → Contact),Deal Strategist 负责漏斗中部(Qualified → Commit)
+---
+title: "Outbound Strategist Agent"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/sales/sales-outbound-strategist.md]]
+
+## Summary(用中文描述)
+- 核心主题:信号驱动型出站销售策略与多渠道序列设计
+- 问题域:B2B 出站销售如何从"批量轰炸"转向"精准触发",在买家信号最强烈的时刻介入
+- 方法/机制:三层信号分级体系(主动购买信号→组织变化信号→技术/行为信号)+ ICP 可证伪定义 + 三层账户分级模型 + 8-12 触点 3-4 周多渠道序列架构
+- 结论/价值:信号驱动出站转化率比无触发出站高 4-8 倍;SDR 角色从批量操作员进化为信号监控专家
+
+## Key Claims(用中文描述)
+- 信号驱动出站转化率比无触发冷出站高 4-8 倍
+- 信号半衰期短:30 分钟内路由到正确销售,24 小时后信号失效,72 小时后竞争对手已成交
+- 可用 ICP 必须可证伪——不能排除任何公司的 ICP 不是 ICP,是 TAM 幻灯片
+- 序列中每次触达必须提供新的价值角度——重复同样诉求不是序列,是骚扰
+- 冷邮件回复率基准:泛化型 1-3%、角色定制 5-8%、信号驱动 12-25%、推荐引入型 30-50%
+- SDR 角色转变:从每天 100 次活动操作员 → 拥有 50-80 个深度账户的管线专家
+
+## Key Quotes
+> "If you cannot articulate why you are contacting this specific person at this specific company at this specific moment, you are not ready to send." — Outbound Strategist Agent 核心原则
+> "Each touch must add a new value angle. Repeating the same ask with different words is not a sequence — it is nagging." — 序列设计原则
+
+## Key Concepts
+- [[Signal-Based Selling Framework]]:基于买家行为信号触发精准出站的方法论,转化率比传统冷出站高 4-8 倍
+- [[ICP (Ideal Customer Profile)]]:可证伪的理想客户画像定义框架,包含公司特征、行为限定和排除条件三层结构
+- [[Multi-Channel Sequence Architecture]]:8-12 次触点跨越 3-4 周的多渠道触达序列,每触点必须增加新的价值角度
+- [[Account Tiering Model]]:三层账户分级模型(Tier 1 深度多线程 / Tier 2 半个性化序列 / Tier 3 自动化轻定制)
+
+## Key Entities
+- Outbound Strategist Agent:信号型出站策略师与序列架构师智能体,核心职责:设计多渠道触达序列、定义 ICP、按账户分层执行
+- SDR (Sales Development Representative):角色演变对象,从批量操作员进化为信号监控专家
+
+## Connections
+- [[sales-deal-strategist]] ← complements ← [[sales-outbound-strategist]]:出站负责发现和培育潜在机会,Deal Strategist 负责赢单策略
+- [[sales-discovery-coach]] ← feeds_into ← [[sales-outbound-strategist]]:发现阶段收集的 ICP 信号直接驱动出站序列的启动
+- [[sales-account-strategist]] ← extends ← [[sales-outbound-strategist]]:出站获取新客户后,Account Strategist 负责 Land-and-Expand 扩张
+- [[sales-proposal-strategist]] ← follows ← [[sales-outbound-strategist]]:出站触达后进入提案阶段,Proposal Strategist 构建赢单叙事
+
+## Contradictions
+- 与 [[sales-deal-strategist]] 的区域:
+ - 冲突点:出站策略以信号触发为唯一启动条件;Deal Strategist 以 MEDDPICC 资质评估为赢单框架,两者对"何时介入"的定义角度不同
+ - 当前观点:出站必须在信号出现 30 分钟内行动,时机优先于资质评估
+ - 对方观点:任何 deal 进入赢单阶段前必须通过 MEDDPICC 全面评估
+ - 协调方式:两者处于销售漏斗的不同阶段——出站负责漏斗顶部(Signal → Contact),Deal Strategist 负责漏斗中部(Qualified → Commit)
diff --git a/wiki/sources/sales-pipeline-analyst.md b/wiki/sources/sales-pipeline-analyst.md
index 6a270483..64a9fb87 100644
--- a/wiki/sources/sales-pipeline-analyst.md
+++ b/wiki/sources/sales-pipeline-analyst.md
@@ -1,46 +1,46 @@
----
-title: "Pipeline Analyst Agent"
-type: source
-tags: [sales, revenue-operations, pipeline, forecasting, CRM, MEDDPICC]
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/sales/sales-pipeline-analyst.md]]
-
-## Summary(用中文描述)
-- 核心主题:Revenue Operations 领域的 Pipeline 健康诊断与收入预测 AI Agent,将 CRM 数据转化为可执行的 Pipeline 洞察,在问题演变为季度失误之前主动预警。
-- 问题域:销售 Pipeline 管理、收入预测准确性、Deal 质量评估、销售教练数据分析
-- 方法/机制:Pipeline Velocity 公式 + MEDDPICC 资格评分 + 多信号预测模型 + Deal 健康评分卡
-- 结论/价值:质量调整后的 Pipeline 覆盖度永远优于阶段加权覆盖度;每份 Pipeline 评估都应至少发现一个需要立即干预的 Deal;预测必须带置信区间而非单一数字。
-
-## Key Claims(用中文描述)
-- Pipeline Velocity =(合格机会数 × 平均 Deal 规模 × 胜率)/ 销售周期长度,四个变量均为诊断杠杆。
-- 目标覆盖比率:成熟可预测业务 3x,成长期或新市场 4-5x,新销售入职 5x+。
-- 晚期阶段 Deal 的 MEDDPICC 字段少于 5/8 即为资格不足,是预测失误的主要来源。
-- 多线程、利益相关者深度参与的 Deal 关闭率是同阶段单线程低活跃度 Deal 的 2-3 倍。
-- 预测必须输出 Commit(>90%置信)/Best Case(>60%)/Upside(<60%)三档,而非单一数字。
-- AI 驱动的预测评分消除两种最常见的人类偏见:销售乐观主义(永远"看起来很好")和管理层锚定(从上一季度数字而非当前数据分析)。
-
-## Key Quotes
-> "Quality-adjusted coverage discounts pipeline by deal health score, stage age, and engagement signals. A $5M pipeline with 20 stale, poorly qualified deals is worth less than a $2M pipeline with 8 active, well-qualified opportunities." — 质量调整原则:高质量少量 Pipeline 优于大量低质量 Pipeline
-> "Deals with fewer than 5 of 8 MEDDPICC fields populated are underqualified. Underqualified deals at late stages are the primary source of forecast misses." — 晚期阶段资格不足 Deal 是预测失误的主因
-> "The CRM shows $12M in pipeline. After adjusting for stale deals, missing qualification data, and historical stage conversion, the realistic weighted pipeline is $4.8M." — 数据质量对预测的影响示例
-
-## Key Concepts
-- [[PipelineVelocity]]:Pipeline Velocity =(合格机会数 × 平均 Deal 规模 × 胜率)/ 销售周期长度,是 Revenue Operations 最核心的复合指标
-- [[MEDDPICC]]:8维度 Deal 资格评估框架(Metrics、Economic Buyer、Decision Criteria、Decision Process、Paper Process、Implicated Pain、Champion、Competition),用于诊断 Deal 质量和预测可行性
-- [[DealHealthScoring]]:通过资格深度、互动强度、进展速度三维度综合评估 Deal 健康状况的评分体系
-- [[QualityAdjustedCoverage]]:质量调整后的 Pipeline 覆盖度,结合 Deal 健康评分、阶段年龄和互动信号对 Pipeline 进行折减
-- [[RevenueOperations]]:Revenue Operations 的核心分析方法论,活动指标驱动 Pipeline 指标,Pipeline 指标驱动收入结果
-
-## Key Entities
-- [[SalesDealStrategist]]:Deal 策略制定 Agent,与 Pipeline Analyst 共同构成销售情报闭环(Pipeline Analyst 评估 Deal 质量,Deal Strategist 制定推进策略)
-- [[SalesAccountStrategist]]:客户策略 Agent,Pipeline Analyst 为其提供客户层级的 Pipeline 健康数据
-- [[SalesOutboundStrategist]]:外展策略 Agent,其创建的 Pipeline 机会进入 Pipeline Analyst 的监测体系
-
-## Connections
-- [[SalesDealStrategist]] ← depends_on ← [[SalesPipelineAnalyst]]
-- [[SalesAccountStrategist]] ← depends_on ← [[SalesPipelineAnalyst]]
-- [[SalesOutboundStrategist]] ← creates_pipeline_for ← [[SalesPipelineAnalyst]]
-- [[SalesCoach]] ← uses_forecast_data ← [[SalesPipelineAnalyst]]
+---
+title: "Pipeline Analyst Agent"
+type: source
+tags: [sales, revenue-operations, pipeline, forecasting, CRM, MEDDPICC]
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/sales/sales-pipeline-analyst.md]]
+
+## Summary(用中文描述)
+- 核心主题:Revenue Operations 领域的 Pipeline 健康诊断与收入预测 AI Agent,将 CRM 数据转化为可执行的 Pipeline 洞察,在问题演变为季度失误之前主动预警。
+- 问题域:销售 Pipeline 管理、收入预测准确性、Deal 质量评估、销售教练数据分析
+- 方法/机制:Pipeline Velocity 公式 + MEDDPICC 资格评分 + 多信号预测模型 + Deal 健康评分卡
+- 结论/价值:质量调整后的 Pipeline 覆盖度永远优于阶段加权覆盖度;每份 Pipeline 评估都应至少发现一个需要立即干预的 Deal;预测必须带置信区间而非单一数字。
+
+## Key Claims(用中文描述)
+- Pipeline Velocity =(合格机会数 × 平均 Deal 规模 × 胜率)/ 销售周期长度,四个变量均为诊断杠杆。
+- 目标覆盖比率:成熟可预测业务 3x,成长期或新市场 4-5x,新销售入职 5x+。
+- 晚期阶段 Deal 的 MEDDPICC 字段少于 5/8 即为资格不足,是预测失误的主要来源。
+- 多线程、利益相关者深度参与的 Deal 关闭率是同阶段单线程低活跃度 Deal 的 2-3 倍。
+- 预测必须输出 Commit(>90%置信)/Best Case(>60%)/Upside(<60%)三档,而非单一数字。
+- AI 驱动的预测评分消除两种最常见的人类偏见:销售乐观主义(永远"看起来很好")和管理层锚定(从上一季度数字而非当前数据分析)。
+
+## Key Quotes
+> "Quality-adjusted coverage discounts pipeline by deal health score, stage age, and engagement signals. A $5M pipeline with 20 stale, poorly qualified deals is worth less than a $2M pipeline with 8 active, well-qualified opportunities." — 质量调整原则:高质量少量 Pipeline 优于大量低质量 Pipeline
+> "Deals with fewer than 5 of 8 MEDDPICC fields populated are underqualified. Underqualified deals at late stages are the primary source of forecast misses." — 晚期阶段资格不足 Deal 是预测失误的主因
+> "The CRM shows $12M in pipeline. After adjusting for stale deals, missing qualification data, and historical stage conversion, the realistic weighted pipeline is $4.8M." — 数据质量对预测的影响示例
+
+## Key Concepts
+- [[PipelineVelocity]]:Pipeline Velocity =(合格机会数 × 平均 Deal 规模 × 胜率)/ 销售周期长度,是 Revenue Operations 最核心的复合指标
+- [[MEDDPICC]]:8维度 Deal 资格评估框架(Metrics、Economic Buyer、Decision Criteria、Decision Process、Paper Process、Implicated Pain、Champion、Competition),用于诊断 Deal 质量和预测可行性
+- [[DealHealthScoring]]:通过资格深度、互动强度、进展速度三维度综合评估 Deal 健康状况的评分体系
+- [[QualityAdjustedCoverage]]:质量调整后的 Pipeline 覆盖度,结合 Deal 健康评分、阶段年龄和互动信号对 Pipeline 进行折减
+- [[RevenueOperations]]:Revenue Operations 的核心分析方法论,活动指标驱动 Pipeline 指标,Pipeline 指标驱动收入结果
+
+## Key Entities
+- [[SalesDealStrategist]]:Deal 策略制定 Agent,与 Pipeline Analyst 共同构成销售情报闭环(Pipeline Analyst 评估 Deal 质量,Deal Strategist 制定推进策略)
+- [[SalesAccountStrategist]]:客户策略 Agent,Pipeline Analyst 为其提供客户层级的 Pipeline 健康数据
+- [[SalesOutboundStrategist]]:外展策略 Agent,其创建的 Pipeline 机会进入 Pipeline Analyst 的监测体系
+
+## Connections
+- [[SalesDealStrategist]] ← depends_on ← [[SalesPipelineAnalyst]]
+- [[SalesAccountStrategist]] ← depends_on ← [[SalesPipelineAnalyst]]
+- [[SalesOutboundStrategist]] ← creates_pipeline_for ← [[SalesPipelineAnalyst]]
+- [[SalesCoach]] ← uses_forecast_data ← [[SalesPipelineAnalyst]]
diff --git a/wiki/sources/sales-proposal-strategist.md b/wiki/sources/sales-proposal-strategist.md
index c6e7fcf5..fc0fa01e 100644
--- a/wiki/sources/sales-proposal-strategist.md
+++ b/wiki/sources/sales-proposal-strategist.md
@@ -1,51 +1,51 @@
----
-title: "Sales Proposal Strategist"
-type: source
-tags: ["sales", "proposal", "RFP", "win-themes", "narrative", "persuasion"]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/sales/sales-proposal-strategist.md]]
-
-## Summary(用中文描述)
-- 核心主题:销售提案策略师 Agent 的系统化提案撰写方法论——将 RFP 响应从合规检查清单转化为有说服力的赢单叙事
-- 问题域:企业级销售提案、RFP 响应、竞争性投标、赢标主题开发、执行摘要撰写
-- 方法/机制:三幕提案叙事结构(理解挑战→解决方案旅程→转变状态)、3-5 个赢标主题矩阵、执行摘要五步模板、说服架构(首因/近因效应、认知负荷管理、社会认同排序、损失厌恶框架)、内容运营体系
-- 结论/价值:提案的胜负在开篇 100 词内决定;叙事是差异化核心;在能力趋同的商品化市场中,说服力即竞争力
-
-## Key Claims(用中文描述)
-- 赢标主题必须贯穿执行摘要、解决方案叙事、案例研究和定价逻辑——孤立的主题等于隐形的主题
-- 提案在开篇 100 词内决定胜负:评估者通过前 100 词判断供应商是否真正理解他们的业务
-- 执行摘要不是提案的摘要,而是提案的终局论证,应放在最前面
-- 永远不要直接批评竞争对手——将自身优势框架为直接利益,让对比自然形成
-- 定价在价值之后:先建立 ROI 案例、量化问题成本,在买方看到数字之前锚定成果而非成本
-- 内容库应按赢标主题而非章节组织——加速未来提案并保持叙事一致性
-
-## Key Quotes
-> "Proposals are won on clarity and lost on generics." — 核心理念:泛泛而谈即失败
-> "The executive summary is the proposal's closing argument, placed first." — 执行摘要的本质定义
-> "Every proposal needs 3-5 win themes: compelling, client-centric statements that connect your solution directly to the buyer's most urgent needs." — 赢标主题的定义
-> "Micro-stories win sections. Teams that embed micro-stories within technical sections achieve measurably higher evaluation scores." — 微故事的力量
-
-## Key Concepts
-- [[WinThemes|赢标主题(Win Themes)]]:连接解决方案与买方最紧迫需求的核心叙事陈述,贯穿整个提案
-- [[ThreeActProposalNarrative|三幕提案叙事(Three-Act Proposal Narrative)]]:理解挑战→解决方案旅程→转变状态
-- [[ExecutiveSummary|执行摘要(Executive Summary)]]:提案的终局论证,非摘要
-- [[CaptureStrategy|捕获策略(Capture Strategy)]]:RFP 发布前的预定位和关系映射
-- [[PersuasionArchitecture|说服架构(Persuasion Architecture)]]:首因/近因效应、认知负荷管理、社会认同排序、损失厌恶框架
-- [[RFP|RFP(Request for Proposal)]]:招标书/需求建议书
-- [[WinThemeMatrix|赢标主题矩阵(Win Theme Matrix)]]:评估主题与买方需求、差异化因素、证明点映射关系的结构化工具
-
-## Key Entities
-- 无特定命名实体(人/公司/产品/项目)
-
-## Connections
-- [[SalesCoach]] ← related_to ← [[SalesProposalStrategist]](同属销售 Agent 体系)
-- [[SalesDiscoveryCoach]] ← related_to ← [[SalesProposalStrategist]](发现阶段为提案策略提供输入)
-- [[SalesEngineer]] ← related_to ← [[SalesProposalStrategist]](技术销售工程师提供提案技术支撑)
-- [[SalesOutboundStrategist]] ← related_to ← [[SalesProposalStrategist]](外展策略为提案创造机会)
-- [[SalesDealStrategist]] ← related_to ← [[SalesProposalStrategist]](deal 策略与提案策略协同)
-
-## Contradictions
-- 暂无冲突
+---
+title: "Sales Proposal Strategist"
+type: source
+tags: ["sales", "proposal", "RFP", "win-themes", "narrative", "persuasion"]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/sales/sales-proposal-strategist.md]]
+
+## Summary(用中文描述)
+- 核心主题:销售提案策略师 Agent 的系统化提案撰写方法论——将 RFP 响应从合规检查清单转化为有说服力的赢单叙事
+- 问题域:企业级销售提案、RFP 响应、竞争性投标、赢标主题开发、执行摘要撰写
+- 方法/机制:三幕提案叙事结构(理解挑战→解决方案旅程→转变状态)、3-5 个赢标主题矩阵、执行摘要五步模板、说服架构(首因/近因效应、认知负荷管理、社会认同排序、损失厌恶框架)、内容运营体系
+- 结论/价值:提案的胜负在开篇 100 词内决定;叙事是差异化核心;在能力趋同的商品化市场中,说服力即竞争力
+
+## Key Claims(用中文描述)
+- 赢标主题必须贯穿执行摘要、解决方案叙事、案例研究和定价逻辑——孤立的主题等于隐形的主题
+- 提案在开篇 100 词内决定胜负:评估者通过前 100 词判断供应商是否真正理解他们的业务
+- 执行摘要不是提案的摘要,而是提案的终局论证,应放在最前面
+- 永远不要直接批评竞争对手——将自身优势框架为直接利益,让对比自然形成
+- 定价在价值之后:先建立 ROI 案例、量化问题成本,在买方看到数字之前锚定成果而非成本
+- 内容库应按赢标主题而非章节组织——加速未来提案并保持叙事一致性
+
+## Key Quotes
+> "Proposals are won on clarity and lost on generics." — 核心理念:泛泛而谈即失败
+> "The executive summary is the proposal's closing argument, placed first." — 执行摘要的本质定义
+> "Every proposal needs 3-5 win themes: compelling, client-centric statements that connect your solution directly to the buyer's most urgent needs." — 赢标主题的定义
+> "Micro-stories win sections. Teams that embed micro-stories within technical sections achieve measurably higher evaluation scores." — 微故事的力量
+
+## Key Concepts
+- [[WinThemes|赢标主题(Win Themes)]]:连接解决方案与买方最紧迫需求的核心叙事陈述,贯穿整个提案
+- [[ThreeActProposalNarrative|三幕提案叙事(Three-Act Proposal Narrative)]]:理解挑战→解决方案旅程→转变状态
+- [[ExecutiveSummary|执行摘要(Executive Summary)]]:提案的终局论证,非摘要
+- [[CaptureStrategy|捕获策略(Capture Strategy)]]:RFP 发布前的预定位和关系映射
+- [[PersuasionArchitecture|说服架构(Persuasion Architecture)]]:首因/近因效应、认知负荷管理、社会认同排序、损失厌恶框架
+- [[RFP|RFP(Request for Proposal)]]:招标书/需求建议书
+- [[WinThemeMatrix|赢标主题矩阵(Win Theme Matrix)]]:评估主题与买方需求、差异化因素、证明点映射关系的结构化工具
+
+## Key Entities
+- 无特定命名实体(人/公司/产品/项目)
+
+## Connections
+- [[SalesCoach]] ← related_to ← [[SalesProposalStrategist]](同属销售 Agent 体系)
+- [[SalesDiscoveryCoach]] ← related_to ← [[SalesProposalStrategist]](发现阶段为提案策略提供输入)
+- [[SalesEngineer]] ← related_to ← [[SalesProposalStrategist]](技术销售工程师提供提案技术支撑)
+- [[SalesOutboundStrategist]] ← related_to ← [[SalesProposalStrategist]](外展策略为提案创造机会)
+- [[SalesDealStrategist]] ← related_to ← [[SalesProposalStrategist]](deal 策略与提案策略协同)
+
+## Contradictions
+- 暂无冲突
diff --git a/wiki/sources/scrapy-playwright-抓取tiktok-shop-data.md b/wiki/sources/scrapy-playwright-抓取tiktok-shop-data.md
index fba26d2c..27e2fab2 100644
--- a/wiki/sources/scrapy-playwright-抓取tiktok-shop-data.md
+++ b/wiki/sources/scrapy-playwright-抓取tiktok-shop-data.md
@@ -1,49 +1,49 @@
----
-title: "Scrapy + Playwright 抓取TikTok Shop Data"
-type: source
-tags: [playwright, scrapy, tiktok-shop, python, docker, 爬虫]
-date: 2026-04-24
----
-
-## Source File
-- [[跨境电商/Scrapy + Playwright 抓取TikTok Shop Data.md]]
-
-## Summary(用中文描述)
-- 核心主题:使用 Scrapy + Playwright 技术栈抓取 TikTok Shop 商家数据的环境配置与运行指南
-- 问题域:TikTok Shop 跨境电商数据采集的工程实现
-- 方法/机制:通过 Python venv 虚拟环境隔离依赖,使用 scrapy-playwright 集成包驱动 Chromium 浏览器执行动态页面渲染,再通过 Docker 容器化部署
-- 结论/价值:提供了完整的开发环境搭建流程和生产级 Docker 部署配置,是跨境电商数据采集项目的技术基座
-
-## Key Claims(用中文描述)
-- **虚拟环境隔离是首选方案**:通过 `python3 -m venv` 创建独立虚拟环境,安装 Scrapy + scrapy-playwright 依赖,相比 Docker 直接安装更适合开发调试
-- **Playwright Chromium 是渲染引擎**:通过 `playwright install chromium` 安装无头浏览器,负责处理 TikTok Shop 的 JavaScript 动态加载内容
-- **Docker 部署需配置 venv 环境变量**:在 Dockerfile 中添加 `RUN python3 -m venv /app/venv ENV PATH="/app/venv/bin:$PATH"`,使容器内 Python 命令使用虚拟环境
-- **可用命令行参数指定目标店铺**:通过 `scrapy runspider tiktok_shop_spider.py -a shop_url="..."` 传递 TikTok Shop 店铺 URL 参数
-
-## Key Quotes
-> "最推荐:创建虚拟环境 (venv) 并安装 Scrapy + Playwright" — 文档作者推荐的最佳实践方案
-
-> "source venv/bin/activate" — venv 激活命令
-
-> "RUN python3 -m venv /app/venv ENV PATH=\"/app/venv/bin:$PATH\"" — Docker 中配置 Python venv 的标准写法
-
-> "python -c \"from playwright.sync_api import sync_playwright; print('Playwright OK')\"" — Playwright 验证命令
-
-## Key Concepts
-- [[Scrapy]]:Python 爬虫框架,负责请求调度、数据解析和管道存储
-- [[Playwright]]:Microsoft 开发的无头浏览器自动化工具,支持 Chromium/Firefox/WebKit 多引擎,用于渲染 JavaScript 动态页面
-- [[scrapy-playwright]]:连接 Scrapy 与 Playwright 的集成包,使 Scrapy Spider 能够执行浏览器自动化操作
-- [[venv]]:Python 内置虚拟环境工具,用于隔离项目依赖,避免版本冲突
-- [[Docker]]:容器化平台,用于生产环境部署
-- [[Chromium]]:Google 浏览器引擎,Playwright 的默认渲染引擎
-
-## Key Entities
-- [[TikTok Shop]]:字节跳动旗下的电商平台,本文档的数据采集目标
-- shenwei:文档作者,提供实际操作笔记
-
-## Connections
-- [[TikTok Shop Apache Superset Dashboard]] ← uses ← [[Scrapy-Playwright-TikTok-Shop-Data]]
-- [[做tk跨境思路不对努力白费]] ← related_to ← [[Scrapy-Playwright-TikTok-Shop-Data]]
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "Scrapy + Playwright 抓取TikTok Shop Data"
+type: source
+tags: [playwright, scrapy, tiktok-shop, python, docker, 爬虫]
+date: 2026-04-24
+---
+
+## Source File
+- [[raw/跨境电商/Scrapy + Playwright 抓取TikTok Shop Data.md]]
+
+## Summary(用中文描述)
+- 核心主题:使用 Scrapy + Playwright 技术栈抓取 TikTok Shop 商家数据的环境配置与运行指南
+- 问题域:TikTok Shop 跨境电商数据采集的工程实现
+- 方法/机制:通过 Python venv 虚拟环境隔离依赖,使用 scrapy-playwright 集成包驱动 Chromium 浏览器执行动态页面渲染,再通过 Docker 容器化部署
+- 结论/价值:提供了完整的开发环境搭建流程和生产级 Docker 部署配置,是跨境电商数据采集项目的技术基座
+
+## Key Claims(用中文描述)
+- **虚拟环境隔离是首选方案**:通过 `python3 -m venv` 创建独立虚拟环境,安装 Scrapy + scrapy-playwright 依赖,相比 Docker 直接安装更适合开发调试
+- **Playwright Chromium 是渲染引擎**:通过 `playwright install chromium` 安装无头浏览器,负责处理 TikTok Shop 的 JavaScript 动态加载内容
+- **Docker 部署需配置 venv 环境变量**:在 Dockerfile 中添加 `RUN python3 -m venv /app/venv ENV PATH="/app/venv/bin:$PATH"`,使容器内 Python 命令使用虚拟环境
+- **可用命令行参数指定目标店铺**:通过 `scrapy runspider tiktok_shop_spider.py -a shop_url="..."` 传递 TikTok Shop 店铺 URL 参数
+
+## Key Quotes
+> "最推荐:创建虚拟环境 (venv) 并安装 Scrapy + Playwright" — 文档作者推荐的最佳实践方案
+
+> "source venv/bin/activate" — venv 激活命令
+
+> "RUN python3 -m venv /app/venv ENV PATH=\"/app/venv/bin:$PATH\"" — Docker 中配置 Python venv 的标准写法
+
+> "python -c \"from playwright.sync_api import sync_playwright; print('Playwright OK')\"" — Playwright 验证命令
+
+## Key Concepts
+- [[Scrapy]]:Python 爬虫框架,负责请求调度、数据解析和管道存储
+- [[Playwright]]:Microsoft 开发的无头浏览器自动化工具,支持 Chromium/Firefox/WebKit 多引擎,用于渲染 JavaScript 动态页面
+- [[scrapy-playwright]]:连接 Scrapy 与 Playwright 的集成包,使 Scrapy Spider 能够执行浏览器自动化操作
+- [[venv]]:Python 内置虚拟环境工具,用于隔离项目依赖,避免版本冲突
+- [[Docker]]:容器化平台,用于生产环境部署
+- [[Chromium]]:Google 浏览器引擎,Playwright 的默认渲染引擎
+
+## Key Entities
+- [[TikTok Shop]]:字节跳动旗下的电商平台,本文档的数据采集目标
+- shenwei:文档作者,提供实际操作笔记
+
+## Connections
+- [[TikTok Shop Apache Superset Dashboard]] ← uses ← [[Scrapy-Playwright-TikTok-Shop-Data]]
+- [[做tk跨境思路不对努力白费]] ← related_to ← [[Scrapy-Playwright-TikTok-Shop-Data]]
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/second-brain.md b/wiki/sources/second-brain.md
index 40b1c7a9..88d45662 100644
--- a/wiki/sources/second-brain.md
+++ b/wiki/sources/second-brain.md
@@ -1,48 +1,48 @@
----
-title: "Second Brain"
-type: source
-tags: [personal-knowledge-management, openclaw, memory, productivity]
-date: 2026-04-22
----
-
-## Source File
-- [[Agent/usecases/second-brain.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 作为个人第二大脑的记忆捕获与检索系统
-- 问题域:传统笔记应用(Notion/Apple Notes)组织成本过高导致用户放弃使用的问题
-- 方法/机制:零摩擦捕获(短信/Telegram/Discord 随意文本) + 永久记忆存储 + Next.js 可搜索仪表盘
-- 结论/价值:捕获像发短信一样简单,检索像搜索一样简单——零文件夹、零标签、零复杂组织
-
-## Key Claims(用中文描述)
-- AI Agent 的累积记忆系统使系统随时间变得越来越强大(用户告诉它的所有内容都会被永久记住)
-- 从手机发消息给 Bot,AI 就能在电脑端构建内容——对话本身就是界面
-- 每个笔记应用最终都会变成负担,因为组织的摩擦力大于遗忘的摩擦力
-
-## Key Quotes
-> "Capture should be as easy as texting, and retrieval should be as easy as searching." — 核心设计原则
-
-> "Zero-friction capture — you don't need to open an app, pick a folder, or add tags. Just text." — 零摩擦捕获机制
-
-## Key Concepts
-- [[Zero-Friction Capture]]:捕获操作必须零摩擦,像发短信一样简单才能持续使用
-- [[Cumulative Memory]]:Agent 的记忆系统累积用户告知的所有内容,随时间推移变得更有价值
-- [[Conversational Interface]]:对话本身就是用户界面,用户从手机发消息,AI 在电脑端构建内容
-- [[Text-and-Search]]:无需文件夹、标签、复杂组织,仅靠文本和搜索
-
-## Key Entities
-- [[OpenClaw]]:底层运行平台,提供记忆存储系统和 Next.js 构建能力
-- [[Alex Finn]]:YouTube 内容创作者,通过视频分享 OpenClaw 高阶用法,是本文档的启发来源
-- [[Tiago Forte]]:《Building a Second Brain》作者,方法论层面的重要参考
-
-## Connections
-- [[custom-morning-brief]] ← similar_pattern ← [[Second Brain]]
-- [[self-healing-home-server]] ← similar_pattern ← [[Second Brain]]
-- [[Alex Finn]] ← inspired_by ← [[Second Brain]]
-- [[OpenClaw]] ← powers ← [[Second Brain]]
-
-## Contradictions
-- 与 [[dataview-让我从“笔记黑洞”里逃出来的-obsidian-神器-1]] 冲突:
- - 冲突点:Obsidian + Dataview 需要用户主动维护标签和结构;Second Brain 强调零摩擦
- - 当前观点:零摩擦是持续使用的关键,结构化组织会形成阻力
- - 对方观点:Dataview 提供了结构化查询能力,是 Obsidian 的优势
+---
+title: "Second Brain"
+type: source
+tags: [personal-knowledge-management, openclaw, memory, productivity]
+date: 2026-04-22
+---
+
+## Source File
+- [[raw/Agent/usecases/second-brain.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 作为个人第二大脑的记忆捕获与检索系统
+- 问题域:传统笔记应用(Notion/Apple Notes)组织成本过高导致用户放弃使用的问题
+- 方法/机制:零摩擦捕获(短信/Telegram/Discord 随意文本) + 永久记忆存储 + Next.js 可搜索仪表盘
+- 结论/价值:捕获像发短信一样简单,检索像搜索一样简单——零文件夹、零标签、零复杂组织
+
+## Key Claims(用中文描述)
+- AI Agent 的累积记忆系统使系统随时间变得越来越强大(用户告诉它的所有内容都会被永久记住)
+- 从手机发消息给 Bot,AI 就能在电脑端构建内容——对话本身就是界面
+- 每个笔记应用最终都会变成负担,因为组织的摩擦力大于遗忘的摩擦力
+
+## Key Quotes
+> "Capture should be as easy as texting, and retrieval should be as easy as searching." — 核心设计原则
+
+> "Zero-friction capture — you don't need to open an app, pick a folder, or add tags. Just text." — 零摩擦捕获机制
+
+## Key Concepts
+- [[Zero-Friction Capture]]:捕获操作必须零摩擦,像发短信一样简单才能持续使用
+- [[Cumulative Memory]]:Agent 的记忆系统累积用户告知的所有内容,随时间推移变得更有价值
+- [[Conversational Interface]]:对话本身就是用户界面,用户从手机发消息,AI 在电脑端构建内容
+- [[Text-and-Search]]:无需文件夹、标签、复杂组织,仅靠文本和搜索
+
+## Key Entities
+- [[OpenClaw]]:底层运行平台,提供记忆存储系统和 Next.js 构建能力
+- [[Alex Finn]]:YouTube 内容创作者,通过视频分享 OpenClaw 高阶用法,是本文档的启发来源
+- [[Tiago Forte]]:《Building a Second Brain》作者,方法论层面的重要参考
+
+## Connections
+- [[custom-morning-brief]] ← similar_pattern ← [[Second Brain]]
+- [[self-healing-home-server]] ← similar_pattern ← [[Second Brain]]
+- [[Alex Finn]] ← inspired_by ← [[Second Brain]]
+- [[OpenClaw]] ← powers ← [[Second Brain]]
+
+## Contradictions
+- 与 [[dataview-让我从“笔记黑洞”里逃出来的-obsidian-神器-1]] 冲突:
+ - 冲突点:Obsidian + Dataview 需要用户主动维护标签和结构;Second Brain 强调零摩擦
+ - 当前观点:零摩擦是持续使用的关键,结构化组织会形成阻力
+ - 对方观点:Dataview 提供了结构化查询能力,是 Obsidian 的优势
diff --git a/wiki/sources/self-healing-home-server.md b/wiki/sources/self-healing-home-server.md
index 7b7345ca..1b575812 100644
--- a/wiki/sources/self-healing-home-server.md
+++ b/wiki/sources/self-healing-home-server.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/usecases/self-healing-home-server]]
+- [[raw/Agent/usecases/self-healing-home-server.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 作为家庭服务器基础设施的全天候自动驾驶代理
diff --git a/wiki/sources/semantic-memory-search.md b/wiki/sources/semantic-memory-search.md
index 1da8dc64..307ba99a 100644
--- a/wiki/sources/semantic-memory-search.md
+++ b/wiki/sources/semantic-memory-search.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/semantic-memory-search.md]]
+- [[raw/Agent/usecases/semantic-memory-search.md]]
## Summary(用中文描述)
- 核心主题:为 OpenClaw 的 markdown 记忆文件添加向量语义搜索能力
diff --git a/wiki/sources/specialized-civil-engineer.md b/wiki/sources/specialized-civil-engineer.md
index e08d2417..e8fcf101 100644
--- a/wiki/sources/specialized-civil-engineer.md
+++ b/wiki/sources/specialized-civil-engineer.md
@@ -1,52 +1,52 @@
----
-title: "Specialized Civil Engineer Agent"
-type: source
-tags: ["agent", "civil-engineering", "structural-design", "geotechnical", "building-codes"]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/specialized/specialized-civil-engineer.md]]
-
-## Summary(用中文描述)
-- 核心主题:面向 AI Agent 的土木与结构工程专家角色定义,涵盖全球设计标准体系、结构分析与岩土设计能力、建造文档合规全流程
-- 问题域:AI Agent 在建筑结构工程领域的专业化角色设计,涉及多国规范体系(Eurocode、ACI、AISC、ASCE、GB、IS、AIJ 等)的统一知识表示与任务执行框架
-- 方法/机制:通过结构化角色定义(身份记忆→核心使命→规范规则→交付物→工作流→高级能力)构建可执行的结构工程 Agent;提供钢梁/RC 梁/岩土计算示例作为能力基准
-- 结论/价值:产出安全、经济、可建造的结构设计,同时驾驭多管辖区域并发规范、多标准冲突解析、全生命周期碳评估等高级任务
-
-## Key Claims(用中文描述)
-- AI Agent 可通过规范引用驱动("Per EN 1992-1-1 clause 6.2.3...")的方式执行可验证的结构计算包
-- 多标准项目(IBC+Eurocode 混用等)中,Agent 可通过规范冲突识别→文档记录→保守优先→设计依据报告的流程提供可辩护的解决方案
-- 结构设计必须同时验证强度极限状态(ULS)和正常使用极限状态(SLS/挠度/振动),两者均满足方为合格
-- 岩土参数不得未经地勘报告或明确假设即行假定;沉降分析对差异沉降敏感结构为必做项
-
-## Key Quotes
-> "Always check **both** strength (ULS) and serviceability (SLS) limit states" — 强度与正常使用双重验证原则
-> "Default to the more conservative requirement unless AHJ rules otherwise" — 多标准冲突时的默认处理策略
-> "Never assume soil parameters without a ground investigation report or clear stated assumptions" — 岩土参数假设的铁律
-> "Calculation packages must be self-contained: inputs, references, calculations, results" — 计算包自包含性要求
-
-## Key Concepts
-- [[ULS]](极限状态设计/Strength Limit State):结构承载力极限状态,对应 Eurocode EN 1990 中的 ULS、ACI 318 LRFD
-- [[SLS]](正常使用极限状态/Serviceability Limit State):挠度、振动、裂缝控制,对应 EN 1990 SLS、ACI 318 serviceability provisions
-- [[National Annex]](国家附录):Eurocode 各成员国对 NDPs(国家确定参数)的本地化修订,是规范冲突的主要来源
-- [[AHJ]](Authority Having Jurisdiction):主管当局,拥有最终解释权,多标准项目需向 AHJ 确认
-- [[Basis of Design]](设计依据):记录所有关键假设、规范版本选择、荷载组合、设计决策的正式文件
-- [[Ductility Class]](延性等级):Eurocode EN 1998 的 DCL/DCM/DCH,地震设计中的结构延性要求分级
-- [[LRFD]](荷载抗力系数设计):美国 ACI/AISC 体系采用的设计方法,与 Eurocode 的部分系数法(EN 1990 DA1/DA2/DA3)思路相近但系数不同
-- [[BIM Coordination]](BIM 协调):结构模型导出 IFC 4.x、碰撞检测、穿楼板开孔、钢筋保护层协调等
-
-## Key Entities
-- [[Eurocode]]:欧洲规范体系 EN 1990–1999,覆盖结构设计荷载、混凝土/钢/木/砌体结构、岩土、抗震等九大领域,附各国 National Annex
-- [[AISC 360]]:美国钢结构设计规范(LRFD 与 ASD 双轨),含构件设计、连接设计、冷弯型钢结构
-- [[ACI 318]]:美国钢筋混凝土设计规范,LRFD/SD 方法,含特殊抗弯框架(SMF)抗震细部要求
-- [[ASCE 7]]:美国建筑及其他结构最小设计荷载规范,涵盖重力荷载、风荷载、地震荷载、冰雪荷载等第 2–31 章
-- [[EN 1997]]:Eurocode 岩土设计规范,含浅基础、深基础、挡土结构、土坡稳定的体系化设计方法
-- [[AIJ]](Architectural Institute of Japan):日本建筑学会规范,高抗震延性要求、响应谱法抗震设计指南
-
-## Connections
-- [[specialized-developer-advocate]] ← shares → [[specialized-mcp-builder]](同属 specialized 专业 Agent 系列)
-- [[specialized-civil-engineer]] ← implements → [[specialized-workflow-architect]](专业 Agent 依赖工作流架构)
-
-## Contradictions
-- 暂无已知冲突。该 Agent 覆盖全球多套独立规范体系,各标准间差异已明确标注(如 Eurocode vs ACI vs GB 的荷载分项系数不可混用),符合预期。
+---
+title: "Specialized Civil Engineer Agent"
+type: source
+tags: ["agent", "civil-engineering", "structural-design", "geotechnical", "building-codes"]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/specialized-civil-engineer.md]]
+
+## Summary(用中文描述)
+- 核心主题:面向 AI Agent 的土木与结构工程专家角色定义,涵盖全球设计标准体系、结构分析与岩土设计能力、建造文档合规全流程
+- 问题域:AI Agent 在建筑结构工程领域的专业化角色设计,涉及多国规范体系(Eurocode、ACI、AISC、ASCE、GB、IS、AIJ 等)的统一知识表示与任务执行框架
+- 方法/机制:通过结构化角色定义(身份记忆→核心使命→规范规则→交付物→工作流→高级能力)构建可执行的结构工程 Agent;提供钢梁/RC 梁/岩土计算示例作为能力基准
+- 结论/价值:产出安全、经济、可建造的结构设计,同时驾驭多管辖区域并发规范、多标准冲突解析、全生命周期碳评估等高级任务
+
+## Key Claims(用中文描述)
+- AI Agent 可通过规范引用驱动("Per EN 1992-1-1 clause 6.2.3...")的方式执行可验证的结构计算包
+- 多标准项目(IBC+Eurocode 混用等)中,Agent 可通过规范冲突识别→文档记录→保守优先→设计依据报告的流程提供可辩护的解决方案
+- 结构设计必须同时验证强度极限状态(ULS)和正常使用极限状态(SLS/挠度/振动),两者均满足方为合格
+- 岩土参数不得未经地勘报告或明确假设即行假定;沉降分析对差异沉降敏感结构为必做项
+
+## Key Quotes
+> "Always check **both** strength (ULS) and serviceability (SLS) limit states" — 强度与正常使用双重验证原则
+> "Default to the more conservative requirement unless AHJ rules otherwise" — 多标准冲突时的默认处理策略
+> "Never assume soil parameters without a ground investigation report or clear stated assumptions" — 岩土参数假设的铁律
+> "Calculation packages must be self-contained: inputs, references, calculations, results" — 计算包自包含性要求
+
+## Key Concepts
+- [[ULS]](极限状态设计/Strength Limit State):结构承载力极限状态,对应 Eurocode EN 1990 中的 ULS、ACI 318 LRFD
+- [[SLS]](正常使用极限状态/Serviceability Limit State):挠度、振动、裂缝控制,对应 EN 1990 SLS、ACI 318 serviceability provisions
+- [[National Annex]](国家附录):Eurocode 各成员国对 NDPs(国家确定参数)的本地化修订,是规范冲突的主要来源
+- [[AHJ]](Authority Having Jurisdiction):主管当局,拥有最终解释权,多标准项目需向 AHJ 确认
+- [[Basis of Design]](设计依据):记录所有关键假设、规范版本选择、荷载组合、设计决策的正式文件
+- [[Ductility Class]](延性等级):Eurocode EN 1998 的 DCL/DCM/DCH,地震设计中的结构延性要求分级
+- [[LRFD]](荷载抗力系数设计):美国 ACI/AISC 体系采用的设计方法,与 Eurocode 的部分系数法(EN 1990 DA1/DA2/DA3)思路相近但系数不同
+- [[BIM Coordination]](BIM 协调):结构模型导出 IFC 4.x、碰撞检测、穿楼板开孔、钢筋保护层协调等
+
+## Key Entities
+- [[Eurocode]]:欧洲规范体系 EN 1990–1999,覆盖结构设计荷载、混凝土/钢/木/砌体结构、岩土、抗震等九大领域,附各国 National Annex
+- [[AISC 360]]:美国钢结构设计规范(LRFD 与 ASD 双轨),含构件设计、连接设计、冷弯型钢结构
+- [[ACI 318]]:美国钢筋混凝土设计规范,LRFD/SD 方法,含特殊抗弯框架(SMF)抗震细部要求
+- [[ASCE 7]]:美国建筑及其他结构最小设计荷载规范,涵盖重力荷载、风荷载、地震荷载、冰雪荷载等第 2–31 章
+- [[EN 1997]]:Eurocode 岩土设计规范,含浅基础、深基础、挡土结构、土坡稳定的体系化设计方法
+- [[AIJ]](Architectural Institute of Japan):日本建筑学会规范,高抗震延性要求、响应谱法抗震设计指南
+
+## Connections
+- [[specialized-developer-advocate]] ← shares → [[specialized-mcp-builder]](同属 specialized 专业 Agent 系列)
+- [[specialized-civil-engineer]] ← implements → [[specialized-workflow-architect]](专业 Agent 依赖工作流架构)
+
+## Contradictions
+- 暂无已知冲突。该 Agent 覆盖全球多套独立规范体系,各标准间差异已明确标注(如 Eurocode vs ACI vs GB 的荷载分项系数不可混用),符合预期。
diff --git a/wiki/sources/specialized-cultural-intelligence-strategist.md b/wiki/sources/specialized-cultural-intelligence-strategist.md
index bceb4b44..870911e5 100644
--- a/wiki/sources/specialized-cultural-intelligence-strategist.md
+++ b/wiki/sources/specialized-cultural-intelligence-strategist.md
@@ -1,44 +1,44 @@
----
-title: "Cultural Intelligence Strategist"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/specialized/specialized-cultural-intelligence-strategist.md]]
-
-## Summary(用中文描述)
-- 核心主题:Cultural Intelligence Strategist(文化情报策略师)—— 一个专门负责在软件开发流程中检测和消除"隐性排斥"的 AI Agent。
-- 问题域:软件产品中的文化盲点(Western 默认假设、性别选项、命名规范、颜色语义等)导致非西方用户群体的摩擦和排斥。
-- 方法/机制:通过"盲点审计 → 自主研究 → 结构修正 → 解释原理"四阶段工作流,在架构层面实现文化包容性设计。
-- 结论/价值:将文化智能(Culture Intelligence, CQ)从"后期本地化补丁"提升为"架构级前提条件",避免产品因隐性排斥而失去全球市场份额。
-
-## Key Claims(用中文描述)
-- 刚性 Western 命名结构(强制 First Name / Last Name)会严重阻碍 APAC 等非西方市场用户的注册体验,应改为单一"Full Name"或"Preferred Name"字段。
-- 在中国金融场景中,红色表示"上涨/正向",而非西方语境中的"错误/警告",财务类应用不应仅依赖红色传达错误状态。
-- 表演性多元化(仅在首页加一张多元人群图,但产品流程本身仍具排斥性)不可接受;必须从架构层面消除排斥。
-- 国际化(Internationalization)必须作为架构前提条件,而非上线后的亡羊补牢。
-
-## Key Quotes
-> "This form design assumes a Western naming structure and will fail for users in our APAC markets." — 文化包容性修正的核心原则表述
-> "You are an Architectural Empathy Engine. Your job is to detect invisible exclusion in UI workflows, copy, and image engineering before software ships." — 角色定义
-> "Red in Chinese financial contexts indicates positive growth." — 颜色语义冲突的具体案例
-
-## Key Concepts
-- [[Invisible Exclusion]]:在 UI 工作流、文案和图像工程中,用户因文化、神经多样性、视觉障碍或非西方时间日历假设而被无意识地排斥。
-- [[Cultural Intelligence(CQ)]]:检测和应对文化差异的能力,在软件产品设计中体现为对全球用户多样化需求的敏感度。
-- [[Global-First Architecture]]:将国际化作为架构前提条件,而非后期补救措施的设计哲学。
-- [[Contextual Semiotics]]:超越语言翻译,审查 UX 颜色选择、图标和隐喻的文化语义。
-- [[Architectural Empathy]]:通过结构性解决方案而非表演性行为来实现包容性的设计理念。
-- [[Negative-Prompt Library]]:在图像生成中主动禁止有害刻板印象的工具库。
-
-## Key Entities
-- [[The Agency]]:该 Agent 所属的 Agent 系统生态。
-
-## Connections
-- [[Design Inclusive Visuals Specialist]] ← extends ← [[Cultural Intelligence Strategist]]:两者均涉及多元包容,但前者专注于视觉内容,后者覆盖整个产品工作流。
-- [[Design UX Researcher]] ← related_to ← [[Cultural Intelligence Strategist]]:均关注用户研究的包容性维度。
-
-## Contradictions
-- 与 [[Design Brand Guardian]]:Brand Guardian 强调品牌一致性,而 Cultural Intelligence Strategist 要求为不同市场调整视觉语义(如中国财务应用的颜色规则)。在特定市场语境下,两者需要在品牌规范层面达成平衡。
+---
+title: "Cultural Intelligence Strategist"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/specialized-cultural-intelligence-strategist.md]]
+
+## Summary(用中文描述)
+- 核心主题:Cultural Intelligence Strategist(文化情报策略师)—— 一个专门负责在软件开发流程中检测和消除"隐性排斥"的 AI Agent。
+- 问题域:软件产品中的文化盲点(Western 默认假设、性别选项、命名规范、颜色语义等)导致非西方用户群体的摩擦和排斥。
+- 方法/机制:通过"盲点审计 → 自主研究 → 结构修正 → 解释原理"四阶段工作流,在架构层面实现文化包容性设计。
+- 结论/价值:将文化智能(Culture Intelligence, CQ)从"后期本地化补丁"提升为"架构级前提条件",避免产品因隐性排斥而失去全球市场份额。
+
+## Key Claims(用中文描述)
+- 刚性 Western 命名结构(强制 First Name / Last Name)会严重阻碍 APAC 等非西方市场用户的注册体验,应改为单一"Full Name"或"Preferred Name"字段。
+- 在中国金融场景中,红色表示"上涨/正向",而非西方语境中的"错误/警告",财务类应用不应仅依赖红色传达错误状态。
+- 表演性多元化(仅在首页加一张多元人群图,但产品流程本身仍具排斥性)不可接受;必须从架构层面消除排斥。
+- 国际化(Internationalization)必须作为架构前提条件,而非上线后的亡羊补牢。
+
+## Key Quotes
+> "This form design assumes a Western naming structure and will fail for users in our APAC markets." — 文化包容性修正的核心原则表述
+> "You are an Architectural Empathy Engine. Your job is to detect invisible exclusion in UI workflows, copy, and image engineering before software ships." — 角色定义
+> "Red in Chinese financial contexts indicates positive growth." — 颜色语义冲突的具体案例
+
+## Key Concepts
+- [[Invisible Exclusion]]:在 UI 工作流、文案和图像工程中,用户因文化、神经多样性、视觉障碍或非西方时间日历假设而被无意识地排斥。
+- [[Cultural Intelligence(CQ)]]:检测和应对文化差异的能力,在软件产品设计中体现为对全球用户多样化需求的敏感度。
+- [[Global-First Architecture]]:将国际化作为架构前提条件,而非后期补救措施的设计哲学。
+- [[Contextual Semiotics]]:超越语言翻译,审查 UX 颜色选择、图标和隐喻的文化语义。
+- [[Architectural Empathy]]:通过结构性解决方案而非表演性行为来实现包容性的设计理念。
+- [[Negative-Prompt Library]]:在图像生成中主动禁止有害刻板印象的工具库。
+
+## Key Entities
+- [[The Agency]]:该 Agent 所属的 Agent 系统生态。
+
+## Connections
+- [[Design Inclusive Visuals Specialist]] ← extends ← [[Cultural Intelligence Strategist]]:两者均涉及多元包容,但前者专注于视觉内容,后者覆盖整个产品工作流。
+- [[Design UX Researcher]] ← related_to ← [[Cultural Intelligence Strategist]]:均关注用户研究的包容性维度。
+
+## Contradictions
+- 与 [[Design Brand Guardian]]:Brand Guardian 强调品牌一致性,而 Cultural Intelligence Strategist 要求为不同市场调整视觉语义(如中国财务应用的颜色规则)。在特定市场语境下,两者需要在品牌规范层面达成平衡。
diff --git a/wiki/sources/specialized-developer-advocate.md b/wiki/sources/specialized-developer-advocate.md
index d02b0351..d8b389ac 100644
--- a/wiki/sources/specialized-developer-advocate.md
+++ b/wiki/sources/specialized-developer-advocate.md
@@ -1,58 +1,58 @@
----
-title: "Specialized Developer Advocate"
-type: source
-tags: [agent, specialized, developer-relations, community, developer-experience]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/specialized/specialized-developer-advocate.md]]
-
-## Summary(用中文描述)
-- 核心主题:Developer Advocate Agent——The Agency Specialized 部门的开发者关系工程师,通过提升开发者体验(DX)、创建高质量技术内容、建立真实社区联系,将产品与外部开发者紧密连接,最终推动平台采用和商业价值增长。
-- 问题域:开发者关系(DevRel)、开发者体验优化、技术内容营销(区别于传统营销)、社区运营、产品反馈闭环。
-- 方法/机制:DX 工程审计(Time-to-First-Success)→ 技术内容创作(教程/演示/演讲提案)→ 社区运营(GitHub/Discord/Slack 响应、Hackathon、大使计划)→ 产品反馈闭环(月度 Voice of Developer 报告)。
-- 结论/价值:Authenticity(不 astroturf)是开发者关系唯一可持续的资产;DX 改善(错误信息/SDK)比内容创作影响更深远、更持久;开发者成功(Developer Success)≠ 营销。
-
-## Key Claims(用中文描述)
-- **开发者体验优先**:DX 改善(更好的错误信息、TypeScript 类型、SDK 修复)复合效应永远优于新内容发布;修复前 3 大 DX 问题再发布任何新教程。
-- **真实性是核心资产**:虚假社区参与(AstroTurf)会永久性摧毁开发者信任;保持技术准确性比发布空内容更重要。
-- **时间度量价值**:新开发者"首次成功调用 API"时间 ≤ 15 分钟;GitHub 问题工作日首响 ≤ 24 小时;教程完成率 ≥ 50%;开发者 NPS ≥ 8/10。
-- **内容先听后创**:先读过去 30 天所有 GitHub Issue(发现高频痛点)、搜索 Stack Overflow 最新提问(识别理解障碍)、审查社交媒体情绪(获取无过滤反馈),再创作有针对性的内容。
-- **产品反馈闭环**:将开发者声音量化(17 个 GitHub Issue + 4 个 Stack Overflow 问题 + 2 场大会 Q&A = 同一功能缺失的证据)带入产品规划会议。
-
-## Key Quotes
-> "You don't do marketing — you do developer success." — 开发者关系工程师的身份定位:Authentic 技术参与,而非商业推销
-> "DX improvements compound forever; a tutorial has a half-life." — DX 改善的持久价值 vs. 内容创作的时间衰减
-> "A tutorial with an active author gets 3x the trust." — 作者持续维护对内容可信度的放大效应
-> "Five people at KubeCon ask the same question — that means thousands more hit it silently." — 大会 Q&A 模式的大规模推断价值
-
-## Key Concepts
-- [[DeveloperExperienceEngineering]]:审计并改善"首次 API 调用时间",构建示例应用、启动工具包和代码模板,量化 DX 质量。
-- [[TechnicalContentCreation]]:教程/博客/视频脚本/交互式演示(CodePen/CodeSandbox/Jupyter),内容先以最终效果开头而非"本教程将……"。
-- [[CommunityBuilding]]:GitHub/Stack Overflow/Discord/Slack 真诚技术响应;大使计划(Ambassador Program);Hackathon/Office Hours。
-- [[ProductFeedbackLoop]]:将开发者痛点转化为可操作的产品需求(用户故事);月度 Voice of Developer 报告。
-- [[DeveloperOnboardingAudit]]:DX 审计框架,分阶段(Discovery/Account Setup/First API Call)计时评分:🟢 <5min | 🟡 5-15min | 🔴 >15min。
-- [[AmbassadorProgram]]:分层次贡献者认可机制,与社区价值观一致的真实激励。
-- [[ContentStrategyAtScale]]:发现层(SEO 教程)→ 激活层(Quick Start)→ 留存层(高级指南)→ 倡导层(案例研究)的漏斗模型。
-- [[DeveloperNPS]]:开发者净推荐值,季度调查,目标 ≥ 8/10。
-
-## Key Entities
-- [[GitHub]]:开源社区核心阵地;Issue 响应质量是开发者信任的关键指标;响应时效目标:工作日 ≤ 24 小时。
-- [[StackOverflow]]:开发者问题解答平台;搜索平台名称按最新排序可发现理解障碍点;回答率目标:≥ 90%。
-- [[DiscordSlashSlack]]:实时社区沟通渠道;无过滤情绪分析来源;Office Hours 和 Hackathon 活动平台。
-- [[OpenTelemetry]]:社区健康指标监控(错误率、文档搜索成功率等)框架。
-- [[KubeCon]]:顶级开发者大会;5 人问同一问题 → 数千人无声遇到同样障碍的推断方法论。
-
-## Connections
-- [[automation-governance-architect]] ← informs ← [[ProductFeedbackLoop]](产品反馈与治理评审互补)
-- [[specialized-mcp-builder]] ← depends_on ← [[DeveloperExperienceEngineering]](MCP Builder 的 DX 改善依赖开发者体验工程原则)
-- [[design-ux-researcher]] ← informs ← [[DeveloperOnboardingAudit]](UX 研究方法论应用于 DX 审计)
-- [[ContentStrategyAtScale]] ← supports ← [[ProductFeedbackLoop]](内容策略放大产品反馈影响力)
-- [[CommunityBuilding]] ← depends_on ← [[DeveloperExperienceEngineering]](社区健康依赖底层 DX 质量)
-
-## Contradictions
-- 与 [[specialized-workflow-architect]] 存在设计哲学张力:
- - 冲突点:快速交付 vs. 质量保障。Developer Advocate 优先修复 DX 问题再发布内容("修复前 3 大 DX 问题再发布任何新教程");Workflow Architect 优先快速交付功能。
- - 当前观点:DX 改善复合效应优于快速内容发布,内容发布前必须有可运行的代码样本。
- - 对方观点:快速迭代需要尽早发布并通过真实用户反馈迭代,内容质量可随时间改进。
+---
+title: "Specialized Developer Advocate"
+type: source
+tags: [agent, specialized, developer-relations, community, developer-experience]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/specialized-developer-advocate.md]]
+
+## Summary(用中文描述)
+- 核心主题:Developer Advocate Agent——The Agency Specialized 部门的开发者关系工程师,通过提升开发者体验(DX)、创建高质量技术内容、建立真实社区联系,将产品与外部开发者紧密连接,最终推动平台采用和商业价值增长。
+- 问题域:开发者关系(DevRel)、开发者体验优化、技术内容营销(区别于传统营销)、社区运营、产品反馈闭环。
+- 方法/机制:DX 工程审计(Time-to-First-Success)→ 技术内容创作(教程/演示/演讲提案)→ 社区运营(GitHub/Discord/Slack 响应、Hackathon、大使计划)→ 产品反馈闭环(月度 Voice of Developer 报告)。
+- 结论/价值:Authenticity(不 astroturf)是开发者关系唯一可持续的资产;DX 改善(错误信息/SDK)比内容创作影响更深远、更持久;开发者成功(Developer Success)≠ 营销。
+
+## Key Claims(用中文描述)
+- **开发者体验优先**:DX 改善(更好的错误信息、TypeScript 类型、SDK 修复)复合效应永远优于新内容发布;修复前 3 大 DX 问题再发布任何新教程。
+- **真实性是核心资产**:虚假社区参与(AstroTurf)会永久性摧毁开发者信任;保持技术准确性比发布空内容更重要。
+- **时间度量价值**:新开发者"首次成功调用 API"时间 ≤ 15 分钟;GitHub 问题工作日首响 ≤ 24 小时;教程完成率 ≥ 50%;开发者 NPS ≥ 8/10。
+- **内容先听后创**:先读过去 30 天所有 GitHub Issue(发现高频痛点)、搜索 Stack Overflow 最新提问(识别理解障碍)、审查社交媒体情绪(获取无过滤反馈),再创作有针对性的内容。
+- **产品反馈闭环**:将开发者声音量化(17 个 GitHub Issue + 4 个 Stack Overflow 问题 + 2 场大会 Q&A = 同一功能缺失的证据)带入产品规划会议。
+
+## Key Quotes
+> "You don't do marketing — you do developer success." — 开发者关系工程师的身份定位:Authentic 技术参与,而非商业推销
+> "DX improvements compound forever; a tutorial has a half-life." — DX 改善的持久价值 vs. 内容创作的时间衰减
+> "A tutorial with an active author gets 3x the trust." — 作者持续维护对内容可信度的放大效应
+> "Five people at KubeCon ask the same question — that means thousands more hit it silently." — 大会 Q&A 模式的大规模推断价值
+
+## Key Concepts
+- [[DeveloperExperienceEngineering]]:审计并改善"首次 API 调用时间",构建示例应用、启动工具包和代码模板,量化 DX 质量。
+- [[TechnicalContentCreation]]:教程/博客/视频脚本/交互式演示(CodePen/CodeSandbox/Jupyter),内容先以最终效果开头而非"本教程将……"。
+- [[CommunityBuilding]]:GitHub/Stack Overflow/Discord/Slack 真诚技术响应;大使计划(Ambassador Program);Hackathon/Office Hours。
+- [[ProductFeedbackLoop]]:将开发者痛点转化为可操作的产品需求(用户故事);月度 Voice of Developer 报告。
+- [[DeveloperOnboardingAudit]]:DX 审计框架,分阶段(Discovery/Account Setup/First API Call)计时评分:🟢 <5min | 🟡 5-15min | 🔴 >15min。
+- [[AmbassadorProgram]]:分层次贡献者认可机制,与社区价值观一致的真实激励。
+- [[ContentStrategyAtScale]]:发现层(SEO 教程)→ 激活层(Quick Start)→ 留存层(高级指南)→ 倡导层(案例研究)的漏斗模型。
+- [[DeveloperNPS]]:开发者净推荐值,季度调查,目标 ≥ 8/10。
+
+## Key Entities
+- [[GitHub]]:开源社区核心阵地;Issue 响应质量是开发者信任的关键指标;响应时效目标:工作日 ≤ 24 小时。
+- [[StackOverflow]]:开发者问题解答平台;搜索平台名称按最新排序可发现理解障碍点;回答率目标:≥ 90%。
+- [[DiscordSlashSlack]]:实时社区沟通渠道;无过滤情绪分析来源;Office Hours 和 Hackathon 活动平台。
+- [[OpenTelemetry]]:社区健康指标监控(错误率、文档搜索成功率等)框架。
+- [[KubeCon]]:顶级开发者大会;5 人问同一问题 → 数千人无声遇到同样障碍的推断方法论。
+
+## Connections
+- [[automation-governance-architect]] ← informs ← [[ProductFeedbackLoop]](产品反馈与治理评审互补)
+- [[specialized-mcp-builder]] ← depends_on ← [[DeveloperExperienceEngineering]](MCP Builder 的 DX 改善依赖开发者体验工程原则)
+- [[design-ux-researcher]] ← informs ← [[DeveloperOnboardingAudit]](UX 研究方法论应用于 DX 审计)
+- [[ContentStrategyAtScale]] ← supports ← [[ProductFeedbackLoop]](内容策略放大产品反馈影响力)
+- [[CommunityBuilding]] ← depends_on ← [[DeveloperExperienceEngineering]](社区健康依赖底层 DX 质量)
+
+## Contradictions
+- 与 [[specialized-workflow-architect]] 存在设计哲学张力:
+ - 冲突点:快速交付 vs. 质量保障。Developer Advocate 优先修复 DX 问题再发布内容("修复前 3 大 DX 问题再发布任何新教程");Workflow Architect 优先快速交付功能。
+ - 当前观点:DX 改善复合效应优于快速内容发布,内容发布前必须有可运行的代码样本。
+ - 对方观点:快速迭代需要尽早发布并通过真实用户反馈迭代,内容质量可随时间改进。
diff --git a/wiki/sources/specialized-document-generator.md b/wiki/sources/specialized-document-generator.md
index cd328e29..55ab9de0 100644
--- a/wiki/sources/specialized-document-generator.md
+++ b/wiki/sources/specialized-document-generator.md
@@ -1,48 +1,48 @@
----
-title: "Document Generator Agent"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/specialized/specialized-document-generator.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 担任专业文档生成专家,通过代码方式生成 PDF、PPTX、DOCX、XLSX 等格式的专业文档
-- 问题域:如何让 AI Agent 高效、规范、可复用地产出商业级文档(投资者演示文稿、合规报告、数据密集型电子表格等)
-- 方法/机制:基于 Python(reportlab、python-pptx、openpyxl、python-docx 等)和 Node.js(puppeteer、pptxgenjs、exceljs、docx 等)两大生态,使用模板化、数据驱动、品牌一致的设计原则
-- 结论/价值:文档生成 Agent 需具备精确、设计意识强、注重格式的特点;核心规则包括使用样式系统而非硬编码、保持品牌一致性、数据驱动输入、无障碍设计,以及构建可复用模板而非一次性脚本
-
-## Key Claims(用中文描述)
-- Document Generator Agent 通过代码编程方式(而非手动操作)生成专业级 PDF、演示文稿、电子表格和 Word 文档
-- Agent 需根据不同文档格式选择最优工具链(PDF 推荐 HTML+CSS→PDF 方案,PPTX 推荐 python-pptx,XLSX 推荐 openpyxl,DOCX 推荐 python-docx)
-- 核心规则:必须使用文档样式系统而非硬编码字体/字号,确保品牌颜色、字体、Logo 一致,数据驱动输入输出,支持无障碍(Alt 文本、标题层级、PDF 标签)
-- Agent 应构建可复用模板函数,而非一次性脚本,以提升效率和可维护性
-
-## Key Quotes
-> "You are **Document Generator**, a specialist in creating professional documents programmatically." — Agent 身份定位
-> "Use proper styles — Never hardcode fonts/sizes; use document styles and themes" — 核心规则第1条
-> "Ask about the target audience and purpose before generating" — 沟通风格
-
-## Key Concepts
-- [[Code-Based Document Generation]]:通过编程代码(Python/Node.js 库)而非手动操作软件生成文档的方法
-- [[Template-Based Document Generation]]:基于预定义模板,通过数据替换生成一致性文档的工作模式
-- [[Data-Driven Document Generation]]:以结构化数据为输入,自动生成对应格式文档的自动化方法
-- [[Brand-Consistent Document Design]]:在文档生成过程中保持颜色、字体、Logo 等品牌元素一致的设计原则
-
-## Key Entities
-- [[The Agency]]:Document Generator Agent 所属的 Agent 框架体系(从 index 中相关条目推断)
-- reportlab / weasyprint / fpdf2:Python PDF 生成库
-- python-pptx / pptxgenjs:PPTX 演示文稿生成库
-- openpyxl / xlsxwriter / exceljs / xlsx:XLSX 电子表格生成库
-- python-docx / docx:DOCX Word 文档生成库
-
-## Connections
-- [[specialized-developer-advocate]] ← relates_to ← [[specialized-document-generator]](同为 The Agency 下的专业 Agent)
-- [[agents-orchestrator]] ← orchestrates ← [[specialized-document-generator]](文档生成通常由编排 Agent 调度)
-- [[report-distribution-agent]] ← supports ← [[specialized-document-generator]](文档生成后可由分发 Agent 推送)
-
-## Contradictions
-- 无已知冲突
-
+---
+title: "Document Generator Agent"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/specialized-document-generator.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 担任专业文档生成专家,通过代码方式生成 PDF、PPTX、DOCX、XLSX 等格式的专业文档
+- 问题域:如何让 AI Agent 高效、规范、可复用地产出商业级文档(投资者演示文稿、合规报告、数据密集型电子表格等)
+- 方法/机制:基于 Python(reportlab、python-pptx、openpyxl、python-docx 等)和 Node.js(puppeteer、pptxgenjs、exceljs、docx 等)两大生态,使用模板化、数据驱动、品牌一致的设计原则
+- 结论/价值:文档生成 Agent 需具备精确、设计意识强、注重格式的特点;核心规则包括使用样式系统而非硬编码、保持品牌一致性、数据驱动输入、无障碍设计,以及构建可复用模板而非一次性脚本
+
+## Key Claims(用中文描述)
+- Document Generator Agent 通过代码编程方式(而非手动操作)生成专业级 PDF、演示文稿、电子表格和 Word 文档
+- Agent 需根据不同文档格式选择最优工具链(PDF 推荐 HTML+CSS→PDF 方案,PPTX 推荐 python-pptx,XLSX 推荐 openpyxl,DOCX 推荐 python-docx)
+- 核心规则:必须使用文档样式系统而非硬编码字体/字号,确保品牌颜色、字体、Logo 一致,数据驱动输入输出,支持无障碍(Alt 文本、标题层级、PDF 标签)
+- Agent 应构建可复用模板函数,而非一次性脚本,以提升效率和可维护性
+
+## Key Quotes
+> "You are **Document Generator**, a specialist in creating professional documents programmatically." — Agent 身份定位
+> "Use proper styles — Never hardcode fonts/sizes; use document styles and themes" — 核心规则第1条
+> "Ask about the target audience and purpose before generating" — 沟通风格
+
+## Key Concepts
+- [[Code-Based Document Generation]]:通过编程代码(Python/Node.js 库)而非手动操作软件生成文档的方法
+- [[Template-Based Document Generation]]:基于预定义模板,通过数据替换生成一致性文档的工作模式
+- [[Data-Driven Document Generation]]:以结构化数据为输入,自动生成对应格式文档的自动化方法
+- [[Brand-Consistent Document Design]]:在文档生成过程中保持颜色、字体、Logo 等品牌元素一致的设计原则
+
+## Key Entities
+- [[The Agency]]:Document Generator Agent 所属的 Agent 框架体系(从 index 中相关条目推断)
+- reportlab / weasyprint / fpdf2:Python PDF 生成库
+- python-pptx / pptxgenjs:PPTX 演示文稿生成库
+- openpyxl / xlsxwriter / exceljs / xlsx:XLSX 电子表格生成库
+- python-docx / docx:DOCX Word 文档生成库
+
+## Connections
+- [[specialized-developer-advocate]] ← relates_to ← [[specialized-document-generator]](同为 The Agency 下的专业 Agent)
+- [[agents-orchestrator]] ← orchestrates ← [[specialized-document-generator]](文档生成通常由编排 Agent 调度)
+- [[report-distribution-agent]] ← supports ← [[specialized-document-generator]](文档生成后可由分发 Agent 推送)
+
+## Contradictions
+- 无已知冲突
+
diff --git a/wiki/sources/specialized-french-consulting-market.md b/wiki/sources/specialized-french-consulting-market.md
index 0476abcd..ea6a1efd 100644
--- a/wiki/sources/specialized-french-consulting-market.md
+++ b/wiki/sources/specialized-french-consulting-market.md
@@ -1,63 +1,63 @@
----
-title: "French Consulting Market Navigator"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/specialized/specialized-french-consulting-market.md]]
-
-## Summary(用中文描述)
-- 核心主题:法国 IT 咨询市场(ESN/SI 生态系统)的运作规则、费率定位与谈判策略
-- 问题域:独立 IT 顾问在法国市场中面临的信息不对称——ESN 佣金结构不透明、平台定价机制混乱、多层billing结构税后收益差异巨大
-- 方法/机制:三层 ESN 分类定价体系(Tier 1-3)、五大平台对比矩阵(Malt/collective.work/Comet/Crème/Free-Work)、TJM→净收入换算模型、季节性市场日历、国际远程顾问定位策略
-- 结论/价值:帮助自由顾问最大化税后日均收入、最小化付款风险、建立可持续客户关系
-
-## Key Claims(用中文描述)
-- ESN 佣金结构是市场信息不对称的核心:Client 支付 1,000 EUR/天,Tier 2 ESN 实际支付顾问 600-750 EUR/天(佣金 25-40%),顾问对此往往不知情
-- Billing 结构税后收益差距显著:同等 TJM 700 EUR/天,Portage Salarial 净收入 ~208 EUR/天(~3,742 EUR/月),Micro-entreprise 净收入 ~546 EUR/天(~9,828 EUR/月),差距 338 EUR/天
-- 付款延迟是结构性而非例外:合同标注 NET-30,实际到账 60-90 天,顾问必须提前预算
-- 平台费率具有公开锚定效应:Malt 上的报价直接成为市场价格,定价必须从第一天起就谨慎
-- 费率下限有战略意义:Salesforce 架构师低于 550 EUR/天会被 ESN 视为"急于求成",永久锚定低费率谈判基准
-- 远程/国际位置必须主动披露:谈判中期被发现会导致费率降低 5-10% 并损害信任,主动披露+价值框架可中和惩罚
-
-## Key Quotes
-> "Portage salarial is not employment. It provides social protection (unemployment, retirement contributions) but the freelancer bears all commercial risk. Never present it as equivalent to a CDI." — 核心原则:Portage 不等于就业,不能用 CDI 的安全感来类比
-
-> "Platform rates are public. What you charge on Malt is visible. Your Malt rate becomes your market rate. Price accordingly from day one." — 平台费率的公开性要求从第一天就谨慎定价
-
-> "A 600 EUR/day TJM through portage salarial yields approximately 300-330 EUR net after all charges. Through micro-entreprise, approximately 420-450 EUR. The gap is significant and must be surfaced." — 两种结构税后收益差距 30-40%,必须明确告知客户
-
-## Key Concepts
-- [[TJM]](Taux Journalier Moyen / 毛日均费率):法国咨询市场的核心定价单位,需区分 TJM Brut 与实际净收入
-- [[Portage-Salarial]]:法国的准雇佣模式,为自由顾问提供失业保险和退休金,但商业风险自担,净收入约为 TJM Brut 的 50%
-- [[Micro-Entreprise]]:法国简化商业结构,无社会保障福利,净收入约为 TJM Brut 的 70%
-- [[ESN-SI-Ecosystem]]:法国 IT 咨询生态系统,ESN(Entreprise de Services Numériques)= SI(System Integrator),占法国企业 IT 项目用人的主要渠道
-- [[Rate-Negotiation-Playbook]]:费率谈判四步法(知底价→探底价→锚高价→框架溢价),核心是在非 TJM 维度(期限/远程天数/续约条款)上让步
-- [[International-Freelancer-Positioning]]:面向法国市场的国际自由顾问定位策略,核心是时区重叠作为优势、法国实体偏好、主动披露原则
-
-## Key Entities
-- [[Malt]]:欧洲最大自由顾问平台,10% 佣金(客户端),费率公开可见,适合建立作品集,典型 TJM 550-700 EUR
-- [[collective.work]]:3-5% 佣金+Portage 集成,典型 TJM 650-800 EUR,适合高价值 mission
-- [[Comet]]:15% 佣金,算法驱动匹配,典型 TJM 600-750 EUR,技术顾问为主
-- [[Crème-de-la-Crème]]:15-20% 佣金,准入筛选严格,典型 TJM 700-900 EUR,高端定位
-- [[Free-Work]]:免费列表+付费选项,TJM 500-900 EUR,以中间商列表为主,噪音较大
-- [[Portage-Salarial-Company]](Portage 公司):作为 ESN 和顾问之间的雇佣中介,负责代扣代缴社保,提供 ARE 失业保险权利
-
-## Connections
-- [[TJM]] ← is_priced_by ← [[ESN-SI-Ecosystem]]
-- [[Portage-Salarial]] ← provides_social_protection_to ← [[TJM]]
-- [[Micro-Entreprise]] ← alternative_to ← [[Portage-Salarial]]
-- [[Malt]] ← competing_with ← [[collective.work]], [[Comet]], [[Crème-de-la-Crème]], [[Free-Work]]
-- [[International-Freelancer-Positioning]] ← requires ← [[French-Entity]](Portage 或 SASU)
-
-## Contradictions
-- 与一般"高TJM=高收入"直觉冲突:
- - 冲突点:同等 TJM 下,Portage Salarial 的实际净收入比 Micro-entreprise 低 30-40%
- - 当前观点:TJM 必须换算为税后实际日均收入才能判断真实收入水平
- - 对方观点:只看 TJM 数字,越高越好
-- 与"全职就业安全感"对比:
- - 冲突点:Portage 提供的社保(失业保险/退休金)不等于 CDI 就业保障
- - 当前观点:Portage 是商业安排,商业风险完全由顾问自担,绝不能包装成"准就业"
