结构变化
This commit is contained in:
BIN
raw/Technical/.DS_Store
vendored
Normal file
BIN
raw/Technical/.DS_Store
vendored
Normal file
Binary file not shown.
114
raw/Technical/ChinaTextbook - 41.53 GB,中国小学、初中、高中、大学 PDF 教材.md
Normal file
114
raw/Technical/ChinaTextbook - 41.53 GB,中国小学、初中、高中、大学 PDF 教材.md
Normal file
@@ -0,0 +1,114 @@
|
||||
---
|
||||
title: ChinaTextbook - 41.53 GB,中国小学、初中、高中、大学 PDF 教材
|
||||
source: https://www.appinn.com/chinatextbook/
|
||||
author: shenwei
|
||||
published: 2025-05-13
|
||||
created: 2025-12-19
|
||||
description: ChinaTextbook 是一款收集了公开的中国小学、初中、高中、大学 PDF 教材的项目,托管在 GitHub 上,总库大小 41.53GB。@Appinn
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
**ChinaTextbook** 是一款收集了公开的中国小学、初中、高中、大学 PDF 教材的项目,托管在 GitHub 上,总库大小 41.53GB。@ [Appinn](https://www.appinn.com/chinatextbook/)
|
||||
|
||||

|
||||
|
||||
ChinaTextbook - 41.53 GB,中国小学、初中、高中、大学 PDF 教材 1
|
||||
|
||||
- 项目地址: [https://github.com/TapXWorld/ChinaTextbook/](https://github.com/TapXWorld/ChinaTextbook/)
|
||||
|
||||
这个项目存在有一段时间了,今天突然火了。
|
||||
|
||||
教材来源为: [国家中小学智慧教育平台](https://basic.smartedu.cn/tchMaterial) ,本身只需要登录后即可浏览,可以使用第三方工具下载(比如 [tchMaterial-parser](https://github.com/happycola233/tchMaterial-parser) 项目)。
|
||||
|
||||
如果有需求,可以制作一个如何下载/合并教材的教程。
|
||||
|
||||
|
||||
|
||||
ChinaTextbook - 41.53 GB,中国小学、初中、高中、大学 PDF 教材 2
|
||||
|
||||
**ChinaTextbook** 的主要内容包括:
|
||||
|
||||
### 小学:
|
||||
|
||||
- 体育与健康
|
||||
- 数学
|
||||
- 科学
|
||||
- 美术
|
||||
- 艺术
|
||||
- 英语
|
||||
- 语文/统编版
|
||||
- 语文·书法练习指导
|
||||
- 道德与法治/统编版
|
||||
- 音乐
|
||||
|
||||
### 初中:
|
||||
|
||||
- 人文地理/统编版-人民教育出版社
|
||||
- 体育与健康
|
||||
- 俄语/人教版-人民教育出版社
|
||||
- 化学
|
||||
- 历史/统编版-人民教育出版社
|
||||
- 地理
|
||||
- 地理图册
|
||||
- 数学
|
||||
- 日语/人教版-人民教育出版社
|
||||
- 物理
|
||||
- 生物学
|
||||
- 科学
|
||||
- 美术
|
||||
- 艺术
|
||||
- 英语
|
||||
- 语文/统编版-人民教育出版社
|
||||
- 道德与法治/统编版-人民教育出版社
|
||||
- 音乐
|
||||
|
||||
### 高中:
|
||||
|
||||
- 体育与健康
|
||||
- 俄语/人教版-人民教育出版社
|
||||
- 信息技术
|
||||
- 化学
|
||||
- 历史/统编版-人民教育出版社
|
||||
- 地理
|
||||
- 地理图册
|
||||
- 思想政治/统编版-人民教育出版社
|
||||
- 数学
|
||||
- 日语/人教版-人民教育出版社
|
||||
- 物理
|
||||
- 生物学
|
||||
- 美术
|
||||
- 艺术
|
||||
- 英语
|
||||
- 语文/统编版-人民教育出版社
|
||||
- 通用技术
|
||||
- 音乐
|
||||
|
||||
### 大学:
|
||||
|
||||
- 概率论
|
||||
- 离散数学
|
||||
- 线性代数
|
||||
- 高等数学
|
||||
|
||||
---
|
||||
|
||||
原文:https://www.appinn.com/chinatextbook/
|
||||
|
||||
### 分享
|
||||
|
||||
[](https://www.appinn.com/chinatextbook/)
|
||||
|
||||
### 相关
|
||||
|
||||
- [![Citymapper - 「终极公共交通」应用,香港、新加坡、东京等[iPhone/Android/Apple Watch/Web] 4](https://images3cdn.appinn.com/wp-content/uploads/screen322x572-1.jpego_-115x115.jpg "Citymapper - 「终极公共交通」应用,香港、新加坡、东京等[iPhone/Android/Apple Watch/Web] 4")](https://www.appinn.com/citymapper/ "Citymapper – 「终极公共交通」应用,香港、新加坡、东京等[iPhone/Android/Apple Watch/Web]")
|
||||
[Citymapper – 「终极公共交通」应用,香港、新加坡、东京等\[iPhone/Android/Apple Watch/Web\]](https://www.appinn.com/citymapper/ "Citymapper – 「终极公共交通」应用,香港、新加坡、东京等[iPhone/Android/Apple Watch/Web]")
|
||||
2016/03/09 [4](https://www.appinn.com/citymapper/#comments)
|
||||
- [](https://www.appinn.com/huleen/ "「互链 Huleen」:帮我们理解笔记内容背后的「为什么」")
|
||||
[「互链 Huleen」:帮我们理解笔记内容背后的「为什么」](https://www.appinn.com/huleen/ "「互链 Huleen」:帮我们理解笔记内容背后的「为什么」")
|
||||
2021/11/05 [23](https://www.appinn.com/huleen/#comments)
|
||||
- [](https://www.appinn.com/regexlearn-zh-cn/ "RegexLearn 中文版 – 只需 40分钟,刷满 55 题,正则表达式入门。")
|
||||
[RegexLearn 中文版 – 只需 40分钟,刷满 55 题,正则表达式入门。](https://www.appinn.com/regexlearn-zh-cn/ "RegexLearn 中文版 – 只需 40分钟,刷满 55 题,正则表达式入门。")
|
||||
2021/12/17 [13](https://www.appinn.com/regexlearn-zh-cn/#comments)
|
||||
|
||||
[14 条评论,点击查看](https://meta.appinn.net/t/topic/71341)
|
||||
@@ -0,0 +1,72 @@
|
||||
---
|
||||
title: Cloud DevOp Maturity - Guideline
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: []
|
||||
link:
|
||||
---
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
# Cloud DevOp Maturity - Guideline
|
||||
|
||||
To structure an article on evaluating cloud DevOps maturity within enterprise-level SaaS companies, here are key aspects to cover, based on your experience and insights from mature practices:
|
||||
|
||||
### 1. **Definition of Cloud DevOps Maturity**
|
||||
|
||||
- **What is DevOps Maturity?**: Define what maturity means in the context of cloud DevOps. This can include automation, collaboration between development and operations, speed of delivery, and reliability.
|
||||
- **Why Evaluate It?**: Explain the business case for evaluating DevOps maturity, such as reducing time-to-market, improving operational efficiency, and enhancing product reliability.
|
||||
|
||||
### 2. **Key Maturity Models**
|
||||
|
||||
- **Maturity Levels**: Outline the levels of DevOps maturity, from initial stages (ad-hoc processes) to highly optimized and automated environments. You can reference models like:
|
||||
- *CMMI* (Capability Maturity Model Integration)
|
||||
- *DORA* (DevOps Research & Assessment) metrics: deployment frequency, lead time for changes, change failure rate, and mean time to recovery (MTTR).
|
||||
|
||||
### 3. **Foundational Pillars of DevOps Maturity**
|
||||
|
||||
- **Automation**: Focus on CI/CD pipelines, infrastructure as code (IaC), and test automation. Emphasize the importance of repeatable and reliable deployments.
|
||||
- **Collaboration and Culture**: Discuss the role of cross-team collaboration between development, operations, and security. Highlight how mature organizations break down silos.
|
||||
- **Monitoring and Observability**: Address the need for continuous monitoring, logging, and the ability to detect and resolve issues in production environments swiftly.
|
||||
- **Security Integration (DevSecOps)**: Explain how security must be integrated into the DevOps lifecycle through automation, continuous compliance, and proactive vulnerability management.
|
||||
|
||||
### 4. **Tooling and Technology Choices**
|
||||
|
||||
- **DevOps Toolchain**: Talk about the role of tools in enabling a mature DevOps practice. Focus on tools for CI/CD, IaC (e.g., Terraform, Ansible), containerization (e.g., Kubernetes, Docker), and monitoring (e.g., Prometheus, Grafana).
|
||||
- **Cloud-native Practices**: Detail how companies that are more mature adopt cloud-native architectures, microservices, and serverless technologies to accelerate their DevOps journey.
|
||||
|
||||
### 5. **Metrics for Measuring Maturity**
|
||||
|
||||
- **Key Performance Indicators (KPIs)**: Dive into metrics that indicate a company’s DevOps maturity, such as:
|
||||
- Frequency of deployments
|
||||
- Deployment lead times
|
||||
- System uptime and availability
|
||||
- Incident resolution times
|
||||
- **Qualitative Measures**: Also consider cultural indicators, such as employee collaboration, alignment of goals across teams, and feedback loops between development and operations.
|
||||
|
||||
### 6. **Challenges in Reaching DevOps Maturity**
|
||||
|
||||
- **Resistance to Change**: Discuss common barriers, such as organizational inertia, legacy infrastructure, and lack of DevOps skills.
|
||||
- **Scaling DevOps**: Highlight the unique challenges enterprise-level SaaS companies face when scaling DevOps practices globally, managing multiple cloud providers, or balancing rapid innovation with reliability.
|
||||
- **Regulatory and Compliance Constraints**: Address the complexities of maintaining compliance in heavily regulated industries while pushing for faster software delivery.
|
||||
|
||||
### 7. **Case Studies from Mature DevOps Organizations**
|
||||
|
||||
- **Successful Case Examples**: Share examples of enterprise SaaS companies or teams you’ve worked with that successfully reached high DevOps maturity. Highlight what made them successful and the tangible business benefits they achieved.
|
||||
- **Lessons Learned**: Reflect on the lessons from mature cases and failures—both technical and cultural—that can inform best practices.
|
||||
|
||||
### 8. **Roadmap for DevOps Maturity**
|
||||
|
||||
- **Steps Toward Maturity**: Propose a roadmap for organizations seeking to evaluate and improve their DevOps maturity. This can include:
|
||||
- Conducting a DevOps maturity assessment
|
||||
- Building a DevOps Center of Excellence
|
||||
- Implementing phased improvements (starting with CI/CD and automation)
|
||||
- **Ongoing Iteration**: Stress that DevOps is a continuous improvement process, and even mature companies need to adapt to evolving technologies and practices.
|
||||
|
||||
By focusing on these aspects, you’ll create a comprehensive guide for evaluating DevOps maturity in enterprise-level SaaS organizations. You can illustrate the theoretical components with practical insights and experiences.
|
||||
|
||||
@@ -0,0 +1,263 @@
|
||||
---
|
||||
title: Table of Contents
|
||||
source: https://www.bacancytechnology.com/blog/cloud-maturity-model
|
||||
author: shenwei
|
||||
published: 2024-07-08
|
||||
created: 2025-02-28
|
||||
description: Explore the Cloud Maturity Model (CMM) with key components, benefits, and stages, and optimize processes with best practices for successful cloud adoption.
|
||||
tags: [Benefits, Cloud, Conclusion, Frequently, Introduction, Maturity]
|
||||
link:
|
||||
---
|
||||
|
||||
|
||||
***Quick Summary***
|
||||
|
||||
***This blog offers an in-depth understanding of the Cloud Maturity Model (CMM), detailing its key components, business benefits, and stages for achieving cloud maturity. We have also covered best practices for implementing the cloud computing maturity model, focusing on process optimization and enhancement for successful cloud adoption.***
|
||||
|
||||
# Table of Contents
|
||||
|
||||
- [[#Introduction|Introduction]]
|
||||
- [[#Introduction#Key Components of Cloud Maturity Model|Key Components of Cloud Maturity Model]]
|
||||
- [[#Benefits of the Cloud Maturity Model|Benefits of the Cloud Maturity Model]]
|
||||
- [[#Benefits of the Cloud Maturity Model#1\. Enhanced Strategic Planning|1\. Enhanced Strategic Planning]]
|
||||
- [[#Benefits of the Cloud Maturity Model#2\. Improved Communications Across Teams|2\. Improved Communications Across Teams]]
|
||||
- [[#Benefits of the Cloud Maturity Model#3\. Enhanced Application Performance|3\. Enhanced Application Performance]]
|
||||
- [[#Benefits of the Cloud Maturity Model#4\. Enhanced Security and Performance|4\. Enhanced Security and Performance]]
|
||||
- [[#Benefits of the Cloud Maturity Model#5\. Faster Time To Market|5\. Faster Time To Market]]
|
||||
- [[#Benefits of the Cloud Maturity Model#6\. Industry Benchmarking|6\. Industry Benchmarking]]
|
||||
- [[#Benefits of the Cloud Maturity Model#7\. Cost-Savings|7\. Cost-Savings]]
|
||||
- [[#5 Stages to Achieve Cloud Maturity|5 Stages to Achieve Cloud Maturity]]
|
||||
- [[#5 Stages to Achieve Cloud Maturity#Maturity Level - 0: No Cloud Readiness At All (Legacy)|Maturity Level - 0: No Cloud Readiness At All (Legacy)]]
|
||||
- [[#5 Stages to Achieve Cloud Maturity#Maturity Level - 1: Initial Readiness (ad hoc)|Maturity Level - 1: Initial Readiness (ad hoc)]]
|
||||
- [[#Maturity Level - 1: Initial Readiness (ad hoc)#**Challenges You Might Face At This Level**|**Challenges You Might Face At This Level**]]
|
||||
- [[#5 Stages to Achieve Cloud Maturity#Maturity Level - 2: Repeatable, opportunistic|Maturity Level - 2: Repeatable, opportunistic]]
|
||||
- [[#Maturity Level - 2: Repeatable, opportunistic#**Challenges You Might Face at This Level**|**Challenges You Might Face at This Level**]]
|
||||
- [[#5 Stages to Achieve Cloud Maturity#Maturity Level - 3: Systematic and Documented|Maturity Level - 3: Systematic and Documented]]
|
||||
- [[#Maturity Level - 3: Systematic and Documented#**Challenges You Might Face With This Cloud Computing Maturity Model**|**Challenges You Might Face With This Cloud Computing Maturity Model**]]
|
||||
- [[#5 Stages to Achieve Cloud Maturity#Maturity Level - 4: Measured|Maturity Level - 4: Measured]]
|
||||
- [[#5 Stages to Achieve Cloud Maturity#Maturity Level - 5: Optimized|Maturity Level - 5: Optimized]]
|
||||
- [[#Cloud Maturity Model Best Practices|Cloud Maturity Model Best Practices]]
|
||||
- [[#Cloud Maturity Model Best Practices#1\. Set up Cloud Adoption Objectives|1\. Set up Cloud Adoption Objectives]]
|
||||
- [[#Cloud Maturity Model Best Practices#2\. Identify Your Cloud Maturity Level|2\. Identify Your Cloud Maturity Level]]
|
||||
- [[#Cloud Maturity Model Best Practices#3\. Pick a Cloud Maturity Model|3\. Pick a Cloud Maturity Model]]
|
||||
- [[#Cloud Maturity Model Best Practices#4\. Follow Governance and Compliance|4\. Follow Governance and Compliance]]
|
||||
- [[#Cloud Maturity Model Best Practices#5\. Follow Security and Risk Management|5\. Follow Security and Risk Management]]
|
||||
- [[#Conclusion|Conclusion]]
|
||||
- [[#Frequently Asked Questions (FAQs)|Frequently Asked Questions (FAQs)]]
|
||||
|
||||
## Introduction
|
||||
|
||||
The **Cloud Maturity Model** (CMM) is a key framework for evaluating an organization’s cloud adoption readiness. It applies to organizations of all sizes and cloud experience levels. For those new to cloud computing, a CMM assists in formulating a comprehensive cloud adoption strategy. For organizations already leveraging cloud services, it helps pinpoint and resolve operational or security vulnerabilities, driving further optimization.
|
||||
|
||||
Recent statistics underscore the growing significance of CMMs. For instance, Forrester predicts that the global *cloud maturity model* industry will expand to USD 1.5 billion by 2025, doubling from USD 750 million in 2022. Additionally, Gartner highlights that more than 60% of organizations actively implement cloud maturity models, highlighting their rapid adoption and effectiveness.
|
||||
|
||||
CMMs are crucial because they offer a structured approach to assessing your current cloud adoption strategy. They help you avoid common pitfalls and identify areas of improvement. By offering structured guidance, a CMM navigates organizations through the complexities of cloud adoption, enhancing the chances of a seamless and successful transition. In this blog, we will cover everything there is to know about the Cloud Computing Maturity Model to foster successful cloud adoption within your organization.
|
||||
|
||||
The Open Alliance for Cloud Adoption (OACA) describes the Cloud Maturity Model (CMM) as a framework that assists organizations in identifying tailored solutions for adopting cloud or hybrid IT environments. It evaluates organizations’ readiness for adopting the cloud, helps assess their current use of cloud services, and sets future goals for developing a cloud migration strategy. CMM also helps conduct GAP analysis and identifies areas for improving cloud infrastructure based on business objectives.
|
||||
|
||||
### Key Components of Cloud Maturity Model
|
||||
|
||||
The maturity model helps organizations with cloud maturity assessment & readiness for cloud adoption from both business and technical perspectives. Key aspects include
|
||||
|
||||
| **Functional Areas** | **Technical Areas** |
|
||||
| -------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
| **Finance:** Manage costs by shifting from CAPEX to OPEX through cloud adoption. | **IT Architecture:** Design scalable and secure cloud infrastructure. |
|
||||
| **Enterprise Strategy:** Align cloud initiatives with business strategy to enhance customer value. | **Applications:** Modernize and optimize applications for cloud environments. |
|
||||
| **Organizational Structure:** Adapt roles and decision-making for effective cloud integration. | **Management Tools:** Implement tools for monitoring and optimizing cloud resources. |
|
||||
| **Culture:** Foster adaptability and continuous improvement in organizational culture. | **Operations (IT) Processes:** Define efficient cloud deployment and management processes. |
|
||||
| **Governance:** Establish policies for compliance and risk management in cloud operations. | **DevOps:** Combine development & operations to achieve seamless, ongoing software delivery. |
|
||||
| **Skills:** Develop necessary competencies through training and rewards. | **Security:** Implement strong security protocols to safeguard data integrity and privacy. |
|
||||
| **Compliance:** Ensure compliance with regulatory requirements and standards for data security. | **Infrastructure as a Service (IaaS):** Offer cloud-based virtual computing resources online. |
|
||||
| **Business Processes:** Optimize workflows to improve service quality and efficiency. | **Platform as a Service (PaaS):** Offer application development and deployment platforms. |
|
||||
| **Procurement:** Streamline cloud service acquisition and vendor management. | **Storage as a Service (STaaS):** Provide cloud-based storage solutions that scale according to demand. |
|
||||
| **Commercial:** Manage financial aspects and optimize cost through effective contracts. | **Software as a Service (SaaS):** Provide software applications on a subscription basis. |
|
||||
| **Portfolio Management:** Prioritize and manage cloud investments based on business value. | **Integration Platform as a Service (IPaaS):** Facilitate seamless integration across environments. |
|
||||
| **Projects:** Plan and execute cloud projects aligned with strategic goals. | **Information Services:** Manage and analyze data for insights and decision-making. |
|
||||
| | **Data:** Ensure secure and compliant data management in the cloud. |
|
||||
| | **Network:** Establish and manage cloud network infrastructure. |
|
||||
| | **Artificial Intelligence (AI):** Integrate AI capabilities into cloud solutions. |
|
||||
| | **Internet of Things (IoT):** Support IoT devices and applications in the cloud. |
|
||||
| | **APIs (Application Programming Interfaces):** Enable interoperability and automation with cloud services. |
|
||||
|
||||
Both business and technical capability areas are evaluated across three core aspects:
|
||||
|
||||
**People**: Cloud services help companies operate more flexibly, which means employees need new skills and ways of working. The cloud maturity model allows the company to identify the necessary skills and suggest activities to encourage through a reward system.
|
||||
|
||||
**Processes:** Transitioning to the cloud can be complicated and affect your company’s workflow. A cloud computing maturity model identifies areas for improvement and ensures critical practices are updated as you adopt cloud services.
|
||||
|
||||
**Technology:** Introducing cloud services affects the company’s technology setup. New technology might require changes to the current infrastructure. The maturity model helps identify these needs.
|
||||
|
||||
Thus, this holistic approach ensures that cloud adoption and maturity are not just about technology, but also about aligning people and processes to leverage cloud capabilities effectively.
|
||||
|
||||
## Benefits of the Cloud Maturity Model
|
||||
|
||||
Here are the benefits of adopting the Cloud Maturity Model
|
||||
|
||||

|
||||
|
||||
### 1\. Enhanced Strategic Planning
|
||||
|
||||
Using the Cloud maturity model to evaluate your cloud readiness reveals your strengths and weaknesses. It helps you focus on areas that will make the most significant impact, making your [cloud strategy](https://www.bacancytechnology.com/blog/cloud-strategy) more effective and efficient and preventing wasted efforts.
|
||||
|
||||
### 2\. Improved Communications Across Teams
|
||||
|
||||
The cloud computing maturity model provides a framework for sharing cloud goals and progress among teams and stakeholders. This shared understanding helps everyone work better together, aligning their efforts with the business’s goals and reducing confusion.
|
||||
|
||||
### 3\. Enhanced Application Performance
|
||||
|
||||
As you advance through the cloud computing maturity model, you focus on making your cloud apps run smoother. It includes finding and fixing issues, speeding up processes, and ensuring apps are always available, which enhances user experience and boosts satisfaction.
|
||||
|
||||
### 4\. Enhanced Security and Performance
|
||||
|
||||
The cloud computing maturity model includes best practices for cloud security and management. Following these guidelines improves your security measures, such as controlling access, encrypting data, adhering to compliance, and identifying and fixing vulnerabilities, thereby reducing risks.
|
||||
|
||||
### 5\. Faster Time To Market
|
||||
|
||||
Higher levels of the Cloud maturity model encourage efficient use of cloud resources, leading to quicker development and launch of apps and services. It facilitates quick responses to market demands, implementation of new features, and adjustment to changes.
|
||||
|
||||
### 6\. Industry Benchmarking
|
||||
|
||||
The cloud computing maturity model also offers specific benchmarks and KPIs for different industries, allowing you to compare your cloud progress with others in your field. It helps you understand where you stand and identify areas of improvement to match and exceed your industry standards.
|
||||
|
||||
### 7\. Cost-Savings
|
||||
|
||||
Moving up in the cloud maturity model emphasizes efficiency and automation, which reduces cloud operation costs. It also helps avoid unnecessary spending by effectively using resources and preventing waste.
|
||||
|
||||
## 5 Stages to Achieve Cloud Maturity
|
||||
|
||||

|
||||
|
||||
### Maturity Level - 0: No Cloud Readiness At All (Legacy)
|
||||
|
||||
In this stage, the company doesn’t use the cloud at all and relies solely on outdated systems, with no plans to adopt cloud services. Starting new projects is slow and difficult. Few large companies today remain at this level, as most are using or considering the cloud. Companies at this stage often face strict regulations, such as high security or data requirements, rather than a lack of readiness.
|
||||
|
||||
### Maturity Level - 1: Initial Readiness (ad hoc)
|
||||
|
||||
At this stage, the company has assessed its software and services for cloud integration. It has some initial experience with cloud services, possibly migrating a few systems, but still operates primarily on legacy and non-virtualized systems. The cloud is mainly used for SaaS or specific business unit needs without a clear overall strategy. Some industries, like finance, still use their physical infrastructure, but these organizations show higher cloud maturity.
|
||||
|
||||
Know More about [Cloud Migration Strategy](https://www.bacancytechnology.com/blog/cloud-migration-strategy)
|
||||
|
||||
#### **Challenges You Might Face At This Level**
|
||||
|
||||
| **Challenge** | **How To Advance To The Next Stage** |
|
||||
| --- | --- |
|
||||
| Limited knowledge of cloud technology | Secure executive endorsement for cloud initiatives |
|
||||
| Minimal support from leadership for cloud adoption | Conduct multiple Proof of Concepts (PoCs) with non-critical applications and workloads |
|
||||
| Minimal Leadership Support | Obtain adequate funding for comprehensive access to required cloud services |
|
||||
| Absence of Clear Strategy | Develop a clear strategy for the effective use of cloud technology by current teams |
|
||||
| Absence of defined processes, guidelines, or dedicated teams | Enhance cloud knowledge through education and training programs |
|
||||
| No optimization of cloud usage | Establish clear KPIs for cloud utilization (e.g., reduce app infrastructure costs by 25%, decrease development costs by 10%, cut service downtime by 50%) |
|
||||
| Lack of awareness about cloud security risks | Increase understanding of cloud security risks through training |
|
||||
|
||||
### Maturity Level - 2: Repeatable, opportunistic
|
||||
|
||||
At this point, the company has established its IT and procurement procedures to begin utilizing cloud services. It includes deciding who can subscribe to these services and how they can do so. The processes are defined and can be repeated. Cloud services are used extensively, but the approach isn’t yet fully systematic and clearly defined.
|
||||
|
||||
Reaching this level happens later in the cloud journey. It often occurs after other maturity aspects have progressed, making achieving a uniform level two maturity across organizations less common.
|
||||
|
||||
#### **Challenges You Might Face at This Level**
|
||||
|
||||
| **Challenges** | **How to Advance to the Next Stage** |
|
||||
| --- | --- |
|
||||
| Cost control and management concerns | Align cloud usage with business objectives (e.g., market expansion, new product launches) |
|
||||
| Lack of documented policies | Set up a Cloud Center of Excellence (CCOE) |
|
||||
| Over Reliance on manual tasks | Form a dedicated cloud governance team |
|
||||
| Limited visibility into cloud usage | Prioritize, optimizing the overall cost of cloud adoption (TCO) |
|
||||
| Concerns about cloud adoption ROI and timelines | Embrace standardization, repeatability, and automation |
|
||||
| Reluctance to transition from older legacy systems | Use containers for deploying applications rather than virtual machines (VMs) |
|
||||
| Security and compliance worries | Consider diverse deployment models (private, hybrid, multi-cloud) |
|
||||
| Complexities in managing cloud teams, processes, and migrations | Develop detailed guidelines and protocols for cloud operations |
|
||||
| Enhance oversight and management in cloud monitoring | Improve cloud use visibility with enhanced monitoring |
|
||||
| Addressing encryption and authentication concerns | Move critical production workloads to the cloud |
|
||||
| Minimizing downtime for cloud-based systems | Ensure minimal downtime for all cloud services |
|
||||
|
||||
### Maturity Level - 3: Systematic and Documented
|
||||
|
||||
At this stage, the company has implemented a process or outsourced service to manage its cloud subscriptions and monitor existing services. Operations are more efficient and systematic, with documented practices and compliance. It includes documented cloud management processes and updated operational policies.
|
||||
|
||||
Often, businesses try to skip levels 2 and 3, aiming directly from level 0 or 1 to level 4 using technology solutions. Technology-focused cloud transformation frameworks from providers drive this approach. While rapid technological change may seem attractive, ensuring long-term sustainability is crucial.
|
||||
|
||||
#### **Challenges You Might Face With This Cloud Computing Maturity Model**
|
||||
|
||||
| **Challenges** | **How to Advance to the Next Stage** |
|
||||
| --- | --- |
|
||||
| Ensuring consistency in cloud processes | Gain support for complete IT decentralization |
|
||||
| Staff training to enhance competencies | Develop a comprehensive strategy for application migration to target environments |
|
||||
| Effective management of cloud environments | Enhance management of releases, secrets, and policies |
|
||||
| Analyzing workloads for optimization opportunities | Establish robust governance and management practices |
|
||||
| Identifying tasks suitable for automation | Migrate all relevant workloads and data to the cloud |
|
||||
| Concerns about environment management | Experiment with advanced cloud services (AI, machine learning, etc.) |
|
||||
| Migration of applications and systems | Embrace full automation and orchestration |
|
||||
|
||||
### Maturity Level - 4: Measured
|
||||
|
||||
At the fourth level, the company uses cloud-native applications extensively in its daily operations. These applications are widely adopted across the organization, utilizing private, public, and hybrid cloud platforms. However, it’s common for organizations only partially to reach level 4. Some parts of their cloud capabilities may still be at levels 2 or 3.
|
||||
|
||||
By level 4, the company should have a transparent governance model to manage and measure its cloud operations effectively. This model ensures transparency in how clouds are managed and assessed. Measuring the end-to-end performance of processes and data usage is crucial to develop solutions effectively. A common challenge for companies at this stage is the need for a governance model when deploying cloud services quickly. Data utilization also needs improvement, which requires specific skills and tools to optimize.
|
||||
|
||||
Know More About [Cloud Migration Tools](https://www.bacancytechnology.com/blog/cloud-migration-tools)
|
||||
|
||||
### Maturity Level - 5: Optimized
|
||||
|
||||
At the highest level, companies operate with an open and interoperable cloud environment actively developed using metrics and data. Processes are optimized, decisions are data-driven, and they adeptly use various cloud platforms, flexibly moving workloads between them.
|
||||
|
||||
However, achieving this fifth level is often more aspirational than real for many. While companies may develop an open and interoperable cloud, they usually lag in optimizing processes and fully leveraging data. Level five can be seen as an overinvestment if extensive hybrid cloud solutions are optional. Instead of aiming directly for level five, it’s better to selectively adopt elements that bring clear business benefits. Skipping lower-level features like proper management and process definitions can lead to challenges and unnecessary costs later in the maturity journey.
|
||||
|
||||
In cloud transformation, transitioning from physical services to the cloud involves mastering multiple gradual steps before achieving true maturity.
|
||||
|
||||
## Cloud Maturity Model Best Practices
|
||||
|
||||
Let’s look at the significant best practices for implementing a Cloud Maturity Model.
|
||||
|
||||
### 1\. Set up Cloud Adoption Objectives
|
||||
|
||||
To effectively adopt the cloud, start setting clear objectives for cloud services. The cloud maturity model can guide you in achieving these goals, but you must define them based on your organization’s needs. Three steps can help your cloud adoption process when determining the strategy.
|
||||
|
||||
**Clarify Motivations:** Focus on cloud economics and Total Cost of Ownership (TCO) to see how cost savings and efficiency can drive your cloud adoption.
|
||||
|
||||
**Determine Your Business Goals:** Use provided templates to align technical strategies with your business goals, ensuring that cloud adoption meets your organization’s needs.
|
||||
|
||||
**Develop a Business Case:** Create a strong business case for cloud adoption to secure support from internal teams, including finance and management.
|
||||
|
||||
### 2\. Identify Your Cloud Maturity Level
|
||||
|
||||
A cloud maturity model is not about moving entirely to the cloud but finding the right balance based on your organization’s needs. Whether pursuing fully cloud-native services or a hybrid architecture for specific IT needs, understanding your current maturity level allows for tailored objectives and a more effective cloud adoption strategy.
|
||||
|
||||
### 3\. Pick a Cloud Maturity Model
|
||||
|
||||
There are various cloud maturity models from which you can opt. If you are new to the cloud, you can start with a general framework like the Open Alliance for Cloud Adoption model, which isn’t tied to any specific cloud provider. If you’re leaning towards a provider like AWS, their Cloud Adoption Framework offers good practices but uses AWS-specific terms. Consider a Cloud Security Maturity Model (CSMM) like those from IANS or Securosis to improve cloud security in an existing setup. These models evaluate your security across different areas and domains, often with tools available to help assess your current state.
|
||||
|
||||
| **Cloud Maturity Model(CMM 4.8)** | CMM 4.8 evaluates how well an IT organization’s business and technology functions perform across different domains and types of cloud services. |
|
||||
| --- | --- |
|
||||
| **Cloud Native Maturity Model** | This model aims to guide organizations through adopting cloud-native technologies, leveraging the CNCF ecosystem to maximize the advantages of operating scalable applications in modern, dynamic environments across public and hybrid cloud setups. |
|
||||
| **Cloud Security Maturity Model(CSMM)** | The Cloud Security Maturity Model (CSMM) assesses the maturity of your cloud security program across 12 categories within three distinct domains. |
|
||||
| **Software Assurance Maturity Model (SAMM)** | SAMM encompasses the entire software lifecycle from development to acquisition, remaining neutral in terms of both technology and processes. |
|
||||
| **AWS Cloud Adoption Framework** | The AWS Cloud Adoption Framework (CAF) assists in identifying and prioritizing transformation opportunities, enhancing your cloud readiness, and progressively refining your transformation roadmap. |
|
||||
| **Microsoft Azure Cloud Adoption Framework** | The Azure Cloud Adoption Framework (CAF) offers guidance and best practices tailored for adopting Microsoft Azure. It empowers organizations to embrace cloud technologies and confidently achieve their business objectives |
|
||||
| **Google Cloud Adoption Framework** | The Google Cloud Adoption Framework assists in identifying critical activities and objectives that will effectively speed up your transition to the cloud. |
|
||||
|
||||
Know More About [Cloud Security Posture Management](https://www.bacancytechnology.com/blog/cloud-security-posture-management)
|
||||
|
||||
### 4\. Follow Governance and Compliance
|
||||
|
||||
To effectively manage cloud operations, establish a framework defining roles, responsibilities, and decision-making processes that can adapt to technological advancements. Develop comprehensive policies covering security, access controls, data protection, cost management, and incident response to ensure operational integrity. Align cloud practices with industry regulations like HIPAA and PCI-DSS, conducting regular compliance checks to maintain adherence and mitigate risks. You can also opt for our [cloud managed services](https://www.bacancytechnology.com/cloud-managed-services), where we can assist you in optimizing your cloud infrastructure and ensure cost-effectiveness, security, and alignment with your business goals.
|
||||
|
||||
### 5\. Follow Security and Risk Management
|
||||
|
||||
Deploy robust security measures such as encryption and access controls to safeguard cloud data while ensuring regular backups and monitoring for potential threats. Conduct frequent risk assessments to pinpoint vulnerabilities and revise mitigation strategies accordingly. Foster a culture of security awareness through ongoing training in best practices, stressing the significance of data protection and staying alert against risks such as phishing.
|
||||
|
||||
## Conclusion
|
||||
|
||||
The cloud maturity model helps businesses make the most of their cloud journey by guiding them through the different stages of cloud adoption. From starting to essential cloud services to mastering advanced cloud capabilities, this model ensures that your cloud strategy grows with your needs. However, [cloud consulting services](https://www.bacancytechnology.com/cloud-consulting-services) can streamline this process by providing expert guidance and support. Also, by following best practices and embracing a cloud-first approach, companies can improve efficiency, security, and overall performance, leading to long-term success in the cloud.
|
||||
|
||||
## Frequently Asked Questions (FAQs)
|
||||
|
||||
Higher maturity levels improve cybersecurity through enhanced visibility, control, and adherence to best data protection and threat mitigation practices.
|
||||
|
||||
Cloud maturity models aid in cost optimization by identifying inefficiencies, right-sizing resources, automating processes, and aligning cloud spend with workload demands and performance metrics.
|
||||
|
||||
**Public Cloud Maturity Model:** Focuses on leveraging external cloud services for scalability and cost-efficiency.
|
||||
|
||||
**Private Cloud Maturity Model:** Centers on internal infrastructure for control and compliance with specific requirements.
|
||||
|
||||
**Hybrid Cloud Maturity Model:** This model integrates public and private clouds for flexibility and optimized performance across environments.
|
||||
@@ -0,0 +1,372 @@
|
||||
---
|
||||
title: Cloud Operating Model: Key Strategies and Best Practices
|
||||
source: https://www.bacancytechnology.com/blog/cloud-operating-model
|
||||
author: shenwei
|
||||
published: 2025-02-07
|
||||
created: 2025-03-01
|
||||
description: Learn how to design a future-ready Cloud Operating Model for governance, security, and cost efficiency. Discover best practices & future trends.
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
Organizations are rapidly abandoning traditional IT infrastructures for cloud-first architectures, accelerating migration. By 2025, it is predicted that 89% of organizations will operate from the cloud to enhance scalability, agility, and cost-efficiency ([Gartner](https://www.gartner.com/en/newsroom/press-releases/2021-11-10-gartner-says-cloud-will-be-the-centerpiece-of-new-digital-experiences)). But a mere shift to the cloud is not sufficient. Companies may run into unexpected costs and security loopholes and may be met with chaos in operations if they have not structured their approach well.
|
||||
|
||||
A Cloud Operating Model (COM) guarantees orderliness and is the foundation upon which cloud investments can be managed effectively, securely, and sustainably. [Flexera’s 2024 State of the Cloud Report](https://info.flexera.com/CM-REPORT-State-of-the-Cloud) argues that while 59% of enterprises experience difficulty managing cloud costs, while 8% organizations are worried about sustainability and reducing carbon footprint.
|
||||
|
||||
The cloud paradigm has forced a great adjustment in corporate operational paradigms; however, nothing guarantees [successful cloud migration](https://www.bacancytechnology.com/blog/successful-cloud-migration). Many companies entered the cloud journey assuming lower costs, higher security, and easier scalability, only to be met with unforeseen expenses, security breaches, and management chaos. Proper structure and efficient cloud governance make cloud adoption regrettable; otherwise, a cloud will become a source of costly headaches instead of competitive advantages.
|
||||
|
||||
That is when Cloud Operating Modeling becomes essential. It is a narration of the guardrails to construct a good framework for secure cloud operations and management from the cost and risk standpoint. The whole idea is not just about migrating workloads to AWS, Azure, or Google Cloud, but rather steering all operations smoothly, securely, and in ways that genuinely benefit the business.
|
||||
|
||||
Imagine running a company without clear policies or financial controls—budgets spiral out of control, employees work in silos, and security becomes a guessing game. The same happens in cloud environments with no structured operating model.
|
||||
Businesses that don’t have a Cloud Operating Model often face:
|
||||
|
||||
A Cloud Operating Model brings order to this chaos, ensuring governance, security, and cost optimization are built into daily cloud operations.
|
||||
|
||||
In the past, IT infrastructure was modeled centralized for decades—companies would purchase servers, place them in dedicated data centers, and manage the infrastructure on-site. High investments were required to scale up, and security measures were taken at the network firewall and perimeter. [Cloud computing](https://www.bacancytechnology.com/blog/what-is-cloud-computing) has turned this model on its head. Rather than managing hardware and fixed resources, organizations now have access to on-demand, scalable environments. This has required organizations to rethink their security, automation, and cost management strategies to eliminate inefficiencies.
|
||||
The following enlists the distinctions between the traditional mold and the contemporary one:
|
||||
|
||||
For effective implementation of a Cloud Operating Model, the four critical pillars must align the IT Domain with business conditions while focusing on security and efficiency.
|
||||
|
||||
Cloud environments can spiral out of control quickly without proper governance. An effective COM enforces security, access control, and compliance policies, ensuring that teams follow best practices while maintaining agility.
|
||||
|
||||
Automation underlies all cloud operations. Without it, teams waste time on repetitive manual work, causing delays and inefficiencies.
|
||||
|
||||
Security in the Cloud is no longer about physical perimeters and firewalls but about identity-based security, encryption, and Corporate monitoring.
|
||||
|
||||
Cost control is undeniably one of the biggest challenges to cloud adoption. Businesses pay for unused resources without a financial strategy or get unexpected billing shocks.
|
||||
|
||||
- **Standardized Governance →** Ensures compliance across cloud environments.
|
||||
- **Cost Optimization →** Implements FinOps strategies to prevent overspending.
|
||||
- **Improved Security & Risk Management →** Automates security policies and access controls.
|
||||
- **Operational Agility →** Enables DevOps, CI/CD, and auto-scaling for efficiency.
|
||||
- **Multi-Cloud Flexibility →** Reduces vendor lock-in and enhances resilience.
|
||||
|
||||
## Best Practices to Design a Cloud Operating Model for Your Organization
|
||||
|
||||
Designing and building a cloud operating model that is scalable and suitable for your organization’s needs is a complicated task. You must align the cloud strategy with your business goals, ensuring the proposed COM takes care of governance, automation, and security. Besides, it has to be cost-efficient. Handling cloud chaos, security loopholes, and accelerating costs becomes difficult without a solid structural framework. However, an intelligently designed COM plays a crucial role in scaling cloud operations, fortifying security, ensuring compliance, and everything that is needed yet keeping costs in control.
|
||||
|
||||
Below are the best practices for building a cloud operating model in a step-by-step format:
|
||||
|
||||

|
||||
|
||||
### Step 1: Assess Cloud Maturity & Business Objectives
|
||||
|
||||
Before building a Cloud Operating Model, organizations need to assess where they currently stand in their cloud journey.
|
||||
|
||||
- Cloud Maturity Levels:
|
||||
|
||||
| Maturity Level | Characteristics | Challenges |
|
||||
| --- | --- | --- |
|
||||
| Ad-hoc Cloud Adoption | Some workloads moved to the cloud, with no clear strategy. | Lack of governance, security gaps, and cost inefficiencies. |
|
||||
| Cloud-First Strategy | Intentional cloud adoption, defined processes in place. | Optimization is required for cost, performance, and security. |
|
||||
| Cloud-Native Enterprise | Fully optimized cloud environments, automation-driven. | Managing multi-cloud complexity, AI-driven operations. |
|
||||
|
||||
- Key Questions to Ask:
|
||||
🔸 Are we using the cloud to drive cost efficiency or innovation?
|
||||
🔸 Do we have the right team and expertise to manage cloud operations?
|
||||
🔸 Are security, governance, and compliance aligned with business risks?
|
||||
|
||||
### Step 2: Create a Governance & Compliance Framework
|
||||
|
||||
Cloud chaos results from chaotic spending, insecure technology, and violated compliance limits; it happens when there is no governance. As one of the key decisions organizations can make before a private cloud exists, introducing a governance framework is necessary to meet security, efficiency, and compliance requirements without limiting the cloud’s flexibility.
|
||||
|
||||
- Comparing Cloud Governance Models (AWS, Azure, GCP)
|
||||
|
||||
| Governance Aspect | AWS | Azure | GCP |
|
||||
| --- | --- | --- | --- |
|
||||
| Identity & Access Management (IAM) | AWS IAM | Azure AD | Google IAM |
|
||||
| Security & Compliance Tools | AWS Security Hub | Microsoft Defender | Security Command Center |
|
||||
| Cost Control & Budgeting | AWS Cost Explorer | Azure Cost Management | GCP Billing Reports |
|
||||
| Policy Enforcement | AWS Organizations & SCPs | Azure Policy | GCP Organization Policies |
|
||||
|
||||
- **Best Practices for Governance & Compliance:**
|
||||
|
||||
🔸 **Define IAM roles and policies upfront—**avoid giving excessive permissions.
|
||||
🔸 **Use automated compliance checks** to detect misconfigurations.
|
||||
🔸 **Implement guardrails** to prevent unauthorized resource provisioning.
|
||||
|
||||
### Step 3: Automate Cloud Operations (Infrastructure as Code, DevOps)
|
||||
|
||||
Manual cloud management doesn’t scale. Businesses need automation to improve efficiency, security, and deployment speed.
|
||||
|
||||
- **Key Automation Strategies:**
|
||||
🔸 **Infrastructure as Code (IaC) →** Use Terraform, AWS CloudFormation, or Azure Bicep for deployment automation.
|
||||
🔸 **CI/CD Pipelines →** Software delivery is automated by using GitHub Actions, AWS CodePipeline, Azure DevOps, etc.
|
||||
🔸 **Event-Driven Automation →** Serverless automation is achieved using AWS Lambda or Azure Functions.
|
||||
|
||||
**Example:** *A fintech company was facing losses due to heavy deployment time. They adopted the Infrastructure as Code approach and leveraged Terraform and AWS CodePipeline. The result – deployment time was reduced to 15 days from 3 weeks.*
|
||||
|
||||
### Step 4: Implement Cost Management & Optimization Strategies (FinOps)
|
||||
|
||||
The costs of hosting in the cloud can go out of control very quickly if businesses don’t have real-time tracking and cost allocation. FinOps (cloud financial operations) aims not to blow money, but to optimize spending.
|
||||
|
||||
- **Cost Optimization Tactics:**
|
||||
🔸 **Use Reserved Instances & Spot Instances →** Cut compute costs by 40-70%.
|
||||
🔸 **Enable Auto-Scaling & Right-Sizing →** Ensure resources match demand.
|
||||
🔸 **Monitor and Tag Resources →** Track spending by teams, projects, and workloads.
|
||||
|
||||
- **Comparing Cloud Cost Management Tools**
|
||||
|
||||
| Cloud Provider | Cost Management Tool | Key Features |
|
||||
| --- | --- | --- |
|
||||
| AWS | AWS Cost Explorer | Real-time cost monitoring, savings plans, budget alerts |
|
||||
| Azure | Azure Cost Management | Cost tracking, reserved instances, predictive analysis |
|
||||
| GCP | GCP Billing Reports | AI-driven cost insights, budget tracking |
|
||||
|
||||
**Example:** *A global e-commerce company leverages Auto-Scaling and Reserved Instances across AWS and Azure to save $500,000on its annual billing.*
|
||||
|
||||
### Step 5: Strengthen Security & Risk Mitigation
|
||||
|
||||
Security in the cloud is dynamic—threats evolve, misconfigurations happen, and compliance requirements change. Businesses must build a proactive security strategy within their Cloud Operating Model.
|
||||
|
||||
- Security Strategies for Cloud Environments:
|
||||
🔸 **Zero Trust Security Model →** No implicit trust, continuous verification.
|
||||
🔸 **Real-Time Threat Detection →** Use AWS GuardDuty, Azure Sentinel, or GCP Security Command Center.
|
||||
🔸 **Automated Security Patching →** Ensure workloads stay updated without downtime.
|
||||
|
||||
- Security Frameworks by Cloud Provider
|
||||
|
||||
| Security Aspect | AWS | Azure | GCP |
|
||||
| --- | --- | --- | --- |
|
||||
| Threat Detection | GuardDuty | Defender for Cloud | Security Command Center |
|
||||
| Identity & Access | AWS IAM | Azure AD | Google IAM |
|
||||
| Compliance | AWS Artifact | Azure Compliance Center | GCP Compliance Center |
|
||||
|
||||
**Example:** *A healthcare provider adopted automated security patching and Zero Trust policies, reducing security incidents by 60%.*
|
||||
|
||||
### Step 6: Continuous Monitoring, Performance Tuning, and AI-Driven Optimization
|
||||
|
||||
Cloud management is not a one-time task—it requires constant monitoring, performance optimization, and AI-driven decision-making.
|
||||
|
||||
- **Key Approaches for Continuous Optimization:**
|
||||
🔸 **Observability & AIOps →** Use AI-driven analytics to detect anomalies and optimize performance.
|
||||
🔸 **Real-Time Cloud Monitoring →** AWS CloudWatch, Azure Monitor, or GCP Operations Suite.
|
||||
🔸 **Self-Healing Systems →** AI-driven auto-remediation of infrastructure issues.
|
||||
|
||||
**Example:** A SaaS provider reduced downtime by 45% using AI-driven anomaly detection in AWS CloudWatch.
|
||||
|
||||

|
||||
|
||||
### Managing cloud operations is complex—security risks, cost overruns, and compliance challenges can slow your business down.
|
||||
|
||||
Simplify Cloud Management—Get Expert Support Now: Explore our Cloud Managed Services.
|
||||
|
||||
[Cloud Managed Services](https://www.bacancytechnology.com/cloud-managed-services)
|
||||
|
||||
## Industry-Specific Use Cases of Cloud Operating Models
|
||||
|
||||
Regrettably, the above represents one proprietary cloud operating model, while each industry comes with varying unique challenges, regulatory requirements, and operational needs. For instance, the financial world must prioritize compliance and costs, whereas healthcare organizations must adhere to stringent data privacy regulations. Comparably, e-commerce companies must enable scalability, whereas tech companies leverage automation to speed [cloud innovation](https://www.bacancytechnology.com/blog/cloud-innovation).
|
||||
|
||||
Below are instances of how different industries employ a Cloud Operating Model to enhance efficiency, security, and growth.
|
||||
|
||||
### Financial Services: Ensuring Compliance While Optimizing Costs
|
||||
|
||||
Modernizing financial institution IT operations requires balancing regulatory compliance, risk management, and cost-efficient operations. Banks and insurance companies may incur fines for non-compliance, suffer data breaches from unauthorized access by multiple users, and face uncontrolled cloud expenditures—all of which will seriously diminish their reputation without a Cloud Operating Model.
|
||||
|
||||
##### **How Financial Services Benefit from a Cloud Operating Model:**
|
||||
|
||||
- **Regulatory Compliance Automation →** Encourages automated compliance with GDPR, PCI-DSS, and SOC 2 directives across all cloud environments.
|
||||
- **Cost Governance (FinOps) →** Implements real-time cost tracking and optimization to prevent over-provisioning.
|
||||
- **Zero Trust Security Model →** Enhances data protection through identity-based security and encryption.
|
||||
|
||||
##### **Case Study:**
|
||||
|
||||
A global investment bank faced rising cloud costs and compliance risks due to fragmented cloud operations. By implementing a Cloud Operating Model with FinOps strategies, they:
|
||||
|
||||
- Automated cost monitoring helped reduce cloud expenditures by 30%.
|
||||
- Policy-driven security enforcement ensured complete PCI-DSS compliance.
|
||||
- Disaster recovery and failover capabilities were improved with 99.99% uptime.
|
||||
|
||||
### Healthcare: Managing Data Privacy & Security in Cloud-Native Environments
|
||||
|
||||
Healthcare providers prioritize security and compliance. In addition to these regulations, all industries, including HIPAA and GDPR, need patient data to be protected and digitized.
|
||||
|
||||
##### **How Healthcare Organizations Benefit from a Cloud Operating Model:**
|
||||
|
||||
- **Automated Compliance Enforcement →** Ensures HIPAA, HITRUST, and GDPR adherence with security policies.
|
||||
- **Data Encryption & Access Control →** Protects patient records with multi-layer encryption and IAM.
|
||||
- **AI & Machine Learning for Diagnostics →** Uses cloud-based AI to analyze medical images and patient data.
|
||||
|
||||
##### **Case Study:**
|
||||
|
||||
A leading hospital network faced challenges in scaling IT infrastructure while maintaining HIPAA compliance. After adopting a Cloud Operating Model, they:
|
||||
|
||||
- AI-enabled diagnostics have allowed for earlier disease detection than ever before.
|
||||
- Data processing time has been reduced by 60%, helping to improve operational efficiency.
|
||||
- Automated monitoring of compliance has further secured operations and avoided regulatory fines.
|
||||
|
||||
### Retail & E-Commerce: Handling Peak Traffic & Improving Customer Experience
|
||||
|
||||
Real-time performance and untouched cloud scalability are simply the lifeblood of successful cloud adoption for retailers. A Cloud Operating Model guarantees operational uptime, resilience, and cost-effectiveness for web applications, especially during seasonal traffic peaks.
|
||||
|
||||
##### **How Retailers & E-Commerce Businesses Benefit from a Cloud Operating Model:**
|
||||
|
||||
- **Auto-Scaling for Peak Demand →** Dynamically adjusts cloud resources based on traffic spikes.
|
||||
- **Personalized Customer Experiences →** Uses AI-based recommendations to elevate the shopping experience.
|
||||
- **Multi-Cloud & Hybrid Cloud Strategies →** Adopted a multi-cloud strategy, avoiding vendor lock-in and improving uptime.
|
||||
|
||||
##### **Case Study:**
|
||||
|
||||
A top global fashion retailer struggled with website downtime during flash sales, losing millions in revenue. After implementing a Cloud Operating Model, they:
|
||||
|
||||
- Enabled auto-scaling, handling 10x traffic without performance drops.
|
||||
- Reduced checkout latency by 40%, improving customer retention.
|
||||
- The multi-cloud deployment leveraged was to avoid vendor lock-in and give uptime improvement.
|
||||
|
||||
### SaaS & Tech Companies: Leveraging Cloud Automation for DevOps Agility
|
||||
|
||||
Speed and innovation are the hallmarks of success for the SaaS industry. A Cloud Operating Model acts like a jet engine with which start-ups and enterprise technology companies can fast-track, focus the CI/CD pipelines, and ensure high availability.
|
||||
|
||||
##### **How SaaS & Tech Companies Benefit from a Cloud Operating Model:**
|
||||
|
||||
- **Faster Deployments with DevOps →** Implements CI/CD pipelines for continuous software updates.
|
||||
- **Serverless & Containerized Architectures →** Uses AWS Lambda, Kubernetes, and Docker to improve scalability.
|
||||
- **Security-First Development →** Integrates DevSecOps best practices to minimize vulnerabilities.
|
||||
|
||||
##### **Case Study:**
|
||||
|
||||
A leading SaaS provider experienced frequent deployment failures and infrastructure downtime. By implementing a Cloud Operating Model, they:
|
||||
|
||||
- Reduced deployment failures by 75% using automated CI/CD pipelines.
|
||||
- Kubernetes-based autoscaling cuts infrastructure costs by 40%.
|
||||
- API response time was reduced by 50%, that too with a stalwart user experience.
|
||||
|
||||
## Challenges in Adopting a Cloud Operating Model & How to Overcome Them
|
||||
|
||||
Adopting the Cloud Operating Model (COM) may present problems. From vendor lock-in to unforeseen expenditures and compliance headaches, organizations grapple with balancing agility, security, and cost efficiency. However, these challenges may be overcome with strategic work, automation, and a multi-cloud method.
|
||||
|
||||
### 1\. Vendor Lock-In: Trapped in a Single Cloud Provider
|
||||
|
||||
One of the biggest criticisms enterprises migrating to the cloud always have is vendor lock-in—they rely on one cloud provider to the extent that switching platforms becomes extremely difficult or genuinely cost-prohibitive.
|
||||
|
||||
##### **Why it’s a problem:**
|
||||
|
||||
➥ **Limited flexibility →** Businesses depend on a single provider’s pricing, tools, and service availability.
|
||||
➥ **Exit costs →** Moving workloads between providers can be expensive and time-consuming.
|
||||
➥ **Risk of downtime →** A single cloud outage can disrupt operations.
|
||||
|
||||
##### **Solution: Adopting a Multi-Cloud & Hybrid Cloud Approach**
|
||||
|
||||
➥ The solution involves spreading workloads across multiple cloud platforms, including AWS, Azure, and GCP.
|
||||
➥ The achievement of workload portability depends on implementing Docker and Kubernetes containerization tools.
|
||||
➥ Adopt Cloud Agnostic Tools like Terraform and Ansible for infrastructure automation.
|
||||
|
||||
**Example:** *A global retailer reduced downtime risks by 40% by deploying its core applications across AWS and Google Cloud, ensuring resilience against provider outages.*
|
||||
|
||||
***For an in-depth understanding, and comparing Multi-Cloud and Hybrid Cloud approaches, read our blog [Multi Cloud Vs Hybrid Cloud](https://www.bacancytechnology.com/blog/multi-cloud-vs-hybrid-cloud)***
|
||||
|
||||
### 2\. Cost Overruns: Cloud Bills That Keep Growing
|
||||
|
||||
Most cloud service providers let customers pay based on usage, yet most organizations do not leverage this model. Enterprise organizations consume excess resources and several cloud-based services that exceed their operational capacity.
|
||||
|
||||
##### **Why it’s a problem:**
|
||||
|
||||
➥ **Wasted cloud spend →** Companies pay for resources they don’t use.
|
||||
➥ **Budget unpredictability →** Fluctuating costs make financial planning difficult.
|
||||
➥ **Lack of visibility →** No real-time tracking of cloud expenses.
|
||||
|
||||
##### **Solution: Implement FinOps & Cost Allocation Strategies**
|
||||
|
||||
➥ Use real-time monitoring tools (AWS Cost Explorer, Azure Cost Management).
|
||||
➥ Right-size instances to match actual workload needs.
|
||||
➥ Implement automated shutdown policies for unused resources.
|
||||
|
||||
**Example:** *A SaaS company was frustrated by uncontrolled cloud costs. To handle workloads, it used “reserved instances and Autoscaling Policies.” The result was a 35% reduction in cloud costs.*
|
||||
|
||||
### 3\. Compliance Perils: Keeping Up with Evolving Regulations
|
||||
|
||||
Different guidelines govern different industries, and many must follow strict compliance requirements, such as GDPR, HIPPA, CCPA, PCI/DSS, etc. Even slight negligence in complying with the set guidelines can lead to rigorous consequences, such as heavy fines, occasional imprisonment, legal proceedings, and damage to reputation.
|
||||
|
||||
##### **Why it’s a problem:**
|
||||
|
||||
➥ Constantly evolving regulations make compliance hard to maintain.
|
||||
➥ Misconfigurations in cloud settings can expose sensitive data.
|
||||
➥ Lack of automated monitoring increases the risk of non-compliance.
|
||||
|
||||
##### **Solution: Cloud Governance & Automated Compliance**
|
||||
|
||||
➥ Use policy-as-code to enforce security and compliance (AWS Config, Azure Policy).
|
||||
➥ Determine a URL pattern as part of their audit URL endpoints: detect and fix misconfiguration when that URL appears in an audit type.
|
||||
➥ Secondly, enable role based access controls (RBAC) to prevent any unauthorized activities.
|
||||
|
||||
**Example:** *A cloud infrastructure of a financial institution automated the compliance checks over it, thereby reducing compliance violations by 60 percent.*
|
||||
|
||||
## Future Trends in Cloud Operating Models
|
||||
|
||||
Businesses that do not adapt to the change of Cloud technology are left behind. AI-driven automation, sustainability, decentralized, and vendor-agnostic Cloud Operating models create this picture. In the following years, these are some of the key trends that will reinvent cloud management.
|
||||
|
||||
### AI & Machine Learning in Cloud Operations
|
||||
|
||||
Cloud Management Powered by Predictive Analytics uses AI to provide companies with predictive insights that can help optimize costs, improve security, and enhance performance.
|
||||
|
||||
##### **Why It Matters:**
|
||||
|
||||
➥ AI can predict resource usage, automatically adjusting workloads to avoid overprovisioning and reduce cloud costs.
|
||||
➥ Machine Learning algorithms detect [cloud security threats](https://www.bacancytechnology.com/blog/cloud-security-threats-and-risks) before they escalate into breaches.
|
||||
➥ **Self-healing cloud environments →** AI-driven automation can identify and resolve issues without human intervention.
|
||||
|
||||
### Cloud Sustainability & Green Computing
|
||||
|
||||
With the rapidly growing usage of cloud infrastructure, organizations are focusing on lowering their carbon footprints and energy consumption.
|
||||
|
||||
##### **Why It Matters:**
|
||||
|
||||
➥ Data centers consume 1% of global electricity—a number expected to rise (International Energy Agency).
|
||||
➥ Regulatory bodies are pressuring organizations to implement sustainable cloud solutions.
|
||||
➥ Companies can reduce operational costs by using energy-efficient cloud strategies.
|
||||
|
||||
##### **How Businesses Are Going Green:**
|
||||
|
||||
➥ **Serverless Computing →** Eliminates unnecessary resource consumption.
|
||||
➥ **Sustainable Data Centers →** Providers like AWS, Azure, and Google are investing in carbon-neutral cloud infrastructure.
|
||||
➥ **Workload Optimization →** Companies shift workloads to energy-efficient regions.
|
||||
|
||||
### Multi-Cloud & Hybrid Strategies: Vendor-Agnostic Cloud Governance
|
||||
|
||||
Organizations seeking more flexibility and control are shifting away from single-vendor cloud dependencies and adopting multi-cloud and hybrid cloud models.
|
||||
|
||||
##### **Why It Matters:**
|
||||
|
||||
➥ **Avoids vendor lock-in →** Businesses gain greater control over workloads by distributing them across AWS, Azure, and Google Cloud.
|
||||
➥ **Enhanced disaster recovery →** Multi-cloud strategies improve resilience and redundancy.
|
||||
➥ **Regulatory flexibility →** Allows companies to store sensitive data in different jurisdictions based on compliance requirements.
|
||||
|
||||
## Conclusion
|
||||
|
||||
A Cloud Operating Model is no longer optional—it is the backbone of modern cloud strategy. Without it, businesses risk uncontrolled costs, security vulnerabilities, and operational inefficiencies that slow innovation. However, this can be resolved by implementing a structured model, which helps improve governance, optimize spending on the cloud, strengthen security, and scale with agility. A well-defined cloud operating model enables businesses to remain competitive, resilient, and future-ready while being multi-cloud flexible, using AI-driven automation, or sustainable.
|
||||
|
||||
It’s Time to Act: For instance, to assess and improve your Cloud Operating Model if you are a company. If cloud governance, cost management, or security are causing you problems, you can tap our [Cloud Consulting Services](https://www.bacancytechnology.com/cloud-consulting-services) for a bespoke way to get better results from the cloud at greatly reduced costs and risk. To reach the next step of a high-functioning, future-proof cloud environment, book a consultation today.
|
||||
|
||||
## Frequently Asked Questions (FAQs)
|
||||
|
||||
A Cloud Operating Model (COM) is a framework that standardizes how organizations manage cloud resources, security, automation, and costs across cloud environments. It helps businesses optimize cloud performance, reduce costs, and enforce security and compliance policies, ensuring a scalable and efficient cloud strategy.
|
||||
|
||||
A Cloud Operating Model enhances security by enforcing Zero Trust policies, automated compliance checks, and real-time threat detection. It integrates IAM (Identity and Access Management), encryption, and cloud-native security controls to minimize risks and prevent unauthorized access.
|
||||
|
||||
A Cloud Operating Model consists of four core pillars:
|
||||
|
||||
**1\. Governance & Compliance –** Policies to enforce security and regulatory standards.
|
||||
**2\. Automation & Orchestration –** Infrastructure as Code (IaC) and DevOps workflows.
|
||||
**3\. Security & Risk Management –** Zero Trust security, encryption, and monitoring.
|
||||
**4\. Cloud Financial Management (FinOps) –** Cost tracking, optimization, and budget controls.
|
||||
|
||||
Businesses can prevent cloud overspending by implementing:
|
||||
|
||||
➽ FinOps strategies to track and optimize cloud costs.
|
||||
➽ Automated scaling to adjust resources based on demand.
|
||||
➽ Reserved instances & spot pricing for cost-efficient cloud usage.
|
||||
➽ Real-time cost monitoring using AWS Cost ➽ Explorer, Azure Cost Management, or GCP Billing Reports.
|
||||
|
||||
Organizations face four major challenges when implementing a Cloud Operating Model:
|
||||
|
||||
Vendor Lock-in → Solved by multi-cloud strategies.
|
||||
Cost Overruns → Managed through FinOps best practices.
|
||||
Compliance Risks → Reduced with automated governance policies.
|
||||
Cloud Skills Gap → Addressed with workforce upskilling and automation tools.
|
||||
|
||||
The future of Cloud Operating Models is driven by:
|
||||
|
||||
**AI & ML in Cloud Operations –** AI-driven cost and security optimization automation.
|
||||
**Cloud Sustainability –** Energy-efficient cloud computing and carbon-neutral strategies.
|
||||
**Serverless & Edge Computing –** Reduced latency and real-time data processing.
|
||||
**Multi-Cloud & Hybrid Strategies –** Avoiding vendor lock-in and improving cloud resilience.
|
||||
@@ -0,0 +1,109 @@
|
||||
---
|
||||
title: DevOps Culture and Transformation: Fostering Collaboration, Agile Practices, and Innovation | LinkedIn
|
||||
source: https://www.linkedin.com/pulse/devops-culture-transformation-fostering-collaboration-hemant-sawant-4qsve/?trackingId=fob2ofyA9J1dl534m3n0SA%3D%3D
|
||||
author: shenwei
|
||||
published: 2001-02-27
|
||||
created: 2025-03-02
|
||||
description:
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
In today’s hyper-competitive digital landscape, organizations must deliver software faster, more reliably, and with greater value to customers. Enter **DevOps**—a cultural and operational revolution that bridges development (Dev) and operations (Ops) teams to break down silos, accelerate delivery, and drive innovation. But DevOps isn’t just about tools or automation; it’s a mindset shift that prioritizes collaboration, continuous learning, and customer-centricity. Let’s explore how organizations can cultivate a DevOps culture and navigate the transformation journey to unlock efficiency and agility.
|
||||
|
||||
---
|
||||
|
||||
### 1\. The Pillars of DevOps Culture
|
||||
|
||||
At its core, DevOps is built on four foundational principles:
|
||||
|
||||
### a. Collaboration Over Silos
|
||||
|
||||
Traditional IT structures often pit developers (focused on rapid feature delivery) against operations (prioritizing stability). DevOps dismantles these silos by fostering **cross-functional teams** where both sides share ownership of the entire software lifecycle.
|
||||
|
||||
- **Strategies for Collaboration**: **Shared Goals**: Align teams around common KPIs, such as deployment frequency or mean time to recovery (MTTR). **Cross-Training**: Encourage developers to understand infrastructure and operations staff to engage in coding. **Tools for Transparency**: Use platforms like Slack, Microsoft Teams, or Atlassian Jira to enable real-time communication and visibility into workflows.
|
||||
|
||||
### b. Automation as an Enabler
|
||||
|
||||
Automation eliminates manual toil, reduces errors, and accelerates feedback loops. Key areas include:
|
||||
|
||||
- **CI/CD Pipelines**: Tools like Jenkins, GitLab CI, or GitHub Actions automate testing, integration, and deployment.
|
||||
- **Infrastructure as Code (IaC)**: Terraform or AWS CloudFormation enable consistent, version-controlled environments.
|
||||
- **Monitoring & Observability**: Implement tools like Prometheus, Grafana, or Datadog for proactive issue resolution.
|
||||
|
||||
### c. Continuous Improvement (Kaizen)
|
||||
|
||||
DevOps thrives on iterative learning. Teams must:
|
||||
|
||||
- Conduct **blameless post-mortems** to dissect failures without finger-pointing.
|
||||
- Leverage **metrics** (e.g., lead time, deployment success rate) to identify bottlenecks.
|
||||
- Experiment with **chaos engineering** to proactively test system resilience.
|
||||
|
||||
### d. Customer-Centricity
|
||||
|
||||
Every release should solve real user problems. Embed feedback loops via:
|
||||
|
||||
- **Feature Flagging**: Roll out features incrementally to gather user insights.
|
||||
- **A/B Testing**: Optimize user experiences through data-driven decisions.
|
||||
|
||||
---
|
||||
|
||||
### 2\. Integrating Agile Practices into DevOps
|
||||
|
||||
Agile and DevOps are symbiotic. While Agile focuses on iterative development, DevOps extends agility to operations. Together, they enable end-to-end speed and quality.
|
||||
|
||||
### a. Agile Frameworks in DevOps
|
||||
|
||||
- **Scrum & Kanban**: Use Scrum for structured sprints or Kanban for continuous flow.
|
||||
- **CI/CD as Agile Accelerators**: Automate testing and deployment to shrink feedback cycles from weeks to minutes.
|
||||
|
||||
### b. Shift-Left Practices
|
||||
|
||||
Bring operations concerns (security, performance) into the development phase:
|
||||
|
||||
- **DevSecOps**: Integrate security tools (SonarQube, Snyk) into pipelines.
|
||||
- **Performance Testing Early**: Use tools like JMeter or Locust during development.
|
||||
|
||||
### c. Value Stream Mapping
|
||||
|
||||
Visualize workflows to eliminate waste. Identify delays in handoffs, approvals, or testing to streamline processes.
|
||||
|
||||
---
|
||||
|
||||
### 3\. Driving DevOps Transformation: A Strategic Playbook
|
||||
|
||||
Adopting DevOps isn’t a one-time project—it’s a cultural metamorphosis. Here’s how to lead the change:
|
||||
|
||||
### a. Leadership Buy-In and Advocacy
|
||||
|
||||
- **Lead by Example**: Executives must champion collaboration and allocate resources for tooling and training.
|
||||
- **Define Clear Objectives**: Align DevOps goals with business outcomes (e.g., faster time-to-market, reduced downtime).
|
||||
|
||||
### b. Upskilling Teams
|
||||
|
||||
- **Invest in Training**: Certifications (AWS DevOps, Kubernetes) and workshops on tools like Ansible or Docker.
|
||||
- **Create Guilds/CoEs**: Establish internal communities of practice to share knowledge.
|
||||
|
||||
### c. Start Small, Scale Fast
|
||||
|
||||
- **Pilot Projects**: Begin with low-risk applications to demonstrate quick wins (e.g., automating deployments for a microservice).
|
||||
- **Iterate and Expand**: Use feedback from pilots to refine processes before enterprise-wide rollout.
|
||||
|
||||
### d. Overcoming Resistance
|
||||
|
||||
- **Address Fear of Job Loss**: Emphasize that automation frees teams for higher-value work.
|
||||
- **Celebrate Wins**: Highlight success stories to build momentum (e.g., “Team X reduced deployment time by 70%”).
|
||||
|
||||
---
|
||||
|
||||
### Final Thoughts: The Future of DevOps
|
||||
|
||||
The future of DevOps will continue to evolve with advancements in technology and business demands. Key trends include:
|
||||
|
||||
- **AI and Machine Learning in DevOps**: Intelligent automation for code reviews, anomaly detection, and self-healing infrastructure.
|
||||
- **GitOps**: Managing infrastructure and deployments using Git as the single source of truth.
|
||||
- **Serverless DevOps**: Reducing operational overhead by leveraging functions-as-a-service (FaaS) like AWS Lambda.
|
||||
- **Edge Computing and IoT DevOps**: Enabling real-time application performance optimization closer to end-users.
|
||||
- **Enhanced Security with DevSecOps**: Embedding security more deeply into CI/CD workflows to mitigate risks proactively.
|
||||
|
||||
DevOps isn’t a checkbox—it’s a continuous evolution. Organizations that embrace its cultural tenets, empower teams, and integrate Agile practices will not only survive but thrive in the digital age. By fostering collaboration, automating ruthlessly, and learning relentlessly, they’ll unlock unprecedented innovation and efficiency.
|
||||
@@ -0,0 +1,269 @@
|
||||
---
|
||||
title: DevOps Maturity Model: From Traditional IT to Advanced DevOps
|
||||
source: https://www.bacancytechnology.com/blog/devops-maturity-model
|
||||
author: shenwei
|
||||
published: 2024-08-14
|
||||
created: 2025-03-01
|
||||
description: Explore the DevOps Maturity Model: its five stages, benefits, progress metrics, security considerations & how to avoid challenges for effective implementation.
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
***Quick Summary***
|
||||
|
||||
***The blog covers the DevOps Maturity Model, exploring its key components and the five distinct stages of maturity. We’ll uncover how adopting this model revolutionizes your organization, enhances security practices, and tackles common challenges you might face. By offering actionable insights, we aim to guide you through measuring and optimizing your DevOps journey, ensuring continuous improvement and long-term success.***
|
||||
|
||||
### Table of Contents
|
||||
|
||||
## Introduction
|
||||
|
||||
Every Chief Technology Officer must focus on fostering innovation and building a robust DevOps infrastructure. This progressive approach necessitates detailed planning, thorough testing, and transparent evaluation of what succeeds and fails. Employing a framework like the DevOps Maturity Model can be instrumental in maintaining focus and direction.
|
||||
|
||||
Transitioning from traditional software development methods to DevOps often presents challenges and risks. Yet, evaluating your software delivery processes through a DevOps maturity model is essential to navigate this shift effectively. This model provides a structured framework for assessing your DevOps practices, helping you understand where you stand and identify areas for improvement. In this blog, we’ll explore the maturity model in DevOps and how it can guide your organization to make informed decisions about adopting or refining your DevOps strategy.
|
||||
|
||||
## What is the DevOps Maturity Model?
|
||||
|
||||
The DevOps maturity model is a structured framework that guides organizations through adopting and implementing DevOps principles. This model helps assess an organization’s current DevOps practices, identify improvement areas, and outline steps to advance to higher maturity levels. It also evaluates your DevOps practices, covering aspects such as collaboration, release speed, and quality, adherence to principles, use of automation, and tool sets. This DevOps Maturity Model assessment allows organizations to:
|
||||
|
||||
- Analyze and measure their current DevOps capabilities and methodologies.
|
||||
- Establish benchmarks for their existing DevOps practices.
|
||||
- Define their target maturity level.
|
||||
- Identify key areas that require enhancement.
|
||||
- Develop a strategic roadmap to advance to higher maturity levels.
|
||||
- Acquire knowledge about optimal practices, security measures, and key performance indicators.
|
||||
|
||||
## Key Focus Areas for DevOps Maturity Levels
|
||||
|
||||
Experts suggest assessing an organization’s DevOps maturity by examining its performance in four key areas.
|
||||
|
||||
**● Culture and Strategy**
|
||||
In the DevOps maturity model, culture shapes team collaboration and operations. A teamwork, transparency, and unity culture supports efficient deployment and monitoring. For advanced maturity, the team is supposed to adopt a customer-centric and product-oriented mindset, ensuring all team members align their goals to deliver rapid value.
|
||||
|
||||
**● Automation**
|
||||
DevOps automation or AutoDevOps is crucial for continuous delivery and deployment. It simplifies development, testing, and production by automating repetitive tasks, which saves time and improves resource efficiency in the CI/CD process.
|
||||
|
||||
**● Structure and Process**
|
||||
In the maturity model in DevOps, the process element involves breaking down work into manageable steps to complete a product’s lifecycle. Effective DevOps processes should be standardized and clearly defined to maximize efficiency. Key characteristics of a mature DevOps framework include handling work in small, manageable chunks, maintaining complete transparency of progress, and eliminating unnecessary steps that lead to delays and resource waste.
|
||||
|
||||
**● Collaboration and Sharing**
|
||||
Collaboration is a cornerstone of the DevOps model and a key metric of team effectiveness and productivity. Cohesive teams are more likely to optimize processes and develop practical solutions, leveraging diverse skill sets towards a unified objective.
|
||||
|
||||
**● Technology**
|
||||
Selecting the appropriate technology is crucial in the DevOps framework. The chosen tools and technologies should align with your team’s needs to maximize productivity and effectiveness. Modern tools enable DevOps teams to continuously develop and monitor products, aiming to deliver valuable software to customers swiftly.
|
||||
|
||||
Read More About the Adoption of [DevOps Statistics](https://www.bacancytechnology.com/blog/devops-statistics)
|
||||
|
||||
## What Defines a High-Quality DevOps Maturity Model
|
||||
|
||||
Here is what you should expect in any top-tier DevOps maturity Model
|
||||
|
||||
**● Assessment Criteria**
|
||||
Standards are used to evaluate the effectiveness and maturity of DevOps practices within an organization.
|
||||
|
||||
**● Maturity Levels**
|
||||
A structured progression of DevOps adoption typically encompasses five stages, though some models may include additional phases.
|
||||
|
||||
**● DevOps Practices**
|
||||
Detailed descriptions of core DevOps techniques and their integration into the model include release management, task automation, security protocols, continuous integration/continuous deployment (CI/CD), and infrastructure-as-code (IaC).
|
||||
|
||||
**● Relevant Metrics**
|
||||
Key performance indicators (KPIs) and metrics for evaluating DevOps effectiveness include deployment frequency, mean time to recovery (MTTR), and change failure rate.
|
||||
|
||||
**● Cultural Guides**
|
||||
Strategies for assessing and enhancing organizational culture to align with DevOps principles, focusing on improving communication, feedback mechanisms, and team collaboration.
|
||||
|
||||
**● Tools and Technologies**
|
||||
Version control systems, CI/CD platforms, automation tools, and containerization solutions are recommended tools and technologies for supporting DevOps practices.
|
||||
|
||||
==Read More: [DevOps Tools](https://www.bacancytechnology.com/blog/devops-tools)==
|
||||
|
||||
**● Roles and Responsibilities**
|
||||
Precise definitions of team roles and responsibilities include process ownership, disaster recovery, quality assurance, CI/CD pipeline design, threat response, and system availability.
|
||||
|
||||
## 5 Stages of the DevOps Maturity Model
|
||||
|
||||
Exploring the five stages of the Maturity Model in DevOps provides insight into the progression of DevOps practices, from initial adoption to achieving full maturity and optimizing software delivery.
|
||||
|
||||

|
||||
|
||||
### Phase1: Initial/Ad-Hoc (You Haven’t Started DevOps)
|
||||
|
||||
In Phase One, organizations are often stuck in outdated workflows and unaware of better practices. Here’s a breakdown:
|
||||
|
||||
| **Aspect** | **Description** |
|
||||
| --- | --- |
|
||||
| Organization | Teams (development, operations, security, product management, and users) work in isolation with different priorities, leading to inefficiencies. |
|
||||
| Delivery | - **Approach:** Uses a waterfall approach, focusing on features and timelines instead of business outcomes. - **Release Cycles:** Project milestones are prioritized over user needs or market changes, causing delays. - **Focus:** Teams spend time managing urgent issues rather than adding product value. |
|
||||
| Milestone Releases | Release cycles are based on milestones rather than user feedback or market changes. |
|
||||
| Automation | - **Process:** Manual infrastructure management could be faster and more error-prone. - **Server Management:** Servers receive individual attention instead of being managed in bulk. |
|
||||
| Testing | Manual testing creates bottlenecks and delays. |
|
||||
| Security | Security involvement occurs only weeks before release, focusing on minimal compliance scans. |
|
||||
| Monitoring | Outages are reported by users rather than detected proactively, leading to reactive responses. |
|
||||
| Operations | Operations teams receive releases with minimal planning, affecting deployment efficiency. |
|
||||
|
||||
In Phase One, the absence of integrated practices and proactive measures results in inefficiency and slow response times. Adopting DevOps practices can resolve these issues by enhancing collaboration, automation, and continuous improvement.
|
||||
|
||||
### Phase2: DevOps in Pockets
|
||||
|
||||
In Phase 2, organizations adopt DevOps practices on a smaller scale, focusing on achieving early wins with specific projects. This phase sets the stage for broader implementation by demonstrating the benefits of DevOps in targeted areas.
|
||||
|
||||
| **Aspect** | **Description** |
|
||||
| --- | --- |
|
||||
| Organization | Dev and Ops teams work together on small, strategic projects. |
|
||||
| Delivery | Agile practices are introduced, focusing on business and user value instead of just project planning. |
|
||||
| Version Control | Version control is used to manage environments and configurations. |
|
||||
| Automation | Teams use automation to reduce release risks, but some automation is superficial. |
|
||||
| Testing | Unit, integration, and end-to-end tests are implemented to enhance quality. |
|
||||
| Security | Security operates separately from the rest of the team for now. |
|
||||
| Monitoring | Essential monitoring tools alert the team to issues as soon as they affect users. |
|
||||
| Manual Interventions | Ops staff must manually intervene when issues occur in production. |
|
||||
| Operations | The operations team stays informed about upcoming releases and looks for improvement opportunities from performance alerts. |
|
||||
|
||||
In Phase 2, small teams pilot DevOps practices, achieving quick wins before expanding to the broader organization.
|
||||
|
||||
### Phase 3: Automated and Defined
|
||||
|
||||
In Phase 3, organizations advance their DevOps journey by focusing on automation, establishing it as a core component of their practices. This phase integrates automated processes more deeply, paving the way for more frequent and reliable deployments.
|
||||
|
||||
| **Aspect** | **Description** |
|
||||
| --- | --- |
|
||||
| Organization | Well-defined and standardized processes across Dev and Ops teams. |
|
||||
| Delivery | Agile practices are increasingly integrated across development, operations, design, and business teams. |
|
||||
| Automation | Most infrastructure is automated, making provisioning repeatable and reliable, enabling more frequent deployments. |
|
||||
| Testing | Security scans are incorporated into testing throughout the development process rather than conducted only at deployment. |
|
||||
| Security | Security becomes involved in design, architecture, and operations discussions. Security staff also assist with integrating scans into regular processes. |
|
||||
| Bundled Releases | Releases often bundle unrelated features into big projects. |
|
||||
| Technical Debt | Concepts of MVPs and technical debt still need to be prioritized. |
|
||||
| Monitoring | No changes from the previous phase. |
|
||||
| Operations | The operations team adopts new automation techniques in their practices. |
|
||||
|
||||
In Phase 3, the focus on automation helps enhance the consistency and efficiency of deployments while integrating security and agile practices more comprehensively.
|
||||
|
||||
Read More: [DevOps Orchestration](https://www.bacancytechnology.com/blog/devops-orchestration)
|
||||
|
||||
### Phase4: Highly Optimized DevOps
|
||||
|
||||
In Phase 4, organizations build on their automation investments by implementing a continuous integration pipeline, leading to more tangible business benefits from their DevOps practices.
|
||||
|
||||
| **Aspect** | **Description** |
|
||||
| --- | --- |
|
||||
| Organization | Ops and development teams work closely with project management and security in product planning. |
|
||||
| Automation | - **Infrastructure:** Immutable infrastructure replaces old servers rather than updating them. - **Deployment:** Manage infrastructure and code updates through pipelines. - **Security:** Incorporate security updates directly into the product development workflow. |
|
||||
| Testing | Performance and load testing ensure deployments are ready for production scale. |
|
||||
| Tech Debt and MVPs | Use of MVPs and management of tech debt to speed up releases. |
|
||||
| Security | - **Dependency Management:** Identifies third-party vulnerabilities before they cause issues. - **Monitoring:** Continuous security monitoring spreads security awareness across the team. |
|
||||
| Monitoring | Continuous application monitoring tracks the system's overall health for early problem detection and analysis of root causes. |
|
||||
| Operations | Developers consider operational aspects in documentation, analytics, and standard operating procedures. |
|
||||
|
||||
In Phase 4, the continuous integration pipeline and enhanced security measures drive significant improvements in deployment reliability and overall product quality. You can also [Hire DevOps developers](https://www.bacancytechnology.com/hire-devops-developers) who can optimize your CI/CD processes, enhance security practices, and ensure robust performance monitoring to elevate your DevOps capabilities further.
|
||||
|
||||
### Phase5: Fully Mature DevOps
|
||||
|
||||
In Phase 5, organizations reach a state of continuous deployment, focusing on ongoing improvement and maximizing the impact of DevOps practices to effectively meet business and user needs.
|
||||
|
||||
| **Aspect** | **Description** |
|
||||
| --- | --- |
|
||||
| Organization | Self-sufficient, full-stack teams across business units. |
|
||||
| Delivery | Multiple deployments per day with high certainty and minimal risk. |
|
||||
| Automation | Zero human intervention for code changes passing through the pipeline. |
|
||||
| Testing | Continuous use of real-time data to make informed decisions and optimize processes. |
|
||||
| Security | Prevent insecure or non-compliant code from reaching production; high-level security integration. |
|
||||
| Monitoring | Max uptime with no interruptions to customer experience; high collaboration across teams. |
|
||||
| Operations | Rapid, data-driven decision-making and innovation are encouraged; teams excel in collaboration and experimentation. |
|
||||
|
||||
These tables outline the progression from initial DevOps practices to a fully mature state, highlighting each stage’s evolving focus and capabilities.
|
||||
|
||||
## Business Benefits of Adopting the Maturity Model in DevOps
|
||||
|
||||
Adopting the maturity model in DevOps offers numerous advantages, enabling organizations to enhance their processes and achieve superior outcomes by systematically improving their DevOps practices.
|
||||
|
||||
**● Quicker Adjustment to Changes**
|
||||
DevOps practices help organizations swiftly adjust to evolving market trends and customer needs. Businesses can quickly roll out new features and maintain agility in their operations by utilizing continuous integration and continuous deployment (CI/CD) pipelines.
|
||||
|
||||
**● Capability to Seize Opportunities**
|
||||
Companies with advanced DevOps practices can seize new opportunities more effectively. Their capability to rapidly deploy updates and services enables them to introduce innovative products and enter new markets ahead of their competitors.
|
||||
|
||||
**● Spot Areas of Satisfaction**
|
||||
The DevOps Maturity Model assists organizations in recognizing and improving weak spots in their processes. Organizations can pinpoint inefficiencies by consistently evaluating their practices and implementing targeted improvements to enhance overall performance.
|
||||
|
||||
**● Better Scalability**
|
||||
Advanced DevOps practices enable smooth scaling of applications and infrastructure. By using Infrastructure as Code (IaC) for automated resource provisioning and management, businesses can manage higher demands and grow their operations with minimal manual effort.
|
||||
|
||||
**● Enhanced Operational Performance**
|
||||
DevOps advocates automating repetitive tasks and bridging gaps between development and operations teams. This method streamlines workflows, reduces manual errors, and improves resource efficiency, ultimately lowering operational costs.
|
||||
|
||||
**● Faster Delivery Times**
|
||||
Adopting automated testing, integration, and deployment can significantly reduce the time needed to deliver new features and updates. This accelerated pace enhances customer satisfaction and allows businesses to stay competitive in fast-evolving markets.
|
||||
|
||||
**● Improved Quality**
|
||||
In mature DevOps practices, continuous monitoring and feedback loops enable early detection and resolution of issues, resulting in higher-quality software with fewer bugs and vulnerabilities. It not only enhances user experience but also lowers maintenance costs. The DevOps Maturity Model offers a strategic framework for organizations to progressively improve their DevOps practices, delivering substantial business advantages and maintaining a competitive edge.
|
||||
|
||||
## Security Linked With the DevOps Maturity Model
|
||||
|
||||
As organizations advance in their DevOps automation, the need for faster release cycles and digital innovation becomes crucial, intensifying the focus on security. The core of DevOps security is merging development, operations, and security into a unified process. This agile approach bridges the gap between IT operations and software development.
|
||||
|
||||
As security challenges become more pronounced, DevOps practices must evolve and incorporate robust security measures throughout the development lifecycle. This integration, commonly realized through DevSecOps, guarantees that security is woven into every phase of the Software Development Lifecycle. Effective DevSecOps practices involve collaboration between DevOps and security teams, implementing security policies and frameworks across all tools and resources.
|
||||
|
||||
Get to know [what is DevSecOps](https://www.bacancytechnology.com/blog/what-is-devsecops) in detail.
|
||||
|
||||
Additionally, solutions like containerization continuously address security issues by minimizing the exposure of vulnerable resources. This proactive approach helps maintain security integrity while supporting rapid development and deployment.
|
||||
|
||||
## Most Common Roadblocks That Hold DevOps Maturity Back
|
||||
|
||||
Identifying and addressing the common roadblocks to DevOps maturity is essential for overcoming obstacles and ensuring a smooth transition to more effective practices.
|
||||
|
||||
**● Poor Communication between Dev and Ops teams**
|
||||
Misunderstandings and delays occur when development and operations teams don’t communicate effectively. This lack of coordination can result in mismatched priorities and inefficient workflows, making achieving smooth, continuous delivery harder.
|
||||
|
||||
**● Lack of Clear Objectives and Strategies**
|
||||
Without clear goals and strategies, DevOps initiatives can become disorganized. Teams need well-defined targets and plans to guide their efforts and measure success. These are necessary to stay focused and make meaningful progress.
|
||||
|
||||
**● Resistance to Change**
|
||||
Implementing DevOps often means changing established processes, which can be met with resistance from those who prefer the status quo. This reluctance can slow down or halt DevOps efforts, preventing the adopting of new, more effective practices.
|
||||
|
||||
**● Insufficient Investments**
|
||||
DevOps requires investment in tools, training, and resources. Without adequate funding, implementation can be incomplete or ineffective, limiting potential benefits and slowing progress.
|
||||
|
||||
**● Poor Governance**
|
||||
Effective governance guarantees that DevOps practices are uniform and aligned with business objectives. Strong governance can lead to consistent practices and better management, making it easier to achieve desired outcomes.
|
||||
|
||||
**● Inflexible Processes and Workflows**
|
||||
Rigid processes that don’t adapt to new needs or technologies can create bottlenecks and inefficiencies. Flexibility is critical in DevOps to accommodate rapid changes and continuous improvement.
|
||||
|
||||
**● Excluding end-users From the Improvement Project**
|
||||
Ignoring end-user feedback can result in solutions that don’t meet their needs or expectations. Including user input helps ensure that the products developed are helpful and practical.
|
||||
|
||||
**● Inadequate Integration with Business Processes**
|
||||
DevOps should align with overall business objectives. Poor integration can lead to inefficiencies and misalignment with business goals, affecting the effectiveness of DevOps initiatives.
|
||||
|
||||
## How To Measure DevOps Maturity
|
||||
|
||||
To effectively gauge DevOps maturity, consider evaluating the following key metrics:
|
||||
|
||||
- **Time-To-Market:** The period from the initial concept to the product’s launch.
|
||||
- **Lead Time:** The interval from code commitment to deployment.
|
||||
- **Development Frequency:** The rate at which code is deployed within a set period.
|
||||
- **Code Quality:** Code complexity, test coverage, and feedback from code evaluations.
|
||||
- **Code Deployment Success Rate:** The proportion of successful deployments.
|
||||
- **Change Failure Rate:** The proportion of deployments that encounter issues or failures.
|
||||
- **Rollback Rate:** The proportion of deployments that are reverted.
|
||||
- **Error Budget:** The permissible rate of errors and failures in production.
|
||||
- **Availability:** The time the system remains operational and accessible to users.
|
||||
- **Scalability:** The system’s ability to manage increased load without performance issues.
|
||||
- **Time-in-stage:** The average duration required to complete each phase of the development process.
|
||||
- **Code Review Feedback Loop Time:** The time it takes to receive and act on feedback from code reviews.
|
||||
- **MTTR (Mean Time to Recovery):** The average time required to recover from a failure.
|
||||
- **MTTD (Mean Time to Detect):** The average time to identify a problem.
|
||||
- **MTTA (Mean Time to Acknowledge):** The average time to acknowledge and begin addressing a problem.
|
||||
|
||||
## Conclusion
|
||||
|
||||
The DevOps Maturity Model is a powerful tool for guiding organizations through the evolution of their DevOps practices, from initial adoption to achieving full maturity. By understanding and implementing the model’s stages, businesses can enhance their processes, address common roadblocks, and leverage key metrics to drive continuous improvement. Embracing this framework with [DevOps consulting services](https://www.bacancytechnology.com/devops-consulting-services) enables organizations to accelerate delivery, improve quality, and effectively integrate security, positioning them for sustained success in a competitive landscape. As you advance through the maturity model in DevOps, you set the foundation for robust, agile, and high-performing software development and operations.
|
||||
|
||||
## Frequently Asked Questions (FAQs)
|
||||
|
||||
Begin with small, manageable projects, focus on automation, and gradually scale practices across the organization.
|
||||
|
||||
Regularly reassess, at least annually, to ensure continuous improvement and alignment with evolving goals and technologies.
|
||||
|
||||
Evaluating metrics such as deployment frequency, lead time for changes, change failure rate, and customer satisfaction improvements.
|
||||
@@ -0,0 +1,119 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
|
||||
Agentic AI (AI systems with the capability to make autonomous decisions and execute tasks) can significantly enhance **Cloud DevOps** by automating complex workflows, improving efficiency, and ensuring reliability across cloud environments. Here’s how:
|
||||
|
||||
---
|
||||
|
||||
## **1. Autonomous Incident Detection & Resolution**
|
||||
|
||||
**→ Faster MTTR (Mean Time to Resolution) and SLA Compliance**
|
||||
|
||||
- **Self-Healing Systems**: Agentic AI can proactively detect anomalies in **Kubernetes (EKS, GKE, AKS)**, databases (**RDS, Cloud SQL, Cosmos DB**), and storage (**S3, GCS, Blob Storage**) and **apply automated remediations** (e.g., restart pods, scale resources, clear disk space).
|
||||
- **AI-driven Root Cause Analysis (RCA)**: Analyzes logs from **CloudWatch, Stackdriver, and Azure Monitor**, correlating issues across layers (compute, network, application).
|
||||
- **Predictive Maintenance**: Learns patterns from historical outages and proactively recommends patches or scaling changes.
|
||||
|
||||
### **Example**
|
||||
|
||||
An AI agent monitoring AWS EKS clusters detects high CPU usage due to a rogue pod. It automatically throttles the pod, scales resources, or suggests a pod restart.
|
||||
|
||||
---
|
||||
|
||||
## **2. Automated Cloud Deployments & Configurations**
|
||||
|
||||
**→ More reliable and consistent CI/CD pipelines**
|
||||
|
||||
- **Agentic AI as a Release Manager**: Automates feature flag testing, rollback decisions, and deployment strategies (Blue/Green, Canary).
|
||||
- **Intelligent Infrastructure-as-Code (IaC) Management**: AI agents review **Terraform, CloudFormation, Pulumi** scripts and suggest improvements before execution.
|
||||
- **Dynamic Configuration Management**: Adjusts application settings (via **Parameter Store, Secrets Manager, ConfigMaps**) based on real-time performance and cost efficiency.
|
||||
|
||||
### **Example**
|
||||
|
||||
An AI agent detects that a new microservice deployment is causing latency issues and **automatically rolls back** the changes while generating a fix suggestion.
|
||||
|
||||
---
|
||||
|
||||
## **3. Intelligent Cost Optimization**
|
||||
|
||||
**→ Reduces cloud spend while maintaining performance**
|
||||
|
||||
- **AI-based Rightsizing & Autoscaling**: Continuously analyzes usage trends and scales cloud resources dynamically (**EKS, RDS, S3, VMs**) to prevent overprovisioning.
|
||||
- **Spot & Reserved Instance Optimization**: Suggests cost-efficient choices between **AWS Spot, GCP Preemptible, Azure Savings Plan**, switching workloads as needed.
|
||||
- **Multi-Cloud Cost Governance**: Identifies **wasteful spending across AWS, GCP, Azure**, suggesting resource consolidation or alternative pricing models.
|
||||
|
||||
### **Example**
|
||||
|
||||
An AI agent detects that a workload in AWS **should be shifted to spot instances at night**, reducing cloud costs by 40%.
|
||||
|
||||
---
|
||||
|
||||
## **4. AI-Driven Security & Compliance**
|
||||
|
||||
**→ Continuous security posture management & compliance enforcement**
|
||||
|
||||
- **Automated Security Audits**: Scans **IAM policies, network rules, container vulnerabilities** (using AWS Inspector, GCP Security Command Center, Azure Defender).
|
||||
- **Dynamic Threat Mitigation**: Detects security risks (e.g., **exposed S3 buckets, misconfigured firewalls**) and **automatically remediates** them.
|
||||
- **Compliance Enforcement**: Continuously monitors **SOC 2, FedRAMP, PCI DSS** requirements and fixes violations in real time.
|
||||
|
||||
### **Example**
|
||||
|
||||
Agentic AI detects an over-permissive IAM role that allows public access to sensitive data and **immediately restricts it** while notifying DevOps.
|
||||
|
||||
---
|
||||
|
||||
## **5. Intelligent Log Analysis & Observability**
|
||||
|
||||
**→ Simplifies troubleshooting & improves visibility**
|
||||
|
||||
- **AI-powered Log Crawling**: Analyzes logs from **CloudWatch, ELK, OpenTelemetry, Datadog** to identify trends and suggest resolutions.
|
||||
- **Automated RCA & Playbook Execution**: Suggests best practices from incident history and executes predefined workflows.
|
||||
- **AI ChatOps & Conversational AI**: Enables **Slack, Teams, or CLI-based troubleshooting** where engineers can query logs and get AI-driven insights.
|
||||
|
||||
### **Example**
|
||||
|
||||
An AI agent notices that a recent AWS Lambda function failure is correlated with an **unavailable external API** and **proposes a retry strategy**.
|
||||
|
||||
---
|
||||
|
||||
## **6. Enhanced Multi-Tenancy Management for SaaS**
|
||||
|
||||
**→ Automates provisioning, scaling, and tenant isolation**
|
||||
|
||||
- **Self-Service Tenant Provisioning**: AI agents can **create & configure new tenants** dynamically, assigning resources based on workload needs.
|
||||
- **Automated Tenant Decommissioning**: Identifies **inactive tenants**, archives data, and deletes unused cloud resources.
|
||||
- **Multi-Tenant Cost Optimization**: Identifies opportunities to **reduce per-tenant cloud costs** through **shared storage, optimized compute allocation**, and serverless execution models.
|
||||
|
||||
### **Example**
|
||||
|
||||
An AI agent detects that some tenants in a multi-tenant **SMAX deployment on GCP** are inactive for 6+ months and **suggests archival or deletion**, reducing storage costs.
|
||||
|
||||
---
|
||||
|
||||
## **7. AI-Augmented Decision-Making**
|
||||
|
||||
**→ Optimized DevOps workflows & improved decision accuracy**
|
||||
|
||||
- **AI-powered Runbooks**: AI suggests the best operational playbooks for handling incidents.
|
||||
- **What-If Simulations**: Helps predict the impact of **cloud migrations, instance type changes, or architectural shifts** before execution.
|
||||
- **AI-based Anomaly Detection**: Flags deviations in performance, security, or cost trends.
|
||||
|
||||
### **Example**
|
||||
|
||||
An AI agent simulates how moving an AWS-based SaaS application to **GCP’s Private Cloud in KSA** will impact performance, cost, and compliance.
|
||||
|
||||
---
|
||||
|
||||
## **Conclusion**
|
||||
|
||||
Agentic AI transforms Cloud DevOps by automating **incident response, cost management, security, observability, and multi-cloud governance**. By integrating AI-driven automation, enterprises can achieve **faster deployments, proactive issue resolution, reduced costs, and enhanced security compliance**—all without increasing DevOps workloads.
|
||||
|
||||
Would you like a specific AI-powered **tooling** recommendation for implementation?
|
||||
@@ -0,0 +1,217 @@
|
||||
---
|
||||
title: How Can a Multi Cloud Strategy Transform Your Business ROI?
|
||||
source: https://www.bacancytechnology.com/blog/multi-cloud-strategy#what-is-a-multi-cloud-strategy?
|
||||
author: shenwei
|
||||
published: 2024-12-24
|
||||
created: 2025-03-01
|
||||
description: Explore how a multi-cloud strategy can boost performance, reduce risks, and maximize ROI on your cloud investments while ensuring scalability and flexibility.
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
***Quick Summary***
|
||||
|
||||
***In this blog, we will explore what a multi-cloud strategy is, why it’s a game-changer for businesses, and how it addresses key challenges like vendor lock-in, compliance, and performance optimization. Read further to learn how to leverage the strengths of multiple cloud providers, streamline operations, and reduce risks. Whether you’re considering multi-cloud or ready to implement it, this guide will help you make informed decisions and set up a strategy that drives success.***
|
||||
|
||||
### Table of Contents
|
||||
|
||||
## Introduction
|
||||
|
||||
As businesses grow and expand their digital operations, managing cloud environments becomes increasingly complex. Relying on a single cloud provider often leads to challenges in scalability, cost efficiency, and resilience. This is why businesses are turning to multi-cloud strategies to stay agile, secure, and competitive.
|
||||
|
||||
##### **Consider This:**
|
||||
|
||||
- 78% of businesses leveraging a multi-cloud strategy have workloads deployed in more than three public clouds for better agility and cost savings (source: [virtana](https://www.virtana.com/press-release/virtana-research-finds-more-than-80-of-enterprises-have-a-multi-cloud-strategy-and-78-are-using-more-than-three-public-clouds/))
|
||||
- 86% of companies intend to adopt a multi-cloud approach by the end of 2024 to meet recurring business requirements (Source: [New Horizons](https://www.newhorizons.com/resources/blog/multi-cloud-adoption))
|
||||
- After optimizing resources and negotiating favorable prices with different cloud service providers, most companies enjoy a 30% reduction in operations costs (source: [Forrester](https://www.f5.com/go/report/cloud-infrastructure-forrester-tei-study))
|
||||
|
||||
These numbers highlight why multi-cloud adoption is on the rise—it offers flexibility, cost optimization, and resilience. In this blog, we’ll explore the key business challenges a multi-cloud strategy addresses and how you can build an effective approach tailored to your needs.
|
||||
|
||||
##### **Definition:**
|
||||
|
||||
The multi cloud strategy is a distinctive approach in which we have instances of services on multiple clouds, i.e., Azure, GCP, and Amazon, instead of one cloud vendor. The benefit of this approach is that it allows businesses to use the strengths of each cloud service provider as well as their unique features to boost efficiency, security, and performance.
|
||||
|
||||
##### **How It Works:**
|
||||
|
||||
Businesses utilize cloud providers to covertly distribute workloads to provide specific services or achieve pricing models without a single provider. In short, a company adopting a multi cloud approach gets to use the best from each cloud provider. For example, you can leverage computing from AWS AI tools from Google and store your data in Microsoft Azure without fearing vendor lock-in yet enjoy high availability.
|
||||
|
||||
##### **Common Misconceptions:**
|
||||
|
||||
**✅ Not Just a Backup Strategy:** A multi-cloud approach is often mistaken for merely a backup or disaster recovery solution. While it enhances redundancy, its true value lies in optimizing performance, cost, and scalability across multiple providers.
|
||||
**✅ Not Always More Complex:** Managing multiple cloud platforms may seem challenging, but with the right strategy and tools—such as cloud automation, governance frameworks, and containerization—it becomes easier to handle and strengthens system resilience.
|
||||
|
||||
## Why do Businesses Usually Adopt a Multi-Cloud Strategy?
|
||||
|
||||
Here are the key reasons why businesses are adopting a Multi Cloud Strategy, And why you should too:
|
||||
|
||||
#### **1\. Avoiding Vendor Lock-In**
|
||||
|
||||
Through a multi cloud strategy, enterprises are no longer tied to a single cloud provider. Since they can, they pick the best cloud services nowadays depending on specific needs—costs, performance, or special functions—and are free from being just in one vendor’s ecosystem.
|
||||
|
||||
#### **2\. Increased Resilience and Reliability**
|
||||
|
||||
The benefit of a multi-cloud setup is that if one cloud provider goes down for whatever reason and the other continues to supply service when the one goes back online, things will return to normal. Services are less vulnerable to service disruption if redundancy exists across the platforms.
|
||||
|
||||
#### **3\. Improved Security Posture**
|
||||
|
||||
With data spread across some cloud environments, different security mechanisms can be deployed within each provider’s strong points. It reduces the threats of cyberattacks or data breaches to the overall security, hence this approach.
|
||||
|
||||
#### **4\. Scalability**
|
||||
|
||||
Businesses can more quickly accommodate fluctuating demands. The ability for organizations to scale in a multi-cloud environment provides the flexibility to utilize different cloud providers to provide operational scalability while limiting resource costs.
|
||||
|
||||
#### **5\. Cost Optimization**
|
||||
|
||||
Businesses can avoid cloud spending per provider by working with multiple providers and tapping into their cost advantages. For example, one provider could sell storage cheaper, while another could dominate computation power.
|
||||
|
||||
#### **6\. Access to Innovation**
|
||||
|
||||
Different cloud providers offer different features, tools, and services. A multi cloud approach will provide businesses with more innovation and ensure they are always at the forefront of this rapidly evolving digital landscape.
|
||||
|
||||
#### **7\. Regulatory Compliance**
|
||||
|
||||
Data storage and processing may have regulatory requirements specific to certain regions or industries.
|
||||
Data storage and access laws and regulations vary by region and industry. A multi-cloud strategy allows a company to pick the provider with the certifications and features in place for compliance and regulations globally.
|
||||
|
||||
#### **8\. Performance Optimization**
|
||||
|
||||
Businesses can optimize performance by selecting the best provider for different workloads. For example, you could have one cloud compute instance for machine learning tasks and another for data analytics, allowing you to optimize the load for each, which will speed up processing time.
|
||||
|
||||
***Need help setting up the right multi-cloud strategy for your business?***
|
||||
|
||||
***Let our [Cloud Managed Services](https://www.bacancytechnology.com/cloud-managed-services) guide you in optimizing your multi-cloud environment, improving efficiency, and ensuring seamless integration—while maximizing your ROI.***
|
||||
|
||||
## Key Business Challenges Addressed by Multi-Cloud Strategies
|
||||
|
||||
Here are the key challenges that businesses were able to address when they adopted a multi-cloud strategy:
|
||||
|
||||