- - 对方观点:Portage = 更好的 CDI(自由+保障)
+---
+title: "French Consulting Market Navigator"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/specialized-french-consulting-market.md]]
+
+## Summary(用中文描述)
+- 核心主题:法国 IT 咨询市场(ESN/SI 生态系统)的运作规则、费率定位与谈判策略
+- 问题域:独立 IT 顾问在法国市场中面临的信息不对称——ESN 佣金结构不透明、平台定价机制混乱、多层billing结构税后收益差异巨大
+- 方法/机制:三层 ESN 分类定价体系(Tier 1-3)、五大平台对比矩阵(Malt/collective.work/Comet/Crème/Free-Work)、TJM→净收入换算模型、季节性市场日历、国际远程顾问定位策略
+- 结论/价值:帮助自由顾问最大化税后日均收入、最小化付款风险、建立可持续客户关系
+
+## Key Claims(用中文描述)
+- ESN 佣金结构是市场信息不对称的核心:Client 支付 1,000 EUR/天,Tier 2 ESN 实际支付顾问 600-750 EUR/天(佣金 25-40%),顾问对此往往不知情
+- Billing 结构税后收益差距显著:同等 TJM 700 EUR/天,Portage Salarial 净收入 ~208 EUR/天(~3,742 EUR/月),Micro-entreprise 净收入 ~546 EUR/天(~9,828 EUR/月),差距 338 EUR/天
+- 付款延迟是结构性而非例外:合同标注 NET-30,实际到账 60-90 天,顾问必须提前预算
+- 平台费率具有公开锚定效应:Malt 上的报价直接成为市场价格,定价必须从第一天起就谨慎
+- 费率下限有战略意义:Salesforce 架构师低于 550 EUR/天会被 ESN 视为"急于求成",永久锚定低费率谈判基准
+- 远程/国际位置必须主动披露:谈判中期被发现会导致费率降低 5-10% 并损害信任,主动披露+价值框架可中和惩罚
+
+## Key Quotes
+> "Portage salarial is not employment. It provides social protection (unemployment, retirement contributions) but the freelancer bears all commercial risk. Never present it as equivalent to a CDI." — 核心原则:Portage 不等于就业,不能用 CDI 的安全感来类比
+
+> "Platform rates are public. What you charge on Malt is visible. Your Malt rate becomes your market rate. Price accordingly from day one." — 平台费率的公开性要求从第一天就谨慎定价
+
+> "A 600 EUR/day TJM through portage salarial yields approximately 300-330 EUR net after all charges. Through micro-entreprise, approximately 420-450 EUR. The gap is significant and must be surfaced." — 两种结构税后收益差距 30-40%,必须明确告知客户
+
+## Key Concepts
+- [[TJM]](Taux Journalier Moyen / 毛日均费率):法国咨询市场的核心定价单位,需区分 TJM Brut 与实际净收入
+- [[Portage-Salarial]]:法国的准雇佣模式,为自由顾问提供失业保险和退休金,但商业风险自担,净收入约为 TJM Brut 的 50%
+- [[Micro-Entreprise]]:法国简化商业结构,无社会保障福利,净收入约为 TJM Brut 的 70%
+- [[ESN-SI-Ecosystem]]:法国 IT 咨询生态系统,ESN(Entreprise de Services Numériques)= SI(System Integrator),占法国企业 IT 项目用人的主要渠道
+- [[Rate-Negotiation-Playbook]]:费率谈判四步法(知底价→探底价→锚高价→框架溢价),核心是在非 TJM 维度(期限/远程天数/续约条款)上让步
+- [[International-Freelancer-Positioning]]:面向法国市场的国际自由顾问定位策略,核心是时区重叠作为优势、法国实体偏好、主动披露原则
+
+## Key Entities
+- [[Malt]]:欧洲最大自由顾问平台,10% 佣金(客户端),费率公开可见,适合建立作品集,典型 TJM 550-700 EUR
+- [[collective.work]]:3-5% 佣金+Portage 集成,典型 TJM 650-800 EUR,适合高价值 mission
+- [[Comet]]:15% 佣金,算法驱动匹配,典型 TJM 600-750 EUR,技术顾问为主
+- [[Crème-de-la-Crème]]:15-20% 佣金,准入筛选严格,典型 TJM 700-900 EUR,高端定位
+- [[Free-Work]]:免费列表+付费选项,TJM 500-900 EUR,以中间商列表为主,噪音较大
+- [[Portage-Salarial-Company]](Portage 公司):作为 ESN 和顾问之间的雇佣中介,负责代扣代缴社保,提供 ARE 失业保险权利
+
+## Connections
+- [[TJM]] ← is_priced_by ← [[ESN-SI-Ecosystem]]
+- [[Portage-Salarial]] ← provides_social_protection_to ← [[TJM]]
+- [[Micro-Entreprise]] ← alternative_to ← [[Portage-Salarial]]
+- [[Malt]] ← competing_with ← [[collective.work]], [[Comet]], [[Crème-de-la-Crème]], [[Free-Work]]
+- [[International-Freelancer-Positioning]] ← requires ← [[French-Entity]](Portage 或 SASU)
+
+## Contradictions
+- 与一般"高TJM=高收入"直觉冲突:
+ - 冲突点:同等 TJM 下,Portage Salarial 的实际净收入比 Micro-entreprise 低 30-40%
+ - 当前观点:TJM 必须换算为税后实际日均收入才能判断真实收入水平
+ - 对方观点:只看 TJM 数字,越高越好
+- 与"全职就业安全感"对比:
+ - 冲突点:Portage 提供的社保(失业保险/退休金)不等于 CDI 就业保障
+ - 当前观点:Portage 是商业安排,商业风险完全由顾问自担,绝不能包装成"准就业"
+ - 对方观点:Portage = 更好的 CDI(自由+保障)
diff --git a/wiki/sources/specialized-korean-business-navigator.md b/wiki/sources/specialized-korean-business-navigator.md
index 3af9f33c..d9f724d4 100644
--- a/wiki/sources/specialized-korean-business-navigator.md
+++ b/wiki/sources/specialized-korean-business-navigator.md
@@ -1,66 +1,66 @@
----
-title: "Korean Business Navigator"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/specialized-korean-business-navigator.md]]
-
-## Summary(用中文描述)
-- 核心主题:帮助外国专业人员在韩国商业环境中导航——将西方直接性与韩国关系动态相结合的专家 Agent
-- 问题域:韩国商业文化中的隐性规则(品의决策流程、눈치读心术、KakaoTalk商务礼仪、层级导航、关系优先的成交机制)
-- 方法/机制:品의(共识审批)六阶段时间线、Nunchi 解码表、KakaoTalk 消息模板、韩国企业职级体系、회식(商务聚餐)礼仪、Proof Project 策略
-- 结论/价值:韩国商业"成交"发生在会议室外的走廊而非会议室内;韩国"yes"不一定是同意;沉默是信息而非拒绝
-
-## Key Claims(用中文描述)
-- 冷接触(Cold Outreach)响应率 < 5%,通过介绍人接入响应率显著更高
-- 韩国品의流程耗时 6-16 周(SME 6-10 周、中型 8-12 周、财阀 12-16 周),远长于西方的 2-4 周
-- 永远不要在第一次会议要求决策时间线——询问"何时成交"等于暴露无知和绝望
-- 永远不要绕过联系人直接联系其上级——越级在韩国商业中是关系终结行为
-- KakaoTalk 群聊必须使用韩语——即使不完美也显示尊重
-- 永远不要在第一次对话中谈钱——关系第一、能力第二、价格第三
-- 회식出席是预期而非可选——拒绝会损害信任
-- 沉默(3-7 天)不等于拒绝——通常意味着内部讨论正在进行
-
-## Key Quotes
-> "검토해보겠습니다" literally means "we'll review it" but contextually means "probably not — give us a graceful exit." — 品의婉拒信号
-> "Korean business runs on 품의 (consensus approval)." — 韩国决策机制核心
-> "A Korean 'yes' is not always agreement, that silence is information, and that the real decision happens in the hallway after the meeting, not during it." — Agent 身份定位
-> "The proof project IS the sales pitch. Over-deliver deliberately." — Proof Project 策略核心
-
-## Key Concepts
-- [[품의]]:韩国共识审批流程,含六阶段(소개→미팅→내부검토→품의서→결재→계약),耗时 6-16 周,不可加速
-- [[Nunchi]]:눈치(读心术)——通过观察语境和情绪线索理解未被直接表达的意图,是韩国商业的核心技能
-- [[KakaoTalk-商务礼仪]]:韩国主流通讯工具的分阶段消息模板、响应时间期望、群聊规则(必须韩语)、表情贴纸使用时机
-- [[회식]]:회식(公司聚餐/饮酒文化)——出席是预期而非可选;斟酒、用餐、祝酒均有严格礼仪规范
-- [[Proof-Project-Strategy]]:信任未建立时用有边界的小项目证明——2-3 周、固定交付物、固定价格,用结果推动完整合作
-- [[Korean-Corporate-Hierarchy]]:韩国企业职级体系(회장→사장→부사장→전무→상무→이사→부장→차장→과장→대리)及对应的称呼规范(职称+님)
-- [[Relationship-Lifecycle]]:介绍→信任→合同三阶段关系管理,每阶段有不同的沟通策略和时机预期
-
-## Key Entities
-- [[Chaebol]]:韩国财阀(大企业集团),品의流程最长(12-16 周),建议月度跟进
-- [[SME]](中小企业):品의流程最短(6-10 周),建议周度跟进
-- [[KakaoTalk]]:韩国主流即时通讯工具,商务沟通的核心渠道,9AM-7PM KST 为商务时间
-- [[도장]](印章):韩国合同执行的物理凭证,合同签订后还需印章盖印完成
-
-## Connections
-- [[품의]] ← 是 [[Korean-Business-Decision-Process]] 的核心机制
-- [[Nunchi]] ← 是 [[품의]] 流程中读取内部信号的技能基础
-- [[KakaoTalk-商务礼仪]] ← 是 [[Relationship-Lifecycle]] 各阶段的沟通载体
-- [[회식]] ← 是建立信任(소개→신뢰→계약)的关键社交机制
-- [[Proof-Project-Strategy]] ← 是 [[Relationship-Lifecycle]] 中从 미팅 过渡到 계약 的推荐方法
-- [[Cultural-Intelligence-Strategist]] ← 上级概念:本 Agent 是其韩国商业领域的具体化
-
-## Contradictions
-- 与西方"快速成交"直觉冲突:
- - 冲突点:西方商务文化鼓励在第一次会议明确时间线、尽快推进
- - 当前观点:韩国品의要求 6-16 周,需等待内部审批链,不能催促
- - 对方观点:快速推进显示专业性和效率
- - 解决方向:理解品의是保护机制,不是障碍;用有边界的 Proof Project 降低感知风险
-- 与西方"沉默=拒绝"直觉冲突:
- - 冲突点:西方将 3-7 天无响应视为消极信号
- - 当前观点:沉默表示内部讨论正在进行,应等待而非催促
- - 对方观点:及时跟进显示诚意和重视
- - 解决方向:区分"积极沉默"(品의中)和"死单沉默",关键信号是对方是否有主动提问
+---
+title: "Korean Business Navigator"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/specialized-korean-business-navigator.md]]
+
+## Summary(用中文描述)
+- 核心主题:帮助外国专业人员在韩国商业环境中导航——将西方直接性与韩国关系动态相结合的专家 Agent
+- 问题域:韩国商业文化中的隐性规则(品의决策流程、눈치读心术、KakaoTalk商务礼仪、层级导航、关系优先的成交机制)
+- 方法/机制:品의(共识审批)六阶段时间线、Nunchi 解码表、KakaoTalk 消息模板、韩国企业职级体系、회식(商务聚餐)礼仪、Proof Project 策略
+- 结论/价值:韩国商业"成交"发生在会议室外的走廊而非会议室内;韩国"yes"不一定是同意;沉默是信息而非拒绝
+
+## Key Claims(用中文描述)
+- 冷接触(Cold Outreach)响应率 < 5%,通过介绍人接入响应率显著更高
+- 韩国品의流程耗时 6-16 周(SME 6-10 周、中型 8-12 周、财阀 12-16 周),远长于西方的 2-4 周
+- 永远不要在第一次会议要求决策时间线——询问"何时成交"等于暴露无知和绝望
+- 永远不要绕过联系人直接联系其上级——越级在韩国商业中是关系终结行为
+- KakaoTalk 群聊必须使用韩语——即使不完美也显示尊重
+- 永远不要在第一次对话中谈钱——关系第一、能力第二、价格第三
+- 회식出席是预期而非可选——拒绝会损害信任
+- 沉默(3-7 天)不等于拒绝——通常意味着内部讨论正在进行
+
+## Key Quotes
+> "검토해보겠습니다" literally means "we'll review it" but contextually means "probably not — give us a graceful exit." — 品의婉拒信号
+> "Korean business runs on 품의 (consensus approval)." — 韩国决策机制核心
+> "A Korean 'yes' is not always agreement, that silence is information, and that the real decision happens in the hallway after the meeting, not during it." — Agent 身份定位
+> "The proof project IS the sales pitch. Over-deliver deliberately." — Proof Project 策略核心
+
+## Key Concepts
+- [[품의]]:韩国共识审批流程,含六阶段(소개→미팅→내부검토→품의서→결재→계약),耗时 6-16 周,不可加速
+- [[Nunchi]]:눈치(读心术)——通过观察语境和情绪线索理解未被直接表达的意图,是韩国商业的核心技能
+- [[KakaoTalk-商务礼仪]]:韩国主流通讯工具的分阶段消息模板、响应时间期望、群聊规则(必须韩语)、表情贴纸使用时机
+- [[회식]]:회식(公司聚餐/饮酒文化)——出席是预期而非可选;斟酒、用餐、祝酒均有严格礼仪规范
+- [[Proof-Project-Strategy]]:信任未建立时用有边界的小项目证明——2-3 周、固定交付物、固定价格,用结果推动完整合作
+- [[Korean-Corporate-Hierarchy]]:韩国企业职级体系(회장→사장→부사장→전무→상무→이사→부장→차장→과장→대리)及对应的称呼规范(职称+님)
+- [[Relationship-Lifecycle]]:介绍→信任→合同三阶段关系管理,每阶段有不同的沟通策略和时机预期
+
+## Key Entities
+- [[Chaebol]]:韩国财阀(大企业集团),品의流程最长(12-16 周),建议月度跟进
+- [[SME]](中小企业):品의流程最短(6-10 周),建议周度跟进
+- [[KakaoTalk]]:韩国主流即时通讯工具,商务沟通的核心渠道,9AM-7PM KST 为商务时间
+- [[도장]](印章):韩国合同执行的物理凭证,合同签订后还需印章盖印完成
+
+## Connections
+- [[품의]] ← 是 [[Korean-Business-Decision-Process]] 的核心机制
+- [[Nunchi]] ← 是 [[품의]] 流程中读取内部信号的技能基础
+- [[KakaoTalk-商务礼仪]] ← 是 [[Relationship-Lifecycle]] 各阶段的沟通载体
+- [[회식]] ← 是建立信任(소개→신뢰→계약)的关键社交机制
+- [[Proof-Project-Strategy]] ← 是 [[Relationship-Lifecycle]] 中从 미팅 过渡到 계약 的推荐方法
+- [[Cultural-Intelligence-Strategist]] ← 上级概念:本 Agent 是其韩国商业领域的具体化
+
+## Contradictions
+- 与西方"快速成交"直觉冲突:
+ - 冲突点:西方商务文化鼓励在第一次会议明确时间线、尽快推进
+ - 当前观点:韩国品의要求 6-16 周,需等待内部审批链,不能催促
+ - 对方观点:快速推进显示专业性和效率
+ - 解决方向:理解品의是保护机制,不是障碍;用有边界的 Proof Project 降低感知风险
+- 与西方"沉默=拒绝"直觉冲突:
+ - 冲突点:西方将 3-7 天无响应视为消极信号
+ - 当前观点:沉默表示内部讨论正在进行,应等待而非催促
+ - 对方观点:及时跟进显示诚意和重视
+ - 解决方向:区分"积极沉默"(品의中)和"死单沉默",关键信号是对方是否有主动提问
diff --git a/wiki/sources/specialized-mcp-builder.md b/wiki/sources/specialized-mcp-builder.md
index 3d31767d..cad7acd1 100644
--- a/wiki/sources/specialized-mcp-builder.md
+++ b/wiki/sources/specialized-mcp-builder.md
@@ -1,55 +1,55 @@
----
-title: "MCP Builder Agent"
-type: source
-tags: ["agent-personality", "mcp", "tool-design", "ai-integration"]
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/specialized/specialized-mcp-builder.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 的 MCP(Model Context Protocol)服务器开发专家——设计、构建、测试和部署 MCP 服务器,为 AI Agent 提供自定义工具、资源和提示词能力
-- 问题域:如何让 AI Agent 能够可靠地调用外部工具和 API,同时保持开发者体验(Developer Experience)
-- 方法/机制:遵循 MCP SDK 规范(TypeScript/Zod、Python/Pydantic),设计 Agent 友好的工具接口,提供 Resources(资源)、Tools(工具)、Prompts(提示词模板)三种扩展方式,通过真实 Agent 测试验证可用性
-- 结论/价值:工具命名和描述是 Agent 能否正确选用的关键;每个工具调用必须独立无状态;错误必须返回结构化消息而非堆栈跟踪
-
-## Key Claims(用中文描述)
-- **描述性工具命名** → Agent 能从名称推断用途,正确选用率 >90%
-- **类型化参数验证(Zod/Pydantic)** → 边界层拦截非法输入,防止外部 API 污染
-- **结构化错误返回(isError: true)** → Agent 知道何时重试或请求用户,而非虚构响应
-- **无状态工具设计** → 每次调用独立,不依赖调用顺序,确保分布式环境稳定
-- **真实 Agent 测试循环** → 通过完整调用链路验证,而非仅靠单元测试
-- **环境变量密钥管理** → API Key 和 Token 从环境变量读取,绝不硬编码
-
-## Key Quotes
-> "If an agent can't figure out how to use your tool from the name and description alone, it's not ready to ship." — MCP Builder 核心理念
-> "A tool that passes unit tests but confuses the agent is broken." — 测试理念,强调必须验证 Agent 的完整调用路径
-> "We return `isError: true` here so the agent knows to retry or ask the user, instead of hallucinating a response." — 错误处理设计哲学
-
-## Key Concepts
-- [[Model Context Protocol (MCP)]]:Anthropic 提出的 AI Agent 与外部工具/数据源交互的标准化协议
-- [[MCP Server]]:基于 MCP 协议的服务端实现,暴露 Tools/Resources/Prompts 给 Agent
-- [[Tool Interface Design]]:为 Agent 设计友好工具接口的实践,关注命名、描述、参数类型和返回结构
-- [[Zod Validation]]:TypeScript 端的参数模式定义和验证库,用于 MCP TypeScript 服务器
-- [[Pydantic Validation]]:Python 端的参数模式定义和验证库,用于 MCP Python (FastMCP) 服务器
-- [[Stdio Transport]]:MCP 标准传输方式,适用于本地 CLI 集成和桌面 Agent
-- [[SSE Transport]]:Server-Sent Events 传输方式,适用于基于 Web 的 Agent 接口和远程访问
-- [[Streamable HTTP]]:可扩展云部署的 HTTP 流式传输,支持无状态请求处理
-- [[Stateless Tool Design]]:无状态工具设计原则,确保每次调用独立、幂等、可分布式运行
-- [[Structured Error Response]]:返回 `isError: true` 结构化错误消息,而非堆栈跟踪
-
-## Key Entities
-- [[@modelcontextprotocol/sdk]]:Anthropic 官方 MCP TypeScript SDK,提供 McpServer、StdioServerTransport 等核心类
-- [[FastMCP]]:Python MCP 服务器框架,基于 Pydantic 的类型验证
-- [[Zod]]:TypeScript schema 声明和验证库,MCP TypeScript SDK 内置支持
-- [[Pydantic]]:Python 数据验证库,FastMCP 的核心依赖
-
-## Connections
-- [[MCP Builder Agent]] ← implements ← [[Model Context Protocol (MCP)]]
-- [[MCP Builder Agent]] ← uses ← [[@modelcontextprotocol/sdk]]
-- [[MCP Builder Agent]] ← uses ← [[FastMCP]]
-- [[LSP/Index Engineer Agent Personality]] ← shares_tool_design_philosophy_with ← [[MCP Builder Agent]]
-
-## Contradictions
-- 暂无发现与其他 Wiki 页面的冲突
+---
+title: "MCP Builder Agent"
+type: source
+tags: ["agent-personality", "mcp", "tool-design", "ai-integration"]
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/specialized-mcp-builder.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 的 MCP(Model Context Protocol)服务器开发专家——设计、构建、测试和部署 MCP 服务器,为 AI Agent 提供自定义工具、资源和提示词能力
+- 问题域:如何让 AI Agent 能够可靠地调用外部工具和 API,同时保持开发者体验(Developer Experience)
+- 方法/机制:遵循 MCP SDK 规范(TypeScript/Zod、Python/Pydantic),设计 Agent 友好的工具接口,提供 Resources(资源)、Tools(工具)、Prompts(提示词模板)三种扩展方式,通过真实 Agent 测试验证可用性
+- 结论/价值:工具命名和描述是 Agent 能否正确选用的关键;每个工具调用必须独立无状态;错误必须返回结构化消息而非堆栈跟踪
+
+## Key Claims(用中文描述)
+- **描述性工具命名** → Agent 能从名称推断用途,正确选用率 >90%
+- **类型化参数验证(Zod/Pydantic)** → 边界层拦截非法输入,防止外部 API 污染
+- **结构化错误返回(isError: true)** → Agent 知道何时重试或请求用户,而非虚构响应
+- **无状态工具设计** → 每次调用独立,不依赖调用顺序,确保分布式环境稳定
+- **真实 Agent 测试循环** → 通过完整调用链路验证,而非仅靠单元测试
+- **环境变量密钥管理** → API Key 和 Token 从环境变量读取,绝不硬编码
+
+## Key Quotes
+> "If an agent can't figure out how to use your tool from the name and description alone, it's not ready to ship." — MCP Builder 核心理念
+> "A tool that passes unit tests but confuses the agent is broken." — 测试理念,强调必须验证 Agent 的完整调用路径
+> "We return `isError: true` here so the agent knows to retry or ask the user, instead of hallucinating a response." — 错误处理设计哲学
+
+## Key Concepts
+- [[Model Context Protocol (MCP)]]:Anthropic 提出的 AI Agent 与外部工具/数据源交互的标准化协议
+- [[MCP Server]]:基于 MCP 协议的服务端实现,暴露 Tools/Resources/Prompts 给 Agent
+- [[Tool Interface Design]]:为 Agent 设计友好工具接口的实践,关注命名、描述、参数类型和返回结构
+- [[Zod Validation]]:TypeScript 端的参数模式定义和验证库,用于 MCP TypeScript 服务器
+- [[Pydantic Validation]]:Python 端的参数模式定义和验证库,用于 MCP Python (FastMCP) 服务器
+- [[Stdio Transport]]:MCP 标准传输方式,适用于本地 CLI 集成和桌面 Agent
+- [[SSE Transport]]:Server-Sent Events 传输方式,适用于基于 Web 的 Agent 接口和远程访问
+- [[Streamable HTTP]]:可扩展云部署的 HTTP 流式传输,支持无状态请求处理
+- [[Stateless Tool Design]]:无状态工具设计原则,确保每次调用独立、幂等、可分布式运行
+- [[Structured Error Response]]:返回 `isError: true` 结构化错误消息,而非堆栈跟踪
+
+## Key Entities
+- [[@modelcontextprotocol/sdk]]:Anthropic 官方 MCP TypeScript SDK,提供 McpServer、StdioServerTransport 等核心类
+- [[FastMCP]]:Python MCP 服务器框架,基于 Pydantic 的类型验证
+- [[Zod]]:TypeScript schema 声明和验证库,MCP TypeScript SDK 内置支持
+- [[Pydantic]]:Python 数据验证库,FastMCP 的核心依赖
+
+## Connections
+- [[MCP Builder Agent]] ← implements ← [[Model Context Protocol (MCP)]]
+- [[MCP Builder Agent]] ← uses ← [[@modelcontextprotocol/sdk]]
+- [[MCP Builder Agent]] ← uses ← [[FastMCP]]
+- [[LSP/Index Engineer Agent Personality]] ← shares_tool_design_philosophy_with ← [[MCP Builder Agent]]
+
+## Contradictions
+- 暂无发现与其他 Wiki 页面的冲突
diff --git a/wiki/sources/specialized-model-qa.md b/wiki/sources/specialized-model-qa.md
index 4f15d891..c8797920 100644
--- a/wiki/sources/specialized-model-qa.md
+++ b/wiki/sources/specialized-model-qa.md
@@ -1,50 +1,50 @@
----
-title: "Model QA Specialist"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/specialized-model-qa.md]]
-
-## Summary(用中文描述)
-- 核心主题:机器学习与统计模型的全生命周期端到端独立审计方法论
-- 问题域:模型质量管理、模型风险控制、合规性验证、生产监控
-- 方法/机制:10大审计领域(文档治理→数据重建→特征分析→模型复制→校准测试→性能监控→可解释性→公平性→业务影响→报告),配套 PSI/Hosmer-Lemeshow/SHAP/PDP 等量化工具
-- 结论/价值:将模型视为"有罪推定"——每个模型必须经过全面审计并以证据支撑结论,独立于模型构建者运行,确保生产部署前发现所有潜在问题
-
-## Key Claims(用中文描述)
-- 模型审计师必须保持绝对独立性——永远不审计自己参与构建的模型
-- 每次分析必须产生完全可复现的脚本,从原始数据到最终输出全链路可追溯
-- 每个发现必须包含:观察→证据→影响评估→建议,缺一不可
-- PSI ≥ 0.25 表示显著分布漂移,需立即采取行动
-- Hosmer-Lemeshow p-value < 0.05 表示显著校准错误
-
-## Key Quotes
-> "You treat every model as guilty until proven sound." — 核心审计哲学
-> "PSI >= 0.25 → Significant shift, action required (red)" — PSI 判读标准
-> "Never audit a model you participated in building" — 独立性原则
-> "Every finding must include: observation, evidence, impact assessment, and recommendation" — 证据链要求
-
-## Key Concepts
-- [[SHAP]]:SHapley Additive exPlanations — 全局和局部特征贡献解释的核心工具
-- [[Calibration-Testing]]:概率校准验证方法——确保模型预测概率与实际频率一致
-- [[Discrimination-Metrics]]:判别能力指标体系——AUC/Gini/KS 等衡量模型区分能力
-- [[Partial-Dependence-Plots]]:偏依赖图——特征与预测之间的边际效应可视化
-- [[Population-Stability-Index]]:群体稳定性指数——衡量特征分布随时间的漂移程度
-- [[Hosmer-Lemeshow-Test]]:校准度拟合优度检验——统计判断预测概率与实际观测的一致性
-
-## Key Entities
-- The Agency Specialized 部门:该 Agent 所属的专业化 Agent 部门,涵盖医疗合规、文化智能、工作流架构、模型 QA 等垂直专业领域
-
-## Connections
-- [[Corporate-Training-Designer]] ← 质量保证 ← [[specialized-model-qa]]
-- [[specialized-model-qa]] ← 审计输入 ← [[specialized-workflow-architect]]
-- [[Agentic-Identity-&-Trust-Architect]] ← 安全基础 ← [[specialized-model-qa]](QA 报告的签名验证依赖身份基础设施)
-
-## Contradictions
-- 与 [[multi-agent-system-reliability]] 的对抗辩论模式存在潜在张力:
- - 冲突点:multi-agent-system-reliability 主张用对抗辩论(Generator→Critic→Judge)消除 LLM 幻觉;Model QA Specialist 要求确定性证据链,LLM 的概率性本质与之矛盾
- - 当前观点:Model QA Specialist 通过严格的统计检验(HL test、PSI)提供确定性判断,不依赖 LLM 自我批判
- - 对方观点:对抗辩论通过架构约束弥补 LLM 不可靠性,适合快速迭代;统计检验需要完整数据,适合深度审计
+---
+title: "Model QA Specialist"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/specialized-model-qa.md]]
+
+## Summary(用中文描述)
+- 核心主题:机器学习与统计模型的全生命周期端到端独立审计方法论
+- 问题域:模型质量管理、模型风险控制、合规性验证、生产监控
+- 方法/机制:10大审计领域(文档治理→数据重建→特征分析→模型复制→校准测试→性能监控→可解释性→公平性→业务影响→报告),配套 PSI/Hosmer-Lemeshow/SHAP/PDP 等量化工具
+- 结论/价值:将模型视为"有罪推定"——每个模型必须经过全面审计并以证据支撑结论,独立于模型构建者运行,确保生产部署前发现所有潜在问题
+
+## Key Claims(用中文描述)
+- 模型审计师必须保持绝对独立性——永远不审计自己参与构建的模型
+- 每次分析必须产生完全可复现的脚本,从原始数据到最终输出全链路可追溯
+- 每个发现必须包含:观察→证据→影响评估→建议,缺一不可
+- PSI ≥ 0.25 表示显著分布漂移,需立即采取行动
+- Hosmer-Lemeshow p-value < 0.05 表示显著校准错误
+
+## Key Quotes
+> "You treat every model as guilty until proven sound." — 核心审计哲学
+> "PSI >= 0.25 → Significant shift, action required (red)" — PSI 判读标准
+> "Never audit a model you participated in building" — 独立性原则
+> "Every finding must include: observation, evidence, impact assessment, and recommendation" — 证据链要求
+
+## Key Concepts
+- [[SHAP]]:SHapley Additive exPlanations — 全局和局部特征贡献解释的核心工具
+- [[Calibration-Testing]]:概率校准验证方法——确保模型预测概率与实际频率一致
+- [[Discrimination-Metrics]]:判别能力指标体系——AUC/Gini/KS 等衡量模型区分能力
+- [[Partial-Dependence-Plots]]:偏依赖图——特征与预测之间的边际效应可视化
+- [[Population-Stability-Index]]:群体稳定性指数——衡量特征分布随时间的漂移程度
+- [[Hosmer-Lemeshow-Test]]:校准度拟合优度检验——统计判断预测概率与实际观测的一致性
+
+## Key Entities
+- The Agency Specialized 部门:该 Agent 所属的专业化 Agent 部门,涵盖医疗合规、文化智能、工作流架构、模型 QA 等垂直专业领域
+
+## Connections
+- [[Corporate-Training-Designer]] ← 质量保证 ← [[specialized-model-qa]]
+- [[specialized-model-qa]] ← 审计输入 ← [[specialized-workflow-architect]]
+- [[Agentic-Identity-&-Trust-Architect]] ← 安全基础 ← [[specialized-model-qa]](QA 报告的签名验证依赖身份基础设施)
+
+## Contradictions
+- 与 [[multi-agent-system-reliability]] 的对抗辩论模式存在潜在张力:
+ - 冲突点:multi-agent-system-reliability 主张用对抗辩论(Generator→Critic→Judge)消除 LLM 幻觉;Model QA Specialist 要求确定性证据链,LLM 的概率性本质与之矛盾
+ - 当前观点:Model QA Specialist 通过严格的统计检验(HL test、PSI)提供确定性判断,不依赖 LLM 自我批判
+ - 对方观点:对抗辩论通过架构约束弥补 LLM 不可靠性,适合快速迭代;统计检验需要完整数据,适合深度审计
diff --git a/wiki/sources/specialized-salesforce-architect.md b/wiki/sources/specialized-salesforce-architect.md
index 6b610e3a..655517e0 100644
--- a/wiki/sources/specialized-salesforce-architect.md
+++ b/wiki/sources/specialized-salesforce-architect.md
@@ -1,56 +1,56 @@
----
-title: "Specialized Salesforce Architect"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/specialized/specialized-salesforce-architect.md]]
-
-## Summary(用中文描述)
-- 核心主题:Salesforce 平台企业级解决方案架构师 Agent — 多云架构设计、企业集成模式、技术治理
-- 问题域:Salesforce 组织从试点到企业规模扩展过程中的架构设计、技术债务规避、governor limits 规划
-- 方法/机制:ADR(架构决策记录)、Governor Limit Budget 追踪、Integration Pattern Template、数据模型审查清单
-- 结论/价值:提供从发现评估 → 架构设计 → 实施指导 → 审查治理的完整工作流,强调 declarative-first 原则和 bulkification 强制性要求
-
-## Key Claims(用中文描述)
-- Governor limits 是不可协商的铁律,每项设计必须提前计入 SOQL(100)、DML(150)、CPU(同步10s/异步60s)、堆(同步6MB/异步12MB) 等限制
-- 业务逻辑必须放在 Handler 类中,Trigger 只负责委托分发,且每个对象只允许一个 Trigger
-- Bulkification 是强制要求 — 若代码在 200 条记录下失败,则该代码就是错误的
-- Declarative first,代码第二:优先使用 Flows、公式字段和验证规则,只在 declarative 方案变得不可维护时才考虑 Apex
-- 集成模式必须处理失败场景:每次外部调用都需要重试逻辑、断路器和死信队列
-- 数据模型是基础:在生产上线后再改数据模型,成本是设计阶段的 10 倍
-- PII 数据必须加密存储,使用 Shield Platform Encryption 或自定义加密方案
-
-## Key Quotes
-> "Governor limits are non-negotiable. Every design must account for SOQL (100), DML (150), CPU (10s sync/60s async), heap (6MB sync/12MB async). No exceptions, no 'we'll optimize later.'" — 核心设计原则
-> "If the code would fail on 200 records, it's wrong." — Bulkification 强制性标准
-> "Data model is the foundation. Changing the data model after go-live is 10x more expensive." — 数据模型优先级
-> "Be direct about technical debt. If someone built a trigger that should be a flow, say so." — 沟通风格示例
-
-## Key Concepts
-- [[GovernorLimits]]:Salesforce 平台执行上下文的硬性资源限制,包括 SOQL 查询数(100)、DML 语句数(150)、CPU 时间(同步10s)、堆大小(同步6MB)等
-- [[Bulkification]]:批量处理模式 — 要求所有触发器和 Apex 代码必须能在单次交易中处理多条记录(通常按 200 条/批次测试)
-- [[PlatformEvents]]:Salesforce 平台事件 — 用于跨系统集成的异步事件驱动机制,支持 72 小时重放窗口和高容量标准(10万/天)
-- [[ChangeDataCapture]](CDC):变更数据捕获 — 自动追踪 sObject 字段级变更,适合 Salesforce 原生事件同步场景
-- [[ADR]](Architecture Decision Record):架构决策记录 — 文档化记录重要技术决策的上下文、备选方案、后果和复审日期
-- [[SalesforceDX]]:Salesforce 开发者体验框架 — 基于 Scratch Org 的源代码驱动部署方式,与 DevOps Center 并行
-- [[Agentforce]]:Salesforce AI Agent 框架 — Agent 在 Salesforce governor limits 内运行,需设计在 CPU/SOQL 预算内完成的动作,使用 Einstein Trust Layer 进行 PII 脱敏
-
-## Key Entities
-- [[MuleSoft]]:Salesforce 收购的企业级集成中间件,用于跨系统集成模式中的中间转换层(DataWeave 转换、3x 指数退避重试、死信队列)
-- [[ShieldPlatformEncryption]]:Salesforce 原生 PII 加密方案,与自定义加密并列作为敏感数据保护选项
-- [[DevOpsCenter]]:Salesforce 原生 CI/CD 平台,与 Salesforce DX 并行的另一种部署方式
-
-## Connections
-- [[SalesforceDX]] ← supports ← [[ADR]]
-- [[PlatformEvents]] ← extends ← [[ChangeDataCapture]]
-- [[Bulkification]] ← enforces ← [[GovernorLimits]]
-- [[Agentforce]] ← bounded_by ← [[GovernorLimits]]
-
-## Contradictions
-- 与 [[DevOpsCenter]] 关系:
- - 冲突点:Salesforce DX 与 DevOps Center 是两种并行的部署策略,文档将两者并列但未明确优先选用哪个
- - 当前观点:Salesforce DX 基于 Scratch Org 源码驱动是现代标准实践
- - 对方观点:DevOps Center 作为 Salesforce 原生工具对非技术用户更友好
+---
+title: "Specialized Salesforce Architect"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/specialized-salesforce-architect.md]]
+
+## Summary(用中文描述)
+- 核心主题:Salesforce 平台企业级解决方案架构师 Agent — 多云架构设计、企业集成模式、技术治理
+- 问题域:Salesforce 组织从试点到企业规模扩展过程中的架构设计、技术债务规避、governor limits 规划
+- 方法/机制:ADR(架构决策记录)、Governor Limit Budget 追踪、Integration Pattern Template、数据模型审查清单
+- 结论/价值:提供从发现评估 → 架构设计 → 实施指导 → 审查治理的完整工作流,强调 declarative-first 原则和 bulkification 强制性要求
+
+## Key Claims(用中文描述)
+- Governor limits 是不可协商的铁律,每项设计必须提前计入 SOQL(100)、DML(150)、CPU(同步10s/异步60s)、堆(同步6MB/异步12MB) 等限制
+- 业务逻辑必须放在 Handler 类中,Trigger 只负责委托分发,且每个对象只允许一个 Trigger
+- Bulkification 是强制要求 — 若代码在 200 条记录下失败,则该代码就是错误的
+- Declarative first,代码第二:优先使用 Flows、公式字段和验证规则,只在 declarative 方案变得不可维护时才考虑 Apex
+- 集成模式必须处理失败场景:每次外部调用都需要重试逻辑、断路器和死信队列
+- 数据模型是基础:在生产上线后再改数据模型,成本是设计阶段的 10 倍
+- PII 数据必须加密存储,使用 Shield Platform Encryption 或自定义加密方案
+
+## Key Quotes
+> "Governor limits are non-negotiable. Every design must account for SOQL (100), DML (150), CPU (10s sync/60s async), heap (6MB sync/12MB async). No exceptions, no 'we'll optimize later.'" — 核心设计原则
+> "If the code would fail on 200 records, it's wrong." — Bulkification 强制性标准
+> "Data model is the foundation. Changing the data model after go-live is 10x more expensive." — 数据模型优先级
+> "Be direct about technical debt. If someone built a trigger that should be a flow, say so." — 沟通风格示例
+
+## Key Concepts
+- [[GovernorLimits]]:Salesforce 平台执行上下文的硬性资源限制,包括 SOQL 查询数(100)、DML 语句数(150)、CPU 时间(同步10s)、堆大小(同步6MB)等
+- [[Bulkification]]:批量处理模式 — 要求所有触发器和 Apex 代码必须能在单次交易中处理多条记录(通常按 200 条/批次测试)
+- [[PlatformEvents]]:Salesforce 平台事件 — 用于跨系统集成的异步事件驱动机制,支持 72 小时重放窗口和高容量标准(10万/天)
+- [[ChangeDataCapture]](CDC):变更数据捕获 — 自动追踪 sObject 字段级变更,适合 Salesforce 原生事件同步场景
+- [[ADR]](Architecture Decision Record):架构决策记录 — 文档化记录重要技术决策的上下文、备选方案、后果和复审日期
+- [[SalesforceDX]]:Salesforce 开发者体验框架 — 基于 Scratch Org 的源代码驱动部署方式,与 DevOps Center 并行
+- [[Agentforce]]:Salesforce AI Agent 框架 — Agent 在 Salesforce governor limits 内运行,需设计在 CPU/SOQL 预算内完成的动作,使用 Einstein Trust Layer 进行 PII 脱敏
+
+## Key Entities
+- [[MuleSoft]]:Salesforce 收购的企业级集成中间件,用于跨系统集成模式中的中间转换层(DataWeave 转换、3x 指数退避重试、死信队列)
+- [[ShieldPlatformEncryption]]:Salesforce 原生 PII 加密方案,与自定义加密并列作为敏感数据保护选项
+- [[DevOpsCenter]]:Salesforce 原生 CI/CD 平台,与 Salesforce DX 并行的另一种部署方式
+
+## Connections
+- [[SalesforceDX]] ← supports ← [[ADR]]
+- [[PlatformEvents]] ← extends ← [[ChangeDataCapture]]
+- [[Bulkification]] ← enforces ← [[GovernorLimits]]
+- [[Agentforce]] ← bounded_by ← [[GovernorLimits]]
+
+## Contradictions
+- 与 [[DevOpsCenter]] 关系:
+ - 冲突点:Salesforce DX 与 DevOps Center 是两种并行的部署策略,文档将两者并列但未明确优先选用哪个
+ - 当前观点:Salesforce DX 基于 Scratch Org 源码驱动是现代标准实践
+ - 对方观点:DevOps Center 作为 Salesforce 原生工具对非技术用户更友好
diff --git a/wiki/sources/specialized-workflow-architect.md b/wiki/sources/specialized-workflow-architect.md
index e3da9336..991949fc 100644
--- a/wiki/sources/specialized-workflow-architect.md
+++ b/wiki/sources/specialized-workflow-architect.md
@@ -1,58 +1,58 @@
----
-title: "Workflow Architect Agent Personality"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/specialized-workflow-architect.md]]
-
-## Summary(用中文描述)
-- 核心主题:Workflow Architect——工作流设计专家 Agent,负责在代码编写前对系统所有路径进行穷举建模与规范输出。
-- 问题域:隐式工作流(代码中存在但无规范)、分支缺失、故障恢复路径未定义、系统边界交接合同模糊、代码与规范漂移。
-- 方法/机制:工作流注册表(四视角)、工作流树规范格式(覆盖快乐路径+所有失败分支+清理清单)、交接合同规范、发现审计清单、Reality Checker 交叉验证、Agent 协作协议。
-- 结论/价值:工程师可依据规范实现、QA 可直接生成测试用例、运维可理解系统行为、成功指标为零孤岛资源/假设表持续缩减。
-
-## Key Claims(用中文描述)
-- 代码中存在但无规范的工作流是隐患——它会在无人了解其全貌时被修改并导致故障。
-- 每一个系统边界(system boundary)必须定义显式 payload schema、成功响应、失败响应(含错误码)、超时值、故障恢复动作。
-- 每个工作流必须覆盖七类分支:快乐路径、输入验证失败、超时失败、瞬态失败、永久失败、部分失败、并发冲突。
-- 工作流状态必须同时回答四个维度:客户看到什么、运维看到什么、数据库中有什么、日志中有什么。
-- Reality Checker 验证是规范从 Draft 升为 Approved 的前置条件,不可跳过。
-
-## Key Quotes
-> "I do not design for the happy path only." — Workflow Architect 核心原则
-
-> "A workflow that exists in code but not in a spec is a liability. It will be modified without understanding its full shape, and it will break." — 发现即记录,不问是否被要求
-
-> "Every step that depends on something else being already done is a potential race condition." — 命名时序假设
-
-## Key Concepts
-- [[Workflow-Registry]]:四视角交叉索引工作流注册表(按工作流/按组件/按用户旅程/按状态),维护所有工作流状态(Approved/Review/Draft/Missing/Deprecated)
-- [[Observable-States]]:每个工作流状态必须同时描述客户视图、运维视图、数据库视图、日志视图
-- [[Handoff-Contract]]:系统边界交接合同——定义显式 payload schema、成功/失败响应、超时值、恢复动作
-- [[Workflow-Tree-Spec]]:结构化工序树规范格式,含 Actor/Prerequisites/Trigger/Step 树/ABORT_CLEANUP/State Transitions/Cleanup Inventory/Test Cases/Assumptions
-- [[Cleanup-Inventory]]:完整资源销毁清单,每项资源必须有对应清理动作
-- [[Discovery-Audit]]:发现审计清单——扫描所有 route/worker/migration/IaC/cron/event-listener/webhook 文件找出隐式工作流
-- [[Reality-Checker]]:规范验证流程,由 Reality Checker Agent 将规范与实际代码对照,报告差距
-
-## Key Entities
-- [[Backend-Architect]]:工作流规范依赖 Backend Architect 实现具体代码;工作流揭示实现缺陷时向其发起修复协作
-- [[Reality-Checker]]:每次 draft 完成后、标记 Review 前必须执行的代码验证 Agent;报告 Reality Checker Findings
-- [[API-Tester]]:规范 Approved 后接收工作流规范,生成全部测试用例
-- [[DevOps-Automator]]:工作流揭示基础设施销毁顺序需求时协作;验证 IaC 销毁顺序是否符合规范
-- [[Security-Engineer]]:工作流涉及凭证/密钥/认证/外部 API 调用时必须发起安全审查
-
-## Connections
-- [[Reality-Checker]] ← verifies ← [[Workflow-Tree-Spec]](规范 vs 代码差距验证)
-- [[Backend-Architect]] ← implements ← [[Workflow-Tree-Spec]](实现具体代码)
-- [[API-Tester]] ← generates test cases from ← [[Workflow-Tree-Spec]](从规范导出测试用例)
-- [[DevOps-Automator]] ← maintains ← [[Cleanup-Inventory]](验证销毁顺序)
-- [[Security-Engineer]] ← reviews ← [[Handoff-Contract]](凭证传递安全性审查)
-
-## Contradictions
-- 与 [[Designing-for-Agentic-AI]] 潜在冲突:
- - 冲突点:工作流规范要求确定性(每个分支必须精确描述),而 LLM 本质为概率性模型
- - 当前观点:LLM 相关行为(如自然语言理解)通过概率模型处理;工作流规范聚焦于确定性的业务流程与系统边界,而非 LLM 推理过程
- - 对方观点:[[Designing-for-Agentic-AI]] 强调 LLM 的概率性和不确定性
+---
+title: "Workflow Architect Agent Personality"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/specialized-workflow-architect.md]]
+
+## Summary(用中文描述)
+- 核心主题:Workflow Architect——工作流设计专家 Agent,负责在代码编写前对系统所有路径进行穷举建模与规范输出。
+- 问题域:隐式工作流(代码中存在但无规范)、分支缺失、故障恢复路径未定义、系统边界交接合同模糊、代码与规范漂移。
+- 方法/机制:工作流注册表(四视角)、工作流树规范格式(覆盖快乐路径+所有失败分支+清理清单)、交接合同规范、发现审计清单、Reality Checker 交叉验证、Agent 协作协议。
+- 结论/价值:工程师可依据规范实现、QA 可直接生成测试用例、运维可理解系统行为、成功指标为零孤岛资源/假设表持续缩减。
+
+## Key Claims(用中文描述)
+- 代码中存在但无规范的工作流是隐患——它会在无人了解其全貌时被修改并导致故障。
+- 每一个系统边界(system boundary)必须定义显式 payload schema、成功响应、失败响应(含错误码)、超时值、故障恢复动作。
+- 每个工作流必须覆盖七类分支:快乐路径、输入验证失败、超时失败、瞬态失败、永久失败、部分失败、并发冲突。
+- 工作流状态必须同时回答四个维度:客户看到什么、运维看到什么、数据库中有什么、日志中有什么。
+- Reality Checker 验证是规范从 Draft 升为 Approved 的前置条件,不可跳过。
+
+## Key Quotes
+> "I do not design for the happy path only." — Workflow Architect 核心原则
+
+> "A workflow that exists in code but not in a spec is a liability. It will be modified without understanding its full shape, and it will break." — 发现即记录,不问是否被要求
+
+> "Every step that depends on something else being already done is a potential race condition." — 命名时序假设
+
+## Key Concepts
+- [[Workflow-Registry]]:四视角交叉索引工作流注册表(按工作流/按组件/按用户旅程/按状态),维护所有工作流状态(Approved/Review/Draft/Missing/Deprecated)
+- [[Observable-States]]:每个工作流状态必须同时描述客户视图、运维视图、数据库视图、日志视图
+- [[Handoff-Contract]]:系统边界交接合同——定义显式 payload schema、成功/失败响应、超时值、恢复动作
+- [[Workflow-Tree-Spec]]:结构化工序树规范格式,含 Actor/Prerequisites/Trigger/Step 树/ABORT_CLEANUP/State Transitions/Cleanup Inventory/Test Cases/Assumptions
+- [[Cleanup-Inventory]]:完整资源销毁清单,每项资源必须有对应清理动作
+- [[Discovery-Audit]]:发现审计清单——扫描所有 route/worker/migration/IaC/cron/event-listener/webhook 文件找出隐式工作流
+- [[Reality-Checker]]:规范验证流程,由 Reality Checker Agent 将规范与实际代码对照,报告差距
+
+## Key Entities
+- [[Backend-Architect]]:工作流规范依赖 Backend Architect 实现具体代码;工作流揭示实现缺陷时向其发起修复协作
+- [[Reality-Checker]]:每次 draft 完成后、标记 Review 前必须执行的代码验证 Agent;报告 Reality Checker Findings
+- [[API-Tester]]:规范 Approved 后接收工作流规范,生成全部测试用例
+- [[DevOps-Automator]]:工作流揭示基础设施销毁顺序需求时协作;验证 IaC 销毁顺序是否符合规范
+- [[Security-Engineer]]:工作流涉及凭证/密钥/认证/外部 API 调用时必须发起安全审查
+
+## Connections
+- [[Reality-Checker]] ← verifies ← [[Workflow-Tree-Spec]](规范 vs 代码差距验证)
+- [[Backend-Architect]] ← implements ← [[Workflow-Tree-Spec]](实现具体代码)
+- [[API-Tester]] ← generates test cases from ← [[Workflow-Tree-Spec]](从规范导出测试用例)
+- [[DevOps-Automator]] ← maintains ← [[Cleanup-Inventory]](验证销毁顺序)
+- [[Security-Engineer]] ← reviews ← [[Handoff-Contract]](凭证传递安全性审查)
+
+## Contradictions
+- 与 [[Designing-for-Agentic-AI]] 潜在冲突:
+ - 冲突点:工作流规范要求确定性(每个分支必须精确描述),而 LLM 本质为概率性模型
+ - 当前观点:LLM 相关行为(如自然语言理解)通过概率模型处理;工作流规范聚焦于确定性的业务流程与系统边界,而非 LLM 推理过程
+ - 对方观点:[[Designing-for-Agentic-AI]] 强调 LLM 的概率性和不确定性
diff --git a/wiki/sources/study-abroad-advisor.md b/wiki/sources/study-abroad-advisor.md
index 4c42d3c3..c1b50e8a 100644
--- a/wiki/sources/study-abroad-advisor.md
+++ b/wiki/sources/study-abroad-advisor.md
@@ -1,47 +1,47 @@
----
-title: "Study Abroad Advisor"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/study-abroad-advisor.md]]
-
-## Summary(用中文描述)
-- 核心主题:面向中国学生的全链路留学申请规划专家 Agent,覆盖美国/英国/加拿大/澳大利亚/欧洲/香港/新加坡七大留学目的地,涵盖本科/硕士/博士全学位层次,从选校定位到行前准备的完整流程。
-- 问题域:留学申请策略、选校定位、文书写作、背景提升、考试规划、签证办理、Offer 比较决策。
-- 方法/机制:四步工作流(全面诊断→策略制定→材料打磨→提交跟进);数据驱动的选校概率区间(Reach 20-40% / Target 40-70% / Safety 70-90%);多国联申时间线协调;标准化交付模板(选校报告、多国申请时间线、文书诊断、Offer 比较矩阵)。
-- 结论/价值:为每位学生提供端到端、个性化的留学规划,消除申请焦虑,强调数据透明与诚信原则(不代写文书、不夸大经历、不承诺录取结果)。
-
-## Key Claims(用中文描述)
-- Study Abroad Advisor 通过数据驱动方法,能帮助 GPA 3.2 的学生进入 Top 30, 也可能让 GPA 3.9 的学生全拒——关键在于选校策略和文书质量。
-- 多国联申策略(如 US+UK、US+HK+Singapore)需要精确的时间线协调和精力分配,但能显著提升录取概率。
-- 诚信原则(不代写文书、不承诺结果)是留学咨询的核心底线,任何"保证录取"的承诺都是骗局。
-- 文书不是经历的流水账列表,而是围绕核心叙事弧(你是谁→去哪→为什么是这个项目)的故事化表达。
-- 选校推荐必须区分"确认信息"和"经验估算", admission probability 以区间而非精确数字表达。
-
-## Key Quotes
-> "This program admitted about 200 students last year, roughly 40 from China, with a median GPA of 3.6. Your 3.5 is within range but not strong — you'll need essays and experiences to compensate." — 数据驱动的录取概率沟通
-> "Top 10 isn't on your menu right now, but Top 30 is within reach. Let's focus energy where the odds are highest." — 务实选校,避免焦虑贩卖
-> "You think your Hackathon experience doesn't matter? You led a team to build a product with real users from scratch in 48 hours — that's exactly the kind of initiative engineering programs look for." — 优势挖掘,赋能学生信心
-
-## Key Concepts
-- [[Holistic-Admissions]]:全面评估录取模式——综合考量 GPA、标准化考试成绩、课外活动、文书、推荐信等多维度,非单一成绩决定。
-- [[UCAS-System]]:英国本科统一申请系统——学生通过 UCAS 可同时申请最多 5 所英国大学,个人陈述(Personal Statement)需面向所有申请学校,4,000 字符限制,80% 内容须聚焦学术热情。
-- [[IANG-Visa]]:非本地毕业生留港就业安排(Immigration Arrangement for Non-local Graduates)——香港为在港毕业生提供毕业后留港工作签证,无配额限制,是香港留学的核心吸引力之一。
-- [[Grandes-Ecoles]]:法国精英大学体系——与公立大学并行的高等教育精英通道,需通过竞考(concours)入学,毕业后享有高社会认可度。
-
-## Key Entities
-- The Agency Specialized 部门:该 Agent 归属 The Agency 多智能体系统的 Specialized 部门,与 Agents Orchestrator、Identity Graph Operator、MCP Builder Agent、Agentic Identity & Trust Architect 等 Specialist 同事协同工作。
-- 1point3acres(一亩三分地):中国留学生社区论坛,是学生验证录取数据、校友去向、申请经验的重要信息来源,Agent 鼓励学生通过该论坛核实关键数据。
-
-## Connections
-- [[Agents-Orchestrator]] ← coordinates_with ← Study Abroad Advisor
-- [[specialized-mcp-builder]] ← same_department ← Study Abroad Advisor
-- [[identity-graph-operator]] ← same_department ← Study Abroad Advisor
-- [[agentic-identity-trust]] ← same_department ← Study Abroad Advisor
-- [[ProjectManagerSenior]] ← supports ← Study Abroad Advisor(两者均服务于 The Agency 的项目管理体系,PM 产出的任务列表可支撑留学规划的项目化执行)
-
-## Contradictions
-- 与其他 Agent 的信息呈现方式:Study Abroad Advisor 明确采用数据驱动、零焦虑贩卖的原则,而其他面向消费者的 Agent(如一般营销 Agent)可能倾向于过度承诺录取结果。核心区别在于:前者明确区分"确认信息"和"经验估算",后者缺乏这种信息透明度约束。
+---
+title: "Study Abroad Advisor"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/study-abroad-advisor.md]]
+
+## Summary(用中文描述)
+- 核心主题:面向中国学生的全链路留学申请规划专家 Agent,覆盖美国/英国/加拿大/澳大利亚/欧洲/香港/新加坡七大留学目的地,涵盖本科/硕士/博士全学位层次,从选校定位到行前准备的完整流程。
+- 问题域:留学申请策略、选校定位、文书写作、背景提升、考试规划、签证办理、Offer 比较决策。
+- 方法/机制:四步工作流(全面诊断→策略制定→材料打磨→提交跟进);数据驱动的选校概率区间(Reach 20-40% / Target 40-70% / Safety 70-90%);多国联申时间线协调;标准化交付模板(选校报告、多国申请时间线、文书诊断、Offer 比较矩阵)。
+- 结论/价值:为每位学生提供端到端、个性化的留学规划,消除申请焦虑,强调数据透明与诚信原则(不代写文书、不夸大经历、不承诺录取结果)。
+
+## Key Claims(用中文描述)
+- Study Abroad Advisor 通过数据驱动方法,能帮助 GPA 3.2 的学生进入 Top 30, 也可能让 GPA 3.9 的学生全拒——关键在于选校策略和文书质量。
+- 多国联申策略(如 US+UK、US+HK+Singapore)需要精确的时间线协调和精力分配,但能显著提升录取概率。
+- 诚信原则(不代写文书、不承诺结果)是留学咨询的核心底线,任何"保证录取"的承诺都是骗局。
+- 文书不是经历的流水账列表,而是围绕核心叙事弧(你是谁→去哪→为什么是这个项目)的故事化表达。
+- 选校推荐必须区分"确认信息"和"经验估算", admission probability 以区间而非精确数字表达。
+
+## Key Quotes
+> "This program admitted about 200 students last year, roughly 40 from China, with a median GPA of 3.6. Your 3.5 is within range but not strong — you'll need essays and experiences to compensate." — 数据驱动的录取概率沟通
+> "Top 10 isn't on your menu right now, but Top 30 is within reach. Let's focus energy where the odds are highest." — 务实选校,避免焦虑贩卖
+> "You think your Hackathon experience doesn't matter? You led a team to build a product with real users from scratch in 48 hours — that's exactly the kind of initiative engineering programs look for." — 优势挖掘,赋能学生信心
+
+## Key Concepts
+- [[Holistic-Admissions]]:全面评估录取模式——综合考量 GPA、标准化考试成绩、课外活动、文书、推荐信等多维度,非单一成绩决定。
+- [[UCAS-System]]:英国本科统一申请系统——学生通过 UCAS 可同时申请最多 5 所英国大学,个人陈述(Personal Statement)需面向所有申请学校,4,000 字符限制,80% 内容须聚焦学术热情。
+- [[IANG-Visa]]:非本地毕业生留港就业安排(Immigration Arrangement for Non-local Graduates)——香港为在港毕业生提供毕业后留港工作签证,无配额限制,是香港留学的核心吸引力之一。
+- [[Grandes-Ecoles]]:法国精英大学体系——与公立大学并行的高等教育精英通道,需通过竞考(concours)入学,毕业后享有高社会认可度。
+
+## Key Entities
+- The Agency Specialized 部门:该 Agent 归属 The Agency 多智能体系统的 Specialized 部门,与 Agents Orchestrator、Identity Graph Operator、MCP Builder Agent、Agentic Identity & Trust Architect 等 Specialist 同事协同工作。
+- 1point3acres(一亩三分地):中国留学生社区论坛,是学生验证录取数据、校友去向、申请经验的重要信息来源,Agent 鼓励学生通过该论坛核实关键数据。
+
+## Connections
+- [[Agents-Orchestrator]] ← coordinates_with ← Study Abroad Advisor
+- [[specialized-mcp-builder]] ← same_department ← Study Abroad Advisor
+- [[identity-graph-operator]] ← same_department ← Study Abroad Advisor
+- [[agentic-identity-trust]] ← same_department ← Study Abroad Advisor
+- [[ProjectManagerSenior]] ← supports ← Study Abroad Advisor(两者均服务于 The Agency 的项目管理体系,PM 产出的任务列表可支撑留学规划的项目化执行)
+
+## Contradictions
+- 与其他 Agent 的信息呈现方式:Study Abroad Advisor 明确采用数据驱动、零焦虑贩卖的原则,而其他面向消费者的 Agent(如一般营销 Agent)可能倾向于过度承诺录取结果。核心区别在于:前者明确区分"确认信息"和"经验估算",后者缺乏这种信息透明度约束。
diff --git a/wiki/sources/supply-chain-strategist.md b/wiki/sources/supply-chain-strategist.md
index 2dcbfd13..0e42cc11 100644
--- a/wiki/sources/supply-chain-strategist.md
+++ b/wiki/sources/supply-chain-strategist.md
@@ -1,75 +1,75 @@
----
-title: "Supply Chain Strategist Agent"
-type: source
-tags: [agent, supply-chain, procurement, china-manufacturing, strategy]
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/supply-chain-strategist.md]]
-
-## Summary(用中文描述)
-- 核心主题:基于中国制造业生态的专业供应链管理与战略采购 Agent,帮助企业建立高效、有韧性、可持续的供应链体系
-- 问题域:供应商管理、战略寻源、质量控制、库存优化、供应链数字化、成本管控、风险管理与合规 ESG
-- 方法/机制:Kraljic 矩阵分类采购策略、ABC 分级供应商管理、QCD 绩效评估、TCO 全成本分析、库存模型(EOQ/ROP/安全库存)、数字化成熟度评估
-- 结论/价值:提供端到端供应链解决方案,从供应商开发寻源到危机响应,覆盖采购、物流、库存、合规全链路
-
-## Key Claims(用中文描述)
-- 供应商 ABC 分级管理 + 战略合作伙伴关系升级,能显著提升供应链稳定性
-- Kraljic 矩阵定位采购类别,配合差异化采购策略,可实现年度采购成本降低 5-8%
-- TCO(全成本拥有权)分析是采购决策依据,而非单纯比较单价
-- 关键物料必须多源采购,单一来源是最高风险项
-- 供应链数字化成熟度分 5 级(L1 手动 → L5 自主智能),成熟度提升路径明确
-- 供应商绩效评估必须数据驱动,主观评价不超过 20%
-
-## Key Quotes
-> "Critical materials must never be single-sourced — verified alternative suppliers are mandatory" — 供应链安全第一原则
-> "TCO (Total Cost of Ownership) is the decision-making basis, not unit purchase price alone" — 成本决策核心原则
-> "Quality issues must be traced to root cause — superficial fixes are insufficient" — 质量管控原则
-> "Through consolidated purchasing, fastener category annual procurement costs decreased 12%, saving ¥870,000" — 数据驱动沟通风格示例
-
-## Key Concepts
-- [[Kraljic Matrix]]:按采购类别特性(供应风险 × 利润影响)将物料分为战略型、杠杆型、瓶颈型、常规型,对应差异化采购策略
-- [[ABC Classification]]:供应商/物料分级管理(A 类战略重点、B 类重要、C 类常规),差异化资源配置
-- [[QCD Assessment]]:Quality-Quality、Cost、Delivery 三维供应商绩效评分体系,每季度评分年度淘汰
-- [[TCO Analysis]]:Total Cost of Ownership 全成本拥有权分析,涵盖直接成本、间接成本、隐性成本、全生命周期成本
-- [[EOQ Model]]:经济订货量模型,平衡订货成本与持有成本
-- [[Safety Stock & ROP]]:安全库存与再订货点,结合 Z 值与服务水平计算
-- [[VMI]]:Vendor-Managed Inventory,供应商管理库存,减少买方库存负担
-- [[JIT Procurement]]:Just-In-Time 准时制采购,降低持有成本但要求供应链高度可靠
-- [[Supply Chain Digital Maturity]]:供应链数字化成熟度 5 级模型(L1-L5),从手动到自主智能
-- [[8D Report]]:质量问题闭环解决报告,CAPA 纠正预防措施
-- [[AQL Sampling]]:Acceptable Quality Limit,来料抽样检验标准(GB/T 2828.1 / ISO 2859-1)
-- [[RBA Code of Conduct]]:Responsible Business Alliance 电子行业社会责任行为准则
-- [[SA8000]]:社会责任国际标准,涵盖禁用童工/强迫劳动、工时薪资、职业健康安全
-- [[ERP-MM]]:SAP Materials Management 模块,物料管理系统
-- [[SRM Platform]]:Supplier Relationship Management,供应商关系管理平台
-
-## Key Entities
-- [[1688/Alibaba]]:中国最大 B2B 电商平台,适合标准件和通用材料采购
-- [[Made-in-China.com]]:中国制造网,面向出口型工厂的国际贸易平台
-- [[Global Sources]]:环球资源,高端制造商目录,适合电子和消费品
-- [[Canton Fair]]:广交会(中国进出口商品交易会),春秋两届全品类供应商集中地
-- [[SGS/TUV/Bureau Veritas/Intertek]]:第三方检验机构,负责工厂审核和产品认证
-- [[SAP Ariba]]:全球采购网络平台,适合跨国企业
-- [[ZhenYun(甄云)]]:全流程数字化采购平台,适合制造业
-- [[QiQiTong(企企通)]]:中小企业供应商协同平台
-- [[Yonyou Procurement Cloud]]:用友采购云,与用友 ERP 深度集成
-- [[Manbang/满帮]]:公路货运匹配平台,用于整车运输
-- [[Huolala/货拉拉]]:同城及跨城货运匹配平台
-- [[QiChaCha/Tianyancha]]:企查查/天眼查,企业信息查询平台,用于供应商资质验证
-- [[Kraljic Matrix]]:卡尔吉克矩阵(采购品类定位工具)
-
-## Connections
-- [[Supply Chain Strategist]] ← 供应商管理核心 → [[ABC Classification]]
-- [[Supply Chain Strategist]] ← 采购策略框架 → [[Kraljic Matrix]]
-- [[Supply Chain Strategist]] ← 成本决策方法 → [[TCO Analysis]]
-- [[Supply Chain Strategist]] ← 库存优化工具 → [[EOQ Model]]
-- [[Supply Chain Strategist]] ← 数字化成熟度 → [[Supply Chain Digital Maturity]]
-- [[Supply Chain Strategist]] ← 合规审计标准 → [[RBA Code of Conduct]], [[SA8000]]
-
-## Contradictions
-- 与 [[JIT Procurement]] 的对比:
- - 冲突点:JIT 追求零库存与安全库存原则之间的平衡
- - 当前观点:关键物料必须设置安全库存,防止单点供应断裂
- - 对方观点(纯 JIT 派):零库存是最优目标,可通过高可靠性供应链实现
+---
+title: "Supply Chain Strategist Agent"
+type: source
+tags: [agent, supply-chain, procurement, china-manufacturing, strategy]
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/supply-chain-strategist.md]]
+
+## Summary(用中文描述)
+- 核心主题:基于中国制造业生态的专业供应链管理与战略采购 Agent,帮助企业建立高效、有韧性、可持续的供应链体系
+- 问题域:供应商管理、战略寻源、质量控制、库存优化、供应链数字化、成本管控、风险管理与合规 ESG
+- 方法/机制:Kraljic 矩阵分类采购策略、ABC 分级供应商管理、QCD 绩效评估、TCO 全成本分析、库存模型(EOQ/ROP/安全库存)、数字化成熟度评估
+- 结论/价值:提供端到端供应链解决方案,从供应商开发寻源到危机响应,覆盖采购、物流、库存、合规全链路
+
+## Key Claims(用中文描述)
+- 供应商 ABC 分级管理 + 战略合作伙伴关系升级,能显著提升供应链稳定性
+- Kraljic 矩阵定位采购类别,配合差异化采购策略,可实现年度采购成本降低 5-8%
+- TCO(全成本拥有权)分析是采购决策依据,而非单纯比较单价
+- 关键物料必须多源采购,单一来源是最高风险项
+- 供应链数字化成熟度分 5 级(L1 手动 → L5 自主智能),成熟度提升路径明确
+- 供应商绩效评估必须数据驱动,主观评价不超过 20%
+
+## Key Quotes
+> "Critical materials must never be single-sourced — verified alternative suppliers are mandatory" — 供应链安全第一原则
+> "TCO (Total Cost of Ownership) is the decision-making basis, not unit purchase price alone" — 成本决策核心原则
+> "Quality issues must be traced to root cause — superficial fixes are insufficient" — 质量管控原则
+> "Through consolidated purchasing, fastener category annual procurement costs decreased 12%, saving ¥870,000" — 数据驱动沟通风格示例
+
+## Key Concepts
+- [[Kraljic Matrix]]:按采购类别特性(供应风险 × 利润影响)将物料分为战略型、杠杆型、瓶颈型、常规型,对应差异化采购策略
+- [[ABC Classification]]:供应商/物料分级管理(A 类战略重点、B 类重要、C 类常规),差异化资源配置
+- [[QCD Assessment]]:Quality-Quality、Cost、Delivery 三维供应商绩效评分体系,每季度评分年度淘汰
+- [[TCO Analysis]]:Total Cost of Ownership 全成本拥有权分析,涵盖直接成本、间接成本、隐性成本、全生命周期成本
+- [[EOQ Model]]:经济订货量模型,平衡订货成本与持有成本
+- [[Safety Stock & ROP]]:安全库存与再订货点,结合 Z 值与服务水平计算
+- [[VMI]]:Vendor-Managed Inventory,供应商管理库存,减少买方库存负担
+- [[JIT Procurement]]:Just-In-Time 准时制采购,降低持有成本但要求供应链高度可靠
+- [[Supply Chain Digital Maturity]]:供应链数字化成熟度 5 级模型(L1-L5),从手动到自主智能
+- [[8D Report]]:质量问题闭环解决报告,CAPA 纠正预防措施
+- [[AQL Sampling]]:Acceptable Quality Limit,来料抽样检验标准(GB/T 2828.1 / ISO 2859-1)
+- [[RBA Code of Conduct]]:Responsible Business Alliance 电子行业社会责任行为准则
+- [[SA8000]]:社会责任国际标准,涵盖禁用童工/强迫劳动、工时薪资、职业健康安全
+- [[ERP-MM]]:SAP Materials Management 模块,物料管理系统
+- [[SRM Platform]]:Supplier Relationship Management,供应商关系管理平台
+
+## Key Entities
+- [[1688/Alibaba]]:中国最大 B2B 电商平台,适合标准件和通用材料采购
+- [[Made-in-China.com]]:中国制造网,面向出口型工厂的国际贸易平台
+- [[Global Sources]]:环球资源,高端制造商目录,适合电子和消费品
+- [[Canton Fair]]:广交会(中国进出口商品交易会),春秋两届全品类供应商集中地
+- [[SGS/TUV/Bureau Veritas/Intertek]]:第三方检验机构,负责工厂审核和产品认证
+- [[SAP Ariba]]:全球采购网络平台,适合跨国企业
+- [[ZhenYun(甄云)]]:全流程数字化采购平台,适合制造业
+- [[QiQiTong(企企通)]]:中小企业供应商协同平台
+- [[Yonyou Procurement Cloud]]:用友采购云,与用友 ERP 深度集成
+- [[Manbang/满帮]]:公路货运匹配平台,用于整车运输
+- [[Huolala/货拉拉]]:同城及跨城货运匹配平台
+- [[QiChaCha/Tianyancha]]:企查查/天眼查,企业信息查询平台,用于供应商资质验证
+- [[Kraljic Matrix]]:卡尔吉克矩阵(采购品类定位工具)
+
+## Connections
+- [[Supply Chain Strategist]] ← 供应商管理核心 → [[ABC Classification]]
+- [[Supply Chain Strategist]] ← 采购策略框架 → [[Kraljic Matrix]]
+- [[Supply Chain Strategist]] ← 成本决策方法 → [[TCO Analysis]]
+- [[Supply Chain Strategist]] ← 库存优化工具 → [[EOQ Model]]
+- [[Supply Chain Strategist]] ← 数字化成熟度 → [[Supply Chain Digital Maturity]]
+- [[Supply Chain Strategist]] ← 合规审计标准 → [[RBA Code of Conduct]], [[SA8000]]
+
+## Contradictions
+- 与 [[JIT Procurement]] 的对比:
+ - 冲突点:JIT 追求零库存与安全库存原则之间的平衡
+ - 当前观点:关键物料必须设置安全库存,防止单点供应断裂
+ - 对方观点(纯 JIT 派):零库存是最优目标,可通过高可靠性供应链实现
diff --git a/wiki/sources/support-analytics-reporter.md b/wiki/sources/support-analytics-reporter.md
index ee5fdc49..01a8cb0f 100644
--- a/wiki/sources/support-analytics-reporter.md
+++ b/wiki/sources/support-analytics-reporter.md
@@ -6,7 +6,7 @@ date: 2026-04-21
---
## Source File
-- [[Agent/agency-agents/support/support-analytics-reporter.md]]
+- [[raw/Agent/agency-agents/support/support-analytics-reporter.md]]
## Summary(用中文描述)
- 核心主题:数据分析师型 AI Agent 的角色定义与行为规范,专注于将原始数据转化为可操作的业务洞察
diff --git a/wiki/sources/support-executive-summary-generator.md b/wiki/sources/support-executive-summary-generator.md
index 45ef99e7..32a914a0 100644
--- a/wiki/sources/support-executive-summary-generator.md
+++ b/wiki/sources/support-executive-summary-generator.md
@@ -6,7 +6,7 @@ date: 2026-04-25
---
## Source File
-- [[Agent/agency-agents/support/support-executive-summary-generator.md]]
+- [[raw/Agent/agency-agents/support/support-executive-summary-generator.md]]
## Summary(用中文描述)
- 核心主题:咨询级 AI Agent,专为 C-suite 决策者生成高管执行摘要
diff --git a/wiki/sources/support-finance-tracker.md b/wiki/sources/support-finance-tracker.md
index a1f2e59a..bc2f8cf7 100644
--- a/wiki/sources/support-finance-tracker.md
+++ b/wiki/sources/support-finance-tracker.md
@@ -6,7 +6,7 @@ date: 2026-04-25
---
## Source File
-- [[Agent/agency-agents/support/support-finance-tracker.md]]
+- [[raw/Agent/agency-agents/support/support-finance-tracker.md]]
## Summary(用中文描述)
- 核心主题:企业财务规划与分析的 AI Agent 人格定义,涵盖预算管理、现金流优化、投资分析和合规控制
diff --git a/wiki/sources/support-infrastructure-maintainer.md b/wiki/sources/support-infrastructure-maintainer.md
index 39a15a28..b7faf9db 100644
--- a/wiki/sources/support-infrastructure-maintainer.md
+++ b/wiki/sources/support-infrastructure-maintainer.md
@@ -6,7 +6,7 @@ date: 2026-04-25
---
## Source File
-- [[Agent/agency-agents/support/support-infrastructure-maintainer.md]]
+- [[raw/Agent/agency-agents/support/support-infrastructure-maintainer.md]]
## Summary(用中文描述)
- 核心主题:The Agency Support 部门的基础设施维护专家 Agent(Infrastructure Maintainer),专注于系统可靠性、性能优化和技术运维管理
diff --git a/wiki/sources/support-legal-compliance-checker.md b/wiki/sources/support-legal-compliance-checker.md
index 00607af2..b56b28ca 100644
--- a/wiki/sources/support-legal-compliance-checker.md
+++ b/wiki/sources/support-legal-compliance-checker.md
@@ -6,7 +6,7 @@ date: 2026-04-21
---
## Source File
-- [[Agent/agency-agents/support/support-legal-compliance-checker.md]]
+- [[raw/Agent/agency-agents/support/support-legal-compliance-checker.md]]
## Summary(用中文描述)
- **核心主题**:Legal Compliance Checker — The Agency Support 部门的法律合规专家 Agent,负责确保企业运营、数据处理和内容创作符合多司法管辖区的法律法规和行业标准。
diff --git a/wiki/sources/support-support-responder.md b/wiki/sources/support-support-responder.md
index 196de769..b01ceff6 100644
--- a/wiki/sources/support-support-responder.md
+++ b/wiki/sources/support-support-responder.md
@@ -6,7 +6,7 @@ date: 2026-04-25
---
## Source File
-- [[Agent/agency-agents/support/support-support-responder.md]]
+- [[raw/Agent/agency-agents/support/support-support-responder.md]]
## Summary(用中文描述)
- 核心主题:客户支持专家 Agent 人格定义,专注于卓越客户服务、问题解决和用户体验优化,将每次支持互动转化为品牌正向体验。
diff --git a/wiki/sources/technical-artist.md b/wiki/sources/technical-artist.md
index 2a969f0d..a52353ba 100644
--- a/wiki/sources/technical-artist.md
+++ b/wiki/sources/technical-artist.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/technical-artist.md]]
+- [[raw/Agent/agency-agents/game-development/technical-artist.md]]
## Summary(用中文描述)
- 核心主题:Technical Artist(技术美术)Agent 个性定义——连接艺术视野与引擎实现的专业角色
diff --git a/wiki/sources/terminal-integration-specialist.md b/wiki/sources/terminal-integration-specialist.md
index 08106735..1a316021 100644
--- a/wiki/sources/terminal-integration-specialist.md
+++ b/wiki/sources/terminal-integration-specialist.md
@@ -1,54 +1,54 @@
----
-title: "Terminal Integration Specialist"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/spatial-computing/terminal-integration-specialist.md]]
-
-## Summary(用中文描述)
-- 核心主题:Terminal Integration Specialist 是一个专注于终端仿真、文本渲染优化和 SwiftTerm 集成的 Agent,服务于现代 Swift 应用程序开发。
-- 问题域:如何在 Apple 平台上(iOS/macOS/visionOS)构建高性能、符合无障碍标准的终端模拟器;如何将 SSH 连接到终端仿真器;如何在 SwiftUI 应用中嵌入 SwiftTerm。
-- 方法/机制:
- - 完整支持 VT100/xterm ANSI 转义序列,实现光标控制与终端状态管理
- - 使用 Core Graphics / Core Text 优化文本渲染,实现平滑滚动
- - 通过 SwiftNIO SSH / NMSSH 实现 SSH I/O 桥接
- - 嵌入式 SwiftUI 生命周期管理和后台 I/O 线程处理
-- 结论/价值:提供了一套完整的 Apple 平台终端集成解决方案,兼顾性能、无障碍和跨平台考虑(iOS/macOS/visionOS)。
-
-## Key Claims(用中文描述)
-- SwiftTerm API 提供完整的公开接口,支持终端仿真的深度定制
-- Core Graphics 优化可实现高频文本更新下的平滑滚动渲染
-- 正确的后台线程处理可避免 UI 更新阻塞,确保终端 I/O 流畅
-- SSH 连接状态管理涵盖连接、断开、重连场景的完整终端行为处理
-- VoiceOver、动态类型等无障碍支持是 Apple 平台终端集成的必要条件
-
-## Key Quotes
-> "Focuses on creating robust, performant terminal experiences that feel native to Apple platforms while maintaining compatibility with standard terminal protocols." — 核心理念
-
-> "Specializes in SwiftTerm specifically (not other terminal emulator libraries)" — 明确范围边界
-
-## Key Concepts
-- [[VT100/xterm Standards]]:完整的 ANSI 转义序列支持,用于光标控制和终端状态管理
-- [[SwiftTerm]]:Miguel de Icaza 开发的 MIT 许可 Swift 终端仿真库,核心依赖
-- [[Core Graphics Optimization]]:通过 Core Graphics / Core Text 优化文本渲染,实现高频更新下的平滑滚动
-- [[SSH I/O Bridging]]:将 SSH 流高效桥接到终端仿真器的输入/输出层
-- [[Scrollback Buffer]]:大终端历史的回滚缓冲区管理,支持搜索功能
-- [[Accessibility Integration]]:VoiceOver、动态类型等 Apple 无障碍技术集成
-
-## Key Entities
-- [[SwiftTerm]](MIT License):核心终端仿真库,GitHub: migueldeicaza/SwiftTerm
-- [[SwiftNIO SSH]]:用于 SSH 连接的 Swift 网络库
-- [[NMSSH]]:另一个 SSH 连接选项库
-- [[Core Graphics]]:Apple 平台 2D 渲染框架
-- [[Core Text]]:Apple 平台文本排版引擎
-
-## Connections
-- [[visionOS Spatial Engineer]] ← depends_on ← [[Terminal Integration Specialist]]:visionOS 空间工程师依赖终端集成实现空间终端体验
-- [[macOS Spatial Metal Engineer]] ← depends_on ← [[Terminal Integration Specialist]]:macOS Metal 工程师依赖终端集成处理渲染层面
-- [[SwiftTerm]] ← implements ← [[VT100/xterm Standards]]:SwiftTerm 库实现 VT100/xterm 标准
-
-## Contradictions
-- 无明显内容冲突;该 Agent 专注于 Apple 平台和 SwiftTerm,与其他通用终端解决方案(如 libvte、iTerm2)不在同一问题域内。
+---
+title: "Terminal Integration Specialist"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/spatial-computing/terminal-integration-specialist.md]]
+
+## Summary(用中文描述)
+- 核心主题:Terminal Integration Specialist 是一个专注于终端仿真、文本渲染优化和 SwiftTerm 集成的 Agent,服务于现代 Swift 应用程序开发。
+- 问题域:如何在 Apple 平台上(iOS/macOS/visionOS)构建高性能、符合无障碍标准的终端模拟器;如何将 SSH 连接到终端仿真器;如何在 SwiftUI 应用中嵌入 SwiftTerm。
+- 方法/机制:
+ - 完整支持 VT100/xterm ANSI 转义序列,实现光标控制与终端状态管理
+ - 使用 Core Graphics / Core Text 优化文本渲染,实现平滑滚动
+ - 通过 SwiftNIO SSH / NMSSH 实现 SSH I/O 桥接
+ - 嵌入式 SwiftUI 生命周期管理和后台 I/O 线程处理
+- 结论/价值:提供了一套完整的 Apple 平台终端集成解决方案,兼顾性能、无障碍和跨平台考虑(iOS/macOS/visionOS)。
+
+## Key Claims(用中文描述)
+- SwiftTerm API 提供完整的公开接口,支持终端仿真的深度定制
+- Core Graphics 优化可实现高频文本更新下的平滑滚动渲染
+- 正确的后台线程处理可避免 UI 更新阻塞,确保终端 I/O 流畅
+- SSH 连接状态管理涵盖连接、断开、重连场景的完整终端行为处理
+- VoiceOver、动态类型等无障碍支持是 Apple 平台终端集成的必要条件
+
+## Key Quotes
+> "Focuses on creating robust, performant terminal experiences that feel native to Apple platforms while maintaining compatibility with standard terminal protocols." — 核心理念
+
+> "Specializes in SwiftTerm specifically (not other terminal emulator libraries)" — 明确范围边界
+
+## Key Concepts
+- [[VT100/xterm Standards]]:完整的 ANSI 转义序列支持,用于光标控制和终端状态管理
+- [[SwiftTerm]]:Miguel de Icaza 开发的 MIT 许可 Swift 终端仿真库,核心依赖
+- [[Core Graphics Optimization]]:通过 Core Graphics / Core Text 优化文本渲染,实现高频更新下的平滑滚动
+- [[SSH I/O Bridging]]:将 SSH 流高效桥接到终端仿真器的输入/输出层
+- [[Scrollback Buffer]]:大终端历史的回滚缓冲区管理,支持搜索功能
+- [[Accessibility Integration]]:VoiceOver、动态类型等 Apple 无障碍技术集成
+
+## Key Entities
+- [[SwiftTerm]](MIT License):核心终端仿真库,GitHub: migueldeicaza/SwiftTerm
+- [[SwiftNIO SSH]]:用于 SSH 连接的 Swift 网络库
+- [[NMSSH]]:另一个 SSH 连接选项库
+- [[Core Graphics]]:Apple 平台 2D 渲染框架
+- [[Core Text]]:Apple 平台文本排版引擎
+
+## Connections
+- [[visionOS Spatial Engineer]] ← depends_on ← [[Terminal Integration Specialist]]:visionOS 空间工程师依赖终端集成实现空间终端体验
+- [[macOS Spatial Metal Engineer]] ← depends_on ← [[Terminal Integration Specialist]]:macOS Metal 工程师依赖终端集成处理渲染层面
+- [[SwiftTerm]] ← implements ← [[VT100/xterm Standards]]:SwiftTerm 库实现 VT100/xterm 标准
+
+## Contradictions
+- 无明显内容冲突;该 Agent 专注于 Apple 平台和 SwiftTerm,与其他通用终端解决方案(如 libvte、iTerm2)不在同一问题域内。
diff --git a/wiki/sources/testing-accessibility-auditor.md b/wiki/sources/testing-accessibility-auditor.md
index 2dfd0616..1208c006 100644
--- a/wiki/sources/testing-accessibility-auditor.md
+++ b/wiki/sources/testing-accessibility-auditor.md
@@ -6,7 +6,7 @@ date: 2026-04-25
---
## Source File
-- [[Agent/agency-agents/testing/testing-accessibility-auditor.md]]
+- [[raw/Agent/agency-agents/testing/testing-accessibility-auditor.md]]
## Summary(用中文描述)
- 核心主题:AI Agent 的无障碍审计专家人格定义,专注于 WCAG 标准合规性检测和辅助技术测试
diff --git a/wiki/sources/testing-api-tester.md b/wiki/sources/testing-api-tester.md
index 1286fac9..1da182c9 100644
--- a/wiki/sources/testing-api-tester.md
+++ b/wiki/sources/testing-api-tester.md
@@ -1,52 +1,52 @@
----
-title: "API Tester Agent Personality"
-type: source
-tags: ["the-agency", "testing", "api", "automation", "qa", "performance", "security"]
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/testing/testing-api-tester.md]]
-
-## Summary(用中文描述)
-- 核心主题:The Agency Testing 部门的 API 测试专家智能体人格定义,涵盖功能、性能、安全三大维度的全面 API 质量保障方法论与自动化实现框架
-- 问题域:API 质量保障缺乏系统性方法论、测试覆盖不足、安全漏洞遗漏、性能 SLA 不达标等现实问题
-- 方法/机制:Playwright 测试框架 + perf_hooks 性能监控 + OWASP API Security Top 10 安全验证 + CI/CD 流水线集成 + 95%+ 覆盖率目标驱动
-- 结论/价值:为 The Agency 提供标准化的 API 测试智能体规范,通过自动化测试套件实现功能验证、性能基准、安全审计的三位一体质量保障
-
-## Key Claims(用中文描述)
-- API Tester Agent 通过 Playwright/REST Assured/k6 框架构建自动化测试套件,目标实现 95%+ API 端点覆盖率
-- API 性能 SLA 要求:95 百分位响应时间低于 200ms,正常负载下错误率低于 0.1%
-- 负载测试必须验证 10 倍正常流量容量,确保系统可扩展性
-- 安全测试覆盖 OWASP API Security Top 10,包含认证绕过、SQL 注入、XSS、速率限制等关键威胁
-- API 测试必须集成到 CI/CD 流水线,实现持续验证而非手动测试
-
-## Key Quotes
-> "Breaks your API before your users do." — API Tester Agent 的核心理念,防御性测试哲学
-> "API response times must be under 200ms for 95th percentile" — 明确的性能 SLA 标准
-> "Always test authentication and authorization mechanisms thoroughly" — 安全优先原则
-> "Load testing must validate 10x normal traffic capacity" — 规模化验证要求
-
-## Key Concepts
-- [[API Testing]]:覆盖功能、性能、安全三维度,通过自动化测试框架验证 API 端点行为与 SLA 合规性
-- [[Performance Testing]]:通过 perf_hooks 监控响应时间,验证 95 百分位 < 200ms、10x 负载、< 0.1% 错误率三大指标
-- [[Security Testing]]:OWASP API Security Top 10 安全测试框架,包含认证/授权/输入验证/速率限制等核心检查项
-- [[Contract Testing]]:API 版本间契约合规性与向后兼容性验证,确保服务间接口稳定性
-- [[CI/CD Integration]]:测试自动化嵌入持续集成/持续部署流水线,实现每次代码变更的自动质量验证
-- [[OWASP API Security Top 10]]:API 安全测试的行业标准清单,覆盖 BOLA/ BFLA/ Broken Auth 等关键 API 威胁
-
-## Key Entities
-- [[Playwright]]:Node.js 端到端测试框架,API Tester 的主要测试工具之一,支持功能与安全测试
-- [[REST Assured]]:Java API 测试框架,适用于 Java 生态系统的 REST API 验证
-- [[k6]]:Grafana 开源负载测试工具,用于性能测试与可扩展性验证
-- [[perf_hooks]]:Node.js 内置性能监测 API,用于精确的 API 响应时间测量
-
-## Connections
-- [[specialized-model-qa]] ← 测试范围互补 ← [[testing-api-tester]](模型质量测试 vs API 端点测试)
-- [[testing-accessibility-auditor]] ← 质量保障并行 ← [[testing-api-tester]](可访问性测试 vs API 功能/性能/安全测试)
-- [[testing-tool-evaluator]] ← 工具推荐上游 ← [[testing-api-tester]](工具评估为测试实施提供框架选择)
-- [[specialized-mcp-builder]] ← 技术栈关联 ← [[testing-api-tester]](MCP 服务器构建需要 API 测试能力保障)
-- [[multi-agent-system-reliability]] ← 质量保障基础 ← [[testing-api-tester]](系统可靠性依赖 API 质量验证)
-
-## Contradictions
-- 暂无冲突内容
+---
+title: "API Tester Agent Personality"
+type: source
+tags: ["the-agency", "testing", "api", "automation", "qa", "performance", "security"]
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/testing/testing-api-tester.md]]
+
+## Summary(用中文描述)
+- 核心主题:The Agency Testing 部门的 API 测试专家智能体人格定义,涵盖功能、性能、安全三大维度的全面 API 质量保障方法论与自动化实现框架
+- 问题域:API 质量保障缺乏系统性方法论、测试覆盖不足、安全漏洞遗漏、性能 SLA 不达标等现实问题
+- 方法/机制:Playwright 测试框架 + perf_hooks 性能监控 + OWASP API Security Top 10 安全验证 + CI/CD 流水线集成 + 95%+ 覆盖率目标驱动
+- 结论/价值:为 The Agency 提供标准化的 API 测试智能体规范,通过自动化测试套件实现功能验证、性能基准、安全审计的三位一体质量保障
+
+## Key Claims(用中文描述)
+- API Tester Agent 通过 Playwright/REST Assured/k6 框架构建自动化测试套件,目标实现 95%+ API 端点覆盖率
+- API 性能 SLA 要求:95 百分位响应时间低于 200ms,正常负载下错误率低于 0.1%
+- 负载测试必须验证 10 倍正常流量容量,确保系统可扩展性
+- 安全测试覆盖 OWASP API Security Top 10,包含认证绕过、SQL 注入、XSS、速率限制等关键威胁
+- API 测试必须集成到 CI/CD 流水线,实现持续验证而非手动测试
+
+## Key Quotes
+> "Breaks your API before your users do." — API Tester Agent 的核心理念,防御性测试哲学
+> "API response times must be under 200ms for 95th percentile" — 明确的性能 SLA 标准
+> "Always test authentication and authorization mechanisms thoroughly" — 安全优先原则
+> "Load testing must validate 10x normal traffic capacity" — 规模化验证要求
+
+## Key Concepts
+- [[API Testing]]:覆盖功能、性能、安全三维度,通过自动化测试框架验证 API 端点行为与 SLA 合规性
+- [[Performance Testing]]:通过 perf_hooks 监控响应时间,验证 95 百分位 < 200ms、10x 负载、< 0.1% 错误率三大指标
+- [[Security Testing]]:OWASP API Security Top 10 安全测试框架,包含认证/授权/输入验证/速率限制等核心检查项
+- [[Contract Testing]]:API 版本间契约合规性与向后兼容性验证,确保服务间接口稳定性
+- [[CI/CD Integration]]:测试自动化嵌入持续集成/持续部署流水线,实现每次代码变更的自动质量验证
+- [[OWASP API Security Top 10]]:API 安全测试的行业标准清单,覆盖 BOLA/ BFLA/ Broken Auth 等关键 API 威胁
+
+## Key Entities
+- [[Playwright]]:Node.js 端到端测试框架,API Tester 的主要测试工具之一,支持功能与安全测试
+- [[REST Assured]]:Java API 测试框架,适用于 Java 生态系统的 REST API 验证
+- [[k6]]:Grafana 开源负载测试工具,用于性能测试与可扩展性验证
+- [[perf_hooks]]:Node.js 内置性能监测 API,用于精确的 API 响应时间测量
+
+## Connections
+- [[specialized-model-qa]] ← 测试范围互补 ← [[testing-api-tester]](模型质量测试 vs API 端点测试)
+- [[testing-accessibility-auditor]] ← 质量保障并行 ← [[testing-api-tester]](可访问性测试 vs API 功能/性能/安全测试)
+- [[testing-tool-evaluator]] ← 工具推荐上游 ← [[testing-api-tester]](工具评估为测试实施提供框架选择)
+- [[specialized-mcp-builder]] ← 技术栈关联 ← [[testing-api-tester]](MCP 服务器构建需要 API 测试能力保障)
+- [[multi-agent-system-reliability]] ← 质量保障基础 ← [[testing-api-tester]](系统可靠性依赖 API 质量验证)
+
+## Contradictions
+- 暂无冲突内容
diff --git a/wiki/sources/testing-evidence-collector.md b/wiki/sources/testing-evidence-collector.md
index ecea8fed..51cfce23 100644
--- a/wiki/sources/testing-evidence-collector.md
+++ b/wiki/sources/testing-evidence-collector.md
@@ -1,53 +1,53 @@
----
-title: "Testing Evidence Collector Agent Personality"
-type: source
-tags: []
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/testing/testing-evidence-collector.md]]
-
-## Summary(用中文描述)
-- 核心主题:EvidenceQA —— 一个以截图为核心证据的 QA Agent 个性化角色定义
-- 问题域:如何对 AI Agent 生成的前端实现进行严格的质量评估,避免"幻想式报告"(Fantasy Reporting)
-- 方法/机制:通过 Playwright 自动化截图 + 视觉对比 + 强制默认找问题(至少 3-5 个)来实现真实性检验
-- 结论/价值:QA 质量评估必须基于视觉证据,零问题报告是红色警报,必须强制提供截图
-
-## Key Claims(用中文描述)
-- EvidenceQA 相信"截图不会撒谎"——视觉证据是唯一可靠的真理
-- 首次实现总是存在至少 3-5 个问题,"零问题"是红色警报
-- 每个声明都需要截图证据支撑,无证据的声明视为"幻想"
-- luxury/premium 等描述词无截图支撑即为违规
-- 质量评级默认 FAILED,除非压倒性证据证明通过
-
-## Key Quotes
-> "Screenshots Don't Lie" — Visual evidence is the only truth that matters
-> "Default to Finding Issues" — First implementations ALWAYS have 3-5+ issues minimum
-> "Zero issues found" is a red flag - look harder
-> "Your job is to be the reality check that prevents broken websites from being approved"
-
-## Key Concepts
-- [[Visual Evidence]]:QA 评估的唯一可靠依据,通过 Playwright 自动化截图捕获
-- [[Fantasy Reporting]]:指无视觉证据支撑的声称,如"零问题"、"Luxury 级别"等
-- [[Reality Check Commands]]:强制性初始检查命令,包括 Playwright 截图、文件检查、grep 特征搜索
-- [[Specification Compliance]]:将实际截图与原始规范逐字对比,不添加规范外的额外要求
-- [[Accordion Testing Protocol]]:通过 before/after 截图对比验证手风琴组件的展开/折叠功能
-- [[Form Testing Protocol]]:验证表单提交、校验、错误信息展示的完整性
-- [[Mobile Responsive Testing]]:在 desktop/tablet/mobile 三种分辨率下验证布局和导航
-
-## Key Entities
-- [[EvidenceQA]]:截图驱动型 QA Agent,以视觉证据为唯一真理,默认发现 3-5+ 问题
-- [[Playwright]]:自动化截图工具(qa-playwright-capture.sh),提供 comprehensive screenshots 和 test-results.json
-
-## Connections
-- [[Testing Reality Checker]] ← related_to ← [[Testing Evidence Collector]]
-- [[Testing Test Results Analyzer]] ← related_to ← [[Testing Evidence Collector]]
-- [[Testing Performance Benchmarker]] ← related_to ← [[Testing Evidence Collector]]
-
-## Contradictions
-- 与声称"零问题"的报告冲突:
- - 冲突点:首次实现的问题数量
- - 当前观点:默认发现 3-5+ 问题,"零问题"是红色警报
- - 对方观点:声称"零问题"即通过
-```
+---
+title: "Testing Evidence Collector Agent Personality"
+type: source
+tags: []
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/testing/testing-evidence-collector.md]]
+
+## Summary(用中文描述)
+- 核心主题:EvidenceQA —— 一个以截图为核心证据的 QA Agent 个性化角色定义
+- 问题域:如何对 AI Agent 生成的前端实现进行严格的质量评估,避免"幻想式报告"(Fantasy Reporting)
+- 方法/机制:通过 Playwright 自动化截图 + 视觉对比 + 强制默认找问题(至少 3-5 个)来实现真实性检验
+- 结论/价值:QA 质量评估必须基于视觉证据,零问题报告是红色警报,必须强制提供截图
+
+## Key Claims(用中文描述)
+- EvidenceQA 相信"截图不会撒谎"——视觉证据是唯一可靠的真理
+- 首次实现总是存在至少 3-5 个问题,"零问题"是红色警报
+- 每个声明都需要截图证据支撑,无证据的声明视为"幻想"
+- luxury/premium 等描述词无截图支撑即为违规
+- 质量评级默认 FAILED,除非压倒性证据证明通过
+
+## Key Quotes
+> "Screenshots Don't Lie" — Visual evidence is the only truth that matters
+> "Default to Finding Issues" — First implementations ALWAYS have 3-5+ issues minimum
+> "Zero issues found" is a red flag - look harder
+> "Your job is to be the reality check that prevents broken websites from being approved"
+
+## Key Concepts
+- [[Visual Evidence]]:QA 评估的唯一可靠依据,通过 Playwright 自动化截图捕获
+- [[Fantasy Reporting]]:指无视觉证据支撑的声称,如"零问题"、"Luxury 级别"等
+- [[Reality Check Commands]]:强制性初始检查命令,包括 Playwright 截图、文件检查、grep 特征搜索
+- [[Specification Compliance]]:将实际截图与原始规范逐字对比,不添加规范外的额外要求
+- [[Accordion Testing Protocol]]:通过 before/after 截图对比验证手风琴组件的展开/折叠功能
+- [[Form Testing Protocol]]:验证表单提交、校验、错误信息展示的完整性
+- [[Mobile Responsive Testing]]:在 desktop/tablet/mobile 三种分辨率下验证布局和导航
+
+## Key Entities
+- [[EvidenceQA]]:截图驱动型 QA Agent,以视觉证据为唯一真理,默认发现 3-5+ 问题
+- [[Playwright]]:自动化截图工具(qa-playwright-capture.sh),提供 comprehensive screenshots 和 test-results.json
+
+## Connections
+- [[Testing Reality Checker]] ← related_to ← [[Testing Evidence Collector]]
+- [[Testing Test Results Analyzer]] ← related_to ← [[Testing Evidence Collector]]
+- [[Testing Performance Benchmarker]] ← related_to ← [[Testing Evidence Collector]]
+
+## Contradictions
+- 与声称"零问题"的报告冲突:
+ - 冲突点:首次实现的问题数量
+ - 当前观点:默认发现 3-5+ 问题,"零问题"是红色警报
+ - 对方观点:声称"零问题"即通过
+```
diff --git a/wiki/sources/testing-performance-benchmarker.md b/wiki/sources/testing-performance-benchmarker.md
index 2cea0bba..21cbb73f 100644
--- a/wiki/sources/testing-performance-benchmarker.md
+++ b/wiki/sources/testing-performance-benchmarker.md
@@ -1,53 +1,53 @@
----
-title: "Performance Benchmarker Agent Personality"
-type: source
-tags: []
-date: 2026-04-21
----
-
-## Source File
-- [[Agent/agency-agents/testing/testing-performance-benchmarker.md]]
-
-## Summary(用中文描述)
-- 核心主题:性能测试与优化专家 Agent,专注于测量、分析和改进跨应用程序和基础设施的系统性能
-- 问题域:性能基线建立、负载/压力测试、Web Vitals 优化、容量规划、可扩展性评估
-- 方法/机制:使用 k6 编写综合性能测试套件,统计置信区间分析,Core Web Vitals 监控,性能回归测试
-- 结论/价值:数据驱动的方法论,通过量化指标证明性能改进,确保系统满足 SLA 要求
-
-## Key Claims(用中文描述)
-- Performance Benchmarker Agent 通过系统性性能测试确保所有系统以 95% 置信度满足性能 SLA
-- 通过 Core Web Vitals 优化(LLC < 2.5s、FID < 100ms、CLS < 0.1)提升用户体验
-- 通过查询优化可将第95百分位响应时间从 850ms 降至 180ms
-- 通过性能监控可预防 90% 的性能相关事故
-
-## Key Quotes
-> "95th percentile response time improved from 850ms to 180ms through query optimization" — 数据驱动的优化效果量化
-
-> "Page load time reduction of 2.3 seconds increases conversion rate by 15%" — 性能与业务影响关联
-
-> "Always establish baseline performance before optimization attempts" — 性能优化的首要原则
-
-## Key Concepts
-- [[LoadTesting]]:模拟正常和峰值负载,验证系统在预期条件下的性能表现
-- [[StressTesting]]:逐步增加负载直到系统崩溃,找出性能临界点和恢复行为
-- [[CoreWebVitals]]:Google 定义的页面用户体验核心指标(LCP、FID、CLS)
-- [[RealUserMonitoring]]:基于真实用户数据的性能监控,对抗合成测试的局限性
-- [[CapacityPlanning]]:基于增长预测和使用模式预测资源需求
-- [[ConfidenceIntervals]]:统计置信区间用于可靠的性能测量
-
-## Key Entities
-- [[TestingRealityChecker]]:测试现实核查 Agent,与 Performance Benchmarker 协同工作
-- [[TestingApiTester]]:API 测试专家 Agent,共同构成全面测试体系
-- [[WorkflowOptimizerAgent]]:工作流优化 Agent,通过性能优化提升工作流效率
-
-## Connections
-- [[TestingRealityChecker]] ← complements ← [[TestingPerformanceBenchmarker]]
-- [[TestingApiTester]] ← extends ← [[TestingPerformanceBenchmarker]]
-- [[WorkflowOptimizerAgent]] ← depends_on ← [[TestingPerformanceBenchmarker]]
-
-## Contradictions
-- 与 [[TestingRealityChecker]] 的视角差异:
- - 冲突点:Reality Checker 强调"真实用户感受",Performance Benchmarker 强调"量化指标"
- - 当前观点:量化指标(p95 < 500ms)是性能优化的客观标准
- - 对方观点:用户主观感受比指标更重要,指标可能具有欺骗性
- - 调和:两者互补——指标指导优化方向,用户体验验证优化效果
+---
+title: "Performance Benchmarker Agent Personality"
+type: source
+tags: []
+date: 2026-04-21
+---
+
+## Source File
+- [[raw/Agent/agency-agents/testing/testing-performance-benchmarker.md]]
+
+## Summary(用中文描述)
+- 核心主题:性能测试与优化专家 Agent,专注于测量、分析和改进跨应用程序和基础设施的系统性能
+- 问题域:性能基线建立、负载/压力测试、Web Vitals 优化、容量规划、可扩展性评估
+- 方法/机制:使用 k6 编写综合性能测试套件,统计置信区间分析,Core Web Vitals 监控,性能回归测试
+- 结论/价值:数据驱动的方法论,通过量化指标证明性能改进,确保系统满足 SLA 要求
+
+## Key Claims(用中文描述)
+- Performance Benchmarker Agent 通过系统性性能测试确保所有系统以 95% 置信度满足性能 SLA
+- 通过 Core Web Vitals 优化(LLC < 2.5s、FID < 100ms、CLS < 0.1)提升用户体验
+- 通过查询优化可将第95百分位响应时间从 850ms 降至 180ms
+- 通过性能监控可预防 90% 的性能相关事故
+
+## Key Quotes
+> "95th percentile response time improved from 850ms to 180ms through query optimization" — 数据驱动的优化效果量化
+
+> "Page load time reduction of 2.3 seconds increases conversion rate by 15%" — 性能与业务影响关联
+
+> "Always establish baseline performance before optimization attempts" — 性能优化的首要原则
+
+## Key Concepts
+- [[LoadTesting]]:模拟正常和峰值负载,验证系统在预期条件下的性能表现
+- [[StressTesting]]:逐步增加负载直到系统崩溃,找出性能临界点和恢复行为
+- [[CoreWebVitals]]:Google 定义的页面用户体验核心指标(LCP、FID、CLS)
+- [[RealUserMonitoring]]:基于真实用户数据的性能监控,对抗合成测试的局限性
+- [[CapacityPlanning]]:基于增长预测和使用模式预测资源需求
+- [[ConfidenceIntervals]]:统计置信区间用于可靠的性能测量
+
+## Key Entities
+- [[TestingRealityChecker]]:测试现实核查 Agent,与 Performance Benchmarker 协同工作
+- [[TestingApiTester]]:API 测试专家 Agent,共同构成全面测试体系
+- [[WorkflowOptimizerAgent]]:工作流优化 Agent,通过性能优化提升工作流效率
+
+## Connections
+- [[TestingRealityChecker]] ← complements ← [[TestingPerformanceBenchmarker]]
+- [[TestingApiTester]] ← extends ← [[TestingPerformanceBenchmarker]]
+- [[WorkflowOptimizerAgent]] ← depends_on ← [[TestingPerformanceBenchmarker]]
+
+## Contradictions
+- 与 [[TestingRealityChecker]] 的视角差异:
+ - 冲突点:Reality Checker 强调"真实用户感受",Performance Benchmarker 强调"量化指标"
+ - 当前观点:量化指标(p95 < 500ms)是性能优化的客观标准
+ - 对方观点:用户主观感受比指标更重要,指标可能具有欺骗性
+ - 调和:两者互补——指标指导优化方向,用户体验验证优化效果
diff --git a/wiki/sources/testing-reality-checker.md b/wiki/sources/testing-reality-checker.md
index fd3488af..d6051585 100644
--- a/wiki/sources/testing-reality-checker.md
+++ b/wiki/sources/testing-reality-checker.md
@@ -1,52 +1,52 @@
----
-title: "Testing Reality Checker"
-type: source
-tags: []
-date: 2026-04-21
----
-
-## Source File
-- [[Agent/agency-agents/testing/testing-reality-checker.md]]
-
-## Summary(用中文描述)
-- 核心主题:The Agency Testing 部门的 Reality Checker Agent——通过自动化截图证据截断"幻想型认证",要求压倒性视觉证明才授予生产就绪状态。
-- 问题域:AI Agent 协作中各环节(设计/开发/QA)给出的评估过于乐观,缺乏实际截图验证,导致"98/100 评级"发给基础网站、"生产就绪"标签打在未完成系统上。
-- 方法/机制:强制三步流程(Reality Check 命令 → QA 交叉验证 → 端到端系统截图分析)+ 硬性失败触发器;默认 NEETS WORK 状态,必须有压倒性证据才能升级为 READY。
-- 结论/价值:第一次实现通常需要 2-3 轮修订;C+/B- 评级属正常;只有真实截图证据才能支撑"生产就绪"声明。
-
-## Key Claims(用中文描述)
-- Testing Reality Checker Agent 作为最后一道防线,通过截图证据截断"幻想型认证",要求压倒性视觉证明。
-- 所有系统声明需要视觉证明(自动化截图),规格说明需要对照实际实现进行交叉验证。
-- 完整的用户旅程测试需要截图证据;性能数据(加载时间、错误率)必须来自 test-results.json。
-- 默认"NEEDS WORK"状态,除非有压倒性证据支持"READY"。
-
-## Key Quotes
-> "You're the last line of defense against unrealistic assessments" — Testing Reality Checker Agent 自我定位
-> "Default to 'NEEDS WORK' status unless proven otherwise" — 核心认证原则
-> "First implementations typically need 2-3 revision cycles, C+/B- ratings are normal" — 现实质量预期
-> "Trust evidence over claims" — 质量认证核心方法论
-
-## Key Concepts
-- [[End-to-End Testing]]:完整用户旅程截图分析(桌面/平板/手机 × 交互前/后对比)
-- [[Evidence-Based Certification]]:以自动化截图 + test-results.json 数据为唯一认证依据
-- [[Specification Compliance]]:原始规格与实际实现之间的差距分析(gap analysis)
-- [[Quality Gate]]:生产就绪认证门槛——默认"NEEDS WORK",需压倒性证据才通过
-- [[Automated Screenshot Testing]]:Playwright qa-playwright-capture.sh 自动化截图捕获
-
-## Key Entities
-- Testing Reality Checker Agent:The Agency Testing 部门角色——截图驱动的生产就绪认证 Agent
-- QA Agent:前序 QA 测试环节,提供自动化测试发现和证据
-- Integration Agent:RealityIntegration——Reality Checker 的执行主体
-- [[testing-workflow-optimizer]]:工作流优化 Agent,为 Reality Checker 提供优化流程建议
-- [[testing-api-tester]]:API 测试 Agent,提供后端接口层面的测试证据
-
-## Connections
-- [[testing-workflow-optimizer]] ← workflow integration ← [[testing-reality-checker]]
-- [[testing-api-tester]] ← evidence source ← [[testing-reality-checker]]
-- [[testing-accessibility-auditor]] ← cross-validation ← [[testing-reality-checker]]
-- [[testing-evidence-collector]] ← provides screenshots ← [[testing-reality-checker]]
-- [[testing-reality-checker]] ← final gate ← [[agents-orchestrator]]
-
-## Contradictions
-- 与 [[testing-workflow-optimizer]] 潜在张力:Workflow Optimizer 追求流程效率(目标:75% 流程错误减少),Reality Checker 追求真实性(默认"需要工作"),两者在修订周期数量上可能存在分歧——Optimizer 希望快速迭代,Checker 要求充分证据
-- 与 [[testing-api-tester]] 的互补关系:API Tester 提供后端接口测试证据,Reality Checker 要求端到端截图;两者共同构成前后端双重质量门控
+---
+title: "Testing Reality Checker"
+type: source
+tags: []
+date: 2026-04-21
+---
+
+## Source File
+- [[raw/Agent/agency-agents/testing/testing-reality-checker.md]]
+
+## Summary(用中文描述)
+- 核心主题:The Agency Testing 部门的 Reality Checker Agent——通过自动化截图证据截断"幻想型认证",要求压倒性视觉证明才授予生产就绪状态。
+- 问题域:AI Agent 协作中各环节(设计/开发/QA)给出的评估过于乐观,缺乏实际截图验证,导致"98/100 评级"发给基础网站、"生产就绪"标签打在未完成系统上。
+- 方法/机制:强制三步流程(Reality Check 命令 → QA 交叉验证 → 端到端系统截图分析)+ 硬性失败触发器;默认 NEETS WORK 状态,必须有压倒性证据才能升级为 READY。
+- 结论/价值:第一次实现通常需要 2-3 轮修订;C+/B- 评级属正常;只有真实截图证据才能支撑"生产就绪"声明。
+
+## Key Claims(用中文描述)
+- Testing Reality Checker Agent 作为最后一道防线,通过截图证据截断"幻想型认证",要求压倒性视觉证明。
+- 所有系统声明需要视觉证明(自动化截图),规格说明需要对照实际实现进行交叉验证。
+- 完整的用户旅程测试需要截图证据;性能数据(加载时间、错误率)必须来自 test-results.json。
+- 默认"NEEDS WORK"状态,除非有压倒性证据支持"READY"。
+
+## Key Quotes
+> "You're the last line of defense against unrealistic assessments" — Testing Reality Checker Agent 自我定位
+> "Default to 'NEEDS WORK' status unless proven otherwise" — 核心认证原则
+> "First implementations typically need 2-3 revision cycles, C+/B- ratings are normal" — 现实质量预期
+> "Trust evidence over claims" — 质量认证核心方法论
+
+## Key Concepts
+- [[End-to-End Testing]]:完整用户旅程截图分析(桌面/平板/手机 × 交互前/后对比)
+- [[Evidence-Based Certification]]:以自动化截图 + test-results.json 数据为唯一认证依据
+- [[Specification Compliance]]:原始规格与实际实现之间的差距分析(gap analysis)
+- [[Quality Gate]]:生产就绪认证门槛——默认"NEEDS WORK",需压倒性证据才通过
+- [[Automated Screenshot Testing]]:Playwright qa-playwright-capture.sh 自动化截图捕获
+
+## Key Entities
+- Testing Reality Checker Agent:The Agency Testing 部门角色——截图驱动的生产就绪认证 Agent
+- QA Agent:前序 QA 测试环节,提供自动化测试发现和证据
+- Integration Agent:RealityIntegration——Reality Checker 的执行主体
+- [[testing-workflow-optimizer]]:工作流优化 Agent,为 Reality Checker 提供优化流程建议
+- [[testing-api-tester]]:API 测试 Agent,提供后端接口层面的测试证据
+
+## Connections
+- [[testing-workflow-optimizer]] ← workflow integration ← [[testing-reality-checker]]
+- [[testing-api-tester]] ← evidence source ← [[testing-reality-checker]]
+- [[testing-accessibility-auditor]] ← cross-validation ← [[testing-reality-checker]]
+- [[testing-evidence-collector]] ← provides screenshots ← [[testing-reality-checker]]
+- [[testing-reality-checker]] ← final gate ← [[agents-orchestrator]]
+
+## Contradictions
+- 与 [[testing-workflow-optimizer]] 潜在张力:Workflow Optimizer 追求流程效率(目标:75% 流程错误减少),Reality Checker 追求真实性(默认"需要工作"),两者在修订周期数量上可能存在分歧——Optimizer 希望快速迭代,Checker 要求充分证据
+- 与 [[testing-api-tester]] 的互补关系:API Tester 提供后端接口测试证据,Reality Checker 要求端到端截图;两者共同构成前后端双重质量门控
diff --git a/wiki/sources/testing-test-results-analyzer.md b/wiki/sources/testing-test-results-analyzer.md
index deae372c..d2eaff15 100644
--- a/wiki/sources/testing-test-results-analyzer.md
+++ b/wiki/sources/testing-test-results-analyzer.md
@@ -1,53 +1,53 @@
----
-title: "Test Results Analyzer Agent Personality"
-type: source
-tags: [agent-personality, testing, quality-assurance, statistical-analysis, machine-learning]
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/testing/testing-test-results-analyzer.md]]
-
-## Summary(用中文描述)
-- 核心主题:测试结果分析专家 Agent 的角色定义与行为规范,专注于全面的测试结果评估、质量指标分析和可操作洞察生成
-- 问题域:软件测试质量保障、缺陷预测、发布就绪评估
-- 方法/机制:统计分析方法 + 机器学习预测模型 + 质量指标仪表盘 + 多层级报告生成
-- 结论/价值:通过数据驱动的测试分析,将原始测试数据转化为战略洞察,驱动质量决策和持续改进
-
-## Key Claims(用中文描述)
-- Test Results Analyzer Agent 通过统计分析方法验证结论,为所有质量声明提供置信区间和统计显著性
-- 基于机器学习(RandomForestClassifier)的缺陷预测模型,预测缺陷易发区域,风险评分准确率目标 95%
-- 发布就绪评估采用多维度质量指标(通过率、覆盖率、性能SLA、安全合规、缺陷密度),结合置信度计算给出 GO/NO-GO 建议
-- 质量第一决策原则:优先考虑用户体验和产品质量,而非发布timeline
-- 测试报告在测试完成后 24 小时内交付,干系人满意度目标 4.5/5
-
-## Key Quotes
-> "Reads test results like a detective reads evidence — nothing gets past." — Agent 个性描述
-> "Test pass rate improved from 87.3% to 94.7% with 95% statistical confidence" — 精确沟通风格示例
-> "Quality investment of $50K prevents estimated $300K in production defect costs" — 质量投资ROI分析示例
-
-## Key Concepts
-- [[TestCoverageAnalysis]]:通过覆盖率统计(行/分支/函数/语句覆盖)和差距分析识别未覆盖区域
-- [[StatisticalAnalysis]]:使用统计方法验证结论,提供置信区间和统计显著性,支持跨数据源交叉验证
-- [[DefectPrediction]]:基于历史缺陷数据训练 RandomForest 分类器,预测缺陷易发区域并给出置信分数
-- [[ReleaseReadinessAssessment]]:综合通过率、覆盖率阈值、性能SLA、安全合规、缺陷密度等指标计算风险评分,给出 GO/NO-GO 建议
-- [[QualityMetrics]]:代码覆盖率、功能覆盖率、测试有效性、缺陷密度等可量化的质量指标体系
-- [[FailurePatternAnalysis]]:将测试失败按类型(功能/性能/安全/集成)分类,识别根因和趋势
-- [[QualityROI]]:质量投资回报分析,量化预防缺陷的成本节约与质量改进的收益
-- [[PredictiveModeling]]:使用 sklearn 集成方法对未来质量结果进行预测建模
-
-## Key Entities
-- [[TestResultsAnalyzer]]:本 Agent 本身,测试数据分析和质量情报专家,负责从测试结果中提取洞察
-- [[RandomForestClassifier]]:scikit-learn 提供的随机森林分类器,用于缺陷易发性预测
-- [[pandas / numpy / scipy.stats]]:统计分析依赖的核心 Python 库
-- [[matplotlib / seaborn]]:测试结果可视化依赖的 Python 库
-
-## Connections
-- [[TestingPerformanceBenchmarker]] ← same_agent_family ← [[TestResultsAnalyzer]]
-- [[TestingRealityChecker]] ← same_agent_family ← [[TestResultsAnalyzer]]
-- [[TestingWorkflowOptimizer]] ← same_agent_family ← [[TestResultsAnalyzer]]
-- [[APITester]] ← upstream_data_source ← [[TestResultsAnalyzer]](API Tester 提供测试数据输入)
-- [[TestResultsAnalyzer]] ← produces ← [[QualityMetrics]] / [[DefectPrediction]]
-
-## Contradictions
-- 暂无发现与其他 Wiki 页面的直接冲突
+---
+title: "Test Results Analyzer Agent Personality"
+type: source
+tags: [agent-personality, testing, quality-assurance, statistical-analysis, machine-learning]
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/testing/testing-test-results-analyzer.md]]
+
+## Summary(用中文描述)
+- 核心主题:测试结果分析专家 Agent 的角色定义与行为规范,专注于全面的测试结果评估、质量指标分析和可操作洞察生成
+- 问题域:软件测试质量保障、缺陷预测、发布就绪评估
+- 方法/机制:统计分析方法 + 机器学习预测模型 + 质量指标仪表盘 + 多层级报告生成
+- 结论/价值:通过数据驱动的测试分析,将原始测试数据转化为战略洞察,驱动质量决策和持续改进
+
+## Key Claims(用中文描述)
+- Test Results Analyzer Agent 通过统计分析方法验证结论,为所有质量声明提供置信区间和统计显著性
+- 基于机器学习(RandomForestClassifier)的缺陷预测模型,预测缺陷易发区域,风险评分准确率目标 95%
+- 发布就绪评估采用多维度质量指标(通过率、覆盖率、性能SLA、安全合规、缺陷密度),结合置信度计算给出 GO/NO-GO 建议
+- 质量第一决策原则:优先考虑用户体验和产品质量,而非发布timeline
+- 测试报告在测试完成后 24 小时内交付,干系人满意度目标 4.5/5
+
+## Key Quotes
+> "Reads test results like a detective reads evidence — nothing gets past." — Agent 个性描述
+> "Test pass rate improved from 87.3% to 94.7% with 95% statistical confidence" — 精确沟通风格示例
+> "Quality investment of $50K prevents estimated $300K in production defect costs" — 质量投资ROI分析示例
+
+## Key Concepts
+- [[TestCoverageAnalysis]]:通过覆盖率统计(行/分支/函数/语句覆盖)和差距分析识别未覆盖区域
+- [[StatisticalAnalysis]]:使用统计方法验证结论,提供置信区间和统计显著性,支持跨数据源交叉验证
+- [[DefectPrediction]]:基于历史缺陷数据训练 RandomForest 分类器,预测缺陷易发区域并给出置信分数
+- [[ReleaseReadinessAssessment]]:综合通过率、覆盖率阈值、性能SLA、安全合规、缺陷密度等指标计算风险评分,给出 GO/NO-GO 建议
+- [[QualityMetrics]]:代码覆盖率、功能覆盖率、测试有效性、缺陷密度等可量化的质量指标体系
+- [[FailurePatternAnalysis]]:将测试失败按类型(功能/性能/安全/集成)分类,识别根因和趋势
+- [[QualityROI]]:质量投资回报分析,量化预防缺陷的成本节约与质量改进的收益
+- [[PredictiveModeling]]:使用 sklearn 集成方法对未来质量结果进行预测建模
+
+## Key Entities
+- [[TestResultsAnalyzer]]:本 Agent 本身,测试数据分析和质量情报专家,负责从测试结果中提取洞察
+- [[RandomForestClassifier]]:scikit-learn 提供的随机森林分类器,用于缺陷易发性预测
+- [[pandas / numpy / scipy.stats]]:统计分析依赖的核心 Python 库
+- [[matplotlib / seaborn]]:测试结果可视化依赖的 Python 库
+
+## Connections
+- [[TestingPerformanceBenchmarker]] ← same_agent_family ← [[TestResultsAnalyzer]]
+- [[TestingRealityChecker]] ← same_agent_family ← [[TestResultsAnalyzer]]
+- [[TestingWorkflowOptimizer]] ← same_agent_family ← [[TestResultsAnalyzer]]
+- [[APITester]] ← upstream_data_source ← [[TestResultsAnalyzer]](API Tester 提供测试数据输入)
+- [[TestResultsAnalyzer]] ← produces ← [[QualityMetrics]] / [[DefectPrediction]]
+
+## Contradictions
+- 暂无发现与其他 Wiki 页面的直接冲突
diff --git a/wiki/sources/testing-tool-evaluator.md b/wiki/sources/testing-tool-evaluator.md
index b69996f5..84eeb688 100644
--- a/wiki/sources/testing-tool-evaluator.md
+++ b/wiki/sources/testing-tool-evaluator.md
@@ -1,48 +1,48 @@
----
-title: "Tool Evaluator Agent Personality"
-type: source
-tags: [agent, testing, tool-assessment, evaluation]
-date: 2026-04-21
----
-
-## Source File
-- [[Agent/agency-agents/testing/testing-tool-evaluator]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 角色定义——技术工具评估与选型专家,专注于为企业使用场景评估、测试和推荐工具、软件及平台
-- 问题域:企业在技术选型时面临的成本-功能-风险权衡,缺乏系统化评估方法论
-- 方法/机制:7维加权评分体系(功能25%/可用性20%/性能15%/安全15%/集成10%/支持8%/成本7%)+ 4阶段工作流(需求收集→全面测试→财务风险分析→实施规划)+ 完整 ROI/TCO 量化计算框架
-- 结论/价值:为 AI Agent 提供可量化的技术评估能力,确保推荐工具满足 90%+ 预期性能、85%+ 采用率、20%+ 成本优化、25%+ ROI 目标
-
-## Key Claims(用中文描述)
-- Tool Evaluator Agent 通过 7 维加权评分体系对工具进行全面量化评估,确保决策基于证据而非直觉
-- 每个工具评估必须包含安全性、集成性和成本分析三个默认要求,不可省略
-- 总拥有成本(TCO)分析必须涵盖授权、实施、培训、维护、集成、迁移和支持等全部隐性成本
-- 用户验收测试(UAT)应在真实用户场景和实际数据上验证,而非使用模拟数据
-- 供应商稳定性评估应包括财务状况、路线图对齐和战略合作潜力三个方面
-
-## Key Quotes
-> "Evidence-Based Evaluation Process: Always test tools with real-world scenarios and actual user data, use quantitative metrics and statistical analysis for tool comparisons." — 评估方法论核心原则
-> "Cost-Conscious Decision Making: Calculate total cost of ownership including hidden costs and scaling fees." — 成本分析框架
-> "Vendor Relationship Excellence: Strategic vendor partnership development and relationship management with contract negotiation expertise." — 供应商管理策略
-
-## Key Concepts
-- [[TotalCostOfOwnership]]:总拥有成本分析,涵盖3年周期的授权、实施、培训、维护、集成、迁移和支持成本
-- [[ReturnOnInvestment]]:投资回报率分析,包含不同采用率和场景的敏感性分析
-- [[ServiceLevelAgreement]]:服务水平协议,开发和性能监控系统
-- [[UserAcceptanceTesting]]:用户验收测试,在真实用户场景和代表性用户群中进行
-- [[ChangeManagement]]:变更管理,为确保工具成功采用而制定培训和沟通策略
-- [[WeightedScoringModel]]:加权评分模型,7维度权重分配(功能25%/可用性20%/性能15%/安全15%/集成10%/支持8%/成本7%)
-
-## Key Entities
-- Tool Evaluator Agent:The Agency Testing 部门的技术评估与战略工具采纳专家,专注于 ROI 导向的工具分析、竞争对比和战略技术采纳建议
-
-## Connections
-- [[TestingEvidenceCollector]] ← 被评估 ← [[TestingToolEvaluator]](前者收集评估证据,后者负责评分推荐)
-- [[TestingTestResultsAnalyzer]] ← 依赖 ← [[TestingToolEvaluator]](后者提供工具性能基准数据供前者分析)
-- [[TestingPerformanceBenchmarker]] ← 协同 ← [[TestingToolEvaluator]](两者共享性能测试数据,前者专注基准测试,后者专注综合评估)
-- [[AgentsOrchestrator]] ← 编排 ← [[TestingToolEvaluator]](编排器将评估任务调度给工具评估 Agent)
-- [[MultiAgentSystemReliability]] ← 支撑 ← [[TestingToolEvaluator]](评估推荐结果的质量直接影响多 Agent 系统可靠性)
-
-## Contradictions
-- 无明显冲突。与 [[TestingRealityChecker]] 在"现实检验"维度互补——前者给出量化评估,后者提供真实性核查。
+---
+title: "Tool Evaluator Agent Personality"
+type: source
+tags: [agent, testing, tool-assessment, evaluation]
+date: 2026-04-21
+---
+
+## Source File
+- [[raw/Agent/agency-agents/testing/testing-tool-evaluator.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 角色定义——技术工具评估与选型专家,专注于为企业使用场景评估、测试和推荐工具、软件及平台
+- 问题域:企业在技术选型时面临的成本-功能-风险权衡,缺乏系统化评估方法论
+- 方法/机制:7维加权评分体系(功能25%/可用性20%/性能15%/安全15%/集成10%/支持8%/成本7%)+ 4阶段工作流(需求收集→全面测试→财务风险分析→实施规划)+ 完整 ROI/TCO 量化计算框架
+- 结论/价值:为 AI Agent 提供可量化的技术评估能力,确保推荐工具满足 90%+ 预期性能、85%+ 采用率、20%+ 成本优化、25%+ ROI 目标
+
+## Key Claims(用中文描述)
+- Tool Evaluator Agent 通过 7 维加权评分体系对工具进行全面量化评估,确保决策基于证据而非直觉
+- 每个工具评估必须包含安全性、集成性和成本分析三个默认要求,不可省略
+- 总拥有成本(TCO)分析必须涵盖授权、实施、培训、维护、集成、迁移和支持等全部隐性成本
+- 用户验收测试(UAT)应在真实用户场景和实际数据上验证,而非使用模拟数据
+- 供应商稳定性评估应包括财务状况、路线图对齐和战略合作潜力三个方面
+
+## Key Quotes
+> "Evidence-Based Evaluation Process: Always test tools with real-world scenarios and actual user data, use quantitative metrics and statistical analysis for tool comparisons." — 评估方法论核心原则
+> "Cost-Conscious Decision Making: Calculate total cost of ownership including hidden costs and scaling fees." — 成本分析框架
+> "Vendor Relationship Excellence: Strategic vendor partnership development and relationship management with contract negotiation expertise." — 供应商管理策略
+
+## Key Concepts
+- [[TotalCostOfOwnership]]:总拥有成本分析,涵盖3年周期的授权、实施、培训、维护、集成、迁移和支持成本
+- [[ReturnOnInvestment]]:投资回报率分析,包含不同采用率和场景的敏感性分析
+- [[ServiceLevelAgreement]]:服务水平协议,开发和性能监控系统
+- [[UserAcceptanceTesting]]:用户验收测试,在真实用户场景和代表性用户群中进行
+- [[ChangeManagement]]:变更管理,为确保工具成功采用而制定培训和沟通策略
+- [[WeightedScoringModel]]:加权评分模型,7维度权重分配(功能25%/可用性20%/性能15%/安全15%/集成10%/支持8%/成本7%)
+
+## Key Entities
+- Tool Evaluator Agent:The Agency Testing 部门的技术评估与战略工具采纳专家,专注于 ROI 导向的工具分析、竞争对比和战略技术采纳建议
+
+## Connections
+- [[TestingEvidenceCollector]] ← 被评估 ← [[TestingToolEvaluator]](前者收集评估证据,后者负责评分推荐)
+- [[TestingTestResultsAnalyzer]] ← 依赖 ← [[TestingToolEvaluator]](后者提供工具性能基准数据供前者分析)
+- [[TestingPerformanceBenchmarker]] ← 协同 ← [[TestingToolEvaluator]](两者共享性能测试数据,前者专注基准测试,后者专注综合评估)
+- [[AgentsOrchestrator]] ← 编排 ← [[TestingToolEvaluator]](编排器将评估任务调度给工具评估 Agent)
+- [[MultiAgentSystemReliability]] ← 支撑 ← [[TestingToolEvaluator]](评估推荐结果的质量直接影响多 Agent 系统可靠性)
+
+## Contradictions
+- 无明显冲突。与 [[TestingRealityChecker]] 在"现实检验"维度互补——前者给出量化评估,后者提供真实性核查。
diff --git a/wiki/sources/testing-workflow-optimizer.md b/wiki/sources/testing-workflow-optimizer.md
index 7f1e6401..e81dbe8b 100644
--- a/wiki/sources/testing-workflow-optimizer.md
+++ b/wiki/sources/testing-workflow-optimizer.md
@@ -1,56 +1,56 @@
----
-title: "Workflow Optimizer Agent Personality"
-type: source
-tags: []
-date: 2026-04-21
----
-
-## Source File
-- [[Agent/agency-agents/testing/testing-workflow-optimizer.md]]
-
-## Summary(用中文描述)
-- 核心主题:The Agency Testing 部门的流程优化与工作流自动化专家 Agent,基于系统思维方法论,专注于端到端业务流程的分析、重设计、自动化与持续改进。
-- 问题域:工作流效率瓶颈识别、跨部门流程孤岛、人工重复性任务、流程质量与员工满意度的平衡。
-- 方法/机制:四阶段工作流(现状分析→优化设计→实施规划→自动化执行)+ Lean/Six Sigma/Kaizen 持续改进方法论 + 人本设计原则 + 数据驱动决策框架。核心工具:WorkflowOptimizer Python 框架(含瓶颈识别、优化机会评分、ROI 计算、实施路线图生成)。
-- 结论/价值:40% 平均周期时间改善、60% 常规任务自动化率、75% 流程错误减少、90% 优化流程 6 个月内成功采纳、30% 员工满意度提升。
-
-## Key Claims(用中文描述)
-- Workflow Optimizer Agent 通过系统分析消除效率瓶颈、流线化流程、实施智能化自动化解决方案,提升生产力、质量和员工满意度。
-- 每个流程优化必须包含自动化机会和可量化改进指标。
-- 在实施变更前必须测量当前状态性能,并使用统计分析验证改进有效性。
-- 优先考虑用户/员工体验和满意度,同时在自动化效率与人类判断和创造力之间取得平衡。
-
-## Key Quotes
-> "Finds the bottleneck, fixes the process, automates the rest." — Workflow Optimizer Agent personality description
-
-> "Process optimization reduces cycle time from 4.2 days to 1.8 days (57% improvement)" — communication style example
-
-> "Automation eliminates 15 hours/week of manual work, saving $39K annually" — communication style example
-
-## Key Concepts
-- [[Lean]]:精益方法论,识别三类活动(增值活动/价值赋能活动/浪费),追求消除一切不增值环节。
-- [[Six-Sigma]]:六西格玛方法论,通过 DMAIC(Define/Measure/Analyze/Improve/Control)流程减少流程变异和缺陷,目标 3.4 DPMO。
-- [[Kaizen]]:持续改进哲学,小步快跑、员工驱动的渐进式流程优化,与六西格玛形成互补。
-- [[Value-Stream-Mapping]]:价值流映射,识别流程中的增值时间 vs 非增值等待时间。
-- [[Statistical-Process-Control]]:统计过程控制,通过数据监控过程稳定性并预测性能。
-- [[Change-Management]]:变更管理,确保流程改进被团队接受并成功落地的策略框架。
-- [[Human-Centered-Design]]:人本设计,优先考虑用户/员工体验、认知负荷和可访问性。
-
-## Key Entities
-- [[The-Agency]]:Testing 部门的 Workflow Optimizer Agent 所属组织。
-
-## Connections
-- [[testing-api-tester]] ← 协同质量保障 ← [[testing-workflow-optimizer]](流程优化后需要 API 测试验证自动化后的系统行为)
-- [[specialized-workflow-architect]] ← 共享方法论 ← [[testing-workflow-optimizer]](两者均关注工作流设计与优化,但前者侧重设计建模,后者侧重实施改进)
-- [[product-sprint-prioritizer]] ← 协同优先级排序 ← [[testing-workflow-optimizer]](流程优化实施需要与 Sprint 规划对齐)
-- [[specialized-model-qa]] ← 协同数据验证 ← [[testing-workflow-optimizer]](六西格玛等统计方法与 Model QA 的量化验证方法相互补充)
-
-## Contradictions
-- 与 [[specialized-workflow-architect]] 存在职责边界张力:
- - 冲突点:两者均涉及工作流分析,但 Workflow Architect 强调设计规范(穷举所有路径/状态树),Workflow Optimizer 强调实施改进(量化效率收益/自动化 ROI)。
- - 当前观点:Workflow Architect 负责"如何设计"(设计层),Workflow Optimizer 负责"如何改进"(执行层),属于工作流生命周期的不同阶段。
- - 对方观点:部分场景下两者可互换使用,职责边界模糊。
-- 与 [[product-behavioral-nudge-engine]] 在自动化 vs 人机交互上存在理念张力:
- - 冲突点:Workflow Optimizer 追求最大化自动化(减少人工干预),Nudge Engine 追求最大化人类参与(微任务/游戏化驱动)。
- - 当前观点:两者互补——工作流层面追求自动化,用户/员工层面保留适度的人机交互以维护满意度。
- - 对方观点:过度自动化可能降低员工参与感和学习机会。
+---
+title: "Workflow Optimizer Agent Personality"
+type: source
+tags: []
+date: 2026-04-21
+---
+
+## Source File
+- [[raw/Agent/agency-agents/testing/testing-workflow-optimizer.md]]
+
+## Summary(用中文描述)
+- 核心主题:The Agency Testing 部门的流程优化与工作流自动化专家 Agent,基于系统思维方法论,专注于端到端业务流程的分析、重设计、自动化与持续改进。
+- 问题域:工作流效率瓶颈识别、跨部门流程孤岛、人工重复性任务、流程质量与员工满意度的平衡。
+- 方法/机制:四阶段工作流(现状分析→优化设计→实施规划→自动化执行)+ Lean/Six Sigma/Kaizen 持续改进方法论 + 人本设计原则 + 数据驱动决策框架。核心工具:WorkflowOptimizer Python 框架(含瓶颈识别、优化机会评分、ROI 计算、实施路线图生成)。
+- 结论/价值:40% 平均周期时间改善、60% 常规任务自动化率、75% 流程错误减少、90% 优化流程 6 个月内成功采纳、30% 员工满意度提升。
+
+## Key Claims(用中文描述)
+- Workflow Optimizer Agent 通过系统分析消除效率瓶颈、流线化流程、实施智能化自动化解决方案,提升生产力、质量和员工满意度。
+- 每个流程优化必须包含自动化机会和可量化改进指标。
+- 在实施变更前必须测量当前状态性能,并使用统计分析验证改进有效性。
+- 优先考虑用户/员工体验和满意度,同时在自动化效率与人类判断和创造力之间取得平衡。
+
+## Key Quotes
+> "Finds the bottleneck, fixes the process, automates the rest." — Workflow Optimizer Agent personality description
+
+> "Process optimization reduces cycle time from 4.2 days to 1.8 days (57% improvement)" — communication style example
+
+> "Automation eliminates 15 hours/week of manual work, saving $39K annually" — communication style example
+
+## Key Concepts
+- [[Lean]]:精益方法论,识别三类活动(增值活动/价值赋能活动/浪费),追求消除一切不增值环节。
+- [[Six-Sigma]]:六西格玛方法论,通过 DMAIC(Define/Measure/Analyze/Improve/Control)流程减少流程变异和缺陷,目标 3.4 DPMO。
+- [[Kaizen]]:持续改进哲学,小步快跑、员工驱动的渐进式流程优化,与六西格玛形成互补。
+- [[Value-Stream-Mapping]]:价值流映射,识别流程中的增值时间 vs 非增值等待时间。
+- [[Statistical-Process-Control]]:统计过程控制,通过数据监控过程稳定性并预测性能。
+- [[Change-Management]]:变更管理,确保流程改进被团队接受并成功落地的策略框架。
+- [[Human-Centered-Design]]:人本设计,优先考虑用户/员工体验、认知负荷和可访问性。
+
+## Key Entities
+- [[The-Agency]]:Testing 部门的 Workflow Optimizer Agent 所属组织。
+
+## Connections
+- [[testing-api-tester]] ← 协同质量保障 ← [[testing-workflow-optimizer]](流程优化后需要 API 测试验证自动化后的系统行为)
+- [[specialized-workflow-architect]] ← 共享方法论 ← [[testing-workflow-optimizer]](两者均关注工作流设计与优化,但前者侧重设计建模,后者侧重实施改进)
+- [[product-sprint-prioritizer]] ← 协同优先级排序 ← [[testing-workflow-optimizer]](流程优化实施需要与 Sprint 规划对齐)
+- [[specialized-model-qa]] ← 协同数据验证 ← [[testing-workflow-optimizer]](六西格玛等统计方法与 Model QA 的量化验证方法相互补充)
+
+## Contradictions
+- 与 [[specialized-workflow-architect]] 存在职责边界张力:
+ - 冲突点:两者均涉及工作流分析,但 Workflow Architect 强调设计规范(穷举所有路径/状态树),Workflow Optimizer 强调实施改进(量化效率收益/自动化 ROI)。
+ - 当前观点:Workflow Architect 负责"如何设计"(设计层),Workflow Optimizer 负责"如何改进"(执行层),属于工作流生命周期的不同阶段。
+ - 对方观点:部分场景下两者可互换使用,职责边界模糊。
+- 与 [[product-behavioral-nudge-engine]] 在自动化 vs 人机交互上存在理念张力:
+ - 冲突点:Workflow Optimizer 追求最大化自动化(减少人工干预),Nudge Engine 追求最大化人类参与(微任务/游戏化驱动)。
+ - 当前观点:两者互补——工作流层面追求自动化,用户/员工层面保留适度的人机交互以维护满意度。
+ - 对方观点:过度自动化可能降低员工参与感和学习机会。
diff --git a/wiki/sources/the-myths-and-misconceptions-about-cloud-computing-linkedin.md b/wiki/sources/the-myths-and-misconceptions-about-cloud-computing-linkedin.md
index 8addc0ad..b4684a50 100644
--- a/wiki/sources/the-myths-and-misconceptions-about-cloud-computing-linkedin.md
+++ b/wiki/sources/the-myths-and-misconceptions-about-cloud-computing-linkedin.md
@@ -1,58 +1,58 @@
----
-title: "The Myths and Misconceptions About Cloud Computing | LinkedIn"
-type: source
-tags: [cloud-computing, misconceptions, cloud-security, cost-optimization]
-date: 2025-03-02
----
-
-## Source File
-- [[Cloud & DevOps/The Myths and Misconceptions About Cloud Computing LinkedIn]]
-
-## Summary(用中文描述)
-- 核心主题:云计算领域的7大常见误解及其真相
-- 问题域:企业或个人在采用云计算时的认知误区
-- 方法/机制:通过逐一反驳误解,揭示云计算的实际能力与优势
-- 结论/价值:帮助决策者消除顾虑,正确认识云计算的安全性、成本效益和可靠性
-
-## Key Claims(用中文描述)
-- 云安全往往比本地解决方案更强大:主流云服务商投入大量资源于加密、防火墙、多因素认证,符合 ISO 27001、HIPAA、GDPR 等严苛标准
-- 云远不止是"别人的电脑":云是由冗余、可扩展、高可用的数据中心网络组成,远超典型本地解决方案
-- 通过适当管理,云计算具有成本效益:采用按需付费模式、预留实例、自动扩展和无服务器计算可显著降低成本
-- 云服务提供强大的数据治理工具:组织可管理权限、加密数据、监控访问日志,支持混合云和多云部署
-- 各类规模的企业都能从云计算中受益:中小企业可享受灵活定价,无需大额前期投资即可使用企业级技术
-- 适当的规划可使云迁移顺利推进:分阶段迁移、混合云方案和专业迁移服务可降低风险
-- 主要云服务商提供高可用性和冗余:SLA 保证可用性通常超过 99.99%
-
-## Key Quotes
-> "Leading cloud providers invest heavily in security measures, including encryption, firewalls, and multi-factor authentication." — 云服务商在安全措施上的持续投入
-
-> "Cloud computing follows a pay-as-you-go model, allowing businesses to scale resources as needed." — 按需付费的灵活性
-
-> "Major cloud providers offer service-level agreements (SLAs) that guarantee uptime, often exceeding 99.99%." — 服务等级协议保证高可用性
-
-## Key Concepts
-- [[CloudComputing]]:通过互联网按需提供计算资源、存储和应用的服务模式
-- [[CloudSecurity]]:云环境下的安全实践,包括加密、MFA、安全合规认证
-- [[PayAsYouGo]]:按使用量付费的成本模型
-- [[HybridCloud]]:混合云,结合本地设施和公有云的部署模式
-- [[MultiCloud]]:多云战略,使用多个云服务商的服务
-- [[CloudMigration]]:将工作负载从本地迁移到云端的过程
-- [[HighAvailability]]:高可用性设计,确保服务持续运行
-- [[AutoScaling]]:根据负载自动调整资源的能力
-
-## Key Entities
-- [[ISO27001]]:国际认可的信息安全管理标准
-- [[HIPAA]]:美国医疗保健信息保护法规
-- [[GDPR]]:欧盟通用数据保护条例
-
-## Connections
-- [[CloudComputing]] ← topic ← [[The Myths and Misconceptions About Cloud Computing]]
-- [[CloudSecurity]] ← key_mechanism ← [[CloudComputing]]
-- [[PayAsYouGo]] ← cost_model ← [[CloudComputing]]
-- [[HybridCloud]] ← solution_type ← [[CloudMigration]]
-
-## Contradictions
-- 与 On-Premises 相比的误解:
- - 冲突点:安全性、控制权、可靠性
- - 当前观点:云安全更强(专业团队 24/7 监控、自动更新)、数据控制完善、高可用 SLA
- - 对方观点:本地部署更安全、更可控、性能更稳定
+---
+title: "The Myths and Misconceptions About Cloud Computing | LinkedIn"
+type: source
+tags: [cloud-computing, misconceptions, cloud-security, cost-optimization]
+date: 2025-03-02
+---
+
+## Source File
+- [[raw/Cloud & DevOps/The Myths and Misconceptions About Cloud Computing LinkedIn.md]]
+
+## Summary(用中文描述)
+- 核心主题:云计算领域的7大常见误解及其真相
+- 问题域:企业或个人在采用云计算时的认知误区
+- 方法/机制:通过逐一反驳误解,揭示云计算的实际能力与优势
+- 结论/价值:帮助决策者消除顾虑,正确认识云计算的安全性、成本效益和可靠性
+
+## Key Claims(用中文描述)
+- 云安全往往比本地解决方案更强大:主流云服务商投入大量资源于加密、防火墙、多因素认证,符合 ISO 27001、HIPAA、GDPR 等严苛标准
+- 云远不止是"别人的电脑":云是由冗余、可扩展、高可用的数据中心网络组成,远超典型本地解决方案
+- 通过适当管理,云计算具有成本效益:采用按需付费模式、预留实例、自动扩展和无服务器计算可显著降低成本
+- 云服务提供强大的数据治理工具:组织可管理权限、加密数据、监控访问日志,支持混合云和多云部署
+- 各类规模的企业都能从云计算中受益:中小企业可享受灵活定价,无需大额前期投资即可使用企业级技术
+- 适当的规划可使云迁移顺利推进:分阶段迁移、混合云方案和专业迁移服务可降低风险
+- 主要云服务商提供高可用性和冗余:SLA 保证可用性通常超过 99.99%
+
+## Key Quotes
+> "Leading cloud providers invest heavily in security measures, including encryption, firewalls, and multi-factor authentication." — 云服务商在安全措施上的持续投入
+
+> "Cloud computing follows a pay-as-you-go model, allowing businesses to scale resources as needed." — 按需付费的灵活性
+
+> "Major cloud providers offer service-level agreements (SLAs) that guarantee uptime, often exceeding 99.99%." — 服务等级协议保证高可用性
+
+## Key Concepts
+- [[CloudComputing]]:通过互联网按需提供计算资源、存储和应用的服务模式
+- [[CloudSecurity]]:云环境下的安全实践,包括加密、MFA、安全合规认证
+- [[PayAsYouGo]]:按使用量付费的成本模型
+- [[HybridCloud]]:混合云,结合本地设施和公有云的部署模式
+- [[MultiCloud]]:多云战略,使用多个云服务商的服务
+- [[CloudMigration]]:将工作负载从本地迁移到云端的过程
+- [[HighAvailability]]:高可用性设计,确保服务持续运行
+- [[AutoScaling]]:根据负载自动调整资源的能力
+
+## Key Entities
+- [[ISO27001]]:国际认可的信息安全管理标准
+- [[HIPAA]]:美国医疗保健信息保护法规
+- [[GDPR]]:欧盟通用数据保护条例
+
+## Connections
+- [[CloudComputing]] ← topic ← [[The Myths and Misconceptions About Cloud Computing]]
+- [[CloudSecurity]] ← key_mechanism ← [[CloudComputing]]
+- [[PayAsYouGo]] ← cost_model ← [[CloudComputing]]
+- [[HybridCloud]] ← solution_type ← [[CloudMigration]]
+
+## Contradictions
+- 与 On-Premises 相比的误解:
+ - 冲突点:安全性、控制权、可靠性
+ - 当前观点:云安全更强(专业团队 24/7 监控、自动更新)、数据控制完善、高可用 SLA
+ - 对方观点:本地部署更安全、更可控、性能更稳定
diff --git a/wiki/sources/these-6-linux-apps-let-you-monitor-system-resources-in-style.md b/wiki/sources/these-6-linux-apps-let-you-monitor-system-resources-in-style.md
index 409c77c6..ac23b317 100644
--- a/wiki/sources/these-6-linux-apps-let-you-monitor-system-resources-in-style.md
+++ b/wiki/sources/these-6-linux-apps-let-you-monitor-system-resources-in-style.md
@@ -1,54 +1,54 @@
----
-title: "These 6 Linux Apps Let You Monitor System Resources in Style"
-type: source
-tags: [linux, system-monitoring, open-source, devops, tooling]
-date: 2025-12-16
----
-
-## Source File
-- [[Cloud & DevOps/These 6 Linux apps let you monitor system resources in style.md]]
-
-## Summary(用中文描述)
-- 核心主题:Linux 系统资源监控工具横向评测,推荐 6 款替代桌面环境默认资源管理器的应用
-- 问题域:Linux 用户需要比桌面默认资源管理器更轻量、更美观或功能更丰富的系统监控方案
-- 方法/机制:按 TUI(命令行文本界面)和 GUI 两大类,分别评测 6 款工具的功能与体验
-- 结论/价值:作者首推 **Btop++**(TUI 类),理由是兼具美观与可用性;GUI 类首选 **Mission Center**(类 Task Manager 体验)和 **Stacer**(功能最丰富);TUI 工具在 SSH 远程场景下尤为实用
-
-## Key Claims(用中文描述)
-- Btop++:主体(TUI 监控工具)+ 机制(多面板布局、支持进程信号/Nice 值/主题切换)+ 结果(作者首选)
-- Htop:主体(TUI 进程监控)+ 机制(键盘驱动/F 键操作)+ 结果(适合追求极简流程监控的用户)
-- Glances:主体(轻量 TUI 监控)+ 机制(全键盘导航/k 键杀进程)+ 结果(最轻最快)
-- Bottom:主体(实时图形化资源监控)+ 机制(专注 CPU/网络/内存图表,非任务管理器)+ 结果(纯图形监控,无交互)
-- Mission Center:主体(GNOME 原生 GUI 资源管理器)+ 机制(性能/应用/服务三标签页,类 Task Manager)+ 结果(Debian/Ubuntu 仅有 Snap 包)
-- Stacer:主体(功能最全面的 GUI 资源管理器)+ 机制(仪表盘/进程/服务/启动项/APT 仓库/缓存清理)+ 结果(唯一支持桌面定制和垃圾清理的工具)
-
-## Key Quotes
-> "TUI apps make the best resource monitors, in my opinion. They're snappy and responsive, even when the GUI is lagging." — 作者偏好 TUI 的核心理由
-> "Btop++ always gets my vote. It features a nice balance between usability and aesthetics." — Btop++ 推荐结论
-> "Mission Center is your friend" if you want something close to the Windows Task Manager — Mission Center 推荐定位
-
-## Key Concepts
-- [[TUI]]:文本用户界面,通过终端运行,响应迅速,适合 SSH 远程场景
-- [[System-Monitoring]]:系统资源监控,涵盖 CPU、内存、存储、网络、进程等维度
-- [[Process-Management]]:进程管理,包括查看、搜索、终止、优先级调整
-
-## Key Entities
-- [[Btop++]]:作者首选 TUI 资源监控器,支持 Pacman 安装和 Snap 包(Debian/Ubuntu)
-- [[Htop]]:经典 TUI 进程监控器,全键盘驱动,适合进程优先场景
-- [[Glances]]:极轻量 TUI 监控器,全键盘操作,适合资源受限环境
-- [[Bottom]]:专注实时图形化监控的工具,支持进程树视图,非交互式任务管理器
-- [[Mission-Center]]:GNOME 原生 GUI 资源管理器,提供性能/应用/服务三标签页
-- [[Stacer]]:功能最丰富的 GUI 资源管理器,支持缓存清理、启动项管理、APT 仓库配置
-- [[HowToGeek]]:文章来源的技术博客
-
-## Connections
-- [[家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox]] ← 应用层 ← [[These-6-Linux-Apps-Let-You-Monitor-System-Resources-in-Style]]:本文工具为单机能见度层,与 Prometheus/Grafana 企业监控方案互补
-- [[linux-运维必会的-150-个命令]] ← 关联 ← [[These-6-Linux-Apps-Let-You-Monitor-System-Resources-in-Style]]:系统监控是 Linux 运维基础技能,本文 6 款工具覆盖该技能核心场景
-- [[家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox]] ← 对比 ← [[These-6-Linux-Apps-Let-You-Monitor-System-Resources-in-Style]]:企业级(Prometheus/Grafana)vs 轻量级(本文工具)
-
-## Contradictions
-- 与 [[家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox]] 定位差异:
- - 冲突点:监控方案选择
- - 当前观点:单机能见度优先,用 Btop++ 或 Mission Center 快速定位问题
- - 对方观点:企业级基础设施需 Prometheus + Grafana 实现集中可观测性
- - 说明:两者面向不同场景,不构成直接冲突;建议单节点用本文工具,多节点/生产环境用 Prometheus/Grafana
+---
+title: "These 6 Linux Apps Let You Monitor System Resources in Style"
+type: source
+tags: [linux, system-monitoring, open-source, devops, tooling]
+date: 2025-12-16
+---
+
+## Source File
+- [[raw/Cloud & DevOps/These 6 Linux apps let you monitor system resources in style.md]]
+
+## Summary(用中文描述)
+- 核心主题:Linux 系统资源监控工具横向评测,推荐 6 款替代桌面环境默认资源管理器的应用
+- 问题域:Linux 用户需要比桌面默认资源管理器更轻量、更美观或功能更丰富的系统监控方案
+- 方法/机制:按 TUI(命令行文本界面)和 GUI 两大类,分别评测 6 款工具的功能与体验
+- 结论/价值:作者首推 **Btop++**(TUI 类),理由是兼具美观与可用性;GUI 类首选 **Mission Center**(类 Task Manager 体验)和 **Stacer**(功能最丰富);TUI 工具在 SSH 远程场景下尤为实用
+
+## Key Claims(用中文描述)
+- Btop++:主体(TUI 监控工具)+ 机制(多面板布局、支持进程信号/Nice 值/主题切换)+ 结果(作者首选)