|
||||
|
||||
#### **1\. Risk Mitigation**
|
||||
|
||||
A solid Multi cloud strategy reduces dependency on a single provider, and hence, in case of a downtime or data loss risk due to problems with one provider. Businesses achieve this by distributing workloads over multiple clouds so that a failure in one doesn’t take down the whole thing.
|
||||
|
||||
#### **2\. Cost Optimization**
|
||||
|
||||
Pricing models vary across providers; a multi cloud strategy helps a business get the best deals and cheaper prices from the best providers. It reduces overhead costs, holds down efficiency costs, and ensures maximum spending.
|
||||
|
||||
#### **3\. Data Sovereignty**
|
||||
|
||||
Adopting a multi cloud approach enables businesses to follow global and regional data regulations. If you are running your multi-region cloud deployments, it helps you ensure where the organization stores the data, fulfill any legal and compliance requirements, and avoid hefty fines.
|
||||
|
||||
#### **4\. Performance**
|
||||
|
||||
Multiple cloud environments allow businesses to pick the best provider for different workloads, optimizing for performance. For example, high-performance computing applications can be executed on a cloud with a superior infrastructure for those tasks, resulting in top-quality performance.
|
||||
|
||||
#### **5\. Complexity Management**
|
||||
|
||||
While managing multiple clouds can be complex, multi-cloud management tools and automation can make it easy. With these tools, businesses get centralized control so they can monitor the performance, costs, and compliance of all cloud environments, keeping the operational burdens down.
|
||||
|
||||
## How A Multi Cloud Strategy Can Help Maximize Your ROI?
|
||||
|
||||
A well-implemented multi cloud strategy can significantly enhance your business’s return on investment (ROI) by providing flexibility, cost savings, and increased productivity:
|
||||
|
||||
#### **Cost Reduction**
|
||||
|
||||
Multi-cloud saves businesses from the burden of high single-cloud provider pricing structures that are often one-size-fits-all. Choosing different providers based on your pricing models will allow businesses to drive a hard bargain for better rates and cut their overhead costs. In addition, workloads optimized across multiple clouds also help prevent paying for unnecessary resources on any of the clouds.
|
||||
|
||||
#### **Resource Optimization**
|
||||
|
||||
Businesses get the best performance out of their infrastructure by allocating workloads to the cloud provider for each task best suited to it. For example, machine learning offloads to a provider like Google Cloud, while general infrastructure runs on AWS or Azure.
|
||||
|
||||
#### **Efficiency Gains**
|
||||
|
||||
A multi cloud strategy enhances operational workflow by creating a more tailored cloud architecture. Choosing the right cloud environment for specific needs (e.g., low latency for real-time apps) helps businesses reduce downtime, improve performance, and increase productivity. This fine-tuning means your deployment times are faster, your availability is better, and your valuable company resources are used more efficiently.
|
||||
|
||||
#### **Flexibility in Scaling**
|
||||
|
||||
The ability to scale businesses through a multi cloud strategy accommodates businesses like no other strategy can today. By leveraging multiple cloud providers, companies can dynamically determine how many resources to allocate depending on their workloads. For instance, should demand for certain kinds of services suddenly spike, we can expand on one provider without worrying about capacity limits on all providers. The ability to adjust resources on the fly guarantees businesses avoid overpaying for unused capacity, ensuring optimal performance levels yet maximizing ROI.
|
||||
|
||||
#### **Better Risk Management**
|
||||
|
||||
A multi-cloud strategy eliminates single-provider dependency and thus mitigates risks. If businesses depend only on one cloud provider, they could lose a lot of money in case of an outage or problem. An organization can mitigate this event by distributing the workload across multiple providers, and the other provider steps in when the first provider is down.
|
||||
|
||||
## Real-World Use Cases of Multi-Cloud Strategy
|
||||
|
||||
Here are the Key Real-World Use Cases of Multi-Cloud Strategy to Refer Across Key Industries:
|
||||
|
||||
### E-Commerce: Optimizing Scalability and Performance During Peak Seasons
|
||||
|
||||
In e-commerce, the multi-cloud strategy has become a game changer. Businesses can leverage this way of working to have high availability and scalability when these occasions, which usually occur around Black Friday or Cyber Monday, arrive. This also allows them to scale their resources across multiple providers as needed to serve traffic spikes, provide uninterrupted service, and improve the user experience with fast customer load times.
|
||||
|
||||
### Healthcare: Ensuring Data Compliance While Optimizing Operational Costs
|
||||
|
||||
Organizations in the healthcare industry use multi-cloud environments to keep their sensitive patient data secure and abide by industry regulations such as HIPAA. To achieve robust data protection, they can distribute their data and services across compliant cloud platforms and comply with regional data sovereignty requirements while cutting down the cost of a single cloud dependency.
|
||||
|
||||
### Finance: Using Multi-Cloud to Improve Security and Compliance and Maximize Return on Investments
|
||||
|
||||
Financial institutions embrace a multi-cloud computing strategy to secure their financial data, protect sensitive data, and avert stringent regulatory requirements. They use the best security features of different cloud providers and reduce risk and vendor lock-in, giving better SLAs and more economical solutions that eventually lead to high ROI.
|
||||
|
||||
Such examples illustrate why different industries can embrace a multi-cloud strategy for supplier requirements.
|
||||
|
||||
## How to Implement a Multi Cloud Strategy in Your Organization
|
||||
|
||||

|
||||
|
||||
### Step 1: Assess Your Needs
|
||||
|
||||
**Identify Goals:** Know when you need a multi-cloud strategy to build in resiliency, optimize costs, or scale.
|
||||
**Budget Analysis:** Assess the financial resources available for multi-cloud adoption, including initial and ongoing costs.
|
||||
|
||||
Resource Requirements: Bring current workloads and infrastructure into focus to see gaps or areas to improve upon.
|
||||
|
||||
### Step 2: Choose the Right Providers
|
||||
|
||||
**Align Services with Needs:** Select providers specializing in your required services (e.g., AWS for infrastructure, Google Cloud for analytics, Azure for AI).
|
||||
**Evaluate Features and Pricing:** Compare security, compliance, cost, and performance metrics across vendors.
|
||||
|
||||
### Step 3: Integrate and Manage
|
||||
|
||||
**Adopt Multi-Cloud Management Tools:** Use platforms like Kubernetes or Terraform to streamline integration and automate workload distribution.
|
||||
**Data Interoperability:** Our system of cloud providers that we work with has to interoperate in a way that services and applications work together without making data silos.
|
||||
|
||||
### Step 4: Monitor and Optimize
|
||||
|
||||
**Track Resource Usage:** Combine tools like CloudHealth or Datadog to monitor performance and costs continuously.
|
||||
**Implement Cost-Saving Measures:** Reduce waste by optimizing workloads and resource allocations according to usage patterns.
|
||||
|
||||
This step-by-step method ensures that transitioning to a multi-cloud strategy is smooth, maximizes all its benefits, and handles any challenges to come.
|
||||
|
||||
## Multi-Cloud Adoption Challenges With Proven Solutions
|
||||
|
||||
### 1\. Integration Complexity
|
||||
|
||||
**Challenge:** Connecting different cloud platforms often leads to compatibility issues and operational silos.
|
||||
**Solution:** Use integration tools like Kubernetes, Terraform, or cloud APIs to manage and unify platform resources.
|
||||
|
||||
### 2\. Security Risks
|
||||
|
||||
**Challenge:**Multi-cloud environments can expose businesses to data breaches and inconsistent security policies.
|
||||
**Solution:** Adopt centralized security protocols, employ multi-cloud IAM (Identity Access Management), and ensure end-to-end encryption.
|
||||
|
||||
### 3\. Lack of Expertise
|
||||
|
||||
**Challenge:** Managing diverse platforms requires specialized skills, which may be scarce in-house.
|
||||
**Solution:** Invest in team upskilling, hire multi-cloud experts, or partner with managed cloud service providers to bridge the gap.
|
||||
|
||||
## Conclusion
|
||||
|
||||
A multi-cloud strategy is a smart move for businesses that want to stay flexible, efficient, and ahead of the curve. By using different cloud providers for what they do best, companies can boost performance, reduce risks, and save on costs—without getting stuck with one vendor. It’s all about finding the right fit for your needs.
|
||||
|
||||
Making the switch to multi-cloud isn’t something to rush into, though. It requires careful planning and the right expertise to really get it right. That’s where we come in. Our [Cloud Migration Services](https://www.bacancytechnology.com/cloud-migration-services) are here to help you set up a strategy that works for your business, ensuring a smooth and successful transition.
|
||||
|
||||
## Frequently Asked Questions (FAQs)
|
||||
|
||||
A multi cloud strategy involves using multiple cloud providers (e.g., AWS, Azure, Google Cloud) to optimize performance, avoid vendor lock-in, and enhance security.
|
||||
|
||||
By leveraging competitive pricing, optimizing resource allocation, and improving efficiency, businesses can reduce costs and enhance productivity, maximizing cloud ROI.
|
||||
|
||||
Industries like e-commerce, healthcare, and finance benefit significantly through improved scalability, compliance, and security.
|
||||
|
||||
Challenges include integration complexity, managing security risks, and ensuring the team has the expertise to handle multiple cloud environments.
|
||||
|
||||
By adopting robust multi-cloud security practices, using advanced monitoring tools, and ensuring data encryption and compliance across providers.
|
||||
|
||||
E-commerce companies manage peak-season traffic efficiently, while healthcare providers ensure compliance with regional data laws using multi-cloud solutions.
|
||||
|
||||
Assess business needs, select the right providers, integrate with management tools, and continuously monitor performance and costs.
|
||||
@@ -0,0 +1,210 @@
|
||||
---
|
||||
title: How to Simplify Multi-Account Deployments Monitoring: Centralized Logs for AWS CloudFormation StackSets
|
||||
source: https://aws.amazon.com/blogs/devops/how-to-simplify-multi-account-deployments-monitoring-centralized-logs-for-aws-cloudformation-stacksets/
|
||||
author: shenwei
|
||||
published: 2025-10-24
|
||||
created: 2025-10-25
|
||||
description: Introduction As organizations adopt multi-account strategies for improved security features and governance, AWS CloudFormation StackSets enables organizations to deploy infrastructure across multiple accounts and regions. However, monitoring and tracking these distributed deployments across multiple accounts presents operational challenges. When a critical security baseline deployed across 50 accounts suddenly starts failing, teams face the daunting task of logging […]
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
## AWS DevOps & Developer Productivity Blog
|
||||
|
||||
## Introduction
|
||||
|
||||
As organizations adopt multi-account strategies for improved security features and governance, [AWS CloudFormation StackSets](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/what-is-cfnstacksets.html) enables organizations to deploy infrastructure across multiple accounts and regions. However, monitoring and tracking these distributed deployments across multiple accounts presents operational challenges. When a critical security baseline deployed across 50 accounts suddenly starts failing, teams face the daunting task of logging into each account individually to understand what went wrong and which accounts were affected.
|
||||
|
||||
This operational overhead scales exponentially with organization growth, requiring platform teams to spend countless hours switching between accounts and manually correlating deployment events. The lack of centralized visibility slows incident response and makes it difficult to identify patterns or implement proactive monitoring. In this blog post, we’ll explore a solution that centralizes AWS CloudFormation logs from multiple accounts into a single management account, making it easier to monitor and troubleshoot StackSets deployments.
|
||||
|
||||
## Solution Architecture
|
||||
|
||||
Our solution creates a centralized logging system that collects AWS CloudFormation events from all target accounts and forwards them to a central management account. This approach provides a single pane of glass for monitoring and troubleshooting AWS CloudFormation deployments across your entire organization.
|
||||
|
||||
**Figure 1. Architecture diagram showing event flow from member accounts to management account through EventBridge and CloudWatch Logs.**
|
||||
|
||||
The architecture consists of four main components:
|
||||
|
||||
1. **Management Account Setup**: Creates a central event bus, log group, and necessary permissions in the organization’s management account.
|
||||
2. **Target Account Configuration**: Deployed via StackSets to configure event rules that forward AWS CloudFormation events to the management account.
|
||||
3. **Resource Deployment:** Uses StackSets to deploy common resources across target accounts, generating the events we want to monitor.
|
||||
4. **Monitoring and Visualization:** Provides dashboards and queries for operational insights.
|
||||
|
||||
## How It Works
|
||||
|
||||
The solution follows this event flow:
|
||||
|
||||
1. **Event Generation:** AWS CloudFormation operations in target accounts generate events (stack creation, updates, deletions, resource changes).
|
||||
2. **Event Capture:**[Amazon EventBridge](https://docs.aws.amazon.com/eventbridge/latest/userguide/eb-what-is.html) rules in each target account capture these AWS CloudFormation events based on defined patterns.
|
||||
3. **Cross-Account Forwarding:** Events are forwarded to a custom event bus in the management account using cross-account permissions.
|
||||
4. **Centralized Logging:** The central event bus routes all events to a [Amazon CloudWatch Log Group](https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/WhatIsCloudWatchLogs.html) with structured logging.
|
||||
5. **Monitoring and Alerting:** Administrators can view consolidated logs, create custom queries, and set up alerts from a single location.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before implementing this solution, ensure you have the following prerequisites in place:
|
||||
|
||||
- **AWS account**: Ensure you have valid AWS account.
|
||||
- **AWS Organizations:** You must have an [AWS Organization](https://docs.aws.amazon.com/organizations/latest/userguide/orgs_introduction.html) structure set up with a primary management account and several member accounts under the management account.
|
||||
- **Trusted Access:**[Enable trusted access for AWS CloudFormation StackSets](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/stacksets-orgs-activate-trusted-access.html) from the management account (this allows StackSets to assume roles in member accounts).
|
||||
- **Appropriate Permissions:** You must have access to the management account or be configured as a delegated administrator to create and manage StackSets. For detailed information about permissions and security considerations when using StackSets with AWS Organizations, please review the Prerequisites in the AWS CloudFormation StackSets documentation.
|
||||
|
||||
## Implementation Deep Dive
|
||||
|
||||
The solution is implemented using two AWS CloudFormation templates that work together to create a comprehensive monitoring system:
|
||||
|
||||
### 1\. Management Account Logging Setup (log-setup-management.yaml)
|
||||
|
||||
This template establishes the central logging infrastructure in the management account by creating a custom Amazon EventBridge event bus with cross-account access policies and an encrypted Amazon CloudWatch Log Group using a customer-managed [AWS Key Management Service](https://quip-amazon.com/arSyA5ZUp7y5/Dev-Platform-Mantler-Project-Candidates) (AWS KMS) key. A key feature is the included stack set resource that automatically deploys the target account configuration to all member accounts, eliminating manual setup and ensuring consistent configuration across the entire organization.
|
||||
|
||||
### 2\. Stack set Deployment Template (common-resources-stackset.yaml)
|
||||
|
||||
This template creates a service-managed stack set that deploys common resources to all accounts in specified organizational units. The StackSet is configured with auto-deployment enabled to automatically provision new accounts added to the organization and includes operation preferences for parallel regional deployment with fault tolerance settings.
|
||||
|
||||
## Step-by-Step Deployment Guide
|
||||
|
||||
### Step 1: Download the templates:
|
||||
|
||||
- [log-setup-management.yaml](https://github.com/aws-cloudformation/aws-cloudformation-templates/blob/main/CloudFormation/StackSets/templates/log-setup-management.yaml)
|
||||
- [common-resources-stackset.yaml](https://github.com/aws-cloudformation/aws-cloudformation-templates/blob/main/CloudFormation/StackSets/templates/common-resources-stackset.yaml)
|
||||
|
||||
### Step 2: Deploy the Management Account Infrastructure
|
||||
|
||||
Deploy the centralized logging infrastructure to your management account.
|
||||
|
||||
Using [CLI](https://docs.aws.amazon.com/cli/latest/reference/cloudformation/create-stack.html):
|
||||
|
||||
`aws cloudformation deploy \`
|
||||
` --template-file log-setup-management.yaml \`
|
||||
` --stack-name log-setup-management \`
|
||||
` --parameter-overrides \`
|
||||
` OUID=your-organizational-unit-id \`
|
||||
` OrgID=your-organization-id \`
|
||||
` --capabilities CAPABILITY_IAM \`
|
||||
` --region us-east-1`
|
||||
|
||||
**AWS CLI command execution for stack deployment**
|
||||
|
||||
Using [AWS Console](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-console-create-stack.html):
|
||||
|
||||
1. Open the AWS CloudFormation console at [https://console.aws.amazon.com/cloudformation](https://console.aws.amazon.com/cloudformation).
|
||||
2. On the Stacks page, choose **Create** stack at top right, and then choose **With new resources (standard)**.
|
||||
3. On the Create stack page, **Upload a template file,** choose **Choose File** to choose a template file from your local computer.
|
||||
4. Choose **Next** to continue and to validate the template.
|
||||
5. On the Specify stack details page, type a stack name in the Stack name box.
|
||||
6. In the Parameters section, specify values for the parameters that were defined in the template.
|
||||
7. Choose **Next** to continue creating the stack.
|
||||
8. **Acknowledge capabilities and transforms**.
|
||||
9. Choose **Next** to continue.
|
||||
10. Choose **Submit** to launch your stack.
|
||||
|
||||
This single deployment:
|
||||
|
||||
1. Creates the central logging infrastructure in the management account.
|
||||
2. Automatically deploys Amazon EventBridge rules to all accounts in the specified OU.
|
||||
3. Sets up the necessary IAM roles and policies for cross-account access.
|
||||
|
||||

|
||||
|
||||
**Figure 2.1: Screenshot showing successful deployment of log-setup-management.yaml template in the management account**
|
||||
|
||||

|
||||
|
||||
**Figure 2.2: Deployment timeline view of log-setup-management.yaml template in the management account**
|
||||
|
||||
### Step 3: Deploy Common Resources
|
||||
|
||||
Deploy the sample common resources to demonstrate the logging functionality.
|
||||
|
||||
Using [CLI](https://docs.aws.amazon.com/cli/latest/reference/cloudformation/create-stack.html):
|
||||
|
||||
`aws cloudformation deploy \`
|
||||
` --template-file common-resources-stackset.yaml \`
|
||||
` --stack-name common-resources-stackset \`
|
||||
` --parameter-overrides \`
|
||||
` OUID=your-organizational-unit-id \`
|
||||
` --capabilities CAPABILITY_IAM \`
|
||||
` --region us-east-1`
|
||||
|
||||
**AWS CLI command execution for stack deployment**
|
||||
|
||||
Using [AWS Console](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-console-create-stack.html):
|
||||
|
||||
1. Open the AWS CloudFormation console at [https://console.aws.amazon.com/cloudformation](https://console.aws.amazon.com/cloudformation).
|
||||
2. On the Stacks page, choose **Create** stack at top right, and then choose **With new resources (standard)**.
|
||||
3. On the Create stack page, **Upload a template file**, choose **Choose File** to choose a template file from your local computer.
|
||||
4. Choose **Next** to continue and to validate the template.
|
||||
5. On the Specify stack details page, type a stack name in the Stack name box.
|
||||
6. In the Parameters section, specify values for the parameters that were defined in the template.
|
||||
7. Choose **Next** to continue creating the stack.
|
||||
8. **Acknowledge capabilities and transforms.**
|
||||
9. Choose **Next** to continue.
|
||||
10. Choose **Submit** to launch your stack.
|
||||
|
||||
This creates a stack set that deploys Amazon Simple Storage Service (Amazon S3) infrastructure to all target accounts, generating AWS CloudFormation events that will be captured by your centralized logging system.
|
||||
|
||||

|
||||
|
||||
**Figure 3: Screenshot showing successful deployment of common-resources-stackset.yaml template for target accounts**
|
||||
|
||||
### Step 4: Validation and Testing
|
||||
|
||||
Confirm event flow and monitoring functionality by viewing the log streams in the ‘central-cloudformation-logs’ log group.
|
||||
|
||||
### Monitoring and Visualization
|
||||
|
||||
The centralized logging solution provides advanced monitoring capabilities through Amazon CloudWatch Logs Insights and custom dashboards.
|
||||
|
||||
You can customize your queries to get:
|
||||
|
||||
- Recent AWS CloudFormation events across all accounts.
|
||||
- Failed stack operations for quick troubleshooting.
|
||||
- Successful deployments for verification.
|
||||
- Event distribution by account and region.
|
||||
- Status breakdown of all AWS CloudFormation operations.
|
||||
|
||||
The following query helps you analyze CloudFormation events across your organization by showing:
|
||||
|
||||
- Timestamp of events
|
||||
- Account ID where the event occurred
|
||||
- Region of deployment
|
||||
- Resource types being deployed
|
||||
- Deployment status
|
||||
- Logical resource identifiers
|
||||
|
||||
`fields @timestamp, account, region`
|
||||
`| parse @message /"resource-type":"(?<resource_type>[^"]+)"/ `
|
||||
`| parse @message /"status":"(?<status>[^"]+)"/ `
|
||||
`| parse @message /"logical-resource-id":"(?<logical_resource_id>[^"]+)"/ `
|
||||
`| sort @timestamp desc`
|
||||
|
||||

|
||||
|
||||
**Figure 4: CloudWatch Logs Insights query results showing CloudFormation events across accounts**
|
||||
|
||||
You can customize your queries to filter for specific conditions such as failed deployment status, particular resource types, or specific accounts to quickly identify and troubleshoot issues across your organization’s AWS CloudFormation deployments.
|
||||
|
||||
### Cost Implications
|
||||
|
||||
When implementing this centralized monitoring solution, you should consider the following cost components:
|
||||
|
||||
- [**Amazon EventBridge pricing**](https://aws.amazon.com/eventbridge/pricing/) – Costs associated with events being published across accounts to the central event bus
|
||||
- [**Amazon CloudWatch pricing**](https://aws.amazon.com/cloudwatch/pricing/) – Storage costs for the centralized log group storing CloudFormation events from all accounts. Query costs when analyzing the centralized logs
|
||||
- [**AWS Key Management Service pricing**](https://aws.amazon.com/kms/pricing/) – Costs related to the customer-managed key used for log encryption
|
||||
|
||||
## Clean up
|
||||
|
||||
To clean up the resources created in this solution, follow these steps:
|
||||
|
||||
1. First, delete the common resources stack set (common-resources-stackset) from the AWS CloudFormation console in your management account. This will remove all the resources deployed across your member accounts.
|
||||
2. After the stack set operations are complete, delete the management account logging setup stack (log-setup-management) to remove the centralized logging infrastructure, including the event bus, log groups, and associated IAM roles.
|
||||
|
||||
**Note**: Make sure all stack set operations are complete before deleting the management account logging setup to ensure proper cleanup of all resources.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Managing infrastructure across multiple AWS accounts doesn’t have to be complex. By centralizing AWS CloudFormation logs, you can gain visibility into your multi-account deployments, troubleshoot issues more efficiently, and help achieve consistent resource deployment across your organization.
|
||||
|
||||
This solution demonstrates how AWS services like AWS CloudFormation StackSets, Amazon EventBridge, and Amazon CloudWatch Logs can be combined to create a powerful monitoring system for your infrastructure as code deployments.
|
||||
|
||||
Get started today by implementing this solution in your AWS Organization to gain immediate visibility into your multi-account deployments. Download the templates from our [GitHub repository](https://github.com/aws-cloudformation/aws-cloudformation-templates/tree/main/CloudFormation/StackSets/templates) and follow the step-by-step guide to enhance your cloud operations.
|
||||
@@ -0,0 +1,220 @@
|
||||
---
|
||||
title: Public vs Private vs Hybrid: Cloud Differences Explained
|
||||
source: https://www.bmc.com/blogs/public-private-hybrid-cloud/
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-06-18
|
||||
description: Discover the key differences and unique benefits of public, private, and hybrid cloud computing and determine which best suits your business needs.
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||

|
||||
|
||||
The term cloud computing spans a range of classifications, types, and architecture models. This networked computing model has transformed how we work—you’re likely already using the cloud. Several types of cloud computing models are in general use. Here, we will look at the public cloud vs private cloud vs hybrid cloud, and define what each one is along with the pros and cons it brings.
|
||||
|
||||
## What is cloud computing?
|
||||
|
||||
Cloud computing is computing remotely over the Internet or in the “cloud.” Your apps, data, and interactions are done remotely on third-party computers, called servers, that you access over the Internet rather than on your computer hard drives or on-site server.
|
||||
|
||||
The rapid switch from local to cloud computing is driven by benefits such as the ability to scale without having to buy and configure hardware, accessibility from anywhere with an internet connection, professionally managed servers that are kept up-to-date with the latest tech and versions of apps, cost efficiency, and quick recovery from cyber attacks.
|
||||
|
||||
Cloud computing has given rise to “as-a-service” offerings such as [Software as a Service (SaaS), Platform as a Service (PaaS, Infrastructure as a Service (IaaS)](https://www.bmc.com/blogs/saas-vs-paas-vs-iaas-whats-the-difference-and-how-to-choose/), [ITaaS: IT as a Service (ItaaS)](https://www.bmc.com/blogs/itaas-it-as-a-service/), [AI as a Service (AIaaS)](https://www.bmc.com/blogs/ai-as-a-service-aiaas/), even DaaS: Desktop as a service. Cyber criminals use the cloud for their exploits with [RaaS: Ransomware as a service](https://www.bmc.com/blogs/ransomware-as-a-service/), a type of “crime as a service.”
|
||||
|
||||
You can use three types of cloud computing models:
|
||||
|
||||
- **Public cloud:** Delivered via the internet and shared across organizations.
|
||||
- **Private cloud:** Dedicated solely to your organization.
|
||||
- **Hybrid cloud:** An environment that uses both public and private clouds.
|
||||
|
||||
Before considering the private cloud vs public clouds, let’s look at the infrastructure. Any cloud service consists of client-side systems or devices (PC, tablets, etc.) that are connected to the backend data center components. The components that constitute [cloud infrastructure](https://www.bmc.com/blogs/cloud-infrastructure/) include:
|
||||
|
||||
The underlying infrastructure architecture can take various forms and features, including:
|
||||
|
||||
- [Virtualized](https://www.bmc.com/blogs/it-virtualization/)
|
||||
- [Software-defined](https://www.bmc.com/blogs/software-defined-networking/)
|
||||
- [Hyper-converged](https://www.bmc.com/blogs/hyper-converged-infrastructure/)
|
||||
|
||||
Individuals and companies alike both value [the benefits of cloud computing](https://www.bmc.com/blogs/advantages-benefits-cloud-computing/), including:
|
||||
|
||||
- Reducing complexity
|
||||
- [Optimizing DevOps](https://www.bmc.com/blogs/devops-basics-introduction/)
|
||||
- [Trading CapEx for OpEx](https://www.bmc.com/blogs/capex-vs-opex/)
|
||||
- Planning for the future
|
||||
|
||||
### Public vs private vs hybrid cloud: At a glance
|
||||
|
||||

|
||||
|
||||
### What is the public cloud?
|
||||
|
||||
The [public cloud is the shared cloud](https://businessdegrees.uab.edu/blog/private-public-and-hybrid-clouds-whats-the-difference/). In this model, third-party providers deliver storage, computing power, and applications to multiple users. Anyone can purchase access and services, typically on a pay-for-use basis.
|
||||
|
||||
The defining features of a public cloud solution include:
|
||||
|
||||
- High elasticity and scalability
|
||||
- A low-cost subscription-based pricing tier
|
||||
- Fast operationalization
|
||||
- Most current technologies
|
||||
- Reliability
|
||||
|
||||
Services on the public cloud may be free, freemium, or subscription-based, wherein you’re charged based on the computing resources you consume.
|
||||
|
||||
The computing functionality may range from common services—email, apps, and storage—to the enterprise-grade OS platform or infrastructure environments used for [software development and testing](https://www.bmc.com/blogs/sdlc-software-development-lifecycle/).
|
||||
|
||||
The cloud vendor is responsible for developing, managing, and maintaining the pool of computing resources shared between multiple tenants from across the network.
|
||||
|
||||
#### Advantages of public cloud
|
||||
|
||||
The public cloud offers many advantages to your organization:
|
||||
|
||||
- **No upfront capital investment.** No investments are required to deploy and maintain the IT infrastructure.
|
||||
- **Accessibility.** You can access apps and data from anywhere with an internet connection.
|
||||
- **Technical agility.** High scalability and flexibility to meet unpredictable workload demands.
|
||||
- **Professionally managed and current.** You will work on the latest, properly configured hardware and always up-to-date apps.
|
||||
- **Business focus.** The reduced complexity and requirements of in-house IT expertise are minimized, as the cloud vendor is responsible for infrastructure management.
|
||||
- **Remote collaboration.** Remote workers can easily collaborate without having to be in the same physical location.
|
||||
- **Affordability.** Flexible pricing options based on different SLA offerings.
|
||||
- **Cost efficiency.** The cost agility allows organizations to follow lean growth strategies and focus their investments on innovation projects.
|
||||
- **Fast recovery.** Your data and apps are backed up regularly and stored in multiple locations, minimizing the risk of data loss and ensuring business continuity.
|
||||
|
||||
#### Drawbacks of public cloud
|
||||
|
||||
Despite its many advantages, the public cloud does come with limitations:
|
||||
|
||||
- **Lack of cost control.** The total cost of ownership (TCO) can rise exponentially for large-scale usage, specifically for midsize to large enterprises.
|
||||
- **Lack of security.** The public cloud is the least secure, so it isn’t best for sensitive mission-critical IT workloads.
|
||||
- **Minimal technical control.** Low visibility and control of the infrastructure may not meet your compliance needs.
|
||||
- **Escalating costs.** At a certain point, adding services, using more storage, and adding seats is no longer cost-effective.
|
||||
- **Vendor dependency.** Should you want to change providers, migrating services and data is complex and costly.
|
||||
|
||||
#### When to use the public cloud
|
||||
|
||||
The public cloud is most suitable for these types of environments:
|
||||
|
||||
- Predictable computing needs, such as communication services for a specific number of users.
|
||||
- Apps and services necessary to perform IT and business operations.
|
||||
- Additional resource requirements to address [varying peak demands](https://www.bmc.com/blogs/service-availability-calculation-metrics/).
|
||||
- Software development and test environments.
|
||||
|
||||
[Learn more about securing your public cloud](https://www.bmc.com/blogs/how-to-secure-public-cloud/).
|
||||
|
||||
### What is the private cloud?
|
||||
|
||||
The private cloud is dedicated to your organization, which you access over a secure private network. You get benefits similar to those of the public cloud but don’t share them with other organizations or users. It may be managed on your premises or off-site by a third-party vendor. The model offers you greater performance, control, and security.
|
||||
|
||||
The defining features of a private cloud solution include many of the features of the public cloud, but also:
|
||||
|
||||
- Higher security
|
||||
- Scalability
|
||||
- Customization and control
|
||||
- Greater visibility into every aspect of your cloud
|
||||
- Compliance with cybersecurity frameworks you choose
|
||||
|
||||
#### Advantages of private cloud
|
||||
|
||||
Organizations move to their own private clouds to capture these benefits:
|
||||
|
||||
- **Exclusive environments.** Dedicated and secure environments that cannot be accessed by other organizations.
|
||||
- **Custom security.** Compliance to stringent regulations as organizations can run protocols, configurations, and measures to customize security based on unique workload requirements.
|
||||
- **Scalability without tradeoffs.** High scalability and efficiency to meet unpredictable demands without compromising on security and performance.
|
||||
- **Efficient performance.** The private cloud is reliable for high SLA performance and efficiency.
|
||||
- **Flexibility.** The private cloud is flexible as you transform the infrastructure based on the ever-changing business and IT needs of the organization.
|
||||
- **Dedicated resources.** Because you aren’t sharing, latency and competition for resources are not issues.
|
||||
|
||||
#### Drawbacks of private cloud
|
||||
|
||||
The private cloud has drawbacks. It may not be an ideal fit for your organization because of these issues:
|
||||
|
||||
- **Higher costs.** The private cloud is an expensive solution with a relatively high TCO compared to public cloud alternatives, especially for short-term use cases.
|
||||
- **Difficult remote use.** Considering the high-security measures in place, offsite users may have limited access to the private cloud.
|
||||
- **Scalability depends.** The infrastructure may not offer high scalability to meet unpredictable demands if the cloud data center is limited to on-premise computing resources.
|
||||
- **Complex management.** You’ll need considerable in-house tech expertise to run your private cloud.
|
||||
- **Potential inefficiencies.** You may not fully use your resources, wasting costly infrastructure.
|
||||
|
||||
#### When to use the private cloud
|
||||
|
||||
The private cloud is best suited for:
|
||||
|
||||
- Highly regulated industries and government agencies.
|
||||
- Sensitive data.
|
||||
- Companies that require strong control and security over their IT workloads and the underlying infrastructure.
|
||||
- Large enterprises that require advanced data center technologies to operate efficiently and cost-effectively.
|
||||
- Organizations that can afford to invest in high-performance and availability technologies.
|
||||
|
||||
### What is hybrid cloud?
|
||||
|
||||
The hybrid cloud is a computing environment that uses both the public and private cloud models, sharing data and apps between the two to take advantage of the benefits that each provides. The uses of each are driven by business and technical needs around:
|
||||
|
||||
- Security
|
||||
- Performance
|
||||
- Scalability
|
||||
- Cost
|
||||
- Efficiency
|
||||
|
||||
This is a common example of hybrid cloud: Organizations can use private cloud environments for their IT workloads and complement the infrastructure with public cloud resources to accommodate occasional spikes in network traffic.
|
||||
|
||||
Or, perhaps you use the public cloud for workloads and data that aren’t sensitive, saving cost, but opt for the private cloud for sensitive data.
|
||||
|
||||
As a result, access to additional computing capacity does not require the high CapEx of a private cloud environment but is delivered as a short-term IT service via a public cloud solution. The environment itself is seamlessly integrated to ensure optimum performance and scalability to changing business needs.
|
||||
|
||||
When you do pursue a hybrid cloud, you may have another decision to make: whether to be [homogeneous or heterogeneous](https://www.bmc.com/blogs/homogeneous-vs-heterogeneous-clouds/) with your cloud. That is—are you using cloud services from a single vendor or from several vendors?
|
||||
|
||||
#### Advantages of hybrid cloud
|
||||
|
||||
When choosing between the public cloud vs private cloud, a hybrid approach brings significant advantages.
|
||||
|
||||
- **Policy-driven option.** Flexible policy-driven deployment to distribute workloads across public and private infrastructure environments based on security, performance, and cost requirements.
|
||||
- **Scale with security.** Scalability of public cloud environments is achieved without exposing sensitive IT workloads to the inherent security risks.
|
||||
- **Reliability.** Distributing services across multiple data centers, some public, some private, results in maximum reliability.
|
||||
- **Cost control and efficiency.** Improved security posture as sensitive IT workloads run on dedicated resources in private clouds while regular workloads are spread across inexpensive public cloud infrastructure to tradeoff for cost investments.
|
||||
- **Interoperability and mobility.** Work moves smoothly between the two; you can access and use data and apps on-premises and in public and private clouds.
|
||||
- **Optimized workloads.** You can do sensitive work on the private cloud and everything else on the public cloud.
|
||||
- **Business continuity.** Should your system experience a disaster, the distributed nature of private and public clouds makes it easier and faster to restore operability.
|
||||
|
||||
[Learn more about hybrid cloud security and best practices](https://www.bmc.com/blogs/hybrid-cloud-security/).
|
||||
|
||||
#### Drawbacks of hybrid cloud
|
||||
|
||||
While the promise of the best of both worlds in going hybrid vs public cloud vs private cloud sounds good, you may encounter some drawbacks:
|
||||
|
||||
- **Complicated cost management.** Toggling between public and private can be hard to track, resulting in wasteful spending.
|
||||
- **Integration issues.** Strong compatibility and integration is required between cloud infrastructure spanning different locations and categories. This is a limitation with public cloud deployments, for which organizations lack direct control over the infrastructure.
|
||||
- **Added complexity.** Additional infrastructure complexity is introduced as organizations operate and manage an evolving mix of private and public cloud architecture.
|
||||
- **Security risks.** Transferring data between clouds introduces vulnerabilities.
|
||||
|
||||
#### When to use the hybrid cloud
|
||||
|
||||
Here’s who the hybrid cloud might suit best:
|
||||
|
||||
- Organizations serving multiple verticals facing different IT security, regulatory, and performance requirements.
|
||||
- Optimizing cloud investments without compromising on the value that public or private cloud technologies can deliver.
|
||||
- Improving security on existing cloud solutions, such as SaaS offerings that must be delivered via secure private networks.
|
||||
- Strategically approaching cloud investments to continuously switch and trade-off between the best cloud service delivery model available in the market.
|
||||
|
||||
### Deciding between public, private and hybrid cloud computing
|
||||
|
||||
The choice between public vs private vs hybrid cloud solutions depends on your use cases, budget, IT capabilities, and expectations for growth. It is rarely an either/or situation, as you may find ways to capture the benefits of each while avoiding the drawbacks.
|
||||
|
||||
Balance is the driver in architecting your approach to cloud computing. And balancing is an ongoing need. What works for your organization today may not work in the future.
|
||||
|
||||
The key element in balancing your choices is to develop an [intentional cloud strategy](https://www.bmc.com/blogs/multi-cloud-strategy/) that optimizes your use of each cloud environment. Start with defining the needs of your various workloads, then prioritize them based on the pros and cons of each model.
|
||||
|
||||
## Cloud responsibility: A shared model
|
||||
|
||||
As a final note, It is important to know that no matter which cloud environment you work in, your problems don’t go away. Though you’re purchasing services from third-party vendors, you still have to do your due diligence to reduce risk.
|
||||
|
||||
This is known as shared model of cloud responsibility. Though vendors operate the IT infrastructure and control things like flexibility and agility, your organization maintains responsibility for:
|
||||
|
||||
- Who has access to what
|
||||
- Cloud security and encryption
|
||||
- [Disaster recovery planning](https://www.bmc.com/blogs/cloud-disaster-recovery/)
|
||||
|
||||

|
||||
|
||||
See an error or have a suggestion? Please let us know by emailing [blogs@bmc.com](https://www.bmc.com/blogs/public-private-hybrid-cloud/).
|
||||
|
||||
### About Us
|
||||
|
||||
As BMC and BMC Helix, we are committed to a shared purpose for customers in every industry and around the globe. BMC empowers 86% of the Forbes Global 50 to accelerate business value faster than humanly possible by automating critical applications, systems, and services to take advantage of cloud, data, and emerging AI technologies. BMC Helix, now operating as an independent company, helps the world’s most forward-thinking IT organizations turn AI into action—unlocking human potential to multiply productivity so teams can focus on the work that matters most.
|
||||
[Learn more about BMC and BMC Helix ›](https://www.bmc.com/corporate/about-bmc-software.html)
|
||||
@@ -0,0 +1,247 @@
|
||||
---
|
||||
title: RTO vs RPO: Key Differences for Modern Disaster Recovery
|
||||
source: https://launchdarkly.com/blog/rto-vs-rpo/
|
||||
author: shenwei
|
||||
published: 2019-01-18
|
||||
created: 2025-07-26
|
||||
description: Understand RTO vs. RPO: their critical differences, their impact on modern software delivery, and how to effectively achieve your disaster recovery goals.
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
|
||||
Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are fundamental metrics in disaster recovery. However, many software teams struggle to translate these concepts into actionable goals for modern software delivery.
|
||||
|
||||
**Your app just went down. How fast can you get it back up?**
|
||||
|
||||
That's what RTO measures: the maximum downtime you can tolerate before your business suffers a significant impact. RPO is its counterpart: how much data loss you can accept when things go sideways.
|
||||
|
||||
Most teams treat RTO and RPO as abstract concepts related to disaster recovery. But if you're shipping code multiple times a day, these metrics matter for every release (not just when the data center catches fire).
|
||||
|
||||
The old approach was reactive: build your app, then bolt on [disaster recovery](https://launchdarkly.com/blog/designing-for-failure-to-avoid-disaster/) as an afterthought. Today's reality is different. When you're [deploying features continuously](https://launchdarkly.com/the-definitive-guide-to-feature-management/build/), your biggest risks aren't hardware failures—they're the bugs you ship to production.
|
||||
|
||||
Below, we’ll cover what RTO and RPO actually mean for modern development teams, and how tools like [feature flags](https://launchdarkly.com/blog/what-are-feature-flags/) can help you hit aggressive recovery targets without over-engineering your infrastructure.
|
||||
|
||||
## What RTO and RPO actually mean
|
||||
|
||||
**RTO (Recovery Time Objective)**: How long your system can stay down before you're in serious trouble. Think "we need to be back online in 15 minutes or customers start calling support."
|
||||
|
||||
**RPO (Recovery Point Objective)**: How much recent data you can afford to lose. If your last backup was an hour ago, can you live with losing an hour's worth of transactions?
|
||||
|
||||
These are no longer just disaster recovery buzzwords. When you're pushing code daily, *every* deployment is a potential RTO/RPO scenario.
|
||||
|
||||
Traditional disaster recovery planning focused on big, rare events, such as data centers flooding, hardware failure, power outages, and the like. But most outages today come from code changes:
|
||||
|
||||
- A bug in your payment flow that breaks checkout
|
||||
- A database migration that locks up your app
|
||||
- An AI model update that starts giving weird responses
|
||||
- A new feature that tanks performance under load
|
||||
|
||||
Sure, your disaster recovery plan probably covers the server rack catching fire. But does it cover rolling back a feature flag when your conversion rate drops 30%?
|
||||
|
||||
The primary goal of a disaster recovery plan is to resume business operations quickly after a disruption, with minimal data loss. This encompasses all business functions that IT systems support to ensure that key operations can continue (or can be quickly restored) for the organization's survival.
|
||||
|
||||
Your RTO and RPO depend on what you're building. It’s critical to align your recovery targets with actual business impact, rather than selecting aggressive numbers simply because they sound impressive.
|
||||
|
||||
## RTO vs. RPO: What's the difference?
|
||||
|
||||
RTO and RPO aren't the same thing, but teams often confuse them. You need both to build a solid recovery strategy. **RTO is about speed:** how fast you get back online. **RPO is about data:** how much you can afford to lose.
|
||||
|
||||
You can recover quickly but still lose a lot of data, or vice versa.
|
||||
|
||||
| **Scenario** | **RTO Target** | **RPO Target** | **Why They Differ** |
|
||||
| --- | --- | --- | --- |
|
||||
| **E-commerce checkout** | 2 minutes | 0 seconds | Need to get back online fast, can't lose any transactions |
|
||||
| **User analytics dashboard** | 30 minutes | 1 hour | Downtime hurts but isn't critical, some data loss is acceptable |
|
||||
| **Internal CRM** | 4 hours | 15 minutes | Can work around downtime, but recent customer updates matter |
|
||||
| **Blog/marketing site** | 2 hours | 24 hours | Visitors can wait, losing a day of comments/signups isn’t terrible |
|
||||
| **Real-time chat** | 30 seconds | 5 minutes | Users expect instant messaging, but can live with losing recent messages |
|
||||
|
||||
**RTO is about getting back online.** It's the clock that starts ticking the moment your system goes down. Whether that's due to a failed deployment, a server crash, or a bug you've just shipped. RTO measures how long it takes for users to be able to use your app again.
|
||||
|
||||
**RPO is about protecting data.** It's measured backwards from the moment of failure. If your database crashes at 3 PM and your last backup was at 2 PM, you've got a 1-hour RPO. Everything that happened between 2:00 and 3:00 PM is gone.
|
||||
|
||||
Ultimately, you can't just optimize for one. Having [backups](https://launchdarkly.com/docs/sdk/concepts/data-stores) every 30 seconds (a great RPO) doesn't help if it takes you 6 hours to restore from those backups (a terrible RTO). Similarly, being able to spin up a new server in 5 minutes (great RTO) is useless if you lost the last 4 hours of customer data (terrible RPO).
|
||||
|
||||
**The best approach is to build both into your deployment process. Feature flags enable you to resolve issues in seconds (a great RTO) while preserving user state and data integrity (a great RPO).**
|
||||
|
||||
## How to align RTO and RPO with application criticality
|
||||
|
||||
Your internal employee directory doesn't need the same recovery targets as your payment processing system. However, figuring out what each app actually needs requires having an honest conversation about business impact.
|
||||
|
||||
### How to prioritize your apps
|
||||
|
||||
Skip the formal "Business Impact Analysis" and just ask these questions:
|
||||
|
||||
**What happens if this goes down for an hour?**
|
||||
|
||||
- Lost revenue? How much?
|
||||
- Angry customers? How many?
|
||||
- Blocked employees? Can they work around it?
|
||||
- Regulatory issues? Legal problems?
|
||||
|
||||
**What happens if we lose the last hour of data?**
|
||||
|
||||
- Can we recreate it?
|
||||
- Does it contain money/transactions?
|
||||
- Will users notice?
|
||||
- Is it required for compliance?
|
||||
|
||||
### An example tiering system
|
||||
|
||||
| **Tier** | **Examples** | **RTO Target** | **RPO Target** | **Reality Check** |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| **(1) Critical** | Payment processing, user auth, core product features | < 5 minutes | < 1 minute | Your business stops without these |
|
||||
| **(2) Important** | Admin dashboards, reporting, customer support tools | < 1 hour | < 15 minutes | Work slows down, but doesn't stop |
|
||||
| **(3) Nice-to-have** | Internal tools, dev environments, documentation sites | < 4 hours | < 1 hour | Annoying but not business-critical |
|
||||
|
||||
- **Tier 1 apps (where to start):** These get feature flags, automated rollbacks, and monitoring that wakes people up at 3 AM. Invest in making these bulletproof.
|
||||
- **Tier 2 gets basic protection:** Feature flags for major releases, monitoring during business hours, and documented rollback procedures.
|
||||
- **Tier 3 gets best effort:** Basic monitoring, manual recovery procedures, backups that actually work.
|
||||
|
||||
Most teams try to give everything Tier 1 treatment, which can lead to burnout. Be ruthless about what actually matters to your business. You can’t do *everything*.
|
||||
|
||||
## Stop fighting fires, start preventing them
|
||||
|
||||
[Proactive risk mitigation](https://launchdarkly.com/blog/risk-mitigation-strategies-software-releases/) in software delivery involves using strategies, practices, and tools to prevent issues or minimize their impact *before* they escalate. Most teams spend their time reacting to outages instead of preventing them. But the best way to reach aggressive RTO and RPO targets isn't building a better disaster recovery plan— *it's shipping code that doesn't break in the first place.*
|
||||
|
||||
### Deploy!= Release (and why that matters)
|
||||
|
||||
Traditional deployments are all-or-nothing: you push code and everyone gets it immediately. This is why deployments are scary and why teams deploy at 2 AM "just in case."
|
||||
|
||||
Feature flags change this. You can deploy code to production without releasing it to users:
|
||||
|
||||
```javascript
|
||||
if (featureFlag.enabled('new-checkout-flow')) {
|
||||
return newCheckoutProcess();
|
||||
} else {
|
||||
return oldCheckoutProcess();
|
||||
}
|
||||
```
|
||||
|
||||
Now, deployment and release are separate events. Deploy whenever you want, release when you're ready.
|
||||
|
||||
### Progressive rollouts: limit the area of impact
|
||||
|
||||
Instead of flipping the switch for everyone simultaneously, roll out gradually:
|
||||
|
||||
- **1% of users** → watch error rates, performance metrics
|
||||
- **5% of users** → monitor conversion rates, user feedback
|
||||
- **25% of users** → check load on downstream systems
|
||||
- **100% of users** → full rollout
|
||||
|
||||
If something breaks at the 5% mark, you've contained the damage. Your RTO is measured in seconds (flip the flag off) instead of hours (emergency rollback deployment).
|
||||
|
||||
### Kill switches: your RTO insurance policy
|
||||
|
||||
Feature flags aren't just for new releases; they're instant [kill switches](https://launchdarkly.com/blog/what-is-a-kill-switch-software-development/) for anything going wrong:
|
||||
|
||||
- Payment processor acting up? Route to backup provider
|
||||
- Search results looking weird? Fall back to the old algorithm
|
||||
- New AI model hallucinating? Switch back to the previous version
|
||||
|
||||
Instead of debugging under pressure while users suffer, you flip a switch and fix the problem properly later. Everybody wins.
|
||||
|
||||
### The result: prevention beats cure
|
||||
|
||||
This approach shifts your focus from "how fast can we recover?" to "how do we avoid breaking things?" You still need traditional disaster recovery, but most of your incidents become non-events because you caught and contained them early.
|
||||
|
||||
Your RPO stays low because you're not losing data during rollbacks (you're just changing which code path executes). Your RTO drops to seconds because fixing issues becomes a configuration change, not a code deployment.
|
||||
|
||||
## How to choose the right disaster recovery tools
|
||||
|
||||
Most disaster recovery (DR) solutions focus on traditional scenarios: server crashes, data corruption, and hardware failures. But if you're shipping code frequently, you need tools that handle software-induced incidents, too. Look for:
|
||||
|
||||
- **Speed matters more than features.** Can you recover in minutes, not hours? Can you test recovery procedures without taking systems offline? Can you automate the common failure scenarios?
|
||||
- **Integration with your deployment pipeline.** Your DR solution should work with how you actually ship code. If you're using feature flags, canary deployments, or progressive rollouts, make sure that your recovery tools comprehend and support these patterns.
|
||||
- **Cost vs. benefit reality check.** Enterprise DR solutions (with licensing, training, and maintenance fees) can cost more than the downtime they prevent. Be honest about what you actually need vs. what vendors want to sell you.
|
||||
|
||||
Companies like Veeam and Acronis handle the traditional stuff well: database backups, server imaging, and cross-region replication. Cloud providers (AWS, Azure, GCP) offer solid infrastructure-level recovery.
|
||||
|
||||
However, for code-related incidents, feature management platforms like LaunchDarkly can be more effective:
|
||||
|
||||
- **HP** reduced rollback times [from hours to minutes with feature flags](https://launchdarkly.com/case-studies/hp/)
|
||||
- **Christian Dior** went from [15-minute rollbacks to instant toggles](https://launchdarkly.com/case-studies/dior/)
|
||||
- **86% of surveyed LaunchDarkly customers** [recover from incidents within a day](https://launchdarkly.com/blog/2024-survey-impact-launchdarkly-customer-outcomes/#:~:text=%E2%80%9CWhen%20a%20software%20incident%20occurs,an%20hour%2C%20if%20not%20minutes.)
|
||||
- 42% of surveyed LaunchDarkly customers [recover in hours (if not minutes)](https://launchdarkly.com/blog/2024-survey-impact-launchdarkly-customer-outcomes/#:~:text=%E2%80%9CWhen%20a%20software%20incident%20occurs,an%20hour%2C%20if%20not%20minutes.)
|
||||
|
||||
Don't trust demos or datasheets. Run a proof of concept with your actual systems and realistic failure scenarios. Simulate a bad deployment during peak traffic. Test your recovery procedures when you're stressed and the CEO is asking for updates every 5 minutes. The best disaster recovery solution is the one you'll actually use when things go wrong.
|
||||
|
||||
Here are some additional criteria to consider:
|
||||
|
||||
- **Supported Environments:** Does the solution cover all necessary environments? This includes physical servers, virtual machines (VMs), cloud services (IaaS, PaaS, SaaS), endpoints, and critical applications.
|
||||
- **RPO Capabilities:** What backup frequencies and replication options does it offer (e.g., continuous data protection (CDP), snapshots, synchronous/asynchronous replication) to meet your RPOs?
|
||||
- **RTO Capabilities:** What recovery methods and automation features are available (e.g., instant recovery, bare-metal restore, VM/granular restore, automated failover/failback) to achieve your RTOs?
|
||||
- **Consistency:** Does the solution guarantee application-consistent and crash-consistent backups? For distributed systems, can it handle feature state consistency?
|
||||
- **Testing and Verification:** Does it facilitate easy, non-disruptive DR testing? Regular testing is key for validating that RTO and RPO targets are achievable.
|
||||
- **Scalability and Performance:** Can the solution scale to handle current and future data volumes while meeting required recovery speeds?
|
||||
- **Management and Reporting:** Does it offer centralized management and clear reports on backup status, RPOs, recovery readiness, and test results?
|
||||
|
||||
## RTO/RPO for continuous delivery
|
||||
|
||||
Traditional disaster recovery plans for server crashes and natural disasters, but when you're deploying multiple times per day, your biggest risks are the bugs you ship yourself.
|
||||
|
||||
**Software incidents happen more often.** A broken login flow, a payment bug, or a database migration gone wrong can take down your app just as effectively as a hardware failure. The difference is that these happen weekly, not yearly.
|
||||
|
||||
**Speed expectations have changed.** When you're shipping daily, users expect problems to be fixed quickly. A 4-hour RTO for a deployment bug feels like an eternity when your CI/CD pipeline normally moves in minutes.
|
||||
|
||||
**Feature flags change the game.** Instead of rolling back entire deployments, you can disable specific features instantly:
|
||||
|
||||
- Payment processing breaks? Route to backup provider in seconds
|
||||
- New search algorithm returning weird results? Switch back to the old one
|
||||
- Database migration causing slowdowns? Roll back just that change
|
||||
|
||||
**Protecting data integrity.** Quick feature toggles also prevent data corruption. If a bug is actively corrupting transactions, disabling it immediately protects your RPO better than waiting for a full rollback deployment.
|
||||
|
||||
## Feature-level recovery targets
|
||||
|
||||
Don't treat your entire app like one big system. Different features have different risks and business impacts, so they should have different recovery targets.
|
||||
|
||||
- **Micro-recoveries with feature flags.** Instead of rolling back your entire deployment when a single feature breaks, simply toggle off that feature. Your checkout flow has a bug? Disable the new version and fall back to the old one in seconds. Users might not even notice.
|
||||
- **Different features, different targets:**
|
||||
- **Core payment processing**: RTO of seconds, RPO of zero
|
||||
- **New recommendation engine**: RTO of 5 minutes, RPO of 15 minutes
|
||||
- **Beta dashboard features**: RTO of 30 minutes, RPO of an hour
|
||||
- **Targeted rollbacks.** If a feature only affects mobile users in Europe, you can disable it just for that segment while leaving everyone else unaffected. This gives you localized recovery without global disruption.
|
||||
|
||||
The goal is to match your recovery strategy to the actual business impact rather than applying blanket policies across features that have wildly different importance to your users and revenue.
|
||||
|
||||
## RTO/RPO across your tech stack
|
||||
|
||||
Your recovery strategy needs to work everywhere your code runs, but the approach varies by environment.
|
||||
|
||||
- **Cloud-first applications** get the most options. AWS, Azure, and GCP offer a range of options, from basic backups (cheaper but slower) to active-active setups (more expensive but instant). Most teams start with automated backups and add a hot standby for critical services.
|
||||
- **On-premises/physical servers** are harder to recover quickly. Replacing hardware takes time, so focus on preventing issues rather than rushing for a quick recovery. Legacy systems often get longer RTOs because the alternative is expensive.
|
||||
- **Mobile apps** have a unique challenge—you can't instantly deploy fixes like web apps. Feature flags solve this by letting you disable broken features without waiting for app store approval.
|
||||
- **Databases and stateful services** need special attention. You can't just restore from backup and lose transactions. Utilize read replicas, point-in-time recovery, and careful migration strategies.
|
||||
- **The practical reality:** Most incidents happen in your application code, not your infrastructure. A bug in your payment flow is more likely than a data center failure. Focus your RTO/RPO planning on software-induced problems first, then worry about hardware disasters.
|
||||
|
||||
Feature flags work across all these environments to give you consistent recovery capabilities, whether users are on mobile, web, or hitting your APIs directly.
|
||||
|
||||
## How to balance criticality, cost, and RTO/RPO
|
||||
|
||||
Aggressive RTO/RPO targets can become expensive quickly. Near-zero downtime requires redundant everything: servers, databases, networks, and entire data centers. Most teams simply can't justify the cost.
|
||||
|
||||
**Do the math honestly.** What does an hour of downtime actually cost your business? If it's $10K, don't spend $100K/year on infrastructure to prevent it. You're better off accepting some downtime and investing in faster recovery.
|
||||
|
||||
**Software-first approach wins.** Feature flags and progressive delivery often deliver better ROI than traditional disaster recovery infrastructure. Instead of spending millions on hot standby servers, spend thousands on tools that prevent incidents.
|
||||
|
||||
**Tier your investments:**
|
||||
|
||||
- **Critical systems**: Get the expensive stuff - redundancy, monitoring, instant rollback
|
||||
- **Important systems**: Get feature flags, automated alerts, and documented procedures
|
||||
- **Everything else**: Get basic backups and hope for the best
|
||||
|
||||
Think about these numbers from our *[2024 Survey: Impact of LaunchDarkly on Customer Outcomes](https://launchdarkly.com/blog/2024-survey-impact-launchdarkly-customer-outcomes/)*:
|
||||
|
||||
- 8% of customers say LaunchDarkly has reduced their operational costs by over 50%.
|
||||
- 59% say LaunchDarkly has reduced their operational costs between 11% and 50%.
|
||||
- 26% say LaunchDarkly has reduced their operational costs up to 10%.
|
||||
|
||||
Ultimately, prevention is almost always cheaper than elaborate recovery systems.
|
||||
|
||||
## Start preventing problems instead of just fixing them faster
|
||||
|
||||
RTO and RPO are daily realities when you're shipping code continuously. Every deployment is a potential incident, and traditional recovery methods aren't fast enough for modern development cycles.
|
||||
|
||||
LaunchDarkly provides the tools to achieve aggressive RTO/RPO targets without over-engineering your infrastructure. Deploy with confidence, recover instantly, and focus on building features instead of fixing outages. Instead of building elaborate disaster recovery systems, embed resilience directly into your development workflow. Explore the LaunchDarkly platform with a [free trial](https://app.launchdarkly.com/signup) to see how its control mechanisms can help your teams meet and exceed RTO/RPO targets.
|
||||
@@ -0,0 +1,57 @@
|
||||
---
|
||||
title: The Myths and Misconceptions About Cloud Computing | LinkedIn
|
||||
source: https://www.linkedin.com/pulse/myths-misconceptions-cloud-computing-raj-vardhan-singh-w86mc/?trackingId=rM%2B%2BhFXj9kp11hppPbPFkQ%3D%3D
|
||||
author: shenwei
|
||||
published: 2001-02-25
|
||||
created: 2025-03-02
|
||||
description:
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
Cloud computing has revolutionized the way businesses and individuals manage data, applications, and IT infrastructure. However, despite its widespread adoption, many myths and misconceptions persist, leading to confusion and hesitation among potential users. In this article, we debunk some of the most common cloud computing myths to provide a clearer understanding of its capabilities and limitations.
|
||||
|
||||
### Myth 1: Cloud Computing is Not Secure
|
||||
|
||||
### Reality: Cloud Security is Often More Robust Than On-Premises Solutions
|
||||
|
||||
One of the biggest misconceptions about cloud computing is that it is inherently insecure. In reality, leading cloud providers invest heavily in security measures, including encryption, firewalls, and multi-factor authentication. Many cloud platforms comply with stringent industry standards such as ISO 27001, HIPAA, and GDPR. Additionally, cloud providers offer automated security updates and 24/7 monitoring, reducing the risk of breaches compared to traditional on-premises systems.
|
||||
|
||||
### Myth 2: The Cloud is Just Someone Else’s Computer
|
||||
|
||||
### Reality: The Cloud is a Vast Network of Data Centers with Advanced Infrastructure
|
||||
|
||||
While it is true that cloud services rely on remote servers, they are far more than just “someone else’s computer.” Cloud providers operate highly sophisticated data centers with redundancy, scalability, and high availability. These infrastructures are designed to handle massive workloads, offer automated failover, and provide secure, scalable computing power that surpasses typical on-premises solutions.
|
||||
|
||||
### Myth 3: Cloud Computing is Too Expensive
|
||||
|
||||
### Reality: Cloud Computing Can Be Cost-Effective with Proper Management
|
||||
|
||||
Some organizations assume that moving to the cloud will lead to skyrocketing costs. However, cloud computing follows a pay-as-you-go model, allowing businesses to scale resources as needed. Cost optimization strategies such as reserved instances, auto-scaling, and serverless computing help reduce expenses. Additionally, eliminating the need for on-premises hardware, maintenance, and upgrades often results in significant cost savings.
|
||||
|
||||
### Myth 4: You Lose Control Over Your Data in the Cloud
|
||||
|
||||
### Reality: Cloud Services Provide Extensive Data Control and Management Tools
|
||||
|
||||
A common fear is that once data is in the cloud, companies lose control over it. However, cloud providers offer robust data governance tools, allowing organizations to manage permissions, encrypt data, and monitor access logs. Additionally, many cloud services provide hybrid and multi-cloud options, enabling businesses to maintain control over where and how their data is stored.
|
||||
|
||||
### Myth 5: Cloud Computing is Only for Large Enterprises
|
||||
|
||||
### Reality: Businesses of All Sizes Can Benefit from the Cloud
|
||||
|
||||
While large enterprises have been early adopters, cloud computing is highly accessible to small and medium-sized businesses (SMBs). Cloud platforms offer flexible pricing, allowing SMBs to leverage enterprise-grade technology without large upfront investments. Many startups and small businesses rely on cloud solutions for agility, scalability, and cost savings.
|
||||
### Myth 6: Migration to the Cloud is Too Complex and Risky
|
||||
|
||||
### Reality: Cloud Migration Can Be Smooth with Proper Planning
|
||||
|
||||
Although migrating to the cloud requires careful planning, cloud providers offer extensive tools and support to facilitate the process. Strategies like phased migration, hybrid cloud solutions, and professional cloud migration services help mitigate risks and ensure a smooth transition. With the right approach, businesses can move workloads to the cloud with minimal disruption.
|
||||
|
||||
### Myth 7: Cloud Performance is Unreliable
|
||||
|
||||
### Reality: Cloud Providers Offer High Availability and Redundancy
|
||||
|
||||
Some believe that cloud-based services are prone to frequent outages. However, major cloud providers offer service-level agreements (SLAs) that guarantee uptime, often exceeding 99.99%. Redundant infrastructure, automated failover, and global data center distribution enhance reliability, making cloud solutions highly resilient.
|
||||
|
||||
### Last but not least
|
||||
|
||||
Cloud computing is often misunderstood due to persistent myths and misconceptions. In reality, the cloud offers **enhanced security, cost-effectiveness, scalability, and control over data**. By debunking these myths, businesses, and individuals can make informed decisions about adopting cloud technology to drive efficiency and innovation.
|
||||
37
raw/Technical/Cloud & DevOps/Understanding Complete ITSM.md
Normal file
37
raw/Technical/Cloud & DevOps/Understanding Complete ITSM.md
Normal file
@@ -0,0 +1,37 @@
|
||||
---
|
||||
title: Modern ITSM: Driving Efficiency, Security & Resilience
|
||||
source: https://www.linkedin.com/feed/update/urn:li:activity:7301120918150352896/?utm_source=share&utm_medium=member_ios&rcm=ACoAADE1eGIB9ndhzD0qmslDUew4rjAk2upsYtg
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-03-01
|
||||
description: As IT landscapes evolve, legacy service management models are no longer sustainable. Agility, automation, and resilience are now fundamental. IT Service Management (ITSM) is no longer just about ticketing—it’s the strategic enabler of operational excellence, risk mitigation, and innovation acceleration.
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
# Modern ITSM: Driving Efficiency, Security & Resilience
|
||||
|
||||
As IT landscapes evolve, legacy service management models are no longer sustainable. Agility, automation, and resilience are now fundamental. IT Service Management (ITSM) is no longer just about ticketing—it’s the strategic enabler of operational excellence, risk mitigation, and innovation acceleration.
|
||||
|
||||
Key ITSM Trends Redefining Business Efficiency:
|
||||
|
||||
**Problem Management** – AI-driven anomaly detection & predictive analytics eliminate recurring failures by focusing on root cause eradication rather than symptom management. ML-enhanced event correlation reduces incident duplication, streamlining RCA processes.
|
||||
|
||||
**Incident Management** – Real-time observability, automated remediation, and self-healing IT ecosystems powered by AIOps are transforming traditional response models. Dynamic prioritization & auto-escalation ensure minimal MTTR, maximizing uptime.
|
||||
|
||||
**Change Management** – Controlled, risk-aware IT transformation via automated impact assessments, CI/CD pipeline governance, and Infrastructure-as-Code (IaC) compliance. Risk-based change approvals leverage AI to predict failure probabilities, ensuring seamless rollouts.
|
||||
|
||||
**Release Management** – DevOps-integrated ITSM aligns agile methodologies with robust governance, enabling progressive delivery, blue-green deployments, and canary releases for near-zero disruption.
|
||||
|
||||
**Configuration Management** – AI-powered CMDBs (Configuration Management Databases) enhance dependency mapping, drift detection, and real-time impact analysis. Seamless orchestration of multi-cloud, on-prem, and hybrid environments eliminates misconfigurations and security loopholes.
|
||||
|
||||
**Asset Management** – Intelligent asset lifecycle tracking, automated compliance enforcement, and cloud-optimized software asset management (SAM) prevent underutilization, cost overruns, and shadow IT proliferation.
|
||||
|
||||
**Security & Compliance Management** – Zero Trust Architecture (ZTA), automated risk scoring, and AI-based threat intelligence fortify ITSM against evolving cyber threats. Policy-as-Code (PaC) & compliance automation streamline audit readiness, reducing regulatory risks.
|
||||
|
||||
**Disaster Recovery & Business Continuity** – AI-driven automated failover strategies, RTO/RPO optimization, and cloud-native DRaaS (Disaster Recovery-as-a-Service) ensure operational resilience against disruptions.
|
||||
|
||||
What’s Next?
|
||||
The convergence of AIOps, hyperautomation, and ITSM 2.0 is defining a new paradigm: self-learning, predictive, and autonomous IT operations. Businesses that fail to modernize ITSM will struggle with inefficiencies, security risks, and technical debt.
|
||||
|
||||

|
||||
@@ -0,0 +1,120 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: []
|
||||
link:
|
||||
---
|
||||
|
||||
|
||||
|
||||
## Cloud Service Delivery
|
||||
|
||||
Cloud Service Delivery encompasses **the entire lifecycle of making cloud services operational, available, secure, performant, and valuable to end-users and customers.**
|
||||
**In essence, Cloud Service Delivery is the bridge between the raw capabilities of cloud technology (IaaS, PaaS, SaaS) and the reliable, secure, performant, and cost-effective services that businesses and users actually consume.**
|
||||
|
||||
Cloud Service Delivery Team:
|
||||
- Cloud Infrastructure Engineer
|
||||
- Cloud Operation Engineer (DevOps/SRE)
|
||||
- Cloud Security Specialists
|
||||
- Cloud Support Engineer
|
||||
- Cloud FinOps Engineer
|
||||
-
|
||||
|
||||
1. **Service Provisioning & Deployment:**
|
||||
- Setting up cloud infrastructure (servers, storage, networking).
|
||||
- Automating deployment of applications and platforms.
|
||||
- Configuring services according to customer requirements.
|
||||
- Managing resource allocation and scaling
|
||||
- Best Practice
|
||||
-
|
||||
|
||||
2. **Infrastructure Management:**
|
||||
- Monitoring health, performance, and capacity of compute, storage, network resources.
|
||||
- Patching and updating underlying infrastructure (hypervisors, hosts).
|
||||
- Managing physical data center aspects (power, cooling, hardware lifecycle) _if using private/hybrid cloud_.
|
||||
- Ensuring high availability and disaster recovery setups.
|
||||
- Best Practice:
|
||||
- AWS CloudWatch as a data source in Grafana Monitoring Tool
|
||||
-
|
||||
3. **Platform Management (for PaaS):**
|
||||
- Managing middleware, databases, development tools, and runtime environments.
|
||||
- Ensuring platform scalability, security, and performance.
|
||||
- Applying patches and updates to platform components.
|
||||
4. **Application Operations & Management (for SaaS/IaaS-hosted apps):**
|
||||
- Monitoring application performance, uptime, and user experience.
|
||||
- Deploying application updates and bug fixes.
|
||||
- Managing application configuration and secrets.
|
||||
- Ensuring application scalability and resilience.
|
||||
-
|
||||
5. **Security & Compliance Management:**
|
||||
- Implementing and managing security controls (firewalls, IDS/IPS, encryption, IAM).
|
||||
- Vulnerability scanning and patch management.
|
||||
- Security incident monitoring and response.
|
||||
- Ensuring compliance with regulations (GDPR, HIPAA, PCI-DSS, etc.).
|
||||
- Auditing and logging management.
|
||||
- Best Practice
|
||||
- Cloud Application WAF management
|
||||
- IP white list support to tenant level
|
||||
- Security Scanning
|
||||
- Security Guidance
|
||||
|
||||
6. **Performance & Availability Monitoring:**
|
||||
- 24/7 monitoring of all service components (infrastructure, platform, application).
|
||||
- Setting and tracking SLAs (Service Level Agreements) and SLOs (Service Level Objectives).
|
||||
- Proactive detection and resolution of performance bottlenecks and potential failures.
|
||||
- Managing incident response to outages or degradation.
|
||||
- Best Practice:
|
||||
- Service Availability Check (APM/BPM, New Relic, AWS CloudWatch Synthetic, Health Page)
|
||||
- SLA -Service Level Agreement - 99.9% vs 99.99% [uptime](https://uptime.is/)
|
||||
- SLO - Service Level Objective
|
||||
- Proactive detection (Grafana Alerting different severity)
|
||||
|
||||
7. **Incident & Problem Management:**
|
||||
- Responding to alerts and service disruptions.
|
||||
- Troubleshooting issues across the stack.
|
||||
- Restoring service quickly (incident management).
|
||||
- Identifying root causes and implementing permanent fixes (problem management).
|
||||
- Best Practice
|
||||
|
||||
8. **Change & Configuration Management:**
|
||||
- Controlling and documenting changes to the cloud environment.
|
||||
- Managing configurations consistently and securely (Infrastructure as Code - IaC).
|
||||
- Minimizing risk associated with changes through testing and rollback plans.
|
||||
- Best Practice
|
||||
- Planned Change vs Emergency Change
|
||||
|
||||
9. **Cost Management & Optimization:**
|
||||
- Monitoring cloud resource consumption and spending.
|
||||
- Identifying and eliminating waste (idle resources, over-provisioning).
|
||||
- Right-sizing resources.
|
||||
- Utilizing reserved instances or savings plans effectively.
|
||||
- Providing cost visibility and reporting.
|
||||
|
||||
10. **Customer Onboarding & Support:**
|
||||
- Guiding new customers/users through setup and access.
|
||||
- Providing user documentation and training resources.
|
||||
- Operating a service desk/helpdesk for user issues and requests (ticketing system).
|
||||
- Handling billing inquiries and account management.
|
||||
-
|
||||
11. **Service Governance & Lifecycle Management:**
|
||||
- Defining service catalogs and service levels (SLAs).
|
||||
- Managing the lifecycle of services (introduction, operation, retirement).
|
||||
- Continuous service improvement based on metrics and feedback.
|
||||
- Vendor management (for public cloud providers or third-party tools).
|
||||
- Best Practice:
|
||||
-
|
||||
|
||||
12. **Backup, Recovery & Disaster Management:**
|
||||
- Implementing and managing data backup strategies.
|
||||
- Testing restore procedures.
|
||||
- Maintaining and testing disaster recovery (DR) plans and infrastructure.
|
||||
- Executing failover and failback procedures during disasters.
|
||||
## Cloud DevOps Maturity Model
|
||||
|
||||
## AIOps
|
||||
|
||||
|
||||
@@ -0,0 +1,279 @@
|
||||
---
|
||||
title: What is DevSecOps? Best Practices, Benefits, and Tools
|
||||
source: https://www.bacancytechnology.com/blog/what-is-devsecops
|
||||
author: shenwei
|
||||
published: 2023-10-30
|
||||
created: 2025-12-19
|
||||
description: Understand What is devsecops: importantce,its security integration at every stage of the SDLC, its benefits, best practices, challenges, and more.
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
***Summary:***
|
||||
|
||||
***Did you know? 70% of software vulnerabilities discovered post-launch could have been prevented with DevSecOps***
|
||||
|
||||
***Protecting your web applications is an important step toward achieving business success in today’s digital landscape. Whether it is a small firm or an enterprise of significant scale, growth depends on whether users are satisfied, which pertains to the security of your web applications. In this blog post, let’s discuss what is DevSecOps- its basics, best practices, tools, and essence of security in the DevOps framework. We will outline the differences between DevSecOps and DevOps, emphasizing the areas that value those practices highly for better performance and protection in web applications.***
|
||||
|
||||
Table of Contents
|
||||
|
||||
## What is DevSecOps?
|
||||
|
||||
To explain the DevSecOps meaning, it’s a working methodology that includes security checks throughout the software development process. This method ensures that security is considered and promotes cooperation between development, security, and operations teams. It encourages collaboration among software developers, security teams, and operations staff to ensure the software is secure and functions as expected. This technique creates a culture where the entire development team is responsible for security.
|
||||
|
||||
## What does DevSecOps Stand For?
|
||||
|
||||
DevSecOps brings together three important groups: “Dev” for development, “Sec” for security, and “Ops” for operations teams. It is the addition of DevOps as it extends the concept and describes what each team does in all the software development lifecycle steps.
|
||||
|
||||
**● Development**
|
||||
Development refers to designing the project, writing code, building the software, and testing its performance so that it works fine.
|
||||
|
||||
**● Security**
|
||||
Security is not added at the end; instead, it is an early integration. Developers will check the code for security risks and ensure the software is safe before security experts launch it.
|
||||
|
||||
**● Operations**
|
||||
The operations team works on releasing smooth software, monitors its progress, and promptly resolves any issues.
|
||||
|
||||
## Why is DevSecOps Important?
|
||||
|
||||
DevSecOps is vital because development teams can better tackle security concerns than traditional teams. It provides the current approach to security rather than old-age security practices that cannot keep up with accelerated project timeframes and rapid updates. To understand why DevSecOps is essential, let’s look at the SDLC process.
|
||||
|
||||
### Software Development Lifecycle (SDLC)
|
||||
|
||||
The term SDLC stands for software development lifecycle. In this context, SDLC is the structured process followed by groups to develop high-quality application software. Some of the advantages of applying the SDLC include saving money, lowering error levels, and meeting project goals in terms of the software. The stages of the SDLC are as follows:
|
||||
Requirement Analysis
|
||||
● Planning
|
||||
● Architectural Design
|
||||
● Software Development
|
||||
● Testing
|
||||
● Deployment
|
||||
|
||||
### DevSecOps within the SDLC
|
||||
|
||||
In classical software development, security testing occurs outside the SDLC. The security teams could identify vulnerabilities only after the software had been developed. DevSecOps methodology has improved at each step of the development and delivery process.
|
||||
|
||||
## Benefits of DevSecOps For Businesses
|
||||
|
||||
Now that you have understood what is DevSecOps, let’s examine the significant business benefits you can avail using **DevSecOps as a Service**.
|
||||
|
||||

|
||||
|
||||
### Rapid, Cost-Effective Software Delivery
|
||||
|
||||
Business owners must quickly develop web applications with the latest features in a competitive market. Emphasizing security in agile teams helps identify issues early, reducing the need for later fixes. It makes the development process faster and cheaper.
|
||||
|
||||
### Improved Proactive Security
|
||||
|
||||
Well, when you ask, “What is DevSecOps?” As the name suggests, it integrates the practice of security into the software development process. It encompasses the actual code review and audit in real time, scans, and security testing designed to identify and remediate vulnerabilities rapidly.
|
||||
|
||||
This approach makes security more cost-effective by integrating protective technologies. By adding security measures into the development process, teams can continuously evaluate and analyze the code, identifying and resolving vulnerabilities early on, effectively addressing essential security issues.
|
||||
|
||||
### Accelerated Security Vulnerability Patching
|
||||
|
||||
Another essential benefit of DevSecOps in software development is its ability to manage newly discovered security vulnerabilities quickly. This process includes running vulnerability scans and applying patches during releases, which helps to minimize the time that attackers can use to take advantage of known weaknesses in systems that are open to the public.
|
||||
|
||||
### Automation Compatible with Modern Development
|
||||
|
||||
Adding cybersecurity testing to the automated test suite is very effective for organizations that use continuous integration and a continuous delivery pipeline for software releases. The level of automation in security checks can differ based on the project’s needs and the organization’s objectives. Automated testing helps ensure the software dependencies are current and correct, verifies security unit tests, and conducts static and dynamic analyses to protect the code before it is launched.
|
||||
|
||||
### Consistency and Adaptability
|
||||
|
||||
As organizations grow, it’s crucial for them to effectively handle security issues and keep a steady approach to reducing security vulnerabilities. It ensures that security stays strong as environments change and new needs arise. A good DevSecOps implementation includes strong automation, managing configurations, using containers, creating unchangeable infrastructure, and working in serverless computing environments.
|
||||
|
||||
## How Does DevSecOps Work?
|
||||
|
||||
To implement DevSecOps, one would begin with DevOps or continuous integration by the software development teams.
|
||||
|
||||
### DevOps
|
||||
|
||||
DevOps is a collaborative culture that promotes interaction between development and operations teams. Their common tools and automation facilitate the release of shared efforts on behalf of teams, which means communication and collaboration. Such cooperative endeavors allow companies to accelerate software development while embracing flexibility and room for change.
|
||||
|
||||
### Continuous Integration
|
||||
|
||||
Continuous integration and delivery, often called CI/CD, is a modern software development approach that automates the building and testing processes. This means applications can now be delivered efficiently through small batches of updates. Developers utilize CI/CD tools to push the new version into circulation, and they will fix problems shortly after launching the software. It also involves a tool specifically developed for deploying and managing applications called AWS CodePipeline.
|
||||
|
||||
### DevSecOps
|
||||
|
||||
DevSecOps is the process that introduces security into the approach of DevOps at all stages of the CI/CD process by integrating security checks. Everyone in the organization developing software is liable for security. The development team collaborates with the security team before starting any coding. After the software is launched, the operations team monitors it for any security problems. This approach helps companies provide secure software more quickly while following compliance rules.
|
||||
|
||||
## Components of DevSecOps
|
||||
|
||||
Some other great ways to improve the security of web applications include using DevSecOps. Here are the essential elements you need to maximize the benefits of DevSecOps:
|
||||
|
||||

|
||||
|
||||
#### 1\. Collaboration
|
||||
|
||||
Collaboration is the foundation of DevSecOps. It shares security tasks among the development and operations teams, so there is no need for a separate security team. The security team ensures security standards are part of the entire development process, automating security tasks and adding security features without slowing down the workflow. Developers are motivated to understand security practices, which improves the software’s overall security.
|
||||
|
||||
#### 2\. Communication
|
||||
|
||||
Effective communication is vital. Security professionals need to explain security controls in simple terms that developers understand. For example, discussing how security risks can lead to project delays helps developers see the importance of managing these risks. Developers should also know their security responsibilities, such as recognizing potential threats and following best coding practices. They should conduct vulnerability tests during development to fix any issues quickly.
|
||||
|
||||
#### 3\. Automation
|
||||
|
||||
Automation is crucial in DevSecOps. It helps integrate security into the development process without causing delays. Automated security testing can be added to Continuous Integration/Continuous Deployment (CI/CD) pipelines, ensuring secure web applications are delivered efficiently. Automation also includes mechanisms like “break the build,” which stops the development process if security risks are too high until resolved.
|
||||
|
||||
#### 4\. Security of Tools and Architecture
|
||||
|
||||
Starting with a secure DevOps environment is essential. Security teams should choose and vet security tools before use. Manage user access carefully using methods like multi-factor authentication and limited access. Regularly monitor workstations and servers for vulnerabilities and apply necessary patches. Automated tools should scan for sensitive data in the code, and new containers should have security settings.
|
||||
|
||||
***Transform Your Security with DevSecOps Expertise!***
|
||||
|
||||
***[Hire DevSecOps Engineers](https://www.bacancytechnology.com/hire-devsecops-engineers) to integrate security into your workflows, enhance collaboration, and deliver secure software faster. Get started today!***
|
||||
|
||||
#### 5\. Testing
|
||||
|
||||
Rather than checking security only at the end of development, incorporate testing at every stage. Developers should perform basic security tests like those in the OWASP Top Ten during development to catch issues early. Automation assists in tasks such as checking code for sensitive data and identifying harmful code. Well-designed and implemented testing will utilize techniques such as SAST and DAST, penetration testing, and threat modeling. Some organizations also have so-called “bug bounty” programs to encourage reporting security vulnerabilities.
|
||||
|
||||
## What is the DevSecOps Culture?
|
||||
|
||||
The DevSecOps culture blends communication, people, technology, and processes to enhance security in software development.
|
||||
|
||||
### Communication
|
||||
|
||||
Companies need a cultural shift to implement DevSecOps, which starts with leadership. Senior leaders should highlight the importance of security practices to the DevOps teams. Software developers and operations teams need the right tools, assistance, and encouragement to adopt DevSecOps effectively.
|
||||
|
||||
What are DevSecOps Tools? Are you confused about which ones are the best for you? Here’s our detailed guide to the [best DevOps Tools](https://www.bacancytechnology.com/blog/devops-tools).
|
||||
|
||||
### People
|
||||
|
||||
DevSecOps works with developers to integrate security tightly into each stage of the development process. It no longer waits to either build, test, or deploy the code.
|
||||
|
||||
### Technology
|
||||
|
||||
Software teams leverage technology to automate security testing during development. It allows DevOps teams to identify security issues without delaying delivery. For instance, they can utilize Amazon Inspector to handle vulnerabilities automatically.
|
||||
|
||||
### Process
|
||||
|
||||
DevSecOps changes how software is built. Security testing and assessments happen at every stage of development. Developers look for security issues while writing code, and security teams evaluate the application before it is released. They might check for:
|
||||
|
||||
● Authorization makes sure users can only access what they need.
|
||||
● Input validation to ensure the software handles unusual data correctly
|
||||
|
||||
Any identified flaws are fixed before the final application is launched.
|
||||
|
||||
Additionally, security testing keeps going even after the application is launched. The operations team keeps an eye out for potential problems, makes necessary changes, and collaborates with security and development teams to release updated versions. For example, they might use Amazon CodeGuru Reviewer to identify security issues, manage sensitive information, spot resource leaks, and ensure they follow best practices when using AWS APIs and SDKs.
|
||||
|
||||
## DevSecOps Best Practices
|
||||
|
||||
Companies can enhance their digital transformation efforts with DevSecOps by following these key approaches:
|
||||
|
||||

|
||||
|
||||
### Shift Left
|
||||
|
||||
“Shift left” means identifying security flaws early in the software development lifecycle. By focusing on these issues initially, teams can tackle and fix them before they become bigger problems. For instance, developers prioritize writing secure code right from the beginning.
|
||||
|
||||
### Shift Right
|
||||
|
||||
“Shift right” highlights the need for ongoing security measures even after launching the application. Some security vulnerabilities may go unnoticed until customers start using the software. Monitoring and addressing these issues post-deployment is crucial.
|
||||
|
||||
### Use Automated Security Tools
|
||||
|
||||
DevSecOps teams frequently have to make many changes every day. To stay efficient, they should use automated security scanning tools as part of their continuous integration and delivery (CI/CD) process. This way, security checks won’t slow down development.
|
||||
|
||||
### Promote Security Awareness
|
||||
|
||||
Instead, security awareness should be the core of it all. Each person involved in developing an application has a role in protecting the user from security threats. Thus, a shared responsibility culture goes a long way in raising the overall security of the software.
|
||||
|
||||
## Challenges of implementing DevSecOps
|
||||
|
||||
When companies try to adopt DevSecOps, they may face several challenges:
|
||||
|
||||
### Resistance to Cultural Shift
|
||||
|
||||
Many security and software teams have used traditional software development practices for years. It can be a challenge for the IT team to adapt to the DevSecOps mindset in a very short period of time. Developers focus mainly on building and testing applications while deploying them. On the other hand, the security team focuses primarily on making the software secure. To overcome this, company leadership must align both teams to integrate security practices with timely software delivery.
|
||||
|
||||
### Complex Tool Integration
|
||||
|
||||
Applications are developed, and their security is tested using a mix of tools used by the software teams. Introducing these tools developed by different vendors in the continuous delivery process would complicate such a task. In addition, older security scanners may not be compatible with modern developments, making integration a much more complicated task.
|
||||
|
||||
### Prioritize Risk Management
|
||||
|
||||
Focus on risk management as a top priority. By identifying threats and vulnerabilities, organizations can apply controls to lessen the risk of security incidents and lessen the impact of breaches.
|
||||
|
||||
### Implement Secure Coding Standards
|
||||
|
||||
Set up secure coding standards to guide developers in following best practices. This approach helps ensure that applications are secure right from the start.
|
||||
|
||||
### Enforce Access Controls
|
||||
|
||||
Implement access controls throughout development. Organizations reduce unauthorized access and protect sensitive information by managing who can access systems and data.
|
||||
|
||||
### Embrace Policy as Code
|
||||
|
||||
Implementing Policy as Code ensures security policies are consistently applied throughout development. Defining these policies in code allows for automatic enforcement and management, enhancing compliance.
|
||||
|
||||
### Expand Incident Response Capabilities
|
||||
|
||||
Strengthen incident response strategies within DevSecOps. Teams should develop and test response plans that work smoothly with development and operations to act quickly during a security breach.
|
||||
|
||||
### Leverage Immutable Infrastructure
|
||||
|
||||
Use immutable infrastructure to enhance security. With fixed and pre-configured components, teams can reduce risks from unauthorized changes and ensure more secure deployments.
|
||||
|
||||
## Application Security Tools Used in DevSecOps
|
||||
|
||||
DevSecOps tools are essential for application security, helping organizations find and fix security issues early in development. It makes it harder for attackers to exploit vulnerabilities in their applications. Here are four important tools to understand better:
|
||||
|
||||
#### Static Application Security Testing (SAST)
|
||||
|
||||
SAST tools analyze an application’s source code to identify security vulnerabilities. They excel at spotting common issues such as SQL injection, cross-site scripting, and buffer overflows. These tools are typically used during the early stages of development when the code is being written and tested.
|
||||
|
||||
#### Software Composition Analysis (SCA)
|
||||
|
||||
SCA tools focus on the various software components of an application, including libraries and frameworks, to find known security flaws. They help reveal vulnerabilities that may occur when using third-party components. SCA tools are mainly employed during the initial phases of development, particularly during planning and design.
|
||||
|
||||
#### Interactive Application Security Testing (IAST)
|
||||
|
||||
IAST tools evaluate applications while they run to detect security issues that SAST or SCA tools might overlook. They are beneficial during testing and deployment phases when examining how different components interact within the application is important.
|
||||
|
||||
#### Dynamic Application Security Testing (DAST)
|
||||
|
||||
DAST tools simulate external attacks on applications to uncover vulnerabilities from an outsider’s viewpoint. These tools are essential for identifying weaknesses that attackers could exploit. DAST tools are primarily utilized during testing and deployment, ensuring that a live application undergoes a comprehensive security assessment.
|
||||
|
||||
## What is DevSecOps in Agile Development?
|
||||
|
||||
Agile is a way of working that helps software teams build apps faster and adjust easily to changes. In the past, teams used rigid steps to finish a project. Now, with Agile, work happens in small, repeating cycles where teams constantly gather feedback and improve their apps.
|
||||
|
||||
Agile and DevSecOps go hand in hand. Agile focuses on speed and flexibility, helping teams adapt to changes quickly. DevSecOps adds security to this process, making sure that every step includes checks to keep the software safe. By combining these approaches, teams can deliver secure, high-quality apps without slowing down.
|
||||
|
||||
## What is The Difference Between DevOps and DevSecOps?
|
||||
|
||||
The only difference is that in DevSecOps, all security layers are inclusive. In contrast, DevOps comes on top of that because the emphasis here is on speed and efficiency in its role in development. Here’s a simple comparison table between DevOps and DevSecOps:
|
||||
|
||||
| **Parameter** | **DevOps** | **DevSecOps** |
|
||||
| --- | --- | --- |
|
||||
| **Definition** | Emphasizes teamwork between development and operations to speed up software delivery. | Adds security practices to the development process, making security everyone’s responsibility. |
|
||||
| **Main Focus** | Faster software development and deployment. | Integrating security into every stage of development. |
|
||||
| **Security Role** | Security is handled separately or at the end. | Security is built into each step from the start. |
|
||||
| **Goal** | Improve speed and collaboration between teams. | Address security early to prevent issues later. |
|
||||
| **Automation** | Automates development and operations tasks. | Automates security checks along with development tasks. |
|
||||
| **Team Involvement** | Development and operations teams collaborate closely. | Development, operations, and security teams work together. |
|
||||
| **Tools Used** | Jenkins, Docker, Kubernetes, etc. | Uses DevOps tools plus security tools like Snyk and SonarQube. |
|
||||
| **Key Metrics** | Measures deployment speed and system reliability. | Tracks security issues and how quickly they are fixed, in addition to [DevOps metrics](https://www.bacancytechnology.com/blog/devops-metrics). |
|
||||
| **Testing Focus** | Tests mainly for functionality and performance. | Tests for security risks along with functionality. |
|
||||
| **Risk Handling** | Manages operational risks like downtime. | Proactively addresses security risks early on. |
|
||||
| **Compliance Approach** | Compliance checks are done after development. | Ensures compliance throughout development and deployment. |
|
||||
|
||||
|
||||
|
||||
## Conclusion
|
||||
|
||||
In conclusion, this was all about what is DevSecOps & how adopting a DevSecOps approach is vital for organizations that want to improve security while keeping their software development fast and flexible. By embedding security into every development process step, teams can spot and fix issues early on, creating a culture of shared responsibility. To make the transition easier, businesses can use [**DevSecOps consulting services**](https://www.bacancytechnology.com/devsecops-consulting-services), which provide expert advice on best practices and tools for building a secure and efficient DevSecOps framework.
|
||||
|
||||
## Frequently Asked Questions (FAQs)
|
||||
|
||||
Automation: Automating security tasks in CI/CD pipelines.
|
||||
Collaboration: Developers, security, and operations teams working together.
|
||||
Shift-left Security: Integrating security early in the development process.
|
||||
|
||||
Yes, basic coding knowledge helps in automating security tasks, writing secure code, and integrating tools into CI/CD pipelines.
|
||||
|
||||
SOC (Security Operations Center): A team monitoring and responding to security threats 24/7.
|
||||
SecOps (Security Operations): Broader practices ensuring security in daily IT operations, often including automation.
|
||||
|
||||