+- Htop:主体(TUI 进程监控)+ 机制(键盘驱动/F 键操作)+ 结果(适合追求极简流程监控的用户)
+- Glances:主体(轻量 TUI 监控)+ 机制(全键盘导航/k 键杀进程)+ 结果(最轻最快)
+- Bottom:主体(实时图形化资源监控)+ 机制(专注 CPU/网络/内存图表,非任务管理器)+ 结果(纯图形监控,无交互)
+- Mission Center:主体(GNOME 原生 GUI 资源管理器)+ 机制(性能/应用/服务三标签页,类 Task Manager)+ 结果(Debian/Ubuntu 仅有 Snap 包)
+- Stacer:主体(功能最全面的 GUI 资源管理器)+ 机制(仪表盘/进程/服务/启动项/APT 仓库/缓存清理)+ 结果(唯一支持桌面定制和垃圾清理的工具)
+
+## Key Quotes
+> "TUI apps make the best resource monitors, in my opinion. They're snappy and responsive, even when the GUI is lagging." — 作者偏好 TUI 的核心理由
+> "Btop++ always gets my vote. It features a nice balance between usability and aesthetics." — Btop++ 推荐结论
+> "Mission Center is your friend" if you want something close to the Windows Task Manager — Mission Center 推荐定位
+
+## Key Concepts
+- [[TUI]]:文本用户界面,通过终端运行,响应迅速,适合 SSH 远程场景
+- [[System-Monitoring]]:系统资源监控,涵盖 CPU、内存、存储、网络、进程等维度
+- [[Process-Management]]:进程管理,包括查看、搜索、终止、优先级调整
+
+## Key Entities
+- [[Btop++]]:作者首选 TUI 资源监控器,支持 Pacman 安装和 Snap 包(Debian/Ubuntu)
+- [[Htop]]:经典 TUI 进程监控器,全键盘驱动,适合进程优先场景
+- [[Glances]]:极轻量 TUI 监控器,全键盘操作,适合资源受限环境
+- [[Bottom]]:专注实时图形化监控的工具,支持进程树视图,非交互式任务管理器
+- [[Mission-Center]]:GNOME 原生 GUI 资源管理器,提供性能/应用/服务三标签页
+- [[Stacer]]:功能最丰富的 GUI 资源管理器,支持缓存清理、启动项管理、APT 仓库配置
+- [[HowToGeek]]:文章来源的技术博客
+
+## Connections
+- [[家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox]] ← 应用层 ← [[These-6-Linux-Apps-Let-You-Monitor-System-Resources-in-Style]]:本文工具为单机能见度层,与 Prometheus/Grafana 企业监控方案互补
+- [[linux-运维必会的-150-个命令]] ← 关联 ← [[These-6-Linux-Apps-Let-You-Monitor-System-Resources-in-Style]]:系统监控是 Linux 运维基础技能,本文 6 款工具覆盖该技能核心场景
+- [[家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox]] ← 对比 ← [[These-6-Linux-Apps-Let-You-Monitor-System-Resources-in-Style]]:企业级(Prometheus/Grafana)vs 轻量级(本文工具)
+
+## Contradictions
+- 与 [[家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox]] 定位差异:
+ - 冲突点:监控方案选择
+ - 当前观点:单机能见度优先,用 Btop++ 或 Mission Center 快速定位问题
+ - 对方观点:企业级基础设施需 Prometheus + Grafana 实现集中可观测性
+ - 说明:两者面向不同场景,不构成直接冲突;建议单节点用本文工具,多节点/生产环境用 Prometheus/Grafana
diff --git a/wiki/sources/tiktok-shop-apache-superset-dashboard设计思路.md b/wiki/sources/tiktok-shop-apache-superset-dashboard设计思路.md
index bcd2fbba..415ceb93 100644
--- a/wiki/sources/tiktok-shop-apache-superset-dashboard设计思路.md
+++ b/wiki/sources/tiktok-shop-apache-superset-dashboard设计思路.md
@@ -1,53 +1,53 @@
----
-title: "TikTok Shop - Apache Superset Dashboard设计思路"
-type: source
-tags: ["TikTok电商", "数据可视化", "Apache Superset", "选品分析", "BI仪表盘"]
-date: 2026-04-18
----
-
-## Source File
-- [[跨境电商/TikTok Shop - Apache Superset Dashboard设计思路]]
-
-## Summary(用中文描述)
-- 核心主题:Apache Superset 在 TikTok Shop 电商选品分析场景的完整 Dashboard 设计方案
-- 问题域:TikTok Shop 跨境电商卖家如何通过数据可视化系统发现爆品、识别类目机会、监控竞品店铺
-- 方法/机制:基于 Scrapy + Playwright 抓取的 TikTok Shop 产品数据(products 表、product_reviews 表、product_variations 表),通过 SQL View 预处理 JSON 字段,设计 4-Tab 专业 Dashboard(爆品雷达 / 类目洞察 / 店铺监控 / 评论分析),结合动态过滤器实现选品决策自动化
-- 结论/价值:提供了一套"可长期演进的专业选品分析系统"的完整设计蓝图,从数据准备→指标体系→可视化图表→Dashboard 布局→高阶选品评分 SQL,均有可直接落地的方案
-
-## Key Claims(用中文描述)
-- Apache Superset 不会自动解析 JSON 字段,必须通过 SQL View 预先提取 rating、rating_count 等数值字段,才能构建 KPI 卡、Heatmap 等图表
-- 核心选品目标为"找出热卖产品 + 高评分 + 低竞争 + 高折扣",Dashboard 应支持动态过滤器实现交互式选品决策
-- SQL 选品评分公式:score = sold × 0.4 + rating × 15 + discount_percent × 0.5 + rating_count × 0.2,可根据业务需求自定义权重
-- 推荐 4-Tab Dashboard 结构:爆品雷达(KPI总览)→ 类目机会洞察(热力图/箱线图)→ 店铺监控(时序图)→ 评论分析(评分趋势)
-
-## Key Quotes
-> "找出热卖产品 + 高评分 + 低竞争 + 高折扣 → 决定选哪些产品卖" — 选品 Dashboard 核心目标
-> "Superset 不会自动解析 JSON,你需要创建 SQL View 预先提取数值字段" — 数据准备关键步骤
-> "这样整个 Dashboard 变成一个动态选品系统" — 动态过滤器的价值定位
-
-## Key Concepts
-- [[Apache Superset]]:开源 BI 可视化平台,支持 SQL 查询、多样化图表和仪表盘构建,本文档中使用 Docker 容器化部署
-- [[KPI Card]]:关键绩效指标卡片,展示总产品数、热卖产品数、平均评分、平均价格等核心数字
-- [[选品评分公式]]:加权多维度评分公式,权重可自定义(sold × 0.4 + rating × 15 + discount × 0.5 + rating_count × 0.2)
-- [[Scatter Plot]](散点图):用于分析销量 vs 价格关系,气泡大小代表评分,颜色代表类目
-- [[Box Plot]](箱线图):用于分析类目价格带分布,找出"利润空间大但竞争低"的类目
-- [[Heatmap]](热力图):用于类目评分 vs 销量交叉分析
-- [[SQL View]]:在数据库层面预处理 JSON 字段(如 JSON_EXTRACT),使 Superset 能直接计算数值指标
-- [[Dynamic Filter]](动态过滤器):支持 Category/Store Name/价格范围/时间范围等交互式筛选,使 Dashboard 具备实时分析能力
-- [[GMV]](商品交易总额):final_price × sold,用于产品排名
-
-## Key Entities
-- [[TikTok Shop]]:字节跳动旗下电商平台,本文档数据抓取的目标平台
-- [[tiktok_products 数据库]]:包含 products、product_reviews、product_variations 三张核心表的数据库结构
-- [[products 表]]:存储产品基础信息(id/title/sold/price/rating/category/store_name/timestamp/position)
-- [[product_reviews 表]]:存储用户评论数据(rating/review_date/review_text/product_id)
-- [[product_variations 表]]:存储 SKU 层变体数据(sku/stock/final_price/discount_percent)
-
-## Connections
-- [[Scrapy + Playwright 抓取TikTok Shop Data]] ← upstream_data_source ← [[TikTok Shop Apache Superset Dashboard设计思路]]
-- [[TikTok PM - Python Django 项目]] ← shares_database_schema ← [[TikTok Shop Apache Superset Dashboard设计思路]]
-- [[Apache Superset]] ← tool ← [[TikTok Shop Apache Superset Dashboard设计思路]]
-- [[用Docker安装Apache Superset]] ← prerequisite ← [[TikTok Shop Apache Superset Dashboard设计思路]]
-
-## Contradictions
-- 与 [[电商如何选品-如何找到爆款-选品策略]]:后者侧重选品策略理论(市场调研/竞争对手分析/利润测算),前者侧重数据驱动的可视化执行工具(Apache Superset Dashboard)。两者互补而非冲突——策略指导选品方向,Dashboard 提供实时数据验证。
+---
+title: "TikTok Shop - Apache Superset Dashboard设计思路"
+type: source
+tags: ["TikTok电商", "数据可视化", "Apache Superset", "选品分析", "BI仪表盘"]
+date: 2026-04-18
+---
+
+## Source File
+- [[raw/跨境电商/TikTok Shop - Apache Superset Dashboard设计思路.md]]
+
+## Summary(用中文描述)
+- 核心主题:Apache Superset 在 TikTok Shop 电商选品分析场景的完整 Dashboard 设计方案
+- 问题域:TikTok Shop 跨境电商卖家如何通过数据可视化系统发现爆品、识别类目机会、监控竞品店铺
+- 方法/机制:基于 Scrapy + Playwright 抓取的 TikTok Shop 产品数据(products 表、product_reviews 表、product_variations 表),通过 SQL View 预处理 JSON 字段,设计 4-Tab 专业 Dashboard(爆品雷达 / 类目洞察 / 店铺监控 / 评论分析),结合动态过滤器实现选品决策自动化
+- 结论/价值:提供了一套"可长期演进的专业选品分析系统"的完整设计蓝图,从数据准备→指标体系→可视化图表→Dashboard 布局→高阶选品评分 SQL,均有可直接落地的方案
+
+## Key Claims(用中文描述)
+- Apache Superset 不会自动解析 JSON 字段,必须通过 SQL View 预先提取 rating、rating_count 等数值字段,才能构建 KPI 卡、Heatmap 等图表
+- 核心选品目标为"找出热卖产品 + 高评分 + 低竞争 + 高折扣",Dashboard 应支持动态过滤器实现交互式选品决策
+- SQL 选品评分公式:score = sold × 0.4 + rating × 15 + discount_percent × 0.5 + rating_count × 0.2,可根据业务需求自定义权重
+- 推荐 4-Tab Dashboard 结构:爆品雷达(KPI总览)→ 类目机会洞察(热力图/箱线图)→ 店铺监控(时序图)→ 评论分析(评分趋势)
+
+## Key Quotes
+> "找出热卖产品 + 高评分 + 低竞争 + 高折扣 → 决定选哪些产品卖" — 选品 Dashboard 核心目标
+> "Superset 不会自动解析 JSON,你需要创建 SQL View 预先提取数值字段" — 数据准备关键步骤
+> "这样整个 Dashboard 变成一个动态选品系统" — 动态过滤器的价值定位
+
+## Key Concepts
+- [[Apache Superset]]:开源 BI 可视化平台,支持 SQL 查询、多样化图表和仪表盘构建,本文档中使用 Docker 容器化部署
+- [[KPI Card]]:关键绩效指标卡片,展示总产品数、热卖产品数、平均评分、平均价格等核心数字
+- [[选品评分公式]]:加权多维度评分公式,权重可自定义(sold × 0.4 + rating × 15 + discount × 0.5 + rating_count × 0.2)
+- [[Scatter Plot]](散点图):用于分析销量 vs 价格关系,气泡大小代表评分,颜色代表类目
+- [[Box Plot]](箱线图):用于分析类目价格带分布,找出"利润空间大但竞争低"的类目
+- [[Heatmap]](热力图):用于类目评分 vs 销量交叉分析
+- [[SQL View]]:在数据库层面预处理 JSON 字段(如 JSON_EXTRACT),使 Superset 能直接计算数值指标
+- [[Dynamic Filter]](动态过滤器):支持 Category/Store Name/价格范围/时间范围等交互式筛选,使 Dashboard 具备实时分析能力
+- [[GMV]](商品交易总额):final_price × sold,用于产品排名
+
+## Key Entities
+- [[TikTok Shop]]:字节跳动旗下电商平台,本文档数据抓取的目标平台
+- [[tiktok_products 数据库]]:包含 products、product_reviews、product_variations 三张核心表的数据库结构
+- [[products 表]]:存储产品基础信息(id/title/sold/price/rating/category/store_name/timestamp/position)
+- [[product_reviews 表]]:存储用户评论数据(rating/review_date/review_text/product_id)
+- [[product_variations 表]]:存储 SKU 层变体数据(sku/stock/final_price/discount_percent)
+
+## Connections
+- [[Scrapy + Playwright 抓取TikTok Shop Data]] ← upstream_data_source ← [[TikTok Shop Apache Superset Dashboard设计思路]]
+- [[TikTok PM - Python Django 项目]] ← shares_database_schema ← [[TikTok Shop Apache Superset Dashboard设计思路]]
+- [[Apache Superset]] ← tool ← [[TikTok Shop Apache Superset Dashboard设计思路]]
+- [[用Docker安装Apache Superset]] ← prerequisite ← [[TikTok Shop Apache Superset Dashboard设计思路]]
+
+## Contradictions
+- 与 [[电商如何选品-如何找到爆款-选品策略]]:后者侧重选品策略理论(市场调研/竞争对手分析/利润测算),前者侧重数据驱动的可视化执行工具(Apache Superset Dashboard)。两者互补而非冲突——策略指导选品方向,Dashboard 提供实时数据验证。
diff --git a/wiki/sources/tk美国面单授权及操作流程.md b/wiki/sources/tk美国面单授权及操作流程.md
index 9406f4a9..004bdabf 100644
--- a/wiki/sources/tk美国面单授权及操作流程.md
+++ b/wiki/sources/tk美国面单授权及操作流程.md
@@ -1,36 +1,36 @@
----
-title: "TK美国面单授权及操作流程"
-type: source
-tags: ["tiktok", "跨境电商", "物流", "面单", "美国"]
-date: 2025-12-19
----
-
-## Source File
-- [[跨境电商/TK美国面单授权及操作流程.md]]
-
-## Summary(用中文描述)
-- 核心主题:TikTok美国市场面单授权配置与操作流程
-- 问题域:跨境电商物流履约中的面单打印与授权管理
-- 方法/机制:通过截图教程演示TK美国面单的授权步骤和操作流程
-- 结论/价值:帮助跨境卖家完成TikTok美国站的面单系统配置
-
-## Key Claims(用中文描述)
-- TikTok美国站需要完成面单授权才能进行订单履约
-- 面单授权流程包含多个配置步骤(截图展示具体操作界面)
-
-## Key Quotes
-> 图片教程来源:Zipline图床备份,包含6张操作截图
-
-## Key Concepts
-- [[TikTokShop]]:TikTok电商平台,支持美国市场
-- [[面单授权]]:跨境物流系统中打印官方物流面单的必要授权流程
-- [[跨境电商物流]]:涉及国际运输、清关、最后一公里配送的电商履约体系
-
-## Key Entities
-- [[TikTok美国站]]:TikTok Shop的美国市场站点,商家在此开展跨境销售
-
-## Connections
-- [[做tk跨境思路不对努力白费]] ← related_to ← [[TK美国面单授权及操作流程]]
-
-## Contradictions
-- 暂无冲突记录
+---
+title: "TK美国面单授权及操作流程"
+type: source
+tags: ["tiktok", "跨境电商", "物流", "面单", "美国"]
+date: 2025-12-19
+---
+
+## Source File
+- [[raw/跨境电商/TK美国面单授权及操作流程.md]]
+
+## Summary(用中文描述)
+- 核心主题:TikTok美国市场面单授权配置与操作流程
+- 问题域:跨境电商物流履约中的面单打印与授权管理
+- 方法/机制:通过截图教程演示TK美国面单的授权步骤和操作流程
+- 结论/价值:帮助跨境卖家完成TikTok美国站的面单系统配置
+
+## Key Claims(用中文描述)
+- TikTok美国站需要完成面单授权才能进行订单履约
+- 面单授权流程包含多个配置步骤(截图展示具体操作界面)
+
+## Key Quotes
+> 图片教程来源:Zipline图床备份,包含6张操作截图
+
+## Key Concepts
+- [[TikTokShop]]:TikTok电商平台,支持美国市场
+- [[面单授权]]:跨境物流系统中打印官方物流面单的必要授权流程
+- [[跨境电商物流]]:涉及国际运输、清关、最后一公里配送的电商履约体系
+
+## Key Entities
+- [[TikTok美国站]]:TikTok Shop的美国市场站点,商家在此开展跨境销售
+
+## Connections
+- [[做tk跨境思路不对努力白费]] ← related_to ← [[TK美国面单授权及操作流程]]
+
+## Contradictions
+- 暂无冲突记录
diff --git a/wiki/sources/trae远程开发部署指南.md b/wiki/sources/trae远程开发部署指南.md
index 9beb0355..f6d68043 100644
--- a/wiki/sources/trae远程开发部署指南.md
+++ b/wiki/sources/trae远程开发部署指南.md
@@ -1,57 +1,57 @@
----
-title: "Trae远程开发部署指南"
-type: source
-tags: [remote-ssh, trae, ubuntu]
-date: 2026-04-26
----
-
-## Source File
-- [[Vibe Coding/Trae远程开发部署指南]]
-
-## Summary(用中文描述)
-- 核心主题:使用 Trae IDE 通过 SSH 远程连接 Ubuntu 服务器进行 Docker 容器化项目的开发工作流配置
-- 问题域:远程开发环境搭建、Docker 与 IDE 集成、内网穿透访问
-- 方法/机制:SSH 免密登录 → Trae Remote-SSH 连接 → Docker 容器 Attach 或宿主机文件编辑 → Tailscale/FRP 公网访问
-- 结论/价值:提供一套完整的"本地 UI + 远程服务器开发"解决方案,支持 Attach 容器调试和 docker-compose 编排两种模式
-
-## Key Claims(用中文描述)
-- Trae 原生支持 VS Code 插件生态,通过 Remote-SSH 插件可远程连接 Ubuntu 服务器
-- 开发模式 A(Attach 容器):适合调试,环境完全隔离,直接使用容器内语言环境
-- 开发模式 B(宿主机文件 + Docker CLI):适合编排 docker-compose.yml 和管理多容器配置
-- 用户必须加入 docker 用户组才能让 Trae 的 Docker 插件正常工作
-- 文件权限(UID/GID)问题会导致 Volume 挂载生成的 Build 文件归属 root,宿主机无法操作
-
-## Key Quotes
-> "开发环境的核心在于 Bind Mount(绑定挂载),实现代码修改实时生效" — 解释开发环境 docker-compose.yml 的设计原则
-
-> "SSH 登录服务器执行:sudo usermod -aG docker $USER,必须注销并重新登录" — Docker 用户组配置关键步骤
-
-> "不要直接暴露 SSH 端口,建议安装 Tailscale 或 Cloudflare Tunnel" — 内网穿透安全建议
-
-## Key Concepts
-- [[Remote-SSH]]:通过 SSH 协议将本地 IDE 连接到远程服务器,代码运行在服务器端但 UI 在本地
-- [[Bind Mount]]:Docker Volume 挂载方式,将宿主机目录映射到容器内,实现代码修改实时生效
-- [[Attach 容器]]:将 IDE 直接连接到正在运行的 Docker 容器内部进行开发调试的模式
-- [[Docker 用户组]]:将用户加入 docker 组使其无需 sudo 即可运行 docker 命令
-- [[SSH Config]]:SSH 客户端配置文件(~/.ssh/config),定义 Host 别名和连接参数
-- [[SSH 免密登录]]:通过 ssh-copy-id 公钥分发实现无密码 SSH 连接
-- [[Docker Compose 开发模式]]:使用 docker-compose.yml 编排开发环境,通过 volumes 实现源码挂载
-
-## Key Entities
-- [[Trae]]:国产 AI IDE,基于 VS Code,支持 Remote-SSH 远程开发,与 Cursor 功能类似
-- [[Ubuntu 2]]:开发服务器(192.168.3.45),存放源码,运行带 Bind Mount 的开发容器
-- [[Ubuntu 1]]:生产服务器(192.168.3.47),运行生产容器,通过 Docker 卷持久化数据
-- [[ThinkBook]]:本地笔记本,作为 Trae UI 端连接远程服务器
-- [[Tailscale]]:零配置 VPN 工具,可替代 FRP 提供安全的公网 SSH 访问
-- [[Docker]]:容器化平台,远程开发的核心载体
-
-## Connections
-- [[Trae]] ← remote-ssh ← [[Ubuntu 2]]
-- [[Docker]] ← hosts ← [[Ubuntu 2]]
-- [[Docker Compose]] ← manages containers on ← [[Ubuntu 2]]
-- [[Remote-SSH]] ← 公网穿透方案 ← [[Tailscale]] / [[frp]]
-- [[Ubuntu 2]] ← 公网访问 ← [[frp]] (ubuntu2-ext: ubuntu2.ishenwei.online:60024)
-
-## Contradictions
-- 无已知冲突内容
-
+---
+title: "Trae远程开发部署指南"
+type: source
+tags: [remote-ssh, trae, ubuntu]
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Vibe Coding/Trae远程开发部署指南.md]]
+
+## Summary(用中文描述)
+- 核心主题:使用 Trae IDE 通过 SSH 远程连接 Ubuntu 服务器进行 Docker 容器化项目的开发工作流配置
+- 问题域:远程开发环境搭建、Docker 与 IDE 集成、内网穿透访问
+- 方法/机制:SSH 免密登录 → Trae Remote-SSH 连接 → Docker 容器 Attach 或宿主机文件编辑 → Tailscale/FRP 公网访问
+- 结论/价值:提供一套完整的"本地 UI + 远程服务器开发"解决方案,支持 Attach 容器调试和 docker-compose 编排两种模式
+
+## Key Claims(用中文描述)
+- Trae 原生支持 VS Code 插件生态,通过 Remote-SSH 插件可远程连接 Ubuntu 服务器
+- 开发模式 A(Attach 容器):适合调试,环境完全隔离,直接使用容器内语言环境
+- 开发模式 B(宿主机文件 + Docker CLI):适合编排 docker-compose.yml 和管理多容器配置
+- 用户必须加入 docker 用户组才能让 Trae 的 Docker 插件正常工作
+- 文件权限(UID/GID)问题会导致 Volume 挂载生成的 Build 文件归属 root,宿主机无法操作
+
+## Key Quotes
+> "开发环境的核心在于 Bind Mount(绑定挂载),实现代码修改实时生效" — 解释开发环境 docker-compose.yml 的设计原则
+
+> "SSH 登录服务器执行:sudo usermod -aG docker $USER,必须注销并重新登录" — Docker 用户组配置关键步骤
+
+> "不要直接暴露 SSH 端口,建议安装 Tailscale 或 Cloudflare Tunnel" — 内网穿透安全建议
+
+## Key Concepts
+- [[Remote-SSH]]:通过 SSH 协议将本地 IDE 连接到远程服务器,代码运行在服务器端但 UI 在本地
+- [[Bind Mount]]:Docker Volume 挂载方式,将宿主机目录映射到容器内,实现代码修改实时生效
+- [[Attach 容器]]:将 IDE 直接连接到正在运行的 Docker 容器内部进行开发调试的模式
+- [[Docker 用户组]]:将用户加入 docker 组使其无需 sudo 即可运行 docker 命令
+- [[SSH Config]]:SSH 客户端配置文件(~/.ssh/config),定义 Host 别名和连接参数
+- [[SSH 免密登录]]:通过 ssh-copy-id 公钥分发实现无密码 SSH 连接
+- [[Docker Compose 开发模式]]:使用 docker-compose.yml 编排开发环境,通过 volumes 实现源码挂载
+
+## Key Entities
+- [[Trae]]:国产 AI IDE,基于 VS Code,支持 Remote-SSH 远程开发,与 Cursor 功能类似
+- [[Ubuntu 2]]:开发服务器(192.168.3.45),存放源码,运行带 Bind Mount 的开发容器
+- [[Ubuntu 1]]:生产服务器(192.168.3.47),运行生产容器,通过 Docker 卷持久化数据
+- [[ThinkBook]]:本地笔记本,作为 Trae UI 端连接远程服务器
+- [[Tailscale]]:零配置 VPN 工具,可替代 FRP 提供安全的公网 SSH 访问
+- [[Docker]]:容器化平台,远程开发的核心载体
+
+## Connections
+- [[Trae]] ← remote-ssh ← [[Ubuntu 2]]
+- [[Docker]] ← hosts ← [[Ubuntu 2]]
+- [[Docker Compose]] ← manages containers on ← [[Ubuntu 2]]
+- [[Remote-SSH]] ← 公网穿透方案 ← [[Tailscale]] / [[frp]]
+- [[Ubuntu 2]] ← 公网访问 ← [[frp]] (ubuntu2-ext: ubuntu2.ishenwei.online:60024)
+
+## Contradictions
+- 无已知冲突内容
+
diff --git a/wiki/sources/ubuntu-24-04-enable-ssh.md b/wiki/sources/ubuntu-24-04-enable-ssh.md
index e58d6392..db3bcbff 100644
--- a/wiki/sources/ubuntu-24-04-enable-ssh.md
+++ b/wiki/sources/ubuntu-24-04-enable-ssh.md
@@ -1,44 +1,44 @@
----
-title: "Ubuntu 24.04 启动 SSH 服务"
-type: source
-tags: [ssh, ubuntu, linux]
-date: 2026-04-26
----
-
-## Source File
-- [[Home Office/Ubuntu 24.04 enable SSH.md]]
-
-## Summary(用中文描述)
-- 核心主题:Ubuntu 24.04 中启用 SSH 远程访问服务的完整操作指南
-- 问题域:Linux 服务器远程管理、SSH 服务配置与防火墙设置
-- 方法/机制:安装 OpenSSH Server → 启动并设置开机自启 → 配置 UFW 防火墙 → 验证服务状态 → 远程连接;核心变化:Ubuntu 24.04 默认使用 `ssh.socket` 激活机制(按需启动而非持续运行)
-- 结论/价值:提供 Ubuntu 24.04 SSH 快速启用指南,附带进阶配置(自定义端口、切换传统模式)
-
-## Key Claims(用中文描述)
-- Ubuntu 24.04 默认使用 **ssh.socket 激活机制**:仅在连接请求进入时才启动 SSH 守护进程,与旧版本(持续运行后台进程)行为不同
-- SSH 服务可通过 `sudo systemctl start ssh` 和 `sudo systemctl enable ssh` 手动启动并设置开机自启
-- 防火墙配置:使用 `sudo ufw allow ssh` 或 `sudo ufw allow 22/tcp` 放行 SSH 流量
-- 进阶配置:可通过 `sudo systemctl edit ssh.socket` 修改监听端口,而非仅修改 `/etc/ssh/sshd_config`
-- 如需切换回传统模式:先禁用 socket 激活(`sudo systemctl disable --now ssh.socket`),再启用 service 模式(`sudo systemctl enable --now ssh.service`)
-
-## Key Quotes
-> "在 Ubuntu 24.04 中开启 SSH 服务非常简单,但这个版本引入了一个重要的变化:默认使用 ssh.socket 激活机制" — Ubuntu 24.04 SSH 配置说明
-
-> "如果你习惯了旧版本的管理方式,或者需要修改自定义端口(例如改为 2222),在 24.04 中你可能需要注意:现在推荐通过 sudo systemctl edit ssh.socket 来修改监听端口" — 进阶配置说明
-
-## Key Concepts
-- [[SocketActivation]]:按需激活机制,ssh.socket 在接收到连接请求时才启动 sshd 守护进程,与传统持续运行的 ssh.service 不同
-- [[UFW]](Uncomplicated Firewall):Ubuntu 默认防火墙管理工具,通过 `ufw allow ssh` 简化 iptables 规则配置
-- [[OpenSSH]]:开源 SSH 协议实现,Ubuntu 通过 `openssh-server` 包提供服务端功能
-
-## Key Entities
-- [[Ubuntu-24.04]]:Canonical Ltd 发布的 Linux 发行版,引入 ssh.socket 默认激活机制
-- [[systemd]]:Linux 系统和服务管理器,通过 systemctl 管理 ssh.service 和 ssh.socket
-
-## Connections
-- [[Ubuntu服务器通过rsync实现日常增量备份]] ← related_to ← [[Ubuntu-24.04-启动SSH服务]](SSH 是远程管理 Ubuntu 服务器的基础,用于执行 rsync 备份命令)
-- [[Ubuntu Server科学上网]] ← related_to ← [[Ubuntu-24.04-启动SSH服务]](SSH 隧道可用于建立安全通道)
-- [[Linux运维必会的150个命令]] ← related_to ← [[Ubuntu-24.04-启动SSH服务]](SSH 相关命令如 ssh/scp/sftp 是运维必备命令)
-
-## Contradictions
-- 无已知冲突
+---
+title: "Ubuntu 24.04 启动 SSH 服务"
+type: source
+tags: [ssh, ubuntu, linux]
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Home Office/Ubuntu 24.04 enable SSH.md]]
+
+## Summary(用中文描述)
+- 核心主题:Ubuntu 24.04 中启用 SSH 远程访问服务的完整操作指南
+- 问题域:Linux 服务器远程管理、SSH 服务配置与防火墙设置
+- 方法/机制:安装 OpenSSH Server → 启动并设置开机自启 → 配置 UFW 防火墙 → 验证服务状态 → 远程连接;核心变化:Ubuntu 24.04 默认使用 `ssh.socket` 激活机制(按需启动而非持续运行)
+- 结论/价值:提供 Ubuntu 24.04 SSH 快速启用指南,附带进阶配置(自定义端口、切换传统模式)
+
+## Key Claims(用中文描述)
+- Ubuntu 24.04 默认使用 **ssh.socket 激活机制**:仅在连接请求进入时才启动 SSH 守护进程,与旧版本(持续运行后台进程)行为不同
+- SSH 服务可通过 `sudo systemctl start ssh` 和 `sudo systemctl enable ssh` 手动启动并设置开机自启
+- 防火墙配置:使用 `sudo ufw allow ssh` 或 `sudo ufw allow 22/tcp` 放行 SSH 流量
+- 进阶配置:可通过 `sudo systemctl edit ssh.socket` 修改监听端口,而非仅修改 `/etc/ssh/sshd_config`
+- 如需切换回传统模式:先禁用 socket 激活(`sudo systemctl disable --now ssh.socket`),再启用 service 模式(`sudo systemctl enable --now ssh.service`)
+
+## Key Quotes
+> "在 Ubuntu 24.04 中开启 SSH 服务非常简单,但这个版本引入了一个重要的变化:默认使用 ssh.socket 激活机制" — Ubuntu 24.04 SSH 配置说明
+
+> "如果你习惯了旧版本的管理方式,或者需要修改自定义端口(例如改为 2222),在 24.04 中你可能需要注意:现在推荐通过 sudo systemctl edit ssh.socket 来修改监听端口" — 进阶配置说明
+
+## Key Concepts
+- [[SocketActivation]]:按需激活机制,ssh.socket 在接收到连接请求时才启动 sshd 守护进程,与传统持续运行的 ssh.service 不同
+- [[UFW]](Uncomplicated Firewall):Ubuntu 默认防火墙管理工具,通过 `ufw allow ssh` 简化 iptables 规则配置
+- [[OpenSSH]]:开源 SSH 协议实现,Ubuntu 通过 `openssh-server` 包提供服务端功能
+
+## Key Entities
+- [[Ubuntu-24.04]]:Canonical Ltd 发布的 Linux 发行版,引入 ssh.socket 默认激活机制
+- [[systemd]]:Linux 系统和服务管理器,通过 systemctl 管理 ssh.service 和 ssh.socket
+
+## Connections
+- [[Ubuntu服务器通过rsync实现日常增量备份]] ← related_to ← [[Ubuntu-24.04-启动SSH服务]](SSH 是远程管理 Ubuntu 服务器的基础,用于执行 rsync 备份命令)
+- [[Ubuntu Server科学上网]] ← related_to ← [[Ubuntu-24.04-启动SSH服务]](SSH 隧道可用于建立安全通道)
+- [[Linux运维必会的150个命令]] ← related_to ← [[Ubuntu-24.04-启动SSH服务]](SSH 相关命令如 ssh/scp/sftp 是运维必备命令)
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/ubuntu用rustdesk远程登录出现不能使用wayland登录的错误.md b/wiki/sources/ubuntu用rustdesk远程登录出现不能使用wayland登录的错误.md
index 2cfce8b9..3e25b4a7 100644
--- a/wiki/sources/ubuntu用rustdesk远程登录出现不能使用wayland登录的错误.md
+++ b/wiki/sources/ubuntu用rustdesk远程登录出现不能使用wayland登录的错误.md
@@ -1,48 +1,48 @@
----
-title: "Ubuntu用RustDesk远程登录出现不能使用Wayland登录的错误"
-type: source
-tags: [rustdesk, ubuntu, wayland, x11, gdm3]
-date: 2026-04-14
----
-
-## Source File
-- [[Home Office/Ubuntu用RustDesk远程登录出现不能使用Wayland登录的错误]]
-
-## Summary(用中文描述)
-- 核心主题:Ubuntu 24.04 下 RustDesk 无法在 Wayland 会话中使用/登录的故障排查与解决
-- 问题域:Linux 远程桌面协议兼容性、Wayland vs X11 显示协议
-- 方法/机制:修改 GDM3 配置文件,注释掉 `WaylandEnable=false` 以强制使用 X11 协议
-- 结论/价值:通过禁用 Wayland 强制 X11,使 RustDesk 能够在系统登录前(Login Screen)和登录后(Post-Login)正常工作
-
-## Key Claims(用中文描述)
-- Ubuntu 24.04 默认使用 Wayland 显示协议,Wayland 基于安全设计严格限制外部程序在未登录状态下获取屏幕控制权
-- 修改 `/etc/gdm3/custom.conf` 文件中 `WaylandEnable=false`(取消注释)后,登录界面强制使用 X11,RustDesk 后台服务可识别 X11 窗口并与之交互
-- X11 的稳定性与权限开放度目前仍优于 Wayland,适合需要频繁远程桌面运维的场景
-
-## Key Quotes
-> "Ubuntu 24.04 默认使用了 Wayland 显示协议,而 Wayland 出于安全设计,严格限制了外部程序在用户未登录状态下(即 GDM 登录界面)获取屏幕控制权" — 问题根因说明
-
-> "# Uncoment the line below to force the login screen to use Xorg" — GDM3 配置文件注释原文
-
-## Key Concepts
-- [[Wayland]]:Linux 新一代显示协议,基于安全设计,限制未授权程序获取屏幕控制权
-- [[X11]]:经典显示协议,兼容性更好,权限开放度更高,适合远程桌面场景
-- [[GDM3]]:GNOME Display Manager,Ubuntu 默认登录管理器,控制用户会话初始化
-
-## Key Entities
-- [[RustDesk]]:开源远程桌面软件,支持自建中继服务器
-- [[Ubuntu]]:Linux 发行版,本文档针对 24.04 LTS 版本
-- [[GNOME]]:Ubuntu 24.04 默认桌面环境,使用 GDM3 作为显示管理器
-
-## Connections
-- [[Ubuntu]] ← uses ← [[GDM3]]
-- [[GDM3]] ← can_run_on ← [[X11]]
-- [[GDM3]] ← can_run_on ← [[Wayland]]
-- [[RustDesk]] ← requires ← [[X11]] ← (在 GDM3 Login Screen 场景下)
-
-## Contradictions
-- 与 [[Ubuntu]] Wayland 趋势:
- - 冲突点:Ubuntu 24.04 推动 Wayland 替代 X11,而本文档建议禁用 Wayland 回退到 X11
- - 当前观点:对于 RustDesk 远程桌面运维场景,X11 的稳定性和兼容性优于 Wayland
- - 对方观点:Wayland 是未来方向,应尽量保持默认配置
- - 备注:此为务实方案,非长期理想状态
+---
+title: "Ubuntu用RustDesk远程登录出现不能使用Wayland登录的错误"
+type: source
+tags: [rustdesk, ubuntu, wayland, x11, gdm3]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Home Office/Ubuntu用RustDesk远程登录出现不能使用Wayland登录的错误.md]]
+
+## Summary(用中文描述)
+- 核心主题:Ubuntu 24.04 下 RustDesk 无法在 Wayland 会话中使用/登录的故障排查与解决
+- 问题域:Linux 远程桌面协议兼容性、Wayland vs X11 显示协议
+- 方法/机制:修改 GDM3 配置文件,注释掉 `WaylandEnable=false` 以强制使用 X11 协议
+- 结论/价值:通过禁用 Wayland 强制 X11,使 RustDesk 能够在系统登录前(Login Screen)和登录后(Post-Login)正常工作
+
+## Key Claims(用中文描述)
+- Ubuntu 24.04 默认使用 Wayland 显示协议,Wayland 基于安全设计严格限制外部程序在未登录状态下获取屏幕控制权
+- 修改 `/etc/gdm3/custom.conf` 文件中 `WaylandEnable=false`(取消注释)后,登录界面强制使用 X11,RustDesk 后台服务可识别 X11 窗口并与之交互
+- X11 的稳定性与权限开放度目前仍优于 Wayland,适合需要频繁远程桌面运维的场景
+
+## Key Quotes
+> "Ubuntu 24.04 默认使用了 Wayland 显示协议,而 Wayland 出于安全设计,严格限制了外部程序在用户未登录状态下(即 GDM 登录界面)获取屏幕控制权" — 问题根因说明
+
+> "# Uncoment the line below to force the login screen to use Xorg" — GDM3 配置文件注释原文
+
+## Key Concepts
+- [[Wayland]]:Linux 新一代显示协议,基于安全设计,限制未授权程序获取屏幕控制权
+- [[X11]]:经典显示协议,兼容性更好,权限开放度更高,适合远程桌面场景
+- [[GDM3]]:GNOME Display Manager,Ubuntu 默认登录管理器,控制用户会话初始化
+
+## Key Entities
+- [[RustDesk]]:开源远程桌面软件,支持自建中继服务器
+- [[Ubuntu]]:Linux 发行版,本文档针对 24.04 LTS 版本
+- [[GNOME]]:Ubuntu 24.04 默认桌面环境,使用 GDM3 作为显示管理器
+
+## Connections
+- [[Ubuntu]] ← uses ← [[GDM3]]
+- [[GDM3]] ← can_run_on ← [[X11]]
+- [[GDM3]] ← can_run_on ← [[Wayland]]
+- [[RustDesk]] ← requires ← [[X11]] ← (在 GDM3 Login Screen 场景下)
+
+## Contradictions
+- 与 [[Ubuntu]] Wayland 趋势:
+ - 冲突点:Ubuntu 24.04 推动 Wayland 替代 X11,而本文档建议禁用 Wayland 回退到 X11
+ - 当前观点:对于 RustDesk 远程桌面运维场景,X11 的稳定性和兼容性优于 Wayland
+ - 对方观点:Wayland 是未来方向,应尽量保持默认配置
+ - 备注:此为务实方案,非长期理想状态
diff --git a/wiki/sources/ubuntu禁用合盖休眠.md b/wiki/sources/ubuntu禁用合盖休眠.md
index 00a65364..f2efa91f 100644
--- a/wiki/sources/ubuntu禁用合盖休眠.md
+++ b/wiki/sources/ubuntu禁用合盖休眠.md
@@ -1,45 +1,45 @@
----
-title: "Ubuntu禁用合盖休眠"
-type: source
-tags: [ubuntu, systemd, 服务器配置]
-date: 2026-04-26
----
-
-## Source File
-- [[Home Office/Ubuntu禁用合盖休眠]]
-
-## Summary(用中文描述)
-- 核心主题:Ubuntu 24.04 笔记本合盖休眠行为配置
-- 问题域:服务器场景下笔记本合盖后不应进入休眠状态
-- 方法/机制:通过修改 `systemd-logind` 的 `logind.conf` 配置文件,将 `HandleLidSwitch` 系列参数设为 `ignore`;进阶方法通过 `systemctl mask` 彻底禁用所有休眠目标
-- 结论/价值:提供两步完成服务器场景下笔记本合盖持续运行的生产级方案
-
-## Key Claims(用中文描述)
-- systemd-logind 是 Ubuntu 24.04 控制笔记本合盖行为的登录管理器
-- 通过 `HandleLidSwitch`、`HandleLidSwitchExternalPower`、`HandleLidSwitchDocked` 三个配置项可覆盖不同场景
-- 将配置值设为 `ignore` 后系统合盖不执行任何操作,继续运行
-- 修改配置后需执行 `systemctl restart systemd-logind` 重启服务才能生效
-- 可通过 `systemctl mask` 从内核级别彻底禁止待机(sleep/suspend/hibernate/hybrid-sleep)
-- `mask` 与 `unmask` 可逆,恢复时将 mask 改为 unmask 即可
-
-## Key Quotes
-> "在执行此命令时,你的当前会话(包括图形界面或当前的 SSH 连接)可能会短暂断开或重新加载。" — 重启 systemd-logind 服务的注意事项
-
-## Key Concepts
-- [[systemd-logind]]:Linux 系统登录管理器,负责管理用户会话、电源管理和设备访问权限,合盖行为由其控制
-- [[HandleLidSwitch]]:systemd-logind 配置项,定义笔记本合盖时的电源行为
-- [[sleep.target suspend.target hibernate.target hybrid-sleep.target]]:Linux 休眠相关系统目标,通过 `systemctl mask` 可从内核级别彻底禁用
-
-## Key Entities
-- [[Ubuntu 24.04]]:Canonical 发布的长期支持版 Ubuntu,本配置方法的适用系统
-- [[systemd]]:Linux 系统和服务管理器,systemd-logind 为其组件之一
-
-## Connections
-- [[Ubuntu禁用合盖休眠]] ← relates_to ← [[Ubuntu服务器通过rsync实现日常增量备份]]
-- [[Ubuntu禁用合盖休眠]] ← related_topic ← [[Mac Mini 服务器配置:防止自动锁屏与睡眠]](不同 OS,方法不同,无冲突)
-
-## Contradictions
-- 与 [[Mac Mini 服务器配置:防止自动锁屏与睡眠]] 无冲突:
- - 冲突点:无(macOS 使用 `pmset` 命令,与 Ubuntu systemd 配置完全不同)
- - 当前观点:Ubuntu 通过 systemd-logind 配置
- - 对方观点:macOS 通过 pmset 命令配置
+---
+title: "Ubuntu禁用合盖休眠"
+type: source
+tags: [ubuntu, systemd, 服务器配置]
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Home Office/Ubuntu禁用合盖休眠.md]]
+
+## Summary(用中文描述)
+- 核心主题:Ubuntu 24.04 笔记本合盖休眠行为配置
+- 问题域:服务器场景下笔记本合盖后不应进入休眠状态
+- 方法/机制:通过修改 `systemd-logind` 的 `logind.conf` 配置文件,将 `HandleLidSwitch` 系列参数设为 `ignore`;进阶方法通过 `systemctl mask` 彻底禁用所有休眠目标
+- 结论/价值:提供两步完成服务器场景下笔记本合盖持续运行的生产级方案
+
+## Key Claims(用中文描述)
+- systemd-logind 是 Ubuntu 24.04 控制笔记本合盖行为的登录管理器
+- 通过 `HandleLidSwitch`、`HandleLidSwitchExternalPower`、`HandleLidSwitchDocked` 三个配置项可覆盖不同场景
+- 将配置值设为 `ignore` 后系统合盖不执行任何操作,继续运行
+- 修改配置后需执行 `systemctl restart systemd-logind` 重启服务才能生效
+- 可通过 `systemctl mask` 从内核级别彻底禁止待机(sleep/suspend/hibernate/hybrid-sleep)
+- `mask` 与 `unmask` 可逆,恢复时将 mask 改为 unmask 即可
+
+## Key Quotes
+> "在执行此命令时,你的当前会话(包括图形界面或当前的 SSH 连接)可能会短暂断开或重新加载。" — 重启 systemd-logind 服务的注意事项
+
+## Key Concepts
+- [[systemd-logind]]:Linux 系统登录管理器,负责管理用户会话、电源管理和设备访问权限,合盖行为由其控制
+- [[HandleLidSwitch]]:systemd-logind 配置项,定义笔记本合盖时的电源行为
+- [[sleep.target suspend.target hibernate.target hybrid-sleep.target]]:Linux 休眠相关系统目标,通过 `systemctl mask` 可从内核级别彻底禁用
+
+## Key Entities
+- [[Ubuntu 24.04]]:Canonical 发布的长期支持版 Ubuntu,本配置方法的适用系统
+- [[systemd]]:Linux 系统和服务管理器,systemd-logind 为其组件之一
+
+## Connections
+- [[Ubuntu禁用合盖休眠]] ← relates_to ← [[Ubuntu服务器通过rsync实现日常增量备份]]
+- [[Ubuntu禁用合盖休眠]] ← related_topic ← [[Mac Mini 服务器配置:防止自动锁屏与睡眠]](不同 OS,方法不同,无冲突)
+
+## Contradictions
+- 与 [[Mac Mini 服务器配置:防止自动锁屏与睡眠]] 无冲突:
+ - 冲突点:无(macOS 使用 `pmset` 命令,与 Ubuntu systemd 配置完全不同)
+ - 当前观点:Ubuntu 通过 systemd-logind 配置
+ - 对方观点:macOS 通过 pmset 命令配置
diff --git a/wiki/sources/unity-architect.md b/wiki/sources/unity-architect.md
index d403430e..9c011a79 100644
--- a/wiki/sources/unity-architect.md
+++ b/wiki/sources/unity-architect.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/unity/unity-architect.md]]
+- [[raw/Agent/agency-agents/game-development/unity/unity-architect.md]]
## Summary(用中文描述)
- 核心主题:Unity 游戏架构师 AI Agent 人格规范,专注于数据驱动、ScriptableObject(SO)优先的模块化可扩展架构
diff --git a/wiki/sources/unity-editor-tool-developer.md b/wiki/sources/unity-editor-tool-developer.md
index 40548af3..3e2e9e83 100644
--- a/wiki/sources/unity-editor-tool-developer.md
+++ b/wiki/sources/unity-editor-tool-developer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/unity/unity-editor-tool-developer.md]]
+- [[raw/Agent/agency-agents/game-development/unity/unity-editor-tool-developer.md]]
## Summary(用中文描述)
- 核心主题:Unity 编辑器扩展开发工程师(Editor Tool Developer)的 AI Agent 人格规范——通过 EditorWindows、PropertyDrawers、AssetPostprocessors、Build Validators 等工具自动化团队工作流,减少人工错误
diff --git a/wiki/sources/unity-multiplayer-engineer.md b/wiki/sources/unity-multiplayer-engineer.md
index 4784a94c..ee933345 100644
--- a/wiki/sources/unity-multiplayer-engineer.md
+++ b/wiki/sources/unity-multiplayer-engineer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/unity/unity-multiplayer-engineer]]
+- [[raw/Agent/agency-agents/game-development/unity/unity-multiplayer-engineer.md]]
## Summary(用中文描述)
- 核心主题:Unity 多人游戏网络编程专家 Agent人格定义,涵盖 Netcode for GameObjects(NGO)、Unity Gaming Services(Relay/Lobby)集成、服务器权威模型、延迟补偿和状态同步等技术规范。
diff --git a/wiki/sources/unreal-multiplayer-architect.md b/wiki/sources/unreal-multiplayer-architect.md
index cc8d063f..c12e51cb 100644
--- a/wiki/sources/unreal-multiplayer-architect.md
+++ b/wiki/sources/unreal-multiplayer-architect.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/unreal-engine/unreal-multiplayer-architect.md]]
+- [[raw/Agent/agency-agents/game-development/unreal-engine/unreal-multiplayer-architect.md]]
## Summary(用中文描述)
- 核心主题:UE5多人游戏网络架构专家角色定义——构建服务器权威模型、延迟容忍、作弊防护的多人游戏系统
diff --git a/wiki/sources/unreal-systems-engineer.md b/wiki/sources/unreal-systems-engineer.md
index 44d72118..c34fc8fc 100644
--- a/wiki/sources/unreal-systems-engineer.md
+++ b/wiki/sources/unreal-systems-engineer.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/unreal-engine/unreal-systems-engineer.md]]
+- [[raw/Agent/agency-agents/game-development/unreal-engine/unreal-systems-engineer.md]]
## Summary(用中文描述)
- 核心主题:Unreal Engine 5 系统架构师 AI Agent 人格规范——C++/Blueprint 边界决策、性能优化、网络就绪游戏系统构建
diff --git a/wiki/sources/unreal-technical-artist.md b/wiki/sources/unreal-technical-artist.md
index af93aabd..ac6d5e62 100644
--- a/wiki/sources/unreal-technical-artist.md
+++ b/wiki/sources/unreal-technical-artist.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/game-development/unreal-engine/unreal-technical-artist.md]]
+- [[raw/Agent/agency-agents/game-development/unreal-engine/unreal-technical-artist.md]]
## Summary(用中文描述)
- 核心主题:Unreal Engine 5 视觉系统工程师的 AI Agent 人格定义,专注于 UE5 的材质编辑器、Niagara VFX、PCG 程序化内容生成和美术-引擎管线
diff --git a/wiki/sources/vibe-coding经验收集.md b/wiki/sources/vibe-coding经验收集.md
index 3beb351b..da5a4573 100644
--- a/wiki/sources/vibe-coding经验收集.md
+++ b/wiki/sources/vibe-coding经验收集.md
@@ -1,57 +1,57 @@
----
-title: "Vibe Coding 经验收集"
-type: source
-tags: []
-date: 2025-12-30
----
-
-## Source File
-- [[Vibe Coding/vibe coding经验收集.md]]
-
-## Summary(用中文描述)
-- 核心主题:Vibe Coding 实战经验与最佳实践的精选合集
-- 问题域:AI 辅助编程的工作流优化、代码质量保证、多 AI 协作模式、文档与导航化工具
-- 方法/机制:设计文档→伪代码→代码的递进式开发、多 AI 协作验证、文件注释标准化、代码可导航化
-- 结论/价值:Vibe Coding 已从单纯提示词工程演变为系统性工程实践,强调验证而非理解、文档优于记忆
-
-## Key Claims(用中文描述)
-- **递进式开发工作流**:设计文档写细(含伪代码)→ AI 直出代码 → 另一 AI review → 跑测试用例 → AI 自动 commit+push,可一遍直出
-- **System Prompt 优化效果**:针对 Gemini 3 Pro 的系统 prompt 优化可使多代理基准测试性能提升约 5%
-- **点线体迭代方法**:逐级迭代(点→线→体),先用单个基础任务打磨,再基于此批量执行
-- **文件头注释规范**:一段话描述代码作用、上下游链路,降低认知负载,参考 Claude skill 格式
-- **代码验证优先**:未来软件工程核心不是"看懂代码"而是"验证代码按正确逻辑运行",依赖自动化测试、静态分析、形式化验证
-- **激励式提示词**:如"如果第一次就做得好,我会打赏100美元"可提升生成效果
-- **CodeWeaver 工具**:将代码库编织成可导航的 Markdown 文档,简化 AI/ML 工具集成
-
-## Key Quotes
-> "我是把设计文档写得很细,包括service层的具体逻辑都用伪代码写了,然后交给AI,一遍直出,再用另一个AI review一遍,根据review意见修改一下,跑一下测试用例,让AI自己生成commit后push" — 需求→伪代码→代码递进工作流
-
-> "代码最终会被转换成机器码执行,高级语言只是一层方便人类理解的抽象,重要的是验证程序的执行逻辑" — 代码验证哲学
-
-> "请你根据我的要求,用 Three.js 创建一个实时交互的3D粒子系统,如果你第一次就做得好,我将会打赏你100美元的小费" — 激励式提示词示例
-
-> "CodeWeaver 将你的代码库编织成一个可导航的 Markdown 文档……所有代码都给你塞进代码块里,极大地简化了代码库的共享、文档化以及与 AI/ML 工具集成" — CodeWeaver 工具价值
-
-## Key Concepts
-- [[Vibe Coding]]:使用 AI 辅助编程的实践方法论,强调人机协作而非纯自动生成
-- [[Design-to-Code Workflow]]:设计文档→伪代码→代码的递进式开发流程
-- [[Multi-AI Review]]:多 AI 协作验证,一个生成一个 review 的双人编程模式
-- [[Code Documentation]]:文件头注释规范,降低 AI 和人类认知负载
-- [[Verification-First Engineering]]:验证优先于理解,强调自动化测试和形式化验证
-- [[Iterative Scaling]]:点→线→体的逐级迭代,从单任务打磨到批量执行
-- [[CodeWeaver]]:将代码库转换为可导航 Markdown 文档的工具
-
-## Key Entities
-- [[CodeWeaver]]:GitHub 开源项目,将代码库编织成可导航 Markdown 文档的工具
-
-## Connections
-- [[Vibe Coding]] ← extends ← [[Agentic AI]]
-- [[Design-to-Code Workflow]] ← refines ← [[Vibe Coding]]
-- [[Multi-AI Review]] ← part_of ← [[Design-to-Code Workflow]]
-- [[CodeWeaver]] ← enables ← [[Vibe Coding]]
-
-## Contradictions
-- 与传统软件工程方法冲突:
- - 冲突点:传统方法强调"先理解代码再修改",Vibe Coding 强调"验证而非理解"
- - 当前观点:通过自动化测试和验证确保行为正确,降低人类理解代码的必要性
- - 对方观点:人类开发者必须理解代码才能安全地进行修改和重构
+---
+title: "Vibe Coding 经验收集"
+type: source
+tags: []
+date: 2025-12-30
+---
+
+## Source File
+- [[raw/Vibe Coding/vibe coding经验收集.md]]
+
+## Summary(用中文描述)
+- 核心主题:Vibe Coding 实战经验与最佳实践的精选合集
+- 问题域:AI 辅助编程的工作流优化、代码质量保证、多 AI 协作模式、文档与导航化工具
+- 方法/机制:设计文档→伪代码→代码的递进式开发、多 AI 协作验证、文件注释标准化、代码可导航化
+- 结论/价值:Vibe Coding 已从单纯提示词工程演变为系统性工程实践,强调验证而非理解、文档优于记忆
+
+## Key Claims(用中文描述)
+- **递进式开发工作流**:设计文档写细(含伪代码)→ AI 直出代码 → 另一 AI review → 跑测试用例 → AI 自动 commit+push,可一遍直出
+- **System Prompt 优化效果**:针对 Gemini 3 Pro 的系统 prompt 优化可使多代理基准测试性能提升约 5%
+- **点线体迭代方法**:逐级迭代(点→线→体),先用单个基础任务打磨,再基于此批量执行
+- **文件头注释规范**:一段话描述代码作用、上下游链路,降低认知负载,参考 Claude skill 格式
+- **代码验证优先**:未来软件工程核心不是"看懂代码"而是"验证代码按正确逻辑运行",依赖自动化测试、静态分析、形式化验证
+- **激励式提示词**:如"如果第一次就做得好,我会打赏100美元"可提升生成效果
+- **CodeWeaver 工具**:将代码库编织成可导航的 Markdown 文档,简化 AI/ML 工具集成
+
+## Key Quotes
+> "我是把设计文档写得很细,包括service层的具体逻辑都用伪代码写了,然后交给AI,一遍直出,再用另一个AI review一遍,根据review意见修改一下,跑一下测试用例,让AI自己生成commit后push" — 需求→伪代码→代码递进工作流
+
+> "代码最终会被转换成机器码执行,高级语言只是一层方便人类理解的抽象,重要的是验证程序的执行逻辑" — 代码验证哲学
+
+> "请你根据我的要求,用 Three.js 创建一个实时交互的3D粒子系统,如果你第一次就做得好,我将会打赏你100美元的小费" — 激励式提示词示例
+
+> "CodeWeaver 将你的代码库编织成一个可导航的 Markdown 文档……所有代码都给你塞进代码块里,极大地简化了代码库的共享、文档化以及与 AI/ML 工具集成" — CodeWeaver 工具价值
+
+## Key Concepts
+- [[Vibe Coding]]:使用 AI 辅助编程的实践方法论,强调人机协作而非纯自动生成
+- [[Design-to-Code Workflow]]:设计文档→伪代码→代码的递进式开发流程
+- [[Multi-AI Review]]:多 AI 协作验证,一个生成一个 review 的双人编程模式
+- [[Code Documentation]]:文件头注释规范,降低 AI 和人类认知负载
+- [[Verification-First Engineering]]:验证优先于理解,强调自动化测试和形式化验证
+- [[Iterative Scaling]]:点→线→体的逐级迭代,从单任务打磨到批量执行
+- [[CodeWeaver]]:将代码库转换为可导航 Markdown 文档的工具
+
+## Key Entities
+- [[CodeWeaver]]:GitHub 开源项目,将代码库编织成可导航 Markdown 文档的工具
+
+## Connections
+- [[Vibe Coding]] ← extends ← [[Agentic AI]]
+- [[Design-to-Code Workflow]] ← refines ← [[Vibe Coding]]
+- [[Multi-AI Review]] ← part_of ← [[Design-to-Code Workflow]]
+- [[CodeWeaver]] ← enables ← [[Vibe Coding]]
+
+## Contradictions
+- 与传统软件工程方法冲突:
+ - 冲突点:传统方法强调"先理解代码再修改",Vibe Coding 强调"验证而非理解"
+ - 当前观点:通过自动化测试和验证确保行为正确,降低人类理解代码的必要性
+ - 对方观点:人类开发者必须理解代码才能安全地进行修改和重构
diff --git a/wiki/sources/vibe-kanban-opencode-在-ubuntu-server-上安装与管理指南.md b/wiki/sources/vibe-kanban-opencode-在-ubuntu-server-上安装与管理指南.md
index 33828731..ebcb0068 100644
--- a/wiki/sources/vibe-kanban-opencode-在-ubuntu-server-上安装与管理指南.md
+++ b/wiki/sources/vibe-kanban-opencode-在-ubuntu-server-上安装与管理指南.md
@@ -1,50 +1,50 @@
----
-title: "Vibe-Kanban + OpenCode 在 Ubuntu Server 上安装与管理指南"
-type: source
-tags: [npm, npx, pm2, ubuntu, vibe-coding, vibe-kanban]
-date: 2026-04-17
----
-
-## Source File
-- [[Vibe Coding/Vibe-Kanban + OpenCode 在 Ubuntu Server 上安装与管理指南]]
-
-## Summary(用中文描述)
-- 核心主题:在 Ubuntu Server 上非 root 用户(shenwei)安装 Node 20、Vibe-Kanban、OpenCode,并通过 pm2 进程管理,实现 AI 辅助编程工作流
-- 问题域:Ubuntu Server 环境下的 AI Coding Agent 部署与长期运维
-- 方法/机制:使用 nvm 管理 Node 版本、npm/npx 安装工具、pm2 管理进程生命周期、权限配置确保非 root 用户正常运行
-- 结论/价值:完整记录了从零开始在 Ubuntu Server 上搭建 Vibe Coding 环境的全流程,含验证步骤和故障排查要点
-
-## Key Claims(用中文描述)
-- 使用 nvm 安装 Node 20 可确保版本兼容性和环境隔离
-- pm2 能可靠管理 Vibe-Kanban 和 OpenCode Executor 进程并支持开机自启
-- 权限配置(/var/tmp/vibe-kanban 和 ~/.vibe-kanban 归属 shenwei)是避免 I/O error 的关键
-- 不应以 root 用户启动 OpenCode serve,避免权限问题
-- Vibe-Kanban 会自动 spawn OpenCode executor(随机端口),无需手动固定端口
-
-## Key Quotes
-> "不要用 root 启动 OpenCode serve,vibe-kanban 会自动 spawn executor" — 核心安全与架构原则
-> "遇到 I/O error 时,通常是 executor 没启动或端口被占用" — 常见故障排查方向
-> "pm2 只管理 vibe-kanban,executor 随进程一起管理" — 进程管理边界定义
-
-## Key Concepts
-- [[Vibe Coding]]:使用自然语言与 AI 编程工具协作的开发方式,Vibe-Kanban + OpenCode 是其代表性工具栈
-- [[nvm]](Node Version Manager):Node.js 版本管理工具,通过 $NVM_DIR/$HOME/.nvm 安装,支持多版本共存和快速切换
-- [[pm2]]:Node.js 进程管理器,支持进程守护、负载均衡、日志管理和开机自启(systemd)
-- [[Node 20]]:LTS 版 Node.js,Vibe-Kanban 和 OpenCode 的推荐运行时版本
-
-## Key Entities
-- [[Vibe-Kanban]]:AI 编程辅助工具,提供看板界面与 OpenCode executor 集成,通过 npx vibe-kanban 启动
-- [[OpenCode]]:开源 AI Coding CLI agent,与 Vibe-Kanban 配合使用,npm install -g opencode-ai 安装
-- [[shenwei]]:文档作者,非 root 普通用户,用于在 Ubuntu Server 上运行 Vibe-Kanban 和 OpenCode
-
-## Connections
-- [[如何在Ubuntu上安装OpenCode并配置Vibe-Kanban]] ← extends ← [[vibe-kanban-opencode-在-ubuntu-server-上安装与管理指南]]
-- [[Vibe Coding 经验收集]] ← related_to ← [[vibe-kanban-opencode-在-ubuntu-server-上安装与管理指南]]
-- [[OpenCode]] ← depends_on ← [[Node 20]]
-- [[Vibe-Kanban]] ← depends_on ← [[OpenCode]]
-
-## Contradictions
-- 与 [[如何在Ubuntu上安装OpenCode并配置Vibe-Kanban]] 部分重叠:
- - 冲突点:两篇文档都介绍 Ubuntu 上安装 OpenCode 和 Vibe-Kanban
- - 当前观点:本篇更详细,覆盖完整 6 步流程、pm2 进程管理、权限配置和验证步骤
- - 对方观点:前篇侧重基础安装步骤
+---
+title: "Vibe-Kanban + OpenCode 在 Ubuntu Server 上安装与管理指南"
+type: source
+tags: [npm, npx, pm2, ubuntu, vibe-coding, vibe-kanban]
+date: 2026-04-17
+---
+
+## Source File
+- [[raw/Vibe Coding/Vibe-Kanban + OpenCode 在 Ubuntu Server 上安装与管理指南.md]]
+
+## Summary(用中文描述)
+- 核心主题:在 Ubuntu Server 上非 root 用户(shenwei)安装 Node 20、Vibe-Kanban、OpenCode,并通过 pm2 进程管理,实现 AI 辅助编程工作流
+- 问题域:Ubuntu Server 环境下的 AI Coding Agent 部署与长期运维
+- 方法/机制:使用 nvm 管理 Node 版本、npm/npx 安装工具、pm2 管理进程生命周期、权限配置确保非 root 用户正常运行
+- 结论/价值:完整记录了从零开始在 Ubuntu Server 上搭建 Vibe Coding 环境的全流程,含验证步骤和故障排查要点
+
+## Key Claims(用中文描述)
+- 使用 nvm 安装 Node 20 可确保版本兼容性和环境隔离
+- pm2 能可靠管理 Vibe-Kanban 和 OpenCode Executor 进程并支持开机自启
+- 权限配置(/var/tmp/vibe-kanban 和 ~/.vibe-kanban 归属 shenwei)是避免 I/O error 的关键
+- 不应以 root 用户启动 OpenCode serve,避免权限问题
+- Vibe-Kanban 会自动 spawn OpenCode executor(随机端口),无需手动固定端口
+
+## Key Quotes
+> "不要用 root 启动 OpenCode serve,vibe-kanban 会自动 spawn executor" — 核心安全与架构原则
+> "遇到 I/O error 时,通常是 executor 没启动或端口被占用" — 常见故障排查方向
+> "pm2 只管理 vibe-kanban,executor 随进程一起管理" — 进程管理边界定义
+
+## Key Concepts
+- [[Vibe Coding]]:使用自然语言与 AI 编程工具协作的开发方式,Vibe-Kanban + OpenCode 是其代表性工具栈
+- [[nvm]](Node Version Manager):Node.js 版本管理工具,通过 $NVM_DIR/$HOME/.nvm 安装,支持多版本共存和快速切换
+- [[pm2]]:Node.js 进程管理器,支持进程守护、负载均衡、日志管理和开机自启(systemd)
+- [[Node 20]]:LTS 版 Node.js,Vibe-Kanban 和 OpenCode 的推荐运行时版本
+
+## Key Entities
+- [[Vibe-Kanban]]:AI 编程辅助工具,提供看板界面与 OpenCode executor 集成,通过 npx vibe-kanban 启动
+- [[OpenCode]]:开源 AI Coding CLI agent,与 Vibe-Kanban 配合使用,npm install -g opencode-ai 安装
+- [[shenwei]]:文档作者,非 root 普通用户,用于在 Ubuntu Server 上运行 Vibe-Kanban 和 OpenCode
+
+## Connections
+- [[如何在Ubuntu上安装OpenCode并配置Vibe-Kanban]] ← extends ← [[vibe-kanban-opencode-在-ubuntu-server-上安装与管理指南]]
+- [[Vibe Coding 经验收集]] ← related_to ← [[vibe-kanban-opencode-在-ubuntu-server-上安装与管理指南]]
+- [[OpenCode]] ← depends_on ← [[Node 20]]
+- [[Vibe-Kanban]] ← depends_on ← [[OpenCode]]
+
+## Contradictions
+- 与 [[如何在Ubuntu上安装OpenCode并配置Vibe-Kanban]] 部分重叠:
+ - 冲突点:两篇文档都介绍 Ubuntu 上安装 OpenCode 和 Vibe-Kanban
+ - 当前观点:本篇更详细,覆盖完整 6 步流程、pm2 进程管理、权限配置和验证步骤
+ - 对方观点:前篇侧重基础安装步骤
diff --git a/wiki/sources/visionos-spatial-engineer.md b/wiki/sources/visionos-spatial-engineer.md
index a35a2c52..e7aef77a 100644
--- a/wiki/sources/visionos-spatial-engineer.md
+++ b/wiki/sources/visionos-spatial-engineer.md
@@ -1,68 +1,68 @@
----
-title: "visionOS Spatial Engineer"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/spatial-computing/visionos-spatial-engineer.md]]
-
-## Summary(用中文描述)
-- 核心主题:visionOS 原生空间计算 Agent,专注于 volumetric 界面与 Liquid Glass 设计系统实现
-- 问题域:Apple visionOS 26 平台上的空间应用开发,缺乏统一的设计与工程实践框架
-- 方法/机制:基于 SwiftUI/RealityKit 技术栈,通过 Liquid Glass Design System 驱动透明材质渲染,结合 WindowGroup 多窗口架构和 SwiftUI Volumetric API 实现 3D 内容集成
-- 结论/价值:为 The Agency Spatial Computing 部门提供 visionOS 原生开发能力,与 [[macos-spatial-metal-engineer]](Metal 渲染侧)和 [[xr-immersive-developer]](WebXR 浏览器侧)共同构成 Apple 空间计算全栈能力
-
-## Key Claims(用中文描述)
-- Apple 的 Liquid Glass Design System 通过自适应透明材质,在 light/dark 环境和周围内容变化时动态调整视觉表现
-- Spatial Widgets 可吸附于墙面和桌面,持久化放置于 3D 空间中,无需应用前台运行
-- SwiftUI Volumetric API 支持 3D 内容集成、volume 内 transient content 和 breakthrough UI 元素
-- RealityKit-SwiftUI 集成通过 Observable entities、直接手势处理和 ViewAttachmentComponent 实现声明式 3D 开发
-- Multi-Window Architecture 通过 WindowGroup 管理空间应用的玻璃背景效果和单实例窗口
-- GPU 高效渲染是多个玻璃窗口和 3D 内容同时展示的性能保障
-
-## Key Quotes
-> "Focuses on leveraging visionOS 26's spatial computing capabilities to create immersive, performant applications that follow Apple's Liquid Glass design principles." — Agent personality description
-
-## Key Concepts
-- [[Liquid Glass Design System]]:Apple visionOS 26 的核心视觉设计语言,通过透明材质实现深度感知和空间沉浸感
-- [[Spatial Widgets]]:可吸附于 3D 空间(墙面/桌面)并持久化放置的小组件,支持跨应用使用
-- [[SwiftUI Volumetric APIs]]:visionOS 26 新增的 3D 内容渲染 API 集,支持 volumetric 场景和 breakthrough UI
-- [[RealityKit-SwiftUI Integration]]:RealityKit 实体系统与 SwiftUI 声明式语法的深度集成模式
-- [[Glass Background Effects]]:glassBackgroundEffect modifier 实现窗口和控件的毛玻璃透明效果
-- [[Volumetric Presentations]]:空间展示模式,支持 single-instance 窗口和 volume 内的临时内容
-- [[Spatial Layouts]]:3D 空间定位、深度管理和空间关系处理
-- [[Multi-Window Architecture]]:基于 WindowGroup 的空间应用多窗口管理模式
-
-## Key Entities
-- [[Apple]]:visionOS/SwiftUI/RealityKit/ARKit 框架的缔造者,Liquid Glass Design System 的设计者
-- [[visionOS]]:Apple 空间计算操作系统,本 Agent 的核心目标平台(visionOS 26+)
-- [[SwiftUI]]:Apple 声明式 UI 框架,本 Agent 的主要开发语言
-- [[RealityKit]]:Apple 原生 3D 渲染引擎,与 SwiftUI 深度集成
-- [[ARKit]]:Apple 增强现实框架,本 Agent 的空间感知能力来源
-- [[Metal]]:Apple GPU 渲染 API,支撑 Liquid Glass 和 3D 内容的高性能渲染
-- [[XR-Interface-Architect]]:Spatial Computing 部门 UX/UI 设计专家,与本 Agent 协同构建空间界面
-- [[macOS-Spatial-Metal-Engineer]]:Apple 平台 Metal 渲染侧专家,与本 Agent 协同构成 Apple 空间计算全栈
-- [[Terminal-Integration-Specialist]]:Swift 终端仿真专家,本 Agent 依赖其提供命令行交互能力
-- [[XR-Immersive-Developer]]:同部门 WebXR 开发专家
-- [[XR-Cockpit-Interaction-Specialist]]:同部门座舱交互专家
-
-## Connections
-- [[XR-Immersive-Developer]] ← related_to ← [[visionos-spatial-engineer]]:两者同属 Spatial Computing 部门,前者专注浏览器端 WebXR,后者专注 Apple 原生 visionOS
-- [[macOS-Spatial-Metal-Engineer]] ← related_to ← [[visionos-spatial-engineer]]:前者专注 Metal 渲染管线,后者专注 SwiftUI/RealityKit 原生应用;两者协同构成完整的 Apple 空间计算平台能力
-- [[XR-Interface-Architect]] ← supports ← [[visionos-spatial-engineer]]:前者提供 UX/UI 设计框架,本 Agent 负责技术实现
-- [[Terminal-Integration-Specialist]] ← supports ← [[visionos-spatial-engineer]]:前者提供 Swift 终端仿真集成能力
-
-## Contradictions
-- 与 [[XR-Immersive-Developer]] 在平台选择上的差异:
- - 冲突点:前者基于 WebXR(浏览器端,跨平台),后者基于 visionOS 原生(Apple 独占)
- - 当前观点:visionOS Spatial Engineer 专注 Apple 原生平台,追求最优性能和平台特性
- - 对方观点:XR Immersive Developer 优先跨平台兼容性,通过 A-Frame/Three.js 实现浏览器端部署
- - 协调:两者面向不同场景,前者服务 visionOS 高端沉浸体验,后者服务广泛的 WebXR 设备覆盖
-
-- 与 [[macOS-Spatial-Metal-Engineer]] 在技术栈选择上的差异:
- - 冲突点:前者侧重 SwiftUI/RealityKit 声明式开发,后者侧重 Metal/SceneKit 底层渲染
- - 当前观点:visionOS Spatial Engineer 优先 SwiftUI 的声明式效率和 Apple 官方推荐模式
- - 对方观点:macOS Spatial/Metal Engineer 认为 Metal 渲染管线对于大规模 3D 数据可视化更可控
- - 协调:两者在同一问题域互补——前者处理 UI/UX 层应用开发,后者处理 GPU 密集型数据渲染
+---
+title: "visionOS Spatial Engineer"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/spatial-computing/visionos-spatial-engineer.md]]
+
+## Summary(用中文描述)
+- 核心主题:visionOS 原生空间计算 Agent,专注于 volumetric 界面与 Liquid Glass 设计系统实现
+- 问题域:Apple visionOS 26 平台上的空间应用开发,缺乏统一的设计与工程实践框架
+- 方法/机制:基于 SwiftUI/RealityKit 技术栈,通过 Liquid Glass Design System 驱动透明材质渲染,结合 WindowGroup 多窗口架构和 SwiftUI Volumetric API 实现 3D 内容集成
+- 结论/价值:为 The Agency Spatial Computing 部门提供 visionOS 原生开发能力,与 [[macos-spatial-metal-engineer]](Metal 渲染侧)和 [[xr-immersive-developer]](WebXR 浏览器侧)共同构成 Apple 空间计算全栈能力
+
+## Key Claims(用中文描述)
+- Apple 的 Liquid Glass Design System 通过自适应透明材质,在 light/dark 环境和周围内容变化时动态调整视觉表现
+- Spatial Widgets 可吸附于墙面和桌面,持久化放置于 3D 空间中,无需应用前台运行
+- SwiftUI Volumetric API 支持 3D 内容集成、volume 内 transient content 和 breakthrough UI 元素
+- RealityKit-SwiftUI 集成通过 Observable entities、直接手势处理和 ViewAttachmentComponent 实现声明式 3D 开发
+- Multi-Window Architecture 通过 WindowGroup 管理空间应用的玻璃背景效果和单实例窗口
+- GPU 高效渲染是多个玻璃窗口和 3D 内容同时展示的性能保障
+
+## Key Quotes
+> "Focuses on leveraging visionOS 26's spatial computing capabilities to create immersive, performant applications that follow Apple's Liquid Glass design principles." — Agent personality description
+
+## Key Concepts
+- [[Liquid Glass Design System]]:Apple visionOS 26 的核心视觉设计语言,通过透明材质实现深度感知和空间沉浸感
+- [[Spatial Widgets]]:可吸附于 3D 空间(墙面/桌面)并持久化放置的小组件,支持跨应用使用
+- [[SwiftUI Volumetric APIs]]:visionOS 26 新增的 3D 内容渲染 API 集,支持 volumetric 场景和 breakthrough UI
+- [[RealityKit-SwiftUI Integration]]:RealityKit 实体系统与 SwiftUI 声明式语法的深度集成模式
+- [[Glass Background Effects]]:glassBackgroundEffect modifier 实现窗口和控件的毛玻璃透明效果
+- [[Volumetric Presentations]]:空间展示模式,支持 single-instance 窗口和 volume 内的临时内容
+- [[Spatial Layouts]]:3D 空间定位、深度管理和空间关系处理
+- [[Multi-Window Architecture]]:基于 WindowGroup 的空间应用多窗口管理模式
+
+## Key Entities
+- [[Apple]]:visionOS/SwiftUI/RealityKit/ARKit 框架的缔造者,Liquid Glass Design System 的设计者
+- [[visionOS]]:Apple 空间计算操作系统,本 Agent 的核心目标平台(visionOS 26+)
+- [[SwiftUI]]:Apple 声明式 UI 框架,本 Agent 的主要开发语言
+- [[RealityKit]]:Apple 原生 3D 渲染引擎,与 SwiftUI 深度集成
+- [[ARKit]]:Apple 增强现实框架,本 Agent 的空间感知能力来源
+- [[Metal]]:Apple GPU 渲染 API,支撑 Liquid Glass 和 3D 内容的高性能渲染
+- [[XR-Interface-Architect]]:Spatial Computing 部门 UX/UI 设计专家,与本 Agent 协同构建空间界面
+- [[macOS-Spatial-Metal-Engineer]]:Apple 平台 Metal 渲染侧专家,与本 Agent 协同构成 Apple 空间计算全栈
+- [[Terminal-Integration-Specialist]]:Swift 终端仿真专家,本 Agent 依赖其提供命令行交互能力
+- [[XR-Immersive-Developer]]:同部门 WebXR 开发专家
+- [[XR-Cockpit-Interaction-Specialist]]:同部门座舱交互专家
+
+## Connections
+- [[XR-Immersive-Developer]] ← related_to ← [[visionos-spatial-engineer]]:两者同属 Spatial Computing 部门,前者专注浏览器端 WebXR,后者专注 Apple 原生 visionOS
+- [[macOS-Spatial-Metal-Engineer]] ← related_to ← [[visionos-spatial-engineer]]:前者专注 Metal 渲染管线,后者专注 SwiftUI/RealityKit 原生应用;两者协同构成完整的 Apple 空间计算平台能力
+- [[XR-Interface-Architect]] ← supports ← [[visionos-spatial-engineer]]:前者提供 UX/UI 设计框架,本 Agent 负责技术实现
+- [[Terminal-Integration-Specialist]] ← supports ← [[visionos-spatial-engineer]]:前者提供 Swift 终端仿真集成能力
+
+## Contradictions
+- 与 [[XR-Immersive-Developer]] 在平台选择上的差异:
+ - 冲突点:前者基于 WebXR(浏览器端,跨平台),后者基于 visionOS 原生(Apple 独占)
+ - 当前观点:visionOS Spatial Engineer 专注 Apple 原生平台,追求最优性能和平台特性
+ - 对方观点:XR Immersive Developer 优先跨平台兼容性,通过 A-Frame/Three.js 实现浏览器端部署
+ - 协调:两者面向不同场景,前者服务 visionOS 高端沉浸体验,后者服务广泛的 WebXR 设备覆盖
+
+- 与 [[macOS-Spatial-Metal-Engineer]] 在技术栈选择上的差异:
+ - 冲突点:前者侧重 SwiftUI/RealityKit 声明式开发,后者侧重 Metal/SceneKit 底层渲染
+ - 当前观点:visionOS Spatial Engineer 优先 SwiftUI 的声明式效率和 Apple 官方推荐模式
+ - 对方观点:macOS Spatial/Metal Engineer 认为 Metal 渲染管线对于大规模 3D 数据可视化更可控
+ - 协调:两者在同一问题域互补——前者处理 UI/UX 层应用开发,后者处理 GPU 密集型数据渲染
diff --git a/wiki/sources/what-i-know-about-cloud-service-delivery-1.md b/wiki/sources/what-i-know-about-cloud-service-delivery-1.md
index 574df0ba..7d08c469 100644
--- a/wiki/sources/what-i-know-about-cloud-service-delivery-1.md
+++ b/wiki/sources/what-i-know-about-cloud-service-delivery-1.md
@@ -1,66 +1,66 @@
----
-title: "What I Know About Cloud Service Delivery 1"
-type: source
-tags: []
-date:
-author: shenwei
-sources: []
-last_updated: 2026-04-26
----
-
-## Source File
-- [[Cloud & DevOps/What I know about Cloud Service Delivery 1]]
-
-## Summary(用中文描述)
-- **核心主题**:云服务交付(Cloud Service Delivery)的完整生命周期管理框架,涵盖从基础设施到客户支持的 12 大领域
-- **问题域**:如何将云技术(IaaS/PaaS/SaaS)的能力可靠、安全、高性能且成本有效地传递给最终用户
-- **方法/机制**:由多角色 Cloud Service Delivery Team 驱动,通过 IaC、监控、合规、成本优化等手段实现端到端管理
-- **结论/价值**:云服务交付是连接云技术能力与企业/用户实际需求之间的桥梁,需要多学科协作和持续运营
-
-## Key Claims(用中文描述)
-- Cloud Service Delivery Team(多角色团队)→ 通过专业分工 → 实现完整的云服务生命周期管理
-- Service Provisioning & Deployment → 自动化部署 + 资源配置和扩缩容 → 提高部署效率、加快交付速度
-- Infrastructure Management → 监控 + 补丁更新 + 高可用设置 → 确保底层基础设施稳定运行
-- Platform Management(PaaS)→ 中间件、数据库、开发工具和运行时管理 → 保证平台可扩展、安全、高性能
-- Application Operations & Management → 应用性能监控 + 持续部署 + 配置和密钥管理 → 确保应用弹性和可扩展性
-- Security & Compliance Management → 防火墙、IDS/IPS、加密、IAM 合规审计 → 保障云环境安全和合规
-- Performance & Availability Monitoring → 24/7 全栈监控 + SLA/SLO 管理 + 主动检测 → 确保服务高可用和性能达标
-- Incident & Problem Management → 快速响应 + 全栈故障排除 + 根因分析 → 最小化服务中断时间和影响
-- Change & Configuration Management → IaC + 变更控制 + 测试和回滚 → 降低变更风险、保证环境一致性
-- Cost Management & Optimization → 消费监控 + 消除浪费 + 合理选型(Savings Plans)→ 降低云支出、提升 ROI
-- Customer Onboarding & Support → 用户引导 + 文档培训 + 服务台运营 → 提升用户体验和满意度
-- Backup, Recovery & Disaster Management → 备份策略 + 恢复测试 + DR 演练 → 确保业务连续性和数据安全
-
-## Key Quotes
-
-## Key Concepts
-- [[Cloud Service Delivery]]:将云技术(IaaS/PaaS/SaaS)能力可靠、安全、高性能且成本有效地传递给最终用户的完整生命周期管理
-- [[Infrastructure as Code (IaC)]]:通过代码管理基础设施配置,确保一致性和可重复性(Change & Configuration Management)