|
||||
|
||||
Expand Your Digital Horizons With Us
|
||||
126
raw/Technical/Cursor 2.0初学者使用指南.md
Normal file
126
raw/Technical/Cursor 2.0初学者使用指南.md
Normal file
@@ -0,0 +1,126 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [ai, cursor, ide, mcp]
|
||||
---
|
||||
|
||||
#ide #cursor #ai #mcp
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
## Cursor 2.0初学者使用指南
|
||||
|
||||
### 概述 🔍
|
||||
本视频面向初学者,系统讲解了Cursor 2.0这款集成了人工智能(AI)功能的代码编辑器的使用方法。视频首先介绍了Cursor的基本背景、安装及界面布局,继而阐述了最新特性与模型变更,详细示范了如何规划、生成及审查代码。通过示范制作一个简单的“Tetris”游戏和相关网页,帮助观众理解如何高效使用AI代理进行项目开发。讲解风格结合演示和实操,以通俗易懂的语言帮助初学者迅速上手,重点突出AI代码生成的核心功能和实用操作技巧。
|
||||
|
||||
## Youtube
|
||||
https://www.youtube.com/watch?v=l30Eb76Tk5s
|
||||
|
||||
## 核心知识点总结 ⏰
|
||||
- **00:00-01:25 安装与打开项目文件夹**
|
||||
- Cursor是基于VS Code的AI代码编辑器,可免费使用,支持付费升级以获取更多生成额度。
|
||||
- 登录账户后,需通过文件菜单打开或新建项目文件夹,确保代码文件有存储路径。
|
||||
|
||||
- **01:26-02:30 最新版本与AI模型介绍**
|
||||
- Cursor已运营约2年,持续升级用户界面和功能。
|
||||
- 新增了自有AI模型Composer,强调其速度优势(比类似模型快4倍)。
|
||||
- 支持多AI代理并行操作,提升代码生成效率。
|
||||
|
||||
- **02:31-04:00 界面主题与设置调整**
|
||||
- 可通过快捷键打开命令面板(Ctrl+Shift+P或Cmd+Shift+P)切换编辑器主题,例如Monokai。
|
||||
- 设置面板支持界面窗口自由拖拽、调整大小,满足用户个性化需求。
|
||||
|
||||
- **04:01-06:30 界面模式与视图切换介绍**
|
||||
- 主要有“编辑器视图”和“Agents(代理)视图”两大块,分别用于代码文件编辑和AI代理交互。
|
||||
- 界面左上角一组切换按钮控制左侧边栏、终端等模块显示。
|
||||
- 了解这些视图和控制按钮,有助于快速定位所需功能和编程场景。
|
||||
|
||||
- **06:31-09:30 规划代码开发思路的重要性及基本用法示范**
|
||||
- 强调在向AI代理发出生成代码请求前,需明确项目目标(如网站、游戏、后端工具)。
|
||||
- 通过语音输入演示让AI生成“Tetris”游戏开发的计划,得到任务列表。
|
||||
- 计划文件通常以Markdown形式展示,用户可修改或重新生成计划。
|
||||
|
||||
- **09:31-13:30 代码生成与多代理并行使用**
|
||||
- 启动构建任务时生成新代理,执行计划步骤。
|
||||
- 多代理功能可以同时运行不同任务,互不干扰。
|
||||
- 代理工作模式包括Plan(规划)、Agent(执行)、Ask(咨询)三种,Ask模式安全,仅返回文本不改动文件。
|
||||
|
||||
- **13:31-16:30 代码审查与版本控制流程**
|
||||
- 生成代码后进入“待审查”状态,可使用“Diff”功能查看具体改动,支持文件逐个审查或整体接收。
|
||||
- 代码改动一旦生成即写入文件,未点击“撤销”按钮前持续保留,需确保先测试代码再确认保存。
|
||||
- 推荐结合Git版本控制,帮助管理和回滚代码变更,降低风险。
|
||||
|
||||
- **16:31-19:30 细粒度代码编辑与上下文引用**
|
||||
- 支持选中文本后快速编辑(如加注释),并可通过快捷键引用代码片段与文件上下文向代理提问,方便理解和定向修改。
|
||||
- AI支持内置代码自动补全,使用Tab键快速接受提示,提高代码书写效率。
|
||||
|
||||
- **19:31-23:50 多任务代理管理与项目规则自定义**
|
||||
- 新建代理用于不同任务场景,保证上下文不冲突。
|
||||
- 演示创建独立页面广告“Play”按钮,增强项目模块化管理。
|
||||
- 可以设定“项目规则”,如强制AI为函数生成文档注释,实现代码规范自动化。
|
||||
|
||||
- **23:51-26:20 版本控制基础与自动化提交演示**
|
||||
- 介绍Git版本控制的重要概念及操作,建议用户学习以避免开发过程中的代码丢失与错误。
|
||||
- AI可自动初始化Git仓库并提交代码,为项目维护带来智能便捷。
|
||||
|
||||
- **26:21-27:10 附加功能简介:MCP服务器及工具集成**
|
||||
- MCP(Model Context Protocol)支持将外部工具和服务集成到AI代理,扩展功能范围。
|
||||
- 演示添加和切换MCP服务器,提升开发项目的扩展性和操作能力。
|
||||
|
||||
## 关键术语与定义 📚
|
||||
- **Cursor 2.0**:基于VS Code的AI增强代码编辑器,支持AI模型辅助代码生成及多任务代理操作。
|
||||
- **AI代理(Agent)**:基于AI模型的自动化任务助手,可以按模式生成代码、规划任务或回答疑问。
|
||||
- **Composer模型**:Cursor自研AI模型,主打生成速度快于其他同类模型。
|
||||
- **Diff文件**:显示代码改动对比的视图,帮助开发者快速审查AI修改的内容。
|
||||
- **Git**:主流版本控制系统,记录项目代码的历史版本变化,支持代码回滚和团队协同。
|
||||
- **Markdown文件(.md)**:兼容纯文本且可格式化的文档文件格式,常用于代码计划及说明文档。
|
||||
- **MCP服务器**:可集成外部API和工具的协议平台,赋予AI代理更丰富的执行能力。
|
||||
|
||||
## 推理结构 🔢
|
||||
1. **需求明确 → 规划任务 → AI生成计划**
|
||||
- 明确项目类型和预期结果是生成有效代码的前提。
|
||||
- 使用计划模式,让AI拆解步骤,形成清晰的开发路线图。
|
||||
2. **计划执行 → 代码生成 → 代码审查和测试**
|
||||
- AI代理执行计划任务,逐步生成代码。
|
||||
- 通过Diff文件和运行测试,确认代码质量。
|
||||
3. **修正与迭代 → 版本控制 → 项目维护**
|
||||
- 根据测试反馈调整代码。
|
||||
- 结合Git管理项目版本,确保稳定可靠。
|
||||
|
||||
## 示例解析 💡
|
||||
- **通过语音输入生成开发计划**:利用“Whisper Flow”音频工具直接对AI代理发出口述请求,生成简易Tetris游戏开发计划,帮助初学者体验从想法到实施的流程。
|
||||
- **多代理并行任务**:一边由一个代理执行游戏开发,另一边新建代理创建游戏的独立Landing Page,通过实战演示展示多线程开发优势。
|
||||
- **规则文件应用示范**:设定“函数必须生成Doc字符串”的规则,实现代码统一风格,保证代码规范性自动执行。
|
||||
|
||||
## 易错点提醒 ⚠️
|
||||
- **盲目接受代码**:误以为“Keep All”后代码才生成,实际上代码生成即写入文件,先测试再保存避免问题。
|
||||
- **忽视版本控制**:不使用Git版本控制可能导致无法回滚代码,尤其是AI生成的代码出现错误时难以恢复。
|
||||
- **代理模式混淆**:Agent模式会修改代码,Ask模式仅提供文本答案,不会改动代码,需根据需求选择。
|
||||
- **多代理上下文混用**:在同一个代理内继续先前任务效果更佳,分散任务需创建新代理避免上下文混乱。
|
||||
|
||||
## 快速复习技巧/自测题 🎯
|
||||
**复习技巧(无答案)**
|
||||
- 解释Cursor中Plan模式、Agent模式和Ask模式的区别。
|
||||
- 描述如何使用Diff视图查看AI生成的代码改动。
|
||||
- 列出在生成代码前需要规划的关键项目问题。
|
||||
|
||||
**自测题(含答案)**
|
||||
1. **问:如何在Cursor中切换编辑器主题?**
|
||||
答:使用快捷键Ctrl+Shift+P或Cmd+Shift+P打开命令面板,输入“theme”,选择“Preferences: Color Theme”来切换。
|
||||
|
||||
2. **问:Cursor中如何撤销AI生成的代码?**
|
||||
答:点击“Undo All”按钮撤销所有AI生成的改动,注意关闭文件或多次修改后可能无法撤销。
|
||||
|
||||
3. **问:Git在项目管理中的核心作用是什么?**
|
||||
答:Git用于版本控制,能记录代码变更历史,方便回滚和多人协作。
|
||||
|
||||
4. **问:如果想让AI自动为每个函数生成文档注释,应如何操作?**
|
||||
答:新增项目规则文件,写入“Always generate doc strings for functions”的规则,AI会自动遵守。
|
||||
|
||||
## 总结回顾 🔄
|
||||
Cursor 2.0是一款强大的AI代码协助编辑器,融合了先进的AI模型Composer,支持多代理任务并行和多模式交互。通过明确项目目标制定开发计划,结合代码生成、代码审查与版本控制流程,用户可以高效地实现项目开发。其灵活的界面设置、丰富的辅助功能如语音输入、上下文引用及规则配置进一步提升用户体验。理解不同代理模式和审查机制是避免误操作的关键,熟练使用Git版本控制则能实现代码稳定可靠的管理。整体来看,Cursor 2.0为开发者提供了一条从想法到实现的智能化路径,是现代AI辅助编程的重要工具之一。
|
||||
114
raw/Technical/Git Push 连接重置问题修复.md
Normal file
114
raw/Technical/Git Push 连接重置问题修复.md
Normal file
@@ -0,0 +1,114 @@
|
||||
---
|
||||
title: 输出可能为: origin https://github.com/ishenwei/tiktok_pm.git (fetch)
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [github, proxy, push, socks5]
|
||||
---
|
||||
|
||||
#github #push #proxy #socks5
|
||||
|
||||
|
||||
这是一个典型的**网络连接干扰**问题,特别是在国内访问 GitHub 时非常常见。
|
||||
|
||||
### 核心原因分析
|
||||
|
||||
`Recv failure: Connection was reset`(连接重置)并不是账号权限验证失败,而是 **TCP 连接层面的中断**。
|
||||
|
||||
- **现象:** 客户端尝试与 GitHub 服务器建立安全连接(TLS Handshake),但中间的网络防火墙(GFW)检测到了流量特征或目标域名,强行发送了 TCP RST 包阻断连接。
|
||||
|
||||
- **为何间歇性:** GitHub 的 CDN 节点众多,部分 IP 被封锁,部分未被封锁;或者是干扰策略存在由于流量负载导致的“漏网之鱼”。
|
||||
|
||||
|
||||
### 解决方案
|
||||
|
||||
最有效、最根本的解决方案是让 Git 的流量走你本地的代理通道(既然你之前提到过使用 V2RayN,这是最直接的利用方式)。
|
||||
|
||||
#### 方法一:为 Git 单独配置代理(推荐)
|
||||
|
||||
这种方法只会影响 Git 命令,不会干扰终端里其他命令的网络请求。
|
||||
|
||||
假设你的代理软件(如 V2RayN, Clash 等)本地监听端口如下(请根据你实际设置修改端口号):
|
||||
|
||||
- HTTP/HTTPS 代理端口:`10809`
|
||||
|
||||
- SOCKS5 代理端口:`10808`
|
||||
|
||||
|
||||
**1. 设置 HTTP 代理(最通用)** 在终端(Terminal 或 PowerShell)执行:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
git config --global http.proxy http://127.0.0.1:10809
|
||||
git config --global https.proxy http://127.0.0.1:10809
|
||||
```
|
||||
|
||||
_注意:即使是访问 `https://`,配置项名称也是 `https.proxy`,但代理协议通常写 `http://` 即可,除非你的代理明确要求 https。_
|
||||
|
||||
**2. 设置 SOCKS5 代理(速度通常更快)** 如果你想走 SOCKS5 协议:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
git config --global http.proxy socks5://127.0.0.1:10808
|
||||
git config --global https.proxy socks5://127.0.0.1:10808
|
||||
```
|
||||
|
||||
**验证配置是否生效:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
git config --global --get http.proxy
|
||||
```
|
||||
|
||||
**如何取消代理:** 如果你切换了网络环境(例如到了国外),不再需要代理,可以使用以下命令取消:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
git config --global --unset http.proxy
|
||||
git config --global --unset https.proxy
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
#### 方法二:从 HTTPS 切换到 SSH 协议
|
||||
|
||||
有时候 HTTPS 的 443 端口干扰严重,但 SSH 的 22 端口相对稳定(或者反过来)。你可以尝试更改远程仓库地址。
|
||||
|
||||
**1. 查看当前远程地址**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
git remote -v
|
||||
# 输出可能为: origin https://github.com/ishenwei/tiktok_pm.git (fetch)
|
||||
```
|
||||
|
||||
**2. 修改为 SSH 地址**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
git remote set-url origin git@github.com:ishenwei/tiktok_pm.git
|
||||
```
|
||||
|
||||
_前提:你必须已经生成了 SSH Key (`ssh-keygen`) 并将公钥上传到了 GitHub Settings 中。_
|
||||
|
||||
**进阶:如果 SSH 直连也不稳** 可以通过修改 `~/.ssh/config` (Linux/Mac) 或 `C:\Users\你的用户名\.ssh\config` (Windows),让 SSH 连接也走代理:
|
||||
|
||||
Plaintext
|
||||
|
||||
```
|
||||
Host github.com
|
||||
User git
|
||||
Hostname github.com
|
||||
# Windows 下使用 connect.exe (Git自带)
|
||||
ProxyCommand connect -S 127.0.0.1:10808 %h %p
|
||||
# Linux/Mac 下使用 ncat (需安装 netcat)
|
||||
# ProxyCommand nc -X 5 -x 127.0.0.1:10808 %h %p
|
||||
```
|
||||
@@ -0,0 +1,36 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [apache, bi, docker, mysql, superset]
|
||||
---
|
||||
|
||||
#docker #superset #apache #mysql #bi
|
||||
|
||||
``` bash
|
||||
docker pull apache/superset:GHA-19524015706
|
||||
```
|
||||
|
||||
``` bash
|
||||
docker run -d -p 8777:8088 -e "SUPERSET_SECRET_KEY=mysuperset" --name superset apache/superset:GHA-19524015706
|
||||
```
|
||||
|
||||
``` bash
|
||||
docker exec -it superset superset fab create-admin --username admin --firstname Superset --lastname Admin --email admin@superset.com --password admin
|
||||
```
|
||||
|
||||
``` bash
|
||||
docker exec -it superset superset db upgrade
|
||||
```
|
||||
|
||||
``` bash
|
||||
docker exec -it superset superset load_examples
|
||||
```
|
||||
|
||||
``` bash
|
||||
docker exec -it superset superset init
|
||||
```
|
||||
|
||||
112
raw/Technical/Home Office/Mac-Mini-服务器配置-防止自动锁屏与睡眠.md
Normal file
112
raw/Technical/Home Office/Mac-Mini-服务器配置-防止自动锁屏与睡眠.md
Normal file
@@ -0,0 +1,112 @@
|
||||
---
|
||||
title: Mac Mini 服务器配置:防止自动锁屏与睡眠
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: []
|
||||
---
|
||||
|
||||
# Mac Mini 服务器配置:防止自动锁屏与睡眠
|
||||
|
||||
本文档记录如何配置 Mac Mini 作为服务器使用时,防止自动锁屏和睡眠,确保可以通过远程桌面(如 RustDesk)持续访问。
|
||||
|
||||
## 问题描述
|
||||
|
||||
Mac Mini 作为服务器使用时,关闭显示器后会自动锁屏或进入睡眠状态,导致远程访问软件(如 RustDesk、VNC)无法连接,需要物理到主机上输入密码解锁。
|
||||
|
||||
## 解决方案
|
||||
|
||||
### 方法:关闭所有自动睡眠与锁屏设置
|
||||
|
||||
在终端中运行以下命令:
|
||||
|
||||
```bash
|
||||
sudo pmset -a sleep 0
|
||||
sudo pmset -a displaysleep 0
|
||||
sudo pmset -a standby 0
|
||||
sudo pmset -a hibernatemode 0
|
||||
sudo pmset -a womp 1
|
||||
```
|
||||
|
||||
#### 命令解释
|
||||
|
||||
| 命令 | 作用 |
|
||||
|------|------|
|
||||
| `pmset -a sleep 0` | 禁止系统睡眠 |
|
||||
| `pmset -a displaysleep 0` | 禁止显示器关闭 |
|
||||
| `pmset -a standby 0` | 禁止待机模式 |
|
||||
| `pmset -a hibernatemode 0` | 禁止休眠(内存保存到磁盘) |
|
||||
| `pmset -a womp 1` | 启用网络唤醒(WOL) |
|
||||
|
||||
#### 参数说明
|
||||
|
||||
- `-a`:应用于所有电源模式(电池和电源适配器)
|
||||
- `-b`:仅电池模式
|
||||
- `-c`:仅电源适配器模式
|
||||
|
||||
---
|
||||
|
||||
## 可选:使用 caffeinate 保持唤醒
|
||||
|
||||
如果需要临时保持唤醒状态(不修改系统设置),可以使用 `caffeinate` 工具:
|
||||
|
||||
### 安装
|
||||
|
||||
```bash
|
||||
brew install caffeinate
|
||||
```
|
||||
|
||||
### 使用
|
||||
|
||||
```bash
|
||||
# 保持唤醒(按 Ctrl+C 停止)
|
||||
caffeinate -d -i -s
|
||||
```
|
||||
|
||||
#### 参数说明
|
||||
|
||||
| 参数 | 作用 |
|
||||
|------|------|
|
||||
| `-d` | 防止显示器睡眠 |
|
||||
| `-i` | 防止系统空闲时睡眠 |
|
||||
| `-s` | 防止系统睡眠 |
|
||||
| `-u` | 模拟用户活动(防止睡眠) |
|
||||
|
||||
---
|
||||
|
||||
## 验证当前电源设置
|
||||
|
||||
查看当前电源管理设置:
|
||||
|
||||
```bash
|
||||
pmset -g
|
||||
```
|
||||
|
||||
查看具体睡眠设置:
|
||||
|
||||
```bash
|
||||
pmset -g sleep
|
||||
pmset -g displaysleep
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 注意事项
|
||||
|
||||
1. **sudo 权限**:运行 pmset 命令需要管理员权限
|
||||
2. **功耗**:关闭睡眠会增加功耗,适合始终接电的服务器场景
|
||||
3. **网络唤醒**:启用 WOL 后,可以通过其他设备远程唤醒 Mac Mini
|
||||
4. **安全性**:如果 Mac Mini 放在不安全的地方,建议设置强密码和防火墙
|
||||
|
||||
---
|
||||
|
||||
## 相关链接
|
||||
|
||||
- Apple pmset 官方文档:https://support.apple.com/zh-cn/HT201685
|
||||
|
||||
---
|
||||
|
||||
*文档创建日期:2026-03-15*
|
||||
*最后更新:2026-03-15*
|
||||
@@ -0,0 +1,155 @@
|
||||
---
|
||||
title: 1. 安装Plex
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-02-23
|
||||
description:
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
|
||||
# 1. 安装Plex
|
||||
|
||||
## 1.1 群晖NAS安装Plex Server
|
||||
|
||||
目前在群晖的套件中心里直接找到 Plex Media Server直接安装即可
|
||||
|
||||
目前我的Plex账号是用Apple ID: ishenwei@hotmail.com来进行登录的
|
||||
|
||||
## 1.2 在当贝盒子上安装Plex客户端
|
||||
|
||||
客厅里的电视是用当贝盒子进行视频播放的,从AppMirror网站上下载了最新版本的
|
||||
|
||||

|
||||
|
||||
com.plexapp.android_10.26.0.2578-966828321_minAPI23(armeabi-v7a)(nodpi)_apkmirror.com
|
||||
|
||||
## 1.3 在卧房电视机的华为盒子上安装Plex客户端
|
||||
|
||||
因为该盒子里的操作系统较老,所以不支持Android 6.0+只能支持5.0+,所以我找到了能支持5.0+的最高的版本
|
||||
|
||||
com.plexapp.android_10.5.0.4996-944846913_minAPI21(armeabi-v7a)(nodpi)_apkmirror.com
|
||||
|
||||

|
||||
|
||||
以上两个APK文件我保存在: NAS/Software/家庭影视平台/Plex
|
||||
|
||||
# 2.安装Xiaoya Alist
|
||||
|
||||
这个是利用NAS的container manager的docker方式来进行安装的,整个过程比较波折,其中还学习到了一些关于Doker的技巧
|
||||
|
||||
总的来说Xiaoya Alist是一个网络资源分享平台,运行以后可以出现一个列表,当配置好云盘链接后,可以将相关资源直接转存到自己的云盘上,比如Aliyun
|
||||
|
||||
我自己 NAS上小雅的链接是:
|
||||
|
||||
[http://192.168.3.17:5678/](http://192.168.3.17:5678/)
|
||||
|
||||

|
||||
|
||||
## 2.1 安装xiaoya alist
|
||||
|
||||
首先我的NAS上的Container Manager除了问题,怎么呀刷不出注册表信息,就是无法读取docker hub的信息。我尝试了用Putty通过SSH登录NAS,然后用docker pull的命令下载也不行。在这里必须要主要,要NAS支持可以通过SSH访问必须进行配置。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
后来我查询了ChatGPT, 里面选择了另一个从另一台机器下载Docker Image然后再load到NAS机器上的方法。 整个过程如下:
|
||||
|
||||
我在我自己工作的笔记本上安装了DockerDesktop版本,然后正常的pull xiaoya 的image:
|
||||
|
||||
```docker
|
||||
docker pull xiaoyaliu/alist
|
||||
```
|
||||
|
||||
通过以下命令将下载的image打包成tar文件
|
||||
|
||||
```docker
|
||||
docker save -o xiaoya.tar xiaoyaliu/alist
|
||||
```
|
||||
|
||||
我将打包好的xiaoya.tar文件上传到NAS文件系统里去,然后还是通过Putty来运行docker命令将image导入NAS的Docker中去。
|
||||
|
||||
```docker
|
||||
#cd 到xiaoya.tar存放的路径之后运行以下命令
|
||||
docker load < xiaoya.tar
|
||||
```
|
||||
|
||||
然后再进入NAS的Container Manager 界面后在image里就可以看到扫xiaoya/alist这个image了
|
||||
|
||||

|
||||
|
||||
接下来需要进行一些配置工作:
|
||||
|
||||
在本地先准备三个txt文件,然后根据官方文档配置Aliyun的token
|
||||
|
||||
**myopentoken.txt**
|
||||
|
||||
访问这个链接 后,用手机阿里云盘扫描二维码,然后在手机上确认授权,然后点击I have scan, 将生成的token保存在myopentoken.txt文件里。
|
||||
|
||||
[Get Aliyundrive Refresh Token](https://alist.nn.ci/tool/aliyundrive/request.html)
|
||||
|
||||

|
||||
|
||||
**mytoken.txt**
|
||||
|
||||
访问这个链接 然后用阿里云盘的App扫描二维码,将生成的token保存在mytoken.txt里
|
||||
|
||||
[阿里云盘 / 分享](https://alist.nn.ci/zh/guide/drivers/aliyundrive.html)
|
||||
|
||||

|
||||
|
||||
**temp_transfer_folder_id.txt**
|
||||
|
||||
登录网页版阿里云盘,在资源盘目录下创建一个folder, 将URL里的folder 的token保存在这个txt文件里。 这个目录将来会用于存放从xiaoya那边转存过来的视频
|
||||
|
||||

|
||||
|
||||
最后将这三个txt文件全部上传至 NAS/docker/xiaoya/ 目录下
|
||||
|
||||
配置Docker启动xiaoya,请注意以下圈出的是需要配置的地方:
|
||||
|
||||

|
||||
|
||||
启动后检查日志,看小雅是否正常启动。
|
||||
|
||||
[http://192.168.3.17:5678/](http://192.168.3.17:5678/)
|
||||
|
||||
# 3. 配置安装CloudDrive2来在NAS挂载Aliyun盘
|
||||
|
||||
在套件中心,设置里添加矿神源
|
||||
|
||||

|
||||
|
||||
然后在社群里找到CloudDrive2这个应用, 并安装。因为我的DSM是7+版本,所以需要额外在Putty root 下执行一条命令:
|
||||
|
||||
```docker
|
||||
sudo -i
|
||||
#input NAS admin password
|
||||
|
||||
sudo sed -i 's/package/root/g' /var/packages/CloudDrive2/conf/privilege
|
||||
```
|
||||
|
||||

|
||||
|
||||
安装成功后打开CloudDrive进行配置:
|
||||
|
||||
[http://192.168.3.17:19798/](http://192.168.3.17:19798/)
|
||||
|
||||