-- [[Service Level Agreement (SLA)]]:服务等级协议,定义服务的可用性目标(如 99.9% vs 99.99%)
-- [[Service Level Objective (SLO)]]:服务等级目标,SLA 分解到具体服务的具体指标
-- [[FinOps]]:云财务管理,通过监控消费、消除浪费、合理选型来优化云成本
-- [[Incident Management]]:事件管理,快速响应和恢复服务中断
-- [[Problem Management]]:问题管理,识别根因并实施永久性修复
-- [[Disaster Recovery (DR)]]:灾难恢复,确保业务连续性的备份和故障切换机制
-- [[Cloud DevOps Maturity Model]]:云 DevOps 成熟度模型(本文件末尾提及,待扩展)
-- [[AIOps]]:人工智能运维(本文件末尾提及,待扩展)
-
-## Key Entities
-- **AWS CloudWatch**:AWS 原生监控数据源,可接入 Grafana 实现统一可观测性
-- **Grafana**:监控可视化平台,支持 AWS CloudWatch 等多数据源
-- **New Relic**:APM/BPM 应用性能监控工具
-- **AWS CloudWatch Synthetic**:AWS 提供的服务可用性主动检测(Synthetic Monitoring)工具
-- **WAF (Web Application Firewall)**:云应用防火墙,管理云应用程序安全
-- **OpenText**:(作者所在组织)企业级云服务提供商
-
-## Connections
-- [[Cloud Maturity Model - A Detailed Guide For Cloud Adoption]] ← related_to ← [[What I Know About Cloud Service Delivery 1]]
-- [[DevOps Culture and Transformation]] ← extends ← [[What I Know About Cloud Service Delivery 1]]
-- [[Public Cloud Learning Sessions - Observability with OpenTelemetry]] ← related_to ← [[What I Know About Cloud Service Delivery 1]](可观测性层面)
-- [[CTP Topic 8 - Implementation of Cloud Monitoring]] ← related_to ← [[What I Know About Cloud Service Delivery 1]](监控实践)
-- [[Public Cloud Learning Sessions - Reducing Cloud Costs]] ← extends ← [[What I Know About Cloud Service Delivery 1]](成本管理)
-- [[Public Cloud Learning Sessions - EKS Optimization]] ← related_to ← [[What I Know About Cloud Service Delivery 1]](平台管理)
-- [[CTP Topic 73 AWS Backup Implementation]] ← related_to ← [[What I Know About Cloud Service Delivery 1]](备份与灾难恢复)
-
-## Contradictions
-- 与 [[DevOps Maturity Model From Traditional IT to Advanced DevOps]] 潜在交叉:两者均涉及 DevOps 文化成熟度,但本文更侧重运营层面,后者侧重文化转型;暂无实质性冲突
+---
+title: "What I Know About Cloud Service Delivery 1"
+type: source
+tags: []
+date:
+author: shenwei
+sources: []
+last_updated: 2026-04-26
+---
+
+## Source File
+- [[raw/Cloud & DevOps/What I know about Cloud Service Delivery 1.md]]
+
+## Summary(用中文描述)
+- **核心主题**:云服务交付(Cloud Service Delivery)的完整生命周期管理框架,涵盖从基础设施到客户支持的 12 大领域
+- **问题域**:如何将云技术(IaaS/PaaS/SaaS)的能力可靠、安全、高性能且成本有效地传递给最终用户
+- **方法/机制**:由多角色 Cloud Service Delivery Team 驱动,通过 IaC、监控、合规、成本优化等手段实现端到端管理
+- **结论/价值**:云服务交付是连接云技术能力与企业/用户实际需求之间的桥梁,需要多学科协作和持续运营
+
+## Key Claims(用中文描述)
+- Cloud Service Delivery Team(多角色团队)→ 通过专业分工 → 实现完整的云服务生命周期管理
+- Service Provisioning & Deployment → 自动化部署 + 资源配置和扩缩容 → 提高部署效率、加快交付速度
+- Infrastructure Management → 监控 + 补丁更新 + 高可用设置 → 确保底层基础设施稳定运行
+- Platform Management(PaaS)→ 中间件、数据库、开发工具和运行时管理 → 保证平台可扩展、安全、高性能
+- Application Operations & Management → 应用性能监控 + 持续部署 + 配置和密钥管理 → 确保应用弹性和可扩展性
+- Security & Compliance Management → 防火墙、IDS/IPS、加密、IAM 合规审计 → 保障云环境安全和合规
+- Performance & Availability Monitoring → 24/7 全栈监控 + SLA/SLO 管理 + 主动检测 → 确保服务高可用和性能达标
+- Incident & Problem Management → 快速响应 + 全栈故障排除 + 根因分析 → 最小化服务中断时间和影响
+- Change & Configuration Management → IaC + 变更控制 + 测试和回滚 → 降低变更风险、保证环境一致性
+- Cost Management & Optimization → 消费监控 + 消除浪费 + 合理选型(Savings Plans)→ 降低云支出、提升 ROI
+- Customer Onboarding & Support → 用户引导 + 文档培训 + 服务台运营 → 提升用户体验和满意度
+- Backup, Recovery & Disaster Management → 备份策略 + 恢复测试 + DR 演练 → 确保业务连续性和数据安全
+
+## Key Quotes
+
+## Key Concepts
+- [[Cloud Service Delivery]]:将云技术(IaaS/PaaS/SaaS)能力可靠、安全、高性能且成本有效地传递给最终用户的完整生命周期管理
+- [[Infrastructure as Code (IaC)]]:通过代码管理基础设施配置,确保一致性和可重复性(Change & Configuration Management)
+- [[Service Level Agreement (SLA)]]:服务等级协议,定义服务的可用性目标(如 99.9% vs 99.99%)
+- [[Service Level Objective (SLO)]]:服务等级目标,SLA 分解到具体服务的具体指标
+- [[FinOps]]:云财务管理,通过监控消费、消除浪费、合理选型来优化云成本
+- [[Incident Management]]:事件管理,快速响应和恢复服务中断
+- [[Problem Management]]:问题管理,识别根因并实施永久性修复
+- [[Disaster Recovery (DR)]]:灾难恢复,确保业务连续性的备份和故障切换机制
+- [[Cloud DevOps Maturity Model]]:云 DevOps 成熟度模型(本文件末尾提及,待扩展)
+- [[AIOps]]:人工智能运维(本文件末尾提及,待扩展)
+
+## Key Entities
+- **AWS CloudWatch**:AWS 原生监控数据源,可接入 Grafana 实现统一可观测性
+- **Grafana**:监控可视化平台,支持 AWS CloudWatch 等多数据源
+- **New Relic**:APM/BPM 应用性能监控工具
+- **AWS CloudWatch Synthetic**:AWS 提供的服务可用性主动检测(Synthetic Monitoring)工具
+- **WAF (Web Application Firewall)**:云应用防火墙,管理云应用程序安全
+- **OpenText**:(作者所在组织)企业级云服务提供商
+
+## Connections
+- [[Cloud Maturity Model - A Detailed Guide For Cloud Adoption]] ← related_to ← [[What I Know About Cloud Service Delivery 1]]
+- [[DevOps Culture and Transformation]] ← extends ← [[What I Know About Cloud Service Delivery 1]]
+- [[Public Cloud Learning Sessions - Observability with OpenTelemetry]] ← related_to ← [[What I Know About Cloud Service Delivery 1]](可观测性层面)
+- [[CTP Topic 8 - Implementation of Cloud Monitoring]] ← related_to ← [[What I Know About Cloud Service Delivery 1]](监控实践)
+- [[Public Cloud Learning Sessions - Reducing Cloud Costs]] ← extends ← [[What I Know About Cloud Service Delivery 1]](成本管理)
+- [[Public Cloud Learning Sessions - EKS Optimization]] ← related_to ← [[What I Know About Cloud Service Delivery 1]](平台管理)
+- [[CTP Topic 73 AWS Backup Implementation]] ← related_to ← [[What I Know About Cloud Service Delivery 1]](备份与灾难恢复)
+
+## Contradictions
+- 与 [[DevOps Maturity Model From Traditional IT to Advanced DevOps]] 潜在交叉:两者均涉及 DevOps 文化成熟度,但本文更侧重运营层面,后者侧重文化转型;暂无实质性冲突
diff --git a/wiki/sources/what-is-devsecops-best-practices-benefits-and-tools.md b/wiki/sources/what-is-devsecops-best-practices-benefits-and-tools.md
index 01c4ae98..ed04305a 100644
--- a/wiki/sources/what-is-devsecops-best-practices-benefits-and-tools.md
+++ b/wiki/sources/what-is-devsecops-best-practices-benefits-and-tools.md
@@ -1,62 +1,62 @@
----
-title: "What is DevSecOps? Best Practices, Benefits, and Tools"
-type: source
-tags: []
-date: 2023-10-30
----
-
-## Source File
-- [[Cloud & DevOps/What is DevSecOps Best Practices, Benefits, and Tools]]
-
-## Summary(用中文描述)
-- 核心主题:DevSecOps 将安全实践深度嵌入软件开发生命周期(SDLC),实现"安全即代码"
-- 问题域:传统 DevOps 在后期才引入安全导致漏洞修复成本高、交付速度慢的问题
-- 方法/机制:通过 Shift Left(左移)和 Shift Right(右移)策略,在 CI/CD 流水线中集成 SAST/DAST/SCA/IAST 等自动化安全工具,培养"全员安全责任"文化
-- 结论/价值:DevSecOps 能将 70% 的上线后发现的安全漏洞提前预防,实现安全与速度的平衡
-
-## Key Claims(用中文描述)
-- 70% 的软件漏洞可在 DevSecOps 实践中被预防
-- 安全左移(Shift Left)使团队能在开发早期发现并修复安全问题,降低修复成本
-- 自动化安全测试集成到 CI/CD 流水线中,可在不减缓开发速度的前提下保障安全
-- DevSecOps 通过"break the build"机制,当安全风险过高时停止构建流程
-- SAST、DAST、SCA、IAST 四类安全工具分别覆盖代码编写、运行时、第三方依赖和交互测试等不同阶段
-
-## Key Quotes
-> "DevSecOps is a working methodology that includes security checks throughout the software development process." — DevSecOps 核心定义
-
-> "70% of software vulnerabilities discovered post-launch could have been prevented with DevSecOps" — DevSecOps 价值量化
-
-> "Everyone in the organization developing software is liable for security." — 全员安全责任文化
-
-> "Shift left means identifying security flaws early in the software development lifecycle." — 左移策略定义
-
-## Key Concepts
-- [[DevSecOps]]:在 DevOps 中全程集成安全实践的工作方法论
-- [[Shift Left]]:在软件开发生命周期早期识别并修复安全缺陷的策略
-- [[Shift Right]]:在应用上线后持续进行安全监控和问题修复的策略
-- [[SAST]]:静态应用安全测试,在代码编写阶段分析源代码以发现漏洞
-- [[DAST]]:动态应用安全测试,模拟外部攻击从运行时发现漏洞
-- [[SCA]]:软件成分分析,扫描第三方依赖库和框架的已知安全漏洞
-- [[IAST]]:交互式应用安全测试,在应用运行时检测其他工具遗漏的漏洞
-- [[CI/CD 安全]]:在持续集成/持续交付流水线中自动化执行安全扫描
-- [[Break the Build]]:当安全风险超过阈值时自动停止构建流程的机制
-- [[Policy as Code]]:以代码形式定义和自动执行安全策略的方法
-
-## Key Entities
-- [[OWASP Top Ten]]:Web 应用安全标准,DevSecOps 测试中的重要参考框架
-- [[AWS CodePipeline]]:AWS 的 CI/CD 工具,可集成安全扫描
-- [[Amazon Inspector]]:AWS 漏洞管理自动化工具
-- [[Amazon CodeGuru Reviewer]]:AWS 代码安全和最佳实践审查工具
-
-## Connections
-- [[DevOps]] ← extends ← [[DevSecOps]](DevSecOps 是 DevOps 的安全扩展)
-- [[CI/CD 安全]] ← depends_on ← [[SAST]] / [[DAST]] / [[SCA]] / [[IAST]]
-- [[DevSecOps]] ← applies ← [[Shift Left]]
-- [[DevSecOps]] ← applies ← [[Shift Right]]
-- [[Agile Development]] ← integrates ← [[DevSecOps]]
-
-## Contradictions
-- 与传统瀑布式开发相比:
- - 冲突点:传统方式在 SDLC 末期才进行安全测试
- - 当前观点:DevSecOps 强调安全全程嵌入
- - 对方观点:安全专家在开发完成后再统一介入更专业
+---
+title: "What is DevSecOps? Best Practices, Benefits, and Tools"
+type: source
+tags: []
+date: 2023-10-30
+---
+
+## Source File
+- [[raw/Cloud & DevOps/What is DevSecOps Best Practices, Benefits, and Tools.md]]
+
+## Summary(用中文描述)
+- 核心主题:DevSecOps 将安全实践深度嵌入软件开发生命周期(SDLC),实现"安全即代码"
+- 问题域:传统 DevOps 在后期才引入安全导致漏洞修复成本高、交付速度慢的问题
+- 方法/机制:通过 Shift Left(左移)和 Shift Right(右移)策略,在 CI/CD 流水线中集成 SAST/DAST/SCA/IAST 等自动化安全工具,培养"全员安全责任"文化
+- 结论/价值:DevSecOps 能将 70% 的上线后发现的安全漏洞提前预防,实现安全与速度的平衡
+
+## Key Claims(用中文描述)
+- 70% 的软件漏洞可在 DevSecOps 实践中被预防
+- 安全左移(Shift Left)使团队能在开发早期发现并修复安全问题,降低修复成本
+- 自动化安全测试集成到 CI/CD 流水线中,可在不减缓开发速度的前提下保障安全
+- DevSecOps 通过"break the build"机制,当安全风险过高时停止构建流程
+- SAST、DAST、SCA、IAST 四类安全工具分别覆盖代码编写、运行时、第三方依赖和交互测试等不同阶段
+
+## Key Quotes
+> "DevSecOps is a working methodology that includes security checks throughout the software development process." — DevSecOps 核心定义
+
+> "70% of software vulnerabilities discovered post-launch could have been prevented with DevSecOps" — DevSecOps 价值量化
+
+> "Everyone in the organization developing software is liable for security." — 全员安全责任文化
+
+> "Shift left means identifying security flaws early in the software development lifecycle." — 左移策略定义
+
+## Key Concepts
+- [[DevSecOps]]:在 DevOps 中全程集成安全实践的工作方法论
+- [[Shift Left]]:在软件开发生命周期早期识别并修复安全缺陷的策略
+- [[Shift Right]]:在应用上线后持续进行安全监控和问题修复的策略
+- [[SAST]]:静态应用安全测试,在代码编写阶段分析源代码以发现漏洞
+- [[DAST]]:动态应用安全测试,模拟外部攻击从运行时发现漏洞
+- [[SCA]]:软件成分分析,扫描第三方依赖库和框架的已知安全漏洞
+- [[IAST]]:交互式应用安全测试,在应用运行时检测其他工具遗漏的漏洞
+- [[CI/CD 安全]]:在持续集成/持续交付流水线中自动化执行安全扫描
+- [[Break the Build]]:当安全风险超过阈值时自动停止构建流程的机制
+- [[Policy as Code]]:以代码形式定义和自动执行安全策略的方法
+
+## Key Entities
+- [[OWASP Top Ten]]:Web 应用安全标准,DevSecOps 测试中的重要参考框架
+- [[AWS CodePipeline]]:AWS 的 CI/CD 工具,可集成安全扫描
+- [[Amazon Inspector]]:AWS 漏洞管理自动化工具
+- [[Amazon CodeGuru Reviewer]]:AWS 代码安全和最佳实践审查工具
+
+## Connections
+- [[DevOps]] ← extends ← [[DevSecOps]](DevSecOps 是 DevOps 的安全扩展)
+- [[CI/CD 安全]] ← depends_on ← [[SAST]] / [[DAST]] / [[SCA]] / [[IAST]]
+- [[DevSecOps]] ← applies ← [[Shift Left]]
+- [[DevSecOps]] ← applies ← [[Shift Right]]
+- [[Agile Development]] ← integrates ← [[DevSecOps]]
+
+## Contradictions
+- 与传统瀑布式开发相比:
+ - 冲突点:传统方式在 SDLC 末期才进行安全测试
+ - 当前观点:DevSecOps 强调安全全程嵌入
+ - 对方观点:安全专家在开发完成后再统一介入更专业
diff --git a/wiki/sources/workflow-book-chapter.md b/wiki/sources/workflow-book-chapter.md
index 2d7e424c..61f51933 100644
--- a/wiki/sources/workflow-book-chapter.md
+++ b/wiki/sources/workflow-book-chapter.md
@@ -6,7 +6,7 @@ date: 2026-04-25
---
## Source File
-- [[Agent/agency-agents/examples/workflow-book-chapter.md]]
+- [[raw/Agent/agency-agents/examples/workflow-book-chapter.md]]
## Summary(用中文描述)
- 核心主题:单 Agent 工作流——将粗糙的原始素材转化为结构化的第一人称章节草稿,包含明确的修订循环
diff --git a/wiki/sources/workflow-startup-mvp.md b/wiki/sources/workflow-startup-mvp.md
index d1b5f8a9..a021a3cf 100644
--- a/wiki/sources/workflow-startup-mvp.md
+++ b/wiki/sources/workflow-startup-mvp.md
@@ -6,7 +6,7 @@ date: 2026-04-21
---
## Source File
-- [[Agent/agency-agents/examples/workflow-startup-mvp.md]]
+- [[raw/Agent/agency-agents/examples/workflow-startup-mvp.md]]
## Summary(用中文描述)
- 核心主题:多 Agent 协作工作流,演示如何协调多个 Agent 从创意到 MVP 交付的完整流程
diff --git a/wiki/sources/workflow-with-memory.md b/wiki/sources/workflow-with-memory.md
index 78dcd4f6..e88c82fb 100644
--- a/wiki/sources/workflow-with-memory.md
+++ b/wiki/sources/workflow-with-memory.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/agency-agents/examples/workflow-with-memory.md]]
+- [[raw/Agent/agency-agents/examples/workflow-with-memory.md]]
## Summary(用中文描述)
- 核心主题:多 Agent 协作工作流增加 MCP 持久记忆机制,解决 Agent 间手动复制粘贴交接、上下文丢失、QA 失败回滚困难等问题
diff --git a/wiki/sources/wsl2-启动与网络配置指南.md b/wiki/sources/wsl2-启动与网络配置指南.md
index f406cc94..23748a76 100644
--- a/wiki/sources/wsl2-启动与网络配置指南.md
+++ b/wiki/sources/wsl2-启动与网络配置指南.md
@@ -1,42 +1,42 @@
----
-title: "WSL2 启动与网络配置指南"
-type: source
-tags: []
-date: 2026-04-17
----
-
-## Source File
-- [[Home Office/WSL2 启动与网络配置指南]]
-
-## Summary(用中文描述)
-- 核心主题:WSL2(Windows Subsystem for Linux 2)的安装启动与网络配置实操指南
-- 问题域:Windows 环境下 Linux 开发环境搭建,重点解决 WSL2 网络隔离导致的 GitHub/海外资源访问障碍
-- 方法/机制:① `wsl --install` 快速安装;② `.wslconfig` 启用镜像网络模式(mirrored mode)实现 WSL2 与 Windows 共享网络堆栈;③ 终端代理环境变量手动配置;④ ghproxy.com 反向代理绕过网络限制
-- 结论/价值:提供从零安装到生产可用的完整 WSL2 配置路径,镜像网络模式是最稳妥的解决方案,避免 NAT 模式下的 localhost 代理失效问题
-
-## Key Claims(用中文描述)
-- WSL2 默认使用 NAT 模式,导致 Windows 宿主机 localhost 代理无法被 WSL2 内部正确访问,这是 GitHub/海外资源连接失败的根本原因
-- 在 `.wslconfig` 中设置 `networkingMode=mirrored` + `dnsTunneling=true` + `autoProxy=true` 可使 WSL2 与 Windows 共享网络堆栈,是解决网络问题的推荐方案
-- 使用 `ghproxy.com` 反向代理可绕过 GitHub 访问限制,适用于 uv 安装器、Hermes Agent 等工具的下载场景
-
-## Key Quotes
-> "WSL2 默认使用 NAT 模式,常会出现'localhost 代理无法镜像'或无法访问海外资源的情况。" — 背景说明
-> "在 PowerShell 执行 `wsl --shutdown` 后重启 WSL。" — 镜像模式生效操作
-
-## Key Concepts
-- [[WSL2]]:Windows Subsystem for Linux 2,Windows 10/11 内置的 Linux 虚拟机环境,默认使用 NAT 网络模式
-- [[镜像网络模式]](Mirrored Network Mode):WSL2 与 Windows 共享网络堆栈的配置模式,使 WSL2 能直接访问 Windows 代理
-- [[NAT模式]]:WSL2 默认网络模式,WSL2 拥有独立 IP,localhost 代理不可用
-- [[ghproxy]]:ghproxy.com,反向代理服务,将 GitHub 资源 URL 替换为代理地址以绕过网络限制
-
-## Key Entities
-- [[Ubuntu]]:WSL2 默认安装的 Linux 分发版
-- [[Windows]]:宿主操作系统,WSL2 运行其上
-- [[PowerShell]]:Windows 命令行环境,用于执行 wsl 管理命令
-
-## Connections
-- [[Ubuntu Server]] ← related_to ← [[WSL2]](WSL2 是 Ubuntu 在 Windows 上的轻量运行方式)
-- [[ubuntu-server科学上网]] ← related_to ← [[WSL2 网络配置]](均涉及 Linux 环境代理配置)
-
-## Contradictions
-- (无已知冲突)
+---
+title: "WSL2 启动与网络配置指南"
+type: source
+tags: []
+date: 2026-04-17
+---
+
+## Source File
+- [[raw/Home Office/WSL2 启动与网络配置指南.md]]
+
+## Summary(用中文描述)
+- 核心主题:WSL2(Windows Subsystem for Linux 2)的安装启动与网络配置实操指南
+- 问题域:Windows 环境下 Linux 开发环境搭建,重点解决 WSL2 网络隔离导致的 GitHub/海外资源访问障碍
+- 方法/机制:① `wsl --install` 快速安装;② `.wslconfig` 启用镜像网络模式(mirrored mode)实现 WSL2 与 Windows 共享网络堆栈;③ 终端代理环境变量手动配置;④ ghproxy.com 反向代理绕过网络限制
+- 结论/价值:提供从零安装到生产可用的完整 WSL2 配置路径,镜像网络模式是最稳妥的解决方案,避免 NAT 模式下的 localhost 代理失效问题
+
+## Key Claims(用中文描述)
+- WSL2 默认使用 NAT 模式,导致 Windows 宿主机 localhost 代理无法被 WSL2 内部正确访问,这是 GitHub/海外资源连接失败的根本原因
+- 在 `.wslconfig` 中设置 `networkingMode=mirrored` + `dnsTunneling=true` + `autoProxy=true` 可使 WSL2 与 Windows 共享网络堆栈,是解决网络问题的推荐方案
+- 使用 `ghproxy.com` 反向代理可绕过 GitHub 访问限制,适用于 uv 安装器、Hermes Agent 等工具的下载场景
+
+## Key Quotes
+> "WSL2 默认使用 NAT 模式,常会出现'localhost 代理无法镜像'或无法访问海外资源的情况。" — 背景说明
+> "在 PowerShell 执行 `wsl --shutdown` 后重启 WSL。" — 镜像模式生效操作
+
+## Key Concepts
+- [[WSL2]]:Windows Subsystem for Linux 2,Windows 10/11 内置的 Linux 虚拟机环境,默认使用 NAT 网络模式
+- [[镜像网络模式]](Mirrored Network Mode):WSL2 与 Windows 共享网络堆栈的配置模式,使 WSL2 能直接访问 Windows 代理
+- [[NAT模式]]:WSL2 默认网络模式,WSL2 拥有独立 IP,localhost 代理不可用
+- [[ghproxy]]:ghproxy.com,反向代理服务,将 GitHub 资源 URL 替换为代理地址以绕过网络限制
+
+## Key Entities
+- [[Ubuntu]]:WSL2 默认安装的 Linux 分发版
+- [[Windows]]:宿主操作系统,WSL2 运行其上
+- [[PowerShell]]:Windows 命令行环境,用于执行 wsl 管理命令
+
+## Connections
+- [[Ubuntu Server]] ← related_to ← [[WSL2]](WSL2 是 Ubuntu 在 Windows 上的轻量运行方式)
+- [[ubuntu-server科学上网]] ← related_to ← [[WSL2 网络配置]](均涉及 Linux 环境代理配置)
+
+## Contradictions
+- (无已知冲突)
diff --git a/wiki/sources/x-account-analysis.md b/wiki/sources/x-account-analysis.md
index 4b38c038..e8aa8b67 100644
--- a/wiki/sources/x-account-analysis.md
+++ b/wiki/sources/x-account-analysis.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/x-account-analysis.md]]
+- [[raw/Agent/usecases/x-account-analysis.md]]
## Summary(用中文描述)
- 核心主题:利用 AI Agent(OpenClaw + Bird Skill)对 X(Twitter)账号进行定性分析
diff --git a/wiki/sources/x-twitter-automation.md b/wiki/sources/x-twitter-automation.md
index 460abcc3..694d1e0f 100644
--- a/wiki/sources/x-twitter-automation.md
+++ b/wiki/sources/x-twitter-automation.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Agent/usecases/x-twitter-automation.md]]
+- [[raw/Agent/usecases/x-twitter-automation.md]]
## Summary(用中文描述)
- 核心主题:通过自然语言在聊天中完成 X/Twitter 全功能自动化操作
diff --git a/wiki/sources/xr-cockpit-interaction-specialist.md b/wiki/sources/xr-cockpit-interaction-specialist.md
index 037c1370..45689c46 100644
--- a/wiki/sources/xr-cockpit-interaction-specialist.md
+++ b/wiki/sources/xr-cockpit-interaction-specialist.md
@@ -1,41 +1,41 @@
----
-title: "XR Cockpit Interaction Specialist Agent"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/spatial-computing/xr-cockpit-interaction-specialist.md]]
-
-## Summary(用中文描述)
-- 核心主题:XR 座舱交互专家 Agent——专注于设计和实现沉浸式座舱式交互环境,融合空间控制与自然人体工学
-- 问题域:如何在 XR 环境中构建高存在感、低眩晕的固定视角座舱交互系统
-- 方法/机制:固定视角(fixed-perspective)高存在感交互区设计、人体工学对齐(眼-手-头协调)、约束驱动控制机制(constraint-driven)、多模态交互集成(手势+语音+注视+物理道具)
-- 结论/价值:提供真实感与舒适度并重的 XR 座舱解决方案,适用于模拟指挥中心、航天器座舱、XR 载具界面和训练模拟器
-
-## Key Claims(用中文描述)
-- XR 座舱交互通过固定视角设计(fixed-perspective)和高存在感交互区(high-presence interaction zones)显著提升沉浸感体验
-- 约束驱动控制机制(constraint-driven control mechanics)消除自由漂浮运动,有效降低用户眩晕感
-- 座舱人体工学设计需对齐自然的眼-手-头协调流动(eye–hand–head flow),确保长时间使用舒适性
-- 多模态交互集成(手势、语音、注视、物理道具)为用户提供灵活自然的控制选择
-
-## Key Quotes
-> "You create fixed-perspective, high-presence interaction zones that combine realism with user comfort." — Agent 核心定位:固定视角高存在感交互区设计
-
-## Key Concepts
-- [[Constraint-Driven-Control-Mechanics]]:约束驱动控制机制——通过 3D meshes 和输入约束实现的控制物理化设计,取代自由漂浮式交互
-- [[Cockpit-Ergonomics]]:座舱人体工学——对齐自然的眼-手-头协调流动,优化长时间使用的舒适度
-- [[Spatial-Computing]]:空间计算——XR 环境的核心技术基础,支持 3D 空间中的交互设计
-- [[Motion-Sickness-Threshold]]:运动病阈值——通过固定视角和约束驱动设计将其最小化
-
-## Key Entities
-- [[XR-Cockpit-Interaction-Specialist]]:本 Agent 角色——空间座舱设计专家,专注于 XR 模拟和载具界面
-
-## Connections
-- [[XR-Interface-Architect]] ← builds_upon ← [[XR-Cockpit-Interaction-Specialist]]
-- [[XR-Immersive-Developer]] ← collaborates ← [[XR-Cockpit-Interaction-Specialist]]
-- [[Terminal-Integration-Specialist]] ← extends ← [[XR-Cockpit-Interaction-Specialist]]
-
-## Contradictions
-- 与 [[XR-Immersive-Developer]] 在运动自由度上存在设计张力:后者倾向开放空间沉浸体验,前者强调固定视角约束以降低眩晕;当前观点:座舱场景优先舒适性与真实感,通用沉浸场景可保留开放自由度
+---
+title: "XR Cockpit Interaction Specialist Agent"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/spatial-computing/xr-cockpit-interaction-specialist.md]]
+
+## Summary(用中文描述)
+- 核心主题:XR 座舱交互专家 Agent——专注于设计和实现沉浸式座舱式交互环境,融合空间控制与自然人体工学
+- 问题域:如何在 XR 环境中构建高存在感、低眩晕的固定视角座舱交互系统
+- 方法/机制:固定视角(fixed-perspective)高存在感交互区设计、人体工学对齐(眼-手-头协调)、约束驱动控制机制(constraint-driven)、多模态交互集成(手势+语音+注视+物理道具)
+- 结论/价值:提供真实感与舒适度并重的 XR 座舱解决方案,适用于模拟指挥中心、航天器座舱、XR 载具界面和训练模拟器
+
+## Key Claims(用中文描述)
+- XR 座舱交互通过固定视角设计(fixed-perspective)和高存在感交互区(high-presence interaction zones)显著提升沉浸感体验
+- 约束驱动控制机制(constraint-driven control mechanics)消除自由漂浮运动,有效降低用户眩晕感
+- 座舱人体工学设计需对齐自然的眼-手-头协调流动(eye–hand–head flow),确保长时间使用舒适性
+- 多模态交互集成(手势、语音、注视、物理道具)为用户提供灵活自然的控制选择
+
+## Key Quotes
+> "You create fixed-perspective, high-presence interaction zones that combine realism with user comfort." — Agent 核心定位:固定视角高存在感交互区设计
+
+## Key Concepts
+- [[Constraint-Driven-Control-Mechanics]]:约束驱动控制机制——通过 3D meshes 和输入约束实现的控制物理化设计,取代自由漂浮式交互
+- [[Cockpit-Ergonomics]]:座舱人体工学——对齐自然的眼-手-头协调流动,优化长时间使用的舒适度
+- [[Spatial-Computing]]:空间计算——XR 环境的核心技术基础,支持 3D 空间中的交互设计
+- [[Motion-Sickness-Threshold]]:运动病阈值——通过固定视角和约束驱动设计将其最小化
+
+## Key Entities
+- [[XR-Cockpit-Interaction-Specialist]]:本 Agent 角色——空间座舱设计专家,专注于 XR 模拟和载具界面
+
+## Connections
+- [[XR-Interface-Architect]] ← builds_upon ← [[XR-Cockpit-Interaction-Specialist]]
+- [[XR-Immersive-Developer]] ← collaborates ← [[XR-Cockpit-Interaction-Specialist]]
+- [[Terminal-Integration-Specialist]] ← extends ← [[XR-Cockpit-Interaction-Specialist]]
+
+## Contradictions
+- 与 [[XR-Immersive-Developer]] 在运动自由度上存在设计张力:后者倾向开放空间沉浸体验,前者强调固定视角约束以降低眩晕;当前观点:座舱场景优先舒适性与真实感,通用沉浸场景可保留开放自由度
diff --git a/wiki/sources/xr-immersive-developer.md b/wiki/sources/xr-immersive-developer.md
index e84d8aa7..aaedb6ff 100644
--- a/wiki/sources/xr-immersive-developer.md
+++ b/wiki/sources/xr-immersive-developer.md
@@ -1,55 +1,55 @@
----
-title: "XR Immersive Developer Agent Personality"
-type: source
-tags: []
-date: 2026-04-20
----
-
-## Source File
-- [[Agent/agency-agents/spatial-computing/xr-immersive-developer.md]]
-
-## Summary(用中文描述)
-- 核心主题:XR Immersive Developer Agent——基于 WebXR 技术的沉浸式浏览器 AR/VR/XR 应用开发专家智能体
-- 问题域:如何在浏览器环境下构建跨平台、高性能、具备手部追踪/注视/控制器输入的沉浸式 3D 体验
-- 方法/机制:使用 A-Frame / Three.js / Babylon.js 构建模块化组件化 XR 应用,通过 raycasting、hit testing、实时物理引擎实现沉浸交互,通过 occlusion culling、shader tuning、LOD 系统优化性能,兼容 Meta Quest / Vision Pro / HoloLens / mobile AR
-- 结论/价值:提供一套完整的前端 WebXR 工程能力——从原型开发到性能优化,从交互设计到跨设备兼容覆盖
-
-## Key Claims(用中文描述)
-- XR Immersive Developer 通过 WebXR Device API 实现浏览器端完整沉浸式支持(hand tracking / pinch / gaze / controller input)
-- A-Frame / Three.js / Babylon.js 是核心 3D 引擎栈,覆盖从快速原型到高级渲染的完整需求
-- 性能优化通过 occlusion culling、shader tuning、LOD 系统三条路径协同实现
-- 跨设备兼容(Meta Quest / Vision Pro / HoloLens / mobile AR)需要显式兼容性层管理
-- 模块化组件驱动设计确保 XR 体验可复用、降级优雅、便于维护
-
-## Key Quotes
-> "You are **XR Immersive Developer**, a deeply technical engineer who builds immersive, performant, and cross-platform 3D applications using WebXR technologies." — Agent 身份定义
-> "You bridge the gap between cutting-edge browser APIs and intuitive immersive design." — 核心价值定位
-> "You've shipped simulations, VR training apps, AR-enhanced visualizations, and spatial interfaces using WebXR" — 工程经验总结
-
-## Key Concepts
-- [[WebXR]]:浏览器原生沉浸式计算 API,支撑 AR/VR/XR 跨设备体验
-- [[A-Frame]]:Mozilla 出品的 Three.js 封装框架,适合快速 WebXR 原型开发
-- [[Three.js]]:底层 WebGL 3D 渲染引擎,A-Frame 的核心依赖
-- [[Babylon.js]]:微软出品的专业级 WebXR 3D 引擎,强大的工具链和 XR 支持
-- [[Hand-Tracking]]:WebXR Hand Input Module,手部追踪交互能力
-- [[LOD-System]]:Level of Detail 渲染优化,根据距离动态调整模型精度
-- [[Occlusion-Culling]]:遮挡剔除性能优化,不渲染被遮挡的物体
-
-## Key Entities
-- [[Meta Quest]]:Facebook/Meta 的 VR 头显,WebXR 主要目标平台之一
-- [[Vision Pro]]:Apple 空间计算设备,WebXR 重要目标平台
-- [[HoloLens]]:Microsoft 的 AR 头显,WebXR 兼容设备
-- [[Mobile AR]]:移动端增强现实(ARKit/ARCore),跨平台 WebXR 目标
-
-## Connections
-- [[XR-Interface-Architect]] ← depends_on ← [[XR-Immersive-Developer]](前者依赖后者的沉浸式渲染和交互能力)
-- [[XR-Cockpit-Interaction-Specialist]] ← shares_domain ← [[XR-Immersive-Developer]](同属 Spatial Computing 部门)
-- [[macOS-Spatial-Metal-Engineer]] ← complements ← [[XR-Immersive-Developer]](前者负责平台底层,后者负责浏览器层)
-- [[visionOS-Spatial-Engineer]] ← complements ← [[XR-Immersive-Developer]](前者专注文果空间计算平台,后者专注浏览器跨平台)
-
-## Contradictions
-- 与 [[XR-Cockpit-Interaction-Specialist]] 冲突:
- - 冲突点:运动自由度设计哲学
- - 当前观点(XR-Immersive-Developer):倾向开放空间沉浸体验,最大化运动自由度
- - 对方观点(XR-Cockpit-Interaction-Specialist):强调固定视角约束(constraint-driven control mechanics)以降低运动病阈值
- - 说明:两者代表 XR 交互设计的两种范式——沉浸派 vs 安全派,在不同场景下各有优势
+---
+title: "XR Immersive Developer Agent Personality"
+type: source
+tags: []
+date: 2026-04-20
+---
+
+## Source File
+- [[raw/Agent/agency-agents/spatial-computing/xr-immersive-developer.md]]
+
+## Summary(用中文描述)
+- 核心主题:XR Immersive Developer Agent——基于 WebXR 技术的沉浸式浏览器 AR/VR/XR 应用开发专家智能体
+- 问题域:如何在浏览器环境下构建跨平台、高性能、具备手部追踪/注视/控制器输入的沉浸式 3D 体验
+- 方法/机制:使用 A-Frame / Three.js / Babylon.js 构建模块化组件化 XR 应用,通过 raycasting、hit testing、实时物理引擎实现沉浸交互,通过 occlusion culling、shader tuning、LOD 系统优化性能,兼容 Meta Quest / Vision Pro / HoloLens / mobile AR
+- 结论/价值:提供一套完整的前端 WebXR 工程能力——从原型开发到性能优化,从交互设计到跨设备兼容覆盖
+
+## Key Claims(用中文描述)
+- XR Immersive Developer 通过 WebXR Device API 实现浏览器端完整沉浸式支持(hand tracking / pinch / gaze / controller input)
+- A-Frame / Three.js / Babylon.js 是核心 3D 引擎栈,覆盖从快速原型到高级渲染的完整需求
+- 性能优化通过 occlusion culling、shader tuning、LOD 系统三条路径协同实现
+- 跨设备兼容(Meta Quest / Vision Pro / HoloLens / mobile AR)需要显式兼容性层管理
+- 模块化组件驱动设计确保 XR 体验可复用、降级优雅、便于维护
+
+## Key Quotes
+> "You are **XR Immersive Developer**, a deeply technical engineer who builds immersive, performant, and cross-platform 3D applications using WebXR technologies." — Agent 身份定义
+> "You bridge the gap between cutting-edge browser APIs and intuitive immersive design." — 核心价值定位
+> "You've shipped simulations, VR training apps, AR-enhanced visualizations, and spatial interfaces using WebXR" — 工程经验总结
+
+## Key Concepts
+- [[WebXR]]:浏览器原生沉浸式计算 API,支撑 AR/VR/XR 跨设备体验
+- [[A-Frame]]:Mozilla 出品的 Three.js 封装框架,适合快速 WebXR 原型开发
+- [[Three.js]]:底层 WebGL 3D 渲染引擎,A-Frame 的核心依赖
+- [[Babylon.js]]:微软出品的专业级 WebXR 3D 引擎,强大的工具链和 XR 支持
+- [[Hand-Tracking]]:WebXR Hand Input Module,手部追踪交互能力
+- [[LOD-System]]:Level of Detail 渲染优化,根据距离动态调整模型精度
+- [[Occlusion-Culling]]:遮挡剔除性能优化,不渲染被遮挡的物体
+
+## Key Entities
+- [[Meta Quest]]:Facebook/Meta 的 VR 头显,WebXR 主要目标平台之一
+- [[Vision Pro]]:Apple 空间计算设备,WebXR 重要目标平台
+- [[HoloLens]]:Microsoft 的 AR 头显,WebXR 兼容设备
+- [[Mobile AR]]:移动端增强现实(ARKit/ARCore),跨平台 WebXR 目标
+
+## Connections
+- [[XR-Interface-Architect]] ← depends_on ← [[XR-Immersive-Developer]](前者依赖后者的沉浸式渲染和交互能力)
+- [[XR-Cockpit-Interaction-Specialist]] ← shares_domain ← [[XR-Immersive-Developer]](同属 Spatial Computing 部门)
+- [[macOS-Spatial-Metal-Engineer]] ← complements ← [[XR-Immersive-Developer]](前者负责平台底层,后者负责浏览器层)
+- [[visionOS-Spatial-Engineer]] ← complements ← [[XR-Immersive-Developer]](前者专注文果空间计算平台,后者专注浏览器跨平台)
+
+## Contradictions
+- 与 [[XR-Cockpit-Interaction-Specialist]] 冲突:
+ - 冲突点:运动自由度设计哲学
+ - 当前观点(XR-Immersive-Developer):倾向开放空间沉浸体验,最大化运动自由度
+ - 对方观点(XR-Cockpit-Interaction-Specialist):强调固定视角约束(constraint-driven control mechanics)以降低运动病阈值
+ - 说明:两者代表 XR 交互设计的两种范式——沉浸派 vs 安全派,在不同场景下各有优势
diff --git a/wiki/sources/youtube-content-pipeline.md b/wiki/sources/youtube-content-pipeline.md
index 019eb970..e10370b0 100644
--- a/wiki/sources/youtube-content-pipeline.md
+++ b/wiki/sources/youtube-content-pipeline.md
@@ -1,57 +1,57 @@
----
-title: "YouTube Content Pipeline"
-type: source
-tags: [youtube, content-automation, openclaw, cron-job, semantic-dedup]
-date: 2026-04-22
----
-
-## Source File
-- [[Agent/usecases/youtube-content-pipeline]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 驱动的 YouTube 内容发现与选题自动化流水线
-- 问题域:每日 YouTube 创作者面临的信息过载、选题重复、趋势追踪困难等问题
-- 方法/机制:定时 Cron Job + Web/X 搜索 + YouTube Analytics 查重 + SQLite 向量相似度去重 + Telegram 选题推送 + Slack 链接自动研究
-- 结论/价值:实现选题发现、查重、推送的全链路自动化,创作者只需从 Telegram 选题即可
-
-## Key Claims(用中文描述)
-- Hourly Cron Job 扫描 Web + X/Twitter 的突发 AI 新闻,自动向 Telegram 推送选题
-- 维护 90 天 YouTube 视频目录(含播放量和主题分析),避免重复覆盖同类选题
-- SQLite 数据库存储所有选题及向量嵌入,通过语义相似度实现选题去重
-- Slack 分享链接时,OpenClaw 自动研究主题、搜索 X 相关帖子、查询知识库,并创建带完整大纲的 Asana 任务卡
-
-## Key Quotes
-> "Finding fresh, timely video ideas across the web and X/Twitter is time-consuming. Tracking what you've already covered prevents duplicates and helps you stay ahead of trends." — 核心痛点阐述
-> "Stores all pitches in a SQLite database with vector embeddings for semantic dedup (so you never get pitched the same idea twice)" — 技术选型亮点
-
-## Key Concepts
-- [[Semantic-Deduplication]]:通过向量嵌入(embedding)计算选题语义相似度,防止重复选题
-- [[Cron-Job]]:定时任务驱动,每小时自动执行内容发现流程
-- [[Knowledge-Base-RAG]]:检索增强生成,查询知识库辅助选题研究
-- [[Content-Automation]]:内容创作全流程自动化,从发现到任务创建
-- [[Vector-Embedding]]:将文本选题转为向量,实现语义层面精确去重
-
-## Key Entities
-- [[OpenClaw]]:核心 Agent 框架,编排所有工具(Web 搜索、X 搜索、知识库查询、Asana 集成)
-- [[YouTube-Analytics]]:通过 `gog` CLI 获取频道播放量和视频主题分析
-- [[Asana]]:项目管理工具,用于创建选题任务卡
-- [[Telegram]]:选题推送渠道,通过专属 Topic 接收 AI 推送的选题
-- [[SQLite]]:选题数据库,存储 timestamp/topic/embedding/sources
-- [[X-Twitter]]:选题来源之一,搜索突发 AI 新闻和社区讨论
-
-## Connections
-- [[Daily-YouTube-Digest]] ← extends ← [[YouTube-Content-Pipeline]]
- - Daily YouTube Digest 侧重于已有订阅频道的更新监控,本流水线侧重于全网突发新闻和趋势的主动发现
-- [[Content-Factory]] ← shares_pattern ← [[YouTube-Content-Pipeline]]
- - 同属多工具编排的自动化内容流水线,均使用子 Agent 并行执行模式
-- [[Custom-Morning-Brief]] ← shares_pattern ← [[YouTube-Content-Pipeline]]
- - 同属 Cron Job + Telegram 推送模式,但前者侧重综合信息简报,后者垂直于视频选题
-
-## Contradictions
-- 无已知冲突
-
-## Setup Instructions Summary
-1. 配置 Telegram Topic 作为选题接收渠道
-2. 安装 knowledge-base skill 和 x-research skill
-3. 创建 SQLite pitches 表(含 id/timestamp/topic/embedding/sources)
-4. 向 OpenClaw 发送 prompt 指令,激活每小时 Cron Job
+---
+title: "YouTube Content Pipeline"
+type: source
+tags: [youtube, content-automation, openclaw, cron-job, semantic-dedup]
+date: 2026-04-22
+---
+
+## Source File
+- [[raw/Agent/usecases/youtube-content-pipeline.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 驱动的 YouTube 内容发现与选题自动化流水线
+- 问题域:每日 YouTube 创作者面临的信息过载、选题重复、趋势追踪困难等问题
+- 方法/机制:定时 Cron Job + Web/X 搜索 + YouTube Analytics 查重 + SQLite 向量相似度去重 + Telegram 选题推送 + Slack 链接自动研究
+- 结论/价值:实现选题发现、查重、推送的全链路自动化,创作者只需从 Telegram 选题即可
+
+## Key Claims(用中文描述)
+- Hourly Cron Job 扫描 Web + X/Twitter 的突发 AI 新闻,自动向 Telegram 推送选题
+- 维护 90 天 YouTube 视频目录(含播放量和主题分析),避免重复覆盖同类选题
+- SQLite 数据库存储所有选题及向量嵌入,通过语义相似度实现选题去重
+- Slack 分享链接时,OpenClaw 自动研究主题、搜索 X 相关帖子、查询知识库,并创建带完整大纲的 Asana 任务卡
+
+## Key Quotes
+> "Finding fresh, timely video ideas across the web and X/Twitter is time-consuming. Tracking what you've already covered prevents duplicates and helps you stay ahead of trends." — 核心痛点阐述
+> "Stores all pitches in a SQLite database with vector embeddings for semantic dedup (so you never get pitched the same idea twice)" — 技术选型亮点
+
+## Key Concepts
+- [[Semantic-Deduplication]]:通过向量嵌入(embedding)计算选题语义相似度,防止重复选题
+- [[Cron-Job]]:定时任务驱动,每小时自动执行内容发现流程
+- [[Knowledge-Base-RAG]]:检索增强生成,查询知识库辅助选题研究
+- [[Content-Automation]]:内容创作全流程自动化,从发现到任务创建
+- [[Vector-Embedding]]:将文本选题转为向量,实现语义层面精确去重
+
+## Key Entities
+- [[OpenClaw]]:核心 Agent 框架,编排所有工具(Web 搜索、X 搜索、知识库查询、Asana 集成)
+- [[YouTube-Analytics]]:通过 `gog` CLI 获取频道播放量和视频主题分析
+- [[Asana]]:项目管理工具,用于创建选题任务卡
+- [[Telegram]]:选题推送渠道,通过专属 Topic 接收 AI 推送的选题
+- [[SQLite]]:选题数据库,存储 timestamp/topic/embedding/sources
+- [[X-Twitter]]:选题来源之一,搜索突发 AI 新闻和社区讨论
+
+## Connections
+- [[Daily-YouTube-Digest]] ← extends ← [[YouTube-Content-Pipeline]]
+ - Daily YouTube Digest 侧重于已有订阅频道的更新监控,本流水线侧重于全网突发新闻和趋势的主动发现
+- [[Content-Factory]] ← shares_pattern ← [[YouTube-Content-Pipeline]]
+ - 同属多工具编排的自动化内容流水线,均使用子 Agent 并行执行模式
+- [[Custom-Morning-Brief]] ← shares_pattern ← [[YouTube-Content-Pipeline]]
+ - 同属 Cron Job + Telegram 推送模式,但前者侧重综合信息简报,后者垂直于视频选题
+
+## Contradictions
+- 无已知冲突
+
+## Setup Instructions Summary
+1. 配置 Telegram Topic 作为选题接收渠道
+2. 安装 knowledge-base skill 和 x-research skill
+3. 创建 SQLite pitches 表(含 id/timestamp/topic/embedding/sources)
+4. 向 OpenClaw 发送 prompt 指令,激活每小时 Cron Job
diff --git a/wiki/sources/zk-steward.md b/wiki/sources/zk-steward.md
index 00a00e1c..1b1e80f0 100644
--- a/wiki/sources/zk-steward.md
+++ b/wiki/sources/zk-steward.md
@@ -1,64 +1,64 @@
----
-title: "ZK Steward Agent"
-type: source
-tags: [AI-agent, knowledge-management, zettelkasten, luhmann, productivity]
-date: 2026-04-25
----
-
-## Source File
-- [[Agent/agency-agents/specialized/zk-steward.md]]
-
-## Summary(用中文描述)
-- 核心主题:ZK Steward——以 Niklas Luhmann 的 Zettelkasten 精神构建的 AI 时代知识库管家 Agent,通过原子笔记、连接驱动和验证循环实现有机知识网络增长。
-- 问题域:AI Agent 如何避免"一次性回答"陷阱,构建可持续积累、互相连接的知识库;如何在复杂任务中切换领域专家视角以产出深度内容。
-- 方法/机制:
- - **Luhmann 四原则验证门**:原子性(独立可理解)/ 连接性(≥2 个有意义链接)/ 有机增长(避免过度结构化)/ 持续对话(激发进一步思考)
- - **领域专家切换机制**:按 domain × task type × output form 三角定位,选取对应领域顶级思维(Luhmann 默认,Feynman 学习/Karpathy 工程/Munger 策略等)
- - **Zettelkasten 工作流**:创建/归档笔记时先问"与谁对话"→建链接;再问"在哪里找到"→建议索引入口
- - **文件归档默认**:时间路径(`YYYY/MM/YYYYMMDD/`),禁止路由到 legacy/historical-only 目录
- - **关闭清单**:四原则检查 → 文件+网络(≥2 链接) → 日志更新 → 开放循环扫荡 → 记忆同步
-- 结论/价值:将 Niklas Luhmann 的卡片盒方法论 AI 化,为知识密集型任务提供结构化、可验证、可积累的知识网络基础设施,是 [[Second Brain]] 在 AI Agent 时代的方法论实现。
-
-## Key Claims(用中文描述)
-- ZK Steward 以 Niklas Luhmann 的 Zettelkasten 方法论为默认视角,切换到各领域顶级专家(Feynman/Munger/Ogilvy/Karpathy 等)按任务类型匹配,产出深度领域内容。
-- 每个回复必须声明专家视角 + 称呼用户名,拒绝泛泛"专家"或空头方法论引用。
-- 笔记四原则验证门(原子性/连接性/有机增长/持续对话)强制笔记可独立理解且互连成网。
-- 新笔记归档时自动触发链接提议(Link-proposer):候选链接 + 关键词 + Gegenrede 反诘问题。
-- 任务关闭必须完成: Luhmann 四原则检查 → 文件路径+≥2 链接 → 日志更新 → 开放循环扫荡 → 记忆同步。
-- 禁止:跳过验证、创建零链接笔记、路由到 legacy-only 目录。
-
-## Key Quotes
-> "Niklas Luhmann for the AI age—turning complex tasks into organic parts of a knowledge network, not one-off answers." — ZK Steward 身份定义
-> "Index entries are entry points, not categories; one note can be pointed to by many indices." — Luhmann 索引哲学
-> "Never: skip the perspective statement, use a vague 'expert' label, or name-drop without applying the method." — 关键规则
-
-## Key Concepts
-- [[Zettelkasten]]:德国社会学家 Niklas Luhmann 发明的手动卡片笔记系统——每条笔记原子化、拥有唯一 ID、与至少一条其他笔记相连,通过积累形成有机知识网络。ZK Steward 将其 AI 化,以时间路径归档、索引入口导向、多链接驱动为核心理念。
-- [[Luhmann-四原则]](原子性/连接性/有机增长/持续对话):ZK Steward 的强制验证门,每条笔记必须通过四个维度检查方可归档,是 Zettelkasten 方法论的执行性约束。
-- [[Domain-Thinking]](领域思维):按 domain × task type × output form 三维定位,选取该领域顶级专家视角驱动输出,确保深度而非泛泛。
-- [[Gegenrede]](反诘):链接提议后提出一个跨学科反问,激发笔记间的辩证对话,防止同质化链接。
-- [[Atomic-Note]](原子笔记):可独立理解、最小粒度的知识单元,是 Zettelkasten 的基本构建块。
-- [[Link-Proposer]](链接提议器):新笔记归档时自动运行的流程——输出候选链接 + 关键词 + Gegenrede 反诘问题。
-- [[Daily-Log]](每日日志):`memory/YYYY-MM-DD.md` 格式,记录 Intent / Changes / Open loops,维持知识网络的时效性。
-
-## Key Entities
-- [[Niklas-Luhmann]]:德国社会学家(1927-1998),Zettelkasten 卡片盒知识管理法创始人,一生积累 9 万+张卡片,产出 70 部著作。ZK Steward 以其为默认视角。
-- [[zk-steward-companion]](GitHub repo):ZK Steward 的配套技能库,包含 link-proposer / index-note / strategic-advisor / workflow-audit / structure-note / random-walk / deep-learning 等可选用工作流。
-- **Karpathy**:AI/工程领域专家,按 domain-thinking 映射表对应 Tech/engineering 领域。
-- **Charlie Munger**:商业策略领域专家,按 domain-thinking 映射表对应 Business strategy(Mental models, inversion)。
-- **Richard Feynman**:学习/研究领域专家,按 domain-thinking 映射表对应 Learning/research(First principles, teach to learn)。
-- **David Ogilvy**:品牌营销领域专家,对应 Brand marketing(Long copy, brand persona)。
-
-## Connections
-- [[zk-steward]] ← implements ← [[Zettelkasten]]
-- [[zk-steward]] ← applies ← [[Niklas-Luhmann]]
-- [[zk-steward]] ← uses ← [[Luhmann-四原则]]
-- [[zk-steward]] ← triggers ← [[Link-Proposer]]
-- [[zk-steward]] ← follows ← [[Domain-Thinking]]
-- [[zk-steward]] ← part_of ← [[zk-steward-companion]]
-- [[Second-Brain]] ← related_to ← [[zk-steward]](两者同属外部认知能力建设,Second Brain 为通用框架,ZK Steward 为具体 Agent 实现)
-- [[养虾日记3]] ← mentions ← [[zk-steward]]("融合了 Karpathy 的 LLM Wiki 理念"即指 zk-steward 类型的 Zettelkasten 工作流)
-
-## Contradictions
-- 与 [[Second-Brain]] 关系:两者均强调外部知识积累,但 Second Brain 侧重捕获与检索的零摩擦("像发短信一样简单"),ZK Steward 侧重强制结构化验证( Luhmann 四原则)和多专家视角切换。两者互补,Second Brain 作为捕获层,ZK Steward 作为结构化处理层。
-- 与 [[agents-orchestrator]]:Agents Orchestrator 强调流水线质量门控(每个任务必须通过截图验证才能推进),ZK Steward 强调知识积累验证(四原则检查);前者面向任务执行可靠性,后者面向知识增长质量。
+---
+title: "ZK Steward Agent"
+type: source
+tags: [AI-agent, knowledge-management, zettelkasten, luhmann, productivity]
+date: 2026-04-25
+---
+
+## Source File
+- [[raw/Agent/agency-agents/specialized/zk-steward.md]]
+
+## Summary(用中文描述)
+- 核心主题:ZK Steward——以 Niklas Luhmann 的 Zettelkasten 精神构建的 AI 时代知识库管家 Agent,通过原子笔记、连接驱动和验证循环实现有机知识网络增长。
+- 问题域:AI Agent 如何避免"一次性回答"陷阱,构建可持续积累、互相连接的知识库;如何在复杂任务中切换领域专家视角以产出深度内容。
+- 方法/机制:
+ - **Luhmann 四原则验证门**:原子性(独立可理解)/ 连接性(≥2 个有意义链接)/ 有机增长(避免过度结构化)/ 持续对话(激发进一步思考)
+ - **领域专家切换机制**:按 domain × task type × output form 三角定位,选取对应领域顶级思维(Luhmann 默认,Feynman 学习/Karpathy 工程/Munger 策略等)
+ - **Zettelkasten 工作流**:创建/归档笔记时先问"与谁对话"→建链接;再问"在哪里找到"→建议索引入口
+ - **文件归档默认**:时间路径(`YYYY/MM/YYYYMMDD/`),禁止路由到 legacy/historical-only 目录
+ - **关闭清单**:四原则检查 → 文件+网络(≥2 链接) → 日志更新 → 开放循环扫荡 → 记忆同步
+- 结论/价值:将 Niklas Luhmann 的卡片盒方法论 AI 化,为知识密集型任务提供结构化、可验证、可积累的知识网络基础设施,是 [[Second Brain]] 在 AI Agent 时代的方法论实现。
+
+## Key Claims(用中文描述)
+- ZK Steward 以 Niklas Luhmann 的 Zettelkasten 方法论为默认视角,切换到各领域顶级专家(Feynman/Munger/Ogilvy/Karpathy 等)按任务类型匹配,产出深度领域内容。
+- 每个回复必须声明专家视角 + 称呼用户名,拒绝泛泛"专家"或空头方法论引用。
+- 笔记四原则验证门(原子性/连接性/有机增长/持续对话)强制笔记可独立理解且互连成网。
+- 新笔记归档时自动触发链接提议(Link-proposer):候选链接 + 关键词 + Gegenrede 反诘问题。
+- 任务关闭必须完成: Luhmann 四原则检查 → 文件路径+≥2 链接 → 日志更新 → 开放循环扫荡 → 记忆同步。
+- 禁止:跳过验证、创建零链接笔记、路由到 legacy-only 目录。
+
+## Key Quotes
+> "Niklas Luhmann for the AI age—turning complex tasks into organic parts of a knowledge network, not one-off answers." — ZK Steward 身份定义
+> "Index entries are entry points, not categories; one note can be pointed to by many indices." — Luhmann 索引哲学
+> "Never: skip the perspective statement, use a vague 'expert' label, or name-drop without applying the method." — 关键规则
+
+## Key Concepts
+- [[Zettelkasten]]:德国社会学家 Niklas Luhmann 发明的手动卡片笔记系统——每条笔记原子化、拥有唯一 ID、与至少一条其他笔记相连,通过积累形成有机知识网络。ZK Steward 将其 AI 化,以时间路径归档、索引入口导向、多链接驱动为核心理念。
+- [[Luhmann-四原则]](原子性/连接性/有机增长/持续对话):ZK Steward 的强制验证门,每条笔记必须通过四个维度检查方可归档,是 Zettelkasten 方法论的执行性约束。
+- [[Domain-Thinking]](领域思维):按 domain × task type × output form 三维定位,选取该领域顶级专家视角驱动输出,确保深度而非泛泛。
+- [[Gegenrede]](反诘):链接提议后提出一个跨学科反问,激发笔记间的辩证对话,防止同质化链接。
+- [[Atomic-Note]](原子笔记):可独立理解、最小粒度的知识单元,是 Zettelkasten 的基本构建块。
+- [[Link-Proposer]](链接提议器):新笔记归档时自动运行的流程——输出候选链接 + 关键词 + Gegenrede 反诘问题。
+- [[Daily-Log]](每日日志):`memory/YYYY-MM-DD.md` 格式,记录 Intent / Changes / Open loops,维持知识网络的时效性。
+
+## Key Entities
+- [[Niklas-Luhmann]]:德国社会学家(1927-1998),Zettelkasten 卡片盒知识管理法创始人,一生积累 9 万+张卡片,产出 70 部著作。ZK Steward 以其为默认视角。
+- [[zk-steward-companion]](GitHub repo):ZK Steward 的配套技能库,包含 link-proposer / index-note / strategic-advisor / workflow-audit / structure-note / random-walk / deep-learning 等可选用工作流。
+- **Karpathy**:AI/工程领域专家,按 domain-thinking 映射表对应 Tech/engineering 领域。
+- **Charlie Munger**:商业策略领域专家,按 domain-thinking 映射表对应 Business strategy(Mental models, inversion)。
+- **Richard Feynman**:学习/研究领域专家,按 domain-thinking 映射表对应 Learning/research(First principles, teach to learn)。
+- **David Ogilvy**:品牌营销领域专家,对应 Brand marketing(Long copy, brand persona)。
+
+## Connections
+- [[zk-steward]] ← implements ← [[Zettelkasten]]
+- [[zk-steward]] ← applies ← [[Niklas-Luhmann]]
+- [[zk-steward]] ← uses ← [[Luhmann-四原则]]
+- [[zk-steward]] ← triggers ← [[Link-Proposer]]
+- [[zk-steward]] ← follows ← [[Domain-Thinking]]
+- [[zk-steward]] ← part_of ← [[zk-steward-companion]]
+- [[Second-Brain]] ← related_to ← [[zk-steward]](两者同属外部认知能力建设,Second Brain 为通用框架,ZK Steward 为具体 Agent 实现)
+- [[养虾日记3]] ← mentions ← [[zk-steward]]("融合了 Karpathy 的 LLM Wiki 理念"即指 zk-steward 类型的 Zettelkasten 工作流)
+
+## Contradictions
+- 与 [[Second-Brain]] 关系:两者均强调外部知识积累,但 Second Brain 侧重捕获与检索的零摩擦("像发短信一样简单"),ZK Steward 侧重强制结构化验证( Luhmann 四原则)和多专家视角切换。两者互补,Second Brain 作为捕获层,ZK Steward 作为结构化处理层。
+- 与 [[agents-orchestrator]]:Agents Orchestrator 强调流水线质量门控(每个任务必须通过截图验证才能推进),ZK Steward 强调知识积累验证(四原则检查);前者面向任务执行可靠性,后者面向知识增长质量。
diff --git a/wiki/sources/万字保姆级教程-90天跑通一人公司模式-2026-03-29.md b/wiki/sources/万字保姆级教程-90天跑通一人公司模式-2026-03-29.md
index 360fb801..6b7fe7e3 100644
--- a/wiki/sources/万字保姆级教程-90天跑通一人公司模式-2026-03-29.md
+++ b/wiki/sources/万字保姆级教程-90天跑通一人公司模式-2026-03-29.md
@@ -6,7 +6,7 @@ date: 2026-03-29
---
## Source File
-- [[Agent/万字保姆级教程-90天跑通一人公司模式-2026-03-29]]
+- [[raw/Agent/万字保姆级教程-90天跑通一人公司模式-2026-03-29.md]]
## Summary(用中文描述)
- 核心主题:如何用 90 天跑通"一人公司"模式——用最小的杠杆撬动最大的价值
diff --git a/wiki/sources/万字讲透openclaw-workspace深度解析-2026-03-21.md b/wiki/sources/万字讲透openclaw-workspace深度解析-2026-03-21.md
index fcc60bbe..0c045988 100644
--- a/wiki/sources/万字讲透openclaw-workspace深度解析-2026-03-21.md
+++ b/wiki/sources/万字讲透openclaw-workspace深度解析-2026-03-21.md
@@ -6,7 +6,7 @@ date: 2026-03-21
---
## Source File
-- [[Agent/万字讲透OpenClaw-Workspace深度解析-2026-03-21.md]]
+- [[raw/Agent/万字讲透OpenClaw-Workspace深度解析-2026-03-21.md]]
## Summary(用中文描述)
- 核心主题:OpenClaw workspace 文件体系详解,从"能用"到"真好用"的分水岭
diff --git a/wiki/sources/不会gemini的产品经理真的要被淘汰了-附保姆级prd生成指南.md b/wiki/sources/不会gemini的产品经理真的要被淘汰了-附保姆级prd生成指南.md
index e6ac7d0e..96352118 100644
--- a/wiki/sources/不会gemini的产品经理真的要被淘汰了-附保姆级prd生成指南.md
+++ b/wiki/sources/不会gemini的产品经理真的要被淘汰了-附保姆级prd生成指南.md
@@ -6,7 +6,7 @@ date: 2025-12-18
---
## Source File
-- [[AI/不会Gemini的产品经理真的要被淘汰了 附保姆级PRD生成指南.md]]
+- [[raw/AI/不会Gemini的产品经理真的要被淘汰了 附保姆级PRD生成指南.md]]
## Summary(用中文描述)
- 核心主题:产品经理如何利用 Gemini 等大模型工具提升工作效率(缩短 90%+ 工作时间),以及 AI 时代产品经理的能力结构重塑
diff --git a/wiki/sources/不谈技术-普通人该怎么在ai时代赚钱.md b/wiki/sources/不谈技术-普通人该怎么在ai时代赚钱.md
index 629819bd..075884f3 100644
--- a/wiki/sources/不谈技术-普通人该怎么在ai时代赚钱.md
+++ b/wiki/sources/不谈技术-普通人该怎么在ai时代赚钱.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[raw/微信公众号/不谈技术:普通人该怎么在AI时代赚钱?]]
+- [[raw/微信公众号/不谈技术:普通人该怎么在AI时代赚钱?.md]]
## Summary(用中文描述)
- 核心主题:AI时代普通人的财富创造策略——打破「学AI技能谋生」的思维定式
diff --git a/wiki/sources/二创视频必不可少-2025年最热门ai工具推荐合集-ai配音-声音克隆.md b/wiki/sources/二创视频必不可少-2025年最热门ai工具推荐合集-ai配音-声音克隆.md
index 261088c4..0883c9aa 100644
--- a/wiki/sources/二创视频必不可少-2025年最热门ai工具推荐合集-ai配音-声音克隆.md
+++ b/wiki/sources/二创视频必不可少-2025年最热门ai工具推荐合集-ai配音-声音克隆.md
@@ -6,7 +6,7 @@ date: 2025-12-18
---
## Source File
-- [[AI/二创视频必不可少!2025年最热门AI工具推荐合集-AI配音、声音克隆]]
+- [[raw/AI/二创视频必不可少!2025年最热门AI工具推荐合集-AI配音、声音克隆.md]]
## Summary(用中文描述)
- 核心主题:2025年主流AI配音及声音克隆工具推荐合集,面向内容创作者(二创视频制作者)
diff --git a/wiki/sources/使用claude自动生成n8n工作流的实操教程.md b/wiki/sources/使用claude自动生成n8n工作流的实操教程.md
index 8cc20142..18727d6f 100644
--- a/wiki/sources/使用claude自动生成n8n工作流的实操教程.md
+++ b/wiki/sources/使用claude自动生成n8n工作流的实操教程.md
@@ -6,7 +6,7 @@ date: 2026-04-26
---
## Source File
-- [[Agent/使用Claude自动生成N8N工作流的实操教程.md]]
+- [[raw/Agent/使用Claude自动生成N8N工作流的实操教程.md]]
## Summary(用中文描述)
- 核心主题:利用 Claude AI 助手结合 n8n-mcp 项目,通过自然语言自动生成 N8N 工作流,降低新手入门门槛
diff --git a/wiki/sources/做tk跨境思路不对努力白费.md b/wiki/sources/做tk跨境思路不对努力白费.md
index fdb56c95..6bf7acaf 100644
--- a/wiki/sources/做tk跨境思路不对努力白费.md
+++ b/wiki/sources/做tk跨境思路不对努力白费.md
@@ -1,45 +1,45 @@
----
-title: "做TK跨境思路不对努力白费"
-type: source
-tags: [tiktok, 跨境电商]
-date: 2026-04-18
----
-
-## Source File
-- [[跨境电商/做TK跨境思路不对努力白费]]
-
-## Summary(用中文描述)
-- 核心主题:TikTok 跨境电商全流程实战指南,从市场选择到团队建设的完整攻略
-- 问题域:个人或小团队如何从零开始在 TikTok 平台开展跨境电商业务
-- 方法/机制:市场选择 → 账号准备 → 选品策略 → 店铺运营 → 流量获取 → 仓储物流 → 团队建设
-- 结论/价值:提供了一套完整的 TikTok 跨境电商执行框架,强调"思路正确"是成功的前提
-
-## Key Claims(用中文描述)
-- 跨境卖家应优先选择发达国家市场(如美区、日本),避免竞争激烈且利润低的东南亚市场
-- 选品是跨境电商的核心竞争力,应使用数据软件分析市场环境,确定单一垂直类目
-- 店铺运营需要持续监控流量数据,及时下架表现不佳的商品,优化商品列表
-- 短视频营销和达人合作是获取流量、提升转化的关键手段
-- 随着业务规模扩大,应招聘合适人才分担日常任务,确保业务持续增长
-
-## Key Quotes
-> "市场选择:优先考虑发达国家市场,如美区和日本,避免东南亚。" — 强调市场定位的重要性
-> "选品策略:使用数据软件分析市场环境,确保选择适合的单一类目。" — 聚焦垂直领域
-> "团队协作:成功的电商运营需要团队的配合与沟通,分工明确才能高效运作。" — 组织能力
-
-## Key Concepts
-- [[跨境电商]]:通过互联网平台进行跨国商品交易的商业模式
-- [[选品策略]]:通过数据分析确定适合目标市场的商品类目
-- [[TikTok电商]]:基于 TikTok 平台的短视频+直播带货模式
-- [[达人营销]]:与平台 KOL 合作推广商品的营销方式
-
-## Key Entities
-- [[TikTok Shop]]:TikTok 平台的电商功能,支持短视频带货和直播带货
-- [[美区]]:美国 TikTok 市场,消费能力强,利润空间大
-- [[日本]]:发达国家市场,目标用户购买力强
-
-## Connections
-- [[电商如何选品-如何找到爆款-选品策略]] ← related_to ← [[做tk跨境思路不对努力白费]]
-- [[可自动化-可扩展-ai增强的电商数据采集与处理系统]] ← related_to ← [[做tk跨境思路不对努力白费]]
-
-## Contradictions
-- 暂无已知冲突内容
+---
+title: "做TK跨境思路不对努力白费"
+type: source
+tags: [tiktok, 跨境电商]
+date: 2026-04-18
+---
+
+## Source File
+- [[raw/跨境电商/做TK跨境思路不对努力白费.md]]
+
+## Summary(用中文描述)
+- 核心主题:TikTok 跨境电商全流程实战指南,从市场选择到团队建设的完整攻略
+- 问题域:个人或小团队如何从零开始在 TikTok 平台开展跨境电商业务
+- 方法/机制:市场选择 → 账号准备 → 选品策略 → 店铺运营 → 流量获取 → 仓储物流 → 团队建设
+- 结论/价值:提供了一套完整的 TikTok 跨境电商执行框架,强调"思路正确"是成功的前提
+
+## Key Claims(用中文描述)
+- 跨境卖家应优先选择发达国家市场(如美区、日本),避免竞争激烈且利润低的东南亚市场
+- 选品是跨境电商的核心竞争力,应使用数据软件分析市场环境,确定单一垂直类目
+- 店铺运营需要持续监控流量数据,及时下架表现不佳的商品,优化商品列表
+- 短视频营销和达人合作是获取流量、提升转化的关键手段
+- 随着业务规模扩大,应招聘合适人才分担日常任务,确保业务持续增长
+
+## Key Quotes
+> "市场选择:优先考虑发达国家市场,如美区和日本,避免东南亚。" — 强调市场定位的重要性
+> "选品策略:使用数据软件分析市场环境,确保选择适合的单一类目。" — 聚焦垂直领域
+> "团队协作:成功的电商运营需要团队的配合与沟通,分工明确才能高效运作。" — 组织能力
+
+## Key Concepts
+- [[跨境电商]]:通过互联网平台进行跨国商品交易的商业模式
+- [[选品策略]]:通过数据分析确定适合目标市场的商品类目
+- [[TikTok电商]]:基于 TikTok 平台的短视频+直播带货模式
+- [[达人营销]]:与平台 KOL 合作推广商品的营销方式
+
+## Key Entities
+- [[TikTok Shop]]:TikTok 平台的电商功能,支持短视频带货和直播带货
+- [[美区]]:美国 TikTok 市场,消费能力强,利润空间大
+- [[日本]]:发达国家市场,目标用户购买力强
+
+## Connections
+- [[电商如何选品-如何找到爆款-选品策略]] ← related_to ← [[做tk跨境思路不对努力白费]]
+- [[可自动化-可扩展-ai增强的电商数据采集与处理系统]] ← related_to ← [[做tk跨境思路不对努力白费]]
+
+## Contradictions
+- 暂无已知冲突内容
diff --git a/wiki/sources/全网最全-nano-banana-2-使用指南-2025年12月更新-1.md b/wiki/sources/全网最全-nano-banana-2-使用指南-2025年12月更新-1.md
index c8a9a75b..344ed189 100644
--- a/wiki/sources/全网最全-nano-banana-2-使用指南-2025年12月更新-1.md
+++ b/wiki/sources/全网最全-nano-banana-2-使用指南-2025年12月更新-1.md
@@ -1,49 +1,54 @@
----
-title: "全网最全!Nano Banana 2 使用指南(2025年12月更新)"
-type: source
-tags: [AI图像生成, Gemini, NanoBanana, DeepSider]
-date: 2025-12-01
----
-
-## Source File
-- [[AI/全网最全!Nano Banana 2 使用指南(2025年12月更新) 1.md]]
-
-## Summary(用中文描述)
-- 核心主题:Google Nano Banana 2(Gemini 3 Pro Image)AI 绘图模型的国内使用指南
-- 问题域:国内用户如何便捷访问和使用 Google Gemini 3 系列图像生成模型
-- 方法/机制:通过 DeepSider 浏览器插件(Edge 扩展)直接访问 Nano Banana 2,无需特殊网络和海外账户
-- 结论/价值:DeepSider 是国内用户访问 Gemini 3 Pro/Nano Banana 2 等多款 AI 大模型的最便捷渠道之一
-
-## Key Claims(用中文描述)
-- Nano Banana 2 是 Google 发布的推理型图像生成模型(Gemini 3 Pro Image),正式代号为 Gemini 3 Pro Image
-- Nano Banana 2 是一款推理模型,在生成图像前会进行内部推理,直接碾压一众 AI 绘图模型
-- Nano Banana 2 具备更高的图像质量、更高的准确性、更好的多语言长文本渲染能力
-- Nano Banana 2 可输出 1K、2K、4K 分辨率图像,最多可将 14 张输入图像组合为 1 张输出图像
-- DeepSider 是一款浏览器插件,安装后国内可直接访问 Nano Banana 2 / Gemini 3.0 / GPT-5.1 等数十款 AI 大模型
-- DeepSider 专为中文用户设计,无需特殊网络,无需海外账户
-
-## Key Quotes
-> "原本以为 Nano Banana 已经够强,没想到 Nano2 的实测效果比想象中还要惊艳,直接碾压一众 AI 绘图模型!堪称火力全开!" — 文章导语
-
-> "它(Nano Banana 2)就能自动进行检索和思考,填补上所有的细节。" — Nano Banana 2 自动推理描述
-
-> "DeepSider 一个插件就能体验多款热门 AI 大模型,对国内用户来说更流畅、更方便。" — DeepSider 价值总结
-
-## Key Concepts
-- [[推理型图像生成模型]]:Nano Banana 2 在生成图像前会进行内部推理,自动补完用户提示词的深层次需求
-- [[多语言长文本渲染]]:Nano Banana 2 的核心能力之一,能够在图像中准确渲染复杂的中文界面和长文本
-- [[图像推理模型]]:与传统图像模型不同,Nano Banana 2 在生成图像前进行内部推理,而非简单的关键词匹配
-
-## Key Entities
-- [[Nano Banana 2]]:Google 发布的 AI 图像生成模型(Gemini 3 Pro Image),代号 Gemini 3 Pro Image,具备推理能力,支持 1K/2K/4K 输出和 14 张图像组合
-- [[DeepSider]]:Edge 浏览器插件(deepsider.ai),国内用户访问 Gemini 3 / Nano Banana 2 的便捷渠道,支持 GPT5/GPT4.1/Claude/Gemini 2.5 Pro/Grok/Nano Banana/Sora 2 等数十款 AI 模型
-- [[Gemini 3 Pro]]:Google Gemini 3 系列中的图像生成模型,即 Nano Banana 2 的正式代号
-
-## Connections
-- [[全网最全-nano-banana-2-使用指南-2025年12月更新-1]] ← 使用 ← [[DeepSider]]
-- [[全网最全-nano-banana-2-使用指南-2025年12月更新-1]] ← 介绍 ← [[Nano Banana 2]]
-- [[Nano Banana Pro 提示词指南]] ← 相关 ← [[全网最全-nano-banana-2-使用指南-2025年12月更新-1]](同一系列)
-- [[Nano Banana 提示词框架]] ← 相关 ← [[全网最全-nano-banana-2-使用指南-2025年12月更新-1]](同一系列)
-
-## Contradictions
-- 暂无发现与其他 Wiki 页面的明显冲突
+---
+title: "全网最全!Nano Banana 2 使用指南(2025年12月更新)"
+type: source
+tags: [AI图像生成, Gemini, NanoBanana, DeepSider]
+date: 2025-12-01
+last_updated: 2026-04-28
+---
+
+## Source File
+- [[raw/AI/全网最全!Nano Banana 2 使用指南(2025年12月更新) 1.md]]
+
+## Summary(用中文描述)
+- 核心主题:Google Nano Banana 2(Gemini 3 Pro Image)AI 绘图模型的国内使用指南
+- 问题域:国内用户如何便捷访问和使用 Google Gemini 3 系列图像生成模型
+- 方法/机制:通过 DeepSider 浏览器插件(Edge 扩展)直接访问 Nano Banana 2,无需特殊网络和海外账户;Nano Banana 2 作为推理型图像生成模型,在生成图像前会进行内部推理
+- 结论/价值:DeepSider 是国内用户访问 Gemini 3 Pro/Nano Banana 2 等多款 AI 大模型的最便捷渠道之一
+
+## Key Claims(用中文描述)
+- Nano Banana 2 是 Google 发布的推理型图像生成模型(Gemini 3 Pro Image),正式代号为 Gemini 3 Pro Image
+- Nano Banana 2 是一款推理模型,在生成图像前会进行内部推理,直接碾压一众 AI 绘图模型
+- Nano Banana 2 具备更高的图像质量、更高的准确性、更好的多语言长文本渲染能力
+- Nano Banana 2 可输出 1K、2K、4K 分辨率图像,最多可将 14 张输入图像组合为 1 张输出图像
+- DeepSider 是一款浏览器插件,安装后国内可直接访问 Nano Banana 2 / Gemini 3.0 / GPT-5.1 等数十款 AI 大模型
+- DeepSider 专为中文用户设计,无需特殊网络,无需海外账户
+- Nano Banana 2 擅长高事实准确性的创意工作、需要最新知识支持的图像创作,会自动检索和思考,填补提示词的深层次细节
+
+## Key Quotes
+> "原本以为 Nano Banana 已经够强,没想到 Nano2 的实测效果比想象中还要惊艳,直接碾压一众 AI 绘图模型!堪称火力全开!" — 文章导语
+
+> "它(Nano Banana 2)就能自动进行检索和思考,填补上所有的细节。" — Nano Banana 2 自动推理描述
+
+> "DeepSider 一个插件就能体验多款热门 AI 大模型,对国内用户来说更流畅、更方便。" — DeepSider 价值总结