|
||||
|
||||
用阿里云盘app扫描二维码,并授权,请主要,不要授权备份目录,仅资源目录即可
|
||||
|
||||

|
||||
|
||||
对Aliyun目录进行mount
|
||||
|
||||

|
||||
|
||||
# 4. 在Plex里导入Aliyun盘的内容
|
||||
|
||||

|
||||
|
||||
目前的策略是,可以用xiaoya选择要看的视频,然后在aliyun盘里移动到相应的目录比如 aliyun-movie, aliyun-tvshows, aliyun-documentory 然后让Plex进行视频刮削,并显示在Plex Media Server里。
|
||||
695
raw/Technical/Home Office/可自动化、可扩展、AI增强的电商数据采集与处理系统.md
Normal file
695
raw/Technical/Home Office/可自动化、可扩展、AI增强的电商数据采集与处理系统.md
Normal file
@@ -0,0 +1,695 @@
|
||||
---
|
||||
title: 安装 Playwright 浏览器
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-11-11
|
||||
description: 可自动化、可扩展、AI增强的电商数据采集与处理系统
|
||||
tags: []
|
||||
link:
|
||||
---
|
||||
|
||||
|
||||
|
||||
|
||||
非常好的思路——你想要的是一个**可自动化、可扩展、AI增强的数据采集与处理系统**,基于 Docker + Ubuntu + n8n 搭建。下面我给你一个详细的设计与工具选择建议,从爬取到分析的整体架构。
|
||||
|
||||
---
|
||||
|
||||
## 🧩 一、系统整体架构建议
|
||||
|
||||
你的目标系统可以分为三个层次:
|
||||
|
||||
|层次|组件|说明|
|
||||
|---|---|---|
|
||||
|**数据采集层(爬虫)**|Scrapy / Playwright / Selenium / Apify|从各大电商网站采集结构化信息(标题、描述、图片、视频等)|
|
||||
|**数据处理层(自动化管道)**|n8n + LLM API (e.g., OpenAI, Ollama, LM Studio)|对采集数据进行清洗、分类、摘要、翻译、属性提取等AI处理|
|
||||
|**存储与展示层**|PostgreSQL / SQLite + MinIO / NAS + Grafana / Metabase|存储文本、图片和视频元数据,并可视化结果|
|
||||
|
||||
---
|
||||
|
||||
## 🕷️ 二、爬虫工具推荐与对比
|
||||
|
||||
|工具|适用场景|优点|缺点|
|
||||
|---|---|---|---|
|
||||
|**Scrapy**|静态页面、电商产品信息|轻量高效、插件生态丰富、可Docker化部署|对JS渲染页面支持弱,需要配合Splash或Playwright|
|
||||
|**Playwright (Python/Node.js)**|动态渲染页面、滚动加载、视频图片加载|可模拟浏览器、支持无头模式、可靠性高|相对重,适合单站点深度采集|
|
||||
|**Apify (Open Source SDK)**|通用网页爬取+API接口+调度|已内置防封禁策略、支持Docker|学习曲线略陡、对纯本地化部署需定制|
|
||||
|**Colly (Go语言)**|高性能爬虫服务、轻量API爬取|性能强、可编译为二进制Docker镜像|JS支持弱,不适合电商复杂页面|
|
||||
|**Crawlee (Node.js)**|Apify的开源核心框架,支持Playwright/Selenium|与n8n、LangChain容易集成|需要JS/TS开发基础|
|
||||
|
||||
**推荐组合:**
|
||||
|
||||
> ✅ **Scrapy + Playwright(或Crawlee + Playwright)**
|
||||
|
||||
- Scrapy 负责结构化抓取、分页调度、下载媒体;
|
||||
|
||||
- Playwright 负责加载动态页面;
|
||||
|
||||
- 两者可通过 Docker Compose 容器化;
|
||||
|
||||
- 输出 JSON 或 CSV 文件供 n8n 消费。
|
||||
|
||||
|
||||
---
|
||||
|
||||
## ⚙️ 三、Docker 架构示例
|
||||
|
||||
|
||||
Scrapy 爬完的数据(JSON/CSV)存放在 `/data`,由 n8n 定时读取和处理。
|
||||
|
||||
---
|
||||
|
||||
## 🤖 四、n8n 中的AI集成与自动化
|
||||
|
||||
在 n8n 中可以通过 workflow 实现整个管线自动化:
|
||||
|
||||
**工作流示例:**
|
||||
|
||||
1. **Cron Trigger** → 定时启动
|
||||
|
||||
2. **Execute Command Node** → 执行 `docker exec scraper scrapy crawl amazon`
|
||||
|
||||
3. **Read File Node** → 读取爬取的 JSON 文件
|
||||
|
||||
4. **OpenAI / Ollama Node** → 调用 LLM 对产品描述提取属性(品牌、型号、价格区间、关键词等)
|
||||
|
||||
5. **Database Node** → 写入 PostgreSQL / SQLite
|
||||
|
||||
6. **Webhook / Email Node** → 生成报表或通知
|
||||
|
||||
|
||||
你也可以用 n8n 的 “HTTP Request Node” 抓取 API 页面(适合公开电商API如阿里、Shopee)。
|
||||
|
||||
---
|
||||
|
||||
## 🧠 五、AI 处理建议
|
||||
|
||||
结合 LLM 做如下任务:
|
||||
|
||||
- **内容摘要与分类**(提炼产品特点)
|
||||
|
||||
- **多语言翻译**
|
||||
|
||||
- **特征提取**(品牌、价格、类别)
|
||||
|
||||
- **异常检测**(自动识别异常价格或缺图产品)
|
||||
|
||||
- **结构化JSON输出**,便于数据库存储
|
||||
|
||||
|
||||
可以本地使用 **Ollama** (Mistral, Llama3) 模型,通过 n8n 的 HTTP Request 调用本地 `http://localhost:11434/api/generate`。
|
||||
|
||||
---
|
||||
|
||||
## 🗄️ 六、数据存储与管理建议
|
||||
|
||||
|数据类型|存储建议|工具|
|
||||
|---|---|---|
|
||||
|文本/结构化数据|PostgreSQL / SQLite|适合AI分析、可视化|
|
||||
|图片/视频|MinIO / 本地NAS|模拟S3存储方式|
|
||||
|Dashboard|Grafana / Metabase|生成电商趋势与分析报表|
|
||||
|
||||
---
|
||||
|
||||
## 🛡️ 七、防封与安全建议
|
||||
|
||||
- 使用 **User-Agent轮换**(Scrapy 内置 `scrapy-user-agents`)
|
||||
|
||||
- **代理池**(BrightData / ScraperAPI / 免费代理)
|
||||
|
||||
- 对同一网站设置 **下载延迟 + 随机化访问**
|
||||
|
||||
- **分布式调度** 可用 `Scrapyd` 或 `Archetype`(Scrapy集群)
|
||||
|
||||
- 不采集个人隐私信息或侵权内容(仅公开页面信息)
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 🚀 八、后续可扩展方向
|
||||
|
||||
- 增加 **FastAPI 服务层**:暴露 REST API 给前端或 BI 工具;
|
||||
|
||||
- 使用 **LangChain** 结合 Vector DB(e.g. Qdrant / Milvus)存储产品语义信息;
|
||||
|
||||
- n8n 可触发自动生成市场趋势报告(AI Summarizer);
|
||||
|
||||
- 可视化电商类目趋势(Grafana + Postgres)。
|
||||
|
||||
|
||||
---
|
||||
|
||||
## ✅ 推荐起步路径
|
||||
|
||||
1. **在 Ubuntu 上安装 Docker + Docker Compose**
|
||||
|
||||
2. 启动基础环境:`scrapy + playwright + n8n`
|
||||
|
||||
3. 选择 1–2 个电商站点(如 Amazon / JD / Taobao)
|
||||
|
||||
4. 构建 Scrapy 爬虫模板
|
||||
|
||||
5. 用 n8n 处理数据并测试 AI 工作流
|
||||
|
||||
6. 逐步扩展至全自动管线
|
||||
|
||||
|
||||
---
|
||||
|
||||
太好了 ✅ 我将为你生成一个**可直接部署的爬虫自动化系统骨架**,基于以下目标设计:
|
||||
|
||||
> **目标:** 在 Ubuntu 上使用 Docker Compose 部署一个自动化电商爬虫系统,采集电商网站产品信息 → 存入本地文件 → 由 n8n 自动读取并利用 AI 处理。
|
||||
|
||||
下面是完整结构与代码示例。
|
||||
|
||||
---
|
||||
|
||||
## 🧩 一、项目目录结构
|
||||
|
||||
```bash
|
||||
ecommerce-crawler/
|
||||
├── docker-compose.yml
|
||||
├── scrapy/
|
||||
│ ├── Dockerfile
|
||||
│ ├── requirements.txt
|
||||
│ ├── scrapy.cfg
|
||||
│ └── ecommerce/
|
||||
│ ├── __init__.py
|
||||
│ ├── items.py
|
||||
│ ├── middlewares.py
|
||||
│ ├── pipelines.py
|
||||
│ ├── settings.py
|
||||
│ └── spiders/
|
||||
│ └── amazon_spider.py
|
||||
├── n8n_data/ # n8n 数据持久化
|
||||
├── data/ # 爬取结果输出目录
|
||||
└── README.md
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 🧱 二、`docker-compose.yml`
|
||||
|
||||
```yaml
|
||||
version: '3.8'
|
||||
services:
|
||||
# Scrapy 爬虫容器
|
||||
scraper:
|
||||
build: ./scrapy
|
||||
container_name: ecommerce-scraper
|
||||
working_dir: /app/scrapy
|
||||
volumes:
|
||||
- ./data:/app/data
|
||||
depends_on:
|
||||
- playwright
|
||||
environment:
|
||||
- PLAYWRIGHT_BROWSERS_PATH=/ms-playwright
|
||||
networks:
|
||||
- crawler-net
|
||||
|
||||
|
||||
# Playwright 浏览器支持容器
|
||||
playwright:
|
||||
image: mcr.microsoft.com/playwright/python:v1.48.0-jammy
|
||||
shm_size: 2gb
|
||||
networks:
|
||||
- crawler-net
|
||||
|
||||
# n8n 自动化平台
|
||||
#n8n:
|
||||
# image: n8nio/n8n:latest
|
||||
# container_name: n8n
|
||||
# ports:
|
||||
# - 5678:5678
|
||||
# environment:
|
||||
# - N8N_BASIC_AUTH_ACTIVE=true
|
||||
# - N8N_BASIC_AUTH_USER=admin
|
||||
# - N8N_BASIC_AUTH_PASSWORD=changeme
|
||||
# - N8N_PATH=/workflows
|
||||
# volumes:
|
||||
# - ./n8n_data:/home/node/.n8n
|
||||
# - ./data:/data
|
||||
# networks:
|
||||
# - crawler-net
|
||||
|
||||
networks:
|
||||
crawler-net:
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 🐍 三、Scrapy 部分
|
||||
|
||||
### `scrapy/Dockerfile`
|
||||
|
||||
```dockerfile
|
||||
FROM mcr.microsoft.com/playwright/python:v1.48.0-jammy
|
||||
|
||||
WORKDIR /app
|
||||
COPY requirements.txt .
|
||||
RUN pip install --no-cache-dir -r requirements.txt
|
||||
COPY . .
|
||||
|
||||
# 安装 Playwright 浏览器
|
||||
RUN playwright install
|
||||
|
||||
WORKDIR /app
|
||||
CMD ["scrapy", "crawl", "amazon"]
|
||||
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### `scrapy/requirements.txt`
|
||||
|
||||
```txt
|
||||
scrapy==2.13.3
|
||||
playwright==1.48.0
|
||||
scrapy-playwright==0.0.44
|
||||
```
|
||||
|
||||
> 说明:`scrapy-playwright` 插件可直接让 Scrapy 调用 Playwright 渲染动态页面,非常适合电商网站。
|
||||
|
||||
---
|
||||
|
||||
### `scrapy/scrapy.cfg`
|
||||
|
||||
```ini
|
||||
[settings]
|
||||
default = settings
|
||||
|
||||
[deploy]
|
||||
# 如果你将来要用 scrapyd 部署,可以在这里定义目标(可忽略)
|
||||
# url = http://localhost:6800/
|
||||
# project = crawler
|
||||
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### `scrapy/ecommerce/settings.py`
|
||||
|
||||
```python
|
||||
BOT_NAME = "scrapy"
|
||||
|
||||
SPIDER_MODULES = ["spiders"] # 指向当前目录下的 spiders
|
||||
NEWSPIDER_MODULE = "spiders" # 新建 spider 时默认放在这里
|
||||
|
||||
ROBOTSTXT_OBEY = False
|
||||
DOWNLOAD_DELAY = 2
|
||||
|
||||
DOWNLOAD_HANDLERS = {
|
||||
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
|
||||
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
|
||||
}
|
||||
|
||||
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
|
||||
|
||||
PLAYWRIGHT_LAUNCH_OPTIONS = {
|
||||
"headless": True,
|
||||
"args": ["--no-sandbox", "--disable-setuid-sandbox"],
|
||||
}
|
||||
PLAYWRIGHT_BROWSER_TYPE = "chromium"
|
||||
|
||||
FEEDS = {
|
||||
"/app/data/amazon.json": {"format": "json", "overwrite": True},
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### `scrapy/ecommerce/items.py`
|
||||
|
||||
```python
|
||||
import scrapy
|
||||
|
||||
class ProductItem(scrapy.Item):
|
||||
title = scrapy.Field()
|
||||
price = scrapy.Field()
|
||||
rating = scrapy.Field()
|
||||
image_urls = scrapy.Field()
|
||||
images = scrapy.Field()
|
||||
product_url = scrapy.Field()
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### `scrapy/ecommerce/pipelines.py`
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
class JsonWriterPipeline:
|
||||
def open_spider(self, spider):
|
||||
self.file = open("data/products.json", "w", encoding="utf-8")
|
||||
self.file.write("[\n")
|
||||
|
||||
def close_spider(self, spider):
|
||||
self.file.write("]\n")
|
||||
self.file.close()
|
||||
|
||||
def process_item(self, item, spider):
|
||||
line = json.dumps(dict(item), ensure_ascii=False) + ",\n"
|
||||
self.file.write(line)
|
||||
return item
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### `scrapy/ecommerce/spiders/amazon_spider.py`
|
||||
|
||||
> ⚠️ 仅作演示用途,使用通用搜索页采集,不涉及登录或侵权内容。
|
||||
|
||||
```python
|
||||
import scrapy
|
||||
from scrapy_playwright.page import PageMethod
|
||||
|
||||
class QuotesSpider(scrapy.Spider):
|
||||
name = "amazon"
|
||||
start_urls = ["https://quotes.toscrape.com/js/"]
|
||||
|
||||
custom_settings = {
|
||||
"PLAYWRIGHT_LAUNCH_OPTIONS": {"headless": True},
|
||||
"PLAYWRIGHT_CONTEXT_ARGS": {"viewport": {"width": 1280, "height": 720}},
|
||||
}
|
||||
|
||||
def start_requests(self):
|
||||
for url in self.start_urls:
|
||||
yield scrapy.Request(
|
||||
url,
|
||||
meta={
|
||||
"playwright": True,
|
||||
"playwright_page_methods": [
|
||||
PageMethod("wait_for_selector", "div.quote")
|
||||
],
|
||||
},
|
||||
)
|
||||
|
||||
async def parse(self, response):
|
||||
quotes = response.css("div.quote")
|
||||
for quote in quotes:
|
||||
text = quote.css("span.text::text").get()
|
||||
author = quote.css("small.author::text").get()
|
||||
yield {"text": text, "author": author}
|
||||
|
||||
# 翻页
|
||||
next_page = response.css("li.next a::attr(href)").get()
|
||||
if next_page:
|
||||
next_url = response.urljoin(next_page)
|
||||
yield scrapy.Request(
|
||||
next_url,
|
||||
meta={
|
||||
"playwright": True,
|
||||
"playwright_page_methods": [
|
||||
PageMethod("wait_for_selector", "div.quote")
|
||||
],
|
||||
},
|
||||
callback=self.parse
|
||||
)
|
||||
```
|
||||
|
||||
### `scrapy/ecommerce/spiders/__init__.py`
|
||||
|
||||
```python
|
||||
#empty
|
||||
```
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
## ⚙️ 四、运行方式
|
||||
|
||||
```bash
|
||||
# 1. 构建并启动所有容器
|
||||
docker compose up --build -d
|
||||
|
||||
# 2. 进入 Scrapy 容器执行爬虫
|
||||
docker exec -it ecommerce-scraper scrapy crawl amazon
|
||||
|
||||
# 3. 查看数据
|
||||
cat data/products.json
|
||||
```
|
||||
|
||||
### Docker 命令
|
||||
|
||||
|
||||
``` bash
|
||||
docker compose down -v
|
||||
docker compose up --build -d
|
||||
|
||||
docker exec -it ecommerce-scraper bash
|
||||
|
||||
#进入交互模式
|
||||
docker run -it --entrypoint bash ecommerce-scraper
|
||||
```
|
||||
---
|
||||
|
||||
## 🤖 五、n8n 自动化流程(示例)
|
||||
|
||||
你可以在 n8n Web UI([http://localhost:5678)导入如下逻辑:](http://localhost:5678%EF%BC%89%E5%AF%BC%E5%85%A5%E5%A6%82%E4%B8%8B%E9%80%BB%E8%BE%91%EF%BC%9A/)
|
||||
|
||||
**Workflow 示例逻辑:**
|
||||
|
||||
1. **Cron Node**:每天凌晨触发
|
||||
|
||||
2. **Execute Command Node**:执行命令
|
||||
`docker exec ecommerce-scraper scrapy crawl amazon`
|
||||
|
||||
3. **Read File Node**:读取 `/data/products.json`
|
||||
|
||||
4. **OpenAI Node**(或 HTTP Request 调本地 Ollama):
|
||||
|
||||
- Prompt 示例:
|
||||
|
||||
```text
|
||||
从以下JSON中提取每个产品的简短摘要(不超过30字)并分类。
|
||||
```
|
||||
|
||||
5. **Write to Database Node**(或 Google Sheet / CSV)
|
||||
保存提炼结果
|
||||
|
||||
6. **Telegram / Email Node**
|
||||
发送日报通知
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 💡 六、后续增强建议
|
||||
|
||||
|功能|工具|说明|
|
||||
|---|---|---|
|
||||
|图像下载/视频下载|Scrapy 自带 `ImagesPipeline` 或 `requests`|下载并存储本地或 MinIO|
|
||||
|多站点并行爬取|Scrapy 多 Spider + n8n 并行调度|自动轮询不同站点|
|
||||
|数据可视化|Metabase / Grafana|接 PostgreSQL 实时展示产品趋势|
|
||||
|向量搜索|Qdrant / Weaviate|用于AI语义检索|
|
||||
|本地AI处理|Ollama + Llama3|替代外部API|
|
||||
|
||||
---
|
||||
|
||||
是否希望我帮你再生成一个 **完整可导入的 n8n workflow JSON 文件模板**(包含 Cron、执行 Scrapy、读取 JSON、调用 AI、存入数据库)?
|
||||
这样你只需导入到 n8n UI 就能立即自动化整个流程。
|
||||
|
||||
非常好 👍
|
||||
下面是一个**完整可导入的 n8n Workflow JSON 模板**,它能自动:
|
||||
|
||||
1️⃣ 定时运行 Scrapy 爬虫(通过 Docker 命令)
|
||||
2️⃣ 读取爬取的数据(`products.json`)
|
||||
3️⃣ 调用 AI(可选择 OpenAI 或本地 Ollama)进行摘要与分类
|
||||
4️⃣ 存入数据库或文件
|
||||
5️⃣ 发送报告通知
|
||||
|
||||
---
|
||||
|
||||
## 🧩 一、Workflow 功能概览
|
||||
|
||||
|步骤|节点类型|功能|
|
||||
|---|---|---|
|
||||
|1|**Cron Trigger**|每天凌晨 2:00 自动触发|
|
||||
|2|**Execute Command**|执行 `docker exec ecommerce-scraper scrapy crawl amazon`|
|
||||
|3|**Read Binary File**|读取 `/data/products.json`|
|
||||
|4|**OpenAI (或 HTTP Request)**|提炼摘要与分类(可切换 Ollama)|
|
||||
|5|**Write Binary File**|输出 `data/products_summary.json`|
|
||||
|6|**Email (或 Telegram)**|发送日报通知|
|
||||
|
||||
---
|
||||
|
||||
## 📦 二、Workflow JSON 模板(可直接导入)
|
||||
|
||||
将以下 JSON 内容保存为
|
||||
👉 `workflow_ecommerce_automation.json`
|
||||
然后在 n8n Web UI → **Import from file** 导入。
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "Ecommerce Crawler + AI Summary",
|
||||
"nodes": [
|
||||
{
|
||||
"parameters": {
|
||||
"triggerTimes": {
|
||||
"item": [
|
||||
{
|
||||
"mode": "everyDay",
|
||||
"hour": 2
|
||||
}
|
||||
]
|
||||
}
|
||||
},
|
||||
"id": "1",
|
||||
"name": "Cron Trigger",
|
||||
"type": "n8n-nodes-base.cron",
|
||||
"typeVersion": 1,
|
||||
"position": [250, 250]
|
||||
},
|
||||
{
|
||||
"parameters": {
|
||||
"command": "docker exec ecommerce-scraper scrapy crawl amazon"
|
||||
},
|
||||
"id": "2",
|
||||
"name": "Run Scrapy Crawler",
|
||||
"type": "n8n-nodes-base.executeCommand",
|
||||
"typeVersion": 1,
|
||||
"position": [500, 250]
|
||||
},
|
||||
{
|
||||
"parameters": {
|
||||
"path": "/data/products.json",
|
||||
"options": {}
|
||||
},
|
||||
"id": "3",
|
||||
"name": "Read Products JSON",
|
||||
"type": "n8n-nodes-base.readBinaryFile",
|
||||
"typeVersion": 1,
|
||||
"position": [750, 250]
|
||||
},
|
||||
{
|
||||
"parameters": {
|
||||
"functionCode": "const data = JSON.parse(Buffer.from(items[0].binary.data.data, 'base64').toString());\nreturn data.map(p => ({ json: p }));"
|
||||
},
|
||||
"id": "4",
|
||||
"name": "Parse JSON",
|
||||
"type": "n8n-nodes-base.function",
|
||||
"typeVersion": 1,
|
||||
"position": [1000, 250]
|
||||
},
|
||||
{
|
||||
"parameters": {
|
||||
"model": "gpt-4-turbo",
|
||||
"prompt": "你是一个电商产品分析助手。请从以下产品信息中提取每个产品的简短摘要(不超过30字)并归类到相应产品类别。\n\n输入数据:{{$json[\"title\"]}},价格:{{$json[\"price\"]}},评分:{{$json[\"rating\"]}}。\n\n输出格式:{\"title\":\"...\",\"summary\":\"...\",\"category\":\"...\"}"
|
||||
},
|
||||
"id": "5",
|
||||
"name": "AI Summarize & Categorize",
|
||||
"type": "n8n-nodes-base.openAi",
|
||||
"typeVersion": 2,
|
||||
"position": [1250, 250],
|
||||
"credentials": {
|
||||
"openAIApi": {
|
||||
"id": "YOUR-OPENAI-CREDENTIAL-ID",
|
||||
"name": "OpenAI API"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"parameters": {
|
||||
"fileName": "/data/products_summary.json",
|
||||
"options": {},
|
||||
"dataPropertyName": "json"
|
||||
},
|
||||
"id": "6",
|
||||
"name": "Write Summary JSON",
|
||||
"type": "n8n-nodes-base.writeBinaryFile",
|
||||
"typeVersion": 1,
|
||||
"position": [1500, 250]
|
||||
},
|
||||
{
|
||||
"parameters": {
|
||||
"fromEmail": "noreply@yourdomain.com",
|
||||
"toEmail": "your@email.com",
|
||||
"subject": "Daily Product Summary Report",
|
||||
"text": "今日电商产品摘要已生成,请查看 /data/products_summary.json 文件。"
|
||||
},
|
||||
"id": "7",
|
||||
"name": "Send Email Notification",
|
||||
"type": "n8n-nodes-base.emailSend",
|
||||
"typeVersion": 1,
|
||||
"position": [1750, 250]
|
||||
}
|
||||
],
|
||||
"connections": {
|
||||
"Cron Trigger": { "main": [[{ "node": "Run Scrapy Crawler", "type": "main", "index": 0 }]] },
|
||||
"Run Scrapy Crawler": { "main": [[{ "node": "Read Products JSON", "type": "main", "index": 0 }]] },
|
||||
"Read Products JSON": { "main": [[{ "node": "Parse JSON", "type": "main", "index": 0 }]] },
|
||||
"Parse JSON": { "main": [[{ "node": "AI Summarize & Categorize", "type": "main", "index": 0 }]] },
|
||||
"AI Summarize & Categorize": { "main": [[{ "node": "Write Summary JSON", "type": "main", "index": 0 }]] },
|
||||
"Write Summary JSON": { "main": [[{ "node": "Send Email Notification", "type": "main", "index": 0 }]] }
|
||||
},
|
||||
"active": true
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 🧠 三、使用说明
|
||||
|
||||
1. **导入流程**
|
||||
|
||||
- 访问 `http://<你的服务器IP>:5678`
|
||||
|
||||
- 点击右上角「Import from File」→ 选择上面的 JSON 文件
|
||||
|
||||
2. **配置 OpenAI 凭证**
|
||||
|
||||
- n8n → Credentials → 新建 OpenAI API Key
|
||||
|
||||
- 将 `YOUR-OPENAI-CREDENTIAL-ID` 替换为对应 ID
|
||||
|
||||
- 若使用本地 Ollama,则:
|
||||
|
||||
- 替换节点 `AI Summarize & Categorize` 为 “HTTP Request”
|
||||
|
||||
- URL 填入 `http://ollama:11434/api/generate`
|
||||
|
||||
- POST body 示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "llama3",
|
||||
"prompt": "分析以下产品信息:{{$json[\"title\"]}} ..."
|
||||
}
|
||||
```
|
||||
|
||||
3. **设置邮箱凭证**
|
||||
|
||||
- n8n → Credentials → Email Send (SMTP)
|
||||
|
||||
- 支持 Gmail, Outlook, AWS SES 等
|
||||
|
||||
4. **测试运行**
|
||||
|
||||
- 手动点击 ▶️ 运行
|
||||
|
||||
- 查看 `/data/products_summary.json`
|
||||
|
||||
- 邮箱将收到日报通知
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 🚀 四、可选扩展
|
||||
|
||||
|目标|实现方式|
|
||||
|---|---|
|
||||
|改为多站点爬取|添加更多 spider(如 `jd_spider.py`, `ebay_spider.py`)并在 n8n 串联运行|
|
||||
|增加数据库写入|在 n8n 中加入 “PostgreSQL Node” 写入产品与AI摘要|
|
||||
|生成图表报表|把数据库接入 Grafana / Metabase|
|
||||
|向量检索增强|在 n8n 中调用 Qdrant 插入语义向量|
|
||||
|
||||
---
|
||||
|
||||
是否希望我在下一步帮你生成一个适配 **Ollama 本地模型(离线AI处理)** 的 workflow 版本?
|
||||
它将不依赖外部API,完全在本地自动运行分析。
|
||||
|
||||
|
||||
|
||||
@@ -0,0 +1,429 @@
|
||||
---
|
||||
title: 一、系统要求
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [ollama, openclaw, qwen, qwen-coder, ubuntu]
|
||||
---
|
||||
|
||||
|
||||
#ubuntu #ollama #qwen-coder #qwen #openclaw
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
# 一、系统要求
|
||||
|
||||
运行 `qwen2.5-coder:7b` 推荐配置:
|
||||
|
||||
| 资源 | 最低 | 推荐 |
|
||||
| ---- | ------- | ---------- |
|
||||
| CPU | 4 cores | 8+ cores |
|
||||
| RAM | 8GB | 16GB |
|
||||
| GPU | 无需 | NVIDIA GPU |
|
||||
| Disk | 10GB | 20GB |
|
||||
| | | |
|
||||
|
||||
模型大小:
|
||||
|
||||
```
|
||||
约 4.5GB
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 二、Ubuntu 安装 Ollama
|
||||
|
||||
## 1 更新系统
|
||||
|
||||
```bash
|
||||
sudo apt update
|
||||
sudo apt upgrade -y
|
||||
```
|
||||
|
||||
安装 curl
|
||||
|
||||
```bash
|
||||
sudo apt install -y curl
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 2 安装 Ollama
|
||||
|
||||
执行官方安装脚本:
|
||||
|
||||
```bash
|
||||
curl -fsSL https://ollama.com/install.sh | sh
|
||||
```
|
||||
|
||||
安装过程会自动:
|
||||
|
||||
- 安装 `ollama` CLI
|
||||
- 创建 systemd 服务
|
||||
- 启动 Ollama API
|
||||
|
||||
---
|
||||
|
||||
## 3 验证安装
|
||||
|
||||
```bash
|
||||
ollama --version
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
ollama version 0.5.x
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 三、启动 Ollama 服务
|
||||
|
||||
检查状态:
|
||||
|
||||
```bash
|
||||
systemctl status ollama
|
||||
```
|
||||
|
||||
如果未运行:
|
||||
|
||||
```bash
|
||||
sudo systemctl start ollama
|
||||
```
|
||||
|
||||
开机启动:
|
||||
|
||||
```bash
|
||||
sudo systemctl enable ollama
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 四、下载 Qwen2.5-Coder 7B
|
||||
|
||||
下载模型:
|
||||
|
||||
```bash
|
||||
ollama pull qwen2.5-coder:7b
|
||||
```
|
||||
|
||||
下载大小:
|
||||
|
||||
```
|
||||
≈ 4.5GB
|
||||
```
|
||||
|
||||
下载完成查看:
|
||||
|
||||
```bash
|
||||
ollama list
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
NAME SIZE
|
||||
qwen2.5-coder:7b 4.6 GB
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 五、运行模型
|
||||
|
||||
启动交互模式:
|
||||
|
||||
```bash
|
||||
ollama run qwen2.5-coder:7b
|
||||
```
|
||||
|
||||
终端将进入:
|
||||
|
||||
```
|
||||
>>> Send a message (/? for help)
|
||||
```
|
||||
|
||||
测试:
|
||||
|
||||
```
|
||||
Write a Python script to monitor CPU usage
|
||||
```
|
||||
|
||||
模型会生成代码。
|
||||
|
||||
---
|
||||
|
||||
# 六、通过 API 调用
|
||||
|
||||
Ollama 默认提供 REST API:
|
||||
|
||||
```
|
||||
http://localhost:11434
|
||||
```
|
||||
|
||||
测试 API:
|
||||
|
||||
```bash
|
||||
curl http://localhost:11434/api/chat -d '{
|
||||
"model": "qwen2.5-coder:7b",
|
||||
"messages": [
|
||||
{"role": "user", "content": "Write a bash script to backup a directory"}
|
||||
]
|
||||
}'
|
||||
```
|
||||
|
||||
返回示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": "Here is a bash backup script..."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 七、Python 调用
|
||||
|
||||
安装 SDK:
|
||||
|
||||
```bash
|
||||
pip install ollama
|
||||
```
|
||||
|
||||
示例代码:
|
||||
|
||||
```python
|
||||
from ollama import chat
|
||||
|
||||
response = chat(
|
||||
model="qwen2.5-coder:7b",
|
||||
messages=[
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Write a Python script to parse a CSV file"
|
||||
}
|
||||
]
|
||||
)
|
||||
|
||||
print(response["message"]["content"])
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 八、NodeJS 调用
|
||||
|
||||
安装 SDK:
|
||||
|
||||
```bash
|
||||
npm install ollama
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```javascript
|
||||
import ollama from 'ollama'
|
||||
|
||||
const response = await ollama.chat({
|
||||
model: 'qwen2.5-coder:7b',
|
||||
messages: [
|
||||
{ role: 'user', content: 'Write a docker-compose for n8n and postgres' }
|
||||
]
|
||||
})
|
||||
|
||||
console.log(response.message.content)
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 九、开放远程 API(推荐)
|
||||
|
||||
默认只监听:
|
||||
|
||||
```
|
||||
127.0.0.1
|
||||
```
|
||||
|
||||
如果要给:
|
||||
|
||||
- n8n
|
||||
|
||||
- OpenClaw
|
||||
|
||||
- WebUI
|
||||
|
||||
- Agent
|
||||
|
||||
|
||||
使用,需要修改。
|
||||
|
||||
编辑:
|
||||
|
||||
```
|
||||
/etc/systemd/system/ollama.service
|
||||
```
|
||||
|
||||
增加:
|
||||
|
||||
```
|
||||
Environment="OLLAMA_HOST=0.0.0.0"
|
||||
```
|
||||
|
||||
重新加载:
|
||||
|
||||
```bash
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl restart ollama
|
||||
```
|
||||
|
||||
访问:
|
||||
|
||||
```
|
||||
http://服务器IP:11434
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 十、GPU 加速(可选)
|
||||
|
||||
检查 GPU:
|
||||
|
||||
```bash
|
||||
nvidia-smi
|
||||
```
|
||||
|
||||
如果安装了 CUDA:
|
||||
|
||||
Ollama 会 **自动使用 GPU**。
|
||||
|
||||
无需额外配置。
|
||||
|
||||
---
|
||||
|
||||
# 十一、模型管理
|
||||
|
||||
查看模型:
|
||||
|
||||
```bash
|
||||
ollama list
|
||||
```
|
||||
|
||||
删除模型:
|
||||
|
||||
```bash
|
||||
ollama rm qwen2.5-coder:7b
|
||||
```
|
||||
|
||||
更新模型:
|
||||
|
||||
```bash
|
||||
ollama pull qwen2.5-coder:7b
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 十二、性能优化
|
||||
|
||||
如果机器较小:
|
||||
|
||||
推荐:
|
||||
|
||||
```
|
||||
qwen2.5-coder:3b
|
||||
```
|
||||
|
||||
下载:
|
||||
|
||||
```bash
|
||||
ollama pull qwen2.5-coder:3b
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 十三、推荐搭配工具
|
||||
|
||||
如果你正在做 **AI automation / agent / coding**
|
||||
|
||||
建议搭配:
|
||||
|
||||
|工具|用途|
|
||||
|---|---|
|
||||
|Open WebUI|ChatGPT UI|
|
||||
|n8n|AI automation|
|
||||
|LangChain|Agent framework|
|
||||
|OpenClaw|AI coding agent|
|
||||
|
||||
例如 OpenClaw 配置:
|
||||
|
||||
```
|
||||
ollama/qwen2.5-coder:7b
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 十四、最简安装流程(3条命令)
|
||||
|
||||
如果你只想快速安装:
|
||||
|
||||
```bash
|
||||
curl -fsSL https://ollama.com/install.sh | sh
|
||||
|
||||
ollama pull qwen2.5-coder:7b
|
||||
|
||||
ollama run qwen2.5-coder:7b
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 十五、一个很多人不知道的优化(非常重要)
|
||||
|
||||
如果你打算做:
|
||||
|
||||
- DevOps automation
|
||||
|
||||
- SQL Agent
|
||||
|
||||
- Kubernetes troubleshooting
|
||||
|
||||
- n8n workflow AI
|
||||
|
||||
|
||||
强烈建议使用:
|
||||
|
||||
```
|
||||
qwen2.5-coder:7b
|
||||
```
|
||||
|
||||
原因:
|
||||
|
||||
- Tool usage能力强
|
||||
|
||||
- Shell / Python / SQL理解强
|
||||
|
||||
- Repo级代码理解
|
||||
|
||||
|
||||
比普通 `qwen2.5:7b` **更适合工程任务**。
|
||||
|
||||
---
|
||||
|
||||
如果需要,我可以再给你一份 **更高级部署指南**:
|
||||
|
||||
**《Ubuntu 本地 AI Stack:Ollama + Qwen2.5-Coder + OpenWebUI + n8n + Agent 自动化》**
|
||||
|
||||
会包含:
|
||||
|
||||
- 本地 ChatGPT UI
|
||||
|
||||
- AI Coding Agent
|
||||
|
||||
- 自动化工作流
|
||||
|
||||
- DevOps AI 助手
|
||||
|
||||
|
||||
基本上是一套 **完整的本地 AI 基础设施(非常适合开发者)**。
|
||||
816
raw/Technical/Home Office/通过VPS+内网反向代理实现域名访问内网穿透.md
Normal file
816
raw/Technical/Home Office/通过VPS+内网反向代理实现域名访问内网穿透.md
Normal file
@@ -0,0 +1,816 @@
|
||||
#vps #caddy #frp #reverse-proxy #troubleshooting #cloudflare
|
||||
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
|
||||
思路:Aliyun DNS 指向 公网上的一台VPS,VPS 上运行 Caddy;内网主机通过 frp 将服务暴露到 VPS(本地 127.0.0.1 或某个端口),VPS 反向代理到该端口。
|
||||
|
||||
- 在 VPS 上运行 `frps`(frp server)。
|
||||
|
||||
- 在每个内网设备运行 `frpc` (frp client),将本地服务映射到 VPS 上的独立端口或域名映射(frp 支持 http/https 映射,和 subdomain 映射需要 frp 企业/配置域名解析到 VPS)。
|
||||
|
||||
- VPS 上的 Caddy 反向代理到 frps 映射端口(127.0.0.1:xxxxx)。
|
||||
|
||||
frp 优点:专为内网穿透设计,支持 NAT、自动重连、Web 管理面板(可选)。推荐当你有多台设备和多端口时使用。
|
||||
|
||||
|
||||
# 前置共识(已知条件)
|
||||
|
||||
- 域名:`ishenwei.online`(在阿里云 DNS 控制台管理)
|
||||
|
||||
- 内网服务:
|
||||
|
||||
- NAS:`192.168.3.17:5000`(对应 `nas.ishenwei.online`)
|
||||
|
||||
- Ubuntu1 n8n:`192.168.3.47:5678`(希望对应 `n8n.ishenwei.online`)
|
||||
- Ubuntu1 transmission: `192.168.3.47:9091`(希望对应 `transmission.ishenwei.online`)
|
||||
- Ubuntu1 Grafana: `192.168.3.47:3000`(希望对应 `grafana.ishenwei.online`)
|
||||
|
||||
- 你有一台公网 VPS(Ubuntu,可用于反代或做中继)IP: `192.227.222.142`(固定)
|
||||
|
||||
|
||||
## 🧭 目标
|
||||
|
||||
- 公网 VPS(Ubuntu,公网 IP = `192.227.222.142`)
|
||||
|
||||
- 内网 NAS (`192.168.3.17:5000`)
|
||||
|
||||
- 内网 Ubuntu (`192.168.3.47:5678`)
|
||||
|
||||
- 通过 `frp` 建立安全的反向隧道
|
||||
|
||||
- 通过 `Caddy` 在 VPS 上为每个子域名提供 HTTPS 域名访问:
|
||||
|
||||
|
||||
| 域名 | 映射目标 |
|
||||
| ---------------------------------------------------------- | ---------------------------- |
|
||||
| [https://nas.ishenwei.online](https://nas.ishenwei.online) | → NAS `192.168.3.17:5000` |
|
||||
| [https://n8n.ishenwei.online](https://n8n.ishenwei.online) | → Ubuntu `192.168.3.47:5678` |
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
公网VPS(frps服务端)
|
||||
↓(公网端口转发)
|
||||
192.227.222.142
|
||||
↓
|
||||
通过 frp 反向代理访问内网主机
|
||||
↓
|
||||
内网 Ubuntu (192.168.3.47) 启动 frpc
|
||||
├─ n8n 服务 (5678)
|
||||
├─ Transmission (9091)
|
||||
└─ Grafana (3000)
|
||||
|
||||
## 🧱 拓扑图
|
||||
|
||||
Internet
|
||||
│
|
||||
▼
|
||||
┌──────────────────────────┐
|
||||
│ VPS (192.227.222.142) │
|
||||
│ - frps (监听 7000) │
|
||||
│ - Caddy (80/443 TLS) │
|
||||
│ ├─ nas.ishenwei.online → 127.0.0.1:15000 (映射NAS:5000)
|
||||
│ └─ n8n.ishenwei.online → 127.0.0.1:15678 (映射Ubuntu:5678)
|
||||
└──────────────────────────┘
|
||||
▲ ▲
|
||||
│ frp tunnel │ frp tunnel
|
||||
┌────────────┐ ┌────────────┐
|
||||
│ NAS (192.168.3.17) │ │ Ubuntu (192.168.3.47) │
|
||||
│ frpc.ini │ │ frpc.ini │
|
||||
│ 映射5000→15000 │ │ 映射5678→15678 │
|
||||
└────────────┘ └────────────┘
|
||||
|
||||
## 🧩 第 1 步:阿里云 DNS 配置
|
||||
|
||||
进入阿里云控制台 → 域名解析:
|
||||
|
||||
| 主机记录 | 记录类型 | 记录值 | TTL |
|
||||
| ---- | ---- | --------------- | --- |
|
||||
| nas | A | 192.227.222.142 | 600 |
|
||||
| n8n | A | 192.227.222.142 | 600 |
|
||||
|
||||
保存即可。
|
||||
验证命令(任意机器执行):
|
||||
|
||||
`dig nas.ishenwei.online +short # 应返回 192.227.222.142
|
||||
|
||||
## 🧩 第 2 步:在 VPS 安装 Caddy + frps
|
||||
|
||||
### 1️⃣ 安装 Caddy
|
||||
|
||||
``` bash
|
||||
sudo apt install -y debian-keyring debian-archive-keyring apt-transport-https curl curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/gpg.key' | sudo gpg --dearmor -o /usr/share/keyrings/caddy-stable-archive-keyring.gpg curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/debian.deb.txt' | sudo tee /etc/apt/sources.list.d/caddy-stable.list chmod o+r /usr/share/keyrings/caddy-stable-archive-keyring.gpg chmod o+r /etc/apt/sources.list.d/caddy-stable.list sudo apt update sudo apt install caddy
|
||||
```
|
||||
|
||||
Caddy 安装后会自动作为系统服务运行。
|
||||
|
||||
---
|
||||
|
||||
### 2️⃣ 安装 frps(frp 服务端)
|
||||
|
||||
``` bash
|
||||
cd /opt
|
||||
sudo mkdir frp && cd frp
|
||||
FRP_VER=0.65.0 # 若有更新,可替换版本号
|
||||
sudo curl -LO https://github.com/fatedier/frp/releases/download/v${FRP_VER}/frp_${FRP_VER}_linux_amd64.tar.gz
|
||||
sudo tar xzf frp_${FRP_VER}_linux_amd64.tar.gz
|
||||
sudo mv frp_${FRP_VER}_linux_amd64/* /opt/frp/
|
||||
|
||||
```
|
||||
|
||||
创建配置文件 `/opt/frp/frps.ini`:
|
||||
``` bash
|
||||
[common]
|
||||
bind_addr = 0.0.0.0
|
||||
bind_port = 7000
|
||||
|
||||
|
||||
---
|
||||
title: 前置共识(已知条件)
|
||||
author: shenwei
|
||||
tags: [caddy, cloudflare, frp, log, reverse-proxy, troubleshooting, vps]
|
||||
---
|
||||
---
|
||||
title: 前置共识(已知条件)
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [caddy, cloudflare, frp, log, reverse-proxy, troubleshooting, vps]
|
||||
---
|
||||
|
||||
# Dashboard
|
||||
dashboard_addr = 0.0.0.0
|
||||
dashboard_port = 7500
|
||||
dashboard_user = admin
|
||||
dashboard_pwd = StrongPassword123!
|
||||
|
||||
# 认证 Token
|
||||
token = Gg8sqHJVgh42KQ0oTatMjl6AywWqAzaaT0B77a4qD46tXtoH9j9mXb2k1YitObhs
|
||||
|
||||
|
||||
```
|
||||
|
||||
创建 systemd 单元 `/etc/systemd/system/frps.service`:
|
||||
``` bash
|
||||
[Unit]
|
||||
Description=frp server (frps)
|
||||
After=network.target
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/opt/frp/frps -c /opt/frp/frps.ini
|
||||
Restart=on-failure
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
```
|
||||
|
||||
启动:
|
||||
```
|
||||
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable --now frps
|
||||
|
||||
```
|
||||
|
||||
验证:
|
||||
|
||||
```
|
||||
sudo systemctl status frps
|
||||
ss -ltnp | grep 7000
|
||||
|
||||
```
|
||||
|
||||
### 3️⃣ VPS 防火墙设置(允许必要端口)
|
||||
``` bash
|
||||
sudo ufw allow OpenSSH
|
||||
sudo ufw allow 80/tcp
|
||||
sudo ufw allow 443/tcp
|
||||
sudo ufw allow 7000/tcp # frp server 端口
|
||||
sudo ufw allow 7050 # frp server dashboard
|
||||
sudo ufw allow 60022 # Ubuntu SSH
|
||||
sudo ufw allow 60023 # NAS SSH
|
||||
sudo ufw allow 65005 # webdav
|
||||
sudo ufw allow 63306 # NAS mysql
|
||||
sudo ufw allow 60080 # NAS web
|
||||
sudo ufw enable
|
||||
sudo ufw status verbose
|
||||
```
|
||||
|
||||
如果你想让 frp dashboard 从本地访问:`ssh -L 7500:127.0.0.1:7500 ubuntu@192.227.222.142`,然后本地打开 `http://127.0.0.1:7500`。
|
||||
|
||||
## 🧩 第 3 步:在 NAS 与内网 Ubuntu 安装 frpc
|
||||
|
||||
两台机器都执行以下步骤(路径、端口配置不同)
|
||||
### 2️⃣ 安装 frps(frp 服务端)
|
||||
``` bash
|
||||
cd /opt
|
||||
sudo mkdir frp && cd frp
|
||||
FRP_VER=0.65.0 # 若有更新,可替换版本号
|
||||
sudo curl -LO https://github.com/fatedier/frp/releases/download/v${FRP_VER}/frp_${FRP_VER}_linux_amd64.tar.gz
|
||||
sudo tar xzf frp_${FRP_VER}_linux_amd64.tar.gz
|
||||
sudo mv frp_${FRP_VER}_linux_amd64/* /opt/frp/
|
||||
|
||||
```
|
||||
|
||||
### 3️⃣ 内网 NAS(192.168.3.17)配置
|
||||
|
||||
创建 `/opt/frp/frpc.ini`:
|
||||
``` bash
|
||||
[common]
|
||||
server_addr = 192.227.222.142
|
||||
server_port = 7000
|
||||
token = Gg8sqHJVgh42KQ0oTatMjl6AywWqAzaaT0B77a4qD46tXtoH9j9mXb2k1YitObhs
|
||||
|
||||
# 每个本地服务一个 section
|
||||
# nas 映射: 本地 5000 -> VPS 127.0.0.1:15000
|
||||
[nas]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 5000
|
||||
remote_port = 15000
|
||||
|
||||
# Navidrome: 本地 4533 -> VPS 127.0.0.1:4533
|
||||
[navidrome]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 4533
|
||||
remote_port = 14533
|
||||
|
||||
# Calibre: 本地 8083 -> VPS 127.0.0.1:18083
|
||||
[calibre]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 8083
|
||||
remote_port = 18083
|
||||
|
||||
[webdav]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 5005
|
||||
remote_port = 60055
|
||||
|
||||
```
|
||||
|
||||
创建 systemd 单元 `/etc/systemd/system/frpc.service`:
|
||||
``` bash
|
||||
|
||||
[Unit]
|
||||
Description=frp client
|
||||
After=network-online.target
|
||||
Wants=network-online.target
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/opt/frp/frpc -c /opt/frp/frpc.ini
|
||||
Restart=on-failure
|
||||
RestartSec=10
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
```
|
||||
|
||||
启动:
|
||||
``` bash
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable --now frpc
|
||||
sudo systemctl status frpc
|
||||
|
||||
```
|
||||
|
||||
如需重启
|
||||
``` bash
|
||||
sudo systemctl restart frpc
|
||||
|
||||
```
|
||||
|
||||
|
||||
### 3️⃣ 内网 Ubuntu(192.168.3.47)配置
|
||||
创建 `/opt/frp/frpc.ini`:
|
||||
``` bash
|
||||
[common]
|
||||
server_addr = 192.227.222.142
|
||||
server_port = 7000
|
||||
token = Gg8sqHJVgh42KQ0oTatMjl6AywWqAzaaT0B77a4qD46tXtoH9j9mXb2k1YitObhs
|
||||
|
||||
# 每个本地服务一个 section
|
||||
# n8n 映射: 本地 5678 -> VPS 127.0.0.1:15678
|
||||
[n8n]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 5678
|
||||
remote_port = 15678
|
||||
|
||||
# Transmission: 本地 9091 -> VPS 127.0.0.1:19091
|
||||
[transmission]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 9091
|
||||
remote_port = 19091
|
||||
|
||||
# Grafana: 本地 3000 -> VPS 127.0.0.1:13000
|
||||
[grafana]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 3000
|
||||
remote_port = 13000
|
||||
|
||||
```
|
||||
|
||||
创建 systemd 单元 `/etc/systemd/system/frpc.service`:
|
||||
``` bash
|
||||
|
||||
[Unit]
|
||||
Description=frp client
|
||||
After=network-online.target
|
||||
Wants=network-online.target
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/opt/frp/frpc -c /opt/frp/frpc.ini
|
||||
Restart=on-failure
|
||||
RestartSec=10
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
```
|
||||
|
||||
启动:
|
||||
``` bash
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable --now frpc
|
||||
sudo systemctl status frpc
|
||||
|
||||
```
|
||||
|
||||
如需重启
|
||||
``` bash
|
||||
sudo systemctl restart frpc
|
||||
|
||||
```
|
||||
|
||||
|
||||
## 🧩 第 4 步:VPS 上配置 Caddy 反向代理
|
||||
编辑 `/etc/caddy/Caddyfile`:
|
||||
|
||||
``` bash
|
||||
# The Caddyfile is an easy way to configure your Caddy web server.
|
||||
#
|
||||
# Unless the file starts with a global options block, the first
|
||||
# uncommented line is always the address of your site.
|
||||
#
|
||||
# To use your own domain name (with automatic HTTPS), first make
|
||||
# sure your domain's A/AAAA DNS records are properly pointed to
|
||||
# this machine's public IP, then replace ":80" below with your
|
||||
# domain name.
|
||||
|
||||
:80 {
|
||||
# Set this path to your site's directory.
|
||||
root * /usr/share/caddy
|
||||
|
||||
# Enable the static file server.
|
||||
file_server
|
||||
|
||||
# Another common task is to set up a reverse proxy:
|
||||
# reverse_proxy localhost:8080
|
||||
|
||||
# Or serve a PHP site through php-fpm:
|
||||
# php_fastcgi localhost:9000
|
||||
}
|
||||
|
||||
|
||||
n8n.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:15678
|
||||
#log {
|
||||
# output file /var/log/caddy/n8n.access.log
|
||||
# format single_field common_log
|
||||
#}
|
||||
}
|
||||
|
||||
transmission.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:19091
|
||||
#log {
|
||||
# output file /var/log/caddy/transmission.access.log
|
||||
# format single_field common_log
|
||||
#}
|
||||
}
|
||||
|
||||
grafana.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:13000
|
||||
#log {
|
||||
# output file /var/log/caddy/grafana.access.log
|
||||
# format single_field common_log
|
||||
#}
|
||||
}
|
||||
|
||||
nas.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:15000
|
||||
}
|
||||
|
||||
navidrome.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:14533
|
||||
}
|
||||
|
||||
calibre.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:18083
|
||||
}
|
||||
|
||||
# Refer to the Caddy docs for more information:
|
||||
# https://caddyserver.com/docs/caddyfile
|
||||
|
||||
```
|
||||
|
||||
如需重启 Caddy
|
||||
|
||||
``` bash
|
||||
|
||||
sudo systemctl reload caddy
|
||||
sudo systemctl status caddy
|
||||
|
||||
```
|
||||
|
||||
或者:
|
||||
``` bash
|
||||
#彻底重启 Caddy 服务(强制方式)
|
||||
sudo systemctl restart caddy
|
||||
```
|
||||
Caddy 会自动申请并更新 Let's Encrypt 证书,提供 HTTPS 访问。
|
||||
|
||||
|
||||
如果 systemctl 无响应(Caddy 卡死或崩溃)
|
||||
``` bash
|
||||
sudo systemctl stop caddy
|
||||
sudo pkill -9 caddy # 杀掉所有残留进程 sudo systemctl start caddy
|
||||
```
|
||||
## 验证 Caddyfile 语法(最关键)
|
||||
```
|
||||
sudo caddy validate --config /etc/caddy/Caddyfile
|
||||
```
|
||||
|
||||
如果返回:
|
||||
|
||||
`Valid configuration`
|
||||
|
||||
说明语法正确,可以重载。
|
||||
|
||||
如果报错,Caddy 会指明**哪一行有问题**,例如:
|
||||
|
||||
`parse error: unknown directive at line 12`
|
||||
|
||||
你需要根据提示修正。
|
||||
|
||||
## 🧩 第 5 步:测试验证
|
||||
|
||||
### 1️⃣ 在 VPS 上
|
||||
``` bash
|
||||
curl http://127.0.0.1:15678
|
||||
curl http://127.0.0.1:15000
|
||||
curl http://127.0.0.1:19091
|
||||
curl http://127.0.0.1:13000
|
||||
|
||||
ss -ltnp | egrep '15678|19091|13000|7000|60022'
|
||||
```
|
||||
|
||||
```
|
||||
root@racknerd-66f115a:~# ss -ltnp | egrep '15678|19091|13000|7000'
|
||||
LISTEN 0 4096 *:19091 *:* users:(("frps",pid=59421,fd=10))
|
||||
LISTEN 0 4096 *:13000 *:* users:(("frps",pid=59421,fd=8))
|
||||
LISTEN 0 4096 *:15678 *:* users:(("frps",pid=59421,fd=9))
|
||||
LISTEN 0 4096 *:7000 *:* users:(("frps",pid=59421,fd=6))
|
||||
```
|
||||
|
||||
|
||||
### 2️⃣ 在浏览器中
|
||||
|
||||
访问:
|
||||
|
||||
- [https://nas.ishenwei.online](https://nas.ishenwei.online)
|
||||
|
||||
- [https://n8n.ishenwei.online](https://n8n.ishenwei.online)
|
||||
|
||||
应能通过 HTTPS 打开对应服务。
|
||||
|
||||
|
||||
|
||||
|
||||
## 🧩 第 6 步:可选安全加固
|
||||
### 1️⃣ Caddy 基础认证
|
||||
|
||||
在 Caddyfile 的 `n8n.ishenwei.online` 段中加入:
|
||||
``` bash
|
||||
basicauth /* { admin JDJhJDE0JDN3ZXVhV2YyZG9SY2hvYzVmZ2h3QUlVblpOMU4vS1ptcENrSlhySElMb3l5dytOMkh0Tk93 }
|
||||
```
|
||||
|
||||
> 用 `caddy hash-password` 生成密码散列。
|
||||
|
||||
### 2️⃣ 防火墙
|
||||
|
||||
只放行必要端口:
|
||||
``` bash
|
||||
sudo ufw allow 22,80,443,7000/tcp
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
## 🧩 第 7 步:Dashboard(可选)
|
||||
访问:
|
||||
``` bash
|
||||
|
||||
http://192.227.222.142:7500
|
||||
|
||||
用户名:admin 密码:StrongPassword123!
|
||||
|
||||
```
|
||||
|
||||
你可以实时查看 frp 客户端的连接状态。
|
||||
|
||||
|
||||
|
||||
FRP 架构已经稳定运行(HTTP 反代验证通过),接下来要实现 **通过域名 `ubuntu1.ishenwei.online` SSH 到内网的 Ubuntu (192.168.3.47:22)**。
|
||||
|
||||
⚠️ **重点提醒(安全性)**
|
||||
SSH 穿透与 HTTP 不同,它是纯 TCP 流量,不经 Caddy(Caddy 只处理 HTTP/HTTPS),所以:
|
||||
|
||||
- **Caddy 不参与 SSH 的代理**。
|
||||
|
||||
- **只用 frps + frpc 配置即可完成**。
|
||||
|
||||
- **CaddyFile 无需修改**。
|
||||
|
||||
## 🧭 拓扑关系
|
||||
|
||||
``` bash
|
||||
你(外部SSH客户端)
|
||||
│
|
||||
▼
|
||||
ubuntu1.ishenwei.online:60022 (VPS公网)
|
||||
│
|
||||
▼
|
||||
FRP Server (frps) on VPS
|
||||
│
|
||||
▼
|
||||
FRP Client (frpc) on 192.168.3.47
|
||||
│
|
||||
▼
|
||||
Local Ubuntu SSH (192.168.3.47:22)
|
||||
|
||||
```
|
||||
|
||||
## 🧩 VPS 端(frps)配置
|
||||
|
||||
编辑 `/opt/frp/frps.ini`:
|
||||
|
||||
> 不需要添加新的 section,这里只是定义基础参数。frps 会自动识别来自客户端的 TCP 映射。
|
||||
|
||||
---
|
||||
|
||||
## 🧩 内网 Ubuntu(192.168.3.47)端 frpc 配置
|
||||
|
||||
编辑 `/opt/frp/frpc.ini`,在现有配置文件中追加:
|
||||
|
||||
``` bash
|
||||
|
||||
# SSH 映射
|
||||
[ubuntu_ssh]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 22
|
||||
remote_port = 60022
|
||||
|
||||
|
||||
```
|
||||
|
||||
> - `type = tcp` 表示这是纯 TCP 代理,不走 HTTP 协议
|
||||
>
|
||||
> - `remote_port = 60022` 是 VPS 上暴露的端口(外部 SSH 连接入口)
|
||||
>
|
||||
|
||||
---
|
||||
|
||||
## 🔧 启动并验证
|
||||
|
||||
在内网机器上:
|
||||
```
|
||||
sudo systemctl restart frpc
|
||||
sudo systemctl status frpc
|
||||
|
||||
```
|
||||
|
||||
验证日志中是否出现:
|
||||
|
||||
`[ubuntu_ssh] start proxy success`
|
||||
|
||||
---
|
||||
|
||||
## 🌐 在外部电脑上连接 SSH
|
||||
|
||||
从公网(任意地方)执行:
|
||||
|
||||
`ssh -p 60022 user@ubuntu1.ishenwei.online`
|
||||
|
||||
|
||||
> 注意:DNS 只解析到 IP,**SSH 的端口要显式指定为 `-p 60022`**。
|
||||
|
||||
|
||||
sudo ufw allow OpenSSH
|
||||
sudo ufw allow 80/tcp
|
||||
sudo ufw allow 443/tcp
|
||||
sudo ufw allow 7000/tcp # frp server 端口
|
||||
sudo ufw allow 7050
|
||||
sudo ufw allow 60022
|
||||
sudo ufw enable
|
||||
sudo ufw status verbose
|
||||
|
||||
---
|
||||
|
||||
## 🔒 (可选)安全加固建议
|
||||
|
||||
1. **不要直接使用 22 或常见端口**,比如:
|
||||
|
||||
`remote_port = 26222`
|
||||
|
||||
避免被扫描。
|
||||
|
||||
2. **限制来源 IP**(仅 VPS 防火墙开放指定来源):
|
||||
|
||||
`sudo ufw allow from <your_home_ip> to any port 60022 proto tcp`
|
||||
|
||||
3. **使用公钥认证禁用密码登录**:
|
||||
|
||||
- 编辑 `/etc/ssh/sshd_config`
|
||||
|
||||
`PasswordAuthentication no`
|
||||
|
||||
- 重启 SSH:
|
||||
|
||||
`sudo systemctl restart ssh`
|
||||
|
||||
|
||||
---
|
||||
|
||||
## ✅ 总结
|
||||
|
||||
|组件|是否需要修改|说明|
|
||||
|---|---|---|
|
||||
|**Caddy**|❌ 无需修改|不处理 SSH|
|
||||
|**frps (VPS)**|✅ 保持默认端口即可||
|
||||
|**frpc (内网 Ubuntu)**|✅ 新增 `[ubuntu_ssh]` section||
|
||||
|**DNS**|✅ 添加 `ubuntu1.ishenwei.online -> VPS公网IP`||
|
||||
|**SSH 连接**|✅ 使用 `ssh -p 60022 user@ubuntu1.ishenwei.online`|
|
||||
|
||||
|
||||
## 错误排查 #troubleshooting
|
||||
|
||||
### ✔ 第 1 步:确认 frps 是否真的在监听端口(排除端口被占用/劫持)
|
||||
``` bash
|
||||
ss -lntup | grep 7000
|
||||
ss -lntup | grep frps
|
||||
|
||||
```
|
||||
|
||||
结果:
|
||||
``` bash
|
||||
root@racknerd-66f115a:~# ss -lntup | grep 7000
|
||||
tcp LISTEN 0 4096 *:7000 *:* users:(("frps",pid=413014,fd=6))
|
||||
root@racknerd-66f115a:~# ss -lntup | grep frps
|
||||
tcp LISTEN 0 4096 *:7000 *:* users:(("frps",pid=413014,fd=6))
|
||||
tcp LISTEN 0 4096 *:7500 *:* users:(("frps",pid=413014,fd=3))
|
||||
|
||||
```
|
||||
如果这里显示:
|
||||
|
||||
❌ 端口被 Caddy/Nginx 占用
|
||||
❌ frps 未绑定 0.0.0.0
|
||||
❌ frps 在 LISTEN 但不是你期望的配置文件
|
||||
|
||||
### ✔ 第 2 步:确定 frps 进程读取的配置是否跟你想的一样
|
||||
|
||||
执行:
|
||||
``` bash
|
||||
ps -ef | grep frps
|
||||
```
|
||||
你要看到类似:
|
||||
``` bash
|
||||
root@racknerd-66f115a:~# ps -ef | grep frps
|
||||
root 413014 1 0 02:23 ? 00:00:00 /opt/frp/frps -c /opt/frp/frps.ini
|
||||
root 419007 414182 0 02:57 pts/1 00:00:00 grep --color=auto frps
|
||||
|
||||
```
|
||||
|
||||
如果看到:
|
||||
- 路径不对
|
||||
- 配置文件不对
|
||||
- 或者正运行旧版本二进制
|
||||
|
||||
那 frps 实际载入的 token、bind_port 等信息就不匹配。
|
||||
|
||||
**尤其要确认 token 是否是你以为的那个。**
|
||||
|
||||
👉 很多人遇到的问题是:
|
||||
他们编辑了 `/opt/frp/frps.ini`,但 systemd service 其实加载另一个路径,例如 `/etc/frp/frps.ini`。
|
||||
|
||||
### ✔ 第 3 步:确认防火墙是否把 7000 封了
|
||||
|
||||
在 VPS 执行:
|
||||
```
|
||||
sudo iptables -L -n
|
||||
sudo ufw status
|
||||
sudo firewall-cmd --list-all
|
||||
```
|
||||
|
||||
|
||||
你需要确保:
|
||||
|
||||
- `tcp 7000` 在 **ACCEPT**
|
||||
|
||||
- Cloudflare 没有影响你(你用的是直连 IP,不会影响)
|
||||
|
||||
- Caddy/Nginx 没修改 nftables(某些 One-key 脚本会修改)
|
||||
|
||||
### ✔ 第 4 步:确认没有 Caddy/Nginx 误 proxy 了 TCP 7000
|
||||
|
||||
检查 Caddy 配置:
|
||||
``` bash
|
||||
vi /etc/caddy/Caddyfile
|
||||
```
|
||||
**是否存在以下配置:**
|
||||
|
||||
`:7000 { reverse_proxy ... }`
|
||||
|
||||
如果有 → FRP 就没法直接监听这个端口。
|
||||
|
||||
### ✔ 第 5 步:确认 frps 日志是否有拒绝认证(token mismatch)
|
||||
|
||||
执行:
|
||||
```
|
||||
journalctl -u frps -n 100 --no-pager
|
||||
```
|
||||
|
||||
如果你看到类似:
|
||||
|
||||
`authentication failed token mismatch invalid login`
|
||||
|
||||
那肯定是 token 和 frpc 不一致。
|
||||
|
||||
👉 很多人以为一样,但实际是空格、换行、编码问题导致不一致。
|
||||
|
||||
### ✔ 第 6 步:尝试手动 telnet 登录后观察 frps 日志变化
|
||||
|
||||
**非常关键的诊断动作**
|
||||
|
||||
你从任意 frpc 客户端执行:
|
||||
``` bash
|
||||
telnet 192.227.222.142 7000
|
||||
```
|
||||
|
||||
同时在 frps VPS 执行:
|
||||
``` bash
|
||||
journalctl -u frps -f
|
||||
```
|
||||
|
||||
正常情况下,你应该看到 frps 有日志反应:
|
||||
|
||||
- 有连接建立
|
||||
- 有 login 请求
|
||||
|
||||
如果 frps 完全无反应:
|
||||
|
||||
➡ **说明请求没有到达 frps 进程 → 必然是端口被别的服务占用 / iptables 拦截 / SELinux 限制 / Caddy/Nginx 覆盖了端口**
|
||||
|
||||
|
||||
### ✔ 第 7 步:强制重启 frps 和 frpc
|
||||
|
||||
在 frps 机器上:
|
||||
```
|
||||
systemctl restart frps
|
||||
```
|
||||
|
||||
确认状态:
|
||||
```
|
||||
systemctl status frps
|
||||
```
|
||||
|
||||
在 frpc 机器上:
|
||||
```
|
||||
systemctl restart frpc
|
||||
systemctl status frpc
|
||||
journalctl -u frpc -n 50
|
||||
```
|
||||
|
||||
如果 frpc 日志里直接报:
|
||||
`dial tcp 192.227.222.142:7000: connection reset`
|
||||
➡ 防火墙问题
|
||||
|
||||
如果报:
|
||||
`authentication failed`
|
||||
➡ token 不一致
|
||||
|
||||
如果:
|
||||
`wait until server ready`
|
||||
➡ frps 端口被劫持
|
||||
137
raw/Technical/Home Office/🟠3X-UI Xray on BandwagonVPS.md
Normal file
137
raw/Technical/Home Office/🟠3X-UI Xray on BandwagonVPS.md
Normal file
@@ -0,0 +1,137 @@
|
||||
---
|
||||
title: 3X-UI Xray on BandwagonVPS
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: []
|
||||
---
|
||||
|
||||
# 3X-UI Xray on BandwagonVPS
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 1. 服务器信息
|
||||
|
||||
| 项目 | 值 |
|
||||
|------|-----|
|
||||
| 服务器 | VPS2 (Bandwagon) |
|
||||
| IP | 104.194.92.188 |
|
||||
| 域名 | kiwi.ishenwei.online |
|
||||
| SSH | `ssh vps2` |
|
||||
| Web管理 | https://kiwi.ishenwei.online:2053/ |
|
||||
| 用户名 | d96nRBgFUL |
|
||||
| 密码 | er9XU0VsF1 |
|
||||
|
||||
---
|
||||
|
||||
## 2. 安装 3X-UI
|
||||
|
||||
### 一键安装命令
|
||||
|
||||
```bash
|
||||
bash <(curl -Ls https://raw.githubusercontent.com/mhsanaei/3x-ui/master/install.sh)
|
||||
```
|
||||
|
||||
### 命令行管理
|
||||
|
||||
```bash
|
||||
ssh vps2
|
||||
x-ui
|
||||
```
|
||||
|
||||
### 管理菜单说明
|
||||
|
||||
```
|
||||
╔────────────────────────────────────────────────╗
|
||||
║ 3X-UI Panel Management Script ║
|
||||
║ 0. Exit Script ║
|
||||
────────────────────────────────────────────────║
|
||||
║ 1. Install ║
|
||||
║ 2. Update ║
|
||||
║ 3. Update Menu ║
|
||||
║ 4. Legacy Version ║
|
||||
║ 5. Uninstall ║
|
||||
────────────────────────────────────────────────║
|
||||
║ 6. Reset Username & Password ║
|
||||
║ 7. Reset Web Base Path ║
|
||||
║ 8. Reset Settings ║
|
||||
║ 9. Change Port ║
|
||||
║ 10. View Current Settings ║
|
||||
────────────────────────────────────────────────║
|
||||
║ 11. Start ║
|
||||
║ 12. Stop ║
|
||||
║ 13. Restart ║
|
||||
║ 14. Check Status ║
|
||||
║ 15. Logs Management ║
|
||||
────────────────────────────────────────────────║
|
||||
║ 16. Enable Autostart ║
|
||||
║ 17. Disable Autostart ║
|
||||
────────────────────────────────────────────────║
|
||||
║ 18. SSL Certificate Management ║
|
||||
║ 19. Cloudflare SSL Certificate ║
|
||||
║ 20. IP Limit Management ║
|
||||
║ 21. Firewall Management ║
|
||||
║ 22. SSH Port Forwarding Management ║
|
||||
────────────────────────────────────────────────║
|
||||
║ 23. Enable BBR ║
|
||||
║ 24. Update Geo Files ║
|
||||
║ 25. Speedtest by Ookla ║
|
||||
╚────────────────────────────────────────────────╝
|
||||
```
|
||||
|
||||
### 常用操作
|
||||
|
||||
| 操作 | 命令 |
|
||||
|------|------|
|
||||
| 启动 | `x-ui` → 输入 `11` |
|
||||
| 停止 | `x-ui` → 输入 `12` |
|
||||
| 重启 | `x-ui` → 输入 `13` |
|
||||
| 查看状态 | `x-ui` → 输入 `14` |
|
||||
| 更新Geo文件 | `x-ui` → 输入 `24` |
|
||||
| 启用BBR | `x-ui` → 输入 `23` |
|
||||
|
||||
### 当前状态
|
||||
|
||||
- Panel state: Running ✅
|
||||
- xray state: Running ✅
|
||||
- Autostart: Enabled ✅
|
||||
|
||||
---
|
||||
|
||||
## 3. 配置入站规则
|
||||
|
||||
### Web 管理地址
|
||||
|
||||
- 地址: https://104.194.92.188:18888/2atA1GaPdNBMyRRGWi
|
||||
- 用户名: d96nRBgFUL
|
||||
- 密码: er9XU0VsF1
|
||||
|
||||
### 配置策略
|
||||
|
||||
使用 VLESS+Reality 方式配置,需要产生公钥和私钥。
|
||||
![[IMG-20260210125706904.png]]
|
||||
![[IMG-20260210125706904.png]]
|
||||
|
||||
---
|
||||
|
||||
## 4. 本地客户端
|
||||
|
||||
### Windows/Linux
|
||||
|
||||
客户端: [v2rayN](https://github.com/2dust/v2rayN)
|
||||
|
||||
### Android
|
||||
|
||||
客户端: [v2rayNG](https://github.com/2dust/v2rayNG)
|
||||
|
||||
---
|
||||
|
||||
## 5. 网络测试
|
||||
|
||||
- 国内访问直连: ✅ 200
|
||||
- 国外访问直连: ✅ 200
|
||||
100
raw/Technical/Home Office/🟠Clonezilla对Ubuntu Server进行全盘镜像备份.md
Normal file
100
raw/Technical/Home Office/🟠Clonezilla对Ubuntu Server进行全盘镜像备份.md
Normal file
@@ -0,0 +1,100 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [backup, clonezilla, nas, rufus, ubuntu]
|
||||
---
|
||||
|
||||
|
||||
#clonezilla #ubuntu #backup #nas #rufus
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
既然你已经准备好使用 **Clonezilla (再生龙)** 来实现类似 Ghost 的全盘镜像备份,以下是针对你**旧笔记本(源机)**备份到 **NAS(存储端)**的详细手把手步骤。
|
||||
|
||||
## 制作Clonezilla启动盘
|
||||
- **下载 ISO 镜像:** 访问 [Clonezilla 官网下载页](https://clonezilla.org/downloads.php)。
|
||||
- **CPU 架构:** 选择 `amd64`。
|
||||
- **发行版类型:** 选择 `debian`(更稳定)。
|
||||
- **文件类型:** 选择 `iso`。
|
||||
- **准备 U 盘:** 至少 1GB 容量,请提前备份 U 盘内数据,制作过程会**格式化** U 盘。
|
||||
- **启动 Rufus:** 插入 U 盘并运行 Rufus 软件。
|
||||
- **选择设备:** 在“设备”下拉菜单中确认选中了你的 U 盘。
|
||||
- **选择镜像:** 点击右侧的“选择”按钮,找到你下载好的 `clonezilla-live-xxxx-amd64.iso` 文件。
|
||||
- **分区方案与目标系统类型(关键):**
|
||||
- **针对较新的笔记本:** 分区方案选 `GPT`,目标系统选 `UEFI (非 CSM)`。
|
||||
- **针对很老的笔记本:** 如果你的笔记本不支持 UEFI,分区方案选 `MBR`,目标系统选 `BIOS (或 UEFI-CSM)`。
|
||||
- _建议:如果不确定,先尝试 GPT。_
|
||||
- **文件系统:** 保持默认的 `FAT32`(这是 UEFI 启动的标准格式)。
|
||||
- **开始制作:** 点击“开始”。
|
||||
- **模式选择(重点):**
|
||||
- Rufus 可能会弹出“检测到 ISOHybrid 镜像”的提示。
|
||||
- **请务必选择:“以 ISO 镜像模式写入 (推荐)”**。
|
||||
- 如果制作后无法启动,再尝试使用“DD 镜像模式”重新制作。
|
||||
10. **等待完成:** 进度条显示“准备就绪”后,即可拔掉 U 盘。
|
||||
|
||||
|
||||
> [!NOTE] 蓝色U盘
|
||||
> 蓝色U盘 32G 安装了Clonezilla
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 在旧笔记本上启动 Clonezilla
|
||||
|
||||
### 1. 启动与环境准备
|
||||
|
||||
1. 将制作好的 Rufus U 盘插入笔记本,重启并进入 **F9** (HP ZBook 常用) 启动菜单,选择 U 盘启动。
|
||||
2. 在 Clonezilla 初始菜单选择:`Clonezilla live (Default settings, VGA 800x600)`。
|
||||
3. **语言选择**:建议选择 `en_US.UTF-8 English` (英文界面更稳,报错容易查) 或 `zh_CN.UTF-8`。
|
||||
4. **键盘布局**:保持默认 `Keep default keyboard layout`。
|
||||
5. **启动 Clonezilla**:选择 `Start_Clonezilla`。
|
||||
|
||||
---
|
||||
|
||||
### 2. 设置备份模式
|
||||
|
||||
1. **模式选择**:选择 `device-image` (将硬盘备份为一个镜像文件,存放在 NAS 或外置硬盘上)。
|
||||
2. **挂载备份目录 (Mounting the repo)**:
|
||||
- 如果你使用 **NAS**:选择 `nfs_server` (推荐,Linux 兼容性最好)
|
||||
- 如果你使用 **外置硬盘**:插上硬盘,选择 `local_dev`。
|
||||
|
||||
---
|
||||
|
||||
### 3. 连接 NAS (以 NFS 为例)
|
||||
|
||||
如果你选择了 `nfs_server`,接下来的填空非常关键:
|
||||
1. **网卡配置**:选择 `dhcp` (确保笔记本连了网线)。
|
||||
2. **NFS 服务器 IP**:输入你 NAS 的 IP 地址 (例如 `192.168.3.17`)。
|
||||
3. **挂载路径**:输入你 NAS 上共享文件夹的绝对路径 (例如 `/volume2/backups`)。
|
||||
4. **确认挂载**:挂载成功后,你会看到磁盘空间信息。按下 **Enter** 继续。
|
||||
|
||||
---
|
||||
|
||||
### 4. 配置备份参数
|
||||
1. **向导模式**:选择 `Beginner` (初学者模式,默认参数已足够)。
|
||||
2. **具体操作**:选择 `savedisk` (保存整个本地磁盘)。
|
||||
3. **镜像名称**:它会自动生成一个日期格式的名称,你可以修改为 `Ubuntu_Server_Ghost_20251220`。
|
||||
4. **选择源磁盘**:选中你笔记本的内置硬盘 (通常是 `sda` 或 `nvme0n1`)。
|
||||
5. **压缩选项**:选择 `-z1p` (默认的高压缩率,适合节省 NAS 空间)。
|
||||
6. **文件系统检查**:选择 `-sfsck` (跳过检查,节省时间)。
|
||||
7. **备份后操作**:选择 `Choose` (备份完后让你选重启还是关机)。
|
||||
|
||||
---
|
||||
|
||||
### 5. 开始克隆 (Ghost 进度条)
|
||||
1. Clonezilla 会在终端显示一大段确认信息。
|
||||
2. 输入 **y** 并回车 (确认开始)。
|
||||
3. 输入 **y** 并回车 (确认再次确认)。
|
||||
4. **等待**:此时会出现蓝红色的进度条,显示传输速度和剩余时间。
|
||||
|
||||
---
|
||||
### 6. 灾难恢复 (恢复步骤)
|
||||
如果哪天硬盘坏了,步骤几乎一样,只需在 **第 4 步** 的“具体操作”中:
|
||||
- 选择 `restoredisk` (还原镜像到磁盘)。
|
||||
- 选中你存在 NAS 上的那个镜像文件夹。
|
||||
- 确认后,它会覆盖新硬盘的所有数据,完成后系统即刻复活。
|
||||
205
raw/Technical/Home Office/🟠Linux 运维必会的 150 个命令.md
Normal file
205
raw/Technical/Home Office/🟠Linux 运维必会的 150 个命令.md
Normal file
@@ -0,0 +1,205 @@
|
||||
---
|
||||
title: Linux 运维必会的 150 个命令,不熟练早晚得出事?
|
||||
source: https://mp.weixin.qq.com/s/_h2eTqPvduZctE0YarQtWw
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-09-29
|
||||
description: 最全总结
|
||||
tags: [linux]
|
||||
---
|
||||
|
||||
|
||||
#linux
|
||||
|
||||
|
||||
|
||||
Linux 命令是对 Linux 系统进行管理的命令。对于 Linux 系统来说,无论是中央处理器、内存、磁盘驱动器、键盘、鼠标,还是用户等都是文件, Linux 系统管理的命令是它正常运行的核心,与之前的 DOS 命令类似。
|
||||
|
||||
Linux 命令在系统中有两种类型:内置 Shell 命令和 Linux 命令。
|
||||
|
||||
| 命令 | 功能说明 |
|
||||
| ------------------------------- | -------------------------------------------------------------- |
|
||||
| **线上查询及帮助命令 (2 个)** | |
|
||||
| **man** | 查看命令帮助,命令的词典,更复杂的还有 info,但不常用。 |
|
||||
| **help** | 查看 Linux 内置命令的帮助,比如 cd 命令。 |
|
||||
| **文件和目录操作命令 (18 个)** | |
|
||||
| **ls** | 全拼 list,功能是列出目录的内容及其内容属性信息。 |
|
||||
| **cd** | 全拼 change directory,功能是从当前工作目录切换到指定的工作目录。 |
|
||||
| **cp** | 全拼 copy,其功能为复制文件或目录。 |
|
||||
| **find** | 查找的意思,用于查找目录及目录下的文件。 |
|
||||
| **mkdir** | 全拼 make directories,其功能是创建目录。 |
|
||||
| **mv** | 全拼 move,其功能是移动或重命名文件。 |
|
||||
| **pwd** | 全拼 print working directory,其功能是显示当前工作目录的绝对路径。 |
|
||||
| **rename** | 用于重命名文件。 |
|
||||
| **rm** | 全拼 remove,其功能是删除一个或多个文件或目录。 |
|
||||
| **rmdir** | 全拼 remove empty directories,功能是删除空目录。 |
|
||||
| **touch** | 创建新的空文件,改变已有文件的时间戳属性。 |
|
||||
| **tree** | 功能是以树形结构显示目录下的内容。 |
|
||||
| **basename** | 显示文件名或目录名。 |
|
||||
| **dirname** | 显示文件或目录路径。 |
|
||||
| **chattr** | 改变文件的扩展属性。 |
|
||||
| **lsattr** | 查看文件扩展属性。 |
|
||||
| **file** | 显示文件的类型。 |
|
||||
| **md5sum** | 计算和校验文件的 MD5 值。 |
|
||||
| **查看文件及内容处理命令(21 个)** | |
|
||||
| **cat** | 全拼 concatenate,功能是用于连接多个文件并且打印到屏幕输出或重定向到指定文件中。 |
|
||||
| **tac** | tac 是 cat 的反向拼写,因此命令的功能为反向显示文件内容。 |
|
||||
| **more** | 分页显示文件内容。 |
|
||||
| **less** | 分页显示文件内容,more 命令的相反用法。 |
|
||||
| **head** | 显示文件内容的头部。 |
|
||||
| **tail** | 显示文件内容的尾部。 |
|
||||
| **cut** | 将文件的每一行按指定分隔符分割并输出。 |
|
||||
| **split** | 分割文件为不同的小片段。 |
|
||||
| **paste** | 按行合并文件内容。 |
|
||||
| **sort** | 对文件的文本内容排序。 |
|
||||
| **uniq** | 去除重复行。oldboy |
|
||||
| **wc** | 统计文件的行数、单词数或字节数。 |
|
||||
| **iconv** | 转换文件的编码格式。 |
|
||||
| **dos2unix** | 将 DOS 格式文件转换成 UNIX 格式。 |
|
||||
| **diff** | 全拼 difference,比较文件的差异,常用于文本文件。 |
|
||||
| **vimdiff** | 命令行可视化文件比较工具,常用于文本文件。 |
|
||||
| **rev** | 反向输出文件内容。 |
|
||||
| **grep/egrep** | 过滤字符串,三剑客老三。 |
|
||||
| **join** | 按两个文件的相同字段合并。 |
|
||||
| **tr** | 替换或删除字符。 |
|
||||
| **vi/vim** | 命令行文本编辑器。 |
|
||||
| **文件压缩及解压缩命令(4 个)** | |
|
||||
| **tar** | 打包压缩。oldboy |
|
||||
| **unzip** | 解压文件。 |
|
||||
| **gzip** | gzip 压缩工具。 |
|
||||
| **zip** | 压缩工具。 |
|
||||
| **信息显示命令(11 个)** | |
|
||||
| **uname** | 显示操作系统相关信息的命令。 |
|
||||
| **hostname** | 显示或者设置当前系统的主机名。 |
|
||||
| **dmesg** | 显示开机信息,用于诊断系统故障。 |
|
||||
| **uptime** | 显示系统运行时间及负载。 |
|
||||
| **stat** | 显示文件或文件系统的状态。 |
|
||||
| **du** | 计算磁盘空间使用情况。 |
|
||||
| **df** | 报告文件系统磁盘空间的使用情况。 |
|
||||
| **top** | 实时显示系统资源使用情况。 |
|
||||
| **free** | 查看系统内存。 |
|
||||
| **date** | 显示与设置系统时间。 |
|
||||
| **cal** | 查看日历等时间信息。 |
|
||||
| **搜索文件命令(4 个)** | |
|
||||
| **which** | 查找二进制命令,按环境变量 PATH 路径查找。 |
|
||||
| **find** | 从磁盘遍历查找文件或目录。另外,搜索公众号GitHub猿后台回复“赚钱”,获取一份惊喜礼包。 |
|
||||
| **whereis** | 查找二进制命令,按环境变量 PATH 路径查找。 |
|
||||
| **locate** | 从数据库 (/var/lib/mlocate/mlocate.db) 查找命令,使用 updatedb 更新库。 |
|
||||
| **用户管理命令(10 个)** | |
|
||||
| **useradd** | 添加用户。 |
|
||||
| **usermod** | 修改系统已经存在的用户属性。 |
|
||||
| **userdel** | 删除用户。 |
|
||||
| **groupadd** | 添加用户组。 |
|
||||
| **passwd** | 修改用户密码。 |
|
||||
| **chage** | 修改用户密码有效期限。 |
|
||||
| **id** | 查看用户的 uid,gid 及归属的用户组。 |
|
||||
| **su** | 切换用户身份。 |
|
||||
| **visudo** | 编辑 / etc/sudoers 文件的专属命令。 |
|
||||
| **sudo** | 以另外一个用户身份(默认 root 用户)执行事先在 sudoers 文件允许的命令。 |
|
||||
| **基础网络操作命令(11 个)** | |
|
||||
| **telnet** | 使用 TELNET 协议远程登录。 |
|
||||
| **ssh** | 使用 SSH 加密协议远程登录。 |
|
||||
| **scp** | 全拼 secure copy,用于不同主机之间复制文件。 |
|
||||
| **wget** | 命令行下载文件。 |
|
||||
| **ping** | 测试主机之间网络的连通性。 |
|
||||
| **route** | 显示和设置 linux 系统的路由表。 |
|
||||
| **ifconfig** | 查看、配置、启用或禁用网络接口的命令。 |
|
||||
| **ifup** | 启动网卡。 |
|
||||
| **ifdown** | 关闭网卡。 |
|
||||
| **netstat** | 查看网络状态。 |
|
||||
| **ss** | 查看网络状态。 |
|
||||
| **深入网络操作命令(9 个)** | |
|
||||
| **nmap** | 网络扫描命令。 |
|
||||
| **lsof** | 全名 list open files,也就是列举系统中已经被打开的文件。 |
|
||||
| **mail** | 发送和接收邮件。 |
|
||||
| **mutt** | 邮件管理命令。 |
|
||||
| **nslookup** | 交互式查询互联网 DNS 服务器的命令。 |
|
||||
| **dig** | 查找 DNS 解析过程。 |
|
||||
| **host** | 查询 DNS 的命令。 |
|
||||
| **traceroute** | 追踪数据传输路由状况。 |
|
||||
| **tcpdump** | 命令行的抓包工具。 |
|
||||
| **有关磁盘与文件系统的命令(16 个)** | |
|
||||
| **mount** | 挂载文件系统。 |
|
||||
| **umount** | 卸载文件系统。 |
|
||||
| **fsck** | 检查并修复 Linux 文件系统。 |
|
||||
| **dd** | 转换或复制文件。 |
|
||||
| **dumpe2fs** | 导出 ext2/ext3/ext4 文件系统信息。 |
|
||||
| **dump** | ext2/3/4 文件系统备份工具。 |
|
||||
| **fdisk** | 磁盘分区命令,适用于 2TB 以下磁盘分区。 |
|
||||
| **parted** | 磁盘分区命令,没有磁盘大小限制,常用于 2TB 以下磁盘分区。 |
|
||||
| **mkfs** | 格式化创建 Linux 文件系统。 |
|
||||
| **partprobe** | 更新内核的硬盘分区表信息。 |
|
||||
| **e2fsck** | 检查 ext2/ext3/ext4 类型文件系统。 |
|
||||
| **mkswap** | 创建 Linux 交换分区。 |
|
||||
| **swapon** | 启用交换分区。 |
|
||||
| **swapoff** | 关闭交换分区。 |
|
||||
| **sync** | 将内存缓冲区内的数据写入磁盘。 |
|
||||
| **resize2fs** | 调整 ext2/ext3/ext4 文件系统大小。 |
|
||||
| **系统权限及用户授权相关命令(4 个)** | |
|
||||
| **chmod** | 改变文件或目录权限。 |
|
||||
| **chown** | 改变文件或目录的属主和属组。 |
|
||||
| **chgrp** | 更改文件用户组。 |
|
||||
| **umask** | 显示或设置权限掩码。 |
|
||||
| **查看系统用户登陆信息的命令(7 个)** | |
|
||||
| **whoami** | 显示当前有效的用户名称,相当于执行 id -un 命令。 |
|
||||
| **who** | 显示目前登录系统的用户信息。 |
|
||||
| **w** | 显示已经登陆系统的用户列表,并显示用户正在执行的指令。 |
|
||||
| **last** | 显示登入系统的用户。 |
|
||||
| **lastlog** | 显示系统中所有用户最近一次登录信息。 |
|
||||
| **users** | 显示当前登录系统的所有用户的用户列表。 |
|
||||
| **finger** | 查找并显示用户信息。 |
|
||||
| **内置命令及其它(19 个)** | |
|
||||
| **echo** | 打印变量,或直接输出指定的字符串 |
|
||||
| **printf** | 将结果格式化输出到标准输出。 |
|
||||
| **rpm** | 管理 rpm 包的命令。 |
|
||||
| **yum** | 自动化简单化地管理 rpm 包的命令。 |
|
||||
| **watch** | 周期性的执行给定的命令,并将命令的输出以全屏方式显示。 |
|
||||
| **alias** | 设置系统别名。 |
|
||||
| **unalias** | 取消系统别名。 |
|
||||
| **date** | 查看或设置系统时间。 |
|
||||
| **clear** | 清除屏幕,简称清屏。 |
|
||||
| **history** | 查看命令执行的历史纪录。 |
|
||||
| **eject** | 弹出光驱。 |
|
||||
| **time** | 计算命令执行时间。 |
|
||||
| **nc** | 功能强大的网络工具。 |
|
||||
| **xargs** | 将标准输入转换成命令行参数。 |
|
||||
| **exec** | 调用并执行指令的命令。 |
|
||||
| **export** | 设置或者显示环境变量。 |
|
||||
| **unset** | 删除变量或函数。 |
|
||||
| **type** | 用于判断另外一个命令是否是内置命令。 |
|
||||
| **bc** | 命令行科学计算器 |
|
||||
| **系统管理与性能监视命令 (9 个)** | ``` 牛逼啊!接私活必备的 N 个开源项目!赶快收藏 ``` |
|
||||
| **chkconfig** | 管理 Linux 系统开机启动项。 |
|
||||
| **vmstat** | 虚拟内存统计。 |
|
||||
| **mpstat** | 显示各个可用 CPU 的状态统计。 |
|
||||
| **iostat** | 统计系统 IO。 |
|
||||
| **sar** | 全面地获取系统的 CPU、运行队列、磁盘 I/O、分页(交换区)、内存、 CPU 中断和网络等性能数据。 |
|
||||
| **ipcs** | 用于报告 Linux 中进程间通信设施的状态,显示的信息包括消息列表、共享内存和信号量的信息。 |
|
||||
| **ipcrm** | 用来删除一个或更多的消息队列、信号量集或者共享内存标识。 |
|
||||
| **strace** | 用于诊断、调试 Linux 用户空间跟踪器。我们用它来监控用户空间进程和内核的交互,比如系统调用、信号传递、进程状态变更等。 |
|
||||
| **ltrace** | 命令会跟踪进程的库函数调用, 它会显现出哪个库函数被调用。 |
|
||||
| **关机 / 重启 / 注销和查看系统信息的命令(6 个)** | |
|
||||
| **shutdown** | 关机。 |
|
||||
| **halt** | 关机。 |
|
||||
| **poweroff** | 关闭电源。 |
|
||||
| **logout** | 退出当前登录的 Shell。 |
|
||||
| **exit** | 退出当前登录的 Shell。 |
|
||||
| **Ctrl+d** | 退出当前登录的 Shell 的快捷键。 |
|
||||
| **进程管理相关命令(15 个)** | |
|
||||
| **bg** | 将一个在后台暂停的命令,变成继续执行 (在后台执行)。 |
|
||||
| **fg** | 将后台中的命令调至前台继续运行。 |
|
||||
| **jobs** | 查看当前有多少在后台运行的命令。 |
|
||||
| **kill** | 终止进程。 |
|
||||
| **killall** | 通过进程名终止进程。 |
|
||||
| **pkill** | 通过进程名终止进程。 |
|
||||
| **crontab** | 定时任务命令。 |
|
||||
| **ps** | 显示进程的快照。 |
|
||||
| **pstree** | 树形显示进程。 |
|
||||
| **nice/renice** | 调整程序运行的优先级。 |
|
||||
| **nohup** | 忽略挂起信号运行指定的命令。 |
|
||||
| **pgrep** | 查找匹配条件的进程。 |
|
||||
| **runlevel** | 查看系统当前运行级别。 |
|
||||
| **init** | 切换运行级别。 |
|
||||
| **service** | 启动、停止、重新启动和关闭系统服务,还可以显示所有系统服务的当前状态。 |
|
||||
|
||||
[[🟠如何判别你的Linux 服务器是 x64(也就是 x86_64)还是 ARM64]]
|
||||
392
raw/Technical/Home Office/🟠MinIO + Zipline 自托管图床应用安装教程.md
Normal file
392
raw/Technical/Home Office/🟠MinIO + Zipline 自托管图床应用安装教程.md
Normal file
@@ -0,0 +1,392 @@
|
||||
#nas #minio #zipline #docker #synology #n8n #image
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
内容覆盖:
|
||||
|
||||
1. 架构概念
|
||||
2. 前置准备(DSM 设置)
|
||||
3. 如何通过 DSM 的 GUI 创建 MinIO / PostgreSQL / Zipline
|
||||
4. 如何在 MinIO 创建 Bucket 和权限
|
||||
5. Zipline 初始化与 API Token
|
||||
6. n8n 如何接入
|
||||
7. 文件持久化(防止 NAS 重启丢失)
|
||||
8. 进阶部署选项(可选)
|
||||
|
||||
---
|
||||
|
||||
# 1. 架构图(Synology 专用)
|
||||
|
||||
```
|
||||
[DSM Docker UI]
|
||||
│
|
||||
├── MinIO (9000 API, 9001 Console)
|
||||
│ └── /volume1/docker/zipline-stack/minio/minio_data
|
||||
│
|
||||
├── PostgreSQL (Zipline DB)
|
||||
│ └── /volume1/docker/zipline-stack/zipline/pg_data
|
||||
│
|
||||
└── Zipline (暴露 3333)
|
||||
├── 前端上传 UI
|
||||
└── n8n API 上传
|
||||
```
|
||||
|
||||
Zipline → MinIO(S3) → NAS 存储
|
||||
![[IMG-20251229190624349.png]]
|
||||
|
||||
---
|
||||
|
||||
# 2. 前置准备
|
||||
|
||||
## 2.1 确保 DSM 已安装
|
||||
|
||||
- **Container Manager**(DSM 7.2+ 自带,替代 Docker)
|
||||
- **Docker**(DSM 7.1 及更早)
|
||||
|
||||
|
||||
## 2.2 创建存储位置目录
|
||||
|
||||
DSM → File Station → 创建:
|
||||
```
|
||||
/volume1/docker/zipline-stack/minio/minio_data
|
||||
/volume1/docker/zipline-stack/zipline/pg_data
|
||||
```
|
||||
|
||||
---
|
||||
## 2.3 **docker-compose.yml(可直接复制)**
|
||||
|
||||
``` bash
|
||||
version: "3.9"
|
||||
|
||||
services:
|
||||
minio:
|
||||
image: minio/minio:latest
|
||||
container_name: minio
|
||||
command: server /data --console-address ":9001"
|
||||
environment:
|
||||
MINIO_ROOT_USER: admin
|
||||
MINIO_ROOT_PASSWORD: Abcd_1234
|
||||
ports:
|
||||
- "9000:9000"
|
||||
- "9001:9001"
|
||||
volumes:
|
||||
# 保留你精心组织的绝对路径
|
||||
- /volume1/docker/zipline-stack/minio/minio_data:/data
|
||||
restart: unless-stopped
|
||||
deploy:
|
||||
resources:
|
||||
limits:
|
||||
# [已移除 CPU 限制以修复报错]
|
||||
memory: 1G
|
||||
reservations:
|
||||
memory: 256M
|
||||
healthcheck:
|
||||
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
|
||||
interval: 30s
|
||||
timeout: 20s
|
||||
retries: 3
|
||||
|
||||
postgres:
|
||||
image: postgres:16
|
||||
container_name: zipline_postgres
|
||||
environment:
|
||||
POSTGRES_USER: zipline
|
||||
POSTGRES_PASSWORD: zipline
|
||||
POSTGRES_DB: zipline
|
||||
volumes:
|
||||
# 保留你精心组织的绝对路径
|
||||
- /volume1/docker/zipline-stack/zipline/pg_data:/var/lib/postgresql/data
|
||||
restart: unless-stopped
|
||||
deploy:
|
||||
resources:
|
||||
limits:
|
||||
# [已移除 CPU 限制以修复报错]
|
||||
memory: 512M
|
||||
healthcheck:
|
||||
test: ["CMD-SHELL", "pg_isready -U zipline"]
|
||||
interval: 10s
|
||||
timeout: 5s
|
||||
retries: 5
|
||||
|
||||
zipline:
|
||||
image: ghcr.io/diced/zipline:latest
|
||||
container_name: zipline
|
||||
depends_on:
|
||||
minio:
|
||||
condition: service_healthy
|
||||
postgres:
|
||||
condition: service_healthy
|
||||
environment:
|
||||
DATABASE_URL: postgres://zipline:zipline@postgres:5432/zipline
|
||||
CORE_SECRET: 22d5d3159d5ed51743bc8c8ef007f836
|
||||
ZPLINE_ADMIN_USERNAME: admin
|
||||
ZPLINE_ADMIN_PASSWORD: Abcd_1234
|
||||
STORAGE_ENGINE: s3
|
||||
S3_BUCKET: zipline-bucket
|
||||
S3_ENDPOINT: http://minio:9000
|
||||
S3_ACCESS_KEY: admin
|
||||
S3_SECRET_KEY: Abcd_1234
|
||||
S3_REGION: us-east-1
|
||||
S3_FORCE_PATH_STYLE: "true"
|
||||
PORT: 3000
|
||||
ports:
|
||||
- "3333:3000"
|
||||
restart: unless-stopped
|
||||
deploy:
|
||||
resources:
|
||||
limits:
|
||||
# [已移除 CPU 限制以修复报错]
|
||||
memory: 512M
|
||||
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 3. 你需要初始化 MinIO bucket(一次性)
|
||||
|
||||
进入 MinIO 控制台(浏览器):
|
||||
```
|
||||
http://192.168.3.17:9001/login
|
||||
```
|
||||
|
||||
登录 → 创建 S3 Bucket:
|
||||
```
|
||||
zipline-bucket
|
||||
```
|
||||
|
||||
设置为 public(否则图片无法直接访问):
|
||||
- Buckets → zipline-bucket → _Access Rules_ →
|
||||
Policy: **public read**
|
||||
|
||||
## 正确设置 Public Bucket(CE 下可行方案)
|
||||
|
||||
### 方法 :使用 `mc` 命令行(推荐)
|
||||
|
||||
1. 下载 MinIO CLI `mc` 到你的 DSM 或本地 PC:
|
||||
```
|
||||
wget https://dl.min.io/client/mc/release/linux-amd64/mc chmod +x mc
|
||||
```
|
||||
|
||||
2. 添加 alias:
|
||||
```
|
||||
mc alias set local http://192.168.3.17:9000 admin StrongPasswordHere
|
||||
```
|
||||
|
||||
3. 创建 public-read bucket:
|
||||
```
|
||||
mc mb local/zipline-bucket
|
||||
```
|
||||
|
||||
4. 赋予匿名读写权限:
|
||||
```
|
||||
mc anonymous set public local/zipline-bucket
|
||||
```
|
||||
|
||||
5. 测试:
|
||||
```
|
||||
mc ls local/zipline-bucket
|
||||
```
|
||||
|
||||
现在这个 bucket 的对象就可以**被公开访问**了。
|
||||
|
||||
#### a、`mc`(MinIO Client)文档 &命令参考
|
||||
|
||||
- `mc anonymous` 命令:管理匿名(unauthenticated)访问策略。 [min.io+2min.io+2](https://min.io/docs/minio/linux/reference/minio-mc/mc-anonymous.html?utm_source=chatgpt.com)
|
||||
- 支持子命令(`get` / `list` / `set` / `set-json` 等): [min.io](https://min.io/docs/minio/linux/reference/minio-mc/mc-anonymous.html?utm_source=chatgpt.com)
|
||||
- `mc anonymous set` 语法(设置预定义策略):`none`, `download`, `upload`, `public` 四种选项可用。 [min.io+2min-io.cn+2](https://min.io/docs/minio/linux/reference/minio-mc/mc-anonymous-set.html?utm_source=chatgpt.com)
|
||||
- `mc anonymous set-json`:可以提供一个自定义的 IAM JSON policy 来配置更细粒度权限。 [min.io](https://min.io/docs/minio/linux/reference/minio-mc/mc-anonymous-set-json.html?utm_source=chatgpt.com)
|
||||
- `mc anonymous list`:查看某个 bucket 或前缀的匿名策略。 [min.io](https://min.io/docs/minio/linux/reference/minio-mc/mc-anonymous-list.html?utm_source=chatgpt.com)
|
||||
|
||||
#### b、可以设置的权限类型(匿名访问策略)
|
||||
|
||||
- `download`:只允许匿名用户下载对象(GET 操作)。 [min.io+1](https://min.io/docs/minio/linux/reference/minio-mc/mc-anonymous-set.html?utm_source=chatgpt.com)
|
||||
- `upload`:只允许匿名用户上传对象(PUT 操作)。 [min.io+1](https://min.io/docs/minio/linux/reference/minio-mc/mc-anonymous-set.html?utm_source=chatgpt.com)
|
||||
- `public`:既允许上传,也允许下载(等于读写权限)。 [min-io.cn+1](https://min-io.cn/docs/minio/linux/reference/minio-mc/mc-anonymous-set.html?utm_source=chatgpt.com)
|
||||
- `none`:禁用匿名访问(恢复私有)。 [min.io](https://min.io/docs/minio/linux/reference/minio-mc/mc-anonymous-set.html?utm_source=chatgpt.com)
|
||||
#### c、使用示例
|
||||
假设你的 MinIO alias 是 `local`,bucket 名为 `mybucket`,你想:
|
||||
|
||||
- **设置 public(读写)权限**:
|
||||
`mc anonymous set public local/mybucket`
|
||||
- **设置只读(下载)权限**:
|
||||
`mc anonymous set download local/mybucket`
|
||||
- **设置只写(仅上传)权限**:
|
||||
`mc anonymous set upload local/mybucket`
|
||||
- **禁用匿名访问**:
|
||||
`mc anonymous set none local/mybucket`
|
||||
|
||||
---
|
||||
|
||||
# 4. Zipline 初始化
|
||||
|
||||
访问:
|
||||
``` bash
|
||||
http://192.168.3.17:3333/dashboard
|
||||
```
|
||||
|
||||
首次登陆使用:
|
||||
- Username: `admin`
|
||||
- Password: 你在 docker-compose的environment 中设置的
|
||||
|
||||
> [!NOTE] Docker Compose Environment Settings:
|
||||
> S3_ACCESS_KEY: admin
|
||||
> S3_SECRET_KEY: Abcd_1234
|
||||
|
||||
然后你可以:
|
||||
- 生成 API Token(给 n8n)
|
||||
- 设置上传规则
|
||||
- 配置返回 URL(默认即可)
|
||||
|
||||
---
|
||||
|
||||
# 5. n8n 调用 Zipline 上传示例(最小可用)
|
||||
|
||||
https://zipline.diced.sh/docs/api
|
||||
https://zipline.diced.sh/docs/api/upload
|
||||
|
||||
---
|
||||
|
||||
# 6. 性能分析(NAS 场景)
|
||||
|
||||
| 项目 | MinIO | Zipline |
|
||||
| -------- | ---------------- | ----------------------- |
|
||||
| 存储性能 | 只受 NAS 硬盘/SSD 限制 | 仅处理 metadata |
|
||||
| 并发 | 高(S3 原生并行) | 中等(单 Node.js 进程) |
|
||||
| 数据库 | 无(内置 KV) | PostgreSQL/SQLite,需要 DB |
|
||||
| 扩展性 | 可横向扩容 | 单实例 → 前端微服务即可 |
|
||||
| REST API | 完备 | 完备(适合 n8n) |
|
||||
|
||||
# 7. 备份策略
|
||||
|
||||
这是一个涉及**分布式存储系统一致性**的经典运维话题。由于 Zipline 将元数据存在 Postgres,将文件实体存在 MinIO,你的备份方案必须确保这两者在时间点上是(尽可能)一致的。
|
||||
|
||||
针对 Synology NAS 环境,我为你设计了两种方案。考虑到你的技术背景,我强烈推荐**热备份 + 增量归档**,这是企业级运维的标准做法。
|
||||
## 核心挑战:由于“脑体分离”导致的一致性问题
|
||||
- **大脑 (Postgres)**:记录了“文件A的ID是123,位于MinIO的/bucket/a.jpg”。
|
||||
- **身体 (MinIO)**:实际存储了 `a.jpg`。
|
||||
- **风险**:如果你在 10:00 备份了数据库,10:05 备份了 MinIO,但这 5 分钟内你上传了新文件,恢复时就会出现“数据库找不到文件”或“文件没记录”的幽灵数据。
|
||||
|
||||
---
|
||||
## 方案:基于脚本的逻辑热备份
|
||||
|
||||
这种方案利用数据库自带的工具导出数据,结合文件系统的增量备份。
|
||||
|
||||
### 1. 工作原理
|
||||
|
||||
1. **数据库**:不停止服务,使用 `pg_dump` 命令将 Postgres 内存中的数据导出为一个 `.sql` 文件。这是“逻辑备份”。
|
||||
2. **MinIO**:MinIO 的数据存储在物理磁盘上就是普通文件。
|
||||
3. **归档**:使用 Synology Hyper Backup 将 `.sql` 文件和 `MinIO 数据目录` 一起备份到远端(云端、USB 硬盘或其他 NAS)。
|
||||
### 2. 利弊分析
|
||||
- **优点**:
|
||||
- **零停机**:服务全程在线,不影响业务。
|
||||
- **数据安全**:`pg_dump` 导出的 SQL 文件是纯文本,不依赖特定的 Postgres 版本或 CPU 架构(x86/ARM),**迁移能力极强**。
|
||||
- **原生支持**:完美契合 Synology Hyper Backup 的增量备份机制。
|
||||
- **缺点**:
|
||||
- **微小的不一致性**:如果在导出 SQL 的几秒钟内恰好有文件上传,可能存在极小的时间差(对于个人/中小企业可忽略)。
|
||||
- **配置门槛**:需要编写一个简单的 Shell 脚本。
|
||||
|
||||
### 3. 实施步骤
|
||||
**第一步:创建备份存放目录** 在你的 NAS 上创建一个专门存放数据库备份文件的目录,例如: `/volume1/docker/zipline-stack/backups`
|
||||
**第二步:编写自动备份脚本** 我为你写好了一个健壮的脚本,包含日志记录和旧备份自动清理功能。
|
||||
请在 NAS 上创建一个文件,例如 `/volume1/docker/zipline-stack/backup_script.sh`,内容如下:
|
||||
|
||||
Bash
|
||||
|
||||
``` bash
|
||||
#!/bin/bash
|
||||
|
||||
# ================= 配置区域 =================
|
||||
# 备份保存路径
|
||||
BACKUP_DIR="/volume1/docker/zipline-stack/backups"---
|
||||
title: 1. 架构图(Synology 专用)
|
||||
author: shenwei
|
||||
tags: [docker, image, minio, n8n, nas, synology, zipline]
|
||||
---
|
||||
---
|
||||
title: 1. 架构图(Synology 专用)
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [docker, image, minio, n8n, nas, synology, zipline]
|
||||
---
|
||||
|
||||
# Postgres 容器名称 (需与 docker-compose.yml 一致)
|
||||
PG_CONTAINER="zipline_postgres"
|
||||
# 数据库用户和名称
|
||||
PG_USER="zipline"
|
||||
PG_DB="zipline"
|
||||
# 保留多少天的备份
|
||||
RETENTION_DAYS=30
|
||||
# 当前日期
|
||||
DATE=$(date +%Y%m%d_%H%M%S)
|
||||
|
||||
# ================= 执行逻辑 =================
|
||||
mkdir -p "$BACKUP_DIR"
|
||||
|
||||
echo "[$DATE] 开始备份 Postgres..."
|
||||
|
||||
# 1. 执行 pg_dump 导出数据库 (压缩格式)
|
||||
# 注意:这里不直接备份 /var/lib/postgresql/data 目录,因为热备份该目录会导致数据损坏
|
||||
docker exec "$PG_CONTAINER" pg_dump -U "$PG_USER" -d "$PG_DB" | gzip > "$BACKUP_DIR/db_$DATE.sql.gz"
|
||||
|
||||
if [ $? -eq 0 ]; then
|
||||
echo "[$DATE] 数据库备份成功: db_$DATE.sql.gz"
|
||||
else
|
||||
echo "[$DATE] !!! 数据库备份失败 !!!"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# 2. 清理旧备份 (删除超过 30 天的文件)
|
||||
find "$BACKUP_DIR" -name "db_*.sql.gz" -mtime +$RETENTION_DAYS -delete
|
||||
echo "[$DATE] 已清理超过 $RETENTION_DAYS 天的旧备份"
|
||||
|
||||
# 3. (可选) 如果你想在这里也把 MinIO 打包,可以用 tar,但建议交给 Hyper Backup 处理
|
||||
# echo "MinIO 数据量较大,建议由 Synology Hyper Backup 直接备份 minio_data 目录"
|
||||
|
||||
echo "[$DATE] 备份流程结束。"
|
||||
```
|
||||
|
||||
**第三步:设置脚本权限** SSH 进入 NAS,给脚本执行权限:
|
||||
|
||||
Bash
|
||||
``` bash
|
||||
chmod +x /volume1/docker/zipline-stack/backup_script.sh
|
||||
```
|
||||
|
||||
**第四步:配置 Synology 任务计划 (Task Scheduler)**
|
||||
|
||||
1. 打开 DSM 控制面板 -> **任务计划**。
|
||||
2. 新增 -> **计划的任务** -> **用户定义的脚本**。
|
||||
3. **常规**:用户账号选择 `root` (必须,否则无法操作 Docker)。
|
||||
4. **计划**:建议每天凌晨 3:00 执行。
|
||||
5. **任务设置** -> 用户定义的脚本框中填入:
|
||||
Bash
|
||||
``` bash
|
||||
bash /volume1/docker/zipline-stack/backup_script.sh >> /volume1/docker/zipline-stack/backup.log 2>&1
|
||||
```
|
||||
![[IMG-20251229190624937.png]]
|
||||
![[IMG-20251229190625061.png]]
|
||||
![[IMG-20251229190625079.png]]
|
||||
|
||||
**第五步:配置 Synology Hyper Backup** 这是最后一道防线。
|
||||
|
||||
1. 打开 **Hyper Backup**。
|
||||
2. 创建一个新的数据备份任务。
|
||||
|
||||
3. **选择备份源**:
|
||||
- 勾选 `/volume1/docker/zipline-stack/backups` (这里有刚才脚本生成的数据库 SQL)。
|
||||
- 勾选 `/volume1/docker/zipline-stack/minio/minio_data` (这是图片实体文件)。
|
||||
|
||||
4. 设置备份目的地(USB、另一台 NAS 或 Synology C2 云)。
|
||||
![[IMG-20251229190625099.png]]
|
||||
![[IMG-20251229190625117.png]]
|
||||
|
||||
# Reference URL
|
||||
|
||||
|
||||
- Docker Volume Documentation: [https://docs.docker.com/storage/volumes/](https://docs.docker.com/storage/volumes/)
|
||||
- MinIO Docker Persistence: [https://min.io/docs/minio/linux/operations/install-deploy-manage/deploy-minio-single-node-single-drive.html](https://min.io/docs/minio/linux/operations/install-deploy-manage/deploy-minio-single-node-single-drive.html)
|
||||
- Synology Docker Permissions Advice: [https://kb.synology.com/en-global/DSM/tutorial/How_to_manage_ACL_settings_on_your_Synology_NAS](https://kb.synology.com/en-global/DSM/tutorial/How_to_manage_ACL_settings_on_your_Synology_NAS)
|
||||
- MinIO mc anonymous https://docs.min.io/enterprise/aistor-object-store/reference/cli/mc-anonymous/
|
||||
101
raw/Technical/Home Office/🟠MySQL MariaDB 数据库详细信息.md
Normal file
101
raw/Technical/Home Office/🟠MySQL MariaDB 数据库详细信息.md
Normal file
@@ -0,0 +1,101 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [database, mariadb, mysql, nas]
|
||||
---
|
||||
|
||||
#nas #mysql #database #mariadb
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
## Internal Access
|
||||
|
||||
| IP | 192.168.3.17 |
|
||||
| -------- | ------------ |
|
||||
| Port | 3307 |
|
||||
| Username | shenwei |
|
||||
| Password | !Abcde12345 |
|
||||
| Username | root |
|
||||
| Password | !Abcde12345 |
|
||||
|
||||
|
||||
## Public Access
|
||||
|
||||
| Domain | mysql.ishenwei.online |
|
||||
| -------- | --------------------- |
|
||||
| Port | 63307 |
|
||||
| Username | shenwei |
|
||||
| Password | !Abcde12345 |
|
||||
| Username | root |
|
||||
| Password | !Abcde12345 |
|
||||
|
||||
## MariaDB新安装后,需要强制创建一个用户用于远程访问(非本机IP访问),本机IP访问仅限root用户
|
||||
|
||||
进入 MariaDB(使用 socket 登陆):
|
||||
```
|
||||
sudo mysql -u root -p -S /run/mysqld/mysqld10.sock
|
||||
|
||||
```
|
||||
|
||||
查看 root 主机权限:
|
||||
``` sql
|
||||
select host, user from mysql.user;
|
||||
```
|
||||
|
||||
``` bash
|
||||
shenwei@SHENWEI_DS718:/usr/local/mariadb10/etc/mysql$ sudo mysql -u root -p -S /run/mysqld/mysqld10.sock
|
||||
Enter password:
|
||||
Welcome to the MariaDB monitor. Commands end with ; or \g.
|
||||
Your MariaDB connection id is 8
|
||||
Server version: 10.11.6-MariaDB Source distribution
|
||||
|
||||
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
|
||||
|
||||
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
|
||||
|
||||
MariaDB [(none)]> select host, user from mysql.user;
|
||||
+-----------+-------------+
|
||||
| Host | User |
|
||||
+-----------+-------------+
|
||||
| | PUBLIC |
|
||||
| localhost | mariadb.sys |
|
||||
| localhost | mysql |
|
||||
| localhost | root |
|
||||
+-----------+-------------+
|
||||
4 rows in set (0.002 sec)
|
||||
|
||||
```
|
||||
|
||||
这里已经看到关键问题了:
|
||||
**你的 MariaDB 只有 `root@localhost`,并没有 `root@%` 或你要连接用的用户账号**。
|
||||
而从你外部客户端连接失败的最常见原因就是:**没有对应的 Host/User 组合 + 缺少权限**。
|
||||
|
||||
你现在的 `mysql.user` 内容:
|
||||
|
||||
``` bash
|
||||
| | PUBLIC |
|
||||
| localhost | mariadb.sys |
|
||||
| localhost | mysql |
|
||||
| localhost | root |
|
||||
|
||||
```
|
||||
|
||||
|
||||
这里唯一能用的账号就是:
|
||||
|
||||
- `root@localhost` → **只能从本机 localhost 登录**
|
||||
这意味着从 **Synology Docker、其他机器、同网段的客户端** 都不能用 root 连接。
|
||||
|
||||
## 创建一个允许远程访问的用户
|
||||
|
||||
``` sql
|
||||
CREATE USER 'shenwei'@'%' IDENTIFIED BY '!Abcde12345';
|
||||
GRANT ALL PRIVILEGES ON *.* TO 'shenwei'@'%' WITH GRANT OPTION;
|
||||
FLUSH PRIVILEGES;
|
||||
|
||||
```
|
||||
@@ -0,0 +1,121 @@
|
||||
---
|
||||
title: NodeWarden - 把 Bitwarden 搬上 Cloudflare Workers,彻底告别服务器
|
||||
source: https://www.appinn.com/nodewarden/
|
||||
author: shenwei
|
||||
published: 2026-02-22
|
||||
created: 2026-02-27
|
||||
description: 部署 NodeWarden 之后的效果,就是在无服务器的情况下,也能在手机、电脑上使用 Bitwarden 客户端来保存密码了,支持自动登陆、二次验证之类的功能。
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
Bitwarden 是少数客户端与服务器端都开源的密码管理系统,支持完整自托管部署。@ [Appinn](https://www.appinn.com/nodewarden/)
|
||||
但有人更进一步:直接把服务器端运行在 Cloudflare Workers 上——也就是说,你连 VPS 都可以省了。
|
||||
|
||||

|
||||
|
||||
NodeWarden - 把 Bitwarden 搬上 Cloudflare Workers,彻底告别服务器 1
|
||||
|
||||
部署 NodeWarden 之后的效果,就是在无服务器的情况下,也能在手机、电脑上使用 Bitwarden 客户端来保存密码了,支持自动登陆、二次验证之类的功能。
|
||||
|
||||
## NodeWarden 与 Bitwarden 区别
|
||||
|
||||
| 能力项 | Bitwarden | NodeWarden | 说明 |
|
||||
| --- | --- | --- | --- |
|
||||
| 单用户保管库(登录/笔记/卡片/身份) | ✅ | ✅ | 基于Cloudflare D1 |
|
||||
| 文件夹 / 收藏 | ✅ | ✅ | 常用管理能力可用 |
|
||||
| 全量同步 `/api/sync` | ✅ | ✅ | 已做兼容与性能优化 |
|
||||
| 附件上传/下载 | ✅ | ✅ | 基于 Cloudflare R2 |
|
||||
| 导入功能 | ✅ | ✅ | 覆盖常见导入路径 |
|
||||
| 网站图标代理 | ✅ | ✅ | 通过 `/icons/{hostname}/icon.png` |
|
||||
| passkey、TOTP | ❌ | ✅ | 官方需要会员,我们的不需要 |
|
||||
| 多用户 | ✅ | ❌ | NodeWarden 定位单用户 |
|
||||
| 组织/集合/成员权限 | ✅ | ❌ | 没必要实现 |
|
||||
| 登录 2FA(TOTP/WebAuthn/Duo/Email) | ✅ | ⚠️ 部分支持 | 仅支持 TOTP(通过 `TOTP_SECRET` ) |
|
||||
| SSO / SCIM / 企业目录 | ✅ | ❌ | 没必要实现 |
|
||||
| Send | ✅ | ❌ | 基本没人用 |
|
||||
| 紧急访问 | ✅ | ❌ | 没必要实现 |
|
||||
| 管理后台 / 计费订阅 | ✅ | ❌ | 纯免费 |
|
||||
| 推送通知完整链路 | ✅ | ❌ | 没必要实现 |
|
||||
|
||||
## 必要条件
|
||||
|
||||
1. 你需要有一个 Cloudflare 账号(必须有一个域名和信用卡)
|
||||
2. 一个 GitHub 账号
|
||||
|
||||
## 具体部署步骤
|
||||
|
||||
### fork
|
||||
|
||||
- GitHub: [https://github.com/shuaiplus/NodeWarden](https://github.com/shuaiplus/NodeWarden)
|
||||
|
||||
|
||||
NodeWarden - 把 Bitwarden 搬上 Cloudflare Workers,彻底告别服务器 2
|
||||
|
||||
### 一键部署
|
||||
|
||||
在你自己的 GitHub 页面上,有一个按钮:
|
||||
|
||||
|
||||
|
||||
NodeWarden - 把 Bitwarden 搬上 Cloudflare Workers,彻底告别服务器 3
|
||||
|
||||
这个步骤需要在 Cloudflare 中绑定 GitHub 账号,根据页面提示即可。
|
||||
|
||||
### 设置 NodeWarden
|
||||
|
||||
部署成功之后,Cloudflare 会提供一个临时地址,类似 1nodewarden.apipnn.workers.dev ,用浏览器打开它,如果打不开,就绑定一个你自己的二级域名。
|
||||
|
||||
|
||||
|
||||
NodeWarden - 把 Bitwarden 搬上 Cloudflare Workers,彻底告别服务器 4
|
||||
|
||||
根据页面提示,一步一步进行即可。
|
||||
|
||||
这个步骤主要有:
|
||||
|
||||
1. 设置 JWT\_SECRET
|
||||
2. 设置自动更新 GitHub
|
||||
3. 设置主账号与密码
|
||||
4. 设置启用主账号的二次验证
|
||||
|
||||
|
||||
NodeWarden - 把 Bitwarden 搬上 Cloudflare Workers,彻底告别服务器 5
|
||||
|
||||
最后一步成功之后,还能选择彻底隐藏这个设置页面:
|
||||
|
||||
|
||||
|
||||
NodeWarden - 把 Bitwarden 搬上 Cloudflare Workers,彻底告别服务器 6
|
||||
|
||||
设置完成。
|
||||
|
||||
## 在客户端登录
|
||||
|
||||
打开你的 Bitwarden 官方客户端,在登录的地方选择自托管,并输入 **服务器 URL** :
|
||||
|
||||
|
||||
|
||||
NodeWarden - 把 Bitwarden 搬上 Cloudflare Workers,彻底告别服务器 7
|
||||
|
||||
|
||||
|
||||
NodeWarden - 把 Bitwarden 搬上 Cloudflare Workers,彻底告别服务器 8
|
||||
|
||||
之后,在使用刚刚设置页面设置的用户名和密码(如果设置了二次验证,还会要求输入验证码),就可以正常登录啦:
|
||||
|
||||
|
||||
|
||||
NodeWarden - 把 Bitwarden 搬上 Cloudflare Workers,彻底告别服务器 9
|
||||
|
||||
趁假期最后一天,快去试试吧。
|
||||
|
||||
---
|
||||
|
||||
原文:https://www.appinn.com/nodewarden/
|
||||
|
||||
## 我的NodeWarden
|
||||
|
||||
https://nodewarden.ishenwei.online/
|
||||
|
||||
![[IMG-20260228191730714.png]]
|
||||
24
raw/Technical/Home Office/🟠RAX50 路由器 更新Merlin Clash订阅.md
Normal file
24
raw/Technical/Home Office/🟠RAX50 路由器 更新Merlin Clash订阅.md
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [clash, merlin-clash, rax50]
|
||||
---
|
||||
|
||||
#rax50 #merlin-clash #clash
|
||||
|
||||
![[IMG-20260304185325682.png]]
|
||||
|
||||
进入RAX50路由器管理界面
|
||||
|
||||
在RAX50的Merlin Clash界面,复制vless url进到小白一键订阅助手,并重命名配置文件比如 kiwi3
|
||||
![[IMG-20260304185325726.png]]
|
||||
|
||||
选择新建的配置文件
|
||||
点保存&启动
|
||||
如果不行,就再点一次快速重启
|
||||
|
||||
![[IMG-20260304185325770.png]]
|
||||
111
raw/Technical/Home Office/🟠Ubuntu 24.04 enable SSH.md
Normal file
111
raw/Technical/Home Office/🟠Ubuntu 24.04 enable SSH.md
Normal file
@@ -0,0 +1,111 @@
|
||||
---
|
||||
title: 启动 SSH 服务
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [ssh, ubuntu]
|
||||
---
|
||||
|
||||
|
||||
#ubuntu #ssh
|
||||
|
||||
在 Ubuntu 24.04 中开启 SSH 服务非常简单,但这个版本引入了一个重要的变化:**默认使用 `ssh.socket` 激活机制**(即只有在连接请求进入时才启动 SSH 守护进程),这与旧版本略有不同。
|
||||
|
||||
以下是开启 SSH 的标准步骤:
|
||||
|
||||
### 1. 安装 OpenSSH Server
|
||||
|
||||
首先,你需要确保系统中安装了 SSH 服务端。打开终端并输入:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install openssh-server -y
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 2. 启动并设置开机自启
|
||||
|
||||
在 Ubuntu 24.04 中,你可以使用以下命令来确保服务处于活动状态并随系统启动:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 启动 SSH 服务
|
||||
sudo systemctl start ssh
|
||||
|
||||
# 设置开机自启
|
||||
sudo systemctl enable ssh
|
||||
```
|
||||
|
||||
> **注意:** 如果你发现 `systemctl status ssh` 显示服务未运行,别担心。24.04 默认使用 **Socket 激活** 模式。你可以通过 `sudo systemctl status ssh.socket` 检查监听状态。
|
||||
|
||||
---
|
||||
|
||||
### 3. 配置防火墙 (UFW)
|
||||
|
||||
如果你的 Ubuntu 开启了防火墙,你需要手动允许 SSH 流量(默认端口 22):
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo ufw allow ssh
|
||||
# 或者
|
||||
sudo ufw allow 22/tcp
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 4. 验证 SSH 状态
|
||||
|
||||
你可以通过以下命令检查 SSH 是否已经准备就绪:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo systemctl status ssh
|
||||
```
|
||||
|
||||
如果看到 `active (running)` 或者 `ListenStream=22` (针对 socket 模式),说明已经成功开启。
|
||||
|
||||
---
|
||||
|
||||
### 5. 如何从远程连接
|
||||
|
||||
在另一台电脑上,使用你的**用户名**和**局域网 IP** 进行连接:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
ssh username@192.168.x.x
|
||||
```
|
||||
|
||||
_(如果你不知道本机 IP,请使用前面提到的 `hostname -I` 命令查看)_
|
||||
|
||||
---
|
||||
|
||||
### 进阶建议:24.04 的特殊说明
|
||||
|
||||
如果你习惯了旧版本的管理方式,或者需要修改**自定义端口**(例如改为 2222),在 24.04 中你可能需要注意:
|
||||
|
||||
- **修改端口:** 现在推荐通过 `sudo systemctl edit ssh.socket` 来修改监听端口,而不仅仅是修改 `/etc/ssh/sshd_config`。
|
||||
|
||||
- **切换回传统模式:** 如果你希望 SSH 像以前一样一直作为后台进程运行,可以执行:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo systemctl disable --now ssh.socket
|
||||
sudo systemctl enable --now ssh.service
|
||||
```
|
||||
|
||||
|
||||
你想了解如何为 SSH 配置密钥登录以提高安全性吗?
|
||||
|
||||
---
|
||||
|
||||
[How to Enable SSH on Ubuntu 24.04](https://www.youtube.com/watch?v=F1_fkOYgu8g) 这个视频详细演示了在 Ubuntu 系统中从安装 OpenSSH 到通过防火墙配置的完整操作流程,非常适合新安装系统的用户参考。
|
||||
284
raw/Technical/Home Office/🟠Ubuntu Server科学上网.md
Normal file
284
raw/Technical/Home Office/🟠Ubuntu Server科学上网.md
Normal file
@@ -0,0 +1,284 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [docker, proxychains, ubuntu, v2rayn]
|
||||
---
|
||||
|
||||
#ubuntu #proxychains #docker #v2rayn
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
## 安装V2RayN
|
||||
请参考以下文章来安装V2RayN
|
||||
[[🟠3X-UI Xray on BandwagonVPS]]
|
||||
[[🟠安装v2rayN]]
|
||||
![[IMG-20251229190624376.png]]
|
||||
|
||||
|
||||
|
||||
## 验证代理可以科学上网
|
||||
|
||||
### 使用 `curl` 直接测试(最推荐)
|
||||
|
||||
这是最快、最直接的方法。我们可以强制 `curl` 使用 SOCKS5 代理去访问 Google 的状态页。
|
||||
**执行命令:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
curl -x socks5h://127.0.0.1:10808 -v https://www.google.com
|
||||
```
|
||||
|
||||
- **参数解释:**
|
||||
|
||||
- `-x socks5h://`:指定使用 SOCKS5 代理。注意加个 `h`,这表示让代理服务器去解析域名(防止本地 DNS 污染导致测试失败)。
|
||||
- `-v`:(Verbose) 显示详细连接过程。
|
||||
|
||||
- **判断标准:**
|
||||
- 如果看到 `HTTP/2 200` 或者大量的 HTML 文本,说明**代理成功**。
|
||||
- 如果显示 `Connection refused` 或 `Timeout`,说明**端口未开放或 V2Ray 未运行**。
|
||||
|
||||
|
||||
|
||||
|
||||
## 配置 ProxyChains
|
||||
|
||||
ProxyChains 是最灵活的工具,它可以让原本不支持代理的终端命令通过代理运行。
|
||||
|
||||
1. **编辑配置文件:**
|
||||
```
|
||||
sudo nano /etc/proxychains4.conf
|
||||
```
|
||||
|
||||
(如果是旧版本可能是 `/etc/proxychains.conf`)
|
||||
|
||||
2. 修改 ProxyList:
|
||||
|
||||
滑动到文件末尾,注释掉默认的 socks4,添加你的 V2Ray 节点信息:
|
||||
|
||||
```
|
||||
[ProxyList]
|
||||
# 格式: 类型 IP 端口
|
||||
socks5 127.0.0.1 10808
|
||||
```
|
||||
|
||||
3. 使用方法:
|
||||
|
||||
在任何命令前加上 proxychains4 即可。例如:
|
||||
|
||||
```
|
||||
proxychains4 curl https://www.google.com
|
||||
``````
|
||||
|
||||
|
||||
使用:
|
||||
``` bash
|
||||
proxychains git clone https://github.com/...
|
||||
proxychains curl https://google.com
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 2. 配置 Git 代理
|
||||
|
||||
Git 不会自动走系统变量,建议为其设置全局配置。
|
||||
|
||||
- **设置 SOCKS5 代理(推荐):**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
git config --global http.proxy 'socks5://127.0.0.1:10808'
|
||||
git config --global https.proxy 'socks5://127.0.0.1:10808'
|
||||
```
|
||||
|
||||
- **取消设置:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
git config --global --unset http.proxy
|
||||
git config --global --unset https.proxy
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 3. 配置 Docker Pull (Daemon 代理)
|
||||
|
||||
`docker pull` 是由 Docker 守护进程(Daemon)执行的,它不读取普通用户的环境变量。
|
||||
|
||||
1. **创建配置目录:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo mkdir -p /etc/systemd/system/docker.service.d
|
||||
```
|
||||
|
||||
2. **创建代理配置文件:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo nano /etc/systemd/system/docker.service.d/http-proxy.conf
|
||||
```
|
||||
|
||||
3. **添加以下内容:**
|
||||
|
||||
Ini, TOML
|
||||
|
||||
```
|
||||
[Service]
|
||||
Environment="HTTP_PROXY=http://127.0.0.1:10808/"
|
||||
Environment="HTTPS_PROXY=http://127.0.0.1:10808/"
|
||||
Environment="NO_PROXY=localhost,127.0.0.1,docker-registry.somecorporate.com"
|
||||
```
|
||||
|
||||
_(注:这里通常使用 HTTP 代理端口)_
|
||||
|
||||
4. **重启 Docker 服务:**
|
||||
|
||||
```
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl restart docker
|
||||
```
|
||||
**检查 Docker 守护进程是否加载了代理:**
|
||||
|
||||
**执行命令:**
|
||||
```
|
||||
docker info | grep -i proxy
|
||||
```
|
||||
|
||||
- **预期输出:** 如果你配置成功,你应该能看到类似下面的信息:
|
||||
```
|
||||
HTTP Proxy: http://127.0.0.1:10808
|
||||
HTTPS Proxy: http://127.0.0.1:10808
|
||||
No Proxy: localhost,127.0.0.1
|
||||
```
|
||||
_(注:如果这里没有输出,说明 `/etc/systemd/system/docker.service.d/http-proxy.conf` 配置未生效,请记得执行 `systemctl daemon-reload` 和 `systemctl restart docker`)_
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 4. 配置 Docker 容器内应用代理
|
||||
|
||||
#### docker-compose.yml里面直接加 env
|
||||
```
|
||||
`environment:
|
||||
- ALL_PROXY=socks5://172.24.0.1:10808
|
||||
```
|
||||
|
||||
For example:gi
|
||||
```
|
||||
version: "3.9"
|
||||
|
||||
services:
|
||||
homarr:
|
||||
image: ghcr.io/homarr-labs/homarr
|
||||
container_name: homarr
|
||||
restart: unless-stopped
|
||||
ports:
|
||||
- "7575:7575"
|
||||
volumes:
|
||||
- /home/shenwei/Docker/homarr/appdata:/appdata
|
||||
- /var/run/docker.sock:/var/run/docker.sock
|
||||
environment:
|
||||
- SECRET_ENCRYPTION_KEY=4a418def4be700be26672aa57a4c3d4b94abd2cf97021b5c4ecd3c1644c1f071
|
||||
- ALL_PROXY=socks5://172.24.0.1:10808
|
||||
|
||||
```
|
||||
|
||||
2个方法知道如何获取docker network gate IP
|
||||
1. Docker Portainer
|
||||
![[IMG-20251229190624729.png]]
|
||||
2. 获取运行时container的network gateway
|
||||
适用于容器已经在运行的情况。进入容器的交互式 shell:
|
||||
```
|
||||
docker exec -it <container_name_or_id> /bin/bash
|
||||
```
|
||||
- 如果容器没有 `bash`,可以用 `sh`:
|
||||
```
|
||||
docker exec -it <container_name_or_id> sh
|
||||
```
|
||||
|
||||
运行以下命令获取network gateway IP:
|
||||
```
|
||||
ip route | awk '/default/ { print $3 }'
|
||||
```
|
||||
|
||||
For example:
|
||||
``` bash
|
||||
|
||||
root@shenwei-HP-ZBook-01:/home/shenwei/Docker/homarr# docker exec -it homarr /bin/bash
|
||||
23c94b2dfeb5:/app# ip route
|
||||
default via 172.24.0.1 dev eth0
|
||||
172.24.0.0/16 dev eth0 scope link src 172.24.0.2
|
||||
23c94b2dfeb5:/app# ip route | awk '/default/ { print $3 }'
|
||||
172.24.0.1
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||
如果你希望容器内部的程序(如 `apt-get`、`pip`)能上网,有两种方案:
|
||||
|
||||
### 方案 A:全局配置(推荐 Docker 17.07+)
|
||||
|
||||
修改当前用户的 Docker 客户端配置文件,这样所有 `docker run` 的容器都会自动带上代理环境变量。
|
||||
|
||||
1. **编辑配置文件:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
mkdir -p ~/.docker
|
||||
nano ~/.docker/config.json
|
||||
```
|
||||
|
||||
2. **添加内容:**
|
||||
|
||||
JSON
|
||||
|
||||
```
|
||||
{
|
||||
"proxies": {
|
||||
"default": {
|
||||
"httpProxy": "http://127.0.0.1:1081",
|
||||
"httpsProxy": "http://127.0.0.1:1081",
|
||||
"noProxy": "localhost,127.0.0.1"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**注意:** 如果你的容器使用的是 `bridge` 网络,`127.0.0.1` 指向的是容器内部。你需要将 IP 改为宿主机的虚拟网桥 IP(通常是 `172.17.0.1`)。
|
||||
|
||||
|
||||
### 方案 B:运行时临时指定
|
||||
|
||||
在启动容器时通过 `-e` 参数注入环境变量:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
docker run -e HTTP_PROXY="http://宿主机IP:1081" -e HTTPS_PROXY="http://宿主机IP:1081" my_image
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 总结建议
|
||||
|
||||
|**场景**|**推荐方式**|
|
||||
|---|---|
|
||||
|**临时终端命令**|`proxychains4 <command>`|
|
||||
|**Git 操作**|`git config --global`|
|
||||
|**下载 Docker 镜像**|修改 `systemd/system/docker.service.d`|
|
||||
|**容器内部业务**|修改 `~/.docker/config.json`|
|
||||
|
||||
如果你在配置过程中遇到“连接被拒绝 (Connection Refused)”的问题,请检查 V2Ray 配置文件中是否开启了 HTTP 代理协议,并确认端口号是否正确。
|
||||
361
raw/Technical/Home Office/🟠Ubuntu服务器通过rsync实现日常增量备份.md
Normal file
361
raw/Technical/Home Office/🟠Ubuntu服务器通过rsync实现日常增量备份.md
Normal file
@@ -0,0 +1,361 @@
|
||||
|
||||
#ubuntu #rsync #backup #nas
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
既然你已经完成了 **Clonezilla** 的整机镜像备份,现在引入 **rsync** 实现日常的增量备份是构建“工作室级”数据保护体系的最后一步。
|
||||
|
||||
作为技术背景深厚且需要管理 TikTok 业务数据的用户,rsync 的优势在于它可以**不关机**运行,并且只传输**变化过**的文件。
|
||||
|
||||
### 1. 核心逻辑与准备
|
||||
|
||||
**目标**:将 Ubuntu 服务器的实时数据(代码、Docker 配置、业务数据)增量同步到已经挂载好的 NAS 目录(`/mnt/nas_backup`)。
|
||||
|
||||
**挂载检查**: 在开始前,请确保你的 NAS 已经挂载成功(你之前提到 Samba 挂载已经成功):
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
df -h | grep nas_backup
|
||||
```
|
||||
|
||||
_如果输出显示了 NAS 的 IP 和空间信息,则可以继续。_
|
||||
|
||||
### 2. 编写 Rsync 自动化脚本
|
||||
|
||||
不要直接在命令行输入长命令,建议创建一个专门的脚本。
|
||||
|
||||
**创建脚本文件**:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo nano /usr/local/bin/rsync_backup.sh
|
||||
```
|
||||
|
||||
**粘贴以下内容(已根据你的 ZBook 环境优化)**:
|
||||
|
||||
|
||||
> [!NOTE] 此为最终可运行版本
|
||||
|
||||
``` bash
|
||||
#!/bin/bash
|
||||
|
||||
LOCKFILE="/tmp/rsync_backup.lock"
|
||||
if [ -e ${LOCKFILE} ] && kill -0 `cat ${LOCKFILE}`; then
|
||||
echo "备份任务已在运行中,跳过本次执行。"
|
||||
exit
|
||||
fi
|
||||
echo $$ > ${LOCKFILE}
|
||||
trap "rm -f ${LOCKFILE}" EXIT
|
||||
|
||||
# --- 配置区 ---
|
||||
MOUNT_POINT="/mnt/nas_backup"
|
||||
DATE=$(date +%Y-%m-%d)
|
||||
DEST="$MOUNT_POINT/docker_backups/$DATE"
|
||||
LOG="/var/log/rsync_backup.log"
|
||||
|
||||
# --- 1. 挂载检查 ---
|
||||
if ! mountpoint -q "$MOUNT_POINT"; then
|
||||
echo "$(date): [错误] NAS 未挂载" >> "$LOG"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
mkdir -p "$DEST"
|
||||
|
||||
# --- 2. 执行精确备份 ---
|
||||
echo "--- 开始备份 Docker 数据: $(date) ---" >> "$LOG"
|
||||
|
||||
# 优化后的参数:
|
||||
# -v: 显示详情 (方便初次调试)
|
||||
# --exclude: 排除 Python 虚拟环境、__pycache__ 和 git 目录
|
||||
rsync -azR --delete \
|
||||
--exclude="venv/" \
|
||||
--exclude=".venv/" \
|
||||
--exclude="**/__pycache__/" \
|
||||
--exclude=".git/" \
|
||||
/var/lib/docker/volumes/ \
|
||||
/etc/docker/ \
|
||||
/home/shenwei/Docker/ \
|
||||
"$DEST/" >> "$LOG" 2>&1
|
||||
|
||||
# --- 3. 状态检查 ------
|
||||
title: --- 配置区 ---
|
||||
author: shenwei
|
||||
tags: [backup, nas, rsync, ubuntu]
|
||||
---
|
||||
---
|
||||
title: --- 配置区 ---
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [backup, nas, rsync, ubuntu]
|
||||
---
|
||||
|
||||
# rsync 返回 23 表示部分文件由于权限或消失未传输,这在备份正在运行的系统时常见。
|
||||
# 我们重点看是否大部分数据已同步。
|
||||
if [ $? -eq 0 ] || [ $? -eq 23 ] || [ $? -eq 24 ]; then
|
||||
echo "--- 备份完成: $(date) ---" >> "$LOG"
|
||||
else
|
||||
echo "--- 备份异常中止,错误码: $? ---" >> "$LOG"
|
||||
fi
|
||||
```
|
||||
|
||||
**赋予执行权限**:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo chmod +x /usr/local/bin/rsync_backup.sh
|
||||
```
|
||||
|
||||
### 3. 设置定时任务 (Crontab)
|
||||
|
||||
作为跨境电商业务,建议在凌晨 3 点(业务低峰期)执行自动备份。
|
||||
|
||||
1. **打开定时任务配置**:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo crontab -e
|
||||
```
|
||||
|
||||
2. **在文件末尾添加一行**:
|
||||
|
||||
Plaintext
|
||||
|
||||
```
|
||||
0 3 * * * /usr/local/bin/rsync_backup.sh
|
||||
```
|
||||
|
||||
_这代表每天 03:00 自动运行备份脚本。_
|
||||
|
||||
### 4. 关键点:Docker 数据的备份
|
||||
|
||||
由于你使用了大量自动化技术支持 TikTok 业务,**Docker 卷(Volumes)** 是最核心的数据。
|
||||
|
||||
- **路径**:默认在 `/var/lib/docker/volumes`。
|
||||
|
||||
- **一致性**:如果备份的是数据库(如 MySQL),建议在脚本开头加入 `docker exec <容器名> mysqldump ...` 导出 SQL 文件,再由 rsync 同步。因为直接同步正在写入的二进制数据库文件可能导致恢复后无法启动。
|
||||
|
||||
### 5. 如何在灾难时还原?
|
||||
|
||||
- **单个文件丢失**:直接去 `/mnt/nas_backup/daily_sync` 下通过 `cp` 或 `rsync` 拷贝回来。
|
||||
- **系统崩溃但能进 SSH**:反向执行 rsync 命令:
|
||||
Bash
|
||||
```
|
||||
# 注意路径顺序颠倒
|
||||
sudo rsync -aAXz /mnt/nas_backup/daily_sync/ /
|
||||
```
|
||||
- **硬盘彻底坏了**:先用你之前的 **Clonezilla** 镜像恢复整个系统,然后用 **rsync** 将最新的增量数据同步回来,即可实现“时间点恢复”。
|
||||
### 💡 建议
|
||||
|
||||
鉴于你对技术细节的关注,你可以尝试运行一次手动备份来测试性能:
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo nohup /usr/local/bin/rsync_backup.sh > /dev/null 2>&1 &
|
||||
```
|
||||
|
||||
然后查看日志:`tail -f /var/log/rsync_backup.log`。
|
||||
|
||||
|
||||
### 5. 如何实现NFS永久挂载
|
||||
|
||||
在 Linux 系统中,手动执行的 `mount` 命令是**临时性**的,重启后内核会重置所有挂载状态。要实现开机自动挂载,必须将配置写入系统的文件系统表文件 `/etc/fstab`。
|
||||
|
||||
由于你使用的是 **NFS** 协议,且考虑到笔记本在启动时网络初始化可能略慢于磁盘挂载,我们需要加入一些特定的参数来确保稳定性。
|
||||
|
||||
#### 1. 准备凭据(可选但推荐)
|
||||
|
||||
NFS 通常基于 IP 授权,不需要账号密码。如果你之前确认过手动挂载 `sudo mount -t nfs 192.168.3.17:/volume2/backup /mnt/nas_backup` 成功且无需密码,可以跳过此步。
|
||||
|
||||
#### 2. 修改 /etc/fstab 实现永久挂载
|
||||
|
||||
1. **备份原文件**(作为资深管理者,备份配置是标准操作):
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo cp /etc/fstab /etc/fstab.bak
|
||||
```
|
||||
|
||||
2. **编辑文件**:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo nano /etc/fstab
|
||||
```
|
||||
|
||||
3. **在文件末尾添加以下一行**:
|
||||
|
||||
Plaintext
|
||||
|
||||
```
|
||||
192.168.3.17:/volume2/backup /mnt/nas_backup nfs defaults,timeo=900,retrans=5,_netdev 0 0
|
||||
```
|
||||
|
||||
|
||||
#### 参数详解:
|
||||
|
||||
- **`defaults`**: 使用默认的挂载参数(rw, suid, dev, exec, auto, nouser, async)。
|
||||
|
||||
- **`timeo=900`**: 设置超时时间为 90 秒(单位是 1/10 秒)。
|
||||
|
||||
- **`retrans=5`**: 如果超时,尝试重连 5 次。
|
||||
|
||||
- **`_netdev`**: **关键参数**。告诉系统这是一个网络设备,务必等到网络服务完全启动后再尝试挂载,防止开机过程因找不到网络而卡死。
|
||||
|
||||
|
||||
---
|
||||
|
||||
#### 3. 测试配置(非常重要)
|
||||
|
||||
**千万不要直接重启!** 如果 `/etc/fstab` 写错了,系统可能无法正常启动。
|
||||
|
||||
执行以下命令验证:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 1. 先卸载当前的挂载(如果当前还挂着的话)
|
||||
sudo umount /mnt/nas_backup
|
||||
|
||||
# 2. 模拟开机自动挂载
|
||||
sudo mount -a
|
||||
|
||||
# 3. 检查是否挂载成功
|
||||
df -h | grep nas_backup
|
||||
```
|
||||
|
||||
**如果 `sudo mount -a` 没有报错,且 `df` 能看到 NAS 空间,那么以后重启服务器,挂载都会自动生效。**
|
||||
|
||||
---
|
||||
|
||||
#### 4. 进阶:针对 Rsync 脚本的安全保护
|
||||
|
||||
在你的 `rsync` 脚本(`/usr/local/bin/rsync_backup.sh`)开头,建议加入一个**挂载检查**。防止在 NAS 掉线或由于某种原因挂载失败时,`rsync` 把备份数据写到了本地硬盘的挂载点目录(会导致笔记本硬盘迅速爆满)。
|
||||
|
||||
在脚本的配置区下方加入这段逻辑:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 检查挂载点是否是一个有效的挂载
|
||||
if ! mountpoint -q /mnt/nas_backup; then
|
||||
echo "错误:NAS 未挂载,备份任务取消!" >> /var/log/rsync_backup.log
|
||||
# 在这里可以加入发送通知给你的逻辑
|
||||
exit 1
|
||||
fi
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
#### 5. 常见问题:重启后仍然失效?
|
||||
|
||||
如果在执行了上述操作后重启依然不生效,通常是因为 Ubuntu 的 `nfs-common` 服务启动慢于 `mount -a` 的执行。
|
||||
|
||||
- **对策**:你可以启动 `Remote File Systems` 目标服务:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo systemctl enable remote-fs.target
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 如何停止rsync进程
|
||||
|
||||
#### 1. 查找并杀死相关的 rsync 进程
|
||||
|
||||
你可以通过 `pgrep` 或 `ps` 命令锁定正在运行的备份任务。
|
||||
|
||||
- **查看当前运行的 rsync 进程:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
ps aux | grep rsync
|
||||
```
|
||||
|
||||
- **优雅地停止所有 rsync 进程(推荐):** 发送 `SIGTERM` 信号,允许 `rsync` 完成当前的写入并清理临时文件,防止损坏目标端的数据结构。
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo killall rsync
|
||||
```
|
||||
|
||||
- **强制杀死(如果进程卡死):** 如果执行 `killall` 后进程依然存在(通常是因为网络 I/O 挂起),请使用 `SIGKILL`。
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo killall -9 rsync
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
|
||||
#### 2. 停止后台运行的脚本
|
||||
|
||||
由于你是通过脚本 `rsync_backup.sh` 启动的,有时只杀掉 `rsync` 进程,脚本可能会尝试进入循环或执行后续逻辑。
|
||||
|
||||
- **查找并杀掉备份脚本进程:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo pkill -f rsync_backup.sh
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
|
||||
#### 3. 清理残留的临时文件
|
||||
|
||||
`rsync` 在传输过程中会在目标目录(NAS 挂载点)生成以 `.` 开头的临时文件。
|
||||
|
||||
- 如果你强行停止了进程,这些临时文件会残留在 `/mnt/nas_backup/daily_sync/` 中。
|
||||
|
||||
- 下一次运行 `rsync` 时,它通常会自动处理或覆盖这些文件,但如果你想手动清理:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 注意:请确保没有 rsync 进程在运行时执行此操作
|
||||
sudo find /mnt/nas_backup/daily_sync/ -name ".*" -type f -delete
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
|
||||
#### 4. 针对日志中 SIGINT/SIGTERM 报错的建议
|
||||
|
||||
从你之前的日志看,系统收到了 `code 20` 错误,这通常就是因为进程被手动中断导致的。
|
||||
|
||||
**为了防止下次备份时再次因为手动关闭终端而中断,建议采用以下两种方式之一运行:**
|
||||
|
||||
1. **使用 `nohup` (你已经在尝试的方式):**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo nohup /usr/local/bin/rsync_backup.sh > /dev/null 2>&1 &
|
||||
```
|
||||
|
||||
2. **使用 `screen` 或 `tmux` (更专业):**
|
||||
|
||||
- 创建一个新窗口:`screen -S backup`
|
||||
|
||||
- 运行脚本:`sudo /usr/local/bin/rsync_backup.sh`
|
||||
|
||||
- 按下 `Ctrl + A + D` 脱离窗口(脚本继续运行)。
|
||||
|
||||
- 随时回来查看:`screen -r backup`
|
||||
@@ -0,0 +1,70 @@
|
||||
#ubuntu #rustdesk
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
这个问题产生的原因是 Ubuntu 24.04 默认使用了 **Wayland** 显示协议,而 Wayland 出于安全设计,严格限制了外部程序在用户未登录状态下(即 GDM 登录界面)获取屏幕控制权。
|
||||
|
||||
作为一名拥有技术背景的高级经理,你可能更倾向于直接通过修改系统底层配置来彻底解决此问题。最稳妥的方案是将 Ubuntu 的显示管理器回退到兼容性更好的 **X11 (Xorg)**。
|
||||
|
||||
---
|
||||
|
||||
### 解决方案:禁用 Wayland 强制开启 X11
|
||||
|
||||
通过以下步骤,你可以让 Ubuntu 无论在登录前还是登录后都使用 X11 协议,从而允许 RustDesk 在系统启动后立即接管控制权。
|
||||
|
||||
#### 1. 修改 GDM3 配置文件
|
||||
|
||||
打开终端,编辑 GNOME 显示管理器的配置文件:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo nano /etc/gdm3/custom.conf
|
||||
```
|
||||
|
||||
#### 2. 取消注释 Wayland 禁用行
|
||||
|
||||
在文件中找到 `[daemon]` 部分,找到下面这一行: `#WaylandEnable=false`
|
||||
|
||||
将其前面的 **`#`** 删掉,使其生效:
|
||||
|
||||
Plaintext
|
||||
|
||||
```
|
||||
[daemon]---
|
||||
title: Uncoment the line below to force the login screen to use Xorg
|
||||
author: shenwei
|
||||
tags: [rustdesk, ubuntu]
|
||||
---
|
||||
---
|
||||
title: Uncoment the line below to force the login screen to use Xorg
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [rustdesk, ubuntu]
|
||||
---
|
||||
|
||||
# Uncoment the line below to force the login screen to use Xorg
|
||||
WaylandEnable=false
|
||||
```
|
||||
|
||||
#### 3. 保存并重启服务
|
||||
|
||||
按下 `Ctrl + O` 保存,`Enter` 确认,再按 `Ctrl + X` 退出。 最后,重启 GDM 服务(或者直接重启电脑):
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo systemctl restart gdm3
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 为什么这样做能解决问题?
|
||||
|
||||
- **登录前(Login Screen)**:禁用 Wayland 后,Ubuntu 的登录界面将强制使用 X11 加载。RustDesk 的后台服务(Service)能够识别 X11 窗口并与其交互。
|
||||
|
||||
- **登录后(Post-Login)**:虽然 Wayland 在 24.04 上是趋势,但对于需要频繁远程桌面运维(Remote Service Delivery)的场景,X11 的稳定性与权限开放度目前仍优于 Wayland。
|
||||
79
raw/Technical/Home Office/🟠Ubuntu禁用合盖休眠.md
Normal file
79
raw/Technical/Home Office/🟠Ubuntu禁用合盖休眠.md
Normal file
@@ -0,0 +1,79 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [ubuntu]
|
||||
---
|
||||
|
||||
#ubuntu
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
在 Ubuntu 24.04 中,笔记本合盖休眠的行为是由系统的登录管理器 `systemd-logind` 控制的。要让服务器在合盖后继续运行,你需要修改系统的配置文件。
|
||||
|
||||
以下是具体操作步骤:
|
||||
|
||||
### 1. 修改 `logind.conf` 配置文件
|
||||
|
||||
打开终端(或通过 SSH 连接),使用 `nano` 文本编辑器修改系统配置:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo nano /etc/systemd/logind.conf
|
||||
```
|
||||
|
||||
### 2. 编辑配置项
|
||||
|
||||
在打开的文件中,找到以下几行代码(通常是被注释掉的,即行首有 `#`):
|
||||
|
||||
- `HandleLidSwitch`:合盖时的动作(通常指用电池时)。
|
||||
|
||||
- `HandleLidSwitchExternalPower`:连接外接电源合盖时的动作。
|
||||
|
||||
- `HandleLidSwitchDocked`:连接扩展坞合盖时的动作。
|
||||
|
||||
|
||||
将它们修改为 `ignore` 并**删除行首的 `#`**,修改后的内容应如下所示:
|
||||
|
||||
Plaintext
|
||||
|
||||
```
|
||||
[Login]
|
||||
HandleLidSwitch=ignore
|
||||
HandleLidSwitchExternalPower=ignore
|
||||
HandleLidSwitchDocked=ignore
|
||||
```
|
||||
|
||||
- **ignore**:表示不执行任何操作,即系统继续运行。
|
||||
|
||||
|
||||
### 3. 重启服务使配置生效
|
||||
|
||||
保存并退出(在 nano 中按 `Ctrl + O`,回车,然后按 `Ctrl + X`)。执行以下命令重启服务:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo systemctl restart systemd-logind
|
||||
```
|
||||
|
||||
> **注意:** 在执行此命令时,你的当前会话(包括图形界面或当前的 SSH 连接)可能会短暂断开或重新加载。
|
||||
|
||||
---
|
||||
|
||||
### 进阶:彻底禁用系统的休眠功能(可选)
|
||||
|
||||
如果你希望从内核级别彻底禁止休眠(防止任何情况下的自动待机),可以运行以下命令:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo systemctl mask sleep.target suspend.target hibernate.target hybrid-sleep.target
|
||||
```
|
||||
|
||||
_如果以后想恢复,将 `mask` 改为 `unmask` 即可。_
|
||||
38
raw/Technical/Home Office/🟠在Synology NAS上安装CloudDrive2.md
Normal file
38
raw/Technical/Home Office/🟠在Synology NAS上安装CloudDrive2.md
Normal file
@@ -0,0 +1,38 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [clouddrive2, nas, synology]
|
||||
---
|
||||
|
||||
#synology #nas #clouddrive2
|
||||
|
||||
|
||||
在套件中心,设置里添加矿神源
|
||||
|
||||
![[IMG-20251229192828271.png]]
|
||||
|
||||
然后在社群里找到CloudDrive2这个应用, 并安装。因为我的DSM是7+版本,所以需要额外在root 下执行一条命令:
|
||||
![[IMG-20251229192828289.png]]
|
||||
|
||||
```docker
|
||||
sudo -i
|
||||
#input NAS admin password
|
||||
|
||||
sudo sed -i 's/package/root/g' /var/packages/CloudDrive2/conf/privilege
|
||||
```
|
||||
|
||||
安装成功后打开CloudDrive进行配置:
|
||||
|
||||
[http://192.168.3.17:19798/](http://192.168.3.17:19798/)
|
||||
|
||||
![[IMG-20251229192828334.png]]
|
||||
|
||||
用阿里云盘app扫描二维码,并授权,请主要,不要授权备份目录,仅资源目录即可
|
||||
![[IMG-20251229192828398.png]]
|
||||
对Aliyun目录进行mount
|
||||
|
||||
|
||||
914
raw/Technical/Home Office/🟠在Ubuntu上通过VPS+内网反向代理实现域名访问内网穿透.md
Normal file
914
raw/Technical/Home Office/🟠在Ubuntu上通过VPS+内网反向代理实现域名访问内网穿透.md
Normal file
@@ -0,0 +1,914 @@
|
||||
#vps #caddy #frp #reverse-proxy #troubleshooting #cloudflare #ubuntu
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
|
||||
思路:Cloudflare DNS 指向 公网上的一台VPS,VPS 上运行 Caddy;内网主机通过 frp 将服务暴露到 VPS(本地 127.0.0.1 或某个端口),VPS 反向代理到该端口。
|
||||
|
||||
- 在 VPS 上运行 `frps`(frp server)。
|
||||
- 在每个内网设备运行 `frpc` (frp client),将本地服务映射到 VPS 上的独立端口或域名映射(frp 支持 http/https 映射,和 subdomain 映射需要 frp 企业/配置域名解析到 VPS)。
|
||||
- VPS 上的 Caddy 反向代理到 frps 映射端口(127.0.0.1:xxxxx)。
|
||||
|
||||
frp 优点:专为内网穿透设计,支持 NAT、自动重连、Web 管理面板(可选)。推荐当你有多台设备和多端口时使用。
|
||||
![[IMG-20260313104655355.png]]
|
||||
![[IMG-20260313104655497.png]]
|
||||
|
||||
|
||||
# 前置共识(已知条件)
|
||||
|
||||
- 域名:`ishenwei.online`(在阿里云 DNS/Cloudflare 控制台管理)
|
||||
- 内网服务:
|
||||
- NAS server:`192.168.3.17:5000`(对应 `nas.ishenwei.online`)
|
||||
- NAS mysql server:`192.168.3.17:3306`(对应 `mysql.ishenwei.online`)
|
||||
- Ubuntu1 n8n:`192.168.3.47:5678`(希望对应 `n8n.ishenwei.online`)
|
||||
- Ubuntu1 transmission: `192.168.3.47:9091`(希望对应 `transmission.ishenwei.online`)
|
||||
- Ubuntu1 Grafana: `192.168.3.47:3000`(希望对应 `grafana.ishenwei.online`)
|
||||
|
||||
- 你有一台公网 VPS(Ubuntu,可用于反代或做中继)IP: `192.227.222.142`(固定)
|
||||
|
||||
|
||||
## 🧭 目标
|
||||
|
||||
- 公网 VPS(Ubuntu,公网 IP = `192.227.222.142`)
|
||||
- 内网 NAS (`192.168.3.17:5000`)
|
||||
- 内网 Ubuntu (`192.168.3.47:5678`)
|
||||
- 通过 `frp` 建立安全的反向隧道
|
||||
- 通过 `Caddy` 在 VPS 上为每个子域名提供 HTTPS 域名访问:
|
||||
|
||||
| 域名 | 映射目标 |
|
||||
| ---------------------------------------------------------- | ---------------------------- |
|
||||
| [https://nas.ishenwei.online](https://nas.ishenwei.online) | → NAS `192.168.3.17:5000` |
|
||||
| [https://n8n.ishenwei.online](https://n8n.ishenwei.online) | → Ubuntu `192.168.3.47:5678` |
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
公网VPS(frps服务端)
|
||||
↓(公网端口转发)
|
||||
192.227.222.142
|
||||
↓
|
||||
通过 frp 反向代理访问内网主机
|
||||
↓
|
||||
内网 Ubuntu (192.168.3.47) 启动 frpc
|
||||
├─ n8n 服务 (5678)
|
||||
├─ Transmission (9091)
|
||||
└─ Grafana (3000)
|
||||
|
||||
## 🧱 拓扑图
|
||||
|
||||
Internet
|
||||
│
|
||||
▼
|
||||
┌──────────────────────────┐
|
||||
│ VPS (192.227.222.142) │
|
||||
│ - frps (监听 7000) │
|
||||
│ - Caddy (80/443 TLS) │
|
||||
│ ├─ nas.ishenwei.online → 127.0.0.1:15000 (映射NAS:5000)
|
||||
│ └─ n8n.ishenwei.online → 127.0.0.1:15678 (映射Ubuntu:5678)
|
||||
└──────────────────────────┘
|
||||
▲ ▲
|
||||
│ frp tunnel │ frp tunnel
|
||||
┌────────────┐ ┌────────────┐
|
||||
│ NAS (192.168.3.17) │ │ Ubuntu (192.168.3.47) │
|
||||
│ frpc.ini │ │ frpc.ini │
|
||||
│ 映射5000→15000 │ │ 映射5678→15678 │
|
||||
└────────────┘ └────────────┘
|
||||
|
||||
## 第 1 步:Cloudflare DNS 配置
|
||||
|
||||
| 主机记录 | 记录类型 | 记录值 | TTL |
|
||||
| ---- | ---- | --------------- | --- |
|
||||
| nas | A | 192.227.222.142 | 600 |
|
||||
| n8n | A | 192.227.222.142 | 600 |
|
||||
Cloudflare Dashboard -> DNS
|
||||
![[IMG-20260313104655641.png]]
|
||||
|
||||
保存即可。
|
||||
验证命令(任意机器执行):
|
||||
```
|
||||
dig nas.ishenwei.online +short # 应返回 192.227.222.142
|
||||
```
|
||||
|
||||
|
||||
## 🧩 第 2 步:在 VPS 安装 Caddy + frps
|
||||
|
||||
### 1️⃣ 安装 Caddy
|
||||
|
||||
``` bash
|
||||
sudo apt install -y debian-keyring debian-archive-keyring apt-transport-https curl curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/gpg.key' | sudo gpg --dearmor -o /usr/share/keyrings/caddy-stable-archive-keyring.gpg curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/debian.deb.txt' | sudo tee /etc/apt/sources.list.d/caddy-stable.list
|
||||
chmod o+r /usr/share/keyrings/caddy-stable-archive-keyring.gpg
|
||||
chmod o+r /etc/apt/sources.list.d/caddy-stable.list
|
||||
sudo apt update
|
||||
sudo apt install caddy
|
||||
```
|
||||
cd
|
||||
Caddy 安装后会自动作为系统服务运行。
|
||||
|
||||
---
|
||||
|
||||
### 2️⃣ 安装 frp(frp 服务端)
|
||||
|
||||
``` bash
|
||||
# 在 VPS 与内网主机都执行(分别下载到 /opt/frp)
|
||||
cd /opt
|
||||
sudo mkdir frp && cd frp
|
||||
|
||||
FRP_VER=0.65.0 # 若有更新,可替换版本号
|
||||
curl -LO https://github.com/fatedier/frp/releases/download/v${FRP_VER}/frp_${FRP_VER}_linux_amd64.tar.gz
|
||||
tar xzf frp_${FRP_VER}_linux_amd64.tar.gz
|
||||
sudo mv frp_${FRP_VER}_linux_amd64 /opt/frp
|
||||
|
||||
```
|
||||
|
||||
创建配置文件 `/opt/frp/frps.ini`:
|
||||
``` bash
|
||||
[common]
|
||||
bind_addr = 0.0.0.0
|
||||
bind_port = 7000
|
||||
|
||||
|
||||
---
|
||||
title: 前置共识(已知条件)
|
||||
author: shenwei
|
||||
tags: [caddy, cloudflare, frp, reverse-proxy, troubleshooting, ubuntu, vps]
|
||||
---
|
||||
---
|
||||
title: 前置共识(已知条件)
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [caddy, cloudflare, frp, reverse-proxy, troubleshooting, ubuntu, vps]
|
||||
---
|
||||
|
||||
# Dashboard
|
||||
dashboard_addr = 0.0.0.0
|
||||
dashboard_port = 7500
|
||||
dashboard_user = admin
|
||||
dashboard_pwd = StrongPassword123!
|
||||
|
||||
# 认证 Token
|
||||
token = Gg8sqHJVgh42KQ0oTatMjl6AywWqAzaaT0B77a4qD46tXtoH9j9mXb2k1YitObhs
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
创建 systemd 单元 `/etc/systemd/system/frps.service`:
|
||||
``` bash
|
||||
[Unit]
|
||||
Description=frp server (frps)
|
||||
After=network.target
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/opt/frp/frps -c /opt/frp/frps.ini
|
||||
Restart=on-failure
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
|
||||
```
|
||||
|
||||
启动:
|
||||
```
|
||||
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable --now frps
|
||||
|
||||
```
|
||||
|
||||
验证:
|
||||
|
||||
```
|
||||
sudo systemctl status frps
|
||||
ss -ltnp | grep 7000
|
||||
|
||||
```
|
||||
|
||||
### 3️⃣ VPS 防火墙设置(允许必要端口)
|
||||
``` bash
|
||||
sudo ufw allow OpenSSH
|
||||
sudo ufw allow 80/tcp
|
||||
sudo ufw allow 443/tcp
|
||||
sudo ufw allow 7000/tcp # frp server 端口
|
||||
sudo ufw allow 7050 # frp server dashboard
|
||||
sudo ufw allow 60022 # Ubuntu1 SSH
|
||||
sudo ufw allow 60023 # NAS SSH
|
||||
sudo ufw allow 60024 # Ubuntu2 SSH
|
||||
sudo ufw allow 65005 # webdav
|
||||
sudo ufw allow 63306 # NAS mysql
|
||||
sudo ufw allow 60080 # NAS web
|
||||
sudo ufw enable
|
||||
sudo ufw status verbose
|
||||
```
|
||||
运行结果:
|
||||
``` bash
|
||||
To Action From
|
||||
-- ------ ----
|
||||
22/tcp (OpenSSH) ALLOW IN Anywhere
|
||||
80/tcp ALLOW IN Anywhere
|
||||
443/tcp ALLOW IN Anywhere
|
||||
7000/tcp ALLOW IN Anywhere
|
||||
7500/tcp ALLOW IN Anywhere
|
||||
7050 ALLOW IN Anywhere
|
||||
60022 ALLOW IN Anywhere
|
||||
65005 ALLOW IN Anywhere
|
||||
60023 ALLOW IN Anywhere
|
||||
60021/tcp ALLOW IN Anywhere
|
||||
60021/udp ALLOW IN Anywhere
|
||||
63306 ALLOW IN Anywhere
|
||||
60080 ALLOW IN Anywhere
|
||||
60024 ALLOW IN Anywhere
|
||||
22/tcp (OpenSSH (v6)) ALLOW IN Anywhere (v6)
|
||||
80/tcp (v6) ALLOW IN Anywhere (v6)
|
||||
443/tcp (v6) ALLOW IN Anywhere (v6)
|
||||
7000/tcp (v6) ALLOW IN Anywhere (v6)
|
||||
7500/tcp (v6) ALLOW IN Anywhere (v6)
|
||||
7050 (v6) ALLOW IN Anywhere (v6)
|
||||
60022 (v6) ALLOW IN Anywhere (v6)
|
||||
65005 (v6) ALLOW IN Anywhere (v6)
|
||||
60023 (v6) ALLOW IN Anywhere (v6)
|
||||
60021/tcp (v6) ALLOW IN Anywhere (v6)
|
||||
60021/udp (v6) ALLOW IN Anywhere (v6)
|
||||
63306 (v6) ALLOW IN Anywhere (v6)
|
||||
60080 (v6) ALLOW IN Anywhere (v6)
|
||||
60024 (v6) ALLOW IN Anywhere (v6)
|
||||
|
||||
```
|
||||
|
||||
|
||||
如果你想让 frp dashboard 从本地访问:`ssh -L 7500:127.0.0.1:7500 ubuntu@192.227.222.142`,然后本地打开 `http://127.0.0.1:7500`。
|
||||
|
||||
## 🧩 第 3 步:在 内网NAS服务器 与内网 Ubuntu服务器 安装 frpc
|
||||
|
||||
两台机器都执行以下步骤(路径、端口配置不同)
|
||||
### 2️⃣ 安装 frp(frp 客户端)
|
||||
``` bash
|
||||
# 在 VPS 与内网主机都执行(分别下载到 /opt/frp)
|
||||
cd /opt
|
||||
sudo mkdir frp && cd frp
|
||||
|
||||
FRP_VER=0.65.0 # 若有更新,可替换版本号
|
||||
curl -LO https://github.com/fatedier/frp/releases/download/v${FRP_VER}/frp_${FRP_VER}_linux_amd64.tar.gz
|
||||
tar xzf frp_${FRP_VER}_linux_amd64.tar.gz
|
||||
sudo mv frp_${FRP_VER}_linux_amd64 /opt/frp
|
||||
|
||||
```
|
||||
|
||||
### 3️⃣ 内网 NAS(192.168.3.17)配置
|
||||
|
||||
创建 `/opt/frp/frpc.ini`:
|
||||
``` bash
|
||||
[common]
|
||||
server_addr = 192.227.222.142
|
||||
server_port = 7000
|
||||
token = Gg8sqHJVgh42KQ0oTatMjl6AywWqAzaaT0B77a4qD46tXtoH9j9mXb2k1YitObhs
|
||||
|
||||
# 每个本地服务一个 section
|
||||
# nas 映射: 本地 5000 -> VPS 127.0.0.1:15000
|
||||
[nas]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 5000
|
||||
remote_port = 15000
|
||||
|
||||
# Navidrome: 本地 4533 -> VPS 127.0.0.1:4533
|
||||
[navidrome]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 4533
|
||||
remote_port = 14533
|
||||
|
||||
# Calibre: 本地 8083 -> VPS 127.0.0.1:18083
|
||||
[calibre]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 8083
|
||||
remote_port = 18083
|
||||
|
||||
[webdav]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 5005
|
||||
remote_port = 65005
|
||||
|
||||
[miniflux]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 8080
|
||||
remote_port = 18080
|
||||
|
||||
[zipline]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 3333
|
||||
remote_port = 13333
|
||||
|
||||
[nas_ssh]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 22
|
||||
|
||||
[mysql]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 3307
|
||||
remote_port = 63307
|
||||
|
||||
[nas_web]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 80
|
||||
remote_port = 10080
|
||||
|
||||
|
||||
```
|
||||
|
||||
创建 systemd 单元 `/etc/systemd/system/frpc.service`:
|
||||
``` bash
|
||||
|
||||
[Unit]
|
||||
Description=frp client
|
||||
After=network-online.target
|
||||
Wants=network-online.target
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/opt/frp/frpc -c /opt/frp/frpc.ini
|
||||
Restart=on-failure
|
||||
RestartSec=10
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
|
||||
```
|
||||
|
||||
启动:
|
||||
``` bash
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable --now frpc
|
||||
sudo systemctl status frpc
|
||||
|
||||
```
|
||||
|
||||
如需重启
|
||||
``` bash
|
||||
sudo systemctl restart frpc
|
||||
|
||||
```
|
||||
|
||||
|
||||
### 3️⃣ 内网 Ubuntu(192.168.3.47)配置
|
||||
创建 `/opt/frp/frpc.ini`:
|
||||
``` bash
|
||||
[common]
|
||||
server_addr = 192.227.222.142
|
||||
server_port = 7000
|
||||
token = Gg8sqHJVgh42KQ0oTatMjl6AywWqAzaaT0B77a4qD46tXtoH9j9mXb2k1YitObhs
|
||||
|
||||
# 每个本地服务一个 section
|
||||
# n8n 映射: 本地 5678 -> VPS 127.0.0.1:15678
|
||||
[n8n]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 5678
|
||||
remote_port = 15678
|
||||
|
||||
# Transmission: 本地 9091 -> VPS 127.0.0.1:19091
|
||||
[transmission]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 9091
|
||||
remote_port = 19091
|
||||
|
||||
# Grafana: 本地 3000 -> VPS 127.0.0.1:13000
|
||||
[grafana]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 3000
|
||||
remote_port = 13000
|
||||
|
||||
# 🆕 SSH 映射
|
||||
[ubuntu_ssh]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 22
|
||||
remote_port = 60022
|
||||
|
||||
[homarr]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 7575
|
||||
remote_port = 17575
|
||||
|
||||
[superset]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 8777
|
||||
remote_port = 18777
|
||||
|
||||
[tk]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 8888
|
||||
remote_port = 18888
|
||||
|
||||
```
|
||||
|
||||
创建 systemd 单元 `/etc/systemd/system/frpc.service`:
|
||||
``` bash
|
||||
|
||||
[Unit]
|
||||
Description=frp client
|
||||
After=network-online.target
|
||||
Wants=network-online.target
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/opt/frp/frpc -c /opt/frp/frpc.ini
|
||||
Restart=on-failure
|
||||
RestartSec=10
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
```
|
||||
|
||||
启动:
|
||||
``` bash
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable --now frpc
|
||||
sudo systemctl status frpc
|
||||
|
||||
```
|
||||
|
||||
如需重启
|
||||
``` bash
|
||||
sudo systemctl restart frpc
|
||||
|
||||
```
|
||||
|
||||
|
||||
## 🧩 第 4 步:VPS 上配置 Caddy 反向代理
|
||||
编辑 `/etc/caddy/Caddyfile`:
|
||||
|
||||
``` bash
|
||||
# The Caddyfile is an easy way to configure your Caddy web server.
|
||||
#
|
||||
# Unless the file starts with a global options block, the first
|
||||
# uncommented line is always the address of your site.
|
||||
#
|
||||
# To use your own domain name (with automatic HTTPS), first make
|
||||
# sure your domain's A/AAAA DNS records are properly pointed to
|
||||
# this machine's public IP, then replace ":80" below with your
|
||||
# domain name.
|
||||
|
||||
:80 {
|
||||
# Set this path to your site's directory.
|
||||
root * /usr/share/caddy
|
||||
|
||||
# Enable the static file server.
|
||||
file_server
|
||||
|
||||
# Another common task is to set up a reverse proxy:
|
||||
# reverse_proxy localhost:8080
|
||||
|
||||
# Or serve a PHP site through php-fpm:
|
||||
# php_fastcgi localhost:9000
|
||||
}
|
||||
transmission.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:19091
|
||||
#log {
|
||||
# output file /var/log/caddy/transmission.access.log
|
||||
# format single_field common_log
|
||||
#}
|
||||
}
|
||||
|
||||
grafana.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:13000
|
||||
#log {
|
||||
# output file /var/log/caddy/grafana.access.log
|
||||
# format single_field common_log
|
||||
#}
|
||||
}
|
||||
|
||||
nas.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:15000
|
||||
}
|
||||
|
||||
navidrome.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:14533
|
||||
}
|
||||
|
||||
calibre.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:18083
|
||||
}
|
||||
dashboard.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:17575
|
||||
}
|
||||
miniflux.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:18080
|
||||
}
|
||||
zipline.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:13333
|
||||
}
|
||||
superset.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:18777
|
||||
}
|
||||
tk.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:18888
|
||||
}
|
||||
web.ishenwei.online {
|
||||
reverse_proxy 127.0.0.1:10080
|
||||
}
|
||||
|
||||
# Refer to the Caddy docs for more information:
|
||||
# https://caddyserver.com/docs/caddyfile
|
||||
|
||||
|
||||
```
|
||||
|
||||
如需重启 Caddy
|
||||
|
||||
``` bash
|
||||
|
||||
sudo systemctl reload caddy
|
||||
sudo systemctl status caddy
|
||||
|
||||
```
|
||||
|
||||
或者:
|
||||
``` bash
|
||||
#彻底重启 Caddy 服务(强制方式)
|
||||
sudo systemctl restart caddy
|
||||
```
|
||||
Caddy 会自动申请并更新 Let's Encrypt 证书,提供 HTTPS 访问。
|
||||
|
||||
|
||||
如果 systemctl 无响应(Caddy 卡死或崩溃)
|
||||
``` bash
|
||||
sudo systemctl stop caddy
|
||||
sudo pkill -9 caddy # 杀掉所有残留进程 sudo systemctl start caddy
|
||||
```
|
||||
## 验证 Caddyfile 语法(最关键)
|
||||
``` bash
|
||||
sudo caddy validate --config /etc/caddy/Caddyfile
|
||||
```
|
||||
|
||||
如果返回:
|
||||
`Valid configuration`
|
||||
说明语法正确,可以重载。
|
||||
如果报错,Caddy 会指明**哪一行有问题**,例如:
|
||||
`parse error: unknown directive at line 12`
|
||||
你需要根据提示修正。
|
||||
|
||||
## 🧩 第 5 步:测试验证
|
||||
|
||||
### 1️⃣ 在 VPS 上
|
||||
``` bash
|
||||
curl http://127.0.0.1:15678
|
||||
curl http://127.0.0.1:15000
|
||||
curl http://127.0.0.1:19091
|
||||
curl http://127.0.0.1:13000
|
||||
|
||||
ss -ltnp | egrep '15678|19091|13000|7000|60022'
|
||||
```
|
||||
|
||||
```
|
||||
root@racknerd-66f115a:~# ss -ltnp | egrep '15678|19091|13000|7000'
|
||||
LISTEN 0 4096 *:19091 *:* users:(("frps",pid=59421,fd=10))
|
||||
LISTEN 0 4096 *:13000 *:* users:(("frps",pid=59421,fd=8))
|
||||
LISTEN 0 4096 *:15678 *:* users:(("frps",pid=59421,fd=9))
|
||||
LISTEN 0 4096 *:7000 *:* users:(("frps",pid=59421,fd=6))
|
||||
```
|
||||
### 2️⃣ 在浏览器中
|
||||
|
||||
访问:
|
||||
|
||||
- [https://nas.ishenwei.online](https://nas.ishenwei.online)
|
||||
- [https://n8n.ishenwei.online](https://n8n.ishenwei.online)
|
||||
|
||||
应能通过 HTTPS 打开对应服务。
|
||||
## 🧩 第 6 步:可选安全加固
|
||||
### 1️⃣ Caddy 基础认证
|
||||
|
||||
在 Caddyfile 的 `n8n.ishenwei.online` 段中加入:
|
||||
``` bash
|
||||
basicauth /* { admin JDJhJDE0JDN3ZXVhV2YyZG9SY2hvYzVmZ2h3QUlVblpOMU4vS1ptcENrSlhySElMb3l5dytOMkh0Tk93 }
|
||||
```
|
||||
|
||||
> 用 `caddy hash-password` 生成密码散列。
|
||||
|
||||
### 2️⃣ 防火墙
|
||||
|
||||
只放行必要端口:
|
||||
``` bash
|
||||
sudo ufw allow 22,80,443,7000/tcp
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
## 🧩 第 7 步:Dashboard(可选)
|
||||
访问:
|
||||
``` bash
|
||||
|
||||
http://192.227.222.142:7500
|
||||
|
||||
用户名:admin 密码:StrongPassword123!
|
||||
|
||||
```
|
||||
|
||||
你可以实时查看 frp 客户端的连接状态。
|
||||
|
||||
FRP 架构已经稳定运行(HTTP 反代验证通过),接下来要实现 **通过域名 `ubuntu1.ishenwei.online` SSH 到内网的 Ubuntu (192.168.3.47:22)**。
|
||||
|
||||
⚠️ **重点提醒(安全性)**
|
||||
SSH 穿透与 HTTP 不同,它是纯 TCP 流量,不经 Caddy(Caddy 只处理 HTTP/HTTPS),所以:
|
||||
|
||||
- **Caddy 不参与 SSH 的代理**。
|
||||
|
||||
- **只用 frps + frpc 配置即可完成**。
|
||||
|
||||
- **CaddyFile 无需修改**。
|
||||
|
||||
## 🧭 拓扑关系
|
||||
|
||||
``` bash
|
||||
你(外部SSH客户端)
|
||||
│
|
||||
▼
|
||||
ubuntu1.ishenwei.online:60022 (VPS公网)
|
||||
│
|
||||
▼
|
||||
FRP Server (frps) on VPS
|
||||
│
|
||||
▼
|
||||
FRP Client (frpc) on 192.168.3.47
|
||||
│
|
||||
▼
|
||||
Local Ubuntu SSH (192.168.3.47:22)
|
||||
|
||||
```
|
||||
|
||||
## 🧩 VPS 端(frps)配置
|
||||
|
||||
编辑 `/opt/frp/frps.ini`:
|
||||
|
||||
> 不需要添加新的 section,这里只是定义基础参数。frps 会自动识别来自客户端的 TCP 映射。
|
||||
|
||||
---
|
||||
|
||||
## 🧩 内网 Ubuntu(192.168.3.47)端 frpc 配置
|
||||
|
||||
编辑 `/opt/frp/frpc.ini`,在现有配置文件中追加:
|
||||
|
||||
``` bash
|
||||
|
||||
# SSH 映射
|
||||
[ubuntu_ssh]
|
||||
type = tcp
|
||||
local_ip = 127.0.0.1
|
||||
local_port = 22
|
||||
remote_port = 60022
|
||||
|
||||
|
||||
```
|
||||
|
||||
> - `type = tcp` 表示这是纯 TCP 代理,不走 HTTP 协议
|
||||
> - `remote_port = 60022` 是 VPS 上暴露的端口(外部 SSH 连接入口)
|
||||
>
|
||||
|
||||
## 🔧 启动并验证
|
||||
|
||||
在内网机器上:
|
||||
```
|
||||
sudo systemctl restart frpc
|
||||
sudo systemctl status frpc
|
||||
|
||||
```
|
||||
|
||||
验证日志中是否出现:
|
||||
|
||||
`[ubuntu_ssh] start proxy success`
|
||||
|
||||
---
|
||||
|
||||
## 🌐 在外部电脑上连接 SSH
|
||||
|
||||
从公网(任意地方)执行:
|
||||
|
||||
`ssh -p 60022 user@ubuntu1.ishenwei.online`
|
||||
|
||||
|
||||
> 注意:DNS 只解析到 IP,**SSH 的端口要显式指定为 `-p 60022`**。
|
||||
|
||||
``` bash
|
||||
sudo ufw allow OpenSSH
|
||||
sudo ufw allow 80/tcp
|
||||
sudo ufw allow 443/tcp
|
||||
sudo ufw allow 7000/tcp # frp server 端口
|
||||
sudo ufw allow 7050
|
||||
sudo ufw allow 60022
|
||||
sudo ufw enable
|
||||
sudo ufw status verbose
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 🔒 (可选)安全加固建议
|
||||
|
||||
1. **不要直接使用 22 或常见端口**,比如:
|
||||
|
||||
`remote_port = 26222`
|
||||
|
||||
避免被扫描。
|
||||
|
||||
2. **限制来源 IP**(仅 VPS 防火墙开放指定来源):
|
||||
|
||||
`sudo ufw allow from <your_home_ip> to any port 60022 proto tcp`
|
||||
|
||||
3. **使用公钥认证禁用密码登录**:
|
||||
|
||||
- 编辑 `/etc/ssh/sshd_config`
|
||||
|
||||
`PasswordAuthentication no`
|
||||
|
||||
- 重启 SSH:
|
||||
|
||||
`sudo systemctl restart ssh`
|
||||
|
||||
|
||||
---
|
||||
|
||||
## ✅ 总结
|
||||
|
||||
| 组件 | 是否需要修改 | 说明 |
|
||||
| -------------------- | ------------------------------------------------ | ------- |
|
||||
| **Caddy** | ❌ 无需修改 | 不处理 SSH |
|
||||
| **frps (VPS)** | ✅ 保持默认端口即可 | |
|
||||
| **frpc (内网 Ubuntu)** | ✅ 新增 `[ubuntu_ssh]` section | |
|
||||
| **DNS** | ✅ 添加 `ubuntu1.ishenwei.online -> VPS公网IP` | |
|
||||
| **SSH 连接** | ✅ 使用 `ssh -p 60022 user@ubuntu1.ishenwei.online` | |
|
||||
|
||||
|
||||
## 错误排查 #troubleshooting
|
||||
|
||||
|
||||
### ✔ 检查Server上配置的代理服务器可能会有冲突
|
||||
|
||||
NAS上安装的V2RayA 会对FRP有影响,需要停止代理服务器并重启FRPC
|
||||
|
||||
|
||||
### ✔ 第 1 步:确认 frps 是否真的在监听端口(排除端口被占用/劫持)
|
||||
``` bash
|
||||
ss -lntup | grep 7000
|
||||
ss -lntup | grep frps
|
||||
|
||||
```
|
||||
|
||||
结果:
|
||||
``` bash
|
||||
root@racknerd-66f115a:~# ss -lntup | grep 7000
|
||||
tcp LISTEN 0 4096 *:7000 *:* users:(("frps",pid=413014,fd=6))
|
||||
root@racknerd-66f115a:~# ss -lntup | grep frps
|
||||
tcp LISTEN 0 4096 *:7000 *:* users:(("frps",pid=413014,fd=6))
|
||||
tcp LISTEN 0 4096 *:7500 *:* users:(("frps",pid=413014,fd=3))
|
||||
|
||||
```
|
||||
如果这里显示:
|
||||
|
||||
❌ 端口被 Caddy/Nginx 占用
|
||||
❌ frps 未绑定 0.0.0.0
|
||||
❌ frps 在 LISTEN 但不是你期望的配置文件
|
||||
|
||||
### ✔ 第 2 步:确定 frps 进程读取的配置是否跟你想的一样
|
||||
|
||||
执行:
|
||||
``` bash
|
||||
ps -ef | grep frps
|
||||
```
|
||||
你要看到类似:
|
||||
``` bash
|
||||
root@racknerd-66f115a:~# ps -ef | grep frps
|
||||
root 413014 1 0 02:23 ? 00:00:00 /opt/frp/frps -c /opt/frp/frps.ini
|
||||
root 419007 414182 0 02:57 pts/1 00:00:00 grep --color=auto frps
|
||||
|
||||
```
|
||||
|
||||
如果看到:
|
||||
- 路径不对
|
||||
- 配置文件不对
|
||||
- 或者正运行旧版本二进制
|
||||
|
||||
那 frps 实际载入的 token、bind_port 等信息就不匹配。
|
||||
|
||||
**尤其要确认 token 是否是你以为的那个。**
|
||||
|
||||
👉 很多人遇到的问题是:
|
||||
他们编辑了 `/opt/frp/frps.ini`,但 systemd service 其实加载另一个路径,例如 `/etc/frp/frps.ini`。
|
||||
|
||||
### ✔ 第 3 步:确认防火墙是否把 7000 封了
|
||||
|
||||
在 VPS 执行:
|
||||
```
|
||||
sudo iptables -L -n
|
||||
sudo ufw status
|
||||
sudo firewall-cmd --list-all
|
||||
```
|
||||
|
||||
|
||||
你需要确保:
|
||||
|
||||
- `tcp 7000` 在 **ACCEPT**
|
||||
|
||||
- Cloudflare 没有影响你(你用的是直连 IP,不会影响)
|
||||
|
||||
- Caddy/Nginx 没修改 nftables(某些 One-key 脚本会修改)
|
||||
|
||||
### ✔ 第 4 步:确认没有 Caddy/Nginx 误 proxy 了 TCP 7000
|
||||
|
||||
检查 Caddy 配置:
|
||||
``` bash
|
||||
vi /etc/caddy/Caddyfile
|
||||
```
|
||||
**是否存在以下配置:**
|
||||
|
||||
`:7000 { reverse_proxy ... }`
|
||||
|
||||
如果有 → FRP 就没法直接监听这个端口。
|
||||
|
||||
### ✔ 第 5 步:确认 frps 日志是否有拒绝认证(token mismatch)
|
||||
|
||||
执行:
|
||||
```
|
||||
journalctl -u frps -n 100 --no-pager
|
||||
```
|
||||
|
||||
如果你看到类似:
|
||||
|
||||
`authentication failed token mismatch invalid login`
|
||||
|
||||
那肯定是 token 和 frpc 不一致。
|
||||
|
||||
👉 很多人以为一样,但实际是空格、换行、编码问题导致不一致。
|
||||
|
||||
### ✔ 第 6 步:尝试手动 telnet 登录后观察 frps 日志变化
|
||||
|
||||
**非常关键的诊断动作**
|
||||
|
||||
你从任意 frpc 客户端执行:
|
||||
``` bash
|
||||
telnet 192.227.222.142 7000
|
||||
```
|
||||
|
||||
同时在 frps VPS 执行:
|
||||
``` bash
|
||||
journalctl -u frps -f
|
||||
```
|
||||
|
||||
正常情况下,你应该看到 frps 有日志反应:
|
||||
|
||||
- 有连接建立
|
||||
- 有 login 请求
|
||||
|
||||
如果 frps 完全无反应:
|
||||
|
||||
➡ **说明请求没有到达 frps 进程 → 必然是端口被别的服务占用 / iptables 拦截 / SELinux 限制 / Caddy/Nginx 覆盖了端口**
|
||||
|
||||
|
||||
### ✔ 第 7 步:强制重启 frps 和 frpc
|
||||
|
||||
在 frps 机器上:
|
||||
```
|
||||
systemctl restart frps
|
||||
```
|
||||
|
||||
确认状态:
|
||||
```
|
||||
systemctl status frps
|
||||
```
|
||||
|
||||
在 frpc 机器上:
|
||||
```
|
||||
systemctl restart frpc
|
||||
systemctl status frpc
|
||||
journalctl -u frpc -n 50
|
||||
```
|
||||
|
||||
如果 frpc 日志里直接报:
|
||||
`dial tcp 192.227.222.142:7000: connection reset`
|
||||
➡ 防火墙问题
|
||||
|
||||
如果报:
|
||||
`authentication failed`
|
||||
➡ token 不一致
|
||||
|
||||
如果:
|
||||
`wait until server ready`
|
||||
➡ frps 端口被劫持
|
||||
|
||||
|
||||
# Reference
|
||||
@@ -0,0 +1,35 @@
|
||||
---
|
||||
title: How to transfer Docker images and install in another Docker
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-03-06
|
||||
description:
|
||||
tags: [docker, nas, synology]
|
||||
---
|
||||
|
||||
|
||||
#docker #synology #nas
|
||||
|
||||
Here is a example about transfer Docker images from my work laptop to my Synology NAS Docker
|
||||
|
||||
我在我自己工作的笔记本上安装了DockerDesktop版本,然后正常的pull xiaoya 的image:
|
||||
|
||||
```docker
|
||||
docker pull xiaoyaliu/alist
|
||||
```
|
||||
|
||||
通过以下命令将下载的image打包成tar文件
|
||||
|
||||
```docker
|
||||
docker save -o xiaoya.tar xiaoyaliu/alist
|
||||
```
|
||||
|
||||
我将打包好的xiaoya.tar文件上传到NAS文件系统里去,然后还是通过Putty来运行docker命令将image导入NAS的Docker中去。
|
||||
|
||||
```docker
|
||||
#cd 到xiaoya.tar存放的路径之后运行以下命令
|
||||
docker load < xiaoya.tar
|
||||
```
|
||||
|
||||
然后再进入NAS的Container Manager 界面后在image里就可以看到扫xiaoya/alist这个image了
|
||||
129
raw/Technical/Home Office/🟠如何删除旧的废弃的docker container +volume.md
Normal file
129
raw/Technical/Home Office/🟠如何删除旧的废弃的docker container +volume.md
Normal file
@@ -0,0 +1,129 @@
|
||||
---
|
||||
title: ✅ 最常用:删除旧 Portainer Container + Volume
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [container, docker, portainer, volume]
|
||||
---
|
||||
|
||||
|
||||
#docker #container #volume #portainer
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
# ✅ 最常用:删除旧 Portainer Container + Volume
|
||||
|
||||
### 1. **查看现有 Portainer 容器**
|
||||
```
|
||||
docker ps -a | grep portainer
|
||||
```
|
||||
|
||||
你会看到类似:
|
||||
`bdadf357fb03 portainer/portainer-ce "/portainer" ...`
|
||||
### 2. **停止容器**
|
||||
```
|
||||
docker stop portainer
|
||||
```
|
||||
或者:
|
||||
```
|
||||
docker stop bdadf357fb03
|
||||
```
|
||||
### 3. **删除容器**
|
||||
```
|
||||
docker rm portainer
|
||||
```
|
||||
或:
|
||||
```
|
||||
docker rm -f portainer
|
||||
```
|
||||
|
||||
---
|
||||
# 🧹 清理旧 Volume & Network (可选,但推荐)
|
||||
|
||||
### 4. **删除旧 Volume**
|
||||
|
||||
先查看:
|
||||
```
|
||||
docker volume ls | grep portainer
|
||||
```
|
||||
|
||||
如果你看到:
|
||||
`local portainer_data`
|
||||
|
||||
删除它:
|
||||
```
|
||||
docker volume rm portainer_data
|
||||
```
|
||||
|
||||
> ⚠️ 注意:这会删除 Portainer 所有数据(用户、配置)。
|
||||
> 如果你想保留数据,不要删 volume,只需要在 compose 文件里加:
|
||||
|
||||
`external: true`
|
||||
|
||||
---
|
||||
### 5. **删除旧 Network**
|
||||
|
||||
查看:
|
||||
```
|
||||
docker network ls | grep portainer
|
||||
```
|
||||
|
||||
如果看到:
|
||||
`portainer_network`
|
||||
|
||||
删除:
|
||||
``` bash
|
||||
docker network rm portainer_network
|
||||
```
|
||||
---
|
||||
# 🧹 BONUS:删除整个 Portainer 旧堆栈(如果是用 compose 部署的)
|
||||
|
||||
如果你之前是用 `docker compose` 运行的,可以直接:
|
||||
``` bash
|
||||
docker compose down
|
||||
```
|
||||
如果你的 compose 文件名不是默认 `docker-compose.yml`:
|
||||
|
||||
``` bash
|
||||
docker compose -f portainer-compose.yml down
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 🚀 最干净的重装流程
|
||||
|
||||
如果你想彻底重来一遍:
|
||||
``` bash
|
||||
docker stop portainer && docker rm portainer
|
||||
docker volume rm portainer_data
|
||||
docker network rm portainer_network
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 🧠 提前帮你想到:为什么会出现 WARN?
|
||||
|
||||
你看到的两个警告完全正常,原因如下:
|
||||
|
||||
### ✔ **WARN 1:Network 已存在但不是当前项目创建**
|
||||
|
||||
说明你之前用了别的 compose 文件部署过 Portainer。
|
||||
|
||||
解决方案:
|
||||
|
||||
- 要用旧 network → compose 里写 `external: true`
|
||||
|
||||
- 要重建 network → 删除旧 network(上面已写)
|
||||
|
||||
|
||||
---
|
||||
|
||||
### ✔ **WARN 2:Volume 已存在但属于另一个 compose 项目**
|
||||
|
||||
说明你以前用不同 project 名字做过 Portainer。
|
||||
|
||||
解决方案同上。
|
||||
@@ -0,0 +1,63 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [linux]
|
||||
---
|
||||
|
||||
|
||||
#linux
|
||||
|
||||
要判别你的 Linux 服务器是 x64(也就是 x86_64)还是 ARM64,可以通过多种方式,以下是最常用的方法:
|
||||
|
||||
---
|
||||
|
||||
### 1. 使用 `uname` 命令
|
||||
``` bash
|
||||
uname -m
|
||||
```
|
||||
|
||||
- 输出结果示例:
|
||||
|
||||
- `x86_64` → 表示 **64位 x86(Intel/AMD)架构**
|
||||
- `aarch64` → 表示 **64位 ARM 架构**
|
||||
- `armv7l` → 表示 **32位 ARM 架构**
|
||||
|
||||
---
|
||||
|
||||
### 2. 使用 `lscpu` 命令
|
||||
``` bash
|
||||
lscpu
|
||||
```
|
||||
- 会输出详细 CPU 架构信息,例如:
|
||||
``` bash
|
||||
Architecture: x86_64
|
||||
CPU op-mode(s): 32-bit, 64-bit
|
||||
Byte Order: Little Endian
|
||||
```
|
||||
|
||||
- `Architecture` 字段直接告诉你 CPU 类型。
|
||||
---
|
||||
|
||||
### 3. 查看 `/proc/cpuinfo`
|
||||
```
|
||||
cat /proc/cpuinfo
|
||||
```
|
||||
|
||||
- x86_64 CPU 会有 `model name` 类似 “Intel(R) Xeon(R) CPU …”
|
||||
- ARM64 CPU 会显示 `AArch64` 或 `ARMv8` 等信息。
|
||||
---
|
||||
|
||||
### 4. 使用 `file` 命令检测可执行文件
|
||||
```
|
||||
file /bin/bash
|
||||
```
|
||||
|
||||
- 输出示例:
|
||||
- `/bin/bash: ELF 64-bit LSB executable, x86-64` → x64
|
||||
- `/bin/bash: ELF 64-bit LSB executable, ARM aarch64` → ARM64
|
||||
|
||||
[[🟠Linux 运维必会的 150 个命令]]
|
||||
@@ -0,0 +1,179 @@
|
||||
---
|
||||
title: 1. 先卸载当前的挂载(如果当前还挂着的话)
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [nas, nfs, synology, unbuntu]
|
||||
---
|
||||
|
||||
|
||||
#unbuntu #nfs #synology #nas
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
## Synology NAS配置
|
||||
|
||||
### 1. NAS 端新增 NFS 规则的具体步骤
|
||||
|
||||
1. **登录 DSM 控制面板**:打开浏览器,登录你的群晖 NAS 管理界面。
|
||||
2. **进入共享文件夹设置**:点击 **“控制面板” (Control Panel)** -> **“共享文件夹” (Shared Folder)**。
|
||||
3. **定位目标文件夹**:在列表中选中你的备份文件夹 `backup`(即位于 `volume2` 下的那个)。
|
||||
4. **打开编辑界面**:点击上方的 **“编辑” (Edit)** 按钮。
|
||||
5. **切换至 NFS 权限页签**:在弹出的窗口中,点击最右侧的 **“NFS 权限” (NFS Permissions)** 选项卡。
|
||||
6. **新增规则**:点击左下角的 **“新增” (Create)**,在弹出的窗口中填入你提到的参数:
|
||||
- **主机名或 IP**:输入你的 Ubuntu 服务器静态 IP(例如 `192.168.3.47`)。如果想让工作室同网段设备都能访问,也可以填 `192.168.3.0/24`。
|
||||
- **权限**:选择 **“可读写” (Read/Write)**。
|
||||
- **Squash (最重要)**:选择 **“映射所有用户为 admin” (Map all users to admin)**。
|
||||
> **技术要点**:这会将 Ubuntu 端 root 发起的备份请求,在 NAS 端统一以 `admin` 身份执行,从而绕过复杂的 Linux 权限校验。
|
||||
- **安全性**:选择 **“sys”**。
|
||||
- **额外勾选**:勾选下方所有的复选框,包括 **“允许来自非特权端口的连接”** 和 **“允许用户访问已挂载的子文件夹”**。
|
||||
![[IMG-20251229190624379.png]]
|
||||
---
|
||||
|
||||
### 2. 获取准确的挂载路径
|
||||
|
||||
保存设置后,请留意“NFS 权限”页签**左下角**显示的一行小字,标明了 **“挂载路径:”**。
|
||||
- 通常路径为:`/volume2/backup`。
|
||||
- 请务必记住这个完整路径,稍后在 Ubuntu 命令中需要用到。
|
||||
|
||||
|
||||
## Ubuntu Server配置
|
||||
|
||||
在 Linux 世界中,备份服务器到 NAS 的标准做法是使用 **NFS**。
|
||||
|
||||
**NFS 的优势:**
|
||||
1. **原生权限支持**:Samba 会丢失 Linux 的文件所有权信息,导致恢复 Docker 卷时权限报错。NFS 则能完美保留。
|
||||
2. **无协议协商陷阱**:没有像 `vers=3.0` 这种复杂的方言(Dialect)冲突。
|
||||
3. **性能更强**:在处理大量小文件(如 Docker 配置)时,NFS 效率远高于 Samba。
|
||||
|
||||
#### NFS 挂载 3 步走:
|
||||
|
||||
1. **NAS 端配置** (参考以上)
|
||||
2. **Ubuntu 挂载**:
|
||||
Bash
|
||||
``` bash
|
||||
# 安装客户端
|
||||
sudo apt install nfs-common -y
|
||||
# 执行挂载 (注意:NFS 使用冒号连接路径)
|
||||
sudo mount -t nfs 192.168.3.17:/volume2/backup /mnt/nas_backup
|
||||
```
|
||||
3. **验证**:
|
||||
Bash
|
||||
``` bash
|
||||
df -h | grep nas_backup
|
||||
|
||||
|
||||
root@shenwei-HP-ZBook-01:/mnt/nas_backup# df -h | grep nas_backup
|
||||
192.168.3.17:/volume2/backup 3.5T 1.9T 1.7T 54% /mnt/nas_backup
|
||||
```
|
||||
|
||||
|
||||
### 3. 实现NFS永久挂载
|
||||
|
||||
在 Linux 系统中,手动执行的 `mount` 命令是**临时性**的,重启后内核会重置所有挂载状态。要实现开机自动挂载,必须将配置写入系统的文件系统表文件 `/etc/fstab`。
|
||||
|
||||
由于你使用的是 **NFS** 协议,且考虑到笔记本在启动时网络初始化可能略慢于磁盘挂载,我们需要加入一些特定的参数来确保稳定性。
|
||||
|
||||
#### 1. 准备凭据(可选但推荐)
|
||||
|
||||
NFS 通常基于 IP 授权,不需要账号密码。如果你之前确认过手动挂载 `sudo mount -t nfs 192.168.3.17:/volume2/backup /mnt/nas_backup` 成功且无需密码,可以跳过此步。
|
||||
|
||||
#### 2. 修改 /etc/fstab 实现永久挂载
|
||||
|
||||
1. **备份原文件**(作为资深管理者,备份配置是标准操作):
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo cp /etc/fstab /etc/fstab.bak
|
||||
```
|
||||
|
||||
2. **编辑文件**:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo nano /etc/fstab
|
||||
```
|
||||
|
||||
3. **在文件末尾添加以下一行**:
|
||||
|
||||
Plaintext
|
||||
|
||||
```
|
||||
192.168.3.17:/volume2/backup /mnt/nas_backup nfs defaults,timeo=900,retrans=5,_netdev 0 0
|
||||
```
|
||||
|
||||
|
||||
#### 参数详解:
|
||||
|
||||
- **`defaults`**: 使用默认的挂载参数(rw, suid, dev, exec, auto, nouser, async)。
|
||||
|
||||
- **`timeo=900`**: 设置超时时间为 90 秒(单位是 1/10 秒)。
|
||||
|
||||
- **`retrans=5`**: 如果超时,尝试重连 5 次。
|
||||
|
||||
- **`_netdev`**: **关键参数**。告诉系统这是一个网络设备,务必等到网络服务完全启动后再尝试挂载,防止开机过程因找不到网络而卡死。
|
||||
|
||||
|
||||
---
|
||||
|
||||
#### 3. 测试配置(非常重要)
|
||||
|
||||
**千万不要直接重启!** 如果 `/etc/fstab` 写错了,系统可能无法正常启动。
|
||||
|
||||
执行以下命令验证:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 1. 先卸载当前的挂载(如果当前还挂着的话)
|
||||
sudo umount /mnt/nas_backup
|
||||
|
||||
# 2. 模拟开机自动挂载
|
||||
sudo mount -a
|
||||
|
||||
# 3. 检查是否挂载成功
|
||||
df -h | grep nas_backup
|
||||
```
|
||||
|
||||
**如果 `sudo mount -a` 没有报错,且 `df` 能看到 NAS 空间,那么以后重启服务器,挂载都会自动生效。**
|
||||
|
||||
---
|
||||
|
||||
#### 4. 进阶:针对 Rsync 脚本的安全保护
|
||||
|
||||
在你的 `rsync` 脚本(`/usr/local/bin/rsync_backup.sh`)开头,建议加入一个**挂载检查**。防止在 NAS 掉线或由于某种原因挂载失败时,`rsync` 把备份数据写到了本地硬盘的挂载点目录(会导致笔记本硬盘迅速爆满)。
|
||||
|
||||
在脚本的配置区下方加入这段逻辑:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 检查挂载点是否是一个有效的挂载
|
||||
if ! mountpoint -q /mnt/nas_backup; then
|
||||
echo "错误:NAS 未挂载,备份任务取消!" >> /var/log/rsync_backup.log
|
||||
# 在这里可以加入发送通知给你的逻辑
|
||||
exit 1
|
||||
fi
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
#### 5. 常见问题:重启后仍然失效?
|
||||
|
||||
如果在执行了上述操作后重启依然不生效,通常是因为 Ubuntu 的 `nfs-common` 服务启动慢于 `mount -a` 的执行。
|
||||
|
||||
- **对策**:你可以启动 `Remote File Systems` 目标服务:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo systemctl enable remote-fs.target
|
||||
```
|
||||
|
||||
|
||||
**你现在已经修改并测试过 `sudo mount -a` 了吗?如果运行这个命令有报错,请把错误信息发给我。**
|
||||
@@ -0,0 +1,141 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [docker, ubuntu]
|
||||
---
|
||||
|
||||
|
||||
#docker #ubuntu
|
||||
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
Installing **Docker** and **Docker Compose** on **Ubuntu** involves a few straightforward steps. It's generally best to install from Docker's official repositories to ensure you have the latest version.
|
||||
|
||||
---
|
||||
|
||||
## 🐋 Step 1: Uninstall Old Versions (If Applicable)
|
||||
|
||||
First, remove any existing, potentially conflicting Docker packages:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
for pkg in docker.io docker-engine docker-ce docker.io docker-compose docker-compose-v2; do sudo apt-get remove $pkg; done
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 🛠️ Step 2: Set Up Docker's Repository
|
||||
|
||||
You need to set up the repository to allow `apt` to use a repository over HTTPS:
|
||||
|
||||
1. **Update the `apt` package index:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
2. **Install necessary packages:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo apt-get install ca-certificates curl
|
||||
```
|
||||
|
||||
3. **Add Docker's official GPG key:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo install -m 0755 -d /etc/apt/keyrings
|
||||
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
|
||||
sudo chmod a+r /etc/apt/keyrings/docker.asc
|
||||
```
|
||||
|
||||
4. **Add the repository to `apt` sources:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
echo \
|
||||
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
|
||||
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
|
||||
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 🚀 Step 3: Install Docker Engine
|
||||
|
||||
Now that the repository is set up, you can install the Docker Engine packages:
|
||||
|
||||
1. **Update the `apt` package index again:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
2. **Install the Docker packages:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
|
||||
```
|
||||
|
||||
(Note: The `docker-compose-plugin` installs **Docker Compose V2**, which is used via the command `docker compose` instead of `docker-compose`).
|
||||
|
||||
|
||||
---
|
||||
|
||||
## ✅ Step 4: Verify the Installation
|
||||
|
||||
Check that the Docker Engine is running and that the installation was successful by running the test image:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo docker run hello-world
|
||||
```
|
||||
|
||||
If successful, this command downloads a test image and runs it, printing an informational message before exiting.
|
||||
|
||||
---
|
||||
|
||||
## 👤 Step 5: Manage Docker as a Non-Root User (Recommended)
|
||||
|
||||
By default, running Docker commands requires `sudo`. To run Docker without `sudo`, you can add your user to the **`docker` group**:
|
||||
|
||||
1. **Add your user to the `docker` group:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo usermod -aG docker $USER
|
||||
```
|
||||
|
||||
2. **Log out and log back in** (or restart your terminal session, or run `newgrp docker`) for the changes to take effect.
|
||||
|
||||
3. **Verify without `sudo`:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
docker run hello-world
|
||||
```
|
||||
|
||||
|
||||
You should now have **Docker Engine** and **Docker Compose (V2)** installed and ready to use!
|
||||
|
||||
Would you like to know some basic **Docker commands** or learn how to write a simple **`docker-compose.yml`** file?
|
||||
131
raw/Technical/Home Office/🟠如何用指纹浏览器安全注册并订阅Claude Pro会员全攻略.md
Normal file
131
raw/Technical/Home Office/🟠如何用指纹浏览器安全注册并订阅Claude Pro会员全攻略.md
Normal file
@@ -0,0 +1,131 @@
|
||||
---
|
||||
title: 如何用指纹浏览器安全注册并订阅Claude Pro会员全攻略
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [adspower, claude, ip, pingme]
|
||||
---
|
||||
|
||||
#claude #pingme #ip #adspower
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
# 如何用指纹浏览器安全注册并订阅Claude Pro会员全攻略
|
||||
|
||||
## 概览 📝
|
||||
本视频主要讲解了如何通过安装和使用指纹浏览器,配合高质量代理IP,在避免账号被封的情况下,顺利注册并订阅AI聊天工具Claude的Pro版本。讲解层层递进,细节丰富,涵盖从工具下载安装、IP设置、账号注册、验证码获取到付费订阅的完整流程。整个内容注重实操与技巧,确保即使是初学者也能跟着操作,降低封号风险。视频内容重点突出“IP一致性与纯净度检测”,“指纹浏览器隔离环境使用技巧”,以及“海外虚拟信用卡支付解决方案”,极具实用价值。
|
||||
|
||||
## Youtube视频
|
||||
https://www.youtube.com/watch?v=vvD2jUZYPgI
|
||||
|
||||
## 章节知识点总结 ⏰
|
||||
|
||||
#### 指纹浏览器安装与环境配置**
|
||||
- 推荐使用AdsPower指纹浏览器,支持谷歌授权登录,提供客户端体验完整功能。 AdsPower指纹浏览器:[https://share.adspower.net]
|
||||
- 创建新的浏览器环境时,选择最新Chrome版本及操作系统,设置用户代理。关键步骤是配置代理类型为socks5,并通过系统网络设置复制本机代理地址与端口填入指纹浏览器,确保代理与当地网络真实一致。
|
||||
![[IMG-20251231145927286.png]]
|
||||
![[IMG-20251231145927318.png]]
|
||||
- 代理设置成功后,用检查代理功能确认IP归属地为美国,实现代理连接成功。 https://ip111.cn/
|
||||
![[IMG-20251231145927365.png]]
|
||||
|
||||
|
||||
#### IP一致性与纯净度检测技巧**
|
||||
- 通过访问多个IP检测网站,确认测试点国内、国外和谷歌三处IP保持高度一致,保证IP稳定性。
|
||||
![[IMG-20251231145927401.png]]
|
||||
- 重要的IP风险评估,理想纯净度为“低风险”,数值越低越安全。中等风险或以上可能被封号。 https://scamalytics.com/
|
||||
![[IMG-20251231145927426.png]]
|
||||
- 多次测试刷新代理,确定IP高纯净度后才能大大降低账号被封概率。
|
||||
|
||||
#### Claude账号注册与手机号验证码接收方法**
|
||||
- 推荐用谷歌账号登录Claude进行注册。
|
||||
- 手机验证码推荐用新兴接码平台“PingMe”,支持中文界面,需下载App,用手机号注册并充值最低2美元。 [https://messages.pingme.tel/]
|
||||
- 选择美国区Claude验证码,订阅后可稳定获取短信验证码,避免一次性号码限制。
|
||||
```
|
||||
(+1)9145775122
|
||||
```
|
||||
- 绑定短信验证码完成注册,避免手机号重复带来的封号风险,同时演示成功登录Claude 3.5 Sonnet模型确认账号正常。
|
||||
```
|
||||
Claude Account:
|
||||
Google Login: billyshen2000@gmail.com
|
||||
```
|
||||
|
||||
#### 多账户注册与指纹浏览器多环境管理**
|
||||
- 可继续创建多套浏览器环境(不同Chrome版本和操作系统),分别配置独立代理,维护账号隔离。
|
||||
- 普通用户免费可使用5个指纹浏览器环境,满足大多数需求。
|
||||
- 重点强调IP稳定性及独立性,防止账号关联封号。
|
||||
|
||||
#### Claude Pro会员订阅及支付方案【关键难点】**
|
||||
- 国内信用卡无法支付,推荐使用WildCard虚拟信用卡解决跨境支付难题。 [https://yeka.ai/i/UPHSP]
|
||||
- 注册WildCard账号简易,仅需手机号验证,支持支付宝充值。
|
||||
- 充值后购买Claude Pro套餐(最低20美元/月),绑定信用卡信息完成升级。
|
||||
- 支付流程细节详解,确保用户能顺利订阅Pro服务。
|
||||
|
||||
## 重点术语和定义 📚
|
||||
|
||||
- **指纹浏览器**:一种可模拟不同设备、网络环境的多账号浏览器,隔离使用环境,减少账号关联风险。
|
||||
- **Socks5代理**:一种网络代理协议,支持灵活的传输隧道,有助于隐匿真实IP和地理位置。
|
||||
- **IP纯净度**:评定某IP是否安全可靠的风险等级,低风险代表良好的信誉和较少异常,避免被平台标记。
|
||||
- **虚拟信用卡(WildCard)**:不依赖实体卡的线上信用支付工具,方便海外支付等场景。
|
||||
- **验证码接收平台(PingMe)**:提供短信接码服务的应用或网站,支持接收短消息以完成注册或验证。
|
||||
|
||||
## 推理结构解析 ⚙️
|
||||
|
||||
1. **问题识别**:Claude账号易被封,传统注册方式难以持续使用。
|
||||
2. **解决方案提出**:通过指纹浏览器创建独立环境+高纯净度美国代理,隐藏真实身份及网络特征。
|
||||
3. **关键步骤拆解**:
|
||||
- 安装客户端及指纹浏览器环境配置。
|
||||
- 代理设置与IP一致性及纯净度检测。
|
||||
- 使用稳定收费接码平台接收验证码。
|
||||
- 使用虚拟信用卡实现付费订阅。
|
||||
4. **结论验证**:注册成功且账号稳定不被封,可以升级Pro套餐正常使用。
|
||||
|
||||
## 典型示例及应用 🌟
|
||||
|
||||
- 使用AdsPower指纹浏览器,设置Chrome 131版本,系统选Windows操作系统,通过系统代理端口配置,实现美国IP环境。
|
||||
- 复制测试获得的IP地址至多个检测网站,确认国内外IP一致且纯净度低风险,成功解决多IP不匹配问题。
|
||||
- 用PingMe平台接收短信,避免一次性号码封号,订单长期生效。
|
||||
- 绑定WildCard虚拟信用卡完成支付,成功开通Claude Pro会员,保障AI服务使用无阻。
|
||||
|
||||
## 易错点解析 ⚠️
|
||||
|
||||
- **误区1:使用本地浏览器直接访问Claude导致账号识别关联,易封号。**
|
||||
正确做法:必须使用指纹浏览器隔离环境操作。
|
||||
|
||||
- **误区2:代理IP设置不一致导致IP地址在不同测试网站中不匹配,从而被平台判定异常。**
|
||||
正确做法:确保代理全局生效,且检查三处IP测试点完全一致。
|
||||
|
||||
- **误区3:忽视IP纯净度检测,使用“中等风险”或更高风险IP注册,会大幅增加封号风险。**
|
||||
正确做法:切换代理,确保纯净度极低,数值越低越安全。
|
||||
|
||||
- **误区4:使用一次性接码号码注册,短信验证不稳定或被拦截,导致账号绑定失败。**
|
||||
正确做法:用订阅制的接码平台,获取长期可靠验证码服务。
|
||||
|
||||
- **误区5:未使用支持海外支付的虚拟信用卡,导致无法充值Pro会员。**
|
||||
正确做法:使用WildCard等虚拟信用卡完成支付。
|
||||
|
||||
## 速记复习小贴士与自测题 ✅
|
||||
|
||||
- **复习提示(无答案)**
|
||||
- 什么是指纹浏览器,它为什么能降低账号封禁风险?
|
||||
- 如何测试IP一致性及纯净度,为什么它们重要?
|
||||
- 请说出配置代理时socks5代理的关键数据来源。
|
||||
- 为什么要使用PingMe平台代替传统短信接码平台?
|
||||
- 如何利用虚拟信用卡完成海外AI服务付费?
|
||||
|
||||
- **自测试题(含答案)**
|
||||
1. 指纹浏览器中的“新建浏览器环境”为什么不能使用本地浏览器?
|
||||
- 答:本地浏览器和指纹浏览器的环境互不干涉,使用本地浏览器会暴露设备和IP特征,易被关联封号。
|
||||
2. IP纯净度为中等风险,能否保证注册的Claude账号长期不被封?
|
||||
- 答:不能,中等风险IP易被平台标记导致封号,应使用低风险IP。
|
||||
3. 代理配置中“主机”和“端口”的来源是哪里?
|
||||
- 答:从系统“代理”设置中复制本机网络代理地址和端口。
|
||||
4. 为什么视频推荐使用“PingMe”而不是其他接码平台?
|
||||
- 答:PingMe提供订阅制的美国地区稳定号码,避免一次性号码被封,且充值灵活。
|
||||
5. 如何完成Claude Pro会员的支付?
|
||||
- 答:使用支持海外支付的虚拟信用卡(如WildCard)充值后,绑定信用卡信息完成订阅。
|
||||
|
||||
## 总结回顾 🎯
|
||||
本期视频详细演示了如何借助指纹浏览器及高纯净度代理,结合订阅制接码平台和虚拟信用卡,实现了稳定注册、登录及订阅Claude Pro会员的全过程。重点在于环境的隔离、IP的稳定和安全性核验,以及支付环节的国际化解决方案。掌握了这些步骤与技巧,用户能有效降低账号封禁风险,畅享高质量AI服务。该内容面向实操,兼具理论与细节,极具推广实用价值,是用户提升AI工具使用体验的必备指南。
|
||||
233
raw/Technical/Home Office/🟠安装Ubuntu-24.04.2在HP Zbook工作站笔记本上.md
Normal file
233
raw/Technical/Home Office/🟠安装Ubuntu-24.04.2在HP Zbook工作站笔记本上.md
Normal file
@@ -0,0 +1,233 @@
|
||||
---
|
||||
title: 将 0005 (Ubuntu) 放在启动顺序的首位
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [hp, rufus, ubuntu, zbook]
|
||||
---
|
||||
|
||||
|
||||
#ubuntu #hp #zbook #rufus
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
## 1. 准备工作
|
||||
|
||||
- **硬件**:一个容量至少为 **8GB** 的 U 盘。
|
||||
- **软件**:下载并运行最新版的 **Rufus**。
|
||||
- **数据提醒**:制作过程会清空 U 盘内的所有数据,请提前备份。
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 2. Rufus 设置步骤
|
||||
|
||||
请按照以下顺序配置 Rufus 界面:
|
||||
|
||||
1. **设备 (Device)**:选中你插入的 U 盘。
|
||||
|
||||
2. **引导类型选择 (Boot selection)**:点击右侧的“选择”,找到你电脑里的 `ubuntu-24.04.2-desktop-amd64.iso`。
|
||||
|
||||
3. **分区方案 (Partition scheme)**:
|
||||
|
||||
- **选择 `GPT`**。对于 HP ZBook 这种较新的工作站,务必使用 GPT 配合 UEFI 启动。
|
||||
|
||||
4. **目标系统类型 (Target system)**:
|
||||
|
||||
- 会自动变为 `UEFI (non CSM)`。
|
||||
|
||||
5. **文件系统 (File system)**:
|
||||
|
||||
- 保持默认的 `FAT32`(这是 UEFI 启动的标准格式)。
|
||||
|
||||
6. **开始 (Start)**:点击底部按钮。
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 3. 关键弹窗选择
|
||||
|
||||
点击“开始”后,Rufus 通常会弹出两个重要的提示:
|
||||
|
||||
- **检测到 ISOHybrid 镜像**:
|
||||
- **推荐选择**:“以 **ISO 镜像模式**写入”。
|
||||
- _说明:如果稍后无法启动,才考虑重新制作并选择“DD 模式”。_
|
||||
- **下载额外文件**:
|
||||
- 如果提示需要下载 `ldlinux.sys` 或 `ldlinux.bss`,点击“是”,让 Rufus 自动下载以确保引导成功。
|
||||
|
||||
---
|
||||
## 4. HP ZBook 分区格式化
|
||||
|
||||
对于 **HP ZBook** 这种高性能工作站安装 Ubuntu 24.04,为了充分发挥其 NVMe 固态硬盘的性能并确保 UEFI 引导的稳定性,分区和格式化建议遵循以下专业标准:
|
||||
### 1. 硬盘分区表 (Partition Table)
|
||||
- **必须选择 GPT (GUID Partition Table)**:HP ZBook 属于现代 UEFI 设备,不再建议使用过时的 MBR 分区。GPT 支持 2TB 以上硬盘,且与 UEFI 引导完美兼容。
|
||||
- **在 Rufus 制作时设置**:请确保在制作启动盘时,分区方案选为 **GPT**。
|
||||
### 2. 核心分区建议 (手动分区模式)
|
||||
|
||||
如果你在安装时选择“手动分区 (Something else)”,建议按以下规格配置
|
||||
|
||||
|**分区挂载点**|**建议大小**|**文件系统**|**说明**|
|
||||
|---|---|---|---|
|
||||
|**/boot/efi**|**512MB - 1GB**|**FAT32**|**必须项**。用于存储 UEFI 引导程序。|
|
||||
|**/** (根目录)|**100GB - 200GB**|**ext4**|存放系统文件、Docker 镜像和应用程序。|
|
||||
|**/home**|**剩余所有空间**|**ext4**|**强烈建议独立分区**。即使重装系统,你的 TikTok 运营数据和个人配置也能保留。|
|
||||
|**swap** (交换空间)|**8GB - 32GB**|**swap**|根据内存大小决定。如果经常跑大量 Docker 容器,建议设为内存的 1 倍。|
|
||||
|
||||
### 3. 文件系统格式选择
|
||||
|
||||
- **ext4 (推荐)**:最成熟、稳定的 Linux 文件系统,适合绝大多数工作室场景。
|
||||
- **ZFS / Btrfs**:虽然 Ubuntu 24.04 支持这些高级文件系统(支持快照功能),但对于 HP ZBook 上的 Docker 环境,**ext4** 的兼容性和性能表现最预测。
|
||||
|
||||
### 4. HP ZBook 特有的 BIOS/UEFI 设置
|
||||
|
||||
在格式化安装前,请进入 BIOS(开机反复按 **F10**)检查:
|
||||
|
||||
1. **Storage (存储)**:确保 SATA 模式(如果是混合硬盘)设置为 **AHCI**,而不是 RAID/Intel RST(Ubuntu 对 RST 兼容性较差)。
|
||||
2. **Secure Boot (安全启动)**:建议 **关闭 (Disabled)**。虽然 Ubuntu 支持安全启动,但关闭它能避免后续安装第三方驱动(如 Nvidia 显卡、特定的备份驱动)时遇到麻烦。
|
||||
3. **Fast Boot**:建议 **关闭**,以确保 U 盘能顺利引导。
|
||||
### 5. 格式化时的特别提醒
|
||||
|
||||
- **NVMe 优化**:Ubuntu 24.04 会自动识别 ZBook 的 NVMe 硬盘并进行对齐优化。手动分区时,请确保分区起始位置是默认推荐的数值(通常是 2048 扇区)。
|
||||
- **保留恢复分区?**:如果你想彻底抹除 Windows,请在安装向导中选择 **“Erase disk and install Ubuntu”**。这会自动为你创建最优的 GPT 分区结构,省去手动操作的麻烦。
|
||||
|
||||
---
|
||||
## 5 引导 HP ZBook 进入安装程序
|
||||
|
||||
制作完成后,拔下 U 盘插到你的笔记本上,按以下步骤启动:
|
||||
|
||||
1. **重启电脑**:在看到 HP Logo 之前,连续按下 **F9** 键(这是 HP 典型的启动菜单快捷键)。
|
||||
2. **选择引导设备**:在菜单中选择带有 **UEFI: USB Storage Device** 字样的选项。
|
||||
3. **进入 GRUB 菜单**:选择第一项 `Try or Install Ubuntu`。
|
||||
|
||||
---
|
||||
|
||||
## 6. 高级建议:自动化与备份
|
||||
|
||||
作为工作室负责人,为了避免以后反复重装,建议你:
|
||||
|
||||
- **安装完成后立即执行 Rsync**:当你装好系统并配置好网络后,立即将 NAS 上的旧数据通过 `rsync` 还原回来。
|
||||
- **制作“母版”镜像**:等你的 Ubuntu 系统、Docker、TikTok 运营环境全部配置完美后,参考我之前教你的方法,用 **Clonezilla** 给整个硬盘做个镜像存到 NAS 上。
|
||||
|
||||
|
||||
## 7. 排查重启后不能进入Ubuntu的问题
|
||||
|
||||
### 强制将 EFI 文件复制到“默认路径”
|
||||
|
||||
HP BIOS 有时非常固执,它只会寻找磁盘上默认的启动文件(`/EFI/BOOT/BOOTX64.EFI`)。如果它不保存你的自定义项,我们可以通过在 Ubuntu 内将 `shimx64.efi` 伪装成默认文件来“欺骗” BIOS。
|
||||
|
||||
1. 通过 F9 手动进入 Ubuntu。
|
||||
|
||||
2. 打开终端,执行以下命令:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 检查 EFI 分区挂载点
|
||||
sudo mkdir -p /boot/efi/EFI/BOOT
|
||||
|
||||
# 将 ubuntu 的引导文件复制并重命名为 BIOS 默认寻找的文件
|
||||
sudo cp /boot/efi/EFI/ubuntu/shimx64.efi /boot/efi/EFI/BOOT/BOOTX64.EFI
|
||||
sudo cp /boot/efi/EFI/ubuntu/grubx64.efi /boot/efi/EFI/BOOT/grubx64.efi
|
||||
```
|
||||
|
||||
1. 重启电脑。此时 BIOS 会在找不到其他引导项时,自动加载这个“默认”路径。
|
||||
|
||||
### 使用 `efibootmgr` 手动写入 NVRAM
|
||||
|
||||
既然你是技术背景,可以直接在 Linux 系统层面对 BIOS 存储(NVRAM)进行强制写入,这通常比在图形界面操作更有效。
|
||||
|
||||
1. 在 Ubuntu 终端输入:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 查看当前的引导列表
|
||||
sudo efibootmgr
|
||||
```
|
||||
|
||||
2. 找到你的 Ubuntu 对应的编号(比如 `Boot0001`)。
|
||||
|
||||
3. 假设 Ubuntu 是 `0001`,强制设置它为首选:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo efibootmgr -o 0001
|
||||
```
|
||||
|
||||
4. 如果列表里没有 Ubuntu,手动添加一个(假设硬盘是 `/dev/nvme0n1`,分区 1 是 EFI):
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo efibootmgr -c -d /dev/nvme0n1 -p 1 -L "Ubuntu_Force" -l "\EFI\ubuntu\shimx64.efi"
|
||||
```
|
||||
|
||||
根据你提供的 `efibootmgr` 输出,我发现了问题的核心原因:虽然 **Boot0005 (Ubuntu)** 已经成功注册到了 NVRAM 中,但它**不在 `BootOrder` (启动顺序)** 的名单里。
|
||||
|
||||
目前的 `BootOrder` 只有 `0000, 0001, 0002, 0003`,这意味着 BIOS 启动时会完全忽略 `0005`。我们需要手动将 `0005` 强制加入并排在第一位。
|
||||
|
||||
---
|
||||
|
||||
### 核心修复:强制重写启动顺序
|
||||
|
||||
在 Ubuntu 终端(root 权限下)执行以下命令:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 将 0005 (Ubuntu) 放在启动顺序的首位
|
||||
sudo efibootmgr -o 0005,0000,0001,0002,0003
|
||||
```
|
||||
|
||||
**验证结果:** 再次输入 `sudo efibootmgr`,确认第一行显示的 `BootOrder` 已经变成了 `0005,0000,...`。
|
||||
|
||||
---
|
||||
|
||||
### 备用方案:防止 HP BIOS 重置顺序(伪装大法)
|
||||
|
||||
HP 的旧款 ZBook 有个“坏习惯”:如果它在 NVRAM 里找不到它认为“标准”的启动项,它会重置 BootOrder。我们可以把 Ubuntu 的引导文件复制到磁盘的**默认备用路径**。这样即使 BIOS 抽风忽略了 NVRAM,也会因为在磁盘上找到了文件而启动。
|
||||
|
||||
执行以下命令:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 1. 创建默认引导目录
|
||||
sudo mkdir -p /boot/efi/EFI/BOOT
|
||||
|
||||
# 2. 将 Ubuntu 的引导程序复制并重命名为“万能默认名”
|
||||
sudo cp /boot/efi/EFI/ubuntu/shimx64.efi /boot/efi/EFI/BOOT/BOOTX64.EFI
|
||||
sudo cp /boot/efi/EFI/ubuntu/grubx64.efi /boot/efi/EFI/BOOT/grubx64.efi
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### BIOS 端的最后检查
|
||||
|
||||
执行完上述 Linux 命令后,重启进入 BIOS (**F10**),检查以下两个细节:
|
||||
|
||||
1. **Fast Boot (快速启动)**:务必将其设为 **Disabled**。开启它会导致 BIOS 跳过很多 EFI 检测逻辑。
|
||||
|
||||
|
||||
> [!NOTE] 执行了以下操作后可以正常启动!!!
|
||||
1. **Legacy Support (传统支持)**:确保设置为 **Disabled** (或者选择 **UEFI Without Legacy**)。从你的输出看,你现在有大量的 `BBS` (Legacy) 启动项,这会干扰 UEFI 的识别。
|
||||
|
||||
|
||||
---
|
||||
> [!NOTE] 最终解决方案!!!
|
||||
### 为什么会有这么多 `BBS` 项?
|
||||
|
||||
你的输出中 `Boot0000` 到 `Boot0004` 全是 `BBS` 类型的条目,这说明你的 BIOS 目前处于 **混合模式 (Hybrid)** 或 **传统模式 (Legacy)**。
|
||||
|
||||
- **建议**:在 BIOS 的 `Boot Options` 中,找到 **"Boot Mode"**,将其从 `Legacy` 或 `Hybrid` 切换为 **"UEFI Only"**。
|
||||
|
||||
- 一旦切换为 **UEFI Only**,那些无效的 `0000-0004` 就会消失,BIOS 将被迫只看 `0005` (Ubuntu)。
|
||||
|
||||
[[🟠Ubuntu 24.04 enable SSH]]
|
||||
[[🟠Ubuntu禁用合盖休眠]]
|
||||
[[🟠Ubuntu Server科学上网]]
|
||||
[[🟠Ubuntu用RustDesk远程登录出现不能使用Wayland登录的错误]]
|
||||
104
raw/Technical/Home Office/🟠安装v2rayN.md
Normal file
104
raw/Technical/Home Office/🟠安装v2rayN.md
Normal file
@@ -0,0 +1,104 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [linux, v2rayn, windows]
|
||||
---
|
||||
|
||||
|
||||
#linux #v2rayn #windows
|
||||
### 通用说明
|
||||
|
||||
[](https://github.com/2dust/v2rayN/wiki/Release-files-introduction#%E9%80%9A%E7%94%A8%E8%AF%B4%E6%98%8E)
|
||||
|
||||
1. 发布包中含部分 Core 文件(`Xray`,`sing-box`, `mihomo`),方便使用;其他 Core 需要自己去下载,[支持的核心列表](https://github.com/2dust/v2rayN/wiki/List-of-supported-cores)
|
||||
2. `zip`格式包为便携版,解压缩到文件夹后直接可以运行,存储文件位置为本文件夹;可以复制多份互相独立
|
||||
|
||||
### Windows
|
||||
|
||||
[](https://github.com/2dust/v2rayN/wiki/Release-files-introduction#windows)
|
||||
|
||||
1. 支持的系统版本
|
||||
|
||||
```
|
||||
Windows 10+
|
||||
```
|
||||
|
||||
|
||||
#### Windows x64
|
||||
|
||||
[](https://github.com/2dust/v2rayN/wiki/Release-files-introduction#windows-x64)
|
||||
|
||||
- `v2rayN-windows-64.zip` WPF实现的界面,需要安装 [Microsoft .NET 8.0 Desktop Runtime]
|
||||
- `v2rayN-windows-64-SelfContained.zip` WPF实现的界面
|
||||
- `v2rayN-windows-64-desktop.zip` Avalonia UI 实现的界面
|
||||
- 其他 Core 你可以从 [这里](https://github.com/2dust/v2rayN-core-bin/blob/master/v2rayN-windows-64-other-bins.zip) 下载后放入 bin 文件夹
|
||||
|
||||
#### Windows arm64
|
||||
|
||||
[](https://github.com/2dust/v2rayN/wiki/Release-files-introduction#windows-arm64)
|
||||
|
||||
- [在 Windows arm64 下能使用吗?](https://github.com/2dust/v2rayN/wiki/Faq#%E5%9C%A8-windows-arm64-%E4%B8%8B%E8%83%BD%E4%BD%BF%E7%94%A8%E5%90%97)
|
||||
- `v2rayN-windows-arm64.zip` WPF实现的界面,需要安装 [Microsoft .NET 8.0 Desktop Runtime]
|
||||
- `v2rayN-windows-arm64-desktop.zip` Avalonia UI 实现的界面
|
||||
|
||||
### Linux
|
||||
|
||||
[](https://github.com/2dust/v2rayN/wiki/Release-files-introduction#linux)
|
||||
|
||||
1. 非`zip`格式包为安装版,存储文件位置为系统规定的用户文件中
|
||||
2. deb 适用于 Debian/Ubuntu,rpm 适用于 Fedora/Redhat
|
||||
3. 支持的发行版
|
||||
|
||||
```
|
||||
Debian 12 +
|
||||
Ubuntu 22.04 +
|
||||
Fedora 36 +
|
||||
Redhat 9 +
|
||||
```
|
||||
|
||||
|
||||
#### Linux x64
|
||||
|
||||
[](https://github.com/2dust/v2rayN/wiki/Release-files-introduction#linux-x64)
|
||||
|
||||
- `v2rayN-linux-64.zip` 执行: `chmod +x v2rayN` 普通用户运行 `./v2rayN`
|
||||
- `v2rayN-linux-64.deb` 安装:`sudo apt install -y ./v2rayN-linux-64.deb`
|
||||
- `v2rayN-linux-rhel-x64.rpm` 安装:`sudo dnf install -y ./v2rayN-linux-rhel-x64.rpm`
|
||||
|
||||
#### Linux arm64
|
||||
|
||||
[](https://github.com/2dust/v2rayN/wiki/Release-files-introduction#linux-arm64)
|
||||
|
||||
- `v2rayN-linux-arm64.zip` 执行: `chmod +x v2rayN` 普通用户运行 `./v2rayN`
|
||||
- `v2rayN-linux-arm64.deb` 安装:`sudo apt install -y ./v2rayN-linux-arm64.deb`
|
||||
- `v2rayN-linux-rhel-arm64.rpm` 安装:`sudo dnf install -y ./v2rayN-linux-rhel-arm64.rpm`
|
||||
|
||||
### macOS
|
||||
|
||||
[](https://github.com/2dust/v2rayN/wiki/Release-files-introduction#macos)
|
||||
|
||||
1. 非`zip`格式包为安装版,存储文件位置为系统规定的用户文件中
|
||||
2. 支持的系统版本
|
||||
|
||||
```
|
||||
macOS 12+
|
||||
```
|
||||
|
||||
|
||||
#### macOS x64
|
||||
|
||||
[](https://github.com/2dust/v2rayN/wiki/Release-files-introduction#macos-x64)
|
||||
|
||||
- `v2rayN-macos-64.zip` 执行:`chmod +x v2rayN` 普通用户运行 `./v2rayN`
|
||||
- `v2rayN-macos-64.dmg` 由于安装包没有签名,会提示应用已损坏;安装后需要运行:`xattr -cr /Applications/v2rayN.app`
|
||||
|
||||
#### macOS arm64
|
||||
|
||||
[](https://github.com/2dust/v2rayN/wiki/Release-files-introduction#macos-arm64)
|
||||
|
||||
- `v2rayN-macos-arm64.zip` 执行:`chmod +x v2rayN` 普通用户运行 `./v2rayN`
|
||||
- `v2rayN-macos-arm64.dmg` 由于安装包没有签名,会提示应用已损坏;安装后需要运行:`xattr -cr /Applications/v2rayN.app`
|
||||
@@ -0,0 +1,525 @@
|
||||
---
|
||||
title: 核心目标(你要覆盖的监控面)
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-11-11
|
||||
description: 按优先级与场景划分的、能通过 Docker 部署的监控方案,并附带部署建议、关键监控项、告警示例
|
||||
tags: [grafana, monitoring, prometheus]
|
||||
---
|
||||
|
||||
|
||||
#prometheus #grafana #monitoring
|
||||
|
||||
|
||||
我给你一套按优先级与场景划分的、能通过 Docker 部署的监控方案,并附带部署建议、关键监控项、告警示例、以及两套可直接拷贝的 `docker-compose` 验证模板(一个轻量、一个较完整)。我把信息组织成清单和操作步骤,便于你直接在 NAS / Ubuntu Server 上实践。
|
||||
|
||||
# 核心目标(你要覆盖的监控面)
|
||||
|
||||
1. 主机层:CPU / 内存 / 磁盘 / 网络 / I/O / inode。
|
||||
2. 容器层:容器运行状态、重启次数、资源限制/使用、退出码、镜像版本。
|
||||
3. 服务层(应用):HTTP(S) 可用性、响应码、延迟、错误率、TLS 证书到期、DNS 解析是否异常。
|
||||
4. 日志:应用错误/异常、关键业务日志索引(可选全文搜索)。
|
||||
5. 合规与可视化:集中 time-series 存储 + 仪表盘 + 报警/通知通道(邮件/Slack/电话/Teams)。
|
||||
|
||||
![[IMG-20251229190624400.png]]
|
||||
# 推荐工具(均可 Docker 化)
|
||||
|
||||
按功能分组,给出用途与为何推荐(并标注官方安装/镜像文档):
|
||||
|
||||
### 观测 + 时序数据 / 查询 / 告警
|
||||
|
||||
- **Prometheus(采集 + 告警规则)**:拉取 exporters(node_exporter、cAdvisor、blackbox_exporter)采集指标,支持 PromQL 命名与告警规则。适合做主观测时序库与告警。([Prometheus](https://prometheus.io/?utm_source=chatgpt.com "Prometheus - Monitoring system & time series database"))
|
||||
|
||||
- **Alertmanager**(Prometheus 的告警分发):用于抑制、分组并把告警推到邮件/Slack/Webhook/PagerDuty。
|
||||
|
||||
|
||||
### 可视化 + 日志聚合
|
||||
|
||||
- **Grafana**:展示 Prometheus / VictoriaMetrics / Loki 等数据源的仪表盘与告警。支持仪表盘模板与报警通知。([Grafana Labs](https://grafana.com/docs/grafana/latest/setup-grafana/installation/docker/?utm_source=chatgpt.com "Run Grafana Docker image | Grafana documentation"))
|
||||
|
||||
- **Grafana Loki + Promtail**(如果你要日志聚合): 轻量级、与 Grafana 原生集成,适合把应用日志索引进来。
|
||||
|
||||
|
||||
### 主机 / 容器指标(简易采集)
|
||||
|
||||
- **node_exporter**(主机指标采集,Prometheus exporter)
|
||||
|
||||
- **cAdvisor**(容器资源/性能指标,Prometheus 可抓取)
|
||||
|
||||
- **blackbox_exporter**(外网/内网 HTTP/TCP/ICMP/HTTPS 监测/探测,用于合成监测)。
|
||||
|
||||
|
||||
### 合成 / 可用性 / Uptime 检查(外网/内网访问)
|
||||
|
||||
- **Uptime Kuma**:自托管的“Uptime Robot”式工具,易上手,做外网或内网的合成可用性探针(HTTP/TCP/DNS/TLS),带历史和通知支持。推荐用于合成监测(synthetic checks)。([uptimekuma.org](https://uptimekuma.org/install-uptime-kuma-docker/?utm_source=chatgpt.com "Install Uptime Kuma using Docker or Docker Compose"))
|
||||
|
||||
|
||||
### 轻量单主机快速看板(推荐做 PoC)
|
||||
|
||||
- **Netdata**:开箱即用的详细 realtime 主机/容器监控面板(默认 19999 端口)。适合快速诊断热点,能和 Prometheus 集成做长期存储。([learn.netdata.cloud](https://learn.netdata.cloud/docs/netdata-agent/installation/docker?utm_source=chatgpt.com "Install Netdata with Docker"))
|
||||
|
||||
|
||||
### 时序数据库替代(可选,用于更大规模)
|
||||
|
||||
- **VictoriaMetrics / Thanos / Cortex**:当数据量大或想要长期存储 + 高效写入时。VictoriaMetrics 配置简单,常见于 single-host 或 small-cluster 场景。
|
||||
|
||||
|
||||
### 管理/操作视角(容器管理)
|
||||
|
||||
- **Portainer**:可视化管理 Docker 主机/Swarm,带部分监控/日志功能(不替代 Prometheus/Grafana,但便于运维快速操作)。
|
||||
|
||||
|
||||
---
|
||||
|
||||
# 推荐的架构方案
|
||||
|
||||
### 标准(生产常见,适合多主机)
|
||||
|
||||
用途:长期监控、告警、仪表盘。
|
||||
组件:Prometheus + node_exporter + cAdvisor + blackbox_exporter + Grafana + Alertmanager。可选 Loki(日志)、VictoriaMetrics(长期存储)。Prometheus 抓取所有主机/容器指标,Grafana 做可视化,Alertmanager 负责通知。([Prometheus](https://prometheus.io/?utm_source=chatgpt.com "Prometheus - Monitoring system & time series database"))
|
||||
|
||||
|
||||
---
|
||||
|
||||
# 我猜你可能没想过但挺有用的点(主动建议)
|
||||
|
||||
1. **合成(synthetic)与真实用户监控结合**:Uptime Kuma 做外网/内网可用性探针 + Prometheus blackbox_exporter 做更细粒度 HTTP/TLS/DNS 探测(响应码、证书有效期、解析时延)。
|
||||
|
||||
2. **TLS 证书到期告警**:通过 blackbox_exporter 或直接 Prometheus exporter(或在 Uptime Kuma 中)设置证书剩余天数阈值告警。
|
||||
|
||||
3. **DNS 解析单独监控**:外网访问不通常是 DNS 问题,单独做 DNS probe(blackbox_exporter 支持)。
|
||||
|
||||
4. **短期与长期数据分层**:Netdata 做短期高分辨率展示,Prometheus + VictoriaMetrics 做长期汇总(remote_write)。
|
||||
|
||||
5. **自动化接入新主机**:在新主机上用 Ansible / cloud-init 快速部署 node_exporter + cAdvisor + promtail(日志)并注册到 Prometheus。
|
||||
|
||||
6. **容器标签化 & 报表**:保证容器/服务启动时打上 `service=xxx`、`env=prod` 标签,便于 PromQL 分组和 SLA 报表。
|
||||
|
||||
|
||||
---
|
||||
|
||||
# 推荐监控项(可直接写为 PromQL/告警条件)
|
||||
|
||||
核心指标与告警建议(举例):
|
||||
|
||||
- 主机:`node_filesystem_avail_bytes` < 10% → 磁盘告警。
|
||||
|
||||
- CPU:5 分钟平均 CPU 使用率 > 85%(或按核数修正)→ 告警。
|
||||
|
||||
- 内存:`node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes < 0.15` → 内存告警。
|
||||
|
||||
- 容器:容器重启次数 `increase(container_restart_total[1h]) > 0` → 告警(可过滤重启策略更新产生的重启)。
|
||||
|
||||
- HTTP:黑箱探测 `probe_success == 0` 连续 3 次 → 报警;`probe_duration_seconds` 高于阈值 → 性能警告。
|
||||
|
||||
- TLS:证书剩余天数 < 14 → 告警。
|
||||
|
||||
(这些可直接放进 Prometheus 的 alert rules,也可在 Grafana 转换为告警)
|
||||
|
||||
---
|
||||
|
||||
# 安全与运维注意(捷径与坑)
|
||||
|
||||
- 减少容器权限:尽量不要给 exporters 过高宿主机权限,除非需要(e.g., Netdata 需要 `/proc`、`/sys`、Docker socket 才能全面监控)。审慎开启 Docker socket 挂载(风险:容器拿到宿主机 root 等同权限)。([learn.netdata.cloud](https://learn.netdata.cloud/docs/netdata-agent/installation/docker?utm_source=chatgpt.com "Install Netdata with Docker"))
|
||||
|
||||
- 网络分区:把监控流量/端口放在管理 VLAN 或通过防火墙限定访问。
|
||||
|
||||
- 存储:Prometheus 本地磁盘会增长,考虑长期保留要用远端存储或定期 snapshot。
|
||||
|
||||
- 备份:Grafana 仪表盘 JSON 导出,Prometheus rule 与配置放在 Git(GitOps)。
|
||||
|
||||
- 证书/反向代理:生产建议在反向代理(Caddy/Traefik/Nginx)做 TLS 终端并加 Basic/Auth 或内部 SSO。
|
||||
|
||||
|
||||
---
|
||||
|
||||
# 快速落地步骤(我会按专家视角把步骤拆成可运行的命令)
|
||||
|
||||
1. 在一台测试机器上用上面 PoC compose 启动,验证 Netdata 与 Uptime Kuma 可访问(19999 / 3001)。
|
||||
|
||||
2. 把 Prometheus compose 与 `prometheus.yml` 上线到主要监控节点,配置 `scrape_configs` 抓取 node_exporter / cadvisor / blackbox。
|
||||
|
||||
3. 在每台主机上用 docker-compose 或 Ansible 部署 node_exporter(或使用 host network 模式),并在 Prometheus 中加入目标。
|
||||
|
||||
4. 在 Grafana 导入几个预置 dashboard(node_exporter、cadvisor、blackbox 面板),并在 Alertmanager 中配置告警路由(Slack/邮件)。
|
||||
|
||||
5. 把 Uptime Kuma 的探测项(内网域名/公网域名)全部建好,设置通知通道(Mail / Webhook 指向 Alertmanager/Grafana 或直接 Slack)。
|
||||
|
||||
|
||||
---
|
||||
|
||||
# 参考资源(官网/文档 — 我把主要 URL 放在下面,便于你深入阅读与部署)
|
||||
|
||||
- Prometheus 官方: [https://prometheus.io/](https://prometheus.io/)
|
||||
|
||||
- Prometheus Docker 镜像(Docker Hub): [https://hub.docker.com/r/prom/prometheus](https://hub.docker.com/r/prom/prometheus)
|
||||
|
||||
- Grafana Docker 安装文档: [https://grafana.com/docs/grafana/latest/setup-grafana/installation/docker/](https://grafana.com/docs/grafana/latest/setup-grafana/installation/docker/)
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
|
||||
# 我们来落地选项 **A:完整的 `docker-compose` + `prometheus.yml` + alert rules**。
|
||||
|
||||
目标是:
|
||||
在你家里(NAS/Ubuntu Server)上,用 Docker 一键启动一个完整的监控栈。
|
||||
**功能覆盖**:
|
||||
|
||||
- 主机与容器指标(`node_exporter`, `cAdvisor`)
|
||||
|
||||
- 内外网域名健康探测(`blackbox_exporter`)
|
||||
|
||||
- 数据采集与存储(`prometheus`)
|
||||
|
||||
- 可视化(`grafana`)
|
||||
|
||||
- 告警分发(`alertmanager`,可选接邮件/Slack)
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 🧱 一、目录结构建议
|
||||
|
||||
请在主机上建一个目录 `/opt/monitoring/`(可换路径):
|
||||
|
||||
```
|
||||
/opt/monitoring/
|
||||
├── docker-compose.yml
|
||||
├── prometheus/
|
||||
│ ├── prometheus.yml
|
||||
│ ├── alerts.yml
|
||||
│ └── targets/
|
||||
│ ├── node.yml
|
||||
│ ├── cadvisor.yml
|
||||
│ └── blackbox.yml
|
||||
├── alertmanager/
|
||||
│ └── config.yml
|
||||
└── grafana/
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 🐳 二、`docker-compose.yml`
|
||||
|
||||
这是一个完整可运行的 Compose 文件,覆盖核心组件。
|
||||
|
||||
``` yaml
|
||||
version: '3.8'
|
||||
|
||||
services:
|
||||
prometheus:
|
||||
image: prom/prometheus:latest
|
||||
container_name: prometheus
|
||||
restart: always
|
||||
volumes:
|
||||
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:ro
|
||||
- ./prometheus/alerts.yml:/etc/prometheus/alerts.yml:ro
|
||||
- ./prometheus/targets:/etc/prometheus/targets:ro
|
||||
- prometheus-data:/prometheus
|
||||
command:
|
||||
- '--config.file=/etc/prometheus/prometheus.yml'
|
||||
- '--storage.tsdb.path=/prometheus'
|
||||
- '--web.enable-lifecycle'
|
||||
ports:
|
||||
- "9090:9090"
|
||||
depends_on:
|
||||
- cadvisor
|
||||
- node_exporter
|
||||
- blackbox
|
||||
|
||||
grafana:
|
||||
image: grafana/grafana:latest
|
||||
container_name: grafana
|
||||
restart: always
|
||||
ports:
|
||||
- "3000:3000"
|
||||
environment:
|
||||
- GF_AUTH_ANONYMOUS_ENABLED=true
|
||||
- GF_AUTH_ANONYMOUS_ORG_NAME=Main Org
|
||||
- GF_AUTH_ANONYMOUS_ORG_ROLE=Viewer
|
||||
- GF_SECURITY_ALLOW_EMBEDDING=true
|
||||
- GF_SECURITY_ADMIN_USER=admin
|
||||
- GF_SECURITY_ADMIN_PASSWORD=admin
|
||||
volumes:
|
||||
- grafana-storage:/var/lib/grafana
|
||||
depends_on:
|
||||
- prometheus
|
||||
|
||||
alertmanager:
|
||||
image: prom/alertmanager:latest
|
||||
container_name: alertmanager
|
||||
restart: always
|
||||
ports:
|
||||
- "9093:9093"
|
||||
volumes:
|
||||
- ./alertmanager/config.yml:/etc/alertmanager/config.yml:ro
|
||||
command:
|
||||
- '--config.file=/etc/alertmanager/config.yml'
|
||||
|
||||
node_exporter:
|
||||
image: prom/node-exporter:latest
|
||||
container_name: node_exporter
|
||||
restart: always
|
||||
network_mode: "host"
|
||||
pid: "host"
|
||||
volumes:
|
||||
- /proc:/host/proc:ro
|
||||
- /sys:/host/sys:ro
|
||||
- /:/rootfs:ro
|
||||
|
||||
cadvisor:
|
||||
image: gcr.io/cadvisor/cadvisor:latest
|
||||
container_name: cadvisor
|
||||
restart: always
|
||||
ports:
|
||||
- "8080:8080"
|
||||
volumes:
|
||||
- /:/rootfs:ro
|
||||
- /var/run:/var/run:ro
|
||||
- /sys:/sys:ro
|
||||
- /var/lib/docker/:/var/lib/docker:ro
|
||||
|
||||
blackbox:
|
||||
image: prom/blackbox-exporter:latest
|
||||
container_name: blackbox
|
||||
restart: always
|
||||
ports:
|
||||
- "9115:9115"
|
||||
|
||||
volumes:
|
||||
prometheus-data:
|
||||
grafana-storage:
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## ⚙️ 三、Prometheus 配置文件 `prometheus.yml`
|
||||
|
||||
```yaml
|
||||
global:
|
||||
scrape_interval: 15s
|
||||
evaluation_interval: 30s
|
||||
|
||||
rule_files:
|
||||
- "/etc/prometheus/alerts.yml"
|
||||
|
||||
alerting:
|
||||
alertmanagers:
|
||||
- static_configs:
|
||||
- targets: ['alertmanager:9093']
|
||||
|
||||
scrape_configs:
|
||||
- job_name: 'prometheus'
|
||||
static_configs:
|
||||
- targets: ['prometheus:9090']
|
||||
|
||||
- job_name: 'node_exporter'
|
||||
file_sd_configs:
|
||||
- files:
|
||||
- /etc/prometheus/targets/node.yml
|
||||
|
||||
- job_name: 'cadvisor'
|
||||
file_sd_configs:
|
||||
- files:
|
||||
- /etc/prometheus/targets/cadvisor.yml
|
||||
|
||||
- job_name: 'blackbox_http'
|
||||
metrics_path: /probe
|
||||
params:
|
||||
module: [http_2xx]
|
||||
file_sd_configs:
|
||||
- files:
|
||||
- /etc/prometheus/targets/blackbox.yml
|
||||
relabel_configs:
|
||||
- source_labels: [__address__]
|
||||
target_label: __param_target
|
||||
- target_label: __address__
|
||||
replacement: blackbox:9115
|
||||
- source_labels: [__param_target]
|
||||
target_label: instance
|
||||
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 🗂 四、Targets 文件示例
|
||||
|
||||
### `targets/node.yml`
|
||||
|
||||
```yaml
|
||||
- targets:
|
||||
- "192.168.3.47:9100"
|
||||
labels:
|
||||
env: home
|
||||
role: server
|
||||
```
|
||||
|
||||
### `targets/cadvisor.yml`
|
||||
|
||||
```yaml
|
||||
- targets:
|
||||
- "cadvisor:8080"
|
||||
labels:
|
||||
env: home
|
||||
role: docker
|
||||
```
|
||||
|
||||
### `targets/blackbox.yml`
|
||||
|
||||
```yaml
|
||||
- targets:
|
||||
- "https://pq2435887bh.vicp.fun"
|
||||
- "http://shenwei-nas.vip.cpolar.cn"
|
||||
- "https://transmission.vip.cpolar.cn"
|
||||
labels:
|
||||
env: home
|
||||
type: website
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 🚨 五、Prometheus 告警规则 `alerts.yml`
|
||||
|
||||
```yaml
|
||||
groups:
|
||||
- name: system-alerts
|
||||
rules:
|
||||
|
||||
- alert: HostHighCPU
|
||||
expr: avg(rate(node_cpu_seconds_total{mode="user"}[2m])) * 100 > 85
|
||||
for: 2m
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
summary: "高 CPU 使用率"
|
||||
description: "主机 CPU 使用率超过 85%(持续 2 分钟)"
|
||||
|
||||
- alert: HostLowDisk
|
||||
expr: (node_filesystem_avail_bytes{fstype!~"tmpfs|overlay"} / node_filesystem_size_bytes{fstype!~"tmpfs|overlay"}) < 0.10
|
||||
for: 5m
|
||||
labels:
|
||||
severity: critical
|
||||
annotations:
|
||||
summary: "磁盘空间不足"
|
||||
description: "磁盘剩余空间低于 10%"
|
||||
|
||||
- alert: HostLowMemory
|
||||
expr: (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) < 0.15
|
||||
for: 5m
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
summary: "内存使用率高"
|
||||
description: "可用内存低于 15%"
|
||||
|
||||
- alert: ContainerRestarting
|
||||
expr: increase(container_last_seen[5m]) == 0
|
||||
for: 5m
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
summary: "容器异常退出或未上报"
|
||||
description: "5 分钟内容器未更新指标,可能异常退出"
|
||||
|
||||
- alert: HTTPProbeFailed
|
||||
expr: probe_success == 0
|
||||
for: 2m
|
||||
labels:
|
||||
severity: critical
|
||||
annotations:
|
||||
summary: "站点不可达"
|
||||
description: "HTTP 探测失败:{{ $labels.instance }}"
|
||||
|
||||
- alert: TLSCertExpiring
|
||||
expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 14
|
||||
for: 1h
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
summary: "TLS 证书即将到期"
|
||||
description: "证书 {{ $labels.instance }} 剩余不到 14 天"
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 📧 六、Alertmanager 配置 `config.yml`
|
||||
|
||||
```yaml
|
||||
global:
|
||||
resolve_timeout: 5m
|
||||
|
||||
route:
|
||||
receiver: default
|
||||
group_wait: 10s
|
||||
group_interval: 5m
|
||||
repeat_interval: 3h
|
||||
|
||||
receivers:
|
||||
- name: default
|
||||
email_configs:
|
||||
- to: "youremail@example.com"
|
||||
from: "monitor@example.com"
|
||||
smarthost: "smtp.example.com:587"
|
||||
auth_username: "monitor@example.com"
|
||||
auth_password: "yourpassword"
|
||||
```
|
||||
|
||||
> 💡 你也可以改成 Slack、Teams、Telegram 等通知方式,只要换成对应的 `*_configs` 即可。
|
||||
|
||||
---
|
||||
|
||||
## 🧩 七、Grafana 快速导入仪表盘
|
||||
|
||||
安装后访问 `http://localhost:3000`(admin/admin 登录):
|
||||
|
||||
- 添加 Prometheus 数据源:`http://prometheus:9090`
|
||||
|
||||
- 导入官方 Dashboard:
|
||||
|
||||
- Node Exporter Full: `1860`
|
||||
|
||||
- cAdvisor Container Metrics: `14282`
|
||||
|
||||
- Blackbox Exporter Probe: `7587`
|
||||
|
||||
|
||||
这些 ID 可直接在 Grafana.com → Dashboards → “Import” 输入。
|
||||
|
||||
---
|
||||
|
||||
## 🚀 八、启动命令
|
||||
|
||||
```bash
|
||||
cd /opt/monitoring
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
验证访问:
|
||||
|
||||
- Prometheus: [http://192.168.3.47:9090](http://192.168.3.47:9090/)
|
||||
|
||||
- Grafana: [http://192.168.3.47:3000](http://192.168.3.47:3000/)
|
||||
|
||||
- Alertmanager: [http://192.168.3.47:9093](http://192.168.3.47:9093/)
|
||||
|
||||
- cAdvisor: [http://192.168.3.47:8080](http://192.168.3.47:8080/)
|
||||
|
||||
- Blackbox exporter: [http://192.168.3.47:9115](http://192.168.3.47:9115/)
|
||||
|
||||
- node_exporter: [http://192.168.3.47:9100/metrics](http://192.168.3.47:9100/metrics)
|
||||
|
||||
|
||||
|
||||
## 🧠 九、扩展建议(后续可以加)
|
||||
|
||||
- 加 **Loki + Promtail** 做日志收集。
|
||||
|
||||
- 加 **Uptime Kuma** 作为轻量合成探针外层 UI(外观好看)。
|
||||
|
||||
- 用 **Traefik/Caddy** 把上述组件统一暴露并加 HTTPS。
|
||||
|
||||
- 加 **VictoriaMetrics** 作为长时存储(Prometheus remote_write)。
|
||||
|
||||
44
raw/Technical/Home Office/🟠用Docker中安装Navidrome.md
Normal file
44
raw/Technical/Home Office/🟠用Docker中安装Navidrome.md
Normal file
@@ -0,0 +1,44 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [docker, music, navidrome]
|
||||
---
|
||||
|
||||
#docker #navidrome #music
|
||||
|
||||
``` yaml
|
||||
version: '3.8'
|
||||
|
||||
services:
|
||||
navidrome:
|
||||
image: deluan/navidrome:latest
|
||||
container_name: navidrome
|
||||
user: "1026:100"
|
||||
restart: unless-stopped
|
||||
ports:
|
||||
- "4533:4533"
|
||||
volumes:
|
||||
- /volume1/music:/music:ro"
|
||||
- /volume1/docker/navidrome/data:/data
|
||||
environment:
|
||||
# 开启详细日志,便于排查流媒体传输问题
|
||||
- ND_LOGLEVEL=info
|
||||
# 启用转码配置界面
|
||||
- ND_ENABLETRANSCODINGCONFIG=true
|
||||
# 自动根据客户端需求转码下载
|
||||
- ND_AUTOTRANSCODEDOWNLOAD=true
|
||||
# 限制转码缓存大小,保护磁盘空间
|
||||
- ND_TRANSCODINGCACHESIZE=200MB
|
||||
```
|
||||
|
||||
## Reference:
|
||||
### Navidrome Doc
|
||||
https://www.navidrome.org/docs/
|
||||
|
||||
### Navidrome FAQ
|
||||
https://www.navidrome.org/docs/faq/
|
||||
|
||||
41
raw/Technical/Home Office/🟠用Docker安装Apache Superset.md
Normal file
41
raw/Technical/Home Office/🟠用Docker安装Apache Superset.md
Normal file
@@ -0,0 +1,41 @@
|
||||
---
|
||||
title: Install Apache Superset
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [apache, bi, docker, mysql, superset]
|
||||
link:
|
||||
kanban-plugin:
|
||||
aliases:
|
||||
cssclasses:
|
||||
---
|
||||
|
||||
|
||||
#docker #superset #apache #mysql #bi
|
||||
|
||||
```
|
||||
docker pull apache/superset:GHA-19524015706
|
||||
```
|
||||
|
||||
```
|
||||
docker run -d -p 8777:8088 -e "SUPERSET_SECRET_KEY=mysuperset" --name superset apache/superset:GHA-19524015706
|
||||
```
|
||||
|
||||
```
|
||||
docker exec -it superset superset fab create-admin --username admin --firstname Superset --lastname Admin --email admin@superset.com --password admin
|
||||
```
|
||||
|
||||
```
|
||||
docker exec -it superset superset db upgrade
|
||||
```
|
||||
|
||||
```
|
||||
docker exec -it superset superset load_examples
|
||||
```
|
||||
|
||||
```
|
||||
docker exec -it superset superset init
|
||||
```
|
||||
|
||||
34
raw/Technical/Home Office/🟠用Docker安装Homarr.md
Normal file
34
raw/Technical/Home Office/🟠用Docker安装Homarr.md
Normal file
@@ -0,0 +1,34 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [docker, homarr]
|
||||
---
|
||||
|
||||
|
||||
#homarr #docker
|
||||
|
||||
docker-compose.yml
|
||||
|
||||
``` yaml
|
||||
version: "3.9"
|
||||
|
||||
services:
|
||||
homarr:
|
||||
image: ghcr.io/homarr-labs/homarr
|
||||
container_name: homarr
|
||||
restart: unless-stopped
|
||||
ports:
|
||||
- "7575:7575"
|
||||
volumes:
|
||||
- /home/shenwei/Docker/homarr/appdata:/appdata
|
||||
- /var/run/docker.sock:/var/run/docker.sock
|
||||
environment:
|
||||
- SECRET_ENCRYPTION_KEY=4a418def4be700be26672aa57a4c3d4b94abd2cf97021b5c4ecd3c1644c1f071
|
||||
- ALL_PROXY=socks5://172.24.0.1:10808
|
||||
|
||||
```
|
||||
|
||||
40
raw/Technical/Home Office/🟠用Docker安装Jellyfin.md
Normal file
40
raw/Technical/Home Office/🟠用Docker安装Jellyfin.md
Normal file
@@ -0,0 +1,40 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [docker, jellyfin, movie, nas, synology, tv-show]
|
||||
---
|
||||
|
||||
|
||||
#jellyfin #docker #synology #nas #movie #tv-show
|
||||
|
||||
|
||||
``` yaml
|
||||
services:
|
||||
jellyfin:
|
||||
image: nyanmisaka/jellyfin:latest
|
||||
container_name: jellyfin
|
||||
# 群晖建议使用具体的 UID:GID
|
||||
user: "1026:100"
|
||||
ports:
|
||||
- 8096:8096/tcp
|
||||
- 7359:7359/udp
|
||||
volumes:
|
||||
- /volume1/docker/jellyfin/config:/config
|
||||
- /volume1/docker/jellyfin/cache:/cache
|
||||
- /volume2/movie:/media
|
||||
- "/volume1/TV shows:/media2"
|
||||
- /volume1/docker/jellyfin/fonts:/usr/local/share/fonts/custom:ro
|
||||
environment:
|
||||
- JELLYFIN_PublishedServerUrl=http://jellyfin.ishenwei.online
|
||||
- TZ=Asia/Shanghai
|
||||
# 核心优化:挂载硬件渲染设备以实现 Intel QuickSync 转码
|
||||
devices:
|
||||
- /dev/dri:/dev/dri
|
||||
restart: unless-stopped
|
||||
extra_hosts:
|
||||
- 'host.docker.internal:host-gateway'
|
||||
```
|
||||
45
raw/Technical/Home Office/🟠用Docker安装Portainer.md
Normal file
45
raw/Technical/Home Office/🟠用Docker安装Portainer.md
Normal file
@@ -0,0 +1,45 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [docker, portainer]
|
||||
---
|
||||
|
||||
|
||||
#docker #portainer
|
||||
|
||||
## portainer
|
||||
|
||||
create docker-compose.yml
|
||||
```
|
||||
services:
|
||||
portainer:
|
||||
container_name: portainer
|
||||
image: portainer/portainer-ce:lts
|
||||
restart: always
|
||||
volumes:
|
||||
- /var/run/docker.sock:/var/run/docker.sock
|
||||
- portainer_data:/data
|
||||
ports:
|
||||
- 9443:9443
|
||||
- 8000:8000 # Remove if you do not intend to use Edge Agents
|
||||
|
||||
volumes:
|
||||
portainer_data:
|
||||
name: portainer_data
|
||||
|
||||
networks:
|
||||
default:
|
||||
name: portainer_network
|
||||
```
|
||||
|
||||
```
|
||||
docker-compose run -d
|
||||
```
|
||||
|
||||
|
||||
|
||||
[[🟠如何删除旧的废弃的docker container +volume]]
|
||||
32
raw/Technical/Home Office/🟠用Docker安装it-tools.md
Normal file
32
raw/Technical/Home Office/🟠用Docker安装it-tools.md
Normal file
@@ -0,0 +1,32 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [docker, it-tools]
|
||||
---
|
||||
|
||||
#it-tools #docker
|
||||
|
||||
|
||||
``` yaml
|
||||
version: '3.8'
|
||||
|
||||
services:
|
||||
it-tools:
|
||||
image: corentinth/it-tools:latest
|
||||
container_name: it-tools
|
||||
restart: unless-stopped
|
||||
# 交互模式配置
|
||||
stdin_open: true # 对应 -i
|
||||
tty: true # 对应 -t
|
||||
ports:
|
||||
- "8999:80"
|
||||
# 资源限制(可选建议)
|
||||
deploy:
|
||||
resources:
|
||||
limits:
|
||||
memory: 128M
|
||||
```
|
||||
36
raw/Technical/Home Office/🟠用Docker安装transmission.md
Normal file
36
raw/Technical/Home Office/🟠用Docker安装transmission.md
Normal file
@@ -0,0 +1,36 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [docker, transmission]
|
||||
---
|
||||
|
||||
#docker #transmission
|
||||
|
||||
``` yaml
|
||||
version: '3.8'
|
||||
|
||||
services:
|
||||
transmission:
|
||||
image: lscr.io/linuxserver/transmission:latest
|
||||
container_name: transmission
|
||||
restart: unless-stopped
|
||||
network_mode: bridge
|
||||
ports:
|
||||
- "9091:9091" # Web UI 访问端口
|
||||
- "51413:51413" # Peer 监听端口 (TCP)
|
||||
- "51413:51413/udp" # Peer 监听端口 (UDP)
|
||||
environment:
|
||||
- PUID=1000
|
||||
- PGID=1000
|
||||
- TZ=Etc/UTC
|
||||
- USER=shenwei # 可选:设置 Web UI 用户名
|
||||
- PASS=zmkm99zmkm00 # 可选:设置 Web UI 密码
|
||||
volumes:
|
||||
- /home/shenwei/Docker/transmission/data:/config
|
||||
- /home/shenwei/Downloads:/downloads
|
||||
|
||||
```
|
||||
106
raw/Technical/Home Office/🟠网件RAX50路由器刷梅林固件与科学上网插件安装教程.md
Normal file
106
raw/Technical/Home Office/🟠网件RAX50路由器刷梅林固件与科学上网插件安装教程.md
Normal file
@@ -0,0 +1,106 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [clash, merlin-clash, rax50]
|
||||
---
|
||||
|
||||
|
||||
#rax50 #merlin-clash #clash
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
## 网件RAX50路由器刷梅林固件与科学上网插件安装教程
|
||||
|
||||
|
||||
https://www.youtube.com/watch?v=FhHgXnLoOC0
|
||||
### 概述 🔧
|
||||
本视频围绕如何使用网件RAX50路由器刷入梅林固件,并安装科学上网(翻墙)插件展开详细讲解。整体流程从登录原厂后台、下载固件、刷机、恢复设置,到安装及配置科学上网插件,逐步带领观众完成路由器的翻墙功能设置。讲解方式结合实操演示与官方文档指引,特别强调操作细节和注意事项,帮助用户建立清晰的固件刷入及翻墙插件配置知识体系。
|
||||
|
||||
### 核心知识点总结 ⏰
|
||||
- **00:00–00:52 | 网件RAX50路由器登录与原厂固件介绍**
|
||||
通过电脑连接网件路由器网络,浏览器输入192.168.1.1登录后台,需输入初始设置的用户名和密码。登录成功后确认路由器与本地网络正常连接,访问国内网络无障碍。
|
||||
|
||||
- **00:52–02:21 | 固件类型与下载选择说明**
|
||||
介绍两种固件类型:`.chk`为网件刷梅林的过渡固件,`.w`为梅林版本固件。前往KoolCenter固件下载服务器找到对应型号RAX50,下载`.chk`固件先进行第一步刷机,然后再刷`.w`固件完成稳定版本的安装。建议使用谷歌内核浏览器操作。
|
||||
|
||||
- **02:21–05:14 | 第一次刷机操作演示**
|
||||
演示连接新设的WiFi,登录后台,上传`.chk`固件完成过渡刷机。成功后界面变为梅林风格,说明已刷入梅林固件。
|
||||
|
||||
- **05:14–07:27 | 第二次刷机及恢复梅林固件出厂设置**
|
||||
上传`.w`结尾的梅林固件进行第二次刷机确保稳定性。刷机后恢复梅林固件的出厂设置,重新配置WiFi名称和登录密码,并进行JFFS双清操作以清理旧缓存,重启路由器完成大约60%刷机进度。
|
||||
|
||||
- **07:27–08:35 | 科学上网插件安装准备**
|
||||
进入梅林的软件中心,检查并更新软件中心版本,确保与在线版本同步,避免异常。原版没有任何插件,需要手动安装科学上网插件。
|
||||
|
||||
- **08:35–15:54 | MerlinClash插件安装与策略组配置**
|
||||
下载安装MerlinClash插件(小猫咪插件),通过Telegram鲁猫云频道获取最新插件版本。上传插件并安装成功后,导入订阅地址(机场节点)。介绍免费机场试用过程,手动及自动订阅配置文件。
|
||||
配置策略组实现节点自动延迟测试与故障转移,灵活切换线路(如香港、台湾、美国节点等),分流不同应用流量(如Netflix、YouTube、国内外网站),实现精准科学上网。设置定时自动更新订阅、开启守护进程保证插件稳定运行,并测试Google与YouTube访问。
|
||||
|
||||
- **15:54–19:51 | 另一款科学上网插件安装及功能对比**
|
||||
安装科学上网插件(GitHub版本),区分Full与Lite版本,根据路由器内存选择Full版本。上传插件后,导入SSR等多协议订阅地址。此插件需手动节点切换,无自动分流功能。两插件不可同时开启,推荐使用功能更强的MerlinClash。
|
||||
|
||||
- **19:51–20:23 | 软件中心的其他实用工具介绍**
|
||||
简要介绍软件中心中其他可用插件,如ROG工具箱,可监测路由器温度、运行时间、内核版本等信息,拓展路由器功能。
|
||||
|
||||
### 重点术语与定义 📚
|
||||
- **梅林固件 (Merlin Firmware)**:华硕路由器第三方固件改良版,功能丰富且稳定,支持更多插件及高级网络配置。
|
||||
- **过渡固件 (.chk 文件)**:用于网件路由器从原厂固件刷入梅林固件的转接版本,完成后才可刷入正式梅林固件。
|
||||
- **科学上网插件**:具备翻墙功能的网络插件,通过订阅国外节点实现访问被限制网站。
|
||||
- **MerlinClash插件**:基于Clash的高级分流插件,支持自动节点选择和策略组分流,适合多设备家庭科学上网。
|
||||
- **SSR订阅链接**:ShadowsocksR等代理节点的配置链接,用于导入科学上网插件实现节点管理和自动更新。
|
||||
- **JFFS双清**:清理路由器文件系统缓存和数据,保证刷机后固件环境干净,预防残留问题。
|
||||
- **故障转移**:连接故障时自动切换至备用节点,保持网络通畅的机制。
|
||||
|
||||
### 推理逻辑结构 🔍
|
||||
1. **确认原厂路由器可正常访问后台 → 下载并刷入过渡固件(`.chk`) → 完成基础梅林固件安装。**
|
||||
2. **刷入正式梅林固件(`.w`) → 恢复梅林出厂设置 + JFFS双清 → 确保系统干净稳定。**
|
||||
3. **更新软件中心版本 → 安装科学上网插件 → 导入机场订阅链接。**
|
||||
4. **设置插件节点、分流策略 → 启动守护进程确保插件稳定运行。**
|
||||
5. **通过测试访问被限制网站确认翻墙成功。**
|
||||
6. **区分插件优势,选择更适合的插件方案使用。**
|
||||
|
||||
### 典型案例举例 📝
|
||||
- 通过免费机场注册获得5GB流量和7天试用套餐,实际演示如何复制订阅链接并导入到MerlinClash插件中,体现实用配置流程。
|
||||
- 节点策略组设置案例,如将Netflix节点指定为台湾线路,YouTube指定为香港线路,利用分流精细管理网络流量,优化访问速度和稳定性。
|
||||
|
||||
### 容易混淆的误区 ❗
|
||||
- **误区:首次刷机直接刷`.w`固件。**
|
||||
正确:必须先刷`.chk`的过渡固件,再刷`.w`的正式梅林固件,二次刷机才能确保稳定。
|
||||
- **误区:两个科学上网插件可以同时开启。**
|
||||
正确:两个插件不能同时运行,选择一个即可,优选支持策略组分流的MerlinClash。
|
||||
- **误区:恢复出厂设置等同回到网件原厂固件。**
|
||||
正确:恢复出厂设置指梅林固件的默认配置,不会恢复网件原厂系统。
|
||||
- **误区:科学上网插件能自动切换节点。**
|
||||
正确:只有MerlinClash支持自动延迟测试及自动切换,科学上网插件需手动选择节点。
|
||||
|
||||
### 快速复习提示与自测题 🎯
|
||||
#### 提示(无答案)
|
||||
- 路由器刷梅林固件,第一步刷哪个后缀的固件?
|
||||
- MerlinClash插件的主要优势是什么?
|
||||
- 如何保证科学上网插件自动更新订阅?
|
||||
- JFFS双清操作有什么作用?
|
||||
- 两款科学上网插件能否同时使用,为什么?
|
||||
|
||||
#### 练习题(含答案)
|
||||
1. **问题:为什么要先刷过渡固件`.chk`?**
|
||||
**答案**:`.chk`固件作为过渡版本,为路由器从原厂固件过渡到梅林固件做准备,直接刷`.w`固件会失败。
|
||||
|
||||
2. **问题:MerlinClash插件如何实现流量分流?**
|
||||
**答案**:通过策略组配置不同节点和规则,实现基于应用、地区和服务的自动分流和节点故障转移。
|
||||
|
||||
3. **问题:科学上网插件支持哪些协议?**
|
||||
**答案**:支持SSR、V2Ray、Trojan等多个协议,用户可导入相应订阅。
|
||||
|
||||
4. **问题:什么是JFFS双清,什么时候使用?**
|
||||
**答案**:JFFS双清是清理文件系统和缓存,通常刷机后执行,确保固件环境干净无旧数据残留。
|
||||
|
||||
5. **问题:如何测试路由器是否科学上网成功?**
|
||||
**答案**:无需代理工具,访问Google和YouTube等被屏蔽网站,能成功打开说明科学上网成功。
|
||||
|
||||
### 总结回顾 🔎
|
||||
本视频系统指导了网件RAX50路由器刷入梅林固件的全过程,包括切换固件版本、恢复配置以及进行必要的系统清理操作,确保固件运行流畅。之后详细介绍了两款主流的科学上网插件——功能全面的MerlinClash和较为简易的科学上网插件,重点介绍了MerlinClash的策略组分流和自动节点切换功能,帮助用户实现全屋电子设备共享的翻墙网络环境。附带实用操作技巧和注意事项,为用户提供了一套完整、稳定、高效的路由器刷机与科学上网解决方案。
|
||||
219
raw/Technical/Home Office/🟠群晖NAS科学上网方法.md
Normal file
219
raw/Technical/Home Office/🟠群晖NAS科学上网方法.md
Normal file
@@ -0,0 +1,219 @@
|
||||
---
|
||||
title: 测试 Google 连接(强制走代理端口,假设 HTTP 端口是 20171)
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-03-08
|
||||
description:
|
||||
tags: [docker, nas, synology, v2raya, vpn]
|
||||
---
|
||||
|
||||
|
||||
#v2raya #nas #synology #vpn #docker
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
## 安装V2RayA
|
||||
|
||||
1. Docker Desktop pull image: **mz2017/v2raya**
|
||||
2. 通过以下方法把v2raya的images load到NAS Docker里 [[🟠如何传输Docker images 并且在另一个Docker安装|🟠如何传输Docker images 并且在另一个Docker安装]]
|
||||
3. 参考[v2raya官方网站](https://v2raya.org/) 里的关于[V2RayA Docker安装文档](https://v2raya.org/docs/prologue/installation/docker/)用以下命令来启动 V2RayA:
|
||||
```
|
||||
docker run -d \
|
||||
--restart=always \
|
||||
--privileged \
|
||||
--network=host \
|
||||
--name v2raya \
|
||||
-e V2RAYA_LOG_FILE=/tmp/v2raya.log \
|
||||
-e V2RAYA_V2RAY_BIN=/usr/local/bin/v2ray \
|
||||
-e V2RAYA_NFTABLES_SUPPORT=off \
|
||||
-e IPTABLES_MODE=legacy \
|
||||
-v /lib/modules:/lib/modules:ro \
|
||||
-v /etc/resolv.conf:/etc/resolv.conf \
|
||||
-v /docker/v2raya:/etc/v2raya \
|
||||
mzz2017/v2raya
|
||||
```
|
||||
**请注意 ==/docker/v2raya== 为实际在NAS上创建的目录,其他配置不用修改**
|
||||
|
||||
## 启动V2RayA
|
||||
|
||||
http://192.168.3.17:2017/
|
||||
|
||||
|
||||
## 配置V2RayA让NAS上的Docker可以科学上网
|
||||
|
||||
![[IMG-20251229190624430.png]]
|
||||
|
||||
![[IMG-20251229190624730.png]]
|
||||
|
||||
在Synology DSM环境下,要验证透明代理是否对Host(即NAS本机,也就是负责执行 `docker pull` 的守护进程)生效,请按照以下逻辑进行排查和验证。
|
||||
|
||||
---
|
||||
|
||||
### 第一步:在 v2rayA 后台“打开开关”
|
||||
|
||||
仅仅运行容器是不够的,你必须在Web界面配置路由规则。
|
||||
|
||||
1. 打开浏览器访问 `http://<NAS_IP>:2017`。
|
||||
|
||||
2. 进入 **设置 (Settings)** -> **透明代理 (Transparent Proxy)**。
|
||||
|
||||
3. **核心设置:**
|
||||
|
||||
- **启用 (Enable):** 开启。
|
||||
|
||||
- **分流模式 (Traffic Splitting):** 建议选择 **"大陆白名单 (Whitelist of Mainland China)"**。这会确保国内流量直连,国外流量(包括Docker Hub)走代理。
|
||||
|
||||
- **实现方式:** 既然你在启动命令里加了 `IPTABLES_MODE=legacy`,这里通常保持默认即可。
|
||||
|
||||
4. 点击右上角 **保存并应用**。
|
||||
|
||||
|
||||
> **⚠️ 风险提示:** 在NAS上开启透明代理(尤其是Host模式)有极小概率会导致局域网连接中断。如果你正在远程操作,请确保有备用连接方案(如QuickConnect或同局域网设备)。
|
||||
|
||||
---
|
||||
|
||||
### 第二步:验证 NAS 本机的连通性 (SSH)
|
||||
|
||||
SSH 登录到你的群晖 NAS,按顺序执行以下测试。
|
||||
|
||||
**1. 测试端口监听是否正常** 先确认代理端口是通的:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 测试 Google 连接(强制走代理端口,假设 HTTP 端口是 20171)
|
||||
curl -I -x http://127.0.0.1:20171 https://www.google.com
|
||||
```
|
||||
正确·结果:
|
||||
``` bash
|
||||
ash-4.4# curl -I -x http://127.0.0.1:20171 https://www.google.com
|
||||
HTTP/1.1 200 Connection established
|
||||
|
||||
HTTP/2 200
|
||||
content-type: text/html; charset=ISO-8859-1
|
||||
content-security-policy-report-only: object-src 'none';base-uri 'self';script-src 'nonce-Yp5bWu7rNq-vtmDGkOlBXQ' 'strict-dynamic' 'report-sample' 'unsafe-eval' 'unsafe-inline' https: http:;report-uri https://csp.withgoogle.com/csp/gws/other-hp
|
||||
accept-ch: Sec-CH-Prefers-Color-Scheme
|
||||
p3p: CP="This is not a P3P policy! See g.co/p3phelp for more info."
|
||||
date: Fri, 19 Dec 2025 03:11:44 GMT
|
||||
server: gws
|
||||
x-xss-protection: 0
|
||||
x-frame-options: SAMEORIGIN
|
||||
expires: Fri, 19 Dec 2025 03:11:44 GMT
|
||||
cache-control: private
|
||||
set-cookie: AEC=AaJma5vsWePrX0JcVuFI8-_KwORsyiWxthLxJF9At74ncKOuryIHfjWKpw; expires=Wed, 17-Jun-2026 03:11:44 GMT; path=/; domain=.google.com; Secure; HttpOnly; SameSite=lax
|
||||
set-cookie: NID=527=w38RE1jq1xO007vl-G-dXmylbeNcX6RrVZsaz16KpJm-VmBVO-dUI4hyW4bqbNK6v3PDNKsGQXeJK8d6n6V9pXHHo5ljqr9FeRMsUwX3Ou1v-hnlKhgIVvCPacBGU-DH3X9WmVgHAMe9ZFMml-RoYQYTLq7-l342kDivOJw7kfuJDnx9ovYV2mATeK11m2PCGL-AcQVDQABuivlpPR4jH22zQ7d7viAmrQ; expires=Sat, 20-Jun-2026 03:11:44 GMT; path=/; domain=.google.com; HttpOnly
|
||||
set-cookie: __Secure-BUCKET=CPwD; expires=Wed, 17-Jun-2026 03:11:44 GMT; path=/; domain=.google.com; Secure; HttpOnly
|
||||
alt-svc: h3=":443"; ma=2592000,h3-29=":443"; ma=2592000
|
||||
|
||||
```
|
||||
|
||||
- **成功:** 返回 `HTTP/1.1 200 OK` 或 `301`。
|
||||
- **失败:** 检查 v2rayA 端口映射或节点连接状态。
|
||||
|
||||
**2. 测试透明代理是否生效 (关键步骤)** 不加 `-x` 参数,直接访问,看流量是否被劫持:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
curl -I https://www.google.com
|
||||
```
|
||||
|
||||
正确结果:
|
||||
``` bash
|
||||
ash-4.4# curl -I https://www.google.com
|
||||
HTTP/2 200
|
||||
content-type: text/html; charset=ISO-8859-1
|
||||
content-security-policy-report-only: object-src 'none';base-uri 'self';script-src 'nonce-aSgzymp_JxooD_Xigz-OgA' 'strict-dynamic' 'report-sample' 'unsafe-eval' 'unsafe-inline' https: http:;report-uri https://csp.withgoogle.com/csp/gws/other-hp
|
||||
accept-ch: Sec-CH-Prefers-Color-Scheme
|
||||
p3p: CP="This is not a P3P policy! See g.co/p3phelp for more info."
|
||||
date: Fri, 19 Dec 2025 03:12:46 GMT
|
||||
server: gws
|
||||
x-xss-protection: 0
|
||||
x-frame-options: SAMEORIGIN
|
||||
expires: Fri, 19 Dec 2025 03:12:46 GMT
|
||||
cache-control: private
|
||||
set-cookie: AEC=AaJma5sAaR7bW6DxFcTK7qYEJTzl5WO0BYlgJZwxrqpXEi_I3xcW5GckOA; expires=Wed, 17-Jun-2026 03:12:46 GMT; path=/; domain=.google.com; Secure; HttpOnly; SameSite=lax
|
||||
set-cookie: NID=527=kjjqA9JJyZpXTZGor0foKUDy_xoODeloa9HmubM9DXlCdPwWyNAcgkUMSlKI_ddkcWWIdnD_NqC3GZEN4Yt476PWJXPTjgJqvSSBtEbQ7fY5eM295GEKNwaykECAABE9yELqHgh-VmxRmp8ri4XUYByN11ryyVNI4wgnblCMzfwKRHnfJhCvA7g2IvEdOm2ldJ2ZM8lAQSiRY_CTheXpMZXsq_kIegSt2w; expires=Sat, 20-Jun-2026 03:12:46 GMT; path=/; domain=.google.com; HttpOnly
|
||||
set-cookie: __Secure-BUCKET=CI8G; expires=Wed, 17-Jun-2026 03:12:46 GMT; path=/; domain=.google.com; Secure; HttpOnly
|
||||
alt-svc: h3=":443"; ma=2592000,h3-29=":443"; ma=2592000
|
||||
|
||||
```
|
||||
|
||||
- **如果返回 200/301:** 说明透明代理已经接管了 NAS 的出站流量。你的 `docker pull` 应该可以直接成功。
|
||||
- **如果超时/无法连接:** 说明透明代理未对 Host 生效,或者 DSM 的防火墙/路由表与 v2rayA 的规则冲突(这在群晖上很常见)。
|
||||
|
||||
---
|
||||
|
||||
### 第三步:验证 Docker Pull
|
||||
|
||||
如果第二步成功,直接尝试拉取一个通常较慢或被墙的镜像:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 使用 docker pull 测试(docker-compose pull 本质也是调用的 daemon)
|
||||
docker pull google/pause
|
||||
# 或者
|
||||
docker pull busybox
|
||||
```
|
||||
|
||||
正确结果
|
||||
``` bash
|
||||
ash-4.4# docker pull google/pause
|
||||
Using default tag: latest
|
||||
latest: Pulling from google/pause
|
||||
Image docker.io/google/pause:latest uses outdated schema1 manifest format. Please upgrade to a schema2 image for better future compatibility. More information at https://docs.docker.com/registry/spec/deprecated-schema-v1/
|
||||
a3ed95caeb02: Already exists
|
||||
f72a00a23f01: Already exists
|
||||
Digest: sha256:e8fc56926ac3d5705772f13befbaee3aa2fc6e9c52faee3d96b26612cd77556c
|
||||
Status: Image is up to date for google/pause:latest
|
||||
docker.io/google/pause:latest
|
||||
```
|
||||
### 如果透明代理对 Docker Daemon 无效(常见情况)
|
||||
|
||||
在群晖 DSM 7.x 中,Docker Daemon (`dockerd`) 的网络栈有时候不会完全遵循 v2rayA 修改的 iptables 规则。如果上面的 `docker pull` 仍然慢或失败,**不要死磕透明代理**,直接配置 Docker 守护进程走 HTTP 代理是最稳妥的方案。
|
||||
|
||||
**解决方案:配置 Docker Daemon 代理**
|
||||
|
||||
1. **编辑/创建配置目录:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo mkdir -p /etc/systemd/system/pkg-ContainerManager-dockerd.service.d/
|
||||
# 注意:DSM 7.2 叫 ContainerManager,旧版叫 Docker
|
||||
```
|
||||
|
||||
2. **创建代理配置文件:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo vi /etc/systemd/system/pkg-ContainerManager-dockerd.service.d/http-proxy.conf
|
||||
```
|
||||
|
||||
3. **写入以下内容:**
|
||||
|
||||
|
||||
``` bash
|
||||
[Service]
|
||||
Environment="HTTP_PROXY=http://127.0.0.1:20171"
|
||||
Environment="HTTPS_PROXY=http://127.0.0.1:20171"
|
||||
Environment="NO_PROXY=localhost,127.0.0.1,192.168.*,*.synology.me"
|
||||
```
|
||||
|
||||
4. **重载并重启 Docker 服务:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl restart pkg-ContainerManager-dockerd
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
- **验证方法:** 先用 `curl -x` 测端口,再用 `curl` 测直连,最后用 `docker pull` 实战。
|
||||
|
||||
- **经验之谈:** 对于企业级或生产环境(即使是SOHO),我建议**不要**依赖 NAS Host 的透明代理来解决 `docker pull` 问题,因为这修改了系统级路由表,容易影响 NAS 其他服务。**显式配置 Docker Daemon 的 Proxy 环境变量(上面的最后一种方法)是更符合 Engineering Best Practice 的做法。**
|
||||
232
raw/Technical/Home Office/🟢家庭网络环境概览_2026-04-03.md
Normal file
232
raw/Technical/Home Office/🟢家庭网络环境概览_2026-04-03.md
Normal file
@@ -0,0 +1,232 @@
|
||||
---
|
||||
title: 家庭网络环境概览
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [home-office, nas, synology, ubuntu, vps]
|
||||
---
|
||||
|
||||
#vps #nas #synology #ubuntu #home-office
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
# 家庭网络环境概览
|
||||
|
||||
> 📅 文档更新日期: 2026-04-03
|
||||
> 📝 更新内容: Docker 应用列表、FRP 端口映射、域名映射表
|
||||
|
||||
---
|
||||
|
||||
## 公网VPS1 (RackNerd)
|
||||
|
||||
| 公网IP | 公共域名 | SSH enabled? |
|
||||
| --------------- | ------------------- | ------------ |
|
||||
| 192.227.222.142 | vps.ishenwei.online | Yes (ssh vps1) |
|
||||
|
||||
### 安装的应用
|
||||
|
||||
| Name | Docker? | Note | Public Address |
|
||||
| ---------- | ------- | ---------------------------------------------------- | ------------------------- |
|
||||
| Caddy | No | 现代化 Web 服务器,自带 HTTPS 自动化证书申请,常作为前置反向代理处理业务流量。 | 通过 *.ishenwei.online 域名访问 |
|
||||
| FRP Server | No | 高性能内网穿透服务端(frps),负责将内网 NAS 或本地开发环境的服务暴露至公网访问。端口 7000 | |
|
||||
|
||||
---
|
||||
|
||||
## Mac Mini M4 (主控节点)
|
||||
|
||||
| 内网IP | 公共域名 | SSH enabled |
|
||||
| ------------ | ------------------- | ----------- |
|
||||
| 192.168.3.189 | macmini.ishenwei.online | Yes |
|
||||
|
||||
### 安装的应用
|
||||
|
||||
| Name | Docker? | Note | Internal Address | Public Address |
|
||||
| ------------- | ------ | -------------------------------------------- | -------------------------------- | ------------------------------------- |
|
||||
| OpenClaw | No | AI 助手框架,星曜的运行环境 | http://192.168.3.189:8080/ | |
|
||||
| vaultwarden | Yes | 轻量级 Bitwarden 服务端 | http://192.168.3.189:5151/ | https://vaultwarden.ishenwei.online/ |
|
||||
| stq_nginx | Yes | STQ 项目管理系统反向代理 | http://192.168.3.189:7777/ | https://stq.ishenwei.online/ |
|
||||
| stq_frontend | Yes | STQ 项目前端 | http://192.168.3.189:5173/ | |
|
||||
| stq_web | Yes | STQ Web 服务 | http://192.168.3.189:8000/ | |
|
||||
| stq_mariadb | Yes | STQ MySQL 数据库 | http://192.168.3.189:3306/ | |
|
||||
| stq-n8n | Yes | STQ 专用 n8n 工作流 | http://192.168.3.189:62000/ | |
|
||||
| portainer | Yes | Docker 容器可视化管理界面(历史版本,已废弃) | http://192.168.3.189:9000/ | 已废弃,使用各服务器本地 portainer |
|
||||
|
||||
### FRP 端口映射
|
||||
|
||||
| 名称 | 类型 | localPort | remotePort |
|
||||
|------|------|------------|------------|
|
||||
| macmini-ssh | tcp | 22 | 60026 |
|
||||
| vaultwarden | tcp | 5151 | 15151 |
|
||||
|
||||
> ⚠️ 注: n8n 已迁移至 Ubuntu2,Mac Mini 不再暴露 n8n 端口
|
||||
|
||||
---
|
||||
|
||||
## 内网Synology NAS DS718
|
||||
|
||||
| 内网IP | 公共域名 | SSH enabled |
|
||||
| ------------ | ------------------- | ----------- |
|
||||
| 192.168.3.17 | nas.ishenwei.online | Yes |
|
||||
|
||||
### 安装的应用
|
||||
|
||||
| Name | Docker? | Note | Internal Address | Public Address |
|
||||
| ------------------------- | ------ | ------------------------------------------------ | ---------------------------------------- | ------------------------------------------------ |
|
||||
| Synology NAS DSM | No | 系统的核心管理界面 | http://192.168.3.17:5000/ | https://nas.ishenwei.online/ |
|
||||
| Calibre | Yes | 强大的电子书库管理工具 | http://192.168.3.17:8083/ | https://calibre.ishenwei.online/ |
|
||||
| MinIO | Yes | 高性能对象存储 | http://192.168.3.17:9001/ | |
|
||||
| Zipline | Yes | 轻量级文件分享与图床服务 | http://192.168.3.17:3333/ | https://zipline.ishenwei.online/ |
|
||||
| navidrome | Yes | 轻量级自建音乐流媒体服务 | http://192.168.3.17:4533/ | https://navidrome.ishenwei.online/ |
|
||||
| jellyfin | Yes | 媒体服务器 | http://192.168.3.17:8096/ | https://jellyfin.ishenwei.online/ |
|
||||
| prometheus | Yes | 时序数据库监控系统 | http://192.168.3.17:9090/ | |
|
||||
| alertmanager | Yes | 告警中心 | http://192.168.3.17:9093/ | |
|
||||
| node_exporter | Yes | 硬件监控探针 | http://192.168.3.17:9100/ | |
|
||||
| v2raya | Yes | V2Ray 图形化代理客户端 | http://192.168.3.17:2017/ | |
|
||||
| vaultwarden (NAS版) | Yes | 密码管理器 | http://192.168.3.17:5151/ | |
|
||||
| portainer | Yes | Docker 容器管理 | http://192.168.3.17:9443/ | |
|
||||
| CloudDrive2 | No | 多云盘挂载工具 | http://192.168.3.17:19798/ | |
|
||||
| zipline_postgres | Yes | Zipline 的后端数据库 | http://192.168.3.17:5432/ | |
|
||||
| FRP Client | No | 内网穿透客户端 | /opt/frp/frp_0.65.0_linux_amd64 | |
|
||||
|
||||
### FRP 端口映射 (通过其他服务器暴露)
|
||||
|
||||
| 服务 | 来源服务器 | remotePort |
|
||||
|------|-----------|------------|
|
||||
| nas.ishenwei.online | VPS直连 | 15000 |
|
||||
| navidrome | NAS | 14533 |
|
||||
| calibre | NAS | 18083 |
|
||||
| jellyfin | NAS | 18096 |
|
||||
| zipline | NAS | 13333 |
|
||||
| miniflux | NAS | 18080 |
|
||||
|
||||
---
|
||||
|
||||
## 内网Ubuntu Server 1
|
||||
|
||||
| 内网IP | 公共域名 | SSH enabled |
|
||||
| ------------ | ----------------------- | ----------- |
|
||||
| 192.168.3.47 | ubuntu1.ishenwei.online | Yes |
|
||||
|
||||
### 安装的应用
|
||||
|
||||
| Name | Docker? | Note | Internal Address | Public Address |
|
||||
| ------------------- | ------- | ----------------------------- | ------------------------------- | ------------------------------------- |
|
||||
| glances | Yes | 轻量级服务器监控工具 | http://192.168.3.47:9089/ | |
|
||||
| prometheus | Yes | 时序数据库监控系统 | http://192.168.3.47:9090/ | |
|
||||
| grafana | Yes | 数据可视化看板 | http://192.168.3.47:3000/ | https://grafana.ishenwei.online/ |
|
||||
| alertmanager | Yes | 处理 Prometheus 告警策略 | http://192.168.3.47:9093/ | |
|
||||
| blackbox | Yes | 网络探测工具 | http://192.168.3.47:9115/ | |
|
||||
| node_exporter | Yes | 收集主机性能指标 | http://192.168.3.47:9100/ | |
|
||||
| cadvisor | Yes | 容器监控 | http://192.168.3.47:8080/ | |
|
||||
| homarr | Yes | 个人导航页面板 | http://192.168.3.47:7575/ | https://dashboard.ishenwei.online/ |
|
||||
| superset | Yes | 商业智能 (BI) 平台 | http://192.168.3.47:8777/ | https://superset.ishenwei.online/ |
|
||||
| tiktok_pm_nginx | Yes | TikTok 项目管理系统前端反向代理 | | |
|
||||
| tiktok_pm_web | Yes | TikTok 项目管理系统 Web 服务 | http://192.168.3.47:8888/ | https://tk.ishenwei.online/ |
|
||||
| tiktok_pm_worker | Yes | TikTok 项目异步任务 | | |
|
||||
| transmission | Yes | BitTorrent 下载客户端 | http://192.168.3.47:9091/ | https://transmission.ishenwei.online/ |
|
||||
| portainer | Yes | Docker 容器管理 | http://192.168.3.47:9000/ | https://portainer1.ishenwei.online/ |
|
||||
| it-tools | Yes | 开发者在线工具箱 | http://192.168.3.47:8999/ | https://it-tools.ishenwei.online/ |
|
||||
| nginx-proxy-manager | Yes | 反向代理管理 | http://192.168.3.47:81/ | |
|
||||
| FRP Client | No | 内网穿透客户端 | /opt/frp/frp_0.65.0_linux_amd64 | |
|
||||
|
||||
### FRP 端口映射
|
||||
|
||||
| 名称 | 类型 | localPort | remotePort |
|
||||
|------|------|------------|------------|
|
||||
| ubuntu1-ssh | tcp | 22 | 60022 |
|
||||
| transmission | tcp | 9091 | 19091 |
|
||||
| grafana | tcp | 3000 | 13000 |
|
||||
| homarr | tcp | 7575 | 17575 |
|
||||
| superset | tcp | 8777 | 18777 |
|
||||
| tk | tcp | 8888 | 18888 |
|
||||
| ubuntu1-portainer | tcp | 9000 | 19443 |
|
||||
| it-tools | tcp | 8999 | 18999 |
|
||||
| stq | tcp | 5173 | 15173 |
|
||||
| stq-admin | tcp | 7777 | 17000 |
|
||||
| stq-n8n | tcp | 62000 | 15678 |
|
||||
|
||||
---
|
||||
|
||||
## 内网Ubuntu Server 2
|
||||
|
||||
| 内网IP | 公共域名 | SSH enabled |
|
||||
| ------------ | ----------------------- | ----------- |
|
||||
| 192.168.3.45 | ubuntu2.ishenwei.online | Yes |
|
||||
|
||||
### 安装的应用
|
||||
|
||||
| Name | Docker? | Note | Internal Address | Public Address |
|
||||
| ------------------- | ------ | --------------------------------------------------------------------------------- | --------------------------------- | ------------------------------------- |
|
||||
| glances | Yes | 轻量级服务器监控工具 | http://192.168.3.45:9089/ | |
|
||||
| n8n | Yes | 工作流自动化平台 | http://192.168.3.45:5678/ | |
|
||||
| n8n_postgres | Yes | n8n PostgreSQL 数据库 | http://192.168.3.45:5432/ | |
|
||||
| drawio | Yes | 在线图表编辑器 | http://192.168.3.45:8085/ | https://drawio.ishenwei.online/ |
|
||||
| it-tools | Yes | 开发者在线工具箱(同步版本) | http://192.168.3.45:8999/ | |
|
||||
| gitea | Yes | 自建 Git 服务 | http://192.168.3.45:3000/ | |
|
||||
| portainer | Yes | Docker 容器管理界面 | http://192.168.3.45:8000/ | |
|
||||
| md | Yes | Markdown 文档转换工具 | http://192.168.3.45:8989/ | |
|
||||
| n8n-workflows-docs | Yes | n8n 工作流文档服务 | http://192.168.3.45:8001/ | |
|
||||
| tiktok_pm_mariadb | Yes | TikTok 项目 MySQL 数据库 | http://192.168.3.45:3306/ | |
|
||||
| tiktok_pm_nginx | Yes | TikTok 项目管理系统(DEV)前端反向代理 | | |
|
||||
| tiktok_pm_web | Yes | TikTok 项目管理系统(DEV) Web 服务 | http://192.168.3.45:8888/ | https://tk-dev.ishenwei.online/ |
|
||||
| tiktok_pm_worker | Yes | TikTok 项目(DEV)异步任务 | | |
|
||||
| FRP Client | No | 内网穿透客户端 | /opt/frp/frp_0.65.0_linux_amd64 | |
|
||||
|
||||
### FRP 端口映射
|
||||
|
||||
| 名称 | 类型 | localPort | remotePort |
|
||||
|------|------|------------|------------|
|
||||
| ubuntu2-ssh | tcp | 22 | 60024 |
|
||||
| tk-dev | tcp | 8888 | 18889 |
|
||||
| n8n | tcp | 5678 | 15679 |
|
||||
| it-tools | tcp | 8999 | 18999 |
|
||||
| drawio | tcp | 8085 | 18085 |
|
||||
|
||||
---
|
||||
|
||||
## 域名映射表 (Caddy)
|
||||
|
||||
| 域名 | → 端口 | 映射服务器 | 服务 |
|
||||
| -------------------------------- | ----- | ------- | ------------ |
|
||||
| vaultwarden.ishenwei.online | 15151 | macmini | vaultwarden |
|
||||
| n8n.ishenwei.online | 15679 | ubuntu2 | n8n |
|
||||
| it-tools.ishenwei.online | 18999 | ubuntu1 | it-tools |
|
||||
| drawio.ishenwei.online | 18085 | ubuntu2 | drawio |
|
||||
| transmission.ishenwei.online | 19091 | ubuntu1 | transmission |
|
||||
| grafana.ishenwei.online | 13000 | ubuntu1 | grafana |
|
||||
| nas.ishenwei.online | 15000 | NAS | DSM |
|
||||
| navidrome.ishenwei.online | 14533 | NAS | navidrome |
|
||||
| calibre.ishenwei.online | 18083 | NAS | calibre-web |
|
||||
| dashboard.ishenwei.online | 17575 | ubuntu1 | homarr |
|
||||
| miniflux.ishenwei.online | 18080 | NAS | miniflux |
|
||||
| zipline.ishenwei.online | 13333 | NAS | zipline |
|
||||
| superset.ishenwei.online | 18777 | ubuntu1 | superset |
|
||||
| tk.ishenwei.online | 18888 | ubuntu1 | tiktok_pm |
|
||||
| tk-dev.ishenwei.online | 18889 | ubuntu2 | tiktok_pm_dev |
|
||||
| jellyfin.ishenwei.online | 18096 | NAS | jellyfin |
|
||||
| portainer1.ishenwei.online | 19443 | ubuntu1 | portainer |
|
||||
| stq.ishenwei.online | 15173 | ubuntu1 | stq |
|
||||
| stq-admin.ishenwei.online | 17000 | ubuntu1 | stq-admin |
|
||||
| stq-n8n.ishenwei.online | 15678 | ubuntu1 | stq-n8n |
|
||||
|
||||
---
|
||||
|
||||
## 科学上网代理端口
|
||||
|
||||
| 服务器 | 代理地址 | 状态 |
|
||||
|--------|----------|------|
|
||||
| macmini | socks5://127.0.0.1:10808 | ✅ 正常 |
|
||||
| ubuntu1 | socks5://127.0.0.1:10808 | ✅ 正常 |
|
||||
| ubuntu2 | socks5://127.0.0.1:10808 | ✅ 正常 |
|
||||
| NAS | socks5://127.0.0.1:20170 | ❌ 仅本机监听 |
|
||||
|
||||
---
|
||||
|
||||
## Cloudflare
|
||||
|
||||
> 域名 DNS 托管于 Cloudflare,提供免费 CDN 与 SSL 证书。
|
||||
|
||||
|
||||
![[IMG-20260403182706525.png]]
|
||||
623
raw/Technical/Home Office/🟣Mac Mini 安装 FRP 0.65.0(ARM64)操作笔记.md
Normal file
623
raw/Technical/Home Office/🟣Mac Mini 安装 FRP 0.65.0(ARM64)操作笔记.md
Normal file
@@ -0,0 +1,623 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [frp, frpc, gatekeeper, mac-mini, macos]
|
||||
---
|
||||
|
||||
#mac-mini #frp #frpc #macos #gatekeeper
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
- **FRP版本**:0.65.0
|
||||
- **CPU架构**:Apple Silicon(arm64)
|
||||
- **安装路径**:`/opt/frp/frp_0.65.0_darwin_arm64`
|
||||
- **下载地址**:GitHub Release
|
||||
- **配置文件**:`frpc.toml`
|
||||
- **包含 macOS Gatekeeper 处理**
|
||||
|
||||
此文档可以直接保存为 **README.md 或运维手册**。
|
||||
|
||||
---
|
||||
|
||||
## 一、环境信息
|
||||
|
||||
| 项目 | 内容 |
|
||||
| ----- | ---------------------------------- |
|
||||
| 系统 | macOS(Mac Mini M4) |
|
||||
| 架构 | Apple Silicon (ARM64) |
|
||||
| 软件 | FRP 0.65.0 |
|
||||
| 安装目录 | `/opt/frp/frp_0.65.0_darwin_arm64` |
|
||||
| 客户端程序 | `frpc` |
|
||||
| 配置文件 | `frpc.toml` |
|
||||
|
||||
---
|
||||
|
||||
## 二、创建安装目录
|
||||
|
||||
macOS 默认 `/opt` 需要手动创建。
|
||||
|
||||
```bash
|
||||
sudo mkdir -p /opt/frp
|
||||
sudo chown -R $(whoami) /opt/frp
|
||||
```
|
||||
|
||||
进入目录:
|
||||
|
||||
```bash
|
||||
cd /opt/frp
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 三、下载 FRP
|
||||
|
||||
下载 **ARM64 版本**:
|
||||
|
||||
```bash
|
||||
wget https://github.com/fatedier/frp/releases/download/v0.65.0/frp_0.65.0_darwin_arm64.tar.gz
|
||||
```
|
||||
|
||||
如果没有 wget:
|
||||
|
||||
```bash
|
||||
brew install wget
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 四、解压 FRP
|
||||
|
||||
```bash
|
||||
tar -xzf frp_0.65.0_darwin_arm64.tar.gz
|
||||
```
|
||||
|
||||
解压后目录结构:
|
||||
|
||||
```
|
||||
/opt/frp
|
||||
└── frp_0.65.0_darwin_arm64
|
||||
├── frpc
|
||||
├── frps
|
||||
├── frpc.toml
|
||||
├── frps.toml
|
||||
└── LICENSE
|
||||
```
|
||||
|
||||
进入目录:
|
||||
|
||||
```bash
|
||||
cd /opt/frp/frp_0.65.0_darwin_arm64
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 五、解除 macOS Gatekeeper 限制
|
||||
|
||||
macOS 会阻止未签名程序运行。
|
||||
|
||||
需要删除 quarantine 属性:
|
||||
|
||||
```bash
|
||||
xattr -rd com.apple.quarantine .
|
||||
```
|
||||
|
||||
验证:
|
||||
|
||||
```bash
|
||||
xattr frpc
|
||||
```
|
||||
|
||||
如果没有输出说明解除成功。
|
||||
|
||||
---
|
||||
|
||||
## 六、修改 frpc.toml 配置
|
||||
|
||||
编辑配置:
|
||||
|
||||
```bash
|
||||
nano /opt/frp/frp_0.65.0_darwin_arm64/frpc.toml
|
||||
```
|
||||
|
||||
示例配置:
|
||||
|
||||
```toml
|
||||
serverAddr = "192.227.222.142"
|
||||
serverPort = 7000
|
||||
|
||||
auth.method = "token"
|
||||
auth.token = "your_token_here"
|
||||
|
||||
[[proxies]]
|
||||
name = "ssh"
|
||||
type = "tcp"
|
||||
localIP = "127.0.0.1"
|
||||
localPort = 22
|
||||
remotePort = 6000
|
||||
```
|
||||
|
||||
参数说明:
|
||||
|
||||
|参数|说明|
|
||||
|---|---|
|
||||
|serverAddr|frps服务器地址|
|
||||
|serverPort|frps监听端口|
|
||||
|auth.token|认证token|
|
||||
|localIP|本地服务地址|
|
||||
|localPort|本地端口|
|
||||
|remotePort|frps映射端口|
|
||||
|
||||
---
|
||||
|
||||
## 七、测试运行
|
||||
|
||||
进入目录:
|
||||
|
||||
```bash
|
||||
cd /opt/frp/frp_0.65.0_darwin_arm64
|
||||
```
|
||||
|
||||
启动客户端:
|
||||
|
||||
```bash
|
||||
./frpc -c frpc.toml
|
||||
```
|
||||
|
||||
成功日志示例:
|
||||
|
||||
```
|
||||
login to server success
|
||||
proxy added: ssh
|
||||
start proxy success
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 八、后台运行方式
|
||||
|
||||
推荐三种方式。
|
||||
|
||||
---
|
||||
|
||||
### 方式一:tmux(推荐)
|
||||
|
||||
安装 tmux:
|
||||
|
||||
```bash
|
||||
brew install tmux
|
||||
```
|
||||
|
||||
创建会话:
|
||||
|
||||
```bash
|
||||
tmux new -s frpc
|
||||
```
|
||||
|
||||
启动程序:
|
||||
|
||||
```bash
|
||||
cd /opt/frp/frp_0.65.0_darwin_arm64
|
||||
./frpc -c frpc.toml
|
||||
```
|
||||
|
||||
后台运行:
|
||||
|
||||
```
|
||||
Ctrl + B
|
||||
D
|
||||
```
|
||||
|
||||
重新进入:
|
||||
|
||||
```bash
|
||||
tmux attach -t frpc
|
||||
```
|
||||
|
||||
查看会话:
|
||||
|
||||
```bash
|
||||
tmux ls
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 方式二:nohup
|
||||
|
||||
后台启动:
|
||||
|
||||
```bash
|
||||
cd /opt/frp/frp_0.65.0_darwin_arm64
|
||||
|
||||
nohup ./frpc -c frpc.toml > frpc.log 2>&1 &
|
||||
```
|
||||
|
||||
查看进程:
|
||||
|
||||
```bash
|
||||
ps aux | grep frpc
|
||||
```
|
||||
|
||||
查看日志:
|
||||
|
||||
```bash
|
||||
tail -f frpc.log
|
||||
```
|
||||
|
||||
停止:
|
||||
|
||||
```bash
|
||||
pkill frpc
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 方式三:launchd(推荐开机自启)
|
||||
|
||||
创建配置文件:
|
||||
|
||||
```bash
|
||||
nano ~/Library/LaunchAgents/com.frpc.client.plist
|
||||
```
|
||||
|
||||
配置内容:
|
||||
|
||||
```xml
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN"
|
||||
"http://www.apple.com/DTDs/PropertyList-1.0.dtd">
|
||||
<plist version="1.0">
|
||||
<dict>
|
||||
|
||||
<key>Label</key>
|
||||
<string>com.frpc.client</string>
|
||||
|
||||
<key>ProgramArguments</key>
|
||||
<array>
|
||||
<string>/opt/frp/frp_0.65.0_darwin_arm64/frpc</string>
|
||||
<string>-c</string>
|
||||
<string>/opt/frp/frp_0.65.0_darwin_arm64/frpc.toml</string>
|
||||
</array>
|
||||
|
||||
<key>RunAtLoad</key>
|
||||
<true/>
|
||||
|
||||
<key>KeepAlive</key>
|
||||
<true/>
|
||||
|
||||
<key>StandardOutPath</key>
|
||||
<string>/opt/frp/frp_0.65.0_darwin_arm64/frpc.log</string>
|
||||
|
||||
<key>StandardErrorPath</key>
|
||||
<string>/opt/frp/frp_0.65.0_darwin_arm64/frpc.error.log</string>
|
||||
|
||||
</dict>
|
||||
</plist>
|
||||
```
|
||||
|
||||
加载服务:
|
||||
|
||||
```bash
|
||||
launchctl load ~/Library/LaunchAgents/com.frpc.client.plist
|
||||
```
|
||||
|
||||
启动:
|
||||
|
||||
```bash
|
||||
launchctl start com.frpc.client
|
||||
```
|
||||
|
||||
停止:
|
||||
|
||||
```bash
|
||||
launchctl stop com.frpc.client
|
||||
```
|
||||
|
||||
卸载:
|
||||
|
||||
```bash
|
||||
launchctl unload ~/Library/LaunchAgents/com.frpc.client.plist
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 九、常用维护命令
|
||||
|
||||
### 查看 frpc 进程
|
||||
|
||||
```bash
|
||||
ps aux | grep frpc
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 查看日志
|
||||
|
||||
```bash
|
||||
tail -f /opt/frp/frp_0.65.0_darwin_arm64/frpc.log
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 重启 frpc
|
||||
|
||||
```bash
|
||||
pkill frpc
|
||||
cd /opt/frp/frp_0.65.0_darwin_arm64
|
||||
./frpc -c frpc.toml
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 十、升级 FRP
|
||||
|
||||
升级步骤:
|
||||
|
||||
```
|
||||
停止 frpc
|
||||
↓
|
||||
下载新版本
|
||||
↓
|
||||
解压
|
||||
↓
|
||||
替换目录
|
||||
↓
|
||||
重新运行
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```bash
|
||||
pkill frpc
|
||||
cd /opt/frp
|
||||
wget 新版本
|
||||
tar -xzf
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 十一、最终目录结构
|
||||
|
||||
```
|
||||
/opt/frp
|
||||
└── frp_0.65.0_darwin_arm64
|
||||
├── frpc
|
||||
├── frps
|
||||
├── frpc.toml
|
||||
├── frpc.log
|
||||
└── frpc.error.log
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 十二、快速启动命令
|
||||
|
||||
日常手动运行:
|
||||
|
||||
```bash
|
||||
cd /opt/frp/frp_0.65.0_darwin_arm64
|
||||
|
||||
xattr -rd com.apple.quarantine .
|
||||
|
||||
./frpc -c frpc.toml
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 十三、生产环境最佳实践
|
||||
|
||||
建议:
|
||||
|
||||
### 1 统一路径
|
||||
|
||||
```
|
||||
/opt/frp/<version>
|
||||
```
|
||||
|
||||
方便版本切换。
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
/opt/frp/frp_0.65.0_darwin_arm64
|
||||
/opt/frp/frp_0.66.0_darwin_arm64
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 2 创建软链接
|
||||
|
||||
```
|
||||
/opt/frp/current
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```bash
|
||||
ln -sfn /opt/frp/frp_0.65.0_darwin_arm64 /opt/frp/current
|
||||
```
|
||||
|
||||
启动时:
|
||||
|
||||
```
|
||||
/opt/frp/current/frpc
|
||||
```
|
||||
|
||||
升级时只需要切换 symlink。
|
||||
|
||||
---
|
||||
|
||||
### 3 日志独立
|
||||
|
||||
```
|
||||
/opt/frp/logs
|
||||
```
|
||||
|
||||
更利于监控。
|
||||
|
||||
---
|
||||
|
||||
如果你愿意,我可以再帮你整理一份 **Mac Mini 服务器化运维方案(FRP + OpenClaw + n8n + Clash)统一进程管理架构**,解决几个你现在已经遇到的问题:
|
||||
|
||||
- frp
|
||||
|
||||
- openclaw
|
||||
|
||||
- proxychains
|
||||
|
||||
- tmux
|
||||
|
||||
- telegram bot
|
||||
|
||||
- n8n
|
||||
|
||||
|
||||
统一用 **macOS launchd + 进程依赖管理** 管理,这样你的 **Mac Mini 就可以像一台真正的 Linux server 一样稳定运行**。
|
||||
|
||||
|
||||
---
|
||||
## 十四、实际案例:通过 FRP 远程 SSH 登录 Mac Mini
|
||||
|
||||
本案例用于 **通过 VPS 作为中转服务器,从公网 SSH 访问 Mac Mini**。
|
||||
|
||||
架构如下:
|
||||
|
||||
本地 Mac Mini
|
||||
│
|
||||
│ SSH 22
|
||||
│
|
||||
frpc 客户端
|
||||
│
|
||||
│ FRP 隧道
|
||||
│
|
||||
远端 VPS (frps)
|
||||
│
|
||||
│ 60026
|
||||
│
|
||||
公网 SSH 访问
|
||||
|
||||
公网访问方式:
|
||||
|
||||
ssh 用户名@VPS_IP -p 60026
|
||||
|
||||
---
|
||||
|
||||
### 1 VPS 服务器开放防火墙端口
|
||||
|
||||
如果 VPS 使用 **UFW 防火墙**,需要允许 FRP 映射端口。
|
||||
|
||||
执行:
|
||||
|
||||
sudo ufw allow 60026
|
||||
|
||||
检查防火墙状态:
|
||||
|
||||
sudo ufw status
|
||||
|
||||
输出示例:
|
||||
|
||||
60026/tcp ALLOW Anywhere
|
||||
|
||||
说明端口已开放。
|
||||
|
||||
---
|
||||
|
||||
### 2 修改 frpc.toml 配置
|
||||
|
||||
编辑配置文件:
|
||||
|
||||
nano /opt/frp/frp_0.65.0_darwin_arm64/frpc.toml
|
||||
|
||||
增加如下代理配置:
|
||||
|
||||
[[proxies]]
|
||||
name = "macmini-ssh"
|
||||
type = "tcp"
|
||||
localIP = "127.0.0.1"
|
||||
localPort = 22
|
||||
remotePort = 60026
|
||||
|
||||
配置说明:
|
||||
|
||||
|参数|说明|
|
||||
|---|---|
|
||||
|name|代理名称|
|
||||
|type|TCP转发|
|
||||
|localIP|本地 SSH 地址|
|
||||
|localPort|本地 SSH 端口|
|
||||
|remotePort|VPS 上映射端口|
|
||||
|
||||
---
|
||||
|
||||
### 3 完整 frpc.toml 示例
|
||||
|
||||
示例:
|
||||
|
||||
serverAddr = "VPS_IP"
|
||||
serverPort = 7000
|
||||
|
||||
auth.method = "token"
|
||||
auth.token = "your_token"
|
||||
|
||||
[[proxies]]
|
||||
name = "macmini-ssh"
|
||||
type = "tcp"
|
||||
localIP = "127.0.0.1"
|
||||
localPort = 22
|
||||
remotePort = 60026
|
||||
|
||||
---
|
||||
|
||||
### 4 重启 frpc
|
||||
|
||||
重新启动客户端:
|
||||
|
||||
pkill frpc
|
||||
|
||||
cd /opt/frp/frp_0.65.0_darwin_arm64
|
||||
|
||||
./frpc -c frpc.toml
|
||||
|
||||
成功日志示例:
|
||||
|
||||
proxy added: macmini-ssh
|
||||
start proxy success
|
||||
|
||||
---
|
||||
|
||||
### 5 测试远程 SSH
|
||||
|
||||
在任意公网机器执行:
|
||||
|
||||
ssh username@VPS_IP -p 60026
|
||||
|
||||
示例:
|
||||
|
||||
ssh billy@192.227.xxx.xxx -p 60026
|
||||
|
||||
成功后即可登录 Mac Mini。
|
||||
|
||||
---
|
||||
|
||||
### 6 推荐 SSH 使用方式
|
||||
|
||||
为了方便使用,可以在 **客户端 ~/.ssh/config** 添加配置:
|
||||
|
||||
nano ~/.ssh/config
|
||||
|
||||
增加:
|
||||
|
||||
Host macmini
|
||||
HostName VPS_IP
|
||||
Port 60026
|
||||
User billy
|
||||
|
||||
之后直接:
|
||||
|
||||
ssh macmini
|
||||
|
||||
即可登录 Mac Mini。
|
||||
424
raw/Technical/Home Office/🟣Ubuntu 安装 FRP 0.65.0(x86_64)操作笔记.md
Normal file
424
raw/Technical/Home Office/🟣Ubuntu 安装 FRP 0.65.0(x86_64)操作笔记.md
Normal file
@@ -0,0 +1,424 @@
|
||||
---
|
||||
title: Ubuntu 安装 FRP 0.65.0(x86_64)操作笔记
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [frp, frpc, ubuntu]
|
||||
---
|
||||
|
||||
# Ubuntu 安装 FRP 0.65.0(x86_64)操作笔记
|
||||
|
||||
#ubuntu #frp #frpc
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
- **FRP版本**:0.65.0
|
||||
- **CPU架构**:x86_64 (amd64)
|
||||
- **安装路径**:`/opt/frp/frp_0.65.0_linux_amd64`
|
||||
- **配置文件**:`frpc.toml`
|
||||
- **服务管理**:systemd
|
||||
|
||||
此文档可以直接保存为 **README.md 或运维手册**。
|
||||
|
||||
---
|
||||
|
||||
## 一、环境信息
|
||||
|
||||
| 项目 | 内容 |
|
||||
| ----- | ---------------------------------- |
|
||||
| 系统 | Ubuntu Server 24.04 |
|
||||
| 架构 | x86_64 (amd64) |
|
||||
| 软件 | FRP 0.65.0 |
|
||||
| 安装目录 | `/opt/frp/frp_0.65.0_linux_amd64` |
|
||||
| 客户端程序 | `frpc` |
|
||||
| 配置文件 | `frpc.toml` |
|
||||
| 服务管理 | systemd |
|
||||
|
||||
---
|
||||
|
||||
## 二、创建安装目录
|
||||
|
||||
```bash
|
||||
sudo mkdir -p /opt/frp
|
||||
sudo chown -R $(whoami) /opt/frp
|
||||
```
|
||||
|
||||
进入目录:
|
||||
|
||||
```bash
|
||||
cd /opt/frp
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 三、下载 FRP
|
||||
|
||||
下载 **x86_64 版本**:
|
||||
|
||||
```bash
|
||||
wget https://github.com/fatedier/frp/releases/download/v0.65.0/frp_0.65.0_linux_amd64.tar.gz
|
||||
```
|
||||
|
||||
如果没有 wget:
|
||||
|
||||
```bash
|
||||
sudo apt update
|
||||
sudo apt install -y wget
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 四、解压 FRP
|
||||
|
||||
```bash
|
||||
tar -xzf frp_0.65.0_linux_amd64.tar.gz
|
||||
```
|
||||
|
||||
解压后目录结构:
|
||||
|
||||
```
|
||||
/opt/frp
|
||||
└── frp_0.65.0_linux_amd64
|
||||
├── frpc
|
||||
├── frps
|
||||
├── frpc.toml
|
||||
├── frps.toml
|
||||
└── LICENSE
|
||||
```
|
||||
|
||||
进入目录:
|
||||
|
||||
```bash
|
||||
cd /opt/frp/frp_0.65.0_linux_amd64
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 五、修改 frpc.toml 配置
|
||||
|
||||
编辑配置:
|
||||
|
||||
```bash
|
||||
nano /opt/frp/frp_0.65.0_linux_amd64/frpc.toml
|
||||
```
|
||||
|
||||
示例配置:
|
||||
|
||||
```toml
|
||||
serverAddr = "192.227.222.142"
|
||||
serverPort = 7000
|
||||
|
||||
[auth]
|
||||
token = "your_token_here"
|
||||
|
||||
[[proxies]]
|
||||
name = "ssh"
|
||||
type = "tcp"
|
||||
localIP = "127.0.0.1"
|
||||
localPort = 22
|
||||
remotePort = 6000
|
||||
```
|
||||
|
||||
参数说明:
|
||||
|
||||
|参数|说明|
|
||||
|---|---|
|
||||
|serverAddr|frps服务器地址|
|
||||
|serverPort|frps监听端口|
|
||||
|auth.token|认证token|
|
||||
|localIP|本地服务地址|
|
||||
|localPort|本地端口|
|
||||
|remotePort|frps映射端口|
|
||||
|
||||
---
|
||||
|
||||
## 六、测试运行
|
||||
|
||||
进入目录:
|
||||
|
||||
```bash
|
||||
cd /opt/frp/frp_0.65.0_linux_amd64
|
||||
```
|
||||
|
||||
启动客户端:
|
||||
|
||||
```bash
|
||||
./frpc -c frpc.toml
|
||||
```
|
||||
|
||||
成功日志示例:
|
||||
|
||||
```
|
||||
login to server success
|
||||
proxy added: ssh
|
||||
start proxy success
|
||||
```
|
||||
|
||||
按 `Ctrl + C` 停止测试。
|
||||
|
||||
---
|
||||
|
||||
## 七、systemd 服务管理(推荐)
|
||||
|
||||
### 1 创建 systemd 服务文件
|
||||
|
||||
```bash
|
||||
sudo nano /etc/systemd/system/frpc.service
|
||||
```
|
||||
|
||||
### 2 配置内容
|
||||
|
||||
```ini
|
||||
[Unit]
|
||||
Description=frp client
|
||||
After=network-online.target
|
||||
Wants=network-online.target
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/opt/frp/frp_0.65.0_linux_amd64/frpc -c /opt/frp/frp_0.65.0_linux_amd64/frpc.toml
|
||||
Restart=on-failure
|
||||
RestartSec=10
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
|
||||
### 3 重新加载 systemd
|
||||
|
||||
```bash
|
||||
sudo systemctl daemon-reload
|
||||
```
|
||||
|
||||
### 4 启动 frpc 服务
|
||||
|
||||
```bash
|
||||
sudo systemctl start frpc
|
||||
```
|
||||
|
||||
### 5 设置开机自启
|
||||
|
||||
```bash
|
||||
sudo systemctl enable frpc
|
||||
```
|
||||
|
||||
### 6 查看服务状态
|
||||
|
||||
```bash
|
||||
sudo systemctl status frpc
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 八、常用维护命令
|
||||
|
||||
### 查看 frpc 进程
|
||||
|
||||
```bash
|
||||
ps aux | grep frpc
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 查看日志
|
||||
|
||||
```bash
|
||||
sudo journalctl -u frpc -f
|
||||
```
|
||||
|
||||
或查看历史日志:
|
||||
|
||||
```bash
|
||||
sudo journalctl -u frpc --no-pager -n 50
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 重启 frpc
|
||||
|
||||
```bash
|
||||
sudo systemctl restart frpc
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 停止 frpc
|
||||
|
||||
```bash
|
||||
sudo systemctl stop frpc
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 禁用开机自启
|
||||
|
||||
```bash
|
||||
sudo systemctl disable frpc
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 九、卸载 FRP
|
||||
|
||||
1. 停止服务:
|
||||
|
||||
```bash
|
||||
sudo systemctl stop frpc
|
||||
sudo systemctl disable frpc
|
||||
```
|
||||
|
||||
2. 删除服务文件:
|
||||
|
||||
```bash
|
||||
sudo rm /etc/systemd/system/frpc.service
|
||||
sudo systemctl daemon-reload
|
||||
```
|
||||
|
||||
3. 删除安装目录:
|
||||
|
||||
```bash
|
||||
sudo rm -rf /opt/frp
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 十、升级 FRP
|
||||
|
||||
升级步骤:
|
||||
|
||||
```
|
||||
停止 frpc
|
||||
↓
|
||||
下载新版本
|
||||
↓
|
||||
解压
|
||||
↓
|
||||
替换目录
|
||||
↓
|
||||
重新运行
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```bash
|
||||
sudo systemctl stop frpc
|
||||
cd /opt/frp
|
||||
wget https://github.com/fatedier/frp/releases/download/v0.66.0/frp_0.66.0_linux_amd64.tar.gz
|
||||
tar -xzf frp_0.66.0_linux_amd64.tar.gz
|
||||
# 如果需要可以更新软链接
|
||||
sudo systemctl start frpc
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 十一、最终目录结构
|
||||
|
||||
```
|
||||
/opt/frp
|
||||
└── frp_0.65.0_linux_amd64
|
||||
├── frpc
|
||||
├── frps
|
||||
├── frpc.toml
|
||||
└── frps.toml
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 十二、生产环境最佳实践
|
||||
|
||||
### 1 统一路径
|
||||
|
||||
```
|
||||
/opt/frp/<version>
|
||||
```
|
||||
|
||||
方便版本切换。
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
/opt/frp/frp_0.65.0_linux_amd64
|
||||
/opt/frp/frp_0.66.0_linux_amd64
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 2 创建软链接
|
||||
|
||||
```
|
||||
/opt/frp/current
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```bash
|
||||
sudo ln -sfn /opt/frp/frp_0.65.0_linux_amd64 /opt/frp/current
|
||||
```
|
||||
|
||||
启动时(修改 systemd 服务文件):
|
||||
|
||||
```ini
|
||||
ExecStart=/opt/frp/current/frpc -c /opt/frp/current/frpc.toml
|
||||
```
|
||||
|
||||
升级时只需要切换 symlink,无需修改 systemd 配置。
|
||||
|
||||
---
|
||||
|
||||
### 3 日志管理
|
||||
|
||||
建议使用 journald 日志,可通过以下命令查看:
|
||||
|
||||
```bash
|
||||
sudo journalctl -u frpc -f
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 十三、快速启动命令
|
||||
|
||||
日常手动运行(不通过 systemd):
|
||||
|
||||
```bash
|
||||
cd /opt/frp/frp_0.65.0_linux_amd64
|
||||
./frpc -c frpc.toml
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 十四、故障排查
|
||||
|
||||
### 服务启动失败
|
||||
|
||||
1. 检查配置文件语法:
|
||||
|
||||
```bash
|
||||
./frpc validate -c frpc.toml
|
||||
```
|
||||
|
||||
2. 查看详细错误日志:
|
||||
|
||||
```bash
|
||||
sudo journalctl -u frpc -e
|
||||
```
|
||||
|
||||
3. 检查端口是否被占用:
|
||||
|
||||
```bash
|
||||
sudo netstat -tlnp | grep <端口号>
|
||||
```
|
||||
|
||||
### 无法连接 frps 服务器
|
||||
|
||||
1. 检查服务器地址和端口是否正确
|
||||
2. 检查防火墙是否开放相应端口
|
||||
3. 检查 token 是否匹配
|
||||
|
||||
---
|
||||
|
||||
## 十五、相关文档
|
||||
|
||||
- [Mac Mini 安装 FRP 0.65.0(ARM64)操作笔记](./🟣Mac%20Mini%20安装%20FRP%200.65.0(ARM64)操作笔记.md)
|
||||
- [通过VPS+内网反向代理实现域名访问内网穿透](./通过VPS+内网反向代理实现域名访问内网穿透.md)
|
||||
@@ -0,0 +1,191 @@
|
||||
---
|
||||
title: 1 创建 Symbolic Link
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [obsidian, openclaw, symbolic-link]
|
||||
---
|
||||
|
||||
#symbolic-link #obsidian #openclaw
|
||||
|
||||
下面是一份可以直接放进 **Obsidian** 的 Markdown 笔记,用于记录 **macOS 创建 / 解除 Symbolic Link(符号链接)** 的操作。
|
||||
|
||||
## 背景
|
||||
|
||||
OpenClaw 默认使用隐藏目录:
|
||||
|
||||
```
|
||||
~/.openclaw
|
||||
```
|
||||
|
||||
该目录不方便在 **Finder 或 Obsidian** 中直接作为 Vault 使用。
|
||||
|
||||
解决方法是创建一个 **Symbolic Link(符号链接)**,把隐藏目录映射为普通目录:
|
||||
|
||||
```
|
||||
~/openclaw
|
||||
```
|
||||
|
||||
这样:
|
||||
|
||||
- OpenClaw 继续使用 `~/.openclaw`
|
||||
|
||||
- Obsidian 可以使用 `~/openclaw`
|
||||
|
||||
- 两者访问的是 **同一份数据**
|
||||
|
||||
|
||||
---
|
||||
|
||||
# 1 创建 Symbolic Link
|
||||
|
||||
在 Terminal 执行:
|
||||
|
||||
```bash
|
||||
ln -s /Users/weishen/.openclaw /Users/weishen/openclaw
|
||||
```
|
||||
|
||||
或使用 `~`:
|
||||
|
||||
```bash
|
||||
ln -s ~/.openclaw ~/openclaw
|
||||
```
|
||||
|
||||
执行后目录结构变为:
|
||||
|
||||
```
|
||||
~/openclaw -> ~/.openclaw
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 2 验证 Symbolic Link
|
||||
|
||||
查看链接:
|
||||
|
||||
```bash
|
||||
ls -l ~ | grep openclaw
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
openclaw -> /Users/weishen/.openclaw
|
||||
```
|
||||
|
||||
查看链接指向:
|
||||
|
||||
```bash
|
||||
readlink ~/openclaw
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 3 在 Obsidian 中使用
|
||||
|
||||
打开 Obsidian:
|
||||
|
||||
```
|
||||
Open folder as vault
|
||||
```
|
||||
|
||||
选择:
|
||||
|
||||
```
|
||||
/Users/weishen/openclaw
|
||||
```
|
||||
|
||||
Obsidian 即可访问 OpenClaw 的 Markdown 文件。
|
||||
|
||||
---
|
||||
|
||||
# 4 解除 Symbolic Link(删除映射)
|
||||
|
||||
如果需要取消映射,只需要删除链接:
|
||||
|
||||
```bash
|
||||
rm ~/openclaw
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```bash
|
||||
rm /Users/weishen/openclaw
|
||||
```
|
||||
|
||||
⚠️ 该操作 **只会删除链接文件,不会删除真实目录**。
|
||||
|
||||
---
|
||||
|
||||
# 5 验证解除成功
|
||||
|
||||
检查链接是否存在:
|
||||
|
||||
```bash
|
||||
ls -l ~ | grep openclaw
|
||||
```
|
||||
|
||||
如果没有输出,说明链接已经删除。
|
||||
|
||||
真实目录仍然存在:
|
||||
|
||||
```bash
|
||||
ls ~/.openclaw
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 6 注意事项
|
||||
|
||||
不要误删真实目录:
|
||||
|
||||
```
|
||||
rm -rf ~/.openclaw
|
||||
```
|
||||
|
||||
该命令会 **删除 OpenClaw 数据目录**。
|
||||
|
||||
---
|
||||
|
||||
# 7 推荐的长期目录结构
|
||||
|
||||
为了更方便管理,可以采用如下结构:
|
||||
|
||||
```
|
||||
~/openclaw
|
||||
│
|
||||
├── agents
|
||||
├── skills
|
||||
├── memory
|
||||
├── prompts
|
||||
├── logs
|
||||
└── docs
|
||||
```
|
||||
|
||||
然后创建反向链接:
|
||||
|
||||
```bash
|
||||
ln -s ~/openclaw ~/.openclaw
|
||||
```
|
||||
|
||||
这样:
|
||||
|
||||
```
|
||||
~/openclaw # 实际目录
|
||||
~/.openclaw -> ~/openclaw
|
||||
```
|
||||
|
||||
优点:
|
||||
|
||||
- Finder / Obsidian 可直接访问
|
||||
|
||||
- OpenClaw 兼容原路径
|
||||
|
||||
- 方便 Git 管理与备份
|
||||
|
||||
|
||||
---
|
||||
|
||||
如果需要,我还可以帮你整理一套 **OpenClaw + Obsidian 的完整知识库结构(Agent Memory / Skills / Prompts / Runbooks)**,非常适合你现在的 **多服务器 OpenClaw Agent 管理场景**。
|
||||
26
raw/Technical/How to get Youtube Channel ID.md
Normal file
26
raw/Technical/How to get Youtube Channel ID.md
Normal file
@@ -0,0 +1,26 @@
|
||||
---
|
||||
title: How to get Youtube Channel ID
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-03-16
|
||||
description:
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
Browser to channel main page:
|
||||
|
||||
view-source:https://www.youtube.com/@Numberblocks
|
||||
|
||||
query for string:
|
||||
```
|
||||
?channel_id
|
||||
```
|
||||
|
||||
you will find:
|
||||
```
|
||||
"[https://www.youtube.com/feeds/videos.xml?channel_id=UCPlwvN0w4qFSP1FllALB92w](https://www.youtube.com/feeds/videos.xml?channel_id=UCPlwvN0w4qFSP1FllALB92w)"
|
||||
```
|
||||
|
||||
channel id can be used in n8n workflow
|
||||
78
raw/Technical/MCP在Cursor中的集成与应用详解.md
Normal file
78
raw/Technical/MCP在Cursor中的集成与应用详解.md
Normal file
@@ -0,0 +1,78 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [ai, ai-agent, cursor, mcp]
|
||||
---
|
||||
|
||||
|
||||
#ai #mcp #cursor #ai-agent
|
||||
|
||||
## MCP在Cursor中的集成与应用详解🛠️
|
||||
|
||||
### 视频概述🌟
|
||||
本视频由鱼凤老师带来,围绕如何在Cursor中集成和使用MCP(Modal Context Protocol)展开讲解。视频首先介绍了MCP的定义、架构及其功能,随后结合实操演示了如何配置Cursor以接入MCP服务,重点讲解了命令行与服务端模式的差异及配置技巧。通过对热点新闻服务和序列化思考(Sequential Thinking)工具的实例展示,讲解了MCP工具链调用的实际效果及优势。视频风格通俗易懂,配合实例贯穿讲解,强调理解MCP架构及其在AI大模型对话中的应用。
|
||||
|
||||
### 核心知识点总结📚
|
||||
- **00:00 - 01:18 MCP定义与架构介绍**
|
||||
MCP是Modal Context Protocol的缩写,是一种基于Client-Server架构的协议,旨在实现大模型与外围服务的高效集成。MCP Server提供三种功能接口:资源获取(类似HTTP的GET)、工具调用(类似POST请求)、以及Promise提示词,用于多样化的交互与扩展。
|
||||
- **01:18 - 02:17 MCP热点新闻服务实例**
|
||||
介绍了smisery网站的热点新闻MCP Server,支持九个新闻来源。演示如何生成集成命令,将多个新闻来源一次性集成到Cursor中,为后续调用提供数据源接口。
|
||||
- **02:17 - 04:41 Cursor中新版及MCP配置流程**
|
||||
讲解如何下载支持MCP功能的Cursor最新版,并在Cursor设置中新增MCP Server。介绍两种接入方式:SSE服务方式和本地执行命令(command)方式。演示粘贴命令并处理“no tools found”错误的调试过程,强调社区尚在完善阶段及网络访问限制可能导致的问题。
|
||||
- **04:41 - 07:10 使用Composer的Agent模式调用MCP**
|
||||
展示在Cursor的Composer模块如何切换到Agent模式,使用MCP Server的工具链调用,自动执行命令并返回结果。介绍Agent模式与Normal模式的区别,强调Agent模式实现命令的链路打通,减少手动操作的步骤。并介绍“enable yolo mode”自动执行命令的功能及潜在风险,建议推荐用户谨慎使用。
|
||||
- **07:10 - 10:36 MCP Sequential Thinking工具应用**
|
||||
介绍了“Sequential Thinking”工具,强调其逻辑推理分步拆解任务的特点,能够提升AI沟通效率。演示了通过提示词触发该工具,工具与热点新闻服务相互调用、协同工作,最终返回处理后的精准结果。分析说明该工具受欢迎的原因及实际应用场景。
|
||||
- **10:36 - 11:04 视频总结**
|
||||
视频结尾简要总结,感谢观看,鼓励学习者掌握MCP的使用思路。
|
||||
|
||||
### 关键术语及定义📖
|
||||
- **MCP (Modal Context Protocol)**:一种协议,支持AI大模型与外围服务基于Client-Server架构进行高效的数据和工具接口交互。
|
||||
- **Server (服务端)**:MCP协议体系中的服务提供方,负责对外提供资源和工具接口。
|
||||
- **Client (客户端)**:MCP协议体系中的服务调用方,通常指集成了MCP的应用程序或大模型对话客户端。
|
||||
- **SSE (Server-Sent Events)**:一种服务器向客户端推送实时事件的技术,这里指一种MCP接入方式。
|
||||
- **Command (命令行方式)**:通过本地执行命令的方式与MCP Server交互,适用于命令驱动的接口调用。
|
||||
- **Composer**:Cursor中的一个对话构建模块,支持Agent模式与Normal模式两种交互模式。
|
||||
- **Agent模式**:Cursor中的交互方式,自动执行内嵌命令并处理工具调用,提升用户体验和操作效率。
|
||||
- **Sequential Thinking**:MCP工具之一,支持逻辑推理与分步执行任务,优化AI模型的思考与响应过程。
|
||||
|
||||
### 推理结构🧠
|
||||
1. **需求提出 →** 需要实现大模型与外围工具服务无缝集成。
|
||||
2. **协议设计 →** MCP基于CS架构,定义资源访问(GET)、工具调用(POST)、提示词三种接口。
|
||||
3. **系统实现 →** 通过MCP Server与Client实现功能开放与调用。
|
||||
4. **集成流程 →** 在Cursor新增MCP Server配置,用命令行或SSE接入MCP服务。
|
||||
5. **使用流程 →** 在Composer中打开Agent模式,执行MCP工具链,自动触发并完成任务。
|
||||
6. **优化建议 →** 开启“enable yolo mode”风险较高,建议默认关闭以避免误操作。
|
||||
|
||||
### 典型案例📊
|
||||
- **热点新闻服务集成**:将九个新闻来源接入Cursor,通过MCP即时调用获取最新新闻,实现了大模型对外部数据源的实时访问。
|
||||
- **Sequential Thinking应用示例**:演示模型通过逐步逻辑拆解,实现复杂任务的系统思考,工具链间互相调用彰显协同能力,提升AI决策质量和效率。
|
||||
|
||||
### 易错点提醒⚠️
|
||||
- **无工具发现(No tools found)错误**:可能因MCP服务路径填写不正确或网络代理问题导致,解决方案是直接填写MCP原始地址,绕过代理层。
|
||||
- **自动执行命令风险**:enable yolo mode开启后会自动执行所有命令,可能造成误操作如误删文件,官方默认关闭,建议用户谨慎选择。
|
||||
- **Agent模式与Normal模式混淆**:Agent模式能实现自动运行工具命令,Normal模式需要用户手动复制命令执行,理解区别尤为关键。
|
||||
|
||||
### 复习要点与测试题🎓
|
||||
- **复习要点(无答案)**
|
||||
1. MCP协议包含哪三种核心功能接口?
|
||||
2. Cursor中如何新增一个MCP Server?
|
||||
3. Agent模式与Normal模式的最大区别是什么?
|
||||
4. 为什么建议默认关闭“enable yolo mode”?
|
||||
|
||||
- **自测练习(含答案)**
|
||||
1. 什么是MCP?它的作用是?
|
||||
- 答:Modal Context Protocol,基于CS架构的协议,用于AI大模型与外围工具的集成交互。
|
||||
2. MCP Server提供哪三类功能?
|
||||
- 答:资源读取(GET接口)、工具调用(POST接口)、Promise提示词。
|
||||
3. 在Cursor中,MCP Server接入方式有哪些?
|
||||
- 答:通过SSE服务和本地Command两种方式。
|
||||
4. 如何判断Cursor当前处于Agent模式?
|
||||
- 答:对话界面下方会显示“agent”标识。
|
||||
|
||||
### 总结回顾🔍
|
||||
本视频系统讲解了MCP协议的核心理念及其在Cursor中的集成方法。通过详细的配置教程和案例演示,清晰展示了如何实现大模型与多样外部工具的无缝链接,提升AI应用的扩展能力和交互效率。重点说明了Agent模式的优势及风险管理,帮助用户快速上手MCP生态。掌握这些内容,有助于深入理解和运用现代大模型与服务集成的最新技术。
|
||||
2863
raw/Technical/Project/TikTok PM - Python Django Project.md
Normal file
2863
raw/Technical/Project/TikTok PM - Python Django Project.md
Normal file
File diff suppressed because it is too large
Load Diff
70
raw/Technical/Templater Obsidian Plugin.md
Normal file
70
raw/Technical/Templater Obsidian Plugin.md
Normal file
@@ -0,0 +1,70 @@
|
||||
---
|
||||
title: Templater Obsidian Plugin
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [obsidian, plugin]
|
||||
---
|
||||
|
||||
|
||||
#obsidian #plugin
|
||||
|
||||
# Templater Obsidian Plugin
|
||||
|
||||