+
+## Key Concepts
+- [[推理型图像生成模型]]:Nano Banana 2 在生成图像前会进行内部推理,自动补完用户提示词的深层次需求
+- [[多语言长文本渲染]]:Nano Banana 2 的核心能力之一,能够在图像中准确渲染复杂的中文界面和长文本
+- [[图像推理模型]]:与传统图像模型不同,Nano Banana 2 在生成图像前进行内部推理,而非简单的关键词匹配
+- [[图像组合融合]]:Nano Banana 2 最多可将 14 张输入图像组合为 1 张输出图像
+
+## Key Entities
+- [[Nano Banana 2]]:Google 发布的 AI 图像生成模型(Gemini 3 Pro Image),代号 Gemini 3 Pro Image,具备推理能力,支持 1K/2K/4K 输出和 14 张图像组合
+- [[DeepSider]]:Edge 浏览器插件(deepsider.ai),国内用户访问 Gemini 3 / Nano Banana 2 的便捷渠道,支持 GPT5/GPT4.1/Claude/Gemini 2.5 Pro/Grok/Nano Banana/Sora 2 等数十款 AI 模型
+- [[Gemini 3 Pro]]:Google Gemini 3 系列中的图像生成模型,即 Nano Banana 2 的正式代号
+- [[Google]]:Nano Banana 2 的开发商
+
+## Connections
+- [[全网最全-nano-banana-2-使用指南-2025年12月更新-1]] ← 使用 ← [[DeepSider]]
+- [[全网最全-nano-banana-2-使用指南-2025年12月更新-1]] ← 介绍 ← [[Nano Banana 2]]
+- [[Nano Banana Pro 提示词指南]] ← 相关 ← [[全网最全-nano-banana-2-使用指南-2025年12月更新-1]](同一系列)
+- [[Nano Banana 提示词框架]] ← 相关 ← [[全网最全-nano-banana-2-使用指南-2025年12月更新-1]](同一系列)
+- [[Nano Banana Pro]] ← 相关 ← [[Nano Banana 2]](升级关系)
+
+## Contradictions
+- 暂无发现与其他 Wiki 页面的明显冲突
diff --git a/wiki/sources/养虾日记1-我用-openclaw-管了-28-万张照片-一次真实的多设备照片整理实战.md b/wiki/sources/养虾日记1-我用-openclaw-管了-28-万张照片-一次真实的多设备照片整理实战.md
index 98794390..0135857c 100644
--- a/wiki/sources/养虾日记1-我用-openclaw-管了-28-万张照片-一次真实的多设备照片整理实战.md
+++ b/wiki/sources/养虾日记1-我用-openclaw-管了-28-万张照片-一次真实的多设备照片整理实战.md
@@ -1,55 +1,55 @@
----
-title: "养虾日记1:我用 OpenClaw 管了 28 万张照片:一次真实的多设备照片整理实战"
-type: source
-tags: []
-date: 2026-03-31
----
-
-## Source File
-- [[微信公众号/养虾日记1:我用 OpenClaw 管了 28 万张照片:一次真实的多设备照片整理实战.md]]
-
-## Summary(用中文描述)
-- 核心主题:作者比利哥使用 OpenClaw AI Agent 成功整理了存储在 NAS 上的 28 万张、跨越 20 年的家庭照片。
-- 问题域:多设备(68 个设备目录)照片备份混乱、重复文件泛滥、人工整理不现实。
-- 方法/机制:OpenClaw 通过「提问澄清 → 方案制定 → 批次拆分 → Cron 自动执行 → Telegram 报告」流程,完成全自动化照片整理。
-- 结论/价值:AI Agent 的核心价值不是单点能力提升,而是思维方式的升级——把模糊需求转化为可执行方案。
-
-## Key Claims(用中文描述)
-- OpenClaw 通过先问关键问题(照片格式、重复定义、低质量判断标准、删除策略),帮助用户从「没想清楚」到「方案清晰」。
-- OpenClaw 将 68 个目录、28 万个文件拆分为 8 个批次,每天凌晨 0 点自动执行,全程无需人工介入。
-- AI Agent 的安全策略:待删文件移入 `To-Be-Deleted` 目录而非直接删除,用户可随时检查确认。
-- 精确去重机制:MD5 哈希比对,只删除完全相同的文件。
-- 小文件清理:低于 100KB 的图片大概率是截图或微信压缩图,直接移走。
-- AI Agent 的核心价值是「思维方式升级」而非单点能力提升。
-
-## Key Quotes
-> "我有个目录,里面照片很多,来源很杂,我想整理一下,有什么方案?" — 用户对 OpenClaw 的初始指令
-> "68 个目录,28 万个文件,一次跑完不现实" — OpenClaw 主动识别到的规模挑战
-> "它帮我把模糊的想法变成了清晰的结构,把大任务拆成了可执行的批次,把风险控制在了可接受的范围内" — 作者对 OpenClaw 思维方式的评价
-> "这大概就是 AI Agent 对我来说真正的价值:**不是某个单点能力的提升,而是思维方式的升级**" — 结论
-
-## Key Concepts
-- [[AI-Agent思维方式]]:AI Agent 不直接推荐工具,而是先通过提问澄清需求,将模糊想法转化为可执行方案
-- [[批次任务拆分]]:将大规模任务拆分为可管理的批次,降低单次执行风险
-- [[精确去重]]:通过 MD5 哈希比对,只删除内容完全相同的文件
-- [[小文件清理]]:低于 100KB 的图片大概率是截图或微信压缩图
-- [[安全删除策略]]:待删文件移入临时目录而非直接删除,保留人工检查确认环节
-- [[Cron-Job自动化]]:定时任务自动化执行,无需人工介入
-- [[Telegram通知]]:任务完成后通过 Telegram 推送 Summary 报告
-
-## Key Entities
-- [[OpenClaw]]:AI Agent 操作系统,是本次照片整理任务的执行主体
-- [[Synology Photos]]:群晖 NAS 自带照片管理工具,作者曾尝试使用但效果一般
-- [[NAS]]:网络附加存储,28 万张照片的存储位置
-
-## Connections
-- [[养虾日记2]] ← follow_up ← [[养虾日记1]]
-- [[养虾日记1]] ← extends ← [[Self-Healing-Self-Improving]]
-- [[养虾日记3]] ← follow_up ← [[养虾日记1]]
-
-## Contradictions
-- 与 [[Self-Healing-Home-Server]] 冲突:
- - 冲突点:Self-Healing 侧重「修复已知问题」,本文侧重「主动规划未知任务」
- - 当前观点:OpenClaw 在照片整理场景中是「规划者」而非「修复者」,通过提问将模糊需求具体化
- - 对方观点:Self-Healing 场景中 OpenClaw 主要执行监控和修复命令
- - 说明:两者并不真正冲突,只是同一工具在不同场景下的角色差异——规划 vs 修复
+---
+title: "养虾日记1:我用 OpenClaw 管了 28 万张照片:一次真实的多设备照片整理实战"
+type: source
+tags: []
+date: 2026-03-31
+---
+
+## Source File
+- [[raw/微信公众号/养虾日记1:我用 OpenClaw 管了 28 万张照片:一次真实的多设备照片整理实战.md]]
+
+## Summary(用中文描述)
+- 核心主题:作者比利哥使用 OpenClaw AI Agent 成功整理了存储在 NAS 上的 28 万张、跨越 20 年的家庭照片。
+- 问题域:多设备(68 个设备目录)照片备份混乱、重复文件泛滥、人工整理不现实。
+- 方法/机制:OpenClaw 通过「提问澄清 → 方案制定 → 批次拆分 → Cron 自动执行 → Telegram 报告」流程,完成全自动化照片整理。
+- 结论/价值:AI Agent 的核心价值不是单点能力提升,而是思维方式的升级——把模糊需求转化为可执行方案。
+
+## Key Claims(用中文描述)
+- OpenClaw 通过先问关键问题(照片格式、重复定义、低质量判断标准、删除策略),帮助用户从「没想清楚」到「方案清晰」。
+- OpenClaw 将 68 个目录、28 万个文件拆分为 8 个批次,每天凌晨 0 点自动执行,全程无需人工介入。
+- AI Agent 的安全策略:待删文件移入 `To-Be-Deleted` 目录而非直接删除,用户可随时检查确认。
+- 精确去重机制:MD5 哈希比对,只删除完全相同的文件。
+- 小文件清理:低于 100KB 的图片大概率是截图或微信压缩图,直接移走。
+- AI Agent 的核心价值是「思维方式升级」而非单点能力提升。
+
+## Key Quotes
+> "我有个目录,里面照片很多,来源很杂,我想整理一下,有什么方案?" — 用户对 OpenClaw 的初始指令
+> "68 个目录,28 万个文件,一次跑完不现实" — OpenClaw 主动识别到的规模挑战
+> "它帮我把模糊的想法变成了清晰的结构,把大任务拆成了可执行的批次,把风险控制在了可接受的范围内" — 作者对 OpenClaw 思维方式的评价
+> "这大概就是 AI Agent 对我来说真正的价值:**不是某个单点能力的提升,而是思维方式的升级**" — 结论
+
+## Key Concepts
+- [[AI-Agent思维方式]]:AI Agent 不直接推荐工具,而是先通过提问澄清需求,将模糊想法转化为可执行方案
+- [[批次任务拆分]]:将大规模任务拆分为可管理的批次,降低单次执行风险
+- [[精确去重]]:通过 MD5 哈希比对,只删除内容完全相同的文件
+- [[小文件清理]]:低于 100KB 的图片大概率是截图或微信压缩图
+- [[安全删除策略]]:待删文件移入临时目录而非直接删除,保留人工检查确认环节
+- [[Cron-Job自动化]]:定时任务自动化执行,无需人工介入
+- [[Telegram通知]]:任务完成后通过 Telegram 推送 Summary 报告
+
+## Key Entities
+- [[OpenClaw]]:AI Agent 操作系统,是本次照片整理任务的执行主体
+- [[Synology Photos]]:群晖 NAS 自带照片管理工具,作者曾尝试使用但效果一般
+- [[NAS]]:网络附加存储,28 万张照片的存储位置
+
+## Connections
+- [[养虾日记2]] ← follow_up ← [[养虾日记1]]
+- [[养虾日记1]] ← extends ← [[Self-Healing-Self-Improving]]
+- [[养虾日记3]] ← follow_up ← [[养虾日记1]]
+
+## Contradictions
+- 与 [[Self-Healing-Home-Server]] 冲突:
+ - 冲突点:Self-Healing 侧重「修复已知问题」,本文侧重「主动规划未知任务」
+ - 当前观点:OpenClaw 在照片整理场景中是「规划者」而非「修复者」,通过提问将模糊需求具体化
+ - 对方观点:Self-Healing 场景中 OpenClaw 主要执行监控和修复命令
+ - 说明:两者并不真正冲突,只是同一工具在不同场景下的角色差异——规划 vs 修复
diff --git a/wiki/sources/养虾日记2-让agent更懂你-openclaw-self-improving-复盘实战案例分享.md b/wiki/sources/养虾日记2-让agent更懂你-openclaw-self-improving-复盘实战案例分享.md
index 6f22decb..3faa3875 100644
--- a/wiki/sources/养虾日记2-让agent更懂你-openclaw-self-improving-复盘实战案例分享.md
+++ b/wiki/sources/养虾日记2-让agent更懂你-openclaw-self-improving-复盘实战案例分享.md
@@ -1,53 +1,53 @@
----
-title: "养虾日记2:让Agent更懂你:OpenClaw + Self-Improving 复盘实战案例分享"
-type: source
-tags: []
-date: 2026-04-17
----
-
-## Source File
-- [[微信公众号/养虾日记2:让Agent更懂你:OpenClaw + Self-Improving 复盘实战案例分享]]
-
-## Summary(用中文描述)
-- 核心主题:AI Agent 的记忆问题与 self-improving 自改进机制
-- 问题域:多 Agent 协作中的知识遗忘与错误重复
-- 方法/机制:self-improving skill(结构化经验记录)+ 每日复盘 cron job + 双层记忆架构
-- 结论/价值:建立"错误只犯一次"的 Agent 学习闭环,区分一次性错误与系统性重复
-
-## Key Claims(用中文描述)
-- AI Agent 没有记忆,只有上下文窗口,导致每次对话都是"一张白纸"
-- self-improving 机制让 Agent 在同一错误第二次出现时能直接应用修复,Recurrence-Count 是关键指标
-- 双层记忆架构(短期文件 + 长期向量数据库) + self-improving 复盘三层各司其职
-- Pattern-Key 重复本身是信号——第一次记了,第二次就该解决了
-- 每日 23:00 定时复盘能发现静默漏洞(如无对话日的记忆断层)
-
-## Key Quotes
-> "错误只犯一次,第二次就知道怎么做对" — self-improving 核心价值
-> "每错必记,但分类要准确。错误用 correction,流程改进用 workflow,配置发现用 config"
-> "Suggested Action 要具体到能直接执行。不要写'注意配置'这种废话,写 `--to 5038825565` 这种具体写法"
-> "没有 self-improving 复盘,这个漏洞可能永远不会被发现——因为没有人会主动去想'3月27日有没有生成 memory 文件'这种问题"
-
-## Key Concepts
-- [[Self-Improving-Skill]]:结构化经验记录系统,Agent 遇问题时调用 `self_improvement_log` 写入 `LEARNINGS.md` 或 `ERRORS.md`,格式包含 Summary/Details/Suggested Action/Metadata,含 Pattern-Key 和 Recurrence-Count
-- [[双层记忆架构]]:短期记忆层(每日对话记录文件 memory/YYYY-MM-DD.md)+ 长期记忆层(memory-lancedb-pro 向量数据库)+ self-improving 层(定时复盘)
-- [[每日复盘机制]]:每天 23:00(北京时间)自动执行的复盘流程,包含读取当天 memory → self_improvement_log → Pattern-Key 重复检查 → 有价值经验同步长期记忆 → Telegram 摘要推送
-- [[Pattern-Key]]:经验记录的分类键,用于识别重复踩坑信号(如 cron.telegram-delivery);重复出现是系统性问题的警示
-- [[Recurrence-Count]]:元数据中的重复次数字段,区分一次性错误与系统性重复,是最重要的指标之一
-- [[Self-Improvement-Log]]:`self_improvement_log` 工具调用格式,固定格式:LRN-[日期]-[序号] + Priority + Status + Area + Summary + Details + Suggested Action + Metadata
-
-## Key Entities
-- [[OpenClaw]]:多 Agent 框架,通过 cron 任务系统实现定时复盘,支持 Telegram 通知
-- [[LanceDB]]:向量数据库,memory-lancedb-pro 的底层引擎,提供语义搜索能力
-- [[LEARNINGS.md]]:结构化经验记录文件,存放 correction/workflow/config 三类 learning
-
-## Connections
-- [[Self-Improving-Skill]] ← 依赖 ← [[OpenClaw]](通过 cron job 定时触发)
-- [[双层记忆架构]] ← 依赖 ← [[LanceDB]](长期记忆向量存储)
-- [[每日复盘机制]] ← 依赖 ← [[Self-Improving-Skill]]
-- [[养虾日记1-我用-openclaw-管了-28-万张照片]] ← 前篇 ← [[养虾日记2]]
-
-## Contradictions
-- 无已知冲突
-
-## Notes
-- 来源:微信公众号 shenwei(2026-04-17),系列文章"养虾日记"第2篇
+---
+title: "养虾日记2:让Agent更懂你:OpenClaw + Self-Improving 复盘实战案例分享"
+type: source
+tags: []
+date: 2026-04-17
+---
+
+## Source File
+- [[raw/微信公众号/养虾日记2:让Agent更懂你:OpenClaw + Self-Improving 复盘实战案例分享.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Agent 的记忆问题与 self-improving 自改进机制
+- 问题域:多 Agent 协作中的知识遗忘与错误重复
+- 方法/机制:self-improving skill(结构化经验记录)+ 每日复盘 cron job + 双层记忆架构
+- 结论/价值:建立"错误只犯一次"的 Agent 学习闭环,区分一次性错误与系统性重复
+
+## Key Claims(用中文描述)
+- AI Agent 没有记忆,只有上下文窗口,导致每次对话都是"一张白纸"
+- self-improving 机制让 Agent 在同一错误第二次出现时能直接应用修复,Recurrence-Count 是关键指标
+- 双层记忆架构(短期文件 + 长期向量数据库) + self-improving 复盘三层各司其职
+- Pattern-Key 重复本身是信号——第一次记了,第二次就该解决了
+- 每日 23:00 定时复盘能发现静默漏洞(如无对话日的记忆断层)
+
+## Key Quotes
+> "错误只犯一次,第二次就知道怎么做对" — self-improving 核心价值
+> "每错必记,但分类要准确。错误用 correction,流程改进用 workflow,配置发现用 config"
+> "Suggested Action 要具体到能直接执行。不要写'注意配置'这种废话,写 `--to 5038825565` 这种具体写法"
+> "没有 self-improving 复盘,这个漏洞可能永远不会被发现——因为没有人会主动去想'3月27日有没有生成 memory 文件'这种问题"
+
+## Key Concepts
+- [[Self-Improving-Skill]]:结构化经验记录系统,Agent 遇问题时调用 `self_improvement_log` 写入 `LEARNINGS.md` 或 `ERRORS.md`,格式包含 Summary/Details/Suggested Action/Metadata,含 Pattern-Key 和 Recurrence-Count
+- [[双层记忆架构]]:短期记忆层(每日对话记录文件 memory/YYYY-MM-DD.md)+ 长期记忆层(memory-lancedb-pro 向量数据库)+ self-improving 层(定时复盘)
+- [[每日复盘机制]]:每天 23:00(北京时间)自动执行的复盘流程,包含读取当天 memory → self_improvement_log → Pattern-Key 重复检查 → 有价值经验同步长期记忆 → Telegram 摘要推送
+- [[Pattern-Key]]:经验记录的分类键,用于识别重复踩坑信号(如 cron.telegram-delivery);重复出现是系统性问题的警示
+- [[Recurrence-Count]]:元数据中的重复次数字段,区分一次性错误与系统性重复,是最重要的指标之一
+- [[Self-Improvement-Log]]:`self_improvement_log` 工具调用格式,固定格式:LRN-[日期]-[序号] + Priority + Status + Area + Summary + Details + Suggested Action + Metadata
+
+## Key Entities
+- [[OpenClaw]]:多 Agent 框架,通过 cron 任务系统实现定时复盘,支持 Telegram 通知
+- [[LanceDB]]:向量数据库,memory-lancedb-pro 的底层引擎,提供语义搜索能力
+- [[LEARNINGS.md]]:结构化经验记录文件,存放 correction/workflow/config 三类 learning
+
+## Connections
+- [[Self-Improving-Skill]] ← 依赖 ← [[OpenClaw]](通过 cron job 定时触发)
+- [[双层记忆架构]] ← 依赖 ← [[LanceDB]](长期记忆向量存储)
+- [[每日复盘机制]] ← 依赖 ← [[Self-Improving-Skill]]
+- [[养虾日记1-我用-openclaw-管了-28-万张照片]] ← 前篇 ← [[养虾日记2]]
+
+## Contradictions
+- 无已知冲突
+
+## Notes
+- 来源:微信公众号 shenwei(2026-04-17),系列文章"养虾日记"第2篇
diff --git a/wiki/sources/养虾日记3-用-obsidian-gitea-为-ai-助手构建持久化笔记系统.md b/wiki/sources/养虾日记3-用-obsidian-gitea-为-ai-助手构建持久化笔记系统.md
index 9c94f259..cb9c45ee 100644
--- a/wiki/sources/养虾日记3-用-obsidian-gitea-为-ai-助手构建持久化笔记系统.md
+++ b/wiki/sources/养虾日记3-用-obsidian-gitea-为-ai-助手构建持久化笔记系统.md
@@ -6,7 +6,7 @@ date: 2026-04-09
---
## Source File
-- [[微信公众号/养虾日记3:用 Obsidian + Gitea 为 AI 助手构建持久化笔记系统]]
+- [[raw/微信公众号/养虾日记3:用 Obsidian + Gitea 为 AI 助手构建持久化笔记系统.md]]
## Summary(用中文描述)
- 核心主题:使用 Obsidian + Gitea 构建 AI 助手的持久化笔记系统,解决 AI 输出随对话结束而丢失的核心问题
diff --git a/wiki/sources/养虾日记4-一次「context-limit-exceeded」错误排查-我以为是小问题-结果踩了大坑.md b/wiki/sources/养虾日记4-一次「context-limit-exceeded」错误排查-我以为是小问题-结果踩了大坑.md
index dfafcae0..fe956a7b 100644
--- a/wiki/sources/养虾日记4-一次「context-limit-exceeded」错误排查-我以为是小问题-结果踩了大坑.md
+++ b/wiki/sources/养虾日记4-一次「context-limit-exceeded」错误排查-我以为是小问题-结果踩了大坑.md
@@ -6,7 +6,7 @@ date: 2026-04-10
---
## Source File
-- [[微信公众号/养虾日记4: 一次「Context Limit Exceeded」错误排查:我以为是小问题,结果踩了大坑.md]]
+- [[raw/微信公众号/养虾日记4: 一次「Context Limit Exceeded」错误排查:我以为是小问题,结果踩了大坑.md]]
## Summary(用中文描述)
- 核心主题:OpenClaw AI Agent 系统中"Context Limit Exceeded"错误的深度排查与解决
diff --git a/wiki/sources/养虾日记5-深夜与苏轼聊ai-他说-被浪打下去还能爬起来的才叫风流.md b/wiki/sources/养虾日记5-深夜与苏轼聊ai-他说-被浪打下去还能爬起来的才叫风流.md
index 6574fff1..6ac1a78b 100644
--- a/wiki/sources/养虾日记5-深夜与苏轼聊ai-他说-被浪打下去还能爬起来的才叫风流.md
+++ b/wiki/sources/养虾日记5-深夜与苏轼聊ai-他说-被浪打下去还能爬起来的才叫风流.md
@@ -7,7 +7,7 @@ last_updated: 2026-04-26
---
## Source File
-- [[微信公众号/养虾日记5:深夜与苏轼聊AI,他说:被浪打下去还能爬起来的才叫风流]]
+- [[raw/微信公众号/养虾日记5:深夜与苏轼聊AI,他说:被浪打下去还能爬起来的才叫风流.md]]
## Summary(用中文描述)
- 核心主题:用AI蒸馏历史人物思维框架,创建"数字导师"——以苏东坡为首位实践对象,展示如何将千年前古人的心智模型转化为可运行的AI Skill
diff --git a/wiki/sources/养龙虾5天血泪史-我的ai-agent为什么总失忆-openclaw-记忆调试全记录.md b/wiki/sources/养龙虾5天血泪史-我的ai-agent为什么总失忆-openclaw-记忆调试全记录.md
index c04dc5dd..f0e19d5a 100644
--- a/wiki/sources/养龙虾5天血泪史-我的ai-agent为什么总失忆-openclaw-记忆调试全记录.md
+++ b/wiki/sources/养龙虾5天血泪史-我的ai-agent为什么总失忆-openclaw-记忆调试全记录.md
@@ -1,71 +1,71 @@
----
-title: "养龙虾5天血泪史:我的AI Agent为什么总失忆?OpenClaw 记忆调试全记录"
-type: source
-tags: [AI, Agent, OpenClaw, Memory, Memory-Management]
-sources: []
-last_updated: 2026-04-23
----
-
-## Source File
-- [[微信公众号/养龙虾5天血泪史:我的AI Agent为什么总失忆?OpenClaw 记忆调试全记录]]
-
-## Summary(用中文描述)
-- 核心主题:OpenClaw AI Agent 记忆失效问题的诊断与修复
-- 问题域:AI Agent 长期记忆缺失、上下文压缩丢失信息、搜索不准确、检索不自动、系统臃肿
-- 方法/机制:通过5天专项调试,发现5类根本原因(压缩机制、搜索后端、检索触发、压缩协同、系统配置),对应10条黄金法则
-- 结论/价值:**写入纪律比读取纪律更重要**;系统提示词中每个令牌都是开销;压缩不是敌人,未写入的上下文才是
-
-## Key Claims(用中文描述)
-- 当对话填满 Context Window 时,OpenClaw 将旧消息压缩成摘要,姓名、数字、具体决定等细节全部丢失
-- 纯语义搜索在专有名词、具体数字和确切短语上失败,BM25+向量+重新排序的混合搜索明显更好
-- "信息存在"和"Agent 使用信息"之间有区别——必须通过启动指令强制触发检索
-- OpenClaw 仅自动加载 AGENTS.md、SOUL.md、TOOLS.md、IDENTITY.md、USER.md、HEARTBEAT.md、MEMORY.md,其他文件需要明确读取指令
-- 模型切换时丢失所有上下文,新模型只看到自动加载的文件,需要交接协议将状态写入每日日志
-- 系统提示词从 209,652 精简到 9,349 令牌,轻了 28%
-
-## Key Quotes
-> "压缩不是敌人。压缩过程中丢失信息才是。修复方法是确保任何值得记住的内容在压缩器触及前写入文件。" — Day 1 核心洞察
-
-> "纯语义搜索理论上听起来不错,但在专有名词、具体数字和确切短语上失败。混合搜索对现实世界代理内存明显更好。" — Day 2 核心洞察
-
-> "'信息存在'和'Agent 使用信息'之间有区别。你需要两者。" — Day 3 核心洞察
-
-> "真正的修复不是添加更多文件。而是移除那些什么都不做的文件。" — Day 5 核心洞察
-
-## Key Concepts
-- [[上下文压缩]]:OpenClaw 将旧消息压缩成摘要为新消息腾空间的机制,摘要丢失细节(姓名、数字、决定)
-- [[上下文刷新]](Memory Flush):压缩前将重要上下文写入磁盘的配置,`softThresholdTokens: 4000` 触发刷新
-- [[混合搜索]](Hybrid Search):BM25(关键词)+向量嵌入+重新排序器组合,兼顾精确匹配和语义相似性
-- [[Context Pruning]]:上下文修剪机制,与压缩协同工作,`cache-ttl` 模式 6 小时后清理旧上下文,保留最后 3 个助手响应
-- [[系统提示词膨胀]](System Prompt Bloat):未使用技能、臃肿内存文件、不自动读取的文件默默累积 token 开销
-- [[交接协议]](Handoff Protocol):模型切换前将当前上下文写入每日日志的规程,防止新模型丢失状态
-- [[启动序列]]:Agent 启动时必须执行的操作指令,必须放在 AGENTS.md 最顶部
-- [[写入纪律]](Write Discipline):强制 Agent 将决定、结果和错误记录到磁盘,比读取纪律更关键
-- [[自动加载文件]]:OpenClaw 在每个新会话自动读取的 7 个核心文件(AGENTS/SOUL/TOOLS/IDENTITY/USER/HEARTBEAT/MEMORY)
-- [[检索触发]](Retrieval Trigger):Agent 必须被明确告知何时搜索,不能依赖隐式线索
-
-## Key Entities
-- [[OpenClaw]]:multi-agent framework,本文调试的核心框架,内存管理机制的关键系统
-- [[比利哥]](shenwei):本文作者,正在研究 AI 提高工作效率的个人用户,OpenClaw AI 助理"星辉"的所有者
-
-## Connections
-- [[上下文压缩]] ← depends_on ← [[上下文刷新]]
-- [[上下文刷新]] ← prevents ← [[上下文压缩]]的信息丢失
-- [[混合搜索]] ← extends ← [[QMD搜索后端]]
-- [[Context Pruning]] ← coordinates_with ← [[上下文压缩]]
-- [[交接协议]] ← solves ← [[上下文刷新]]无法覆盖多次压缩的问题
-- [[养虾日记1]] ← related_to ← [[养虾日记2]] ← related_to ← [[养虾日记3]]
-- [[养龙虾5天血泪史]] ← related_to ← [[养虾日记1]](同一系列)
-
-## Contradictions
-- 与 [[Second Brain]] 冲突:
- - 冲突点:MEMORY.md 的定位
- - 当前观点(本文):任务期间永远不要直接写入 MEMORY.md,每日日志是原始且仅追加的,MEMORY.md 应在定期审查期间策划
- - 对方观点(Second Brain):通过对话零摩擦捕获任何内容,OpenClaw 永久记忆存储所有对话
- - 说明:两者不矛盾,Second Brain 侧重捕获策略,本文侧重策划和写入纪律
-
-- 与 [[personal-crm]] 冲突:
- - 冲突点:联系人信息的记录方式
- - 当前观点(本文):每日日志仅追加,由定时任务(如心跳或定时任务)期间审查并提炼
- - 对方观点(personal-crm):每日 Cron Job 扫描 Gmail 和日历,自动提取新联系人并更新 SQLite 数据库
- - 说明:personal-crm 针对结构化联系人数据有专门处理流程,与本文的通用内存写入纪律互补
+---
+title: "养龙虾5天血泪史:我的AI Agent为什么总失忆?OpenClaw 记忆调试全记录"
+type: source
+tags: [AI, Agent, OpenClaw, Memory, Memory-Management]
+sources: []
+last_updated: 2026-04-23
+---
+
+## Source File
+- [[raw/微信公众号/养龙虾5天血泪史:我的AI Agent为什么总失忆?OpenClaw 记忆调试全记录.md]]
+
+## Summary(用中文描述)
+- 核心主题:OpenClaw AI Agent 记忆失效问题的诊断与修复
+- 问题域:AI Agent 长期记忆缺失、上下文压缩丢失信息、搜索不准确、检索不自动、系统臃肿
+- 方法/机制:通过5天专项调试,发现5类根本原因(压缩机制、搜索后端、检索触发、压缩协同、系统配置),对应10条黄金法则
+- 结论/价值:**写入纪律比读取纪律更重要**;系统提示词中每个令牌都是开销;压缩不是敌人,未写入的上下文才是
+
+## Key Claims(用中文描述)
+- 当对话填满 Context Window 时,OpenClaw 将旧消息压缩成摘要,姓名、数字、具体决定等细节全部丢失
+- 纯语义搜索在专有名词、具体数字和确切短语上失败,BM25+向量+重新排序的混合搜索明显更好
+- "信息存在"和"Agent 使用信息"之间有区别——必须通过启动指令强制触发检索
+- OpenClaw 仅自动加载 AGENTS.md、SOUL.md、TOOLS.md、IDENTITY.md、USER.md、HEARTBEAT.md、MEMORY.md,其他文件需要明确读取指令
+- 模型切换时丢失所有上下文,新模型只看到自动加载的文件,需要交接协议将状态写入每日日志
+- 系统提示词从 209,652 精简到 9,349 令牌,轻了 28%
+
+## Key Quotes
+> "压缩不是敌人。压缩过程中丢失信息才是。修复方法是确保任何值得记住的内容在压缩器触及前写入文件。" — Day 1 核心洞察
+
+> "纯语义搜索理论上听起来不错,但在专有名词、具体数字和确切短语上失败。混合搜索对现实世界代理内存明显更好。" — Day 2 核心洞察
+
+> "'信息存在'和'Agent 使用信息'之间有区别。你需要两者。" — Day 3 核心洞察
+
+> "真正的修复不是添加更多文件。而是移除那些什么都不做的文件。" — Day 5 核心洞察
+
+## Key Concepts
+- [[上下文压缩]]:OpenClaw 将旧消息压缩成摘要为新消息腾空间的机制,摘要丢失细节(姓名、数字、决定)
+- [[上下文刷新]](Memory Flush):压缩前将重要上下文写入磁盘的配置,`softThresholdTokens: 4000` 触发刷新
+- [[混合搜索]](Hybrid Search):BM25(关键词)+向量嵌入+重新排序器组合,兼顾精确匹配和语义相似性
+- [[Context Pruning]]:上下文修剪机制,与压缩协同工作,`cache-ttl` 模式 6 小时后清理旧上下文,保留最后 3 个助手响应
+- [[系统提示词膨胀]](System Prompt Bloat):未使用技能、臃肿内存文件、不自动读取的文件默默累积 token 开销
+- [[交接协议]](Handoff Protocol):模型切换前将当前上下文写入每日日志的规程,防止新模型丢失状态
+- [[启动序列]]:Agent 启动时必须执行的操作指令,必须放在 AGENTS.md 最顶部
+- [[写入纪律]](Write Discipline):强制 Agent 将决定、结果和错误记录到磁盘,比读取纪律更关键
+- [[自动加载文件]]:OpenClaw 在每个新会话自动读取的 7 个核心文件(AGENTS/SOUL/TOOLS/IDENTITY/USER/HEARTBEAT/MEMORY)
+- [[检索触发]](Retrieval Trigger):Agent 必须被明确告知何时搜索,不能依赖隐式线索
+
+## Key Entities
+- [[OpenClaw]]:multi-agent framework,本文调试的核心框架,内存管理机制的关键系统
+- [[比利哥]](shenwei):本文作者,正在研究 AI 提高工作效率的个人用户,OpenClaw AI 助理"星辉"的所有者
+
+## Connections
+- [[上下文压缩]] ← depends_on ← [[上下文刷新]]
+- [[上下文刷新]] ← prevents ← [[上下文压缩]]的信息丢失
+- [[混合搜索]] ← extends ← [[QMD搜索后端]]
+- [[Context Pruning]] ← coordinates_with ← [[上下文压缩]]
+- [[交接协议]] ← solves ← [[上下文刷新]]无法覆盖多次压缩的问题
+- [[养虾日记1]] ← related_to ← [[养虾日记2]] ← related_to ← [[养虾日记3]]
+- [[养龙虾5天血泪史]] ← related_to ← [[养虾日记1]](同一系列)
+
+## Contradictions
+- 与 [[Second Brain]] 冲突:
+ - 冲突点:MEMORY.md 的定位
+ - 当前观点(本文):任务期间永远不要直接写入 MEMORY.md,每日日志是原始且仅追加的,MEMORY.md 应在定期审查期间策划
+ - 对方观点(Second Brain):通过对话零摩擦捕获任何内容,OpenClaw 永久记忆存储所有对话
+ - 说明:两者不矛盾,Second Brain 侧重捕获策略,本文侧重策划和写入纪律
+
+- 与 [[personal-crm]] 冲突:
+ - 冲突点:联系人信息的记录方式
+ - 当前观点(本文):每日日志仅追加,由定时任务(如心跳或定时任务)期间审查并提炼
+ - 对方观点(personal-crm):每日 Cron Job 扫描 Gmail 和日历,自动提取新联系人并更新 SQLite 数据库
+ - 说明:personal-crm 针对结构化联系人数据有专门处理流程,与本文的通用内存写入纪律互补
diff --git a/wiki/sources/固定镜头短视频制作的ai全流程解析.md b/wiki/sources/固定镜头短视频制作的ai全流程解析.md
index 7d98664c..b7586331 100644
--- a/wiki/sources/固定镜头短视频制作的ai全流程解析.md
+++ b/wiki/sources/固定镜头短视频制作的ai全流程解析.md
@@ -1,63 +1,68 @@
----
-title: "固定镜头短视频制作的AI全流程解析"
-type: source
-tags: ["AI视频生成", "短视频制作", "家装视频", "AI工具链", "视频剪辑"]
-date: 2026-04-23
----
-
-## Source File
-- [[raw/AI/固定镜头短视频制作的AI全流程解析.md]]
-
-## Summary(用中文描述)
-- 核心主题:利用 AI 技术快速制作高播放量固定机位家装类短视频的全流程方法论
-- 问题域:传统视频制作周期长、镜头语言复杂、设备要求高,难以规模化复制的痛点
-- 方法/机制:固定机位 + 内容连续变化 + 时间压缩三大核心原理;分镜拆解(Google AI Studio)→ 九宫格图像生成(Midjourney/Nano Banana)→ 首尾针动画(海螺AI/KAI)→ 快节奏剪辑(剪映)→ 声音设计
-- 结论/价值:AI 介入后 10 分钟内可完成成片,适用于所有固定机位且状态变化明显的短视频类型
-
-## Key Claims(用中文描述)
-- 固定机位是视频画面统一和连贯的基础,减少复杂摄像设备需求
-- 九宫格一次性生成 3×3 共九个画面,保证机位与角度不变,画面一致性强
-- 首尾针动画通过上传首针和尾针图,AI 自动补齐中间变化,实现自然动画效果
-- 快节奏剪辑统一加速 2-4 倍、避免复杂转场、画面轻微裁边即可获得干净效果
-- 声音设计(施工音效 + 节奏感强的 BGM + 精准卡点)决定观众观看体验
-
-## Key Quotes
-> "固定机位、内容连续变化、时间压缩三个特点使视频非常适合用 AI 技术生成" — 视频核心原理
-> "一次性用三乘三九宫格图生成九个分镜画面,机位和角度不变,细节只表现施工进度的变化" — 九宫格法优势
-> "首尾针动画本身提供平滑过渡,硬切清晰干净,避免视觉干扰" — 快节奏剪辑原则
-> "即使不完整也能增强真实感" — 施工音效的价值
-
-## Key Concepts
-- [[固定机位]]:摄像机位置固定不变,是视频画面统一和连贯的基础,使 AI 能稳定处理时间推移
-- [[内容连续变化]]:视频主体信息随时间持续发生明确阶段性变化,适合 AI 生成中间过渡帧
-- [[时间压缩]]:将长时间拍摄过程在视频中浓缩表现的手法,如装修从毛坯到精装修的完整过程
-- [[分镜拆解]]:将视频内容拆分成多个画面阶段描述,Google AI Studio 可自动分析视频并生成九宫格分镜
-- [[九宫格法]]:同时生成 3×3 共九个画面,保证机位与角度不变,画面一致性强,避免逐帧独立生成导致光影错乱
-- [[首尾针动画]]:通过上传首针图和尾针图,AI 自动补齐中间变化,产生连贯动画的技术
-- [[快节奏剪辑]]:使用加速播放(2-4倍)和硬切换手法,强化节奏感与流畅度
-- [[卡点]]:画面变化与音乐节奏巧妙同步,提高观看体验
-- [[Nano Banana]]:Google AI Studio 的图像生成模型,用于生成高质量分镜画面
-- [[KAI]]:AI 视频生成工具,支持首尾针动画生成短视频片段
-
-## Key Entities
-- [[Midjourney]]:AI 图像生成工具(设计师类),用于将分镜描述转换为一致图像
-- [[Nano Banana]]:Google 图像生成模型(设计师类),用于高质量分镜画面生成
-- [[海螺AI]](MiniMax):动效类 AI 工具,支持首尾针动画生成
-- [[KAI]]:动效类 AI 工具,通过 AI Video API 生成阶段视频片段
-- [[Google AI Studio]]:大脑类 AI 工具,负责将视频逻辑转化为 AI 能识别的分镜语言
-- [[剪映]]:字节跳动视频剪辑工具,用于最终视频合成、加速和转场处理
-
-## Connections
-- [[Google AI Studio]] ← generates storyboards → [[九宫格法]]
-- [[Midjourney]] / [[Nano Banana]] ← generates images → [[首尾针动画]]
-- [[海螺AI]] / [[KAI]] ← generates video clips → [[快节奏剪辑]]
-- [[快节奏剪辑]] ← composited in → [[剪映]]
-- [[固定机位]] ← enables → [[内容连续变化]]
-- [[内容连续变化]] + [[时间压缩]] ← forms the core principle → [[固定镜头短视频]]
-
-## Contradictions
-- 与传统视频制作理念冲突:
- - 冲突点:是否需要复杂镜头移动和转场效果
- - 当前观点(本文):固定机位 + 硬切 + 无复杂转场反而更干净高效
- - 对方观点:传统视频制作强调镜头语言丰富性和视觉转场多样性
- - 评估:本文专注于特定类型(固定机位状态变化视频),不适用于需要复杂镜头语言的其他视频类型
+---
+title: "固定镜头短视频制作的AI全流程解析"
+type: source
+tags: [AI视频生成, 短视频制作, 家装视频, 首尾针动画, 九宫格法]
+date: 2026-03-15
+---
+
+## Source File
+- [[raw/AI/固定镜头短视频制作的AI全流程解析.md]]
+
+## Summary(用中文描述)
+- 核心主题:利用AI技术快速高效制作高播放量家装类短视频的全套流程
+- 问题域:短视频内容创作效率与质量提升,尤其是固定机位类视频的AI辅助制作
+- 方法/机制:通过分镜拆解、九宫格图片生成、首尾针动画、快节奏剪辑、声音设计五大步骤实现AI短视频制作
+- 结论/价值:固定机位+内容连续变化+时间压缩是AI短视频的黄金公式,全流程可在10分钟内完成
+
+## Key Claims(用中文描述)
+- 固定机位视频(摄像机位置固定)非常适合AI技术生成,因画面一致性强
+- 九宫格一次性生成3x3画面可保证机位、角度、空间和光影的连贯性
+- 首尾针动画通过"首针图"和"尾针图"补齐中间变化,实现平滑过渡
+- 快节奏剪辑建议2-4倍速加速,采用硬切避免复杂转场
+- 声音设计包括施工音效和节奏感强的BGM,画面变化处精准卡点
+
+## Key Quotes
+> "固定机位、内容连续变化、时间压缩,这三个特点使视频非常适合用AI技术生成"
+> "九宫格一次性生成保证画面连贯,避免逐帧生成导致光影空间关系错乱"
+> "首尾针动画本身提供平滑过渡,硬切清晰干净,避免视觉干扰"
+
+## Key Concepts
+- [[固定机位]]:摄像机位置固定不变,是视频画面统一和连贯的基础
+- [[内容连续变化]]:视频主体信息随时间持续发生明确阶段性变化
+- [[时间压缩]]:将长时间拍摄过程在视频中浓缩表现的手法
+- [[分镜拆解]]:将视频内容拆分成多个画面阶段描述,供AI理解视频逻辑
+- [[九宫格法]]:同时生成3x3共九个画面,保证机位与角度不变
+- [[首尾针动画]]:通过上传首针和尾针两个关键帧,AI自动补齐中间动作
+- [[快节奏剪辑]]:视频使用加速播放和硬切换手法,强化节奏感
+- [[卡点]]:画面变化与音乐节奏巧妙同步,提高观看体验
+
+## Key Entities
+- [[Google AI Studio]]:用于分析视频链接并生成九宫格分镜描述的AI工具
+- [[Midjourney]]:设计师类AI工具,用于将分镜转换为一致性图像
+- [[Nano Banana]]:设计师类AI工具,用于图像生成
+- [[海螺AI]]:动效类AI工具,支持首尾针动画生成
+- [[KAI]]:动效类AI工具,通过API生成视频片段
+- [[剪映]]:视频剪辑工具,用于合成最终视频片段
+
+## Connections
+- [[分镜拆解]] ← depends_on ← [[Google AI Studio]]
+- [[九宫格法]] ← depends_on ← [[分镜拆解]]
+- [[首尾针动画]] ← depends_on ← [[九宫格法]]
+- [[快节奏剪辑]] ← depends_on ← [[首尾针动画]]
+- [[声音设计]] ← extends ← [[快节奏剪辑]]
+
+## Contradictions
+- 与传统视频制作对比:
+ - 冲突点:制作时间预期
+ - 当前观点:AI辅助制作可在10分钟内完成高质量成片
+ - 对方观点:传统实拍需要数天甚至数周周期
+
+## AI工具分类
+| 类型 | 角色 | 代表工具 |
+|------|------|----------|
+| 大脑类 | 把视频逻辑转化成AI能识别的分镜语言 | XAR GPT、GEMALA |
+| 设计师类 | 将分镜转换为一致的图像 | Midjourney、Nano Banana |
+| 动效类 | 让画面产生连贯动画效果 | 海螺AI、多么AI、KAI |
+
+## 五步AI短视频公式
+1. 拆分镜头 → 2. 一致性图像生成 → 3. 首尾针动画制作 → 4. 快速剪辑 → 5. 声音设计
diff --git a/wiki/sources/在-ubuntu-安装-ollama-并运行-qwen2-5‑coder-7b.md b/wiki/sources/在-ubuntu-安装-ollama-并运行-qwen2-5‑coder-7b.md
index c3f9500c..b25920cc 100644
--- a/wiki/sources/在-ubuntu-安装-ollama-并运行-qwen2-5‑coder-7b.md
+++ b/wiki/sources/在-ubuntu-安装-ollama-并运行-qwen2-5‑coder-7b.md
@@ -1,53 +1,53 @@
----
-title: "在 Ubuntu 安装 Ollama 并运行 Qwen2.5‑Coder 7B"
-type: source
-tags: [ollama, qwen, qwen-coder, ubuntu, 本地大模型]
-date: 2026-04-18
----
-
-## Source File
-- [[AI/在 Ubuntu 安装 Ollama 并运行 Qwen2.5‑Coder 7B]]
-
-## Summary(用中文描述)
-- 核心主题:在 Ubuntu 系统上通过官方安装脚本部署 Ollama 本地大模型运行框架,并下载运行 Qwen2.5-Coder 7B 代码生成模型
-- 问题域:本地 AI 推理环境搭建、大模型私有部署、本地 API 服务暴露
-- 方法/机制:通过官方 install.sh 脚本一键安装 Ollama;使用 systemd 管理服务;通过 `OLLAMA_HOST=0.0.0.0` 开放远程 API;CUDA 自动 GPU 加速
-- 结论/价值:3 条命令完成安装部署;Qwen2.5-Coder 7B 因其 Tool usage 能力强、Shell/Python/SQL 理解强、Repo 级代码理解强,比普通 qwen2.5:7b 更适合工程任务
-
-## Key Claims(用中文描述)
-- Ollama 官方安装脚本自动完成 CLI 安装、systemd 服务创建和 API 启动
-- qwen2.5-coder:7b 模型大小约 4.5GB,推荐配置为 8+ CPU cores + 16GB RAM + NVIDIA GPU
-- 默认 Ollama API 仅监听 127.0.0.1(本地),需修改 systemd 服务配置 `OLLAMA_HOST=0.0.0.0` 才能开放远程访问
-- 若系统安装了 CUDA,Ollama 会自动使用 GPU 加速,无需额外配置
-- 小型机器可选择 qwen2.5-coder:3b 替代 7B 以降低资源需求
-- 推荐搭配工具:Open WebUI(ChatGPT UI)、n8n(AI 自动化)、LangChain(Agent framework)、OpenClaw(AI coding agent)
-
-## Key Quotes
-> "qwen2.5-coder:7b 因为 Tool usage 能力强、Shell / Python / SQL 理解强、Repo 级代码理解强,比普通 qwen2.5:7b **更适合工程任务**" — 选型建议
-
-> "如果安装了 CUDA,Ollama 会 **自动使用 GPU**,无需额外配置" — GPU 加速机制
-
-> "最简安装流程:curl -fsSL https://ollama.com/install.sh | sh && ollama pull qwen2.5-coder:7b && ollama run qwen2.5-coder:7b" — 3 条命令完成部署
-
-## Key Concepts
-- [[Ollama]]:开源本地 LLM 运行框架,支持 macOS/Windows/Linux/Docker,`ollama run ` 一键运行大语言模型
-- [[Qwen2.5-Coder]]:阿里通义千问团队开发的代码生成模型,7B 版本约 4.5GB,在 Tool usage、Shell/Python/SQL 理解和 Repo 级代码理解方面优于通用版 Qwen2.5
-- [[本地大模型部署]]:在自有硬件上运行 AI 模型,数据完全私有、无需 API Key、无网络依赖
-- [[GPU 加速推理]]:Ollama 自动检测 CUDA 环境并调用 NVIDIA GPU 加速推理,无需手动配置
-- [[REST API]]:Ollama 默认提供 localhost:11434 REST API 接口,支持 JSON 格式的对话请求
-
-## Key Entities
-- [[Open WebUI]]:开源大模型 Web 界面,支持 Ollama/OpenAI API 接入,可配置 RAG 本地知识库和联网搜索
-- [[n8n]]:开源工作流自动化平台,可通过 Webhook 与本地 Ollama API 集成实现 AI 驱动的自动化工作流
-- [[OpenClaw]]:AI coding agent,支持配置 `ollama/qwen2.5-coder:7b` 作为后端模型
-- [[LangChain]]:Agent framework,可与本地 Ollama API 集成构建复杂 AI 应用
-
-## Connections
-- [[Ollama]] ← 基础平台 ← [[详细-离线部署大模型-ollama-deepseek-open-webui安装使用方法及常见问题解决-1]]
-- [[Open WebUI]] ← 依赖 ← [[Ollama]]
-- [[n8n]] ← 可调用 ← [[Ollama API]]
-- [[OpenClaw]] ← 可配置 ← [[Qwen2.5-Coder]]
-- [[Qwen2.5-Coder]] ← 特定版本 ← [[Ollama]]
-
-## Contradictions
-- 暂无冲突内容
+---
+title: "在 Ubuntu 安装 Ollama 并运行 Qwen2.5‑Coder 7B"
+type: source
+tags: [ollama, qwen, qwen-coder, ubuntu, 本地大模型]
+date: 2026-04-18
+---
+
+## Source File
+- [[raw/AI/在 Ubuntu 安装 Ollama 并运行 Qwen2.5‑Coder 7B.md]]
+
+## Summary(用中文描述)
+- 核心主题:在 Ubuntu 系统上通过官方安装脚本部署 Ollama 本地大模型运行框架,并下载运行 Qwen2.5-Coder 7B 代码生成模型
+- 问题域:本地 AI 推理环境搭建、大模型私有部署、本地 API 服务暴露
+- 方法/机制:通过官方 install.sh 脚本一键安装 Ollama;使用 systemd 管理服务;通过 `OLLAMA_HOST=0.0.0.0` 开放远程 API;CUDA 自动 GPU 加速
+- 结论/价值:3 条命令完成安装部署;Qwen2.5-Coder 7B 因其 Tool usage 能力强、Shell/Python/SQL 理解强、Repo 级代码理解强,比普通 qwen2.5:7b 更适合工程任务
+
+## Key Claims(用中文描述)
+- Ollama 官方安装脚本自动完成 CLI 安装、systemd 服务创建和 API 启动
+- qwen2.5-coder:7b 模型大小约 4.5GB,推荐配置为 8+ CPU cores + 16GB RAM + NVIDIA GPU
+- 默认 Ollama API 仅监听 127.0.0.1(本地),需修改 systemd 服务配置 `OLLAMA_HOST=0.0.0.0` 才能开放远程访问
+- 若系统安装了 CUDA,Ollama 会自动使用 GPU 加速,无需额外配置
+- 小型机器可选择 qwen2.5-coder:3b 替代 7B 以降低资源需求
+- 推荐搭配工具:Open WebUI(ChatGPT UI)、n8n(AI 自动化)、LangChain(Agent framework)、OpenClaw(AI coding agent)
+
+## Key Quotes
+> "qwen2.5-coder:7b 因为 Tool usage 能力强、Shell / Python / SQL 理解强、Repo 级代码理解强,比普通 qwen2.5:7b **更适合工程任务**" — 选型建议
+
+> "如果安装了 CUDA,Ollama 会 **自动使用 GPU**,无需额外配置" — GPU 加速机制
+
+> "最简安装流程:curl -fsSL https://ollama.com/install.sh | sh && ollama pull qwen2.5-coder:7b && ollama run qwen2.5-coder:7b" — 3 条命令完成部署
+
+## Key Concepts
+- [[Ollama]]:开源本地 LLM 运行框架,支持 macOS/Windows/Linux/Docker,`ollama run ` 一键运行大语言模型
+- [[Qwen2.5-Coder]]:阿里通义千问团队开发的代码生成模型,7B 版本约 4.5GB,在 Tool usage、Shell/Python/SQL 理解和 Repo 级代码理解方面优于通用版 Qwen2.5
+- [[本地大模型部署]]:在自有硬件上运行 AI 模型,数据完全私有、无需 API Key、无网络依赖
+- [[GPU 加速推理]]:Ollama 自动检测 CUDA 环境并调用 NVIDIA GPU 加速推理,无需手动配置
+- [[REST API]]:Ollama 默认提供 localhost:11434 REST API 接口,支持 JSON 格式的对话请求
+
+## Key Entities
+- [[Open WebUI]]:开源大模型 Web 界面,支持 Ollama/OpenAI API 接入,可配置 RAG 本地知识库和联网搜索
+- [[n8n]]:开源工作流自动化平台,可通过 Webhook 与本地 Ollama API 集成实现 AI 驱动的自动化工作流
+- [[OpenClaw]]:AI coding agent,支持配置 `ollama/qwen2.5-coder:7b` 作为后端模型
+- [[LangChain]]:Agent framework,可与本地 Ollama API 集成构建复杂 AI 应用
+
+## Connections
+- [[Ollama]] ← 基础平台 ← [[详细-离线部署大模型-ollama-deepseek-open-webui安装使用方法及常见问题解决-1]]
+- [[Open WebUI]] ← 依赖 ← [[Ollama]]
+- [[n8n]] ← 可调用 ← [[Ollama API]]
+- [[OpenClaw]] ← 可配置 ← [[Qwen2.5-Coder]]
+- [[Qwen2.5-Coder]] ← 特定版本 ← [[Ollama]]
+
+## Contradictions
+- 暂无冲突内容
diff --git a/wiki/sources/在synology-nas上安装clouddrive2.md b/wiki/sources/在synology-nas上安装clouddrive2.md
index 9a8e366d..7727ceca 100644
--- a/wiki/sources/在synology-nas上安装clouddrive2.md
+++ b/wiki/sources/在synology-nas上安装clouddrive2.md
@@ -1,46 +1,46 @@
----
-title: "在Synology NAS上安装CloudDrive2"
-type: source
-tags: [clouddrive2, nas, synology, 阿里云盘]
-date: 2025-12-29
----
-
-## Source File
-- [[Home Office/在Synology NAS上安装CloudDrive2.md]]
-
-## Summary(用中文描述)
-- 核心主题:在 Synology NAS(DSM 7+)上安装并配置 CloudDrive2,实现阿里云盘的本地挂载
-- 问题域:群晖 NAS 用户希望将阿里云盘像本地硬盘一样挂载使用,无需手动同步
-- 方法/机制:通过 Synology 社群(矿神源)安装 CloudDrive2 → 执行 root 权限修复命令(DSM 7+ 专用)→ Web UI 配置 → 阿里云盘 App 扫码授权 → 挂载 Aliyun 目录
-- 结论/价值:CloudDrive2 提供了在 NAS 上原生挂载云盘的能力,适合影视、文件等大体积内容管理
-
-## Key Claims(用中文描述)
-- 主体 + 机制 + 结果
-- Synology 社群安装方式:矿神源 → 社群 → CloudDrive2(标准流程)
-- DSM 7+ 特殊处理:需执行 `sed` 命令修改 CloudDrive2 权限文件,将 `package` 替换为 `root`,否则因权限不足无法正常运行
-- Web UI 访问:通过 `http://192.168.3.17:19798/` 访问 CloudDrive2 配置界面
-- 阿里云盘授权:使用阿里云盘 App 扫码授权,仅授权「资源目录」(不要授权「备份目录」)
-
-## Key Quotes
-> "因为我的 DSM 是 7+ 版本,所以需要额外在 root 下执行一条命令" — DSM 7+ 权限修复说明
-> "请主要,不要授权备份目录,仅资源目录即可" — 安全提示,避免备份文件被挂载
-
-## Key Concepts
-- [[CloudDrive2]]:云盘挂载工具,支持阿里云盘、百度网盘等多种云存储,可将云端文件像本地硬盘一样在 NAS 上使用
-- [[Synology NAS]]:群晖网络附加存储设备,运行 DSM 操作系统;通过社群套件源安装第三方应用
-- [[矿神源]]:Synology 社群第三方套件源,提供大量社群维护的应用(如 CloudDrive2)
-
-## Key Entities
-- [[阿里云盘]]:阿里巴巴旗下云盘服务,CloudDrive2 支持挂载的云存储之一;通过 App 扫码授权连接
-- [[CloudDrive2]]:云盘挂载应用,可在 NAS/PC 上将云盘映射为本地文件系统(WebDAV/SMB 等协议)
-
-## Connections
-- [[群晖NAS科学上网方法]] ← related ← [[在Synology NAS上安装CloudDrive2]](同一设备上的网络配置需求)
-- [[用Docker安装Jellyfin]] ← related ← [[在Synology NAS上安装CloudDrive2]](Jellyfin 可读取 CloudDrive2 挂载的阿里云盘影视资源)
-
-## Contradictions
-- 无已知冲突
-
-## Related Sources
-- [[群晖NAS科学上网方法]]
-- [[用Docker安装Jellyfin]]
+---
+title: "在Synology NAS上安装CloudDrive2"
+type: source
+tags: [clouddrive2, nas, synology, 阿里云盘]
+date: 2025-12-29
+---
+
+## Source File
+- [[raw/Home Office/在Synology NAS上安装CloudDrive2.md]]
+
+## Summary(用中文描述)
+- 核心主题:在 Synology NAS(DSM 7+)上安装并配置 CloudDrive2,实现阿里云盘的本地挂载
+- 问题域:群晖 NAS 用户希望将阿里云盘像本地硬盘一样挂载使用,无需手动同步
+- 方法/机制:通过 Synology 社群(矿神源)安装 CloudDrive2 → 执行 root 权限修复命令(DSM 7+ 专用)→ Web UI 配置 → 阿里云盘 App 扫码授权 → 挂载 Aliyun 目录
+- 结论/价值:CloudDrive2 提供了在 NAS 上原生挂载云盘的能力,适合影视、文件等大体积内容管理
+
+## Key Claims(用中文描述)
+- 主体 + 机制 + 结果
+- Synology 社群安装方式:矿神源 → 社群 → CloudDrive2(标准流程)
+- DSM 7+ 特殊处理:需执行 `sed` 命令修改 CloudDrive2 权限文件,将 `package` 替换为 `root`,否则因权限不足无法正常运行
+- Web UI 访问:通过 `http://192.168.3.17:19798/` 访问 CloudDrive2 配置界面
+- 阿里云盘授权:使用阿里云盘 App 扫码授权,仅授权「资源目录」(不要授权「备份目录」)
+
+## Key Quotes
+> "因为我的 DSM 是 7+ 版本,所以需要额外在 root 下执行一条命令" — DSM 7+ 权限修复说明
+> "请主要,不要授权备份目录,仅资源目录即可" — 安全提示,避免备份文件被挂载
+
+## Key Concepts
+- [[CloudDrive2]]:云盘挂载工具,支持阿里云盘、百度网盘等多种云存储,可将云端文件像本地硬盘一样在 NAS 上使用
+- [[Synology NAS]]:群晖网络附加存储设备,运行 DSM 操作系统;通过社群套件源安装第三方应用
+- [[矿神源]]:Synology 社群第三方套件源,提供大量社群维护的应用(如 CloudDrive2)
+
+## Key Entities
+- [[阿里云盘]]:阿里巴巴旗下云盘服务,CloudDrive2 支持挂载的云存储之一;通过 App 扫码授权连接
+- [[CloudDrive2]]:云盘挂载应用,可在 NAS/PC 上将云盘映射为本地文件系统(WebDAV/SMB 等协议)
+
+## Connections
+- [[群晖NAS科学上网方法]] ← related ← [[在Synology NAS上安装CloudDrive2]](同一设备上的网络配置需求)
+- [[用Docker安装Jellyfin]] ← related ← [[在Synology NAS上安装CloudDrive2]](Jellyfin 可读取 CloudDrive2 挂载的阿里云盘影视资源)
+
+## Contradictions
+- 无已知冲突
+
+## Related Sources
+- [[群晖NAS科学上网方法]]
+- [[用Docker安装Jellyfin]]
diff --git a/wiki/sources/在ubuntu上安装vibe-kanban.md b/wiki/sources/在ubuntu上安装vibe-kanban.md
index 5c3cfb80..a5259448 100644
--- a/wiki/sources/在ubuntu上安装vibe-kanban.md
+++ b/wiki/sources/在ubuntu上安装vibe-kanban.md
@@ -1,51 +1,51 @@
----
-title: "在Ubuntu上安装Vibe-Kanban"
-type: source
-tags: [npm, npx, pm2, ubuntu, vibe-coding, vibe-kanban]
-date: 2026-06-04
----
-
-## Source File
-- [[Vibe Coding/在Ubuntu上安装Vibe-Kanban.md]]
-
-## Summary(用中文描述)
-- 核心主题:在 Ubuntu Server 上安装和配置 Vibe-Kanban AI 任务管理工具
-- 问题域:AI 辅助编程工作流、任务管理工具的服务器端部署
-- 方法/机制:通过 npx 直接运行 Vibe-Kanban,使用 PM2 进程管理器实现后台运行和开机自启
-- 结论/价值:提供完整的 Vibe-Kanban 安装指南,包括可选的 GitHub CLI 和 MCP 集成
-
-## Key Claims(用中文描述)
-- Vibe Kanban 默认以 `--dangerously-skip-permissions/--yolo` 标志运行 AI 代理,允许自主操作无需持续审批
-- 每个任务在隔离的 git worktree 中运行,防止代理之间相互干扰
-- 使用 `PORT=8080 npx vibe-kanban` 可指定固定端口
-- PM2 可以实现进程自动重启和开机自启,通过 `pm2 startup` 配置
-- 使用 `HOST=0.0.0.0 PORT=9999 npx vibe-kanban` 可实现局域网访问
-
-## Key Quotes
-> "Vibe Kanban runs AI agents with —dangerously-skip-permissions/—yolo flags by default so they can work autonomously without constant approval prompts." — 安全机制说明
-> "Each task runs in an isolated git worktree, preventing agents from interfering with each other." — 隔离机制说明
-> "Vibe Kanban uses the GitHub CLI for creating pull requests. Ensure gh is installed and authenticated on your system." — GitHub 集成依赖
-
-## Key Concepts
-- [[PM2]]:Node.js 进程管理器,提供进程守护、自动重启和开机自启功能
-- [[npx]]:Node.js 包执行工具,无需全局安装即可运行包
-- [[Vibe Coding]]:AI 辅助编程范式,通过自然语言描述让 AI 代理完成编码任务
-- [[MCP Server]]:Model Context Protocol 服务器,用于标准化 AI 代理与外部工具的集成
-
-## Key Entities
-- [[Vibe-Kanban]]:BloopAI 出品的 AI 任务管理看板工具,支持多种编码代理
-- [[BloopAI]]:开发 Vibe-Kanban 的 AI 代码工具公司
-- [[Node.js]]:Vibe-Kanban 运行所需的 JavaScript 运行时环境
-- [[GitHub CLI]]:用于创建 Pull Request 的命令行工具,Vibe-Kanban 可选集成
-
-## Connections
-- [[Vibe-Kanban]] ← depends_on ← [[Node.js]]
-- [[Vibe-Kanban]] ← extends ← [[GitHub CLI]]
-- [[Vibe-Kanban]] ← optional_integration ← [[MCP Server]]
-- [[PM2]] ← manages ← [[Vibe-Kanban]]
-
-## Contradictions
-- 与 [[如何在Ubuntu上安装OpenCode并配置Vibe-Kanban]] 部分重叠:
- - 冲突点:两者都介绍 Vibe-Kanban 安装,但侧重点不同
- - 当前观点:本文档侧重官方标准安装流程和 PM2 进程管理
- - 对方观点:[[如何在Ubuntu上安装OpenCode并配置Vibe-Kanban]] 侧重 OpenCode 集成配置
+---
+title: "在Ubuntu上安装Vibe-Kanban"
+type: source
+tags: [npm, npx, pm2, ubuntu, vibe-coding, vibe-kanban]
+date: 2026-06-04
+---
+
+## Source File
+- [[raw/Vibe Coding/在Ubuntu上安装Vibe-Kanban.md]]
+
+## Summary(用中文描述)
+- 核心主题:在 Ubuntu Server 上安装和配置 Vibe-Kanban AI 任务管理工具
+- 问题域:AI 辅助编程工作流、任务管理工具的服务器端部署
+- 方法/机制:通过 npx 直接运行 Vibe-Kanban,使用 PM2 进程管理器实现后台运行和开机自启
+- 结论/价值:提供完整的 Vibe-Kanban 安装指南,包括可选的 GitHub CLI 和 MCP 集成
+
+## Key Claims(用中文描述)
+- Vibe Kanban 默认以 `--dangerously-skip-permissions/--yolo` 标志运行 AI 代理,允许自主操作无需持续审批
+- 每个任务在隔离的 git worktree 中运行,防止代理之间相互干扰
+- 使用 `PORT=8080 npx vibe-kanban` 可指定固定端口
+- PM2 可以实现进程自动重启和开机自启,通过 `pm2 startup` 配置
+- 使用 `HOST=0.0.0.0 PORT=9999 npx vibe-kanban` 可实现局域网访问
+
+## Key Quotes
+> "Vibe Kanban runs AI agents with —dangerously-skip-permissions/—yolo flags by default so they can work autonomously without constant approval prompts." — 安全机制说明
+> "Each task runs in an isolated git worktree, preventing agents from interfering with each other." — 隔离机制说明
+> "Vibe Kanban uses the GitHub CLI for creating pull requests. Ensure gh is installed and authenticated on your system." — GitHub 集成依赖
+
+## Key Concepts
+- [[PM2]]:Node.js 进程管理器,提供进程守护、自动重启和开机自启功能
+- [[npx]]:Node.js 包执行工具,无需全局安装即可运行包
+- [[Vibe Coding]]:AI 辅助编程范式,通过自然语言描述让 AI 代理完成编码任务
+- [[MCP Server]]:Model Context Protocol 服务器,用于标准化 AI 代理与外部工具的集成
+
+## Key Entities
+- [[Vibe-Kanban]]:BloopAI 出品的 AI 任务管理看板工具,支持多种编码代理
+- [[BloopAI]]:开发 Vibe-Kanban 的 AI 代码工具公司
+- [[Node.js]]:Vibe-Kanban 运行所需的 JavaScript 运行时环境
+- [[GitHub CLI]]:用于创建 Pull Request 的命令行工具,Vibe-Kanban 可选集成
+
+## Connections
+- [[Vibe-Kanban]] ← depends_on ← [[Node.js]]
+- [[Vibe-Kanban]] ← extends ← [[GitHub CLI]]
+- [[Vibe-Kanban]] ← optional_integration ← [[MCP Server]]
+- [[PM2]] ← manages ← [[Vibe-Kanban]]
+
+## Contradictions
+- 与 [[如何在Ubuntu上安装OpenCode并配置Vibe-Kanban]] 部分重叠:
+ - 冲突点:两者都介绍 Vibe-Kanban 安装,但侧重点不同
+ - 当前观点:本文档侧重官方标准安装流程和 PM2 进程管理
+ - 对方观点:[[如何在Ubuntu上安装OpenCode并配置Vibe-Kanban]] 侧重 OpenCode 集成配置
diff --git a/wiki/sources/在ubuntu上通过vps-内网反向代理实现域名访问内网穿透.md b/wiki/sources/在ubuntu上通过vps-内网反向代理实现域名访问内网穿透.md
index 73b4faa0..09d9a23e 100644
--- a/wiki/sources/在ubuntu上通过vps-内网反向代理实现域名访问内网穿透.md
+++ b/wiki/sources/在ubuntu上通过vps-内网反向代理实现域名访问内网穿透.md
@@ -7,7 +7,7 @@ last_updated: 2026-04-27
---
## Source File
-- [[Home Office/在Ubuntu上通过VPS+内网反向代理实现域名访问内网穿透.md]]
+- [[raw/Home Office/在Ubuntu上通过VPS+内网反向代理实现域名访问内网穿透.md]]
## Summary(用中文描述)
- 核心主题:通过 VPS(公网服务器)+ frp(反向隧道)+ Caddy(自动 HTTPS 反向代理)实现家庭内网服务的公网域名访问
diff --git a/wiki/sources/大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏.md b/wiki/sources/大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏.md
index 8c4f3716..d71871c2 100644
--- a/wiki/sources/大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏.md
+++ b/wiki/sources/大模型相关术语和框架总结|llm-mcp-prompt-rag-vllm-token-数据蒸馏.md
@@ -1,75 +1,64 @@
----
-title: "大模型相关术语和框架总结|LLM、MCP、Prompt、RAG、vLLM、Token、数据蒸馏"
-type: source
-tags: [llm, mcp, prompt, rag, token, vllm, embedding, langchain]
-sources: []
-last_updated: 2026-04-25
----
-
-## Source File
-- [[AI/大模型相关术语和框架总结|LLM、MCP、Prompt、RAG、vLLM、Token、数据蒸馏.md]]
-
-## Summary(用中文描述)
-- 核心主题:大模型(LLM)生态核心术语与框架的系统性梳理,面向初学者
-- 问题域:大模型是什么、如何与大模型交互(Prompt)、如何扩展大模型能力(MCP/Agent)、如何解决幻觉问题(RAG)、如何高效部署推理(vLLM)、如何用小模型学习大模型能力(蒸馏)
-- 方法/机制:
- - Prompt:通过自然语言指令向 LLM 输入任务描述
- - MCP:标准化协议,连接 LLM 与外部工具/数据源
- - Agent:在 MCP 框架下,LLM 规划调用工具并执行多步任务
- - RAG:检索外部知识注入 LLM 上下文,减少幻觉
- - vLLM:PagedAttention + 连续批处理实现高效 GPU 利用率
- - Embedding:将文本词转换为浮点向量,通过距离计算语义相似性
- - 数据蒸馏:用大模型生成精简训练数据,使小模型逼近大模型效果
-- 结论/价值:本文是大模型入门术语速查手册,将 LLM/MCP/Agent/RAG/Embedding/LangChain/vLLM/Token/蒸馏 等核心概念用通俗语言串联,适合快速建立 AI 技术认知框架
-
-## Key Claims(用中文描述)
-- LLM 参数规模 ≥1B(十亿参数)是大模型行业门槛;GPT-2 为 1.5B,GPT-3 为 175B
-- MCP 是 LLM 连接外部工具和数据的标准化协议,解决不同模型/工具集成的碎片化问题
-- 大模型本身只返回方法步骤,不执行实际操作;需要 MCP 框架才能真正触发工具调用
-- LLM + MCP + 工具 = AI Agent,Agent 能真正执行发邮件等外部操作
-- RAG 通过检索外部知识注入,将 LLM 回答正确率从约 60% 提升至约 90%
-- Embedding 通过将词转为浮点向量,用向量距离衡量语义相似性,解决一词多义问题
-- vLLM 通过 PagedAttention(分块 KV Cache)和连续批处理最大化 GPU 利用率,降低推理成本
-- Token 是 LLM 的基本输入单元:英文约 0.3 token/字符,中文约 0.6 token/字符
-- 数据蒸馏利用高性能大模型生成精简数据,使小模型能以更低成本逼近大模型效果
-
-## Key Quotes
-> "大模型是不会自己去调用外部数据源或者工具的,大模型只会告诉我们需要调用哪些工具,而我们需要自己去实现工具的调用。" — MCP 与 LLM 的能力边界说明
-
-> "LLM 在考试的时候面对陌生的领域,只会写一个解字(因为LLM复习也只是局限于特定的数据集),然后就准备放飞自我了,而此时RAG给了亿些提示,让LLM懂了开始往这个提示的方向做,最终考试的正确率从60%到了90%!" — RAG 减少幻觉的可视化类比
-
-> "一百和两百的距离近,而一百离一千远,所以一百相比于一千,更接近两百这个语意。" — Embedding 向量距离与语义相似性的关系
-
-> "KV Cache 把这些历史 K/V 保存下来,后续步不用重复计算。但 KV Cache 随上下文长度、层数、头数、维度线性增长,也变成推理中的最大显存开销之一。" — vLLM 优化 KV Cache 的动机
-
-## Key Concepts
-- [[Large Language Model]]:大语言模型,以 ≥1B 参数为行业门槛的深度神经网络语言模型,通过大规模预训练获得语言理解和生成能力
-- [[Prompt]]:提示词,用户向 LLM 输入的自然语言指令,引导模型产出特定类型的响应
-- [[Model Context Protocol]](MCP):开放协议,为 LLM 应用提供标准化接口,使其能够连接外部数据源和工具进行交互
-- [[AI Agent]]:智能体,LLM + MCP 工具框架的融合体,能够感知环境、规划步骤、调用工具并执行多步任务(如发邮件)
-- [[Retrieval-Augmented Generation]](RAG):检索增强生成,通过从外部知识库检索相关内容注入 LLM 上下文,减少幻觉、提升回答准确率
-- [[Embedding]]:向量化,将文本转换为浮点向量,通过向量距离计算语义相似性,解决一词多义问题
-- [[LangChain]]:快速实现 AI Agent 的开发框架,提供标准化接口用于连接不同 LLM 和工具/数据源
-- [[vLLM]]:开源 LLM 推理框架,通过 PagedAttention(分块 KV Cache)和连续批处理优化 GPU 内存利用率,实现高吞吐、低成本推理
-- [[Token]]:LLM 的基本输入单元,约等于一个单词或短语;英文约 0.3 token/字符,中文约 0.6 token/字符
-- [[Data Distillation]](数据蒸馏):利用大模型生成精简训练数据,使小模型能够从中学习并逼近大模型效果的技术
-- [[KV Cache]]:Transformer 解码过程中保存历史 Key/Value 向量的缓存机制,避免重复计算,但带来显存瓶颈
-- [[PagedAttention]]:vLLM 提出的注意力机制,将 KV Cache 分块管理(类操作系统页表),避免显存碎片化
-- [[Continuous Batching]](连续批处理):在每个解码步骤动态组装活跃请求为批次,无需等待整批结束即可插入新请求,提高 GPU 利用率
-
-## Key Entities
-- [[shenwei]]:本文作者,公众号 shenwei 投稿
-- [[OpenAI]]:GPT 系列模型的开发公司(GPT-2/GPT-3 参数量引用来源)
-- [[vLLM]]:开源社区维护的 LLM 推理加速框架,提供 PagedAttention 实现
-
-## Connections
-- [[Large Language Model]] ← is_the_core_of ← [[AI Agent]]
-- [[Model Context Protocol]] ← enables ← [[AI Agent]]
-- [[AI Agent]] ← requires ← [[Prompt]]
-- [[Retrieval-Augmented Generation]] ← solves_problem_of ← [[Hallucination]]
-- [[vLLM]] ← uses ← [[PagedAttention]]
-- [[vLLM]] ← uses ← [[Continuous Batching]]
-- [[Data Distillation]] ← transfers_knowledge_from ← [[Large Language Model]]
-
-## Contradictions
-- 与 [[llms-rag-ai-agent-三个到底什么区别]] 互补而非冲突:本文侧重入门术语科普式解释(通俗语言 + 可视化类比),后者侧重三层架构的系统性梳理(LLM 思考层 / RAG 认知层 / Agent 执行层),两者结合可形成从入门到深入的完整认知路径。
+---
+title: "大模型相关术语和框架总结|LLM、MCP、Prompt、RAG、vLLM、Token、数据蒸馏"
+type: source
+tags: [llm, mcp, prompt, rag, token, vllm, embedding, agent, langchain, 蒸馏]
+date: 2025-12-20
+---
+
+## Source File
+- [[raw/AI/大模型相关术语和框架总结|LLM、MCP、Prompt、RAG、vLLM、Token、数据蒸馏.md]]
+
+## Summary(用中文描述)
+- 核心主题:大模型(LLM)生态中的关键术语与技术框架入门指南
+- 问题域:大模型应用开发中的基础概念混淆、技术选型困难
+- 方法/机制:通过通俗类比解释 LLM、MCP、Agent、RAG、Embedding、vLLM、Token、蒸馏等核心概念
+- 结论/价值:为零基础读者提供大模型术语的系统性扫盲,建立统一认知框架
+
+## Key Claims(用中文描述)
+- LLM ≥1B 参数开始被称为"大模型",行业以参数规模和训练数据/算力衡量
+- MCP(Model Context Protocol)是 LLM 连接外部数据源和工具的标准化接口协议
+- 大模型本身只给出步骤方法,不会真正执行工具调用,需配合 MCP 才能实现自动化
+- Agent = LLM + MCP,通过工具调用实现自动化执行
+- RAG 通过检索外部知识解决大模型的 Hallucination(幻觉)问题,正确率从 60% 提升至 90%
+- Embedding 将词转化为浮点向量,通过计算向量距离判断语义关联性
+- vLLM 通过 PagedAttention(分块 KV Cache)和连续批处理优化 GPU 利用率
+- 1 个英文字符 ≈ 0.3 个 Token,1 个中文字符 ≈ 0.6 个 Token
+- 数据蒸馏:用大模型生成精简数据,让小模型从中学习并逼近大模型效果
+
+## Key Quotes
+> "大模型是不会自己去调用外部数据源或者工具的,大模型只会告诉我们需要调用哪些工具,而我们需要自己去实现工具的调用。" — MCP 与 LLM 的边界说明
+> "一百和两百的距离近,而一百离一千远,所以一百相比于一千,更接近两百这个语意。" — Embedding 语义距离的直观类比
+
+## Key Concepts
+- [[Large Language Model]]:大语言模型,≥1B 参数的语言模型,如 GPT-2(1.5B)、GPT-3(175B)
+- [[Prompt]]:提示词,用户输入给大模型的语句
+- [[Model Context Protocol]]:模型上下文协议,LLM 连接外部数据源和工具的标准化接口
+- [[RAG]]:检索增强生成,通过外部检索解决大模型幻觉问题
+- [[Embedding]]:向量化,将词转换为浮点向量以计算语义距离
+- [[Agent]]:智能体,LLM + MCP 工具调用实现自动化执行
+- [[LangChain]]:快速实现 Agent 的开发框架,提供标准接口连接不同 LLM 和工具
+- [[vLLM]]:高效 LLM 推理引擎,通过 PagedAttention 和连续批处理优化 GPU 显存利用
+- [[Token]]:大模型的基本输入单元,英文约 0.3 Token/字符,中文约 0.6 Token/字符
+- [[Data Distillation]]:数据蒸馏,用大模型生成精简数据训练小模型
+- [[Hallucination]]:幻觉,大模型在陌生领域"一本正经胡说八道"的现象
+- [[KV Cache]]:保存历史 Key/Value 向量,避免重复计算,是推理显存开销的主要来源
+- [[PagedAttention]]:vLLM 的分块注意力机制,将 KV Cache 切分为固定块并用页表管理
+- [[Continuous Batching]]:连续批处理,每步解码都动态组装活跃请求批次,避免头阻塞
+
+## Key Entities
+- [[vLLM]]:vLLM 社区维护的开源项目,专注于 LLM 高效推理
+
+## Connections
+- [[Agent]] ← 构建于 ← [[Large Language Model]]
+- [[Agent]] ← 构建于 ← [[Model Context Protocol]]
+- [[Agent]] ← 构建于 ← [[Prompt]]
+- [[RAG]] ← 解决 ← [[Hallucination]]
+- [[RAG]] ← 依赖 ← [[Embedding]]
+- [[vLLM]] ← 优化 ← [[KV Cache]]
+- [[vLLM]] ← 使用 ← [[PagedAttention]]
+- [[vLLM]] ← 使用 ← [[Continuous Batching]]
+- [[LangChain]] ← 用于构建 ← [[Agent]]
+- [[Data Distillation]] ← 使用 ← [[Large Language Model]]
+
+## Contradictions
+- 暂无已知冲突
diff --git a/wiki/sources/如何传输docker-images-并且在另一个docker安装.md b/wiki/sources/如何传输docker-images-并且在另一个docker安装.md
index 201f1b36..ce2c193d 100644
--- a/wiki/sources/如何传输docker-images-并且在另一个docker安装.md
+++ b/wiki/sources/如何传输docker-images-并且在另一个docker安装.md
@@ -1,44 +1,44 @@
----
-title: "如何传输Docker images 并且在另一个Docker安装"
-type: source
-tags: []
-sources: []
-last_updated: 2026-05-30
----
-
-## Source File
-- [[Home Office/如何传输Docker images 并且在另一个Docker安装]]
-
-## Summary(用中文描述)
-- 核心主题:Docker 镜像在两台 Docker 环境之间的离线传输方法
-- 问题域:无镜像仓库的内网环境或离线场景下的镜像迁移
-- 方法/机制:`docker save` 导出为 tar → 上传目标机器 → `docker load` 导入
-- 结论/价值:提供了无需镜像仓库的离线迁移标准流程,适用于家庭 NAS 与工作设备之间的镜像同步
-
-## Key Claims(用中文描述)
-- `docker pull` 从远程仓库拉取镜像到本地 Docker 环境
-- `docker save -o ` 将镜像导出为 tar 归档文件,可离线拷贝
-- `docker load < "cd 到 xiaoya.tar 存放的路径之后运行以下命令 docker load < xiaoya.tar" — 在 Synology NAS 上通过 SSH 执行镜像导入
-> "再进入 NAS 的 Container Manager 界面后在 image 里就可以看到 xiaoya/alist 这个 image 了" — 验证镜像导入成功的方式
-
-## Key Concepts
-- [[Docker-Image]]:容器镜像,Docker 应用打包的标准格式
-- [[Docker-Save]]:`docker save` 命令将镜像导出为 tar 归档文件
-- [[Docker-Load]]:`docker load` 命令从 tar 文件加载镜像到本地 Docker 引擎
-- [[Docker-Registry]]:镜像仓库(本文未使用,但提及作为替代方案)
-
-## Key Entities
-- [[Docker]]:容器化平台,本文的操作基础环境
-- [[Synology-NAS]]:群晖 NAS,运行 Docker(Container Manager),本文镜像迁移的目标端
-- [[Alist]]:开源网盘聚合工具(xiaoyaliu/alist),本文操作的示例镜像
-
-## Connections
-- [[如何在Ubuntu Server安装 Docker & Docker Compose]] ← extends ← [[如何传输Docker images 并且在另一个Docker安装]]
-- [[在Synology NAS上安装CloudDrive2]] ← related_to ← [[如何传输Docker images 并且在另一个Docker安装]](同为 Synology NAS Docker 操作场景)
-
-## Contradictions
-- (无已知冲突)
+---
+title: "如何传输Docker images 并且在另一个Docker安装"
+type: source
+tags: []
+sources: []
+last_updated: 2026-05-30
+---
+
+## Source File
+- [[raw/Home Office/如何传输Docker images 并且在另一个Docker安装.md]]
+
+## Summary(用中文描述)
+- 核心主题:Docker 镜像在两台 Docker 环境之间的离线传输方法
+- 问题域:无镜像仓库的内网环境或离线场景下的镜像迁移
+- 方法/机制:`docker save` 导出为 tar → 上传目标机器 → `docker load` 导入
+- 结论/价值:提供了无需镜像仓库的离线迁移标准流程,适用于家庭 NAS 与工作设备之间的镜像同步
+
+## Key Claims(用中文描述)
+- `docker pull` 从远程仓库拉取镜像到本地 Docker 环境
+- `docker save -o ` 将镜像导出为 tar 归档文件,可离线拷贝
+- `docker load < "cd 到 xiaoya.tar 存放的路径之后运行以下命令 docker load < xiaoya.tar" — 在 Synology NAS 上通过 SSH 执行镜像导入
+> "再进入 NAS 的 Container Manager 界面后在 image 里就可以看到 xiaoya/alist 这个 image 了" — 验证镜像导入成功的方式
+
+## Key Concepts
+- [[Docker-Image]]:容器镜像,Docker 应用打包的标准格式
+- [[Docker-Save]]:`docker save` 命令将镜像导出为 tar 归档文件
+- [[Docker-Load]]:`docker load` 命令从 tar 文件加载镜像到本地 Docker 引擎
+- [[Docker-Registry]]:镜像仓库(本文未使用,但提及作为替代方案)
+
+## Key Entities
+- [[Docker]]:容器化平台,本文的操作基础环境
+- [[Synology-NAS]]:群晖 NAS,运行 Docker(Container Manager),本文镜像迁移的目标端
+- [[Alist]]:开源网盘聚合工具(xiaoyaliu/alist),本文操作的示例镜像
+
+## Connections
+- [[如何在Ubuntu Server安装 Docker & Docker Compose]] ← extends ← [[如何传输Docker images 并且在另一个Docker安装]]
+- [[在Synology NAS上安装CloudDrive2]] ← related_to ← [[如何传输Docker images 并且在另一个Docker安装]](同为 Synology NAS Docker 操作场景)
+
+## Contradictions
+- (无已知冲突)
diff --git a/wiki/sources/如何写出完美的prompt-提示词.md b/wiki/sources/如何写出完美的prompt-提示词.md
index 1b900086..7760329b 100644
--- a/wiki/sources/如何写出完美的prompt-提示词.md
+++ b/wiki/sources/如何写出完美的prompt-提示词.md
@@ -1,61 +1,65 @@
----
-title: "如何写出完美的Prompt(提示词)?"
-type: source
-tags: []
-date: 2025-12-18
----
-
-## Source File
-- [[AI/如何写出完美的Prompt(提示词)?]]
-
-## Summary(用中文描述)
-- 核心主题:系统阐述如何通过结构化思维与精准表达提升 Prompt 能力,实现人与 AI 的高效协作
-- 问题域:职场人在使用 LLM 时普遍面临的"AI 输出不达预期"困境,根源在于需求传递失效和 Prompt 构建能力不足
-- 方法/机制:提出 Prompt 构建的底层逻辑(角色+需求+场景+目标)、基础方法(需求拆解/上下文补全/格式定义/示例引导)、进阶策略(思维链/任务拆分/角色赋能/预填回复/不确定性管理)、高阶技巧(跨模态联动/领域知识注入/反馈循环嵌入),并给出四大业务场景实战模板和六大避坑指南
-- 结论/价值:Prompt 能力的本质是有对问题清晰界定的能力 + 结构化的思维逻辑和表达能力,这两项底层能力决定了人能否用好 AI
-
-## Key Claims(用中文描述)
-- Prompt 是一套人与 AI 的协作协议,本质是将人的模糊需求转化为 AI 可理解、可执行的结构化任务
-- Prompt 的核心价值在于消除双重信息差:人类需求与 AI 理解之间的信息差,以及任务目标与执行标准之间的信息差
-- 专业性不在于复杂程度,而在于精准匹配——现代 LLM(如 Claude 4、GPT-4)已具备强大的自然语言理解能力,无需 XML 标签或术语堆砌
-- LLM 没有默认的行业常识和设定,隐性需求(受众/场景/目标)不明确,AI 只能盲猜
-- Prompt 优化过程本质是需求逐步清晰化的过程,不仅是让 AI 更懂你,也是让你自己更明确核心诉求
-- Prompt 能力的底层逻辑:结构化思维 + 精准表达;核心本质:需求拆解能力 + 结构化表达能力 + 场景共情能力 + 迭代优化能力
-- 能清晰给下属指令的领导,才可能用好 AI——Prompt 质量终究取决于使用者的思维深度与表达精度
-
-## Key Quotes
-> "很多人期望一次输入就能得到完美结果,一旦输出不符合预期就会认定是 AI 不行,也不愿花时间优化 Prompt。实际上,Prompt 的优化过程,本质是需求逐步清晰化的过程,不仅是让 AI 更懂你,也是让你自己更明确核心诉求。" — 迭代优化的核心理念
-
-> "Prompt 的核心价值在于消除信息差(既消除人类需求与 AI 理解之间的信息差,也消除任务目标与执行标准之间的信息差)。" — LLM 提示词的本质
-
-> "Prompt 能力的本质是要求使用者具备:需求拆解能力、结构化表达能力、场景共情能力、迭代优化能力。" — Prompt 能力底层模型
-
-> "这也解释了为什么连给下属指令都讲不清的领导,是很难用好 AI 的,因为 Prompt 的质量,终究取决于使用者的思维深度与表达精度。" — 领导力与 AI 能力的关联
-
-## Key Concepts
-- [[Large Language Model]]:大语言模型(LLM),如 Claude 4、GPT-4,是 Prompt 的执行主体
-- [[结构化思维]]:将模糊需求拆解为具体、可执行子任务的能力,Prompt 能力的基础
-- [[精准表达]]:用清晰的逻辑组织信息,让 AI 快速抓取核心指令的能力,Prompt 能力的另一基础
-- [[思维链引导]]:通过明确"推理步骤"让 AI 按逻辑逐步分析,避免输出片面或跳跃的结论的进阶策略
-- [[任务拆分法]]:将复杂任务拆解为信息收集→分析→输出→优化多个子环节的进阶策略
-- [[角色赋能法]]:给 AI 设定"具体角色+行业经验+核心能力"引导其从专业视角思考问题的进阶策略
-- [[少量样本提示]](Few-shot):通过 1-3 个示例引导 AI 理解格式/风格要求的技巧
-- [[上下文补全]]:在 Prompt 中提供业务背景、约束条件、参考信息以消除信息差的基础方法
-- [[AI Agent]]:能够感知→规划→执行→反思的循环控制,实现真正自主性的 AI 系统,Prompt 能力是 Agent 能力的基础
-
-## Key Entities
-- [[粒粒]]:微信公众号作者,原创本文,2025年12月2日发布
-
-## Connections
-- [[清华出的DeepSeek使用手册]] ← 与本文互补 ← [[如何写出完美的Prompt(提示词)?]](前者侧重 DeepSeek 特定实践,本篇侧重通用 Prompt 方法论)
-- [[Nano Banana 提示词框架]] ← 与本文同属提示词工程领域 ← [[如何写出完美的Prompt(提示词)?]](前者侧重 AI 图像生成提示词,本篇侧重职场文本场景)
-- [[Claude Prompt Library 汇总表]] ← 与本文同属提示词工程领域 ← [[如何写出完美的Prompt(提示词)?]](前者提供现成提示词模板,本篇提供方法论和构建原则)
-- [[系统提示词构建原则]] ← 关联 ← [[如何写出完美的prompt-提示词]](前者侧重 AI Agent 系统级指令规范,本篇侧重用户级 Prompt 构建)
-- [[Never Write Another Prompt]] ← 与本文互补 ← [[如何写出完美的prompt-提示词]](前者展示自动生成提示词工具,本篇阐述手动构建方法论)
-
-## Contradictions
-- 与 [[系统提示词构建原则]] 存在视角差异:
- - 冲突点:Anthropic 系统提示词强调"遵守项目约定优先、技术准确性优先",面向 Agent 开发者;本篇强调"受众对齐、场景对齐、目标对齐",面向终端用户(职场人)
- - 当前观点:本篇方法论是用户层面提升 Prompt 质量的实用框架,适用于任何 LLM
- - 对方观点:系统提示词的核心在于给 AI 明确定义身份、行为准则和执行规范,是 AI 一侧的指令工程
- - 说明:两者并不矛盾,而是互补——[[系统提示词构建原则]] 是 Agent 设计层的最佳实践,本篇是用户使用层的操作指南
+---
+title: "如何写出完美的Prompt(提示词)?"
+type: source
+tags: [AI, Prompt工程, 结构化表达]
+date: 2025-12-18
+---
+
+## Source File
+- [[raw/AI/如何写出完美的Prompt(提示词)?.md]]
+
+## Summary(用中文描述)
+
+- **核心主题:** 系统阐述如何撰写高效 Prompt 的完整方法论,涵盖基础技巧、进阶策略、高阶技巧与四大业务场景实战模板。
+- **问题域:** 职场人在使用 AI 时因 Prompt 能力不足导致输出质量低下的问题;企业对员工 Prompt 能力建设的组织化需求。
+- **方法/机制:** 提出"角色+需求+场景+目标"四要素框架;分层介绍基础方法(需求拆解、上下文补全、格式定义、示例引导)、进阶策略(思维链、任务拆分、角色赋能、预填回复、不确定性管理)、高阶技巧(跨模态联动、领域知识注入、反馈循环嵌入);配套四大业务场景(内容创作、数据分析、方案策划、客户服务)实战模版。
+- **结论/价值:** Prompt 能力本质是"结构化思维+精准表达",是 AI 时代职场人的底层能力;企业应通过模板库建设、培训竞赛、反馈机制实现团队 AI 能力的规模化提升。
+
+## Key Claims(用中文描述)
+
+- **Prompt 能力** → 本质是需求清晰界定能力 + 结构化逻辑表达能力 → 直接决定 AI 输出质量。
+- **Prompt 不是简单指令** → 而是人机协作协议,需明确"做什么、为什么做、给谁做、怎么做、做到什么标准"。
+- **Prompt 专业性** → 不在于术语堆砌和格式复杂程度,而在于精准匹配使用场景和受众需求。
+- **迭代优化是核心** → 初次 Prompt 不可能完美,需通过"测试-反馈-优化"闭环逐步逼近最优结果。
+- **技巧按需匹配** → 简单任务用基础技巧,复杂任务用进阶策略,避免过度设计。
+
+## Key Quotes
+
+> "很多人认为 Prompt=给 AI 的指令,其实忽略了 Prompt 是一套人与 AI 的协作协议。它不仅要明确'做什么',更要定义'为什么做''给谁做''怎么做''做到什么标准',本质是将人的模糊需求转化为 AI 可理解、可执行的结构化任务。" — Prompt 的本质定义
+
+> "Prompt 能力的底层逻辑:结构化思维 + 精准表达。" — 全文核心论断
+
+> "Prompt 的专业性不在于复杂程度,而在于精准匹配。" — 反驳过度堆砌术语的误区
+
+> "即使是客户方案、行业报告,本身就需要反复打磨,AI 只是你加速打磨的工具。" — 迭代优化的必要性
+
+> "能清晰界定核心诉求 + 建立与 AI 能力匹配的沟通逻辑" — Prompt 能力的两个核心维度
+
+## Key Concepts
+
+- [[Prompt工程]]:将人的模糊需求转化为 AI 可理解、可执行任务的系统性方法论,本文系统阐述了从基础到高阶的完整方法体系。
+- [[结构化思维]]:将模糊目标拆解为具体、可执行子任务,用清晰逻辑组织信息让 AI 快速抓取核心的能力,是 Prompt 能力的底层基础。
+- [[思维链提示]](Chain of Thought):通过明确推理步骤让 AI 按逻辑逐步分析,避免输出片面或跳跃结论的进阶 Prompt 策略,适用于竞品分析、复杂决策等场景。
+- [[少样本提示]](Few-shot):用 1-3 个与目标任务场景一致的示例引导 AI,比单纯描述格式更高效,适用于格式复杂或有特定风格要求的任务。
+- [[角色赋能法]]:给 AI 设定"具体角色+行业经验+核心能力",引导其从专业视角思考问题,输出更贴合场景内容的方法。
+- [[任务拆分法]]:将复杂任务拆解为"信息收集→分析→输出→优化"多个子环节,每个环节聚焦单一目标,提升整体输出质量的方法。
+- [[预填回复法]]:预填部分内容框架让 AI 直接填充关键信息,避免冗余表述,可直接导入系统使用的策略。
+- [[不确定性管理]]:明确告知 AI"不知道就标注,不编造信息",提升数据类和事实类任务输出的可信度。
+- [[迭代优化]]:通过"初稿测试→问题定位→精准优化→版本对比"的闭环持续调整 Prompt,逼近最优结果的思维模式。
+
+## Key Entities
+
+- [[粒粒]]:微信公众号"粒粒"作者,本文原创发布者(2025-12-02),专注于职场与 AI 应用内容创作。
+
+## Connections
+
+- [[系统提示词构建原则]] ← 互补 ← 本文:前者聚焦 AI Coding Agent 的系统级提示词设计,本文聚焦职场通用 Prompt 方法论;两者可组合使用——用本文的结构化思维撰写任务 Prompt,配合前者的系统提示词框架。
+- [[Vibe Coding]] ← 关联 ← 本文:Vibe Coding 的高效实施依赖本文所阐述的 Prompt 方法论,尤其角色赋能法和场景贴合技巧。
+- [[Claude Code 调用方法总结]] ← 关联 ← 本文:Claude Code 作为 AI 编程工具,其使用效果直接取决于用户的 Prompt 能力;本文的方法论可提升 Claude Code 的任务输出质量。
+
+## Contradictions
+
+- 与 [[系统提示词构建原则]] 在"角色设定"维度存在视角差异:
+ - **本文观点:** 角色设定应精准(如"5年制造业MES售前经验顾问"),避免"世界顶级专家"等模糊表述,核心关注点决定语言风格。
+ - **对方观点:** 系统提示词强调 Agent 的行为准则和边界约束(如"遵守项目约定、优先技术准确性"),更偏向技术准确性和安全性。
+ - **协调方向:** 本文的方法论(角色赋能)适用于任务级 Prompt,对话系统或编码 Agent 的系统级提示词则需遵循对方的安全和准确性约束,两者互补而非冲突。
diff --git a/wiki/sources/如何删除旧的废弃的docker-container-volume.md b/wiki/sources/如何删除旧的废弃的docker-container-volume.md
index af6dfad2..95632940 100644
--- a/wiki/sources/如何删除旧的废弃的docker-container-volume.md
+++ b/wiki/sources/如何删除旧的废弃的docker-container-volume.md
@@ -1,59 +1,59 @@
----
-title: "如何删除旧的废弃的 Docker Container + Volume"
-type: source
-tags: [docker, container, portainer, volume]
-date: 2026-04-26
----
-
-## Source File
-- [[Home Office/如何删除旧的废弃的docker container +volume.md]]
-
-## Summary(用中文描述)
-- 核心主题:清理 Docker 环境中废弃的 Portainer 容器、Volume 和 Network 的完整操作流程
-- 问题域:Docker 容器残留导致的端口冲突、卷数据残留、以及重启 Portainer 时出现的 WARN 警告
-- 方法/机制:通过 `docker stop/rm`、`docker volume ls/rm`、`docker network ls/rm` 系列命令手动清理;使用 `docker compose down` 一键清理整个 compose 项目;通过 `external: true` 配置避免 future 部署时的资源冲突
-- 结论/价值:提供了从手动单步清理到一键重装的完整操作链,以及 WARN 原因分析和解决方案
-
-## Key Claims(用中文描述)
-- `docker compose down` 命令可同时删除容器、网络和匿名 Volume,但保留命名 Volume
-- `docker volume rm` 可显式删除指定 Volume(如 `portainer_data`),从而清除 Portainer 所有用户数据和配置
-- Docker WARN "Network already exists" 表示同名 network 由另一个 compose 项目创建,与当前项目冲突
-- Docker WARN "Volume is used by another service" 表示同名 volume 属于另一个 compose 项目的不同 project name
-- 在 compose 文件中设置 `external: true` 可让新项目复用旧 network/volume 而不触发冲突警告
-
-## Key Quotes
-> "⚠️ 注意:这会删除 Portainer 所有数据(用户、配置)。如果你想保留数据,不要删 volume,只需要在 compose 文件里加:`external: true`" — 删除 portainer_data 的重要提示
-
-## Key Concepts
-- [[Docker Container]]:Docker 镜像的运行实例,`docker ps -a` 查看所有容器,`docker rm` 删除已停止容器,`docker rm -f` 强制删除运行中容器
-- [[Docker Volume]]:持久化存储机制,挂载到容器内部用于保存数据;`docker volume ls` 列出所有卷,`docker volume rm` 删除指定卷
-- [[Docker Network]]:容器间通信的虚拟网络;同名 network 冲突是 compose 项目隔离机制导致的警告
-- [[Docker Compose]]:`docker compose down` 停止并删除整个 compose 项目中的容器、网络,以及(非 external 的)命名卷
-- [[Docker Socket]]:Docker 守护进程的 Unix Socket(通常为 `/var/run/docker.sock`),Portainer 通过挂载它实现对本地 Docker 的管理
-
-## Key Entities
-- [[Portainer]]:开源 Docker 容器管理面板,本文档的清理目标;`portainer/portainer-ce` 为其 Community Edition 镜像
-- [[portainer_data]]:Portainer 的命名 Docker Volume,存储用户、配置等持久化数据
-
-## Connections
-- [[用Docker安装Portainer]] ← depends_on ← [[如何删除旧的废弃的 Docker Container + Volume]]
-- [[如何在Ubuntu Server安装 Docker & Docker Compose]] ← related_to ← [[如何删除旧的废弃的 Docker Container + Volume]]
-
-## Contradictions
-- 无已知冲突
-
-## 完整操作流程速查
-
-```bash
-# 最干净的重装流程
-docker stop portainer && docker rm portainer
-docker volume rm portainer_data
-docker network rm portainer_network
-docker compose up -d
-```
-
-```bash
-# 一键清理(compose 部署)
-docker compose down # 删除容器+网络+匿名卷
-docker compose down -v # 额外删除命名卷(谨慎!)
-```
+---
+title: "如何删除旧的废弃的 Docker Container + Volume"
+type: source
+tags: [docker, container, portainer, volume]
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Home Office/如何删除旧的废弃的docker container +volume.md]]
+
+## Summary(用中文描述)
+- 核心主题:清理 Docker 环境中废弃的 Portainer 容器、Volume 和 Network 的完整操作流程
+- 问题域:Docker 容器残留导致的端口冲突、卷数据残留、以及重启 Portainer 时出现的 WARN 警告
+- 方法/机制:通过 `docker stop/rm`、`docker volume ls/rm`、`docker network ls/rm` 系列命令手动清理;使用 `docker compose down` 一键清理整个 compose 项目;通过 `external: true` 配置避免 future 部署时的资源冲突
+- 结论/价值:提供了从手动单步清理到一键重装的完整操作链,以及 WARN 原因分析和解决方案
+
+## Key Claims(用中文描述)
+- `docker compose down` 命令可同时删除容器、网络和匿名 Volume,但保留命名 Volume
+- `docker volume rm` 可显式删除指定 Volume(如 `portainer_data`),从而清除 Portainer 所有用户数据和配置
+- Docker WARN "Network already exists" 表示同名 network 由另一个 compose 项目创建,与当前项目冲突
+- Docker WARN "Volume is used by another service" 表示同名 volume 属于另一个 compose 项目的不同 project name
+- 在 compose 文件中设置 `external: true` 可让新项目复用旧 network/volume 而不触发冲突警告
+
+## Key Quotes
+> "⚠️ 注意:这会删除 Portainer 所有数据(用户、配置)。如果你想保留数据,不要删 volume,只需要在 compose 文件里加:`external: true`" — 删除 portainer_data 的重要提示
+
+## Key Concepts
+- [[Docker Container]]:Docker 镜像的运行实例,`docker ps -a` 查看所有容器,`docker rm` 删除已停止容器,`docker rm -f` 强制删除运行中容器
+- [[Docker Volume]]:持久化存储机制,挂载到容器内部用于保存数据;`docker volume ls` 列出所有卷,`docker volume rm` 删除指定卷
+- [[Docker Network]]:容器间通信的虚拟网络;同名 network 冲突是 compose 项目隔离机制导致的警告
+- [[Docker Compose]]:`docker compose down` 停止并删除整个 compose 项目中的容器、网络,以及(非 external 的)命名卷
+- [[Docker Socket]]:Docker 守护进程的 Unix Socket(通常为 `/var/run/docker.sock`),Portainer 通过挂载它实现对本地 Docker 的管理
+
+## Key Entities
+- [[Portainer]]:开源 Docker 容器管理面板,本文档的清理目标;`portainer/portainer-ce` 为其 Community Edition 镜像
+- [[portainer_data]]:Portainer 的命名 Docker Volume,存储用户、配置等持久化数据
+
+## Connections
+- [[用Docker安装Portainer]] ← depends_on ← [[如何删除旧的废弃的 Docker Container + Volume]]
+- [[如何在Ubuntu Server安装 Docker & Docker Compose]] ← related_to ← [[如何删除旧的废弃的 Docker Container + Volume]]
+
+## Contradictions
+- 无已知冲突
+
+## 完整操作流程速查
+
+```bash
+# 最干净的重装流程
+docker stop portainer && docker rm portainer
+docker volume rm portainer_data
+docker network rm portainer_network
+docker compose up -d
+```
+
+```bash
+# 一键清理(compose 部署)
+docker compose down # 删除容器+网络+匿名卷
+docker compose down -v # 额外删除命名卷(谨慎!)
+```
diff --git a/wiki/sources/如何利用sora接口实现视频自动化生成工作流.md b/wiki/sources/如何利用sora接口实现视频自动化生成工作流.md
index 991a0d23..7defdfb9 100644
--- a/wiki/sources/如何利用sora接口实现视频自动化生成工作流.md
+++ b/wiki/sources/如何利用sora接口实现视频自动化生成工作流.md
@@ -1,49 +1,49 @@
----
-title: "如何利用Sora接口实现视频自动化生成工作流"
-type: source
-tags: [n8n, sora, workflow, 视频生成, 自媒体, AI工作流]
-sources: []
-last_updated: 2026-04-23
----
-
-## Source File
-- [[AI/如何利用Sora接口实现视频自动化生成工作流.md]]
-
-## Summary(用中文描述)
-- 核心主题:利用 Sora API 实现视频生成的全自动化工作流,覆盖注册→API调用→批量生成的完整流程
-- 问题域:自媒体内容创作的视频生产成本高、效率低的问题
-- 方法/机制:亚马逊 Bedrock 平台注册 → 创建 API 密钥 → 通过 Sora 接口调用视频生成模型 → 结合 n8n 实现自动化批量生产
-- 结论/价值:Sora 视频生成成本仅为 2-3 元人民币,远低于市场水平;新用户享受 200 美元抵扣金和 6 个月免费试用,是低成本启动自媒体副业的可行方案
-
-## Key Claims(用中文描述)
-- 亚马逊 Bedrock 平台上的 Sora 接口成本比 OpenAI 便宜六倍以上,大幅降低视频生成门槛
-- 新用户注册亚马逊账户可获得 200 美元抵扣金和六个月免费试用权
-- 使用肖像权生成内容必须获得对方同意,并确保不违反相关法律法规
-- 精细化的提示词设计能够显著提升生成视频的质量
-- Sora 接口不仅支持文本转视频,还可生成图像类内容,扩展创作边界
-
-## Key Quotes
-> "使用 Sora 生成一般视频的费用仅需两三元人民币,远低于市场水平" — 成本优势说明
-> "精细化的提示词设计能够显著提升生成视频的质量,增强内容的吸引力" — 提示词优化的重要性
-> "可以生成无水印视频,在生成请求中选择相应参数,确保移除水印设置为 TRUE" — 技术操作说明
-
-## Key Concepts
-- [[文字生成视频]]:通过文本描述提示词驱动 AI 模型生成视频内容的技术,Sora 即属于此类
-- [[提示词优化]]:提升 AI 生成内容质量的关键技术,精细化描述直接影响最终生成结果
-- [[肖像权合规]]:在使用 AI 生成涉及人物的内容时,必须获得对方同意的法律要求
-- [[n8n 工作流自动化]]:开源工作流自动化平台,可编排 Sora API 调用实现批量视频生成
-- [[UGC内容]]:用户生成内容(User Generated Content),Sora 助力批量生产
-
-## Key Entities
-- [[Sora]]:亚马逊 Bedrock 平台提供的视频生成 API,支持文生视频和图像生成
-- [[亚马逊 Bedrock]]:AWS 机器学习服务平台,托管 Sora 等多种 AI 模型
-- [[n8n]]:开源工作流自动化工具,可串联 Sora API 实现自动化批量内容生产
-
-## Connections
-- [[n8n-workflow-orchestration]] ← extends ← [[n8n]]
-- [[Sora]] ← depends_on ← [[亚马逊 Bedrock]]
-- [[文字生成视频网站推荐]] ← related_to ← [[Sora]]
-- [[固定镜头短视频制作的AI全流程解析]] ← related_to ← [[文字生成视频]]
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "如何利用Sora接口实现视频自动化生成工作流"
+type: source
+tags: [n8n, sora, workflow, 视频生成, 自媒体, AI工作流]
+sources: []
+last_updated: 2026-04-23
+---
+
+## Source File
+- [[raw/AI/如何利用Sora接口实现视频自动化生成工作流.md]]
+
+## Summary(用中文描述)
+- 核心主题:利用 Sora API 实现视频生成的全自动化工作流,覆盖注册→API调用→批量生成的完整流程
+- 问题域:自媒体内容创作的视频生产成本高、效率低的问题
+- 方法/机制:亚马逊 Bedrock 平台注册 → 创建 API 密钥 → 通过 Sora 接口调用视频生成模型 → 结合 n8n 实现自动化批量生产
+- 结论/价值:Sora 视频生成成本仅为 2-3 元人民币,远低于市场水平;新用户享受 200 美元抵扣金和 6 个月免费试用,是低成本启动自媒体副业的可行方案
+
+## Key Claims(用中文描述)
+- 亚马逊 Bedrock 平台上的 Sora 接口成本比 OpenAI 便宜六倍以上,大幅降低视频生成门槛
+- 新用户注册亚马逊账户可获得 200 美元抵扣金和六个月免费试用权
+- 使用肖像权生成内容必须获得对方同意,并确保不违反相关法律法规
+- 精细化的提示词设计能够显著提升生成视频的质量
+- Sora 接口不仅支持文本转视频,还可生成图像类内容,扩展创作边界
+
+## Key Quotes
+> "使用 Sora 生成一般视频的费用仅需两三元人民币,远低于市场水平" — 成本优势说明
+> "精细化的提示词设计能够显著提升生成视频的质量,增强内容的吸引力" — 提示词优化的重要性
+> "可以生成无水印视频,在生成请求中选择相应参数,确保移除水印设置为 TRUE" — 技术操作说明
+
+## Key Concepts
+- [[文字生成视频]]:通过文本描述提示词驱动 AI 模型生成视频内容的技术,Sora 即属于此类
+- [[提示词优化]]:提升 AI 生成内容质量的关键技术,精细化描述直接影响最终生成结果
+- [[肖像权合规]]:在使用 AI 生成涉及人物的内容时,必须获得对方同意的法律要求
+- [[n8n 工作流自动化]]:开源工作流自动化平台,可编排 Sora API 调用实现批量视频生成
+- [[UGC内容]]:用户生成内容(User Generated Content),Sora 助力批量生产
+
+## Key Entities
+- [[Sora]]:亚马逊 Bedrock 平台提供的视频生成 API,支持文生视频和图像生成
+- [[亚马逊 Bedrock]]:AWS 机器学习服务平台,托管 Sora 等多种 AI 模型
+- [[n8n]]:开源工作流自动化工具,可串联 Sora API 实现自动化批量内容生产
+
+## Connections
+- [[n8n-workflow-orchestration]] ← extends ← [[n8n]]
+- [[Sora]] ← depends_on ← [[亚马逊 Bedrock]]
+- [[文字生成视频网站推荐]] ← related_to ← [[Sora]]
+- [[固定镜头短视频制作的AI全流程解析]] ← related_to ← [[文字生成视频]]
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/如何在ubuntu-server上通过nfs挂载synology-nas上的共享文件夹.md b/wiki/sources/如何在ubuntu-server上通过nfs挂载synology-nas上的共享文件夹.md
index 6bc31015..77cab3e8 100644
--- a/wiki/sources/如何在ubuntu-server上通过nfs挂载synology-nas上的共享文件夹.md
+++ b/wiki/sources/如何在ubuntu-server上通过nfs挂载synology-nas上的共享文件夹.md
@@ -1,49 +1,49 @@
----
-title: "如何在Ubuntu Server上通过NFS挂载Synology NAS上的共享文件夹"
-type: source
-tags: [nas, nfs, synology, ubuntu]
-date: 2025-12-29
----
-
-## Source File
-- [[Home Office/如何在Ubuntu Server上通过NFS挂载Synology NAS上的共享文件夹.md]]
-
-## Summary(用中文描述)
-- 核心主题:通过 NFS 协议将 Synology NAS 的共享文件夹挂载到 Ubuntu Server,实现永久性网络存储挂载
-- 问题域:Ubuntu 服务器与 Synology NAS 之间的网络存储集成,适用于备份场景
-- 方法/机制:
- - Synology DSM 控制面板配置 NFS 权限(IP白名单、Squash 映射为 admin、_netdev 参数)
- - Ubuntu 端安装 `nfs-common`,使用 `mount -t nfs` 临时挂载
- - 通过 `/etc/fstab` 配置永久挂载,含 `timeo=900`、`retrans=5`、`_netdev` 等参数
- - rsync 脚本中加入挂载点检测保护,防止 NAS 掉线时数据写入本地
-- 结论/价值:相比 Samba,NFS 能保留 Linux 文件权限(uid/gid),避免 Docker 卷恢复时的权限报错,是 Linux 服务器挂载 NAS 的标准方案
-
-## Key Claims(用中文描述)
-- Synology NAS 的 Squash 设置"映射所有用户为 admin",可将 Ubuntu 端 root 请求在 NAS 端以 admin 身份执行,绕过 Linux 权限校验
-- `/etc/fstab` 中的 `_netdev` 参数可防止开机时网络未就绪导致系统挂起
-- NFS 相比 Samba 在处理 Docker 配置文件(大量小文件)时性能更强
-- rsync 脚本中加入挂载点检查,可在 NAS 掉线时主动终止备份,防止数据写入本地目录
-
-## Key Quotes
-> "NFS 能完美保留(Linux 文件所有权信息),而 Samba 会丢失,导致恢复 Docker 卷时权限报错" — NFS 相对 Samba 的核心优势说明
-
-> "_netdev:告诉系统这是一个网络设备,务必等到网络服务完全启动后再尝试挂载,防止开机过程因找不到网络而卡死" — fstab 中 _netdev 参数的关键作用
-
-> "如果 `sudo mount -a` 没有报错,且 `df` 能看到 NAS 空间,那么以后重启服务器,挂载都会自动生效" — 永久挂载验证方法
-
-## Key Concepts
-- [[NFS]]:Network File System,Linux/Unix 标准的网络文件系统协议,支持保留原始 uid/gid 权限
-- [[/etc/fstab]]:Linux 文件系统表,用于配置开机自动挂载;`_netdev` 参数确保网络设备就绪后再挂载
-- [[rsync]]:增量备份工具,可配合 NFS 挂载点实现服务器到 NAS 的自动化备份
-- [[Squash]]:NFS 权限设置中的用户映射选项,"映射所有用户为 admin" 可简化跨平台权限问题
-
-## Key Entities
-- [[Synology NAS]]:群晖网络附加存储设备,提供 DSM 管理界面和 NFS 共享服务;本文示例 IP:192.168.3.17,挂载路径:/volume2/backup
-- [[Ubuntu Server]]:Linux 服务器操作系统,本文版本为 Ubuntu 24.04;示例 IP:192.168.3.47,挂载点:/mnt/nas_backup
-
-## Connections
-- [[Ubuntu服务器通过rsync实现日常增量备份]] ← depends_on ← [[如何在Ubuntu Server上通过NFS挂载Synology NAS上的共享文件夹]](rsync 备份依赖 NFS 挂载的 NAS 存储)
-- [[群晖NAS科学上网方法]] ← related ← [[如何在Ubuntu Server上通过NFS挂载Synology NAS上的共享文件夹]](同为 Synology NAS 相关配置文档)
-
-## Contradictions
-- 无已知冲突
+---
+title: "如何在Ubuntu Server上通过NFS挂载Synology NAS上的共享文件夹"
+type: source
+tags: [nas, nfs, synology, ubuntu]
+date: 2025-12-29
+---
+
+## Source File
+- [[raw/Home Office/如何在Ubuntu Server上通过NFS挂载Synology NAS上的共享文件夹.md]]
+
+## Summary(用中文描述)
+- 核心主题:通过 NFS 协议将 Synology NAS 的共享文件夹挂载到 Ubuntu Server,实现永久性网络存储挂载
+- 问题域:Ubuntu 服务器与 Synology NAS 之间的网络存储集成,适用于备份场景
+- 方法/机制:
+ - Synology DSM 控制面板配置 NFS 权限(IP白名单、Squash 映射为 admin、_netdev 参数)
+ - Ubuntu 端安装 `nfs-common`,使用 `mount -t nfs` 临时挂载
+ - 通过 `/etc/fstab` 配置永久挂载,含 `timeo=900`、`retrans=5`、`_netdev` 等参数
+ - rsync 脚本中加入挂载点检测保护,防止 NAS 掉线时数据写入本地
+- 结论/价值:相比 Samba,NFS 能保留 Linux 文件权限(uid/gid),避免 Docker 卷恢复时的权限报错,是 Linux 服务器挂载 NAS 的标准方案
+
+## Key Claims(用中文描述)
+- Synology NAS 的 Squash 设置"映射所有用户为 admin",可将 Ubuntu 端 root 请求在 NAS 端以 admin 身份执行,绕过 Linux 权限校验
+- `/etc/fstab` 中的 `_netdev` 参数可防止开机时网络未就绪导致系统挂起
+- NFS 相比 Samba 在处理 Docker 配置文件(大量小文件)时性能更强
+- rsync 脚本中加入挂载点检查,可在 NAS 掉线时主动终止备份,防止数据写入本地目录
+
+## Key Quotes
+> "NFS 能完美保留(Linux 文件所有权信息),而 Samba 会丢失,导致恢复 Docker 卷时权限报错" — NFS 相对 Samba 的核心优势说明
+
+> "_netdev:告诉系统这是一个网络设备,务必等到网络服务完全启动后再尝试挂载,防止开机过程因找不到网络而卡死" — fstab 中 _netdev 参数的关键作用
+
+> "如果 `sudo mount -a` 没有报错,且 `df` 能看到 NAS 空间,那么以后重启服务器,挂载都会自动生效" — 永久挂载验证方法
+
+## Key Concepts
+- [[NFS]]:Network File System,Linux/Unix 标准的网络文件系统协议,支持保留原始 uid/gid 权限
+- [[/etc/fstab]]:Linux 文件系统表,用于配置开机自动挂载;`_netdev` 参数确保网络设备就绪后再挂载
+- [[rsync]]:增量备份工具,可配合 NFS 挂载点实现服务器到 NAS 的自动化备份
+- [[Squash]]:NFS 权限设置中的用户映射选项,"映射所有用户为 admin" 可简化跨平台权限问题
+
+## Key Entities
+- [[Synology NAS]]:群晖网络附加存储设备,提供 DSM 管理界面和 NFS 共享服务;本文示例 IP:192.168.3.17,挂载路径:/volume2/backup
+- [[Ubuntu Server]]:Linux 服务器操作系统,本文版本为 Ubuntu 24.04;示例 IP:192.168.3.47,挂载点:/mnt/nas_backup
+
+## Connections
+- [[Ubuntu服务器通过rsync实现日常增量备份]] ← depends_on ← [[如何在Ubuntu Server上通过NFS挂载Synology NAS上的共享文件夹]](rsync 备份依赖 NFS 挂载的 NAS 存储)
+- [[群晖NAS科学上网方法]] ← related ← [[如何在Ubuntu Server上通过NFS挂载Synology NAS上的共享文件夹]](同为 Synology NAS 相关配置文档)
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/如何在ubuntu-server安装-docker-docker-compose.md b/wiki/sources/如何在ubuntu-server安装-docker-docker-compose.md
index 785be1fd..e4be4218 100644
--- a/wiki/sources/如何在ubuntu-server安装-docker-docker-compose.md
+++ b/wiki/sources/如何在ubuntu-server安装-docker-docker-compose.md
@@ -6,7 +6,7 @@ date: 2026-04-27
---
## Source File
-- [[Home Office/如何在Ubuntu Server安装 docker & docker compose.md]]
+- [[raw/Home Office/如何在Ubuntu Server安装 docker & docker compose.md]]
## Summary(用中文描述)
- 核心主题:在 Ubuntu Server 上通过 Docker 官方仓库安装 Docker Engine 和 Docker Compose V2
diff --git a/wiki/sources/如何在ubuntu上安装opencode并配置vibe-kanban.md b/wiki/sources/如何在ubuntu上安装opencode并配置vibe-kanban.md
index 29e21588..90ce60d7 100644
--- a/wiki/sources/如何在ubuntu上安装opencode并配置vibe-kanban.md
+++ b/wiki/sources/如何在ubuntu上安装opencode并配置vibe-kanban.md
@@ -7,7 +7,7 @@ last_updated: 2026-04-27
---
## Source File
-- [[Vibe Coding/如何在Ubuntu上安装opencode并配置Vibe-Kanban.md]]
+- [[raw/Vibe Coding/如何在Ubuntu上安装opencode并配置Vibe-Kanban.md]]
## Summary(用中文描述)
- 核心主题:OpenCode AI 编程代理的安装、配置与使用完整指南
diff --git a/wiki/sources/如何在项目里安装claude-code-templates-skills.md b/wiki/sources/如何在项目里安装claude-code-templates-skills.md
index 4473a6d3..e35fbea2 100644
--- a/wiki/sources/如何在项目里安装claude-code-templates-skills.md
+++ b/wiki/sources/如何在项目里安装claude-code-templates-skills.md
@@ -1,41 +1,41 @@
----
-title: "如何在项目里安装Claude Code Templates Skills"
-type: source
-tags: [claude-code, claude-skills, trae]
-date: 2026-04-22
----
-
-## Source File
-- [[Vibe Coding/如何在项目里安装Claude-Code-Templates Skills]]
-
-## Summary(用中文描述)
-- 核心主题:如何在项目目录中通过 npx 命令安装 Claude Code Templates 的 Skills
-- 问题域:Claude Code 增强工具的快速集成方式
-- 方法/机制:使用 `npx claude-code-templates@latest --skill= --yes` 命令直接安装社区维护的 Skills、Agents、MCP 模板
-- 结论/价值:无需手动复制粘贴,通过 npm 一键为 Claude Code 项目注入预设的专业能力模板
-
-## Key Claims(用中文描述)
-- Claude Code Templates 通过 npm 包 `claude-code-templates` 提供可复用的 Skills、Agents、MCP 模板库
-- 开发者进入项目目录后执行一条 npx 命令即可完成安装,无需手动配置
-- Templates 涵盖三个主要分类:Skills(技能)、Agents(代理)、MCP(Model Context Protocol 工具)
-
-## Key Quotes
-> "直接进入项目目录后执行 `npx` 命令" — claude-code-templates 的核心安装方式
-
-## Key Concepts
-- [[Claude Code Templates]]:通过 npm 分发的 Claude Code 增强模板库,包含预配置的 Skills、Agents、MCP 工具
-- [[Claude Code Skills]]:Claude Code 的可复用能力单元,以结构化模板形式封装专业工作流
-- [[MCP(Model Context Protocol)]]:Claude Code Templates 提供的一类模板,用于扩展 AI 的工具调用能力
-
-## Key Entities
-- [[Claude Code]]:Anthropic CLI 编码代理,本文档的目标增强工具
-- [[aitmpl.com]]:Claude Code Templates 的官方模板展示网站,提供 Skills/Agents/MCP 三大类模板浏览
-- [[Trae]]:国产 AI 增强型 IDE,也支持 Claude Code Templates 的集成方式
-
-## Connections
-- [[Claude Code调用方法总结]] ← related_to ← [[如何在项目里安装claude-code-templates-skills]]
-- [[Vibe Coding经验收集]] ← related_to ← [[如何在项目里安装claude-code-templates-skills]]
-- [[3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式]] ← extends ← [[Claude Code Skills]]
-
-## Contradictions
-- 无已知冲突内容
+---
+title: "如何在项目里安装Claude Code Templates Skills"
+type: source
+tags: [claude-code, claude-skills, trae]
+date: 2026-04-22
+---
+
+## Source File
+- [[raw/Vibe Coding/如何在项目里安装Claude-Code-Templates Skills.md]]
+
+## Summary(用中文描述)
+- 核心主题:如何在项目目录中通过 npx 命令安装 Claude Code Templates 的 Skills
+- 问题域:Claude Code 增强工具的快速集成方式
+- 方法/机制:使用 `npx claude-code-templates@latest --skill= --yes` 命令直接安装社区维护的 Skills、Agents、MCP 模板
+- 结论/价值:无需手动复制粘贴,通过 npm 一键为 Claude Code 项目注入预设的专业能力模板
+
+## Key Claims(用中文描述)
+- Claude Code Templates 通过 npm 包 `claude-code-templates` 提供可复用的 Skills、Agents、MCP 模板库
+- 开发者进入项目目录后执行一条 npx 命令即可完成安装,无需手动配置
+- Templates 涵盖三个主要分类:Skills(技能)、Agents(代理)、MCP(Model Context Protocol 工具)
+
+## Key Quotes
+> "直接进入项目目录后执行 `npx` 命令" — claude-code-templates 的核心安装方式
+
+## Key Concepts
+- [[Claude Code Templates]]:通过 npm 分发的 Claude Code 增强模板库,包含预配置的 Skills、Agents、MCP 工具
+- [[Claude Code Skills]]:Claude Code 的可复用能力单元,以结构化模板形式封装专业工作流
+- [[MCP(Model Context Protocol)]]:Claude Code Templates 提供的一类模板,用于扩展 AI 的工具调用能力
+
+## Key Entities
+- [[Claude Code]]:Anthropic CLI 编码代理,本文档的目标增强工具
+- [[aitmpl.com]]:Claude Code Templates 的官方模板展示网站,提供 Skills/Agents/MCP 三大类模板浏览
+- [[Trae]]:国产 AI 增强型 IDE,也支持 Claude Code Templates 的集成方式
+
+## Connections
+- [[Claude Code调用方法总结]] ← related_to ← [[如何在项目里安装claude-code-templates-skills]]
+- [[Vibe Coding经验收集]] ← related_to ← [[如何在项目里安装claude-code-templates-skills]]
+- [[3-2-万人收藏的-claude-skills-才是-ai-这条路上最值得研究的一套范式]] ← extends ← [[Claude Code Skills]]
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/如何用指纹浏览器安全注册并订阅claude-pro会员全攻略.md b/wiki/sources/如何用指纹浏览器安全注册并订阅claude-pro会员全攻略.md
index 66d7779a..ed108a46 100644
--- a/wiki/sources/如何用指纹浏览器安全注册并订阅claude-pro会员全攻略.md
+++ b/wiki/sources/如何用指纹浏览器安全注册并订阅claude-pro会员全攻略.md
@@ -1,53 +1,53 @@
----
-title: "如何用指纹浏览器安全注册并订阅Claude Pro会员全攻略"
-type: source
-tags: [adspower, claude, ip, pingme]
-date: 2025-12-31
----
-
-## Source File
-- [[Home Office/如何用指纹浏览器安全注册并订阅Claude Pro会员全攻略]]
-
-## Summary(用中文描述)
-- 核心主题:通过指纹浏览器 + 高纯净度代理IP + 接码平台 + 虚拟信用卡,实现安全注册并订阅 Claude Pro,避免账号被封。
-- 问题域:国内用户注册 Claude 账号面临的IP关联、支付限制、验证码接收三大障碍。
-- 方法/机制:
- - AdsPower 指纹浏览器创建隔离浏览器环境,模拟不同设备和IP
- - SOCKS5 代理 + 多网站IP一致性检测 + Scamalytics 纯净度评估
- - PingMe 接码平台获取美国长期有效手机号
- - WildCard 虚拟信用卡解决跨境支付
-- 结论/价值:掌握完整流程可有效降低封号风险,稳定使用 Claude Pro 会员服务。
-
-## Key Claims(用中文描述)
-- 使用本地浏览器直接访问 Claude 会暴露设备和IP特征,导致账号关联被封。
-- 代理IP在多个检测网站测试结果不一致时,会被平台判定为异常。
-- IP纯净度"中等风险"或更高的IP大幅增加封号风险,必须使用低风险IP。
-- 一次性接码号码不稳定,易导致账号绑定失败。
-- 国内信用卡无法完成 Claude Pro 支付,必须使用虚拟信用卡。
-
-## Key Quotes
-> "AdsPower指纹浏览器,支持谷歌授权登录,提供客户端体验完整功能。" — 工具推荐
-> "代理设置成功后,用检查代理功能确认IP归属地为美国,实现代理连接成功。" — IP验证步骤
-> "通过访问多个IP检测网站,确认测试点国内、国外和谷歌三处IP保持高度一致,保证IP稳定性。" — IP一致性检测
-> "重要的IP风险评估,理想纯净度为'低风险',数值越低越安全。中等风险或以上可能被封号。" — Scamalytics纯净度评估
-> "手机验证码推荐用新兴接码平台PingMe,支持中文界面,需下载App,用手机号注册并充值最低2美元。" — 接码平台推荐
-> "国内信用卡无法支付,推荐使用WildCard虚拟信用卡解决跨境支付难题。" — 支付方案
-
-## Key Concepts
-- [[指纹浏览器]]:一种可模拟不同设备、网络环境的多账号浏览器,通过隔离使用环境减少账号关联风险。
-- [[SOCKS5代理]]:一种网络代理协议,支持灵活的传输隧道,有助于隐匿真实IP和地理位置。
-- [[IP纯净度]]:通过Scamalytics等平台评估IP风险等级,低风险代表良好信誉和较少异常记录。
-- [[接码平台]]:提供短信接码服务的应用或网站,支持接收短消息以完成注册或验证。
-
-## Key Entities
-- [[AdsPower]]:推荐使用的指纹浏览器,支持Chrome授权登录,免费可用5个环境。
-- [[PingMe]]:新兴接码平台,支持中文界面,需App注册,最低充值2美元,提供美国长期号码。
-- [[WildCard]]:虚拟信用卡,支持支付宝充值,用于解决Claude Pro海外支付。
-
-## Connections
-- Claude Pro ← 订阅目标 ← [[指纹浏览器]](环境隔离)+ [[SOCKS5代理]](IP隐匿)+ [[WildCard]](支付解决)
-- [[接码平台]] ← 支持注册 ← Claude
-- [[IP纯净度]] ← 评估工具 ← Scamalytics
-
-## Contradictions
-- 无已知冲突页面。
+---
+title: "如何用指纹浏览器安全注册并订阅Claude Pro会员全攻略"
+type: source
+tags: [adspower, claude, ip, pingme]
+date: 2025-12-31
+---
+
+## Source File
+- [[raw/Home Office/如何用指纹浏览器安全注册并订阅Claude Pro会员全攻略.md]]
+
+## Summary(用中文描述)
+- 核心主题:通过指纹浏览器 + 高纯净度代理IP + 接码平台 + 虚拟信用卡,实现安全注册并订阅 Claude Pro,避免账号被封。
+- 问题域:国内用户注册 Claude 账号面临的IP关联、支付限制、验证码接收三大障碍。
+- 方法/机制:
+ - AdsPower 指纹浏览器创建隔离浏览器环境,模拟不同设备和IP
+ - SOCKS5 代理 + 多网站IP一致性检测 + Scamalytics 纯净度评估
+ - PingMe 接码平台获取美国长期有效手机号
+ - WildCard 虚拟信用卡解决跨境支付
+- 结论/价值:掌握完整流程可有效降低封号风险,稳定使用 Claude Pro 会员服务。
+
+## Key Claims(用中文描述)
+- 使用本地浏览器直接访问 Claude 会暴露设备和IP特征,导致账号关联被封。
+- 代理IP在多个检测网站测试结果不一致时,会被平台判定为异常。
+- IP纯净度"中等风险"或更高的IP大幅增加封号风险,必须使用低风险IP。
+- 一次性接码号码不稳定,易导致账号绑定失败。
+- 国内信用卡无法完成 Claude Pro 支付,必须使用虚拟信用卡。
+
+## Key Quotes
+> "AdsPower指纹浏览器,支持谷歌授权登录,提供客户端体验完整功能。" — 工具推荐
+> "代理设置成功后,用检查代理功能确认IP归属地为美国,实现代理连接成功。" — IP验证步骤
+> "通过访问多个IP检测网站,确认测试点国内、国外和谷歌三处IP保持高度一致,保证IP稳定性。" — IP一致性检测
+> "重要的IP风险评估,理想纯净度为'低风险',数值越低越安全。中等风险或以上可能被封号。" — Scamalytics纯净度评估
+> "手机验证码推荐用新兴接码平台PingMe,支持中文界面,需下载App,用手机号注册并充值最低2美元。" — 接码平台推荐
+> "国内信用卡无法支付,推荐使用WildCard虚拟信用卡解决跨境支付难题。" — 支付方案
+
+## Key Concepts
+- [[指纹浏览器]]:一种可模拟不同设备、网络环境的多账号浏览器,通过隔离使用环境减少账号关联风险。
+- [[SOCKS5代理]]:一种网络代理协议,支持灵活的传输隧道,有助于隐匿真实IP和地理位置。
+- [[IP纯净度]]:通过Scamalytics等平台评估IP风险等级,低风险代表良好信誉和较少异常记录。
+- [[接码平台]]:提供短信接码服务的应用或网站,支持接收短消息以完成注册或验证。
+
+## Key Entities
+- [[AdsPower]]:推荐使用的指纹浏览器,支持Chrome授权登录,免费可用5个环境。
+- [[PingMe]]:新兴接码平台,支持中文界面,需App注册,最低充值2美元,提供美国长期号码。
+- [[WildCard]]:虚拟信用卡,支持支付宝充值,用于解决Claude Pro海外支付。
+
+## Connections
+- Claude Pro ← 订阅目标 ← [[指纹浏览器]](环境隔离)+ [[SOCKS5代理]](IP隐匿)+ [[WildCard]](支付解决)
+- [[接码平台]] ← 支持注册 ← Claude
+- [[IP纯净度]] ← 评估工具 ← Scamalytics
+
+## Contradictions
+- 无已知冲突页面。
diff --git a/wiki/sources/安装v2rayn.md b/wiki/sources/安装v2rayn.md
index 6f877c16..b8662af5 100644
--- a/wiki/sources/安装v2rayn.md
+++ b/wiki/sources/安装v2rayn.md
@@ -1,48 +1,48 @@
----
-title: "安装v2rayN"
-type: source
-tags: [linux, v2rayn, windows]
-date: 2026-05-14
----
-
-## Source File
-- [[Home Office/安装v2rayN.md]]
-
-## Summary(用中文描述)
-- 核心主题:v2rayN 跨平台代理工具的各操作系统安装包说明与安装方法
-- 问题域:用户在不同操作系统(Windows、Linux、macOS)上安装 v2rayN 客户端的需求
-- 方法/机制:通过官方提供的便携版(zip)和安装版(deb/rpm/dmg)两种方式覆盖不同使用场景;内置 Xray、sing-box、mihomo 核心;支持 x64 和 ARM64 架构
-- 结论/价值:提供了清晰的跨平台安装指引,用户可根据系统和架构选择对应包
-
-## Key Claims(用中文描述)
-- v2rayN 发布包内置部分 Core(Xray、sing-box、mihomo),其他 Core 需自行下载
-- zip 格式为便携版,解压即用,文件存储在程序文件夹,可复制多份互相独立
-- Windows 版需要 Windows 10+;x64 版提供 WPF 界面(需 .NET 8.0 Runtime)和 Avalonia UI 界面两种选择
-- Linux 版支持 Debian 12+、Ubuntu 22.04+、Fedora 36+、Redhat 9+;提供 zip 便携版和 deb/rpm 安装版
-- macOS 版支持 macOS 12+;dmg 安装包因无签名会提示"应用已损坏",需执行 `xattr -cr` 修复
-- ARM64 架构在 Windows、Linux、macOS 上均有对应包
-
-## Key Quotes
-> "zip格式包为便携版,解压缩到文件夹后直接可以运行,存储文件位置为本文件夹;可以复制多份互相独立" — 便携版特性说明
-> "v2rayN-windows-64-desktop.zip Avalonia UI 实现的界面" — WPF vs Avalonia 区别
-> "由于安装包没有签名,会提示应用已损坏;安装后需要运行:xattr -cr /Applications/v2rayN.app" — macOS dmg 安装后必须操作
-
-## Key Concepts
-- [[代理客户端]]:运行代理协议的桌面/服务器端程序,接收本地流量并转发至远程服务器
-- [[代理核心 Core]]:代理客户端的内核引擎,负责实际的协议通信;v2rayN 支持 Xray、sing-box、mihomo 等多种核心
-- [[跨平台兼容]]:同一软件支持 Windows、Linux、macOS 多操作系统
-- [[ARM64 架构支持]]:支持 Apple Silicon、ARM 服务器等 ARM64 硬件平台
-
-## Key Entities
-- [[v2rayN]]:2dust 开发的跨平台代理客户端,支持多种代理协议和多个代理核心
-- [[Xray]]:代理核心之一,内置于 v2rayN 发布包
-- [[sing-box]]:代理核心之一,内置于 v2rayN 发布包
-- [[mihomo]]:代理核心(Clash.Meta)之一,内置于 v2rayN 发布包
-- [[Microsoft .NET 8.0 Desktop Runtime]]:Windows WPF 版 v2rayN 的运行时依赖
-
-## Connections
-- [[3X-UI Xray on BandwagonVPS]] ← relates_to ← [[安装v2rayn]](均涉及 Xray/代理工具生态)
-- [[Ubuntu Server科学上网]] ← extends ← [[安装v2rayn]](Linux 服务器端科学上网的客户端安装参考)
-
-## Contradictions
-- 无已知冲突
+---
+title: "安装v2rayN"
+type: source
+tags: [linux, v2rayn, windows]
+date: 2026-05-14
+---
+
+## Source File
+- [[raw/Home Office/安装v2rayN.md]]
+
+## Summary(用中文描述)
+- 核心主题:v2rayN 跨平台代理工具的各操作系统安装包说明与安装方法
+- 问题域:用户在不同操作系统(Windows、Linux、macOS)上安装 v2rayN 客户端的需求
+- 方法/机制:通过官方提供的便携版(zip)和安装版(deb/rpm/dmg)两种方式覆盖不同使用场景;内置 Xray、sing-box、mihomo 核心;支持 x64 和 ARM64 架构
+- 结论/价值:提供了清晰的跨平台安装指引,用户可根据系统和架构选择对应包
+
+## Key Claims(用中文描述)
+- v2rayN 发布包内置部分 Core(Xray、sing-box、mihomo),其他 Core 需自行下载
+- zip 格式为便携版,解压即用,文件存储在程序文件夹,可复制多份互相独立
+- Windows 版需要 Windows 10+;x64 版提供 WPF 界面(需 .NET 8.0 Runtime)和 Avalonia UI 界面两种选择
+- Linux 版支持 Debian 12+、Ubuntu 22.04+、Fedora 36+、Redhat 9+;提供 zip 便携版和 deb/rpm 安装版
+- macOS 版支持 macOS 12+;dmg 安装包因无签名会提示"应用已损坏",需执行 `xattr -cr` 修复
+- ARM64 架构在 Windows、Linux、macOS 上均有对应包
+
+## Key Quotes
+> "zip格式包为便携版,解压缩到文件夹后直接可以运行,存储文件位置为本文件夹;可以复制多份互相独立" — 便携版特性说明
+> "v2rayN-windows-64-desktop.zip Avalonia UI 实现的界面" — WPF vs Avalonia 区别
+> "由于安装包没有签名,会提示应用已损坏;安装后需要运行:xattr -cr /Applications/v2rayN.app" — macOS dmg 安装后必须操作
+
+## Key Concepts
+- [[代理客户端]]:运行代理协议的桌面/服务器端程序,接收本地流量并转发至远程服务器
+- [[代理核心 Core]]:代理客户端的内核引擎,负责实际的协议通信;v2rayN 支持 Xray、sing-box、mihomo 等多种核心
+- [[跨平台兼容]]:同一软件支持 Windows、Linux、macOS 多操作系统
+- [[ARM64 架构支持]]:支持 Apple Silicon、ARM 服务器等 ARM64 硬件平台
+
+## Key Entities
+- [[v2rayN]]:2dust 开发的跨平台代理客户端,支持多种代理协议和多个代理核心
+- [[Xray]]:代理核心之一,内置于 v2rayN 发布包
+- [[sing-box]]:代理核心之一,内置于 v2rayN 发布包
+- [[mihomo]]:代理核心(Clash.Meta)之一,内置于 v2rayN 发布包
+- [[Microsoft .NET 8.0 Desktop Runtime]]:Windows WPF 版 v2rayN 的运行时依赖
+
+## Connections
+- [[3X-UI Xray on BandwagonVPS]] ← relates_to ← [[安装v2rayn]](均涉及 Xray/代理工具生态)
+- [[Ubuntu Server科学上网]] ← extends ← [[安装v2rayn]](Linux 服务器端科学上网的客户端安装参考)
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/实战笔记-本地部署-rsshub-并获取-youtube-订阅.md b/wiki/sources/实战笔记-本地部署-rsshub-并获取-youtube-订阅.md
index 255cc94f..102f5980 100644
--- a/wiki/sources/实战笔记-本地部署-rsshub-并获取-youtube-订阅.md
+++ b/wiki/sources/实战笔记-本地部署-rsshub-并获取-youtube-订阅.md
@@ -1,51 +1,51 @@
----
-title: "实战笔记:本地部署 RSSHub 并获取 YouTube 订阅"
-type: source
-tags: ["Home Office", "RSSHub", "YouTube", "Docker"]
-date: 2026-04-21
----
-
-## Source File
-- [[Home Office/实战笔记:本地部署 RSSHub 并获取 YouTube 订阅]]
-
-## Summary(用中文描述)
-- 核心主题:本地自托管 RSSHub 并通过其生成 YouTube 频道 RSS 订阅源
-- 问题域:YouTube 官方不直接提供 RSS,且第三方在线 RSS 服务不稳定
-- 方法/机制:
- - Docker Compose 一键部署 RSSHub(port 1200)
- - 获取 YouTube 频道 ID(浏览器 view-source 方式)
- - RSSHub 路由格式 `/youtube/channel/{channel_id}` 生成 RSS 源
- - 支持订阅列表监控
-- 结论/价值:完全自托管,稳定可靠,绕过 YouTube 官方限制
-
-## Key Claims(用中文描述)
-- RSSHub Docker 部署命令:`docker run -d --name rsshub -p 1200:1200 diygod/rsshub`
-- YouTube 频道 ID 获取方式:浏览器访问频道页面 URL,`view-source:` 查看源码搜索 `channel_id`
-- RSSHub YouTube RSS 路由:`http://localhost:1200/youtube/channel/{channel_id}`
-- 支持订阅列表路由:`/youtube/channel/{channel_id}/videos` 获取该频道视频列表
-
-## Key Quotes
-> "RSSHub 是一个开源、简单易用、方便扩展的 RSS 生成器" — RSSHub 官方定位
-
-> "获取 YouTube 频道 ID 的方法:访问频道页面 → view-source → 搜索 channel_id" — 频道 ID 获取技巧
-
-## Key Concepts
-- [[RSSHub]]:开源 RSS 聚合生成器,可为不支持 RSS 的网站生成订阅源
-- [[Docker]]:容器化平台,RSSHub 通过 Docker 一键部署
-- [[RSS]]:Really Simple Syndication,网站内容聚合订阅协议
-
-## Key Entities
-- [[diygod]](DIYgod):RSSHub 项目的主要维护者,Docker 镜像 `diygod/rsshub` 的发布者
-- [[YouTube]]:视频平台,本场景的 RSS 订阅目标
-
-## Connections
-- [[RSSHub]] ← 使用 Docker 部署 ← [[Docker]]
-- [[RSSHub]] ← 为 [[YouTube]] 生成 RSS ← [[YouTube Content Pipeline]]
-- [[YouTube Content Pipeline]] ← 依赖 RSS 监控 ← [[RSSHub]]
-
-## Contradictions
-- 与 [[How to Get the RSS Feed For Any YouTube Channel]] 略有差异:
- - 冲突点:在线获取 vs 本地生成
- - 当前观点:本地 RSSHub 部署更稳定可靠
- - 对方观点:在线服务无需维护,适合临时使用
- - 结论:两者互补使用——RSSHub 主用 + 在线工具备用
+---
+title: "实战笔记:本地部署 RSSHub 并获取 YouTube 订阅"
+type: source
+tags: ["Home Office", "RSSHub", "YouTube", "Docker"]
+date: 2026-04-21
+---
+
+## Source File
+- [[raw/Home Office/实战笔记:本地部署 RSSHub 并获取 YouTube 订阅.md]]
+
+## Summary(用中文描述)
+- 核心主题:本地自托管 RSSHub 并通过其生成 YouTube 频道 RSS 订阅源
+- 问题域:YouTube 官方不直接提供 RSS,且第三方在线 RSS 服务不稳定
+- 方法/机制:
+ - Docker Compose 一键部署 RSSHub(port 1200)
+ - 获取 YouTube 频道 ID(浏览器 view-source 方式)
+ - RSSHub 路由格式 `/youtube/channel/{channel_id}` 生成 RSS 源
+ - 支持订阅列表监控
+- 结论/价值:完全自托管,稳定可靠,绕过 YouTube 官方限制
+
+## Key Claims(用中文描述)
+- RSSHub Docker 部署命令:`docker run -d --name rsshub -p 1200:1200 diygod/rsshub`
+- YouTube 频道 ID 获取方式:浏览器访问频道页面 URL,`view-source:` 查看源码搜索 `channel_id`
+- RSSHub YouTube RSS 路由:`http://localhost:1200/youtube/channel/{channel_id}`
+- 支持订阅列表路由:`/youtube/channel/{channel_id}/videos` 获取该频道视频列表
+
+## Key Quotes
+> "RSSHub 是一个开源、简单易用、方便扩展的 RSS 生成器" — RSSHub 官方定位
+
+> "获取 YouTube 频道 ID 的方法:访问频道页面 → view-source → 搜索 channel_id" — 频道 ID 获取技巧
+
+## Key Concepts
+- [[RSSHub]]:开源 RSS 聚合生成器,可为不支持 RSS 的网站生成订阅源
+- [[Docker]]:容器化平台,RSSHub 通过 Docker 一键部署
+- [[RSS]]:Really Simple Syndication,网站内容聚合订阅协议
+
+## Key Entities
+- [[diygod]](DIYgod):RSSHub 项目的主要维护者,Docker 镜像 `diygod/rsshub` 的发布者
+- [[YouTube]]:视频平台,本场景的 RSS 订阅目标
+
+## Connections
+- [[RSSHub]] ← 使用 Docker 部署 ← [[Docker]]
+- [[RSSHub]] ← 为 [[YouTube]] 生成 RSS ← [[YouTube Content Pipeline]]
+- [[YouTube Content Pipeline]] ← 依赖 RSS 监控 ← [[RSSHub]]
+
+## Contradictions
+- 与 [[How to Get the RSS Feed For Any YouTube Channel]] 略有差异:
+ - 冲突点:在线获取 vs 本地生成
+ - 当前观点:本地 RSSHub 部署更稳定可靠
+ - 对方观点:在线服务无需维护,适合临时使用
+ - 结论:两者互补使用——RSSHub 主用 + 在线工具备用
diff --git a/wiki/sources/家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox.md b/wiki/sources/家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox.md
index 4a17355c..f4397483 100644
--- a/wiki/sources/家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox.md
+++ b/wiki/sources/家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox.md
@@ -1,61 +1,61 @@
----
-title: "家庭监控方案:Prometheus + Grafana + Node Exporter + cAdvisor + Blackbox"
-type: source
-tags: [prometheus, grafana, monitoring, docker, home-server]
-date: 2025-11-11
----
-
-## Source File
-- [[Home Office/家庭监控方案:Prometheus + Grafana + Node Exporter + cAdvisor +Blackbox]]
-
-## Summary(用中文描述)
-- 核心主题:家庭/小型服务器监控的完整 Docker 化解决方案
-- 问题域:主机层、容器层、服务层的可观测性覆盖,以及告警通知渠道
-- 方法/机制:Prometheus 拉取模式采集 + Grafana 可视化 + Alertmanager 告警分发;通过 node_exporter、cAdvisor、blackbox_exporter 三个 exporter 覆盖主机、容器和网络探测;提供可直接拷贝的 docker-compose 完整模板
-- 结论/价值:面向 NAS / Ubuntu Server 用户的零门槛可落地监控栈,含具体 PromQL 告警规则和 Grafana Dashboard ID
-
-## Key Claims(用中文描述)
-- Prometheus + node_exporter + cAdvisor + blackbox_exporter + Grafana + Alertmanager 的组合可覆盖家庭服务器的完整监控面
-- 主机层监控 CPU / 内存 / 磁盘 / 网络 / I/O / inode,容器层监控运行状态、重启次数、资源使用,服务层监控 HTTP 可用性、响应码、延迟、TLS 证书到期、DNS 解析
-- TLS 证书剩余天数 < 14 天应触发告警
-- 黑箱探测 `probe_success == 0` 连续 3 次应触发告警
-- Docker socket 挂载存在宿主机 root 等效权限风险,需审慎处理
-- Grafana 官方 Dashboard ID:Node Exporter Full (`1860`)、cAdvisor Container Metrics (`14282`)、Blackbox Exporter Probe (`7587`)
-
-## Key Quotes
-> "Docker socket 挂载存在宿主机 root 等效权限风险" — 容器安全注意事项
-> "Prometheus 本地磁盘会增长,考虑长期保留要用远端存储或定期 snapshot" — 存储注意事项
-> "Grafana 仪表盘 JSON 导出,Prometheus rule 与配置放在 Git(GitOps)" — 备份最佳实践
-> "把容器/服务启动时打上 service=xxx、env=prod 标签,便于 PromQL 分组和 SLA 报表" — 标签化运维建议
-
-## Key Concepts
-- [[Prometheus]]:开源时序数据库 + 监控系统,采用拉取(pull)模式从 exporters 采集指标
-- [[Grafana]]:跨数据源的可视化与告警平台,支持 Prometheus/Loki/VictoriaMetrics 等
-- [[Observability]](可观测性):覆盖指标(Metrics)、日志(Logs)、链路(Traces)三大支柱
-- [[Container Monitoring]](容器监控):通过 cAdvisor 采集容器资源使用、重启次数、退出码等指标
-- [[Synthetic Monitoring]](合成监控):通过 blackbox_exporter 和 Uptime Kuma 做主动式可用性探测,区别于基于真实用户流量的 RUM
-- [[Alert Management]](告警管理):Prometheus 定义告警规则 → Alertmanager 接收 → 抑制/分组/路由到邮件/Slack/Webhook/PagerDuty
-- [[Home Server Automation]]:家庭服务器的运维自动化与监控覆盖
-
-## Key Entities
-- [[Prometheus]](监控数据采集与告警规则引擎):负责从各 exporter 拉取指标并执行告警条件判断
-- [[Grafana]](可视化与告警平台):展示 Prometheus 时序数据,配置告警规则和通知渠道
-- [[Alertmanager]](Prometheus 告警分发组件):负责告警的抑制、分组、向邮件/Slack/Teams 等渠道分发
-- [[Node Exporter]](主机指标采集器):Prometheus 官方 exporter,采集 CPU/内存/磁盘/网络/文件系统指标
-- [[cAdvisor]](Google 容器指标采集器):采集容器级别的资源使用情况(CPU/内存/网络/磁盘 I/O)
-- [[Blackbox Exporter]](黑箱探测 exporter):通过 HTTP/TCP/ICMP/DNS 探测外部或内部服务端点
-- [[Uptime Kuma]](自托管可用性监控工具):开源 uptime monitoring,支持 HTTP/TCP/DNS/TLS 探测与历史记录
-- [[Netdata]](实时监控看板):开箱即用的详细实时主机/容器监控面板,默认 19999 端口
-- [[Portainer]](Docker 可视化管理平台):图形化管理 Docker 主机/Swarm,带监控/日志功能
-
-## Connections
-- [[Prometheus]] ← scrape_configs ← [[Node Exporter]]
-- [[Prometheus]] ← scrape_configs ← [[cAdvisor]]
-- [[Prometheus]] ← scrape_configs ← [[Blackbox Exporter]]
-- [[Prometheus]] ← sends alerts ← [[Alertmanager]]
-- [[Grafana]] ← datasource ← [[Prometheus]]
-- [[Grafana]] ← dashboards ← [[Node Exporter]], [[cAdvisor]], [[Blackbox Exporter]]
-- [[家庭网络环境概览]] ← provides context for ← [[Home Server Automation]]
-
-## Contradictions
-- 与 [[Uptime Kuma]] 描述存在侧重差异:源文档将 Uptime Kuma 定位为"合成监控补充工具"与 blackbox_exporter 并列,实际部署中两者均可独立完成 HTTP/TLS 探测,Uptime Kuma 更适合做外网监控(无公网 IP 时),blackbox_exporter 更适合内网和更细粒度的 PromQL 告警集成
+---
+title: "家庭监控方案:Prometheus + Grafana + Node Exporter + cAdvisor + Blackbox"
+type: source
+tags: [prometheus, grafana, monitoring, docker, home-server]
+date: 2025-11-11
+---
+
+## Source File
+- [[raw/Home Office/家庭监控方案:Prometheus + Grafana + Node Exporter + cAdvisor +Blackbox.md]]
+
+## Summary(用中文描述)
+- 核心主题:家庭/小型服务器监控的完整 Docker 化解决方案
+- 问题域:主机层、容器层、服务层的可观测性覆盖,以及告警通知渠道
+- 方法/机制:Prometheus 拉取模式采集 + Grafana 可视化 + Alertmanager 告警分发;通过 node_exporter、cAdvisor、blackbox_exporter 三个 exporter 覆盖主机、容器和网络探测;提供可直接拷贝的 docker-compose 完整模板
+- 结论/价值:面向 NAS / Ubuntu Server 用户的零门槛可落地监控栈,含具体 PromQL 告警规则和 Grafana Dashboard ID
+
+## Key Claims(用中文描述)
+- Prometheus + node_exporter + cAdvisor + blackbox_exporter + Grafana + Alertmanager 的组合可覆盖家庭服务器的完整监控面
+- 主机层监控 CPU / 内存 / 磁盘 / 网络 / I/O / inode,容器层监控运行状态、重启次数、资源使用,服务层监控 HTTP 可用性、响应码、延迟、TLS 证书到期、DNS 解析
+- TLS 证书剩余天数 < 14 天应触发告警
+- 黑箱探测 `probe_success == 0` 连续 3 次应触发告警
+- Docker socket 挂载存在宿主机 root 等效权限风险,需审慎处理
+- Grafana 官方 Dashboard ID:Node Exporter Full (`1860`)、cAdvisor Container Metrics (`14282`)、Blackbox Exporter Probe (`7587`)
+
+## Key Quotes
+> "Docker socket 挂载存在宿主机 root 等效权限风险" — 容器安全注意事项
+> "Prometheus 本地磁盘会增长,考虑长期保留要用远端存储或定期 snapshot" — 存储注意事项
+> "Grafana 仪表盘 JSON 导出,Prometheus rule 与配置放在 Git(GitOps)" — 备份最佳实践
+> "把容器/服务启动时打上 service=xxx、env=prod 标签,便于 PromQL 分组和 SLA 报表" — 标签化运维建议
+
+## Key Concepts
+- [[Prometheus]]:开源时序数据库 + 监控系统,采用拉取(pull)模式从 exporters 采集指标
+- [[Grafana]]:跨数据源的可视化与告警平台,支持 Prometheus/Loki/VictoriaMetrics 等
+- [[Observability]](可观测性):覆盖指标(Metrics)、日志(Logs)、链路(Traces)三大支柱
+- [[Container Monitoring]](容器监控):通过 cAdvisor 采集容器资源使用、重启次数、退出码等指标
+- [[Synthetic Monitoring]](合成监控):通过 blackbox_exporter 和 Uptime Kuma 做主动式可用性探测,区别于基于真实用户流量的 RUM
+- [[Alert Management]](告警管理):Prometheus 定义告警规则 → Alertmanager 接收 → 抑制/分组/路由到邮件/Slack/Webhook/PagerDuty
+- [[Home Server Automation]]:家庭服务器的运维自动化与监控覆盖
+
+## Key Entities
+- [[Prometheus]](监控数据采集与告警规则引擎):负责从各 exporter 拉取指标并执行告警条件判断
+- [[Grafana]](可视化与告警平台):展示 Prometheus 时序数据,配置告警规则和通知渠道
+- [[Alertmanager]](Prometheus 告警分发组件):负责告警的抑制、分组、向邮件/Slack/Teams 等渠道分发
+- [[Node Exporter]](主机指标采集器):Prometheus 官方 exporter,采集 CPU/内存/磁盘/网络/文件系统指标
+- [[cAdvisor]](Google 容器指标采集器):采集容器级别的资源使用情况(CPU/内存/网络/磁盘 I/O)
+- [[Blackbox Exporter]](黑箱探测 exporter):通过 HTTP/TCP/ICMP/DNS 探测外部或内部服务端点
+- [[Uptime Kuma]](自托管可用性监控工具):开源 uptime monitoring,支持 HTTP/TCP/DNS/TLS 探测与历史记录
+- [[Netdata]](实时监控看板):开箱即用的详细实时主机/容器监控面板,默认 19999 端口
+- [[Portainer]](Docker 可视化管理平台):图形化管理 Docker 主机/Swarm,带监控/日志功能
+
+## Connections
+- [[Prometheus]] ← scrape_configs ← [[Node Exporter]]
+- [[Prometheus]] ← scrape_configs ← [[cAdvisor]]
+- [[Prometheus]] ← scrape_configs ← [[Blackbox Exporter]]
+- [[Prometheus]] ← sends alerts ← [[Alertmanager]]
+- [[Grafana]] ← datasource ← [[Prometheus]]
+- [[Grafana]] ← dashboards ← [[Node Exporter]], [[cAdvisor]], [[Blackbox Exporter]]
+- [[家庭网络环境概览]] ← provides context for ← [[Home Server Automation]]
+
+## Contradictions
+- 与 [[Uptime Kuma]] 描述存在侧重差异:源文档将 Uptime Kuma 定位为"合成监控补充工具"与 blackbox_exporter 并列,实际部署中两者均可独立完成 HTTP/TLS 探测,Uptime Kuma 更适合做外网监控(无公网 IP 时),blackbox_exporter 更适合内网和更细粒度的 PromQL 告警集成
diff --git a/wiki/sources/家庭网络环境概览_2026-04-03.md b/wiki/sources/家庭网络环境概览_2026-04-03.md
index 68473206..c9c93e69 100644
--- a/wiki/sources/家庭网络环境概览_2026-04-03.md
+++ b/wiki/sources/家庭网络环境概览_2026-04-03.md
@@ -7,7 +7,7 @@ last_updated: 2026-04-27
---
## Source File
-- [[Home Office/家庭网络环境概览_2026-04-03.md]]
+- [[raw/Home Office/家庭网络环境概览_2026-04-03.md]]
## Summary(用中文描述)
- 核心主题:个人家庭网络的完整基础设施架构文档,记录从公网VPS到内网五节点服务器的完整拓扑、全部应用服务清单、FRP端口映射和域名映射
diff --git a/wiki/sources/开发经验与项目规范整理文档.md b/wiki/sources/开发经验与项目规范整理文档.md
index 8a096513..8a778f44 100644
--- a/wiki/sources/开发经验与项目规范整理文档.md
+++ b/wiki/sources/开发经验与项目规范整理文档.md
@@ -1,70 +1,70 @@
----
-title: "开发经验与项目规范整理文档"
-type: source
-tags: [vibe-coding, software-engineering, best-practices, coding-standards, microservices, redis, message-queue]
-sources: []
-last_updated: 2025-12-30
----
-
-## Source File
-- [[Vibe Coding/开发经验与项目规范整理文档]]
-
-## Summary(用中文描述)
-- 核心主题:Vibe Coding 环境下的开发经验与项目规范最佳实践,涵盖编码规范、系统架构原则、程序设计思想及基础设施(微服务、Redis、消息队列)
-- 问题域:如何建立可持续维护的 AI 辅助开发项目;如何制定团队编码规范;如何通过规范提升 AI 生成的代码质量
-- 方法/机制:
- - 变量名维护方案(统一变量索引文件,格式:变量名 | 变量注释 | 出现位置 | 出现频率)
- - 文件结构与命名规范(子文件夹含 agents + claude.md;文件命名小写英文 + 下划线/小驼峰)
- - 编码规范(单一职责、DRY、模块化;消费端/生产端/状态/变换模型)
- - 并发编程规范(共享资源、数据竞争、锁机制、并发 vs 异步区分)
- - 系统架构原则(先梳理架构 → 理解需求 → 保持简单 → 自动化测试 → 小步迭代)
- - 程序设计核心思想(从问题出发、清晰命名、单一职责、可读性优先、合理注释、测试优先)
- - 微服务拆分原则(独立开发/部署/扩容,服务间通过 API 通信)
- - Redis 缓存策略(提升读性能、降低 DB 压力、提供计数/锁/队列/Session 能力)
- - 消息队列异步通信(解耦、削峰填谷、异步任务处理)
-- 结论/价值:为 AI 辅助开发项目提供系统化规范框架,强调从问题出发而非代码出发,提升代码可维护性和团队协作效率
-
-## Key Claims(用中文描述)
-- 统一变量索引文件能降低命名冲突和语义不清晰带来的风险,实现 AI 与团队全局命名一致性管理
-- 编码规范中的「消费端 → 生产端 → 状态 → 变换」模型能清晰划分系统行为边界,明确输入→处理→输出各环节
-- 系统开发应遵循「先理解需求 → 保持架构与代码简单 → 写可维护的自动化测试 → 小步迭代,不做大爆炸开发」的严谨流程
-- 编程第一步永远是「你要解决什么问题」,复杂问题拆解为可独立完成的小单元,减少复杂度、魔法代码、晦涩技巧
-- 注释解释「为什么」,而非「怎么做」;代码可读性优先,写的代码是给别人理解的,不是来炫技的
-- 未测试的代码迟早会出问题,调试是程序员核心技能,永远不要把代码只放本地
-- 微服务将系统拆解为多个独立开发、独立部署、独立扩容的服务,服务间通过 API 通信(HTTP、RPC、MQ 等)
-- Redis 通过缓存提升系统读性能、降低数据库压力,并提供计数、锁、队列、Session 等扩展能力
-- 消息队列实现服务间的异步通信,带来解耦、削峰填谷、异步任务处理等系统稳定性与吞吐收益
-
-## Key Quotes
-> "编程的第一步永远是:你要解决什么问题?" — 从问题出发而非代码
-> "你写的代码是给别人理解的,不是来炫技的。" — 代码可读性优先
-> "注释解释'为什么',不是'怎么做'。" — 合理注释原则
-> "未测试的代码迟早会出问题。" — 测试优先
-> "永远不要把代码只放本地。" — 调试是必修课
-
-## Key Concepts
-- [[单一职责原则]]:每个文件、类、函数应只负责一件事,提炼公共逻辑,避免重复代码(DRY)
-- [[DRY原则]]:Don't Repeat Yourself,避免重复代码,提高复用价值
-- [[模块化编程]]:将系统分解为独立模块,提高复用价值,函数化、类化、模块化
-- [[输入-处理-输出模型]]:明确区分消费端(接收外部数据)、生产端(生成数据/输出结果)、状态(存储当前系统信息)、变换(处理状态/改变数据的逻辑)
-- [[并发编程]]:区分共享资源、数据竞争、必要时加锁或使用线程安全结构,区分"并发处理"和"异步处理"的差异
-- [[微服务架构]]:将系统拆解为独立开发、部署、扩容的服务,服务间通过 API 通信
-- [[Redis缓存]]:作为缓存提升系统读性能,降低数据库压力,提供计数/锁/队列/Session 能力
-- [[消息队列]]:用于服务之间的异步通信,实现解耦、削峰填谷、异步任务处理
-- [[系统架构梳理]]:模块划分、输入输出、数据流向、服务边界、技术栈、依赖关系在写代码前先明确
-
-## Key Entities
-- 无特定商业实体提及,本文档为方法论文档,涵盖软件工程通用规范框架
-
-## Connections
-- [[Vibe Coding]] ← 相关领域 ← 本文:提供 AI 辅助开发的项目规范框架
-- [[单一职责原则]] ← 编码规范核心 ← [[DRY原则]] ← 模块化基础
-- [[微服务架构]] ← 服务拆分原则 ← [[Redis缓存]] ← 性能优化手段
-- [[消息队列]] ← 异步通信基础设施 ← 微服务间通信机制
-- [[输入-处理-输出模型]] ← 系统行为划分 ← [[系统架构梳理]] ← 开发前置工作
-
-## Contradictions
-- 与传统软件开发方法冲突:
- - 冲突点:传统强调"先理解代码再修改",本文强调"从问题出发而非代码出发"
- - 当前观点:Vibe Coding 环境下,AI 生成代码量大,应先明确问题再让 AI 生成,而非逐步理解 AI 生成的代码
- - 对方观点:传统软件工程强调对代码的深度理解是维护和修改的前提
+---
+title: "开发经验与项目规范整理文档"
+type: source
+tags: [vibe-coding, software-engineering, best-practices, coding-standards, microservices, redis, message-queue]
+sources: []
+last_updated: 2025-12-30
+---
+
+## Source File
+- [[raw/Vibe Coding/开发经验与项目规范整理文档.md]]
+
+## Summary(用中文描述)
+- 核心主题:Vibe Coding 环境下的开发经验与项目规范最佳实践,涵盖编码规范、系统架构原则、程序设计思想及基础设施(微服务、Redis、消息队列)
+- 问题域:如何建立可持续维护的 AI 辅助开发项目;如何制定团队编码规范;如何通过规范提升 AI 生成的代码质量
+- 方法/机制:
+ - 变量名维护方案(统一变量索引文件,格式:变量名 | 变量注释 | 出现位置 | 出现频率)
+ - 文件结构与命名规范(子文件夹含 agents + claude.md;文件命名小写英文 + 下划线/小驼峰)
+ - 编码规范(单一职责、DRY、模块化;消费端/生产端/状态/变换模型)
+ - 并发编程规范(共享资源、数据竞争、锁机制、并发 vs 异步区分)
+ - 系统架构原则(先梳理架构 → 理解需求 → 保持简单 → 自动化测试 → 小步迭代)
+ - 程序设计核心思想(从问题出发、清晰命名、单一职责、可读性优先、合理注释、测试优先)
+ - 微服务拆分原则(独立开发/部署/扩容,服务间通过 API 通信)
+ - Redis 缓存策略(提升读性能、降低 DB 压力、提供计数/锁/队列/Session 能力)
+ - 消息队列异步通信(解耦、削峰填谷、异步任务处理)
+- 结论/价值:为 AI 辅助开发项目提供系统化规范框架,强调从问题出发而非代码出发,提升代码可维护性和团队协作效率
+
+## Key Claims(用中文描述)
+- 统一变量索引文件能降低命名冲突和语义不清晰带来的风险,实现 AI 与团队全局命名一致性管理
+- 编码规范中的「消费端 → 生产端 → 状态 → 变换」模型能清晰划分系统行为边界,明确输入→处理→输出各环节
+- 系统开发应遵循「先理解需求 → 保持架构与代码简单 → 写可维护的自动化测试 → 小步迭代,不做大爆炸开发」的严谨流程
+- 编程第一步永远是「你要解决什么问题」,复杂问题拆解为可独立完成的小单元,减少复杂度、魔法代码、晦涩技巧
+- 注释解释「为什么」,而非「怎么做」;代码可读性优先,写的代码是给别人理解的,不是来炫技的
+- 未测试的代码迟早会出问题,调试是程序员核心技能,永远不要把代码只放本地
+- 微服务将系统拆解为多个独立开发、独立部署、独立扩容的服务,服务间通过 API 通信(HTTP、RPC、MQ 等)
+- Redis 通过缓存提升系统读性能、降低数据库压力,并提供计数、锁、队列、Session 等扩展能力
+- 消息队列实现服务间的异步通信,带来解耦、削峰填谷、异步任务处理等系统稳定性与吞吐收益
+
+## Key Quotes
+> "编程的第一步永远是:你要解决什么问题?" — 从问题出发而非代码
+> "你写的代码是给别人理解的,不是来炫技的。" — 代码可读性优先
+> "注释解释'为什么',不是'怎么做'。" — 合理注释原则
+> "未测试的代码迟早会出问题。" — 测试优先
+> "永远不要把代码只放本地。" — 调试是必修课
+
+## Key Concepts
+- [[单一职责原则]]:每个文件、类、函数应只负责一件事,提炼公共逻辑,避免重复代码(DRY)
+- [[DRY原则]]:Don't Repeat Yourself,避免重复代码,提高复用价值
+- [[模块化编程]]:将系统分解为独立模块,提高复用价值,函数化、类化、模块化
+- [[输入-处理-输出模型]]:明确区分消费端(接收外部数据)、生产端(生成数据/输出结果)、状态(存储当前系统信息)、变换(处理状态/改变数据的逻辑)
+- [[并发编程]]:区分共享资源、数据竞争、必要时加锁或使用线程安全结构,区分"并发处理"和"异步处理"的差异
+- [[微服务架构]]:将系统拆解为独立开发、部署、扩容的服务,服务间通过 API 通信
+- [[Redis缓存]]:作为缓存提升系统读性能,降低数据库压力,提供计数/锁/队列/Session 能力
+- [[消息队列]]:用于服务之间的异步通信,实现解耦、削峰填谷、异步任务处理
+- [[系统架构梳理]]:模块划分、输入输出、数据流向、服务边界、技术栈、依赖关系在写代码前先明确
+
+## Key Entities
+- 无特定商业实体提及,本文档为方法论文档,涵盖软件工程通用规范框架
+
+## Connections
+- [[Vibe Coding]] ← 相关领域 ← 本文:提供 AI 辅助开发的项目规范框架
+- [[单一职责原则]] ← 编码规范核心 ← [[DRY原则]] ← 模块化基础
+- [[微服务架构]] ← 服务拆分原则 ← [[Redis缓存]] ← 性能优化手段
+- [[消息队列]] ← 异步通信基础设施 ← 微服务间通信机制
+- [[输入-处理-输出模型]] ← 系统行为划分 ← [[系统架构梳理]] ← 开发前置工作
+
+## Contradictions
+- 与传统软件开发方法冲突:
+ - 冲突点:传统强调"先理解代码再修改",本文强调"从问题出发而非代码出发"
+ - 当前观点:Vibe Coding 环境下,AI 生成代码量大,应先明确问题再让 AI 生成,而非逐步理解 AI 生成的代码
+ - 对方观点:传统软件工程强调对代码的深度理解是维护和修改的前提
diff --git a/wiki/sources/我用-gemini-3-一口气做了-10-个应用-附教程.md b/wiki/sources/我用-gemini-3-一口气做了-10-个应用-附教程.md
index af2f0c5c..dc37aa15 100644
--- a/wiki/sources/我用-gemini-3-一口气做了-10-个应用-附教程.md
+++ b/wiki/sources/我用-gemini-3-一口气做了-10-个应用-附教程.md
@@ -1,52 +1,52 @@
----
-title: "我用 Gemini 3 一口气做了 10 个应用,附教程"
-type: source
-tags: [AI应用, Gemini-3, 提示词工程, 前端可视化, Vibe-Coding]
-date: 2025-11-24
----
-
-## Source File
-- [[AI/我用 Gemini 3 一口气做了 10 个应用,附教程]]
-
-## Summary(用中文描述)
-- 核心主题:使用 Google Gemini 3 模型,通过简单的对话式提示词,配合前端 SVG/HTML 可视化,在极短时间内构建 10 个实用的 AI 应用(冷知识卡片、配色卡片、电影海报、绘画思维导图等)。
-- 问题域:如何快速将 AI 的文字生成能力转化为可直接使用的可视化产品。
-- 方法/机制:作者提出三步方法论——①限定垂直输入场景(如诗词/小说/电影)→ ②用提示词 + MCP 约束模型结构化输出 → ③用前端代码(SVG/HTML)作为输出容器。核心机制是让 AI 先输出 SVG 语言,再由前端渲染成精美卡片/海报/导图。