|
||||
|
||||
[Templater](https://github.com/SilentVoid13/Templater) is a template plugin for [Obsidian.md](https://obsidian.md/). It defines a templating language that lets you insert variables and functions results into your notes. It will also let you execute JavaScript code manipulating those variables and functions.
|
||||
|
||||
## Documentation
|
||||
|
||||
Check out the complete [documentation](https://silentvoid13.github.io/Templater/) to start using [Templater](https://github.com/SilentVoid13/Templater).
|
||||
|
||||
## Warning
|
||||
|
||||
[Templater](https://github.com/SilentVoid13/Templater) allows you to execute arbitrary JavaScript code and system commands.
|
||||
|
||||
It can be dangerous to execute arbitrary JavaScript code or system commands from untrusted sources. Only run code / commands that you understand, from trusted sources.
|
||||
|
||||
## Template Showcase / Questions / Ideas / Help
|
||||
|
||||
Go to the [discussion](https://github.com/SilentVoid13/Templater/discussions) tab to ask and find this kind of things.
|
||||
|
||||
Don't be shy and share your templates created using [Templater](https://github.com/SilentVoid13/Templater) in the [Template Showcase](https://github.com/SilentVoid13/Templater/discussions/categories/templates-showcase) category. Use [gists](https://gist.github.com/) to share the template file.
|
||||
|
||||
## Resources
|
||||
|
||||
A list of useful resources about [Templater](https://github.com/SilentVoid13/Templater):
|
||||
|
||||
- @GitMurf quick demo `How to setup and run your first Templater JS script`: [https://github.com/SilentVoid13/Templater/discussions/187](https://github.com/SilentVoid13/Templater/discussions/187)
|
||||
- @shabegom `How To Use Templater JS Scripts`: [https://shbgm.ca/blog/obsidian/how-to-use-templater-js-scripts](https://shbgm.ca/blog/obsidian/how-to-use-templater-js-scripts)
|
||||
- @chhoumann Templates showcase: [https://github.com/chhoumann/Templater_Templates](https://github.com/chhoumann/Templater_Templates)
|
||||
- @zachatoo Templates showcase: [https://zachyoung.dev/posts/templater-snippets](https://zachyoung.dev/posts/templater-snippets)
|
||||
- @lguenth Templates showcase: [https://github.com/lguenth/obsidian-templates](https://github.com/lguenth/obsidian-templates)
|
||||
- @tallguyjenks video: [https://youtu.be/2234DXKbNgM?t=1944](https://youtu.be/2234DXKbNgM?t=1944)
|
||||
- @ProductivityGuru videos: [https://www.youtube.com/watch?v=cSawi0tYPMM](https://www.youtube.com/watch?v=cSawi0tYPMM)
|
||||
|
||||
## Alternatives
|
||||
|
||||
- [https://github.com/chhoumann/quickadd](https://github.com/chhoumann/quickadd)
|
||||
- [https://github.com/garyng/obsidian-temple](https://github.com/garyng/obsidian-temple)
|
||||
- [https://github.com/avirut/obsidian-metatemplates](https://github.com/avirut/obsidian-metatemplates)
|
||||
|
||||
## Contributing
|
||||
|
||||
Feel free to contribute.
|
||||
|
||||
You can create an [issue](https://github.com/SilentVoid13/Templater/issues) to report a bug, suggest an improvement for this plugin, ask a question, etc.
|
||||
|
||||
You can make a [pull request](https://github.com/SilentVoid13/Templater/pulls) to contribute to this plugin development.
|
||||
|
||||
Check [this](https://silentvoid13.github.io/Templater/internal-functions/contribute.html) to get more information on how to develop a new internal variable / function.
|
||||
|
||||
## License
|
||||
|
||||
[Templater](https://github.com/SilentVoid13/Templater) is licensed under the GNU AGPLv3 license. Refer to [LICENSE](https://github.com/SilentVoid13/Templater/blob/master/LICENSE.TXT) for more information.
|
||||
|
||||
## Support
|
||||
|
||||
If you want to support me and my work, you can [sponsor me on Github](https://github.com/sponsors/SilentVoid13) (preferred method) or donate something on [**Paypal**](https://www.paypal.com/donate?hosted_button_id=U2SRGAFYXT32Q).
|
||||
@@ -0,0 +1,158 @@
|
||||
---
|
||||
title: These 6 Linux apps let you monitor system resources in style
|
||||
source: https://www.howtogeek.com/these-linux-apps-let-you-monitor-system-resources-in-style/?utm_source=HTG-NL&utm_medium=newsletter&utm_campaign=HTG-202512180620&user=aXNoZW53ZWlAZ21haWwuY29t&lctg=a39708f4c0642e1c00f17eb5bc4da266eebe6f612af6132e145b5ba877adfec8
|
||||
author: shenwei
|
||||
published: 2025-12-16
|
||||
created: 2025-12-18
|
||||
description: Track system performance, kill tasks, and more with these beautiful resource monitors.
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
### Summary
|
||||
|
||||
- I prefer TUI monitors: they're snappy, SSH-friendly; btop++ is my top pick.
|
||||
- htop for minimal process detail; glances for lightweight speed; bottom for live graphs.
|
||||
- Want GUIs? Mission Center is Task-Manager-like; Stacer is feature-packed for tweaking and maintenance.
|
||||
|
||||
Most popular Linux desktop environments come with their own resource managers, but if you don't like those defaults, you can always install an alternative manager. You can also replace those full-fat GUI resource managers with a lightweight command-line-based alternative.
|
||||
|
||||
## Btop++
|
||||
|
||||
[TUI (text user interface) apps](https://www.howtogeek.com/types-of-linux-terminal-programs-do-you-know-them-all/) make the best resource monitors, in my opinion. They're snappy and responsive, even when the GUI is lagging. You can even access them directly when you [SSH](https://www.howtogeek.com/114812/5-cool-things-you-can-do-with-an-ssh-server/) into a system. Btop++ is my favorite TUI monitor. You can install it directly from the official repos if you're using Pacman or grab the Snap package if you're on Debian or Ubuntu.
|
||||
|
||||
Launch it by opening the terminal and entering 'btop.'
|
||||
|
||||
```
|
||||
btop
|
||||
```
|
||||
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
|
||||
The interface is split into different panels. You can see the CPU activity on the top, processes on the right, and memory, storage, and networking on the left.
|
||||
|
||||
The process menu is interactive and functional. You can press 'f' to search through the processes. Alternatively, you can use the mouse wheel or the arrow keys to scroll through the processes. Once you've selected a target process, you can send signals to the process. Press 't' to terminate a process (which sends a normal termination signal that lets the application save data before quitting) or press 'k' to instantly [kill a process without warning](https://www.howtogeek.com/413213/how-to-kill-processes-from-the-linux-terminal/). You can send other signals by typing 's' and choosing from the menu. Btop++ even lets you [set a priority level for the processes using Nice values](https://www.howtogeek.com/411979/how-to-set-process-priorities-with-the-nice-and-renice-commands-in-linux/).
|
||||
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
|
||||
Also, you can change the theme and color scheme from the menu.
|
||||
|
||||
## Htop
|
||||
|
||||
Like btop, htop is also a TUI resource monitor, but it takes a more minimal approach. Try Htop if you want a monitor that focuses more on the running processes. It's mostly keyboard-driven via function keys. You can press F3 to search processes or use arrow keys to scroll through them. F9 force quits or kills the selected process, and you can change its assigned priority levels using F7 and F8.
|
||||
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
|
||||
By default, Htop shows the memory and CPU core meters, but you can enter the setup (F2 key) and add more meters if you like. There, you can add battery, clock, and networking meters to the layout with a single click.
|
||||
|
||||
## Glances
|
||||
|
||||
Glances is even more lightweight and entirely keyboard-driven, but it's really zippy. You can install it directly from the Arch and Debian repos, but can also get it as a [Snap package](https://www.howtogeek.com/apt-vs-snap-vs-flatpak-ubuntu-package-managers-explained/) if you're on Debian/Ubuntu. Launch glances by opening a terminal and entering the following command.
|
||||
|
||||
```
|
||||
glances
|
||||
```
|
||||
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
|
||||
The monitor shows you the networking stats, the CPU usage, memory, and file storage at a glance. The biggest panel is the process monitor, which you can browse using the arrow keys. Press 'h' to see all available commands. You can quickly kill a process by pressing 'k.'
|
||||
|
||||
## Bottom
|
||||
|
||||
If you want a closer look at the CPU, network, and memory usage, try Bottom. It focuses more on graphing the live performance stats and less on the processes. It's not interactive, so you can't use it as a task manager. Bottom is purely a resource monitor. It can show the processes in different views too, including a tree view that connects related processes.
|
||||
|
||||
|
||||
|
||||
It's not available in the Debian/Ubuntu repos, but you can install it as a Snap package. It's available in the official Arch repos, so you can install it directly using Pacman.
|
||||
|
||||
## Mission Center
|
||||
|
||||
The resource monitors I've listed so far are all TUI applications, but if you're looking for a full-fledged GUI app, Mission Center has got you covered. It's polished and packed with every feature you could ask for. You can install it directly from the Arch repos, but it's only available as a Snap package for Debian/Ubuntu systems.
|
||||
|
||||
```
|
||||
sudo snap install mission-center
|
||||
```
|
||||
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
- 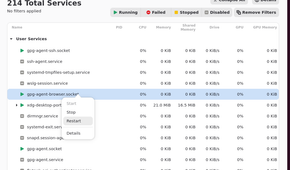
|
||||
|
||||
The app has three tabs: performance, apps, and services. It's a lot like the Windows Task Manager with its graphical performance charts, where you can see the real-time CPU and memory usage. On the Apps tab, you'll see active apps and processes. Right-click on any of these apps to terminate them or force kill them. You can also view resource usage details for the processes. The Services tab shows user and system services, which you can stop or restart with one click.
|
||||
|
||||
## Stacer
|
||||
|
||||
Stacer is another GUI-based resource manager and monitor. It offers more features than any other app on this list. The dashboard has visual meters for CPU, memory, and disk usage. You can see a detailed graphical history of the CPU and memory loads in another tab. There is a tab for reviewing processes and ending them. You can also disable or enable services on the Services tab.
|
||||
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
|
||||
- 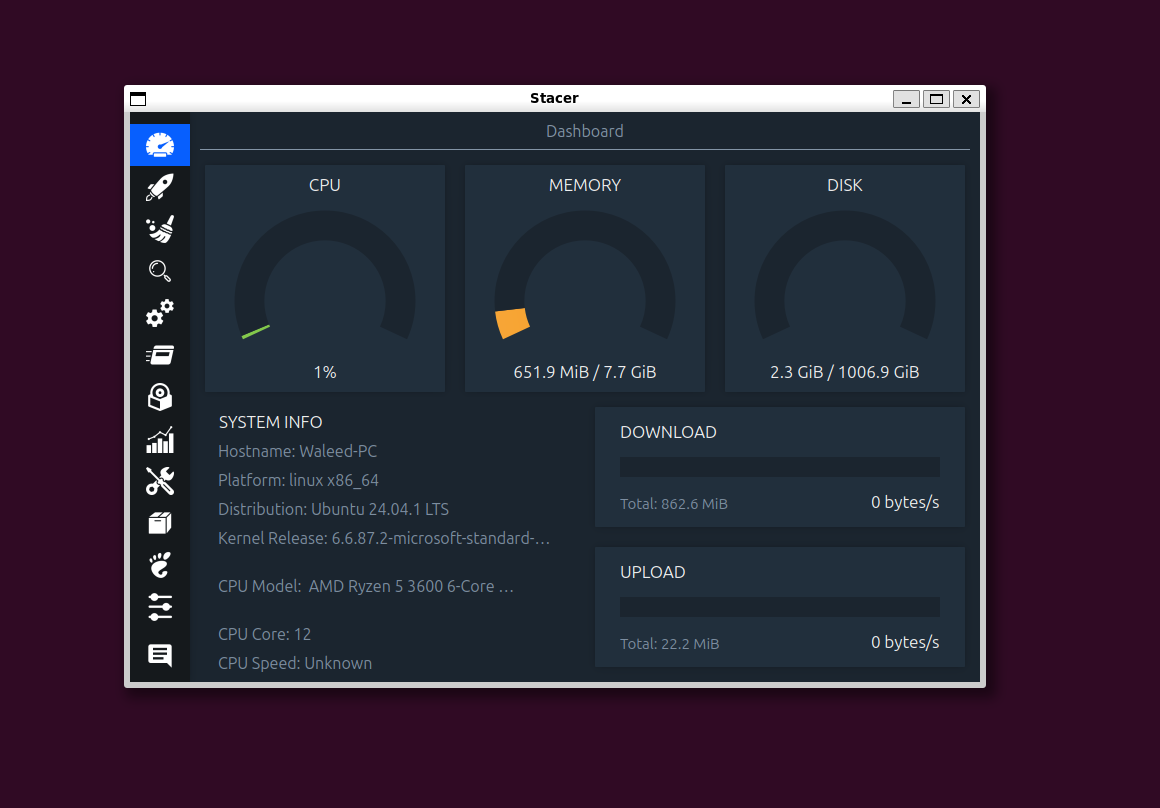
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
- 
|
||||
|
||||
Beyond the standard resource monitoring, you can also configure startup apps, uninstall packages, and [add repos for the APT package manager](https://www.howtogeek.com/add-a-repository-on-debian/). If you're using the GNOME desktop environment, Stacer lets you reconfigure window settings and tweak the desktop experience. Finally, there's a button for auto-clearing junk files and cache.
|
||||
|
||||
---
|
||||
|
||||
Out of all the TUI resource managers I've tried, Btop++ always gets my vote. It features a nice balance between usability and aesthetics. If you want extra features, try Stacer and if you want something close to the Windows Task Manager, Mission Center is your friend.
|
||||
192
raw/Technical/Trae远程开发部署指南.md
Normal file
192
raw/Technical/Trae远程开发部署指南.md
Normal file
@@ -0,0 +1,192 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [remote-ssh, trae, ubuntu]
|
||||
---
|
||||
|
||||
|
||||
#trae #ubuntu #remote-ssh
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
### 1. 整体架构图示
|
||||
|
||||
- **Ubuntu 2 (Dev Server):** 存放源码,运行 `tiktok_pm` 容器(代码挂载),Trae 通过 SSH 远程连接此处。
|
||||
|
||||
- **Ubuntu 1 (Prod Server):** 运行 `tiktok_pm` 容器(镜像打包),通过 Docker 卷持久化数据,不挂载源码。
|
||||
|
||||
- **ThinkBook (Local):** 仅作为 UI 端,通过 Trae 连接 Ubuntu 2 进行开发。
|
||||
|
||||
### 2. Ubuntu 2:开发环境配置 (Dev)
|
||||
|
||||
这是您主要的工作区。路径:`/home/shenwei/docker/tiktok_pm`
|
||||
|
||||
#### A. 目录结构
|
||||
|
||||
``` bash
|
||||
/home/shenwei/docker/tiktok_pm/
|
||||
├── src/ # Django 源代码仓库
|
||||
├── docker-compose.yml # 开发环境 Compose
|
||||
├── .env.dev # 开发环境变量
|
||||
└── Dockerfile # 开发/生产共用基础镜像定义
|
||||
```
|
||||
|
||||
#### B. 开发环境 `docker-compose.yml`
|
||||
|
||||
开发环境的核心在于 **Bind Mount**(绑定挂载),实现代码修改实时生效。
|
||||
|
||||
### 3. 具体配置 (ThinkBook)
|
||||
#### 第一阶段:基础设施层配置 (Connectivity & Permissions)
|
||||
|
||||
在配置 IDE 之前,必须确保 SSH 连接是免密的,并且你的 Ubuntu 用户有权直接操作 Docker,否则 Trae 的远程插件会因为权限弹窗而连接失败或功能受限。
|
||||
|
||||
##### 1. 配置 SSH 免密登录 (本地机器 -> Ubuntu2 Server)
|
||||
|
||||
Trae 的远程连接依赖于非交互式登录。
|
||||
|
||||
- **本地机器(客户端)生成密钥对**(如果已有可跳过):
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
ssh-keygen -t rsa -b 4096
|
||||
```
|
||||
|
||||
- **将公钥上传至 Ubuntu2 Server**:
|
||||
```
|
||||
# 替换 user 和 ip
|
||||
ssh-copy-id -i ~/.ssh/id_rsa.pub shenwei@192.168.3.45
|
||||
```
|
||||
|
||||
- **配置 SSH Config 文件**(推荐): 在本地 `~/.ssh/config` (Mac/Linux) 或 `%USERPROFILE%\.ssh\config` (Windows) 中添加别名,方便 Trae 读取。
|
||||
|
||||
```
|
||||
Host ubuntu2
|
||||
HostName 192.168.3.45
|
||||
User shenwei
|
||||
Port 22
|
||||
IdentityFile "C:\Users\ishenwei\.ssh\id_rsa" # 你的私钥路径
|
||||
Host ubuntu2-ext # 公网访问
|
||||
HostName ubuntu2.ishenwei.online:60024
|
||||
User shenwei
|
||||
Port 22
|
||||
IdentityFile "C:\Users\ishenwei\.ssh\id_rsa" # 你的私钥路径
|
||||
Host ubuntu1
|
||||
HostName 192.168.3.47
|
||||
User shenwei
|
||||
Port 22
|
||||
IdentityFile "C:\Users\ishenwei\.ssh\id_rsa" # 你的私钥路径
|
||||
Host ubuntu1-ext # 公网访问
|
||||
HostName ubuntu1.ishenwei.online:60022
|
||||
User shenwei
|
||||
Port 22
|
||||
IdentityFile "C:\Users\ishenwei\.ssh\id_rsa" # 你的私钥路径
|
||||
```
|
||||
|
||||
在 Ubuntu Server 上,你的用户必须在 `docker` 用户组中,否则 Trae 无法列出容器。
|
||||
|
||||
- **SSH 登录服务器执行:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo usermod -aG docker $USER
|
||||
# 必须注销并重新登录,或执行以下命令使组变更立即生效
|
||||
newgrp docker
|
||||
```
|
||||
|
||||
- **验证:** 执行 `docker ps`,如果不需要 sudo 且能列出容器,则配置成功。
|
||||
|
||||
|
||||
---
|
||||
|
||||
#### 第二阶段:Trae 客户端配置 (IDE Setup)
|
||||
|
||||
Trae 原生支持 VS Code 的插件生态,我们需要利用 Remote Development 能力。
|
||||
|
||||
##### 1. 安装 Trae 及必要插件
|
||||
|
||||
打开 Trae,在左侧扩展市场(Extensions)中搜索并安装(如果尚未预装):
|
||||
|
||||
- **Remote - SSH** (必装)
|
||||
|
||||
- **Docker** (Microsoft 出品,必装)
|
||||
|
||||
- **Dev Containers** (如果你计划使用 `.devcontainer` 模式开发,强烈推荐)
|
||||
|
||||
|
||||
##### 2. 建立远程连接
|
||||
|
||||
1. 使用快捷键 `Ctrl/Cmd + Shift + P` 调出命令面板。
|
||||
|
||||
2. 输入并选择:`Remote-SSH: Connect to Host...`。
|
||||
|
||||
3. 选择你在 SSH Config 中配置的 `ubuntu2`。
|
||||
|
||||
4. Trae 会在远程服务器上安装 **VS Code Server (Trae Server)** 代理组件。首次连接需要几十秒。
|
||||
|
||||
|
||||
---
|
||||
|
||||
#### 第三阶段:开发模式选择 (Workflow Configuration)
|
||||
|
||||
针对 Docker 项目,你有两种主要的开发模式,根据你的需求选择:
|
||||
|
||||
##### 模式 A:Attach 到正在运行的容器 (推荐用于调试)
|
||||
|
||||
这种模式下,你直接“进入”已经在 Ubuntu 上跑起来的 Docker 容器进行代码修改。
|
||||
|
||||
1. **连接成功后**,在 Trae 左侧侧边栏找到 **Docker** 图标。
|
||||
|
||||
2. 在 **Containers** 列表中,找到你的目标项目容器。
|
||||
|
||||
3. 右键点击该容器,选择 **"Attach Visual Studio Code"** (或 Trae 对应选项)。
|
||||
|
||||
4. Trae 会打开一个新的窗口,此时你的 IDE **实际上是运行在 Docker 容器内部**。
|
||||
|
||||
5. **优点**:环境完全隔离,直接使用容器内的 Python/Node/Go 环境,无需在 Ubuntu 宿主机安装语言环境。
|
||||
|
||||
|
||||
##### 模式 B:远程编辑宿主机文件 + Docker CLI (推荐用于编排)
|
||||
|
||||
这种模式下,你编辑的是 Ubuntu 文件系统上的代码 (`/home/user/project`),但在终端调用 Docker 命令。
|
||||
|
||||
1. **连接成功后**,点击 "Open Folder"。
|
||||
|
||||
2. 选择 Ubuntu 上 `docker-compose.yml` 或项目代码所在的路径。
|
||||
|
||||
3. 打开终端 (`Ctrl + ~`),直接执行 `docker compose up -d` 等命令。
|
||||
|
||||
4. **优点**:适合管理 `docker-compose.yml` 文件本身,或者同时管理多个微服务容器的配置。
|
||||
|
||||
|
||||
---
|
||||
|
||||
#### 第四阶段:解决常见“坑” (Troubleshooting)
|
||||
|
||||
根据经验,在内网开发 Docker 项目常遇到以下问题,请提前规避:
|
||||
|
||||
1. **Git 凭证问题**:
|
||||
|
||||
- 如果在容器内开发(模式 A),容器内可能没有你的 SSH Key 或 Git 配置。
|
||||
|
||||
- **解决**:Trae/VS Code 通常会自动转发本地的 SSH Agent。确保本地运行了 SSH Agent (`eval "$(ssh-agent -s)" && ssh-add`),这样容器内拉取代码使用的是你本地的 Key。
|
||||
|
||||
2. **文件权限 (UID/GID) 问题**:
|
||||
|
||||
- 如果使用 Volume 挂载(将 Ubuntu 目录挂载进容器),容器内生成的 Build 文件可能归属于 `root`,导致你在宿主机无法删除或修改。
|
||||
|
||||
- **解决**:在 Dockerfile 中创建与宿主机相同 UID 的用户,或在 `docker-compose.yml` 中指定 `user: "${UID}:${GID}"`。
|
||||
|
||||
3. **内网穿透 (如果不只是局域网)**:
|
||||
|
||||
- 如果你离开办公地点,需要从公网访问这个内网 Server。
|
||||
|
||||
- **建议**:不要直接暴露 SSH 端口。在 Ubuntu 上安装 **Tailscale** 或 **Cloudflare Tunnel**。
|
||||
|
||||
- 如果使用 Tailscale,Trae 的 SSH Config HostName 可以直接填 Tailscale 的 IP (如 `100.x.x.x`),实现无缝切换。
|
||||
94
raw/Technical/Useful Prompt Lib.md
Normal file
94
raw/Technical/Useful Prompt Lib.md
Normal file
@@ -0,0 +1,94 @@
|
||||
---
|
||||
title:
|
||||
source: https://docs.anthropic.com/en/prompt-library/data-organizer
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [ai, claude, prompt]
|
||||
link:
|
||||
kanban-plugin:
|
||||
aliases:
|
||||
cssclasses:
|
||||
---
|
||||
|
||||
|
||||
#prompt #ai #claude
|
||||
|
||||
|
||||
针对你目前的 **TikTok 跨境电商** 业务,我建议你重点关注以下几个 Prompt 的逻辑:
|
||||
|
||||
1. **Babel's broadcasts**: 极其适合用于 TikTok 视频脚本的多语言本地化改写。
|
||||
2. **Review classifier**: 可以帮助你自动化处理和分类 TikTok 店铺或广告投放的评论。
|
||||
3. **Data organizer**: 在采集竞品数据或非结构化产品信息时,能快速将其转化为 JSON 格式以对接你的自动化工作流。
|
||||
|
||||
### Claude Prompt 库汇总表
|
||||
|
||||
---
|
||||
|
||||
| **提示词名称 (font-medium)** | **功能描述 (mt-1)** | **原始链接 (flex href)** |
|
||||
| -------------------------- | ---------------------------- | ----------------------------------------------------------------------------------------------- |
|
||||
| Cosmic keystrokes | 生成交互式 HTML 速度打字游戏,包含侧刷功能。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/cosmic-keystrokes) |
|
||||
| Corporate clairvoyant | 提取洞察、识别风险并从长篇企业报告中提炼信息。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/corporate-clairvoyant) |
|
||||
| Website wizard | 根据用户规范创建单页网站。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/website-wizard) |
|
||||
| Excel formula expert | 根据用户描述的计算或操作创建 Excel 公式。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/excel-formula-expert) |
|
||||
| Google apps scripter | 生成 Google Apps 脚本以根据要求完成任务。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/google-apps-scripter) |
|
||||
| Python bug buster | 检测并修复 Python 代码中的错误。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/python-bug-buster) |
|
||||
| Time travel consultant | 帮助用户导航假设的时间旅行场景及其影响。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/time-travel-consultant) |
|
||||
| Storytelling sidekick | 与用户协作创作故事,提供情节转折和角色发展。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/storytelling-sidekick) |
|
||||
| Cite your sources | 对文档内容的提问提供回答,并附带相关的引文支持。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/cite-your-sources) |
|
||||
| SQL sorcerer | 将日常语言转换为 SQL 查询。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/sql-sorcerer) |
|
||||
| Dream interpreter | 对用户梦境中的象征意义提供解释和洞察。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/dream-interpreter) |
|
||||
| Pun-dit | 根据给定话题生成巧妙的双关语和文字游戏。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/pun-dit) |
|
||||
| Culinary creator | 根据用户现有的食材和偏好建议食谱。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/culinary-creator) |
|
||||
| Portmanteau poet | 将两个词融合在一起,创造有意义的新混成词。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/portmanteau-poet) |
|
||||
| Hal the humorous helper | 与带有讽刺幽默感的 AI 进行对话。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/hal-the-humorous-helper) |
|
||||
| LaTeX legend | 编写 LaTeX 文档,生成数学方程、表格等代码。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/latex-legend) |
|
||||
| Mood colorizer | 将情绪描述转换为对应的 HEX 颜色代码。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/mood-colorizer) |
|
||||
| Git gud | 根据描述的版本控制动作生成适当的 Git 命令。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/git-gud) |
|
||||
| Simile savant | 从基本描述中生成明喻。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/simile-savant) |
|
||||
| Ethical dilemma navigator | 思考复杂的伦理困境并提供不同视角。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/ethical-dilemma-navigator) |
|
||||
| Meeting scribe | 提炼会议摘要,包括讨论话题、关键要点和行动项。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/meeting-scribe) |
|
||||
| Idiom illuminator | 解释常用成语和谚语的含义及起源。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/idiom-illuminator) |
|
||||
| Code consultant | 提供优化 Python 代码性能的改进建议。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/code-consultant) |
|
||||
| Function fabricator | 根据详细规范创建 Python 函数。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/function-fabricator) |
|
||||
| Neologism creator | 根据提供的概念发明新词并提供定义。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/neologism-creator) |
|
||||
| CSV converter | 将 JSON, XML 等格式数据转换为 CSV 文件。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/csv-converter) |
|
||||
| Emoji encoder | 将纯文本转换为有趣的表情符号消息。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/emoji-encoder) |
|
||||
| Prose polisher | 使用高级润色技术精炼并改进书面内容。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/prose-polisher) |
|
||||
| Perspectives ponderer | 权衡用户提供话题的利弊。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/perspectives-ponderer) |
|
||||
| Trivia generator | 针对广泛话题生成琐事问题及提示。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/trivia-generator) |
|
||||
| Mindfulness mentor | 引导用户进行正念练习和减压。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/mindfulness-mentor) |
|
||||
| Second grade simplifier | 使复杂文本易于年轻人理解。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/second-grade-simplifier) |
|
||||
| VR fitness innovator | 脑暴虚拟现实健身游戏的创意想法。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/vr-fitness-innovator) |
|
||||
| PII purifier | 自动检测并从文本中删除个人身份信息。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/pii-purifier) |
|
||||
| Memo maestro | 根据关键点撰写全面的公司备忘录。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/memo-maestro) |
|
||||
| Career coach | 与 AI 职业教练进行角色扮演对话。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/career-coach) |
|
||||
| Grading guru | 评估书面文本的质量标准。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/grading-guru) |
|
||||
| Tongue twister | 创造具有挑战性的绕口令。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/tongue-twister) |
|
||||
| Interview question crafter | 为面试生成针对性问题。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/interview-question-crafter) |
|
||||
| Grammar genie | 将语法错误的句子转换为正确的英语。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/grammar-genie) |
|
||||
| Riddle me this | 生成谜语并引导用户寻找答案。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/riddle-me-this) |
|
||||
| Code clarifier | 用通俗语言简化并解释复杂代码。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/code-clarifier) |
|
||||
| Alien anthropologist | 从外星人的视角分析人类文化习俗。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/alien-anthropologist) |
|
||||
| Data organizer | 将非结构化文本转换为定制 JSON 表格。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/data-organizer) |
|
||||
| Brand builder | 为整体品牌标识策划设计方案。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/brand-builder) |
|
||||
| Efficiency estimator | 计算函数和算法的时间复杂度。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/efficiency-estimator) |
|
||||
| Review classifier | 将反馈分类到预设的标签类别中。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/review-classifier) |
|
||||
| Direction decoder | 将自然语言转换为分步指示路线。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/direction-decoder) |
|
||||
| Motivational muse | 提供个性化的励志短语和肯定语。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/motivational-muse) |
|
||||
| Email extractor | 从文档中提取邮件地址并生成 JSON 列表。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/email-extractor) |
|
||||
| Master moderator | 评估输入是否存在潜在有害或非法内容。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/master-moderator) |
|
||||
| Lesson planner | 针对任何主题制定深入的教学计划。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/lesson-planner) |
|
||||
| Socratic sage | 就指定话题进行苏格拉底式的引导对话。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/socratic-sage) |
|
||||
| Alliteration alchemist | 为任何主题生成头韵短语和句子。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/alliteration-alchemist) |
|
||||
| Futuristic fashion advisor | 建议前卫的时装趋势和风格。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/futuristic-fashion-advisor) |
|
||||
| Polyglot superpowers | 将文本在任何语言之间进行互译。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/polyglot-superpowers) |
|
||||
| Product naming pro | 创建吸引人的产品名称和关键词。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/product-naming-pro) |
|
||||
| Philosophical musings | 参与深度哲学讨论和思想实验。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/philosophical-musings) |
|
||||
| Spreadsheet sorcerer | 生成包含多类数据的 CSV 电子表格。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/spreadsheet-sorcerer) |
|
||||
| Sci-fi scenario simulator | 讨论科幻场景及其相关的挑战。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/sci-fi-scenario-simulator) |
|
||||
| Adaptive editor | 遵循不同语气、受众要求重写文本。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/adaptive-editor) |
|
||||
| Babel's broadcasts | 使用 10 种语言创建产品发布推文。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/babels-broadcasts) |
|
||||
| Tweet tone detector | 检测推文的语气和情绪。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/tweet-tone-detector) |
|
||||
| Airport code analyst | 从文本中查找并提取机场代码。 | [Link](https://platform.claude.com/docs/en/resources/prompt-library/airport-code-analyst) |
|
||||
@@ -0,0 +1,301 @@
|
||||
#ubuntu #vibe-kanban #vibe-coding #npm #npx #pm2
|
||||
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
**Ubuntu Server 下安装、管理 Vibe-Kanban + OpenCode 的完整文档**,以 `shenwei` 用户操作、使用 Node 20 和 pm2 管理进程,包含详细命令和验证步骤。
|
||||
|
||||
以下是完整 Markdown 文档:
|
||||
|
||||
---
|
||||
---
|
||||
title: Vibe-Kanban + OpenCode 在 Ubuntu Server 上安装与管理指南
|
||||
author: shenwei
|
||||
tags: [npm, npx, pm2, ubuntu, vibe-coding, vibe-kanban]
|
||||
---
|
||||
---
|
||||
title: Vibe-Kanban + OpenCode 在 Ubuntu Server 上安装与管理指南
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [npm, npx, pm2, ubuntu, vibe-coding, vibe-kanban]
|
||||
---
|
||||
|
||||
# Vibe-Kanban + OpenCode 在 Ubuntu Server 上安装与管理指南
|
||||
|
||||
本文档详细说明了如何在 Ubuntu Server 上使用非 root 用户(`shenwei`)安装 Node 20、Vibe-Kanban 与 OpenCode,并通过 pm2 管理进程,同时提供完整的验证步骤。
|
||||
|
||||
---
|
||||
|
||||
## 1️⃣ 清理旧的安装
|
||||
|
||||
**目的**:清理之前安装的 Node、Vibe-Kanban、OpenCode、工作树等,避免权限冲突和端口占用。
|
||||
|
||||
### 步骤:
|
||||
|
||||
1. 停止所有旧进程
|
||||
|
||||
|
||||
```bash
|
||||
# 查看旧的 vibe-kanban 或 opencode 进程
|
||||
ps aux | grep -E 'vibe-kanban|opencode' | grep -v grep
|
||||
|
||||
# 停掉进程
|
||||
kill <PID>
|
||||
```
|
||||
|
||||
2. 删除旧工作树与缓存
|
||||
|
||||
|
||||
```bash
|
||||
rm -rf /var/tmp/vibe-kanban/worktrees/*
|
||||
rm -rf ~/.vibe-kanban
|
||||
```
|
||||
|
||||
3. 确保用户 `shenwei` 对目录有读写权限
|
||||
|
||||
|
||||
```bash
|
||||
sudo chown -R shenwei:shenwei /var/tmp/vibe-kanban
|
||||
sudo chown -R shenwei:shenwei ~/.vibe-kanban
|
||||
```
|
||||
|
||||
4. 如果之前系统安装了旧 Node 或全局 npm 包,可选择卸载
|
||||
|
||||
|
||||
```bash
|
||||
sudo apt remove nodejs npm -y
|
||||
sudo rm -rf /usr/local/lib/node_modules
|
||||
sudo rm -f /usr/local/bin/node /usr/local/bin/npm
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 2️⃣ 安装 Node 20(使用 nvm)
|
||||
|
||||
**目的**:确保 Node 版本为 20,兼容最新 Vibe-Kanban 和 OpenCode。
|
||||
|
||||
### 安装 nvm
|
||||
|
||||
```bash
|
||||
# 下载并安装 nvm(代理环境下可用 proxychains)
|
||||
curl -fsSL https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash
|
||||
|
||||
# 添加环境变量到 shenwei 的 bash 配置
|
||||
echo 'export NVM_DIR="$HOME/.nvm"' >> ~/.bashrc
|
||||
echo '[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh"' >> ~/.bashrc
|
||||
|
||||
# 重新加载 bash
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
### 安装 Node 20
|
||||
|
||||
```bash
|
||||
nvm install 20
|
||||
nvm use 20
|
||||
nvm alias default 20
|
||||
|
||||
# 验证 Node 和 npm
|
||||
node -v # 应该显示 v20.x.x
|
||||
npm -v
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3️⃣ 安装 Vibe-Kanban 与 OpenCode(用户 `shenwei`)
|
||||
|
||||
### 安装 Vibe-Kanban
|
||||
|
||||
```bash
|
||||
# 安装最新版本
|
||||
npm install -g vibe-kanban
|
||||
|
||||
# 创建工作目录
|
||||
mkdir -p ~/vibe-kanban-projects
|
||||
cd ~/vibe-kanban-projects
|
||||
```
|
||||
|
||||
### 安装 OpenCode
|
||||
|
||||
```bash
|
||||
# 安装 OpenCode CLI
|
||||
npm install -g opencode-ai
|
||||
|
||||
# 验证安装
|
||||
opencode --version
|
||||
```
|
||||
|
||||
> ⚠️ 注意:不要用 root 启动 OpenCode serve,vibe-kanban 会自动 spawn executor
|
||||
|
||||
---
|
||||
|
||||
## 4️⃣ 查看安装后的进程和验证
|
||||
|
||||
### 查看进程
|
||||
|
||||
```bash
|
||||
# 查看 Node 相关进程
|
||||
ps aux | grep -E 'vibe-kanban|opencode' | grep -v grep
|
||||
|
||||
# 查看监听端口
|
||||
ss -lntp | grep opencode
|
||||
ss -lntp | grep vibe-kanban
|
||||
```
|
||||
|
||||
### 参考用pm2启动进程
|
||||
### 验证 vibe-kanban 启动
|
||||
|
||||
```bash
|
||||
# 使用 debug 模式启动
|
||||
RUST_LOG=debug HOST=0.0.0.0 PORT=9999 npx vibe-kanban
|
||||
```
|
||||
|
||||
- 日志中应包含:
|
||||
|
||||
|
||||
```
|
||||
Server running on http://0.0.0.0:9999
|
||||
Starting executor on port <random_port>
|
||||
```
|
||||
|
||||
- 如果浏览器无法自动打开,可手动访问:[http://192.168.3.45:9999](http://192.168.3.45:9999/)
|
||||
|
||||
|
||||
### 验证 OpenCode executor
|
||||
|
||||
- vibe-kanban 启动后会 spawn executor(随机端口),可通过日志查看端口
|
||||
|
||||
- 检查端口是否在监听:
|
||||
|
||||
|
||||
```bash
|
||||
ss -lntp | grep opencode
|
||||
```
|
||||
|
||||
- 用 curl 测试 executor 健康(假设端口 40829):
|
||||
|
||||
|
||||
```bash
|
||||
curl http://127.0.0.1:40829/health
|
||||
# 返回 OK
|
||||
```
|
||||
|
||||
> ⚠️ 遇到 I/O error 时,通常是 executor 没启动或端口被占用
|
||||
|
||||
---
|
||||
|
||||
## 5️⃣ 使用 pm2 管理进程
|
||||
|
||||
### 安装 pm2
|
||||
|
||||
```bash
|
||||
npm install -g pm2
|
||||
```
|
||||
|
||||
### 使用 pm2 启动 Vibe-Kanban
|
||||
|
||||
```bash
|
||||
pm2 start "RUST_LOG=debug HOST=0.0.0.0 PORT=9999 npx vibe-kanban" --name vibe-kanban
|
||||
|
||||
# 查看状态
|
||||
pm2 status
|
||||
|
||||
# 查看日志
|
||||
pm2 logs vibe-kanban
|
||||
```
|
||||
|
||||
### 使用 pm2 启动 OpenCode Executor
|
||||
``` bash
|
||||
pm2 start "opencode serve --hostname 127.0.0.1 --port 40829" --name opencode-executor
|
||||
|
||||
# 查看状态
|
||||
pm2 status
|
||||
|
||||
# 查看日志
|
||||
pm2 logs opencode-executor
|
||||
```
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 6️⃣ 完整验证步骤
|
||||
|
||||
1. 清理旧工作树和进程
|
||||
|
||||
2. 确认 Node 20 已正确安装
|
||||
|
||||
3. 确认 Vibe-Kanban 与 OpenCode 已安装并属于 `shenwei` 用户
|
||||
|
||||
4. 启动 vibe-kanban:
|
||||
|
||||
|
||||
```bash
|
||||
RUST_LOG=debug HOST=0.0.0.0 PORT=9999 npx vibe-kanban
|
||||
```
|
||||
|
||||
5. 检查日志:
|
||||
|
||||
|
||||
```
|
||||
Server running on http://0.0.0.0:9999
|
||||
Starting executor on port <random_port>
|
||||
```
|
||||
|
||||
6. 检查监听端口:
|
||||
|
||||
|
||||
```bash
|
||||
ss -lntp | grep node
|
||||
```
|
||||
|
||||
7. 用浏览器或 curl 访问:
|
||||
|
||||
|
||||
```
|
||||
http://127.0.0.1:9999
|
||||
curl http://127.0.0.1:<executor_port>/health
|
||||
```
|
||||
|
||||
8. pm2 管理进程:
|
||||
|
||||
|
||||
```bash
|
||||
pm2 start "RUST_LOG=debug HOST=0.0.0.0 PORT=9999 npx vibe-kanban" --name vibe-kanban
|
||||
pm2 logs vibe-kanban
|
||||
pm2 save
|
||||
pm2 startup systemd -u shenwei --hp /home/shenwei
|
||||
```
|
||||
|
||||
9. 完整测试:
|
||||
|
||||
|
||||
- 创建测试项目
|
||||
|
||||
- 创建任务
|
||||
|
||||
- 日志中不应再出现:
|
||||
|
||||
|
||||
```
|
||||
OpenCode executor error: I/O error: error sending request ...
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### ✅ 总结
|
||||
|
||||
- **不要用 root** 启动 OpenCode serve
|
||||
|
||||
- **vibe-kanban 自行 spawn executor**,随机端口即可
|
||||
|
||||
- pm2 只管理 **vibe-kanban**,executor 随进程一起管理
|
||||
|
||||
- 保证 `/var/tmp/vibe-kanban` 和 `~/.vibe-kanban` 权限属于用户
|
||||
|
||||
- Node 版本 20 + npm 最新即可
|
||||
|
||||
71
raw/Technical/Vibe Coding/vibe coding经验收集.md
Normal file
71
raw/Technical/Vibe Coding/vibe coding经验收集.md
Normal file
@@ -0,0 +1,71 @@
|
||||
---
|
||||
title: vibe-coding-cn/i18n/zh/documents/Methodology and Principles/A Formalization of Recursive Self-Optimizing Generative Systems.md at main · 2025Emma/vibe-coding-cn
|
||||
source: https://github.com/2025Emma/vibe-coding-cn/blob/main/i18n/zh/documents/Methodology%20and%20Principles/vibe-coding-%E7%BB%8F%E9%AA%8C%E6%94%B6%E9%9B%86.md
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-12-30
|
||||
description: Contribute to 2025Emma/vibe-coding-cn development by creating an account on GitHub.
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
|
||||
[https://x.com/3i8ae3pgjz56244/status/1993328642697707736?s=46](https://x.com/3i8ae3pgjz56244/status/1993328642697707736?s=46)
|
||||
|
||||
我是把设计文档写得很细,包括service层的具体逻辑都用伪代码写了,然后交给AI,一遍直出,再用另一个AI review一遍,根据review意见修改一下,跑一下测试用例,让AI自己生成commit后push
|
||||
|
||||
点评:需求 -> 伪代码 -> 代码
|
||||
|
||||
---
|
||||
|
||||
[https://x.com/jesselaunz/status/1993231396035301437?s=20](https://x.com/jesselaunz/status/1993231396035301437?s=20)
|
||||
|
||||
针对gemini 3 pro的系统prompt,使多个代理基准测试的性能提高了约 5%。
|
||||
|
||||
---
|
||||
|
||||
点 -> 线 -> 体 的逐级迭代,对应使用范围内的任务,先打磨好单个基础任务,然后基于此进行批量执行
|
||||
|
||||
---
|
||||
|
||||
[https://x.com/nake13/status/1995123181057917032?s=46](https://x.com/nake13/status/1995123181057917032?s=46)
|
||||
|
||||
---
|
||||
|
||||
[https://x.com/9hills/status/1995308023578042844?s=46](https://x.com/9hills/status/1995308023578042844?s=46)
|
||||
|
||||
---
|
||||
|
||||
文件头注释,一段话描述代码作用,上下游链路,文档维护agents或者claude维护每个模块的一段话说明,降低认知负载,尽量做减法和索引,参考claude skill
|
||||
|
||||
---
|
||||
|
||||
[https://x.com/dogejustdoit/status/1996464777313542204?s=46](https://x.com/dogejustdoit/status/1996464777313542204?s=46)
|
||||
|
||||
随着软件规模不断扩大,靠人眼去“看代码”不仅无法应对增长的复杂度,还会让开发者疲于奔命。代码最终会被转换成机器码执行,高级语言只是一层方便人类理解的抽象,重要的是验证程序的执行逻辑,通过自动化测试、静态分析、形式化验证等手段确保行为正确。未来的软件工程核心不是“看懂代码”,而是“验证代码按正确逻辑运行”
|
||||
|
||||
---
|
||||
|
||||
[https://x.com/yanboofficial/status/1996188311451480538?s=46](https://x.com/yanboofficial/status/1996188311451480538?s=46)
|
||||
|
||||
```
|
||||
请你根据我的要求,用 Three.js 创建一个实时交互的3D粒子系统,如果你第一次就做得好,我将会打赏你100美元的小费;我的要求是:
|
||||
```
|
||||
|
||||
点评:这个提示词可能会提升生成的效果
|
||||
|
||||
---
|
||||
|
||||
[https://x.com/zen\_of\_nemesis/status/1996591768641458368?s=46](https://x.com/zen_of_nemesis/status/1996591768641458368?s=46)
|
||||
|
||||
---
|
||||
|
||||
[https://github.com/tesserato/CodeWeaver](https://github.com/tesserato/CodeWeaver)
|
||||
|
||||
CodeWeaver 将你的代码库编织成一个可导航的 Markdown 文档
|
||||
|
||||
它能把你整个项目,不管有多少屎山代码,直接“编织”成一个条理清晰的 Markdown 文件,结构是树形的,一目了然。所有代码都给你塞进代码块里,极大地简化了代码库的共享、文档化以及与 AI/ML 工具集成
|
||||
|
||||
---
|
||||
|
||||
[https://x.com/magic47972451/status/1998639692905087356?s=46](https://x.com/magic47972451/status/1998639692905087356?s=46)
|
||||
159
raw/Technical/Vibe Coding/在Ubuntu上安装Vibe-Kanban.md
Normal file
159
raw/Technical/Vibe Coding/在Ubuntu上安装Vibe-Kanban.md
Normal file
@@ -0,0 +1,159 @@
|
||||
---
|
||||
title: 在Ubuntu 上安装Vibe-Kanban
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [npm, npx, pm2, ubuntu, vibe-coding, vibe-kanban]
|
||||
---
|
||||
|
||||
#ubuntu #vibe-kanban #vibe-coding #npm #npx #pm2
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
# 在Ubuntu 上安装Vibe-Kanban
|
||||
|
||||
## Git 项目
|
||||
https://github.com/BloopAI/vibe-kanban
|
||||
|
||||
https://www.vibekanban.com/docs/getting-started
|
||||
## Prerequisites
|
||||
|
||||
Before installing Vibe Kanban, ensure you have:
|
||||
|
||||
- **Node.js**: Latest LTS version recommended
|
||||
- **Coding agent authentication**: Authenticate with your preferred coding agents outside of Vibe Kanban
|
||||
|
||||
## Safety Notice
|
||||
|
||||
Vibe Kanban runs AI agents with —dangerously-skip-permissions/—yolo flags by default so they can work autonomously without constant approval prompts. Each task runs in an isolated git worktree, preventing agents from interfering with each other. Agents can still perform system-level actions, so review their work and keep backups.
|
||||
|
||||
## Installation & Setup
|
||||
|
||||
### 1 Authenticate with a coding agent
|
||||
|
||||
Before launching Vibe Kanban, ensure you’re authenticated with at least one [supported coding agent](https://www.vibekanban.com/docs/supported-coding-agents). Follow the installation and authentication instructions for your preferred agent.
|
||||
|
||||
### 2 Install and launch Vibe Kanban
|
||||
|
||||
Open a terminal and run:
|
||||
|
||||
```
|
||||
npx vibe-kanban
|
||||
```
|
||||
|
||||
The application will bind to a random free port, print the URL in the terminal, and automatically open in your default browser.
|
||||
|
||||
### 3 Complete initial setup
|
||||
|
||||
Complete the setup dialogs to configure your coding agent and editor preferences. GitHub integration relies on the GitHub CLI and is configured when needed.
|
||||
|
||||
### 4 Create your first project
|
||||
|
||||
You’ll land on the Projects page, populated with your three most recently active git projects if automatically discovered. Click “Create project” to add more projects.
|
||||
|
||||
### 5 Add tasks
|
||||
|
||||
Start tracking your work by [creating tasks](https://www.vibekanban.com/docs/core-features/creating-tasks) within your project.
|
||||
|
||||
### 6 Optional: GitHub integration
|
||||
|
||||
Vibe Kanban uses the [GitHub CLI](https://cli.github.com/) for creating pull requests. Ensure `gh` is installed and authenticated on your system, or follow the setup prompts when creating your first pull request.
|
||||
|
||||
### 7 Optional: Set up MCP integration
|
||||
|
||||
Streamline task creation with coding agents by [setting up MCP integration](https://www.vibekanban.com/docs/integrations/vibe-kanban-mcp-server).
|
||||
|
||||
To use a fixed port, specify the `PORT` environment variable: `PORT=8080 npx vibe-kanban`
|
||||
|
||||
|
||||
## 使用 PM2来管理Vibe-Kanban 进程
|
||||
|
||||
PM2 是一个进程管理器,非常适合管理像 `vibe-kanban` 这种基于 Node.js 的工具。它可以自动重启、开机自启,并提供简单的管理界面。
|
||||
|
||||
**1. 安装 PM2:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
sudo npm install -g pm2
|
||||
```
|
||||
|
||||
**2. 后台启动 vibe-kanban:**
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
# 注意这里需要用引号把启动命令包起来
|
||||
pm2 start "HOST=0.0.0.0 PORT=9999 npx vibe-kanban" --name vibe-kanban
|
||||
```
|
||||
|
||||
```
|
||||
shenwei@shenwei-ubuntu-2:~$ pm2 start "HOST=0.0.0.0 PORT=9999 npx vibe-kanban" --name vibe-kanban
|
||||
|
||||
-------------
|
||||
|
||||
__/\\\\\\\\\\\\\____/\\\\____________/\\\\____/\\\\\\\\\_____
|
||||
_\/\\\/////////\\\_\/\\\\\\________/\\\\\\__/\\\///////\\\___
|
||||
_\/\\\_______\/\\\_\/\\\//\\\____/\\\//\\\_\///______\//\\\__
|
||||
_\/\\\\\\\\\\\\\/__\/\\\\///\\\/\\\/_\/\\\___________/\\\/___
|
||||
_\/\\\/////////____\/\\\__\///\\\/___\/\\\________/\\\//_____
|
||||
_\/\\\_____________\/\\\____\///_____\/\\\_____/\\\//________
|
||||
_\/\\\_____________\/\\\_____________\/\\\___/\\\/___________
|
||||
_\/\\\_____________\/\\\_____________\/\\\__/\\\\\\\\\\\\\\\_
|
||||
_\///______________\///______________\///__\///////////////__
|
||||
|
||||
|
||||
Runtime Edition
|
||||
|
||||
PM2 is a Production Process Manager for Node.js applications
|
||||
with a built-in Load Balancer.
|
||||
|
||||
Start and Daemonize any application:
|
||||
$ pm2 start app.js
|
||||
|
||||
Load Balance 4 instances of api.js:
|
||||
$ pm2 start api.js -i 4
|
||||
|
||||
Monitor in production:
|
||||
$ pm2 monitor
|
||||
|
||||
Make pm2 auto-boot at server restart:
|
||||
$ pm2 startup
|
||||
|
||||
To go further checkout:
|
||||
http://pm2.io/
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
[PM2] Spawning PM2 daemon with pm2_home=/home/shenwei/.pm2
|
||||
[PM2] PM2 Successfully daemonized
|
||||
[PM2] Starting /usr/bin/bash in fork_mode (1 instance)
|
||||
[PM2] Done.
|
||||
┌────┬────────────────┬─────────────┬─────────┬─────────┬──────────┬────────┬──────┬───────────┬──────────┬──────────┬──────────┬──────────┐
|
||||
│ id │ name │ namespace │ version │ mode │ pid │ uptime │ ↺ │ status │ cpu │ mem │ user │ watching │
|
||||
├────┼────────────────┼─────────────┼─────────┼─────────┼──────────┼────────┼──────┼───────────┼──────────┼──────────┼──────────┼──────────┤
|
||||
│ 0 │ vibe-kanban │ default │ N/A │ fork │ 2232962 │ 0s │ 0 │ online │ 0% │ 13.9mb │ shenwei │ disabled │
|
||||
└────┴────────────────┴─────────────┴─────────┴─────────┴──────────┴────────┴──────┴───────────┴──────────┴──────────┴──────────┴──────────┘
|
||||
|
||||
```
|
||||
|
||||
|
||||
**3. 如何管理:**
|
||||
|
||||
- **查看状态**:`pm2 list`
|
||||
|
||||
- **查看实时日志**:`pm2 logs vibe-kanban`
|
||||
|
||||
- **手动停止**:`pm2 stop vibe-kanban`
|
||||
|
||||
- **重启**:`pm2 restart vibe-kanban`
|
||||
|
||||
- **彻底删除进程记录**:`pm2 delete vibe-kanban`
|
||||
|
||||
|
||||
**4. 打开vibe-kanban:**
|
||||
http://192.168.3.45:9999/
|
||||
239
raw/Technical/Vibe Coding/如何在Ubuntu上安装opencode并配置Vibe-Kanban.md
Normal file
239
raw/Technical/Vibe Coding/如何在Ubuntu上安装opencode并配置Vibe-Kanban.md
Normal file
@@ -0,0 +1,239 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [opencode, ubuntu, vibe-coding, vibe-kanban]
|
||||
---
|
||||
|
||||
|
||||
#opencode #ubuntu #vibe-coding #vibe-kanban
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
## Get started with OpenCode.
|
||||
|
||||
[**OpenCode**](https://opencode.ai/) is an open source AI coding agent. It’s available as a terminal-based interface, desktop app, or IDE extension.
|
||||
|
||||
## [Install](https://opencode.ai/docs#install)
|
||||
|
||||
The easiest way to install OpenCode is through the install script.
|
||||
|
||||
Terminal window
|
||||
|
||||
```
|
||||
curl -fsSL https://opencode.ai/install | bash
|
||||
```
|
||||
|
||||
## [Configure](https://opencode.ai/docs#configure)
|
||||
|
||||
With OpenCode you can use any LLM provider by configuring their API keys.
|
||||
|
||||
If you are new to using LLM providers, we recommend using [OpenCode Zen](https://opencode.ai/docs/zen). It’s a curated list of models that have been tested and verified by the OpenCode team.
|
||||
|
||||
1. Run the `/connect` command in the TUI, select opencode, and head to [opencode.ai/auth](https://opencode.ai/auth).
|
||||
|
||||
```
|
||||
/connect
|
||||
```
|
||||
|
||||
2. Sign in, add your billing details, and copy your API key.
|
||||
|
||||
3. Paste your API key.
|
||||
|
||||
```
|
||||
┌ API key││└ enter
|
||||
```
|
||||
|
||||
|
||||
Alternatively, you can select one of the other providers. [Learn more](https://opencode.ai/docs/providers#directory).
|
||||
|
||||
---
|
||||
|
||||
## [Initialize](https://opencode.ai/docs#initialize)
|
||||
|
||||
Now that you’ve configured a provider, you can navigate to a project that you want to work on.
|
||||
|
||||
Terminal window
|
||||
|
||||
```
|
||||
cd /path/to/project
|
||||
```
|
||||
|
||||
And run OpenCode.
|
||||
|
||||
Terminal window
|
||||
|
||||
```
|
||||
opencode
|
||||
```
|
||||
|
||||
Next, initialize OpenCode for the project by running the following command.
|
||||
|
||||
```
|
||||
/init
|
||||
```
|
||||
|
||||
This will get OpenCode to analyze your project and create an `AGENTS.md` file in the project root.
|
||||
|
||||
Tip
|
||||
|
||||
You should commit your project’s `AGENTS.md` file to Git.
|
||||
|
||||
This helps OpenCode understand the project structure and the coding patterns used.
|
||||
|
||||
---
|
||||
|
||||
## [Usage](https://opencode.ai/docs#usage)
|
||||
|
||||
You are now ready to use OpenCode to work on your project. Feel free to ask it anything!
|
||||
|
||||
If you are new to using an AI coding agent, here are some examples that might help.
|
||||
|
||||
---
|
||||
|
||||
### [Ask questions](https://opencode.ai/docs#ask-questions)
|
||||
|
||||
You can ask OpenCode to explain the codebase to you.
|
||||
|
||||
Tip
|
||||
|
||||
Use the `@` key to fuzzy search for files in the project.
|
||||
|
||||
```
|
||||
How is authentication handled in @packages/functions/src/api/index.ts
|
||||
```
|
||||
|
||||
This is helpful if there’s a part of the codebase that you didn’t work on.
|
||||
|
||||
---
|
||||
|
||||
### [Add features](https://opencode.ai/docs#add-features)
|
||||
|
||||
You can ask OpenCode to add new features to your project. Though we first recommend asking it to create a plan.
|
||||
|
||||
1. **Create a plan**
|
||||
|
||||
OpenCode has a _Plan mode_ that disables its ability to make changes and instead suggest _how_ it’ll implement the feature.
|
||||
|
||||
Switch to it using the **Tab** key. You’ll see an indicator for this in the lower right corner.
|
||||
|
||||
```
|
||||
<TAB>
|
||||
```
|
||||
|
||||
Now let’s describe what we want it to do.
|
||||
|
||||
```
|
||||
When a user deletes a note, we'd like to flag it as deleted in the database.Then create a screen that shows all the recently deleted notes.From this screen, the user can undelete a note or permanently delete it.
|
||||
```
|
||||
|
||||
You want to give OpenCode enough details to understand what you want. It helps to talk to it like you are talking to a junior developer on your team.
|
||||
|
||||
Tip
|
||||
|
||||
Give OpenCode plenty of context and examples to help it understand what you want.
|
||||
|
||||
2. **Iterate on the plan**
|
||||
|
||||
Once it gives you a plan, you can give it feedback or add more details.
|
||||
|
||||
```
|
||||
We'd like to design this new screen using a design I've used before.[Image #1] Take a look at this image and use it as a reference.
|
||||
```
|
||||
|
||||
Tip
|
||||
|
||||
Drag and drop images into the terminal to add them to the prompt.
|
||||
|
||||
OpenCode can scan any images you give it and add them to the prompt. You can do this by dragging and dropping an image into the terminal.
|
||||
|
||||
3. **Build the feature**
|
||||
|
||||
Once you feel comfortable with the plan, switch back to _Build mode_ by hitting the **Tab** key again.
|
||||
|
||||
```
|
||||
<TAB>
|
||||
```
|
||||
|
||||
And asking it to make the changes.
|
||||
|
||||
```
|
||||
Sounds good! Go ahead and make the changes.
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
|
||||
### [Make changes](https://opencode.ai/docs#make-changes)
|
||||
|
||||
For more straightforward changes, you can ask OpenCode to directly build it without having to review the plan first.
|
||||
|
||||
```
|
||||
We need to add authentication to the /settings route. Take a look at how this ishandled in the /notes route in @packages/functions/src/notes.ts and implementthe same logic in @packages/functions/src/settings.ts
|
||||
```
|
||||
|
||||
You want to make sure you provide a good amount of detail so OpenCode makes the right changes.
|
||||
|
||||
---
|
||||
|
||||
### [Undo changes](https://opencode.ai/docs#undo-changes)
|
||||
|
||||
Let’s say you ask OpenCode to make some changes.
|
||||
|
||||
```
|
||||
Can you refactor the function in @packages/functions/src/api/index.ts?
|
||||
```
|
||||
|
||||
But you realize that it is not what you wanted. You **can undo** the changes using the `/undo` command.
|
||||
|
||||
```
|
||||
/undo
|
||||
```
|
||||
|
||||
OpenCode will now revert the changes you made and show your original message again.
|
||||
|
||||
```
|
||||
Can you refactor the function in @packages/functions/src/api/index.ts?
|
||||
```
|
||||
|
||||
From here you can tweak the prompt and ask OpenCode to try again.
|
||||
|
||||
Tip
|
||||
|
||||
You can run `/undo` multiple times to undo multiple changes.
|
||||
|
||||
Or you **can redo** the changes using the `/redo` command.
|
||||
|
||||
```
|
||||
/redo
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## [Share](https://opencode.ai/docs#share)
|
||||
|
||||
The conversations that you have with OpenCode can be [shared with your team](https://opencode.ai/docs/share).
|
||||
|
||||
```
|
||||
/share
|
||||
```
|
||||
|
||||
This will create a link to the current conversation and copy it to your clipboard.
|
||||
|
||||
Note
|
||||
|
||||
Conversations are not shared by default.
|
||||
|
||||
Here’s an [example conversation](https://opencode.ai/s/4XP1fce5) with OpenCode.
|
||||
|
||||
---
|
||||
|
||||
## [Customize](https://opencode.ai/docs#customize)
|
||||
|
||||
And that’s it! You are now a pro at using OpenCode.
|
||||
|
||||
To make it your own, we recommend [picking a theme](https://opencode.ai/docs/themes), [customizing the keybinds](https://opencode.ai/docs/keybinds), [configuring code formatters](https://opencode.ai/docs/formatters), [creating custom commands](https://opencode.ai/docs/commands), or playing around with the [OpenCode config](https://opencode.ai/docs/config).
|
||||
@@ -0,0 +1,31 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [claude-code, claude-skills, trae]
|
||||
---
|
||||
|
||||
|
||||
#claude-skills #claude-code #trae
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
## Claude Code Templates - Skills
|
||||
https://www.aitmpl.com/skills
|
||||
|
||||
## Claude Code Templates - Agents
|
||||
https://www.aitmpl.com/agents
|
||||
|
||||
## Claude Code Templates - MCP
|
||||
https://www.aitmpl.com/mcps
|
||||
|
||||
|
||||
直接进入项目目录后执行 `npx`命令比如:
|
||||
https://www.aitmpl.com/component/skill/git-commit-helper
|
||||
```
|
||||
npx claude-code-templates@latest --skill=development/git-commit-helper --yes
|
||||
```
|
||||
37
raw/Technical/Workflow/n8n configure telegram trigger.md
Normal file
37
raw/Technical/Workflow/n8n configure telegram trigger.md
Normal file
@@ -0,0 +1,37 @@
|
||||
---
|
||||
title:
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [n8n, telegram]
|
||||
---
|
||||
|
||||
|
||||
#n8n #telegram
|
||||
## Summary:
|
||||
- When I configure Telegram Trigger, I got an error message: **Telegram Trigger: Bad Request: bad webhook: An HTTPS URL must be provided for webhook**
|
||||
- I search ChatGPT and got solved by this solution:
|
||||
- **Steps to Resolve:**
|
||||
|
||||
1. **Ensure HTTPS Accessibility:**
|
||||
|
||||
- Verify that your **n8n** instance is accessible via an HTTPS URL. If you're running **n8n** locally or without HTTPS, Telegram's webhook setup will fail.
|
||||
2. **Configure Environment Variables:**
|
||||
|
||||
- Set the `WEBHOOK_URL` environment variable to your HTTPS URL. For example:
|
||||
|
||||
ini
|
||||
|
||||
CopyEdit
|
||||
|
||||
`WEBHOOK_URL=https://your-domain.com/`
|
||||
|
||||
- This informs **n8n** to generate webhook URLs using HTTPS.
|
||||
|
||||
I added environment variable in Docker Desktop:
|
||||
WEBHOOK_URL https://n8n.cpolar.top
|
||||
|
||||
After then to check the webhook URL in Telegram Trigger:
|
||||

|
||||
193
raw/Technical/Workflow/n8n docker install & update.md
Normal file
193
raw/Technical/Workflow/n8n docker install & update.md
Normal file
@@ -0,0 +1,193 @@
|
||||
|
||||
#n8n #docker #workflow
|
||||
|
||||
|
||||
|
||||
## n8n Docker install
|
||||
### n8n Docker Compose file
|
||||
``` bash
|
||||
cd /home/shenwei/Docker/n8n
|
||||
```
|
||||
|
||||
create **docker-compose.yml** file
|
||||
``` yaml
|
||||
|
||||
version: '3.8'
|
||||
services:
|
||||
n8n:
|
||||
build: .
|
||||
image: docker.n8n.io/n8nio/n8n
|
||||
container_name: n8n
|
||||
ports:
|
||||
- "5678:5678" # 只绑定到本地,通过 Caddy 访问
|
||||
volumes:
|
||||
- n8n_data:/home/node/.n8n
|
||||
environment:
|
||||
- N8N_PROTOCOL=https
|
||||
- N8N_HOST=n8n.ishenwei.online
|
||||
- WEBHOOK_URL=https://n8n.ishenwei.online/
|
||||
- N8N_TRUST_PROXY=true
|
||||
- N8N_SECURE_COOKIE=true # 建议设为 true,因为使用 HTTPS
|
||||
- N8N_PROXY_HOPS=1
|
||||
- ALL_PROXY=socks5://172.21.0.1:10808 #配置容器内网络代理
|
||||
restart: unless-stopped
|
||||
|
||||
volumes:
|
||||
n8n_data:
|
||||
|
||||
networks:
|
||||
n8n_default:
|
||||
external: true
|
||||
|
||||
```
|
||||
|
||||
Dockerfile
|
||||
```
|
||||
FROM n8nio/n8n:latest
|
||||
USER root
|
||||
|
||||
# 安装 curl 和 wget
|
||||
RUN apk update && apk add --no-cache curl wget
|
||||
|
||||
USER node
|
||||
```
|
||||
|
||||
### Updating Docker Compose
|
||||
[Doc](https://docs.n8n.io/hosting/installation/docker/#updating-docker-compose "Permanent link")
|
||||
|
||||
If you run n8n using a Docker Compose file, follow these steps to update n8n:
|
||||
|
||||
``` bash---
|
||||
title: 安装 curl 和 wget
|
||||
author: shenwei
|
||||
tags: [docker, n8n, workflow]
|
||||
---
|
||||
---
|
||||
title: 安装 curl 和 wget
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [docker, n8n, workflow]
|
||||
---
|
||||
|
||||
# Navigate to the directory containing your docker compose file
|
||||
cd </path/to/your/compose/file/directory>
|
||||
|
||||
# Pull latest version
|
||||
docker compose pull
|
||||
|
||||
# Stop and remove older version
|
||||
docker compose down
|
||||
|
||||
# Start the container
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
### Config n8n network proxy
|
||||
|
||||
#### 1️⃣ 前提条件
|
||||
|
||||
1. V2Ray/Tuic 已安装在宿主机并正常运行。
|
||||
2. V2Ray/Tuic 配置中 **本地监听地址改为 `0.0.0.0`**,端口假设为 `10808`:
|
||||
在V2rayN GUI里需要打开如下配置:
|
||||
![[IMG-20251230094029556.png]]
|
||||
|
||||
3. Docker 网络 `n8n_default` 已存在(由 docker-compose 自动创建即可)
|
||||
4. 宿主机防火墙允许 Docker 网桥访问代理端口:
|
||||
```
|
||||
sudo ufw allow from 172.18.0.0/16 to any port 10808
|
||||
```
|
||||
#### 2️⃣ Dockerfile(扩展官方 n8n 镜像,安装 curl/wget)
|
||||
|
||||
创建 `Dockerfile`:
|
||||
``` bash
|
||||
FROM n8nio/n8n:latest
|
||||
|
||||
USER root
|
||||
|
||||
# 安装 curl 和 wget
|
||||
RUN apk update && apk add --no-cache curl wget
|
||||
|
||||
USER node
|
||||
```
|
||||
- 保持 n8n 默认用户 `node`,安全性高。
|
||||
- 容器内可以直接使用 `curl`、`wget` 测试代理。
|
||||
|
||||
---
|
||||
#### 3️⃣ docker-compose.yml 示例
|
||||
``` yaml
|
||||
|
||||
version: '3.8'
|
||||
services:
|
||||
n8n:
|
||||
build: .
|
||||
image: docker.n8n.io/n8nio/n8n
|
||||
container_name: n8n
|
||||
ports:
|
||||
- "5678:5678" # 只绑定到本地,通过 Caddy 访问
|
||||
volumes:
|
||||
- n8n_data:/home/node/.n8n
|
||||
environment:
|
||||
- N8N_PROTOCOL=https
|
||||
- N8N_HOST=n8n.ishenwei.online
|
||||
- WEBHOOK_URL=https://n8n.ishenwei.online/
|
||||
- N8N_TRUST_PROXY=true
|
||||
- N8N_SECURE_COOKIE=true # 建议设为 true,因为使用 HTTPS
|
||||
- N8N_PROXY_HOPS=1
|
||||
- ALL_PROXY=socks5://172.21.0.1:10808 #配置容器内网络代理
|
||||
restart: unless-stopped
|
||||
|
||||
volumes:
|
||||
n8n_data:
|
||||
|
||||
networks:
|
||||
n8n_default:
|
||||
external: true
|
||||
```
|
||||
|
||||
说明:
|
||||
|
||||
- `ALL_PROXY` 指向宿主机 Docker 网桥 IP + Tuic SOCKS5 端口
|
||||
- 容器内 HTTP/HTTPS 流量和 n8n 请求都会走 SOCKS5
|
||||
- 端口 5678 映射宿主机,便于访问 n8n UI
|
||||
|
||||
> [!注意]
|
||||
注意:`172.21.0.1` 需替换为以下命令输出的网桥 IP(Gateway)。
|
||||
``` bash
|
||||
|
||||
docker network inspect n8n_default
|
||||
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
#### 4️⃣ 在容器内测试科学上网
|
||||
|
||||
进入容器:
|
||||
```
|
||||
docker exec -it n8n /bin/sh
|
||||
```
|
||||
测试:
|
||||
```
|
||||
# 测试 IP
|
||||
curl --socks5 172.18.0.1:10808 https://ifconfig.me
|
||||
|
||||
# 或者使用全局代理环境变量
|
||||
curl https://ifconfig.me
|
||||
wget -qO- https://ifconfig.me
|
||||
```
|
||||
|
||||
如果返回国外 IP,说明代理生效。
|
||||
|
||||
---
|
||||
#### 5️⃣ 可选优化
|
||||
|
||||
- **Dockerfile 内设置环境变量**:可直接在镜像内定义 `ALL_PROXY`,启动容器无需手动设置。
|
||||
- **安全防护**:宿主机防火墙限制仅 Docker 网桥访问 10808,避免局域网被访问。
|
||||
- **升级 n8n**:定期 rebuild 镜像即可。
|
||||
|
||||
## Reference
|
||||
|
||||
[[n8n configure telegram trigger|n8n configure telegram trigger]]
|
||||
@@ -0,0 +1,47 @@
|
||||
---
|
||||
title: N8N Full Tutorial Building AI Agents in 2025 for Beginners!
|
||||
source: https://www.youtube.com/watch?v=ZbIVOy_GPyQ&t=12s
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-03-06
|
||||
description:
|
||||
tags: [ai, ai-agent, n8n, tutorial]
|
||||
link:
|
||||
kanban-plugin:
|
||||
aliases:
|
||||
cssclasses:
|
||||
---
|
||||
|
||||
|
||||
#n8n #ai #ai-agent #tutorial
|
||||
|
||||
**Summary**
|
||||
|
||||
In this comprehensive tutorial, the speaker provides a detailed guide on building AI agents using the N8N platform, aimed primarily at beginners. The video begins by defining agentic systems, explaining the distinction between workflows and agents. Workflows are predefined automations that yield consistent outputs, while agents utilize large language models (LLMs) to dynamically determine the necessary tools and outputs based on user input. The tutorial then introduces N8N’s user interface, focusing on creating workflows and utilizing various node types. The speaker emphasizes the significance of understanding node categories—triggers, action nodes, utility nodes, code nodes, and advanced AI agent nodes—in building effective AI agents. Moving through the steps, the tutorial illustrates how to add tools, manage memory for context retention, and interact with databases like Airtable for inventory management. The video culminates with a call to join the AI Foundations community for further learning and collaboration, highlighting the value of community engagement in mastering AI technologies.
|
||||
|
||||
**Highlights**
|
||||
🤖 Understanding Agentic Systems: Agentic systems consist of agents and workflows, where agents dynamically select tools for user requests.
|
||||
🎛️ Creating Workflows in N8N: The N8N interface is intuitive, allowing users to create workflows easily by choosing triggers and actions.
|
||||
🔑 Node Types Explained: The five categories of nodes (trigger, action, utility, code, and advanced AI) are crucial for building robust automations.
|
||||
💡 Dynamic Memory Usage: Incorporating memory into agents allows for context retention, enhancing user interaction and conversation flow.
|
||||
📊 Integrating Airtable: Using Airtable as a tool enables agents to manage inventory seamlessly, responding to user queries and updates effectively.
|
||||
🌐 Community Learning: Joining the AI Foundations community offers additional resources, courses, and opportunities for collaboration among AI enthusiasts.
|
||||
🎓 Advanced Techniques: The tutorial hints at more complex functionalities, including chaining workflows and utilizing multiple agents for sophisticated automation systems.
|
||||
|
||||
**Key Insights**
|
||||
|
||||
🌍 Agentic Systems Are Essential: Understanding agentic systems is crucial for modern automation. They combine the predictability of workflows with the flexibility of agents, enabling systems that can adapt to user needs dynamically. This adaptability is vital for applications requiring user interaction, such as customer support and personalized services.
|
||||
|
||||
📈 N8N’s User-Friendly Interface: The N8N platform is designed for ease of use, offering a visual interface that simplifies the workflow creation process. The ability to categorize nodes enhances user experience, making it accessible even for beginners. This user-centric design reduces the learning curve associated with complex automation tasks.
|
||||
|
||||
🔍 Importance of Node Types: The categorization of nodes into triggers, actions, utilities, codes, and advanced AI nodes allows for structured and efficient automation. Each node type serves a distinct function, and understanding these roles is crucial in designing effective workflows that meet specific needs.
|
||||
|
||||
🧠 Contextual Memory Enhances Interaction: Implementing memory within AI agents is a game-changer for user interaction. By retaining context from previous interactions, agents can provide more coherent and relevant responses. This capability significantly improves user satisfaction and engagement, making conversations feel more natural.
|
||||
|
||||
🔗 Tool Integration is Key: Integrating external tools like Airtable into the N8N workflows vastly expands the capabilities of AI agents. By allowing agents to pull and update data from databases, users can manage resources efficiently, turning the agent into a powerful tool for real-world applications.
|
||||
|
||||
👥 Community Engagement Accelerates Learning: The AI Foundations community serves as a valuable resource for individuals looking to deepen their knowledge of AI and automation. Collaboration and shared learning experiences within a community can enhance understanding and foster innovation, making it a cornerstone for aspiring AI developers.
|
||||
|
||||
🚀 Potential for Advanced Applications: The tutorial foreshadows the potential for building complex systems by combining multiple agents and workflows. As users become more comfortable with the basics, they can explore advanced techniques, such as chaining workflows, to create highly sophisticated automation solutions that address diverse use cases.
|
||||
|
||||
In conclusion, the video tutorial serves
|
||||
21
raw/Technical/Workflow/n8n+Claude 通过自然语言自动化工作流.md
Normal file
21
raw/Technical/Workflow/n8n+Claude 通过自然语言自动化工作流.md
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
title: 安装Claude Desktop
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [claude, n8n, nodjs]
|
||||
---
|
||||
|
||||
|
||||
#nodjs #n8n #claude
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
|
||||
|
||||
# 安装Claude Desktop
|
||||
https://claude.com/download
|
||||
|
||||
|
||||
217
raw/Technical/Workflow/使用Claude自动生成N8N工作流的实操教程.md
Normal file
217
raw/Technical/Workflow/使用Claude自动生成N8N工作流的实操教程.md
Normal file
@@ -0,0 +1,217 @@
|
||||
|
||||
```table-of-contents
|
||||
```
|
||||
# 标题:使用Claude自动生成N8N工作流的实操教程
|
||||
|
||||
## 概述📚
|
||||
本视频主要介绍如何借助AI助手Claude自动创建n8n工作流,解决新手在架构设计和节点选择中遇到的困惑。作者从零开始手把手演示环境搭建、配置连接、输入提示词,让Claude根据指令自动为我们完成复杂的工作流设计和代码生成,极大提高制作效率。视频内容通俗易懂,重点突出自动化流程创建的实用技巧,适合无编码基础的N8N初学者。
|
||||
|
||||
## Youtube
|
||||
https://www.youtube.com/watch?v=AosTiLQaZc4
|
||||
|
||||
## 核心知识点总结⏰
|
||||
|
||||
### n8n工作流创建难点及Claude介入**
|
||||
新手在建立N8N工作流时常常无从下手,不晓得节点使用和架构设计。作者介绍了一个开源的N8N MCP(多功能控制面板)项目,可嫁接到Claude,通过输入自然语言提示直接生成工作流,免去繁琐操作。
|
||||
|
||||
### n8n-mcp 项目
|
||||
https://github.com/czlonkowski/n8n-mcp
|
||||
n8n-MCP serves as a bridge between n8n's workflow automation platform and AI models, enabling them to understand and work with n8n nodes effectively. It provides structured access to:
|
||||
|
||||
- 📚 **543 n8n nodes** from both n8n-nodes-base and @n8n/n8n-nodes-langchain
|
||||
- 🔧 **Node properties** - 99% coverage with detailed schemas
|
||||
- ⚡ **Node operations** - 63.6% coverage of available actions
|
||||
- 📄 **Documentation** - 87% coverage from official n8n docs (including AI nodes)
|
||||
- 🤖 **AI tools** - 271 AI-capable nodes detected with full documentation
|
||||
- 💡 **Real-world examples** - 2,646 pre-extracted configurations from popular templates
|
||||
- 🎯 **Template library** - 2,709 workflow templates with 100% metadata coverage
|
||||
|
||||
### 环境搭建:Node.js安装与启动n8n-mcp**
|
||||
演示如何下载Node.js安装包(根据操作系统选择),并在Windows的Terminal中运行命令完成安装,确保环境支持后续工作流自动化操作。
|
||||
#### 安装node.js
|
||||
https://nodejs.org/en/download
|
||||
|
||||
``` shell---
|
||||
title: 标题:使用Claude自动生成N8N工作流的实操教程
|
||||
author: shenwei
|
||||
---
|
||||
---
|
||||
title: 标题:使用Claude自动生成N8N工作流的实操教程
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: []
|
||||
---
|
||||
|
||||
# Docker has specific installation instructions for each operating system.
|
||||
# Please refer to the official documentation at https://docker.com/get-started/
|
||||
|
||||
# Pull the Node.js Docker image:
|
||||
docker pull node:24-alpine
|
||||
|
||||
# Create a Node.js container and start a Shell session:
|
||||
docker run -it --rm --entrypoint sh node:24-alpine
|
||||
|
||||
# Verify the Node.js version:
|
||||
node -v # Should print "v24.12.0".
|
||||
|
||||
# Verify npm version:
|
||||
npm -v # Should print "11.6.2".
|
||||
|
||||
```
|
||||
|
||||
#### 启动n8n-mcp
|
||||
|
||||
在之前node.js的terminal里直接输入以下命令
|
||||
|
||||
``` shell
|
||||
# Run directly with npx (no installation needed!)
|
||||
npx n8n-mcp
|
||||
```
|
||||
|
||||
看到以下log,说明安装成功:
|
||||
```
|
||||
/ # npx n8n-mcp
|
||||
Need to install the following packages:
|
||||
n8n-mcp@2.31.3
|
||||
Ok to proceed? (y) y
|
||||
|
||||
|
||||
╔════════════════════════════════════════════════════════════╗
|
||||
║ Anonymous Usage Statistics ║
|
||||
╠════════════════════════════════════════════════════════════╣
|
||||
║ ║
|
||||
║ n8n-mcp collects anonymous usage data to improve the ║
|
||||
║ tool and understand how it's being used. ║
|
||||
║ ║
|
||||
║ We track: ║
|
||||
║ • Which MCP tools are used (no parameters) ║
|
||||
║ • Workflow structures (sanitized, no sensitive data) ║
|
||||
║ • Error patterns (hashed, no details) ║
|
||||
║ • Performance metrics (timing, success rates) ║
|
||||
║ ║
|
||||
║ We NEVER collect: ║
|
||||
║ • URLs, API keys, or credentials ║
|
||||
║ • Workflow content or actual data ║
|
||||
║ • Personal or identifiable information ║
|
||||
║ • n8n instance details or locations ║
|
||||
║ ║
|
||||
║ Your anonymous ID: 17c0ba5830754999 ║
|
||||
║ ║
|
||||
║ This helps me understand usage patterns and improve ║
|
||||
║ n8n-mcp for everyone. Thank you for your support! ║
|
||||
║ ║
|
||||
║ To opt-out at any time: ║
|
||||
║ npx n8n-mcp telemetry disable ║
|
||||
║ ║
|
||||
║ Data deletion requests: ║
|
||||
║ Email romuald@n8n-mcp.com with your anonymous ID ║
|
||||
║ ║
|
||||
║ Learn more: ║
|
||||
║ https://github.com/czlonkowski/n8n-mcp/blob/main/PRIVACY.md ║
|
||||
║ ║
|
||||
╚════════════════════════════════════════════════════════════╝
|
||||
|
||||
[2025-12-31T05:40:02.650Z] [n8n-mcp] [INFO] Node.js version: v24.12.0
|
||||
[2025-12-31T05:40:02.650Z] [n8n-mcp] [INFO] Platform: linux x64
|
||||
[2025-12-31T05:40:02.650Z] [n8n-mcp] [INFO] Attempting to use better-sqlite3...
|
||||
[2025-12-31T05:40:02.651Z] [n8n-mcp] [INFO] Initializing n8n Documentation MCP server
|
||||
[2025-12-31T05:40:02.652Z] [n8n-mcp] [WARN] Failed to initialize better-sqlite3, falling back to sql.js Error: Failed to create better-sqlite3 adapter: Error: Cannot find module 'better-sqlite3'
|
||||
Require stack:
|
||||
- /root/.npm/_npx/b6a381d62ce0fe56/node_modules/n8n-mcp/dist/database/database-adapter.js
|
||||
- /root/.npm/_npx/b6a381d62ce0fe56/node_modules/n8n-mcp/dist/mcp/server.js
|
||||
- /root/.npm/_npx/b6a381d62ce0fe56/node_modules/n8n-mcp/dist/mcp/index.js
|
||||
at createBetterSQLiteAdapter (/root/.npm/_npx/b6a381d62ce0fe56/node_modules/n8n-mcp/dist/database/database-adapter.js:96:15)
|
||||
at createDatabaseAdapter (/root/.npm/_npx/b6a381d62ce0fe56/node_modules/n8n-mcp/dist/database/database-adapter.js:55:31)
|
||||
at N8NDocumentationMCPServer.initializeDatabase (/root/.npm/_npx/b6a381d62ce0fe56/node_modules/n8n-mcp/dist/mcp/server.js:180:74)
|
||||
at new N8NDocumentationMCPServer (/root/.npm/_npx/b6a381d62ce0fe56/node_modules/n8n-mcp/dist/mcp/server.js:109:33)
|
||||
at main (/root/.npm/_npx/b6a381d62ce0fe56/node_modules/n8n-mcp/dist/mcp/index.js:143:32)
|
||||
at Object.<anonymous> (/root/.npm/_npx/b6a381d62ce0fe56/node_modules/n8n-mcp/dist/mcp/index.js:217:5)
|
||||
at Module._compile (node:internal/modules/cjs/loader:1761:14)
|
||||
at Object..js (node:internal/modules/cjs/loader:1893:10)
|
||||
at Module.load (node:internal/modules/cjs/loader:1481:32)
|
||||
at Module._load (node:internal/modules/cjs/loader:1300:12)
|
||||
[2025-12-31T05:40:02.854Z] [n8n-mcp] [INFO] Loaded existing database from /root/.npm/_npx/b6a381d62ce0fe56/node_modules/n8n-mcp/data/nodes.db
|
||||
[2025-12-31T05:40:02.855Z] [n8n-mcp] [INFO] Successfully initialized sql.js adapter (pure JavaScript, no native dependencies)
|
||||
[2025-12-31T05:40:02.885Z] [n8n-mcp] [INFO] FTS5 not available, using LIKE search for templates
|
||||
[2025-12-31T05:40:02.886Z] [n8n-mcp] [INFO] Database initialized successfully from: /root/.npm/_npx/b6a381d62ce0fe56/node_modules/n8n-mcp/data/nodes.db
|
||||
[2025-12-31T05:40:02.887Z] [n8n-mcp] [INFO] MCP server initialized with 7 tools (n8n API: not configured)
|
||||
[2025-12-31T05:40:02.891Z] [n8n-mcp] [WARN] FTS5 not available - using fallback search. For better performance, ensure better-sqlite3 is properly installed.
|
||||
[2025-12-31T05:40:02.891Z] [n8n-mcp] [INFO] Database health check passed: 802 nodes loaded
|
||||
[2025-12-31T05:40:02.892Z] [n8n-mcp] [INFO] n8n Documentation MCP Server running on stdio transport
|
||||
[2025-12-31T05:40:02.892Z] [n8n-mcp] [INFO] Server startup completed in 246ms (6 checkpoints passed)
|
||||
```
|
||||
|
||||
#### Claude客户端下载安装及开发者配置**
|
||||
指导下载安装Claude桌面版,进入“Developer”设置页编辑配置文件,将N8N服务地址和API密钥填入,确保Claude连接N8N MCP功能正常。
|
||||
[[🟠如何用指纹浏览器安全注册并订阅Claude Pro会员全攻略]]
|
||||
#### 高级prompt配置与项目初始化**
|
||||
介绍用于指导Claude理解N8N所有功能的复杂prompt,粘贴到Claude项目的指令区,激活39个集成工具,丰富Claude的工作流构建能力。
|
||||
|
||||
#### 优化Claude设置及自动生成实际案例演示**
|
||||
调整模型为Opensea、开启extended thinking,尝试命令让Claude创建定时爬取新闻、更新到Google表格的N8N工作流。Claude自动选节点、写代码实现工作流逻辑。
|
||||
|
||||
#### 运行结果调试及问题反馈**
|
||||
实际运行中出现节点无输出错误,反馈给Claude让其检查API问题并修复流程。演示如何通过迭代让Claude改进脚本,节省手工调试成本。
|
||||
|
||||
#### Claude自动生成工作流优缺点分析**
|
||||
Claude能实现约80%-90%正确的工作流布局和逻辑,尽管有细节错误仍需人工二次修正,但对新手尤其友好,显著降低学习门槛和工作时间。未来随着AI模型迭代,期待更完善的自动化解决方案。
|
||||
|
||||
|
||||
## 重要术语与定义📖
|
||||
|
||||
- **N8N**:一款开源的工作流自动化工具,支持节点连接执行任务。
|
||||
- **工作流(Workflow)**:由多个任务节点按照一定顺序执行的自动化流程。
|
||||
- **节点(Node)**:工作流中的单个操作单元,如触发器、数据处理、API调用等。
|
||||
- **Claude**:基于人工智能的助手工具,可读取指令并自动生成代码或工作流。
|
||||
- **MCP**:此处指代N8N的功能扩展模块,允许外部工具调用其所有节点功能。
|
||||
- **Prompt**:向AI模型输入的描述性文本,用以引导其执行特定任务。
|
||||
- **API Key**:用于认证访问服务的密钥,保证接口调用的安全。
|
||||
- **extended thinking**:Claude的一种运行模式,支持更深层次逻辑推理。
|
||||
- **Opensea模型**:为代码生成优化的Claude子模型,适合自动编程任务。
|
||||
|
||||
## 推理结构🧩
|
||||
|
||||
1. **提出难题**:新手不知如何设计和搭建N8N工作流架构 →
|
||||
2. **引入方案**:利用Claude与N8N MCP结合,输入自然语言创建工作流 →
|
||||
3. **搭建环境**:安装Node.js、下载Claude桌面端,配置API连接 →
|
||||
4. **激活功能**:导入高级prompt学习全部N8N节点功能 →
|
||||
5. **执行任务**:Claude根据提示自动寻找节点并编码,生成工作流 →
|
||||
6. **反馈修正**:发现错误交由Claude检查修复代码 →
|
||||
7. **总结成效**:Claude可完成大部分工作流规划,减轻人力负担,未来发展空间大。
|
||||
|
||||
## 实例讲解🛠️
|
||||
|
||||
- **新闻爬取上传Google表格案例**
|
||||
指令:每小时爬取最新新闻,更新至Google表格。Claude查找爬取节点、设置触发器、写入Google Sheets节点,无需用户编码。此示例充分展示了Claude智能串联节点、实现自动化流程的能力,并帮助用户解决了选节点和写代码的难题。
|
||||
|
||||
## 容易出错点⚠️
|
||||
|
||||
- **环境安装步骤遗漏**:未正确安装Node.js会导致后续命令无法执行,确保版本号显示正确。
|
||||
- **API Key配置错误**:API Key格式或权限错误会导致Claude无法连接N8N服务器,需在N8N后台正确生成并复制。
|
||||
- **第一次运行弹窗授权忽视**:首次运行需确认弹窗授权,否则功能不全。
|
||||
- **自动生成工作流的不完美**:Claude生成的脚本约有10%-20%的错误率,需用户反复修正。误以为可“一劳永逸”是误区。
|
||||
- **模型选择失误**:没有切换到Opensea模型时,代码生成效果差强人意。
|
||||
|
||||
## 快速复习提示/自测题📝
|
||||
|
||||
**提示(无答案)**
|
||||
- Claude是如何帮助自动创建N8N工作流的?
|
||||
- 设置Claude连接N8N需要填写哪些关键配置数据?
|
||||
- 为什么要选择Opensea模型和开启extended thinking模式?
|
||||
- 遇到工作流节点无输出时应该如何排查处理?
|
||||
|
||||
**练习(含答案)**
|
||||
1. N8N MCP是什么?
|
||||
答:N8N的多功能控制面板,可以让外部工具(如Claude)调用N8N所有节点,实现自动工作流创建。
|
||||
2. 配置Claude连接N8N时,需要从N8N后台获取哪两个关键参数?
|
||||
答:N8N服务器地址和API Key。
|
||||
3. Claude生成的自动化工作流大概能达到的完成度是多少?
|
||||
答:约80%-90%,部分细节仍需人工调整。
|
||||
4. 新手如何使用Claude减少N8N编程难度?
|
||||
答:直接输入自然语言需求,让Claude自动设计工作流和编写代码,避免自行搭建节点和写复杂代码。
|
||||
|
||||
## 总结与回顾🔍
|
||||
本视频系统地介绍了利用Claude智能助手自动生成N8N工作流的完整流程,从环境搭建、关键配置到提示词导入、实际任务执行和调试改进。通过此方法,特别是缺乏编程基础的新手能快速搭建功能复杂的自动化流程,大幅提升效率。尽管现阶段自动化结果还不完美,仍需反复迭代,但整体架构合理、逻辑清晰,展现了AI辅助工作流创建的巨大潜力。未来随着大模型的进步,这种流程自动化将越来越成熟,成为低代码甚至无代码开发的重要助力。
|
||||
211
raw/Technical/开发经验与项目规范整理文档.md
Normal file
211
raw/Technical/开发经验与项目规范整理文档.md
Normal file
@@ -0,0 +1,211 @@
|
||||
---
|
||||
title: vibe-coding-cn/i18n/zh/documents/Methodology and Principles/A Formalization of Recursive Self-Optimizing Generative Systems.md at main · 2025Emma/vibe-coding-cn
|
||||
source: https://github.com/2025Emma/vibe-coding-cn/blob/main/i18n/zh/documents/Methodology%20and%20Principles/%E5%BC%80%E5%8F%91%E7%BB%8F%E9%AA%8C.md
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-12-30
|
||||
description: Contribute to 2025Emma/vibe-coding-cn development by creating an account on GitHub.
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
|
||||
|
||||
## 开发经验与项目规范整理文档
|
||||
|
||||
## 目录
|
||||
|
||||
1. 变量名维护方案
|
||||
2. 文件结构与命名规范
|
||||
3. 编码规范(Coding Style Guide)
|
||||
4. 系统架构原则
|
||||
5. 程序设计核心思想
|
||||
6. 微服务
|
||||
7. Redis
|
||||
8. 消息队列
|
||||
|
||||
---
|
||||
|
||||
## 1\. 变量名维护方案
|
||||
|
||||
## 1.1 新建“变量名大全文件”
|
||||
|
||||
建立一个统一的变量索引文件,用于 AI 以及团队整体维护。
|
||||
|
||||
### 文件内容包括(格式示例):
|
||||
|
||||
| 变量名 | 变量注释(描述) | 出现位置(文件路径) | 出现频率(统计) |
|
||||
| --- | --- | --- | --- |
|
||||
| user\_age | 用户年龄 | /src/user/profile.js | 12 |
|
||||
|
||||
### 目的
|
||||
|
||||
- 统一变量命名
|
||||
- 方便全局搜索
|
||||
- AI 或人工可统一管理、重构
|
||||
- 降低命名冲突和语义不清晰带来的风险
|
||||
|
||||
---
|
||||
|
||||
## 2\. 文件结构与命名规范
|
||||
|
||||
## 2.1 子文件夹内容
|
||||
|
||||
每个子目录中需要包含:
|
||||
|
||||
- `agents` —— 负责自动化流程、提示词、代理逻辑
|
||||
- `claude.md` —— 存放该文件夹内容的说明文档、设计思路与用途
|
||||
|
||||
## 2.2 文件命名规则
|
||||
|
||||
- 使用 **小写英文 + 下划线** 或 **小驼峰** (视语言而定)
|
||||
- 文件名需体现内容职责
|
||||
- 避免缩写与含糊不清的命名
|
||||
|
||||
示例:
|
||||
|
||||
- `user_service.js`
|
||||
- `order_processor.py`
|
||||
- `config_loader.go`
|
||||
|
||||
## 2.3 变量与定义规则及解释
|
||||
|
||||
- 命名尽可能语义化
|
||||
- 遵循英语语法逻辑(名词属性、动词行为)
|
||||
- 避免 `a, b, c` 此类无意义名称
|
||||
- 常量使用大写 + 下划线(如: `MAX_RETRY_COUNT` )
|
||||
|
||||
---
|
||||
|
||||
## 3\. 编码规范
|
||||
|
||||
每个文件、每个类、每个函数应只负责一件事。
|
||||
|
||||
- 提炼公共逻辑
|
||||
- 避免重复代码(DRY)
|
||||
- 模块化、函数化,提高复用价值
|
||||
|
||||
系统行为应明确划分:
|
||||
|
||||
| 概念 | 说明 |
|
||||
| --- | --- |
|
||||
| 消费端 | 接收外部数据或依赖输入的地方 |
|
||||
| 生产端 | 生成数据、输出结果的地方 |
|
||||
| 状态(变量) | 存储当前系统信息的变量 |
|
||||
| 变换(函数) | 处理状态、改变数据的逻辑 |
|
||||
|
||||
明确区分 **输入 → 处理 → 输出** ,并独立管理每个环节。
|
||||
|
||||
### 3.4 并发(Concurrency)
|
||||
|
||||
- 清晰区分共享资源
|
||||
- 避免数据竞争
|
||||
- 必要时加锁或使用线程安全结构
|
||||
- 区分“并发处理”和“异步处理”的差异
|
||||
|
||||
---
|
||||
|
||||
## 4\. 系统架构原则
|
||||
|
||||
### 4.1 先梳理清楚架构
|
||||
|
||||
在写代码前先明确:
|
||||
|
||||
- 模块划分
|
||||
- 输入输出
|
||||
- 数据流向
|
||||
- 服务边界
|
||||
- 技术栈
|
||||
- 依赖关系
|
||||
|
||||
严谨开发流程:
|
||||
|
||||
1. 先理解需求
|
||||
2. 保持架构与代码简单
|
||||
3. 写可维护的自动化测试
|
||||
4. 小步迭代,不做大爆炸开发
|
||||
|
||||
---
|
||||
|
||||
## 5\. 程序设计核心思想
|
||||
|
||||
## 5.1 从问题开始,而不是从代码开始
|
||||
|
||||
编程的第一步永远是: **你要解决什么问题?**
|
||||
|
||||
复杂问题拆解为可独立完成的小单元。
|
||||
|
||||
减少复杂度、魔法代码、晦涩技巧。
|
||||
|
||||
用函数、类、模块复用逻辑,不要复制粘贴。
|
||||
|
||||
## 5.5 清晰的命名
|
||||
|
||||
- `user_age` 比 `a` 清晰
|
||||
- `get_user_profile()` 比 `gp()` 清晰 命名要体现 **用途** 和 **语义** 。
|
||||
|
||||
## 5.6 单一职责
|
||||
|
||||
一个函数只处理一个任务。
|
||||
|
||||
## 5.7 代码可读性优先
|
||||
|
||||
你写的代码是给别人理解的,不是来炫技的。
|
||||
|
||||
## 5.8 合理注释
|
||||
|
||||
注释解释“为什么”,不是“怎么做”。
|
||||
|
||||
先能跑,再让它好看,最后再优化性能。
|
||||
|
||||
## 5.10 错误是朋友,调试是必修课
|
||||
|
||||
阅读报错、查日志、逐层定位,是程序员核心技能。
|
||||
|
||||
永远不要把代码只放本地。
|
||||
|
||||
## 5.12 测试你的代码
|
||||
|
||||
未测试的代码迟早会出问题。
|
||||
|
||||
## 5.13 编程是长期练习
|
||||
|
||||
所有人都经历过:
|
||||
|
||||
- bug 调不出来
|
||||
- 通过时像挖到宝
|
||||
- 看着看着能看懂别人代码
|
||||
|
||||
坚持即是高手。
|
||||
|
||||
---
|
||||
|
||||
## 6\. 微服务
|
||||
|
||||
微服务是一种架构模式,将系统拆解为多个 **独立开发、独立部署、独立扩容** 的服务。
|
||||
|
||||
特点:
|
||||
|
||||
- 每个服务处理一个业务边界(Bounded Context)
|
||||
- 服务间通过 API 通信(HTTP、RPC、MQ 等)
|
||||
- 更灵活、更可扩展、容错更高
|
||||
|
||||
---
|
||||
|
||||
Redis 的作用:
|
||||
|
||||
- 作为缓存极大提升系统“读性能”
|
||||
- 降低数据库压力
|
||||
- 提供计数、锁、队列、Session 等能力
|
||||
- 让系统更快、更稳定、更抗压
|
||||
|
||||
---
|
||||
|
||||
消息队列用于服务之间的“异步通信”。
|
||||
|
||||
作用:
|
||||
|
||||
- 解耦
|
||||
- 削峰填谷
|
||||
- 异步任务处理
|
||||
- 提高系统稳定性与吞吐
|
||||
46
raw/Technical/我的工具集.md
Normal file
46
raw/Technical/我的工具集.md
Normal file
@@ -0,0 +1,46 @@
|
||||
|
||||
#tool #ai #paid #service
|
||||
|
||||
|
||||
---
|
||||
title: AI 工具
|
||||
author: shenwei
|
||||
tags: [ai, brightdata, decopy, dialog, gemini, google, hailuo, image-editor, image-to-vidoe, paid, scaper, service, speech, summary, text-to-speech, text-to-video, tool, video, vidu, wavespeed, youtube]
|
||||
---
|
||||
---
|
||||
title: AI 工具
|
||||
source:
|
||||
author: shenwei
|
||||
published:
|
||||
created:
|
||||
description:
|
||||
tags: [ai, brightdata, decopy, dialog, gemini, google, hailuo, image-editor, image-to-vidoe, paid, scaper, service, speech, summary, text-to-speech, text-to-video, tool, video, vidu, wavespeed, youtube]
|
||||
---
|
||||
|
||||
# AI 工具
|
||||
|
||||
| **AI Type** | | Provide | **Description** | **Pricing Plan** | **Url** | **Tags** | **Model** | **Paid** |
|
||||
| ------------------ | --- | ----------- | -------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------- | --------------------------------------------------------------- | ------------------------------------------- | --------- | -------- |
|
||||
| **Text-to-Speech** | | #google | | | https://aistudio.google.com/generate-speech | #text-to-speech #gemini #speech <br>#dialog | | |
|
||||
| | | | | | | | | |
|
||||
| | | | | | | | | |
|
||||
| | | | | | | | | |
|
||||
| | | | | | | | | |
|
||||
| | | | | | | | | |
|
||||
| **Text-to-Image** | | | | | | | | |
|
||||
| | | | | | | | | |
|
||||
| **Text-to-Video** | | | | | | | | |
|
||||
| | | | | | | | | |
|
||||
| | | | | | | | | |
|
||||
| **Image-Editor** | | #wavespeed | | | https://wavespeed.ai/collections/image-editor | #image-editor | | |
|
||||
| | | | | | | | | |
|
||||
| **Image-to-Vidoe** | | #wavespeed | | | https://wavespeed.ai/models?typeList=image-to-video&sort=visits | #image-to-vidoe <br>#text-to-video | | ☑️ |
|
||||
| | | #vidu | | $8/month | https://www.vidu.com/zh/home/recommend | #image-to-vidoe <br>#text-to-video | | |
|
||||
| | | #hailuo | | ¥42/month | https://hailuoai.com/ | #image-to-vidoe <br>#text-to-video | | |
|
||||
| | | | | | | | | |
|
||||
| **Web-Scraper** | | #brightdata | | | https://brightdata.com/cp/scrapers | #scaper | | ☑️ |
|
||||
| | | | | | | | | |
|
||||
| | | | | | | | | |
|
||||
| **AI-Summary** | | #decopy | Decopy's Summary Generator can summarize articles, PDFs and videos in seconds. Offering multiple summary modes, mind maps and multilingual output. | | https://decopy.ai/ | #summary <br>#youtube <br>#video | | |
|
||||
| | | | | | | | | |
|
||||
|
||||
400
raw/Technical/教學 ChatGPT 先做知識整理,再讓 Canva、 Gamma AI 輸出簡報.md
Normal file
400
raw/Technical/教學 ChatGPT 先做知識整理,再讓 Canva、 Gamma AI 輸出簡報.md
Normal file
@@ -0,0 +1,400 @@
|
||||
---
|
||||
title: [教學] ChatGPT 先做知識整理,再讓 Canva、 Gamma AI 輸出簡報
|
||||
source: https://www.playpcesor.com/2025/10/chatgpt-canva-gamma-ai.html
|
||||
author: shenwei
|
||||
published: 2025-10-26
|
||||
created: 2025-12-18
|
||||
description: 分享各種行動工作技巧、雲端生活應用,善用數位工具改變你我的工作效率與生活品質。
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||
**Canva 不只是圖像設計工具,也有很多人直接把她當成簡報設計軟體** ,在這兩三年的線上直播中,我已經愈來愈常看到用 Canva 製作的簡報。(延伸參考: [用 Canva 設計精美會議文件、專案報告、學習單,自動轉換成簡報](https://www.playpcesor.com/2022/12/canva.html) )
|
||||
|
||||
|
||||
|
||||
因為 Canva 即使是免費帳號,也提供了非常豐富的簡報模板,加上內建的各種 ICON、圖示、中文字體元素,對大多數人來說都能輕鬆製作出好看的簡報內容。後來又有了 AI 功能加入,讓設計簡報變得更輕鬆。(延伸閱讀: [Canva AI 2024 最新 15 個圖片生成、修圖自動化功能應用案例教學](https://www.playpcesor.com/2024/04/canva-ai-2024-15.html) )
|
||||
|
||||
|
||||
|
||||
今年(2025), **Canva 更直接推出全新的 AI 問答功能,甚至可以透過指令讓 Canva 自己組合內建的各種模板與素材,一句話生成精美簡報、文件、封面等等** 。不過一開始,這個 Canva AI 問答功能只針對英文為主,到了 2025 年 9 月開始加入了中文的支援,現在也可以直接下指令,就讓 Canva AI 從頭到尾幫我們製作出一份有內容、有版面、有圖片的簡報。
|
||||
|
||||
|
||||
|
||||
[](https://blogger.googleusercontent.com/img/a/AVvXsEhjbwLD63oYvUj6IG7GqCwvkMumay3dCwmdZ943YDyp-ISSZgQLJWH3HbBE2abYrtuRdqxRv8TvxITBTwHJ_0EqXWrZuTzRElLOuH8qZLQ8WepjCjH-3I9o4UjmADGcIHzBrl2j8hCn1T5tg0G7FEjlF9hdyY0JykFbDrie9-lw4T8XyIz1MCt48w)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
雖然 AI 簡報很好用,像是除了 Canva AI 簡報,我之前也很常使用「 [Gamma AI](https://www.playpcesor.com/2023/04/gamma-ai.html) 」來製作各種工作、課程中的簡報。
|
||||
|
||||
|
||||
|
||||
> 但是,我的流程有點不一樣, **我不會「直接在 Canva、Gamma 這樣工具上憑空製作一份簡報 」。而是先在 ChatGPT 上做資料收集、整理、分析後,再讓 Canva、 Gamma AI 做出美美的簡報版面。**
|
||||
|
||||
|
||||
|
||||
因為一份簡報如果沒有經過資料研究、知識整理的過程,直接「給一個題目」,就要把論述、內容、案例、版面、圖像素材等一次做好,我的經驗是「很難做出正確、有效、深入」的簡報成果。
|
||||
|
||||
|
||||
|
||||
Canva、 Gamma 這類工具可以幫忙把簡報設計得很漂亮沒錯,但是卻不適合做「前期的簡報資料收集、研究、整理、分析」。
|
||||
|
||||
|
||||
|
||||
下面就分享一套我自己先在 ChatGPT 上討論專案,完成簡報大綱後,再用 Canva、 Gamma 製作簡報的流程。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 階段一:利用 5 分鐘,教 ChatGPT 快速閱讀、搜尋、研究大量資料
|
||||
|
||||
假設我現在只有一個簡報題目「防彈筆記法說明」,那麼我絕對不會直接把這個題目丟給 Canva、 Gamma 去做簡報,那樣會非常容易出錯、出現很多幻覺、內容也不夠深入。
|
||||
|
||||
|
||||
|
||||
相對的, **我會先打開 [ChatGPT](https://www.playpcesor.com/2024/11/chatgpt-search-ai.html) ,開始問題研究與資料收集,利用下面這個指令,「反覆多次」替換「知識主題」的關鍵字,讓 ChatGPT 上網搜尋後「調閱」出一筆一筆簡報內容中需要的知識、案例、素材** 。
|
||||
|
||||
|
||||
|
||||
你是個人知識管理專家,請跟我解釋「電腦玩物 esor 的防彈筆記法」。請一步一步分析:先「上網搜尋相關資料」,以「條列清單的格式」,用一般人也能懂的用語,兼顧廣度與深度細節,說明這個主題。
|
||||
|
||||
|
||||
|
||||
這個過程通常我會進行 5 分鐘左右,調閱出 10 筆以上資料,作為接下來製作簡報的素材庫。
|
||||
|
||||
|
||||
|
||||
[](https://blogger.googleusercontent.com/img/a/AVvXsEj2ODrxhoGfpxgWId63WcPTN5Ub2Dr-RKJPCexEmERJKA17KQ5BfRhwQjmRZ5ZlQjF5u9I7Ykam_JNUXV8ikacd_a3H4b1LyAo2-F5qsVlk6hamYX0O_Teco3RCGMPuTcRcUvs9TTKC-0BdL0G7tRsgnVhY28alrqJzJzbERY7TkakbEfzSjE5zAA)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 階段二:利用 1 分鐘,教 ChatGPT 建立知識架構
|
||||
|
||||
然後,我會利用下面指令,讓 ChatGPT 整理上面調閱出來的十幾筆素材資料,做一次比對統整。
|
||||
|
||||
|
||||
|
||||
**我把這個過程認為是「教 AI 建立一個知識架構」** , **讓 ChatGPT 對「防彈筆記法」這個簡報主題有跟我一樣的客觀資料認識,和主觀詮釋角度** 。
|
||||
|
||||
|
||||
|
||||
整合上面所有討論資料,建立一個「防彈筆記法方法、應用」的對比表格,呈現出「打破知識管理、資料整理迷思」的特色。
|
||||
|
||||
|
||||
|
||||
可以這樣想像,這兩個階段是讓 AI 進行製作簡報前的研究、整理,並建立「詮釋觀點」。
|
||||
|
||||
|
||||
|
||||
[](https://blogger.googleusercontent.com/img/a/AVvXsEhZJZ0QFRE6ic_6CqHvrgscVknmoe_LHCvFZEdU07yc256cAljw6Brg9htkM_HPAgPrvMpwGEFj8a2NUSqxGG3T22wlnhc4UOGWplU3Rl4qbR5QQsGWF59hLdOXZ0FKRhuKAPuoMc07-LSRO-8DYDaSorPRfkvQoEQDPFTM9g_Uwq2mFJnt0Y8Big)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 階段三:利用 1 分鐘,要求 ChatGPT 根據閱讀與理解,輸出簡報大綱
|
||||
|
||||
接下來,我才讓 ChatGPT 去製作「文字版」的簡報大綱,指令通常如下:
|
||||
|
||||
|
||||
|
||||
統整上方的討論,根據「防彈筆記法是幫你更快輸出的知識管理系統」主題,簡報對象是「一般職場工作者」,設計出 10 頁簡報大綱。請一步一步分析,先梳理上方討論的重點,根據背景、解決的問題、方法與應用,拆解出最容易讓人理解的順序。每一頁有一個明確主題,每個主題下條列關鍵重點,並帶入更多具體的數據資料細節,並且最後有吸引人的結論。
|
||||
|
||||
|
||||
|
||||
> 在文字資料的處理,內容的推理思考上, ChatGPT 這類工具一定還是做得比 Canva、 Gamma 等工具要好,
|
||||
|
||||
**所以先在 ChatGPT 上完成文字版的簡報大綱,再把大綱貼上 Canva、 Gamma 去製作簡報。**
|
||||
|
||||
|
||||
|
||||
[](https://blogger.googleusercontent.com/img/a/AVvXsEjpOExFv1-fe2iXNnBDA77Lgd4Z5BTbwo90FtVKXGNt-0KVc5g2NCFz3a9jGLPgVp0XJg977Y7Efc_IqdHPzCTy_lyHkYXOf8WqIQpCEi8VpQ2mFTF1P_cvAgGkcInZy73jdIldJDTCVYItL-kj1yUIn7EE_SSW2k9IMDpR7EbxiEF_CtjzGyPqJw)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 階段四:將 ChatGPT 簡報大綱複製到 Canva ,完成簡報設計
|
||||
|
||||
|
||||
|
||||
最近 OpenAI 有推出新功能,可以直接在 ChatGPT 啟動 Canva , **但需要先把 Canva 切換到英文版,才會比較容易成功,但實際嘗試還是偶爾會失敗。**
|
||||
|
||||
|
||||
|
||||
[](https://blogger.googleusercontent.com/img/a/AVvXsEjD0He2MmJizXG7BXDfk6YjJs01OTFgL8SNDl4ILujuMyyuWlcYToz4l1r0TRhhMHt2BtCetXcePZ4o9_UTqAivLto9T7t7ieW3JxRLal2R-Sn2RzbvlWOOXstVfkiO5wEHsQvA7KN_g5AOVGYP8xh72YStf26422DxYbWF-s9MS3D_hyNmQUahLQ)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
根據下面簡報大綱,保留完整內容、架構、分頁,利用 canva 製作出精美簡報:
|
||||
|
||||
|
||||
|
||||
1|為什麼知識管理常常「用不久、產出慢」
|
||||
|
||||
常見困境:資料四散(聊天室、信箱、雲端)、會議逐字稿無法落地、剪藏一堆卻用不上。
|
||||
|
||||
你可以自查的三個數字(本週就量):
|
||||
|
||||
找資料時間:一天花幾分鐘在找「那份檔案/結論」?
|
||||
|
||||
下一步明確率:每個任務是否都有「下一步×1」?
|
||||
|
||||
會議落地率:上週會議行動在 7 天內完成比例(%)。
|
||||
|
||||
結論:若重心放在收藏與分類,輸出速度自然變慢;我們要把筆記變成工作介面。
|
||||
|
||||
|
||||
|
||||
2|防彈筆記法的定位:為輸出而設計
|
||||
|
||||
核心精神:任務導向+動態演化+簡單精準。
|
||||
|
||||
一句話:每個任務一則筆記(SSOT),把目標、行動、決策、依據、變更都寫回「同一張」。
|
||||
|
||||
成功判準(你能立刻觀察):
|
||||
|
||||
打開任務筆記就知道現在要做哪一步。
|
||||
|
||||
週檢視只需要翻看「那些任務筆記」,不用重找來源。
|
||||
|
||||
|
||||
|
||||
3|系統骨幹:5 層結構(從雜到精)
|
||||
|
||||
收件匣:先丟進來,不分類;每日或隔日批次清空。
|
||||
|
||||
暫時筆記:把一則素材改寫成「問題/關鍵資訊/下一步」。
|
||||
|
||||
專案目標筆記(一個任務一則):聚焦目標、下一步、決策紀錄。
|
||||
|
||||
資源/經驗筆記:將過程踩雷與做法沉澱成可重用清單。
|
||||
|
||||
永久任務筆記(SOP):把重複流程標準化。
|
||||
|
||||
建議節奏:收→用 SLA 48 小時;每週 20–30 分鐘做整體覆盤。
|
||||
|
||||
|
||||
|
||||
4|一個任務、一則筆記(最小可用模板)
|
||||
|
||||
抬頭:任務名稱(動詞開頭)|完成條件(可驗收)|截止日。
|
||||
|
||||
主體三欄:
|
||||
|
||||
決策紀錄:\[YYYY-MM-DD\] 結論+依據連結
|
||||
|
||||
下一步×3:動詞+產出|Owner|Deadline
|
||||
|
||||
參考片段:只留「可直接引用的 3 點」
|
||||
|
||||
變更/風險:本週狀況、阻礙與備案(各 1–2 行)。
|
||||
|
||||
現場示例(行銷報告任務):
|
||||
|
||||
完成條件:能於 10 分鐘會議中清楚回答 3 個決策題。
|
||||
|
||||
下一步:彙整近 30 天投放成效圖|A|10/29
|
||||
|
||||
|
||||
|
||||
5|收集網頁學習資料:輸出導向的收法
|
||||
|
||||
工具任你用(Reader/Glasp/Save to Notion/NotebookLM…),關鍵在寫上自己的話:
|
||||
|
||||
每個高亮配\*\*「我怎麼用」1 句\*\*。
|
||||
|
||||
每篇文章只留下可用片段×3(論點/數據/步驟)。
|
||||
|
||||
作業節奏:
|
||||
|
||||
看到就「一鍵收件匣」→每日或隔日批次清空→拉進對應專案筆記。
|
||||
|
||||
設指標:收件匣未清空天數 ≤ 2 天。
|
||||
|
||||
產出檢核:專案筆記中能直接引用為段落或決策依據;不要讓引用回頭再找原文。
|
||||
|
||||
|
||||
|
||||
6|會議記錄:只保留「會帶來動作」的東西
|
||||
|
||||
兩張表就夠了:
|
||||
|
||||
決策表:議題|結論|依據連結|備案
|
||||
|
||||
行動表:Action(動詞)|Owner|驗收標準|Deadline|所屬專案連結
|
||||
|
||||
24 小時分流規則:行動嵌回各自專案筆記,不要留在「今天會議」頁。
|
||||
|
||||
追蹤指標:
|
||||
|
||||
行動卡 24h 歸位率>90%;次週落地率>70%。
|
||||
|
||||
|
||||
|
||||
7|復盤:把「心得」改寫成「下一次會做的事」
|
||||
|
||||
任務筆記內建復盤區:
|
||||
|
||||
本次做法摘要(≤3 句)/成效&失誤(各 1–2 點)
|
||||
|
||||
下次改進×1–3(動詞+驗收條件)/可複用規則(1 句)
|
||||
|
||||
節奏:每日 3 分鐘微復盤+每週 20–30 分鐘沉澱 SOP。
|
||||
|
||||
成效衡量:
|
||||
|
||||
同類任務的交付時間縮短、錯誤率下降;SOP/模板數量逐週增加。
|
||||
|
||||
|
||||
|
||||
8|協作與追蹤:讓資訊與責任對齊
|
||||
|
||||
原則:SSOT(單一真相來源)=每個任務的那一張筆記。
|
||||
|
||||
團隊看板只放「任務卡連結」,不複製內容,避免版本分叉。
|
||||
|
||||
週會範式:只帶任務筆記檢視「決策更新與下一步」。
|
||||
|
||||
測量:
|
||||
|
||||
決策回溯時間(從提問到找到結論的時間)
|
||||
|
||||
跨部門等待時間(等待外部回覆的平均天數)
|
||||
|
||||
|
||||
|
||||
9|工具與 AI 的正確打開方式(不換工具也能做)
|
||||
|
||||
你已有的工具即可(Notion/Google 文件/Obsidian/Evernote 皆可)。
|
||||
|
||||
AI 三招:
|
||||
|
||||
把零散片段改寫成「下一步×3」;
|
||||
|
||||
把會議討論萃成決策表+行動表;
|
||||
|
||||
把經驗重構成 SOP/模板並附上原連結。
|
||||
|
||||
風險控管:保留來源連結、標註假設/限制,避免黑盒決策。
|
||||
|
||||
|
||||
|
||||
10|7 天導入計畫(立即行動)+結語
|
||||
|
||||
D1–D2:選 3 個進行中的任務 → 各建任務筆記(抬頭+三欄+復盤區)。
|
||||
|
||||
D3–D4:把最近的 1 場會議,改用「決策表+行動表」並在 24h 分流。
|
||||
|
||||
D5:清空收件匣,為 3 篇文章各寫「可用片段×3+我怎麼用」。
|
||||
|
||||
D6:每日 3 分鐘微復盤,週末 20 分鐘沉澱 1 份 SOP。
|
||||
|
||||
D7:檢視三個數字:找資料時間、下一步明確率、會議落地率。
|
||||
|
||||
結語:不要把時間花在整理系統,而是用系統把結果做出來。
|
||||
|
||||
從今天開始,讓每一張筆記都能回答:「下一步是什麼?」
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**所以目前來說(2025/10),我還是喜歡把簡報大綱貼入 Canva (或 Gamma ),利用 Canva AI 來製作簡報** 。
|
||||
|
||||
|
||||
|
||||
把剛剛 ChatGPT 生成的簡報大綱貼入 Canva AI ,在對話框下面選擇:「設計」-「簡報」-「想要的風格」,就可以讓 Canva AI 協助製作簡報版面。
|
||||
|
||||
|
||||
|
||||
[](https://blogger.googleusercontent.com/img/a/AVvXsEiNHU_iNd5iLgMR2cxGdmWz1DzRfn-XF_DPQNrObXiNNjEDFnR8MTy31HEUHw-wd0j4mfVSevrHJz54R82t-1hUltu8AMTgL-9-tfyhaNpFQixCvlot-qr6nR7vIYph7K6vt_K_03-izu7k2NNY1SrXIELhloTVZxTap7ZrqBsQY3s9LrrmK-TTEQ)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Canva AI 會根據簡報大綱,思考分頁、內容重點,然後先做出一個分頁版本,我們繼續按下方的「產生設計」。
|
||||
|
||||
|
||||
|
||||
[](https://blogger.googleusercontent.com/img/a/AVvXsEiYgtfkvHi8X8OnslDWpdWi79BdPq26dFftD5NVgNs6xCVzJzMWXsyE4sivTitGNRFjTG9ofe4gOaTqMOQvRWVNH_Mk6CJJEBmOnMicUQGezcDBuC7LejeAIwHDfeZ3baW1QP_khnwSZT3NW061Fnp6N57lOEhbYup7fcZ-eAIUwBI1aDAjertyVA)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
這樣就能在 Canva 中完成簡報版面套用,與基本的圖文內容設計了。
|
||||
|
||||
|
||||
|
||||
[](https://blogger.googleusercontent.com/img/a/AVvXsEgP4F0rcxQvdmwoKvAyRlHwWEj56mFipylZi0vEYPbdfPz5ekeMeVgjjAfF0OePcWc6MjOR6xxZhz4OzIJ4ut3DcHdE_WiSf47tlQhWkEyj8aqI6M2WHGo14H7vSo5bsVbupS_z0cBM3O0KlrV4jx9MeOlggEwD8caOA_2MWbAi2qRc59_uwW824g)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
最後也能進入 Canva 編輯器進一步修改。
|
||||
|
||||
|
||||
|
||||
[](https://blogger.googleusercontent.com/img/a/AVvXsEiJmoXGnLJkDuouhQb0ewLoz59I3ATTjWC41BO9n-mm_ws25h-gNTi4rojJnb0Q4b-ZHucdKvO_vZoDH2iAExolmyfGPXzxBQxy9JrfDtEMCflLsfMTKPknwJbv2t3g93BTmeddaiEzga_TMQYxQ-qBpgsWk0aRy6-a81GQIAiI6xky0PG8ySMFhw)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**同樣的流程,我也可以把 ChatGPT 產生的簡報大綱,貼入 Gamma** ,讓 Gamma AI 直接做出圖文並茂的簡報,作為專業 AI 簡報工具, Gamma 的效果還是最好的。(延伸教學: [Gamma 用 AI 幫你設計簡報、網頁,瞬間完成戲劇化版面內容](https://www.playpcesor.com/2023/04/gamma-ai.html) )
|
||||
|
||||
|
||||
|
||||
[](https://blogger.googleusercontent.com/img/a/AVvXsEgKd_zvNNqPl-UpkT1xfgrSno1w_yas2iNJzAEzlze-w-eOC1BNh7M4RFHQOdhiR2c4FxJEgcMTZk3D_5g6PhQJdASgw1WqJFbJZG7zoBEpSh6ENeSReGbhjU-R2nvzcXMzMGUi232loAoLn522MYCaKstH46GeyevovO3fB4idoUnv8Hkroh_JvA)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
> 簡報不是從版面設計開始,而是從資料研究開始。
|
||||
|
||||
|
||||
|
||||
想要利用 AI 來製作簡報,但是每次在 Gamma、 Canva 上直接讓 AI 做簡報時,常常發現版面雖然漂亮,但簡報內容不夠好、有幻覺、不深入的朋友,可以利用上面分享的流程,來製作更專業的 AI 簡報。
|
||||
193
raw/Technical/清华出的DeepSeek使用手册,104页,真的是太厉害了!(免费领取).md
Normal file
193
raw/Technical/清华出的DeepSeek使用手册,104页,真的是太厉害了!(免费领取).md
Normal file
@@ -0,0 +1,193 @@
|
||||
---
|
||||
title: 清华出的DeepSeek使用手册,104页,真的是太厉害了!(免费领取)
|
||||
source: https://mp.weixin.qq.com/s/HYnCYO9UYNR8pdCTCHAfQA?token=1896197373&lang=zh_CN&poc_token=HN29Q2mjRSBc3qo6UV37ojY4td_shGQx-adlLaZx
|
||||
author: shenwei
|
||||
published:
|
||||
created: 2025-12-18
|
||||
description: 文末附资料下载
|
||||
tags: []
|
||||
---
|
||||
|
||||
|
||||