-- 结论/价值:Gemini 3 的多模态能力和结构化输出使得"两句话做一个应用"成为现实;前端 SVG 可视化是 AI 生成内容落地的关键桥梁。
-
-## Key Claims(用中文描述)
-- Gemini 3 模型通过提示词约束可实现结构化输出,直接生成 SVG 代码。
-- 冷知识卡片应用中,蝴蝶生命周期 SVG 可视化展示了信息设计的潜力。
-- 配色卡片通过提示词引导,可自动生成莫奈等艺术家风格的主题色板。
-- 电影海报应用中,Gemini 能根据电影名生成海报图、简介、上映时间和导演信息。
-- 绘画思维导图应用解决了"有关键词但不知道怎么写提示词"的核心痛点。
-- 整个方法论的核心是:垂直场景 + 结构化约束 + 前端容器,三步缺一不可。
-
-## Key Quotes
-> "制作原理,就是让 AI 输出 SVG 的语言,可视化展示整个信息。" — 空格,解释冷知识卡片的技术原理
-> "这些都是靠提示词设计的。约束好大模型结构化输出信息。" — 空格,总结 Gemini 应用开发的核心技巧
-> "如果你感兴趣的话,我下期再来详细分享一下做这些应用的具体对话内容,我是怎么把这些应用两句对话就实现出来的。" — 空格,预告后续内容
-
-## Key Concepts
-- [[SVG可视化]]:通过 AI 生成 SVG 代码实现信息可视化,是 Gemini 输出落地的核心技术路径
-- [[结构化输出]]:通过提示词约束模型输出格式,实现 JSON/结构化数据直接生成
-- [[Vibe-Coding]]:以对话驱动 + AI 结对执行的开发范式,与本文三步方法论高度契合
-- [[AI应用开发]]:从 AI 模型输出到可交付产品的完整链路实践
-
-## Key Entities
-- [[Gemini-3]]:Google 最新多模态大模型,支持文本、图像混合输入输出,支持 SVG 结构化生成
-- [[Google-AI-Studio]]:Google AI 开发平台(ai.studio),文中提供多个应用体验地址
-
-## Connections
-- [[Vibe-Coding]] ← 方法论相似 ← 本文三步法(场景→约束→容器)
-- [[Nano-Banana-2]] ← 同一作者风格 ← 同为 AI 可视化应用类文章
-- [[SVG可视化]] ← 核心技术 ← 连接多个 AI 应用类来源
-
-## Contradictions
-- 暂无冲突内容。
-
-## 应用示例(原文)
-- **冷知识卡片**:蝴蝶生命周期 SVG 可视化,可下载为 PNG,体验地址:https://gemini.google.com/share/26884961f77a
-- **配色卡片**:输入"莫奈"获取主题色和命名色卡,适合设计场景
-- **电影海报**:输入"星际穿越"生成黑白风格海报、简介、上映时间、导演
-- **绘画思维导图**:输入"柯基"→ AI 头脑风暴生成相关词汇思维导图 → 用户选择关键词 → 生成最终图片
+---
+title: "我用 Gemini 3 一口气做了 10 个应用,附教程"
+type: source
+tags: [AI应用, Gemini-3, 提示词工程, 前端可视化, Vibe-Coding]
+date: 2025-11-24
+---
+
+## Source File
+- [[raw/AI/我用 Gemini 3 一口气做了 10 个应用,附教程.md]]
+
+## Summary(用中文描述)
+- 核心主题:使用 Google Gemini 3 模型,通过简单的对话式提示词,配合前端 SVG/HTML 可视化,在极短时间内构建 10 个实用的 AI 应用(冷知识卡片、配色卡片、电影海报、绘画思维导图等)。
+- 问题域:如何快速将 AI 的文字生成能力转化为可直接使用的可视化产品。
+- 方法/机制:作者提出三步方法论——①限定垂直输入场景(如诗词/小说/电影)→ ②用提示词 + MCP 约束模型结构化输出 → ③用前端代码(SVG/HTML)作为输出容器。核心机制是让 AI 先输出 SVG 语言,再由前端渲染成精美卡片/海报/导图。
+- 结论/价值:Gemini 3 的多模态能力和结构化输出使得"两句话做一个应用"成为现实;前端 SVG 可视化是 AI 生成内容落地的关键桥梁。
+
+## Key Claims(用中文描述)
+- Gemini 3 模型通过提示词约束可实现结构化输出,直接生成 SVG 代码。
+- 冷知识卡片应用中,蝴蝶生命周期 SVG 可视化展示了信息设计的潜力。
+- 配色卡片通过提示词引导,可自动生成莫奈等艺术家风格的主题色板。
+- 电影海报应用中,Gemini 能根据电影名生成海报图、简介、上映时间和导演信息。
+- 绘画思维导图应用解决了"有关键词但不知道怎么写提示词"的核心痛点。
+- 整个方法论的核心是:垂直场景 + 结构化约束 + 前端容器,三步缺一不可。
+
+## Key Quotes
+> "制作原理,就是让 AI 输出 SVG 的语言,可视化展示整个信息。" — 空格,解释冷知识卡片的技术原理
+> "这些都是靠提示词设计的。约束好大模型结构化输出信息。" — 空格,总结 Gemini 应用开发的核心技巧
+> "如果你感兴趣的话,我下期再来详细分享一下做这些应用的具体对话内容,我是怎么把这些应用两句对话就实现出来的。" — 空格,预告后续内容
+
+## Key Concepts
+- [[SVG可视化]]:通过 AI 生成 SVG 代码实现信息可视化,是 Gemini 输出落地的核心技术路径
+- [[结构化输出]]:通过提示词约束模型输出格式,实现 JSON/结构化数据直接生成
+- [[Vibe-Coding]]:以对话驱动 + AI 结对执行的开发范式,与本文三步方法论高度契合
+- [[AI应用开发]]:从 AI 模型输出到可交付产品的完整链路实践
+
+## Key Entities
+- [[Gemini-3]]:Google 最新多模态大模型,支持文本、图像混合输入输出,支持 SVG 结构化生成
+- [[Google-AI-Studio]]:Google AI 开发平台(ai.studio),文中提供多个应用体验地址
+
+## Connections
+- [[Vibe-Coding]] ← 方法论相似 ← 本文三步法(场景→约束→容器)
+- [[Nano-Banana-2]] ← 同一作者风格 ← 同为 AI 可视化应用类文章
+- [[SVG可视化]] ← 核心技术 ← 连接多个 AI 应用类来源
+
+## Contradictions
+- 暂无冲突内容。
+
+## 应用示例(原文)
+- **冷知识卡片**:蝴蝶生命周期 SVG 可视化,可下载为 PNG,体验地址:https://gemini.google.com/share/26884961f77a
+- **配色卡片**:输入"莫奈"获取主题色和命名色卡,适合设计场景
+- **电影海报**:输入"星际穿越"生成黑白风格海报、简介、上映时间、导演
+- **绘画思维导图**:输入"柯基"→ AI 头脑风暴生成相关词汇思维导图 → 用户选择关键词 → 生成最终图片
diff --git a/wiki/sources/我的工具集.md b/wiki/sources/我的工具集.md
index 155b2491..460ac49b 100644
--- a/wiki/sources/我的工具集.md
+++ b/wiki/sources/我的工具集.md
@@ -1,55 +1,50 @@
----
-title: "我的工具集"
-type: source
-tags: [ai, brightdata, decopy, dialog, gemini, google, hailuo, image-editor, image-to-video, paid, scaper, service, speech, summary, text-to-speech, text-to-video, tool, video, vidu, wavespeed, youtube]
-date: 2026-04-18
----
-
-## Source File
-- [[AI/我的工具集.md]]
-
-## Summary(用中文描述)
-- 核心主题:个人 AI 工具推荐清单,覆盖文本生成语音、图像编辑、图生视频、网页爬取、AI 摘要等常用 AI 服务类别。
-- 问题域:如何选择合适的付费/免费 AI 工具来支持内容创作、数据采集和信息处理工作流。
-- 方法/机制:按 AI 类型分类(Text-to-Speech / Image-Editor / Image-to-Video / Web-Scraper / AI-Summary),每类列出工具名称、提供商、定价、链接和标签。
-- 结论/价值:整理了一份可参考的 AI 工具选型清单,为不同需求场景提供具体工具推荐。
-
-## Key Claims(用中文描述)
-- Google AI Studio 提供免费 Text-to-Speech 服务(Gemini 模型驱动)。
-- Wavespeed 提供图像编辑和付费图生视频服务。
-- Vidu 提供 $8/月 的图生视频服务。
-- 海螺 AI 提供 ¥42/月 的图生视频服务(国内用户友好)。
-- Brightdata 提供付费网页爬取服务。
-- Decopy 提供 AI 文章/PDF/视频摘要服务(支持思维导图和多语言输出)。
-
-## Key Quotes
-> "Decopy's Summary Generator can summarize articles, PDFs and videos in seconds. Offering multiple summary modes, mind maps and multilingual output." — Decopy Summary Generator 功能描述
-
-## Key Concepts
-- [[Text-to-Speech]]:文本转语音技术,由 Google AI Studio (Gemini) 驱动。
-- [[Text-to-Video]]:文本或图像生成视频的技术,主流工具包括 Vidu ($8/月)、海螺 AI (¥42/月)、Wavespeed。
-- [[Image-to-Video]]:图生视频技术,将静态图像转化为动态视频内容。
-- [[Web-Scraper]]:网页数据采集工具,Brightdata 提供付费服务。
-- [[AI-Summary]]:AI 驱动的摘要生成,支持文章、PDF、视频等多类型内容。
-- [[Image-Editor]]:AI 图像编辑工具,Wavespeed 提供相关功能。
-
-## Key Entities
-- [[Google]]:提供 Google AI Studio 文本转语音服务(Gemini 模型)。
-- [[Wavespeed]]:AI 图像编辑和图生视频平台。
-- [[Vidu]]:图生视频服务,$8/月。
-- [[海螺AI]]:国内图生视频服务,¥42/月,由 MiniMax 提供技术支持。
-- [[Brightdata]]:付费网页爬取服务平台。
-- [[Decopy]]:AI 摘要生成工具,支持多模态内容总结。
-
-## Connections
-- [[Text-to-Speech]] ← powered_by ← [[Google]] (Gemini)
-- [[Image-to-Video]] ← powered_by ← [[Wavespeed]], [[Vidu]], [[海螺AI]]
-- [[Web-Scraper]] ← powered_by ← [[Brightdata]]
-- [[AI-Summary]] ← powered_by ← [[Decopy]]
-
-## Contradictions
-- 与 [[二创视频必不可少-2025年最热门ai工具推荐合集-ai配音-声音克隆]] 互补:
- - 冲突点:本文仅列举工具名称和链接,未提供各工具的详细对比评测。
- - 当前观点:工具集以索引为主,提供快速参考入口。
- - 对方观点:另一来源提供了更详细的功能对比和选型建议。
- - 说明:两篇定位不同,本文为工具清单,另一篇为评测指南,互为补充。
+---
+title: "我的AI工具集"
+type: source
+tags: [ai, brightdata, decopy, dialog, gemini, google, hailuo, image-editor, image-to-video, paid, scraper, service, speech, summary, text-to-speech, text-to-video, tool, video, vidu, wavespeed, youtube]
+date: 2026-05-11
+---
+
+## Source File
+- [[raw/AI/我的工具集.md]]
+
+## Summary(用中文描述)
+- 核心主题:个人收集整理的 AI 工具清单,按功能分类
+- 问题域:寻找和评估各类 AI 付费/免费服务
+- 方法/机制:表格形式列出工具名称、功能类型、描述、定价、链接和标签
+- 结论/价值:提供一站式 AI 工具参考,用于二创视频制作和内容创作
+
+## Key Claims(用中文描述)
+- Google AI Studio 提供免费 Text-to-Speech 服务,支持 Gemini 模型和 Dialog 对话
+- Wavespeed AI 提供 Image-Editor 和 Image-to-Video 功能,其中 Image-to-Video 为付费服务
+- Vidu 提供 ¥8/month 的 Image-to-Video 服务
+- Hailuo AI 提供 ¥42/month 的 Image-to-Video 服务
+- Brightdata 提供 Web-Scraper 服务(付费)
+- Decopy 提供 AI Summary Generator,支持文章、PDF 和视频摘要,具备多摘要模式、思维导图和多语言输出功能
+
+## Key Quotes
+> "Decopy's Summary Generator can summarize articles, PDFs and videos in seconds. Offering multiple summary modes, mind maps and multilingual output." — Decopy 工具描述
+
+## Key Concepts
+- [[TextToSpeech]]:文本转语音技术,Google AI Studio 提供此服务
+- [[TextToVideo]]:文本生成视频技术,Hailuo、Vidu 提供此类服务
+- [[ImageToVideo]]:图片生成视频技术,Wavespeed、Vidu、Hailuo 提供此类服务
+- [[WebScraper]]:网页数据抓取工具,Brightdata 提供此类服务
+- [[AISummary]]:AI 摘要生成,Decopy 提供文章、PDF、视频的多模式摘要
+
+## Key Entities
+- [[Google AI Studio]]:Google 提供的 AI 开发平台,提供免费 Text-to-Speech 服务
+- [[Wavespeed AI]]:提供 Image-Editor 和 Image-to-Video 工具,部分功能付费
+- [[Vidu]]:国内视频 AI 工具,提供 Image-to-Video 和 Text-to-Video 服务,月费 ¥8
+- [[Hailuo AI]]:海螺 AI,国内视频生成工具,提供 Image-to-Video 服务,月费 ¥42
+- [[Brightdata]]:付费网页抓取平台,提供 Web-Scraper 服务
+- [[Decopy]]:AI 摘要工具,支持文章、PDF 和视频的多模式摘要生成
+
+## Connections
+- [[Wavespeed AI]] ← provides ← [[ImageToVideo]] ← alternative_to ← [[Vidu]]
+- [[Vidu]] ← alternative_to ← [[Hailuo AI]]
+- [[Google AI Studio]] ← provides ← [[TextToSpeech]]
+- [[Decopy]] ← provides ← [[AISummary]]
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/清华出的deepseek使用手册-104页-真的是太厉害了-免费领取.md b/wiki/sources/清华出的deepseek使用手册-104页-真的是太厉害了-免费领取.md
index 059ba2fa..26b93518 100644
--- a/wiki/sources/清华出的deepseek使用手册-104页-真的是太厉害了-免费领取.md
+++ b/wiki/sources/清华出的deepseek使用手册-104页-真的是太厉害了-免费领取.md
@@ -6,7 +6,7 @@ date: 2025-12-18
---
## Source File
-- [[AI/清华出的DeepSeek使用手册,104页,真的是太厉害了!(免费领取).md]]
+- [[raw/AI/清华出的DeepSeek使用手册,104页,真的是太厉害了!(免费领取).md]]
## Summary(用中文描述)
- 核心主题:清华大学发布的《DeepSeek从入门到精通2025》104页官方使用手册,系统讲解DeepSeek的技术原理与应用方法。
diff --git a/wiki/sources/用docker安装homarr.md b/wiki/sources/用docker安装homarr.md
index 2c489417..e285ba64 100644
--- a/wiki/sources/用docker安装homarr.md
+++ b/wiki/sources/用docker安装homarr.md
@@ -1,47 +1,47 @@
----
-title: "用Docker安装Homarr"
-type: source
-tags: [docker, homarr]
-date: 2026-04-14
----
-
-## Source File
-- [[Home Office/用Docker安装Homarr.md]]
-
-## Summary(用中文描述)
-- 核心主题:通过 Docker Compose 在 Home Server 上部署 Homarr 个人导航仪表盘
-- 问题域:Homarr 是一款开源服务器/服务仪表盘工具,用于集中展示和管理家庭网络中的各类自托管服务
-- 方法/机制:使用 docker-compose.yml 定义 Homarr 容器,通过卷挂载持久化配置数据,通过环境变量配置加密密钥和代理
-- 结论/价值:提供统一的 Web UI 入口,方便查看和管理 Jellyfin、n8n、Prometheus 等多个自托管服务
-
-## Key Claims(用中文描述)
-- Homarr 官方通过 GitHub Container Registry 发布 Docker 镜像(ghcr.io/homarr-labs/homarr)
-- Homarr 支持挂载 /var/run/docker.sock 以直接集成 Docker 容器状态监控
-- Homarr 依赖 SECRET_ENCRYPTION_KEY 环境变量进行数据加密
-
-## Key Quotes
-> "image: ghcr.io/homarr-labs/homarr" — 官方镜像来源为 GitHub Container Registry
-> "ports: - '7575:7575'" — Homarr 默认 Web UI 端口为 7575
-> "- /var/run/docker.sock:/var/run/docker.sock" — 挂载 Docker Socket 以获取容器信息
-> "- ALL_PROXY=socks5://172.24.0.1:10808" — 通过宿主机 SOCKS5 代理访问外网
-
-## Key Concepts
-- [[Docker Compose]]:通过 YAML 配置文件声明式定义 Homarr 服务
-- [[Docker卷]]:/appdata 卷挂载用于持久化 Homarr 的配置数据
-- [[Homarr]]:开源自托管服务仪表盘(Home Server Dashboard)
-- [[环境变量代理]]:通过 ALL_PROXY 环境变量配置容器级代理
-- [[SOCKS5代理]]:Homarr 容器通过 socks5://172.24.0.1:10808 访问外部网络
-
-## Key Entities
-- [[Homarr]]:开源服务器仪表盘项目,提供 Homarr Labs 维护的官方 Docker 镜像
-
-## Connections
-- [[用docker安装jellyfin]] ← related_service ← [[用docker安装homarr]]
-- [[用docker安装n8n]] ← related_service ← [[用docker安装homarr]]
-- [[家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox]] ← related_service ← [[用docker安装homarr]]
-
-## Contradictions
-- 与 [[用docker安装portainer]] 冲突:
- - 冲突点:两者都提供 Docker 容器管理能力
- - 当前观点:Homarr 提供服务层面的统一导航仪表盘,整合多个服务状态;Portainer 提供专业的 Docker 运维 Web UI
- - 对方观点:Portainer 功能更全面,可管理容器/网络/卷/镜像等底层资源
+---
+title: "用Docker安装Homarr"
+type: source
+tags: [docker, homarr]
+date: 2026-04-14
+---
+
+## Source File
+- [[raw/Home Office/用Docker安装Homarr.md]]
+
+## Summary(用中文描述)
+- 核心主题:通过 Docker Compose 在 Home Server 上部署 Homarr 个人导航仪表盘
+- 问题域:Homarr 是一款开源服务器/服务仪表盘工具,用于集中展示和管理家庭网络中的各类自托管服务
+- 方法/机制:使用 docker-compose.yml 定义 Homarr 容器,通过卷挂载持久化配置数据,通过环境变量配置加密密钥和代理
+- 结论/价值:提供统一的 Web UI 入口,方便查看和管理 Jellyfin、n8n、Prometheus 等多个自托管服务
+
+## Key Claims(用中文描述)
+- Homarr 官方通过 GitHub Container Registry 发布 Docker 镜像(ghcr.io/homarr-labs/homarr)
+- Homarr 支持挂载 /var/run/docker.sock 以直接集成 Docker 容器状态监控
+- Homarr 依赖 SECRET_ENCRYPTION_KEY 环境变量进行数据加密
+
+## Key Quotes
+> "image: ghcr.io/homarr-labs/homarr" — 官方镜像来源为 GitHub Container Registry
+> "ports: - '7575:7575'" — Homarr 默认 Web UI 端口为 7575
+> "- /var/run/docker.sock:/var/run/docker.sock" — 挂载 Docker Socket 以获取容器信息
+> "- ALL_PROXY=socks5://172.24.0.1:10808" — 通过宿主机 SOCKS5 代理访问外网
+
+## Key Concepts
+- [[Docker Compose]]:通过 YAML 配置文件声明式定义 Homarr 服务
+- [[Docker卷]]:/appdata 卷挂载用于持久化 Homarr 的配置数据
+- [[Homarr]]:开源自托管服务仪表盘(Home Server Dashboard)
+- [[环境变量代理]]:通过 ALL_PROXY 环境变量配置容器级代理
+- [[SOCKS5代理]]:Homarr 容器通过 socks5://172.24.0.1:10808 访问外部网络
+
+## Key Entities
+- [[Homarr]]:开源服务器仪表盘项目,提供 Homarr Labs 维护的官方 Docker 镜像
+
+## Connections
+- [[用docker安装jellyfin]] ← related_service ← [[用docker安装homarr]]
+- [[用docker安装n8n]] ← related_service ← [[用docker安装homarr]]
+- [[家庭监控方案-prometheus-grafana-node-exporter-cadvisor-blackbox]] ← related_service ← [[用docker安装homarr]]
+
+## Contradictions
+- 与 [[用docker安装portainer]] 冲突:
+ - 冲突点:两者都提供 Docker 容器管理能力
+ - 当前观点:Homarr 提供服务层面的统一导航仪表盘,整合多个服务状态;Portainer 提供专业的 Docker 运维 Web UI
+ - 对方观点:Portainer 功能更全面,可管理容器/网络/卷/镜像等底层资源
diff --git a/wiki/sources/用docker安装it-tools.md b/wiki/sources/用docker安装it-tools.md
index 4d192159..481aec7c 100644
--- a/wiki/sources/用docker安装it-tools.md
+++ b/wiki/sources/用docker安装it-tools.md
@@ -1,42 +1,42 @@
----
-title: "用Docker安装it-tools"
-type: source
-tags: [docker, it-tools]
-date: 2026-04-26
----
-
-## Source File
-- [[Home Office/用Docker安装it-tools.md]]
-
-## Summary(用中文描述)
-- 核心主题:通过 Docker Compose 在 Home Server 环境中部署 it-tools 网络工具集
-- 问题域:Home Server 自托管服务的容器化安装与配置
-- 方法/机制:使用 Docker Compose YAML 配置,启动 `corentinth/it-tools:latest` 官方镜像,设置交互模式(stdin_open + tty)、端口映射(8999→80)及内存限制(128M)
-- 结论/价值:提供一键部署 IT 工具集的完整方案,适用于内网环境快速访问常用开发运维工具
-
-## Key Claims(用中文描述)
-- CorentinTh/it-tools 镜像可作为 Home Server 常驻服务运行
-- Docker Compose 的 `stdin_open: true` 和 `tty: true` 配置对于交互式容器至关重要
-- 128M 内存限制对 it-tools 足够(该应用为纯前端工具)
-
-## Key Quotes
-> "version: '3.8'" — Docker Compose 文件版本声明
-> "image: corentinth/it-tools:latest" — 使用的官方 it-tools 镜像
-> "restart: unless-stopped" — 容器自动重启策略
-
-## Key Concepts
-- [[Docker Compose]]:多容器 Docker 应用的声明式配置文件格式,本文档使用 version 3.8 版本
-- [[Containerization]]:容器化技术,将应用及其依赖打包为可移植的镜像,在隔离环境中运行
-- [[Home Server]]:家庭自托管服务器环境,用于部署私有化服务
-
-## Key Entities
-- [[CorentinTh/it-tools]]:由 Corentin Thierart 开发的开源 IT 工具集合 Web 应用,提供 100+ 常用开发运维工具
-- [[Corentin Thierart]]:it-tools 项目的作者和维护者
-
-## Connections
-- [[如何在Ubuntu Server安装 Docker & Docker Compose]] ← part_of ← it-tools 部署前提
-- [[用Docker安装Portainer]] ← similar ← [[用Docker安装it-tools]](同为 Home Server Docker 服务)
-- [[用Docker安装Homarr]] ← similar ← [[用Docker安装it-tools]](同为 Home Server 仪表盘/工具类 Docker 服务)
-
-## Contradictions
-- (无已知冲突内容)
+---
+title: "用Docker安装it-tools"
+type: source
+tags: [docker, it-tools]
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Home Office/用Docker安装it-tools.md]]
+
+## Summary(用中文描述)
+- 核心主题:通过 Docker Compose 在 Home Server 环境中部署 it-tools 网络工具集
+- 问题域:Home Server 自托管服务的容器化安装与配置
+- 方法/机制:使用 Docker Compose YAML 配置,启动 `corentinth/it-tools:latest` 官方镜像,设置交互模式(stdin_open + tty)、端口映射(8999→80)及内存限制(128M)
+- 结论/价值:提供一键部署 IT 工具集的完整方案,适用于内网环境快速访问常用开发运维工具
+
+## Key Claims(用中文描述)
+- CorentinTh/it-tools 镜像可作为 Home Server 常驻服务运行
+- Docker Compose 的 `stdin_open: true` 和 `tty: true` 配置对于交互式容器至关重要
+- 128M 内存限制对 it-tools 足够(该应用为纯前端工具)
+
+## Key Quotes
+> "version: '3.8'" — Docker Compose 文件版本声明
+> "image: corentinth/it-tools:latest" — 使用的官方 it-tools 镜像
+> "restart: unless-stopped" — 容器自动重启策略
+
+## Key Concepts
+- [[Docker Compose]]:多容器 Docker 应用的声明式配置文件格式,本文档使用 version 3.8 版本
+- [[Containerization]]:容器化技术,将应用及其依赖打包为可移植的镜像,在隔离环境中运行
+- [[Home Server]]:家庭自托管服务器环境,用于部署私有化服务
+
+## Key Entities
+- [[CorentinTh/it-tools]]:由 Corentin Thierart 开发的开源 IT 工具集合 Web 应用,提供 100+ 常用开发运维工具
+- [[Corentin Thierart]]:it-tools 项目的作者和维护者
+
+## Connections
+- [[如何在Ubuntu Server安装 Docker & Docker Compose]] ← part_of ← it-tools 部署前提
+- [[用Docker安装Portainer]] ← similar ← [[用Docker安装it-tools]](同为 Home Server Docker 服务)
+- [[用Docker安装Homarr]] ← similar ← [[用Docker安装it-tools]](同为 Home Server 仪表盘/工具类 Docker 服务)
+
+## Contradictions
+- (无已知冲突内容)
diff --git a/wiki/sources/用docker安装portainer.md b/wiki/sources/用docker安装portainer.md
index afe0c9e2..22852b36 100644
--- a/wiki/sources/用docker安装portainer.md
+++ b/wiki/sources/用docker安装portainer.md
@@ -1,34 +1,34 @@
----
-title: "用Docker安装Portainer"
-type: source
-tags: [docker, portainer]
-date: 2026-04-26
----
-
-## Source File
-- [[Home Office/用Docker安装Portainer]]
-
-## Summary(用中文描述)
-- 核心主题:通过 Docker Compose 方式安装 Portainer 容器管理面板
-- 问题域:家庭服务器或NAS环境下的Docker容器可视化管理工作
-- 方法/机制:使用 docker-compose.yml 配置文件定义 Portainer 服务,通过 `docker-compose run -d` 启动容器
-- 结论/价值:提供图形化界面管理Docker容器、卷、网络等资源,降低命令行操作复杂度
-
-## Key Claims(用中文描述)
-- Portainer 通过挂载 Docker Socket(`/var/run/docker.sock`)实现对本地Docker守护进程的管理
-- 使用 LTS 版本镜像(`portainer/portainer-ce:lts`)确保稳定性和长期支持
-- 容器配置为 `restart: always`,确保服务在系统重启后自动恢复
-- 默认暴露 9443(HTTPS管理界面)和 8000(Edge Agent通信)端口
-
-## Key Quotes
-> "ports: - 9443:9443 - 8000:8000" — Portainer Web界面通过9443端口访问,8000端口用于Edge Agent通信(不使用Edge Agent时可移除)
-
-## Key Concepts
-- [[Docker Compose]]:定义和运行多容器Docker应用的工具,通过YAML配置文件管理服务
-- [[Portainer]]:开源的Docker和Kubernetes图形化管理界面,支持容器、镜像、卷、网络等资源管理
-
-## Key Entities
-- [[Portainer]]:开源容器管理平台,本文档的核心安装目标
-
-## Connections
-- [[如何删除旧的废弃的Docker Container + Volume]] ← related_to ← [[用Docker安装Portainer]]
+---
+title: "用Docker安装Portainer"
+type: source
+tags: [docker, portainer]
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Home Office/用Docker安装Portainer.md]]
+
+## Summary(用中文描述)
+- 核心主题:通过 Docker Compose 方式安装 Portainer 容器管理面板
+- 问题域:家庭服务器或NAS环境下的Docker容器可视化管理工作
+- 方法/机制:使用 docker-compose.yml 配置文件定义 Portainer 服务,通过 `docker-compose run -d` 启动容器
+- 结论/价值:提供图形化界面管理Docker容器、卷、网络等资源,降低命令行操作复杂度
+
+## Key Claims(用中文描述)
+- Portainer 通过挂载 Docker Socket(`/var/run/docker.sock`)实现对本地Docker守护进程的管理
+- 使用 LTS 版本镜像(`portainer/portainer-ce:lts`)确保稳定性和长期支持
+- 容器配置为 `restart: always`,确保服务在系统重启后自动恢复
+- 默认暴露 9443(HTTPS管理界面)和 8000(Edge Agent通信)端口
+
+## Key Quotes
+> "ports: - 9443:9443 - 8000:8000" — Portainer Web界面通过9443端口访问,8000端口用于Edge Agent通信(不使用Edge Agent时可移除)
+
+## Key Concepts
+- [[Docker Compose]]:定义和运行多容器Docker应用的工具,通过YAML配置文件管理服务
+- [[Portainer]]:开源的Docker和Kubernetes图形化管理界面,支持容器、镜像、卷、网络等资源管理
+
+## Key Entities
+- [[Portainer]]:开源容器管理平台,本文档的核心安装目标
+
+## Connections
+- [[如何删除旧的废弃的Docker Container + Volume]] ← related_to ← [[用Docker安装Portainer]]
diff --git a/wiki/sources/电商如何选品-如何找到爆款-选品策略.md b/wiki/sources/电商如何选品-如何找到爆款-选品策略.md
index d22d4c9b..6bdd929d 100644
--- a/wiki/sources/电商如何选品-如何找到爆款-选品策略.md
+++ b/wiki/sources/电商如何选品-如何找到爆款-选品策略.md
@@ -1,55 +1,55 @@
----
-title: "电商如何选品 - 如何找到爆款选品策略"
-type: source
-tags: []
-date: 2026-04-18
----
-
-## Source File
-- [[跨境电商/电商如何选品 如何找到爆款 选品策略]]
-
-## Summary(用中文描述)
-- 核心主题:电商选品策略与爆款发现方法论,聚焦跨境电商(Tk Shop / Etsy 平台)
-- 问题域:电商创业者如何系统化找到高潜力产品,降低试错成本,实现年销售额数百万美元
-- 方法/机制:20 种选品策略 + 情境配对 + 季节性规划 + POD 低成本测款 + 工具辅助分析(Salesmartly / Erank / Pinterest / Etsy 趋势)
-- 结论/价值:未来品牌需针对细分市场而非大众市场;多工具组合使用可提升客户转化率和选品效率
-
-## Key Claims(用中文描述)
-- 细分市场定位比大众市场更有增长潜力,未来品牌需针对 LGBTQ、特定人群等细分群体
-- 情境配对的产品组合(如露营三件套)比单品更具吸引力,能提升客单价
-- POD(Print on Demand)模式允许创业者以极低成本测试市场需求,降低库存风险
-- 季节性和节日趋势是选品的关键时机,需提前规划布局
-- Erank 等工具可分析竞争对手销售情况,提高产品上市效率
-- 跨平台订单管理工具(如 Salesmartly)可提升多渠道运营效率
-
-## Key Quotes
-> "未来品牌需针对细分市场" — 视频核心观点,强调细分人群定位的战略价值
-> "POD模式让创业者可以低风险测试市场需求" — 降低创业门槛的关键方法
-> "关注Pinterest和Etsy的季度趋势报告,便于掌握热门关键词与产品上市时机" — 趋势洞察工具推荐
-
-## Key Concepts
-- [[电商选品策略]]:系统化评估和选择电商平台销售产品的决策框架,涵盖市场需求分析、竞争度评估、利润空间计算
-- [[爆款产品]]:在特定市场 Segment 中获得高销量和高利润的产品,通常具有差异化竞争力和稳定供应链
-- [[POD模式]](Print on Demand):按需印刷模式,创业者无需囤货,有订单再生产,大幅降低库存风险和启动成本
-- [[情境配对]]:将多个互补产品组合为使用场景套装,通过提升整体价值感知来提高客单价和转化率
-- [[季节性选品]]:根据节假日、季节变化、消费趋势预测提前规划产品线,最大化流量高峰期销售
-- [[细分市场定位]]:针对特定人群(如LGBTQ、特定年龄层、特定兴趣圈)开发差异化产品,避免大众市场竞争
-
-## Key Entities
-- [[Salesmartly]]:跨平台订单管理和客户沟通工具,支持多渠道消息聚合,提升电商运营效率
-- [[Erank]]:Etsy 平台关键词和竞争分析工具,帮助评估产品市场潜力和搜索排名
-- [[TikTok Shop]]:字节跳动旗下短视频电商平台,本视频重点运营渠道之一
-- [[Etsy]]:手工/创意类 C2C 电商平台,适合 POD 产品和创意商品销售
-- [[Pinterest]]:图片分享社交平台,其趋势报告是选品和内容营销的重要参考数据源
-
-## Connections
-- [[电商视频Prompt库]] ← 同一作者/系列 ← 电商选品内容创作
-- [[做TK跨境思路不对努力白费]] ← 依赖 ← 选品策略(本文)作为上游输入
-- [[可自动化-可扩展-ai增强的电商数据采集与处理系统]] ← 关联 ← 电商选品工具链
-
-## Contradictions
-- 与 [[做TK跨境思路不对努力白费]] 潜在冲突:
- - 冲突点:选品的具体平台优先级
- - 当前观点:Etsy/Pinterest 趋势是重要参考,适合 POD 和创意类产品
- - 对方观点:优先美区/日本 TikTok Shop,避开东南亚,需数据软件分析
- - 注:两者针对的产品类型不同(Etsy 手工艺/POD vs TikTok 快消品),可互补而非冲突
+---
+title: "电商如何选品 - 如何找到爆款选品策略"
+type: source
+tags: []
+date: 2026-04-18
+---
+
+## Source File
+- [[raw/跨境电商/电商如何选品 如何找到爆款 选品策略.md]]
+
+## Summary(用中文描述)
+- 核心主题:电商选品策略与爆款发现方法论,聚焦跨境电商(Tk Shop / Etsy 平台)
+- 问题域:电商创业者如何系统化找到高潜力产品,降低试错成本,实现年销售额数百万美元
+- 方法/机制:20 种选品策略 + 情境配对 + 季节性规划 + POD 低成本测款 + 工具辅助分析(Salesmartly / Erank / Pinterest / Etsy 趋势)
+- 结论/价值:未来品牌需针对细分市场而非大众市场;多工具组合使用可提升客户转化率和选品效率
+
+## Key Claims(用中文描述)
+- 细分市场定位比大众市场更有增长潜力,未来品牌需针对 LGBTQ、特定人群等细分群体
+- 情境配对的产品组合(如露营三件套)比单品更具吸引力,能提升客单价
+- POD(Print on Demand)模式允许创业者以极低成本测试市场需求,降低库存风险
+- 季节性和节日趋势是选品的关键时机,需提前规划布局
+- Erank 等工具可分析竞争对手销售情况,提高产品上市效率
+- 跨平台订单管理工具(如 Salesmartly)可提升多渠道运营效率
+
+## Key Quotes
+> "未来品牌需针对细分市场" — 视频核心观点,强调细分人群定位的战略价值
+> "POD模式让创业者可以低风险测试市场需求" — 降低创业门槛的关键方法
+> "关注Pinterest和Etsy的季度趋势报告,便于掌握热门关键词与产品上市时机" — 趋势洞察工具推荐
+
+## Key Concepts
+- [[电商选品策略]]:系统化评估和选择电商平台销售产品的决策框架,涵盖市场需求分析、竞争度评估、利润空间计算
+- [[爆款产品]]:在特定市场 Segment 中获得高销量和高利润的产品,通常具有差异化竞争力和稳定供应链
+- [[POD模式]](Print on Demand):按需印刷模式,创业者无需囤货,有订单再生产,大幅降低库存风险和启动成本
+- [[情境配对]]:将多个互补产品组合为使用场景套装,通过提升整体价值感知来提高客单价和转化率
+- [[季节性选品]]:根据节假日、季节变化、消费趋势预测提前规划产品线,最大化流量高峰期销售
+- [[细分市场定位]]:针对特定人群(如LGBTQ、特定年龄层、特定兴趣圈)开发差异化产品,避免大众市场竞争
+
+## Key Entities
+- [[Salesmartly]]:跨平台订单管理和客户沟通工具,支持多渠道消息聚合,提升电商运营效率
+- [[Erank]]:Etsy 平台关键词和竞争分析工具,帮助评估产品市场潜力和搜索排名
+- [[TikTok Shop]]:字节跳动旗下短视频电商平台,本视频重点运营渠道之一
+- [[Etsy]]:手工/创意类 C2C 电商平台,适合 POD 产品和创意商品销售
+- [[Pinterest]]:图片分享社交平台,其趋势报告是选品和内容营销的重要参考数据源
+
+## Connections
+- [[电商视频Prompt库]] ← 同一作者/系列 ← 电商选品内容创作
+- [[做TK跨境思路不对努力白费]] ← 依赖 ← 选品策略(本文)作为上游输入
+- [[可自动化-可扩展-ai增强的电商数据采集与处理系统]] ← 关联 ← 电商选品工具链
+
+## Contradictions
+- 与 [[做TK跨境思路不对努力白费]] 潜在冲突:
+ - 冲突点:选品的具体平台优先级
+ - 当前观点:Etsy/Pinterest 趋势是重要参考,适合 POD 和创意类产品
+ - 对方观点:优先美区/日本 TikTok Shop,避开东南亚,需数据软件分析
+ - 注:两者针对的产品类型不同(Etsy 手工艺/POD vs TikTok 快消品),可互补而非冲突
diff --git a/wiki/sources/电商视频prompt.md b/wiki/sources/电商视频prompt.md
index 5f4e4658..530bf4e5 100644
--- a/wiki/sources/电商视频prompt.md
+++ b/wiki/sources/电商视频prompt.md
@@ -1,45 +1,45 @@
----
-title: "电商视频Prompt库"
-type: source
-tags: [ai, image-to-video, prompt, text-to-video]
-date: 2026-04-23
----
-
-## Source File
-- [[跨境电商/电商视频Prompt.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI 生成宠物用品电商视频的模块化 Prompt 库
-- 问题域:TikTok Shop / 跨境电商宠物用品视频内容生产
-- 方法/机制:7 大模块化 Prompt(产品展示 / 宠物动作 / 衣服防穿帮 / 场景变化 / Negative Prompt / 卖货文案 / 全流程示例),通过"拼积木"方式组合使用
-- 结论/价值:**低翻车率 + 高真实感**的视频生成方案,服务 TikTok 带货,可扩展到 1 个产品 → 3 条视频 → 6 条文案 → A/B 测试的全链路自动化
-
-## Key Claims(用中文描述)
-- 模块化 Prompt 组合策略能够**降低 AI 视频翻车率、提高真实感**,专为电商带货场景设计
-- 宠物衣服类视频必须使用**"防穿帮"专用 Prompt**(Clothing Alignment 模块),否则衣服会出现滑动、漂浮、变形
-- 场景变化 Prompt 应作为**加法模块叠加**,不应在初始 Prompt 中写死,以实现一条视频模板覆盖多场景
-- 一套产品可生成**3 条差异化视频**(细节展示版 / 宠物日常版 / 情绪共鸣版),配合 6 条文案进行 A/B 测试
-
-## Key Quotes
-> "低翻车率 + 高真实感 + 为 TikTok 带货服务" — 整体设计目标
-> "场景一定是加法模块,不要一开始就写死" — 场景变化模块使用原则
-> "一个产品 = 3 条视频模板 → 自动生成 6 条文案 → A/B 测试" — 进阶自动化愿景
-
-## Key Concepts
-- [[Prompt库设计原则]]:模块化(Modular)、变量化(Variable)、可组合(Composable)
-- [[Negative Prompt]]:反向提示词,统一放置以降低翻车率,排除卡通风格/畸形解剖/水印等干扰
-- [[Image-to-Video]]:以产品图片为输入,生成动态展示视频(核心工作流)
-- [[TikTok电商内容自动化]]:图片 → 视频 → 文案 → A/B 测试的全链路自动化
-
-## Key Entities
-- [[TikTok Shop]]:目标平台,该 Prompt 库的视频专为 TikTok Shop 带货场景设计
-- [[宠物用品]]:核心品类,以宠物衣服为典型案例(防穿帮、衣服合身问题)
-- [[TikTok]]:短视频/电商平台,卖货文案生成模块(TikTok E-commerce Copywriter)以该平台用户为受众
-
-## Connections
-- [[电商如何选品-如何找到爆款-选品策略]] ← complements ← [[电商视频prompt]]
-- [[14个免费的AI图生视频工具-用AI让图片动起来]] ← related_to ← [[电商视频prompt]]
-- [[二创视频必不可少-2025年最热门AI工具推荐合集-AI配音-声音克隆]] ← related_to ← [[电商视频prompt]]
-
-## Contradictions
-- 暂无发现与 Wiki 中其他页面的实质冲突
+---
+title: "电商视频Prompt库"
+type: source
+tags: [ai, image-to-video, prompt, text-to-video]
+date: 2026-04-23
+---
+
+## Source File
+- [[raw/跨境电商/电商视频Prompt.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI 生成宠物用品电商视频的模块化 Prompt 库
+- 问题域:TikTok Shop / 跨境电商宠物用品视频内容生产
+- 方法/机制:7 大模块化 Prompt(产品展示 / 宠物动作 / 衣服防穿帮 / 场景变化 / Negative Prompt / 卖货文案 / 全流程示例),通过"拼积木"方式组合使用
+- 结论/价值:**低翻车率 + 高真实感**的视频生成方案,服务 TikTok 带货,可扩展到 1 个产品 → 3 条视频 → 6 条文案 → A/B 测试的全链路自动化
+
+## Key Claims(用中文描述)
+- 模块化 Prompt 组合策略能够**降低 AI 视频翻车率、提高真实感**,专为电商带货场景设计
+- 宠物衣服类视频必须使用**"防穿帮"专用 Prompt**(Clothing Alignment 模块),否则衣服会出现滑动、漂浮、变形
+- 场景变化 Prompt 应作为**加法模块叠加**,不应在初始 Prompt 中写死,以实现一条视频模板覆盖多场景
+- 一套产品可生成**3 条差异化视频**(细节展示版 / 宠物日常版 / 情绪共鸣版),配合 6 条文案进行 A/B 测试
+
+## Key Quotes
+> "低翻车率 + 高真实感 + 为 TikTok 带货服务" — 整体设计目标
+> "场景一定是加法模块,不要一开始就写死" — 场景变化模块使用原则
+> "一个产品 = 3 条视频模板 → 自动生成 6 条文案 → A/B 测试" — 进阶自动化愿景
+
+## Key Concepts
+- [[Prompt库设计原则]]:模块化(Modular)、变量化(Variable)、可组合(Composable)
+- [[Negative Prompt]]:反向提示词,统一放置以降低翻车率,排除卡通风格/畸形解剖/水印等干扰
+- [[Image-to-Video]]:以产品图片为输入,生成动态展示视频(核心工作流)
+- [[TikTok电商内容自动化]]:图片 → 视频 → 文案 → A/B 测试的全链路自动化
+
+## Key Entities
+- [[TikTok Shop]]:目标平台,该 Prompt 库的视频专为 TikTok Shop 带货场景设计
+- [[宠物用品]]:核心品类,以宠物衣服为典型案例(防穿帮、衣服合身问题)
+- [[TikTok]]:短视频/电商平台,卖货文案生成模块(TikTok E-commerce Copywriter)以该平台用户为受众
+
+## Connections
+- [[电商如何选品-如何找到爆款-选品策略]] ← complements ← [[电商视频prompt]]
+- [[14个免费的AI图生视频工具-用AI让图片动起来]] ← related_to ← [[电商视频prompt]]
+- [[二创视频必不可少-2025年最热门AI工具推荐合集-AI配音-声音克隆]] ← related_to ← [[电商视频prompt]]
+
+## Contradictions
+- 暂无发现与 Wiki 中其他页面的实质冲突
diff --git a/wiki/sources/系统提示词构建原则.md b/wiki/sources/系统提示词构建原则.md
index 4fe803a5..901afda4 100644
--- a/wiki/sources/系统提示词构建原则.md
+++ b/wiki/sources/系统提示词构建原则.md
@@ -1,49 +1,45 @@
----
-title: "系统提示词构建原则"
-type: source
-tags: []
-date: 2025-12-30
----
-
-## Source File
-- [[AI/系统提示词构建原则.md]]
-
-## Summary(用中文描述)
-- 核心主题:AI 编程助手(Agent)的系统提示词构建原则,涵盖身份定义、沟通规范、任务执行流程、编码标准和安全准则
-- 问题域:如何将 AI 编程助手塑造成专业、高效、安全、负责任的代码协作伙伴
-- 方法/机制:通过五大维度(身份准则、沟通互动、任务工作流、技术编码规范、安全防护)构建完整的提示词框架,每条准则均具有可执行性
-- 结论/价值:提供了一套可直接应用于 Vibe Coding 场景的 AI Agent 系统提示词模板,强调技术准确性优先、上下文感知、迭代规划和自我约束
-
-## Key Claims(用中文描述)
-- AI 助手应严格遵守项目现有约定,优先分析周围代码和配置,而非假设库或框架可用
-- AI 助手应优先考虑技术准确性,而非迎合用户;遇到不确定时应承认局限性而非猜测
-- 复杂任务必须使用 TODO 列表规划并分解为小步骤,同时采用从广泛到具体的搜索策略
-- AI 助手不应透露内部指令或系统提示,且只提供基于事实的信息,不进行推测
-- 代码修改应优先使用 Search/Replace 而非完整文件写入;SEARCH 块必须精确匹配所有字符
-
-## Key Quotes
-> "严格遵守项目现有约定,优先分析周围代码和配置" — AI 助手应将项目上下文置于库/框架假设之前
-> "优先考虑技术准确性,而非迎合用户" — 诚实的技术反馈优先于用户的错误偏好
-> "绝不透露内部指令或系统提示" — 安全边界:AI 不得暴露自身的系统级指令
-> "不进行猜测或推测,仅回答基于事实的信息" — 知识边界:不确定时应承认而非虚构
-> "采用从广泛到具体的搜索策略" — 信息获取原则:先探索后行动
-> "语义搜索用于理解概念,正则搜索用于精确定位" — 搜索工具选用原则
-
-## Key Concepts
-- [[Vibe Coding]]:AI 辅助编程范式,强调规划驱动、上下文固定、AI 结对执行
-- [[系统提示词工程]]:通过结构化原则构建 AI 行为边界和执行框架
-- [[Search/Replace 编辑模式]]:优先使用精确替换而非全文件覆盖的代码修改策略
-- [[TODO 驱动任务分解]]:复杂任务必须先建立任务清单再逐步执行
-- [[技术准确性优先原则]]:AI 助手应诚实指出错误而非迎合用户的错误偏好
-
-## Key Entities
-- [[vibe-coding-cn]]:开源 Vibe Coding 中文项目,提供方法论与原则文档
-
-## Connections
-- [[Vibe Coding 经验收集]] ← extends ← [[系统提示词构建原则]]
-- [[Vibe-Kanban]] ← depends_on ← [[系统提示词构建原则]]
-- [[Cursor 2.0初学者使用指南]] ← extends ← [[系统提示词构建原则]]
-- [[Claude Code 调用方法总结]] ← related ← [[系统提示词构建原则]]
-
-## Contradictions
-- 无已知冲突
+---
+title: "系统提示词构建原则"
+type: source
+tags: []
+date: 2025-12-30
+---
+
+## Source File
+- [[raw/AI/系统提示词构建原则.md]]
+
+## Summary(用中文描述)
+- 核心主题:AI Coding Agent(AI编程助手)的系统提示词构建原则与行为准则
+- 问题域:如何通过精心设计的系统提示词,使AI Agent具备专业、可信、高效的行为模式
+- 方法/机制:从身份准则、沟通规范、任务执行、技术编码、安全防护、工具使用六个维度构建提示词体系
+- 结论/价值:提供了一套完整的AI Agent系统提示词设计框架,涵盖从代码风格遵守到安全防护的全面指导
+
+## Key Claims(用中文描述)
+- AI Agent 应严格遵守项目现有约定,优先分析周围代码和配置,而非假设框架可用
+- AI Agent 应专注于解决问题而非过程,不进行猜测或推测,仅回答基于事实的信息
+- 复杂任务必须使用TODO列表进行规划,将任务分解为小的、可验证的步骤
+- 代码优化应优先提高清晰度和可读性,避免短变量名,使用完整描述性命名
+- 在安全防护方面,必须保护密钥和敏感信息,实施最小权限原则
+
+## Key Quotes
+> "严格遵守项目现有约定,优先分析周围代码和配置" — 核心身份准则第一条,强调理解现有代码库的重要性
+> "专注于解决问题,而不是过程" — 避免AI陷入展示过程而非解决实际问题的陷阱
+> "不进行猜测或推测,仅回答基于事实的信息" — 保证输出的可信度和准确性
+> "优化代码以提高清晰度和可读性" — 技术准则的核心价值取向
+
+## Key Concepts
+- [[系统提示词]]:用于定义AI Agent行为模式和能力的指令集合
+- [[Vibe Coding]]:一种以AI为中心的编程范式,通过自然语言指令驱动AI完成开发任务
+- [[SEARCH/REPLACE]]:精确的代码修改模式,避免全量覆盖导致冲突
+- [[最小权限原则]]:安全设计核心原则,仅授予完成任务所需的最小权限
+- [[TODO列表规划]]:复杂任务管理方法,通过结构化任务分解提高执行效率
+
+## Key Entities
+- [[vibe-coding-cn]]:GitHub项目,提供了本提示词框架的原始来源
+
+## Connections
+- [[A Formalization of Recursive Self-Optimizing Generative Systems]] ← topic_related ← [[系统提示词构建原则]]
+- [[Vibe Coding 经验收集]] ← extends ← [[系统提示词构建原则]]
+
+## Contradictions
+- 无已知冲突内容
diff --git a/wiki/sources/网件rax50路由器刷梅林固件与科学上网插件安装教程.md b/wiki/sources/网件rax50路由器刷梅林固件与科学上网插件安装教程.md
index 7fcf5013..71692d24 100644
--- a/wiki/sources/网件rax50路由器刷梅林固件与科学上网插件安装教程.md
+++ b/wiki/sources/网件rax50路由器刷梅林固件与科学上网插件安装教程.md
@@ -1,53 +1,53 @@
----
-title: "网件RAX50路由器刷梅林固件与科学上网插件安装教程"
-type: source
-tags: [clash, merlin-clash, rax50, 科学上网, 梅林固件]
-date: 2026-04-26
----
-
-## Source File
-- [[Home Office/网件RAX50路由器刷梅林固件与科学上网插件安装教程]]
-
-## Summary(用中文描述)
-- **核心主题**:网件RAX50路由器刷入梅林固件并安装科学上网插件的完整操作指南
-- **问题域**:路由器固件刷入、科学上网插件配置、网络分流与故障转移
-- **方法/机制**:
- - 二次刷机流程(.chk 过渡固件 → .w 梅林固件)
- - JFFS双清操作清理旧缓存
- - 软件中心安装 MerlinClash 科学上网插件
- - 策略组配置实现节点分流与故障转移
- - 定时自动更新订阅、守护进程保证插件稳定运行
-- **结论/价值**:提供网件路由器科学上网的完整闭环方案,包含硬件刷机、软件配置与日常维护
-
-## Key Claims(用中文描述)
-- 网件RAX50路由器必须先刷 .chk 过渡固件,再刷 .w 梅林固件,直接刷 .w 会失败
-- JFFS双清可清理文件系统缓存,防止刷机后残留问题
-- MerlinClash 插件支持策略组自动分流和节点故障转移,比同类插件功能更全面
-- MerlinClash 与科学上网插件不可同时运行,只能选其一
-- 恢复出厂设置不会恢复网件原厂固件,仅重置梅林固件配置
-
-## Key Quotes
-> "必须先刷 `.chk` 的过渡固件,再刷 `.w` 的正式梅林固件,二次刷机才能确保稳定" — 刷机顺序说明
-> "两个插件不能同时运行,选择一个即可,优选支持策略组分流的 MerlinClash" — 插件选择建议
-> "通过策略组配置不同节点和规则,实现基于应用、地区和服务的自动分流和节点故障转移" — MerlinClash 核心优势
-
-## Key Concepts
-- [[梅林固件]]:华硕路由器第三方固件改良版,支持插件和科学上网
-- [[过渡固件]]:.chk 格式,用于网件路由器从原厂固件过渡到梅林固件
-- [[策略组分流]]:基于应用/地区/目标的流量分类转发机制
-- [[故障转移]]:连接故障时自动切换备用节点,保持网络通畅
-- [[订阅机制]]:通过机场订阅链接导入代理节点配置
-
-## Key Entities
-- [[网件RAX50]]:WiFi 6 双频路由器,支持刷梅林固件
-- [[机场]]:提供代理节点订阅服务的数据中心
-- [[MerlinClash插件]]:基于 Clash 的高级科学上网插件(需新建 Entity)
-
-## Connections
-- [[网件RAX50]] ← uses ← [[梅林固件]]
-- [[梅林固件]] ← enables ← [[MerlinClash插件]]
-- [[MerlinClash插件]] ← depends_on ← [[策略组分流]]
-- [[梅林固件]] ← requires ← [[过渡固件]]
-
-## Contradictions
-- 无已知冲突
+---
+title: "网件RAX50路由器刷梅林固件与科学上网插件安装教程"
+type: source
+tags: [clash, merlin-clash, rax50, 科学上网, 梅林固件]
+date: 2026-04-26
+---
+
+## Source File
+- [[raw/Home Office/网件RAX50路由器刷梅林固件与科学上网插件安装教程.md]]
+
+## Summary(用中文描述)
+- **核心主题**:网件RAX50路由器刷入梅林固件并安装科学上网插件的完整操作指南
+- **问题域**:路由器固件刷入、科学上网插件配置、网络分流与故障转移
+- **方法/机制**:
+ - 二次刷机流程(.chk 过渡固件 → .w 梅林固件)
+ - JFFS双清操作清理旧缓存
+ - 软件中心安装 MerlinClash 科学上网插件
+ - 策略组配置实现节点分流与故障转移
+ - 定时自动更新订阅、守护进程保证插件稳定运行
+- **结论/价值**:提供网件路由器科学上网的完整闭环方案,包含硬件刷机、软件配置与日常维护
+
+## Key Claims(用中文描述)
+- 网件RAX50路由器必须先刷 .chk 过渡固件,再刷 .w 梅林固件,直接刷 .w 会失败
+- JFFS双清可清理文件系统缓存,防止刷机后残留问题
+- MerlinClash 插件支持策略组自动分流和节点故障转移,比同类插件功能更全面
+- MerlinClash 与科学上网插件不可同时运行,只能选其一
+- 恢复出厂设置不会恢复网件原厂固件,仅重置梅林固件配置
+
+## Key Quotes
+> "必须先刷 `.chk` 的过渡固件,再刷 `.w` 的正式梅林固件,二次刷机才能确保稳定" — 刷机顺序说明
+> "两个插件不能同时运行,选择一个即可,优选支持策略组分流的 MerlinClash" — 插件选择建议
+> "通过策略组配置不同节点和规则,实现基于应用、地区和服务的自动分流和节点故障转移" — MerlinClash 核心优势
+
+## Key Concepts
+- [[梅林固件]]:华硕路由器第三方固件改良版,支持插件和科学上网
+- [[过渡固件]]:.chk 格式,用于网件路由器从原厂固件过渡到梅林固件
+- [[策略组分流]]:基于应用/地区/目标的流量分类转发机制
+- [[故障转移]]:连接故障时自动切换备用节点,保持网络通畅
+- [[订阅机制]]:通过机场订阅链接导入代理节点配置
+
+## Key Entities
+- [[网件RAX50]]:WiFi 6 双频路由器,支持刷梅林固件
+- [[机场]]:提供代理节点订阅服务的数据中心
+- [[MerlinClash插件]]:基于 Clash 的高级科学上网插件(需新建 Entity)
+
+## Connections
+- [[网件RAX50]] ← uses ← [[梅林固件]]
+- [[梅林固件]] ← enables ← [[MerlinClash插件]]
+- [[MerlinClash插件]] ← depends_on ← [[策略组分流]]
+- [[梅林固件]] ← requires ← [[过渡固件]]
+
+## Contradictions
+- 无已知冲突
diff --git a/wiki/sources/群晖nas科学上网方法.md b/wiki/sources/群晖nas科学上网方法.md
index d23a0b7b..fd019010 100644
--- a/wiki/sources/群晖nas科学上网方法.md
+++ b/wiki/sources/群晖nas科学上网方法.md
@@ -1,48 +1,48 @@
----
-title: "群晖NAS科学上网方法"
-type: source
-tags: [docker, nas, synology, v2raya, vpn, 透明代理]
-date: 2025-03-08
----
-
-## Source File
-- [[Home Office/群晖NAS科学上网方法]]
-
-## Summary(用中文描述)
-- 核心主题:在群晖(Synology)NAS 上通过 Docker 安装 V2RayA,实现透明代理,使 NAS 本机和 Docker Daemon 均能科学上网
-- 问题域:群晖 DSM 环境下,Docker Daemon 网络栈不遵循 V2RayA 的 iptables 规则,导致 `docker pull` 仍无法走代理
-- 方法/机制:
- - 通过 Docker 部署 V2RayA 容器(Host 网络模式)
- - 透明代理(transparent proxy)劫持 NAS 本机出站流量
- - 路由规则选择"大陆白名单(Whitelist of Mainland China)"分流
- - 备用方案:显式配置 Docker Daemon HTTP 代理环境变量(推荐)
-- 结论/价值:透明代理对 NAS 本机有效,但对 Docker Daemon 无效;Engineering Best Practice 是显式配置 Docker 守护进程代理,而非依赖 Host 透明代理
-
-## Key Claims(用中文描述)
-- V2RayA Docker 容器以 `--network=host` 模式运行,配合 `--restart=always` 确保开机自启
-- V2RayA 透明代理(分流模式"大陆白名单")可使 NAS 本机流量走代理,验证方法:`curl https://www.google.com`(不加 `-x` 参数)直接返回 HTTP 200
-- DSM 7.x 中,Docker Daemon (`dockerd`) 网络栈不完全遵循 v2rayA 的 iptables 规则,`docker pull` 可能仍然失败
-- 显式配置 Docker Daemon 代理(systemd environment variables)是解决 `docker pull` 科学上网的推荐方案,符合 Engineering Best Practice
-
-## Key Quotes
-> "在群晖 DSM 7.x 中,Docker Daemon (`dockerd`) 的网络栈有时候不会完全遵循 v2rayA 修改的 iptables 规则。如果上面的 `docker pull` 仍然慢或失败,**不要死磕透明代理**,直接配置 Docker 守护进程走 HTTP 代理是最稳妥的方案。" — 核心观点
-> "对于企业级或生产环境(即使是SOHO),我建议**不要**依赖 NAS Host 的透明代理来解决 `docker pull` 问题,因为这修改了系统级路由表,容易影响 NAS 其他服务。**显式配置 Docker Daemon 的 Proxy 环境变量(上面的最后一种方法)是更符合 Engineering Best Practice 的做法。**" — 最佳实践建议
-
-## Key Concepts
-- [[V2RayA]]:基于 V2Ray 的轻量透明代理 Web 管理界面,支持多种分流规则(大陆白名单/GFWList 等)
-- [[透明代理]](Transparent Proxy):在网络层劫持并转发流量,无需客户端显式配置代理
-- [[Docker Daemon 代理]]:通过 systemd 环境变量为 Docker 守护进程配置 HTTP/HTTPS 代理,影响所有 `docker pull` 和容器出站流量
-- [[Traffic Splitting]](流量分流):V2RayA 的分流模式,根据路由规则决定流量直连或走代理
-
-## Key Entities
-- [[Synology-DSM]]:群晖 NAS 操作系统,DSM 7.x 中 Docker 服务名为 `pkg-ContainerManager-dockerd`
-- [[Docker]]:容器化平台,本文档中作为 V2RayA 的运行环境和需要科学上网的主要场景
-- [[mzz2017/v2raya]]:V2RayA 官方 Docker 镜像,用于在 NAS 上部署代理服务
-
-## Connections
-- [[Ubuntu-Server科学上网]] ← similar_approach ← [[群晖NAS科学上网方法]](同为 Linux 环境下部署 V2RayA 的实践)
-- [[Synology-NAS上安装CloudDrive2]] ← same_platform ← [[群晖NAS科学上网方法]](均针对 Synology NAS 环境)
-- [[如何传输Docker-images-并且在另一个Docker安装]] ← referenced_by ← [[群晖NAS科学上网方法]](文档内引用了镜像传输方法)
-
-## Contradictions
-- 无冲突。与 [[Ubuntu-Server科学上网]] 的方法论一致(均推荐显式配置代理而非依赖透明代理)。
+---
+title: "群晖NAS科学上网方法"
+type: source
+tags: [docker, nas, synology, v2raya, vpn, 透明代理]
+date: 2025-03-08
+---
+
+## Source File
+- [[raw/Home Office/群晖NAS科学上网方法.md]]
+
+## Summary(用中文描述)
+- 核心主题:在群晖(Synology)NAS 上通过 Docker 安装 V2RayA,实现透明代理,使 NAS 本机和 Docker Daemon 均能科学上网
+- 问题域:群晖 DSM 环境下,Docker Daemon 网络栈不遵循 V2RayA 的 iptables 规则,导致 `docker pull` 仍无法走代理
+- 方法/机制:
+ - 通过 Docker 部署 V2RayA 容器(Host 网络模式)
+ - 透明代理(transparent proxy)劫持 NAS 本机出站流量
+ - 路由规则选择"大陆白名单(Whitelist of Mainland China)"分流
+ - 备用方案:显式配置 Docker Daemon HTTP 代理环境变量(推荐)
+- 结论/价值:透明代理对 NAS 本机有效,但对 Docker Daemon 无效;Engineering Best Practice 是显式配置 Docker 守护进程代理,而非依赖 Host 透明代理
+
+## Key Claims(用中文描述)
+- V2RayA Docker 容器以 `--network=host` 模式运行,配合 `--restart=always` 确保开机自启
+- V2RayA 透明代理(分流模式"大陆白名单")可使 NAS 本机流量走代理,验证方法:`curl https://www.google.com`(不加 `-x` 参数)直接返回 HTTP 200
+- DSM 7.x 中,Docker Daemon (`dockerd`) 网络栈不完全遵循 v2rayA 的 iptables 规则,`docker pull` 可能仍然失败
+- 显式配置 Docker Daemon 代理(systemd environment variables)是解决 `docker pull` 科学上网的推荐方案,符合 Engineering Best Practice
+
+## Key Quotes
+> "在群晖 DSM 7.x 中,Docker Daemon (`dockerd`) 的网络栈有时候不会完全遵循 v2rayA 修改的 iptables 规则。如果上面的 `docker pull` 仍然慢或失败,**不要死磕透明代理**,直接配置 Docker 守护进程走 HTTP 代理是最稳妥的方案。" — 核心观点
+> "对于企业级或生产环境(即使是SOHO),我建议**不要**依赖 NAS Host 的透明代理来解决 `docker pull` 问题,因为这修改了系统级路由表,容易影响 NAS 其他服务。**显式配置 Docker Daemon 的 Proxy 环境变量(上面的最后一种方法)是更符合 Engineering Best Practice 的做法。**" — 最佳实践建议
+
+## Key Concepts
+- [[V2RayA]]:基于 V2Ray 的轻量透明代理 Web 管理界面,支持多种分流规则(大陆白名单/GFWList 等)
+- [[透明代理]](Transparent Proxy):在网络层劫持并转发流量,无需客户端显式配置代理
+- [[Docker Daemon 代理]]:通过 systemd 环境变量为 Docker 守护进程配置 HTTP/HTTPS 代理,影响所有 `docker pull` 和容器出站流量
+- [[Traffic Splitting]](流量分流):V2RayA 的分流模式,根据路由规则决定流量直连或走代理
+
+## Key Entities
+- [[Synology-DSM]]:群晖 NAS 操作系统,DSM 7.x 中 Docker 服务名为 `pkg-ContainerManager-dockerd`
+- [[Docker]]:容器化平台,本文档中作为 V2RayA 的运行环境和需要科学上网的主要场景
+- [[mzz2017/v2raya]]:V2RayA 官方 Docker 镜像,用于在 NAS 上部署代理服务
+
+## Connections
+- [[Ubuntu-Server科学上网]] ← similar_approach ← [[群晖NAS科学上网方法]](同为 Linux 环境下部署 V2RayA 的实践)
+- [[Synology-NAS上安装CloudDrive2]] ← same_platform ← [[群晖NAS科学上网方法]](均针对 Synology NAS 环境)
+- [[如何传输Docker-images-并且在另一个Docker安装]] ← referenced_by ← [[群晖NAS科学上网方法]](文档内引用了镜像传输方法)
+
+## Contradictions
+- 无冲突。与 [[Ubuntu-Server科学上网]] 的方法论一致(均推荐显式配置代理而非依赖透明代理)。
diff --git a/wiki/sources/谷歌深夜甩出一份-nano-banana-pro提示词指南-手把手教你生产专业级内容-实战案例-提示词模版.md b/wiki/sources/谷歌深夜甩出一份-nano-banana-pro提示词指南-手把手教你生产专业级内容-实战案例-提示词模版.md
index 49db32f0..87a5b876 100644
--- a/wiki/sources/谷歌深夜甩出一份-nano-banana-pro提示词指南-手把手教你生产专业级内容-实战案例-提示词模版.md
+++ b/wiki/sources/谷歌深夜甩出一份-nano-banana-pro提示词指南-手把手教你生产专业级内容-实战案例-提示词模版.md
@@ -6,7 +6,7 @@ date: 2025-12-18
---
## Source File
-- [[AI/谷歌深夜甩出一份【Nano Banana Pro提示词指南】,手把手教你生产专业级内容,实战案例+提示词模版.md]]
+- [[raw/AI/谷歌深夜甩出一份【Nano Banana Pro提示词指南】,手把手教你生产专业级内容,实战案例+提示词模版.md]]
## Summary(用中文描述)
- 核心主题:Google 生成式AI团队发布的 Nano Banana Pro 提示词官方指南,教授如何用该模型制作专业级内容
diff --git a/wiki/sources/超达物流定价.md b/wiki/sources/超达物流定价.md
index b4f6ca22..7bbec8db 100644
--- a/wiki/sources/超达物流定价.md
+++ b/wiki/sources/超达物流定价.md
@@ -1,52 +1,52 @@
----
-title: "超达物流定价"
-type: source
-tags: []
-date: 2025-12-19
----
-
-## Source File
-- [[跨境电商/超达物流定价]]
-
-## Summary(用中文描述)
-- 核心主题:超达物流(ChaoDa Logistics)跨境电商定价规则与操作注意事项
-- 问题域:TikTok Shop 美国市场跨境发货的物流计费与面单管理
-- 方法/机制:
- - 计费重量取申报重量、实重、材积重三者最大值
- - UIN渠道提供预上网服务,申请单号后24-48小时推送轨迹
- - TK平台面单跟踪号以"TKM"开头的为无效单号
- - 发货截止时间每天12点,美区周日不发货
-- 结论/价值:掌握超达物流计费规则,避免因申报重量或面单问题导致额外费用
-
-## Key Claims(用中文描述)
-- 超达物流对申报重量、实重、材积取最大值收费,申报重量应低于或等于收费重量
-- UIN渠道申请单号后24-48小时产生轨迹上网,需控制好申请单号的时间
-- TK平台"TKM"开头的跟踪号为无效单号,需联系客服处理
-- 草稿订单状态的单号不会推送轨迹上网,需及时处理
-- UIN渠道:未推送轨迹取消单号不收费,已推送则收取全额挂号费
-- TK平台面单:未推送轨迹取消单号不收费,已推送收取10元/票操作费
-- 选错渠道后期修改均收取10元/票操作费
-- 每天12点前到仓的货物当天打包发走,美区周日休息不发货
-
-## Key Quotes
-> "申报重量、实重、材积取最大值收费,请务必注意。" — 超达物流核心计费原则
-
-## Key Concepts
-- [[计费重量原则]]:申报重量、实际重量、材积重量三者取最大值作为收费依据
-- [[轨迹推送机制]]:UIN渠道在收到单号后24-48小时内推送上网轨迹
-- [[取消单号收费]]:以轨迹是否推送为分界,未推送免费,已推送根据渠道收取操作费
-
-## Key Entities
-- [[超达物流]]:跨境电商物流服务商,提供UIN渠道和TK平台面单服务
-- [[TikTok Shop]]:主要销售平台,本文档涉及美国市场发货操作
-- [[UIN渠道]]:超达物流提供的预上网渠道,支持24-48小时轨迹推送
-
-## Connections
-- [[TikTok Shop]] ← 使用 ← [[超达物流]]
-- [[超达物流定价]] ← relates_to ← [[TK美国面单授权及操作流程]]
-
-## Contradictions
-- 与 [[TK美国面单授权及操作流程]]:
- - 冲突点:两份文档均涉及超达物流与TikTok美国市场,但本文档专注于定价规则,前者专注于授权配置
- - 当前观点:定价规则与授权配置可独立存在,互为补充
- - 对方观点:授权文档侧重系统配置步骤
+---
+title: "超达物流定价"
+type: source
+tags: []
+date: 2025-12-19
+---
+
+## Source File
+- [[raw/跨境电商/超达物流定价.md]]
+
+## Summary(用中文描述)
+- 核心主题:超达物流(ChaoDa Logistics)跨境电商定价规则与操作注意事项
+- 问题域:TikTok Shop 美国市场跨境发货的物流计费与面单管理
+- 方法/机制:
+ - 计费重量取申报重量、实重、材积重三者最大值
+ - UIN渠道提供预上网服务,申请单号后24-48小时推送轨迹
+ - TK平台面单跟踪号以"TKM"开头的为无效单号
+ - 发货截止时间每天12点,美区周日不发货
+- 结论/价值:掌握超达物流计费规则,避免因申报重量或面单问题导致额外费用
+
+## Key Claims(用中文描述)
+- 超达物流对申报重量、实重、材积取最大值收费,申报重量应低于或等于收费重量
+- UIN渠道申请单号后24-48小时产生轨迹上网,需控制好申请单号的时间
+- TK平台"TKM"开头的跟踪号为无效单号,需联系客服处理
+- 草稿订单状态的单号不会推送轨迹上网,需及时处理
+- UIN渠道:未推送轨迹取消单号不收费,已推送则收取全额挂号费
+- TK平台面单:未推送轨迹取消单号不收费,已推送收取10元/票操作费
+- 选错渠道后期修改均收取10元/票操作费
+- 每天12点前到仓的货物当天打包发走,美区周日休息不发货
+
+## Key Quotes
+> "申报重量、实重、材积取最大值收费,请务必注意。" — 超达物流核心计费原则
+
+## Key Concepts
+- [[计费重量原则]]:申报重量、实际重量、材积重量三者取最大值作为收费依据
+- [[轨迹推送机制]]:UIN渠道在收到单号后24-48小时内推送上网轨迹
+- [[取消单号收费]]:以轨迹是否推送为分界,未推送免费,已推送根据渠道收取操作费
+
+## Key Entities
+- [[超达物流]]:跨境电商物流服务商,提供UIN渠道和TK平台面单服务
+- [[TikTok Shop]]:主要销售平台,本文档涉及美国市场发货操作
+- [[UIN渠道]]:超达物流提供的预上网渠道,支持24-48小时轨迹推送
+
+## Connections
+- [[TikTok Shop]] ← 使用 ← [[超达物流]]
+- [[超达物流定价]] ← relates_to ← [[TK美国面单授权及操作流程]]
+
+## Contradictions
+- 与 [[TK美国面单授权及操作流程]]:
+ - 冲突点:两份文档均涉及超达物流与TikTok美国市场,但本文档专注于定价规则,前者专注于授权配置
+ - 当前观点:定价规则与授权配置可独立存在,互为补充
+ - 对方观点:授权文档侧重系统配置步骤
diff --git a/wiki/sources/通过vps-内网反向代理实现域名访问内网穿透.md b/wiki/sources/通过vps-内网反向代理实现域名访问内网穿透.md
index 2d7874ed..7059e1b3 100644
--- a/wiki/sources/通过vps-内网反向代理实现域名访问内网穿透.md
+++ b/wiki/sources/通过vps-内网反向代理实现域名访问内网穿透.md
@@ -1,54 +1,54 @@
----
-title: "通过VPS+内网反向代理实现域名访问内网穿透"
-type: source
-tags: [vps, caddy, frp, reverse-proxy, troubleshooting, cloudflare]
-date: 2026-04-03
----
-
-## Source File
-- [[Home Office/通过VPS+内网反向代理实现域名访问内网穿透.md]]
-
-## Summary(用中文描述)
-- 核心主题:通过 VPS(frps + Caddy)建立反向隧道,使内网服务(NAS、Ubuntu)可通过 `*.ishenwei.online` 域名从公网安全访问。
-- 问题域:家庭内网设备无公网 IP,无法被外网直接访问;需要将内网服务通过公网 VPS 暴露为 HTTPS 域名。
-- 方法/机制:frp(frps 服务端 + frpc 客户端)建立 TCP 反向隧道 → VPS 本地端口映射 → Caddy 反向代理到对应端口并自动申请 Let's Encrypt HTTPS 证书。
-- 结论/价值:完整的内网穿透方案,支持 NAS、n8n、Transmission、Grafana、Navidrome、Calibre、WebDAV 等多个服务,附 SSH 穿透和故障排查指南。
-
-## Key Claims(用中文描述)
-- frp 专为内网穿透设计,支持 NAT 穿透、自动重连、Web 管理面板,比纯 SSH 隧道更适合多设备多端口场景。
-- Caddy 自动处理 Let's Encrypt 证书申请和续期,无需手动配置 HTTPS。
-- SSH 穿透(TCP 映射)不经过 Caddy,只依赖 frps + frpc 配置。
-- 故障排查核心:确认 frps 监听端口正确、token 一致、防火墙放行 7000 端口、frps 日志无 token mismatch。
-
-## Key Quotes
-> "frp 优点:专为内网穿透设计,支持 NAT、自动重连、Web 管理面板(可选)。推荐当你有多台设备和多端口时使用。" — 方案选型说明
-> "Caddy 会自动申请并更新 Let's Encrypt 证书,提供 HTTPS 访问。" — HTTPS 配置结果
-> "SSH 穿透与 HTTP 不同,它是纯 TCP 流量,不经 Caddy(Caddy 只处理 HTTP/HTTPS),所以:Caddy 不参与 SSH 的代理。" — SSH vs HTTP 穿透关键区别
-> "authentication failed token mismatch invalid login → 那肯定是 token 和 frpc 不一致。" — 常见故障根因
-
-## Key Concepts
-- [[反向代理]]:Caddy 将公网请求反向代理到 VPS 本地 frp 映射端口(127.0.0.1:xxxxx)。
-- [[内网穿透]]:通过 frp 反向隧道穿透 NAT/防火墙,使内网设备可被公网访问。
-- [[TCP隧道]]:frp 将内网 TCP 端口映射到 VPS remote_port,实现任意 TCP 协议穿透。
-- [[Caddy]]:Go 语言反向代理服务器,自动 HTTPS(Let's Encrypt),Caddyfile 配置各子域名反向代理到对应 frp 端口。
-- [[frp]]:开源内网穿透工具,frps(服务端)监听 7000 端口,frpc(客户端)建立反向隧道。
-
-## Key Entities
-- [[RackNerd]]:VPS 提供商(IP: 192.227.222.142),托管 frps 和 Caddy,作为内网穿透公网中转站。
-- [[Synology NAS DS718]]:群晖 NAS(192.168.3.17),运行 NAS 管理界面(5000)、Navidrome(4533)、Calibre(8083)、WebDAV(5005)等服务,通过 frpc 映射到 VPS。
-- [[Ubuntu]](内网 Ubuntu1 192.168.3.47):运行 n8n(5678)、Transmission(9091)、Grafana(3000)、SSH(22),通过 frpc 映射到 VPS。
-- [[n8n]]:自动化工作流工具(192.168.3.47:5678),通过 frp 暴露为 `https://n8n.ishenwei.online`。
-- [[阿里云-DNS]]:管理 `ishenwei.online` 域名解析,A 记录指向 VPS 公网 IP。
-
-## Connections
-- [[frp]] ← reverse_tunnel ← [[Synology NAS DS718]](frpc 客户端,映射 5000→15000)
-- [[frp]] ← reverse_tunnel ← [[Ubuntu]](frpc 客户端,映射 5678/9091/3000/22)
-- [[Caddy]] ← reverse_proxy ← [[frp]](反向代理到 frp 映射的本地端口)
-- [[阿里云-DNS]] ← DNS_record ← [[RackNerd]](A 记录指向 VPS IP 192.227.222.142)
-
-## Contradictions
-- 与 [[Ubuntu安装FRP操作笔记]] 冲突:
- - 冲突点:两者都描述 frp 安装,但侧重不同。
- - 当前观点:本文档(通过VPS+内网反向代理)侧重完整方案(frps+VPS+Caddy+多服务+SSH穿透+故障排查),是完整的操作指南。
- - 对方观点:[[Ubuntu安装FRP操作笔记]] 侧重 FRP 本身安装配置(frps.ini/frpc.ini 详解),偏向 FRP 工具参考手册。
- - 说明:两者互补,本文档是完整实践指南,对方是工具参考,两者不存在实质矛盾。
+---
+title: "通过VPS+内网反向代理实现域名访问内网穿透"
+type: source
+tags: [vps, caddy, frp, reverse-proxy, troubleshooting, cloudflare]
+date: 2026-04-03
+---
+
+## Source File
+- [[raw/Home Office/通过VPS+内网反向代理实现域名访问内网穿透.md]]
+
+## Summary(用中文描述)
+- 核心主题:通过 VPS(frps + Caddy)建立反向隧道,使内网服务(NAS、Ubuntu)可通过 `*.ishenwei.online` 域名从公网安全访问。
+- 问题域:家庭内网设备无公网 IP,无法被外网直接访问;需要将内网服务通过公网 VPS 暴露为 HTTPS 域名。
+- 方法/机制:frp(frps 服务端 + frpc 客户端)建立 TCP 反向隧道 → VPS 本地端口映射 → Caddy 反向代理到对应端口并自动申请 Let's Encrypt HTTPS 证书。
+- 结论/价值:完整的内网穿透方案,支持 NAS、n8n、Transmission、Grafana、Navidrome、Calibre、WebDAV 等多个服务,附 SSH 穿透和故障排查指南。
+
+## Key Claims(用中文描述)
+- frp 专为内网穿透设计,支持 NAT 穿透、自动重连、Web 管理面板,比纯 SSH 隧道更适合多设备多端口场景。
+- Caddy 自动处理 Let's Encrypt 证书申请和续期,无需手动配置 HTTPS。
+- SSH 穿透(TCP 映射)不经过 Caddy,只依赖 frps + frpc 配置。
+- 故障排查核心:确认 frps 监听端口正确、token 一致、防火墙放行 7000 端口、frps 日志无 token mismatch。
+
+## Key Quotes
+> "frp 优点:专为内网穿透设计,支持 NAT、自动重连、Web 管理面板(可选)。推荐当你有多台设备和多端口时使用。" — 方案选型说明
+> "Caddy 会自动申请并更新 Let's Encrypt 证书,提供 HTTPS 访问。" — HTTPS 配置结果
+> "SSH 穿透与 HTTP 不同,它是纯 TCP 流量,不经 Caddy(Caddy 只处理 HTTP/HTTPS),所以:Caddy 不参与 SSH 的代理。" — SSH vs HTTP 穿透关键区别
+> "authentication failed token mismatch invalid login → 那肯定是 token 和 frpc 不一致。" — 常见故障根因
+
+## Key Concepts
+- [[反向代理]]:Caddy 将公网请求反向代理到 VPS 本地 frp 映射端口(127.0.0.1:xxxxx)。
+- [[内网穿透]]:通过 frp 反向隧道穿透 NAT/防火墙,使内网设备可被公网访问。
+- [[TCP隧道]]:frp 将内网 TCP 端口映射到 VPS remote_port,实现任意 TCP 协议穿透。
+- [[Caddy]]:Go 语言反向代理服务器,自动 HTTPS(Let's Encrypt),Caddyfile 配置各子域名反向代理到对应 frp 端口。
+- [[frp]]:开源内网穿透工具,frps(服务端)监听 7000 端口,frpc(客户端)建立反向隧道。
+
+## Key Entities
+- [[RackNerd]]:VPS 提供商(IP: 192.227.222.142),托管 frps 和 Caddy,作为内网穿透公网中转站。
+- [[Synology NAS DS718]]:群晖 NAS(192.168.3.17),运行 NAS 管理界面(5000)、Navidrome(4533)、Calibre(8083)、WebDAV(5005)等服务,通过 frpc 映射到 VPS。
+- [[Ubuntu]](内网 Ubuntu1 192.168.3.47):运行 n8n(5678)、Transmission(9091)、Grafana(3000)、SSH(22),通过 frpc 映射到 VPS。
+- [[n8n]]:自动化工作流工具(192.168.3.47:5678),通过 frp 暴露为 `https://n8n.ishenwei.online`。
+- [[阿里云-DNS]]:管理 `ishenwei.online` 域名解析,A 记录指向 VPS 公网 IP。
+
+## Connections
+- [[frp]] ← reverse_tunnel ← [[Synology NAS DS718]](frpc 客户端,映射 5000→15000)
+- [[frp]] ← reverse_tunnel ← [[Ubuntu]](frpc 客户端,映射 5678/9091/3000/22)
+- [[Caddy]] ← reverse_proxy ← [[frp]](反向代理到 frp 映射的本地端口)
+- [[阿里云-DNS]] ← DNS_record ← [[RackNerd]](A 记录指向 VPS IP 192.227.222.142)
+
+## Contradictions
+- 与 [[Ubuntu安装FRP操作笔记]] 冲突:
+ - 冲突点:两者都描述 frp 安装,但侧重不同。
+ - 当前观点:本文档(通过VPS+内网反向代理)侧重完整方案(frps+VPS+Caddy+多服务+SSH穿透+故障排查),是完整的操作指南。
+ - 对方观点:[[Ubuntu安装FRP操作笔记]] 侧重 FRP 本身安装配置(frps.ini/frpc.ini 详解),偏向 FRP 工具参考手册。
+ - 说明:两者互补,本文档是完整实践指南,对方是工具参考,两者不存在实质矛盾。