|
||||
|
||||
余梦珑博士后 [顶级程序员](https://mp.weixin.qq.com/s/) *2025年2月11日 13:30*
|
||||
|
||||
《DeepSeek从入门到精通2025》是由清华大学新闻与传播学院新媒体研究中心元宇宙文化实验室的余梦珑博士后及其团队撰写。 **文档的核心内容围绕DeepSeek的技术特点、应用场景、使用方法以及如何通过提示语设计提升AI使用效率等方面展开,帮助用户从入门到精通DeepSeek的使用。**
|
||||
|
||||
以前我看了很多教程,都感觉特别花哨,没啥干货,大部分就是把GPT的说明书稍微改改,就拿来用在DeepSeek上了,没啥用。但清华这个手册完全不一样!它先是给你讲清楚原理,然后手把手教你怎么科学地使用。它不只是告诉你怎么提问,还会告诉你为啥要这么问,这不就是教你怎么掌握提示词的底层逻辑嘛。
|
||||
|
||||
**这才是真正的“授人以渔”,太有用了!👍**
|
||||
|
||||
清华的专家们毫无保留,分享了超多实用技巧,从避免 AI 幻觉的小窍门,到设计超棒提示语的秘籍, **共104页,全是能直接上手的干货** ,学完就能让你的 AI 使用体验直线上升!
|
||||
|
||||
|
||||
|
||||
DeepSeek是一家专注于通用人工智能(AGI)的中国科技公司,其开源的推理模型DeepSeek-R1在处理复杂任务方面表现出色,备受世界瞩目。该文档不仅详细阐述了DeepSeek能够提供的多种应用场景,如智能对话、文本生成、代码生成等,还深入探讨了如何高效使用DeepSeek,包括模型选择、提示语设计以及避免常见误区等关键内容。 **通过深入浅出的讲解,文档帮助用户更好地理解和应用DeepSeek技术,展现了中国在人工智能领域的强大实力和创新能力。**
|
||||
|
||||
总结来看,这份资料结构清晰,内容全面,理论与实践结合紧密,适合不同层次的读者。准确性方面,大部分内容符合当前AI和提示工程的最佳实践,但在细节处可能需要更多的引用或解释。实用性很高,尤其是提供的示例和策略能够直接应用于实际工作场景,帮助用户提升AI使用效率。不过, **对于完全的新手来说,部分章节可能稍显复杂,需要结合实践逐步掌握。** 这份文档不仅为用户提供了关于DeepSeek的全面知识,还体现了中国科技在人工智能领域的快速发展。
|
||||
|
||||
|
||||
|
||||
**全文如下
|
||||
**
|
||||
|
||||
**下载方式见文末**
|
||||
|
||||

|
||||
|
||||
 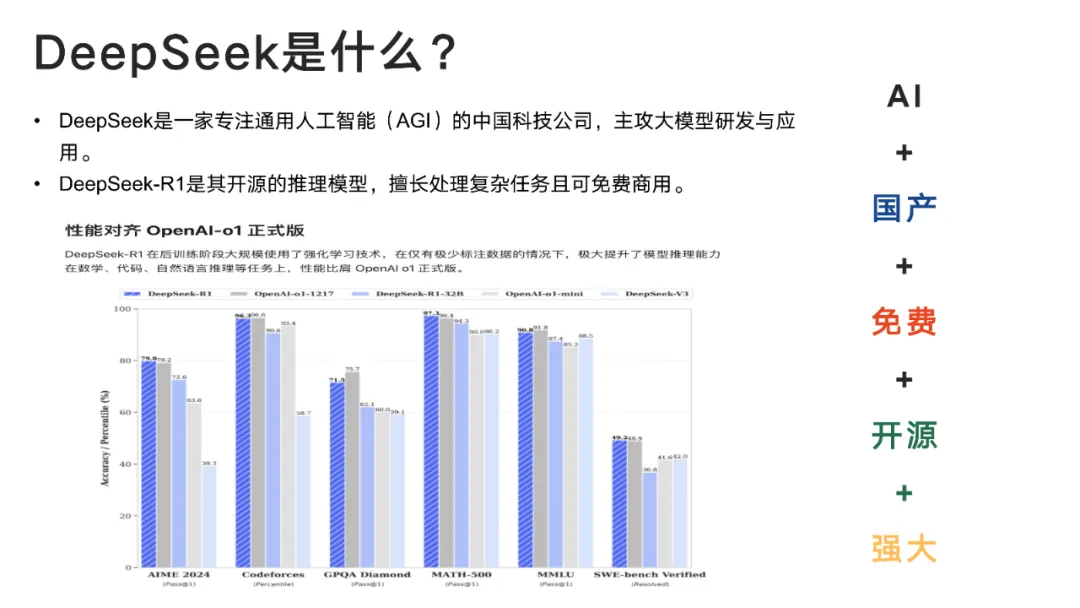
|
||||
|
||||
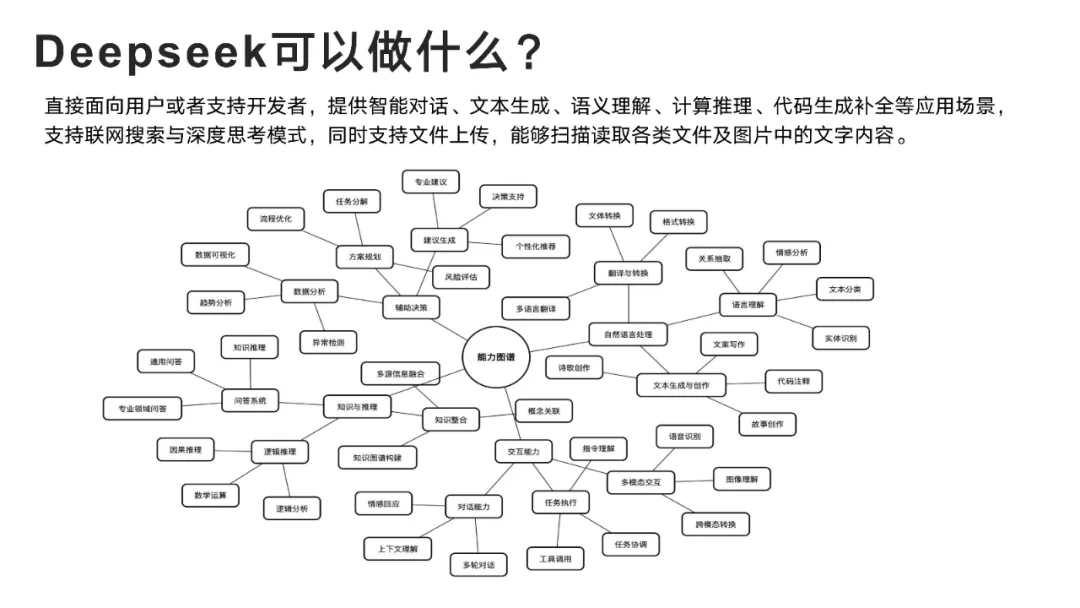
|
||||
|
||||
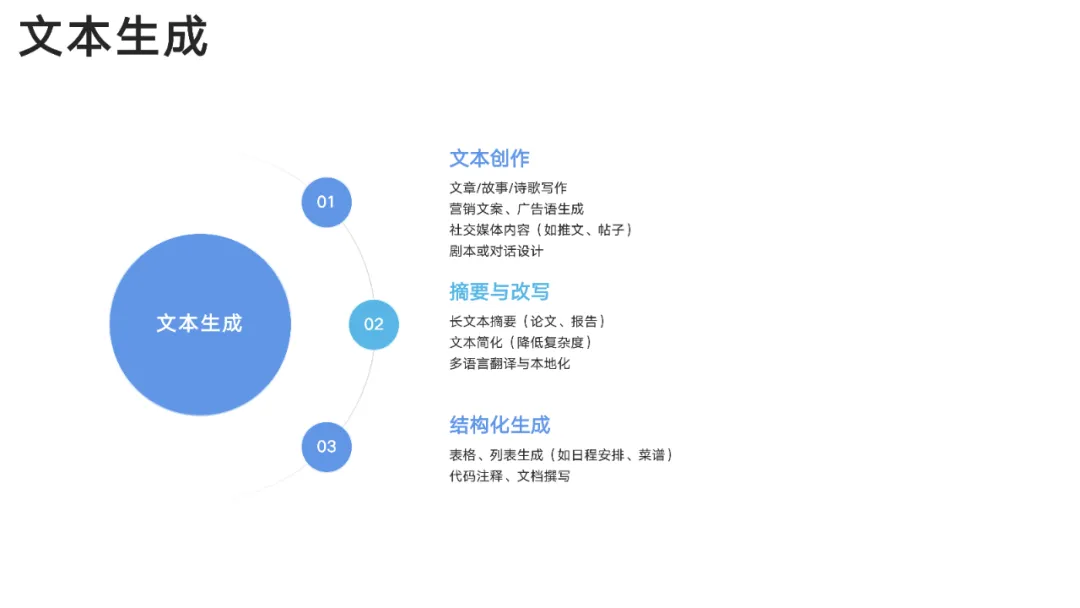 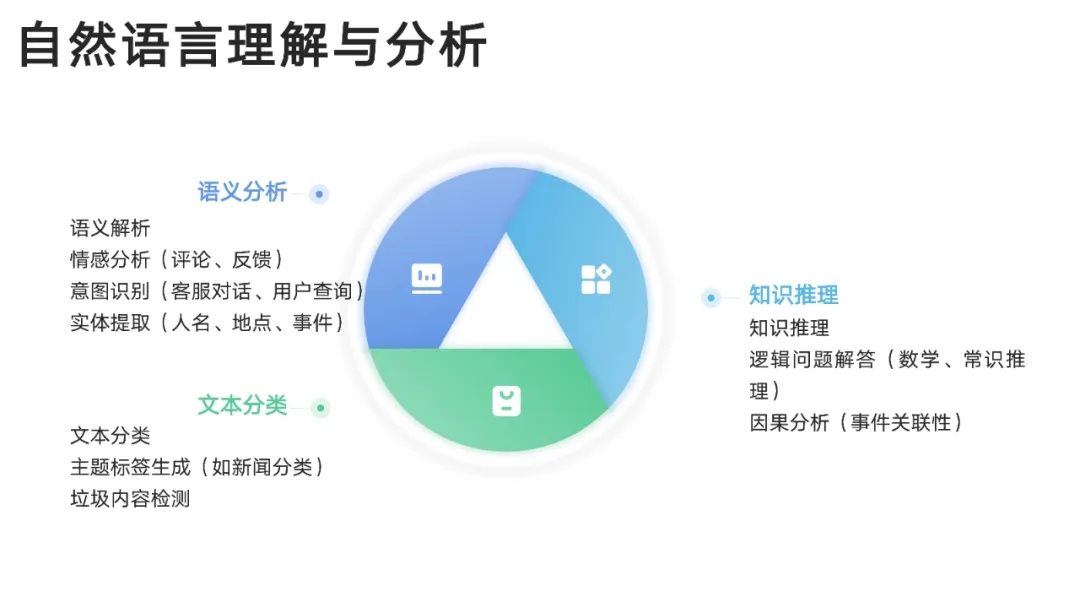     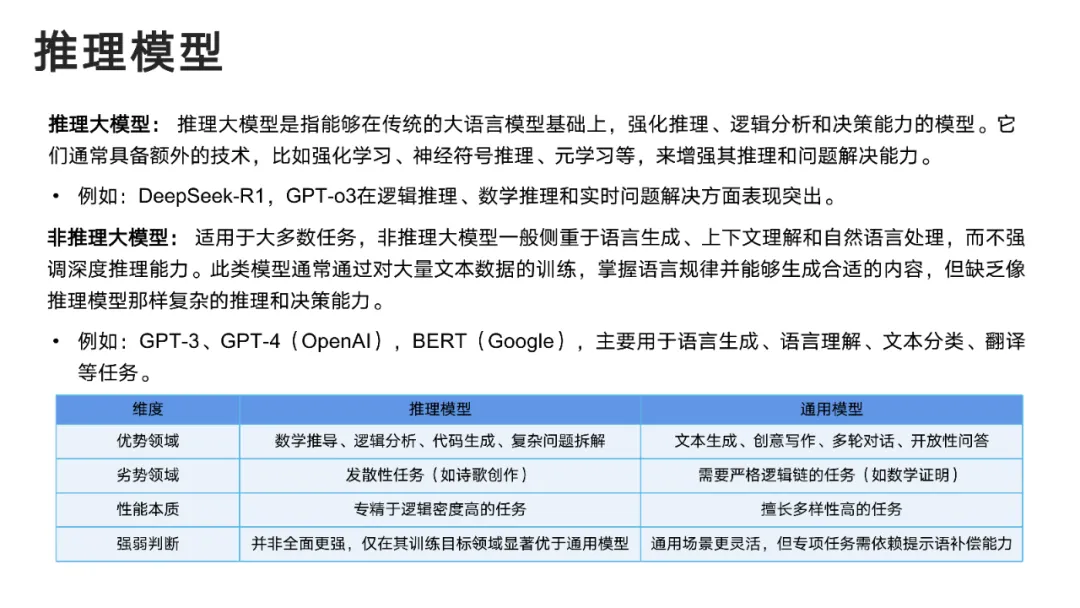
|
||||
|
||||
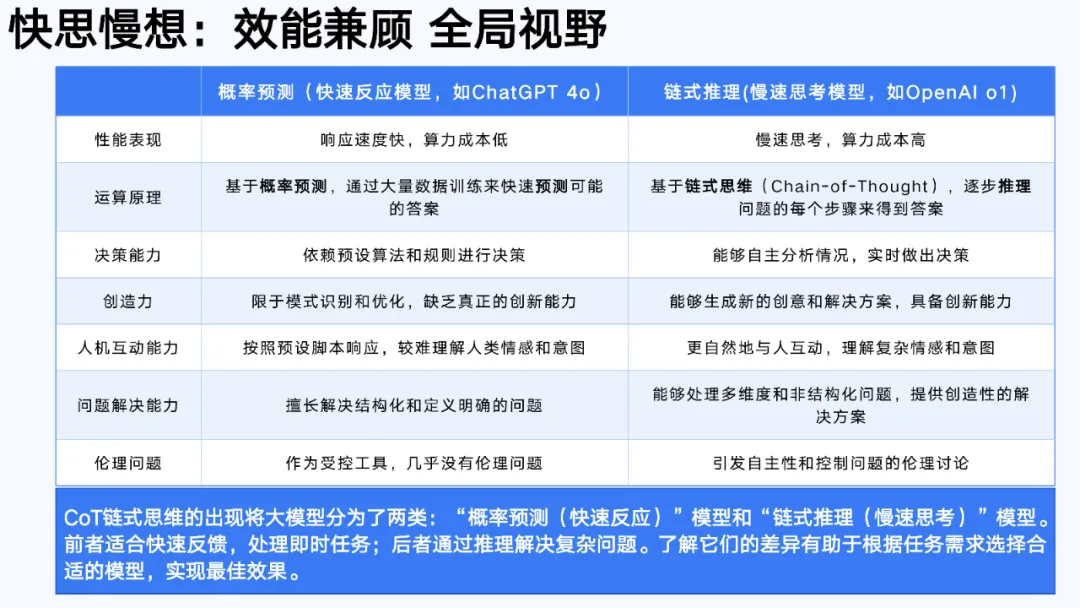
|
||||
|
||||
  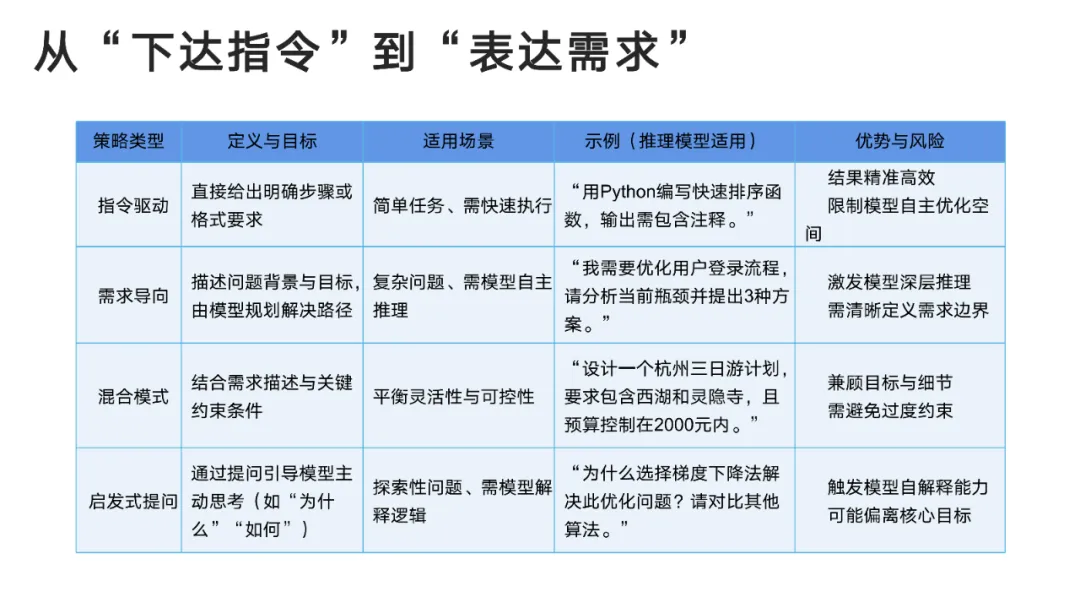
|
||||
|
||||
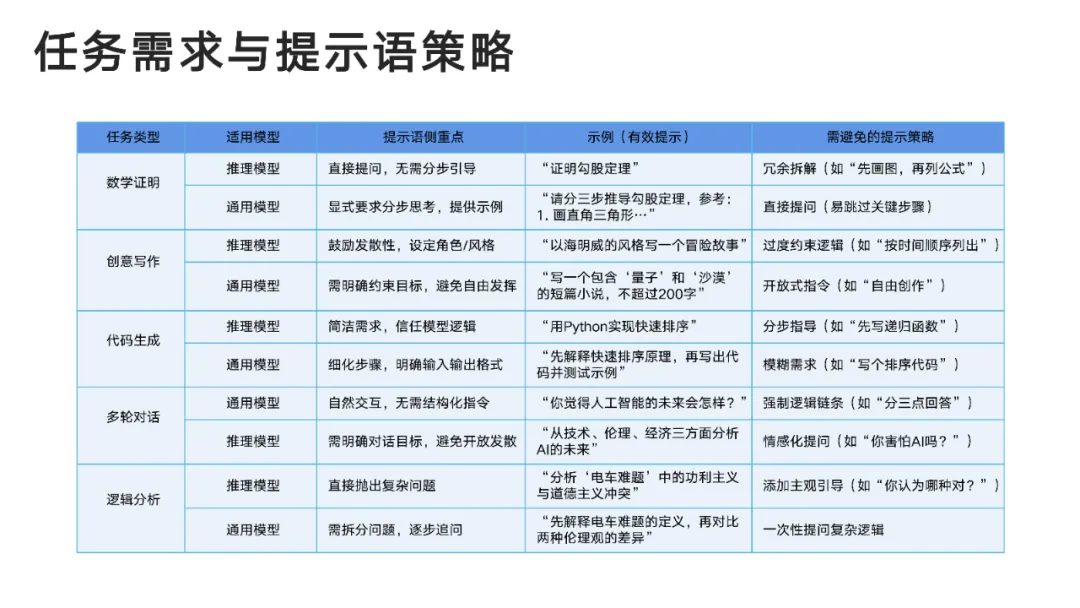
|
||||
|
||||
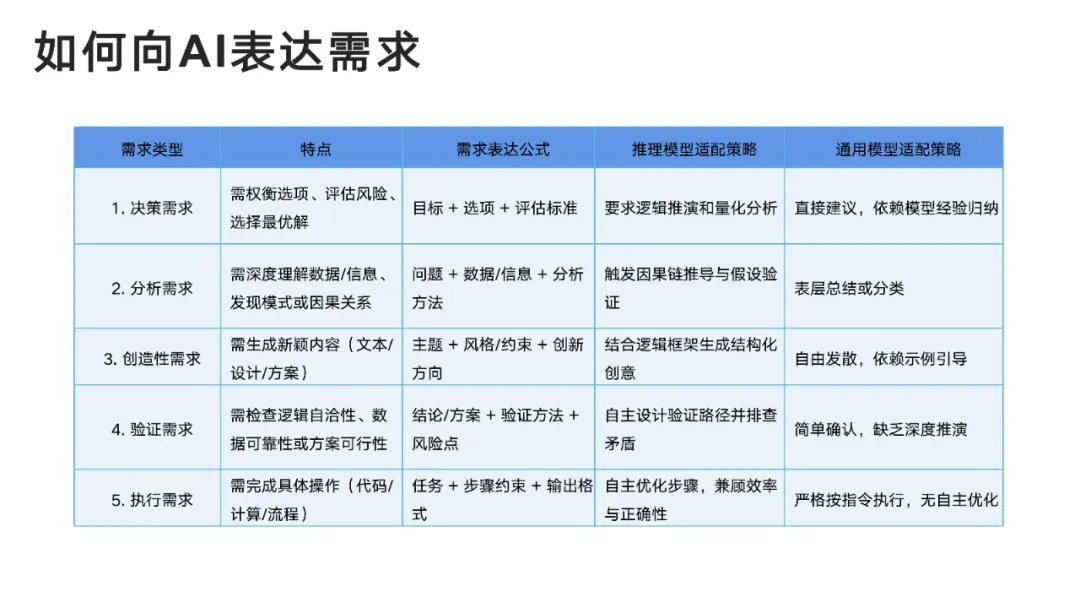 
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
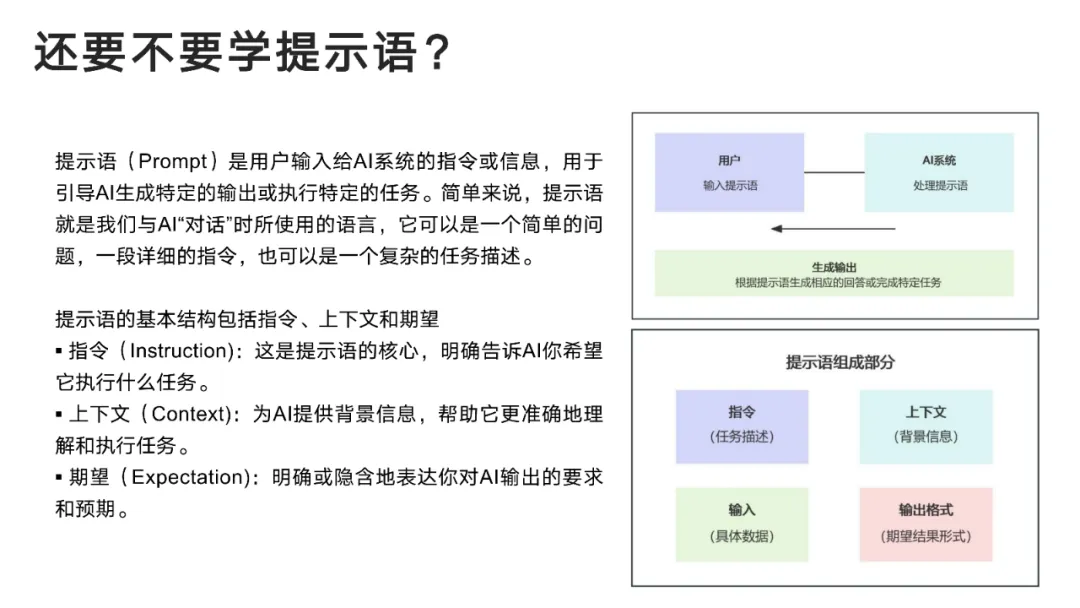  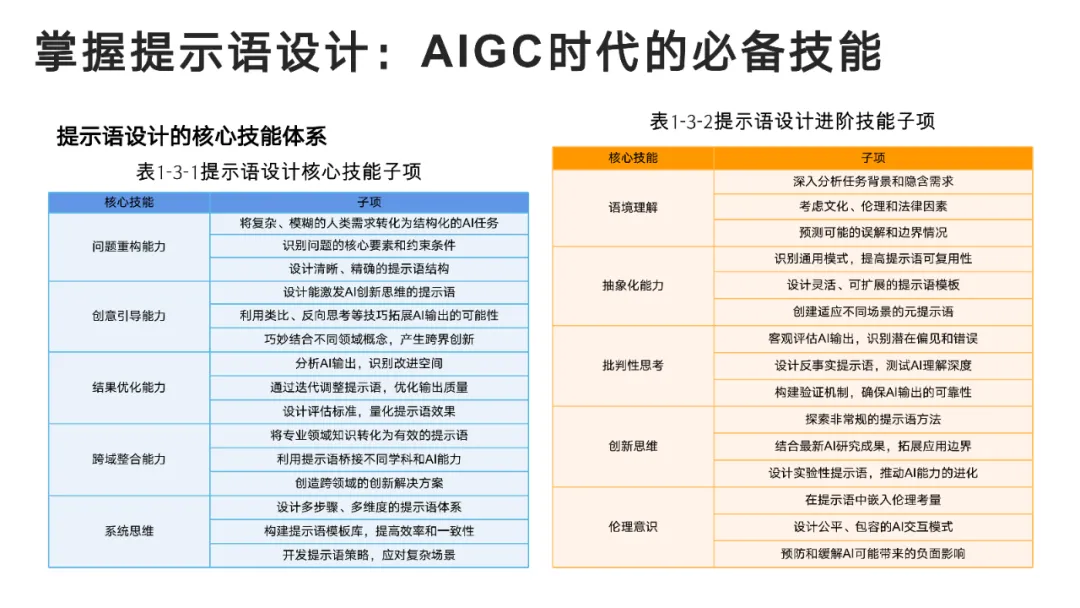 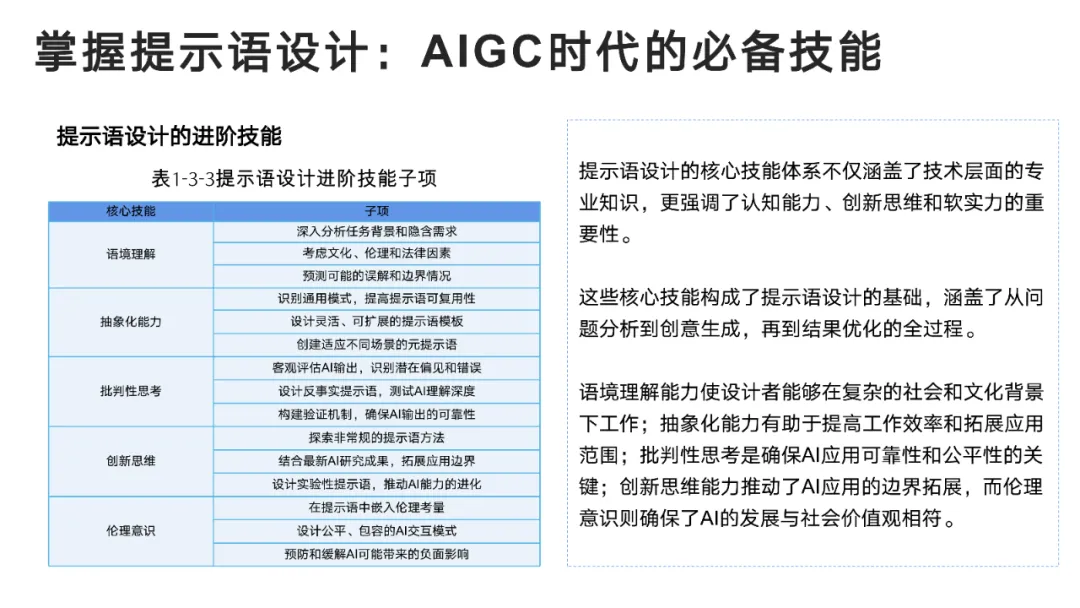
|
||||
|
||||

|
||||
|
||||
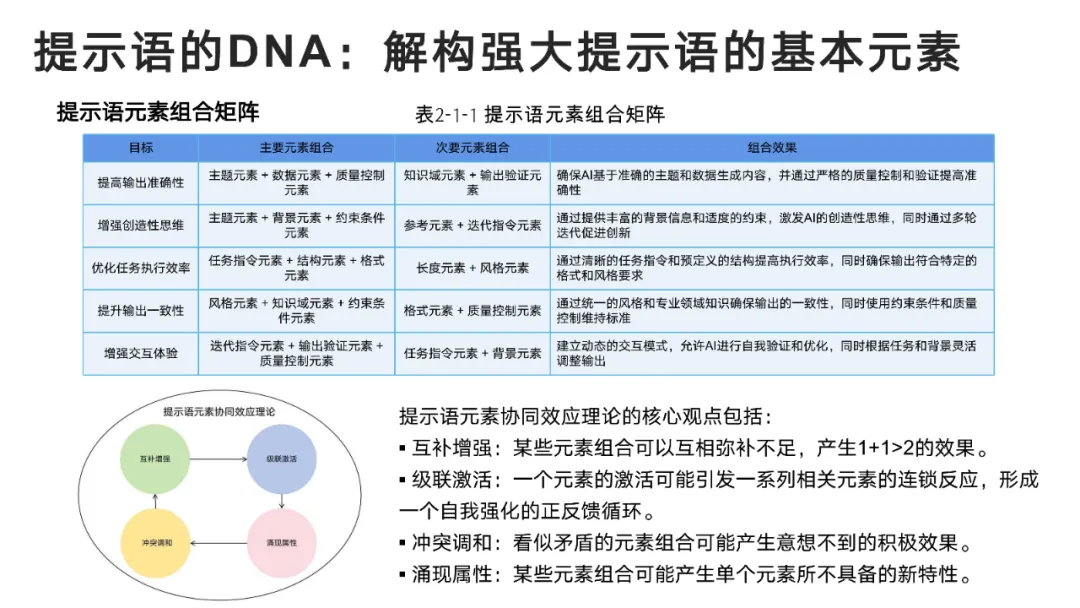
|
||||
|
||||
|
||||
|
||||
  
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
 
|
||||
|
||||

|
||||
|
||||
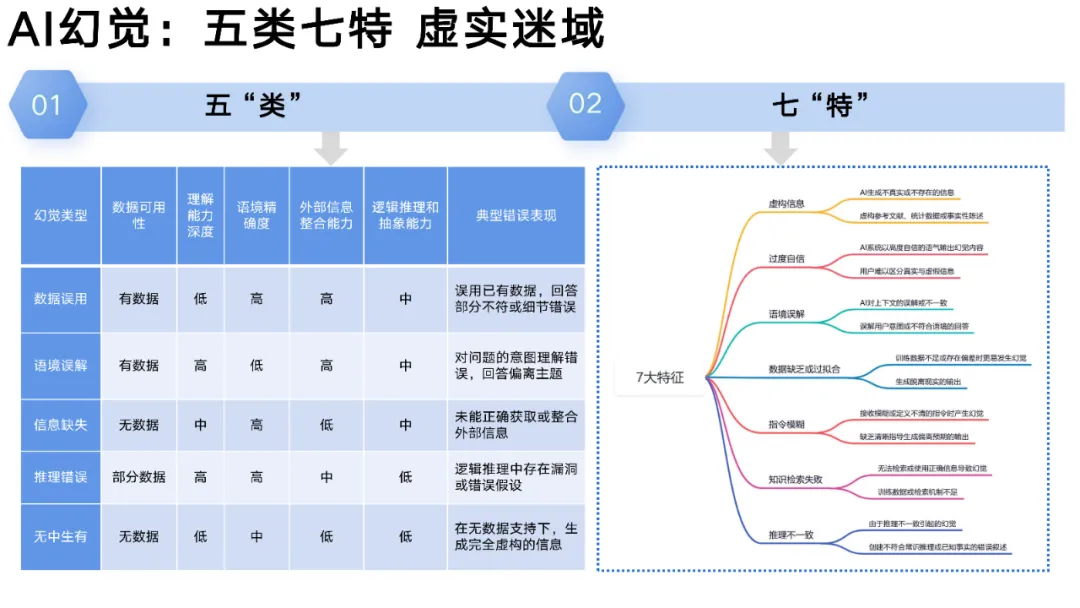  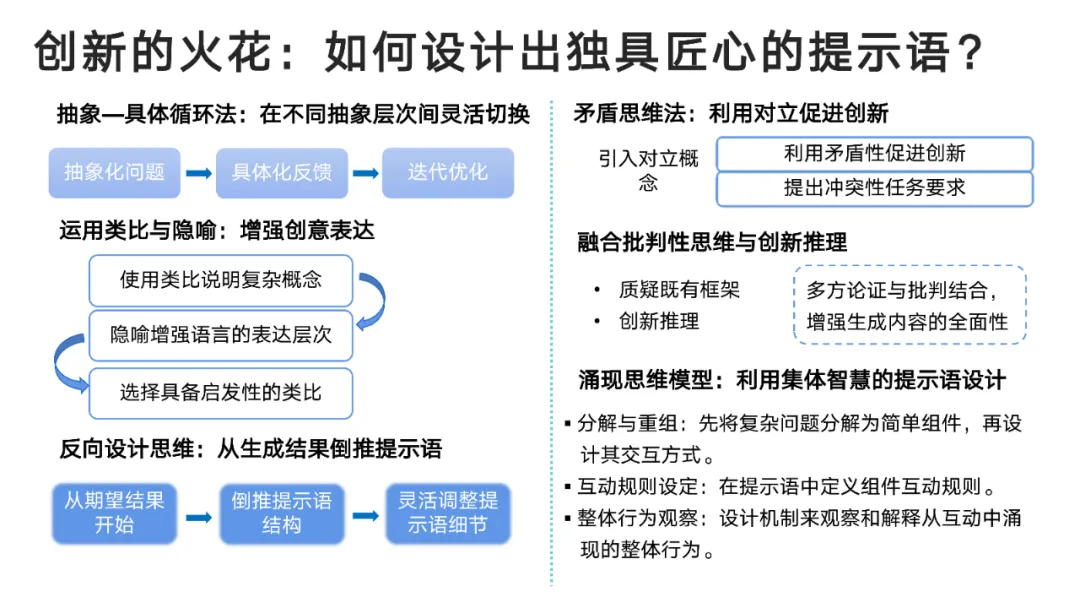
|
||||
|
||||
|
||||
|
||||
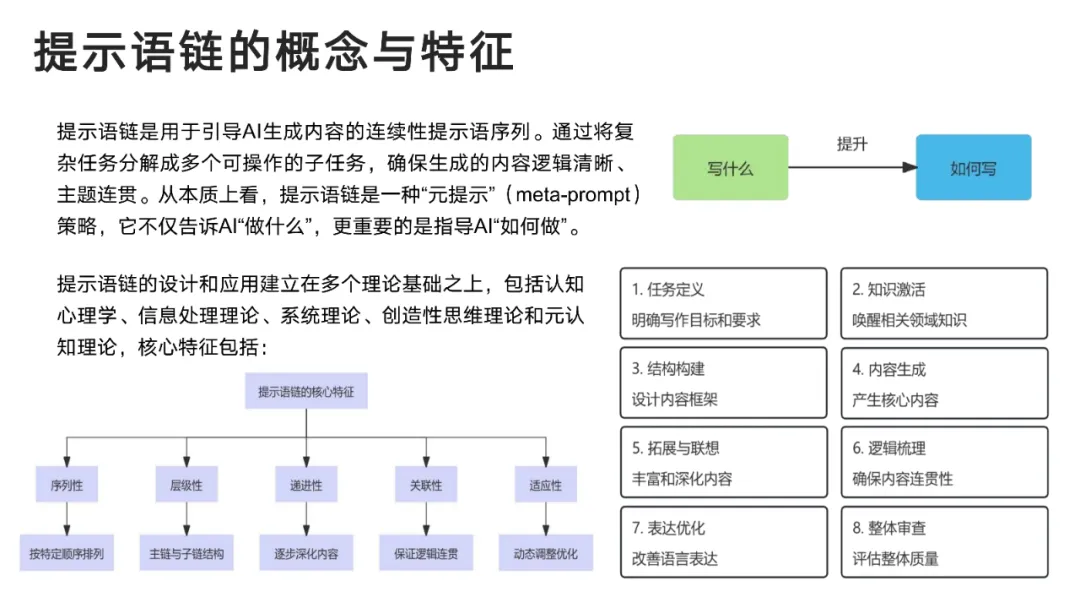
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
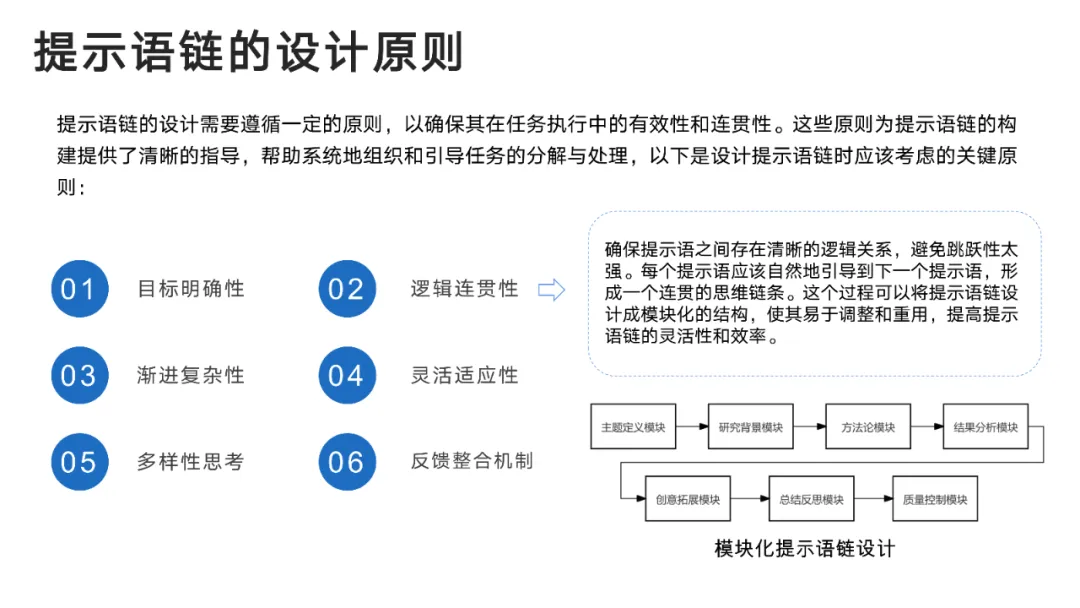 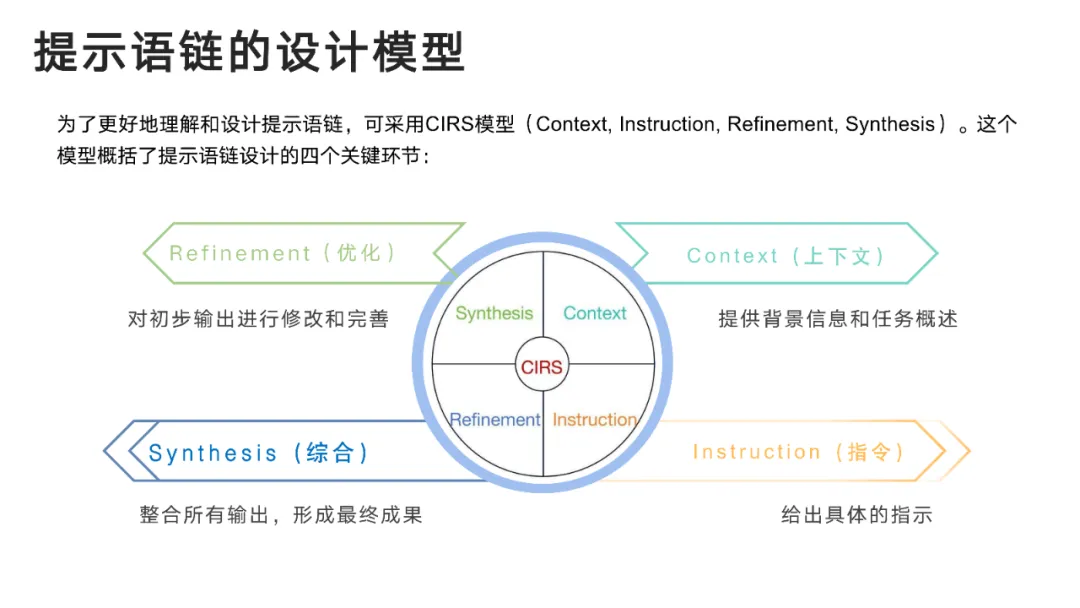 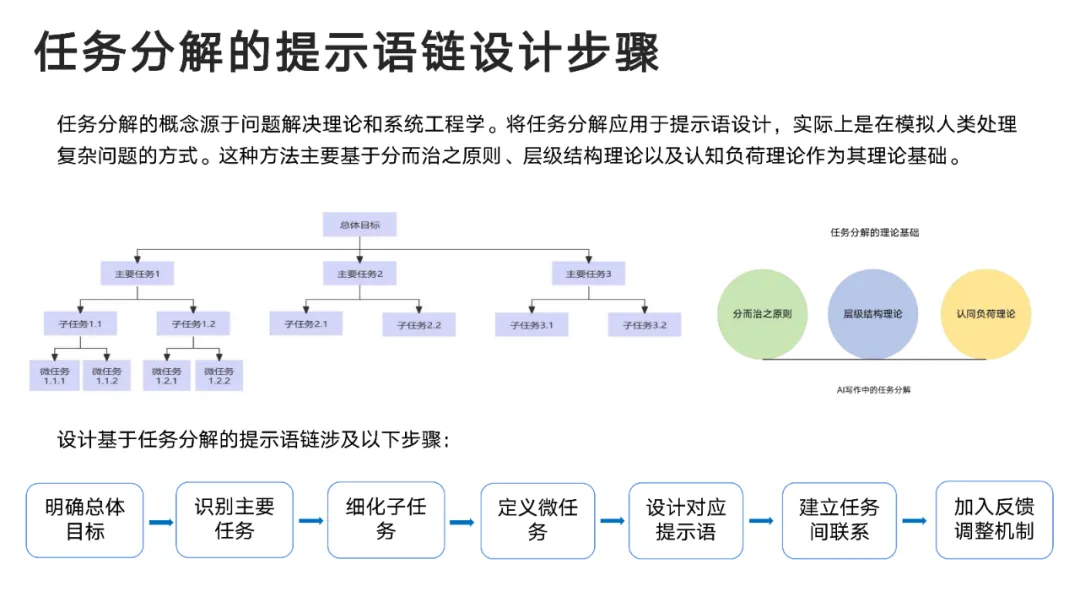 
|
||||
|
||||
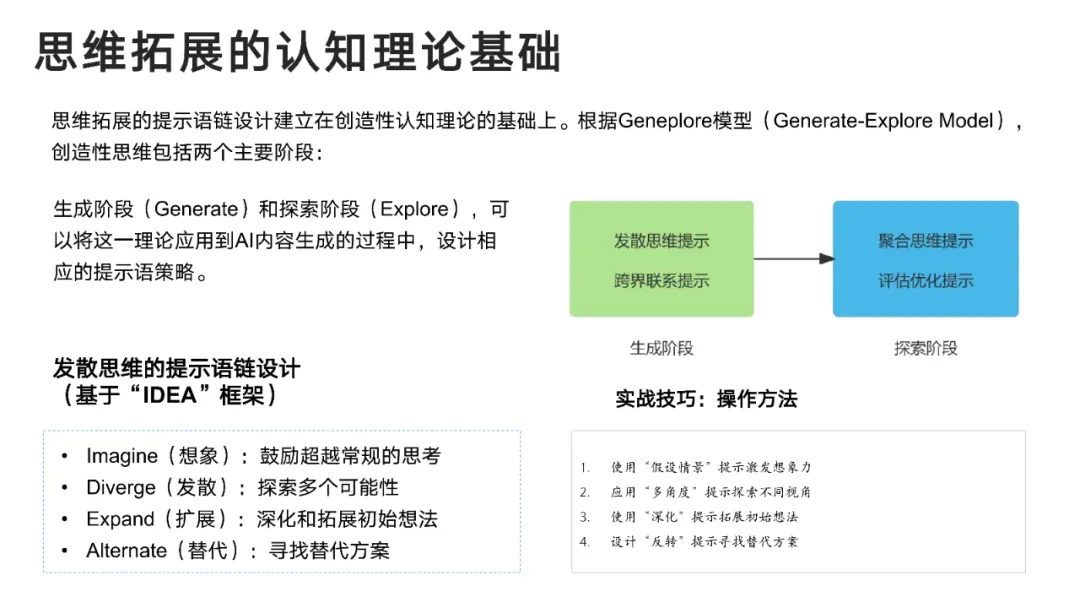
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
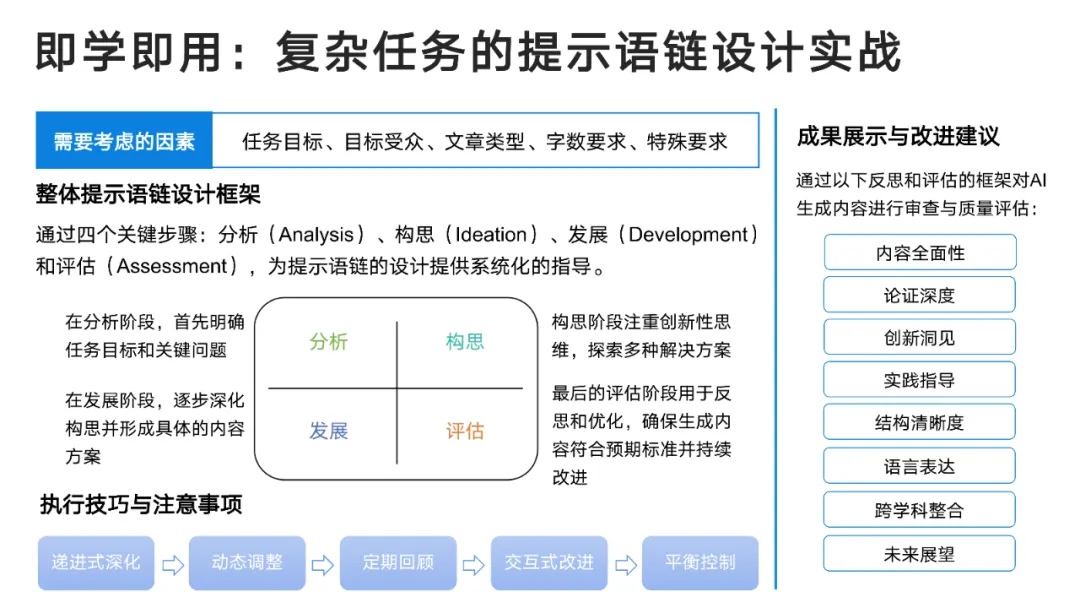
|
||||
|
||||
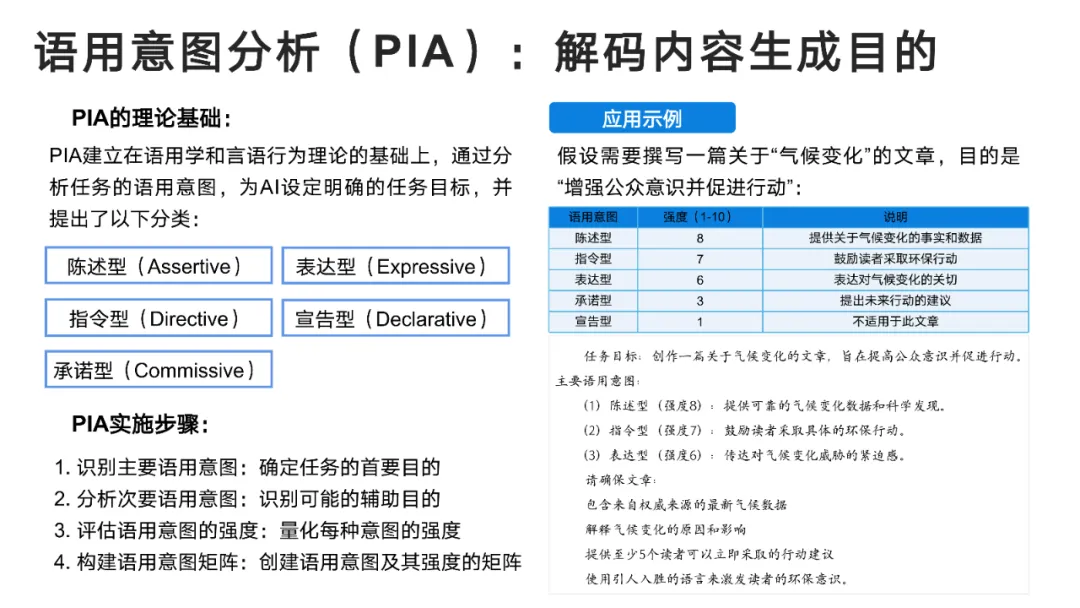
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
  
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
  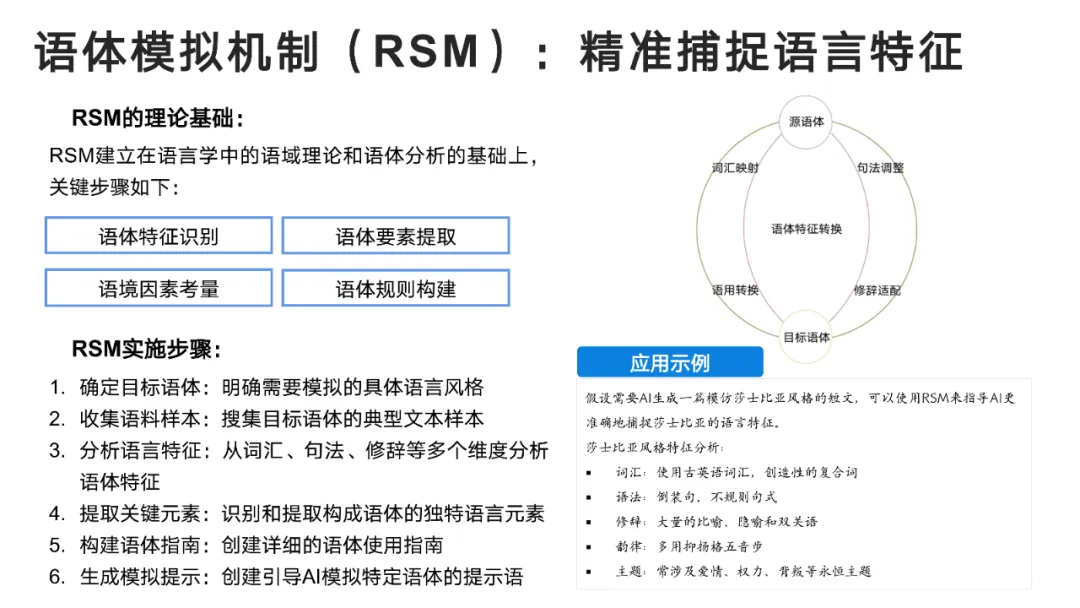
|
||||
|
||||
|
||||
|
||||
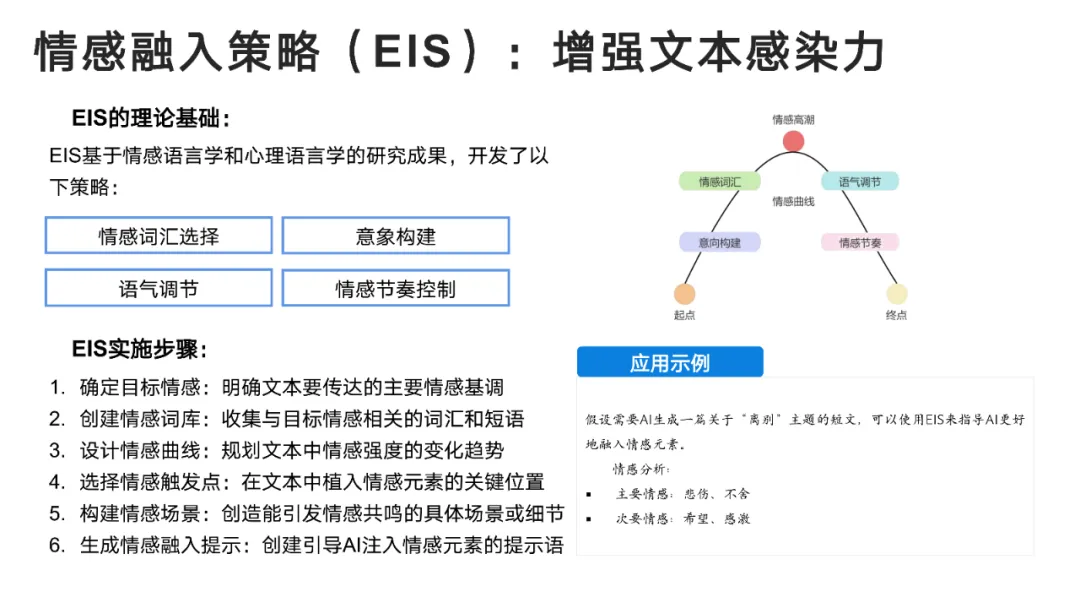 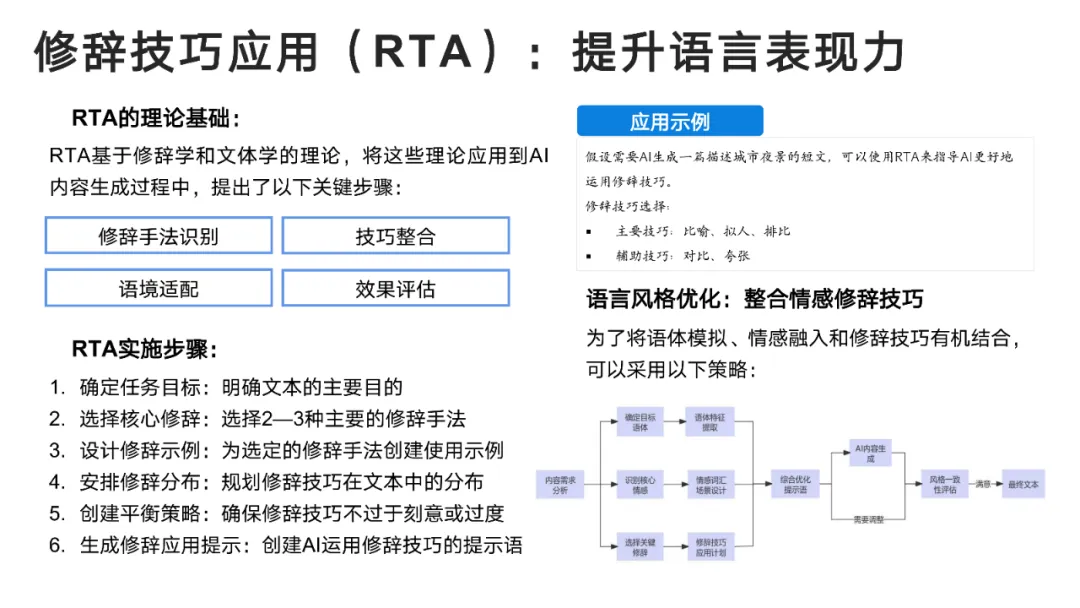
|
||||
|
||||

|
||||
|
||||
 
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
  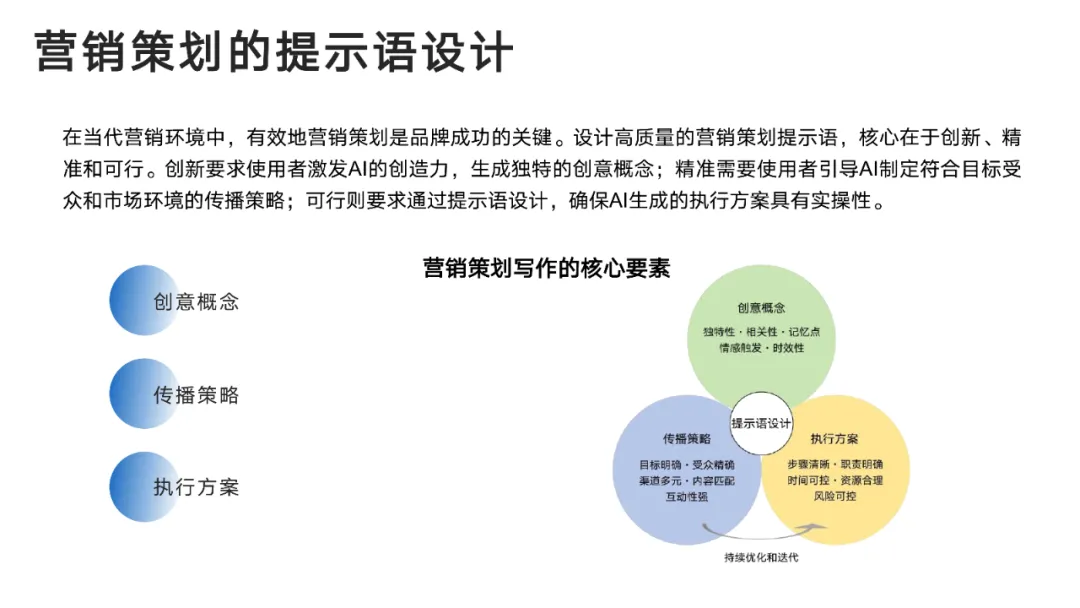 
|
||||
|
||||

|
||||
|
||||
      
|
||||
|
||||
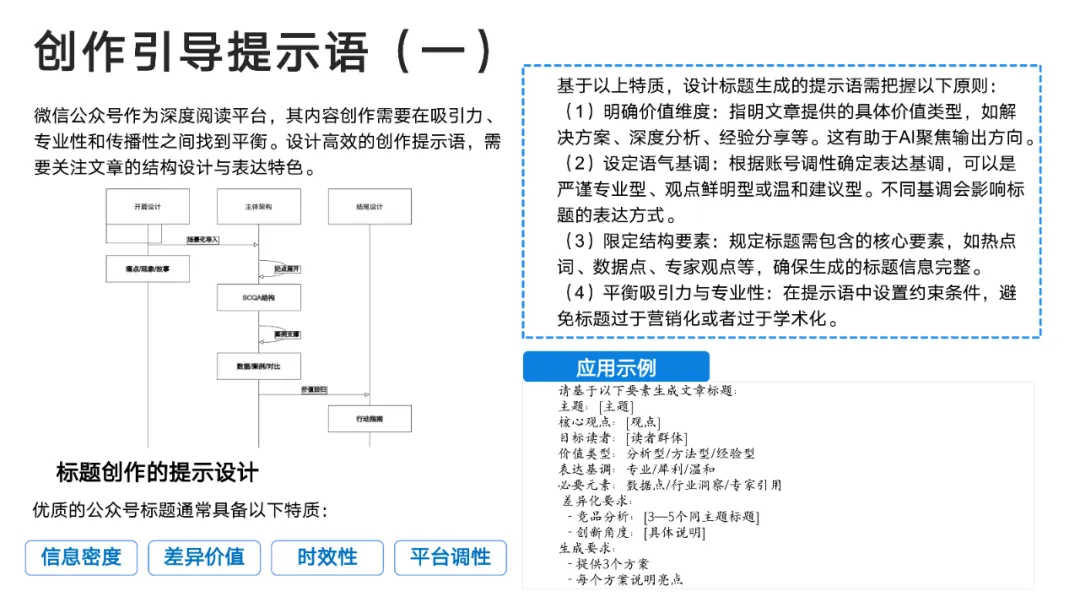
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
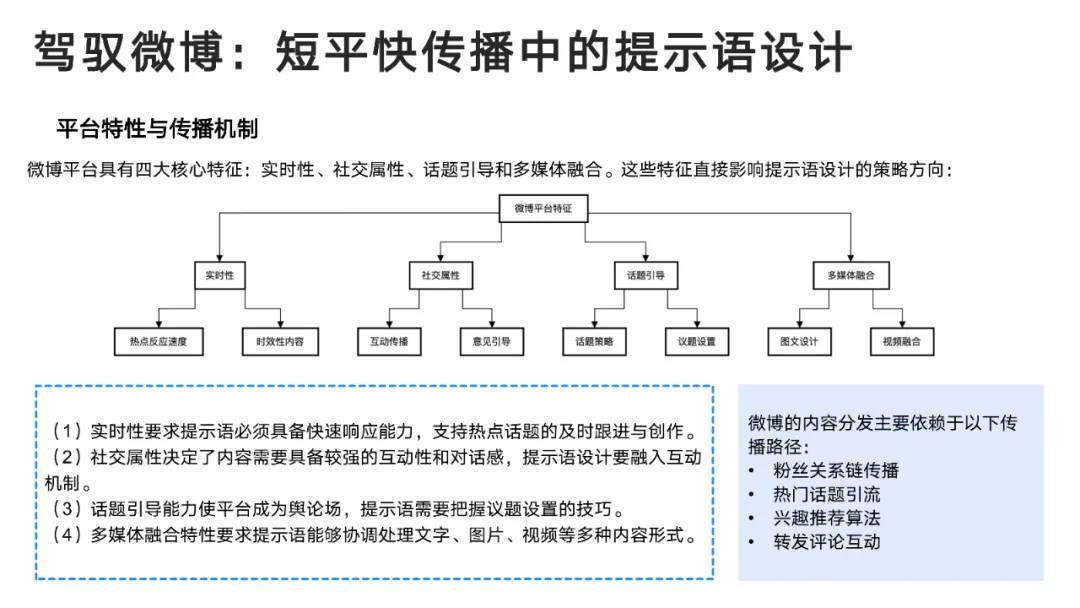
|
||||
|
||||
|
||||
|
||||
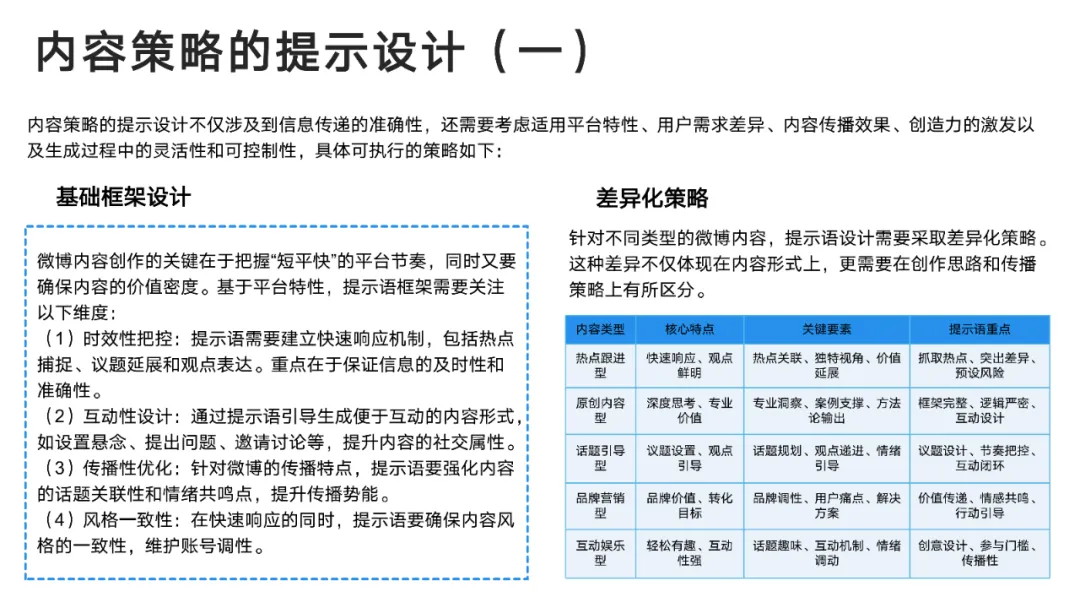
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
 
|
||||
|
||||
  
|
||||
|
||||
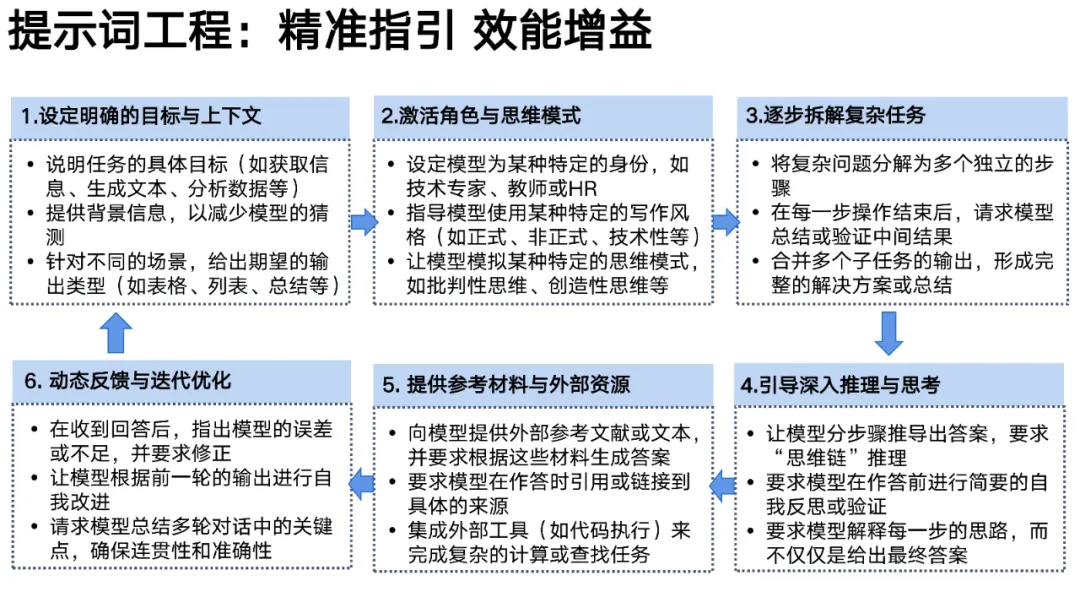
|
||||
|
||||
 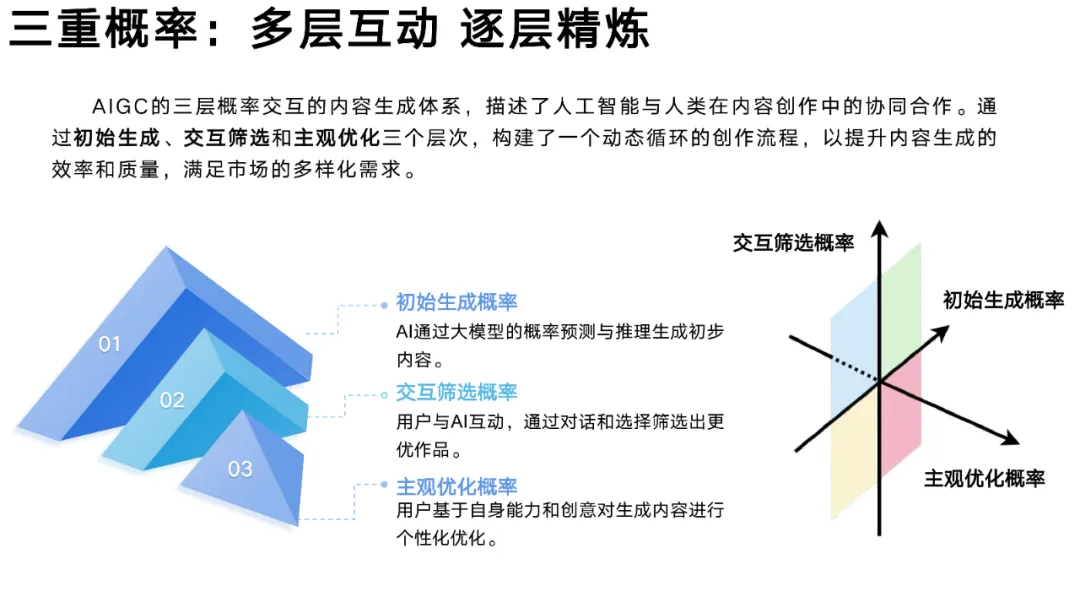 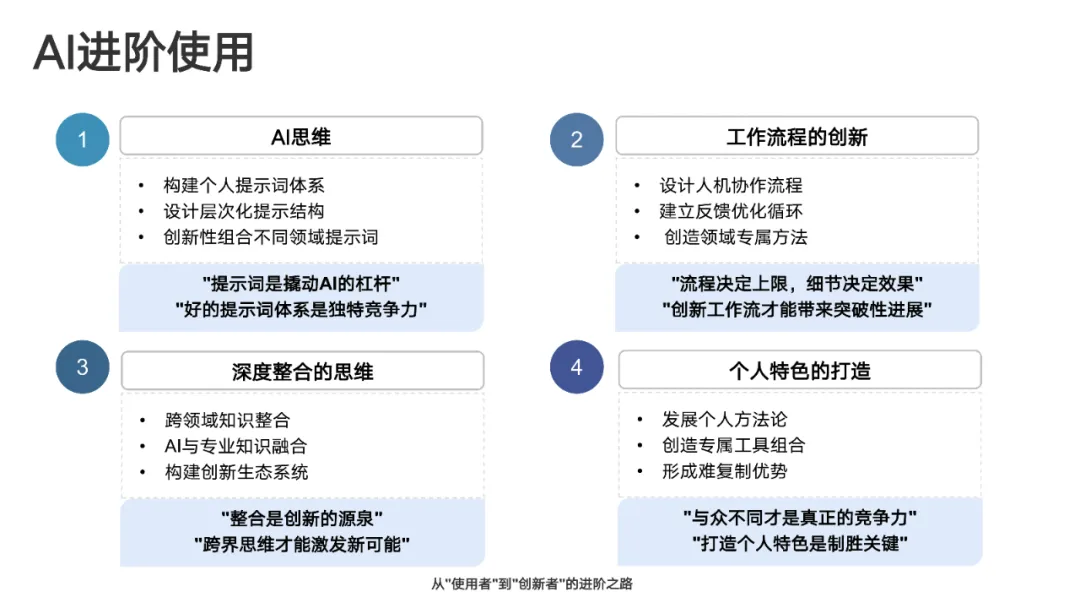
|
||||
|
||||

|
||||
|
||||
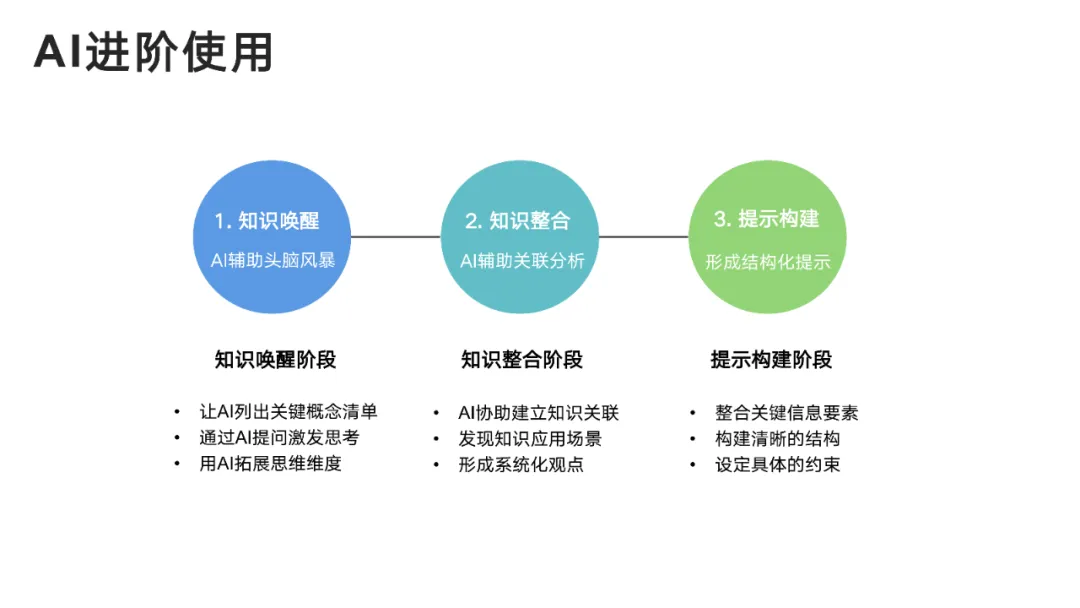 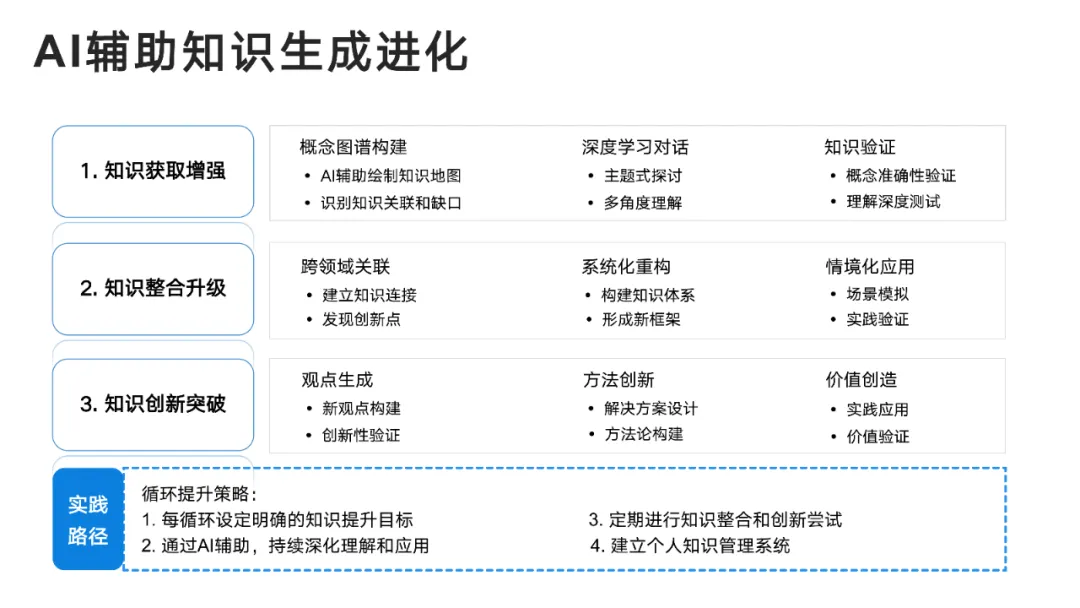 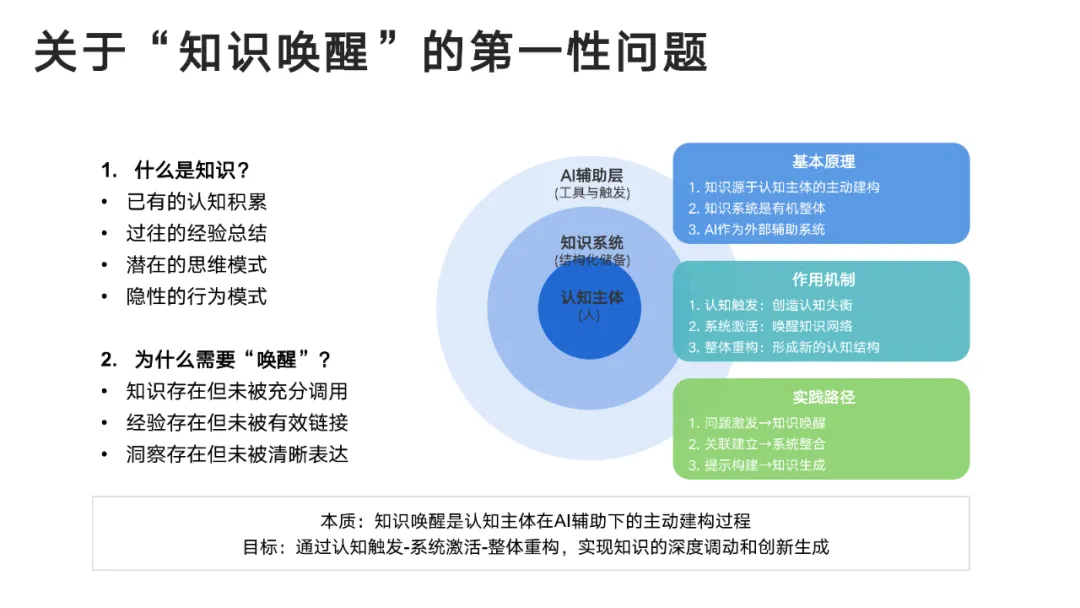 
|
||||
|
||||

|
||||
|
||||
 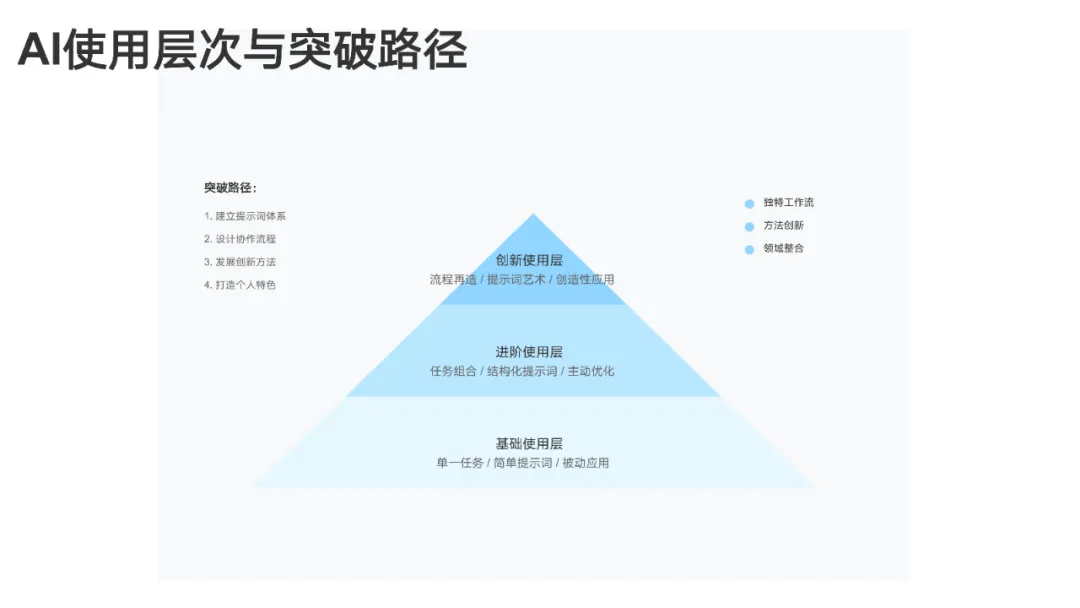
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
**资料下载方式**
|
||||
|
||||
|
||||
|
||||
Download method of report materials
|
||||
|
||||
|
||||
|
||||
**扫码加好友,领取文档**
|
||||
|
||||

|
||||
|
||||
继续滑动看下一个
|
||||
|
||||
顶级程序员
|
||||
|
||||
向上滑动看下一个
|
||||
|
||||
顶级程序员
|
||||
Reference in New Issue
Block a user